tutora prof. doctor sonia frutos - … · en el presente artículo de investigación se...
TRANSCRIPT

ARTICULO DE INVESTIGACION
PAUTAS DE UN MODELO PARA EL ANALISIS DEL TRAFICO HTTP TUTORA ........................PROF. DOCTOR SONIA FRUTOS
AUTORA..........................LILYAM PAOLINO C.I. 1 179 178-1
FECHA ............................. 2005-09-02 PLAN DOCTORAL UPM-ORT(Uruguay) SEGUNDO AÑO

1
INDICE DEL ARTICULO DE INVESTIGACIÓN INTRODUCCION 5 CAPITULO 1. Algunos problemas del tráfico WEB 7 1.1 Síntomas y causas de la problemática WEB 8
1.1.1 Bajas velocidades de conexión y de transmisión. 8 1.1.2 Ralentización del tiempo de descarga en los
nodos intermedios 10
1.1.3 Ancho de banda insuficiente 10 1.1.4 Variablidad en la carga de trabajo en la WEB 12 1.1.5 Tiempo de pensamiento 12 1.1.6 Tiempos en las conexiones 14 1.1.7 Impacto de los retardos en los protocolos 15 1.1.8 Fluctuación 16 1.1.9 Sobreescrituras en datagramas y buffers 17
1.1.10 Capacidad de los routers y cuellos de botellas 17 1.1.11 Congestionamientos 18 1.1.12 Errores de diseños 19 1.1.13 Multiplicidad de protocolos 20 Tabla 1. Síntesis de los principales problemas del Tráfico WEB
21 Conclusiones del capítulo 1 22

2
INDICE DEL ARTICULO DE INVESTIGACIÓN(Continuación) CAPITULO 2. Agentes y Sistemas multiagentes (MAS)
2.1 Concepto de agentes 23 Tabla 2. Síntesis de las principales características de los agentes 24
2.2 Sistemas multiagentes (MAS) 25 2.3 Porqué usar un sistema multiagente para analizar tráfico WEB 27
Tabla Nro. 3. Algunas características de agentes MAS
aplicables en el tráfico WEB. 32
Tabla Nro. 4 Beneficios para el tráfico WEB al usar Sistemas MAS 33
2.4 Características generales de los agentes a incorporar 34
Síntesis de las proposiciones planteadas en el punto 2.4 38 2.5 Interacción entre agentes según el modelo propuesto 39 2.6 Interacción entre agentes y entorno según el
modelo propuesto 41
2.7 Formas de organización de los agentes en el presente modelo 42 Síntesis del punto 2.7 45 2.8 Generalidades sobre la especificación de tareas de los agentes en el modelo propuesto 46 2.9 Síntesis del capítulo 2 47
CAPITULO 3.Pautas para la proposición de un modelo
3.1 Aplicación de las características MAS al sistema propuesto 48 Gráfico Nro 1. Simbolización de los 3 niveles de abstracción en el modelo propuesto 50 Tabla Nro. 5- Algunas áreas de abordaje al modelo 51 3.2 Fases para el diseño del modelo propuesto 52 Tabla Nro. 6- Características del modelo propuesto 54

3
INDICE DEL ARTICULO DE INVESTIGACIÓN(Continuación)
3.3 Arquitectura del primer nivel de abstracción del modelo 55 A) Subsistema de recepción de solicitudes 55 B) Subsistema de control de legitimidad y coherencia 56 C) Subsistema de gerenciamiento de agentes 57 D) Subsistema de búsquedas 58 E) Subsistema de generación de conocimientos 54 F) Subsistema de interacción entre agentes 58 G) Subsistema de interacción agentes-entorno 59 3.4 Arquitectura del segundo nivel de abstracción del modelo 59 A) Agentes de subsistema de recepción de solicitudes 61 B) Agentes de subsistema de control de legitimidad 62
y coherencia 63 C) Agentes de subsistema de gerenciamiento de agentes 63 D)Agentes de subsistema de búsquedas 63 E) Agentes de subsistema de generación de conocimientos 63 F) Agentes de subsistema de interacción entre agentes 64 G) Agentes de subsistema de interacción agentes-entorno 65
Tabla Nro. 6 – Características de los principales subsistemas del modelo 66
3.5 Arquitectura del tercer nivel de abstracción del modelo Especificación de interacciones entre subsistemas 67 Gráfico Nro. 2- Diseño general preliminar del modelo 67 Descripción del gráfico 68 Tabla Nro. 7- Sintesis de las interelaciones más importan- Tes del modelo 69
3.6. Algunos de los agentes más importantes que se incluirán 70 3.7 Síntesis de las proposiciones del capítulo 3 71
CAPITULO 4- Conclusiones finales del artículo 72
Referencias bibliográficas 74 Glosario de términos 80
Palabras claves 82

4
Indice de tablas Tabla Nro1-------------------------------------------------------------------------21 Síntomas y problemas del tráfico WEB Tabla Nro2 Características de los agentes del modelo..............................................24 Tabla Nro3 Algunas características de agentes MAS aplicables al modelo ........32 Tabla Nro4 Beneficios para el tráfico WEB al usar sistemas MAS .......................33 Tabla Nro5 Algunas áreas de abordaje preliminar en el modelo ..........................51 Tabla Nro6 Características generales del modelo propuesto ................................54 Tabla Nro. 7 Características de los principales subsistemas del modelo ...............69 Indice de gráficos Gráfico Nro. 1 Simbolización de los 3 niveles de abstracción en el modelo ...........50 Gráfico Nro. 2 Diseño general y preliminar del modelo propuesto........................ 67

5
JUSTIFCACION DE UN MODELO MULTIAGENTE PARA EL ANÁLISIS DEL TRAFICO WEB.
INTRODUCCION La llamada “autopista de la información”, la Internet o Red internacional de comunicación, está formada por conjunto de miles de miles de redes informáticas unidas entre sí, formadas por millones de computadoras funcionando a lo largo de todo el mundo. Esta característica de Internet de posibilitar las transmisiones de informaciones entre las redes integrantes, hace que se la pueda ver como un gran sistema abierto distribuido. El protocolo HTTP que regula el tráfico WEB, es un protocolo transaccional a nivel de aplicación, usado en sistemas de información hipermedia, distribuidos y colaborativos, cuyo objetivo central fue el de permitir la comunicación entre las redes, intercambiando documentos de diferente tipos. Si bien el objetivo principal de la Internet es el aumento de la disponibilidad de los recursos informáticos (documentos, software en general, etc.) para que pudiesen ser accedidos ilimitadamente a nivel mundial conectando entre sí diferentes redes, eso trajo una serie de consecuencias no siempre deseables, tales como la sobrecarga de tráfico en La Red y por consiguiente una degradación en el funcionamiento general de La Red. El mundo de la Internet es esencialmente dinámico y estando totalmente en expansión genera un tráfico en donde el manejo de la calidad en las transferencias se torna complejo de mantener. Eso trae una serie de consecuencias no deseadas para el tráfico WEB como las dificultades para las transferencias en tiempo y forma de la información enviada, la pérdida de información, etc. . Si bien esto es percibido por el usuario como una degradación en el funcionamiento de La Red, ya que se manifiesta a través de una serie de síntomas que se podrían sintetizar en la falta de concordancia entre los tiempos de respuesta esperados por los usuarios y los obtenidos en la realidad, los problemas del tráfico WEB tienen su explicación por una serie de causas, cuyo estudio se intentará analizar en el presente artículo. El aumento en la transmisión de archivos de gráficos, imágenes, videos con movimiento y aplicaciones multimedia , así como el aumento en la cantidad de usuarios que acceden a dichos servicios, representan exigencias cada vez mayores que justifican el análisis del tráfico WEB mediante un modelo. Buscando efectivizar el estudio de la problemática WEB, se propondrá en el presente artículo de investigación, la creación de un modelo basado en sistemas multiagentes, para estudiar en forma científica el funcionamiento del tráfico en Internet. En el presente Artículo de Investigación se justificará la necesidad de creación de un modelo basado en un Sistema Multiagente que posibilite el análisis del tráfico en la WEB, que permita la evaluación de la calidad de servicio, entendiendo como tal el rendimiento de extremo a extremo, el que debería estar garantizado siguiendo las niveles especificados en las políticas de calidad de servicio de los requerimientos de La Red y de sus usuarios. Para ello, en el primer capítulo se analizarán los principales problemas detectados en el tráfico WEB y se relacionarán las causas de dichos problemas con la visión que el usuario tiene de esos problemas, vistos a través de sus síntomas.

6
En el segundo capítulo se hará una introducción al concepto de Agentes y a las principales características de los Sistemas Multiagentes, y se justificará el porqué se piensa proponer un modelo basado en un sistema multiagente para el análisis del tráfico WEB, se analizará cuales son los aspectos de toda la teoría de agentes que pueden ser aplicables para el presente trabajo de investigación, se describirán los tipos de agentes que se incorporarán en el modelo propuesto, se describirán como interactuarán los agentes integrantes del sistema MAS entre sí y con el entorno. En el tercer capítulo se describirán las pautas que caracterizarán específicamente al sistema multiagente que se propondrá. Es el mismo se describirán aspectos generales del modelo propuesto, sus ventajas concretas, las eventuales debilidades que deberán ser atendidas, se desarrollará la arquitectura del modelo con sus diferentes niveles de abstracción, se describirán los diferentes subsistemas del sistema, se detallará la interacción entre ellos y se hará una descripción de los agentes más importantes que participarán en el modelo. En el cuarto capítulo se describirán las conclusiones generales del presente artículo, y se hará una referencia a posteriores etapas de investigación, de las cuales este artículo será la piedra inicial. La implementación concreta del modelo será objeto de posteriores etapas de la investigación. El trabajo consta, al final, de un glosario donde se especifica el contenido de las siglas usadas en el mismo y de un capítulo final que contiene la descripción de las palabras claves usadas en el presente artículo de investigación.

7
1) ALGUNOS PROBLEMAS DEL TRAFICO WEB Palabras claves : La Red, Routers, Buffers
Como objeto de la presente investigación, se tendrá en cuenta los enlaces y demás aspectos que componen y caracterizan a la Red de Redes, conectadas a través del protocolo Internet, por lo cual es llamada comúnmente Internet, de aquí en más llamada La Red. La fundamentación de llamarle La Red radica en que, si bien el modelo se estructurará pensando en las características de la red Internet y para el análisis del modelo se hará referencia a las características del tráfico HTTP, una vez estructurado el modelo, el mismo tendrá tal grado de independencia respecto a los protocolos y plataformas de las redes integrantes, que podrá aplicarse a cualquier tipo de red que implique interconexión de redes.
Pero dentro de La Red, se considerarán a los efectos del presente trabajo de investigación, aquellos enlaces que integran lo que Kurose y Ross, [ Kurose & Ross, 2004] , llaman el núcleo de la red, y que está integrado por la malla de routers que interconectan entre sí a los Sistemas Terminales de Internet.
Lo que el usuario final puede percibir, en general, es una falta de concordancia entre los tiempos de respuesta esperados y los reales. Esta situación se debe a una serie de problemas, algunos de los cuales, los que interesan para el estudio del presente trabajo de investigación, se analizan más detalladamente en el punto 1.1
Dentro de dichos problemas se puede diferenciar a aquellos que son fácilmente detectables por los usuarios, los cuales son, en general, la cara visible de la problemática de fondo, son sus síntomas, de las causas reales que conducen inexorablemente a dichos síntomas.
Entre los síntomas del problema de fondo se encuentra la pérdida de información, la ralentización de los tiempos de descarga en función muchas veces del tipo de solicitud efectuada y del tipo de información a transmitir, los a veces inaceptables tiempo de pensamiento que La Red ocupa en procesar las tareas requeridas, y la fluctuación del tráfico que incide en el diferente comportamiento de los puntos antes mencionados, en función del día u hora de conexión.
Las causas más importantes que conducen a dicha problemática, pueden enmarcarse en factores estrictamente físicos de la red, o a factores estrictamente lógicos o, más comúnmente factores donde confluyen ambos componentes, formando un híbrido que muchas veces es complejo de desentrañar.
Dentro de las causas físicas más importantes se encuentran las bajas velocidades de conexión y de transmisión, el ancho de banda insuficiente para el tipo de transmisión requerida, la forma en que arriban los paquetes de solicitudes a La Red, las características físicas de los dispositivos ( en especial la de los routers, por ser estos los

8
dispositivos más importante en todo este proceso de interconexión de redes, las velocidades de acceso a las interfases de los mismos, etc).
Dentro de las causas lógicas principales que inciden en toda esta problemática, están los problemas de diseño de La Red, el amplio espectro de protocolos que funcionan la mayoría de las veces embebidos o cooperativamente provocando una gran sobrecarga en el tráfico que circula por La Red. Dichas causas serán estudiadas en detalle en el punto 1.1 En el análisis de los problemas del tráfico WEB, se tratarán aquellos temas que podrían ser objetos de aplicación de un Sistema Multiagente.
La Internet pública es una red que interconecta millones de dispositivos de cómputos a nivel mundial.(PCs, servidores que transfieren información y mensajes, dispositivos no tradicionales, etc.), ubicados en los extremos de La Red, por lo cual reciben el nombre de Sistemas Terminales. Quedan, por lo tanto, por fuera del presente estudio, todo lo referente a los Sistemas Terminales, o sea aquellos aspectos que se ubican en el ámbito exclusivamente usuario.
1.1 SINTOMAS Y CAUSAS DE LA PROBLEMÁTICA WEB.
1.1.1 Bajas velocidades de conexión y de transmisión.
Pueden influir muchos elementos para que las velocidades de conexión a La Red y la transmisión de tráfico dentro de ella sean lentas. Por ejemplo, a nivel físico puede deberse a ruidos, interferencias, según la hora de conexión o de tráfico, la calidad del o de los enlaces estipulados, etc. Si bien las características de los enlaces se determinan fundamentalmente en el ámbito físico, también pueden incidir en ello especificaciones lógicas, por ejemplo el grado de calidad exigido para el enlace configurado por el servicio de Control de Enlace Lógico , el LLC, del protocolo PPP, o los diferente niveles de estabilidad y confiabilidad de la ruta de datos, el mal uso de los protocolos estipulados, etc. Según lo fundamenta William Stallings [ Stallings, 2004], habiendo llegado a una categorización de la carga esperada en la red, se puede llegar a determinar las velocidades de transmisión y el tamaño necesario de los buffers de los dispositivos.
Un canal de Entrada-Salida, está definido por Stallings como aquel medio que permite la transferencia de datos entre la memoria temporal de un dispositivo origen y una memoria temporal del dispositivo destino, limitándose sólo a desplazar los contenidos de usuario desde un dispositivo a otro, sin tener en cuenta el formato o significado de los datos. De modo que, a este nivel, los canales sólo gestionan las transferencias, proporcionando control de flujo y detección y recuperación de errores mínimos y los estrictamente necesarios para que pueda efectuarse la transferencia. La interconexión entre las redes, en la WEB, a nivel de los enlaces, está planteada por los diseñadores para combinar las velocidades de las comunicaciones del canal con la flexibilidad y la interconectividad que caracterizan a las comunicaciones de redes basadas en los protocolos.

9
Para ello, según Stallings, es necesario que los enlaces tengan en cuenta una serie de factores, como la multiplexión completa de tráfico entre múltiples destinos, la posibilidad de interconexión con otras tecnologías, los soportes para cubrir grandes distancias, el empleo de alta capacidad, independientemente de la distancia, la amplia disponibilidad de los enlaces, el soporte para múltiples niveles de costo/rendimiento, los protocolos de transmisión adecuados, etc.
El núcleo de la red, según Kurose y Ross [ Kurose & Ross, 2004] puede construirse sobre la base de conmutación de circuitos o conmutación de paquetes. La diferencia fundamental entre ambos es que en la conmutación de circuitos, los recursos que se necesitan a lo largo del recorrido para lograr la comunicación entre los sistemas terminales, están reservados para la sesión de la comunicación, mientras ella tenga lugar. En cambio, en la comunicación de paquetes, no hay recursos reservados, sino que en la sesión se usan los recursos bajo demanda, y por lo tanto, puede suceder que los paquetes tengan que esperar, o sea encolarse, para poder acceder a los recursos del enlace de comunicación. Puede suceder, que en algunas comunicaciones, aunque una conexión haga una reserva, se deba de tener que esperar por los recursos congestionados. En dichas situaciones puede haber ambos tipos de conmutaciones que estén trabajando conjuntamente. Un circuito es un enlace implementado con multiplexado por división de frecuencia (FDM) o con multiplexado por división de tiempo (TDM), en donde el espectro de frecuencia o el tiempo disponible para transmitir los datos está compartido por las conexiones establecidas a lo largo del enlace. Las ventajas que argumentan los defensores de las conmutaciones de paquetes son que ofrecen un ancho de banda mejor que la conmutación de circuitos, que es más sencilla, más eficiente y menos costosa. Los contrarios a la conmutación de paquetes, en cambio, argumentan que la misma no es adecuada para servicios en tiempo real, debido a sus retardos variables e impredecibles. En la conmutación de paquetes, cada router tiene un buffer de salida (o cola de salida), donde el router almacena los paquetes que se van a enviar hacia otro enlace. Este buffer es fundamental en la conmutación de paquetes, pues si un paquete a ser transmitido hacia el enlace encuentra dicho enlace ocupado, el paquete debe esperar en el buffer de salida. Por lo tanto, además de los retardos de almacenar y reenviar, los paquetes sufren retardos de cola en el buffer de salida. Puesto que la cantidad de espacio del buffer es finito, un paquete que llega puede encontrarse con que el buffer está completamente lleno con otros paquetes que esperan para ser transmitidos.. En este caso puede ocurrir la pérdida de paquetes, algunos de los paquetes que llegan, o uno de los paquetes ya encolados, pueden ser abandonados por falta de disponibilidad de recursos para poder ser atendidos. Existen, además, factores físicos que inciden aumentando los problemas. Según lo expresado en Teleinformática [ Teleinformática, Nro. 4 ] los factores que, a nivel físico, limitan la capacidad de transmisión son la potencia de la señal y el ruido en el conductor.

10
Al aumentar la potencia, aumenta la capacidad de la línea y posibilita una mayor propagación de la señal, sin embargo, una potencia excesiva puede destruir algún componente del sistema. El medio de transmisión define el máximo de ancho de banda que se dispone para la comunicación, por lo que la elección del medio depende de la velocidad o cantidad de señal que se quiera transmitir. El ruido en la línea es un problema que no se puede eliminar, y se origina por el movimiento constante aleatorio de los electrones en el conductor y fija un límite a la capacidad del canal. La resistencia al ruido depende fundamentalmente del medio de transmisión. La potencia al ruido es proporcional al ancho de banda, por ello un incremento del ancho de banda origina un incremento del ruido. Para reducir el ruido se usa una técnica electrónica llamada filtrado. 1.1.2 Ralentización del tiempo de descarga en los nodos intermedios
Dependiendo de una serie de factores, como por ejemplo el volumen y tipo de información a transmitir ( voz, imagen, texto, etc.), el tamaño de la ventana de recepción, (o sea la cantidad de datos que pueden recibir los nodos intermedios hasta llegar a un destino), el tamaño de los paquetes IP, el tamaño de la MTU ( ella debe de ser lo más grande posible, pero tratando de evitar, en lo posible, la fragmentación de los paquetes en la red), etc. todo ello puede provocar la posibilidad de perder paquetes por sobrecarga de datos de los buffers de dichos nodos intermedios. La existencia de grandes volúmenes y diferentes tipos de información a transmitir, implica que puede haber diferentes protocolos trabajando, y por lo tanto mandando a la red diferentes tramas o paquetes, los cuales muchas veces viajen embebidos y exige a los nodos intermedios la necesidad de interpretar dichos paquetes. 1.1.3 Ancho de banda insuficiente Si bien no hay definiciones unánimes sobre ancho de banda, para los electrónicos es la banda de frecuencias que se pueden transmitir por la línea de comunicación sin que se produzca atenuación. [ATV Informática] . El punto 1.1.2 está íntimamente relacionado con el presente punto, ya que para los informáticos el concepto de ancho de banda está relacionado con la cantidad de información a transmitir o a recibir por unidades de tiempo. [Cisco, 2004]-
La capacidad de comunicación entre 2 puntos depende del ancho de banda entre ambos. El ancho de banda es directamente proporcional a la cantidad de datos transmitidos o recibidos por unidad de tiempo. En sentido cualitativo es proporcional a la complejidad de los datos para un nivel dado de rendimiento de un sistema. En los sistemas digitales, el ancho de banda es la velocidad de datos medidos en bps. ( bits por segundos). En la WEB el ancho de banda se asimila al diámetro de una tubería que sirve para canalizar el flujo de datos, es la capacidad de una línea para transmitir información, en la cual compiten muchos paquetes. Pero la línea está compartida frecuentemente para transmitir información, por lo tanto está en relación con la cantidad de usuarios que

11
comparten esa línea en un momento dado, por lo que hay que evaluar la cantidad de conexiones simultáneas que puedan existir en un momento dado.
Para los electrónicos, el ancho de banda de una línea es la banda de frecuencias que se pueden transmitir por la línea de comunicación. Cuanto mayor sea el ancho de banda, mejor es la transmisión de datos. En las redes de banda base, la señal se transmite sin modulación. Por lo tanto cada vez que se realiza una transmisión, se usa todo el ancho de banda del medio.
Según Cisco [Cisco, 2004], el ancho de banda es la medición de la cantidad de información que puede fluir desde un lugar hacia otro en un período de tiempo determinado. La unidad de transferencia de información es el bit por segundo, para lograr una compatibilización con redes viejas. Existen dos usos comunes del término ancho de banda: uno se centra en el estudio de las señales analógicas y otro en las digitales. Al ser el ancho de banda la capacidad de una línea para transmitir información, hay que considerar que, en los hechos, la línea está generalmente compartida por muchos usuarios. Por lo tanto sirve poco saber el ancho de banda que tiene un proveedor, si no se sabe cuantos usuarios comparten esa línea en un momento determinado. Hay pequeños proveedores con pocos clientes que usan una línea estrecha, a pesar de lo cual pueden ofrecer mejores tiempos de acceso que otros proveedores con canales más potentes, porque éstos tienen demasiados usuarios compartiendo la línea. Por lo tanto, al ser el ancho de banda la máxima velocidad de transferencia de datos entre dos extremos de la red, el límite no solo lo impone la infraestructura de los enlaces, (esta sería la cota superior), sino también los flujos procedentes de otros nodos origen-destino, que comparten algunos de los enlaces de la ruta en cuestión. Por consiguiente, el ancho disponible está en función del número de conexiones simultáneas que el proveedor tiene en cada momento determinado. Nicholas Negroponte, [Negroponte N, 1995], plantea que el ancho de banda es como una telesilla a la cual muchos paquetes quieren subirse, y compiten para ello, formándose largas colas de acceso a la misma. Además hay paquetes que son “perezosos” y tardan mucho tiempo para subirse a la tesesilla, otros lo son poco inteligentes, o tontos, y permiten a otros paquetes saltarse la cola. Por ejemplo, para ir desde California a Salamanca, hay que hacer cola en más de 6 telesillas. Según la Asociación de Usuarios de Internet [Asociación de Usuarios de Internet ], el acceso a los backbones de tránsito en La Red, debe de garantizar el ancho de banda contratado, sin colisionar con otros clientes de tránsito. Esto significa que la suma de las capacidades de los enlaces de acceso en cada punto de enganche, debe ser igual o inferior a la suma de las capacidades salientes hacia el backbone . Esto está en relación con la forma de evitar la congestión, para lo que cual hay que plantearse la capacidad de los troncales con suficiente anticipación, monitoreando su uso en forma permanente. Por ejemplo, si el tráfico aumentase por encima de un cierto umbral, durante cierto tiempo puede ser un síntoma de que la demanda está por encima de la capacidad disponible. Como solución, ello puede indicar que sería necesario aumentar el ancho de banda o poner nuevos enlaces.

12
A pesar de que el ancho de banda de Internet y la capacidad de los servidores de Web se han visto ampliados sensiblemente, en los últimos años, los problemas de performance de los sitios Web continúan siendo unos de los puntos de atención para los desarrolladores y equipos de prueba. Esta situación se agrava más aún si se toma en cuenta la diversidad de las aplicaciones que corren o que se usan en la WEB, así como de las características tan cambiables del tráfico en dichos sitios. El ancho de banda que los paquetes de un sitio Web están utilizando al ser transportados de una red a otra, puede tener un impacto significativo sobre el diseño general, la implementación y el testeo del tráfico WEB. El acceso al backbone de tránsito debe de garantizar el ancho de banda contratado, sin colisionar con otros clientes de tránsito. Esto significa que la suma de las capacidades de los enlaces de acceso en cada punto de enganche, debe de ser igual o inferior a la suma de las capacidades salientes hacia el backbone.
1.1.4 Variabilidad de la carga de trabajo en la WEB
Según Hung Nguyen ,[Hung Nguyen, 1999-2005] las características de los procesos
son una de las principales temas a considerar en el tráfico WEB. Muchas transacciones ocurren más frecuentemente que otras. La performance de un sistema distribuido con muchas redes, y muchos clientes, depende en gran parte, de las características de la carga de trabajo, tal como lo fundamentan Menacé y Almeida [Menacé & Almeida, 1998]. Dichos autores definen la carga de trabajo de un sistema como el conjunto de entradas que el sistema recibe de su entorno durante un período dado de tiempo. La carga de trabajo real puede verse, según dichos autores, como un conjunto de componentes heterogéneos, por lo cual, dicha carga de trabajo puede ser analizada a través de particiones. Esta técnica de particionar la carga de trabajo, puede efectuarse dividiendo sus componentes en una serie de clases, las que conservan, no obstante, algunos componentes homogéneos y comunes a todas. El tráfico en la WEB es esencialmente dinámico, impredecible y distribuido. La responsabilidad en la causa por las demoras en estos tipos de tráfico es , frecuentemente, imposible de determinar, al ser muy variables las características de las cargas de trabajo.
1.1.5 Tiempo de pensamiento
Según lo especifican Menascé y Almeida [Menascé & Almeida, 1998], los servicios WEB proveen accesos a documentos, imágenes, sonidos, ejecutables y a otras aplicaciones que pueden ser bajadas de La Red ( por ejemplo de aplicaciones Java), a través del protocolo HTTP ( Hyper Transfer Protocol). El tiempo de pensamiento, generalmente, es considerado como el tiempo tomado desde que un cliente ( proceso que solicita un servicio WEB) recibe el último paquete para la página Web que esta viendo actualmente hasta el momento que ese cliente solicite una nueva página. Los componentes básicos de la carga de trabajo, en entornos WEB, según los autores anteriormente referidos, están en relación a la cantidad de procesos ejecutados

13
simultáneamente, al tiempo de llegada y a la cantidad de clientes que soliciten los servicios. Dado que el objetivo del presente artículo es el de plantear un modelo para la detección de los grandes problemas en el tráfico HTTP, es recomendable recordar los pasos a seguir en ese tráfico, siguiendo las pautas generales establecidas por dicho protocolo y por los protocolos de transporte y de intered involucrados en las comunicaciones. En un entorno HTTP, a partir de la versión 3.0, los agentes usuarios allí involucrados quedaron facultados a “puxar”, o introducir los mensajes al servidor, y el servidor a atenderlos. Cada vez que un cliente realiza una petición al servidor HTTP, se ejecutan una serie de pasos, que se pueden sintetizar así : A)Un usuario accede a una URL B)El cliente WEB decodifica la URL, separando sus partes. C) Se abre una conexión TCP/IP con el servidor, llamando al puerto TCP pertinente D) Se realiza la petición, enviando el comando pertinente (GET, POST, HEAD, etc.) E) El servidor devuelve la respuesta al cliente F) Se cierra la conexión TCP. Cada transacción HTTP es una comunicación distinta, conteniendo diferentes comandos y opciones del protocolo, siendo los mensajes las unidades básicas de comunicación HTTP formadas por una secuencia estructurada de octetos ordenados con formato válido y transmitidos por la conexión. Este proceso implica la necesidad de un gran tráfico circundante por La Red, ya que se repite en cada acceso al servidor HTTP. Según López Franco [López Franco, 2001], el proceso de conexión HTTP es, por lo tanto, lento y costoso, y contribuye a aumentar la saturación interna de La Red. Hubieron en la actualidad algunas mejoras introducidas a esta forma de trabajo, lo cual si bien fue un avance , no solucionó los problemas de fondo vistos en el punto 1, fundamentalmente el del enlentecimiento. Una de esas mejoras fue la de permitir que una misma conexión se mantenga activa un cierto período de tiempo, para poder ser usada en conexiones posteriores En este punto cobra importancia el concepto de latencia de los dispositivos. La latencia, según el Diccionario Informático mundo del PC significa “retraso” o “delay” en inglés y expresa el tiempo que tarda un paquete de datos en salir de un punto de la red y llegar a otro. Pero a ese tiempo de transferencia en necesario sumarle el tiempo de latencia de los dispositivos, que implica el tiempo que demora el dispositivo en realizar las tareas que le son específicas. Las situaciones se complican cuando algún emisor rápido envía más paquetes que lo que un receptor más lento pueda recibir y procesar. Es por ello que se usan los buffers y los cachés, para almacenar esos datos que no pueden ser procesados en el momento

14
1.1.6 Tiempos en las comunicaciones Aún cuando el número de usuarios permanezca constante, las peticiones de red , en general, no llegan espaciadas, sino que llegan en masa, en ráfagas largas que pueden producir una alta tasa de transferencia en un poco tiempo, saturando La Red. Y esto es, según Kurose y Ross [Kurose y Ross, 2004] debido a los tipos de retardo experimentados en las redes de conmutación de paquetes. Los autores plantean que en las redes de conmutación de paquetes, los retardos que se deben de considerar son de diferentes tipos, a saber : el retardo de procesamiento nodal, el retardo de cola, el retardo de transmisión y el retardo de propagación. El retardo de procesamiento es el tiempo que le insume al router el analizar la cabecera del paquete para poder decidir hacia donde lo va a enviar. El retardo de cola es el tiempo que espera el paquete para ser transmitido en el enlace. Este tiempo de demora está en función de la cantidad de paquetes que estén esperando para ser enviados. El retardo de transmisión en un router, o llamado también retardo de almacenar y reenviar, es la cantidad de tiempo requerido para introducir todos los bits del paquete en el enlace. El retardo de propagación es el tiempo que demora en propagarse los paquetes entre los routers que integran el enlace, estando determinado por la velocidad de propagación del enlace. Por lo tanto el tiempo total que lleva desde que los paquetes se almacenan delante de un router hasta que se almacenen frente al siguiente, es la suma del retardo de transmisión y el retardo de propagación. Los primeros bits de un paquete pueden llegar a un router, mientras que los restantes bits pueden estar esperando a ser transmitidos por el router siguiente. El tiempo de retardo nodal es la suma del retardo de procesamiento + el retardo de cola + el retardo de transmisión + el retardo de propagación. Los retardos de transmisión pueden ser significativos en La Red. El retardo de cola depende de la cantidad de paquetes que se hayan instalado frente al router en espera a ser enviados, siendo totalmente diferente en un momento u otro. El retardo de cola depende, en gran medida, de la tasa a la que llegue el tráfico a la cola, de la velocidad de transmisión del enlace y del tipo de tráfico que llegue Si la velocidad media a la que los bits llegan a la cola supera la velocidad a la que pueden ser transmitidos, la cola tenderá a aumentar ilimitadamente, y el retardo de cola se aproximará al infinito. Otro factor que influye en el tiempo de retardo de cola es como vienen los paquetes. Si ellos vienen periódicamente y en forma espaciada o sea habiendo transcurridos espacios de tiempos entre ellos, cada paquete encontrará la cola vacía. En cambio, si ellos llegan periódicamente, pero en masa, el retardo de cola puede aumentar significativamente.

15
Si la tasa de llegada excede la capacidad de transmisión, se acumulan los paquetes de llegada y por consiguiente las colas, aumentando rápidamente el retardo de cola. Cualquier evento que produjera un aumento en la intensidad del tráfico de paquetes, producirá un aumento porcentual mucho más grande en el retardo. La intensidad de tráfico, por lo tanto, no debe nunca ser mayor que uno. El modelado del tráfico, en la WEB , implica que el emisor controle la forma en que se realiza la transmisión de los datos, ajustándolo a determinada tasa promedio, de forma tal que la red pueda soportar dicho tráfico sin problemas. Las velocidades de acceso a las interfases de los routers, si bien este aspecto estuvo mencionado en el punto anterior, debido a la importancia que tiene en el tráfico HTTP, es necesario detallarlo más profundamente y merece ser objeto de atención especial. Los routers que interconectan las distintas redes dentro de La Red, pueden manejar una cantidad limitada de tráfico IP. Se entiende por velocidad, aquí, la cantidad de datos que pueden moverse desde un origen a un destino. Si bien la velocidad de un backbone puede ir desde 622 Mbps a 50.2 Gbps o más, debido a que las rutas pueden ser largas y complejas se debe de tener en cuenta además, los tiempos de latencia. La latencia es el tiempo que le toma un paquete para llegar a su destino. La latencia puede incrementar cuando los routers se sobrecargan. Entonces puede pasar que la velocidad del tráfico que llega sea mayor que la velocidad de salida del router. [RFC 2729, diciembre 1999 ] Por lo tanto, siempre se debe confrontar la velocidad especificada teóricamente de los componentes con la latencia real. 1.1.7 Impacto de los retardos en los protocolos. Por lo tanto, cuando mayor sea el tiempo que tarda un paquete para llegar desde un origen a un destino, mayor será el esfuerzo del protocolo de transporte TCP para funcionar eficazmente, pues la red tendrá que soportar más datos en tránsito, lo que afectará, además a todos los componentes asociados con el protocolo ( por ejemplo los contadores , temporizadores, etc.) El protocolo TCP ajusta dinámicamente la velocidad de envío al flujo de información realimentada desde el receptor, usando para ello las notificaciones ACK ( tramas que implican la confirmación del éxito de la llegada correcta de los paquetes a su destino final). Al crecer el retardo emisor-receptor, este control de flujo se va volviendo cada vez más insensible a los cambios dinámicos en la carga de la red. En aquellas transmisiones que, por naturaleza, no admitan otro tipo que las de tiempo real, tales como las basadas en UDP, por ejemplo las transmisiones de voz y de video, el aumento del retardo hace que la respuesta de la red sea tan pobre que prácticamente la transmisión resulte sin sentido.[Tanenbaum. Redes de Computadoras, 1997]

16
Por lo tanto, el servicio de tránsito debe de proporcionar datos sobre el retardo extremo a extremo y entre cualquiera de los nodos del backbone. [ Control de congestión] 1.1.8. Fluctuación Para complicar aún más las situaciones reales, la tasa de retardos en La Red, no siempre son permanentes, sino que suelen variar entre los extremos. A tal variación se le llama fluctuación. La fluctuación , según lo expresa Black [Black U, 1997], mide la regularidad del arribo de los paquetes al host de destino. Es un factor que, en la WEB, es dependiente del tipo de aplicación a transmitir. Por ejemplo, el video y el audio a demanda requieren fluctuaciones bajas porque cualquier aumento en el nivel de la misma produce una interrupción considerable en ella. En cambio, para el acceso a otras aplicaciones WEB, las exigencias de fluctuación no son tan estrictas. Los aumentos de las fluctuaciones provocan que el protocolo TCP pueda hacer estimaciones que no sean totalmente reales sobre el tiempo de ida y de vuelta, llamado RTT ( RTT, round tip time). Esto traería como consecuencia la falta de eficacia para reestablecer el flujo de datos si se superaran los umbrales de tiempos preestablecidos ( timeouts). Cuando las aplicaciones deban de hacerse en tiempo real, dichas fluctuaciones provocan una señal distorsionada, lo que afectaría mayoritariamente a algún tipo de señales, como las que exigen sesiones interactivas ( por ejemplo las audio/video, etc.) El aumento de las fluctuaciones puede, además, estar provocado por las características del tráfico en La Red, ya que los flujos de los paquetes de extremo a extremo pueden tomar rutas divergentes. Una medida que puede disminuir notablemente la fluctuación, aunque trae un considerable aumento del retardo, es el almacenamiento en el buffer del receptor de los datos recibidos antes que sean interpretados por la aplicación, siendo ésta una de las técnicas de control de tráfico en la WEB. Este buffer de envío entre el transmisor y la red, deja pasar en determinado tiempo solo una cantidad de paquetes hace la red, y una vez lleno, cualquier paquete que llegue será descartado. El objetivo de esto es crear un flujo constante y uniforme a La Red, tratando de evitar los congestionamientos. Los buffers de los routers juegan un papel fundamental en la gestión del tráfico ya que en ellos se colocan los paquetes luego de haber sido examinados para poder salir por la interfase seleccionada en el momento en que ella esté disponible. Si el buffer del router está lleno, frente a la imposibilidad de ubicación de los paquetes, ellos son descartados. Por lo tanto, una buena medida en la gestión del tráfico, sería reservar parte de estos buffers para tenerlos disponibles al momento en que el flujo los necesite.

17
1.1.9. Sobreescrituras de datagramas (overlapping) y de buffers (buffer-overrun) Se trata de un ataque que consiste en falsear los datos de posición y/o longitud de forma que el datagrama se sobrescriba (overlapping) y produzca un error de sobre escritura del buffer (buffer-overrun) al tratar con desplazamientos negativos. Esta forma de ataque es lo que Kurose y Ross [Kurose & Ross,2004 ], le llaman la denegación de servicios, provocando que un componente importantísimo de la red como los routers, no puedan ser utilizados por sus legítimos usuarios, muchas veces incrementando excesivamente la carga de la infraestructura atacada y provocando así que no pueda cumplir con sus tareas específicas. Una forma de producir esto es inundando con paquetes SYNC , a través de la falsificación de direcciones IP , que son atendidas al no tener forma los servidores de poder controlar y diferenciar las peticiones verdaderas de las falsas. El tercer paso de las comunicaciones TCP nunca se cumplen, y entonces, quedan conexiones parcialmente abiertas. Un ejemplo de posibles efectos no deseados en las comunicaciones WEB son las ventanas o páginas emergentes, las que son generalmente de menor tamaño y se levantan sobre las otras posibles ventanas abiertas cuando se accede a un link, o por algún estímulo automático. Pueden ser deseadas por el servicio que prestan ( por ejemplo para publicidad de fotos), pero no siempre lo son, y ahí deviene el problema.
1.1.10 Capacidad de los routers y cuellos de botellas.
La mala administración del caché por ejemplo, aporta gran parte de los cuellos de botella en la red. Estos cuellos de botella son el resultado de configuraciones de servidores defectuosas o recursos escasos de memoria. Esta ultima situación indica que los sistemas necesitan más capacidad de memoria, la razón pro la cual muchas veces las aplicaciones se ven forzadas a ir a disco (swap). En este caso la respuesta es mucho más lenta, (para tener una idea del problema, el promedio del acceso a memoria es de 3 nanosegundos, mientras que en el disco es de 17 milisegundos). Un ejemplo de este inconveniente es el combinar las utilidades de un sitio Web y las aplicaciones de un servidor en una misma CPU, esto pueden disminuir rápidamente los recursos del servidor, haciéndolo mas lento, ineficaz y hasta colapsar. El router es una de las herramientas para protegernos de los Cuellos de botella por congestionamiento de datos, y lograr un buen flujo de la información por la WEB. La necesidad de gestionar miles de conexiones de abonados y de enviar datos a estos hacia y desde la Internet u otros servicios obliga hoy en día, a contar con este tipo de herramientas de descongestionamiento.
Mientras los proveedores de servicio han estado utilizando routers tradicionales para proveer estas funciones, estos equipos no han sido diseñados para gestionar miles de abonados. Los routers pueden ser muy útiles, pero sin una buena configuración de sus servicios y una mala diagramación de las necesidades que ellos tendrán que afrontar, este tipo de problemas se acrecentarán.

18
Los ciclos de CPU de los routers son recursos fundamentales para evitar que el ruteador se sobrecargue en el momento de procesar un paquete. 1.1.11 Congestionamientos Los congestionamientos se dan cuando la carga ofrecida por cualquier red es mayor que lo que la red puede manejar. Está relacionada con el tráfico y con los distintos caminos que el mismo puede recorrer en la red. Estas situaciones se producen cuando cada paquete que se envía a la red experimenta un retardo excesivo debido a que ésta se encuentra sobrecargada por paquetes.[Stallings, 2004] Algunas de las causas desencadenantes de las congestiones son : Un ajuste demasiado grande del TTL (tiempo de vida útil de los paquetes), puede provocar que los paquetes se almacenen haciendo loops durante demasiado tiempo, causando fallas del servicio. El efecto de esto es que un sitio muy distante puede ser inalcanzable, mientras que otro cercano puede ser accesible. Otra causa de los congestionamientos es la memoria insuficiente de los conmutadores, lo que provoca el saturamiento de los buffers. Si, por ejemplo, llegasen cadenas de paquetes por diferentes líneas de entrada a los routers y si esos paquetes necesitasen la misma línea de salida, se generará una cola de paquetes. Si no hubiese suficiente memoria en los dispositivos para contenerlos a todos, se perderán paquetes. Esto puede provocar que se llene el buffer de la línea de salida del router. Esta situación de agravaría si hubiese congestión en otros nodos, ya que las colas no liberarían la información de los paquetes transmitidos, información ésta que es esencial para los casos en que hay necesidad de retransmitir paquetes. Otra causa es la existencia de líneas que garantizan poco ancho de banda situación analizada, en el punto 1.1.3 El aumentar la memoria a los routers, ayuda a solucionar el problema de salida por una misma línea de N paquetes que esperan ser enviados por el enlace. Sin embargo, según describiera Nagle en 1987, el aumentar indefinidamente la memoria de los routers, no soluciona el problema, sino que lo empeora, pues las colas que se generan en el router serían muy grandes y los tiempos de espera para mensajes del final de la cola caducarían y entonces los emisores enviarían duplicados que provocarían un aumento en las colas de espera. Este proceso se repetiría para cada router desde el origen al receptor.[Tanenbaum A, 2003] Otra causa de problemas es el contar con CPU de enrutadores lentos. Si el enrutador no puede procesar los paquetes que le llegan a través de otro enrutador que es más rápido, el lento no podrá procesar en tiempo y forma todos los paquetes que le llegan. Esta situación provocará que se saturen las colas, ya que el enrutador no podrá cumplir con las tareas de administración que sus funciones le exige, tales como actualizar sus buffers de encolamientos, actualización de sus tablas de enrutamientos, etc. Todo esto puede provocar que se alarguen las colas, aún cuando existan capacidad suficiente en las líneas.

19
El problema mayor que presentan los congestionamiento, es que estas situaciones tienden a retroalimentarse, ya que si un enrutador no tiene buffers libres, debe de ignorar los paquetes recibidos, y a su vez, el enrutador que transmitió debe de finalizar su temporización y retransmitirlo, con lo cual se está acumulando el congestionamiento. Los mecanismos de control de congestión tienen dos grandes vertientes de solución: las de ciclo abierto o estáticas y de ciclo cerrado o dinámicas. Las estáticas o de ciclo abierto intentan resolver los problemas de congestionamientos, a través de un buen diseño de red, que asegure que no ocurra nunca un congestionamiento en La Red. Las variables que el diseñador debería de tener en cuenta al momento de diseñar la red para evitar la existencia de congestionamientos serían, entre otras: las decisiones de cuando aceptar tráfico nuevo, cuando descartar paquetes. Estas decisiones son independientes de la evaluación de los estados de la red al momento de tomar dichas decisiones. Las estrategias dinámicas, en cambio, funcionan al momento de que se detecten problemas . Ello se puede lograr monitoreando la red, por ejemplo, detectando los porcentajes de los paquetes descartados a causa de incapacidad en los espacios de los buffers de los routers, el tiempo promedio de retardo de los paquetes, las desviaciones estándares de los paquetes. En todos los casos un aumento de estas cifras estarían indicando un aumento en los congestionamientos. El envío de la información de congestión por parte del router al nodo origen del tráfico implica una mayor carga en la línea, lo que a veces se subsana indicando en los paquetes algún campo extra que indique el estado del monitoreo, para que los nodos modifiquen el enrutado de sus paquetes y así eviten congestiones mayores. Otra posibilidad es hacer que los enrutadores envíen periódicamente paquetes de prueba preguntando sobre la existencia de congestionamiento. En dichas situaciones, los routers que reciben dicha información, harán alguna acción de control de congestión, como enviar los paquetes por rutas alteras, y así aliviar las rutas congestionadas, pero se estaría aumentando el tráfico en La Red con estos paquetes de control. 1.1.12- Errores de diseños Según UTN- FRSF , [ UTN- FRSF], la selección de la tecnología es quizás la primera decisión importante que se debe tomar en la fase de diseño de un nuevo servicio. Una errónea selección de plataformas o una mala implementación de las mismas, considerando como partes los sistemas de ejecución de las aplicaciones y los sistemas de bases de datos, junto con un mal diseño de los elementos que intervienen en el servicio y la interacción entre los mismos, provocan que dichos componentes no den el servicio de forma correcta. Tal como está planteado hoy el tráfico en al WEB, esto condiciona muchas de las decisiones futuras que se deben de tomar para solucionar problemas que se ocasionaran debido a estos malos acoples de plataformas, y hasta en ocasiones retrasa el buen funcionamiento del servicio al tener que pensar en los problemas que ocasionó una mala elección de las tecnologías. De modo que al momento actual, a pesar de que se intenta llevar adelante diseños independientes de las plataformas, en la práctica esto no es totalmente aplicable

20
1.1.13 Multiplicidad de protocolos La configuración de diferentes protocolos y el grado de compatibilidad entre ellos puede afectar seriamente la performance de la red. Por ejemplo, si se analizan algunos de estos protocolos, se concluirá de que cuanto más protocolos trabajen embebidos, peor será la performance de la red. Entre estos protocolos, están el IP, el HDLC y el PPP, a lo cual se le debe de considerar la tecnología empleada, por ejemplo ATM sobre IP. El encapsulamiento de los datagramas IP en tramas, la estructura cooperativa entre diferentes protocolos, las conexiones a nivel de transporte si se usara el protocolo TCP, la multiplicidad de algoritmos de ruteo y de entrega de los paquetes atravesando generalmente diferentes redes, las frecuentes necesidades de fragmentación de los datagramas y su posterior ensamblaje, provocan serios trastornos a nivel de tráfico
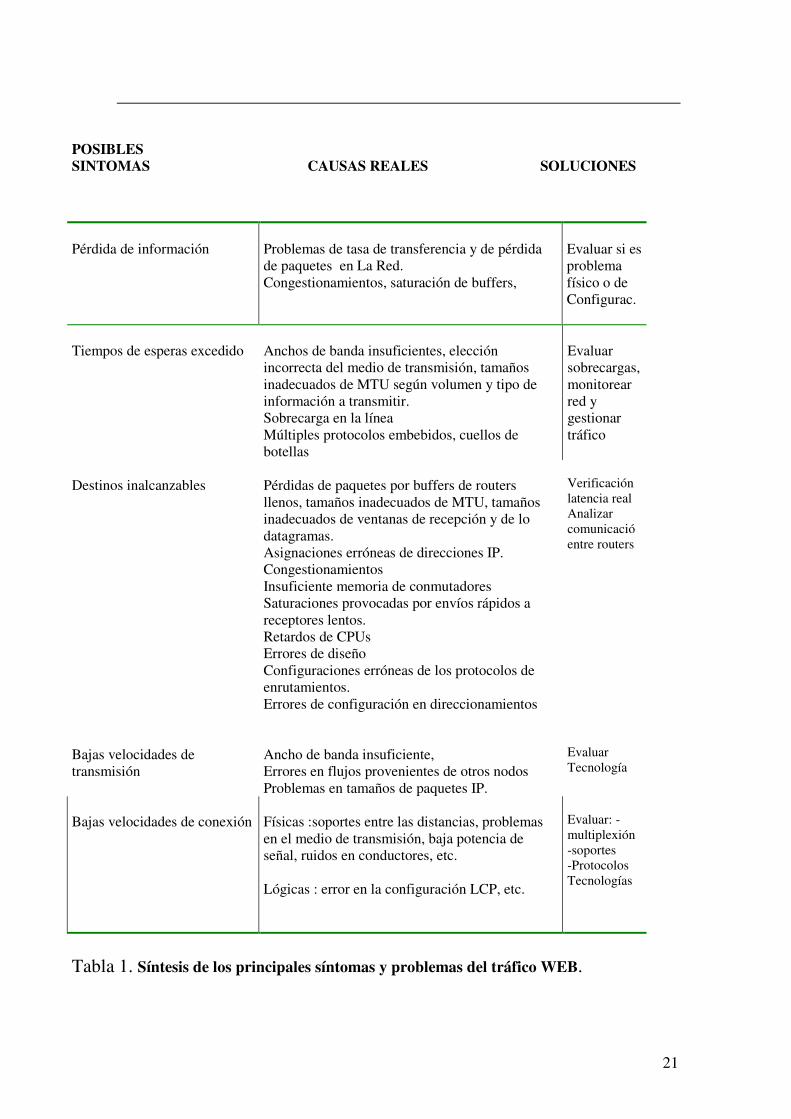
21
POSIBLES SINTOMAS CAUSAS REALES SOLUCIONES
Pérdida de información
Problemas de tasa de transferencia y de pérdida de paquetes en La Red. Congestionamientos, saturación de buffers,
Evaluar si es problema físico o de Configurac.
Tiempos de esperas excedido
Anchos de banda insuficientes, elección incorrecta del medio de transmisión, tamaños inadecuados de MTU según volumen y tipo de información a transmitir. Sobrecarga en la línea Múltiples protocolos embebidos, cuellos de botellas
Evaluar sobrecargas,monitorear red y gestionar tráfico
Destinos inalcanzables
Pérdidas de paquetes por buffers de routers llenos, tamaños inadecuados de MTU, tamaños inadecuados de ventanas de recepción y de lo datagramas. Asignaciones erróneas de direcciones IP. Congestionamientos Insuficiente memoria de conmutadores Saturaciones provocadas por envíos rápidos a receptores lentos. Retardos de CPUs Errores de diseño Configuraciones erróneas de los protocolos de enrutamientos. Errores de configuración en direccionamientos
Verificación latencia real Analizar comunicació entre routers
Bajas velocidades de transmisión
Ancho de banda insuficiente, Errores en flujos provenientes de otros nodos Problemas en tamaños de paquetes IP.
Evaluar Tecnología
Bajas velocidades de conexión
Físicas :soportes entre las distancias, problemas en el medio de transmisión, baja potencia de señal, ruidos en conductores, etc. Lógicas : error en la configuración LCP, etc.
Evaluar: -multiplexión -soportes -Protocolos Tecnologías
Tabla 1. Síntesis de los principales síntomas y problemas del tráfico WEB.

22
CONCLUSIONES DEL CAPITULO 1 Los problemas del tráfico WEB tienen múltiples causas, muchas de las cuales son vistas por los usuarios finales a través de sus síntomas. Sin embargo, a nivel de administradores, es de suma importancia la detección precoz y el análisis profundo de dichas causales, para poder incidir en el mejoramiento de la performance de La Red. Dichas causales suelen trabajar cooperativamente, lo que hace más complejo aún el análisis del problema. Por consiguiente, si bien el estudio de las causales de dichos problemas se dan en forma aisladas, porque así lo justifica las características diferentes de cada temática, en cambio, dado de que Internet es, esencialmente, una red de procesos distribuidos, es necesario el análisis y la puesta en práctica de soluciones integrales, más cercanas a las realidades actuales, pero con necesidad de proyección para que las soluciones propuestas puedan ajustarse a las tan cambiantes realidades de La Red. La necesidad de contar con un modelo para el análisis del tráfico WEB, se justifica por las exigencias de tener servicios seguros y confiables, que se ajusten a las necesidades solicitadas para las transferencias en la WEB, brindando además rapidez y eficacia en la provisión de los servicios y en forma independiente de las plataformas, protocolos y tecnologías existentes en cada una de las redes integrantes en una realidad dinámica y cambiante permanentemente. Hay, además en el área, la necesidad de evaluar la performance dentro de la WEB en etapas tempranas del diseño y funcionamiento de La Red, como forma no solo de informar sobre el estado de la misma, sino como forma de control del propio usuario final para cotejar los servicios contratados con los recibidos en realidad. Hay, además, en el mercado una especialización de las ofertas, que brindan parámetros específicos de transporte, que además de ser entendibles por los usuarios, deberían de brindar los mayores criterios de seguridad. Analizar si tales ofertas se ajustan a los estándares, es una tarea no fácil que se facilitaría si se contara con un modelo específico de análisis del tráfico. Por consiguiente existe una necesidad imperiosa de analizar el tráfico en La Red, independientemente de las normas y herramientas usadas. Por consiguiente, es indispensable tener un modelo para el análisis y seguimiento del tráfico WEB , que pueda ser aplicable a situaciones escalables dentro de La Red, pues ésta es una característica inherente a la misma. Se propondrá en el presente trabajo un modelo de sistemas multiagente para analizar el tráfico WEB pues, al ser la WEB un sistema abierto distribuido, se adapta fácilmente a un modelo con agentes interactuantes pero al mismo tiempo autónomos, siendo muy factible la posibilidad de volver a usar los conocimientos transmitidos por otros agentes.Este planteamiento se adapta bien a la estructura de funcionalidad distribuida en capas de las redes, y más aún a la estructura de interconexión de redes entre sí, que, aunque autónomas constituyen una unidad lógica que permite la transmisión de extremo a extremo.

23
2. Agentes y Sistemas Multiagentes
Palabras claves : Agentes Inteligentes, Sistemas Distribuidos, Inteligencia Artificial Distribuida, Sistemas Multiagentes, interacción, coherencia, movilidad. 2.1 Concepto de agentes
Según lo expresado por Weiss, [Weiss Gerhard, 2004 ] , un agente es una entidad computacional como un programa de software o un robot, que puede recibir una percepción de un entorno, y actuar de acuerdo al mismo. Todo agente es autónomo en su comportamiento y depende parcialmente de su propia experiencia; es una entidad inteligente y opera flexible y racionalmente bajo variadas circunstancias de entorno dadas. Si bien un agente está preparado para actuar a favor de un usuario, posee total autonomía para resolver problemas. En el presente trabajo de investigación se entenderá por usuario a todo proceso, persona o agente, que tenga como finalidad la de solicitar algún servicio que La WEB ofrezca..
Los agentes se comportan, en general, de una manera flexible y razonable, y pueden llegar a resolver problemas tanto en el área de planificación como en el de decisión, y a su vez pueden aprender de su propia actuación.
Lo fundamental que caracteriza a los agentes es el o los objetivos que justifican su existencia, y además la posibilidad de coordinar entre los diferentes agentes. Las coordinaciones se pueden dar tanto en tareas de cooperación como en tareas de competencia. En cooperación, muchos agentes tratan de combinar sus esfuerzos para complacer como grupo lo que individualmente no pueden realizar. En el caso de competir varios agentes, tratan de lograr lo que cada uno de ellos pudiera obtener en forma individual.
Para poder llevar adelante las tareas de coordinación, es necesario la concurrencia de métodos especiales que los capaciten para interactuar logrando un desempeño igual o mejor que los humanos, y poder comprender mejor la interacción entre las entidades inteligentes, sean estas entidades computacionales, humanas, o ambas. Esto permitiría resolver una gran cantidad de desafíos centrados en una cuestión esencial, siendo el problema central a resolver el de determinar cuando, como y con quien deben interactuar los agentes. Los agentes cumplen sus objetivos, y ejecutan sus tareas de tal forma que optimizan la ejecución de los mismos, lo cual no significa que no pueden equivocarse, ni que no puedan fracasar en el intento de lograrlos. Los agentes en un sistema MAS brindan a los otros agentes la información a la que han arribado, siguiendo siempre sus percepciones y capacidades, habilidades éstas que les son innatas o aprendidas. Las arquitecturas de Inteligencia Artificial Distribuida (DAI) permiten resolver problemas, hacer búsquedas, decidir, y que los agentes puedan aprender lo que fuera

24
posible, y mostrar flexibilidad y racionalidad en su comportamiento y en la realización de procesos en escenarios de agentes. El carácter adaptativo de los agentes, según Ramón María Gómez Labrador [Labrador R ], implica que los agentes deben de poder configurarse según las preferencias de sus usuarios y su experiencia previa, debiéndose además poder adaptarse a los cambios de su entorno.
Características Descripción Autonomía Entidades autónomas, con iniciativa,
orientados a objetivos, capaces de aceptar peticiones de alto nivel , colaborativos, flexibles
Adaptación Entidades capaces de adaptarse a cambios del entorno, y de autoconfigurarse
Continuidad temporal Entidades o procesos en continua ejecución
Comunicación Con posibilidad de compleja comunicación con otros agentes mediante lenguajes comunes.
Carácter Poseen un estado intrínseco bien definido
Movilidad Algunos agentes pueden ser transmitidos de una máquina a otra a través de diferentes arquitecturas y plataformas.
Capacidad de decisión Capacidad de aprendizaje usada para la toma de decisiones
Toman decisiones de acuerdo a sus objetivos, y se basan en su experiencia propia o en lo que aprenden.
Proactividad
Con capacidad para iniciar acciones por cuenta propia.
TABLA 2. Síntesis de las principales características de los agentes del modelo que se propondrá

25
2.2 Sistemas multiagentes (MAS)
El tema de AID fue evolucionando hasta que se convirtió en el área de Multiagentes, plantea Lemaitre [Lemaitre Ch, 2000]. El gran dilema que impulsó hasta llegar al surgimiento de los sistemas multiagentes era hacer que los sistemas computacionales integrados, hasta entonces, por componentes autónomos pudieran evolucionar al punto de que pudiesen resolver problemas mucho más complejos que los que podrían resolver cada uno de sus componentes por separado. Según lo expresa Frederico Luiz Goncalves [Goncalves F., 2002], la Inteligencia Artificial clásica se basaba en que una entidad resolvía los problemas propuestos basándose en un tipo de inteligencia atomizada pues se restringía a aspectos se su propia racionalidad. En cambio, la Inteligencia Artificial Distribuida, sobre la que se basan los sistemas multiagentes, le agregan al tratamiento de los problemas un encare social , al integrar en la solución de los problemas propuestos, el aporte de las acciones e interacciones productivas entre los agentes miembros de una misma sociedad. Un sistema basado en agentes es aquel que usa el concepto de agentes como mecanismo de abstracción, pero este concepto solo no alcanza para definir un sistema multiagente, pues los agentes podrían también ser usados en estructuras de software tradicionales. En cambio un sistema multiagente es aquel que se diseña e implementa teniendo presente que el modelo estará formado por agentes con capacidad para interactuar entre sí. Según Weiss [Weiss Gerhard, 2004 ], en un artículo publicado en Readins in Agentes, el problema central consiste en determinar como los agentes pueden colectivamente aprender a coordinar sus acciones de tal forma que puedan resolver juntos tareas pertenecientes a un entorno dado. Para ello, según el autor, habrá que tener en cuenta aquellas tareas que son mutuamente excluyentes e incompatibles además de las limitaciones que hacen referencia a los ámbitos locales. Que los agentes en un sistema multiagente sean entidades interactivas implica que ellos pueden verse afectados en sus resoluciones por otros agentes, y también por factores humanos La interacción entre los agentes puede efectuarse directamente entre ellos ( por ejemplo compartiendo un mismo lenguaje, o compartiendo las informaciones o las decisiones que cada uno tenga o tome), o indirectamente, a través de otros dispositivos, o del entorno en el que ellos están embebidos, por ejemplo eliminando una acción que afecta el estado del dispositivo. Los sistemas multiagentes, son definidas por Lemaitre [Lemaitre CH, 2000], como sistemas de colecciones de agentes informáticos con capacidad de interactuar y a su vez de tener cierta autonomía. Una de las características principales de los sistemas Multiagentes, siguiendo las líneas de trabajo de los investigadores de LANIA descriptas por Lemaitre, fue el concentrarse en aplicaciones potenciales, en un primer momento, y luego el plantearse su evolución hacia el apoyo a la automatización en diferentes áreas dentro de las Instituciones.

26
Plantean Hernández y Rosenblueth [Hernández V & Rosenblueth E A ], que el contar con equipos de agentes organizados en un sistema MAS permite obtener un mayor y mejor nivel de abstracción, una mejor flexibilidad para expresar el comportamiento de los agentes, y una mejor satisfacción de los requerimientos de los usuarios. A través de este enfoque de Sistemas Multiagentes, las interacciones de sus agentes se dan simultáneamente en el tiempo e interactúan dentro del espacio virtual predefinido por la Institución. Según The International Journal of Advanced Manufacturing Technology [ The International Journal of Advanced Manufacturing Technology de F.T.S. de Chau, J.Zhang], un sistema multiagente es un sistema dinámico y abierto con la capacidad para adaptarse y adecuarse a cambios radicales en la estructura y prácticas de los sistemas y con capacidad para interactuar. En dichos sistemas, los agentes que lo integran deben de convergir en pos de la realización de sus metas comunes. La comunicación directa entre agentes genera los Sistemas de Agentes Cognitivos, los cuales para comunicarse, deben de tener por lo menos una instancia de protocolo común, cuya sintaxis, semántica y objetivos deben ser fácilmente entendibles por los agentes que pretenden interactuar. Los agentes cognitivos pueden ser peer to peer o cliente-servidor. Los agentes peer to peer basan su interacción en la expresividad de sus comunicaciones y en la riqueza semántica de sus mensajes. El modelo peer to peer basa la interacción entre agentes en el envío de múltiples mensajes. El modelo cliente-servidor, en cambio, basa la interacción entre sus agentes en otras pautas, como accesos remotos, parámetros de seguridad, y rapidez en las comunicaciones. La pauta central de los modelos de agentes cognitivos clientes-servidores, es la posibilidad de ejecución remota de procedimientos con pasaje de parámetros. Los mensajes, por ejemplo, solo pueden ser ejecutados en el servidor. Los agentes, en ambos modelos, almacenan los conocimientos adquiridos en bases de conocimientos, para esperar en los próximos momentos, el uso o reusabilidad de los mismos. En las interacciones entre los agentes se deben de seguir una serie de pautas tales como que la forma de comunicación entre ellos, la cual debería de ser sencilla, totalmente entendible entre los agentes interactuantes. Los agentes para poder comunicarse entre sí deben de tener alguna instancia de protocolo de comunicación común. A través de ese protocolo, los agentes se pueden enviar mensajes escritos con el objetivo de intercambiar conocimientos, metas o hechos, para poder cooperar o negociar. La importancia de los modelos de comunicación es la de posibilitar el intercambio de información. En todo el proceso de modelaje, es siempre muy recomendable una RDP (Resolución Distribuida de Problemas)

27
Desde el punto de vista del agente, la escalabilidad está pautada por el aumento en la capacidad de conocimientos que el agente posee 2.3 Porqué usar un sistema multiagente para analizar el tráfico WEB ? Las plataformas de redes informáticas, en la actualidad, pretenden ser abiertas, grandes, y heterogéneas. Las arquitecturas DAI prometen ser necesarias para la administración de altos niveles entre las redes y la interacción entre las redes modernas, siendo fácilmente adaptables en las tareas de gestión y control de tráfico entre ellas. La interconexión de las Redes entre sí, puede ser visto como una gran sociedad, donde sobresale la necesidad de interrelacionar productivamente las distintas funciones de sus agentes miembros, para poder reusar y aprovechar cada uno de los conocimientos, funcionalidades y objetivos de cada integrante. De la interacción de cada uno de los agentes en un sistema MAS, surgirán las acciones, toma de decisiones, revisiones de decisiones anteriores, todo lo cual puede ser hecho en un marco de cooperación, o de conflicto, o a veces de ambas formas A su vez, los agentes deben de poder conservar su característica de autonomía para poder cumplir a cabalidad las tareas que les son específicas. Los problemas que, de acuerdo a lo expresado en el punto 1, se pueden encontrar dentro de la WEB, son múltiples y de diferentes órdenes, están íntimamente relacionados entre sí, y muchas veces para resolver alguno de ellos, es necesario tener información de cómo fue resuelta alguna otra situación relacionada a la misma. Estos problemas, a su vez, tienen lugar tratando de cumplir con las especificaciones estipuladas por los protocolos que intervienen en el tráfico. Los agentes son entidades activas dentro de un sistema MAS, funcionan inmersos en un entorno que constituyen las entidades pasivas , y se comunican entre sí a través de protocolos de comunicaciones donde deben de estar garantizados las características de autonomía de cada uno de ellos. En el caso de la WEB, el entorno sería la interconexión de las redes entre sí, los protocolos serían los que permiten la comunicación entre los agentes y los dispositivos Según se establece en la revista de investigación NewLetters [NewLetters, 1996] , en el caso de redes distribuidas y redes abiertas, es difícil definir de antemano el tipo de interacciones que los agentes podrán tener en el futuro. Por ejemplo los tiempos de transferencias dentro de la WEB dependen , entre otros, de la carga en la línea, del tiempo de latencia de los dispositivos, etc. , siendo imposible determinar el mismo con total exactitud. La comunicación entre los agentes debe de poder manejar, en las redes, protocolos de comunicación, que a veces son complejos, debiendo posibilitar a los mismos de la capacidad de negociación entre los agentes, en un entorno variable de un momento a otro. Los agentes que compongan los sistemas MAS deben de comportarse más como individuos de una sociedad de agentes, que como sub-componentes clásicos de un sistema

28
multiagente, a pesar de que para su análisis se los ubicará como integrantes de diferentes subsistemas del sistema MAS a modelar. Existen, por lo tanto ciertas características de los MAS de utilidad en las Redes. Los sistemas MAS constituyen una red de sistemas que interactúan para resolver temas que superan las capacidades individuales, lo que los hace adaptables a la inmensidad de problemas detectados en el tráfico WEB. Plantea Christian Lemaitre y Victor Sánchez, [Lemaitre & Sánchez, 1995 ] que se debe de generar agentes que puedan actuar en representación de los usuarios, atendiendo las solicitudes de éstos y que pudieran comunicarse con otros agentes representantes de otras solicitudes. Esto, según ese autor, debería de darse tanto en La Red de Redes, como en las Intranets. Las soluciones multiagentes para las WEBs sería crear sistemas semi-autónomos que jueguen ese papel, capaces de efectuar solicitudes, de hacer seguimientos de las solicitudes efectuadas, y por lo tanto, deberían de conocer las actividades del usuario y las actividades de los demás agentes, pudiendo comunicarse y negociar soluciones conjuntas a problemas comunes. Si bien estas consideraciones fueron hechas específicamente para la atención de los servicios solicitados por usuarios de una red, para este artículo de investigación se concebirá como “usuario” en sentido amplio, no solo la persona ubicada en los procesos terminales de La Red, sino también como todo proceso , persona física o agente integrante del sistema MAS que solicite un recurso. Con esta concepción, podrían ser “usuarios” los procesos relacionados con algún ruteador de red que, solicitase a otro ruteador algún servicio , por ejemplo, información sobre las mejores rutas, o que le pidiesen información sobre su estado, a través de mensajes Keep-alive. Se debe de tener en cuenta que, entre los hosts, también, se deben de contar los dispositivos, los cuales no son más que hosts especiales por sus funcionalidades. Un ejemplo de intercomunicación entre los agentes de redes, sería la necesidad de poder analizar direccionamientos o estado de las rutas en el caso de los routers, o hacer balanceo de carga en el caso de los servidores, etc. La capacidad de aprendizaje de los agentes , hace su uso sumamente conveniente en el entorno de la WEB, en donde muy frecuentemente tal capacidad es altamente necesaria, por ejemplo, las entradas de las tablas ARP se arman luego que los dispositivos apr0enden la relación entre direcciones físicas y lógicas, resultado obtenido a través su propia búsqueda, o de los resultados de búsquedas efectuadas por otros dispositivos. La propia búsqueda de las mejores rutas, se efectivizan cuando los dispositivos almacenan los resultados de las búsquedas anteriores para usarlos en situaciones nuevas, en la medida de lo posible. La característica de los agentes de ser reactivos al entorno, se manifiesta, también, en la misma naturaleza dinámica de la WEB, la que obliga muchas veces a tomar nuevas decisiones por cambios experimentados en el entorno físico.

29
Son así frecuentes la necesidad de cambios en la toma de decisiones de rutas debido al saturamiento o caída de los enlaces, o la elección de nuevas rutas ante el surgimiento de rutas menos costosas para obtener el destino planteado. Todo esto se encuadra en las características de los agentes de ser entidades altamente racionales, o sea que todas sus acciones persiguen el cumplimiento de sus objetivos y metas planteadas La característica de los agentes de ser altamente sociables, es fundamental en el funcionamiento de La Red, ya que los dispositivos necesitan frecuentemente comunicarse con sus homólogos para lograr el mejor cumplimiento de sus funciones. Caso típico de ello son los routers, que necesitan de la información enviada por sus pares vecinos, o lejanos, para poder buscar las mejores rutas, o para enviar los paquetes, o para informarse del estado de las rutas. Al poseer, los agentes, capacidad de razonar les permite interpretar resultados enviados por otros agentes así como usar conocimientos propios para resolver problemas. Esta capacidad le permitirá a un router decidir, por ejemplo, que paquete dejará o no pasar por sus interfases, o a que otro router le pasará un paquete que le llegó con dirección desconocida, o hasta que punto puede recibir paquetes, antes de que su buffer se sature y se genere una congestión. Los agentes poseen la capacidad, no solo para percibir el entorno y cambiar en función de él, sino también poder actuar sobre el entorno, produciendo modificaciones en el mismo y alterar sus condicionantes. Un ejemplo que justificaría el empleo de esta característica de los agentes en La Red es la capacidad de los routers para percibir la carga en la línea, o el tamaño máximo de los paquetes cuando ellos superan su propia MTU (Unidad Máxima de Transferencia), o la posibilidad de reducir la ventana en tráfico TCP frente al caso de que se vea sobrecargado por demasiados envíos simultáneos. Otra capacidad de los agentes, que los hace muy aplicables en entornos de Red, y específicamente en WEB, dado el amplio espectro de redes interconectadas entre sí mediante rutas y enlaces diferentes, es la posibilidad de contar con agentes móviles. Los agentes, en un sistema MAS aplicable sobre el trafico WEB, deberían de poder moverse entre los distintos hosts, para poder captar la situación de los componentes de la red , tomar decisiones y volver al nodo desde el cual se inició su itinerario. Los agentes móviles son programas autónomos que trabajan en redes móviles, por lo tanto pueden moverse de máquina en máquina, en redes heterogéneas, bajo un control propio. Su ejecución se puede suspender en cualquier momento desde cualquier punto, y dependiendo del tipo de agentes, su ejecución se podría o no reanudar desde otra máquina. Los agentes podrían interactuar con los recursos sin necesidad de transmitir datos a través de La Red, lo cual permitiría mejorar el ancho de banda necesario en la transmisión. Además, pueden responder a las necesidades de los usuarios, en forma rápida. Se pueden mover visitando distintas máquinas en paralelo, y pueden enviar agentes hijos. Algunos investigadores, especializados en agentes móviles, tales como Barcia, Mengual y Yagues [Barcia N ],[Mengual, ], [Yagues, ], sostienen que el gran aporte de los agentes móviles significó un mayor avance en tanto permite y estimula el procesamiento entre módulos que, si bien pueden cooperar entre sí, no tienen porqué ubicarse en espacios

30
geográficamente cercanos, mediante el uso de entidades computacionales con capacidad para ejecutar tareas en entornos que pueden migrar desde una red virtual a otra. La gran ventaja de estos tipos de entidades , llamadas agentes móviles, aprovechable en el tráfico HTTP, es la descentralización de los procesos, lo que conlleva a lograr una menor latencia al fomentar la reducción del tráfico en la red, ya que el mismo logra una mayor dispersión física, sin afectar la capacidad de procesamiento de La Red, en general. Los agentes móviles, según dichos investigadores, deben de contar con ciertas características, como son: su autonomía intrínseca, su flexibilidad de comportamiento, su inteligencia, su seguridad, su movilidad, su capacidad migratoria y de interacción con otros agentes. Surge, entonces, para dichos autores, un nuevo paradigma de programación caracterizado por la programación remota en el entorno redes, basado en el mantenimiento e implementación de los sistemas distribuidos. Todas estas características de los agentes móviles los hace fácilmente adaptables para el tráfico HTTP, por las características descriptas del mismo. En todo esto es necesario tener en cuenta de que en los procesos de interacción se relacionan nodos que suelen ser muy heterogéneos, y que en estos procesos generalmente debe de llevarse a cabo tareas que les son delegadas a dichos nodos. Según dichos investigadores, y para poder cumplir dichas tareas, es necesario analizar como interactuan entre sí los agentes integrantes de un MAS, y como ellos se organizan para lograr la coordinación necesaria para cumplir con sus metas, para lo cual, frecuentemente las tareas se subdividen en subtareas. Para poder asignar tareas y subtareas a todos los agentes,en general, es necesario previamente analizar los roles que cada uno de ellos debe de cumplir en la organización en que están inmersos. Analizando el tipo de comunicación que puede darse entre los agentes, la relación entre ellos puede ser desde una relación sin comunicación a una comunicación de alto nivel. En las relaciones sin comunicación se deduce el comportamiento por señales, sin interpretación fija. En el ámbito de estudio del presente artículo, un ejemplo de este tipo de comunicación sería, por ejemplo, la detección de señales eléctricas para saber si el canal está ocupado o no, simplemente sensando la portadora, o la detección de las señales eléctricas entre un DTE y un DCE, en las interfases físicas de la WAN La comunicación de alto nivel se logra mediante el diálogo entre agentes. Otra de las características de los agentes en un sistema MAS es la capacidad de coordinación. En un mismo entorno pueden convivir distintos agentes, y por lo tanto en estas situaciones es imperioso la necesidad de coordinar entre ellos. Por ejemplo, para prevenir el caos en las transmisiones es imprescindible coordinar sobre cuanta carga de tráfico se va a aceptar por la red, o cual es el ancho de banda asignado en cada transmisión, etc. Otra característica es la necesidad de coherencia entre los componentes de un sistema MAS. Esto implica que el sistema de agentes actúe como una unidad, más allá de la autonomía de cada uno de sus agentes.

31
Por ejemplo en las redes, si para un router la mejor ruta es una determinada, cuando se envía esta decisión a otro router, este segundo la acepta como que así es, salvo que aparezca una ruta mejor. Otra característica es la capacidad para negociar. Los agentes actúan en un entorno compartido, y muchas veces ellos pertenecen a diferentes organizaciones y las negociaciones entre ellos son, muchas veces, independientes del entorno en que ellos están inmersos. Por ejemplo , según los describen Huhns & Singh [Huhns N & Singh P, 1998] , los agentes pueden subcontratar a otros agentes por la ejecución de alguna tarea, por lo que pueden pagarles por esos servicios. Estos procesos de subcontratación pueden implicar dividir una tarea grande en varias subtareas, o a la inversa, agrupar en una tarea varias tareas más chicas. Se realiza una especie de contrato entre los agentes, que luego de efectuado debe de cumplirse . También pueden los agentes estar unidos en esos compromisos a través de protocolos de negociación.

32
Características de agentes en MAS
Aplicación en el análisis del tráfico WEB
Posibilidad de resolución de problemas complejos
Tener presentes la gama de complejidad de problemas enunciados en punto 1
Posibilidad de interactuar con otros agentes. Manteniendo su individualidad
Ver cada módulo especificado en punto 1 como atendido por uno o varios agentes, y la necesidad de interactuar dinámicamente entre ellos para la toma de decisiones. (ej. Transmisión de decisiones, de evaluaciones de rutas, de sucesores, etc.)
Posibilidad de interactuar con el entorno
Ver los agentes de cada módulo interactuando dinámicamente con La Red ( con : enlaces, dispositivos, protocolos, etc.)
Posibilidad de tomar decisiones rápidas
Necesidad imperiosa en la WEB, de agilización del tráfico, mejorando performances
Capacidad de variabilidad de comportamientos
Necesidad de conductas dinámicas según Cambios de entornos. (ej. Por : tomar nuevas rutas por caídas de enlaces, o por congestionamientos o por arribo de información con grandes exigencias de ancho banda, etc.)
Proactividad
Posibilidad de incidir y cambiar el entorno (ej. Fragmentaciones de paquetes, eliminación de rutas activas por declaraciones de no confiables )
Capacidad de control y seguimientos rápidos de los comportamientos de los componentes del sistema.
Necesidad de tomar control sobre las decisiones propias y eventualmente necesidad de cambiar el entorno. (ej. Fragmentaciones de paquetes, cambios de rutas, etc.)
Capacidad de seguir reglas para dirigir comportamientos y prioridades, independientemente de infraestructuras subyacentes.
Experiencias en el tráfico WEB de seguir protocolos estandarizados, independientemente de las plataformas y arquitecturas de las redes componentes.
TABLA 3. Algunas características de agentes en MAS aplicables en análisis WEB.

33
CAPACIDAD DE AGENTES EN MAS BENEFICIOS PARA EL ANALISIS
DEL TRAFICO WEB Interactuar
Enriquece las tomas de decisiones
Aprender
Amplia las bases de conocimientos
Proactividad con entorno
Mejora la situación del entorno
Movilidad de algunos agentes
Fomenta la reducción del tráfico WEB, al descentralizar los procesos de análisis Efectiviza los tiempos de ejecución al permitir la suspensión y luego reanudar las ejecuciones en otros nodos.
Coordinar y negociar con otros agentes
Previene errores Da posibilidad, eventualmente, de adoptar la mejor decisión, si hubiera varias posibles
Autonomía
Permite la profundización y dominio en un área específica
Coherencia con los demás componentes del sistema
Permite tratar La Red como una unidad, a pesar de sus individualidades.
Posibilidad de subcontratar agentes
Agiliza la ejecución de tareas
TABLA 4- Beneficios para el análisis del tráfico WEB al usar sistemas MAS.

34
2.4 Características generales de los agentes a incorporar en el presente modelo.
Existen muy diversos criterios de clasificación de los agentes, pero en el presente artículo se tomará en cuenta aquellos criterios que pueden ser de utilidad a los efectos de ser empleados en un sistema multiagente para el análisis del tráfico WEB. Se tendrán en cuenta, para este artículo, solo aquellos que Jiménez y Ramos, [Jiménez S , Ramos E, 2000 ] en su artículo de investigación llaman Agentes Inteligentes, o sea aquellos agentes caracterizados por actuar en un ambiente en particular y ser capaces de realizar ciertas acciones basadas en percepciones tomadas del ambiente, hasta alcanzar la meta para la cual fueron diseñados. Los agentes del presente modelo deben de poder analizar como funciona y evoluciona el entorno en una realidad totalmente cambiante, como el agente puede incidir sobre el entorno, y a su vez, como hacer para que el entorno no le incida de forma indeseable en el funcionamiento de sus tareas específicas. Por lo tanto, aplicado este concepto al tema del tráfico HTTP, una de las características esenciales en los agentes propuestos por el presente artículo, será el conocimiento que dichos agentes deben de poseer del ambiente con el cual interactuarán, así como de las acciones que ellos realizarán, basándose en reglas, para satisfacer las metas propuestas. La realidad del tráfico HTTP es sumamente cambiante de un instante a otro, por lo tanto, no alcanzará con tener agentes que interpreten el entorno, a través de instrucciones dadas solamente por una serie de reglas del tipo condición-acción, como plantean Jiménez y Ramos [Jiménez S, Ramos E, 2000], refiriéndose a un tipo especial de agentes que actúan confrontando el mundo con las reglas a la que ellos tienen acceso, en cuyo caso, si encuentran alguna coincidencia entre ambas, los agentes quedarán habilitados para disparar determinada acción. En el caso de los agentes aplicables para el tráfico HTTP, es necesario que ellos, puedan evaluar no solo las situaciones actuales de La Red, sino además las que sucedieron en instantes anteriores y preveer las situaciones futuras con cierto grado de certeza Esto se fundamenta en las características de las situaciones problemas en el tráfico WEB, las que son interesantes evaluarlas en un proceso, pues generalmente tales problemas se van incrementando si no se produce alguna acción de rápida detección y solución. Por lo tanto, tales agentes deben de poder discernir cual es la evolución que experimentó el ambiente y como eventualmente evolucionará si se suceden determinadas condicionantes, y conocer como afectaría a ese ambiente las acciones que los propios agentes tomen. Por lo tanto, mediante el uso del modelo planteado, se debería de preveer la necesidad de codificar conocimientos respecto a la situaciones actuales del entorno y a los eventuales cambios que podría experimentar el entorno, las acciones que los agentes podrían tomar frente a dichos cambios tratando de satisfacer de manera eficiente y eficaz las metas propuestas, y los impactos de dichas acciones tanto sobre el entorno, como sobre el propio estado interno de los agentes mismos.

35
De modo que a los agentes que actúen en el modelo que se propondrá, se les asignará, entre otras, tareas de búsqueda y recuperación de información para evaluar las situaciones de La Red en determinado momento, basándose en las percepciones del entorno y en todo conocimiento incorporado al agente. Para ello, los agentes deben de estar capacitados para emprender acciones que favorezcan el cumplimiento de sus objetivos, obteniendo al máximo su medida de rendimiento. Por lo tanto, dichos agentes serían del tipo agentes inteligentes racionales. Estos agentes trabajarán en un muy complejo entorno, dado la multiplicidad de problemas con los que se pueden encontrar, y con un alta carga de información. Por lo tanto, los agentes en el presente modelo, tendrán asignadas de forma muy precisa las metas que cada uno de ellos debe de lograr y las formas de organización entre ellos. En función de las metas propuestas para cada agente, ellos lograrán la identificación del problema, siendo para algunos agentes sus problemas el de búsqueda e identificación de situaciones críticas, o el de evaluar una situación específica dada en La Red, o el de intercambiar información sobre dichos problemas, o el de definir la acción a emprender frente a algún problema detectado, etc. Además de las tareas que ellos tendrán asignadas, podrán ejecutar las acciones que consideren necesarias para el cumplimiento de sus metas específicas. Por supuesto que en esto, siempre habrá un seguimiento de la realización de estas acciones, por parte de agentes competentes, eventualmente integrantes de otros componentes del sistema MAS. En el presente modelo deben, por lo tanto existir agentes de detección o diagnóstico de los problemas que ocurran en un momento determinado en La Red. Otros agentes funcionarán como alertas y monitorearán los peligros inminentes de La Red frente a la posibilidad de que sucedan algunos de los problemas analizados en el punto 1.1, otros agentes se encargarán de procesar la información obtenida, otros se encargarán de efectuar las recomendaciones necesarias para poder neutralizar o solucionar los problemas detectados o sobre los que exista una presunción bastante importante de que puedan existir. En el modelo a proponer, los agentes se deben de poder moverse en entornos inciertos, no predecibles totalmente, pero controlables mediante su capacidad de aprendizaje . Este aprendizaje se obtendrá automáticamente a través del análisis de determinados parámetros , o de experiencias pasadas, o de percepciones que captan de La Red. En el modelo planteado en el presente artículo, los agentes son esencialmente móviles, aunque ellos también actuarán cooperativamente con agentes fijos. Los agentes móviles, tal como se plantea en Telm@tica [Telem@tica, 2003], podrán saltar de un nodo a otro y encapsular acciones que podrán ser ejecutadas en el lugar en que se las necesite, buscar información a través de diferentes redes y regresar con los datos solicitados al punto en el cual se les hizo la solicitud inicial. Por lo tanto, este tipo de agentes son más fácilmente adaptables a la realidad WEB que los agentes estáticos, dado las realidades tan heterogéneas de los entornos de La Red permitiendo además, trabajar mejor en entornos escalables.

36
Si bien la movilidad entre los nodos de La Red, es la característica principal de estos agentes, no es suficiente solamente su capacidad para migrar, sino que además deben de poder actuar en forma autónoma, inteligente y segura. Durante su migración, los agentes del presente modelo, deben de poder realizar acciones, recabar información sobre la situación del entorno y tomar decisiones. El uso de agentes móviles para el análisis del tráfico en La Red, traería como ventaja la reducción de la carga de red, ya que implicaría menor cantidad de transferencia en La Red, al eliminarse los mensaje que antes intercambiaban los protocolos, mejorando así la latencia de La Red. Habría una descentralización de los procesos necesarios para el cumplimiento de los objetivos, ya que como la búsqueda de información se plantea aplicando la meta objetiva , se lograría deshechar o al menos disminuir el envío de información irrelevante. En definitiva, los agentes móviles darían una gran flexibilidad al modelo que se plantea en este artículo, pues se trataría aquí de un sistema con gran analogía a los sistemas distribuidos al ejecutarse en forma asíncrona y automáticamente. Estos tipos de agentes permitirían ahorrar ancho de banda pues, al ir ellos hacia los datos, y al llevar solo los resultados contribuirían a disminuir la latencia en la red. Además, podrán pedir información a nombre del proceso que los disparó.
Cumpliendo los agentes del modelo propuesto, con la meta de detección y aislamiento de fallos, dichos agentes son deliberativos por excelencia, ya que describirán la situación en la zona del entorno a la cual accedieron de alguna forma, directa o indirectamente a través de otros agentes. También serían reactivos, ya que al momento de que detectan algún problema, realizan alguna acción para intentar llegar a una solución frente al problema detectado. Los agentes que se propondrán necesitarán comunicarse directamente entre sí y con los usuario (entendiendo como tal en el sentido de usuario especificado en el presente artículo), mediante comunicaciones , directas o indirectas, integrando una comunidad de agentes. Estos agentes, con su dinamismo característico, podrán entrar y salir en función de las necesidades. El hecho de que los agentes no siempre deban necesariamente pasar por un punto central, sino que en algunos casos, según sus necesidades, puedan comunicarse entre sí directamente reducirá el tráfico en La Red y contribuirá a la descentralización de los controles. En cada operación de interacción entre los agentes, o entre algún agente y el entorno, se transportarán mensajes. Por lo tanto, existirán en el presente modelo, algunos agentes cuyas metas serán la de distribuir e intercambiar mensajes, los que deberán ser totalmente independiente de las aplicaciones. Los agentes de mensajes estarán presentes en cada acción que se dispare. También existirán los llamados agentes del entorno, que actuarán directamente sobre los dispositivos y enlaces de La Red, y que se diferenciarán del software tradicional, debido al principio de racionalidad.
De acuerdo a la jerarquía y alcance de las funciones de cada agente, en el presente modelo existirán aquellos agentes centrales o de primer nivel que estarán presentes en cualquier nivel de abstracción del que se mire el sistema , y aquellos otros agentes que, como decía Aguilar & Peroz& Ferre& Vizcarrondo [Aguilar J, Peroz N, Ferrer E, Vizcarrondo J] en su artículo de investigación., son agentes que integran niveles de

37
abstracción inferiores. Los primeros agentes son componentes esenciales del sistema y los últimos son componentes de algún subsistema que integra el SMA, el cual se ha subdivido en aplicación del principio para resolución de los problemas de “divide y vencerás”. En el presente modelo, ya que se como se expresó se usarán agentes móviles que trabajarán combinadamente con agentes fijos, y siendo unos de los problemas cruciales el de la seguridad en los agentes móviles, se hace indispensable determinar el grado de confiabilidad ofrecido por cada agente. Así habrán agente que ofrezcan alto grado de confiabilidad, otros que no lo serán tanto, y otros que serán realmente inseguros. Habrá, además, agentes especializados en el control y seguimiento de la seguridad y legitimidad dentro del MAS. Los agentes a usarse en el presente modelo tendrán integrado dos tecnologías : tanto la cliente-servidor como la peer to peer. La fundamentación de su conveniencia en un ámbito WEB, la da en el artículo del investigador Petrie [Petrie, Charles, 1996], quien entiende que encara de esta forma los agentes en la WEB favorecen el diseño y las aplicaciones de ingeniería.

38
SINTESIS DE LAS PROPOSICIONES PLANTEADAS EN PUNTO 2.4 Tipos de agentes que se integrarán el modelo a proponer 1.Según sus funciones :
agentes de detección, de diagnóstico de problemas, de alarmas y monitoreo en general(deliberativos) agentes de recuperación de información
agentes de procesamiento de información recibida (mantienen actualizada la información recibida) agentes de coherencia ( vigilan la coherencia del sistema )
agentes de distribución e intercambio de mensajes agentes de aislamiento de fallos (reactivos)
agentes que efectúen recomendaciones (reactivos) agentes que evaluarán impacto de acciones recomendadas.
Agentes monitores : dan información al sistema cuando se da un evento que genera un cambio, general o parcial, sobre el sistema.
2. Según su movilidad: agentes fijos agentes móviles
3. Según su ámbito de funciones
agentes internos( sus funciones principales radican en el corazón del MAS)
agentes de entorno (sobre routers, enlaces, backbones)
4. Según el grado de integración en el MAS agentes generales del MAS(planificadores, administradores, coordinadores, gestores generales, etc.)
agentes locales, integrantes de algún subsistema del MAS 5. Según la confiabilidad brindada : agentes con alto grado de confiabilidad
agentes con grado de confiabilidad media agentes no confiables
6. Según tecnologías de interconexión interagentes :
agentes cliente-servidor agentes peer-to-peer híbridos
7. Según sus formas de operación : agentes de reflejo simple ( operación basada exclusivamente en reglas preestablecidas, incambiables) agentes con capacidad de discernir cambios del entorno

39
2.5 Interacción entre agentes en el modelo propuesto Siendo el modelo a proponer de un sistemas MAS, es indispensable que los agentes puedan y deban interactuar. La interacción entre los agentes del sistema MAS propuesto, tal como se expresa en un artículo expuesto en las XXV Jornadas de Automática en Ciudad Real, por González & otros, [González E.J, Hamilton A.F., Torres S, Torres J.M, Sigut M] será visto como la posibilidad de intercambiar información y conocimiento que sea mutuamente entendido por los agentes integrantes. Plantean estos autores que lo importante en un sistema MAS es el poder gestionar el flujo lógico en una conversación entre agentes. Los agentes en el presente modelo deben de poder entender los problemas suscitados en el tráfico HTTP. Para ello, deben de poder observar las situaciones en La Red, y sobre esa base poder sacar conclusiones sobre las situaciones al momento de la observación y predicciones sobre situaciones futuras. Los agentes del presente modelo deben de poder compartir sus experiencias y conclusiones, para poder agilizar los tiempos de tomas de decisiones. De esta forma, en el modelo planteado los agentes contarán con grandes caudales de conocimientos, algunos adquiridos por cada uno de ellos, y otras a través de la transmisión de conocimientos por parte de otros agentes integrantes del sistema MAS. En el presente modelo, la interacción implicará, no solamente una transmisión pasiva de conocimientos, sino que frente al caso de que un agente obtenga un conocimiento más avanzado o más eficiente que el que poseía otro agente, el primero podrá provocar un cambio en las bases de conocimiento del último agente. Para lograr esto, es necesario que los agentes se comuniquen entre sí mediante lenguajes de entendimiento mutuamente comprensibles. Como la interoperatividad entre los agentes va a ser muy amplia y compleja , se necesitará un lenguaje común. En el presente modelo en el momento en que se establezca una interacción entre agentes para realizar una tarea común o para intercambiar información, ese lenguaje común podrá ser elegido entre una gama de lenguajes altamente probados. La interacción entre los agentes implicará intercambio de mensajes, los cuales estarán regulados por un agente regulador de mensajes, llamado ARM. El objetivo de los agentes ARM es efectivizar las comuniciones entre agentes, contemplando además ciertos criterios de seguridad en las comunicaciones. Los ARM se encargarán de enviar y recibir mensajes y de distribuirlos a los agentes destinatarios. El agente ARM evaluará, además, si los mensajes recibidos provienen de un agente válido, si el estado del agente fuente no ha sido modificado, y de así ser, el ARM evaluará si el cambio experimentado fue originado por una situación válida o si por el contrario hubiera seguridad o presunción de que el cambio fuera malintencionado. Uno de los grandes problemas de los agentes a usar en La Red es el control de la seguridad, de modo que los agentes ARM podrían ser una forma de afirmar la confiabilidad en los agentes de este sistema MAS. Un agente ARM permitiría, además, ordenar el tráfico en la WEB al dirigir los mensajes hacia el destinatario correspondiente.

40
Debería de existir, además, un protocolo de comunicación entre los agentes y los ARM, para que el agente ARM pueda fácilmente detectar quien es el origen y quien el destino del mensaje y si es un mensaje válido de acuerdo a las competencias propias del agente fuente del mensaje. A su vez, para los agentes bases, los agente ARM, le permiten distinguir quien es el agente ARM a quien deben de referenciarse. Uno de los grandes problemas a definir en los temas de interacción entre agentes es, según está especificado en un artículo de investigación del Instituto Tecnológico de Ciudad Madero, �������������� ��������������������, es como capacitar a los agentes para que se comuniquen entre sí e interactúen, sobre que bases deben o pueden interactuar, que lenguajes y que protocolos de comunicación usarán para relacionarse, sobre que formatos se harán los intercambios de las comunicaciones, como harán para sincronizarse manteniendo la coherencia del sistema MAS, etc. Como pauta general, el presente modelo, definirá los lenguajes de comunicación entre agentes en forma totalmente independiente de las plataformas que se puedan encontrar en los hosts que son visitados por los agentes móviles cuando están buscando la realización de las metas planteadas. Los lenguajes de comunicación entre agentes distribuidos del presente modelo, debe de permitir el intercambio de conocimientos, de comunicaciones, de contenidos semánticos. Todos los vocabularios usados en las comunicaciones deben de estar descriptas en diccionarios apropiados para las distintas áreas de comunicaciones entre los agentes. Debe además de existir un formato estandarizado para la transmisión de mensajes entre agentes. Debe de existir una capa linguística en el modelo a proponer, donde esté contemplado todas estas especificaciones. Un ejemplo de posibilidades de lenguaje que podría permitir la interacción entre los agentes del presente sistema MAS a proponer, es el lenguaje llamado ACL( Agent Communication Languaje). ACL contiene un vocabulario llamado KIF( Knowledge Interchange Format) y un lenguaje de comunicación llamado KQML (Knowledge Query Manipulation Languaje) Todo mensaje ACL, si se usase en la etapa de implementación del modelo, tendrá un contenido específico, basado en cálculos de predicados, según lo establece la anotación formal expresada en KIF. Además, todo mensaje ACL tendría el formato de oraciones KI F y el vocabulario a usar se tomará de un diccionario de palabras. Los formatos de los mensajes estarían determinados por el protocolo de mensaje KQML. No obstante la definición del lenguaje de comunicación usado para la interacción, será decisión a tomar en posteriores etapas de investigación. En estas etapas, solo se plantea la necesidad de contar con un lenguaje estandar específico de comunicación, y la descripción de lo que eso implicaría.

41
2.6. Interacción entre agentes y entorno en el modelo propuesto
El entorno en los que actuarán los sistemas multiagentes del modelo MAS propuesto, tiene de por sí, ciertas características que deben de tenerse en cuenta al determinar la forma en la que los agentes cumplirán con los objetivos planteados. El entorno de La Red es esencialmente abierto, dinámico, incierto y debería ser independiente de las plataformas usadas en los nodos que la integran. Las propias tareas y acciones que exige el tráfico en La WEB, así lo exigen. Por, ejemplo el enrutamiento en La Red es esencialmente dinámico, ya que, salvo configuración estática excepcional, no se sabe de antemano las rutas concretas que elegirá un router para llegar a un destino, y las decisiones deben de tomarse, generalmente, en cada momento según las situaciones. El entorno es generalmente incierto, por ejemplo en el tráfico IP en La Red, los paquetes salen, y no se saben cuando llegan ni en que orden van a llegar, ni siquiera si van a llegar. El entorno es generalmente complejo, por ejemplo, se eligen las rutas de acuerdo a métricas muchas veces compuestas, donde entran en juego la comunicación de diferentes elementos en la elección de las rutas intermedias. Los agentes del modelo MAS presentado en este artículo, distribuirán datos, controles o experiencias, en un entorno inseguro, variable y en donde se presentan generalmente un cúmulo de problemas, algunos de ellos ya descriptos en el punto 1.1 del artículo. Algunos ejemplos de transmisiones de datos que se transfieren en las redes: información del estado de las rutas, direcciones lógicas de destino, etc. Ejemplos de transmisiones de control son los envíos de ACK, las transmisiones referentes a la cantidad de paquetes recibidos, perdidos, la información sobre ltasa de error residual la que evalúa la cantidad de paquetes recibidos sobre un total de paquetes transmitidos, etc. Ejemplos de transmisiones de experiencias son los envíos hechos por los routers a los demás dispositivos pares, de los estados de los enlaces propios en las situaciones de caídas de dichos enlaces. Los agentes en este modelo MAS serán, como se plantea en el documento de tesis [Un marco de comunicación Inter_Agentes en una Biblioteca Digital.] son entidades autónomas que viajan por la red, se instalan en algún nodo y usan sus recursos en beneficio del nodo que los envió. Se usarán, en este modelo, lo que en al artículo de investigación se llama nodos de red. El itinerario del viaje de los agentes muchas veces deberá ser impreciso al momento de la salida, muchas veces con múltiples destinos con el fin de recabar información a través de diferentes fuentes. Además de la información que los agentes transfieren, por la Red, deberá de circular otro tráfico accesorio relacionado con el estado de los agentes , el control de la información que se va recabando, teniendo siempre presente la coherencia general del sistema.

42
Además por el entorno se deberá transferir componentes que informen sobre eventuales cambios detectados en los entornos o en los propios agentes. El modelo planteado deberá controlar la incidencia de los cambios , tanto en los agentes como en el entorno. En su transferencia por La Red, los agentes deben de poder mantener su estado interno, debiendo poder reanudar su ejecución cuando migren a otro nodo. Los agentes, mientras viajen por La Red, transfieren una serie de tareas que desarrollarán cuando lleguen a destino para lograr el cumplimiento de sus metas, pero los agentes deberán poder cambiar sus itinerarios cuando las circunstancias cambien. Las circunstancias de cambio pueden provenir de los propios agentes, o del entorno, mediante la sucesión de una serie de eventos.
Dentro del entorno están las aplicaciones, los otros agentes y los recursos. De modo que el entorno sería todo lo que rodea a los agentes : recursos, o aplicaciones, u otros agentes.
2.7. Forma de organización de los agentes en el presente modelo.
Los agentes actuarán, en el presente modelo, investigando e informando todo aquello que podría conducir a algunos de los problemas planteados en el punto 1.1. y recomendando acciones para solucionar o evitar que se den las situaciones problemáticas planteadas en el punto 1.1 Por consiguiente, sus entornos de trabajo serán, fundamentalmente los routers de interconexión de los backbones y los enlaces entre ellos. Pero, para la realización de sus objetivos, es necesario que el modelo defina las tareas específicas de cada agente, las relaciones de los agentes entre sí, y entre los agentes y las aplicaciones y entre los agentes y su entorno en general.
Desde el punto de vista de su organización, los agentes para el presente modelo, podrán ser: agentes simples ( por ejemplo, los que se aplican en cada router específico) o agentes complejos ( los que están formados por organizaciones workflown, las que incluyen tareas de agentes que están relacionadas con otros agentes, también pueden ser organizaciones colaborativas.
Todo esto está relacionado con la comunicación, o sea con la sociabilidad de los agentes, concretada a través del intercambio de información entre agentes y el conocimiento entre dos o más agentes a través de un canal de comunicaciones. El espectro organizativo de los agentes entre sí de este modelo irán desde sistemas sin comunicación a sistemas con comunicación de alto nivel, dependiendo de el tipo de metas planteadas para cada agente.
En cuanto a la estructura que se darán los componentes funcionales del sistema, sus responsabilidades, su forma de comunicarse, se permitirá diferentes tipos estructurales, según como se adecuen mejor a las situaciones concretas. Se permitirá lo que Horfan y Ovalle [Horfan D, Ovalle D] , refiriéndose a la estructura organizacional del sistema, le llamaron estructura “ad hoc”. Este tipo de estructura permite combinaciones de

43
diferentes formas de interacción entre los agentes del sistema : tanto permite una estructura centralizada ( donde un agente controla todos los demás agentes los cuales están todos en un mismo nivel ), como una estructura horizontal, (en la cual todos los agentes están en un plano de igualdad jerárquica y no existe ningún agente Controlador) , y una estructura jerárquica ( donde existen diferente niveles de agentes con diferentes niveles de abstracción, existiendo una estructura horizontal entre los agentes que tienen un mismo nivel, pero recibiendo órdenes de un agente superior). Esta estructura “ad hoc”, que es una mezcla de las estructuras posibles, permite un gran nivel de dinamismo, pues adecua la estructura a la situación concreta a resolver, y por ello es la que más se adapta a la situación de La Red. Una de las cuestiones a definir es determinar en que situaciones el modelo permitiría o no la comunicación directa entre los agentes entre sí, y en que casos necesitaría de otro procedimiento remoto que, en general mediante pasaje de parámetros, haría el lazo entre ellos.
En las situaciones en que se permitan la comunicación directa entre los agentes, se debe de posibilitar el diálogo múltiple entre ellos, tanto para emitir como para recibir mensajes, pudiendo ser iniciada la comunicación por cualquier agente. Para el análisis del tráfico WEB, los mensajes entre agentes podrían tener como objetivo el disparar una negociación o el comienzo del reuso de algunos de los componentes, o el de obtener un conocimiento necesario para la toma de decisión por parte del agente que lo solicitó. En los casos en que las comunicaciones entre los agentes deba efectuarse a través de un proceso servidor, centralizador de las mismas, ese mensaje se ejecutaría exclusivamente en el servidor, quien elegiría el método oportuno a ser ejecutado.
En ambos casos, es importante a tener en cuenta, el lenguaje común con que los agentes, directa o indirectamente, puedan comunicarse y usar parámetros comunes de ejecuciones, aún cuando los objetos y métodos sean diferentes.
Dado la amplia gama de problemas a analizar en el tráfico WEB, el modelo propuesto aplicará ambos abordajes, tanto las comunicaciones directas entre agentes, o las comunicaciones a través de un proceso servidor, dependiendo de las circunstancias concretas. En aquellos casos donde el conocimiento y análisis de la situación está determinado exclusivamente por el agente, y donde la intervención totalmente autónoma del o los agentes no comprometa el funcionamiento general del sistema, en esos casos es suficiente la participación exclusiva de los agentes, sin necesidad de participación de procesos centrales que dirijan las comunicaciones interagentes.
En cambio, sería necesaria la intervención de procesos centrales en aquellos casos donde el análisis implicase la consideración de situaciones que se extienden al ámbito estrictamente de los agentes involucrados en ella, o donde el análisis afecta a cuestiones centrales que escapen a la órbita de los agentes locales.
De modo que, para el presente artículo, la decisión de la forma de comunicación entre agentes, será dependiente del tipo y características de la comunicación.

44
Todo esto se aplicaría en un entorno esencialmente dinámico, donde los agentes pueden cambiar su comportamiento en función de cambios del entorno, por ejemplo, si apareciera un nuevo agente, por lo que las interfases deben de ser flexibles, dinámicas.
En cuanto a los tipos de relaciones que pueden existir entre los agentes, ellas estarán pautadas a través de sus capacidades de negociación y de cooperación. Al tener los agentes creencias, intenciones y deseos comunes, deben de poder lograr acuerdos comunes. La cooperación se refiere al trabajo conjunto entre agentes para lograr un objetivo global, entendiendo por tal un tipo de objetivo que interesa o incide en todo el sistema en general. En el caso del análisis del tráfico HTTP, basándose en los resultados obtenidos por los demás agentes, por ejemplo si los agentes de búsqueda de situaciones críticas detectan la existencia de rutas que se preveen se saturarán a corto plazo, el agente encargado de dar la alerta a los demás, realizará su tarea enviando mensajes y activando todo el sistema de alertas. También se puede llegar a negociaciones competitivas, debiendo de existir coherencia, o sea que el sistema de agentes debe de comportarse como una unidad, a pesar de que para lograr alguna resolución común se haya tenido que transitar por la negociación de diferentes propuestas competitivas. Los agentes, en el presente modelo, podrán estar agrupados en grupos, que no es más que la agregación de agentes, y cada agente podrá pertenecer a uno o más grupos. En el diseño del presente modelo, la integración de los agentes en grupos se definirá en función del tipo de meta propuesta para cada agente. A veces será necesario una estructura de workflow para definir la asignación de tareas, de recursos y las restricciones con las que se manejará cada agente. Los agentes del presente modelo, debido a la necesidad de multiplicidad de funciones a desarrollar , deberán de poder trabajar concurrentemente.
Para no superponer la ejecución de las tareas que les son inherentes a cada agente, o grupo de agentes, es que tal como lo plantea Horfan y Ovalle en su artículo de investigación [Horfan A., Ovalle D.], se permitirá la solución de los problemas de La Red mediante la descomposición en subproblemas. En el presente modelo, se hará la programación de tareas para cada agente, para poder ser efectuadas en forma paralela, y no serial, pues dentro de los objetivos planteados está el de optimizar el funcionamiento del tráfico HTTP, para lo que se intentará reducir los tiempos de ejecución de tareas y obtener un mayor aprovechamiento de los recursos. Lo interesante del artículo de Horfan y Ovalle, que podría aplicarse en el presente modelo, es la optimización del tiempo de ejecución y un mejor aprovechamiento de los recursos. Para lograr esto, los investigadores plantean una serie de pasos: en primer lugar una correcta planificación que resulte en una adecuada distribución de la carga de trabajo entre los agentes, y luego la optimización del tiempo de ejecución mediante la creación de un agente planificador que asigne tareas y subtareas y la creación de un módulo de

45
clonación que realice la distribución concreta de las tareas y subtareas y la introducción de un módulo de clonación que permita la distribución de las tareas de un agente entre otros localizados en la misma máquina o en otra estación comunicada por red. La comunicación entre los agentes solo será posible si existe un lenguaje de comunicación común entre ellos, y reglas precisas para optimizar su funcionamiento. Es importante, en el presente modelo, la definición de las técnicas o habilidades propias de cada agente. Una de ellas, para el presente artículo, es la capacidad de cada agente de generar un agente con las mismas o diferentes capacidades a sí mismo. En general, estos agentes creados por otro agente, se encargan de realizar subtareas. SINTESIS DEL PUNTO 2.7 Síntesis de formas de organización de los agentes dentro del SMA planteado en el modelo del presente artículo Objetivo general de un SMA :
cumplimiento de metas planteadas optimizar tiempos de ejecución con buen aprovechamiento de recursos
Medios :
distribución de carga de trabajo entre agentes Rol del agente central planificador y gestor asignación y distribución de tares y subtareas capacidad de generar agentes hijos
Formas de comunicación entre agentes : Algunos agentes sin comunicación con el resto La mayoría de los agentes con comunicación Tipos de comunicación inter-agentes: Negociación Cooperación Competencia Forma de organización de los agentes
(según incidencia del servicio sobre el MAS) Estructura centralizada ( un agente controlador y todos los demás agentes Controlados) Jerárquica ( varios niveles de abstracción. En cada nivel: estructura Horizontal y en cada nivel, controlado por un agente Controlador).
Forma de trabajo
concurrente entre agentes Descomposición de tareas en subtareas Integración en grupos de agentes. (un agente puede pertenecer a varios grupos).

46
2.8 Generalidades sobre la especificación de tareas de los agentes en el MAS.
Los agentes en el modelo propuesto, deberán en general, llevar adelante las tareas para los que permitan cumplir con las metas planteadas para cada agente. Para llevar adelante esas metas planteadas, ellos deberán realizar una serie de tareas más pequeñas y concretas en el marco del tráfico WEB. La especificación de esas tareas son muy generales, pero se permitirá en el modelo que un agente pueda realizar más de una tarea y que una tarea pueda haber sido realizada por varios agentes. La especificación de tareas que a continuación se detalla, no implica que todos los agentes lleven adelante todas las tareas, sino que por el contrario, habrá distintos tipos de agentes, que desarrollen tareas específicas. En función de todo lo desarrollado anteriormente, en el modelo MAS propuesto, los diferentes agentes, en general, desempeñarán las siguientes tareas :
� Indagar para conocer el estado del entorno � Indagar para autoevaluar su propio estado interno � Buscar y recuperar información relevante para el análisis del tráfico WEB. � Buscar, detectar e identificar situaciones críticas en ese tráfico . � Monitorear la situación del entorno � Procesar la información obtenida � Control de coherencia del sistema � Control de seguridad � Cooperar con otros agentes � Distribuir y asignar tareas a otros agentes � Evaluar el cumplimiento de las tareas asignadas a otros agentes � Distribución e intercambio de mensajes entre agentes � Definición de recomendaciones basadas en el procesamiento de la información � Definición de acciones para la satisfacción de sus metas � Intercambio de la información obtenida � Asignación de roles a otros agentes � Administrar recursos � Aprender de sus propias experiencias y de las de los demás agentes � Prognosticar estados futuros sobre sí mismo, sobre los demás agentes y el entorno � Planificar acciones concurrentes Cabe destacar que no todos los agentes realizarán todas las tareas, sino que ellas se distribuirán a los agentes o grupos de agentes dependiendo, dentro del modelo, del nivel de abstracción en que se esté considerando y de la ubicación y jerarquía del agente en el sistema MAS.

47
2.9 Síntesis del capítulo 2 En el presente artículo se propone un modelo de un sistema multiagente (MAS) para el análisis del tráfico HTTP por ser este tipo de sistema el que se ajusta, más naturalmente, a la realidad WEB a analizar . Las propias características de los agentes integrantes del sistema no solo son aplicables a esta realidad, sino que además, al poder incidir sobre el entorno, los agentes del modelo MAS planteado, traerían beneficios a ese tipo de tráfico. Por tratarse de un sistema MAS, la principal cualidad de los agentes integrantes del mismo, será la capacidad de interacción entre sí y con el entorno. Si bien todos los agentes integrantes del sistema gozarán de la capacidad de interactuar, Se describieron como tipo de comunicaciones entre los agentes del modelo, la negociación, cooperación y competencia. Uno de los desafíos del modelo es definir que agentes, y cuando ellos interactuarán. Habrá una multiplicidad de agentes en el sistema a proponer, clasificados según la función que cumplan en el modelo, según su lugar de actuación dentro del modelo, su capacidad de migrar o no por los nodos de La Red, según su grado de integración al sistema, según su forma de agrupación y de operación.
En el capítulo 2 se especifica, a nivel general, las grandes tareas que los agentes del sistema propuesto deberán realizar, en cumplimiento de las metas propuestas para cada agente del sistema. Es importante destacar que, a pesar de las acciones y tareas específicas de cada agente en el modelo se respetará la coherencia del sistema, la que se garantizará a través de control y seguimientos de las decisiones y acciones de sus agentes integrantes mediante agentes especializados en gestión y validación .
El modelo pretenderá lograr la flexibilidad adecuada para contemplar situaciones escalables y cambiantes dentro del tráfico HTTP, para lo que los agentes pondrán en práctica sus capacidades de aprendizaje, y de preveer situaciones que puedan darse en un tráfico futuro. El adelantarse a las situaciones futuras , aún cuando pueda existir algún margen de error tolerable, podría ser más beneficioso que pretender solucionar los problemas de tráfico, cuando ellos ya están instalados en La Red. El capítulo 3 , en base a las conclusiones abordadas en los capítulos 1 y 2, será una definición más detallada de la arquitectura del modelo propuesto en el artículo, con especificación de las funciones y componentes de cada uno de los principales subsistemas del modelo.

48
3. Pautas para la proposición de un modelo MAS.
3.1 Aplicación de las características de todo MAS, en el sistema MAS propuesto Plantea, en su tesis doctoral, Frederico Luiz Goncalves De Freitas [Goncalves De Freitas F, 2002], que en el abordaje de los problemas de la WEB, se pueden seguir dos tipos de modelos : los basados en grafos, en los que los punteros representan los arcos del grafo y se adaptan a problemas de búsqueda, y los modelos basados en datos semi-estructurados, en los cuales las partes de la WEB poseen entidades y atributos cuyo esquema no es completamente conocido, tolerándose en ella solicitudes que no se ajustan completamente al esquema general, avocándose a tareas sobre todo de sumarización y extracción de datos y tratan solo algunas partes de la WEB, aquella basadas en datos semiestructurados. Un sistema Multiagente permitiría el uso de un modelo basado en entidades y en sus interacciones, más que en la relación entre valores medibles, permitiría evaluar la dinámica general de los resultados del sistema y la interacción entre las entidades. Los modelos matemáticos, en cambio, como lo fundamenta Gaiti [Gaiti D, ] en su artículo de investigación , no permiten visualizar la estructura de las entidades que componen el sistema, no hay en ellos un detalle de cómo interactúan los componentes y como son modificados y como modifican el entorno. Por lo tanto, un sistema MAS permitiría un análisis más cercano de la realidad que los modelos matemáticos. Mediante el MAS a proponer se podría, por ejemplo, estudiar los modos de la organización y los métodos de las resoluciones colectivas y de los problemas que existen en la realidad. No obstante, por la propia realidad de la WEB, el sistema MAS propuesto, si bien es la mejor alternativa , va a encontrase con una serie de dificultades a las que, en etapas posteriores de investigación , serán analizadas más profundamente y a las que se les buscará la solución adecuada. En el caso de los agentes para el MAS propuesto, la asignación de tareas a los agentes podría dificultarse pues el entorno WEB es totalmente abierto ya que los agentes no saben con qué tipo de agentes se van a encontrar, y uno de los problemas principales a resolver es la forma como interacturán los agentes entre sí. Para que la interacción pueda ser válida, es necesario que los agentes cuenten con protocolos de comunicación comunes , con vocabularios comunes. Cuanto más y mejor puedan cooperar los agentes entre sí, más efectiva será el logro de las metas propuestas, en este caso, lograr un mejor y más eficaz análisis de los problemas del tráfico WEB. A su vez, los agentes del sistema MAS propuesto, están en continuo cambio y sus bases de conocimientos están siempre enriqueciéndose con nuevos y permanentes aportes de otros agentes. También está el problema de la seguridad, la que en entornos abiertos como la WEB queda más vulnerable. Por lo tanto, las eventuales dificultades que, en estos aspectos, puede traer el uso del sistema multiagente, no invalida la aplicación del modelo para el tema propuesto, sino que implica un desafío para que, fundamentalmente en futuras etapas de investigación, se

49
busquen las soluciones adecuadas a las dificultades que puedan surgir en las distintas áreas. Los sistemas multiagentes ofrecen un nivel de abstracción elevado, lo que ofrece mayores garantías para la satisfacción de las expectativas de los usuarios, pero, es necesario partir de un buen diseño del sistema, para que no signifique un aumento de la carga en La Red, debido al valor agregado que toda tecnología pueda provocar. En este punto del presente artículo se planteará los lineamientos generales de un modelo basado en un sistema MAS, cuya arquitectura se basa en la especificación de subsistemas de agentes que usarán, para el cumplimiento de sus objetivos, especificaciones y datos semi-estructurados, estándo por lo tanto más cercano al planteamiento del segundo tipo de modelo planteado por Goncalves De Freitas. Como se desprende de lo detallado en el punto 1 del presente artículo, los problemas en el tráfico WEB, pueden ser múltiples y de diverso índole. Se seguirá un análisis top-down para el diseño del modelo del MAS con varios niveles de abstracción. El primer nivel de abstracción en el planteamiento del modelo MAS a proponer en el presente artículo de investigación, es el de distinguir cuales serían las grandes áreas funcionales, cuales serían los objetivos específicos de esas areas, cuales serían sus particularidades, para integrar estas áreas en subsistemas de agentes con funciones específicas. Aplicando el principio de “dividir para reinar”, tan usado en el mundo de las redes, los problemas pueden ser divididos en subproblemas, lo que traducido al modelo MAS propuesto, implicará identificar como integrantes del sistema, diferentes subsistemas. Cad uno de estos subsistemas se diferenciarán entre sí por las metas a las que estarán abocados. Las diferencias entre ellos estarán, fundamentalmente, en las funciones que les son propias, y en el tipo de agentes que llevarán adelante dichas funciones . No obstante, por las características del modelo, que pretende ser lo más abierto posible, pueden existir tareas y acciones que no sean exclusivas de algún agente en particular, sino que pueda ser ejecutada por varios tipos de agentes. En un segundo nivel de abstracción, el modelo diseñará preliminarmente cuales serán los principales agentes que trabajarán en cada una de esas subsistemas. Cada área , si bien tienen funciones específicas, deben de converger para lograr alcanzar los grandes objetivos del sistemas MAS propuest. Para ello, los subsistemas interactúan entre sí, lo cual se traduce en el envío de mensajes, las sincronizaciones para mejorar la performance de La Red, etc. Por lo tanto un tercer nivel de abstracción del modelo enfoca al análisis preliminar de la interacción entre los subsistemas del modelo propuesto.

50
..... Cada subsistema ..... Diferentes agentes de cada subsistema .....Interacciones entre los subsistemas Gráfico Nro1 - Simbolización de los tres niveles de abstracción en el modelo propuesto
Al estudiar el tráfico HTTP a través de un sistema MAS, que permita analizar algunos de los problemas planteados en el punto 1, surgen una serie de áreas que deberían de ser abordadas para satisfacer los objetivos propuestos para el modelo. Tales áreas se diferencian, fundamentalmente por los objetivos y metas propuestas para cada una . Dichas áreas de abordaje del modelo propuesto, con sus nombres y descripciones, están sintetizadas en la tabla Nro. 5

51
Areas de abordaje del modelo Descripción general de esas áreas Procesos y entidades participantes
Definición y descripción de los procesos Definición de agrupación de agentes, tipos de agentes, sus comportamientos, estados. Definición de reglas adecuando el comportamiento de los agentes a los problemas específicos. Definición de pertenencia o no, de los agentes a uno o varios grupos Asignación concreta de tareas para agentes.
Formas de comunicación general entre entidades participantes
Diferentes formas, dependiendo de los propósitos, del tipo y alcance de la comunicación
Interfaces
Descripción de características generales de interfaces entre procesos y con usuarios, tendiendo a lograr interfaces flexibles, dinámicas, ágiles, con cortos tiempos de respuestas .
Interacciones entre agentes
Definición de formas de interacciones Definición de contenidos de aprendizajes Definición de protocolos y lenguajes comunes
Contexto
Definición del entorno. Incidencia del entorno sobre el funcionamiento de los agentes. Incidencia de los agentes sobre el entorno.
Generación de conocimientos y su distribución
Definición de la transformación desde los datos a los conocimientos
TABLA 5. Algunas áreas de abordaje preliminar del presente modelo.

52
3.2 Fases para el diseño del modelo propuesto
Para poder cumplir con los objetivos planteados al sistema, se deberán de realizar una serie de definiciones concretas respecto a una multiplicidad de temas. Entre estos aspectos a definir están : las características y funciones de las entidades que existirán en el modelo, sus interacciones, las especificaciones del comportamiento de cada una, las formaciones de las agrupaciones de agentes, sus roles, sus recursos, las interacciones entre ellos y las aplicaciones, los tipo de inteligencia y de autonomía que tendrá cada agente, los estados de comportamiento que podrá tener cada agente, cuales son los posibles estados de los agentes y que medios de control aseguran las transiciones de estado entre ellos, que tareas se asocia a cada uno o a que grupo de agente para que ese agente o grupo pueda cumplir con sus objetivos, cual es la capacidad de aprendizaje que el agente necesita para realizar sus metas, como pueden los agentes acceder a los recursos , y como definir dicho acceso si los recursos solicitados por varios agentes fueran insuficiente para satisfacer las necesidades de todos, como gestionar las diferentes sesiones entre agentes, etc. etc.
Para poder lograr la especificación de todos estos puntos, se empezará en esta etapa de la investigación a analizar desde los aspectos más generales, con un criterio top-down, para llegar a análisis detallados que conduzcan a precisiones más profundas y concretas de los componentes específicos de las grandes áreas que se considerarán en el presente modelo.
El método que se propone en el presente artículo para la elaboración del modelo MAS, implicaría precisar definiciones concretas en torno a 3 fases: 1) La primera fase sería descomponer la realidad en componentes que interactuan entre sí
, reproduciendo los fenómenos reales. Esto requiere una visión distribuida del fenómeno real Si bien el modelo debe ser adaptativo, o sea que las entidades cambian en función del cambio de las entidades de su entorno, ya en esta etapa se realizará una representación de la arquitectura general de La Red, donde se modelará los grandes módulos o subsistemas integrantes del modelo. Los subsistemas integrantes del MAS propuesto, son diferenciaciones virtuales efectuadas según las funcionalidades, metas y agentes integrantes de cada uno de estos componentes, sin perder la perspectiva de que , junto con los demás subsistemas, están integrando un único sistema MAS.
2) La segunda fase es modelar los agentes que integran cada módulo , o subsistema,
definir sus objetivos principales, sus metas, su forma de organización.
3) La tercera fase es la descripción de las interacciones más importantes entre los subsistemas definidos en la primera fase. La especificación de las objetivos planteados para cada uno de los subsistemas del primer nivel de abstracción está determinado para obtener la información necesaria para detectar y hacer recomendaciones frente a los problemas del tráfico HTTP, expuestos en el capítulo 1.

53
Las especificaciones de las características de los agentes, sus tareas, y las posibles interacciones entre las entidades participantes, correspondientes al segundo y tercer nivel de abstracción para este modelo, son esencialmente cambiantes en el tiempo. La realidad dinámica de Internet exigirá, a este nivel, la permanente confrontación entre lo definido en momentos anteriores, y lo real del momento a analizar. Las definiciones concretas de tareas, para cada agente o grupo de agente, es sumamente cambiante en La Red.

54
CARACTERÏSTICAS GENERALES
VENTAJAS EVENTUALES DEBILIDADES A CONSIDERAR
Diseño top-down
Alto nivel de abstracción, siguiendo el flujo lógico de los procesos de búsquedas, generación y distribución de conocimientos
____________________
Basado en datos Semiestructurados Estructura áreas funcionales siguiendo parámetros de fenómenos reales
Cercano a las expectativas de usuarios
____________________
Permite ajustes de componentes , de tareas y seguimientos a través del tiempo
Adaptativo y dinámico
Cambios continuos , podrían dificultar la asignación de tareas.
Automatización de los procesos Posibilidad de trabajos concurrentes
Cubre necesidades de tiempo real
__________________
Inserción de agentes móviles
Reduce tráfico en La Red
Ver tema de seguridad e incidencia del entorno sobre los agentes
Inserción de gestión de agentes
Aumenta control de seguridad
___________________
Estratificación de subsistemas por funcionalidad
Aumenta robustez y flexibilidad del sistema
____________________
TABLA NRO 6 - Características generales del modelo propuesto

55
3.3 Arquitectura del primer nivel de abstracción del modelo En el presente artículo se usará el término de arquitectura , en el mismo sentido que lo expresa el artículo de investigación de Marc & Scott [Marc J R & Scott A. D] una abstracción que permite el uso de una serie de componentes de una forma particular. Según lo planteado por Carlos Angel Iglesias[Iglesias Fernández, C A, 1997], la arquitectura de agentes descubre la interconexión de módulos software-hardware, que permite a un agente exhibir la enunciadas en las teorías de agentes. La arquitectura de la primera fase del modelo consistirá, según lo expresado en el punto 3.2, en la descomposición de la realidad en componentes, reproduciendo los fenómenos reales. En este primer nivel de abstracción del modelo se visualizará la realidad como un sistema único, una unidad con coherencia , a pesar de sus componentes específicos, los que serán analizados como subsistemas integrantes de esa unidad general. El objetivo del modelo será el de facilitar el análisis de los procesos, usando un sistema MAS, Los componentes, o subsistemas, que integrarán la arquitectura general del modelo MAS propuesto serán: A) Subsistema de recepción de solicitudes. B) Subsistema de controles de legitimidad y de coherencia. C) Subsistema de gerenciamiento de agentes D) Subsistema de búsquedas de información. E) Subsistema de generación de conocimientos. F) Subsistema de interacción entre agentes G) Subsistema de interacción agentes-entorno H) Subsistema de distribución de mensajes I) Subsistema de intercambio de conocimientos
Cada uno de estos subsistemas, cumple una función específica en el modelo
A) Subsistema de recepción de solicitudes Las solicitudes de algún servicio o información especial, podrán ser efectuadas por los usuarios, o por algún agente o grupo de agentes que emprende acciones o solicita servicios para satisfacer sus objetivos. Es conveniente determinar el concepto de usuario, que para este artículo, hace referencia tanto a personas físicas como a procesos que solicitan alguna información de la situación de La Red, como también puede ser un agente el que inicia la ejecución de lo estipulado en el modelo. Las personas, generalmente administradores de algunos de los dispositivos de La Red y que solicitan alguna información sobre el estado de los mismos, o de las rutas o de los enlaces.

56
Dentro de los procesos, suele existir frecuentemente una relación entre procesos productores y consumidores de servicios. Los primeros, como plantea Tanembaum [Tanembaum A, 1995], generan los servicios que luego van a ser usados por los procesos productores. En el ámbito del tráfico HTTP existe gran cantidad de procesos que solicitan o usan servicios o informaciones generadas por otros procesos de La Red. En este ámbito de relación entre procesos, muchas veces no es necesario la intervención de los seres humanos. En este módulo se recibirían las solicitudes de los usuarios y de los agentes que inicien las ejecuciones. Luego de realizados los procesos determinados en el modelo, se enviarían a los usuarios y a los agentes que iniciaron el proceso, los resultados de sus solicitudes. El subsistema de recepción de requerimientos debe analizar la legitimidad preliminar de las peticiones, para lo cual se deberá de contar con bases de solicitudes. No obstante, la legitimidad de una solicitud deberá de ser ratificada por el módulo de control de seguridad. Estos agentes receptores de solicitudes, según lo expresado en un artículo de AAAI Press / The MIT Press [AAAI Press/The MIT Press, 1997], ayudan a los usuarios y/o agentes recibiendo instrucciones implícitas o explícitas de dichos usuarios, o pidiendo consejos o información a otros agentes. En las relaciones agentes-personas, en el análisis detallado, se deberá de definir cuestiones centrales como la forma como las personas instruirán los agentes, cómo las personas harán un seguimiento del cumplimiento de las solicitudes efectuadas, la forma como se dará la interacción agente-persona.
B) Subsistema de controles de legitimidad y de coherencia .
Este subsistema tiene como función principal la de mantener coherente, como una unidad lógica los distintos módulos o subsistemas del modelo, aunque sus componentes sean heterogéneos. Este subsistema sería el corazón del modelo, ya que controlaría que todos los demás subsistemas cumplan con las especificaciones generales planteadas en el modelo. Este subsistema prevee la colaboración entre los diferentes subsistemas del modelo, monitoreando o realizando seguimientos de los resultados obtenidos en cada subsistema al tratar de satisfacer sus metas específicas. Para poder cumplir con estas tareas, en este subsistema se trabajará con protocolos, pedidos de ayuda a otros subsistemas, componentes y mecanismos que posibilite el control de que lo que se plantea ejecutar, aún a nivel local, no colisiones con los grandes objetivos del sistema general. A través de este subsistema, se validaría las solicitudes de servicios al sistema, el ingreso de agentes, la permanencia de agentes en el sistema, la persistencia y actualidad de la información recabada, el permitir o denegar ingresos de nuevos conocimientos a las bases de conocimientos.

57
También en este subsistema se regulará el orden de ejecución de las transacciones simultáneas sobre la base de conocimientos, para mantener la coherencia e integridad de la base. Para realizar estos propósitos, es necesario la definición de reglas precisas que definan cuando una solicitud, un agente, un conocimiento, son válidos para el sistema. En este subsistema se evaluarán y se realizarán listas de inconsistencias. Si el que efectuó la solicitud es un agente, este subsistema solicitará los servicios del subsistema de gerenciamiento de agentes, con el objetivo de validar al agente solicitante. C) Subsistema de gerenciamiento de agentes.
Los objetivos de dicho subsistema será el de identificar y legitimizar los agentes que participan en la ejecución de lo planteado en el modelo, así como determinar el grado de subordinación entre agentes. Los agentes del sistema MAS que se propondrá, podrán entrar y salir del sistema, de acuerdo a la que necesiten satisfacer alguna meta específica, o que ya hayan satisfecho sus metas y no amerite su estadía en el sistema, al menos momentáneamente. Los agentes que ya hayan cumplido con sus objetivos, no mueren físicamente, sino que quedan en un estado inactivo, latentes, y podrán ser invocados o ellos mismos podrán reiniciar sus actividades si fuera necesario. El objetivo de esta posibilidad que tienen los agentes, es para controlar y disminuir el tráfico innecesario dentro de La Red, efectivizando el uso de los recursos de La Red. Los agentes pueden ser identificados según lo establecido en el punto 2.4, sintetizado en el esquema que aparece a continuación según diferentes criterios. Los agentes del presente módulo deberán de ser capaces de identificar, en concreto, cual es el tipo de agente que realiza una solicitud o envía una información, o está realizando cualquier tipo de tarea. La importancia de la identificación de los agentes participantes radica en poder determinar el alcances de sus competencias, el grado de jerarquía del agente dentro del modelo, con quien podrá o no podrá interactuar, cual será su ciclo esperado de vida, etc.
D) Subsistema de búsquedas La función principal de este subsistema es la de indagar, siguiendo tanto las solicitudes expresadas en el subsistema anterior, como las propias iniciativas de los agentes. Los objetivos de las búsquedas es localizar informaciones relevantes para poder cumplir con alguna meta específica. Para ello la primera búsqueda se harán en las bases con las que se contará en el subsistema, en caso de no encontrar allí la información requerida, los agentes de búsqueda, podrán migrar para tratar de encontrar la información o servicio solicitado en cualquier otro punto de La Red. Luego de obtenida la información necesaria, ella será validada en los subsistemas que tengan esta competencia, reordenar la información recibida, clasificada según criterios predeterminadas y registrada en los lugares correspondientes para luego ser transferido al subsistema de procesamiento de información.

58
E) Subsistema de generación de conocimientos El objetivo de este subsistema es la producción de conocimientos para la satisfacción de las metas u objetivos planteados por algún subsistema de agentes, o por el sistema MAS en su totalidad. Este subsistema trabaja con información que puede provenir de la búsqueda efectiva lograda por el subsistema de búsqueda, o puede provenir de experiencias acumulada de algún agente o grupo de agentes, a través de instancias de aprendizajes de estos agentes. Cualquiera sea el origen de la información, sea cual fuera el origen de esa información, previa validación en el subsistema competente para ello, esa información validada, será sometida a un procesamiento adecuado en este subsistema, a los efectos de generar conocimientos. Estos conocimientos se registran en bases de conocimientos, de forma tal que puedan ser usados y vueltos a usar mientras fueran necesarios y útiles . En las tareas de procesamiento de la información, se deberá de ponderar cuales son las informaciones relevantes para el sistema, y cuales pueden o deben ser descartadas. Existe entonces, entre las tareas de obtención de información y la de generación de conocimientos, una serie de tareas de selección de información y de descarte de información irrelevante para las metas propuestas. F) Subsistema de interacción entre agentes La función principal de este subsistema es la de definir las formas como los agentes individuales pueden trabajar juntos para resolver problemas complejos ,como por ejemplo la toma de una decisión importante que podría necesitar del diagnóstico de cada agente individual. Para realizar este tipo de funciones, en este subsistema deben de estar contempladas las funciones de coordinación, negociación , comunicación y resolución de conflictos. Las funciones de comunicación en el subsistema podrán tener dos objetivos principales: o bien como indagatoria para ver si existen algunos agentes que puedan satisfacer algún objetivo específico, o bien como solicitud imperiosa de ayuda de parte de un agente a otro agente para que lo auxilie en la realización de una tarea específica para la cual el primero carece de elementos o experiencia para solucionar. Para lograr las funciones típicas de este subsistema, es imprescindible contar con , por lo menos un protocolo y un lenguaje comunes entre los agentes integrantes. A ese nivel de la investigación, aún no se ha definido en concreto el lenguaje a usar, quedando esa decisión para ser tomada en etapas posteriores de investigación. Pero como supuestos imprescindibles del lenguaje común, se define que el lenguaje común a usara deberá de tener un diccionario de palabras, un lenguaje de contenido semántico, por ejemplo, del tipo KIF u otro similar, y un lenguaje de comunicación, tipo KQML. El lenguaje de comunicación de agentes definirá el formato de los mensajes, tarea que es del ámbito del subsistema de distribución de información.

59
Según lo demuestran investigadores del tema interacción entre agentes, como González & otros [González J.M, Hamilton A.F, Méndez J.A., Torres S., Torres J.M. , Sigut M.], también en este subsistema se definirá la forma como se organizarán los diferentes componentes para llevar adelante la interacción. Esta forma de interacción está analizada y definida en el punto 2.7 del presente artículo. G) Subsistema de Interacción Agentes-Entorno La función principal del subsistema es definir las relaciones entre los agentes y el entorno, entendiendo como tal las aplicaciones, los dispositivos, los recursos, etc. Este subsistema realizará las tareas para poder satisfacer sus objetivos, de acuerdo a los principios ya establecidos y probados , expuestos en el artículo de investigación de Alonso & otros [Alvarez A, Villar Flecha J R, Benavides Cuellar C, García Rodríguez I Rodríguez Sedano F J ], en donde se concluye que el entorno tiene ciertas propiedades que se deben de tener en cuenta cuando se le atribuyan funciones a los agentes de entorno. Estas características son que el entorno es impredecible, incierto, pero que a pesar de ello, el entorno puede ser controlable en tanto se podría hacer un control mediante el aprendizaje automático de los parámetros no predecibles . Los autores del artículo plantean, además, que se debían de usar experiencias pasadas en la toma de decisiones presentes. El entorno, a su vez, no debe ser considerado de tiempo real, y los atributos del entorno pueden cambiar en el tiempo. 3.4 Arquitectura del segundo nivel de abstracción del modelo Este nivel de abstracción se encargará de la especificación de las tareas de los agentes de cada uno de los componentes del modelo. No obstante las particularidades de cada agente, según el subsistema al que esté integrado, existen tipos generales de agentes que pueden trabajar en diferentes subsistemas. Amerita explicar que la “integración” de los agentes a los subsistemas son funcionales, en tanto implica que los agentes tienen como metas principales el cumplimiento de los objetivos generales de los subsistemas de los que son parte. Tomando en cuenta el valor jerárquico que pueda tener cada agente dentro del sistema, independientemente del subsistema específico que integre, los agentes podrán ser, en el modelo propuesto, agentes monitores o agentes subordinados. Los agentes monitores son los actores principales dentro de un subsistema pues ejercen su autoridad sobre el resto de los agentes del mismo o de otro subsistema. Los agentes monitores les darán directivas a los agentes subordinados, podrán decidir sobre ellos, provocándoles cambios de comportamientos, tratarán los mensajes que vienen de otros nodos, tomarán decisiones, aprenderán y posibilitarán comunicaciones de alto nivel y dan información sobre el estado de los componentes que ellos tienen subordinados ( por ejemplo otros agentes, los nodos, etc.) Es el agente principal que informa a los agentes jerárquicamente inferiores, sobre cambios de nivel de servicio.

60
Para poder cumplir con estas tareas de monitores, los agentes monitores deben de poder acceder a los recursos de La Red, fundamentalmente a los recursos más importantes dentro del tráfico de La Red, como por ejemplo, los buffers de los nodos , los procesos de comunicación y las tablas de ruteo. Los nodos, a su vez, podrán diseñarse en el modelo propuesto como agentes y deben de poseer buffers, colas de tareas de procesamientos y tablas de ruteos . Ellos deben de dar información sobre los tiempos de respuesta específicos en cada lugar, para permitir los ajustes necesarios. Cuando un paquete llega a un nodo, él debería de ubicarse en standby en el buffer, Los buffers tienen un tamaño limitado y autorizan a conocer la velocidad de acceso, en tiempo real, y el número de respuestas que han sido descartados de acuerdo a sus clases, etc. Habrá agentes administradores de colas, los que son reactivos pues pueden provocar acciones que actúen directamente sobre el entorno. Estos agentes solo tienen acceso a los buffers y deciden sobre el tratamiento a dar a los paquetes que llegan a las entradas de los enlaces , ubicándolos en lugares de almacenamientos temporales, siguiendo las directivas marcadas por agentes principales. Ellos solo tienen acceso a los buffers. Estos paquetes ubicados en los buffers, serán luego tratados por otro tipo de agentes : los agentes de servicio, los que enviarán los paquetes a través del o los enlaces correspondientes, de acuerdo a reglas definidas. Para que los agentes puedan cumplir con las tareas que lo son específicas, se definirán agentes generales cuya función sea la de detectar la situación planteada en el tráfico WEB. En primer lugar deberían de detectar frente a que tipo de situación se estaría: podría ser una situación-problema o una situación-normal. En la asignación de sus funciones, y en el cumplimiento de las mismas, se tendrá en cuenta lo especificado en la Tabla Nro 2.
Por lo tanto, los agentes detectores de situaciones deberían de validar las solicitudes , y en general cualquier operación efectuada para poder definir el tipo de situación planteada , clasificar la situación y ubicar el resultado de esta búsqueda en una base de datos distribuida y estructurada según situaciones detectadas.
Estos agentes buscadores analizarían la situación al momento de una solicitud WEB, lo que no implica que tal situación sea la situación real en todo momento, pues ella podría haber cambiado en función de cambios del entorno. Por lo tanto, los agentes buscadores y clasificadores de situación deberían de actuar, tanto al inicio de una solicitud WEB, como en cualquier momento en que se produzca un tráfico WEB.
Estos agentes, para que puedan trabajar, necesitan una especificación de sus características y funciones . Así, por ejemplo, más detalladamente respecto al punto anterior, habrá agentes jerárquicamente superiores encargados de definir funciones dinámicas para otros agentes ubicados en niveles inferiores a ellos. Habría otros agentes dedicados a la recepción de solicitudes, otros dedicados a definir los datos considerados válidos para cada solicitud, otros dedicados a validar esas solicitudes, otros dedicados a ubicar dichas solicitudes en las bases de datos pertinentes, etc.

61
Ya en este enfoque, los agentes para poder realizar sus tareas, muchas veces necesiten de otros agentes, por lo cual habrá agentes específicos encargados de las conexiones y cooperaciones entre agentes, otros encargados de definir los mensajes y acciones entre agentes, otros de estandarizar las formas de comunicación entre agentes, etc. Para el cumplimiento de estas funciones, se tendrá en cuenta lo especificado en la tabla Nro 3 y Tabla Nro. 4 del presente artículo.
Además de estos tipos de agentes, con funciones generales en el sistema MAS propuesto, habrán agentes específicos cuyas metas será satisfacer los objetivos particulares de cada uno de los subsistemas planteados en el punto 3.3 A) Agentes del subsistema de Recepción de Solicitudes Los agentes que trabajan en este módulo, sea en la relación con humanos, como con procesos, o con otros agentes, serían del tipo de agentes llamados en las teorías de agentes como los agentes de interfaz . Estos agentes son similares a los que llamados agentes AUI (Agentes de Interfaz de Usuario) en el proyecto de la Universidad de Michigan [University of Michigan Digital Library ] Los llamados Agentes AUI en el proyecto UMDL(University of Michigan Digital Library), son similares a los agentes del presente subsistema, en tanto estos agentes administrarán la interfase entre los recursos y los usuarios. El concepto de usuario usado aquí es en el sentido amplio de usuario, especificado en el punto anterior, y el concepto de recursos hace referencia a los recursos de La Red. Estos agentes podrán realizar algún control en los aspectos sintácticos y semánticos, a las solicitudes presentadas, tal cual como se plantea en el proyecto de Ingenias[Ingenias, sección del WEB de GRASIA ], donde se especifica el rol de los agentes de interfaz de usuarios en el ciclo de vida de los agentes en el modelo que este proyecto plantea Estos agentes se encargarán de recibir peticiones, realizarles un análisis preliminar de legitimidad y enviarlas a los agentes correspondientes que controlarán en profundidad la legitimidad y coherencia de las mismas , quienes en otras instancias decidirán si corresponde o no darle tránsito a la solicitud efectuada. En el modelo propuesto, se les dará a estos agentes, solo algunos conocimientos, los que luego serán registrados a una base de conocimientos. Pero lo sustancial del conocimiento que ellos usarán para la toma de decisiones, lo aprenderán de los propios usuarios, tal como se expresa en la Monografía de María Angélica Calixto de Andrade Cardieri [Calixto de Andrade M, 1998] . De esta forma, según Calixto de Andrade, se ahorrará en esfuerzos de parte del usuario final, aumentando el grado de confiabilidad frente a estos agentes, ya que los agentes de interfaz ejecutarán sus tareas basándose en el comportamiento de los propios usuarios.
Estos agentes podrán, además, tener iniciativas propias, en beneficio de los intereses de los usuarios, aunque esas acciones no les hayan sido expresamente ordenadas.

62
De modo que estos agentes reciben las solicitudes de los usuarios, y envían dichas solicitudes a otros subsistemas para su evaluación más profunda y definitiva. Una vez que dichas solicitudes sigan los procesos que correspondan, los agentes de este subsistema, estos agentes enviarán a los usuarios los resultados de esas solicitudes.
B)Agentes del Control de seguridad y legitimidad Tal como se plantea en algunos otros Proyectos que plantean la existencia en los sistemas MAS de uno o varios agentes que funcionen como control de las funciones y componentes que podrían afectar al funcionamiento general del sistema, por ejemplo en el proyecto de Marc y Scott [Marc J R & Scott A. D], estos agentes están asociados a la idea de guardianes del sistema. Los agentes Guardianes, podrán ser de varios tipos : algunos tendrán su ámbito de acción a nivel central, pero la mayoría serán de alcance local, para cada subsistema, dependiendo de lo que cada uno de ellos controle, específicamente. Los agentes guardianes centrales contarán con procesos que fueron almacenados previamente, en los que se definirán reglas generales que permitan evaluar la legitimidad de las solicitudes, de los agentes o de los conocimientos que se pretenden ingresar al sistema. Los agentes guardianes locales actuarán en un principio de acuerdo a reglas generales, pero a medida de que aprendan de sus nuevas experiencias, luego de una serie de casos, podrán integrar nuevas reglas, bajo condición de que la modificación de estas reglas puedan ser avaladas por agentes guardianes generales. La forma de avalar las solicitudes, los agentes y los conocimientos, podrá ser mediante claves de identificación u otras formas de control de seguridad, todo lo cual se definirá explícitamente en etapas de investigación siguientes a la culminación de este trabajo . Los agentes guardianes serán responsables del control de seguridad, mediante un diseño que les permita evaluar diferentes tipos de solicitudes o decisiones.. Además habrá otros agentes guardianes que se encargarán de la prevención de algunos errores, como la escritura y lectura simultánea en una misma base de conocimiento. Estos últimos agentes se encargarán de mantener la coherencia dentro del sistema, resguardando que no exista ninguna operación que pueda atentar contra ella.
C) Agentes del subsistema Gerenciamiento de agentes
Está integrado por Agentes jerárquicamente superiores, en relación a los demás agentes, que manejan información y gestionan respecto a las identidades de los agentes, a sus estados internos, sus competencias, etc. Son los que permitirán o negarán, por ejemplo, el ingreso al sistema MAS de un nuevo agente, o que permitirán u ordenarán la salida de un agente del sistema, o el cambio de estado, o su puesta en “standby”, etc. Cuando un agente es enviado, o decide ir a recabar información a un nodo remoto de La Red, los agentes de este subsistema realizan el seguimiento del estado de estos agentes en el nodo remoto, verificando periódicamente su estado para controlar el grado de incidencia que el entorno podrá tener sobre el agente.

63
Se tratará de que cada agente tenga un control propio sobre su estado interno , pero además, ese estado interno podrá ser alterado por estos agentes de gestión que son jerárquicamente superiores a los agentes comunes. D) Agentes de subsistema de Búsqueda Los agentes destinados a las búsquedas además de ubicar y extraer la información necesaria para cumplir con determinados objetivos, también para efectivizar esas búsquedas, una vez que obtienen la información, la deben de ordenar o indexar. De esta forma, en posteriores búsquedas sobre un tema cuya información aparezca indexada, habría una reducción del tiempo de búsqueda. De modo que estos agentes tendrían como tareas las de conseguir, gerenciar, ordenar las informaciones básicas para la toma de decisiones. Podrían presentarse problemas en el mantenimiento actualizado de la información previamente clasificada, tal como se planteó en un seminario de pos-graduación en la Universidad de Minas Gerais, Brasil , en un trabajo presentado por Ferreira Loureiro & Campos Costa [ Loureiro & Costa, 1998] Si bien estos autores plantean el problema pensando en agentes generales de búsqueda de información dentro de la WEB, la esencia de la problemática puede aplicarse a cualquier tipo de búsqueda efectuada en La Red, pues plantea como mantener actualizado un cúmulo de información en un medio que es esencialmente cambiable y desorganizado. El gran desafío para estos agentes será el de tener actualizada toda las bases de informaciones, para lo que deberán de tomar sus propias iniciativas, realizando nuevas búsquedas para confrontar siempre la realidad con la información ya registrada, para ver si aún ellas están de acuerdo. Estos agentes deberán ser esencialmente reactivos, ya que deben de estar sensando permanentemente el medio y reaccionar frente a cambios del mismo, o frente a informaciones recibidas de otros agentes. Estos agentes son esencialmente móviles, por lo que , tal como lo expresa el Seminario de Desarrollo de Proyectos de Investigación del Instituto Tecnológico de Ciudad Madero [Instituto Tecnológico de Ciudad Madero ] podrán viajar por las redes, interactuar con los hosts, pedir información en representación del usuario y regresar a su lugar de origen Esto hace que puedan ser más eficientes, baratos y podrían contribuir a solucionar los problemas más rápidamente. E) Agentes del subsistema Generación de Conocimientos. Estos agentes, debido al tipo de tareas a desempeñar, son esencialmente agentes inteligentes. En el presente artículo se entiende por “agente inteligente”, tal como lo especificaba Reddy [Reddy, 96] , sería todo aquel agente que podría generar su o sus propios objetivos. Los agentes que trabajen en este módulo podrán, si así lo consideran necesario, elaborar sus propios objetivos y, sobre la información recibida, generar nuevos conocimientos aunque estos conocimientos no estén previstos, o no hayan sido

64
previstos ni solicitados. Estos nuevos conocimientos podrán generar a su vez, nuevos conocimientos. Existirán, tal como en este punto fue propuesto en la Conferencia internacional sobre Man, y Cibernética de China [ IEEE International Conference on System, Man and Cybernetics, 1996], en el modelo propuesto, dos grandes tipos de agentes del conocimiento: aquellos que generan la base de conocimiento común para cualquier agente del sistema MAS, y aquellos que generan conocimientos que pueden ser accedidos solo por algún grupo o grupos limitados de agentes. La tarea de generar conocimiento es una de las principales en el modelo propuesto, pues eventualmente estos conocimientos serán la base de las decisiones y recomendaciones a realizarse. Por lo tanto, estos agentes, antes de generar estos conocimientos, deben de validar la autenticidad de los mismos, la legitimidad de quien los solicita y , en un grado mayor de optimización, también validar la necesidad de la utilización de los conocimientos generados. Esto último en aras de ir regulando el tráfico en La Red, ya que según se especificó en el punto 1, la sobrecarga en el tráfico es uno de los problemas principales del tráfico HTTP. Estos agentes generarán conocimientos, basándose fundamentalmente en reglas específicas que ellos tienen predefinidas, o que van creando a partir de la combinación de las predefinidas con las obtenidas a través de sus propias experiencias. F) Agentes de Subsistema de Interacción entre Agentes En este nodo habrá un agente que trabajará como administrador central, y que se encargará de gestionar las tareas de comunicación entre agentes, identificando y caracterizando los agentes que interactúan, incoporando al sistema aquellos agentes que lo solicitasen, si fuera necesario replicar los agentes en los repositorios remotos, migrando agentes hacia los lugares donde hubiera alguna demanda que de otra forma no pudiese satisfacer, agrupar en grupos de agentes a aquellos con características semejantes, detectar el estado actual de los agentes participantes, provocar cambios de estado de los agentes si estos cambios fueran necesarios para la interacción , etc.
En principio, los agentes podrán estar en estado activo, inactivo, o reactivado . Los estados de los agentes son dinámicos y pueden cambiar en el tiempo. Los agentes integrantes de este subsistema , si los cambios de las situaciones así lo necesitase, podrán provocar cambios de estado en los agentes que quieran interactuar o luego de una interacción. También cualquier agente podrá, salvo especificación en contrario, regular su propio estado interno, provocando por sí mismo, cambios en ese estado. Los agentes de interacción de agentes gestionarán, para el caso de que exista, o e que haya voluntad de existir, una interacción entre agentes , todas las características de los agentes que, en situaciones fuera de una interacción, son regulados por el Gestor de Agentes( especificado en el punto C)

65
G) Agentes del Subsistema de Interacción Agentes-Entorno Los agentes de este subsistema contendrán las estructuras básicas para que puedan realizar las interacciones necesarias con las plataformas y con el entorno en general. Pero, al ser el entorno tan cambiante, se deberá especificar el momento preciso al cual se refiere la interacción Gestionan la interacción con el entorno, administrando los recursos de hardware y de software necesarios para la búsqueda de información y realización de otras tareas que involucren a recursos del entorno. También se encargarán de la actualización del estado del entorno, así como también podrán incidir sobre el mismo, iniciando acciones que determinen cambios en ese entorno. Estos agentes podrán desactivar un recurso, eliminarlo como recurso activo, informar sobre su estado, y modificarlo. Mediante estos agentes, se pretende lograr un uso eficiente de los recursos , optimizando el acceso y la disponibilidad de los mismos. Estos agentes podrán incidir sobre el entorno, pero uno de los aspectos a considerar, en la etapa de implementación del modelo, es el de neutralizar la posible incidencia que el entorno podría efectuar sobre estos agentes, fundamentalmente sobre aquellos agentes que , usando su capacidad de movilidad, migran por diferentes nodos dentro de La Red. Este tema será objeto de especial investigación en etapas posteriores de profundización.
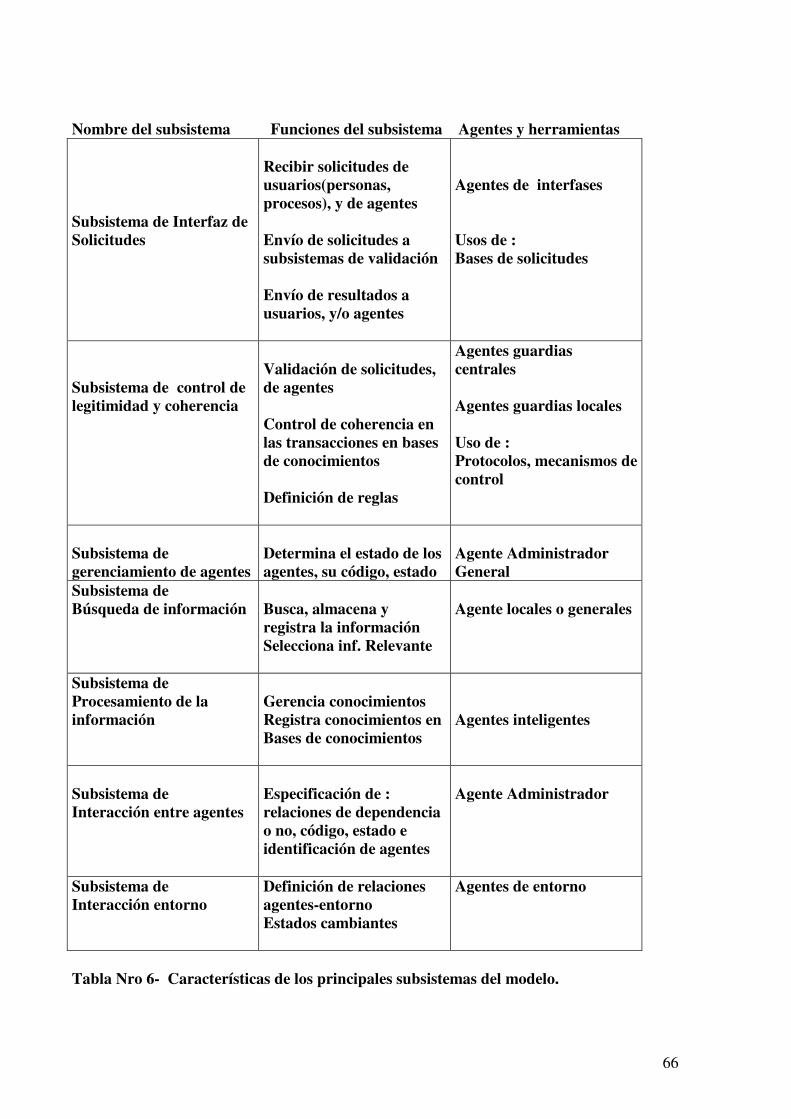
66
Nombre del subsistema Funciones del subsistema Agentes y herramientas Subsistema de Interfaz de Solicitudes
Recibir solicitudes de usuarios(personas, procesos), y de agentes Envío de solicitudes a subsistemas de validación Envío de resultados a usuarios, y/o agentes
Agentes de interfases Usos de : Bases de solicitudes
Subsistema de control de legitimidad y coherencia
Validación de solicitudes, de agentes Control de coherencia en las transacciones en bases de conocimientos Definición de reglas
Agentes guardias centrales Agentes guardias locales Uso de : Protocolos, mecanismos de control
Subsistema de gerenciamiento de agentes
Determina el estado de los agentes, su código, estado
Agente Administrador General
Subsistema de Búsqueda de información
Busca, almacena y registra la información Selecciona inf. Relevante
Agente locales o generales
Subsistema de Procesamiento de la información
Gerencia conocimientos Registra conocimientos en Bases de conocimientos
Agentes inteligentes
Subsistema de Interacción entre agentes
Especificación de : relaciones de dependencia o no, código, estado e identificación de agentes
Agente Administrador
Subsistema de Interacción entorno
Definición de relaciones agentes-entorno Estados cambiantes
Agentes de entorno
Tabla Nro 6- Características de los principales subsistemas del modelo.

67
3.5 Arquitectura del tercer nivel de abstracción del modelo
Especificación de las interacciones entre los subsistemas integrantes del modelo. Si bien, los subsistemas fueron considerados en el punto anterior como componentes del modelo, diferenciados fundamentalmente por los objetivos que deben cumplir, por los agentes que llevarán adelante esas tareas, y por las herramientas que se usarán para llevar a la práctica tales objetivos, en realidad, tales subsistemas estarán en la práctica íntimamente relacionados. La interrelación de los subsistemas está en función de la coherencia que debe de tener el sistema MAS propuesto. Los distintos subsistemas tienen, a menudo, áreas coincidentes. Si bien en el modelo propuesto hay un orden lógico de ejecución de tareas, ese orden no siempre es lineal, sino que frecuentemente se darán idas y venidas en las ejecuciones de las tareas específicas. 8.
2. 7. Area A 9. Subsistema de Control de Legitimidad.y
personas agentes 9. 3. 3. Coherencia - SCOLECO
1. Subsistema de
4. Gerenciamiento de Agentes SGA
Subsistema de Gerenciamiento De Entorno SGE
6 . 5. SIS : Subsistema de Interfaz de Solicitudes SCOLECO : Subsistems de Control de Legitimidad y Coherencia SGA : Subsistema de Gerenciamiento de Agentes SGE : Subsistema de Gerenciamiento de Entorno SBI : Subsistema de Búsqueda de Información SGC : Subsistema de Generación de Conocimientos SDC : Subsistema de Distribución de Conocimientos AREA 0 : Area virtual de interacción entre los subsistemas SGA, SGE y SCOLECO GRAFICO NRO. 2- DISEÑO GENERAL Y PRELIMINAR DEL MODELO PROPUESTO
Subsistema de Procesamiento de información y generación de conocimientos SGC
Subsistema de Interfaz de Solicitudes (SIS)
Subsistema de Búsqueda de Información (SBI)
Subsistema deDistribución de conocimiento (SDC)

68
Descripción del gráfico anterior 1.Recepción de solicitudes enviadas al SIS por agentes , grupos de agentes, procesos, personas. Evaluación preliminar de sintaxis y semántica en SIS Resultado : desechar solicitud o
transferencia para evaluación
2. Transferencia de solicitudes para evaluaciones más profundas
Tipo de evaluación Subsistema responsable de evaluación legitimidad, procedencia, conveniencia : SCOLECO, SGA, SGE
coherencia : SCOLECO 3. Luego de validación y legitimación,, transferencias a SBI 4. Traslado a subsistema que corresponda para obtener información( Un subsistema o varios) Subsistemas posibles destinatarios de busquedas : SGA.SGE,SOLECO 5. Obtenida la información solicitada: pasaje a SGC( de lo contrario : solicitud
deshechada) 6. Generado el conocimiento correspondiente, pasaje al o los sistemas correspondientes
para validación Pasaje a SGA,SGE y/o SOLECO
7. Validado el conocimiento generado, pasaje a SDC para evaluar a que subsistema o subsistemas le serían de interés poseer el nuevo conocimiento.( de lo contrario : solicitud deshechada)
8. Si SDC lo considerara oportuno, pasaje a SIS 9. Pasaje de SIS al o los usuarios que solicitaron el servicio o solicitud NOTA : La llamada área 0 es el área en la que pueden confluir los distintos subsistemas
en sus tareas de validación, legitimación, o solicitudes a servicios que necesiten el involucramiento o cooperación de otro y/o otros de los subsistemas del MAS.
_____________________________________________________________

69
SINTESIS DE LAS INTERRELACIONES MAS IMPORTANTES ENTRE LOS SUBSISTEMAS SIS SBI SGC SDC SGA SCOLECO SGE Puede recibir solicitudes de : SGA SGE USUARIO AGENTES SCOLECO Puede Enviar para control a: SCOLECO
Puede recibir solicitud de SCOLECO SIS Puede Enviar informac. Búscada a : SIS SGA SGE SCOLECO SGC
Puede recibir/ Pedir informac. de: SBI SGC Puede enviar Conoci- Mientos a: SCOLECO (para validar) SDC (validados para distribuir)
Puede recibir conocim. de SGC SCOLECO Puede enviar a : SCOLECO (para validar) SGC (para pedir revisión o ampliación) Puede enviar para obtener servicios a: SGA,SGE
Puede recibir de : SIS Solicitudes SGC Pedidos SGE SCOLECO SDC Puede enviar a: :SCOLECO (para validar) :SGE (para transmisión de un servicio) SGC (transmisión de un conocimiento)
Puede recibir para validar de : SGA, SIS, SGE, SBI, SDC Puede enviar a : SDC Para distribución
Puede recibir solicitudes, servicios de : SIS SGA SGC SCOLECO SDC Puede enviar a: SCOLECO (para validar) SGA SGC
Tabla Nro. 7 – Síntesis de las interrelaciones más importantes del modelo propuesto SIS : Subsistema de Interfaz de Solicitudes SCOLECO : Subsistems de Control de Legitimidad y Coherencia SGA : Subsistema de Gerenciamiento de Agentes SGE : Subsistema de Gerenciamiento de Entorno SBI : Subsistema de Búsqueda de Información SGC : Subsistema de Generación de Conocimientos SDC : Subsistema de Distribución de Conocimientos AREA 0 : Area virtual de interacción entre los subsistemas SGA, SGE y SCOLECO
No significa que necesariamente en un mismo momento estén en el área 0 estén todos los subsistemas interactuando, sino que el modelo habilita para que lo pudieran hacer.

70
3.6 Algunos de los agentes más importantes que se incluirán en el MAS En el sistema propuesto, habrá algunos agentes que estarán presentes en todos los subsistemas, y que tendrán las mismas funciones en todos. Al manejarse en cada subsistema con solicitudes que entran al subsistema, y que luego de ser procesadas son enviadas a través de una salida, hacia otro subsistema .
Por consiguiente, van a existir, siempre en cada subsistema un :
AgenteIdentificadorSolicitante, AgenteProcesadorSolicitud AgentedeTransferencia AgentedeMonitoreo AgentesdeRecomendación
Los AgentesdeTransferencia tienen como función la de navegar por La red, recordando automáticamente direcciones, sitios, nodos, etc. Los AgentesdeMonitoreo darán ,al sistema, información oportuna y eficaz cuando ocurra un evento. Los AgentesdeRecomendación realizarán sus recomendaciones frente a la sucesión de determinados eventos, y para ello se basarán en lo que aprendieron a partir de sus propias experiencias, de los conocimientos que obtuvieron de otros agentes, y de lo que pudieran captar en bases de datos que contengan información pertinente.
Dado que los temas controles y validaciones están centrados fundamentalemente en el subsistema SCOLECO, es allí donde residirán los agentes de controles más importantes del sistema. Dentro de estos agentes de seguridad, los principales serán : AgenteCentralIdentificador AgenteCentralLegitimidad AgenteCentralControlCoherencia AgenteCentralExclusiónDelSistema AgenteCentralInclusiónAlSistema AgenteCentraldeTransferenciaASitiosRemotos Estos agentes centrales de seguridad y control de coherencia tendrán como función principal la de gestionar y controlar a todos los demás agentes que trabajen, en los distintos módulos, con estos temas. Desde los subsistemas SGA y SGE trabajarán los agentes centrales que se encarguen de dirigir a los agentes que , en todos los demás subsistemas, se encarguen de gestionar agentes. Por ejemplo, centralmente en SGA y SGE se contará con : AgenteCentralDetecciónEstadosAgentes AgenteCentralModificaciónEstadosAgentes AgenteCentralInteracciónAgentes AgenteCentralOntología En el subsistema SGC, dado que la función del mismo, es regular todo lo referente al procesamiento del conocimiento, trabajarán los siguientes agentes :

71
AgenteCentralGeneradorConocimientos AgenteCentral ActualizaciónConocimientos AgenteCentralReusoConocimientos AgenteCentralAprendizaje En el subsistema SDC, dado de que lo más importante ahí es la distribución del conocimiento obtenido, el agente central ahí será el AgenteCentralDistribuciónConocimientos Además de estos agentes centrales, en cada subsistema, habrán agentes que realicen esas tareas, pero que deban de rendir cuentas de sus resultados al central periódicamente, o en la medida de que se produzcan cambios.
La implementación concreta a nivel de agentes de los diferentes subsistemas, los mecanismos concretos de transportes por La Red, las herramientas concretas a usar, las plataformas tecnológicas, serán detalles concretos de la implementación del modelo cuya arquitectura fue definida en el presente trabajo, y que se concretará en las posteriores etapas de investigación.
3.7 Síntesis de lo planteado en el capítulo 3. EL capítulo comienza analizando las ventajas que, en concreto, brindaría el tener un modelo MAS para el análisis del tráfico WEB. Entre otras ventajas permitirá informar sobre las interacciones entre los distintos componentes de La Red, siguiendo el flujo lógico de los procesos. Se especificaron las características generales del modelo propuesto : se trata de un modelo con análisis top-down, basado en datos semi-estructurados, en donde los agentes de diferentes tipos actuarán siguiendo los principios de interacción, cooperación, negociación , agrupados en diferentes subsistemas, manteniendo sus individualidades en cuanto a los objetivos que les son específicos, pero velando siempre por mantener la coherencia del sistema.
En esta etapa de diseño del modelo, a nivel de su arquitectura, se identificaron 3 grandes fases : la especificación general de los grandes subsistemas integrantes del MAS, la definición de los principales agentes en cada uno de los subsistemas, y las relaciones de interacción entre los subsistemas. La primera y la última fase están simbolizadas mediante el gráfico Nro. 1 y el gráfico Nro. 2 respectivamente.
El capítulo 4 brindará, conclusiones generales del presente artículo , las que serán usadas en etapas posteriores de investigación para la implementación del modelo que se propuso en este artículo.

72
4.Conclusiones finales del artículo
Las transferencias de los muy variados tipos de información en Internet, presuponen procesos muy heterogéneos y complicados que afectan a gran cantidad de sitios generalmente remotos de redes con arquitecturas frecuentemente muy diferentes. El gran crecimiento de Internet, con la posibilidad de transferencia de diferentes tipos de información, trajo como consecuencia un aumento del caos dentro de la trasferencia WEB, en donde La Red convive a diario con los tipos de problemas especificados en el punto 1 del presente artículo. Por consiguiente, siendo la WEB, una de las caras visibles de la Internet, existe una necesidad práctica de detectar esos problemas en las primeras fases del proceso de transferencia, pues cuanto antes se detecten menor será el impacto negativo de dichos problemas en La Red. Para lograr una detección de tales problemas lo antes posible, en forma efectiva y ágil, en el presente artículo de investigación se plantea la necesidad de creación de un modelo basado en un sistema de multiagentes inteligentes. El principal motivo de haber planteado un modelo basado en sistemas multiagentes, surge de la necesidad de gestionar, sistemas y subsistemas de transferencias complejos, que interactuan entre sí, pero que a su vez constituyen un sistema aparentemente único y coherente. Las características de que Internet sea por naturaleza un gran sistema distribuido, y que en la WEB las transferencias se realicen siguiendo tales principios, lo hacen fácilmente adaptable a las características de un sistema multiagentes, tal como se especificó en el punto 2 del presente artículo. Cada sistema y subsistema integrantes de la WEB, podrían tener un alcance geográfico específico, que en general es irrelevante. Lo importante para este modelo, es que hay en cada componente un alcance funcional definido, lo que posibilita el entendimiento con sistemas de igual o similar funcionalidad , independientemente de su ubicación geográfica. Las cuestiones de tráfico en los sistemas o subsistemas, y entre los subsistemas, en aquellos aspectos definidos como problemas para el presente artículo de investigación, estarían regulados a través de un sistema multiagente. Al caracterizarse los sistemas multiagentes por estar formados por agentes que interactúan entre sí, de tal forma que juntos puedan cumplir con las funciones y metas planteadas, es necesario crear un modelo de sistema que exija un alto nivel de abstracción en su diseño, identificar funcionalidades, coordinaciones, negociaciones, percepciones del entorno, aprendizajes, etc. Ya en los últimos capítulos del presente artículo se expresa que el modelo que se diseñe, deberá de concretarse en una serie de reglas de razonamiento para lograr un nivel mayor de formalización. El motivo principal de ello es que luego de aplicar procesos de inferencia a dichas reglas, se podría obtener guías para la acción.

73
Si bien estas reglas se basarán en la capacidad de razonamiento de los agentes en sí, como esa capacidad debería ser ilimitada, esas reglas podrían dar lugar a nuevas reglas, si las capacidades de razonamiento se ampliaran o si cambiaran las ópticas de enfoque de los problemas. Esto constituiría la esencia del proceso de aprendizaje de los agentes integrantes del sistema multiagentes, por lo cual se debería de concluir que el proceso de aprendizaje de los agentes debería ser permanente e interminable. De todo esto se desprende que el mundo de los sistemas multiagentes, que irrumpió con gran vigor en diferentes áreas, al dar la posibilidad de crear sistemas descentralizados, concurrentes, emergentes, dando soluciones ágiles a los problemas dentro de sistemas tratados como unidades, sería altamente conveniente su aplicación en el mundo de la WEB.
Las tareas de diseño e implementación de un modelo de sistemas multiagentes, deberían, además, estar pensadas previendo que en un futuro no muy lejano se debería de llegar a la comunicación entre diversos sistemas multiagentes, formando así las grandes sociedad de agentes. Esto tiene su fundamentación en el hecho de que los sistemas multiagentes están siendo hoy desarrollados en múltiples áreas. Además hay una necesidad actual de comunicación entre las diferentes áreas, a pesar de la especificidad de cada una de ellas, por lo que sería altamente conveniente y útil el aprovechar, en la medida de lo posible, los resultados provenientes de sistemas multiagentes pertenecientes a otras áreas. Por lo tanto el presente artículo pretendió ser la etapa inicial de investigación de un proyecto que incluye por lo menos una etapa posterior que intentará profundizar sobre el diseño detallado e implementación de un modelo multiagente que permita hoy analizar el tráfico WEB, pero que pretende, en principio, poder ser usado en cualquier interconexión de redes, motivo por el cual al referirse a estos tipos de redes de interconexión, se le llamó La Red. El modelo MAS propuesto trata de seguir el flujo lógico de los fenómenos naturales, para lo cual se diseñó la arquitectura del modelo siguiendo un análisis topdown, partiendo de la especificación de los objetivos de los más grandes subsistemas del sistema MAS, para luego detallar los tipos, funciones y características de los principales agentes que integrarán esos módulos para terminar por un análisis del modelaje de la interacción entre los subsistemas. Justificadas la necesidad y ventajas de un modelo MAS para el análisis del tráfico HTTP y especificadas las características del modelo MAS elegido, y definida su arquitectura, y el diseño preliminar del modelo, con sus diferentes niveles de abstracción, así como la categorización de los agentes principales, y las interacciones entre los subsistemas, en las posteriores etapas de investigación se profundizará en el análisis del diseño detallado, la implementación concreta del modelo, la elección de las herramientas, protocolos y lenguajes de comunicación entre sus diferentes componentes.

74
REFERENCIAS BIBLIOGRAFICAS
[ Stallings, 2004] . Stallings, William. Redes e Internet de Alta Velocidad, Rendimiento y Calidad de Servicio, Segunda Edición. Publicado por Pearson Educación. Madrid. 2004. Págs. 16,17,30. [ Kurose & Ross, 2004 ] James F.Kurose, Keith W.Ross. Redes de Computadores, Enfoque Descendente Basado en Internet, Segunda Edición. concepto del núcleo de La Red. Publicado por Pearson Educación. Madrid 2004. Págs 14-21. Pág. 632, 633. [ Teleinformática, Nro. 1 ] .Teleinformática, 1 era. Edición Volumen 1 y Teleinformática 2da. Edición, volumen 1.
[ Teleinformática, Nro 4]. www.institucional.frc.utr.edu.ar/htm.electronica/revista/Revista%20N4/Teleinformatica [ATV Informática]. Ayuda Internet, Diccionario
www.servitel.es/atv/AYU/Internet/DICCIO/diccio.htm
[Cisco, 2004]- Academia de Networking de Cisco System. Guía del primer año. CCNA 1 y 2 . Tercera Edición Pearson Educación, Madrid 2004. Págs. 53,54
[Negroponte N, 1995]. Nicholas Negroponte . El mundo digital Ediciones B, Barcelona – Tema : ancho de banda
[Asociación de Usuarios de Internet]. http://www.aui.es. [Hung Nguyen, 1999-2005] . Hung Nguyen Testing applications on the Web 1999-2005. Automated QA www.automatedQA.com [Menascé & Almeida, 1998 ] Daniel Menascé y Virgilio Almeida Capacity Planning for WEB PERFORMANCE Prentice Hall PTR. New Jersey. USA. 07458 . págs. 121-134.
Diccionario Informático- Mundo del PC
Mundo PC Net- sección glosario www.murdopc.net/ginformatico/d/dminpd/php

75
[Tanenbaum Andrew, 2003] Andrés Tanembaum Redes de Computadores . 4ta. Ed. México Prentice-Hall, 2003 [Latency Enumeration Transactional Internet Agent- LETIA ]– http://www.cs.vu.nl/ jmeijer/simorg5/ [ UTN- FRSF ] UTN – FRSF Evaluación y Modelado de Redes Informáticas Ingeniería en Sistemas de Información [Black U, 1997] Ulysess Black Redes de computadoras. Protocolos, normas e interases. Mexico : Alfaomega Grupo Editor. [Weiss Gerhard, 2004 ] . Gerhard Weiss Sistemas Multiagentes artículo publicado en Readings in Agentes. Institut fur Informatik, Technische Universitát Múnchen Learning to Coordinate Actions in Multi-Agent- System [Readings in Agents, 1998]. Edited by Michael N. Huhns & Munindar P. Singh Morgan Kaufmann Publishers, Inc. Michael N. Huhns. University of South Carolina. Minundar P. Singh. North Carolina Sate University [RFC 2729 ,diciembre 1999 ] Taxonomy of Communication Requirementes Applications for Large Scale Multicast Applications [Latency Enumeration Transactional ], Artículo Latency Enumeration Transactional Internet Agent- LETIA – http://www.cs.vu.nl/ jmeijer/simorg5/ Gerhard Weiss [ Lemaitre & Sánchez, 1995 ] . Christian Lemaitre & Victor Sánchez, Instituto Tecnológico y de Estudios Superiores de Monterrey, NL, Mejico [Lemaitre Ch, 2000] Artículo de Christian Lemaitre Publicado en Biblioteca/Newsleters/Año 9, Vol.33 y 34, Otoño-Invierno 2000
[Labrador R ]. Ramón María Gómez Labrador Tesis Doctoral. Programación Orientada a Objetos Distribuída. CORBA- Equipo LSI-US. Grupo de Investigaciones en Ingeniería del “Software”. Departamento de Lenguajes y Sistemas Informáticos. Universidad de Sevilla.

76
[Hernández V , Rosenblueth E A]- Hernández Valdemar, Eugenio Arturo Rosenblueth Fundación Arturo Rosenblueth Agentes : Un cambio en la concepción del software http://www.resenblueth.mx/InterFAR/Vol1Num3/doc/Vol1Num3.53.html [NewLetters, 1996] Inicio/biblioteca/newsletters/año 4, Vols 17 y 18 otoño/invierno 1996 [López Franco, 2001 ]. Jose Manuel López Franco . El protocolo HTTP Http://trevinca.ei.uvigo.es/ txapi/espanol/proyecto/superior/memoria/node40.html
[Barcia.N ]. Barcia, Nicolás. [email protected] http://halley.ls.fi.upm.es/~ni [Mengual] . Mengual, Luis. [email protected] http://pegaso.ls.fi.upm.es/~lmengual
[Yaguez]: Javier Yagüez García http://:[email protected]
[Goncalves De Freitas, 2002]. Frederico Luiz Goncalves de Freitas. Universidades Federal de Santa Catarina. Programa de Pos-Graduacao en Engenharia Elétrica. Tesis doctoral Sistemas mltiagentes congnitivos para a recuperacao, classificacao e extracao integradas de informacao da WEB. [Gaiti D, Pujolle G ] Dominique Gaiti, Guy Pujolle- Network Control and Engineering for QoS, Security and Mobility II Conference on Network Control and Engineering for QoS NetCOm 2003- oktober 13-15 2003. [email protected] [email protected] )
[ Mascontrol : Sistema Multiagente para la Identificación y control de sistemas] XXV Jornadas de Automática Ciudad Real del 8 al 10 de septiembre de 2004
[Performance Evoluction of Computer and Telecommunication System ] 2004. International Symposium www.scs.org www.scs.org/scarchive/getDoc.cfm
[Huhns N & Singh P, 1998] Michael N. Huhns & Minindar P. Singh. Readings in Agents, Morgan Kaufmann Puvlishers, Inc. San Francisco. USA
[Jiménez S , Ramos E, 2000 ] Silvestre Jiménez & Esmeralda Ramos. Agentes Inteligentes. ND 2000-01 Lecturas en Ciencias de la Computación. ISSN 1316-6239, abril 2000.
Publicado en CISI(Centro de Información en Sistemas de Información. Escuela de Computación- Facultad de Ciencias Universidad Central de Venezuela. [email protected]

77
[Telm@tica, 2003]. Telem@atica Año II Nro. 12. Septiembre 18, 2003. Aplicación de laInteligencia Artificial Distribuída en la Gestión de Redes. Ing. Non Carballo Escalona.
[Horfan D. , Ovalle D]. Daniel Horfan Alvarez, Denterio A. Ovalle Carranza. Método para manejar el Problema de la Recarga de Trabajo en los Sistemas Multi-Agente. Caso de estudio : Sistema Multi-Agente de Planificación para la Ubicación de Zonas de Depósito “SMAP-UZD”
[Aguilar J, Perozo N, Ferrer E, Vizcarrondo J] José Aguilar, Niriaska Perozo, Edgar Ferrer, Jaun Vizcarrondo. Arquitectura de un sistema operativo WEB basado en sistemas multiagentes. Artículo publicado en http://www.unab.edu.co/editorialunab/revistas/rcc/pdfs/r52_art1_c.pdf
[Petrie, Charles, 1996] Charles J. Petrie. Stanford Center for Design Research Agent-Based Engineering, the WEB, and Intelligence. Artículo de diciembre 1996 de IEEE Expert.
[Un marco de comunicación inter-agentes en un Biblioteca Digital] Documento de Tesis Centro de BioInformática del Jardín Botánico de Missouri y de la Universidad de las Américas – Puebla.
[Instituto Tecnológico de Ciudad Madero], Ingeniería en Sistemas Computacionales. Seminario de Desarrollo de Proyectos de Investigación. Nombre del artículo : “Estudio y Diseño de Agentes Móviles” [Tanembaum A, 1995] Andrew Tanembaum Sistemas Operativos Modernos Prentice-Hall 1995
[University of Michigan Digital Library, 1997 ] Biblioteca Digital de la Universidad de Michigan. Project Mission. http://www.nw.com/zonel/WWW/top.html [AAAI Press/The MIT Press,1997]
AAAI Press/The MIT Press, Menlo Park, CA, USA, 1997 Jeffrey M. Bradshaw, editor Software Agents
[Calixto de Andrade M.1998] María Angélica Calixto de Andrade Cardieri Agentes Inteligentes

78
[ Loureiro & Costa, 1998] Antonio Alfredo Ferreira Loureiro & Patricia Campos Costa Una Interfase para la creación de Agentes de consulta en la WEB II Semana de Pós-Graduacao em Ciencia da Comutacao (SPG´98) Departamento de Ciencia de Computación Universidad Federl de Minas Gerais
[email protected] [email protected]
[Reddy, 96]
Reddy, R. To Dream th possible Dream” 1996 Turing Award Lecture in Communications of the ACM, 39:5, May 1996
[ IEEE International Conference on System, Man and Cybernetics, 1996], 1996 Beijing, China A multiagent System for the Support of Concurrent Engineering Hu Youngton, Liu Ping, Yan Yuhong, Zhen Danian, Ma Changchao, Jurgen Bode, Ren Shouju Automated Department Tsinghua University Beijing, 100084, P.R. China [email protected] www.cs.unb.ca/profs/yyuhong/publications/SMC96.pdf
[Marc J R & Scott A. D, 2000] Raphael J. Marc & Deloach A. Scott A knowledge base for Knowledge-based multiagent sytem construction National Aerospace and Electronics Conference (NAECON) Dayton, OH, October 10-12-2000 www.cis.ksm.edu/∼sdelocachs/publications/conference/aramsnaecon.pdf [Ingenias, sección del WEB de GRASIA ] http://grasia.fdiucm.es/ingenias/Spain/index.plp [Iglesias Fernández, C A, 1997] Carlos Angel Iglesias Fernández Fundamentos de los Agentes Inteligentes, Informe Técnico UPM/DIT/GSI 16/97 Departamento de Ingeniería de Sistemas Telemáticos- UPM [Alonso Alvarez A, Villar Flecha J R, Benavides Cuellar C, García Rodríguez I Rodríguez Sedano F J ] Angel Alonso Alvarez, José Ramón Villar Flecha, Carmen Benavides Cuellar, Isaías García Rodriguez, Francisco Jesús Rodriguez Sedano Experiencia en el desarrollo de un Sistema Multiagente www.cea.ifac.es/actividades/jornales/XXII/documentos/B-01-CI.pdf

79
[González J.M, Hamilton A.F, Méndez J.A., Torres S., Torres J.M. , Sigut M., 2004] Mascontrol : Sistema Multiagente para la Identificación y Control de Sistemas Grupo de Computadoras y Control XXV Jornadas de Automática. Ciudad Real del 8 al 10 de septiembre de 2004 [email protected] [ Gerard W, 1999] Multiagent System
Massachusetts Institue of Technology

80
GLOSARIO DE TERMINOS
WEB . Aplicación de red que permite a los usuarios obtener bajo demanda, documentos de los servidores web. El protocolo de capa de aplicación WEB, el HTTP es una de las partes de la aplicación WEB.
HTTP ( HyperText Transfer Protocol, Protocolo de Transferencia de Hipertexto). Protocolo de nivel de aplicación usados por navegadores y servidores WEB para la transferencia de información en Internet, es orientado a objetos y permite que los sistemas se construyan independientemente de la información que se transfiere MAS (MultiAgent System). Son una asociación de agentes que trabajan juntos para resolver problemas que van más allá de sus capacidades individuales. IA (Inteligencia Artificial). Un área del conocimiento cuyo objetivo es imitar a través de máquinas tantas actividades mentales como sea posible e intentar mejorar las que llevan a cabo los seres humanos. IAD(Inteligencia Artificial Distribuida). A la Inteligencia Artificial clásica se le agrega la capacidad de distribución, o sea, aplicable para el presente artículo, la capacidad de conseguir , controlar y procesar transmisiones en redes de localización independiente, mejorando las características de escalabilidad, distribución de recursos y fiabilidad.
RDP (resolución Distribuida de Problemas). Procesamiento de tareas y resolución de problemas siguiendo los principios de descentralización distribuida. PPP ( Point to Point Protocol, Protocolo Punto a Punto). Protocolo de capa de enlace que opera sobre un enlace punto a punto, o sea un enlace que conecta directamente dos nodos, cada uno en cada extremo del enlace.
LLC (Logik Link Control, Control de Enlace Lógico). Se encarga de la iniciación, mantenimiento , informe de errores y cierre de un enlace PPP.
MTU( Maximum Transfer Unit. Unidad Máxima de Transferencia). Cantidad máxima de datos que puede transportar un paquete de capa de enlace. FDM (Multiplexión por división de frecuencia) TDM (Multiplexión por división de tiempo) UBR (Unespecified Bit Rate. Régimen no especificado de bits).Especificación de un servicio ATM DAI ( Inteligencia Artificial Distribuída ) KQML ( Knowledge Query Manipulation Language)

81
KEEPALIVE .Mensaje enviado por un dispositivo de la red para informar a otro dispositivo de la red de que el circuito virtual entre ellos todavía está activo. RTT ( Round Trip Time). Tiempo de ida y de vuelta mide el tiempo desde que un paquete sale de una fuente, llega a un receptor y vuelve al emisor. TTL (Time to Live). Originariamente, en el datagrama IP, el temporizador que indicaba el tiempo máximo en que un paquete IP podía vagar por la red antes de llegar a su destino. Actualmente indica la cantidad de saltos máximo hasta llegar a un destino. ACK (Ackowledgent, Reconocimiento). ACK positivo Es un acuse de recibo que envía el receptor al emisor para confirmarle que todo le llegó en tiempo y forma. SYNC (bit de sincronización). Bit que indica que un emisor y un receptor están intentando sincronizarse en una comunicación TCP. ATM(Asynchronous transfer mode. Mode de Transferencia Asíncrona). Conocido como retransmisión de celdas. Proporciona conmutación de paquetes, permite tansmisiones a altas velocidades , basada en procesamiento de celdas WORKFLOW ( Flujos de trabajo) . Tecnología que permite la gestión de flujos de trabajos y de áreas. QoS(Quality of Service- Calidad de servicio). Es el rendimiento de extremo a extremo de los servicios electrónicos de la red, tal como lo percibe el usuario. TDM(Multiplexión por división de tiempo). Se comparte un mismo enlace físico por divisiones fijas de tiempo de uso FDM(Multiplexión por división de frecuencia). Se comparte un mismo enlace físico por divisiones fijas de frecuencias. Congestionamientos- Situaciones de descarte de paquetes, generalmente debido a saturaciones de los buffers de los routers.

82
PALABRAS CLAVES USADAS EN EL ARTICULO Agentes inteligentes. Entidades conformadas por piezas de software que ejecutan una tareas dada utilizando información recolectada del ambiente con la finalidad de completar una tareas de manera exitosa. Agentes de interfaz : Agentes cuya finalidad es la de brindar información a los usuarios de la información que poseen, haciendo comprensibles las interfases. Autonomía. Capacidad de los agentes de poder actuar sin necesidad de intervención directa ni de los humanos ni de otro agente. Proactividad. Capacidad de los agentes de exhibir un comportamiento especial, dependiendo de los objetivos planteados. Racionalidad. Capacidad de los agentes de actuar de manera tal de satisfacer sus objetivos Continuidad. Capacidad de los agentes de estar continuamente ejecutando procesos
Sistemas MAS...... Sistemas integrados por agentes que convergen en sus acciones para el logro de sus metas . Esos sistemas son herramientas muy efectivas un gran rango de aplicaciones, frecuentemente caracterizadas por la resolución de problemas distribuidos, que están más allá de la capacidad y conocimiento individual de cada entidad. Sistemas Distribuidos ..... Sistemas en los que la heterogeneidad está dada por diferentes protocolos o sistemas operacionales dentro de una misma red. A nivel de redes , se espera que sus usuarios de las distintas redes contribuyan con sus recursos propios, en aras de un proyecto compartido. Los recursos de la red se comparten. Inteligencia Artificial Distribuida .... (según Avouris,1992) La AID es un subcampo de la IA que se centra en los comportamientos inteligentes colectivos que son el producto de la cooperación de diversas entidades(agentes) La heterogeneidad está dada por los agentes que poseen bases de conocimiento en diferentes formalismos de representación. Debe de existir una ontología común, o compartida, usada como vocabulario de comunicación a nivel de conocimiento. Aquí las bases de conocimientos son portables si ella está escrita según algún formalismo que puede ser fácilmente entendible por otro formalismo. Los agentes se definen aquí en un plano más conceptual en tanto que los objetos son concebidos más en el plano de la implementación.
Modelo peer-to-peer. Aquí los agentes intercambian sus conocimientos mediante ontologías y formalidades compartidas por ellos. Modelo cliente-servidor. Las comunicaciones entre los agentes se basan en llamadas a procedimientos remotos, a través de comunicaciones del tipo solicitud-respuesta.

83
Escalabilidad de un agente. Se da cuando un agente recibe más bases de conocimientos o consigue aumentar significativamente una base existente. Reglas. Formalismos de presentación de los conocimientos La Red- Usada en el presente artículo como sinónimo de La Red Internet, o sea la Red de redes, que sigue el modelo TCP/IP, que implica la interconexión de redes generalmente heterogéneas y cuyo objetivo principal es la conexión de redes generalmente heterogéneas. Se usa este término debido a que el presente modelo , si bien está pensado en el tráfico Internet, una vez funcionando, podría aplicarse en cualquier red de interconexión de redes, independientemente del modelo de la red y de sus protocolos. Movilidad de agentes ....Es una de las características de los agentes destinados a Internet. La movilidad de los agentes les da la capacidad de transportarse, de cambiar de localización de un entorno a otro, ya sea dentro del mismo equipo o a través de una red de computadoras. Este cambio de ubicación no altera al agente ya que él llega a su nuevo entorno con los mismos conocimientos que tenía en el entorno anterior, pasándose a ejecutarse remotamente si su cambio de ubicación así lo exigiera. Ontologías. Vocabulario de uso común entre los agentes de un mismo dominio para representar los conceptos de ese dominio. Es una forma de estructurar y especificar conocimientos. En Inteligencia Artificial, puede especificar un dominio , y generalmente está organizada en jerarquías de conceptos o taxonomías. Coherencia. Relación armónica entre las acciones de los agentes integrantes del sistema multiagente, de tal forma que las acciones de ninguno de ellos perjudique los objetivos del sistema. Esto es lo que hace que el sistema multiagente pueda ser visto como una unidad, y los agentes como partes autónomos del mismo. Reusabilidad. Característica de los conocimientos de poder ser vueltos a usar, si así lo ameritaren las situaciones. Interacción- Característica de incidencia que define la forma de relacionamiento entre los agentes entre sí y entre los agentes con el entorno (al cual se le suele llamar, también, agentes pasivos, para distinguirlos de los agentes activos, que serían los agentes propiamente dichos) Grupos de agentes- Nucleamientos de agentes según diferentes criterios, por ejemplo, las funcionalidades de los mismos. Ancho de banda. Cantidad de información que puede fluir desde un lugar a otro en un período determinado de tiempo Router- Dispositivo o funcionalidad de software de capa 3 cuyo objetivo es la conmutación de paquetes, por lo que conectan redes lógicas diferentes. Buffer. Lugares de almacenamientos temporales de los routers, donde se almacenan los paquetes antes de ser transmitidos.

84