+reuniónago172014 03
TRANSCRIPT

INSTITUTO PARA LA CALIDAD DE LA EDUCACIÓNSECCIÓN DE POSTGRADO
DIPLOMADO DE ESPECIALIZACIÓN DE POSTGRADO EN ASESORÍA DE TESIS
MÓDULO: DISEÑO DE INVESTIGACIÓN Y OPERACIONALIZACIÓN DE VARIABLES
EXPOSITOR: RONALD JOSÉ TORRES MARTÍNEZ
AGOSTO/17 – 2014

CLASE-03:
PROCESO ESTADISTICO Y FORMULACION DEL PROBLEMA DE
INVESTIGACIÓN:
1. PROCESO ESTADISTICO.
2. FORMULACIÓN DEL PROBLEMA DE INVESTIGACIÓN, OBJETIVOS E
HIPÓTESIS DE INVESTIGACIÓN
3. DISEÑO DE INVESTIGACIÓN, CONCEPTO Y CARACTERÍSTICAS
CONTENIDOS 01
FRECUENCIA FRECUENCIA
FRECUENCIA FRECUENCIA
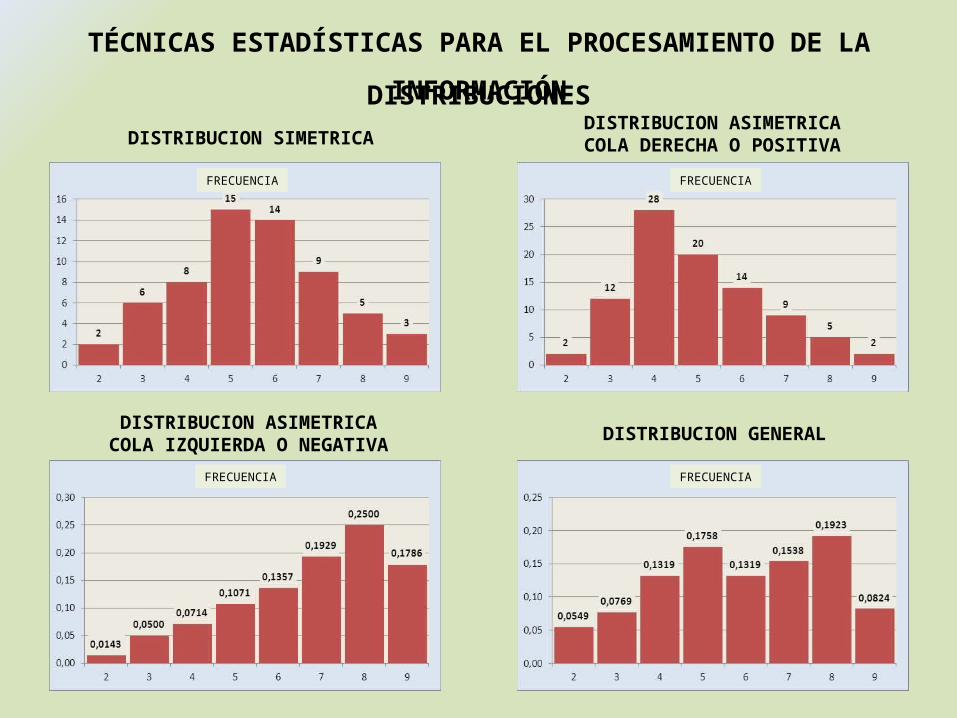
TÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
DISTRIBUCION SIMETRICADISTRIBUCION ASIMETRICACOLA DERECHA O POSITIVA
DISTRIBUCION ASIMETRICACOLA IZQUIERDA O NEGATIVA DISTRIBUCION GENERAL
DISTRIBUCIONES

TÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
DISTRIBUCIONES ESTADÍSTICAS
DISTRIBUCIÓN NORMAL DISTRIBUCIÓN t DE STUDENT
DISTRIBUCIÓN CHI CUADRADODISTRIBUCIÓN F
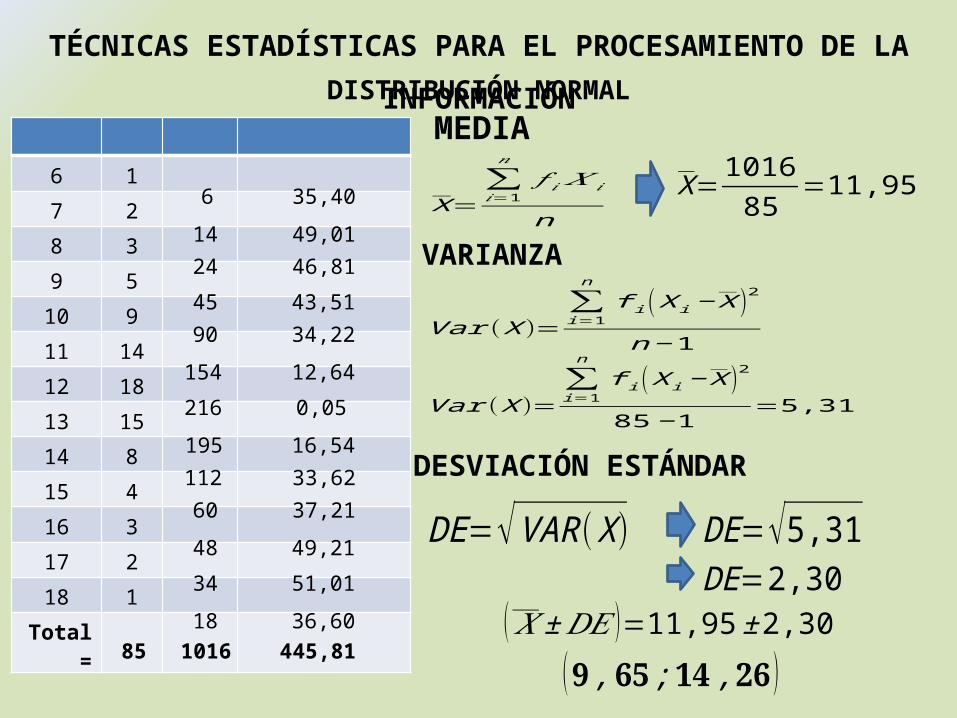
TÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓNDISTRIBUCIÓN NORMAL
6 1
7 2
8 3
9 5
10 9
11 14
12 18
13 15
14 8
15 4
16 3
17 2
18 1
Total =
6
1424
4590
154
216
19511260
48
34
1885 1016
35,40
49,0146,81
43,5134,22
12,64
0,05
16,5433,6237,21
49,21
51,01
36,60445,81
X=∑𝑖=1
𝑛
𝑓 𝑖 𝑋 𝑖
n
X=101685
=11,95
Var (X )=∑i=1
n
f i (X i− X )2
n−1
Var (X )=∑i=1
n
f i (X i− X )2
85−1=5,31
VARIANZA
MEDIA
DESVIACIÓN ESTÁNDAR
DE=√VAR(X ) DE=√5,31DE=2,30
( 𝑋 ±𝐷𝐸 )=11,95±2,30
(𝟗 ,𝟔𝟓 ;𝟏𝟒 ,𝟐𝟔)
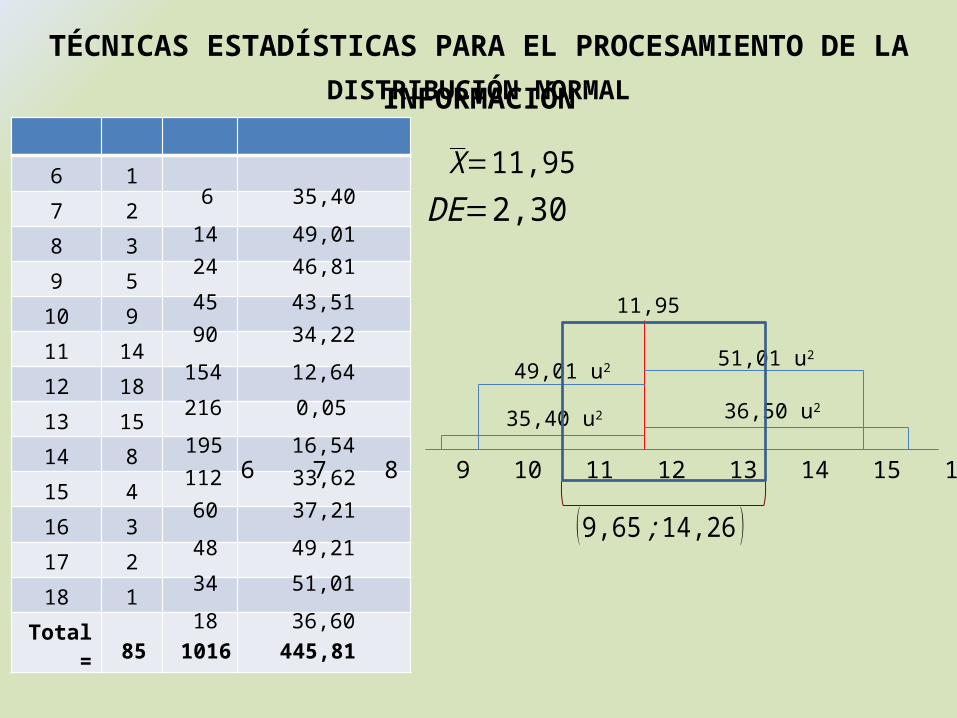
TÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓNDISTRIBUCIÓN NORMAL
6 1
7 2
8 3
9 5
10 9
11 14
12 18
13 15
14 8
15 4
16 3
17 2
18 1
Total =
6
1424
4590
154
216
19511260
48
34
1885 1016
35,40
49,0146,81
43,5134,22
12,64
0,05
16,5433,6237,21
49,21
51,01
36,60445,81
6 7 8 9 10 11 12 13 14 15 16 17 18
X=11,95DE=2,30
11,95
35,40 u2
49,01 u2
36,50 u2
51,01 u2
(9,65 ;14,26 )
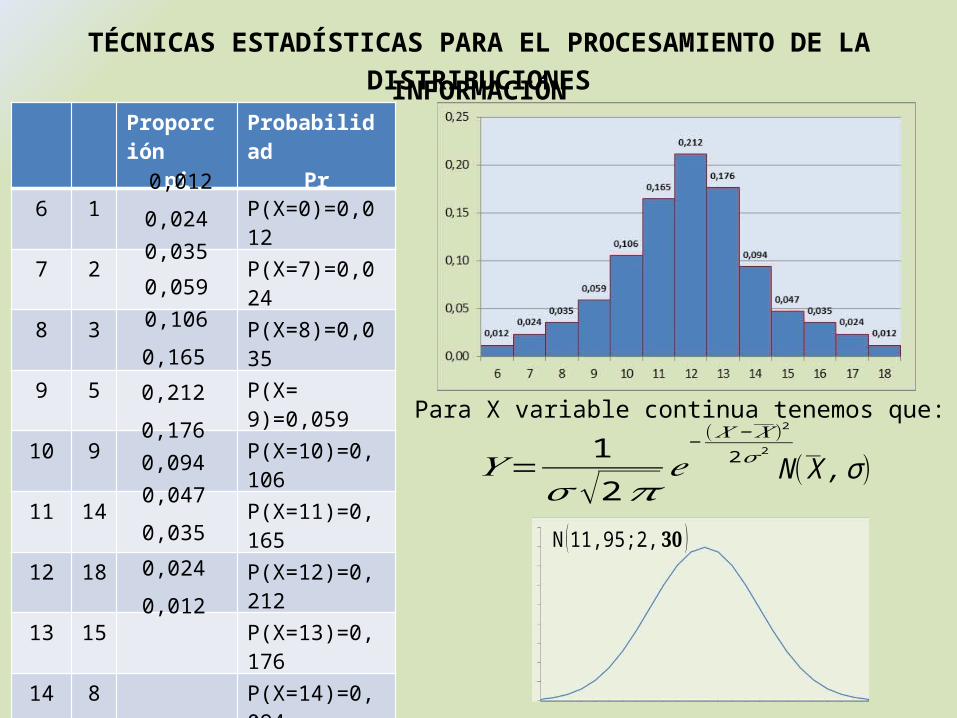
TÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓNDISTRIBUCIONES
Proporciónpi
ProbabilidadPr
6 1 P(X=0)=0,012
7 2 P(X=7)=0,024
8 3 P(X=8)=0,035
9 5 P(X= 9)=0,059
10 9 P(X=10)=0,106
11 14 P(X=11)=0,165
12 18 P(X=12)=0,212
13 15 P(X=13)=0,176
14 8 P(X=14)=0,094
15 4 P(X=15)=0,047
16 3 P(X=16)=0,035
17 2 P(X=17)=0,024
18 1 P(X=18)=0,012
Total 85 1016 P(6≤X≤18)=1,0
0,012
0,0240,035
0,0590,106
0,165
0,212
0,1760,0940,047
0,035
0,024
0,012
Para X variable continua tenemos que:
𝑌= 1𝜎 √2𝜋
𝑒−
(𝑋 −𝑋 )2
2𝜎2
N (X ,σ )
N (11,95;2,𝟑𝟎)
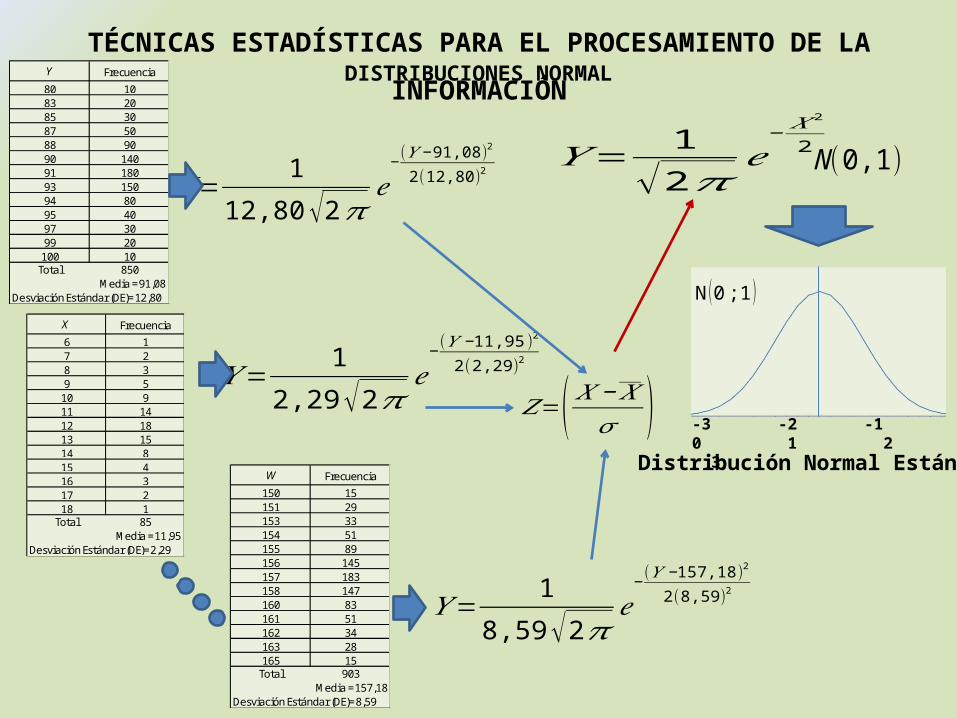
DISTRIBUCIONES NORMAL
X Frecuencia
6 17 28 39 5
10 911 1412 1813 1514 815 416 317 218 1
Total 85 Media = 11,95
Desviación Estándar (DE)= 2,29
Y Frecuencia
80 1083 2085 3087 5088 9090 14091 18093 15094 8095 4097 3099 20
100 10Total 850
Media = 91,08Desviación Estándar (DE)= 12,80
W Frecuencia
150 15151 29153 33154 51155 89156 145157 183158 147160 83161 51162 34163 28165 15
Total 903
Desviación Estándar (DE)= 8,59 Media = 157,18
𝑌=1
12,80√2𝜋𝑒−
(𝑌 −91,08)2
2(12,80)2
𝑌=1
2,29√2𝜋𝑒−
(𝑌 −11,95)2
2(2,29 )2
𝑌=1
8,59√2𝜋𝑒−
(𝑌 −157,18)2
2(8,59)2
𝑍=( 𝑋 −𝑋𝜎 )
𝑌=1
√2𝜋𝑒− 𝑋 2
2N (0,1)
-3 -2 -1 0 1 2 3
N (0 ;1 )
Distribución Normal Estándar
TÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
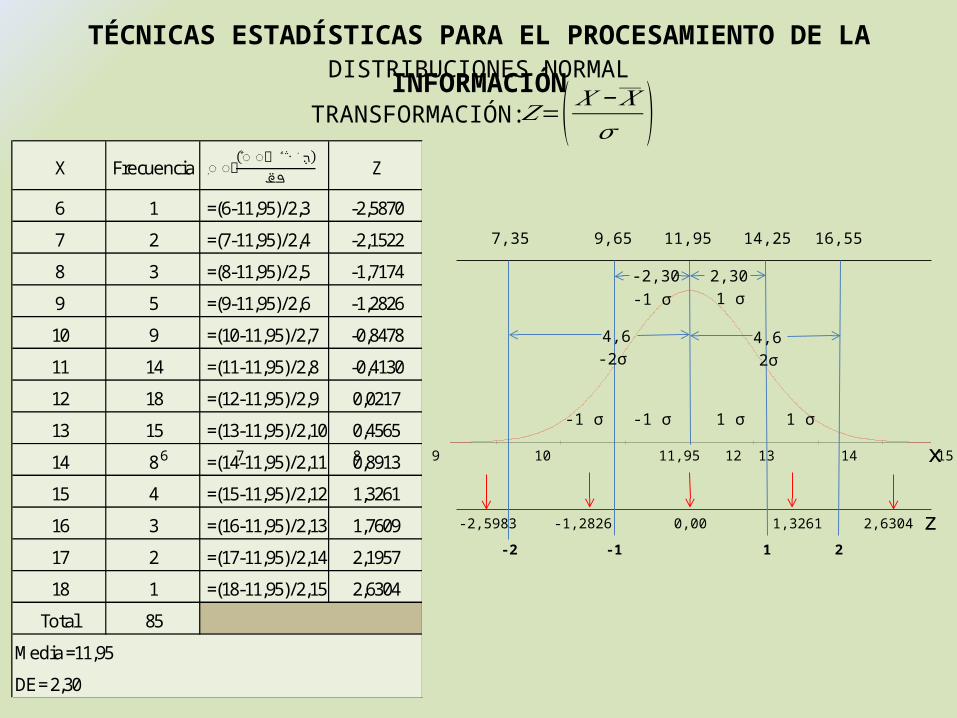
X Frecuencia Z
6 1 =(6-11,95)/2,3 -2,5870
7 2 =(7-11,95)/2,4 -2,1522
8 3 =(8-11,95)/2,5 -1,7174
9 5 =(9-11,95)/2,6 -1,2826
10 9 =(10-11,95)/2,7 -0,8478
11 14 =(11-11,95)/2,8 -0,4130
12 18 =(12-11,95)/2,9 0,0217
13 15 =(13-11,95)/2,10 0,4565
14 8 =(14-11,95)/2,11 0,8913
15 4 =(15-11,95)/2,12 1,3261
16 3 =(16-11,95)/2,13 1,7609
17 2 =(17-11,95)/2,14 2,1957
18 1 =(18-11,95)/2,15 2,6304
Total 85
Media =11,95
DE = 2,30
� ൌ��� ൌܯ�����
ܦܧ
TÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓNDISTRIBUCIONES NORMAL
TRANSFORMACIÓN:𝑍=( 𝑋 −𝑋𝜎 )
6 187 17 8 169 1510 14 11,95 12 13
-2,5983 2,6304 0,00-1,2826 1,3261
2,30
11,95 14,25
1 σ 1 σ
16,559,65
-1 σ
7,35
-1 σ
4,6
1 σ
2σ
1 2-1
-1 σ-2,30
4,6-2σ
-2
z
x

0,00000
0,05000
0,10000
0,15000
0,20000
0,25000
0,30000
0,35000
0,40000
0,45000
-3,00
-2,75
-2,50
-2,25
-2,00
-1,75
-1,50
-1,25
-1,00
-0,75
-0,50
-0,25 0,0
00,2
50,5
00,7
51,0
01,2
51,5
01,7
52,0
02,2
52,5
02,7
53,0
0
0,00000
0,05000
0,10000
0,15000
0,20000
0,25000
0,30000
0,35000
0,40000
0,45000
-3,00
-2,75
-2,50
-2,25
-2,00
-1,75
-1,50
-1,25
-1,00
-0,75
-0,50
-0,25 0,0
00,2
50,5
00,7
51,0
01,2
51,5
01,7
52,0
02,2
52,5
02,7
53,0
0
0,00000
0,05000
0,10000
0,15000
0,20000
0,25000
0,30000
0,35000
0,40000
0,45000
-3,00
-2,75
-2,50
-2,25
-2,00
-1,75
-1,50
-1,25
-1,00
-0,75
-0,50
-0,25 0,0
00,2
50,5
00,7
51,0
01,2
51,5
01,7
52,0
02,2
52,5
02,7
53,0
00 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
𝑌= 1𝜎 √2𝜋
𝑒−
(𝑋 −𝑋 )2
2𝜎2
N (X ,σ )
N (8 ,𝜎 2)
DISTRIBUCIONES NORMAL INTERPRETACIÓN GEOMÉTRICA
N (14 ,𝜎 2)N (19 ,𝜎2)
Podemos interpretar la media como un factor de TRASLACIÓN, para una Desviación Estándar constante:
La Desviación estándar como un factor de ESCALA, grado de dispersión, para una Media Constante:
0,00000
0,05000
0,10000
0,15000
0,20000
0,25000
0,30000
0,35000
0,40000
0,45000
-3,00
-2,75
-2,50
-2,25
-2,00
-1,75
-1,50
-1,25
-1,00
-0,75
-0,50
-0,25 0,0
00,2
50,5
00,7
51,0
01,2
51,5
01,7
52,0
02,2
52,5
02,7
53,0
00,00000
0,05000
0,10000
0,15000
0,20000
0,25000
0,30000
0,35000
0,40000
0,45000
-3,0
0
-2,7
5
-2,5
0
-2,2
5
-2,0
0
-1,7
5
-1,5
0
-1,2
5
-1,0
0
-0,7
5
-0,5
0
-0,2
5
0,0
0
0,2
5
0,5
0
0,7
5
1,0
0
1,2
5
1,5
0
1,7
5
2,0
0
2,2
5
2,5
0
2,7
5
3,0
0 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
N (𝑋 ,2,29)
N (𝑋 ,2,89)
TÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
0,00000
0,05000
0,10000
0,15000
0,20000
0,25000
0,30000
0,35000
0,40000
0,45000
-3,0
0
-2,7
5
-2,5
0
-2,2
5
-2,0
0
-1,7
5
-1,5
0
-1,2
5
-1,0
0
-0,7
5
-0,5
0
-0,2
5
0,0
0
0,2
5
0,5
0
0,7
5
1,0
0
1,2
5
1,5
0
1,7
5
2,0
0
2,2
5
2,5
0
2,7
5
3,0
0
N ¿
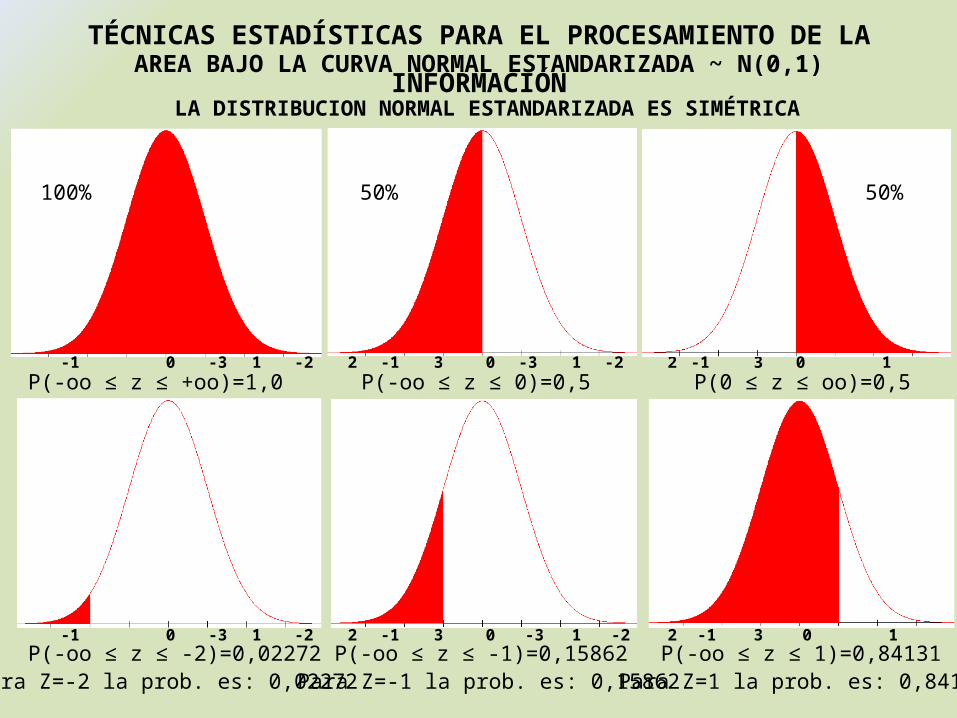
AREA BAJO LA CURVA NORMAL ESTANDARIZADA ~ N(0,1)
LA DISTRIBUCION NORMAL ESTANDARIZADA ES SIMÉTRICA
-3 -2 -1 0 1 2 3
100%
P(-oo ≤ z ≤ +oo)=1,0-3 -2 -1 0 1 2 3
50%
P(-oo ≤ z ≤ 0)=0,5-3 -2 -1 0 1 2 3
50%
P(0 ≤ z ≤ oo)=0,5
P(-oo ≤ z ≤ -2)=0,02272-3 -2 -1 0 1 2 3
Para Z=-2 la prob. es: 0,02272P(-oo ≤ z ≤ -1)=0,15862
-3 -2 -1 0 1 2 3
Para Z=-1 la prob. es: 0,15862P(-oo ≤ z ≤ 1)=0,84131
-3 -2 -1 0 1 2 3
Para Z=1 la prob. es: 0,84131
TÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

𝛼2
𝛼2
1−𝛼
=2,5% 1−𝛼=95% =2,5%
==-1,96Z
Z
=DOS COLAS
DOS COLAS
AREA BAJO LA CURVA NORMAL ESTANDARIZADA ~ N(0,1)TÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
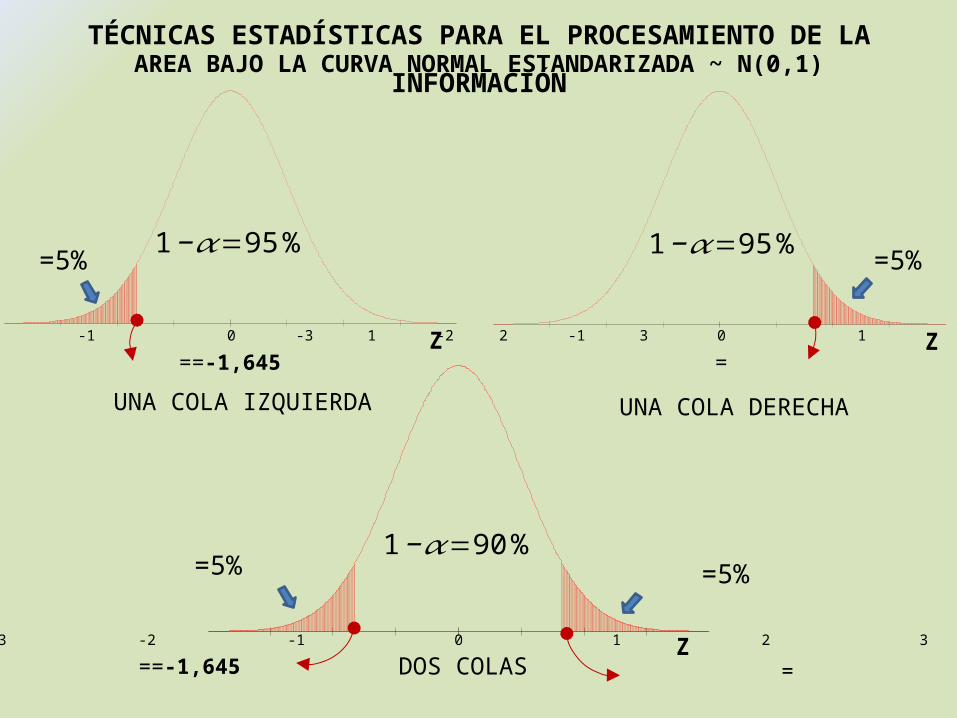
-3 -2 -1 0 1 2 3
-3 -2 -1 0 1 2 3 -3 -2 -1 0 1 2 3
=5% 1−𝛼=95%
==-1,645 Z
=
UNA COLA IZQUIERDA
1−𝛼=95%=5%
Z
UNA COLA DERECHA
=5%1−𝛼=90%
=5%
==-1,645Z
=DOS COLAS
AREA BAJO LA CURVA NORMAL ESTANDARIZADA ~ N(0,1)TÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
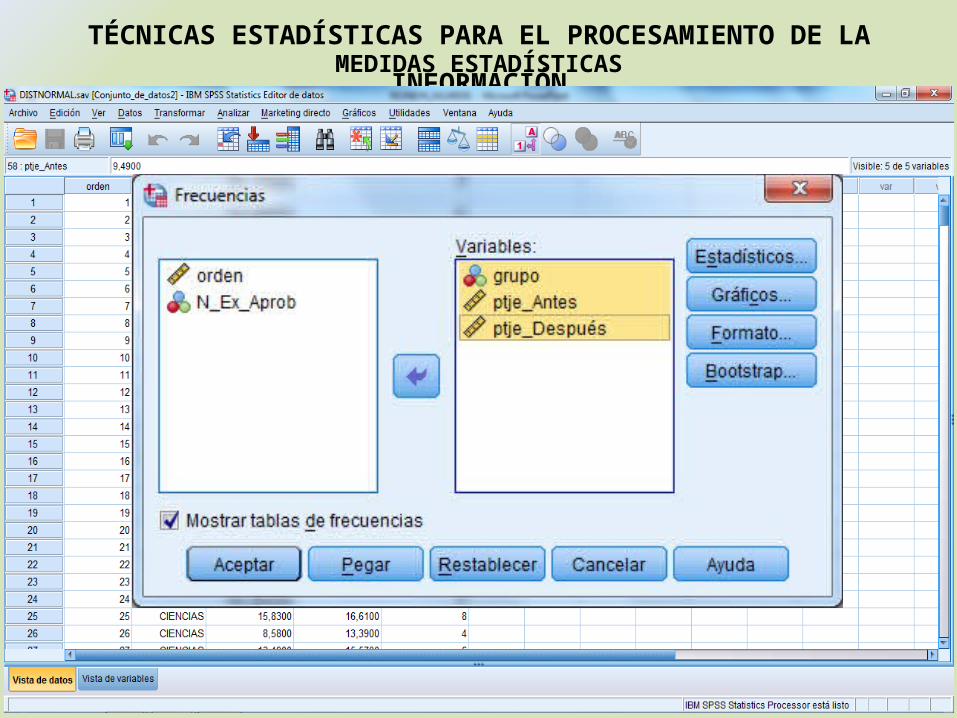
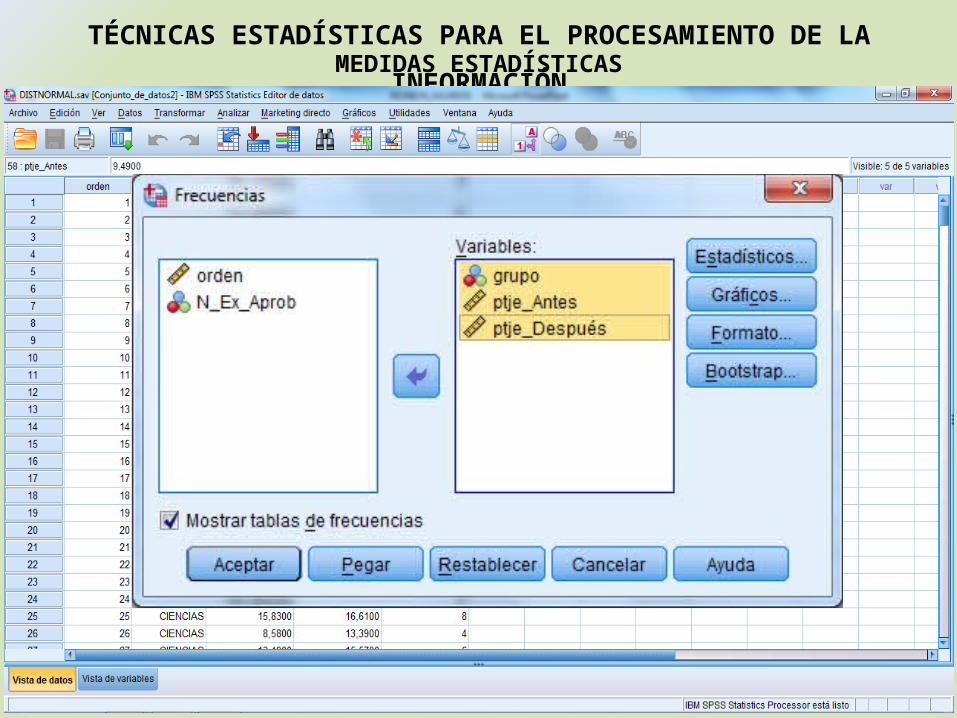
VARIABLES:
GRUPO: ESTUDIANTES DE CIENCIAS ESTUDIANTES DE SOCIALES
ptje_Antes: Promedio de 4 pruebas Antes de la intervención
ptje_Después: Promedio de 4 pruebas Después de la intervención
N_Ex_Aprob: Número de exámenes Aprobados, realizados antes y después de la intervención
PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

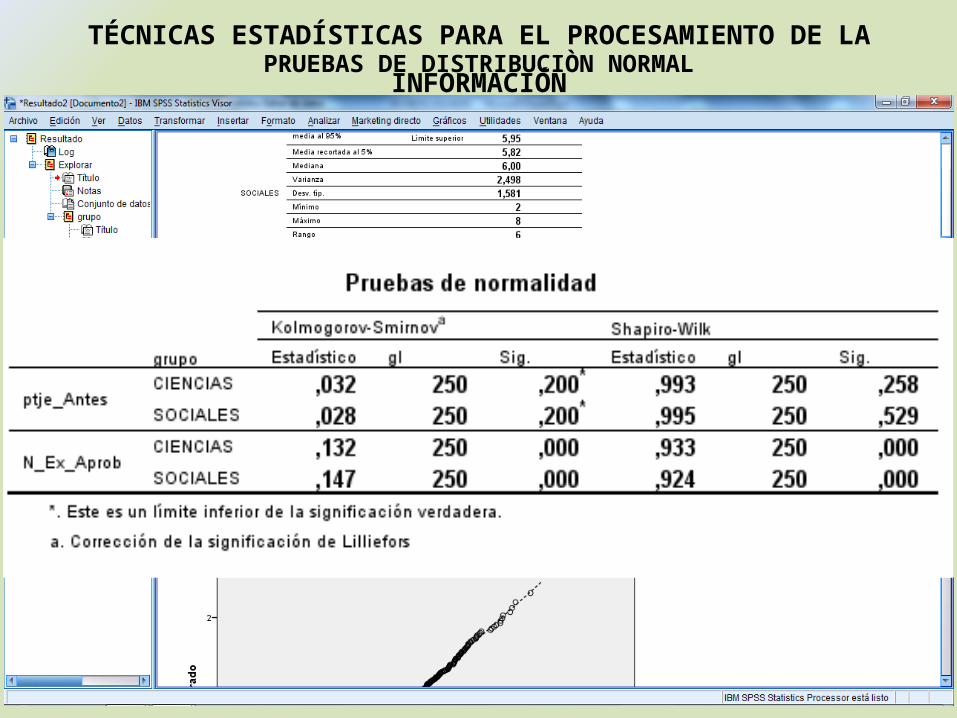
CIENCIAS: Sig=p=0,200>0,05 → Distribución Normal.
SOCIALES: Sig=p=0,200>0,05 → Distribución Normal.
El Las Pruebas de Normalidad es un contraste de ajuste que se utiliza para comprobar si unos datos determinados (X1, X2,…, Xn) han sido extraídos de una población normal. Los parámetros de la distribución no tienen porqué ser conocidos.
El test de Kolgomorov Smirnov.
Ho :Datos presentan distribuci ón normalH a :Datos No presentan distribuci ón normal
=p<0,05 se rechaza Ho y seacepta Ha.
PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
CIENCIAS: Sig=p=0,000<0,05 → Distribución No Normal.
SOCIALES: Sig=p=0,000<0,05 → Distribución No Normal.
Ptje_Antes
N_Ex_Aprob
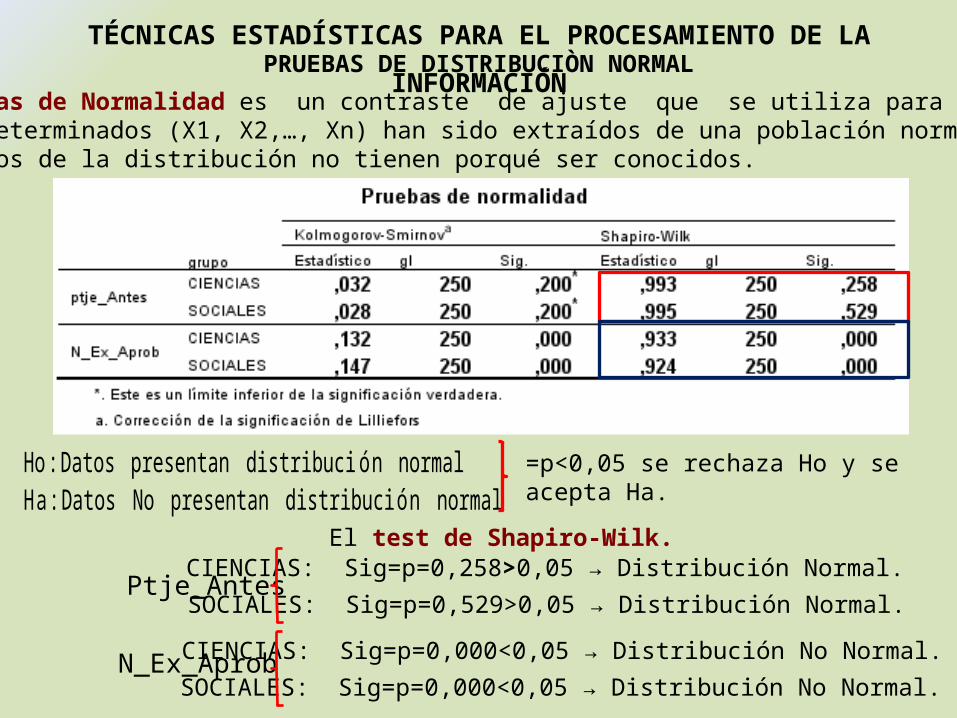
CIENCIAS: Sig=p=0,258>0,05 → Distribución Normal.
SOCIALES: Sig=p=0,529>0,05 → Distribución Normal.
El Las Pruebas de Normalidad es un contraste de ajuste que se utiliza para comprobar si unos datos determinados (X1, X2,…, Xn) han sido extraídos de una población normal. Los parámetros de la distribución no tienen porqué ser conocidos.
El test de Shapiro-Wilk.
Ho :Datos presentan distribuci ón normalH a :Datos No presentan distribuci ón normal
=p<0,05 se rechaza Ho y seacepta Ha.
PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
CIENCIAS: Sig=p=0,000<0,05 → Distribución No Normal.
SOCIALES: Sig=p=0,000<0,05 → Distribución No Normal.
Ptje_Antes
N_Ex_Aprob

PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
gráfico Q-Q Normal: Este gráfico permiten comprobar si las poblaciones de las que se han extraído las muestras presentan distribución normal.
Si los datos proceden de una distribución normal los puntos aparecen agrupados en torno a la línea recta esperada.PRESENTA DISTRIBUCIÓN NORMAL

PRUEBAS DE DISTRIBUCIÒN NORMALTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
El gráfico Q-Q Normal sin tendencia se basa en las diferencias entre los valores observados y los valores esperados bajo la hipótesis de normalidad.
Si estas diferencias se distribuyen aleatoriamente alrededor del eje de abscisas puede suponerse que la hipótesis de normalidad es sostenible.PRESENTA DISTRIBUCIÓN NORMAL
MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
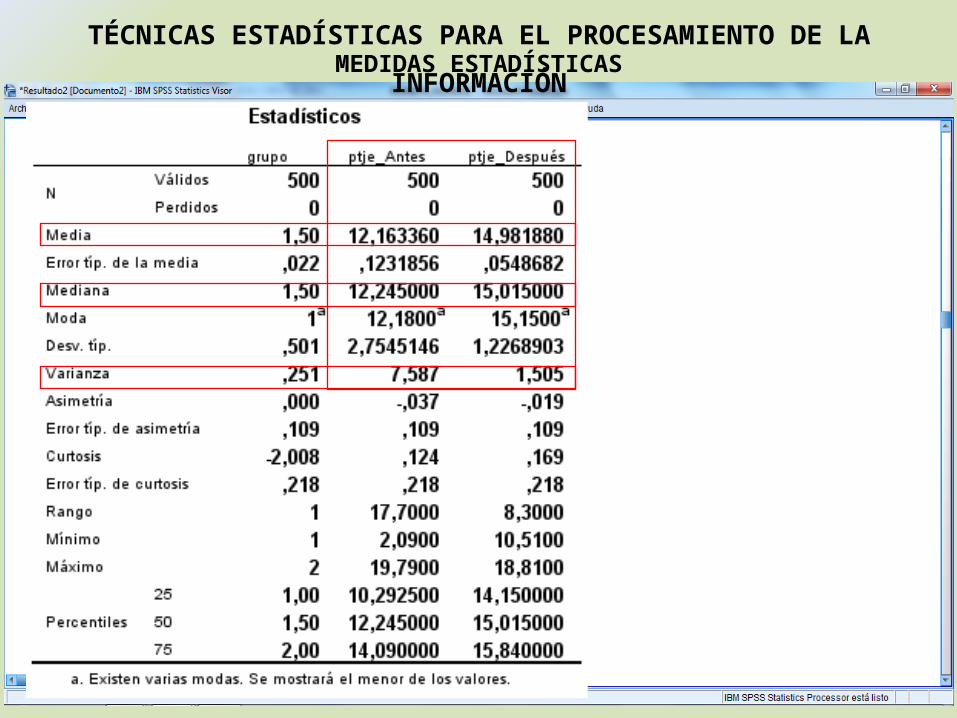
MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
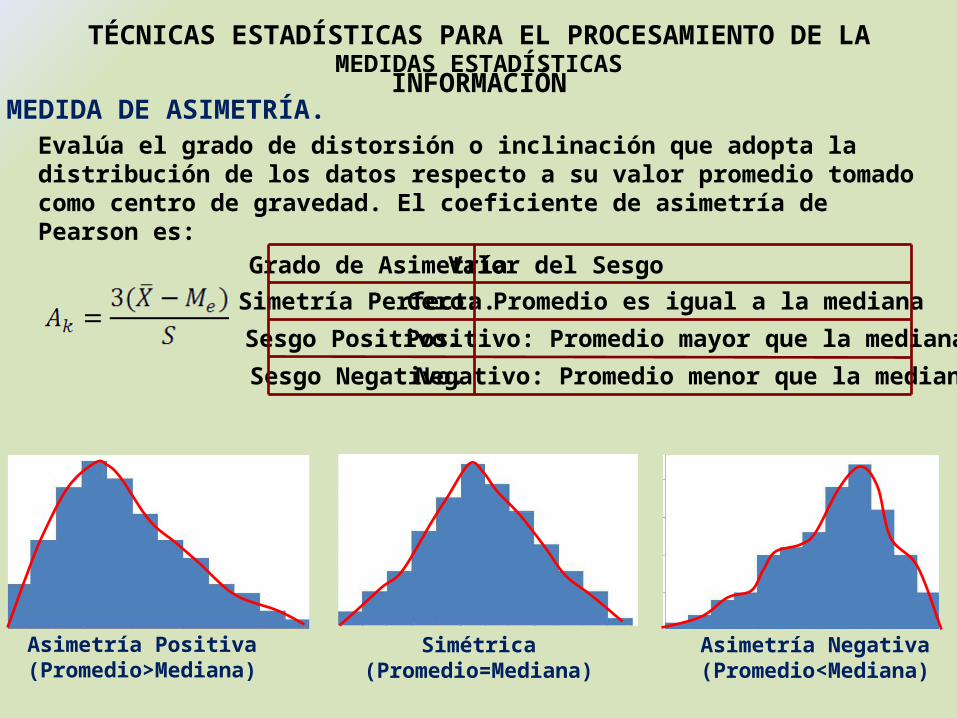
MEDIDA DE ASIMETRÍA.Evalúa el grado de distorsión o inclinación que adopta la distribución de los datos respecto a su valor promedio tomado como centro de gravedad. El coeficiente de asimetría de Pearson es:
Grado de Asimetría Valor del SesgoSimetría Perfecta. Cero: Promedio es igual a la mediana
Sesgo Positivo. Positivo: Promedio mayor que la mediana)
Sesgo Negativo. Negativo: Promedio menor que la mediana
Asimetría Positiva(Promedio>Mediana)
Simétrica(Promedio=Mediana)
Asimetría Negativa(Promedio<Mediana)
MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN

MEDIDA DE CURTOSIS.Evalúa el grado de apuntamiento de la distribución, el coeficiente es K:
Grado de Apuntamiento Valor del SesgoMesocúrtica (Distribución Normal). 0.263
Leptocúrtica (Elevada). Mayor a 0.263 ó se aproxima a 0.5
Platicúrtica (Aplanada). Menor a 0.263 ó se aproxima a 0
MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
Mesocúrtica LeptocúrticaPlaticúrtica
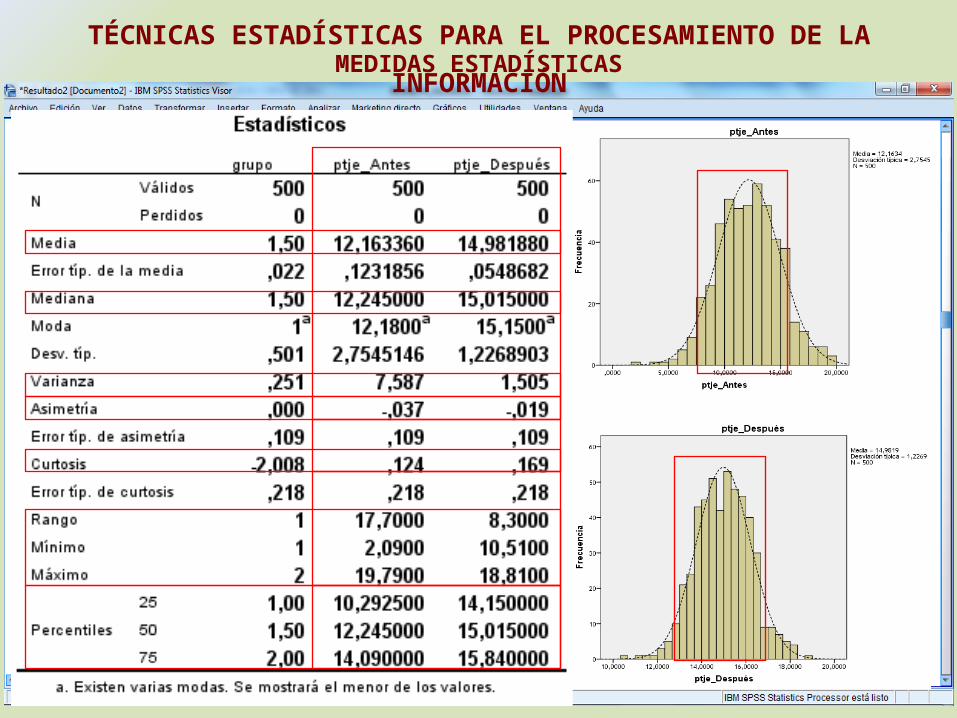
MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
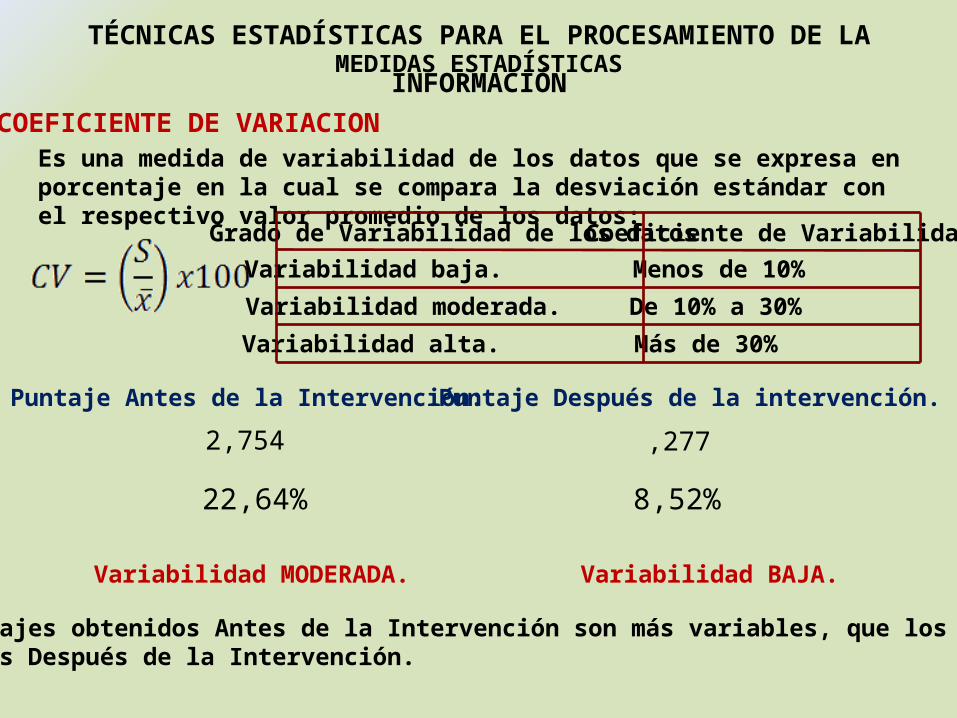
MEDIDAS ESTADÍSTICASTÉCNICAS ESTADÍSTICAS PARA EL PROCESAMIENTO DE LA INFORMACIÓN
COEFICIENTE DE VARIACIONEs una medida de variabilidad de los datos que se expresa en porcentaje en la cual se compara la desviación estándar con el respectivo valor promedio de los datos:
Grado de Variabilidad de los datos. Coeficiente de VariabilidadVariabilidad baja. Menos de 10%
Variabilidad moderada. De 10% a 30%
Variabilidad alta. Más de 30%
Puntaje Antes de la Intervención: Puntaje Después de la intervención.
Variabilidad MODERADA. Variabilidad BAJA.
Los puntajes obtenidos Antes de la Intervención son más variables, que los puntajesobtenidos Después de la Intervención.
2,754 ,277
22,64% 8,52%

TAMAÑO DE MUESTRA
POBLACIÓN HOMOGENEA
ESTRATIFICAR LA POBLACIÓN
ESTRATO 1 ESTRATO 2
POBLACIÓN HETEROGENEA
MUESTRAREPRESENTATIVA
MUESTRAREPRESENTATIVA
ESTRATO 1
MUESTRAREPRESENTATIVA
ESTRATO 2

TAMAÑO DE MUESTRA¿CÓMO SELECCIONAR UNA MUESTRA?
Seleccionar una muestra apropiada para la investigación requiere:
1. DEFINIR LOS SUJETOS U OBJETOS QUE VAN A SER MEDIDOS.
PREGUNTA DE INVESTIGACIÓN UNIDAD DE ANÁLISIS ERRONEA UNIDAD DE ANÁLISIS CORRECTA
Error: No hay grupo de comparación
Error: La pregunta propone indagar sobre actitudes individuales y esta unidad de análisis denota datos agregados en una estadística laboral y macrosocial
Error: Se procederá a describir únicamente como perciben los adolescentes la relación con sus padres
¿Discriminan a las mujeres en los anuncios de televisión?
¿Hay problemas de comunicación entre padres e
hijos?
Mujeres que aparecen en los anuncios de la televisión
Contar el número de conflictos sindicales registrados en Conciliación y Arbitraje durante los últimos cinco años.
Grupo de adolescentes se aplicara cuestionario
Mujeres y hombres que aparecen en los anuncios de televisión para comparar y determinar si hay diferencias entre los dos grupos
Muestra de obreros que trabajan en el área metropolitana cada uno de los cuales contestara a las preguntas de un cuestionario
Grupo de padres e hijos. A ambas partes se les aplicará el cuestionario
¿Están los obreros del área metropolitana satisfechos con
su trabajo?

TAMAÑO DE MUESTRA¿CÓMO SELECCIONAR UNA MUESTRA?
Seleccionar una muestra apropiada para la investigación requiere:
2. DELIMITAR LA POBLACIÓN.
PREGUNTA DE INVESTIGACIÓN UNIDAD DE ANÁLISIS POBLACION DELIMITADA
¿Discriminan a las mujeres en los anuncios de televisión?
¿Hay problemas de comunicación entre padres e
hijos?
Mujeres y hombres que aparecen en los anuncios de televisión para comparar y determinar si hay diferencias entre los dos grupos
Muestra de obreros que trabajan en el área metropolitana cada uno de los cuales contestara a las preguntas de un cuestionario
Grupo de padres e hijos. A ambas partes se les aplicará el cuestionario
¿Están los obreros del área metropolitana satisfechos con
su trabajo?
Selección de spots publicitarios transmitidos durante los meses de septiembre y octubre del 2013.
Obreros de construcción civil en planillas en compañías constructoras formalizadas.
Padres e hijos católicos de colegios parroquiales de Lima metropolitana.
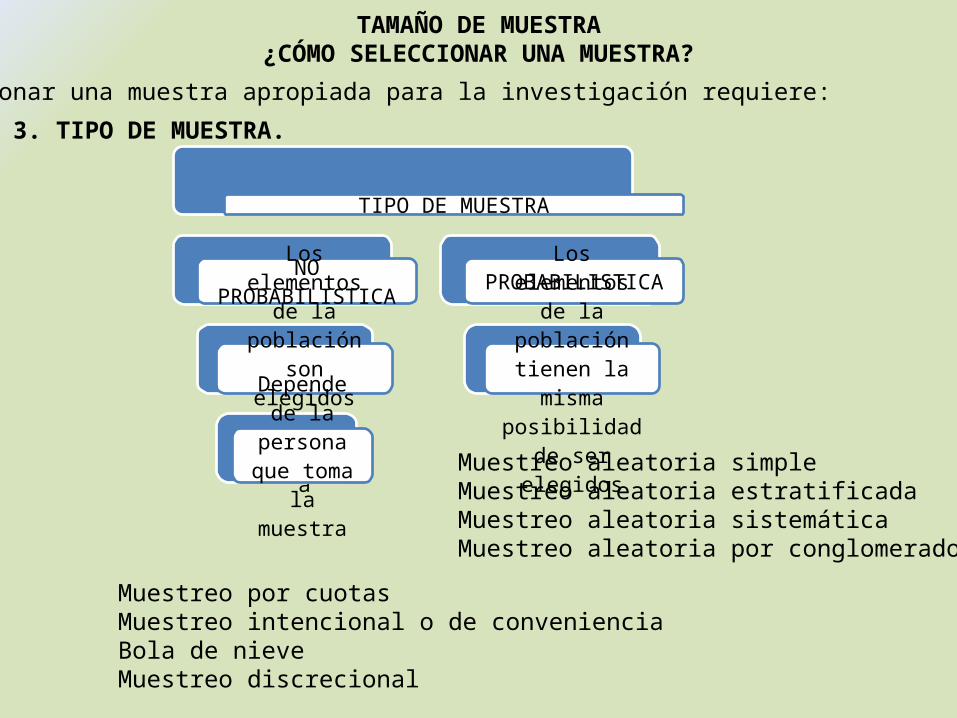
TAMAÑO DE MUESTRA¿CÓMO SELECCIONAR UNA MUESTRA?
Seleccionar una muestra apropiada para la investigación requiere:
3. TIPO DE MUESTRA.
TIPO DE MUESTRA
NO PROBABILISTICA
Los elementos de la población
son elegidos por convenienciaDepende de la persona
que toma la muestra
PROBABILISTICA
Los elementos de la población tienen la misma posibilidad de ser elegidos
Muestreo aleatoria simpleMuestreo aleatoria estratificadaMuestreo aleatoria sistemáticaMuestreo aleatoria por conglomerados
Muestreo por cuotasMuestreo intencional o de convenienciaBola de nieveMuestreo discrecional
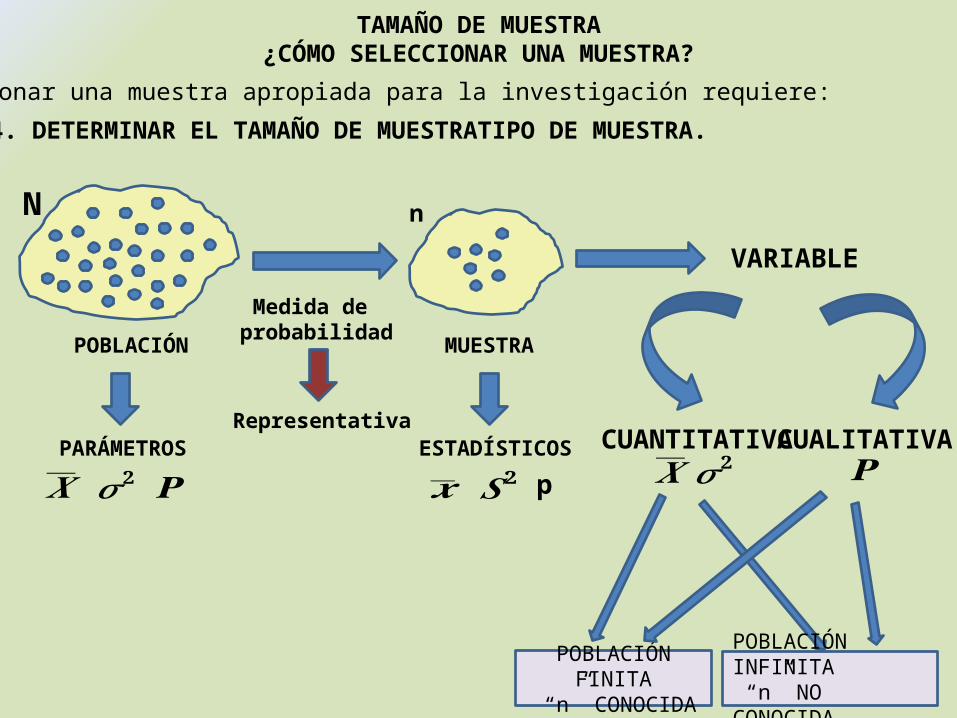
nN
POBLACIÓN
PARÁMETROS
𝑿𝝈𝟐𝐏
Medida de probabilidad
Representativa
MUESTRA
ESTADÍSTICOS
𝒙𝑺𝟐 p
VARIABLE
CUANTITATIVA CUALITATIVA𝑿𝝈𝟐 𝐏
POBLACIÓN FINITA “n” CONOCIDA
POBLACIÓN INFINITA “n” NO CONOCIDA
Seleccionar una muestra apropiada para la investigación requiere:
4. DETERMINAR EL TAMAÑO DE MUESTRATIPO DE MUESTRA.
TAMAÑO DE MUESTRA¿CÓMO SELECCIONAR UNA MUESTRA?
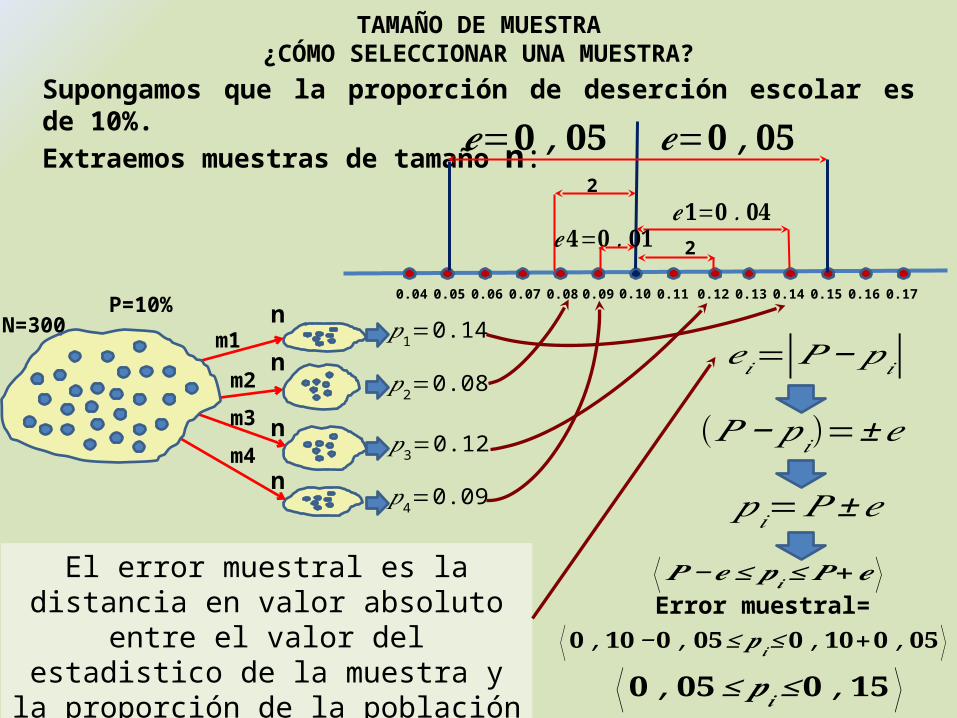
El error muestral es la distancia en valor absoluto entre el valor del estadistico de la
muestra y la proporción de la población tomada como verdadera.
Supongamos que la proporción de deserción escolar es de 10%.Extraemos muestras de tamaño n:
nm1 𝑝1=0.14
nm2 𝑝2=0.08
nm3𝑝3=0.12
nm4
𝑝4=0.09
0.100.09 0.11 0.12 0.13 0.14 0.16 0.170.150.080.070.060.050.04
𝒆𝟏=𝟎 .𝟎𝟒
P=10%N=300
2
2𝒆𝟒=𝟎 .𝟎𝟏
𝒆=𝟎 ,𝟎𝟓 𝒆=𝟎 ,𝟎𝟓
𝑒𝑖=|𝑃−𝑝𝑖|
(𝑃 −𝑝𝑖)=±𝑒
𝑝𝑖=𝑃±𝑒
⟨𝑷−𝒆≤𝒑𝒊≤𝑷+𝒆⟩Error muestral=
TAMAÑO DE MUESTRA¿CÓMO SELECCIONAR UNA MUESTRA?
⟨𝟎 ,𝟏𝟎−𝟎 ,𝟎𝟓≤𝒑𝒊≤𝟎 ,𝟏𝟎+𝟎 ,𝟎𝟓 ⟩⟨𝟎 ,𝟎𝟓≤𝒑𝒊≤𝟎 ,𝟏𝟓⟩
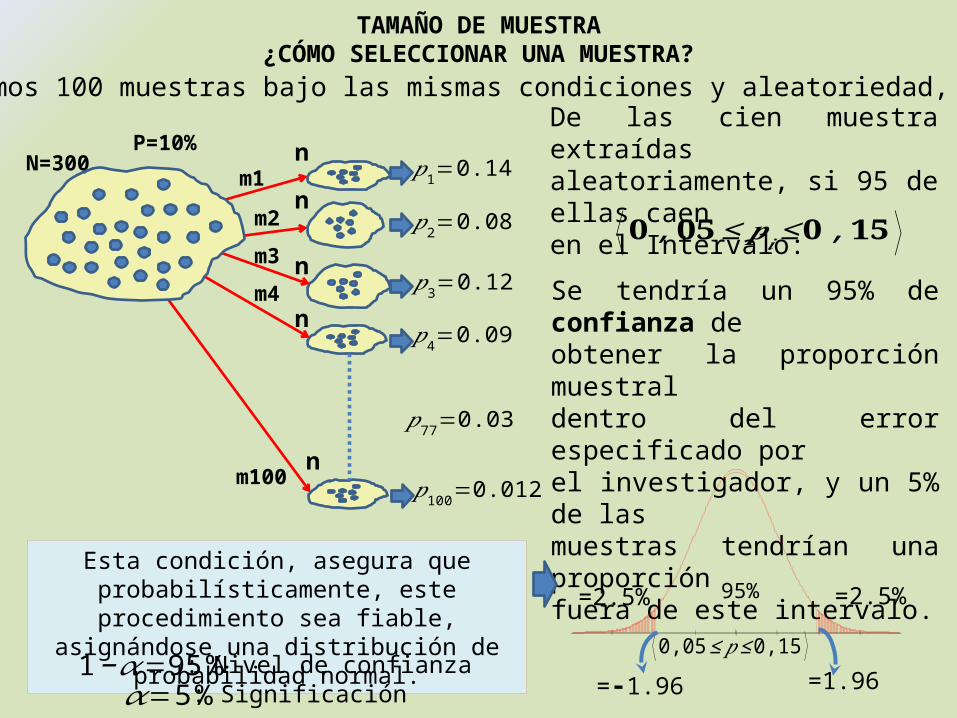
Si eligiéramos 100 muestras bajo las mismas condiciones y aleatoriedad, tendríamos:
nm1 𝑝1=0.14
nm2 𝑝2=0.08
nm3𝑝3=0.12
nm4
𝑝4=0.09
P=10%N=300
nm100 𝑝100=0.012
𝑝77=0.03
De las cien muestra extraídas aleatoriamente, si 95 de ellas caenen el Intervalo:
Se tendría un 95% de confianza deobtener la proporción muestraldentro del error especificado porel investigador, y un 5% de lasmuestras tendrían una proporciónfuera de este intervalo.
95% =2.5%=2.5%
⟨0,05≤𝑝≤0,15 ⟩
Esta condición, asegura que probabilísticamente, este procedimiento sea fiable, asignándose una
distribución de probabilidad normal.
=1.96=-1.961−𝛼=95%: Nivel de confianza
𝛼=5% : Significación
TAMAÑO DE MUESTRA¿CÓMO SELECCIONAR UNA MUESTRA?
⟨𝟎 ,𝟎𝟓≤𝒑𝒊≤𝟎 ,𝟏𝟓⟩

Se sabe que para una proporción se cumple la siguiente relación:
95%=2.5%=2.5%
⟨ 𝑃−𝑒≤𝑝≤ 𝑃+𝑒 ⟩=1.96=-1.96
𝑍=𝑃 −𝑝𝑖
√𝑝𝑖(1−𝑝𝑖)𝑛
Además para un: obtenemos despejando,𝑍1− 𝛼
2
)=
(𝑃 −𝑝𝑖)=±𝑒
⟨𝑃 −𝑒≤𝑝𝑖≤ 𝑃+𝑒 ⟩Despejando:
=Despejando n, obtenemos: 𝑛=
(𝑍1− 𝛼2
2 )𝑝 (1−𝑝)
𝑒2
TAMAÑO DE MUESTRA¿CÓMO SELECCIONAR UNA MUESTRA?

VARIABLE
CUANTITATIVACUALITATIVA
𝑛=(𝑍1− 𝛼
2
2 )𝑝 (1−𝑝)
𝑒2
𝑛=
𝑁 (𝑍1−𝛼2
2 )𝑝(1−𝑝)
𝑒2 (𝑁−1 )+(𝑍1−𝛼2
2 )𝑝(1−𝑝)
POBLACIÓNINFINITA
POBLACIÓNFINITA
𝑝=𝑝𝑟𝑜𝑝𝑜𝑟𝑐𝑖ó𝑛𝑜𝑝𝑟𝑒𝑣𝑎𝑙𝑒𝑛𝑐𝑖𝑎𝑒=𝑒𝑟𝑟𝑜𝑟𝑚𝑢𝑒𝑠𝑡𝑟𝑎𝑙
1−α=𝑁𝑖𝑣𝑒𝑙𝑑𝑒𝑐𝑜𝑛𝑓𝑖𝑎𝑛𝑧𝑎
𝑛=(𝑍1− 𝛼
2
2 )𝑆2
𝑒2
𝑛=
𝑁 (𝑍1−𝛼2
2 )𝑆2
𝑒2 (𝑁−1 )+(𝑍1−𝛼2
2 )𝑆2
𝑆2=𝑝𝑟𝑜𝑝𝑜𝑟𝑐𝑖 ó𝑛𝑜𝑝𝑟𝑒𝑣𝑎𝑙𝑒𝑛𝑐𝑖𝑎𝑒=𝑒𝑟𝑟𝑜𝑟𝑚𝑢𝑒𝑠𝑡𝑟𝑎𝑙
1−α=𝑁𝑖𝑣𝑒𝑙𝑑𝑒𝑐𝑜𝑛𝑓𝑖𝑎𝑛𝑧𝑎
Si se cumple la siguiente condición:N>n(n-1), n es el tamaño de muestra Adecuado, si no calcular:
𝑛∗=𝑛
1−𝑛𝑁
TAMAÑO DE MUESTRA ALEATORIA SIMPLE¿CÓMO SELECCIONAR UNA MUESTRA?

1. PROBLEMAS DE APLICACIÓN:
TAMAÑO DE MUESTRA ALEATORIA SIMPLE¿CÓMO SELECCIONAR UNA MUESTRA?
¿Cuál es el número óptimo para un estudio de 60000 personas inscritas en cursos de formación, en el cual se establece un nivel de confianza de 95%, un margen de error de 3%. Suponemos que la opción por inscribirse en cursos de formación, o no, es del 50%?
Datos:
N=60000
1−𝛼=0,950,030,50
0,50
𝑛=
𝑁 (𝑍1−𝛼2
2 )𝑝(1−𝑝)
𝑒2 (𝑁−1 )+(𝑍1−𝛼2
2 )𝑝(1−𝑝)
𝑛=60000 (3,8416 )(0,50)(1−0,50)
(0,03)2 (60000−1 )+ (3,8416 )(0,50)(1−0,50)
𝑍 0,952 =(1,96)2=3,8416
𝑛=382
𝑛∗=382
1+382
60000
𝑛∗=380
se ajusta el tamaño muestral
60000<382(382−1) 60000<145542

El Ministerio de Trabajo planea un estudio con el interés de conocer el promedio de horas semanales trabajadas por las mujeres del servicio doméstico. La muestra será extraída de una población de 10000 mujeres que figuran en los registros de la Seguridad Social y de las cuales se conoce a través de un estudio piloto que su varianza (S2) es de 9.648. Trabajando con un nivel de confianza de 0.95 y estando dispuestos a admitir un error máximo de 0,1, ¿Cuál debe ser el tamaño muestral que empleemos?.
2. PROBLEMAS DE APLICACIÓN:
TAMAÑO DE MUESTRA ALEATORIA SIMPLE¿CÓMO SELECCIONAR UNA MUESTRA?
Datos:
N=10000
1−𝛼=0,950,1S2=9,648
𝑛=
𝑁 (𝑍1−𝛼2
2 )𝑆2
𝑒2 (𝑁−1 )+(𝑍1−𝛼2
2 )𝑆2
𝑛=10000 (3,8416 )(9,648)2
(0,1)2 (10000−1 )+(3,8416 )𝑆2
𝑍 0,952 =(1,96)2=3,8416
𝑛=850 se ajusta el tamaño muestral
10000<852(852−1) 10000<725052𝑛∗=
852
1+852
10000
𝑛∗=785

INSTITUTO PARA LA CALIDAD DE LA EDUCACIÓNSECCIÓN DE POSTGRADO
DIPLOMADO DE ESPECIALIZACIÓN DE POSTGRADO EN ASESORÍA DE TESIS
MÓDULO: DISEÑO DE INVESTIGACIÓN Y OPERACIONALIZACIÓN DE VARIABLES
EXPOSITOR: RONALD JOSÉ TORRES MARTÍNEZ
AGOSTO/17 – 2014