analisis de datos
DESCRIPTION
Análisis de datos es la técnica que consiste ene l estudio de los hechos y el uso de sus expresiones en cifras para lograr información, la cual debe ser válida y confiable. 1. Objetivos que se proponen los investigadores cuando analizan datosEn general, el análisis pretende “hacer explicitas las propiedades, notas y rasgos de todo tipo que, en relación a las variables estudiadas, se derivan de las tablas en las que se condensa la clasificación”, mientras que en la interpretación intenta precisar la significación y alcance de las propiedades y rasgos.Greenberg, Goldstucker y Bellenger señalaron con énfasis que pretenden los investigadores cuando analizan datos:• Hallar lo que hay en los datos.• Conocer que variaciones ocurren en los datos.• Como están distribuidos los datos.• Que relación existe entre las variables.• Las estimaciones que resultan de los datos.• Describir las diferencias entre grupos y variables.• Determinar variables que causan variación en otras variables.TRANSCRIPT

ANÁLISIS DE DATOS
1. Concepto:Análisis de datos es la técnica que consiste ene l estudio de los hechos y el uso de sus expresiones en cifras para lograr información, la cual debe ser válida y confiable.
2. Objetivos que se proponen los investigadores cuando analizan datosEn general, el análisis pretende “hacer explicitas las propiedades, notas y rasgos de todo tipo que, en relación a las variables estudiadas, se derivan de las tablas en las que se condensa la clasificación”, mientras que en la interpretación intenta precisar la significación y alcance de las propiedades y rasgos.
Greenberg, Goldstucker y Bellenger señalaron con énfasis que pretenden los investigadores cuando analizan datos: Hallar lo que hay en los datos. Conocer que variaciones ocurren en los datos. Como están distribuidos los datos. Que relación existe entre las variables. Las estimaciones que resultan de los datos. Describir las diferencias entre grupos y variables. Determinar variables que causan variación en otras variables.
3. Clases de análisis de datos
Existen diversos ordenamientos de los análisis de datos que dependen del criterio de clasificación de que se disponga. En efecto, de acuerdo al número de variables, es decir si tenemos en cuenta cuantas variables se analizan multivariables y multivariable. De acuerdo al carácter del análisis, puede ser: exploratorio, si se quiere encontrar nuevas hipótesis; si se quiere verificar las que anteriormente se formularon, entonces en este último caso el análisis será confirmado.Según la naturaleza del análisis, vale decir de acuerdo a lo que es el análisis, este puede ser cuantitativo si su naturaleza es formal (estadístico o matemático). Puede ser también cualitativo si su naturaleza es no formal: usa precisiones conceptuales y entonces sería cualitativo. Según el objetivo que pretende el análisis, este será causal, cuando se quiere llegar a las causas; será un análisis de cambios se pretende llegar a las modificaciones de los fenómenos; de decisiones si lo que se logra conocer es la adopción de medidas; de grupos si se aspira a conocer determinados conjuntos; y de sistemas si lo que se quiere conocer son estructuras: conjuntos, ordenados en relaciones determinadas.
He aquí un cuadro sintético de las clases de análisis:Uso del análisis según el número de variables
4. Usodel análisis según el número de variables
En la investigación universitaria destacamos este análisis puesto que permite al investigador la ejecución de las siguientes operaciones:
A. Sintetizar lo que se observa en una variable.B. Comparar lo que se observa en dos variables.C. Expresar la asociación que existe entre dos o más variables.

D. Inferir conocimientos a partir de los logros a), b) y c).
En la investigación universitaria destacamos este análisis puesto que permite al investigador la ejecución de las siguientes operaciones:
E. Sintetizar lo que se observa en una variable.F. Comparar lo que se observa en dos variables.G. Expresar la asociación que existe entre dos o más variables.H. Inferir conocimientos a partir de los logros a), b) y c).
5. Importancia de la distinción de variables para usar las técnicas estadísticas
Precisar las clases de variables es importante en la instancia del análisis de datos, puesto que es según el tipo de variable que se usaran las técnicas estadísticas. Las variables pueden clasificarse entonces según su utilidad para expresar cálculos estadísticos:
I. Variables nominales. Se caracterizan porque los números se asignan a las categorías se usan como símbolos o códigos para su ulterior clasificación. Por ejemplo, se asigna a los alumnos el numero “1” para la categoría de aprobados y “2” para desaprobados.
II. Variables ordinales. Son aquellas variables cuyos números se asignan a quienes tienen una característica determinada, lo cual permite el ordenamiento o el rango. Así, por ejemplo queremos establecer un orden entre los alumnos de un aula, de un año escolar en un colegio, o entre los alumnos de todas las aulas del tercer año de secundaria de Lima Metropolitana. Para cumplir con el objetivo planteado, asignamos el numero “1” para alumnos que obtienen la clasificación entre 17 y 20 en sus promedios de clasificación anual, “2” para alumnos que obtienen la clasificación entre 14 y 16, etc. Como podemos apreciar, “1”, “2”, y otros números solo permiten establecer un rango, un orden, una clasificación entre los alumnos.
III. Variables intervalares. Son aquellas variables que se caracterizan distancias iguales entre objetivos que se estudian tomando como referencia una determinada propiedad. Por ejemplo, un estudiante obtuvo de promedio de calificaciones 15, otro 13, otro 11 y otro 9. La distancia entre 15 y 13 es igual entre 11 y 9, es decir, 2.El cero (0) en las variables intervalares no es real, pues que un alumno tenga 0 en u promedio no quiere decir que no sabe nada.
IV. Variables proporcionales. Son variable que tienen las mismas características que las variables intervalares, pero además poseen el cero real. Por ejemplo: la edad de las personas. En este caso existe n cero real, al igual que en los años de estudios (escolaridad) y en los ingresos en un periodo de tiempo determinado.
6. Técnicas estadísticas que se puede usar con las clases de variables
Insistimos en nuestra afirmación anterior. No todas las técnicas estadísticas se deben emplear usando cualquier variable. Guillermo Briones hizo emplear con el uso de determinadas variables.Que con las variables nominales solo se pueden usar las técnicas estadísticas siguientes: distribución de frecuencias, el coeficiente de contingencia, la prueba de chi cuadrado y la moda como medida de asociación.
a) Que con técnicas de estadísticas del análisis univariado que puede emplear quien elabora una tesis las variables nominales solo se pueden usar la técnicas estadísticas siguientes: distribución de frecuencia, el coeficiente de rango y mediana. Quiere decir

que con valores de este tipo de variables no se pueden calcular medias aritméticas, varianza no desviaciones estándares.
b) Que con las variables proporcionales se pueden emplear todas las técnicas estadísticas. c) Con las variables intervalares se pueden aplicar todas las técnicas estadísticas menos el
coeficiente de variación.
7. Técnicas de estadísticas del análisis univariado que puede emplear quien elabora una tesis:
En el análisis de una sola variable, tomando como recurso las técnicas estadísticas, el investigador universitario puede ofrecer medidas de tendencia central: media aritmética, mediana y modo. También puede ofrecer medidas de variabilidad: varianza, desviación estándar y coeficiente de variación.La interpretación es posible para el investigador en tanto este pueda comparar los resultados entre sí o también compararlos con otros resultados ofrecidos en otras circunstancias.Es posible ofrecer un panorama del proceso que sigue el investigador cuando lleva a cabo el análisis e interpretación de datos. He aquí una presentación de los pasos:
a) El investigador toma como punto de partida los resultados estadísticos b) Ejecuta la normalización de los resultados, lo cual quiere decir que el investigador
formula las pautas para realizar comparaciones.c) Hace la comparación entre unos valores de la variable (comparación interna),
correspondiente al mismo grupo poblacional y puede también hacer comparaciones con valores de otra poblaciones (comparación externa).
d) Enuncia los estadísticos que reflejan las conclusiones del análisis estadístico.e) Contrasta sus hallazgos con la teoría existente respecto del os que estudia.
8. Propiedad que se describen cuando se estudia una variable:Cuando se estudia una variable se describen tres propiedades, llamadas también características mayores:
PosiciónDispersión Forma
8.1) Medidas descriptivas con las que se representa las propiedades de posición, dispersión y forma.
El siguiente cuadro resume que propiedades de datos se describen cuando se estudia una variable. Las medidas descriptivas que corresponden a cada una de las tres propiedades (posición, dispersión y forma), así como sus expresiones.
Estudio de datos de una variable
Propiedad Tipo de medida Expresiones (estadísticos)Posición Medidas de tendencia
centralMedia aritméticaMediana Moda o modo
Medida de tendencia no central
Cuantíles
Dispersión Medidas de dispersión o variabilidad
Recorrido Varianza Desviación estándar

Coeficiente de variaciónForma Simetría Asimetría o sesgada
Simétrica o con sesgamientoModalidad Modos en una distribución Curtosis Razón de momentos de Pearson
8.1) Conceptos de las propiedades o características mayores
Aquí ofrecemos las definiciones que permiten precisar los conceptos de las propiedades o características mayores que corresponden al análisis de datos de una varianza.
Posición : Características – la mas importante – que permite describir o resumir la ubicación de un grupo de datos, expresándola estadísticamente con medidas de tendencia central (media aritmética, mediana y modo) y con medidas de tendencia no central: los cuantiles.
Dispersión: Propiedad o característica que expresa la cantidad de variación o disminución expresada en los datos. Las medidas que mas se usan para expresar la magnitud de la dispersión son: el recorrido, la varianza, la desviación estándar y el coeficiente de variación.
Forma: Propiedad o característica mayor que expresa la manera en que se distribuyen los datos. Los tipos de medida que se usa para expresar la forma de los datos son la simetría, la modalidad y la curtosis.
9. Concepto de medidas de tendencia central Se denomina medidas de tendencia central a aquellas medidas que describen la localización de los valores de las variables que se estudian. La media aritmética, la mediana y el modo (o moda) son medidas de tendencia central.
10. Concepto y reglas para el uso de cada una de las medidas de la tendencia central
10.1. Media aritmética (x)
Se denomina media aritmética (x) a aquella medida que caracteriza a un grupo de estudio con un solo valor y que se expresa como el cociente que resulta de dividir la suma de todos los valores o puntajes entre el numero total de los mismos.El investigador sabe que para hallar la media aritmética debe usar las siguientes formulas:
a) Cuando se usa datos no agrupados
x=∑ x1n
Donde:x = Media aritmética∑ = Sumax1= Valores individuales de la variablen = numero de valores o casos.
Ejemplo:
A seis estudiantes se les interroga: ¿Cuántas veces a la semana acuden a la biblioteca de la facultad a la que pertenecen? Y ellos respondieron de la siguiente manera:

1 - 2 - 2 – 1 – 3 – 3 (seis respuestas, es decir, el primero respondió que una vez a la semana acude a la biblioteca de su facultad, el segundo contestó que dos, el tercero que dos, le cuarto que una, el quinto que tres y el sexto que tres), entonces, aplicando la formula anterior, es decir, reemplazando las expresiones de la fórmula pro sus valores respectivos, tenemos:
x=1+2+2+1+3+36
=126
=2
Según el resultado, los alumnos acuden a la biblioteca de la facultad, en promedio, dos veces a la semana.
b) Cuando se usa datos agrupados
x=∑ f 1(x¿¿1)
n¿
Donde: x1 = punto medio de la clasef 1 = frecuencia dela clase i de la distribución ∑ = suma de productos f1 x1
El investigador tendrá presente que para aplicar la formula dela media aritmética usando datos agrupados se requiere que las categorías tengan sus límites claramente establecidos. No podrá usar por tanto categorías abiertas.El investigador tiene presente que ha de cumplir con las siguientes exigencias:
Establecer las categorías Determinar el punto medio (P.M.) de cada clase de intervalo, que se obtiene
sumando el valor del intervalo y dividiendo entre dos. Precisar las frecuencias en cada una de las categorías Multiplicar la frecuencia por cada uno de los puntos medios Obtener la sumatoria de las multiplicaciones anteriores Lograr la media aritmética de casos agrupados dividiendo la sumatoria entre el
número de casos.
Usar la media aritmética en la investigación universitaria sirve para:I. Expresar globalmente una información que frecen los datos
II. Expresar una media estableIII. Tener una media consistenteIV. Obtener un dato fundamental para otros estadístico
Es importante observar que la primera ventaja señalada, que la media aritmética expresa globalmente una información, puede convertirse en una desventaja cuando los datos están mas cargados a un lado que a otro, lo cual sería un caso de falsa localización da la distribución.
10.2. La mediana (Mdn)
Es la medida de tendencia central que expresa el valor que ocupa el lugar central entre los valores ordenados según su magnitud.Ejemplo de mediana:

La producción diaria en una fábrica de calzado en la cual se trabaja los siete días de la semana, expresada en docenas de calzado y presentada ordenadamente, es como sigue:
40 42 43 47 48 50 51Se observa fácilmente que el valor central es 47.Vamos al siguiente cuadro en el cual se expresan los años de estudio de un grupo de trabajadores de una fábrica:En este caso, como es un fenómeno acumulativo se tiene el siguiente cuadro de frecuencias:
X1 F1
116
161819
32721
Los valores obtenidos son los siguientes
11 11 11 6 6 16 16 16 16 16 16 16 18 18 19Al ordenar los valores seobtiene:6 6 11 11 11 16 16 16 16 16 16 16 18 18 19Al apreciar el valor central, se tiene 16
10.2.1. Proceso para obtener la mediana cuando el número de valores es par
En el caso en que el número de valores ordenados sea par, se considera el promedio de los dos valores centrales. Por ejemplo: si el registro de los valores fuera:
10 42 43 47 53 55 59 60 61 63Los valores centrales son 53 y 55, para considerar su promedio se tiene:
53+552
=1082
=54
La mediana en este caso es 54
10.2.2 ¿Cuándo se usa la mediana?
Los investigadores usan la medida cuando los valores están muy seguidos y hay dato con valor extremo. La mediana no es afectada por el hecho de que los valores apareados aparezcan cargados a un extremo, pues se trata de un valor que esta entre 50% de unos y 50% de otros.Como dicen Nuria Cortada y J. Manuel Carro, quienes reconociendo que la mediana se usa la indicación anterior, dicen enfáticamente: “úsese la mediana cuando:
a) Tenemos una escalera ordinal de intervalos iguales o de cocientes;b) Cuando existen observaciones externas no compensadas;c) Cuando existen clases de intervalo”
10.2.3 La moda (Mo)
La moda o modo es el valor típico o común en un conjunto de datos, es decir, el valor que mas se repite, el que se presenta con mayor frecuencia.En el ejemplo de los años de estudios de un grupo de trabajadores de una fabrica, expuesta anteriormente:

x1 f1
116
161819
32721
15El valor que más se repite es 16.
10.3.1 Los datos bimodales
Cuando los datos presentan situaciones en las que son dos los valores que se repiten con mas frecuencia, los datos se llaman bimodales.Por ejemplo: Considérese que la sección maestría de una escuela de posgrado tiene 14 aulas. En cada aula hay diferentes números de carpetas, según la siguiente tabla:
x1 f1
2025262830
14432
14Tal como se puede observar fácilmente, los valores que hay mas se repiten son dos: 25 y 26, los que se reconocen como datos bimodales.Cuando no se repite ningún valor no hay moda.
10.3.2 Cuando usar la moda
Aunque la moda se puede usar con todas las escalas, se usa preferentemente cuando se trabaja con escalas nominales. En realidad el uso de la moda la restringe el investigador solo a los casos en los c pretende ofrecer una idea aproximada acerca de donde esta la mayor concentración de observaciones.
10.3.3 Aplicación de la relación de Pearson
La relación de Pearson es una estimación práctica del modo, siempre que la distribución no sea bimodal y se acerque bastante a la modal. Pearson estableció una relación – que lleva su nombre – y que se expresa formalmente así:
11. Medidas de tendencia no central
11.1. Concepto
Son medidas útiles para una posición “no central”, empleadas para resumir y describir un conjunto de datos. Estas medidas de tendencia no central se denominan cuantíles.
11.2. Concepto de cuantíles
Mo = 3 Mdn – 2 x

Los cuantíles o cuantilos, constituyen una “clase de los (n-1) valores de participación de una aleatoria que dividen a la frecuencia total de una población o de una muestra dado n de partes iguales.
11.3. Clases de cuantíles
Los cuantíles dividen de una distribución de n partes iguales. Cuando estas partes son cuatro se denominan cuartiles. Si se divide en diez partes son deciles y si se dividen en cien, percentiles. Si s tiene una distribución cuyo total de observaciones las dividimos en cuatro partes iguales, para expresarla gráficamente requerimos de tres cuartiles, como lo muestra el siguiente grafico:
1er. Cuartil: Q1
2do. Cuartil: Q2
3er. Cuartil: Q3
Donde Q1 divide las observaciones en dos grupos: el 25% de las observaciones son menores al valor del Q1 y 75% de las observaciones son mayores.Q2 es la mediana: ya sabemos que el50% de las observaciones son menores a la mediana (que en este caso coincide con el segundo cuartíl) y 50% de las observaciones son menores que ella.Q3 divide a las observaciones en dos grupos: 75% de ellas son menores al Q3 y el 25% son mayores.
11.4. Concepto de rango aplicado a los cuartiles
Se denomina rango de cuartiles a las posiciones que les corresponde a los cuartiles les corresponderán los siguientes rangos:
Rango del primer cuartíl =n+14
Rango del segundo cuartíl =n+12
Rango del tercer cuartíl =3(n+1)4
11.5. Obtención de los deciles y percentiles
Para obtener los deciles se divide el total de frecuencias entre diez, mientras que para la obtención de los percentiles necesitamos dividir el total de frecuencias entre 100.
11.6. Importancia de los percentiles
Trabajar con los percentiles es importancia para el investigador. Le permite comparar unos datos con otros que participan en los mismos hechos. Como dice Joan Welkowitz, en un ejemplo: si un estudiante universitario en un examen obtiene una puntuación de 41, con una prueba de 50 puntos, necesita saber hasta que punto su clasificación es buena: necesita sacar conclusiones del hecho – por ejemplo – de que su clasificación representa el 82 por ciento del total; pero necesitara comparar su clasificación con las demás del grupo especifico. En efecto, si el examen fue fácil para la mayor pare de los estudiantes, su calificación de 41 puede representar incluso un rendimiento inferior a la media. Pero si el examen fue difícil para la mayoría de los estudiantes, su calificación puede aparecer como de las más altas.Los percentiles

como valores transformados resultan ser un valor que permite pasar de la puntuación original, llamada puntuación directa, a otra a fin de mostrar la situación del individuo en comparación con otros del mismo conjunto. El papel del percentil es, pues, mostrar como un valor concreto se compara con otros de un grupo determinado.
11.7. Concepto de rango del percentil
Se denomina el rango del percentil de un valor dado al numero que expresa el tanto por ciento de casos en el grupo es pacifico de referencia y cuyo valor es igual o inferior al dado. Así, si al puntaje de 41 le corresponde un rango de 85, entonces esto significa que el 85% del grupo que dio examen obtuvo una puntuación igual o menor que 41 mientras que solo el15% obtuvo calificaciones mas altas. Pero, si a 41 le corresponde un rango de 55, esto significa que el 55% de los que dieron examen obtuvo puntuaciones iguales o mas bajas, pero también significa que el 45% logro calificaciones mas altas, y por tanto su calificación de 85 no es alta como parecía al comienzo.
11.8. Calculo del grupo percentil cuando se conoce el valor bruto
Esta operación estadística consiste en determinar el rango del percentil cuando se conoce el valor bruto, es decir, la puntuación origina o puntuación directa.Tomemos como referencia el ejemplo de Welkowitz. Para efecto de una captación más inmediata hemos hecho modificaciones en la presentación del caso pero no en la naturaleza del conocimiento.Las calificaciones de los estudiantes que conforman el grupo al que pertenece nuestro personaje que obtuvo 41 puntos fueron las siguientes.
Intervalo de clase Frecuencia (f) Frecuencia acumulada (fa)48 – 5045 – 4742 – 44
36 – 3833 – 3530 – 3227 – 2924 – 2621 – 2318 – 2015 – 1712 – 14 9 – 11
134
79
148
1084335
858481
716455413323151185
Para obtener el rango del percentil se sigue el proceso que pasamos a describir:
a) Se localiza el intervalo de clase al que pertenece la clasificación. Para una mejor ilustración este intervalo aparece recuadrado: es la cuarta línea en el cuadro anterior.
b) Se clasifican las frecuencias (f) de las tres categorías, las que corresponden a las tres clases de clasificaciones:
Calificaciones superiores al intervalo crítico. Calificaciones del intervalo crítico.
39 – 41 6 6 intervalo critico 77LIR
(Línea del intervalo critico)
71 Intervalo .inferior
Intervalo superior

Calificaciones inferiores al intervalo crítico.c) Logro de porcentajes de intervalos. Para el logro del porcentaje de intervalo de cada caso
se divide la frecuencia del intervalo correspondiente entre la frecuencia acumulada:Por lo tanto, el proceso para hallar cada uno de los intervalos es el siguiente:
Intervalos superiores: f:8 8/85 9,4% (S%)Intervalos critico: f:6 6/85 71,5% (C%)Intervalos inferiores: f:71 71/85 83,5% (I%)En el cuadro puede apreciarse que:8 persona obtuvieron puntajes superiores al intervalo crítico.6 persona obtuvieron puntajes en el intervalo crítico.71 persona obtuvieron puntajes inferiores al intervalo crítico.
(Esta cifra se obtiene siempre tomando nota de las frecuencias acumuladas para el intervalo inmediatamente inferior al intervalo crítico)
S%, representa el porcentaje de persona con calificaciones superiores a las del intervalo crítico y se lee “porcentaje superior”C%, se lee porcentaje critico, representa el porcentaje de calificaciones que puntúan en el intervalo crítico.I%, porcentaje de la suma de las frecuencias inferiores, representa el porcentaje de la suma de calificaciones que puntúan debajo del intervalo inferior.
d) Determinación del límite del intervalo crítico. Es conveniente señalar – como podría creerse – que el límite del intervalo crítico no es 39. En efecto, tenemos que ponernos en el caso de que alguien obtenga una puntuación decimal y en este caso habría una dificultad, puesto que l intervalo crítico seria mas estrecho que el que le corresponde. Fácilmente se aprecia que la puntuación se cargaría a favor del intervalo inferior.El límite entre el intervalo – que comprende los puntajes del 39 al 41- y el intervalo que comprende los puntajes del 36 al 38 es el promedio entre 38 y 39, es decir, 38,5. Por lo tanto, cualquier puntaje que se sea inferior a 38,5 pertenece al intervalo inferior, y cualquier puntuación superior a 38,5 pero inferior a 41,5 pertenece al intervalo crítico.
e) Determinación del tamaño del intervalo. El tamaño del intervalo es la distancia existente entre los puntajes que comprende cada uno de los intervalos. Así, entre los puntajes 9 y 11 del primer intervalo inferior es 3, entre12 y 14, es 3, igualmente entre los otros restantes.En el ejemplo, motivo del análisis el tamaño del intervalo es 3
11.9. Obtención del rango del percentil
Para la obtención del rango del percentil se suma el porcentaje de la suma de las frecuencias inferiores con el producto del intervalo expresado en fracción por el porcentaje crítico (C%).Como vimos, la suma del porcentaje de las frecuencias inferiores es 83,5; el tamaño del intervalo es 3, pero expresado en fracción – en el caso del ejemplo- equivale a 2,5/3 puntos, o sea 0,83; y también, vimos que C% es 7,1, entonces el rango del percentil será:
Rango del percentil = 83,5% (0,83) (7,1%)= 83,5 5,98%= 89,4%
11.10. Formula abreviada para obtener el rango del percentil

Rangodel percentil=I%+(Calificaciónobtenida−LIRh
.C )
Donde:I % = porcentaje de la suma de las frecuencias inferiores. Calificación obtenida = en
el ejemplo, 41.LIR = limite de intervalo crítico. En este ejemplo (véase la tabla de intervalos de
frecuencias) = 38,5C% = porcentaje de calificaciones que se ubican en el intervalo crítico.h = tamaño del intervalo.
Reemplazando las expresiones de la formula por cifras correspondientes en el ejemplo, se tiene:
Rangodel percentil=83,5+( 41−38,53.7,1%)
¿83,5+( 2,53 .7,1%)¿83,5+5,89%
Rangodel percentil=89,4%
12. Las medidas de desviación
12.1. Concepto de medidas de desviación
Se denominan medidas de desviación aquellas medidas que usa el investigador para ofrecer información de la heterogeneidad u homogeneidad de los datos, es decir, aquellas medidas que se refieren a las variaciones o dispersiones de los datos en su conjunto.El calculo de las medidas de desviación es una tarea complementaria que no puede eludir el investigador, sobre todo considerando que es posible que en el análisis de unos datos puede encontrarse que tiene una misma medida de tendencia central pero distintas medidas de dispersión.
12.2. Medidas que se usan para medir la dispersión de datos
Las medidas que más usan los investigadores para expresarla dispersión de los datos son: el rango (denominado también recorrido), la varianza (o variancia), la desviación estándar y el coeficiente de variación.
12.2.1. El rango o recorrido
Se denomina rango o recorrido a la diferencia entre el valor máximo y el valor mínimo en un conjunto de datos ordenados.Por ejemplo, si hay un grupo de alumnos que ingreso a la Facultad de Estomatología en 1995, y dentro de el hay seis que tienen la menor edad (15 años); hay uno que tiene la mayor edad (62 años) y los otros tienen diversas edades, pero mayores que 15 y menores que 62. En este caso el valor máximo es 62 y el mínimo es 15.El recorrido se obtendrá por la diferencia: se resta el valor mínimo al valor máximo.

Recorrido = 62 – 15 = 47El recorrido o rango es fácil de obtener, pero la desventaja de esta medida radica en el hecho de que no informa absolutamente nada acerca de la distribución de los datos entre los valores extremos.
12.2.2. La varianza o medida de lo cuadrados
La varianza o medida de cuadrados es la medida de la variabilidad mas usada para apreciar las diferencias entre los hechos: expresa el grado de dispersión o diseminación de los valores respecto a los valores de una serie con relación a su media aritmética. La gran importancia de calcular la media y la varianza de grupos experimentales esta en el hecho de que cumple con una tarea fundamental en la investigación: estudiar relaciones entre hechos.Kerlinger afirma que “la varianza es una medida de dispersión del conjunto de puntuaciones”.Un caso de uso de varianza en la investigación en el área de educación es el siguiente:Se estudia un grupo de alumnos – por ejemplo el de un colegia X que tiene rendimiento heterogéneo en la asignaturas del área de matemática. En este estudio nos servirá la varianza para expresar las diferencias entre puntajes con relación a otro grupo que se considera homogéneo en el rendimiento en la misma área.
12.2.2.1 Las clases de varianza
Según el uso del investigador le da a la varianza en tanto medida de variabilidad, suelen distinguirse diversos tipos de varianza. De acuerdo a la extensión de la población que estudia puede ser de población y varianza de muestra. Según el conocimiento de las influencias: varianza sistemática (debidas a influencias conocidas) y de error (debida a la casualidad). Entre las varianzas sistemáticas se destaca la varianza entre grupos o varianza experimental.
Haremos, a continuación, algunas precisiones referentes a estas clases de varianza
12.2.2.1.1. Varianzas según la extensión de los grupos que se estudian
De acuerdo a la extensión de los grupos que se estudian, las varianzas pueden ser de población o de muestras.
a) Varianza de población Se denomina así a la varianza que estudia la dispersión de datos correspondientes a una población completa, es decir, a un universo. Cuando se reconocen todas la medidas de un universo que se estudia, entonces la varianza también es conocida. Tal hecho no ocurre siempre, por lo que los investigadores se preocupan por estudiar y de aplicar otro tipo de varianza: la varianza de muestras.
b) Varianza de muestrasLa varianza de muestras es aquella varianza que se usa cuando no es posible estudiar toda la población o universo o no hay dificultades para estudiar todo el universo o, también, cuando se prefiere no causar problemas por las condiciones para poder estudiar toda una población completa, como el dinero requiere, el tiempo de dedicación o la paralización de una población.

Veamos el siguiente ejemplo: se quiere estudiar la duración de todo los fluorescentes. ¿Habría que paralizar todas las fábricas de fluorescentes? Indudablemente que no. Habría que recurrir a las muestras.
12.2.2.1.2 Varianzas según el conocimiento de las influenciasSegún el conocimiento de las influencias, las varianzas pueden ser varianzas sistemáticas o varianzas de error.
a) Varianza sistemáticaSe denomina varianza sistemática a aquella variabilidad que encuentra su explicación en las influencias que se conocen.las influencias de fenómenos naturales, así como las producidas por el hombre y que se pueden predecir con influencias sistemática.Un ejemplo de varianza sistemática es el siguiente: la variabilidad de las puntuaciones obtenidas por los estudiantes que reciben entrenamiento en comprensión de lectura, las cuales tienden a ser “sistemáticamente más altas que las puntuaciones de los estudiantes que no reciben la misma clase de entrenamiento”, y si el aprendizaje es repetitivo, con mayor intensidad aún.
b) La varianza entre grupos de medidas o experimentalLa varianza entre grupos o varianza experimental es una clase de varianza sistemática, que se denomina así por expresar diferencias sistemáticas entre grupos de medida.Las dispersiones de daros, como la cita diferencia de puntuaciones de compresión de lectura, establecen diferencias entre grupos y propiamente entre individuos de un grupo. Pero es posible hacer distinciones respecto de puntajes de compresión de lectura entre estudiantes de grupo distintos de procedencia: de universidades nacionales y de universidades privadas. Cabe hablar de varianza intragrupos, cuando se distingue subgrupos dentro de uno existente y reconocido, y de varianza extragrupos, cuando se trata de variabilidad entre grupos existentes y reconocidos. También es posible estudiar las varianzas entre individuos.He aquí un ejemplo de cómo se puede aplicar la medida de desviación conocida como varianza al estudio de grupos:La aplicación de métodos de ventas A y B a dos grupos de clientes: se aplica el diseño clásico de investigación, que dispone de grupos experimentales y testigos, que control y manipula la variable independiente y en el cual se hacen variar los resultados del grupo experimental –denominados “medidas de criterios”- tanto en el sentido de acumulación de puntuaciones como de su disminución, en tanto que las medidas del grupo se conservan en un mismo nivel. Aquí se da una varianza entre grupos.La apreciación de varianza en estudios no experimentales no siempre tiene la misma claridad que con los casos experimentales. En la medida en que existen diferencias entre grupos, el investigador supone racionalmente que la variable independiente ha operado o actuado; y a la inversa, si hay poca diferencia entre los grupos, el investigador supondrá que hay variables independientes que no hicieron cambiar a la variable dependiente, que los efectos que produce son muy débiles, tanto que el investigador no los percibe o que la influencia que ejerce fue neutralizada por la acción de otras variables independientes.
c) La varianza de errorSe denomina varianza de error a la dispersión de datos medidos y que obedecen a la causalidad, debido a hechos que ignora o no conocer bien el investigador

Por más providencias que tome el investigador ocurren dispersiones de datos por hechos que el investigador no identifica cono controla. Lógico es que si los conociera, sil os identificara, entonces adoptaría una estrategia.
12.2.3. La desviación estándar
Se denomina desviación estándar a la medida de dispersión de datos relacionada con la varianza, pues en tanto que esta ultima se expresa en unidades elevadas al cuadrado, y de acuerdo a las unidades de los valores elevados al cuadrado (metros al cuadrado, dólares al cuadrado, etc.), para hacer practico el enunciado, se usa la medida de desviación estándar, que por esta razón es la raíz cuadrada positiva dela varianza.La formula para hallar la desviación estándar (S) es:
S=√∑ f 1(xi−x)2
nDonde: S = desviación estándar
Xi = valores individualesx = media aritmética f1 =frecuencia del valor xn = casos
12.2.4. El coeficiente de variación
Es la medida de dispersión de datos que mide el grado de desviación con relación a la media, de allí que se le conciba como una medida de dispersión relativa. Se expresa en términos de porcentajes.
El coeficiente de variación se usa en casos de que exista una diferencia grande entre las medias de las diferentes muestras.
Para hallar el coeficiente de variación se aplica la siguiente formula:
V= Sx
Donde: V = coeficiente de variación S = desviación estándar x = Media Aritmética
12.2.4.1. Importancia del uso de la desviación estándar en comparación con otras medidas de dispersión
La desviación estándar resulta más estable de un muestreo a otro Sus propiedades permiten que los investigadores puedan hacer interpretaciones
que se aplican en las aferencias estadísticas. Se aplica en el análisis de inversión y medio con de riesgos. Los investigadores
saben que a menor desviación estándar, menor el riesgo del proyecto.
13. La presentación de datos:

13.1. Concepto
La presentación de datos es la forma en que el investigador expone al jurado calificador y a los lectores de su informe, los datos que encontró al aplicar sus instrumentos de medición.
13.2. Las formas posibles de presentar los datos
Un investigador que hace una tesis tiene un conjunto de posibilidades de presentar los datos. Generalmente combina los diversos recursos, esmerándose en alcanzar la información al jurado y sus lectores.
Entre las formas de presentación de datos están: las tablas de frecuencia y la presentación gráfica.
Vemos seguidamente estos recursos.
13.2.1 La tabla de frecuencias
Consiste propiamente en un método por el cual se clasifican y ordenan los datos en clases o intervalos, de tal manera que quera claramente definida la frecuencia con que se producen los hechos. El numero de observaciones que registra, está tratando de tal manera que puede manejarse con versatilidad aunque implique cantidades considerables
Para elaborar una tabla de frecuencia el investigador que hace una tesis sigue las siguientes prescripciones.
a) El título expresa las variables, de las cuales se ofrecen datos.b) Seguidamente se establecen las clases o intervalos.c) La tabla expresa el tamaño del muestreo.d) Hacer el conteo de cada clase o intervalo y presentarlo en forma de frecuencia.e) Se el investigador presenta datos secundarios, incluirá una nota indicando allí las
fuentes.f) El número de clases o intervalos, así como su tamaño debe definirse de tal manera que
cada uno de los números pertenezca siempre sólo a una clase o intervalo.
13.2.2. ¿Cómo establecer las clases de distribución?
Para establecer las clases de distribución se siguen los siguientes pasos:
a) Determinar el rango.b) Se decide el numero de clases (para algunos autores, el numero de clases no debe ser
mayor de 15 ni menor de 5). Es recomendable el siguiente criterio: extraer la raíz cuadrada del tamaño del muestreo.
c) Se establece la amplitud de la clase o intervalo. Se sugiere establecer esta amplitud dividiendo el rango entre el número de clases.
d) Establecer los intervalos preliminares. Para lograr este paso se considera un numero por debajo del valor mas pequeño del limite inferior; para establecer el límite inferior con la amplitud de clase.
e) Presentar claramente las clases, es decir, el investigador no puede dar pie para que la distribución que presente, admita la repetición de un mismo número en dos clases diferentes.

En este caso de que el investigador use números continuos, instrumentará el signo “<”, de tal manera que en las clases o intervalos aparezcan expresiones como:2 a < 55 a < 88 a < 11, etc.Veamos un ejemplo que nos presenta Naghi. He aquí el registro de la producción mensual de una fábrica textil en los últimos 28 meses:
Producción de la fabrica textil X en millones de metros
121,114,490,754,813,566,577,3
100,019,213,2
112,629,238,746,2
33,745,1
116,4119,199,8
100,058,1
72,981,359,545,3
121,6108,139,7
Donde: Rango: 10,4Raíz cuadrada del muestreo= 5,3 y se consideran 6 clasesAmplitud de clase: 108/6 = 18Límite inferior de la clase = 13Límite superior: 13 + 18 = 31
13.2.3. Distribución de frecuencias
Es la frecuencia acumulada. Veamos al siguiente cuadro:
Cuadro de distribución de frecuencias
Clase Frecuencia13 a < 3131 a < 4949 a < 6767 a < 85
85 a < 103 103 a <121…
564346
13.2.4. Distribución de frecuencias y determinación de porcentajes.
Una vez que el investigador estableció las frecuencias, determina los porcentajes correspondientes, pues busca tener criterio para comparar categorías y para ello considera como si tuviera 100 elementos. Los porcentajes hacen lo mismo que las frecuencias relativas, pero estas últimas suman 1, mientras que los porcentajes suman 100.

Cuando un presentador presenta tablas con porcentajes, debe indicar la base numérica sobre la que descansa la tabla: nunca obtener porcentajes basados en cifras menores que 20. La ley de los grandes números sustenta la estabilidad de los porcentajes y frecuencias relativas en cifras mayores de 20 y no de cifras menores a ella. Es por esta razón que se confía más en 50% sustentando en 5000 que 50% sustentado en 6.
Para la precisión de los datos se prefiere usar números enteros, sin embargo, hay un peligro. Cuando se “redondean” cifras, el redondeo puede hacer que se acumulen decimales que inmediatamente pueden incomodar con la exactitud.
Ejemplo de distribución de frecuencias de datos nominales: una empresa de gaseosas discute el incremento de remuneraciones de sus trabajadores: estudia un incremento por asignación familiar a partir de este año. Pero la empresa necesita precisar el estado civil de sus trabajadores. La averiguación a esta fecha, arrojó los siguientes resultados.
14. Análisis e interpretación bivariado
14.1. Ejemplo de correlación de variables
En el mundo empresarial, los administradores saben que existen relaciones que los hachos comparten. Por ejemplo, por su experiencia se puede afirmar que mientras más retroalimentación del trabajo en las distinta fases del trabajo, mejores resultados habrá y mayor será el logro de la calidad del producto. Cierto es que podría darse el caso de que algunos apliquen la retroalimentación del trabajo y no siempre logren resultados positivos; es decir, que a pesar de la aplicación de la retroalimentación no se consigue una mejora de la calidad del producto. Pese a que se reconoce esto último, hay sin embargo una tendencia general que puede expresarse en estos términos: poca retroalimentación o ausencia de ella en el trabajo traerá consigo baja calidad del producto, mientras que más retroalimentación producirá el logro mayor de la calidad. En este caso se afirma que, estadísticamente, la retroalimentación del trabajo y loro de mayor calidad están correlacionados. Según la estadística, mientras más expresiva la correlación entre dos variables, mayor posibilidad de lograr una predicción.La vigencia de esta última expresión es lo que permite obtener logros en la investigación, cuando se aplican estadísticas.
14.2. ¿Qué es correlación? ¿Qué es correlación entre variables?
El Diccionario de términos estadísticos dice: “En su sentido general, correlación denota la independencia entre datos cuantitativos o cualitativos. En este sentido, incluiría la asociación de atributos clasificados conforme a múltiples características. El concepto es bastante general y puede ser extendido a más de dos variables aleatorias. El empleo más frecuente del concepto tiene un significado un tanto más limitado y se refiere a la relación entre variables aleatorias medibles o entre rangos. Los autores italianos distinguen estos dos sentidos mediante el empleo de palabras diferentes para el más restringido”Y respecto a la covarianza el mismo Diccionario de términos estadísticos dice: “Correlación de los rangos que mide la intensidad de correlación entre o conjuntos de ordenamientos y el grado de correspondencia entre ellos. Hay dos coeficientes principales de correlación de los rangos, de Kandall (1938) y de Spearman (1904)”. En esta oportunidad nos preocupamos de la correlación entre variables.

14.3. Concepto de análisis bivariado
El análisis bivariado es un análisis estadístico cuyo objetivo principal es el hallazgo de una relación posible entre dos variables, para lo cual se usa dos técnicas: la regresión lineal para efectos de la predicción, y el análisis de correlación lineal para medir la fortaleza de la asociación entre dos variables.El nombre de “análisis bivariado” proviene del punto de vista matemático: las expresiones de datos bivariado son pares ordenados que se designan así: (x, y) x es el valor de la primera variable e y es el valor de la segunda.Se afirma que son pares porque se admite que hay un nexo tal entre ambas variables que se enuncian conjuntamente, y que están ordenados porque x aparece primero e y después.
14.4. Concepto de diagrama de dispersión
Diagrama de dispersión es una gráfica en dos dimensiones (bidimensional) en la cual es posible el registro simultáneo de los valores de dos variables que están asociadas a un hecho o evento.He aquí algunos ejemplos de relación entre variables en un evento específico y que se puedan registrar simultáneamente en el diagrama de dispersión:
El tiempo diario dedicado al estudio fuera del aula y las calificaciones en promedio que obtienen los estudiantes.
El rendimiento en test de aptitud matemática (de los alumnos Y) y el rendimiento de una prueba de ciencias.
La temperatura del día y la venta de helados.
14.5. El cuadro de registro de datos de dos variables
El cuadro de registro de datos de dos variables es una presentación según el registro de una variable que ocurre primero (x) y también, al lado de cada uno de los datos correspondiente a la otra variable (y).
Conforme a su ordenamiento, que en general los alumnos que se dedican más horas a estudiar fuera de clase obtienen mayores calificaciones en promedio. Pero también se observan excepciones. Por ejemplo, llama la atención que Raúl, quien tiene el promedio más alto solo le dedica 5 horas, ocupando el cuarto lugar en la dedicación al estudio adicional fuera de las horas de clase, y a la inversa que el caso anterior, Lizette le dedica, más horas al estudio adicional fuera del aula y solo ocupa el tercer lugar en rendimiento. Sin embargo, pese a los hechos y datos señalados, no obstaculiza la formulación general fuera del aula, mayor el rendimiento promedio y, a la inversa, mientras menos horas adicionales de estudio fuera del aula, el rendimiento es menor.

14.6. ¿Para qué nos sirve el diagrama de dispersión?
Tal como se puede apreciar e el ejemplo anterior y la respectiva elaboración de su diagrama de dispersión, este permite – como en todos los casos – registrar simultáneamente los valores de dos variables: en el caso de Carlos, se señala que él estudia dos horas y que a la vez su promedio es 12. Así, también Gaby estudia dos horas adicionales diarias y tiene un rendimiento promedio de 13. Estos dos últimos sucesos se registran de lado a lado en el diagrama de dispersión.
Una utilidad práctica que presta al investigador el uso de diagramas de dispersión es que permite visualizar rápidamente si existe relación entre las variables, cada una de las cuales se registra en sendas coordenadas cartesianas. No olvidar que el eje horizontal de las ordenadas (x) se registró la que ocurre primero y en el eje vertical de las abscisas se registra la variable que ocurre después (y).
Los puntos que obtenemos en el diagrama de dispersión nos permiten visualizar una relación lineal entre los valores que se registran en ambas coordenadas.
14.7. Las clases de correlación
Para los efectos de análisis de datos de la tesis universitaria, seguiremos la recomendación de diccionario de términos estadísticos. Evitaremos usar, y así lo recomendamos en este manual, el termino correlación lineal, que aun se usa en manuales que circulan en nuestro medio. El diccionario dice al respecto que correlación lineal es una expresión fuera de uso empleada en su tiempo para denotar (a) la correspondiente fueran lineales; (b) un coeficiente de correlación construido por medio de funciones lineales de las observaciones. Es mejor evitar completamente la expresión.
Lo mismo vale para el caso: “correlación no lineal: expresión referida a la correlación entre variables aleatorias en las que la regresión no es lineal. En estos términos es una nomenclatura equivocada: la correlación, siendo un número puro, no puede ser no lineal. El empleo de la expresión no esta recomendado”.
Teniendo en cuenta el criterio del sentido de las modificaciones, las correlaciones pueden ser: positivas, negativas y nulas.
14.8. La correlación positiva
Existe correlación positiva entre dos variables X e Y cuando la variación es directa, esto significa que si aumenta la variable X, entonces aumenta la variable Y, y si disminuye la variable X, entonces disminuye la variable Y.
14.9. La correlación negativa

Existe una correlación negativa entre dos variables X y Y cuando hay una relación inversa, es decir, que al aumentar X disminuye Y, y al disminuir X aumenta Y.
Ejemplos de correlación negativa serían las siguientes:
A más inasistencias menos rendimiento A menores preocupaciones familiares, mayor concentración y aprovechamiento A mayor desaseo en la practica de ingerir alimentos, mayor adquisición de
enfermedades
14.10. Correlación nula
Existe correlación nula cuando las variables no están relacionadas entre sí. Los siguientes son ejemplos de relación nula:
La practica del tenis y el rendimiento en matemáticas El número de veces que se asiste al año a la iglesia y el rendimiento académico Cantidad de llamadas que se hace diariamente por teléfono y el número de libros
que posee en casa
A continuación presentaos un cuadro en el cual no existe una relación entre variables:
Nº de sujetos Variable X Variable Y1 Cantidad de llamadas
diarias por teléfonoNúmeros de
libros que posee123456789
10
345678
10101111
304
994
1525
508
40
14.11. Coeficiente de correlación
Se denomina coeficiente de correlación o coeficiente de asociación a los índices numéricos obtenidos que se logra haciendo operaciones estadísticas que expresan con exactitud el grado de correlación que existe entre dos variables.
El grado de correlación entre dos variables oscila entre dos cifras numéricas: de 0 a 1 ó -1 a 1
14.11.1 Importancia de que el investigador use el coeficiente de correlación
La importancia de que un investigador haga uso del coeficiente de correlación está en el hecho de que así puede determinar el grado de asociación entre variables y establecer de

esta manera en qué medida corrobora la hipótesis que en un determinado momento formuló.
14.11.2. Clasificación de los tipos de coeficiente de correlación
Restituto Sierra Bravo presenta las clasificaciones de los coeficientes de correlación que con ligeras modificaciones reproducimos a continuación.
14.11.3. El coeficiente de correlación de Pearson
Se denomina cuantitativa que se usa para detectar y medir la asociación entre variables intervalos o de razón. Los valores del coeficiente oscilan entre 1 y -1. El valor 1 indica una relación perfecta, en tanto que -1 expresa una relación nula.
14.11.4. Fórmula para hallar la correlación entre variables intervalares
El coeficiente de correlación entre variables intervalares supone que las variables intervalares racionales ofrecen información como valores de igualdad, rango y distancia. No sólo ofrecen el valor de la relación, es decir, como la variable independiente influye en la variable dependiente.
La formula para hallar la correlación de intervalos es:
V=n (∑ xy )−(∑ x ) (∑ y )
√n (∑ x2 )−(∑ x )2√n(∑ y2 )− (∑ y )
2
Ejemplo: un mayorista distribuye una producto en 29 ciudades pero tiene 10 vendedores. Algunos vendedores viven cerca de su zona de venta y otros no. El mayorista desea saber si existe una relación con la distancia a la que se encuentra el vendedor respecto de su zona de ventas.
Para resolver el problema planteado, nuestro mayorista hace una estrategia: escoge un cliente minorista al azar, luego corresponde registrar su ingreso de venta que obtiene así como la distancia respecto de su zona de venta.
Como puede observarse, la solución del ejercicio exige registrar los datos de distancia de kilómetros y también del registro por ventas. Si a los primeros datos designados por x y a los segundos por y, es posible obtener datos secundarios Ʃx y Ʃy, acumulando los datos primarios. Pero vemos que la formula nos pide también las cifras siguientes Ʃx2, que se obtiene elevando al cuadrado cada una de las cifras de x, y luego sumándolas. La cifra Ʃy2, correspondientemente, se obtiene mediante la misma operación con y. La expresión Ʃxy se obtiene con la suma de todos los productos de los elementos constitutivos de los respectivos pares ordenados.
14.11.5 La prueba de significación de coeficiente de correlación (Z calculada)
La formula es:

zcalculada=1.15131 log10
1+r1−r
−0
1
√n−3
Ho valor poblacional de r = 0Hi valor poblacional de r ≠ 0
Se compara el valor de Z calculada con el valor de Z de la tabla. En el caso de que: -Z critica ≤ Z calculada ≤ +Z crítica, no se rechaza Ho
14.11.6 Correlación entre dos variables nominales
Como lo afirma Galtung: “puesto que en la escala nominal los valores son completamente arbitrarios, no existe modo alguno en que se puedan usar estos valores para definir coeficientes. Por lo tanto, todos los coeficientes tienen que estar basados en una comparación dencia” permite rigorizar la relación entre las variables nominales. “Existe solamente una innovación en el campo de la correlación nominal, también expuesta por Goodman y Kruskal. Ellos utilizan la idea de la ganancia en predecibilidad si el valor es conocido.
Veamos un caso:
Un profesor estudia la prederencia de los métodos de enseñanza en las universidades nacionales. Al estudiar la preferencia de los estudiantes de Letras en las universidades nacionales se abocó a la Universidad de San Marcos y halló lo siguiente:
Sexo de estudiantes
Preferencia de métodos Pedagógicos Total
Método lectivo Dinámica de gruposVaronesMujeres
20320
980280
1000600
total 340 1260 1600
Como se puede apreciar el total de entrevistas fue de 1600 alumnos, mil de los cuales fueron varones y 600 mujeres. Los varones tienen una preferencia significativa y muy predominante por el método de la dinámica de grupos, mientras que las mujeres prefieren el método electivo per no tan predominantemente. En conjunto, la preferencia por el método de dinámica de grupos es también alta debido a que la preferencia muy alta de los varones permite tal fenómeno de preferencia
Veamos un cuadro con los mismos datos pero expresados con porcentajes:
Sexo de estudiantes
Preferencia de métodos Pedagógicos Total
Método lectivo Dinámica de gruposVaronesMujeres
2%53%
98%47%
100%100%

El cuadro anterior permite comprender el comportamiento de los grupos , así como posibilita el conocimiento de la relación entre hechos, por lo tanto, el cuadro permite al investigador hacer afirmaciones y también algunas predicciones. Por ejemplo, si se invitara a los alumnos sigue simultáneamente, el método lectivo y el de dinámica de grupos, podemos afirmar que probablemente el 98% de los varones asistirá al reforzamiento por el método de dinámica de grupo, pero solo el 47% de las mujeres haría lo mismo.
Es posible que se conciba que la preferencia por métodos pedagógicos pueda ser influido por variables distintas al sexo. Po ejemplo es sustentable que los factores ideológicos-político participen en el hecho providencias para controlar las variables extrañas. Veamos el siguiente cuadro para apreciar como el investigador toma medidas para controlar la variable ideologico-politica:
Estudiantes definidos ideológicaY politicamente Total
%Casos
estudiadosPreferencia de métodos pedagógicosMétodo electivo Dinámica de grupos
Varonesmujeres
2.4%53,4%
97.6%46.6%
100%100%
Estudiantes sin definición Ideológica y política
Preferencia de métodos pedagógicos Casos estudiadosMétodo electivo Dinámica de grupos
Varonesmujeres
2.5%53.2%
97.5%46.8%
100%100%
Comparar ambos cuadros es importante: se aprecia que la identificación ideológicos-político no interfiere en la relación sexo- preferencia por un método pedagógico. Queda, pues, confirmado el aserto anterior.
En el vocabulario estadístico, a la relación entre dos variables se le denomina relación cero grados; cuando en la relación entre dos variables hay una variable de control se le llama relación de primer grados; y si se sigue aumentando otra variable de control, la relación se denominará relación en segundo grado… y así sucesivamente.
14.11.7. Medidas de la correlación cuando los datos tienen dos y más categorías
Cuando las variables tienen sólo dos categorías, es posible expresar tal relación con la correlación ϕ (phi). Y cuando las variables nominales tienen varias categorías se aplica la correlación λ (lambda).
ϕ se halla con la siguiente fórmula:
φ= ab−bc
[(a+bxc+d) ] [(a+cxb+d )1/2 ]
Donde a, b, c y d son frecuencias. Veamos el siguiente cuadro esquemático:

Los (+) y (-) sirven para ayudar al investigados en la interpretación, así, si las variables que se estudian son: sexo, cuya subvariables son varón y mujer, y la otra variable es nivel de estudios, con dos subvariables: primaria y secundaria, a representará (véase el cuadro) aquellos que son varones y a la vez tiene nivel primario de estudios, mientras que b serán los varones que tienen nivel secundario, y así sucesivamente.
14.11.8. Tabla de interpretación de ϕ
Algunos autores consideran que como el rango de correlación ϕ es de -1 a 1, los extremos expresan una relación perfecta mientras que el valor 0 indica inexistencia de relación. Es posible usar la tabla que sigue para efectos de interpretación:
Tabla de interpretación de ϕ
Valor absoluto de
la correlación
Interpretación de
la relación
Mas de 0,80
De 0,61 a 0,80
De 0,41 a 0,60
De 0,21 a 0,40
De 0,00 a 0,20
Muy fuerte
Mas o menos fuerte
Débil
Muy débil
Imperfecta o baja
El valor cuadrado de la correlación ϕ muestra la proporción de la varianza de las dos variables explicada por la otra.
14.11.9. Prueba de significancia de la correlación
Teniendo en cuenta que la correlación ϕ se calcula sobre la base de datos de un muestreo, cuando el investigador use la medida de correlación ϕ tendrás que precisar la probabilidad de error muestral que produce la correlación, por lo que se aplica una prueba usando el chi cuadrado, aplicando la fórmula:
x2=∑.
R
∑.
C (Oij−E ij)2
E ij
Donde:
R = número de categorías en las variables de región
C = número de categorías en las variables de columna
Oij = frecuencia del valor observado en la celda ij
Eij = frecuencia del valor observado en la celda ij
14.11.10. Relación entre variables ordinales

La relación entre variables ordinales resulta más compleja que la relación entre variables nominales. La complejidad deriva de las propiedades de igualdad y ordenamiento. En efecto, en vez de ocurrir una relación – como en la relación entre variable, entonces, conjuntamente, ocurre otra categoría, usando la escala ordinal de medición se establece que dos variables que covarían (varían conjuntamente) en una dirección particular, es decir, que bien una variable se incrementa cuando otra también se incrementa, o bien se incrementa cuando la otra decrece: las variables cambian en un mismo sentido o en sentido distinto.
14.11.11. El coeficiente de Spearman o correlación por rangos (r) para medir la relación entre . Variables ordinales
Un procedimiento para medir la asociación entre variables ordinales es el coeficiente ρ (rho) propuesto en 1960 por Spearman, quien sostuvo que si los ordenamientos son aibi y se define: di
= ai - bi, con i = 1, 2, … n, el coeficiente está dado por:
ρ=1−6∑i−1
n
d i2
n2−1
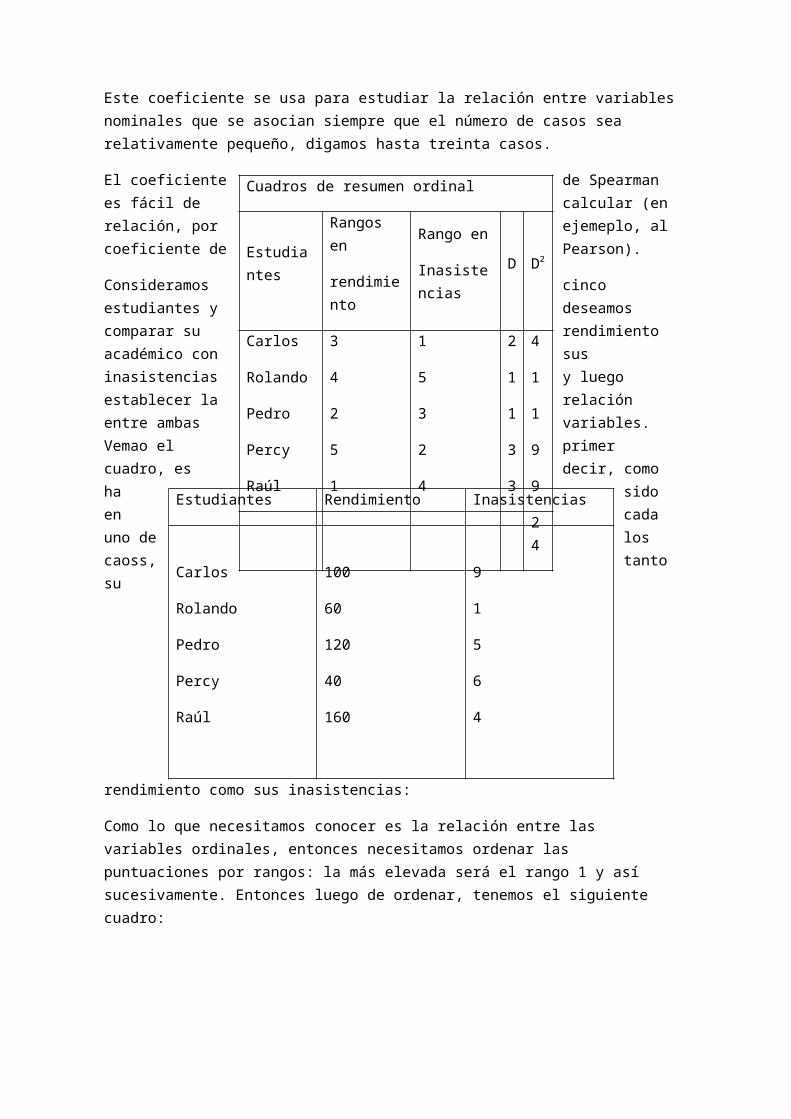
Este coeficiente se usa para estudiar la relación entre variables nominales que se asocian siempre que el número de casos sea relativamente pequeño, digamos hasta treinta casos.
El coeficiente de Spearman es fácil de calcular (en relación, por ejemeplo, al coeficiente de Pearson).
Consideramos cinco estudiantes y deseamos comparar su rendimiento académico con sus inasistencias y luego establecer la relación entre ambas variables. Vemao el primer cuadro, es decir, como ha sido en cada uno de los caoss, tanto su rendimiento como sus inasistencias:
Como lo que necesitamos conocer es la relación entre las variables ordinales, entonces necesitamos ordenar las puntuaciones por rangos: la más elevada será el rango 1 y así sucesivamente. Entonces luego de ordenar, tenemos el siguiente cuadro:
Estudiantes Rendimiento Inasistencias
Carlos
Rolando
Pedro
Percy
Raúl
100
60
120
40
160
9
1
5
6
4

Una vez que el investigador determina los rangos, el cuadrado de las diferencias de los rangos nos ofrece la medida de las divergencias entre los rangos.
Al aplicar la formula de ρ de Spearman se tiene:
1−(6 ) (24 )
(5 ) (52−1 )=1−144
120=1−1,20=−0,20
Como se puede apreciar por el resultado y según el cuadro de la tabla de interpretación de ρ podemos afirmar que la asociación entre las variables (ordinales) encontrada es imperfecta o baja y negativa.
La aplicación practica del coeficiente de ρ de Spearman plantea un problema al investigador cuando se presenta dos o más casos que tienen la misma puntuación (“unidades de observación con la misma puntuación en la misma variable”). La manera de resolverla es la siguiente: se saca el rango promedio de los casos que tienen (u obtuvieron) los mismos valores.
14.11.12. Prueba de significancia de ρ
Teniendo en cuenta que la correlación ρ se calcula sobre la base de los datos de un muestreo, cuando el investigador usa la medida de correlación ρ, tendrá que apreciar la probabilidad de error muestral que produce la correlación. Para llevar a efecto esta prueba el investigador supone:
Ho: el valor ρ poblacional es = 0
Ha: el valor ρ poblacional es ≠ 0
Entonces usará el estadístico Z para la estimación de la significación:
Cuadros de resumen ordinal
Estudiantes
Rangos en
rendimiento
Rango en
Inasistencias
D D2
Carlos
Rolando
Pedro
Percy
Raúl
3
4
2
5
1
1
5
3
2
4
2
1
1
3
3
4
1
1
9
9
24

Z=R H 0−01 /√n−1
Luego se compara el valor Z calculado con el valor Ho: el valor ρ poblacional es = 0 de la tabla. El investigador acepta Ho cuando hay relación y cando no existe relación se rechaza Ha
14.11.13. Limitación del uso del coeficiente de ρ
Una limitación para usar el coeficiente de ρ es la siguiente: los datos tienen que se mayores de 10; además, no debe hacer muchos pares.
15. Análisis de varianza
15.1. Concepto
Se denomina análisis de varianza – ANOVA, de: analysis of variance – al procedimiento estadístico investigado por Ronald Fisher, que consiste en descomponer la variación total existente en un conjunto de datos en los distintos elementos que lo componen. Cada elemento o componente se identifica con un origen o causa de variación conocida, a demás hay un componente que represe4nta la variación que obedece a factores incontrolables (llamados errores).
El diccionario de términos estadísticos define el análisis de varianza como “la variación total de un conjunto de observaciones, medida por la suma de los cuadrados de las desviaciones con respecto a la media, (que) puede, en ciertas circunstancias, ser separada en componentes asociados a fuentes definidas de variación utilizadas como criterio de clasificación para las observaciones. Una análisis de este tipo es llamado análisis de variancia aunque, en rigor, es un análisis de sumas de cuadrados. Son múltiples las situaciones corrientes que pueden reducirse a la forma de análisis de varianza”
En general, puede afirmarse que si aplicamos el análisis de varianza cuando se tiene n observaciones y su media y, entonces la variación total con respecto a la media queda comprendida en una suma de las desviaciones de y al cuadrado, lo cual se denomina suma de cuadrados total (scr). El análisis de varianza descompone la suma de cuadrados en dos grupos: aquella que es fuente de variaciones (tratamientos) y aquella que es debida al error.
15.2. Factores que intervienen en la varianza
Los factores que intervienen en la varianza son dos: los que se dan dentro de los grupos (varianza intragrupos) y los que ocurren entre los grupos (varianza intergrupos).
15.3. La varianza total
De acuerdo a la conceptualización de los factores que intervienen en la varianza, la varianza total es la suma de la varianza intragrupos más la varianza intergrupos.
15.4. La varianza intergrupos

La varianza intergrupos es la modificación que ocurre en cada uno de los grupos cuando estos se someten a un tratamiento, es decir a una manipulación experimental. De acuerdo al tratamiento los frupos y sus medias defieren: habrá una varianza intergrupos.
15.4. La varianza intragrupos
Se define la varianza intragrupos como el error aleatorio. Es la varianza que se da por equivocaion en el muestreo, por la división de los grupos, etc. Se trata de una varianza de las mediciones.
La varianza intragrupos o interclase es la varianza que se da en el análisis de varianza de datos sujetos a clasificaron multiple. Esta varianza ocurre porque hay fenómenos que no se pueden explicar debido a que no existe posibilidad de identificar algunos hechos, por lo que el control no es posible.
15.6. Cálculo de la variación total
La variación total se ogra disponiendo de la tabla de ANOVA, que se conoce como tabla de análisis de varianza de ANOVA y su calculo se obtiene mediante la razón F (razón de Fisher)
F= varianza intergruposvarianza intragrupos
Como vimos, la varianza intergrupos se debe a los tratamientos mientras que la varianza intragrupos es por el error.
Se denomina tratamiento a la acción del investigador consistente en dividir la variable total en variaciones intergrupos, y se llama error a la variación intragrupos. El error se divide en variaciones causadas por cada una de las variables o factores y la variación que responde a las interacciones de los factores.
15.6.1 Tabla de ANOVA
La tabal de ANOVA es una elaboración condensada den la cual se expresa el conjunto de relaciones que se dan en el análisis de varianza, tal como se aprecia a continuación:
Tabal de Anova
Fuente de
Variación
Grado de
libertad
Suma de
cuadradosCuadrados medios Fe Ft
Tratamiento K - 1 SCTR CMTR SCTRK−1
CMTRCME
Fn−KK−1
Con
α = ,05
Error n - k SCE CME SCEn−K
total n - k SCT

Donde:
SCTR = Ʃnj( y j− y…)2
SCE = - ƩƩ(xij− y , j)2
SCT = ƩƩ( yi j− y)2
F se puede obtener mediante la formula:
F=SCT /k−1SCE /n−1
Lo cual puede obtener que el investigador obtiene k a partir de los datos observados y compara los resultados con las tablas de distribución F con grado de libertad de tratamiento (k - 1) y grado de libertar de error (n – k con nivel de confianza α).
He aquí un cuadro en el cual se sintetiza el análisis de varianza:
Tratamientos
Observación 1 2 3 k total
1
2
3
n
Y11
Y21
Y31
Yn1
Y12
Y22
Y32
Yn2
Y13
Y23
Y33
Yn3
Y1K
Y2K
Y3K
YnK
Total
Media
Nº de observ.
Y.1
Y.1
n1
Y.2
Y.2
n2
Y.3
Y.3
n3
Y.K
Y.K
nk
Y …
Y …
15.6.2. El ANOVA de un solo factor
El análisis de varianza de un solo factor (que en la literatura se conoce como ANOVA de un solo factor), es el análisis más simple de varianza, que consiste en analizar el efecto de un solo factor (variable independiente no métrica) que en términos de posiniolidad influye en una variable dependiente.

En el análisis de varianza de un solo factor la variable independiente puede tener varios tratamientos.
15.7. El análisis de varianza de dos variables 8diseño factorial)
En este tipo de análisis de varianza se estudia el efecto de dos o más variables independientes no métricas sobre una variable dependiente métrica. A este análisis de lo denomina anlisi8s factorial. Puede ocurrir que las variables independientes cambien cada una de ellas y actúen sobre la variable dependiente o interactúen entre sí y produzcan una variación en la variable dependiente.
Cuando el investigador plantea y después analizar las interacciones simultáneamente de dos o más variables, se obtiene un logro significativo en el diseño experimental.
En el análisis de varianza de dos factores existen cuatro fuentes de variación.
1) Entre columnas
2) Entre reglones
3) Interacciones
4) El error (varianza de error)
La varianza de error es la varianza intragrupo mientras que las otras tres son varianzas intergrupo. La varianza de error es varianza de factores incontrolables y sirve como denominador en todas las razones F en la tabla de ANOVA.
La prueba de significancia de las diferencias entre las medias de k columnas y r renglones y las interacciones de los dos factores exige que se calcula tres razones de F y se prueben los topos de hipótesis
El análisis factorial (análisis e varianza de dos factores) solo permite conocer el efecto de dos factores conjunto acerca de cual es la relación especifica.
16. Análisis de regresión
16.1. Concento
La regresión es una técnica estadística que describe un relación entre una variable dependiente y una o más variables independientes mediante una línea o ecuación matemática. Con el análisis de regresión el investigador determina la significación estadística de la relación entre variable dependiente y la variable independiente (variables independientes según el caso), su grado, así como la naturaleza y cuantificación de su forma. El termino “regresión” fue empleada por primera vez por Galton “para indicar ciertas relaciones en la teoría de la herencia biológica aunque con posterioridad ha llegado a significar el método estadístico desarrollado para investigar tales relaciones”
16.2. ¿Qué concibe la regresión?

La regresión concibe si una variable es aleatoria y está formada por dos componentes: una variable aleatoria y uun elemento sistematico F (x) dependiente de la variable x, es decir, si
Y = f(x) + ϵ
Se dice que la regresión de y sobre x es la ecuación
Y= f (x)
En la que se supone que la esperanza de ϵ es cero. Esta concepción de la regresión vale también para lo casos en que x es un conjunto de variables: x1, x2, etc.
“la forma f(x) más frecuentemente considerada es la de un polinomio, particularmente una función lineal, resultando la regresión de y sobre x”
Y = Bo + B1xo+ … + Bpxp
Las expresiones anteriores se llaman “ecuaciones de regresion” en las cuales x representa variables “independientes” o “predictivas” o “predictoras” o “regresoras”, en tanto que y se denomina variable aleatoria, “dependiente”, “predicha” o “regresada”
El análisis de regresión expresa solo la relación matemática que existe y sirve para predecir los valores futuros de una variable: como el incremento de producción de una empresa, en relación con la cantidad de trabajadores; el aumento del consumo de luz por el aumento de uso de focos prendidos durante las horas de trabajo, etc.
16.3. Un ejemplo de análisis de regresión simple
Se desea conocer la relación entre las horas de trabajo de los obreros y el número de decenas de sillas fabricadas en “Stylo Lima”. Se tiene los siguientes datos:
Puede observar en el diagrama que los puntos de intersección de las dos variables originan una línea.

El modelo de regresión lineal se formula así:Y = bo + b1 x
boes la ordenada de origen bi es la pendiente de la línea y es la variable dependiente y x la variable independiente. Es posible graficar la relación entre las dos variables: El modelo estadístico es el siguiente:
yi = bo + b1 x1 + iteniendo en cuenta que i = 1, … ny donde:
y1 = variable dependiente ibo = intercepciónb1 = pendiente de la líneax1 = variable independiente
17. Análisis de regresión múltipleSe denomina regresión múltiple a las correlaciones de la variable dependiente y de variable independiente tomadas por separado y además, a la interpretación de las variables independientes entre sí y a su correlación con la variable dependiente.
17.1. ¿Cómo se observa la correlación (r) entre variables dadas?
Tenemos un ejemplo que trata de estudiar una correlación, la más simple: la correlación entre una variable dependiente y dos variables independientes. Veamos:
Variable independiente Variable dependiente1. Puntaje de una prueba de aptitud2. Edad
1. Cantidad de graduados
Mostremos los resultados de las mediciones de las variables y sus respectivas representaciones graficas.Notemos los resultados (mediciones) de las variables que “nos llaman la atención”. El bloque A nos impresiona puesto que es el puntaje más bajo (20 graduados); en sentido contrario, fácilmente, dirigimos la mirada a R (70 graduados), ya que su diferencia es mayor que cualquier otro sentido que se escoja, sea hilera o columna.
Además, si observamos los bloques que van de izquierda a derecha (A, N, P), nos percatamos de que el numero de graduados aumenta conforme disminuye la edad (considerando la misma aptitud) y si los bloques H, I y J, y después los bloques P, Q, R. los primeros bloques tienen el mismo nivel de edad (23 años), y hay una relación observable: el números de graduados aumenta según la aptitud. Lo propio ocurre con cada uno de los otros grupos de bloques que tienen otros niveles de edad, y lo que se infiere es idéntico: el número de graduados se incrementa según la aptitud.De lo anterior podemos hacer una predicción, teniendo en cuenta dos variables conjuntas (independientes) y relacionados con otra (dependiente). En este caso son variables independientes: puntaje en una prueba de aptitud y edad, y variable dependiente: cantidad de graduados.

Si se mantiene las condiciones que se dan en el fenómeno estudiado, entonces, probablemente, habrá en otros hechos a estudiar una relación que se cumple: a menor edad y más aptitud de los egresados mayor cantidad de graduados.El análisis de regresión nos permite hacer “predicciones”, entendiendo que predicción es el proceso de pronosticar la magnitud de variables estadificas para algún tiempo futuro. En contextos estadísticos aparece también la palabra con un sentido apenas diferente, G.g en una ecuación de regresión por la que se exprese4 una variable aleatoria y en función de las variables independientes x, el valor de y para un conjunto especifico de valores de las x es llamado valor predicho, aun cuando no implique el proceso ningún elemento temporal.
17.2. Usos de la regresión múltiple en la investigación científica
La regresión múltiple tiene varios usosa) Como un modelo descriptivo para hacer predicciones, en tanto permite hallar la mejor
ecuación lineal específica o conjunto de variablesb) Como modelo de inferencias para probar hipótesis, puesto que evalúa valores
poblacionales mediante datos muestrales. Por ejemplo, se desea saber (prever, predecir) la condición de liquidez de una empresa luego de una devaluación de 100%. Se aprecia entonces que la variable independiente está constituida por deuda externa contraída por la empresa, deuda interna, costo fijo y participación del mercado. Es posible conocer la ecuación que indica como evaluar las puntuaciones de las variables independientes para predecir la condición de la empresa después de establecida la relación. También puede usarse la regresión múltiple para pronosticar puntajes.Otro uso inferencial es determinar influencias. Por ejemplo, como las deudas (internas, externas) ejercen una influencia en la condición de liquidez de la empresa.
c) Como un modelo estadístico en la prueba de hipótesis estadísticas específicas: el investigador trata de probar la hipótesis nula Ho, (cuyo valor es 0) contra la Ha (hipótesis alterna) cuyo valor es mayor o menor que 0.
En el análisis de regresión, las hipótesis que se plantean los investigadores tienen las siguientes formas:a) No existe relación lineal entre la variable dependiente y un conjunto de variables
independientes. Por ejemplo: el rendimiento promedio de los alumnos de primaria no depende de la cantidad de libro que tienen los padres, del nivel de escolaridad de los padres, de la distancia que hay entre el colegio y la vivienda del escolar.
b) Una variable independiente no tiene relación lineal con la variable dependiente: liquidez y deuda externa tienen más bien una relación por fluctuaciones muestrales.
El modelo de regresión múltiple se expresa con la siguiente fórmula:
Y= a + b1 x1 + b2 x2+ … + bnxn
Donde:
a = valor de y cuando os x son cerosb1 = coeficiente de regresión asociada con cada unidad de x1
17.3. ¿Cómo interpretar el coeficiente de regresión?

La ecuación Y= a + b1 x1 + b2 x2 + … + bnxn expresa el cambio esperado en y con un cambio de unidades determinadas en x, siempre que x2 esté sujeto al control.Es posible una interpretación combinada, la cual se sustenta en la relación existente entre las variables y lo que en ellas ocurre: y sufre una modificación cuando se dan modifica iones. Si x1 y x2 cambian una unidad, entonces el cambio que se espera en y sería b1 + b2
17.4. Evaluación de la significación de regresión
Luego de que se ha establecido la relación entre las variables independientes y dependientes se impone probar el modelo de regresión. Para cumplir con la tarea de evaluar del significado de regresión se usa el coeficiente de correlación múltiple R.
17.5. Uso del coeficiente de correlación múltiple R
Para usar el coeficiente de correlación múltiple R se tiene en cuenta que la suma cuadrada de y es igual a la suma cuadrada de la regresión más la suma cuadrada del residual.En términos formales sería:
Ʃ( y− y)2 = Ʃ( y− y)2 + Ʃ( y− y)2
La proporción de la variación y que da cuenta del modelo de regresión en su totalidad se examina por el cuadrado del coeficiente de correlación múltiple:
R2 = sumacuadrada y−sumacuadrada residual
sumacuadrada y
= sumacuadrada deregresió n
sumacuadrada y
= var . en y explicadascon la influencialineal combinadade var . ind
variaicontotalde y =
El coeficiente de correlación múltiple R, como también el coeficiente de determinación R2
tienen un rango que va de 0 a 1,0.Las hipótesis específicas que son susceptibles de prueba de significancia estadística son:
Ho: b1 = b2 …bk = 0Ha: no todos los bs son = 0
Para este caso se usa la estadística F, que se puede calcular como la razón de los cuadrados de las variables, asociándose cada variable con el grado de libertad que le corresponde.
F x12 (grado de libertar 1) x1
2 (grado de libertad 2)
La regla de decisión para la prueba de significancia es:Si F calculado ≤ F (valor crítico según tabla) aceptamos H0
Si F calculado > F (valor crítico según tabla) rechazamos H0
Es posible calcular F teniendo en cuenta la siguiente fórmula:
F= sumacuadrada deregresion /ksumacuadradaresidual /(n−k−1)
F= R2/k(1−R2 ) /(n−k−1)
Donde:K = número de variables independientesN = tamaño de la muestra
El investigador tiene en cuenta que F no proporciona información acerca de la significancia tampoco informa acerca del grado de relación entre las variables.
17.6. Determinación del grado de relación entre variables (determinación del grado de _______ - significancia sustantivas del modelo de regresión)
Para evaluar la significación sustantiva del modelo de regresión el investigador toma en cuenta la relación entre el número de variables y el tamaño del muestreo. Si la relación entre el número de variables y el tamaño del muestreo. Si el número de variables (k) se acerca al tamaño del muestreo n, entonces R2 se acerca a 1,0. Quiere decir que si el número de variables es igual al número de casos, entonces es R2 1,0, dándose una relación perfecta. Por lo tanto, para k variables y n tamaño de muestreo, el R2 esperado es:
R2 esperado = k−1n−1
El investigador tiene en cuenta que R2 exagera la relación cuando la tasa del numero de variables al examinar el numero de casos es relativamente grande, razón por la cual R2 tienen que ajustarse.
17.7. Cómo ajustar la R2
La formula más divulgada para ajustar R2 es la siguiente:
R2=1 (1−R2 ) n−1(n−k)
Donde:R2 Es el coeficiente de determinación ajustada, a fin de minimizar el efecto de exageración de R2.Para este caso, debe tenerse cuatro veces más casos que variables. En otros términos, el investigador debe disponer de un muestreo cuatro veces mayor que el número de variables.
18. Prueba de hipótesis
18.1 Superación de la estadística clásica en el tratamiento de las investigaciones de la conducta
La obra de SidneySiegel Estadística no paramétrica para la ciencia de la conducta, publicada en 1956, produjo una renovación en las investigaciones de la conducta. En efecto, la estadística clásica, desarrollada por la escuela inglesa, en ela cual destacaron Galton, Pearson, Gosset, Yule, Kendall, Fisher, se sustentó en gran medida en los supuestos de la

escala intervalar y universos uniformemente distribuidos y desarrollo una abundante e impresionante estadística disponiendo de ka matemática clásica, aplicándose con éxito en ciencias como la biología. No existía motivación en las disciplinas cuantitativas probabilísticas, porque era necesario concebir parámetros que no exigieran los requisitos de la escala intervalar (pues no paramétrico designa paramétrico de escala intervalar) y universos no distribuidos normalmente. La estadística no paramétrica y de la distribución libre se ha desarrollado rápidamente, superando los supuestos de la estadística clásica.
18.2. La inferencia estadística y su importancia en la prueba de hipótesis
La inferencia estadística es una de las categorías con que se designa un conjunto de procedimientos que se usan para estudiar las estimaciones de la población, basados en el muestreo, que vimos anteriormente, y que conducen a la prueba de hipótesis.
18.3. El procedimiento estratégico que sigue la prueba de hipótesis
Al probar hipótesis el investigador sigue criterios estadísticos, esto quiere decir que dispone de modelos estadísticos consistentes.Si un investigador desea probar que los que estudian mayor cantidad de horas obtienen mejor rendimiento académico, siento este el objetivo, la formulación hipotética podría ser:a) Existe una relación positiva entre la cantidad de horas de estudio y el rendimiento
académicob) siempre que se mida a un estudiante con más cantidad de horas de estudio, tal
medición se corresponderá con otra en rendimiento académico que será siempre mayor que la de los estudiantes con menos horas de estudio.
En los casos precedentes las hipótesis están formuladas en términos de estadística descriptiva, es decir, como correlación o media.
La hipótesis estadística siempre incluye a la población en estudio. En efecto, no se requiere hacer estadísticas cuando accedemos directamente a la población. Hacemos inferencias cuando muestreamos a la población. Una hipótesis es falsa cuando los valores de ella son distintos a los valores de la población.
Los valores o resultados del muestreo no se interpretan directamente porque se necesita seguir reglas de decisión para aceptar o rechazar la hipótesis de la población que se estudia, ciñéndose a los resultados obtenidos en la muestra.
El procedimiento estratégico que sigue el investigador en la prueba de hipótesis le permite afirmar si el resultado del muestreo está en un rango de causalidad o si no lo está
18.4 Etapas del procedimiento estratégico en la prueba de hipótesis
El investigador sigue los siguientes pasos cuando procede a probar sus hipótesis:
a) formula sus hipótesis nulas y alternasb) escoge la distribución muestral y los procedimientos estadísticosc) especifica el nivel de significancia (α) y define el área de rechazod) hace el calculo para rechazar (o no rechazar) las hipótesis nulas, haciendo uso de
pruebas estadísticas

El investigador se preocupa por determinar si la diferencia en el promedio muestral ocurre por casualidad o por fluctuaciones muestrales (error muestral). Hay dos formas o maneras de realizar la prueba de significancia:
1) haciendo una comparación del estadístico (valor muestral) con el parámetro (valor poblacional)
2) comparando dos a más muestras
18.6. Hipótesis que se distinguen en la prueba de hipótesis
En un proceso de prueba de hipótesis se distinguen dos tipos:a) la hipótesis nula (H0), que afirma que no existe diferencia entre el valor muestral
(estadístico) y el valor poblacional (parámetro) y que cualquier diferencia entre el estadístico y el parámetro depende de la causalidad de las fluctuaciones muestrales.Se formula en el proceso de prueba para se posiblemente rechazada.
b) La hipótesis alterna (Ha), que afirma operacionalmente lo que el investigador desea conocer y se opone a la afirmación de la H0, “En teoría de la prueba de hipótesis: cualquier hipótesis admisible, alternativa a otra sometida a pruebas”.
Veamos el siguiente ejemplo ilustrativoEn una empresa se tiene cuentas por cobrar en sucursales. Se toman muestras de los clientes por cobrar en tres sucursales: en la sucursal A el promedio es de 49 días, en la sucursal B la muestra de las cuentas por cobrar tiene un promedio de 52 días; y en la otra sucursal C, el promedio es de 55 días. Los promedios son indicadores de diferencia en vigilancia de políticas de la empresa con respecto a las cuentas por cobrar.
Veamos como serían las hipótesis. La hipótesis nula se puede expresar así:H0: NO HAY CAMBIOS EN LA POLÍTICA DE COBRANZA DE 50 DÍASLa hipótesis alterna se puede expresar, se3gun la definición sus críticas arriba, de diversas maneras. Por ejemplo la hipótesis alterna puede ser la siguiente:H: la política de cobranza cambió: ya no es de 50 díasH: la política de cobranza actual es mayor que la política inicialEn símbolos, las hipótesis pueden formularse de la siguiente manera:
H0: μ = 50 días Ha: μ ≠ 50 días
O también H0: μ = 50 días Ha: μ > 50 días
18.6 ¿Por qué la necesidad de formular dos hipótesis?
La necesidad de formular dos hipótesis deriva del hecho de que la hipótesis nula esta basada en una inferencia negativa para evitar la consecuencia afirmativa, razón por la cual se debe eliminar la hipótesis falsa en lugar de aceptar la hipótesis verdadera. (no olvidar el criterio siguiente: si un hecho contradice la hipótesis, esta es falsa; en cambio, si un hecho es concertante con la hipótesis, ésta es falsa; en cambio, si un hecho es concordante co0n la hipótesis ésta tan sólo sigue o se confirma).
18.7. Mecanismo de la prueba de hipótesis

El mecanismo de la prueba consiste en que el investigador confronta las hipótesis con los resultados de la muestra H0: μ1 = μ2, para lo cual el investigador toma una muestra al azar de cada una de las poblaciones; en el ejemplo anterior, las muestras al azar fueron las que correspondieron a las sucursales.El investigador compara las dos medias muestrales ( x1 y x2), y luego hace la inferencia a las sucursalesTiene en cuenta el investigador que el resultado del muestreo está sujeto a errores muestrales, lo cual quiere decir que no siempre expresa como es la realidad. Al tomar muestras del mismo tamaño en dos poblaciones, los resultados casi siempre difieren.Para determinar la precisión de los valores muestrales, se compara los valores de la muestra con los modelos estadísticos que son conocidos como distribución muestral.Para obtener la distribución muestral de un estadístico (X o P) se toman varias muestras (del mismo tamaño de una población definida por el investigador). Se procede a calcular la media de cada una de las muestras; luego se compara la distribución normal para verificar la significancia estadística: cuando la distribución es normal no se rechaza la Ho.
18.8. El nivel de significancia y los tipos de error
Se denomina niveles de significancia a la suma de probabilidades de que los resultados de las muestras estén en la zona de rechazo. Los niveles de significancia se expresan con porcentajes, por ejemplo 5%, y sus valores que se atribuyen son arbitrarios. Los valores más comunes son 5, 1 y 0,1 por ciento. Que el nivel de significancia sea 0.05 ó 0.01 significa que la hipótesis nula es rechazada.
18.9. Reglas para probar las hipótesis
Para probar una hipótesis se siguen las siguientes normas:1) Si el análisis muestra que no se puede rechazar la Ho, se acepta y por lo tanto no se
pueden tomar acciones correctivas.2) Si hay diferencias significativas, entonces se rechaza la Ho, y se acepta la hipótesis
alterna, y entonces se adoptan las acciones convenientes. Al adoptar las medidas, existe el peligro de tomar las medidas en forma indebida, pues se puede aceptar la Ho cuando debería rechazarla, o rechazarla cuando se deba aceptarla.
Existe por lo tanto un problema decisional pues la Ho se puede rechazar o se puede aceptar, y por otro lado la hipótesis es correcta o es falsa. Luego hay dos decisiones que son correctas y dos decisiones que son incorrectas.
Veamos el problema decisional en la prueba de hipótesis.Problema decisional en la prueba de hipótesis
Rechazar la Ho
Aceptar la Ho
Planteamientos hipotéticosLa hipótesis es correcta La hipótesis es falsa
Error de tipo I (α)Decisión correcta
Decisión correctaError tipo II (β)
El error tipo I (α) consiste en rechazar la hipótesis correcta. El valor de α es el nivel de significancia, o sea la probabilidad de rechazar la Ho.En el error tipo II (β) se acepta la Ho que es falsa.

18.10. Análisis de un ejemplo de error
Si, considerando el ejemplo anterior, la política de cobranzas ha cambiado y suponiendo que:a) El promedio poblacional es de 50 días (política inicial)b) La desviación estándar es de 10 díasc) Las muestras son las cuentas por cobrar (de clientes): n = 25
Con estos datos se calcula el error estándar del promedio (X ), es decir la desviación estándar del promedio muestral, que es dos días:
σx= σ
√n= 10
√25=2d í as
19. Uso del computador para utilizar técnicas estadísticas
19.1. Usos del SPSS
Se usan paquetes estadísticos especializados para resolver los problemas estadísticos del investigador. Uno de ellos es el SPSS que es la abreviatura en inglés de Paquete Estadístico para las Ciencias Sociales.A continuación mencionamos, a manera de motivación solamente, los usos que puede tener el SPSS. Contiene programas estadísticos que permiten hacer lo siguiente:a) Operaciones de estadística descriptiva. Medidas de tendencia central, y distribución de
frecuencias, usando el subprograma Breakdown.b) Elaboración de tablas de contingencia y tabulaciones cruzadas, abreviando así tiempo y
esfuerzo, aparte de la calidad de la presentación; se logra disponiendo del subprograma Crosstabs.
c) Correlaciones entre dos variables. Permite establecer si existe o no relación entre dos variables; se consigue estos conocimientos acudiendo el subprograma Crosstabs.
d) Regresiones múltiples. El investigador puede llegar a saber si existe una relación (o no) entre una variable independiente que se estudia y propone en una investigación y una o más variables dependientes; manejando el subprograma Regression.
e) Análisis de varianza, para estudiar la significancia de diferencias existentes dentro de los grupos como las diferencias entre grupos. Permite determinar la significancia de las diferencias entre las medias de las poblaciones en el vector correspondiente. Para disponer de estos conocimientos se acude al subprograma ANOVA y también Oneway.
f) Análisis discriminatorios, que permiten la obtención de muestras representativas de varias poblaciones, así como la obtención de un perfil distintivo de las poblaciones considerando sus variables. Con este análisis es posible obtener una combinación de variables entre muestras, facilitando los criterios de ubicación de los individuos en una clasificación. Para este análisis se dispone del subprograma Discriminant.
g) Análisis factorial, útil para hacer taxonomías de diversas variables, cuantificar cada una de las variables en un constructo, así como proporcionar valores cuantitativos a cada uno de los constructos obtenidos. Se puede aplicar este análisis acudiendo al subprograma Factor que es tan potente que puede incluso hacer correlacione canónicas: caso de regresión múltiple en el que se relaciona una variable independiente con varias variables dependientes.

h) Análisis de escalograma. Con esta técnica se logra apreciar y medir la coherencia entre las actitudes de las personas y otros aspectos o variables. Para esta clase de estudios se remite al subprograma GuttmanScale.
19.2. Uso del STATPAC
El StatisticalAnalysisPackage dispone de un conjunto de programas aplicables a la investigación científica. El conjunto de operaciones de las que puede disponer el investigador con el uso de este paquete estadístico es el siguiente:a) Parámetros: permite conocer una cantidad que el planteamiento de un problema
aparece como desconocida y que varia de acuerdo a un conjunto de valoresb) Distribución de frecuencias, que permite especificar la manera en la que se distribuye
una población según los valores de las variables aleatorias que le corresponden.c) Estadísticas descriptivas: medidas de tendencia central, medidas de dispersión y
varianza.d) Tabulación cruzada y (chi cuadrado) que permite comparar los resultados empíricos con
formulaciones teóricas, según alguna distribución o hipótesis teórica. De este modo se conoce el nivel de probabilidad (significación) estableciéndose si los resultados se espera.
e) Correlaciones: se establecen relaciones entre variables. Útiles para determinar si existe real y efectivamente una relación entre variables que se estudia o formula.
f) Regresiones: es posible conocer la relación entre una variable independiente y otra dependiente (análisis lineal) o entre una variable independiente y más de una variable dependiente (regresión).
g) Análisis de varianza: permite conocer las variaciones e influencias entre grupos.