series de tiempo - econometria ii · la técnica de alisado exponencial, medias móviles, modelos...
TRANSCRIPT

CCAAPPIITTUULLOO IIII
SERIES DE TIEMPO 1º INTRODUCCIÓN
La mayoría de las empresas y agentes económicos precisan realizar predicciones sobre el comportamiento de su evolución y del entorno donde actúan.
Estas predicciones se utilizan para tomar decisiones operativas y, a veces, estratégicas.
El conocimiento de acontecimientos futuros estará obviamente afectado de un alto grado de incertidumbre, lo que implica la utilización de probabilidades asociadas al proceso de predicción, y de modelos estadísticos y econométricos.
1.1. REGRESIÓN ESPURIA
Este problema surge porque si las dos series de tiempo involucradas presentan tendencias fuertes (movimientos sostenidos hacia arriba o hacia abajo), el alto R2 observado se debe a la presencia de la tendencia y no a la verdadera relación entre las dos. Por consiguiente es muy importante averiguar si la relación entre las variables económicas es verdadera o es espuria.
Como lo han sugerido Granger y Newbold : una buena regla práctica para sospechar que la regresión estimada sufre de regresión espuria es que R2 > D-W.
Cuando las series de tiempo son no estacionarias, no se debe depender de los valores "t" estimados. Si las series de tiempo están cointegradas, entonces los resultados de la regresión estimada pueden no ser espurios y las pruebas "t" y "F" usuales son válidas. Como lo afirma Granger: "Una prueba de cointegración puede ser considerada como una prueba previa para evitar situaciones de regresión espuria". Por ejemplo: Se tiene las series anuales (1936-1972) del PNB nominal en Estados Unidos (datos en miles de millones de dólares), y de la Incidencia del melanoma en la población masculina (datos ajustados de edad) en el estado de Connecticut.
0
200
400
600
800
0
1
2
3
4
5
6
1940 1945 1950 1955 1960 1965 1970
GNP MELANOMA
Observando los gráficos, ambas series mantienen una relación lineal. Conceptualmente resulta absurdo relacionarlas.
100
200
300
400
500
600
700
800
0 1 2 3 4 5 6
MELANOMA
GN
P

Dependent Variable: GNP Method: Least Squares Simple: 1936 1972 Included observations: 37
Variable Coefficient Std. Error t-Statistic Prob. C 118.5659 23.72897 4.996675 0.0000
MELAMONA 118.9808 7.814147 15.22633 0.0000 R-squared 0.868836 Mean dependent var 443.6730
Adjusted R-squared 0.865088 S.D. dependent var 171.4417 Log likelihood -204.7517 F-statistic 231.8413 Durbin-Watson stat 0.879122 Prob(F-statistic) 0.000000
La estimación de una regresión en donde el PNB actúa como variable
endógena y la incidencia de melanoma como variable explicativa nos muestra que: * Todos los coeficientes son estadísticamente significativos, y el R2 (86.7%) es
muy elevado. * El coeficiente estimado implica que, si aumentara la incidencia de melanoma
en un caso, cabría esperar un aumento del PNB de 119.000 millones de dólares.
Si relacionamos las variables en primeras diferencias, la tendencia suele desaparecer y, con ella, la relación espúrea.
-0.5
0.0
0.5
1.0
1.5
2.0
-60
-40
-20
0
20
40
60
1940 1945 1950 1955 1960 1965 1970
D(MELANOMA) D(GNP)
Dependent Variable: D(GNP) Method: Least Squares Sample (adjusted): 1937 1972 Included observations: 36 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. C 16.56841 3.179332 5.211287 0.0000
D(MELAMONA) 0.706295 6.585765 0.107246 0.9152 R-squared 0.000338 Mean dependent var 16.65278
Log likelihood -155.0594 F-statistic 0.011502 Durbin-Watson stat 1.262415 Prob(F-statistic) 0.915224
-60
-40
-20
0
20
40
60
-0.5 0.0 0.5 1.0 1.5 2.0
D(MELAMONA)
D(G
NP
)

Consecuentemente, la relación de regresión entre las variables transformadas no resulta significativa
1.2. TIPOS DE PREDICCIONES
Según el horizonte de predicción se clasifican: 1 º Inmediato, hasta 3 mese, para decisiones operativas, control presupuestario.
Por ejemplo: gestión de inventarios en establecimientos detallistas.
2º Corto Plazo de 3 a 12 meses, para tomar las decisiones operativas, control presupuestario o decisiones de compra. Por ejemplo: Compra de bienes de temporada para venta al por menor.
2º Medio Plazo, comprendidas entre 1 y 3 años, para las decisiones estratégicas.
Por ejemplo: Leasing de plantas y equipos, formación de empleados para nuevos procesos.
3º Largo Plazo, de 3 a 10 años, para las decisiones estratégicas incluyendo las de
expansión. Por ejemplo: investigación y desarrollo, compra de activos, adquisiciones y absorciones.
4º Muy Largo Plazo, mayor a 10 años, para las decisiones estratégicas
incluyendo aquellas de cambio de las características principales de la empresa. Por ejemplo: predicción tecnológica en apoyo de investigación y desarrollo y planificación estratégica.
1.3. CLASIFICACIÓN DE LAS TÉCNICAS DE PREVISIÓ N 1º Históricas, la evolución de una magnitud tiene inercia temporal, lo que
permite construir un modelo basado en el análisis de series temporales. 2º Causales, se basa en la interrelación entre varias variables; en un modelo
econométrico o en un modelo de variables latentes, algunas magnitudes son causa de las variaciones de otras, y se pueden usar como predictores.
3º Otros, como las encuestas de opinión a expertos, método Delphi, previsiones
por consumo y otras técnicas subjetivas. 1.4. TIPO DE PREVISIÓN DE LOS MODELOS
Según a las situaciones a las que se aplican tenemos: 1º Medios Escasos:
Corto Plazo.- La técnica de alisado exponencial, Medias móviles, Modelos Naïve y Desestacionalización.
Medio Plazo.- Ajuste de tendencia. Largo plazo.- Curva en S.

2º Medios Normales:
Corto Plazo.- ARIMA univariante, análisis de intervención, X-11 ARIMA y Funciones de transferencia.
Medio Plazo.- Modelos econométricos uniecuacionales, modelos econométricos de pequeño tamaño y Modelos VAR.
Largo plazo.- Modelos con cambio estructural. 3º Medios Altamente Profesionalizados:
Corto Plazo.- Análisis espectral, Modelos dinámicos y Filtros. Medio Plazo.- Modelos multiecuacionales de gran tamaño, Simulación y
Input/Output. Largo plazo.- Modelos con cambio estructural y Escenarios.
1.5. ANÁLISIS DE SERIES TEMPORALES
Una serie temporal está formada por un conjunto de observaciones medidas a lo largo del tiempo. Es frecuente que se observen varias magnitudes simultáneamente, en cuyo caso se tiene una serie temporal multivariante.
1.6. OBJETIVO DEL ANÁLISIS DE UNA SERIE TEMPO RAL
El objetivo básico perseguido al realizar el análisis de una serie temporal es la predicción, es decir, la extrapolación de valores futuros de la serie a partir de los datos disponibles.
Otro objetivo es la modelización, o conocimiento de la estructura temporal del proceso generador de los datos.
Un último objetivo es la actuación externa o control, sobre el sistema a partir de las predicciones sucesivas (éste es el caso típico de un proceso de control de calidad industrial o de servicios).
1.7. FORMAS DE ANÁLISIS DE UNA SERIE TEMPORAL
Una serie temporal se puede analizar: 1º En el dominio del tiempo, consiste en construir un modelo econométrico
dependiente del tiempo. 2º En el dominio de las frecuencias, o análisis espectral, trata sobre la detección
de posibles componentes cíclicos y de la aportación que realizan las distintas frecuencias en la variabilidad de la serie. El análisis espectral no persigue la construcción de modelos de predicción, sino simplemente investigar la estructura interna del proceso estocástico generador de una serie.

1.8. MÉTODOS USADOS EN EL DOMINIO DEL TIEMPO
El análisis en el dominio temporal se realiza generalmente usando dos tipos de técnicas:
1º Los métodos clásicos, como los de regresión, alisado exponencial, o medias
móviles, empleados si el número de observaciones es pequeño (hasta 40). 2º Los métodos de Box y Jenkins o utilización de modelos ARIMA, si se dispone
de suficiente material estadístico. Existen otros modelos derivados o relacionados con esta metodología.
1.9. TIPOS DE MODELOS DE SERIES TEMPORALES
En el enfoque inicialmente propuesto por Box y Jenkins, se suelen dividir cinco clases de modelos con un grado creciente de complejidad y que pueden denominarse:
1º Univariante, Se enlaza con la más clásica tradición de tratamiento aislado de una
serie temporal, cuya evolución se explica por los valores pasados de dicha serie y un cierto término de error. Es decir:
2º Función de transferencia, La función de transferencia del filtro es el cociente de los dos
polinomiales de retardos definidos, , de la siguiente forma:
Con los mismos polinomiales de retardos definidos, de orden p y q,
entonces puede definirse el modelo (simple) de función de transferencia, con ruido, como:
donde Yt puede interpretarse, a su vez, como la salida de dos filtros lineales,
uno sobre la variable de input y otro sobre la componente de ruido.
( ) ( )Φ Β Θ ΒY ut t=
( )( )Y ut t=
Θ ΒΦ Β
( )( )
( )( )Y X ut t t= +
ωδ
ΒΒ
Θ ΒΦ Β
( )( )
Θ ΒΦ Β

Generalizando al caso de más de una variable explicativa, con K cocientes distintos de polinomiales de retardos, uno por cada input; es:
3º Intervención, Cuando en el modelo de función de transferencia las variablesX jt son
ficticias. 4º Multivariantes, Se trata de modelos de varias variables de salida, considerando que
todos los polinomiales pueden ser distintos (tanto en orden como en valor de los parámetros) la expresión formal matricial condensada es:
representando m ecuaciones en retardos sobre las m series temporales con retardos también en m variables de error.
Puede considerarse que los polinomiales en posiciones de diagonal
principal comienzan con la unidad, mientras que los restantes comienzan con una potencia de Β ; entonces cada uno de las ecuaciones se entiende que
explica el comportamiento de cada una de las variables Z jt
.
5º Funciones de transferencia mutlivariante, Obtenido como generalización del modelo de función de transferencia
para un output único. Una posible expresión consiste en definir, para K variables de input
(exógenas) y G variables output (endógenas), la matriz ( )V Β de G x K
polinomiales del tipo ( )( )
ϖδ
ij
ij
ΒΒ
, así como las matrices m x n de polinomiales
( )Φ Β y ( )Θ Β para los términos de error, con lo que:
2º ANÁLISIS BÁSICO DE UNA SERIE DE TIEMPO
Definimos una serie temporal como un conjunto de mediciones de un determinado fenómeno repetidas de forma homogénea con una frecuencia determinada. De forma genérica podemos representar una serie temporal de T observaciones como:
( )( )
( )( )Y X ut
j
jj
K
jt t= +=∑
ωδ
ΒΒ
Θ ΒΦ Β1
( ) ( )H Z F Ut tΒ Β=
( ) ( ) ( )Y V X Ut t t= + −Β Φ Β Θ Β1
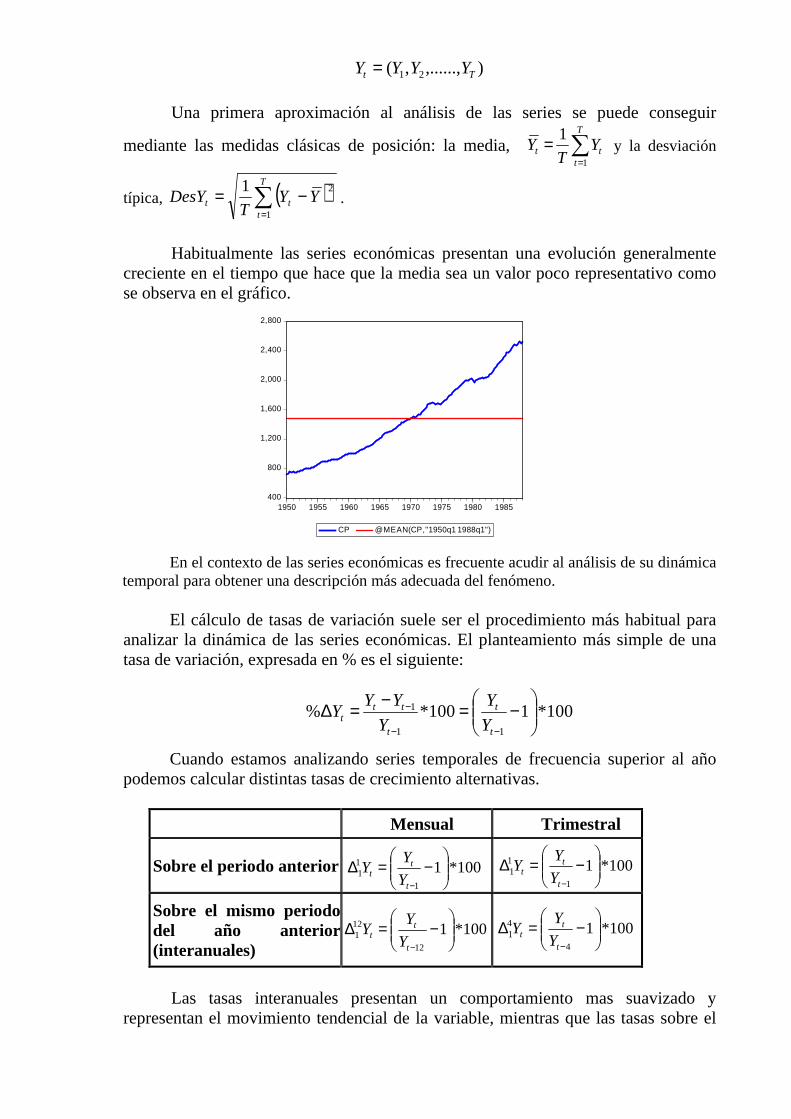
),......,,( 21 Tt YYYY =
Una primera aproximación al análisis de las series se puede conseguir
mediante las medidas clásicas de posición: la media, ∑=
=T
ttt Y
TY
1
1 y la desviación
típica, ( )∑=
−=T
ttt YY
TDesY
1
21.
Habitualmente las series económicas presentan una evolución generalmente
creciente en el tiempo que hace que la media sea un valor poco representativo como se observa en el gráfico.
400
800
1,200
1,600
2,000
2,400
2,800
1950 1955 1960 1965 1970 1975 1980 1985
CP @MEAN(CP,"1950q1 1988q1")
En el contexto de las series económicas es frecuente acudir al análisis de su dinámica
temporal para obtener una descripción más adecuada del fenómeno.
El cálculo de tasas de variación suele ser el procedimiento más habitual para analizar la dinámica de las series económicas. El planteamiento más simple de una tasa de variación, expresada en % es el siguiente:
Cuando estamos analizando series temporales de frecuencia superior al año podemos calcular distintas tasas de crecimiento alternativas.
Mensual Trimestral
Sobre el periodo anterior
Sobre el mismo periodo del año anterior (interanuales)
Las tasas interanuales presentan un comportamiento mas suavizado y
representan el movimiento tendencial de la variable, mientras que las tasas sobre el
100*1100*%11
1
−=−=∆
−−
−
t
t
t
ttt Y
Y
Y
YYY
100*11
11
−=∆
−t
tt Y
YY 100*1
1
11
−=∆
−t
tt Y
YY
100*112
121
−=∆
−t
tt Y
YY 100*1
4
41
−=∆
−t
tt Y
YY
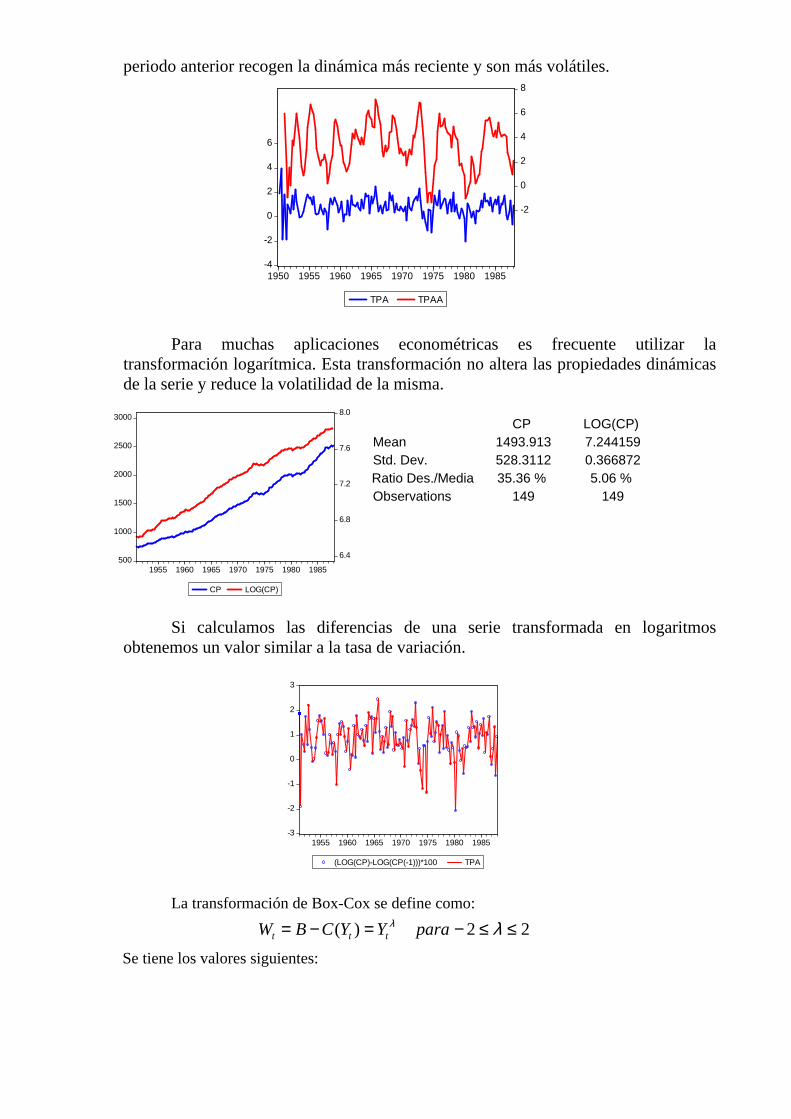
periodo anterior recogen la dinámica más reciente y son más volátiles.
-4
-2
0
2
4
6
-2
0
2
4
6
8
1950 1955 1960 1965 1970 1975 1980 1985
TPA TPAA
Para muchas aplicaciones econométricas es frecuente utilizar la
transformación logarítmica. Esta transformación no altera las propiedades dinámicas de la serie y reduce la volatilidad de la misma.
CP LOG(CP)
Mean 1493.913 7.244159 Std. Dev. 528.3112 0.366872 Ratio Des./Media 35.36 % 5.06 % Observations 149 149
Si calculamos las diferencias de una serie transformada en logaritmos obtenemos un valor similar a la tasa de variación.
-3
-2
-1
0
1
2
3
1955 1960 1965 1970 1975 1980 1985
(LOG(CP)-LOG(CP(-1)))*100 TPA
La transformación de Box-Cox se define como:
Se tiene los valores siguientes:
500
1000
1500
2000
2500
3000
6.4
6.8
7.2
7.6
8.0
1955 1960 1965 1970 1975 1980 1985
CP LOG(CP)
22)( ≤≤−=−= λλ paraYYCBW ttt
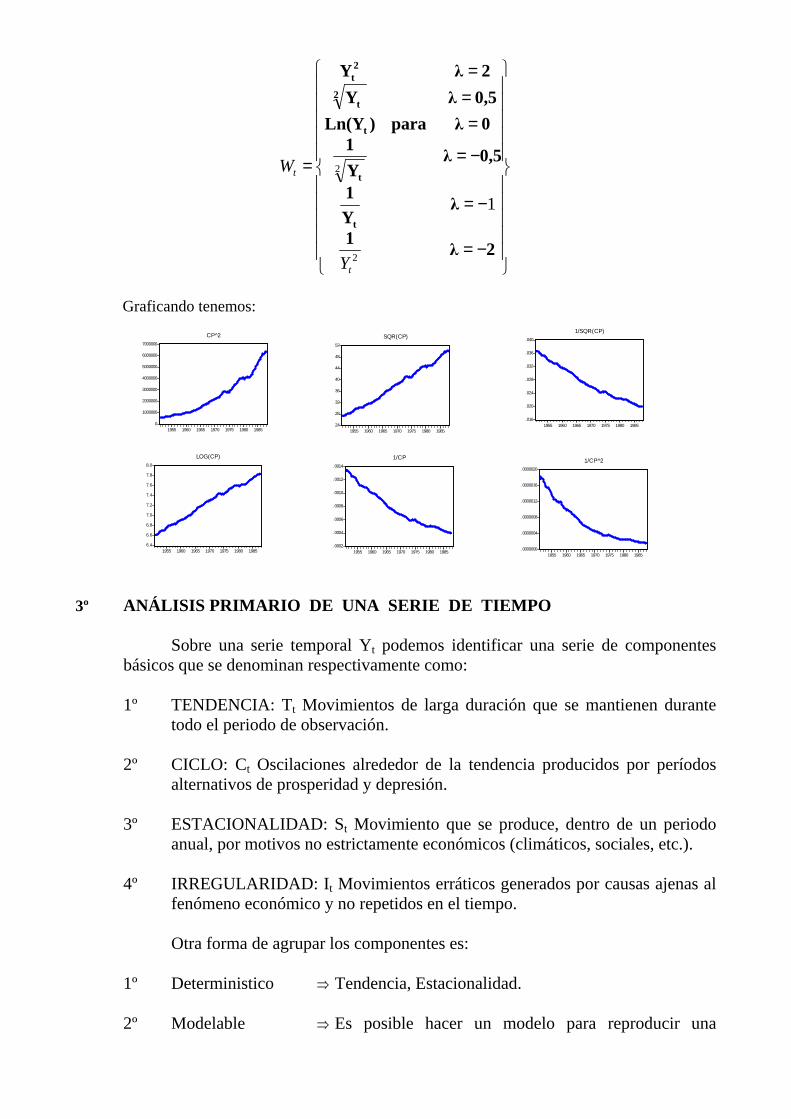
−=
−=
−=
===
=
2λ1
λY1
0,5λY
10λpara)Ln(Y
0,5λY
2λY
t
t
t
2t
2t
2
2
1
t
t
Y
W
Graficando tenemos:
0
1000000
2000000
3000000
4000000
5000000
6000000
7000000
1955 1960 1965 1970 1975 1980 1985
CP^2
24
28
32
36
40
44
48
52
1955 1960 1965 1970 1975 1980 1985
SQR(CP)
6.4
6.6
6.8
7.0
7.2
7.4
7.6
7.8
8.0
1955 1960 1965 1970 1975 1980 1985
LOG(CP)
.016
.020
.024
.028
.032
.036
.040
1955 1960 1965 1970 1975 1980 1985
1/SQR(CP)
.0002
.0004
.0006
.0008
.0010
.0012
.0014
1955 1960 1965 1970 1975 1980 1985
1/CP
.0000000
.0000004
.0000008
.0000012
.0000016
.0000020
1955 1960 1965 1970 1975 1980 1985
1/CP^2
3º ANÁLISIS PRIMARIO DE UNA SERIE DE TIEMPO
Sobre una serie temporal Yt podemos identificar una serie de componentes básicos que se denominan respectivamente como:
1º TENDENCIA: Tt Movimientos de larga duración que se mantienen durante todo el periodo de observación.
2º CICLO: Ct Oscilaciones alrededor de la tendencia producidos por períodos
alternativos de prosperidad y depresión. 3º ESTACIONALIDAD: St Movimiento que se produce, dentro de un periodo
anual, por motivos no estrictamente económicos (climáticos, sociales, etc.). 4º IRREGULARIDAD: It Movimientos erráticos generados por causas ajenas al
fenómeno económico y no repetidos en el tiempo.
Otra forma de agrupar los componentes es: 1º Deterministico ⇒ Tendencia, Estacionalidad.
2º Modelable ⇒ Es posible hacer un modelo para reproducir una

estructura. El componente modelable es estocástico. 3º Irregulares ⇒ Error, no se puede modelar ni deterministicamente ni
estocásticamente.
Podemos plantear diferentes esquemas alternativos de descomposición de una serie temporal:
1º ADITIVO:
2º MULTIPLICATIVO:
3º MIXTO:
Generalmente, el proceso de descomposición de una serie se realiza, en el enfoque clásico, mediante un proceso secuencial de identificación y separación de componentes.
Por regla general el orden en el que se van identificando los sucesivos
componentes es el siguiente (para estructura aditiva):
1º Estacionalidad 2º Tendencia 3º Ciclo 4º Componente irregular
3.1. DESESTACIONALIZACIÓN
Es frecuente antes de aplicar un proceso de desestacionalización realizar un análisis de LABORALIDAD y efecto PASCUA (Semana Santa). * LABORALIDAD: Corrección de los datos originales en función del número de
días laborables de cada mes. Por ejemplo, una serie mensual se puede homogeneizar a meses de 30 días, multiplicando los datos de enero por 30/31, los de febrero por 30/28 o por 30/29 si el año es bisiesto, etc. En este tratamiento previo, se aconseja realizar un gráfico temporal de la serie.
* Efecto PASCUA: Corrección que se aplica a los meses de Abril o Marzo en
función de las fechas de Semana Santa.
ttttt ISCTY +++=
ttttt ISCTY ***=
ttttt ISCTY +++= )1(*)1(*
)(ˆtt YfS =
ttt SYY ˆ1 −=
)(ˆ 1tt YfT = ttt TYY ˆ12 −=
)(ˆ 2tt YfC =
ttt CYI ˆ2 −=
A las series de las que se han eliminado estos efectos se les denomina SERIES CORREGIDAS DE CALENDARIO. Las series temporales de datos económicos presentan generalmente características estacionales cuando se observan a una frecuencia inferior a la anual, ya sea mediante datos trimestrales, mensuales, bimestrales o semanales.
Estas características se deben a que las decisiones tomadas por los agentes económicos en un determinado trimestre (bimestre, mes, o semana) del año puede estar correlacionado con las decisiones tomadas en el mismo trimestre (bimestre, mes o semana) de otros años.
La identificación del elemento estacional es importante cuando el objetivo es explicar el comportamiento de la variable endógena, dado que una parte de las fluctuaciones de esta se manifiesta por el solo hecho de encontrarse en una época del año.
También es importante cuando el objetivo es predecir, puesto que las diferencias estacionales motivan que aun siendo idénticos los valores de las variables exógenas en cada parte del año se deberá predecir diferentes valores para la variable endógena.
Este fenómeno se puede detectar:
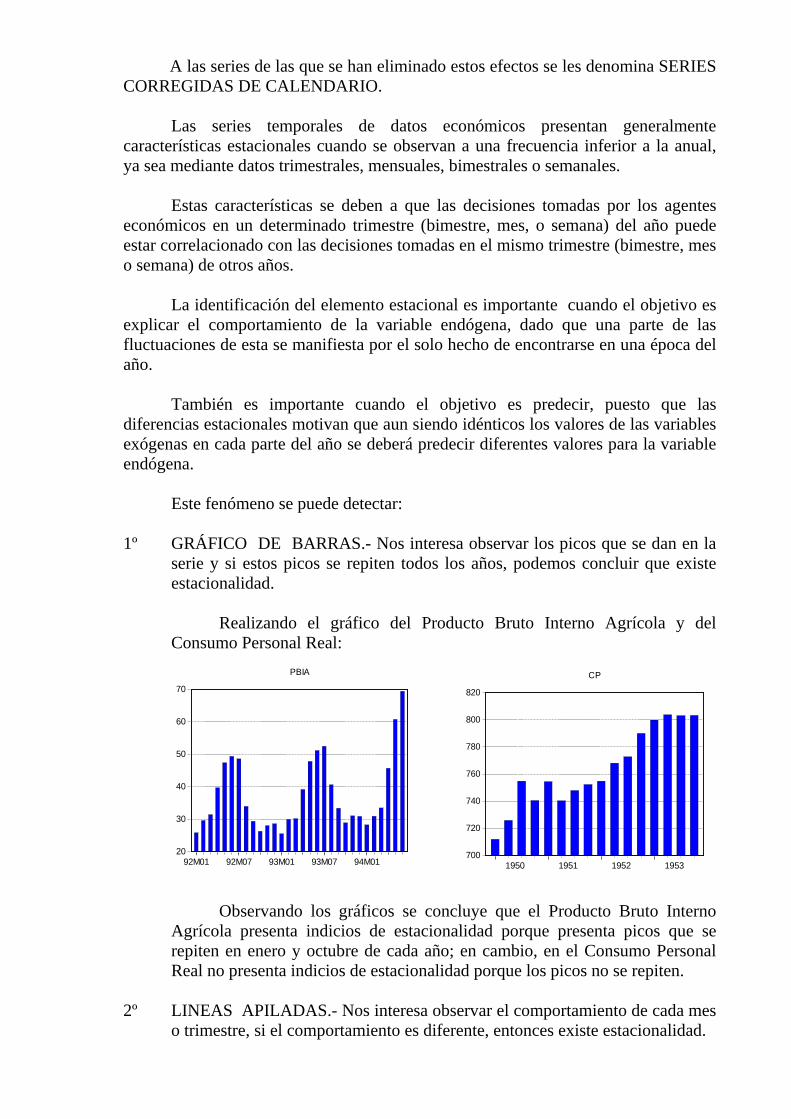
1º GRÁFICO DE BARRAS.- Nos interesa observar los picos que se dan en la
serie y si estos picos se repiten todos los años, podemos concluir que existe estacionalidad.
Realizando el gráfico del Producto Bruto Interno Agrícola y del
Consumo Personal Real:
20
30
40
50
60
70
92M01 92M07 93M01 93M07 94M01
PBIA
Observando los gráficos se concluye que el Producto Bruto Interno Agrícola presenta indicios de estacionalidad porque presenta picos que se repiten en enero y octubre de cada año; en cambio, en el Consumo Personal Real no presenta indicios de estacionalidad porque los picos no se repiten.
2º LINEAS APILADAS.- Nos interesa observar el comportamiento de cada mes
o trimestre, si el comportamiento es diferente, entonces existe estacionalidad.
700
720
740
760
780
800
820
1950 1951 1952 1953
CP

Realizando el gráfico del Producto Bruto Interno Agrícola y del
Consumo Personal Real:
20
30
40
50
60
70
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
Means by Season
PBIA by Season
Observando los gráficos se concluye que el Consumo Personal Real no presenta estacionalidad y el Producto Bruto Interno agrícola si presenta estacionalidad.
3º LINEAS SEPARADAS.- Nos interesa observar el comportamiento de cada
mes o trimestre, si el comportamiento es diferente, entonces existe estacionalidad.
Realizando el gráfico del Producto Bruto Interno Agrícola y del
Consumo Personal Real:
Observando los gráficos se concluye que el Consumo Personal Real no
presenta estacionalidad y el Producto Bruto Interno agrícola si presenta estacionalidad.
4º CORRELOGRAMA.-
Para analizar la estacionalidad de una serie introduciremos un concepto de gran interés en el análisis de series temporales: la función de autocorrelación.
La función de autocorrelación mide la correlación entre los valores de la serie distanciados un lapso de tiempo k.
La función de autocorrelación es el conjunto de coeficientes de autocorrelación rk desde 1 hasta un máximo que no puede exceder la mitad de
20
30
40
50
60
70
1992 1993 1994
JanFebMarAprMayJunJulAugSepOctNovDec
PBIA by Season
400
800
1200
1600
2000
2400
2800
CP Means by Season
Q1 Q2 Q3 Q4
CP by Season
400
800
1200
1600
2000
2400
2800
1950 1955 1960 1965 1970 1975 1980 1985
Q1Q2Q3Q4
CP by Season

los valores observados, y es de gran importancia para estudiar la estacionalidad de la serie, ya que si ésta existe, los valores separados entre sí por intervalos iguales al periodo estacional deben estar correlacionados de alguna forma. Es decir que el coeficiente de autocorrelación para un retardo igual al periodo estacional debe ser significativamente diferente de 0.
Debemos obtener el correlograma considerando 25 retardos si la serie
es mensual, 9 retardos si la serie es trimestral, etc.. Se tiene que observar los picos que se dan en el correlograma y si estos picos se repiten en el mismo periodo en los siguientes años, podemos concluir que existe estacionalidad.
El correlograma del Producto Bruto Interno Agrícola se obtiene
siguiendo la instrucción siguiente:
Abrir el PBIA ⇒ View ⇒ Correlogram... ⇒ se marca level y se escribe
25 lag ⇒ OK y se muestra el siguiente resultado para el PBIA:
Sample: 1992M01 1995M12 Included observations: 30
Autocorrelation Partial Correlation AC PAC Q-Stat Prob . |***** | . |***** | 1 0.672 0.672 14.927 0.000
. |**. | ***| . | 2 0.234 -0.396 16.798 0.000 . *| . | .**| . | 3 -0.150 -0.222 17.596 0.001 ***| . | . *| . | 4 -0.350 -0.069 22.131 0.000 ***| . | . *| . | 5 -0.408 -0.141 28.534 0.000 ***| . | .**| . | 6 -0.398 -0.199 34.869 0.000 ***| . | . *| . | 7 -0.330 -0.127 39.414 0.000 .**| . | . *| . | 8 -0.247 -0.177 42.085 0.000 . | . | . |* . | 9 -0.024 0.160 42.112 0.000 . |**. | . |* . | 10 0.246 0.127 45.015 0.000 . |*** | . |* . | 11 0.458 0.115 55.594 0.000 . |**** | . | . | 12 0.484 0.031 68.113 0.000 . |*** | . | . | 13 0.330 0.001 74.278 0.000 . |* . | . | . | 14 0.095 -0.000 74.816 0.000 . *| . | . | . | 15 -0.133 -0.022 75.956 0.000 .**| . | . | . | 16 -0.245 0.045 80.088 0.000 .**| . | . | . | 17 -0.291 -0.023 86.322 0.000 .**| . | . | . | 18 -0.264 0.030 91.891 0.000 . *| . | . |* . | 19 -0.141 0.164 93.636 0.000 . | . | . *| . | 20 -0.027 -0.066 93.705 0.000 . | . | .**| . | 21 0.017 -0.216 93.735 0.000 . | . | . *| . | 22 0.047 -0.067 94.000 0.000 . | . | . *| . | 23 0.041 -0.186 94.235 0.000 . | . | . *| . | 24 0.000 -0.176 94.235 0.000 . | . | . | . | 25 0.000 0.033 94.235 0.000
Si observamos el correlograma del producto bruto interno agrícola se
visualiza que el pico del retardo 5 se repite en el retardo 17, por lo tanto, podemos concluir que el producto bruto interno agrícola es estacional.

El correlograma del Consumo Personal Real se obtiene siguiendo la instrucción siguiente:
Abrir el CP ⇒ View ⇒ Correlogram... ⇒ se marca level y se escribe 9
lag ⇒ OK y se muestra el siguiente resultado para el CP:
Sample: 1950Q1 1988Q1 Included observations: 153
Autocorrelation Partial Correlation AC PAC Q-Stat Prob .|*******| .|*******| 1 0.955 0.955 142.33 0.000
.|*******| .|. | 2 0.911 -0.014 272.69 0.000 .|*******| .|. | 3 0.868 -0.014 391.73 0.000 .|****** | .|. | 4 0.825 -0.012 500.15 0.000 .|****** | .|. | 5 0.786 0.008 599.06 0.000 .|****** | .|. | 6 0.747 -0.010 689.07 0.000 .|***** | .|. | 7 0.711 0.006 771.12 0.000 .|***** | .|. | 8 0.677 0.008 846.07 0.000 .|***** | .|. | 9 0.645 0.008 914.68 0.000
El comportamiento del coeficiente de autocorrelación del consumo personal real no presenta picos, por lo tanto, concluimos que el consumo personal real no es estacional.
Los métodos para cuantificar la estacionalidad y desestacionalizar la
serie son: 1º REGRESIÓN CON VARIABLES DUMMY.-
En el método de regresión se utiliza una serie de variables mudas para capturar los efectos estacionales:
ttkkt YDDY εγβββ +++++= −1110 ..... donde cada variable Di toma valores 1 en el período que ésta representa (p. e., enero de cada año) y cero en cualquier otro período. El modelo puede ser extendido para incluir otras variables explicativas o un proceso más complejo (aunque estacionario) para el error (p. e., un ARMA).
En la medida en que los coeficientes iβ sean estadísticamente
significativos, habrá componentes estacionales. Consecuentemente, la serie desestacionalizada SE
tY se calcula como:
kktSE
t DDYY βββ −−−−= .....110 donde iβ son los parámetros estimados para cada componente estacional que resulten significativos.
Como es evidente, al modelar la estacionalidad de esta manera se
asume que el efecto estacional sea determinístico (o constante en valor esperado), es decir, que en cada año el cambio en la variable por razones estacionales sea exactamente el mismo. Ello no es un supuesto adecuado para

muchas de las variables económicas debido a que el comportamiento estacional se determina por numerosas y muy heterogéneas fuentes, lo que sugiere que éste sea modelado como una variable aleatoria.
El uso de variables mudas para modelar estacionalidad en un análisis de
regresión presenta el problema de inducir correlaciones espurias entre las variables, en tanto que su uso para predecir variables en modelos de series de tiempo (p.e., ARIMA, VAR) produce predicciones fuera de muestra que son de peor calidad que las que se obtienen de otros métodos (X-11 o la variación en x-períodos), en especial en modelos multivariados.
No obstante, este método satisface algunas características que son
deseables en cualquier método de remoción de estacionalidad: que se preserve el promedio de la serie original, que los componentes estacionales sean ortogonales entre sí, y que al aplicar el método a la serie desestacionalizada no se obtengan nuevos factores estacionales (idempotencia).
Aplicando este método a la serie Consumo personal real tenemos:
Dependent Variable: CP Method: Least Squares Sample (adjusted): 1950Q2 1988Q1 Included observations: 152 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. C 0.940573 3.380101 0.278268 0.7812
@SEAS(1) 2.577797 2.784144 0.925885 0.3560 @SEAS(2) 1.529906 2.784490 0.549438 0.5835 @SEAS(3) 4.609948 2.784212 1.655746 0.0999
CP(-1) 1.006017 0.001863 539.9100 0.0000 R-squared 0.999496 Mean dependent var 1479.040
En la regresión ninguna de las variables dummy son significativas, por lo tanto el consumo personal real no presenta estacionalidad.
En GRETL se obtiene el mismo resultado:
Modelo 1: MCO, usando las observaciones 1950:2-1988:1 (T = 152) Variable dependiente: CP
Coeficiente Desv. Típica Estadístico t Valor p Const 0,940573 3,3801 0,2783 0,78120 dq1 2,5778 2,78414 0,9259 0,35602 dq2 1,52991 2,78449 0,5494 0,58354 dq3 4,60995 2,78421 1,6557 0,09991 * CP_1 1,00602 0,0018633 539,9100 <0,00001 *** Media de la vble. dep. 1479,040 D.T. de la vble. dep. 533,5063 Suma de cuad. residuos 21648,89 D.T. de la regresión 12,13554 R-cuadrado 0,999496 R-cuadrado corregido 0,999483 F(4, 147) 72922,06 Valor p (de F) 3,0e-241

Log-verosimilitud -592,5497 Criterio de Akaike 1195,099 Criterio de Schwarz 1210,219 Crit. de Hannan-Quinn 1201,241 Rho 0,147941 h de Durbin 1,818406
Aplicándolo en Eviews para Producto bruto interno agrícola resulta:
Dependent Variable: PBIA Method: Least Squares Sample (adjusted): 1992M02 1994M06 Included observations: 29 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. C -11.66865 3.817922 -3.056282 0.0075
@SEAS(1) -3.149474 1.741879 -1.808090 0.0894 @SEAS(2) 4.600756 1.631591 2.819797 0.0123 @SEAS(3) 1.089949 1.591708 0.684767 0.5033 @SEAS(4) 8.744458 1.611761 5.425405 0.0001 @SEAS(5) 5.446288 2.162990 2.517944 0.0228 @SEAS(6) -4.584691 3.175343 -1.443841 0.1681 @SEAS(7) -8.288786 3.077233 -2.693585 0.0160 @SEAS(8) -21.88337 3.103516 -7.051155 0.0000 @SEAS(9) -9.241514 1.983766 -4.658570 0.0003 @SEAS(10) -4.739175 1.756342 -2.698321 0.0158 @SEAS(11) 2.503367 1.757713 1.424218 0.1736
PBIA(-1) 1.402257 0.122378 11.45837 0.0000 R-squared 0.986385 Mean dependent var 37.99448
En la regresión, siete de las variables dummy son significativas, por lo tanto el Producto bruto interno agrícola presenta estacionalidad. Entonces se aplica el método aditivo para desestacionalizar.
2º MEDIA MÓVIL.- Se desestacionaliza transformando la serie original en la
que las nuevas observaciones para cada periodo son un promedio de las observaciones originales. El orden de la media móvil indica el número de observaciones a promediar.
Mensuales Orden 12 Trimestrales Orden 4
Sin centrar
Centrada
Con ω = 0.5 para r=-6 y +6 y ω = 1 el resto.
Con ω = 0,5 para r = -2 y +2 y ω = 1 el resto.
∑=
−=11
0
12
12
1
rrtt YYMM ∑
=−=
3
0
4
4
1
rrtt YYMM
∑+
−=−=
6
6
12
12
1
rrtt YYMMc ω ∑
+
−=−=
2
2
4
4
1
rrtt YYMMc ω

Aplicando la media móvil sin centrar al consumo personal real nos daría los siguientes factores estacionales:
En el Eviews se sigue la instrucción siguiente:
Genr mvscp = @movav(cp,4) y se obtiene la serie desestacionalizada empleando la media móvil sin centrar. Genr mvccp = (0.5*cp(-2)+cp(-1)+cp+cp(+1)+0.5*cp(+2))/4 y se obtiene la serie desestacionalizada empleando la media móvil central.
En Gretl se sigue la instrucción siguiente:
Marcamos CP ⇒ Variable ⇒ Filtrar ⇒ Media Móvil simple ⇒
marcar serie suavizada ⇒ Aceptar, para obtener la media móvil sin centrar.
Marcamos CP ⇒ Variable ⇒ Filtrar ⇒ Media Móvil simple ⇒
marcar centrada y serie suavizada ⇒ Aceptar, para obtener la media móvil centrada.
3º RATIO DE MEDIO MÓVIL.- Los pasos para obtener el ratio de promedio móvil son:
1) Se calcula el promedio móvil central de Yt como:
2) Se considera el ratio:
3) Calculamos el índice estacional ( )im como el promedio del ratio de
promedio móvil para ese mes o trimestre en el periodo analizado.
1) El factor estacional es el ratio entre el índice estacional y la media geométrica de los índices estacionales, así:
X
Y Y Y Y Ymensual
Y Y Y Y Ytrimestral
t
t t t t t
t t t t t=
+ + + + + +
+ + + +
+ + − −
+ + − −
05 05
1205 05
4
6 5 5 6
2 1 1 2
. ... ... .
. .
rY
Xtt
t
=
s
i
i i imensuales
i
i i i itrimestres
m
m=
1 2 1212
1 2 3 44
...

En el Eviews se sigue la instrucción siguiente:
Abrir el CP ⇒ Proc ⇒ Seasonal Adjusment ⇒ se marca Ratio to
moving average - Multiplicative ⇒ OK y se muestra el siguiente resultado para el CP:
Sample: 1950Q1 1988Q1 Included observations: 153 Ratio to Moving Average Original Series: CP Adjusted Series: CPSA
Scaling Factors: 1 1.000019
2 0.999470 3 1.000848 4 0.999663
4º DIFERENCIA DE PROMEDIO MÓVIL.- Los pasos para obtener la
diferencia de promedio móvil son:
1.- Se calcula el promedio móvil central de Yt como:
2.- Se considera la diferencia:
3.- Calculamos el índice estacional ( )im como el promedio de la diferencia
de promedio móvil para ese mes o trimestre en el periodo analizado. 4.- El factor estacional es la diferencia entre el índice estacional y el
promedio de los índices estacionales, así:
En el Eviews se sigue la instrucción siguiente:
Abrir el CP ⇒ Proc ⇒ Seasonal Adjusment ⇒ Difference from moving
average - Additive ⇒ OK y se muestra el siguiente resultado para el CP:
X
Y Y Y Y Ymensual
Y Y Y Y Ytrimestral
t
t t t t t
t t t t t=
+ + + + + +
+ + + +
+ + − −
+ + − −
05 05
1205 05
4
6 5 5 6
2 1 1 2
. ... ... .
. .
d Y Xt t t= −
s i ij j= −

Sample: 1950Q1 1988Q1 Included observations: 153 Difference from Moving Average Original Series: CP Adjusted Series: CPSA1
Scaling Factors: 1 -0.132086
2 -0.941545 3 1.444906 4 -0.371275
5º ALISADO.- Las técnicas de alisado exponencial se utilizan en situaciones en
las que existen pocos datos (muestra pequeña), y si es necesario ir actualizando el modelo empleado cada vez que se obtiene un nuevo dato. Son muy simples en su aplicación pero limitados.
El Modelo de Holt-Winters, para series con tendencia polinomial, ciclo
estacional y componente aleatoria, tanto para tipo aditivo como multiplicativo.
El Alisado exponencial estacional con triple parámetro (Holt-Winters estacional-multiplicativo) es:
La predicción es:
Válido para series con tendencia lineal y estacionalidad. El factor
estacional no es fijo en el ajuste a periodo muestral. En el Eviews se sigue la instrucción siguiente:
Abrir el PBIA ⇒ Proc ⇒ Exponential Smoothing ⇒ Holt-Winters
Multiplicativo ⇒ OK y se muestra el siguiente resultado:
Sample: 1992M01 1994M06 Included observations: 30 Method: Holt-Winters Multiplicative Seasonal Original Series: PBIA Forecast Series: PBIASM
( ) ( )( ) ( )
( ) st
t
tt
tttt
ttst
tt
sY
Ys
bYYb
bYs
YY
−
−−
−−−
−+=
−+−=
+−+=
δδ
ββ
αα
1ˆ
*1ˆˆ*
ˆ*1*ˆ
11
11
( ) kstttkt skbYY +−+ += **ˆˆ

Parameters: Alpha 0.8700
Beta 1.0000 Gamma 0.0000
Sum of Squared Residuals 42.98890 Root Mean Squared Error 1.197065
End of Period Levels: Mean 49.38024 Trend 4.217104 Seasonals: 1993M07 1.406998 1993M08 1.032589 1993M09 0.865693 1993M10 0.758299 1993M11 0.807855 1993M12 0.810340 1994M01 0.735470 1994M02 0.848620 1994M03 0.874647 1994M04 1.113844 1994M05 1.338879 1994M06 1.406765
El Alisado exponencial estacional con triple parámetro (Holt-Winters
estacional-aditivo) es:
La predicción es:
Válido para series con tendencia lineal y estacionalidad. El factor
estacional no es fijo en el ajuste a periodo muestral. En el Eviews se sigue la instrucción siguiente:
Abrir el PBIA ⇒ Proc ⇒ Exponential Smoothing ⇒ Holt-Winters
Aditivo ⇒ OK y se muestra el siguiente resultado:
Sample: 1992M01 1994M06 Included observations: 30 Method: Holt-Winters Additive Seasonal Original Series: PBIA Forecast Series: PBIASM1
Parameters: Alpha 0.9400 Beta 1.0000 Gamma 0.0000
Sum of Squared Residuals 54.46170
( ) ( ) ( )( ) ( )( ) ( ) stttt
tttt
ttsttt
sYYs
bYYb
bYsYY
−
−−
−−−
−+−=
−+−=
+−+−=
δδ
ββ
αα
1ˆ*
*1ˆˆ*
ˆ*1*ˆ
11
11
kstttkt skbYY +−+ ++= *ˆˆ

Root Mean Squared Error 1.347364 End of Period Levels: Mean 54.92442 Trend 6.410787 Seasonals: 1993M07 14.64229 1993M08 1.253542 1993M09 -4.815208 1993M10 -8.758958 1993M11 -6.982708 1993M12 -6.931458 1994M01 -9.250208 1994M02 -5.313958 1994M03 -4.442708 1994M04 4.013542 1994M05 12.04479 1994M06 14.54104
6º METODO X11.- Un procedimiento de estimación de los componentes de una
serie temporal es el desarrollo por J. Siskin en la Oficina del Censo de los Estados Unidos.
Este programa X11 se usa en numerosos organismos públicos, así
como en el sector financiero, y permite ajustar series mensuales y trimestrales mediante el método aditivo, multiplicativo y mixto. Incluye numerosas opciones para tener en cuenta las fiestas, los días no laborables, e incluso para detectar y corregir automáticamente los datos anormales.
Los resultados que muestra el método son: a.- Estimación de la tendencia. b.- Determinación de unos coeficientes estacionales. c.- Estimación de la componente aleatoria, y d.- Varios contrastes para detectar la estacionalidad. Dispone de numerosas opciones, en las que se proporcionan muy
variadas y extensas tablas relativas a las componentes, en las distintas fases de la estimación, ya que el procedimiento realiza varias iteraciones antes de estimar finalmente las componentes del modelo, incluido el modelo ARIMA para la componente aleatoria.
En unas iteraciones iniciales, se estiman las componentes de la serie y
se corrigen los datos en función de los días laborables (si se elige esta opción). Se identifican las observaciones extremas o anormales, y así se llega a unas estimaciones finales de las componentes.
En la primera iteración, con una media móvil centrada de amplitud 12,
se obtiene una estimación inicial de la tendencia y ciclo, eliminando variación estacional e irregular, que se estiman por diferencia o por cociente según el tipo de modelo.

En la segunda etapa, se aplican medias móviles a la serie que incluye las componentes estacionales y la irregular, para estimar esta última, y se obtiene también su desviación típica mensual. De esta forma se estiman y corrigen los valores extremos, y con una nueva media móvil se estima la componente estacional. Los índices estacionales se usan para obtener una primera aproximación de la serie desestacionalizada, a partir de la cual, y mediante una media móvil ponderada, se obtienen una segunda estimación de las componentes agregadas de tendencia y ciclo no estacional.
El mismo procedimiento se utiliza para obtener una segunda estimación
de la serie desestacionalizada y de la componente irregular, que es de nuevo corregida en sus valores extremos o anormales.
En una tercera y última iteración, se estiman finalmente los índices
estacionales, y las componentes irregular y tendencial. En el Eviews se tiene: T representa la tendencia de la serie y los ciclos no estacionales. S componente estacional. I componente aleatoria o irregular. En el Eviews se sigue la instrucción siguiente:
Abrir el CP ⇒ Proc ⇒ Seasonal Adjusment ⇒ X11 (Historical) ⇒
Census X11-Multiplicative y se escribe en Factor: FEM ⇒ OK.
7º CENSUS X12-ARIMA.- es un programa de código abierto creado por el U.S. Census Bureau. Este es un programa de corrección estacional que incorpora algunas mejoras con respecto al programa X11-ARIMA (Statistics Canada) como el desarrollo de nuevas medidas de identificación de modelos y de diagnóstico de ajustes. Además es un programa de reajuste estacional. También el Census X12-ARIMA es un método basado en promedios móviles, los cuales se sustentan en el dominio del tiempo o en el de frecuencias. Census X12-ARIMA logra el ajuste estacional con el desarrollo de un sistema de los factores que explican la variación estacional en una serie.
En años recientes, el Census X12-ARIMA ha adquirido relevancia en vista de que entre sus innovaciones se encuentran procedimientos basados en modelos (“model based”) como el Seats, el cual supone un modelo ARIMA para cada uno de los componentes de la serie de tiempo de interés. Específicamente, considera los modelos RegARIMA, los cuales son modelos de regresión cuyos errores siguen un proceso ARIMA. Por lo anterior, este programa es muy utilizado en varios bancos centrales, así como en varias oficinas de estadística como la de la Unión Europea (Eurostat) y la de Perú.

En el Eviews se sigue la instrucción siguiente:
Abrir el CP ⇒ Proc ⇒ Seasonal Adjusment ⇒ Census X12 ⇒ se marca Multiplicative, Final seasonally adjusted serie y Final seasonal factors ⇒ OK.
8º TRAMO/SEATS.- las siglas de Tramo significan “Time Series Regression
with ARIMA Noise, Missing Observations, and Outliers” y las de Seats “Signal Extraction in ARIMA Time Series”. Estos programas (que normalmente se usan juntos) han sido desarrollados por Víctor Gómez y Agustín Maravall del Banco de España.
Tramo es un programa para estimar y pronosticar modelos de regresión con errores posiblemente no estacionarios como los ARIMA (Autoregressive Integrated Moving Average) y cualquier serie de observaciones ausentes, también identifica y corrige observaciones atípicas como por ejemplo: el efecto Pascua, Calendario y el relacionado a formas de variables de intervención. El programa es eficiente en el ajuste estacional de series, y más en la extracción de señales estocásticas. El ajuste de la serie con el programa Tramo, corresponde al procedimiento que realizaba SCA (Scientific Computing Associates).
Seats es un programa para la estimación de los componentes no observados en series temporales, siguiendo el método “basado en modelos ARIMA”. Se estima y se obtienen predicciones de la tendencia, el componente estacional, el componente irregular y los componentes cíclicos. Además se obtienen los estimadores con error cuadrático medio mínimo (ECMM) de los componentes, así como sus predicciones también. Seats puede usarse para un análisis profundo de series o para aplicaciones rutinarias masivas. La estimación que realiza Seats corresponde a la metodología que llevaba a cabo X11- ARIMA.
Citando la descripción de Tramo/Seats dada en el sitio Web del Banco
de España1, “Los programas están dirigidos fundamentalmente al análisis de series temporales económicas y sociales, de frecuencia mensual o más baja. Aunque están estructurados para satisfacer las necesidades de un analista experto, pueden utilizarse también de forma totalmente automática. Sus principales aplicaciones son predicción, ajuste estacional, detección y corrección de observaciones atípicas, estimación de efectos especiales, y control de calidad de los datos”.
En conjunto, Tramo/Seats realiza la estimación ARIMA y la
descomposición en componentes aditivos o multiplicativos; por lo que Tramo hace la estimación, mientras que Seats hace la descomposición. Asimismo se recomienda el uso de este programa para obtener un buen punto de partida al ajustar alguna serie.
En el Eviews se sigue la instrucción siguiente:

Abrir el CP ⇒ Proc ⇒ Seasonal Adjusment ⇒ Tramo/Seats ⇒ se
marca Seasonally adjusted y seasonal factor ⇒ OK.
3.2. TENDENCIA
Es un movimiento de larga duración que se mantiene durante el período de observación. Una primera idea sobre la presencia de tendencia en la serie la obtendremos en su representación gráfica.
En general es difícil diferenciar entre el componente tendencial y el cíclico y, habitualmente, se obtienen de forma conjunta eliminando de la serie desestacionalizada el componente irregular, obteniéndose una nueva serie denominada de CICLO-TENDENCIA. Se tiene los métodos siguientes: 1º MEDIA MÓVIL CENTRADA.- Una forma sencilla de eliminar el
componente irregular consiste en calcular una media móvil centrada de orden bajo (p.e. 3) sobre la serie previamente desestacionalizada.
El componente irregular se obtendría por diferencia (método aditivo) entre la serie desestacionalizada y la de Ciclo-Tendencia, así:
En el Eviews se sigue la instrucción siguiente:
Genr mvc3cp = (cp(-1)+cp+cp(+1))/3 y se obtiene el ciclo-tendencia siguiente:
Modified: 1950Q1 1988Q1 // mvc3cp = (cp(-1)+cp+cp(+1))/3 1950Q1 NA 730.8333 740.3667 749.9000 1951Q1 745.0667 747.5000 746.8000 751.6000 1952Q1 758.3667 765.1667 776.9333 787.5000 1953Q1 797.8333 802.2000 803.3667 804.5000 1954Q1 808.2333 816.2333 827.9667 841.6333 1955Q1 855.5667 867.4667 879.9333 888.6000
2º FUNCIONES DE TIEMPO.- se obtiene la nueva serie de componente
tendencial ajustando los datos observados a una especificación en función del tiempo, calculándose los parámetros de la función de tiempo forma que se minimicen las diferencias cuadráticas entre la serie original y la estimada. Es decir:
∑+
−=−=
1
13
1
s
SEst
CTt YY
CTt
SEt
It YYY −=
222 )ˆ(/),(ˆtttt YYMintfYY −== ββ
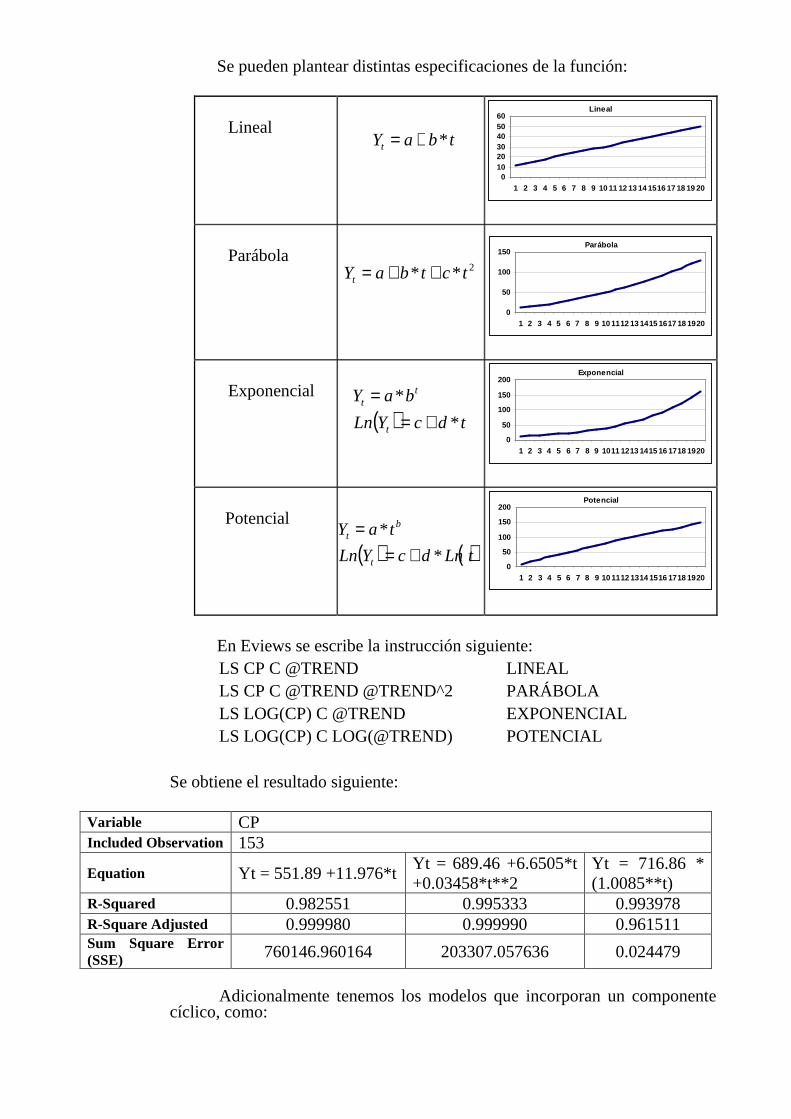
Se pueden plantear distintas especificaciones de la función:
Lineal
Parábola
Exponencial
Potencial
En Eviews se escribe la instrucción siguiente: LS CP C @TREND LINEAL LS CP C @TREND @TREND^2 PARÁBOLA LS LOG(CP) C @TREND EXPONENCIAL LS LOG(CP) C LOG(@TREND) POTENCIAL
Se obtiene el resultado siguiente:
Variable CP Included Observation 153
Equation Yt = 551.89 +11.976*t Yt = 689.46 +6.6505*t +0.03458*t**2
Yt = 716.86 * (1.0085**t)
R-Squared 0.982551 0.995333 0.993978 R-Square Adjusted 0.999980 0.999990 0.961511 Sum Square Error (SSE) 760146.960164 203307.057636 0.024479
Adicionalmente tenemos los modelos que incorporan un componente
cíclico, como:
tbaYt *+=
Lineal
0102030405060
1 2 3 4 5 6 7 8 9 10 11 12 13 14 1516 17 18 19 20
2** tctbaYt ++=
Parábola
0
50
100
150
1 2 3 4 5 6 7 8 9 10 1112 13 1415 1617 18 1920
( ) tdcYLn
baY
t
tt
*
*
+==
Exponencial
0
50
100
150
200
1 2 3 4 5 6 7 8 9 1011 1213 1415 16 1718 1920
( ) ( )tLndcYLn
taY
t
bt
*
*
+==
Potencial
0
50
100
150
200
1 2 3 4 5 6 7 8 9 10 1112 1314 1516 1718 1920

1.- Modelo de tendencia senoidal simple.-
El modelo es:
donde w es el número de observaciones en un año.
En Eviews, primero hay que generar el ángulo, así: GENR O = (2*3.14159*@TREND)/12 GENR O = (2*3.14159*@TREND)/4
y a continuación se escribe la instrucción siguiente: LS CP C @TREND @SIN(O) @COS(O) @TREND*@SIN(O) @TREND*@COS(O)
Resulta:
Dependent Variable: CP Method: Least Squares Sample: 1950Q1 1988Q1 Included observations: 153
Variable Coefficient Std. Error t-Statistic Prob. C 563.7933 11.56697 48.74167 0.0000
@TREND 11.97613 0.131602 91.00294 0.0000 @SIN(O) 6.007610 16.48854 0.364351 0.7161 @COS(O) 2.679173 16.22456 0.165131 0.8691
@TREND*@SIN(O) -0.080349 0.187892 -0.427635 0.6695 @TREND*@COS(O) -0.020915 0.184291 -0.113487 0.9098
R-squared 0.982576 Mean dependent var 1474.026
Adjusted R-squared 0.981984 S.D. dependent var 535.3530 S.E. of regression 71.85795 Akaike info criterion 11.42569 Sum squared resid 759044.1 Schwarz criterion 11.54453 Log likelihood -868.0650 F-statistic 1657.947 Durbin-Watson stat 0.033761 Prob(F-statistic) 0.000000
2.- Modelo de tendencia senoidal cuadrático.- El modelo es:
donde w es el número de observaciones en un año.
Y t sent
w
t
wtsen
t
wt
t
wut t= + +
+
+
+
+α α α
πα
πα
πα
π0 1 2 3 4 5
2 2 2 2cos cos
Y t t sent
w
t
wtsen
t
w
tt
wt sen
t
wt
t
wu
t
t
= + + +
+
+
+
+
+
+
α α α απ
απ
απ
απ
απ
απ
0 1 22
3 4 5
6 72
82
2 2 2
2 2 2
cos
cos cos

En Eviews, primero hay que generar el ángulo, así:
GENR O = (2*3.14159*@TREND)/12 GENR O = (2*3.14159*@TREND)/4
y a continuación se escribe la instrucción siguiente: LS CP C @TREND @TREND^2 @SIN(O) @COS(O) @TREND*@SIN(O)
@TREND*@COS(O) @TREND^2*@SIN(O) @TREND^2*@COS(O)
Obteniendo:
Dependent Variable: CP Method: Least Squares Sample: 1950Q1 1988Q1 Included observations: 153
Variable Coefficient Std. Error t-Statistic Prob. C 696.2372 9.007112 77.29860 0.0000
@TREND 6.716405 0.273801 24.53023 0.0000 @TREND^2 0.034602 0.001744 19.84635 0.0000
@SIN(O) 0.011491 12.93618 0.000888 0.9993 @COS(O) -1.803156 12.52636 -0.143949 0.8857
@TREND*@SIN(O) 0.018841 0.393081 0.047933 0.9618 @TREND*@COS(O) 0.086830 0.380987 0.227907 0.8200 @TREND^2*@SIN(O) -0.000200 0.002504 -0.079986 0.9364 @TREND^2*@COS(O) -0.000709 0.002425 -0.292256 0.7705
R-squared 0.995339 Mean dependent var 1474.026
Adjusted R-squared 0.995080 S.D. dependent var 535.3530 S.E. of regression 37.55118 Akaike info criterion 10.14631 Sum squared resid 203053.1 Schwarz criterion 10.32457 Log likelihood -767.1926 F-statistic 3843.774 Durbin-Watson stat 0.104706 Prob(F-statistic) 0.000000
3º ALISADO.- Las técnicas de alisado exponencial se utilizan en situaciones en
las que existen pocos datos, y si es necesario ir actualizando el modelo empleado cada vez que se obtiene un nuevo dato. Son muy simples en su aplicación pero limitados.
Alisado exponencial simple:
Predicción: Válido para series sin tendencia. La predicción no aporta información
adicional.
( )
( )∑−
=−
−
−=
−+=1
0
1
1*ˆ
ˆ*1*ˆ
N
sst
st
ttt
YY
YYY
αα
αα
0ˆˆ >∀=+ kYY tkt

En el Eviews se sigue la instrucción siguiente:
Abrir el PBIA ⇒ Proc ⇒ Exponential Smoothing ⇒ Single ⇒ OK y se muestra el siguiente resultado:
Sample: 1992M01 1994M06 Included observations: 30 Method: Single Exponential Original Series: PBIA Forecast Series: PBIASM
Parameters: Alpha 0.9990
Sum of Squared Residuals 1345.407 Root Mean Squared Error 6.696782
End of Period Levels: Mean 69.42131
Alisado exponencial doble (Brown): Predicción: Válido para series con tendencia lineal. La predicción es una recta con
ordenada en el origen y pendiente . En el Eviews se sigue la instrucción siguiente:
Abrir el PBIA ⇒ Proc ⇒ Exponential Smoothing ⇒ Double ⇒ OK y se muestra el siguiente resultado:
Sample: 1992M01 1994M06 Included observations: 30 Method: Double Exponential Original Series: PBIA Forecast Series: PBIASM
Parameters: Alpha 0.8560
Sum of Squared Residuals 1320.795 Root Mean Squared Error 6.635247
End of Period Levels: Mean 69.53286 Trend 10.11279
( ) ( )( ) 1
1
11
ˆ*1ˆ*ˆ
ˆ*1*ˆ
−−+=
−+=
ttt
ttt
YYY
YYY
αα
αα
( ) ( )
( ) ( )
−−
+−=
=
−+−
−+=+
kYYYY
Yk
Yk
Y
tttt
ttkt
ˆˆ1
ˆˆ*2
ˆ*1
1ˆ*1
2ˆ
11
1
αα
αα
αα
tt YY ˆˆ*2 1 − ( ) ( )αα −− 1ˆˆ1tt YY

El Alisado exponencial lineal con doble parámetro (Holt-Winters) es:
Los valores iniciales pueden ser:
La predicción es:
Válido para series con tendencia lineal. La predicción es una recta con ordenada en el origen y pendiente .
En el Eviews se sigue la instrucción siguiente:
Abrir el PBIA ⇒ Proc ⇒ Exponential Smoothing ⇒ Holt-Winters-No
Seasonal ⇒ OK y se muestra el siguiente resultado:
Sample: 1992M01 1994M06 Included observations: 30 Method: Holt-Winters No Seasonal Original Series: PBIA Forecast Series: PBIASM
Parameters: Alpha 1.0000 Beta 0.8100
Sum of Squared Residuals 1002.241 Root Mean Squared Error 5.779969
End of Period Levels: Mean 69.43000 Trend 9.713274
4º FILTRADO DE SERIES.- los medios más utilizados para detectar y eliminar la tendencia de una serie se basan en la aplicación de filtros a los datos. Un filtro no es más que una función matemática que aplicada a los valores de la serie produce una nueva serie con unas características determinadas.
Según Baxter y King, un método óptimo de extracción de ciclos
económicos debe cumplir con 6 objetivos:
• El filtro debe extraer un rango específico de periodicidades, sin variar sus propiedades inherentes (la varianza, correlaciones y otras medidas exploratorias de los datos).
• No debe producir un movimiento de fase (es decir, que no altere las
( ) ( )( ) ( ) 11
11
*1ˆˆ*
ˆ*1*ˆ
−−
−−
−+−=
+−+=
tttt
tttt
bYYb
bYYY
ββ
αα
0;ˆ111 == bYY
( )12222 ;ˆ YYbYY −==
kbYY ttkt *ˆˆ +=+
1t̂Y tb

relaciones temporales de las series a ninguna frecuencia). Este aspecto y el anterior definen un promedio móvil ideal, con ponderaciones simétricas para rezagos y adelantos.
• El método debe ser una aproximación óptima de un filtro ideal. Esto se puede determinar midiendo la diferencia de los resultados obtenidos con un filtro ideal y uno aproximado.
• La aplicación de un filtro debe producir una serie de tiempo estacionaria cuando se aplica a cifras que presentan tendencia.
• El método debe ser independiente de la longitud de la serie. • El método debe ser operacional, esto es, de fácil aplicación y uso.
Los requisitos para el filtro ideal conllevan el establecer un equilibrio
entre el estimar un filtro óptimo, lo cual implica agregar la mayor cantidad de rezagos y adelantos como explicativos de una variable y el perder observaciones al inicio y al final del período, lo cual reduce la cantidad de datos para el análisis. Los autores recomiendan utilizar como mínimo 6 años cuando se trabaja con datos trimestrales y anuales.
En la actualidad existen dos filtros:
1.- HODRICK-PRESCOTT.- partiendo del supuesto de que la serie está
compuesta por un componente tendencial más un componente cíclico, se obtiene la nueva serie de componente tendencial que sea “lo mas suave posible” (penalizándose con el parámetro λ la volatilidad de la nueva serie) y que minimize las diferencias cuadráticas frente a la serie original. Tendríamos:
Los propios autores proponen unos valores de λ para cada tipo de series: Anual = 100, Trimestral =:1600 y Mensual =14400.
En términos matriciales podemos expresar el problema de
minimización como:
Donde:
Igualando a cero la primera derivada y despejando la serie 2tY
obtenemos:
)ˆ()ˆ()ˆ()'ˆ( 2222tttttt YAYAYYYYMin ′+−− λ
−
−−
−
=
2
23
22
21
2
ˆ
ˆ
ˆ
ˆ
*
12100000
00012100
00001210
00000121
ˆ
n
t
Y
Y
Y
Y
YA
M
L
MMMOMMMMM
L
L
L
112 )(ˆtt YAAIY −′+= λ
( ) ( ) ( )( )∑∑==
−+−−−+−=
N
t
N
ttt tttttt
YYYYYYMinYT2
22222
1
2212
11
ˆˆˆˆˆ/ˆ λ

Posee una serie de características ideales según los criterios de Baxter y King, por ejemplo: • Como el filtro es simétrico, no produce movimientos de fase. • Aproxima bien a un filtro ideal cuando se utiliza un 1600=λ para
datos trimestrales. • Produce series estacionarias, cuando éstas están integradas hasta el
orden cuarto. • El método es operacional.
Adolece de los problemas siguientes: • Las ponderaciones van a depender del tiempo, por lo que el filtro
dejará de ser independiente del largo de la serie. • Por construcción el filtro no perderá ningún dato al inicio o al final
de la serie. Sin embargo, las propiedades de la serie filtrada en puntos iniciales y finales es significativamente distinta de un filtro ideal, no así en los valores intermedios de la misma.
• Se relaciona con la elección un tanto arbitraria del parámetro λ . Para datos con periodicidad anual es una mala aproximación de un filtro ideal, por cuanto incluye comportamientos cíclicos que debería omitir y viceversa. Para datos anuales no existe consenso y la utilización del parámetro de suavización va desde λ = 10 hasta λ= 400.
En el Eviews se sigue la instrucción siguiente:
Abrir CP ⇒ Proc ⇒ Hodrick-Prescott Filter ⇒ OK y se muestra el siguiente resultado:
-80
-40
0
40
80
500
1000
1500
2000
2500
3000
1950 1955 1960 1965 1970 1975 1980 1985
CP Trend Cycle
Hodrick-Prescott Filter (lambda=1600)
2.- BAXTER-KING.- su objetivo es encontrar un método útil para medir
ciclos económicos y que éste sea óptimo, por ejemplo, que cumpla con las especificaciones sobre ciclos asignadas por el investigador.
Su procedimiento se resume en dos pasos: primero se mide el
ciclo, para lo cual el investigador debe especificar ciertas características del mismo y posteriormente se le aísla, aplicando promedios móviles a los datos.

Desarrolla 3 tipos de filtro lineal: “low-pass”, “high-pass” y “bandpass”.
Un filtro de tipo “low-pass” sólo retendrá los componentes que
se mueven lento en los datos, esto es, que se producen con frecuencias muy bajas. Entre menor sea la frecuencia mayor va a ser la cantidad de períodos que abarca un ciclo.
Un filtro de tipo “high-pass” equivale a una frecuencia
relativamente alta, por lo que se espera que incluya elementos más frecuentes de la serie, como los irregulares o estacionales.
El filtro band-pass son los períodos mínimo y máximo a incluir
en el ciclo, es un tipo de construcción de promedios móviles que aísla los componentes periódicos de una serie de tiempo económica que cae en una banda de frecuencias específica.
La cantidad de rezagos a incluir en el filtro es muy importante,
por cuanto estos definen la precisión de los ponderadores. Según Baxter y King, no existe un número ideal de rezagos, pero sí ocurre que entre más rezagos se incorporen en el promedio móvil, mejor será la aproximación con el filtro ideal, a costa de una mayor pérdida de datos por encima y por debajo del valor de interés, aspecto que cobra mayor importancia al final de la serie. Por ello, la elección de k dependerá en gran medida de la cantidad de datos disponibles y de lo necesario que sea aproximar el filtro al ideal.
Este filtro cumple con la mayoría de las características:
• es simétrico, por lo que no produce movimientos de fase. • aproxima relativamente bien un filtro ideal. • produce series estacionarias. • es un método operacional. • es superior a otros en la medida que permite introducir la definición
del investigador del ciclo económico y no produce variación en las propiedades de la variable al final de las series.
Habrá una pérdida de datos al inicio y al final de la serie igual a
dos veces la cantidad de rezagos que el investigador incluya. Se recomienda utilizar los siguientes valores de parámetros:
Series anuales upper =2 lower =8 nma =3 arpad =1 Series trimestrales upper =2 lower =32 nma =12 arpad =4 Series mensuales upper =2 lower =96 nma =12 arpad=12
Donde: Upper: número de períodos mínimos que se incluirán en el filtro,
correspondientes a frecuencias altas.
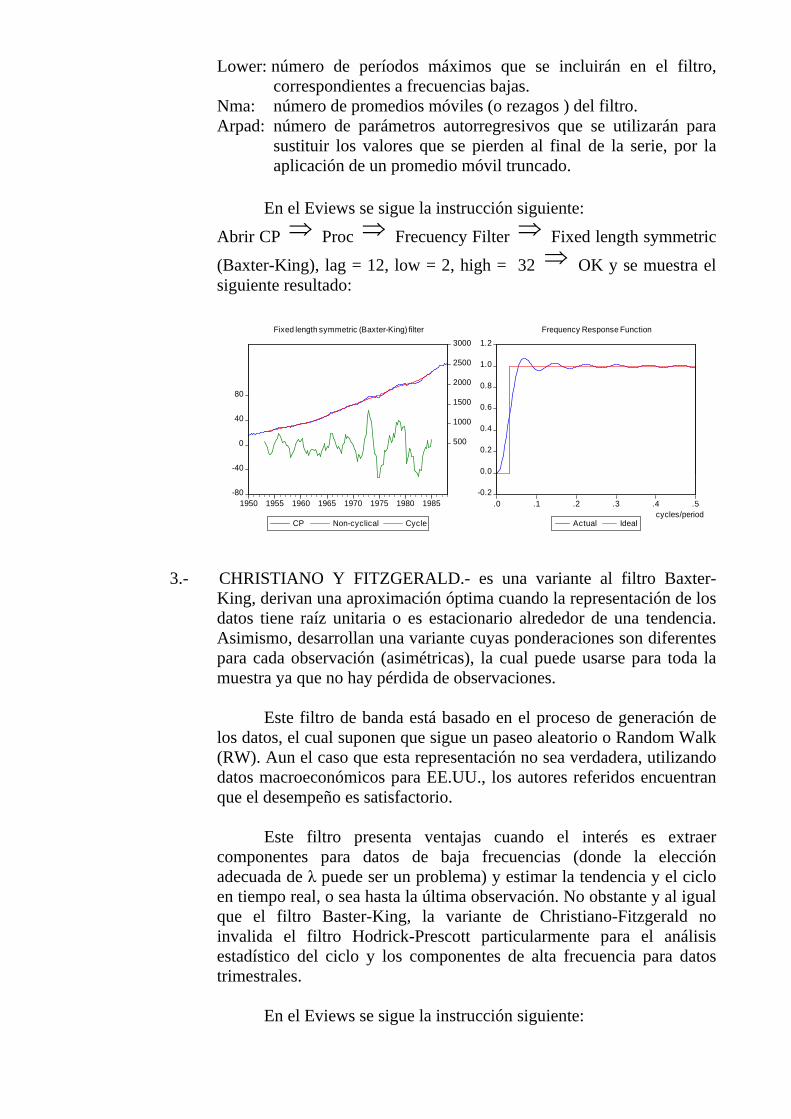
Lower: número de períodos máximos que se incluirán en el filtro, correspondientes a frecuencias bajas.
Nma: número de promedios móviles (o rezagos ) del filtro. Arpad: número de parámetros autorregresivos que se utilizarán para
sustituir los valores que se pierden al final de la serie, por la aplicación de un promedio móvil truncado.
En el Eviews se sigue la instrucción siguiente:
Abrir CP ⇒ Proc ⇒ Frecuency Filter ⇒ Fixed length symmetric
(Baxter-King), lag = 12, low = 2, high = 32 ⇒ OK y se muestra el siguiente resultado:
-80
-40
0
40
80
500
1000
1500
2000
2500
3000
1950 1955 1960 1965 1970 1975 1980 1985
CP Non-cyclical Cycle
Fixed length symmetric (Baxter-King) filter
-0.2
0.0
0.2
0.4
0.6
0.8
1.0
1.2
.0 .1 .2 .3 .4 .5
Actual Ideal
Frequency Response Function
cycles/period
3.- CHRISTIANO Y FITZGERALD.- es una variante al filtro Baxter-King, derivan una aproximación óptima cuando la representación de los datos tiene raíz unitaria o es estacionario alrededor de una tendencia. Asimismo, desarrollan una variante cuyas ponderaciones son diferentes para cada observación (asimétricas), la cual puede usarse para toda la muestra ya que no hay pérdida de observaciones.
Este filtro de banda está basado en el proceso de generación de
los datos, el cual suponen que sigue un paseo aleatorio o Random Walk (RW). Aun el caso que esta representación no sea verdadera, utilizando datos macroeconómicos para EE.UU., los autores referidos encuentran que el desempeño es satisfactorio.
Este filtro presenta ventajas cuando el interés es extraer
componentes para datos de baja frecuencias (donde la elección adecuada de λ puede ser un problema) y estimar la tendencia y el ciclo en tiempo real, o sea hasta la última observación. No obstante y al igual que el filtro Baster-King, la variante de Christiano-Fitzgerald no invalida el filtro Hodrick-Prescott particularmente para el análisis estadístico del ciclo y los componentes de alta frecuencia para datos trimestrales.
En el Eviews se sigue la instrucción siguiente:

Abrir CP ⇒ Proc ⇒ Frecuency Filter ⇒ Fixed length symmetric (Ghristiano-Fitzgerald), lag = 12, low = 2, high = 32, I(1)-random walk ⇒ OK y se muestra el siguiente resultado:
-80
-40
0
40
80
500
1000
1500
2000
2500
3000
1950 1955 1960 1965 1970 1975 1980 1985
CP Non-cyclical Cycle
Fixed length symmetric (Christiano-Fitzgerald) filter
0.0
0.2
0.4
0.6
0.8
1.0
1.2
.0 .1 .2 .3 .4 .5
Actual Ideal
Frequency Response Function
cycles/period
3.3. CICLO
Para extraer y predecir el componente cíclico se utiliza el ajuste de funciones periódicas.
Una función periódica es aquella que repite sus valores en el tiempo cada p
periodos y puede venir expresada como:
donde: A amplitud de la oscilación. P período. θ desfase. N número total de observaciones.
A efectos de ajustar y predecir series cíclicas podemos utilizar la expresión
alternativa:
0ω es lo que se denomina frecuencia básica y es igual a N/*2 π .
Paso 1: Identificar el número de máximos (mínimos) cíclicos p y construir las series:
Paso 2: Ajustar mediante regresión el modelo:
+= θπN
pAYt
2cos*
-1,5
-1
-0,5
0
0,5
1
1,5
1 8 15 22 29 36 43 50 57 64 71 78 85 92 99
A
T
-1,5
-1
-0,5
0
0,5
1
1,5
1 8 15 22 29 36 43 50 57 64 71 78 85 92 99
DESFASE = PI/2
)**(*)**cos(* 00 tpsentpYt ωβωα +=
)**/1416.3*2()**/1416.3*2cos( tpNsenSENPytpNCOSP tt ==
Paso 3: Calcular los errores (residuos) y si tienen comportamiento cíclico repetir el proceso añadiendo nuevos términos al modelo.
Para determinar el valor del periodo p, podríamos utilizar, como primera aproximación, el número de máximos (o mínimos) locales que presenta la serie a analizar.
4º ANÁLISIS EN EL DOMINIO DE FRECUENCIAS
Una función periódica se repite transcurrido T (período), por lo tanto presentará la máxima correlación con el retardo T y sus múltiplos enteros. Puede demostrarse que la autocorrelación de una función periódica es periódica, del mismo período que dicha función. Veamos los gráficos:
Para visualizar la periodicidad de una serie, tenemos:
1.- EL PERIODOGRAMA.- se asimila a un “sintonizador” de un receptor de radio, así, la serie que observamos sería la señal emitida por una radio y el periodograma no sería mas que el dial que busca en que frecuencia se “oye” mejor la señal emitida.
“Modelo” que sigue la serie observada: Asumimos que las frecuencias, iω , denominadas Frecuencias de
Fourier son:
Los parámetros, a y b, se pueden estimar por MCO o bien, de forma
directa como:
N
pii
πω 2=
ttt SENPCOSPY ** 21 ββ +=
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
-40 -20 0 20 40
FUNCION DE AUTOCORRELACION
∑=
++=k
itiiipt tbtaY
1
)sencos( εωω
kpi ,...,1=( )
−=imparesNsiN
paresNsiNk
212
∑=
=N
t
t
N
Ya
10ˆ∑
=
=N
totp tpY
Na
1
cos2
ˆ ω ∑=
=N
totp tpY
Nb
1
sen2ˆ ω
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
20 40 60 80 100 120 140 160 180 200
COS(2*PI*@TREND/(200/10))

Se calcula el periodograma I(w): El periodograma mide aportaciones a la varianza total de la serie de
componentes periódicos de una frecuencia determinada (w). Si el periodograma presenta un “pico” en una frecuencia, indica que dicha frecuencia tiene mayor “importancia” en la serie que el resto.
De izquierda. a derecha. aumenta la frecuencia (disminuye el período):
El periodograma está basado en una herramienta matemática denominada Transformada de Fourier, según la cual una serie, que cumpla determinados requisitos, puede descomponerse como suma de un número finito o infinito de frecuencias. Del mismo modo, a partir de la representación frecuencial puede recuperarse la serie original a través de la Transformada Inversa de Fourier.
Las series periódicas presenta un periodograma discreto, es decir, solo
existe "masa" espectral en aquellas frecuencias contenidas en la serie, siendo éstas un número discreto.
0
22
2
)()(
ωω pp
p
baI
+=
-1.0
-0.8
-0.6
-0.4
-0.2
0.0
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
20 40 60 80 100 120 140 160 180 200
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
20 40 60 80 100 120 140 160 180 200
Tendencia Ciclo – Estacionalidad (Ciclo anual) Irregular
0
1
2
3
4
0 50 100 150

Las series aperiódicas presentan un periodograma continúo, es decir,
existe "masa" en un "infinito" número de frecuencias.
Las series estocásticas presentan densidad espectral en un rango
continúo de frecuencias.
2.- EL ESPECTRO.- o densidad espectral se define para procesos estocásticos estacionarios como la transformada de Fourier de la función de autocovarianza (teorema de Wiener-Khintchine). Su estimador “natural” es el periodograma, antes visto. Como hemos comprobado es un instrumento adecuado para la detección de procesos periódicos puros, sin embargo en el caso de procesos estocásticos presenta serias limitaciones, las más importantes son la inconsistencia y la correlación asintóticamente nula entre ordenadas del periodograma. Esto implica que no converja al verdadero “espectro” cuando la muestra se amplia y que el periodograma muestre un comportamiento errático.
Los métodos paramétricos, parten de suponer “conocido” el PGD, y
modelizado en general a través de un proceso ARMA, a partir del cual se puede recuperar una estimación del espectro.
Si la serie observada responde a un modelo ARMA (p,q):
El espectro equivale a:
qtqtttptpttt bbbYaYaYaY −−−−−− ++++=++++ εεεε ...... 22112211
-3
-2
-1
0
1
2
3
20 40 60 80 100 120 140 160 180 200
0
20
40
60
80
100
20 40 60 80 100 120 140 160 180 200
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
20 40 60 80 100 120 140 160 180 200
0
5
10
15
20
0 50 100 150
FREC
PE
RD
G
0
2000
4000
6000
8000
10000
12000
0 50 100 150
FREC
PE
RD
G
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
0 50 100 150
FREC
PERDG

5º PROCESO ESTOCÁSTICO Siempre que estudiamos el comportamiento de una variable aleatoria a lo largo del tiempo, estamos ante un proceso estocástico. En general, trabajamos con procesos estocásticos en cualquier caso en que intentamos ajustar un modelo teórico que nos permita hacer predicciones del comportamiento futuro de un proceso. Si podemos encontrar patrones de regularidad en diferentes secciones de una serie temporal, podremos también describirlas mediante modelos basados en distribuciones de probabilidad. Tenemos las definiciones siguientes: 1.- La secuencia ordenada de variables aleatorias X(t) y su distribución de
probabilidad asociada. 2.- Es el modelo matemático para una serie temporal. 3.- Es una colección {Yt; t = 1, 2, ……, T} de variables aleatorias ordenadas en
el tiempo. {Yt; t ∈ T} es un proceso continuo si −∞ < t < ∞. Si T is finito, {Y t} es un proceso discreto.
Cualquier serie de tiempo puede ser generada por un proceso estocástico o aleatorio; y un conjunto concreto de información, puede ser considerado como una realización (particular) del proceso estocástico subyacente. La distinción entre un proceso estocástico y su realización es semejante o la distinción entre la información de corte transversal poblacional y muestral.
PROCESO ESTOCÁSTICO ESTACIONARIO
Un Proceso Estocástico Discreto (PED) es una sucesión de variables aleatorias { }ty , donde t= -4, ..., -2, -1, 0, 1, 2, ... 4. Dos ejemplos de PED podrían ser: El ruido blanco y el camino aleatorio.
Consideremos el PED {y-4, ...y1,...yT,...,y4} y centrémonos en dos de sus miembros: yt y yt-k. Este PED se denomina “estacionario” de un tipo particular si determinadas propiedades estocásticas de yt y yt-k no dependen de t y t-k (su ubicación absoluta en la secuencia) pero dependen sólo de k (su separación relativa en la secuencia). Se tiene los tipos de estacionariedad siguiente:
1.- Estricta: Se verifica si las distribuciones de yt y yt-k (conjunta y marginal) no
dependen de t pero sólo de k.
πσω ε
ωωω
ωωω
2...1
...1)(
2
2221
2221
ipp
ii
iqq
ii
Y
eaeaea
ebebebh
−−−
−−−
++++
++++= πωπ ≤≤−

Un proceso estocástico es estacionario en sentido estricto cuando su función de distribución conjunta es invariante respecto a un desplazamiento en el tiempo.
Considerando que t1; t2; .... ; tk corresponden a periodos sucesivos de tiempo que denominamos como t; t + 1;.. ; t + k, entonces:
);...;;();...;;( 1mt1t mktmtktt yyyfyyyf +++++++ =
2.-Débil: Se verifica cuando los dos primeros momentos de yt y yt-k dependen
posiblemente de k pero no de t, i.e. E(yt) = E(yt-k) y Var(yt) = Var(yt-k) y Cov(ytyt-k) depende posiblemente de k pero no de t.
[ ]( )
( ) ( )( ) ( )1 2 1 2
2
1 2,
t Y
t Y
t t t Y t Y
E Y
Var Y
COV Y Y E Y Y t t
µ
σ
µ µ λ
=
=
= − − = −
En el caso que las series sean estacionarias en el sentido débil, se podrán modelar a través de un conjunto de especificaciones conocidas como los modelos AR, MA y ARMA. El objetivo de los mismos es explicar el componente cíclico de la serie (o su componente estacionario) a través de su pasado por medio de diferentes tipos de relaciones.
Una serie de tiempo es estacionaria si su distribución es constante a lo largo
del tiempo; para muchas aplicaciones prácticas es suficiente considerar la llamada estacionariedad débil, esto es, cuando la media y la varianza de la serie son constantes a lo largo del tiempo. Muchas de las series de tiempo que se analizan en Econometría no cumplen con esta condición, cuando tienen una tendencia.
5º PRUEBA DE ESTACIONARIEDAD
Existen varias pruebas para verificar estacionariedad y se clasifican en los
tipos siguiente:
5.1. MÉTODO DE BOX - JENKINS
El procedimiento para verificar estacionariedad de la serie es:
1º El examen visual de la trayectoria de la serie a lo largo del tiempo puede dar una idea de si es o no estacionaria en media. Si existe algún valor en torno al cual la serie va oscilando pero sin alejarse de forma permanente de dicho valor, entonces se puede considerar que la serie es estacionaria en media.
2 º Si los coeficientes de AC no decaen rápidamente sería un indicio claro de que
la serie es no estacionaria.
3º El primer coeficiente de PAC es significativo (es decir, mayor o igual a 0.9)

entonces la serie es no estacionaria.
Si la serie es no estacionaria, la serie debería someterse a la primera diferencia, y se volvería a analizar siguiendo los pasos anteriores. De esta forma se continuaría hasta obtener una serie diferenciada de orden d. En la práctica, es suficiente con tomar d = 1 o d = 2 para obtener una serie estacionaria en media.
EJEMPLO
1º Si observamos el ploteo del consumo personal agregado real se visualiza que
no oscila alrededor de su media, por lo tanto es no estacionaria.
400
800
1200
1600
2000
2400
2800
1950 1955 1960 1965 1970 1975 1980 1985
CP @MEAN(CP,"1950q1 1988q1")
2º Según el correlograma del consumo personal agregado real cae lentamente,
por lo tanto no es estacionaria.
Abrir la serie ⇒ View ⇒ Correlogram... ⇒ se marca nivel y se escribe
12 lag ⇒ OK y se muestra el siguiente resultado:
Sample: 1950Q1 1988Q1 Included observations: 153
Autocorrelation Partial Correlation AC PAC Q-Stat Prob .|*******| .|*******| 1 0.955 0.955 142.33 0.000
.|*******| .|. | 2 0.911 -0.014 272.69 0.000 .|*******| .|. | 3 0.868 -0.014 391.73 0.000 .|****** | .|. | 4 0.825 -0.012 500.15 0.000 .|****** | .|. | 5 0.786 0.008 599.06 0.000 .|****** | .|. | 6 0.747 -0.010 689.07 0.000 .|***** | .|. | 7 0.711 0.006 771.12 0.000 .|***** | .|. | 8 0.677 0.008 846.07 0.000 .|***** | .|. | 9 0.645 0.008 914.68 0.000 .|***** | .|. | 10 0.616 0.011 977.69 0.000 .|**** | .|. | 11 0.590 0.012 1035.8 0.000 .|**** | .|. | 12 0.565 0.010 1089.5 0.000
3º Examinando el primer coeficiente de autocorrelación parcial del consumo

personal agregado real es significativo (0.955 > 0.9), entonces el ingreso personal disponible no es estacionario.
Como el consumo personal agregado real no es estacionario, tenemos que
examinar la primera diferencia de la serie y repetir el procedimiento de Box-Jenkins.
1º Si observamos el ploteo de la primera diferencia del consumo personal agregado real se visualiza que oscila alrededor de su media, por lo tanto es estacionaria.
-60
-40
-20
0
20
40
60
1950 1955 1960 1965 1970 1975 1980 1985
D(CP) @MEAN(D(CP),"1950q1 1988q1")
2º Obtenemos el correlograma de la primera diferencia del consumo personal
agregado real se obtiene siguiendo la instrucción siguiente:
Abrir la serie ⇒ View ⇒ Correlogram... ⇒ se marca 1st difference y
se escribe 12 lag ⇒ OK y se muestra el siguiente resultado:
Sample: 1950Q1 1988Q1 Included observations: 152
Autocorrelation Partial Correlation AC PAC Q-Stat Prob .|** | .|** | 1 0.204 0.204 6.4803 0.011
.|** | .|* | 2 0.223 0.189 14.251 0.001 .|** | .|* | 3 0.217 0.153 21.681 0.000 .|* | .|* | 4 0.165 0.075 26.010 0.000 .|. | *|. | 5 0.021 -0.089 26.082 0.000 .|* | .|. | 6 0.077 0.013 27.021 0.000 .|. | .|. | 7 0.049 0.010 27.408 0.000 *|. | **|. | 8 -0.151 -0.193 31.104 0.000 .|. | .|. | 9 0.018 0.058 31.156 0.000 .|. | .|. | 10 -0.011 0.023 31.176 0.001 .|. | .|. | 11 -0.023 0.021 31.267 0.001 *|. | .|. | 12 -0.072 -0.046 32.134 0.001
De la observación del gráfico podemos deducir que la primera diferencia del consumo personal agregado real es estacionaria.
3º Examinando el primer coeficiente de autocorrelación parcial de la primera

diferencia del consumo personal agregado real no es significativo (0.204 < 0.9), entonces la primera diferencia del consumo personal agregado real es estacionaria.
Por lo tanto, la primera diferencia del consumo personal agregado real es
estacionaria.
5.2. PRUEBA DE RAÍZ UNITARIA
Las series de tiempo no estacionarias que presentan raíces unitarias son un caso muy especial de las series no estacionarias, tanto por su frecuencia en economía como por lo que se conoce de sus propiedades estadísticas; en los últimos años se ha realizado una gran cantidad de trabajos para el diseño de pruebas de hipótesis de que una serie tiene raíces unitarias.
Consideremos el siguiente modelo:
donde u es el término de error estocástico que sigue los supuestos clásicos, a saber:
tiene media cero, varianza constante (σ2) y no está autocorrelacionada; es decir, el
término de error es ruido blanco.
Si el coeficiente de Yt −1 es en realidad igual a 1, surge lo que se conoce como
el problema de raíz unitaria, o sea, una situación de no estacionariedad. En econometría, una serie de tiempo que tiene una raíz unitaria se conoce como un camino aleatorio. Por lo tanto, se estima la regresión:
y se encuentra que ρ = 1
, entonces se dice que la variable estocástica Yt tiene una
raíz unitaria.
5.2.1. DICKEY FULLER NORMAL De modo que podemos contrastar la hipótesis de no estacionareidad probando
la hipótesis nula ρ = 1 contra la alternativa |ρ| < 1 o simplemente ρ < 1.
Si restamos Yt −1 en ambos miembros de la ecuación ( 2 ), resulta:
sacando factor común y definiendo
∆∆
Y Y u
Y Y ut t t
t t t
= − += +
−
−
( )ρδ
1 1
1
Y Y ut t t= +−1 ( 1 )
Y Y ut t t= +−ρ 1 ( 2 )
Y Y Y Y ut t t t t− = − +− − −1 1 1ρ

Entonces, tendríamos la siguiente implicación con la prueba de hipótesis: H0 : ρ = 1 ⇒ H0 : δ = 0 H0 : ρ < 1 ⇒ H0 : δ < 0
Cuando las series en una regresión no son estacionarias, el uso del estadístico t
para contrastar hipótesis δ = 0 es inadecuado pues este no sigue la distribución t Student. Esta tabla es limitada, pero Mac Kinnon preparó tablas más extensas, que están incorporadas en el Eviews.
Además de probar si una serie es una caminata aleatoria, Dickey y Fuller
desarrollaron también valores críticos para la presencia de una caminata aleatoria con desplazamiento y con tendencia determinística, es decir bajo tres distintas hipótesis nulas:
ttt
ttt
ttt
tYY
YY
YY
εαδαεδα
εδ
+++=∆++=∆
+=∆
−
−
−
210
10
1
Series como tY , las cuales se convierten en estacionarias después de tomar la
primera diferencia, se conocen como integradas de orden 1 y se designa como I(1). Las series estacionarias son series integradas de orden 0, I(0).
En general, si una serie debe ser diferenciada d veces para alcanzar
estacionaridad se dice que es integrada de orden d o I(d).
5.2.2. DICKEY FULLER AUMENTADO Al realizar la prueba de DF se supuso que el término de error ε t no estaba
correlacionado.
Dickey y Fuller, Said y Dickey (1984), Phillips y Perron (1988) y otros,
desarrollaron modificaciones de las pruebas de Dickey y Fuller cuando ε t , no es ruido blanco. Se conocen con el nombre de pruebas “aumentadas” de Dickey y Fuller.
No todos los procesos de series de tiempo pueden ser representadas por un
proceso autoregresivo de primer orden. Considerando un proceso autoregresivo de orden p, como:
y y y yt t t p t p t= + + + + +− − −α α α α ξ0 1 1 2 2 ....
adicionando y sustrayendo el término α p t py − +1 , nos resulta:
∆ ∆y y yt t i t ii
p
t= + + +− − +=∑α δ β ξ0 1 1
2

donde,
−−= ∑
=
p
ii
1
1 αδ y ∑=
=p
ijji αβ .
Donde ξt es un término de error puro con ruido blanco. El número de términos de
diferencia rezagados que se debe incluir, con frecuencia se determina de manera empírica, siendo la idea incluir los términos suficientes para que el término de error no esté serialmente relacionado. Considerando las tres posibilidades tenemos:
∆ ∆
∆ ∆
∆ ∆
y y y
y y y
y y y t
t t i t ii
p
t
t t i t ii
p
t
t t i t ii
p
t
= + +
= + + +
= + + + +
− − +=
− − +=
− − +=
∑
∑
∑
δ β ξ
α δ β ξ
α δ β α ξ
1 12
0 1 12
0 1 12
2
En la DFA se sigue probando δ = 0 y además esta prueba sigue la misma
distribución asintótica que el estadístico DF, por lo que se puede utilizar los mismos valores críticos.
Para elegir p se tiene los siguientes criterios: 1) Incluir retardos de tY hasta que el error sea ruido blanco. 2) Incluir retardos de tY significativos. 3) Utilizar AIC, SBC, etc. (“information criteria”), para elegir p.
Sin embargo, la prueba de Dickey-Fuller es frágil siempre hay que utilizar
información adicional (inspección visual de la serie, sentido común, historia, teoría) antes de aceptar o rechazar lo que sugiere la prueba de Dickey-Fuller
Si hay variables innecesarias en la regresión, es más difícil rechazar la hipótesis nula (existencia de raíz unitaria) cuando en realidad es 0<δ . Por consiguiente, existen tres pruebas:
1) Sin la constante y sin el término de tendencia. 2) Con la constante pero sin el término de tendencia. 3) Con la constante y el término de tendencia.
5.2.3. PRUEBA DE PHILLIPS - PERRON
Phillips y Perron (1988) proponen una alternativa (no paramétrico) método de control de la correlación serial cuando se realiza la prueba de raíz unitaria. Al igual
que la prueba ADF, la prueba PP es una prueba de hipótesis sobre ρ = 1 en la

ecuación:
∆Y Y tt t t= + + +−α δ β ε1 y modifica el t del coeficiente δ de modo que la correlación serial no afecta la distribución asintótica de la prueba estadística. La prueba PP se basa en la estadística:
( ) ( )( )sf
sefT
ftt
21
0
002
1
0
0
2
ˆˆ~ δγγδδ
−−
=
donde ( )δ̂se es el error estándar de coeficiente δ , s es el error estándar de la regresión de la prueba, 0γ es una estimación consistente de la varianza del error
(calculado como ( ) TskT /2− , donde k es el número de regresores) y 0f es un estimador del espectro residual en la frecuencia cero. Hay dos opciones que usted tendrá que hacer para realizar la prueba PP. En primer lugar, debe decidir si incluir una constante, una constante y una tendencia en el tiempo lineal, o ninguno, en la regresión de la prueba. En segundo lugar, usted tendrá que elegir un método para estimar 0f . Eviews apoya estimadores para 0f basados en el núcleo basado en suma-de-covarianzas, o sobre estimación de la densidad espectral autorregresivos. La distribución asintótica de la relación de PP es la misma que la de la estadística de ADF. La hipótesis nula del test de Phillips-Perron es la trayectoria de raíz unitaria con tendencia y la alternativa la estacionariedad con tendencia, si el valor t-Student
asociado al coeficiente de Yt−1es mayor en valor absoluto al valor crítico de
MacKinnon, se rechaza la hipótesis de existencia de raíz. La distribución asintótica de la prueba PP es la misma que la prueba DFA.
5.2.4. PRUEBA DE DICKEY – FULLER CON ELIMINACION D E LA TENDENCIA (DFGLS)
En los test anteriores, se puede optar por incluir una constante, o una constante y una tendencia en el tiempo lineal, en la prueba de regresión ADF. Para estos dos casos, el ERS (1996) proponen una simple modificación de las pruebas de ADF en el que los datos son sin tendencias a fin de que las variables explicativas son "sacadas" de los datos antes de ejecutar la prueba de regresión. ERS define una cuasi-diferencia de tY que depende del valor que representa la alternativa punto concreto contra el que deseamos probar la hipótesis nula:
( )
>−=
=− 1
1
1 tifaYY
tifYaYD
tt
tt
Se considera una regresión de MCO de la cuasi-diferenciada de datos ( )aYD t
sobre la cuasi-diferenciados ( )aXD t , es decir:

( ) ( ) ( ) ttt aaXDaYD εδ +′=
que tX contiene ya sea una constante, o una constante y la tendencia, y ( )aδ̂ son las estimaciones de MCO de esta regresión. Todo lo que necesitamos ahora es un valor para a . ERS recomienda el uso de
aa = , cuando:
{ }{ }
=−
=−=
tXifT
XifTat
t
,15.131
171
Definimos ahora el GLS sin tendencia de datos d
tY , utilizando las estimaciones relacionadas con a :
( )aXYY ttd
t δ̂′−= Entonces la prueba DFGLS consiste en calcular la ecuación siguiente:
td
ptpd
td
td
t YYYY υββα +∆++∆+=∆ −−− .....111
Si bien el DFGLS que es el ratio t sigue una distribución de Dickey-Fuller, en el caso de única constante, la distribución asintótica es diferente cuando se incluyen tanto una constante y tendencia. ERS simula los valores críticos de la estadística de prueba en este escenario para { }∞= ,200,100,50T . La hipótesis nula es rechazada por los valores que caen por debajo de estos valores críticos.
5.2.5. PRUEBA DE KWIATKOWSKI, PHILLIPS, SCHMIDT, Y SHIN (KPSS)
La prueba KPSS (1992) difiere de las otras pruebas de raíz unitaria, en que la
serie se supone que es estacionaria bajo la hipótesis nula. La estadística KPSS se basa en el los residuos de la regresión de MCO de tY en las variables exógenas tX :
ttt uXY +′= δ
El estadístico LM es definido como:
( ) ( )∑=
=T
t
fTtSLM1
022 /
donde 0f , es un estimador del espectro residual en la frecuencia cero y en caso de ( )tS es una función residual acumulativa:
( ) ∑=
=t
rrutS
1
ˆ
sobre la base de los residuos ( )0ˆˆ δttt XYu ′−= . Se señala que el estimador de δ
utilizado en este cálculo difiere del estimador δ utilizado para GLS con eliminación de la tendencia, ya que se basa en una regresión con los datos originales y no en la cuasi-datos diferenciados.
Para especificar la prueba KPSS, debe especificar el conjunto de regresores exógenos tX y un método para la estimación de 0f . Los valores reportados crítico

para la estadística de prueba LM se basan en los resultados presentados en KPSS asintótica.
5.2.6. PRUEBA DE ELLIOT, ROTHENBERG, AND STOCK POINT OPTIMAL
(ERS)
El estudio del punto óptimo de ERS se basa en la cuasi-regresión de
diferenciación que se define:
( ) ( ) ( ) ttt aaXDaYD εδ +′=
Definir los residuos de la ecuación como ( ) ( ) ( ) ( )aaXDaYDa ttt δε ˆˆ ′−= , y dejar
que ( ) ( )∑=
=T
tt aaSSR
1
2ε̂ sea la suma de los residuos al cuadrado. El ERS (posible) el
punto óptimo de la estadística de prueba de la hipótesis nula que 1=a frente a la alternativa que aa = , es definido como:
( ) ( )( )0
1f
SSRaaSSRPT−=
donde 0f , es un estimador del espectro residual en la frecuencia cero.
Para calcular la prueba de ERS, debe especificar el conjunto de regresores exógenos tX y un método para estimar 0f . Los valores críticos para la estadística de prueba ERS se calculan por interpolación de los resultados de la simulación prevista por el ERS para { }∞= ,200,100,50T .
5.2.7. PRUEBA DE NG Y PERRON (NP)
Ng y Perron (2001) construye cuatro pruebas estadísticas que se basan en los datos del GLS sin tendencia d
tY . Estas pruebas estadísticas modifican las formas del estadístico Phillips y Perron aZ y tZ , el estadístico Bhargava (1986) 1R y el estadístico ERS punto óptimo. En primer lugar, definimos el término:
( )∑=
−=T
t
dt TY
2
22
1 /κ
Las estadísticas modificadas puede escribirse como:
( )( ) ( )
( )( )( ) { }
( ) ( )( ) { }
=−+=−=
=
×=
−=
−
−
−
tXiffYTcc
XiffYTccMP
fMSB
MSBMZMZ
fYTMZ
td
T
td
TdT
adt
dT
da
,1/1
1/
/
2/
0
2120
212
21
0
0
21
κκ
κ
κ
donde: { }
{ }
=−=−
=tXif
Xifc
t
t
,15.13
17

Las pruebas NP requieren una especificación para tX y la elección de un método para la estimación de 0f .
5.2.8. CRÍTICAS DE LAS PRUEBAS DE RAÍZ UNITARIA
Existen varias pruebas de raíz unitaria porque difieren en el tamaño y potencia
de dichas pruebas. Por tamaño de la prueba se quiere entender el nivel de significancia (es decir,
la probabilidad de cometer error de tipo I) y por potencia de una prueba se entiende la probabilidad de rechazar la hipótesis nula cuando es falsa.
La potencia de una prueba se calcula restando la probabilidad de un error de
tipo II de uno. La mayoría de las pruebas del tipo DF tienen poco poder; es decir, tienden
aceptar la nulidad de la raíz unitaria con más frecuencia de la que se garantiza. En otras palabras, estas pruebas pudieran encontrar una raíz unitaria, aunque ésta no exista.
Perron (1989) sostuvo que los tradicionales test de raíz unitaria (Dickey-
Fuller, Dickey-Fuller Aumentado y Phillips-Perron) tenían poco poder para diferenciar una trayectoria de raíz unitaria de una estacionaria cuando había cambio estructural. En consecuencia, como estos test estaban sesgados hacia el no rechazo de la hipótesis nula de raíz unitaria, a menudo se rechazaba incorrectamente la hipótesis alternativa de estacionariedad. Perron encontró, por ejemplo, que las series de agregados macroeconómicos y financieros utilizados por Nelson y Plosser (1982) eran en su mayoría estacionarias con cambio estructural, en oposición a lo que los citados autores señalaban.
5.2.9. EJERCICIO
Considerando el consumo personal agregado real y observando su ploteo con
la media, deducimos que tiene tendencia e intercepto, además consideramos cuatro rezagos y el criterio Schwarz para elegir el retardo óptimo.
Se obtiene los resultados siguientes:
¿Existe Raíz Unitaria? Nivel de significancia Tipo de Test
Estadístico t
Valor crítico 1 % / 5 %
1 % 5 % NIVELES
Hipótesis Nula: Existe raíz unitaria (no estacionaria) Dickey-Fuller Aumentado (ADF) -1.117406 -4.019561 / -3.439658 SI SI Elliott-Rothenberg-Stock (DF-GLS) -0.809523 -3.520000 / -2.980000 SI SI Phillips-Perron (PP) -1.451289 -4.019561 / -3.439658 SI SI Elliott-Rothenberg-Stock punto óptimo. 94.95858 4.148700 / 5.650600 NO NO
Hipótesis Nula: No existe raíz unitaria (estacionaria) Kwiatkowski-Phillips-Schmidt-Shin 0.289358 0.216000 / 0.146000 SI SI

Por lo tanto, el consumo personal agregado real es no estacionaria, es decir, tiene raíz unitaria. Ahora debemos seguir el mismo procedimiento con la primera diferencia.
Observando el ploteo de la primera diferencia del consumo personal agregado
real con su media, concluimos que no tiene tendencia y si tiene intercepto (t=11.78070 > 2), además consideramos cuatro rezagos y el criterio Schwarz para elegir el retardo óptimo.
Obtenemos los siguientes resultados:
¿Existe Raíz Unitaria? Nivel de significancia Tipo de Test
Estadístico t
Valor crítico 1 % / 5 %
1 % 5 % PRIMERA DIFERENCIA
Hipótesis Nula: Existe raíz unitaria (no estacionaria) Dickey-Fuller Aumentado (ADF) -4.625715 -3.474567 / -2.880853 NO NO Elliott-Rothenberg-Stock (DF-GLS) -4.546566 -2.580574 / -1.942982 NO NO Phillips-Perron (PP) -10.75407 -3.473967 / -2.880591 NO NO Elliott-Rothenberg-Stock punto óptimo. 0.935116 1.929200 / 3.141200 SI SI
Hipótesis Nula: No existe raíz unitaria (estacionaria) Kwiatkowski-Phillips-Schmidt-Shin 0.496796 0.739000 / 0.463000 NO NO
Por lo tanto, la primera diferencia del consumo personal agregado real es
estacionaria, es decir, el consumo personal agregado real es integrado de orden uno.
6º CAMBIO ESTRUCTURAL
Nos interesa evaluar la presencia de un cambio en alguno de los elementos determinísticos que caracterizan a la serie: el intercepto, y/o la tendencia. Es decir, tenemos los modelos siguientes:
tttt
ttt
ttt
utDtDY
utDtY
uDY
++++=+++=
++=
3210.
210
10
ααααααα
αα
Zivot y Andrews (1992) elaboraron un test en la que la fecha del punto de quiebre era determinada endógenamente. Con esta finalidad se desarrollo un programa preparado para E-Views , correspondiente al test de Z&A, realizado de manera secuencial, esto último se refiere a que el programa evalúa la posible presencia de quiebre estructural en cada observación de la serie analizada (genera variables Dummy a partir de la 75ava observación y termina en la observación N-75). Zivot & Andrews elaboraron un test en el que se diferencia una trayectoria de raíz unitaria de una estacionaria cuando había cambio estructural, debido a que los tradicionales test ADF y PP estaban sesgados hacia el no rechazo de la hipótesis nula de raíz unitaria, puesto que a menudo se rechazaba incorrectamente la hipótesis alternativa de estacionariedad. La hipótesis nula es la presencia de raíz unitaria con tendencia y la alternativa, la de estacionariedad con tendencia y cambio estructural (en el nivel y/o pendiente).

Zivot y Andrews presentan un gráfico F con tres líneas: La línea roja (FT) muestra el resultado del test F aplicado secuencialmente, para posibles quiebres en tendencia, la línea verde (FM), muestra el mismo test, pero para posibles quiebres en media, la línea azul (F) es el test F, para ambos casos; se observa la línea que alcanza valores más altos, por lo que podemos concluir que existe evidencia de un POSIBLE quiebre (en tendencia, media o ambos), o dicho de otra forma, si existe quiebre en la serie (y no raíz unitaria), este sería quiebre (en tendencia, media o ambos) y estaría alrededor de tal observación.
Asimismo, se presentan tres gráficos en la que se plotean por un lado, la trayecoria de la distribución t o t’s de Zivot, y por el otro los valores de la distribución t crítico; si el valor t-Zivot cruza los valores críticos (VCRIT), existe suficiente evidencia estadística para rechazar la hipótesis nula de raíz unitaria, por lo que la(s) serie(s) evaluadas muestra una trayectoria de raíz unitaria. Contrariamente, si la distribución de valores t Zivot no cruza el t crítico, no existe evidencia para rechazar la hipótesis nula de raíz unitaria (no estacionariedad).
6.1. EJERCICIO Considerando el consumo personal agregado real y aplicando el programa de
Zivot y Andrews, nos da el resultado siguiente:
4000
6000
8000
10000
12000
14000
16000
18000
25 50 75 100 125 150
F FT FM
GRÁFICO N° 01
-5
-4
-3
-2
-1
30 40 50 60 70 80 90 100 110 120 130
ZIVOTM VCRITM
GRÁFICO N° 02
-4.5
-4.0
-3.5
-3.0
-2.5
-2.0
-1.5
30 40 50 60 70 80 90 100 110 120 130
ZIVOTT VCRITT
GRÁFICO N° 03
-5.2
-4.8
-4.4
-4.0
-3.6
-3.2
-2.8
-2.4
-2.0
30 40 50 60 70 80 90 100 110 120 130
ZIVOT VCRIT
GRÁFICO N° 04
Como se aprecia en el gráfico N° 01, existe un posible quiebre estructural en tendencia y en los otros tres gráficos, los valores t Zivot no cruzan el t crítico, no existe evidencia para rechazar la hipótesis nula de raíz unitaria (no estacionariedad).