universidad de castilla-la mancha escuela … · universidad de castilla-la mancha escuela superior...
TRANSCRIPT

UNIVERSIDAD DE CASTILLA-LA MANCHA
ESCUELA SUPERIOR DE INFORMÁTICA
INGENIERÍA
EN INFORMÁTICA
PROYECTO FIN DE CARRERA
PROLETOOL: Una herramienta para el apoyo en el estudio y la enseñanzade la asignatura Procesadores de Lenguajes
Pedro Antonio Santos Cano
Septiembre, 2005

UNIVERSIDAD DE CASTILLA-LA MANCHA
ESCUELA SUPERIOR DE INFORMÁTICA
Informática
PROYECTO FIN DE CARRERA
PROLETOOL: Una herramienta para el apoyo en el estudio y la enseñanzade la asignatura Procesadores de Lenguajes
Autor: Pedro Antonio Santos CanoDirector: José Jesús Castro Sánchez
Septiembre, 2005

TRIBUNAL:
Presidente:Vocal:Secretario:
FECHA DE DEFENSA:
CALIFICACIÓN:
PRESIDENTE VOCAL SECRETARIO
Fdo.: Fdo.: Fdo.:

RESUMEN.
En la asignatura de Procesadores de Lenguajes, se aprenden las técnicas de diseño y cons-trucción de traductores, haciendo especial énfasis en las técnicas de diseño del analizadorsintáctico. Para que los alumnos, aprendan de forma sólida estos métodos de diseño, es muyimportante que dispongan de ejercicios resueltos. Pero a menudo no hay tantos como ellosquisieran. Es en este contexto, donde se hace necesario la construcción de una herramienta,que permita al alumno la comprobación de las soluciones obtenidas a ejercicios propuestospor otros o por él mismo.
Pero el proyecto no sólo está dirigido a los alumnos de la asignatura de Procesadores deLenguajes, en general, está dirigido a cualquier estudiante de la comunidad universitaria.
Otro aspecto importante del proyecto es la construcción de la herramienta. Uno de losprincipales objetivos en el diseño interno de la herramienta, ha sido la de ser la base para laconstrucción futura de más herramientas para la enseñanza de Teoría de Autómatas y Lengua-jes Formales. Para poder cumplir este objetivo, se ha buscado lo máximo posible, que la he-rramienta fuera muy fácil de ampliar. Ha sido de gran ayuda para cumplir este objetivo lautilización de las arquitecturas multicapa y los patrones de diseño.
Para concluir, hay que decir, que parte del curso pasado la herramienta ya estuvo en fun-cionamiento y en vista de los resultados obtenidos se prevé que seguirá en uso en los próximoscursos. En el tiempo que ha estado en pruebas, el nivel de uso de la herramienta ha sido bas-tante alto: los usuarios han resuelto 784 ejercicios de análisis sintáctico y 71 simulaciones deanalizadores sintácticos. Pero además, los usuarios, no sólo han utilizado la herramienta, sinoque han aportado sus sugerencias y opiniones sobre la misma. Lo mejor de todo es que losusuarios, lo que han valorado más positivamente de la herramienta, ha sido la utilidad de laherramienta a la hora de estudiar. Lo cual hace pensar que se ha cumplido el principal objetivodel proyecto y es el ser una herramienta de apoyo a la enseñanza y estudio de la asignatura deProcesadores de Lenguajes.
Desde esta web puede acceder a la herramienta:http://personal.oreto.inf-cr.uclm.es/jjcastro/Docencia/PrimerSegundoCiclo/PL/materiales
2

DEDICATORIA.
Este proyecto está dedicado a mis padres y hermanos, gracias por vuestro continuo apoyoy confianza en mí.
AGRADECIMIENTOS.
Quiero expresar mi agradecimiento al director de este proyecto, José Jesús Castro Sánchez,por su ayuda y consejos para la realización del mismo.
También se lo quiero agradecer a la Escuela Superior de Informática de la Universidad deCastilla-La Mancha, ya que el proyecto ha sido desarrollado bajo su programa de monitoresde laboratorio, para la asignatura de Procesadores de Lenguajes.
3

ÍNDICE GENERAL
1. Introducción 121.1. Introducción a la Compilación. . . . . . . . . . . . . . . . . . . . . . . . . 121.2. Introducción a la Asignatura de Procesadores de Lenguajes. . . . . . . . . . 19
1.2.1. Introducción a los traductores. . . . . . . . . . . . . . . . . . . . . 191.2.2. Análisis léxico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.2.3. Análisis Sintáctico. . . . . . . . . . . . . . . . . . . . . . . . . . . 201.2.4. Análisis sintáctico descendente. . . . . . . . . . . . . . . . . . . . . 201.2.5. Análisis sintáctico ascendente. . . . . . . . . . . . . . . . . . . . . 211.2.6. Traducción dirigida por la sintaxis. . . . . . . . . . . . . . . . . . . 211.2.7. Comprobación de tipos. . . . . . . . . . . . . . . . . . . . . . . . . 221.2.8. Lenguajes intermedios. . . . . . . . . . . . . . . . . . . . . . . . . 221.2.9. Organización y gestión de la memoria. . . . . . . . . . . . . . . . . 221.2.10. Generación de código. . . . . . . . . . . . . . . . . . . . . . . . . 231.2.11. Optimización de código. . . . . . . . . . . . . . . . . . . . . . . . 23
2. Objetivos 24
3. Enseñanza y estudio de la asignatura 273.1. Introducción. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .273.2. Gramáticas libres de contexto (GLC). . . . . . . . . . . . . . . . . . . . . . 283.3. Derivación y árbol de análisis sintáctico. . . . . . . . . . . . . . . . . . . . 293.4. Algoritmo de Cocke-Younger-Kasami. . . . . . . . . . . . . . . . . . . . . 313.5. Algoritmo de Early . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323.6. Funciones útiles para el análisis sintáctico. . . . . . . . . . . . . . . . . . . 33
3.6.1. Cálculo de los símbolos anulables. . . . . . . . . . . . . . . . . . . 333.6.2. Cálculo de los símbolos iniciales. . . . . . . . . . . . . . . . . . . . 343.6.3. Cálculo de los símbolos seguidores. . . . . . . . . . . . . . . . . . 35
3.7. Análisis Sintáctico Descendente. . . . . . . . . . . . . . . . . . . . . . . . 373.7.1. Analizador sintáctico recursivo con retroceso. . . . . . . . . . . . . 373.7.2. Gramáticas LL(1). . . . . . . . . . . . . . . . . . . . . . . . . . . . 373.7.3. Analizador sintáctico recursivo sin retroceso. . . . . . . . . . . . . 40
3.8. Análisis Sintáctico Ascendente. . . . . . . . . . . . . . . . . . . . . . . . . 443.8.1. Implantación de una analizador por desplazamiento-reducción. . . . 463.8.2. Analizador sintáctico LR. . . . . . . . . . . . . . . . . . . . . . . . 473.8.3. Generación de la tabla de análisis. . . . . . . . . . . . . . . . . . . 493.8.4. Construcción de las tablas de análisis SLR. . . . . . . . . . . . . . . 55
4

3.8.5. Construcción de las tablas de análisis LR. . . . . . . . . . . . . . . 583.8.6. Construcción de las tablas de análisis LALR. . . . . . . . . . . . . 62
4. Análisis y diseño de la herramienta 654.1. Análisis de requisitos generales. . . . . . . . . . . . . . . . . . . . . . . . . 654.2. Análisis de casos de uso. . . . . . . . . . . . . . . . . . . . . . . . . . . . 684.3. Diseño de la arquitectura de la herramienta. . . . . . . . . . . . . . . . . . 754.4. Diseño del compilador. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
4.4.1. Diseño del lenguaje de entrada. . . . . . . . . . . . . . . . . . . . . 764.4.2. Diseño del lenguaje de salida. . . . . . . . . . . . . . . . . . . . . . 89
5. Implementación del compilador 925.1. Arquitectura del compilador. . . . . . . . . . . . . . . . . . . . . . . . . . 935.2. Interfaz del compilador. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 945.3. Etapa de análisis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5.3.1. Implementación del analizador léxico. . . . . . . . . . . . . . . . . 965.3.2. Implementación del analizador sintáctico. . . . . . . . . . . . . . . 995.3.3. Implementación final del parser. . . . . . . . . . . . . . . . . . . .1015.3.4. Tabla de símbolos. . . . . . . . . . . . . . . . . . . . . . . . . . .1025.3.5. Implementación del analizador semántico. . . . . . . . . . . . . . . 1045.3.6. Gramática con atributos. . . . . . . . . . . . . . . . . . . . . . . .106
5.4. Acoplamiento entre la etapa de análisis y la de síntesis. . . . . . . . . . . . 1095.5. Etapa de síntesis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .110
5.5.1. Comunicación entre la etapa de análisis y síntesis. . . . . . . . . . . 1115.5.2. Estructura de datos. . . . . . . . . . . . . . . . . . . . . . . . . . .1125.5.3. Generadores de tablas de análisis. . . . . . . . . . . . . . . . . . .1145.5.4. Generación de los archivos de salida(XML). . . . . . . . . . . . . . 1225.5.5. Simulador. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1265.5.6. Sistema de control de eventos. . . . . . . . . . . . . . . . . . . . .130
5.6. Sistema de pruebas para el compilador. . . . . . . . . . . . . . . . . . . . .131
6. Implementación de la herramienta 1346.1. Diseño. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .134
6.1.1. Arquitectura de la Web. . . . . . . . . . . . . . . . . . . . . . . . .1346.1.2. Procesamiento general de las peticiones. . . . . . . . . . . . . . . . 1376.1.3. Comunicación entre la Web y el Compilador. . . . . . . . . . . . . 1376.1.4. Diseño de la interfaz. . . . . . . . . . . . . . . . . . . . . . . . . .1406.1.5. Login . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1446.1.6. Obtención del usuario actual. . . . . . . . . . . . . . . . . . . . . .1456.1.7. Alta de usuarios. . . . . . . . . . . . . . . . . . . . . . . . . . . . .1476.1.8. Recordar password. . . . . . . . . . . . . . . . . . . . . . . . . . .1486.1.9. Control de acceso. . . . . . . . . . . . . . . . . . . . . . . . . . . .1496.1.10. Gestión de sobrecargas. . . . . . . . . . . . . . . . . . . . . . . . .1506.1.11. Log de errores. . . . . . . . . . . . . . . . . . . . . . . . . . . . .1526.1.12. Envío de noticias. . . . . . . . . . . . . . . . . . . . . . . . . . . .154
5

6.1.13. Generación de resultados(tablas de análisis). . . . . . . . . . . . . . 1556.1.14. Diseño de la base de datos. . . . . . . . . . . . . . . . . . . . . . .156
6.2. Tecnología utilizada. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1586.2.1. Script del servidor. . . . . . . . . . . . . . . . . . . . . . . . . . .1586.2.2. Base de datos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .158
7. Conclusiones y Propuestas 1617.1. Conclusiones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1617.2. Propuestas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .164
8. Manual de usuario 1658.1. Pantalla de inicio. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .165
8.1.1. Login . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1668.1.2. Compilar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1678.1.3. Simulación. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1758.1.4. Formato de los listados. . . . . . . . . . . . . . . . . . . . . . . . .177
8.2. Funciones de administración. . . . . . . . . . . . . . . . . . . . . . . . . .1788.2.1. Gestión de usuarios. . . . . . . . . . . . . . . . . . . . . . . . . . .1798.2.2. Gestión de la configuración. . . . . . . . . . . . . . . . . . . . . .1848.2.3. Reset de la base de datos. . . . . . . . . . . . . . . . . . . . . . . .1868.2.4. Gestión de ejemplos. . . . . . . . . . . . . . . . . . . . . . . . . .1878.2.5. Gestión de noticias. . . . . . . . . . . . . . . . . . . . . . . . . . .1898.2.6. Estadísticas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .190
9. Anexos 1959.1. El generador de analizadores léxicos JFlex. . . . . . . . . . . . . . . . . . .1959.2. El generador de analizadores sintácticos LALR JCup. . . . . . . . . . . . . 197
6

ÍNDICE DE FIGURAS
2.1. Esquema de la herramienta. . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.1. Interacción entre el analizador léxico y el sintáctico. . . . . . . . . . . . . . 273.2. Ejemplo de árbol sintáctico. . . . . . . . . . . . . . . . . . . . . . . . . . . 303.3. Ejemplo de gramática ambigua. . . . . . . . . . . . . . . . . . . . . . . . . 313.4. Eliminación de la recursividad por la izquierda. . . . . . . . . . . . . . . . 383.5. Analizador sintáctico predictivo no recursivo. . . . . . . . . . . . . . . . . 403.6. Analizador sintáctico LR. . . . . . . . . . . . . . . . . . . . . . . . . . . . 483.7. Autómata finito generado mediante el método SLR. . . . . . . . . . . . . . 543.8. Autómata finito generado mediante el método LR. . . . . . . . . . . . . . . 603.9. Autómata finito generado mediante el método LALR. . . . . . . . . . . . . 63
4.1. Diagrama de casos de uso para el usuario. . . . . . . . . . . . . . . . . . . 734.2. Diagrama de casos de uso para el administrador. . . . . . . . . . . . . . . . 744.3. Arquitectura cliente/servidor de la herramienta.. . . . . . . . . . . . . . . . 764.4. Descripción BNF del lenguaje. . . . . . . . . . . . . . . . . . . . . . . . . 854.5. Esquema XML para la solución de los ejercicios de análisis sintáctico. . . . 904.6. Esquema XML para la salida de la simulación. . . . . . . . . . . . . . . . . 91
5.1. Arquitectura del compilador. . . . . . . . . . . . . . . . . . . . . . . . . . 935.2. Utilización del compilador con la interfaz por consola. . . . . . . . . . . . . 955.3. Generación del analizador léxico. . . . . . . . . . . . . . . . . . . . . . . . 975.4. Generación del analizador sintáctico. . . . . . . . . . . . . . . . . . . . . .1005.5. Compilación del lexer y el parser. . . . . . . . . . . . . . . . . . . . . . . .1015.6. Diagrama de clases del Parser. . . . . . . . . . . . . . . . . . . . . . . . .1015.7. Diagrama de clases de la tabla de símbolos. . . . . . . . . . . . . . . . . . .1035.8. Tratamiento de los grupos de producciones. . . . . . . . . . . . . . . . . .1045.9. Árbol de análisis sintáctico utilizado en la gramática con atributos. . . . . . 1085.10. Progresión de la pila en el análisis sintáctico. . . . . . . . . . . . . . . . . .1095.11. Acoplamiento entre la etapa de análisis y síntesis. . . . . . . . . . . . . . . 1095.12. Comunicación entre la etapa de análisis y síntesis. . . . . . . . . . . . . . . 1115.13. Diagrama de clases de las estructuras de datos. . . . . . . . . . . . . . . . .1125.14. Diagrama de clases de los generadores de tablas de análisis. . . . . . . . . . 1155.15. Creación de un nuevo generador. . . . . . . . . . . . . . . . . . . . . . . .1175.16. Formato de la generación del autómata. . . . . . . . . . . . . . . . . . . . .1215.17. Diagrama de clases del generador del XML. . . . . . . . . . . . . . . . . .122
7

5.18. Generación del XML de salida. . . . . . . . . . . . . . . . . . . . . . . . .1255.19. Diagrama de clases del simulador. . . . . . . . . . . . . . . . . . . . . . .1275.20. Diagrama de secuencia de simulación. . . . . . . . . . . . . . . . . . . . .1275.21. Integración del simulador en el sistema de generación. . . . . . . . . . . . . 1295.22. Gestión de eventos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1305.23. Diagrama de clases del gestor de eventos. . . . . . . . . . . . . . . . . . . .131
6.1. Arquitectura de 3 capas. . . . . . . . . . . . . . . . . . . . . . . . . . . . .1356.2. Diagrama de paquetes de la web. . . . . . . . . . . . . . . . . . . . . . . .1366.3. Interacción general entre presentación y dominio. . . . . . . . . . . . . . . 1376.4. Generación del .xml de salida. . . . . . . . . . . . . . . . . . . . . . . . . .1396.5. Comunicación entre el script y el compilador. . . . . . . . . . . . . . . . .1396.6. Estructura de la interfaz. . . . . . . . . . . . . . . . . . . . . . . . . . . . .1406.7. Diagrama de clases del sistema de formularios. . . . . . . . . . . . . . . . .1416.8. Diagrama de secuencia para la generación del formulario. . . . . . . . . . . 1426.9. Generación de la página de inicio. . . . . . . . . . . . . . . . . . . . . . . .1426.10. Registro de la cookie en el cliente. . . . . . . . . . . . . . . . . . . . . . .1436.11. Envío posterior de la cookie. . . . . . . . . . . . . . . . . . . . . . . . . .1446.12. Diagrama de secuencia de login. . . . . . . . . . . . . . . . . . . . . . . .1456.13. Obtención del usuario actual. . . . . . . . . . . . . . . . . . . . . . . . . .1466.14. Alta de un nuevo usuario. . . . . . . . . . . . . . . . . . . . . . . . . . . .1476.15. Diagrama de secuencia para recordar el password. . . . . . . . . . . . . . . 1486.16. Control de acceso. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1506.17. Control de sobrecargas. . . . . . . . . . . . . . . . . . . . . . . . . . . . .1516.18. Creación de sesiones de compilación. . . . . . . . . . . . . . . . . . . . . .1526.19. Registro de un error en el log del sistema. . . . . . . . . . . . . . . . . . . .1536.20. Envío de noticias. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1546.21. Formateo de las tablas de análisis(HTML). . . . . . . . . . . . . . . . . . .1556.22. Estructura de la base de datos. . . . . . . . . . . . . . . . . . . . . . . . . .156
7.1. Porcentaje de los tipos de análisis realizados. . . . . . . . . . . . . . . . . .1627.2. Porcentaje de los tipos de simulaciones realizados. . . . . . . . . . . . . . . 163
8.1. Interfaz de entrada. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1668.2. Interfaz de login. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1678.3. Formas de introducir el texto fuente. . . . . . . . . . . . . . . . . . . . . .1688.4. Cuadro de navegación. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1688.5. Cuadro con la gramática de entrada. . . . . . . . . . . . . . . . . . . . . . .1698.6. Tabla de análisis LL(1) con conflictos. . . . . . . . . . . . . . . . . . . . .1708.7. Símbolos iniciales de la gramática LL(1). . . . . . . . . . . . . . . . . . . .1708.8. Ejemplo de tabla de estados. . . . . . . . . . . . . . . . . . . . . . . . . . .1718.9. Ejemplo de tabla de análisis descendente. . . . . . . . . . . . . . . . . . . .1728.10. Ejemplo de tabla de análisis ascendente. . . . . . . . . . . . . . . . . . . .1738.11. Interfaz de entrada para la simulación. . . . . . . . . . . . . . . . . . . . .1758.12. Traza de salida de la simulación. . . . . . . . . . . . . . . . . . . . . . . .176
8

8.13. Traza de salida de la simulación con errores. . . . . . . . . . . . . . . . . .1778.14. Formato de los listados. . . . . . . . . . . . . . . . . . . . . . . . . . . . .1788.15. Control de acceso mediante password. . . . . . . . . . . . . . . . . . . . .1788.16. Pantalla para agregar un nuevo usuario. . . . . . . . . . . . . . . . . . . . .1798.17. Interfaz para cargar usuarios. . . . . . . . . . . . . . . . . . . . . . . . . .1808.18. Interfaz para confirmar la carga de usuarios. . . . . . . . . . . . . . . . . .1808.19. Listado de usuarios. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1818.20. Interfaz para agregar un nuevo usuario. . . . . . . . . . . . . . . . . . . . .1828.21. Interfaz para la activación de usuarios. . . . . . . . . . . . . . . . . . . . .1838.22. Interfaz para recordar el password. . . . . . . . . . . . . . . . . . . . . . .1838.23. Configuración de los parámetros de un usuario. . . . . . . . . . . . . . . . .1848.24. Configuración de los perfiles. . . . . . . . . . . . . . . . . . . . . . . . . .1858.25. Cambio del password. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1858.26. Configuración del email. . . . . . . . . . . . . . . . . . . . . . . . . . . . .1868.27. Reset de la base de datos. . . . . . . . . . . . . . . . . . . . . . . . . . . .1878.28. Edición de ejemplos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1888.29. Listado de ejemplos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1888.30. Interfaz para agregar nuevas noticias. . . . . . . . . . . . . . . . . . . . . .1898.31. Interfaz para listar noticias. . . . . . . . . . . . . . . . . . . . . . . . . . .1898.32. Sumario de las estadísticas. . . . . . . . . . . . . . . . . . . . . . . . . . .1918.33. Gráfica circular. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1928.34. Gráfica circular 3D. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1938.35. Gráfica de barras. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1938.36. Gráfica de barras 3D. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .194
9

ÍNDICE DE TABLAS
3.1. Traza del analizador sintáctico predictivo con la entradaid + id * id . . . . . 423.2. Tabla de análisis LL(1), utilizada en la simulación de la Tabla3.1 . . . . . . . 443.3. Ejemplo de análisis por desplazamiento/reducción de la cadenaa b b c d e . . 473.4. Tabla de análisis del ejemplo SLR. . . . . . . . . . . . . . . . . . . . . . . 563.5. Tabla de análisis del ejemplo LR. . . . . . . . . . . . . . . . . . . . . . . . 623.6. Tabla de análisis del ejemplo LALR. . . . . . . . . . . . . . . . . . . . . . 64
4.1. Lista de palabras reservadas. . . . . . . . . . . . . . . . . . . . . . . . . . 78
7.1. Resumen de las compilaciones. . . . . . . . . . . . . . . . . . . . . . . . .1627.2. Simulaciones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .163
10

ÍNDICE DE ALGORITMOS
1. Algoritmo CYK . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322. Cálculo de los símbolos anulables de una gramática. . . . . . . . . . . . . . 333. Cálculo de los iniciales de una gramática. . . . . . . . . . . . . . . . . . . . 354. Cálculo de los seguidores de una gramática. . . . . . . . . . . . . . . . . . 365. Eliminación de la recursividad por la izquierda de una gramática. . . . . . . 396. Programa de análisis sintáctico predictivo no recursivo. . . . . . . . . . . . 417. Generación de la tabla de análisis LL(1). . . . . . . . . . . . . . . . . . . . 438. Programa de análisis sintáctico LR. . . . . . . . . . . . . . . . . . . . . . . 499. Cálculo del cierre. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5210. Cálculo del sucesor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5211. Cálculo del conjunto de estados. . . . . . . . . . . . . . . . . . . . . . . . 5312. Generación de la tabla de acción. . . . . . . . . . . . . . . . . . . . . . . . 5513. Generación de la tabla Ir_A. . . . . . . . . . . . . . . . . . . . . . . . . . . 5614. Cálculo del Cierre. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5915. Generación de la tabla de acción. . . . . . . . . . . . . . . . . . . . . . . . 61
11

CAPÍTULO 1.
INTRODUCCIÓN
1.1. Introducción a la Compilación.
Los ordenadores son máquinas simples que lo único que pueden hacer es ejecutaruna secuencia de órdenes expresadas en unlenguaje máquinaentendible por el ordenador.El lenguaje máquina es un conjunto de códigos numéricos, que le indican a la máquina lasoperaciones que éste debe realizar. Estas operaciones son muy simples(sumas, restas, mul-tiplicaciones), y agrupadas en un conjunto mayor conforman un programa que realiza lasfunciones para las cuales se han creado.
Pero existe un problema y es que estos códigos de operación son dependientes de lamáquina en cuestión, es decir, que hacer el mismo programa para otra máquina implica volvera codificar dicho programa otra vez en los códigos de operación para esa nueva máquina. Estoes algo costoso tanto en tiempo como en esfuerzo.
Los programas escritos en lenguaje máquina tienen la ventaja de ejecutarse muy efi-cientemente, ya que el programador escribe el programa de forma específica para la máquinaen cuestión, pudiendo aprovecharse de las características especificas de la máquina, obte-niendo de ella el máximo rendimiento. Sin embargo, la creación de programas en lenguajemáquina tiene más inconvenientes que ventajas. La primera dificultad es que es una tareadifícil y engorrosa para la forma de trabajar humana. Ya que para crear un buen programaen lenguaje máquina se hace necesario tener un alto conocimiento de las características in-ternas de la máquina en cuestión. Una de las facilidades que se tiene para la codificaciónen lenguaje máquina es la utilización dellenguaje ensamblador. Este lenguaje utiliza unanotación simbólica para representar los códigos de operación, estos códigos son más fácilesde recordar que el lenguaje máquina. Pero aún utilizando ellenguaje ensambladorpara lacreación de programas, dicha tarea sigue siendo difícil y engorrosa. En la actualidad, como eslógico pensar, la tarea de generar el código máquina es una tarea que la realizan las máquinasautomáticamente.
0La introducción está basada en el Proyecto Docente e Investigador del Profesor José Jesús Castro Sánchez,para el concurso al cuerpo de Profesores Titulares de la Universidad. Área: Lenguajes y Sistemas Informáti-cos(Escuela Superior de Informática)[33]
12

Lo más deseable para un humano es que se pudieran crear programas en un lengua-je lo más cercano a nuestra forma de trabajar. Lo ideal, podría ser por ejemplo el lenguajehumano, pero hoy en día esta forma de crear programas no está lo suficientemente desarro-llada. Lo que sí se ha conseguido en la actualidad es que los lenguajes de programación seanindependientes de la máquina. De esta forma no hace falta crear completamente diferentesversiones de un mismo programa para diferentes máquinas. A esta característica se le llamaportabilidad, la cual ahorra mucho tiempo de trabajo al codificar un sólo programa para dife-rentes máquinas, que en definitiva significa reducción de costes.
A principios de los años 50, John Backus dirigió para I.B.M una investigación so-bre el lenguaje algebraico, la cual dio como resultado el lenguaje FORTRAN(FORmulaeTRANslator). Este lenguaje puede ser considerado como el primer lenguaje de alto nivel.Este lenguaje fue necesario hacerlo ejecutable en una máquina. Surge así por primera vezel concepto de traductor y más concretamente el concepto de compilador, que es empleadocuando el lenguaje a traducir es de alto nivel y el lenguaje traducido es de bajo nivel.
En Europa, mientras tanto, la investigación en algunas universidades se centraba enla definición de un lenguaje que fuese independiente de la máquina. Esta investigación hacíauso de los resultados obtenidos por Chomsky, dentro de su estudio de los lenguajes naturales,sobre gramáticas libres de contexto.
De este modo, en la Universidad de Munich, el profesor F.L. Bauer lidera un grupo,que junto con el comité de la ACM en el que participa J. Backus, define un lenguaje deuso múltiple independiente de la máquina. A finales de 1958, la ACM publicó una descrip-ción sobre este lenguaje, denominado IAL(International Algebraic Language). Más tarde estelenguaje pasaría a llamarse ALGOL (ALGOritmic Language), modificando su nombre concada una de las revisiones que sufrió denominándose ALGOL 60 y ALGOL 68.
Este lenguaje no tuvo mucho éxito comercial, sin embargo es considerado como ellenguaje más importante de la época, por su influencia en el desarrollo de lenguajes de progra-mación posteriores. En ALGOL aparecen por primera vez conceptos que hoy en día incorpo-ran la mayoría de los lenguajes. Por ejemplo, el concepto de variables locales a un bloque decódigo, la declaración explícita de tipo para todos los identificadores, las estructuras iterativasmás generales, la recursividad, el paso de parámetros por valor y por referencia. También fueel primer lenguaje descrito con la notación BNF(Backus-Naur Form).
La programación en un lenguaje de alto nivel o en un lenguaje ensamblador re-quiere, por tanto, algún tipo de interfaz con el lenguaje máquina para que el programa puedaejecutarse. Las tres interfaces más comunes son: un ”ensamblador”, un ”compilador” y un”interprete”. El ensamblador y el compilador traducen el programa a otro lenguaje equiva-lente en el lenguaje máquina como un paso separado antes de la ejecución. Por otra parte, elinterprete, no genera un programa objeto, sino que ejecuta directamente las instrucciones dellenguaje de alto nivel.
13

En la década de los 50, la construcción de compiladores se consideró como un traba-jo difícil, destacar un dato en este sentido, el primer compilador FORTRAN necesitó 18 añosde trabajo en grupo [23]. Sin embargo, el desarrollo de nuevos lenguajes de programación dealto nivel supone el avance en la investigación de la técnica de compilación y la aparición detécnicas sistemáticas para el manejo de tareas que surgen en la compilación.
A finales de la década de los 50, en el año 1958, se ofrece una solución al problemade que un compilador fuera utilizable por varias máquinas, ésta consistía en dividir el compi-lador en dos etapas, una inicial(de análisis) y otra final(de síntesis), que se denominan ”frontend” y ”back end”. En la etapa inicial se analiza el programa fuente y en la etapa final seproduce la generación de código para la máquina objeto. La unión de estas dos etapas se real-iza por medio de un lenguaje intermedio universal, este lenguaje, ampliamente discutido peronunca implementado, se denominó UNCOL(UNiversal Computer Oriented Language)[38].Se demostró como se podían construir compiladores por medio del ensamblado de una etapainicial para un determinado lenguaje con una etapa final para una determinada máquina obje-to, utilizando UNCOL como paso intermedio.
Esta idea de división del proceso en dos etapas enlazadas por medio de un lenguajeintermedio ha sido uno de los avances más significativos de la técnica de la compilación. Lasventajas de dividir un compilador en dos etapas se analizaron en el informe[21, 22].
Esta idea origina la división del trabajo de un compilador en tareas o fases y lainvestigación en cada una de ellas. Estas fases serán:
Análisis lexicográfico.Su trabajo consiste en descomponer el programa fuente en suselementos o símbolos constituyentes(denominados tokens), tales como palabras reser-vadas, operadores, identificadores, números, separadores, . . .
Análisis sintáctico.Examina la estructura del programa y comprueba que está escritoconforme a la sintaxis del lenguaje de programación. La sintaxis establece como debenescribirse los programas.
Análisis semántico.Verifica si el significado de las construcciones sintácticas es cor-recto conforme a la semántica del lenguaje de programación y recoge información útilpara las fases posteriores.
Generador de código intermedio.Se genera una representación explícita del programafuente. Esta representación intermedia debe tener dos propiedades importantes: ser fácilde producir y de traducir al lenguaje objeto.
Optimizaciones.En esta fase se analizará el código intermedio con el objetivo de mejo-rarlo.
Generador de código.Se encarga de generar el código objeto definitivo, que podrá serdirectamente ejecutable, o necesitar de otros pasos previos a la ejecución, tales comoensamblado, encadenado y carga.
14

Las tres primeras fases conforman la etapa de análisis del compilador (front end)mientras que las tres últimas corresponden a la etapa de síntesis (back end).
A continuación, se describe como se ha producido la investigación en cada una deesas fases del proceso de compilación, comenzando por el análisis léxico, donde los estu-dios de Rabin y Schott [45] sobre la equivalencia entre autómatas finitos determinísticos yno determinísticos en cuanto a su capacidad para reconocer lenguajes, fueron utilizados paraespecificar e implantar analizadores léxicos, ya que éstos pueden ser considerados como re-conocedores de lenguajes. En 1960, McNaughton y Yamada [49] describen un algoritmo paraconstruir un autómata finito determinístico directamente a partir de una expresión regular. Lasexpresiones regulares fueron estudiadas por primera vez por Kleene[34], y utilizadas poste-riormente para desarrollar herramientas que fueran útiles a la hora de construir analizadoresléxicos [41].
En 1975, se presenta el compilador LEX [28], que es un compilador que genera unanalizador léxico a partir de una especificación de un lenguaje regular expresada en lenguajelex. Así, se introduce el concepto de generador automático de analizadores léxicos, que hasido utilizado para la construcción de analizadores léxicos de muchos compiladores.
La investigación en la fase de análisis sintáctico se beneficia de los trabajos de NoamChomsky[29]. Así las gramáticas libres de contexto y la teoría de los lenguajes formales ha-cen que los métodos de análisis sintáctico sean más sistemáticos. La aparición de la notaciónBNF(Backus-Naur Form), inicialmente propuesta para la descripción del lenguaje de progra-mación ALGOL 60 [31] y formalizada por Knuth en 1964 [10] para la descripción sintácticade los lenguajes de programación, junto con la demostración de la equivalencia existente en-tre la notación BNF y las gramáticas libres de contexto, ayudan a establecer una guía para eldesarrollo del análisis sintáctico.
En esta época se desarrollan diversos métodos generales de análisis sintáctico paragramáticas libres de contexto. Una de las primeras es la técnica de programación dinámi-ca descubierta independientemente por Cocke[13], Younger y Kasami[37]. Early, en 1970,desarrolla otro método general de análisis sintáctico para gramáticas libre de contexto [24].Estos métodos permiten analizar cualquier gramática, a costa de ineficiencia.
En la década de los 60 se desarrollaron otros métodos de análisis sintáctico ascen-dentes, citar entre otros los métodos de precedencia simple [48], el de acotamiento de contexto[16, 18], la precedencia de estrategia simple [39] y el de precedencia débil [53].
Se investigan métodos más eficientes que son válidos solamente para un conjunto degramáticas restringidas, pero que son lo suficientemente expresivas para describir la mayoríade las construcciones sintácticas de los lenguajes de programación, tales son los métodos LLy LR, que trabajan sobre las gramáticas LL y LR, respectivamente.
Las gramáticas LL fueron estudiadas por Lewis y Stearns [52] y sus propiedades sedesarrollaron en [51]. El primero que estudió los analizadores sintácticos descendentes LL
15

fue Donald Knuth [27]. La conversión de gramáticas a la forma LL(1) se estudia en los traba-jos de Foster [17], [42], [35] y [46].
El análisis sintáctico por descenso recursivo predictivo es una de las formas de análi-sis que han sido usadas con mayor frecuencia, debido sobre todo a su gran flexibilidad.
En 1965, Donald Knuth introdujo las gramáticas y analizadores sintácticos ascen-dentes LR [26]. En los primeros años de la década de los 70, se inventan los analizadoresSLR y LALR [8, 9], que trabajan sobre gramáticas SLR y LALR, respectivamente. Estosmétodos son más simples y sencillos que el método LR. La técnica LR se convirtió en elmétodo elegido para los generadores automáticos de analizadores sintácticos. De este modo,a mediados de los 70, [25] crea el generador de analizadores sintácticos YACC que funcionabajo un entorno UNIX. Esta herramienta parte de la especificación de una gramática LR(1) ygenera un analizador sintáctico LALR(1).
La segunda mitad de la década de los 70, la investigación se dedicó a la construcciónde analizadores sintácticos LR, al estudio del uso de gramáticas ambiguas en el análisis[2, 14], en la mejora del método LR [50, 36, 4, 7] y al desarrollo de técnicas de recuperaciónde errores en los analizadores sintácticos [55, 5, 54, 19, 43].
Simultáneamente al desarrollo e investigación del análisis sintáctico, también se fuedesarrollando el análisis semántico, encargado de chequear aquellos aspectos del lenguajeque no se podían o era difíciles de representar por medio de una gramática libre de contexto.La investigación dentro de esta fase ha sido y es muy independiente de las característicasde los lenguajes de programación y consecuentemente se ha ido realizando conforme éstosevolucionaban.
A continuación destacamos por su importancia, la evolución de los sistemas de tiposen los lenguajes de programación y su implicación en la investigación y desarrollo de la fasede análisis semántico. En los primeros lenguajes, FORTRAN y ALGOL 60, los tipos de datoseran muy simples, por lo que la comprobación de tipos a realizar durante el análisis semán-tico no suponía ningún problema. En estos lenguajes no existía la coerción de tipos, puesera un asunto difícil y era más fácil no permitirlo. Los primeros trabajos sobre técnicas decomprobación de tipo, basados en búsqueda de equivalencias estructurales aparecen duranteel desarrollo de ALGOL 68 [32], lenguaje en el que se permite la construcción sistemáticade tipos, característica principal de la mayoría de los lenguajes diseñados en la década de los70. En el lenguaje EL1 [40], se señalan los dos tipos de equivalencias de tipos existentes,equivalencia por nombre y estructural, y se deja clara la diferencia que hay entre ambos.
Otros avances como la coerción, la sobrecarga, . . . hacen que se estudien mecanismosy técnicas para la resolución de la coerción y sobrecarga en el momento de la compilación,en la inferencia de tipos. . .
El análisis semántico y generador de código intermedio pueden ser descritos en tér-minos de ”anotación” de ”decoración” de árboles sintácticos. Estas anotaciones pueden ser
16

consideradas como atributos de los nodos del árbol. Los valores de los atributos se calculanmediante ”reglas semánticas” asociadas a las producciones gramaticales. Numerosos méto-dos han sido investigados y propuestos para la evaluación de estas reglas dependiendo deldetalle de implantación y de la libertad asignada al usuario. Las características de los lengua-jes muchas veces permiten que la evaluación semántica y generación de código intermediose pueda realizar de manera simultanea al análisis sintáctico. El uso de atributos sintetizadospara especificar la traducción de un lenguaje aparece en Iros [20]. La investigación en anal-izadores sintácticos que ejecutan reglas semánticas es llevada a cabo inicialmente por Samel-son y Bauer [47] y Brooker y Morris [44]. Los atributos heredados, los grafos de dependenciacomo mecanismo para determinar el orden de avaluación de las reglas semánticas y las prue-bas de circularidad aparecen en Knuth [11]. Motivados por la idea de realizar la traduccióndurante el análisis sintáctico, Lewis, Rosenkratz y Stearns [30] definen las gramáticas conatributos por la izquierda, Engelfriet [15] examina los métodos para la evaluación de atribu-tos.
A la hora de generar código, hay que tener en cuenta la relación ente las instruccionesde un programa concreto con las acciones que deben ocurrir en el momento de la ejecuciónpara implantar dicho programa. Durante la ejecución se tienen que tratar aspectos como larelación entre los nombres utilizados en el programa y objetos de datos utilizados para repre-sentarlos en la máquina(enlace de nombres). Esta relación viene determinada por la semánticade los procedimientos y suele ser llevada a cabo por medio de un paquete de apoyo durantela ejecución, que consta de rutinas que se cargan en el código objeto generado.
Para la asignación y desasignación de objetos de datos, durante la activación y de-sactivación de los procedimientos, se propuso la utilización de las estructuras de datos tipopila. El manejo de la memoria como la implementación tipo pila se usó por primera vez en1958, en un proyecto de implantación de LISP. El uso de procedimientos y bloques recursivosen ALGOL 60, potenció el uso de la pila como mecanismo eficiente y sencillo de manejo dememoria.
Los compiladores utilizan una estructura denominada ”tabla de símbolos” para lle-var un control de la información sobre el ámbito y el enlace de nombres. En la primera mitadde la década de los setenta, Knuth [12] y Aho, Hopcroft y Ullman [1] estudian las estructuraspara tablas de símbolos y los algoritmos para manejarlas. En McKeeman se desarrollaron másestudios sobre técnicas de organización de las tablas de símbolos.
En este contexto, también se han investigado y desarrollado estrategias para mejorarlas rutinas de entrada y salida de los procedimientos y se han estudiado distintos mecanismospara realizar las sustituciones y el paso de parámetros a un procedimiento.
La aparición de lenguajes que permiten datos que pueden ser creados y destruidosen cualquier momento(y no a la entrada y salida de un bloque), es decir datos de localizacióndinámica, requieren el desarrollo de mecanismos de gestión de memoria más generales y com-plejos que la pila. Las peticiones para almacenar este tipo de datos en tiempo de ejecución sonmanejados por medio de la estrategia de manejo de memoria conocida como heap(montículo).
17

A lo largo de la década de los 70 se desarrollaron e investigaron distintas técnicas para lagestión del heap y los problemas que aparecen con él, como son las referencias colgadas y larecogida de basura.
Como ya ha sido comentado, en el modelo de dos etapas(análisis y síntesis) de uncompilador, la etapa inicial traduce un programa fuente a una representación intermedia apartir de la cual la etapa final genera el código objeto. La investigación dentro de esta fase seha centrado en el estudio de las ventajas e inconvenientes del uso de lenguajes intermedios[21]. La búsqueda del lenguaje intermedio universal (UNCOL) [38], el diseño y desarrollode distintos lenguajes intermedios, tales como árboles, grafos dirigidos acíclicos, notaciónpolaca, tercetos, cuartetos, . . .
Hasta ahora sólo se ha comentado como se ha realizado la investigación dentro de laprimera etapa en la construcción de un compilador, la etapa de análisis. Ahora la introducciónse va a centrar un poco en la investigación dentro de la etapa de síntesis.
Durante la etapa de síntesis, se genera código objeto ejecutable en la máquina des-tino. Este código generado debe ser correcto y de gran calidad, utilizando eficientemente losrecursos de la máquina objeto. Para permitir esto, se comienzan a investigar técnicas de gen-eración de código y de optimización de código.
La investigación de las técnicas para la optimización de código, se dividen en téc-nicas de optimización dependientes e independientes de la máquina. De este modo, dentrode las primeras se desarrollaron técnicas para el uso eficiente de registros, la reordenacióndel código, la selección del conjunto más eficiente de instrucciones propias de la máquina,etc. Dentro de las segundas, caben destacar las técnicas para la detección de subexpresionescomunes, la realización de transformaciones que preservan la función, eliminación de códigoinactivo, optimizaciones de lazos, etc.
En la década de los 70, se investigan las técnicas de análisis de flujo de datos [3, 6].Estas técnicas han sido muy influyentes en el desarrollo e investigación de técnicas de opti-mización independientes de la máquina.
Todas estas investigaciones realizadas hacen que hoy en día, el proceso de compi-lación sea un proceso bien fundamentado, perfectamente dividido en fases y con multitudde técnicas asentadas para la realización del trabajo de cada fase. En la actualidad, los tra-ductores de lenguajes y más concretamente los compiladores son unas herramientas perfec-tamente conocidas por los profesionales de la informática. Sin embargo, aún hoy se llevan acabo investigaciones en el campo de la compilación. Estas investigaciones tratan de revisar,adaptar y optimizar el proceso de compilación con respecto a las nuevas características quesurgen con la aparición de los nuevos lenguajes de programación o paradigmas de progra-mación.
En este sentido y como ejemplo para ilustrar las líneas de investigación actuales, laaparición del lenguaje de programación Java, cuyo principal objetivo es proporcionar la má-
18

xima portabilidad a los programas escritos y compilados con él, requiere que el compiladorno genere código para una máquina concreta sino para una máquina virtual, la Java VirtualMachine(JVM), que será ejecutado localmente en cada máquina por un interprete incluidonormalmente en el navegador de Internet.
A continuación se pasa a describir los temas y contenidos que se estudian en laasignatura de Procesadores de Lenguajes del plan de estudios de Ingeniería Informática en laEscuela Superior de Informática de la Universidad de Castilla-La Mancha.
1.2. Introducción a la Asignatura de Procesadores de Lenguajes.
El objetivo general es que el alumno conozca la organización de los programasprocesadores, traductores, compiladores e interpretes de un lenguaje y que sea capaz deaplicar las técnicas necesarias en la resolución de los problemas que se puedan plantear ala hora de construir un programa de este tipo.
Como se podrá observar en el temario de la asignatura, buena parte del mismo sededica al estudio de la fase de análisis sintáctico ya que es una de las partes más importantesde un compilador. Además, otras fases del compilador(análisis semántico, comprobación detipos, generación de código), están íntimamente relacionadas con dicha fase, siendo necesariauna comprensión sólida de la misma para afrontar su estudio.
1.2.1. Introducción a los traductores.
En este tema se da una idea general del proceso de traducción, para ello se partede una introducción a los lenguajes de programación, mostrando la necesidad del uso detraductores. A continuación, se introducen los conceptos básicos de la materia, tales comolenguaje fuente, lenguaje objeto, lenguaje intermedio, traductores, compiladores, interpretes,etc. Asimismo, se recuerdan conocimientos, necesarios para la comprensión de la asignatura,sobre lenguajes formales, gramáticas y sus maquinas reconocedoras. Por último, se describenbrevemente los componentes de un traductor y algunos enfoques generales a adoptar cuandose construye un compilador.
1.2.2. Análisis léxico.
En este tema se estudia la primera fase de un traductor, es decir, su análisis lexi-cográfico. Se explica en que consiste el análisis léxico, se presentan los conceptos básicos deeste análisis y se establece su relación con el resto de las fases. A continuación, se tratan las
19

técnicas para especificar e implantar analizadores léxicos(manuales y automáticas), mostran-do el uso de autómatas finitos y expresiones regulares en los analizadores léxicos y en lasherramientas generadoras de analizadores léxicos. Para finalizar el tema, se introducen el tipode errores que se pueden presentar durante el análisis léxico y la forma de solucionarlos.
1.2.3. Análisis Sintáctico.
El problema principal de la traducción es el análisis sintáctico, encargado de com-probar la corrección de la cadena de entrada. En este tema, se estudia la noción de árbolsintáctico, como representación gráfica del proceso de reconocimiento o derivación de unacadena de entrada. Por último, se muestra dos formas de construir el árbol sintáctico y comoestas formas conducen a dos concepciones distintas de realización del análisis sintáctico enprofundidad, la descendente(top-down) y la ascendente(bottom-up).
Aunque en sí mismo el analizador sintáctico, es una parte muy importante de uncompilador, otras fases posteriores como el análisis semántico, comprobación de tipos, gen-eración de código, . . . dependen de como se realice el análisis sintáctico. Por dicha razón sehace especial hincapié en la enseñanza y estudio de la fase de análisis sintáctico.
1.2.4. Análisis sintáctico descendente.
Este tema se dedica al estudio de los analizadores sintácticos descendentes, pre-stando especial atención a los analizadores sintácticos descendentes sin retroceso LL(1),aplicable únicamente a las gramáticas LL(1). Es por ello que en el tema también hay unapartado dedicado a la presentación de las gramáticas LL(k) y LL(1).
A continuación, se analizan las condiciones para que una gramática sea LL(1), pre-sentándose un algoritmo para la construcción de las tablas de análisis LL(1) y del analizadorcorrespondiente. Se dan también unas reglas para intentar convertir una gramática a LL(1) encaso de que no lo sea.
Por último, se estudian los distintos métodos para el tratamiento de error en el análi-sis LL(1) y se discute las propiedades de este tipo de análisis sintáctico.
20

1.2.5. Análisis sintáctico ascendente.
En este tema se estudia el análisis sintáctico ascendente, prestando especial atencióna una técnica eficiente que se puede utilizar para analizar la clase más amplia de gramáticaslibres del contexto. Esta técnica se denomina análisis sintáctico LR(k).
Después se introducen tres técnicas para construir la tabla de análisis que el métodousa. La primera técnica es la denominada, LR simple o SLR, este método construye tablasútiles sólo para un tipo de gramáticas, denominadas SLR. La segunda técnica es las máspoderosa y construye tablas aplicables a un mayor número de gramáticas, se denomina LRcanónico. La última técnica, LR con examen por anticipado LALR, se sitúa en poder entre lasdos anteriores y funciona con la mayoría de las gramáticas de los lenguajes de programación.
Para finalizar el tema, se estudia los mecanismos de tratamiento de error en este tipode analizador y se estudia las propiedades de este método.
1.2.6. Traducción dirigida por la sintaxis.
En este tema se introduce a un mecanismo para comprobar aquellos aspectos dellenguaje fuente que no pueden ser expresados o es complejo hacerlo por medio de unagramática. Se presenta el concepto de gramática con atributos y reglas semánticas, tambiéndenominadas rutinas o acciones. Se describe como pueden ser utilizadas estas reglas semán-ticas para completar la definición de un lenguaje y para realizar la traducción del lenguajefuente al lenguaje intermedio.
Para finalizar, se introduce las principales ideas de la traducción dirigida por la sin-taxis, que son utilizadas en el resto de temas tanto para especificar como para implantar tra-ducciones. Desde el punto de vista teórico las distintas fases de análisis son independientes ysecuenciales, pero en la práctica hay solapamiento. El concepto de traducción dirigida por lasintaxis permite implantar los analizadores sintácticos y semánticos como un único subpro-grama, facilitando enormemente la creación del analizador semántico. Por esta razón se le datanta importancia al análisis sintáctico en la asignatura deProcesadores de Lenguajes.
21

1.2.7. Comprobación de tipos.
Un comprobador de tipos se asegura de que el tipo de una construcción coincida conel previsto en su contexto. En este tema, se estudia la representación de los tipos y la cuestiónsobre cuándo hay equivalencia entre tipos. Asimismo, se estudia la conversión de tipos im-plícita y explícita. Para finalizar el tema, se trata el tema de la sobrecarga y el polimorfismo.
Esta parte del compilador también está guiada por el análisis sintáctico.
1.2.8. Lenguajes intermedios.
El tema comienza con un análisis de los lenguajes intermedios, se muestra distintostipos de lenguajes intermedios, algunas clases de representaciones intermedias que han sidopropuestas y después se muestra como se puede traducir a código intermedio las construc-ciones de los lenguajes de programación comunes.
1.2.9. Organización y gestión de la memoria.
Un tema importante es el almacenamiento y el manejo de la memoria del ordenador,durante una compilación y su posterior ejecución. En este tema, se establece la relación entreel programa estático escrito en el lenguaje fuente y las acciones que deben ocurrir en el mo-mento de la ejecución del programa.
Inicialmente, se estudia la tabla de símbolos y su papel fundamental como almacénde los objetos del programa fuente, y como estructura para llevar un registro de la informa-ción sobre el ámbito y el enlace de los nombres. Además, se resaltará la necesidad de utilizaruna buena estructura de datos para conseguir compiladores más eficientes. Se examinarán lasestructuras de datos más adecuadas para implementar una tabla de símbolos en un compilador.
A continuación se estudian las estructuras de datos más importantes utilizadas porlos lenguajes de programación y como se almacenan dentro del ordenador. Se estudia co-mo determinados aspectos del lenguaje de programación afectan a la manera de gestionar lamemoria. Posteriormente, se estudia distintas estrategias, dinámicas o estáticas, para realizarla gestión propiamente dicha de la memoria. Para finalizar, se trata en detalle distintas técnicaspara la gestión dinámica de memoria.
22

1.2.10. Generación de código.
Para comenzar el tema, se establece como requisito necesario a la hora de diseñar unbuen generador de código, el tener una familiaridad con la máquina objeto y su conjunto deinstrucciones.
Posteriormente se introducen los bloques básicos, grafos de flujo y los grafos dirigi-dos acíclicos, y se muestra su utilidad a la hora de generar código.
1.2.11. Optimización de código.
La optimización de código es compleja y muy especializada, por lo que en estetema, sólo se pretende únicamente dar unas nociones sobre la necesidad de la realización deoptimizaciones en el código y los tipos de optimizaciones existentes, dependientes e indepen-dientes de la máquina.
23

CAPÍTULO 2.
OBJETIVOS
A la hora de construir un traductor, saber como afrontar el diseño y construcciónde un analizador sintáctico, es un tema primordial. Ya que, muchas otras fases posterioresal análisis sintáctico(análisis semántico, comprobación de tipos, generación de código) de-penden del enfoque que se le haya dado al mismo. Esta importancia puede comprobarse enel propio temario de la asignatura de Procesadores de Lenguajes. La mayor parte del mismoestá dedicado al análisis sintáctico. Del análisis sintáctico se pueden destacar los métodos deanálisis descendentes(LL1) y ascendentes(SLR1, LR1, LALR1).
Para aprender estos métodos de forma sólida y eficiente, es muy importante disponerde ejercicios prácticos resueltos. Cuando se realizan ejercicios no es fácil comprobar si estánhechos correctamente, ya que el resultado es difícil de evaluar. No es como algunos tipos deejercicios (por ejemplo de cálculo) donde se puede comprobar el resultado de una forma másdirecta. La forma más fácil de comprobar si el ejercicio es correcto, es tener la solución almismo. Pero existen varios problemas:
El alumno tiene el problema de que frecuentemente tiene muchos libros donde se ex-plica la teoría de traductores, pero estos libros tienen pocos ejercicios resueltos.
El profesor no puede hacer en clase todos los ejercicios que le gustaría al alumno, yaque el tiempo de clase es limitado y el temario de la asignatura es muy extenso.
En este contexto es donde se hace necesario la implementación de una herramienta,que permita al alumno la comprobación de las soluciones obtenidas a ejercicios propuestospor otros o por él mismo.
Para la ayuda al estudio y la enseñanza de la asignatura de procesadores de lenguajesya existen algunas herramientas:
SEPa!: Este proyecto se dedica a la construcción de herramientas para la ayuda a la en-señanza de la teoría y tecnología involucrada en los procesos de diseño y construcciónde traductores de lenguajes formales.
24

Este proyecto está compuesto de varios programas:
• Chalchalero. Es una herramienta orientada a la enseñanza y aprendizaje de autó-matas, autómatas finitos, gramáticas regulares, analizadores lexicográficos, autó-matas a pila y los compiladores como autómatas.
• Kakuy. Muestra de forma animada el funcionamiento de las técnicas de parsingYounger-Cocke-Kasami y Earley.
JFlap(Universidad de Duke): Es un paquete de herramientas gráficas usadas para elaprendizaje de los Lenguajes Formales. Permite trabajar con:
• Lenguajes regulares.
• Gramáticas libres de contexto.
• Máquinas de Turing.
• Sistemas L.
Sefalas(Universidad de Granada):Es una herramienta para el apoyo a la docenciateórica de procesadores de lenguajes, que muestra el transcurso de la fase de análisisléxico y sintáctico.
Estas herramientas están bien para el aprendizaje de las técnicas de construcción detraductores, pero tienen los siguientes inconvenientes:
Necesidad de instalación.En general cuando se utiliza un software para la docencia esdeseable que su instalación sea lo más sencilla posible, ya que este tipo de herramientasse suelen instalar en muchos ordenadores de los laboratorios de las Universidades, y sila instalación es engorrosa dificulta la implantación de la herramienta.
No hacen un seguimiento de utilización de la herramienta.Estas herramientas sólodan soporte a mostrar como funcionan las técnicas de análisis, no dan soporte a unseguimiento sobre la utilización de la herramienta por parte de los alumnos.
Edición de los ejercicios.La edición de los ejercicios en la herramientaJFlap, se hacede forma visual. Esta forma de trabajar, en un principio puede parecer mejor, pero sihay muchos ejercicios al final se hace un proceso tedioso. Lo más deseable es que laherramienta acepte los ejercicios desde un archivo de texto plano. De esta forma, losejercicios se editan más rápidamente y se pueden crear desde cualquier editor de texto.
Las herramientas del proyecto SEPa! están muy sobrecargadas.
El objetivo del proyecto es construir una herramienta sencilla, que pueda ser emplea-da para la enseñanza y el aprendizaje de las técnicas de análisis sintáctico descendentes (LL1)y ascendentes (SLR1, LR1, LALR1). Además, que proporcione soporte para el seguimientode la utilización de la herramienta por parte de los alumnos.
25

Las funciones que debería tener esta herramienta, hay que separarlas según esténdestinadas al alumno o al profesor:
1. Para el alumno, esencialmente la herramienta a construir debería aceptar como entradalos ejercicios propuestos y generar como salida la solución(ver Fig.2.1).
Ejercicios Herramienta Soluciones
Figura 2.1: Esquema de la herramienta
Además, debería permitirle al alumno:
a) Instalar la herramienta de la forma más sencilla posible.
b) Usarla fácilmente, ya que por muy buena que sea una herramienta si no es fácilde usar, será rechazada de inmediato por los alumnos.
c) Facilitar la entrada de ejercicios lo máximo posible. Este aspecto es muy impor-tante, si la de entrada de ejercicios no se diseña adecuadamente la herramientaperdería mucha utilidad.
d) Escribir varios ejercicios de análisis sintáctico de una vez. Algunas veces, puederesultar engorroso proporcionarle los ejercicios uno a uno a la herramienta. O porejemplo, se quiere generar la solución de todos los ejercicios a la vez para podercomparar sus resultados.
e) Generar la solución a los ejercicios de análisis sintáctico, mostrando los resultadosde forma sencilla y amigable.
f ) Obtener información adicional, que sea importante, del proceso de generación deuna solución de un ejercicio, aparte del resultado final del ejercicio.
g) Mostrar el funcionamiento de un analizador sintáctico.
2. Para el profesor la herramienta le debería permitir:
a) Usar la herramienta sin necesitar instalación, o facilitarla lo máximo posible.
b) Utilizarla como herramienta de soporte para hacer el seguimiento del interés de laasignatura por parte de los alumnos. De esta forma, podrá saberse si los alumnostienen interés por la asignatura o en qué tipo de ejercicios de análisis sintáctico,los alumnos tienen más problemas.
c) Utilizarla como herramienta de soporte para uso en clase. Por ejemplo, si en algúnmomento en el que el profesor está dando clase, surge alguna duda, la cual seexplica mejor con un ejemplo, la herramienta debería estar disponible para ayudaral profesor a resolverle la duda al alumno.
d) Configurar y gestionar todos los recursos de la herramienta.
26

CAPÍTULO 3.
ENSEÑANZA Y ESTUDIO DE LA ASIGNATURA
En este capítulo se describirá la base teórica del tipo de ejercicios con los que la he-rramienta a construir trabajará. En la primera sección de darán los fundamentos del analizadorsintáctico, después en la sección3.2se realiza una descripción de la teoría de las gramáticaslibres de contexto, escritura, derivación, . . . Por último se realiza la descripción de la parte másimportante del análisis sintáctico, los analizadores sintácticos descendente y ascendentes. Encada uno de estos analizadores se describirá su estructura, la forma en que trabajan y la formade construirlos. Lo cual es el principal objetivo de la herramienta.
3.1. Introducción.
La primera fase del compilador es el analizador léxico, su función es la de leer el tex-to de entrada y generar una lista de tokens utilizables por el analizador sintáctico. La funcióndel analizador sintáctico es la de leer estos tokens y comprobar si la cadena de entrada que seestá evaluando, puede ser generada por la gramática que establece la estructura del lenguajedefinido. En la Fig.3.1 se muestra la forma en que interaccionan el analizador léxico y elsintáctico.
carácter tokenEntrada
Figura 3.1: Interacción entre el analizador léxico y el sintáctico
Existen diferentes formas de realizar el análisis sintáctico, hay métodos generalesde análisis sintáctico como es el algoritmo de Cocke-Younger-Kasami y el de Early. Estosdos métodos, tienen la ventaja de que pueden analizar cualquier gramática(hasta gramáticasambiguas), pero en la práctica no son utilizados ya que son demasiado ineficientes(son algo-ritmos no lineales). Los métodos de análisis sintácticos que se emplean en la práctica son los
27

métodosdescendentesy ascendentes, los cuales sí que realizan el análisis en un tiempo lineal
El método de análisisdescendente(que se estudiará con más profundidad en la sec-ción 3.7), trata de construir el árbol de análisis sintáctico desde la raíz hasta las hojas. Encambio losascendentestratan de hacerlo al contrario que los descendentes, desde las hojashasta la raíz.
Las cadenas válidas para un determinado lenguaje se pueden establecer por mediode gramáticas libres de contexto.
3.2. Gramáticas libres de contexto (GLC).
Las gramáticas libres de contexto son muy importantes en la práctica, ya que per-miten definir la mayoría de los lenguajes de programación. Por ejemplo, las gramáticas libresde contexto son útiles para la descripción de estructuras recursivas o la definición de es-tructuras de bloque del tipobegin/end. Ninguna de estas construcciones se puede expresarmediante expresiones regulares.
Informalmente una gramática libre de contexto es un conjunto de variables(no ter-minales), cada una de las cuales representa un lenguaje. Los lenguajes representados por estasvariables son descritos recursivamente por otras variables y por otros símbolos llamadoster-minales. Las reglas que relacionan las variables(no terminales) y los terminales se llamanproducciones.
Formalmente una gramática es una 4-tupla, G=(V, T, P, S), donde:
T: Los terminales son los tokens del lenguaje definido.
V: Los no terminales son variables que contienen conjuntos de cadenas.
S: En la gramática existe un símbolo no terminal a partir del cual se empieza a derivar,este no terminal es el símbolo inicial.
P: Las producciones indican la forma de relacionar terminales y no terminales paraformar cadenas válidas para la gramática definida. Las producciones son de la formaA→ α, dondeA∈V y α∈ (V∪T)+. Además, también se permiten producciones nulasA→ ε.
Por ejemplo, la siguiente gramática expresa la estructura de expresiones matemáticassimples.
E→E +E | E−EE→E ∗E | E/EE→(E) | Nat
28

Los símbolos en mayúsculas son los no terminales y los operadores y el símbolo’Nat’ son los terminales. Por ejemplo, una cadena válida para la gramática anterior sería:(Nat + Nat) * Nat.
El símbolo ’|’ es una forma de expresar en una producción varias partes derechaspara una misma parte izquierda.
Otro tema importante es saber si una cadena pertenece al lenguaje establecido poruna gramática. Existen varias formas de saberlo, una de ellas es mediante la derivación y laotra mediante la construcción del árbol de análisis sintáctico.
3.3. Derivación y árbol de análisis sintáctico.
El concepto dederivacióntrata a las producciones como reglas donde el no terminalde la izquierda se sustituye por la cadena del lado derecho de la producción. Informalmenteel proceso de derivación consta de los siguientes pasos:
1. Comenzar con el símbolo inicial de la gramática como cadena de entrada.
2. Seleccionar un símbolo no terminalN en la cadena y una producciónN → S1 . . .Sk ycambiar laN por losS1 . . .Sk en la cadena.
3. Repetir el paso 2, hasta que se tenga una cadenaω formada únicamente por símbolosterminales(ω es una cadena generada por la gramática).
Si realizando este proceso, a partir del símbolo inicial se consigue obtener la cadenaque se está evaluando, esta cadena pertenece al lenguaje definido por la gramática.
Si el símbolo que se elige en el paso 2 para la sustitución es el símbolo que está mása la izquierda, entonces la derivación se llamaDerivación más a la izquierda. Por ejemplo, sise tiene la siguiente gramática:
E→E +E | E−EE→E ∗E | E/EE→(E) | Nat
Se puede comprobar que la cadenaNat + Nat ∗ Nat puede ser generada por dichagramática:
E ⇒ E +E ⇒ Nat+E ⇒ Nat+E ∗E ⇒ Nat+Nat∗E ⇒ Nat+Nat∗Nat
Como se puede ver el no terminal que se elige para realizar la sustitución ha sido elque estaba más a la izquierda.
Si el símbolo que se elige es el símbolo que está más a la derecha entonces laderivación se llamaDerivación más a la derecha.
29

E ⇒ E +E ⇒ E +E ∗E ⇒ E +E ∗Nat⇒ E +Nat∗Nat⇒ Nat+Nat∗Nat
Otra forma saber si una cadena de entrada concuerda con una determinada gramáti-ca es construyendo suárbol sintáctico. El árbol sintáctico indica de forma gráfica, cómo sepuede derivar a partir del símbolo inicial de la gramática la cadena que se está evaluando.
Definición de árbol sintáctico:
La etiqueta de un nodo pertenece al conjunto(V ∪T ∪ ε).
La etiqueta de un nodo hoja siempre es un terminal.
La etiqueta de los nodos que no son hoja, son no terminales.
La raíz del árbol es el símbolo inicial de la gramática.
Si un nodo tiene como etiqueta el símboloB y sus nodos hijoss1s2, . . . ,sk tienen comoetiquetas los símbolosx1x2 . . .xk, entonces la producciónB→ x1x2, . . . ,xk pertenece alconjunto de producciones de la gramática.
Si un nodo está etiquetado con la palabra vacía, entonces es un nodo hoja del árbol y elúnico hijo de dicho nodo.
Por ejemplo la Fig.3.2es un ejemplo de árbol sintáctico de la gramática anterior.
E
E + E
Nat E * E
Nat Nat
Figura 3.2: Ejemplo de árbol sintáctico
Al igual que en la derivación, en la generación del árbol sintáctico, puede salir unárbol diferente dependiendo del nodo que se expanda. Igual que antes se pueden hacer deriva-ciones más a la izquierda o más a la derecha.
30

Si se encuentran dos árboles sintácticos distintos para una misma cadena de entrada,entonces la gramática es ambigua. Normalmente en el análisis sintáctico no interesa trabajarcon gramáticas ambiguas. Por ejemplo, la Fig.3.3es un ejemplo de una gramática ambigua,ya que para una misma cadena de entrada, se generan dos árboles sintácticos distintos.
E
E + E
Nat E * E
Nat Nat
E
E+E
NatE*E
NatNat
Figura 3.3: Ejemplo de gramática ambigua
3.4. Algoritmo de Cocke-Younger-Kasami.
Como ya se ha comentado anteriormente, este algoritmo es uno de los métodos queexisten para comprobar si una cadena pertenece al lenguaje definido por una gramática. Elalgoritmo de CYK se basa en la construcción de una tabla de análisis, donde cada entradarepresenta la solución a un determinado subproblema. El algoritmo va analizando partes de lacadena cada vez de mayor longitud, hasta analizar toda la cadena. Este procedimiento puedeverse en el Alg.1.
31

Algoritmo 1 Algoritmo CYKRequiere: La gramática en FNC y la cadena de entradax.Salida: La tabla de análisis sintáctico V.
1: for i := 1 to n do2: Vi1 := {A | A → a es una producción y el i-ésimo símbolo de x es a}3: end for4: for j := 2 to n do5: for i := 2 to n− j +1 do6: Vi j := /07: for k := 1 to j−1 do8: Vi j := Vi j ∪ {A | A → BC es una producción, B está enVik y C esta enVi+k, j−k}9: end for
10: end for11: end for
3.5. Algoritmo de Early.
El algoritmo de Early es un método descendente en el que los análisis parciales seguardan en una tabla, para no tener que repetirlos en otro momento de las derivaciones.
Para una frase de N palabras, se crea una tabla de N + 1 entradas. En cada entradade la tabla se registra una lista de estados que representan las estructuras derivados hasta esemomento de análisis. Cada estado es una tupla< A→ B, i, j > donde:
A→ B: es la regla aplicada para la derivación de la subestructura.
i, j: indican la posición de inicio y final de la subestructura.
Al final de la derivación la tabla recoge de forma compacta todos los análisis posiblesde la cadena de entrada.
32

3.6. Funciones útiles para el análisis sintáctico.
Antes de entrar en los detalles de cómo generar un analizador sintáctico, es necesariodescribir estas funciones que se utilizarán en secciones posteriores para realizar el análisissintáctico.
3.6.1. Cálculo de los símbolos anulables.
Los símbolos anulablesson los no terminales de la gramática que se pueden anular,es decir, que pueden generar la palabra vacía. Un no terminal es anulable cuando existe unaproducción del tipoX → ε. Pero otros no terminales indirectamente también pueden ser anu-lables. Por ejemplo, si se tiene una producción del tipoX → S1S1 . . .Sk y todos los símbolosS1S1 . . .Sk son anulables entoncesX también es anulable. El procedimiento para el cálculo delos anulables puede verse en el Alg.2.
Por ejemplo, en la siguiente gramática:
S→a | aABA→a | εB→A | bB
A sería un símbolo anulable, porque existe una producción directa dondeA se anula(A→ ε). El otro símbolo anulable esB, porque aunque no exista una producción directa quelo anule, indirectamente se anula mediante la producciónB→ A.
Algoritmo 2 Cálculo de los símbolos anulables de una gramáticaRequiere: Conjunto de no terminales(V)Salida: El diccionario Anulable registra si un símbolo es anulable o no.
1: for all X ∈V do2: Anulable[X] := false3: end for4: repeat5: for cada producciónX → S1 . . .Sk do6: if not esAnulable(X)and S1 . . .Sk son todos anulablesthen7: Anulable[X] := true8: end if9: end for
10: until no hay más cambios
33

3.6.2. Cálculo de los símbolos iniciales.
Los inicialesde una cadenaγ son el conjunto de terminales que pueden comenzarcualquier cadena generada por la cadenaγ. Dondeγ puede estar compuesta de terminales yno terminales.
Para calcular losinicialesde un símboloX se siguen las siguientes reglas(ver Alg.3):
1. Si X es un terminal, entonces losinicialesdeX son {X}.
2. Si X es un no terminal yX → S1S2 . . .Sk es una producción, entonces agregar a losiniciales deX, los iniciales deS1. Además, siSi es anulable añadir los iniciales deSi+1.
Por ejemplo, en la siguiente gramática:
Z→d | XYZY→c | εX→a | Y
sus iniciales serían:
X:{a, c}Y:{c}Z:{a, c, d}
Los iniciales deY son los más fáciles de calcular, ya que aparte de la producciónnula sólo tiene otra producción y en su parte derecha hay un terminal. Con lo cual en losiniciales deY, sólo está el terminal ’c’. En los iniciales deX está el símbolo ’a’, este símboloes debido directamente a la producciónX → a. El símbolo ’c’ viene dado por la producciónX →Y, ya que en los iniciales deY estaba el símbolo ’c’. Con los iniciales de laZ se haceigual. El primer inicial que hay que agregarle es la ’d’, que es debido a la producciónZ→ d.Después hay que agregarle los iniciales de laX, ya que es el primer símbolo de la producciónX→XYZ. Además, como el símboloX es anulable también hay que agregarle los de laY. Porúltimo, como el símboloY también es anulable, también hay que agregarle los del símboloZ, que ya están añadidos.
34

Algoritmo 3 Cálculo de los iniciales de una gramáticaRequiere: Conjunto de terminales(T)Salida: El diccionario Iniciales, donde la clave es un símbolo y el valor es el conjunto de
iniciales para dicho símbolo.1: for all t ∈ T do2: Iniciales[t] := {t}3: end for4: for cada producciónX → S1 . . .Sk do5: Iniciales[X] := Iniciales[X]∪ Iniciales[S1]6: for i := 2 to k do7: if esAnulable(Si−1) then8: Iniciales[X] := Iniciales[X]∪ Iniciales[Si ]9: else
10: break11: end if12: end for13: end for
3.6.3. Cálculo de los símbolos seguidores.
Los seguidores de un no terminalX son el conjunto de símbolos terminales, quepueden aparecer inmediatamente después del símbolo no terminalX. Por ejemplo, si se tienela cadenaαXtβ, el terminalt habría que agregarlo a los seguidores deX, ya que está despuésdel no terminalX.
El procedimiento para el cálculo de los seguidores puede verse en el Alg.4.
Por ejemplo en la siguiente gramática:
Z→d | XYZY→c | εX→a | Y
se obtendrían los siguientes seguidores:
X:{a, c, d}Y:{a, c, d}Z:{$}
Por defecto el símbolo inicial de la gramática tiene al símbolo final(’$’) como primerseguidor. El símboloZ ya no tiene más seguidores ya que aunque aparece en la producciónZ→ XYZ, aparece al final de la producción. Por lo tanto no hay que agregar ningún seguidormás. Lo seguidores deX son los símbolos {a, c, d}, ya que el no terminalX aparece en laproducciónZ → XYZ. Estos seguidores se calculan con los iniciales del no terminalY, y alserY anulable también se incluyen los deZ.
35

Algoritmo 4 Cálculo de los seguidores de una gramáticaRequiere: Conjunto de no terminales(V), donde S es el símbolo inicial de la gramática.Salida: Conjunto de símbolos seguidores.
/* inicializar diccionario de seguidores*/1: for all X ∈V do2: Seguidores[X] := {}3: end for
/*El seguidor del símbolo inicial es el símbolo final*/4: Seguidores[S] := {$}5: repeat6: for cada producciónX → S1 . . .Sk do7: for i := 1 to k-1do8: if Si ∈V then9: Seguidores[Si ] := Seguidores[Si ] ∪ Iniciales[Si+1]
10: j := i +211: while esAnulable(Sj−1) and j<=k do12: Seguidores[Si ] := Seguidores[Si ] ∪ Iniciales[Sj ]13: j := j +114: end while15: if esAnulable(Sk) and j>k then16: Seguidores[Si ] := Seguidores[Si ] ∪ Seguidores[X]17: end if18: end if19: end for20: if Sk ∈V then21: Seguidores[Sk] := Seguidores[Sk] ∪ Seguidores[X]22: end if23: end for24: until no hay más cambios
36

3.7. Análisis Sintáctico Descendente.
El análisis sintáctico descendente, consiste en encontrar una derivaciónmás a laizquierdapara la cadena de entrada o hablando desde el punto de vista de los árboles sintác-ticos, se puede considerar el construir el árbol sintáctico empezando desde la raíz hasta lashojas.
Existen dos posibilidades a la hora de construir el analizador sintáctico descendente,con retroceso o sin retroceso. En las siguientes secciones se explicará cada uno de ellos endetalle.
3.7.1. Analizador sintáctico recursivo con retroceso.
Este tipo de analizadores sintácticos no se suele emplear en la práctica, ya que elretroceso es ineficiente y además para reconocer la mayoría de los lenguajes de programaciónel retroceso es innecesario.
El funcionamiento de este tipo de analizadores es el siguiente:
1. Expandir siempre la primera producción disponible para el símbolo no terminal más ala izquierda.
2. Si son todos los símbolos terminales, finalizar, sino volver al paso 1.
Actuando de esta forma pueden ocurrir dos cosas, la primera es que se alcance a re-conocer la cadena de entrada y la otra opción es que no se reconozca la cadena de entrada. Sino se reconoce, hay que buscar la subcadena de la cadena encontrada que no coincide con laque se busca y volver hacia atrás hasta el punto en el que se empezó a generar esa subcadena.
Este tipo de análisis tiene un problema y es que se hace demasiada vuelta atrás yademás para gramáticas recursivas por la izquierda, el analizador no puede parar.
3.7.2. Gramáticas LL(1).
Antes de entrar en detalles sobre el analizador sin retroceso conviene definir lasgramáticas LL(1), ya que el analizador que se va a estudiar después sólo trabaja con este tipode gramáticas.
Para que una gramática sea LL(1) debe cumplir una serie de condiciones:
37

No debe ser ambigua. Una gramática es ambigua si una cadena puede ser generadapor dos árboles sintácticos diferentes. Para eliminar la ambigüedad no existe un algoritmoconcreto, sólo se resuelve modificando la gramática adecuadamente.
No puede ser recursiva por la izquierda. Una gramática es recursiva por la izquier-da si tiene un no terminalS tal que exista una derivación del tipoS→ Sα.
Para eliminar la recursividad por la izquierda hay que transformar la gramática G enotra gramática G’, la cual no sea recursiva por la izquierda. En la Fig.3.4 puede observarseque G y G’ producen árboles de derivación diferentes, pero obtienen el mismo lenguaje.
A
A
A
A
A
A
A
A
G G’
α1
βj
α2
αp
βj
αp
α2
α1
Figura 3.4: Eliminación de la recursividad por la izquierda
Para transformar la gramática G a la gramática G’ se procede de la siguiente forma:
Si la producción es de la formaA→ Aa|b, transformarla a una estructura del tipo:
A→bA′
A′→aA′ | ε
Si la recursividad izquierda indirecta:
S→Aa | bA→Sd | Ac | ε
No se puede eliminar de la misma manera que se hace para la recursividad izquierdadirecta. Normalmente lo que se hace es transformar la recursividad izquierda indirectaen recursividad izquierda directa. Para ello se elimina el termino que provoca la re-cursividad izquierda y se pone en la producción anterior que está en el camino de larecursividad. Por ejemplo si la gramática anterior se pone de la forma:
38

S→Aa | Sda| bA→Ac | ε
Se ha conseguido eliminar de la producciónA→Sd|Ac|ε, el términoSd, que provocabala recursividad izquierda indirecta. Dicho termino se ha subido a la producción que estáen el camino recursivo, es decir, a la producciónS→ Aa|b. Como se puede ver ahoralo que se tiene es una recursividad izquierda directa que se puede eliminar fácilmente.El procedimiento de eliminación de la recursividad izquierda puede verse en el Alg.5.
Algoritmo 5 Eliminación de la recursividad por la izquierda de una gramáticaRequiere: Gramática GSalida: Gramática G’, no recursiva por la izquierda.
1: Ordenar los no terminales con un ordenA1,A2, . . . ,An
2: for i := 1 to n do3: for j := 1 to i - 1 do4: Sustituir cada producción de la formaAi → A jγ por las producciones
Ai → δ1γ|δ2γ| . . . |δkγ, dondeA j → δ1|δ2| . . . |δk son todas las producciones actualesdeA j
5: end for6: Eliminar la recursividad por la izquierda entre las producciones deAi
7: end for
Además de las condiciones citadas anteriormente para ser una gramática LL(1), co-mo son la ambigüedad y la recursividad, cada producción debe cumplir la siguiente condición:
Para cada producciónX → α1|α2| . . . |αk se tiene que cumplir:
1. Iniciales(αi) ∩ Iniciales(α j ) = /0, para todoi 6= j.
2. Si X es anulable entonces Iniciales(α1) ∩ Seguidores(X) = /0
Si no se cumplen estas condiciones es que la gramática no es LL(1), pero se puedetransformar la gramática a LL(1) haciendo una factorización por la izquierda.
Factorización por la izquierda. La idea de la factorización es que si se tiene unaproducción del tipoX → αβ1|αβ2 hay que transformarla a una estructura como la siguiente:
X→αX′
X′→β1|β2
Con ello se consigue retrasar la decisión de qué producción expandir. Esta factor-ización hay que ir aplicándola a las producciones conflictivas hasta llegar a una gramáticaque cumpla las condiciones para ser LL(1). Este método tiene el inconveniente de que lagramática final puede quedar un poco engorrosa y difícil de entender.
39

3.7.3. Analizador sintáctico recursivo sin retroceso.
Como ya se ha dicho antes, para poder aplicar el análisis sintáctico recursivo sinretroceso, la gramática debe ser LL(1), es decir, debe cumplir las condiciones anteriormentecitadas para este tipo de gramáticas.
La construcción de un analizador sintáctico predictivo no recursivo es sencilla, elesquema de bloques del mismo puede verse en la Fig.3.5.
���������
��������
�������
������
��������
����
�������
Figura 3.5: Analizador sintáctico predictivo no recursivo
Un analizador sintáctico predictivo no recursivo tiene los siguientes componentes:
Buffer de entrada: El buffer de entrada contiene la cadena de entrada a ser analizada.Para poder conocer cuando se acaba la cadena de entrada se pone un símbolo especial($)al final del buffer.
Pila: Sirve para ir registrando el proceso de derivación, inicialmente contiene el sím-bolo inicial de la gramática.
Tabla de análisis: La tabla de análisis le indica al programa analizador la producciónque debe expandir con la configuración actual(símbolo en la cima de la pila y primersímbolo de la entrada).
Programa analizador: Es el programa de control del analizador sintáctico.
40

El funcionamiento del analizador sintáctico es el siguiente. En cada momento elprograma de control mira el símbolo que hay en la cima de la pila y en el buffer de entrada,dependiendo de estos símbolos se procede de diferentes formas(ver Alg.6):
Si el símbolo de la cima de la pila y el de la entrada es el mismo y es el símbolofinal(’$’), entonces la cadena de entrada se ha reconocida con éxito.
Si el símbolo de la cima de la pila es igual al de la entrada(pero diferente al símbolofinal), entonces se avanza al siguiente símbolo de la entrada y se elimina el símbolo dela cima de la pila.
Si el símbolo de la cima de la pila es un no terminal, el programa de control consultaen la tabla de análisis qué producción expandir. Para consultar la tabla, como índicede filas se utiliza el símbolo de la cima de la pila y de columnas el símbolo de lacabecera del buffer de entrada. Si al realizar la consulta el valor de la entrada indicaque es un error, significa que no hay ninguna producción válida. Por lo tanto, hay unerror sintáctico y la cadena de entrada no es válida. Si no es una entrada errónea, dichaentrada indicará la producción por la cual hay que realizar la expansión. Para realizarla expansión lo que se hace es eliminar el no terminal de la cima de la pila e introduciren orden inverso la parte derecha de la producción a expandir. Por ejemplo, si hay queexpandir la producciónE → TE′, en la pila se introduciríaTE′, estando en la cima dela pila el símboloT.
Algoritmo 6 Programa de análisis sintáctico predictivo no recursivoRequiere: Una cadena de entrada y una tabla de análisis sintáctico.
1: /*P y E son los símbolos que están en la cima de la pila y como símbolo actual de laentrada, respectivamente.”$” es el símbolo final*/
2: repeat3: if P es un terminal oP == E then4: if P == E then5: Eliminar símbolo de la cima de la Pila y avanzar la entrada al siguiente símbolo6: else7: Error.8: end if9: else
10: if Tabla[P, E] ==X →Y1Y2 . . .Yk then11: Eliminar cima de la pila.12: Meter en la pilaY1Y2 . . .Yk dejandoYk en la cima.13: else14: Error.15: end if16: end if17: until P == $
41

Pila Entrada Producción$ E id + id * id $ T[E, id] = E→ T E’$ E’ T id + id * id $ T[T, id] = T → F T’$ E’ T’ F id + id * id $ T[F, id] = F→ id$ E’ T’ id id + id * id $$ E’ T’ + id * id $ T[T’, +] = T’ → ε$ E’ + id * id $ T[E’, +] = E’ → + T E’$ E’ T + + id * id $$ E’ T id * id $ T[T, id] = T → F T’$ E’ T’ F id * id $ T[F, id] = F→ id$ E’ T’ id id * id $$ E’ T’ * id $ T[T’, *] = T’ → * F T’$ E’ T’ F * * id $$ E’ T’ F id $ T[F, id] = F→ id$ E’ T’ id id $$ E’ T’ $ T[T’, $] = T’ → ε$ E’ $ T[E’, $] = E’ → ε$ $ Aceptar
Tabla 3.1: Traza del analizador sintáctico predictivo con la entradaid + id * id
Por ejemplo, sea la siguiente gramática la cual es LL(1):
E →T E’E’→+ T E’ | εT →F T’T’→* F T’ | εF →(E) | id
En la Tabla3.1 puede verse la traza de ejecución de un analizador sintáctico pre-dictivo, para la gramática anterior y la cadena de entradaid + id * id . Como puede verse loque hace el analizador es que cuando el símbolo de la entrada y el de la cima de la pila sonterminales y son iguales los elimina. Pero si el de la cima de la pila es un no terminal, loexpande por la producción adecuada. La producción a expandir lo indica la tabla de análisis.
42

Generación de la tabla de análisis LL(1).
Una vez se ha visto el funcionamiento del analizador sintáctico, sólo queda la cuestiónde la generación de la tabla de análisis, que es el objetivo principal del proyecto. La idea bási-ca de la construcción de la tabla es la siguiente.
Si se tiene una producción del tipoX → α y además se tiene el conjunto de inicialesdeα, entonces cuando en la cima de la pila se encuentre el no terminalX y a la entrada al-guno de los iniciales deα, hay que utilizar la producciónX → α para realizar la expansión.Si además,X es anulable, también hay que realizar la expansión por esta producción en losseguidores deX. Este proceso puede verse en el Alg.7
En la Tabla3.2 puede verse un ejemplo de generación de la tabla de análisis parala gramática anterior. Por ejemplo, la entrada(E′,+) tiene la producciónE′ → +TE′, yaque el inicial de+TE′ es el símbolo ’+’. Otra entrada como la(E, id) tiene a la producciónE → TE′, ya que el terminalid pertenece a los iniciales deTE′.
Algoritmo 7 Generación de la tabla de análisis LL(1)Salida: Tabla de análisis(Tabla)
1: for cada producciónX → γ do2: for all c ∈ Iniciales[γ] do3: Tabla[X, c] := Tabla[X, c]∪ { X → γ}4: end for5: if esAnulable(γ) then6: for all a∈ Seguidores[X]do7: Tabla[X, a] := Tabla[X, a]∪ { X → γ}8: end for9: end if
10: end for
Al generar la tabla de análisis puede plantearse un problema, y si en la tabla hayentradas con definiciones múltiples. Entonces significa que la gramática no es LL(1) y habráque comprobar si es ambigua o es recursiva por la izquierda o hay que factorizarla por laizquierda.
43

id + * ( ) $E E→ T E’ E→ T E’E’ E’ → + T E’ E’ → ε E’ → εT T → F T’ T → F T’T’ T’ → ε T’ → * F T’ T’ → ε T’ → εF F→ id F→ (E)
Tabla 3.2: Tabla de análisis LL(1), utilizada en la simulación de la Tabla3.1
3.8. Análisis Sintáctico Ascendente.
Al contrario que el analizador descendente, el ascendente(también conocido comodesplazamiento/reducción) utiliza derivaciones más a la derecha, construyendo el árbol sin-táctico desde las hojas hasta la raíz. Es decir, se parte desde la cadena de entrada a evaluar ya partir de ella se intenta llegar al símbolo inicial de la gramática. En cada paso, el analizadorlo que hace es reducir una parte de la cadena por la parte izquierda de alguna producción,donde su parte derecha concuerde con la subcadena que se está reduciendo. Sería como haceruna derivación más a la derecha pero en orden inverso, es decir, partir de la cadena a evaluary terminar en el símbolo inicial de la gramática.
Por ejemplo con la siguiente gramática:
S→aBCaB→bbC→c
La cadenaabbcase podría reducir al símboloS inicial de la gramática de formaascendente con los siguientes pasos.
1.- abbca2.- aBca Reduciendo por la producciónB→ bb3.- aBCa Reduciendo por la producciónC→ c4.- S Reduciendo por la producciónS→ aBCa
Lo primero que se hace es ver la cadena de entrada, y buscar una subcadena dedicha entrada que concuerde con alguna parte derecha de alguna producción. En este caso lasubcadenabb concuerda con la parte derecha de la producciónB→ bb, con ello se obtienela cadenaaBca. Después la subcadenac concuerda con la parte derecha de la producciónC → c, reduciendo dicha subcadena por la parte izquierda de esta producción se obtiene lacadenaaBc. Finalmente esta subcadena concuerda con la parte derecha de la primera pro-ducción, haciendo esta última reducción se consigue llegar al símbolo inicial de la gramática,con lo que se ha conseguido analizar con éxito la cadena de entrada. Como se puede ver esteproceso es una derivación más a la derecha.
S⇒ aBCa⇒ aBca⇒ abbca
44

Antes de entrar en detalles sobre el análisis ascendente es preciso definir algunostérminos.
Forma sentencial
Sea G=(V, T, P, S) una gramática libre de contexto yS→ α1 → α2 → . . .→ αn unasecuencia de derivaciones, dondeαn es una sentencia (αn ∈ T∗), entonces a cadaαi se ledenominaforma sentencial(αi ∈ (V ∪T∗)).
Si S→∗mi αn entonces cadaαi es unaforma sentencial a la izquierda.
Si S→∗md αn entonces cadaαi es unaforma sentencial a la derecha.
Frase y frase simple
Sea G=(V, T, P, S) una gramática libre de contexto yα1βα2 una forma sentencial ala derecha:
Si S→∗md α1Aα2, A∈V y A→+ β, β se denomina frase de la forma sentencialα1βα2.
Si S→∗md α1Aα2, A∈ V y A→ β, β se denomina frase simple de la forma sentencial
α1βα2.
Pivote
Sea G=(V, T, P, S) una gramática libre de contexto yα1βα2 una forma sentencial ala derecha, dondeβ es una frase simple, entonces siβ es la frase simple más a la izquierdaentonces se le denominapivote.
De manera informal un pivote de una cadena es una subcadena que es igual a la partederecha de una producción y al reducir dicha parte derecha por el no terminal de la izquierda,es un paso de una derivación más a la izquierda, pero hecha en orden inverso.
La clave para realizar un análisis sintáctico correcto es saber elegir correctamente elpivote.
Prefijo viable
Sea G=(V, T, P, S) una gramática libre de contexto yαi = µβω una cadena de unaetapa de la derivación, dondeβ es el pivote, se llamaprefijo viable deαi a cualquier prefijodeµβ. Es decir, siµβ = µ1µ2 . . .µm dondeµi ∈ (V ∪T) y cualquier subcadenaµ1µ2 . . .µj , con1 < j ≤m es un prefijo viable.
En el ejemplo anterior, para la subcadenaa A b c, prefijos viables válidos serían:
45

a
a A
a A b
a A b c
3.8.1. Implantación de una analizador por desplazamiento-reducción.
Una forma de implantar un analizador por desplazamiento-reducción es medianteuna pila y un buffer para la cadena de entrada. El análisis sintáctico consiste en leer los to-kens de la entrada e irdesplazándolosa la pila(prefijos viables), de forma que se puedanexplorar losn tokens superiores que contiene y ver si se corresponden con la parte derecha delas producciones(pivote). Si es así, se realiza unareducción, que consiste en sacar de la pilaestosn tokens y en su lugar meter el símbolo de la parte izquierda de esa producción. Estospasos se repiten hasta conseguir reducir la cadena de entrada por el símbolo inicial, es decir,tener en la cima de la pila al símbolo inicial y el buffer de entrada vacío.
Por ejemplo, en la Tabla3.3puede verse el análisis sintáctico por desplazamiento/re-ducción de la siguiente gramática y de la cadenaa b b c d e.
S→aABeA→Abc|bB→d
Como puede verse en la Tabla3.3, cuando se hace un desplazamiento se pasa elsímbolo que hay en la entrada a la cima de la pila. Y en las reducciones se sustituye unasecuencia de símbolos(terminales y no terminales) por un símbolo no terminal.
46

Pila Entrada Acción$ a b b c d e $ Desplazar$a b b c d e $ Desplazar$a b b c d e $ ReducirA→ b$a A b c d e $ Desplazar$a A b c d e $ Desplazar$a A b c d e $ ReducirA→ Abc$a A d e $ Desplazar$a A d e $ ReducirB→ d$a A B e $ Desplazar$a A B e $ ReducirS→ aABe$S $ Aceptar
Tabla 3.3: Ejemplo de análisis por desplazamiento/reducción de la cadenaa b b c d e
3.8.2. Analizador sintáctico LR.
El analizador sintáctico LR es el que más se utiliza en la práctica en la construcciónde compiladores. Este tipo de analizadores se utiliza porque la mayoría de los lenguajes deprogramación se pueden construir con analizadores LR. Además, es un método general deanálisis que no necesita retroceso, por lo tanto es eficiente y detecta los errores tan prontocomo es posible.
Pero con este método no todo son ventajas, ya que es muy costoso el construir unanalizador sintáctico LR manualmente. Para solucionar este problema se han construido her-ramientas como el YACC, Bison, JCup que construyen automáticamente un analizador LR apartir de una gramática.
En la Fig.3.6puede verse un esquema de un analizador sintáctico LR. Básicamenteun analizador sintáctico LR es un autómata finito a pila que reconoce prefijos viables y vaconstruyendo el árbol sintáctico desde las hojas hasta la raíz.
Antes de entrar en detalles sobre la estructura del analizador, conviene definir qué esunaconfiguración. Unaconfiguraciónes una tupla donde el primer componente es la pila yel segundo es la entrada restante por procesar.
(S0X1S1X2S2 . . .XmSm,aiai+1 . . .an$).
Un analizador sintáctico LR tiene los siguientes componentes:
Buffer de entrada: Contiene la cadena a ser analizada.
Pila: En este caso guarda más información que el analizador sintáctico descenden-
47

��������
��
��� ���
� �� ����
��������� �
�
��
�����������������
Figura 3.6: Analizador sintáctico LR
te predictivo. Los elementos registrados en la pila son de la formaS0X1S1X2 . . .XmSm,dondeSm es el símbolo de la cima de la pila. LosSm son estados que resumen el con-tenido de la pila. Los símbolosXm son símbolos de la gramática, tanto terminales comono terminales.
Tabla de análisis: La tabla de análisis tiene la misma función que en el analizadorsintáctico predictivo, pero esta vez la tabla se divide en dos partes.
Tabla de acción.En las filas están los estados del autómata y en las columnas los sím-bolos terminales de la gramática. El contenido de las entradas de la tabla pueden ser:
• Aceptar: El análisis sintáctico ha sido completado con éxito.
• Error: El analizador sintáctico ha encontrado un error sintáctico.
• Acción[Si ,a j ] = Desplazar ySk: Sk es el siguiente estado al que hay que ir des-pués de desplazar. La acción sería meter en la pila el símbolo actual de la entrada,avanzar la entrada y meter en la pila el estadoSk. Por ejemplo, laconfiguraciónantes del desplazamiento debe ser:
(S0X1S1X2 . . .Sm−1XmSi ,a ja j+1 . . .an$)
Después de realizar el desplazamiento sería:
(S0X1S1X2 . . .Sm−1XmSia jSk,a j+1 . . .an$)
48

• Acción[Si ,a j ] = Reducir Rk : A → α: Se extraen 2∗ |α| símbolos de la pi-la, se introduce en la pila la A y se calcula el nuevo estado con la tabla Ir_A,Ir_A[Sm−2×|α|,A] = Sx.
Tabla de Ir_A.Tiene el mismo formato que laTabla de acción. Cuando se realiza unareducción en la cima de la pila se queda un símbolo, pero siempre en la cima de la piladebe haber un símbolo de estado. La tabla de Ir_a sirve para saber cuál es el siguienteestado después de hacer una reducción.
Programa analizador: El funcionamiento exacto del programa analizador puede verseen el Alg.8.
Algoritmo 8 Programa de análisis sintáctico LRRequiere: Tabla de Acción y la Tabla de Ir_A.
1: El símboloSes el estado actual que está en la cima de la pila y el símboloa es el terminalactual de la entrada.
2: loop3: if Acción[S, a] = Desplazar ySj then4: Meter en la Pila a ySj y avanzar en la cadena de entrada.5: else ifAcción[S, a] = Reducir porRk : A→ α then6: Sacar 2∗ |α| símbolos de la pila. Sea S’ el símbolo del tope de la pila, poner A y
luego Ir_a[S’, A] en el tope de la pila.7: else ifAcción[S, a] = Aceptarthen8: terminar9: else
10: Error11: end if12: end loop
3.8.3. Generación de la tabla de análisis.
En esta sección se explica la generación de las tablas de análisis. Existen tres formasde generar dicha tabla:
SLR(1): Es la forma más sencilla de construirla, pero tiene el inconveniente de quereconoce un número reducido de gramáticas.
LR(1): El LR(1) es la técnica más general, pudiendo reconocer una número mayor degramáticas que el SLR(1).
LALR(1): En potencia está entre el SLR(1) y el LR(1), pero tiene la ventaja de que lastablas de análisis tienen un tamaño más reducido.
49

Las tablas de análisis que se estudiarán en próximas secciones, serán las tablas deanálisis SLR(1), LR(1) y LALR(1), el ’(1)’ se sobrentenderá.
Antes de entrar en los detalles de la generación de la tabla, hay que definir el terminoitem de análisis sintáctico(en adelanteitem). Un item, es una producción de la gramática conun marcador. Como se verá después, el marcador sirve para registrar hasta que zona de laparte derecha de una producción ha sido reconocida por el autómata. Por ejemplo, para laproducciónS→ if C then B, se podrían tener los siguientes items.
S→• if C then BS→if • C then BS→if C • then BS→if C then• BS→if C then B•
El primer item indica que todavía no se ha procesado nada de la entrada y queda porver if C then B, en cambio el segundo de ellos indica que ya se ha procesado en la entrada elif y queda por procesarC then B.
La producciónS→ ε, genera el itemS→•
La idea básica del método SLR es construir un autómata finito determinista parareconocer los prefijos viables. Para facilitar la construcción del analizador no se trabaja direc-tamente con la gramática, se trabaja con una gramática aumentada. La gramática aumentadaes la misma, pero se le añade una producción más, donde su parte izquierda es el nuevo sím-bolo inicial y su parte derecha es el antiguo símbolo inicial de la gramática. Es decir, si setuviera la siguiente gramática:
S→CCC→cCC→d
su gramática extendida sería:
S’→SS→CCC→cCC→d
La razón para hacer esta modificación es porque de esta manera es más fácil recono-cer cuando se ha reconocido con éxito la cadena de entrada. Ya que una forma fácil de sabersi el análisis ha finalizado con éxito, es cuando se reduzca el itemS′→ S.
Para la construcción de la tabla de análisis SLR, se utilizan las funciones presentadasa continuación.
50

Cálculo del cierre.
Esta función parte de un conjuntoI de items cualquiera, donde inicialmente todoitem del conjuntoI pertenece al cierre deI , ahora con cada item deI aplicar la siguiente regla.
SeaS→ α •Aβ un item del cierre de I yA → γ una producción de la gramática.Entonces hay que agregar el itemA→•γ al cierre de I(si no se había agregado previa-mente). Este procedimiento hay que aplicarlo continuamente hasta que ya no se puedanagregar más item al conjunto del cierre.
De manera informal lo que hace el cierre, es calcular todos los items que a partir deun item pueden ser generados en el análisis sintáctico. Es decir, si se tiene el itemS→ •CC,es posible que en la entrada exista una cadena que derive en alguna producción de C.
Por ejemplo, si se tiene la siguiente gramática(ya es la gramática extendida):
S’→SS→CCC→cCC→d
Y se parte del conjuntoI , con su primer item{S′→•S}, el cierre deI , daría como resultado:
S’→•SS→•CCC→•cCC→•d
Como se puede ver en el ejemplo anterior lo único que hay que hacer es expandir losno terminales de los items donde el marcador esté delante de un símbolo no terminal.
El procedimiento para calcular el cierre puede verse en el Alg.9.
51

Algoritmo 9 Cálculo del cierreRequiere: I, conjunto de items de una gramática ampliadaG′ = (V ′,T,P′,S′)Salida: I∗
1: I := I∗
2: repeat3: for all A→ α•Bβ ∈ I∗ do4: for all B→ ϕ ∈ P′ do5: if [B→•ϕ] /∈ I∗ then6: I∗ := I∗∪{[B→•ϕ]}7: end if8: end for9: end for
10: until no hay cambio
Cálculo del sucesor.
La función sucesor parte deI , un conjunto de items yX, un símbolo de la gramática.La función sucesor es la cerradura del conjunto de todos los elementosA→ αX •β siemprey cuandoA→ α•Xβ exista previamente en I.
De manera informal lo que hace la función sucesor es calcular el siguiente estado, alcual se puede ir a partir del símboloX, con los items deI , en los cuales el marcador está dela forma:A→ α•Xβ.
El procedimiento para calcular el sucesor puede verse en el Alg.10.
Algoritmo 10 Cálculo del sucesorRequiere: I, conjunto de items de una gramática ampliadaG′ = (V ′,T,P′,S′)
X ∈ (V ∪T), X es un símbolo de la gramática(terminal o no terminal)Salida: Conjunto sucesor.
1: S := /02: for all A→ α•Xβ ∈ I do3: S := S∪{[A→ αX •β]}4: end for5: return Cierre(S)
52

Cálculo del conjunto de estados.
Por último, sólo queda la función del cálculo de todos los estados. Partiendo delestado inicial se calcula el cierre de dicho estado y el sucesor de ese estado con todos lossímbolos terminales de la gramática. Con los nuevos estados se procede de igual forma hastaque no se puedan agregar más estados al conjunto de estados. Este procedimiento puede verseen el Alg.11.
Algoritmo 11 Cálculo del conjunto de estadosRequiere: G es la gramática aumentada para la que se construye el analizador sintácticoSalida: C
1: i := 02: Si := Cierre([S′→•S])3: C := C∪{Si}4: while C cambiedo5: for all S∈C do6: for all X ∈V ∪T do7: J := Sucesor(S, X)8: if (J 6= /0) and (J /∈ C) then9: i := i +1
10: Si := J11: C := C∪{Si}12: end if13: end for14: end for15: end while
Por ejemplo sea la siguiente gramática:
E→E +TE→TT→(E)T→num
Una vez creada la gramática extendida aplicando el Alg.11, se genera el autómataque reconoce los prefijos viables(ver Fig.3.7).
53

S’→•E E →•E + T E →•T T →•(E) T →•num
0
S’→E• E →E• + T
1
E
T→(•E) E →•E + T E →•T T →•num T→•(E)
3
T
(
(
T →num•4
num
num
E→E+•T T→•(E) T→•num 5
E →E+T•8
E →E+T•7
T →(E•) E →E•+T 6
T
) +
E
num
+
E →T•2
T
Figura 3.7: Autómata finito generado mediante el método SLR
Una vez creado el autómata sólo queda generar las tablas de análisis.
54

3.8.4. Construcción de las tablas de análisis SLR.
La generación de la tabla de análisis se hace en dos pasos: generación de la tabla deacción y generación de la tabla Ir_A.
Generación de la tabla de acción.
La idea básica del algoritmo es sencilla, el algoritmo hace lo siguiente. Para el j-ésimo item del i-ésimo estado hacer(ver Alg.12):
Si el item es un desplazamiento(A→ α•aβ), agregar la acción: ”Desplazar a i”. Dondei es el índice del i-ésimo estado.
Si el item es una reducción(A→ α•), agregar la acción: ”Reducir por A→ α”.
Si es el itemS′→ S•, agregar la acción: ”Aceptar”
Cualquier otra entrada no rellenada de la tabla ponererror .
Algoritmo 12 Generación de la tabla de acciónRequiere: C, la colección canónica de estados del autómata.Salida: Tabla de Acción
1: for all Si ∈C do2: for all item∈ Si do3: if [A→ α•aβ] and Sucesor(Si ,a) = Sj then4: Acción[Si ,a] = Desplazar ySj
5: else if[A→ α•] then6: for all a∈ Seguidores(A) do7: Acción[Si ,a] = Reducir porA→ α8: end for9: end if
10: if [S′→ S•] then11: Acción[Si ,$] = Aceptar12: end if13: end for14: end for15: Para las restantes entradas de la tabla que no están rellenadas ponerERROR.
55

+ ( ) num $ E T0 d3 d4 1 21 d5 Aceptar2 r2 r2 r23 d3 d4 6 24 r4 r4 r45 d3 d4 76 d5 d87 r1 r1 r18 r3 r3 r3
Tabla 3.4: Tabla de análisis del ejemplo SLR
Generación de la tabla Ir_A.
Para generar la tabla lo único que hay que hacer es ver en cada estado, las transi-ciones que hay debidas a no terminales. En ese estado y con dicho no terminal hay que ponerel identificador del estado destino. En el Alg.13 se describe este procedimiento de maneramás formal.
Algoritmo 13 Generación de la tabla Ir_ARequiere: C, la colección canónica de estados del autómata.Salida: Tabla de Ir_A
1: for all X ∈C do2: if Sucesor(Si ,X) = Sj then3: Ir_A[Si ,X] = Sj
4: else5: ERROR6: end if7: end for
En la Tabla 3.4 puede verse un ejemplo de generación de la tabla de análisis uti-lizando el método SLR. Esta tabla ha sido generada a partir del autómata de la Fig.3.7. Porejemplo, en el estado 0 hay dos desplazamientos, el debido al símbolo ’(’ y al del símbolo’num’. Por eso en la tabla de análisis en la fila 0 y en las correspondientes columnas hay una’d’ y un número indicando el siguiente estado. También en ese estado se rellena la parte deIr_A, ya que hay dos transiciones con los no terminales ’E’ y ’T’. En resumen, en cada estadosólo hay que comprobar que tipo de acción realizar y anotarla en la tabla.
56

Problemas del análisis SLR.
En algunas situaciones el análisis SLR genera conflictos, este tipo de problemas tam-bién se pueden dar en el análisis LR y LALR, pero al ser el análisis SLR el más restrictivo deellos es más fácil que se generen conflictos.
Una conflicto ocurre cuando en la tabla de análisis generada hay más de una acciónpara alguna entrada de la tabla. Los conflictos pueden ser de los siguientes tipos:
Desplazamiento/Reducción.Por ejemplo, en la siguiente gramática
S→A | xbA→aAb | BB→x
al calcular el cierre, uno de los estados queda de la siguiente forma:
S→x•bB→x•
Al generar la tabla de acción en este estado con lab hay que hacer un desplazamientoy una reducción. El problema es que en los seguidores de laB, está lab, y es donde segenera el conflicto. Es decir, con lab hay que realizar dos acciones, un desplazamientoy una reducción, lo cual es un conflicto.
Reducción/Reducción.Por ejemplo, en la siguiente gramática
S→Ab | BcA→aB→aA→Bb
uno de los estados generados al calcular el autómata sería:
A→a•B→a•
En este estado hay que realizar dos reducciones, el problema está en que en los seguidoresde B y en los seguidores deA hay un terminal común que es lab. Por lo tanto no sesabe la reducción que hay que aplicar y se genera un conflicto.
57

El motivo de estos conflictos, viene dado por el hecho de que a la hora de reducirpor un no terminalX en un estado, se hace uso de un símbolo que vendrá dado por losseguidores deX en todos los estados posibles. Como se verá después lo que hace el métodoLR es mantener un conjunto desímbolos de anticipaciónmás discriminante. Para ello hayque modificar la definición deitemhecha anteriormente. En la nueva definición, alitemse leincorpora un elemento más que es un conjunto de símbolos de anticipación. De esta forma, encadaitemse van registrando los símbolos de anticipación por los que hacer la reducción. Estossímbolos de anticipación sólo tienen efecto en las reducciones no en los desplazamientos.
3.8.5. Construcción de las tablas de análisis LR.
La clave del análisis LR son las reducciones, mientras que en análisis SLR se hacíala reducción por todos los seguidores de la parte izquierda del item a reducir, en el LR sólo sehace la reducción por los símbolos de anticipación del item.
Para realizar el análisis LR hay que modificar la función decierre y la de la gen-eración de la tabla de acción.
Cálculo del cierre.
Al calcular el cierre de un item de un estado en el análisis SLR, lo que se hacía eraver el símbolo a la derecha del marcador y crear nuevos items(si no existían previamente), conlas producciones donde el símbolo marcado sea la parte izquierda. En cambio, en el análisisLR, se registra que símbolos pueden aparecer detrás del símbolo marcado, para cuando setenga que realizar la reducción, reducir sólo por estos símbolos y no por todos los seguidores.Por ejemplo, si se tuviera el siguiente item:
[A→ α•Bβ,a]
el nuevo item que se genera es
[B→•γ, iniciales(βa)]
Como se puede ver lo único que hay que hacer es a los nuevos items agregarles losiniciales de la parte que le sigue al símbolo marcado(ver Alg.14). Por ejemplo:
58

S’→SS→AbS→BcA→aB→aA→cBb
el cierre deI sería:
S’→S,$S→Ab,$S→Bc,$A→a,bB→a,bA→cBb,c
Si al rellenar la tabla se llega a un conflicto(desplazamiento/reducción, reducción/re-ducción), el método no es aplicable y la gramática no es LR. Si no existen conflictos entoncesla gramática es LR.
La ventaja del método LR es que reconoce un número mayor de lenguajes que elSLR, pero tiene el inconveniente de que las tablas de análisis son mayores.
Algoritmo 14 Cálculo del CierreRequiere: I, conjunto de elementos de una gramática ampliadaG′ = (V ′,T,P′,S′)Salida: I∗
1: I := I∗
2: repeat3: for all [A→ α•Bβ,a] ∈ I∗ do4: for all B→ ϕ ∈ P′ do5: for all b∈ Iniciales(βa) do6: if [B→•ϕ,b] /∈ I∗ then7: I∗ := I∗∪{[B→•ϕ,b]}8: end if9: end for
10: end for11: end for12: until no hay cambio
Por ejemplo sea la siguiente gramática:
S→C CC→c CC→d
59

Aplicando el mismo método que se aplicó para generar la tabla de análisis SLR,pero con las nuevas versiones para el LR se generaría el autómata que se puede ver en la Fig.3.8. Ahora con el método LR los items incorporan los símbolos de anticipación, a diferenciadel análisis LR. Por ejemplo, con el método SLR los estados 3 y 6 no hubieran existido porseparado, sólo hubiera habido uno de ellos. En cambio, con el método LR como sí tiene encuenta los símbolos de anticipación, sí que son estados diferentes.
S’→ • S, $ S → • CC, $ C → • cC, c|d C → • cC, c|d
0
S’→ S •, $1
S → C • C, $ C → • cC, $ C → • d, $
2
C → c • C, c|d C → • cC, c|d C → • d, c|d
3
C→ d •, c|d4
S → c • C, $ C → • cC, $ C → • d, $
6
C→ CC •, $
C→ d •, $
C→ cC •, c|d
C→ cC •, $
5
7
8
9
S
C
c
dd
cd
c
Cc
d
C
C
Figura 3.8: Autómata finito generado mediante el método LR
60

Generación de la tabla de acción.
La parte de esta función que hay que modificar con respecto al análisis SLR, es laparte concerniente a la reducción. En vez de reducir por todos los símbolos seguidores, sólohay que reducir por los símbolos de anticipación(ver Alg.15).
Algoritmo 15 Generación de la tabla de acciónRequiere: C, la colección canónica de estados del autómata.Salida: Tabla de Acción
1: for all Si ∈C do2: for all item∈ Si do3: if [A→ α•aβ,b] and Sucesor(Si ,a) = Sj then4: Acción[Si ,a] = Desplazar ySj
5: else if[A→ α•,b] then6: Acción[Si ,b] = Reducir porA→ α7: end if8: if [S′→ S•] then9: Acción[Si ,$] = Aceptar
10: end if11: end for12: end for13: Para las restantes entradas de la tabla que no están rellenadas poner ERROR.
En la Tabla. 3.5 puede verse la generación de la tabla de análisis a partir del autómatade la Fig.3.8. Como puede verse ahora cuando se hace una reducción, sólo se reduce por lossímbolos de anticipación. Por ejemplo, en el estado 9 hay una reducción, al generar la tablade análisis si se utilizara el método SLR, habría que poner dicha reducción en todos losseguidores del no terminalC, que son los terminales{c, d, $}. En cambio al utilizar el métodoLR sólo se pone la reducción en su símbolo de anticipación.
61

c d $ S C0 d3 d4 1 21 Aceptar2 d6 d7 53 d3 d4 84 r3 r35 r16 d6 d7 97 r38 r2 r29 r2
Tabla 3.5: Tabla de análisis del ejemplo LR
3.8.6. Construcción de las tablas de análisis LALR.
El análisis LALR(lookahead-LR), es el que se utiliza normalmente en la prácticaporque las tablas de análisis que genera son mucho más pequeñas que las del análisis LRcanónico. Por ejemplo, un analizador LR para un lenguaje como Pascal puede tener miles deestados, mientras que con un análisis SLR o LALR se pueden tener sólo cientos de estados.La reducción de estados es bastante significativa.
El inconveniente es que el conjunto de gramáticas que reconoce es menor que el LR,pero con el análisis LALR se pueden expresar la mayoría de los lenguajes de programación.
Lo que se hace en el análisis LALR es buscar estados con el mismo núcleo, es decir,estados que se diferencian únicamente en los símbolos de anticipación. Y se fusionan forman-do un único estado. Por ejemplo en el autómata de la Fig.3.8se puede ver que los estados 3y 6 tienen el mismo núcleo.
Estado 3:
C→c•C,c/dC→•cC,c/dC→•d,c/d
Estado 6:
C→c•C,$C→•cC,$C→•d,$
al realizar la fusión quedaría
62

C→c•C,c/d/$C→•cC,c/d/$C→•d,c/d/$
El resultado final de fusionar los estados equivalentes puede verse en la Fig.3.9. Co-mo puede verse los estados equivalentes eran el (3, 6), (8, 9) y el (4, 7). Con lo que se puedecomprobar que la reducción del número de estados es considerable.
������� �������������� ��������������� �������������� �������
�
��������� �������
������� ����������������� �������������� �������
�
���� ������������� ������������� ��������
��
�������� ��������
��
�������� ��������
�������� ��������
�
�
�
�
��
�
�
�
Figura 3.9: Autómata finito generado mediante el método LALR
Ahora sólo queda saber las consecuencias de realizar esta fusión de estados. Supón-gase que se tiene una gramática LR que no tiene conflictos de análisis. A continuación sefusionan los estados con el mismo núcleo, ahora queda resolver la cuestión de saber las con-secuencias de dicha fusión. La fusión hecha puede tener un conflicto nuevo que no existíaen el análisis LR, pero no es probable. El único conflicto nuevo que se puede generar, es unconflicto reducción/reducción, porque al unir dos estados puede pasar que en dos items dereducción de dos estados se tenga algún símbolo de anticipación común. Al estar separadosen el análisis LR, no hay conflicto pero al juntarlos se genera el conflicto. Por ejemplo, en lasiguiente gramática
S→aAd|bBd|aBe|bAeA→cB→c
Al hacer el análisis LR no se genera ningún conflicto, pero al juntar los estados 6 y9 se genera un conflicto nuevo reducción/reducción.
63

c d $ S C0 d36 d47 1 21 Aceptar2 d36 d47 536 d36 d47 8947 r3 r3 r35 r189 r2 r2 r2
Tabla 3.6: Tabla de análisis del ejemplo LALR
Estado 6:
A→c•,dB→c•,e
Estado 9:
A→c•,eB→c•,d
Nuevo estado:
A→c•,e/dB→c•,d/e
Como puede verse hay dos items que reducen por el mismo terminal(d), con lo cualse genera un nuevo conflicto (reducción/reducción), que no existía en el análisis LR.
El otro conflicto es el desplazamiento/reducción, pero en el análisis LALR sólopuede ocurrir si previamente el análisis LR ya lo tenía, ya que la fusión de estados tieneque ver con juntar los símbolos de anticipación y estos símbolos no tienen nada que ver conlos desplazamientos.
Construcción de la tabla de Acción/Ir_A.
Las tablas de análisis LALR se pueden construir directamente a partir de una gramáti-ca, pero es más fácil construirlas a partir del conjunto de estados LR. Lo primero que se hacees fusionar los estados con el mismo núcleo, y a partir de este nuevo conjunto de estadosgenerar de la misma forma que el análisis LR la tabla de acción y la de Ir_A.
En la Tabla. 3.6, puede verse el resultado de generar la tabla de análisis del autómatade la Fig.3.9. Como puede verse el método LALR ha conseguido reducir de 10 estados quegeneraba el LR a los 7 del LALR.
64

CAPÍTULO 4.
ANÁLISIS Y DISEÑO DE LA HERRAMIENTA
4.1. Análisis de requisitos generales.
Antes de entrar en los detalles del análisis de requisitos, hay que aclarar que se va ahacer una separación desde el principio, diferenciando los requisitos para el alumno(usuario),para el profesor(administrador) y para la propia herramienta.
1. Alumno. Los requisitos necesarios para el alumno esencialmente son los que se refierena la resolución de ejercicios de análisis sintáctico y a la simulación de analizadores sin-tácticos.
Requisitos:
a) Debe permitir la generación de las tablas de análisis de los analizadores sintácticospara las gramáticas de entrada. Además de generar las tablas de análisis se debegenerar:
1) Las tablas de estados de los análisis ascendentes.2) La información adicional utilizada en el proceso de análisis: anulables, ini-
ciales, seguidores, . . .3) Los mensajes importantes del proceso de generación de la solución, por ejem-
plo los mensajes de salida del compilador(errores, avisos, . . . ).4) Los conflictos que se produzcan al generar las tablas de análisis(conflicto
LL1, desplazamiento/reducción, . . . ). Además se deberá identificar claramentela posición de la tabla de análisis donde ha ocurrido el conflicto.
b) Se debe poder simular el comportamiento de un analizador sintáctico, tanto des-cendente, como ascendente. En la simulación lo único que deberá proporcionar elusuario es la gramática y el texto a simular. Como salida la herramienta producirála traza de salida de los componentes de un analizador sintáctico(pila, entrada yacción).
c) La herramienta aceptará los ejercicios de análisis sintáctico de dos formas:
1) Lo más seguro es que el usuario tenga guardados sus ejercicios de análisis sin-táctico en archivos. La herramienta debe proporcionar un sistema para cargarlos ejercicios a partir de dichos archivos.
65

2) Pero el usuario, también debe poder escribir los ejercicios de análisis sintác-tico, en la propia herramienta.
d) Como se pueden resolver varios ejercicios al mismo tiempo, la herramienta debeproporcionar ayuda para navegar entre las distintas soluciones de cada ejercicio.
e) La herramienta le debe proporcionar al usuario un mecanismo para poder regis-trarse o editar algún parámetro de su registro.
f ) Debe existir un sistema para autentificar al usuario legítimo de la herramienta. Lonormal es que el sistema de autentificación, sea un sistema clásico pornombre deusuarioy password.
g) La herramienta le debe proporcionar un mecanismo al usuario para que se puedaautentificar aunque haya olvidado supassword.
2. Profesor/Administrador.
Además de las operaciones permitidas al usuario(resolver ejercicios y simular), el pro-fesor requiere más funciones de la herramienta:
a) Para hacer el seguimiento del uso de la herramienta por parte de los usuarios, elprofesor debe poder dar de alta/baja, a los usuarios del sistema.
b) El profesor deberá tener la posibilidad de poder publicar ejemplos de ejerciciosde análisis sintáctico(gramáticas) desde la propia herramienta. Como siempre, laherramienta dispondrá de algún sistema para gestionar los ejemplos(crear, borrar,editar, . . . ).
c) Se deben poder configurar los permisos que tengan los usuarios para acceder alos recursos de la herramienta. Por ejemplo, si el profesor manda un ejercicio deanálisis sintáctico y quien lo resuelva se le puntúa. Lo más normal es que la herra-mienta temporalmente, no permita corregir ese tipo de ejercicios, ya que el alumnose verá tentado a utilizar la herramienta para resolverlo y no hacerlo por él mismo.
Para ello los usuarios se podrán registrar bajo dos perfiles:
Registrado. Este perfil es para los usuarios que se registren exteriormente, yque no pertenezcan a la asignatura de Procesadores de Lenguajes.
Alumno. Este perfil es para los alumnos de la asignatura de Procesadores deLenguajes.
La herramienta tendrá dos perfiles de usuario especiales:
Anónimo. Perfil para los usuarios del sistema que no estén registrados.
Admin. Perfil para el administrador.
d) Se debe poder publicar noticias en referente a la propia herramienta o a la asig-natura de Procesadores de Lenguajes y que les llegue a los alumnos automática-mente. Además, se deberá proporcionar algún sistema de gestión de dichas noti-cias(alta, baja, . . . ).
66

e) La herramienta debe registrar las estadísticas de uso. En dichas estadísticas sedeberá guardar todas las operaciones que los usuarios realicen con la herramienta:resolución de ejercicios, información referente a cada resolución(tipos de análisishechos, número de gramáticas en un mismo ejercicio, . . . ), simulaciones(con sucorrespondiente información sobre la simulación), . . .
f ) Las estadísticas que lo permitan, además de numéricamente, también se tienenque mostrar gráficamente(diagramas de barras, diagrama circular, . . . ).
g) El sistema debe mostrar un resumen con las estadísticas totales. En este resumense debe mostrar los porcentajes de los tipos de análisis realizados, tipos de simu-laciones, numero de ejercicios resueltos, . . .
h) El profesor (o en quien delegue el profesor) debe poder configurar todos losparámetros necesarios para el funcionamiento de la herramienta.
i) La herramienta tiene que disponer de algún mecanismo para recoger las valo-raciones del usuario, comentarios y sugerencias. De la herramienta los usuariospodrán valorar:
Utilidad.
Facilidad de uso.
3. Herramienta. Además de las funciones derivadas por los requisitos del usuario y delprofesor, la herramienta tendrá los siguientes requisitos:
a) La herramienta deberá proporcionar un sistema de autentificación, para protegerlos recursos de la misma que sólo estén disponibles para el administrador
b) El mantenimiento es un aspecto muy importante de cualquier sistema. La mayorparte del tiempo de vida del software, se gasta en mantenimiento. La herramientatendrá un sistema automático, para comunicar los errores que ocurran. De estaforma, el administrador no tendrá que estar mirando continuamente loslogs delsistema.
c) La estructura de la herramienta debe permitir que se modifique fácilmente. Paraincorporarle nuevas funciones en el futuro.
d) La arquitectura de la herramienta debe permitir que su instalación sea lo mássencilla posible o incluso no necesitar instalación.
e) Al permitir usar la herramienta a usuarios ajenos a la asignatura de Procesadoresde Lenguajes, el sistema deberá tener algún sistema para controlar las sobrecargasdel sistema.
67

4.2. Análisis de casos de uso.
En esta sección se desarrollará el análisis de caso de uso del sistema, conforme a losrequisitos obtenidos en la sección anterior. Antes de entrar en la descripción de los mismos,hay que explicar la notación empleada en los casos de uso. De cada caso de uso se muestra:
Caso de uso: Es el nombre identificador del caso de uso.Actores: Son los actores implicados en el caso de uso.Referencias: Son los identificadores de los requisitos o funciones que se tratan de
cumplir en este caso de uso.Descripción: Es la descripción del caso de uso.
Además, algunos casos de uso se mostrarán en un formato expandido. Con esteformato se muestra la interacción entre el actor y el sistema.
Casos de uso:
Casos de uso para la gestión de noticias.
Caso de uso: Crear noticiaActores: AdministradorReferencias: R.2dDescripción: El administrador crea una nueva noticia en el sistema y éste además de
registrarla, se la envía a los usuarios.
Curso normal de eventos
Acción del actor Respuesta del sistema
1. Este caso de uso comienza cuando el admi-nistrador crea una nueva noticia.
2. El sistema la registra en la basede datos.3. El sistema le envía la nueva noti-cia a todos los usuarios registradospor correo electrónico.
68

Caso de uso: Borrar noticiaActores: AdministradorReferencias: R.2dDescripción: Forma parte de la administración de noticias, la borra del sistema sin
mayor repercusión.
Caso de uso: Editar noticiaActores: AdministradorReferencias: R.2dDescripción: El administrador edita una noticia previamente creada.
Casos de uso para la gestión de los ejemplos.
Caso de uso: Crear ejemploActores: AdministradorReferencias: R.2bDescripción: El administrador agrega un nuevo ejemplo proporcionando el texto del
ejemplo, un nombre que lo identifique y un comentario.
Caso de uso: Borrar ejemploActores: AdministradorReferencias: R.2bDescripción: Se borra el ejemplo sin mayor repercusión.
Caso de uso: Editar ejemploActores: AdministradorReferencias: R.2bDescripción: El administrador edita algún campo de un ejemplo previamente creado.
Los cambios del ejemplo editado se registran en el sistema.
Gestionar usuarios.
Caso de uso: Crear usuarioActores: AdministradorReferencias: R.2aDescripción: Registra al usuario en el sistema directamente, el administrador in-
troduce todos los datos identificativos del nuevo usuario(nombre deusuario, password, email, . . . ).
69

Caso de uso: Crear usuarioActores: UsuarioReferencias: R.1eDescripción: Por cuestiones de seguridad, el registro de un nuevo usuario se realiza
en dos pasos: primero se debe dar de alta y luego debe confirmarlo.
Curso normal de eventos
Acción del actor Respuesta del sistema
1. Este caso de uso comienza cuando el usuariointroduce en un formulario sus datos(nombre deusuario, password, email, . . . ) para darse de altaen el sistema.
2. Si no hay error al registrar alusuario, el sistema le envía a lacuenta de correo electrónico intro-ducida en el formulario de entradaun código de activación.
3. El usuario obtiene el código de activación desu cuenta de correo y lo introduce en el sistema
5. El sistema registra definitiva-mente al usuario.
Caso de uso: Recordar passwordActores: UsuarioReferencias: R.1gDescripción: Este caso de uso sirve para que un usuario legítimo pueda acceder al
sistema aunque haya olvidado su password.
Curso normal de eventos
Acción del actor Respuesta del sistema
1. El caso de uso comienza cuando el usuariointroduce la dirección de correo electrónico queusó para darse de alta en el sistema.
2. El sistema comprueba si dicha di-rección es válida(está registrada enel sistema) y le envía a dicha direc-ción de correo su nombre de usuarioy password.
70

Resolver ejercicios.
Caso de uso: Resolver ejercicioActores: Usuario, administradorReferencias: R.1a, R.3e, R.2cDescripción: Un usuario o el administrador, quiere resolver un ejercicio, para obtener
las tablas de análisis. Antes de ello se comprueba que tiene permisos yque el sistema no está sobrecargado.
Curso normal de eventos
Acción del actor Respuesta del sistema
1. El caso de uso comienza cuando el usuariointroduce el ejercicio, bien en la propia herra-mienta o desde un archivo.
2. Antes de nada, el sistema com-prueba que el usuario tiene per-misos, para la operación solicita-da(si tiene permisos para el tipo deanálisis solicitado). Además, tam-bién comprueba que no hay demasi-ados usuarios utilizando en este mo-mento el sistema(control de sobre-cargas)3. El sistema resuelve el ejercicioactualizando las estadísticas con lanueva operación.4. El sistema le devuelve el resulta-do en el formato indicado en el re-quisito R.1a.
4. El usuario recibe el ejercicio resuelto.
Simular.
Caso de uso: SimularActores: Usuario, administradorReferencias: R.1b, R.3e, R.2cDescripción: Un usuario o el administrador, quiere realizar en el sistema un ejercicio
de simulación. Antes de ello se comprueba que tiene permisos y que elsistema no está sobrecargado.
71

Curso normal de eventos
Acción del actor Respuesta del sistema
1. El caso de uso comienza cuando el usuario in-troduce el ejercicio, compuesto por la gramáti-ca y el texto a simular. La gramática la puedeintroducir desde un archivo o en la propia he-rramienta
2. Antes de nada el sistema com-prueba que el usuario tiene per-misos, para la operación solicitada.Además, también comprueba queno hay demasiados usuarios uti-lizando en este momento el sis-tema(control de sobrecargas)3. El sistema genera la traza de sa-lida del simulador y se lo devuelveen el formato indicado en el requi-sito R.1b.
4. El usuario recibe el ejercicio resuelto.
Configurar.
Caso de uso: ConfigurarActores: AdministradorReferencias: R.2hDescripción: En este caso de uso el administrador configura los parámetros del sis-
tema: password de administración, permisos de cada perfil, servidorpara el correo saliente, . . .
Estadísticas.
Caso de uso: Gestionar estadísticasActores: AdministradorReferencias: R.2e, R.2iDescripción: Desde este caso de uso el administrador puede gestionar todas las es-
tadísticas registradas en el sistema. Las estadísticas que se pueden so-licitar son:
• Listado de los ejercicios resueltos y simulaciones.
• Gráficas de los porcentajes de los tipos de análisis de los ejerciciosresueltos y de las simulaciones.
• Listado con el feedback de los usuarios.
72

Casos de uso para el feedback.
Caso de uso: Introducir feedbackActores: UsuarioReferencias: R.2iDescripción: Con este caso de uso el sistema recibe el feedback del usuario.
Para facilitar la legibilidad de los diagramas de casos de uso, se ha separado los delusuario(Fig.4.1) y los del administrador del sistema(Fig.4.2).
Usuario Crear Usuario
Editar su Cuentade Usuario
Recordar Password
Resolver Ejercicio
Simular
Introducir Feedback
Figura 4.1: Diagrama de casos de uso para el usuario
73

Crear Noticia
Borrar Noticia
Editar NoticiaAdministrador
Crear Ejemplo
Borrar Ejemplo
EditarEjemplo
Crear Usuario
Borrar Usuario
Editar Usuario
Configurar
GestionarEstadísticas
Simular
Resolver Ejercicio
Figura 4.2: Diagrama de casos de uso para el administrador
74

4.3. Diseño de la arquitectura de la herramienta.
En los objetivos y requisitos de la herramienta se hacía especial hincapié en la formade introducir los ejercicios en la herramienta. La forma más adecuada para definir este tipo deejercicios es mediante la creación de un lenguaje específico. El utilizar un lenguaje tiene laventaja de que para crear los ejercicios de análisis sintáctico se puede utilizar cualquier editorde textos. Además, cuando se aprende el lenguaje es muy rápido crear los ejercicios.
Para procesar dicho lenguaje hay que crear su correspondiente compilador. Éste debecomprobar que el ejercicio esté escrito conforme a las reglas sintácticas del lenguaje definido.A su vez debe recoger la información necesaria para generar la solución. En próximas sec-ciones se describirá con más detalle las características del mismo.
Otro de los requisitos era que se debía facilitar la instalación y uso de la herramienta.Además, se debía crear algún sistema para gestionar a los usuarios de la herramienta y desus operaciones. Una forma de cumplir todos estos requisitos es utilizando una arquitecturacliente/servidor. Con esta arquitectura se consigue:
Que la aplicación no necesite instalación, lo único que necesita el usuario es un BrowserWeb. Esto es muy útil si la herramienta la utilizan los alumnos en clase de prácticas, alser una arquitectura Web, no hace falta instalarla en los laboratorios.
Que toda la carga caiga en la parte del servidor, de esta forma el cliente es muy ligero.
Al ser un sistema centralizado, desde el servidor se pueden registrar todas las opera-ciones de los usuarios(para hacer el seguimiento de uso).
En la Fig.4.3 puede verse la arquitectura de la herramienta y su funcionamiento.Lo primero que hace el usuario es conectarse con su cliente Web al servidor y enviarle losejercicios a resolver. Una vez le han llegado al servidor, los scripts del servidor llaman al com-pilador, que es el que verdaderamente resuelve los ejercicios y se los devuelve en el lenguajede salida del compilador. El script del servidor se encarga de transformar estos resultados aHTML, que es lo que finalmente le llega al usuario. Como se puede ver con esta forma detrabajar el cliente es muy ligero, y toda la carga cae en el servidor. En este proceso además deresolver los ejercicios, se registran en la base de datos las operaciones hechas por los usuarios.
75

Cliente Servidor web
INTERNET
Scripts
3:Ejercicio
6:S
oluc
ión(
HTM
L)
1:Ejercicio a resolver
8:Ejercicio resuelto(HTML)
2:Ejercicio a resolver
7:Ejercicio resuelto(HTML)
Compilador5:Solución
4:Ejercicio
Base de Datos
Figura 4.3: Arquitectura cliente/servidor de la herramienta.
4.4. Diseño del compilador.
Básicamente, un compilador se puede ver como una caja negra, el cual acepta unaentrada escrita en un determinado lenguaje y produce una salida en otro lenguaje. Es muyimportante hacer un buen diseño de dichos lenguajes.
4.4.1. Diseño del lenguaje de entrada.
En el diseño del lenguaje se ha puesto mucho cuidado, ya que si no se define correc-tamente, repercutirá muy negativamente en la utilidad de la herramienta.
El lenguaje diseñado tiene las siguiente características:
El lenguaje se parece mucho a los lenguajes utilizados normalmente para expresargramáticas libres de contexto. De esta forma, con la experiencia que ya tenga el usuarioen este tipo de lenguajes, le será más fácil aprender a utilizarlo. Para su diseño se hatomado como base la notación BNF y la de lenguajes de generadores de analizadoressintácticos como JCup y YACC.
Permite expresar una o varias gramáticas en el mismo archivo. La razón para permitirlo,es para no obligar al usuario a escribir cada gramática en un archivo diferente. Algunasveces es deseable poder escribir varias gramáticas en un mismo archivo, porque éstaspueden estar relacionadas y se quiere mostrar las diferencias entre las mismas. O porejemplo, un usuario puede tener definidas varias gramáticas y quiere compilarlas todasde una vez, porque su tiempo de acceso a la Web es limitado.
76

El lenguaje permite expresar el tipo de análisis que se quiere realizar para cada gramáti-ca del archivo de entrada(se puede realizar uno o varios). Los análisis permitidos son elLL(1), SLR(1), LR(1) y el LALR(1).
El lenguaje permite hacer declaraciones globales. Con estas declaraciones se puedenhacer definiciones comunes necesarias para varias gramáticas. Los elementos que sepueden declarar globalmente son:
• Terminales y no terminales.Estos símbolos serán validos para todas las gramáti-cas, no haciendo falta declararlos de nuevo.
• Grupos de producciones. En la zona global se permite definir un grupo deproducciones identificadas por un nombre. De esta forma, si hay un grupo deproducciones que se utiliza con frecuencia en varias gramáticas, sólo hace faltadefinirlo una vez. Con poner dentro de esas gramáticas el nombre identificadordel grupo, dichas gramáticas tendrán dentro a esas producciones.
• Definición de análisis.Si se indica en esta sección un tipo de análisis, se realizaráeste tipo de análisis para todas las gramáticas que se declaren en el archivo.
Una vez presentadas las características del lenguaje, en próximas secciones se expli-cará en profundidad cada una de las partes del lenguaje: léxico, sintáctico y semántico.
Definición Léxica.
Una característica importante a comentar antes de describir los aspectos léxicos dellenguaje definido, es que el lenguaje escase sensitive. Es decir, que importa si las palabras seescriben con mayúsculas o minúsculas.
Definiciones:
Comentarios: El lenguaje diseñado permite dos tipos de comentarios:
• Comentario de línea: Normalmente cualquier lenguaje permite definir comen-tarios de una línea. Todos los caracteres que estén dentro de dicha línea seráneliminados y no se tendrán en cuenta en el análisis sintáctico.
Para iniciar un comentario de línea hay que poner el símbolo: ’//’. Ejemplo:
/ / Es to es un comen ta r i o de l í n e a
• Comentario de bloque: Los comentarios de línea son suficientes, pero algunasveces se tienen que comentar bloques enteros y puede resultar tedioso utilizar
77

Palabra reservada Descripciónglobal Inicio de la zona global
analysis Indica el tipo de análisisterminal y nonterminal Tipos de símbolos de la gramática
grammar Indica que se va a declarar una gramáticaLL1, SLR1, LR1 y LALR1 Tipos de análisis sobre la gramática
Tabla 4.1: Lista de palabras reservadas
comentarios de línea. Para ello, al lenguaje también se le han agregado los co-mentarios de bloque. Todo lo que esté dentro del bloque, se considera comentarioy por lo tanto será eliminado.
Para definir un comentario de bloque se ha elegido el comentario de bloque dellenguaje C/C++. Es decir, el comentario de bloque se inicia con el símbolo’/*’ yse termina con el símbolo’*/’ . Ejemplo:
/∗
∗ Esto es un comen ta r io de b loque .
∗ /
Palabras reservadas: Estas palabras ya no se pueden utilizar como identificadores.En la Tabla4.1puede verse el listado de las palabras reservadas del lenguaje.
Identificadores: Los identificadores se utilizan para identificar los símbolos termi-nales, los no terminales y los nombres de las gramáticas.
Los identificadores tienen el siguiente patrón:
[_A-Za-z0-9]+
La estructura de un identificador es una secuencia de numeros, letras o el símbolo ’_’.Por ejemplo, identificadores válidos son: gramática_1, _gramatica0001, otroIdentifi-cadorValido . . .
Los únicos identificadores que no se pueden declarar son las palabras reservadas.
Caracteres especiales:Además de los identificadores, hay otro tipo de símbolos ter-minales que se pueden declarar. Estos símbolos se encierran entre comillas simples,y sólo pueden ser terminales. Ejemplo: ’!’, ’(’, ’)’, . . . Las letras y los números no sepueden poner entre comillas, ya que estos símbolos ya se pueden poner directamentecomo identificadores.
78

Este tipo de símbolos se ha incorporado porque para definir algunos tipos de gramáti-cas resulta engorroso hacerlo con identificadores normales. Por ejemplo, si se quisieraexpresar una gramática para definir expresiones matemáticas, se podría hacer de la si-guiente forma:
grammar e x p r e s i o n e s _ m a t e m a t i c a s
{
grammar id , mas , menos , por , d iv , pa r_ i zq , p a r _ d e r ;
nonterminal E , T , F ;
E := T mas E | T menos E | T ;
T := F por T | F d iv E | F ;
F := i d | p a r _ i z q E p a r _ d e r ;
}
Pero como se puede ver, algunos de los terminales hacen que la gramática pierda clari-dad. Por ejemplo, el terminalpar_izq representa a un paréntesis izquierdo. Sería mejorpoder poner este terminal directamente con el carácter del paréntesis ’(’. La siguientegramática es la misma que la anterior, pero utilizando este tipo de caracteres. Como sepuede ver esta forma de escribir la gramática aporta mayor claridad que la anterior.
grammar e x p r e s i o n e s _ m a t e m a t i c a s
{
grammar i d ;
nonterminal E , T , F ;
E := T ’+’ E | T ’-’ E | T ;
T := F ’*’ T | F ’/ E | F;
F := id | ’ ( ’ E ’ ) ’;
}
79

Definición Sintáctica.
Aspectos a destacar del lenguaje:
Sintacticamente se identifican dos partes, la primera zona es la global, la cual sirve parahacer definiciones globales(esta parte es opcional), la otra es la parte de definicioneslocales.
/ /− p a r t e g l o b a l
g l o b a l
{
}
/ /− f i n p a r t e g l o b a l
/ /− p a r t e l o c a l
grammar g rama t i c a_1
{
}
grammar g rama t i c a_2
{
}
/ /− f i n p a r t e l o c a l
La parte global es opcional pero debe haber como mínimo una gramática local declara-da. El contenido de la parte global y de las gramáticas locales va encerrado entre llaves.Dentro del cuerpo de las declaraciones globales y gramáticas locales se puede poner lomismo a excepción de los grupos de producciones, que ya se explicará en otro apartado.En el cuerpo de la parte global lo primero que se pone es el tipo de análisis a realizar,para declararlo se pone la palabra reservadaanalysisseguida de una lista con los análi-sis que se quiere realizar. Esta lista no puede ser vacía y como máximo se puedendeclarar 4 tipos de análisis. Ejemplo:
g l o b a l
{
/ / se ha e l e g i d o e l a n á l i s i s LL1 y LR1 .
a n a l y s i s LL1 , LR1 ;
}
80

La declaración del tipo de análisis sólo se puede hacer una vez(en cada gramática oglobalmente). Además es opcional, si se quiere no hace falta ponerla, por defecto se re-alizará un análisis LL(1). Los tipos válidos de análisis son: LL1, SLR1, LR1, LALR1.
Otro elemento que se puede declarar son los símbolos de las gramáticas, estos símbolospueden ser terminales y no terminales. Su declaración también es opcional, no impor-tando ni el orden ni el número de veces que se declaren.
g l o b a l
{
t e rm ina l a , b , c , d ;
nonterminal A, J , P ;
/ / no impor ta e l orden y se puede poner mas de uno
nonterminal Uno , Dos , Tres ;
t e rm ina l k , l ;
}
Como se puede ver la declaración de terminales está precedida de la palabra reservada’ terminal ’, y los no terminales de la palabra ’nonterminal’. Ejemplo resumen de laparte de declaraciones:
g l o b a l
{
a n a l y s i s LL1 , SLR1 ;
nonterminal A, J , P ;
t e rm ina l a , b , c , d ;
}
Formato de las producciones.
Una producción tiene dos partes:
• Parte izquierda: La parte izquierda sólo puede ser un no terminal.
• Parte derecha: En la derecha se ponen listas de terminales y no terminales. Laestructura de dichos símbolos son simples identificadores o caracteres especialesentre comillas. Los caracteres, como se ha dicho antes, no hace falta declararlosen la lista de terminales, ya que por defecto siempre son terminales. Para poner lapalabra vacía simplemente hay que dejar la parte derecha en blanco. Además, elsímbolo’|’ tiene el significado de la ’or’. Ejemplo:
81

grammar g r a m a t i c a _ d e _ p r u e b a
{
nonterminal A, B , C ;
t e rm ina l a , b , c ;
A := a ’+’ b ;
/ / s i se de ja en b lanco e n t o n c e s es l a pa lab ra v a c í a
A := ;
/ / l o a n t e r i o r también se pod r ía haber p u e s t o en una
/ / ún i ca s e n t e n c i a u t i l i z a n d o l a or .
A := a ’+’ b | ;
}
Aspectos a destacar en la escritura de las producciones:
◦ El final de cualquier producción siempre termina con el símbolo ’;’.
◦ La parte izquierda y derecha de una producción va separada por el símbolo’:=’.
◦ Los símbolos de la parte derecha de una producción se separan con espacios,si se ponen dos identificadores seguidos. Si entre medias se pone un carác-ter(’+’, ’/’, ...) no hace falta poner espacios. Ejemplo: p := a’+’b
◦ Con el símbolo ’|’ se consigue declarar varias producciones en una mismaexpresión.
◦ Si se deja en blanco la parte derecha de una producción significa la palabravacía.
• Sentencias específicas de la parte global.
Todo lo dicho anteriormente es válido para la parte global y para las gramáticaslocales. En la parte global además se pueden hacer declaraciones de grupos deproducciones. Se usan para no repetir declaraciones de producciones si estas pro-ducciones se van a utilizar en varias gramáticas.
Estas declaraciones de grupo se colocan después de la parte de declaraciones(análisis,terminales y no terminales). Cada sentencia de grupo tiene un nombre y dentro seponen las producciones que están dentro de dicha sentencia de grupo.
82

Ejemplo de declaración de grupo:
g l o b a l
{
nonterminal A, B ;
t e rm ina l a , b , c ;
/ / e s t o es un grupo
p r o d s _ g l o b a l e s =
{
A := a c | b ;
B := a ;
}
}
• Sentencias específicas de la parte local.
Las declaraciones de grupo no se pueden hacer en gramáticas locales, lo que sí sepuede hacer es utilizar dichas declaraciones de grupo. En el siguiente ejemplo sedeclara una sentencia de grupo que se instancia en la gramática local. Ejemplo:
83

g l o b a l
{
nonterminal A, B ;
t e rm ina l a , b , c ;
/ / e s t o es un grupo .
p r o d s _ g l o b a l e s =
{
A := a c | b ;
B := a ;
}
}
grammar g r a m a t i c a _ l o c a l
{
nonterminal Uno , Dos ;
t e rm ina l k1 , k2 , k3 ;
/ / ahora e s t a g ramát i ca i n c o r p o r a l a s p r o d u c c i o n e s
/ / d e l grupo p r o d s _ g l o b a l e s
p r o d s _ g l o b a l e s ;
/ / pero también puede t e n e r p r o d u c c i o n e s l o c a l e s .
Uno := k1 k2 ;
/∗
∗ Como se puede ver en una producc ión l o c a l
∗ se pueden i n c o r p o r a r s ímbo los d e c l a r a d o s
∗ l o c a l m e n t e y s ímbo los d e c l a r a d o s g loba lmen te .
∗ /
Dos := k1 k2 a ;
}
La representación BNF del lenguaje puede verse en la Fig.4.4.
84

CUERPO_GLC ::= BLQ_GLOBAL LISTA_BLQ_LOCAL | LISTA_BLQ_LOCALBLQ_GLOBAL ::= global ’{’ CUERPO_GLOBAL ’}’CUERPO_GLOBAL ::= [DEC_ANALISIS] LISTA_DEC_SIMBOLOS LISTA_SENT_GLOBALESDEC_ANALISIS ::=analysisTIPO_ANALISIS [’;’ TIPO_ANALISIS] [’;’TIPO_ANALISIS] [’;’
TIPO_ANALISIS] ’;’TIPO_ANALISIS ::=LL1 | SLR1 | LR1 | LALR1LISTA_DEC_SIMBOLOS ::= {DEC_SIMBOLOS}DEC_SIMBOLOS ::= DEC_TERMINAL | DEC_NO_TERMINALDEC_TERMINAL ::= terminal id {’,’ id} ’;’DEC_NO_TERMINAL ::=nonterminal id {’,’ id} ’;’LISTA_SENT_GLOBALES ::= {SENT_GRUPO}SENT_GRUPO ::=id ’=’ ’{’ LISTA_SENT_PROD ’}’LISTA_SENT_PROD ::= {PRODUCCION}PRODUCCION ::=id ’:=’ LISTA_PARTE_DERECHA ’;’LISTA_PARTE_DERECHA ::= PARTE_DERECHA {’|’ PARTE_DERECHA}PARTE_DERECHA ::= {SIMB_PARTE_DERECHA}SIMB_PARTE_DERECHA ::=idBLQS_LOCAL ::= DEC_LOCAL {DEC_LOCAL}DEC_LOCAL ::=grammar id ’{’ CUERPO_LOCAL ’}’CUERPO_LOCAL ::= [DEC_ANALISIS] [DEC_SIMBOLOS] LISTA_SENT_LOCALESLISTA_SENT_LOCALES ::= {SENT_LOCAL}SENT_LOCAL ::= LISTA_SENT_PROD | INSTANCIACION_GRUPOINSTANCIACION_GRUPO ::=id ’;’
Figura 4.4: Descripción BNF del lenguaje
85

Definición Semántica.
En el semántico se controlan aspectos del lenguaje que son difíciles (o imposible)de controlar en el análisis sintáctico. La lista de restricciones semánticas es la siguiente:
Declaración de símbolos: Antes de usar cualquier símbolo es necesario declararlopara definir su tipo. Exceptuando los símbolos especiales que van entre comillas sim-ples, este tipo de símbolos siempre son terminales. Ejemplo:
grammar g rama t i ca_1
{
nonterminal A;
t e rm ina l a , b , c ;
/ / hay que d e c l a r a r l o s s í mbo lo s a n t e s de
/ / poder u s a r l o s
A := a c | b ;
/ / una p roducc ión e r rónea s e r í a l a s i g u i e n t e
/ / no se ha dec la rado e l s ímbo lo B
B := a c ;
}
Resolución de ámbito: Todos los símbolos declarados globalmente, son accesiblesdesde todas las gramáticas locales, es decir, si se declaran globalmente no hace faltavolver a declararlos localmente. Lo que no está permitido es definir en un mismo ám-bito dos veces el mismo símbolo. Ejemplo:
86

g l o b a l {
nonterminal A, B , C ;
t e rm ina l a , b ;
/ / no se puede d e c l a r a r dos v e c e s un s ímbo lo
/ / e s t o g e n e r a r í a un e r r o r .
t e rm ina l a , B ;
}
grammar gram_1
{
/ / no hace f a l t a d e c l a r a r A , a , b
/ / ya que e s t á n d e c l a r a d o s g loba lmen te .
A := a b ;
}
Si se declara un símbolo globalmente y este mismo símbolo se vuelve a declarar local-mente, tiene más prioridad el local. Si al declararlo de forma local es del mismo tipono pasa nada, pero si se declara localmente de un tipo diferente al global tiene másprecedencia el local. Ejemplo:
g l o b a l {
/ / en l a p a r t e g l o b a l se d e c l a r a como no t e r m i n a l
nonterminal A;
}
grammar gram_1
{
nonterminal S ;
/ / e s t a d e c l a r a c i ó n t i e n e mas p r i o r i d a d que l a g l o b a l
/ / por l o t a n t o ’A ’ es un t e r m i n a l .
t e rm ina l A;
S := A;
}
87

El nombre de una gramática es un símbolo global, si se vuelve a declarar localmente,por ejemplo como un terminal, siempre tiene más precedencia la declaración local.
Todos los símbolos declarados localmente en una gramática no interfieren en otragramática y se pueden volver a declarar. Ejemplo:
grammar gram_1
{
t e rm ina l uno , dos ;
}
grammar gram_2
{
/ / e s t o no genera c o n f l i c t o a l s e r g ramá t i cas d i s t i n t a s
t e rm ina l uno , dos ;
}
Corrección en la escritura de las producciones:En las producciones hay que com-probar que se escriban correctamente. Para ello se comprueba que en la parte izquierdasólo pueda haber no terminales. En cambio en la parte derecha puede haber terminales,no terminales y la palabra vacía.
88

4.4.2. Diseño del lenguaje de salida.
El formato elegido debe tener las siguientes características:
Debe ser fácil de generar.
Debe ser fácil de utilizar por las aplicaciones externas.
Preferiblemente que sea un archivo de texto, ya que tiene la ventaja de ser entendiblepor los humanos.
Con estas premisas es fácil imaginar que el formato elegido sea un archivo XML. Elutilizar el formato XML cumple las premisas anteriormente citadas:
Se genera fácilmente ya que se puede generar como un simple archivo de texto, o existela posibilidad de generarlo automáticamente con herramientas. Por ejemplo, en Java sepuede utilizar el paquete para el tratamiento de XML(DOM). No sólo para leer archivosXML sino también para generar el árbol XML y que el paquete genere el archivo(detexto) de salida. Se ha considerado que ésta es la mejor forma de hacerlo, porque lib-era al programador de cuestiones de formato. Por ejemplo, hay determinados tipos decaracteres que no se pueden escribir en el archivo directamente(’"’, <, >). Si el XMLse genera manualmente, es decir, escribiendo el texto directamente en el archivo, hayque hacer la conversión manualmente. En cambio, si el archivo XML se genera con elpaquete DOM, este tipo de conversiones se hacen automáticamente.
Al utilizar un formato estándar ya no hay que construir un parser para acceder a lainformación del archivo. Ya existen parsers que se pueden utilizar gratuitamente. Elparser te abstrae del formato, presentándote la información como un árbol jerárquico.
El archivo XML es un archivo de texto plano.
Una vez definido el formato del lenguaje de salida del compilador, hay que definirsu estructura interna. De la especificación de requisitos hecha al principio se puede obtenerque en el XML de salida se debe registrar la siguiente información:
Gramáticas: Normalmente si el compilador se va a utilizar desde una herramientaexterna no basta con generar las tablas de análisis, lo más seguro es que la herramientaexterna necesite información detallada de las gramáticas compiladas.
Información adicional: Cuando se hacen ejercicios de análisis sintáctico, hay infor-mación adicional que es muy útil. Esta información(anulables, iniciales y seguidores)también se debería incluir en el archivo de salida.
Estados: En los métodos ascendentes también se proporciona una información com-pleta del autómata reconocedor de prefijos viables. La información de cada estado nosólo son los items que tiene, sino los enlaces entre estados. De esta forma una herra-mienta exterior puede dibujar el autómata de reconocimiento.
89

Raíz
Gramáticaanalizada
1..*
1
Gramática
Producción Información adicional
Lista de anulables
Lista de iniciales
Lista de seguidores
1
Análisis
Tabla de análisis
Lista de estados
1..*
1..*
1 1 1
0..1 1
Figura 4.5: Esquema XML para la solución de los ejercicios de análisis sintáctico
Tablas de análisis: Este es el resultado final del análisis.
En la Fig.4.5 puede verse el esquema del archivo XML de salida, para el resul-tado de ejercicios de análisis sintáctico. Como puede verse, en un mismo archivo XML sepueden analizar más de una gramática. Por cada gramática analizada se registra la gramáticaen cuestión, sus producciones, la información adicional(anulables, iniciales, seguidores, . . . )y todos los análisis hechos a dicha gramática. Al final, por cada análisis realizado se registranlos estados(si es ascendente) y la tabla de análisis.
Para la simulación el archivo de salida es mucho más sencillo, pues lo único que senecesita registrar es la traza de la simulación. En la traza de una simulación se registran loscomponentes del analizador sintáctico.
Como puede verse en la Fig.4.6, el formato de salida para la simulación tiene lassiguientes características:
En un mismo archivo se puede realizar varias simulaciones.
Cada simulación es una traza, la cual es una lista de entradas.
90

Cada entrada está compuesta de los siguientes elementos.
• Pila: Es el contenido actual de la pila del analizador sintáctico.
• Entrada: Es el contenido actual del buffer de entrada.
• Acción: Es la acción a realizar con la configuración actual(pila, buffer de entra-da). La acción depende del método de análisis empleado, en el descendente seindica la producción a expandir y en los ascendentes se indica si es un desplaza-miento o una reducción.
Raíz
Traza
1..*
1
Pila Acción
1
Entry
1..*
1
Entrada
Figura 4.6: Esquema XML para la salida de la simulación
91

CAPÍTULO 5.
IMPLEMENTACIÓN DEL COMPILADOR
El compilador es el componente más importante del proyecto, ya que del enfoqueempleado en éste, depende cualquier otra herramienta que se quiera implementar. Por dicharazón, se ha tenido mucho cuidado en el diseño del mismo. El compilador tiene las siguientescaracterísticas:
Portable. En general la portabilidad siempre es deseable, ya que si se quiere portarel compilador a otro sistema, cuanto más portable sea menos costará hacerlo. En estecaso se ha conseguido implementando el compilador en Java, un lenguaje interpretadoy muy portable. Además, no se ha utilizado ningún paquete externo que no tenga ladistribución estándar deJava.
Fácil acoplamiento. Los compiladores se pueden utilizar directamente, pero es de-seable poderlo integrar en otras aplicaciones. Por ejemplo, en los entornos integradosde desarrollo como el Visual Estudio de Microsoft, por un lado está su compilador ypor otro el entorno en sí. La mayoría de los compiladores profesionales están diseñadoscon esta filosofía. De esta forma el compilador es más fácil de utilizar y se pueden crearotros entornos diferentes para el mismo compilador.
Extensible. El compilador está diseñado para generar las tablas de análisis y parasimular analizadores sintácticos. Pero en el futuro se prevé que se pueda ampliar sufuncionalidad para otro tipo de ejercicios, por ejemplo para lenguajes regulares. Por lotanto la arquitectura de la herramienta facilitará su extensión.
92

5.1. Arquitectura del compilador.
Uno de los pasos más importantes en el diseño de un sistema software es el diseñode la arquitectura del sistema. La arquitectura que se va a emplear es la arquitectura clásicade un compilador.
El compilador se estructura en dos etapas, la primera de ellas es la etapa dependientedel lenguaje(análisis) y la segunda la independiente del lenguaje(síntesis). La arquitectura delcompilador puede verse en la Fig.5.1.
La etapa de análisis divide al texto fuente en sus elementos componentes y crea unarepresentación intermedia del texto fuente. En la etapa de análisis se encuentran los siguientescomponentes:
Analizador léxico. Se encarga de transformar el texto fuente de entrada, en una se-cuencia de tokens para el analizador sintáctico. Además, también se encarga de eliminarelementos innecesarios, como los comentarios.
Analizador sintáctico. Se encarga de comprobar la validez sintáctica de la entrada.
Analizador semántico.Se encarga de comprobar la validez semántica(comprobacionesdifíciles de hacer en el sintáctico).
La etapa de síntesis construye el producto objeto(archivo XML) a partir de la repre-sentación interna generada por la etapa de análisis.
Lexer(léxico)
Generador de las tablas de análisis y del simulador
Archivo fuente
XML
Parser(sintáctico/semántico)
Análisis.Dependiente del
lenguaje
Síntesis.Independiente del
lenguaje
Figura 5.1: Arquitectura del compilador
93

En las próximas secciones se explicará detalladamente la implementación de cadauno de estos componentes.
5.2. Interfaz del compilador.
La mayoría de los compiladores utilizan la misma interfaz, la cual es la interfaz delínea de comandos(consola). El compilador se puede utilizar como cualquier otro programadesde la línea de comandos.
El utilizar la interfaz de la línea de comandos tiene las siguientes ventajas:
Portable. La consola es un elemento que existe en cualquier sistema operativo, pordicha razón da igual el sistema operativo que se use, el compilador siempre se va apoder usar desde la línea de comandos.
Rapidez. Cuando se conocen los comandos, la utilización de la línea de comandos esmucho más rápida que las interfaces gráficas.
Interconexión. El utilizar la línea de comandos facilita la interconexión con otrasaplicaciones, ya que es más fácil la comunicación entre las aplicaciones.
Facilidad de uso. La línea de comandos es la interfaz que normalmente usan todos loscompiladores porque es muy fácil de usar. Por ejemplo elgcclo usa, y los compiladoresde Microsoft también.
El primer punto a definir ha sido la interfaz del mismo, ahora quedan por definir lossiguientes elementos:
Entrada: El formato de entrada es como la de cualquier compilador, es decir, hayque indicarle el archivo de entrada donde está el texto fuente. También se le puededar el texto fuente mediante la entrada estándar, esta forma existe para permitir a lasaplicaciones comunicarse sin tener que crear archivos físicos.
Salida: En la sección4.4.2ya se indicó que la salida del compilador es un archivoXML. Pero al igual que para la entrada, la salida se puede guardar en un archivo o sepuede enviar a la salida estándar. El objetivo de permitir esta forma, es el mismo quepara la entrada, utilizar el compilador sin tener que crear archivos físicos.
Mensajes de información del compilador:Cuando se encuentra un error sintáctico oléxico se deben comunicar al usuario. La forma normal que usan los compiladores decomunicar estos mensajes es mediante la salida estándar de error.
En definitiva, la entrada se realiza mediante un archivo de texto, la salida la generaen un archivo XML y la salida de mensajes en la salida estándar de error. En la Fig.5.2puedeverse el esquema de comunicación del compilador.
94

Archivo fuente
XML
Mensajes del compilador
Aplicación
Figura 5.2: Utilización del compilador con la interfaz por consola
Como se puede ver en la Fig.5.2, para que una aplicación utilice el compilador loúnico que debe hacer es darle al compilador el archivo con el texto fuente y el compiladorproducirá dos elementos, las tablas de análisis y los mensajes de compilación.
Como el compilador está hecho en Java, los programas en Java además de poder us-ar el compilador de la misma forma que la usa cualquier otro programa, pueden usarlo comoun paquete de Java. Esta forma de utilizarlo permite a las aplicaciones acceder a determina-dos servicios que no están accesibles desde la interfaz por consola. Estos servicios son lossiguientes:
Control de los mensajes del compilador.En la versión de consola los mensajes delcompilador, están mezclados y la única forma de diferenciarlos es parseando la salidaestándar de error. En cambio si el compilador se utiliza como un paquete, la aplicaciónse puede registrar al canal de eventos y podrá acceder a la información adicional delos eventos más fácilmente. El sistema de eventos se verá con más profundidad en lassiguientes secciones.
Interfaz más sencilla. Esta forma de utilizarlo es más sencilla, ya que para utilizarlosólo hay que incluirlo como una paquete más de Java, teniendo acceso a todas susclases.
Diversidad del formato de entrada. La entrada con las gramáticas a compilar no sólotiene por que ser un archivo, se puede compilar una cadena de texto, un archivo, . . . Engeneral cualquier objeto que se pueda convertir en un flujo de caracteres.
Modificar la salida del compilador. Como ya se explicará en las posteriores sec-ciones, la arquitectura del compilador permite modificar el comportamiento de partesdel mismo de una forma sencilla. Por ejemplo, si un programa no quisiera que se gen-erase el archivo XML de salida y quisiese las tablas de análisis directamente(en suformato original), lo podría hacer fácilmente sustituyendo un único componente.
95

5.3. Etapa de análisis.
Como ya se ha comentado antes, la función de la etapa de análisis es la de crearuna representación intermedia del texto fuente para que pueda ser utilizada por la etapa desíntesis. En las próximas secciones se describirán cada uno de los componentes de la etapa deanálisis.
5.3.1. Implementación del analizador léxico.
El analizador léxico se puede implementar de dos formas:
Implementación manual. Una forma de implementarlo es manualmente, es decir, im-plementar manualmente un autómata finito para reconocer los componentes léxicos.Esta forma de hacerlo tiene la ventaja de que se puede crear una analizador léxico rápi-do. Ya que al implementarlo específicamente se puede optimizar más. Pero tiene ungran inconveniente y es que es muy poco flexible, es decir, es muy costosa la modifi-cación. Esta forma de implementación sólo es aconsejable cuando el léxico del lenguajees muy sencillo.
Implementación mediante un generador de analizadores léxicos.Con este sistemase utiliza un programa para generar automáticamente el analizador léxico. Aunque nosea tan óptimo como implementarlo manualmente, tiene la ventaja de que cuesta muypoco implementarlo. Lo único que hay que hacer es definir las expresiones regularesque definen los lexemas. A partir de estas expresiones regulares el generador creará elanalizador léxico.
De entre las posibilidades que había para implementar el analizador léxico, por susventajas, la elegida es un generador automático de analizadores léxicos. Para la elección delmismo se ha tenido en cuenta que sea lo más compatible con el generador de analizadoressintácticos utilizado.
El generador de analizadores léxicos utilizado ha sido el JFlex(ver Anexo9.1). Seha elegido este generador porque es el generador que normalmente se ha utilizado en la Uni-versidad, en las asignaturas de Autómatas y Lenguajes Formales y en la de Procesadores deLenguajes. Además, JFlex es un buen generador de analizadores léxicos que tiene las siguien-tes características:
Genera analizadores léxicos muy rápidos.
Independiente de la plataforma, ya que genera analizadores sintácticos en Java.
Es compatible con los generadores de analizadores sintácticos JCup(es el utilizado enel analizador sintáctico), y BYacc/J.
96

La implementación del analizador léxico es muy sencilla, lo único que hay que ha-cer es al JFlex darle un archivo, con los patrones de los componentes léxicos del lenguajey JFlex genera una clase ”.java”, con un analizador léxico. Lo dicho puede verse de formaesquemática en la Fig.5.3.
Programa escrito en JFlex
Generador de analizadores
léxicosJFlex
Programa fuenteAnalizador léxico
Lexer.java
Figura 5.3: Generación del analizador léxico
Un tema importante es el hacer compatible el analizador léxico con el sintácti-co(JCup). Para ello JCup define los siguientes elementos:
Interfaz Scanner. Esta es la interfaz que debe tener cualquier analizador léxico com-patible con JCup. El analizador léxico que genera JFlex implementa esta interfaz paraser compatible con JCup.
Para indicarle a JFlex que genere el analizador léxico compatible con JCup hay quedarle la directiva:%cup
Esta interfaz tiene un único método llamadonext_token, este método es al que lla-ma el analizador sintáctico cada vez que necesita un token. Los tokens los devuelveencapsulados en instancias de la claseSymbol.
Clase Symbol. Esta clase es la utilizada por el analizador léxico para encapsular lostokens, esta clase tiene los siguientes atributos:
• sym. Identificador numérico de cada token.
• left. Fila del archivo donde estaba el token.
• right. Columna del archivo donde estaba el token.
• value. Es el valor del token, por ejemplo si se reconoce el token IDENTIFI-CADOR, el atributovalue tendría el valor de dicho identificador.
Interfaz sym. En esta interfaz se definen los identificadores numéricos de los tokensdel lenguaje definido en el analizador sintáctico. Estos identificadores son los valoresque toma el atributosym de la claseSymbol.
97

Elementos a destacar de la especificación para JFlex.
Comentario de línea. El carácter elegido para el comentario de línea es ’//’. La expre-sión regular para los comentarios de línea es la siguiente:
"//" [ ^ \ r \ n ] ∗ { /∗ pasar ∗ / }
Comentario de bloque. El comentario de bloque se ha implementado con estados, elcódigo JFlex para el comentario de bloque es el siguiente:
<COMENTARIO_BLOQUE>
{
[ ^ ∗ \ n ]∗ { /∗ pasar ∗ / }
"*" + [ ^ ∗ / \ n ]∗ { /∗ pasar ∗ / }
"\n" { /∗ pasar ∗ / }
"*"+"/" { yybeg in ( YYINITIAL ) ; }
}
Palabras reservadas.El patrón para las palabras reservadas es el lexema de la propiapalabra reservada. Ejemplos:
"global" { re turn symbol ( sym .GLOBAL) ; }
"analysis" { re turn symbol ( sym . ANALISIS ) ; }
"terminal" { re turn symbol ( sym .TERMINAL) ; }
El métodosymbol lo que hace es devolver una instancia de la claseSymbol.
Identificadores. En los identificadores además de devolver el token identificador, sedevuelve el valor de dicho identificador(mediante el métodoyytext()).
/∗ pa t rón para reconoce r un i d e n t i f i c a d o r∗ /
[ _A−Za−z0−9]+ { re turn new Symbol ( sym . ID , y y t e x t ( ) ) }
Otro aspecto que se trata en el análisis léxico son los errores, los únicos errores quese controlan en el análisis léxico son los errores por introducir lexemas no permitidos. Aligual que cualquier evento, los errores léxicos se mandan al canal de eventos del compilador.Si se utiliza desde una aplicación externa el error se imprime con el siguiente formato:
archivo:fila:columna:error:información adicional del error.
98

El siguiente texto es un ejemplo de la salida del compilador al encontrar erroresléxicos:
prueba.glc:24:1: error: carácter ilegal ’%’
prueba.glc:24:7: error: carácter ilegal ’$’
2 errors, 0 warnings
El formato con el que se imprimen los errores no se ha elegido al azar, este formatode comunicar los errores es el mismo que el formato que utiliza el compiladorgcc. Esteformato tiene la ventaja de que hay editores de texto(como el Emacs) que lo reconocen. Deesta forma cuando se producen errores de compilación, el propio editor puede ir a la posiciónexacta del error(archivo, fila, columna).
5.3.2. Implementación del analizador sintáctico.
Al contrario que el analizador léxico, el analizador sintáctico es muy costoso imple-mentarlo manualmente. Para la generación del analizador sintáctico se ha utilizado un gen-erador automático de analizadores sintácticos(JCup). El analizador sintáctico implementadotiene las siguientes características:
Compilador de una pasada. El análisis del archivo de entrada se puede realizar enuna única pasada. Por lo tanto es un compilador más rápido que si se hiciese en variaspasadas.
Continuación de la compilación ante errores. Cuando el compilador se encuentraun error sintáctico, no para de compilar, prosigue hasta finalizar o encontrar un errorirrecuperable. Esta característica es muy importante para los compiladores, ya que si elcompilador se para al primer error, entonces se tardaría mucho tiempo en depurar loserrores.
Trazado de errores. Cuando se produce un error sintáctico, además de informar delerror propiamente dicho, se informa de su localización. Es decir, se indica el archivo,fila y columna donde se produjo el error.
La implementación del analizador sintáctico es sencilla, básicamente lo que hay quehacer es definir en el lenguaje del generador de analizadores sintácticos(JCup), la gramáticadel lenguaje. Para ello se parte de la gramática diseñada en BNF, vista en la Fig.4.4.
99

Programa escrito en Jcup(parser.cup)
Generador de analizadores sintácticos
JCup
Programa fuenteAnalizador sintáctico
Parser.java
Interfaz con la definición de los tokens(sym.java)
Figura 5.4: Generación del analizador sintáctico
Al ejecutar JCup con la gramática JCup generará dos clases(ver Fig.5.4):
Parser. Es la clase que implementa el parser.
sym. Como ya se ha comentado antes, esta clase contiene los identificadores de todoslos tokens definidos en la gramática.
Otro tema es el control de errores, en el analizador sintáctico se hace mediante lasproducciones de error. Las producciones de error se ponen en puntos de la gramática dondese maximice el número de veces que el analizador se pueda recuperar del error y seguir con lacompilación. Por ejemplo, en la declaración de listas ya sean de terminales o no terminales,hay que poner una producción de error. De esta forma si en alguno de los símbolos reconoci-dos hay error, el compilador puede proseguir con la compilación.
l i s t a _ d e c _ t e r m i n a l e s : : = l i s t a _ d e c _ t e r m i n a l e s COMA d e c _ t e r m i n a l
|
d e c _ t e r m i n a l
;
d e c _ t e r m i n a l : : =
ID
|
e r r o r ;
Como puede verse en el código anterior, se ha puesto una producción de error por sien la regla encargada de reducir el terminal se produce un error.
100

Poco más hay que decir del control de errores, ya que todo lo demás lo controlaautomáticamente el parser.
5.3.3. Implementación final del parser.
Una vez se han generado el analizador léxico y el sintáctico por separado, sólo quedacompilarlos para generar el parser final(ver Fig.5.5).
Programa fuenteAnalizador léxico
Lexer.java
Compilador del lenguaje fuente
Programa ejecutable
Programa fuenteAnalizador sintáctico
Parser.java
Figura 5.5: Compilación del lexer y el parser
La relación final de todas las clases comentadas en estos apartados puede verse enla Fig. 5.6. El Parser tiene como atributo a suScannergenérico, y accede a los tokens deentrada mediante el métodonext_token. Los tokens que devuelve elScanner los devuelveencapsulados en instancias de la claseSymbol, de ahí la dependencia. Y por último quedala interfazsym, que es generada por JCup y contiene los identificadores de los tokens. Estainterfaz la utiliza elLexer.
Lexer
+parse()
Parser
+next_token()
java_cup.runtime.Scanner
1
-lexer
1
sym
Symbol
Figura 5.6: Diagrama de clases del Parser
101

5.3.4. Tabla de símbolos.
Antes de entrar en los detalles del analizador semántico conviene explicar la tabla desímbolos, una estructura de datos indispensable para el analizador semántico.
Los compiladores utilizan la tabla de símbolos para registrar información sobre lossímbolos declarados. A la tabla de símbolos se accede cada vez que se encuentra un nombreen el texto fuente, para hacer comprobaciones. Por ejemplo, cuando se declaran los símboloshay que comprobar que un símbolo no se defina dos veces, para ello se consulta la tabla desímbolos.
La tabla de símbolos debe permitir dos funciones esenciales:
Agregar nuevas entradas.Cuando se declara un nuevo símbolo, si no existe previa-mente, hay que agregarlo a la tabla de símbolos.
Encontrar entradas existentes.Cuando se declara un símbolo hay que comprobar sieste símbolo ya existía previamente.
Hay varias formas de implementar la tabla de símbolos:
Con una lista. La estructura de datos más sencilla y fácil para implementar la tabla desímbolos es una lista lineal. Se utiliza una matriz(si es una lista con memoria estática) ouna lista enlazada(si es con memoria dinámica), para guardar los símbolos en la tabla.Este tipo de estructura tiene la ventaja de que es muy sencilla de implementar, pero tieneun gran inconveniente y es que las búsquedas cuando la lista es grande son muy lentas,lo cual es un gran inconveniente, ya que las búsquedas son una de las operaciones máscomunes en el proceso de compilación.
Con una tabla de dispersión(HashTable)Esta técnica es la usada en la mayoría de loscompiladores actuales. La gran ventaja de las tablas de dispersión es que permiten quelas búsquedas sean muy eficientes, lo cual es ideal para la implementación de la tablade símbolos. Cada entrada de una tabla de dispersión se indexa mediante una clave.
Como en el lenguaje existen dos ámbitos(local y global), la tabla de símbolos se hadividido en dos partes(el diagrama de clases puede verse en la Fig.5.7):
Ámbito global. En esta tabla se registran los símbolos declarados globalmente(terminales,no terminales, grupos de producciones).
Ámbito local. En la parte local sólo se registran los terminales y no terminales declara-dos en cada gramática.
102

TablaSimbolos Hashtable
1
-local
1
Hashtable
1
-global
1
Figura 5.7: Diagrama de clases de la tabla de símbolos
Una vez definida la estructura de la tabla de símbolos, sólo queda por definir el tipode objeto que se utiliza como clave de dispersión y los atributos que guardará en cada entradade la tabla.
Clave. Para definir la clave hay que ver el tipo de objetos que se van a guardar en latabla de símbolos. En la tabla se guardan:
• Símbolos terminales.Los terminales se identifican por una cadena de texto(tipoString).
• Símbolos no terminales.Los no terminales también se identifican por una cadenade texto.
• Nombres de gramáticas.Es una simple cadena de texto.
• Grupos de producciones. Los grupos de producciones son un vector de pro-ducciones, pero como identificador tienen un nombre. Este nombre(el cual es unacadena de texto)va a ser la clave.
Como se puede suponer la clave a utilizar va a ser una cadena de texto, ya que todos loselementos a registrar en la tabla se identifican por una cadena de texto.
Valor. Normalmente cuando se guardan terminales, no terminales y nombres de gramáti-cas, el valor es el propio símbolo(instancias de la claseTerminal y NoTerminal). Perocuando es un grupo de producciones lo que se guarda es un vector con las produccionesdel grupo.
En la Fig.5.8 puede verse el proceso de como se tratan los grupos de producciones.Cuando se está realizando el análisis y se encuentra la definición de un grupo, se co-pian a la tabla de símbolos todas las producciones del grupo. Después, cuando en unagramática local se encuentra la definición de un grupo, se busca en la tabla de símbolossi existe dicho grupo y se expanden las producciones del grupo que se está tratando.
103

global { grupo = { S := a b; S := b; }}
Tabla de símbolos
aa
bb
S := a bS := bgrupo1:Subir las producciones identificadas
por ’grupo’
grammar gramatica { grupo;}
2:Leer de la tabla de símbolos las producciones identificadas por ‘grupo’
grammar gramatica { S := a b; S := b;}
3:expandir las
producciones
Figura 5.8: Tratamiento de los grupos de producciones
5.3.5. Implementación del analizador semántico.
Lo bueno de utilizar los generadores automáticos de analizadores sintácticos, es quepermiten realizar el análisis semántico a la misma vez que se realiza el análisis sintáctico. Elanálisis semántico se implementa en el propio archivo donde se especifica la sintaxis.
En la definición del lenguaje ya se realizó una exposición de las restricciones semán-ticas del lenguaje. En esta sección se dará una visión de la forma de implementar dichasrestricciones semánticas:
Declaración de símbolos: Básicamente el control de la declaración de símbolos, esdecir, la declaración de un símbolo antes de usarlo o la repetición en la declaración desímbolos, se controla mediante la tabla de símbolos.
La declaración de símbolos depende del contexto que se esté analizando:
• Contexto global. Si el símbolo no existía previamente se agrega a la parte globalde la tabla de símbolos. Si ya existía se genera un error.
• Contexto local. Primero se comprueba si dicho símbolo existe en la parte localde la tabla de símbolos. Sólo se mira en la parte local de la tabla de símbolos para
104

mantener la precedencia de la parte local. Si el símbolo existía previamente segenera un error, si no existe se agrega a la parte local de la tabla de símbolos.
El cambio del contexto global al local se produce cuando se analiza la primera gramáti-ca local. Es decir, cuando se encuentra el primer tokengrammar.
En resumen, cada símbolo que se declara en el texto fuente se registra en la tabla de sím-bolos, para posteriormente poder utilizarlo. No sólo se registra el símbolo en cuestión,también se registra su tipo, es decir, si es un terminal, no terminal, nombre de gramáticao un grupo de producciones.
Por ejemplo, si se analizara la siguiente gramática:
grammar g r a m a t i c a _ d e _ p r u e b a
{
t e rm ina l a , b , c ;
nonterminal S , A;
}
El estado de la tabla de símbolos sería el siguiente(parte local de la tabla):
Clave Tipo Valora Terminal ab Terminal bc Terminal cS No terminal SA No terminal A
Resolución de ámbito:Como ya se comentó en la definición del lenguaje, la declaraciónde los símbolos depende del ámbito de declaración de los mismos. Los símbolos declara-dos localmente tienen más precedencia que los declarados globalmente. La imple-mentación de esta restricción también se hace mediante la tabla de símbolos. Para ello,lo que se hace es que cuando se realizan las búsquedas en la tabla de símbolos, primerose busca en la tabla local y después en la global. Por lo tanto los símbolos que están enla tabla local, son encontrados antes que los que están en la global. Por ejemplo, supón-gase que se declara el símbolo global ’S’ como terminal, este símbolo se registraríaen la parte global de la tabla de símbolos. Si ahora en una gramática local se vuelve adeclarar el mismo símbolo como no terminal, no pasa nada, dicho símbolo se agregaráa la tabla local. La clave está en las búsquedas, cuando se busca un símbolo en la tablade símbolos primero se busca en la parte local. Por lo tanto lo encontrará y lo devolverácomo no terminal.
105

Comprobación de tipos: En el control de tipos se controla que:
• El símbolo de la parte izquierda de la producción es un no terminal.
• Los símbolos de la parte derecha de la producción deben ser terminales o no ter-minales.
Estas comprobaciones se implementan mirando el tipo de cada símbolo en la tabla desímbolos.
Como se puede ver prácticamente todo el control de la semántica se realiza con laayuda de la tabla de símbolos.
5.3.6. Gramática con atributos.
Cuando se está realizando el análisis semántico en algunas situaciones hay queguardar listas del símbolos. Por ejemplo, en la declaración de los terminales, no terminales,producciones, . . .
Hay dos formas de hacer esto:
La primera de ellas es usando variables globales, pero esta forma en un principio no esdeseable. El propio analizador sintáctico proporciona otros métodos más elegantes.
La segunda de ellas es utilizar las gramáticas con atributos. En las reglas sintácticashechas en el análisis sintáctico, los símbolos declarados pueden guardar información.A esta información se puede acceder durante el proceso de análisis sintáctico, de estaforma no hace falta el tener que declarar variables globales.
Con la gramática con atributos en los símbolos no terminales de las producciones sepuede guardar información(atributos) y antes de realizar la reducción por el no terminal dela parte izquierda de la producción se puede realizar alguna acción(código incrustado por elprogramador). Esta forma en que se hace el proceso está condicionada a como se realiza elanálisis sintáctico. Ya que el analizador sintáctico que genera JCup es una analizador sintác-tico ascendente.
Para entender como se aplica las gramáticas con atributos en el compilador, lo mejores mostrarlo mediante un ejemplo(en el Anexo9.2hay una breve descripción de JCup).
Supóngase que se tiene una gramática para la declaración de una lista de tipos(enteros)en lenguaje C.
S →int LISTALISTA→LISTA , IDLISTA→ID
106

Como puede verse lo primero es el tipo y después se declara la lista de identifi-cadores. Su correspondiente traducción al lenguaje JCup sería(en JCup no se pueden ponerlos símbolos como la ’,’ hay que poner un identificador, por ejemplocoma):
S : : = i n t LISTA
LISTA : : = LISTA coma ID
LISTA : : = ID
Ahora sólo queda poner las acciones para reconocer la lista de símbolos declarados.Lo primero es definir el atributo que se guarda en cada símbolo. Por ejemplo como se va adevolver una lista, el símbolo ’S’ es un Vector y ’LISTA’ también. Una vez hecho esto sóloqueda indicar las acciones para cada producción.
S : : = i n t LISTA : l i s t a
{ :
RESULT = l i s t a ;
: }
LISTA : : = LISTA : l coma ID : v a l o r
{ :
/ / agregar nuevo s ímbo lo
l . addElement ( v a l o r ) ;
RESULT = l ;
: }
|
LISTA : : = ID : v a l o r
{ :
/ / e s t e es e l caso base de l a l i s t a
RESULT = new Vec to r ( ) ;
RESULT . addElement ( v a l o r ) ;
: }
El primer caso es el caso raíz, y en el no terminal LISTA ya está toda la lista desímbolos recogidos(en una instancia de la clase Vector). La producción ’LISTA ::= LISTA:lcoma ID:valor’, es el caso recursivo de la lista. En el no terminal LISTA ya hay un Vector,con los símbolos guardados hasta el momento, y lo que hay que hacer es agregarle el nuevosímbolo(ID). Nunca hay que olvidar devolver el vector que se esté utilizando hasta este mo-
107

mento a la pila(RESULT = l;). El otro caso es el caso base de la recursión, en el cual se creaun nuevo vector y se le agrega el primer símbolo.
El la Fig.5.9puede verse el árbol de derivación generado al reconocer la cadena ’inta, b, c’. Los nodos hojas(terminales), son los cuadrados, los círculos son los no terminales ylas etiquetas R1, R2, y R3 indican puntos donde se hacen reducciones destacables.
L
,
S
IDL
L , ID
ID
a b c, ,
int
int
R1
R2
R3
Figura 5.9: Árbol de análisis sintáctico utilizado en la gramática con atributos
La Fig. 5.10muestra el estado de la pila a lo largo del proceso de análisis. Comopuede verse en el primer estado de la pila se ha reconocido el símbolo ’a’. El símbolo estáguardado en un vector. Este vector se creó en el caso base de la gramática. Después se hadesplazado a la pila la coma y el símbolo ’b’. Con esta configuración se hace la primerareducción aplicando el caso recursivo de la gramática ’LISTA ::= LISTA:l coma ID:valor’.Antes de aplicar la reducción lo que se hace es coger el vector(identificado con la ’l’) que en elmomento actual tiene el símbolo ’a’ y agregarle el símbolo ’b’ reconocido. Dicho vector es elque se devuelve como atributo para guardarlo el la pila como atributo del no terminal ’LISTA’.Después se reconoce otra coma y otro nuevo símbolo(se desplazan a la pila) y se aplica lareducción(R2). Con esta reducción en la pila ya se tiene el vector con los tres símbolos. Enla última reducción se reduce el no terminal ’LISTA’ por el no terminal ’S’, dejándole comoatributo el vector con los tres símbolos.
108
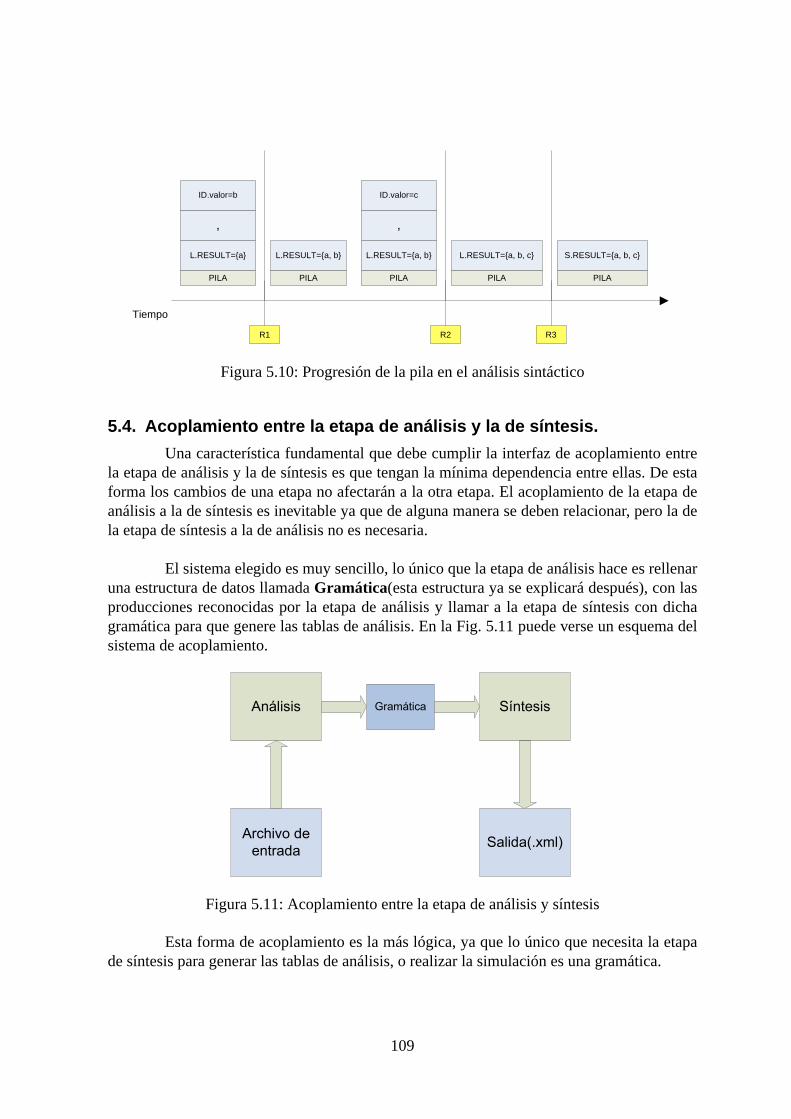
L.RESULT={a}
,
ID.valor=b
L.RESULT={a, b} L.RESULT={a, b}
,
ID.valor=c
L.RESULT={a, b, c} S.RESULT={a, b, c}
PILA PILA PILA PILA PILA
R1 R2 R3
Tiempo
Figura 5.10: Progresión de la pila en el análisis sintáctico
5.4. Acoplamiento entre la etapa de análisis y la de síntesis.
Una característica fundamental que debe cumplir la interfaz de acoplamiento entrela etapa de análisis y la de síntesis es que tengan la mínima dependencia entre ellas. De estaforma los cambios de una etapa no afectarán a la otra etapa. El acoplamiento de la etapa deanálisis a la de síntesis es inevitable ya que de alguna manera se deben relacionar, pero la dela etapa de síntesis a la de análisis no es necesaria.
El sistema elegido es muy sencillo, lo único que la etapa de análisis hace es rellenaruna estructura de datos llamadaGramática(esta estructura ya se explicará después), con lasproducciones reconocidas por la etapa de análisis y llamar a la etapa de síntesis con dichagramática para que genere las tablas de análisis. En la Fig.5.11puede verse un esquema delsistema de acoplamiento.
�������� ������ �������
�����������
����� ��������
Figura 5.11: Acoplamiento entre la etapa de análisis y síntesis
Esta forma de acoplamiento es la más lógica, ya que lo único que necesita la etapade síntesis para generar las tablas de análisis, o realizar la simulación es una gramática.
109

5.5. Etapa de síntesis.
Como ya se ha comentado anteriormente, la función de la etapa de síntesis es la detransformar la representación intermedia generada por la etapa de análisis, al producto de sa-lida del compilador.
Antes de entrar en los detalles de la etapa de síntesis hay que aclarar que básicamenteen esta etapa lo que se hace es la implementación de los algoritmos vistos en el capítulo3.Por lo tanto sólo se explicarán los detalles que se salgan fuera de estos algoritmos.
La etapa de síntesis se ha diseñado con las siguientes características:
Salida fácil de utilizar. Esto ya se ha comentado anteriormente, la salida de la etapade síntesis debe ser muy fácil de utilizar para facilitar el trabajo a otras herramientas.Para ello la salida del mismo es un archivo XML.
Fácil de extender. Esta característica es muy importante, ya que hay que dejar el com-pilador preparado para poder extenderlo fácilmente. Por ejemplo, en un futuro se podríaquerer que el compilador realizara otros tipos de análisis o que además de generar elarchivo XML con las tablas de análisis generara otra información adicional.
En próximas secciones se indicará la forma de conseguirlo y se darán ejemplos realesde como se ha extendido la funcionalidad del compilador fácilmente.
La etapa de síntesis está compuesta de los siguientes módulos:
Estructura de datos. Este paquete se encarga de gestionar las estructuras de datospara registrar las producciones de una gramática. Además, también ofrece otras fun-cionalidades para obtener información adicional de las gramáticas, necesaria para poderrealizar los análisis(iniciales, seguidores, . . . ).
Generadores de tablas de análisis.Este paquete gestiona las clases encargadas degenerar las tablas de análisis. LL(1), SLR(1), LR(1), . . .
Generación de los archivos de salida(XML). Este paquete se encarga de la gen-eración de los informes de salida. Por ejemplo, se encarga de generar el archivo desalida(.xml).
Simulador. Este paquete se encarga de la simulación de analizadores sintácticos.
En próximas secciones se desarrollarán cada uno de los paquetes con más profundi-dad.
110

5.5.1. Comunicación entre la etapa de análisis y síntesis.
El proceso general de comunicación entre la etapa de análisis y la de síntesis puedeverse en la Fig.5.12. En el análisis sintáctico, en el proceso de análisis se llega a ciertopunto donde se consigue reunir todas las producciones de una gramática(en el diagrama elmétodo se llamaparsear)y también se consigue saber los análisis a aplicar. Después conestas producciones se construye una instancia de la claseGramatica y se llama a la interfazde la etapa de síntesis (ReportGenerator), para que procese esta gramática. Esta clase leaplicará los análisis indicados y los agregará al XML de salida. Este proceso se verá en lossiguientes apartados.
:Parser
loop
parse()
[!fin]
prods, analisis:=parsear()
Esta llamada no existe como método,es el proceso de parseo del analizador sintáctico
:ReportGenerator
processGrammar(gram, analisis)
gram:Gramatica
create(prods)
mientras existan gramáticaspor procesar
Figura 5.12: Comunicación entre la etapa de análisis y síntesis
111
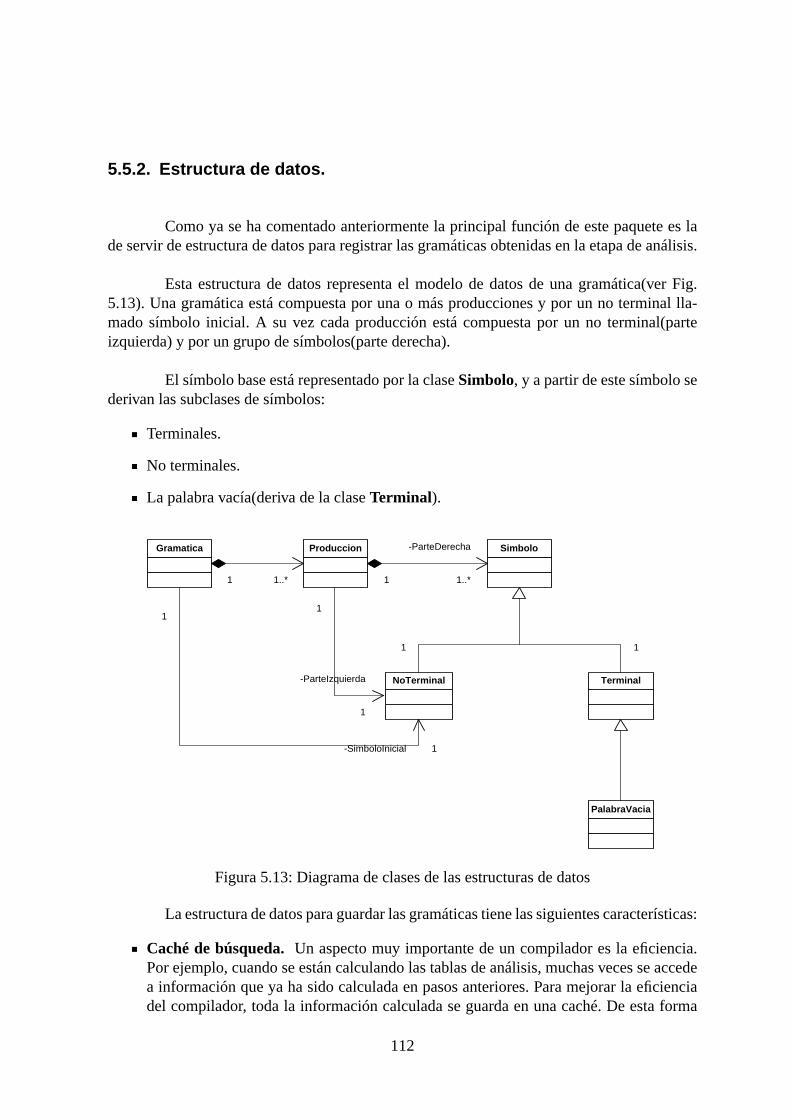
5.5.2. Estructura de datos.
Como ya se ha comentado anteriormente la principal función de este paquete es lade servir de estructura de datos para registrar las gramáticas obtenidas en la etapa de análisis.
Esta estructura de datos representa el modelo de datos de una gramática(ver Fig.5.13). Una gramática está compuesta por una o más producciones y por un no terminal lla-mado símbolo inicial. A su vez cada producción está compuesta por un no terminal(parteizquierda) y por un grupo de símbolos(parte derecha).
El símbolo base está representado por la claseSimbolo, y a partir de este símbolo sederivan las subclases de símbolos:
Terminales.
No terminales.
La palabra vacía(deriva de la claseTerminal ).
Simbolo
TerminalNoTerminal
11
PalabraVacia
Gramatica Produccion
1
-ParteDerecha
1..*
1
-ParteIzquierda
1
1 1..*
1
-SimboloInicial 1
Figura 5.13: Diagrama de clases de las estructuras de datos
La estructura de datos para guardar las gramáticas tiene las siguientes características:
Caché de búsqueda.Un aspecto muy importante de un compilador es la eficiencia.Por ejemplo, cuando se están calculando las tablas de análisis, muchas veces se accedea información que ya ha sido calculada en pasos anteriores. Para mejorar la eficienciadel compilador, toda la información calculada se guarda en una caché. De esta forma
112

la información adicional de la gramática(iniciales, anulables, seguidores, . . . ) sólo secalcula una vez.
Control de restricciones. No sólo es importante hacer un buen diseño de clases paralas estructuras de datos, igual de importante es que cumpla las restricciones que no sepueden aplicar sólo con el diagrama de clases. El cumplimiento de estas restriccionesse ha implementado mediante excepciones.
Estructura de datos completa. La claseGramática encapsula toda la informaciónnecesaria para realizar los análisis. No sólo registra las producciones de una gramática,sino que proporciona métodos para acceder a la información adicional necesaria pararealizar los análisis(anulables, iniciales, seguidores, . . . ).
Por las características de la claseGramática, ya se puede entender por qué se haelegido como interfaz entre la etapa de análisis y la de síntesis. Esta clase encapsula toda lainformación necesaria para que la etapa de síntesis pueda realizar su función.
Otro aspecto a resolver es la forma de acceso a dos símbolos especiales(el símboloinicial y el símbolo final). El problema que plantean es que a estos símbolos se accede desdemuchos sitios y además siempre es el mismo símbolo, es decir, que sólo existe una única in-stancia en todo el sistema. Por ejemplo, se accede en la etapa de análisis(análisis sintáctico ysemántico) y en la de síntesis. Para resolver esta situación se ha utilizado el patrón de diseñoSingleton. Con este patrón sólo existe una única instancia de una determinada clase en todoel sistema. De esta forma sólo habrá una instancia del símbolo inicial y final. Para accedera la única instancia de estos símbolos se utiliza un método estático(no hace falta crear unainstancia). El siguiente listado es un ejemplo de uso de una instancia de una clase utilizandoel patrón Singleton.
/∗ como se puede ver se puede acede
∗ a l a ún ica i n s t a n c i a d e l s ímbo lo f i n a l
∗ median te e l método e s t á t i c o g e t I n s t a n c i a ( ) .
∗ /
S imbo loF ina l s imbo lo = S imbo loF ina l . g e t I n s t a n c i a ( ) ;
113

5.5.3. Generadores de tablas de análisis.
Este módulo se encarga de la generación de las tablas de análisis. Para diseñar estemódulo se han buscado las siguientes características:
Extensible: El sistema de generación se debe extender fácilmente, porque en un futurose puede querer agregar otros análisis.
Reutilizable: Como se puede ver en la sección de análisis sintáctico, los métodos deanálisis sintáctico ascendentes se hacen de la misma forma, lo único que cambian sonciertos aspectos a la hora de generar el autómata. Por eso es importante que el diseñopermita reutilizar lo máximo posible y definir la parte específica de cada método deanálisis.
El diagrama de clases con los generadores de las tablas de análisis puede verse enla Fig. 5.14. Como puede verse lo que crean todos los generadores es la tabla de análisis.A partir del generador base se deriva el descendente y el ascendente. De los ascendentes elbásico es el SLR1 y a partir de él, con mínimas modificaciones se construyen los otros dos.
El funcionamiento de los generadores de las tablas de análisis es sencillo, lo únicoque hay que darles es la gramática y generan como salida la tabla de análisis.
El procedimiento básico para crear un generador es heredar de la interfazGener-ador, y sobrescribir el métodogenerarTablaAnalisis. Este método recibe como entrada unainstancia de la claseGramatica y como salida produce la tabla de análisis correspondiente.
El primer generador a estudiar es elGeneradorLL1, este generador se implemen-ta de forma independiente a los ascendentes como se puede ver en la Fig.5.14. La imple-mentación de este generador es muy sencilla, pues lo único que hay que hacer es implementarel Alg. 7 estudiado anteriormente. Además, todas las funciones necesarias para implementareste algoritmo(iniciales, seguidores, . . . ) las proporciona la estructura de datosGramática.
Al igual que en el descendente la implementación de los generadores ascendentes,básicamente es la implementación de los algoritmos vistos en la sección de Análisis Sintácti-co Ascendente(sección3.8). En la construcción de los analizadores ascendentes se ha podidoreutilizar la mayor parte del código. Por su simplicidad, el primer generador que se ha imple-mentado es el SLR1, a partir del cual se ha derivado el LR1 y el LALR1. La mayor parte delcódigo del SLR1 es válido para el LR1. Lo único que hay que hacer es sobrescribir la parteque es diferente. Por ejemplo, una diferencia entre el análisis SLR1 y el LR1 es la funcióndecierre. Una forma de hacerlo es sobrescribir completamente esta función en el generadorLR1, pero de esta forma se está repitiendo código y no se está haciendo un buen uso de lareutilización. Otra forma mejor es utilizar el patrón de diseñoMétodo plantilla .
114

+generarTablaAnalisis()
«interfaz»Generador
GeneradorLL1 GeneradorSLR1
1 1
GeneradorLR1
GeneradorLALR1
TablaAnalisis
1
-genera
1
Figura 5.14: Diagrama de clases de los generadores de tablas de análisis
Este patrón lo que hace es dividir el cuerpo de un algoritmo en parte común y otraspartes que son específicas se sobrescriben en la subclase. Ejemplo:
pub l i c vo id m e t o d o P l a n t i l l a ( )
{
p a r t e C o m u n I n i c i a l ( ) ;
p a r t e E s p e c i f i c a ( ) ;
pa r teComunF ina l ( ) ;
}
Como puede verse en este método hay partes específicas y partes comunes. Las sub-clases lo único que deben hacer es sobrescribir la parte específica, de esta forma se evita tenerque repetir innecesariamente código.
El siguiente listado muestra parte del código del cálculo del cierre en la claseGener-adorSLR1. El métodoexpandirNoTerminalCierre es la parte específica mencionada antesen el método plantilla y es este método el que hay que sobrescribir en elGeneradorLR1. Deesta forma no hay que modificar nada del método del cálculo del cierre.
115

pub l i c Estado c i e r r e ( Es tado e s t a d o )
{
. . .
i f ( ! i temAct . e s R e d u c i b l e ( ) )
{
I t e r a t o r p rods = m_gram . p r o d u c c i o n e s ( ( Simbolo ) i temAct .
s imboloMarcado ( ) ) ;
whi le ( p rods . hasNext ( ) )
{
i f ( i temAct . s imboloMarcado ( ) i n s t a n c e o f NoTerminal )
e x p a n d i r N o T e r m i n a l C i e r r e ( nuevosI tems , ( P roducc ion )
p rods . nex t ( ) , i temAct ) ;
}
}
. . .
}
116

+generarTablaAnalisis()
«interfaz»Generador
GeneradorLL GeneradorSLR1
1 1
GeneradorLR1
GeneradorLALR1
TablaAnalisis
1
-genera
1
NuevoGenerador1
1
Figura 5.15: Creación de un nuevo generador
Finalmente como puede verse, el agregar un nuevo análisis es muy sencillo. Porejemplo, si se quisiera agregar un nuevo análisis, lo único que habría que hacer es crear unasubclase de la interfazGenerador. El diagrama puede verse en la Fig.5.15.
Tabla de análisis.
La función de esta estructura de datos es la de guardar el resultado de los gener-adores, es decir, ser la tabla de análisis. Las tablas de análisis se podrían haber generadodirectamente en formato XML, pero no es recomendable, ya que se está acoplando el sistemade generación de las tablas de análisis al XML de salida, es más recomendable crear una ab-stracción intermedia. Esta clase debe ser una tabla bidimensional, donde los índices de filasy de columnas deben permitir que sean cualquier tipo de objeto. La tabla de análisis creadatiene la siguiente estructura:
Filas: Las filas de la tabla pueden ser cualquier objeto. Por ejemplo, para las tablasdel generador descendente las filas son los símbolos no terminales y para el análisisascendente los identificadores de filas son números enteros.
117

Columnas: Los identificadores de columnas pueden ser objetos de cualquier tipo.Normalmente son objetos de la claseSimbolo, tanto para el análisis descendente comopara el ascendente.
Entradas de la tabla: En las tablas se guardan elementos del tipoTableEntry . Estaclase registra las acciones(si hay más de una, entonces hay un conflicto) y los conflictosque hay en dicha entrada(Desplazamiento/Reducción, Reducción/Reducción, . . . ).
De esta forma, esta clase es genérica y no se acopla al formato de las acciones delanálisis descendente y al ascendente. En un futuro podría servirle a otros tipos de análisis.
Esta tabla de análisis es el punto de partida de otros componentes:
El sistema de generación del XML de salida parte de estas tablas para generar el XMLde salida.
El simulador utiliza la tabla de análisis para realizar el proceso de simulación.
Sistema de creación de los generadores.
Otro aspecto a comentar es el sistema para elegir el análisis que hay que aplicar auna gramática. Una de las formas de hacerlo es conocer el análisis que se quiere realizar, crearlos generadores y llamar al método de generación. Este método tiene el problema de que si seagregan más métodos de análisis habría que modificar esta parte.
Hay una solución mejor, que es utilizar el patrón de diseñoFactoría. Para usarlo loque se ha hecho es crear una interfaz llamadaGeneratorFactory, a la cual se le da una listaindicando los tipos de análisis que se quiere realizar y devuelve una lista con los generadorescreados. La idea básica de este patrón es la de centralizar el lugar donde se crean objetos,normalmente donde se crean objetos de una misma ”familia”. De este modo el sistema sedesacopla de la creación de los generadores, confinando la creación de generadores en unasola clase. Si se quisiera agregar un nuevo análisis sólo habría que modificar esta clase, sinmodificar ninguna otra parte del sistema. Por ejemplo, el siguiente código se utiliza para lacreación de la lista de generadores:
118

/∗ ∗
∗ F a c t o r i a para l a c r e a c i ó n de generado res .
∗ /
pub l i c c l a s s G e n e r a t o r F a c t o r y I m p l
implements G e n e r a t o r F a c t o r y
{
pub l i c L i s t c r e a t e G e n e r a t o r L i s t (i n t t y p e s )
{
L i s t l i s t a = new Vec to r ( ) ;
i f ( ( t y p e s & Generador . ANALISIS_LL1 ) != 0)
l i s t a . add (new GeneradorLL1 ( ) ) ;
i f ( ( t y p e s & Generador . ANALISIS_SLR1 ) != 0)
l i s t a . add (new GeneradorSLR1 ( ) ) ;
i f ( ( t y p e s & Generador . ANALISIS_LR1 ) != 0)
l i s t a . add (new GeneradorLR1 ( ) ) ;
i f ( ( t y p e s & Generador . ANALISIS_LALR1 ) != 0)
l i s t a . add (new GeneradorLALR1 ( ) ) ;
/ / en e s t e punto se pod r ía agregar
/ / c u a l q u i e r o t r o generador .
re turn l i s t a ;
}
}
Como se puede ver la factoría acepta a la entrada un entero indicando los tipos de análisis ydevuelve una lista de los generadores que se soliciten. Si se quieren agregar más análisis sólohay que crear el generador correspondiente y agregarlo a la factoría.
Generación de las tablas de análisis de los métodos ascendentes.
Otro aspecto importante es conocer la forma en que en los análisis ascendentes segeneran los estados del autómata, ya que dos tablas de análisis pueden ser equivalentes yno parecerlo, porque se han podido numerar los estados(utilizados para generar las tablas deanálisis) de forma diferente. Si no se fija una manera de numerar los estados, la herramientapierde mucha utilidad. Porque para comprobar si un ejercicio está resuelto correctamente, elusuario debe identificar antes la equivalencia de los estados hechos por el usuario y los gen-erados por la herramienta.
119

El orden en que el compilador numera los estados es el orden natural, es como si elanálisis se hiciera manualmente. Cuando se tiene un estado y se le van a calcular las transi-ciones a otros estados los items dentro de dicho estado están ordenados de la siguiente forma:
1. Primero los items que proceden de una transición desde otro estado, si hay varios se or-denan por el orden en que la producción relacionada con el item aparece en la gramáti-ca.
2. Después están los items calculados a partir del cierre de los items iniciales. El orden enque se va calculando el cierre es desde la parte superior del estado hasta la inferior. Lositems con la misma parte izquierda calculados en el cierre, si hay varios, se ordenanentre ellos por el orden en que aparece su producción asociada en la gramática.
Las transiciones se van calculando en el orden en que están puestos los items dentrodel estado. Por ejemplo, si se tuviera la siguiente gramática:
1: E−→E + T2: E−→T3: E−→( E )4: T−→num
Parte del autómata que se generaría se puede ver en la siguiente Fig.5.16.Del estado0 visto en la figura anterior se puede destacar lo siguiente:
El primer item del estado es el item por el que empezó el estado:S′ −→ E.
Después están los items calculados por el cierre de dicho item.
Los items que tienen la misma parte izquierda, están ordenados por el orden en que susproducciones fueron declaradas en la gramática. Si en la gramática se hubiera puestoE −→ T antes queE −→ E +T entonces en el estado el itemE −→ T hubiera estadoantes.
Los estados generados a partir del primer estado se van generando en el orden, en quese va recorriendo sus items. Es decir, primero la transición del itemS′ −→ E, despuésla del itemE −→ T, . . .
La forma en que se ha generado estos estados se repite con todos los estados.
En resumen la ordenación es como si el cálculo del autómata se hiciera manual-mente. Sabiendo la forma en que siempre el sistema genera los estados, si el usuario al hacerlos ejercicios manualmente los hace de esta forma, después será mucho más fácil comprobarlos resultados de los propios ejercicios.
El generar los estados de la forma anteriormente comentada no es tan fácil comopuede parecer en un principio. Ya que los algoritmos y las estructuras de datos que se uti-lizaron desde el principio no imponen esta ordenación de estados. Para reordenar de forma
120

���������
�����������
���������
� ���������
������������
���������
������������
�
�����������
�
����������
������������
���������
�����������
����������
��������������
�
� �
��
�
��
��
Figura 5.16: Formato de la generación del autómata
121

adecuada los estados lo que se ha hecho es que una vez se ha generado el autómata se llamaa un método que se encarga de realizar la reordenación. De esta forma la ordenación de losestados no está acoplada a como se generan dichos estados. En un paso posterior se puedenreordenar como se quieran.
5.5.4. Generación de los archivos de salida(XML).
En el diseño de los generadores(LL1, SLR1, . . . ) se buscaba que fuera fácil de am-pliar. Pero es esta característica la que más se busca en este módulo. Ya que es fácil que ensiguientes versiones del compilador se quiera generar información adicional. Por ejemplo,además del archivo XML de salida donde están todas las gramáticas compiladas se podríaquerer generar un archivo ’.log’ con el log de generación de las tablas de análisis.
Para diseñar el sistema que genera el XML de salida, se ha buscado un sistema quesea flexible, es decir, que sea fácil ampliarlo en el futuro para generar otros productos.
Básicamente para generar el archivo XML de salida hace falta conocer dos elemen-tos:
Las gramáticas.
Los tipos de análisis.
�������������� �� ������
� �
��������������
�
���������
�
Figura 5.17: Diagrama de clases del generador del XML
Para conseguir que sea fácil de extender, el sistema ha utilizado el patrón de diseñoBuilder . Con este patrón se consigue separar la construcción de un objeto complejo de surepresentación. De esta forma el XML de salida siempre se va a construir de la misma forma,pero el contenido del mismo puede ser diferente. Por ejemplo, cuando se utiliza para analizar,el XML contiene las tablas de análisis. En cambio en la simulación contendrá la traza de si-mulación. Esto es un ejemplo de una misma forma de construcción pero diferente contenido.
122

El diagrama de clases del generador puede verse en la Fig.5.17. Como puede verseel sistema de generación está compuesto de 3 clases:
ReportGenerator: Esta clase hace el papel de controlador, es la interfaz que se conocedesde la etapa de análisis para generar el XML de salida.
GeneratorFactory: Esta clase ya se ha explicado en secciones anteriores, es la factoríapara crear los generadores de análisis.
XMLBuilder: Esta clase es el constructor del XML de salida, si se quiere generar otrotipo de XML basta con crear otra subclase.
Desde la parte de análisis se llama alReportGenerator con cada gramática obteni-da del texto fuente y la claseReportGenerator alimenta al Builder con cada nueva gramáticapara ir completando el XML de salida.
La construcción del XML de salida conlleva la llamada a los siguientes métodos delBuilder(la ordenación es importante):
1. initialize: Este método se llama al principio, y es para inicializar el Builder.
2. beginGrammar: Indica al Builder que se va a procesar una nueva gramática.
3. beginAnalysis: Indica al Builder que se ha hecho un determinado análisis, como en-trada recibe: la gramática, la tabla de análisis y el generador utilizado para generarla.
4. endAnalysis: Indica al Builder que se ha finalizado el análisis actual. Dentro delprocesado de una gramática se puede llamar más de una vez a los métodos de análi-sis(beginAnalysis, endAnalysis).
5. endGrammar: Indica al Builder que se ha terminado de procesar una gramática.
6. close: Indica al Builder que se han terminado de procesar todas las gramáticas. Alllamar a este método se genera el XML de salida.
En la Fig.5.18 puede verse el diagrama de secuencia que se sigue para la cons-trucción del XML de salida. Como puede verse la generación del XML de salida sigue lospasos del Builder:
1. Se obtiene las referencias a la fabrica de generadores(LL1, SLR1, . . . ), y también lareferencia alXMLBuilder .
2. Se utiliza la fábrica de generadores para obtener la lista con los generadores solicitados.Los análisis a realizar se determinan en el archivo de entrada del compilador.
3. Se manda un mensajebeginGrammar al XMLBuilder , indicándole que se va iniciarel procesado de una gramática. Por ejemplo, al recibir este mensaje elXMLBuilder ,escribirá en el XML de salida la gramática.
123

4. Por cada generador(LL1, SLR1, . . . ) de la lista se siguen los siguientes pasos:
a) Se genera la tabla de análisis del análisis en cuestión.
b) Se le indica alXMLBuilder que se ha hecho un nuevo análisis(beginAnalysis/endAnalysis).
5. Se finaliza cuando se han completado todos los análisis de la lista.
De esta forma el Builder tiene el control absoluto de cuando se inicia y se acabael procesamiento de una gramática. Y cuando se inicia y acaba un análisis. Algo que esfundamental para construir el XML de salida.
124
ReportGenerator
fact: getGeneratorFactory()
fact:GeneratorFactory
b: getXMLBuilder()
b:XMLBuilder
list: createGeneratorList()
gen:Generador
beginGrammar(gram)
generarTablaAnalisis(gram)
beginAnalysis(gram, tab, gen)
endAnalysis()
endGrammar()
loop[for gen in list]]
tab
Figura 5.18: Generación del XML de salida
125

5.5.5. Simulador.
Básicamente el simulador es el analizador sintáctico visto en la sección de análisissintáctico. El simulador está compuesto de una pila, un buffer de entrada y una tabla de análi-sis. Este esquema es común al simulador ascendente y al descendente. En la Fig.5.19puedeverse el diagrama de clases del simulador.
Como puede verse está compuesto de los siguientes elementos:
Simulator: Es una clase genérica para crear los simuladores.
Scanner: Es una interfaz genérica que actúa como analizador léxico.
TraceListener: Básicamente lo que produce el simulador es una traza de la simula-ción. La traza está formada por el estado de la pila, el estado de la entrada y la acciónrealizada. Para no acoplar al simulador a ningún formato de generación de la traza loque se ha hecho es crear una interfaz para recibir la traza. De esta forma, se puedeconfigurar en cualquier momento el objeto que recibe la traza.
SimuladorAscendente: Es un simulador ascendente, que implementa el Alg.8 vistoen la sección3.8.2.
SimuladorDescendente:Al igual que el ascendente, lo único que se hace es imple-mentar el algoritmo de un analizador descendente predictivo(Alg.6 visto en la sección3.7.3).
De forma genérica el proceso de simulación puede verse en la Fig.5.20. Al llamaral métodostart el simulador entra en un bucle para analizar la cadena de entrada. Los to-kens de la cadena de entrada los proporciona elScannergenérico que se explicará después.Una vez obtenido el token se procesa, la forma de procesarlo depende del tipo de simuladorque se esté utilizando(ascendente/descendente). Durante este proceso cada paso se notificaráal TraceListener, para registrarlo. La clase que genera el XML de salida, implementa estainterfaz y guarda la traza en el XML.
126

�������� ��������
��� ������
������������������ �������������������
� �
�
� �������������
�
��������
������
�
��������� �����
�
Figura 5.19: Diagrama de clases del simulador
:Simulator
start()
:Scanner :TraceListener
loop
[!fin]
next()
token
procesarToken(token)
trace()
Figura 5.20: Diagrama de secuencia de simulación
127

Formato del texto de entrada en la simulación.
Otro aspecto a definir es el formato de entrada para la simulación. En este aspectohay un problema y es que el analizador léxico debe ser genérico, ya que el usuario lo únicoque hace es dar una gramática y un texto a simular. El usuario no va a proporcionar por suparte un analizador léxico. Una solución sencilla para crear un analizador léxico genérico estomar a los símbolos terminales de la gramática, como los lexemas del lenguaje. Por ejemplo,si se introduce la siguiente gramática como entrada:
grammar c a l c
{
a n a l y s i s LALR1 ;
nonterminal E , T , F ;
t e rm ina l i d ;
E := E ’+’ T | E ’-’ T | T ;
T := T ’*’ F | T ’/’ F | F ;
F := ’(’ E ’)’ ;
F := i d ;
}
Los símbolos válidos del lenguaje serían: ’id’, ’+’, ’-’, ’*’, ’/’, ’(’, ’)’. Un ejemplo de unacadena de entrada a simular sería la siguiente:
(id + id) * id
Hay una restricción que hay que mantener, y es que los lexemas deben ir separados por espa-cios, ya que sino, no se podrían distinguir los lexemas entre sí. Por ejemplo, el lexemaididcómo se tomaría, como dos lexemasid seguidos o como un nuevo lexemaidid . Los caracteresespeciales del tipo +, -, *, . . . , no hace falta separarlos con espacios. Sólo hace falta separarloscon espacios si se ponen dos seguidos. Por ejemplo ’–’, habría que separarlo con espacios:’- -’.
128

��������
�����������
��� ������
�������� ������ ��������
�
� �����
�
Figura 5.21: Integración del simulador en el sistema de generación
Integración del simulador en el generador del XML.
Primero se implementó la generación de las tablas de análisis y después se agrególas simulación. Pero gracias a la arquitectura abierta(ya explicada anteriormente) del sistemade generación del XML, agregarlo fue muy sencillo.
En la Fig.5.21puede verse el esquema de integración del simulador, en el sistemade generación del XML. Lo único que ha hecho falta es crear una subclase deXMLBuilder .Esta clase utiliza dos clases más:
Simulator: Es una referencia al simulador que se está utilizando(descendente o ascen-dente).
TraceListener: Como ya se había comentado antes, los simuladores envían la traza desimulación a esta interfaz. Pues lo que hace elSimulatorBuilder es implementarla. Deesta forma, puede recibir la traza de simulación y escribirla en el XML de salida.
La integración con el generador XML es muy sencilla, lo único que se ha tenido quehacer es crear un nuevoXMLBuilder y llamar al simulador para generar la traza de salida.La claseXMLBuilder implementa la interfazTraceListener pudiendo recibir la traza de si-mulación generada por el simulador. ElXMLBuilder la escribirá en el archivo XML.
Ahora se puede comprobar una de las ventajas del patrón Builder, el XML de salidacuando se compila y cuando se simula se generan de la misma manera pero su contenido esdiferente(misma interfaz distinta representación interna).
129

5.5.6. Sistema de control de eventos.
Un componente muy importante del compilador es el sistema de gestión de eventos,cuando ocurre un evento en el compilador, ya sea porque hay un error de sintaxis, léxico oalgún conflicto en la gramática, hay que comunicarlo al usuario de alguna forma. Una formasimple de hacerlo es por la salida estándar de error, se imprime y no hace falta hacer nada más.Esto es suficiente para las aplicaciones que utilicen el compilador externamente, pero para lasaplicaciones Java se les da la posibilidad, de que reciban los eventos del compilador de unaforma más fácil y además aportando más información. Para diseñar el sistema de eventos seha utilizado el patrónObservador.
La estructura del sistema de eventos puede verse en la Fig.5.23. Con este patrón seconsigue desacoplar al compilador de las aplicaciones que quieran recibir los eventos.
El funcionamiento es muy sencillo(ver Fig.5.22), lo primero que debe hacer el com-ponente que quiere escuchar los eventos es heredar de la claseGlccEventHandler y regis-trarse en el canal de eventos(setGlccEventHandler). Después cuando se genere un mensaje,por ejemplo un error, el canal de eventos (GlccEventChannel), obtiene el manejador de loseventos y le comunicará al observador que el compilador ha detectado un error. De esta formase está consiguiendo desacoplar al compilador de quien quiera recibir los eventos.
�������������� �������
������������������
����������������
��������������������
�������
�������
Figura 5.22: Gestión de eventos
Los eventos de compilación pueden ser de los siguientes tipos:
Errores. Pueden ser errores sintácticos, semánticos, léxicos, o errores internos del com-pilador.
130

GlccEventChannel«interfaz»GlccEventHandler
-ReceptorEvento
1 1
Aplicacion
1
-CanalEventos 1
Figura 5.23: Diagrama de clases del gestor de eventos
Warnings. Son avisos, es decir, no es un error, pero sería recomendable resolverlo. Porejemplo, si se declaran símbolos terminales y luego no se usan, se genera un aviso.
La información adicional que se le incorpora a los eventos, puede ser de cualquiertipo. Actualmente la información adicional es la localización del evento(archivo, fila y colum-na).
5.6. Sistema de pruebas para el compilador.
Cuando se está construyendo un sistema y se está probando, existen algunos proble-mas a resolver.
1. Separación del código de pruebas.Es deseable que el código utilizado para las prue-bas esté separado del código de la aplicación. De esta forma, no se quita claridad alcódigo normal de la aplicación.
2. Reutilización de las pruebas.Normalmente cuando se están probando pequeños com-ponentes del sistema se realizan las pruebas y este código de prueba o se elimina o no sesabe muy bien qué hacer con él. Después si en fases posteriores del desarrollo se quierevolver a probar estos mismos componentes hay que volver a codificar las pruebas.
3. Automatización de las pruebas.El proceso de pruebas suele ser un proceso manualy bastante engorroso.
4. Seguridad ante cambios.Otro de los problemas son los cambios, cuando el sistemaestá funcionando y hay que cambiar algo, siempre existe el temor de que el cambio pue-da provocar que una parte que antes funcionaba ahora no funcione. Sería deseable tenerla confianza de que nuevos cambios no provoquen que partes que antes funcionabandejen de funcionar.
131

Para solventar estos problemas existen frameworks de pruebas que intentan resolverlos problemas anteriormente planteados. En concreto el framework de pruebas utilizado paraJava es el JUnit. Este framework solventa los problemas antes plantados:
1. Separación del código de pruebas.JUnit permite una total separación del código depruebas y del código de la aplicación. Ya que el código de pruebas de JUnit se crea enclases totalmente a parte del código de la aplicación.
2. Reutilización de las pruebas.La pruebas se crean, y se utilizan para el componenteque se esté poniendo aprueba. Pero en fases posteriores de desarrollo se pueden volvera utilizar las pruebas anteriormente creadas.
3. Automatización de las pruebas. Las pruebas se pueden aplicar automáticamente,JUnit le aplicará al componente todas las pruebas creadas. Si alguna prueba falla JUnitinformará del fallo.
4. Seguridad ante cambios.Como ya se ha comentado en el apartado anterior, JUnit per-mite automatizar las pruebas. De esta forma cuando se realice alguna modificación en elsistema, se vuelve a pasar al sistema todo el banco de pruebas para comprobar que todosigue funcionando correctamente. Esto proporciona una gran seguridad y tranquilidadante los cambios.
Las pruebas creadas son pruebas globales, es decir, prueban el funcionamiento delcompilador, no prueban componentes por separado. Las pruebas se realizan haciendo la si-mulación de una gramática. Con esto se están probando dos componentes:
1. El primer componente que se está probando es el compilador, es decir, se está com-probando que se generan las tablas de análisis correctamente. Si las tablas de análisisson correctas o no, lo comprueba la simulación. Ya que si las tablas de análisis no soncorrectas las simulación fallará, porque aparecerán errores sintácticos.
2. El segundo componente que se prueba es el simulador, se comprueba que se ha imple-mentado correctamente.
Por cada gramática que se prueba, para tener mayor seguridad, se hacen dos tipos depruebas:
Primero se hace una prueba con una gramática y un texto que pertenece al lenguajedefinido por la gramática. Es decir, el simulador debe reconocer como válido el textode entrada. De esta forma se está comprobando que las tablas de análisis generadas soncorrectas y que el simulador funciona correctamente.
La segunda prueba que se hace es con una gramática y un texto que no pertenece allenguaje definido por la gramática. Con esto se está comprobando que las tablas deanálisis sólo reconocen las cadenas definidas por la gramática.
132

Como se puede ver es un sistema de pruebas bastante robusto, comprueba todos loscomponentes del compilador. Y como ya se ha comentado antes, el banco de pruebas se puedeaplicar automáticamente. Por eso ante cualquier cambio que se realice por lo menos se tienecierta seguridad de que todo sigue funcionando. Además, otra ventaja de utilizar este sistemade pruebas es que funciona independientemente del formato de generación de las tablas deanálisis, e incluso de como se genere el autómata en los análisis ascendentes. Ya que el testque se utiliza es una comprobación booleana, sólo se comprueba si la simulación de unagramática es correcta o no.
133

CAPÍTULO 6.
IMPLEMENTACIÓN DE LA HERRAMIENTA
6.1. Diseño.
6.1.1. Arquitectura de la Web.
Una de las decisiones más importantes en la construcción de cualquier sistema es laelección de la arquitectura, ya que de esta decisión dependerá en gran medida la calidad delsistema construido. La arquitectura elegida es una arquitectura multicapa, antes de entrar endetalles de la implementación de la arquitectura se realizará una descripción de las arquitec-turas multicapas.
Los sistemas que utilizan capas son unas de las arquitecturas más usadas en la cons-trucción de sistemas software. En las arquitecturas multicapa cada capa proporciona serviciosa la capa inmediatamente superior y se sirve de los servicios dados por la capa inmediatamenteinferior. De esta forma la complejidad y el acoplamiento entre capas se reduce, pues, una capasólo conoce a sus adyacentes.
En una arquitectura multicapa, la conexión entre capas se definen mediante protoco-los, los cuales determinan la forma de interacción entre capas. Este sistema de capas imponela restricción, más o menos rigurosa, que exige que cada capa sólo puede interaccionar consus capas adyacentes, y los elementos de dentro de una capa sólo pueden interaccionar conlos elementos de su misma capa. Se considera que si se cumplen estas restricciones el sistemamulticapa es más puro, pero en la realidad algunas veces se flexibiliza esta restricción. Algu-nas veces se permite que una capa acceda a los servicios de alguna capa inferior, aunque nosea la adyacente. La justificación de permitir esto es cuestión de rendimiento.
134

Datos
Escriba texto
Figura 6.1: Arquitectura de 3 capas
Las ventajas de los sistemas multicapas son las siguientes:
1. La arquitectura soporta un diseño basado en niveles de abstracción crecientes, lo cualpermite la partición de un problema complejo en una secuencia de pasos incrementales.
2. La arquitectura permite optimizar fácilmente componentes de una capa sin afectar a lasotras capas.
3. Uno de los beneficios más importantes es la reutilización. Por ejemplo, se tiene cons-truido un sistema utilizando la arquitectura multicapa. El sistema ya está funcionando,pero ahora se quiere ampliar el sistema y se quiere hacer lo mismo pero quitando lacapa de nivel superior. Esta arquitectura permite hacer esto fácilmente, ya que lo úni-co que debe hacer la nueva capa es utilizar la interfaz de su capa inferior, no hay quecambiar ningún componente más del sistema.
De entre las arquitecturas multicapa, una muy utilizada en el desarrollo de sistemasinformáticos donde existe una interfaz para el usuario es la arquitectura de 3 capas(ver Fig.6.1). Las capas son las siguientes:
1. Presentación. Los objetos de la capa de presentación son pantallas, frames, cuadrosde diálogo, que reciben las órdenes del usuario. Lo más que realizan es algún tipo devalidación de los datos y los pasan a la capa de dominio para ejecutar la función. Des-pués estos resultados se muestran en la capa de presentación. Es importante establecerlas relaciones de dependencia entre la capa de dominio y presentación. Sólo algunosobjetos de la capa de presentación deben conocer a los de la capa de dominio, peroninguno de la capa de dominio debería conocer a los de presentación.
2. Dominio. Los objetos de la capa de dominio son los que verdaderamente implementanla lógica de la aplicación. Hay que diseñarlos para que se tenga que modificar lo mínimoposible. Como ya se ha comentado anteriormente, la capa de dominio no debe depender
135

Presentación Dominio Persistencia
Figura 6.2: Diagrama de paquetes de la web
del tipo de interfaz que se utilice, por lo cual ningún objeto de la capa de dominio debehacer referencia al tipo de interfaz utilizada.
3. Persistencia. En las dos capas anteriores se soluciona el problema de la interfaz y dela lógica de dominio. Pero en algún momento los objetos de la capa de dominio debenser guardados de forma persistente. Normalmente se utilizará una base de datos, por lotanto hay que establecer algún mecanismo para comunicarse con la base de datos. Poreso no hay más remedio que crear una relación de dependencia entre la capa de dominioy la de persistencia. Esta relación de dependencia suele ser bidireccional, ya que paraque la capa de persistencia haga a los objetos de la capa de dominio persistente, la capade persistencia los debe conocer(ver Fig.6.2).
En el diseño de la herramienta a cada capa se le han asignado las siguientes respon-sabilidades:
1. Presentación. En esta capa se mostrarán las interfaces en formato Web, para interac-cionar con el usuario.
2. Dominio. En esta capa se implementa la lógica de dominio para realizar la compi-lación, simulación, gestión de usuarios, . . .
3. Persistencia.En esta capa se accede a la base de datos, el acceso a la misma se hace através de un agente intermediario.
Una vez hecho el análisis de requisitos y establecida la arquitectura del sistema, hayque hacer el diseño del sistema. Hay varios aspectos que se comentarán con respecto al diseñodel sistema.
El primer tema que se tratará será el sistema de generación de las páginas web. Enesta sección se abordará como se generan todas las páginas con el mismo formato, utilizandoun sistemas de plantillas. Además, también se mostrará como se gestiona el tema de las se-siones en la generación de las páginas Web.
Otro tema a tratar es el sistema para la comunicación entre el script de servidor yel compilador. Como ya se ha comentado anteriormente el script de servidor está hecho enPython y el compilador en Java. Por lo tanto hay que establecer un mecanismo para la comu-nicación entre ambos.
Por último, hay que decir que en esta sección no se van a mostrar una por una lasfunciones de la Web. Ya que la mayoría de ellas son simples llamadas a la base de datos, sólose mostrarán las funciones implementadas en las que haya algo que destacar.
136

6.1.2. Procesamiento general de las peticiones.
De manera general, la forma en que se procesan las peticiones puede verse en laFig. 6.3. Lo primero que hace el usuario es rellenar algún tipo de formulario, con los datosnecesarios para la función a realizar. Después, el usuario pulsa algún botón de aceptación y elBrowser del cliente enviará los datos al servidor. Éste llama al script del servidor encargadode gestionar la petición(estos scripts están en la capa de presentación). Desde la capa de pre-sentación se llama a un controlador de la capa de dominio, encargado de gestionar la petición.Éste devolverá la respuesta y el script de servidor la formateará en HTML, para devolvérselaal cliente.
script
<<introducir datos>>
<<aceptar>>
Browser Cliente Servidor web
GET/POST
Usuario
procesarPeticion()
respuesta
repuesta
respuesta
controlador
respuesta
peticion()
formatearRespuesta()
Figura 6.3: Interacción general entre presentación y dominio
6.1.3. Comunicación entre la Web y el Compilador.
Un problema importante a resolver es la comunicación entre el script del servi-dor(Python) y el compilador (Java). La forma más fácil de hacerlo es desde Python ejecutar alcompilador, como si fuera una aplicación normal. El sistema elegido para ejecutar programasdebe ofrecer las siguientes funciones:
137

Debe permitir acceder a los flujos estándar del programa a ejecutar, ya que de estosflujos se obtiene información de salida del compilador(por ejemplo, los mensajes deerror).
Se debe poder conocer el código de retorno del programa ejecutado, para saber si hayun error al compilar.
La ejecución debe ser bloqueante, es decir, debe bloquearse hasta que el programaejecutado termine.
En Python hay varias formas de ejecutar programas pero no cumplen todas las carac-terísticas propuestas. El módulo seleccionado de Python es el módulopopen2, en este móduloestá la clasePopen3la cual cumple las características propuestas.
El proceso de ejecución del compilador es el siguiente(ver Fig.6.4). Lo primero quese hace es crear archivos temporales para el texto fuente y para la salida(.xml). Estos archivostemporales se borran automáticamente al cerrarlos. Después se copia el texto fuente al archivoque va a ser utilizado para la entrada del compilador. Una vez se han establecido los archivospara la entrada y salida del compilador, se ejecuta llamando al métodowait. Al terminar laejecución, este método devuelve el código de salida del programa ejecutado. De esta formase puede comprobar si se ha generado algún error en la compilación. Como resultado final seobtiene lo siguiente:
Archivo xml. El xml lo obtiene del archivo ’fout’.
Código de salida.Si el código de salida es distinto de cero significa que hubo un erroren la ejecución.
Flujo de errores. Flujo estándar de error, donde se puede obtener los mensajes desalida del compilador(errores léxicos, sintácticos, conflictos, . . . ).
En resumen el script le da al compilador el texto fuente, y el compilador le devuelveel xml(con la solución a los ejercicios) y los mensajes de error(ver Fig.6.5).
Una vez generado el xml, en la capa de presentación se generará la solución enformato HTML, que será devuelta al usuario.
138

:compile :tempfile
NamedTemporaryFile()
fin
utils
copyFile(grammar, fin)
executeGlcc(grammar)
NamedTemporaryFile()
fout
p:Popen3
create(fin, fout)
wait()
codigo de salida, ferr
Figura 6.4: Generación del .xml de salida
Script servidor(python)
Archivo fuente
XML
STD-ERR:Mensajes del compilador
Figura 6.5: Comunicación entre el script y el compilador
139

6.1.4. Diseño de la interfaz.
La interfaz se ha diseñado bajo el principio de la sencillez, todas las páginas de laherramienta se dividen en tres zonas(ver Fig.6.6):
Menú. Esta es la zona de la parte izquierda y están todos los accesos directos a lasprincipales funciones de la Web.
Encabezado.Muestra el logo al grupo al cual pertenece el proyecto(Oreto) y el títulodel mismo.
Cuerpo. Ésta es la parte específica de cada interfaz y su contenido depende de lafunción que se esté realizando.
CABECERA
MENÚ CUERPO
Figura 6.6: Estructura de la interfaz
Como todas las páginas Web tienen el mismo formato se ha generado una plantil-la(una clase), en la que se genera estos elementos(menú, encabezado, cuerpo). Para generaruna nueva página sólo hay que generar una subclase de esta plantilla y generar el contenidode la nueva página(ver Fig.6.7). Las clases predefinidas son las siguientes:
GlccForm. Clase base que define el esqueleto para la generación de las páginas web.
DefaultGlccForm. El formulario anterior era la raíz de cualquier formulario, en cam-bio, este formulario es donde se implementa de verdad la generación del título, delencabezado y del cuerpo de la Web.
140

ListForm. Este formulario se ha creado porque se van a generar continuos listados. Porejemplo, se hace listado de los usuarios registrados, de las noticias, de los ejemplos, yde las estadísticas. Para no repetir código, esta clase se encarga de generar los listadosfácilmente.
GlccForm
DefaultGlccForm
ListForm
Figura 6.7: Diagrama de clases del sistema de formularios
Generación de las páginas Web.
Como ya se ha comentado en la sección anterior el contenido de cada Web se generamediante una plantilla. En la plantilla se genera la sección del menú, y del encabezado. Loúnico que no se genera es el cuerpo de la Web, que se delega a la subclase correspondiente.El proceso de generación de la Web puede verse en la Fig.6.8. El método a partir del cual seinicia la generación de la Web es el método ”printForm”. Desde este método en la clase basese llamará al método para generar el inicio, la cabecera, el menú, . . . Al último método que sellama es al método ”printContent”, que es el que la subclase debe implementar para generarla parte del cuerpo de la Web.
141

:GlccForm
printStart()
printHead()
printMenu()
printHeader()
printContent()
printForm()
otro modulo
Figura 6.8: Diagrama de secuencia para la generación del formulario
Por ejemplo, la página de inicio se genera de esta forma, en el método ’printCon-tent’, que está delegado a las subclases para que generen el contenido. Se imprime el mensajede entrada a la Web, y las novedades. Todo lo demás, es decir, el menú y el encabezado logenera la plantilla automáticamente(ver Fig.6.9).
En resumen todas las páginas de la Web se generan utilizando este método, sólodeben crear una subclase, y sobrescribir el método ’printContent’.
:GlccForm
Imprimir plantilla
printForm()
otro modulo :MainForm
printContent()
Figura 6.9: Generación de la página de inicio
142

Sesiones.
El control de las sesiones de los usuarios es llevada a cabo por la capa de dominio,pero hay parte de la sesión que la controla la capa de presentación. Las sesiones se guardanen dos sitios:
Las sesión se registra en la base de datos por cuestiones de seguridad, esta parte lacontrola la capa de dominio.
Pero hay que guardar parte del estado de la sesión en el Browser cliente, es decir, quecomo hay que comunicarse con el browser cliente, hay que utilizar la capa de pre-sentación.
El problema está en que el protocolo HTTP es un protocolo sin estado, lo cual sig-nifica que el servidor no guarda ningún tipo de información de las conexiones conlos clientes. Es decir, que si un cliente hace una conexión y proporciona sus datos deidentificación(nombre de usuario y password) y se desconecta. Si después vuelve aconectarse, tendrá que volver a proporcionar otra vez la identificación. Para solucionareste problema el protocolo HTTP proporciona las cookies. Con las cookies se puedeguardar información de estado, que necesita el servidor, en el propio cliente.
:Browser Cliente :Servidor Script servidor
GET/POST
GET/POST
cookie:=guardarEstadoCliente()
cookie
cookie
guardarCookie()
Figura 6.10: Registro de la cookie en el cliente
143

El funcionamiento de la gestión de las sesiones es el siguiente. En la primera peticióndel cliente al servidor, el servidor genera la información de estado del cliente y se la envíacomo respuesta al cliente en forma de cookie(ver Fig.6.10). El cliente(browser) registra estainformación y cada vez que le haga una petición el cliente al servidor, junto a los datos de lapetición, le enviará la información de estado(ver Fig.6.11).
:Browser Cliente :Servidor Script servidor
GET/POST(cookie)
GET/POST(cookie)
cookie:=getCookie()
cookie:=getCookie()
Figura 6.11: Envío posterior de la cookie
En resumen, lo que se hace es mantener la información de estado del cliente, en elpropio cliente, y se le envía al servidor en cada petición.
6.1.5. Login.
Como siempre el módulo encargado de gestionar el login es un módulo controlador.Este controlador como todos está dentro de la capa de dominio. Lo primero que hace elcontrolador es buscar en la base de datos si el usuario esta registrado, si es así, y el passwordcoincide con el del usuario, inicia una nueva sesión de usuario. Como siempre al iniciar unanueva sesión, se devuelve la cookie para que la capa de presentación se la envíe al cliente,imprimiendo el formulario de respuesta(ver Fig.6.12).
144

:users
<<introducir login y password>>
:usersCtrl
login(username, password)
user:User
user:=getUser(login)
:session
userPass:getPassword()
opt
[password == userPass]
newUserSession(username)
cookie
:form
cookie
printMessage(cookie)
Figura 6.12: Diagrama de secuencia de login
6.1.6. Obtención del usuario actual.
Cada vez que un usuario quiere realizar alguna operación en la Web, normalmentese comprobará en el sistema la identidad del usuario actual. La obtención del usuario actu-al se podría haber implementado simplemente registrando su nombre en una Cookie y cadavez que el cliente realice una petición, se podría obtener el nombre del usuario actual de lapropia Cookie. Pero esta forma de proceder no es segura, ya que cualquiera podría manipularal Browser cliente y hacerse pasar por otro usuario.
Una forma de darle seguridad es utilizar sesiones. Cada vez que un usuario legí-timo inicia una sesión, es decir, introduce su nombre de usuario y el password, se registrauna sesión en la base de datos y se crea una cookie. En la cookie se guarda una clave desesión(sid), esta clave es un código generado aleatoriamente que identifica la sesión de dichousuario. Dicha sesión tiene un tiempo de caducidad. En el Browser cliente el tiempo de ca-ducidad es cuando se cierre el Browser , en el servidor la sesión tiene un tiempo máximo de 60minutos. El darle un tiempo máximo en el servidor es para prevenir olvidos del usuario. Porejemplo, el usuario se podría dejar olvidada la sesión abierta y tiempo después otro usuariopodría acceder con su sesión. Limitando el tiempo de vida de la sesión en el servidor, se pre-viene en cierta medida este tipo de problemas. Dicho esto, sólo queda describir el proceso de
145
obtención del usuario actual.
Lo primero que hay que hacer es obtener la clave de sesión, la cual ha sido enviadapor el Browser cliente en forma de Cookie. Una vez obtenida la clave de sesión, se compruebasi la sesión sigue activa en la base de datos. Si es así, se devuelve el nombre del usuario actual.Este proceso puede verse en la Fig.6.13.
:session Cookie.SimpleCookie
create(os.environ['HTTP_COOKIE'])
cookie
s:=getSession(cookie['sid'].value)
:DBBroker
executeQueryOneRow('SELECT')
s
modulo
getCurrentUser()
[s['type'] = 'user']cookie['user'].value
[s['type'] <> 'user']defaultUser
Figura 6.13: Obtención del usuario actual
146

6.1.7. Alta de usuarios.
El alta de usuarios se hace en dos pasos:
Primero se registra al usuario en una tabla temporal(candidatos).
Después si el usuario confirma el registro, se le da de alta definitivamente en la base dedatos.
Como ya se vio en el análisis de casos de usos la razón de hacer el proceso de alta endos pasos, es la de prevenir que algunos usuarios realicen esta operación con datos no válidos.
En la Fig.6.14puede verse el primer paso en el proceso de alta. Lo primero que serealiza es llamar al método ”updateCandidatos”, este método lo que hace es borrar de la tabla”candidatos”, los usuarios que se hayan intentado registrar pero que no han confirmado el altade la nueva cuenta. El tiempo en el cual caduca la petición son siete días. Una vez hecho estose genera un número aleatorio, utilizado como código de activación. Después se registra alnuevo usuario en la tabla de candidatos y se le envía al usuario un email, con el código deactivación, para que confirme el alta.
:usersCtr
addUser()
updateCandidatos()
:utils
createRandomNumber()
codigoActivacion
:DBBroker
executeCommand("INSERT ..")
sendMail()
Figura 6.14: Alta de un nuevo usuario
Si el alta de usuarios lo realiza el administrador, el e-mail no se envía y el usuario seregistra directamente en la base de datos.
147

6.1.8. Recordar password.
Como ya se indicó en los requisitos, la herramienta dispone de un sistema para recor-dar el password. Para recordar los datos lo que debe introducir el usuario es el e-mail queutilizó cuando se dio de alta en el sistema. Si el e-mail existe en el sistema, se le enviarán adicha dirección de correo la cuenta o cuentas que tenga el usuario con dicho e-mail(ver Fig.6.15)
:usersCtrl:users
rememberPass(email)
loop
[For user in users]
user:User :utils
getLogin()
login
getPassword()
password
msg:=createMessage(login, password)
sendMail(email, msg)
users:=getUsers()
Figura 6.15: Diagrama de secuencia para recordar el password
Este sistema podría parecer poco seguro, ya que un usuario podría conocer el e-mailde otra persona registrada y utilizarlo para obtener el login y la contraseña de dicho usuario.Pero aunque haga esto y se lo envíe, el login y el password a la dirección de correo al final aesta información sólo podrá acceder el propietario legítimo de la cuenta de correo.
148

6.1.9. Control de acceso.
La función básica de este módulo es controlar que el acceso a determinadas partes dela Web, sólo lo pueda hacer el administrador. Este módulo tiene una función llamada ”open-Form”, y sirve para abrir páginas Web en las que hay que hacer un control de acceso. A estafunción se le pasa a la entrada el formulario que se desea abrir. Si se comprueba que se en-cuentra dentro de una sesión de usuario normal, se muestra una pantalla para que introduzcael password. Si introduce el password válido de administración se inicia una sesión de admi-nistración.
La comprobación del password puede verse en la Fig.6.16. Lo primero que se hacees obtener el password escrito por el usuario. El password se transmite como variable de en-torno. El módulo ”utils”, se encarga de las funciones para el acceso a estas variables. Tambiénse obtiene el password del administrador que está registrado en la base de datos. Si los pass-word coinciden se llama a la función ”newAdminSession()”, para iniciar una nueva sesiónde administración. Esta función devuelve la cookie que debe enviar al Browser cliente, paramantener la sesión. La cookie se guarda en el formulario como una cabecera HTTP, la cualserá enviada al Browser cliente, al devolverle la página HTML.
149

opt
sessionaccessControl
[pass==currentPass]
printForm()
configCtrl
newAdminSession()
f:Form
openForm(f)
utils
getCGIVar('password')
pass
getVar('pass')
currentPass
cookie
addHTTPHeaders(cookie)
Figura 6.16: Control de acceso
6.1.10. Gestión de sobrecargas.
Las sobrecargas se controlan limitando el número de operaciones permitidas al mis-mo tiempo. Para ello lo que se hace es que cada vez que un usuario solicita una operación, yasea un análisis o una simulación, se comprueba en la base de datos el número de operacionesque se estén realizando en ese momento. Si es menor a un numero máximo fijado, se permitela operación, sino se deniega la petición.
En la Fig.6.17puede verse como se comprueba si hay sobrecarga. Se llama al mó-dulo ”session” a la función ”newCompilationSession()”. Si la clave que devuelve es None,significa que hay sobrecarga y se registra una nueva sobrecarga en la base de datos.
Otro tema es cómo saber el número de operaciones que se están realizando en esemomento. Una forma de hacerlo es con un simple contador, pero este método no es muy se-guro. Por ejemplo, al iniciar una operación, se incrementa el contador y al acabarla se vuelve
150

compile:
checkMaxClients()
:session
newCompilationSession()
key
:compilerStatistics
[key == None]setOverloaded(true)
Registra en la base de datos que hay una sobrecarga
Figura 6.17: Control de sobrecargas
a decrementar. Pero si al terminar la operación ocurre un error y no se decrementa el conta-dor, se quedaría incrementado. Si esta situación pasase varias veces podría llegar un momentodonde el contador llegara al máximo permitido y ninguna operación se permitiría.
El mecanismo elegido ha sido un mecanismo de sesiones. Lo que se hace al iniciaruna operación es crear una sesión en la base de datos(con el módulo encargado de gestionarlas sesiones), esta sesión es temporal, con un tiempo de duración de 30 segundos. Para sabersi hay sobrecarga sólo hay que contar el número de sesiones activas, si es menor al máximose permite la operación.
En la Fig.6.18 pueden verse los pasos que se llevan a cabo en la función que sellama para iniciar una sesión temporal. Lo primero que se hace es llamar al método ”update-Sessions()”, este método actualiza la tabla de sesiones de la base de datos. Las sesiones queestén caducadas son eliminadas. Después se llama al método ”createRandomString()”, quegenera un identificador único para la sesión. El penúltimo paso es calcular la fecha en quedicha sesión debe caducar. Normalmente caducará a los 30 segundos. Y el último paso esguardar la nueva sesión en la base de datos.
151

:session
key:=newCompilationSession()
:DBBroker
expires:=calcularTiempoExpiracion()
executeCommand("INSERT ..", key, expires)
:utils
createRandomString()
key
updateSessions()
Figura 6.18: Creación de sesiones de compilación
6.1.11. Log de errores.
Como ya se comentó en la especificación de casos de uso, la herramienta dispone deun sistema de mantenimiento, para enviar los errores de forma automática. El funcionamientoes muy sencillo, cada vez que hay un error lo primero que se hace es generar la traza del error.Esta traza es el rastro de llamadas que se han hecho en el programa, hasta llegar al puntodonde se ha generado el error. Es muy útil a la hora de depurar saber la traza de llamadas.Por ejemplo si se produce un error en la página principal, el formato de la traza quedaría dela siguiente forma:
Traceback (most recent call last): File "main.py", line 48,
in execute f.printForm()
File "form.py", line 111, in printForm self.printContent()
File "main.py", line 18, in printContent
ctrl = noticiasCtrl.getInstance()
File "dominio\noticiasCtrl.py", line 20, in getInstance
g_instance = UsersControler()
File "dominio\noticiasCtrl.py", line 43, in __init__ inicializarBroker()
152

NameError: global name ’inicializarBroker’ is not defined
Esta traza se genera fácilmente con el módulo ”traceback” de python. Una vez se hagenerado la traza, se envía un mensaje de error(con la traza del mismo), al correo electrónicodel administrador. De esta forma el administrador no tendrá que estar mirando los logs deerrores. Este proceso puede verse en la Fig.6.19
modulo :debug
logError()
:utils
getTraceback()
traceback
:DBBroker
executeCommand("INSERT..", tracetext)
sendMail(tracetext)
Figura 6.19: Registro de un error en el log del sistema
153

6.1.12. Envío de noticias.
Cada vez que se crea una nueva noticia, además de registrarse en la base de datospuede enviarse a los usuarios registrados. La implementación de esta función es sencilla, loprimero que se hace es obtener de la base de datos la nueva noticia y la lista de usuarios.Después a cada usuario se le envía a su email la nueva noticia(ver Fig.6.20).
noticiasCtrl :DBBroker
executeQueryOneRow(SELECT)
msg
executeQueryAllRow('SELECT')
users
user:User
loop
[For user in users] getEmail()
:utils
sendMail(email, msg)
Figura 6.20: Envío de noticias
154

6.1.13. Generación de resultados(tablas de análisis).
Ya se ha comentado anteriormente que el producto de salida del compilador(hechoen Java) es un archivo ’.xml’. El texto fuente con los ejercicios propuestos, lo manda elusuario desde su Browser. Una vez recibidos se obtiene el texto fuente llamando al método”getInputGrammar()” y se llama al compilador(”executeGlcc()”) para que genere el ’.xml’.Una vez hecho esto, se llama al módulo encargado de generar el HTML de salida, a partir del’.xml’. El HTML final se le devuelve al Browser cliente(ver Fig.6.21).
:compile
gram:=getInputGrammar()
xml:=executeGlcc()
:compilerReport
compilerReport(xml)
HTML(tablas análisis)
Browser Cliente
POST(texto fuente)
HTML(tablas análisis)
Figura 6.21: Formateo de las tablas de análisis(HTML)
155

6.1.14. Diseño de la base de datos.
El diseño de la base de datos es sencillo, la mayoría de las tablas son tablas paraguardar datos sin tener que relacionarlos con otras tablas. En un principio se podría pensarque como no hay muchas relaciones, a lo mejor no era necesario utilizar una base de datosrelacional. Aun así las ventajas de utilizar una base de datos relacional son suficiente razónpara utilizarla. Las tablas que si están relacionadas principalmente son las tablas para man-tener a los usuarios y sus operaciones. En la Fig.6.22puede verse el esquema de la base dedatos, en este esquema sólo se muestran las tablas y las relaciones no se detalla su contenido.
Usuarios
PK id
fechaloginnombreapellidospassperfilemail
Candidatos
PK codigo_activacion
fechalogin
UsuariosTemporales
PK login
Compilaciones
PK,FK1 id
usuariofecha
Simulaciones
PK,FK1 id
usuariofecha
FeedBacks
PK,FK1 id
usuariofecha
Sesiones
PK clave_sesion
tiempo_expiraciontipousuario
Log
PK id
fechamensaje
Errores
PK id
fechamensaje
Ejemplos
PK nombre
fechacomentariogramatica
Config
passerror_mail_smtp_servererror_mail_usererror_mail_passworderror_mail_from
Noticias
PK id
fechamensaje
Perfiles
anonimo_comp_ll1anonimo_comp_slr1anonimo_comp_lr1anonimo_comp_lalr1
Figura 6.22: Estructura de la base de datos
Las tablas de la bases de datos son las siguientes:
Usuarios. En esta tabla se guardan todos los usuarios de la web. Además, de los usuar-ios registrados, por defecto, hay una cuenta para el usuario anónimo y otra para eladministrador. Las columnas de esta tabla son las siguientes:
156

• ID. Es un código numérico que identifica al usuario, este código es único paracada usuario.
• Fecha. Es la fecha de alta del usuario.
• Login y Pass.Son los datos para el acceso a la web.
• Nombre y Apellidos. Estos datos son sobre todo para los usuarios con el perfilalumno.
• Perfil. Es el perfil del usuario, los valores pueden ser: ”anonimo”, ”registrado”,”admin”, ”alumno”.
• Email. Es la dirección de contacto, utilizada para la comunicación de las novedadesde la Web, para el alta de un nuevo usuario, . . .
Compilaciones. Guarda las compilaciones hechas de cada usuario. La clave ajena”usuario” identifica al usuario de la compilación. Los datos que registra esta tabla acer-ca de la compilación son datos referentes al contenido del ejercicio compilado: númerode gramáticas que había en el ejercicio, tipos de análisis realizados(LL1, SLR1, . . . ),numero de producciones por cada gramática, . . . Además, para ver el rendimiento delcompilador también se registra el tiempo de operación, que es el tiempo en realizar todala operación, y el tiempo de compilación, que es el tiempo en que el compilador generala solución.
También hay que decir que si un usuario se borra, hay una sentencia definida en estatabla para que se borren también sus operaciones(compilaciones, simulaciones, feed-backs).
Simulaciones. Igual que la tabla anterior pero para las simulaciones.
Feedbacks.Son las sugerencias y las calificaciones hechas por los usuarios.
Noticias y Ejemplos. Estas dos tablas registran las noticias de la web y los ejemplos.
Candidatos y Usuarios_temporales.Se utilizan temporalmente en el proceso de darde alta a nuevos usuarios.
Log y Errores. La tabla ’Log’ registra el Log de la Web y ’Errores’ registra los erroresproducidos en la Web.
Config. Esta tabla registra la configuración de la Web, los datos más importantes queregistra son los de la cuenta de correo utilizada para los envíos de correo(servidorSMTP, nombre de usuario, password, . . . ).
Perfiles. Guarda los permisos de simulación y de compilación que tiene cada perfilde usuario. Por ejemplo la entrada ’anonimo_comp_ll1’, es una variable booleana. Sies true indica que el usuario anónimo puede compilar gramáticas LL(1). Si es false nopuede hacerlo.
Sesiones.Registra las sesiones activas.
157

6.2. Tecnología utilizada.
Las decisiones tecnológicas más importantes tomadas, han sido las concernientes allos lenguajes empleados y al gestor de base de datos. En esta sección se indicarán los motivospara seleccionar estas tecnologías.
6.2.1. Script del servidor.
El lenguaje utilizado para implementar el script de servidor es el lenguaje Python.Este lenguaje tiene las siguientes características:
Es un lenguaje de programación muy expresivo, es decir, en poco espacio puede crearseun programa que costaría cientos de líneas codificarlo en un lenguaje como C/C++.
Es una lenguaje muy legible. La sintaxis de python es muy limpia, por ejemplo, paracrear bloques no utiliza símbolos como C/C++(’{’, ’}’) o como Pascal(begin/end).Python utiliza la indentación, es decir, para crear un bloque nuevo simplemente hayque indentarlo hacia la derecha.
Ofrece un entorno interactivo muy útil para hacer pruebas en cualquier momento.
Es un lenguaje orientado a objetos, simple pero muy eficaz.
En el propio lenguaje posee un rico paquete de estructuras de datos. Además, son muyeficientes(listas, pilas, tablas hash, . . . ).
Posee un rico conjunto de paquetes. Por ejemplo, posee paquetes para programas apli-caciones que usen ftp, http, bases de datos, . . .
El motivo de utilizar a Python como script de servidor es por conveniencia con elentorno donde va a ser instalado.
6.2.2. Base de datos.
Una función básica de la herramienta es la de mantener la persistencia de los datosrecogidos de los usuarios. Existen diversas formas de mantener la persistencia de los datos:
Archivos. Una forma sencilla de mantener la información de forma persistente esguardándola en archivos(los archivos pueden ser binarios o de texto). La ventaja deeste sistema es que es fácil implementarlo. Pero tiene el gran inconveniente de que sila cantidad de datos es muy elevada el acceso a los archivos es ineficiente. Además, sise debe acceder a los datos de forma concurrente, el control de la concurrencia hay queimplementarlo.
158

Serialización. Existen paquetes que implementan automáticamente la serialización delos datos. Estos paquetes consiguen hacer persistente la información de forma automáti-ca. Pero sigue teniendo el mismo inconveniente que el anterior sistema, y es que si lacantidad de datos es muy grande, el acceso a la información es ineficiente. Y al igualque antes no suelen implementar mecanismos de concurrencia.
Sistemas de Gestión de Bases de Datos.Este es el sistema que se suele emplear dadaslas ventajas que tiene:
• Globalización de la información: Permite a los diferentes usuarios considerarla información como un recurso corporativo que carece de dueños específicos.
• Eliminación de información inconsistente:Si existen dos o más archivos con lamisma información, los cambios que se hagan a éstos deberán hacerse a todas lascopias del archivo.
• Permite compartir información.
• Permite mantener la integridad en la información: La integridad de la infor-mación es una de sus cualidades altamente deseable y tiene por objetivo que sólose almacene la información correcta.
• Independencia de datos:El concepto de independencia de datos es quizás el quemás ha ayudado a la rápida proliferación del desarrollo de Sistemas de Bases deDatos. La independencia de datos implica un divorcio entre programas y datos.
Existen varios modelos de bases de datos:
• Modelo jerárquico de datos: Una clase de modelo lógico de bases de datosque tiene una estructura arborescente. Un registro subdivide en segmentos quese interconectan en relaciones padre e hijo y muchos más. Los primeros sistemasadministradores de bases de datos eran jerárquicos. Puede representar dos tipos derelaciones entre los datos: relaciones de uno a uno y relaciones de uno a muchos.
• Modelo de datos en red: Es una variación del modelo de datos jerárquico. Dehecho las bases de datos pueden traducirse de jerárquicas a redes y viceversa conel objeto de optimizar la velocidad y la conveniencia del procesamiento.
• Modelo relacional de datos: Es el más reciente de estos modelos, supera algu-nas de las limitaciones de los otros dos anteriores. El modelo relacional de datosrepresenta todos los datos en la base de datos como sencillas tablas de dos dimen-siones llamadas relaciones. Las tablas son semejantes a los archivos planos, perola información en más de un archivo puede ser fácilmente extraída y combinada.
La decisión de qué sistema utilizar no sólo depende de la información a registrarsino también de las prestaciones que ofrezca el sistema para acceder a la información. Detodos los sistemas el que más facilidades da son las bases de datos relacionales. Ya que a lainformación se accede mediante el lenguaje SQL, el cual facilita mucho el acceso a los datosde la base de datos.
159

De entre las bases de datos relacionales gratuitas se ha elegido PostgreSQL, ya quees la base de datos que aun siendo gratuita ofrece prestaciones cercanas a las comerciales.
Características de PostgreSQL:
Integridad de datos. Una de las características críticas de cualquier sistema de gestiónde bases de datos es la integridad de los datos.
Características avanzadas.PostgreSQL soporta muchas de las características de basesde datos como Oracle, DB2 o MS-SQL, incluyendo triggers, vistas, herencia, secuen-cias, procedimientos almacenados, cursores, y datos definidos por el usuario.
Procedimientos almacenados y triggers.PostgreSQL soporta PL/pgSQL para losprocedimientos almacenados, un lenguaje muy similar al PL/SQL de Oracle. Además,los procedimientos almacenados y triggers de PostgreSQL pueden ser escritos en otroslenguajes como PL/TCL, PL/Perl y PL/Python.
Índices. Soporta índices de una columna simple, multicolumna, la restricción de uni-cidad e índices en claves primarias.
Tipos de datos. Soporta la mayoría de los tipos de datos, almacenamiento de grandesobjetos, definición de tipos por el usuario. También soporta almacenamiento de datosgeográficos conocido como GIS (Geographic Information System).
Replicación. Ésta es una de las características más importantes cuando se necesitarendimiento.
Soporte multiplataforma. PostgreSQL es soportado por la mayoría de las plataformasexistentes: Windows, Linux, FreeBSD, and MacOSX, . . .
Interfaces de bases de datos.Soporta ODBC y JDBC y métodos nativos de acceso abases de datos.
Backups. PostgreSQL tiene scripts para facilitar una backup en simples archivos detexto. También soporta recuperación de errores no críticos. PostgreSQL usa un sistemallamado Write Ahead Logging que proporciona la consistencia de la base de datos.
Herramientas de soporte. Hay diversas herramientas gráficas para la administraciónde la base de datos.
Migración de datos. PostgreSQL tiene herramientas para ayudar a la migración desdebases de datos comerciales.
160

CAPÍTULO 7.
CONCLUSIONES Y PROPUESTAS
7.1. Conclusiones.
Una vez construida la herramienta y hechas sus correspondientes pruebas se ha lle-gado a la conclusión de que cumple los objetivos propuestos inicialmente.
El periodo de evaluación de la herramienta comenzó el día 19 de abril de 2005 yterminó el 7 de agosto de 2005. En este tiempo, se ha podido evaluar la aceptación de la he-rramienta por parte de los usuarios y mejorar su funcionamiento gracias a las sugerencias delos mismos.
Se han recibido 33 mensajes para valorar la herramienta por parte de los usuarios.La calificación puesta por los usuarios ha sido la siguiente(en el rango de 1 a 5):
Facilidad de uso media: 3.9
Utilidad media: 4.2
Como puede verse la valoración del usuario ha sido bastante buena, de ella se puededestacar que la nota más alta se ha obtenido en la característica de lautilidad . Es en esta car-acterística en la que se puede concluir que el proyecto cumple sus objetivos iniciales, es decir,ser una herramienta de apoyo a la docencia de la asignatura de Procesadores de Lenguajes.
Aunque la característica de la facilidad de uso también ha obtenido una buena nota,ha sido un poco más baja que la de la utilidad. Pero la facilidad de uso de la herramienta seirá mejorando con el tiempo con las sugerencias de los usuarios.
Como se esperaba el uso más frecuente de la herramienta es la de generar las tablasde análisis. Además, como puede verse en la Tabla7.1 el número de compilaciones y el degramáticas compiladas es diferente. Esto quiere decir que en algunos casos, en un mismoarchivo fuente se ha compilado más de una gramática. Algo que de partida ya se suponía quepodía resultar útil.
161
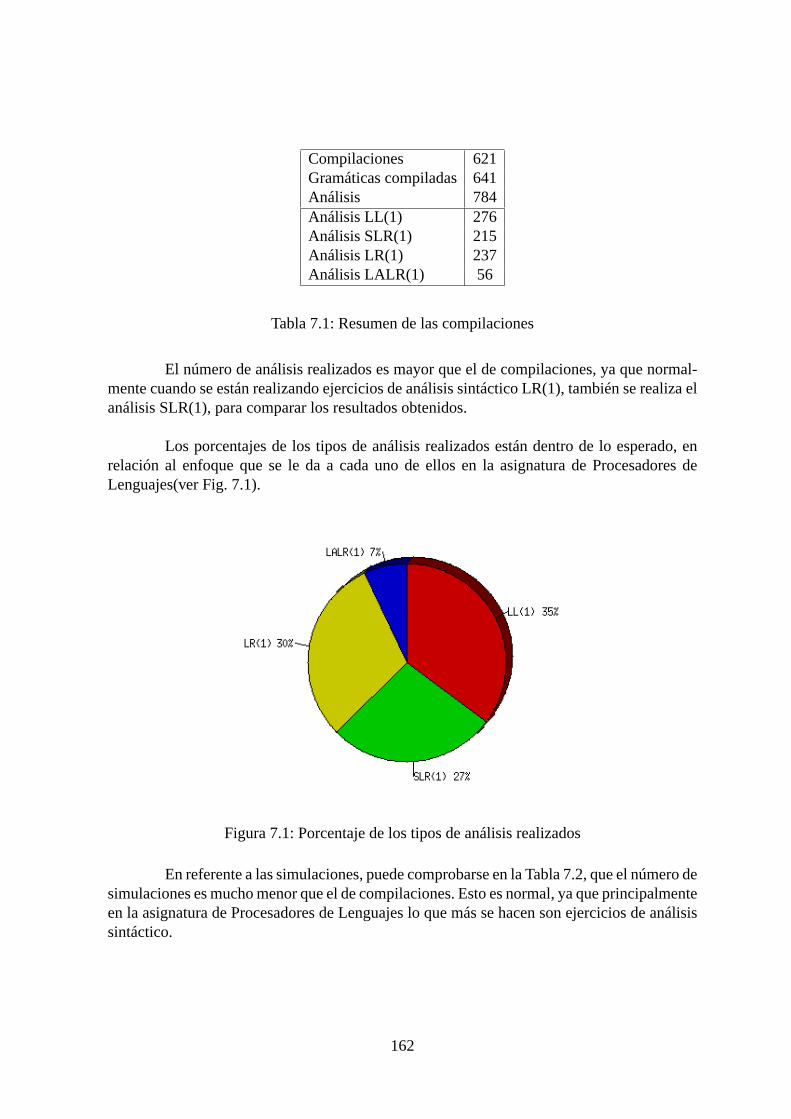
Compilaciones 621Gramáticas compiladas641Análisis 784Análisis LL(1) 276Análisis SLR(1) 215Análisis LR(1) 237Análisis LALR(1) 56
Tabla 7.1: Resumen de las compilaciones
El número de análisis realizados es mayor que el de compilaciones, ya que normal-mente cuando se están realizando ejercicios de análisis sintáctico LR(1), también se realiza elanálisis SLR(1), para comparar los resultados obtenidos.
Los porcentajes de los tipos de análisis realizados están dentro de lo esperado, enrelación al enfoque que se le da a cada uno de ellos en la asignatura de Procesadores deLenguajes(ver Fig.7.1).
Figura 7.1: Porcentaje de los tipos de análisis realizados
En referente a las simulaciones, puede comprobarse en la Tabla7.2, que el número desimulaciones es mucho menor que el de compilaciones. Esto es normal, ya que principalmenteen la asignatura de Procesadores de Lenguajes lo que más se hacen son ejercicios de análisissintáctico.
162

Simulaciones 71Simulaciones LL(1) 14Simulaciones SLR(1) 9Simulaciones LR(1) 37Simulaciones LALR(1) 11
Tabla 7.2: Simulaciones
Los porcentajes en el tipo de simulación realizados están dentro de lo esperado (verFig. 7.2).
Figura 7.2: Porcentaje de los tipos de simulaciones realizados
Las conclusiones anteriores están hechas desde el punto de vista del uso de la he-rramienta por parte del alumno. Desde el punto de vista del profesorado la herramienta hamostrado ser de gran utilidad, porque le permite:
Resolver las dudas de los alumnos en la propia clase, apoyándose en la herramienta.
Conocer el seguimiento de la asignatura por parte del alumno.
Conocer los tipos de análisis en los que el alumno, hace mayor hincapié.
Otro aspecto a destacar ha sido el aprendizaje del lenguaje. Las pruebas hechas conel lenguaje han sido satisfactorias, se aprende rápidamente y no se han recibido quejas so-bre el mismo. Esto ya se esperaba, ya que el lenguaje se diseñó teniendo como modelo loslenguajes utilizados normalmente para la especificación de gramáticas.
Desde el punto de vista tecnológico las conclusiones han sido las siguientes:
El hacer la arquitectura del compilador extensible, ha facilitado los cambios. Por ejem-plo lo primero que se implementó fue la parte de generación de las tablas de análisis.El agregarle la parte de simulación, gracias a la arquitectura, fue muy fácil.
163

El utilizar XML como formato de salida del compilador, ha facilitado mucho el acoplamien-to entre el compilador y la Web.
El utilizar patrones de diseño a la hora de asignar responsabilidades ha facilitado muchola tarea de diseño.
JUnit ha facilitado mucho el realizar las pruebas del compilador.
Para finalizar, una conclusión que se obtiene es que con este proyecto se abre unalínea que permite crear herramientas para la enseñanza de Teoría de Autómatas y LenguajesFormales.
7.2. Propuestas.
Sería útil poder escribir ejercicios de lenguajes regulares, transformación de autó-matas, transformación de expresiones regulares, . . .
En los análisis ascendentes, además de generar el autómata de análisis de formatabular, se podría generar de forma gráfica. Aunque de forma tabular se puede comprobarfácilmente si la solución a un ejercicio es correcta, el generarlo de forma gráfica mejoraría laapariencia del resultado.
Las estadísticas en vez de generarlas de forma global, se podrían mostrar las estadís-ticas personales de cada usuario. Además, se podría mostrar el sumario agrupado por perfiles:usuarios anónimos, registrados, alumnos.
También sería interesante agregarle a la herramienta, algún módulo que facilitara lacolaboración entre los alumnos, para ayudarse entre ellos al estudio de la asignatura de Proce-sadores de Lenguajes.
Por último estaría interesante agregarle a la herramienta un sistema de correcciónautomática de ejercicios, de esta forma los alumnos se podrían autoevaluar.
164

CAPÍTULO 8.
MANUAL DE USUARIO
En las próximas secciones se explicarán cada una de las interfaces de la Web, tantodel usuario como las del administrador.
8.1. Pantalla de inicio.
En la pantalla de inicio de la Web hay tres secciones(ver Fig.8.1):
Menú. En esta sección se presenta un menú con las diferentes opciones:
• Compilar. Interfaz de entrada para la generación de las tablas de análisis.
• Administrador. Administración de los recursos de la web(sólo para el adminis-trador).
• Ejemplos. Listado de todos los ejemplos propuestos por el administrador.
• Ayuda. Manual de usuario del compilador y de la Web.
• Login. Se utiliza para hacer el login a la Web.
Entrada. Sección central donde se indican los objetivos de la Web.
Novedades.Sección donde el administrador puede ir publicando noticias.
165

Figura 8.1: Interfaz de entrada
8.1.1. Login.
Según lo establezca el administrador, el acceso a algunos recursos de la Web(compilaro simular), puede estar restringido a los usuarios registrados en la base de datos de la Web.La interfaz del login sirve para autentificar a un usuario legítimo de la Web. Para el login hayque introducir el nombre de usuario y el password. Si el usuario está registrado y su passwordes válido, el usuario puede utilizar los recursos de la Web(ver Fig.8.2).
Por defecto si no se realiza el login, el usuario activo es el usuario anónimo.
166

Figura 8.2: Interfaz de login
8.1.2. Compilar.
Como ya se ha comentado anteriormente la principal función de la herramientaes la de poder generar la solución de los ejercicios de análisis sintáctico. Esta función estádisponible en la seccióncompilar.
El texto fuente con los ejercicios a corregir se puede dar en dos formatos(ver Fig.8.3):
El texto fuente se puede cargar desde un archivo que se tenga guardado. Para cargar elarchivo hay que hacer click sobre el botónBrowse...y seleccionar el archivo de entrada.
En la Web hay un cuadro donde directamente se pueden escribir los ejercicios. Estaforma de dar el texto fuente se ha puesto porque algunas veces es más fácil escribir elejercicio directamente en la Web, que escribirlo en un archivo. Además, a lo mejor nose quiere guardar el ejercicio escrito simplemente se quiere hacer una prueba.
167

Figura 8.3: Formas de introducir el texto fuente
Una vez seleccionado el texto fuente, para compilar y generar las tablas de análisishay que darle al botónCompilar . Al hacerlo aparecerá en pantalla la siguiente información:
Cuadro de navegación.Si se compilan varios ejercicios al mismo tiempo, los resulta-dos se generan en forma de lista, es decir, uno detrás de otro. Para facilitar la localiza-ción de los resultados también se genera un cuadro(ver Fig.8.4), desde el cual se tieneun enlace para acceder a las siguientes secciones:
Figura 8.4: Cuadro de navegación
168

• Enlace a la gramática. Al compilar una gramática en los resultados se vuelvea copiar la gramática, para poder comprobar mejor los resultados obtenidos(verFig. 8.5).
Figura 8.5: Cuadro con la gramática de entrada
Después de la gramática también se genera la información adicional. Esta infor-mación son los símbolos anulables, iniciales y seguidores. La cual es muy útilcuando se corrigen ejercicios. Por ejemplo, supóngase la siguiente gramática:
grammar prueba {
nonterminal S , A, B , C ;
t e rm ina l a , b ;
S := A | B ;
A := a a ;
B := C b ;
C := a A;
}
169

Al generar la tabla de análisis se produce un conflicto LL(1), como puede verseen la Fig.8.6.
Figura 8.6: Tabla de análisis LL(1) con conflictos
El conflicto indica que con una’S’ en la cima de la pila y una’a’ en la entradahay un conflicto. Esto significa que los dos no terminales’A’ y ’B’ deben teneren sus iniciales el terminal’a’ , lo cual puede comprobarse en la tabla de iniciales(Fig. 8.7).
Figura 8.7: Símbolos iniciales de la gramática LL(1)
• Tabla de estados.En los análisis ascendentes se proporciona un enlace al autó-mata correspondiente.
Este autómata se da de forma tabular, donde cada entrada de la tabla representaun estado de autómata. Dentro del estado están los items de dicho estado, dondede estos items se obtiene la siguiente información(de izquierda a derecha):
◦ El número a la izquierda de los dos puntos es el identificador de la produc-ción.
170

◦ A la derecha de los dos puntos está la producción a partir de la cual se hagenerado el item.
◦ El círculo rojo es el marcador.
◦ Los símbolos encerrados entre llaves son los símbolos de predicción(si lostiene).
◦ Encerrado entre corchetes está la transición si es un desplazamiento, o lapalabra reducir si es una reducción.
En la Fig.8.8puede verse un ejemplo de parte de una tabla de estados.
Figura 8.8: Ejemplo de tabla de estados
• Tabla de análisis descendente.En las filas están los no terminales y en lascolumnas los terminales, ordenándose la cabecera de la tabla alfabéticamente. Enla cabecera de la tabla al final siempre se encuentra el símbolo ’$’.
En la tabla pueden haber dos tipos de elementos:
◦ Producciones: Es la producción a utilizar por el analizador sintáctico con laconfiguración actual(símbolo en la cima de la pila y símbolo a la entrada)
◦ Errores: Las casillas en blanco indican que si se llega a esa configuración(fila y columna) se ha llegado a un error sintáctico.
171

Las casillas marcadas en rojo indican que existe un conflicto LL(1), lo cual signifi-ca que dentro habrá más de una producción. Los conflictos también se muestranen la parte deMensajes de salida del compilador. Un ejemplo de tabla de análisisLL(1) con conflictos puede verse en la Fig.8.9.
Figura 8.9: Ejemplo de tabla de análisis descendente
• Tabla de análisis ascendente.Las columnas se dividen en dos partes(están som-breadas de color diferente), la primera de ellas es la tabla deaccióny la otra esla parte deIr_A . Como en las descendentes, éstas también están ordenadas pororden alfabético. Un ejemplo de ello se puede ver en la Fig.8.10.
El significado de los símbolos dentro de la tabla son:
◦ Desplazamientos:Van precedidos por la letra’d’ . Por ejemplo ’d5’.
◦ Reducciones:Van precedidos por la letra’r’ . Por ejemplo ’r3’.
◦ Transición de estado: Están en la parte de la tabla deIr_A , e indican elidentificador del estado de la transición.
◦ Aceptación: Es el estado de aceptación y está identificado con la palabra’Aceptar’
◦ Error: Entradas de la tabla para las que no hay definida una acción, estasson las entradas con el símbolo ’-’
Al igual que en la descendente si hay un conflicto, la casilla conflictiva estarámarcada en rojo.
172

Figura 8.10: Ejemplo de tabla de análisis ascendente
Mensajes de salida del compilador.Como ya se ha comentado anteriormente, cuan-do se realiza el proceso de compilación, además de las tablas de análisis, también semostrarán los mensajes del compilador(si los hay). Los tipos de mensajes del compi-lador son los siguientes:
• Errores. Hay distintos tipos de errores, en la mayoría de ellos los dos primeroscampos son la fila y la columna en el archivo fuente donde está el error.
◦ Léxicos. Ocurren al encontrar en el archivo fuente caracteres ilegales. Porejemplo:
45:18: carácter ilegal: &
◦ Sintácticos. Ocurren cuando el analizador sintáctico encuentra un error sin-táctico. Por ejemplo:
173

:35:28: Syntax error en ’kkk’
◦ Semánticos.Por ejemplo, usar un símbolo sin haberlo declarado es un errorsemántico, o repetir su declaración:
35:29: En ’gram_ll1’: el símbolo ’Z3’ ya esta definido.
• Conflictos. Los tipos de conflictos son los siguientes:
El formato en que se dan los conflictos es el siguiente:
[<Análisis>] En ’<Nombre>’: Conflicto <Tipo>[<X>][<Y>]
Donde:
◦ Análisis. Es el nombre del tipo de análisis(LL1, SLR1, . . . ).
◦ Nombre. Es el nombre de la gramática donde se ha producido el conflicto.
◦ Tipo. Descripción del tipo de conflicto(ll1, desplazamiento/reducción, . . . )
◦ X, Y. Posición en la tabla de análisis donde está el error.
◦ Conflicto LL(1): Se muestran las producciones que han entrado en conflic-to. Ejemplo de conflicto LL(1):
[ll1] : En ’gram_ll1’: Conflicto LL(1) [X][a]:
Producción: X -> Y
Producción: X -> a
◦ Conflicto SLR(1), LR(1) o LALR(1): El tipo de conflicto puede ser D/R oR/R. Ejemplo de un conflicto D/R:
[slr1] : En ’gramática’: Conflicto D/R [3][b]:
Desplazamiento : S -> x * b | {=>6}
Reducción : B -> x *|
Como se puede ver si el conflicto es D/R se muestra el item de desplazamientoy el de reducción. Si el conflicto es R/R se muestran los items que han entradoen conflicto.
174

◦ Warnings: Por ejemplo se muestra un warning cuando se declara dos vecesla misma producción, no es un error, pero es conveniente avisarlo. Ejemplo:
En ’gram_ll1’: ’Z -> b Z2 ’ esta repetida
Si se realiza un análisis LL(1) y la gramática es recursiva por la izquierda,también se le avisará al usuario, indicando el camino recursivo.
8.1.3. Simulación.
La simulación se realiza de forma muy sencilla, desde el cuadro de navegación(verFig. 8.4) generado al compilar hay que pulsar el botón deSimular. De esta forma se estáeligiendo la gramática y el tipo de análisis a simular. Una vez hecho esto aparecerá en otraventana, la gramática y un cuadro de texto donde se puede introducir el texto que se quieresimular(ver Fig.8.11).
Figura 8.11: Interfaz de entrada para la simulación
175

Figura 8.12: Traza de salida de la simulación
Al darle al botónSimular se generará una tabla con la traza de la simulación. El for-mato de la traza es el mismo visto en las secciones anteriores de los analizadores sintácticos.La primera columna es la pila del analizador, la segunda el buffer de entrada y la última es laacción a realizar(ver Fig.8.12).
Si se encuentra un error sintáctico, el proceso de simulación se detendrá, mostrandoel token que ha producido el error(ver Fig.8.13).
176

Figura 8.13: Traza de salida de la simulación con errores
8.1.4. Formato de los listados.
Normalmente todos los listado hechos tienen el mismo formato(como ejemplo verla Fig.8.14):
Si se hace click sobre algún campo de la cabecera de la tabla, la ordenación se realizapor dicho campo. Si se vuelve hacer click sobre dicho campo se cambia el sentido deordenación(ascendente/descendente). Normalmente por defecto los listados se ordenanpor la fecha en sentido descendente.
En la parte izquierda de cada fila hay uncheckbox, al darle al botónBorrar selecciona-dosse borrarán las filas seleccionadas. Si se selecciona elcheckboxde la cabecera seseleccionarán todas las filas. Antes de borrar los registros se pregunta al usuario paraconfirmar el borrado de los mismos.
La última sección es para navegar entre las distintas páginas.
177

Figura 8.14: Formato de los listados
Figura 8.15: Control de acceso mediante password
8.2. Funciones de administración.
Las funciones de administración sólo están accesibles para el administrador de laWeb. Si un usuario quiere acceder a estas funciones, antes se presentará una pantalla para queintroduzca el password(ver Fig8.15).
178

Figura 8.16: Pantalla para agregar un nuevo usuario
8.2.1. Gestión de usuarios.
En la gestión de usuarios hay que diferenciar las funciones que puede realizar unusuario externo y las que puede realizar el administrador.
Funciones del administrador.
Funciones que se pueden realizar:
Alta de usuarios. La interfaz para el alta de usuarios puede verse en la Fig.8.16.
Los datos a introducir son:
• Nombre y apellidos. Estos datos no son obligatorios, normalmente los intro-ducirán sólo los alumnos.
• Login. Es el identificador de usuario utilizado para acceder a la Web.
• Password. La longitud del password debe ser como mínimo de 8 caracteres.
• E-mail. Dirección de correo electrónico utilizada para la activación de la nuevacuenta de usuario. Debe ser una dirección de correo válida.
179

Figura 8.17: Interfaz para cargar usuarios
Figura 8.18: Interfaz para confirmar la carga de usuarios
• Perfil. El usuario se puede registrar con dos perfiles, el primero es el deusuarioexternoy el otro el dealumno. El elegir el perfil sólo está disponible para eladministrador. Si esta operación la hace un usuario externo, sólo puede tener elperfil de usuario externo.
Al darle al botón”Aceptar” , si el usuario no existe previamente o no hay ningún pro-blema, se registra el nuevo usuario en la base de datos.
Carga de usuarios.Esta operación está hecha para cargar un grupo de nuevos usuariosdesde un archivo. Normalmente se utilizará para cargar como usuarios a los alumnos dela asignatura de Procesadores de Lenguajes. Su uso es muy sencillo, lo único que hayque hacer es proporcionar el archivo con los nuevos usuarios(ver Fig.8.17).
Después de seleccionar el archivo y aceptar se mostrará un log con las entradas noválidas y otro con los usuarios válidos. Al administrador se le preguntará si quiere con-firmar el alta de estos nuevos usuarios. Si se confirma se agregarán a la base de datosy se enviará un email a cada nuevo usuario. En este e-mail se le indica el nombre deusuario generado y el password de acceso(ver Fig.8.18).
180

Figura 8.19: Listado de usuarios
El formato del archivo de entrada con los usuarios es el siguiente:
nombre;apellidos;email
Donde el primer campo es el nombre del alumno, el segundo sus apellidos y el últimosu e-mail.
Listado de usuarios. Permite conocer los usuarios registrados en el sistema. Bási-camente la información que se muestra de cada usuario es la que se solicita en elformulario de alta de usuarios. Inicialmente los usuarios se ordenan por la fecha dealta(descendentemente), pero el listado se puede ordenar por cualquier campo. Si sehace click en el campologin, se mostrará una ventana para la edición del usuario.(verFig. 8.19)
Para eliminar a algún usuario hay que marcar su casilla y darle al botónBorrar se-leccionados. Antes de borrar siempre se pide la confirmación. Hay que saber que si seborra un usuario también se borrarán sus acciones(compilaciones, simulaciones, . . . ).
181

Figura 8.20: Interfaz para agregar un nuevo usuario
Funciones de usuario.
Las funciones disponibles para el usuario son básicamente las relacionadas con elalta de un nuevo usuario.
Funciones disponibles:
Alta de usuarios. La interfaz para el alta de nuevos usuarios puede verse en la Fig.8.20. Como puede verse es muy similar a la del administrador, pero la diferencia es queno puede elegir el tipo de perfil.
Después de rellenar el formulario y darle al botón deAceptar se le enviará a la cuentade correo del usuario un código para activar al nuevo usuario. Para activar la cuenta loúnico que hay que hacer es introducir el código de activación(ver Fig.8.21).
Si el código de activación no se introduce en 7 días, el código de activación se invali-dará.
Recordar contraseña. Si a un usuario se le ha olvidado la contraseña, puede utilizareste método para recordarla. Debe introducir el e-mail(ver Fig.8.22) que utilizó paradar de alta su cuenta. Si el usuario es válido(la dirección de correo está registrada) se leenviará un correo electrónico con su nombre de usuario y su password.
182

Figura 8.21: Interfaz para la activación de usuarios
Figura 8.22: Interfaz para recordar el password
Modificar cuenta de usuario. Es la misma interfaz que para agregar un nuevo usuario,pero con los campos de datos rellenados. Desde esta interfaz el usuario puede editar sucuenta(ver Fig.8.23).
183

Figura 8.23: Configuración de los parámetros de un usuario
8.2.2. Gestión de la configuración.
Esta opción sólo está disponible para el administrador, se pueden configurar los si-guientes elementos:
Configuración de los perfiles.Existen 3 perfiles:
• Usuarios anónimos.Son los usuarios no registrados.
• Usuarios registrados.
• Alumnos. Son los alumnos de la asignatura de Procesadores de Lenguajes.
Como puede verse en la Fig.8.24, a cada perfil se le puede indicar el tipo de análisisque puede realizar(LL1, SLR1, . . . ) y el tipo de simulación que se le permite.
Cambio del password.Se utiliza para cambiar el password del administrador(ver Fig.8.25).
Configuración del e-mail. Para enviar los correos electrónicos se necesita un servidorde correo saliente. En esta pantalla se puede configurar los datos del servidor de correo(ver Fig.8.26). Estos datos son los siguientes:
184

Figura 8.24: Configuración de los perfiles
Figura 8.25: Cambio del password
185

Figura 8.26: Configuración del email
• Servidor SMTP: Dirección ip del servidor de correo de subida.
• Usuario: Identificación del usuario.
• From: Dirección de correo electrónico del emisor de los correos.
• To: Dirección de correo electrónico a la que se envían los mensajes, cuando seproduce en error en la Web.
• Password: Palabra clave de acceso al servidor de correo.
8.2.3. Reset de la base de datos.
Esta pantalla se utiliza para el reset de la base de datos. Las tablas que se puedeninicializar son las siguientes(ver Fig.8.27):
Usuarios registrados. Se eliminan las cuentas de todos los usuarios que se han reg-istrado externamente. También se eliminan sus acciones(compilaciones, simulaciones,. . . ).
Alumno. Alumnos de la asignatura de Procesadores de Lenguajes.
Log del sistema.
Log de errores.
Log de compilaciones.
Log de simulaciones.
186

Figura 8.27: Reset de la base de datos
8.2.4. Gestión de ejemplos.
Las funciones disponibles son las siguientes:
Agregar nuevos ejemplos. Para agregar un nuevo ejemplo hay que introducir lossiguientes datos(ver Fig.8.28):
• Texto fuente. El cuerpo del ejemplo se puede escribir directamente en el cuadrode texto o cargarlo desde un archivo.
• Nombre. Es el nombre identificador del ejemplo.
• Comentario.
Una vez se han rellenado los campos adecuados si se quiere se puede hacer una pruebade compilación, pulsando al botónCompilar .
Al guardar el ejemplo si ya existía previamente, siempre se pregunta al usuario si quieresobrescribir el ejemplo.
Listado de ejemplos. En el listado de ejemplos se muestran todos los ejemplos regis-trados(se ordenan por fecha). Si se hace click sobre elnombre del ejemplo se puedevolver a editar el ejemplo(ver Fig.8.29).
Borrado. Como cualquier listado los ejemplos se pueden borrar seleccionándolos ypulsando el botónBorrar Seleccionados.
187
Figura 8.28: Edición de ejemplos
Figura 8.29: Listado de ejemplos
188

Figura 8.30: Interfaz para agregar nuevas noticias
Figura 8.31: Interfaz para listar noticias
8.2.5. Gestión de noticias.
Las operaciones con las noticias son las mismas que con los ejemplos. Hay unainterfaz para agregar nuevas noticias y para listarlas.
Agregar noticias. La interfaz es sencilla sólo hay que introducir el texto de la nuevanoticia(ver Fig.8.30).
Listar noticias. El formato del listado de las noticias es como en todos los listados(verFig. 8.31).
189

8.2.6. Estadísticas.
En la pantalla inicial de las estadísticas se muestra un sumario con el resumen de usode la herramienta(ver Fig.8.32). En el sumario se muestran los siguientes datos:
Sobrecargas del servidor.El sistema limita el número de operaciones(compilaciones,simulaciones) que se pueden hacer, el número de sobrecargas se registra en la base dedatos.
Compilaciones. Es el número de compilaciones de gramáticas que se han realizado.
Gramáticas compiladas. Como en un mismo texto fuente puede haber más de unagramática, también se registra el número total de gramáticas compiladas.
Análisis. Al igual que antes en cada gramática se pueden realizar varios análisis. Estavariable registra el número de análisis realizados.
Análisis LL(1). Es el número de análisis LL(1) realizados, contándolos de forma sep-arada, se puede saber el análisis que más se realiza.
Análisis SLR(1). Es el número de análisis SLR(1) realizados.
Análisis LR(1). Es el número de análisis LR(1) realizados.
Análisis LALR(1). Es el número de análisis LALR(1) realizados.
Feedbacks.Número de feedbacks realizados
Utilidad media. Es una calificación dada por los usuarios de la Web.
Facilidad de uso media.Es una calificación dada por los usuarios de la Web.
Simulaciones.Número de simulaciones realizadas.
Simulaciones LL(1). Número de simulaciones de gramáticas LL(1).
Simulaciones SLR(1).Número de simulaciones de gramáticas SLR(1).
Simulaciones LR(1). Número de simulaciones de gramáticas LR(1).
Simulaciones LALR(1). Número de simulaciones de gramáticas LALR(1).
Los log son los siguientes:
Log del sistema.Es un log sobre el funcionamiento del sistema.
Feedbacks. Son los feedback de los usuarios. En cada feedback se registra, la fecha,el comentario y la nota de calificación para el sistema.
Compilaciones. Muestra las compilaciones de cada usuario.
190

Figura 8.32: Sumario de las estadísticas
191

Figura 8.33: Gráfica circular
Simulaciones.Muestra las simulaciones de cada usuario.
Gráficas de análisis.En esta pantalla se muestra gráficamente las estadísticas del tipode análisis que se hacen más a menudo. Las gráficas se pueden mostrar en 4 formatos:
• Circular. Es una gráfica circular donde cada porción muestra el porcentaje deuso de cada tipo de análisis(ver Fig.8.33).
• Circular 3D. Es el mismo de antes pero en 3D(ver Fig.8.34).
• Barras. Muestra en forma de barras, el número de análisis hechos de cada tipo(verFig. 8.35).
• Barras 3D. Igual que el anterior pero las barras son en 3D(ver Fig.8.36).
Simulaciones. El formato de las gráficas es igual que las de análisis, pero aquí semuestra el numero de simulaciones de cada tipo.
192

Figura 8.34: Gráfica circular 3D
Figura 8.35: Gráfica de barras
193

Figura 8.36: Gráfica de barras 3D
194

CAPÍTULO 9.
ANEXOS
9.1. El generador de analizadores léxicos JFlex.
Una especificación JFlex consta de 3 partes separadas por % %. En JFlex hay lassiguientes secciones:
Código de usuario.Esta sección contiene el código adicional del usuario. Por ejemplopara importar paquetes o hacer la declaración ”package”.
Opciones y declaraciones.Esta sección es para activar opciones de JFlex. Las op-ciones disponibles son:
• %class. Sirve para indicarle a JFlex el nombre de la clase del analizador léxico.
• %unicode. Sirve para activar el reconocimiento de caracteres UNICODE.
• %cup. Genera un Lexer compatible con JCup.
• %line y %column. Activando estas opciones se puede saber la fila y la columnadel patrón reconocido.
Las macros tienen el formato:
identificador = expresión regular
También sirve para declarar macros y definiciones utilizables después en la zona dereglas léxicas.
Reglas léxicas. En esta sección es donde se especifican las expresiones regulares areconocer. Cada regla léxica tiene el siguiente formato:
expresion1 {acción 1}
expresion2 {acción 2}
expresion3 {acción 3}
195

Donde la parte izquierda son las expresiones regulares y la parte derecha la acción arealizar cuando se reconozca la expresión regular. Esta acción se escribe en Java, y nor-malmente lo que se hace en esta sección es devolver el tipo de token reconocido. Si ellexer se hace compatible con JCup se devuelve encapsulado en instancias de la claseSymbol. El siguiente texto es un ejemplo de cómo se reconocería un identificador y laacción al reconocerlo.:
/∗ pa t rón para reconoce r un i d e n t i f i c a d o r∗ /
[ _A−Za−z ] [ _A−Za−z0−9]∗ { re turn new Symbol ( sym . ID , y y t e x t ( ) ) }
Las expresiones regulares se pueden formar de la siguiente manera:
Si a y b son expresiones regulares:
• Unión. a | b reconoce unaa o unab.
• Concatenación. a breconoce unaa seguida de unab.
• Clausura. a∗ reconoce cero o más repeticiones de laa.
• Clausura positiva. a+ reconoce una o más repeticiones de laa.
• Opción. a? reconoce cero o unaa.
196

9.2. El generador de analizadores sintácticos LALR JCup.
Un archivo de entrada para JCup consta de las siguientes secciones:
Sección de sentencias ”package” e ”imports” (opcional).Sirve para lo mismo queen un programa normal de Java. Con una declaraciónpackagese puede hacer que elparser generado pertenezca a un determinado paquete.
Componentes de código de usuario(opcional).Puede contener los siguientes ele-mentos:
• Declaración de las variables y rutinas utilizadas en el código de usuario embebido.
action code {: . . . :}
• Declaración de métodos y variables que se incluyen dentro del código de la clasedel analizador generado.
parser code {: . . . :}
• Declaración de código que debe ejecutar el analizador antes de recoger el primer”token”. Por ejemplo, código para inicializar el escáner, tablas o cualquier otrotipo de estructuras de datos:
init with {: . . . :}
• Especificación de cómo el analizador debería preguntar por el próximo ”token” alescáner:
scan code {: . . . :}
Sección de lista de símbolos de la gramática(obligatoria).Puede contener los si-guientes elementos:
• Declaración de símbolos terminales:
terminal classname name1, name2, . . .
• Declaración de símbolos no terminales:
non terminal classname name1, name2, . . .
• Sección de declaración de precedencias(opcional): Es útil para el análisis de gramáti-cas ambiguas. Existen tres tipos de declaraciones de precedencia/asociatividad:
◦ precedence leftterminal{, terminal...};
◦ precedence rightterminal{, terminal...};
◦ precedence nonassoc terminal{, terminal...};
197

El orden de precedencia va desde el final del archivo hasta el principio, es decir,que los declarados más abajo tiene más precedencia que los declarados al princi-pio.
• Sección de especificación de la gramática(obligatoria).Contiene la gramáticajunto con las acciones a realizar cuando se reconozca una producción de la misma.
Comentarios:
◦ start with non-terminal. Especifica el símbolo inicial de la gramática.
◦ Las producciones tienen el siguiente formato:
no terminal := producción {| producción . . . };
Donde la producción es una lista de símbolos terminales y no terminales,separados por espacios.
◦ Las acciones de cada producción se ponen entre los símbolos ’{:’, ’:}’. Porejemplo.
exp ::= exp:e1 mas exp:e2{: RESULT = e1.intValue() + e2.intValue() :}
Como se puede ver al no terminal de la izquierda se le identifica por RESULTy a los otros mediante una etiqueta(e1, e2).
198

BIBLIOGRAFÍA
[1] A. Aho, S. Hopcroft, and J. Ullman.The Design and Analysis of Computer Algorithms.Addison-Wesley, 1974.17
[2] A. Aho, S. Johnson, and J. Ullman. Deterministic parsing of ambiguos grammars.Co-munications of ACM, pages 441–452, 1975.16
[3] F. Allen. Control flow analysis.ACM SIGPLAN Notices, pages 1–19, 1970.18
[4] R. Backhouse. An alternative approach to the improvement of lr parsers.Acta Infor-mática, pages 277–296, 1976.16
[5] J. Ciesinger. A bibliography of error handling.ACM SIGPLAN Notices, pages 16–26,1979.16
[6] J. Cocke. Global common subexpresion elimination.ACM SIGPLAN Notices, pages20–24, 1970.18
[7] A. Demers. Elimination of single productions and merging of nonterminal symbol inlr(1) grammars.Journal Computer Languages, pages 105–119, 1975.16
[8] F. DeRemer. Practical translator for lr(k) languages.Tesis Doctoral M.I.T. Cambrige,Massachusetts, 1969.16
[9] F. DeRemer. Simple lr(k) grammars.Comunications of ACM, pages 453–460, 1971.16
[10] D.Knuth. Backus normal form vs. backus naur form.Communications of the ACM,pages 735–736, 1964.15
[11] D.Knuth. Semantics of the context-free languages.Mathematical Systems Theory, pages127–145, 1968.17
[12] D.Knuth. The Art of Computer Programming. Addison-Wesley, 1973.17
[13] D.Younger. Recognition and parsing of context-free languages in time n3.Informationand Control, pages 189–208, 1967.15
[14] J. Early. Ambiguity and precednce in syntac descriptions.Acta informática, pages183–192, 1975.16
199

[15] J. Engenlfriet. Attributed evaluation methods.En Lorho(1984), pages 103–138, 1984.17
[16] R. Floyd. Bounded context syntactic analysis.Communications of the ACM, pages62–67, 1964.15
[17] J. Foster. A syntax improving program.Computer Journal, pages 31–34, 1968.16
[18] R. Graham. Bounded context translation. AFIPS Spring Joint Computer Conference 40,1964.15
[19] E. Irons. An error correcting parse algorithm.Communications of the ACM, pages669–673, 1973.16
[20] E. Iros. A syntax directed compiler for algol 60.Communications of the ACM, pages51–55, 1961.17
[21] J. Strong, J.Wegstein, A.Tritter, J.Olsztyn, O.Mock, and T.Steel. The problem of pro-graming communication with changin machines:a proposed solution.Communicationsof ACM, pages 12–18, 1958.14, 18
[22] J. Strong, J.Wegstein, A.Tritter, J.Olsztyn, O.Mock, and T.Steel. The problem of pro-graming communication with changin machines:a proposed solution.Communicationsof ACM, pages 9–15, 1958.14
[23] J.Backus, R.Beeber, S.Best, R. Golberg, L.Haibt, and H.Herrick. The fortran automaticcoding system.Westerm Joint Computer Conference., pages 29–47, 1957.14
[24] J.Early. An efficient context-free parsing algorithm.Communications of the ACM, pages94–102, 1970.15
[25] J.Johnson. Yacc - ye another compiler compiler.Computing Science Technical Report32, AT&T Bell Laboratories, Murray Hill, New Jersey, 1975.16
[26] D. Knuth. On the translation of languages from left to right.Information and Control,pages 607–639, 1965.16
[27] D. Knuth. Top-down syntx analysis.Acta Informática, pages 79–110, 1971.16
[28] M. Lesk. Lex - a lexical analyser generator.Computing Science Technical Report 39,AT&T Bell Laboratories, Murray Hill, New Jersey, pages 805–813, 1975.15
[29] N.Chomsky. Three models for the description of language.IRE Trans. On InformationTheory, pages 113–124, 1956.15
[30] P. Lewis, D. Rosenkratz, and R. Stearns. Attributed translations.Journal of computerand System Sciences, pages 279–307, 1974.17
[31] P.Ñaur. Revised report on the algorithmic language algol 60.Communications of theACM, pages 1–17, 1963.15
200

[32] P.Ñaur. Checking of operand types in algol compilers.BIT, pages 151–163, 1965.16
[33] José Jesús Castro Sanchez. Proyecto Docente e Investigador para el concurso al cuer-po de Profesores Titulares de la Universidad. Área: Lenguajes y Sistemas Informáti-cos(Escuela Superior de Informática). pages 114–124, 2003.12
[34] S.Kleene. Representation of events in nerve nets.Shannon y McCarthy, pages 3–40,1960.15
[35] R. Stearns. Deterministic top-down parsing.Proc. 5th Annual Priceton Conf. on Infor-mation Sciences and Systems, pages 182–188, 1971.16
[36] T. Anderson, J. Eve, and J. Horning. Efficient lr(1) parsers.Acta Informática, pages12–39, 1973.16
[37] T.Kasami. An efficient recognition and syntx analysis algorithm for context free lan-guage. AFCRL-65-758, Air Force Cambrige Research Laboratory, Bedford, Mass-chusetts, 1965.15
[38] T.Steel. A first version of uncol. InWesterm Joint Computer Conference., pages 371–378, 1961.14, 18
[39] W. McKeeman, J. Horning, and D. Wortman.A Compiler Generator. Prentice-Hall,1970.15
[40] B. Wegbreit. The treatment of data types in el1.Communications of the ACM, pages251–264, 1974.16
[41] W.Johnson, J.Porter, S.Ackley, and D.Ross. Automatic generation of efficient lexicalprocessors using finite state techniques.Comunications of ACM, pages 805–813, 1968.15
[42] D. Wood. The teory of left factored languages.Computer Journal, pages 349–356,1969.16
[43] J. Mauney y C. Fisher. A forward move algorithm for ll and lr parsers.ACM SIGPLANNotices, pages 79–87, 1982.16
[44] R. Brooker y D. Morris. A general translation program for pharse structure languages.Journal ACM, pages 1–10, 1962.17
[45] M. Rabin y D. Scott. Finite automata and their decision problems.IBM J. Research andDevelopmen, pages 114–125, 1959.15
[46] E.Soisalon-Soinimen y EUkkonen. A method for tranforming grammars into ll(k) form.Acta Informática, pages 339–369, 1979.16
[47] K. Samelson y F. Bauer. Sequential formula translation.Communications of the ACM,pages 76–83, 1970.17
201

[48] N.Wirth y H. Weber. Euler: a generalization of algol and its formal definition 1 parte.Communications of the ACM, pages 13–23, 1966.15
[49] R.McNaughton y H.Yamada. Regular expresions and state graphs for automata.IRETrans. On Electronic Computers, pages 38–47, 1960.15
[50] A. Aho y J.Ullman. A technique for speeding up lr(k) parsers.SIAM J.Computing,pages 106–127, 1973.16
[51] D. Rosenkratz y R. Stearns. Properties of deterministic top-down grammars.Informa-tion and Control, pages 226–256, 1970.15
[52] P. Lewis y R. Stearns. Syntax-directed transduction.Journal of the ACM, pages 465–488, 1968.15
[53] J. Ichbiah y S. Morse. A technique for generating almost optimal floyd-evans produc-tions for precedence grammars.Communications of the ACM, pages 501–508, 1970.15
[54] S. Graham y S. Rhodes. Practical syntactic error recovery.Communications of the ACM,pages 639–650, 1975.16
[55] A. Aho y T. Peterson. A minimun distance error-correcting parser for context-free lan-guages.SIAM J. Computing, pages 305–312, 1972.16
202