sesión 1 – introducción y repaso 2. estimación e … · banco central de reserva del perú...
TRANSCRIPT

Banco Central de Reserva del Perú 55º Curso de Extensión Universitaria
Econometría Prof. Juan F. Castro
���� Sesión 1 – Introducción y repaso
2. Estimación e inferencia en el Modelo Lineal
General (MLG) 2.1. Los cinco supuestos del MLG
¿Por qué nos interesa hacer supuestos sobre la manera como
han sido generados los datos?
¿Cuáles son estos supuestos?
S1. X es una matriz (T x k) de rango completo.
[ ]
[ ]
dim Col(X) dimesión del espacio conformado por
todas las combinaciones lineales de los vectores en X
(X) dim Col(X)
(X) k
≡
ρ ≡
ρ =
S2. El modelo puede representarse:
y X ; E( ) 0= β + ε ε =

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
2
S3. Las variables explicativas “no están relacionadas” o “son
exógenas” respecto al error.
S3F. { }jtX x , t 1,...,T; j 1,...,k= = = son no estocásticas.
S3Ei. { }jtX x , t 1,...,T; j 1,...,k= = = son estocásticas e
independientes de s t,s, jε ∀ .
S3Eim. { }jtX x , t 1,...,T; j 1,...,k= = = son estocásticas y
s sε ∀ son independientes en media de X:
E X c 0 (S2) ε = = . Este supuesto es suficiente para
garantizar el insesgamiento de MICOβ̂ .
S3Enc. { }jtX x , t 1,...,T; j 1,...,k= = = son estocásticas y
no presentan correlación con tε (no presentan
correlación contemporánea con el error):
t jt t jtE x 0, t, j Cov ,x 0 ε = ∀ ⇔ ε = . Este supuesto es
suficiente para garantizar la consistencia de MICOβ̂ .
S4. El error presenta una matriz de varianzas-covarianzas
escalar: 2
2 2t t
t s t s
E( ') I
E( ) Var( )
E( ) Cov( , ) 0 t s
εε = σ
− ε = ε = σ
− ε ε = ε ε = ∀ ≠

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
3
S5N. El error se distribuye normal:
ε∼2N(0, I)σ
2.2. La Geometría de Mínimos Cuadrados Ordinarios
2.2.1 Nuestro setting
En adelante, cada vector representará todas las observaciones
para determinada variable. De modo que los ejes
corresponderán a las observaciones en lugar de a las
variables mismas.
El siguiente gráfico muestra la manera como
representaremos los datos contenidos en y y X como
vectores. Cada columna de X es un vector. En el gráfico, la
matriz X tiene dos columnas representadas por los vectores
X1 y X2.
El plano que contiene todos los vectores en X se denota
como Col(X). Formalmente: Col(X) ≡ subespacio
conformado por todas las combinaciones lineales de los
vectores en X.

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
4
Gráfico 1 : Representación vectorial de los datos
2.2.2 De regreso a Mínimos Cuadrados Ordinarios
Todos sabemos que Mínimos Cuadrados Ordinarios (MICO)
resuelve:
MICOˆ arg min (y X ) '(y X )
β
β ≡ − β − β
En palabras, MICOβ̂ es el valor de β que minimiza el
cuadrado de la distancia entre y y los posibles Xβ .

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
5
Es posible explicar la solución al problema planteado como
un proceso en dos etapas.
(i) En la primera etapa se halla el vector en Col(X)
más cercano a y. Denotamos a este vector como µ̂ .
Formalmente: 2
Col(X)
ˆ arg min yµ∈
µ ≡ − µ
Este vector (µ̂) viene dado por la proyección
ortogonal de y sobre Col(X).
Gráfico 2 : Etapa 1. La proyección ortogonal
De hecho, si µ̂ es la proyección ortogonal de y
sobre Col(X) y µ es cualquier otro vector en
Col(X), se cumple que ˆ ˆ( ) '(y ) 0µ − µ − µ = .

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
6
A partir de la relación anterior y el teorema de
Pitágoras ( )2 2 2
1 2 1 2 1 2z z z z z z⊥ ⇒ + = + es
posible demostrar que 2 2
ˆy y− µ ≥ − µ . Es decir,
que µ̂ es, por lo menos, tan cercano a y como
cualquier otro Col(X)µ∈ .
(ii) En la segunda etapa se descompone µ̂ como la
suma de los vectores obtenidos de multiplicar las
columnas de X por los coeficientes estimados (β̂).
Formalmente, encontramos β̂ como la solución a:
ˆˆ Xµ = β .
Gráfico 3 : Etapa 2. La descomposición de µ̂

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
7
Es importante tomar en cuenta que la solución asociada a la
primera etapa es única mientras que pueden existir diversas
soluciones para la segunda. De hecho, es posible probar la
unicidad de µ̂ a partir de las relaciones anteriores.
Con estas nociones en mente, es posible resumir la
naturaleza geométrica de MICO de la siguiente manera:
(i) El vector de valores predichos µ̂ es la proyección
ortogonal (única) de y sobre Col(X).
(ii) El vector de errores (residuos) predichos ˆy − µ es
ortogonal a Col(X).
(iii) Si dim[Col(X)] = k entonces
MICOˆ arg min (y X ) '(y X )
β
β ≡ − β − β
tiene una solución única dada por:
1
MICOˆ (X 'X) X 'y
−β =
De hecho, sabemos que ˆ(y ) Col(X)− µ ⊥ (el vector de
errores es ortogonal al subespacio conformado por todas las
combinaciones lineales de los vectores en X).

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
8
Por lo mismo, podemos partir de la condición de
ortogonalidad ˆX '(y ) 0− µ = (primera etapa) y hallar β̂ como
la solución a ˆˆ Xµ = β (segunda etapa).
ˆX '(y ) 0
ˆX '(y X ) 0
ˆX 'X X'y
− µ =
− β =
β =
El sistema anterior tiene una solución única ( ˆˆ Xµ = β es una
combinación lineal única de las columnas de X) si y sólo si
los vectores en X son linealmente independientes.
La independencia lineal de los vectores en X implica que el
espacio que éstos conforman tiene una dimensión igual al
número de vectores: dim[Col(X)] = k (S1). Esto garantiza
que la matriz X'X sea invertible.
Por contradicción: si X no tiene rango completo, entonces
existe un vector a (k x 1) (a 0≠ ) tal que:
1
Xa 0 X'Xa 0 no (X 'X)−= ⇒ = ⇒ ∃
Un ejemplo:
N = 3, k = 2, [ ]12
1 2 22
32
1 x
X X X 1 x
1 x
= =

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
9
Gráfico 4 : La proyección de MICO en tres dimensiones
¿Pueden identificar al vector de residuos ˆy − µ?
¿Cómo representarían la regresión de y sobre un conjunto de
variables que la contiene? ¿y la regresión de una identidad?
Nótese que en este caso dim[Col(X)] = k = 2.
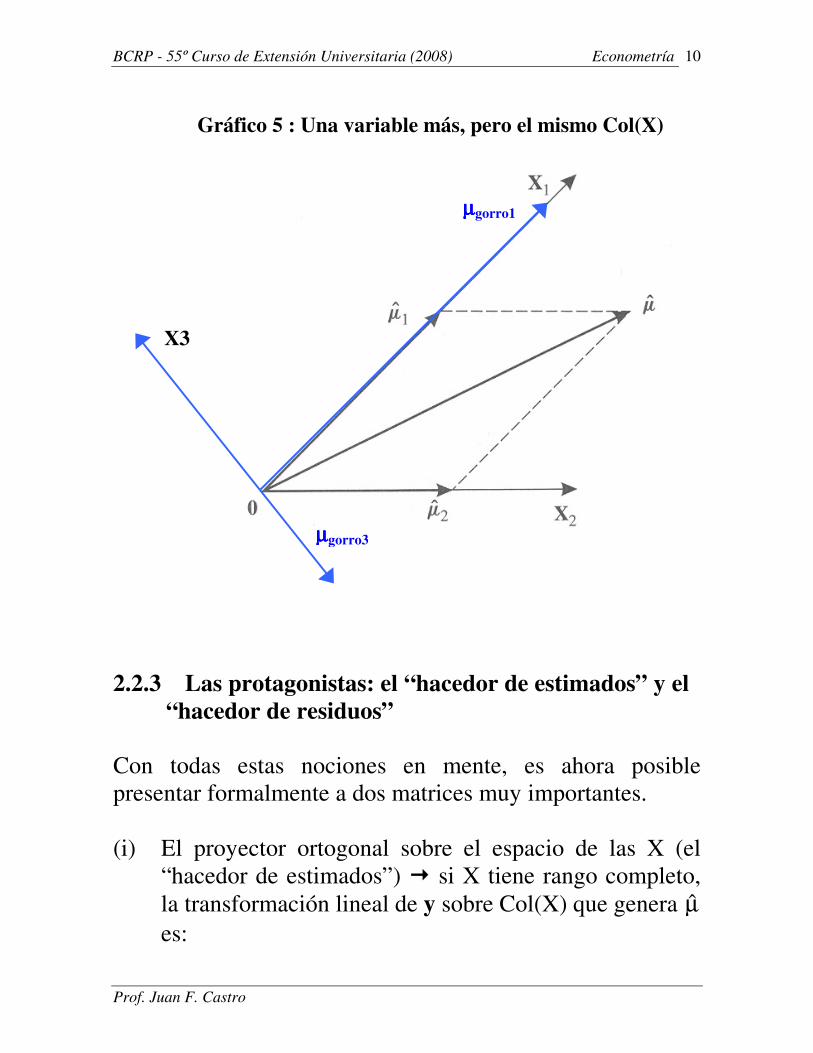
¿Qué pasaría si incluimos un tercer vector en X de tal forma
que la dimensión de Col(X) siga siendo igual a 2? Es decir,
dim[Col(X)] = 2 < k = 3.
- ¿Es única la proyección ortogonal?
- ¿Es única la descomposición del vector µ̂?
BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
10
Gráfico 5 : Una variable más, pero el mismo Col(X)
2.2.3 Las protagonistas: el “hacedor de estimados” y el
“hacedor de residuos”
Con todas estas nociones en mente, es ahora posible
presentar formalmente a dos matrices muy importantes.
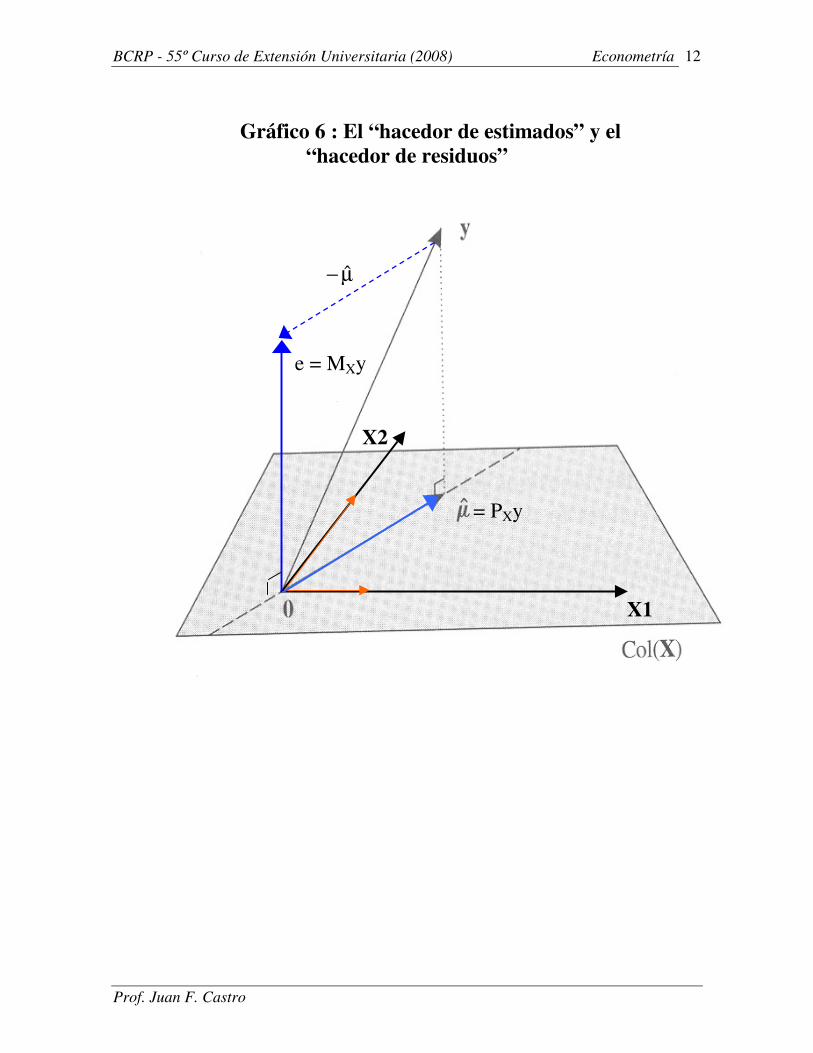
(i) El proyector ortogonal sobre el espacio de las X (el
“hacedor de estimados”) � si X tiene rango completo,
la transformación lineal de y sobre Col(X) que genera µ̂
es:
X3
µµµµgorro1
µµµµgorro3

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
11
1X
X
P X(X 'X) X'
ˆ P y
−=
µ =
Para cada Z Col(X)∈ existe un vector a tal que Xa Z= . Por
lo mismo: 1
X XP Z P Xa X(X 'X) X 'Xa Xa Z−= = = = � XP no
modifica cualquier vector Col(X)∈ .
Para un vector
XZ Col(X) X 'Z 0 X Col(X) P Z 0⊥ → = ∀ ∈ ⇒ = � XP
transforma vectores Col(X)⊥ al vector nulo.
(ii) El proyector ortogonal sobre el espacio de los errores
(el “hacedor de residuos”):
X
X
X
X X
ˆe y M y
ˆy X y P y
(I P )y
M I P
= − µ =
= − β = −
= −
⇒ = −
Estas matrices son ortogonales entre sí, simétricas e
idempotentes.
BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
12
Gráfico 6 : El “hacedor de estimados” y el
“hacedor de residuos”
X1
X2
e = MXy
= PXy
µ− ˆ

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
13
2.3. ¿Qué nos dice la regresión particionada?
1 1 2 2
y X
X X
= β + ε
= β + β + ε
El sistema de ecuaciones normales:
1 1 1 2 1 1
2 1 2 2 22
ˆX 'X X 'X X 'y
ˆX 'X X 'X X 'y
β =
β
( ) ( )
1 1 1 1 2 2 1
1 1
1 1 1 1 1 1 1 2 2
ˆ ˆX 'X X 'X X 'y
ˆ ˆX 'X X 'y X 'X X 'X− −
→ β + β =
β = − β
¿Qué nos dice esta expresión para 1β̂ ?
( )
( )
2 1 1 2 2 2 2
1 12 1 1 1 1 2 1 1 1 1 2 2 2 2 2 2
1 12 1 1 1 1 2 2 2 1 1 1 1
2 1 2 2 2 1
1
2 2 1 2 2 1
ˆ ˆX 'X X 'X X 'y
ˆ ˆX 'X (X 'X ) X 'y X 'X (X 'X ) X 'X X 'X X 'y
ˆX ' I X (X 'X ) X ' X ' X ' I X (X 'X ) X ' y
ˆX 'M X X 'M y
ˆ X 'M X X 'M y
− −
− −
−
→ β + β =
− β + β =
− β = −
β =
β =
¿Qué nos dice esta expresión para 2β̂ ?
¿Qué ocurre cuando el modelo incluye intercepto?

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
14
Educación
Edad
Ingreso
MICO utiliza la información en el área azul para estimar
el beta de Edad y la información en el área verde para
estimar el beta de Educación.
BetaEducación: área verde (variación en Y que responde
únicamente a la variación en educación)
Blanco + verde = IngresoMEdad
Celeste + verde = EducaciónMEdad
¿Qué ocurriría si no controlamos por Edad? Tendríamos
una estimación sesgada del efecto de Educación. Este beta
recogería también el efecto de Edad.

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
15
Otro ejemplo...la importancia de los “controles”:
“Which is more dangerous, a gun or a swimming pool?”
“Consider the parents of an eight-year-old girl named, say,
Molly. Her two best friends, Amy and Imani, each live
nearby. Molly’s parents know that Amy’s parents keep a gun
in their house, so they have forbidden Molly to play there.
Instead, Molly spends a lot of time at Imani’s house, which
has a swimming pool in the backyard. Molly’s parents feel
good about having made such a smart choice to protect their
daughter.
But according to the data, their choice isn’t smart at all. In a
given year, there is one drowning of a child for every 11,000
residential pools in the United States. (In a country with 6
million pools, this means that roughly 550 children under the
age of ten drown each year.) Meanwhile, there is 1 child
killed by a gun for every 1 million-plus guns. (In a country
with an estimated 200 million guns, this means that roughly
175 children under ten die each year from guns.) The
likelihood of death by pool (1 in 11,000) versus death by gun
(1 in 1 million-plus) isn’t even close: Molly is roughly 100
times more likely to die in a swimming accident at Imani’s
house than in gunplay at Amy’s.”
Freakonomics, Levitt & Dubner

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
16
2.4. El trade-off sesgo varianza
(i) Omisión de una variable relevante:
Supongamos: 1 1 2 2y X X= β + β + ε y se plantea el estimador 1
1 1 1 1(X 'X ) X 'y−β =% en lugar de
11 1 2 1 1 2
ˆ (X 'M X ) X 'M y−β = .
Verifiquemos lo siguiente: el estimador 1β% presenta sesgo
(¿siempre?) pero una menor varianza.
(ii) Inclusión de una variable redundante:
Supongamos: 1 1y X= β + ε y se plantea el estimador 1
1 1 2 1 1 2(X 'M X ) X 'M y−β =% en lugar de
11 1 1 1
ˆ (X 'X ) X 'y−β = .
Verifiquemos lo siguiente: el estimador 1β% no presenta sesgo
pero tiene una mayor varianza.
¿Cómo concilian estos resultados con lo que sabemos acerca
de la eficiencia del estimador minimocuadrático?
En el caso (i), donde 1β% presenta menor varianza, ¿cuándo es
1β% el MELI de 1β ?...¿si 1 1y X= β ?, ¿si 1 2X 'X 0= ?
¿Recuerdan qué ocurre con el estimador de Mínimos
Cuadrados Restringidos?
¿Cuál es la implicancia práctica de esta discusión?

BCRP - 55º Curso de Extensión Universitaria (2008) Econometría
Prof. Juan F. Castro
17
2.5. Breve repaso del concepto de inferencia, tamaño y
potencia de una prueba
En el proceso de inferencia....
En la típica prueba t de significancia individual, ¿estamos
preguntando si el valor estimado de un coeficiente es igual
cero?
Si pudiese repetir nuevamente el proceso de muestreo,
¿obtendría un valor distinto para el vector de coeficientes?
¿Qué estamos preguntando entonces en el proceso de
inferencia?
Para comprender mejor lo anterior, veamos la prueba más
general (la prueba F para un conjunto de j restricciones
lineales) partiendo de que β̂∼ 2 1N , (X 'X)− β σ .
¿Qué hemos supuesto para llegar hasta la expresión que
todos conocemos?
¿Cómo se relaciona esto con el concepto de significancia o
tamaño de una prueba?...¿y con el concepto de potencia de
prueba?