tarea 1: clasificador bayesiano de dos clases · web viewen el presente informe se muestran los...
TRANSCRIPT

EL4106 Inteligencia Computacional
Tarea 1:Clasificador Bayesiano de dos clases
Matías Mattamala A.15 de Abril de 2013
Prof. Javier Ruiz del SolarAux. Daniel HerrmannAyud. Felipe Valdés

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
Contenido
Introducción...................................................................................................................................2Bases de Datos.............................................................................................................................3Modelo con Histogramas...........................................................................................................4Modelo con Gaussianas.............................................................................................................8Comparación de métodos - Resultados.............................................................................11
Curva ROC................................................................................................................................11Rendimiento............................................................................................................................14
Conclusiones...............................................................................................................................16Anexos...........................................................................................................................................17
1

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
Introducción
En el presente informe se muestran los resultados de la implementación de un Clasificador Bayesiano de dos clases, con costos asociados a la decisión. Como bien fue visto en clases, este es un método de clasificación de datos basado en la estadística de una muestra de características, con las que es posible discernir si un cierto elemento pertenece a una u otra clase, basado en su verosimilitud con la clase.
En el caso particular del trabajo, lo que se busca es diseñar un clasificador de vinos, utilizando la base de datos Wine Data Set del Repositorio de Aprendizaje de Máquinas de la Universidad de California, Irvine.
Los vinos están definidos por 11 características químicas, las que abarcan:
Acidez fija ( Fixed acidity) Acidez volátil (Volatile acidity) Acido cítrico (Citric acid) Azúcar residual (Residual sugar) Cloruros (Chloride) Dióxido de azufre libre (Free sulfur dioxide) Dióxido de azufre total (Total sulfur dioxide) Densidad (density) Medida de acidez (pH) Sulfatos (sulphates) Alcohol.
Para realizar el clasificador, se utilizarán dos modelos: uno basado en histogramas, que podríamos considerarlo como un modelo discreto y aproximado; mientras que el otro está basado en distribuciones gaussianas multidimensionales, que correspondería a un caso más continuo y preciso.
2

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
Posteriormente se compararán los dos métodos utilizando como parámetro las curvas ROC asociadas a cada modelo para distintos valores del discretizado de los histogramas, lo que permitirá apreciar sus diferencias. Finalmente se compartirán las principales conclusiones de los métodos utilizados y del trabajo realizado.
Bases de Datos
La base de datos proporcionada cuenta con 2506 muestras, cada una de las cuales posee 11 características y un último dato que indica si el vino es tinto o blanco. Para diseñar el Clasificador, en primer lugar se realizó una división de los datos, de modo de obtener dos conjuntos: conjunto de entrenamiento y conjunto de prueba. Para efectos prácticos de la tarea, se obvió el conjunto de validación, sin embargo debería haber sido considerado dado que estamos comparando dos métodos que deberían haber sido sintonizados.
Para realizar la división, se diseñó una función seudo aleatoria, divideSets, que dado que la cantidad de muestras asociadas a un vino tinto y blanco es conocida, realizó una división proporcional a la cantidad original, formando un conjunto de entrenamiento con el 80% de las muestras, mientras que el 20% restante corresponde al test. La función fue diseñada de modo tal que permite escoger el porcentaje de elementos que querían ser asociados al conjunto de entrenamiento y, por consiguiente, el de test. Se observa que la proporción entre ambas clases en cada conjunto es similar al original, variando sólo en un pequeño porcentaje (se puede ejecutar el script META_Script para observar los porcentajes). En el caso de las muestras utilizadas, la cantidad de vino tinto y vino blanco es aproximadamente la misma, donde los porcentajes son ~49% y ~51% respectivamente.
La función es anteriormente señalada es:divideSets(Data, trainingPerc)
donde Data denota el conjunto de datos de entrada (en este caso, wine_data), y trainingPerc denota el porcentaje que se asignará al
3

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
conjunto de entrenamiento. La salida de la función es un struct con los dos conjuntos Entrenamiento y Prueba.
La división se realiza porcentualmente con el porcentaje asignado, como también dependiendo del número de muestras de vino tinto y vino blanco existentes, de modo que los conjuntos de salida también sean representativos, que es lo que se señaló anteriormente.
Modelo con Histogramas
Para desarrollar el clasificador con histogramas que detecta Vino Blanco, en primer lugar es importante notar que por motivos de simplicidad n oes conveniente realizar un histograma de 11 dimensiones, asociadas a las 11 características de los vinos, con el cual obtener la función de probabilidad que describe al conjunto completo. Para ello, se utilizó una aproximación denominada Naive Bayes (Bayes Ingenuo), el cual, asumiendo que las características son independientes entre sí, y por tanto, su distribución de probabilidad conjunta también es independiente para cada caso, es posible expresar la probabilidad condicional para todas las características x i como:
P ( x⃗|αi )=P ( x1|αi ) ⋅… ⋅P(xn∨α i)
Con ello, el problema se reduce a calcular los histogramas para cada característica de cada clase, y obtener la verosimilitud a una determinada clase α i como el producto de las verosimilitudes de cada característica de la clase.
Para realizar este cálculo, se desarrollaron 5 funciones:
P2HistogramsModel: Función principal que permite obtener la curva ROC. Recibe como entradas el conjunto de entrenamiento, el conjunto de
4

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
pruebas, el número de bins de los histogramas que se utilizarán y un valor que determina el rango que cubren las iteraciones para variar el parámetro θ que determina la curva ROC.
getClassesHist: Función que permite obtener los histogramas asociados a las clases Vino tinto y Vino blanco, dado un cierto conjunto de entrenamiento. También entrega las probabilidades asociadas a cada clase, todo esto en una variable struct. Sus entradas son el conjunto de entrenamiento y el número de bins.Función 1: histograms (conjunto de entrenamiento, número de bins)
function histograms = getClassesHist( trainingSet, bins)
[rows columns] = size(trainingSet);typeRed = [];typeWhite = [];
for i=1:rows type = trainingSet(i,12);
if type == 1 typeRed = [typeRed; trainingSet(i,:) ];
else typeWhite = [typeWhite; trainingSet(i,:) ]; endend
histRed = cell(1, columns-1);histWhite = cell(1, columns-1);
for i=1:(columns-1) histRed{i} = verosim1D(typeRed(:,i),bins); histWhite{i} = verosim1D(typeWhite(:,i),bins);end
histograms = struct('redHist', {histRed}, 'whiteHist', {histWhite}, 'redProb', (length(typeRed)/rows), 'whiteProb', (length(typeWhite)/rows));
verosim1D: Función auxiliar que es sutilizada por getClassesHist, que permite calcular el histograma de una determinada característica, dado
5

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
un conjunto de muestras y el número de bins, datos que justamente corresponden a sus entradas. La salida es un vector con los valores máximo de cada barra del histograma, junto al conjunto de bins asociados.
bayesHistClassifier: Función que permite calcular el cuociente de las probabilidades condicionales de pertenecer a cada clase, dado un cierto vector de características.
P ( x⃗|vinoblanco )P ( x⃗|vinotinto¿
¿
Recibe como entradas el conjunto de pruebas que se desea evaluar, además del conjunto de histogramas de las características de una determinada clase.Función 2: bayesHistClassifier(conjunto de prueba, histogramas)
function y = bayesHistClassifier( setTest, histograms)
characVerosim = ones(length(setTest), 1);
for i=1:length(setTest) whiteP = naiveBayesVerosim(setTest(i,:), histograms.whiteHist); redP = naiveBayesVerosim(setTest(i,:), histograms.redHist);
% P(x|red) / P(x|white) characVerosim(i) = whiteP/redP;end
y = characVerosim;
naiveBayesVerosim: Esta función calcula la probabilidad de un vector de características de pertenecer a una determinada clase, utilizando el conjunto de histogramas de las características y la aproximación Naive Bayes, señalada anteriormente. Recibe el vector de características a evaluar y el conjunto de histogramas.Función 3: naiveBayesVerosim(vector de características, histogramas de una clase)
6

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
function verosim = naiveBayesVerosim(charVec, classHist)
if length(charVec) >=12 charVec = charVec(:,1:11);end
%Anonymous functionisInto = @(x,a,b)(x>a&&x<b)||(x==a)||(x==b);
verosimilitude = ones(1,length(charVec));verosim = 1;
for i=1:11 xHist = classHist{i};
for j=1:(length(xHist)-1); if isInto(charVec(i),xHist(j), xHist(j+1)) verosimilitude(i) = classHist{i}(j,2); verosim = verosim*(classHist{i}(j,2));
end endend
Existe una última función, más general y común al Modelo con Histogramas y el Modelo Gaussiano, denominada classify, que permite realizar la clasificación de las muestras del conjunto de prueba, dada su cuociente de verosimilitud, los pesos asociados a cada clase, y las probabilidades de pertenecer a cada clase. Prácticamente realiza la comparación:
P ( x⃗|vinoblanco )P ( x⃗|vinotinto¿
¿≥θ, θ= cblanco ⋅P(vinotinto )ctinto ⋅P(vi noblanco )
Los resultados de la curva ROC se presentarán más adelante junto a los resultados del Clasificador Gaussiano. Sn embargo, desde ya se señala que se observó una gran relación entre el número de bins utilizados y los resultados de la curva ROC.Función 4: classify (vector cuociente de probabilidades, costo vino blanco, costo vino tinto, probabilidad vino blanco,
7

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
probabilidad vino tinto)
function y = classify( quoVector, whiteLoss, redLoss, whiteProb, redProb)
%Theta = (C_red/C_white)* (P(red)/P(white))theta = (whiteLoss/redLoss)*(redProb/whiteProb);
classification = ones(length(quoVector),1);
% Iteration to decide if is red or white wine.for i=1:length(quoVector) if quoVector(i) >= theta classification(i) = 0; % White wine else classification(i) = 1; %Red wine endendy = classification;
8

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
Modelo con Gaussianas
El segundo método que se pide probar, corresponde a la implementación clásica del Clasificador Bayesiano, utilizando distribuciones gaussianas en vez de histogramas. Esto tiene la ventaja de que se requiere mucha menos información para caracterizar la distribución, además del hecho de que es posible caracterizar matemáticamente una distribución gaussiana de N dimensiones, y en este caso particular, 11. La función de distribución de una gaussiana de N dimensiones es:
1
(2π )N2 ⋅|Σ|
12
e(−12 ( x−μ )T Σ−1 ( x−μ))
Donde:
N : denota el número de dimensiones.
Σ :denota la matriz de covarianza de la distribución.
μ :corresponde a la media, como un vector de N dimensiones.
x :es el vector que se desea evaluar en la distribución.
En MATLAB, existe una función que permite utilizar esta distribución, denominada mvnpdf (Multi Variate Normal Probability Density Function), que recibe como parámetros X, MU y SIGMA, correspondientes al vector x, μ y Σ respectivamente.
Para implementar este clasificador, de modo análogo al clasificador anterior, se desarrollaron 4 funciones:
P3GaussianModel: Función principal que también permite obtener la curva ROC, pero utilizando el modelo gaussiano. Recibe como entradas el conjunto de entrenamiento, el conjunto de pruebas, y un valor que
9

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
determina el rango que cubren las iteraciones para variar el parámetro θ que determina la curva ROC.
getGaussianParam: Función que permite obtener los valores que caracterizan a las distribuciones gaussianas asociadas a cada clase, como su media y covarianza, como así también las probabilidades de la clase Vino tinto y Vino blanco, en una variable struct. Su única entrada es el conjunto de entrenamiento, de la cual obtiene la información.Función 5: getGaussianParam (conjunto de entrenamiento)
function params = getGaussianParam( trainingSet )
[rows columns] = size(trainingSet);
typeRed = [];typeWhite = [];
for i=1:rows type = trainingSet(i,12);
if type == 1 typeRed = [typeRed; trainingSet(i,:) ]; %typeRed(i,:) = trainingSet(i,:);
else typeWhite = [typeWhite; trainingSet(i,:) ]; %typeWhite(i,:) = trainingSet(i,:);
endend
redMu = mean(typeRed(:,1:11));redSigma = cov(typeRed(:,1:11));whiteMu = mean(typeWhite(:,1:11));whiteSigma = cov(typeWhite(:,1:11));
params = struct('redMu', redMu, 'redSigma', redSigma, 'whiteMu', whiteMu, 'whiteSigma', whiteSigma, 'redProb',length(typeRed)/rows, 'whiteProb', length(typeWhite)/rows);
10

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
bayesGaussianClassifier: Análogamente a bayesHistClassifier, calcula el cuociente de las probabilidades condicionales de pertenecer a cada clase, dado un cierto vector de características.
P ( x⃗|vinoblanco )P ( x⃗|vinotinto¿
¿
Tiene como entrada el conjunto de pruebas, además del conjunto de parámetros que definen las gaussianas.Función 6: bayesGaussianClassifier(conjunto de test, parámetros de gaussiana)
function y = bayesGaussianClassifier( setTest, params)
characVerosim = ones(length(setTest), 3);
for i=1:length(setTest) whiteP = gaussianVerosim(setTest(i,:), params.whiteMu, params.whiteSigma); redP = gaussianVerosim(setTest(i,:), params.redMu, params.redSigma);
% P(x|white) / P(x|red) characVerosim(i) = whiteP/redP;end
y = characVerosim;
gaussianVerosim: Calcula la probabilidad de un vector de características de pertenecer a una determinada clase, utilizando la distribución gaussiana multivariable descrita anteriormente. Para ello se utilizó la función mvnpdf de MATLAB, por lo que sus entradas son el vector de características, la media y la covarianza.
Posteriormente, el criterio de decisión para decidir si se pertenece o no a la clase Vino Blanco se realiza utilizando la misma función classify.Función 7: gaussianVerosim (vector de características, media, varianza
function verosim = gaussianVerosim(charVec, mu, sigma)
if length(charVec) >=12 charVec = charVec(:,1:11);
11

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
end
charVec = charVec';mu = mu';
verosim = mvnpdf(charVec, mu, sigma);
12

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
Comparación de métodos - Resultados
Curva ROC
Como fue señalado anteriormente, en esta sección se presentan los resultados asociados a cada modelo utilizado. Para ello se presentará la curva ROC, donde se presenta la curva con los valores de la Tasa de verdaderos Positivos (TVP) y Tasa de Falsos Positivos (TFP) normalizados al rango [0,1], además de otro gráfico que presenta la curva con escalas diferenciadas, TVP ∈ [0, 1] y TFP ∈ [0, 0.1], lo que permite apreciar de mejor manera el comportamiento en el crecimiento de la curva.
Es importante señalar que para comparar ambas curvas se realizaron pruebas con varios casos, donde se fue cambiando el número de bins asociados al modelo con histogramas, de modo que se pudieran observar los cambios producidos por la variación de este parámetro. En esta sección sólo se presentarán 3 casos, pero existen más gráficos adjuntos al anexo del informe.
En el Gráfico 1, se observan los resultados para 20 bins. Claramente se observa un rendimiento menor en el caso del Clasificador con Histogramas, dado de que no se aproxima a TVP = 1, quedando acotada su capacidad de clasificar correctamente a alrededor del 96%. Caso contrario ocurre en el Clasificador Gaussiano, el cual presenta un comportamiento bastante bueno, como se observa también en el gráfico inferior, donde se comparan ambos clasificadores en un rango más acotado, para observar su comportamiento para valores de θ pequeños.
Otro fenómeno que se observa también, es que la curva del clasificador con histogramas es más “corta” que la del clasificador gaussiano, fenómeno que se observará cambiar frente a distintos valores de bins. Esto se debe a que ambos gráficos fueron calculados evaluando el mismo número de puntos, pero el carácter discreto del clasificador con
13

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
histogramas produce que muchos valores de θ utilizados produzcan valores muy similares, lo que en definitiva produce puntos redundantes en el gráfico de la curva ROC. Esto podría evitarse buscando una relación entre el número de bins utilizados y el número de valores de theta utilizados, relación que no fue buscada en el desarrollo de este trabajo, pero que podría realizarse eventualmente.
14

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.2
0.4
0.6
0.8
1Curva ROC: Clasificador con Histogramas (20 bins) y con Gaussiana Multidimensional
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.10
0.2
0.4
0.6
0.8
1Curva ROC - Acercamiento al rango TVP [0, 0.1]
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
Gráfico 1: Curva ROCpara 20 bins
15

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.2
0.4
0.6
0.8
1Curva ROC: Clasificador con Histogramas (2 bins) y con Gaussiana Multidimensional
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.10
0.2
0.4
0.6
0.8
1Curva ROC - Acercamiento al rango TVP [0, 0.1]
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
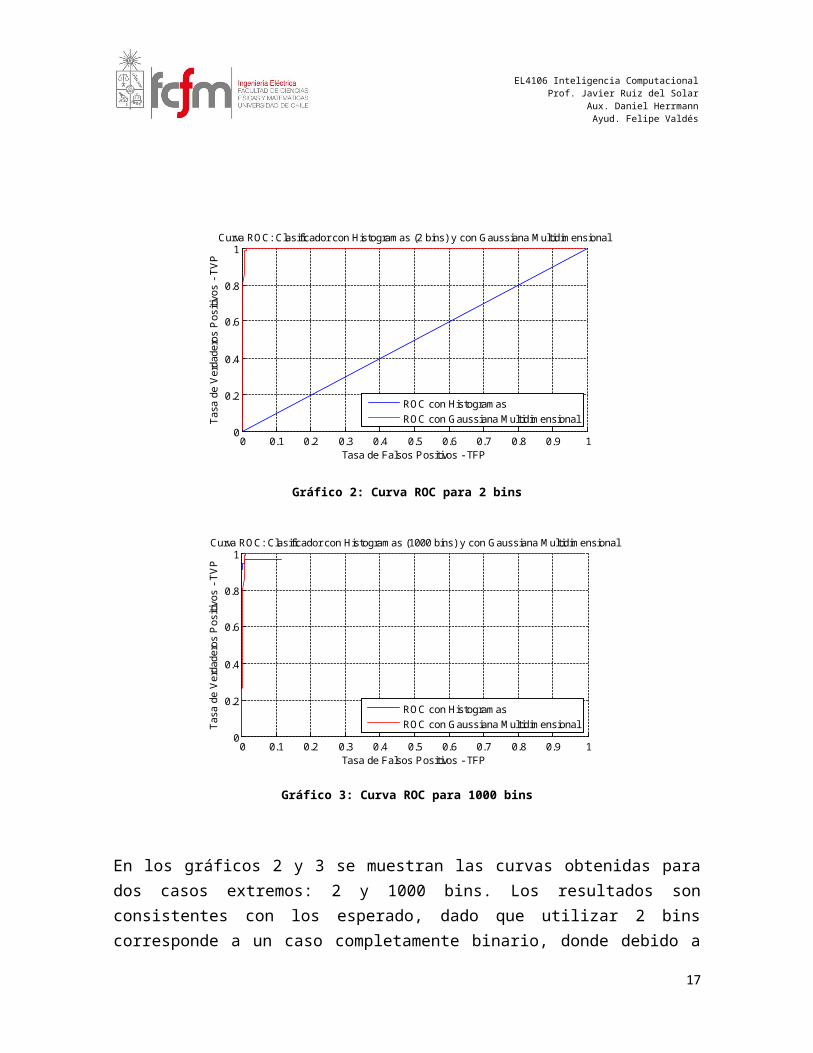
Gráfico 2: Curva ROC para 2 bins
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.2
0.4
0.6
0.8
1Curva ROC: Clasificador con Histogramas (1000 bins) y con Gaussiana Multidimensional
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.10
0.2
0.4
0.6
0.8
1Curva ROC - Acercamiento al rango TVP [0, 0.1]
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
Gráfico 3: Curva ROC para 1000 bins
En los gráficos 2 y 3 se muestran las curvas obtenidas para dos casos extremos: 2 y 1000 bins. Los resultados son consistentes con los esperado, dado que utilizar 2 bins corresponde a un caso completamente binario, donde debido a que la probabilidad de pertenecer a una clase u otra es prácticamente la misma (basta recordar los porcentajes señalados anteriormente), la curva ROC refleja fielmente estos resultados.
16
EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
Para el caso de 1000 bins, no se observan muchas mejoras respecto al caso de 20, y se manifiesta la misma tendencia del gráfico a reducir su “longitud”, llegando a cubrir valores de TFP no mayores a 0.2. Además se observa una pérdida de precisión para valores pequeños de θ, donde prácticamente no existen valores para la curva:0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0
0.2
0.4
0.6
0.8
1Curva ROC: Clasificador con Histogramas (1000 bins) y con Gaussiana Multidimensional
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.10
0.2
0.4
0.6
0.8
1Curva ROC - Acercamiento al rango TVP [0, 0.1]
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
Gráfico 4: Acercamiento a la curva ROC para 1000 bins
Rendimiento
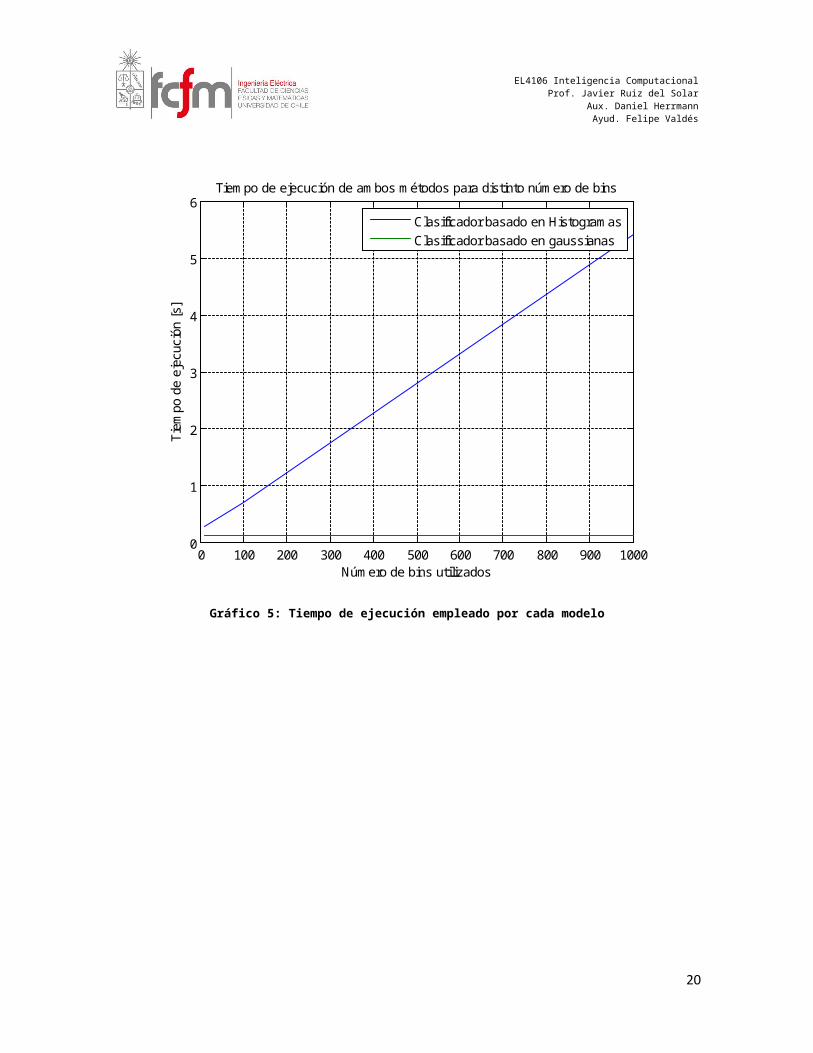
Respecto al rendimiento de ambos procedimientos, se observa claramente que el modelo gaussiano es independiente de alguna variable adicional al número de muestras, por lo que su resultado es único para una muestra de entrenamiento dada. Caso contrario ocurre con el modelo con histogramas, el cual claramente depende de un parámetro adicional, el número de bins, el que produce un trade-off entre la precisión del clasificador y su tiempo de ejecución.
El problema asociado a la precisión del clasificador puede apreciarse claramente en los casos extremos anteriores: el caso de dos bins produce un resultado que abarca el rango TFP = [0, 1], pero produce un
17

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
área bajo la curva mucho menor; mientras que el caso de 1000 bins produce una curva que debería ser más aproximada a la ideal, y de un área mucho mayor, pero lamentablemente pierde información en los valores de θ pequeños, que ya fue señalado anteriormente.
Respecto al tiempo de ejecución del modelo con histogramas, realizando una prueba sencilla (que también puede realizarse ejecutando META_Script), se observa que el tiempo utilizado es relativamente lineal con el número de bins utilizados, lo que puede apreciarse en el gráfico que se presenta a continuación.
0 100 200 300 400 500 600 700 800 900 10000
1
2
3
4
5
6Tiempo de ejecución de ambos métodos para distinto número de bins
Número de bins utilizados
Tiem
po d
e ej
ecuc
ión
[s]
Clasificador basado en HistogramasClasificador basado en gaussianas
Gráfico 5: Tiempo de ejecución empleado por cada modelo
18

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
Conclusiones
El trabajo anteriormente realizado, permitió comprender el modelo del Clasificador Bayesiano estudiado en clases, realizando dos implementaciones donde se observó claramente el modo de diseño, como así también los problemas que existen para ello.
Los dos modelos implementados tienen ventajas y desventajas, que fueron observadas claramente: Mientras que el clasificador gaussiano obtiene resultados mucho mejores, con un menor tiempo de ejecución, requiere poseer a priori un mecanismo rápido para el cálculo de las probabilidades de cada vector de características, el cual va a depender del sistema donde se esté implementando el modelo y de sus capacidades técnicas.
El modelo con histogramas entrega un mecanismo más sencillo y bastante más intuitivo, pero mucho más lento en su ejecución. Es importante no olvidar que el modelo implementado también es una aproximación, por lo que su tiempo de ejecución es mucho menor, pero sus resultados no son tan confiables, tema que ya fue tocado anteriormente. Además existe el problema con el número de bins que se utilizarán, el cual claramente produce cambios notables en el desempeño del clasificador.
Por último, respecto al clasificador bayesiano en general, se observa que depende claramente de la confiabilidad de la muestra utilizada en su etapa de entrenamiento: Como en todo sistema estadístico, si la muestra no es representativa, sus resultados serán inválidos, porque su construcción está basada en ellos. Además, los modelos vistos no poseen alguna etapa correctiva o de aprendizaje en su ejecución, por lo que sus resultados dependen completamente de la muestra utilizada en el conjunto de entrenamiento. Sin embargo a pesar de lo anterior, se observa que en general dada una muestra representativa (que considere tanto una buena proporción de las clases a clasificar, como así también características útiles para la decisión), y un sistema que soporte los
19
EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
cálculos y operaciones necesarias para su implementación, el clasificador bayesiano es una herramienta bastante confiable al momento de identificar la pertenencia a clases de un determinado objeto o individuo. Queda pendiente ahora estudiar y probar los otros métodos de clasificación que serán vistos durante el curso, de modo de tener una visión más amplia de los mecanismos que existen, con sus ventajas y desventajas, para ser capaces de decidir cuál es el mejor que se puede utilizar dependiendo del problema que se desea resolver.
20

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
Anexos
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.2
0.4
0.6
0.8
1Curva ROC: Clasificador con Histogramas (2 bins) y con Gaussiana Multidimensional
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.10
0.2
0.4
0.6
0.8
1Curva ROC - Acercamiento al rango TVP [0, 0.1]
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
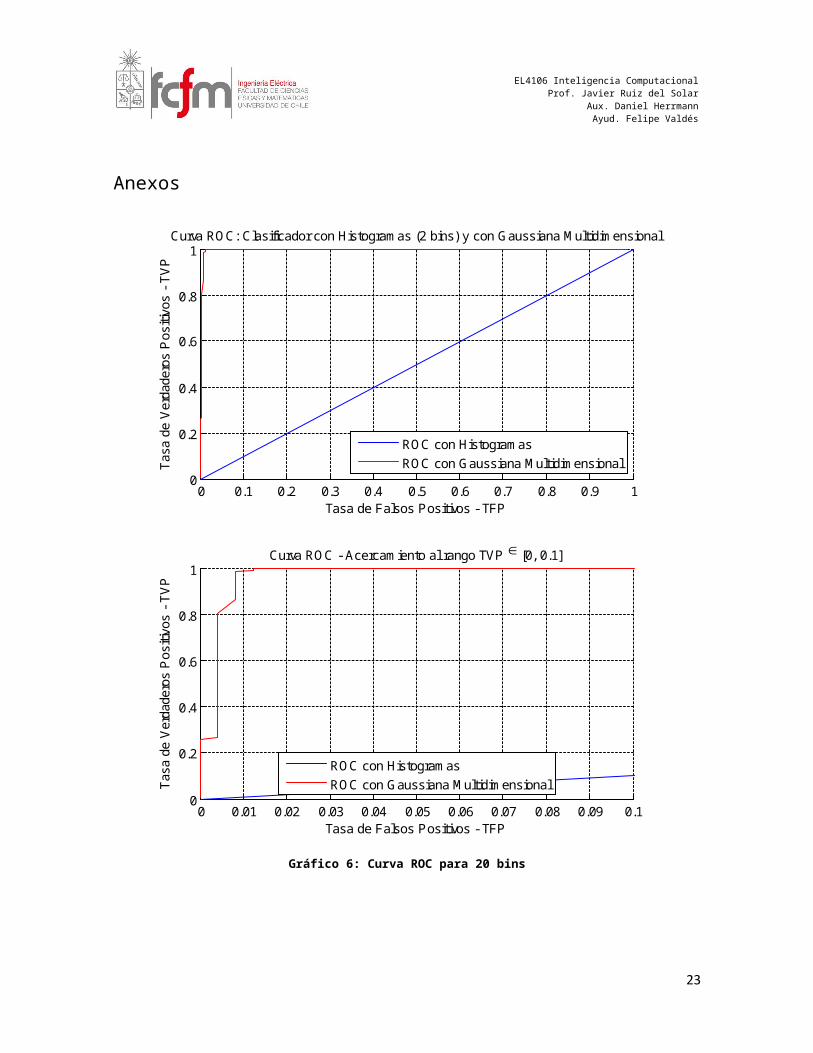
Gráfico 6: Curva ROC para 20 bins
21

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.2
0.4
0.6
0.8
1Curva ROC: Clasificador con Histogramas (5 bins) y con Gaussiana Multidimensional
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.10
0.2
0.4
0.6
0.8
1Curva ROC - Acercamiento al rango TVP [0, 0.1]
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
Gráfico 7: Curva ROC para 5 bins
22
EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.2
0.4
0.6
0.8
1Curva ROC: Clasificador con Histogramas (10 bins) y con Gaussiana Multidimensional
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.10
0.2
0.4
0.6
0.8
1Curva ROC - Acercamiento al rango TVP [0, 0.1]
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
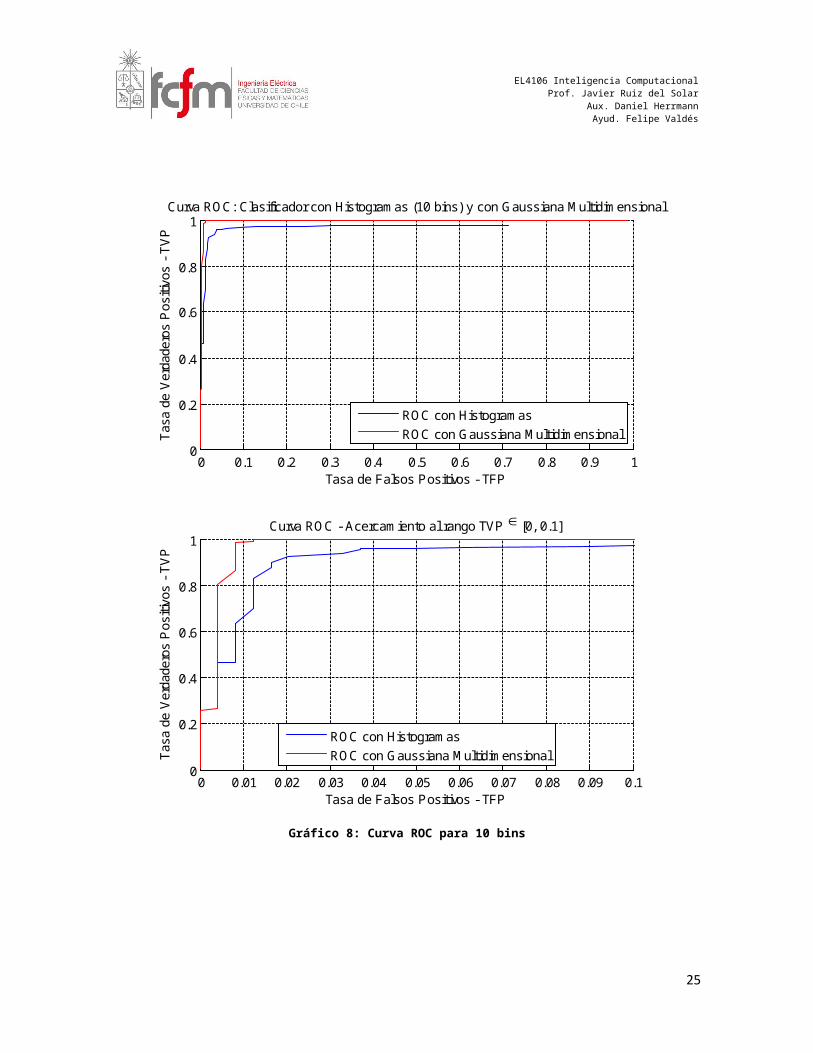
Gráfico 8: Curva ROC para 10 bins
23

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.2
0.4
0.6
0.8
1Curva ROC: Clasificador con Histogramas (20 bins) y con Gaussiana Multidimensional
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.10
0.2
0.4
0.6
0.8
1Curva ROC - Acercamiento al rango TVP [0, 0.1]
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
Gráfico 9: Curva ROC para 20 bins
24
EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.2
0.4
0.6
0.8
1Curva ROC: Clasificador con Histogramas (100 bins) y con Gaussiana Multidimensional
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.10
0.2
0.4
0.6
0.8
1Curva ROC - Acercamiento al rango TVP [0, 0.1]
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
Gráfico 10: Curva ROC para 100 bins
25

EL4106 Inteligencia ComputacionalProf. Javier Ruiz del Solar
Aux. Daniel HerrmannAyud. Felipe Valdés
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.2
0.4
0.6
0.8
1Curva ROC: Clasificador con Histogramas (1000 bins) y con Gaussiana Multidimensional
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.10
0.2
0.4
0.6
0.8
1Curva ROC - Acercamiento al rango TVP [0, 0.1]
Tasa de Falsos Positivos - TFP
Tasa
de
Ver
dade
ros
Pos
itivo
s - T
VP
ROC con HistogramasROC con Gaussiana Multidimensional
Gráfico 11: Curva ROC para 1000 bins
26