big data — oportunidades y desaf´ıos · el algoritmo de recomendaci´on ademas deja de recibir...
TRANSCRIPT

Big data mdash oportunidades y desafıos
Big data mdash oportunidades y desafıos
Elisa Schaeffer
FIME UANL
01112017
Big data mdash oportunidades y desafıos
Agradecimientos
Lo de hoy esta principalmente basada en el artıculoiquestDatos Grandes o Datos Correctos de Ricardo
Baeza-Yates (httpwwwbaezacl) que es unatraduccion que hicimos de su artıculo en ingles1
para la revista de la SMIA Komputer Sapiens
7(2) 5ndash10 httpsmiamxkomputersapiens
1R Baeza-Yates (2013) ldquoBig Data or Right Datardquo En Proc of the 7th Alberto
Mendelzon International Workshop on Foundations of Data Management Ed porLoreto Bravo y Maurizio Lenzerini Vol 1087 CEUR Workshop Proceedings urlhttpceur-wsorgVol-1087
Big data mdash oportunidades y desafıos
Introduccion
Definicion
Conjuntos de datos que por su tamano y complejidad resultandifıciles de procesar con herramientas tradicionales
Tambien depende del contexto ldquogranderdquo en el ambito delcomputo movil es de menor tamano que ldquogranderdquo paracomputadoras y lo imposible para computadoras de escritorio essencillo para centros de supercomputo
Big data mdash oportunidades y desafıos
Introduccion
httpdilbertcomstrip2012-07-29
Big data mdash oportunidades y desafıos
Introduccion
Campos de aplicacion
Se utilizan para busqueda extraccion de informacion y muchosotros problemas de minerıa de datos
La necesidad para todo esto surge en los negocios en lainvestigacion medica en desarrollo tecnologico entre otros areas
Los ejemplos de hoy tendran que ver mayormente con la web unarea de expertise de Ric
Big data mdash oportunidades y desafıos
Introduccion
Fuentes de datos
Muchas veces los datos procesados son logs (es decir registros deacceso consulta o compra por ejemplo) generados por sistemascomputacionales
En ciencias naturales una fuente comun son equipos cientıficos demedicion o analisis
Cuando los datos provienen de la gente esto se llama sabidurıa de
la gente (ldquowisdom of the crowdsrdquo en ingles)2
2J Surowiecki (2004) The Wisdom of Crowds Why the Many Are Smarter Than the
Few and How Collective Wisdom Shapes Business Economies Societies and NationsRandom House
Big data mdash oportunidades y desafıos
Introduccion
iquestBusqueda versus la minerıa de datos
En la primera se sabe lo que se busca mientras que el segundocaso el objetivo es el descubrimiento de algo inusual iquestque tiene deinteresante un nuevo conjunto de datos
Tıpicamente el buen uso de la minerıa de datos surge a partir deun problema y se fundamenta en preguntas tales como
iquestQue datos se necesitan
iquestCuantos y de que manera de recolectaran
Big data mdash oportunidades y desafıos
Introduccion
httpsxkcdcom1838
Big data mdash oportunidades y desafıos
Introduccion
Recopilacion transferencia y almacenaje
Por lo general son multiples fuentes de datos que generan entradasde manera simultanea y esto hay que meterlo todo en algun clasede base de datos
Se acumula mucho y no conviene analizarlo ahı mismo sino en unacomputadora aparte
La transferencia de un petabyte sobre una conexion de Internetrapida a 100 Mbps por segundo necesita iexclmas de dos anos
Ademas ocupamos disco para los datos su preprocesamiento ytodos nuestros resultados intermedios y finales
Big data mdash oportunidades y desafıos
Introduccion
Antes de iniciar la minerıa
iquestSon datos unicos o hay que filtrar por duplicados
iquestSon datos confiables o hay spam
iquestCuanto ruido hay en los datos
iquestHay sesgos que afectan la interpretacion de los datos
iquestHay datos privados que se deben anonimizar
Big data mdash oportunidades y desafıos
Introduccion
iquestComo y con que procesar
iquestEs factible procesar todos los datos
iquestSera capaz el algoritmo de escalar
Si debo limitarme a un subconjunto iquestcuales son los datoscorrectos
Big data mdash oportunidades y desafıos
Introduccion
Nuestro temario hoy
El manejo de esas cantidades de datos plantea muchos retos
1 escalabilidad
2 privacidad
3 redundancia
4 sesgo
5 dispersion
6 ruido
7 basura
8 complejidad
9 heterogeneidad
Big data mdash oportunidades y desafıos
Escalabilidad
Broncas causadas por excesos
Puede resultar poco factible la transferencia almacenamiento yprocesamiento de cantidades elevadas de datos por
las limitaciones del ancho de banda de los canales decomunicacion
el espacio disponible en los dispositivos de almacenamientodigital y
el desempeno de los algoritmos utilizados
Ademas contar con mas datos puede resultar en un aumento delnivel de ruido dentro de los mismos lo que se discutira masadelante
Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Agradecimientos
Lo de hoy esta principalmente basada en el artıculoiquestDatos Grandes o Datos Correctos de Ricardo
Baeza-Yates (httpwwwbaezacl) que es unatraduccion que hicimos de su artıculo en ingles1
para la revista de la SMIA Komputer Sapiens
7(2) 5ndash10 httpsmiamxkomputersapiens
1R Baeza-Yates (2013) ldquoBig Data or Right Datardquo En Proc of the 7th Alberto
Mendelzon International Workshop on Foundations of Data Management Ed porLoreto Bravo y Maurizio Lenzerini Vol 1087 CEUR Workshop Proceedings urlhttpceur-wsorgVol-1087
Big data mdash oportunidades y desafıos
Introduccion
Definicion
Conjuntos de datos que por su tamano y complejidad resultandifıciles de procesar con herramientas tradicionales
Tambien depende del contexto ldquogranderdquo en el ambito delcomputo movil es de menor tamano que ldquogranderdquo paracomputadoras y lo imposible para computadoras de escritorio essencillo para centros de supercomputo
Big data mdash oportunidades y desafıos
Introduccion
httpdilbertcomstrip2012-07-29
Big data mdash oportunidades y desafıos
Introduccion
Campos de aplicacion
Se utilizan para busqueda extraccion de informacion y muchosotros problemas de minerıa de datos
La necesidad para todo esto surge en los negocios en lainvestigacion medica en desarrollo tecnologico entre otros areas
Los ejemplos de hoy tendran que ver mayormente con la web unarea de expertise de Ric
Big data mdash oportunidades y desafıos
Introduccion
Fuentes de datos
Muchas veces los datos procesados son logs (es decir registros deacceso consulta o compra por ejemplo) generados por sistemascomputacionales
En ciencias naturales una fuente comun son equipos cientıficos demedicion o analisis
Cuando los datos provienen de la gente esto se llama sabidurıa de
la gente (ldquowisdom of the crowdsrdquo en ingles)2
2J Surowiecki (2004) The Wisdom of Crowds Why the Many Are Smarter Than the
Few and How Collective Wisdom Shapes Business Economies Societies and NationsRandom House
Big data mdash oportunidades y desafıos
Introduccion
iquestBusqueda versus la minerıa de datos
En la primera se sabe lo que se busca mientras que el segundocaso el objetivo es el descubrimiento de algo inusual iquestque tiene deinteresante un nuevo conjunto de datos
Tıpicamente el buen uso de la minerıa de datos surge a partir deun problema y se fundamenta en preguntas tales como
iquestQue datos se necesitan
iquestCuantos y de que manera de recolectaran
Big data mdash oportunidades y desafıos
Introduccion
httpsxkcdcom1838
Big data mdash oportunidades y desafıos
Introduccion
Recopilacion transferencia y almacenaje
Por lo general son multiples fuentes de datos que generan entradasde manera simultanea y esto hay que meterlo todo en algun clasede base de datos
Se acumula mucho y no conviene analizarlo ahı mismo sino en unacomputadora aparte
La transferencia de un petabyte sobre una conexion de Internetrapida a 100 Mbps por segundo necesita iexclmas de dos anos
Ademas ocupamos disco para los datos su preprocesamiento ytodos nuestros resultados intermedios y finales
Big data mdash oportunidades y desafıos
Introduccion
Antes de iniciar la minerıa
iquestSon datos unicos o hay que filtrar por duplicados
iquestSon datos confiables o hay spam
iquestCuanto ruido hay en los datos
iquestHay sesgos que afectan la interpretacion de los datos
iquestHay datos privados que se deben anonimizar
Big data mdash oportunidades y desafıos
Introduccion
iquestComo y con que procesar
iquestEs factible procesar todos los datos
iquestSera capaz el algoritmo de escalar
Si debo limitarme a un subconjunto iquestcuales son los datoscorrectos
Big data mdash oportunidades y desafıos
Introduccion
Nuestro temario hoy
El manejo de esas cantidades de datos plantea muchos retos
1 escalabilidad
2 privacidad
3 redundancia
4 sesgo
5 dispersion
6 ruido
7 basura
8 complejidad
9 heterogeneidad
Big data mdash oportunidades y desafıos
Escalabilidad
Broncas causadas por excesos
Puede resultar poco factible la transferencia almacenamiento yprocesamiento de cantidades elevadas de datos por
las limitaciones del ancho de banda de los canales decomunicacion
el espacio disponible en los dispositivos de almacenamientodigital y
el desempeno de los algoritmos utilizados
Ademas contar con mas datos puede resultar en un aumento delnivel de ruido dentro de los mismos lo que se discutira masadelante
Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Introduccion
Definicion
Conjuntos de datos que por su tamano y complejidad resultandifıciles de procesar con herramientas tradicionales
Tambien depende del contexto ldquogranderdquo en el ambito delcomputo movil es de menor tamano que ldquogranderdquo paracomputadoras y lo imposible para computadoras de escritorio essencillo para centros de supercomputo
Big data mdash oportunidades y desafıos
Introduccion
httpdilbertcomstrip2012-07-29
Big data mdash oportunidades y desafıos
Introduccion
Campos de aplicacion
Se utilizan para busqueda extraccion de informacion y muchosotros problemas de minerıa de datos
La necesidad para todo esto surge en los negocios en lainvestigacion medica en desarrollo tecnologico entre otros areas
Los ejemplos de hoy tendran que ver mayormente con la web unarea de expertise de Ric
Big data mdash oportunidades y desafıos
Introduccion
Fuentes de datos
Muchas veces los datos procesados son logs (es decir registros deacceso consulta o compra por ejemplo) generados por sistemascomputacionales
En ciencias naturales una fuente comun son equipos cientıficos demedicion o analisis
Cuando los datos provienen de la gente esto se llama sabidurıa de
la gente (ldquowisdom of the crowdsrdquo en ingles)2
2J Surowiecki (2004) The Wisdom of Crowds Why the Many Are Smarter Than the
Few and How Collective Wisdom Shapes Business Economies Societies and NationsRandom House
Big data mdash oportunidades y desafıos
Introduccion
iquestBusqueda versus la minerıa de datos
En la primera se sabe lo que se busca mientras que el segundocaso el objetivo es el descubrimiento de algo inusual iquestque tiene deinteresante un nuevo conjunto de datos
Tıpicamente el buen uso de la minerıa de datos surge a partir deun problema y se fundamenta en preguntas tales como
iquestQue datos se necesitan
iquestCuantos y de que manera de recolectaran
Big data mdash oportunidades y desafıos
Introduccion
httpsxkcdcom1838
Big data mdash oportunidades y desafıos
Introduccion
Recopilacion transferencia y almacenaje
Por lo general son multiples fuentes de datos que generan entradasde manera simultanea y esto hay que meterlo todo en algun clasede base de datos
Se acumula mucho y no conviene analizarlo ahı mismo sino en unacomputadora aparte
La transferencia de un petabyte sobre una conexion de Internetrapida a 100 Mbps por segundo necesita iexclmas de dos anos
Ademas ocupamos disco para los datos su preprocesamiento ytodos nuestros resultados intermedios y finales
Big data mdash oportunidades y desafıos
Introduccion
Antes de iniciar la minerıa
iquestSon datos unicos o hay que filtrar por duplicados
iquestSon datos confiables o hay spam
iquestCuanto ruido hay en los datos
iquestHay sesgos que afectan la interpretacion de los datos
iquestHay datos privados que se deben anonimizar
Big data mdash oportunidades y desafıos
Introduccion
iquestComo y con que procesar
iquestEs factible procesar todos los datos
iquestSera capaz el algoritmo de escalar
Si debo limitarme a un subconjunto iquestcuales son los datoscorrectos
Big data mdash oportunidades y desafıos
Introduccion
Nuestro temario hoy
El manejo de esas cantidades de datos plantea muchos retos
1 escalabilidad
2 privacidad
3 redundancia
4 sesgo
5 dispersion
6 ruido
7 basura
8 complejidad
9 heterogeneidad
Big data mdash oportunidades y desafıos
Escalabilidad
Broncas causadas por excesos
Puede resultar poco factible la transferencia almacenamiento yprocesamiento de cantidades elevadas de datos por
las limitaciones del ancho de banda de los canales decomunicacion
el espacio disponible en los dispositivos de almacenamientodigital y
el desempeno de los algoritmos utilizados
Ademas contar con mas datos puede resultar en un aumento delnivel de ruido dentro de los mismos lo que se discutira masadelante
Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Introduccion
httpdilbertcomstrip2012-07-29
Big data mdash oportunidades y desafıos
Introduccion
Campos de aplicacion
Se utilizan para busqueda extraccion de informacion y muchosotros problemas de minerıa de datos
La necesidad para todo esto surge en los negocios en lainvestigacion medica en desarrollo tecnologico entre otros areas
Los ejemplos de hoy tendran que ver mayormente con la web unarea de expertise de Ric
Big data mdash oportunidades y desafıos
Introduccion
Fuentes de datos
Muchas veces los datos procesados son logs (es decir registros deacceso consulta o compra por ejemplo) generados por sistemascomputacionales
En ciencias naturales una fuente comun son equipos cientıficos demedicion o analisis
Cuando los datos provienen de la gente esto se llama sabidurıa de
la gente (ldquowisdom of the crowdsrdquo en ingles)2
2J Surowiecki (2004) The Wisdom of Crowds Why the Many Are Smarter Than the
Few and How Collective Wisdom Shapes Business Economies Societies and NationsRandom House
Big data mdash oportunidades y desafıos
Introduccion
iquestBusqueda versus la minerıa de datos
En la primera se sabe lo que se busca mientras que el segundocaso el objetivo es el descubrimiento de algo inusual iquestque tiene deinteresante un nuevo conjunto de datos
Tıpicamente el buen uso de la minerıa de datos surge a partir deun problema y se fundamenta en preguntas tales como
iquestQue datos se necesitan
iquestCuantos y de que manera de recolectaran
Big data mdash oportunidades y desafıos
Introduccion
httpsxkcdcom1838
Big data mdash oportunidades y desafıos
Introduccion
Recopilacion transferencia y almacenaje
Por lo general son multiples fuentes de datos que generan entradasde manera simultanea y esto hay que meterlo todo en algun clasede base de datos
Se acumula mucho y no conviene analizarlo ahı mismo sino en unacomputadora aparte
La transferencia de un petabyte sobre una conexion de Internetrapida a 100 Mbps por segundo necesita iexclmas de dos anos
Ademas ocupamos disco para los datos su preprocesamiento ytodos nuestros resultados intermedios y finales
Big data mdash oportunidades y desafıos
Introduccion
Antes de iniciar la minerıa
iquestSon datos unicos o hay que filtrar por duplicados
iquestSon datos confiables o hay spam
iquestCuanto ruido hay en los datos
iquestHay sesgos que afectan la interpretacion de los datos
iquestHay datos privados que se deben anonimizar
Big data mdash oportunidades y desafıos
Introduccion
iquestComo y con que procesar
iquestEs factible procesar todos los datos
iquestSera capaz el algoritmo de escalar
Si debo limitarme a un subconjunto iquestcuales son los datoscorrectos
Big data mdash oportunidades y desafıos
Introduccion
Nuestro temario hoy
El manejo de esas cantidades de datos plantea muchos retos
1 escalabilidad
2 privacidad
3 redundancia
4 sesgo
5 dispersion
6 ruido
7 basura
8 complejidad
9 heterogeneidad
Big data mdash oportunidades y desafıos
Escalabilidad
Broncas causadas por excesos
Puede resultar poco factible la transferencia almacenamiento yprocesamiento de cantidades elevadas de datos por
las limitaciones del ancho de banda de los canales decomunicacion
el espacio disponible en los dispositivos de almacenamientodigital y
el desempeno de los algoritmos utilizados
Ademas contar con mas datos puede resultar en un aumento delnivel de ruido dentro de los mismos lo que se discutira masadelante
Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Introduccion
Campos de aplicacion
Se utilizan para busqueda extraccion de informacion y muchosotros problemas de minerıa de datos
La necesidad para todo esto surge en los negocios en lainvestigacion medica en desarrollo tecnologico entre otros areas
Los ejemplos de hoy tendran que ver mayormente con la web unarea de expertise de Ric
Big data mdash oportunidades y desafıos
Introduccion
Fuentes de datos
Muchas veces los datos procesados son logs (es decir registros deacceso consulta o compra por ejemplo) generados por sistemascomputacionales
En ciencias naturales una fuente comun son equipos cientıficos demedicion o analisis
Cuando los datos provienen de la gente esto se llama sabidurıa de
la gente (ldquowisdom of the crowdsrdquo en ingles)2
2J Surowiecki (2004) The Wisdom of Crowds Why the Many Are Smarter Than the
Few and How Collective Wisdom Shapes Business Economies Societies and NationsRandom House
Big data mdash oportunidades y desafıos
Introduccion
iquestBusqueda versus la minerıa de datos
En la primera se sabe lo que se busca mientras que el segundocaso el objetivo es el descubrimiento de algo inusual iquestque tiene deinteresante un nuevo conjunto de datos
Tıpicamente el buen uso de la minerıa de datos surge a partir deun problema y se fundamenta en preguntas tales como
iquestQue datos se necesitan
iquestCuantos y de que manera de recolectaran
Big data mdash oportunidades y desafıos
Introduccion
httpsxkcdcom1838
Big data mdash oportunidades y desafıos
Introduccion
Recopilacion transferencia y almacenaje
Por lo general son multiples fuentes de datos que generan entradasde manera simultanea y esto hay que meterlo todo en algun clasede base de datos
Se acumula mucho y no conviene analizarlo ahı mismo sino en unacomputadora aparte
La transferencia de un petabyte sobre una conexion de Internetrapida a 100 Mbps por segundo necesita iexclmas de dos anos
Ademas ocupamos disco para los datos su preprocesamiento ytodos nuestros resultados intermedios y finales
Big data mdash oportunidades y desafıos
Introduccion
Antes de iniciar la minerıa
iquestSon datos unicos o hay que filtrar por duplicados
iquestSon datos confiables o hay spam
iquestCuanto ruido hay en los datos
iquestHay sesgos que afectan la interpretacion de los datos
iquestHay datos privados que se deben anonimizar
Big data mdash oportunidades y desafıos
Introduccion
iquestComo y con que procesar
iquestEs factible procesar todos los datos
iquestSera capaz el algoritmo de escalar
Si debo limitarme a un subconjunto iquestcuales son los datoscorrectos
Big data mdash oportunidades y desafıos
Introduccion
Nuestro temario hoy
El manejo de esas cantidades de datos plantea muchos retos
1 escalabilidad
2 privacidad
3 redundancia
4 sesgo
5 dispersion
6 ruido
7 basura
8 complejidad
9 heterogeneidad
Big data mdash oportunidades y desafıos
Escalabilidad
Broncas causadas por excesos
Puede resultar poco factible la transferencia almacenamiento yprocesamiento de cantidades elevadas de datos por
las limitaciones del ancho de banda de los canales decomunicacion
el espacio disponible en los dispositivos de almacenamientodigital y
el desempeno de los algoritmos utilizados
Ademas contar con mas datos puede resultar en un aumento delnivel de ruido dentro de los mismos lo que se discutira masadelante
Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Introduccion
Fuentes de datos
Muchas veces los datos procesados son logs (es decir registros deacceso consulta o compra por ejemplo) generados por sistemascomputacionales
En ciencias naturales una fuente comun son equipos cientıficos demedicion o analisis
Cuando los datos provienen de la gente esto se llama sabidurıa de
la gente (ldquowisdom of the crowdsrdquo en ingles)2
2J Surowiecki (2004) The Wisdom of Crowds Why the Many Are Smarter Than the
Few and How Collective Wisdom Shapes Business Economies Societies and NationsRandom House
Big data mdash oportunidades y desafıos
Introduccion
iquestBusqueda versus la minerıa de datos
En la primera se sabe lo que se busca mientras que el segundocaso el objetivo es el descubrimiento de algo inusual iquestque tiene deinteresante un nuevo conjunto de datos
Tıpicamente el buen uso de la minerıa de datos surge a partir deun problema y se fundamenta en preguntas tales como
iquestQue datos se necesitan
iquestCuantos y de que manera de recolectaran
Big data mdash oportunidades y desafıos
Introduccion
httpsxkcdcom1838
Big data mdash oportunidades y desafıos
Introduccion
Recopilacion transferencia y almacenaje
Por lo general son multiples fuentes de datos que generan entradasde manera simultanea y esto hay que meterlo todo en algun clasede base de datos
Se acumula mucho y no conviene analizarlo ahı mismo sino en unacomputadora aparte
La transferencia de un petabyte sobre una conexion de Internetrapida a 100 Mbps por segundo necesita iexclmas de dos anos
Ademas ocupamos disco para los datos su preprocesamiento ytodos nuestros resultados intermedios y finales
Big data mdash oportunidades y desafıos
Introduccion
Antes de iniciar la minerıa
iquestSon datos unicos o hay que filtrar por duplicados
iquestSon datos confiables o hay spam
iquestCuanto ruido hay en los datos
iquestHay sesgos que afectan la interpretacion de los datos
iquestHay datos privados que se deben anonimizar
Big data mdash oportunidades y desafıos
Introduccion
iquestComo y con que procesar
iquestEs factible procesar todos los datos
iquestSera capaz el algoritmo de escalar
Si debo limitarme a un subconjunto iquestcuales son los datoscorrectos
Big data mdash oportunidades y desafıos
Introduccion
Nuestro temario hoy
El manejo de esas cantidades de datos plantea muchos retos
1 escalabilidad
2 privacidad
3 redundancia
4 sesgo
5 dispersion
6 ruido
7 basura
8 complejidad
9 heterogeneidad
Big data mdash oportunidades y desafıos
Escalabilidad
Broncas causadas por excesos
Puede resultar poco factible la transferencia almacenamiento yprocesamiento de cantidades elevadas de datos por
las limitaciones del ancho de banda de los canales decomunicacion
el espacio disponible en los dispositivos de almacenamientodigital y
el desempeno de los algoritmos utilizados
Ademas contar con mas datos puede resultar en un aumento delnivel de ruido dentro de los mismos lo que se discutira masadelante
Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Introduccion
iquestBusqueda versus la minerıa de datos
En la primera se sabe lo que se busca mientras que el segundocaso el objetivo es el descubrimiento de algo inusual iquestque tiene deinteresante un nuevo conjunto de datos
Tıpicamente el buen uso de la minerıa de datos surge a partir deun problema y se fundamenta en preguntas tales como
iquestQue datos se necesitan
iquestCuantos y de que manera de recolectaran
Big data mdash oportunidades y desafıos
Introduccion
httpsxkcdcom1838
Big data mdash oportunidades y desafıos
Introduccion
Recopilacion transferencia y almacenaje
Por lo general son multiples fuentes de datos que generan entradasde manera simultanea y esto hay que meterlo todo en algun clasede base de datos
Se acumula mucho y no conviene analizarlo ahı mismo sino en unacomputadora aparte
La transferencia de un petabyte sobre una conexion de Internetrapida a 100 Mbps por segundo necesita iexclmas de dos anos
Ademas ocupamos disco para los datos su preprocesamiento ytodos nuestros resultados intermedios y finales
Big data mdash oportunidades y desafıos
Introduccion
Antes de iniciar la minerıa
iquestSon datos unicos o hay que filtrar por duplicados
iquestSon datos confiables o hay spam
iquestCuanto ruido hay en los datos
iquestHay sesgos que afectan la interpretacion de los datos
iquestHay datos privados que se deben anonimizar
Big data mdash oportunidades y desafıos
Introduccion
iquestComo y con que procesar
iquestEs factible procesar todos los datos
iquestSera capaz el algoritmo de escalar
Si debo limitarme a un subconjunto iquestcuales son los datoscorrectos
Big data mdash oportunidades y desafıos
Introduccion
Nuestro temario hoy
El manejo de esas cantidades de datos plantea muchos retos
1 escalabilidad
2 privacidad
3 redundancia
4 sesgo
5 dispersion
6 ruido
7 basura
8 complejidad
9 heterogeneidad
Big data mdash oportunidades y desafıos
Escalabilidad
Broncas causadas por excesos
Puede resultar poco factible la transferencia almacenamiento yprocesamiento de cantidades elevadas de datos por
las limitaciones del ancho de banda de los canales decomunicacion
el espacio disponible en los dispositivos de almacenamientodigital y
el desempeno de los algoritmos utilizados
Ademas contar con mas datos puede resultar en un aumento delnivel de ruido dentro de los mismos lo que se discutira masadelante
Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Introduccion
httpsxkcdcom1838
Big data mdash oportunidades y desafıos
Introduccion
Recopilacion transferencia y almacenaje
Por lo general son multiples fuentes de datos que generan entradasde manera simultanea y esto hay que meterlo todo en algun clasede base de datos
Se acumula mucho y no conviene analizarlo ahı mismo sino en unacomputadora aparte
La transferencia de un petabyte sobre una conexion de Internetrapida a 100 Mbps por segundo necesita iexclmas de dos anos
Ademas ocupamos disco para los datos su preprocesamiento ytodos nuestros resultados intermedios y finales
Big data mdash oportunidades y desafıos
Introduccion
Antes de iniciar la minerıa
iquestSon datos unicos o hay que filtrar por duplicados
iquestSon datos confiables o hay spam
iquestCuanto ruido hay en los datos
iquestHay sesgos que afectan la interpretacion de los datos
iquestHay datos privados que se deben anonimizar
Big data mdash oportunidades y desafıos
Introduccion
iquestComo y con que procesar
iquestEs factible procesar todos los datos
iquestSera capaz el algoritmo de escalar
Si debo limitarme a un subconjunto iquestcuales son los datoscorrectos
Big data mdash oportunidades y desafıos
Introduccion
Nuestro temario hoy
El manejo de esas cantidades de datos plantea muchos retos
1 escalabilidad
2 privacidad
3 redundancia
4 sesgo
5 dispersion
6 ruido
7 basura
8 complejidad
9 heterogeneidad
Big data mdash oportunidades y desafıos
Escalabilidad
Broncas causadas por excesos
Puede resultar poco factible la transferencia almacenamiento yprocesamiento de cantidades elevadas de datos por
las limitaciones del ancho de banda de los canales decomunicacion
el espacio disponible en los dispositivos de almacenamientodigital y
el desempeno de los algoritmos utilizados
Ademas contar con mas datos puede resultar en un aumento delnivel de ruido dentro de los mismos lo que se discutira masadelante
Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Introduccion
Recopilacion transferencia y almacenaje
Por lo general son multiples fuentes de datos que generan entradasde manera simultanea y esto hay que meterlo todo en algun clasede base de datos
Se acumula mucho y no conviene analizarlo ahı mismo sino en unacomputadora aparte
La transferencia de un petabyte sobre una conexion de Internetrapida a 100 Mbps por segundo necesita iexclmas de dos anos
Ademas ocupamos disco para los datos su preprocesamiento ytodos nuestros resultados intermedios y finales
Big data mdash oportunidades y desafıos
Introduccion
Antes de iniciar la minerıa
iquestSon datos unicos o hay que filtrar por duplicados
iquestSon datos confiables o hay spam
iquestCuanto ruido hay en los datos
iquestHay sesgos que afectan la interpretacion de los datos
iquestHay datos privados que se deben anonimizar
Big data mdash oportunidades y desafıos
Introduccion
iquestComo y con que procesar
iquestEs factible procesar todos los datos
iquestSera capaz el algoritmo de escalar
Si debo limitarme a un subconjunto iquestcuales son los datoscorrectos
Big data mdash oportunidades y desafıos
Introduccion
Nuestro temario hoy
El manejo de esas cantidades de datos plantea muchos retos
1 escalabilidad
2 privacidad
3 redundancia
4 sesgo
5 dispersion
6 ruido
7 basura
8 complejidad
9 heterogeneidad
Big data mdash oportunidades y desafıos
Escalabilidad
Broncas causadas por excesos
Puede resultar poco factible la transferencia almacenamiento yprocesamiento de cantidades elevadas de datos por
las limitaciones del ancho de banda de los canales decomunicacion
el espacio disponible en los dispositivos de almacenamientodigital y
el desempeno de los algoritmos utilizados
Ademas contar con mas datos puede resultar en un aumento delnivel de ruido dentro de los mismos lo que se discutira masadelante
Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Introduccion
Antes de iniciar la minerıa
iquestSon datos unicos o hay que filtrar por duplicados
iquestSon datos confiables o hay spam
iquestCuanto ruido hay en los datos
iquestHay sesgos que afectan la interpretacion de los datos
iquestHay datos privados que se deben anonimizar
Big data mdash oportunidades y desafıos
Introduccion
iquestComo y con que procesar
iquestEs factible procesar todos los datos
iquestSera capaz el algoritmo de escalar
Si debo limitarme a un subconjunto iquestcuales son los datoscorrectos
Big data mdash oportunidades y desafıos
Introduccion
Nuestro temario hoy
El manejo de esas cantidades de datos plantea muchos retos
1 escalabilidad
2 privacidad
3 redundancia
4 sesgo
5 dispersion
6 ruido
7 basura
8 complejidad
9 heterogeneidad
Big data mdash oportunidades y desafıos
Escalabilidad
Broncas causadas por excesos
Puede resultar poco factible la transferencia almacenamiento yprocesamiento de cantidades elevadas de datos por
las limitaciones del ancho de banda de los canales decomunicacion
el espacio disponible en los dispositivos de almacenamientodigital y
el desempeno de los algoritmos utilizados
Ademas contar con mas datos puede resultar en un aumento delnivel de ruido dentro de los mismos lo que se discutira masadelante
Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Introduccion
iquestComo y con que procesar
iquestEs factible procesar todos los datos
iquestSera capaz el algoritmo de escalar
Si debo limitarme a un subconjunto iquestcuales son los datoscorrectos
Big data mdash oportunidades y desafıos
Introduccion
Nuestro temario hoy
El manejo de esas cantidades de datos plantea muchos retos
1 escalabilidad
2 privacidad
3 redundancia
4 sesgo
5 dispersion
6 ruido
7 basura
8 complejidad
9 heterogeneidad
Big data mdash oportunidades y desafıos
Escalabilidad
Broncas causadas por excesos
Puede resultar poco factible la transferencia almacenamiento yprocesamiento de cantidades elevadas de datos por
las limitaciones del ancho de banda de los canales decomunicacion
el espacio disponible en los dispositivos de almacenamientodigital y
el desempeno de los algoritmos utilizados
Ademas contar con mas datos puede resultar en un aumento delnivel de ruido dentro de los mismos lo que se discutira masadelante
Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Introduccion
Nuestro temario hoy
El manejo de esas cantidades de datos plantea muchos retos
1 escalabilidad
2 privacidad
3 redundancia
4 sesgo
5 dispersion
6 ruido
7 basura
8 complejidad
9 heterogeneidad
Big data mdash oportunidades y desafıos
Escalabilidad
Broncas causadas por excesos
Puede resultar poco factible la transferencia almacenamiento yprocesamiento de cantidades elevadas de datos por
las limitaciones del ancho de banda de los canales decomunicacion
el espacio disponible en los dispositivos de almacenamientodigital y
el desempeno de los algoritmos utilizados
Ademas contar con mas datos puede resultar en un aumento delnivel de ruido dentro de los mismos lo que se discutira masadelante
Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Escalabilidad
Broncas causadas por excesos
Puede resultar poco factible la transferencia almacenamiento yprocesamiento de cantidades elevadas de datos por
las limitaciones del ancho de banda de los canales decomunicacion
el espacio disponible en los dispositivos de almacenamientodigital y
el desempeno de los algoritmos utilizados
Ademas contar con mas datos puede resultar en un aumento delnivel de ruido dentro de los mismos lo que se discutira masadelante
Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Escalabilidad
Desempeno algorıtmico
Los algoritmos utilizados para el analisis de datos nonecesariamente escalan de forma adecuada
Si un algoritmo es O(n) un conjunto de doble tamano implica quesu procesamiento va a tardar dos veces el tiempo original
Para algoritmos con comportamiento superlineal casi nunca espractico
Soluciones tıpicas incluyen la paralelizacion yo la distribucion delprocesamiento
Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Escalabilidad
Diseno algorıtmico
Una opcion mas barata pero que requiere bastante talento yconocimiento es disenar algoritmos mas rapidos (posiblementeaproximados en vez de exactos)
Esto es fructıfero cuando los beneficios de poder incorporar unamayor cantidad de datos son mayores que la perdida de calidaddebida al nuevo algoritmo las ganancias en terminos de ahorro detiempo de computacion permite procesar mas datos que ojalacontraponga la disminucion en la calidad
Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Escalabilidad
Ejemplo de etiquetado lexico
Chamba = reconocer las entidades nombradas dentro de un textoLos mejores algoritmos en existencia tienen una complejidadsuperlineal Ciaramita y Altun3 presentan un algoritmo O(n) conalta calidad
La idea es esta supongamos que se puede obtener un resultado demayor calidad con un algoritmo O(n log n) Denotemos el aumentoen la calidad por ∆q y la calidad obtenida por un algoritmo linealpor Q Para que convenga el numero de entidades correctamenteetiquetadas por unidad de tiempo debe ser mayor Si ejecutamosambos por la misma cantidad de tiempo habra un n = O(β∆qQ)con β gt 1 para el cual el numero de entidades correctamenteetiquetadas sera mayor
3M Ciaramita e Y Altun (2006) ldquoBroad-Coverage Sense Disambiguation and In-formation Extraction with a Supersense Sequence Taggerrdquo En EMNLPrsquo08 urlhttpsourceforgenetprojectssupersensetag
Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Escalabilidad
Paradigmas de procesamiento
El grado de paralelizacion alcanzable depende del problema que seesta resolviendo
No todos los problemas se adaptan bien al conocido paradigma deldquomap-reducerdquo4
Se necesita mas investigacion para crear paradigmas mas potentes
Ademas hay que considerar la naturaleza dinamica de los datos yaque se puede presentar la necesidad de procesar los datos en lıneaexiste una iniciativa llamada SAMOA5 para el procesamientoescalable de flujos de datos
4J Dean y S Ghemawat (2004) ldquoMapReduce Simplified Data Processing on LargeClustersrdquo En OSDIrsquo04 pags 137-149
5A Bifet (2013) SAMOA Scalable Advanced Massive Online Analysis urlhttp20samoa-projectnet
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Redundancia y sesgo
Elementos redundantes
En cualquier red sensora que rastrea multiples objetos enmovimiento todos los nodos sensores cercanos a un objetoproducen datos redundantes
En la web la situacion es peor ya que se estima que laredundancia lexica (es decir plagiarismo de contenido) es del256 y la redundancia semantica (lo mismo significado expresadoen diferentes palabras o lenguajes) es un porcentaje aun mayor delcontenido de la web7
6F Radlinski PN Bennett y E Yilmaz (2011) ldquoDetecting duplicate web documentsusing click-through datardquo En Proceedings of the fourth ACM international conference
on Web search and data mining pags 147-1567A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en la busqueda
Uno de los ejemplos conocidos de sesgo son las selecciones querealizan los usuarios en las paginas de resultados de buscadoresweb mdash sus decisiones estan afectadas tanto por el ordenamientode los resultados como por la interfaz de usuario8
Hay evidencia de que algunos proveedores de contenido en la webgeneran nuevo contenido seleccionando material conseguido atraves de busquedas9
8O Chapelle e Y Zhang (2009) ldquoA dynamic bayesian network click model for websearch rankingrdquo En WWWrsquo09 pags 1-10 G Dupret y B Piwowarski (2008) ldquoA userbrowsing model to predict search engine click data from past observationsrdquo En Procof the 31st annual international ACM SIGIR conference on Research and development
in information retrieval pags 331-3389A Pereira Jr R Baeza-Yates y N Ziviani (2008) ldquoGenealogical trees on the Web asearch engine user perspectiverdquo En WWWrsquo08 pags 367-376
Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Redundancia y sesgo
Sesgo en etiquetado
Imagine que en el momento de compartir contenido (por ejemploimagenes) se le proporcione al usuario etiquetas recomendadaspara asociar a dicho contenido
Al rato la mayorıa de las etiquetas asociadas al contenido serangeneradas por el sistema de recomendacion y en realidad no poruna contribucion explıcita de los usuarios
El espacio de etiquetas resultante ya no se puede considerar unafolksonomıa sino mas bien un producto combinado de la gente y elalgoritmo que genera las recomendaciones
El algoritmo de recomendacion ademas deja de recibir nuevasentradas generadas por los usuarios
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Leyes de potencia
Muchos conjuntos de datos siguen leyes de potencia (ldquopower lawrdquoen ingles)
Para la ldquocabezardquo de la distribucion la minerıa de datos funcionamuy bien pero apesta para la cola larga
La atencion adecuada a estas colas largas es una tarea crıtica yaque todas las personas tienen sus comportamientos regulares yespeciales (es decir todas las personas tienen tambien una colalarga)10
10S Goel y col (2010) ldquoAnatomy of the long tail ordinary people with extraordinarytastesrdquo En WSDMrsquo10 pags 201-210
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Binning to the rescue
Al juntar datos a nivel de usuario sin embargo frecuentementeocurre que no hay suficientes datos disponibles en la cola largapara personalizar la experiencia de este usuario mdash en esos casos esmejor agrupar a personas y contextualizar la experiencia de usuario
A veces la cabeza llega a ahogar la cola cuando una consultapuede referir a dos cosas diferentes una de ellos muy popular yfrecuentemente consultada11 discuten estos temas ademas deotros como la privacidad con respecto a la dispersion de los datos
11R Baeza-Yates e Y Maarek (2012) ldquoUsage Data in Web Search Benefits and Limita-tionsrdquo En SSDBMrsquo12 Ed por A Ailamaki y S Bowers Vol 7338 LNCS Springerpags 495-506
Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Dispersion ruido y basura
Spam wonderful spam
Un empeoramiento de los resultados puede ser causado por lapresencia de contenido o accion cuyo proposito es de manipular
Casos tıpicos son los intentos de mejorar el posicionamiento de unsitio web dentro de los resultados de un buscador12 aunque yaexisten una multitud de tecnicas para combatirlos13
Aun ası este tipo de manipulacion sigue sucediendo a todos losniveles desde calificaciones de hoteles hasta los conteos de citas enGoogle Scholar14
12R Baeza-Yates y B Ribeiro-Neto (2011) Modern Information Retrieval The Concepts
and Technology behind Search 2a ed Addison-Wesley13N Spirin y J Han (2011) ldquoSurvey on web spam detection principles and algorithmsrdquoEn ACM SIGKDD Explorations Newsletter 132 pags 50-64
14E Delgado Lopez-Cozar N Robinson-Garcıa y DTorres-Salinas (2012) Manipulating
Google Scholar Citations and Google Scholar Metrics simple easy and tempting Inftec arXivorg url httparxivorgabs12120638
Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Privacidad
Proteccion de datos privados
Por ley las instituciones que manejan datos personales debengarantizar que no se compartan con terceros
Se han formulado polıticas de retencion de datos para asegurar alegisladores los medios de comunicacion y naturalmente a sususuarios que cumplen con todos los reglamentos legales sobre elmanejo de informacion personal
Por ejemplo los logs de busqueda se anonimizan a los seis meses yse des-identifican en un ano y medio
Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Privacidad
k-anonimizacion
Introducida por15 propone la supresion o generalizacion deatributos hasta que cada valor del conjunto es identico a por lomenos k minus 1 otras personas
Los proponentes demuestran que pocos atributos son suficientespara identificar caracterısticas principales de la mayorıa de laspersonas por ejemplo cruzando bases de datos publicamentedisponibles se podıa identificar al 87 de los ciudadanosestadounidenses a nivel de su codigo postal fecha de nacimiento ygenero
15L Sweeney (2001) ldquok-anonymity a model for protecting privacyrdquo En InternationalJournal on Uncertainty Fuzziness and Knowledge-based Systems 105 pags 557-570
Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Privacidad
Desafıos de anonimizacion
No es suficiente anonimizar los datos
Por ejemplo los patrones de consulta puedan exponer algunosaspectos de la vida privada intereses o personalidad de los usuariosque preferirıan no compartir preferencias sexuales problemas desalud o hasta detalles que parecen carecer de importancia como suspasatiempos o su gusto en pelıculas
Las consultas realizadas y los enlaces activados en los resultadosespecıficos proveen tanta informacion que gran parte del negociode mercadotecnia computacional se basa en su analisis
Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Privacidad
El famoso incidente de America Online
En el verano del 2006 AOL el proveedor mas grande de Internetde Estados Unidos en ese momento decidio publicar un registroanonimo de consultas en su sitio web
Usando estos datos dos periodistas del New York Times lograronidentificar un usuario especıfico a partir de este registro anonimode consultas16
Los periodistas rentabilizaron multiples consultas hechas por unmismo usuario mdash que incluıan un apellido especıfico y ubicacionesparticulares ademas de otros datos publicos que les permitieronconectar el usuario anonimo con una senora que les confirmo queesas consultas habıan sido hechas por ella
16M Barbaro y T Z Jr (2006) ldquoA face is exposed for AOL searcher no 4417749rdquo EnThe New York Times
Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Privacidad
Leccion aprendida
No basta con reemplazar el usuario con un numero ldquoanonimordquopara ocultar la identidad de una persona
Se pueden determinar con bastante precision atributos tales comoel sexo o la edad a partir de registros de consulta anonimizados17Ademas todo el mundo googlea a si mismo de vez en cuando
17R Jones y col (2007) ldquoldquoI know what you did last summerrdquo query logs and userprivacyrdquo En CIKMrsquo07 pags 909-914
Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Privacidad
Complejidad
Sin importar la cantidad de datos que uno tenga esos datospueden ser sencillos o complejos El segundo refiere a situacionesdonde se cuenta con diversos fuentes de datos con tasas variadasen multiples tipos de dato a distintos niveles de detalle lo quecomplica su recoleccion el procesamiento el modelado y el analisis
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Aun cuando todos losdatos vienen de un mismo fuenteen un mismo formato a una mismatasa lo que representan esos datossuele contener subpoblacionescon caracterısticas distintas
Datos18 sobre la propensidad dehacer retweet en Twitter parecentener una tendencia logarıtmica
httpwpsigmodorgwp-contentuploads201310figure1jpg
18K Lerman (2013) THe curses of heterogeneity in big data ACM SIGMOD Blog urlhttpwpsigmodorgp=960
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-
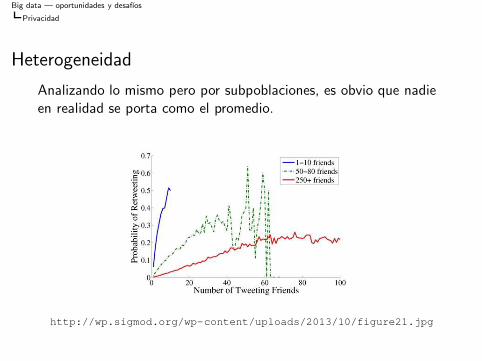
Big data mdash oportunidades y desafıos
Privacidad
Heterogeneidad
Analizando lo mismo pero por subpoblaciones es obvio que nadieen realidad se porta como el promedio
httpwpsigmodorgwp-contentuploads201310figure21jpg
Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Conclusiones
iquestEntonces
Hemos explorado preguntas fundamentales que hay que atender altratar grandes conjuntos de datos
Hay muchos problemas a resolver tanto sobre la preparacion de losdatos como su procesamiento
Los problemas de escalabilidad y privacidad tienen relacion con elprocesamiento de los datos mientras que todos los otros temastratados conciernen a la preparacion de ellos
Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Conclusiones
Aun esta de moda el concepto de datos grandes
Busqueda realizada en httpstrendsgooglecom
Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Conclusiones
Mas informacion
Para aprender que tecnologıas existenhttpspixelasticgithubiopokemonorbigdata
Para mantenerse al tanto de lo que sucedehttpstwittercombigdatabatman
Para aprender hacer cosas uno mismohttpanalyticscosmcomhow-to-become-a-data-scientist-2
(necesitas saber matematicas estadıstica programacion bases dedatos visualizacion cientıfica inteligencia artificial y mucho mas)
Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-

Big data mdash oportunidades y desafıos
Conclusiones
Contacto
elisaschaeffergmailcom
- Introduccioacuten
- Escalabilidad
- Redundancia y sesgo
- Dispersioacuten ruido y basura
- Privacidad
- Conclusiones
-