universidad de san buenaventura cali...
TRANSCRIPT

Incidencia de la orientación vocacional media técnica en el desempeño académico en matemáticas
de los estudiantes de colegios públicos y privados en los resultados de las pruebas PISA 2012 en
Colombia
Vanessa Méndez Obando 1106307
Diana M. Buitrago Galindo 1115364
Director o tutor de proyecto:
Edy Lorena Burbano Vallejo
Proyecto de grado para optar por el título de economista
UNIVERSIDAD DE SAN BUENAVENTURA CALI
FACULTAD DE CIENCIAS ECONOMICAS
PROGRAMA DE ECONOMIA
SANTIAGO DE CALI, 2014

Agradecimientos
Agradecemos a todas aquellas personas que han colaborado en la realización del presente
trabajo, a la profesora Edy Lorena Vallejo, directora de este proyecto, por la orientación y
el seguimiento de la misma.
Y finalmente a toda nuestra familia por el apoyo y la paciencia durante este proceso

Contenido
Introducción ............................................................................................................................ 6
Preguntas de investigación ..................................................................................................... 8
Hipótesis ................................................................................................................................. 9
Objetivos ................................................................................................................................. 9
Objetivo general ..................................................................................................................... 9
Objetivos específicos ............................................................................................................ 10
1. Literatura previa ............................................................................................................... 11
1.1 Estado del Arte ............................................................................................................... 11
1.2. Marco teórico ................................................................................................................. 14
1.2.1. Modelo Teórico ......................................................................................................... 14
2 Metodología. Información a utilizar .................................................................................. 16
2.1. Acerca de las pruebas PISA .......................................................................................... 16
2.2 Tipo de Muestreo y su relación con la potencia estadística ........................................... 19
2.3. Tratamiento de los datos ................................................................................................ 21
2.4 Valores plausibles ........................................................................................................... 22
2.5. Estadísticas descriptivas ................................................................................................ 23
2.6. Modelo analítico ............................................................................................................ 27
2.7. Modelo con intercepto aleatorio. ................................................................................... 28
2.7.1. Modelo nulo ................................................................................................................ 28
2.7.2. Modelo nulo con intercepto aleatorio: Componentes de la varianza.......................... 30
2.8. Supuestos del modelo con intercepto y pendientes aleatorias incluyendo covariables de
nivel 1 y 2. ............................................................................................................................ 31
2.8.1. Modelo con intercepto aleatorio y pendientes aleatorias. Procedimientos de
Estimación. ........................................................................................................................... 37
2.9. Mínimos Cuadrados Ordinarios. ................................................................................... 38
2.9.1 Mínimos Cuadrados Generalizados. ............................................................................ 40
2.9.2 Estimación simultanea de los efectos fijos y componentes de la varianza. ................. 41
2.9.3 Máxima verosimilitud: procedimientos de estimación con datos no balanceados. ..... 42
2.9.4 Estimación Máximo Verosímil Restringida ................................................................ 44

2.9.5 Estimación máxima verosimilitud con el algoritmo E-M. ....................................... 46
2.10. Descripción de las variables ........................................................................................ 49
3. Estimaciones ..................................................................................................................... 54
3.1. Estimación modelo nulo ................................................................................................ 54
3.2. Reportando resultados del análisis multinivel. .............................................................. 56
4 Conclusiones ...................................................................................................................... 59
Referencias Bibliográficas .................................................................................................... 64
Anexos .................................................................................................................................. 67

Resumen
El siguiente trabajo realiza un análisis sobre la incidencia de la educación media técnica
ofrecida por los colegios públicos y privado en el desempeño académico de los estudiantes
de Colombia con los resultados de las pruebas internacionales PISA en matemáticas para el
año 2012 desarrollado por la OECD, utilizando el análisis del modelo multinivel. Como
resultado se obtiene que la orientación vocacional técnica incide significativamente de
manera negativa en el rendimiento académico del estudiante en el área de matemáticas,
reflejando que aquellos estudiantes dentro de las escuelas públicas y privadas con
orientación académica presentan un mejor desempeño en las pruebas.
Palabras claves: Calidad educativa, función de producción educativa, orientación
vocacional, tipo de escuelas.
Abstract
The following thesis analyzes the incidence of technical education offered by public and
private schools in the academic performance of students in Colombia with the results of the
PISA international tests in mathematics for 2012 developed by the OECD, using multilevel
model analysis. Results obtained indicated that technical vocational orientation
significantly affects negatively on the student's academic performance in the area of
mathematics, showing that students in public and private schools have better academic
orientation test performance.
Key words: educational quality, School performance, educational production function,
vocational orientation.

Introducción
La educación es una de las principales variables para la formación de capital humano; así
las personas con mejor educación pueden presentar altos ingresos lo que a su vez se ve
reflejado en un mayor crecimiento económico. En Colombia la educación juega un papel
importante para la búsqueda de desarrollo económico y social del país, además, de ser el
principal factor de competitividad.
Pese a la importancia de la educación para la incorporación al mercado laboral, hay una
participación del Estado en la Formación para el trabajo (Fpt) por dos fundamentos
económicos: Fallas en el mercado laboral y consideraciones redistributivas (Saavedra y
Medina 2012). Como es bien sabido el Estado interviene ante este tipo de fallos, por
ejemplo, en la escasa formación en competencias cuando se deja en manos de la iniciativa
privada, produciendo un resultado socialmente ineficiente1.
Para la definición de la Fpt se utiliza la consagrada en el decreto 2020 de 2006 el cual
define la Fpt como “el proceso educativo, formativo, organizado y sistemático, mediante el
cual las personas adquieren y desarrollan a lo largo de su vida competencias laborales,
especificas o transversales, relacionadas con uno o varios campos ocupacionales referidos a
la Clasificación Nacional de Ocupaciones, que le permiten ejercer una actividad productiva
como empleado o emprendedor de forma individual o colectiva”.
1 Toda vez que una empresa no puede garantizar la permanencia de sus empleados después de capacitarlos y puesto que la capacitación trae consigo un aumento en la productividad laboral que se considera la misma en todas las empresas, no es rentable ante esta incertidumbre que las empresas tengas incentivos para ofrecer capacitación en Fpt (Becker, 1994)

El Estado colombiano interviene de tres formas en la Fpt. La primera mediante la
educación media vocacional técnica ofrecida por instituciones públicas, la segunda es la
formación profesional técnica y tecnológica y la tercera es la formación complementaria.
Ahora, no solo las instituciones públicas pueden ofrecer formación para el trabajo dentro de
sus currículos, pues también se reconocen los programas que desarrollan las empresas
privadas. Sin embargo, la orientación ofrecida por las escuelas públicas y privadas es
diferente, la primera ofrece saberes para el trabajo en áreas industrial, comercial,
agropecuaria o pedagógica, mientras que la segunda ofrece saberes en las áreas de
contabilidad, administración de negocios, comunicaciones y tecnologías informáticas.
La orientación vocacional media técnica tiene un efecto diferenciado por tipo de escuelas,
siendo el 25% de las escuelas públicas un enfoque industrial y el 64% comercial.
Entretanto, solo el 4% de las escuelas privadas con esta orientación tienen un enfoque
industrial y el 92% tienen enfoque comercial. (Bettinger et al, 2010)
De acuerdo con lo anterior, surge un interrogante que es acerca de la incidencia de la
orientación vocacional técnica en el rendimiento académico, dado que este tipo de
orientación tiene asignado al menos el 25 % del tiempo total de clase a actividades de esta
índole, por lo tanto se intuye que hay rendimiento diferentes según el tipo de orientación
vocacional, dado que tienen menos contenido en horas de clase de cursos como ciencias,
matemáticas y lenguaje, esto sin contar con el tipo de pasantías por tipo de escuela y su
interrelación con las actividades académicas. (Saavedra y Medina, 2012)
Estos autores encuentran que en términos de desempeño académico medidos por los
puntajes de las pruebas de Estado, hay poca diferencia, en promedio, entre los graduados de

las escuelas con orientación media técnica respecto aquellas de media académica. Los
autores llegan a esta conclusión sin discriminar por tipo de escuela, los autores en su
investigación no discriminan por tipo de escuela, además debe tenerse en cuenta que no
utilizan la información de PISA para llegar a sus conclusiones, sino que utilizan las bases
de datos de ICFES, Sena y otras instituciones que prestan el servicio de formación para el
trabajo.
Se constituye entonces la hipótesis a probar mediante la estimación de un modelo
multinivel, en que la orientación vocacional media técnica por tipo de escuela, incide en el
rendimiento académico en matemáticas, generando así resultados diferentes en sus logros
académicos.
Así, el estudio abordado presenta una literatura escasa en Colombia, dado que la primera
evaluación realizada por PISA fue en el año 2006, y a partir de este, se han realizado
trabajos sobre los factores que inciden en el rendimiento académico, sin embargo este es el
primer trabajo que propone la variable orientación vocacional por tipo de escuela.
La estructura como está planteado este trabajo es la siguiente: en el capítulo 1 se expone la
literatura previa. El capítulo 2 se encuentra la metodología. Capítulo 3 las estimaciones y el
capítulo 4 las conclusiones.
Preguntas de investigación
¿Cuál fue la incidencia de la educación con orientación vocacional técnica en el desempeño
académico de los estudiantes de colegios privados y públicos en Colombia en los resultados
en el área de matemáticas de las pruebas PISA para el año 2012?

¿Cómo afecta el nivel socioeconómico como fuente de inequidad al desempeño académico
de los estudiantes? ¿Existen variables que capturen la dimensión de equidad y que sean
estadísticamente significativas el momento de explicar el desempeño académico de los
estudiantes?
¿Una mayor disponibilidad de bienes económicos, educativos y culturales afecta el
desempeño de los estudiantes en la prueba PISA 2012?
Hipótesis
Existe un efecto diferencial de la orientación vocacional sobre el desempeño académico que
exhibe dinámicas distintas dependiendo de si la escuela es pública o privada.
El desempeño académico de los estudiantes en la prueba PISA 2012 esta relacionado con
una inequidad debida al estatus socioeconómico.
La combinación de diversos bienes en el hogar y la familia está asociada con el desempeño
de los estudiantes en la prueba de matemáticas.
Hay variables de la escuela que pueden producir diferencias estadísticamente
significativas en el desempeño en matemáticas de los estudiantes.
Objetivos
Objetivo general
Analizar el efecto diferencial de la orientación vocacional sobre el desempeño académico
de los estudiantes de colegios públicos y privados en el resultado en el área de matemáticas
de las pruebas PISA para el año 2012.

Objetivos específicos
• Estimar un modelo nulo que permita la justificación de modelos multinivel
para la estimación de una función de producción educativa.
• Evaluar mediante un modelo multinivel los factores que incurrieron en el
desempeño académico en matemáticas de las pruebas PISA 2012.
• Justificar la existencia de un desempeño diferenciado en matemáticas por
tipo de orientación vocacional según tipo de escuela, sea pública o privada.
• Identificar las principales variables del estudiante a nivel socioeconómico,
de dotación de recursos educativos, estructura familiar y variables de la escuela
tales como dotación de recursos y capital humano (docentes cualificados), que
incidan en el desempeño del estudiante
• Generar modelos alternativos con el fin de identificar el modelo más cercano
al modelo poblacional.

1. Literatura previa
1.1 Estado del Arte
El interés por realizar estudios acerca del rendimiento escolar de los estudiantes y la
eficiencia del sistema educativo es un tema nuevo, desde mediados de los años 60 y a partir
de los trabajos de Carroll (1963) y del informe Coleman (1966) nació una corriente de la
Economía de la Educación, donde se estudia la función de producción educativa, que
resulta siendo apropiado para la aplicación de una política educativa.
El informe Coleman, es considerado ya un clásico en la literatura sobre producción
educativa, intentaba determinar qué factores, escolares y no escolares, estaban relacionados
con los resultados obtenido por los estudiantes norteamericanos. A través de información
de más de medio millón de alumnos, Coleman et al. (1966), analizaron que inputs de los
que entran en el proceso educativo (variables independientes) eran los más importantes en
la determinación del logro académico de los estudiantes (variable dependiente).
Hanushek (1989) concluyó que no existe una relación robusta en entre los recursos
escolares y los resultados de los estudiantes, teniendo un control de las características de los
alumnos como el nivel socioeconómico, un mayor gasto por parte de las escuelas no se
traduce necesariamente en un mayor rendimiento escolar.
En España, López et al. (2009) los autores relacionan el rendimiento obtenido por los
alumnos españoles en la evaluación PISA 2006 con variables del entorno del estudiante
tales como: sexo, si el estudiantes en inmigrante, índice de recursos educativos del hogar,

nivel socioeconómico, entre otros, para la escuela se utilizó: tamaño de la clase, índice de
calidad de los recursos de la escuela, ratio profesor alumno.
El análisis se ha llevado a cabo mediante la técnica de análisis multinivel, con los
resultados obtenidos se evidenció una relación entre las variables de recursos, tanto de
alumno (por ejemplo recursos educativos, posesiones culturales en casa) como de centro
(titularidad o número de ordenadores por alumno, entre otras) con el rendimiento
académico.
En los últimos años la tendencia por el tema de la producción educativa va en aumento, por
ejemplo, en América Latina se han presentado numerosos trabajos que tienen como
objetivo comprobar si existe relación entre recursos a la educación y mejoras en los
resultados de los estudiantes.
En México, el Instituto Nacional para la Evaluación de la Educación (2008) analiza
mediante modelos multinivel los resultados que obtuvo en las pruebas PISA 2006 en el área
de ciencias, siendo esta la variable dependiente. Entre las variables relevantes que se usan
en el análisis tomadas directamente de la base de datos de PISA se encuentra el género,
nivel socioeconómico, expectativas educativas, recursos educativos disponibles en el hogar
y estructura familiar para el estudiante. Las variables consideradas para la escuela fueron el
nivel socioeconómico, calidad de los recursos y nivel del profesorado entre otras. Como
conclusiones se llegó que las mujeres obtienen menor puntaje que los hombres, los recursos
educativos del hogar juegan un papel muy importante y el estudio sugiere que el estudiante
y su familia dentro de su alcance económico tengan acceso a recursos educativos para
lograr beneficios en este tipo de desempeño académico. Desde el punto de vista de la

escuela, el estudio concluye que la intervención de los maestros y directivos son influyentes
de manera positiva en los resultados de la prueba en ciencias tanto como la dotación de
ordenadores para un uso exclusivo de tipo académico
En Costa Rica, Fernández y Del Valle (2013) se evidencia que los estudiantes que asisten a
colegios privados obtienen mejores puntajes que aquellos de colegios públicos. Sin
embargo, mediante una función de producción educativa, se demuestra que esta brecha no
es solo por tipo de administración del centro educacional, sino más bien a los factores
familiares y las características personales de los estudiantes, especialmente al año escolar
que cursa el joven en el momento de realizar la prueba PISA.
En Colombia, Piñeros y Rodríguez (1998) estudian los componentes escolares y no
escolares que afectan el desempeño académico de los estudiantes de secundaria para el año
1997 con los resultados de las pruebas ICFES, utilizando el método de análisis multinivel,
donde se encontró que los componentes no escolares como el nivel socioeconómico tiene
efectos positivos sobre el rendimiento académico, mientras que las variables escolares
como las escuelas tienen un efecto pequeño y significativo sobre el rendimiento.
Casas, Gamboa y Piñeros (2002) buscan entender como la importancia de la escuela en la
predicción del logro del estudiante en el año 2000 se vio afectada por el cambio de la
conceptualización del examen del ICFES, apoyándose en el análisis multinivel,
concluyendo que con esta nueva forma del examen el efecto escuela queda limitado en la
sección del núcleo común.
Martínez (2012), analizo el efecto de pares sobre el rendimiento académico para Colombia
en los resultado de las pruebas PISA 2006, utilizando el método de la técnica multinivel

utilizando algunas variables como: sexo, grado, nivel socioeconómico, recursos del hogar,
tipo de escuela, dotación escolar, entre otros, concluyó que hay una evidencia del efecto par
ya que un aumento en el nivel socioeconómico de los compañeros de clase muestra un
aumento general de los puntajes de las pruebas académicas.
Gonzales (2014) analizó la incidencia de la dotación escolar en el rendimiento académico
en lectura de los alumnos en secundaria, medido a través de las pruebas PISA 2009
haciendo uso del análisis del modelo multinivel con una muestra de los estudiantes de siete
países. Algunas de las variables que el autor utilizo para el modelo econométrico son: sexo,
tamaño de clase, tipo de escuela, escases de material en la biblioteca, entre otros. En su
trabajo se encontró que existen dotaciones significativas asociadas tanto al entorno escolar
(calidad de escuelas) como al entorno familiar (background familiar) en los logros
académicos, entre países pueden llegar a explicarse debido a las diferencias observables en
las dotaciones.
1.2. Marco teórico
1.2.1. Modelo Teórico
Teoría del capital humano y economía de la educación
La teoría del capital humano, destaca la inversión en las personas como un factor
fundamental para el crecimiento y desarrollo económico de los países, al tener en cuenta
que las personas con mayor educación podrá tener una mejor remuneración y aumentar su
calidad de vida. Diferentes autores han dado relevancia a la teoría del capital humano:
Solow (1950), Schultz (1961), Becker (1964), Mincer (1974).

A principios de los años 60 los economistas Denison, Schultz y Becker dieron un nuevo
sentido a la teoría sobre las inversiones de capital humano. En 1964 Gary Becker publica su
obra el Capital Humano, donde afirma mediante un modelo neoclásico que el
comportamiento racional de los individuos los lleva a invertir en educación hasta que la
tasa de retorno sea como mínimo el tipo interés de mercado.
En la década siguiente se derivaron críticas a la teoría del capital humano por parte de
autores de las corrientes credencialistas, institucionalistas y radicales que generaron un
cambio a la teoría.
Función de producción educativa
Conocer cuál es la productividad relativa de cada uno de los recursos empleados en
educación con relación a los costos de producción permite lograr una mayor eficiencia en
el empleo de dichos recursos. La importancia de la función de producción educativa radica
en identificar la relación entre las entradas y los resultados del proceso educativo toda vez
que podría pronosticarse que sucedería con el desempeño de los estudiantes si los recursos
variaran (Martin et al 2009).
La función de producción al relacionar estadísticamente los recursos y los resultados toma
la siguiente especificación básica (Hanushek, 1989; Levin 1996):
𝒀𝒊𝒋 = 𝒇(𝑿𝒊𝒋,𝑾𝒊𝒋)
𝑿𝒊𝒋=características a nivel del estudiante (incluyen las características familiares)
𝑾𝒊𝒋= recursos y características de la escuela
Siendo el subíndice i correspondiente al estudiante y j a la escuela

El trabajo pionero de Coleman (1966) estableció las relaciones entre el rendimiento escolar
y las variables del estudiante y de la escuela mediante un análisis de regresión. Si bien a
este trabajo se le critica lo pertinente a la técnica, ejerció gran influencia en el área
encontrando, entre otros resultados, que las variables asociadas a la escuela no tienen gran
impacto en el desempeño de los estudiantes.
La anterior conclusión vuelve a ser corroborada por Hanushek (1989) donde analizó la
relación entre los gastos básicos en educación y el rendimiento de los estudiantes.
Específicamente el autor encuentra que la ratio profesor-estudiantes y la formación de la
planta docente no ejercen un impacto significativo en el rendimiento estudiantil.
2 Metodología. Información a utilizar
2.1. Acerca de las pruebas PISA
El propósito principal de PISA es evaluar en qué medida los estudiantes de 15 años sin
distinguir el grado y la modalidad de enseñanza en la cual se encuentren, han adquirido
conocimientos y habilidades esenciales para insertarse plenamente en la sociedad.
Con el fin de objetivo de que los resultados sean comparables entre países, el estudio PISA
evalúa poblaciones semejantes aun cuando la estructura de los sistemas educativos de los
países no sea comparable internacionalmente. Es por esta razón que para validar las
comparaciones entre estudiantes de diferentes países, que PISA, opto por definir la
población objetivo con referencia a una edad determinada, en este caso, 15 años.

Si bien la evaluación se centra en tres competencias: matemáticas, lectura y ciencias
(incluye biología, geología, química y tecnología), el objetivo del presente estudio está
puesto en las puntuaciones que obtienen los alumnos en la prueba de matemáticas,
utilizando los valores plausibles (que constituyen las variables dependientes) e incluyendo
datos socioeconómicos, demográficos y académicos a nivel del país sin discriminar por
ciudades.
Desde el 2000, la prueba se realiza cada tres años, esto permite conocer la evolución de los
resultados en el tiempo. Cada aplicación tiene énfasis en una de las tres áreas: 2000 en
lectura, 2003 en matemáticas, 2006 en ciencias, 2009 nuevamente en lectura y 2012 en
matemáticas. Para la prueba de 2012, que es de lo que se ocupa la presente investigación,
la muestra en Colombia se compuso de 9.073 estudiantes de 352 instituciones educativas
(públicas y privadas, urbanas y rurales) en representación de 560 mil estudiantes.
Asimismo, se contó con sobremuestras para Bogotá, Cali, Manizales y Medellín.2
Dado que el interés de la presente investigación es identificar los determinantes del
desempeño académico, se postula un modelo lineal jerárquico multinivel, con el cual se
determina la participación de las variables independientes tanto a nivel del estudiante como
de la escuela, sobre el desempeño de los estudiantes en la prueba de matemáticas.
La base de datos disponible para todos los investigadores es suministrada por PISA está
disponible un año después de realizado el estudio. Para este caso que se tomó el año más
reciente del estudio que fue 2012, la base de datos estuvo disponible en 2013. Es de anotar
que el consorcio PISA coloca a disposición en su sitio web, los códigos para que la base de
2En el trabajo se planteó que no se discriminaría por ciudades el desempeño del estudiante, razón por la cual
no se procedió a incorporar esta variable.

datos sea leída en formato SAS o SPSS. En este caso la información fue procesada en SPSS
aunque inicialmente también se utilizó el programa HLM para la estimación del modelo
nulo.
Dado que una de las preguntas de investigación es indagar como la orientación vocacional
afecta el desempeño académico por tipo de escuela, debe tenerse que la orientación
vocacional es una decisión que el estudiante toma a partir del grado decimo de educación.
En este orden de ideas se escoge una muestra que incluya escuelas en las cuales estén
presentes las dos orientaciones vocacionales, tanto la técnica como la académica en ambos
tipos de estructuras educativas como lo son las escuelas públicas y las escuelas privadas.
Dicha muestra conto con 264 escuelas y 5021 estudiantes de grados decimo y once tanto de
escuelas públicas como privadas.
Inicialmente se comienza con la estimación del modelo de dos niveles incondicional, esto
es, sin variables explicativas, esto con el objetivo de identificar la forma en que la varianza
del desempeño académico en Matemáticas se distribuyen entre los dos niveles citados:
estudiante y escuela.
Para la presente investigación se definen como variables del estudiante se define a un
conjunto de variables propias del alumno o de su entorno que inciden en los resultados del
desempeño académico de la prueba PISA. En este punto se plantea una pregunta de
investigación.
Dado que uno de los intereses del presente estudio es identificar como variables de equidad
socioeconómica afectan el desempeño académico, se incluye como variable explicativa un

índice socioeconómico que construye PISA y que denomina ESCS. Adicional a este índice
se incluyeron otros índices que forman parte del mismo índice ESCS.
Se estimaron modelos por separado para confirmarla interdependencia entre los distintos
índices que componen el índice socioeconómico ESCS con este justificando de paso el ,
simplificar el modelo más parsimonioso utilizando ESCS (adicional con una variable
riqueza) junto con otras variables que reflejan recursos educacionales y clima en el hogar3.
En el nivel 2 se incluyeron variables relacionadas con los recursos de la escuela, tanto de
infraestructura, como organización y recursos humanos. En el primer caso se toma como
variable a la proporción de computadoras para uso académico (IRATCOMP) y el número
de computadoras conectadas a internet (COMPUWEB). Otra variable a nivel de la escuela
son la proporción de profesores certificados (PROPCERT)
2.2 Tipo de Muestreo y su relación con la potencia estadística
Las encuestas en educación y especialmente las de tipo internacional como lo es en este
caso PISA no suelen seleccionar los estudiantes mediante un muestreo aleatorio simple. En
vez de ello un diseño muestral por etapas es usado donde las escuelas son seleccionadas
usualmente utilizando entidades subnacionales como regiones, ciudades o estratos, y
dentro de estas clasificaciones (de tercer nivel) se seleccionan las escuelas y dentro de cada
escuela los estudiantes. (PISA, 2009)4
3Para evitar incluir variables altamente correlacionadas entre sí en el mismo modelo, se dejaron índices que componen el índice ESCS como CULTPOSS y HOMEPOS el nivel educativo de los padres PARED. 4 Se revisa el technical report de las pruebas del año 2009, dado que no se ha publicado para el año 2012

Debe tenerse en cuenta entonces la primera etapa de estratificación (regiones, ciudades o
estratos) toda vez que las personas tienden a vivir en áreas de acuerdo a sus recursos
económicos. Es intuitivo que los jóvenes usualmente estudiaran en escuelas que están cerca
de sus hogares aumentando la probabilidad de que los estudiantes asistan a una escuela con
similares antecedentes económicos y sociales que los de su familia. El diseño estratificado
en este caso es explicito por PISA en su reporte técnico, el cual tiene consecuencias sobre
las estimaciones de los parámetros. Siendo las variable de respuesta homogénea dentro de
los estratos, las estimaciones provenientes de la muestra serán más precisas que si se
hubieran extraído de un muestreo aleatorio simple (MAS).
Estratificar explícita o implícitamente entonces es una de las soluciones al problema del
diseño muestral por clúster toda vez que este diseño garantiza que diferentes tipos de
personas o unidades sean incluidas en la muestra garantizando representatividad de la
muestra. Interesa conocer si la muestra con la que se estiman los modelos, permite
estimaciones insesgadas de los parámetros del modelo.
En su trabajo Mass y Hox (2005) muestran que aunque los estimadores de los efectos fijos
y de los componentes de la varianza son insesgados (bajo condiciones que se consideran
apropiadas para el número de grupos y tamaños dentro del grupo), los errores estándar de
los coeficientes de nivel 2 tienden a estar sesgados hacia abajo cuando se consideran menos
de 30 unidades de segundo nivel5. En consonancia con los anteriores trabajos, estos autores
encuentran que para la estimación de los efectos fijos de primer nivel son más importantes
los tamaños muéstrales a nivel de grupo que los tamaños muéstrales a nivel individual. En
5Así las cosas, la potencia (1-probabilidad de no rechazar H0 cuando esta es falsa o 1- error tipo II) para detectar efectos de segundo nivel es mas sensible al número de grupos, en oposición al número de unidades de primer nivel dentro de los grupos (Stapleton y Tomas, 2008).

este caso con 264 unidades de nivel 2, la propiedad de la insesgadez de las estimaciones se
mantiene.
2.3. Tratamiento de los datos
Para Colombia el consorcio PISA muestreo un total de 352 escuelas con un total de 9.073
estudiantes. Sobre esta primera muestra se escogieron las escuelas que ofrecían tanto la
orientación académica como la orientación técnica, pues se postula que esta variable es de
primer nivel. Con el objetivo entonces de que el estudiante pueda elegir el tipo de
orientación vocacional, se utilizan 264 escuelas que ofrecen ambos tipos de orientaciones,
vocacional y académica con un total de 5021 estudiantes. La información utilizada para el
presente estudio como bien se mencionó se deriva del Estudio PISA 2012, cuya
información está disponible en la red para los estudiosos del tema. PISA, ofrece unos
programas de lectura para la base de datos (denominados también Sintax) tanto para el
software SPSS y SAS. Dada la disponibilidad de este último se optó por procesar la base de
datos en SPSS.
Debe anotarse que el Consorcio PISA realiza una serie de pruebas a la información de los
estudiantes para garantizar su consistencia y confiabilidad. Los datos de los estudiantes se
sometieron a controles adicionales después de la recolección de variables. Comprobaciones
de coherencia combinan la información de dos o más preguntas para detectar datos
sospechosos o atípicos (OECD, 2012 PISA 2009 Technical Report). En este orden de ideas
la información recolectada por PISA es depurada para evitar la presencia de datos atípicos,
lo cual es hecho para cada país. Específicamente en lo referente a los “outliers”, PISA, las
respuestas numéricas de los cuestionarios en las escuelas fueron estandarizadas, y los

valores “outliers” (± 3 desviaciones estándar) fueron retornados a los centros nacionales de
procesamiento para su depuración.
Sin la presencia de datos atípicos, se procedió a escoger una submuestra con la información
escuelas con orientación vocacional y académica, procediendo a conformar el conjunto de
variables que fueron elegidas para construir el modelo. Es de anotar que las variables
dicotómicas fueron obtenidas recodificando las variables originales (que en el caso de
variables categóricas toman solo dos valores, 1 y 2)
2.4 Valores plausibles6
Las puntuaciones de los estudiantes en PISA, vienen dadas mediante cinco valores
plausibles7. Los valores plausibles no son las puntuaciones reales de las pruebas sino que se
trata de valores imputados a partir de técnicas estadísticas y, por tanto, recogen los valores
que podrían ser razonablemente asignados a cada individuo aunque sujetos a una cierta
aleatoriedad.
Las evaluaciones internacionales a gran escala como lo es la prueba PISA y TIMSS suele
administrar lo que se denomina una matriz de muestreo, en la cual diferentes test cortos son
administrados a los estudiantes en un tiempo limitado. Esto se hace con el fin de ofrecer
6Por razones de limitación del software SPSS no se estima con valores plausibles, solo el software HLM
permite la estimación con estos valores, no obstante dada la limitación de la versión libre de permitir pocas
variables en la estimación se optó por el desarrollo del modelo en un programa alternativo atendiendo la
sugerencia de los evaluadores iniciales. 7 Los valores plausibles fueron desarrollados para el análisis de 1983-84 NAEP (Evaluación Nacional de
Progreso Educativo) por Mislevy, Johnson Y Muraki (1990), basado en el trabajo de Rubin (1978) sobre
múltiples imputaciones. Esta metodología fue utilizada en todos los estudios posteriores de NAEP, TIMSS y
ahora PISA.

información comparable sobre las habilidades del estudiante y conocimiento en las áreas
como matemáticas, lenguaje y ciencias.
Dado que los estudiantes no completan los diferentes test (no obstante cada uno termina
una parte de su evaluación), luego el desempeño en las distintas pruebas no puede ser
obtenido a través de los tradicionales pruebas si no que se basa en valores plausibles. Los
valores plausibles son valores imputados que se asemejan a las puntuaciones de las pruebas
individuales y tienen aproximadamente la misma distribución del rasgo latente que se está
midiendo.
Desarrollados como una aproximación computacional para obtener estimaciones
consistentes de características de la población, estos permiten acercase de manera confiable
a la verdadera distribución de los desempeños. En el caso de PISA y TIMSS, un conjunto
de cinco valores plausibles debe ser usado para generar estimaciones de los estadísticos de
interés.
Utilizados para obtener una estimación precisa de la capacidad del estudiante, los valores
plausibles en si no constituyen los puntajes de las pruebas de manera que deben ser
combinados apropiadamente para ser utilizados en análisis multinivel.
2.5. Estadísticas descriptivas
En este apartado se presentan las estadísticas descriptivas referentes a las variables propias
del estudiante y la escuela

En el cuadro No.1 se evidencia el puntaje promedio según el género, donde se observa que
en promedio un estudiante hombre tiene mejor desempeño con 390 puntos respecto a una
estudiante mujer, 364 puntos.
Cuadro No 1. Puntaje promedio según genero
Fuente: PISA, OECD, 2012
De acuerdo a la organización para la cooperación y desarrollo económico OCED, en el año
2012 El puntaje promedio de la prueba de matemáticas es menor para las escuelas públicas
que en la escuelas privadas. Esta regularidad empírica justifica la inclusión del tipo de
escuela como determinante fundamental del desempeño académico (Ver Cuadro No. 2)
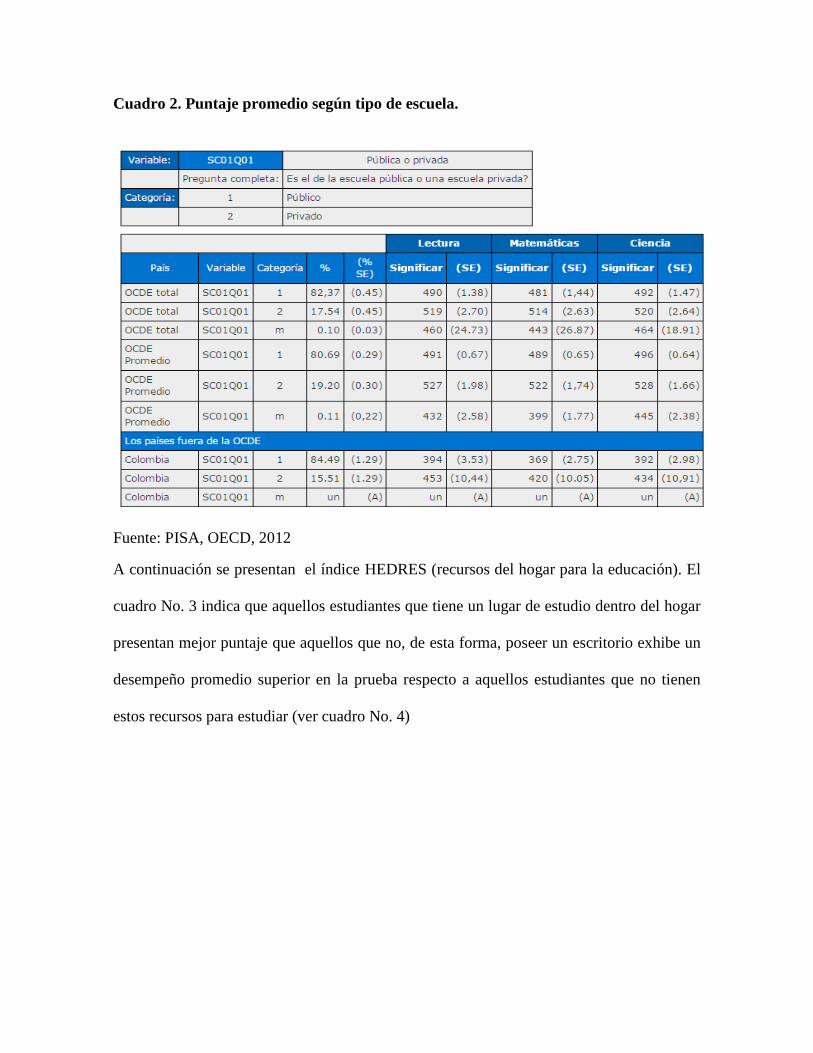
Cuadro 2. Puntaje promedio según tipo de escuela.
Fuente: PISA, OECD, 2012
A continuación se presentan el índice HEDRES (recursos del hogar para la educación). El
cuadro No. 3 indica que aquellos estudiantes que tiene un lugar de estudio dentro del hogar
presentan mejor puntaje que aquellos que no, de esta forma, poseer un escritorio exhibe un
desempeño promedio superior en la prueba respecto a aquellos estudiantes que no tienen
estos recursos para estudiar (ver cuadro No. 4)

Cuadro 3. Puntaje promedio según la presencia de un lugar de estudio dentro de la
casa.
Cuadro 4. Escritorio para estudiar.
.

2.6. Modelo analítico
En ciencias sociales a menudo los problemas de investigación están inmersos en estructuras
jerárquicas en las cuales las unidades se agrupan en diferentes niveles o etapas. Tal como lo
anota Goldstein (2002) la existencia de estructuras jerárquicas en los datos no es accidental
y por lo tanto no puede ignorarse. El término de datos multinivel es típicamente usado
para describir este tipo de estructura en la cual las unidades de análisis de nivel 1 son
consideradas un subconjunto de unidades de nivel 28.
En este caso el puntaje de la prueba PISA está en el nivel 1 (nivel más bajo)
correspondiente a los estudiantes y las variables explicativas se encuentran en diferentes
niveles de la estructura jerárquica9. La inmediata consecuencia es que las hipótesis de las
relaciones entre las variables se definen en diferentes niveles de la estructura jerárquica.
A nivel conceptual el modelo multinivel puede ser visto como un sistema jerárquico de
ecuaciones, el cual permite obtener estimaciones estadísticamente más eficientes en
relación al análisis tradicional que ignora esta estructura jerárquica. (Hox, 2010).
En este trabajo se modela la función de producción educativa a partir de la base de datos
PISA 2012 desarrollado por la OECD, utilizando modelos multinivel cuya variable a
explicar es el rendimiento en matemáticas de dicha prueba, postulando como determinante
fundamental la orientación vocacional técnica por tipo de escuela.
8Variables del estudiante y de la escuela, con la inmediata consecuencia de que las hipótesis sobre las
relaciones entre las variables se definen en diferentes niveles de la estructura jerárquica. 9Un modelo de regresión lineal que no tenga en cuenta la estructura jerárquica de datos, no diferenciara entre
la varianza que es debida del estudiante y la debida a la escuela, en contraste con el modelo multinivel el cual
logra diferenciar que parte del logro es explicado por el estudiante y que parte por la escuela.

Los modelos multinivel constituyen la metodología de análisis más adecuada para tratar
datos “jerarquizados” o “anidados” (por ejemplo, los estudiantes en aulas, o las aulas en
escuelas), lo que la convierte en una estrategia imprescindible para la investigación
educativa de carácter cuantitativo. Así, además de mejorar la calidad de los resultados,
posibilita realizar análisis novedosos, tales como estimar la aportación de cada nivel de
análisis (la del efecto del aula o la escuela) o las interacciones entre variables de distintos
niveles. De esta forma se está en mejores condiciones de realizar estudios sobre factores
asociados, sobre valor agregado o sobre equidad educativa, entre otros (Murillo, 2008).
2.7. Modelo con intercepto aleatorio.
2.7.1. Modelo nulo
La estimación del modelo nulo con intercepto aleatorio como primer paso, constituye una
justificación de la utilización de modelos multinivel donde parte de la varianza de la
variable dependiente es explicada por las variables de segundo nivel10.Siendo Yij el
desempeño en matemáticas del estudiante i en la escuela j. El hecho de que la varianza del
puntaje pueda descomponerse en dos niveles, y que esta descomposición sea significativa
estadísticamente, permite la modelación multinivel con la inclusión de variables de nivel 2.
Tomando
10Se estima el siguiente modelo utilizando el software HLM 7.0 el cual tiene en cuenta los valores plausibles.

Modelo nivel 1:
Yij = β0j + eij [1]
Modelo nivel 2:
β0j = β00 + u0j
Como se observa el modelo de nivel 2 constituye un modelo para el intercepto aleatorio.
Este intercepto que consiste en la media del puntaje de matemáticas para la escuela que es
explicada por la media de todas las escuelas y un error aleatorio.
La estimación de los modelos nivel 1 y nivel 2, utiliza información de los estudiantes
ubicados en el nivel ISCED 3, el cual hace parte de la variable ISCED donde clasifica los
programas de educación en cinco niveles, siendo el de nivel 3, correspondiente a secundaria
superior, esto es grados decimo y once. Esta clasificación tiene su origen en la Clasificación
Internacional Standard de educación (ISCED por su sigla en inglés) adoptada por la
conferencia general de la UNESCO.
Utilizar este índice permite alcanzar uno de los objetivos del estudio PISA, el cual es
comparar los desempeños educativos de estudiantes de distintos países.
ISCED permite hacer comparables la estructura de sistemas educativos los cuales varían
ampliamente entre los países, lo cual es requisito para la producción de estadísticas
educativas comparables internacionalmente (OECD, 1999).

2.7.2. Modelo nulo con intercepto aleatorio: Componentes de la
varianza
Partiendo de la ecuación [1] se observa que cada puntaje individual difiere de la media del
puntaje total β00por un residuo total ξij. En este caso la descomposición de la comienza
con el cálculo de la varianza de la variable dependiente:
Var(Yij) = E {(Yij − E(Yij))2
}
Dados los supuestos acerca de los dos términos de error se tiene:
E(Yij) = E(β00) + E(ξij)
E(u0j + eij) = 0
E(Yij) = β00
Var(Yij) = E {(Yij − β00)2} = E {(ξij)
2} = E {(u0j + eij)
2}
Var(Yij) = E(u0j2) + 2cov(u0j, eij) + E(eij
2)
Var(Yij) = σu02 + σe
2
Con el fin de estimar el peso de los diferentes niveles en el análisis se considera la
participación de cada componente de la varianza en el total de la varianzaσe2 + σu0
2 . El
porcentaje de la variación observada en la variable dependiente atribuible a características
de la escuela puede calcularse como el cociente entre σu02 y la varianza total:
ρ = σu0
2
σu02 + σe
2
Referida como correlación “dentro del nivel 2”, o “correlación intraclase” es siempre
positiva y contenida en el intervalo 0-1. Este coeficiente ρ es similar al coeficiente de

bondad de ajuste R2 en un modelo de regresión lineal toda vez que expresa la proporción de
la variabilidad total que es explicada por las variables de segundo nivel11. De enorme
utilidad, ρ permite vislumbrar la importancia de los diferentes niveles en el análisis al
considerar la participación de cada componente de la varianza en el total de la
varianzaσe2 + σu0
2 .
Por otra parte la ratio de σe2 sobre el total de la varianza indica la importancia del nivel 1
dentro del análisis. El porcentaje de la varianza atribuible a las características del
estudiantes puede calcularse como:
1 − ρ = 1 −σu0
2
σu02 + σe
2=
σe2
σu02 + σe
2
2.8. Supuestos del modelo con intercepto y pendientes aleatorias
incluyendo covariables de nivel 1 y 2.
La especificación del modelo multinivel está incompleto sin la especificación de los
supuestos. Si bien el modelo que se estima en una sección posterior tiene varias variables
de nivel 1 y de nivel 2, se partirá de un modelo con una sola variable en cada nivel con
variación aleatoria tanto del intercepto como de la pendiente. Partiendo del siguiente
modelo de dos niveles con parámetros aleatorios y covariables de nivel 1 y 2.
Nivel 1:
Yij = β0j + β1jXij + eij
Nivel 2
β0j = β00 + β01Wj + u0j
11Si se encontrara una significativa varianza para u0j es deseable incluir variables macro o de nivel 2 para
tener en cuenta parte de esta variación.

β1j = β10 + β11Wj + u1j
Abordando los supuestos de los errores de primer nivel, eij se asumen sigue una
distribución normal con media 0 y varianza σe2.
E (eij) = 0 var(eij) = σe2
Entre tanto los errores a nivel de la escuela uj son asumidos con media 0 y matriz de
varianzas-covarianzasΣ. Puesto que los niveles de error del nivel escuelas son las
“desviaciones de las escuelas” esto es equivalente a asumir que los coeficientes βj siguen
una distribución normal multivariada (Joop j Hox, 2010). Resumiendo:
E(u0j) = E(u1j)=0
var(u0j) = σu02
var(u1j) = σu12
Cov(u0j, u1j)=σu01
Este último supuesto significa que los errores de nivel 2 sobre pueden estar correlacionados
(Steenbergen y Jones, 2002). Los anteriores cuatro supuestos implican que los errores de
nivel 2 están distribuidos normal bivariado con media cero y matriz de varianzas y
covarianzas:
Σ = [σu0
2 σu01
σu01 σu12 ]
Retomando el modelo con pendiente e intercepto aleatorios, incluyendo covariables de
nivel 1 y 2 o de la escuela (Wj):
Yij = β0j + β1jXij + eij
β0j = β00 + β01Wj + u0j

β1j = β10 + β11Wj + u1j
Yij = [β00 + β10Xij + β01Wj + β11WjXij] + εij
εij = [u0j+u1jXij + eij]
Se analizan ahora los supuestos del término de error compuestoεij:
var[εij]=E [(u0j+u1jXij + eij)2]
=E[u0j2 ] + Xij
2E[u1j2 ] + E[eij
2] + 2XijE[u0ju1j] + 2E[u0jeij] + 2XijE[u1jeij]
=σu02 + Xij
2σu12 + σe
2 + 2Xijσu01
La covarianza será nula siempre y cuando u0j y u1j sean iguales a cero, lo que llevaría a la
conclusion de que la variable Wj da cuenta perfecta del movimiento de los movimientos
del intercepto y la pendiente de las unidades de nivel 1 a través de las unidades de nivel 2.
Es en este punto donde los modelos multinivel son necesarios dado que los datos agrupados
violan el supuesto de independencia de las observaciones (Maas y Hox, 2004).Puede
observarse entonces que los modelos multinivel se adaptan mejor a estructuras de datos
jerárquicas en los cuales la varianza no es constante en contraste con el tradicional análisis
OLS el cual asume varianza constante.
Es claro que aun siendo los errores de nivel 1 homocedásticos, la varianza de εij no es
constante al ser función de las variables de nivel 1. La única manera en que el termino de
error εij sea homocedastico es que el error u1j sea cero lo cual significaría que la
variableWj es suficiente para modelar las diferencias en la pendiente de Xij a través de las
unidades de nivel 2 (Steenbergen y Jones, 2002).
El segundo supuesto que se viola en los modelos multinivel es el de no autocorrelación para
los términos de perturbación de nivel 1,εij anidados dentro de las mismas unidades de nivel
2:

cov(εij, εkj) = E[(u0j+u1jXij + eij)(u0j+u1jXkj + ekj)]
=E[u0j2 ] + XijE[u0ju1j] + E[eiju0j]+ XkjE[u1ju0j] + XijXkjE[u1ju1j] + XijE[u1jekj] +
E[eiju0j] + XkjE[eiju1j] + E[eijekj]
=σu02 + Xijσu01 + Xkjσu01 + XijXkjσu1
2
La covarianza será nula siempre y cuando u0j y u1j sean iguales a cero, lo que llevaría a la
conclusión de que la variable Wj da cuenta perfecta del movimiento de los movimientos
del intercepto y la pendiente de las unidades de nivel 1 a través de las unidades de nivel 2.
Es en este punto donde los modelos multinivel son necesarios dado que los datos agrupados
violan el supuesto de independencia de las observaciones (Maas y Hox, 2004).Puede
observarse entonces que los modelos multinivel se adaptan mejor a estructuras de datos
jerárquicas en los cuales la varianza no es constante en contraste con el tradicional análisis
OLS el cual asume varianza constante.
De otro lado, se asume término de error de nivel 1 y las variables independientes. Es decir
las características no observables de los estudiantes incluidos en el término de error no
deben estar correlacionadas con las características observables de los estudiantes:
cov(Xij, eij)=0
En la misma vía las variables independientes del nivel 2 no están correlacionadas con el
término de error del nivel 2, esto es, las características no observables de la escuela
incluidas en el término de error no deben estar correlacionadas con las características
observables X̅.j y Wj (𝑐𝑎𝑟𝑎𝑐𝑡𝑒𝑟𝑖𝑠𝑡𝑖𝑐𝑎𝑠 𝑑𝑒 𝑙𝑎 𝑒𝑠𝑐𝑢𝑒𝑙𝑎):
cov(Wj, u0j)= cov(Wj, u1j)=0
Complementan los anteriores supuestos el que las variables independientes en cada nivel no
están correlacionadas con los términos de error del otro nivel, esto es, cualquier

característica observable de la escuela no debe estar correlacionada con características no
observables del estudiante.
cov(Wj, eij)=0 cov(X̅.j, eij)=0
Asimismo cualquier característica observable del estudiante no debe estar relacionada con
las características no observables de la escuela.
cov(Xij, u0j)= cov(Xij, u1j)=0
La violación de los anteriores supuestos se traduce en endogeneidad, la cual surge cuando
existen covariables no observables (e incluidas en el término de error) que afectan la
respuesta y están correlacionadas con las covariables incluidas en el modelo. En este caso
donde se trabajan con modelos multinivel de efectos aleatorios con un término de error en
cada nivel, el problema de endogeneidad puede ocurrir en cualquiera de los niveles.
cov(Xij, u0j) ≠ 0, cov(Xij, u1j) ≠0
No controlar apropiadamente por los determinantes a nivel del grupo que están
correlacionados con las variables individuales, se traducirá en un sesgo para los
coeficientes de nivel 1 al contener el verdadero efecto causal a nivel individual, adicional a
una parte del efecto a nivel del grupo.
Dado que la endogeneidad de nivel 2 se produce básicamente por la omisión de variables
relevantes a nivel del clúster, la estrategia a seguir es eliminar el sesgo tanto como sea
posible introduciendo variables contextuales de la escuela, cuya omisión se sospecha son la
principal fuente de endogeneidad. (Rangvid, 2008).

En particular el nivel socioeconómico y cultural de la familia se cree condiciona la
elección de los padres de los “pares académicos” de los estudiantes. En este orden de ideas
algunas omitir efectos contextuales de la escuela como por ejemplo el “efecto par”, puede
generar un sesgo por endogeneidad (Hanchane et al, 2010). La solución en este caso es
incluir la media del nivel socioeconómico de la escuela lo cual no solo corrige la
endogeneidad de nivel 2 sino que también de paso incluye la modelación del “efecto par”
dentro del modelo12.
Concluyendo, los supuestos subyacentes en el modelo multinivel son similares a los de un
modelo de regresión que ignora estructuras jerárquicas: normalidad y distribución normal
de los errores. Es conocido en la econometría tradicional, que la violación del supuesto de
homocedasticidad (en este caso en el nivel 1) afecta la eficiencia de los estimadores de
nivel 1 (Snijders y Bosker, 2012).
Debe anotarse que aunque en modelos multinivel, el supuesto de homocedasticidad se
refiere a todos los niveles, se hace énfasis en la homocedasticidad de nivel 1 dado el interés
en obtener estimadores eficientes de los efectos fijos. Constituyendo una medida de
incorrecta especificación del modelo, la heterocedasticidad surge cuando variables de nivel
1 siendo omitidas, están distribuidas con varianza no constante a través de las unidades de
nivel 213 (Raudenbush y Brick, 1999)14.
12 En el modelo se incluye la media del efecto par, denominada MEANESCS (media del índice socioeconómico ESCS) la cual permite corregir problemas de endogeneidad de nivel 2. Es de anotar que tanto el programa SPSS como STATA, no permite en las opciones para estimación, probar cada uno de los supuestos del modelo. Solo un software especializado como HLM (Hierarchical Lineal Model) contempla entre sus opciones de estimación dichas pruebas. 13Siento esta la causa más probable de Heterocedasticidad, otra forma de incorrecta especificación seria
considerar un efecto fijo cuando en realidad constituye un efecto aleatorio

Respecto al supuesto de normalidad en los errores de nivel 1, una primera aproximación
sería la de tomar un el grafico para estos residuo de la densidad de kernel y compararlo con
una función de densidad normal15. Desafortunadamente en este programa no es posible
acceder a los residuos de nivel 1.
La prueba de normalidad de los residuos de nivel 2 utiliza dos variables; de un lado la
distancia de Mahalanobis (mdist) como una medida de la distancia del estimador empírico
de Bayes de los efectos cuyos valores ajustados son dados por el modelo multinivel
estimado. La segunda variable utilizada son los valores teóricos de una χ2 con v grados de
libertad igual al número de factores aleatorios. Una aproximación a un test de normalidad
de nivel 2 lo constituye un diagrama de dispersión entre las dos variables. De nuevo, esta
prueba no está disponible en este programa solo estando disponible en el software HLM 7.0
2.8.1. Modelo con intercepto aleatorio y pendientes aleatorias.
Procedimientos de Estimación.
Se deja el modelo nulo con solo intercepto aleatorio que permite la justificación de utilizar
modelos multinivel a modelos tanto con intercepto aleatorio como con pendientes
aleatorias. La especificación de este tipo de modelos es:
Yij = β0j + β1jXij + eij
β0j = β00 + β01Wj + u0j
β1j = β10 + β11Wj + u1j
14 Desafortunadamente el software SPSS no tiene como probar estos supuestos. Solo el programa HLM 7.0
(Hierarquichal Linear Model) está habilitado para hacerlo.
15 HLM 7.0 permite entre sus opciones guardar los residuos de nivel 1 y nivel 2. Esto facilita realizar test
sobre estos términos de error.

Con Xij se denota a las variables de nivel 1(variables del estudiante) y con Wj variables de
la escuela. La inclusión de covariables de nivel 2 se justifica si en la estimación del modelo
la descomposición de la varianza es significativa en los dos niveles. A continuación se
establecen los diversos procedimientos de estimación para modelos con pendientes e
intercepto aleatorio.
2.9. Mínimos Cuadrados Ordinarios.
Cuando los componentes de la varianza son tratadas como conocidas durante la
estimación de los efectos fijos o cuando estos componentes son estimados simultáneamente
con los efectos fijos (este último enfoque es el más utilizado en la mayoría de los estudios).
En el caso de varianzas conocidas dos métodos son utilizados por excelencia: Mínimos
cuadrados Ordinarios y Mínimos Cuadrados Generalizado.
Este procedimiento es apropiado cuando los errores son asumidos como independientes y
homocedasticos, es decir la varianza de los errores es σ2. Para ilustrar el procedimiento se
utilizara un modelo con parámetros aleatorios sin covariables de nivel 2, solo incluyendo de
nivel 1.
Nivel 1:
Yij = β0j + β1jXij + eij
Nivel 2
β0j = β00 + β01Wj + u0j
β1j = β10 + β11Wj + u1j

Utilizando notación matricial para expresar las ecuaciones de nivel 1 y nivel 2:
y = Xβ + e
β = Wγ + u
En este caso el vector de coeficientes de regresión β se obtiene minimizando la función:
∑ei2 = eé = (y − Xβ)´(y − Xβ)
N
i=1
Donde εj ∼ N(σ2[Xj´Xj]
−1)
Estrictamente hablando el supuesto de normalidad no es necesario en este punto, solo es
necesario para determinar la distribución de los estimadores (Swaminathan y Rogers, 2008)
Combinando las ecuaciones:β = Wγ + u y β̂j = βj + εjse obtiene:
𝛽𝑗 = 𝑊𝑗𝛾 + 𝑢𝑗 + 𝜀𝑗
Denotando como T a la matriz de varianzas y covarianzas de uj y a la matriz de varianzas y
covarianzas de εj como σ2[Xj´Xj]
−1 y asumiendo εjy uj independientes, se tiene que:
var(β̂j) = var(uj + εj) = T + σ2[Xj´Xj]
−1= Δj
El modelo de dos niveles dado en la ecuación es análogo a un modelo lineal múltiple con
múltiples variables dependientes, siendo los coeficientes de nivel 1 las variables
dependientes. Si las mismas variables explicativas son usadas para β0, β1 y β2 y el mismo
número de observaciones son usadas a través de las unidades de nivel 1 (es decir
σ2[Xj´Xj]
−1 es la misma a través de las unidades de nivel 1) luego las matrices de varianza y
covarianza de los coeficientes βj son las mismas a través de las unidades de nivel 1y

tenemos en el nivel 2 el clásico modelo de regresión multivariado (Swaminathan y Rogers,
2008). En este escenario los mínimos cuadrados ordinarios (MCO) es un procedimiento
apropiado. Al nivel 2 el criterio para minimizar de MCO es:
∑(𝛽𝑗 − 𝑊𝑗𝛾)´(𝛽𝑗 − 𝑊𝑗𝛾)
𝐽
𝑗=1
Del proceso de minimización anterior se obtiene el estimador de los efectos fijos γ :
γ̂ = (∑Wj´Wj
J
j=1
)
−1
(∑Wj´β̂j
J
j=1
)
2.9.1 Mínimos Cuadrados Generalizados. Asumiendo que Δj es la misma a través de los clúster de igual tamaño se puede utilizar
MCO. Si los clúster tienen distinto número de observaciones, luego la varianza Δj variara
a través de los distintos cluster. En este escenario, se requiere de un método de estimación
que tenga en cuenta la heterogeneidad de Δj, siendo este método el de Minimos Cuadrados
Generalizados (GLS) el cual da más peso a aquellas observaciones con menor varianza.
Existen otras situaciones en las cuales el estimador GLS también es útil. Si en el segundo
nivel se utilizan distintas variables explicativas para distintos coeficientes de regresión del
nivel 1. Este modelo fue introducido por Zellner con su modelo denominado Ecuaciones
Aparentemente no Relacionadas (SUR por las iníciales en inglés). En estos modelos las
matrices de varianzas-covarianzas son heterogéneas siendo los estimadores GLS más
apropiados que los de OLS. (Swaminathan y Rogers, 2008).

En el modelo de un solo nivel y = Xβ + e, se tiene que:
var(e) = Σ
Donde Σ ≠ σ2I, luego la función a ser minimizada por GLS es:
φ = (y − Xβ)´Σ−1(y − Xβ)
Resolviendo para β El estimador GLS para los coeficientes de nivel 1 es:
β = (X´Σ−1X)−1(X´Σ−1X)
Aplicando al modelo multinivel y dado que Δj no es igual a través de todos los cluster, la
función objetivo para minimizar es:
∑(βj − Wjγ)´Δj−1(βj − Wjγ)
J
j=1
El estimador GLS para los parámetros de segundo nivel γ es:
γ̂ = (∑Wj´Δj−1Wj
J
j=1
)
−1
(∑Wj´Δj−1β̂j
J
j=1
)
2.9.2 Estimación simultanea de los efectos fijos y componentes de la
varianza. Los procedimientos anteriores están basados sobre el supuesto de que los componentes de
la varianza son conocidos o que pueden ser estimados separadamente antes de la
estimación de los efectos fijos. Lo usual es que los componentes de la varianza no sean
conocidos no obstante una situación que permite la utilización de GLS es que se trabaje con
datos balanceados de tal suerte que permita la estimación separada de los efectos fijos y de

los componentes de la varianza16. Dado que en el estudio PISA los datos no son
balanceados se requieren de métodos más complejos que estimen simultáneamente los
efectos fijos y los componentes de la varianza de manera simultánea. A continuación se
exponen estos métodos.
2.9.3 Máxima verosimilitud: procedimientos de estimación con
datos no balanceados17. Asumiendo distribuciones normales para los errores tanto del nivel y como del nivel 2, el
método MV obtiene los estimadores de los efectos fijos y los componentes de la varianza
que maximizan la función de verosimilitud18. Como es ya conocido MV tiene propiedades
deseables como lo es la de estimadores consistentes y asintóticamente eficientes cuando el
supuesto de normalidad se mantiene. No obstante cuando el supuesto de normalidad sea
violado, el estimador de los efectos fijos es consistente (Goldstein, 2002).
Siguiendo el desarrollo de Swaminathan H. y Rogers J. (2008) se retoma el modelo de dos
niveles con covariables de nivel 1 y nivel 2 y parámetros aleatorios (intercepto y pendientes
incluidos en el vector (β):
Modelo de nivel 1
yj = Xjβ + ej
Modelo de nivel 2
β = Wj𝛾 + uj
16 Datos balanceados se refiere a que todas las unidades de nivel 2 en este caso escuelas tengan la misma
cantidad de observaciones de nivel 1, en este caso estudiantes. 17 Datos balanceados se refieren a cuando las unidades de nivel 2 (escuela) tienen las mismas unidades de
nivel 1 (estudiantes). En este caso tenemos datos no balanceados pues las escuelas no tienen todos los
mismos números de estudiantes. 18 Estos supuestos serán testeados posteriormente cuando se realicen los test sobre los supuestos sobre los
términos de error y correcta especificación del modelo.

Combinando las dos ecuaciones y obteniendo el modelo mixto:
yj = XjWjγ + Xjuj + ej
Siendo Aj = XjWj, se tiene que:
yj = XjWjγ + Xjuj + ej = γAj + Xjuj + ej
var(yj) = var(Xjuj + ej)=XjTXj′ + σe
2I ≡ Ψj
Bajo el supuesto de que uj y ej tienen distribución normal multivariada:
yj~N(Ajγ,Ψj)
La función de verosimilitud es:
L(y: γ, σe2, T) = ∏
1
|Ψj|exp {−
1
2(yj − Ajγ)
′Ψj
−1(yj − Ajγ) }
J
j=1
Tomando el logaritmo de la función:
logL(y: γ, σe2, T) = ∑ log(|Ψj|)
Jj=1 −
1
2−
1
2∑ (yj − Ajγ)
,Jj=1 Ψj
−1(yj − Ajγ) 13.36
Las estimaciones de máxima verosimilitud son obtenidas resolviendo las siguientes
ecuaciones19:
∂
∂θlogL(y: γ, T, σ2) =
[
∂
∂γlogL(y: γ, T, σ2)
∂
∂σ2logL(y: γ, T, σ2)
∂
∂TlogL(y: γ, T, σ2)
]
19Denotando a 𝜃 como el vector de parámetros

Existen dos metodologías de estimación por máxima verosimilitud que son comúnmente
usadas en modelos multinivel lineales. El primero es Full Máxima Verosimilitud (FML) el
cual incluye los coeficientes de regresión y los componentes de la varianza en la función
de verosimilitud. El segundo método de estimación es el de Máxima Verosimilitud
Restringida (REML), el cual solo incluye en la función mencionada a los componentes de
la varianza; ambas metodologías tienen como supuesto que los residuos en el nivel más
bajo se distribuyen normal con media 0 y varianza 𝜎𝑒2.
2.9.4 Estimación Máximo Verosímil Restringida Uno de los problemas con la estimación de máxima verosimilitud es que las estimaciones
de los componentes de la varianza son sesgados. La cuestión radica en la función de
verosimilitud involucra el vector de parámetros fijos los cuales deben ser estimados junto
los componentes de la varianza lo cual resulta en perdida de grados de libertad que surge en
la estimación de los efectos fijos. Esta cuestión no es tenida en cuenta en la estimación de
los componentes de la varianza. Partiendo del modelo mixto de dos niveles:
y = XWγ + Xu + e
Este puede transformarse de manera que el valor esperado de y sea cero de manera que el
vector de efectos fijos, γ, no aparezca en la función de verosimilitud. En esta via, Patterson
y Thompson (1971) sugiere una metodología llamada “Error Constrast” el cual remueve los
efectos fijos. Esta metodología consiste de un conjunto de combinaciones lineales de la
variable dependiente tal que el valor esperado de la variable transformada es cero.
Dado que E(y) = XWγ = Aγ siendo XW = A, se sigue que E(C´y) = 0 escogiendo una
matriz C que sea ortogonal a A es decir tal que C´A=0. La estimación basada en la función

de máxima verosimilitud que utiliza la anterior transformación se denomina Restringida
Maxima Verosimilitud (REML, por sus iniciales en inglés). Para la presente investigación
se utiliza el método de máxima verosimilitud junto con el algoritmo E-M.
La diferencia entre ambos métodos es que FML trata las estimaciones de los coeficientes
como cantidades conocidas cuando los componentes de la varianza son estimados, mientras
que REML trata las estimaciones de los parámetros como si tuvieran cierto grado de
incertidumbre. En este orden de ideas REML es más realista y debería en teoría guiar a
mejores estimaciones especialmente cuando el número de grupos es pequeño (Raudenbush
y Bryk, 2002)20. En la presente investigación es el método REML el utilizado
En una situación ideal para la estimación de un modelo multinivel como lo es un diseño
balanceado de los datos (igual número de unidades de nivel 1 por unidades de nivel 2), las
ecuaciones de máxima verosimilitud dadas en la ecuación, pueden ser resueltas
analíticamente en la forma cerrada, es decir una ecuación por separado puede ser resuelta.
Cuando no se tienen datos balanceados (como en este caso en el cual las escuelas tienen
distinto número de estudiantes), las tres ecuaciones (componentes de la varianza y los
efectos fijos) deben ser resueltas simultáneamente y dado que se trata de ecuaciones no
lineales, una solución explicita no es posible. En este caso una solución iterativa es
alcanzada mediante el empleo de métodos numéricos, entre cuyas alternativas se
encuentran el algoritmo de Newton-Raphson, el algoritmo de puntuación de Fisher, los
mínimos cuadrados generalizados factibles (IGLS) y el algoritmo de maximización E-M; se
expondrá brevemente este último dado que está programado en la rutina de estimación del
software utilizado, SPSS (al igual que en STATA y HLM).
20La estimación por Full Máxima Verosimilitud solo está presente en el programa HLM, en SPSS solo está
disponible los métodos de máxima verosimilitud y restringida máxima verosimilitud.

2.9.5 Estimación máxima verosimilitud con el algoritmo E-M.
Siguiendo el desarrollo Swaminathan H. y Rogers J. (2008) se expone este método para un
modelo nulo de dos niveles sin covariables.
Yij = β00 + u0j + eij
Con:
var(u0j) = σu0 2 y var(eij) = σe
2
Si u0j es observado luego Yij∗ = (Yij − u0j) y los parámetros de interés pueden ser
estimados. Puesto que los u0j no son observados, el conjunto de datos Yij son
denominados datos incompletos y losu0j considerados “missing”. En situaciones de datos
faltantes, se procede a derivar un procedimiento que reemplace los valores faltantes por
cantidades observables en orden a estimar los parámetros.
Son los autores Dempster, Laird y Rubin (1977) quienes desarrollan un algoritmo para
estimar parámetros en modelos complejos. Demuestran que sustituir la expectativas
condicionadas de los estadísticos para los valores “missing” en la función de máxima
verosimilitud, maximiza la función al momento de obtener las estimaciones.
Requiriendo la esperanza condicional de u0j, se condicionara sobre Y̅j dado que es
equivalente condicionar sobre Yij toda vez que el modelo puede ser expresado como21:
Y̅j = β00 + u0j + e̅j
21 Por motivos de simplicidad se utilizara el modelo nulo para esta exposición.

La esperanza condicional de u0j dado Y̅j esta dado por la usual expresión:
E(u0j|Y̅j) = E(u0j) +cov(u0j, Y̅j)
var(Y̅j) + [Y̅j − E(Y̅j)]
De la ecuación y dado el supuesto deE(u0j) = 0, se tiene que
E(Y̅j) = β00y var(Y̅j) = σu02 +
σu02
nj
Calculando la covarianza:
cov(u0j, Y̅j)= cov(u0j, u0j + e̅j)= cov(u0j, u0j) + cov(u0j, e̅j) = σu02
E(u0j|Y̅j) = E(u0j) + σu02 [σu0
2 +σu0
2
nj]
−1
+ [Y̅j − E(Y̅j)] = λj(Y̅j − β00)
Siendo:
λj =σu0
2
σu02 + σe
2 nj⁄
El algoritmo E-M requiere de valores iníciales para los parámetros que en este caso se les
denota con un subíndice adicional, β000, σu00 2 y σe0
2 , los cuales son obtenidos mediante un
análisis ANOVA. Obtenidos estos valores iníciales se calcula λj el cual entra en el calculo
de uj∗ = λj0(Y̅j − β000). Este valor uj
∗ es usado después para calcular en la estimación de
los efectos fijos.
Para el cálculo de los componentes de la varianza σu02 y σe
2 se requiere la esperanza
condicional de uj2, E(u0j|Y̅j)
2la cual se obtiene a continuación:
Var(u0j|Y̅j) ≡ E{[u0j − E(u0j)]|Y̅j}2
= E{[u0j − u0j∗ ]|Y̅j}
2

E{[u0j − u0j∗ ]|Y̅j}
2= E{[u0j
2 − 2u0ju0j∗ + u0j
∗ 2]|Y̅j}
Dónde:
E(u0j2|Y̅j) = uj
∗ + E(uj2) = uj
∗2 + vj
vj = var(uj) [1 −cov(u0j, y̅j)
2
var(u0j)var(Y̅j)] = σu0
2 [1 −(σu0
2 )2
σu02 (σu0
2 + σe2 nj⁄ )
] = σu02 (1 − λj)
β̂00 =∑ ∑ (Yij − uj
∗)nj
i=1Jj=1
N
σu02 =
∑ (u0j∗ 2
+ vj)Jj=1
J
σe2 =
∑ ∑ [(Yij − β̂00 − uj∗) + vj]
nj
i=1Jj=1
N
Resumiendo el procedimiento que sigue le algoritmo E-M, en un primer paso se obtienen
los valores iníciales para β00, λj, σe2 y σu0
2 . Una vez calculados en un segundo paso se
calculan las esperanzas condicionalesE(u0j|Y̅j), E(u0j2|Y̅j)y E {(Yij − β̂00 − uj)
2| Y̅j}. Por
último se calculan las estimaciones ML de los parámetros mediante la sustitución de las
expectativas en las ecuaciones Los pasos 2 y 3 se repiten hasta que se alcance la
convergencia con un criterio preestablecido que para el software HLM es 0.00001
(Raudenbush, S and Brick, A, Y. D Cheong and R. Congdon, 2004).
Aunque el algoritmo E-M es de fácil implementación, se argumenta que su convergencia es
lenta frente a lo cual el software HLM 7.0 hace uso del acelerador Aitkin, mejorándola
velocidad de convergencia al nivel del algoritmo de Newton Raphson22
22 Nótese que la elección del modelo se realiza independiente de la elección del método y este a su vez se elige independiente de la elección del algoritmo, y la elección del algoritmo de la elección del Software (Raudenbush et al 2002)

2.10. Descripción de las variables
Variables del estudiante
En este apartado se definen un conjunto de variables propias del estudiante o de su entorno
en el hogar que inciden en los resultados del desempeño en matemáticas (PV1MATH) de la
prueba PISA.
Postulando como primera variable explicativa la orientación vocacional23 como uno de los
principales determinantes del desempeño académico a nivel de escuelas, se incluye como
variable de primer nivel dentro del modelo jerárquico. La construcción de esta variable
dicotómica se basa en la variable ISCED, la cual realiza una clasificación del nivel ISCED
3 en dos categorías: tipo 1 o general (académica) y tipo 3 o vocacional (técnica).
La variable orientación vocacional de naturaleza dicotómica se define de la siguiente
manera:
𝑉𝑂𝐶𝐴𝐶𝐼𝑂𝑁𝐴𝐿𝑖𝑗 = {1 𝑂𝑟𝑖𝑒𝑛𝑡𝑎𝑐𝑖𝑜𝑛 𝑇𝑒𝑐𝑛𝑖𝑐𝑎0 𝑂𝑟𝑖𝑒𝑛𝑡𝑎𝑐𝑖𝑜𝑛 𝐴𝑐𝑎𝑑𝑒𝑚𝑖𝑐𝑎
Según ISCED, la orientación general no está diseñada explícitamente para preparar a los
estudiantes para una ocupación o para entrar a posteriores programas técnicos. Entretanto,
la educación vocacional prepara a los estudiantes para entrar directamente sin
entrenamiento adicional a ocupaciones específicas (OECD, 1999).
Se postulan como covariables adicionales de nivel 1, el género y el índice socioeconómico
ESCS24. Se sostiene que el rendimiento del estudiante tiene una relación directa con los
23 La orientación vocacional técnica en Colombia, tal como la mide PISA no discrimina si la orientación
técnica es con énfasis industrial o comercial. Este aspecto se constata la examinar el informe de PISA. Ningún
país cuenta con esta información, pues la información no se discrimina. 24Esta variable tiene en cuenta cinco índices. Ver anexo 2.1

recursos económicos y posición social de la familia. Debe anotarse que PISA construye tres
índices que son usados para medir el ambiente en el hogar. El primero de ellos es un índice
de recursos del hogar para la educación (HEDRES)25; derivado del cuestionario de los
estudiantes, refleja la disponibilidad del número de diccionarios, un lugar adecuado para
estudiar, un escritorio de estudio, libros de texto, diccionario y calculadoras, referente a
estos índices se espera una relación directa donde se demuestra que entre más recursos en el
hogar tenga el estudiante mejor será el puntaje obtenido en la prueba.
El segundo índice se refiere a la inclusión de actividades culturales (CULTPOSS)26 que
indica cuan a menudo los estudiantes visitan un museo o una galería de arte en el año
precedente a la prueba, atendieron a una ópera, ballet, concierto de música clásica o una
obra de teatro.
Este índice constituiría una medida del interés de los padres en los niños en temas de
educación o interés en general. Un último índice se refiere a las posesiones del hogar
(HOMEPOS)27. Dada la alta relación entre los índices mencionados, se incluye en el
modelo los índices ESCS y HEDRES, excluyendo los índices HOMEPOS y CULTPOSS,
dado que resultaron no significativas por problemas de multicolinealidad28.
Dado que la variable HOMEPOS no fue incluida por problemas de multicolinealidad con
los restantes índices se incluyó un índice WEALTH29, de bienestar familiar el cual
constituye una proxy del índice mencionado. Se incluyen por ultimo variables del hogar
25 Esta variable agrupa los recursos necesarios para la educación en el hogar. Ver anexo 2.2 26 Indica la accesibilidad a actividades y lugares culturales estimulada desde hogar. Ver anexo 2.4 27 HOMEPOSS incluye las respuestas de las preguntas de WEALTH, CULPOSS Y HEDRES. 28 Véase en Anexos modelo alternativo 3 y 4 en los cuales se estiman modelos con los cuatro índices y sin
algunos índices para mostrar como la alta multicolinealidad afecta la significancia individual 29 Posesiones del hogar para el bienestar familiar. Ver anexo 2.3

que permitan capturar un índice de atención de los padres a las actividades académicas de
sus hijos. Se incluye entonces la variable ESTRUCFAM la cual constituye una variable
dicotómica que nos indica si el estudiante vive con un padre o con los dos padres, al ser
variable dicotómica se espera un signo negativo donde se evidencie que vivir con un solo
padre afecta el puntaje del estudiante de manera negativa.
𝐸𝑆𝑇𝑅𝑈𝐶𝐹𝐴𝑀𝑖𝑗 = {1 𝑣𝑖𝑣𝑒 𝑐𝑜𝑛 𝑢𝑛 𝑠𝑜𝑙𝑜 𝑝𝑎𝑑𝑟𝑒0 𝑉𝑖𝑣𝑒 𝑐𝑜𝑛 𝑎𝑚𝑏𝑜𝑠 𝑝𝑎𝑑𝑟𝑒𝑠
Un índice de clima de disciplina en el hogar, DISCLIMA también es incluido dentro del
modelo, el cual mide cuanta disciplina por parte de los padres está presente en el hogar.
Por último y dado que se argumenta que en las pruebas de matemáticas, el mejor
desempeño está a favor de los hombres en relación a las mujeres, se incluye el género como
variable de nivel 1. A continuación se observa la anterior regularidad empírica30.
Denotando la variable dicotómica género:
GENEROij = {1 Hombre0 Mujer
Aunque pareciera relevante la inclusión de una variable que mida el tiempo de estudio
dedicado a las matemáticas, esta (MMINS) no resulto significativa dentro de la estimación
de modelos alternativos (Véase en Anexos 1.6, modelo alternativo No 5).
Variables de la escuela
La presencia de una estructura jerárquica en los datos produce una heterogeneidad no
observada, en el que la media de la variable dependiente varía a través de los clúster. Con
30 En anexos se incluye información sobre el diferencial de puntajes en matemáticas a favor de los hombres,
incluido Colombia. Solo tres países de la muestra mostraron evidencia a favor de las mujeres.

el fin de modelar esta regularidad, variables de nivel 2 deben ser incluidas pues la variación
en el desempeño en matemáticas no puede atribuirse solo a variables del estudiante.
La necesidad de explicar las diferencias en los puntajes discriminando en los niveles
individuales (estudiantes) y grupales (escuela) justifica la utilización de la técnica de
análisis multinivel. Como bien se examinará posteriormente, las pendientes del modelo
resultaron fijas siendo el intercepto el único parámetro con variación aleatoria, lo cual abre
la opción de incluir variables de nivel de la escuela para su modelación. Se postulan dos
componentes que explican el promedio a nivel de la escuela. De un lado se incluye la
variable tipo de escuela (PUBLICA) esto es si es pública o privada:
PUBLICAj = {1 Publica0 Privada
La otra variable se postula afecta el rendimiento promedio en la escuela j es el efecto
contextual cuya proxy es el promedio del nivel socioeconómico de la escuela (MEANESC)
la cual se coloca como variable explicativa de segundo nivel31. Esta variable captura un
efecto contextual de la escuela constituyéndose en lo que la literatura denomina el “efecto
par”, que es el efecto de contexto socioeconómico del salón de clases Si los “efectos par”
resultan significativos el proceso de aprendizaje en la escuela depende de cómo los efectos
contextuales se combinan con las variables de nivel 2. La inclusión de la variable
MEANESCS en el nivel 2 para modelar intercepto es intuitivo, toda vez que las brechas
socioeconómicas entre las escuelas tienen un impacto sobre el promedio del desempeño
académico.
31 Esta variable no está directamente en la base de PISA. Se calculó tomando por escuela la media del índice socioeconómico ESCS.

Dado que es necesario evaluar el impacto de la dotación de la escuela sobre el desempeño
académico del estudiante, se escogió la variable IRATCOMP, que es la ratio de
computadores en relación al número total de estudiantes de la escuela. Adicional a esta
variable se postula la cantidad de computadores conectados a internet (COMPUWEB) se
postula que la disponibilidad del internet en las escuelas es fundamental para el desempeño
del estudiante, se esperan en el modelo final signos positivos dado que al tener mayor
acceso a computadores se espera mayor puntaje en la prueba.
No menos importante es la presencia de profesores certificados o cualificados (PROPCER)
los cuales son actores activos dentro del proceso de aprendizaje.
Por último se adicionan efectos interacción entre el tipo de escuela (sea pública o privada)
y la orientación vocacional (sea académica o técnica). Para los efectos de interacción se
computaron las siguientes variables dicotómicas adicionales.
PRIVADAj = {1 Privada0 Publica
𝐴𝐶𝐴𝐷𝐸𝑀𝐼𝐶𝐴𝑖𝑗 = {1 𝑂𝑟𝑖𝑒𝑛𝑡𝑎𝑐𝑖𝑜𝑛 𝐴𝑐𝑎𝑑𝑒𝑚𝑖𝑐𝑎0 𝑂𝑟𝑖𝑒𝑛𝑡𝑎𝑐𝑖𝑜𝑛 𝑇𝑒𝑐𝑛𝑖𝑐𝑎
Se calculan entonces los 4 efectos interacción de la siguiente manera:
VOCAPUBLICA=VOCACIONAL*PUBLICA
VOCAPRIVA=VOCACIONAL*PRIVADA
ACADEPRIVA=ACADEMICA*PRIVADA
PUBLICA32
Al colocar las variables dicotómicas orientación vocacional y tipo de escuela por aparte sin
presentar interacciones, se genera un supuesto, donde el tipo de orientación no dependería
del tipo de escuela, siendo la hipótesis a probar que el tipo de orientación vocacional varia
32 El efecto de la opción académica publica se obtiene de restar a la variable PUBLICA (que incluye ambos tipos de orientaciones la opción de vocacional publica) la variable o efecto VOCAPUBLICA, para obtener el puntaje que ceteris paribus las demás variables obtiene un estudiante de la orientación académica pública.

por tipo de escuela, se procedió a realizar interacciones para mirar el efecto sobre el puntaje
la variable vocacional según escuela
Se omite el intercepto con el objetivo de que las cuatros interacciones estuvieran presentes
en el modelo, en el momento de incluirlo se omite una de las variables dicotómicas por
problemas de multicolinealidad perfecta. Se anota que el modelo teórico no contempla un
intercepto, es decir, este no tiene una interpretación directa, si bien, debe estar presente en
modelos lineales para que se cumplan algunas propiedades del modelo, por ejemplo, que el
𝑅2 este acotado entre cero y uno, en este tipo de modelos no es estrictamente necesario
pues este tipo de medida de ajuste del modelo no está disponible para modelos multinivel
3. Estimaciones
3.1. Estimación modelo nulo A Continuación se presenta la estimación del Modelo Nulo (ver Tabla No. 1)
TABLA 1. Modelo nulo del desempeño en matemáticas (PV1MATH)33
Efectos Fijos
Coeficiente Error st. T-est. Prob
Intercepto(β00) 406.371906 2.667160 152.062 0.000
Efectos Aleatorios
Varianza
G.d.l
Chi-cuadrado Probabilidad
Variabilidad entre
escuelasσu02
1621.77842 263 2915.45128 0.000
Variabilidad dentro de
la escuela σe2
3156.90144
Correlaciónintraclase 0.339
Confiabilidad , β0j 0.888
Desviance
(2 parametrosest.)
55276.44
Fuente: PISA OECD. Estimación con el software HML 7.0
33 Véase en Anexos la estimación del modelo nulo mediante el software HLM 7.0 student versión.

La significancia estadística de la varianza “entre escuelas” indica que el promedio del
desempeño académico en matemáticas varía a través de las escuelas lo cual justifica la
inclusión de variables de nivel 2. A esta conclusión también se llega a calcular el
coeficiente de correlación intraclase:
ρ =σu0
2
σu02 + σe
2 =
(1621.77842)
(1621.77842 + 3156.90144)= 33.9
En efecto el 33.9% de la varianza total en el desempeño en matemáticas es atribuible a las
escuelas, mientras que 66.1% es atribuible a los estudiantes. Con el fin de disminuir la
variabilidad deben ingresarse al modelo covariables de nivel 2 (en el modelo definitivo
después de incluir covariables de nivel 2, el coeficiente de intracorrelacion cae a 16.6%)
Recordando que el intercepto β0jindica el promedio del desempeño en matemáticas para
las J escuelas (j=1,2,…, J) varía a través de las escuelas, el coeficiente de confiabilidad
para β0j(acotado en el intervalo 0-1) mide el grado en el cual se puede discriminar el
promedio del desempeño académico entre escuelas; la representación de este estadístico es
como sigue:
1
J∑
σu02
σu02 + σ00j
2
J
j=1
El coeficiente de confiabilidad mide el grado de variación de las estimaciones MCO de
nivel 1 (i) a través del conjunto de unidades de nivel 2, (J). Un valor bajo para este
coeficiente sugeriría que es difícil discriminar entre escuelas sobre la base de su promedio
de desempeño académico (MA et al 2008). Con un valor de 0.888 el modelo indica que el
desempeño en la prueba de matemáticas puede discriminarse entre escuelas.
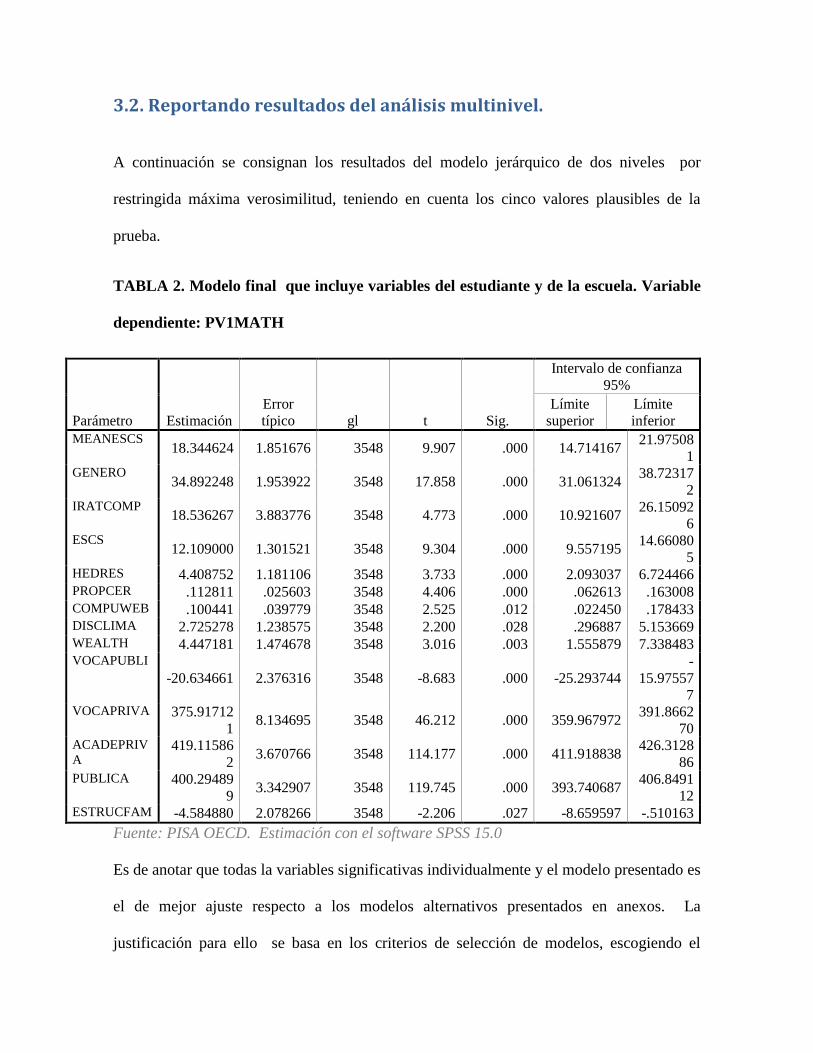
3.2. Reportando resultados del análisis multinivel.
A continuación se consignan los resultados del modelo jerárquico de dos niveles por
restringida máxima verosimilitud, teniendo en cuenta los cinco valores plausibles de la
prueba.
TABLA 2. Modelo final que incluye variables del estudiante y de la escuela. Variable
dependiente: PV1MATH
Parámetro Estimación
Error
típico gl t Sig.
Intervalo de confianza
95%
Límite
superior
Límite
inferior
MEANESCS 18.344624 1.851676 3548 9.907 .000 14.714167
21.97508
1 GENERO
34.892248 1.953922 3548 17.858 .000 31.061324 38.72317
2 IRATCOMP
18.536267 3.883776 3548 4.773 .000 10.921607 26.15092
6 ESCS
12.109000 1.301521 3548 9.304 .000 9.557195 14.66080
5 HEDRES 4.408752 1.181106 3548 3.733 .000 2.093037 6.724466 PROPCER .112811 .025603 3548 4.406 .000 .062613 .163008 COMPUWEB .100441 .039779 3548 2.525 .012 .022450 .178433 DISCLIMA 2.725278 1.238575 3548 2.200 .028 .296887 5.153669 WEALTH 4.447181 1.474678 3548 3.016 .003 1.555879 7.338483 VOCAPUBLI
-20.634661 2.376316 3548 -8.683 .000 -25.293744
-
15.97557
7 VOCAPRIVA 375.91712
1 8.134695 3548 46.212 .000 359.967972
391.8662
70 ACADEPRIV
A 419.11586
2 3.670766 3548 114.177 .000 411.918838
426.3128
86 PUBLICA 400.29489
9 3.342907 3548 119.745 .000 393.740687
406.8491
12 ESTRUCFAM -4.584880 2.078266 3548 -2.206 .027 -8.659597 -.510163
Fuente: PISA OECD. Estimación con el software SPSS 15.0
Es de anotar que todas la variables significativas individualmente y el modelo presentado es
el de mejor ajuste respecto a los modelos alternativos presentados en anexos. La
justificación para ello se basa en los criterios de selección de modelos, escogiendo el

criterio de Schwarz por ser el más exigente (además de consistente para encontrar el
modelo correcto) con la inclusión de variables.
Con el signo esperado del índice ESCS, nos dice que un aumento de una unidad en el
índice (ESCS) incrementa el puntaje del estudiante en 12.10 puntos. Esta regularidad
confirma lo encontrado en otros estudios y es a saber que existe una relación positiva entre
el desempeño del estudiante y el nivel socioeconómico de la familia. De otro lado el
coeficiente asociado al índice HEDRES, señala que un aumento de una unidad en este
índice de recursos educativos en el hogar, incrementa el puntaje del estudiante en 4.4, es
decir si el estudiante tiene recursos que le permitan un ambiente adecuado de estudio, su
productividad es más elevada lo cual se ve reflejado en un mayor puntaje de la prueba de
matemáticas.
Asociado al índice socioeconómico, se incluyó un índice de bienestar familiar, el cual tiene
un efecto positivo en el desempeño académico del estudiante. Específicamente un aumento
de una unidad en este índice incrementa el puntaje del estudiante en 4.44 puntos, esto
confirma el valor del signo positivo de la variable.
Un clima de disciplina en el colegio mejora el desempeño de los estudiantes, se confirma el
signo positivo en el índice. DISCLIMA, dice que un incremento de una unidad en este
índice eleva el puntaje del estudiante en la prueba de matemáticas en 2.72 puntos.
Una variable referente a la estructura familiar y que va de la mano con la atención de los
padres al proceso educativo del estudiante es la variable estructura familiar, ESTRUCFAM.
Esta variable nos indica que un estudiante que vive con un solo padre tiene menor
desempeño (4.5 puntos) respecto a un estudiantes que vive con ambos padres. Por último y

para cerrar la lectura del impacto de las variables sobre el desempeño académico, la
variable genero indica lo encontrado de manera generalizada para todos los países en el
informe PISA 2012, y es a saber, que los estudiantes hombres aventajan a sus pares
mujeres en la prueba con un diferencial a favor de los primeros de 34.89 puntos.
Respecto a las variables de la escuela se encuentran los signos que se esperaban. En cuanto
a dotación se refieren, la dotación de computadoras por estudiante (IRATCOMP), con un
signo positivo, nos indica que un aumento en una unidad de este índice, incrementa el
desempeño del estudiante en 18.53 puntos, mientras que el número de computadoras
conectadas a internet tiene un efecto positivo y significativo en el desempeño aunque casi
imperceptible (0.10).
Respecto a la planta docente, se confirma el signo positivo; el modelo muestra un efecto
significativo (aunque relativamente bajo) de la proporción de profesores certificados
(titulados) sobre el desempeño del estudiante.
Por último se analizan los efectos interacción para las variables orientación vocacional y
tipo de escuela. El modelo arroja resultados respecto al tipo de escuela encontrados en
otros trabajos. Entrando a analizar por tipo de orientación vocacional, se encuentra que la
escuela privada con orientación vocacional académica tiene un mejor desempeño 419.11
frente a estas mismas escuelas con orientación vocacional, 375.9 De otro lado el
desempeño en una escuela pública con orientación académica es de 400.29, entre tanto el
puntaje de un estudiante con orientación vocacional dentro de una escuela pública es de
420.92 (400.29-(-20.63)).

Cabe anotar que solo el valor del coeficiente esperado para el efecto de orientación
vocacional dentro de una escuela pública no era el esperado, al ser mayor que el efecto de
orientación académica dentro de una escuela con financiación estatal. Se esperaba que
siguiera el mismo patrón observado en la escuela privada, en el cual la orientación
académica supera la vocacional. Siendo los coeficientes significativos, se encuentra que
medir el impacto del tipo de escuela asumiendo que la orientación vocacional es la misma
para la escuela pública que para la escuela privada, es incorrecto, lo cual se confirma al
mirar la significancia estadística de los efectos interacción.
4 Conclusiones
El documento presenta un enfoque alternativo a los tradicionales estudios que se han
limitado a una comparación académica de puntaje entre las escuelas públicas y privadas,
donde se tiene en cuenta dinámicas diferenciales por orientación vocacional, al interior de
las escuelas, evidenciando determinantes sobre el desempeño académico en matemáticas de
los estudiantes de los grados decimo y once.
Inicialmente se puede confirmar las regularidades empíricas en los tradicionales estudios, a
saber que el género y el tipo de escuela tienen impacto sobre el desempeño académico
individual. En efecto los estudiantes hombres aventajan a sus similares mujeres en la
prueba de matemáticas, mientras que pertenecer a una escuela pública impacta
negativamente el mencionado desempeño.
Visto sólo como cualidad de género podría parecer algo intrínseco de la persona no
obstante si se percibe como parte de un escenario sociocultural que interactúa con el

individuo, surge el interés de analizar por qué el género influye en el desempeño
académico.
Este resultado se explica por el menor tiempo que tienen los estudiantes con orientación
vocacional técnica para dedicar a las actividades académicas, toda vez que al menos el 25%
del total de horas de clase deben ser destinadas al aprendizaje y practica de saberes
laborales adquiridos durante la práctica.
Respecto a interacción entre la orientación vocacional y el tipo de escuela se encuentra
que al interior de la escuela privada, los estudiantes con orientación vocacional académica
tienen puntajes significativamente más altos que sus pares con orientación vocacional
técnica (45 puntos de diferencia). Caso contrario ocurre al interior de las escuelas públicas,
donde aquellos estudiantes con orientación vocacional técnica aventajan en la prueba a
aquellos estudiantes con orientación vocacional académica.
En resumen, debe anotarse que sin entrar a diferenciar por tipo de escuela, se encuentra que
los estudiantes con orientación vocacional técnica muestran un desempeño académico
inferior a los que tienen orientación vocacional académica.
La concentración de la orientación vocacional en la escuela privada a favor del enfoque
comercial estaría explicada por una mejor adaptación de las escuelas privadas a un
cambiante entorno económico en el cual la tercerización es cada vez más acentuada. Para
cerrar la disertación alrededor del efecto de la orientación vocacional.
El estudio confirma la conclusión a la que llegan Piñeros y Rodríguez (1998) sobre la
existencia de una relación directa entre el nivel socioeconómico del estudiante y el
desempeño académico. Adicionalmente si se incluye el efecto contextual o efecto par, se

encuentra que el estatus socioeconómico de la escuela interviene en los resultados,
pudiendo afirmar que el ambiente en el que se desenvuelven los estudiantes cuenta mucho
en su desempeño, de esta manera se corrobora lo expuesto por Martínez (2012). Como
sugerencia se establece que las directivas de las escuelas deben propiciar mejores
condiciones de aprendizaje y de desarrollo socioeconómico de la institución, donde se
aproveche el estatus mismo de los estudiantes que ingresan en ella.
Se confirma con el modelo nulo que el intercepto tiene variación aleatoria, es decir, el
promedio del desempeño académico en matemáticas varia a través de las 264 escuelas de
la muestra siendo necesarias la inclusión de variables de nivel 2.
Las variables de dotaciones de la escuela resultaron significativas, en lo referente a la
relación de computadores por estudiante y la cantidad de estos conectados a internet,
llegando a la misma conclusión de Gonzalez (2014). La proporción de computadoras para
fines educativos parece ser la variable de mayor importancia en el desempeño de los
estudiantes De este resultado puede desprenderse que los responsables a nivel regional y
estatal de las políticas educativas deberán considerar la conveniencia de inyectar una gran
inversión de recursos, especialmente en los niveles bajos, para poder obtener incrementos
significativos en el desempeño de los estudiantes.
Significativa, aunque con poco impacto, la calificación de los profesores muestra una
relación positiva en el desempeño de los estudiantes. La presencia de profesores
calificados y su continua capacitación pueden ayudar a mejorar los procesos cognitivos de
los estudiantes. Para cerrar la disertación respecto a variables de la escuela se encuentra que

un mejor clima de disciplina en el plantel educativo impacta positivamente el desempeño
de sus estudiantes.
Dentro de las variables del hogar se confirma que la existencia de recursos que permitan al
estudiantes adelantar de manera más eficaz sus deberes académicos (medido en el índice
HEDRES), es fundamental; es así como la existencia de un lugar adecuado para estudiar
dentro de la casa, presencia de escritorio, libros para adelantar los trabajos etc., son
recursos que tienen un impacto significativo en el desempeño académico. Es relativamente
fácil incidir de manera relativamente el índice HEDRES pues para la familia es
relativamente menos costoso acceder a una mayor dotación de libros de cultura general y
material educativo pasando por recursos informáticos respecto a otros bienes materiales.
Por último la variable estructura familiar muestra un impacto positivo en el desempeño
académico del estudiante, lo cual se explica desde la vía de un mayor monitoreo de los
padres respecto al proceso educativo del estudiante como de una mayor estabilidad
emocional dentro del hogar lo que podría permitirle una mayor rendimiento educativo.
Las Pruebas PISA reflejan la baja calidad de la educación en Colombia para todos los
colegios participantes, además, de las brechas entre los colegios públicos y privados con las
diferentes orientaciones vocacional técnica y académica, con esto se entiende que la
mayoría de los estudiantes mayores de 15 años no tienen la capacidad de formular, emplear
e interpretar las matemáticas en distintos contextos.
Las condiciones de pobreza y desigualdad en el país son un obstáculo para acceder a la
educación, lo que genera un círculo vicioso, así, los estudiantes de bajos recursos no podrán
acceder a una educación de calidad y de esta manera no acceder al mercado laboral.

No obstante, el gobierno ha generado políticas para la reducción de la pobreza y
desigualdad, orientado especialmente a la primera infancia (Programa Nacional de
Atención Integral a la Primera Infancia (PAIPI) - Estrategia Nacional De Cero a Siempre).
Ahora el debate no es solo de cobertura, también de calidad, para ellos el Ministerio de
Educación formuló en el 2012 las bases de “Todos a Aprender”: Programa de
Transformación de la Calidad Educativa – PTCE, pese a esto, el reto sigue siendo grande
para Colombia
Es importante que Colombia siga participando en evaluaciones internacionales y además
que aprende de ellas, de esta manera se obtiene un punto de referencia que ayudara a
establecer metas que mejoren el sistema educativo. El rendimiento académico de Colombia
en PISA indica que debe mejorar las expectativas acerca de lo que los estudiantes deben
saber y las habilidades.

Referencias Bibliográficas
Amato, P. (2000). The Journald Marriage and family. The consequences of divorce for
adults and children. Vol 62, pp 1269-1287
Arnold, D. y Doctoroff, G. (2003).The early education of socioeconomically
disadvantaged children.Annual review of psychology, 54.
Casas, A; Gamboa L y Piñeros L (2002). El efecto escuela en Colombia, 1999-2000.
Universidad del Rosario.
Calvo, P, García A., Marrero, G (2005). La disciplina en el contexto escolar. Las palmas de
gran canaria. Universidad de las palmas de gran canaria.
Coleman, J. 1966. Equality of educational opportunity.U.S.Department of Education.
Washington, D.C.
Congreso de la República. Ley 115 de 1994, por la cual se expide la Ley General de
Educación. Bogotá: El Congreso, 1994. Colombia
Fernández A, Del valle R. (2013) Desigualdad educativa en costa rica: la brecha entre
estudiantes entre colegios públicos y privados. Análisis con los resultados de la
evaluación internacional PISA. Revista CEPAL No. 111. P, 37- 57.
Gamboa, L y Waltenberg, F (2011). Inequality of Opportunity in educational achievement
in latinoamerica: evidence from PISA 2006-209. Economics of education review.
Pp 694-708.
Goldstein, H (1986). Multilevel mixed linear model using iterative generalized least
squared. Biometrika, 73, 43-56.
Goldstein, H and Rasbash, J (1996).Improved approximations for multilevel models with
binary responses.Journal of the Royal Statistical Society: Series A, Vol 159, No 3,
505-513.
Goldstein, H (2002). Multilevel statitiscal models (3nd Ed.). London: Arnold Publishing.
Gonzalez M. (2014).Incidencia de la dotación escolar en el rendimiento académico en
lectura de los alumnos de secundaria. Comparaciones internacionales con base
en las pruebas PISA 2009. Universidad del Valle. Cali, Colombia.

Hanchane, S and Mostafa, T (2010). Endogeneity problems in multilevel estimation of
education production functions: an analysis usinf PISA data. Centre for
Learning and Life Chances in Knowledge Economies and Societies.LLAKES
research paper, Recuperado el 24 de octubre de 2014 de http://www.llakes.org/wp-
content/uploads/2010/11/HanchaneMostafa-14-final-online.pdf
Hanushek E (1989). The Impact of Differential Expenditures ON School Performance,
Educational Researcher, Vol. 18, pp 45-51
Hanushek, E. (1996). Measuring Investment in Education.The Journal of Economic
Perspectives, Vol. 10, No 4, 9-30.
Hanushek, E. Kain y Rivkin (2005). Teacher, School, and Academic Achievement.
Econometrica. Vol 73 No. 2, pp. 417-458. March 2005.
Hesketh S & Skrondal A (2012).Multilevel and longitudinal modeling using data.Stata
press.Volumen 1
Hox, J (2010). Multilevel Analysis, Techniques and Applications.Routledge.
ICFES (2012). Estudios sobre la calidad de la educación en Colombia.
INEE (2008). Análisis multinivel de la calidad educativa en Mexico ante los datos de PISA
2006
Lopez, E. (2009). Estudio de variables determinantes de eficiencia a través de los modelos
jerárquicos lineales en la evaluación PISA 2006: el caso de España. Archivos
analíticos de políticas académicas. Vol 17. España
Maas, C. J. M., & Hox, J. J. (2004). The influence of violations of assumptions on
multilevel parameter estimates and their standard errors.Computational
statistics & data analysis, 26, 427-440.
Maccoach, D and Black, A (2008). Evaluation of Model Fit and Adequacy.In A.A.
O’Connell and D. B. McCoach (Eds.), Multilevel modeling of educational
data (pp. 245-271). Charlotte, NC: Information Age Publishing.
Manski, C. (1993) “Identification of Endogenous Social Effects: The Reflection Problem,”
Review of Economic Studies, LX, 531–542
Ma, X. ,Ma, L., Bradley K, (2008). Using multilevel modeling to investigate school
effects.In A.A. O’Connell and D. B. McCoach (Eds), Multilevel modeling of
educational data (pp. 245-271).Charlotte, NC: InformationAge Publishing.

Murillo F J (2008), Los modelos multinivel como herramienta para la investigación
educativa. Magis, Vol. 1, pp. 45-62.
OECD (1999).Classifying Educational Programmes Manual for ISCED-97 Implementation
in OECD Countries.Organisationfor Economic Co-operation and
Development.
Piñeros, L. y Rodríguez, A. (1998). Los insumos escolares en la educación secundaria y su
efecto sobre el rendimiento académico de los estudiantes: Un estudio en Colombia.
Banco Mundial, Departamento de Desarrollo Humano, LCSHD Paper Series No.
36, diciembre.
Raudenbush, S &Brik, A. (2002).Herarchical linear models.Sagepublication.Volumen 1
Rangvid, B (2008). Source country differences in test score gaps: evidence from Denmark.
University PressofSouthernDenmark, Study Paper no 22.
Saavedra, J.E y Medina, C (2012).Formación para el Trabajo en Colombia. Documentos
CEDE, No 35. Facultad de Economía, Universidad de los Andes.
Bogotá, Colombia.
Stapleton, L. M., & Thomas, S. L. (2008).Sources and issues in the use of national datasets
for pedagogy and research.In O’Connell, A., & McCoach, B. (Eds).Multilevel
Analysis of Educational Data (pp. 11-57).Greenwich, CT: Information Age
Publishing.
Steenbergen, M and Jones, B (2002).Modeling multilevel data structures.American Journal
of Political Science, Vol 46, No 1.

Anexos
1. PRESENTACION DEL MODELO NULO, DEFINITIVO Y MODELOS
ALTERNATIVOS
1.0 MODELO NULO
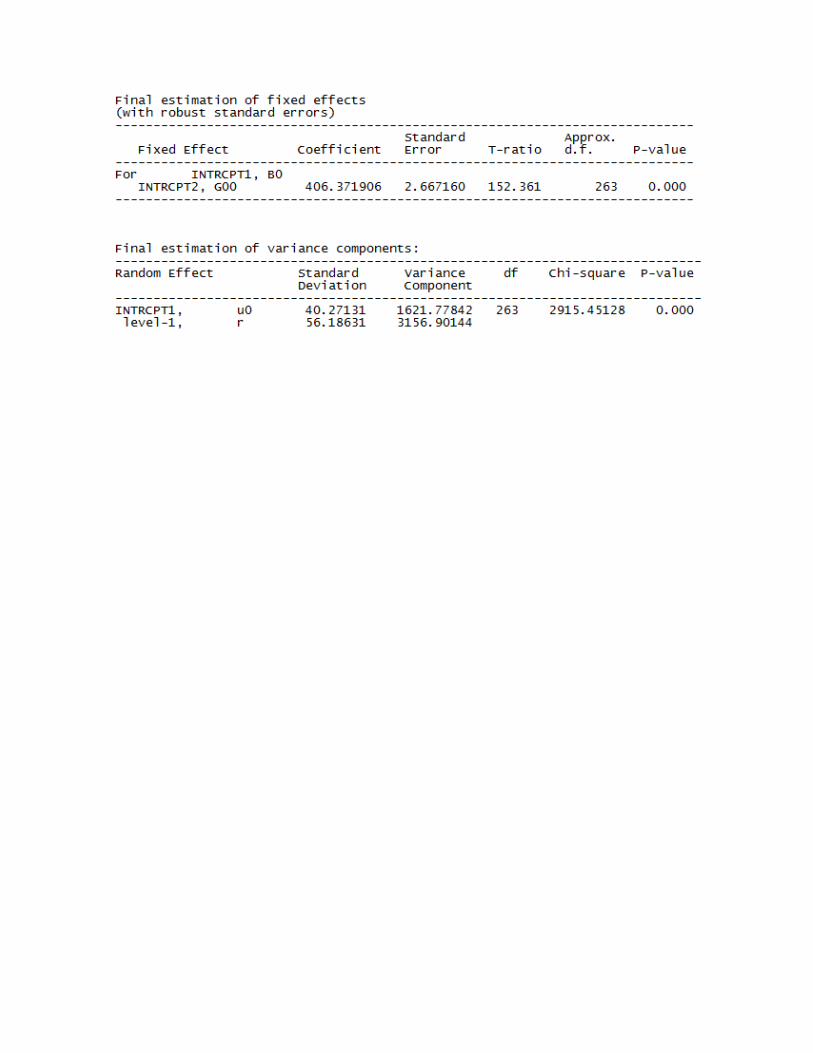
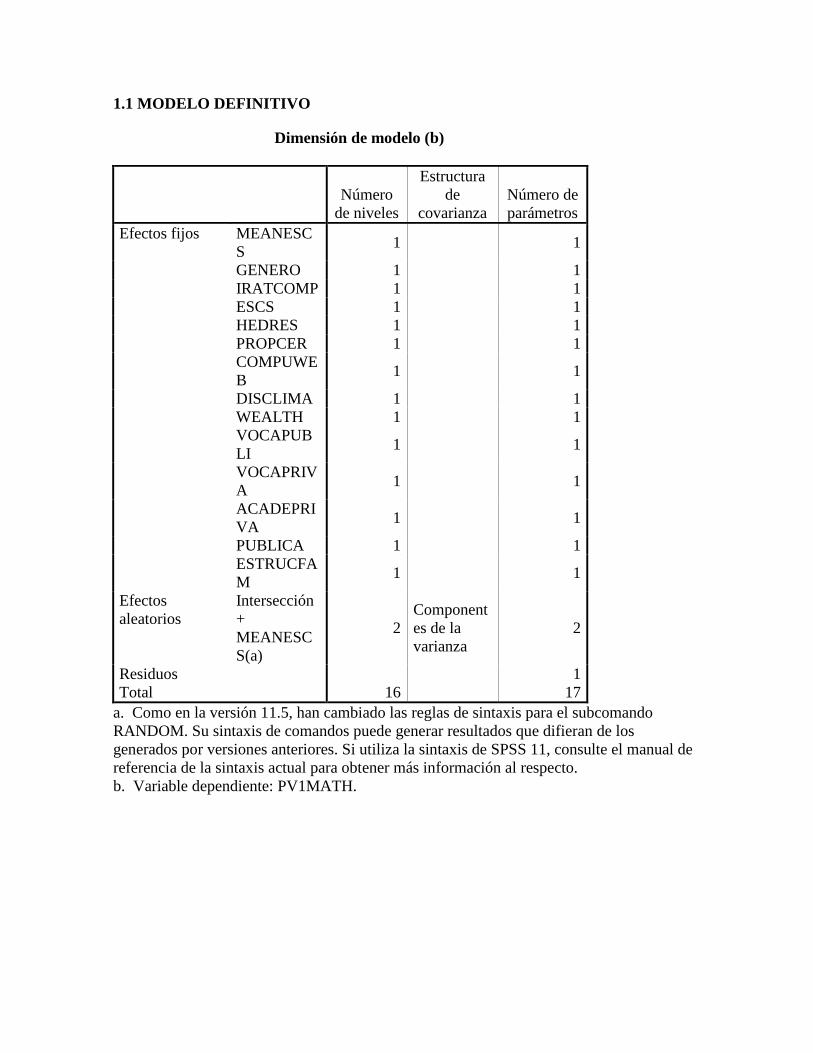
1.1 MODELO DEFINITIVO
Dimensión de modelo (b)
Número
de niveles
Estructura
de
covarianza
Número de
parámetros
Efectos fijos MEANESC
S 1 1
GENERO 1 1
IRATCOMP 1 1
ESCS 1 1
HEDRES 1 1
PROPCER 1 1
COMPUWE
B 1 1
DISCLIMA 1 1
WEALTH 1 1
VOCAPUB
LI 1 1
VOCAPRIV
A 1 1
ACADEPRI
VA 1 1
PUBLICA 1 1
ESTRUCFA
M 1 1
Efectos
aleatorios
Intersección
+
MEANESC
S(a)
2
Component
es de la
varianza
2
Residuos 1
Total 16 17
a. Como en la versión 11.5, han cambiado las reglas de sintaxis para el subcomando
RANDOM. Su sintaxis de comandos puede generar resultados que difieran de los
generados por versiones anteriores. Si utiliza la sintaxis de SPSS 11, consulte el manual de
referencia de la sintaxis actual para obtener más información al respecto.
b. Variable dependiente: PV1MATH.
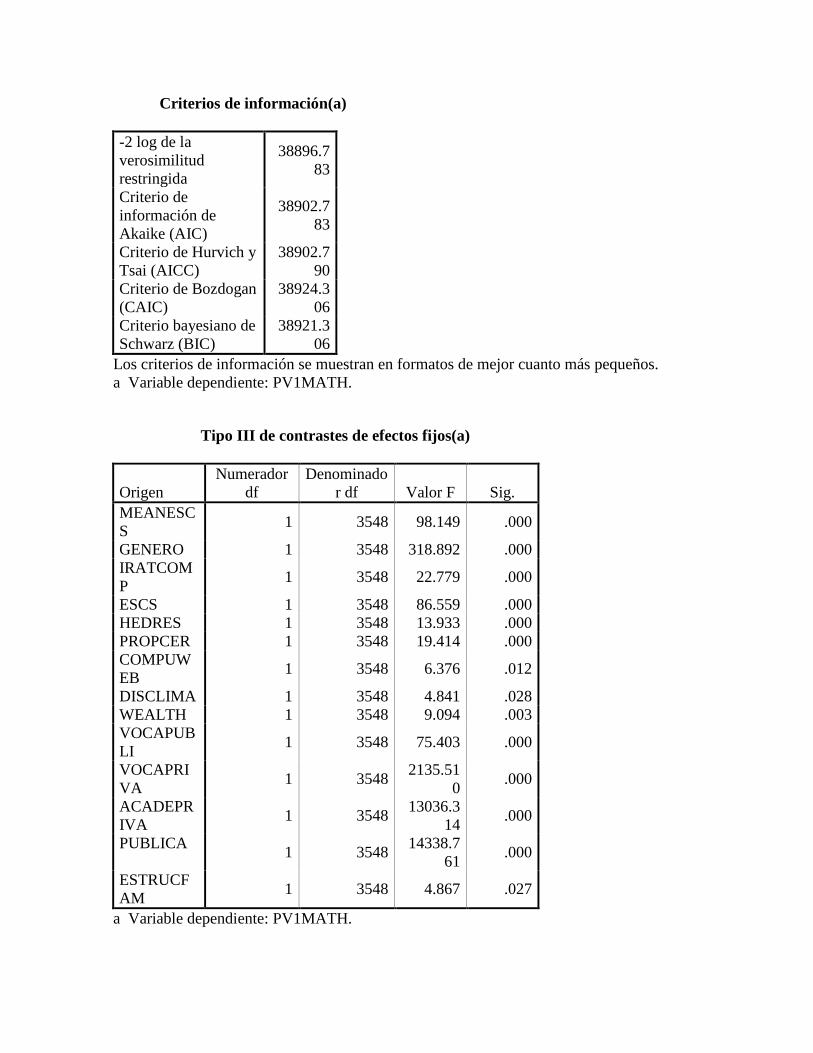
Criterios de información(a)
-2 log de la
verosimilitud
restringida
38896.7
83
Criterio de
información de
Akaike (AIC)
38902.7
83
Criterio de Hurvich y
Tsai (AICC)
38902.7
90
Criterio de Bozdogan
(CAIC)
38924.3
06
Criterio bayesiano de
Schwarz (BIC)
38921.3
06
Los criterios de información se muestran en formatos de mejor cuanto más pequeños.
a Variable dependiente: PV1MATH.
Tipo III de contrastes de efectos fijos(a)
Origen
Numerador
df
Denominado
r df Valor F Sig.
MEANESC
S 1 3548 98.149 .000
GENERO 1 3548 318.892 .000
IRATCOM
P 1 3548 22.779 .000
ESCS 1 3548 86.559 .000
HEDRES 1 3548 13.933 .000
PROPCER 1 3548 19.414 .000
COMPUW
EB 1 3548 6.376 .012
DISCLIMA 1 3548 4.841 .028
WEALTH 1 3548 9.094 .003
VOCAPUB
LI 1 3548 75.403 .000
VOCAPRI
VA 1 3548
2135.51
0 .000
ACADEPR
IVA 1 3548
13036.3
14 .000
PUBLICA 1 3548
14338.7
61 .000
ESTRUCF
AM 1 3548 4.867 .027
a Variable dependiente: PV1MATH.

Estimaciones de efectos fijos(a)
Parámetro
Estimació
n
Error
típico gl t Sig.
Intervalo de confianza
95%
Límite
superior
Límite
inferior
MEANESC
S 18.344624 1.851676 3548 9.907 .000 14.714167
21.9750
81
GENERO 34.892248 1.953922 3548 17.858 .000 31.061324
38.7231
72
IRATCOM
P 18.536267 3.883776 3548 4.773 .000 10.921607
26.1509
26
ESCS 12.109000 1.301521 3548 9.304 .000 9.557195
14.6608
05
HEDRES 4.408752 1.181106 3548 3.733 .000 2.093037
6.72446
6
PROPCER .112811 .025603 3548 4.406 .000 .062613 .163008
COMPUW
EB .100441 .039779 3548 2.525 .012 .022450 .178433
DISCLIMA 2.725278 1.238575 3548 2.200 .028 .296887
5.15366
9
WEALTH 4.447181 1.474678 3548 3.016 .003 1.555879
7.33848
3
VOCAPUB
LI -
20.634661 2.376316 3548 -8.683 .000 -25.293744
-
15.9755
77
VOCAPRI
VA
375.91712
1 8.134695 3548 46.212 .000 359.967972
391.866
270
ACADEPR
IVA
419.11586
2 3.670766 3548 114.177 .000 411.918838
426.312
886
PUBLICA 400.29489
9 3.342907 3548 119.745 .000 393.740687
406.849
112
ESTRUCF
AM -4.584880 2.078266 3548 -2.206 .027 -8.659597 -.510163
a Variable dependiente: PV1MATH.

Estimaciones de parámetros de covarianza (b)
Parámetro
Estimació
n
Error
típico Wald Z Sig.
Intervalo de confianza
95%
Límite
inferior
Límite
superior
Residuos 3273.3140
16
77.71607
6 42.119 .000
3124.48302
0
3429.23
4397
Intersecció
n
Varianza 161997.92
2232
233246.9
93225 .707 .480
10756.4067
34
2750294
.404504
b Variable dependiente: PV1MATH.
Estimando con efectos aleatorios: Parámetros de covarianza Estimaciones de parámetros de covarianza(b)
Parámetro Estimación Error típico
Residuos 3273.314016
77.716076
ESCS Varianza .000000(a) .000000
GENERO Varianza .000000(a) .000000
DISCLIMA Varianza .000000(a) .000000
ESTRUCFAM Varianza .000000(a) .000000
WEAL Varianza .000000(a) .000000
HEDRES Varianza .000000(a) .000000
a Este parámetro de covarianza es redundante. b Variable dependiente: Valor plausible 1.

1.1 MODELO ALTERNATIVO 1:
Asume que el efecto de la vocación sobre el puntaje del estudiante es constante por el tipo
de escuela.
Dimensión de modelo (b)
Número
de niveles
Estructura
de
covarianza
Número de
parámetros
Efectos fijos Intersección 1 1
VOCACION
AL 1 1
GENERO 1 1
MEANESC
S 1 1
IRATCOMP 1 1
ESCS 1 1
HEDRES 1 1
tipoesc 1 1
SC09Q21 1 1
SC10Q03 1 1
DISCLIMA 1 1
ESTRUCFA
M 1 1
WEALTH1 1 1
Efectos
aleatorios
Intersección
+
MEANESC
S(a)
2
Component
es de la
varianza
2
Residuos 1
Total 15 16
a Como en la versión 11.5, han cambiado las reglas de sintaxis para el subcomando
RANDOM. Su sintaxis de comandos puede generar resultados que difieran de los
generados por versiones anteriores. Si utiliza la sintaxis de SPSS 11, consulte el manual de
referencia de la sintaxis actual para obtener más información al respecto.
b Variable dependiente: PV1MATH.

Criterios de información(a)
-2 log de la
verosimilitud
restringida
38910.2
39
Criterio de
información de
Akaike (AIC)
38916.2
39
Criterio de Hurvich y
Tsai (AICC)
38916.2
46
Criterio de Bozdogan
(CAIC)
38937.7
63
Criterio bayesiano de
Schwarz (BIC)
38934.7
63
Los criterios de información se muestran en formatos de mejor cuanto más pequeños.
a Variable dependiente: PV1MATH.
Tipo III de contrastes de efectos fijos(a)
Origen
Numerador
df
Denominado
r df Valor F Sig.
Intersecció
n 1 3549
13343.1
65 .000
VOCACIO
NAL 1 3549 97.045 .000
GENERO 1 3549 321.110 .000
MEANES
CS 1 3549 102.380 .000
IRATCO
MP 1 3549 21.038 .000
ESCS 1 3549 87.305 .000
HEDRES 1 3549 13.562 .000
PUBLICA 1 3549 17.778 .000
PROPCER 1 3549 18.454 .000
COMPUW
EB 1 3549 6.590 .010
DISCLIM
A 1 3549 4.226 .040
ESTRUCF
AM 1 3549 4.838 .028
WEALTH 1 3549 9.065 .003
a Variable dependiente: PV1MATH.

Estimaciones de efectos fijos (a)
Parámetro
Estimació
n
Error
típico gl t Sig.
Intervalo de confianza
95%
Límite
superior
Límite
inferior
Intersecció
n
417.29750
8 3.612571 3549 115.513 .000 410.214583
424.380
432
VOCACIO
NAL -
22.467681 2.280717 3549 -9.851 .000 -26.939328
-
17.9960
33
GENERO 35.032641 1.954998 3549 17.920 .000 31.199609
38.8656
74
MEANES
CS 18.704646 1.848597 3549 10.118 .000 15.080226
22.3290
66
IRATCO
MP 17.784761 3.877414 3549 4.587 .000 10.182576
25.3869
46
ESCS 12.170151 1.302498 3549 9.344 .000 9.616431
14.7238
71
HEDRES 4.352816 1.181989 3549 3.683 .000 2.035369
6.67026
3
PUNLICA -
15.706964 3.725246 3549 -4.216 .000 -23.010802
-
8.40312
6
PROPCER .109993 .025605 3549 4.296 .000 .059791 .160194
COMPUW
EB .102193 .039809 3549 2.567 .010 .024141 .180244
DISCLIM
A 2.544817 1.237908 3549 2.056 .040 .117733
4.97190
0
ESTRUCF
AM -4.575428 2.080134 3549 -2.200 .028 -8.653807 -.497049
WEALTH 4.444050 1.476005 3549 3.011 .003 1.550147
7.33795
4
a Variable dependiente: PV1MATH.

Estimaciones de parámetros de covarianza (b)
Parámetro
Estimació
n
Error
típico Wald Z Sig.
Intervalo de confianza
95%
Límite
inferior
Límite
superior
Residuos 3279.2091
65
77.84507
1 42.125 .000
3130.13065
2
3435.38
7831
a Variable dependiente: PV1MATH.
1.3MODELO ALTERNATIVO 2
Dimensión de modelo (b)
Número
de niveles
Estructura
de
covarianza
Número de
parámetros
Efectos fijos GENERO 1 1
MEANESC
S 1 1
ESCS 1 1
VOCAPU
BLI 1 1
VOCACION
AL 1 1
Efectos
aleatorios
Intersección
+
MEANESC
S(a)
2
Component
es de la
varianza
2
Residuos 1
Total 7 8
a Como en la versión 11.5, han cambiado las reglas de sintaxis para el subcomando
RANDOM. Su sintaxis de comandos puede generar resultados que difieran de los
generados por versiones anteriores. Si utiliza la sintaxis de SPSS 11, consulte el manual de
referencia de la sintaxis actual para obtener más información al respecto.
b Variable dependiente: PV1MATH.
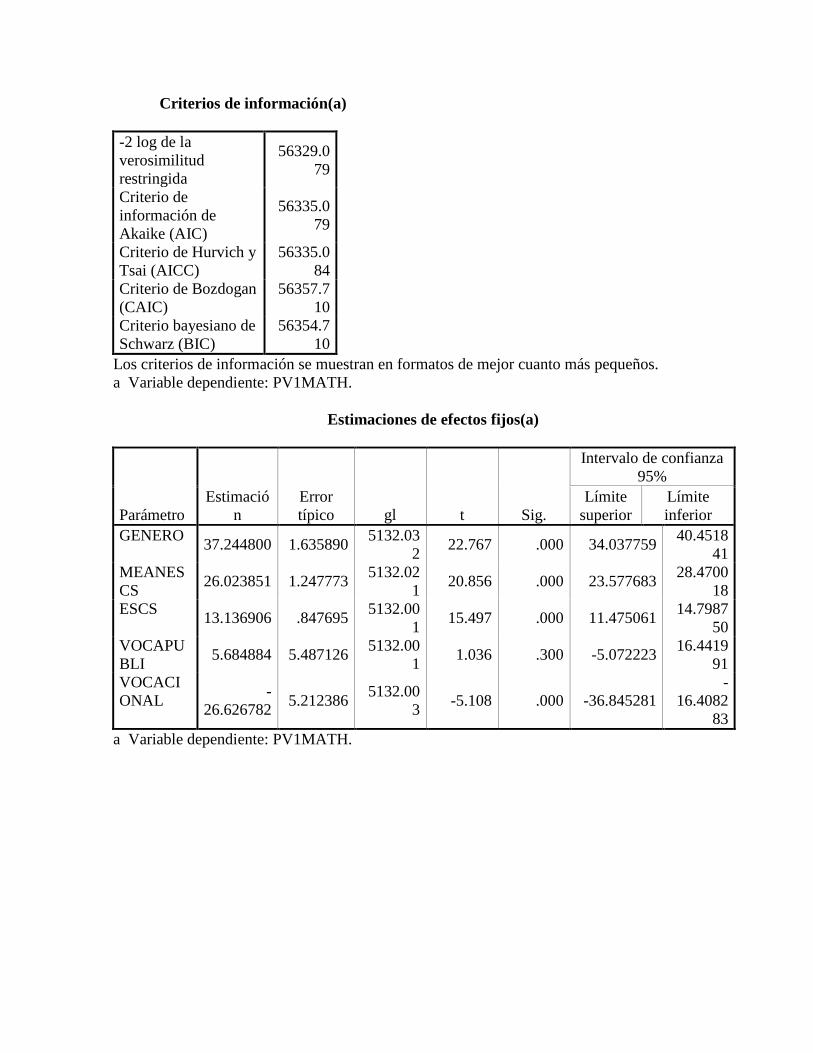
Criterios de información(a)
-2 log de la
verosimilitud
restringida
56329.0
79
Criterio de
información de
Akaike (AIC)
56335.0
79
Criterio de Hurvich y
Tsai (AICC)
56335.0
84
Criterio de Bozdogan
(CAIC)
56357.7
10
Criterio bayesiano de
Schwarz (BIC)
56354.7
10
Los criterios de información se muestran en formatos de mejor cuanto más pequeños.
a Variable dependiente: PV1MATH.
Estimaciones de efectos fijos(a)
Parámetro
Estimació
n
Error
típico gl t Sig.
Intervalo de confianza
95%
Límite
superior
Límite
inferior
GENERO 37.244800 1.635890
5132.03
2 22.767 .000 34.037759
40.4518
41
MEANES
CS 26.023851 1.247773
5132.02
1 20.856 .000 23.577683
28.4700
18
ESCS 13.136906 .847695
5132.00
1 15.497 .000 11.475061
14.7987
50
VOCAPU
BLI 5.684884 5.487126
5132.00
1 1.036 .300 -5.072223
16.4419
91
VOCACI
ONAL -
26.626782 5.212386
5132.00
3 -5.108 .000 -36.845281
-
16.4082
83
a Variable dependiente: PV1MATH.

Estimaciones de parámetros de covarianza (b)
Parámetro
Estimació
n
Error
típico Wald Z Sig.
Intervalo de confianza
95%
Límite
inferior
Límite
superior
Residuos 3383.6985
14
66.79798
1 50.656 .000
3255.27732
6
3517.18
5937
Intersecció
n
Varianza 183999.84
2071
260218.0
72442 .707 .480
11508.6081
64
2941792
.908462
a Variable dependiente: PV1MATH.
1.4 MODELO ALTERNATIVO 3: Incluye los tres índices HEDRES, HOMEPOS,
ESCS, CULTPOSS
Dimensión de modelo (b)
Número
de niveles
Estructura
de
covarianza
Número de
parámetros
Efectos fijos GENERO 1 1
MEANESC
S 1 1
ESCS 1 1
VOCACION
AL 1 1
CULTPOSS 1 1
HEDRES 1 1
HOMEPOS 1 1
IRATCOMP 1 1
PUBLICA 1 1
SC10Q01 1 1
COMPWEB 1 1
Efectos
aleatorios
Intersección
+
MEANESC
S(a)
2
Component
es de la
varianza
2
Residuos 1
Total 13 14
a Como en la versión 11.5, han cambiado las reglas de sintaxis para el subcomando
RANDOM. Su sintaxis de comandos puede generar resultados que difieran de los
generados por versiones anteriores. Si utiliza la sintaxis de SPSS 11, consulte el manual de
referencia de la sintaxis actual para obtener más información al respecto.
b Variable dependiente: PV1MATH

Criterios de información(a)
-2 log de la
verosimilitud
restringida
47193.8
68
Criterio de
información de
Akaike (AIC)
47199.8
68
Criterio de Hurvich y
Tsai (AICC)
47199.8
73
Criterio de Bozdogan
(CAIC)
47221.9
70
Criterio bayesiano de
Schwarz (BIC)
47218.9
70
Los criterios de información se muestran en formatos de mejor cuanto más pequeños.
a Variable dependiente: PV1MATH.

Estimaciones de efectos fijos(a)
Parámetro
Estimació
n
Error
típico gl t Sig.
Intervalo de confianza
95%
Límite
superior
Límite
inferior
genero 34.937343 1.771354
4304.02
9 19.724 .000 31.464576
38.4101
09
MEANES
CS 20.554851 1.694050
4304.00
5 12.134 .000 17.233640
23.8760
62
ESCS 10.899663 1.197100
4304.00
7 9.105 .000 8.552731
13.2465
96
VOCACI
ONAL -
23.593171 2.122400
4304.00
0 -11.116 .000 -27.754168
-
19.4321
75
CULTPOS
S 1.688661 1.249961
4304.02
6 1.351 .177 -.761907
4.13923
0
HEDRES 4.615486 1.345172
4304.02
2 3.431 .001 1.978255
7.25271
6
HOMEPO
S -2.614984 1.745488
4304.05
0 -1.498 .134 -6.037041 .807073
IRATCO
MP 18.308074 4.134188
4304.17
7 4.428 .000 10.202936
26.4132
12
PUBLICA
-9.009692 3.269721 4304.17
6 -2.755 .006 -15.420030
-
2.59935
4
SC10Q01 .026272 .007240
4304.03
6 3.629 .000 .012077 .040467
COMPUW
EB .112875 .041161
4304.00
0 2.742 .006 .032178 .193573
a Variable dependiente: PV1MATH.
b. SC10Q01: Número de estudiantes de la escuela

Estimaciones de parámetros de covarianza (b)
Parámetro
Estimació
n
Error
típico Wald Z Sig.
Intervalo de confianza
95%
Límite
inferior
Límite
superior
Residuos 3292.1319
99
70.96694
4 46.390 .000
3155.93672
9
3434.20
4810
Intersecció
n
Varianza 171431.54
0027
242457.1
47545 .707 .480
10720.8404
90
2741275
.084180
a Variable dependiente: PV1MATH.
1.5 MODELO ALTERNATIVO 4: EXCLUYENDO DEL MODELO 3 A LOS
INDICES ESCS Y HOMEPOS
Dimensión de modelo (b)
Número
de niveles
Estructura
de
covarianza
Número de
parámetros
Efectos fijos genero 1 1
MEANESC
S 1 1
vocacion 1 1
CULTPOSS 1 1
HEDRES 1 1
IRATCOMP 1 1
tipoesc 1 1
SC10Q01 1 1
SC10Q03 1 1
Efectos
aleatorios
Intersección
+
MEANESC
S(a)
2
Component
es de la
varianza
2
Residuos 1
Total 11 12
a Como en la versión 11.5, han cambiado las reglas de sintaxis para el subcomando
RANDOM. Su sintaxis de comandos puede generar resultados que difieran de los
generados por versiones anteriores. Si utiliza la sintaxis de SPSS 11, consulte el manual de
referencia de la sintaxis actual para obtener más información al respecto.
b Variable dependiente: PV1MATH.

Criterios de información(a)
-2 log de la
verosimilitud
restringida
47361.0
06
Criterio de
información de
Akaike (AIC)
47367.0
06
Criterio de Hurvich y
Tsai (AICC)
47367.0
12
Criterio de Bozdogan
(CAIC)
47389.1
14
Criterio bayesiano de
Schwarz (BIC)
47386.1
14
Los criterios de información se muestran en formatos de mejor cuanto más pequeños.
a Variable dependiente: PV1MATH.
Estimaciones de efectos fijos(a)
Parámetro
Estimació
n
Error
típico gl t Sig.
Intervalo de confianza
95%
Límite
superior
Límite
inferior
GENERO 36.197871 1.782402
4312.02
7 20.308 .000 32.703446
39.6922
96
MEANES
CS 25.799414 1.586899
4312.00
1 16.258 .000 22.688274
28.9105
53
VOCACI
ONAL -
23.221988 2.137841
4312.00
0 -10.862 .000 -27.413256
-
19.0307
19
CULTPOS
S 2.764768 1.147240
4312.00
6 2.410 .016 .515587
5.01394
8
HEDRES 7.717141 .931104
4312.00
0 8.288 .000 5.891698
9.54258
4
IRATCO
MP 16.875075 4.172869
4312.17
9 4.044 .000 8.694106
25.0560
44
PUBLICA -
10.688780 3.287628
4312.19
6 -3.251 .001 -17.134221
-
4.24333
9
SC10Q01 .025801 .007315
4312.03
9 3.527 .000 .011459 .040142
COMPUW
EB .113168 .041481
4312.00
0 2.728 .006 .031843 .194493
a Variable dependiente: PV1MATH.

Estimaciones de parámetros de covarianza (b)
Parámetro
Estimació
n
Error
típico Wald Z Sig.
Intervalo de confianza
95%
Límite
inferior
Límite
superior
Residuos 3365.1293
82
72.47319
2 46.433 .000
3226.04071
1
3510.21
4773
Intersecció
n
Varianza 171997.92
2232
243256.9
93225 .707 .480
10756.4067
34
2750294
.404504
a Variable dependiente: PV1MATH.
1.6. MODELO 5 ALTERNATIVO. INCLUYENDO TIEMPO PARA ESTUDIAR
(MMINS)
Estadísticos descriptivos
Recuent
o Media
Desviación
típica
Coeficiente
de
variación
PV1MATH 4270
404.637
7 68.59158 17.0%
MEANESCS 4270 -.9213 .77606 -84.2%
sexo de la persona 4270 .4468 .49722 111.3%
Ratio of computers
and school size 4270 .37107 .284814 76.8%
Index of economic,
social and cultural
status (WLE)
4270 -.8821 1.16953 -132.6%
Learning time
(minutes per week) -
Mathematics
4270 231.412
9 108.13129 46.7%
PUBLICA 4270 .8326 .37342 44.9%
VOCAPUBLI 4270 .2019 .40145 198.9%
VOCAPRIVA 4270 .0272 .16259 598.5%
ACADEPRIVA 4270 .1403 .34732 247.6%
Se omitirán los totales que se agreguen sobre una sola categoría de una variable o una
variable de archivo segmentado.

Criterios de información(a)
-2 log de la
verosimilitud
restringida
46719.6
23
Criterio de
información de
Akaike (AIC)
46725.6
23
Criterio de Hurvich y
Tsai (AICC)
46725.6
29
Criterio de Bozdogan
(CAIC)
46747.6
95
Criterio bayesiano de
Schwarz (BIC)
46744.6
95
Los criterios de información se muestran en formatos de mejor cuanto más pequeños.
a Variable dependiente: PV1MATH.
Tipo III de contrastes de efectos fijos(a)
Origen
Numerador
df
Denominado
r df Valor F Sig.
MEANESC
S 1 4261 163.493 .000
GENERO 1 4261 403.748 .000
IRATCOM
P 1 4261 12.686 .000
ESCS 1 4261 210.558 .000
MMINS 1 4261 .135 .714
PUBLICA 1 4261
20222.7
80 .000
VOCAPUB
LI 1 4261 64.578 .000
VOCAPRI
VA 1 4261
3699.94
9 .000
ACADEPR
IVA 1 4261
13049.5
14 .000
a Variable dependiente: PV1MATH.
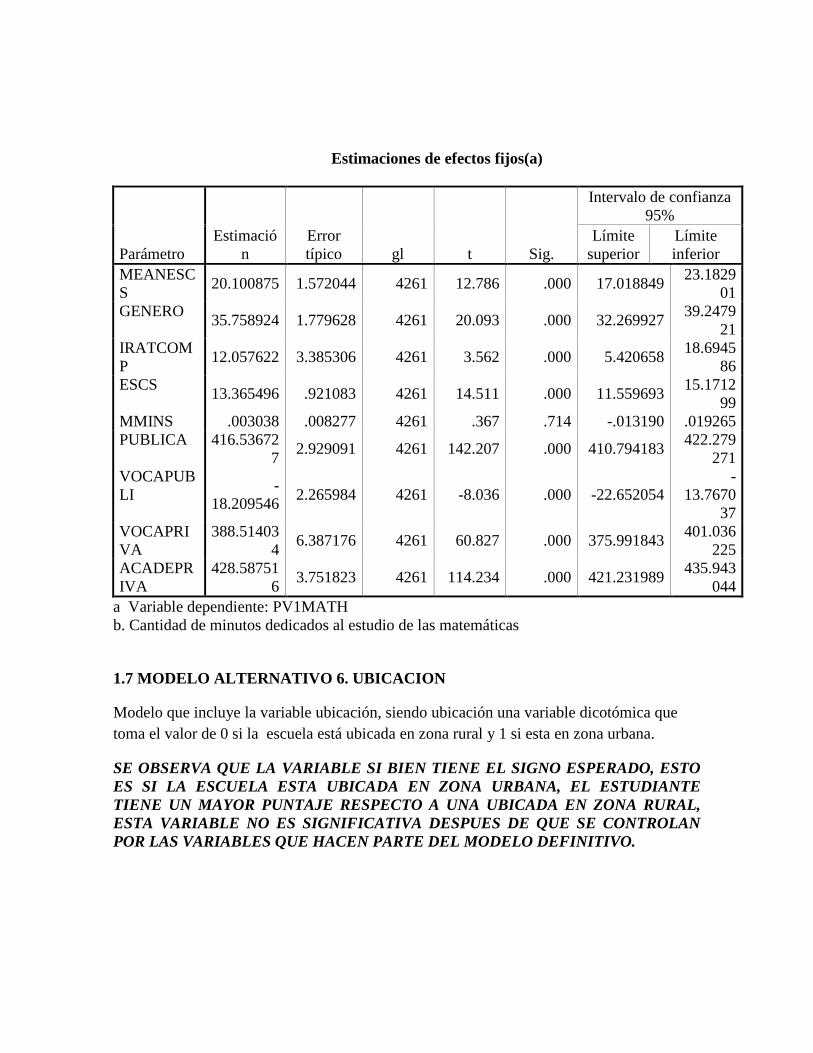
Estimaciones de efectos fijos(a)
Parámetro
Estimació
n
Error
típico gl t Sig.
Intervalo de confianza
95%
Límite
superior
Límite
inferior
MEANESC
S 20.100875 1.572044 4261 12.786 .000 17.018849
23.1829
01
GENERO 35.758924 1.779628 4261 20.093 .000 32.269927
39.2479
21
IRATCOM
P 12.057622 3.385306 4261 3.562 .000 5.420658
18.6945
86
ESCS 13.365496 .921083 4261 14.511 .000 11.559693
15.1712
99
MMINS .003038 .008277 4261 .367 .714 -.013190 .019265
PUBLICA 416.53672
7 2.929091 4261 142.207 .000 410.794183
422.279
271
VOCAPUB
LI -
18.209546 2.265984 4261 -8.036 .000 -22.652054
-
13.7670
37
VOCAPRI
VA
388.51403
4 6.387176 4261 60.827 .000 375.991843
401.036
225
ACADEPR
IVA
428.58751
6 3.751823 4261 114.234 .000 421.231989
435.943
044
a Variable dependiente: PV1MATH
b. Cantidad de minutos dedicados al estudio de las matemáticas
1.7 MODELO ALTERNATIVO 6. UBICACION
Modelo que incluye la variable ubicación, siendo ubicación una variable dicotómica que
toma el valor de 0 si la escuela está ubicada en zona rural y 1 si esta en zona urbana.
SE OBSERVA QUE LA VARIABLE SI BIEN TIENE EL SIGNO ESPERADO, ESTO
ES SI LA ESCUELA ESTA UBICADA EN ZONA URBANA, EL ESTUDIANTE
TIENE UN MAYOR PUNTAJE RESPECTO A UNA UBICADA EN ZONA RURAL,
ESTA VARIABLE NO ES SIGNIFICATIVA DESPUES DE QUE SE CONTROLAN
POR LAS VARIABLES QUE HACEN PARTE DEL MODELO DEFINITIVO.
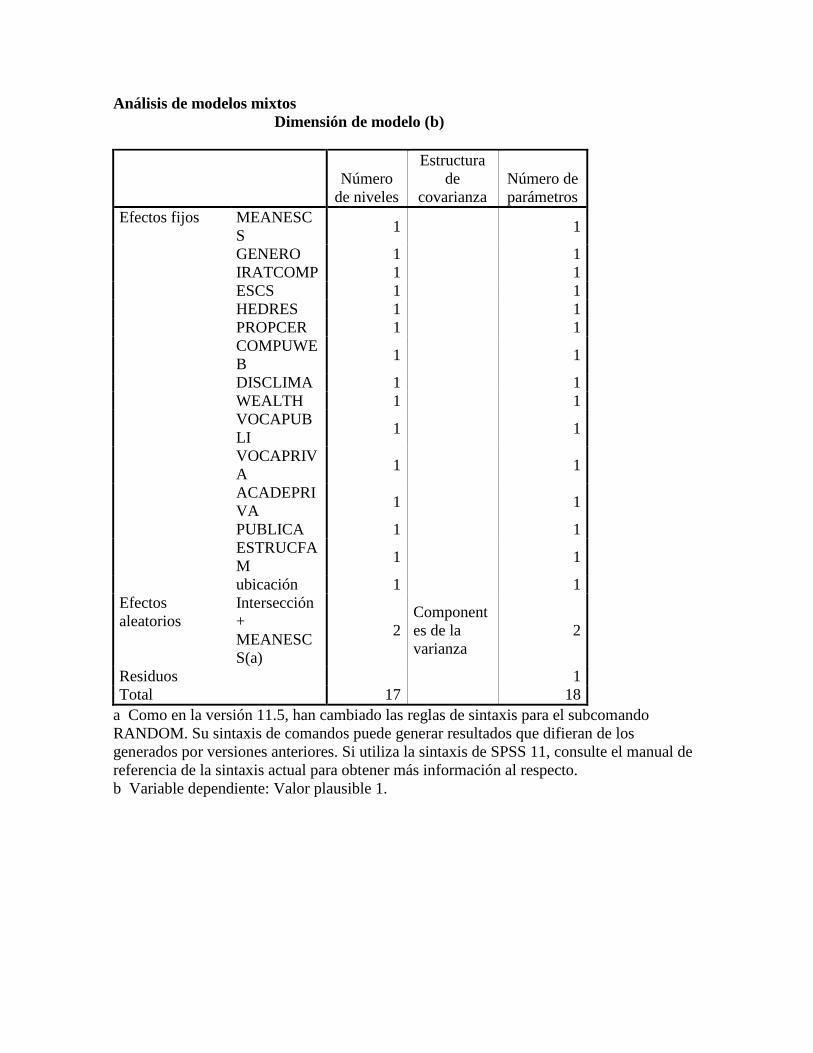
Análisis de modelos mixtos
Dimensión de modelo (b)
Número
de niveles
Estructura
de
covarianza
Número de
parámetros
Efectos fijos MEANESC
S 1 1
GENERO 1 1
IRATCOMP 1 1
ESCS 1 1
HEDRES 1 1
PROPCER 1 1
COMPUWE
B 1 1
DISCLIMA 1 1
WEALTH 1 1
VOCAPUB
LI 1 1
VOCAPRIV
A 1 1
ACADEPRI
VA 1 1
PUBLICA 1 1
ESTRUCFA
M 1 1
ubicación 1 1
Efectos
aleatorios
Intersección
+
MEANESC
S(a)
2
Component
es de la
varianza
2
Residuos 1
Total 17 18
a Como en la versión 11.5, han cambiado las reglas de sintaxis para el subcomando
RANDOM. Su sintaxis de comandos puede generar resultados que difieran de los
generados por versiones anteriores. Si utiliza la sintaxis de SPSS 11, consulte el manual de
referencia de la sintaxis actual para obtener más información al respecto.
b Variable dependiente: Valor plausible 1.
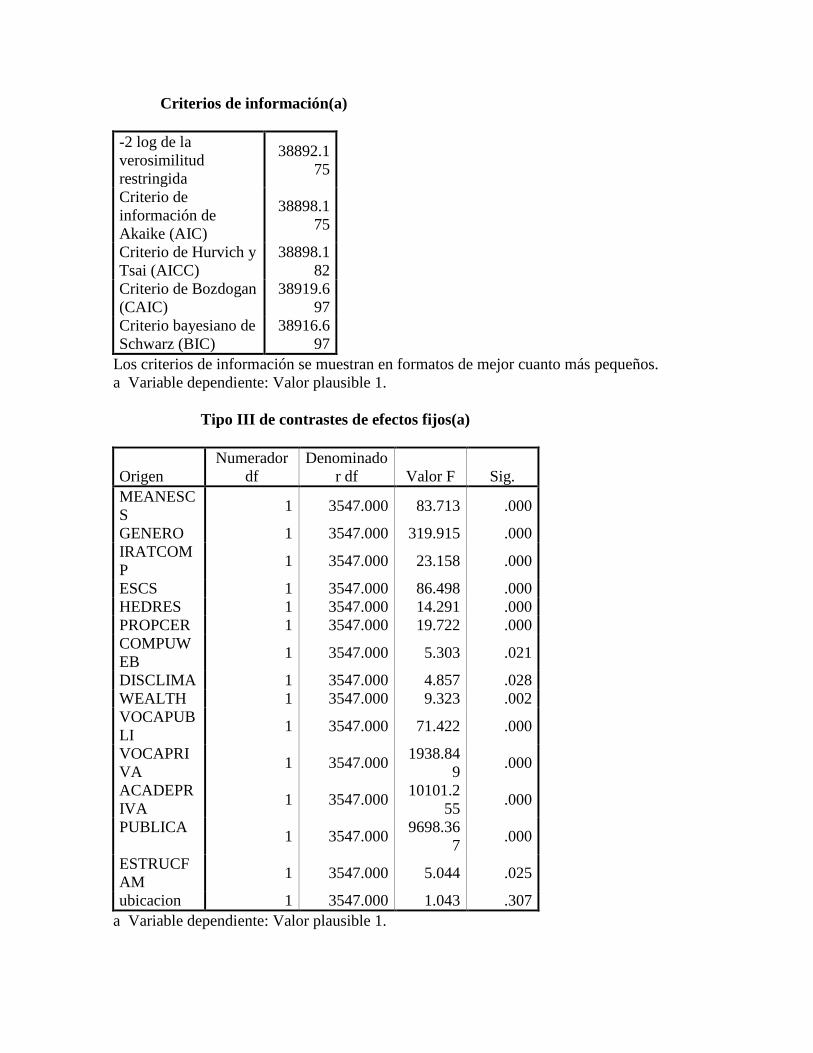
Criterios de información(a)
-2 log de la
verosimilitud
restringida
38892.1
75
Criterio de
información de
Akaike (AIC)
38898.1
75
Criterio de Hurvich y
Tsai (AICC)
38898.1
82
Criterio de Bozdogan
(CAIC)
38919.6
97
Criterio bayesiano de
Schwarz (BIC)
38916.6
97
Los criterios de información se muestran en formatos de mejor cuanto más pequeños.
a Variable dependiente: Valor plausible 1.
Tipo III de contrastes de efectos fijos(a)
Origen
Numerador
df
Denominado
r df Valor F Sig.
MEANESC
S 1 3547.000 83.713 .000
GENERO 1 3547.000 319.915 .000
IRATCOM
P 1 3547.000 23.158 .000
ESCS 1 3547.000 86.498 .000
HEDRES 1 3547.000 14.291 .000
PROPCER 1 3547.000 19.722 .000
COMPUW
EB 1 3547.000 5.303 .021
DISCLIMA 1 3547.000 4.857 .028
WEALTH 1 3547.000 9.323 .002
VOCAPUB
LI 1 3547.000 71.422 .000
VOCAPRI
VA 1 3547.000
1938.84
9 .000
ACADEPR
IVA 1 3547.000
10101.2
55 .000
PUBLICA 1 3547.000
9698.36
7 .000
ESTRUCF
AM 1 3547.000 5.044 .025
ubicacion 1 3547.000 1.043 .307
a Variable dependiente: Valor plausible 1.

Estimaciones de efectos fijos(a)
Parámetro
Estimació
n
Error
típico gl t Sig.
Intervalo de confianza
95%
Límite
superior
Límite
inferior
MEANESC
S 17.752567 1.940280
3547.00
0 9.149 .000 13.948389
21.5567
44
GENERO 35.023531 1.958134
3547.00
0 17.886 .000 31.184349
38.8627
12
IRATCOM
P 18.706811 3.887341
3547.00
0 4.812 .000 11.085163
26.3284
60
ESCS 12.104693 1.301520
3547.00
0 9.300 .000 9.552890
14.6564
95
HEDRES 4.470949 1.182667
3547.00
0 3.780 .000 2.152172
6.78972
5
PROPCER .113778 .025620
3547.00
0 4.441 .000 .063547 .164010
COMPUW
EB .093091 .040424
3547.00
0 2.303 .021 .013834 .172348
DISCLIMA 2.729594 1.238575
3547.00
0 2.204 .028 .301203
5.15798
4
WEALTH 4.506179 1.475800
3547.00
0 3.053 .002 1.612676
7.39968
1
VOCAPUB
LI -
20.287222 2.400527
3547.00
0 -8.451 .000 -24.993774
-
15.5806
70
VOCAPRI
VA
373.46478
7 8.481598
3547.00
0 44.032 .000 356.835485
390.094
089
ACADEPR
IVA
417.13759
2 4.150416
3547.00
0 100.505 .000 409.000149
425.275
035
PUBLICA 397.97568
2 4.041171
3547.00
0 98.480 .000 390.052429
405.898
936
ESTRUCF
AM -4.671563 2.079986
3547.00
0 -2.246 .025 -8.749652 -.593473
ubicacion 2.421980 2.371335
3547.00
0 1.021 .307 -2.227338
7.07129
9
a Variable dependiente: Valor plausible 1.

Parámetros de covarianza
Estimaciones de parámetros de covarianza
ANEXO 2 variables del primer nivel
ANEXO 2.1
ANEXO 2.2
Estimaciones de parámetros de covarianza
3273.2742 77.726084 42.113 .000 3124.424510 3429.215
Parámetro
Residuos
Estimación Error típico Wald Z Sig. Límite inf erior
Límite
superior
Interv alo de conf ianza 95%

ANEXO 2.3
ANEXO 2.4
ANEXO 2.5
Fuente: PISA, 2012
