universidad nacional de colombia curso análisis … en estadística se llama análisis de...
TRANSCRIPT

Universidad Nacional de Colombia
Curso Análisis de Datos Cuantitativos
Profesor Iván Fernando Camacho
Caso 1: Dos variables cuantitativas

Escalas de medición
� NOMINAL
� ORDINAL
� INTERVALO
� RAZÓN
Variables Cualitativas
Variables Cuantitativas

Al relacionar dos variables existen
tres posibilidades o casos:
1. Dos variables cuantitativas2. Dos variables cualitativas3. Cuantitativa Vs cualitativa

TIPOS DE VARIABLES
� Ejemplos: � En economía: precios, oferta y demanda.
� Correlación entre la estatura de los padres y sus respectivos hijos.
� Series de tiempo numéricas. P ej. evolución del PIB a través de los años.
� Análisis:� Correlaciones:
� Lineal: Covarianza, Correlaciones, Coeficiente de Correlación. Regresión lineal.
� No lineal: Regresión con modelo lineal generalizado, modelos no paramétricos.
� Si se manejan muestras : Pruebas de hipótesis, intervalos de confianza, regresión lineal y generalizada, modelos no paramétricos etc. etc. etc…..
Caso 1. Dos variables cuantitativas

El concepto de relación en estadística coincide con lo que se entiende por relación en el lenguaje habitual: dos variables están relacionadas si
varían conjuntamente.
Si los sujetos tienen valores, altos o bajos, simultáneamente en dos variables, tenemos una relación positiva.
Por ejemplo peso y altura en una muestra de niños de 5 a 12 años: los mayores en edad son también los más altos y pesan más, y los más jóvenes son los que pesan menos y son más bajos de estatura; decimos que peso y altura son dos variables que están relacionadas porque los más altos pesan más y los más bajos pesan menos.
Si los valores altos en una variable coinciden con valores bajos en otra variable, tenemos una relación negativa.
Por ejemplo edad y fuerza física en una muestra de adultos de 30 a 80 años de edad: los mayores en edad son los menores en fuerza física; hay una relación, que puede ser muy grande, pero negativa: según los sujetos aumentan en una variable (edad) disminuyen en la otra (fuerza física).
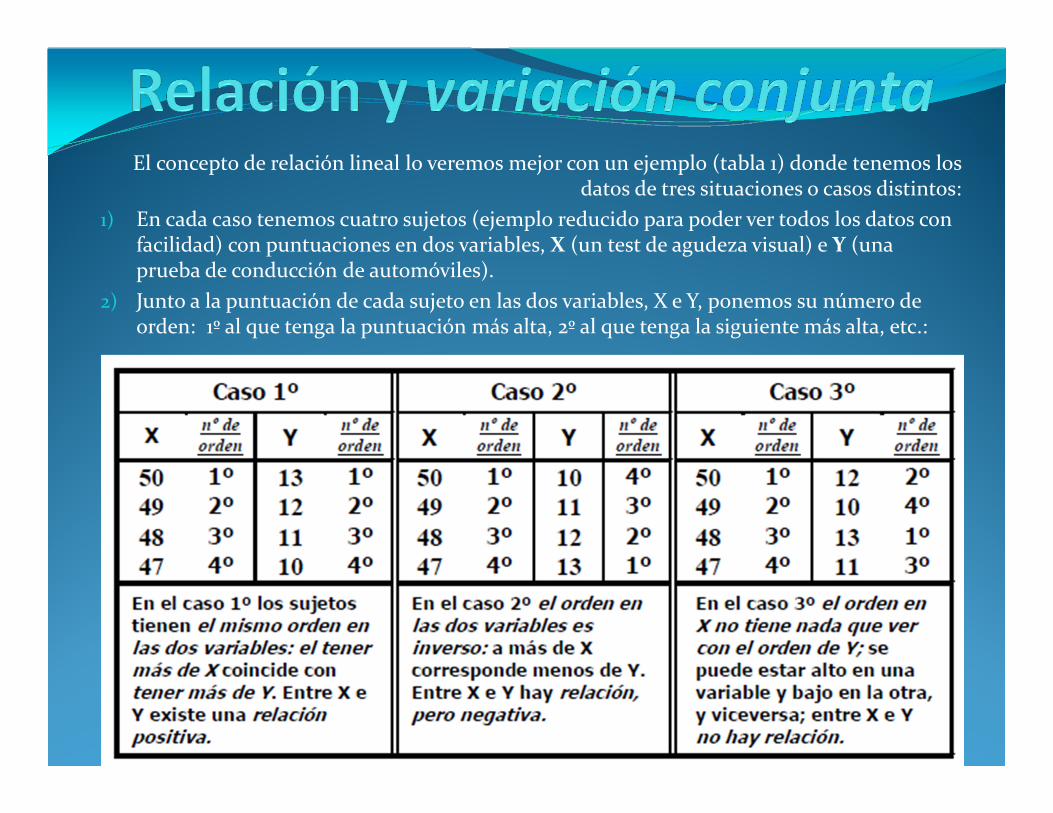
El concepto de relación lineal lo veremos mejor con un ejemplo (tabla 1) donde tenemos los datos de tres situaciones o casos distintos:
1) En cada caso tenemos cuatro sujetos (ejemplo reducido para poder ver todos los datos con facilidad) con puntuaciones en dos variables, X (un test de agudeza visual) e Y (una prueba de conducción de automóviles).
2) Junto a la puntuación de cada sujeto en las dos variables, X e Y, ponemos su número de orden: 1º al que tenga la puntuación más alta, 2º al que tenga la siguiente más alta, etc.:

La representación gráfica de estos pares de puntuaciones se denomina diagrama de dispersión, y también nos ayuda a entender el mismo concepto de relación.
Puede existir relación entre dos variables sin que ésta sea lineal. Las medidas estadísticas que detectan la relación lineal entre variables NO detectan las relaciones que no son lineales. En tal caso se deben utilizar métodos mas complejos (P. ej. regresión no lineal, regresión no paramétrica).

La correlación se define como la co-variación (co = con, juntamente: variar a la vez).
En estadística existen muchas formas de medir correlación lineal entre variables dependiendo del interés investigativo y el tipo de variable (nominal, ordinal, numérica). Los más importantes conceptualmente son la covarianza y la correlación.
Correlación y covarianza son términos conceptualmente equivalentes, expresan lo mismo. La covarianza (Cov, ) es una medida de relación, lo mismo que el coeficiente de correlación de Pearson (r).
Habitualmente se utiliza el coeficiente de correlación (r de Pearson), pero es útil entender antes qué es la covarianza, y entenderlo precisamente en este contexto, el de las medidas de relación.

Sin diferencias en las dos variables no podemos encontrar variaciónconjunta: si todos los sujetos tienen idéntica puntuación en X nopodemos ver si los altos en X son también altos en Y, porque en X sontodos iguales.La correlación y la covarianza dicen de dos variables lo mismo que lavarianza (o la desviación típica) dice de una variable: hasta qué puntolos sujetos son distintos simultáneamente en las dos variables. De lamisma manera que la varianza es una medida de dispersión en unavariable, la correlación (y la covarianza) son también medidas dedispersión, pero de dos variables tomadas a la vez.

Correlación, covarianza y dispersión:
importancia de las diferencias
Por ejemplo, si queremos comprobar si la altura está relacionada con la capacidad de encestar (jugando al baloncesto) necesitaremos jugadores de distintas alturas, para ver si los más altos encestan más y los más bajos encestan menos.
Si todos los jugadores tienen la misma altura (x), no podemos comprobar esa relación; no podemos comprobar si las diferencias en altura se corresponden con diferencias en la habilidad de encestar (y), porque todos tienen idéntica altura.
Y también necesitaremos que unos encesten más y otros menos. Los sujetos deben ser distintos en las dos características cuya relación queremos comprobar.En el caso de los dos gráficos de arriba no podremos evaluar la relación entre las dos variables, pues una de ellas es constante.
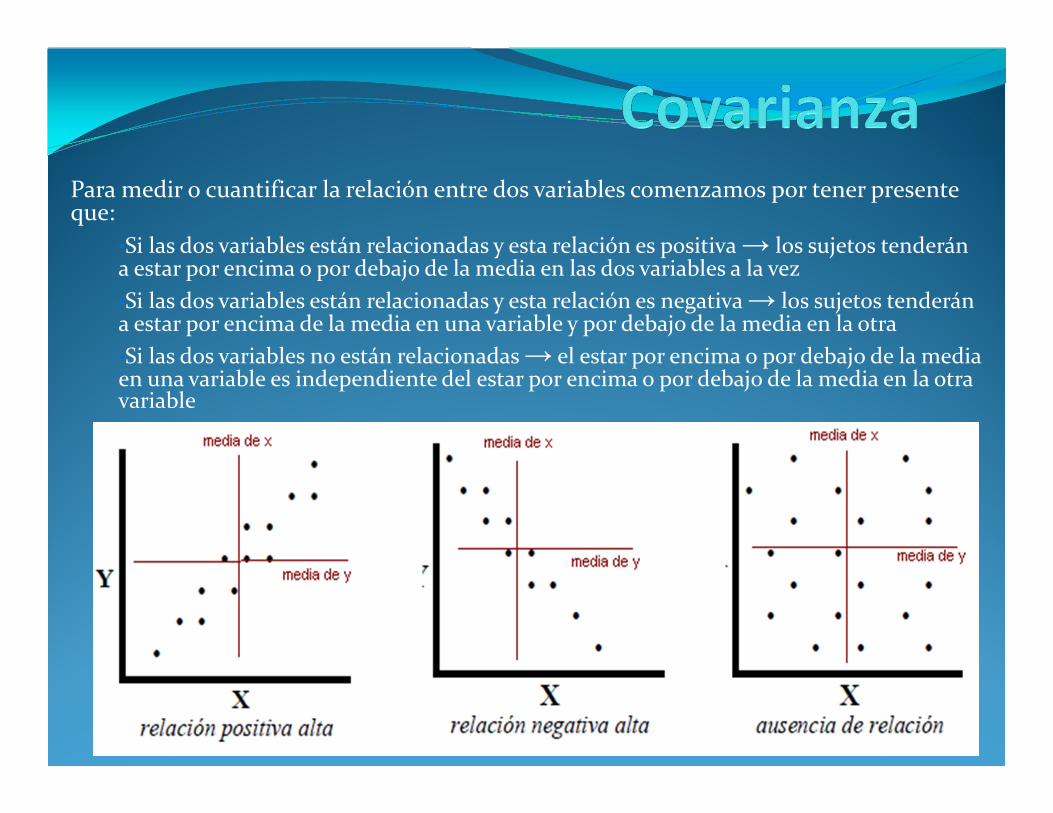
Para medir o cuantificar la relación entre dos variables comenzamos por tener presente que:
•Si las dos variables están relacionadas y esta relación es positiva → los sujetos tenderán a estar por encima o por debajo de la media en las dos variables a la vez
•Si las dos variables están relacionadas y esta relación es negativa → los sujetos tenderán a estar por encima de la media en una variable y por debajo de la media en la otra
•Si las dos variables no están relacionadas → el estar por encima o por debajo de la media en una variable es independiente del estar por encima o por debajo de la media en la otra variable

Este estar por encima o por debajo de la media en dos variables simultáneamente nos permite cuantificar el grado de relación.
Lo explicamos por pasos:1. La distancia o diferencia de un dato de un sujeto con
respecto a la media la podemos representar restando cada puntuación de la media (la llamaremos d con subíndice X ó Y
dependiendo de la variable ):
Tenemos que si un dato está por encima de la media, la diferencia será positiva, y si está por debajo de la media, la diferencia será negativa.

Lo explicamos por pasos:
2. Podemos multiplicar para cada individuo las diferencias en X y en Y, y luego sumar todos esos productos:

Covarianza:� Teniendo en cuenta lo anterior, una buena medida de
la variación simultánea de dos variables es la covarianza, que no es mas que un promedio de las distancias anteriormente expuestas :

A la hora de interpretar es bien difícil hacerlo directamente, pues el valorde la covarianza depende de la escala en que medimos las variables X y Y.Por ejemplo, si estamos mirando la relación entre estura y peso las unidadesde medida serían metros*kilos. ¿Cómo se interpreta eso?Para solucionar ese problema se usa el coeficiente de correlación de Pearson(r) que no tiene unidad de medida y siempre irá con valores de -1(correlación total negativa) a 1 (correlación total positiva), pasando por elcero (ausencia total de relación entre las dos variables).Para lograr el ajuste, se divide la covarianza entre el producto de lasdesviaciones estándar de las dos variables:

El coeficiente de correlación expresa en qué grado los sujetos (u objetos, elementos…) están variando simultáneamente en las dos variables y qué tan lineal es esa relación.
Los valores extremos son 0 (ninguna relación) y ±1 (máxima relación).
En últimas, el coeficiente de correlación r de Pearson nos dice que tanto se
ajustan unos datos emparejados a una recta, sea cual sea ésta.
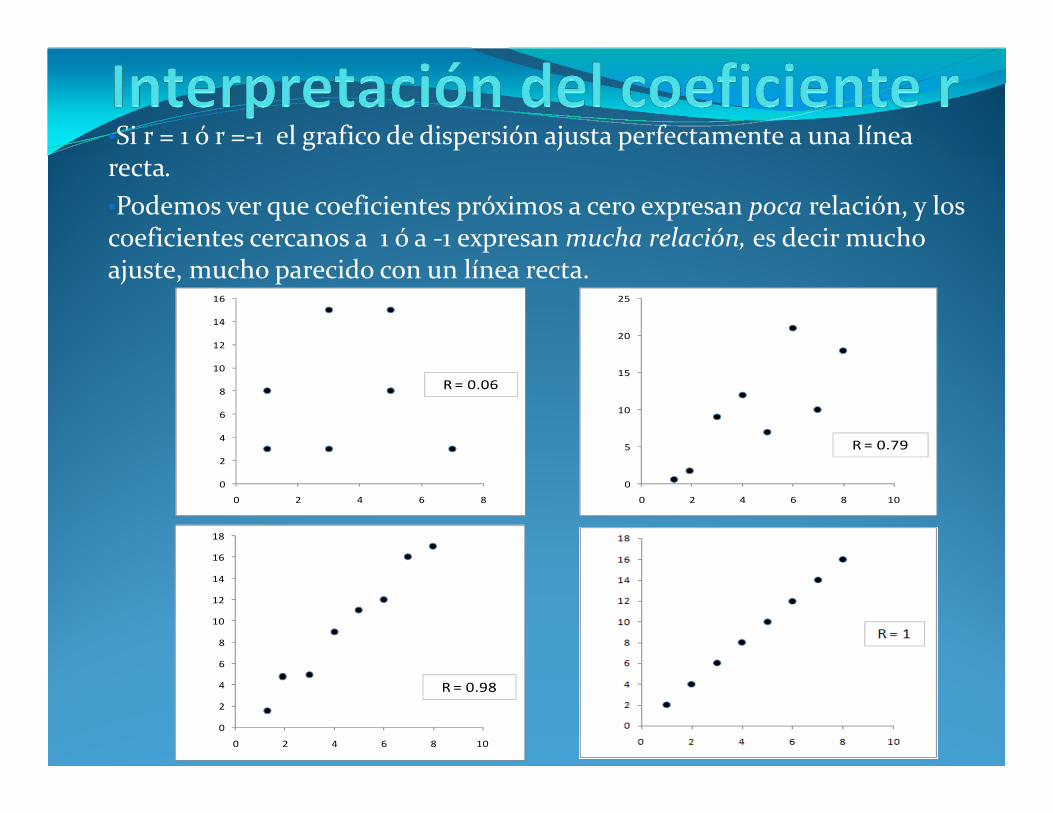
•Si r = 1 ó r =-1 el grafico de dispersión ajusta perfectamente a una línea recta.
•Podemos ver que coeficientes próximos a cero expresan poca relación, y los coeficientes cercanos a 1 ó a -1 expresan mucha relación, es decir mucho ajuste, mucho parecido con un línea recta.
0
2
4
6
8
10
12
14
16
0 2 4 6 8
R = 0.06
0
5
10
15
20
25
0 2 4 6 8 10
R = 0.79
0
2
4
6
8
10
12
14
16
18
0 2 4 6 8 10
R = 0.98
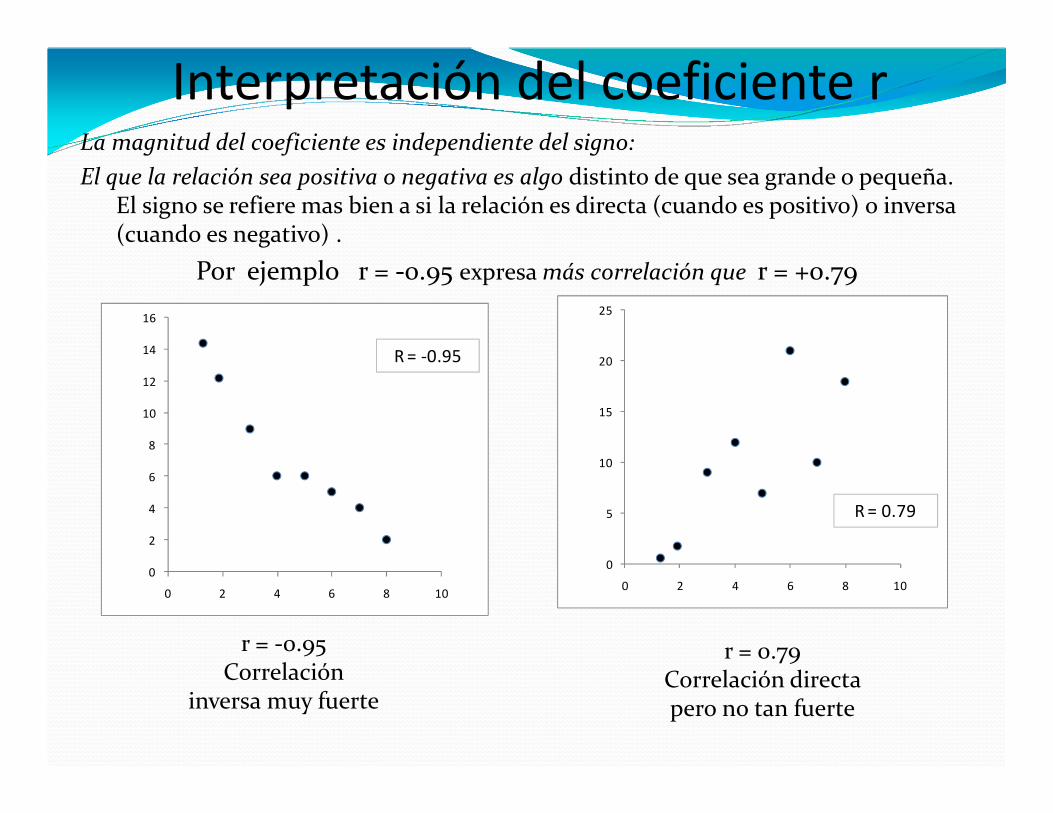
La magnitud del coeficiente es independiente del signo:
El que la relación sea positiva o negativa es algo distinto de que sea grande o pequeña. El signo se refiere mas bien a si la relación es directa (cuando es positivo) o inversa (cuando es negativo) .
Por ejemplo r = -0.95 expresa más correlación que r = +0.79
Interpretación del coeficiente r
0
2
4
6
8
10
12
14
16
0 2 4 6 8 10
R = -0.95
0
5
10
15
20
25
0 2 4 6 8 10
R = 0.79
r = -0.95Correlación
inversa muy fuerte
r = 0.79Correlación directa pero no tan fuerte

La magnitud del coeficiente de correlación es independiente de la pendiente de la recta:
Para toda serie de datos emparejados existe siempre una recta que es la que mejor ajusta a los datos. Sin embargo, dos series de datos pueden tener igual coeficiente de correlación y ajustarse a rectas de diferente pendiente.
Interpretación del coeficiente de correlación r
En últimas, el coeficiente de
correlación r de Pearson nos dice
que tanto se ajustan unos datos
emparejados a una recta, pero no nos
habla sobre la pendiente de ésa
recta.

Existe otro enfoque sobre la correlación lineal que tiene que ver con la varianza decada una de las dos variables implicadas.Cabe preguntarse, ¿Todo cambio en X implica un cambio proporcional en Y? O en
otras palabras, X es el único factor que explica a Y?Por ejemplo cabría preguntarnos si la estatura es el único factor que determina lacapacidad de hacer cestas de baloncesto, o si hay otros factores como elentrenamiento, la habilidad innata, e incluso el estado anímico del jugador.Si la estatura fuera el único factor que determina la habilidad de encestar tendríamosque los datos se ajustan perfectamente a una línea recta.Lo que sería igual a decir que con solo saber la estatura de una persona sabemos ypodemos calcular* sin error su capacidad de encestar.Gráficamente esto sería la línea recta, es decir, a cada valor de estatura le correspondeun solo valor posible de habilidad de encestar.
* Para esto pueden hacerse modelos matemáticos lineales a partir de un conjunto de datos, es lo que en estadística se llama análisis de regresión lineal, metodología que no veremos en este curso.

En este modelo matemático (Ecuación a la derecha del gráfico) la línea representa lo que podríamos predecir acerca del numero de cestas en 20 lanzamientos sabiendo la estatura de una persona.
Numero de cestas = (20*estatura)-29Es decir que si una persona midiera 2.10, según este modelo, esperamos que haga 13 cestas en 20 lanzamientos.
Estatura en
metros
Cestas en 20
lanzamientos
Jugador 1 1,6 3
Jugador 2 1,65 4
Jugador 3 1,7 5
Jugador 4 1,75 6
Jugador 5 1,8 7
Jugador 6 1,85 8
Jugador 7 1,9 9
Jugador 8 1,95 10
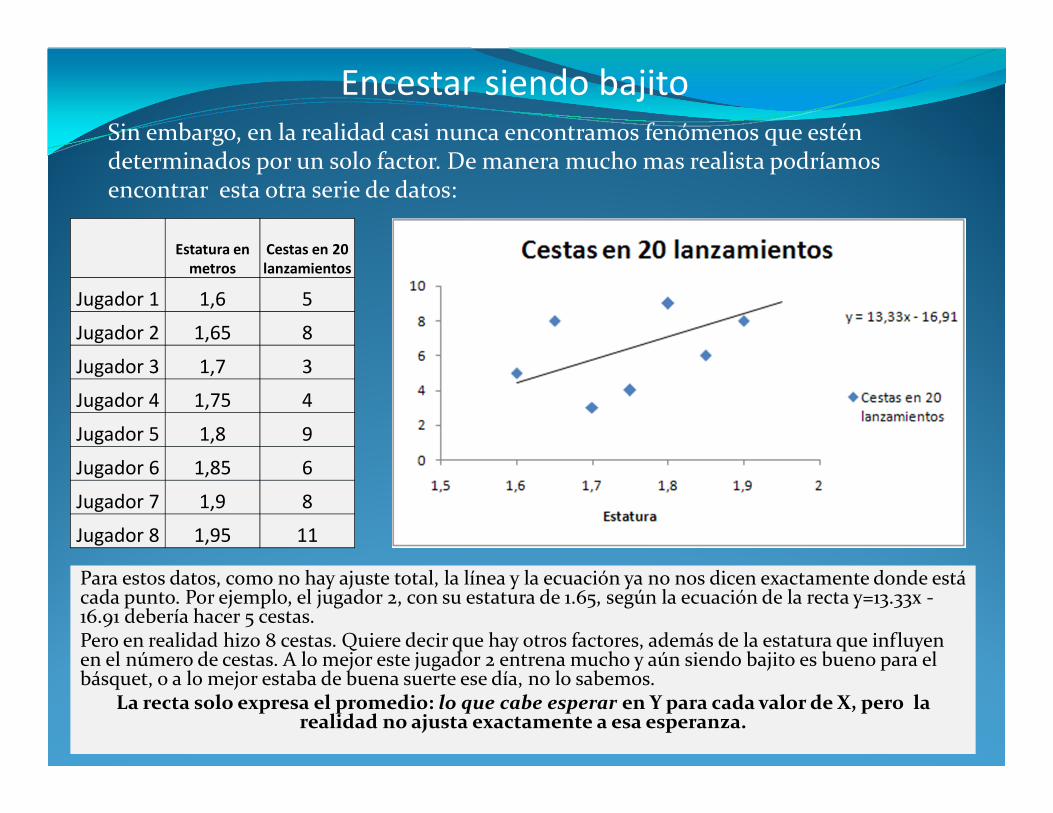
Sin embargo, en la realidad casi nunca encontramos fenómenos que estén determinados por un solo factor. De manera mucho mas realista podríamos encontrar esta otra serie de datos:
Estatura en
metros
Cestas en 20
lanzamientos
Jugador 1 1,6 5
Jugador 2 1,65 8
Jugador 3 1,7 3
Jugador 4 1,75 4
Jugador 5 1,8 9
Jugador 6 1,85 6
Jugador 7 1,9 8
Jugador 8 1,95 11
Para estos datos, como no hay ajuste total, la línea y la ecuación ya no nos dicen exactamente donde está cada punto. Por ejemplo, el jugador 2, con su estatura de 1.65, según la ecuación de la recta y=13.33x -16.91 debería hacer 5 cestas. Pero en realidad hizo 8 cestas. Quiere decir que hay otros factores, además de la estatura que influyen en el número de cestas. A lo mejor este jugador 2 entrena mucho y aún siendo bajito es bueno para el básquet, o a lo mejor estaba de buena suerte ese día, no lo sabemos.
La recta solo expresa el promedio: lo que cabe esperar en Y para cada valor de X, pero la realidad no ajusta exactamente a esa esperanza.
Encestar siendo bajito
Media de X
Media de Y
Distancia en X
Distancia en Y
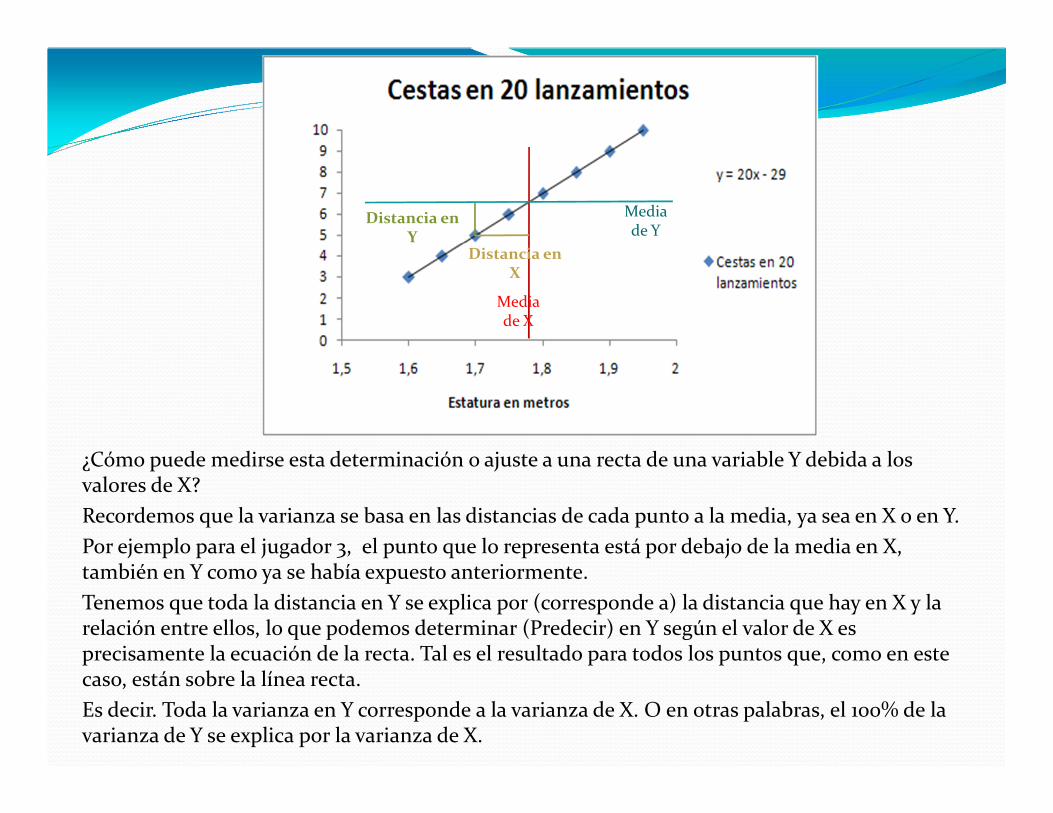
¿Cómo puede medirse esta determinación o ajuste a una recta de una variable Y debida a los valores de X?
Recordemos que la varianza se basa en las distancias de cada punto a la media, ya sea en X o en Y.
Por ejemplo para el jugador 3, el punto que lo representa está por debajo de la media en X, también en Y como ya se había expuesto anteriormente.
Tenemos que toda la distancia en Y se explica por (corresponde a) la distancia que hay en X y la relación entre ellos, lo que podemos determinar (Predecir) en Y según el valor de X es precisamente la ecuación de la recta. Tal es el resultado para todos los puntos que, como en este caso, están sobre la línea recta.
Es decir. Toda la varianza en Y corresponde a la varianza de X. O en otras palabras, el 100% de la varianza de Y se explica por la varianza de X.
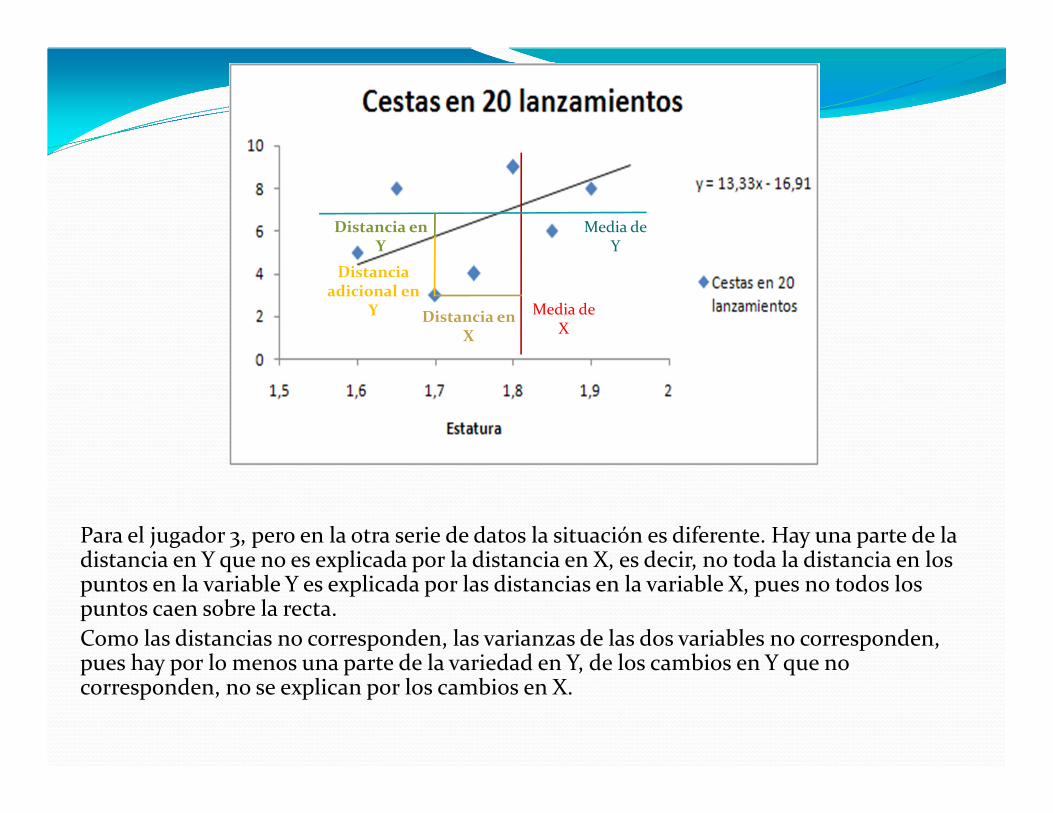
Para el jugador 3, pero en la otra serie de datos la situación es diferente. Hay una parte de la distancia en Y que no es explicada por la distancia en X, es decir, no toda la distancia en los puntos en la variable Y es explicada por las distancias en la variable X, pues no todos los puntos caen sobre la recta. Como las distancias no corresponden, las varianzas de las dos variables no corresponden, pues hay por lo menos una parte de la variedad en Y, de los cambios en Y que no corresponden, no se explican por los cambios en X.
Media de X
Media de Y
Distancia en X
Distancia en Y
Distancia adicional en
Y

Podemos entonces tratar de saber qué porcentaje de los cambios en Y son explicados por los cambios en X. Es decir, averiguar el porcentaje de la habilidad de un jugador para hacer cestas que depende de su estatura.
Se ha demostrado matemáticamente que este porcentaje puede evaluarse y es el resultado de elevar al cuadrado el coeficiente de correlación de Pearson. Siempre nos dará un resultado entre 0 y 1, siendo 1 un 100% de determinación de la variable Y según los valores de X.
Coeficiente de determinación

Teniendo en cuenta lo anterior, tenemos que en la primera serie de datos el 100% de los cambios en la habilidad de
encestar son explicados por la estatura de la persona, pues: r=1 entonces r2=1=100%

Para la segunda serie de datos tenemos que la estatura solo explica el 36% del éxito al encestar en 20 intentos, pues el r2 es de 0.36
Se presenta un resumen de los cálculos:

Bibliografía
� Morales Vallejo, Pedro (2008) Estadística aplicada a las Ciencias Sociales. Madrid: Universidad Pontificia. http://www.upcomillas.es/personal/peter/estadisticabasica/correlacion.pdf
� BEHRENS, JOHN T. (1997). Toward a Theory and Practice of Using Interactive Graphics in Statistics Education. In GARFIEL, J. B. and BURRILL G. (Eds.) Research on the Role of Technology in Teaching and Learning Statistics (pp. 111-121). Voorburg, The Netherlands: Internacional Statistical Institute http://www.stat.auckland.ac.nz/~iase/publications/8/10.Behrens.pdf
� GUILFORD, J. P. AND FRUCHTER, B. (1973). Fundamental Statistics in Psychology and Education. New York: McGraw-Hill (en castellano, Estadística aplicada a la psicología y la educación, 1984, México: McGraw-Hill).