el método de la potencia y agrupamiento espectral de...
TRANSCRIPT

El Metodo de la Potencia y Agrupamiento Espectral deDatos
Dr. Humberto Madrid de la Vega
Universidad Autonoma de Coahuila. Mexico
VII Encuentro Cuba–Mexico de Metodos Numericos y Optimizacion.Habana, Cuba
Marzo 2018
Humberto Madrid (UAdeC) 1 / 50

Temas
Introduccion
Resumen de agrupamiento espectral
Grafos, matriz de afinidad ALaplaciano L = D − ACorte y Corte normalizadoLaplaciano normalizado simetrico Lsim = I − D−1/2AD−1/2
Laplaciano normalizado probabilistico Lrw = I − D−1ARelacion entre los dos Laplacianos
Propiedades de W = D−1A
Resumen del metodo de la potencia
El metodo de la potencia aplicado a W = D−1A
Analisis de la convergenciaCriterio de paro
Ejemplos de agrupamiento
Extensiones
Humberto Madrid (UAdeC) 2 / 50

Agrupamiento espectral
Agrupamiento espectral
Humberto Madrid (UAdeC) 3 / 50

Agrupamiento espectral
Humberto Madrid (UAdeC) 4 / 50
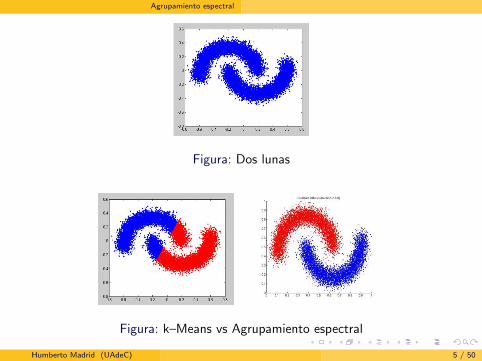
Agrupamiento espectral
Figura: Dos lunas
Figura: k–Means vs Agrupamiento espectral
Humberto Madrid (UAdeC) 5 / 50

Agrupamiento de datos
Agrupamiento de datos
Reorganiza los datos para encontrar grupos que tengan algunapropiedad en comun.
Bases de datos −→ matriz
Variedad de bases de datos, variedad de matrices de datos, variedadde metodos de agrupamiento.
Humberto Madrid (UAdeC) 6 / 50
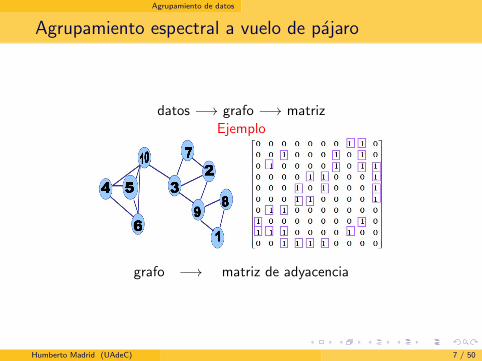
Agrupamiento de datos
Agrupamiento espectral a vuelo de pajaro
datos −→ grafo −→ matrizEjemplo
grafo −→ matriz de adyacencia
Humberto Madrid (UAdeC) 7 / 50

Agrupamiento de datos
L = D − A: Laplaciano,A: matriz de adyacenciaD: matriz diagonal, Dii = suma renglon i de A
Humberto Madrid (UAdeC) 8 / 50
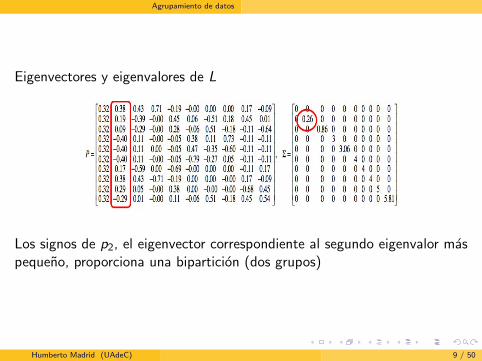
Agrupamiento de datos
Eigenvectores y eigenvalores de L
Los signos de p2, el eigenvector correspondiente al segundo eigenvalor maspequeno, proporciona una biparticion (dos grupos)
Humberto Madrid (UAdeC) 9 / 50

Agrupamiento de datos
Humberto Madrid (UAdeC) 10 / 50

Agrupamiento de datos
Humberto Madrid (UAdeC) 11 / 50
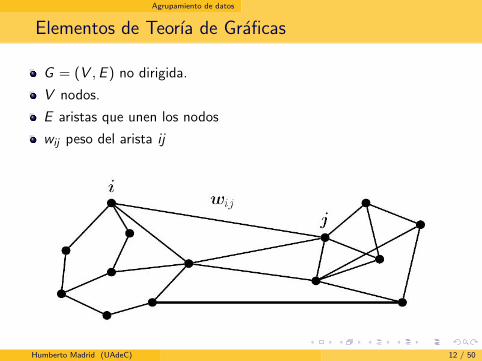
Agrupamiento de datos
Elementos de Teorıa de Graficas
G = (V ,E ) no dirigida.
V nodos.
E aristas que unen los nodos
wij peso del arista ij
Humberto Madrid (UAdeC) 12 / 50

Agrupamiento de datos
Particion de la grafica
A y B, A ∪ B = V y A ∩ B = φ. Una medida de la relacion entre A y Besta dada por
cut(A,B) =∑
i∈Aj∈Bwij
Un criterio de segmentacion: min cut(A.B) (No siempre es bueno)
Humberto Madrid (UAdeC) 13 / 50
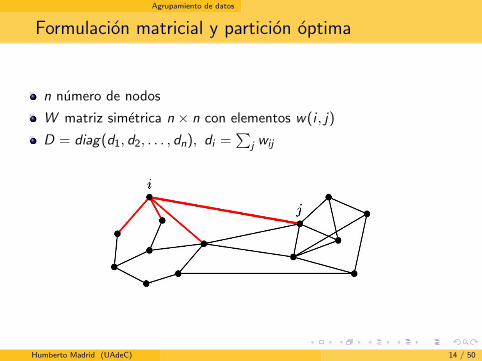
Agrupamiento de datos
Formulacion matricial y particion optima
n numero de nodos
W matriz simetrica n × n con elementos w(i , j)
D = diag(d1, d2, . . . , dn), di =∑
j wij
Humberto Madrid (UAdeC) 14 / 50

Agrupamiento de datos
Sea x el vector indicador: xi =
{1 si i ∈ A−1 si i ∈ B
4
nCut(A,B) =
xTLx
xT x
Donde L = D −W . Laplaciano
L1 = 0
mınx 6=0
Cut(A,B) =n
4mınx 6=0
xTLx
xT xx ⊥ 1
Humberto Madrid (UAdeC) 15 / 50

Agrupamiento de datos
Corte normalizado
J. Shi and J. Malik, Normalized cuts and image segmentation. 2000
Ncut(A,B) = cut(A,B)vol(A) + cut(A,B)
vol(B)
vol(A) =∑
u∈A,t∈Vw(u, t)
vol(B) =∑
v∈B,t∈Vw(v , t)
Humberto Madrid (UAdeC) 16 / 50

Agrupamiento de datos
qi =
√
v2v1
si i ∈ V1
−√
v1v2
si i ∈ V2
donde v1 = vol(G1), v2 = vol(G2), entonces
Ncut(A,B) =qTLq
qTDq
con qTD1 = 0, donde 1 = [1, 1, 1, . . . , 1]T
Humberto Madrid (UAdeC) 17 / 50

Agrupamiento de datos
mınx
Ncut(x) = mınq
qTLq
qTDq
con la condicion qTD1 = 0
mınx
Ncut(x) = mıny
yT `y
yT y
donde ` = D−12LD−
12 . Laplaciano normalizado
Humberto Madrid (UAdeC) 18 / 50

Agrupamiento de datos
λ2 = mıny
yT `y
yT y; yTD
12 1 = 0
` es semi positiva y λ1 = 0 es el valor propio mas pequeno
λ2 segundo valor propio mas pequeno de ` = D−12 (D −W )D−
12 .
y2 vector propio correspondiente nos da la solucion, (vector de Fiedler)
Los signos de los elementos de y2 indican cuales nodos pertenecen aun subconjunto u otro.
Humberto Madrid (UAdeC) 19 / 50

Agrupamiento de datos
Ejemplos de W
Wij = 1/d(xi , xj)
Wij = e−d(xi ,xj )2
σ2
Humberto Madrid (UAdeC) 20 / 50
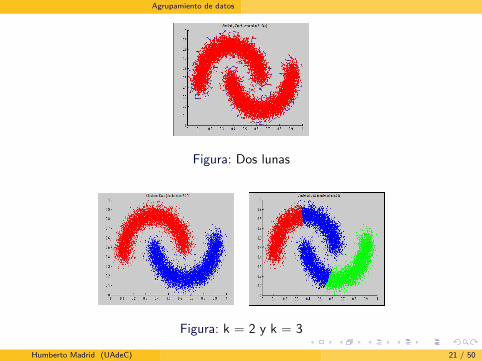
Agrupamiento de datos
Figura: Dos lunas
Figura: k = 2 y k = 3
Humberto Madrid (UAdeC) 21 / 50
Agrupamiento de datos
Humberto Madrid (UAdeC) 22 / 50
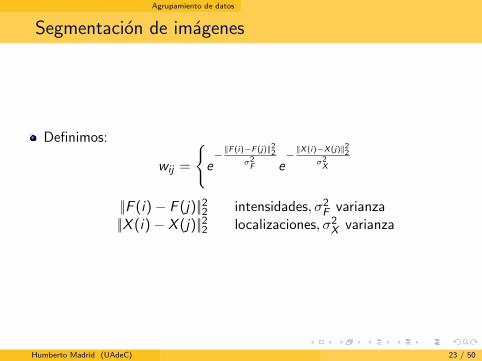
Agrupamiento de datos
Segmentacion de imagenes
Definimos:
wij =
{e− ||F (i)−F (j)||22
σ2F e
− ||X (i)−X (j)||22σ2X
||F (i)− F (j)||22 intensidades, σ2F varianza
||X (i)− X (j)||22 localizaciones, σ2X varianza
Humberto Madrid (UAdeC) 23 / 50

Agrupamiento de datos
0 60 150 250 (1, 1) (1, 2) (1, 3) (1, 4)60 180 90 150 (2, 1) (2, 2) (2, 3) (2, 4)
150 90 180 60 (3, 1) (3, 2) (3, 3) (3, 4)250 150 60 0 (4, 1) (4, 2) (4, 3) (4, 4)
Intensidades Localizaciones
Grafica asociada de 16 nodos, W , D y Laplaciano normalizado (16× 16)
Humberto Madrid (UAdeC) 24 / 50

Agrupamiento de datos
F =
060
150250
60180
90150150
90180
60250150
600
,X =
(1, 1)(1, 2)(1, 3)(1, 4)(2, 1)(2, 2)(2, 3)(2, 4)(3, 1)(3, 2)(3, 3)(3, 4)(4, 1)(4, 2)(4, 4)(4, 4)
Humberto Madrid (UAdeC) 25 / 50
Agrupamiento de datos
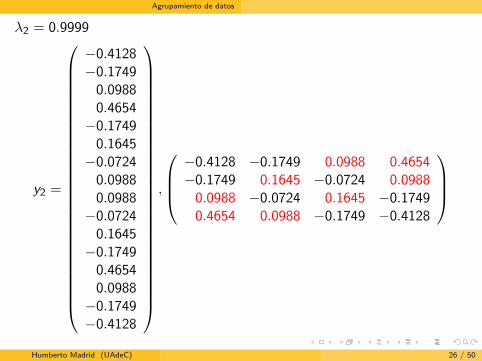
λ2 = 0.9999
y2 =
−0.4128−0.1749
0.09880.4654−0.1749
0.1645−0.0724
0.09880.0988−0.0724
0.1645−0.1749
0.46540.0988−0.1749−0.4128
,
−0.4128 −0.1749 0.0988 0.4654−0.1749 0.1645 −0.0724 0.0988
0.0988 −0.0724 0.1645 −0.17490.4654 0.0988 −0.1749 −0.4128
Humberto Madrid (UAdeC) 26 / 50

Agrupamiento de datos
A = (1, 1), (1, 2), (2, 1), (2, 3), (3, 2), (3, 4), (4, 3), (4, 4)B = (1, 3), (1, 4), (2, 2), (2, 4), (3, 1), (3, 3), (4, 1), (4, 2)
imagen segmentada imagen original
Humberto Madrid (UAdeC) 27 / 50

Agrupamiento de datos
Grafica de y2
y2 ordenado es mas o menos constante por tramos
Humberto Madrid (UAdeC) 28 / 50
Agrupamiento de datos
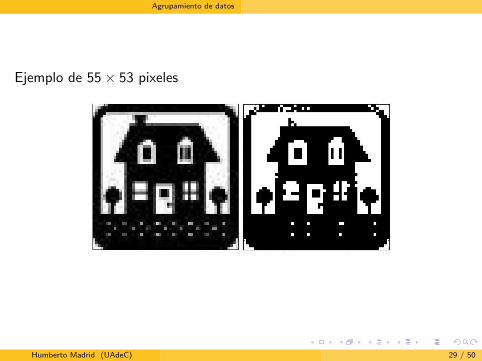
Ejemplo de 55× 53 pixeles
Humberto Madrid (UAdeC) 29 / 50

Agrupamiento de datos
Problema numerico
Imagen n × n W n2 × n2
10× 10 100× 100100× 100 10, 000× 10, 000103 × 103 106 × 106
¡Matrices enormes!
Humberto Madrid (UAdeC) 30 / 50

Agrupamiento de datos
Observaciones
El resultado es una biparticion
Para encontrar mas grupos se puede repetir el proceso en los gruposresultantes
Si para cada nodo se considera solamente la relacion con sus vecinoscercanos, la matriz Laplaciana es de banda
El problema de calcular el vector propio desead escomputacionalmente caro
Humberto Madrid (UAdeC) 31 / 50

Agrupamiento de datos
Observaciones
El resultado es una biparticion
Para encontrar mas grupos se puede repetir el proceso en los gruposresultantes
Si para cada nodo se considera solamente la relacion con sus vecinoscercanos, la matriz Laplaciana es de banda
El problema de calcular el vector propio desead escomputacionalmente caro
Humberto Madrid (UAdeC) 31 / 50

Agrupamiento de datos
Observaciones
El resultado es una biparticion
Para encontrar mas grupos se puede repetir el proceso en los gruposresultantes
Si para cada nodo se considera solamente la relacion con sus vecinoscercanos, la matriz Laplaciana es de banda
El problema de calcular el vector propio desead escomputacionalmente caro
Humberto Madrid (UAdeC) 31 / 50

Agrupamiento de datos
Observaciones
El resultado es una biparticion
Para encontrar mas grupos se puede repetir el proceso en los gruposresultantes
Si para cada nodo se considera solamente la relacion con sus vecinoscercanos, la matriz Laplaciana es de banda
El problema de calcular el vector propio desead escomputacionalmente caro
Humberto Madrid (UAdeC) 31 / 50

Agrupamiento de datos
Modificacion
Ng, Jordan, Weiss. On spectral clustering: Analysis and an algorithm. 2002
Datos: x1, x2, . . ., xn, k: numero de clusters
1 Formar la matriz de afinidad A y la matriz diagonal D
2 Contruir el Laplaciano L = I − D−1/2AD−1/2
3 Calcular los primeros k vectores propios de L, u1, u2, . . ., uk4 Sea U la matriz cuyas columnas son u1, u2, . . ., uk5 Normalizar los renglones de U
6 Aplicar k-means a los renglones de la matriz resultante para formar kclusters
7 En base a los ındices de los renglones en cada cluster, agrupar losdatos x1, x2, . . ., xn, en k clusters
Humberto Madrid (UAdeC) 32 / 50

Agrupamiento de datos
Laplacianos
Cambio de notacionA = W , matriz de afinidad = matriz de adyacenciaLsim = `
Laplaciano L = D − A
Laplaciano normalizado simetrico Lsim = I − D−1/2AD−1/2
Laplaciano normalizado probabilistico Lrw = I − D−1A
Humberto Madrid (UAdeC) 33 / 50

Agrupamiento de datos
Lsimx = λx
(I − D−1/2AD−1/2)x = λx
D−1/2(D − A)D−1/2x = λx
D−1/2LD−1/2x = λx
LD−1/2x = λD1/2x = λD(D−1/2x)
Ly = λDy
donde y = D−1/2x , entonces x = D1/2y
x y y tienen los mismos signos ası que basta con resolver Lx = λDx
Humberto Madrid (UAdeC) 34 / 50

Agrupamiento de datos
Lrwx = λx
(I − D−1A)x = λx
D−1(D − A)x = λx
(D − A)x = λDx
Lx = λDx
Los valores y vectores propios de Lsimx = λx son los mismos que los deLx = λDx
Humberto Madrid (UAdeC) 35 / 50

Propiedades de W = D−1A
Sea W = D−1A
Lrwx = λx
(I − D−1A)x = λx
(I −W )x = λx
x −Wx = λx
Wx = (1− λ)x
Los vectores propios de W y Lrw son los mismos.
Si λ es un valor propio de Lrw , (1− λ) es un valor propio de W .
Los valores propios mas pequenos de Lrw son los valores propios masgrandes de W .
El valor propio mas grande de W es 1.
Humberto Madrid (UAdeC) 36 / 50

Propiedades de W = D−1A
Recordemos que D = diag(d11, d22, . . . , dnn)
dii =∑
jAij
A1 =
d11
d22...
dnn
Ası que
W1 = D−1A1 = 1
λ1 = 1 es el mayor valor propio de W y 1 es un vector propio asociado.
Humberto Madrid (UAdeC) 37 / 50

Propiedades de W = D−1A
Meila and Shi, A random walks view of spectral segmentation. 2001
Los vectores propios del 2 al k son aproximadamente constantes portramos con respecto a los clusters subyacentes, cada uno separando uncluster del resto de los datos
¡La combinacion lineal de vectores constantes por tramos, tambien esconstante por tramos!
W = D−1A tiene n vectores propios linealmente independientes
Humberto Madrid (UAdeC) 38 / 50

El Metodo de la Potencia
El Metodo de la Potencia
Humberto Madrid (UAdeC) 39 / 50

El Metodo de la Potencia
A matriz n × n
Idea basica: v0 6= 0, formar
v1 = Av0
v2 = Av1 = A2v0
vj = Avj−1 = Ajv0
Conviene normalizar
v0 6= 0 arbitraria
v1 = Av0/ ‖v0‖v2 = Av1/ ‖v1‖vj = Avj−1/ ‖vj−1‖
Bajo ciertas condiciones esta sucesion converge al mayor valor propio envalor absoluto.
Por ejemplo si la matriz A tiene n vectores propios linealmenteindependientes
Humberto Madrid (UAdeC) 40 / 50

El Metodo de la Potencia
A matriz n × n
Idea basica: v0 6= 0, formar
v1 = Av0
v2 = Av1 = A2v0
vj = Avj−1 = Ajv0
Conviene normalizar
v0 6= 0 arbitraria
v1 = Av0/ ‖v0‖v2 = Av1/ ‖v1‖vj = Avj−1/ ‖vj−1‖
Bajo ciertas condiciones esta sucesion converge al mayor valor propio envalor absoluto.
Por ejemplo si la matriz A tiene n vectores propios linealmenteindependientes
Humberto Madrid (UAdeC) 40 / 50

El Metodo de la Potencia
A matriz n × n
Idea basica: v0 6= 0, formar
v1 = Av0
v2 = Av1 = A2v0
vj = Avj−1 = Ajv0
Conviene normalizar
v0 6= 0 arbitraria
v1 = Av0/ ‖v0‖
v2 = Av1/ ‖v1‖vj = Avj−1/ ‖vj−1‖
Bajo ciertas condiciones esta sucesion converge al mayor valor propio envalor absoluto.
Por ejemplo si la matriz A tiene n vectores propios linealmenteindependientes
Humberto Madrid (UAdeC) 40 / 50

El Metodo de la Potencia
A matriz n × n
Idea basica: v0 6= 0, formar
v1 = Av0
v2 = Av1 = A2v0
vj = Avj−1 = Ajv0
Conviene normalizar
v0 6= 0 arbitraria
v1 = Av0/ ‖v0‖v2 = Av1/ ‖v1‖
vj = Avj−1/ ‖vj−1‖
Bajo ciertas condiciones esta sucesion converge al mayor valor propio envalor absoluto.
Por ejemplo si la matriz A tiene n vectores propios linealmenteindependientes
Humberto Madrid (UAdeC) 40 / 50

El Metodo de la Potencia
A matriz n × n
Idea basica: v0 6= 0, formar
v1 = Av0
v2 = Av1 = A2v0
vj = Avj−1 = Ajv0
Conviene normalizar
v0 6= 0 arbitraria
v1 = Av0/ ‖v0‖v2 = Av1/ ‖v1‖vj = Avj−1/ ‖vj−1‖
Bajo ciertas condiciones esta sucesion converge al mayor valor propio envalor absoluto.
Por ejemplo si la matriz A tiene n vectores propios linealmenteindependientes
Humberto Madrid (UAdeC) 40 / 50

El Metodo de la Potencia
A matriz n × n
Idea basica: v0 6= 0, formar
v1 = Av0
v2 = Av1 = A2v0
vj = Avj−1 = Ajv0
Conviene normalizar
v0 6= 0 arbitraria
v1 = Av0/ ‖v0‖v2 = Av1/ ‖v1‖vj = Avj−1/ ‖vj−1‖
Bajo ciertas condiciones esta sucesion converge al mayor valor propio envalor absoluto.
Por ejemplo si la matriz A tiene n vectores propios linealmenteindependientes
Humberto Madrid (UAdeC) 40 / 50

El Metodo de la Potencia
A matriz n × n
Idea basica: v0 6= 0, formar
v1 = Av0
v2 = Av1 = A2v0
vj = Avj−1 = Ajv0
Conviene normalizar
v0 6= 0 arbitraria
v1 = Av0/ ‖v0‖v2 = Av1/ ‖v1‖vj = Avj−1/ ‖vj−1‖
Bajo ciertas condiciones esta sucesion converge al mayor valor propio envalor absoluto.
Por ejemplo si la matriz A tiene n vectores propios linealmenteindependientes
Humberto Madrid (UAdeC) 40 / 50

El Metodo de la Potencia
A matriz n × n
Idea basica: v0 6= 0, formar
v1 = Av0
v2 = Av1 = A2v0
vj = Avj−1 = Ajv0
Conviene normalizar
v0 6= 0 arbitraria
v1 = Av0/ ‖v0‖v2 = Av1/ ‖v1‖vj = Avj−1/ ‖vj−1‖
Bajo ciertas condiciones esta sucesion converge al mayor valor propio envalor absoluto.
Por ejemplo si la matriz A tiene n vectores propios linealmenteindependientes
Humberto Madrid (UAdeC) 40 / 50

Power Iteration Clustering
Power Iteration Clustering
Humberto Madrid (UAdeC) 41 / 50

Power Iteration Clustering
F. Lin, W. Cohen. Power Iteration Clustering. 2010
Datos
X = {x1, x2,. . . , xn}
Medida de similitud
s(xi , sj) =
exp
(−‖xi−xj‖
2
σ2
), i 6= j
0 si i = j
s(xi , xj) = s(xj , xi )
Humberto Madrid (UAdeC) 42 / 50

Power Iteration Clustering
F. Lin, W. Cohen. Power Iteration Clustering. 2010
Datos
X = {x1, x2,. . . , xn}
Medida de similitud
s(xi , sj) =
exp
(−‖xi−xj‖
2
σ2
), i 6= j
0 si i = j
s(xi , xj) = s(xj , xi )
Humberto Madrid (UAdeC) 42 / 50

Power Iteration Clustering
Matriz de afinidad A
Aij = s(xi , sj)
Matriz diagonal D
dii =∑
jAij
dii grado del nodo i
Matriz de afinidad normalizada
W = D−1A
Humberto Madrid (UAdeC) 43 / 50

Power Iteration Clustering
Dado que el maximo valor propio de W es 1 y 1 es un vector propio, elmetodo de la potencia converge a un vector constante.
Aparentemente no tiene sentido aplicar el metodo de la potencia.
Lo interesante es como converge la sucesion
Humberto Madrid (UAdeC) 44 / 50

Power Iteration Clustering
Dado que el maximo valor propio de W es 1 y 1 es un vector propio, elmetodo de la potencia converge a un vector constante.
Aparentemente no tiene sentido aplicar el metodo de la potencia.
Lo interesante es como converge la sucesion
Humberto Madrid (UAdeC) 44 / 50

Power Iteration Clustering
Dado que el maximo valor propio de W es 1 y 1 es un vector propio, elmetodo de la potencia converge a un vector constante.
Aparentemente no tiene sentido aplicar el metodo de la potencia.
Lo interesante es como converge la sucesion
Humberto Madrid (UAdeC) 44 / 50

Power Iteration Clustering
Humberto Madrid (UAdeC) 45 / 50
Power Iteration Clustering
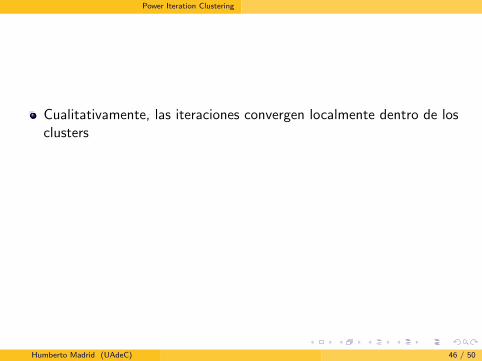
Cualitativamente, las iteraciones convergen localmente dentro de losclusters
Cuando j = 400 los puntos dentro de cada cluster tienenaproximadamente el mismo valor
Despues de la convergencia global los segmentos de recta se vanacercando entre sı mas lentamente
Humberto Madrid (UAdeC) 46 / 50

Power Iteration Clustering
Cualitativamente, las iteraciones convergen localmente dentro de losclusters
Cuando j = 400 los puntos dentro de cada cluster tienenaproximadamente el mismo valor
Despues de la convergencia global los segmentos de recta se vanacercando entre sı mas lentamente
Humberto Madrid (UAdeC) 46 / 50

Power Iteration Clustering
Cualitativamente, las iteraciones convergen localmente dentro de losclusters
Cuando j = 400 los puntos dentro de cada cluster tienenaproximadamente el mismo valor
Despues de la convergencia global los segmentos de recta se vanacercando entre sı mas lentamente
Humberto Madrid (UAdeC) 46 / 50

Power Iteration Clustering
u1, u2, . . ., un, base de vectores propios de W
Si Wu = λu, entonces W 2u = λ2u, . . ., W ju = λju
λn < λn−1 < . . . < λ2 < λ1
Seav0 = c1u1 + c2u2 + · · ·+ cnun
Entonces
vj = W jv0
= c1Wju1 + c2W
ju2 + · · ·+ cnWjun
= c1λj1u1 + c2λ
j2u2 + · · ·+ cnλ
jnun
Humberto Madrid (UAdeC) 47 / 50

Power Iteration Clustering
vj
c1λj1
= u1 +c2
c1
(λ2
λ1
)j
u2 + · · ·+ ckc1
(λkλ1
)j
uk +ck+1
c1
(λk+1
λ1
)j
uk+1 + · · ·
Los ultimos sumandos convergen mas rapido a cero
Para j suficientemente grande
vj ≈ c1λj1u1 + c2λ
j2u2 + · · ·+ ckλ
jkuk
vj contiene la informacion necesaria para efectuar el agrupamiento en kgrupos.Es llamado un seudo vector propio
Humberto Madrid (UAdeC) 48 / 50

Power Iteration Clustering
vj
c1λj1
= u1 +c2
c1
(λ2
λ1
)j
u2 + · · ·+ ckc1
(λkλ1
)j
uk +ck+1
c1
(λk+1
λ1
)j
uk+1 + · · ·
Los ultimos sumandos convergen mas rapido a cero
Para j suficientemente grande
vj ≈ c1λj1u1 + c2λ
j2u2 + · · ·+ ckλ
jkuk
vj contiene la informacion necesaria para efectuar el agrupamiento en kgrupos.Es llamado un seudo vector propio
Humberto Madrid (UAdeC) 48 / 50

Power Iteration Clustering
Criterio de convergencia
Velocidad en el paso j : δj = vj − vj−1
Aceleracion en el paso j : εj = δj − δj−1
Se para cuando ‖εj‖∞ < ε0
Humberto Madrid (UAdeC) 49 / 50

Power Iteration Clustering
Criterio de convergencia
Velocidad en el paso j : δj = vj − vj−1
Aceleracion en el paso j : εj = δj − δj−1
Se para cuando ‖εj‖∞ < ε0
Humberto Madrid (UAdeC) 49 / 50

Power Iteration Clustering
Criterio de convergencia
Velocidad en el paso j : δj = vj − vj−1
Aceleracion en el paso j : εj = δj − δj−1
Se para cuando ‖εj‖∞ < ε0
Humberto Madrid (UAdeC) 49 / 50

Power Iteration Clustering
Criterio de convergencia
Velocidad en el paso j : δj = vj − vj−1
Aceleracion en el paso j : εj = δj − δj−1
Se para cuando ‖εj‖∞ < ε0
Humberto Madrid (UAdeC) 49 / 50

Power Iteration Clustering
Algorithm. The PIC algorithm
Input: A row-normalized afinity matrix W and the number of clusters kPick an initial vector v0
repeat
Set vj+1 ←Wvj
‖Wvj‖ and δj ← |vj − vj−1|Increment juntil |δj − δj−1| ≈ 0Use k-means to cluster points on vjOutput: Clusters C1, C2,. . ., C1
Boutsidis, Gittens, Kambadur.Spectral Clustering via the Power Method - Provably. 2017?
Humberto Madrid (UAdeC) 50 / 50

Power Iteration Clustering
Algorithm. The PIC algorithm
Input: A row-normalized afinity matrix W and the number of clusters kPick an initial vector v0
repeat
Set vj+1 ←Wvj
‖Wvj‖ and δj ← |vj − vj−1|Increment juntil |δj − δj−1| ≈ 0Use k-means to cluster points on vjOutput: Clusters C1, C2,. . ., C1
Boutsidis, Gittens, Kambadur.Spectral Clustering via the Power Method - Provably. 2017?
Humberto Madrid (UAdeC) 50 / 50