desarrollo de software - senati virtualvirtual.senati.edu.pe/curri/file_curri.php/curri/pdsd... ·...
TRANSCRIPT

SERVICIO NACIONAL DE ADIESTRAMIENTO EN TRABAJO INDUSTRIAL
MANUAL DE APRENDIZAJE
CÓDIGO: 89001718
Profesional Técnico
INGENIERÍA DE SOFTWARE II
DESARROLLO DE SOFTWARE




INGENIERÍA DE SOFTWARE II I. COMPRENDER Y DEFINIR LOS DIAGRAMAS DE CLASE DE UML.
OPERACIONES: Tipos de relaciones: Asociación, Agregación, Composición, Herencia,
Dependencia. Diagrama de Interacción: objetos, mensajes, retornos, invocaciones. Diagrama de transición de Estados. Diagrama de Actividades, Diagrama de componentes. Diagrama de
deployment (despliegue). EQUIPOS Y MATERIALES:
Computadora con microprocesadores Core 2 Duo o mayor capacidad. Sistema operativo Windows. Acceso a internet. Software visual Studio 2012, Block de Notas.
ORDEN DE EJECUCIÓN:
Reconocer la Estructura de Relaciones en todos sus aspectos. Reconocer el Manejo de Diagramas Interacción y de Estados en UML. Reconocer el Manejo de Diagramas de Actividades y Componentes.
1.1. TIPOS DE RELACIONES.
UML: El Lenguaje de Modelamiento Unificado (UML - Unified Modeling Language) es un lenguaje gráfico que permite visualizar, especificar de modo grafico secuencial y documentar cada una de las partes que comprende el desarrollo de un software. UML Este Lenguaje, permite modelar el análisis de manera conceptual, como lo son procesos de negocio y funciones de sistema, además de cosas concretas como podrían ser las clases en un lenguaje determinado, estructuras de bases de datos y componentes del software que interactuaran.
El lenguaje unificado de diagrama o notación (UML) permite especificar, visualizar y documentar esquemas de sistemas de software orientado a objetos. UML no es precisamente un método de desarrollo, lo que quiere decir que no servirá para determinar qué se deberá hacer como primer lugar o cómo se debe de diseñar el sistema; sino, básicamente permite visualizar el diseño y a hacerlo más accesible para otros. UML está controlado y basado, por el
ESCUELA DE TECNOLOGÍAS DE INFORMACIÓN 7

INGENIERÍA DE SOFTWARE II grupo de administración de objetos también conocido como OMG, que viene hacer el estándar de descripción de esquemas de software, técnicas que se utilizan para el diseño e implementación de los mismos.
UML, como se puede entender está básicamente diseñado para el uso con software orientado a objetos o también conocido como POO, y la desventaja es que tiene un uso limitado en otro tipo de estructuras de programación.
UML, se compone de muchos elementos de esquematización que van a representar los distintos métodos o partes de un sistema de software. Estos elementos UML se utilizan para poder crear diagramas, que van a representar alguna parte o estructura del sistema.
UML, permite realizar el análisis del software por medio de Diagramas, los cuales se derivan del diseño que se va realizando de manera conceptual. Los diagramas más utilizados y frecuentes son los siguientes:
• Diagrama de casos de uso: Este diagrama, muestra a los actores del sistema u otros usuarios del sistema, los casos de uso representan las situaciones que se producen cuando utilizan el sistema y sus relaciones.
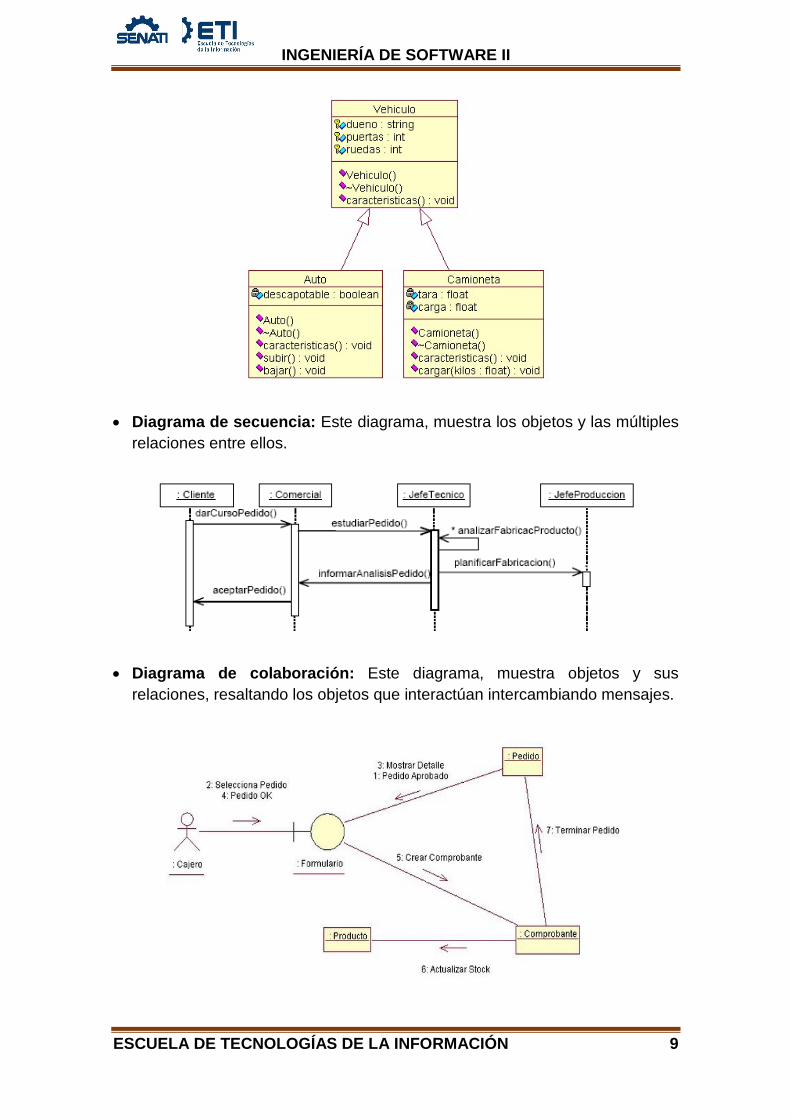
• Diagrama de clases: Este diagrama, muestra las clases y la relaciones entre ellas, las cuales determinaran sus comportamientos y características.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 8
INGENIERÍA DE SOFTWARE II
• Diagrama de secuencia: Este diagrama, muestra los objetos y las múltiples relaciones entre ellos.
• Diagrama de colaboración: Este diagrama, muestra objetos y sus relaciones, resaltando los objetos que interactúan intercambiando mensajes.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 9

INGENIERÍA DE SOFTWARE II • Diagrama de estado: Este diagrama, muestra estados, los cambios de
estado y los eventos que se realizan en un objeto o en parte de un sistema.
• Diagrama de actividad: Este diagrama, muestra las actividades, así mismo,
resalta los cambios de las actividades con los eventos que se suscitan en ciertas partes del sistema.
• Diagrama de componentes: Este diagrama, muestra los componentes que más se utilizan y de mayor nivel en la programación.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 10
INGENIERÍA DE SOFTWARE II
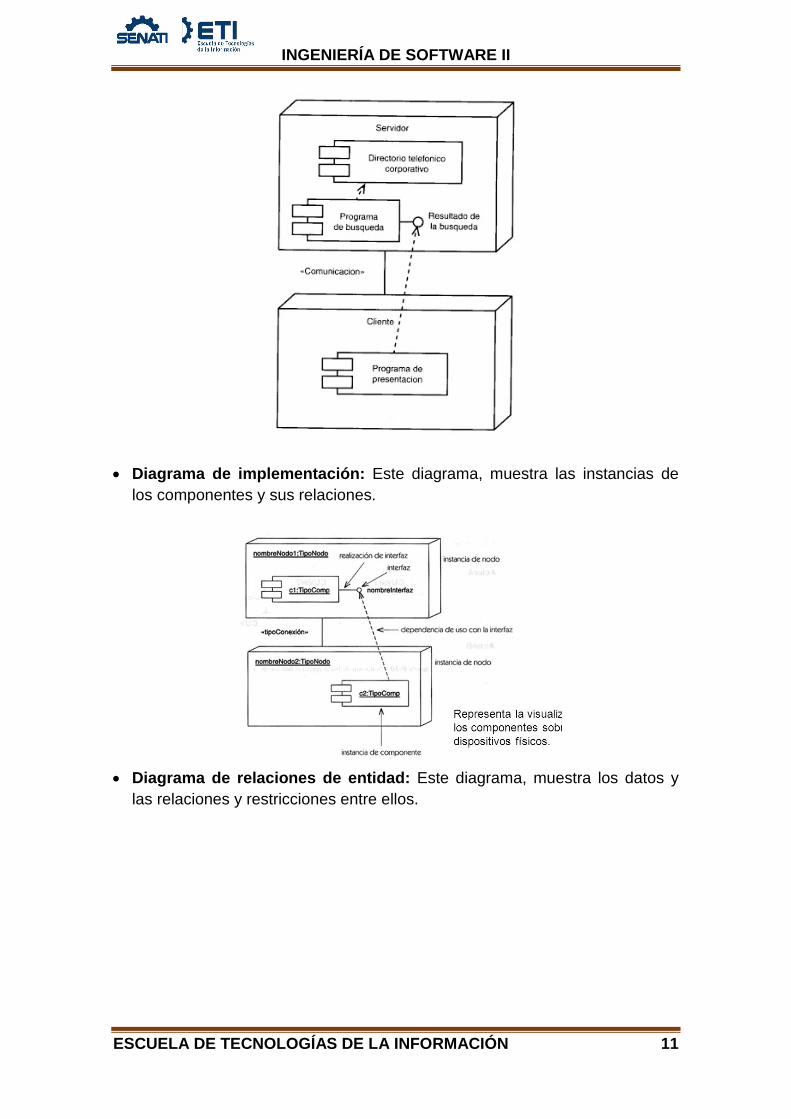
• Diagrama de implementación: Este diagrama, muestra las instancias de los componentes y sus relaciones.
• Diagrama de relaciones de entidad: Este diagrama, muestra los datos y
las relaciones y restricciones entre ellos.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 11

INGENIERÍA DE SOFTWARE II
Los diagramas en UML son herramientas prácticas para poder identificar el análisis y diseños de un software a implementarse:
Diagramas de clase:
Los diagramas de clases permiten identificar las diferentes clases que componen y participan en un sistema y que tipo de relaciones tendrán entre ellas. Los diagramas de clases son diagramas estáticos, ya que muestran las clases, junto con sus métodos y atributos, así también permiten visualizar las relaciones estáticas entre ellas; por ejemplo se podría preguntar: qué clases se conocen, a qué otras clases se conocen, o qué clases son parte de otras clases, pero no visualizan los métodos mediante los que se invocan entre ellas.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 12

INGENIERÍA DE SOFTWARE II Los Diagramas de Clases son de estructura estática que muestran las clases del sistema y sus interrelaciones, este tipo de relaciones pueden ser de herencia, agregación, asociación, etc. Los diagramas de clase son el punto básico del modelado UML, siendo estos utilizados para mostrar lo que el sistema puede hacer, lo que vendría a ser el análisis, y también utilizados para mostrar cómo puede ser construido el sistema, lo que vendría a ser el diseño.
El diagrama de clases de más alto nivel, será lógicamente un dibujo de los paquetes que componen el sistema. Las clases se pueden representar con una descripción de lo que realizan dentro del sistema, indicando sus métodos y sus atributos. Las relaciones entre clases se documentan con una descripción de propósito, sus objetivos que intervienen en la relación y su opcionalidad.
Un diagrama de clases permite visualizar las relaciones entre las clases que interactúan en el sistema. Un diagrama de clases está compuesto por los siguientes elementos:
• Clase: Que contiene los atributos, métodos y visibilidad. • Relaciones: Herencia, Composición, Agregación, Asociación y Uso
Clase:
En una clase se define los atributos y los métodos de una serie de objetos. Todos los objetos de esta clase, conocidas también como instancias de esa clase, tienen el mismo comportamiento y el mismo conjunto de atributos, cabe resaltar que cada objetos tiene el suyo propio. En ocasiones se utiliza el término “Tipo” en lugar de clase, pero se debe de tener en cuenta que no son lo mismo, y que el término tipo tiene un significado más general.
Tipo, es la unidad básica que va a encapsular toda la información de un Objeto. El Objeto viene a ser una instancia de una clase. A través de la clase se puede modelar el entorno en estudio, por ejemplo: una clase Casa, Auto, Cuenta Corriente, etc. En UML, una clase es representada por un rectángulo que posee tres divisiones:
Superior: Contiene el nombre de la Clase. Intermedio: Contiene los atributos (o variables de instancia) que
caracterizan a la Clase (pueden ser private, protected o public).
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 13

INGENIERÍA DE SOFTWARE II Inferior: Contiene los métodos u operaciones, los cuales son la forma como
interactúa el objeto con su entorno (dependiendo de la visibilidad: private, protected o public).
Ejemplo de Clase:
Atributos:
Existen tipos de atributos, los cuales pueden ser de tres características:
• Tipo Protected: Indica que el atributo no es accesible desde fuera de la clase, pero si podrá ser utilizado por métodos de la clase, así mismo podría utilizarse por las subclases que se deriven.
• Tipo Private: Indica que el atributo sólo es accesible desde dentro de la clase, es decir que sólo sus métodos lo pueden utilizar.
• Tipo Public: Indica que el atributo será visible tanto dentro como fuera de la clase, es decir, que puede ser utilizado y ser accedido desde otros lados.
Métodos:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 14

INGENIERÍA DE SOFTWARE II Los métodos u operaciones de una clase son la forma en como ésta interactúa con su entorno, éstos pueden tener las características:
• Tipo Public: Indica que el método será visible tanto dentro como fuera de la clase, es decir, puede ser accedido desde todos lados.
• Tipo Private: Indica que el método sólo será accesible desde dentro de la clase, es decir, que sólo otros métodos de la clase pueden utilizarlo.
• Tipo Protected: Indica que el método no podrá ser utilizado desde fuera de la clase, pero si podrá ser utilizado por métodos de la clase además de métodos de las subclases que se puedan derivar.
TIPOS DE RELACIONES:
Existen tipos de relaciones en los diagramas de clases de UML, las cuales se utilizaran según su estructura y necesidad de lo diseñado, entre este tipo de relaciones, existen:
- Asociación: Este tipo de relación entre clases conocida como Asociación, permite asociar objetos que colaboran entre sí. Cabe destacar que no es una relación fuerte, es decir, el tiempo de vida de un objeto no depende del otro. Una Asociación es una relación estructural que describe una conexión entre objetos.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 15

INGENIERÍA DE SOFTWARE II
Ejemplo: Utilizar el programa StarUML, para realizar el ejemplo de Diagrama de Clase – Asociación: • Menú File (Archivo) - New (Nuevo)
• Crear una Nueva Clase: Class
• Generar la Clase “Curso” y agregar los atributos “profesor: Profesor” y “nombre: String”, se está indicando que la clase curso contiene atributos como un profesor y un nombre del curso
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 16

INGENIERÍA DE SOFTWARE II
• Agregar los métodos u operaciones, en este caso se indica que se imprimirá el profesor y se imprimirá el nombre del curso
• Insertar la Clase Profesor, con el atributo Nombre de tipo String y se ingresara el método u operador getNombre de tipo String para el ingreso de un profesor.
• Generar la relación de Asociación entre las clases Curso y Profesor:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 17

INGENIERÍA DE SOFTWARE II
- Agregación: Es muy similar a la relación de Asociación solo varía en la multiplicidad ya que en lugar de ser una relación "uno a uno" es de "uno a muchos". Se representa con una flecha que parte de una clase a otra en cuya base hay un rombo de color blanco.
- Composición: Similar a la relación de Agregación solo que la Composición es una relación más fuerte. Aporta documentación conceptual ya que es una "relación de vida", es decir, el tiempo de vida de un objeto está condicionado por el tiempo de vida del objeto que lo incluye. Se representa con una flecha que parte de una clase a otra en cuya base hay un rombo de color negro.
- Herencia: Este tipo de relación también es conocida como Generalización y Especialización. La herencia entre una superclase y sus subclases. Objetos de
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 18

INGENIERÍA DE SOFTWARE II distintas clases pueden tener atributos similares y exhibir comportamientos parecidos. Ejemplo: Seres Humanos, Hombres y Mujeres. La Relación entre elementos conocidos como Hijo – Padre: El Hijo, tiene la misma especificación que el Padre, la cual se puede extender; este tipo de Relación la clase hijo hereda todas las características de la clase padre, así mismo sus comportamientos.
Ejemplo: Una Clase “Figura”, la cual tendrá unas Clase Hijo “Rectángulo”, “Circulo” y “Polígono”.
- Dependencia: Representa un tipo de relación muy particular, en la que una clase es instanciada (su instanciación es dependiente de otro objeto/clase). Se denota por una flecha punteada. El uso más particular de este tipo de relación es para denotar la dependencia que tiene una clase de otra, como por ejemplo una aplicación grafica que instancia una ventana (la creación del Objeto Ventana está condicionado a la instanciación proveniente desde el objeto Aplicación). Cabe destacar que el objeto creado, en este caso la ventana gráfica, no se almacena dentro del objeto que lo crea. Este tipo de relación es más débil que una asociación, que muestra la relación entre un cliente y el proveedor de un servicio usado por el cliente. Cliente es el objeto que solicita un servicio. Servidor es el objeto que provee el servicio solicitado.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 19

INGENIERÍA DE SOFTWARE II
Ejercicio 1: Crear un diagrama de clases y generar el Código para el lenguaje Java. Trabajar en StarUML: - Archivo (File) – Nuevo (New); Seleccionar el tipo de Archivo a Generar:
- Seleccionar el tipo de diagrama (Clase) tipo de proyecto y modelamiento a generar. Clic a Ok
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 20

INGENIERÍA DE SOFTWARE II
- Generar un nuevo paquete de trabajo: Clic derecho al Logical View – Seleccionar Package. Ingresar el Nombre “Ejercicio1”
- Generar las Clases Instituto, Alumno y Profesor; para ello dar clic derecho –
Nuevo (New) - Clase (Class). Ingresar de Nombre “Instituto”, “Alumno” y “Profesor”
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 21

INGENIERÍA DE SOFTWARE II
- Se puede observar todas las clases generadas en el visor de componentes:
- Generar un Diagrama de Clases. Clic derecho a Ejercicio1 – Nuevo (New) –Diagrama de Clases (Class Diagram) – Ingresar el Nombre “Diagrama de clases)
- Dar doble clic al Diagrama de Clases para abrir su estructura y arrastrar las Clases en el interior del Diagrama
- Agregar los Atributos a las Clases. Clic derecho a la Clase Instituto – Nuevo Atributo (New Attribute). Una vez ingresado el primer Atributo presionar
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 22

INGENIERÍA DE SOFTWARE II
Enter para agregar el siguiente Atributo. Clic Izquierdo fuera de la clase para ya no ingresar más atributos. Ingresar los Atributos “IdInstituto”, “NombreInstituto”
- Agregar los Métodos u Operaciones para las Clases. Clic derecho a la Clase
– Nueva Operación (New Operation) – Ingresar el Nombre para la Operación; presionar Enter para agregar otro Operador o clic izquierdo fuera de la clase para ya no ingresar más operaciones. Operaciones “CrearInstituto”, “ModificarInstituto” y “EliminarInstituto”
- Crear los Atributos y Operadores para todas las Clases del Diagrama:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 23

INGENIERÍA DE SOFTWARE II
- Modificar los Atributos Id de las Clases, por privadas:
- Crear la Relación entre Clases, Seleccionar la Herramienta de Relación de
Asociación y arrastrar desde la tabla Alumno hasta la tabla Instituto:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 24

INGENIERÍA DE SOFTWARE II
- Realizar la misma relación entre las clases Profesor e Instituto:
- Seleccionar la Flecha de Relación, para cambiar la cardinalidad e indicar algunos atributos de la Relación creada. En el Panel de la Izquierda, Desactivar la opción Navigable, Seleccionar su Multiplicidad, en este caso de “1…*” (de Uno a Muchos).
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 25

INGENIERÍA DE SOFTWARE II - Seleccionar la segunda referencia “Alumno”, Seleccionar la Multiplicity “1”.
- La cardinalidad entre la Clase Profesor y la Clase Instituto será igual,
“Instituto” desactivar “Navigable”, Multiplicity “1…n”, y el “Profesor”, seleccionar la Multiplicity “1”. La Relación de las Clases quedaría de la siguiente manera:
- Seleccionar todos los Componentes del Diagrama seleccionando arrastrando con el Clic izquierdo. Menú Tareas (Tools). Seleccionar la Plataforma para la cual se requiere generar el Código, para el Ejercicio, Seleccionar Java y luego Generar Código (Generate Code). Tener en cuenta que se puede seleccionar el tipo de plataforma para lo que se requiere el código. Así mismo, se debe de seleccionar todo lo de la ventana Diagrama de Clases.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 26
INGENIERÍA DE SOFTWARE II
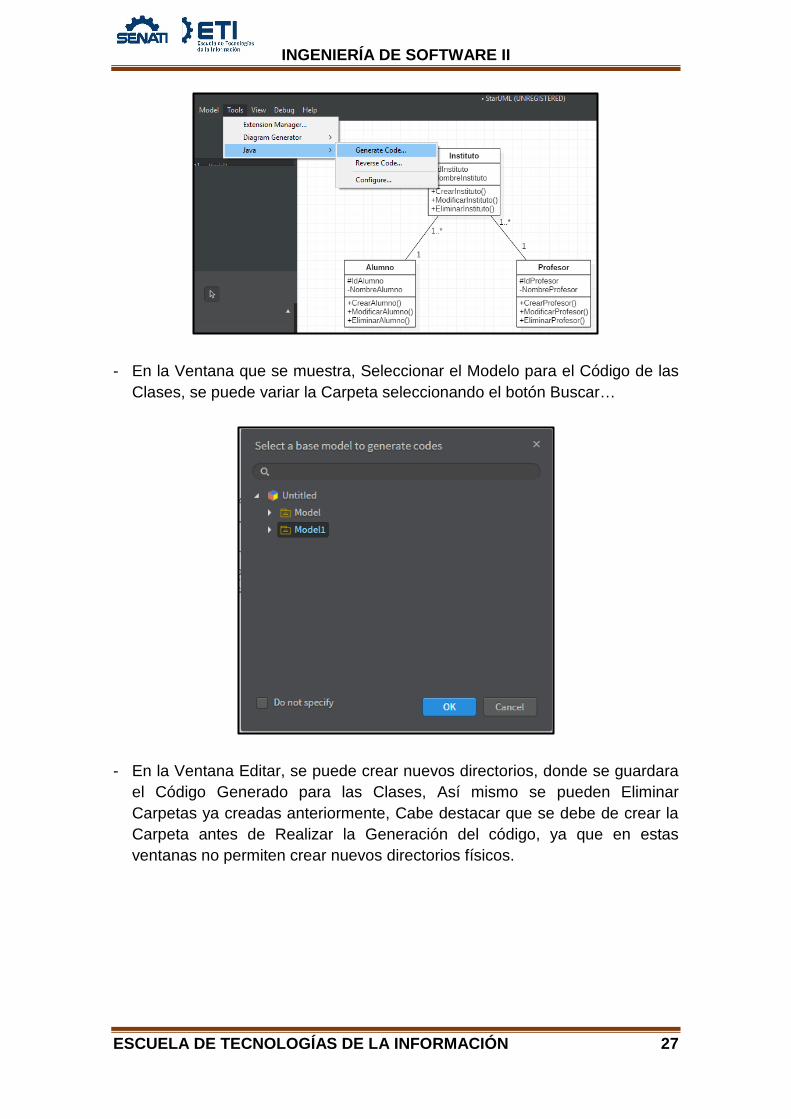
- En la Ventana que se muestra, Seleccionar el Modelo para el Código de las Clases, se puede variar la Carpeta seleccionando el botón Buscar…
- En la Ventana Editar, se puede crear nuevos directorios, donde se guardara
el Código Generado para las Clases, Así mismo se pueden Eliminar Carpetas ya creadas anteriormente, Cabe destacar que se debe de crear la Carpeta antes de Realizar la Generación del código, ya que en estas ventanas no permiten crear nuevos directorios físicos.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 27

INGENIERÍA DE SOFTWARE II
- Seleccionar Nuevo para crear el Directorio. Luego seleccionar Carpeta (Directory)
- Seleccionar la Carpeta que se ha creado para Guardar el Código:
- Verificar en la Carpeta donde se ha determinado la Generación de Código.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 28

INGENIERÍA DE SOFTWARE II
- Abrir los Archivos generados de las Clases y verificar el Código.
Código Clase Alumno:
//Source file: C:\\Java\\Ejercicio1\\Alumno.java
Package Ejercicio1;
Public class Alumno
{
Protected int IdAlumno;
Private int NombreAlumno;
/**
@roseuid 5651FF2502BA
*/
Public Alumno()
{
}
/**
@roseuid 5651F1E5026D
*/
Public void CrearAlumno()
{
}
/**
@roseuid 5651F1EB01C8
*/
Public void ModificarAlumno()
{
}
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 29

INGENIERÍA DE SOFTWARE II /**
@roseuid 5651F1F50043
*/
Public void EliminarAlumno()
{
}
}
Código Clase Profesor:
//Source file: C:\\Java\\Ejercicio1\\Profesor.java
Package Ejercicio1;
Public class Profesor
{
Protected int IdProfesor;
Private int NombreProfesor;
/**
@roseuid 5651FF25030E
*/
Public Profesor()
{
}
/**
@roseuid 5651F1FE02D5
*/
Public void CrearProfesor()
{
}
/**
@roseuid 5651F20300EE
*/
Public void ModificarProfesor()
{
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 30

INGENIERÍA DE SOFTWARE II }
/**
@roseuid 5651F2090130
*/
Public void EliminarProfesor()
{
}
}
Código Clase Instituto:
//Source file: C:\\Java\\Ejercicio1\\Instituto.java
Package Ejercicio1;
Public class Instituto
{
protected int IdInstituto;
Private int NombreInstituto;
/**
@roseuid 5651FF250345
*/
Public Instituto()
{
}
/**
@roseuid 5651F0F703AE
*/
Public void CrearInstituto()
{
}
/**
@roseuid 5651F0FF01F2
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 31

INGENIERÍA DE SOFTWARE II */
Public void ModificarInstituto()
{
}
/**
@roseuid 5651F108013F
*/
Public void EliminarInstituto()
{
}
}
Nota: Ejercicio N° 1 del Capítulo 1 del Manual; nombre aplicación: “Ejercicio1”
Ejercicio 2: Se desarrollara un Caso Práctico; Sistema de Gestión de Pedidos:
Se desea implementar un sistema de Gestión de Pedidos, sabiendo que:
• Un Cliente Puede realizar varios Pedidos en un periodo de tiempo (un pedido es realizado por un Solo Cliente)
• Cada pedido está formado por varias líneas de pedido, cada una de las cuales se refiere a un solo producto
• Se diferencian dos tipos de Clientes, el Cliente Personal y el Cliente Corporativo. La diferencia entre los dos tipos de clientes es que el cliente personal pagará mediante una tarjeta de crédito, mientras el cliente corporativo tiene un contrato con la empresa y un límite de crédito
• Además, los vendedores de la empresa se encargan de atender las peticiones de los clientes corporativos, de forma de cada vendedor se hace cargo de una cartelera de clientes corporativos, y a cada cliente corporativo sólo le atiende un vendedor.
Paso1 – Identificar Clases: - Crear un nuevo Archivo de Modelado. - File – New – Package “SistemaPedidos”
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 32

INGENIERÍA DE SOFTWARE II
- Agregar un nuevo Diagrama de Clases:
- Identificar y Crear las Clases que van a Interactuar en el Sistema de Pedidos:
Paso 2 – Establecer las relaciones entre Clases. - Determinar algunos Atributos y las Relaciones y sus tipos según la
necesidad de comunicación entre las Clases
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 33

INGENIERÍA DE SOFTWARE II - Entre las Clases Cliente, Cliente Personal y Cliente Corporativo existe una
relación de Tipo Generalización, Cliente es una Clase General y que se puede particularizar en dos tipos.
- La Clase Sistema de Pago, como Clase General y se puede particularizar en dos tipos Tarjeta de Crédito o mediante un Contrato que se realiza entre el Cliente Corporativo y la Empresa.
- Entre la Clase Cliente y la Clase Pedido existe una Relación de tipo Asociación, de forma que a cada cliente se le pueda asociar los pedidos realizados, indicando que existe una Multiplicidad que un cliente puede tener 1 o más pedidos y que un Pedido solo pertenece a un solo cliente.
- Entre la Clase Pedido y Clase Línea de Pedido existe una relación de Tipo Asociación de tipo Composición, ya que un Pedido está formado por un conjunto de Líneas de Pedido.
- Entre la Clase Línea de Pedido y la Clase Producto existe una Relación de Asociación de tipo Agregación, esto quiere decir que una Línea de Pedido consta de uno o más Productos, pero existe dependencia, si esta relación se rompe, la Clase Productos puede seguir existiendo.
- Existe una Relación de Asociación entre las Clases Cliente Personal con la Clase Tarjeta de Crédito.
- Existe una Relación de Asociación entre las Clases Cliente Corporativo y la Clase Contrato.
- Existe una Relación de Asociación entre las Clases Cliente Corporativo y la Clase Vendedor. Un vendedor tiene una cartera de clientes corporativos por ello la multiplicidad es de 1 a muchos, pero un Cliente Corporativo solo puede tener un solo vendedor.
- Existe una Relación de Dependencia entre las Clases Vendedor y la Clase Sistema Pago, de forma, que cuando se realiza una venta en el sistema, esta tiene asociado un sistema de pago en concreto con lo que se realizara la operación.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 34

INGENIERÍA DE SOFTWARE II Nota: Ejercicio N° 2 del Capítulo 1 del Manual; nombre aplicación: “Modelamiento de Clases”
1.2. DIAGRAMA DE INTERACCIÓN.
El Diagrama de Interacción, es el modelo que permite describir a un grupo de objetos que van a colaborar para llegar a un objetivo. Estos objetos van a interactuar entre sí para poder realizar de manera colectiva los servicios que ofrecen las aplicaciones.
En sí, este tipo de diagrama muestra cómo se comunican los objetos en una interacción.
Estos Diagramas, muestran objetos, así como los mensajes que se pasan entre ellos. Básicamente se puede decir que el Diagrama de Interacción captura el Comportamiento de un Caso de Uso
Existen dos tipos de diagramas de Interacción, los cuales son:
• Diagrama de Colaboración. • Diagrama de Secuencia.
• Diagrama de Colaboración: Este tipo de Diagrama permite representar la
interacción entre objetos. Alterna al diagrama de secuencia, a diferencia de estos, el diagrama de colaboración pueden mostrar el contexto de la operación y los ciclos en la ejecución. Estos diagramas se prestan más al descubrimiento de abstracciones, ya que permite representar los objetos en una disposición próxima a la realidad.
Como se ha explicado, un Diagrama de Colaboración se realiza después de haber creado un Diagrama de Casos de Uso.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 35

INGENIERÍA DE SOFTWARE II Ejercicio 3: Primero se deberá de desarrollar el Diagrama de Casos de Uso, para un sistema de Matriculas. Se utilizara StarUML, para ello realizar los siguientes pasos: Paso 1: Diagrama de Casos de Uso. - Crear un Nuevo Diagrama de Casos de Uso.
- Añadir tres Actores, que para este ejercicio será “Alumno”, “Secretaria” y
“Sistema”
- Crear un Caso de Uso “Registrar Matricula”
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 36

INGENIERÍA DE SOFTWARE II - Indicar la participación de los Actores con el caso de uso. Generar una
Asociación Directa
Paso 2: Diagrama de Colaboración. - Clic derecho al Diagrama de Caso de Uso “Registro Matricula”, Nuevo (New)
– Diagrama de Colaboración (Collaboration Diagram) - StarUML “Collaboration”
- Se genera el Diagrama de Colaboración. Ingresar el Nombre “Diagrama de Colaboración – Reg. Matricula” – StarUML “Communication Diagram”
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 37

INGENIERÍA DE SOFTWARE II
- Arrastrar los Actores al Diagrama de Colaboración.
- Generar los Objetos de Conexión (Object Link) – StarUML “Connector”.
- Insertar los objetos del Diagrama, para los Mensajes (Link Message) y Conexión de Mensajes de Reserva (Reverse Link Message).
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 38

INGENIERÍA DE SOFTWARE II
• Diagrama de Secuencia: Este tipo de Diagrama permite representar la secuencia de manera cronológica de mensajes entre objetos durante un escenario concreto. Cada objeto es representado por una barra horizontal. La representación de la secuencia se realiza de arriba abajo. Si existiese demora entre la comunicación de un objeto u otro, se representa con una línea oblicua.
La exactitud temporal solo tomara importancia en las aplicaciones que se ejecutan en tiempo real, esto conlleva a que los ejes de tiempo contengan marcas temporales. El orden horizontal que se muestra para los objetos no tiene importancia. Se puede decir, que un Diagrama de Secuencia va a mostrar a los objetos participantes y los mensajes que cambian entre ellos a los largo del tiempo de la ejecución de la aplicación.
Un objeto o Actor puede enviarse un mensaje así mismo:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 39

INGENIERÍA DE SOFTWARE II
Objeto o Actor
Objeto o Actor
Mensaje
Las Instrucciones Condicionales se podrían representar de la siguiente manera:
Para una Instrucción de interacciones o Repetitivas, se podría representar de la siguiente manera:
Ejercicio 4: Utilizando el ejercicio anterior donde se creó un Diagrama de Casos de Uso para el Registro de Matricula, y se generó el diagrama de Colaboración. Se creara un Diagrama de Secuencia para el “Registro de Matriculas”
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 40

INGENIERÍA DE SOFTWARE II - Clic derecho al Diagrama de Caso de Uso Registro Matricula – Nuevo (New)
– Diagrama de Secuencia (Sequence Diagram). Ingresar el nombre “Diagrama de Secuencia – Reg. Matricula”.
- En el diagrama de secuencia, arrastrar desde los actores del caso de uso hacia el diagrama, quedando de la siguiente manera:
- Seleccionar Mensaje Libre (Message To Self), para empezar el proceso “Generar Nuevo Registro”, con ello se dará inicio al proceso.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 41

INGENIERÍA DE SOFTWARE II
- Agregar un Mensaje de Secretaria a Alumno “Solicitar Nombres”
- Agregar Mensaje de Alumno a Secretaria “Dictar Nombres”
- Ir Ingresando los Mensajes de interacción en el sistema:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 42

INGENIERÍA DE SOFTWARE II
Nota: Ejercicio N° 3 del Capítulo 1 del Manual; nombre aplicación: “Modelamiento”. Ejercicio N° 4 del Capítulo 1 del Manual, nombre aplicación: “Modelamiento - DS”
1.3. DIAGRAMA DE TRANSICIÓN DE ESTADOS: El Diagrama de Transición, permite observar las transiciones que se producen como consecuencia de los eventos y los procesos que se puedan realizar. Permiten a su vez describir los comportamientos normales de un sistema. También permite observar los comportamientos excepcionales de un sistema, estos pueden ser Errores, Excepciones, etc. Se debe de tener en cuenta que muchos de los eventos son provocados por el usuario.
Como conclusión se puede decir que los diagramas de transición de estados es la representación de un conjunto de estados por los que pasa un objeto durante
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 43

INGENIERÍA DE SOFTWARE II su ciclo de vida en respuesta a eventos y acciones; en estos encontraremos qué eventos pueden cambiar el estado o comportamiento de los objetos. Reconocer los componentes del Diagrama de Transición de Estados: Transiciones: Vienen a ser las líneas de comunicación, es lo que une un estado con otro, está compuesta por los eventos y las acciones a ejecutar. La representación gráfica es una flecha en línea con la punta abierta. Estados: Son aquellos que dan lugar a un cambio en el comportamiento del sistema o a un momento significativo en su evolución, por ejemplo un método de una clase. Diagrama de Estados: Es aquel que influye en el comportamiento y evolución del sistema, los estados siempre han de pertenecer a una clase y representa un resumen de los valores y atributos que puede tener la clase, un Diagrama de Estados, describe el estado interno de un objeto de una clase particular. Además se puede decir que tiene lugar en un punto del tiempo pero no posee duración respecto a la granularidad temporal del sistema. No todos los cambios en los atributos de un objeto deben de estar representados por estados, solo aquellos en lo que el cambio afecta significativamente su comportamiento.
Tipos de Estado:
Inicio: Es el estado inicial en el que se inicia el objeto en su ciclo de vida, ningún evento puede retornar un objeto a este estado. Gráficamente está representado con un círculo negro.
Fin: Es el estado final en el que queda un objeto al final de su ciclo de vida, ningún evento puede sacar a un objeto de este estado. Gráficamente está representado con un círculo negro rodeado de otro círculo.
Estado: Son los diferentes estados por lo que puede pasar un objeto a lo largo de su ciclo de vida, de ellos se puede salir, quedarse en él y retornar. Gráficamente está representado por un rectángulo.
Transiciones: Es el momento en donde un objeto pasa de un estado a otro mediante un evento. Se representa mediante una Flecha.
Anulado
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 44

INGENIERÍA DE SOFTWARE II
Partes de un Diagrama de Estado:
Estado: Se identifica como un periodo de tiempo del objeto, en el cual dicho objeto se encuentra esperando alguna operación o suceso. Inicia con un estado característico a la espera de estímulos para su desencadenante.
Eventos: Es básicamente una ocurrencia que puede ser causada por la transición de un estado.
Mensajes: Permite representar una acción por medio de mensajes que van de un objeto a otro.
Transición Simple: Viene a ser una relación entre dos estados que permite indicar que un objeto en el primer estado puede ingresar al segundo estado y ejecutar un grupo de operaciones, cuando se suscita el evento.
Transición Interna: En este tipo de transición el objeto permanece en el mismo estado, en vez de trabajar con dos estados distintos. Va a representar un evento que no causara cambios de estados.
Transición compleja: En este tipo de transición interactúan tres o más estados, ya que es una transición de múltiples fuentes o destinos.
SubEstados: Un estado se puede dividir en subestados, que pueden poseer transiciones entre ellos y conexiones a nivel superior; estas conexiones se ven al nivel inferior como estados de inicio o fin.
Acciones: Se puede especificar la solicitud de un servicio a otro objeto como consecuencia de la transición. Se puede determinar al ejecutar una acción como resultado de entrar, salir, estar en un estado, o por la ocurrencia de un evento.
Ejercicio 5: Desarrollar un Diagrama de Estado para generar una solicitud de permiso en el Instituto:
- Generar un nuevo Archivo en StarUML. Archivo (File) – Nuevo (New). Presionar la Tecla Esc (Escape) para no indicar que tipo de Proyecto se va a realizar. No es necesario.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 45

INGENIERÍA DE SOFTWARE II
- Menú Model – Modelo – Diagrama de Estado (Statechart Diagram). Ingresar el Nombre “EstadoSolicitud”
- Doble Clic al Diagrama y Maximizar. Agregar los Estados (State) “Tramitado”, “Aceptada Solicitud” y “Finalizado”
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 46

INGENIERÍA DE SOFTWARE II - Agregar un Estado de Inicio (Start State), un Estado Final (End State) y los
Estados de Transición (State Transition)
- Dar Doble Clic en el Estado de Transición del Estado “Tramitado” y
“Aceptada Solicitud”, para dar la Especificación de la Transición del Estado (State Transition Specification). Ingresar el Evento: “Presentar Solicitud”. Dar Aceptar (Ok)
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 47

INGENIERÍA DE SOFTWARE II - Dar Doble Clic en el Estado de Transición del Estado “Aceptada Solicitud” y
“Finalizado”, para dar la Especificación de la Transición del Estado (State Transition Specification). Ingresar el Evento: “Comprobante de Solicitud”. Dar Aceptar (Ok).
- Se podría complementar con más estados, dependiendo de la necesidad de
representación que el análisis requiera, así mismo se podría ingresar las transiciones entre estados indicando como va cambiando cada estado según su comportamiento.
- Finalmente el Diagrama de Estado quedara de la siguiente manera:
Nota: Ejercicio N° 5 del Capítulo 1 del Manual; nombre aplicación: “Diagrama Estado - Solicitud”
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 48
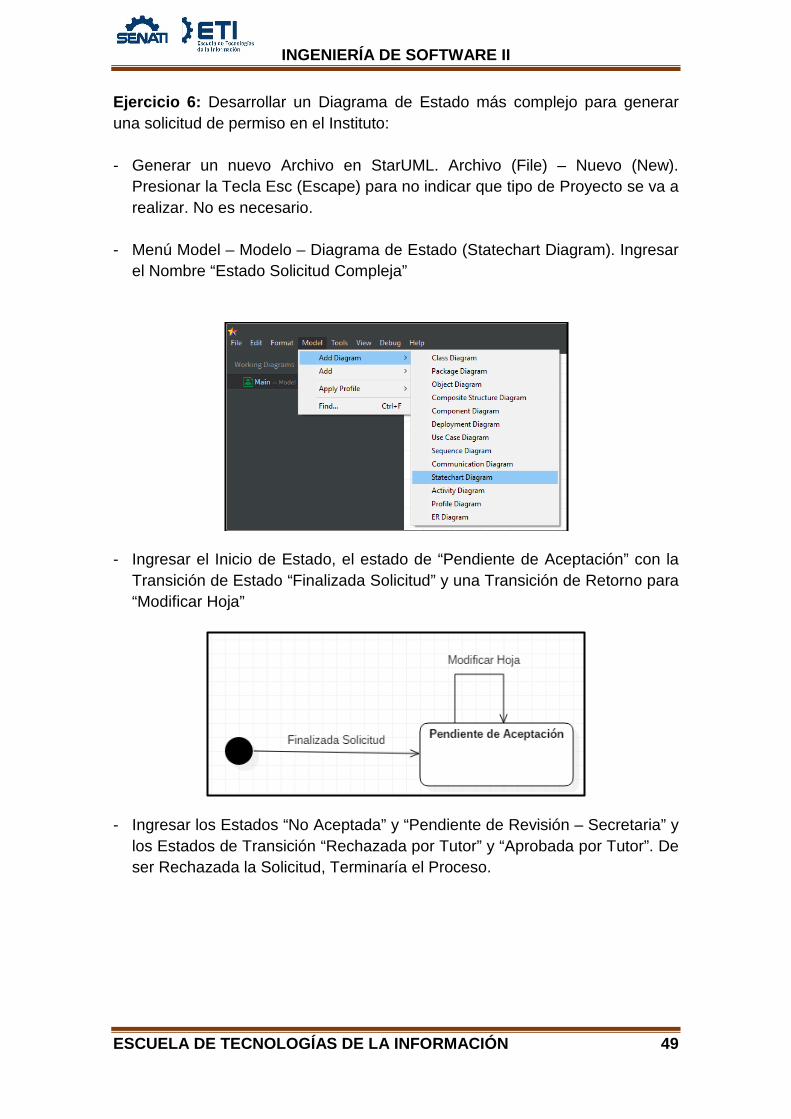
INGENIERÍA DE SOFTWARE II Ejercicio 6: Desarrollar un Diagrama de Estado más complejo para generar una solicitud de permiso en el Instituto: - Generar un nuevo Archivo en StarUML. Archivo (File) – Nuevo (New).
Presionar la Tecla Esc (Escape) para no indicar que tipo de Proyecto se va a realizar. No es necesario.
- Menú Model – Modelo – Diagrama de Estado (Statechart Diagram). Ingresar
el Nombre “Estado Solicitud Compleja”
- Ingresar el Inicio de Estado, el estado de “Pendiente de Aceptación” con la Transición de Estado “Finalizada Solicitud” y una Transición de Retorno para “Modificar Hoja”
- Ingresar los Estados “No Aceptada” y “Pendiente de Revisión – Secretaria” y los Estados de Transición “Rechazada por Tutor” y “Aprobada por Tutor”. De ser Rechazada la Solicitud, Terminaría el Proceso.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 49

INGENIERÍA DE SOFTWARE II
- Ingresar los Estados “En Realización” y “Aprobada”, Ingresar los Estados de Transición “Revisión de Secretaria” y “Firma y Sello de Aprobación”. Una Transición de Retorno “Verificación de Adjuntos”. Finalmente Ingresar un Estado Final.
Nota: Ejercicio N° 6 del Capítulo 1 del Manual; nombre aplicación: “Diagrama Estado Complejo - Solicitud”
1.4. DIAGRAMA DE ACTIVIDADES, CALLES DEL DIAGRAMA DE COMPONENTES:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 50

INGENIERÍA DE SOFTWARE II Diagrama de Actividades: Este tipo de diagrama, permite mostrar el flujo de acciones, también conocidos como Nodos de un proceso; respetando una secuencia mostrando así los resultados de las actividades realizadas.
Este diagrama captura las acciones internas que se realizan en un proceso; captura las especificaciones que genera un diagrama de casos de uso para así mostrar los flujos entre los procesos del negocio.
La representación gráfica que utiliza es similar al diagrama de estados:
• Nodo Inicial: Determina el inicio o punto de partida del flujo de acciones o actividades; se representa por un circulo Negro
• Acción / Actividad: Es la imagen representativa para las actividades o acciones. Esta actividad normalmente utiliza un verbo. Se representa con un rectángulo con las puntas ovaladas.
• Flujo de secuencia / Transición: Es el paso de las ejecuciones entre una actividad u otra. Se representa mediante una Flecha con una punta.
• Decisión o Condicional: Muestra un punto donde se tomara una decisión de
acuerdo a las condiciones establecidas; determinara con que actividad se continuara trabajando. Pueden salir más de dos flujos. Su representación gráfica es un Rombo.
• Unión o Merge: Normalmente llegan a él dos flujos de actividades y el
proceso continuara con cualquiera de los dos flujos. Se representa por un rombo.
• Sincronización o Concurrencia: También conocido como Bifurcación o
Entrada; Indica el inicio de varias actividades que se pueden realizar al
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 51

INGENIERÍA DE SOFTWARE II
mismo tiempo, de la cual pueden salir varias líneas para las siguientes actividades. Así mismo puede indicar que en este punto terminan varias actividades. Se representa como una línea pronunciada.
• Swinlanes (Calles): Muestra un objeto que puede pasar de una actividad a
otra. Se representa como un rectángulo general en el diagrama, con el nombre subrayado dentro de la figura.
• Nodo Final: Representa el final del Flujo de las Actividades, por ende el final del Diagrama. Su representación gráfica es un círculo negro encerrado en otro círculo.
Ejercicio 7: Desarrollar un Diagrama de Actividades para generar el Ingreso de un Password o Acceso a un Sistema:
- Generar un nuevo Archivo en StarUML. Archivo (File) – Nuevo (New). Presionar la Tecla Esc (Escape) para no indicar que tipo de Proyecto se va a realizar.
- Menú Model – Modelo – Diagrama de Actividades (Activity Diagram). Ingresar el Nombre “Actividad”
- Insertar el Nodo Inicial, dos actividades “Solicitar Password” y “Permitir Acceso”, ingresar el Nodo Final.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 52

INGENIERÍA DE SOFTWARE II
- Se insertará la condicional para determinar si la contraseña es correcta o no, y las transiciones del flujo de actividades
Nota: Ejercicio N° 7 del Capítulo 1 del Manual; nombre aplicación: “Diagrama Actividades – Ingreso Sistema” Ejercicio 8: Desarrollar un Diagrama de Actividades para generar el Ingreso de Productos al sistema, basándose en un caso de uso de determinar origen de un producto, se puede determinar que participaran dos actores Director y Coordinador, para los cuales se les aplicara dos calles en simultaneo; cada actor tendrá su esquema de actividades:
- Generar un nuevo Archivo en StarUML. Archivo (File) – Nuevo (New). Presionar la Tecla Esc (Escape) para no indicar que tipo de Proyecto se va a realizar.
- Menú Model – Modelo – Diagrama de Actividades (Activity Diagram). Ingresar el Nombre “Actividad de Producto”.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 53

INGENIERÍA DE SOFTWARE II - Ingresar dos Swimlane (Línea de Tiempo) para el Coordinador y Director:
- Se trabajará inicialmente con el Coordinador; Insertar el Inicio de actividades, e insertar la actividad de Recepción del Producto y relacionarlo.
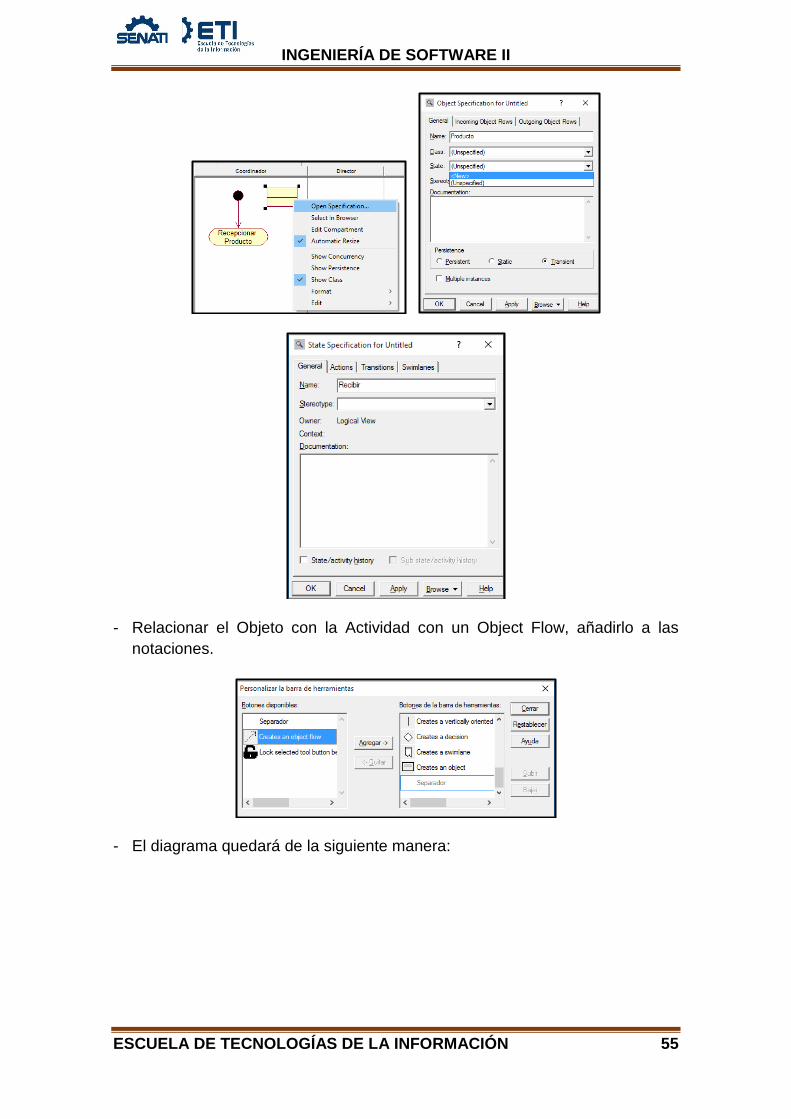
- Insertar el Objeto “Producto” e indicar el estado que tendrá. Clic derecho al objeto – Open Specification – Ingresar Name – State – New – Name: Recibir – Ok.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 54
INGENIERÍA DE SOFTWARE II
- Relacionar el Objeto con la Actividad con un Object Flow, añadirlo a las notaciones.
- El diagrama quedará de la siguiente manera:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 55

INGENIERÍA DE SOFTWARE II
- Ingresar otro objeto “Producto” pero indicarle un Estado nuevo que será “Recibido” y asignarle una relación saliente. En el explorador de diagramas, se encuentra el Objeto Producto, por lo cual solo basta arrastrarlo al diagrama (no es necesario crear un nuevo objeto). Con eso se daría terminada la primera fase del diagrama
- En el actor director que es el que determinara el origen del producto, agregar una nueva actividad “Determinar Origen del Producto”. Relacionar el objeto Producto con la actividad.
- Se realizará la consulta si el producto fue una compra o un ingreso por devolución de alguna área. Si no fuera una compra, se ingresara un documento y terminara la actividad. Se ingresara el rombo de la condicional, la actividad de llenado de documento y el final de las actividades.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 56

INGENIERÍA DE SOFTWARE II
- Si la acción es una compra, generar la actividad “Verificar Documento de
Compra”, relacionarla con la condicional indicando que si es una compra.
- Crear el objeto “Documento de compra” con el estado “Verificado”.
Relacionar la actividad con el objeto.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 57

INGENIERÍA DE SOFTWARE II - Agregar una condición para verificar si el documento es correcto o tiene
alguna falla, la condición será “Conforme”; si no está conforme, terminaría el Proceso.
- Si el Documento es conforme, ingresar la actividad “Aprobar Documento”. Insertar el objeto “Documento de Compra”, agregándole un nuevo estado “Aprobado” y finalizar toda la actividad.
- Se debe tener en cuenta que nunca existe una relación de actividad a actividad, siempre debe de existir un objeto o una condicional.
- Finalmente el diagrama quedaría estructurado de la siguiente manera:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 58

INGENIERÍA DE SOFTWARE II Nota: Ejercicio N° 8 del Capítulo 1 del Manual; nombre aplicación: “Diagrama Actividades – Verificación de Producto”
Diagrama de Componentes: Este tipo de diagrama UML representa la estructura física del código. Permiten ilustrar los componentes del software que conforman un sistema, tiene un nivel alto de abstracción a diferencia del diagrama de clases. Está compuesto por:
- Componentes: Es la parte física del sistema, que puede representar los módulos, los ejecutables o las bases de datos. Se determina por componente a una o más clases ya que una abstracción que cuenta con atributos y métodos se pueden representar en componentes. Su representación gráfica es un rectángulo en el cual va el nombre acompañado de dos pequeños rectángulos al lado izquierdo.
-
Los Componentes se pueden agrupar en paquetes, así mismo pueden generar entre ellos relaciones de generalización, asociación, agregación y realización.
Se puede encontrar cinco estereotipos de componentes, los cuales son:
• Ejecutable; es aquel componente que se puede ejecutar. • Library; compuesta por una biblioteca de objetos estáticos o dinámicos. • Table; este tipo de componente representa una tabla de una base de datos. • File; este componente es representado por un documento que contendrá los
códigos fuentes del software o los datos del mismo. • Document; este componente se representa mediante un documento.
- Interfaces: Viene a ser la unión entre uno o más componentes
Relaciones y Puntos de Entrada: Las relaciones se pueden realizar de dos maneras, añadiendo una interfaz conectándolo con una flecha; la otra manera es embeberlo en el componente.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 59

INGENIERÍA DE SOFTWARE II
Relaciones de Dependencia de los DC: Se pueden agrupar en paquetes así como los objetos de clases, además pueden tener entre ellos relaciones, tales como:
• Generalización. • Asociación. • Agregación. • Realización. • Dependencia.
Paquetes o subsistemas. Los distintos componentes pueden agruparse en paquetes según un criterio lógico y con vistas a simplificar la implementación. Esto básicamente son paquetes estereotipados en Subsistemas.
- Funcionalidad de los Subsistemas: o Los subsistemas organizan la vista de realización de un sistema. o Cada subsistema puede contener componentes y otros subsistemas. o La descomposición en subsistemas no es necesariamente una
descomposición funcional. o La relación entre paquetes y clases en el nivel lógico es el que existe
entre subsistemas y componentes en el nivel físico. o Paquetes o categorías y clases en el nivel lógico. o Paquetes o subsistemas y componentes en el nivel físico.
Pasos para elaborar un diagrama de componentes:
- Debe estar generado antes el Diagrama de Clases. - Se debe de identificar todas las clases que participan en el sistema o
subsistema que se va a desarrollar. - Identificar los métodos. - Los métodos pasaran a ser módulos con líneas de código independientes. - Los módulos serán los componentes del diagrama.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 60

INGENIERÍA DE SOFTWARE II II. RECONOCER LAS ARQUITECTURAS DE SOFTWARE.
OPERACIONES: - Arquitectura del Software. - Patrones de creación, patrones de estructura y patrones de comportamiento. - Framework. EQUIPOS Y MATERIALES: - Computadora con microprocesadores Core 2 Duo o mayor capacidad. - Sistema operativo Windows. - Acceso a internet.
ORDEN DE EJECUCIÓN: - Reconocer las Arquitecturas de Software. - Reconocer el Funcionamiento de Patrones de Ingeniería de Software. - Reconocer el funcionamiento de los Frameworks.
2.1. ARQUITECTURA DEL SOFTWARE. Reconocer la arquitectura del SW. Estilos arquitectónicos. Patrones de diseño. Se debe de tener como premisa, que el diseño de un software siempre debe de empezar con el análisis y la estructuración de los datos que participaran en él, ya que es el fundamento principal de todos los demás elementos del diseño.
La arquitectura de un software se puede determinar por etapas:
La primera etapa técnica, consiste en producir un modelo de representación técnica del software que se va a desarrollar. La arquitectura permitirá identificar todos los elementos que van a participar e interactuar, así como las relaciones entre ellos; se podría decir que la arquitectura del software brindara una visión global del sistema.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 61

INGENIERÍA DE SOFTWARE II
Toda arquitectura del sistema, inicia con el diseño de datos, para proceder con las representaciones de la estructura y comportamientos de la información que estarán involucradas en el sistema informático.
Se debe de tener en cuenta que toda la arquitectura de software es diseño, pero no todo el diseño es arquitectura. La arquitectura representa las decisiones del diseño que serán significativas y que le darán forma al sistema a desarrollar. Es la organización de un sistema de acuerdo a sus componentes, los cuales pueden incluir subsistemas y sus múltiples relaciones entre ellos. La arquitectura debe de ser coherente para establecer los patrones de abstracción, así permitirá trabajar a los desarrolladores en una misma línea.
Una arquitectura de software sigue un patrón o un conjunto de patrones que son proporcionados por la lógica del negocio, además debe de contemplar la mantenibilidad, auditabilidad, flexibilidad e interacción con otros sistemas. Se podría decir que la arquitectura de software es una forma de representar los sistemas de información complejos mediante el uso de la abstracción.
Estilos Arquitectónicos:
Vienen a ser una transformación que se impone al diseño de todo el sistema. El objetivo es establecer una estructura para todos los componentes del sistema.
Arquitecturas:
- Centradas en los Datos. - Flujo de Datos. - Llamada y Regresión. - Capas.
- Centradas en los Datos: En este tipo de arquitectura el componente principal es el almacenamiento de datos, el cual será accedido frecuentemente por el resto de componentes que se ejecutan para añadir, modificar y eliminar. Se puede entender que el software que hará de cliente accederá a un almacenamiento de datos vacío. Este tipo de arquitectura proporcionan integridad, es decir que los componentes que ya existen en el
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 62

INGENIERÍA DE SOFTWARE II
sistema pueden cambiar o modificarse e inclusive pueden añadirse más componentes sin que afecte ello a otros clientes.
Este tipo de arquitectura también es conocida como Clientes – Servidores. Cuando se habla de un servidor se asume que este viene a ser una base de datos.
- Flujo de Datos: Este tipo de arquitectura se basa en la acción de la transformación de los datos de entrada en datos de salida, dicha acción se realiza mediante una serie de componentes que manipularon la data. Esto se basa en un patrón de Filtros, que se encuentran conectados por tubos que permiten transmitir los datos de un componente a otro. Cada filtro trabaja de manera independiente de los componentes que estarán antes o después del filtro. El resultado de ello serán los resultados en formatos específicos.
- Llamada y Regresión: Este tipo de arquitectura permite obtener una
estructura de programa que es relativamente fácil de modificar y escalar, esta estructura puede contener subestilos.
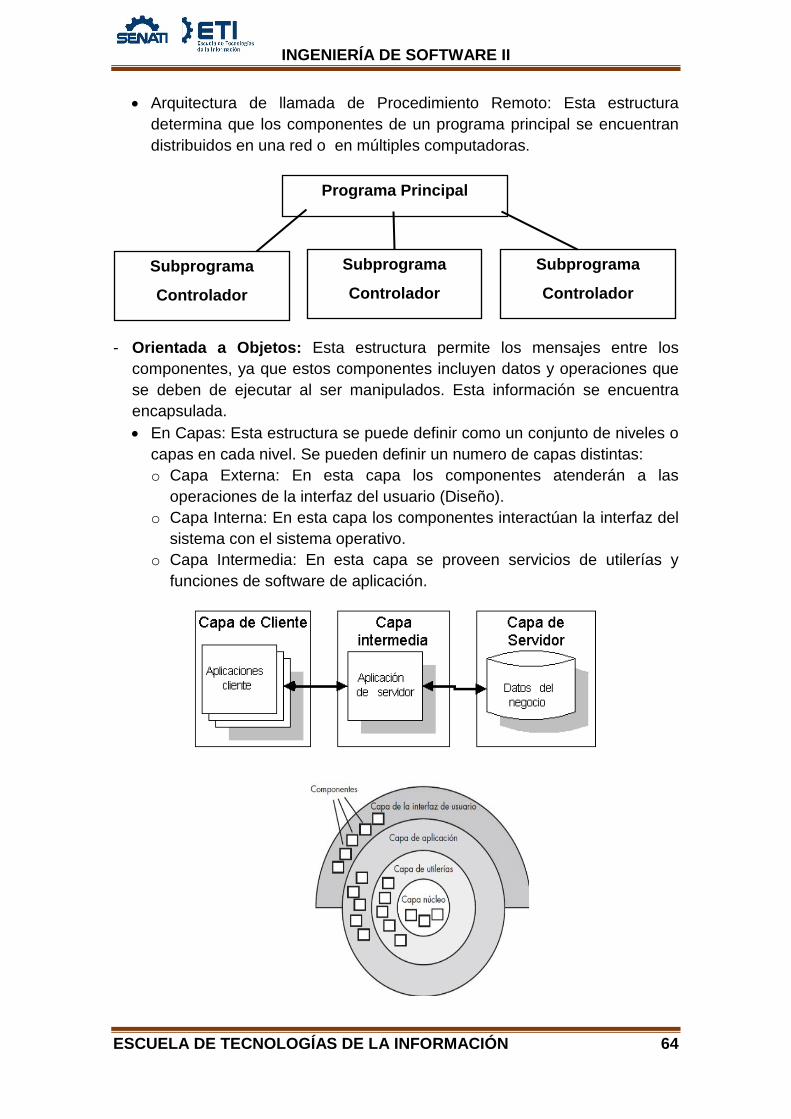
• Arquitectura de Programa Principal / Subprograma: Esta estructura de
programa permite descomponer una función en jerarquías de control por lo que el programa principal hará la invocación a un número de componentes, y a su vez estos invocaran a otros.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 63
INGENIERÍA DE SOFTWARE II
• Arquitectura de llamada de Procedimiento Remoto: Esta estructura determina que los componentes de un programa principal se encuentran distribuidos en una red o en múltiples computadoras.
- Orientada a Objetos: Esta estructura permite los mensajes entre los componentes, ya que estos componentes incluyen datos y operaciones que se deben de ejecutar al ser manipulados. Esta información se encuentra encapsulada. • En Capas: Esta estructura se puede definir como un conjunto de niveles o
capas en cada nivel. Se pueden definir un numero de capas distintas: o Capa Externa: En esta capa los componentes atenderán a las
operaciones de la interfaz del usuario (Diseño). o Capa Interna: En esta capa los componentes interactúan la interfaz del
sistema con el sistema operativo. o Capa Intermedia: En esta capa se proveen servicios de utilerías y
funciones de software de aplicación.
Subprograma
Controlador
Programa Principal
Subprograma
Controlador
Subprograma
Controlador
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 64

INGENIERÍA DE SOFTWARE II 2.2. PATRONES DE DISEÑO. Los Patrones son básicamente una solución de tipo arquitectónica que servirá como base para el diseño de la arquitectura del diseño de un software. Se enfrentan a un problema de aplicación específico. Ejemplo, el modelo de requerimientos para cualquier aplicación de comercio electrónico; que ofrece una gran variedad de bienes a un grupo amplio de consumidores y permite que lo puedan comprar on line.
Patrones de Creación: Estos patrones proporcionan la ayuda para crear objetos desde la toma de decisiones, aunque sea de forma dinámica. Permiten estructurar y encapsular estas decisiones. En algunas oportunidades solo existe un patrón adecuado, otra en la que varios patrones podrían ser los adecuados y algunas otras en las que se pueden combinar múltiples patrones. Existen dos maneras de clasificar los patrones de diseño de software de creación que se basan en las clases de objetos que se crean. Una forma es clasificar las clases que crean los objetos (Factory Method) y la otra forma se trata de la composición de objetos (objeto responsable de conocer las clases de los objetos producto). En este tipo de características, colaboran los patrones Abstract Factory, Builder o Prototype. Abstract Factory: Si lo que se desea es crear diferentes objetos, todos pertenecientes a la misma familia, como puede ser un sistema de librerías necesarias para crear interfaces gráficas. Se podría decir que lo que intenta solucionar el patrón de diseño software de creación Abstract Factory es crear diferentes familias de objetos. El patrón Abstract Factory, se recomienda cuando se va a utilizar la inclusión de nuevas familias de productos en un futuro, pero esto podría resultar contraproducente si es que se necesita añadir más productos o modificar los que ya existen, ya que tendría repercusión en todas las familias creadas.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 65

INGENIERÍA DE SOFTWARE II Componentes: Cliente: Es la entidad que hará la llamada para crear uno de los objetos
(ProductoA, ProductoB). AbstractFactory: Es la interfaz que se va a utilizar en las diferentes factorías.
Se debe ofrecer un método para la obtención de cada objeto que se pueda crear. ("crearProductoA()" y "crearProductoB()").
Concrete Factories: Aquí se representaran las diferentes familias de productos. Provee la instancia concreta del objeto que se encarga de crear.
Abstract Product: Se definen las interfaces para la familia de productos genéricos. En el diagrama son "ProductoA" y "ProductoB". El cliente trabajará directamente sobre esta interfaz, que será implementada por los diferentes productos.
Concrete Product: Aquí se realiza la implementación específica de los diferentes productos.
Diagrama de Clases general con Patrón de Creación Abstract Factory:
Nota: Ejercicio N° 1 del Capítulo 2 del Manual; nombre aplicación: “Código de Java para Abstract Factory” Factory Method: Este patrón de diseño de software de creación, se basa en utilizar una clase constructora abstracta con unos métodos definidos y otro que sea abstracto. El Factory Method, es el Abstract Factory simplificado. El patrón de diseño de software de creación Factory Method puede ser utilizado cuando: La creación de un objeto impide que se vuelva a utilizar sin una importante
duplicación de código.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 66

INGENIERÍA DE SOFTWARE II La creación de un objeto requiere acceso a la información o recursos que no
deberían estar contenidos en la clase de composición. La administración de la duración de los objetos generados debe ser
centralizada para garantizar un comportamiento coherente en la aplicación. Los componentes del patrón de creación Factory Method serían: Product: Permite definir una interfaz de un objeto que el método Factory
creará. ConcreteProduct: Permite implementar la interfaz Product para crear un
producto en concreto. Creator: Permite declarar el método Factory que devolverá un objeto del tipo
Product. ConcreteCreator: Permite sobrescribir el método Factory del Creator que
devolverá una instancia de un producto en concreto (ConcreteProduct). Este sería el diagrama de clases general de este patrón de creación:
Nota: Ejercicio N° 2 del Capítulo 2 del Manual; nombre aplicación: “Código de Java para Factory Method”. Prototype: El patrón Prototype, permite crear el duplicado de un objeto, utiliza el método de la clonación. Utiliza una instancia de ese objeto que ya haya sido creada. El patrón tiene que especificar el tipo de objeto que se requiere clonar, creando así un 'prototipo' de esa instancia. Este tipo o clase de objetos deberá contener en su interfaz el procedimiento que permita solicitar esa copia, siendo desarrollado luego por las clases concretas del patrón que deseen crear ese clon. Diagrama de clases general del patrón:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 67

INGENIERÍA DE SOFTWARE II
Los actores que intervienen en el patrón de creación Prototype, son: Cliente: Es el actor solicitante de la clonación de los nuevos objetos a partir
de los prototipos. Prototipo Concreto: Es el actor o la clase que presenta unas características
concretas que serán podrán se reproducidas en los nuevos objetos y que presenta la implementación necesaria para clonarse.
Prototipo: Viene a ser la declaración de una interfaz, a la que accede el cliente, y sirve para la clonación de objetos.
Nota: Ejercicio N° 3 del Capítulo 2 del Manual; nombre aplicación: “Código de Java para Prototype” Singleton: El patrón Singleton, busca restringir la creación de objetos pertenecientes a una clase o el valor de un tipo a un único objeto. Su intención es garantizar que una clase sólo sea instanciada una vez y, además, proporcionar un único punto de acceso global a la misma. Esto lo consigue gracias a que es la propia clase la responsable de crear esa única instancia, (declarando el constructor de la clase como privado) y a que se permite el acceso global a dicha instancia mediante un método de clase. Para implementar el patrón Singleton hay que crear un método que instancie al objeto sólo si todavía no existe ninguna otra instancia. Para asegurar que no vuelva a ser instanciado, se limita al constructor con atributos protegidos o privados. Diagrama de clases general del patrón de creación Singleton:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 68

INGENIERÍA DE SOFTWARE II
Nota: Ejercicio N° 4 del Capítulo 2 del Manual; nombre aplicación: “Código de Java para Singleton”. - Patrones de Estructura: Los patrones de diseño estructurales están
enfocados en la gestión de la forma en la que las clases y los objetos se combinan para dar lugar a estructuras más complejas. Al igual que en las otros tipos de patrones, podemos hablar de patrones estructurales asociados a clases (Adapter) y asociados a objetos (Bridge, Composite, Decorator, Facade, Flyweight, Proxy). Los primeros utilizan la herencia mientras que los segundos se basan en la composición.
Adapter: El patrón Adapter convierte la interfaz de una clase en la que otra necesita, permitiendo que clases con interfaces incompatibles trabajen juntas. Se puede decir que el uso de este patrón estructural está indicado cuando se quiere usar una clase ya implementada y su interfaz no es similar con la necesitada o cuando se desea crear una clase reusable que coopere con clases no relacionadas o que tengan interfaces compatibles. Sin embargo, hay que hacer distinción entre si se quiere adaptar un objeto o una clase o interfaz completa.
Sin embargo, un adaptador de objetos permite que un único Adapter trabaje con muchos Adaptees. De este modo, el Adapter también puede agregar funcionalidad a todos los Adaptees de una sola vez.
Los participantes de este patrón serían los siguientes:
Client: Es el principal agente en la formación de objetos para la interfaz Target.
Target: Interfaz del dominio específico que usa el Client. Adaptee: Es la interfaz ya existente que necesita adaptarse. Adapter: Es quien adapta la interfaz del Adaptee a la interfaz Target.
Este sería el diagrama de clases general del patrón:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 69

INGENIERÍA DE SOFTWARE II
Nota: Ejercicio N° 5 del Capítulo 2 del Manual; nombre aplicación: “Código de Java del Patrón Adapter”
Composite: El patrón Composite sirve para construir objetos que estén formados por tres objetos más simples, pero siempre similares entre sí, gracias a la composición recursiva. Al tener todos estos objetos una misma interfaz, el Composite simplifica el tratamiento de los mismos. El patrón Composite es utilizado en el tratamiento de interfaces de usuario en las que se necesita, representar un conjunto de elementos de una interfaz gráfica. Algunos de estos elementos serán simples, mientras que otros serán más complejos y estarán formados por varios elementos simples. Por tanto, el comportamiento y/o la información que proporciona un elemento complejo están determinada por los elementos que lo componen.
Los Componentes del patrón serían los siguientes:
Client: Manipula objetos a través de la interfaz proporcionada por Component.
Component: Declara la interfaz para los objetos de la composición, es la interfaz de acceso y manipulación de los componentes hijo e implementa algunos comportamientos por defecto.
Composite: Define el comportamiento de los componentes compuestos, almacena a los hijos e implementa las operaciones de manejo de los componentes.
Leaf: Definen comportamientos para objetos primitivos del compuesto.
Según esto, este sería el diagrama de clases general del patrón:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 70

INGENIERÍA DE SOFTWARE II
Nota: Ejercicio N° 6 del Capítulo 2 del Manual; nombre aplicación: “Código de Java del Patrón Composite”
Decorator: El patrón de diseño estructural Decorator facilita la tarea de añadir dinámicamente funcionalidades a un objeto. De este modo, elimina de necesidad de crear clases que fuesen heredando de la primera, incorporando no sólo la nueva funcionalidad, sino también otras nuevas y asociarlas a ella.
Este ejemplo de patrones estructurales de diseño software es útil cuando:
Queremos añadir o expandir las funcionalidades de objetos de forma dinámica y transparente.
Necesitamos que ciertas responsabilidades de un objeto puedan ser retiradas de forma sencilla en un futuro.
No es posible o no compensa realizar esta expansión de funcionalidades mediante herencia.
Existe la necesidad de expandir dinámicamente la funcionalidad de un objeto y/o eliminar la funcionalidad extendida.
Visto esto, señalar que los participantes de este patrón serían los siguientes:
Component: Define la interface de los objetos a los que se le puede adicionar responsabilidades dinámicamente.
ConcreteComponent: Define el objeto al que se le puede adicionar una responsabilidad.
Decorator: Mantiene una referencia al objeto Component y define una interface de acuerdo con la interface de Component.
ConcreteDecorator: Es el encargado de sumar la responsabilidad al componente. Puede haber varios ConcreteDecorator.
Por lo tanto, este sería el diagrama de clases general del patrón:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 71

INGENIERÍA DE SOFTWARE II
Nota: Ejercicio N° 7 del Capítulo 2 del Manual; nombre aplicación: “Código de Java del Patrón Decorator”
Proxy: Esta patrón estructural tiene como propósito proporcionar un intermediario para controlar el acceso a un objeto. Por ello tiene distintas aplicaciones:
Proxy Remoto: Denominado así cuando representa a un objeto remoto. Proxy Virtual: Usado para crear objetos bajo demanda. Proxy de Referencia "inteligente": Cuando sirve como sustituto de un puntero
que realiza operaciones adicionales cuando accede al objeto. Proxy de Protección: Denominado así cuando se usa para controlar el
acceso al objeto original.
La finalidad principal del patrón de diseño estructural Proxy, sería proporciona un representante o sustituto de otro objeto para controlar el acceso a éste. Esto lo hace según la motivación de Motivación: retrasar el coste de crear e inicializar un objeto hasta que sea realmente necesario. Por lo tanto, es usado cuando se necesita una referencia a un objeto más flexible o sofisticado que un puntero.
Los componentes en el patrón, serían las siguientes:
Proxy: Mantiene una referencia al objeto real, mientras que proporciona una interfaz idéntica a la del objeto real (Real Subject) y controla el acceso a este objeto, siendo responsable de crearlo y borrarlo.
Subject: Define una interfaz común para el proxy y el objeto real. RealSubject: Clase del objeto real que el proxy representa.
Según esto, este sería el diagrama de clases general del patrón:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 72

INGENIERÍA DE SOFTWARE II
Nota: Ejercicio N° 8 del Capítulo 2 del Manual; nombre aplicación: “Código de Java del Patrón Proxy”
- Patrones de Comportamiento: Los patrones de diseño software de comportamiento son aquellos que están relacionados con algoritmos y con la asignación de responsabilidades a los objetos. Describen no solamente patrones de objetos o de clases, sino que también engloban patrones de comunicación entre ellos. Al igual que los otros tipos de patrones, se pueden clasificar en función de que trabajen con clases (Template Method, Interpreter) u objetos (Chain of Responsability, Command, Iterator, Mediator, Memento, Observer, State, Strategy, Visitor).
Command: El patrón de diseño software de comportamiento Command permite realizar una operación sobre un objeto sin conocer realmente las instrucciones de esta operación ni el receptor real de la misma. Esto se consigue encapsulando la petición como si fuera un objeto, además se facilita la parametrización de los métodos. Los Componentes del patrón de comportamiento Command serían: Facilitar la parametrización de las acciones a realizar. Implementar estructuras de CallBack, especificando qué órdenes queremos
que se ejecuten de frente a qué situaciones. Independizar los eventos de "petición" y "ejecución". Dar un soporte factible a la operación "deshacer". Desarrollar sistemas utilizando órdenes de alto nivel que se construyen con
primitivas. Los principales agentes de este patrón son: Command: Declara la interface para la ejecución de la operación.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 73

INGENIERÍA DE SOFTWARE II ConcreteCommand: Define la relación entre el objeto Receiver y una acción,
Implementa el método básico Execute() al invocar las operaciones correspondientes en Receiver.
Client: Crea un objeto ConcreteCommand y lo relaciona con su Receiver. Invoker: Envía las solicitudes al objeto Command. Receiver: Es la clase que gestiona la ejecución de las operaciones.
Este sería el diagrama de clases general del patrón de comportamiento Command:
Nota: Ejercicio N° 9 del Capítulo 2 del Manual; nombre aplicación: “Código de Java del Patrón Command”
Iterator: El patrón de diseño de comportamiento Iterator es uno de los mayores exponentes de los patrones de comportamiento. Presenta la interfaz que declara los métodos necesarios para acceder, de forma secuencial, a los objetos de una colección. Permite cubrir la necesidad de acceder a los elementos de un contenedor de objetos sin tener que trabajar con su estructura interna.
Las entidades participantes en el esquema general de este patrón de diseño software de comportamiento son:
Iterator: Interfaz que se usará para recorrer el contenedor y acceder a los objetos o elementos que albergue.
ConcreteIterator: Clase que implementa la interfaz propuesta por el Iterator. Mantendrá la posición actual en el recorrido de la estructura almacenándola en el aggregate, sabiendo así cuál será el siguiente objeto en el recorrido.
Aggregate: Es la interfaz que se usará para la fabricación de iteradores. ConcreteAggregate: Implementa la estructura de datos y el método de
fabricación de iteradores que crea un iterador específico para su estructura.
Este sería el diagrama de clases general de este patrón de comportamiento:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 74

INGENIERÍA DE SOFTWARE II
Nota: Ejercicio N° 10 del Capítulo 2 del Manual; nombre aplicación: “Código de Java del Patrón Iterator”
Observer: El patrón de comportamiento Observer define una interacción entre objetos, de manera que cuando uno de ellos cambia su estado, el Observer se encarga de notificar este cambio a los demás. Por tanto, la razón de ser de este patrón es desacoplar las clases de los objetos. La idea básica del patrón es que el objeto de datos (o sujeto) contenga atributos mediante los cuales cualquier objeto observador (o vista) se pueda suscribir a él pasándole una referencia a sí mismo. Dadas estas propiedades, el patrón Observer suele emplearse en el desarrollo de frameworks de interfaces gráficas orientados a objetos, enlazando 'listeners' a los objetos que pueden disparar eventos.
Las clases participantes en el esquema general de este patrón de comportamiento son:
Subject: Es el que conoce a sus observadores, proporcionando una Interfaz para que se suscriban los objetos de tipo Observer.
Observer: Define la interfaz para actualizar los objetos a los que se deben notificar los cambios en el objeto Subject.
ConcreteSubject: Guarda el estado de interés para los objetos ConcreteObserver y envía una notificación a sus observadores cuando cambia su estado.
ConcreteObserver: Mantiene una referencia a un objeto ConcreteSubject, guardando el estado que debería permanecer sincronizado con el objeto observado,
Este sería el diagrama de clases general del patrón de comportamiento Observer:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 75

INGENIERÍA DE SOFTWARE II
Nota: Ejercicio N° 11 del Capítulo 2 del Manual; nombre aplicación: “Código de Java del Patrón Observer”
Strategy: Este es un patrón de diseño software de comportamiento que determina la forma de implementar el intercambio de mensajes entre diferentes objetos que realizan diferentes tareas, pero que comparten elementos comunes. El patrón de comportamiento Strategy permite gestionar un conjunto de operaciones de entre los cuales el cliente puede elegir el que le convenga más en cada situación, e intercambiarlo, de forma dinámica, cuando lo necesite.
En este punto, el cliente puede elegir el algoritmo que prefiera de entre los implementados en las estrategias del sistema, o dejar al contexto la tarea de elegir al más apropiado para cada situación concreta. Por lo tanto, cualquier sistema que presente un servicio o función determinada, que pueda o deba ser realizada de varias maneras dependiendo del contexto, será indicado gestionarlo con el patrón Strategy.
Las clases participantes en el esquema general de este patrón de comportamiento son:
Context: Actor que necesita de las operaciones concretas de las diferentes estrategias, referenciando a estas últimas.
Strategy: Es la interfaz común para todos los algoritmos implementados en las diferentes estrategias. Será lo que use el Context para invocar a la estrategia concreta que necesite.
ConcreteStrategy: Clases donde se implementan los algoritmos necesarios, usando para ello la interfaz Strategy.
Este sería el diagrama de clases general del patrón de comportamiento Strategy:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 76

INGENIERÍA DE SOFTWARE II
Nota: Ejercicio N° 12 del Capítulo 2 del Manual; nombre aplicación: “Código de Java del Patrón Strategy”. Frameworks: Un Framework se podría definir como una armazón, es decir que viene a ser una estructura que se va a utilizar para colocar elementos según la necesidad de lo que se va a realizar. Es una abstracción en la que cierto código provee una funcionalidad que puede ser escrita o especializada de forma selectiva por medio de código especifico provisto por los clientes del framework. Se podría decir que el framework es una solución incompleta pero concreta a un problema recurrente, a diferencia de los estilos arquitectónicos o de los patrones de diseño.
El Framework permite el desarrollo de software dando a los diseñadores la posibilidad de no preocuparse por los detalles de bajo nivel para obtener un sistema funcional. Por ejemplo, una empresa desarrolladora de software, se encarga de la implementación de un sistema bancario a nivel Web, al tener la posibilidad de trabajar con un framework de desarrollo web, se puede enfocar en el desarrollo de las aplicaciones de retiro y transferencias, en vez de enfocarse en la mecánica del manejo de las sesiones de los usuarios y el estado de la aplicación. Instanciación de Frameworks: Los Frameworks están compuestos por Zonas Congeladas (Frozen Spots) y Zonas Calientes (Hot Spots). Las Zonas Congeladas definen la arquitectura
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 77

INGENIERÍA DE SOFTWARE II general de un sistema de software, lo cual indica que se encargara de los componentes básicos y la relaciones entre estas; estas partes permanecen inalterables (congeladas) en cualquier instancia del Framework. Las Zonas Calientes sin embargo, representan las zonas en las que los programadores deben ingresar su propio código para la funcionalidad específica del proyecto. Un Framework no es ejecutable, como si lo es la aplicación desarrollada. Este Framework es utilizado en una aplicación particular, que trabajara con las Zonas calientes, para satisfacer los requerimientos dentro del contexto de funcionamiento particular, a esta acción se le conoce como “Instanciación” del Framework.
Caja Blanca y Caja Negra en Frameworks: Caja Blanca (White Box), requiere que los usuarios tengan conocimiento de la estructura de código interno del framework, generalmente vienen con el código fuente y normalmente su comportamiento se extiende por medio del uso de subclases y herencias. Caja Negra (Black Box), no requiere un entendimiento o conocimiento profundo del funcionamiento interno es decir, la estructura del código, del framework. Generalmente el framework se extiende componiendo y delegando comportamiento entre objetos, muchos de los cuales son las extensiones del usuario. Lo ideal sería realizar un framework completamente en Caja Negra. Componentes de un Framework: Inversión de Control (Inversion of Control – IOC): El desarrollador ya no mantiene el flujo de control, es decir, el código no es manejado por el invocador o por el código cliente, si no, que será manejado por el framework en sí mismo. Comportamiento por Defecto: El framework brinda cierto comportamiento por defecto, de modo que el cliente pueda decidir personalizar o agregar funcionalidad en ciertos puntos o simplemente conformarse con el comportamiento por defecto provisto por el framework.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 78

INGENIERÍA DE SOFTWARE II Extensibilidad: Debe de ser posible extender el Framework, bien sea sobrescribiendo cierto código o añadiendo algún tipo de extensión o plug-in. Es decir, se debe ser posible cambiar el comportamiento por defecto predefinido en el frameworks. En general los puntos de extensión deben estar muy claros. Implementación de un Framework: Existen tres opciones para implementar un Framework: Opción 1: Desarrollar el Framework desde Cero (From Scratch). Se debe de: • Definir la arquitectura del software, arquitectura general, estilos
arquitectónicos, etc. • Codificar, validar y probar la arquitectura. • Codificar la funcionalidad propia del software, aunque esto algunas veces se
hace mezclando con la codificación de la arquitectura. • Encontrar errores y problemas en la arquitectura, refinar la arquitectura,
rehacer parte de la funcionalidad, hacer refactors en el código, etc. Opción 2: Esta opción no implica un framework en sí mismo: • Adaptar y comprender la aplicación framework existente. • Utilizar la arquitectura ya definida para poder codificar la funcionalidad. Opción 3: Tomar un Framework ya existente: • Comprender y utilizar un Framework.
Utilizar la arquitectura ya definida para utilizar el framework seleccionado y codificar la funcionalidad.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 79

INGENIERÍA DE SOFTWARE II III. ANALIZAR LOS CONCEPTOS BÁSICOS DE PRUEBA.
OPERACIONES: Conceptos básicos y definiciones. Noción de error: equivocación, defecto,
falla. Prueba para el hallazgo de defectos. Limitaciones de la prueba. Prueba versus Análisis Estático, Depuración, Debugueo, Codificación. EQUIPOS Y MATERIALES:
Computadora con microprocesadores Core 2 Duo o de mayor capacidad. Sistema operativo Windows. Acceso a internet.
ORDEN DE EJECUCIÓN:
Reconocer los Errores, Equivocaciones, Defectos y Fallas de un Software. Realizar las Pruebas para detección de Errores. Tipos de Pruebas a utilizarse en un Proyecto de Software.
3.1. COMPRENDER LOS CONCEPTOS BÁSICOS Y DEFINICIONES. Pruebas del Software: Las pruebas en un proyecto de desarrollo de software, es una actividad en la que se ejecuta el funcionamiento del mismo y sus componentes, estos resultados se podrán observar y se registraran para realizar las evaluaciones necesarias. Viene a ser básicamente el elemento crítico para la garantía de la calidad de software y representara una revisión final de las especificaciones del diseño y la codificación. Se debe de considerar que todo se basa en el análisis desarrollado por los analistas y la implementación de código por los programadores. Muchas veces se comete errores de concepto y de interpretación de lo que pide el cliente y lo que finalmente se desarrolla.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 80

INGENIERÍA DE SOFTWARE II
Un error conocido también como Bugs, puede aparecer en cualquier etapa del ciclo de vida del software, aun cuando se intenta detectarlos después de cada fase de desarrollo, utilizando técnicas como la inspección, sin embargo algunos errores no llegan a ser descubiertos. Es muy probable que el código final contenga errores de requerimiento y diseño. Estas pruebas de software son parte muy importante en el proceso de desarrollo del software, e inclusive se puede determinar que comprende el 40% aproximado del costo del software, pero se debe de tener en cuenta que un error no detectado puede generar mayores pérdidas. La forma más común de organizar las actividades relacionadas al proceso de pruebas, son: - Planeación: Permite Fijar las metas y establecer una estrategia general de
pruebas. - Preparación: Permite describir el procedimiento general de pruebas y se
pueden generar los casos de prueba específicos que se necesiten. - Ejecución: Contiene la observación y la medición del comportamiento del
producto. - Análisis: Contiene la verificación y el análisis de resultados para poder
determinar si se detectaron fallas. - Seguimiento: Si la detección de fallas se verifica, se iniciara un monitoreo
para asegurar que se elimine el origen de estas. - Generar Casos de Pruebas Efectivos: Esto permitirá mostrar la presencia
de fallas, esta parte es fundamental para el éxito del proceso de pruebas, estas son las etapas de preparación.
- Idealización: Se podrá determinar un conjunto de casos de prueba para que su ejecución exitosa muestre que no hay errores en el proyecto de software desarrollado. Normalmente el objetivo ideal no se llega a realizar por las limitaciones prácticas y teóricas.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 81

INGENIERÍA DE SOFTWARE II Objetivos del proceso de pruebas: • Permite maximizar el número de errores que se serán detectados. • Permite reducir al mínimo el número de casos de prueba a desarrollar. Noción de Error: Defecto: Se puede determinar como una definición de datos incorrecta, es un paso de procesamiento incorrecto en el programa. Un defecto básicamente provoca que un programa no cumpla de manera completa y efectiva aquello para lo que fue creado. Es algo concreto y objetivo ya que se puede identificar, describir y contabilizar. Se puede decir que los defectos tienen un costo.
Tipos: Existen diferentes tipos de defectos que por su naturaleza podrían ser: - Documentación. - Sintaxis. - Organización, Gestión de cambios, librerías, control de versiones, etc. - Asignación, declaraciones de ámbitos o nombres duplicados. - Interfaz, dentro del mismo sistema o con otros sistemas externos. - Chequeo, de mensajes de error, trazas, validaciones, etc. - Datos, por estructura o contenido. - Función, por errores lógicos, bucles o recursividad. - Sistema, por configuración, instalación o explotación. - Entorno, por su diseño, compilación o pruebas.
Fallo: Es la incapacidad de un sistema para realizar las funciones requeridas dentro de los requisitos de rendimiento especificados. Equivocación o Error: Es un defecto, un resultado incorrecto, se trata de la acción humana que conlleva a un resultado incorrecto.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 82

INGENIERÍA DE SOFTWARE II Se puede decir que el error de un programador, es introducir un defecto y que al final este producirá un fallo. Pruebas para el hallazgo de defectos: Generalmente se comienza por probar las partes más pequeñas del sistema y luego se continúa por las más grandes y complejas. Para el software convencional, El Modulo o componente se debe de revisar y probar primero, para posteriormente continuar con la integración de los módulos. Para un software orientado a objetos, se prueba primero las clases, y dentro de ellas los atributos, métodos y colaboradores. Se debe concentrar en probar cada componente de manera individual apara si asegurar que el sistema funcione de manera apropiada como se espera. Limitaciones de prueba: Algunas de las limitaciones existentes a nivel de pruebas de software son: - No existe una recopilación formal que especifique y describa los tipos de
prueba que se deben aplicar a una pieza de software y se detalle la implementación precisa de cada uno de ellos. Por otro lado, y aunque ISO plantea en normas como la ISO/FDIS 9126 ciertos aspectos en los cuales el producto de software debe ser conforme, no es suficientemente especifico como para ligarlo con una prueba de software con pormenores de ejecución, llevando esto a que a que dicho estándar por si solo sea poco práctico.
- Las técnicas de pruebas generalmente son subestimadas como útiles, en tanto que no se usan en la práctica para el diseño de casos de prueba formales. En general y en entornos productivos, las técnicas utilizadas para la detección de errores son del tipo suposición de errores y en el mejor de los casos de tipo aleatorio el cual por sus características propias no es un método que aporte mucho a la detección de errores en el producto de software.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 83

INGENIERÍA DE SOFTWARE II - Los estándares existentes que se refieren a pruebas de software y
aseguramiento de la calidad del producto tanto en ISO como en la IEEE tienen un acceso muy restringido, siendo difícil lograr adquirir la documentación relacionada.
- Los estándares y modelos planteados en torno al aseguramiento de la calidad de los productos de software por su carácter de universales y genéricos son muy poco específicos a la hora de describir la forma de realizar implementaciones en entornos productivos reales.
- Tomando en cuenta que una organización debe estar basada en un modelo de calidad que permita un tratamiento global de los procesos, y que adicionalmente deben existir un conjunto de estándares, reglas, prácticas y normativas extras no especificadas en el modelo aplicado a la misma, la inexistencia casi total de una descripción formal que encierre en conjunto un modelo de calidad, un modelo de pruebas, una metodología y unas prácticas específicas en pruebas de software que sean concordantes entre si y entre las políticas generales de un modelo de calidad determinado; en cambio de ello toda la información está desagregada mediante modelos y estándares.
- La razón por la cual la industria no adopta metodologías y estándares es la dificultad de la utilización de estos para pruebas de software. En las pequeñas y medianas empresas la dificultad radica en la necesidad que estas tienen de competir mediante tiempos y precios y dada la poco practicidad que los estándares tienen asociados se incurre en consumos de recursos poco tolerables; Es importante competir mediante calidad y para lograr un buen indicador se deben implementar los diferentes metodologías y estándares que garanticen la madurez de los procesos.
- Implementar un proceso de pruebas al interior de una compañía es costoso, además el proceso debe madurar para que se adapte a las necesidades específicas de la organización; este hecho obliga a muchas empresas a subcontratar los procesos de pruebas. En ocasiones esta es una buena opción puesto que evita posibles sesgos en las pruebas pero en general puede conllevar serios problemas al interior de la organización que van desde la confidencialidad de la información hasta el incremento de los tiempos de desarrollo.
- Las pruebas de software más complejas basan su diseño y su ejecución en los artefactos desarrollados en etapas de análisis y diseño; si estos artefactos no son construidos o tienen deficiencias como falta de consistencia y coherencia; aparte de afectar todo el proceso de desarrollo se
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 84

INGENIERÍA DE SOFTWARE II
verá comprometido el aseguramiento de la calidad y dentro de esté las pruebas los tipos de pruebas de software que buscan hallar defectos más profundos. La buena ingeniería de software se convierte en una necesidad básica para el correcto desarrollo de las pruebas de software.
- En general, diversos son los problemas que se encuentran en un proceso de pruebas; algunos de ellos son:
o Los probadores desconocen el dominio o los tipos y técnicas a utilizar
cuando se requieren pruebas de alto nivel, en general este problema se da al tener personal poco capacitado para la labor.
o Los proveedores de pruebas generalmente posponen la labor de pruebas a las etapas finales del ciclo de vida del software, lo que ocasiona problemas por retrasos. Estos retrasos se dan generalmente por que el equipo de pruebas debe adquirir el conocimiento del dominio necesario y diseñar las pruebas, tareas que se pueden realizar de forma transversal al proceso de desarrollo optimizando los recursos disponibles.
o En ocasiones los probadores no cuentan con los insumos necesarios para realizar un proceso de pruebas maduro y completo. Estos insumos corresponden a una buena documentación y a un completo y correcto levantamiento de requisitos, que orienten al probador, tanto en la ejecución y desarrollo de las pruebas como en el aprendizaje del dominio.
o Muchas organizaciones contemplan su proceso de QA basado en las pruebas de software lo cual trae perjuicios en la calidad de los productos al no incluir procesos como medición, análisis, verificación y validación, todos ellos componentes esenciales de QA.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 85

INGENIERÍA DE SOFTWARE II Prueba vs. Análisis Estático. Análisis Estático: El Análisis Estático es una evaluación del código generado para buscar defectos con la particularidad de que se realiza sin necesidad de ejecutar ese código. Un aspecto importante para este análisis es el lenguaje de programación usado. La norma EN 50128 presenta una lista de lenguajes recomendables. En general son preferibles lenguajes altamente estructurados y muy restrictivos como el Ada, Modula-2 o Pascal, pero en la realidad, debido a la gran difusión del C/C++ en el sector industrial la mayoría de los desarrollos se realizan en este lenguaje y en Ada. El análisis de valores extremos busca defectos en el manejo de las variables en los extremos de su rango de validez o en valores típicamente propensos a error como el cero en el caso de las divisiones o el uso de punteros. Igualmente se comprueban los accesos a arrays y elementos con un límite, fuentes habituales de problemas. El análisis del flujo de control busca problemas en la estructura lógica del programa los cuales pueden ser reflejo de defectos.
También hay que evitar fragmentos de código de complejidad innecesaria puesto ésta puede ocultar problemas y verificar que todos los bucles tienen condición de salida. El análisis del flujo de datos busca errores en las estructuras de datos y en los accesos a las mismas. Los tipos de problemas habituales que deben comprobarse son: En resumen, el análisis Estático se puede determinar como: Las herramientas de análisis estático prestan su asistencia al ingeniero del software a efectos de derivar casos prácticos. Se utilizan tres tipos distintos de herramientas estáticas de comprobación en la industria: herramientas de comprobación basadas en código, lenguajes de comprobación especializados,
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 86

INGENIERÍA DE SOFTWARE II y herramientas de comprobación basadas en requisitos. Las herramientas de comprobación basadas en código admiten un código fuente (o PDL) como entrada y efectúan un cierto número de análisis que can lugar a la generación de casos de prueba. Análisis Dinámico (Pruebas): Las herramientas de análisis dinámico interactúan con un programa que se esté ejecutando, comprueban la cobertura de rutas, comprueban las afirmaciones acerca del valor de variables específicas y en general instrumentan el flujo de ejecución del programa. Las herramientas dinámicas pueden ser bien intrusivas, bien no intrusivas. Las herramientas intrusivas modifican el software que hay que comprobar mediante sondas que se insertan (instrucciones adicionales) y que efectúan las actividades mencionadas anteriormente. Las herramientas de comprobación no intrusivas utilizan un procesador hardware por separado que funciona en paralelo con el procesador que contenga el programa que se está comprobando. Depuración: La depuración de un software es la corrección de un error que fue detectado como resultado de una prueba. Aunque el proceso de prueba es un proceso sistemático, la depuración en ocasiones no lo es tanto. Esto se debe a que el resultado de una prueba es la manifestación de un error, pero no necesariamente es el error en sí, así que el proceso de depuración es en sí una búsqueda del origen de ese error para corrección. Los cuales pueden ser: - Inexactitud en el redondeo de los resultados. - Error humano. - Interacción de dos módulos. - Sincronización de los procesos. - Ruido introducido por el ambiente, en especial, en software de tiempo real. - Problemas de hardware. - Encadenamiento de procesos. Debugueo: Un depurador (en inglés, debugger), es un programa usado para probar y depurar (eliminar) los errores de otros programas (el programa "objetivo"). El código a ser examinado puede alternativamente estar corriendo en un simulador de conjunto de instrucciones (ISS), una técnica que permite gran potencia en su capacidad de detenerse cuando son encontradas condiciones específicas pero será típicamente algo más lento que ejecutando el código directamente en el apropiado (o el mismo) procesador. Algunos depuradores ofrecen dos modos de operación - la simulación parcial o completa, para limitar este impacto. Codificación: Una vez que los algoritmos de una aplicación han sido diseñados, ya se puede iniciar la fase de codificación. En esta etapa se tienen
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 87

INGENIERÍA DE SOFTWARE II que traducir dichos algoritmos a un lenguaje de programación específico; es decir, las acciones definidas en los algoritmos hay que convertirlas a instrucciones. Para codificar un algoritmo hay que conocer la sintaxis del lenguaje al que se va a traducir. Sin embargo, independientemente del lenguaje de programación en que esté escrito un programa, será su algoritmo el que determine su lógica. Código Fuente: El código fuente de un programa informático (o software) es un conjunto de líneas de texto que son las instrucciones que debe seguir la computadora para ejecutar dicho programa. Por tanto, en el código fuente de un programa está escrito por completo su funcionamiento. El código fuente de un programa que está escrito por un programador en algún lenguaje de programación, pero en este primer estado no es directamente ejecutable por la computadora, sino que debe ser traducido a otro lenguaje (el lenguaje máquina o código objeto) que sí pueda ser ejecutado por el hardware de la computadora. Para esta traducción se usan los llamados compiladores, ensambladores, intérpretes y otros sistemas de traducción. Pseudocódigo: Comencemos aclarando que no es una forma de programación. Se trata de una herramienta que los analistas de sistemas utilizan para comunicar a los programadores la estructura del programa que van a realizar, de forma de tener una idea bien clara de lo que se necesita programar. Digamos que el pseudocódigo es una forma de diagramar un algoritmo para resolver un determinado problema, sin atenerse a ningún lenguaje de programación en especial. Un algoritmo es un conjunto de procedimientos que permiten resolver un problema. En vez de escribir el programa directamente en un lenguaje de programación determinado (C, Basic, etc.), crearemos un borrador entendible para todos, para luego de tener bien en claro lo que se debe hacer, pasar a la programación propiamente dicha. El principal objetivo del pseudocódigo es el de representar la solución a un algoritmo de la forma más detallada posible, y a su vez lo más parecida posible al lenguaje que posteriormente se utilizara para la codificación del mismo. Código Máquina: En primer lugar, tenemos un Lenguaje de Programación en la que un usuario se encarga de redactar los procedimientos y las reglas específicas bajo unas normas predeterminadas, siendo considerado como Lenguaje de Alto Nivel, en el cual se elabora el Código Fuente, con un conjunto de órdenes y palabras que son entendidas por los usuarios, permitiendo su lectura, análisis y redacción (además de la corrección de errores).
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 88

INGENIERÍA DE SOFTWARE II En Programación, se define como el Código Máquina a aquel que es el proveniente de la tarea de compilación efectuada directamente sobre el Código Fuente, con el que se obtiene posteriormente el Código de Bytes (en inglés, Bytecode) que es la conglomeración de distintos archivos que forman parte de ejecutables para que el ordenador pueda hacer uso del código anteriormente programado.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 89

INGENIERÍA DE SOFTWARE II IV. EXPLICAR LOS NIVELES DE PRUEBA.
OPERACIONES: Reconocer los niveles de prueba alcance versus objetivo. Prueba unitaria, de integración, del sistema. Objetivos: De aceptación, de instalación, pruebas alfa y beta. EQUIPOS Y MATERIALES:
Computadora con microprocesadores Core 2 Duo o de mayor capacidad. Sistema operativo Windows. Acceso a internet. Software visual Studio 2012, Block de Notas.
ORDEN DE EJECUCIÓN:
Reconocer la estructura de discos, carpetas y archivos V.B. Reconocer el manejo de propiedades y atributos. Desarrollar entornos de trabajo para compresión y descompresión.
4.1. RECONOCER LOS NIVELES DE PRUEBA. ALCANCE VS. OBJETIVO.
4.2. PRUEBAS UNITARIAS. Este tipo de prueba verifican el funcionamiento aislado de piezas de software que pueden ser probadas de forma separada, estas podrían ser: • Subprogramas – Módulos individuales. • Componentes que incluyen varios subprogramas o módulos. Estas pruebas suelen llevarse a cabo con: • Acceso al Código Fuente probado. • Ayuda de herramientas de depuración. • Participación de los programadores que escribieron el código.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 90
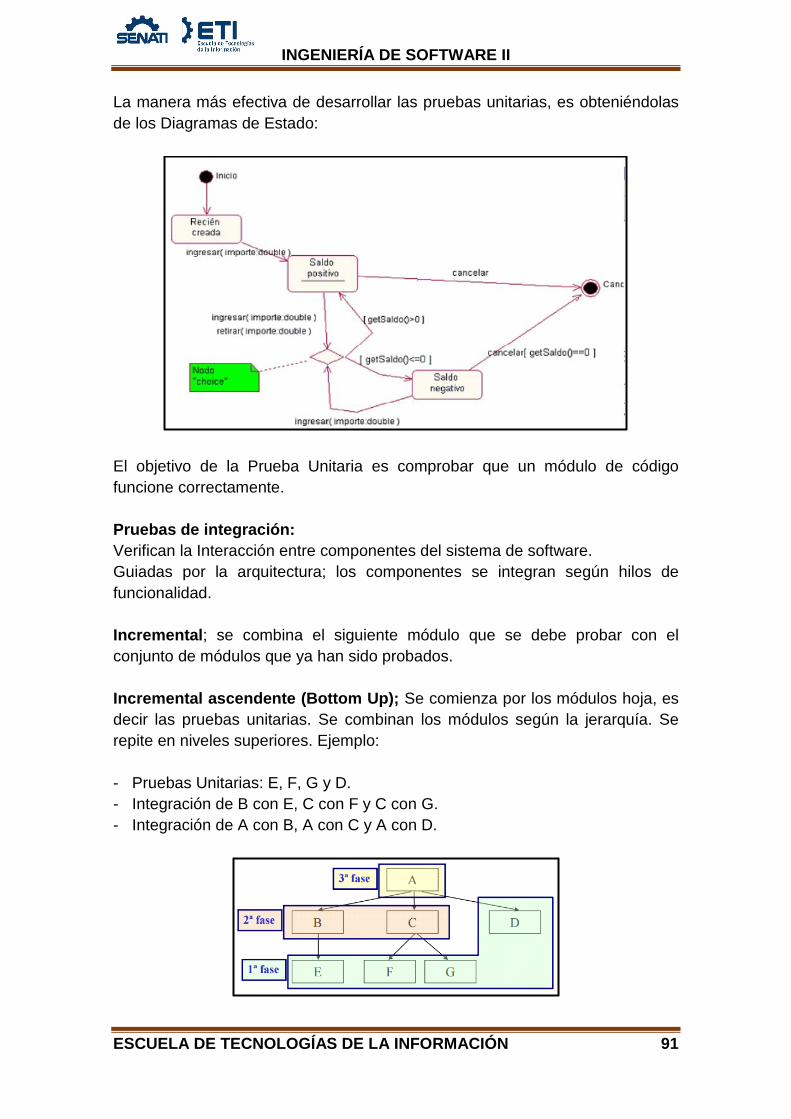
INGENIERÍA DE SOFTWARE II La manera más efectiva de desarrollar las pruebas unitarias, es obteniéndolas de los Diagramas de Estado:
El objetivo de la Prueba Unitaria es comprobar que un módulo de código funcione correctamente. Pruebas de integración: Verifican la Interacción entre componentes del sistema de software. Guiadas por la arquitectura; los componentes se integran según hilos de funcionalidad. Incremental; se combina el siguiente módulo que se debe probar con el conjunto de módulos que ya han sido probados. Incremental ascendente (Bottom Up); Se comienza por los módulos hoja, es decir las pruebas unitarias. Se combinan los módulos según la jerarquía. Se repite en niveles superiores. Ejemplo: - Pruebas Unitarias: E, F, G y D. - Integración de B con E, C con F y C con G. - Integración de A con B, A con C y A con D.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 91

INGENIERÍA DE SOFTWARE II
Incremental descendente (Top Down); Primero en profundidad, completando las ramas del árbol. Primero en anchura, completando los niveles de jerarquía. El objetivo de las Pruebas de Integración es comprobar que los módulos que componen el código desarrollado funcionan correctamente una vez que estos están integrados entre sí.
Para resolver este tipo de problemas surgen dos herramientas: Stub y Mock. Son objetos “sustitutos” que simulan el funcionamiento de aquellos elementos no implementados. Stub: Los stubs implementan la misma lógica de funcionamiento que la parte sustituida pero de una forma más sencilla. No tendría sentido que el tiempo y los recursos necesarios para construir un Stub determinado fueran iguales o
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 92

INGENIERÍA DE SOFTWARE II similares a los necesarios para construir el objeto real, ya que de ser así, sería mejor implementar el real. El principal problema de utilizar stubs radica en que implementar la lógica de un sistema u objeto no siempre es sencillo y se corre el riesgo de cometer errores o no ser preciso en dicha simulación. Al mismo tiempo, si el sistema cambia durante el desarrollo mantener los stubs suele ser bastante complicado. Mock: Los mocks simulan el funcionamiento de la parte sustituida ofreciendo el mismo comportamiento que el esperado pero de forma artificial, es decir, un Mock no implementa la lógica del objeto a sustituir, en lugar de ello, lo que hace es simular las salidas esperadas para unas entradas concretas. Los mocks suelen emplearse cuando es necesario realizar pruebas muy concretas sobre un funcionamiento en particular. Los mocks permiten controlar de forma precisa el comportamiento del sistema ante unas entradas concretas. También suele utilizarse esta técnica cuando implementar la lógica de un Stub es demasiado costoso o complicado.
Pruebas de Sistema: Verifican el comportamiento del sistema en su conjunto, Determinan los fallos funcionales que se suelen detectar en los otros dos niveles anteriores. Este nivel es el más adecuado para comprobar los requisitos no funcionales, como pueden ser: la seguridad, la velocidad, la exactitud y la fiabilidad. También pueden determinar las interfaces externas con otros sistemas, las utilidades, las unidades físicas y el entorno operativo. Software Testing: Como toda metodología, el Software Testing cuenta con una serie de principios que configuran las “buenas prácticas” que se deben emplear cuando se quiera testear un sistema. La utilización de estos principios no garantiza que la tarea de validar y verificar un producto software tenga éxito pero aumenta las posibilidades de que lo tenga.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 93

INGENIERÍA DE SOFTWARE II - Una parte necesaria de una prueba, es una definición de la salida o de los
resultados esperados.
- Un programador debe evitar intentar probar su propio programa. El programador tiende a ver lo que se supone que debe hacer el código en lugar de lo que hace.
- Una organización de programación no debería probar sus propios programas. Las organizaciones suelen dar más importancia a los plazos de entrega que a la fiabilidad del software.
- Cualquier proceso de prueba debe incluir una minuciosa inspección de los resultados de cada test. Por norma general los errores que se encuentran en pruebas tardías suelen haber sido omitidos en pruebas previas.
- Una correcta organización de los test permite una mejor localización de los errores y facilita su corrección.
- Deben escribirse casos de prueba para condiciones de entrada que sean inválidas o inesperadas, así como para aquellas que son válidas y esperadas.
- Examinar un programa para ver si no hace lo que se supone que debe hacer es sólo la mitad del trabajo, la otra mitad es comprobar que el programa hace lo que se supone que no debe hacer.
- Todas las pruebas tienen valor en cuanto a que dotan de valor al producto software. Las pruebas requieren una inversión de tiempo y recursos importantes que deben computarse y, al mismo tiempo, generan documentación sobre el funcionamiento del sistema y sobre sus posibles límites y fallos lo que puede servir como garantía de calidad (valor añadido) o como contrato entre el cliente y el desarrollador.
- No planificar una prueba asumiendo que no se van a encontrar errores. Es un error común y suele producirse por un exceso de confianza al asumir que una parte o un programa entero no necesita ser probado por ser correcto o no contener errores.
- La probabilidad de existencia de más errores en una sección de un programa es proporcional al número de errores ya encontrados en dicha selección. Suele existir una relación lineal entre el número de errores encontrados y el número de errores por descubrir.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 94

INGENIERÍA DE SOFTWARE II - Las pruebas de software son una tarea extremadamente creativa y un reto
intelectual. Es probable que probar un programa grande o muy complejo sea más complicarlo que diseñarlo.
Test Driven Development. TDD es un modelo de desarrollo de software dirigido por pruebas, es decir, las pruebas constituyen el motor que va guiando y estructurando todo el proceso de creación de software. TDD involucra dos prácticas: Escribir las pruebas primero (Test First Development) y Refactorización (Refactoring). A grandes rasgos, se escribe una prueba y se verifica que la prueba falla. Funcionamiento del TDD:
4.3. OBJETIVOS: DE ACEPTACIÓN, DE INSTALACIÓN, PRUEBAS ALFA Y
BETA. Funcional o de correctitud, confiabilidad, de regresión, de desempeño, de esfuerzo, de comparación, de configuración y de usabilidad PRUEBAS DE ACEPTACIÓN. Estas pruebas se realizan para que el cliente certifique que el sistema es válido para él. La planificación detallada de estas pruebas debe haberse realizado en etapas tempranas del desarrollo, con el objetivo de utilizar los resultados como indicador de su validez, si se ejecutan las pruebas documentadas a satisfacción del cliente, el producto se considera correcto y, por tanto, adecuada para su puesta en producción. Las pruebas de aceptación, son básicamente pruebas funcionales sobre el sistema completo, y buscan comprobar que se satisfacen los requisitos establecidos.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 95

INGENIERÍA DE SOFTWARE II Su ejecución es facultativa del cliente, y en el caso de que no se realicen explícitamente, se dan por incluidas dentro de las pruebas del sistema. Es decir, las pruebas de aceptación son, a menudo, responsabilidad del usuario o del cliente, aunque cualquier persona involucrada en el negocio puede realizarlas. La ejecución de las pruebas de aceptación requiere un entorno de pruebas que represente el entorno de producción. Esta fase o nivel toma como punto de partida la línea base de aceptación del producto ya instalado en el entorno de certificación. A partir de dicha línea base se acepta el producto, tomando como referencia la especificación de requisitos y comprobando que el sistema cubre satisfactoriamente los requisitos del cliente. Objetivos. Las pruebas de aceptación tienen como objetivo obtener la aceptación final del cliente antes de la entrega del producto para su paso a producción. Cuando la organización ha realizado las pruebas del sistema y ha corregido la mayoría de sus defectos, el sistema será entregado al usuario o al cliente para que dé su aprobación. La validación del sistema se consigue mediante la realización de pruebas de caja negra que demuestran la conformidad de requisitos y que se recogen en el plan de pruebas, el cual define las verificaciones a realizar y los casos de prueba asociados. Dicho plan está diseñado para asegurar que se satisfacen todos los requisitos funcionales especificados por el usuario teniendo en cuenta también los requisitos no funcionales relacionados con el rendimiento, seguridad de acceso al sistema, a los datos y procesos, así como a los distintos recursos del sistema. Herramientas: - CANOO: Es una herramienta de software libre para automatizar las pruebas
de aplicaciones web de una forma muy efectiva. http://webtest.canoo.com/webtest/manual/webtesthome.html
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 96

INGENIERÍA DE SOFTWARE II - CONCORDION: Es un framework java de software libre que permite
convertir especificaciones en texto común sobre requerimientos en pruebas automatizadas. http://dosideas.com/wiki/concordion
- FITNESSE: Es una herramienta colaborativa para el desarrollo de software; permite a los clientes, testers y programadores, aprender lo que su software debería hacer, y automáticamente compara lo que realmente hace. Compara las expectativas de los clientes a los resultados reales. http://www.dosideas.com/wiki/fitnesse
- JBEHAVE: Es un framework java para mejorar la colaboración entre desarrolladores QA, analistas de negocio, dueño del producto y todos los miembros del equipo a través de escenarios automatizados y legibles. http://www.dosideas.com/wiki/jbehave
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 97

INGENIERÍA DE SOFTWARE II
- JMETER: Es un proyecto de Apache jakarta que puede ser utilizado para realizar una prueba de carga, para así analizar y mediar la performance de aplicaciones de distinto tipo, aunque con especial foco en aplicaciones web. http://jakarta.apache.org/jmeter o http://www.dosideas.com/wiki/jmeter
- SAHI: Es una herramienta de automatización de pruebas para aplicaciones web, con la facilidad de grabar y reproducir scripts. Esta desarrollado en JavaScript, la herramienta usa simplemente JavaScript para ejecutar los eventos en el browser. http://www.dosideas.com/wiki/sahi
- SELENIUM: Es una herramienta de software libre para pruebas de aplicaciones web. Las pruebas de selenium se ejecutan directamente en un navegador y facilitan las pruebas de compatibilidad en navegadores, también como pruebas funcionales de aceptación de aplicaciones web. http://www.dosideas.com/wiki/selenium
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 98

INGENIERÍA DE SOFTWARE II
- SOAPUI: Es una herramienta de software libre gráfica, está basada en java y sirve para el testeo de web service y generación de cliente de web service. http://www.dosideas.com/wiki/soapui
- WATIR: Es una librería simple de código abierto para la automatización web en los navegadores. Permite escribir pruebas que sean fáciles de leer y fáciles de mantener. Se han optimizado para la simplicidad y flexibilidad. http://watir.com
Pruebas de Instalación: Verificar y validar que el sistema se instala apropiadamente en cada cliente, bajo las siguientes condiciones: Instalar versiones viejas en máquinas previamente instaladas con el sistema. Las pruebas de instalación tienen dos propósitos. El primero es asegurar que el sistema puede ser instalado en todas las configuraciones posibles, tales como nuevas instalaciones, actualizaciones, instalaciones completas o
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 99

INGENIERÍA DE SOFTWARE II personalizadas, y bajo condiciones normales o anormales; estas últimas incluyen insuficiente espacio en disco, falta de privilegios para algunas tareas, etc. El segundo propósito es verificar que, una vez instalado, el sistema opera correctamente. Esto usualmente implica correr un número significativo de pruebas de Funcionalidad. - Diseñar scripts para validar las condiciones de la máquina a instalar. - Realizar la instalación. - Las transacciones de la aplicación se ejecutan sin fallas. Pruebas Alfa y Beta: Cuando se construye software a medida para un cliente, se lleva a cabo una serie de pruebas de aceptación apara permitir que el cliente valide todos los requisitos. La mayoría de los desarrolladores de productos de software llevan a cabo un proceso denominado pruebas alfa y beta para descubrir errores que parezca que solo el usuario final pueda descubrir.
Prueba Alfa: Se lleva a cabo por un cliente, en lugar de un desarrollador. Se utiliza el software de forma natural con el desarrollador como observador del usuario y registrando los errores y problemas de uso. Las pruebas alfa se llevan a cabo en un entorno controlado. Las pruebas alfa consisten en invitar al cliente a que pruebe el sistema en el entorno de desarrollo. Se trabaja en un entorno controlado y el cliente siempre tiene un experto a mano para ayudarle a usar el sistema. El desarrollador va registrando los errores detectados y los problemas de uso. Prueba Beta: Las pruebas beta se realizan con posterioridad a las pruebas alfa, y se desarrollan en el entorno del cliente. En este caso, el cliente se queda
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 100

INGENIERÍA DE SOFTWARE II a solas con el producto y trata de encontrarle fallos de los que informa al desarrollador. Se llevan a cabo por los usuarios finales del software en los lugares de trabajo de los clientes. A diferencia de la prueba alfa, el desarrollador no está presente normalmente. Así, la prueba beta es una aplicación en vivo del software en un entorno que no puede ser controlado por el desarrollador. El cliente registra todos los problemas que encuentra durante la prueba beta e informa a intervalos regulares al desarrollador. Prueba Funcional o de Correctitud: Se asegura el trabajo apropiado de los requisitos funcionales, incluyendo la navegación, entrada de datos, procesamiento y obtención de resultados. Las pruebas Funcionales deben enfocarse en los requisitos funcionales, las pruebas pueden estar basadas directamente en los Casos de Uso (o funciones de negocio), y las reglas del negocio. Las metas de estas pruebas son: - Verificar la apropiada aceptación de datos. - Verificar el procesamiento y recuperación y la implementación adecuada de
las reglas del negocio
Este tipo de pruebas están basadas en técnicas de caja negra, que es, verificar la aplicación (y sus procesos internos) mediante la interacción con la aplicación vía GUI y analizar la salida (resultados). Lo que se identifica a continuación es un diseño preliminar de las pruebas recomendadas para cada aplicación. Se ejecuta cada caso de uso, flujo de caso de uso, o función, usando datos válidos e inválidos, para verificar lo siguiente: - Que los resultados esperados ocurran cuando se usen datos válidos. - Que sean desplegados los mensajes apropiados de error y precaución
cuando se usan datos inválidos. - Que se aplique apropiadamente cada regla de negocio. - Todas las pruebas planeadas han sido ejecutadas. - Todos los defectos que se identificaron han sido tenidos en cuenta. Pruebas de Confiabilidad: Se refiere a la precisión con la que una aplicación proporciona, sin errores, los servicios que se establecieron en las especificaciones originales. La confiabilidad del software se refiere a la precisión con la que una aplicación proporciona, sin errores, los servicios que se establecieron en las especificaciones originales. El diseño para favorecer la confiabilidad, además de referirse al tiempo de funcionamiento de la aplicación antes de que se produzca algún error, está relacionado también con la consecución de resultados correctos y con el control de la detección de errores y de la recuperación para evitar que se produzcan errores.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 101

INGENIERÍA DE SOFTWARE II
Se producen errores en la aplicación por distintos motivos: - Comprobación inadecuada. - Problemas relacionados con cambios en la administración. - Falta de control y análisis continuados. - Errores en las operaciones. - Código poco consistente. - Ausencia de procesos de diseño de software de calidad. - Interacción con aplicaciones o servicios externos. - Condiciones de funcionamiento distintas (cambios en el nivel de uso,
sobrecargas máximas). - Sucesos inusuales (errores de seguridad, desbordamientos en la difusión). - Errores de hardware (discos, controladores, dispositivos de red, servidores,
fuentes de alimentación, memoria, CPU). - Problemas de entorno (red eléctrica, refrigeración, incendios, inundaciones,
polvo, catástrofes naturales). Procedimientos recomendados para la confiabilidad. El objetivo de conseguir un software de calidad abarca todo el ciclo vital de desarrollo del programa. Se recomiendan los siguientes procedimientos para crear aplicaciones confiables: Pensar en la confiabilidad: Las aplicaciones confiables han de ser compatibles con operaciones confiables y necesitan también procesos de implementación confiables. Céntrese en el modo en que se proporciona el servicio y busque posibles problemas allí donde las alternativas de diseño o de procedimiento permitan reducir las causas de error. Invertir en personal: El personal de operaciones y los programadores deben conocer a fondo las prácticas de administración del ciclo de vida y de la arquitectura, poniendo especial atención en la prevención de los errores más comunes. Cree una referencia cultural de equipo en la que la confiabilidad sea un aspecto crítico. Proporcione educación sobre los procedimientos de la
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 102

INGENIERÍA DE SOFTWARE II compañía, las herramientas de programación, las tecnologías de aplicación y los conceptos de confiabilidad. Eliminar los puntos con errores desde el diseño de aplicaciones: Un sistema confiable es más fácil de mejorar que un sistema no confiable (con eventos de error ocultos y distribuidos por todo el programa), que es muy costoso cambiar. Utilizar un sistema operativo consistente. Invertir en procesos de diseño de software de calidad: - Utilizar una metodología de ciclo vital de desarrollo. - Uso de revisiones de código y estándares de codificación. - Desarrollo de procedimientos de recuperación. - Uso de procedimientos de control de cambios probados. Utilizar pruebas inteligentes Los procesos de prueba de control de calidad deberán proporcionar una respuesta a tres cuestiones importantes: ¿Están correctamente implementadas en la aplicación las funciones descritas en las especificaciones? ¿Satisface la aplicación las situaciones de usuario previstas sin producir errores? ¿Se ajusta el perfil de confiabilidad de la aplicación a los requisitos originales o los supera? Cuando el nivel de calidad y confiabilidad no sea aceptable, deberá corregirse el software hasta que se alcance el nivel deseado. - Implementar cambios con cautela. - Prestar atención al presupuesto. La comprobación de la confiabilidad consiste en probar una aplicación para descubrir y eliminar errores antes de que se implemente el sistema. Puesto que hay infinidad de combinaciones distintas de recorridos alternativos a lo largo de una aplicación, no es muy probable que encuentre todos los errores posibles de una aplicación compleja. No obstante, puede probar las situaciones más probables bajo condiciones normales de uso y confirmar que la aplicación proporciona el servicio previsto. Si dispone de tiempo suficiente, puede realizar pruebas más complicadas para detectar defectos menos evidentes. Pruebas de Regresión: Es cualquier tipo de pruebas de software que intentan descubrir las causas de nuevos errores (bugs), carencias de funcionalidad, o divergencias funcionales con respecto al comportamiento esperado del software, inducidos por cambios recientemente realizados en partes de la aplicación que anteriormente al citado cambio no eran propensas a este tipo de error. En la mayoría de las situaciones del desarrollo de software se considera una buena práctica que
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 103

INGENIERÍA DE SOFTWARE II cuando se localiza y corrige un bug, se grabe una prueba que exponga el bug y se vuelvan a probar regularmente después de los cambios subsiguientes que experimente el programa.
Herramientas de Software: Permiten detectar este tipo de errores de manera parcial o totalmente automatizada, la práctica habitual en programación extrema es que este tipo de pruebas se ejecuten en cada uno de los pasos del ciclo de vida del desarrollo del software. Herramienta de Software: Zeta Test Ambiente de administración de pruebas integrado que le permite ejecutar pruebas de caja-negra, caja-blanca, pruebas de regresión o pruebas de administración de cambio de programas de aplicación. Zeta Test le ayuda a planificar, ejecutar, registrar, verificar y documentar las pruebas, para luego evaluar los resultados de las pruebas. No es suficiente probar sólo los componentes modificados o añadidos, o las funciones que en ellos se realizan, sino que también es necesario controlar que las modificaciones no produzcan efectos negativos sobre el mismo u otros componentes. Las pruebas de regresión pueden incluir: - La repetición de los casos de pruebas que se han realizado anteriormente y
están directamente relacionados con la parte del sistema modificada. - La revisión de los procedimientos manuales preparados antes del cambio,
para asegurar que permanecen correctamente. La obtención impresa del diccionario de datos de forma que se compruebe que los elementos de datos que han sufrido algún cambio son correctos. Tipos de regresión: • Clasificación de ámbito. • Local: Los cambios introducen nuevos errores. • Desenmascarada: Los cambios revelan errores previos.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 104

INGENIERÍA DE SOFTWARE II • Remota: Los cambios vinculan alguna otra parte del programa (módulo) e
introducen errores en ella. • Clasificación temporal. • Nueva característica: Los cambios realizados con respecto a nuevas
funcionalidades en la versión introducen errores en otras novedades en la misma versión del software.
• Característica preexistente: Los cambios realizados con respecto a nuevas funcionalidades introducen errores en previas versiones.
Pruebas de Desempeño: Las Pruebas de Desempeño permiten simular escenarios críticos, como grandes cantidades de usuarios concurrentes, que ayudan a detectar y reducir riesgos relacionados con la no disponibilidad o la respuesta tardía de la aplicación, y evitar con ello las pérdidas que esto puede ocasionar. Con las Pruebas de Desempeño se puede, entre otras cosas, detectar el número de usuarios y la cantidad de datos/transacciones/peticiones que la aplicación puede soportar sin que su rendimiento se vea degradado. Pero si ese número de usuarios no es el requerido, con estas pruebas se obtendrá información para detectar los segmentos de la aplicación que ocasionan la baja de rendimiento, de forma que sean corregidos, para que luego se pueda verificar nuevamente si el rendimiento es el requerido. Pruebas de Esfuerzo: El esfuerzo es la medida o cantidad de trabajo que un equipo de desarrolladores debe aplicar en determinada tarea o etapa para lograr un objetivo en común, ya sean objetivos específicos o generales. El esfuerzo debe dividirse creando unidades o subequipos de trabajo con el fin de optimizar el tiempo y trabajo. Pruebas de Comparación: Este tipo de prueba se asegura de que el colocar piezas de código a correr en una computadora del cliente pueda ser hecho fácilmente. Pruebas de Configuración: Se enfocan en evaluar las diferentes variaciones de una aplicación integrada, contra sus requerimientos de configuración. Hacer que la aplicación falle en cumplir sus requerimientos de configuración, de manera que los defectos escondidos sean identificados, analizados, arreglados, y prevenidos en el futuro. El objetivo es: - Validar la aplicación parcialmente. - Causar fallas para identificar defectos no identificados en las pruebas
unitarias, y en las pruebas de integración. - Reportar estas fallas a los desarrolladores. - Determinar el efecto de añadir o modificar los recursos de hardware.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 105

INGENIERÍA DE SOFTWARE II - Determinar la configuración óptima del sistema.
Ejemplos: - Múltiples variables funcionales. - Soporte para la internacionalización. - Soporte para la personalización Los requerimientos de configuración pueden ser especificados: - Existen múltiples variables. - Los componentes pasaron las pruebas unitarias. - El equipo está entrenado para aplicar estas pruebas. - El ambiente de prueba está listo. - Al menos existe un test suite por cada requerimiento. - Estos suites corren con éxito en la configuración apropiada
Pruebas de Usabilidad: Determina cuán bien el usuario podrá usar y entender la aplicación. Identifica las áreas de diseño que hacen al sistema de difícil uso para el usuario. La prueba de usabilidad detecta problemas relacionados con la conveniencia y practicidad del sistema desde el punto de vista del usuario. Verificar que la aplicación no presenta los siguientes problemas de usabilidad típicos: - El sistema es demasiado complejo y difícil de usar. - Es difícil instalar y entender el sistema. - La recuperación de errores es pobre y los mensajes de error no tienen
significado. - La sintaxis de los comandos es difícil de aprender y recordar. - El sistema obliga al usuario a recordar formatos y secuencias fijas. - Los procedimientos no son simples ni obvios. - El sistema no tiene instrucciones de ayuda por computadora y tiene
manuales pobres. - Los diagramas, pantallas, reportes y gráficos son de calidad y apariencia
pobre. - El sistema carece de herramientas de construcción adecuadas y requiere
múltiples comandos. - La lógica y conveniencia de los botones, switches, displays y mensajes de
ayuda deben ser testeados. (La prueba de usabilidad puede ser conducida por un grupo separado si es posible.
- Se deben crear casos de prueba para comprobar que se puede operar en el sistema de forma adecuada.
- Todas las pruebas planeadas han sido ejecutadas.
Todos los defectos que se identificaron han sido tenidos en cuenta.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 106

INGENIERÍA DE SOFTWARE II
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 107

INGENIERÍA DE SOFTWARE II V. GENERAR DISEÑO DE PRUEBAS
OPERACIONES:
Trabajar con las técnicas basadas en la experiencia y la intuición. Trabajar con las técnicas basadas en la especificación o caja negra. Trabajar con las técnicas basadas en el código o caja blanca y errores. Trabajar con las técnicas basadas en la naturaleza de la aplicación selección
de pruebas. Trabajar con criterio de selección, criterio de suficiencia. EQUIPOS Y MATERIALES:
Computadora con microprocesadores Core 2 Duo o de mayor capacidad. Sistema operativo Windows. Acceso a internet.
ORDEN DE EJECUCIÓN:
Reconocer las técnicas de experiencia e intuición, especificación. Reconocer el funcionamiento de las cajas negras y cajas blancas. Desarrollar pruebas de criterio de selección y suficiencia.
GENERAR DISEÑO DE PRUEBAS CONCEPTOS: FUNDAMENTOS DE PRUEBAS DE SOFTWARE. Las pruebas de software (testing en inglés) son los procesos que permiten verificar y revelar la calidad de un producto software antes de su puesta en marcha. Básicamente, es una fase en el desarrollo de software que consiste en probar las aplicaciones construidas.
Las pruebas de software se integran dentro de las diferentes fases del ciclo de vida del software dentro de la Ingeniería de software. En este sentido, se ejecuta el aplicativo a probar y mediante técnicas experimentales se trata de descubrir qué errores tiene.
Otros especialistas de pruebas manifiestan que las pruebas de software son actividades claves para que los procesos de validación y verificación tengan éxito, ya que ayudan a entregar el producto con la calidad suficiente para satisfacer las necesidades del cliente y con la certeza de que el producto
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 108

INGENIERÍA DE SOFTWARE II cumple las especificaciones definidas. En este sentido, las pruebas pueden considerarse como un proceso que intenta proporcionar confianza en el software y cuyo objetivo fundamental es demostrar al desarrollador y al cliente que el software satisface sus requisitos.
Como parte del proceso de validación y verificación, se debería tomar decisiones sobre quién debería ser responsable de las diferentes etapas de las pruebas. Dichas etapas de pruebas se integran dentro de las diferentes fases del ciclo del software dentro de la Ingeniería de Software.
Modelo de cómo las etapas de pruebas se integran en el ciclo de vida de desarrollo de software genérico.
La eficiencia consiste en conseguir el efecto deseado de la manera correcta, es decir, sin desaprovechamiento de recursos, ni de tiempo ni de dinero. Por consiguiente, la eficiencia está relacionada con dos conceptos: productividad y ausencia de pérdidas. Para conseguir esta eficiencia deseada durante el proceso de pruebas, se pueden considerar los siguientes aspectos:
• Evitar redundancias: Las redundancias traen consigo una pérdida o desaprovechamiento de tiempo por lo que hay que intentar ejecutar las pruebas más adecuadas a cada situación y lo más rápido posible. Es importante encontrar los errores que más impacto puedan tener sobre el producto lo más rápido posible. Aunque sea aconsejable no desaprovechar el tiempo, no hay que olvidarse de la planificación, preparación de las pruebas, y de prestar atención a todos los detalles. No abandonar las estrategias previamente establecidas ante la primera señal de problemas o retrasos.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 109

INGENIERÍA DE SOFTWARE II • Reducir costes: Para reducir costes se debería prestar especial atención a
la adquisición de elementos que puedan ayudar a la ejecución de pruebas, del tipo de herramientas para la ejecución de pruebas o entornos de pruebas. Habría que cerciorarse de que realmente fueran necesarias y de que existe el tiempo y las habilidades suficientes para emplearlas de manera ventajosa. También, es aconsejable evaluar las herramientas antes de comprarlas y ser capaz de justificar estos gastos frente al análisis de costos-beneficios.
Un posible flujo del proceso de pruebas, identificando distintas actividades y entregables se muestra en la siguiente figura.
TIPOS DE PRUEBAS. La disciplina de pruebas es una de las más costosas del ciclo de vida software. En sentido estricto, deben realizarse las pruebas de todos los artefactos generados durante la construcción de un producto, lo que incluye especificaciones de requisitos, casos de uso, diagramas de diversos tipos y, por supuesto, el código fuente y el resto de productos que forman parte de la aplicación (por ejemplo, la base de datos), e infraestructura. Obviamente, se aplican diferentes técnicas de prueba a cada tipo de producto software. A continuación, se describirá los tipos de pruebas en función de qué conocemos, según el grado de automatización y en función de qué se prueba.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 110

INGENIERÍA DE SOFTWARE II
A. Pruebas de caja negra: En este tipo de prueba, tan sólo, podemos probar
dando distintos valores a las entradas. Los datos de prueba se escogerán atendiendo a las especificaciones del problema, sin importar los detalles internos del programa, a fin de verificar que el programa corra bien. Este tipo de prueba se centra en los requisitos funcionales del software y permite obtener entradas que prueben todos los flujos de una funcionalidad (casos de uso).
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 111

INGENIERÍA DE SOFTWARE II Con este tipo de pruebas se intenta encontrar:
- Funcionalidades incorrectas o ausentes. - Errores de interfaz. - Errores en estructuras de datos o en accesos a las bases de datos externas. - Errores de rendimiento. - Errores de inicialización y finalización.
B. Pruebas de caja blanca: Consiste en realizar pruebas para verificar que
líneas específicas de código funcionan tal como está definido. También se le conoce como prueba de caja-transparente.
La prueba de la caja blanca es un método de diseño de casos de prueba que usa la estructura de control del diseño procedimental para derivar los casos de prueba.
Las pruebas de caja blanca intentan garantizar que:
- Se ejecutan al menos una vez todos los caminos independientes de cada módulo.
- Se utilizan las decisiones en su parte verdadera y en su parte falsa. - Se ejecuten todos los bucles en sus límites. - Se utilizan todas las estructuras de datos internas. - Para esta prueba, se consideran tres importantes puntos.
Conocer el desarrollo interno del programa, determinante en el análisis de
coherencia y consistencia del código. Considerar las reglas predefinidas por cada algoritmo. Comparar el desarrollo del programa en su código con la documentación
pertinente.
Según el grado de automatización.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 112

INGENIERÍA DE SOFTWARE II A. Pruebas manuales: Una prueba manual es una descripción de los pasos de
prueba que realiza un evaluador (usuario experto). Las pruebas manuales se utilizan en aquellas situaciones donde otros tipos de prueba, como las pruebas unitarias o las pruebas Web, serían demasiado difíciles de realizar o su creación y ejecución sería demasiado laboriosa. También, podría utilizar una prueba manual en situaciones donde no sea posible automatizar los pasos, por ejemplo, para averiguar el comportamiento de un componente cuando se pierde la conexión de red; esta prueba podría realizarse de forma manual, desenchufando el cable de red.
B. Pruebas automáticas: A diferencia de las pruebas manuales, para este tipo de pruebas, se usa un determinado software para sistematizarlas y obtener los resultados de las mismas. Por ejemplo, verificar un método de ordenación. La suite de IBM Rational nos provee varias herramientas que permiten automatizar las pruebas de un sistema.
En función de qué se prueba:
A. Pruebas unitarias: Se aplican a un componente del software. Podemos considerar como componente (elemento indivisible) a una función, una clase, una librería, etc. Estas pruebas las ejecuta el desarrollador, cada vez que va probando fragmentos de código o scripts para ver si todo funciona como se desea. Estas pruebas son muy técnicas. Por ejemplo, probar una consulta, probar que un fragmento de código envíe a imprimir un documento, probar que una función devuelva un flag, etc.
Tabla E/S y roles de prueba de unitarias.
Para que una prueba unitaria, tenga éxito se deben cumplir los siguientes requisitos:
• Automatizable: no debería existir intervención manual. Esto es, especialmente, útil para la integración continua.
• Completas: deben cubrir la mayor cantidad de código • Repetibles o Reutilizables: no se deben crear pruebas que sólo puedan ser
ejecutadas una sola vez. También, es útil para integración continua. • Independientes: la ejecución de una prueba no debe afectar a la ejecución
de otra. • Profesionales: las pruebas deben ser consideradas igual que el código,
con la misma profesionalidad, documentación, etc.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 113

INGENIERÍA DE SOFTWARE II El objetivo de las pruebas unitarias es aislar cada parte del programa y mostrar que las partes individuales son correctas. Proporcionan un contrato escrito que el fragmento de código debe satisfacer. Estas pruebas aisladas proporcionan cinco ventajas básicas: - Fomentan el cambio: Las pruebas unitarias facilitan que el programador
cambie el código para mejorar su estructura (lo que se llama refactorización), puesto que permiten hacer pruebas sobre los cambios y así asegurarse de que los nuevos cambios no han introducido errores.
- Simplifica la integración: Puesto que permiten llegar a la fase de integración con un grado alto de seguridad de que el código está funcionando correctamente.
- Documenta el código: Las propias pruebas son documentación del código puesto que ahí se puede ver cómo utilizarlo.
- Separación de la interfaz y la implementación: Dado que la única interacción entre los casos de prueba y las unidades bajo prueba son las interfaces de estas últimas, se puede cambiar cualquiera de los dos sin afectar al otro.
- Los errores están más acotados y son más fáciles de localizar: dado que tenemos pruebas unitarias que pueden desenmascararlos.
B. Pruebas de integración: Consiste en construir el sistema a partir de los distintos componentes y probarlo con todos integrados. Estas pruebas deben realizarse progresivamente. El foco de atención es el diseño y la construcción de la arquitectura de software.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 114

INGENIERÍA DE SOFTWARE II
Tabla E/S y roles de prueba de Integración.
C. Pruebas de Aceptación: Son las únicas pruebas que son realizadas por los
usuarios expertos, todas las anteriores las lleva a cabo el equipo de desarrollo. Consiste en comprobar si el producto está listo para ser implantado para el uso operativo en el entorno del usuario. Podemos distinguir entre dos tipos de pruebas; en ambas existe retroalimentación por parte del usuario experto:
• Pruebas alfa: Las realiza el usuario en presencia de personal de
desarrollo del proyecto haciendo uso de una máquina preparada para las pruebas.
• Pruebas beta: Las realiza el usuario después de que el equipo de desarrollo les entregue una versión casi definitiva del producto.
Tabla E/S y roles de prueba de aceptación.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 115

INGENIERÍA DE SOFTWARE II
D. Pruebas funcionales: Este tipo de prueba se realiza sobre el sistema funcionando, comprobando que cumpla con la especificación (normalmente a través de los casos de uso). Para estas pruebas, se utilizan las especificaciones de casos de prueba.
E. Pruebas de rendimiento: Las pruebas de rendimiento se basan en comprobar que el sistema puede soportar el volumen de carga definido en la especificación, es decir, hay que comprobar la eficiencia (por ejemplo, se ha montado una página web sobre un servidor y hay que probar qué capacidad tiene el estado de aceptar peticiones, es decir capacidad de concurrencia).
DISEÑO DE CASO DE PRUEBAS.
Un caso de prueba es un conjunto de entradas, condiciones de ejecución y resultados esperados, desarrollado para conseguir un objetivo particular o condición de prueba como, por ejemplo, verificar el cumplimiento de un requisito específico. Para llevar a cabo un caso de prueba, es necesario definir las precondiciones y post condiciones, identificar unos valores de entrada, y conocer el comportamiento que debería tener el sistema ante dichos valores. Tras realizar ese análisis e introducir dichos datos en el sistema, se observará si su comportamiento es el previsto o no y por qué. De esta forma se determinará si el sistema ha pasado o no la prueba. De ahí su importancia durante la ejecución de pruebas.
Caso práctico para realizar un diseño de caso de prueba:
Teniendo como referencia el siguiente código se extraerá unos posibles errores cuando el usuario interactúe con la aplicación.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 116

INGENIERÍA DE SOFTWARE II
Se observa en el siguiente cuadro las pruebas realizadas referentes al código mostrado:
Se observa que se realizaron cuatro pruebas de las cuales dos fallaron entonces el testeador deberá informar al programador de los siguientes errores obtenidos; Una vez que el programador solucione los errores deberá entregarlas de nuevo al testeador para que pueda seguir realizando los casos de prueba:
Observar el siguiente código que fue modificado:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 117

INGENIERÍA DE SOFTWARE II
Se puede observar la siguiente tabla mostrando los resultados obtenidos:
Tomando en cuenta que es un ejercicio práctico de realizar un caso de prueba existen diversos métodos para realizar estos testing, y así mejorar la calidad de software.
ADMINISTRACIÓN DE PRUEBAS.
Sin importar la metodología utilizada por un equipo de desarrollo, las pruebas realizadas sobre el producto, ya sean unitarias, de integración o de sistema, reflejan si los objetivos planteados a nivel de requerimientos son satisfechos por el producto desarrollado. Este proceso, típicamente involucra el diseño e implementación de las pruebas, su ejecución, el reporte de los defectos encontrados, la planeación de las correcciones y la implementación de dichas correcciones.
Por otro lado, los responsables del proceso de pruebas deben considerar optimizar las pruebas. Para ello, es necesaria la definición de una buena estrategia, es decir, definir una serie de principios e ideas que puedan ayudar a guiar las actividades de pruebas.
Estrategia de pruebas: Existen distintas estrategias de pruebas, y dependiendo de su alineamiento con el objetivo de las pruebas y con los propios proyectos, estas estrategias pueden tener éxito o fallar. Otro punto a tener en cuenta es que no tiene por qué elegirse una sola estrategia. Puede utilizarse una estrategia de manera dominante y utilizar otras de complemento.
Algunos autores como Krutchen, Pressman, Pfleger, Cardoso y Sommerville afirman que el proceso de ejecución de pruebas debe ser considerado durante todo el ciclo de vida de un proyecto, para así obtener un producto de alta calidad. Su éxito dependerá del seguimiento de una estrategia de prueba adecuada.
Los tipos de estrategia de pruebas más importantes se describen a continuación:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 118

INGENIERÍA DE SOFTWARE II
A. Estrategia analítica: Las estrategias de pruebas analíticas tienen en común
el uso de alguna técnica analítica formal o informal normalmente durante la etapa de gestión de requisitos y de diseño del proyecto. Por ejemplo:
• Estrategia orientada a objetos: Para determinar el enfoque de las
pruebas, se presta atención a los requisitos, el diseño, y la implementación de objetos. Estos objetos pueden incluir especificaciones de requisitos, especificaciones de diseño, diagramas UML, casos de uso, código fuente, esquemas de base de datos y diagramas entidad-relación. Este enfoque se basa en una buena documentación, por lo que la ausencia de la misma implica no poder utilizarla.
• Estrategia basada en riesgos: Consiste en identificar riesgos estudiando el sistema, documentación de proyectos anteriores, objetivos de la configuración y cualquier otro dato que pueda encontrarse o que pueda aportar la gente involucrada en el proyecto. El diseño, desarrollo y ejecución de pruebas basadas en el conocimiento previo puede ser beneficioso. Este enfoque es apropiado si se dispone de tiempo para investigar el sistema.
B. Estrategia basada en modelo: Las estrategias de pruebas basadas en
modelo desarrollan modelos que representan cómo el sistema debería comportarse o trabajar. Las estrategias de pruebas basadas en modelo tienen en común la creación o selección de algún modelo formal o informal para simular comportamientos de sistemas críticos, normalmente durante las etapas de requisitos y diseño del proyecto. Existen distintos tipos de estrategias basadas en modelos: • En el mundo orientado a objetos, se podría usar una estrategia basada en
casos de uso, donde se confíe en documentos de diseño orientados a objetos conocidos como casos de uso. Estos casos de uso son modelos
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 119

INGENIERÍA DE SOFTWARE II
de cómo el usuario, clientes y otras partes involucradas en el negocio utilizan el sistema y cómo debería trabajar bajo estas condiciones.
• Con una estrategia basada en el dominio se puede analizar diferentes dominios de datos de entrada aceptados por el sistema, procesamiento de datos del sistema, y datos de salida entregados por el sistema. Se decidirá cuál será el mejor caso de pruebas para cada dominio, se determinará la probabilidad de errores, frecuencia de uso y entornos desplegados.
• Con una estrategia basada en un modelo, se diseñan, desarrollan y ejecutan las pruebas que cubran los modelos que se hayan construido. Esta estrategia será útil dependiendo de la capacidad del modelo para capturar los aspectos esenciales o potencialmente problemáticos del sistema.
C. Estrategia metódica: La estrategia metódica tiende a seguir una línea
relativamente informal pero con un enfoque ordenado y predecible que ayuda a comprender dónde probar.
• Estrategia basada en el aprendizaje: Se utilizan listas de control que se
han desarrollado para guiar el proceso de pruebas. Para desarrollar estas listas de control puede ser de ayuda el basarse en los errores que se han encontrado previamente, en lecciones aprendidas de otros proyectos y en cualquier otra fuente.
• Estrategia basada en funciones: Se identifica y se prueba cada función del sistema por separado. Lo mismo ocurre con la estrategia basada en estados, donde se identifica y prueba cada estado y cada posible transición de estados que pueda ocurrir.
• Estrategia basada en la calidad: Se utiliza una jerarquía de calidad, como la que ofrece la ISO 9126, para identificar y probar la importancia de cada una de las características de la jerarquía como, por ejemplo, la facilidad de uso, el rendimiento, la funcionalidad o la escalabilidad.
D. Estrategia orienta al proceso o estándar conformista: Las estrategias de
pruebas orientadas al proceso llevan el enfoque metódico un paso más allá a la hora de regular el proceso de pruebas. Estas estrategias siguen un desarrollo externo orientado a pruebas a menudo con pocas posibilidades de personalización. Un ejemplo de este tipo de estrategias es la estrategia de pruebas estandarizada, se sigue un estándar oficial y reconocido, por ejemplo el estándar IEEE 829 orientado a la documentación de las pruebas.
E. Estrategia dinámica: Las estrategias de pruebas dinámicas, como las estrategias de pruebas ágiles, minimizan la planificación por adelantado y prueban el diseño. Adaptan todo lo posible el sistema bajo prueba a las condiciones que habrá cuando se libere. Típicamente, enfatizan las últimas
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 120

INGENIERÍA DE SOFTWARE II
etapas de pruebas. Se trata de crear un pequeño conjunto de pautas de pruebas que se enfoquen en debilidades conocidas del software.
• Con una estrategia de pruebas intuitiva: se puede probar acorde a la
experiencia e instinto del equipo de pruebas. • Con una estrategia de pruebas exploratoria: se puede aprender
simultáneamente sobre el comportamiento y diseño de pruebas, a la vez que las pruebas se van ejecutando y se van encontrando errores. Se irá refinando el enfoque de las pruebas en función de los resultados obtenidos de las pruebas.
Las estrategias de pruebas dinámicas valoran la flexibilidad y la facilidad de encontrar errores. Estas estrategias no producen buena información normalmente acerca de cobertura, mitigación sistemática de riesgos ni ofrecen la oportunidad de detectar defectos en las primeras fases del ciclo de vida del producto.
F. Estrategia de pruebas filosófica: Las estrategias de pruebas filosóficas comienzan con una filosofía o creencia de las pruebas.
• Cuando se usa una estrategia de pruebas exhaustiva: se asume que
todo puede tener errores. Es decir, se decide que la posibilidad de que haya fallos latentes es inaceptable por lo que se soportará un considerable esfuerzo al encontrar todos los errores.
• Con la estrategia de pruebas shotgun: Se asume que todo y nada puede tener y tendrá errores. Sin embargo, en este caso, se acepta que no se puede probar todo. Cuando se llegue al punto de no tener una idea sólida acerca de por dónde empezar a probar, se intentará distribuir de manera aleatoria el esfuerzo de pruebas teniendo en cuenta las restricciones de recursos y la agenda.
• Con una estrategia guiada externamente: no sólo se acepta que no se puede probar todo, sino que también se asume que no se sabe dónde están los errores. Sin embargo, se confía en que otras personas puedan tener una buena idea sobre dónde están. Para ello, se pedirá ayuda a estas personas sobre la decisión a tomar acerca de si los resultados obtenidos son o no correctos.
Por ejemplo, se puede preguntar a los usuarios, personas que den soporte técnico, analistas de negocio o desarrolladores del sistema sobre qué probar o incluso confiar en ellos para hacer las pruebas. Enfatizan las últimas etapas de pruebas simplemente debido a la falta de reconocimiento del valor de pruebas tempranas.
G. Regresión: La regresión es la mala conducta de una función, atributo o característica previamente correctos. La palabra regresión también se suele
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 121

INGENIERÍA DE SOFTWARE II
usar para definir el descubrimiento de un error que previamente no se encontró durante la ejecución de una prueba. La regresión normalmente está asociada a algún cambio en el sistema, como añadir una característica o arreglar un error.
La regresión puede ser de tres tipos:
• Regresión local: al producirse un cambio o arreglarse un error se crea un nuevo error.
• Regresión de exposición: al producirse un cambio o arreglarse un error se identifican errores ya existentes.
• Regresión remota: un cambio o el arreglo de un error en un determinado área produce un fallo en otro área del sistema.
La regresión remota es la regresión más difícil de detectar, ya que los usuarios, clientes y el resto de los interesados en el proyecto tienden a confiar en las características ya existentes del sistema. Por ello, los técnicos de pruebas deberían tener estrategias que sean efectivas en contra de todas las causas y efectos de las regresiones. Roles y Responsabilidades. En RUP se definen los siguientes roles: - Administrador de pruebas. - Analista de pruebas. - Diseñador de pruebas. - Ejecutor de pruebas. A. Administrador de pruebas: Es el responsable del éxito total de la prueba.
Involucra calidad y aprobación de la prueba, recurso de planeación, dirección, y solución a de los problemas que impiden el éxito de la prueba. El Administrador de pruebas es responsable de los siguientes artefactos: Plan de Pruebas, Resumen de Resultado de Pruebas, Lista de Problemas y Cambios de Requerimientos.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 122

INGENIERÍA DE SOFTWARE II
El Plan de Pruebas: contiene la definición de las metas y objetivos a probar dentro del alcance de cada iteración del proyecto. Proporciona el marco de trabajo en el que el equipo llevará a cabo la prueba dentro del horario coordinado.
1. El Resumen de Resultados de Pruebas: organiza y presenta un análisis resumen de los resultados de las pruebas y las medidas clave para revisar y definir estas, típicamente por los Stakeholders claves. Además, puede contener una declaración general de calidad relativa, puede mantener las recomendaciones de las pruebas que se realizaran a futuro.
2. La Lista de los Problemas: proporciona una manera de registrar para el Administrador del Proyecto los: problemas, excepciones, anomalías, u otras tareas incompletas que requieren atención que relaciona a la dirección del proyecto.
3. Cambios de Requerimientos: Se proponen cambios a los artefactos de desarrollo a través de Cambios de requerimientos (CR). Se usan los Cambios de requerimientos para documentar los problemas, las mejoras solicitadas y cualquier otro tipo de solicitud para un cambio en el producto. El beneficio de CR es que proporcionan un registro de decisiones, debido a su proceso de valoración, asegura los impactos del cambio que puedan darse en el proyecto.
B. Analista de pruebas: Es el responsable de identificar y definir las pruebas
requeridas, mientras supervisa el progreso de la comprobación detallada y resultado por cada ciclo de realización de las pruebas.
El Analista de pruebas es responsable de los siguientes artefactos: Casos de Pruebas, Modelo de Análisis de Carga de Trabajo, Datos de Prueba, Resultados de Pruebas.
• Casos de Prueba. El propósito de estos artefactos es especificar y
comunicar las condiciones específicas que necesitan ser validadas para permitir una definición de algunos aspectos particulares de los ítems de prueba objetivo.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 123

INGENIERÍA DE SOFTWARE II
• El Modelo de Análisis de la carga de Trabajo: Trata de definir acertadamente las condiciones de carga bajo los cuales, los ítems de prueba objetivo deben operar en su entorno de configuración del sistema.
• Datos de Prueba: es la definición (usualmente formal) de una colección de valores de entrada de prueba que son consumidos durante la ejecución de una prueba.
• Resultados de Pruebas: es una colección de información sumaria determinada del análisis de unas o más peticiones de los registros y del cambio de la prueba.
C. Diseñador de pruebas: Es el responsable de definir la estrategia de
pruebas y de asegurar su puesta en práctica acertadamente. El rol implica identificar técnicas, herramientas y pautas apropiadas para poner en ejecución las pruebas requeridas, y dotar de los recursos necesarios para conducir los requisitos de la prueba.
El Diseñador de pruebas es responsable de los siguientes artefactos: Plan de Estrategia, Arquitectura de Automatización, Configuración del Entorno de Pruebas, Suite de Pruebas. • El Plan de Estrategia: define el plan estratégico de como el esfuerzo de
la prueba será conducido contra uno o más aspectos del sistema. Una estrategia de prueba necesita poder convencer a la gestión y a otros Stakeholders que el acercamiento es alcanzable.
• Arquitectura de automatización: es útil cuando la ejecución automatizada de las pruebas del software se debe mantener y ampliar durante ciclos múltiples de prueba. Proporciona una descripción arquitectónica comprensible del sistema de automatización de las pruebas, usando un número de diversas visiones arquitectónicas para representar diversos aspectos del sistema.
• Configuración del entorno de pruebas: Es la especificación para un
arreglo de hardware, software, y ajustes asociados al entorno que se requieran para permitir las pruebas exactas a ser conducidas que evaluarán uno o más ítems de la prueba objetivo.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 124

INGENIERÍA DE SOFTWARE II
• Suite de Pruebas: Es un tipo de paquete que agrupa las colecciones de pruebas, para ordenar la ejecución de esas pruebas y para proporcionar un sistema útil y relacionado de información del registro de prueba del cual los resultados de prueba pueden ser determinados.
D. Ejecutor de pruebas: Es el responsable de todas las actividades de las pruebas. El rol implica verificar y ejecutar pruebas, y analizar y recoger las ejecuciones de errores.
El Ejecutor de pruebas es responsable de los siguientes artefactos: registro de pruebas, script de pruebas. • El registro de las pruebas (Test Log): es una colección de salidas
capturadas durante la ejecución de una o más pruebas, usualmente representa la salida resultante de la ejecución de un conjunto de pruebas para un ciclo de pruebas.
• Scripts de prueba (Test Script): son instrucciones paso a paso de cómo realizar una prueba, permitiendo su ejecución de una manera efectiva y eficiente.
TÉCNICAS DE PRUEBAS.
Existen distintas técnicas de pruebas de software, con sus debilidades y sus puntos fuertes. Cada una de ellas es buena para encontrar un tipo específico de defectos. Las pruebas realizadas en distintas etapas del ciclo de desarrollo del software encontrarán diferentes tipos de defectos.
Las pruebas dinámicas sólo se aplican sobre el código del producto para detectar defectos y determinar atributos de calidad del software, por lo que estarían más orientadas al área de validación. Por otra parte, las técnicas de pruebas estáticas son útiles para evaluar o analizar documentos de requisitos, documentación de diseño, planes de prueba, o manuales de usuario, e incluso para examinar el código fuente antes de ejecutarlo. En este sentido, ayudan más a la implementación del proceso de verificación.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 125

INGENIERÍA DE SOFTWARE II Técnicas de pruebas dinámicas.
Las técnicas de pruebas dinámicas ejecutan el software. Para ello introducen una serie de valores de entrada, y examinan la salida comparándola con los resultados esperados.
A. Basadas en la especificación: Son conocidas como técnicas de pruebas de caja negra o conducida por entradas/salidas, porque tratan el software como una caja negra con entradas y salidas, pero no tienen conocimiento de cómo está estructurado el programa o componente dentro de la caja. Esencialmente, el técnico de pruebas se concentra en qué hace el software y no en cómo lo hace. Las técnicas basadas en especificaciones obtienen los casos de prueba directamente de las especificaciones o de otros tipos de artefactos que contengan lo que el sistema debería hacer. • Particionamiento de equivalencia: Esta técnica consiste en dividir un
conjunto de condiciones de prueba en grupos o conjuntos que puedan ser considerados iguales por el sistema. Esta técnica requiere probar sólo una condición para cada partición. Esto es así porque se asume que todas las condiciones de una partición serán tratadas de la misma manera por el software. Si una condición en una partición funciona, se asume que todas las condiciones en esa partición funcionarán. De la misma forma, si una de las condiciones en una partición no funciona, entonces se asume que ninguna de las condiciones en esta partición en concreto funcionará.
• Análisis de valor frontera: Los errores generados por los programadores tienden a agruparse alrededor de las fronteras. Por ejemplo, si un
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 126

INGENIERÍA DE SOFTWARE II
programa debería aceptar una secuencia de números entre 1 y 10, el error más probable será que los valores justo fuera del rango sean aceptados de forma incorrecta o que los valores justo en los límites del rango sean rechazados. El análisis del valor frontera está basado en probar los valores frontera de las particiones.
• Tablas de decisión: Las técnicas de particionamiento de equivalencia y análisis del valor frontera son aplicadas con frecuencia a situaciones o entradas específicas. Sin embargo, si diferentes combinaciones de entradas dan como resultado diferentes acciones, resulta más difícil usar las técnicas anteriores. Las especificaciones suelen contener reglas de negocio para definir las funciones del sistema y las condiciones bajo las que cada función opera. Las decisiones individuales son normalmente simples, pero el efecto global de las condiciones lógicas puede ser muy complejo.
• Transición de estados: La técnica anterior (tabla de decisión) es particularmente útil cuando las combinaciones de condiciones de entrada producen varias acciones. La técnica de transición de estados se utiliza con sistemas en los que las salidas son desencadenadas por cambios en las condiciones de entrada, o cambios de “estado”. Las pruebas de transición de estados se usan cuando alguno de los aspectos del sistema se puede describir en lo que se denomina una “máquina de estados finitos”. Esto significa que el sistema puede estar en un número (finito) de estados, y las transiciones de un estado a otro están determinadas por las reglas de la “máquina”. Este es el modelo en el que se basan el sistema y las pruebas. Cualquier sistema en el que se puedan conseguir diferentes salidas con la misma entrada, dependiendo de lo que haya pasado antes, es un sistema de estados finitos. Un sistema de estados finitos se suele representar mediante un diagrama de estados.
• Pruebas de casos de uso: Las pruebas de caso de uso son una técnica que ayuda a identificar casos de prueba que ejerciten el sistema entero transición a transición desde el principio al final. Un caso de uso es una descripción de un uso particular del sistema por un actor (un usuario del sistema). Cada caso de uso describe las interacciones que el actor tiene con el sistema para conseguir una tarea concreta (o, al menos, producir algo de valor al usuario). Los actores son generalmente gente pero pueden ser también otros sistemas. Resumidamente, los casos de uso son una secuencia de pasos que describen las interacciones entre el actor y el sistema. Los casos de uso están definidos en términos del actor, no del sistema, describiendo qué hace y ve el actor, más que qué entradas o salidas espera el sistema. De forma muy frecuente, usan el lenguaje y términos de negocio más que términos técnicos, especialmente cuando el actor es un usuario de negocio. Sirven como fundamento para desarrollar casos
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 127

INGENIERÍA DE SOFTWARE II
de prueba, en su mayoría, en los niveles de pruebas de sistema y pruebas de aceptación.
B. Basadas en la estructura: Las pruebas estructurales son una aproximación
al diseño de casos de prueba donde las pruebas se derivan a partir del conocimiento de la estructura e implementación del software. Esta aproximación se denomina a veces pruebas de caja blanca. La comprensión del algoritmo utilizado en un componente puede ayudar a identificar particiones adicionales y casos de prueba, asegurando así un mayor rango de pruebas. Las técnicas más sofisticadas proporcionan, de forma incremental, una cobertura de código completa. A continuación, se detallarán las técnicas basadas en la estructura más comunes.
• Pruebas de sentencia: El objetivo de las pruebas de sentencia es ir
probando las distintas sentencias a lo largo del código. Si se prueban todas y cada una de las sentencias ejecutables del código, habrá una cobertura de sentencia total. Es importante recordar que estas pruebas sólo se centran en sentencias ejecutables a la hora de medir la cobertura. Es muy útil el uso de gráficos de flujo de datos para identificar este tipo de sentencias, que se representan mediante rectángulos. Generalmente, la cobertura de las sentencias es demasiado débil para ser considerada una medida adecuada para probar la efectividad.
• Pruebas de decisión: El objetivo de estas pruebas es asegurar que las decisiones en un programa son realizadas adecuadamente. Las decisiones son parte de las estructuras de selección e iteración, por ejemplo, aparecen en construcciones tales como: IF THEN ELSE, o DO WHILE, o REPEAT UNTIL. Para probar una decisión, es necesario ejecutarla cuando la condición que tiene asociada es verdadera y también cuando es falsa. De esta forma, se garantiza que todas las posibles salidas de la decisión se han probado. Al igual que las pruebas de sentencias, las pruebas de decisión tienen una medida de cobertura asociada e intentan conseguir el 100% de la cobertura de decisión.
• Pruebas de caminos: Las pruebas de caminos son una estrategia de pruebas estructurales cuyo objetivo es probar cada camino de la ejecución independientemente. En todas las sentencias condicionales, se comprueban los casos verdadero y falso. En un proceso de desarrollo orientado a objetos, pueden utilizarse las pruebas de caminos cuando se prueban los métodos asociados a los objetos. Las pruebas de caminos no prueban todas las posibles combinaciones de todos los caminos en
C. Basadas en la experiencia: Las técnicas basadas en experiencia son
aquellas a las que se recurre cuando no hay una especificación adecuada desde la que crear casos de prueba basados en especificación, ni hay
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 128

INGENIERÍA DE SOFTWARE II
tiempo suficiente para ejecutar la estructura completa del paquete de pruebas.
• Adivinar errores: Las técnicas basadas en experiencia usan la
experiencia de los usuarios y de los técnicos de pruebas para determinar las áreas más importantes de un sistema y ejercitar dichas áreas de forma que sean consistentes con el uso que se espera que tengan.
• Pruebas exploratorias: Técnicas de pruebas más sofisticadas que se realizan sobre la base del conocimiento y experiencia de los técnicos de pruebas; dicha base es un factor decisivo para el éxito de las pruebas.
Técnicas de control estáticas. Aunque las técnicas estáticas son utilizadas cada vez más, las pruebas dinámicas siguen siendo las técnicas predominantes de validación y verificación. Las técnicas estáticas permiten encontrar las causas de los defectos. Aplicar un proceso de pruebas estáticas sobre el proceso de desarrollo permite una mejora del proceso evitando cometer errores similares en el futuro. Las técnicas de pruebas estáticas proporcionan una forma de mejorar la productividad del desarrollo del software. El objetivo fundamental de las pruebas estáticas es mejorar la calidad de los productos software, ayudando a los ingenieros a reconocer y arreglar sus propios defectos en etapas tempranas del proceso de desarrollo. Aunque las técnicas de este tipo de pruebas son muy efectivas, no conviene que sustituyan a las pruebas dinámicas.
A. Revisiones: Las revisiones son una técnica estática que consiste en realizar un análisis de un documento con el objetivo de encontrar y eliminar errores. El tipo de una revisión varía en función de su nivel de formalidad. En este caso, ‘formalidad’ se refiere a nivel de estructura y documentación asociada
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 129

INGENIERÍA DE SOFTWARE II
con la revisión. Unos tipos de revisión son completamente informales mientras que otros son muy formales.
No existe una revisión perfecta, sino que cada una tiene un propósito distinto durante las etapas del ciclo de vida del documento. Los principales tipos de revisiones se describen a continuación:
• Informal: Dar un borrador de un documento a un colega para que lo lea
es el ejemplo más simple de revisión. Es una forma de conseguir beneficios (limitados) a un bajo costo ya que no siguen ningún proceso formal a seguir. La revisión puede implementarse mediante ‘pares de programadores’, donde uno revisa el código del otro, o mediante un técnico que lidere el diseño de las revisiones y el código.
• Walkthrough: Un walkthrough se caracteriza porque el autor del documento bajo revisión va guiando al resto de participantes a través del documento exponiendo sus ideas para conseguir un entendimiento común y recoger respuestas. Es especialmente útil si los asistentes no están relacionados con el software, o no son capaces de entender los documentos de desarrollo de software.
• Revisión técnica: Una revisión técnica es una reunión que se centra en conseguir consenso sobre el contenido técnico de un documento, por lo que es posible que sea dirigida por un experto técnico. Los expertos necesarios para una revisión técnica son, por ejemplo, responsables del diseño y usuarios clave. El objetivo principal de este tipo de revisiones es evaluar el valor de conceptos técnicos y alternativas del entorno del proyecto y del propio producto. Este tipo de revisión a menudo se lleva a cabo por “pares” (mirar opciones) y para facilitar su ejecución suelen utilizarse listas de comprobación o listas de registro.
• Inspección: La inspección es el tipo de revisión más formal. El documento bajo inspección es preparado y validado minuciosamente por revisores antes de la reunión, se compara el producto con sus fuentes y otros documentos, y se usan listas de comprobación. En la reunión de la inspección, se registran los defectos encontrados y se pospone toda discusión para la fase de discusión. Todo esto hace que la inspección sea una reunión muy eficiente.
B. Análisis estático: El análisis estático, al igual que las revisiones, busca defectos sin ejecutar el código. Sin embargo, el análisis estático se lleva a cabo una vez que se escribe el código. Su objetivo es encontrar defectos en el código fuente y en los modelos del software.
Existen distintos tipos de análisis sintáctico, entre los que se encuentran:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 130

INGENIERÍA DE SOFTWARE II
• Análisis de flujo de control: Comprueba los bucles con múltiples puntos de entrada o salida, encuentra códigos inalcanzables.
• Análisis de uso de los datos: Detecta variables no inicializadas, variables escritas dos veces sin que intervenga una asignación, variables que se declaran pero nunca se usan.
• Análisis de interfaz: Comprueba la consistencia de una rutina, las declaraciones del procedimiento y su uso.
• Análisis de flujo de información: Identifica las dependencias de las variables de salida. No detecta anomalías en sí pero resalta información para la inspección o revisión del código.
• Análisis de caminos: Identifica los caminos del programa y arregla las sentencias ejecutadas en el camino. Es potencialmente útil en el proceso de revisión.
HERRAMIENTAS DE PRUEBAS.
Mediante la utilización de herramientas se puede conseguir reproducir cierto trabajo previamente realizado, obteniendo resultados consistentes.
Esta característica es especialmente útil para confirmar que un defecto se ha arreglado, o para introducir datos de entrada a pruebas.
Los principales beneficios que aporta el uso de herramientas como medio para llevar a cabo el proceso de pruebas son:
- Reducir el trabajo repetitivo. - Mejorar la consistencia. - Facilitar las evaluaciones objetivas. - Facilitar el acceso a información relacionada con pruebas.
Las herramientas están clasificadas dependiendo de las áreas o actividades de pruebas a las que se enfocan. La mayoría de las herramientas comerciales pueden usarse para diferentes funciones.
A. Herramientas de soporte para la gestión de pruebas: La gestión de pruebas se aplica sobre el conjunto del ciclo de vida de desarrollo del software, por lo que una herramienta de gestión de pruebas debería de ser la primera en usarse en el proyecto. Esta área abarcaría cuatro tipos de pruebas:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 131

INGENIERÍA DE SOFTWARE II
• Herramientas de gestión de pruebas: Estas herramientas ayudan a recoger, organizar y comunicar información sobre las pruebas en un proyecto. Esta información puede usarse para monitorear el proceso de pruebas y decidir las acciones a tomar. Asimismo, estas herramientas también proporcionan información sobre el componente o sistema que es probado.
• Herramientas de gestión de requisitos: Son útiles para las pruebas dado que éstas se basan en los requisitos. De esta forma, cuanto mayor sea la calidad de los requisitos, más fácil será desarrollar pruebas para comprobar que son correctos. Asimismo, es importante mantener una trazabilidad bidireccional entre los requisitos y las pruebas, y estas herramientas pueden ser de gran ayuda en esta tarea.
• Herramientas de gestión de incidencias: Facilitan el mantenimiento del registro de incidencias a lo largo del tiempo. Este tipo de herramientas permiten identificar defectos, problemas, anomalías o posibles mejoras.
• Herramientas de gestión de configuración: Las herramientas de gestión de configuración no son estrictamente herramientas de pruebas, sin embargo, una buena gestión de configuración es crítica para controlar las pruebas. Es necesario conocer exactamente qué debe ser probado así como la versión exacta de todos los componentes del sistema.
B. Herramientas de soporte para pruebas estáticas: Las herramientas de las
que se habla en este apartado pueden dar soporte a las actividades de prueba descritas en el apartado relativo a las pruebas estáticas. Esta área abarca tres tipos de pruebas, a continuación se describen.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 132

INGENIERÍA DE SOFTWARE II
• Herramientas de revisión de procesos: Las herramientas de revisión de procesos se hacen especialmente útiles para revisiones formales, donde hay mucha gente involucrada o donde las personas implicadas están en lugares geográficamente separados. Es cierto que mediante el uso de hojas de cálculo o documentos de texto se puede llevar un seguimiento de toda la información del proceso de revisión, pero también hay que recordar que una herramienta de revisión está diseñada exclusivamente para este propósito, y por lo tanto será más probable conseguir un buen resultado utilizándola. Otra ventaja que ofrece este tipo de herramientas es que facilitan mucho el trabajo de recogida de información del proceso de pruebas.
• Herramientas de análisis estático: Las herramientas de análisis estático, normalmente, son utilizadas por desarrolladores como parte del proceso de pruebas. La característica principal de estas herramientas es que el código no se ejecuta, sino que sirve de elemento o dato de entrada a la herramienta. Algunas de las características de estas herramientas son que calculan métricas (p.ej., complejidad ciclomática), imponen estándares de codificación, analizan estructuras y dependencias, identifican anomalías en el código, entre otras.
• Herramientas de modelado: Ayudan a validar modelos del sistema, por ejemplo, validando la consistencia de los objetos en una base de datos o encontrando inconsistencias y defectos. Estas herramientas son de gran utilidad en el diseño de software.
C. Herramientas de soporte para la especificación de pruebas. Estas
herramientas dan soporte a actividades de pruebas tales como el análisis de pruebas, el diseño de pruebas o la implementación de pruebas. En este apartado destacamos dos tipos de esta categoría de herramientas.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 133

INGENIERÍA DE SOFTWARE II
• Herramientas de diseño de pruebas: Estas son de gran utilidad a la
hora de comenzar con el diseño de pruebas, aunque no harán todo el trabajo. El beneficio que ofrece este tipo de herramientas es que pueden identificar de manera rápida y sencilla las pruebas a ejecutar sobre todos los elementos del sistema. Es decir, ayuda a que el proceso de pruebas sea más exhaustivo. Las herramientas de diseño de pruebas también pueden ayudar a identificar valores de entradas a las pruebas (requisitos, modelos de diseño, condiciones de prueba…), a construir casos de pruebas, a seleccionar los factores a tener en cuenta para asegurar que todos los pares de combinación son probados, etc.
• Herramientas de preparación de datos de pruebas: Establecer datos de pruebas puede ser una tarea tediosa, especialmente si se contempla un gran volumen de datos para las pruebas. Las herramientas de preparación de datos de prueba sirven de ayuda en esta área. Estas herramientas suelen usarse por los desarrolladores, aunque también se utilizan durante las pruebas de sistema y de aceptación. Son especialmente útiles en las pruebas de rendimiento, donde es imprescindible trabajar con gran cantidad de datos realistas.
D. Herramientas para ejecución y registro de pruebas: En este apartado, se
van a definir tres tipos de herramientas relacionadas con la ejecución y registro de pruebas.
• Herramientas de ejecución de pruebas: La mayoría de las herramientas de este tipo ofrecen un mecanismo para la captura y registro de pruebas.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 134

INGENIERÍA DE SOFTWARE II
Estas herramientas suelen utilizar un lenguaje de scripting, por lo que si los técnicos de pruebas desean utilizar una herramienta de ejecución de pruebas necesitarán tener habilidades de programación sobre la creación y modificación de scripts.
• Comparadores de pruebas: La esencia de las pruebas es comprobar si el software produce el resultado correcto, y para ello deben comparar lo que el software produce y lo que debería producir. Los comparadores de pruebas ayudan a automatizar estos aspectos. Hay dos maneras de llevar a cabo esta comparación. De manera dinámica, donde la comparación es realizada dinámicamente, es decir, mientras la prueba se está ejecutando, o post- ejecución, donde la comparación se realiza después de que la prueba haya acabado y el software bajo prueba no se vuelva a ejecutar.
• Herramientas de seguridad: Hay numerosas herramientas que protegen
a los sistemas de ataques externos, por ejemplo, los cortafuegos. Las herramientas de pruebas de seguridad se utilizan para probar la seguridad que tienen los sistemas, intentado acceder a un sistema, por ejemplo. También, se encargan de identificar virus, simular ataques externos, detectar intrusos, etc.
E. Herramientas de monitorización y rendimiento: Las herramientas
descritas en esta sección soportan pruebas que pueden llevarse a cabo durante el propio proceso de pruebas o después de la liberación del sistema. En esta sección se tratarán dos de estas herramientas.
• Herramientas de análisis dinámico: Las herramientas de análisis dinámico se llaman así porque son “dinámicas”, es decir, requieren que el código se esté ejecutando, y porque no ejecutan pruebas como tal, sino que analizan lo que ocurre cuando el software se está ejecutando.
• Herramientas de monitorización: Las herramientas de monitorización se utilizan para realizar un seguimiento del estado del sistema en uso, con el objetivo de conseguir avisos tempranos de los problemas y de mejorar el servicio. Hay herramientas de monitorización para servidores, redes, bases de datos, seguridad, rendimiento, páginas web y uso de internet, y para aplicaciones.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 135

INGENIERÍA DE SOFTWARE II VI. CONOCER LA EJECUCIÓN DE PRUEBA.
OPERACIONES: Desarrollar ambiente de prueba y preparación del ambiente. Ciclo de vida de un incidente y clasificación de defectos. Evaluación de resultados. Registro y seguimiento de incidentes. Automatización de la ejecución de pruebas y Herramientas. EQUIPOS Y MATERIALES:
Computadora con microprocesadores Core 2 Duo o de mayor capacidad. Sistema operativo Windows. Acceso a internet.
ORDEN DE EJECUCIÓN:
Reconocer el ambiente de pruebas y preparación. Reconocer los ciclos de vida de los incidentes y sus clasificaciones. Desarrollar registros y seguimientos de incidentes.
6.1. DESARROLLAR AMBIENTE DE PRUEBA.
El desarrollo de software en estos tiempos se caracteriza por los múltiples equipos de proyectos y mantenimiento trabajando de forma simultánea, bajo un cronograma de trabajo cada vez más exigentes y desarrollando sistemas que interoperan con variedad de otras aplicaciones y plataformas.
Desarrollar el ambiente de prueba adecuado bajo escenarios múltiples, la gestión de los ambientes (entornos) de pruebas integrales (System Integration Tests, o SIT), adquiere gran importancia para asegurar que el Software sea puesto en producción con los niveles necesarios de calidad.
Pruebas del Sistema. Cualquier tipo de software, desarrollado o adquirido, debe ser probado, ya sea para decidir si mejora algún proceso de la empresa, para analizar fallas durante la ejecución del software, tales como seguridad y rendimiento. A este tipo de pruebas donde se estudia el producto completo se le llama Pruebas de Sistema.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 136

INGENIERÍA DE SOFTWARE II La prueba de sistemas usualmente es de caja negra, especialmente si el encargo de probar el sistema no tiene acceso al código fuente del sistema a probar, que es lo más frecuente. Visión sistemática de la prueba. Para realizar pruebas, debe mantenerse un enfoque sistémico, es decir integral. Al Hablar de enfoque sistémico se indica que: a) Todo sistema tiene una serie de objetivos que le dan objetivos. Esos
objetivos están asociados con indicadores de éxito que permiten determinar si los objetivos se cumplen y en qué medida.
b) Todo sistema tiene una serie de elementos que lo forman y la interacción de tales elementos se orienta a satisfacer objetivos.
c) Ningún sistema existe en aislamiento; siempre interaccionan con otros sistemas constituyendo un sistema mayor.
Al aplicar estos conceptos a la prueba de software, se obtienen una serie de principios que servirán de base para la prueba: 1. Antes de probar el software debe conocer con precisión los objetivos del
software a probar, así como sus indicadores de éxitos. Estos elementos se localizan en los documentos obtenidos en la etapa de recolección de requerimientos, así como en las especificaciones del software. Esta información será la base indispensable para preparar el plan de pruebas y seria la base para iniciar el desarrollo de los casos de prueba.
2. Deben determinar las entradas y salidas del sistema aprobar. Este aspecto es necesario en la preparación de los casos de prueba y también en el establecimiento de procedimientos de prueba, orientados especialmente a los casos de prueba.
3. Considerar el sistema mayor donde opera el software a probar. Generalmente es un ambiente organizacional, formado por elementos de hardware, de software y personas (usuarios). Todos estos elementos influyen en el sistema y ayudan en preparar los casos de prueba de situaciones no deseadas, relacionadas con datos inadecuados, ausencia de elementos necesarios y ocurrencia de excepciones.
Vista general de la prueba de sistemas. El proceso de prueba de un sistema tiene dos etapas: la preparación de pruebas y la aplicación de las mismas. La primera está muy ligada a la obtención de requerimientos , mientras que en la segunda requiere del sistema completo, como se denomina a un sistema
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 137

INGENIERÍA DE SOFTWARE II parcial, aún no liberado, para poder aplicar las pruebas, por lo que ocurre en etapas avanzadas del proyecto. La etapa de preparación de pruebas incluye al menos tres actividades: a) Preparar un plan de pruebas. b) Preparar una lista de verificación. c) Preparar casos de prueba. Para ejecutar la segunda y la tercera actividad se requiere contar con el documento de requerimientos. La primera etapa de pruebas provee retroalimentación para el análisis de requerimientos. También provee valiosas sugerencias para el diseño y la implementación del sistema, si apenas se está desarrollando. La etapa de aplicación de pruebas requiere el plan de pruebas y de una versión del sistema que sea ejecutable (una integración). Sobre esta se aplicaran los casos de prueba que se prepararon, se analizaron los resultado y se identifican posibles fallas. Esta segunda etapa provee retroalimentación a la implementación y al diseño, mostrando posibles fallas que deben ser corregidas. También provee información de utilidad para la aceptación del sistema, la estimación de su confiabilidad y el mantenimiento del mismo. En la siguiente imagen se muestra el proceso de prueba del sistema y su relación con otros procesos.
Las pruebas de sistema tienen varias partes importantes: a) Cada unidad (módulos) que forma el sistema ha sido probada por separado
y se han eliminado sus defectos. b) Las interfaces han sido probadas también por separado.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 138

INGENIERÍA DE SOFTWARE II c) Se han realizado pruebas de integración para analizar la interacción entre
partes del sistema y se han eliminado los defectos identificados. Procedimientos a implementar para una buena gestión de ambientes de pruebas integrales. • Todas las fase de pruebas funcionales, incluyendo: Unitarias, integración,
aceptación, desempeño (estrés), pruebas no funcionales, requieren de ambientes de pruebas, por lo que deben definirse procedimientos específicos de gestión de ambientes en cada etapa de los proyectos.
• Encargar la labor de planeación y operación a un Gerente de Operaciones o de Cambios, preferiblemente distinto al del ambiente de desarrollo y producción para evitar posibles fallas.
• Establecer la solicitud de requisitos de ambiente de pruebas por parte de todos los equipos que tengan que utilizar el ambiente. Deben especificarse los requisitos de configuración y las herramientas e infraestructura requeridos.
• Los requerimientos de ambientes deben ser incluidos en la documentación de requerimientos de todos los mantenimientos o proyectos.
• Procedimientos de Gestión de la creación, build, actualización (upgrade) y soporte de ambientes.
• Definir procesos auditables para: - Asignación de ambientes. - Uso compartido. - Accesos múltiples. - Acuerdos de nivel de servicio. - Actualizaciones. - Instalaciones. - Desincorporación. - Preparación de datos de prueba.
• Procedimientos de preparación, conectividad y asistencia a los equipos de pruebas de todas las fases.
• Contar con herramientas para debugging. No es posible probar completamente un programa. Para probar completamente un sistema se deben ejercitar todos los caminos posibles del programa a probar. Myers mostró en 1979 un programa que contenía un loop y unos pocos if, este programa tenía 100 trillones de caminos, un tester podía probarlos todos en un billón de años. La prueba exhaustiva requiere probar el comportamiento de un programa para todas las combinaciones validas e invalidas de entradas.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 139

INGENIERÍA DE SOFTWARE II Además se debe probar esto en cada punto donde se ingresan datos, bajo cada estado posible del programa en ese punto. Esto no es posible, ya que el tiempo requerido es prohibitivo. En un mundo ideal, desearíamos probar cada permutación posible de un programa.
El objetivo debe ser maximizar la producción de las pruebas, esto es, maximizar el número de los errores encontrados por un número finito de los casos de prueba. La forma en cómo se seleccionan los casos de prueba es una de las principales decisiones a tomar, teniendo en cuenta las siguientes consideraciones:
PREPARACIÓN DEL AMBIENTE.
Procedimientos de uso de los ambientes por los equipos de pruebas. • Definir las especificaciones de ambientes de prueba que necesita el equipo. • Antes de iniciar cualquier ciclo de pruebas, deben ejecutarse
actividades para verificar que el ambiente ha sido configurado adecuadamente.
• No todas las pruebas se ejecutan en el ambiente de pruebas integrales de software, por ejemplo, pruebas de componente de software, en las que se revisa el código se realizan en el ambiente de desarrollo.
• Si durante la ejecución de las pruebas integrales se realizan cambios de configuración, será necesario identificar las pruebas afectadas y ejecutar nuevamente dichos casos de prueba.
• Para proyectos de mantenimiento o migración de plataformas tecnológicas (por ejemplo una actualización de base de datos), es necesario incluir pruebas operacionales, para lo cual es necesario configurar y probar un ambiente de pruebas similar al de producción.
• Ajustes al cronograma de pruebas dada la disponibilidad o no disponibilidad de ambientes de pruebas. Los reportes de incidencias deben hacer referencia al ambiente en el que se está probando y cualquier aspecto especifico de configuración.
Prueba: Es una actividad realizada para evaluar la calidad del producto y mejorarla, identificando defectos y problemas. La Prueba de software: Es la verificación dinámica del comportamiento de un programa contra el comportamiento esperado, usando un conjunto finito de casos de prueba, seleccionados de manera adecuada desde el dominio infinito de ejecución.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 140

INGENIERÍA DE SOFTWARE II Dinámica: Implica que para realizar las pruebas hay que ejecutar el programa para los datos de entrada. El comportamiento esperado: Debe ser posible decidir cuando la salida observada de la ejecución del programa es aceptable o no, de otra forma el esfuerzo de la prueba es inútil. Características que deben tener los ambientes. Debe residir en un computador distinto al personal del desarrollador. Preferiblemente en un servidor compartido por los equipos de pruebas de software. Utilizar nombres de dominio (no direcciones IP) distintos a los de producción y desarrollo para evitar confusión del personal de pruebas. Ser lo más similarmente posible al ambiente de producción, incluyendo: - Aplicaciones locales, cliente servidor, web, etc. - Configuración de servidores. - Manejadores de Bases de datos de producción, de las mismas versiones. - Configuración de base de datos. - Cuentas de usuario de sistema operativo, bases de datos y aplicaciones con
la misma configuración y privilegios de acceso. - Componentes de infraestructura deben ser similares. - Versiones de software. - Réplicas de todos los componentes con los que el Software desarrollado
tendrá interoperación, incluyendo: Otras aplicaciones, otros middleware, interfaces, demonios (Daemons), utilidades FTP, entre otros.
Instalar las herramientas de gestión de casos de prueba e incidencias en una maquina o servidor distinto al del ambiente de pruebas integrales, compartido por los equipos de pruebas. Capacidad de servir a múltiples audiencias, por ejemplo administradores de sistemas, usuarios finales, desarrolladores. En todos los casos sólo para ejecución de pruebas. Debe apoyarse en herramientas de control de versiones, especialmente cuando existen múltiples proyectos en paralelo probando distintas funcionalidades.
Ciclo de Vida de un incidente. Un proceso es una serie de pasos que involucran actividades, restricciones y recursos que producen una determinada salida esperada. Cuando el proceso implica la construcción de algún producto (sistema), suele referirse al proceso como ciclo de vida. El proceso de desarrollo de software suele denominarse ciclo de vida del software y describe la vida de un producto de software desde su concepción hasta su entrega, utilización y mantenimiento
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 141

INGENIERÍA DE SOFTWARE II La definición de un proceso puede ser un procedimiento, una política o un estándar. Los modelos de ciclo de vida del software sirven como definiciones de alto nivel de las fases que ocurren durante el desarrollo. No tienen como objetivo brindar información detallada, pero sí proveer las principales actividades y sus interdependencias. Ejemplos de modelos de ciclos de vida son el modelo en cascada, el de desarrollo evolutivo, desarrollo iterativo e incremental o modelo espiral.
Los procesos pueden ser definidos en diferentes niveles de abstracción, varios elementos de un proceso pueden ser definidos, por ejemplo: actividades, productos (artefactos) y recursos.
El modelo básico usado en los principios del software fue el “Code & fix” que tiene dos etapas:
• Escribir un código que resuelva un problema dado. • Arreglar los problemas en el código. Se codifica y luego se piensa en los
requerimientos, diseño, pruebas, mantenimiento.
En este modelo las etapas se representan una tras otra en el tiempo: Requerimientos, Diseño, Implementación, Prueba y Mantenimiento. Para comenzar una etapa se debe haber completado la anterior. El mayor problema con este modelo es que no refleja realmente la forma en que se desarrolla el software, ya que el software se desarrolla con cierto grado de repetición que la cascada no incluye. Actualmente, los modelos más modernos, intentan reflejar este comportamiento dividiendo el desarrollo en fases, realizando el desarrollo en forma iterativa e incremental.
Incidente. Un incidente en la seguridad de la información se define como un acceso o falla de pruebas antes de la ejecución del software, para ello se realiza un análisis de los posibles errores que puede tener (testing), es por eso que las empresa prueban el software por horas para ver el funcionamiento a lo largo del día. El ciclo de vida de un incidente se divide en diferentes fases: 1. Fase inicial (preparación y prevención, y detección y pre análisis) 2. Contención, erradicación y recuperación (notificación, análisis, contención
y erradicación). 3. Recuperación del incidente (recuperación). 4. Actividad después del incidente (reflexión y documentación).
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 142

INGENIERÍA DE SOFTWARE II
Modelo V.
El modelo V fue concebido en 1992 como una serie de directivas que describen los procedimientos, los métodos que se aplicarán, y los requerimientos funcionales para las herramientas utilizadas en los sistemas de. El modelo V es una variación del modelo en cascada que demuestra cómo se relacionan las actividades de prueba con las de análisis y diseño.
En la imagen se puede ver que la punta de la V es la codificación, con el análisis y el diseño a la izquierda y la prueba y el mantenimiento a la derecha.
El modelo V sugiere que la prueba unitaria y de integración sea hecha también para verificar el diseño, verificando que todos los aspectos del diseño del programa se han implementado correctamente en el código, la prueba del sistema debe verificar el diseño del sistema, asegurando que todos los aspectos del diseño están correctamente implementados. La prueba de aceptación que es dirigida por el cliente, valida los requerimientos.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 143

INGENIERÍA DE SOFTWARE II La vinculación entre la parte izquierda y derecha del modelo V implica que si se encuentran problemas durante la verificación y la validación entonces el lado izquierdo de la V puede ser ejecutado nuevamente para solucionar el problema y mejorar los requerimientos, el diseño y el código antes de retomar las pruebas del lado derecho.
Clasificación de defectos:
- El primer paso para administrar los defectos es conocerlos para luego prevenirlos.
- Llevar un registro de todos los defectos encontrados en el programa. - Registrar información adicional para comprender el error.
Cuadro de clasificación de defectos:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 144

INGENIERÍA DE SOFTWARE II Ejemplo: el tipo 20 Errores de sintaxis, nombre de funciones, falta de puntuación. Encontrando defectos en la etapa de desarrollo: Por medio del compilador: El compilador solo encuentra errores de codificación, sintaxis, no encuentra errores de diseño. Por medio del testeo: Depende de los datos que preparemos para las pruebas. ¿Cuándo revisas el código? Después de finalizar la codificación. Para poder llevar un control de las fallas durante el proceso de desarrollo.
“La Calidad del Producto Final depende de la calidad del desarrollo” Encontrando defectos en la etapa final: Las pruebas representan una importante cantidad de los costes totales del desarrollo de proyectos. Por eso hay modelos que permiten encontrar los defectos que trae el software para evitar posibles fallas. Modelos Básicos:
- Test Maturity Model (TMM). - Test Process Improvement (TPI). - Critical Test process (CTP). - Systematic Test and Evolution Process (STEP). - Capability Matury Model Integration (CMMI).
Criterios Comunes: 1. Iniciar. 2. Medir. 3. Priorizar/Planificar. 4. Redefinir. 5. Operar. 6. Validad. 7. Evolucionar.
Iniciar
Evolucionar
Medir
Redefinir
Priorizar / Planificar
Operar
Validad
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 145

INGENIERÍA DE SOFTWARE II Comparativo de los Modelos Básicos:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 146

INGENIERÍA DE SOFTWARE II Evaluación de resultados:
Para evaluar el software, a continuación se muestran una seria de pruebas importantes, entre ellas, el rendimiento, el desempeño y la confiabilidad.
Las pruebas se realizaran principalmente sobre el mediador, que están basados en el supuesto caso de que la base de datos, el punto de acceso y el servidor tienen un funcionamiento normal que no afecte de manera indirecta el sistema.
Pruebas de Humo (Smoke Testing o Ad Hoc)
Objetivos: - Probar el sistema constantemente. - Garantizar poco esfuerzo en la integración final del sistema. - Asegurar los resultados de las pruebas unitarias. - Se reducen los riesgos y a baja calidad.
Descripción de la prueba: Toma éste nombre debido a que su objetivo es probar el sistema constantemente buscando que saque “humo” o falle. En algunos proyectos este tipo de prueba va junto con las pruebas funcionales. Permite detectar problemas que por lo regular no son detectados en las pruebas normales.
Este tipo de pruebas es útil en la programación extrema (extremme
programming) y de sistemas complejos. Pruebas del Sistema. Objetivos: Asegurar la apropiada navegación dentro del sistema, ingreso de datos, procesamiento y recuperación. Descripción de la prueba: Las pruebas del sistema deben enfocarse en requisitos que puedan ser tomados directamente de casos de uso y reglas y funciones de negocios. El objetivo de estas pruebas es verificar el ingreso, procesamiento y recuperación apropiado de datos, y la implementación apropiada de las reglas de negocios. Este tipo de pruebas se basan en técnicas de caja negra, esto es, verificar el sistema (y sus procesos internos), la interacción con las aplicaciones que lo usan vía GUI y analizar las salidas o resultados. En esta prueba se determina
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 147

INGENIERÍA DE SOFTWARE II qué pruebas de Sistema (usabilidad, volumen, desempeño, etc.) asegurarán que la aplicación alcanzará sus objetivos de negocio. La prueba incluye: - Prueba funcionalidad. - Prueba de usabilidad. - Prueba de performance. - Prueba de documentación y procedimientos. - Prueba de seguridad y controles. - Prueba de volumen. - Prueba de esfuerzo (Stress). - Prueba de recuperación. - Prueba de múltiples sitios. Para sistemas web se recomienda especialmente realizar mínimo el siguiente grupo de pruebas de sistema: - Humo. - Usabilidad. - Performance. - Funcionalidad.
Para capitalizar el trabajo hasta ahora completado, los casos de prueba de las pruebas previas realizadas pueden frecuentemente ser reorganizados y rehusados durante la prueba de sistema. La prueba de sistema es compleja porque intenta validar un número de características al mismo tiempo, a diferencia de otras pruebas que sólo se centran en uno o dos aspectos del sistema al mismo tiempo. Técnica: - Ejecute cada caso de uso, flujo básico o función utilizando datos válidos e
inválidos, para verificar que: Los resultados esperados ocurren cuando se utiliza un dato válido. Los mensajes de error o de advertencia aparecen en el momento adecuado, cuando se utiliza un dato inválido. Cada regla de negocios es aplicada adecuadamente.
Criterio de Completitud: - Todas las pruebas planeadas han sido ejecutadas. - Todos los defectos que se identificaron han sido tenidos en cuenta.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 148

INGENIERÍA DE SOFTWARE II Pruebas de Desempeño. Objetivo: Validar el tiempo de respuesta para las transacciones o funciones de negocios bajo las siguientes dos condiciones: - Volumen normal anticipado. - Volumen máximo anticipado. Descripción de la Prueba: Las pruebas de desempeño miden tiempos de respuesta, índices de procesamiento de transacciones y otros requisitos sensibles al tiempo. El objetivo de las pruebas de desempeño es verificar y validar los requisitos de desempeño que se han especificado (en este caso, el desempeño ofrecido por el proponente). Las pruebas de desempeño usualmente se ejecutan varias veces, utilizando en cada una, carga diferente en el sistema. La prueba inicial debe ser ejecutada con una carga similar a la esperada en el sistema. Una segunda prueba debe hacerse utilizando una carga máxima. Adicionalmente, las pruebas de desempeño pueden ser utilizadas para perfilar y refinar el desempeño del sistema como una función de condiciones tales como carga o configuraciones de hardware Las principales actividades son: - Comparar el desempeño del sistema actual con los requisitos. - Poner a punto el sistema para mejorar las métricas de desempeño y
proyectar la capacidad futura de carga del sistema. - Los objetivos de nivel de servicio definidos deben guiar la prueba de
performance. Algunas características que afectan el desempeño son: Errores lógicos: - Procesamiento ineficiente. - Diseño pobre: muchas interfaces, instrucciones y entradas/salidas. - Cuellos de botella en discos, CPU o canales de entrada/salida. - Salidas del sistema. - Tiempos de respuesta. - Capacidad de almacenamiento. - Tasa de entrada/salida de datos. - Número de transacciones que pueden ser manejadas simultáneamente. - Las pruebas de desempeño utilizan las técnicas de caja blanca y caja negra. Técnica:
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 149

INGENIERÍA DE SOFTWARE II - Utilice los procedimientos de prueba desarrollados para las pruebas del
modelo del negocio (Pruebas del Sistema). - Modifique archivos de datos (para incrementar el número de transacciones)
o los scripts para incrementar el número de veces que ocurre cada transacción.
- Los scripts deben ser ejecutados en una máquina y deben ser repetidos con múltiples clientes.
Criterio de completitud: - Un Usuario / Una Transacción. Se completaron las pruebas sin ninguna falla
y dentro del tiempo esperado o requerido por transacción. - Múltiples transacciones, múltiples usuarios. Se completaron las pruebas de
los scripts sin ninguna falla y dentro del tiempo esperado. Unas pruebas de desempeño integrales incluyen tener una carga en background en el servidor. Hay varios métodos que pueden ser utilizados para hacer esto: - Transacciones dirigidas directamente al servidor, usualmente en forma de
sentencias SQL. - Creación de usuarios virtuales para simular muchos clientes (usualmente
varios cientos). Se utilizan herramientas de Emulación de Terminales Remotas para obtener esta carga. Esta técnica también puede ser utilizada para cargar de tráfico la red.
- Use múltiples clientes físicos, cada uno corriendo los scripts de prueba. - La Base de datos utilizada para pruebas de desempeño debe ser de un
tamaño real o proporcionalmente más grande que la diseñada Pruebas de Carga. Objetivo: Verificar el tiempo de respuesta del sistema para transacciones o casos de uso de negocios, bajo diferentes condiciones de carga. Descripción de la prueba: Las pruebas de carga miden la capacidad del sistema para continuar funcionando apropiadamente bajo diferentes condiciones de carga. La meta de las pruebas de carga es determinar y asegurar que el sistema funciona apropiadamente aún más allá de la carga de trabajo máxima esperada.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 150

INGENIERÍA DE SOFTWARE II Adicionalmente, las pruebas de carga evalúan las características de desempeño (tiempos de respuesta, tasas de transacciones y otros aspectos sensibles al tiempo). Técnica: - Use los scripts desarrolladas para pruebas del negocio. - Modifique archivos de datos (para incrementar el número de transacciones o
veces que cada transacción ocurre). - Criterio de Completitud. - Múltiples transacciones, múltiples usuarios. Se completaron las pruebas de
los scripts sin ninguna falla y dentro del tiempo esperado.
Consideraciones Especiales: - Las pruebas de carga deben ser ejecutadas en una máquina dedicada o en
un tiempo dedicado. Esto permite control total y medidas precisas. - La Base de datos utilizada para pruebas de desempeño debe ser de un
tamaño real o proporcionalmente más grande que la diseñada.
Pruebas de Stress. Objetivo: Verificar que el sistema funciona apropiadamente y sin errores, bajo estas condiciones de stress: - Memoria baja o no disponible en el servidor. - Máximo número de clientes conectados o simulados (actuales o físicamente
posibles). - Múltiples usuarios desempeñando la misma transacción con los mismos
datos. - El peor caso de volumen de transacciones (ver pruebas de desempeño).
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 151

INGENIERÍA DE SOFTWARE II La meta de las pruebas de stress también es identificar y documentar las condiciones bajo las cuales el sistema FALLA. Descripción de la prueba: Las pruebas de stress se proponen encontrar errores debidos a recursos bajos o completitud de recursos. Poca memoria o espacio en disco puede revelar defectos en el sistema que no son aparentes bajo condiciones normales. Las pruebas de stress identifican la carga máxima que el sistema puede manejar. El objetivo de esta prueba es investigar el comportamiento del sistema bajo condiciones que sobrecargan sus recursos. Es aplicable, sin embargo, a programas que trabajan bajo cargas variables, interactivas, de tiempo real y de control de proceso. Aunque muchas pruebas de esfuerzo representan condiciones que el programa encontrará realmente durante su utilización, muchas otras serán en verdad situaciones que nunca ocurrirán en la realidad. Esto no implica, sin embargo, que estas pruebas no sean útiles. Si se detectan errores durante estas condiciones “imposibles”, la prueba es valiosa porque es de esperar que los mismos errores puedan presentarse en situaciones reales, algo menos exigentes. Técnica: - Use los scripts utilizados en las pruebas de desempeño. - Para probar recursos limitados, las pruebas se deben correr en un servidor
con configuración reducida (o limitada). - Para las pruebas de stress restantes, deben utilizarse múltiples clientes, ya
sea corriendo los mismos scripts o scripts complementarios para producir el peor caso de volumen de transacciones.
Criterio de Completitud: Todas las pruebas planeadas han sido ejecutadas y excedidas sin que el sistema falle. Consideraciones Especiales: - Producir stress en la red puede requerir herramientas de red para
sobrecargarla de tráfico. - El espacio en disco utilizado para el sistema debe ser reducido
temporalmente para limitar el espacio disponible para el crecimiento de la Base de datos.
Sincronización de varios clientes accediendo simultáneamente los mismos registros.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 152

INGENIERÍA DE SOFTWARE II Pruebas de Volumen Objetivo: Verificar que la aplicación funciona adecuadamente bajo los siguientes escenarios de volumen: - Máximo (actual o físicamente posible) número de clientes conectados (o
simulados), todos ejecutando la misma función (peor caso de desempeño) por un período extendido.
- Máximo tamaño de base de datos (actual o escalado) y múltiples consultas ejecutadas simultáneamente.
Descripción de la Prueba: Las pruebas de volumen hacen referencia a grandes cantidades de datos para determinar los límites en que se causa que el Sistema falle. También identifican la carga máxima o volumen que el sistema puede manejar en un período dado. El objetivo de esta prueba es someter al sistema a grandes volúmenes de datos para determinar si el mismo puede manejar el volumen de datos especificado en sus requisitos. Algunos ejemplos de escenarios de prueba de volúmenes: - Un compilador puede ser alimentado por un programa para compilar que sea
absurdamente grande. - Un editor de nexos puede recibir un programa que contenga miles de
módulos. - Un simulador de circuito electrónico puede recibir un circuito diseñado con
miles de componentes.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 153

INGENIERÍA DE SOFTWARE II Puesto que obviamente, la prueba de volumen es una prueba costosa, tanto en tiempo de máquina como en personal, se debe tratar de no exceder los límites. Sin embargo, todo programa debería ser expuesto, al menos, a algunas pruebas de volumen. Técnica: - Utilice los scripts diseñados para las pruebas de desempeño. - Deben usarse múltiples clientes, ya sea corriendo las mismas pruebas o
pruebas complementarias para producir el peor caso de volumen (ver pruebas de stress) por un período extendido.
- Se utiliza un tamaño máximo de Base de datos. (actual, escalado o con datos representativos) y múltiples clientes para correr consultas simultáneamente para períodos extendidos.
Criterio de Completitud: Todas las pruebas planeadas han sido ejecutadas y los límites especificados en el sistema se han conseguido o excedido sin que el sistema falle. Pruebas de Recuperación y Tolerancia a fallas. Objetivo: Verificar que los procesos de recuperación (manual o automática) restauran apropiadamente la Base de datos, aplicaciones y sistemas, y los llevan a un estado conocido o deseado. Los siguientes tipos de condiciones deben incluirse en la prueba: - Interrupción de electricidad en el cliente. - Interrupción de electricidad en el servidor. - Interrupción en la comunicación hacia el servidor (caídas de red). - Interrupción en la comunicación con los controladores de disco. - Ciclos incompletos (procesos de consultas interrumpidos, procesos de
sincronización de datos interrumpidos). - Llaves o apuntadores de base de datos inválidos. - Elementos corruptos o inválidos en la base de datos.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 154

INGENIERÍA DE SOFTWARE II Descripción de la Prueba: Estas pruebas aseguran que una aplicación o sistema se recupere de una variedad de anomalías de hardware, software o red con pérdidas de datos o fallas de integridad. Las pruebas de tolerancia a fallas aseguran que, para aquellos sistemas que deben mantenerse corriendo, cuando una condición de falla ocurre, los sistemas alternos o de respaldo pueden tomar control del sistema sin pérdida de datos o transacciones. Las pruebas de recuperación son contrarias a las pruebas en que la aplicación o sistema es expuesto a condiciones extremas (o condiciones simuladas), tales como fallas en dispositivos en entrada/salida o llaves o apuntadores inválidos de base de datos. El objetivo de esta prueba es determinar la habilidad del sistema para recuperarse de una falla de hardware o software. Esta prueba evalúa las características de contingencia construidas en el sistema para procesar interrupciones y para volver a puntos específicos en el ciclo de procesamiento del sistema. La recuperación debe ser considerada en el proceso de diseño. Errores de programación o de datos pueden ser incorporados ex profeso en un sistema para determinar si se puede recuperar de ellos. Las fallas de equipo (por ejemplo errores de paridad en memoria, errores en dispositivos de entrada/salida) pueden ser simuladas. Técnica: Se deben utilizar las pruebas creadas para la Funcionalidad del sistema y Procesos de Negocios para crear una serie de transacciones. Una vez se alcanza el punto inicial de las pruebas de recuperación, se deben realizar o simular las siguientes acciones: - Interrupción de electricidad en el cliente. - Interrupción de electricidad en el servidor: simular o iniciar. - Procedimientos de pérdida de energía para el servidor. - Interrupción de la comunicación en la red. (Desconectar físicamente los
cables o apagar los hubs o routers). - Interrupción de la comunicación con los controladores de disco: simular o
eliminar físicamente la comunicación con uno o más controladores o dispositivos.
- Una vez se realizan estas acciones, se deben ejecutar series de transacciones, y luego, una vez alcanzado el segundo punto de pruebas, se deben invocar los procedimientos de recuperación.
Las pruebas para ciclos incompletos utilizan la misma técnica que se describe arriba, excepto que los procesos de Base de datos deban ser abortados o terminados prematuramente. Las pruebas para estas condiciones requieren que se llegue a un estado conocido previamente en la Base de datos. Algunos
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 155

INGENIERÍA DE SOFTWARE II campos, apuntadores y llaves deben ser modificados manualmente, valiéndose de las herramientas que ofrezca la SSPD. Las transacciones adicionales deben ser ejecutadas utilizando las pruebas para Funcionalidad de la aplicación y para Procesos de Negocios. Criterio de Completitud: En todos los casos mencionados, la Base de datos, aplicación y otros sistemas deben retornar a un estado conocido y deseado, una vez se completan los procedimientos de recuperación. Este estado podría incluir que el daño de datos se limite solamente a los campos, llaves o apuntadores que se sabe que fueron alterados, y reportes indicando los procesos o transacciones que no fueron completadas debido a las interrupciones producidas. Consideraciones Especiales: Las pruebas de recuperación pueden llegar a ser molestas. Se requiere la participación de personal de la red, administradores de la base de datos. Estas pruebas deben ser ejecutadas en horas no laborables o en máquinas aisladas. Prueba de Múltiples Sitios. Objetivo: Detectar fallas en configuraciones y comunicaciones de datos entre múltiples sitios. Descripción de la Prueba: El propósito de esta prueba es evaluar el correcto funcionamiento del sistema o subsistema en múltiples instalaciones. Técnica: Realizar casos de prueba que verifiquen mínimo lo siguiente: - Consistencia de las opciones de configuración para el sistema a través de
los sitios. - Empaquetamiento del sistema para múltiples instalaciones. - Sincronización de datos entre sitios. - Comunicación de datos entre sistemas en diferentes sitios. - Rompimiento de funciones de sistema a través de los sitios. Consistencia de controles y seguridad a través de los sitios. Criterio de Completitud: - Todas las pruebas planeadas han sido ejecutadas. - Todos los defectos que se identificaron han sido tenidos en cuenta.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 156

INGENIERÍA DE SOFTWARE II Prueba de Compatibilidad y Conversión. Objetivo: Buscar problemas de compatibilidad y conversión en los sistemas. Descripción de la prueba: El propósito es demostrar que los objetivos de compatibilidad no han sido logrados y que los procedimientos de conversión no funcionan. La mayoría de los programas que se desarrollan no son completamente nuevos; con frecuencia son reemplazos de partes deficientes, ya sea de sistemas de procesamiento de datos, o sistemas manuales. Como tales, los programas tienen a menudo objetivos específicos con respecto a su compatibilidad y a sus procedimientos de conversión con el sistema existente. Técnica: Desarrollar casos de prueba que permitan detectar deficiencias con: - Compatibilidad entre programas. - Conversión de datos.
Criterio de completitud: - Todas las pruebas planeadas han sido ejecutadas. - Todos los defectos que se identificaron han sido tenidos en cuenta. Pruebas de Integridad de Datos y Base de Datos Objetivo: Asegurar que los métodos de acceso y procesos funcionan adecuadamente y sin ocasionar corrupción de datos. Descripción de la prueba: La Base de datos y los procesos de Base de datos deben ser probados como sistemas separados del proyecto. Estos sistemas deberían ser probados sin usar interfaces de usuario (como las interfaces de datos). Se necesita realizar investigación adicional en el DBMS para identificar las herramientas y técnicas que podrían existir para soportar las pruebas identificadas más adelante. Técnica: - Invoque cada método de acceso y proceso de la Base de datos, utilizando
en cada uno datos válidos e inválidos. - Analice la Base de datos, para asegurar que los datos han sido grabados
apropiadamente, que todos los eventos de Base de datos se ejecutaron en forma correcta y revise los datos retornados en diferentes consultas.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 157

INGENIERÍA DE SOFTWARE II
Criterio de completitud: Todos los métodos de acceso y procesos de la Base de datos funcionan como fueron diseñados y sin corrupción de datos. Consideraciones especiales: - Las pruebas pueden requerir un ambiente de DBMS o controladores para
ingresar o modificar datos directamente en la Base de datos. - Se debe utilizar un conjunto pequeño de datos para incrementar la visibilidad
de cualquier evento anormal o inesperado. - Los procesos pueden ser invocados manualmente. Pruebas de Seguridad y Control de Acceso. Objetivo: Nivel de seguridad de la aplicación: Verifica que un actor solo pueda acceder a las funciones y datos que su usuario tiene permitido. Nivel de Seguridad del Sistema: Verificar que solo los actores con acceso al sistema y a la aplicación están habilitados para accederla. Descripción de la Prueba: Las pruebas de seguridad y control de acceso se centran en dos áreas claves de seguridad: - Seguridad del sistema, incluyendo acceso a datos o Funciones de negocios
y - Seguridad del sistema, incluyendo ingresos y accesos remotos al sistema.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 158

INGENIERÍA DE SOFTWARE II Las pruebas de seguridad de la aplicación garantizan que, con base en la seguridad deseada, los usuarios están restringidos a funciones específicas o su acceso está limitado únicamente a los datos que están autorizados a acceder. Por ejemplo, cada usuario puede estar autorizado a crear nuevas cuentas, pero sólo los administradores pueden borrarlas. Si existe seguridad a nivel de datos, la prueba garantiza que un usuario “típico” 1 puede ver toda la información de clientes, incluyendo datos financieros; sin embargo, el usuario 2 solamente puede ver los datos institucionales del mismo cliente. El objetivo de esta prueba es evaluar el funcionamiento correcto de los controles de seguridad del sistema para asegurar la integridad y confidencialidad de los datos. El foco principal es probar la vulnerabilidad del sistema frente a accesos o manipulaciones no autorizadas. Una manera de encontrar esos casos de prueba es estudiar problemas conocidos de seguridad en sistemas similares y tratar de mostrar la existencia de problemas parecidos en el sistema que se examina. - Algunas consideraciones de prueba son:
Controles de acceso físico. Acceso a estructuras de datos específicas a través de los programas de aplicación. Seguridad en sitios remotos. Existencia de datos confidenciales en reportes y pantallas. Controles manuales, incluyendo aquellos para autorización y aprobación, formularios, documentación numerada, transmisión de datos, balances y conversión de datos. Controles automáticos, incluyendo aquellos para edición de datos, chequeo de máquinas, errores del operador, acceso a datos elementales y archivos, acceso a funciones, auditoría, entre otros.
Técnica: - Funciones / Seguridad de Datos: Identificar cada tipo de usuario y las
funciones y datos a los que se debe autorizar. - Crear pruebas para cada tipo de usuario y verificar cada permiso, creando
transacciones específicas para cada tipo de usuario. - Modificar tipos de usuarios y volver a ejecutar las pruebas. En cada caso,
verificar si los datos o funciones adicionales quedan correctamente permitidos o denegados.
- Acceso al sistema (ver consideraciones especiales) Criterio de Completitud: Para cada tipo de usuario conocido, las funciones y datos apropiados y todas las transacciones funcionan como se esperaba.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 159

INGENIERÍA DE SOFTWARE II Consideraciones Especiales: El acceso al sistema debe ser revisado y discutido con los administradores de la red y/o del sistema. Esta prueba puede no ser requerida como tal, sino como una función de los administradores de red o del sistema. Registro y seguimiento de incidentes. Un incidente es encontrado porque causa una FALLA, la cual es una desviación del resultado esperado.
Registro: Evaluación del sistema hubo durante el proceso final, para después ser enviado con las previas correcciones. Seguimiento: Determinar si los productos de una fase dad satisfacen las condiciones impuestas al inicio de la fase. El modelo en cascada. Según Royce (1970), el modelo de cascada se derivó de procesos de sistemas más generales. Éste modelo se muestra en la figura 2.22 y sus principales etapas se transforman en actividades fundamentales del desarrollo: 1. Análisis y definición de requerimientos. Los servicios restricciones y metas
del sistema se definen a partir de las consultas con los usuarios. Entonces, se definen en detalle y sirven de manera específica al sistema.
2. Diseño del sistema y del software. El proceso de diseño del sistema divide los requerimientos en sistemas ya sea hardware Soto. Establece una arquitectura completa del sistema, el diseño del software identifique describe
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 160

INGENIERÍA DE SOFTWARE II
los elementos abstractos que son fundamentales para el software y sus relaciones.
3. Implementaciones prueba de unidades. Durante esta etapa el diseño del software se lleva a cabo como un conjunto de unidades de programas, la prueba de unidades implica verificar que cada una cumpla con su función específica.
4. Integración y prueba del sistema. Los programas o las unidades individuales de programas se integran y se prueban como un sistema completo para así asegurar que se cumplan los requerimientos del software, después se entrega al cliente.
5. Funcionamiento y mantenimiento. En esta fase el sistema se instala y se pone en funcionamiento práctico el mantenimiento implica corregir errores no descubiertos en las etapas anteriores del ciclo de vida, mejorar la implementación de las unidades del sistema y resaltar los servicios del sistema una vez que se descubren en nuevos requerimientos.
El modelo de desarrollo evolutivo (espiral). El modelo en espiral que Boehm propuso es un modelo de proceso de software evolutivo que conjuga la naturaleza iterativa de la construcción de prototipos con los aspectos controlados y sistemáticos del modelo en cascada. Cuando se aplica este modelo en espiral, el software se desarrolla en una serie de entregas evolutivas. Cada una de las actividades del marco de trabajo representa un segmento de la ruta en espiral. Este modelo se basa en la idea de desarrollar una implementación inicial, exponiéndola a los comentarios del usuario y refinándola a través de las diferentes versiones que se generan hasta que se desarrolle un sistema adecuado. Las actividades de especificación, desarrollo y validación se entrelazan en vez de separarse, con una rápida retroalimentación entre estas. Existen dos tipos de desarrollo evolutivo: 1. Desarrollo exploratorio, en este caso el objetivo del proceso es trabajar con
el cliente para explorar sus requerimientos y entregar un sistema final. El desarrollo empieza con las partes del sistema que se comprenden mejor. El sistema evoluciona agregando nuevos atributos propuestos por el cliente.
2. Prototipos desechables, el objetivo de este proceso de desarrollo evolutivo es comprender los requerimientos del cliente para así desarrollar una definición mejorada de los requerimientos para el sistema. El prototipo se centra en experimentar los requerimientos del cliente que no se comprenden del todo.
La ventaja de un software que se basa en un enfoque evolutivo es que las especificaciones se pueden desarrollar de forma creciente. Tan pronto como
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 161

INGENIERÍA DE SOFTWARE II los usuarios desarrollen un mejor entendimiento de su problema, esto se puede reflejar en el software. Sin embargo, desde la perspectiva de ingeniería y de gestión, el enfoque evolutivo tiene dos problemas: 1. El proceso no es visible. Esto significa que los administradores tienen que
hacer entregas regulares para medir el progreso del producto. Si los sistemas se desarrollan rápidamente, no es rentable producir documentos que reflejen cada versión del sistema.
2. A menudo los sistemas tienen una estructura deficiente. Esto hace referencia que los cambios continuos tienden a corromper la estructura del software. Incorporar cambios en él se convierte cada vez más en una tarea difícil y costosa.
Para sistemas pequeños y de tamaño medio (hasta 500,000 líneas de código), el enfoque evolutivo de desarrollo es el mejor. Los problemas del desarrollo evolutivo se hacen particularmente agudos para sistemas grandes y complejos con un período de vida largo, donde diferentes equipos desarrollan distintas partes del sistema. El modelo de desarrollo basado en componentes. En la mayoría de los proyectos de desarrollo de software existe la reutilización. Por lo general esto sucede informalmente cuando las personas conocen diseños o códigos similares al requerido. Los buscan, los modifican según lo creen necesario y los incorporan en un nuevo sistema. El enfoque evolutivo, la reutilización es indispensable para el desarrollo más ágil de un sistema. Esta reutilización es independiente del proceso de desarrollo que se utilice. Etapas: • Análisis de componentes. En esta se buscan los componentes para
implementar los con base en su especificación. Por lo general, no existe una concordancia exacta y los componentes que se utilizan sólo proporcionan parte de la funcionalidad requerida.
• Modificación de requerimientos. En esta etapa los requerimientos se analizan utilizando información acerca de los componentes que se han descubierto. Entonces dichos componentes se modifican para reflejar los componentes disponibles, la actividad de análisis de componentes se puede llevar a cabo para buscar soluciones alternativas.
• Diseño del sistema con reutilización. En esta fase los diseñadores tienen en cuenta los componentes que se reutiliza y que se organizan el marco de trabajo para que los satisfaga. Si dichos componentes no están disponibles se puede diseñar nuevos software.
• Desarrollo e integración. El software que no se puede adquirir externamente se desarrolla y se integra a los componentes. En este modelo, la integración
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 162

INGENIERÍA DE SOFTWARE II
del sistema es parte del proceso de desarrollo, más que una actividad separada.
El modelo de desarrollo de software basado en componentes. Creado por Boehm (1988), tiene la ventaja de reducir la cantidad de software que se debe desarrollar y por ende reduce los costos y los riesgos. También permite una entrega más rápida del software. Sin embargo, los compromisos a los requerimientos son inevitables y esto da lugar a un sistema que no cumpla con las necesidades reales de los usuarios. Automatización de la ejecución de prueba. Es la parte en la que el software es utilizado para controlar la ejecución de pruebas, comparación de resultado, preparar las precondiciones y realizar informes. Fases en la que se puede automatizar las pruebas:
Tipos de pruebas automatizadas: - Funcional. - Regresión. - Excepción.
- Tensión. - Carga.
Ventajas Inconvenientes
- Pocas Herramientas. - Menos Recursos. - Evitamos pruebas obsoletas
- Mayor rapidez de ejecución - Necesitan una “base” a menudo inexistente - Conjunto pobre de pruebas
Herramientas. Las herramientas nos permiten saber si el sistema tiene errores que pueden ser subsanados, y a los que el código es tan "propenso" en general. Los tiempos de desarrollo, los entornos de programación, las diferentes versiones,
Reportes: Peticiones de cambios Inputs de prueba.
Evaluación: Resultados Métricas.
Ejecución: Ing. Pruebas.
Implementación: Desarrollador
Casos de prueba requisitos: Analistas.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 163

INGENIERÍA DE SOFTWARE II todo influye para que, incluso con la máxima dedicación, pueda tener fallas el sistema y eso generaría perdidas en la empresa. Para evitar estos problemas surge la calidad del software. Algunas de las herramientas para testear el software son: Rational Function Tester: Rational Functional Tester de IBM ofrece características que permiten automatizar el testeo. Para usar la característica de grabación, grabe una actividad de prueba y guárdela como un script de prueba. Se podrá ejecutar el script de prueba cada vez que desee realizar la misma prueba. Cuando desee ingresar datos mientras esté realizando el testeo, se podrá utilizar la característica test datapool (grupo de datos de prueba) durante la grabación. Si utiliza esta característica, podrá cambiar los datos de entrada antes de ejecutar el script de prueba sin tener que volver a grabar la actividad de prueba.
Se Puede utilizar la característica de punto de verificación, a través de la cual Rational Functional Tester compara los valores reales con los valores esperados y luego genera un informe con datos detallados que le muestra si usted obtuvo o no los resultados esperados. Sin embargo, una posible molestia al utilizar la característica de grabación es tener que volver a grabar la actividad de prueba cuando se cambie la aplicación que se va testear.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 164

INGENIERÍA DE SOFTWARE II
Instalación de Rational Function Tester. • Se puede instalar Rational Functional Tester desde el soporte de instalación
o desde un paquete de descarga disponible en el sitio de IBM Passport Advantage. Antes de comenzar la instalación, obtenga el soporte o descargue el paquete.
• Compruebe que su sistema cumple los requisitos y complete las tareas de preinstalación.
• Para permitir que Installation Manager busque las versiones más recientes de los paquetes en el repositorio de actualización de IBM predeterminado, asegúrese de que su sistema está conectado a Internet.
Procedimiento. Para instalar Rational Functional Tester en los sistemas operativos Windows o Linux: 1. Si está utilizando el soporte de instalación, inserte el soporte en la unidad de
disco. Si está utilizando el paquete de descarga, extraiga los archivos del paquete .Zip descargado a un directorio temporal.
2. Abra el programa Launchpad para iniciar la instalación del paquete: - En Windows: Pulse en launchpad.exe. - En Linux: Pulse en launchpad.sh.
3. Pulse Instalar Rational Functional Tester. 4. En la página Inicio de IBM Installation Manager, pulse Instalar. 5. La página Instalar paquetes lista todos los paquetes encontrados en los
repositorios en los que ha buscado Installation Manager. Si se descubren dos versiones de un paquete, sólo se muestra la versión del paquete más reciente o recomendada. Si Installation Manager no está instalado en su
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 165

INGENIERÍA DE SOFTWARE II
sistema, Installation Manager está listado en la página Instalar paquetes con Rational Functional Tester. • Para visualizar todas las versiones de los paquetes que encuentre
Installation Manager, pulse en Mostrar todas las versiones. Nota: Para buscar las ubicaciones de repositorio de actualización de IBM predefinidas para los paquetes instalados, asegúrese de que se ha seleccionado Buscar en los repositorios de servicio durante la instalación y las actualizaciones en la página de preferencias de Repositorios. Esta preferencia está seleccionada de forma predeterminada. 6. Si se encuentran actualizaciones para el paquete de IBM Rational Functional
Tester, se visualizarán en la lista Paquetes de instalación de la página Instalar paquetes debajo su producto correspondiente. Se muestran las últimas actualizaciones de forma predeterminada. • Para encontrar otras versiones, arreglos y extensiones para los paquetes
disponibles en las ubicaciones del repositorio de actualización, pulse Comprobar otras versiones, arreglos y extensiones.
• Para ver todas las actualizaciones encontradas para los paquetes disponibles, pulse Mostrar todas las versiones.
• Para visualizar una descripción de paquete en Detalles, pulse en el nombre del paquete. Si hay disponible información adicional sobre el paquete como, por ejemplo, un archivo readme o las notas de release, se incluye un enlace Más información al final del texto de descripción. Pulse el enlace para mostrar la información adicional en un navegador. Para conocer en profundidad el paquete que está instalando, revise toda la información de antemano.
7. Seleccione la versión necesaria de Rational Functional Tester, y Installation Manager si es necesario. Pulse Siguiente. Las actualizaciones con dependencias se seleccionan automáticamente y se borran de forma conjunta Nota: Si instala varios paquetes a la vez, todos los paquetes se instalan en el mismo grupo de paquetes.
8. En la página de licencias, deberá leer el acuerdo de licencia para el paquete
seleccionado. Si se selecciona más de un paquete para la instalación, es posible que exista un acuerdo de licencia para cada paquete. En la parte izquierda de la página Licencia, pulsar la versión de cada paquete para que se visualice su acuerdo de licencia. Las versiones de paquete que ha decidido instalar (por ejemplo, el paquete base y una actualización) se enumeran en el nombre del paquete. • Si está de acuerdo con los términos de todos los acuerdos de licencia,
pulse Acepto los términos de los acuerdos de licencia.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 166

INGENIERÍA DE SOFTWARE II
• Pulse Siguiente para continuar. Nota: En el paquete Rational Test Workbench también se incluye a Rational Functional Tester. Utilice la licencia de Rational Functional Tester al instalar Rational Functional Tester mediante el paquete Rational Test Workbench. Sin embargo, si Rational Test Workbench está instalado en Microsoft Windows 2012, no es posible instalar ni utilizar Rational Functional Tester en el mismo sistema operativo.
9. En la página Ubicación, teclee la vía de acceso para el directorio de recursos
compartidos en el campo Directorio de recursos compartidos o acepte la vía de acceso predeterminada. El directorio de recursos compartidos contiene recursos que pueden ser compartidos por uno o varios grupos de paquetes. Pulse Siguiente para continuar. Nota: Si realiza la instalación en Windows Vista, para habilitar a los usuarios sin privilegios de Administrador para que trabajen con Rational Functional Tester, no elija un directorio dentro del directorio Program Files (C:\Program Files\). La vía de acceso predeterminada es: • Para Windows: C:\Archivos de programa\IBM\IBMIMShared • Para Linux:/opt/IBM/IBMIMShared Nota: Puede especificar el directorio de recursos compartidos sólo la primera vez que instale un paquete. Para ello, utilice el disco con más capacidad para ayudar a garantizar que se dispone del espacio adecuado para los recursos compartidos de futuros paquetes. No es posible cambiar la ubicación del directorio a menos que se desinstalen todos los paquetes.
10. En la página Ubicación especifique si desea crear un grupo de paquetes
para instalar el paquete IBM Rational Functional Tester en un grupo de paquetes nuevo o si prefiere utilizar un grupo de paquetes ya existente para compartir Shell con otra oferta. Un grupo de paquetes representa un directorio en el cual los paquetes comparten recursos con otros paquetes en el mismo grupo. Para crear un nuevo grupo de paquetes: • Pulsar Crear nuevo grupo de paquetes.
a. Escriba la vía de acceso del directorio de instalación para el grupo de
paquetes. El nombre del grupo de paquetes se crea automáticamente. La vía de acceso predeterminada es: • Para Windows:C:\Archivos de programa\IBM\SDP • Para Linux:/opt/IBM/SDP Nota: Si va a efectuar la instalación en Linux, asegúrese de no incluir ningún espacio en la vía de acceso del directorio. En Windows Vista, el directorio Archivos de programa se suele virtualizar para que los usuarios
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 167

INGENIERÍA DE SOFTWARE II
que no se ejecutan como administrador puedan tener acceso de escritura en este directorio protegido. Sin embargo, el método alternativo a la virtualización no es compatible con Rational Functional Tester.
b. Pulse Siguiente para continuar. 11. En la página Ubicación siguiente, puede optar por ampliar el entorno de
desarrollo integrado Eclipse ya instalado en el sistema y añadir la funcionalidad en los paquetes que está instalando. Se debe tener Eclipse versión 3.6.2 con las actualizaciones más recientes de eclipse.org para seleccionar esta opción. • Si no desea ampliar un entorno de desarrollo integrado Eclipse existente,
pulse Siguiente para continuar. • Para ampliar un entorno de desarrollo integrado Eclipse existente:
a. Seleccione Ampliar un Eclipse existente. b. En el campo Entorno de desarrollo integrado Eclipse, escriba o vaya a la
ubicación de la carpeta que contiene el archivo ejecutable de Eclipse (eclipse.exe o eclipse.bin). Installation Manager comprobará si la versión del entorno de desarrollo integrado de Eclipse es válido para el paquete que se está instalando. El campo JVM de IDE de Eclipse muestra la máquina virtual Java™ (JVM) del IDE especificado.
c. Pulse Siguiente para continuar. 12. En la página Características de Idiomas, seleccione los idiomas para el
grupo de paquetes. Se instalarán las traducciones del idioma nacional correspondiente de la interfaz de usuario y la documentación del paquete IBM Rational Functional Tester.
13. En la siguiente página Características, seleccione las características del
paquete que desea instalar. • Opcional: Para ver las relaciones de dependencia entre las
características, seleccione Mostrar dependencias. a. Opcional: Pulse en una característica para ver una breve descripción de la
misma en Detalles. b. Seleccione o desmarque las características en los paquetes. Installation
Manager establecerá automáticamente todas las dependencias con otras características y mostrará los requisitos de espacio en disco y tamaño de descarga actualizados para la instalación.
c. Pulse Siguiente para continuar.
14. En la página Características del sistema de ayuda, seleccione la opción requerida para acceder al contenido de la ayuda del producto. Para obtener más información sobre la configuración de la ayuda, consulte el apartado.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 168

INGENIERÍA DE SOFTWARE II 15. En la página Resumen, revise las opciones antes de instalar el paquete
IBM Rational Functional Tester. Un indicador de progreso muestra que se ha completado el porcentaje de la instalación.
16. Cuando el proceso de instalación haya completado, un mensaje confirmará que el proceso se ha realizado correctamente. • Pulse Ver archivo de registro para abrir el archivo de registro de
instalación de la sesión actual en una ventana nueva. a. Las características que ha instalado se muestran en una lista en la
sección Qué programa desea iniciar. Seleccione la característica que desee iniciar: Rational Functional Tester Eclipse Integration o Rational Functional Tester Microsoft Visual Studio Integration. Para salir de Installation Manager sin iniciar ninguna de las características instaladas, seleccione Ninguna.
b. Pulse Finalizar. QuickTest Professional (más usado). QuickTest es una herramienta de automatización de registros de reproducción de interfaz gráfica. Es capaz de trabajar con cualquier aplicación cliente web, java o ventanas. Prueba rápida le permite probar objetos web estándar y controles ActiveX. Además de estos entornos, QuickTest Professional también te permite probar los applets de Java y aplicaciones y objetos multimedia en aplicaciones, así como aplicaciones estándar de Windows, Basic 6 aplicaciones visuales y aplicaciones .NET Framework. • QTP es la herramienta de pruebas funcionales Mercury Interactive. • QTP significa prueba de calidad profesional.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 169

INGENIERÍA DE SOFTWARE II Mercurio QuickTest Profesional: Proporciona la mejor solución del mercado para la automatización de pruebas de ensayo y la regresión funcional - abordar todas las aplicaciones de software más importantes y el medio ambiente. QuickTest Professional le permite probar aplicaciones estándar de Windows, objetos Web, controles ActiveX y aplicaciones de Visual Basic. También puede adquirir QuickTest complementos adicionales para una serie de ambientes especiales (como Java, Oracle, soluciones SAP, .NET Windows y Web Forms, Siebel, PeopleSoft, servicios Web y aplicaciones de emulador de terminal). - QTP se basa en dos conceptos: Grabación y Reproducción.
- QTP utiliza scripts VB. - El proceso de prueba QTP contempla siete pasos:
• Preparación para la recodificación. • Grabación. • Mejora de la secuencia de comandos. • Depuración. • Ejecutar. • Analizar. • Informe de Defectos (mas).
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 170

INGENIERÍA DE SOFTWARE II
RATIONAL Robot. Rational Robot es un conjunto completo de componentes para la automatización de las pruebas de aplicaciones cliente / servidor y de Internet de Microsoft Windows. El componente principal del robot le permite iniciar la grabación de las pruebas en tan sólo dos clics del ratón. Después de la grabación, Robot reproduce las pruebas en una fracción del tiempo que tomaría para repetir las acciones manualmente.
Componentes de Rational Robot. • Administrador de Rational - Crear y administrar Proyectos racionales para
almacenar sus pruebas información.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 171

INGENIERÍA DE SOFTWARE II • Rational TestManager - Revisar y analizar resultados de la prueba. • Propiedades del objeto, texto, Cuadrícula, e Imagen. • Comparadores - Ver y analizar los resultados de reproducción de punto de
verificación. • SiteCheck Racional - Administrar Internet y • Los sitios web de intranet. • Automatizado funcional. • Pruebas de regresión. • Prueba funcional: Pruebas funcionales son diseñado para asegurarse de que
la aplicación realiza como estaba previsto.
Prueba de Regresión: Una prueba de regresión es una prueba en la que una solicitud se somete a un conjunto de pruebas funcionales en cada generación para asegurarse de que todo lo que trabajó continúa trabajando.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 172

INGENIERÍA DE SOFTWARE II VII. COMPRENDE LOS PRINCIPIOS DE LA REINGENIERÍA VS LA
INGENIERÍA INVERSA.
OPERACIONES: Reingeniería. Ingeniería Inversa. Trabajar la tendencia de emplear la Reingeniería vs Ingeniería Inversa.
EQUIPOS Y MATERIALES:
Computadora con microprocesadores Core 2 Duo o de mayor capacidad. Sistema operativo Windows. Acceso a internet. Software visual Studio 2012, bock de notas.
ORDEN DE EJECUCIÓN:
Reconocer el Manejo de la Reingeniería. Reconocer el Manejo de la Ingeniería Inversa. Comparaciones entre técnicas.
7.1. TRABAJAR LA TENDENCIA DE EMPLEAR LA REINGENIERÍA VS
INGENIERÍA INVERSA. CONCEPTOS: ¿Qué es la Ingeniería de Sistemas? La Ingeniería de Sistemas nos permite estudiar y comprender la realidad, con el propósito de implementar, diseñar y optimizar sistemas complejos. Ingeniería inversa. En la ingeniería inversa no es generar códigos, sino que, el código fuente es examinado, analizado y convertido en entidades para el depósito. Su primer paso es cargar, en el conjunto de herramientas el código de programas existen, según ese conjunto de herramientas.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 173

INGENIERÍA DE SOFTWARE II
- Grado de Abstracción: Se refiere a la sofisticación del diseño que es
obtenido del código fuente. Conforme aumenta el nivel se obtiene información que permitirá entender de mejor manera los diferentes programas .
- Completitud: Se refiere al grado de detalle que se ofrece en un grado de abstracción, lo cual provee de una mejora en proporción directa con la cantidad de análisis que efectúa quien realiza la ingeniería inversa. Además tomamos en cuenta la interactividad refiriéndose al grado en que el humano está integrado con las herramientas para crear un proceso de ingeniería inversa efectivo. En consecuencia con el aumento de los puntos antes mencionados se deberá incrementar la completitud.
- Direccionalidad: Tiene que ver en dos sentidos, para el caso de ser
unidireccional, la información obtenida del código fuente servirá en cualquier actividad de mantenimiento. Por otra parte si es bidireccional, la información alimentara a herramientas de REINGENIERIA que reestructurara o regenerara el software anterior.
El proceso de ingeniería inversa. El proceso de ingeniería se representa en la siguiente figura. Antes de que puedan comenzar las actividades de ingeniería inversa, el código fuente no estructurada se reestructura para que solamente contenga construcciones de programación estructurada. Esto hace que el código fuente sea más fácil de leer, y es lo que proporciona la base para todas las actividades subsiguiente de ingeniería inversa.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 174

INGENIERÍA DE SOFTWARE II
BENEFICIOS DE LA INGENIERÍA INVERSA. • Reducir la complejidad del sistema: Al intentar comprender el software se
facilita su mantenimiento y la complejidad existente disminuye. • Generar diferentes alternativas: Del punto de partida del proceso,
principalmente código fuente, se generan representaciones gráficas lo que facilita su comprensión.
• Recuperar y/o actualizar la información perdida (cambios que no se documentaron en su momento): En la evolución del sistema se realizan cambios que no se suele actualizar en las representaciones de nivel de abstracción más alto, para lo cual se utiliza la recuperación de diseño.
• Detectar efectos laterales: los cambios que se puedan realizar en un sistema puede conducirnos a que surjan efectos no deseados, esta serie de anomalías puede ser detectados por la ingeniería inversa.
• Facilitar la reutilización: por medio de la ingeniería inversa se pueden detectar componentes de posible reutilización de sistemas existentes, pudiendo aumentar la productividad, reducir los costes y los riesgos de mantenimiento.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 175

INGENIERÍA DE SOFTWARE II
TIPOS DE INGENIERÍA INVERSA. • Ingeniería inversa de interfaces de usuario: Se aplica con objeto de
mantener la lógica interna del programa para obtener los modelos y especificaciones que sirvieron de base para la construcción de la misma, con objeto de tomarlas como punto de partida en procesos de ingeniería directa que permitan modificar dicha interfaz.
• Ingeniería inversa de datos: Se aplica sobre algún código de bases datos (aplicación, código SQL, etc.) para obtener los modelos relacionales o sobre el modelo relacional para obtener el diagrama entidad-relación.
• Ingeniería inversa de lógica o de proceso: Cuando la ingeniería inversa se aplica sobre código de un programa para averiguar su lógica o sobre cualquier documento de diseño para obtener documentos de análisis o de requisitos.
HERRAMIENTAS PARA LA INGENIERÍA INVERSA. • Los depuradores. Un depurador es un programa que se utiliza para
controlar otros programas. Permite avanzar paso a paso por el código, rastrear fallos, establecer puntos de control y observar las variables y el estado de la memoria en un momento dado del programa que se esté depurando. Los depuradores son muy valiosos a la hora de determinar el flujo lógico del programa.
• Las herramientas de inyección de fallos. Las herramientas que pueden proporcionar entradas malformadas con formato inadecuado a procesos del software objetivo para provocar errores son una clase de herramientas de inserción de fallos. Los errores del programa pueden ser analizados para determinar si los errores existen en el software objetivo. Algunos fallos tienen implicaciones en la seguridad, como los fallos que permiten un acceso directo del asaltante al ordenador principal o red.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 176

INGENIERÍA DE SOFTWARE II • Los desensambladores. Se trata de una herramienta que convierte código
máquina en lenguaje ensamblador. El lenguaje ensamblador es una forma legible para los humanos del código máquina. Los desensambladores revelan que instrucciones máquinas son usadas en el código. El código máquina normalmente es específico para una arquitectura dada del hardware. De forma que los desensambladores son escritor expresamente para la arquitectura del hardware del software a desensamblar.
• Los descompiladores. Un descompilador es una herramienta que transforma código en ensamblador o código máquina en código fuente en lenguaje de alto nivel. También existen descompiladores que transforman lenguaje intermedio en código fuente en lenguaje de alto nivel. Estas herramientas son sumamente útiles para determinar la lógica a nivel superior como bucles o declaraciones if-then de los programas que son descompilados.
• La herramienta CASE. Las herramientas de ingeniería de sistemas asistida por ordenador (Computer-Aided Systems Engineering – CASE) aplican la tecnología informática a las actividades, las técnicas y las metodologías propias de desarrollo de sistemas para automatizar o apoyar una o más fases del ciclo de vida del desarrollo de sistemas.
REINGENIERÍA DE SOFTWARE. Se puede definir como el proceso completo de convertir el código de programa al diseño CASE, modificar el diseño y volver a generar el nuevo código. El término se usa en distintas áreas de la ingeniería, programación y negocios. Con respecto a los negocios, es una forma de darle una nueva orientación a los procesos claves de una organización, de esta manera el rol de los analistas de sistemas radica en el uso de tecnologías de información novedosas, como consecuencia a los cambios requeridos.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 177

INGENIERÍA DE SOFTWARE II
- ¿Quién la hace? En el ámbito de las organizaciones, la reingeniería la llevan a cabo especialistas en negocios. En nuestro ámbito lo realizan los ingenieros de software.
- ¿Por qué es importante? Por qué nos permite mantenernos en el ritmo de
las exigencias de las nuevas tecnologías.
- ¿Cuáles son los pasos? El proceso de reingeniería de software incluye
análisis de inventarios, restructuración de documentos, ingeniería inversa, reestructuración de programas y datos, e ingeniería avanzada.
- ¿Cuál es el producto obtenido? Se produce una diversidad de productos
de trabajo de reingeniería. Ejemplo: Modelos de análisis, modelos de diseño, procedimientos de prueba, entre otros.
- ¿Cómo puedo estar seguro de que lo he hecho correctamente?
Utilizando las mismas prácticas de SQA que se aplican a cualquier proceso de ingeniería del software: las revisiones técnicas formales evalúan los modelos de análisis y de diseño; las revisiones especializadas consideran la aplicabilidad y la compatibilidad en el negocio; y las pruebas se aplican para descubrir errores en contenido, funcionalidad e interoperabilidad.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 178

INGENIERÍA DE SOFTWARE II BENEFICIOS DE LA REINGENIERÍA DE SOFTWARE. Entre los beneficios de aplicar reingeniería a un producto existente se puede incluir: • Pueden reducir los riegos evolutivos de una organización. • Puede ayudar a las organizaciones a recuperar sus inversiones en
software. • Puede hacer el software más fácilmente modificable. • Amplía las capacidades de las herramientas CASE. • Es un catalizador para la automatización del mantenimiento del software. • Puede actuar como catalizador para la aplicación de técnicas de
inteligencia artificial para resolver problemas de reingeniería. PASOS PARA LA REINGENIERIA DE SOFTWARE.
• Análisis de inventario: Todas las organizaciones de software deberían tener un inventario de todas sus aplicaciones. Los candidatos a la reingeniería aparecen cuando se ordena esta información en función de su importancia para el negocio, longevidad, mantenibilidad actual y otros criterios localmente importantes. Es importante señalar que el inventario deberá visitarse con regularidad, el estado de las aplicaciones puede cambiar en función del tiempo y, como resultado, cambiarán las prioridades para la reingeniería.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 179

INGENIERÍA DE SOFTWARE II • Restauración de documentos: La documentación debe actualizarse pero
se tiene recursos limitados. Se utiliza un enfoque de “documentar cuando se toque”. El sistema es crucial para el negocio y debe volver a documentarse por completo incluso en este caso un enfoque inteligente es recortar la documentación a un mínimo esencial. Cada una de estas opciones es viable. Una organización de software debe elegir la más apropiada para cada caso.
• Ingeniería Inversa: La Ingeniería inversa es un proceso de recuperación de
diseño. Con las herramientas de la ingeniería inversa se extraerá del programa existente información del diseño arquitectónico y de proceso, e información de los datos.
• Restructuración de códigos: Llevar a cabo esta actividad requiere analizar
el código fuente empleando una herramienta de reestructuración, se indican las violaciones de las estructuras de programación estructurada, y entonces se reestructura el código (esto se puede hacer automáticamente). El código reestructurado resultante se revisa y se comprueba para asegurar que no se hayan introducido anomalías.
• La reestructuración de datos: Es una actividad de reingeniería a gran
escala. En la mayoría de los casos, la reestructuración de datos comienza con una actividad de ingeniería inversa. La arquitectura de datos actual se analiza con minuciosidad y se define los modelos de datos necesarios, se identifican los objetivos de datos y los atributos, y después se revisa la calidad de las estructuras de datos existentes.
• Ingeniería directa: La ingeniería directa no solo recupera la información de
diseño a partir del software existente, también utiliza esta información para alterar o reconstruir el sistema existente con la finalidad de mejorar su calidad global. En la mayoría de los casos el software sometido a reingeniería vuelve a implementar la función del sistema existente y también añade nuevas funciones o mejoras.
Economía de la Reingeniería: P1 COSTO DE MANTENIMIENTO ANUAL. P2 COSTO DE OPERACIÓN ANUAL. P3 VALOR DE NEGOCIOS. P4 COSTO DE MANT PREDICHO. P5 COSTO DE OPERACIÓN ANUAL PREDICHO. P6 VALOR DE NEGOCIOS PREDICHO. P7 COSTO ESTIMADO. P8 FECHA ESTIMADO. P9 FACTOR RIESGO.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 180

INGENIERÍA DE SOFTWARE II L VIDA ESPERADA. Fórmula para el Cálculo: Costo mantenimiento: (p3 – (p1+ p2) * L Costo reingeniería: (p6 – (p4+ p5)*(L – p8) – (p7*p9)). Costo beneficio: Costo reingeniería - Costo mantenimiento REINGENIERIA DE PROCESOS DE NEGOCIO (RPN). La (RPN) rebasa el ámbito de las tecnologías de la información y de la ingeniería de software. Una de las definiciones más relevantes pala la (RPN) en la publicada por la revista fortune “La búsqueda e implementación de un cambio radical en el proceso de negocios para lograr resultados de vanguardia”. Procesos de negocios. Es un conjunto de tareas lógicamente relacionadas que se ejecutan para lograr un resultado de negocios específico; dentro de este se combina la gente, el equipo, los recursos materiales y los procedimientos del negocio para producir un resultado específico. Los ejemplos de proceso de negocios incluyen el diseño de un nuevo producto, la compra de servicios y suministros, la contratación de un nuevo empleado y el pago a proveedores. Cada uno demanda un conjunto de tareas y también emplea diversos recursos dentro del negocio. Cada proceso de negocio tiene un cliente definido: una persona o grupo que recibe el resultado. Además los procesos de negocio traspasan las fronteras de la organización. Cada sistema de negocio está compuesto de uno o más procesos de negocio, y cada proceso de negocio lo define un conjunto de subprocesos. Un Modelo de RPN. La RPN es iterativa, las metas del negocio y los procesos con que se logran se deben adaptar a un entorno de negocios cambiante. Por tal razón no existe principio ni fin para la RPN.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 181

INGENIERÍA DE SOFTWARE II
Definición del negocio: El mismo que se identifica con cuatro controladores clave: Reducción de costo. Reducción de tiempos. Mejora de la calidad. Desarrollo y fortalecimiento del personal. Identificación del proceso: Se identifican los procesos claves para así lograr las metas precisas en la definición del negocio. Evaluación del Proceso: Se realiza un análisis del proceso existente así como también identificamos las tareas del proceso, tomamos nota de los costos y el tiempo que consumen las tareas; aislando los problemas de calidad y desempeño. Especificación y diseño del proceso: Se preparan casos de uso para cada proceso que será rediseñado. Aquí los casos de uso identifican un escenario que entrega cierto resultado a un cliente. Con el caso de uso como la especificación del proceso se diseña un nuevo conjunto de tareas para el proceso. Elaboración de Prototipos: Un proceso de negocios rediseñado debe convertirse en prototipo antes de que sea integrado por completo en el negocio.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 182

INGENIERÍA DE SOFTWARE II Refinamiento y particularización: Con base en la retroalimentación del prototipo, el proceso de negocio se refina y luego se particulariza dentro de un sistema de negocio. La reingeniería de software involucra diferentes actividades, como son: análisis de inventarios, reestructuración de documentos, ingeniería inversa, reestructuración de programas y datos, e ingeniería directa; con la finalidad de crear versiones de programas ya existentes que sean de mejor calidad y los mismos tengan una mayor facilidad de mantenimiento. MANTENIMIENTO DEL SOFTWARE. El mantenimiento del software se define identificando cuatro actividades diferentes como son: mantenimiento correctivo, mantenimiento adaptativo, mejora o mantenimiento de perfeccionamiento y mantenimiento preventivo o reingeniería. Según estadísticas el 20 % del trabajo de mantenimiento se emplea en “componer errores”. El restante 80% se dedica a adaptar los sistemas existentes a los en su entorno externo. Un modelo de Proceso de Reingeniería del software.
Análisis de Inventarios: Las organizaciones de software deberían tener un inventario de todas sus aplicaciones. El inventario tal vez no sea más que un modelo en una hoja de cálculo que contenga información que proporcione una descripción detallada (tamaño, edad, importancia para el negocio) de las aplicaciones activas. Es importante señalar que el inventario deberá visitarse con regularidad, el estado de las aplicaciones puede cambiar en función del tiempo y, como resultado, cambiaran las prioridades para la reingeniería.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 183

INGENIERÍA DE SOFTWARE II Reestructuración de documentos: La documentación débil es la marca de muchos sistemas heredados. ¿Pero que se hace acerca de ello? ¿Cuáles son las opciones? .Crear documentación consume mucho tiempo, si el sistema funciona vivirá con lo que tenga. La documentación debe actualizarse pero se tiene recursos limitados. Se utilizara un enfoque de “documentar cuando se toque”. El sistema es crucial para el negocio y debe volver a documentarse por completo incluso en este caso un enfoque inteligente es recortar la documentación a un mínimo esencial. Cada una de estas opciones es viable. Una organización de software debe elegir la más apropiada para cada caso. Ingeniería Inversa: Es el proceso de analizar un programa con la finalidad de crear una representación del programa en un mayor grado de abstracción que el código fuente. La ingeniería inversa es un proceso de recuperación de diseño. Las herramientas de la ingeniería inversa obtienen información del diseño de datos, arquitectónico y de procedimientos a partir de un programa existente. Reestructuración de código: El tipo más común de reingeniería es la reestructuración de código, se lo puede hacer con módulos individuales que se codifican de una manera que dificultan comprenderlos, probarlos y mantenerlos. Llevar a cabo esta actividad requiere analizar el código fuente empleando una herramienta de reestructuración. Reestructuración de datos: La reestructuración de datos es una actividad de reingeniería a gran escala. En la mayoría de los casos, la reestructuración de datos comienza con una actividad de ingeniería inversa. La arquitectura de datos actual se analiza con minuciosidad y se define los modelos de datos necesarios, se identifican los objetivos de datos y los atributo, y después se revisa la calidad de las estructuras de datos existentes. Ingeniería directa: La ingeniería directa, también llamada renovación o reclamación, no solo recupera la información de diseño a partir del software existente, también utiliza esta información para alterar o reconstruir el sistema existente con la finalidad de mejorar su calidad global. En la mayoría de los casos el software sometido a reingeniería vuelve a implementar la función del sistema existente y también añade nuevas funciones o mejora el desempeño global. Para comprender datos: Es una de las primeras tareas de reingeniería, ya que la frecuente ocurrencia de los datos en distintos niveles de abstracción, las estructuras de los datos internos son sometidos a esta tarea para ajustarlos con los paradigmas de la gestión de BBDD, con lo cual se establecen escenarios para la introducción a bases de datos nuevas que contengan todo el sistema.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 184

INGENIERÍA DE SOFTWARE II Estructura de datos internos: Enfoca a la definición de clases de objetos para examinar el código con el fin de agrupar las variables que se pueden relacionar. Estructura de Base de Datos: Permite comprender los objetos existentes y sus respectivas relaciones. Se deben seguir los siguientes pasos: 1. Construcción de un modelo inicial de objeto. 2. Determinación de los candidatos claves. 3. Refinar las clases tentativas. 4. Definición de generalidades. 5. Descubrimiento de asociaciones. Luego se realiza una serie de transformaciones para correlacionar con el modelo anterior con la nueva. Para comprender el procesamiento: Trata de comprender y extraer abstracciones de los procedimientos que se representan en el código. Para esto se debe analizar en grados variables de abstracción como sistema, programas componentes, patrones y planteamiento. Además se debe considerar la funcionalidad de forma global. Interfaz de Usuario: Antes de reconstruir cualquier interfaz de usuario se realiza actividades de II, se requiere especificar estructuras y comportamientos de las interfaces. Reestructuración: Modifica el código o los datos con la finalidad de adecuarlos para futuros cambios. No modifica la arquitectura sino que se enfoca sobre detalles de diseño de los módulos y en la estructura de datos. Existen 3 niveles: Nivel de Análisis: Se transforman los modelos de análisis en otros más
comprensibles. Nivel de Diseño: Se transforman unos modelos de diseños en otros. Nivel de Implementación: Las representaciones obtenidas pueden
enfocarse tanto a datos como a procesos. Reestructuración de Código: Genera un diseño que produzca la misma función del programa pero con mayor calidad. El objetivo es tomar una porción de código y derivar el diseño de procedimientos que concuerden con la filosofía del mismo.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 185

INGENIERÍA DE SOFTWARE II
Reestructuración de datos: 1. Primero se realiza el ANÁLISIS del código. 2. Se evalúan las definiciones de los datos, archivos, O/I e Interfaces. 3. Extraer elementos y objetos de datos para obtener información del flujo de
datos y comprender la estructura. 4. Rediseño de datos trata de que exista consistencia de los mismos (nombres
y formatos de registro) en la estructura o archivo. 5. Racionalización de nombre asegura que el nombramiento de datos
concuerden con el estándar local y elimina los pseudónimos (flujo de datos a través del sistema)
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 186

INGENIERÍA DE SOFTWARE II
LA INGENIERÍA DIRECTA.
Se puede trabajar modificación tras modificación y luchar con el diseño para implementar los cambios. Intentar conocer el funcionamiento interno del Software para realizar modificaciones eficientes. Rediseñar, recodificar y. probar el Software en un enfoque de Ingeniería de Software.
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 187

INGENIERÍA DE SOFTWARE II
ESCUELA DE TECNOLOGÍAS DE LA INFORMACIÓN 188