tema 1 an´alisis de la varianza - uc3m · 2009-02-09 · tema 1 an´alisis de la varianza 1.1....
TRANSCRIPT

Tema 1
Analisis de la varianza
1.1. Introduccion
El analisis de la varianza (ANalysis Of VAriance, ANOVA) es un procedimientopara descomponer la variabilidad de un experimento en componentes independientesque puedan asignarse a causas distintas.
A grandes rasgos, el problema es el siguiente:
1. Tenemos n elementos que se diferencia en un factor (estudiantes de distintasclases, vehıculos de distintas marcas, productos manufacturados en distintosprocesos. . . ).
2. En cada elemento (personas, vehıculos, productos. . . ) observamos una carac-terıstica que varıa aleatoriamente de un elemento a otro: las notas de los estu-diantes, el consumo de gasolina de los vehıculos, los tiempos de fabricacion delos productos. . .
3. Se desea establecer si hay o no relacion entre el valor medio de la caracterısti-ca estudiada y el factor: ¿tienen todas las clases la misma nota media? ¿losvehıculos el mismo consumo? ¿los productos el mismo tiempo de fabricacion?
Veamoslo con un ejemplo:
Ejemplo 1
Los siguientes datos se refieren al numero de muertos por cada 10000 habitantes enGotham City durante las distintas estaciones de cinco anos consecutivos:

2 Estadıstica II
Invierno Primavera Verano Otono33.6 31.4 29.8 32.132.5 30.1 28.5 29.935.3 33.2 29.5 28.734.4 28.6 33.9 30.137.3 34.1 28.5 29.4
A un nivel de significacion del 5 %, ¿podemos garantizar que la tasa de mortalidadno depende de la estacion?
Mortalidad
Invierno
Otoño
Primavera
Verano
28
30
32
34
36
38
1.2. El modelo
A traves del ejemplo anterior, iremos definiendo los distintos elementos que in-tervienen en un modelo ANOVA.
Sea y la variable de interes.
y = tasa de mortalidad.
Definimos el factor del estudio como la variable que influye sobre los valores dela variable de interes. Sea F el factor que influye en los valores de y.
F = estacion del ano.
Sea I el numero de niveles (grupos) de F . En nuestro caso, tenemos cuatroestaciones, por lo que
I = 4.

Tema 1. Analisis de la varianza 3
Sea ni, i = 1, . . . , I, el numero de observaciones tomadas para el nivel i. No tienepor que haber el mismo numero de observaciones para todos los grupos. Sin embargo,en este caso, sı coincide:
n1 = n2 = n3 = n4 = 5.
Ahora, para i = 1, . . . , I, j = 1, . . . , ni, sea
yij = µi + µij,
con
yij = j-esima observacion del i-esimo grupo,µi = media del i-esimo grupo,µij = perturbacion medida para la j-esima observacion.
Como µij = yij − µi, se puede ver como la desviacion de la j-esima observaciondel grupo i respecto de la media del grupo.
Otra forma de escribir el modelo es
yij = µ + αi + µij,
con
µ = media de todas las observaciones,αi = efecto diferencial del grupo (αi = µi − µ).
No obstante, salvo mencion explıcita de lo contrario, usaremos el primero de losmodelos propuestos: yij = µi + µij.
Las perturbaciones µij representan la variabilidad intrınseca del experimento: sonvariables aleatorias. Asumiremos para ellas las siguientes hipotesis:
1. El promedio de las perturbaciones es cero.
E(µij) = 0 ∀i, j.
2. La variabilidad es la misma en todos los grupos (homocedasticidad).
V ar(µij) = σ2 ∀i, j.
3. La distribucion de las perturbaciones es normal.
µij ≡ N(0, σ2) ∀i, j.
Esto implica que sus desviaciones respecto de la media son simetricas y pocasobservaciones (el 5 %) se alejan mas de dos desviaciones tıpicas respecto de lamedia.

4 Estadıstica II
4. Las perturbaciones son independientes.
Como µij ≡ N(0, σ2), entonces yij ≡ N(µi, σ2).
1.3. Estimacion de los parametros
Nuestro modelo es
yij = µi + µij, yij ≡ N(µi, σ2), i = 1, . . . , I, j = 1, . . . , ni.
Este modelo tiene I + 1 parametros desconocidos: las medias µ1, . . . , µI y lavarianza σ2. Vamos a estimarlos usando el metodo de maxima verosimilitud.
La funcion de densidad para la observacion yij es
f(yij|µi, σ2) =
1√2πσ2
exp−(yij − µi)2
2σ2,
por lo que la funcion de maxima verosimilitud de la muestra es
L(µ, σ2) = (2πσ2)−n2 exp−
I∑
i=1
ni∑
j=1
(yij − µi)2
2σ2.
Tomando logaritmos:
ln L = −n
2ln (2πσ2) − 1
2σ2
I∑
i=1
ni∑
j=1
(yij − µi)2.
Ası:
0 =∂ ln L
∂µi
=1
σ2
ni∑
j=1
(yij − µi) =n
σ2(yi· − µi);
µi = yi·
En consecuencia, un estimador de la perturbacion µij sera µij = yij − µi.
A la estimacion del error se la denomina residuo:
eij = yij − yi·.
El residuo mide la variabilidad no explicada.

Tema 1. Analisis de la varianza 5
Busquemos ahora una estimacion de la varianza del error:
0 =∂ ln L
∂σ2= − n
2σ2+
1
2(σ2)2
I∑
i=1
ni∑
j=1
(yij − µi)2;
0 = −n +1
σ2
I∑
i=1
ni∑
j=1
(yij − µi)2;
σ2 =
I∑
i=1
ni∑
j=1
(yij − µi)2
n=
I∑
i=1
ni∑
j=1
(yij − yi)2
n=
I∑
i=1
ni∑
j=1
e2ij
n.
Sin embargo, este estimador es sesgado. En su lugar, emplearemos la varianzaresidual
S2R =
I∑
i=1
ni∑
j=1
e2ij
n − I.
Puede reescribirse como la media ponderada de las cuasivarianzas de cada grupo:
S2R =
I∑
i=1
(ni − 1)S2i
n − I.
Como(ni−1)S2
i
σ2 ≡ χ2ni−1, entonces
(n−I)S2
R
σ2 ≡ χ2n−I .
Ejemplo 2
En nuestro caso, las estimaciones de las medias para las estaciones son:
Invierno: µ1 = 34.62.
Primavera: µ2 = 31.48.
Verano: µ3 = 30.04.
Otono: µ4 = 30.04.
Ademas, la varianza residual vale S2R = 3.7325.

6 Estadıstica II
1.4. Propiedades de los estimadores de las medias
1.4.1. Esperanza
El estimador µi es centrado:
E(µi) = E
(∑ni
j=1 yij
ni
)=
∑ni
j=1 E(yij)
ni
=
∑ni
j=1 µi
ni
= µi.
1.4.2. Varianza
Como, por hipotesis, las perturbaciones µij son independientes, entonces las va-riables yij tambien lo son. Por lo tanto,
V ar(µi) = V ar
(∑ni
j=1 yij
ni
)=
∑ni
j=1 V ar(yij)
n2i
=
∑ni
j=1 σ2
n2i
=σ2
ni
.
Ademas, como µi es combinacion lineal de variables aleatorias independientesnormales, entonces tambien esta distribuida normalmente. Luego
µi ≡ N
(µi,
σ2
ni
).
Un intervalo de confianza para µi es
µi ± zα/2σ√ni
.
Pero como σ no suele conocerse, se usa
µi ± tni−1,α/2
√S2
i
ni
.
1.5. Descomposicion de la variabilidad
El objetivo del analisis es saber si el factor que se estudia es o no influyente. Enel modelo, esto significa que hay que comprobar si todas las medias son iguales o siexiste alguna que sea diferente. Es decir, se trata del contraste:

Tema 1. Analisis de la varianza 7
H0 : µ1 = · · · = µI ,H1 : ∃ i, j ∈ {1, . . . , I} / µi 6= µj.
Aunque estemos analizando medias, hablamos de analisis de la varianza porque lavariabilidad de los datos es fundamental para decidir si las medias son o no distintas.
Las desviaciones entre los datos observados y la media general pueden expresarsemediante la identidad
yij − y = (yi· − y) + (yij − yi).
Esta igualdad descompone la variabilidad entre los datos y la media general endos terminos: la variabilidad entre las medias y la media general y la variabilidadresidual (variabilidad de los grupos).
Elevando al cuadrado y sumando para los n terminos:
I∑
i=1
ni∑
j=1
(yij − y)2 =I∑
i=1
ni∑
j=1
(yi·− y)2 +I∑
i=1
ni∑
j=1
(yij − yi·)2 +2
I∑
i=1
ni∑
j=1
(yi·− y)(yij − yi·) =
=I∑
i=1
ni(yi· − y)2 +I∑
i=1
ni∑
j=1
e2ij.
A continuacion se definen las siguientes expresiones:
VT = variabilidad total =I∑
i=1
ni∑
j=1
(yij − y)2,
VE = variabilidad explicada =I∑
i=1
ni(yi· − y)2.
VNE = variabilidad no explicada =I∑
i=1
ni∑
j=1
(yij − yi·)2.
De este modo, VT = VE + VNE.
La variabilidad explicada es la variabilidad debida a la existencia de los distintosgrupos. Mide la variabilidad entre ellos. Si VE es pequena, entonces las medias seransimilares.
La variabilidad no explicada es la variabilidad debida al error experimental. Midela variabilidad dentro de los grupos.

8 Estadıstica II
Definimos el coeficiente de determinacion como
R2 =V E
V T.
Nos da una medida relativa de la variabilidad explicada por los grupos.
Puesto que VT = VE + VNE, entonces 0 ≤ R2 ≤ 1.
Ejemplo 3
En el caso que estamos estudiando, V E = 69.95 y V T = 129.67. Ası que el coeficientede determinacion es
R2 =69.95
129.67= 0.54.
Es decir, el dividir las muertes por estaciones explica la variabilidad en un 54 %.
Aunque no es posible comparar VE y VNE porque desconocemos como estandistribuidas, sı sabemos que:
1. V NEσ2 ≡ χ2
n−I .
2. Si µ1 = · · · = µI (la hipotesis nula es cierta), entonces V Eσ2 ≡ χ2
I−1.
En consecuencia, cuando se cumple la hipotesis nula, se tiene que
V E/(I − 1)
V NE/(n − I)≡ FI−1,n−I .
En la tabla ANOVA siguiente se muestra toda la informacion asociada al con-traste:
Fuentes de Suma de Grados de Varianza Test Fvariabilidad cuadrados libertad
VE: entre gruposI∑
i=1
ni(yi· − y)2 I − 1 S2e =
I∑
i=1
ni(yi· − y)2
I−1S2
e
S2R
VNE: residualI∑
i=1
ni∑
j=1
(yij − yi·)2 n − I S2
R =
I∑
i=1
ni∑
j=1
(yij − yi·)2
n−I
VT: totalI∑
i=1
ni∑
j=1
(yij − y)2 n − 1 S2y =
I∑
i=1
ni∑
j=1
(yij − y)2
n−1

Tema 1. Analisis de la varianza 9
Si S2e
S2
R
> FI−1,n−I;α, entonces se rechaza la hipotesis nula.
Ejemplo 4
En el ejemplo de las tasas de mortalidad,
y1· = 34.62, y2· = 31.48, y3· = 30.04, y4· = 30.04;
S21 = 3.307, S2
2 = 5.007, S23 = 4.998, S2
4 = 1.618.
Ası:y = 31.545, S2
e = 23.3165 y S2R = 3.7325,
por lo que
F =S2
e
S2R
=23.3165
3.7325= 6.247.
ComoFI−1,n−I;α = F3,16;0.05 = 3.24,
entonces cabe concluir que no toda las medias son iguales. Es decir, la tasa de mor-talidad no es la misma para las distintas estaciones del ano
Ahora bien, ¿existen algunas que puedan considerarse iguales?
1.6. Estimacion de la diferencia de medias
Una vez sabemos que las medias son distintas, nos interesa saber si al menosalgunas de ellas son iguales. Para ello, una posibilidad es compararlas dos a dosmediante el contraste
H0 : µ1 = µ2,H1 : µ1 6= µ2.
Como la varianza es desconocida, para el contraste tenemos el estadıstico
t =y1· − y2·√
(n1−1)S2
1+(n2−1)S2
2
n1+n2−2
(1n1
+ 1n2
) .
Si |t| > tn1+n2−2,α/2, entonces se rechaza H0.
Ejemplo 5
En el caso de las tasas de mortalidad:

10 Estadıstica II
(i,j) |t|(1,2) 2.44(1,3) 3.55(1,4) 4.61(2,3) 1.02(2,4) 1.25(3,4) 0.00
Como t8,0.025 = 2.306, aceptamos que, dos a dos, son iguales todos los pares aexcepcion de (1,2), (1,3) y (1,4). Es decir, todos en los casos en los que comparamoslas muertes en invierno con las de cualquier otra estacion.
Metodo de Fischer o LSD (Least Significative Distance)
Si, aunque desconocida, estamos aceptando que todas las varianzas son iguales,entonces podemos estimar la varianza informacion de todas las muestras y no solo
la de los dos grupos que intervienen en el contraste: empleamos S2R.
El estadıstico es
t =y1· − y2·√(1n1
+ 1n2
)S2
R
.
Si |t| > tn−I,α/2, entonces se rechaza H0.
Con el metodo de Fischer podemos detectar diferencias mas pequenas.
Ejemplo 6
En el caso de las tasas de mortalidad:
(i,j) |t|(1,2) 2.57(1,3) 3.75(1,4) 3.75(2,3) 1.18(2,4) 1.18(3,4) 0.00
Como t16,0.025 = 2.120, extraemos nuevamente las mismas conclusiones: todos lospares de estaciones son iguales, excepto aquellos en que aparece el invierno.

Tema 1. Analisis de la varianza 11
Un intervalo de confianzas para la diferencia de medias es
(y1· − y2·) ± tn−I,α/2
√(1
n1
+1
n2
)S2
R.
El metodo se denomina LSD (Least Significative Difference) porque si la distancia
entre las medias, |y1· − y2·| es mayor que el valor tLSD = tn−I,α/2
√(1n1
+ 1n2
)S2
R,
entonces se consideran distintas.
Ejemplo 7
En el caso de las tasas de mortalidad:
(i,j) yi − yj
(1,2) 3.14(1,3) 4.48(1,4) 4.48(2,3) 1.44(2,4) 1.44(3,4) 0.00
Como tLSD = tn−I,α/2
√(1n1
+ 1n2
)S2
R = 2.59, vemos facilmente que todos los
grupos son iguales excepto el asociado a las muertes en invierno.
Metodo de Bonferroni
En un contraste de hipotesis, aceptamos la hipotesis nula H0 salvo que haya unaclara evidencia de que es falsa.
α = P (rechazar H0|H0 es cierta).
Al utilizar el metodo de Fisher, son necesarios I(I − 1)/2 contrastes. En general,si hacemos m contrastes independientes, cada uno con nivel de significacion α, laprobabilidad de rechazar alguna hipotesis nula cierta es:
αT = P (rechazar algun H0|H0) = 1−P (aceptar todos los H0|H0) = 1−(1−α)m > α.
Como αT es el nivel de significacion global que queremos alcanzar, necesitamosque
αT = P (rechazar algun H0|H0) ≤ P (rechazar un H0|H0) = mα.

12 Estadıstica II
En consecuencia, hacemos α = αT /m para los contrastes por parejas. Puesto queα es mas pequeno que en el metodo de Fisher, los intervalos de confianza seran demayor amplitud.
Al tener α valores muy pequenos que no aparecen en las tablas usuales para ladistribucion t, se suele usar la aproximacion
tn,α ≈ zα
(1 − 1 + zα
4n
)−1
.
Ejemplo 8
En el caso de las tasas de mortalidad que hemos estado manejando, αT = 0.05, por
lo que α = 0.056
= 0.0083. Ası, tn−I,α/2 = t16,0.0041 ≈ z0.0041
(1 − 1+z0.0041
4·16
)= 2.80.
Luego tLSD = 2.80
√2S2
R
5= 3.42.
Concluimos que todos los pares son iguales, salvo (1,3) y (1,4). Observemos que,al ser el α de los contrastes muy pequeno, somos mas reacios a rechazar la hipotesisnula (igualdad del par de medias).
1.7. Diagnosis
Finalmente, hay que comprobar que se verifican las distintas hipotesis sobre losresiduos eij.
Normalidad: histograma de residuos, grafico probabilıstico normal.
Homocedasticidad: residuos frente a valores predichos.
Independencia: residuos en el orden de recogida de los datos.
1.8. Analisis de la varianza para dos factores
En el modelo que hemos estudiado, podemos analizar el efecto de un solo factorsobre un conjunto de datos. Sin embargo, en ocasiones puede ser interesante estudiarde forma simultanea el efecto de dos factores.
Ejemplo 9
Cinco estudiantes se sometieron a cuatro tests de lecturas diferentes. Sus puntuacio-nes fueron las siguientes:

Tema 1. Analisis de la varianza 13
EstudianteExamen 1 2 3 4 5
1 75 73 60 70 862 78 71 64 72 903 80 69 62 70 854 73 67 63 80 92
Se trata de un conjunto de 20 datos con dos factores que actuan sobre el valor:tipo de examen y numero de estudiante. El primer factor tiene cuatro niveles mientrasque el segundo tiene cinco.
El modelo
En general, supongamos que tenemos I valores posibles para el primer factor(factor fila, factor principal, proceso o tratamiento) y J valores posibles para elsegundo factor (factor columna, factor secundario, operario o bloque). Sea yij elvalor obtenido para la variable de estudio que se encuentra al nivel i para el primerfactor y al nivel j para el segundo. Podemos representar los datos como sigue:
y11 y12 . . . y1j . . . y1J
y21 y22 . . . y2j . . . y2J...
.... . .
.... . .
...yi1 yi2 . . . yij . . . yiJ...
.... . .
.... . .
...yI1 yI2 . . . yIj . . . yIJ
Ademas, suponemos que el orden de los datos es aleatorio y que hay un solo datopara cada par de niveles de los factores. Es decir, hay IJ datos.
En el modelo con el que vamos a trabajar, asumimos que las diferencias sondebidas a dos efectos que se suman: el del factor principal y el del factor secundario.Ademas, interviene una perturbacion exclusiva de la observacion. Ası, nuestro modelosera
yij = µ + αi + βj + µij, i = 1, . . . , I, j = 1, . . . , J.
Por hipotesis, las perturbaciones µij son independientes y siguen distribucionesnormales N(0, σ2).
Este modelo descompone la respuesta como suma de los siguientes efectos:
1. Un efecto global µ que mide el nivel medio de respuesta para todas las obser-vaciones.

14 Estadıstica II
2. Un efecto αi del factor principal. Supondremos que
I∑
i=1
αi = 0.
3. Un efecto βj del factor bloque. Supondremos que
J∑
j=1
βj = 0.
4. Un efecto aleatorio µij que refleja otras causas de variabilidad.
Estimacion del modelo
Los parametros a estimar son µ, {αi}Ii=1, {βj}J
j=1 y σ2. Como los {αi} estanligados por una igualdad, esto supone un parametro menos a estimar (solo I − 1).Lo mismo sucede con los {βj} (solo hay que estimar J − 1 de dichos parametros).Por lo tanto, en total deben estimarse
1 + (I − 1) + (J − 1) + 1 = I + J parametros.
Si usamos el metodo de maxima verosimilitud para estimarlos, obtenemos que
µ = y··, αi = yi· − y··, βj = y·j − y··, σ2 =
I∑
i=1
J∑
j=1
e2ij
IJ,
siendo eij = yij − µ − αi − βj = yij − yi· − y·j + y··.
Propiedades de los estimadores
Los estimadores anteriormente indicados,
µ = y··, αi = yi· − y·· y βj = y·j − y··,
son centrados para µ, αi y βj, respectivamente, i = 1, . . . , I, j = 1, . . . , J . Ademas,siguen distribuciones normales.
Por otra parte, el estimador σ2 =
I∑
i=1
J∑
j=1
e2ij
IJno es centrado para σ2. En su lugar,
usamos
S2R =
I∑
i=1
J∑
j=1
e2ij
(I − 1)(J − 1),

Tema 1. Analisis de la varianza 15
que sı lo es.
Analisis de la varianza
La hipotesis principal del modelo ANOVA con dos factores (tambien conocidocomo diseno de bloques aleatorizados) es que el factor principal no influye. Tambieninteresa contrastar si los bloques (factor secundario) son realmente distintos: si fueseniguales, podrıamos agrupar todas las observaciones y considerar el modelo ANOVAcon un unico factor (el factor principal).
Si razonamos de un modo analogo a como hicimos en el caso de un factor, podemosdescomponer la variabilidad como
V T = V E(α) + V E(β) + V NE,
siendo
V T = variabilidad total =I∑
i=1
J∑
j=1
(yij − y··)2,
V E(α) = variabilidad entre filas = JI∑
i=1
(yi· − y··)2 = J
I∑
i=1
α2i ,
V E(β) = variabilidad entre columnas = IJ∑
j=1
(y·j − y··)2 = I
J∑
j=1
β2j ,
V NE = variabilidad no explicada (residual) =I∑
i=1
J∑
j=1
e2ij.
Toda esta informacion es posible reunirla en la siguiente tabla ANOVA para dosfactores:

16 Estadıstica II
Fuentes de Suma de Grados de Varianza Test Fvariabilidad cuadrados libertad
Entre filas JI∑
i=1
(yi· − y··)2 = I − 1 S2
α =
J
I∑
i=1
α2i
I−1S2
α
S2R
(distintos αi) = J
I∑
i=1
α2i
Entre columnas IJ∑
j=1
(y·j − y··)2 = J − 1 S2
β =
I
J∑
j=1
β2j
J−1
S2
β
S2R
(distintos βj) = I
J∑
j=1
β2j
ResidualI∑
i=1
J∑
j=1
e2ij (I − 1)(J − 1) S2
R =
I∑
i=1
J∑
j=1
e2ij
(I−1)(J−1)
TotalI∑
i=1
J∑
j=1
(yij − y··)2 IJ − 1 S2
y =
I∑
i=1
J∑
j=1
(yij − y··)2
IJ−1
El contraste principal es que los grupos del factor principal son iguales (es decir,las desviaciones de estos grupos respecto de la media es nula):
H0 : αi = 0, i = 1, . . . , I,H1 : Existe i ∈ I tal que αi 6= 0.
El contraste se hace con el estadıstico F = S2α/S2
R, que sigue una distribucionF(I−1),(I−1)(J−1). Si F > F(I−1),(I−1)(J−1);α, entonces se rechaza H0. Es decir, los gruposen que se divide el factor principal son diferentes.
El contraste de que los bloques no influyen es el siguiente:
H0 : βj = 0, j = 1, . . . , J ,H1 : Existe j ∈ J tal que βj 6= 0.
El contraste se hace con el estadıstico F = S2β/S2
R, que sigue una distribucionF(J−1),(I−1)(J−1). Si F > F(J−1),(I−1)(J−1);α, entonces se rechaza H0. Es decir, los blo-ques influyen en obtener distintos valores.

Tema 1. Analisis de la varianza 17
Finalmente, para “medir” la procedencia de las distintas variabilidades, definimoslos siguientes coeficientes de determinacion parcial :
Coeficiente de determinacion parcial para el factor principal:
R2α =
V E(α)
V T.
Coeficiente de determinacion parcial para el factor secundario:
R2β =
V E(β)
V T.
Coeficiente de determinacion:
R2 =V E
V T=
V E(α) + V E(β)
V T= R2
α + R2β.
Estimacion de las diferencias
Si el analisis de la varianza concluye que hay diferencias entre los distintos gruposdel factor principal, podemos hacer un contraste de diferencia de medias para cadapar de grupos, determinando ası si sus influencias son identicas o si son diferentes:
H0 : α1 = α2,H1 : α1 6= α2.
Usamos el estadıstico
t =y1· − y2·√
2S2R/J
,
que sigue una distribucion t(I−1)(J−1). Por lo tanto, si |t| > t(I−1)(J−1),α/2, entonces serechaza H0.
Un intervalo de confianza para α1 − α2 es
(y1· − y2·) ± t(I−1)(J−1),α/2
√2S2
R/J.
Ejemplo 10
Realicemos el estudio ANOVA bifactorial para el ejemplo de los examenes y losestudiantes. En este caso, I = 4 y J = 5.
En primer lugar, calculamos las distintas medias que necesitamos:
y·· = 74, y1· = 72.8, y2· = 75, y3· = 73.2, y4· = 75,
y·1 = 76.5, y·2 = 70, y·3 = 62.75, y·4 = 73, y·5 = 88.25.

18 Estadıstica II
En consecuencia, tenemos los siguientes estimadores para los distintos efectos:
µ = 74, α1 = 72.8 − 74 = −1.2, α2 = 75 − 74 = 1, α3 = 73.2 − 74 = −0.8,
α4 = 75−74 = 1, β1 = 76.5−74, β2 = 70−74 = −4, β3 = 62.25−74 = −11.75,
β4 = 73 − 74 = −1, β5 = 88.25 − 74 = 14.25.
Las distintas varianzas que intervienen en nuestro estudio son:
S2α =
JI∑
i=1
α2i
I − 1= 6.8,
S2β =
I
J∑
j=1
β2j
J − 1= 364.375,
S2R =
I∑
i=1
J∑
j=1
e2ij
(I − 1)(J − 1)= 11.51.
Realizamos el contraste de diferencia entre filas (es decir, la hipotesis nula es quelos examenes han dados distintos resultados):
F =S2
α
S2R
=6.8
11.51= 0.59.
Como F(I−1),(I−1)(J−1);α = F3,12;0.05 = 3.49, no podemos rechazar que todos los exame-nes han dado resultados parejos.
Ahora realizamos el contraste de diferencia entre columnas (en este caso, lahipotesis nula sera que los estudiantes han obtenidos resultados distintos):
F =S2
β
S2R
=364.375
11.51= 31.66.
Como F(J−1),(I−1)(J−1);α = F4,12;0.05 = 3.26, rechazamos la hipotesis nula y concluimosque no todos los estudiantes han obtenido notas similares.
1.9. Apendice
1. Cuasivarianza muestral de una variable X a partir de una muestra {x1, . . . , xm}:
S2X =
n∑
i=1
(xi − x)2
n − 1.

Tema 2
Regresion lineal simple
2.1. Introduccion
Nuestro objetivo es obtener un modelo que permita establecer relaciones entre dosvariables: la variable y (variable dependiente, respuesta o de interes) y la variable x(variable independiente, predictora o explicativa).
Si es posible establecer una relacion determinista entre las variables, es decir,de la forma y = f(x), entonces la prediccion no tiene ningun error. Por ejemplo,un circuito electrico compuesto por una alimentacion de 10 voltios conectada a unaresistencia de 5 ohmios dara lugar a una intensidad de I=V/R=10/5=2 amperios. Elerror obtenido al medirla es despreciable, por lo que mediciones sucesivas obtendransiempre intensidades de dos amperios.
Como se observa en el grafico, todos los puntos se ajustan a la perfeccion a lalınea recta.
R=5 constante
0
5
10
15
20
25
30
35
0 2 4 6 8
Intensidad (A)
Dif
eren
cia
de
po
ten
cial
(V
)
20 Estadıstica II
Sin embargo, en la mayorıa de las ocasiones, las relaciones entre las variables nosson desconocidas o los errores de medicion no son negligibles. Bajo estas circunstan-cias de relacion no determinista, la relacion puede expresarse como
y = f(x) + u,
donde u es una perturbacion desconocida (una variable aleatoria). La presencia deese error aleatorio significa que dos observaciones identicas para x pueden dar lugara observaciones distintas para y (y viceversa). De particular interes en este curso sonaquellos modelos en los que la funcion f(x) es lineal:
y = β0 + β1x + u.
La variable y varıa linealmente con la variable x, pero no queda totalmente expli-cada por ella a causa de la presencia del error u. Los parametros β0 y β1 se denominancoficientes de regresion; en particular, β0 es el intercepto y β1 es la pendiente.
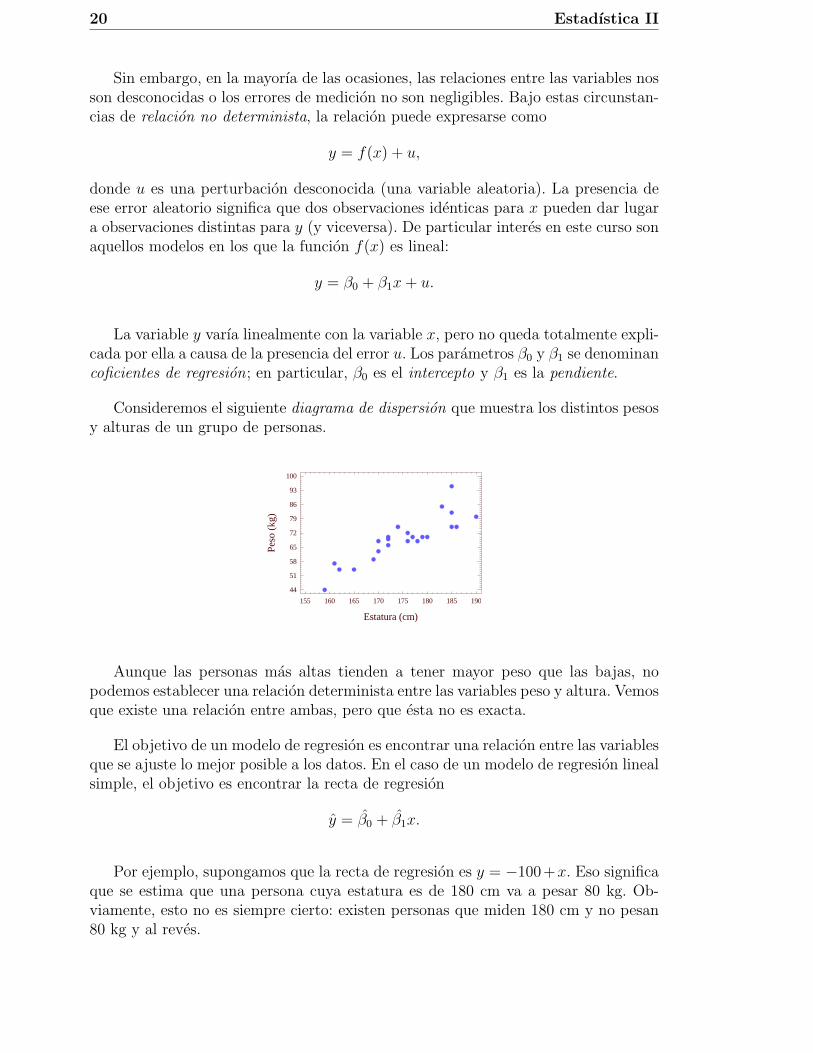
Consideremos el siguiente diagrama de dispersion que muestra los distintos pesosy alturas de un grupo de personas.
Estatura (cm)
Peso
(kg
)
155 160 165 170 175 180 185 190
44
51
58
65
72
79
86
93
100
Aunque las personas mas altas tienden a tener mayor peso que las bajas, nopodemos establecer una relacion determinista entre las variables peso y altura. Vemosque existe una relacion entre ambas, pero que esta no es exacta.
El objetivo de un modelo de regresion es encontrar una relacion entre las variablesque se ajuste lo mejor posible a los datos. En el caso de un modelo de regresion linealsimple, el objetivo es encontrar la recta de regresion
y = β0 + β1x.
Por ejemplo, supongamos que la recta de regresion es y = −100+x. Eso significaque se estima que una persona cuya estatura es de 180 cm va a pesar 80 kg. Ob-viamente, esto no es siempre cierto: existen personas que miden 180 cm y no pesan80 kg y al reves.

Tema 2. Regresion lineal simple 21
Estatura (cm)
Peso
(kg
)
150 160 170 180 190
44
54
64
74
84
94
104
La diferencia entre el valor yi de una variable (p.ej., peso) y su estimacion yi esel residuo ei:
ei = yi − yi.
Graficamente, es la distancia vertical entre una observacion y su estimacion a travesde la recta de regresion.
2.2. Hipotesis del modelo
Para ser valido, el modelo de regresion lineal simple necesita que se satisfaganlas siguientes hipotesis:
1. linealidad,
2. homogeneidad,
3. homocedasticidad,
4. independencia,
5. normalidad.
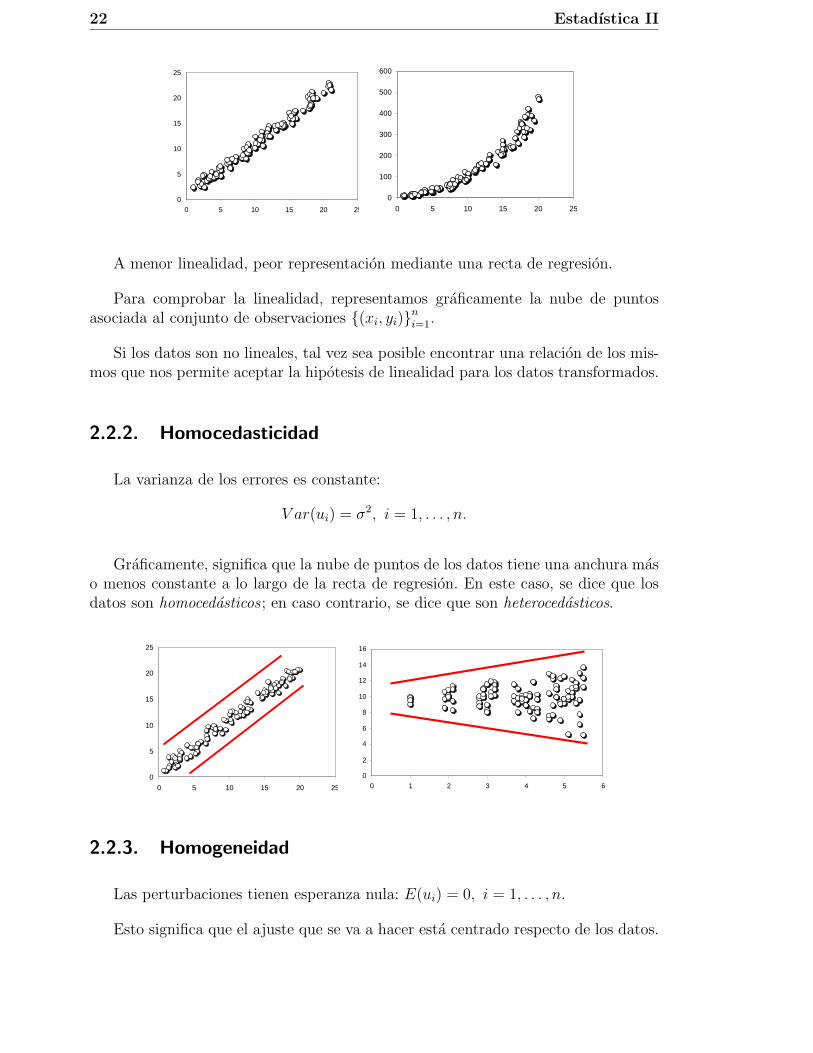
2.2.1. Linealidad
Si pretendemos ajustar una lınea recta a un conjunto de datos es fundamentalque estos tengan un aspecto compatible con el de una recta.
22 Estadıstica II
0
5
10
15
20
25
0 5 10 15 20 25
0
100
200
300
400
500
600
0 5 10 15 20 25
A menor linealidad, peor representacion mediante una recta de regresion.
Para comprobar la linealidad, representamos graficamente la nube de puntosasociada al conjunto de observaciones {(xi, yi)}n
i=1.
Si los datos son no lineales, tal vez sea posible encontrar una relacion de los mis-mos que nos permite aceptar la hipotesis de linealidad para los datos transformados.
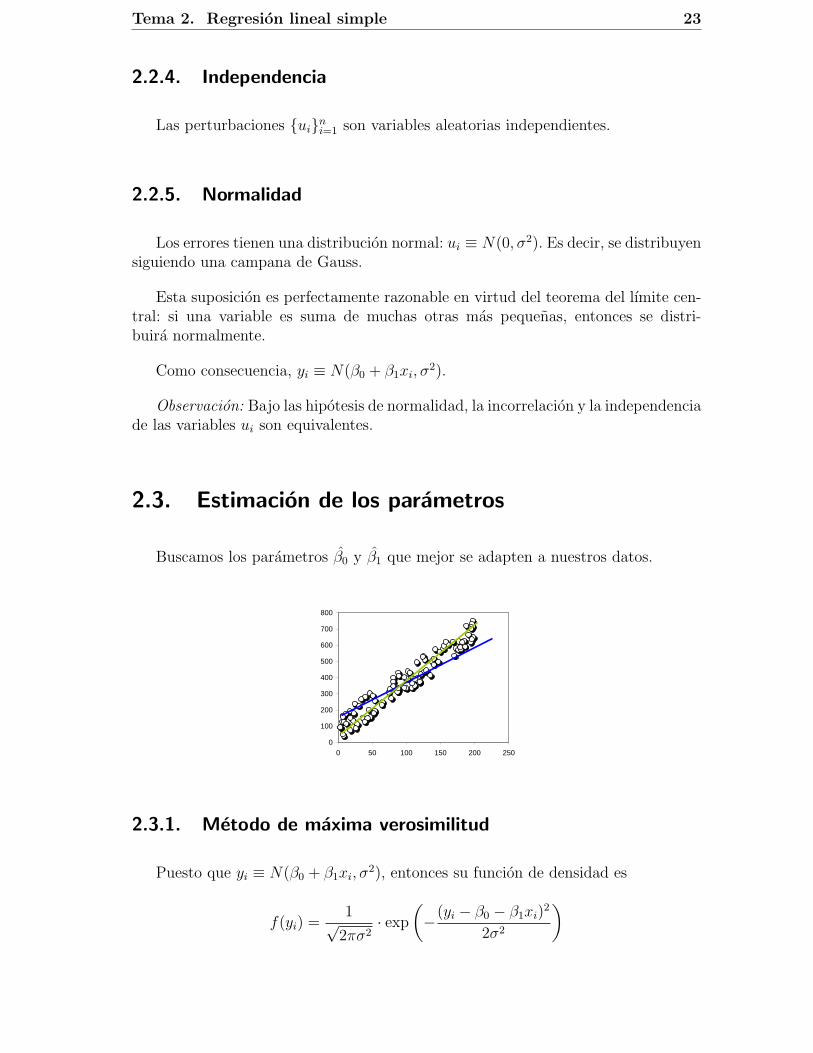
2.2.2. Homocedasticidad
La varianza de los errores es constante:
V ar(ui) = σ2, i = 1, . . . , n.
Graficamente, significa que la nube de puntos de los datos tiene una anchura maso menos constante a lo largo de la recta de regresion. En este caso, se dice que losdatos son homocedasticos ; en caso contrario, se dice que son heterocedasticos.
0
5
10
15
20
25
0 5 10 15 20 25
0
2
4
6
8
10
12
14
16
0 1 2 3 4 5 6
2.2.3. Homogeneidad
Las perturbaciones tienen esperanza nula: E(ui) = 0, i = 1, . . . , n.
Esto significa que el ajuste que se va a hacer esta centrado respecto de los datos.
Tema 2. Regresion lineal simple 23
2.2.4. Independencia
Las perturbaciones {ui}ni=1 son variables aleatorias independientes.
2.2.5. Normalidad
Los errores tienen una distribucion normal: ui ≡ N(0, σ2). Es decir, se distribuyensiguiendo una campana de Gauss.
Esta suposicion es perfectamente razonable en virtud del teorema del lımite cen-tral: si una variable es suma de muchas otras mas pequenas, entonces se distri-buira normalmente.
Como consecuencia, yi ≡ N(β0 + β1xi, σ2).
Observacion: Bajo las hipotesis de normalidad, la incorrelacion y la independenciade las variables ui son equivalentes.
2.3. Estimacion de los parametros
Buscamos los parametros β0 y β1 que mejor se adapten a nuestros datos.
0
100
200
300
400
500
600
700
800
0 50 100 150 200 250
2.3.1. Metodo de maxima verosimilitud
Puesto que yi ≡ N(β0 + β1xi, σ2), entonces su funcion de densidad es
f(yi) =1√
2πσ2· exp
(−(yi − β0 − β1xi)
2
2σ2
)

24 Estadıstica II
y su funcion de maxima verosimilitud es
L(β0, β1, σ2) =
1
(2πσ2)n2
exp
−
n∑
i=1
(yi − β0 − β1xi)2
2σ2
.
A continuacion derivamos parcialmente respecto de las variables β0, β1 and σ2.
∂ ln L∂β0
= 0,
∂ ln L∂β1
= 0,
∂ ln L∂σ2 = 0.
Las dos primeras ecuaciones se denominan ecuaciones normales de la regresion.
∂ ln L∂β0
= 1σ2
n∑
i=1
(yi − β0 − β1xi).
∂ ln L∂β1
= 1σ2
n∑
i=1
xi(yi − β0 − β1xi).
∂ ln L∂σ2 = − n
2σ2 + 12σ4
n∑
i=1
(yi − β0 − β1xi)2.
Igualando a cero obtenemos que los estimadores β0, β1 y σ2 deben satisfacer
n∑
i=1
yi = nβ0 + β1
n∑
i=1
xi, (2.1)
n∑
i=1
xiyi = β0
n∑
i=1
xi + β1
n∑
i=1
x2i , (2.2)
σ2 =
n∑
i=1
(yi − β0 − β1xi)2
n=
n∑
i=1
e2i
n. (2.3)
Comenzamos trabajando la ecuacion (2.1):
ny = nβ0 + nβ1x;
y = β0 + β1x;

Tema 2. Regresion lineal simple 25
β0 = y − β1x.
Seguimos con (2.2):nxy = nβ0x + nβ1x2;
xy =(y − β1x
)x + β1x2 = xy − β1x
2 + β1x2;
xy − xy = β1
(x2 − x2
);
SX,Y = β1s2X ;
β1 =SX,Y
s2
X
.
Finalmente, sustituyendo β0 y β1 en (2.3), se obtiene que
σ2 = s2Y
(1 − S2
X,Y
s2
Xs2
Y
).
Por ultimo, evaluando la matriz hessiana con los valores obtenidos para los esti-madores, se comprueba que se trata de un mınimo (local).
Por lo tanto, la recta de regresion lineal de la variable Y sobre la variable X parauna muestra {(xi, yi)}n
i=1 es
y = y + SXY
s2
X
(x − x).
Algunas propiedades que se derivan para estos estimadores son las siguientes:
1. La pendiente de la recta es proporcional a la covarianza entre las variables.
2. Como y = β0 + β1x, entonces
yi = y + β1(xi − x), i = 1, . . . , n.
3. La recta de regresion simple pasa por la media muestral de los datos (x, y).
4. Las ecuaciones normales se pueden escribir como
n∑
i=1
ei = 0,n∑
i=1
eixi = 0.

26 Estadıstica II
2.3.2. Metodo de mınimos cuadrados
En este caso se busca que sea mınima la suma de los cuadrados de las distanciasverticales entre los puntos y sus estimaciones a traves de la recta de regresion.
0
2
4
6
8
10
12
14
16
0 2 4 6 8 10
La suma de los cuadrados de los residuos es
S(β0, β1) =n∑
i=1
(yi − β0 − β1xi)2.
Al minimizar, obtenemos los mismos estimadores para los parametros que en elmetodo de maxima verosimilitud bajo la hipotesis de normalidad, pues
ln L(β0, β1, σ2) = −n
2ln (2πσ2) − 1
2σ2
n∑
i=1
(yi − β0 − β1xi)2
y las derivadas parciales de S(β0, β1) nos llevan a las ecuaciones normales ya cono-cidas
n∑
i=1
ei = 0,n∑
i=1
eixi = 0.
2.3.3. Estimacion de la varianza
Hemos visto que el estimador maximo verosımil es
σ2 =
n∑
i=1
e2i
n.
Sin embargo, se puede comprobar que E(σ2) = (n−2)σ2
n, por lo que el estimador no
es insesgado. En su lugar, usaremos la varianza residual

Tema 2. Regresion lineal simple 27
S2R =
n∑
i=1
e2i
n−2,
que sı es insesgado.
2.4. Propiedades de los estimadores
2.4.1. Coeficientes de regresion
Normalidad
Al ser yi = β0 + β1xi + ui, entonces yi ≡ N(β0 + β1xi, σ2). Obtendremos que los
estimadores β0 y β1 se distribuyen normalmente por ser combinaciones lineales devariables normales.
β1 =n∑
i=1
(xi − x)(yi − y)
ns2x
=n∑
i=1
(xi − x)yi
ns2x
−n∑
i=1
(xi − x)y
ns2x
.
Comon∑
i=1
(xi − x)y
ns2x
=y
ns2x
n∑
i=1
(xi − x) = 0,
entonces
β1 =n∑
i=1
(xi − x)yi
ns2x
=n∑
i=1
wiyi,
con wi = xi−xns2
x.
Ahora
β0 = y − β1x =n∑
i=1
yi
n− x
n∑
i=1
wiyi =n∑
i=1
(1
n− xwi
)yi.
Luego β0 y β1 son combinaciones lineales de variables normales e independientes.En consecuencia, tambien siguen una distribucion normal.
Esperanza
Veremos que tanto β0 como β1 son estimadores centrados.

28 Estadıstica II
E(β1) = E
(n∑
i=1
wiyi
)=
n∑
i=1
wiE(yi) =n∑
i=1
wi(β0 + β1xi) =
= β0
n∑
i=1
wi + β1
n∑
i=1
wixi = β0 · 0 + β1 · 1 = β1.
E(β0) = E
[n∑
i=1
(1
n− xwi
)yi
]=
n∑
i=1
(1
n− xwi
)E(yi) =
=n∑
i=1
(1
n− xwi
)(β0 + β1xi) = β0 +
n∑
i=1
(1
n− xwi
)+ β1
n∑
i=1
(1
n− xwi
)xi =
= β0(1 − x · 0) + β1(x − x · 1) = β0.
Ası pues, β0 y β1 son estimadores insesgados.
Varianza
Como las variables yi son independientes, entonces
V ar(β1) = V ar
(n∑
i=1
wiyi
)=
n∑
i=1
w2i V ar(yi) =
n∑
i=1
w2i σ
2 =
= σ2
n∑
i=1
(xi − x)2
n2 (s2x)
2)= σ2 s2
x
n2 (s2x)
2)=
σ2
ns2x
.
La varianza de β1 mide el error que cometemos al estimar la pendiente de larecta. Disminuira si:
aumenta n, es decir, se tiene una muestra de mayor tamano;
aumenta s2x, es decir, los puntos estan mas dispersos.
V ar(β0) =n∑
i=1
(1
n− xwi
)2
V ar(yi) = σ2
n∑
i=1
(1
n− xwi
)2
=
σ2
n∑
i=1
(1
n2+ x2w2
i −2
nxwi
)= σ2
(1
n+ x2
n∑
i=1
w2i −
2
nx
n∑
i=1
wi
)=

Tema 2. Regresion lineal simple 29
σ2
(1
n+ x2 · 1
ns2x
+ 0
)=
σ2
n
(1 +
x2
s2x
).
Sin embargo, la varianza σ2 suele ser un dato desconocido, por lo que se defineel error estandar estimado siguiente como medida de precision de la estimacion delos coeficientes:
S(β0) =
√S2
R
n
(1 + x2
s2x
), S(β1) =
√S2
R
ns2x.
2.5. Inferencia respecto a los parametros
Despues de estimar los valores de los parametros es conveniente analizar el gradode precision de la estimacion. Para ello nos valdremos de dos herramientas:
- intervalos de confianza y
- contrastes de hipotesis.
2.5.1. Intervalos de confianza
Recordemos que si β ≡ N(β, σ2), entonces un intervalo de confianza para β anivel de confianza 1 − α viene dado por
β ± zα/2
√σ2,
con P (N(0, 1) > zα/2) = α/2.
Sabemos que
β0 ≡ N
(β0,
σ2
n
(1 +
x2
s2x
))
y
β1 ≡ N
(β1,
σ2
ns2x
).
Pero como σ2 no es desconocida, la estimamos mediante S2R. En consecuencia, los
intervalos de confianza se obtienen ahora para una variable aleatoria con varianzadesconocida y son
β0 ± tn−2,α/2
√S2
R
n
(1 + x2
s2x
)

30 Estadıstica II
y
β1 ± tn−2,α/2
√S2
R
ns2x
para β0 y β1, respectivamente.
Se demuestra (no lo haremos) teniendo en cuenta que
n∑
i=1
e2i
σ2≡ χ2
n−2 y
βi−βi√V ar(βi)√
S2
R
σ2
≡ tn−2.
Observacion: Si se tiene mas de 30 observaciones y se quiere un nivel de confianzadel 95 % (α=0.05), entonces tn−2,α/2 ≈ 2. Ası, los intervalos de confianza seran
βi ± 2S(βi).
O sea, hay (aproximadamente) una probabilidad del 95 % de que el parametro βi
se encuentre en el intervalo(βi − 2S(βi), βi + 2S(βi)
).
Cuanto mas estrecho sea este intervalo, mejor sera la estimacion. Si el intervalode confianza contiene el valor cero, entonces no podemos descartar la posibilidad deque β1 (la pendiente) sea cero, es decir, que las variables X e Y no esten relacionadas(linealmente).
2.5.2. Contraste de hipotesis
Un modo de comprobar si β1 es cero es comprobar si el cero es un valor admisiblepara el intervalo de confianza. Otro metodo es realizar el contraste de hipotesis
H0 : β1 = 0,H1 : β1 6= 0.
Bajo la hipotesis nula, se tiene que β1
S(β1)≡ tn−2, por lo que la region de rechazo
de la hipotesis nula es ∣∣∣∣∣β1
S(β1)
∣∣∣∣∣ > tn−2,α/2.

Tema 2. Regresion lineal simple 31
De nuevo, si n > 30 y α = 0.05, entonces podemos aceptar que β1 = 0 sien el contraste obtenemos un valor para el estadıstico que este entre -2 y 2. Encaso contrario, podemos asegurar que β1 no es nula para ese nivel de confianza (lasvariables X e Y sı estan relacionadas linealmente).
2.5.3. Contraste de regresion y descomposicion de la variabilidad
El contraste de regresion estudia la posibilidad de que la recta teorica tengapendiente nula (β1 = 0). Aunque acabamos de ver ese contraste, vamos a tratarloahora desde el punto de vista del analisis de la varianza. Mas adelante, en el modelode regresion lineal multiple, se mostrara el interes de este contraste.
La Variabilidad Total (VT) del modelo esn∑
i=1
(yi − y)2 y podemos descomponerla
de la siguiente manera:
V T =n∑
i=1
(yi−y)2 =n∑
i=1
(yi−yi+yi−y)2 =n∑
i=1
(yi−yi)2+
n∑
i=1
(yi−y)2+2n∑
i=1
(yi−yi)(yi−y)
Ahora se tiene que
n∑
i=1
(yi − yi)(yi − y) =n∑
i=1
ei · β1(xi − x) = β1
(n∑
i=1
eixi − x
n∑
i=1
ei
)= 0,
por lo queV T = V E + V NE,
con
VT = variabilidad total =n∑
i=1
(yi − y)2,
VE = variabilidad explicada =n∑
i=1
(yi − y)2,
VNE = variabilidad no explicada =n∑
i=1
(yi − yi)2 =
n∑
i=1
e2i .
Si VE es pequena, la recta de regresion no explica bien la variabilidad de losdatos.
No podemos comparar VE y VNE porque, en general, desconocemos su distribu-cion. Pero se puede demostrar que si β1 = 0, entonces
V E
V NE/(n − 2)≡ F1,n−2 (distribucion F de Snedecor).

32 Estadıstica II
Fuentes de Suma de Grados de Varianza Test Fvariacion cuadrados libertad
VEn∑
i=1
(yi − y)2 1 S2e
S2e
S2
R
VNEn∑
i=1
(yi − yi)2 n − 2 S2
R
VTn∑
i=1
(yi − y)2 n − 1
Tabla 2.1: Tabla ANOVA
2.5.4. Coeficiente de determinacion
El coeficiente de determinacion R2 describe en que medida la variable x describela variabilidad de y.
R2 =V E
V T=
n∑
i=1
(yi − y)2
n∑
i=1
(yi − y)2
=
n∑
i=1
(yi − y)2
ns2Y
.
A mayor valor, mayor es la relacion entre las variables.
2.6. Prediccion
En un modelo de regresion hay dos objetivos fundamentales:
- conocer la relacion entre la variable respuesta y la explicativa,
- utilizar el modelo ajustado para predecir el valor de la variable respuesta.
En este segundo punto surgen dos tipos de situaciones en funcion de la preguntaque queramos responder:
1. Estimacion de la respuesta media: “¿Cual es el peso medio de las personas quemiden 180 cm de estatura?”
2. Prediccion de una nueva observacion: “Sabiendo que una persona mide 180 cm,¿cual es su peso esperado?”

Tema 2. Regresion lineal simple 33
En ambos caso el valor estimado se obtiene mediante la recta de regresion. Porejemplo, si esta es y = x − 100, entonces para x0 = 180 cm obtendremos un pesoy0 = 80 kg. No obstante, la precision de las estimaciones es diferente.
En el primer caso, el intervalo de confianza es
y0 ± tn−2,α/2
√S2
R
(1n
+ (x0−x)2
ns2x
).
En el segundo obtendremos un intervalo mas amplio denominado intervalo deprediccion:
y0 ± tn−2,α/2
√S2
R
(1 + 1
n+ (x0−x)2
ns2x
).
Este intervalo tiene mayor amplitud (menos precision) porque no buscamos pre-decir un valor medio sino un valor especıfico.
2.7. Diagnosis mediante residuos
Despues de haber obtenido la recta de regresion, hay que comprobar si se cumplenlas hipotesis iniciales.
2.7.1. Linealidad
Con el grafico de dispersion X-Y vemos si los datos iniciales presentan una estruc-tura lineal. Esta es una comprobacion que realizamos antes de comenzar el analisisde regresion.
Despues de obtener los parametros de regresion, estudiaremos el grafico de resi-duos frente a valores predichos. Este grafico debe presentar un aspecto totalmentealeatoria, sin estructura alguna.

34 Estadıstica II
Valores predichos
Residuos
0 200 400 600 800
-1,8
-0,8
0,2
1,2
2,2
Si tienen algun tipo de estructura, entonces no se satisface la hipotesis de linea-lidad.
Valores predichos
Residuos
0 100 200 300
-6
-4
-2
0
2
4
6
2.7.2. Homocedasticidad
Al analizar los residuos , tambien hay que verificar que su varianza sea mas omenos constante. Nos seran utiles los graficos de residuos frente a valores ajustadosy de residuos frente a X.
X
Residuos
0 40 80 120 160 200
-9
-6
-3
0
3
6
9
Valores predichos
Residuos
0 50 100
-9
-6
-3
0
3
6
9
2.7.3. Independencia
Esta hipotesis es muy importante. Aunque existen contrastes para comprobarla(contraste de Durbin-Watson), no profundizaremos en ese aspecto.
Tema 2. Regresion lineal simple 35
Simplemente hay que tener en cuenta que si los datos son temporales (por ejem-plo, combustible utilizado y rendimiento en dıas sucesivos), entonces no debe em-plearse un modelo de regresion lineal.
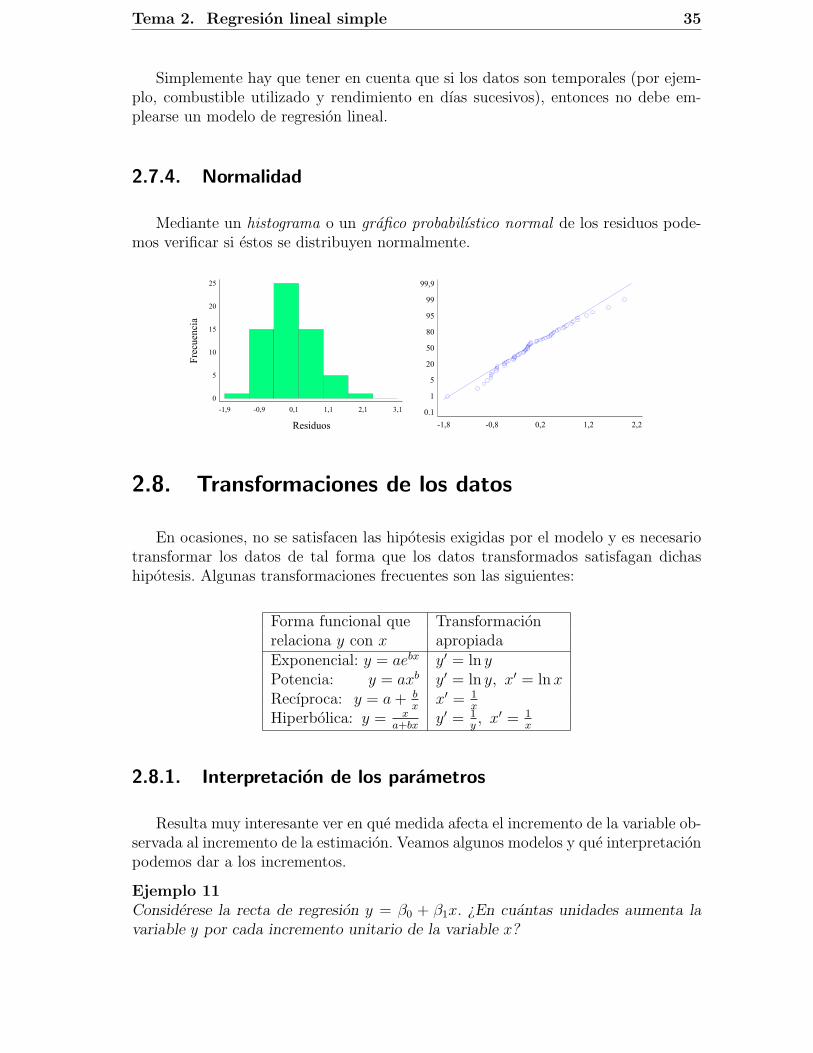
2.7.4. Normalidad
Mediante un histograma o un grafico probabilıstico normal de los residuos pode-mos verificar si estos se distribuyen normalmente.
Residuos
Frecuencia
-1,9 -0,9 0,1 1,1 2,1 3,1
0
5
10
15
20
25
-1,8 -0,8 0,2 1,2 2,2
0.1
1
5
20
50
80
95
99
99,9
2.8. Transformaciones de los datos
En ocasiones, no se satisfacen las hipotesis exigidas por el modelo y es necesariotransformar los datos de tal forma que los datos transformados satisfagan dichashipotesis. Algunas transformaciones frecuentes son las siguientes:
Forma funcional que Transformacionrelaciona y con x apropiadaExponencial: y = aebx y′ = ln yPotencia: y = axb y′ = ln y, x′ = ln xRecıproca: y = a + b
xx′ = 1
x
Hiperbolica: y = xa+bx
y′ = 1y, x′ = 1
x
2.8.1. Interpretacion de los parametros
Resulta muy interesante ver en que medida afecta el incremento de la variable ob-servada al incremento de la estimacion. Veamos algunos modelos y que interpretacionpodemos dar a los incrementos.
Ejemplo 11
Considerese la recta de regresion y = β0 + β1x. ¿En cuantas unidades aumenta lavariable y por cada incremento unitario de la variable x?

36 Estadıstica II
Solucion:
El incremento es
∆ = y(x + 1) − y(x) = [β0 + β1(x + 1)] − [β0 + β1x] = β1.
La variable y aumenta en β1 unidades.
Ejemplo 12
Considerese la recta de regresion ln y = β0 + β1x. ¿En que porcentaje aumenta lavariable y por cada incremento unitario de la variable x?Solucion:
El incremento (unitario) es
∆ =y(x + 1)
y(x)− 1;
∆ + 1 =y(x + 1)
y(x);
ln (∆ + 1) = ln
(y(x + 1)
y(x)
)= ln [y(x + 1)]−ln [y(x)] = [β0 + β1(x + 1)]−[β0 + β1x] = β1;
∆ + 1 = eβ1 ;
∆ = eβ1 − 1.
La variable y aumenta en un 100(eβ1 − 1) %.
Si asumimos la aproximacion ex ≈ 1+x (especialmente util para valores pequenosde x), entonces
∆ ≈ 1 + β1 − 1 = β1;
el incremento de y es aproximadamente del 100β1 %.
Ejemplo 13
Considerese la recta de regresion ln y = β0 + β1 ln x. ¿En que porcentaje aumenta lavariable y por cada incremento porcentual unitario de la variable x?Solucion:
El incremento (unitario) es
∆ =y(1.01x)
y(x)− 1;
ln (∆ + 1) = ln
[y(1.01x)
y(x)
]= ln [y(1.01x)] − ln [y(x)] =
= [β0 + β1 ln (1.01x)] − [β0 + β1 ln x] = β1 ln 1.01;
∆ + 1 = (1.01)β1 ;

Tema 2. Regresion lineal simple 37
∆ = (1.01)β1 − 1.
La variable y aumenta en un 100((1.01)β1 − 1
)%.
Este incremento podemos aproximarlo. En primer lugar, ln (1 + x) ≈ x si |x| < 1.Ası
ln (∆ + 1) = β1 ln 1.01 ≈ β11.01;
∆ + 1 ≈ e0.01β1 .
Ahora, haciendo uso de la aproximacion para la funcion exponencial que se vio en elejemplo anterior:
∆ ≈ e0.01β1 − 1 ≈ 1 + 0.01β1 − 1 = 0.01β1.
Luego la variable y aumenta aproximadamente en un β1 %.
2.9. Apendice
1. Varianza muestral de una variable X:
s2X =
n∑
i=1
(xi − x)2
n= x2 − x2.
2. Covarianza muestral de dos variables X e Y :
SX,Y =
n∑
i=1
(xi − x)(yi − y)
n= xy − xy.
3. Si wi = xi−xns2
x, entonces:
i)n∑
i=1
wi = 0,
ii)n∑
i=1
wixi = 1.
Demostracion:
i)
n∑
i=1
wi =n∑
i=1
xi − x
ns2x
=1
s2x
n∑
i=1
xi
n−
n∑
i=1
x
n
=1
s2x
(x − x) = 0.

38 Estadıstica II
ii)
n∑
i=1
wixi =n∑
i=1
(xi − x
ns2x
)xi =
1
s2x
n∑
i=1
x2i
n− x
n∑
i=1
xi
n
=x2 − x2
s2x
=s2
x
s2x
= 1.
4. Esperanza y varianza de combinaciones lineales de variables aleatorias.
i) Si a ∈ R y X es una variables aleatoria, entonces
E(aX) = aE(X),
V ar(aX) = a2V ar(X).
ii) Si a1, . . . , an ∈ R y X1, . . . , Xn son variables aleatorias, entonces
E
(n∑
i=1
aiXi
)=
n∑
i=1
aiE(Xi).
iii) Si a1, . . . , an ∈ R y X1, . . . , Xn son variables aleatorias independientes,entonces
V ar
(n∑
i=1
aiXi
)=
n∑
i=1
a2i V ar(Xi).
5. Como las distribuciones normal y t de Student son simetricas respecto delorigen, entonces zα = −z1−α y tn,α = −tn,1−α.

Tema 3
Regresion lineal multiple
3.1. Introduccion
Hasta ahora hemos estudiado un modelo en el que hay una unica variable expli-cativa. Sin embargo, es razonable pensar que puedan existir varias variables indepen-dientes xi que contribuyan a explicar la variable dependiente y. Es entonces cuandose utiliza el modelo de regresion lineal multiple
y = β0 + β1x1 + . . . + βkxk + u.
Si tenemos n observaciones {(xi1, . . . , xik)}ni=1, entonces
yi = β0 + β1xi1 + . . . + βkxik + ui, i = 1, . . . , n.
3.2. Hipotesis del modelo
El modelo de regresion lineal multiple requiere diversas condiciones analogas alas del modelo de regresion lineal simple.
3.2.1. Linealidad
Los datos deben satisfacer una relacion lineal
yi = β0 + β1xi1 + . . . + βkxik.
39

40 Estadıstica II
Si hay solo dos variables explicativas,
yi = β0 + β1xi1 + β2xi2,
entonces los datos deben estar aproximadamente contenidos en un plano. Para treso mas variables explicativas, la ecuacion de regresion es un hiperplano y no podemosvisualizar los datos graficamente.
3.2.2. Homocedasticidad
La varianza debe ser constante: V ar(ui) = σ2, i = 1, . . . , n.
3.2.3. Homogeneidad
La perturbacion tiene esperanza nula: E(ui) = 0, i = 1, . . . , n.
3.2.4. Independencia
Las perturbaciones ui son independientes entre sı.
3.2.5. Normalidad
Las perturbaciones ui tienen distribucion normal: ui ≡ N(0, σ2), i = 1, . . . , n.
En consecuencia, yi ≡ N(β0 + β1xi1 + . . . + βkxik, σ2), ı = 1, . . . , n.
3.2.6. Otras hipotesis
Hipotesis adicionales son:
El numero de datos n es mayor que k + 1.
Ninguna variable explicativa es una combinacion lineal de las demas, es decir,las variables xi son linealmente independientes.

Tema 3. Regresion lineal multiple 41
Forma matricial del modelo
El modelo puede expresarse mediante matrices de la forma siguiente:
Y = Xβ + U,
con
Y =
y1
y2...
yn
, X =
1 x11 . . . x1k
1 x21 . . . x2k...
.... . .
...1 xn1 . . . xnk
, β =
β0
β1...
βk
, U =
u1
u2...
un
.
Con esta notacion matricial:
U ≡ N(0n, σ2In), Y ≡ N(Xβ, σ2In).
3.3. Estimacion de los parametros
Buscamos estimar los parametros de regresion β0, β1, . . . , βk.
Como consecuencia de las hipotesis del modelo, van a coincidir los estimadoresobtenidos mediante los metodos de maxima verosimilitud y mınimos cuadrados.
3.3.1. Coeficientes de regresion
Calculemos β0, . . . , βk mediante mınimos cuadrados:
L(β0, β1, . . . , βk) =n∑
i=1
(yi − β0 − β1xi1 − . . . − βkxik)2.
Derivando parcialmente, {β0, β1, . . . , βk} es la solucion de
∂L
∂βj
= 0, j = 0, . . . , k;
0 = ∂L∂β0
= −2n∑
i=1
(yi − β0 − β1xi1 − . . . − βkxik),
0 = ∂L∂βj
= −2n∑
i=1
(yi − β0 − β1xi1 − . . . − βkxik)xij, j = 1, . . . , k.

42 Estadıstica II
Llamando ei = yi − yi = yi − β0 − β1xi1 − · · · − βkxik, entonces
n∑
i=1
ei = 0,
n∑
i=1
euixij = 0, j = 1, . . . , k.
Estas ecuaciones podemos resolverlas facilmente si trabajamos con la expresionmatricial del modelo: Y = Xβ + U . Ası,
L(β) = (Y − Xβ)t(Y − Xβ) = Y tY − 2Y tXβ + βtX tXβ.
Derivando parcialmente esta expresion:
0 =∂L
∂β= −2X tY + 2X tXβ;
X tXβ = X tY ;
β = (X tX)−1X tY.
3.3.2. Varianza
Para estimar la varianza usaremos la varianza residual :
S2R =
n∑
i=1
e2i
n−k−1.
Este estimador es insesgado para σ2. Se puede demostrar que
n∑
i=1
e2i
σ2 ≡ χ2n−k−1.
3.3.3. Comentarios
Como y = β0 +k∑
i=1
βixi e y = β0 +k∑
i=1
βixi, entonces y − y =k∑
i=1
βi(xi − xi).

Tema 3. Regresion lineal multiple 43
Si
Y = Y − Y =
y1 − y...
yn − y
, b =
β1...
βk
y
X =
x11 − x1 . . . x1k − xk
x21 − x1 . . . x2k − xk...
. . ....
xn1 − x1 . . . xnk − xk
,
entonces Y = Xb.
Sean ahora SX,X = 1nX tX y SX,Y = 1
nX tY , es decir, SX,X es la matriz de va-
rianzas y covarianzas muestrales de las variables explicativas y SX,Y el vector decovarianzas muestrales entre las variables explicativas y la variables respuesta. Setiene que
Y = Xb;
X tY = X tXb;
b = (X tX)−1X tY = S−1X,XSX,Y .
Si las variables xi son incorreladas, entonces SXX es una matriz diagonal y resultaque
bi = βi =Cov(y, xi)
V ar(xi),
coincidiendo con el coeficiente de regresion obtenido para el modelo de regresionlineal simple.
3.4. Propiedades de los estimadores
3.4.1. Normalidad
Sabemos que Y = Xβ + U tiene una distribucion normal, Y ≡ N(Xβ, σ2In).Como β = (X tX)−1X tY , entonces β es una funcion lineal de Y . En consecuencia,tambien se distribuye normalmente.
3.4.2. Esperanza
El estimador β es insesgado para β.

44 Estadıstica II
E(β) = E[(X tX)−1X tY
]= (X tX)−1X tE(Y ) = (X tX)−1X tXβ = β.
3.4.3. Varianza
V ar(β) = V ar[(X tX)−1X tY
]= (X tX)−1X tV ar(Y )X(X tX)−1 =
= (X tX)−1X tσ2InX(X tX)−1 = σ2(X tX)−1.
En concreto,
V ar(βi) = σ2 (X tX)−1ii ,
Cov(βi, βj) = σ2 (X tX)−1ij .
Ası, βi ≡ N(βi, σ2(X tX)−1
ii ).
Sin embargo, la varianza σ2 suele ser desconocida. Por lo tanto, definimos el errorestandar estimado como
S(βi) =
√(X tX)−1
ii S2R.
3.5. Inferencia
Puede resultar interesante realizar contrastes de hipotesis y obtener intervalos deconfianza para cada coeficiente de regresion. Ası podemos determinar la influenciade cada variable explicativa sobre el modelo de regresion.
3.5.1. Contrastes para los coeficientes de regresion
Estamos interesados en saber si la variable xi afecta o no a la respuestas (en cuyocaso convendrıa eliminarla del modelo). Para ello realizamos el contraste
H0 : βi = 0H1 : βi 6= 0.

Tema 3. Regresion lineal multiple 45
Sabemos que βi ≡ N(βi, σ2(X tX)−1
ii ), por lo que βi−βi√σ2(XtX)−1
ii
≡ N(0, 1).
Como σ2 no suele conocerse, en su lugar empleamos la varianza residual S2R.
Puesto que(n−k−1)S2
R
σ2 ≡ χ2n−k−1, entonces el siguiente estimador sigue una distribu-
cion tn−k−1:
N(0, 1)√χ2
n−k−1
n−k−1
=βi − βi√
S2R(X tX)−1
ii
=βi − βi
S(βi).
Ahora, bajo la hipotesis nula se tiene que βi
S(βi)≡ tn−k−1. Por lo tanto, si
∣∣∣∣∣βi
S(βi)
∣∣∣∣∣ > tn−k−1,α/2,
entonces rechazamos que βi pueda ser cero. En concreto, si n−k−1 > 30 y α = 0.05,entonces tn−k−1,α/2 ≈ 2.
3.5.2. Intervalos de confianza
Puesto que βi−βi
S(βi)≡ tn−k−1, se tiene que
P
(−tn−k−1,α/2 ≤
βi − βi
S(βi)≤ tn−k−1,α/2
)= 1 − α;
P(βi − tn−k−1,α/2S(βi) < βi < βi + tn−k−1,α/2S(βi
)= 1 − α.
Ası que(βi − tn−k−1,α/2S(βi), βi + tn−k−1,α/2S(βi)
)es un intervalo de confianza
para βi con nivel de confianza 1 − α. Analogamente a lo ya visto, si n − k − 1 > 30y α = 0.05, el intervalo puede aproximarse por βi ± 2S(βi).
3.5.3. Contraste de regresion
Al igual que sucede en el modelo de regresion lineal simple, se tiene la relacionV T = V E + V NE, donde
VT = variabilidad total =n∑
i=1
(yi − y)2,

46 Estadıstica II
VE = variabilidad explicada =n∑
i=1
(yi − y)2,
VNE = variabilidad no explicada =n∑
i=1
(yi − yi)2 =
n∑
i=1
e2i .
El contraste de regresion establece si existe relacion lineal entre la variable res-puesta y los coeficientes de regresion:
H0 : β1 = β2 = · · · = βk = 0,H1 : ∃j ∈ {1, . . . , k} / βj 6= 0.
Por una parte, sabemos que V NEσ2 ≡ χ2
n−k−1. Por otra parte, se puede demostrarque V E
σ2 ≡ χ2k. En consecuencia,
V E/k
V NE/(n − k − 1)≡ Fk,n−k−1.
Fuentes de Suma de Grados de Varianza Test Fvariacion cuadrados libertad
VE (modelo)n∑
i=1
(yi − y)2 k S2e = V E
kF = S2
e
S2
R
VNE (residual)n∑
i=1
e2i n − k − 1 S2
R
VTn∑
i=1
(yi − y)2 n − 1
Tabla 3.1: Tabla ANOVA
Buscamos el valor Fk,n−k−1;α tal que P (F > Fk,n−k−1;α) = α. Por lo tanto, si elvalor del estadıstico es mayor que Fk,n−k−1;α, entonces rechazaremos la hipotesis nulay concluiremos que el modelo explica una parte significativa de y. En caso contrario,concluiremos que el modelo no explica conjuntamente nada.
3.5.4. El coeficiente de determinacion corregido
Para construir una medida que describa el ajuste global del modelo se utiliza elcociente entre las variabilidades explicada y total del modelo. Es lo que se llama elcoeficiente de determinacion.
R2 =V E
V T=
n∑
i=1
(yi − y)2
(yi − y)2= 1 − V NE
V T.

Tema 3. Regresion lineal multiple 47
Por definicion, 0 ≤ R2 ≤ 1. En particular, si R2 = 1, entonces existe una relacionlineal exacta entre la variable respuesta y las variables explicativas.
Aunque el valor R2 da una medida de lo adecuado que es el modelo, un mayor R2
no tiene por que implicar un mejor modelo. La razon es que R2 aumenta siempreque se introduce una nueva variable, aunque esta no sea significativa.
Para solventar este problema, el coeficiente R2 se corrige por el numero de gradosde libertad del modelo. Esto penaliza el numero de variables que se introducen.Ası obtenemos el coeficiente de determinacion corregido
R2 = 1 − V NE/(n − k − 1)
V T/(n − 1)= 1 − S2
R
V T/(n − 1).
De este modo, R2 solo aumenta si disminuye S2R.
3.6. Prediccion
Tanto para predecir el valor medio como el de una observacion especıfica, laestimacion se obtiene sustituyendo el valor de la observacion xh en el modelo deregresion:
yh = β0 + β1xh1 + · · · + βkxhk.
Para el valor medio, un intervalo de confianza a nivel 1 − α es
yh ± tn−k−1,α/2
√S2
R(1+xthS−1
XXxh)
n,
donde xh = (x1h − x1, . . . , xkh − xk) no incluye la entrada correspondiente al unode β0 y SXX es la matriz de varianzas y covarianzas entre las xi.
Un intervalo de prediccion para una observacion especıficas es
yh ± tn−k−1,α/2
√S2
R
(1 +
1+xthS−1
XXxh
n
),
Si en lugar de usar la matriz S−1XX usamos la matriz (X tX)−1, los intervalos de
prediccion son, respectivamente,
yh ± tn−k−1,α/2
√S2
Rxth(X
tX)−1xh,

48 Estadıstica II
y
yh ± tn−k−1,α/2
√S2
R(1 + xth(X
tX)−1xh).
Ejemplo 14
Se han recogido los siguientes datos de una encuesta sobre presupuestos familiaresmensuales:
y x1 x2
50 2 2160 3 4120 5 3240 8 6320 12 10
siendo y el gasto familiar, x1 el gasto en telefono y x2 el tamano de la familia (losgastos en decenas de euros).
1. Construye e interpreta un modelo que explique el gasto familiar en funcion delgasto telefonico y el numero de miembros de la familia.
2. Calcula el coeficiente de determinacion, el coeficiente de determinacion corre-gido y la varianza residual.
3. Construye un intervalo de confianza al 95 % para la pendiente del gasto te-lefonico.
4. Indica que coeficientes son significativos.
Solucion:
1. Buscamos construir un modelo de regresion lineal multiple de la forma
y = β0 + β1x1 + β2x2.
En primer lugar, escribimos los datos en notacion matricial:
Y =
5080
160240320
, X =
1 2 21 3 41 5 31 8 61 12 10
.

Tema 3. Regresion lineal multiple 49
Como
(X tX
)−1
=
0.8276 0.0209 −0.15060.0209 0.1674 −0.2050−0.1506 −0.2050 0.2762
,
entonces
β =
17.1663.657
28.654
.
Por lo tanto, el modelo que se obtiene es
y = 17.166 + 3.657x1 + 28.654x2.
2. El vector de residuos es
Y − Xβ =
−31.78817.247−1.41321.654
−27.590
.
En consecuencia,
S2R =
n∑
i=1
e2i
n − k − 1=
(Y − Xβ)t(Y − Xβ
2= 1270.0182.
La variabilidad total es V T =∑5
i=1(yi − y)2 = 44080. Ası,
R2 =V E
V T= 1 − V NE
V T= 1 − 2S2
R
V T= 0.9424,
y
R2 = 1 − S2R
V T/(n − 1)= 0.8848.
3. El IC es β1 ± tn−k−1,α/2S(β1). Como
tn−k−1,α/2 = t2,0.025 = 4.303
y
S(β1) =
√S2
R (X tX)−111 =
√1270.0182 · 0.1674 = 14.58,
entones el intervalo es
3.657 ± 62.741 = (−59.084, 66.398).
50 Estadıstica II
4. Para realizar el contraste
H0 : β1 = β2 = 0,H1 : β1 6= 0 o β2 6= 0,
calculamos
F =S2
e
S2R
=V E/k
S2R
=(V T − V NE)/k
S2R
2 = 16.35.
Como F < F2,2;0.05 = 19, no podemos rechazar H0. En consecuencia, conclui-mos que el modelo no explica bien el gasto familiar. �
3.7. Regresion con variables cualitativas
3.7.1. Variables dicotomicas
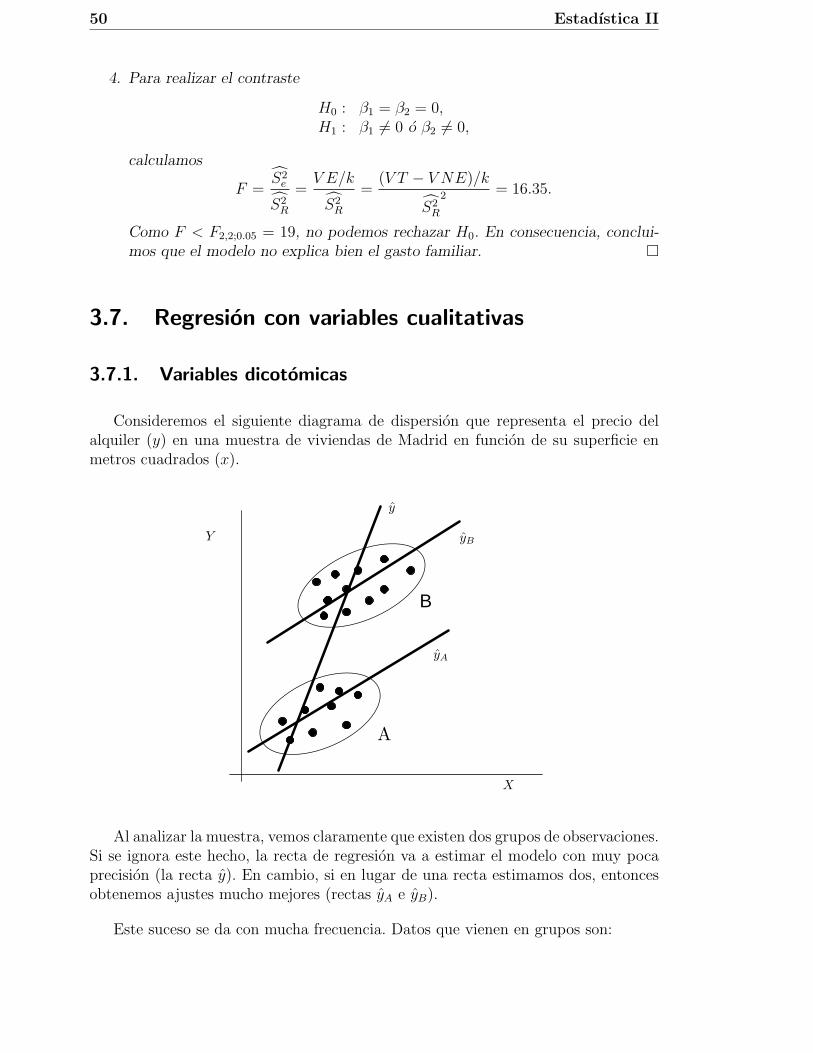
Consideremos el siguiente diagrama de dispersion que representa el precio delalquiler (y) en una muestra de viviendas de Madrid en funcion de su superficie enmetros cuadrados (x).
yB
yA
y
B
A
X
Y
Al analizar la muestra, vemos claramente que existen dos grupos de observaciones.Si se ignora este hecho, la recta de regresion va a estimar el modelo con muy pocaprecision (la recta y). En cambio, si en lugar de una recta estimamos dos, entoncesobtenemos ajustes mucho mejores (rectas yA e yB).
Este suceso se da con mucha frecuencia. Datos que vienen en grupos son:

Tema 3. Regresion lineal multiple 51
peso y altura en funcion del sexo,
densidad de un material y temperatura del proceso en funcion de la presenciao ausencia de un metal,
consumo de un motor y potencia en funcion del tipo de motor (diesel o gasoli-na).
Para resolver este problema, se introducen unas variables binarias (dicotomicas)denominadas variables ficticias, indicadoras o dummies :
zi =
{0 si la observacion i pertenece al grupo A,
1 si la observacion i pertenece al grupo B.
Tras definir la variable z de este modo, se ajusta un modelo de la forma
y = β0 + β1x + β2z + u.
Este modelo tiene la propiedad de ajustar las dos rectas de regresion. Si la ob-servacion i pertenece al grupo A, entonces
yi = β0 + β1xi,
mientras que si pertenece al grupo B, entonces
yi = (β0 + β2) + β1xi.
Supongamos que zi vale 1 si la observacion i pertenece a un hombre y 0 si per-tenece a una mujer. Si ajustamos un modelo como el que acabamos de ver pararelacionar peso (y) y altura (x), obtendremos que un hombre pesa β2 kg mas queuna mujer de la misma altura. Ahora bien, de acuerdo con el modelo, el ratio decrecimiento (la pendiente β1) es el mismo para ambos generos, cosa que podrıa noser cierta.

52 Estadıstica II
Para ver si el hecho de ser hombre o mujer (la variable cualitativa) afecta al ratiode crecimiento (la pendiente de la recta de regresion), estudiaremos la interaccionentre ambas mediante un modelo de la forma
y = β0 + β1x + β2z + β3xz + u.
Ası, para una observacion i:
si zi = 0, entonces yi = β0 + β1xi,
si zi = 1, entonces yi = (β0 + β2) + (β1 + β3)zi.
3.7.2. Variables politomicas
Sucede a menudo que las variables cualitativas no se limitan a tomar valores endos categorıas (sı/no), sino que recorren ua gama mas amplia (estudios primarios,medios o superiores; satisfaccion ninguna, poca, regular, bastante o completa. . . ).Modelizar estas situaciones es bastante sencillo: si tenemos s categorıas, entoncesintroduciremos s − 1 variables dicotomicas zt donde
zi =
{1 si la observacion i pertenece a la categorıa t,
0 en caso contrario.
Por ejemplo, si se esta calentando una serie de barras para estudiar su dilatacion yel proceso puede ser realizado en una las de cuatro maquinas disponibles, las distintasvariables del modelo son: y (dilatacion en centımetros), x (temperatura en gradoscentıgrados) y
zi =
{1 si la maquina i es la empleada en el proceso,
0 en caso contrario.
El modelo sera
y = β0 + β1x + β2z1 + β3z2 + β4z3 + u.
3.8. Multicolinealidad
El problema de la multicolinealidad se da con frecuencia a la hora de ajustarun modelo de regresion multiple: se presenta cuando las variables cualitativas estan

Tema 3. Regresion lineal multiple 53
altamente interrelacionadas. Si una variable explicativa esta relacionada exactamentecon las demas, entonces no es posible estimar sus efectos.
Hay que destacar que no es un problema del modelo sino de los datos: a la horade calcular (X tX)−1, puede suceder que det(X tX) sea cero o este muy cerca de serlo.
Podemos detectar que hay multicolinealidad de diferentes maneras:
1. Las variables explicativas son significativas en el modelo de regresion linealsimple, pero dejan de serlo en el modelo de regresion multiple (estadısticos tbajos). Tambien se detecta la multicolinealidad porque, aunque el contraste tde valores bajos, el contraste F indica que una parte importante de la variabi-lidad del modelo es explicada (valor alto del estadıstico) y/o el coeficiente dedeterminacion corregido es alto.
2. Indice de condicionamiento: Sean λ1 ≤ · · · ≤ λk+1 los autovalores de X tX. Sedefine el ındice de condicionamiento como
IC =
√λk+1
λ1
≥ 1.
Si 10 ≤ IC ≤ 30, se dice que hay multicolinealidad moderada. Si IC > 30, sedice que hay multicolinealidad alta.
La idea es que si hay multicolinealidad, entonces alguno de los autovaloresde X tX estara proximo a cero.
Para reducir el problema de multicolinealidad, una posible solucion es eliminaralguna de las variables explicativas que dependa fuertemente de otras.
3.9. Diagnosis
El proceso de diagnosis en regresion multiple es mas complejo porque no es posiblevisualizar los datos correctamente.
Ademas de las tecnicas ya vistas en regresion simple para comprobar las hipotesisde linealidad, heterocedasticidad y normalidad, en regresion multiple tambien es utilrealizar graficos de residuos frente a las variables explicativas xi. Permiten identificarsi alguna variable produce los efectos de falta de linealidad y heterocedasticidad.

54 Estadıstica II
3.10. Apendice 1: Mınimos cuadrados restringidos
En ocasiones, el analisis de regresion debe realizarse teniendo en cuenta unasciertas relaciones lineales entre los parametros (por ejemplo, que su suma es igualuno).
Supongamos que se tiene r relaciones lineales y que estas vienen dadas en formamatricial por Hβ = C.
Para determinar el valor de los parametros de regresion, usamos el metodo demınimos cuadrados restringidos, esto es, el metodo de mınimos cuadrados pero bajolas restricciones de igualdad.
Queremos minimizar (Y −Xβ)t(Y −Xβ) bajo Hβ = C. Para ello, anadimos unmultiplicador de Lagrange λ ∈ R
r y obtenemos la funcion
L(β, λ) = (Y − Xβ)t(Y − Xβ) + λt(Hβ − C),
que derivamos respecto de ambos parametros (que, recordemos, son vectores).
Ası, llamando β al vector de parametros de regresion por mınimos cuadradosusual y βr al asociado al caso restringido:
0 = ∂L∂β
= −2X tY + 2X tXβr + H tλ,
0 = ∂L∂λ
= Hβr − C.
Despejando βr en la primera ecuacion:
2X tXβr = 2X tY − H tλ;
X tXβr = X tY − 1
2H tλ;
βr = (X tX)−1
(X tY − 1
2H tλ
)= β − 1
2(X tX)−1H tλ.
Sustituyendo βr en la otra expresion:
H
(β − 1
2(X tX)−1H tλ
)= C;
H(X tX)−1H tλ = 2(Hβ − C);
Como H(X tX)−1H t es cuadrada de orden r y (X tX)−1 es definida positiva, sepuede demostrar que existe la inversa de la primera matriz. Por lo tanto,
λr = 2[H(X tX)−1H t
]−1
(Hβ − C).

Tema 3. Regresion lineal multiple 55
En consecuencia,
βr = β − 1
2(X tX)−1H tλr = β − (X tX)−1H t
[H(X tX)−1H t
]−1
(Hβ − C).
Si multiplicamos por X, entonces tenemos que
Yr = Y − M(Hβ − C),
siendoM = X(X tX)−1H t
[H(X tX)−1H t
]−1
.
Si quisiesemos contrastarH0 : Hβ = C,H1 : Hβ 6= C,
usamos el estadıstico de contraste
F =(Hβ − C)t [H(X tX)−1H t]
−1(Hβ − C)
S2R
.
Si F > Fr,n−k−1;α, entonces rechazamos H0.
Este estadıstico F se puede expresar tambien como
F =V NE(H0) − V NE
rS2R
,
siendo V NE(H0) la variabilidad no explicada para el modelo restringido por Hβ = Cy V NE la variabilidad no explicada para el modelo no restringido.
3.11. Apendice 2
1. Si y, a ∈ Rn, entonces
∂yta
∂a= y.
2. Si a ∈ Rn y X ∈ R
n×n, entonces
∂atXa
∂a= 2Xa.
3. Si A ∈ Rm×n e Y ∈ R
n, entonces:
a) E(AY ) = AE(Y );
b) V ar(AY ) = AV ar(Y )At.
4. Los autovalores de la matriz A ∈ Rn×n se calculan resolviendo la ecuacion
|A − λIn| = 0.