c de alto rendimiento (hpc) & big data
TRANSCRIPT

CÓMPUTO DE ALTO RENDIMIENTO (HPC) & BIG DATA
DR. FABIAN GARCIA NOCETTI IIMAS-UNAM / INFOTEC
Junio 2014

2
CONTENIDO
• COMPUTACION DE ALTO RENDIMIENTO
• BIG DATA Y ANALYTICS
• S/W PARA BIG DATA
• ESTUDIO DE CASO • CONCLUSIONES

3
COMPUTACION DE ALTO RENDIMIENTO
• La computación de alto rendimiento (HPC) es el uso de procesamiento paralelo para ejecutar aplicaciones avanzadas de manera eficiente, confiable y rápida.
• El término se aplica en especial sistemas que operan arriba de un teraflops (1012).
• El término se usa, a veces, como sinónimo de super cómputo.
• Algunas supercomputadoras trabajan a más de un petaflops (1015).

4
COMPUTACION DE ALTO RENDIMIENTO
• Usuarios frecuentes HPC: investigadores científicos, ingenieros e instituciones académicas.
• Agencias gubernamentales (seguridad y defensa) utilizan HPC para aplicaciones complejas.
• A mayor demanda mayor poder de procesamiento y velocidad, la HPC interesa también a empresas, particularmente para procesar transacciones y almacenamiento de datos (data warehouses)

5
COMPUTACION DE ALTO RENDIMIENTO
Aplicaciones de la HPC
• La simulación de terremotos para identificar áreas
especialmente sensibles y predecir sus condiciones.
• Modelado del clima. Modelos computaciones
pueden ser usados con datos viejos para evaluar su
utilidad.
• Modelaje de prototipos físicos es caro y lleva
mucho tiempo.
• Manufactura digital. El uso de la HPC (modelado,
simulación y analítica) para definir productos y
procesos manufactureros (The National Center for
Manufacturing Sciences, NCMS).
• Big data: manejo de grandes cantidades de datos y
de decisiones o rutinas complejas.

6
COMPUTACION DE ALTO RENDIMIENTO
Beneficios en la innovación usando HPC
• El tiempo de ajuste en un laboratorio es de unos 9 meses, HPC puede reducir a menos de una semana.
• El análisis de un componente cuesta en promedio 50,000 USD en un laboratorio, mientras que mediante HPC se puede hacer por 3,000 USD.
• Prototipos virtuales y modelados en gran escala con base en HPC aceleran y racionalizan los procesos.
• Se mejoran la I&D, el diseño y la ingeniería, así como también los procesos de negocios (minería de datos, logística, CRM, etc.)

7
COMPUTACION DE ALTO RENDIMIENTO
Economía de la HPC
• El valor total del mercado mundial de HPC era de unos $26 mil millones (2010).
• Se estima que alcanzará los $30 mil millones (2015)
• Nuevos modelos de negocios mediante internet y la computación en la nube
• Los recursos de HPC en la nube son cada vez más accesibles, lo que permite que los consumidores los consideren un servicio

8
COMPUTACION DE ALTO RENDIMIENTO
Evolución de la HPC a nivel mundial
• Cambios tecnológicos acelerados determinados por la competencia internacional
• Servidores son los principales componentes de costo, pero están declinando como porcentaje de las inversiones
• Mayores tasas de crecimiento se registran en los servicios y el almacenamiento de datos

9
COMPUTACION DE ALTO RENDIMIENTO
Barreras al uso del HPC
• Barreras educacionales y de capacidades (falta de científicos computacionales)
• Obstáculos técnicos
los códigos heredados deben ser actualizados
hay rezago en la formulación de nuevos códigos
brecha entre los procesadores más veloces y otros sistemas tecnológicos
• Las empresas ven al HPC como un costo, no como una inversión
• Dificultad para medir el retorno de inversión (ROI)
CEPAL 04-2013

10
BIG DATA Y ANALYTICS
Big data
• ¿Qué es? Conjuntos de datos cuyo tamaño está más allá de la capacidad de las herramientas de software de bases de datos típicas para capturar, almacenar, gestionar y analizar información.
• ¿Cómo se origina? Por la explosión en la cantidad (velocidad y frecuencia) y diversidad de datos digitales generados en tiempo real como resultado del rol cada vez mayor de la tecnología en las actividades diarias.
• ¿Para qué sirve? Permite generar información y conocimiento con base en información completa en tiempo real.

11
BIG DATA Y ANALYTICS
Tipos de datos
• Compras y transacciones
• Datos de gestión empresarial
• Búsqueda (consulta, trayectoria recorrida, historia)
• Sociales (datos de identidad, información general)
• Intereses personales (que me gusta, tweets, etc.)
• Ubicación, sensores físicos (GPS, patrones de tráfico, Internet of Things, etc.)
• Contenido (SMS, llamadas, e-mails)

12
BIG DATA Y ANALYTICS
Implicaciones
• Era caracterizada por la abundancia de datos.
• Ha alcanzado todos los sectores en la economía
• Los datos son un nuevo factor de producción y de ventaja competitiva
• Oportunidad: Aprender sobre el comportamiento humano para diversos fines.
• Creación de valor vía innovación, eficiencia y competitividad
• Nuevas formas de competencia y nuevos negocios Almacenamiento y gestión de datos.
• Análisis de datos empresariales. En 2010 se estimaba el valor de esta industria en más de $ 100 mil millones, creciendo a casi un 10% al año

13
BIG DATA Y ANALYTICS
Big data para la creación de valor • Segmentación de mercado y población para
personalizar acciones
• Innovación en nuevos modelos de negocios, productos y servicios Mejora de productos existentes
• Desarrollo de nuevos productos (masa y personalización)
• Nuevos modelos de servicio a nivel empresarial y gubernamental
• Apoyo a la toma de decisiones con software inteligente
• Transparencia y eficiencia por compartir datos
• Mejor y más oportuno análisis de desempeño de las organizaciones y ajustes en acción.

14
BIG DATA Y ANALYTICS
Analytics: capacidades
• La analítica de grandes datos se refiere a las herramientas y metodologías para transformar cantidades masivas de datos brutos en “datos sobre datos” con propósitos analíticos
• Se originó en las áreas de biología intensiva en cómputo, ingeniería biomédica, medicina y electrónica
• Algoritmos para detectar patrones, tendencias y correlaciones, en varios horizontes temporales, en los datos
• Uso de técnicas avanzadas de visualización: datos que hacen sentido

15
BIG DATA Y ANALYTICS
Problemas • Disponibilidad de datos: asimetrías
• Las redes sociales generan datos abiertos
• Los gobiernos los están abriendo, pero lentamente
• Los datos de empresas siguen cerrados (¿filantropía de datos?)
• Diferentes capacidades de buscar y analizar datos
• Falta de incentivos para compartir datos
• Privacidad y los límites al anonimato de conjuntos de datos
• Una buena parte de las nuevas fuentes de datos reflejan sólo percepciones, intenciones y deseos
• Apophenia: ver patrones donde no hay; cantidades masivas de datos abren conexiones en todos los sentidos (error de Tipo I)
• CEPAL 04-2013

16
BIG DATA Y ANALYTICS
• ¿Qué sucede cuando las técnicas de análisis tradicionales se encuentran con sus límites?
• ¿Cuándo llega el momento en que la minería de datos no aporta las soluciones esperadas?
• ¿Cómo se enfrentan al desafío de los grandes datos y su expresión más desestructurada?

17
BIG DATA Y ANALYTICS
• Aquí es donde entra data science (técnicas necesarias para manipular y tratar la información desde un punto de vista estadístico/matemático).
• Data Science está basado en algoritmos, aplicados al problema de big data, entre otros.
• Implica hallar correlaciones, aplicar algoritmos más complejos y proporcionar niveles de visibilidad que transforman el contacto de una entidad con su entorno,
• También la capacidad de descubrir y estudiar oportunidades.
• Incorporar la figura del data scientist en la organización.

18
BIG DATA Y ANALYTICS
• Un proyecto de desarrollo de software orientado hacia la computación distribuida.
• Hadoop busca resolver parte de los problemas asociados a big data y a la aparición del data science.
• Ofrece capacidad de almacenamiento y procesamiento local. • Permite escalar desde unos pocos servidores
hasta miles de máquinas, todas ellas ofreciendo calidad de servicio.
• Permite el procesamiento distribuido de grandes conjuntos de datos en clusters de computadoras utilizando modelos sencillos de programación.

19
BIG DATA Y ANALYTICS
Los dos conceptos en los que se apoya Hadoop son, por un lado, la técnica de MapReduce y, por otro, el sistema distribuido de archivos HDFS.
• HDFS (Hadoop Distributed File System) sistema de archivos distribuido, escalable y portátil. • MapReduce: es el modelo de programación utilizado por Google para dar soporte a la computación paralela. Trabaja sobre grandes colecciones de datos en grupos decomputadoras o clusters.

20
BIG DATA Y ANALYTICS
Principales características de MapReduce • Distribución y paralelización (automáticas). • Tolerancia a fallas y a redundancias. • Transparecia. • Escalabilidad • Localización de los datos (se desplaza el algoritmo a
los datos y no al contrario. • Dispone de herramientas de monitorización.

21
BIG DATA Y ANALYTICS
Fases de Big Data y sus soluciones con Hadoop 1. Descubrimiento de grandes datos
• Definir cuáles son los datos de interés. • Encontrar sus fuentes (históricos o Social Media, entre
otros). • Grabar los datos en el sistema. • Determinar cómo serán procesados.
2. Extracción y limpieza de los grandes volúmenes de datos • Extraer los datos de la fuente de origen datos. • Perfilar y limpiar los datos. • Adecuarlos a las necesidades. • Aplicar los estándares de calidad de datos.

22
BIG DATA Y ANALYTICS
Fases de Big Data y sus soluciones con Hadoop 3. Estructuración y análisis de big data
• Dotar de estructura lógica a los conjuntos de datos tratados.
• Almacenar los datos en el repositorio elegido (puede ser una base de datos o un sistema)
• Analizar los datos disponibles para hallar relaciones.
4. Modelado de datos • Aplicar algoritmos a los datos. • Aplicar procesos estadísticos. • Resolver las peticiones lanzadas mediante el modelado de
datos en base a técnicas de minería.
5. Interpretación de grandes datos • Interpretar las distintas soluciones. • Aportar un resultado final.

23
ESTUDIO DE CASO
Analysis of Seismic Records Based on Self-Organized Maps (SOM Neural Networks) and
Wavelet Transform
Rubio-Acosta E. Brandi-Purata J., Molino-Minero E., García-Nocceti F., Benítez-Pérez H.
Instituto de Investigaciones en Matemáticas Aplicadas y en Sistemas
Universidad Nacional Autónoma de México

Introduction
• A methodology for graphical analysis of seismic records based on self-organizing maps (SOM neural networks) and wavelet transform is proposed.
• This may help petroleum engineers to recognize areas where there may be oil.
• The methodology considers a seismic cube that includes at least one well and a geological horizon of interest.
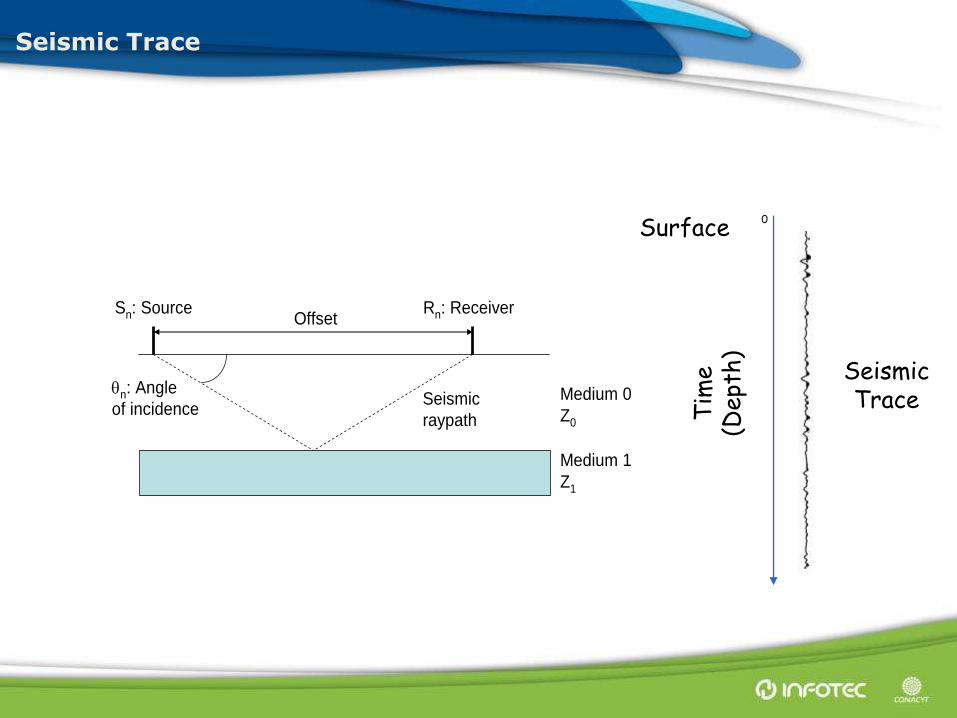
Seismic Trace
Sn: Source Rn: Receiver
n: Angle
of incidenceSeismic
raypath
Offset
Medium 0
Z0
Medium 1
Z1
Tim
e
(Dep
th)
Surface 0
Seismic Trace

Seismic Gather
Offset T
ime
(Dept
h)
0
0
Surface Point on surface
Seismic Gather
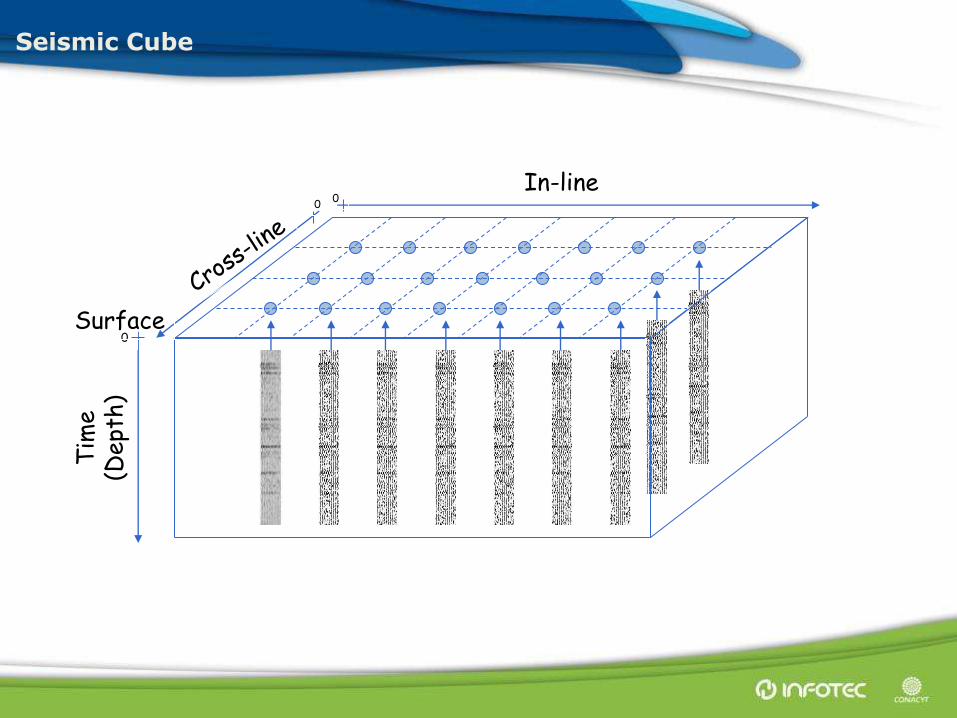
Seismic Cube
In-line 0
0
Tim
e (D
ept
h)
0 Surface

Oil Well and Horizon
In-line
Oil Well
Horizon
Tim
e
(Dept
h)
0 Surface
0 0
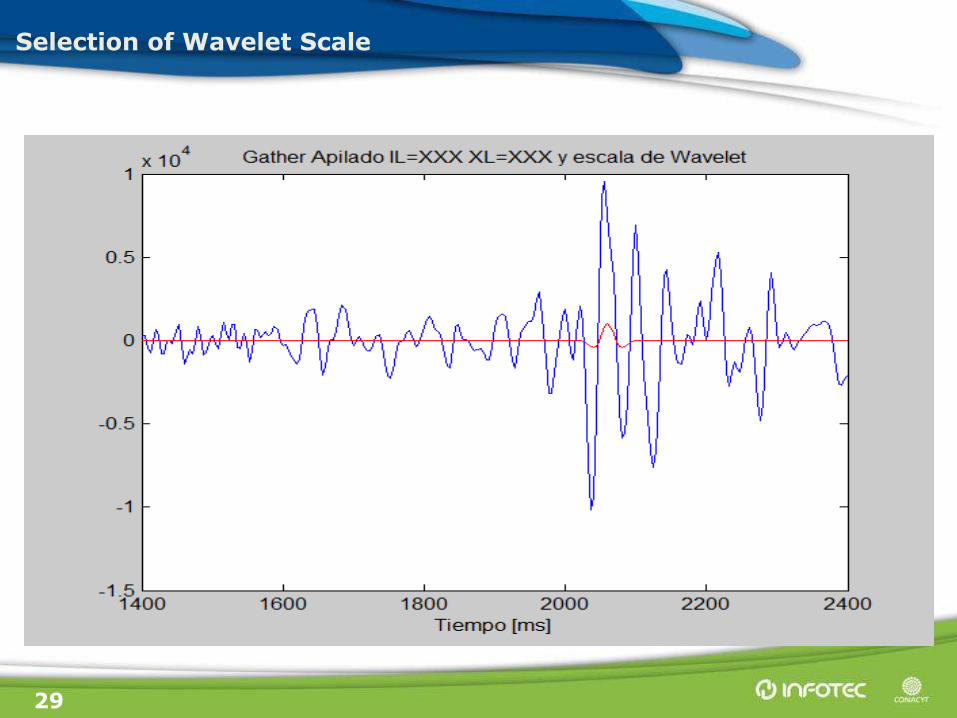
29
Selection of Wavelet Scale
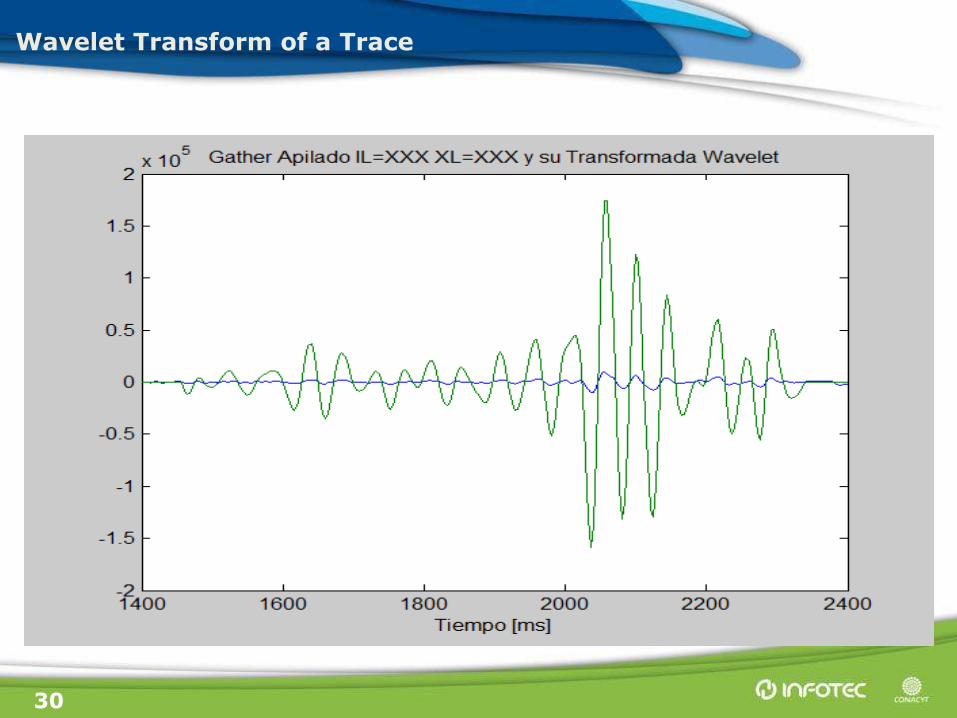
30
Wavelet Transform of a Trace

Self-Organized Maps
A self-organizing map (SOM) is a type of artificial neural network that is trained using unsupervised learning to produce a low-dimensional discretized representation of the input space of the training samples, called a map. Self-organizing maps are different from other artificial neural networks in the sense that they use a neighborhood function to preserve the topological properties of the input space.
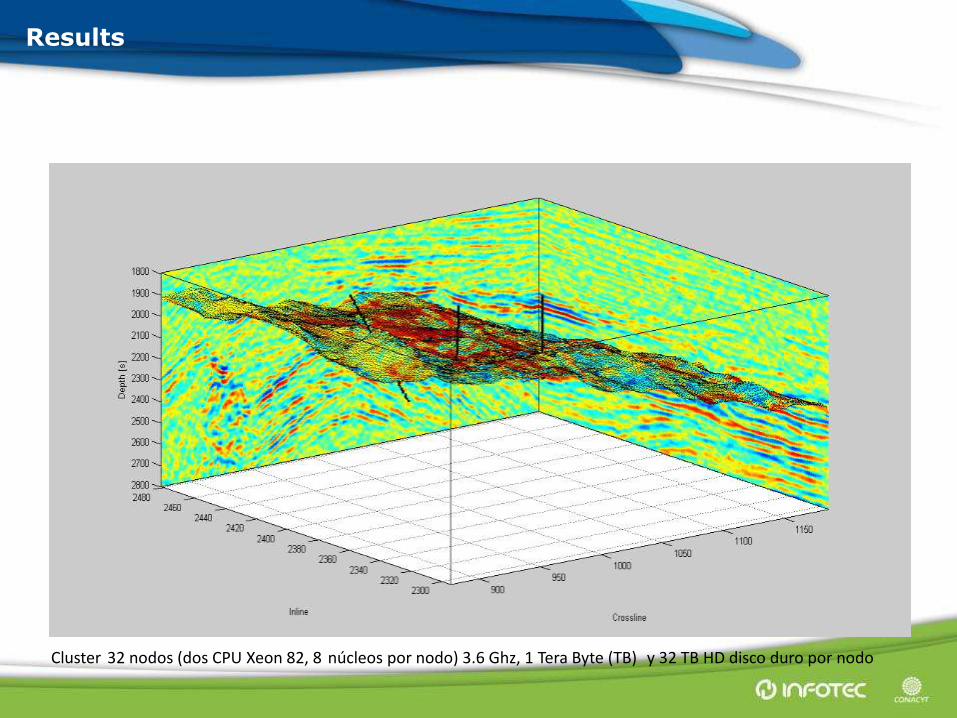
Results
Cluster 32 nodos (dos CPU Xeon 82, 8 núcleos por nodo) 3.6 Ghz, 1 Tera Byte (TB) y 32 TB HD disco duro por nodo

Results
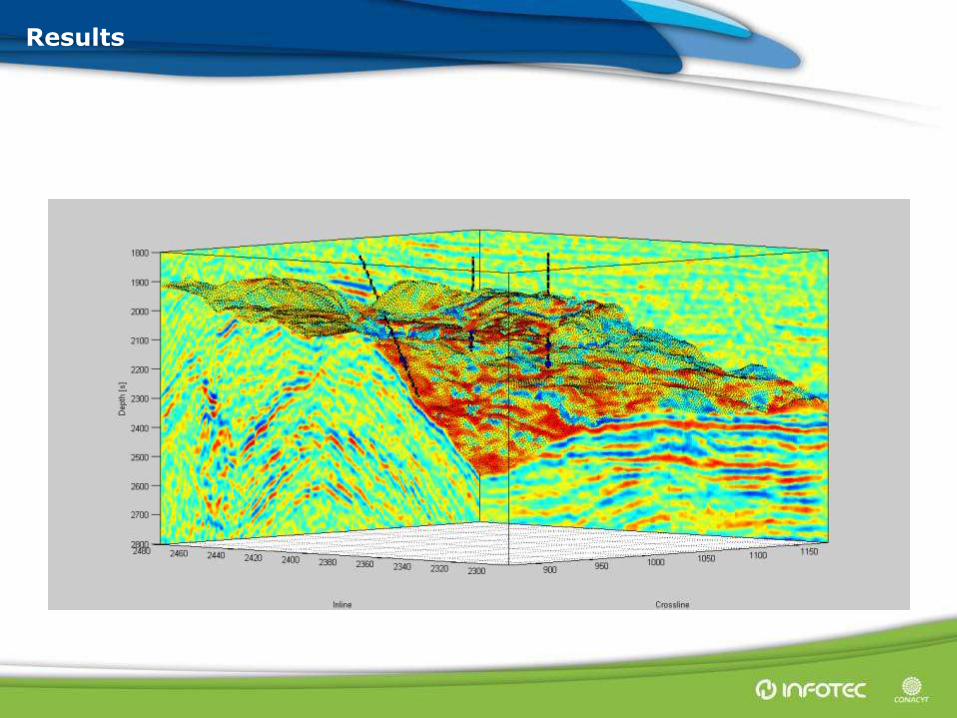
Results

Results (Class 1)
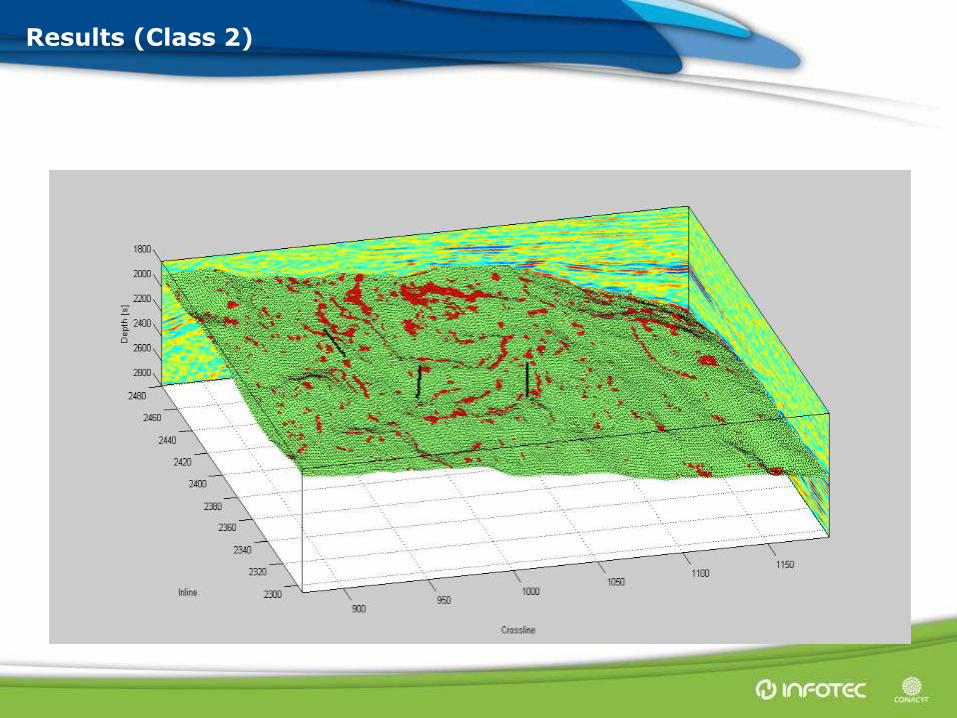
Results (Class 2)
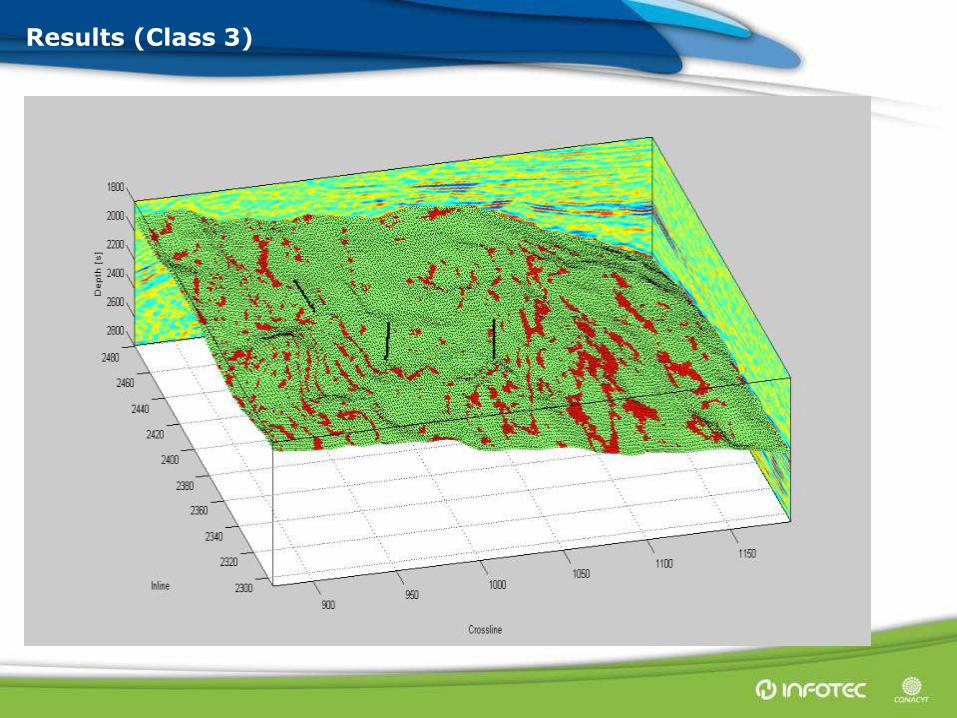
Results (Class 3)

Results (Class 4)
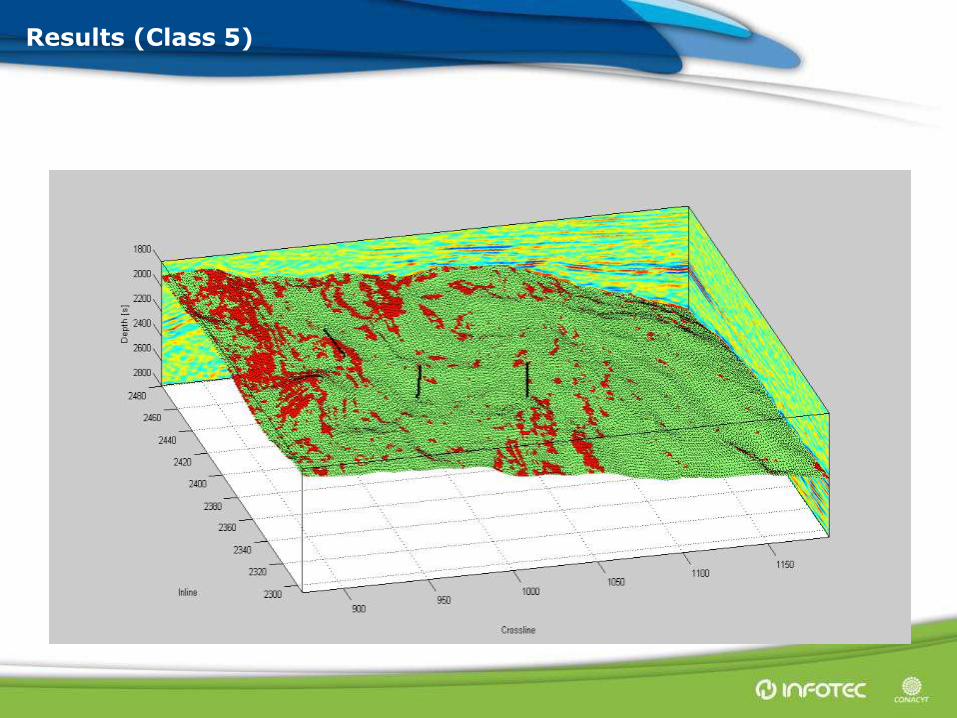
Results (Class 5)
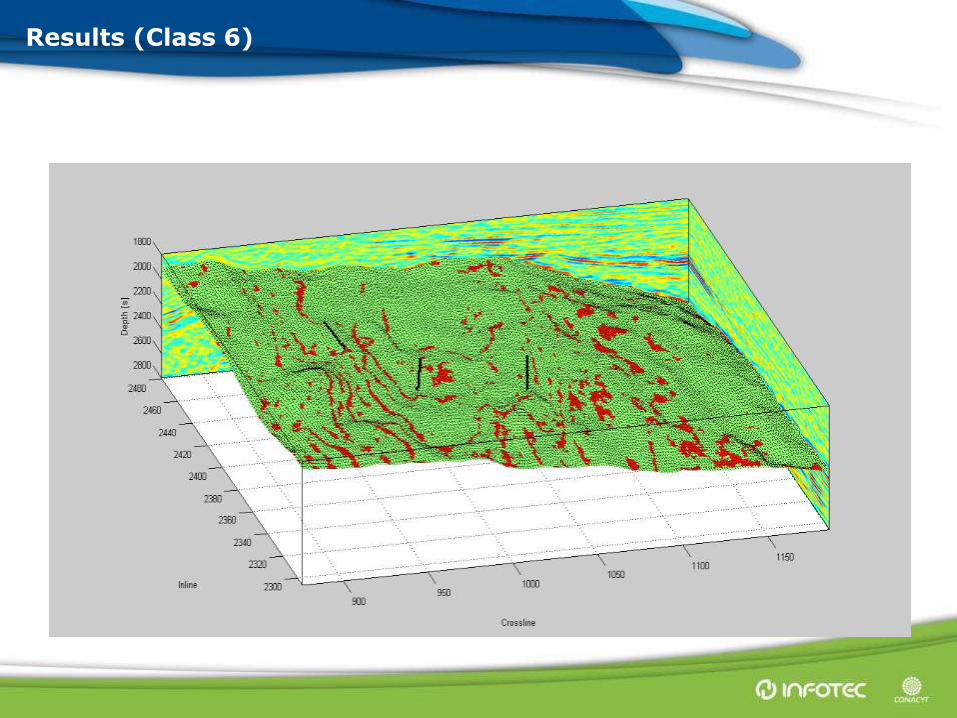
Results (Class 6)
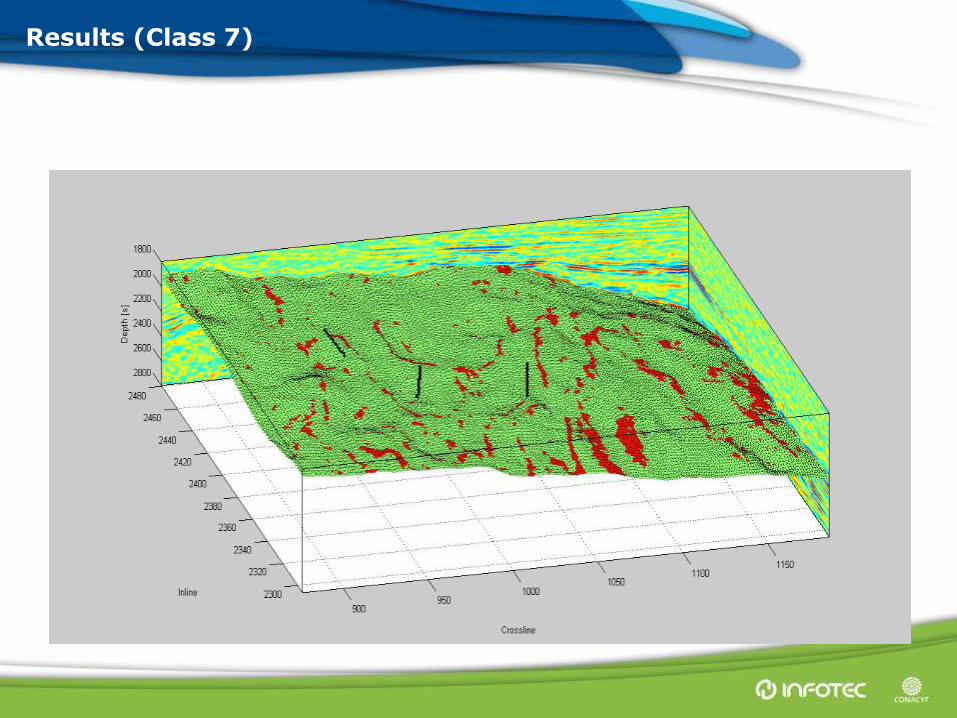
Results (Class 7)

Results (Class 8)

Results (Class 9)

Conclusions
• Research in progress.
• Preliminary results.
• Geometric analysis.
• Not physical or causal analysis.
• Making comparison with AVO analysis.