robótica inteligente
DESCRIPTION
Robótica Inteligente. L. Enrique Sucar Marco López ITESM Cuernavaca. Manejo de Incertidumbre. Introducción Repaso de probabilidad Clasificador bayesiano simple Redes bayesianos. Incertidumbre. La incertidumbre surge porque se tiene un conocimiento incompleto / incorrecto del - PowerPoint PPT PresentationTRANSCRIPT

Robótica Inteligente
L. Enrique SucarMarco López
ITESM Cuernavaca

Manejo de Incertidumbre
• Introducción
• Repaso de probabilidad
• Clasificador bayesiano simple
• Redes bayesianos

Incertidumbre
La incertidumbre surge porque se tiene un
conocimiento incompleto / incorrecto del
mundo o por limitaciones en la forma de
representar dicho conocimiento, por ejemplo:• Un sistema experto médico • Un robot móvil• Un sistema de análisis financiero• Un sistema de reconocimiento de voz o imágenes

Incertidumbre
• Un robot móvil tiene incertidumbre respecto a lo que obtiene de sus sensores y del resultado de sus acciones, así como de su conocimiento del mundo

Existen varias causas de incertidumbre que tienen que ver con la información, el conocimiento y la representación.
Existen varias causas de incertidumbre que tienen que ver con la información, el conocimiento y la representación.
Causas de Incertidumbre Causas de Incertidumbre

• Incompleta • Poco confiable • Ruido, distorsión
• Incompleta • Poco confiable • Ruido, distorsión
Información Información

• Impreciso • Contradictorio • Impreciso • Contradictorio
Conocimiento Conocimiento

• No adecuada • Falta de poder descriptivo • No adecuada • Falta de poder descriptivo
RepresentaciónRepresentación

Manejo de Incertidumbre
• Para tratar la incertidumbre, hay que considerarla en forma explícita en la representación e inferencia
• Para ello se han desarrollado diversas formas de representar y manejar la incertidumbre

* Lógicas no-monotónicas * Sistemas de mantenimiento de verdad (TMS, ATMS) * Teoría de endosos
* Lógicas no-monotónicas * Sistemas de mantenimiento de verdad (TMS, ATMS) * Teoría de endosos
Técnicas Simbólicas Técnicas Simbólicas

• Probabilistas• Cadenas de Markov (ocultas)• Campos de Markov• Redes bayesianas• Redes de decisión• Procesos de decisión de Markov
• Alternativas * Empíricas (MYCIN, Prospector) * Lógica difusa * Teoría de Dempster-Shafer
• Lógicas probabilistas
• Probabilistas• Cadenas de Markov (ocultas)• Campos de Markov• Redes bayesianas• Redes de decisión• Procesos de decisión de Markov
• Alternativas * Empíricas (MYCIN, Prospector) * Lógica difusa * Teoría de Dempster-Shafer
• Lógicas probabilistas
Técnicas Numéricas Técnicas Numéricas
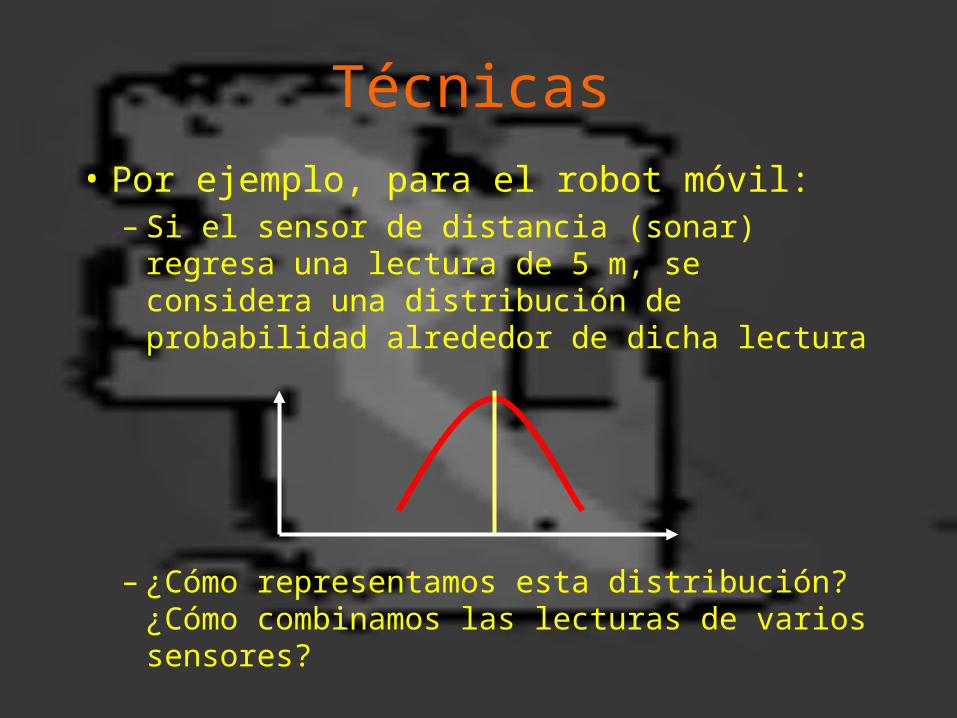
Técnicas
• Por ejemplo, para el robot móvil:– Si el sensor de distancia (sonar) regresa una
lectura de 5 m, se considera una distribución de probabilidad alrededor de dicha lectura
– ¿Cómo representamos esta distribución? ¿Cómo combinamos las lecturas de varios sensores?

Técnicas
• Ejemplo de un “mapa probabilista” construido considerando la incertidumbre de los sensores y de la odometría
¿Qué es probabilidad?
• Definición matemática
• Principales reglas
• Variables aleatorias

Definición
• Dado un experimento E y el espacio de muestreo S, a cada evento A le asociamos un número real P(A), el cual es la probabilidad de A y satisface los siguientes axiomas
S
A

Axiomas
• 0 P(A) 1
• P(S) = 1
• P(A B) = P(A) + P(B),
A y B mutuamente exclusivas

Teoremas
• P (0) = 0
• P (¬A) = 1 – P(A)
• P(A B) = P(A) + P(B) – P(A B)

Probabilidad Condicional
P(A | B) = P(A B) / P(B)
• Probabilidad de que ocurra un evento dado que ocurrió otro:– Dado que el dado cayó impar, cuál es
probabilidad de que sea un número primo?– Dado que tiene catarro, cuál es la probabilidad
de que tenga gripe?

Regla de Bayes
• De la definición de probabilidad condicional se puede deducir:
P(B | A) = P(B) P(A | B) / P(A), dado P(A) > 0
• Esto permite “invertir” las probabilidades, por ejemplo obtener la P de una enfermedad dado un síntoma, con conocimiento de la P de los síntomas dado que alguien tiene cierta enfermedad
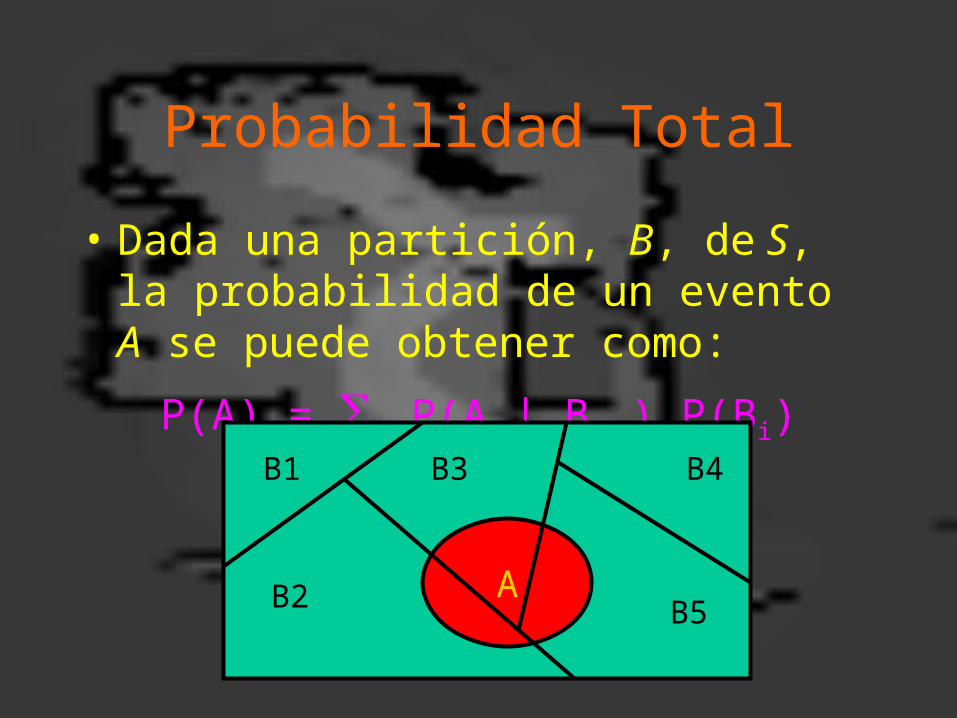
Probabilidad Total
• Dada una partición, B, de S, la probabilidad de un evento A se puede obtener como:
P(A) = i P(A | Bi ) P(Bi)
A
B1
B2
B3 B4
B5

Teorema de Bayes
• Con la definición de probabilidad total, el teorema de Bayes se puede escribir como:
P(B | A) = P(B) P(A | B) / i P(A | Bi ) P(Bi)

Eventos independientes
• Dos eventos son independientes si la ocurrencia de uno no altera la probabilidad de ocurrencia del otro:
P(A | B) = P(A) óP(B | A) = P(B)
• Lo que es equivalente a:P(A B) = P(A) P(B)
• Independientes mutuamente exclusivos

Variables Aleatorias
• A cada evento A se le asigna un valor numérico X(A) = k, de forma que a cada valor le corresponde una probabilidad P(X = k)
• X es una variable aleatoria• Ejemplos:
– X = Número de águilas en N lanzamientos– Y = Número del dado al lanzarlo– Z = Valor de lectura de un sensor

Tipos de Variables Aleatorias
• Discretas: el número de valores de X (rango) es finito o contablemente finito
• Continua: puede asumir todos los posibles valores en cierto intervalo a – b , ejemplos:– X = temperatura ambiente– Y = tiempo en el que falle cierto dispositivo– Z = distancia del robot a la pared

Distribución de probabilidad
• Variables discretas: p(X):
p(X) 0
p(X) = 1
• Variables continuas: f(x):
f(x) 0
f(x) = 1

Estadísticas
• Moda: valor de mayor probabilidad• Mediana: valor medio (divide el área en 2)• Promedio: valor “esperado”:
E(X) = x X p(X)
• Varianza: dispersión
2(X) = x (X – E(X))2 p(X)
• Desviación estandar(X) = 2

Formulación
• Muchos problemas se pueden formular como un conjunto de variables sobre las que tenemos cierta información y queremos obtener otra, por ejemplo:– Diagnóstico médico o industrial– Percepción (visión, voz, sensores)– Clasificación (bancos, empleadores, ...)– Modelado de estudiantes, usuarios, etc.

Formulación
• Desde el punto de vista de probabilidad se puede ver como:– Un conjunto de variables aleatorias: X1, X2,
X3, ...– Cada variable es generalmente una partición del
espacio– Cada variable tiene una distribución de
probabilidad (conocida o desconocida)
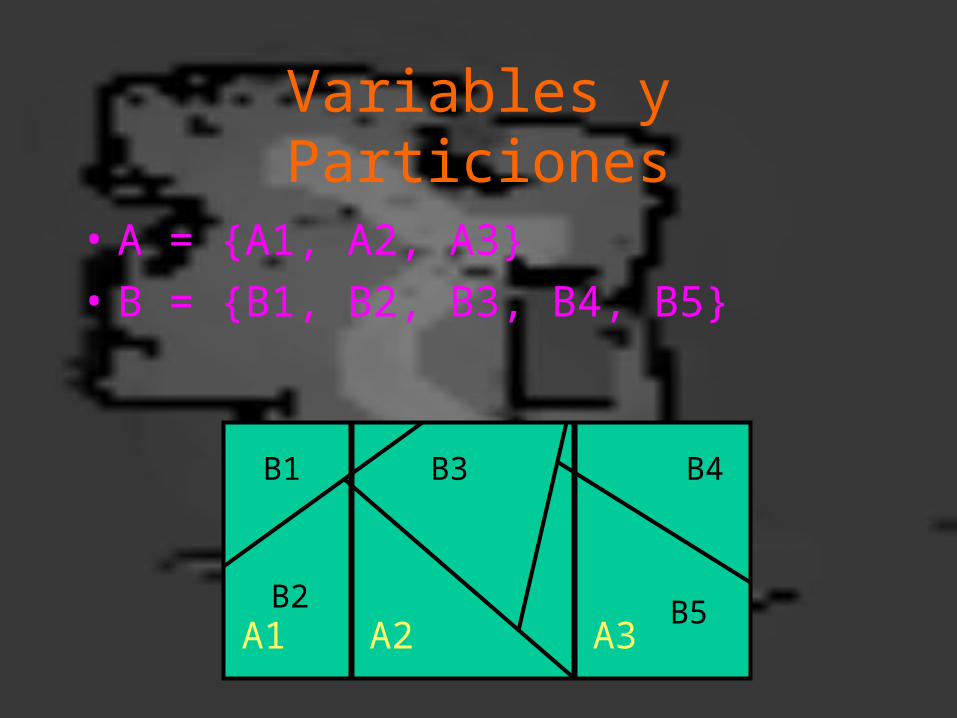
Variables y Particiones
• A = {A1, A2, A3}
• B = {B1, B2, B3, B4, B5}
B1
B2
B3 B4
B5A1 A2 A3
Preguntas
• Dada cierta información (como valores de variables y probabilidades), se requiere contestar ciertas preguntas, como:– Probabilidad de que una variable tome cierto
valor [marginal a priori]– Probabilidad de que una variable tome cierto
valor dada información de otra(s) variable(s) [condicional o a posteriori]

Ejemplo
• Supongamos que se tiene 3 sensores infrarrojos que pueden regresan el valor de intensidad de 0 a 9:– 0 – negro– 9 – blanco
• Dada cierta configuración de los sensores determinar la probabilidad de que la línea blanca este en el “centro”, “izquierda” o “derecha”
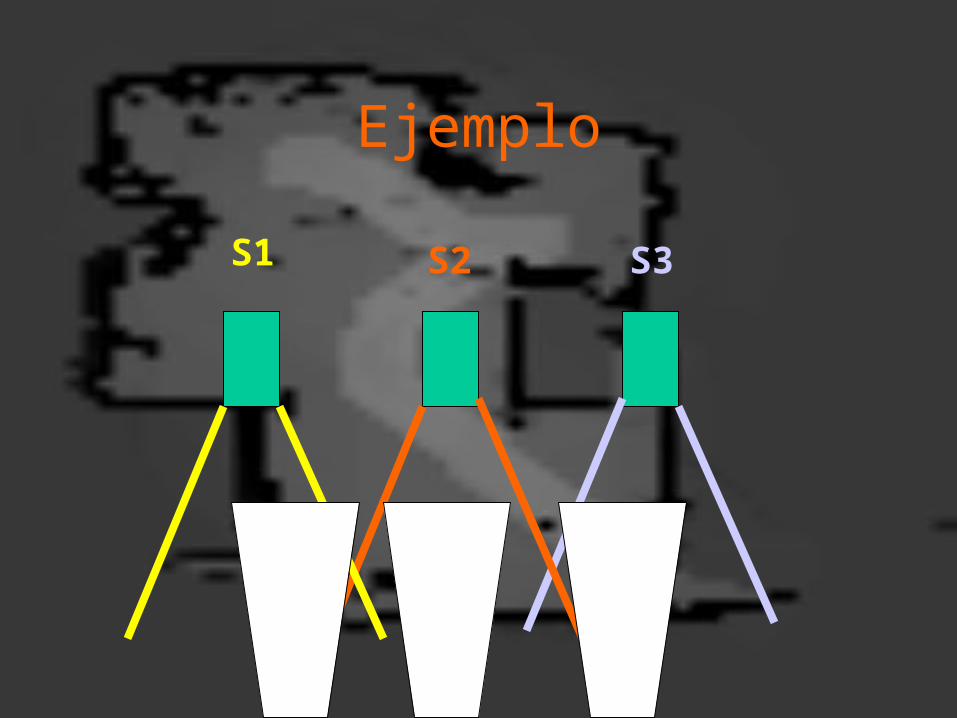
Ejemplo
S1 S2 S3

Clasificación
• El concepto de clasificación tiene dos significados:– No supervisada: dado un conjunto de datos,
establecer clases o agrupaciones (clusters)– Supervisada: dadas ciertas clases, encontrar una
regla para clasificar una nueva observación dentro de las clases existentes

Clasificación
• El problema de clasificación (supervisada) consiste en obtener el valor más probable de una variable (hipótesis) dados los valores de otras variables (evidencia, atributos)
ArgH [ Max P(H | E1, E2, ...EN) ]
ArgH [ Max P(H | EE) ]
EE = {E1, E2, ...EN}

Tipos de Clasificadores
• Métodos estadísticos clásicos– Clasificador bayesiano simple (naive Bayes)– Descriminadores lineales
• Modelos de dependencias– Redes bayesianas
• Aprendizaje simbólico– Árboles de decisión, reglas
• Redes neuronales

Clasificación
• Consideraciones para un clasificador:– Exactitud – proporción de clasificaciones
correctas– Rapidez – tiempo que toma hacer la
clasificación– Claridad – que tan comprensible es para los
humanos– Tiempo de aprendizaje – tiempo para obtener o
ajustar el clasificador a partir de datos

Regla de Bayes
• Para estimar esta probabilidad se puede hacer en base a la regla de Bayes:
P(H | EE) = P(H) P(EE | H) / P(EE)
P(H | EE) = P(H) P(EE | H) / i P(EE | Hi ) P(Hi)
• Normalmente no se require saber el valor de probabilidad, solamente el valor más probable de H

Valores Equivalentes
• Se puede utilizar cualquier función monotónica para la clasificación:
ArgH [ Max P(H | EE) ]
ArgH [ Max P(H) P(EE | H) / P(EE) ]
ArgH [ Max P(H) P(EE | H) ]
ArgH [ Max log {P(H) P(EE | H)} ]
ArgH [ Max log P(H) + log P(EE | H) ]

Clasificador bayesiano simple
• Estimar la probabilidad: P(EE | H) es complejo, pero se simplifica si se considera que los atributos son independientes dada la hipotesis:P(E1, E2, ...EN | H) = P(E1 | H) P(E2 | H) ... P(EN | H)
• Por lo que la probabilidad de la hipótesis dada la evidencia puede estimarse como:
P(H | E1, E2, ...EN) = P(H) P(E1 | H) P(E2 | H) ... P(EN | H)
P(EE)• Esto se conoce como el clasificador bayesiano simple

Clasificador bayesiano simple
• Como veíamos, no es necesario calcular el denominador:
P(H | E1, E2, ...EN) ~
P(H) P(E1 | H) P(E2 | H) ... P(EN | H)
• P(H) se conoce como la probabilidad a priori, P(Ei | H) es la probabilidad de los atributos dada la hipotesis (verosimilitud), y P(H | E1, E2, ...EN) es la probabilidad posterior

Ejemplo - CBS
• Determinar la probabilidad de que la línea este a la izquierda o derecha (clase) dado el valor de los sensores (atributos)
P(posición | sensor1, sensor2) =
k P(posición) P(s1 | posición) P(s2 | posición)

Ejemplo - CBS
Hoja de cálculo de
Microsoft Excel

Redes Bayesianas• Introducción
• Representación estructural
• Representación paramétrica
• Inferencia

Las redes bayesianas son una representación gráfica de dependencias para razonamiento probabilístico, en la cual los nodos y arcos representan:
Las redes bayesianas son una representación gráfica de dependencias para razonamiento probabilístico, en la cual los nodos y arcos representan:
RepresentaciónRepresentación
• Nodo: Variable proposicional. • Arcos: Dependencia probabilística. • Nodo: Variable proposicional. • Arcos: Dependencia probabilística.
La variable a la que apunta el arco es dependiente (causa-efecto) de la que está en el origen de éste.
La variable a la que apunta el arco es dependiente (causa-efecto) de la que está en el origen de éste.
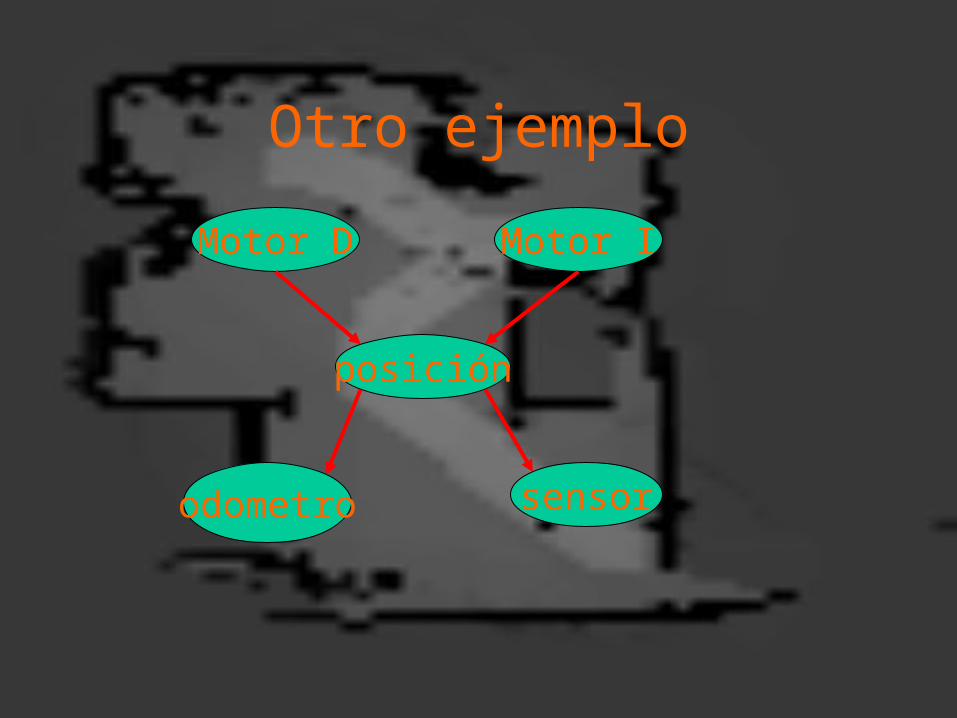
Otro ejemplo
posición
odometro sensor
Motor IMotor D

La topología o estructura de la red nos da información sobre las dependencias probabilísticas entre las variables.
La red también representa las independencias condicionales de una variable (o conjunto de variables) dada otra variable(s).
La topología o estructura de la red nos da información sobre las dependencias probabilísticas entre las variables.
La red también representa las independencias condicionales de una variable (o conjunto de variables) dada otra variable(s).
EstructuraEstructura

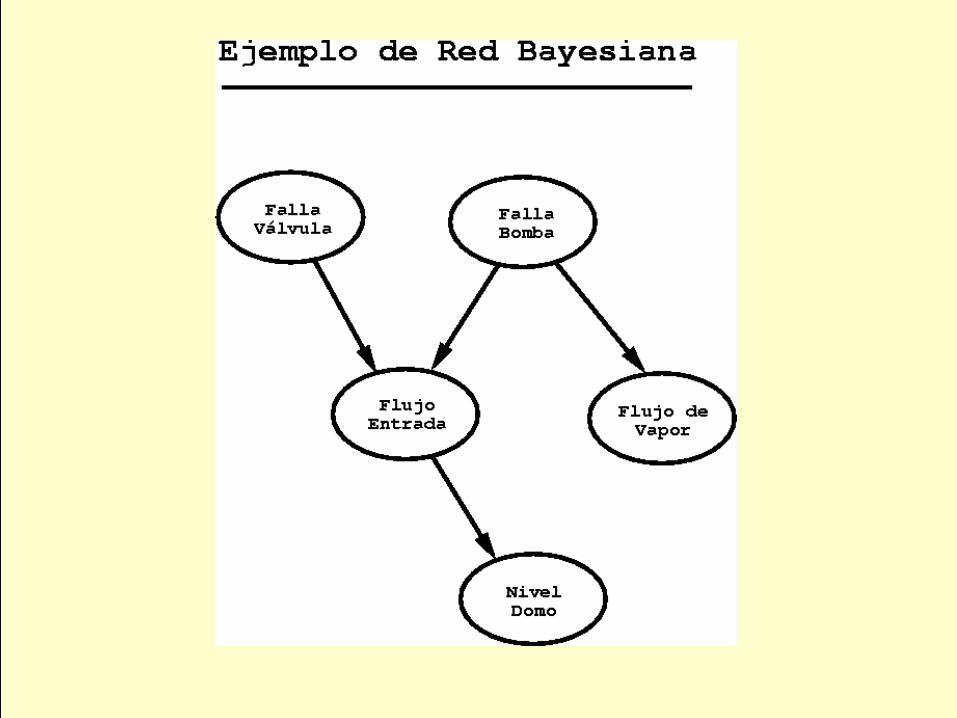
Ej.: {Fva} es cond. indep. de {Fv, Fe, Nd} dado {Fb}
Esto es: P(Fva | Fv, Fe, Nd, Fb)= P(Fva | Fb)
Ej.: {Fva} es cond. indep. de {Fv, Fe, Nd} dado {Fb}
Esto es: P(Fva | Fv, Fe, Nd, Fb)= P(Fva | Fb)
Esto se representa gráficamente por el nodo Fb separando al nodo Fva del resto de las variables.
Formalmente, la independencia condicional se verifica mediante el criterio de separación-D
Esto se representa gráficamente por el nodo Fb separando al nodo Fva del resto de las variables.
Formalmente, la independencia condicional se verifica mediante el criterio de separación-D
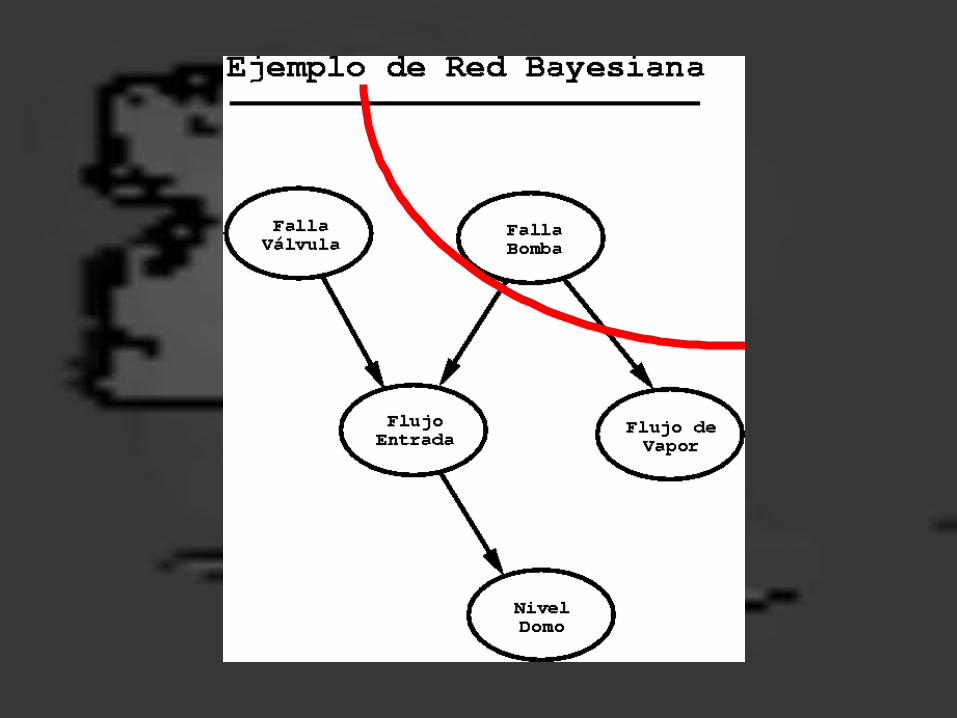

En una RP todas la relaciones de independencia condicional representadas en el grafo corresponden a relaciones de independencia en la distribución de probabilidad.
Dichas independencias simplifican la representación del conocimiento (menos parámetros) y el razonamiento (propagación de las probabilidades).
En una RP todas la relaciones de independencia condicional representadas en el grafo corresponden a relaciones de independencia en la distribución de probabilidad.
Dichas independencias simplifican la representación del conocimiento (menos parámetros) y el razonamiento (propagación de las probabilidades).

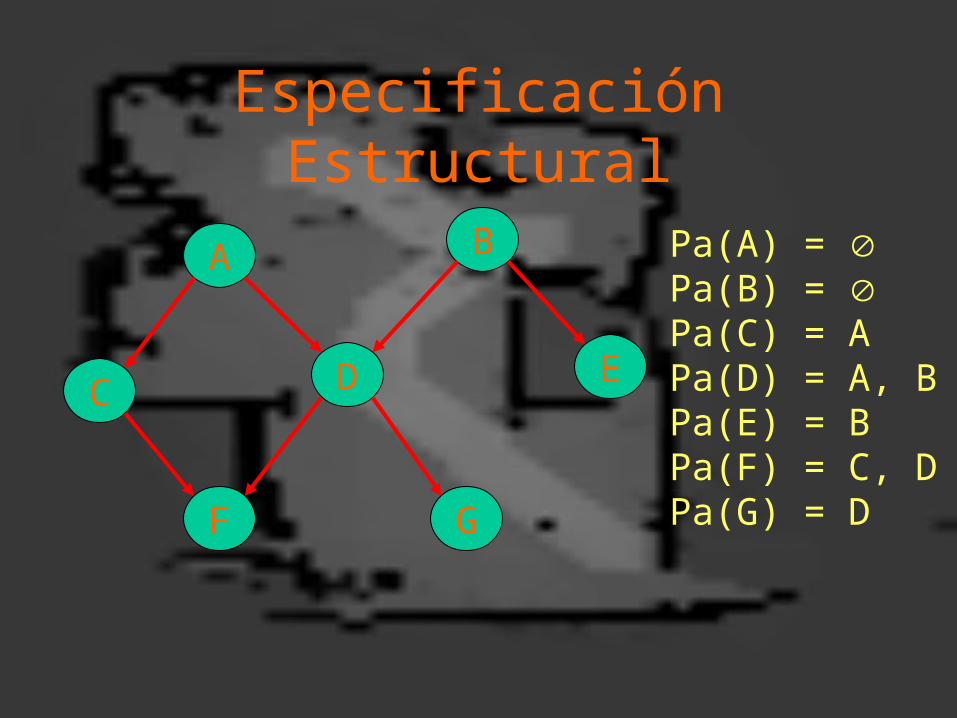
Especificación Estructural
• En una RB, cualquier nodo X es independiente de todos los nodos que no son sus descendientes dados sus nodos padres Pa(X) – “contorno de X”
• La estructura de una RB se especifica indicando el contorno (padres) de cada variable
Especificación Estructural
A
DC
F G
B
E
Pa(A) = Pa(B) = Pa(C) = APa(D) = A, BPa(E) = BPa(F) = C, DPa(G) = D

Complementa la definición de una red bayesiana las probabilidades condicionales de cada variable dados sus padres.
Nodos raíz: vector de probabilidades marginales
Otros nodos: matriz de probabilidades condicionales dados sus padres
Complementa la definición de una red bayesiana las probabilidades condicionales de cada variable dados sus padres.
Nodos raíz: vector de probabilidades marginales
Otros nodos: matriz de probabilidades condicionales dados sus padres
ParámetrosParámetros
Especificación Paramétrica
A
DC
F G
B
E
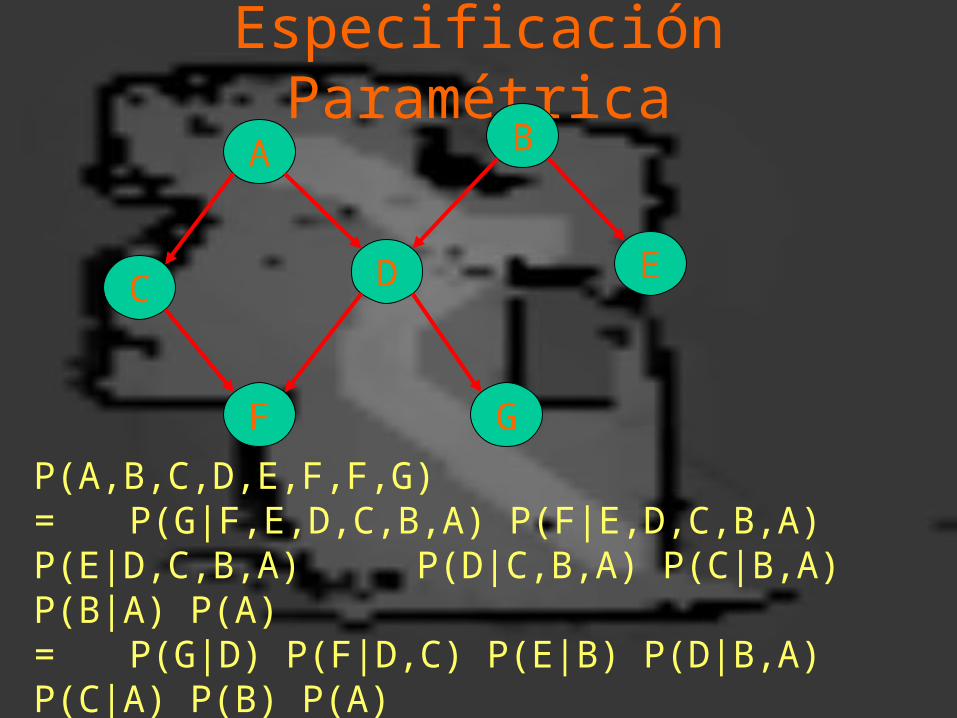
P(A,B,C,D,E,F,F,G)= P(G|F,E,D,C,B,A) P(F|E,D,C,B,A) P(E|D,C,B,A) P(D|C,B,A) P(C|B,A) P(B|A) P(A)= P(G|D) P(F|D,C) P(E|B) P(D|B,A) P(C|A) P(B) P(A)

Especificación Paramétrica
• En general, la probabilidad conjunta se especifica por el producto de las probabilidades de cada variable dados sus padres:
P(X1,X2, ..., Xn) = P(Xi | Pa(Xi))
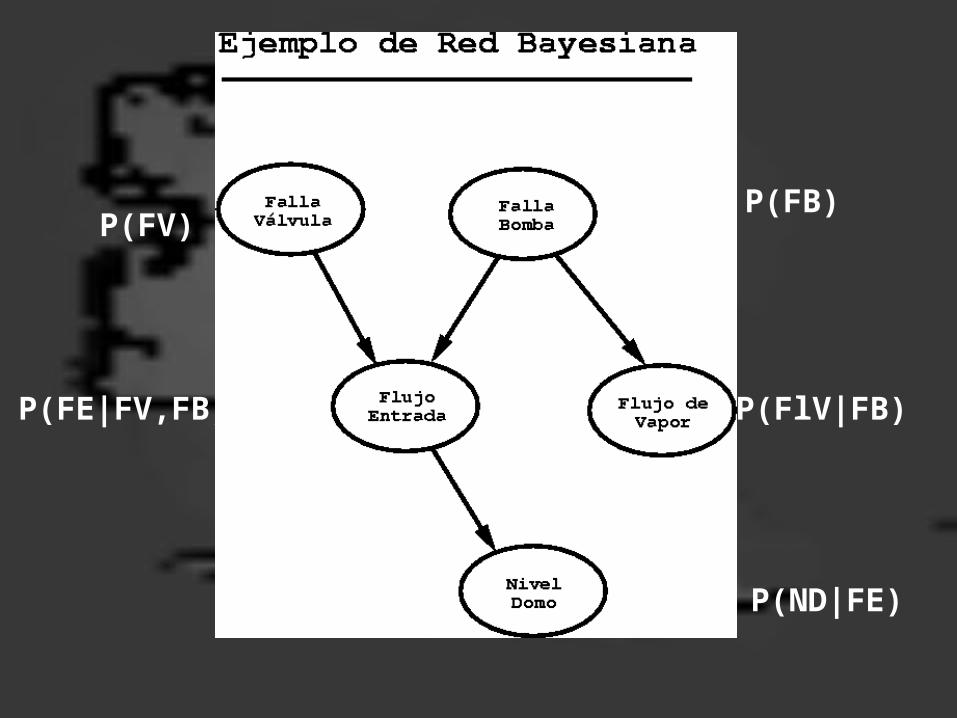
P(FV)
P(FE|FV,FB)
P(FB)
P(FlV|FB)
P(ND|FE)

El razonamiento probabilístico o propagación de probabilidades consiste en propagar de los efectos de la evidencia a través de la red paraconocer la probabilidad a posteriori de las variables.
El razonamiento probabilístico o propagación de probabilidades consiste en propagar de los efectos de la evidencia a través de la red paraconocer la probabilidad a posteriori de las variables.
Propagación de ProbabilidadesPropagación de Probabilidades

La propagación consiste en darle valores a ciertas variables (evidencia), y obtener la probabilidad posterior de las demás variables dadas las variables conocidas (instanciadas).
La propagación consiste en darle valores a ciertas variables (evidencia), y obtener la probabilidad posterior de las demás variables dadas las variables conocidas (instanciadas).
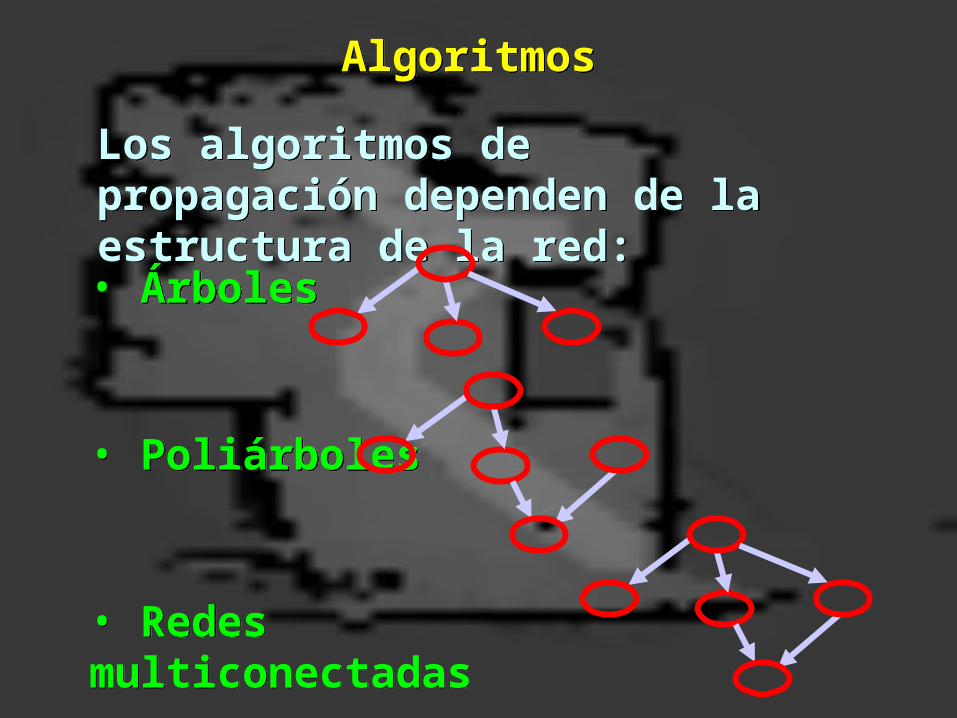
Los algoritmos de propagación dependen de la estructura de la red:Los algoritmos de propagación dependen de la estructura de la red:
AlgoritmosAlgoritmos
• Árboles
• Poliárboles
• Redes multiconectadas
• Árboles
• Poliárboles
• Redes multiconectadas

Cada nodo corresponde a una variable discreta, B{B 1, B 2,…, B n) con su respectiva matriz de probabilidad condicional, P(B|A)=P(Bj| Ai)
Cada nodo corresponde a una variable discreta, B{B 1, B 2,…, B n) con su respectiva matriz de probabilidad condicional, P(B|A)=P(Bj| Ai)
Propagación en Árboles .Propagación en Árboles .
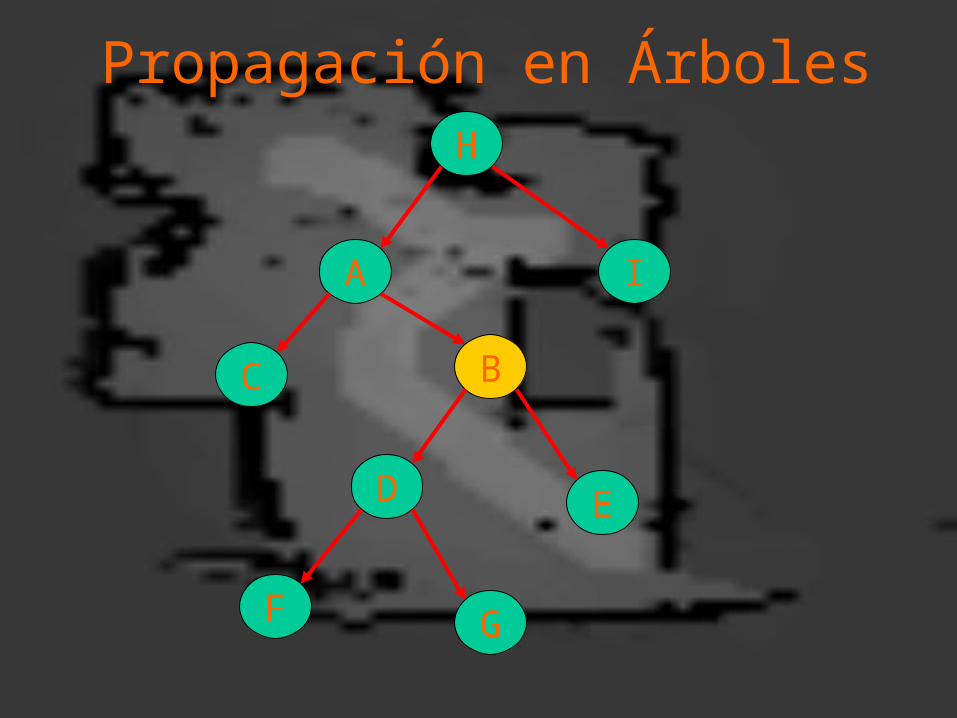
Propagación en Árboles
A
D
C
F G
B
E
H
I

Dada cierta evidencia E --representada por la instanciación de ciertas variables-- la probabilidad posterior de cualquier variable B, por el teorema de Bayes:
Dada cierta evidencia E --representada por la instanciación de ciertas variables-- la probabilidad posterior de cualquier variable B, por el teorema de Bayes:
P( Bi | E)=P( Bi ) P(E | Bi) / P( E )P( Bi | E)=P( Bi ) P(E | Bi) / P( E )
B
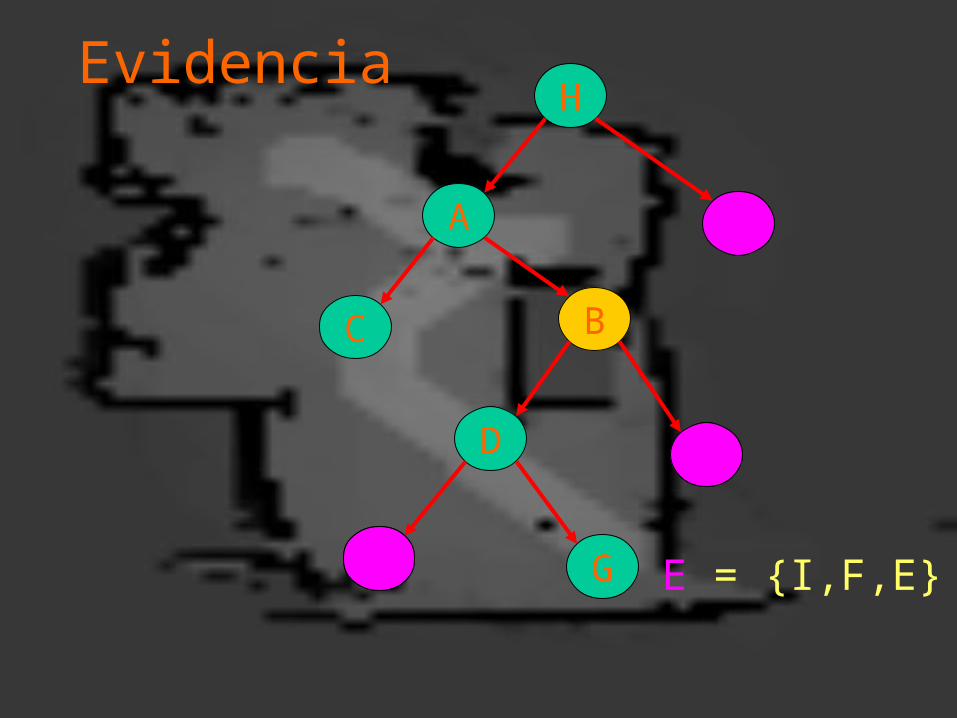
Evidencia
A
D
C
F G
B
E
H
I
E = {I,F,E}

Ya que la estructura de la red es un árbol, el Nodo B la separa en dos subárboles, por lo que podemos dividir la evidencia en dos grupos:
E-: Datos en el árbol que cuya raíz es B
E+: Datos en el resto del árbol
Ya que la estructura de la red es un árbol, el Nodo B la separa en dos subárboles, por lo que podemos dividir la evidencia en dos grupos:
E-: Datos en el árbol que cuya raíz es B
E+: Datos en el resto del árbol
EvidenciaEvidencia
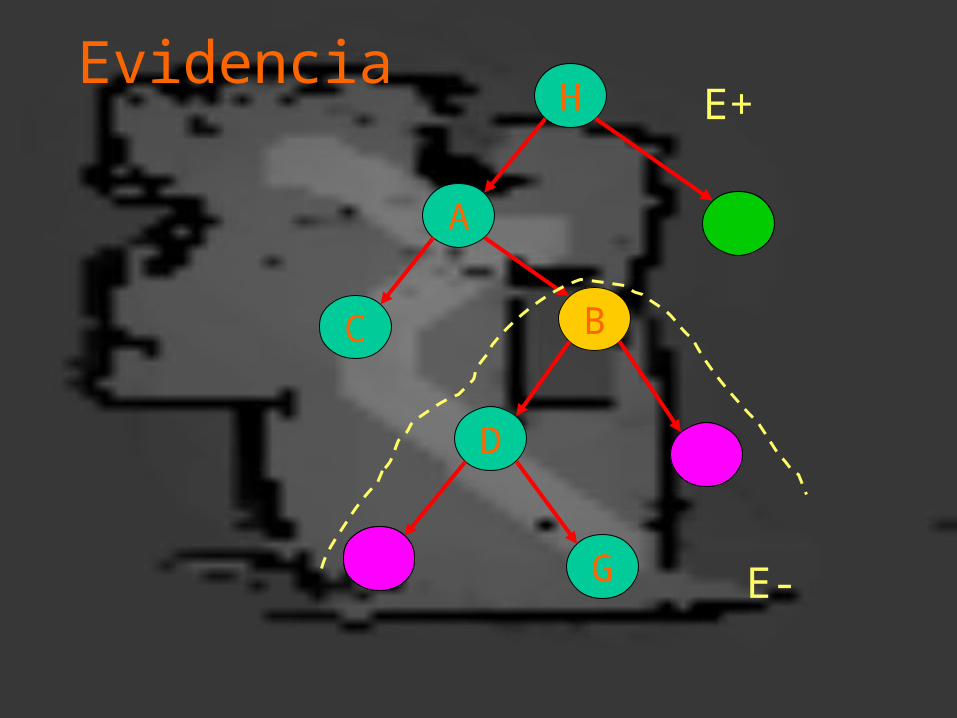
Evidencia
A
D
C
F G
B
E
H
I
E+
E-

Entonces: P( Bi | E ) = P ( Bi ) P ( E-,E+ | Bi ) / P(E)
Pero dado que ambos son independientes y aplicando nuevamente Bayes:
Entonces: P( Bi | E ) = P ( Bi ) P ( E-,E+ | Bi ) / P(E)
Pero dado que ambos son independientes y aplicando nuevamente Bayes:
P( Bi | E ) = P ( Bi | E+ ) P(E- | Bi ) P( Bi | E ) = P ( Bi | E+ ) P(E- | Bi )
Donde es una constante de normalización

Si definimos los siguientes términos:Si definimos los siguientes términos:
Definiciones:Definiciones:
(Bi)= P ( E- | Bi) (Bi)= P ( E- | Bi)
Entonces:Entonces:
(Bi)= P (Bi | E+ )(Bi)= P (Bi | E+ )
P(Bi | E )= (B i) (B i) P(Bi | E )= (B i) (B i)

Desarrollo
• En base a la ecuación anterior, se puede integrar un algoritmo distribuido para obtener la probabilidad de un nodo dada cierta evidencia
• Para ello se descompone el cálculo de cada parte:– Evidencia de los hijos ()– Evidenica de los demás nodos ()
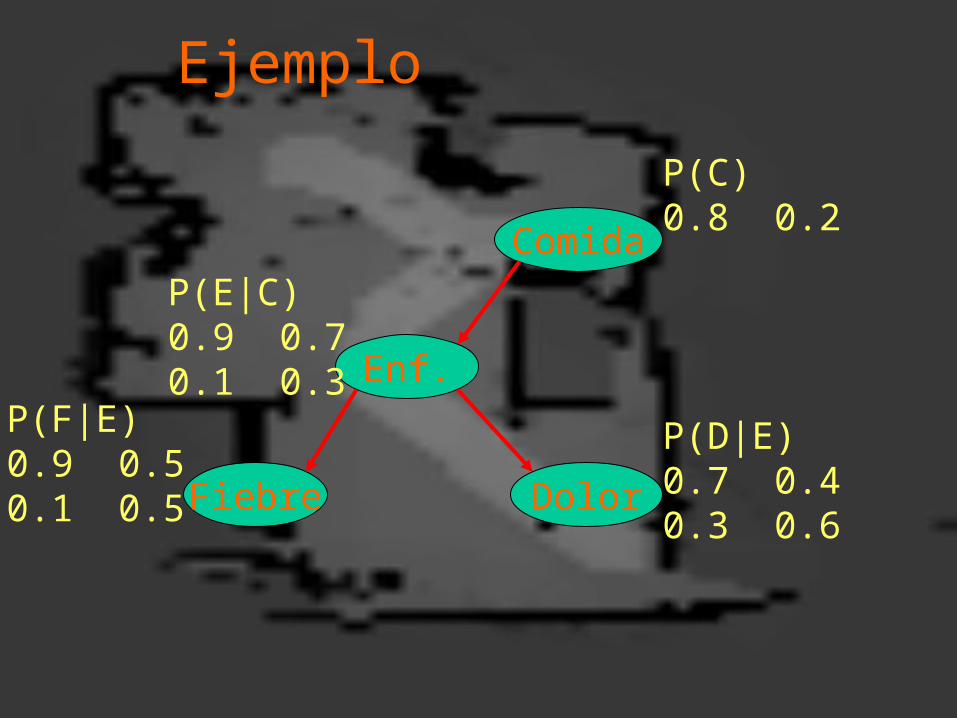
Ejemplo
Enf.
Fiebre Dolor
Comida
P(F|E)0.9 0.50.1 0.5
P(D|E)0.7 0.40.3 0.6
P(E|C)0.9 0.70.1 0.3
P(C)0.8 0.2
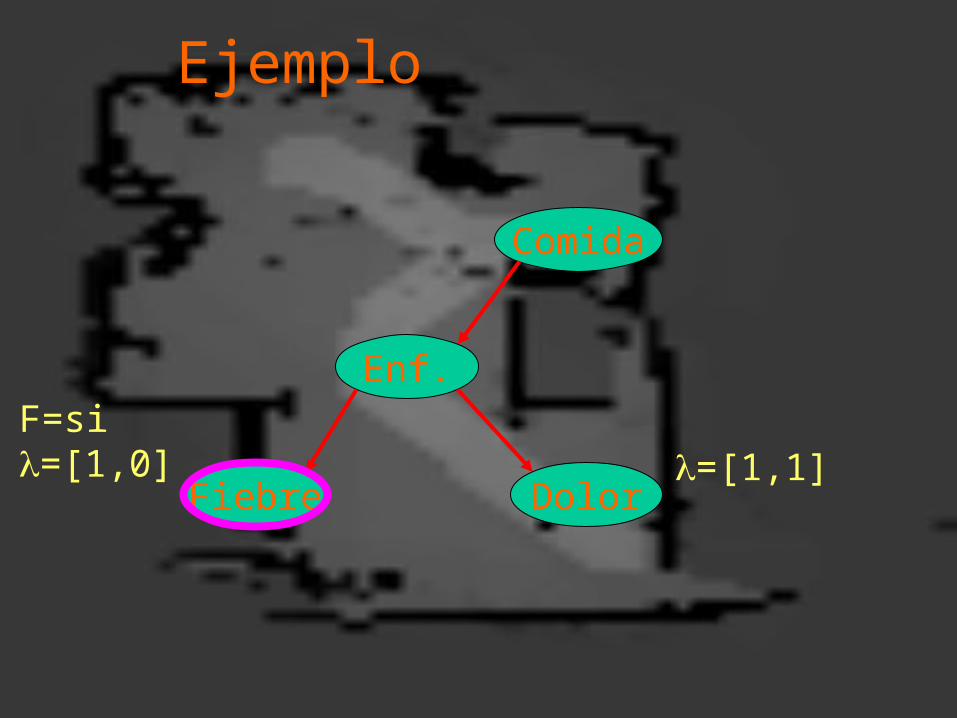
Ejemplo
Enf.
Fiebre Dolor
Comida
F=si=[1,0] =[1,1]
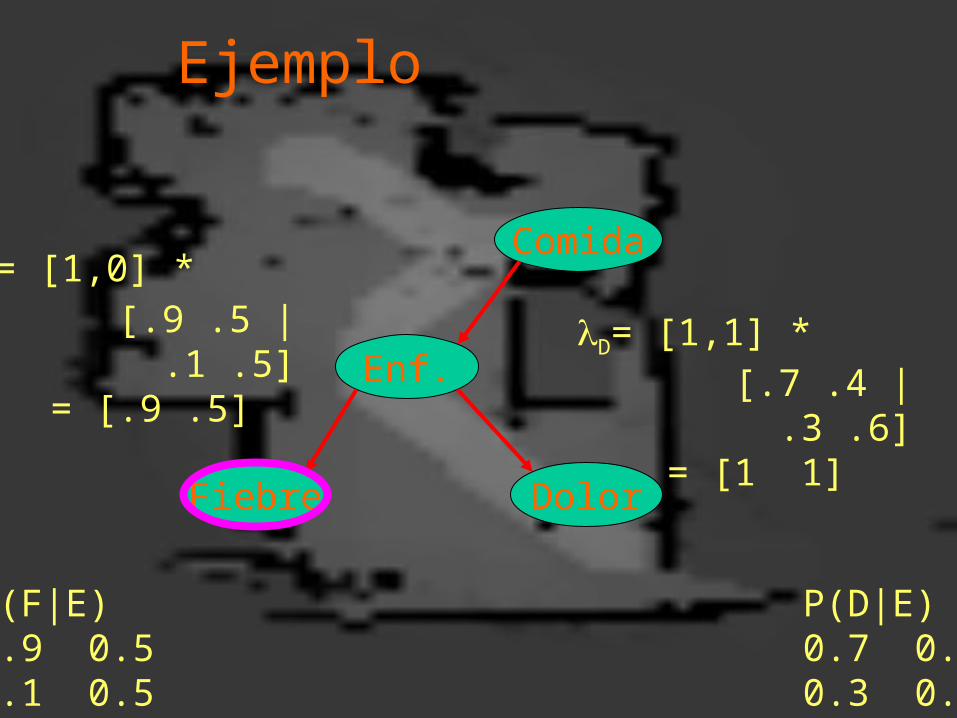
Ejemplo
Enf.
Fiebre Dolor
ComidaF= [1,0] * [.9 .5 | .1 .5] = [.9 .5]
D= [1,1] * [.7 .4 | .3 .6] = [1 1]
P(D|E)0.7 0.40.3 0.6
P(F|E)0.9 0.50.1 0.5
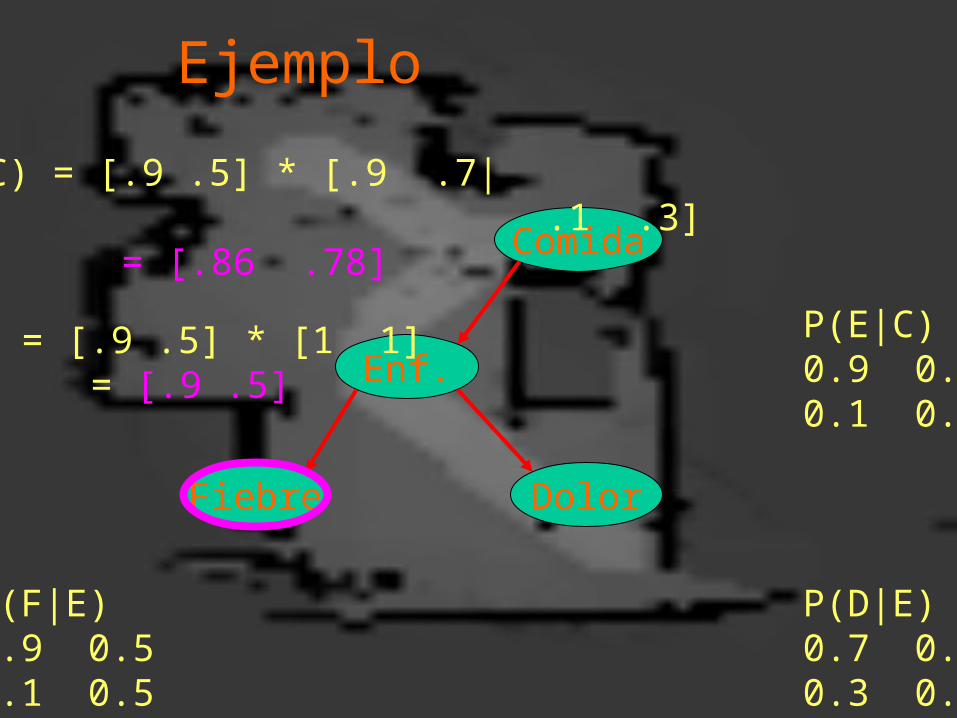
Ejemplo
Enf.
Fiebre Dolor
Comida
(E) = [.9 .5] * [1 1] = [.9 .5]
P(D|E)0.7 0.40.3 0.6
P(F|E)0.9 0.50.1 0.5
(C) = [.9 .5] * [.9 .7| .1 .3] = [.86 .78]
P(E|C)0.9 0.70.1 0.3
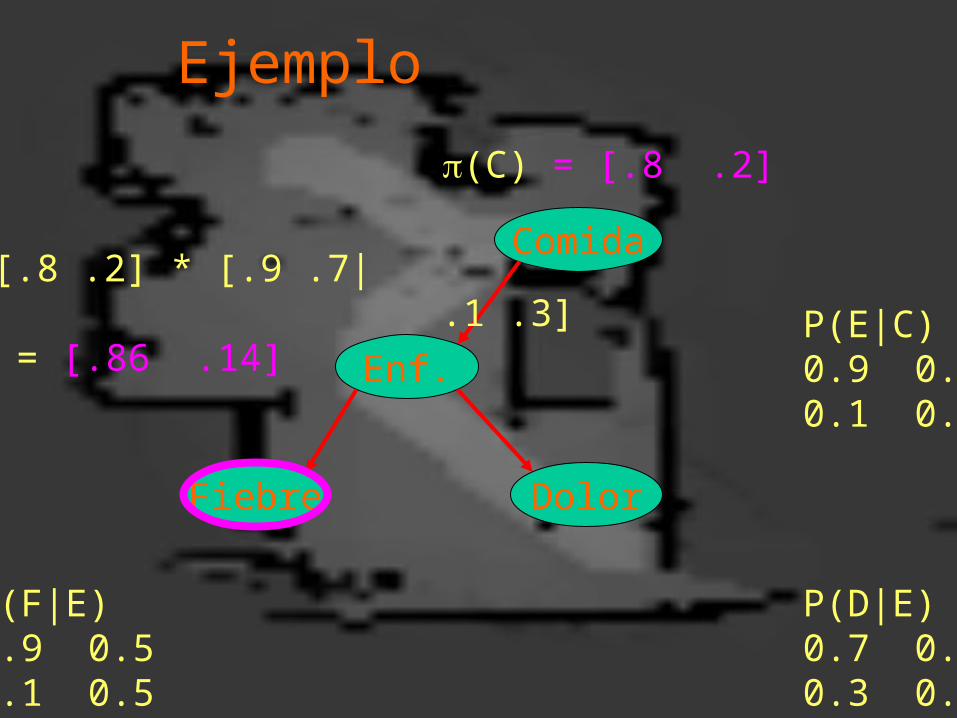
Ejemplo
Enf.
Fiebre Dolor
Comida(E) = [.8 .2] * [.9 .7| .1 .3] = [.86 .14]
P(D|E)0.7 0.40.3 0.6
P(F|E)0.9 0.50.1 0.5
(C) = [.8 .2]
P(E|C)0.9 0.70.1 0.3
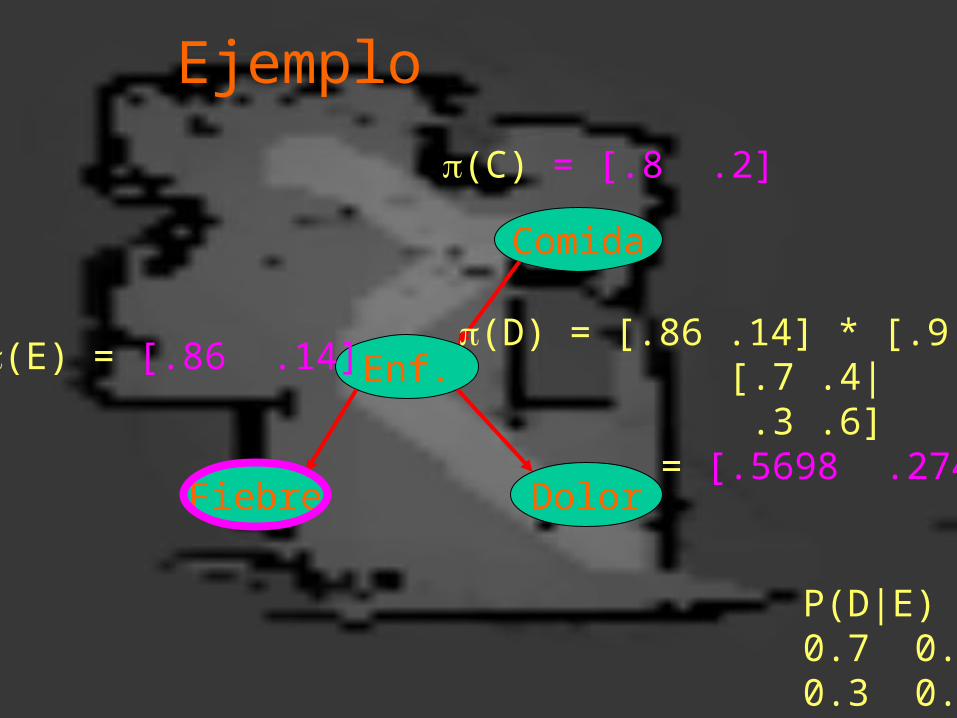
Ejemplo
Enf.
Fiebre Dolor
Comida
(E) = [.86 .14]
P(D|E)0.7 0.40.3 0.6
(C) = [.8 .2]
(D) = [.86 .14] * [.9 .5] [.7 .4| .3 .6] = [.5698 .2742]
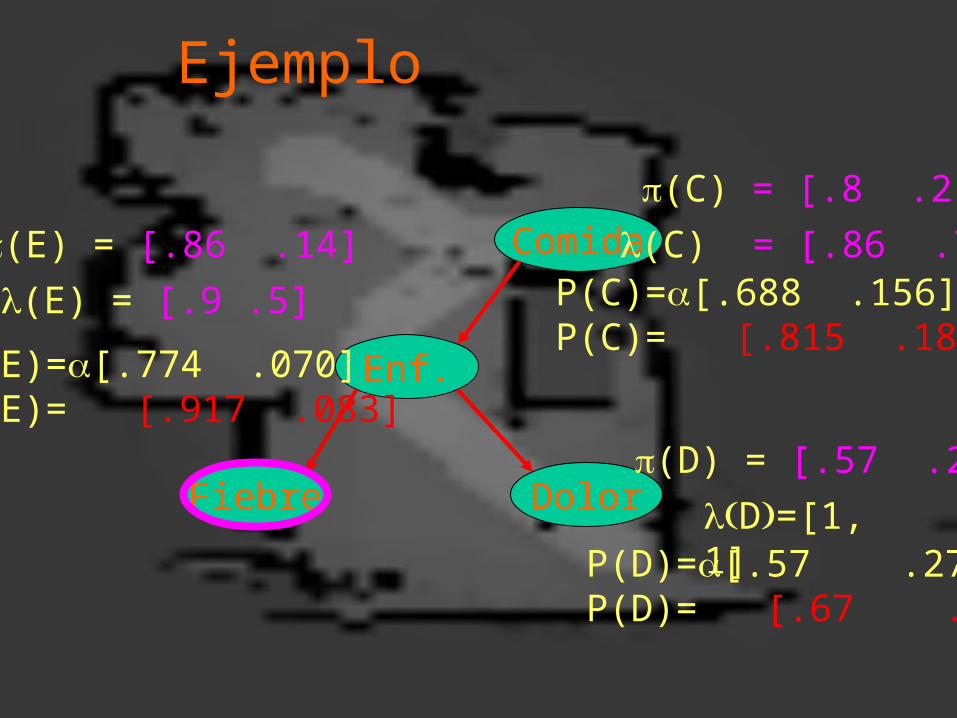
Ejemplo
Enf.
Fiebre Dolor
Comida(E) = [.86 .14]
(C) = [.8 .2]
(D) = [.57 .27]
D=[1,1]
(E) = [.9 .5]
(C) = [.86 .78]P(C)=[.688 .156]P(C)= [.815 .185]
P(E)=[.774 .070]P(E)= [.917 .083]
P(D)=[.57 .27]P(D)= [.67 .33]
Una red multiconectada es un grafo no conectado en forma sencilla, es decir, en el que hay múltiples trayectorias entre nodos (MCG).
En este tipo de RP los métodos anteriores ya no aplican, pero existen otras técnicas alternativas:
Una red multiconectada es un grafo no conectado en forma sencilla, es decir, en el que hay múltiples trayectorias entre nodos (MCG).
En este tipo de RP los métodos anteriores ya no aplican, pero existen otras técnicas alternativas:
Propagación en Redes MulticonectadasPropagación en Redes Multiconectadas
• Condicionamiento • Simulación estocástica • Agrupamiento
• Condicionamiento • Simulación estocástica • Agrupamiento

Referencias
• [Russell y Norvig] – Cap
• Pearl, Probabilistic reasoning in intelligent systems
• Neapolitan, Probabilistic reasoning in expert systems

Tarea
• Terminar 2do prototipo para concurso de Querétaro
• Preparar presentación y reporte– Demostración preliminar: jueves 25 de abril– Presentación y demostración final: lunes 29 de
abril (examen parcial)