xi escuela de probabilidad y estad stica cimat · 2012-03-02 · de las propiedades de la normal...
TRANSCRIPT

XI Escuela de Probabilidad y EstadısticaCIMAT
Estadıstica Espacial
Rogelio Ramos Quiroga
Guanajuato, Gto. 29 de febrero de 2012.
1

Una Introduccion al Tema
2

Geoestadıstica, version simplificada
0 1 2 3 4 5 6
01
23
45
6
x
y
2 2 2 2 2
2 3 3 3 2
2 3 4 3 2
2 3 3 3 2
2 2 2 2 2
1 1
11
0 1 2 3 4 5 6
01
23
45
6
Predicción
x
y
1.5 2 2.5 3 3.5
0 1 2 3 4 5 6
01
23
45
6
Errores estándar de predicción
x
y
0.05 0.1 0.15 0.2 0.25 0.3
3
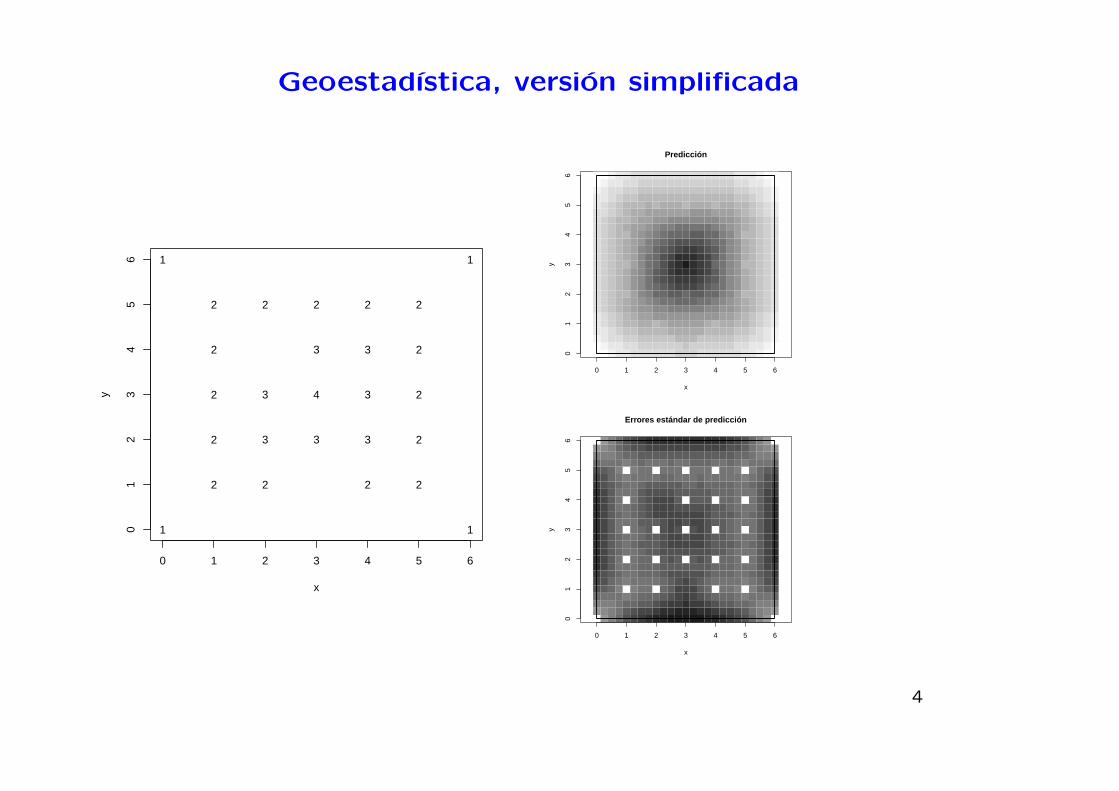
Geoestadıstica, version simplificada
0 1 2 3 4 5 6
01
23
45
6
x
y
2 2 2 2
2 3 3 3 2
2 3 4 3 2
2 3 3 2
2 2 2 2 2
1 1
11
0 1 2 3 4 5 6
01
23
45
6
Predicción
x
y
0 1 2 3 4 5 6
01
23
45
6
Errores estándar de predicción
x
y
4

Aplicaciones de Estadıstica Espacial
5

Hidrologıa
Niveles piezometricos de un acuıfero. ( Cressie (1991) ).
6

Procesamiento de Imagenes: Texturas
( Winkler (2003), Cross & Jain (1983), Geman & Geman (1984) )
7

Ecologıa
Densidad de arboles (en region de 4 has). ( Cressie (1991) ).
8

Agronomıa
%��� �� ��' ���� ?���@ ��� �������� ��������� #�� ? ����#@ �� ��� #�����+���� ��� �����- ��� ��� ��' ����� ������"�� �������� ��� ��# �� �� ��� ��������� ���# � ���� �����B ��� ���&�� ��� ��"��� ��� ����� ��� �����B'���� ��"�� �������� ���� �� '���� �� ��� '� ��������, ���������� ��� ��'� ��� ��� �������� '���� ��� '����������
( Besag & Higdon (1999) )
9
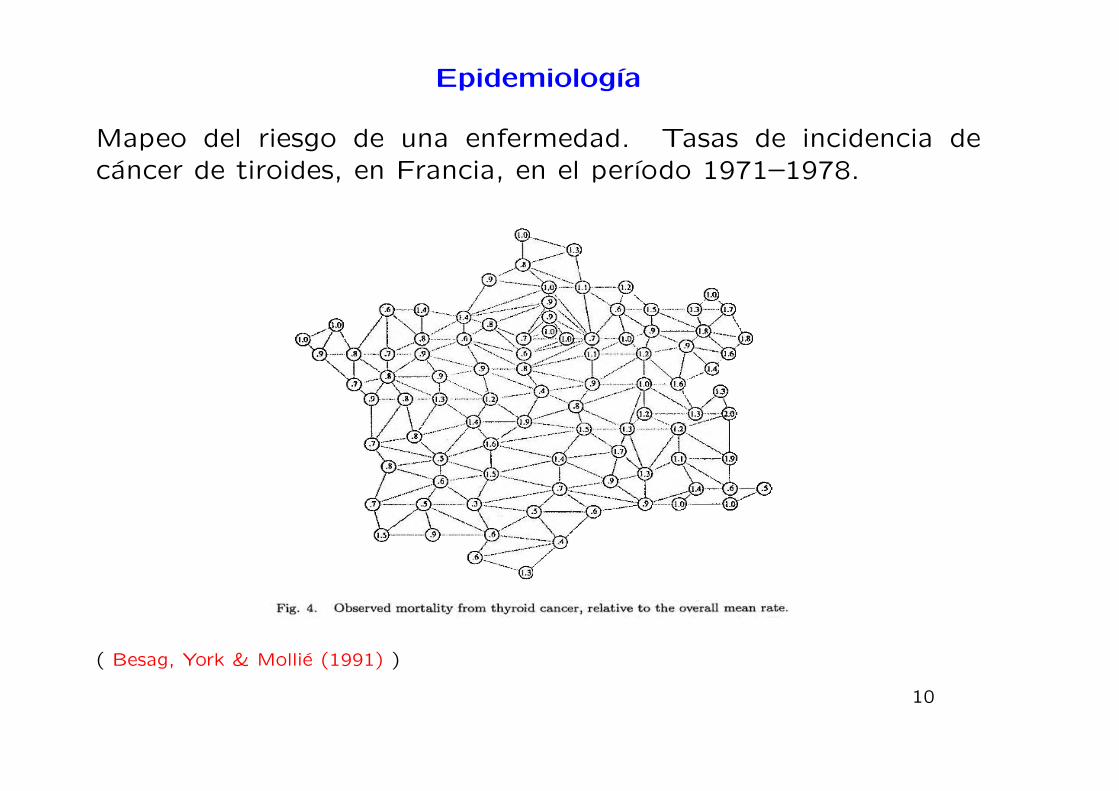
Epidemiologıa
Mapeo del riesgo de una enfermedad. Tasas de incidencia decancer de tiroides, en Francia, en el perıodo 1971–1978.
( Besag, York & Mollie (1991) )
10
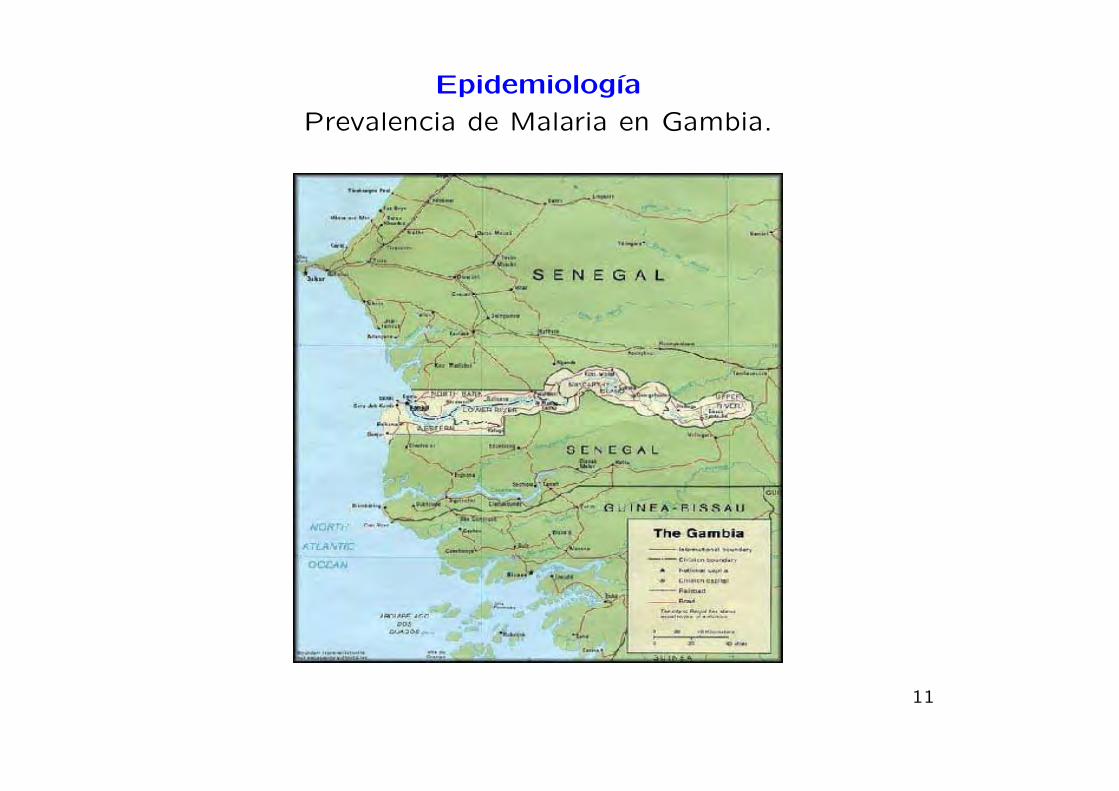
Epidemiologıa
Prevalencia de Malaria en Gambia.
11

Epidemiologıa
300 350 400 450 500 550 600
1350
1400
1450
1500
1550
1600
Prevalencia de Malaria en Gambia
O−E (kilómetros)
S−
N (
kiló
met
ros)
Región Oeste
Región Este
Región Central
12

Pero primero, lo primero: Antecedentes
13

Los inicios de la Geoestadıstica
• D.G. Krige en los 1950’s
– Prediccion del grado de mineral para regiones, basadas en muestreopuntual.
– Sin supuestos de i.i.d., solo vectores de observaciones espacialmentecorrelacionadas.
– Impacto fuerte en minerıa.
• G. Matheron en los 1950’s y 60’s
– Primeras publicaciones detalladas sobre geoestadıstica y kriging (acunoeste termino en honor de Krige).
– Lıder de la llamada Escuela de Fontainbleau en Francia (en la Escuelade Minas).
14

Geoestadıstica y Estadıstica Espacial
Geoestadıstica
• Krige (1951)
• Matheron (1963)
Estadıstica Espacial
• Kolmogorov (1941)
• Matern (1960)
• Whittle (1962)
• Bartlett (1964)
• Besag (1974)
Estamos hablando de lo mismo
• Watson (1972)
• Ripley (1981)
• Cressie (1993)
15

Kriging
16

Prediccion con Error Cuadratico Mınimo
Sea T una variable aleatoria cuyo valor queremos predecir basandonos
en las realizaciones de y = (y1, · · · , yn)T . Sea T = t(y) un predictor
puntual. El Error Cuadratico Medio de T se define como:
ECM(T ) = E[(T − T )2]
Haciendo p = E(T |y), note que
ECM(T ) = Ey
[ET
{(T − T )2|y
} ]= Ey
[ET
{(T − p+ p− T )2|y
} ]= Ey
[ET
{(T − p)2|y
} ]+Ey
[ET
{(T − p)2|y
} ]= Ey
[(T − p)2
]+Ey [ Var(T |y) ] ≥ Ey [ Var(T |y) ]
El predictor con mınimo error cuadratico medio es
T = p = E(T |y).
A Var(T |y) se le llama Varianza de Prediccion.
17

Geoestadıstica Basada en Modelos
Especificacion del modelo:
• Proceso estacionario gaussiano S(x), x ∈ R2:
i. E {S(x)} = µ.
ii. Cov{S(x), S(x′)
}= σ2ρ(||x− x′||).
• Observaciones independendientes, yi|S(·) ∼ N(S(xi), τ2), condi-
cionadas al proceso subyacente.
El modelo gaussiano implica que: yi = S(xi) + ei con ei indepen-
diente de S(xi) y ei ∼ N(0, τ2).
18

Prediccion con Error Cuadratico Mınimo
Tambien, el modelo gaussiano implica que:
y = (y1, · · · , yn)T ∼ Nn(µ1, σ2V )
donde V = R+ (τ2/σ2)I y Rij = ρ(||xi − xj||).
Si deseamos efectuar una prediccion de T = S(x) donde x es
un sitio no muestreado, entonces el predictor con mınimo error
cuadratico medio es
T = p = E(T |y)
para ello necesitamos la conjunta de y y T . Puede verse que[Ty
]∼ N1+n
([µµ1
], σ2
[1 rT
r V
])
donde r = (r1, · · · , rn)T y ri = ρ(||x− xi||).19

Recordar: Propiedades de Normal Multivariada
Si y ∼ N(µ,Σ) y particionamos los diferentes vectores y matrices
como
y =
[y1y2
], µ =
[µ1µ2
]Σ =
[Σ11 Σ12Σ21 Σ22
]
entonces, la distribucion condicional de y1 | y2, es Normal con
E(y1 | y2) = µ1 +Σ12Σ−122 (y2 − µ2)
Var(y1 | y2) = Σ11 −Σ12Σ−122Σ21
20

Prediccion con Error Cuadratico Mınimo
De las propiedades de la normal multivariada se tiene que el pre-
dictor optimo (en el sentido de error cuadratico medio) es:
T = E(T |y) = µ+ rTV −1(y − µ1)
y la varianza de prediccion es
Var(T |y) = σ2(1− rTV −1r)
• Kriging Simple: µ = y.
• Kriging Ordinario: µ = (1TV −11)−11TV −1y.
21

Prediccion Optima
T = E(T |y) = µ+ rTV −1(y − µ1)
En general, la estimacion de µ no presenta gran dificultad, aun enpresencia de tendencias o covariables. Sin embargo, la parte real-mente crıtica del predictor es la estimacion de V . Los enfoquesasociados a su estimacion dan lugar a dos escuelas en Geoes-tadıstica:
• Enfoque clasico: Estimar V usando el Variograma empırico.
• Enfoque basado en modelos: Estimar V postulando modelosprobabilısticos especıficos (comunmente el modelo normal) yusar las herramientas de inferencia usuales basadas en Verosimil-itud.
22

Prediccion Optima
T = E(T |y) = µ+ rTV −1(y − µ1)
• Enfoque clasico: Kriging ⇒ encontrar la combinacion lineal de
las observaciones y1, · · · , yn que mejor prediga el valor de la
superficie en una localidad arbitraria x.
• Enfoque basado en modelos: Kriging ⇒ prediccion con mınimo
error cuadratico bajo supuestos de normalidad.
23

Enfoque Clasico: Variogramas
24

Variograma Teorico
El variograma de un proceso y(x) es la funcion:
V (x, x′) =1
2Var
{y(x)− y(x′)
}En el caso del modelo gaussiano, se tiene, con u = ||x− x′||
V (u) = τ2 + σ2 {1− ρ(u)}V (u) provee un resumen de los parametros basicos de la estructurade un proceso espacial gaussiano.
En la practica, cuando el diseno muestral especifica una sola ob-servacion en cada sitio, el parametro τ2 tiene una doble inter-pretacion: Como la varianza del error de medicion o como la vari-abilidad espacial a una escala menor que la distancia mas pequenaentre puntos del diseno. Se le llama “efecto Pepita” (nugget) pueslos depositos de alto grado de mineral tienden a estar concentradosen venas.
25
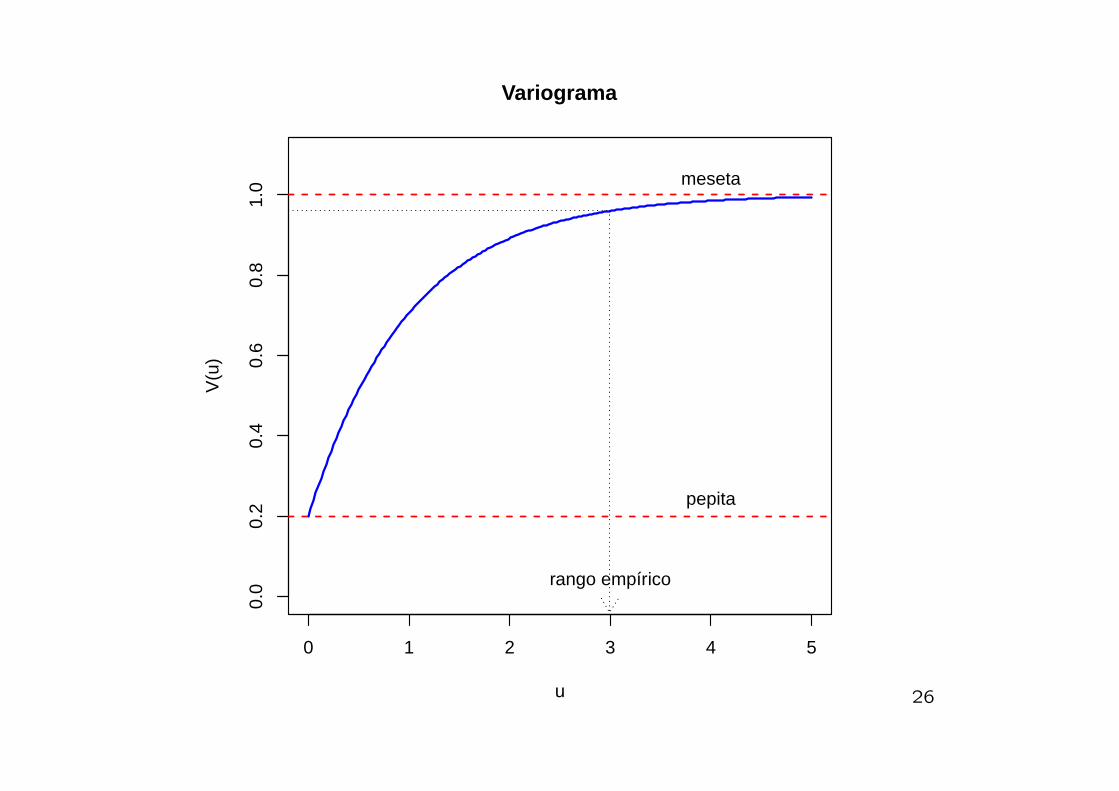
0 1 2 3 4 5
0.0
0.2
0.4
0.6
0.8
1.0
Variograma
u
V(u
)
meseta
rango empírico
pepita
26

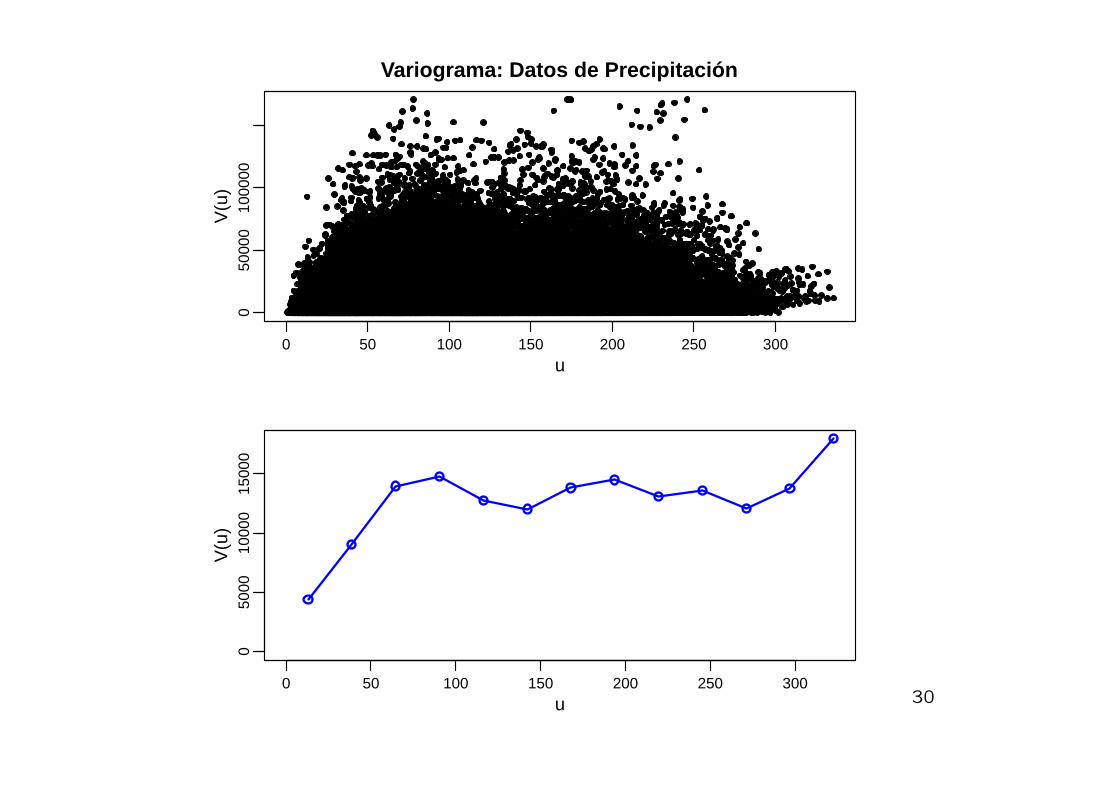
Variograma Empırico
La contraparte del variograma teorico
V (x, x′) =1
2Var
{y(x)− y(x′)
}es el Variograma Empırico que consiste de la grafica de puntos
(uij, vij), donde
uij = ||xi − xj|| y vij = [ y(xi)− y(xj) ]2/2
El variograma empırico suaviza la nube de puntos promediando
sobre intervalos u− h/2 ≤ uij < u+ h/2.
En procesos con media no-constante (e.g. cuando incluımos co-
variables), el variograma se calcula sobre residuales
r(xi) = y(xi)− µ(xi)
para obtener las vij’s.
27
28
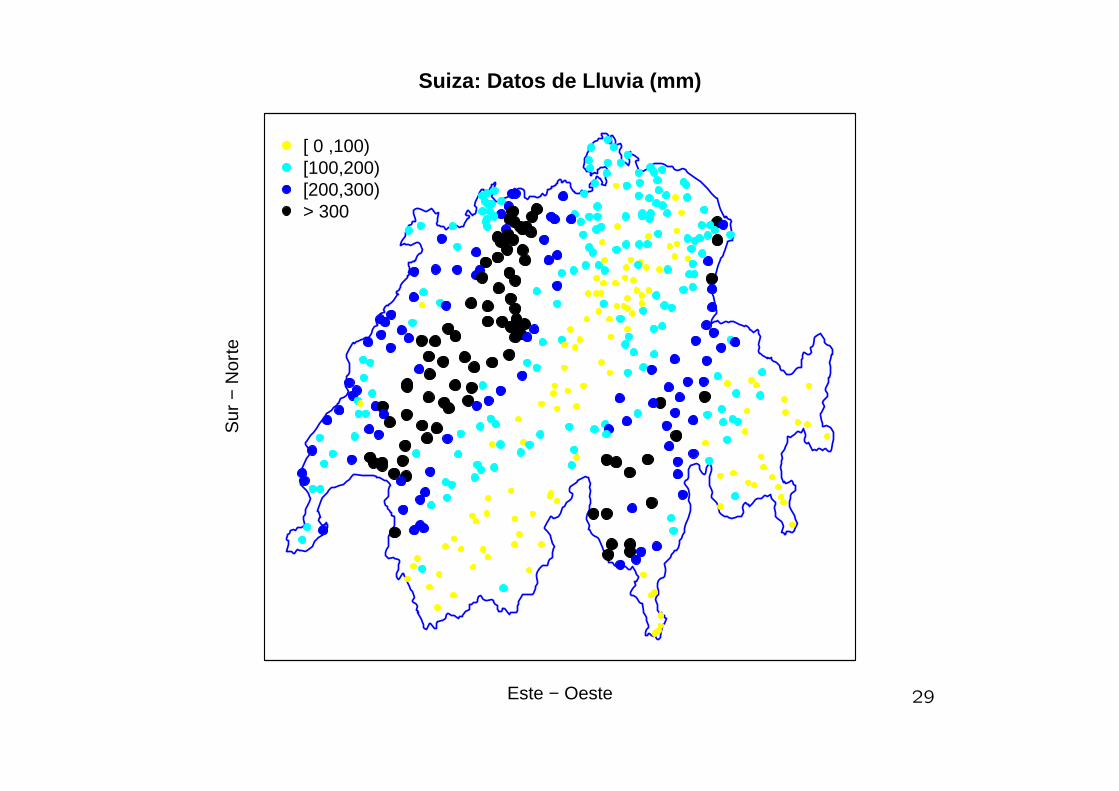
Suiza: Datos de Lluvia (mm)
Este − Oeste
Sur
− N
orte
[ 0 ,100)[100,200)[200,300)> 300
29
0 50 100 150 200 250 300
050
000
1000
00
Variograma: Datos de Precipitación
u
V(u
)
0 50 100 150 200 250 300
050
0010
000
1500
0
u
V(u
)
30

Estimacion de parametros en base al Variograma
Mediante el ajuste del variograma empırico al teorico se obtienen
estimaciones de los parametros de la matriz de varianzas y covar-
ianzas. Tıpicamente se opta por un ajuste vıa mınimos cuadrados
ponderados:
W (θ) =∑k
nk[Vk − V (uk; θ)
]2donde θ es el vector de parametros de covarianza y Vk es el prome-
dio de nk valores del variograma vij.
31

Estimacion de parametros en base al Variograma
minθ
W (θ) =∑k
nk[Vk − V (uk; θ)
]2 con V (u) = τ2+σ2 {1− ρ(u)}
Modelos mas usados:
• Exponencial: ρ(u) = exp {−(u/ϕ)κ}, con 0 < κ ≤ 2.
• Esferico: ρ(u) = 1− 3/2 (u/ϕ) + 1/2 (u/ϕ)3, 0 ≤ u ≤ ϕ.
• Gaussiano: ρ(u) = exp{−(u/ϕ)2
}.
• Matern: ρ(u) ={2κ−1Γ(κ)
}−1(u/ϕ)κ Kκ (u/ϕ).
32

Comentarios
• La nube del variograma puede ser inestable, tanto a nivel pun-
tual como en su forma global.
• El efecto pepita (τ2) es difıcil de estimar pues ocurre en un
extremo de la region de distancias alrededor del origen.
• Las ordenadas, vij, del variograma estan correlacionadas. Esto
puede inducir un forma del variograma que es independiente
del variograma teorico mismo.
• El ajuste es sensible a la estimacion de la media (i.e. si se
ajusta una tendencia o no).
33

Enfoque Basado en Modelos: Maxima Verosimilitud
34

La familia de funciones de correlacion de Matern
ρ(u) ={2κ−1Γ(κ)
}−1(u/ϕ)κ Kκ (u/ϕ) , κ > 0, ϕ > 0
• Kκ(·) : Funcion modificada de Bessel de orden κ.
• ρ(u) = exp{−(u/ϕ)} corresponde a κ = 0.5.
• ρ(u) = exp{−(u/ϕ)2} corresponde a κ → ∞.
• ρ(u) decrece conforme la distancia entre sitios, u, crece.
35

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Funciones de correlación de Matérn
u
ρ(u)
κ = 0.5, φ = 0.25κ = 1.5, φ = 0.16κ = 2.5, φ = 0.13
36
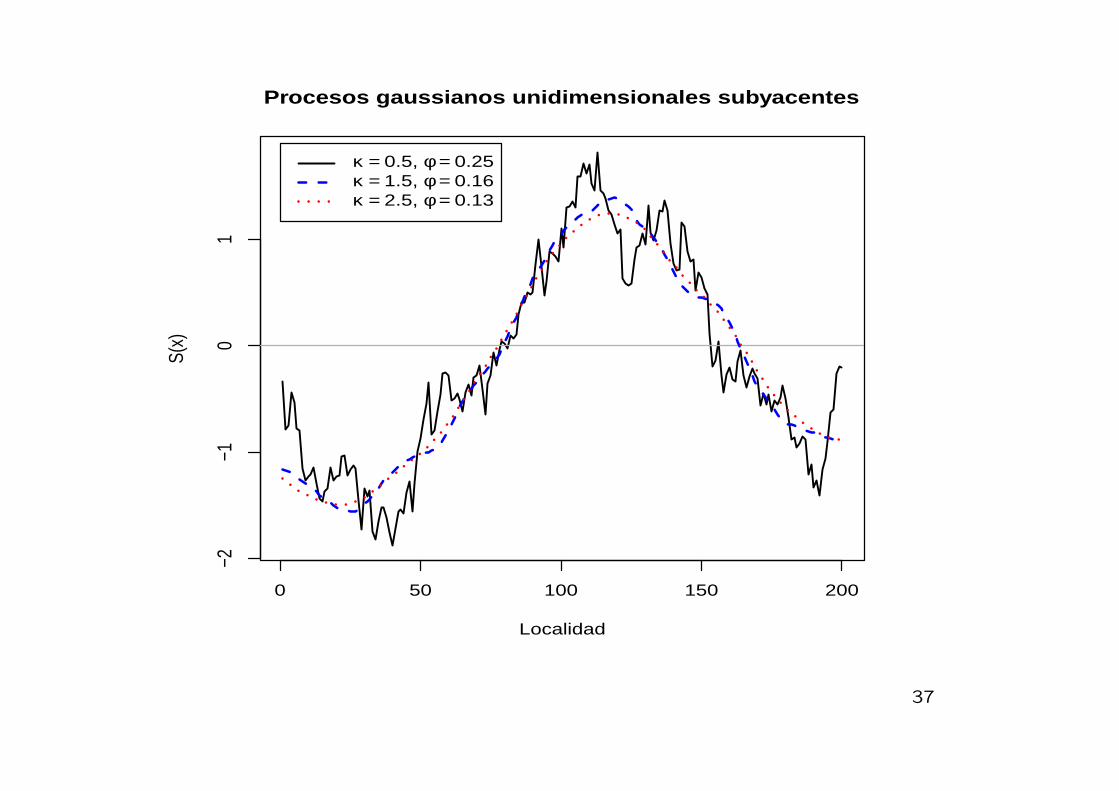
0 50 100 150 200
−2−1
01
Procesos gaussianos unidimensionales subyacentes
Localidad
S(x)
κ = 0.5, φ = 0.25κ = 1.5, φ = 0.16κ = 2.5, φ = 0.13
37

Maxima Verosimilitud
Recordemos el modelo gaussiano: y ∼ Nn(µ1, σ2R + τ2I), donde
R tiene elementos Rij = ρ(uij) y uij = ||xi − xj||.
Mas general, incluyendo covariables,
µ(xi) =k∑
j=1
dk(xi)βk = dTi β
donde di = (d1(xi), · · · , dk(xi))T es un vector de covariables aso-
ciado a la localidad i. Entonces el modelo gaussiano reformulado
es
y ∼ Nn(Dβ, σ2R+ τ2I)
38

Maxima Verosimilitud
La logverosimilitud asociada a y ∼ Nn(Dβ, σ2R(θ) + τ2I) es
l(β, σ2, τ2, θ) = −1
2
{C + log |σ2R(θ) + τ2I|+ (y −Dβ)T [σ2R(θ) + τ2I]−1(y −Dβ)
}Reparametrizando, ν2 = τ2/σ2 y haciendo V = R(θ) + ν2I, te-
nemos que, para V fija, el maximizador para β esta dado por
(mınimos cuadrados generalizados):
β(V ) = (DTV −1D)−1DTV −1y
y
σ2(V ) = (y −Dβ)TV −1(y −Dβ)/n
La logverosimilitud perfil para θ y ν2 queda como:
l(ν2, θ) = −1
2
{C + nlog σ2(V ) + log |V |+ n
}la cual hay que maximizar numericamente con respecto a ν2 y θ.
39

0 50 100 150 200 250 300
050
100
150
200
250
Suiza: Precipitación Media Predicha
Este − Oeste
Sur
− N
orte
100 200 300 400
40
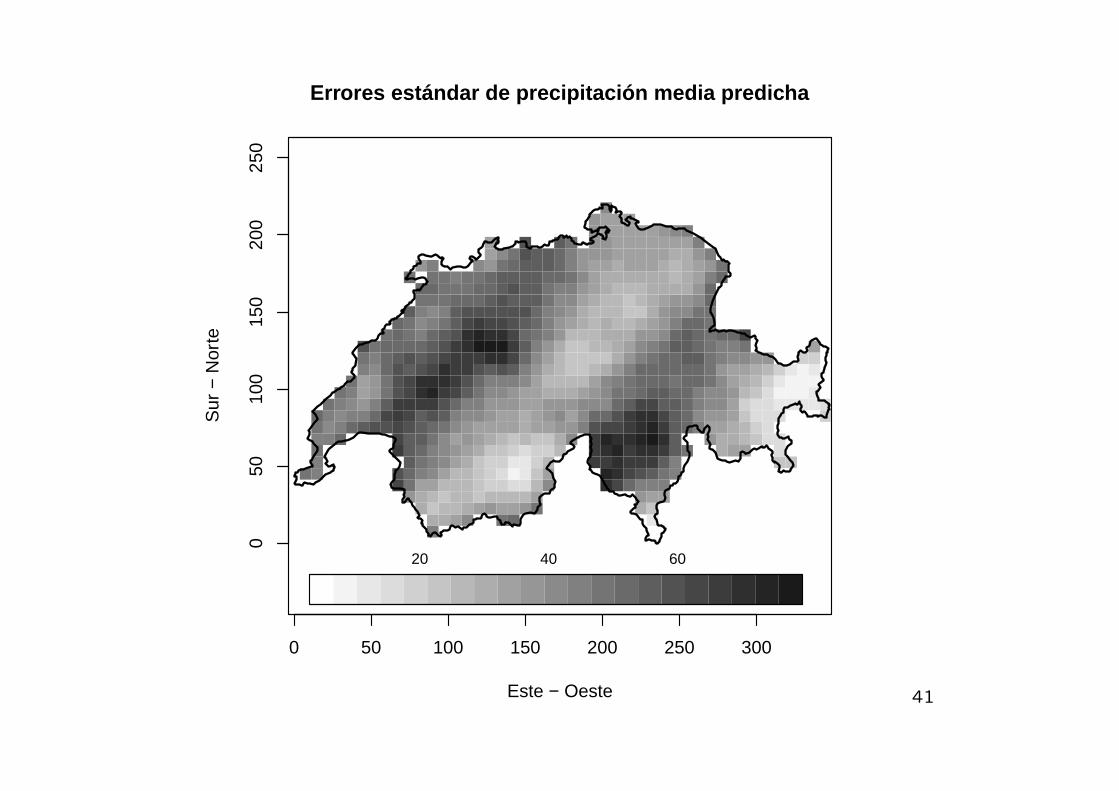
0 50 100 150 200 250 300
050
100
150
200
250
Errores estándar de precipitación media predicha
Este − Oeste
Sur
− N
orte
20 40 60
41

Prediccion de Funcionales No-Lineales
El predictor optimo no es invariante ante transformaciones no-
lineales. Una forma de abordar el problema de prediccion es vıa
simulacion. Por ejemplo, si queremos predecir la probabilidad de
que en cierta localidad, x, ocurra un evento de precipitacion que
exceda el umbral de 200, entonces, T , la variable aleatoria de
interes puede considerarse como una variable Bernoulli con p =
P[y(x) > 200]. Resumenes numericos apropiados de la simulacion
repetida de S(x)|y nos permiten efectuar esta prediccion.
42

Dist. predictiva de excedencias a 200 mm
A200
Fre
quen
cy
0.36 0.38 0.40 0.42
050
100
150
43

0 50 100 150 200 250 300
050
100
150
200
250
Probabilidad de exceder 200 mm
Este − Oeste
Sur
− N
orte
0.2 0.4 0.6 0.8
44

Comentarios Finales
• La Geoestadıstica (y, consecuentemente, la Estadıstica Espacial) tienen ungran campo de aplicabilidad: Meteorologıa, Hidrologıa, Minerıa, Cienciasdel Suelo, Epidemiologıa, Agronomıa.
• Las tecnicas estandar de interpolacion no incorporan informacion sobre laestructura de correlacion espacial. La Estadıstica Espacial sı.
• Tıpicamente, las tecnicas de interpolacion no proveen medidas de incer-tidumbre puntual en sus ajustes. Kriging sı, lo cual permite evaluar labondad de las predicciones.
• El balance se inclina hacia el uso de prediccion basada en modelos; sinembargo no son la panacea pues, por supuesto, son dependientes de lavalidez del modelo. Aunque hay herramientas para evaluar esa validez.Estimacion basada en variogramas tiene la ventaja de ser “distributionfree”, lo cual es un punto a su favor en terminos de robustez.
45

Bibliografıa
1. Diggle, P.J. & Ribeiro, P.J. (2007). Model-based Geostatistics. Springer.
2. Cressie, N. (1993). Statistics for Spatial Data. Wiley.
3. R Development Core Team (2011). R: A language and environmentfor statistical computing. R Foundation for Statistical Computing, Vienna,Austria. ISBN 3-900051-07-0, URL http://www.R-project.org/.
4. Ribeiro, P.J. & Diggle, P.J. (2001). geoR: A package for geostatisticalanalysis. R-NEWS, Vol.1, No.2, 15-18. ISSN 1609-3631.
5. Tøgersen, F.A. & Badsberg, J.H. (2003). Geostatistics and Spa-tial Modelling. http://gbi.agrsci.dk/statistics/courses/JBS-Geostatistics-2003/
46