
REPUBLICA BOLIVARIANA DE VENEZUELA
UNIVERSIDAD DEL ZULIA
FACULTAD DE INGENIERÍA
DIVISIÓN DE POSTGRADO
PROGRAMA DE POSTGRADO EN INGENIERÍA AMBIENTAL
INDICE DE VEGETACIÓN NORMALIZADO COMO HERRAMIENTA PARA
LA ESTIMACIÓN DE DISPONIBILIDAD DE AGUA SUPERFICIAL EN
CUENCAS HIDROGRÁFICAS
Trabajo de Grado presentado como requisito para optar al Grado académico de
MAGÍSTER SCIENTIARUM EN INGENIERÍA AMBIENTAL
Autor: Ing. Víctor Hugo, Malavé Girón.
Tutor: MSc. Giovanni A., Royero O.
Maracaibo, enero de 2009

58
Malavé Girón, Víctor Hugo. Índice de vegetación normalizado como herramienta para la
estimación de disponibilidad de agua superficial en cuencas hidrográficas. (2009). Trabajo de
Grado. Universidad del Zulia. Facultad de Ingeniería. División de Postgrado. Maracaibo,
Venezuela. 283p. Tutor: Prof. Giovanni Royero.
RESUMEN
Los elementos que reportan las imágenes capturadas por sensores remotos a través de técnicas de
Teledetección permiten establecer modelos del comportamiento de una cantidad importante de
variables naturales, entre ellas, la vegetación. En esta investigación se usaron cinco imágenes
multiespectrales Landsat de la región nororiental de Venezuela. Utilizando técnicas de
procesamiento digital de imágenes fueron calculados cuatro Índices de Vegetación, sobre la
Cuenca del Río Areo, ubicada en esa región del país, para caracterizar el comportamiento de la
masa vegetal y usar esta información, conjuntamente con registros de precipitación pluvial
obtenidos de ocho Estaciones Climatológicas ubicada en las cercanías de la cuenca, con el objeto
de generar un modelo matemático que describa el comportamiento de los caudales de escorrentía
superficial, a partir del conocimiento de los valores de Índices de Vegetación. El cálculo de la
Precipitación efectiva se hizo por el método del Servicio de Conservación de Suelo de los
Estados Unidos, a partir del número de curva estimado para la zona. Los caudales se simularon
con Hidrograma Unitario construido por el método Clark (1943). Las imágenes espectrales
fueron procesadas a través del programa ENVI en combinación con el Módulo AtmosC de Idrisi
Andes para la corrección atmosférica y el cálculo de reflectividades. De los tres métodos
ejecutados para la corrección de Bandas espectrales todos resultaron con valores que no muestran
diferencias significativas. La evaluación de cuatro Índices de Vegetación arrojó resultados no
significativos en la diferencia de sus medias, por lo que, basándose en el comportamiento
mostrado por los Índices evaluados en una Matriz de gráficos de dispersión y comparación de
medias, el NDVI fue seleccionado como más representativo del universo de datos disponibles. Se
obtuvo un caudal promedio mensual de escorrentía superficial cercano a los 400 l/s, el cual puede
ser simulado usando el modelo matemático de grado tres elaborado mediante análisis de
regresión estructurado de la forma y = 4824.9x3 - 1457.4x
2 + 861.21x - 98.9.
Palabras Clave: Teledetección, Hidrología, NDVI, Caudales, Cuencas hidrográficas.
E-mail del autor: [email protected]

59
Malavé Girón, Víctor Hugo. Index of vegetation normalized as tool for the estimation of
availability of superficial water in hydrographic basins. (2008). Work of degree. Universidad del
Zulia. Facultad de Ingeniería. División de Postgrado. Maracaibo, Venezuela. 283p. Tutor: Prof.
Giovanny Royero.
ABSTRACT
Remote sensing is a discipline that allows to obtain information of elements that operate on the
terrestrial surface without having physical contact with them, through the capacities that show the
sensors of radiant energy for capturing this energy, to discriminate against it for wave longitude,
to compress it, to store it and to send it to stations in Earth for its prosecution, distribution and
analysis. The elements that report the ghastly images allow establishing models of the behavior of
an important quantity of natural variables, among them, the vegetation. In these investigation five
images Landsat of the region oriental of Venezuela was used. Using technical of digital
prosecution of images four Indexes of Vegetation were calculated, on Basin of the River Areo,
located in that region of the country, to characterize the behavior of the vegetable mass and to use
this information, jointly with obtained registrations of pluvial precipitation of eight
Climatologically Stations located in the proximities of the basin, in order to generating a
mathematical model that describes the behavior of the flows of superficial drainage, starting from
the knowledge of the values of Indexes of Vegetation. The calculation of the effective
Precipitation was made by the method of the Service of Conservation of Soil of the United States,
starting from the curve number estimated for the area. The flows were simulated with Unitary
Hidrograma built by the method Clark (1943). The images were processed through the program
ENVI in combination with the Module AtmosC of Idrisi Andes for the atmospheric correction
and the calculation of reflectivity. Of the three methods executed for the correction of Bands all
result with values that don't show significant differences. The evaluation of four Indexes of
Vegetation hurtled been not significant in the difference of its means, for that that, being based on
the behavior shown by the Indexes evaluated in a Matrix of dispersion graphics and comparison
of means, NDVI was selected as more representative of the universe of available data. A flow
monthly average of superficial drainage was obtained to the 400 l/s, which can be simulated
using the mathematical pattern of grade three elaborated by way of regression analysis of type
y = 4824.9x3 - 1457.4x
2 + 861.21x - 98.9.
Key Words: Remote sensing, Hydrology, NDVI, Flows, Hydrographic Basins.
Author e-mail [email protected]

60
para Nelly, Martín y Moisés

61
AGRADECIMIENTO
A la Ilustre Universidad del Zulia.
Al Profesor Giovanni Royero, por su desinteresado apoyo, constancia, paciencia y camaradería.
A la Profesora Altamira Díaz, siempre atenta y colaboradora.
A mi esposa, Nelly. Sin su apoyo esta etapa no hubiera sido posible.

62
TABLA DE CONTENIDO
Página
RESUMEN……………………………………………………………………………... 3
ABSTRACT……………………………………………………………………………. 4
DEDICATORIA………………………………………………………………………... 5
AGRADECIMIENTO………………………………………………………………….. 6
TABLA DE CONTENIDO…………………………………………………………….. 7
LISTA DE TABLAS…………………………………………………………………… 10
LISTA DE FIGURAS…………………………………………………………………... 11
INTRODUCCIÓN…………………………………………………………… 14
Capítulo
I REVISION DE LITERATURA……………………………………………….
16
Capítulo
II DESCRIPCIÓN DEL ÁREA DE ESTUDIO…………………………………
57
Capítulo
III MATERIALES Y MÉTODOS………………………………………………
63
4.1. Materiales…………………………………………………………… 63
4.2. Equipos y Software…………………………………………………. 64
4.3. Metodología………………………………………………………… 65
4.3.1. Fase de Evaluación Hidrológica………………………………… 65
1. Vectorización digital de la cuenca……………………………….. 65
2. Construcción del Hidrograma Unitario para la Cuenca…………… 66
2.1. Cálculo Tiempo de Concentración…………………………….. 72
2.2.Dibujo de Líneas Isocronas…………………………………….. 75
2.3.Cálculo Hidrograma Unitario Instantáneo……………………… 76
2.4. Cálculo Caudal de escorrentía superficial……………………... 79
4.3.2. Fase de Teledetección…………………………………………… 82
1. Ubicación del área de estudio……………………………………... 83
2. Ubicación y obtención de imágenes satelitales del área de interés.. 83
3. Pre-procesamiento del material espectral disponible……………... 87

63
3.1. Organización del material de trabajo……………………………. 88
3.2. Configuración del Polígono de la Cuenca………………………. 88
3.3. Elaboración de composición de imágenes………………………. 89
3.4. Georreferenciación de Bandas…………………………………... 95
3.4.1. Metodología en ENVI para Georreferenciar imágenes de
satélite usando “Puntos de Control” de imagen a imagen…...
96
3.5. Corrección atmosférica………………………………………….. 98
3.6. Cálculo de Índices de Vegetación……………………………….. 107
3.6.1. Visualización de valores de Índices de Vegetación en ENVI. 110
3.7. Cálculo de NDVI y otros Índices usando Idrisi Andes…………. 110
3.7.1 Visualización de Índices de Vegetación usando Idrisi Andes.. 112
4.3.3. Fase de Análisis Estadístico……………………………………… 112
1. Estadística descriptiva…………………………………………….. 113
2. Análisis de Varianza………………………………………………. 118
3. Construcción de Modelo matemático……………………………... 120
Capítulo
IV RESULTADOS Y DISCUSIÓN…………………………………………..
122
5.1. Fase de Evaluación Hidrológica…………………………………... 122
5.1.1. Parámetros morfométricos………………………………………. 125
5.1.2. Cálculo y dibujo de Líneas Isocronas…………………………… 129
5.1.3. Polígonos de Thiessen…………………………………………... 132
5.1.4. Hidrograma Unitario Instantáneo……………………………….. 133
5.2. Fase de Teledetección……………………………………………….. 136
5.2.1. Ubicación y obtención de imágenes de satélite………………… 136
5.2.2.Corrección geométrica…………………………………………... 138
5.2.3. Corrección atmosférica…………………………………………. 139
5.2.3.1. Resultados de la corrección atmosférica por Método de
Corrección por el Mínimo Valor del Histograma (MVH)…..
140
5.2.3.2. Resultados de la corrección atmosférica por el Cálculo de
reflectividad ………………………………………………...
141
5.2.3.3. Resultados de la corrección atmosférica y cálculo de
reflectividad, por la aplicación de Modelo Cos(t) del
Módulo AtmosC de Idrisi Andes……………………………
145
5.2.4. Índices de Vegetación………………………………………….. 145
5.2.4.1. Índices de Vegetación calculados sobre Bandas derivadas
de Corrección por el Método del Valor Mínimo del

64
Histograma (HMM)………………………………………… 147
5.2.4.2. Índices de Vegetación calculados sobre Bandas con ND
transformados a Reflectividad aparente……………………..
153
5.2.4.3. Índices de Vegetación calculados sobre Bandas procesadas
con el Módulo AtmosC de Idrisi Andes…………………….
159
5.2.4.4.- Selección del método de corrección de Bandas espectrales.. 166
5.2.4.5.- Selección de Índices de Vegetación……………………….. 168
5.3. Construcción del modelo matemático………………………………. 170
Capítulo
V CONCLUSIONES……………………………………………………………...
176
REFERENCIAS BIBLIOGRÁFICAS…………………………………………………. 177
ANEXOS……………………………………………………………………………….. 180
1. Datos de Precipitación…………………………………………………………… 181
2. Hojas Cartográficas……………………………………………………………… 188
3. Curva relación TL vs TC………………………………………………………… 192
APÉNDICES.................................................................................................................... 193
1. Código en lenguaje “R” para cálculo de Hidrograma Unitario…………………. 194
2. Resultado Cálculo de Precipitación Efectiva…………………………………….. 197
3. Resultado Corrección de Bandas espectrales a través del Mínimo Valor
del Histograma……………………………………………………………………
218
4. Resultado Corrección de Bandas espectrales. Modelo AtmosC de Idrisi……….. 234
5. Resultado Transformación de ND de Bandas a reflectividad…………………… 243
6. Índice de Vegetación de Bandas corregidas Mínimo Valor del Histograma……. 252
7. Índice de Vegetación de Bandas con reflectividades calculadas………………… 265
8. Índice de Vegetación de Bandas con corrección atmosférica y cálculo
de reflectividades…………………………………………………………..
276

65
LISTA DE TABLAS
Tabla Página
1 Número de curva de escorrentía para uso selector de tierras agrícolas,
sub urbanas y urbanas………………………………………………………..
28
2 Resolución espectral de los sensores TM y ETM+…………………………. 38
3 Coeficientes de calibración de Bandas TM y valor de Irradiancia para cada
intervalo de longitud de onda..........................................................................
46
4 Clasificación de suelos del Municipio Cedeño, Estado Monagas………….. 58
5 Clasificación de suelos. Unidades cartográficas. Capacidad de uso del
Municipio Cedeño, Estado Monagas………………………………………...
60
6 Características físicas Unidades que conforman la Cuenca del Río Areo….. 61
7 Características químicas Unidades que conforman la Cuenca del Río Areo.. 62
8 Estaciones climatológicas consideradas para el cálculo de Precipitación
Media de la Cuenca del Río Areo……………………………………………
64
9 Valores de E0,k tomados del Science Data Users Handbook del programa Landsat.. 103
10 Valores de K reportados en el Sciencie Data Users Handbook del programa
Landsat……………………………………………………………………….
104
11 Fórmulas utilizadas en cada Banda espectral, según la escena, para el
cálculo de reflectividades……………………………………………………
104
12 Expresiones resumidas para el cálculo de reflectividades en las Bandas 1, 3
y 4 del material evaluado…………………………………………………….
105
13 Fórmulas para cálculo de Índices de Vegetación en ENVI…………………. 109
14 Coordenadas UTM del perímetro de la Cuenca del Río Areo………………. 123
15 Datos para cálculo de elevación media……………………………………… 125
16 Datos para cálculo de elevación mediana…………………………………… 126
17 Longitud total de curvas de nivel…………………………………………… 127
18 Áreas entre curvas Isocronas de la Cuenca del Río Areo…………………… 130
19 Fechas, sensores y atributos de las imágenes espectrales utilizadas………... 137
20 Valores del día juliano, k y ángulo cenital ………………………………... 141
21 Estadística de los valores de reflectividad para todas las Bandas del
material evaluado…………………………………………………………….
142
22 Índices de Vegetación calculados sobre Bandas corregidas por el
Valor Mínimo del Histograma.........................................................................
147
23 Índices de Vegetación calculados sobre Bandas corregidas por el cálculo
de reflectividad aparente……………………………………………………
154
24 Índices de Vegetación calculados sobre Bandas corregidas
atmosféricamente usando el Módulo AtmoC de Idrisi Andes……………
162

66
LISTA DE FIGURAS
Figura Página
1 Factor de forma.............................................................................................. 19
2 Esquema Del Tiempo de Concentración sobre una Cuenca Hidrográfica
y Perfil del Hidrograma Unitario…………………………………………..
24
3 Distribución de la lámina de agua precipitada en una Cuenca Hidrográfica. 31
4 Elementos que dan forma al proceso de Teledetección……………………. 32
5 Espectro electromagnético............................................................................. 36
6 Imagen NDVI de Venezuela para febrero 2004 elaborada a partir de datos
del Sensor AVHRR………………………………………………………….
48
7 Influencia de la lluvia en la vegetación…………………………………….. 50
8 Estado fisiológico de las plantas según el valor del NDVI………………… 50
9 Gráfico de dos modelos de tercer orden……………………………………. 56
10 Índice Cartográfico usado para la ubicación de Hojas Cartográficas de la
Cuenca del Río Areo………………………………………………………...
63
11 Organización de los datos en un archivo texto para cálculo de Tiempo
de Concentración……………………………………………………………
74
12 Ventana para cambio de directorio del área de trabajo del programa
estadístico “R”……………………………………………………………...
75
13 Metodología para evaluación de cambio en el vigor de la vegetación de un
área específica………………………………………………………………
82
14 Escenas de la familia de satélites Landsat que abarcan la geografía
Venezolana…………………………………………………………………..
84
15 Dirección 002/053 (Path-Row) de la escena Landsat correspondiente al
área de interés………………………………………………………………..
84
16 Ventana principal del portal Web de la GLCF mostrando zona de
Búsqueda…………………………………………………………………….
85
17 Ventana de selección de sensores ETM+, TM y de magnificación del
área de interés………………………………………………………………..
85
18 Ventana para selección definitiva de área de interés……………………….. 86
19 Ventana de identificación de cantidad de imágenes disponibles en la
Base de datos de la GLCF…………………………………………………….
86
20 Ventana de pre visualización de imágenes disponibles…………………... 87
21 Archivos que componen la escena ETM+ p002r053 de fecha 01/07/199… 89
22 Ventana de visualización de lista de bandas disponibles y configuración
de composición cartográfica………………………………………………….
91

67
23 Grupo de visualización de imágenes de ENVI, mostrando la ciudad de
Cumaná, Estado Sucre, en la ventana principal………………………………
92
24 Ventana para la búsqueda de región de interés tipo vector……………….. 92
25 Ventana Vector Parameter mostrando el archivo POLIGONO CUENCA
AREO.dxf……………………………………………………………………
93
26 Ventana para ajuste de parámetros a la imagen de salida………………… 94
27 Ventana para configuración de la región de sub conjunto en función de la
cual se almacena la imagen de salida……………………………………...
94
28 Ventana para la selección de región de interés…………………………… 95
29 Ventana para la selección de Banda de referencia y Banda a
georreferenciar…………………………………………………………….
97
30 Ventana Registration Parameter para configurar “Ajustte” sobre imagen
georreferenciada…………………………………………………………..
98
31 Procedimiento para almacenar Banda seleccionada………………………. 100
32 Procedimiento para inserción de vector de referencia sobre imagen a
almacenar…………………………………………………………………..
101
33 Recuperación de “estadístico” de píxel para una Banda desde la ventana
Abailable Band List……………………………………………………….
101
34 Extracto de una visualización típica de Histograma donde se observan
los valores mínimo, máximo, promedio y desviación estándar de ND por
Banda……………………………………………………………………….
102
35 Ventana donde se asigna las Bandas a una ecuación……………………... 102
36 Ventana para ajuste de parámetros del Módulo AtmosC de Idrisi Andes... 106
37 Ventana para la selección de Imagen sobre la que se calcula NDVI……... 108
38 Parámetros de configuración de imágenes para cálculo de NDVI………... 108
39 Módulo VEGEINDEX de Idrisi Andes…………………………………… 111
40 Ventana de la Función Imagen Calculator de Idrisi Andes………………. 111
41 Ventana para ejecución de Módulo Histo en Idrisi Andes………………... 112
42 Ubicación relativa de la Cuenca del Río Areo en el Estado Monagas y
parte del Estado Anzoátegui………………………………………………..
122
43 Perímetro Cuenca del Río Areo……………………………………………. 124
44 Elevación media……………………………………………………………. 126
45 Elevación modal……………………………………………………………. 127
46 Resultados del cálculo de Tiempo de Concentración………………………. 129
47 Líneas Isocronas sobre Cuenca del Río Areo………………………………. 131

68
48 Área de influencia de las Estaciones climatológicas sobre la Cuenca del
Río Areo……………………………………………………………………..
132
49 Resultado del cálculo del Hidrograma Unitario Instantáneo………………. 134
50 Caudal de escorrentía superficial para la Cuenca del Río Areo en el
periodo 1986-2005…………………………………………………………..
135
51 Resultado de la consulta de disponibilidad de imágenes para los sensores
TM y ETM+ en la base de datos de la GLCF………………………………..
137
52 Ventana para la selección de puntos de control…………………………... 138
52 Disposición de los puntos de control sobre la Banda 2 (015065) de fecha
28/02/2001…………………………………………………………………
139
54 Patrón de comportamiento espectral de las Bandas evaluadas…………… 143
55 Resumen de los seis estadísticos principales para el conjunto de datos de
reflectividades calculadas sobre cada Banda espectral…………………….
144
56 Resultados de corrección atmosférica y conversión a reflectividades
sobre Banda 1de la escena 28/12/1986……………………………………
145
57 Resumen numérico de los estadísticos principales del conjunto de
Índices, reportados por el summary en R…………………………………..
148
58 Comparación de Índices de Vegetación obtenidos de Bandas corregidas
por MVH…………………………………………………………………..
149
59 Evaluación de los rangos de existencia de los Índices de Vegetación
Calculados…………………………………………………………………
150
60 Matriz de gráficos de dispersión para los datos de Índices de Vegetación
derivados de Bandas espectrales con Histograma Corregidos…………….
152
61 Resumen estadístico de Índices de Vegetación calculados a partir de
Bandas con valores de reflectividad………………………………………
154
62 Comparación del promedio global de Índices de Vegetación calculados a
partir de Bandas espectrales con reflectividad aparente…………………..
155
63 Comportamiento global promedio de los Índices de Vegetación
calculados sobre Bandas espectrales con valores de reflectividad aparente.
156
64 Matriz de gráficos de dispersión para los datos de Índices de Vegetación
derivados de Bandas espectrales con reflectividad aparente calculada……
157
65 Resumen numérico de Índices de Vegetación calculados a partir de
Bandas corregidas atmosféricamente y con valores digitales expresados
como reflectividad…………………………………………………………
162
66 Comportamiento individual promedio de Índices calculados a partir de
Bandas corregidas con el Módulo AtmosC de Idrisi Andes………………
163
67 Comparación entre Índices de Vegetación obtenidos a partir de Bandas

69
espectrales corregidas con Módulo AtmosC de Idrisi Andes…………….. 164
68 Matriz de gráficos de dispersión para los datos de Índices de Vegetación
derivados de Bandas espectrales con corrección atmosférica usando el
Módulo AtmosC de Idrisi Andes………………………………………….
165
69 Resultados ANAVA para evaluar métodos de corrección de Bandas
espectrales…………………………………………………………………
167
70 Resultado análisis de varianza…………………………………………… 169
71 Promedios de Índices de Vegetación obtenidos desde Bandas espectrales
con corrección atmosférica hecha a través del Módulo AtmosC de Idrisi
Andes………………………………………………………………………
171
72 Comparación promedios de Índices de Vegetación a través de gráficos de
Caja………………………………………………………………………...
172
73 Comparación de Residuales para modelos evaluados…………………… 175

70
INTRODUCCIÓN
El diseño de obras hidráulicas, al igual que los programas de conservación de cuencas
hidrográficas requieren del conocimiento de una cantidad importante de variables ambientales,
entre las que destacan la precipitación, evaporación, temperatura, velocidad y dirección del
viento, humedad relativa, radiación solar, así como el caudal aforado de los cuerpos de agua
superficial de donde se derivará ésta para la obra o actividad que se proyecta. En Venezuela, el
Organismo encargado de recolectar dicha información es el actual Ministerio del Poder Popular
para el Ambiente, el cual tiene en funcionamiento, una importante red hidrometeorológica, con
la que se cuenta para la obtención de algo de la información requerida, pues es normal ubicar
una cantidad importante de datos que carecen de la calidad necesaria para el diseño de una obra
con la seguridad que esta requiere.
A los efectos de abordar esta problemática se abordó la presente investigación, para
establecer la relación matemática existente entre el vigor de la vegetación que se desarrolla en el
espacio geográfico delimitado por una Cuenca y los valores de caudal que por ella escurren. El
indicador del vigor de la vegetación es un índice que puede obtenerse a través del procesamiento
digital de imágenes de satélite: el Índice de Vegetación de Diferencia Normalizada (NDVI). Los
valores de caudales se obtienen usando modelos de simulación hidrológica diseñados para
procesar datos de precipitación y características de la Cuenca.
El área de estudio comprende una Cuenca hidrográfica del oriente de Venezuela, la
Cuenca del Río Areo ubicada en el Estado Monagas y con una pequeña porción en el Estado
Anzoátegui. De esta Cuenca se dispone de cierta información hidroclimática que la hace apta
para esta investigación. Con dicha información se ejecutan los cálculos de caudales a través del
Método de Clark, para con estos resultados establecer su correlación con los valores de NDVI
que se calculen de las imágenes de satélite disponibles empleando para ello programas de
Procesamiento Digital y armar el modelo matemático que simule el comportamiento de dichas
variables.

71
CAPÍTULO I
REVISIÓN DE LITERATURA
La Cuenca hidrográfica se define como una unidad territorial delimitada por las líneas
divisorias de aguas superficiales que convergen hacia un mismo cauce, y conforman espacios en
el cual se desarrollan complejas interacciones e interdependencias entre los componentes bióticos
y abióticos, sociales, económicos y culturales, a través de flujo de insumos información y
productos (Ley de Aguas, 2007).
El estudio de las cuencas hidrográficas parte del interés de comprender el comportamiento
de los terrenos drenados por un mismo sistema de cursos de agua, la manera cómo los ríos y las
quebradas discurren a través de la superficie terrestre hasta llegar a un cuerpo de agua principal,
ya sea lago, laguna, río o mar, y sus implicaciones para el entorno inmediato. Esta orientación se
evidencia en los conceptos empleados para describir esas unidades hidrológicas por diferentes
instituciones y autores, quienes coinciden en señalar que una cuenca hidrográfica es el área de la
superficie terrestre drenada por un único sistema fluvial, cuyos límites están formados por las
divisorias de aguas que la separan de zonas adyacentes pertenecientes a otras cuencas fluviales.
Esas concepciones utilizadas para definir las cuencas hidrográficas obedecen a que esos
espacios representan la unidad que fundamental y tradicionalmente ha sido empleada por los
estudiosos de la hidrología para comprender el comportamiento del agua en y sobre el medio
ambiente (Moreno, M. 2005:1).
De igual manera las cuencas hidrográficas pueden ser definidas señalando que
corresponde a unidades delimitadas topográficamente, que desaguan mediante un sistema fluvial,
descrito y utilizado como unidades físico-biológicas y en muchas ocasiones como unidades
socioeconómico-políticas para la planificación y ordenación de los recursos naturales (Lacoste,
2003:25).
Las cuencas hidrológicas, es decir, las áreas drenadas por un río o un sistema fluvial,
desempeñan un papel esencial y determinante, pues cumplen con una serie de funciones que van
desde las relacionadas estrictamente con el agua, como la captación de flujos, el almacenamiento
y la descarga, pasando por aspectos ecológicos, al crear medios específicos y propiciar las

72
interacciones entre los elementos físicos biológicos, hasta componentes ambientales, como los
relacionados con el germoplasma y los ciclos biogeoquímicos. Por el lado de la actividad humana
hay que agregar una larga serie de actividades en las que se aprovechan las cuencas: agricultura,
industria, generación de electricidad, reciclaje de materia, suministro de agua, disposición de
desechos (Lacoste, 2003:123).
A pesar de que el agua se halla profusamente repartida por todo el planeta, su distribución
es muy desigual. Y el hecho de que sea un elemento esencial para la vida hace que a menudo los
seres humanos deban librar verdaderas batallas para poder acceder a ella. En ocasiones se trata
de luchar contra la naturaleza con increíbles obras de ingeniería destinadas a obtener y preservar
este precioso líquido, pero también hay que realizar esfuerzos para protegerse de sus peligros
(Lacoste, 2003:8).
El estudio de las cuencas hidrográficas de cualquier país casi siempre tiene como objetivo
principal la conservación de sus recursos naturales, renovables y no renovables, o el manejo de
los mismos en su sentido más amplio. Esto lleva a considerar no sólo la conservación de dichos
recursos, sino su aprovechamiento y administración, en la mayoría de los casos con una visión o
una meta de manejo sustentable o de uso racional (Matute, P. 2005:11).
Partiendo de los enfoques tradicionales de la concepción de cuencas hidrográficas, se
consideran como cuerpos de agua receptores finales de los escurrimientos producidos en el
territorio venezolano seis cuencas hidrográficas principales u hoyas: la del Orinoco, que abarca
una superficie de casi 1.100.000 km2, de los cuales el 70 por ciento se encuentra en territorio
venezolano y el resto en la República de Colombia; la cuenca del Lago de Maracaibo y Golfo de
Venezuela, que tiene una extensión de 90.000 km2, de los cuales 74.000 se localizan en el país y
16.000 en Colombia; la cuenca del río Cuyuní, que cubre una extensión aproximada de 40.000
km2; la hoya del Mar Caribe, abarcando más de 80.000 km
2; la cuenca del río Negro, la cual
forma parte integral de la hoya del río Amazonas y se comunica con el río Orinoco a través del
Brazo Casiquiare; y finalmente la hoya endorreica del lago de Valencia que posee una superficie
aproximada de 3.000 km2.
El Ministerio del Ambiente y de los Recursos Naturales atendiendo al potencial de
recursos hídricos del territorio nacional, jerarquizó las unidades hidrológicas para disponer de una
lista ordenada de las mismas atendiendo a la importancia de las cuencas hidrográficas de acuerdo
con su potencial como productoras de electricidad, de agua para consumo humano, para la
industria, su grado de deterioro, etc., para así canalizar la inversión de los recursos en los

73
espacios calificados como prioritarios.
Con ese objetivo ser realizó el Inventario Nacional de Cuencas Hidrográficas (INCH), a
través del cual se cuantificaron más de 450 unidades hidrográficas, considerando que las mismas
cumplieran al menos algunas de las siguientes condiciones: superficie mayor o igual a 100 km2,
la inversión en infraestructura hidráulica, situación o condición estratégica (ser una cuenca
hidrográfica internacional, presencia de ecosistemas frágiles, áreas bajo régimen de
administración especial (Abrae), y abastecer grandes poblaciones), para de esa manera ordenarlas
atendiendo a los requerimientos de aprovechamiento y conservación. La jerarquización de las
cuencas hidrográficas por recursos naturales permitió organizarlas de manera tal de dejar en
evidencia su potencial para el desarrollo de determinadas actividades (Moreno, M. 2005:1).
2.1.- Parámetros morfométricos.
El término parámetro es definido por García (1976:2) como “una cantidad característica
de un sistema hidrológico que permanece constante en el tiempo”. En este sentido cuando se
habla de parámetros morfométricos se hace referencia a aquellas características propias de las
cuencas hidrográficas que no cambian en el tiempo. Por otro lado, el término “Variable” es
igualmente definido por García (1976:2) como “una característica del sistema la cual puede ser
medida y que asume diferentes valores numéricos cuando se mide a diferentes tiempos”.
Los parámetros morfométricos son definidos por Bautista y col., (1996) como:
Área: es la superficie comprendida dentro de la divisoria de aguas hasta un punto de un cauce
que se determina sobre mapas topográficos hechos a escala expresados en ha o km2.
Longitud axial (Lax): es la distancia desde el punto de drenaje hasta el punto más remoto de la
cuenca.
Factor de forma (Ff): el factor de forma compara la forma de la cuenca con un cuadrado (Ff =
1); alargada (Ff < 1), donde es menos probable que ocurra una lluvia intensa simultáneamente
sobre toda la extensión que en un área de igual tamaño pero con un factor de forma mayor;
achatada (Ff > 1) tal y como se muestran en la figura 1.
Coeficiente de compatibilidad (K): es un índice de la irregularidad de la cuenca, es decir, es la
relación entre el perímetro de la cuenca y el perímetro de la circunferencia de un círculo de área
equivalente al área de la cuenca.
APK /*28.0 (1)

74
K = coeficiente de compactibilidad.
P = perímetro de la cuenca. A = área de la cuenca.
Figura 1. Factor de forma (Bautista S, y col. (1996).
Elevación media: (E media): esta relacionada con la distribución y presencia de precipitación en
la cuenca. La presencia de montañas produce la elevación de las masas de aire produciendo
precipitaciones.
Para el cálculo de este factor existen dos métodos; métodos de las intercepciones y el
método del área entre curvas de nivel hasta ahora es el método mas usado.
Elevación mediana: la elevación mediana se obtiene a través de la curva hipsométrica, que no es
mas que una curva de distribución de frecuencia relativa acumulada, y representa el porcentaje de
área que hay por encima de una o varias alturas.
Elevación modal: es la elevación que tiene mayor área. La mejor forma de observarla es través
de un histograma que se logra graficando por el eje de las (X) la elevación parcial y por el eje de
las (Y) el % de área.
Pendiente media de la cuenca (S): está es definida por la pendiente media ponderada de las
pendientes correspondientes a superficies elementales en las cuales las pendientes se pueden
considerar constantes.
La pendiente media de una cuenca es uno de los principales parámetros que caracterizan
el relieve de la misma permitiendo hacer comparaciones entre cuencas y es importante para el
escurrimiento.
Se obtiene multiplicando la longitud total de las curvas por el intervalo entre ellas y
dividiendo entre el área de la cuenca
S = (D/A)* L (2)
Ff = 1
Ff < 1
Ff > 1

75
Donde: D = intervalo entre curvas de nivel.
A = área total de la cuenca.
L = longitud total de las curvas de nivel.
Densidad de drenaje: es la capacidad de drenaje de la cuenca que se expresa mediante la
relación:
Dd = L/A (3)
Donde:
L = longitud total de los cauces (m)
A = área de las cuenca km2
Para Bautista y colaboradores se considera como una cuenca a toda aquella parte del
terreno cuya agua de lluvia que corre por la superficie se concentra y pasa por un punto del cauce
principal que lo drena (Bautista, Rincón, Godoy y Domínguez, 1996).
A los efectos de esta investigación es importante pasar a definir algunos términos
directamente relacionados con el procedimiento que más adelante se aplica. Estos términos son
tomados de García (1976) el cual los expone de la siguiente forma:
Simulación: es una técnica de análisis que consiste en el desarrollo de un modelo para
investigar indirectamente el comportamiento de un sistema dinámico, sujeto a ciertas limitaciones
y funciones de entrada.
Modelo: representación simplificada de un sistema hidrológico; pudiendo ser físico,
analógico y/o matemático.
Modelo Matemático: es aquél en el cual el comportamiento del sistema se representa por
un conjunto de ecuaciones, unidas por declaraciones lógicas, que expresan la relación entre los
parámetros y las variables.
Sistema: puede definirse como una combinación de objetos y procesos que se
interrelacionan entre sí, de manera que operan en forma colectiva como un todo.

76
2.2.- Disponibilidad de agua superficial.
Una definición de la expresión “disponibilidad de agua superficial” es hecha por
Bolinaga (1995:65) como “la cuantificación de las cantidades existentes a lo largo de las
diferentes fases o etapas del ciclo hidrológico”. De igual manera resalta la importancia del
conocimiento de estas cantidades considerando que las mismas permiten la correcta definición de
un proyecto hidráulico siendo el dato más importante para ello ya que conjuntamente con las
demandas son las variables que determinan el desarrollo de la ingeniería de detalle de los
mismos.
Por su parte Chow y col., (1994:130) definen específicamente el agua superficial como “la
que se almacena o se encuentra fluyendo sobre la superficie de la Tierra”; mientras que para
Horton (1933) citado por Chow y col., (1994:131) el flujo superficial es definido como:
“despreciando la intercepción por vegetación la escorrentía superficial es aquella parte de la
lluvia que no es absorbida por el suelo mediante infiltración”. Esta concepción presenta como
limitante que sólo es aplicable en circunstancias particulares: “superficies impermeables en áreas
urbanas y a superficies naturales con capas delgadas de suelo y con baja capacidad de infiltración
como ocurre en tierras semiáridas y áridas” Chow y col., (1994:132).
Refiriéndose a la determinación de las disponibilidades de agua Amisial (1979:7) señala
que “el objetivo de la predicción de las disponibilidades de agua es determinar el origen, la
ocurrencia, la calidad y variabilidad en el tiempo y espacio de las aguas para su control y uso”.
En la Gaceta Oficial de la República de Venezuela Nº 2.823 están señaladas las Unidades
de Medidas del Sistema Legal Venezolano en donde las mediciones de los volúmenes de agua
que escurren por unidad de tiempo en un punto determinado de un cauce se expresan como
Caudal Volumétrico en m3/s.
Es importante manejar el comportamiento de las precipitaciones en Venezuela. Referido a
esto Guiliarte (1989:38) señala que:
El año en Venezuela se divide en dos temporadas, una seca, conocida como verano y una
temporada de lluvias, llamada invierno. Estos términos de “invierno” y “verano” no coinciden
con los términos astronómicos para las estaciones del año. En general la estación de sequía
abarca los meses de diciembre hasta abril, inclusive, y la estación lluviosa va de mayo hasta

77
noviembre.
De igual importancia resulta las definiciones de lluvia diaria, mensual, anual o total, y
lluvia media que son expuestas por Guevara (2004:243) en los términos siguientes:
a) La lluvia diaria se obtiene directamente del pluviómetro al efectuar la lectura a las 8:00 am de
cada día. Este valor corresponde a las últimas 24 horas y debe coincidir con la banda del
pluviógrafo. Los datos diarios se publican luego en los anuarios por mes y año.
b) La lluvia mensual. Es la suma de las lluvias diarias durante el lapso de un mes: 28, 30 ó 31
días.
c) Lluvia anual o total. Es la suma de las precipitaciones diarias en el año o las sumas de las
lluvias mensuales.
d) Lluvia media. Es el promedio de la lluvia caída durante un periodo determinado: media diaria,
media mensual, media anual, media estacional. Cuando se dice media en los datos
pluviométricos, se trata de medias de datos acumulados.
A los efectos del cálculo de las disponibilidades de agua superficial producto de las
precipitaciones, el exceso de precipitación o precipitación efectiva juega un papel importante. En
este sentido Chow y colaboradores (1994:138) la definen como la precipitación que no se retiene
en la superficie terrestre y tampoco se infiltra en el suelo. De igual manera comentan que después
de fluir a través de la superficie de la cuenca, el exceso de precipitación se convierte en
escorrentía directa a la salida de la cuenca bajo la suposición de flujo superficial hortoniano.
Cuando el exceso de precipitación se grafica en función del tiempo se construye lo que se
conoce como histograma de exceso de precipitación. De igual manera es posible construir el
histograma de lluvia total que se observa, graficando dicha lluvia en función del tiempo, y al
establecer la diferencia entre la lluvia total y la lluvia que escurre se obtienen las abstracciones o
pérdidas.
A su vez, la estimación de las disponibilidades es un problema que puede ser abordado
desde diferentes plataformas. De acuerdo con lo expresado por Bolinaga (1995:79):
Haciendo abstracción de la calidad de las aguas, las disponibilidades a efecto de
planificación de proyectos hidráulicos vienen por lo general expresadas como eventos
secuenciales (volúmenes escurridos o gastos ordenados cronológicamente en un largo
período), eventos aislados (similar al anterior en un corto período), y eventos extremos
(gastos o volúmenes máximo o mínimos sin ninguna indicación cronológica).
Usualmente se hace necesario el estudio de las precipitaciones y otros parámetros
climáticos como apoyo al análisis de las disponibilidades, o bien para uso directo en la
definición de algún proyecto hidráulico. Existen numerosos métodos tradicionales para

78
estimar eventos extremos, que se podrían clasificar en directos o indirectos. Los
primeros hacen uso solamente de los datos de escorrentía y en los segundo se obtiene
la escorrentía en base a las precipitaciones. El método directo sólo puede ser aplicado
cuando existe una serie suficientemente larga de valores registrados o generados
mediante métodos no tradicionales. Los eventos aislados mayormente requeridos son
la tormenta y el hidrograma de una crecida. El primer evento es útil por ser
frecuentemente necesario para definir los hidrogramas, tanto cuando se utilizan
metodologías tradicionales como con modelos matemáticos de un solo evento. La
tormenta es la distribución espacial y cronológica de las precipitaciones generadoras de
los hidrogramas. Se han desarrollado numerosas técnicas indirectas para construir
sintéticamente hidrogramas unitarios y de estas la más utilizada en Venezuela ha sido
la desarrollada por C. O. Clark, pero al igual que las otras, presenta serias dificultades
en la estimación de los escurrimientos (definición de las pérdidas).
El hidrograma resulta ser una de las mejores representaciones gráficas del comportamiento
de variables hídricas que ha sido muy utilizada con el pasar del tiempo. Guilarte (1989:79) lo
define en los términos siguientes:
Un hidrograma, es un gráfico de altura o de caudal contra tiempo. Se pueden usar varias
maneras de elaborar estos gráficos de acuerdo al propósito de los mismos. Para mostrar un
registro pasado, se pueden usar medidas mensuales o anuales, o escurrimientos totales. Este
consta de tres partes: limbo ascendente, segmento de la cresta y recesión.
La construcción de un Hidrograma depende de las líneas isocronas. Son líneas que unen
puntos de igual tiempo de concentración (Tc). Este último es el tiempo que tarda una gota de
agua desde un punto determinado hasta el punto de drenaje común. A los efectos de la cuenca
hidrográfica, el Tiempo de Concentración de la Cuenca es el tiempo que tarda en llegar al punto
de drenaje común la gota que está más alejada de dicho punto, aguas arriba, en el extremo más
alto del cauce principal.

79
Figura 2. Esquema del Tiempo de Concentración sobre una Cuenca Hidrográfica y Perfil
del Hidrograma Unitario (www.meted.ucar.edu/hydro)
Algunas fórmulas disponibles para el cálculo del tiempo de concentración son expuestas
por Carciente (1999) las cuales representan un cálculo empírico:
Fórmula del Guaire:
595.0*355.0
S
ATc (4)
Fórmula de Bureau of Reclamation:
385.0**886.03
H
LTc (5)
Fórmula de Kirpich:
S
LsiendoKKTc 77.00195.0 (6)
Fórmula de Kirpich modificada:
Tc = 0.0078 * (L0.77
/S0.383
) (7)
Donde: A = área de la cuenca km2.
L = longitud del cauce principal en km. H = diferencia de cota entre los puntos
extremos del cauce principal en m.
S = pendiente en m/ km. Tc = tiempo de concentración.
Para la ecuación de Kirpich modificada las unidades de la pendiente (S) son en m/m y la
longitud (L) en metros.
Guilarte (1999) sugiere algunos aspectos para el trazado de las curvas: se adopta un
tiempo de valor unitario T representativo de las equidistancias entre curvas y luego se calculan
los valores T, 2T, 3T y sucesivos. El tiempo unitario se adopta en función del área de la cuenca.
Para el cálculo de los puntos de ubicación de las isocronas se cuenta con el trazado de la red de
drenaje de la cuenca en estudio las que clasifican los tributarios según el siguiente criterio: 1) el
cauce principal, ya visto, desde la desembocadura hasta su punto mas alto en la cabecera de la
cuenca; 2) los cauce secundarios y canales (en esta clasificación se encuentran comprendidos los

80
de segundo, tercer y más ordenes y los canales construidos); y finalmente 3) las trayectorias
correspondientes al flujo superficial el cual se considera laminar, las que representan el camino
que toma el agua superficial no encausada . El intervalo entre las líneas isocronas se toma como
un submúltiplo del tiempo de concentración de la cuenca. Por ejemplo, si el tiempo de
concentración es igual a 20 T horas puede tomarse 10 intervalos de 2 horas.
Una de las principales desventajas que se ha encontrado para el uso del Hidrograma como
herramienta de evaluación de la disponibilidad de caudales es el poco sofisticado sistema que
tiene para el cálculo de las pérdidas, las cuales son definidas por Bolinaga (1999:83) de la
siguiente forma:
“Las pérdidas son aquellas cantidades de aguas precipitadas que no se reflejan en
el escurrimiento, al menos dentro de un período de tiempo razonable, en lo que se refiere a
eventos aislados. Su conocimiento es indispensable para transformar la tormenta de diseño en
escurrimiento o lluvia efectiva y ésta, a su vez, en un hidrograma”.
Según Bolinaga (1999) las pérdidas son ocasionadas por varias razones y existen dos
métodos comúnmente aceptados para su estimación. Estos son: el Método porcentual, que se
fundamenta en asignar un porcentaje constante de pérdidas a la precipitación total con lo que
supone, de manera incorrecta, una distribución uniforme de las pérdidas en el tiempo; y el
Método basado en curvas empíricas de infiltración, que se fundamenta en el empleo de un
conjunto de fórmulas que estiman las cantidades infiltradas y su variación en el tiempo,
destacándose como una de las más utilizadas la del U. S. Soil Conservation Service (SCS),
también conocido como el Método del Servicio de Conservación de Suelos de los Estados,
Unidos, diseñado para la estimación de las pérdidas en un evento de precipitación(Bolinaga,
1999:83).
Como agua absorbida por infiltración con algo de intercepción y almacenamiento
superficial Chow y colaboradores (1994:139) definen el término “pérdidas” al cual también
asocia con igual significado al término “abstracciones”. De igual manera destaca que
precisamente las abstracciones por intercepción y almacenamiento en depresiones se estiman con
base en la naturaleza de la vegetación y de la superficie del terreno o se suponen despreciables en
una tormenta de duración significativa. Según este investigador, el Método del SCS para el
cálculo de las abstracciones establece que en una Tormenta como un todo, la profundidad de

81
exceso de precipitación o escorrentía directa puede ser menor o igual, pero nunca superar, a la
precipitación total o bruta; así como que después de que la escorrentía se inicia, la profundidad
adicional del agua retenida en la cuenca es menor o igual a alguna retención potencial máxima,
la cual se identifica con la letra S. Con base a esto y a otras consideraciones la fórmula que
permite calcular la precipitación o escorrentía se desarrollo a través del SCS en los términos
siguientes:
P e = (P – 0,2S)2 / (P + 0,8S) (8)
La letra S fue descrita anteriormente como la retención potencial máxima; Pe es la
precipitación o escorrentía directa y P la precipitación total o bruta. El valor de S está relacionado
con un parámetro propio de una cuenca hidrográfica para un periodo en estudio conocido como el
Número de Curva (CN) el cual se incluye para estandarizar los resultados. Esta variable fluctúa
en un rango que va desde cero a cien (0 ≤ CN≤100) correspondiendo el valor de 100 a superficies
impermeables o superficies de agua, y los valores menores de 100 para todas las superficies
naturales. Luego, para relacionar S con el CN se emplea la ecuación siguiente:
S = (1000/CN) – 10 (9)
Para la determinación del CN se usa el cuadro “numero de curva escorrentía para usos
selectos de tierra agrícola, suburbana y urbana” tabulado por Soil Conservation Service con base
en el tipo de suelo y el uso de la tierra, tomada de Chow y col., 1994. Según este investigador
cuatro grupos de suelo son definidos:
Grupo A: arena profunda, suelos profundos depositados por el viento, limos, agregados.
Grupo B: suelos poco profundos depositados por el viento, marga arenosa.
Grupo C: Margas arcillosas, margas arenosas poco profundas, suelos con bajo contenido orgánico
y suelos con altos contenidos de arcilla.
Grupo D: suelos que se expanden significativamente cuando se mojan, arcillas altamente
plásticas y ciertos suelos salinos.
El número de curva CN puede ser usado directamente para la estimación de escorrentía
superficial, asociándolo a la precipitación y a una condición del suelo conocida como abstracción
inicial. Acevedo (2004) propone una función para ser ejecutada en el programa estadístico R, con

82
la cual, puede simularse el comportamiento de la escorrentía para diferentes condiciones. A
continuación se transcribe el modelo propuesto por Acevedo.
#función para calcular la escorrentía diaria dada la precipitación
runoff.cn<-function(cn,rain,Ia.par) {
#parámetro de retención en mm
s<- 254 * (100/cn -1)
#Abstracción inicial
Ia<- Ia.par * s
#la precipitación debe exceder a la abstracción para que ocurra escurrimiento
if (rain >= Ia)
runoff <-((rain-Ia)^2)/(rain + (1 – Ia.par) * s)
else runoff <- 0
#abstracción (retención)
abst<-rain –runoff
return (abst, runoff)
}
La información relativa al número de curva (CN) se muestra en la Tabla 1. El código
anterior se implementa en el programa estadístico R. Para solicitar su ejecución se invoca la
función runoff.cn, la cual es dependiente del número de curva (cn), la precipitación (rain) para la
cual se quiere calcular la escorrentía, y la retención o abstracción inicial. Estos valores se
incorporan a la expresión runoff.cn para invocar la función: runoff .cn (cn,rain,Iapar), el cual
reporta la escorrentía superficial expresada en unidad de lámina de agua (mm).
El tiempo de concentración es definido por Chow y col., (1994:170) como el tiempo en el
cual toda la cuenca empieza a contribuir con escorrentía para un evento de precipitación; es el
tiempo de flujo desde el punto más alejado hasta la salida de la cuenca. Este valor puede ser
calculado por alguna de las ecuaciones que han sido elaboradas para tal fin. Una de las más
empleadas para los estudios hidrológicos en Venezuela es la ecuación de Kirpich (1940)
expresada de la siguiente forma:

83
Tabla 1. Número de Curva Característica de la superficie de Escorrentía para Usos Selectos de
Tierra Agrícola, Suburbana y Urbana (condiciones antecedentes de humedad II, Ia = 0.2S)
(Servicio de Conservación de Suelos de los Estados Unidos.)
Descripción del Uso de la tierra Grupo Hidrológico del suelo
A B C D
Tierra cultivada: Sin tratamiento de conservación.
Con tratamiento de conservación.
72
62
81
71
88
78
91
81
Pastizales: Condiciones pobres.
Condiciones óptimas.
68
39
79
61
86
74
89
80
Vegas de ríos: Condiciones óptimas. 30 58 71 78
Bosques: Troncos delgados, cubierta pobre, sin hierbas.
Cobertura buena.
45
25
66
55
77
70
83
77
Áreas abiertas, césped, parques, campos de golf,
Cementerios, etc. Óptimas condiciones:
Cubierta de pasto en el 75% o más
Cubierta de pasto en el 50 a 75%
39
49
61
69
74
79
80
84
Áreas comerciales de negocios (85% impermeable) 89 92 94 95
Distritos industriales (72% impermeables) 81 88 91 93
Residencial:
Tamaño promedio del lote Porcentaje promedio
Impermeable
1/8 Acres o menos 65
¼ Acres 38
1/3 Acres 30
½ Acres 25
1 Acre 20
77
61
57
54
51
85
75
72
70
68
90
83
81
80
79
92
87
86
85
84
Parqueaderos pavimentados, techos, accesos, etc. 98 98 98 98
Calles y carreteras:
Pavimentos con cunetas y alcantarillados
Grava
Tierras
98
76
72
98
85
82
98
89
87
98
91
89

84
KTc *078.0 (10)
Donde:
385.0
77.0
S
LK (11)
L = longitud del cauce principal en metros. S = pendiente en m/ m. Tc = tiempo de
Concentración.
Treviño (2004) al referirse acerca de los métodos disponibles para la estimación de
caudales señala que, entre otros, los métodos hidrológicos han alcanzado un elevado grado de
aceptación al contar con ecuaciones más exactas para estimar la lluvia efectiva. Especialmente
dos de estos métodos han acumulados, dada su difusión, una dilatada experiencia: método
racional modificado por Témez (1991) y el Hidrograma Unitario.
En la presente investigación se usa el Hidrograma Unitario Instantáneo tomando en cuenta
el tipo de datos disponible, utilizando la metodología propuesta por Clark, basado en las
modificaciones hechas por Cunge a las ecuaciones Munkingun (McCarthy, 1939).
Para la determinación de la disponibilidad de caudales usando el método propuesto por O.
C. Clark, según Guilarte (1989), en principio se calcula el caudal (m3/s) que por unidad de
precipitación (mm) que escurre por la cuenca, que ha sido divida sobre un plano cartográfico en
segmentos delimitados por líneas de separación equidistante que evocan curvas de nivel, pero que
para este cálculo en lugar de señalar diferencias de cotas señalan diferencias de tiempo. Estas
líneas son conocidas como Isocronas: une puntos de igual tiempo de concentración. Estas líneas,
al ser representadas sobre la cuenca la dividen en sub cuencas. Según Guilarte (1989:104) el
fundamento del método de Clark para la estimación del Hidrograma Unitario, considera que el
hidrograma total de la cuenca es el resultado de la suma de los hidrogramas parciales modificados
por el almacenaje que ocurre entre las sub cuencas y el lugar donde se desea obtener el
hidrograma total.
El método de Muskimgum, de acuerdo con lo comentado por Guilarte (1989) es un
método de tránsito hidrológico que se usa comúnmente para manejar relaciones
caudal/almacenamiento variables. Este método modela el almacenamiento volumétrico de
creciente en un canal de un río mediante la combinación del almacenamiento de cuña y prisma.
Durante el avance de la onda creciente, el caudal de entrada es mayor que el caudal de salida,

85
siendo un almacenamiento de cuña. Durante la recesión, el caudal de salida es mayor que el
caudal de entrada resultando un almacenamiento de prisma. La ecuación de tránsito por el
método de Muskimgum es, según Guillarte (1989) de la forma:
jjjj QCICICQ 21101 (12)
Donde:
1
10
*5.0
*5.0
TK
TC
(13)
1
10
*5.0
*5.0
TK
TC
(14)
1
12
*5.0
*5.0
TK
TKC
(15)
K es un Coeficiente de Proporcionalidad o Constante de Almacenamiento, es el tiempo de
tránsito de una onda creciente a través del tramo de canal.
)(__
10*)_(___ 2
sisocronasentretiempo
kmCuencaladeáreaEU (16)
Donde EU es el escurrimiento unitario. Al ser afectado por el factor 10, permite obtener la unidad
de expresión en m3/s * mm.
T1 = Tiempo entre Isocronas.
Distribución de la precipitación:
La Figura 3 muestra un ejemplo de cómo se distribuye, espacialmente y en términos de
magnitud, la precipitación sobre una cuenca hidrográfica. Es una confirmación de que no todo lo
registrado en la Estación climatológica puede considerarse como representativo del área total de
la cuenca. En este sentido, a los efectos de calcular los caudales de escorrentía producto de un
evento de precipitación sobre una cuenca, apoyándose en el método del Servicio de Conservación
de Suelos de los Estados Unidos para el cálculo del número de curva, es prudente afectar el área
de la cuenca por un factor de peso que permita simular la contribución parcial de la misma a la
escorrentía total. Esta simulación es propuesta en el presente trabajo como metodología del
cálculo de caudales. Se configuró a través de un código de programación elaborado en lenguaje

86
R, donde para cada corrida de simulación se estableció la selección aleatoria y diferente de una
porción de la cuenca en estudio.
Figura 3. Distribución de la lámina de agua precipitada en una Cuenca Hidrográfica
(http://www.noaa.gov/wx.html)
2.3.- Teledetección
Para definir la Teledetección Pinilla, C. (1995) usa los siguientes argumentos:
El término Teledetección fue el adoptado en los países de habla hispana como
traducción del inglés remote sensing, utilizándose a partir del año 1960 para describir las
observaciones de un objeto efectuadas sin mediar contacto físico con él. Este tipo de
adquisición de información solamente puede ser posible mediante la detección y medida
de los cambios que el objeto observado induce en su entorno, bien sean en forma de
perturbaciones electromagnéticas, bien como ondas acústicas reflejadas o alteradas, o
como perturbaciones del campo magnético o gravitatorio debidas a la presencia del
objeto. Con carácter más restrictivo, el término teledetección se reserva a las técnicas
electromagnéticas de adquisición de información en las zonas del espectro
electromagnético comprendidas entre las ondas de radio de baja frecuencia y los rayos X,
gamma e, incluso, cósmicos.
De igual manera Lillesand y Kiefer (2000:1) definen la Teledetección como “una ciencia y
un arte de obtener información acerca de un objeto, área o fenómeno a través del análisis de datos
adquiridos por un dispositivo que no está en contacto con el objeto, área o fenómeno bajo
investigación”.
A manera de introducción Fernández y Herrero (2001:3) comentan que:
La existencia de sensores situados en plataformas espaciales dio origen a la
teledetección. La teledetección es empleada como complemento a estudios

87
orientados al medio ambiente en las distintas áreas de la ciencia: oceanografía,
recursos pesqueros, estudios costeros, contaminación, hidrogeología, estimación de
cosechas, control de plagas, producción agrícola, planificación urbana, entre las
aplicaciones más comunes.
Chuvieco (1996:24) por su parte establece que “el rango de acción de la teledetección
abarca varios procesos cuando dice que no sólo engloba los mecanismos que permiten obtener
una imagen, sino también su posterior tratamiento, en el contexto de una determinada
aplicación”. Igualmente señala que para efecto de la captura de la imagen debe existir entre el
sensor y la superficie de la Tierra una interacción energética ya sea por reflexión de la energía
solar o de un haz energético artificial, ya por emisión propia; y termina comentando, a efectos
del marco introductorio que un sistema de teledetección espacial incluye los siguientes
elementos:
a.- Fuente de energía, que supone el origen de la radiación electromagnética que detecta el
sensor.
b.- Cubierta terrestre, formada por distintas masas de vegetación, suelos, agua o construcciones
humanas, que reciben la señal energética procedente de la fuente.
c.- Sistema sensor, compuesto por el sensor propiamente dicho, y la plataforma que lo alberga.
d.- Sistema de recepción-comercialización, en donde se recibe la información trasmitida por la
plataforma, se graba en un formato apropiado, y tras las oportunas correcciones se envía a los
interesados.
e.- Intérprete, que convierte esos datos en información temática de interés, ya sea visual o
digitalmente, de cara a facilitar la evaluación del problema en estudio.
La Figura 4 esquematiza el proceso de teledetección en función de los elementos que en él
actúan.
Por lo antes expuesto es posible señalar los procesos que intervienen en la Teledetección
como un conjunto de fases que se categorizar como sigue (Pinilla, C., 1995):
a.- Emisión de radiación electromagnética desde una fuente
b.- Interacción de la radiación con la superficie terrestre
c.- Interacción de la radiación con la atmósfera
e.- Recepción de las ondas electromagnéticas en instrumentos a bordo de una plataforma.

88
Figura 4. Elementos que dan forma al proceso de Teledetección (Parra, 2007)
Como se nota en el párrafo anterior, Pinilla (1995), sólo señala los procesos hasta la fase
de recepción, mientras de Chuvieco (1996) estima conveniente agregar los pasos siguientes
como parte de los procesos que implican esta disciplina:
f.- Almacenamiento de la información adquirida y distribución de la misma a los interesados
g.- Análisis e interpretación de la información y su aplicación a áreas específicas del dominio
ambiental.
En general, y de forma esquemática puede usarse la representación que hace Lillesand y
Kiefer (2000:3) para describir el proceso de teledetección: Emisión de energía - Propagación a
través de la atmósfera - Interacción de esta energía con la superficie de la tierra (absorción y
reflexión) – Retransmisión a través de la atmósfera – Recepción en los sistemas sensores –
Almacenamiento en los sensores y/o distribución de la información – Análisis e Interpretación –
Obtención del producto de la Interpretación – Consumo de la información por parte de los
Usuarios.
2.3.1.- Sensores remotos
Según lo expresado por Parra (2007:1-55):
Los satélites de recursos naturales reciben este nombre porque fueron diseñados
explícitamente para la observación de la Tierra en procura de la evaluación de los
recursos que en ella pueden observarse. Entre ellos los más conocidos son los
satélites de la familia Landsat, los SPOT y los EOS Terra/Aqua. Ellos se caracterizan
por ser de órbita polar y presentar una resolución espacial de apreciable acercamiento.

89
En relación al origen del programa Landsat, Pinilla (1995:59) comenta que:
En 1972 se puso en órbita el primero de la serie de satélites ERTS (Earth Resource
Technollogy Satellite), destinados, como su propio nombre indica, al estudio de los
recursos naturales. A partir del segundo lanzamiento, el programa se redenominó
LANDSAT, y con él se han llegado a poner en órbita cinco satélites más,
constituyendo un proyecto de gran rendimiento en cuanto a explotación de
información. El diseño de esta familia de satélites está orientado al inventario
agronómico y previsión de cosechas, evaluación y control de zonas regables,
planificación de los recursos hídricos en el contexto de la cuenca hidrográfica, a la
cartografía de los usos del suelo, al estudio de los recursos litorales, estudios
geológicos y de los glaciares, así como al control de la contaminación de aguas y
suelos.
Chuvieco (1996:123) refiriéndose al programa Landsat comenta que:
Esta familia de satélites es el proyecto más fructífero de teledetección espacial
desarrollado hasta el momento. La buena resolución de sus sensores, el carácter
global y periódico de la observación que realizan y su buena comercialización,
explican su profuso empleo por expertos de muy variados campos en todo el mundo.
A continuación se resumen algunas características más resaltantes de la familia de satélites
Landsat de acuerdo con lo señalado por Pinilla (1995:60):
Los satélites Landsat 1, 2 y 3, puestos en órbita en 1972, 1975 y 1978, respectivamente,
tenían una configuración muy similar. El peso total de cada uno de ellos era de 960 kg.
Las órbitas eran heliosincrónicas, esto es, sus trazas atravesaban el ecuador a la misma
hora local y eran prácticamente polares, con una inclinación de 99,1º. La altura orbital
era de 917 km, por lo que la periodicidad resultante era de 103 minutos. En
consecuencia, describían un total de 14 órbitas diarias. A partir de los datos anteriores,
puede deducirse fácilmente que el satélite pasaba por la vertical del mismo lugar cada
18 días. Los satélites Landsat 4 y 5 fueron modificaciones sustanciales de los
anteriores, variándose la altura orbital a 705 km, por lo que el periodo resultante es de
98 minutos y el ciclo de cobertura de 16 días.
En este orden de ideas Parra (2007:1-56) expresa que:
Los tres primeros Landsat incorporaban un equipo de barrido multiespectral
denominado MSS (Multiespectral Scanner) y un conjunto de tres cámaras de video
(RBV, Retur Beam Vidicon). El Landsat 5 fue lanzado en 1984, es el satélite de la
serie que más tiempo lleva en órbita y significó salto cualitativo de gran importancia.
Landsat 5 combina el sensor MSS (Multiespectral Scanner) de los satélites más
antiguos con un nuevo sensor, el TM (Thamatic Mapper) con capacidades ampliadas.
El sensor TM, fue diseñado, como su nombre lo indica, para la cartografía temática y
cuenta además con mayor resolución radiométrica (8 bits).
Lillesand y Kiefer (2000:399), reportaron, que con más de dos décadas de experiencia el

90
programa Landsat sufre su primer revés con el lanzamiento el 5 de octubre de 1993 de la misión
Landsat 6. El mismo fue diseñado para ocupar una órbita idéntica a la de los Landsat 4 y 5 pero
no logró ajustarse a la misma.
El último satélite Landsat (el 7), lanzado el 15 de abril de 1999, según lo comentado por
Parra (2007:1-57):
Incorpora el sensor ETM+ (Enhanced Thematic Mapper) que añade a las bandas ya
disponibles en el TM un canal pancromático (0,52 – 0,92 µm) con resolución espacial
de 15 metros, y aumenta la resolución espacial de la banda térmica a 60 m. La
inclusión del canal pancromático está siendo de gran utilidad para obtener productos
cartográficos de mayor calidad, aplicando técnicas de fusión de imágenes.
2.3.2.- Pre-procesamiento de la imagen.
Para los efectos del Pre-procesamiento digital de una Imagen de satélite es necesario
manejar los términos referidos a la resolución del sensor. Este término se discrimina en varios
tipos de resolución, tales como: resolución espacial, espectral, radiométrica y temporal. De igual
manera, el primer paso que debe cumplirse a la hora de embarcarse en un proceso de
Teledetección es el de la selección del material de trabajo en función al tipo de sensor, de la fecha
de adquisición de los datos y del soporte de las imágenes, para luego abordar la fase de selección
del método de análisis, bien sea visual o digital.
A los efectos de la definición del término resolución del sensor Chuvieco (1996:90)
expresa que es la “habilidad para discriminar información de detalle”. Referido a esta definición
Parra (2007:1-40) considera:
Los términos de la definición “discriminar” e “información de detalle” merecen una
breve reflexión. Ambos son relativos al propósito y al entorno geográfico del
proyecto que se esté abordando. La discriminación refiere a la capacidad de
distinguir un objeto de otros. Esa distinción puede referirse a una simple
determinación de qué está ahí (detección) o a una delimitación precisa de su contorno
(identificación). En cuanto al significado de «información de detalle», conviene
considerar que se refiere no sólo al detalle espacial que proporciona el sensor, sino
también al número y anchura de las bandas del espectro que alberga, a su cadencia
temporal y a su capacidad para distinguir variaciones en la energía que detecta. En
definitiva el concepto de resolución implica diversas manifestaciones, las más
habituales en la literatura especializada han sido la espacial, espectral, radiométrica y
temporal. En los últimos años a éstas podemos añadir también la resolución angular,
que haría referencia a la capacidad de un sistema de observar el mismo objeto desde
distintas posiciones.
Particularmente para Pinilla (1995:39) “el concepto de resolución aplicado a los

91
instrumentos ópticos tradicionales se refiere fundamentalmente al poder de separación espacial
del sistema de lentes”.
Con respecto a las características del sensor Lillesand y Kiefer (2000:38) expresan que
“ningún sensor es sensible a todas las longitudes de onda. Todos tienen un límite fijo de
sensibilidad espectral”.
Refiriéndose a la Resolución Espacial Parra (2007:1-41) menciona que “este término
designa al objeto más pequeño que puede ser distinguido sobre una imagen”. Mientras que una
definición un tanto más general para este término la hacen Lillesand y Kiefer (2000:38) al
comentar que es una “expresión de la calidad óptica de una imagen producida por un sistema de
cámara en particular”; y para Pinilla (1995:40) el término resolución espacial denota “la
capacidad del sistema para distinguir el objeto más pequeño posible en una imagen”. En términos
ya más generales Parra (2007:1-41) comenta que “en un sistema fotográfico suele medirse como
la mínima separación a la cual los objetos aparecen distintos y separados en la fotografía. Se mide
en milímetros sobre la foto o metros sobre el terreno, y depende de la longitud focal de la cámara
y de su altura sobre la superficie. En los sensores óptico-electrónicos se prefiere utilizar el
concepto de campo de observación instantáneo (del inglés instantaneous fiel of view, IFOV)”.
Para definir la Resolución Espectral el mismo Pinilla (1995:42) expresa que es “la
capacidad que tiene el sensor para discriminar la radiancia detectada en distintas longitudes de
onda del espectro electromagnético”. Por otro lado, es definida como “el número y anchura de las
bandas espectrales que puede discriminar el sensor” de acuerdo a lo comentado por Chuvieco
(1996:92). De igual manera continúa sus comentarios señalando que un sensor mostrará un
mejor desenvolvimiento de sus funciones en la medida que sea mayor el número de bandas con el
que presente la información ya que con esto se logra una mejor caracterización espectral de las
diferentes cubiertas que recoge de la superficie terrestre.
Cuando se habla del espectro electromagnético se hace referencia a las diferentes
longitudes de ondas que muestra la fuente de energía, siendo la más importante el sol, de donde
emana la radiación electromagnética que funciona como transmisor de información (Parra,
2007:1-5). Según Guevara (2004:50) “el Sol emite dos tipos de radiaciones muy distintas: la
radiación ondulatoria o electromagnética y la radiación corpuscular”. La fuente de energía es
considerada como uno de los principales elementos que abarca la Teledetección, en tal sentido es
importante hacer una breve explicación de lo que ella implica y cómo debe ser concebida en
función de la resolución espectral.

92
La Figura 5 detalla la distribución de las Frecuencias y Longitudes de onda del espectro
electromagnético.
Figura 5- Espectro electromagnético (http://www.geocities.com/elerness/pdi_3.gif)
Cuando Parra (2007) trata este aspecto comienza argumentando que la energía en la
naturaleza puede ser transmitida en tres diferentes formas: conducción, convección y radiación.
La radiación es la única forma de transmisión que se hace sin contacto material entre el emisor y
el receptor, siendo su forma de transmisión explicada generalmente por dos teorías: la Teoría
Ondulatoria (según la cual la energía se transmite de un lugar a otro siguiendo un modelo
armónico y continuo, a la velocidad de la luz) y la Teoría Cuántica (que establece que la energía
viaja como un flujo de unidades discretas de energía, o de partículas conocidas como fotones).
La primera de las teorías, la Ondulatoria, introduce dos conceptos de corriente aplicación que
son: La Longitud de Onda y la Frecuencia, permitiendo esto definir cualquier tipo de energía
radiante en función de dichos términos. La longitud de onda (generalmente expresada con el
término lambda, λ) es la distancia que separa dos picos de onda y es medida en micrómetros, μm.
El espectro electromagnético se muestra como una sucesión de valores de longitud de
onda continua, permitiendo establecer una serie de regiones (conocidas como canal o banda), en
donde la radiación electromagnética manifiesta un comportamiento similar, siendo una de las
habilidades de los sensores, montados en plataformas, su capacidad de captar información para
diferentes regiones del espectro.

93
Para hacer una descripción de los diferentes canales o bandas que conforman el espectro
electromagnético Parra (2007:1-7) menciona que:
Desde el punto de vista de la teledetección, conviene destacar una serie de bandas
espectrales, que son las más frecuentemente empleadas con la tecnología actual. Su
denominación y amplitud varían según distintos autores, si bien la terminología más común es la
siguiente:
• Espectro visible (0,4 a 0,7 μm). Se denomina así por tratarse de la única radiación
electromagnética que puede ser percibida por el ojo humano, coincidiendo con las longitudes de
onda donde es máxima la radiación solar.
• Infrarrojo cercano (IRC, 0,7 a 1,3 μm). También se denomina infrarrojo próximo,
reflejado o fotográfico, puesto que parte de él puede detectarse a partir de películas dotadas de
emulsiones especiales. Esta banda espectral resulta de especial importancia por su capacidad
para discriminar masas vegetales y concentraciones de humedad.
• Infrarrojo medio (1,3 a 8 μm). En esta región se entremezclan los procesos de reflexión
de la luz solar y de emisión de la superficie terrestre. La primera banda se sitúa entre 1,3 y 2,5
μm, y se denomina infrarrojo de onda corta (Short Wave Infrared, SWIR), que resulta idónea para
estimar el contenido de humedad en la vegetación o los suelos. La segunda, comprendida
principalmente en torno a 3,7 μm, se conoce propiamente como infrarrojo medio (IRM), siendo
determinante para la detección de focos de alta temperatura (incendios o volcanes activos).
• Infrarrojo lejano o térmico (IRT, 8 a 14 μm), que incluye la porción emisiva del espectro
terrestre, en donde se detecta el calor proveniente de la mayor parte de las cubiertas terrestres.
• Microondas (M, por encima de 1 mm) con gran interés por se un tipo de energía bastante
transparente a la cubierta nubosa.
La Tabla 2 que se muestra a continuación esquematiza la descripción de los anchos de bandas
para los cuales están diseñados los sensores TM y ETM+.
Tabla 2. Resolución espectral de los sensores TM y ETM+ (Fernández y Herreno, 2001:7)

94
Cuando se refiere a Resolución Radiométrica Pinilla (1995:45) la define “como la
capacidad del sensor para discriminar niveles o intensidades de radiancia espectral”. De igual
manera Chuvieco (1996:95) la define como “la sensibilidad del sensor, o como su capacidad para
detectar variaciones en la radiancia espectral que recibe, por lo que suele identificarse como el
rango de valores que codifica el sensor. Aquí se introduce el término Nivel Digital, el cual es
definido por Chuvieco (19996:562) como un “valor entero que traduce la intensidad radiométrica
recibida por un sensor óptico-electrónico”. Agrega también que se le conoce como Digital
Number y como Píxel Velue.
La frecuencia de cobertura que proporciona el sensor es identificada por Chuvieco
(1996:96) como Resolución Temporal. Por su parte Pinilla (1995:45) la define como la
“capacidad del sistema para discriminar los cambios temporales sufridos por la superficie en
estudio”, comentando que “este concepto no hace referencia sino a la periodicidad con que el
sensor puede adquirir una nueva imagen del mismo punto de la superficie terrestre”. Este tipo de
resolución adquiere su mayor importancia cuando se pretende evaluar la evolución de un
fenómeno y no tiene mayor importancia si el uso que se le da a las imágenes es para cartografiar
un área en particular (Pinilla, 1995:46). Mientras que una definición un tanto más explícita es la
señalada por Parra (2007:1-45) al señalar que es la periodicidad con la que un satélite adquiere
imágenes de la misma porción de la superficie terrestre, siendo el caso específico del Landsat
ETM+ una resolución temporal de 16 días.
Tomando en cuenta que es un término relativamente reciente la Resolución Angular Parra
(2007:1-46) la define como la capacidad que tiene el sensor de hacer observaciones de la misma
área simultáneamente desde diferentes ángulos con lo que se mejora el proceso de captura de la
información ya que esto le imprime calidad a la resolución en general. Para cerrar culmina
comentando que son muy pocos los sensores que muestran esta capacidad y que entre ellos se
cuenta al sensor MISR (Multi-angle Imaging Spectroradiometer).
Lillesand y Kiefer (2000:190) hacen una simple definición de interpretación visual
comentando que esta se produce cuando es posible identificar lo que se ve en la imagen y lo visto
puede ser comunicado a otros. Continúan diciendo que la utilidad de la interpretación de
imágenes Landsat ha sido demostrada en muchos campos, tales como: agricultura, botánica,
cartografía, ingeniería civil, monitoreo ambiental, recursos forestales, geografía, geología
geofísica, análisis de recursos naturales, planificación en el uso de la tierra, oceanografía y
análisis de recursos hídricos.

95
Con el propósito de manejar los términos que describen los formatos en los cuales
generalmente se graban los Niveles Digitales (ND) de una imagen es importante definirlos a
continuación. Existen tres tipos de formatos más comunes, no siendo los únicos. El formato
Bandas secuenciales (Band Sequential, BSQ) presenta los ND de manera continua, uno a
continuación del otro, hasta completar los píxeles que la forman, y se completan todas las bandas
espectrales de la imagen situando los ND de una banda a continuación de la otra. El segundo tipo
de formato se conoce con el nombre de Bandas intercaladas por línea (Band Interleaved by Line,
BIL) donde en lugar de organizarse por bandas como en el caso anterior, los ND se organizan por
líneas, organizándose de manera consecutiva los ND que corresponde a todas las bandas, para
cada línea, antes de comenzar la línea siguiente, por lo que se verán de manera organizada tras los
ND de la línea 1, banda 1, los correspondientes a la línea 1 banda 2, continuando los de la banda
2, 4 etc., hasta completar el número total de bandas, para luego, tras la primera línea de la última
banda se sitúa la segunda línea de la banda 1, de la banda 2, y así hasta completar la imagen. Por
último se tiene el formato de grabación conocido como Banda intercalada por píxel (Band
Ineterleaved by Píxel, BIP) en donde los ND en lugar de alternarse en cada línea se alternan en
cada píxel, siendo este un formato muy poco empleado en la actualidad (Parra, 2007:2-7).
A los efectos de definir la escala de trabajo y el grado de desagregación la decisión sobre
estos elementos se fundamenta en el tipo de sensor escogido, específicamente en su resolución
espacial. La Asociación Cartográfica Internacional recomienda según Parra (2007: 1-43) que la
escala de trabajo para evaluaciones desarrolladas con imágenes adquiridas del sensor Landsat-
TM/ETM+ puede variar entre 1:50.000 a 1:100.000. Con respecto a estos factores Chuvieco
(1996:152) señala que la escala de trabajo condiciona la unidad más pequeña de información que
se debe incluir en el mapa y suele denominarse mínima unidad cartografiable (MUC) valor este
que también condiciona el número y desagregación de las categorías a discriminar conjuntamente
con la complejidad del terreno.
Alteraciones tanto del tipo radiométricas como del tipo Geométricas están presentes en las
imágenes obtenidas por sensores remotos, por lo que es necesario emprender las labores que
permitan reducir tales distorsiones y mejorar la calidad del material destinado a Procesamiento
Digital cualquiera sea el objetivo de este último.
En la mayoría de los casos, antes de iniciar la Fase de Procesamiento Digital de Imágenes,
resulta obligatorio evaluar el proceso de Corrección Geométrica, mejor conocido como
georreferenciación. La ejecución de esta corrección dependerá de la revisión que se haga del

96
material espectral con el que se trabaja, verificando si éste está georreferenciado, ya que en
muchas ocasiones es necesario incluir alguna información cartográfica auxiliar o simplemente
una región de interés, como es el caso de las Cuencas Hidrográficas, previamente digitalizada y
delimitada en formatos tales como .dxf derivados de aplicaciones propias de AUTOCAD.
Parra (2007:4-15) cuando trata lo concerniente a la georreferenciación de imágenes, señala
que:
El proceso de georreferenciación consiste en dar a cada píxel su localización en un
sistema de coordenadas estándar (UTM, Lambert, coordenadas geográficas). Existen
fundamentalmente dos métodos para realizar la georreferenciación. El primero, la
corrección orbital, requiere del conocimiento de las características de la órbita del
satélite como las del sensor. El segundo es el enfoque empírico que modela la
distribución de errores en la imagen utilizando puntos de control. El primero es más
automático conociendo la información necesaria y las ecuaciones de transformación; es
el que se suele suministrar cuando los datos e piden georreferenciados. El segundo es
más simple en cuanto a su formulación y acorrige mejores los errores aleatorios. Su
inconveniente es que es más trabajoso.
Cuando Chuvieco (1996) define la corrección geométrica de una imagen señala que
“incluye cualquier cambio en la posición que ocupan los píxeles que la forman”, y que “por
contraposición con las correcciones radiométricas, aquí no se pretende modificar los ND de
los píxeles de la imagen, sino sólo su posición, sus coordenadas”.
Una afirmación semejante reproduce Pinilla (1995) cuando dice que “las
correcciones geométricas son transformaciones puntuales, consistentes en cambiar de
posición las celdillas originales de la imagen sin alterar sus ND.
Sin embargo, Parra (2007:4-13) comenta algunos elementos de consideración, en los
términos siguientes:
Tradicionalmente las correcciones geométricas se han concebido como un
proceso previo e imprescindible a cualquier análisis posterior de la imagen. En
los últimos años, sin embargo, se prefiere restringir estas correcciones,
relegándolas, siempre que sea posible, a la fase final del trabajo, una vez que se
hayan obtenido los resultados finales de la interpretación. La razón es doble: por
un lado, se reduce el tiempo de tratamiento, pues, en lugar de corregir todas las
bandas originales, basa corregir una, la que contiene la imagen resultado; por
otro, se aborda la clasificación con los valores originales, evitando el efecto de
promedio parejo ejecutado en la fase de remuestreo del proceso de corrección.
Según la opinión de Pinilla (1995) el método de corrección más empleado es el que se
basa en puntos de control, que consiste en la selección de puntos presentes en una imagen
georreferenciada comunes, y fácilmente detectables sobre una imagen por georreferenciar,

97
frecuentemente situados sobre lugares singulares del terreno, como vértices geodésicos, cruces
de carreteras o caminos, esquinas de polígonos, etc. Este investigador igualmente comenta que el
proceso de corrección implica aplicación de funciones que transforman las coordenadas actuales
de los puntos de control en coordenadas corregidas en una determinada proyección cartográfica.
El procedimiento de georreferenciación involucra tres fases según lo señalado por
Chuvieco (1996): “localización de los puntos comunes a la imagen y al mapa (o a otra imagen
de referencia), cálculo de las funciones de transformación entre las coordenadas de la imagen y
las del mapa, y transferencia de los ND originales a la nueva posición definida por la
transformación previa.
A los efectos de la selección de los puntos comunes en la imagen a georreferenciar con
los de la imagen o mapa de referencia, Parra (2007:4-15), al hacer referencia a las utilidades del
programa de procesamiento digital de imágenes ENVI, comenta que, con este programa los
puntos de control del terreno son seleccionados usando la ventana de la Imagen y la ventana de
Zoom para la referenciación imagen-a-imagen e imagen-a-mapa; y que es posible visualizar las
coordenadas tanto para la imagen de referencia como para la imagen no corregida, junto con los
términos del error para los algoritmos de ajuste especificados; finalizando con el hecho de que la
predicción del siguiente punto de control permite simplificar el proceso de selección de dichos
puntos.
En el programa ENVI, según la explicación dada por Parra (2007:4-5), el ajuste se realiza
usando remuestreo, escalado y traslación (RST= resampling scaling translation), funciones
polinómicas (de orden 1 hasta n), o triangulación de Delaunay. Los métodos de remuestreo que
ofrece este programa incluyen vecino más cercano, interpolación bilineal, y la convolución
cúbica.
Durante el proceso de selección de puntos de control es prudente la observación de los
errores existente entre las coordenadas de los puntos seleccionados en la imagen de referencia, y
los equivalentes seleccionados en la imagen que se procesa. La relación dada por estos errores es
lo que Chuvieco (1996:268) define como la bondad del grado de ajuste. Comenta que se mide a
través de lo que se conoce como residual de la regresión, definida como la diferencia entre el
valor estimado y el observado, para cada uno de los puntos muestrales empleados en el proceso.
La calidad del juste es medida por la magnitud de esta diferencia. Mientras mayor sea la
diferencia, menor el ajuste. Para esta comparación se utiliza lo que Chuvieco (1996:268) señala
como el error medio cuadrático (Root Mean Squared, RMS).

98
Cuando se emprenden trabajos de evaluación de cambios a través de Teledetección, como
son las evaluaciones multitemporales, esto se hace, según Chuvieco (1996), comparando píxel a
píxel los ND de las distintas imágenes, según lo cual es necesario eliminar previamente cualquier
cambio en los ND de la escena que no sea debido a cambios reales en la cubierta. Esto implica
ajustar con precisión, tanto radiométrica como geométricamente las imágenes que intervienen en
el análisis.
Estas labores se enmarcan dentro de los que se conoce como Preprocesamiento de la
imagen y constituyen todos los procesos que tienden a corregir cualquier anomalía detectada en
la misma, ya sea en su localización (geometría) o en la calidad de los niveles digitales
(radiometría) de los píxeles que la componen.
Cuando Parra (2007) toca el tema relativo al Preprocesamiento de imágenes establece que
el mismo opera en dos fases diferentes: una orientada a hacer correcciones sobre la calidad de la
información contenida en los píxel, y la otra dirigida a corregir la posición de los mismos en el
espacio real.
La calidad de la información contenida en los píxel de las imágenes se logra a través de
las Correcciones Radiométricas, término que para Pinilla (1995) engloba las técnicas que
modifican los ND originales, con el objeto de acercarlos a los que estarían presentes en la imagen
en caso de una recepción ideal.
Tal como lo argumenta Parra (2007), dentro del término Corrección Radiométrica se
incluyen los procedimientos encaminados a resolver los problemas derivados del mal
funcionamiento del sensor; también las correcciones atmosféricas; y por último están aquellos
que implican la obtención de magnitudes físicas (reflectividad y temperatura).
La Restauración de líneas o píxeles perdidos y Corrección del Bandeo de la Imagen, son
las técnicas que mejoran la calidad de la información contenida en los píxeles (Parra, 2007).
La Corrección Atmosférica de la imagen es una tarea que debe ejecutarse luego de las
correcciones de restauración y bandeo. Este tipo de corrección, destinada a mitigar los efectos
atmosféricos en los valores de radiancia espectral medidos por el sensor, luego de aplicarse,
conserva los valores de ND en las unidades originales, variables entre cero y 255.
Para Paz et al (2005) los diferentes esquemas de corrección atmosférica utilizados
actualmente pueden ser clasificados como: Método de objetos invariantes, Método del objeto
oscuro; Método del ajuste de histogramas; y Método de reducción del contraste. Para estos
investigadores la mayoría de los métodos se basan en hipótesis de invarianza absoluta de los

99
objetos terrestres, por lo que su confiabilidad es limitada a la validez de esta hipótesis
fundamental.
Cabe destacar que la Corrección Atmosférica es una actividad de obligatorio
cumplimiento dentro del Preprocesamiento de imágenes debido a que, tal como lo explica
Chuvieco (1996), los componentes líquidos y gaseosos de la atmósfera producen un efecto de
absorción y dispersión, que modifican, a veces notablemente, la señal procedente de la cubierta,
afectando en mayor magnitud a la radiancia espectral de longitud de onda corta.
Para cumplir con el procedimiento de Corrección Atmosférica Pinilla (1995) comenta que
existen varias alternativas, unas más complejas que otras, así como relativamente diferentes entre
ellas, siendo la que se destaca por su factibilidad de aplicación, en la mayoría de los casos, la
conocida como Corrección del Histograma por sus valores Mínimos, que consiste en desplazar
hacia el cero el histograma de cada banda.
El empleo del histograma es considerado por Chuvieco (1996) como una metodología que
se apoya en los datos de la propia imagen, que permite obtener, a partir de los valores de las
distintas bandas, una estimación del efecto atmosférico. Continúa Chuvieco argumentando
elementos que permiten ubicar este procedimiento en función de su precisión y aplicabilidad,
cuando expresa que es un método bastante preciso para la corrección atmosférica en el térmico,
pero que en el visible resulta sólo una aproximación.
El Histograma Minimum Method (HMM) así llamado por Campbell (1987) citado por
Chuvieco (1995) es una sencilla aproximación a la corrección atmosférica que consiste en restar a
todos los ND de cada banda el mínimo de esa misma banda, situando el origen del histograma en
cero:
kkjikji NDNDND min,,,,, (17)
esto es, el ND del píxel (i,j) en la banda k, se ajusta restándole el ND mínimo de esa misma
banda”.
El histograma resultante de la operación anterior es similar al de la imagen de referencia
por lo que su empleo resulta factible si se considera que el hecho de que sean similares significa
que el brillo medio, contraste y distribución de niveles de grises son también parecidos.
Para el año 1996, en un trabajo publicado en la Revista Photogrammetric Engineering
and Remote Sensing, Chávez propone mejoras a los métodos de corrección atmosférica
propuestos para la fecha. Introduce el Método Cost(t), en el que, al igual que en el Método del
valor Mínimo del Histograma, la irradiancia espectral asume un mínimo de cero, pero donde la

100
transmitancia atmosférica es estimada como el Coseno del ángulo cenital solar (que resulta de
restar 90 al ángulo de elevación solar) y la alteración de la radiancia debida a las condiciones
atmosférica es estimada por la especificación del ND de objetos que deben tener radiancia cero.
Este enfoque se considera como un procedimiento mejorado para la estimación de los
efectos de absorción por gases presentes en la atmósfera y de difusión Rayleigh. En este método
la irradiancia difusa espectral del cielo es asumida como cero.
Considerando que si se usa como método de corrección atmosférica el HMM, sólo se
logra una aproximación a los valores de radiancia (expresados aún como ND) que debería recibir
y leer el sensor en condiciones atmosféricas óptimas, por lo que aún es necesario desarrollar el
cálculo de reflectividades para transformar los valores de ND de cada píxel en valores físicos.
En este sentido, el último paso a desarrollar a los efectos de mejorar la calidad de la
información obtenida de manera remota, es la transformación de los ND a valores de
reflectividad. Para esto es necesaria la aplicación de un conjunto de fórmulas sobre cada banda
espectral. Las mismas se describan a continuación:
Fórmula general:
cos*
**
,0
,
k
ksen
E
LK (18)
K es el factor corrector de la distancia Tierra – Sol
Lsen,k es la radiancia espectral recibida por el sensor en la banda k (W m2 sr
-1)
E0,k es la irradiancia solar en el techo de la atmósfera para una banda específica.
es el ángulo cenital de flujo incidente, formado por la vertical y los rayos solares (es el
complemento del ángulo de elevación solar, que se incluye en el archivo texto que describe las
características de la imagen, generalmente conocido como “cabecera” de la imagen.
El valor de K se determina por la siguiente fórmula:
2))365/)5.93(2((0167.01( DsenK (19)
La radiancia espectral Lsen,k viene dada por la ecuación:
kkkksen NDaaL ,1,0, (20)

101
Los valores de a0,k, a1,k se conocen como coeficientes de calibración para una determinada
Banda y son tomados de Pinilla (1995) de donde se reporta la Tabla 3 que incluye los valores de
Irradiancia espectral solar extraterrestre (E0,k).
Tabla 3. Coeficientes de calibración de las Bandas TM y valor de la irradiancia para cada
intervalo de longitud de onda. (Pinilla, 1995)
Banda Coeficientes
a0,k a1,k
Irradiancia esp.
E0,k(W/m2)
1 -0.06662095 0.04197408 138.25
2 -0.15732250 0.10345120 139.04
3 -0.11269370 0.06499743 89.1
4 -0.23285630 0.11705160 147.7
5 -0.08640033 0.02726504 44.6
7 -0.05113922 0.01692211 21.33
Para abordar el tipo de análisis más idóneo para un objetivo específico, sea visual o
digital, resaltan algunos aspectos a considerar propios de la tecnología disponible así como de los
recursos económicos (Chuvieco, 1996:158). A continuación se describen algunos de estos
aspectos referidos al tema de Transformaciones, en las que es posible extraer información de las
imágenes de satélite, de manera indirecta, y a su vez desarrollar modelos que permitan inferir
acerca de variables no medidas directamente por los sensores.
2.3.3.-Índice de Vegetación.
Como Transformaciones desarrolladas para caracterizar las cubiertas vegetales reforzando
la contribución espectral debida a ella, Pinilla (1995), define los Índices de Vegetación. Comenta
que estos valores minimizan la influencia de factores distorsionantes, como el suelo, la
irradiancia solar, el ángulo de elevación del Sol y la propia atmósfera. En general son clasificados
dentro de lo que se conoce como Índices Espectrales, los cuales son combinaciones entre bandas
que intentan enfatizar alguna variable de interés: vegetación, agua, minerales, entre otros (Parra,
2007).
La determinación del NDVI es un procedimiento netamente digital, donde intervienen
algoritmos especialmente diseñados para este propósito que son aplicados a través de programas

102
computarizados, ENVI, MULTISPEC, SPRING, ILWIS, para mencionar algunos. También es
posible desarrollar estos cálculos usando programas computacionales con capacidad para
desarrollar cálculos sobre matrices, es el caso del programa estadístico R y del programa
orientado al cálculo matemático, MatLab, entre otros.
Aprovechando las características radiométricas que muestran las masas vegetales es
posible emplear cocientes entre ND de dos bandas para discriminar dicha vegetación. Un
cociente o razón en términos de teledetección implica realizar una división, píxel a píxel entre los
ND almacenados en dos o más bandas de la misma imagen. Este cociente permite mejorar la
diferenciación entre dos cubiertas que tengan un comportamiento reflectivo muy diferente entre
dos bandas, con lo que el realce de suelo y vegetación se ve favorecido especialmente en las
bandas del visible e infrarrojo cercano; ya que mientras en la región visible (0,6 a 0,7 μm) los
pigmentos de la hoja absorben la mayor parte de la energía que reciben, estas sustancias apenas
afectan al infrarrojo cercano (0,7 a 1,1 μm), por lo que se produce un destacado contraste
espectral entre la baja reflectividad de la banda roja del espectro y la del infrarrojo cercano lo que
permite separar con relativa claridad la vegetación sana de otras cubiertas. De igual manera
permite reducir el efecto del relieve cuando se quiere caracterizar espectralmente distintas
cubiertas (Chuvieco, 1996:339).
Según Pinilla (1995) existen varios Índices de Vegetación, y en conjunto pueden ser
clasificados en dos grupos: Índices basados en transformaciones ortogonales (similares a las
realizadas en el análisis de componentes principales, y los Índices basados en los cocientes entre
bandas, siendo estos últimos los mayormente empleados dada su sencillez y robustez en los
resultados.
Para la mayoría de los investigadores consultados (Chuvieco 1996, Pinilla 1995, Sender,
2004, entre otros) unos de los índices de vegetación más difundidos es el índice de vegetación de
diferencia normalizada NDVI (Normalized Difference Vegetation Index) definido
matemáticamente a través del cociente de bandas:
RIRp
RIRpNDVI
(21)
Donde:
IRp es el ND de la banda correspondiente al Infrarrojo próximo o cercano, y
R es el ND de la banda correspondiente al visible en el canal Rojo.

103
El intervalo de existencia de este cociente de bandas está acotado entre -1 y +1 lo que
según Pinilla (1995) facilita la comparación y la interpretación de los resultados. La Figura 6
muestra una imagen resultado del cálculo de NDVI sobre Venezuela para febrero 2004, donde las
tonalidades de verde indican diferentes tipos o vigor de la vegetación, y los tonos oscuros indican
mayor actividad clorofílica.
Con el propósito de ilustrar de manera más detallada la concepción del NDVI resulta
interesante destacar lo descrito por el I.E.S Ramón J. Sender (2004:4): todo organismo vegetal
contiene pigmentos que captan diversas ondas del espectro de luz que la utilizan en las reacciones
fotosintéticas. Dos bandas del espectro, la azul (430 nm) y la roja (600nm) muestran la cantidad
de energía absorbida por las plantas.
Estas dos frecuencias de la luz son las más absorbidas por las plantas, por consiguiente
poco reflectadas. En contraste, la banda del infrarrojo cercano (750-1100 nm) actúa justo de
forma inversa; es reflejado casi en su totalidad. La mayor absorción del rojo y azul, junto con la
fuerte reflexión del infrarrojo cercano es la diferencia espectral de la respuesta de toda la
vegetación. Ninguna otra cubierta refleja de forma semejante, y por lo tanto, esta peculiaridad ha
sido usada durante mucho tiempo para poder diferenciar las superficies con vegetación de las
demás superficies.
Figura 6. Imagen NDVI de febrero de 2.004, elaborada a partir del sensor AVHRR.
(http://www.fii.org/wwwcpdi/antena/servicios.htm)

104
Igualmente refiriéndose a la definición del NDVI Parimbelli (2005:2) señala: el empleo de
cocientes o índices para identificar masas vegetales, tiene su base en el particular
comportamiento radiométrico de la vegetación. Una masa vegetal en óptimas condiciones, es
decir en buen estado sanitario, posee una firma espectral que se caracteriza por un claro contraste
entre las bandas visibles, y en especial la banda que corresponde al rojo (0.6 a 0.7 μm) y el
infrarrojo cercano (0.7 a 1.1 μm). Esto se da debido a que la mayor parte de la radiación solar
recibida por la planta en el visible, es absorbida por los pigmentos de las hojas, mientras que
éstos apenas afectan a la radiación recibida en el infrarrojo cercano, por lo que se presenta un alto
contraste entre una baja reflectividad en el visible y una alta reflectividad en el infrarrojo cercano.
Por lo tanto este comportamiento permite separar con relativa facilidad, la vegetación sana de
otras cubiertas.
Con mayor formalidad, la ecuación que describe el cociente NDVI se detalla a
continuación:
NDVI = (ρi IRC - ρi R) / ( ρi IRC + ρi R) (22)
Donde:
ρi corresponde a valores de reflectividad de la imagen.
Tal como se mostró en la Tabla 2, las bandas del IRC y del R presentan las siguientes
longitudes de onda: .75 a .90 y .63 a .690; partiendo de estos valores y basado en la ecuación 6
esta puede ser escrita en función del número de banda de la siguiente manera:
NDVI= (Banda 4 - Banda 3) / (Banda 4 + Banda 3) (23)
El cálculo del NDVI junto con otros procesos o cálculos, es conocido en el campo de la
Teledetección como “Transformaciones”, las cuales son definidas por Chuvieco (2006) como un
“proceso que permite generar nuevas bandas que mejoren la interpretación de la imagen”, donde
aparecen procedimientos como: Tasseled Cap (Pinilla, 1995:198); y el HIS (transformación por
Intensidad, Tono y Saturación. Parra 2007:3-15).
La Figura 7 establece la relación existente entre los valores de precipitación ocurridos en
dos estaciones del año 1967 para una zona geográficamente no descrita (Tamayo citado por
Chuvieco 2006) con los valores de NDVI leídos para esas estaciones. Las figuras se basan en un

105
análisis de regresión lineal en donde es posible observar que los valores de precipitación
ocurridos en primavera reportan mayores valores de NDVI que los observados para la estación de
invierno. Igualmente se destaca que existe una tendencia importante hacia la relación lineal de
primer orden entre estas variables.
Cuando se refiere a los resultados el I.E.S. Ramón J. Sender (2004) señala que: el
intervalo de valores obtenido del NDVI, varía entre (-1) y el (+1). De ellos, sólo los valores
positivos corresponden a zonas de vegetación. Los valores negativos, pertenecen a nubes, nieve,
agua, zonas de suelo desnudo y rocas; ya que sus patrones espectrales son generados por una
mayor reflectancia en el visible que en el infrarrojo.
La Figura 8 ilustra la interacción entre el espectro electromagnético y una superficie vegetal
en dos estados fisiológicos marcadamente diferentes, los cuales pueden ser evaluados y
diferenciados a través del cálculo del NDVI. Mientras mayor es el valor del NDVI mayor es el
vigor de la vegetación detectada.
Figura 7. Influencia de la lluvia en la vegetación
(Tamayo citado por Chuvieco 2006)

106
Figura 8. Estados fisiológicos de una planta según el valor de NDVI. (Chuvieco, 2006)
Es necesario aplicar correcciones atmosféricas sobre las bandas a las que se les
determinará los Índices de Vegetación, e igualmente deben hacerse los cálculos de
transformación de ND a valores de reflectividades. No obstante según comenta Chuvieco (1996)
algunos autores no tienen inconvenientes en utilizar directamente los ND de las imágenes
siempre que no se pretenda conceder un valor físico a los resultados.
Buscando contrarrestar el efecto atmosférico sobre los valores de los ND de imágenes que
no han recibido corrección radiométrica de ningún tipo, Guyout y Cu (1994) citados por
Chuvieco (1996) proponen una corrección que hace equivalente el cálculo con ND o con
reflectividades. La ecuación que proponen para las escenas Landsat TM es:
RIRC
RIRC
NDND
NDNDNDVI
801.0
801.0
(24)
Para Sánchez et al (2000) el uso del NDVI calculado sobre imágenes obtenidas por el
satélite NOAA-AVHRR está plenamente justificado dado su sencillez y tomando en cuenta la
baja resolución del material de referencia, lo que hace prácticamente imposible el cálculo de
NDVI más complejos, pero presenta un problema cuando se trabaja en zonas con baja densidad
de vegetación, y es muy sensible a la reflectividad del suelo sobre el que se sitúa el material

107
vegetal evaluado. Por tal razón Sánchez et al (2000) considerando que en zonas de baja densidad
de vegetación el valor del NDVI es muy similar al de zonas de suelo desnudo, y es imposible
detectar la presencia de vegetación.
Por esta razón se han construido, probado y expandido otros Índices que tienen
capacidades especiales en la mitigación de ciertos elementos que para el NDVI son perjudiciales.
Entre los más usados están el Índice de Vegetación Ajustado al Suelo (SAVI), aplicable para
zonas donde la vegetación es escasa por lo que el suelo pudiera aportar una contribución
importante a la radiancia espectral medida por el sensor, debido a lo cual el NDVI no resulta una
medida muy consistente de las condiciones de la vegetación.
El SAVI, diferenciándose del NDVI, incorpora un parámetro (L) relacionado con la
reflectividad del suelo, calculándose de la siguiente forma:
)1(,,
,,
, LLii
iiSAVI
RjiIRCji
RjiIRCji
ji
(25)
siendo el factor L una constante para ajustar la línea de vegetación-suelo al origen. Este valor
según Chuvieco (1999) puede establecerse en el orden de 0.5.
Otro Índice que merece especial atención es el Índice de Vegetación Atmosféricamente
Resistente (ARVI). Como su nombre lo indica, este índice es relativamente resistente a los
factores atmosféricos. El valor de este Índice tiene un rango desde -1 a +1. Se fundamenta en el
uso de la reflectividad en el azul para corregir la reflectividad en el rojo debida a la dispersión
atmosférica. Se recomienda su empleo en regiones de intensa actividad agrícola. Está definido a
través de la siguiente ecuación (Kaufman y Tanre, 1996):
)2(
)2(
BLUEREDNIR
BLUEREDNIRARVI
(26)
De igual manera se ha reportado el empleo del Índice de Vegetación Mejorado (EVI) el
cual fue desarrollado para mejorar el enfoque propuesto a través del NDVI, optimizándose la
señal de la vegetación usando la reflectividad en el azul para corregir la contribución de la
reflectividad del suelo y reducir la influencia atmosférica. Es comúnmente usado en regiones
donde los valores de NDVI muestran saturación. El valor de este Índice tiene un rango desde -1 a

108
+1. Está representado por la siguiente ecuación (Huete, A.R., H. Liu, K. Batchily, y W. van
Leeuwen, 1997):
15.76*5.2
BLUEREDNIR
REDNIREVI
(27)
En general el Índice SAVI está orientado a corregir distorsiones debidas al factor suelo,
diferenciándose del NDVI al incorporar un factor L relacionado con la reflectividad del suelo.
Por otro lado, el Índice ARVI contrarresta los efectos debidos a la atmósfera al incorporar
una tercera Banda espectral, la Banda del Azul. Y por último, el Índice EVI, manipulando al
igual que el Índice ARVI, la Banda espectral del Azul, muestra las capacidades del ARVI y del
SAVI, al reducir la influencia atmosférica y al corregir la contribución de la reflectividad del
suelo.
2.4.- Principios estadísticos para análisis de datos.
Una sencilla definición de Estadística es expuesta por Namakforoosh, M. (2005)
considerándola como la “ciencia de los datos”; y que implica la colección, clasificación, síntesis,
organización, análisis e interpretación de los datos.
Mendenhall (1995) hace dos definiciones destacadas en lo relativo a los Diseño de
Experimento y el Análisis de Varianza. Diseño de Experimentos es el procedimiento para
seleccionar datos de muestra, y Análisis de Varianza es el procedimiento estadístico mediante el
cual se comparan las medias de población; mientras que para Verzani (2005) el Análisis de
Varianza es un método para comparar medias, basado en la variación de las medias y puede ser
considerado como una forma especial de desarrollar modelos lineales.
Otro procedimiento que es de obligatoria definición en esta investigación es el relativo a
Regresión. Namakforoosh, M. (2005) lo define como una técnica estadística que intenta
desarrollar una línea recta o ecuación matemática lineal que describa la relación entre una
variable dependiente y una o más variables independientes. Comenta que a través del Análisis de
Regresión el investigador puede determinar la significancia estadística de la relación, medir el
grado de relación y cuantificar naturaleza y forma de la relación.

109
En el análisis estadístico donde intervienen más de dos variables uno de los primeros pasos
es representar gráficamente las variables individualmente, mediante histogramas o diagrama de
caja. Estas representaciones son muy útiles para detectar asimetría, heterogeneidad y datos
atípicos, entre otros. Un segundo paso, en materia de representación gráfica, de acuerdo con
Peña (2002), es el de construir diagramas de dispersión de las variables por pares, que al
disponerse en forma de matriz permite entender el tipo de relación existente entre pares de
variables, e identificar puntos atípicos en la relación bivariante.
Al tratar lo relativo al número de repeticiones más apropiado con el que debe desarrollarse
un experimento correctamente diseñado, Khuehl (2001), comenta que “cuando no es posible
realizar el experimento completo en un solo periodo, o en un mismo lugar, con el número de
réplicas necesario, se puede repetir varias veces o en distintos lugares. Comenta que, por ejemplo,
si se requieren ocho réplicas y no se pueden realizar al mismo tiempo, entonces se ejecutan dos
veces con cuatro réplicas. Cierra su comentario asegurando que “puede ocurrir diferente número
de réplicas debido a la pérdida de algunas unidades experimentales durante el estudio, o por otras
razones”; y asegura que la “pérdida de observaciones de un grupo de tratamiento tiene como
consecuencia una pérdida proporcional en la precisión de las estimaciones de la media de ese
grupo con respecto a las de los grupos con todos los datos".
Define el Error Experimental como el valor que “describe la variación entre las unidades
experimentales tratadas de manera idéntica e independiente”. Expone que “los distintos orígenes
del error experimental son: 1) variación natural entre unidades experimentales; 2) la variabilidad
en la medición de la respuesta; 3) la imposibilidad de reproducir las condiciones del tratamiento
con exactitud de una unidad a otra; 4) la interacción de los tratamientos con las unidades
experimentales, y 5) cualquier otro factor externo que influya en las características medidas”.
De igual manera, para Khuehl (2001) la estimación de la Varianza del Error Experimental
es un importante objetivo de los cálculos estadísticos, y asegura que “en su forma más simple el
error experimental es la varianza en unidades de las observaciones del experimento, cuando las
diferencias entre éstas se pueden atribuir sólo al error experimental”. En este sentido, para este
investigador, el control local es un valor que “describe las acciones que emplea un investigador
para reducir o controlar el error experimental, incrementar la exactitud de las observaciones y
establecer la base de inferencia de un estudio”.
Para Namakforoosh (2005) el Diseño de la investigación “es un programa que especifica el
proceso de realizar y controlar un proyecto de investigación, es decir, es el arreglo escrito y

110
formal de las condiciones para recopilar y analizar la información, de manera que combine la
importancia del propósito de la investigación y la economía del procedimiento”.
Paralelamente el Diseño de investigación está conformado, según Khuehl (2001) por la
hipótesis de investigación, el diseño del tratamiento y el diseño del estudio experimental o por
observación. El diseño del tratamiento debe encontrarse dentro del diseño del experimento. El
investigador debe decidir qué constituye una unidad experimental, cuántas réplicas de unidades
experimentales exige cada tratamiento y qué tratamiento asignar a cada una de ellas. Para él un
Análisis de varianza “es el procedimiento estadístico mediante el cual se comparan las medias de
población”, donde el Número de réplicas “afecta la precisión de las estimaciones de las medias
de los tratamientos y la potencia de las pruebas estadísticas para detectar las diferencias entre las
medias de los grupos en tratamiento. Pero este investigador considera que “el costo de conducir
estudios de investigación restringe las réplicas a un número razonable”, concluyendo entonces
que “el número de réplicas está determinado por las restricciones prácticas que se pueden asignar
al problema.
Al tratar acerca de uno de los elementos que conforma un Experimento Diseñado para
evaluar estadísticamente las medias de la población, Mendenhall (1995) define los Factores
como las variables independientes que pueden estar relacionadas con una variable de respuesta
“y”. Por su parte Kuehl (2001), ejemplifica el término Factores como un grupo específico de
tratamientos: temperatura, humedad y tipos de suelo, los cuales pueden ser considerados como
un factor cada uno. Mientras que al referirse a los Niveles de un factor y los Tratamientos,
Mendenhall (1995) los define como el grado de intensidad que un factor asume en un
experimento; y como las combinaciones específicas de niveles de los factores que intervienen en
un él, respectivamente.
Otros de los términos referidos a los Experimentos Diseñados son los Grados de libertad.
Son definidos por Royero, (1993), como la redundancia de las observaciones, argumentando que
“se puede pensar en los grados de libertad como el número de elementos estadísticamente
independientes en las sumas de cuadrados. Igualmente para Spiegel, (1970), se definen como el
número N de observaciones independientes de la muestra (es decir, el tamaño muestral) menos el
número k de parámetros de la población que deben estimarse a partir de las observaciones de la
muestra.
Uno de los aspectos que ha alcanzado cierta relevancia en el ámbito de la Estadística es la
Construcción de modelos matemáticos. Para Mendenhall, (1997), la construcción de un modelo

111
se refiere a escribir una ecuación que se ajuste bien a un conjunto de datos y proporcione buenas
estimaciones del valor medio de “y”, así como buenas predicciones de valores futuros de “y”
dados valores de las variables independientes. Para este investigador “los modelos lineales más
comunes para relacionar “y” con una sola variable independiente cuantitativa “x” son los que se
derivan de una expresión polinómica del tipo que se muestra a continuación:
E (y) = β0 + β1x + β2x2 + β3x
3 +……+ βpx
p
donde p es un número entero y β0, β1….βp son parámetros desconocidos que deben estimarse.
Explica Mendenhall, (1997) que “se usa un modelo de primer orden cuando se espera que la
tasa de cambio de “y” por unidad de cambio de “x” se mantenga más o menos estable dentro de
la gama de valores de “x” para los cuales se quiere predecir “y”. De igual manera, un modelo de
segundo orden describe una parábola que se abre hacia abajo (β2 ‹ 0) o hacia arriba (β2 › 0) y
“puesto que la mayor parte de las relaciones tienen cierta curvatura, un modelo de segundo orden
es en muchos casos una buena elección para relacionar “y” con “x”. Termina el comentario
Mendenhall, (1997) explicando que las inversiones de la curvatura no son comunes, pero tales
relaciones pueden modelarse mediante polinomios de tercer orden u orden superior, como puede
verse en la Figura 9.
Figura 9. Gráficas de dos modelos de tercer orden. (Mendenhall, W. 1997)

112
CAPÍTULO II
DESCRIPCIÓN DEL ÁREA DE ESTUDIO
En la recientemente publicada Ley de Aguas (Gaceta Oficial de la República Bolivariana
de Venezuela Nº 38.595, de fecha 02/01/07) se establecen 16 regiones hidrográficas y se señala
las cuencas que la integran. La cuenca del Río Areo es subcuenca del Río Amana y ésta se
encuentra ubicada en la región hidrográfica Nº 7 conocida como “Oriental”.
La mayor parte de la superficie de la cuenca en estudio está comprendida en el Municipio
Cedeño del Estado Monagas, y ocupa una pequeña porción del Municipio Freites del Estado
Anzoátegui.
El estado Monagas ocupa 28.900 Km2 en la región nororiental de Venezuela. Presenta
cuatro paisajes naturales bien definidos: Montaña (Serranía del Turimiquire), Altiplanicies o
mesas (llanos altos) y Planicies (llanos bajos). Los llanos ocupan el 90% del Estado. Esta
variedad de paisajes hace posible la abundancia de recursos naturales, así como un alto potencial
agrícola y forestal, dentro de las tres grandes unidades de paisajes descritas se diferencia el
paisaje de Valles, el cual se caracteriza por su forma alargada, relativamente plana, cuyo eje es un
curso de agua. En la Tabla 4 se muestran las características físicas de los suelos del Municipio
Cedeño del Estado Monagas.
El Municipio Cedeño, está situado al Norte del Estado Monagas, entre las coordenadas
63º 28` Longitud Oeste y 09º 33`- 10º 05`de Latitud Norte. Por el Norte limita con los Estados
Anzoátegui y Sucre y con el Municipio Acosta; por el Este con los Municipios Piar y Maturín,
por el Sur con el Municipio Ezequiel Zamora y por el Oeste con el Estado Anzoátegui. Posee una
superficie de 1.695 Km2. Su capital es Caicara de Maturín.
Este Municipio, presentó una población para el año 1991 de 26.516 habitantes, y según
estimaciones del Instituto Nacional de Estadísticas su población para 2010 será de 37.385
habitantes distribuida principalmente entre Caicara de Maturín, San Félix de Caicara, Areo,
Viento Fresco, Potrerito, Quebrada Seca, Caicarita y los Cardones.

113
Tabla 4. Características físicas de los suelos del Municipio Cedeño, Estado Monagas, Venezuela (Cova, J. 2000).
PAISAJE SISTEMA DE RELIEVE UNIDAD DE
RELIEVE
UNIDAD CARTOGRAFICA SUPERFICIE
COMPOSICIÓN TAXONOMICA SIMBOLO ha %
MONTAÑA
M*
Masivo cretácico en Medio Arcillas
– Arenisca M8.A* Vertiente Rectilínea disectada
Asoc. Áreas rocosas - Tipic Dystropepts
Tipic Haplustults, fases montañosas AR-5C-9Ba 10.644 6,17
Masivo cretácico en Medio de
conglomerados M8 B* Vertiente Irregular Disectada
Asoc. Tipic Haplustults, fases montañosas
Tipic Dystropepts - Áreas rocosas 9Ba-5C-AR 2.444 1,42
Masivo Terciario en Medio Arcillas – Arenisca M17*
Vertiente Concava- Rectilínea Asoc. Áreas rocosas
Tipic Dystropepts - fase montañosa AR-5C 19.044 11,05
Estructural en cuñas Cretacico
Terciario en medio lulitas – calizas, M15-24*
Tipic Ustropepts, fase inclinada 5Ad 6.015 3,49
PIEDEMONTE
P*
Conos y Abanicos P1*
Asoc. Áreas rocosas
Tipic Dystropepts, fases montañosas
Ustic Dystropepts, fase Piedemente
AR-5CBb 2.438 1,41
Glasis P2* Tipic Paleustults, fase extremadamente gravosa 9Ae 3.941 2,29
COLINAR C*
Lomas C14*
Lomas Terciarias -
Cuaternarias de topes
redondeados
Asoc. Ustic Dystropepts
Tipic Ustropepts, 5BA 10.583 6,14
Lomas C14* Lomas Terciarias -
Cuaternarias de topes
alargados
Asoc. Tipic Paleustults fase extremadamente gravosa Tipic Ustropepts
Ustic Dystropepts
9Ae-5AB 4.983 2,89
Colinas Cc* Colinas terciarias Asoc. Tipic Ustropepts
Ustic Dystropepts 5AB 8.277 4,80
ALTIPLANICIE
A*
Mesa conservada Plano - Ondulada Asoc. Tipic Haplustults Tipic Paleustults
9BA 39.380 22,84
Mesa disectada
ME*
Moderadamente Disectada Asoc. Tipic Haplustults
Ustic Dystropepts 9B-5B 11.974 6,95
Extremadamente Disectada Asoc. Tipic Paleustults - Tipic Haplustults
Bad lands - Ustic Dystropepts 9AB-BD-5B 24.022 13,93
VALLES V*
Acumulaciones Indiferenciadas
Depresiones intramontanas Asoc. Tipic Ustropepts, fase de valles
Aquic Dystropepts 5AcE 3.499 2,03
Valles Coluvio -Aluviales Grupo Fluventic Eutropepts, No Aquic Dystropepts o Tipic Ustropepts, fase de Asoc.
Valle
5D/E/Ac 12.111 7,02
Acumulaciones Diferenciadas Valles aluviales con varios
niveles de terrazas
Asoc. Tipic Ustropepts, fase de valles
Fluventic Eutropepts, 5AcD 13.045 7,57
TOTAL 172.400 100

114
El Municipio muestra una destacada variedad de suelos, entre los que se mencionan:
Suelos de Montaña; que corresponde a los ubicados en la serranía del Turimiquire, en
donde las condiciones geológicas y de pendiente originan suelos poco evolucionados,
moderadamente profundos y algunas veces vinculados con afloramientos rocosos.
Suelos de Altiplanicie (mesa); también denominados suelos de llanos altos orientales,
ubicados en un altiplano, con altitud entre 10 y 430 msnm, y pendiente general de 2-6%, cuya
geología superficial lo constituye la formación mesa. Los suelos son en término generalizado, de
textura predominante arenosa. Son suelos lavados (lixiviados), de baja fertilidad, con diferentes
grados de drenabilidad, erosión y pedregosidad dependiendo la posición que ocupa dentro del
paisaje.
Suelos de planicie o llanos bajos; se desarrollan en ambientes de inundaciones frecuentes
por lluvias y desbordamientos de ríos, influenciados, además, por efectos de mareas, en zonas
adyacentes al Delta del Orinoco. Presentan características generalizadas de mal drenado (baja
conductividad hidráulica) texturas finas y altos contenidos de materia orgánica.
Suelos de valles; son suelos de acumulación, relativamente “jóvenes” profundos, con alto
contenido de materia orgánica, afectados, en su mayoría por inundaciones frecuentes. A pesar de
su aparente homogeneidad, es posible diferenciar los suelos de valles, de acuerdo al relieve
circundante: suelos de valles intramontano ubicados en el Turimiquire, suelos de valle de mesa de
piedemonte: son los suelos de mayor valor agrícola, por calidad y cantidad; suelos en valle de
mesa plana y suelos de Morichales, estos últimos de gran valor ecológico e hidrológico, son
dominantemente arenosos, con alto contenido de materia orgánica, vinculado a un bosque de
galería permanentemente inundado, con predominio de la palma Moriche.
La composición del suelo representativa del área ocupada por la cuenca del Río Areo, está
conformada por un gran número de unidades; son las que se encuentran sombreadas en la Tabla
5. De cada unidad se describen tanto la caracterización física como química de los mismos,
(Tabla 6 y Tabla 7).

115
Tabla 5. Clasificación de Suelo – Unidades Cartográficas – Clasificación Capacidad de Uso del
Municipio Cedeño Estado Monagas (Cova, J. 2000).
SIMBOLO COMPOSICIÓN TAXONÓMICA
CLASIFICACION
CAPACIDAD DE
USO (SUB
CLASES)
SUPERFICIE
ha %
AR-5C-9Ba Asoc. Áreas rocosas - Tipic Dystropepts
Tipic Haplustults, fases montañosas VIIItes/Vites 10.644 6,17
9Ba-5C-AR Asoc. Tipic Haplustults, fases montañosas
Tipic Dystropepts - Áreas rocosas VIts/VIIIts 2.444 1,42
AR-5C Asoc. Áreas rocosas
Tipic Dystropepts - fase montañosa VIIItes/VItes 19.044 11,05
5Ad Tipic Ustropepts, fase inclinada VIt 6.015 3,49
AR-5CBb
Asoc. Áreas rocosas
Tipic Dystropepts, fases montañosas
Ustic Dystropepts, fase Piedemente
IVts 2.438 1,41
9Ae Tipic Paleustults, fase extremadamente gravosa IVts 3.941 2,29
5BA Asoc. Ustic Dystropepts
Tipic Ustropepts, IIIt 10.583 6,14
9Ae-5AB
Asoc. Tipic Paleustults fase extremadamente gravosa
Tipic Ustropepts
Ustic Dystropepts
Vts 4.983 2,89
5AB Asoc. Tipic Ustropepts
Ustic Dystropepts IIIt 8.277 4,80
9BA Asoc. Tipic Haplustults
Tipic Paleustults IIIs 39.380 22,84
9B-5B Asoc. Tipic Haplustults
Ustic Dystropepts IIIts 11.974 6,95
9AB-BD-5B Asoc. Tipic Paleustults - Tipic Haplustults
Bad lands - Ustic Dystropepts VItes 24.022 13,93
5AcE Asoc. Tipic Ustropepts, fase de valles
Aquic Dystropepts IIIsd 3.499 2,03
5D/E/Ac
Grupo Fluventic Eutropepts,
No Aquic Dystropepts o Tipic Ustropepts, fase de
Asoc. Valle
IIIsd 12.111 7,02
5AcD Asoc. Tipic Ustropepts, fase de valles
Fluventic Eutropepts, IIsd 13.045 7,57
TOTAL 172.400 100
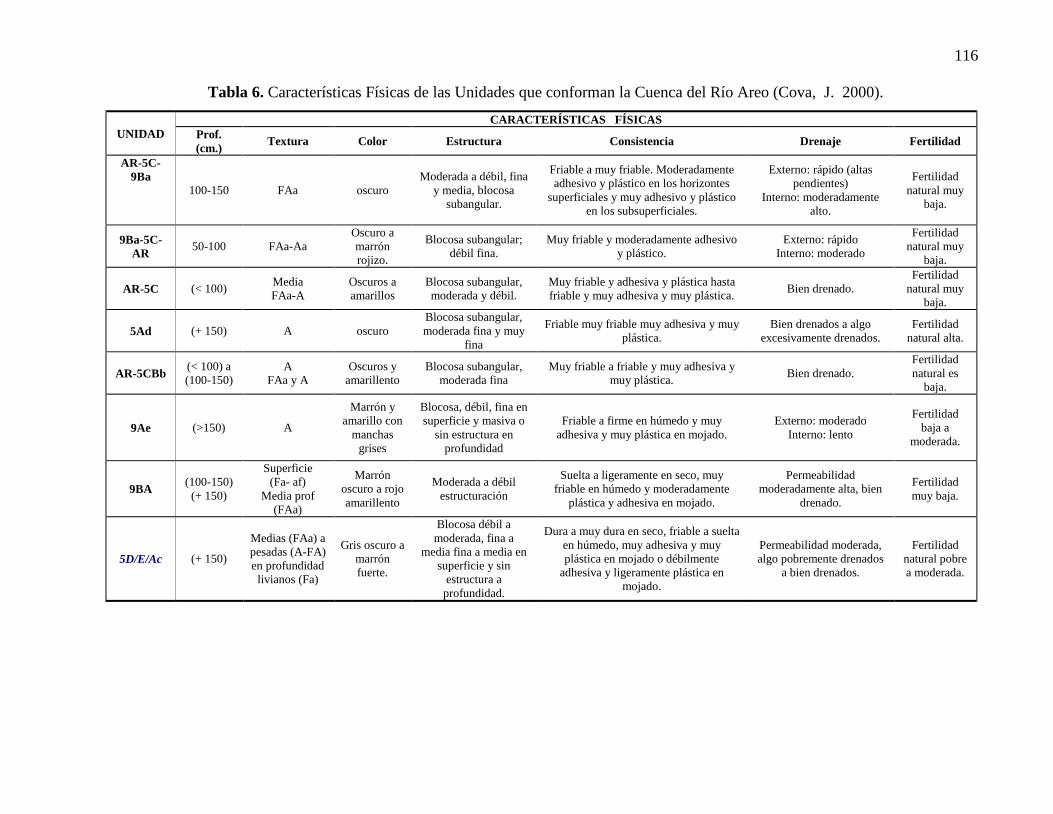
116
Tabla 6. Características Físicas de las Unidades que conforman la Cuenca del Río Areo (Cova, J. 2000).
UNIDAD
CARACTERÍSTICAS FÍSICAS
Prof.
(cm.) Textura Color Estructura Consistencia Drenaje Fertilidad
AR-5C-
9Ba
100-150 FAa oscuro
Moderada a débil, fina
y media, blocosa
subangular.
Friable a muy friable. Moderadamente
adhesivo y plástico en los horizontes
superficiales y muy adhesivo y plástico
en los subsuperficiales.
Externo: rápido (altas
pendientes)
Interno: moderadamente
alto.
Fertilidad
natural muy
baja.
9Ba-5C-
AR 50-100 FAa-Aa
Oscuro a
marrón
rojizo.
Blocosa subangular;
débil fina.
Muy friable y moderadamente adhesivo
y plástico.
Externo: rápido
Interno: moderado
Fertilidad
natural muy
baja.
AR-5C (< 100) Media
FAa-A
Oscuros a
amarillos
Blocosa subangular,
moderada y débil.
Muy friable y adhesiva y plástica hasta
friable y muy adhesiva y muy plástica. Bien drenado.
Fertilidad
natural muy
baja.
5Ad (+ 150) A oscuro
Blocosa subangular,
moderada fina y muy
fina
Friable muy friable muy adhesiva y muy
plástica.
Bien drenados a algo
excesivamente drenados.
Fertilidad
natural alta.
AR-5CBb (< 100) a
(100-150)
A
FAa y A
Oscuros y
amarillento
Blocosa subangular,
moderada fina
Muy friable a friable y muy adhesiva y
muy plástica. Bien drenado.
Fertilidad
natural es
baja.
9Ae (>150) A
Marrón y
amarillo con
manchas
grises
Blocosa, débil, fina en
superficie y masiva o
sin estructura en
profundidad
Friable a firme en húmedo y muy
adhesiva y muy plástica en mojado.
Externo: moderado
Interno: lento
Fertilidad
baja a
moderada.
9BA (100-150)
(+ 150)
Superficie
(Fa- af)
Media prof
(FAa)
Marrón
oscuro a rojo
amarillento
Moderada a débil
estructuración
Suelta a ligeramente en seco, muy
friable en húmedo y moderadamente
plástica y adhesiva en mojado.
Permeabilidad
moderadamente alta, bien
drenado.
Fertilidad
muy baja.
5D/E/Ac (+ 150)
Medias (FAa) a
pesadas (A-FA)
en profundidad
livianos (Fa)
Gris oscuro a
marrón
fuerte.
Blocosa débil a
moderada, fina a
media fina a media en
superficie y sin
estructura a
profundidad.
Dura a muy dura en seco, friable a suelta
en húmedo, muy adhesiva y muy
plástica en mojado o débilmente
adhesiva y ligeramente plástica en
mojado.
Permeabilidad moderada,
algo pobremente drenados
a bien drenados.
Fertilidad
natural pobre
a moderada.

Tabla 7. Características Químicas de las unidades que conforman la Cuenca del Río Areo
(Cova, J. 2000).
UNIDAD
CARACTERÍSTICAS QUÍMICAS
pH CIC
(meq/100gr) %SB % CO % N FOSFORO
AR-5C-9Ba Muy acido
(4,5-5,0)
Mediano
(8-20)
Mediano
(15-30)
Normal
(1,5-2,5)
Pobre
(< 0,20)
Muy pobre
(trazas)
9Ba-5C-AR Muy acido
(5,0)
Baja
(≈10)
Mediano
(20)
Normal
(1,5)
Bajo
(0,15)
Bajo
(trazas)
AR-5C Muy acido
(4,6)
Media
(10-20)
Media
(30)
Normal
(1,5)
Pobre
(0,10-0,15)
Pobre
(trazas)
5Ad Casi neutro a
neutro (6,4-7,9)
Alto
(20-30)
Alto
(+80)
Normal
(1,5-2,5)
Normal
(0,15-0,25)
Bajo
(0-0,9ppm)
AR-5CBb Muy ácido
(4,0-4,5)
Alta
(15-40)
Alta
(30-50)
Normal
(1,5-3,5)
Normal
(0,15-0,30) Bajo (trazas)
9Ae
Ligeramente
acido a neutro
(5,5-7,5)
Media a alta
(10- 25)
Alta
(40-50)
Bajo
(1,0- 1,5)
Bajo
(0,0-0,1)
Bajo
(trazas)
9BA Acido
(4,5-5,0)
Muy baja
(2-5)
Media a alta
(30-60)
Muy pobre
(0-1,0)
Muy pobre
(0.10)
Bajo
(trazas)
5D/E/Ac Acido a alcalino
(5,1-8,1)
Baja a mediana
(8-20)
Alta a muy alta
(30-60)
Muy bajo a bajo
(0-1,5)
Muy bajo
(0,20)
Bajo
(trazas)

123
CAPÍTULO III
MATERIALES Y MÉTODOS
4.1 MATERIALES
- Reportes de precipitación de las estaciones climatológicas cercanas al área de estudio,
disponibles en el MARN. Los datos de precipitación se muestra en el Anexo 1. Los nombres y
ubicación geográfica de las Estaciones Climatológicas están indicados en la Tabla 8.
- Imágenes de satélite del área de interés, disponibles en el portal Web de la
Universidad de Maryland: http://glcfapp.umiacs.umd.edu:8080/esdi/index.jsp.
- Hojas cartográficas a escala 1:25000 de la zona en estudio solicitadas al IGVSB:
7445 – IV – NO, 7445 – IV – SO, 7445 – III – NO, 7445 – III – NE, 7445 – III – SE, 7446 – III –
NO, 7446 – III – SO, 7445 – IV – SE.
Estas Cartas se muestran en el Anexo 2. En la Figura 10 se observa una extracto del
cubrimiento cartográfico oficial, disponible en el portal Web del Instituto Geográfico de
Venezuela Simón Bolívar, donde se visualiza el índice cartográfico que abarca la Cuenca del Río
Areo de donde se obtuvo la lista de hojas señaladas anteriormente.
Figura 10. Índice Cartográfico usado para ubicación de hojas cartográficas de la Cuenca del
Río Areo. (Instituto Geográfico de Venezuela Simón Bolívar, 2006)

124
Tabla 8. Estaciones Climatológicas consideradas para el Cálculo de la Precipitación Media en la
cuenca del Río Areo (Cova, J. 2000).
ESTACIÓN SERIAL LAT LONG ALTITUD
msnm
COORDENADAS UTM ESTADO
Norte Este
El tejero 2834 09º 38’ 63º 40’ 240 1066093.91 426183.11 Monagas
La pinta 2836 09º 55’ 63º 52’ 440 1096335.03 404985.92 Monagas
La trampa 1898 10º 05’ 63º 47’ 955 1114744.41 412948.63 Monagas
Mundo nuevo 2718 09º 57’ 64º 03’ 600 1100079.00 384896.49 Anzoátegui
Sabana de
Neverí 1780 10º 08’ 64º 00’ 1580 1120335.25 390439.85 Sucre
Urica 2730 09º 43’ 64º 00’ 243 1075488.77 390304.86 Anzoátegui
Viento fresco 2802 09º 46’ 63º 40’ 195 1079701.28 425661.62 Monagas
Nota. Coordenadas transformadas a través del programa de computación TRANSFORVEN, coordenadas
geográficas de las estaciones.
4.2 EQUIPOS y SOFTWARE
- Escáner.
- Unidad de procesamiento de datos: Computador Intel Celeron, 1.46 GHz, 1.5 GB en
memoria RAM.
- Impresora multifuncional.
- Software para el análisis cartográfico: Auto CAD Land y Transforven.
- Software para el procesamiento digital de imágenes de satélite: ENVI e Idrisi Andes.
- Software para el análisis estadístico de los datos: R

125
4.3.- METODOLOGÍA
4.3.1 Fase de evaluación Hidrológica
1.- Vectorización digital de la cuenca
El proceso de vectorización digital de la cuenca consiste en la transformación del
material ráster disponible en formato imagen digital (TIFF) a formato vectorial a través de
manipulación asistida por computadora (.dwg).
La cuenca se vectorizó a partir de las hojas cartográficas disponibles en escala 1:25.000
editadas por el Instituto Geográfico de Venezuela Simón Bolívar. La vectorización y
determinación de parámetros morfométricos se hizo a través de Autocad Land en combinación
con el software de construcción de Sistemas de Información Geográfica (SIG) Arc Map, y la
representación cartográfica resultante se trabajó a escala 1:50.000.
Las hojas cartográficas, en su formato original, fueron adquiridas con extensión .tiff.
Cuando son importadas sobe la consola de Autocad Land se muestran con un fondo negro que
puede resultar incómodo para quien desarrolla la digitalización. Por tal motivo, para mejorar su
visualización mostrándola tal como se observan cuando son impresas en papel fue necesario
transformarlas a formato JPEG utilizando Paint, una aplicación para manejo de imágenes que
corre en el sistema operativo Windows XP. Cada una de las imágenes fue abierta con Paint e
inmediatamente guardadas en formato JPEG.
Posterior al cambio de formato de la imagen, fue necesario eliminar de ellas la
información marginal que no se necesitaron para su vectorización. Esta información es la relativa
a escala gráfica, índice de cartas, mapa de ubicación relativa, leyenda, que vienen con la imagen,
ubicada al borde de ésta. Se usó otra aplicación diseñada para el manejo de imágenes: Microsoft
Office Picture Manager, donde a cada imagen se le “recortó” toda la información marginal
haciendo la presentación de la misma, apta para su inserción y manipulación en Autocad Land.
Las imágenes luego de manipularse en cuanto a cambio de formato y eliminación de
información marginal, fueron insertadas, escaladas, georreferenciadas y vectorizadas en Autocad
Land, cuidando de asignar los atributos diferentes en capas separadas.

126
El proceso de “vectorización” consiste en “dibujar” sobre la imagen de fondo los atributos
que ésta muestra: curvas de nivel, vialidad, construcciones e hidrografía. Cada atributo se dibuja
usando el comando polilínea de AutoCad y se genera y guarda en capas (layers) diferentes.
Uno de los primeros elementos que se vectoriza es el perímetro de la cuenca. Consiste en
resaltar la red hidrográfica o afluentes del río, ya que sus extremos que ocupan la posición más
alta, señalan las divisorias de aguas o “parte agua” que lo separan de zonas adyacentes
pertenecientes a otras cuencas hidrográficas. Una forma de ayudarse con la demarcación del
perímetro de la cuenca es imprimir el mosaico de hojas cartográficas que contiene la Cuenca, y
hacer la divisoria de aguas sobre el papel impreso para tenerla de referencia al momento de
hacerla en formato digital.
Finalizada la demarcación del perímetro de la cuenca se emprende la determinación de los
parámetros morfométricos de la misma, así como las líneas isocronas, los polígonos de Thiessen
y las curvas isoyetas.
Los parámetros morfométricos que se calcularon para esta cuenca se listan a continuación:
Área
Longitud axial
Elevación media
Factor de forma (Ff)
Coeficiente de compatibilidad (K)
Elevación mediana
Elevación modal
Pendiente media de la cuenca (S).
El área de la cuenca y la longitud axial del cauce se determinaron utilizando comandos
básicos de AutoCad. El resto de los elementos morfométricos se calcularon aplicando las
ecuaciones correspondientes.
2.- Construcción del Hidrograma de la Cuenca
2.1.- Se elaboró el hietograma de lluvia total que se obtuvo de los datos reportados por las
Estaciones Climatológicas seleccionada para el estudio.
2.2.- Se estimó las abstracciones usando el Método del SCS (Chow y colaboradores,
1991; Bolinaga, 1999).

127
2.3.- Conocidas las abstracciones fue posible construir el hietograma de exceso de lluvia
(Precipitación efectiva). Este resultado se reportó en tablas y figuras.
2.4.- Se dibujaron las líneas isocronas. Ver procedimiento indicado en los puntos 2.4.1 y
2.4.2.
2.5.- Se determinó el área encerrada entre las líneas isocronas, usando AUTOCAD.
2.6.- Se calculó el Hidrograma Unitario Instantáneo (m3/s*mm). Ver procedimiento
descrito a continuación.
2.7.- El Hidrograma de caudales se calculó a partir del Hidrograma Unitario Instantáneo.
Los pasos 2.1, 2.2, 2.3, 2.6 y 2.7 fueron desarrollados usando códigos de programación
generados en el programa Estadístico R.
A continuación se describe el procedimiento para la determinación de los valores que
conforman el Hidrograma Unitario Instantáneo (HUI) y el Hidrograma de Caudales (HC),
señalado en el punto 2.6.
Se usó el Método de C. O. Clark
Se aplicó la ecuación de Tránsito de Muskimgum
jjjj QCICICQ 21101 , descrita en las Ecuaciones (12), (13), (14) y (15) cuyo
cálculo se desglosa en el siguiente esquema:
1.- Construcción de Tabla para cálculo del Hidrograma Unitario Instantáneo (HUI), e
Hidrograma de Caudales (HC) compuesta por ocho columnas que se identifican como:
Tiempo(h)
(1)
Inter. Área %
(2) (3)
Co + C1
(4)
C2
(5)
(4) + (5)
(6)
HUI
(m3/s/mm)
Q
m3/s
2.- Fijación del tiempo de tránsito del caudal en horas (Columna 1). Debe ser mayor que tiempo
de concentración para darle tiempo a toda la precipitación a acceder al punto de control donde se
construye el HUI.
La columna (2) sólo contiene valores en las líneas del Tiempo (h) de la columna (1) que
coinciden con los Tiempos de Concentración. Son los valores de las áreas existentes entre líneas
isocronas.
3.- Cálculo de C0 ecuación (13)
4.- Cálculo de C1 C1 = C0
5.- Cálculo de Co + C1

128
6.- Cálculo de C2 ecuación (15)
7.- Cálculo de C0 + C1 + C2 = Columna (6)
8.- Cálculo del Escurrimiento Unitario usando la fórmula 16 indicada en el Capítulo I.
9.- Cálculo de HUI= EU * Valor de la Columna (6)
10.- Transformación de P (efectiva) en caudal Q = Pe * HU
11.- Cálculo de caudal promedio (Q) para el evento de precipitación. Es el valor de caudal que se
reporta.
La P (efectiva) se calculó aplicando la ecuación de Pe reportada por el SCS (fórmula 8
indicada en el Capítulo I).
Los valores calculados para el paso 10 representan los valores del Hidrograma de Caudal.
Es el caudal que se quiere simular a través del método aplicado.
El Hidrograma de Caudal muestra la distribución de este valor durante todo el tiempo en
el que se considera ocurre la precipitación y se genera escurrimiento. A los efectos de la presente
investigación, considerando que se disponen de los valores promedios mensual de la
precipitación para cada Estación Climatológica, se escoge aquella Estación que abarca la mayor
área de influencia sobre la zona de interés (usando Polígonos de Thiessen), y el Hidrograma de
Caudal se construye calculando el exceso de precipitación y combinando éste con el Hidrograma
Unitario, para las mismas unidades de tiempo de las que se dispone de los datos de precipitación,
de lo que se obtiene el Hidrograma Mensual de la Cuenca, que muestra los valores de caudal para
cada mes del año considerado.
Para el cálculo del Hidrograma de Caudal, a partir del Hidrograma Unitario Instantáneo,
se calcularon los valores de la Precipitación Efectiva, para cada mes, a partir de los datos anuales
disponibles. Para los 12 meses de cada uno de los años disponibles se determinó la Precipitación
Efectiva. La Precipitación Efectiva se calculó aplicando la ecuación de Pe reportada por el SCS
(fórmula 8 indicada en el Capítulo I). Para el desarrollo de esta ecuación se construyó y corrió un
código de programación elaborado en el programa Estadístico R. Con el propósito de calcular los
caudales de escorrentía a partir de la Precipitación Efectiva, según las consideraciones planteadas
por Chow y colaboradores (1994), en el código se incluyen líneas configuradas para la
determinación de dicho caudal, considerando el área de la Cuenca. Sobre este valor de área de la
Cuenca se hace un ajuste de modo que sólo parte de dicha cuenca contribuya con el caudal
escurrido.

129
A continuación se transcribe y explica el código construido para ser corrido en el
programa Estadístico R, con el cual se calculó la precipitación efectiva para cada uno de los
meses de cada año de registro de precipitación neta (también conocida como Precipitación Total
o Precipitación Bruta) disponibles.
##CÁLCULO DE LA PRECIPITACIÓN EFECTIVA A PARTIR DE LA PRECIPITACIÓN
##NETA
##DATOS NECESARIOS:
##ÁREA DE LA CUENCA: SE OBTIENE DEL PLANO DE LA CUENCA
##NÚMERO DE CURVA: SE OBTIENE DE LA TABLA 5.5.2 PAGINA 154 DEL #TEXTO
HIDROLOGÍA APLICADA DE VEN TE CHOW (1999) O DE LA PÁGINA ##461 DEL
TEXTO: SIMULATION OF ECOLOGICAL AND ENVIRONMENTAL ##MODELS, DE
MIGUEL ACEVEDO (2004)
##VALORES DE PRECIPITACIÓN: EL CÓDIGO ESTÁ HECHO PARA CALCULAR #LA
PRECIPITACIÓN EFECTIVA MENSUAL A PARTIR DE LA PRECIPITACIÓN
##PROMEDIO MENSUAL.
## EL CÓDIGO BUSCA LOS VALORES DE PRECIPITACIÓN EN UN ARCHIVO ##TEXTO
DONDE ESTÁN ORDENADOS DESDE ENERO HASTA DICIEMBRE ##DICHOS
VALORES POR LO QUE HACE DOCE CÁLCULOS DE PRECIPITACIÓN #EFECTIVA.
## ESTOS DATOS DEBEN OBTENERSE DE LA ESTACIÓN CLIMÁTÓLICA DE
##MAYOR INFLUENCIA
## FUNDAMENTO MATEMÁTICO:
## SE USA LA ECUACIÓN DE Pe DEL SERVICIO DE CONSERVACIÓN DE ##SUELOS
DE USA.
##INGRESE AQUÍ EL VALOR DEL NÚMERO DE CURVA CORRESPONDIENTE:
cn = 65
##INGRESE AQUÍ EL NÚMERO DE MESES POR AÑO Y UNA FRACCIÓN DEL ##ÁREA
DE LA CUENCA:
n = 12
AreaCuenca= 110
##CONFIGURACIÓN PARA LECTURA QUE ARCHIVO QUE CONTIEN LOS
##DATOS P_NETA

130
precipitaciones<-read.table("datosgenerales.txt",header=T,row.name=1)
precipitaciones<-t(precipitaciones)
precipitaciones<-data.frame(precipitaciones)
attach(precipitaciones)
MESES<-c(1,2,3,4,5,6,7,8,9,10,11,12)
##PARA EL PRESENTE TRABAJO SE DISPONÍA DE DATOS DE PRECIPITACIÓN
##PARA VEINTE AÑOS, DESDE 1986 HASTA 2005
##GENERACIÓN DE ARCHIVOS INDIVIDUALES PARA CADA AÑO
Año1986<-data.frame(MESES,X1986);colnames(Año1986)=c("Mes","P_Neta")
Año1987<-data.frame(MESES,X1987);colnames(Año1987)=c("Mes","P_Neta")
Año1988<-data.frame(MESES,X1988);colnames(Año1988)=c("Mes","P_Neta")
Año1989<-data.frame(MESES,X1989);colnames(Año1989)=c("Mes","P_Neta")
Año1990<-data.frame(MESES,X1990);colnames(Año1990)=c("Mes","P_Neta")
Año1991<-data.frame(MESES,X1991);colnames(Año1991)=c("Mes","P_Neta")
Año1992<-data.frame(MESES,X1992);colnames(Año1992)=c("Mes","P_Neta")
Año1993<-data.frame(MESES,X1993);colnames(Año1993)=c("Mes","P_Neta")
Año1994<-data.frame(MESES,X1994);colnames(Año1994)=c("Mes","P_Neta")
Año1995<-data.frame(MESES,X1995);colnames(Año1995)=c("Mes","P_Neta")
Año1996<-data.frame(MESES,X1996);colnames(Año1996)=c("Mes","P_Neta")
Año1997<-data.frame(MESES,X1997);colnames(Año1997)=c("Mes","P_Neta")
Año1998<-data.frame(MESES,X1998);colnames(Año1998)=c("Mes","P_Neta")
Año1999<-data.frame(MESES,X1999);colnames(Año1999)=c("Mes","P_Neta")
Año2000<-data.frame(MESES,X2000);colnames(Año2000)=c("Mes","P_Neta")
Año2001<-data.frame(MESES,X2001);colnames(Año2001)=c("Mes","P_Neta")
Año2002<-data.frame(MESES,X2002);colnames(Año2002)=c("Mes","P_Neta")
Año2003<-data.frame(MESES,X2003);colnames(Año2003)=c("Mes","P_Neta")
Año2004<-data.frame(MESES,X2004);colnames(Año2004)=c("Mes","P_Neta")
Año2005<-data.frame(MESES,X2005);colnames(Año2005)=c("Mes","P_Neta")
##CÁLCULO DE LA RETENCIÓN POTENCIAL MÁXIMA "S"
S<-254*(100/cn -1)
##CÁLCULO DE LA PRECIPITACIÓN EFECTIVA PARA UN AÑO
Pr_Neta<-matrix(nrow=12,ncol=1)
Pr_Efectiva<-matrix(nrow=12,ncol=1)

131
Abst<-matrix(nrow=12,ncol=1)
##INDICAR EL AÑO PARA EL CUAL SE HACE EL CÁLCULO DE P EFECTIVA:
attach(Año2005)
##CONFIGURACIÓN PARA CÁLCULO DE P EFECTIVA:
for (i in 1:n) {
if ((P_Neta[i]) >=0.2*S)
Pr_Efectiva[i]<-((P_Neta[i])-0.2*S)^2/((P_Neta[i])+ 0.8*S)
else Pr_Efectiva[i]<- (0)
Pr_Neta[i]<-(P_Neta[i])
Abst[i]<-(P_Neta[i])- Pr_Efectiva[i]
}
Q_mensual<-matrix(nrow=12,ncol=1)
for (i in 1:n) {
Q_mensual[i]<-Pr_Efectiva[i]*1000000*AreaCuenca/2592000
}
Q_mensual
##CONFIGURACIÓN PARA GENERACIÓN DE TABLA DE RESULTADOS:
meses<-c("Enero","Febrero","Marzo","Abril","Mayo","Junio","Julio","Agosto",
"Septiembre","Octubre","Noviembre","Diciembre")
Pr_Neta<-round(Pr_Neta,2)
Pr_Efectiva<-round(Pr_Efectiva,2)
Abst<-round(Abst,2)
Q_mensual<-round(Q_mensual,2)
resultados<-data.frame(meses,Pr_Neta,Pr_Efectiva,Abst,Q_mensual)
colnames(resultados)=c("Mes","P_neta","P_efectiva","Abstracción","Caudal(l/s)")
attach(resultados)
##CONFIGURACIÓN PARA GUARDAR UN ARCHIVO TEXTO CON LOS
#RESULTADOS:
##AQUÍ DEBE INDICARSE EL AÑO PARA EL CUAL CORRESPONDE ESTOS
##CÁLCULOS
write.table(resultados,file="LLUVIA-ESCORRENTÍA AÑO 2000.txt",row.name=Mes,
sep= " ")

132
##CONFIGURACIÓN PARA ELABORACIÓN DE GRÁFICOS
##HIETOGRAMAS DE PRECIPITACIÓN NETA: COLOCAR EL AÑO EN EL TÍTULO
par(mfrow=c(2,2))
plot(MESES,P_neta,las=2,axes=F,type="b",cex.axis=0.7,main=c("Histograma de Precipitación
Neta año 2000"));box();axis(2,cex.axis=0.8,las=2);
axis(1,1:12,paste(c("Enero","Febrero","Marzo","Abril","Mayo","Junio","Julio","Agosto",
"Septiembre","Octubre","Noviembre","Diciembre")),cex.axis=0.8,las=2)
plot(MESES,P_efectiva,type="b",las=2,cex.axis=0.7,main=c("Hietograma de Precipitación
Efectiva año 2000"));box();axis(2,cex.axis=0.8,las=2)
axis(1,1:12,paste(c("Enero","Febrero","Marzo","Abril","Mayo","Junio","Julio","Agosto",
"Septiembre","Octubre","Noviembre","Diciembre")),cex.axis=0.8,las=2)
barplot(rbind(P_neta,P_efectiva),beside=T,axes=F,names.arg=meses,
xlab=c("Meses"),ylab=c("P_Neta y P_Efectiva en mm"),las=1,cex.names=1,main=c("Evento
Precipitación vs Evento Escorrentía para el Año 2000")); box(); axis(2,cex.axis=0.8,las=2)
resultados
##FIN DE CÓDIGO
Para calcular la Escorrentía que origina la precipitación se consideró el Grupo de Suelo
con el que se trabajó y la condición de humedad antecedente. El Grupo de suelo en función de la
humedad antecedente está definido en la Tabla 1 incluida en el Capítulo I de este material. Con él
es posible seleccionar el número de curva (CN), valor con el que se determina la “retención
potencial máxima” (S) que se calcula aplicando la ecuación 9.
2.1.- Cálculo Tiempo de Concentración
Tiempo de concentración de la cuenca es el tiempo que tarda en llegar al punto de drenaje
en común la gota que cae en el punto más alejado de la cuenca. Existen varias fórmulas para su
determinación las cuales fueron comentadas en el Capítulo I de este material. Atendiendo a
razones prácticas, para la construcción de las líneas Isocronas, que parte de la determinación de
un conjunto variable de Tiempos de Concentración de puntos ubicados de manera aleatoria sobre
la cuenca, se elaboró un código de programación para ser usado sobre el programa Estadístico R.

133
Este conjunto de instrucciones hace relativamente fácil el cálculo de los diferentes TC que se
usan posteriormente para calcular y dibujar las líneas Isocronas en AUTOCAD.
A continuación se transcribe el código usado en el programa Estadístico R para la
determinación del TC:
##CÓDIGO PARA CÁLCULO DE TIEMPO DE CONCENTRACIÓN USANDO LA
##FÓRMULA DE KIRPICH:
##IMPOTACIÓN DEL ARCHIVO QUE CONTIENE LA LONGITUD Y DESNIVEL
datos<-read.table("datos.txt",header=T); attach(datos)
##INDIQUE AQUÍ, EN EL VALOR DE n, EL NÚMERO DE DATOS DISPONIBLES:
n <- 21
##CÁLCULO BASADO EN LA ECAUCIÓN DE KIRPICH
pendiente<-matrix(nrow=n,ncol=1) ; TC <- matrix(nrow=n,ncol=1)
Nro<-seq(1:n)
for (i in 1:n) {
pendiente[i]<- Desnivel[i]/L[i]
TC[i]<-0.0078*(L[i]^0.77/pendiente[i]^0.385)
}
##ORGANIZACIÓN DE LA TABLA DE RESULTADOS:
TC<-round(TC,2); pendiente<-round(pendiente,2)
resultados<-data.frame(Nro,L,Desnivel,pendiente,TC)
colnames=c("Nro","Longitud","Desnivel","S","T de C")
write.table(resultados,file="TC de varios puntos sobre la cuenca.txt")
resultados
## FIN DEL CÓDIGO
La primera línea del código: datos<-read.table("datos.txt",header=T) busca un archivo
texto que contiene los datos disponibles para el cálculo de los TC. Los datos que contiene este
archivo fueron determinados sobre el plano de la cuenca, trabajando en el programa AUTOCAD.
Sobre la cuenca se dibujaron 21 puntos, que fueron identificados con una numeración creciente
desde el número uno hasta el número 21 acompañado de la nomenclatura TC. Cada punto TC se
dibujó sobre un cauce tributario del Río Areo. A partir de dicha posición se midió la distancia que
recorrería una gota de agua hasta llegar a la desembocadura de dicho tributario sobre el
mencionado río. Esta distancia se midió usando la función list disponible en la barra de

134
herramientas Inquiry de AUTOCAD, luego de seleccionar el vector que determina el recorrido.
El desnivel existente entre la posición donde se dibujó el punto TC y la unión del tributario con
el río principal se determinó restando los valores de cotas conocidos para cada punto. Los
valores de Número de TC (Pto.), longitud (L) y Desnivel fueron organizados en un archivo texto
y guardados en una carpeta de dirección conocida con el nombre “datos.txt”. Al abrir este archivo
para su revisión se observa que los datos quedaron organizados como se muestra en la Figura 11.
Figura 11. Organización de los datos, en un archivo texto, para el cálculo de TC
Para correr el código en el programa Estadístico R, primeramente se ubicó el “área de
trabajo” de dicho programa en la misma carpeta donde se guardó el archivo “datos.txt”. Esto se
hace desde la barra de menú del programa haciendo clic en la siguiente secuencia: Archivo---
Cambiar dir… y navegando a través de la ventana emergente (Figura 12) hasta ubicar la carpeta
de trabajo. Para esta investigación se creó una carpeta identificada con el nombre CÁLCULOS
EN R, y dentro de ésta, otra carpeta identificada como TC, cuya dirección completa se muestra en
la ventana Choose directory del programa Estadístico R (Figura 12). Esta ventana surge para
hacer la navegación y el cambio de directorio del “área de trabajo” de R.

135
Figura 12. Ventana para cambio de directorio del área de trabajo de R.
En el código aparece la instrucción: write.table(resultados,file="TC de varios puntos
sobre la cuenca.txt"). Esta función es una de las formas disponibles en el programa Estadístico R
para guardar los resultados en un archivo texto, de modo que estos puedan ser usados
eventualmente para otro tipo de cálculos. El archivo se guardó con el nombre “TC de varios
puntos sobre la cuenca.txt”.
2.2.- Dibujo de líneas Isocronas
Las líneas isocronas son curvas que unen puntos de igual tiempo de concentración.
Surgen de unir puntos de igual tiempo de traslado de una gota de agua en el curso del cauce
principal, en los cursos secundarios y en las trayectorias del flujo laminar.
El dibujo de estas líneas se hace con el propósito de construir a partir de ellas el
hidrograma unitario, ya que es necesario calcular el área existente entre dichas líneas pues se usa
como uno de los elementos en el Método de Clark (Guilarte, 1989).
Se dibujan empleando la metodología que opera para el dibujo de las curvas de nivel,
donde los puntos a interpolar son los valores de “Tiempo de Concentración” calculados sobre
algunos puntos de la red de drenaje. Se empleó el software de diseño asistido por computadora
Autocad Land para la interpolación y dibujo de las líneas de la misma forma como se dibujan las
curvas de nivel para un levantamiento topográfico.
Para el trazado de líneas Isocronas Guilate (1989) sugiere que sobre un plano de la cuenca
se subdivida esta en sub cuencas de igual tiempo de concentración (sub múltiplos del tiempo de
concentración total de la cuenca) resultando las denominadas isocronas.

136
Las áreas encerradas entre las curvas isocronas fueron calculadas usando el comando Área
disponible en el programa AutoCad Land. Esta información fue organizada en forma tabular para
usarse en el cálculo del Hidrograma Unitario a través del Método de Clark.
Los datos de precipitaciones usados para calcular el Hidrograma Unitario en el presente
estudio, están disponibles en la Dirección de Hidrología y Meteorología del Ministerio del Poder
Popular para el Ambiente, DEA-Monagas, donde fueron solicitadas las coordenadas de las
Estaciones Climatológicas más cercanas al área en estudio, para su ubicación en el plano de la
respectiva cuenca, con el propósito de escoger aquella Estación, que en función de un análisis
basado en los Polígonos de Thiessen, presentó la mayor área de influencia.
Del análisis hidrológico de dicha cuenca hidrográfica se obtuvo una serie de datos
referentes a caudales escurridos por su río principal en periodos de tiempo que están
determinados por la amplitud de los registros disponibles. Los caudales con los que se trabajó en
la cuenca del río Areo fueron caudales simulados, pues fueron obtenidos de manera indirecta a
través de la transformación de las precipitaciones en escorrentía usando varios métodos, entre
ellos el Método de Clark; este conjunto de datos, se organizó en tablas para su empleo en un
Análisis de Varianza como la variable respuesta, siendo la variable Tratamiento el Índice
Normalizado de Vegetación (NDVI).
2.3.- Cálculo del Hidrograma Unitario Instantáneo (HUI)
La aplicación de la ecuación de tránsito por el método de Muskimgum (Guillarte, 1989)
está orientada a calcular los elementos siguientes:
T1 = Tiempo entre Isocronas
K (Coeficiente de Proporcionalidad) = Este valor se estima a través de la curva que
relaciona TL y TC elaborada por la antigua División del MOP (Carciente, 1999). La curva
se incluye en el Anexo 3.
1
10
*5.0
*5.0
TK
TC
1
11
*5.0
*5.0
TK
TC
1
12
*5.0
*5.0
TK
TKC
)(__
10*)_(___ 2
sisocronasentretiempo
kmCuencaladeáreaEU

137
El desarrollo de estas ecuaciones se hizo a través de la construcción y aplicación de un
código de programación ejecutable en el programa Estadístico R. Dicho código se reproduce a
continuación:
##CÁLCULO DEL CUADRO DE HIDROGRAMA UNITARIO
##LECTURA DEL ARCHIVO QUE CONTIENE LOS DATOS:
Areas<-read.table("areasisocronas.txt",header=T)
##HACER DISPONIBLES LAS COLUMNAS DEL ARCHIVO DE FORMA #INDIVIDUAL
attach(Areas)
##GENERA LA SUMA DE TODAS LAS ÁREAS ENTRE ISOCRONAS
areatotal<-sum(areas)
##Ingrese aquí el intervalo de tiempo entre isocronas en minutos:
T = 20
##CÁLCULO DEL TIEMPO ENTRE ISOCRONAS EN FRACCIONES DE HORAS:
T = T/60
##INGRESE NÚMERO DE HORAS EN LAS QUE ESCURRIRÁ LA LLUVIA:
N = 12
##GENERACIÓN DE COLUMNA QUE INDIQUE EL PASO DEL TIEMPO:
Tiempo<-seq(from=1,to=12,by=T)
Tiempo<-round(Tiempo,2)
##CÁLCULO DEL NÚMERO DE LÍNEAS QUE TENDRÁ LA TABLA DE #RESULTADOS
n = N/T -2
##GENERAR COLUMNA QUE CONTENGA LAS ÁREAS ENTRE ISOCRONAS.
#TOMADAS DEL ARCHIVO QUE CONTIENE LOS DATOS
AreasIso<-matrix(nrow=n+1,ncol=1)
for (i in 1:n){
AreasIso[i]<-areas[i]
}
##CÁLCULO DEL PORCENTAJE DE CADA ÁREA CON RESPECTO AL TOTAL
Intervalo<-matrix(nrow=n+1,ncol=1)
for (i in 1:n){
Intervalo[i]<-AreasIso[i]/areatotal * 100
}

138
Intervalo<-round(Intervalo,2)
##CÁLCULO DE LOS COEFICIENTES DE MUSKINGUM:
##Ingrese aquí el valor de K tomado del Anexo 3
K = 2
C0= 0.5*T/(K+0.5*T) ;C1=C0 ; C2 = (K - 0.5*T)/(K+0.5*T) ;
EU= (sum(areas)/1000000)*10/(T*3600)
##CONSTRUCCIÓN DE MATRICES PARA EL MANEJO DE LOS COEFICIENTES ##DE
MUSKINGUM
Musk1<-matrix(nrow=n+1,ncol=1); Musk2<-matrix(nrow=n+1,ncol=1);
Musk3<-matrix(nrow=n+1,ncol=1); Musk2[1]= 0
##CÁLCULO DE LOS COEFICIENTES DE MUSKINGUM:
for (i in 1:n){
Musk1[i]<-(C0 + C1)* Intervalo[i]
Musk3[i]= Musk1[i]+Musk2[i]
Musk2[i+1]<-Musk3[i]*C2
}
Musk1<-round(Musk1,2)
Musk2<-round(Musk2,2)
Musk3<-round(Musk3,2)
##CÁLCULO DEL HIDROGRAMA UNITARIO INSTANTÁNEO:
HUI<-matrix(nrow=n+1,ncol=1)
for (i in 1:n) {
HUI[i] <- EU * Musk3[i]
}
HUI<-round(HUI,2)
##GENERACIÓN DE TABLA DE RESULTADOS PARCIAL:
resultados1<-data.frame(Musk1,Musk2,Musk3,HUI)
##EXPORTACIÓN DE TABLA DE RESULTADOS PARCIAL:
write.table(resultados1,file="resultados1.txt")
##IMPORTACIÓN DE TABLA DE RESULTADOS PARCIAL:
resultados1<-read.table("resultados1.txt",header=T,nrow=n)

139
##GENERACIÓN DE TABLA DE RESULTADOS DEFINITIVOS:
resultados2<-data.frame(Tiempo,TC,areas,resultados1)
resultados2
#FIN DE CÓDIGO
La primera acción que ejecuta este código es importar el archivo texto, a la memoria de R,
que contiene los datos de los Tiempos de Concentración y las áreas entre isocronas. Ese archivo
debe ser construido y guardado con nombre “areasisocronas.txt” en una carpeta de dirección
conocida. Hacia dicha carpeta debe mudarse el “directorio de trabajo” del programa R aplicando
el procedimiento ya comentado. De este modo, cuando se aplique la instrucción: Areas<-
read.table("areasisocronas.txt",header=T) el programa R busca el archivo sin necesidad de
indicarle una dirección de búsqueda y lo incorpora en su memoria para ejecutar el resto del
código, trabajando con los datos que este archivo contiene y los que se ingresan en el código en
las secciones donde son solicitados.
El archivo texto que contiene los datos de TC y áreas entre isocronas fue manipulado de
una forma especial antes de correr el código. Fue necesario rellenar con ceros las columnas de TC
y áreas que contiene el archivo, hasta completar el número de filas con las que es reportado el
cuadro de resultados. Este número de filas (n) se calcularse de forma manual, ya que la
diferencia entre este valor y el número de filas que contiene originalmente el archivo determina
la cantidad de ceros que hacen falta colocar en las columnas indicadas para completar la
configuración del mismo:
n = N/T -2 donde N es el número de horas en las que se deja escurrir la lluvia, y T es el
intervalo de tiempo entre curvas isocronas expresado en fracción con respecto a una hora.
T = intervalo de tiempo entre isocronas / 60. Este intervalo de Tiempo entre isocronas fue
el tiempo escogido para la equidistancia en el dibujo del plano de Isocronas elaborado en
AUTOCAD.
2.4.- Cálculo Caudal de escorrentía superficial
Se construyó un código de programación para ser usado en el programa Estadístico R con
el propósito de determinar los caudales de escorrentía superficial para cada valor de Precipitación
Efectiva y en función del HUI. A continuación se transcribe el mencionado código.

140
##CÓDIGO PARA LA TRANSFORMACIÓN DE LA PRECIPITACIÓN EFECTIVA DE
##CADA AÑO EN CAUDAL
##LOS DATOS DE PARTIDA SON LOS ARCHIVOS "LLUVIA-ESCORRENTÍA AÑO
##1987.txt" GENERADOS CON EL CÓDIGO: CÓDIGO PRECIPITACIÓN Y CAUDAL #POR
##MES.r, LOS CUALES SON COMBINADOS CON EL ARCHIVO #"HIDROGRAMA
UNITARIO.txt"
##ESTOS ARCHIVOS DEBEN ESTAR COLOCADOS EN UNA ÚNICA CARPETA
##DONDE ES DIRECCIONADA EL ÁREA DE TRABAJO DEL PROGRAMA
#ESTADÍSTICO R.
##CADA ARCHIVO CONTIENE LA INFORMAICÓN DE PRECIPITACIÓN DE UN #AÑO
##SE HACE EL CÁLCULO DEL CAUDAL PARA CADA AÑO A PARTIR DE CADA
##ARCHIVO.
##CONFIGURACIÓN PARA IMPORTACIÓN DE LOS ARCHIVOS QUE CONTIENEN
#LOS DATOS:
hidrograma<-read.table("HIDROGRAMA UNITARIO.txt",header=T)
lluvias<-read.table("LLUVIA-ESCORRENTÍA AÑO 2005.txt",header=T); attach(lluvias)
#GENERACIÓN DE VECTOR CON VALORES DEL UI
hui<-matrix(nrow=34,ncol=1)
for (i in 1:34){
hui[i]<-hidrograma$HUI[i]*1
}
##ASIGNACIÓN DE UN CAUDAL BASE:
QB = 1
##CÁLCULO DE CAUDALES
Caudal<-matrix(nrow=12,ncol=1)
for (i in 1:12){
if (P_efectiva[i]> 0)
Caudal[i]<-mean(P_efectiva[i]*hui)
else Caudal[i]<-QB
}
Q2005<-round(Caudal,1); Q2005

141
##NOTA: PRIMERO DEBE EJECUTARSE EL CÓDIGO TANTAS VECES COMO AÑOS
#DE REGISTRO EXISTAN, CAMBIANDO EL NÚMERO QUE IDENTIFICA DICHO
##AÑO PARA CADA CORRIDA.
##EL AÑO SE CAMBIA EN LAS SIGUIENTES INSTRUCCIONES:
##lluvias<-read.table("LLUVIA-ESCORRENTÍA AÑO 2005.txt",header=T)
##Q2005<-round(Caudal,1)
##Q2005
##LUEGO DE DETERMINADOS LOS CAUDALES PARA CADA AÑO SE PROCEDE ##A
CORRER LA SIGUIENTE PARTE DEL CÓDIGO, CON LA CUAL SE GENERA #LA
TABLA DE RESULTADOS
##GENERACIÓN DE LA TABLA DE RESULTADOS
MESES<-c("ENE","FEB","MAR","ABR","MAY","JUN","JUL","AGO",
"SEP","OCT","NOV","DIC")
Caudalanual<-data.frame(MESES,Q1986,Q1987,Q1988,Q1989,Q1990,Q1991,Q1992,Q1993,
Q1994,Q1995,Q1996,Q1997,Q1998,Q1999,Q2000,Q2001,Q2002,Q2003,Q2004,Q2005)
colnames(Caudalanual)=c("Mes","Q1986","Q1987","Q1988","Q1989","Q1990","Q1991",
"Q1992","Q1993","Q1994","Q1995","Q1996","Q1997","Q1998","Q1999","Q2000","Q2001",
"Q2002","Q2003","Q2004","Q2005")
Caudalanual
##FIN DEL CÓDIGO.

142
4.3.2. Fase de Teledetección
La evaluación del cambio en el vigor (a través del NDVI) que ha experimentado la masa
vegetal ubicada en un espacio geográfico definido incluye una serie de pasos que se muestran en
la Figura 13.
Figura 13.- Metodología para evaluación de cambio en el vigor de la vegetación de un área
específica.
Cada uno de los pasos mostrados en la Figura 13 representa las diferentes fases en las que
se divide el estudio y cuenta con una metodología concreta. A continuación se detalla, de forma
general, tanto los procedimientos como los equipos e insumos necesarios, así como una
aproximación a la forma de representación de los resultados esperados.
1º
Ubicación y cuantificación del área
de interés
2º
Ubicación y pre procesamiento de las imágenes
de satélite del área de interés
3º
Procesamiento Digital de las imágenes: cálculo del
NDVI
4º
Interpretación de cambios y modelación
de escenarios futuros.

143
1.- Ubicación del área de interés
El Paso 1, relativo a la ubicación y cuantificación del área de interés ya fue manejado en
la sección referida a la evaluación Hidrológica, específicamente en lo relativo a la Vectorización
digital de la cuenca. La ejecución de este paso permite determinar la ubicación del área de
trabajo y cuantificar su magnitud (superficie), generando un polígono digital de la cuenca, que
para la Fase de Teledetección se usa como Región de Interés (ROI, por sus siglas en inglés) el
cual se exporta desde el programa de procesamiento digital de imágenes, en formato .dxf para su
inserción sobre la imagen que se esté manejando y la generación de la composición cartográfica.
2.- Ubicación y “descarga” de las imágenes de satélite del área de interés
Orbitando la Tierra se encuentran una cantidad importante de satélites artificiales,
diseñados para diferentes propósitos, administrados y gobernados por varias organizaciones,
tanto privadas como gubernamentales. Entre ellos se encuentra la familia de satélites Landsat que
ha sido bautizada como el adjetivo de satélites de evaluación de recursos naturales. Para esta
investigación se recopiló información disponible de los años 2000-2001-2002 del programa
Landsat 7 ya que para mayo de 2003 el sensor de este satélite sufrió una falla técnica y las
imágenes que a partir de esa fecha se han producido presentan serias distorsiones.
Para este rango de tiempo se cuenta con un aproximado de 66 imágenes. De ellas se
seleccionaron aquellas que presentaron el menor porcentaje de nubosidad de modo que los
valores de NDVI calculados luego de la corrección atmosférica se vieran afectados por esta
variable en la menor cuantía posible.
La Figura 14 muestra la nomenclatura que identifica las escenas que genera la familia de
satélites Landsat para la región de Venezuela y áreas vecinas. El área de interés de la presente
investigación se ubica hacia el sector oriental de Venezuela, más concretamente en el Estado
Monagas. La dirección de la fila y columna de la escena que abarca la cuenca hidrográfica en
estudio es 2053, la cual puede observarse en detalle en la Figura 15.

144
Figura 14.- Escenas de la familia de satélites Landsat que abarcan la geografía venezolana
(http://landsat.usgs.gov/slc_off.html).
Figura 15.- Dirección 002-053 (Path-Row) de la escena Landsat correspondiente al área de
interés (http://landsat.usgs.gov/slc_off.html).
La Figura 16 muestra la página principal del portal Web de donde se descargaron, sin
costo monetario, las imágenes que fueron utilizadas para esta investigación. Es la página Web de
la Universidad de Maryland, ubicada en los Estados Unidos de Norte América
(http://glcfapp.umiacs.umd.edu:8080/esdi/index.jsp).
Una vez dentro del portal Web de la Global Land Cover Facility (GLCF)
(http://glcfapp.umiacs.umd.edu:8080/esdi/index.jsp) la búsqueda de las imágenes se hizo a través
Área de interés

145
del Buscador de Mapas (Map Search) haciendo clic en el recuadro correspondiente tal como se
observa en la Figura 16.
Figura 16.- Ventana principal de la GLCF mostrando zona de búsqueda de imágenes
(http://glcf.umiacs.umd.edu/index.shtml).
Esta operación da acceso a una nueva ventana donde se selecciona el tipo de sensor que
se quiere, que en este caso fueron los sensores ETM+ y TM y dentro de la pestaña Date/Type
(que se indica en la Figura 17) se selecciona el icono de Zoom In y se hace clic sobre la parte que
corresponde a Venezuela hasta lograr un detalle en la visualización de la sección de interés
parecido al que se señala en la Figura 18.
Figura 17.- Ventanas de selección de Sensores ETM+, TM y de magnificación del área de
interés (http://glcf.umiacs.umd.edu/index.shtml).

146
Figura 18.- Ventana para selección definitiva del área de interés
(http://glcf.umiacs.umd.edu/index.shtml).
Para la selección definitiva del área de interés se activó el icono con el cual se hizo
clic sobre dicha área para indicarle al “servidor” exactamente el número de la escena a descargar
activando posteriormente el menú ubicado en el margen inferior de la ventana identificado como
Update Map, para que el portal Web indique el número de imágenes disponibles en una
presentación semejante a la que se señala en la Figura 19.
Figura 19.- Ventana de identificación de cantidad de imágenes disponibles
(http://glcf.umiacs.umd.edu/index.shtml).
Esta ventana informa que del área seleccionada, y para los sensores indicados (ETM+ y
TM), la base de datos de la GLCF posee un cierto número de imágenes. En el ejemplo de la
ÁREA DE
INTERÉS

147
Figura 18 se muestra un reporte de siete imágenes disponibles en la base de datos tomadas con
los sensores ya mencionados.
Haciendo clic sobre Preview&Download se ingresó a la página siguiente del portal de la
GLCF donde se muestra en forma de tabla una serie de atributos de las imágenes disponibles:
fecha de adquisición, la localización, el tipo de ordenamiento de las bandas, entre otros. La
Figura 20 reseña lo anterior.
Estas imágenes fueron revisadas en una vista previa y descargadas sólo aquellas que
presentaron la menor cobertura de nubes. El conjunto de imágenes así seleccionadas determinó
el rango de tiempo en el que se fundamenta el estudio.
Haciendo clic sobre cada uno de los ID de la tabla mostrada en la figura anterior fue
posible observar una vista previa de las imágenes allí contenidas y hacer una selección en función
del menor grado de cobertura de nubes para el área de interés.
Una vez seleccionada la imagen a descargar se accedió a la ventana de descarga haciendo
clic sobre el botón Downlad, donde se siguieron las instrucciones para la descarga final.
Figura 20.- Ventana de pre visualización de imágenes disponibles
(http://glcf.umiacs.umd.edu/index.shtml).
3.- Pre-procesamiento del material espectral disponible
Cada una de estas imágenes fue procesada digitalmente para la obtención de los Índices
de Vegetación, usando para ello el programa de procesamiento digital de imágenes de satélites
ENVI (Environment for Visualizing Images), con licencia del Laboratorio de Geodesia Físicay
Satelital de la Escuela de Ingeniería Geodésica, adscrita a la Facultad de Ingeniería de La

148
Universidad del Zulia, en combinación con el programa diseñado para Sistemas de Información
Geográfica, Idrisi Andes (versión DEMO), a través de sus módulos de procesamiento digital de
imágenes.
Del análisis de estas imágenes se obtuvieron valores de los diferentes Índices de
Vegetación, que varían de -1 a 1, sobre el espacio que delimita la cuenca hidrográfica en estudio.
Estos resultados fueron organizados en tablas y son considerados en el Análisis de Varianza
como los tratamientos a evaluar.
Se explica en detalle el procedimiento de modo que los resultados del mismo puedan ser
validados a través de otras investigaciones siguiendo los pasos aquí señalados.
3. 1.- Organización del material de trabajo
Se creó una Carpeta, en el disco duro del computador donde se hizo el trabajo, y se
incluyó en ella todos los archivos contentivos de las Imágenes de Satélite que se procesan. De
igual manera en dicha Carpeta se almacenaron los archivos resultantes del procesamiento. Dentro
de esta Carpeta se crearon sub carpetas, y a su vez, dentro de éstas se almacenaron las escenas de
manera individual.
En estas sub carpetas se descomprimieron los archivos que se descargaron del portal Web
de la GLCF (Universidad de Maryland), los que originalmente se obtuvieron comprimidos en
formato .rar, para lo cual se usó el programa WinRar. La Figura 21 muestra un ejemplo del
número de archivos que componen la escena identificada en la Figura 19 con la nomenclatura
042-898 de fecha 1999-07-01, sensor ETM+.
3. 2.- Configuración del polígono la cuenca
Con el término “Configuración” se hace referencia a los ajustes que se le aplican al
polígono que comprende la Cuenca del Río Areo que fue elaborado en la Fase de Vectorización
Digital de la Cuenca. Dicho polígono fue construido en AutoCad Land. Se generó y almacenó un
archivo con el polígono de dicha cuenca, con la extensión .dxf en lugar de la extensión .dwg que
por defecto el programa usa para guardar los mapas. Para guardar el polígono con esa extensión
se operó a través de la opción File – Save As, luego de lo cual se asignó nombre del mismo y la
extensión .dxf en la opción Type.

149
Figura 21. Archivos que componen la escena ETM+ p002r053 de fecha 01/07/1999.
El primero de los programas que se usa para Procesamiento Digital de las Imágenes en
esta investigación, ENVI, tiene capacidad de importar los archivos con extensión .dxf, para
incorporarlo en la visualización de la imagen e incluirlo como un Sub Conjunto (Subset) a los
efectos del procesamiento digital. De este modo se generaron nuevas bandas de tamaño reducido
y específico en función del tamaño de la cuenca que se evaluó.
3.3.- Construcción de composición de imágenes
Con el propósito de disponer de representaciones gráficas del área estudiada, vista con
imágenes de satélite, se construyó una composición de imágenes en una combinación de Bandas
3-4-1, en los Canales R (rojo), G (verde), B (azul), RGB-341 conocida como falso color porque
constituye un rango espectral diferente del color verdadero. Se escogió esta composición por
dos razones: en principio el fondo de la composición es de color verde, lo cual puede relacionarse
con la presencia de masas vegetales, y en segundo lugar, porque es una composición que incluye
las tres bandas que se requieren para el cálculo de los Índices de Vegetación.
El procedimiento que se explica a continuación fue el aplicado a las bandas de la escena
042-898 de fecha 1999-07-01, sensor ETM+: sólo se manipulan las Bandas 3-4-1 a los efectos de

150
crear la composición de imagen. Esta escena fue descargada del portal Web de la Universidad de
Maryland (GLCF) ya georreferenciada y almacenada en formato GeoTiff.
a.- Inicio del Programa ENVI
Se activó el programa ENVI a través de los procedimientos comunes con los que se hace
esta operación cuando se trabaja en ambiente Windows: haciendo doble clic sobre el icono de
acceso directo ubicado en la pantalla del computador donde se trabaja.
b.- Incorporación de Bandas y creación de composición de imágenes
Desde la Barra de Menú principal se hizo clic con el botón izquierdo del dispositivo de
interfaz humana (Mouse) a la secuencia: File --- Open External File --- Landsat ---- GeoTIFF.
Se “navegó” hasta ubicar la carpeta que donde estaban las bandas de la escena de interés,
de donde sólo se seleccionan las Bandas 3, 4, 1, ya que una composición de imagen debe ser
creada con tres bandas (una para cada color del espectro visible) y, para esta investigación, la
composición con la que se trabajó debía incluir la Banda 3 (que corresponde al Rojo en el
Espectro Electromagnético) y la Banda 4 (que corresponde a las longitudes de onda del Infrarrojo
Cercano en el Espectro Electromagnético), ya que son éstas las que intervienen en el cálculo del
NDVI.
La selección de dichas bandas se hizo de manera simultánea, de modo que fueron
incorporadas las tres juntas en una sola operación en la memoria del programa. Al hacer esto se
desplegó una ventana identificada como Available Bands List que es la ventana que muestra las
bandas disponibles (Lista de Bandas Disponibles). Esta ventana se divide en tres sectores
principales: el superior que corresponde al área donde se visualiza la Lista de Bandas Disponible;
un sector central que gobierna el tipo de imagen a presentar que pude ser en escala de Grises o en
Color, y un tercer sector donde se ubican los “Canales” del espectro visible. En este último sector
se indica qué banda ocupa cada canal para la construcción de la composición de imagen.
La Figura 22 muestra la ventana de Lista de Bandas Disponibles (Available Bands List)
con la selección de las bandas 1, 3 y 4 de la escena 042-898 de fecha 1999-07-01, sensor ETM+,
y la combinación 143 para la visualización de dicha composición. Esto es: en el canal Rojo (Red)
se incorpora la Banda 1, en el Canal Verde (Green) se incorpora la Banda 4, y en el Canal Azul
(Blue) se incorpora la Banda 3. Con este ajuste se activó el botón Load RGB para visualizar la
composición.

151
Al pulsar el Botón Load RGB el sistema despliega tres ventanas que muestran una
representación particular de la Composición creada en el paso anterior. Este grupo de ventanas se
conoce como Grupo de Visualización (Display Group). La Figura 23 muestra este conjunto de
ventanas. La primera ventana se conoce como la Ventana de visualización principal (Main
Display Windows). La segunda (extremo inferior izquierdo de la Figura 23) es la ventana de
Desplazamiento (Scroll Window) y la tercera es la Ventana de Zoom.
Figura 22. Ventana para visualización de Lista de Bandas Disponibles y configuración de
Composición Cartográfica.
Figura 23. Grupo de Visualización mostrando Cumaná, la Capital del Estado Sucre en el Oriente
de Venezuela, ubicada en la ventana principal; toda el área que cubre la escena, en la ventana
Scroll, y un detalle ampliada en la ventana Zoom.

152
c.- Incorporación de Región de Interés sobre la composición de imagen
Desde la barra de menú de la Ventana de Visualización Principal se aplicó la secuencia:
Overlay --- Vector.., esta operación genera acceso a una ventana como la mostrada en la Figura
24 desde donde se “importa” el archivo que contiene el Polígono de la Cuenca de interés. Esta
ventana se identifica en la barra de título como Vector Parameters: Cursor Query. Desde la Barra
de Menú de dicha ventana se aplicó la secuencia: File --- Open Vector File para ingresar a la
ventana desde donde se “navegó” hasta encontrar el archivo que contiene la Región de Interés
que en este caso es el POLÍGONO CUENCA AREO.dxf. La Figura 25 muestra la presentación
de la ventana Vector Parameters, una vez seleccionado el archivo de interés, lo que
simultáneamente genera la incorporación de dicho polígono en las ventanas del Grupo de
Visualización.
Figura 24. Ventana para la búsqueda de Región de Interés tipo vector.

153
Figura 25. Ventana Vector Parameters mostrando el archivo POLIGONO CUENCA AREO.dxf
Desde la ventana Vector Parameters se ejecutó la secuencia Options ---Hide Window para
ocultar dicha ventana manteniendo fijo el polígono incorporado a la presentación como un vector
que muestra el perímetro de la Cuenca de interés.
d.- Almacenamiento de la composición de imagen
Para almacenar la composición arriba realizada, desde la Ventana de Visualización
Principal aplicó la secuencia de comandos: File --- Save Image As --- Image File…con lo que se
tuvo acceso a la ventana de salida del archivo tipo imagen, identificada en la barra de título
como: Output Display to Image File donde a través de sus tres secciones principales se ajustaron
los parámetros solicitados para el almacenamiento de la Imagen. En la primera sección se ajustó
la resolución de la imagen. Se escogió la opción 24-bit Color (BIL) ya que con este tipo de
organización de los datos (Bandas Intercaladas por Línea) es posible utilizar dicha imagen en otro
tipo de procesos que requieren este formato. La Figura 26 muestra la ventana Output Display to
Image File.
En la segunda sección se activó el botón Spatial Subset donde se especificó el tamaño de
la imagen al correspondiente comprendido por el Polígono de la Cuenca. Al activar dicho botón
se desplegó la ventana Select Spatial Subset (Figura 27) desde donde seleccionó el botón
ROI/EVG se accede a otra ventana, identificada en la barra de título como Subset Imagen by

154
ROI/EVF Extent, donde luego de mostrada se seleccionó la capa que contenía el POLÍGONO
CUENCA AERO.dxf que fue importado en el paso anterior.
Figura 26. Ventana para ajuste de parámetros a la imagen de salida.
Figura 27. Ventana para configuración de la región de sub conjunto en función de la cual se
almacena la imagen de salida.
La Figura 28 muestra la ventana donde se seleccionó la región de interés. Posteriormente,
en la ventana Select Spatial Subset se aceptó la selección pulsando el botón ok, lo que hizo que se
actualizara el tamaño de la imagen; actualización ésta que se observó en los renglones Sample y
Lines ubicados en el segundo sector de dicha ventana. Continuando con el procedimiento de
almacenamiento de la composición de imagen, de nuevo el programa activó la ventana Output
Display to Image File. En el renglón Output File Tipe se mantuvo la opción que por defecto

155
mostró el programa: Tipo ENVI, y en Output Result to se activó el botón de selección que
corresponde a File para guardar la imagen en la carpeta previamente seleccionada. La opción
Enter Output Filename permitió escoger la carpeta donde se guardó la imagen de salida y sele
asignó el nombre a la misma.
Figura 28. Ventana para selección de región de interés.
3.4.- Georreferenciación de bandas
Para las escenas que se descargaron del portal Web de la Universidad de Maryland
(http://glcfapp.umiacs.umd.edu:8080/esdi/index.jsp) que no estaban georreferenciadas, y que no
se visualizan manipulando sus atributos a través de su edición de acuerdo con el contenido del
archivo cabecera, se aplicó el siguiente procedimiento:
Se tomó la banda 3 de la escena 042-898 de fecha 01/07/1988 para cumplir la función de
banda de referencia. Esta Banda, al igual que el conjunto de Bandas que forman toda la
escena, se descargó del portal Web ya georreferenciada.
Se usó el método “Puntos de Control” por su simplicidad en cuanto a la formulación y su
mayor capacidad de corrección de errores aleatorios, en comparación con el método de
“Corrección Orbital” (Parra, 200).
Se cuidó de mantener el promedio de los residuales, conocido como Error Medio
Cuadrático (Root Mean Squared Error, RMS) por debajo de un umbral fijado en valor de
un piexel (Chuvieco, 1990).
El método de ajuste para la asignación de la función de Transformación fue el de Función
Polinómica de tercer orden, para lo cual se ajustaron un mínimo de diez puntos de control sobre
las imágenes (Chuvieco, 1990).

156
El procedimiento utilizado para el remuestreo, que consiste en la Transferencia de los
Niveles Digitales originales a la posición corregida se hizo a través del vecino más cercano
(nearer neighbor).
En general los pasos para la georreferenciación usando puntos de control fueron:
a.- Asignación de más de 10 puntos de control, cuidando un RMSE menor o igual a uno.
b.- Aplicación de la Función Polinómica de tercer orden como método de ajuste.
c.- Empleo del vecino más cercano como método de remuestreo.
A continuación se detalla los pasos anteriores usando el programa de procesamiento
digital de imágenes ENVI.
3.4.1.- Metodología en ENVI para georreferenciar imágenes de satélites usando
“Puntos de Control” de imagen a imagen
1.- Se abrió y presentó en el Display 1 una banda que estaba georreferenciada. Para este
trabajo se usó Banda 3 de la escena 042-898 de fecha 01/07/1988 para cumplir la función de
banda de referencia. Esta Banda se obtuvo en formato GeoTiff, por lo que para abrirla y hacerla
disponible en la memoria del ENVI, se opera de la forma ya comentada de apertura de imágenes.
El procedimiento de georreferenciación se hizo banda por banda. A los efectos de esta
fase sólo se procesaron las Bandas 1, 3 y 4 de las escenas 015-065, de fecha 28/02/2001, por ser
esta la única escena que requirió de una georreferenciación explícita. Las Bandas de las escenas
del 03/07/1991 y las del 01/10/1992 (descargadas del portal ya mencionado en formato .B)
reciben georreferenciación al momento de su apertura, editando su posicionamiento usando los
datos disponibles en el archivo cabecera de cada escena.
2.- Se abrió y presentó en el Display 2 una banda (cualquiera entre la 1, 3, ó 4) del primer
conjunto de bandas a georreferenciar.
3.- Desde el menú principal de ENVI se aplicó la secuencia: Map --- Registration – Select GCPs:
Image to Image.
4.- El paso anterior generó la aparición de la ventana de identificación de Banda de referencia
(aquella que está georreferenciada) y Banda a georreferenciar. Esta ventana se muestra en la
Figura 29.

157
Figura 29. Ventana para la selección de Banda de referencia y Banda a georreferenciar.
La selección en la ventana Image to Image Registration se hizo tal como se muestra en la
Figura 29.
5.- Luego del paso anterior se desplegó la ventana Ground Control Points Selection donde fue
posible adicionar los puntos de control, uno por uno en la medida que estos fueron seleccionados
en las imágenes. Para la selección de los puntos de control se usaron las ventanas de Scroll,
Ventana principal y Ventana de Zoom. En esta última ventana es donde se definió con exactitud
la ubicación de dichos puntos de control en las dos imágenes. Este paso es el que gobierna la
exactitud de la selección de los puntos. Mientras más exacta sea dicha selección menor será el
RSME, el cual debe mantenerse en valores menores que un píxel. En general, luego que el punto
es ubicado con precisión en ambas imágenes, es adicionado al sistema pulsando el botón Add
Point ubicado en la ventana Ground Control Points Selection. Progresivamente dicha ventana
fue indicando el número de puntos ya seleccionados y luego que fueron seleccionados más de tres
puntos, la ventana muestreó el valor del RMSE.
Para mejorar la selección de los puntos, la ventana Ground Control Points Selection
ofrece el botón Predict que permitió ajustar la selección del punto en la imagen a georreferenciar
en función del valor predicho. Esto fue posible luego de seleccionar más de tres puntos de
control. Esto permitió reducir el RMSE.
Una vez hecha la selección de los puntos de acuerdo con el valor umbral de RMSE, se
exportaron a un archivo de texto, para usarlos en la georreferenciación de las bandas siguientes
haciendo con esto el proceso de georreferenciación más cómodo. La exportación de dichos
puntos se hizo desde el menú File—Save GCPs to ASCII en la ventana Ground Control Points
Selection, asignándole como nombre: 20PTOS DE CONTROL.

158
6.- Una vez hecha la selección de los puntos de control a satisfacción y guardados como archivo
texto, se procedió con las operaciones de Ajuste y Remuestreo. Esto se hizo desde el menú
Options ----- Warp displayed Band en la ventana Ground Control Points Selection. La Figura 30
muestra la ventana emergente donde se configuró este procedimiento.
Figura 30. Ventana Registration Parameters para configurar el “Ajuste” sobre imagen
georreferenciada.
Como método de ajuste se usó una función polinómica de tercer grado, y como método de
remuestreo se aplicó Vecino más cercano. Ambos procedimientos generan un resultado más
exacto.
3.5.-Corrección atmosférica
Se usaron tres métodos de corrección atmosférica. Las bandas generadas por cada método
fueron procesadas para el cálculo del NDVI, y los resultados revisados y discutidos.
El primer método utilizado fue el propuesto por Chávez (1989) citado por Chuvieco
(1995), que se apoya en los datos de la propia imagen obteniendo a través de los valores de
distintas bandas una estimación del efecto atmosférico. Se identifica como el HMM o Método del
Mínimo del Histograma. Su ejecución consistió en la aplicación de la ecuación (17). De acuerdo
con esa ecuación, la corrección atmosférica se logró desarrollando una simple resta, ejecutada
con la opción Band Math disponible en ENVI desde la función Basic Tool. La función Band
Math hace disponible en ENVI una calculadora de imágenes.

159
La ecuación configurada sobre Band Math para este propósito fue la siguiente:
float(b3-mínimo valor de píxel) (28)
Sólo fueron corregidas las bandas necesarias para el cálculo del NDVI: Banda 4, Banda 3
y Banda 1 que son la Banda del Infrarrojo Cercano, la Banda del Rojo y la Banda del Azul,
respectivamente.
En ENVI el procedimiento desarrollado fue:
1.- Incorporación de la Banda 4, Banda 3 y Banda 1 en la ventana de Available Band List
mediante la secuencia de comandos: File—Open External File—Landsat.
2.- Almacenamiento de cada Banda (una por una), desde la barra de menú principal (Figura 31),
con la asignación del vector que delimita la cuenca de interés a través de la opción Spacial
Subset, a la cual se accede desde la ventana Output TIFF/GeoTIFF Input que emerge al aplicar la
secuencia de funciones mostrada en la Figura 31. En la ventana Output TIFF/GeoTIFF Input
Filename, se seleccionó, la banda a guardar, y se activó la asignación de un vector a través del
botón Spatial Subset (para guardar la imagen en función del tamaño del polígono de la cuenca de
interés), operación ésta que desplegó una nueva ventana identificada como Select Spatial Subset,
desde donde se ubicó el archivo que contenía el sub conjunto, que en este caso es el polígono de
la cuenca del Río Areo, construido en AUTOCAD y guardado como un archivo .dxf.
Este vector fue importado desde la ventana Select Spatial Subset activando el botón
Open, por medio cual se accedió a una ventana de búsqueda del archivo por donde se navegó
luego de desplegar de la ventana Tipo la opción .DXF, procurando que el programa identificara el
archivo de interés. La secuencia de pasos se muestra en la Figura 32.
El último paso para guardar correctamente la imagen a procesar, teniendo como referencia
el archivo vector que contiene el perímetro de la cuenca, fue seleccionar el nombre y la carpeta
donde este archivo se almacenó. La Figura 32 señala como último paso la selección de este
directorio pulsando el botón Choose en la ventana Output File to TIFF/GeoTIFF.

160
3.- Identificación del valor mínimo de los píxel de cada banda:
Las Bandas, luego de ser guardadas en formato GeoTIFF fueron incorporadas a la ventana
“Available Band List”. Una vez en dicha ventana la identificación del ND mínimo presente en
cada banda se hizo aplicando clic con el botón derecho del “mouse” sobre la banda de interés
ubicada en la Available Band List”, y del menú emergente se seleccionó la opción Quic Sats, tal
como lo indica la Figura 33.
El procedimiento explicado permitió acceder a los valores mínimos de ND presentes en la
Banda seleccionada. Este valor se observa en la ventana del Histograma que el programa hace
disponible luego de la operación recién explicada. La Figura 34 muestra un extracto de esta
ventana.
Figura 31. Procedimiento para almacenar Banda seleccionada
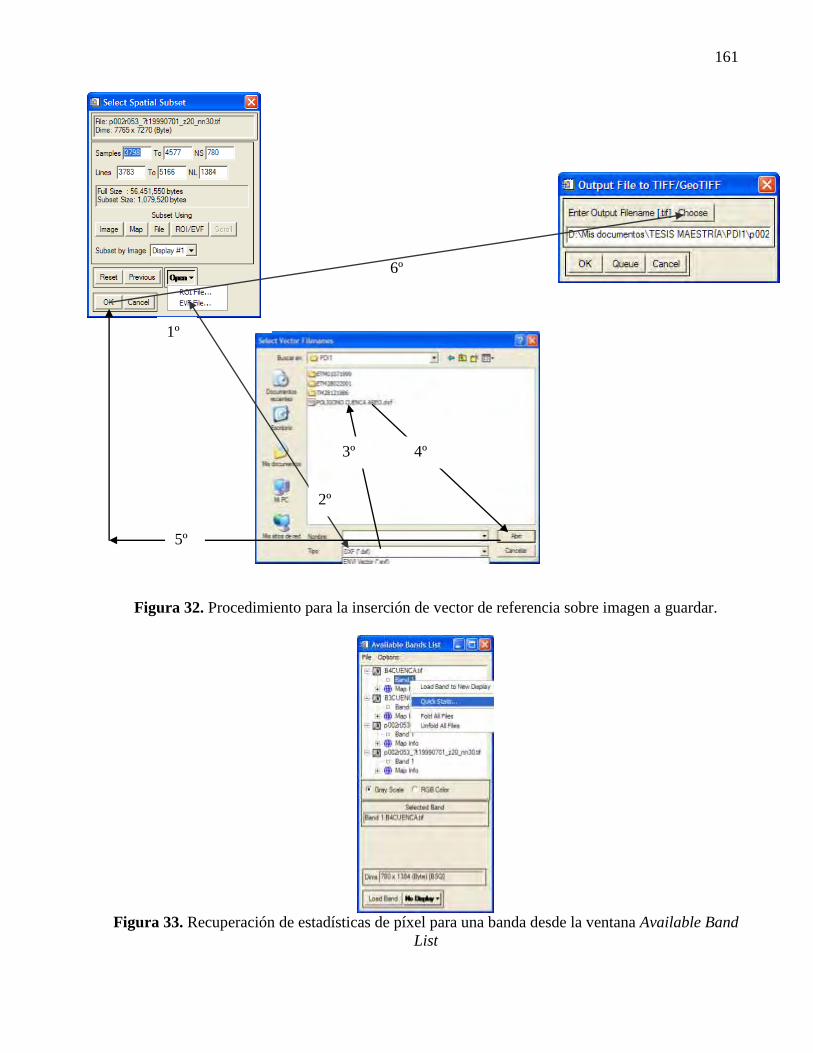
161
Figura 32. Procedimiento para la inserción de vector de referencia sobre imagen a guardar.
Figura 33. Recuperación de estadísticas de píxel para una banda desde la ventana Available Band
List
1º
2º
3º 4º
5º
6º
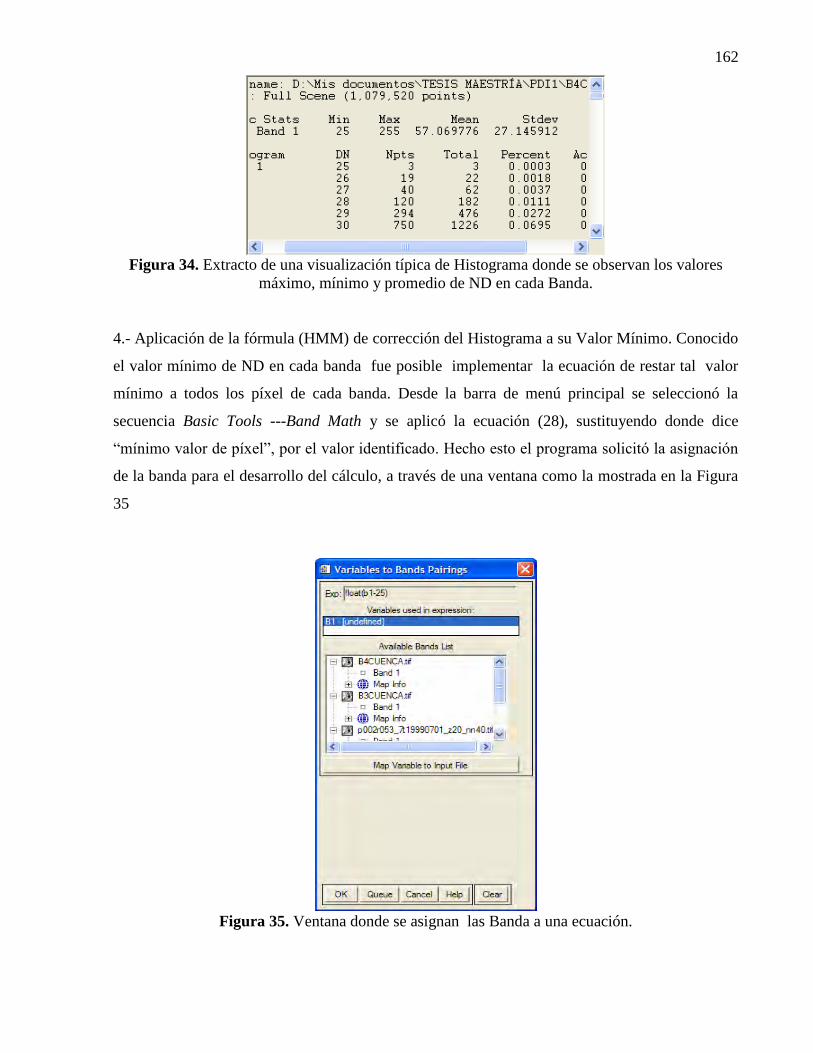
162
Figura 34. Extracto de una visualización típica de Histograma donde se observan los valores
máximo, mínimo y promedio de ND en cada Banda.
4.- Aplicación de la fórmula (HMM) de corrección del Histograma a su Valor Mínimo. Conocido
el valor mínimo de ND en cada banda fue posible implementar la ecuación de restar tal valor
mínimo a todos los píxel de cada banda. Desde la barra de menú principal se seleccionó la
secuencia Basic Tools ---Band Math y se aplicó la ecuación (28), sustituyendo donde dice
“mínimo valor de píxel”, por el valor identificado. Hecho esto el programa solicitó la asignación
de la banda para el desarrollo del cálculo, a través de una ventana como la mostrada en la Figura
35
Figura 35. Ventana donde se asignan las Banda a una ecuación.

163
5.- Almacenamiento de la banda resultante de la operación anterior: se indicó el nombre de la
banda espectral que se creó luego de la resta de los ND, y se asignó la ubicación de dicha banda
en el directorio de trabajo. Las Bandas así obtenidas fueron procesadas en el cálculo de los
Índices de Vegetación.
Como segundo método de corrección atmosférica se aplicó la transformación de ND de
cada banda a valores de reflectividad utilizando para ello la ecuación (18). Para calcular la
radiancia espectral Lsen,k , los valores de a0,k, a1,k fueron tomados de la Tabla 3. Los valores de
Irradiancia espectral solar extraterrestre (E0,k), según el número de la banda que se procesó,
fueron los reportados por el Science Data users Handbook del programa Landsat, los cuales se
muestran en la Tabla 9.
El valor de K (factor corrector de la distancia tierra-sol) usado en este trabajo se tomó de
la tabla que para dicho parámetro reporta el Science Data Users Handbook del Programa
Landsat, y que se muestra en la Tabla 10. Los valores de K reportados en esta Tabla fueron
elevados al cuadro para su introducción en la Fórmula general de cálculo de reflectividad.
Tabla 9. Valores de E0,k tomados del Science Data Users Handbook del programa Landsat (http://landsathandbook.gsfc.nasa.gov/handbook/handbook_htmls/chapter11/chapter11.html)
Banda Watts/(m2 * µm)
1 1969.00
2 1840.00
3 1551.00
4 1044.00
5 225.70
7 82.07
8 1368.00
Se construyeron las fórmulas a aplicar en cada Banda en función de cada escena. Para
cada escena cambia el valor del Factor K , y E0,k; mientras que para cada Banda espectral
cambian los valores de a0,k, y a1,k. La Tabla 11 muestra las fórmulas utilizadas para cada
situación.

164
Tabla 10. Valores de K reportados en el Sciencie Data Users Handbook del programa Landsat
(http://landsathandbook.gsfc.nasa.gov/handbook/handbook_htmls/chapter11/chapter11.html)
Día
Juliano
Distancia Día
Juliano
Distancia Día
Juliano
Distancia Día
Juliano
Distancia Día
Juliano
Distancia
1 .9832 74 .9945 152 1.0140 227 1.0128 305 0.9925
15 .9836 91 .9993 166 1.0158 242 1.0092 319 0.9892
32 .9853 106 1.0033 182 1.0167 258 1.0057 335 0.9860
46 .9878 121 1.0076 196 1.0165 274 1.0011 349 0.9843
60 .9909 135 1.0109 213 1.0149 288 .9972 365 0.9833
Tabla 11. Fórmulas utilizadas en cada Banda espectral, según la escena, para el cálculo de
reflectividades
(http://landsathandbook.gsfc.nasa.gov/handbook/handbook_htmls/chapter11/chapter11.html)
FECHA B )*(**cos/* ,1,0,0 NDaaEK kkk
28/02/2001 1 [0.98188281*pi/(cos 35.67*1969)]*(-0.06662095+0.04197408*B1)
3 [0.98188281*pi/(cos 35.67*1551)]*(-0.11269370+0.06499743*B3)
4 [0.98188281*pi/(cos 35.67*1044)]*(-0.23285630+0.11705160*B4)
01/10/1992 1 [1.00220121*pi/(cos 34.45*1969)]*(-0.06662095+0.04197408*B1)
3 [1.00220121*pi/(cos 34.45*1551)]* (-0.11269370+0.06499743*B3)
4 [1.00220121*pi/(cos 34.45*1044)]* (-0.23285630+0.11705160*B4)
28/12/1986 1 [0.9687889*pi/(cos 48.52*1969)]*(-0.06662095+0.04197408*B1)
3 [0.9687889*pi/(cos 48.52*1551)]* (-0.11269370+0.06499743*B3)
4 [0.9687889*pi/(cos 48.52*1044)]* (-0.23285630+0.11705160*B4)
03/07/1991 1 [1.03367889*pi/(cos 38.54*1969)]*(-0.06662095+0.04197408*B1)
3 [1.03367889*pi/(cos 38.54*1551)]*( -0.11269370+0.06499743*B3)
4 [1.033678896*pi/(cos 38.54*1044)]*( -0.23285630+0.11705160*B4)
01/07/1999 1 [1.033504606*pi/(cos 29.92*1969)]*(-0.06662095+0.04197408*B1)
3 [1.033504606*pi/(cos 29.92*1551)]*( -0.11269370+0.06499743*B3)
4 [1.033504606*pi/(cos 29.92*1044)]*( -0.23285630+0.11705160*B4)

165
Las expresiones contenidas en la Tabla 10 fueron procesadas y expresadas de manera
resumida para ser copiadas y pegadas directamente en el Band Math de ENVI agregándole la
definición de los valores con la expresión “float”. La Tabla 12 muestra las expresiones de la
Tabla 10 de manera resumida.
Tabla 12. Expresiones resumidas para el cálculo de reflectividades en las Bandas 1, 3 y 4 del
material evaluado.
FECHA B )*(**cos/* ,1,0,0 NDaaEK kkk
28/02/200
1
1 (-0.000128472632+0.000080943315*b1)
3 (-0.00027588834+0.000159121881*b3)
4 (-0.0008469017141+0.0004257189356*b4)
01/10/199
2
1 (-0.0001291861495+0.000081392861*b1)
3 (-0.0002774205887+0.0001600056196*b3)
4 (-0.0008516052742+0.0004280833122*b4)
28/12/198
6
1 (-0.000155471565+0.00009795381044*b1)
3 (-0.000333867161+0.0001925618511*b3)
4 (-0.001024880804+0.0005151851243*b4)
03/07/199
1
1 (-0.0001404745339+0.00008850503217*b1)
3 ( -0.0003016618115+0.0001739870328*b3)
4 ( -0.0009260191988+0.000465489561*b4)
01/07/199
9
1 (-0.000126749784+0.00007985784609*b1)
3 ( -0.0002721886194+0.0001569880192*b3)
4 ( -0.0008355445605+0.0004200099433*b4)

166
La aplicación de las ecuaciones anteriores, sobre cada una de las Bandas seleccionadas,
generó un conjunto de nuevas Bandas. Estas fueron utilizadas para el cálculo de los Índices de
Vegetación.
El tercer método de corrección atmosférica utilizado fue el ejecutado a través del Modelo
Cos(t) propuesto igualmente por Chávez (1996) como una revisión y mejora a los métodos
propuestos anteriormente. Su aplicación se conduce a través del Módulo AtmosC incorporado en
la última versión del software orientado a Sistemas de Información Geográfica Idrisi, conocida
como Idrisi Andes.
El Módulo AtmosC de Idrisi Andes permite desarrollar con cierta facilidad los cálculos
necesarios para la corrección de imágenes de satélite por perturbaciones causadas debidas a
factores atmosféricos. Este módulo muestra cuatro modelos: Modelo de Substracción de Objetos
Oscuros, el modelo Cost(t) propuesto por Chávez (1996), el Modelo de la Ecuación de
Transferencia Radiativa Completa, y el Modelo de Reflectividad Aparente (ARM). Para cada
caso se obtiene como resultado una imagen que muestra la reflectividad proporcional expresada
en valores que van de cero a uno.
En esta investigación sólo se trabajó con el Modelo Cost(t) el cual requiere el ingreso de
parámetros propios de la Banda espectral que se procesa: fecha y hora de captura de la escena,
ángulo de elevación solar, los posibles valores de radiancia mínimo y máximo en la misma ó en
su defecto los valores Gain/Offset (tomados del archivo de documentación de la escena), y el
valor central de la longitud de onda de la Banda (tomado de Meléndez, 2002). La Figura 36
muestra la ventana con la que se configuran los parámetros para la ejecución del Módulo AtmosC
de Idrisi Andes.
Las Bandas espectrales, 1, 3 y 4, procesadas son las que se guardaron en formato TIFF
mediante el procedimiento explicado anteriormente, donde se ajustó el tamaño de las mismas al
área de interés: la Cuenca del Río Areo. Este procedimiento genera, para cada Banda, de cada
escena, una nueva Banda, que es usada para el cálculo de los Índices de Vegetación.

167
Figura 36. Ventana para ajuste de parámetros del Módulo AtmosC de Idrisi Andes.
3.6.-Cálculo del Índice de Vegetación
Para el cálculo de los Índices de Vegetación evaluados en el presente trabajo se ejecutaron
varios procedimientos, a través de funciones disponibles en ENVI. Se aplicaron las opciones de
cálculos de Índices a través del empleo de la Band Math. El NDVI también se calculó de forma
más directa usando la función de Transformación NDVI. ENVI también dispone de la función
Vegetation Analysis – Vegetation Index Calculador, con la cual es posible determinar varios
Índices, de acuerdo con la información espectral disponible en la composición de imagen que
ingresa a este módulo. A esta función se accede desde la opción Spectral ubicada en la barra de
menú principal del programa.
La primera operación que se ejecuto fue la de hacer disponibles las bandas sobre las que
se operan los cálculos, en la memoria del programa, ubicándolas en la ventana de Bandas
Disponibles. Fueron cargadas las Bandas 1, 3 y 4 requeridas para el cálculo del NDVI, SAVI,
EVI y ARVI. Para cada escena se aplicaron los procedimientos de cálculo de Índices de
Vegetación de manera particular.
La función para el cálculo del NDVI se considera en ENVI como una función de
Transformación, por lo que se accedió a ella desde la barra de menú principal a través de la
secuencia: Transform --- NDVI lo que en principio arrojó la ventana (NDVI Calculation Input
File) para seleccionar el archivo de entrada sobre el cual se hace el cálculo. Para esta función es

168
necesario crear y cargar una composición en falso color, integrada por las tres bandas de interés,
ya que dicha función no trabaja sobre bandas individuales. La Figura 37 muestra la ventana, que
resulta de la operación anterior, donde aparecen las imágenes disponibles.
Se seleccionó la composición de imagen de interés. En este caso se aplicó la función de
Transformación sobre una composición en falso color, para sobre ella hacer el cálculo de NDVI,
y se acepta dicha selección pulsando el botón ok.
Figura 37. Ventana para selección de imagen sobra la que se calcula el NDVI.
La banda 4 es la banda del infrarrojo cercano en el espectro electromagnético y ocupa la
posición 2 en la composición cartográfica. Por esta razón se colocó el número 1 en la banda del
Red y el número 2 en la banda del Near IR.
En la opción Output Result to se activó el círculo de selección correspondiente a File para
guardar la imagen resultante en el disco del computador. Para la opción Enter Output Filename
se activó el botón Choose para acceder a la ventana donde se le asignó nombre a la imagen y se
seleccionó el destino de la misma. En Output Data Type se dejó la opción que por defecto ofrece
ENVI que es Floating Point, y se aceptó esta configuración pulsando el botón ok. En la Figura
38 se muestra la configuración de la ventana NDVI Calculation Parameters.

169
Figura 38. Parámetros de configuración de imagen para cálculo de NDVI.
El sistema incluyó la nueva imagen en la sección de Bandas Disponibles desde donde se
seleccionó para ser vista en una nueva presentación, pulsando en el botón Display #1 para
seleccionar un New Display del menú emergente. Se seleccionó la nueva imagen cargada en el
punto anterior en la Lista de Bandas Disponibles y se pulsó el botón Load Band para mostrar
dicha imagen en una nueva presentación.
La imagen así desplegada puedo ser objeto de consulta de su Histograma para visualizar
la distribución de los valores digitales de sus píxeles de entre los que se obtuvo el valor de NDVI
requerido.
El empleo de la función Band Math para el cálculo de Índices de Vegetación se presentó
como una opción más cómoda. No fue necesario trabajar sobre una composición que incluyera
varias Bandas. Está diseñado para seleccionar de forma individual las Bandas que participan en el
cálculo del Índice.
A continuación se explica el procedimiento empleado con ENVI para calcular los diversos
Índices de Vegetación usando la función Band Math.
A la función Band Math se accedió desde el comando Basic Tools en el menú principal de
ENVI. Al invocarlo generó una ventana de configuración donde se ingresan las fórmulas. La
fórmula que se aplicó se ingresó en la sección Enter an expression. Cuando se hace operaciones
con varias Bandas, es necesario encerrar el nombre de cada una con un paréntesis precedido del
término float. Con esta expresión se le indica al programa el tipo de variable con el que se está
trabajando. La Tabla 13 muestra las fórmulas empleadas.

170
Tabla 13. Fórmulas para cálculo de Índices de Vegetación en ENVI
La aplicación de las fórmulas se hizo para cada escena. Primeramente las bandas de
interés se cargaron en la ventana de Bandas Disponibles de ENVI. La aplicación de cada
ecuación generó una nueva imagen. Todas fueron almacenadas luego de asignarle el nombre
correspondiente. Las fórmulas se aplicaron a las Bandas derivadas de los tres procedimientos de
corrección señalados en la sección anterior.
3.6.1.-Visualización de valores de Índices de Vegetación en ENVI
Sobre la imagen desplegada se hizo clic con el botón derecho del “mouse” y se seleccionó
la opción Quick Stats con lo cual se mostró la ventana Statistics Results de la imagen. Esta
ventana contiene, entre otros, el valor promedio del Nivel Digital del Píxel (ND) correspondiente
a la imagen, que representó el valor del NDVI calculado.
También es posible ver el resultado del cálculo haciendo clic con botón derecho del ratón
sobre la
imagen correspondiente en la ventana de Bandas Disponibles y del menú emergente seleccionar
la opción Quick Stats. El valor así obtenido se anota y almacena de forma conveniente para su
posterior empleo.
IV Fórmula
NDVI (float(b4)-float(b3))/(float(b4)+float(b3))
SAVI (float(b4)-float(b3))/(float(b1)+float(b2))
EVI 2.5*((float(b4)-float(b3))/((float(b4)+float(6*b3)-float(7.5*b1)+1))
ARVI (float(b1)-float(b2))/(float(b1)+float(b2))

171
Considerando la posibilidad de seleccionar directamente las bandas de interés a través de
la función Band Math, se usó este procedimiento como estándar para el cálculo de todos los
Índices en la presente investigación.
Cada una de las escenas seleccionadas para este estudio recibió el tratamiento antes
descrito. Se obtuvo en consecuencia una serie de valores correspondientes a los diferentes Índices
que mostró la zona evaluada para las diferentes fechas en la que fueron tomadas las imágenes.
Estos valores fueron tabulados y organizados con los correspondientes valores de precipitación, y
fueron procesados en un Análisis Estadístico.
3.7.- Cálculo de NDVI y otros Índices de Vegetación usando Idrisi Andes
Para apoyarse en las versatilidades gráficas que ofrece el programa Idrisi Andes, se
describe a continuación la metodología empleada para la determinación de Índices de Vegetación
operando con la función de Calculadora de Bandas o con funciones predeterminadas en el
programa que desarrollan algunos de estos cálculos.
El módulo VegIndex de Idrisi Andes fue empleado para calcular varios Índices de
Vegetación, con sólo ingresar los archivos de las Bandas espectrales que corresponden a cada
Índice en particular. Con él pueden calcularse 19 Índices de Vegetación. En la Figura 39 pueden
verse cada uno de los Índices, así como las ventanas para ingreso de las Bandas
espectrales correspondientes y la ventana para configuración de nombre de archivo de salida y
ubicación del mismo.
Figura 39. Módulo VEGEINDEX de Idrisi Andes

172
De los Índices de interés en la presente investigación, el Módulo VEGINDEX sólo
permite calcular dos: el NDVI y el SAVI, por esta razón para el desarrollo de todos los cálculos
se operó a través de la Calculadora de Bandas conocida como Image Calculator. Esta función
permitió el ingreso de las ecuaciones correspondientes para cada Índice de interés, facilitando
igualmente la búsqueda de las Bandas espectrales necesarias para cada cálculo. La Figura 40
muestra la organización de los elementos en la función Image Calculator.
Figura 40. Ventana de la Función Imagen Calculator de Idrisi Andes
La Función Image Calculator muestra los operadores matemáticos más comunes
disponibles para ser activados través de botones. En ella las Bandas espectrales para cada cálculo
de Índice de Vegetación ingresaron a través del botón Inser Image y una vez planteada la
ecuación la misma se ejecutó a través del botón Process Expresion. Si las Bandas para cada
escena fueron guardadas con igual nombre, es útil guardar las expresiones formuladas para ser
usadas directamente sin necesidad de volver a escribirlas, sobre todas las Bandas que componen
el material a evaluar. La operación de almacenamiento de dichas expresiones se hizo a través del
botón Save Expresion.
3.7.1.-Visualización de valores de Índices de Vegetación en Idrisi Andes
Para registrar los resultados de cualquier cálculo que se haga sobre los píxeles de
composiciones en color o sobre Bandas espectrales individuales, se activó el módulo Histo de
Idrisi Andes. Con él se confeccionaron los Histograma del material tanto original como
resultante de un procesamiento, permitiendo visualizar y reportar los resultados tanto en forma de
gráficas como en forma numérica. La Figura 41 muestra la configuración de los elementos en el

173
módulo Histo. En el Módulo se configuró el tipo de archivo de entrada, que en este caso es del
tipo Image file, se buscó e ingresó la composición o banda de interés a través de la sub ventana
Input file, e igualmente en esta sub ventana se decidió si la salida es en forma gráfica o numérica,
indicando el ancho de banda en Class width o bien el número de clases a través de Number of
classes. Al ingresar la composición o Banda de interés, el módulo muestreó el rango en el que se
distribuyen los valores digitales señalando el valor mínimo y el valor máximo a ser presentado en
el Histograma.
Figura 41. Ventana para ejecución del Módulo HISTO en Idrisi Andes
4.3.3. Fase de Análisis Estadístico
Esta fase de la investigación se dividió en dos niveles. En el primer nivel se evaluó a
través de procedimientos propios de estadística descriptiva el comportamiento de los Índices de
Vegetación obtenidos a partir de Bandas espectrales derivadas de cada uno de los tres métodos de
corrección. En el segundo nivel se aplicó el análisis estadístico planificado para la evaluación de
correlación entre las variable estudiadas, que implica la ejecución del Análisis de Varianza y la
construcción del Modelo Matemático.
Se ejecutaron tres métodos para la corrección del material espectral (Bandas). Sobre las
Bandas corregidas por cada método se desarrollaron los cálculos para la determinación de cuatro
Índices de Vegetación. A través de resúmenes numérico, detección de valores aberrantes, gráficos
de control y Matriz de gráficos de dispersión se evaluaron los tres grupos de Índices de
Vegetación y se determinó cuál de los grupos resultó ser el más homogéneo y de mayor ajuste a
los fundamentos teóricos, según lo cual se decidió usar tal grupo de valores para continuar el
análisis estadístico en un segundo nivel.
1.- Estadística Descriptiva

174
Toda la evaluación estadística se hizo sobre la plataforma computacional del programa
“R” para lo que se diseñaron las funciones en líneas de códigos ajustadas a los requerimientos de
cada prueba. Cada método de corrección espectral generó un grupo de datos consistente en una
tabla donde se reporta el valor promedio para cada Índice de Vegetación generado para cada
escena. Se evaluaron cinco escenas, con fechas que van desde diciembre de 1986 a febrero de
2001. Cada tabla, contentiva de los promedios reportados para cada Índice en cada escena, en
función del método de corrección, fue almacenada como un archivo tipo texto y guardada en una
“carpeta” hacia la cual se cambió el directorio de trabajo de “R” a fin de hacer la importación de
los archivos que contienen los datos de una forma más cómoda. A cada grupo de datos se le
aplicaron los códigos para el reporte de su estadística descriptiva. La evaluación de la estadística
descriptiva se hace grupo por grupo. A continuación se incluyen los códigos usados para cada
grupo de datos. La diferencia en el código usado para cada grupo está en el nombre del archivo
que se importa al directorio de trabajo de “R”. Este código se corrió por partes, atendiendo a las
indicaciones del mismo.Con el código que se describe a continuación fue posible generar:
1.- Reporte de resúmenes numéricos: mínimo, máximo, media, mediana, 1ero y 3er cuartil
2.- Detección de datos aberrantes: reporta existencia de valores extremos.
3.- Gráfica de medias: dibuja un gráfico que muestra los promedios de cada grupo
4.- Gráfica tipo caja: muestra gráficamente el resumen numérico para cada grupo
5.- Gráficas Combinadas: un mismo gráfico dibuja el comportamiento de cada grupo.
6.- Matriz de gráficos de dispersión: muestra la comparación bivariante.
##GENERACIÓND DE ESTADÍSTICA DESCRIPTIVA.
##APLICAR ESTE CÓDIGO, POR SEPARADO, A CADA GRUPO DE DATOS
#DERIVADOS DE CADA MÉTODO DE CORRECCIÓN DE BANDAS.
##ESTE CÓDIGO DEBE EJECUTARSE POR PARTES SEGÚN INSTRUCCIONES #DADAS
##EJECUTAR ESTA PRIMERA INSTRUCCIÓN. ES COMÚN PARA
##TODAS LAS DEMÁS INSTRUCCIONES.
##IMPORTAR EL ARCHIVO QUE CONTIENE LOS DATOS PARA CADA GRUPO.
indices<-read.table("indicesatmosCorregidos.txt",header=T)
attach(indices)

175
##SELECCIONAR DESDE AQUÍ PARA VISUALIZAR REPORTE DE DATOS
##ABERRANTES Y REPORTE DE RESÚMENES NUMÉRICOS
##PARA ALMACENAR REPORTE DE RESUMENES NUMÉRICOS
resumen_numérico<-summary(indices) ##reporta los seis estadísticos principales
rango<-range(indices) ##reporta el valor mínimo y máximo general
medias<-mean(indices) ##reporta el promedio de cada Índice evaluado
##DETERMINACIÓN DE VALORES ABERRANTES
##INGRESO DE LOS ARCHIVOS A EVALUAR. CON LA FUNCIÓN "scan" SE LEEN
##LOS DATOSDE MANERA SECUENCIA. CON LA FUNCIÓN "skip=1" SE SALTA ##LA
LECTURA DE LA PRIMERA LÍNEA.
indicesatmosCorregidos<-scan("indicesatmosCorregidos.txt",skip=1)
##CONSTRUCCIÓN DE FUNCIÓN PARA EVALUACIÓN DE DATOS #ABERRANTES
datos.aberrantes<-function(x){
umbral<-4
if (sd(indicesatmosCorregidos)>=umbral*mad(indicesatmosCorregidos))
cat("El conjunto de datos contiene valores aberrantes","\n")
else
cat("Datos sin valores aberrantes","\n")
}
##VISUALIZACIÓN DE RESÚMENES NUMÉRICOS
datos.aberrantes(indicesatmosCorregidos)
resumen_numérico
rango
medias
##SELECCIONAR HASTA AQUÍ PARA VISUALIZAR REPORTE DE DATOS
##ABERRANTES Y REPORTE DE RESÚMENES NUMÉRICOS
##SELECCIONES DESDE AQUÍ PARA PLOTEAR LAS MEDIAS DE LOS ÍNDICES
plot(medias,type="b",axes=F,main=c("Medias globales de Índices de Vegetación"),

176
xlab=c(" "),ylab=c("Promedios"),sub=c("Índices de Vegetación evaluados"))
box()
axis(2,cex.axis=0.8,las=1)
axis(1,1:4,paste(c("NDVI","SAVI","EVI","ARVI")),cex.axis=0.8)
abline(h=mean(medias))
text(locator(1),c("Promedio General"))
##SELECCIONES HASTA AQUÍ PARA PLOTEAR LAS MEDIAS DE LOS ÍNDICES
##DIBUJO DE GRÁFICAS INDIVIDUALES, PARA CADA ÍNDICE, EN UNA ##MISMA
HOJA ESTA PARTE DEL CÓDIGO SE CORRE DE FORMA ##INDIVIDUAL. SE
SELECCIONA Y SE MANDA A CORRER DESDE EL ##QUINTO ICONO, DE IZQ. A
DRECHA, UBICADOEN LA TERCERA BARRA #DE HERRAMIENTAS DE ESTE "IDE".
######DESDE AQUÍ SE SELECCIONA EL CÓDIGO PARA GENEAR GRUPO DE
####GRÁFICAS
##DIVIDE LA PANTALLA EN DOS FILAS Y DOS COLUMNA
par(mfrow=c(2,2),cex.main=1.5) S
##PLOTEA EL PRIMER ÍNDICE: NDVI
plot(NDVI,type="h",las=2,axes=F,cex.axis=0.7,ylim=c(-0.1,0.79),xlab=c(""),
ylab=c("NDVI"), main=c("NDVI"))
box()
axis(2,cex.axis=0.8,las=1)
axis(1,1:5,paste(c("Dic86","Jul91","Oct92","Jul99","Feb01")),
cex.axis=1.5,las=1)
abline(h=0,col=2)
##PLOTEA EL SEGUNDO ÍNDICE: SAVI
plot(SAVI,type="h",las=2,axes=F,xlab=c(""),ylim=c(-0.1,0.40),ylab=c("SAVI"),
main=c("SAVI"))
box()
axis(2,cex.axis=0.8,las=1)
axis(1,1:5,paste(c("Dic86","Jul91","Oct92","Jul99","Feb01")),
cex.axis=1.5,las=1)
abline(h=0,col=2)

177
##PLOTEA EL TERCER ÍNDICE: EVI
plot(EVI,type="h",las=2,axes=F,cex.axis=0.7,ylim=c(-0.1,1.1),xlab=c(""),
ylab=c("EVI"),main=c("EVI"))
box()
axis(2,cex.axis=0.8,las=1)
axis(1,1:5,paste(c("Dic86","Jul91","Oct92","Jul99","Feb01")),
cex.axis=1.5,las=1)
abline(h=0,col=2)
##PLOTEA EL CUARTO ÍNDICE: ARVI
plot(ARVI,type="h",las=2,axes=F,cex.axis=0.7,ylim=c(-0.1,1.1),xlab=c(""),
ylab=c("ARVI"),main=c("ARVI"))
box()
axis(2,cex.axis=0.8,las=1)
axis(1,1:5,paste(c("Dic86","Jul91","Oct92","Jul99","Feb01")),
cex.axis=1.5,las=1)
abline(h=0,col=2)
####HASTA AQUÍ SE SELECCIONA EL CÓDIGO PARA GENERAR EL GRUPO
####DE GRÁFICAS
##DIBUJAR LOS GRÁFICOS, TIPO CAJA, DE CADA ÍNDICE PARA COMPARAR
##LOS PROMEDIOS ENTRE ELLOS.
####SELECCIONAR DESDE AQUÍ PARA DIBUJAR GRÁFICOS DE CAJA
promediosindices<-c(NDVI,SAVI,EVI,ARVI)
Indices<-rep(c("1NDVI","2SAVI","3EVI","4ARVI"),c(5,5,5,5))
boxplot(promediosindices~Indices,ylab=c("Promedios Indices de Veg."),main=c("
Comparación de Promedios Indices de Vegetación"))
###SELECCIONAR HASTA AQUÍ PARA DIBUJAR GRÁFICOS DE CAJA
##DIBUJO DE GRÁFICAS COMBINADAS. SE MUSTRAN TODAS LAS
##GRÁFICASDE TODOS LOS ÍNDICES DE VEGETACIÓN EN UN MISMO EJE

178
##"X-Y".ESTA PARTE DEL CÓDIGO FINALIZA CUANDO EL OPERADOR #HACE CLIC
EN UN PUNTO SOBRE LA GRÁFICA DONDE DESEA COLOCAR
##LA LEYENDA.
##SELECCIONE DESDE AQUÍ PARA GENERAR LA GRÁFICA COMBINADA
fechas<-c(1,2,3,4,5)
plot(NDVI,type="b",pch=1,las=2,axes=F,cex.axis=0.7,xlab=c(" "),
ylim=c(-1.1,1.1),ylab=c("Indices de Veg."),
main=c("Índices de Vegetacion (promedio) derivados de Bandas espectrales
corregidas atmosféricamente con el Módulo AtmosC de Idrisi Andes"))
box()
axis(2,cex.axis=0.8,las=1)
axis(1,1:5,paste(c("Dic86","Jul91","Oct92","Jul99","Feb01")),
cex.axis=1.5,las=1)
abline(h=-1,col=2)
abline(h=1,col=2)
abline(h=0,col=3)
lines(fechas,SAVI,type="b",pch=2)
lines(fechas,EVI,type="b",pch=3)
lines(fechas,ARVI,type="b",pch=4)
legend(locator(1),legend=c("NDVI","SAVI","EVI","ARVI"),
pch=1:4)
##SELECCIONE HASTA AQUÍ PARA GENERAR LA GRÁFICA COMBINADA
##GENERACIÓN DE MATRIZ DE GRÁFICOS DE DISPERSIÓN
##SELECCIONES DESDE AQUÍ PARA GENERAR MATRIZ DE GRÁFICOS
plot(indices, main=c("Matriz de gráficos de dispersión.
Bandas espectrales con corrección atmosférica"),cex.main=0.9)
##SELECCIONES HASTA AQUÍ PARA GENERAR MATRIZ DE GRÁFICOS
##FIN DE CÓDIGO.
La selección del método de corrección de Bandas espectrales se hizo a través de la
evaluación de la estadística descriptiva para los resultados derivados de cada método. La

179
estadística descriptiva está contenida en los seis puntos recién mencionados derivados de la
aplicación del código en “R” arriba descrito.
2.- Análisis de Varianza
Luego de seleccionado el método de corrección atmosférica AtmosC de Idrisi, por ser el
que generó el comportamiento de promedios más ajustado al fundamento teórico, los promedios
para cada índice fueron evaluados en un análisis de varianza para hacer la comparación de medias
y determinar la existencia de diferencias significativas entre ellas.
El código en “R” utilizado para el análisis de varianza fue el siguiente:
##CÓDIGO EN “R” PARA CÁLCULO DE ANALISIS DE VARIANZA
##LECTURA DEL ARCHIVO QUE CONTIENE LOS ÍNDICES DE VEGETACIÓN
##PROMEDIO
indices<-read.table("indicesatmosCorregidos.txt",header=T)
indices
##HACER DISPONIBLES LOS DATOS INCLUIDOS EN CADA COLUMNAS AL
##LLAMARLOS POR LAS ETIQUETAS QUE LAS IDENTIFICAN.
attach(indices)
##CREAR UN ARCHIVO QUE CONTENGA EN FORMA SECUENCIAL (UNO ##DETRÁS
DEL OTRO) LOS VALORES PROMEDIOS DE LOS ÍDNICES. PRIMERO ##LOS DE LA
PRIMERA COLUMNA, LUEGO LOS DE LA SEGUNDA COLUMNA, Y ##ASÍ HASTALA
ÚLTIMA, FORMANDO UNA CADENA
promediosindices<-c(NDVI,SAVI,EVI,ARVI)
##CREAR EL ARCHIVO QUE CONTIENE LAS ETIQUETAS PARA CADA ÍNDICE ##DEL
PASO ANTERIOR. CADA VALOR DEL PASO ANTERIOR DEBE ESTAR ##ASOCIADO
CON EL ÍNDICE DEL CUAL SE DERIVA. ESTE ÍNDICE ES LA ##ETIQUETA DE DICHO
VALOR. PRIMERO SE CREA EL ARCHIVO QUE ##CONTIENE LAS ETIQUETAS Y
LUEGO SE TRANSFORMA DICHO ARCHIVO A ##"FACTOR" PARA QUE “R” LO
IDENTIFIQUECOMO TAL
Indices<-rep(c("1NDVI","2SAVI","3EVI","4ARVI"),c(5,5,5,5))
Indices<-factor(Indices)

180
##DIBUJAR LOS GRÁFICOS DE CADA ÍNDICE PARA COMPARAR LOS ##PROMEDIOS
DE CADA INDICE ENTRE ELLOS.
boxplot(promediosindices~Indices,ylab=c("Promedios Indices de Veg."),main=c("
Comparación de Promedios Indices de Vegetación"))
##FORMULAR EL PLANTEAMIETO PARA EL ANALISIS DE VARIANZA
anovageneral<-aov(promediosindices~Indices)
##CONSULTAR LOS RESULTADOS DEL ANAVA
anovageneral
summary(anovageneral)
RESUMEN CÓDIGOS USADO EN “R” PARA CÁLCULO DE ANAVA
indices<-read.table("indicesatmosCorregidos.txt",header=T)
attach(indices)
promediosindices<-c(NDVI,SAVI,EVI,ARVI)
Indices<-rep(c("NDVI","SAVI","EVI","ARVI"),c(5,5,5,5))
Indices<-factor(Indices)
anovageneral<-aov(promediosindices~Indices)
anovageneral
summary(anovageneral)
##FIN DE CÓDIGO
3.- Construcción del modelo matemático
Una vez evaluada la existencia o no de diferencias significativas entre los Índices de
Vegetación, usando el método summary de la función aov del programa estadístico R, aplicado
con el código señalado en la sección anterior, se decidió con cuál de ellos se construiría el
modelo matemático de correlación. La decisión se fundamentó en la evaluación de una
representación gráfica que mostró el promedio de Índice obtenido más cercano con el promedio
global.
La construcción del modelo matemático se hace combinando la variable Índice de
Vegetación como variable independiente, y la variable Caudal de escorrentía superficial, como
variable dependiente.

181
Se construyó una tabla que contiene en la primera columna los valores del Índice de
Vegetación seleccionado del procedimiento anterior, y en otra columna los valores de Caudal de
escorrentía superficial que coinciden con las fechas en las que se tomaron las imágenes de satélite
de donde se derivaron los Índices. Este tratamiento de los datos resulta en extremo riguroso. Su
aplicación obedece a la dificultad de contar con el número apropiado de material espectral para
correr una evaluación más flexible.
Para el cálculo del modelo matemático a través de regresión lineal se usó la función lm()
disponible en el programa estadístico “R”. El formato básico para la fórmula a través de esa
función es: respuesta~predictor, donde el símbolo ~ (tilde) se lee como “es modelado por” y es
usado para separar la variable respuesta de la variable predictora.
La formulación del código para ejecución de los cálculos en “R” fue la siguiente:
##MODELO DE REGRESIÓN
##Ingreso de valores de NDVI
NDVI5<-c(0.191,0.475,0.540,0.657,0.145)
##Ingreso de valores de Caudal
Caudal5<-c(46,498.4,38.5,1206.1,10)
##Formulación modelo lineal simple
modelo1<-lm(Caudal5~NDVI5)
##Reporte de resultado Análisis de Regresión para modelo1
summary(modelo1)
##Formulación modelo Potencia 2º
modelo2<-lm(Caudal5~NDVI5+I(NDVI5^2))
##Reporte de resultado Análisis de Regresión para modelo2
summary(modelo2)
##Formulación modelo Potencia 3º
modelo3<-lm(Caudal5~NDVI5+I(NDVI5^2)+I(NDVI5^3))
##Reporte de resultado Análisis de Regresión para modelo3
summary(modelo3)
Una vez evaluado el reporte de resultados para cada modelo, a través de los métodos
summary(nombre_del_modelo) señalados en el código anterior, se revisó el valor del coeficiente
de correlación r2, y se plotearon los residuales para cada modelo en una gráfica comparativa. En

182
el reporte de resultados para cada modelo se identificó el valor para cada coeficiente que
constituye la expresión de la función. En función de tales coeficientes se construyó la ecuación de
acuerdo con el modelo seleccionado.
CAPÍTULO IV
RESULTADOS Y DISCUSIÓN
5.1.- Fase de evaluación Hidrológica
La Cuenca del Río Areo se encuentra ubicada en su mayor parte al occidente del Estado
Monagas, teniendo una pequeña porción de su territorio ubicada en el Municipio Freites del
Estado Anzoátegui. La Figura 42 muestra la ubicación relativa de la Cuenca en toda su
extensión.
MUNICIPIO PUNCERES
UBICACIÓN RELATIVA CUENCA DEL RÍO AREO
EN EL ESTADO MONAGAS Y ESTADO ANZOÁTEGUI
MUNICIPIO CARIPE
MUNIC
IPIO
PIA
R
MUNIC
IPIO
ACOSTA
MUNICIPIO SANTA
BÁRBARA
MUNICIPIO EZEQUIEL
ZAMORA
MUNICIPIO AGUASAY
MUNICIPIO SOTILLO
MUNICIPIO URACOA
MUNICIPIO BOLIVAR
MUNICIPIO MATURÍN
MUNICIPIO LIBERTADOR
MUNICIPIO CEDEÑO
ED
O.
AN
ZO
ÁT
EG
UI
ESTADO MONAGAS
Cuenca del Río Areo

183
Figura 42.- Ubicación relativa de la Cuenca del río Areo en el Estado Monagas y parte del
Estado Anzoátegui (Mapa sin escala)
Geográficamente se ubica entre las siguientes coordenadas
Desde los 09º 43’ 06” de Latitud Norte y 63º 49’ 15” de Longitud Oeste
hasta los 10º 06’ 05” de Latitud Norte y 63º 56’ 43” de Longitud Oeste.
La Tabla 14 contiene el cuadro de coordenadas determinadas en la proyección
cartográfica UTM del Datum REGVEN, para el perímetro de la Cuenca del Río Areo.
Tabla 14.- Cuadro de coordenadas UTM para el perímetro de la Cuenca Río Areo.
Datum REGVEN, Huso 20
VERTICE NORTE ESTE
V1 1073850 409896
V2 1078490 403309
V3 1087939 392427
V4 1097707 391983
V5 1107083 393520
V6 1112337 395118
V7 1104434 402067
V8 1094204 401882
V9 1090058 409065
V10 1078956 413076
Para el desarrollo de esta investigación, la cuenca fue digitalizada usando las hojas
cartográficas disponibles en escala 1:25.000, editadas por el Instituto Geográfico de Venezuela
Simón Bolívar (IGVSB). Para la digitalización y determinación de parámetros morfométricos se
usó AutoCad Land en combinación con el software de construcción de Sistemas de Información
Geográfica (SIG) ArcMap, y la representación cartográfica resultante se trabajó a escala

184
1:50.000. El mapa mostrado en la Figura 43 contiene el perímetro de la Cuenca del Río Areo.
Las hojas cartográficas usadas para la fase de vectorización digital de la Cuenca se muestran en el
Anexo 2.
Figura 2.3.- Perímetro Cuenca del Río Areo
2
POLÍGONO DE CUENCA RÍO AREO
AREA = 420,88 km
COORDENADAS UTM. DATUM REGVEN
V-1 1073850.56 409896.14
V-2 1078490.12 403309.95
V-3 1087939.51 392427.64
V-4 1097707.43 391983.15
V-5 1107083.61 393520.62
V-6 1112337.45 395118.06
V-7 1104434.77 402067.72
V-8 1094204.28 401882.88
V-9 1090058.53 409065.47
V-10 1078956.25 413076.14

185
Figura 43.- Perímetro de Cuenca Río Areo.
5.1.- Parámetros morfométricos.
La determinación de los parámetros morfométricos arrojó el siguiente grupo de valores:
Área de la cuenca:
Área = 420.877.646,60 m2 = 420.88 km
2.
Longitud axial (Lax):
Cuenca Río Areo: Lax = 41869.28 m Lax = 41.87 km.
Factor de forma (Ff):
Cuenca Río Areo: alargada) forma de ( 24.0 cuencaFf
Coeficiente de compatibilidad (K):
APK /*28.0 P = 123.61 Km.
A = 42.88km2
288.42/61.123*28.0 kmkmK 29.5K
Tabla 15. Datos de cálculo para Elevación Media
Curvas de
nivel m.s.n.m
Elevaciones
parciales (ei)
(m)
Longitud (m) Área (ai) km2
ei * ai
(m/km2)
200 – 400 300 179.104,12 194,63 58.389
400 – 600 500 244.772,95 81,26 40.630
600 – 800 700 211.326.93 62, 58 43.806
800 – 1000 900 64.946,74 13,42 12.078
1000 – 1200 1100 83.045,08 13,20 14.520
1200 – 1400 1300 86.224,75 12,10 15.730
1400 – 1600 1500 83.335,65 10,39 15.585
1600 – 1800 1700 58.705,39 10,14 17.238
1800 – 2000 1900 36.090,91 5,13 9.747
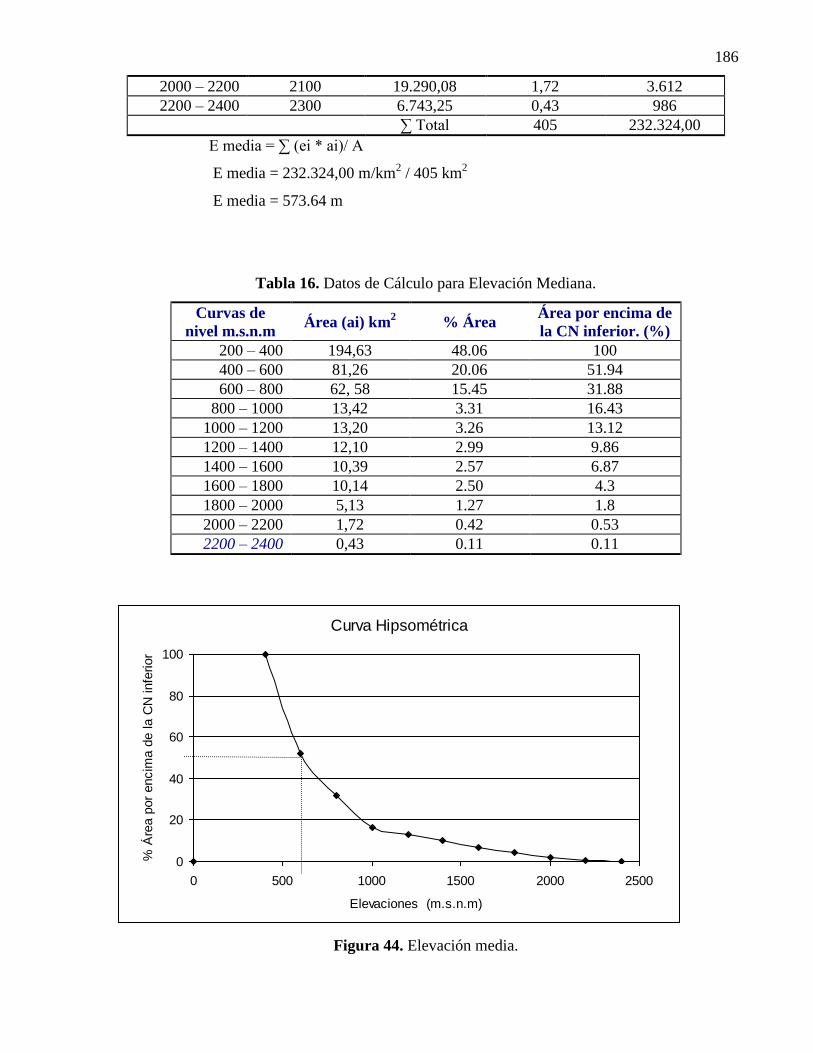
186
2000 – 2200 2100 19.290,08 1,72 3.612
2200 – 2400 2300 6.743,25 0,43 986
∑ Total 405 232.324,00
E media = ∑ (ei * ai)/ A
E media = 232.324,00 m/km2 / 405 km
2
E media = 573.64 m
Tabla 16. Datos de Cálculo para Elevación Mediana.
Curvas de
nivel m.s.n.m Área (ai) km
2 % Área
Área por encima de
la CN inferior. (%)
200 – 400 194,63 48.06 100
400 – 600 81,26 20.06 51.94
600 – 800 62, 58 15.45 31.88
800 – 1000 13,42 3.31 16.43
1000 – 1200 13,20 3.26 13.12
1200 – 1400 12,10 2.99 9.86
1400 – 1600 10,39 2.57 6.87
1600 – 1800 10,14 2.50 4.3
1800 – 2000 5,13 1.27 1.8
2000 – 2200 1,72 0.42 0.53
2200 – 2400 0,43 0.11 0.11
Curva Hipsométrica
0
20
40
60
80
100
0 500 1000 1500 2000 2500
Elevaciones (m.s.n.m)
% Á
rea p
or
encim
a d
e la C
N infe
rior
Figura 44. Elevación media.

187
Tal como se identifica en la grafica, la elevación mediana es aquella donde el 50 % del
área tiene elevaciones mayores y el otro 50 % tiene elevaciones menores.
Elevación mediana = 620 m.s.n.m.
Elevación modal: esta representa la elevación que tiene mayor área para observarlo más
claramente se construye un histograma tal como se muestra en la Figura 45.
Elevación modal
0
5
10
15
20
25
30
35
40
45
50
200-
400
400-
600
600-
800
800-
1000
1000-
1200
1200-
1400
1400-
1600
1600-
1800
1800-
2000
2000-
2200
2200-
2400
Elevación (m.s.n.m)
% A
rea
Figura 45. Elevación modal.
Elevación modal = 300 m
Pendiente media de la cuenca:
Tabla 17. Datos De Longitud Total de las Curvas de Nivel.
CN 200 400 600 800 1000 1200 1400 1600 1800 2000 2200 2400
L 43,16 93,49 105,27 47,75 36,16 46,57 36,66 40,78 20,80 12,17 3,18 1,71
S = (D/A)* L
donde: D = intervalo entre curvas de nivel.
A = área total de la cuenca.
L = longitud total de las curvas de nivel.
S = (D/A)* L

188
S = 200 m / 420.88Km2 * 487.70 Km.
S = 240.84 m/Km.
Longitud del cauce principal:
Para la determinación de la longitud se divide el cauce principal en tres tramos el primero
desde 200 metros hasta 400; desde 400 hasta 800 y desde 800 a 2400 metros.
Aplicando la formula antes descrita, se obtiene la longitud de cada tramo para que luego
la sumatoria de las longitudes sea igual a la longitud verdadera del cauce principal.
Tramo # 1:
Proyección horizontal: 39277,96 m.
Diferencia de altura: 400 – 200 = 200 m. mL 46.39778)20096,39277( 221
Tramo # 2:
Proyección horizontal: 13869.92 m.
Diferencia de altura: 800 – 400 = 400 m. mL 69.13875)40092.13869( 22
2
Tramo # 3:
Proyección horizontal: 9592.85m.
Diferencia de altura: 2400 – 800 = 600 m. mL 60.9611)60085.9592(3 22
Longitud verdadera: Tramo # 1 + Tramo # 2 + Tramo # 3 =
Longitud verdadera. 39778,46 m +13875,69 m + 9611,60 m =
Lv = 63.265,75 m
Lv = 63,27 km.
Pendiente del cauce principal:
Haciendo la consulta de longitud total del cauce principal en el programa AutoCad, el
resultado fue 62,74 km, y calculando la diferencia entre cota mayor y cota menor de los extremos

189
del cauce se determinó el desnivel con un valor de 2375 m. La pendiente media se obtuvo según
la expresión:
S = ∑ (Hi)/ L kmmkm
mS /85,37
74,62
2375
Densidad de Drenaje:
Dd = L/A kmmm
Dd /07.14988.420
73,62740 Dd = 149.07 m /km.
5.1.2.- Cálculo y Dibujo de líneas Isocronas.
El dibujo, en dicha cuenca, de las líneas isocronas, con el propósito de la elaboración del
hidrograma unitario, se hizo a través de la metodología que opera para el dibujo de las curvas de
nivel, donde los puntos a interpolar serán valores de tiempo de concentración calculados sobre
algunos puntos de la red de drenaje de cada una. Para este dibujo de líneas isocronas se usó el
software de diseño asistido por computadora Autocad Land. Obtenidas las curvas isocronas, se
calcularon las áreas encerradas entre curvas como parte de los requerimientos del Método de
Clark para la construcción del Hidrograma Unitario.
La Figura 46 es un extracto de la consola del programa Estadístico R que muestra los
Resultados del cálculo de Tiempo de Concentración para varios puntos sobre la cuenca:

190
Figura 46.- Resultados cálculo del TC para toda la cuenca
En la Figura 46. L es la longitud media sobre un cauce, desde el punto donde se mide el
Tiempo de Concentración (TC) hasta la desembocadura de dicho cauce sobre el río principal (Río
Areo). El Desnivel, es la diferencia de nivel (diferencia de cotas) existente entre el punto sobre el
terreno donde se calcula el TC y su desembocadura en el río principal. Y la pendiente, cociente
la resultante de dividir Desnivel entre L. Por último TC, es Tiempo de Concentración, que según
la fórmula aplicada, está expresado en minutos.
El plano que muestra las líneas Isocronas dentro de la Cuenca del Río Areo está contenido
en la Figura 47. Muestra 9 áreas en las que es dividida la Cuenca automáticamente al hacer el
cálculo sobre ella de dichas líneas. Fueron escogidos 21 puntos de manera aleatoria sobre igual
número de tributarios que drenan hacia el cauce principal de la cuenca. La cuantía de cada una de
esas áreas en relación a la línea Isocrona a la que corresponde se muestra en la Tabla 18.
Tabla 18. Áreas entre curvas Isocronas de la Cuenca Río Areo.
Nro Curva (Tc)
min
Área
(m2)
1 210 28895375.29
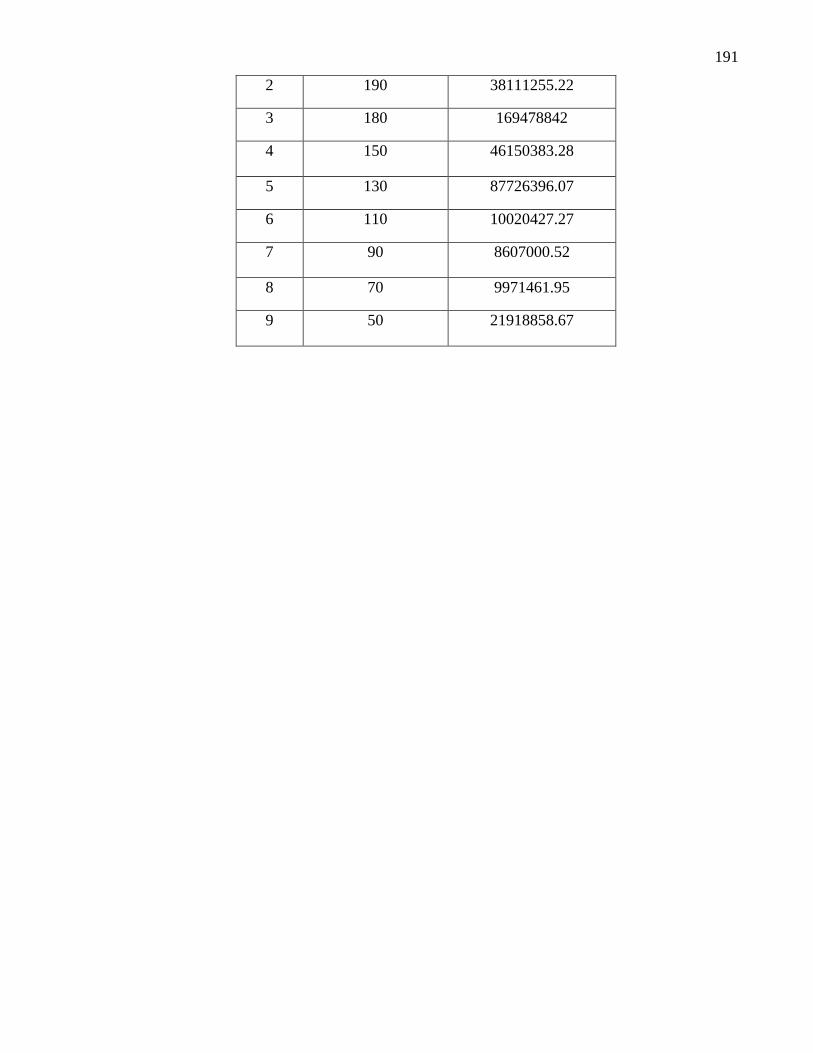
191
2 190 38111255.22
3 180 169478842
4 150 46150383.28
5 130 87726396.07
6 110 10020427.27
7 90 8607000.52
8 70 9971461.95
9 50 21918858.67

192
Figura 47.- Líneas Isocronas sobre Cuenca del Río Areo

193
5.1.3.- Polígonos de Thiessen.
A través de la construcción de los Polígonos de Thiessen fue posible identificar el área de
influencia de las Estaciones Climatológicas cercanas a la Cuenca en estudio. Se determinó que la
Estación La Pinta es la que muestra mayor influencia. Se utilizaron los datos de precipitación de
dicha Estación para los cálculos de caudales.
La Figura 48 muestra los polígonos sombreados para destacar el área de influencia que
abarca cada Estación.
Figura 48. Área de influencia, sobre de la Cuenca del Río Areo, de las Estaciones
Climatológicas más cercanas.

194
5.1.4.- Hidrograma Unitario Instantáneo y caudales simulados
A continuación se muestran los resultados obtenidos con la aplicación del Método de
tránsito conocido como método de Muskingum, desarrollados con el propósito de determinar el
Hidrograma Unitario Instantáneo.
El tiempo entre Isocronas fue establecido para el dibujo de estas líneas de acuerdo con los
valores de Tiempo de Concentración usados para la interpolación de las mismas empleando el
programa AUTOCAD LAND. Este tiempo se fijó como una equidistancia (variación entre el
tiempo de una línea y el tiempo de la siguiente y la anterior) de 20 minutos, es decir, 0.33 horas.
T1 = Tiempo entre Isocronas = 0.33 horas (1200 segundos)
K (Coeficiente de Proporcionalidad) = 2 Este valor se estima a través de la curva que
relaciona TL y TC elaborada por la antigua División del MOP (Carciente, 1999). La curva se
incluye en el Anexo 3.
1
10
*5.0
*5.0
TK
TC
C0 = 0.5 * 0.33 / 2 + 0.5 * 0.33 = 0.0762
1
11
*5.0
*5.0
TK
TC
C1 = C0 = 0.33
1
12
*5.0
*5.0
TK
TKC
C2 = 2 – 0.5 * 0.33 / 2 + 0.5* 0.33 = 0.8475
)(__
10*)_(___ 2
sisocronasentretiempo
kmCuencaladeáreaEU = 420.82 km
2 * 10 / 1200 = 3.50
El cálculo del Hidrograma Unitario Instantáneo se hizo a través de la corrida del código
ejecutable en el programa Estadístico R elaborado para tal fin. Este código puede verse en el
Capítulo III de este material. El resultado se indica en la Figura 49. Contiene el tiempo,
espaciado en la fracción calculada, en el que se hace escurrir toda la lluvia. En este caso se
escogió un tiempo mayor al tiempo de Concentración de la cuenca, de 12 horas. La segunda
columna muestra los valores de los TC, así como las áreas entre curvas Isocronas.

195
Las columnas 4, 5 y 6, identificadas como Musk1, Musk2 y Musk3 respectivamente, son
los valores resultantes de la manipulación de los Coeficientes de Muskingum. La última columna
es el valor de la escorrentía expresada en m3/s por cada milímetro de lluvia efectiva que cae sobre
la cuenca (m3/s.mm). Luego, este valor se multiplicó por la precipitación efectiva calculada para
la Estación La Pinta, y de esa manera se obtuvo los caudales que dichas precipitaciones
generaron para el tiempo del registro de datos que se manejó. El resultado se muestra en la Figura
50.
Figura 49. Resultados del cálculo del Hidrograma Unitario Instantáneo.

196
Figura 50. Caudal promedio de escorrentía superficial (m3/s) calculado para la Cuenca del Río Areo en el periodo 1986-2005

197
La Figura 50 muestra el caudal de escorrentía superficial promedio calculado usando el
Hidrograma Unitario Instantáneo, a partir de la Precipitación Efectiva que se determinó usando el
método del Servicio de Conservación de Suelos de los Estados Unidos.
La Precipitación Efectiva de cada mes, para todos los años de registro disponible, puede
observarse en el Apéndice 2, donde se muestran 20 Figuras que contienen, cada una: 1.- una
representación en forma de hietograma, de la precipitación neta (o precipitación bruta); 2.- una
representación, igualmente en forma de hietograma, de la precipitación efectiva; 3.- una gráfica
de barras que compara la precipitación efectiva de cada mes con el caudal de escorrentía
superficial que dicha precipitación genera, calculado según el método del Servicio de
Conservación de Suelos, expuesto por Chow y colaboradores (1999). Por último, en cada una de
las 20 Figuras incluidas en el Apéndice 2 se incluyó una tabla que resume los valores de
Precipitación Neta, Precipitación Efectiva, Abstracción y Caudal. Todas las gráficas y la tabla
resumen se hicieron ejecutando el código de programación elaborado para el programa
Estadístico R mencionado en el Capítulo III de este material.
5.2.- Fase de Teledetección
5.2.1.-Ubicación y descarga de Imágenes de Satélite
Luego de una laboriosa búsqueda de imágenes de satélite en diferentes instancias, tanto
privadas (ESRI de Venezuela), como gubernamentales (Centro de Procesamiento Digital de
Imágenes de Satélites, CPDI, del Instituto de Ingeniería, adscrito al Ministerio del Poder Popular
para la Ciencia y Tecnología), y educativas (Laboratorio de Geodesia Física y Satelital del
Departamento de Geodesia Superior, de la Escuela de Ingeniería Geodésica, de La Universidad
del Zulia; Instituto de Fotogrametría de la Facultad de Ingeniería de la Universidad de los Andes,
Centro Interamericano de Desarrollo e Investigación, CIDIAT, de la Universidad de los Andes)
se decidió trabajar con las imágenes que están disponibles para su descarga, sin costo monetario,
en el portal Web (http://glcfapp.umiacs.umd.edu:8080/esdi/index.jsp) administrado por la
Universidad de Maryland .
De la consulta hecha al portal Web de la Universidad de Maryland el Sistema arroja como
resultado de la información mostrada en la Figura 51.

198
Figura 51. Resultado de la consulta de disponibilidad de imágenes para los sensores TM y
ETM+, en la base de datos de la GLCF.
Para la zona seleccionada, identificada por su dirección de Path 002 y Row 053 (ver
Figura 14 en el Capítulo III), específicamente para los sensores TM y ETM+, el Sistema muestra
siete escenas o imágenes disponibles. De ellas, una vez evaluada la cobertura de nubes a través
de una vista previa disponible en formato .jpg, se decidió descargar para su procesamiento en el
presente estudio sólo las indicadas en la Tabla 19
Tabla 19. Fecha, sensor y atributo de las imágenes usadas en el presente estudio.
Día Mes Año Sensor Atributo
28 12 1986 TM Ortho, Geocover
03 07 1991 TM L1G
01 10 1992 TM L1G
01 07 1999 ETM Ortho, Geocover
28 02 2001 ETM L1G

199
5.2.2.- Corrección geométrica.
En la Figura 50 se observan los atributos con los que cuentan estas imágenes. Sólo las
imágenes de fecha 28/12/1986 y 01/07/1999 están disponibles ya georreferenciadas. Sólo la
escena del 28/02/2001 fue georreferenciada, y para esto se usó el método de Image to Image,
empleando la opción Polynomial de tercer orden, como Método de Ajuste, y el Vecino Más
Cercano como Método de Remuestreo.
Las dos escenas restantes, dadas las características del formato en el que fueron
descargadas, requirieron de un procedimiento especial para lograr su visualización en el
programa ENVI, diferente al aplicado a las escenas anteriores. Este procedimiento implicó un
paso de “edición” del archivo de documentación de dichas escenas, haciendo la edición
específicamente en los parámetros de posición espacial de la misma, donde se indicó el Datum, la
Zona, y las coordenadas de las esquinas. Este proceso sólo se hizo para la primera banda y el
programa automáticamente aplicó la configuración al resto.
Para ilustrar la corrección geométrica aplicada a la escena del 28/12/2001, la Figura 52
muestra la ventana Ground Control Points Selection con la que se seleccionaron 20 puntos de
control que reportaron un RMSE menor al umbral establecido. Dichos puntos fueron exportados
como un archivo de texto y usados en la georreferenciación del resto de las imágenes.
Figura 52. Ventana de Selección de puntos de control.
En la Figura 53 está representada la disposición de los puntos de control seleccionados,
vistos sobre la Banda 2 de la escena 015-065 de fecha 28/02/2001.

200
Figura 53. Disposición de los puntos de control sobre Banda 2 (015-065) de fecha 28/02/2001
tomado de la ventana Scroll del programa ENVI.
Completado la Corrección Geométrica, todas las bandas de todas las escenas
manipuladas, recibieron la inserción de la Cuenca Hidrográfica de interés, cuyo polígono fue
generado en la fase de Vectorización Digital ya comentada. Posteriormente el material fue
“salvado” en formato TIFF especificando como subconjunto espacial (Spacial Subset en ENVI),
la referida Cuenca Hidrográfica.
5.2.-3.- Corrección atmosférica
Las Bandas espectrales generadas en el punto anterior redujeron su peso de
aproximadamente 55 MB a 1.06 MB, por el ajuste de su tamaño al polígono de referencia. A
partir de dichas bandas se ejecutaron tres procedimientos diferentes para la generación de unas
nuevas Bandas, sobre las que se aplicaron los cálculos de los Índices de Vegetación.
El primero fue la Corrección Atmosférica aplicando el Método de Corrección por Valores
Mínimos del Histograma propuesto por Chávez (1988). A partir de las Bandas así obtenidas se
calcularon los Índices de Vegetación.
El segundo método de obtención de corrección de Bandas consiste en el cálculo de
reflectividades. Los valores ND de cada Banda fueron transformados a Reflectividad aparente
usando las fórmulas indicadas por Chuvieco (1995) que fueron explicadas en el Capítulo I de este
material. De igual manera, a partir de las Bandas así obtenidas se aplicaron los cálculos de

201
Índices de Vegetación. El tercer método de corrección aplicado fue igualmente propuesto por
Chávez (1996) como una revisión y mejora al método anterior. Se conoce como el Modelo Cos(t)
y su aplicación fue de una forma semiautomática a través del Módulo AtmosC que incluye la
última versión del programa diseñado para Sistemas de Información Geográfica: Idrisi Andes.
Sobre las Bandas corregidas por este método se aplicaron los procedimientos para el cálculo de
los Índices de Vegetación.
5.2.3.1.-Resultados de la corrección atmosférica por la aplicación del HMM Método
de Corrección por Valores Mínimos del Histograma
Los resultados de esta fase fueron reportados como histogramas donde pueden observarse
los valores mínimos, promedio, máximo y desviación estándar de cada conjunto de valores para
cada Banda espectral. El programa utilizado para este procedimiento fue ENVI. Se muestran las
Bandas originales y las Bandas corregidas. Ver Apéndice 3.
En cada todas las Figuras del Apéndice 3 se nota cómo luego de aplicar la resta del valor
mínimo de ND reportado por la Banda original, la Banda resultante muestra el Histograma
“movido” hacia la izquierda, y como valor inicial para cada Banda cero.
Nótese que los valores que muestran los píxeles siguen siendo valores ND, y adquieren
un mínimo de cero. Esta es la corrección propuesta por Chuvieco (1995) cuando no se disponen
de datos para desarrollar el cálculo de reflectividad real de la superficie.
Este procedimiento no transforma los valores de ND a valores físicos, en este caso de
Reflectividad. Sólo permite obtener una aproximación hacia los valores de radiancia espectral
que en condiciones atmosféricas ideales (sin perturbaciones por dispersión ni presencia de
aerosol) pudo haber capturado el sensor.
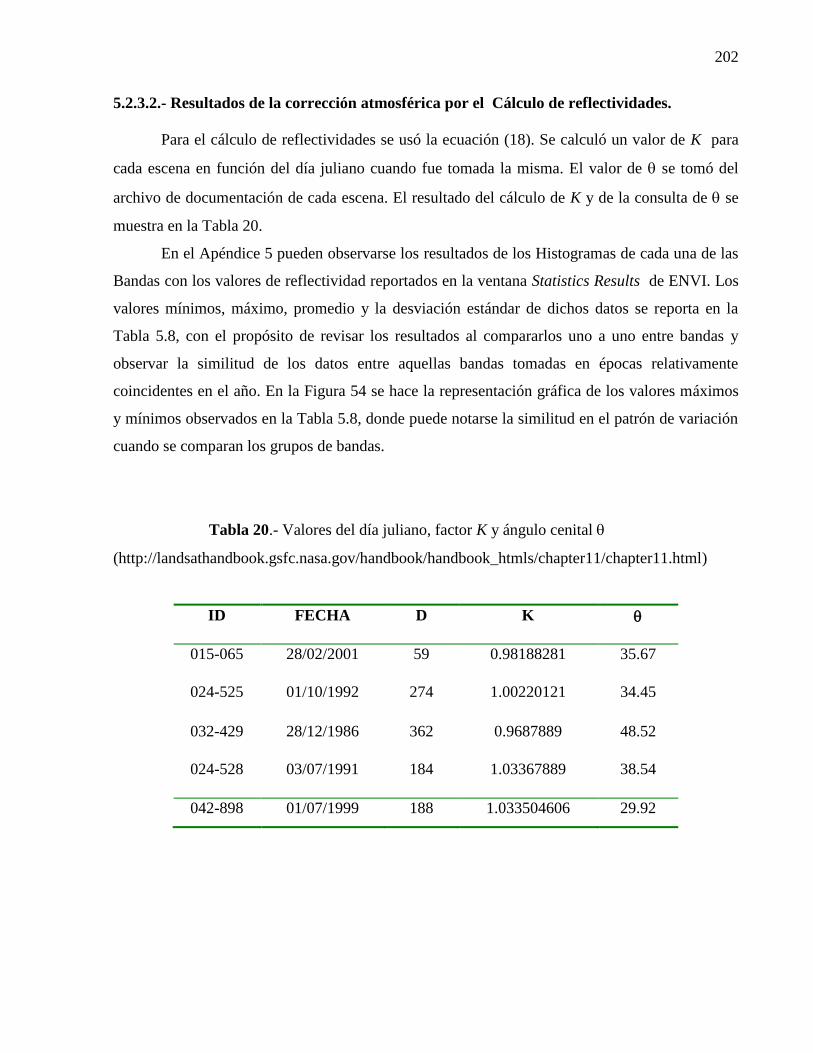
202
5.2.3.2.- Resultados de la corrección atmosférica por el Cálculo de reflectividades.
Para el cálculo de reflectividades se usó la ecuación (18). Se calculó un valor de K para
cada escena en función del día juliano cuando fue tomada la misma. El valor de se tomó del
archivo de documentación de cada escena. El resultado del cálculo de K y de la consulta de se
muestra en la Tabla 20.
En el Apéndice 5 pueden observarse los resultados de los Histogramas de cada una de las
Bandas con los valores de reflectividad reportados en la ventana Statistics Results de ENVI. Los
valores mínimos, máximo, promedio y la desviación estándar de dichos datos se reporta en la
Tabla 5.8, con el propósito de revisar los resultados al compararlos uno a uno entre bandas y
observar la similitud de los datos entre aquellas bandas tomadas en épocas relativamente
coincidentes en el año. En la Figura 54 se hace la representación gráfica de los valores máximos
y mínimos observados en la Tabla 5.8, donde puede notarse la similitud en el patrón de variación
cuando se comparan los grupos de bandas.
Tabla 20.- Valores del día juliano, factor K y ángulo cenital
(http://landsathandbook.gsfc.nasa.gov/handbook/handbook_htmls/chapter11/chapter11.html)
ID FECHA D K
015-065 28/02/2001 59 0.98188281 35.67
024-525 01/10/1992 274 1.00220121 34.45
032-429 28/12/1986 362 0.9687889 48.52
024-528 03/07/1991 184 1.03367889 38.54
042-898 01/07/1999 188 1.033504606 29.92

203
Tabla 21. Estadística de los valores de reflectividad para todas las Bandas del material evaluado
FECHA B MIN MAX MEDIA DES.EST.
28/12/1986 1 0.005 0.025 0.10 0.005
3 0.002 0.049 0.10 0.01
4 0.008 0.13 0.041 0.002
03/07/1991 1 0.008 0.022 0.012 0.004
3 0.005 0.044 0.012 0.008
4 0.014 0.118 0.045 0.015
01/10/1992 1 0.002 0.021 0.009 0.004
3 0.002 0.041 0.010 0.007
4 0.014 0.018 0.041 0.013
01/07/1999 1 0.004 0.02 0.006 0.002
3 0.004 0.04 0.009 0.004
4 0.01 0.106 0.023 0.011
28/02/2001 1 0.004 0.021 0.009 0.004
3 0.003 0.04 0.014 0.01
4 0.006 0.108 0.032 0.019
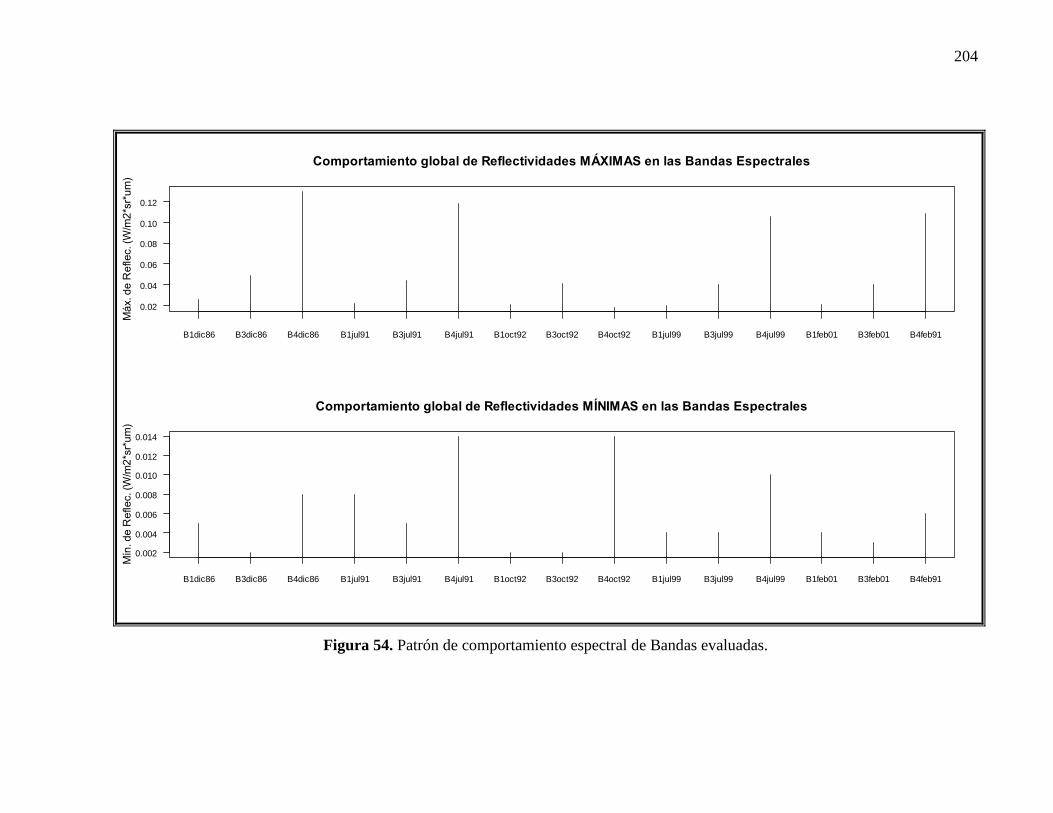
204
Comportamiento global de Reflectividades MÁXIMAS en las Bandas Espectrales
Má
x. d
e R
efle
c. (W
/m2
*sr*
um
)
0.02
0.04
0.06
0.08
0.10
0.12
B1dic86 B3dic86 B4dic86 B1jul91 B3jul91 B4jul91 B1oct92 B3oct92 B4oct92 B1jul99 B3jul99 B4jul99 B1feb01 B3feb01 B4feb91
Comportamiento global de Reflectividades MÍNIMAS en las Bandas Espectrales
Mín
. d
e R
efle
c. (W
/m2
*sr*
um
)
0.002
0.004
0.006
0.008
0.010
0.012
0.014
B1dic86 B3dic86 B4dic86 B1jul91 B3jul91 B4jul91 B1oct92 B3oct92 B4oct92 B1jul99 B3jul99 B4jul99 B1feb01 B3feb01 B4feb91
Figura 54. Patrón de comportamiento espectral de Bandas evaluadas.

205
En la Figura 54 se detalla el comportamiento espectral de las Bandas evaluadas para cada
época en la que fueron tomadas las escenas. Se evaluaron tres bandas por escenas, por lo que la
revisión de la Figura 54 debe hacerse considerando grupos de tres bandas, y al comparar la
variación entre los grupos se nota un patrón relativamente uniforme de variación entre las Bandas
dentro del grupo y entre grupos. La Figura 555 se usa como una herramienta de evaluación de la
calidad del cálculo de reflectividades, considerando que este es un procedimiento
semiautomático, donde se manipulan una importante cantidad de valores numéricos que deben
ser ingresados por teclado, siendo ésta una fuente de error que debe ser revisada.
La manipulación de estos datos en el programa estadístico R permitió obtener un resumen
de los cinco estadísticos más representativos que maneja este programa para el reporte de los
resultados. A continuación se incluye este resumen, donde se observan los valores mínimos,
máximos, el primer y tercer cuartil, la media y la mediana.
Figura 55. Resumen de los seis estadísticos principales para el conjunto de datos de
reflectividades calculadas sobre cada Banda espectral.
La Figura 55 permite identificar el rango global en el que se ubican los valores de
reflectividades: el mínimo del rango es el Min para los valores MIN, 0.002, y el máximo para el
rango es el Max para los valores MAX, 0.13; el promedio general de todos los valores reportados
por el cálculo de reflectividades se observa en el reporte del summary de R, para el valor Mean
de MEDIA, 0.03087. En este sentido, los valores de reflectividades fluctúan entre cero y uno.

206
5.2.3.3.-Resultados de corrección atmosférica y cálculo de reflectividades usando el
Modelo Cos(t) del Módulo AtmosC de Idrisi Andes
El resultado de la aplicación de este Modelo de corrección se visualiza a través de los
Histograma de las Bandas ya corregidas. En él pueden observarse los valores mínimo, máximo y
promedio que adquieren los píxeles en cada una de estas Bandas. La Figura 56 presenta el
Histograma de la Banda 1, escena 28/12/1986, corregida con el Modelo Cos(t). El resto de los
Histogramas pueden verse en el Apéndice 4.
Figura 56. Resultados corrección atmosférica y conversión a reflectividades sobre Banda 1,
escena del 28/12/1986.
5.2.4.- Índices de vegetación.
Se calcularon cuatro Índices de Vegetación: NDVI, SAVI, EVI y ARVI. El cálculo se
hizo a partir de los tres juegos de escenas generadas desde las Bandas originales, y procesadas
por tres diferentes métodos de corrección:
1.- Cinco escenas corregidas por el Método del Valor Mínimo del Histograma
2.- Cinco escenas corregidas a partir del cálculo de reflectividad aparente.
3.- Cinco escenas corregidas por el Método Cos(t) incluido en el Módulo AtmosC
de Idrisi Andes.
El esquema que se muestra en la siguiente página resume los procedimientos aplicados
desde la imagen original hasta la obtención de los Índices de Vegetación.

207
ESQUEMA DE PREPROCESAMIENTO Y PROCESAMIENTO DEL MATERIAL
ESPECTRAL DISPONIBLE PARA LA DETERMINACIÓN DE ÍNDICES DE
VEGETACIÓN (Malavé, 2008)
BANDA ORIGINAL
(~56MB)
Aplicar Corrección Geométrica
Abrir banda
Insertarle Cuenca
Guardarla como TIFF
al tamaño de la Cuenca
(~1.06MB)
BANDA CON CUENCA
Corrección atmosférica por
Minino Valor del Histograma
Rango ND:
Mín= 0
Máx= Max. Origi – Min. Origi.
Calcular Índices de Vegetación
Corrección atmosférica por
COS(T) DE ATMOSC
Rango ND:
Mín= -1
Máx= <1
Transformar ND a
Reflectividad
Aparente
Rango ND: Mín= 0
Máx= <1
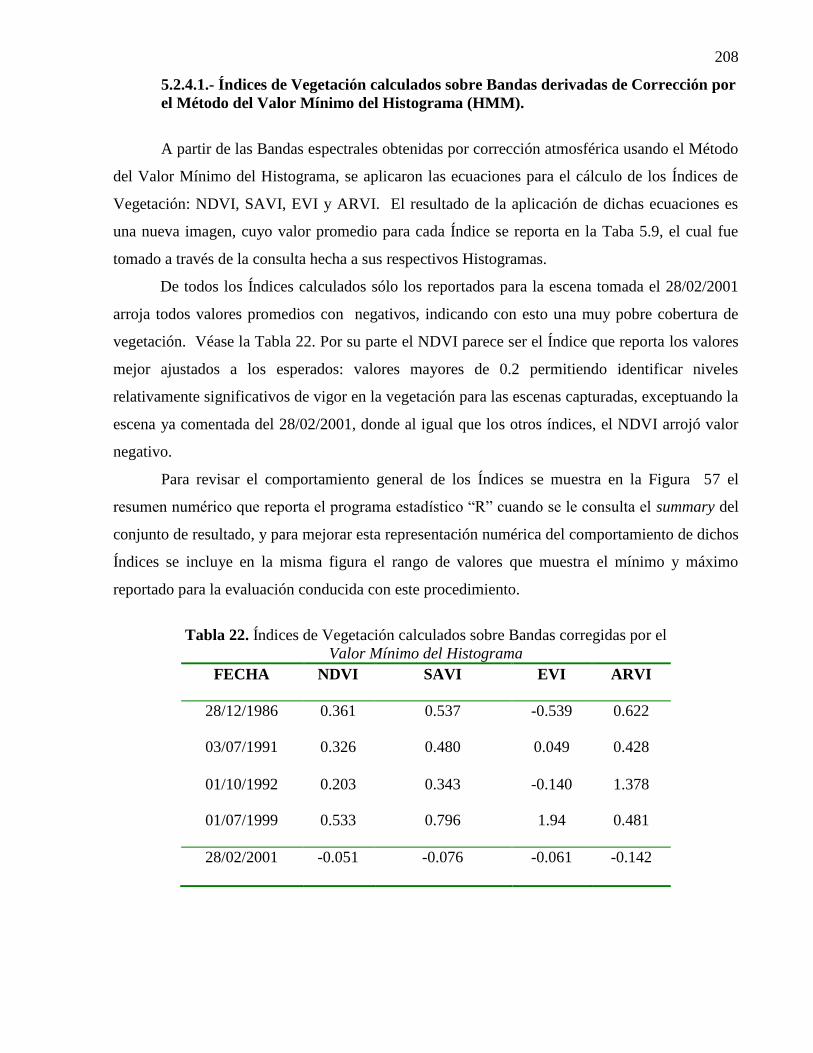
208
5.2.4.1.- Índices de Vegetación calculados sobre Bandas derivadas de Corrección por
el Método del Valor Mínimo del Histograma (HMM).
A partir de las Bandas espectrales obtenidas por corrección atmosférica usando el Método
del Valor Mínimo del Histograma, se aplicaron las ecuaciones para el cálculo de los Índices de
Vegetación: NDVI, SAVI, EVI y ARVI. El resultado de la aplicación de dichas ecuaciones es
una nueva imagen, cuyo valor promedio para cada Índice se reporta en la Taba 5.9, el cual fue
tomado a través de la consulta hecha a sus respectivos Histogramas.
De todos los Índices calculados sólo los reportados para la escena tomada el 28/02/2001
arroja todos valores promedios con negativos, indicando con esto una muy pobre cobertura de
vegetación. Véase la Tabla 22. Por su parte el NDVI parece ser el Índice que reporta los valores
mejor ajustados a los esperados: valores mayores de 0.2 permitiendo identificar niveles
relativamente significativos de vigor en la vegetación para las escenas capturadas, exceptuando la
escena ya comentada del 28/02/2001, donde al igual que los otros índices, el NDVI arrojó valor
negativo.
Para revisar el comportamiento general de los Índices se muestra en la Figura 57 el
resumen numérico que reporta el programa estadístico “R” cuando se le consulta el summary del
conjunto de resultado, y para mejorar esta representación numérica del comportamiento de dichos
Índices se incluye en la misma figura el rango de valores que muestra el mínimo y máximo
reportado para la evaluación conducida con este procedimiento.
Tabla 22. Índices de Vegetación calculados sobre Bandas corregidas por el
Valor Mínimo del Histograma
FECHA NDVI SAVI EVI ARVI
28/12/1986 0.361 0.537 -0.539 0.622
03/07/1991 0.326 0.480 0.049 0.428
01/10/1992 0.203 0.343 -0.140 1.378
01/07/1999 0.533 0.796 1.94 0.481
28/02/2001 -0.051 -0.076 -0.061 -0.142

209
Figura 57. Resumen numérico de los estadísticos principales del conjunto de Índices, reportados
por el summary en R.
En las Figuras 58 y 59 se observa la representación gráfica de los valores arrojados por el
cálculo de los Índices de Vegetación derivados de Bandas espectrales corregidas por el método
del Mínimo Valor del Histograma (Chávez, 1988, reportado por Chuvieco, 1995).
La Figura 58 muestra los promedios de cada Índice por separado en una representación en
forma de líneas verticales emulando barras. Se observa el resultado para todos los promedios de
Índices en cada una de las fechas a las que corresponden las escenas evaluadas. La representación
gráfica está elaborada con la intención de mostrar cuáles promedio de Índices reportaron valores
negativos en los resultados. Todos los promedios muestran estos valores negativos, ya que la
escena del ETM+ del 28/02/2001 arrojó todos los resultados con este signo, siendo una escena
muy particular en cuanto a este comportamiento.

210
NDVI
ND
VI
0.0
0.1
0.2
0.3
0.4
0.5
Dic
86
Jul9
1
Oct9
2
Jul9
9
Feb01
SAVI
SA
VI
0.0
0.2
0.4
0.6
0.8
Dic
86
Jul9
1
Oct9
2
Jul9
9
Feb01
EVI
EV
I
-0.5
0.0
0.5
1.0
1.5
2.0
Dic
86
Jul9
1
Oct9
2
Jul9
9
Feb01
ARVI
AR
VI
0.0
0.5
1.0
Dic
86
Jul9
1
Oct9
2
Jul9
9
Feb01
Figura 58. Comparación de Índices de Vegetación obtenidos de Bandas corregidas por MVH.

211
Comparación de los I de V calculados sobre Bandas espectrales corregidas por MVH
Ind
ice
s d
e V
eg
.
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
Dic86 Jul91 Oct92 Jul99 Feb01
NDVI
SAVI
EVI
ARVI
Figura 59. Evaluación de los rangos de existencia de los Índices de Vegetación calculados.

212
El promedio del Índice EVI fue el que mayor cantidad de resultados negativos arrojó: diciembre del 86, octubre del 92 y
febrero del 2001. Esto aparece mejor ilustrado en la Figura 58, donde se incluyeron tres líneas horizontales marcando valores de
Índices de Vegetación indicadores: las líneas rojas marcan los valores extremos en los que teóricamente deben estar
contenidos todos los Índices, entre los valores de -1 y 1; la línea verde marca el valor cero para los Índices, con el propósito de
verificar cuáles de ellos mostraron estos valores por debajo de esta línea.
En la Figura 59 se observa el promedio del EVI como el Índice que arrojó un comportamiento más errático. Presenta el valor
positivo (promedio) más alto de todos los índices, por encima del extremo superior establecido como tope para este y los otros Índices:
muestra un resultado por encima del valor +1. De igual manera es el Índice que mayor cantidad de valores negativos arrojó, fenómeno
esto que claramente puede percibirse en la Figura 59, donde la línea horizontal en color rojo, que parte del valor cero para el eje “y”
establece la frontera de los valores positivos y negativos.
El NDVI y el SAVI, fueron los Índices que mostraron, en la evaluación de sus promedios, un comportamiento más
“regular”, en el sentido que no arrojan valores negativos, y para todas las escenas evaluadas se mantienen dentro del rango teórico de -
1 y +1. Por otro lado, se observa la correlación matemática entre estos Índices ya que muestran un comportamiento muy similar,
estando el SAVI siempre por encima del NDVI, al comparar sus valores absolutos, manteniendo casi la misma pendiente entre ellos.
Este comportamiento puede ser explicando al observar las ecuaciones que gobiernan cada cálculo.
La diferencia entre el SAVI y el NDVI está en el factor de ajuste a la línea de suelo, que implica sumar dicho factor en el
denominar de la ecuación, y el resultado de la división incrementarlo en un porcentaje igual a 100 veces el factor empleado, expresado
en porcentaje. En este caso el factor de corrección tiene valor de 0.5; se suma 0.5 en el denominador (de la fórmula simple de NDVI) y
el resultado de la división se incrementa en un valor igual a 100 veces 0.5, esto es: 0.5 * 100 = 50%, por lo que el incremento se logra
multiplicando el resultado de la división por 1.5, tal como se expresa en la fórmula del SAVI.
En la Figura 60 se incluye la Matriz de gráficos de dispersión construida en el programa estadístico R para los datos de Índices de
Vegetación derivados de Bandas espectrales corregidos por el HMM. Este gráfico se elabora para evaluar la posible relación existente
entre los diferentes Índices que se manipulan, considerando que ellos se calculan a partir de Bandas espectrales similares, con
ecuaciones que sólo se diferencia por la inclusión de algunos factores.

213
NDVI
0.0 0.2 0.4 0.6 0.8 0.0 0.5 1.0
0.0
0.2
0.4
0.0
0.2
0.4
0.6
0.8
SAVI
EVI
-0.5
0.0
0.5
1.0
1.5
2.0
0.0 0.1 0.2 0.3 0.4 0.5
0.0
0.5
1.0
-0.5 0.0 0.5 1.0 1.5 2.0
ARVI
Comparación bivariante de Índies de Vegetacion
derivados de Bandas corregidas por MVH
Figura 60. Matriz de gráficos de dispersión para los datos de Índices de Vegetación
derivados de Bandas espectrales con Histograma Corregidos

214
En toda la primera fila, al igual en toda la primera columna, se muestra la relación del
NDVI con los otros Índices. Sólo parece existir una relación lineal entre el NDVI y el SAVI. Esta
relación es menos marcada entre el SAVI y el EVI, mientras que para el resto de las
comparaciones no existe un patrón de similitud.
5.2.4.2.- Índices de Vegetación calculados sobre Bandas con ND transformados a
Reflectividad aparente
Un segundo método de corrección de Bandas espectrales se desarrolló transformando los
ND de cada una en valores de reflectividad aparente. Se busca con esto manipular el material
evaluado de modo que pueda usarse para hacer comparaciones entre las diferentes épocas en las
cuales fueron tomadas las escenas. La reflectividad es uno de los componentes de la radiancia
espectral, información esta medida por el sensor del satélite artificial. La reflectividad fue
definida como el cociente que resulta de dividir la energía incidente sobre una superficie, entre la
energía reflejada.
Esta energía reflejada, antes de ser medida por el sensor se ve afectada por el ángulo
cenital de incidencia de la energía radiante, es igualmente afectada, de acuerdo con su longitud de
onda, por la irradiancia solar en el tope de la atmósfera y debe ser ajustada por un factor corrector
de la distancia Tierra-Sol. El conocimiento de todos estos elementos, sumados a la transmisividad
ascendente y descendente permite determinar los valores de reflectividad real que es la que sale
de la superficie. Los modelos matemáticos creados para cumplir con esta tarea son exigentes en
cuanto a las variables que usan, provocando que este cálculo resulte en extremo laborioso.
Los ND de las Bandas espectrales disponibles para esta investigación fueron procesadas
usando la función Band Math de ENVI, para aplicarle las ecuaciones revisadas en el Capítulo I de
este material. Las Bandas obtenidas a partir de ese procedimiento fueron usadas para el cálculo
de cuatro Índices de Vegetación. El valor promedio reportado por estos Índice fue organizado en
la Tabla 23. Estos datos fueron analizados en el programa estadístico R para la obtención de la
estadística básica que permite definir el patrón de comportamiento de los mismos. Los resultados
de esta evaluación pueden verse numérica y gráficamente representados en las Figuras 61, 62 y
63. En la Figura 5.23 se incluye la Matriz de gráficos de dispersión para este conjunto de datos.

215
Tabla 23. Índices de Vegetación calculados sobre Bandas corregidas por el
cálculo de reflectividad aparente.
FECHA NDVI SAVI EVI ARVI
28/12/1986 -0.459 -0.019 -0.016 -0.269
03/07/1991 0.572 0.087 0.079 0.586
01/10/1992 0.634 0.084 0.075 0.640
01/07/1999 0.454 0.004 0.035 0.364
28/02/2001 0.387 0.047 0.041 0.256
Figura 61. Resumen estadístico de Índices de Vegetación calculados a partir de bandas con
valores de reflectividad.
En la representación numérica de los resultados, arrojada por la función summary del
programa estadístico R, (Figura 61) se revisan los valores reportados para los seis estadísticos
más destacados. Nótese que se está trabajando con los valores promedios reportados a través de
la consulta hecha a los Histogramas de cada Índice. El rango general de cada Índice puede
observarse en dichos histogramas incluidos en el Apéndice 6.

216
NDVI
ND
VI
-0.4
-0.2
0.0
0.2
0.4
0.6
Dic86 Jul91 Oct92 Jul99 Feb01
SAVI
SA
VI
-0.02
0.00
0.02
0.04
0.06
0.08
Dic86 Jul91 Oct92 Jul99 Feb01
EVI
EV
I
0.00
0.02
0.04
0.06
0.08
Dic86 Jul91 Oct92 Jul99 Feb01
ARVI
AR
VI
-0.2
0.0
0.2
0.4
0.6
Dic86 Jul91 Oct92 Jul99 Feb01
Figura 62. Comparación Índices de Vegetación derivados de cálculos sobre bandas espectrales con valores de reflectividad aparente.

217
Índices de Vegetacion (promedio) derivados de Bandas espectrales
con valores digitales transformados
a reflectividad
Ind
ice
s d
e V
eg
.
-1.0
-0.5
0.0
0.5
1.0
Dic86 Jul91 Oct92 Jul99 Feb01
NDVI
SAVI
EVI
ARVI
Figura 63. Comportamiento global promedio de los Índices de Vegetación calculados sobre Bandas espectrales con valores de
reflectividad aparente.

218
NDVI
-0.02 0.00 0.02 0.04 0.06 0.08 -0.2 0.0 0.2 0.4 0.6
-0.4
0.0
0.2
0.4
0.6
-0.0
20.0
20.0
6
SAVI
EVI
0.0
00.0
40.0
8
-0.4 -0.2 0.0 0.2 0.4 0.6
-0.2
0.0
0.2
0.4
0.6
0.00 0.02 0.04 0.06 0.08
ARVI
Comparación bivariante de Índices de Vegetación
derivados de Bandas con reflectivad aparente calcualda
Figura 64. Matriz de gráficos de dispersión para los datos de Índices de Vegetación
derivados de Bandas espectrales con reflectividad aparente calculada.

219
En la Figura 62 es fácil identificar cuáles escenas muestran, dentro de ellas, valores
negativos en los promedios evaluados. Se incluyó una línea horizontal que parte del cero en el eje
“y”, con pendiente igual a cero, para destacar la presencia de valores negativos dentro de cada
Índice. El resultado es consistente con lo obtenido para la evaluación de los Índices derivados de
Bandas con histogramas corregidos. La escena del 28/12/1986 se muestra como la única que
arroja todos los resultados con valores por debajo de cero, aunque siempre por encima del umbral
mínimo que es -1.
Cuando se revisan por separado cada Índice destacan los meses de julio y octubre como
los que reportan los valores mayores. El hecho de que para todos los Índices el comportamiento
sea semejante es indicador de la precisión del cálculo de los mismos.
Al evaluar estos promedios, que son los valores a usar en el Análisis de Varianza, se observa que
todos los Índices están dentro del rango teórico de -1 a +1. A diferencia de los Índices reportados
por el procedimiento anterior, los obtenidos a través de Banda espectrales con valores de
reflectividad muestran un patrón de comportamiento más acorde con los fundamentos teóricos.
Existe una similitud importante en los resultados mostrados en la Figura 63 para los
Índices SAVI y EVI. Las gráficas que los describen señalan valores muy cercanos, con el mismo
comportamiento para todas las escenas evaluadas. El EVI es un Índice configurado de tal manera
que permite mitigar los efectos de la reflectividad del suelo y los efectos de las perturbaciones
atmosféricas, mientras que el SAVI se concentra en la reducción de los efectos del suelo. La
homogeneidad en sus resultados promedios pudiera explicarse considerando la ventaja que aporta
el cálculo de reflectividad, con el que se consigue cierta corrección atmosférica, pues en él
intervienen parámetros que la modelan tales como la irradiancia incidente en su tope, y el ángulo
cenital de proyección de la energía solar. La manipulación de estos factores de alguna manera
controla el efecto de la atmósfera, de forma tal que al aplicarse el ENVI en estas circunstancias
sólo estaría mitigando los efectos de la superficie de suelo desnudo, por los que sus valores
tienden a coincidir con los del Índice SAVI.
Con un argumento semejante es posible explicar la similitud de resultados obtenidos para
los Índices NDVI y ARVI. Considérese en principio que los datos con los que se está trabajando
en esta oportunidad son datos que han sido manipulados a través de un conjunto de fórmulas que
de alguna forma controlan el efecto atmosférico, y precisamente el ARVI está concebido como
un Índice resistente a los efectos atmosféricos. Ante la ausencia de estos, los resultados tienden a
parecerse a los de NDVI que no consideran estos procedimientos de control.

220
Casi todas las escenas, exceptuando la de diciembre de 1986, muestran valores positivos
en los promedios de los Índices obtenidos en esta fase de la evaluación. Dos cosas pueden
deducirse de esta condición. La primera, que los Índices de vegetación fueron capaces de detectar
presencia de vegetación con cierto vigor; y la segunda que en la época evaluada, la zona
estudiada muestra cierta cobertura vegetal de lo cual pueden derivarse algunas consideraciones.
Trabajar con valores de reflectividad no sólo permite inferir acerca de la física de los
elementos detectados por los sensores de satélites artificiales. También hace coincidentes las
variables que se estudian en el marco de las Transformaciones que pueden recibir las escenas con
las que se trabaje. Esta afirmación se sustenta en la evaluación hecha a la Figura 64 donde se
visualizan la Matriz de gráficos de dispersión. Existe una relación lineal, en un caso mayor que
en otros para los Índices: NDVI con todos los demás, el SAVI con el EVI, y el EVI con el ARVI.
5.2.4.3.- Índices de Vegetación calculados sobre Bandas procesadas con el Módulo
AtmosC de Idrisi Andes
El programa diseñado para la construcción de Sistemas de Información Geográfica, Idrisi,
versión Andes (demo), fue usado para aprovechar las capacidades que muestra en materia de
procesamiento digital de imágenes de satélite. Así como el Idrisi tiene capacidad para procesar
material espectral, otros software, diseñados para SIG, muestran esta condición: SPRING,
ILWIS, GRASS, todos estos de libre acceso a través de la Web. El programa ArcMap de ESRI,
integrante de la familia de programas conocida como ArcGis, incluye algunas funciones que
permiten trabajar con este tipo de material, tomando en cuenta que es un programa que muestra
sus mayores fortalezas en el manejo de atributos vectoriales.
A través de la consulta del Help de Idrisi se accede a la explicación de las funciones para
las que está diseñado AtmoC. Señala la referencia que con él es posible desarrollar corrección
atmosférica de las bandas, y que los resultados son expresados en términos de reflectividad, toda
vez que el módulo solicita el ingreso de los parámetros Offset/Gain ó Lmin/Lmax, con los cuales,
en un primer paso, los ND de cada Banda son transformados a valores de radiancia espectral.
A los efectos de completar el cálculo de reflectividad y conducir la corrección
atmosférica, el programa pide el ingreso de la fecha y hora cuando se tomó la escena, así como el
ángulo cenital de incidencia de la energía sobre la superficie terrestre (). Los resultados son
arrojados con valores que se ubican en el rango teórico de reflectividad: entre cero y uno. Cada

221
Banda espectral se procesó con este módulo, y buena parte de la información requerida para este
cálculo se encuentra en los archivos tipo texto identificados como archivos de documentación de
la escena o también conocido como archivo cabecera de la imagen. Los resultados de este
proceso se observa en el Apéndice 4 donde están representados todos los Histograma de cada
Banda.
Ese es considerado el tercer procedimiento para la corrección de Bandas empleado en este
trabajo. Con las Bandas generadas por cada procedimiento se calcularon los Índices de
Vegetación NDVI, SAVI, EVI y ARVI, para certificar cuál de estos procedimientos de
corrección genera los Índices que muestran un comportamiento ajustado a los parámetros
teóricos.
El resultado de la determinación de los Índices a partir de Bandas corregidas con el
Módulo AtmosC se discute a continuación. En la Tabla se reportan los valores promedios para
cada variable en la fecha que corresponde a cada escena.
En una primera revisión se nota que todos los Índices muestran valores positivos, y la
mayoría de ellos arrojan resultados cercanos y mayor a 0.2. Como se recordará el rango de
valores en el que se ubica el registro de masas vegetales de relativa a considerablemente densas
es 0.2 a 0.8.
Igualmente los resultados arrojan valores muy cercanos al cero: 0.038, 0.071, para el
Índice ARVI y el Índice SAVI, respectivamente, siendo coincidentes en su fecha de aparición:
febrero de 2001. Cada uno de estos Índices controla uno de los factores que mayormente influyen
sobre la respuesta espectral.
El ARVI es un Índice resistente a los efectos atmosféricos, mientras que el SAVI lo es
para los efectos del suelo desnudo. En la mayoría de las escenas se cumple el mismo patrón de
valores cercanos a cero para ambos Índices.
La Figura 65 muestra el resumen numérico que se obtiene con la función summary en el
programa estadístico “R” sobre los valores promedios de Índices calculados a partir de Bandas
corregidas con el Módulos AtmosC de Idrisi Andes. Esta Figura muestra los resultados tal y
como los arroja el programa R en su Consola (“área de trabajo”). Contiene los seis estadísticos
más destacados en un análisis básico. Entre los promedios, el menor valor promedio es reportado
por el Índice SAVI, seguido por el Índice EVI, NDVI y el ARVI. Según esto, el menor reporte de
vigor vegetal es hecho por el Índice que controla los efectos del suelo desnudo sobre los valores
de radiancia leídos por el sensor.

222
Evaluando las Figuras 66, Figura 67 y Figura 68 puede definirse con mayor comodidad el
comportamiento de entre Índices en el marco de sus valores promedios.
El comportamiento individual de los promedios reportados por cada Índice está reflejado
en la Figura 66. Igual que en las representaciones anteriores para este grupo de comportamiento,
se configuró las gráficas de modo que mostraran una línea horizontal que parte del valor cero en
el eje “y”. Esto para identificar la frontera de valores positivos y negativos y determinar la
presencia de valores negativos en los promedios de Índices reportados. Nótese que, como ya fue
comentado, todos los promedios de Índices están en el rango de valores positivos.
Tabla 24. Índices de Vegetación calculados sobre Bandas corregidas atmosféricamente usando el
Módulo AtmoC de Idrisi Andes.
FECHA NDVI SAVI EVI ARVI
28/12/1986 0.191 0.212 0.646 0.156
03/07/1991 0.475 0.245 0.288 0.536
01/10/1992 0.540 0.317 1.094 1.05
01/07/1999 0.657 0.391 0.432 0.608
28/02/2001 0.145 0.071 0.077 0.038
Figura 65. Resumen numérico de Índices de Vegetación calculados a partir de Bandas
corregidas atmosféricamente y con valores digitales expresados como reflectividad.

223
El valor promedio reportado para la escena de diciembre de 1986, que en los tres Índices
anteriores reportó negativo, para esta evaluación arrojó valores positivos, y para el caso del SAVI
y del EVI fue un valor relativamente alto al compararlo con el resto de valores dentro de cada
grupo. La presencia o ausencia de valores negativos puede ser considerada como un indicador de
la capacidad del método de corrección en arrojar Bandas donde sea posible la identificación de
masas vegetales de menor vigor.
El NDVI y el SAVI son los Índices que reportan los valores promedios uniformes al
compararlos internamente dentro de cada grupo, sin hacer comparaciones entre ellos. Los valores
promedios menos uniformes los arroja el Índice ARVI, dentro de él existe mayor variabilidad de
los datos.
De nuevo el NDVI y el SAVI son coincidentes al registrar el mayor valor promedio para
el mes de julio 1999, mientras que el EVI y el ARVI reportan este valor para la escena tomada en
octubre de 92.

224
NDVI
ND
VI
0.0
0.2
0.4
0.6
0.8
Dic86 Jul91 Oct92 Jul99 Feb01
SAVI
SA
VI
-0.1
0.0
0.1
0.2
0.3
0.4
Dic86 Jul91 Oct92 Jul99 Feb01
EVI
EV
I
0.0
0.2
0.4
0.6
0.8
1.0
Dic86 Jul91 Oct92 Jul99 Feb01
ARVI
AR
VI
0.0
0.2
0.4
0.6
0.8
1.0
Dic86 Jul91 Oct92 Jul99 Feb01
Figura 66. Comportamiento individual promedio de Índices calculados a partir de
Bandas corregidas con el Módulo AtmosC de Idrisi Andes.
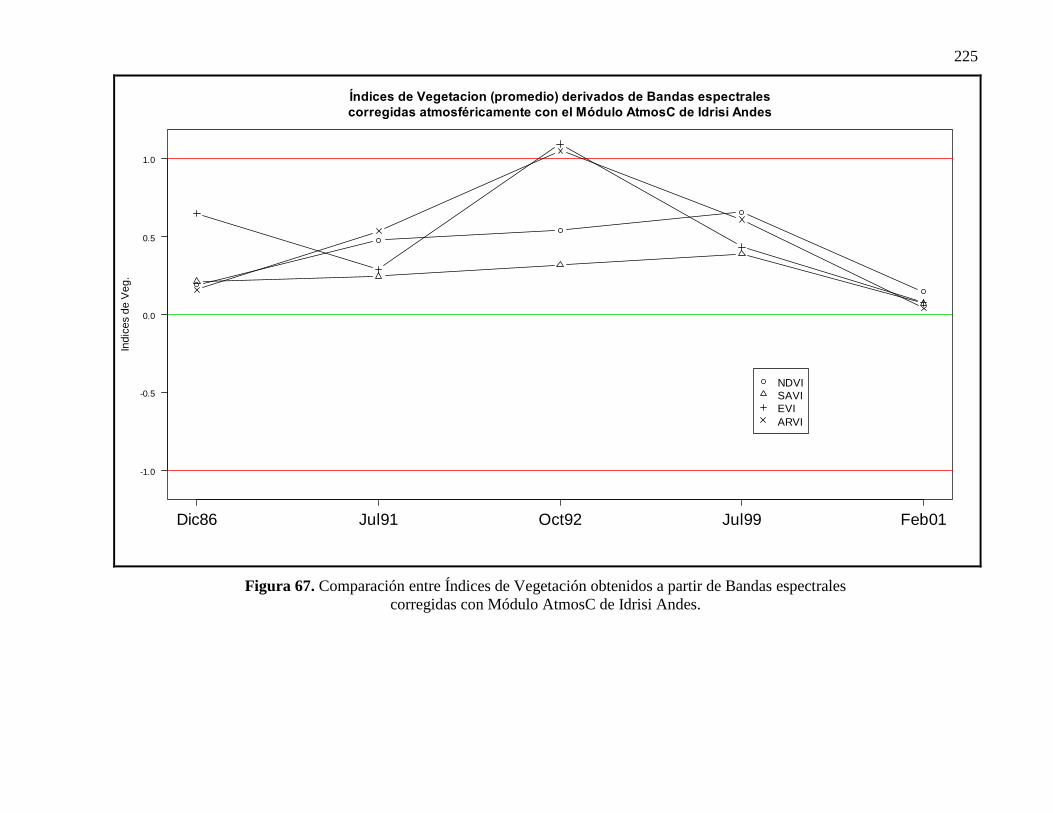
225
Índices de Vegetacion (promedio) derivados de Bandas espectrales
corregidas atmosféricamente con el Módulo AtmosC de Idrisi Andes
Ind
ice
s d
e V
eg
.
-1.0
-0.5
0.0
0.5
1.0
Dic86 Jul91 Oct92 Jul99 Feb01
NDVI
SAVI
EVI
ARVI
Figura 67. Comparación entre Índices de Vegetación obtenidos a partir de Bandas espectrales
corregidas con Módulo AtmosC de Idrisi Andes.
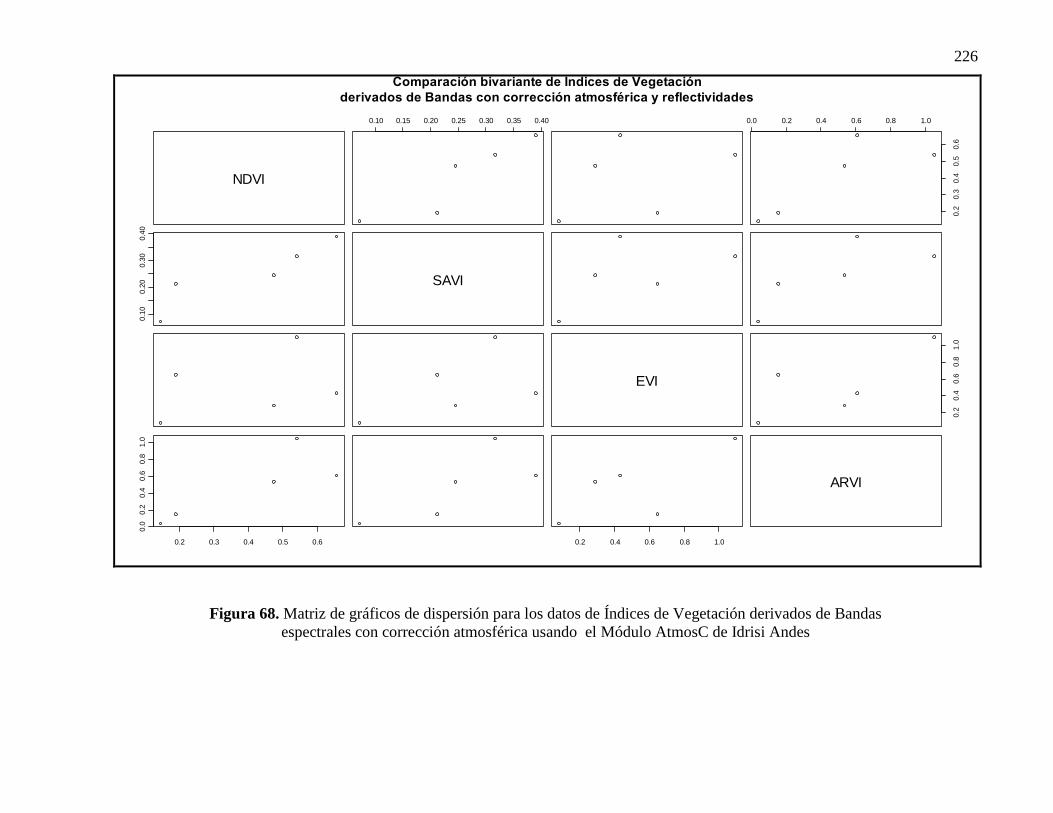
226
NDVI
0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.0 0.2 0.4 0.6 0.8 1.0
0.2
0.3
0.4
0.5
0.6
0.1
00.2
00.3
00.4
0
SAVI
EVI
0.2
0.4
0.6
0.8
1.0
0.2 0.3 0.4 0.5 0.6
0.0
0.2
0.4
0.6
0.8
1.0
0.2 0.4 0.6 0.8 1.0
ARVI
Comparación bivariante de Índices de Vegetación
derivados de Bandas con corrección atmosférica y reflectividades
Figura 68. Matriz de gráficos de dispersión para los datos de Índices de Vegetación derivados de Bandas
espectrales con corrección atmosférica usando el Módulo AtmosC de Idrisi Andes

227
La mayor amplitud entre sus valores particulares la muestra el Índice EVI, seguido muy
de cerca por el ARVI, y un tanto distanciado del NDVI y el SAVI. Esto es la diferencia entre el
valor mayor y el valor menor promedio reportado dentro de cada Índice:
max(NDVI)-min(NDVI) = 0.512 ; max(SAVI)-min(SAVI) = 0.32
max(EVI)-min(EVI) = 1.017; max(ARVI)-min(ARVI) = 1.012
En la comparación de todos los Índices entre ellos, reportada en la Figura 67, y
complementada en la Figura 68, es fácil identificar en una primera revisión varios patrones.
En principio, para la escena de octubre del 92, Figura 67, los Índices EVI y ARVI se
escapan del rango teórico establecido entre -1 y +1. Nótese cómo ambos índices superan la línea
tope de este rango teórico. El resto de los Índices se mantiene dentro de dicho rango para todas
las escenas evaluadas, aunado al hecho de que todos están por encima de la frontera de negativos
y positivos delimitada por la línea horizontal del cero.
El comportamiento más errático, que muestra una mayor variabilidad, se nota en la gráfica
del Índice ARVI, fenómeno éste igualmente observado en la Figura 66. Por otro lado, al
comparar el NDVI con el SAVI, se nota cómo en la mayoría de las escenas el NDVI supera el
valor del SAVI, pero ambos muestran un comportamiento relativamente semejante en cuanto a la
dirección y pendiente de sus respectivas gráficas.
Para las escenas ubicadas en los extremos, diciembre 1986 y febrero 2001, todos los
Índices muestran sus menores valores promedio, existiendo un solape que dificulta identificar el
valor menor para la mayoría de ellos.
5.2.4.4.- Selección del método de corrección de Bandas espectrales.
Esta investigación fue concebida para ser analizada estadísticamente bajo el enfoque de
un diseño experimental del tipo “completamente aleatorizado” con el propósito de certificar la
significancia del vigor de la vegetación (evaluado a través de diferentes Índices de Vegetación)
sobre los caudales que escurren en una cuenca hidrográfica.
Se corrió un Análisis de Varianza sobre los resultados obtenidos para los Índices de
Vegetación derivados de los tres métodos de corrección, con el propósito de evaluar la existencia
de diferencias significativas entre los métodos. El código que se construyó sobre la plataforma
del programa estadístico “R” y los resultados obtenidos se visualizan en la Figura 69, la cual

228
consiste en una captura de “procedimiento-ejecutado/resultado-obtenido” sobre su Consola (área
de trabajo).
Figura 69. Resultados ANAVA para evaluar métodos de corrección de Bandas espectrales.
El valor de Pr reportado en el summary del ANAVA (análisis de varianza, también
conocido como ANOVA) es mayor de 0.1 por lo que no se rechaza la Ho de igualdad entre
medias, esto es, no existe diferencias significativas, para un nivel de significancia del 10% entre
las medias de Índices de Vegetación reportadas por los tres métodos de corrección evaluados,
según lo cual es válida la selección de cualquiera de los grupos de Índices para continuar con los
análisis posteriores.
Por tal razón la revisión de la Figura 68, que contiene la Matríz de gráficos de dispersión
para los resultados obtenidos por la aplicación del Módulo AtmosC de Idrisi Andes, es
determinante en la selección del método de corrección idóneo, y por ende del grupo de promedios
de Índices, para continuar con el análisis estadístico de resultados dado que el primer ANAVA
reporta diferencias de medias estadísticamente no significativas.
En esta Figura se observa una mayor correlación lineal entre todos los promedios de
Índices comparados. Todos los gráficos, vistos entre filas o vistos entre columnas, reportan
linealidad en las relaciones. Las Bandas corregidas por el Modelo AtmosC de Idrisi Andes, al

229
recibir corrección atmosférica y transformación de niveles digitales en valores de reflectividad, se
muestran como Bandas más uniformes en la variabilidad de su información espectral,
permitiendo la manifestación de relaciones lineales entre los diferentes Índices evaluados,
característica esta que le imprime calidad a los resultados.
De no ser por la escena octubre del 92, donde el EVI y el ARVI se escapan del rango
teórico, en una segunda revisión es posible afirmar que el método de corrección de Bandas
espectrales usando el Módulo AtmosC de Idrisi Andes arroja Índices de Vegetación con un
patrón de comportamiento más ajustado a los valores teóricos, al revisar sus valores promedios.
Por esta razón, y con el apoyo de las relaciones lineales vista en la Matriz de gráficos de
dispersión de la Figura 68, se decide continuar con los Índices de Vegetación promedio
calculados sobre Bandas espectrales tratadas con el mencionado Módulo para los efectos de la
segunda parte del análisis estadístico de la cual se deriva la construcción de modelos
matemáticos.
Son los valores promedios los de mayor interés, pues son los usados posteriormente en el
Análisis de Varianza para evaluar el grado de influencia que ejerce cada Índice sobre los valores
de caudales determinados por métodos de simulación a partir de los valores de precipitación.
5.2.4.5.- Selección de Índices de Vegetación
Los valores de Índices de Vegetación constituyen una representación numérica que
indican el verdor que la vegetación presentaba el momento cuando fue capturada la escena por el
sensor artificial. Estos valores son manipulados en conjunto con los valores de Caudal que fueron
simulados para la región analizada, en función de los registros de precipitación disponibles. Se
busca determinar la relación matemática entre el elemento reportado por Teledetección (Índices
de Vegetación) y los valores determinados por simulación (caudales de escorrentía superficial).
A partir de esta relación matemática, expresada como modelo de regresión se evalúa la capacidad
del mismo en determinar los caudales escurridos en la zona, y predecir estos en un mediano
plazo.
En esta investigación se evaluaron cuatro Índices de Vegetación tomando en cuenta que
tres de ellos son presentados por varios investigadores (Sánchez (2000), Parra (2007), entre otros)
como resultado de mejoras aplicadas al NDVI. Para la construcción del modelo matemático que
relacione la variable Índice de Vegetación con la variable Caudal es necesario hacer la selección
de uno de estos Índices que cumplirá el papel, en dicho modelo, de variable independiente.

230
En principio se evaluó la existencia de diferencias estadísticamente significativas entre los
valores promedios de los Índices derivados del método de corrección por aplicación del Módulo
AtmosC de Idrisi Andes, para luego determinar cuál de estos Índices muestra una mejor
correlación con la variable caudal. Esta evaluación se hizo a través del Análisis de Varianza. Se
planteó la hipótesis nula de que no existe tal diferencia, en cuyo caso resultaría igual continuar el
estudio usando cualquiera de los índices evaluados.
El Análisis de Varianza se aplicó a través de la construcción y ejecución de un código de
programación en la plataforma del programa estadístico “R” usando la función “aov”. Los datos
empleados en esta evaluación fueron los mostrados en la Tabla 24. Las líneas de código pueden
verse en el la sección relativa al Análisis Estadístico del Capítulo III (Materiales y Métodos) de
este trabajo.
La aplicación del código diseñado para el análisis de varianza generó los siguientes
resultados que se toman directamente de la consola del programa “R” y se reportan en la Figura
70.
Figura 70. Resultado análisis de varianza.

231
En la última columna reportada en el summary (Figura 70) se observa el resultado para
Pr(>F). Este valor es el indicador de la existencia o ausencia de significancia estadística para una
prueba de comparación de medias. Como el valor de Pr(>F) es mayor de 0.1, no se rechaza la
hipótesis de nula para un nivel de significancia de 10%, según lo cual resulta estadísticamente
igual trabajar con cualquiera de los índices a los efectos de construir el modelo matemático.
Partiendo del hecho de que no existe diferencia en los promedios reportado para los
Índices evaluados, es necesario recurrir a la gráfica que muestra los promedios globales de cada
Índice en procura de seleccionar aquel que reporte su promedio global más cerca del promedio
general derivado de la suma de todos los Índices. El NDVI presenta su promedio más cerca del
promedio general que el resto de los Índices (Figura 71), por tal razón es seleccionado para la
construcción del modelo matemático de relación entre Índices de Vegetación y Caudal de
escorrentía superficial en la Cuenca del Río Areo. De igual forma la Figura 72 hace la
representación a través de gráficas de caja, de la semejanza entre los promedios de Índices
obtenidos para el tercer método de corrección.
5.3.- Construcción del Modelo Matemático.
Las técnicas de regresión generalmente son usadas para estimar valores de una variable de
interés a partir de otra que está fuertemente asociada con ella. Esa asociación se mide a partir de
observaciones comunes a ambas variables, a partir de las cuales se ajusta una función que las
relaciona a través de un modelo matemático. Existen varias técnicas de regresión, siendo la más
usada la regresión lineal, donde la variable dependiente se calcula a partir de la variable
independiente. Para el caso de esta investigación, la variable independiente es el Índice de
Vegetación, y la dependiente, o la que se quiere simular, es el Caudal de escorrentía superficial.
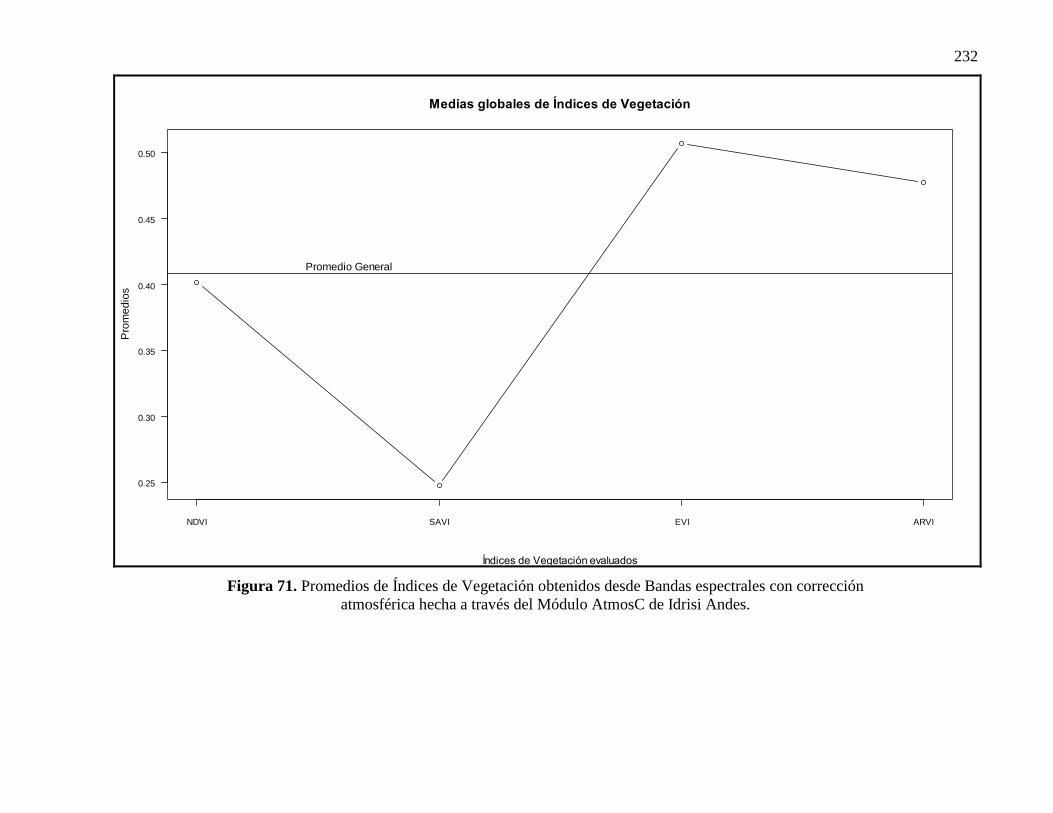
232
Medias globales de Índices de Vegetación
Índices de Vegetación evaluados
Pro
me
dio
s
0.25
0.30
0.35
0.40
0.45
0.50
NDVI SAVI EVI ARVI
Promedio General
Figura 71. Promedios de Índices de Vegetación obtenidos desde Bandas espectrales con corrección
atmosférica hecha a través del Módulo AtmosC de Idrisi Andes.

233
1NDVI 2SAVI 3EVI 4ARVI
0.0
0.2
0.4
0.6
0.8
1.0
Comparación de Promedios Indices de VegetaciónP
rom
ed
ios In
dic
es d
e V
eg
.
Figura 72. Comparación promedios de Índices de Vegetación a través de gráficos de Caja.

La técnica de regresión más utilizada es la lineal, en la cual la variable a estimar
(denominada dependiente) se calcula a partir de otra auxiliar (independiente) con una
ecuación del tipo: y = a + bx, donde “a” es el intercepto de la recta de regresión con el eje
“y” y “b” es la pendiente de la recta que agrupa la nube de puntos en la gráfica. En la
ecuación, “y” representa la respuesta del modelo (el caudal) y “x” a la variable predictora
(el índice de vegetación).
A través de las formulaciones de cálculo disponibles en el programa estadístico “R”
se evaluaron varios modelos de regresión y se seleccionó el que reportó las funciones de
repuesta con mayor ajuste para el coeficiente de correlación lineal r2.
Para el ingreso de los datos en el área de trabajo de “R” se crearon dos vectores: un
vector llamado NDVI5, que contiene los Índices de Vegetación (NDVI) reportados para las
cinco escenas disponibles; y un vector identificado como Caudal5, que incluye los cinco
valores de caudales que coinciden con los Índices por sus respectivas fechas.
A continuación se ilustra la forma cómo ingresan los vectores mencionados en el
área de trabajo del software:
NDVI5<-c(0.191,0.475,0.540,0.657,0.145)
Caudal5<-c(46,498.4,38.5,1206.1,10)
Los Índices de Vegetación son considerados las variables predictoras, mientras que
los Caudales son las variables respuestas. El análisis de regresión en “R” a través de la
función lm() especificando dentro del paréntesis una expresión que indica “variable
respuesta” modelada por “variable predictora”, resultado para este caso de la siguiente
manera:
lm(Caudal5~NDVI5)
El resultado de la expresión anterior genera una estadística que en el programa “R”
se almacenó en un vector para su consulta.
modelo<-lm(Caudal5~NDVI5)
Se probaron varios modelos con diferencia en el orden de la ecuación:
modelo1<-lm(Caudal5~NDVI5) para la forma y = a + bx,

181
modelo2<-lm(Caudal5~NDVI5+I(NDVI5^2)) para la forma y = a + bx + bx2
modelo3<-lm(Caudal5~NDVI5+I(NDVI5^2)+I(NDVI5^3)) para la forma y = a + bx + bx2
+ bx3
El cálculo de los residuales arrojó los resultados siguientes: el residual mínimo
mostrado por el modelo3 fue de -288.39, contra -555.02 del modelo1 y -412.97 del
modelo2. Para los valores máximos, el modelo3 arrojó 272, mientras que el modelo 1
reportó 414 y el modelo 2 mostró 295. El modelo de tercer grado contiene los residuales
más cercanos al cero comportándose como un predictor de mayor calidad que los otros dos
modelos. Para la selección del modelo se consideró el coeficiente de correlación lineal r2 y
el comportamiento de los residuales. El coeficiente de correlación para cada uno de los
modelos evaluados fue: Modelo 1 = 0.5383; Modelo 2 = 0.7344; Modelo 3 = 0.8197. De
acuerdo con eso se seleccionó el “modelo3”, que implica un polinomio de tercer grado,
cuya expresión como función es la siguiente:
y = 55488x3
- 62836x2+ 22402x -2185
donde “y” es la variable caudal que se busca predecir y “x” es la variable NDVI que
funciona como variable predictora.
Los resultados obtenidos con respecto a la calidad del modelo para predecir los
caudales obligan a una segunda revisión de los valores de NDVI y su correspondencia con
los caudales. Para esto se hace un arreglo de los pares evaluados (NDVI vs caudal)
ordenando en forma creciente los vectores numéricos evaluados tomando como referencia
la columna de valores de NDVI. Originalmente estos vectores fueron:
NDVI5<-c(0.191,0.475,0.540,0.657,0.145)
Caudal5<-c(46,498.4,38.5,1206.1,10)
Un nuevo arreglo de los vectores, ordenados en forma creciente con respecto a la
columna NDVI5 permite obtener los vectores siguientes.
NDVI5<-c(0.145,0.191,0.475,0.54,0.657)
Caudal5<-c(10,46,498.4,38.5,1206.1).
El comportamiento gráfico de estos vectores puede observarse en la Figura 73
donde es notorio el efecto de un valor de NDVI asociado a un valor de caudal que rompe
con la uniformidad de una curva creciente. Cuando se elimina el valor aberrante (0.54 vs
38.5) la curva adquiere un comportamiento uniforme creciente, y al procesar los vectores

182
resultantes en un análisis de regresión arroja un polinomio de tercer grado con coeficiente
de correlación r2 = 1, y residuales con valor de cero.
0.2 0.3 0.4 0.5 0.6
02
00
40
06
00
80
01
00
01
20
0
NDVI5
Ca
ud
al5
Figura 73.- Comportamiento del NDVI vs Caudales ordenados en forma ascendente con
respecto a la ocurrencia del NDVI.
La formulación numérica del modelo resultante es la siguiente:
y = 4824.9x3 - 1457.4x
2 + 861.21x - 98.9
En el programa estadístico R es posible solicitar el cálculo de los caudales aplicando
el polinomio anterior para cada uno de los valores de NDVI conocidos usando la función
modelo3$fitted.values. Los resultados coinciden exactamente con los valores originales,
confirmando el ajuste de correlación lineal de valor 1.
> modelo3$fitted.values
1 2 3 4
10.0 46.0 498.4 1206.1

183
Luego de revisados estos ajustes se considera el empleo definitivo del polinomio de
tercer grado descrito anteriormente a los efectos de modelar los caudales de la cuenca del
río Areo a partir de valores de NDVI medidos a través de sensores remotos.
CAPÍTULO V
CONCLUSIONES
1.- El Índice de Vegetación de Diferencia Normalizada, NDVI, representa las condiciones
del estado de la vegetación en la Cuenca Hidrográfica del Río Areo con menor variabilidad
en sus valores, al mostrar un rango de máximo y mínimo dentro del intervalo teórico de -1
y +1, y comportarse como el Índice con un promedio general más cercano al promedio
global arrojado por la evaluación de otros índices.
2.- Para el intervalo de tiempo evaluado, según resultados obtenidos por simulación, en la
Cuenca del Río Areo circuló un promedio diario de 403 l/s, cuando se corrió la simulación
con un caudal base de 10 l/s; reportándose valores extremos de 0.20 y 2326.40 l/s. La
variabilidad de los datos está gobernada por el patrón de precipitaciones dados para el
intervalo evaluado.
3.- Se construyó un modelo matemático que define el comportamiento de la variable
caudal de escorrentía superficial en función a las variaciones de la variable Índice de
Vegetación. El modelo de grado tres y = 4824.9x3 - 1457.4x
2 + 861.21x - 98.9 arrojó
valores residuales iguales a cero para la prueba de ajuste realizada.
4.- El NDVI mostró una correlación positiva sobre los caudales asociados, con un valor de
correlación lineal igual a 1, por lo que puede ser empleado para la estimación de esta
variable hidrológica en la cuenca evaluada.
5.- Los métodos de corrección de Bandas espectrales usados en esta investigación arrojaron
resultados con valores promedios que no muestran diferencias estadísticamente

184
significativas, por lo que, de acuerdo con la información disponible para su aplicación, la
selección de un método u otro, no influye en los resultados.
6.- La Cuenca del Río Areo no muestra sensibilidad ante el cambio de Índices empleados
para la evaluación del vigor de su vegetación. Los cuatro Índices evaluados reportan
resultados estadísticamente semejantes.
REFERENCIAS BIBLIOGRÁFICAS
Acevedo, M. (2004). Simulation of Ecological and Environmental Models. Department of
Geography Institute of Applied Science. University of North Texas. XanEdu. USA.
Amisial, R. (1979). Disponibilidad de Agua Superficial. Centro Interamericano de
Desarrollo Integral de Aguas y Tierras (CIDIAT). Mérida, Venezuela.
Bautista, S., Rincón, B., Godoy, J. y Domínguez M. (1996). Guía Práctica de
Hidrológica. Venezuela: Escuela de Ingeniería Civil. Universidad del Zulia.
Bolinaga, J. y col. (1999). Disponibilidades de agua. Proyectos de ingeniería hidráulica.
Vol. I. 1era Edición. Fundación Polar. Caracas, Venezuela.
Campos A., D., (2000). Tránsito Hidrológico de crecientes en ríos con flujo lateral.
Agrociencia, año/vol. 34, nº 003. México.
Carciente J. (1999). Carreteras Estudios y Proyectos. Caracas, Venezuela: Vega.
Chow V, Maidment D. y Mays L. (1994). Hidrología aplicada. Santafé de Bogotá,
Colombia: McGRAW - HILL INTERAMERICANA.
Chuvieco, E. (1995). Fundamentos de Teledetección Espacial. 3ra Edición. Rialp S. A.,
Madrid, España.
Cifuentes S., V. (1999). Determinación del índice de superficie foliar (leaf area index) en
masas forestales usando imágenes landsat-tm. Conclusiones de un primer estudio en la
sierra norte de córdoba. Mapping, Revista Internacional de Ciencias de la Tierra.
Disponible en [http://www.mappinginteractivo./plantill-ante.asp?id_articulo=696]. Julio 20,
2007.

185
Cova, J. (2000). Estudio preliminar de suelos piedemonte del Turimiquire Estado
Monagas municipio Cedeño. Ministerio del ambiente y de los recursos naturales.
(MINAMB). Dirección general sectorial de cuencas hidrográficas, centro edafológico
regional oriental. Venezuela: Autor.
Gaceta Oficial de la República de Venezuela (1981). Unidades de Medida del Sistema
Legal Venezolano. Nº 2.823 (Extraordinario), Julio 14, 1981.
Guevara, J. (2004). Meteorología. 2da. Edición. Consejo de Desarrollo Científico y
Humanístico. Universidad Central de Venezuela, Caracas, Venezuela.
Guilarte, J. (1989). Manual de hidrología: Hidrología práctica para ingenieros.
Instituto de Mejoramiento Profesional. Sociedad Venezolana de Ingeniería Hidráulica.
Colegio de Ingenieros de Venezuela.
Huete, A.R., H. Liu, K. Batchily, and W. van Leeuwen, 1997. A Comparison of Vegeta-
tion Indices Over a Global Set of TM Images for EOS-MODIS. Remote Sensing of
Environment 59(3):440-451.
Kaufman, Y.J. and D. Tanre, 1996. Strategy for Direct and Indirect Methods for Correc-
ting the Aerosol Effect on Remote Sensing: from AVHRR to EOS-MODIS. Remote
Sensing of Environment 55:65-79.
Khuehl, R. (2001). Diseño de Experimentos. 2da Edición. Thomson-Learning. México.
Lacoste, Y. (2003). El agua. La lucha por la vida. Colección Larousse. SPES Editorial,
S.L.
Lilesand, T. y Kiefer, R. (2000). Remote Sensing and Image Interpretation. 4ta Edición.
John Wiley & Sons, Inc. New Yok. USA.
Landsat 7. (2008). Science Data Handbook. Disponible en http://landsathandbook.gsfc.
nasa.gov/handbook/handbook_htmls/chapter11/chapter11.html. Recuperado 20/06/2008.
Meléndez S., J. (2002). Teledetección desde Satélites. Departamento de Física,
Universidad Carlos III de Madrid, España. Disponible en [http://bacterio.uc3m.es/
docencia/profesores/melendez/docuopt/Satelites_2002.pdf]. Recuperado 07/05/2007.
Mendenhall, W. y Sincich, T. (1997). Probabilidad y Estadística para Ingeniería y
Ciencias. 4ta Edición. Prentice Hall. México.
Moreno M., F. (2005). Cuencas hidrográficas e inversiones extranjeras. Serie Mención
Publicación, CENDES-UCV. Caracas, Venezuela.

186
Namakforoosh, M. (2005). Metodología de la investigación. 2da Edición. Limusa.
México.
Parra, A. (2007). Procesamiento Digital de Imágenes de Satélite. Manual de Curso con
ENVI. Instituto de Fotogrametría. Universidad de Los Andes, Mérida, Venezuela.
Peña, D. (2002). Análisis de datos multivariantes. 1º Edición. Mc. Graw Hill. España.
Pinilla, C. (1995). Elementos de Teledetección. Rama. Madrid, España.
Sánchez, R. et al. (2000). Comparación del NDVI con el PVI y el SAVI como Indicadores
para la Asignación de Modelos de Combustible para la Estimación del Riesgo de Incendios
en Andalucía. Tecnologías Geográficas para el Desarrollo Sostenible Departamento de
Geografía. Universidad de Alcalá, 164-174. Disponible en [http://age.ieg.csic.es/metodos
/docs/IX_2/Sanchez_Esperanza.PDF -], Marzo 22, 2008.
Triviño P., A., Ortiz R., S., (2004) Metodología para la modelación distribuida de
escorrentía superficial y la delimitación de zonas inundables en rablas y ríos-rambla
mediterráneos. Investigaciones Geográficas, nº 35 (2004) pp. 67-83. Instituto Universitario
de Geografía. Universidad de Alicante. España. Disponible en
[http:/dialnet.unirioja.es/servlet/fichero_articulo?articulo=1065441&orden=61392].
Recuperado 20/05/2007
Paz, F., et al. (2005). Correcciones atmosféricas usando patrones invariantes en el espacio
del rojo e infrarrojo cercano. Revista Latinoamericana de Recursos Naturales, 2 (1): 3-16,
2006. Disponible en [www.itson.mx/drn/Revista/Vol_2_2006/Art_5_Paz%20et
%20al.pdf]. Recuperado 07/05/2007
Radiometric Scaling Parameters for Landsat 7 ETM+ Level 1G Products. (2001).
Disponible en [http://landsathandbook.gsfc.nasa.gov/handbook/handbook_
htmls/chapter11/htmls/LMIN_LMAX.html]. Recuperado 22/11/2007
Versani, J. (2005). Using R for Introductory Statistics. 1ra Edición. CRC Press, USA.

187
ANEXOS

188
ANEXO 1 DATOS DE LAS ESTACIONES CLIMATOLÓGICAS
Tabla A1.1. Datos de Precipitación de la estación Mundo Nuevo (2718) Estado Anzoátegui.
A
ñ
o
/
M
e
s
E
N
E
F
E
B
M
A
R
A
B
R
M
A
Y
J
U
N
J
U
L
A
G
O
S
E
P
O
C
T
N
O
V
D
I
C
A
N
U
A
L
1
9
8
6
1
6
,
1
0
3
,
7
0
9
,
7
0
8
,
8
0
1
1
9
,
4
0
1
5
9
,
2
0
1
2
6
,
6
0
9
0
,
6
0
5
3
,
5
0
7
7
,
6
0
1
9
,
4
5
1
4
1
,
5
5
8
2
6,
2
0
1
9
8
7
6
3
,
6
0
1
,
9
0
0
,
0
0
1
,
3
0
1
7
8
,
8
0
1
0
7
,
2
0
9
3
,
8
0
1
5
8
,
9
0
1
1
3
,
6
8
1
4
1
,
4
0
8
6
,
0
0
3
6
,
9
0
9
8
3,
5
0
1
9
8
8
1
1
,
3
0
9
,
4
0
0
,
0
0
6
,
9
0
3
,
7
0
2
5
5
,
7
0
1
9
8
,
4
0
3
4
1
,
6
0
6
6
,
2
0
1
7
1
,
7
4
1
1
0
,
1
5
4
7
,
1
8
1
1
7
5,
1
0
1
9
8
9
5
,
0
2
8
,
1
0
3
1
,
6
0
0
,
4
0
1
9
,
7
0
1
1
0
,
8
0
1
1
6
,
7
0
4
2
,
6
0
1
5
9
,
6
7
2
3
0
,
4
2
1
1
9
,
2
0
1
8
,
1
0
9
0
9,
5
0
1 1 4 1 2 1 1 1 2 7 8 5 2 1







