redes neuronales artificiales
DESCRIPTION
Redes neuronales artificialesTRANSCRIPT

Clase 07 - Redes Neuronales Artificiales
Julián D. Arias LondoñoProfesor Asistente Departamento de Ingeniería de Sistemas Grupo de Simulación de Comportamiento de Sistemas - SICOIS Universidad de Antioquia,Medellín, Colombia [email protected]
Una de las principales razones que inspiró la aparición de las redes neuronales artificiales (en inglés Artificial Neural Networks - ANN), es el hechode que las tareas cognitivas complejas realizadas por el ser humano, requieren un nivel de paralelismo el cual es llevado a cabo a través de unacompleja red de neuronas interconectadas.
In [5]: from IPython.display import Imagei = Image(filename='FiguresClass/RNA1.png')i
Out[5]:
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
1 of 18 16/06/14 18:02

Algunas estadísticas interesantes que nos ayudan a entender el poder de la red de neuronas en el ser humano:Se estima que el cerebro humano contiene una densa red de neuronas interconectadas de alrededor de neuronas.Cada neurona se conecta en promedio con otras neuronas.La actividad de las neuronas es típicamente exitada o inhibida a través de las conexiones con otras neuronas.La velocidad de cambio de estado de una neurona en el mejor de los casos es del orden de seg. Comparado con los computadores actualeses estramadamente lento. Sin embargo los humanos pueden tomar decisiones sorprendentemente complejas en muy poco tiempo. Por ejemplo Udrequiere aproximadamente segs reconocer visualmente a su madre.
El perceptrón
Uno de los tipos más usados de RNA está basado en una unidad llamada Perceptr´on. Un perceptrón toma un vector de valores reales comoentrada, calcula una combinación lineal de dichas entradas y produce una salida 1 si el resultado es mayor a algún umbral y -1 en otro caso.
In [2]: from IPython.display import Imagei = Image(filename='FiguresClass/Perceptron.png')i
De manera más precisa, dada una muestra , la salida computada por el perceptrónes:
1011
104
10−3
10−1
Out[2]:
x = { , , . . . , }x1 x2 xd O(x) = O( , , . . . , )x1 x2 xd
O( , , . . . , ) = {1 si + + + ⋯ + > 0x1 x2 xd w0 w1x1 w2x2 wdxd
O( , , . . . , ) = {−1 en otro casox1 x2 xd
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
2 of 18 16/06/14 18:02

donde es una constante real o peso que determina la contribución de la entrada a la salida del perceptrón. Note que es el umbral quela combinación sopesada de entradas debe sobrepasar para que la salida del perceptrón sea 1.
Una forma alternativa de pensar el perceptrón, y que para nosotros es familiar, es asumir que existe una entrada adicional con valor constante 1,, de tal forma que la inecuación anterior se puede escribir como:
o en forma matricial, simplemente . La determinación del valor a la salida del perceptrón se representa normalmente como la funciónsigno (sgn), entonces la función de salida del perceptrón se puede reescribir como:
donde
El perceptrón puede se visto como la representación de una superficie de decisión en el espacio -dimensional en el cual se ubican las muestras. Elperceptrón asigna valores 1 para las muestras (puntos) que se ubican a un lado del hiperplano y −1 para las que se ubican al otro lado.
wi xi −w0
+ + ⋯ +w1x1 w2x2 wdxd
= 1x0
> 0∑i=0
d
wixi
x > 0wT
O(x) = sgn( x)wT
sgn(u) = {1 si u > 0sgn(u) = {−1 en otro caso
d
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
3 of 18 16/06/14 18:02

In [8]: from IPython.display import Imagei = Image(filename='FiguresClass/Perceptron2.png')i
Entrenamiento del perceptrón
Una forma de entrenar un vector de pesos es comenzar con pesos aleatorios, aplicar iterativamente el perceptrón a cada muestra de entrenamientomodificando los pesos cada vez que una muestra sea mal clasificada y repitiendo el procedimiento tantas veces como sea posible hasta que todaslas muestras sean bien clasificadas:
donde
donde es la salida deceseada para la muestra . Sin embargo este procedimiento solo funciona cuando las muestras son linealmenteseparales.
Una forma alternativa que puede ser utilizada aún cuando las muestras no sean linealmente separables, es definir una medida de error e intentarminizarlo a través de una regla de gradiente. Es decir, si asumimos:
Out[8]:
← + Δwi wi wi
Δ = η( − O( ))wi yj xj xji
yj xj
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
4 of 18 16/06/14 18:02

podemos utilizar la regla del gradiente descedente para encontrar el conjunto de pesos que hagan el error mínimo (no tiene que ser cero). El únicoinconveniente es que la salida del percetrón depende de la función sgn y la regla del gradiente necesita calcular la derivada. Sin embargo podemosasumir que si tiende a 1 (o −1 según sea del caso), la aplicación de la función sgn obtendrá por consiguiente un buen resultado.
Consideremos ahora el tipo de problemas que podremos resolver utilizando un solo perceptron.
In [9]: from IPython.display import Imagei = Image(filename='FiguresClass/ORANDXOR.png')i
La gráfica anterior nos muestra 3 problemas de clasifiación haciendo una analogía a las funciones Booleanas OR, AND y XOR. Es posible observarque los dos primeros problemas de clasificación se pueden resolver a partir de una frontera de decisión lineal, sin embargo, en la última gráfica noes posible separa las círculos negros de los círculos blancos utilizando únicamente una función lineal.
Como sabemos, la función XOR se puede construir a partir de funciones AND y funciones OR. De la misma forma podemos resolver el problema dela gráfica 3 utilizando la combinación de dos fronteras de decisión lineales:
E = ( − O( )1N
∑j=1
N
yj xj )2
xwT
Out[9]:
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
5 of 18 16/06/14 18:02

In [10]: from IPython.display import Imagei = Image(filename='FiguresClass/XOR.png')i
Si utilizamos la combinación de perceptrones mostrada en la figura, podremos obtener una salida del modelo para la zona sombreada yuna salida para el resto del espacio, obteniendo de esa manera una clasificación perfecta. La red de perceptrones interconectados de lafigura anterior coresponde entonces a una Red Neuronal Artificial, en la que cada neurona es un perceptrón y la combinación de los perceptrones,que son modelos simples, permitió la solución de un problema más complejo.
El problema que surge en este momento, es que el algoritmo de entrenamiento que fue descrito para un único perceptrón no puede ser aplicado eneste caso, debido a que ahora en la salida de toda la red intervienen varios perceptrones, razón por la cual es necesario aplicar la función sgn antesde poder obtener la salida final de la red y por consiguiente el método de gradiente no puede ser aplicado porque la función de salida de la rednuevamente es NO derivable.
Para poder resolver el problema, debemos entonces encontrar una función equivalente a la función sgn, pero que pueda ser derivable para poderusar el error cuadrático medio como criterio de entrenamiento. Una solución es la función sigmoide:
Out[10]:
a = 1a = 0
f(u) =exp(u)
1 + exp(u)
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
6 of 18 16/06/14 18:02

In [11]: u=linspace(-10,10,100)g = np.exp(u)/(1 + exp(u))plt.plot(u,g)
La función sigmoide es derivable: .
También se suele usar la tangente hiperbólica:
Out[11]: [<matplotlib.lines.Line2D at 0x3134710>]
= f(u)(1 − f(u))∂f(u)∂wi
∂u
∂wi
f(u) =exp(u) − exp(−u)exp(u) + exp(−u)
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
7 of 18 16/06/14 18:02
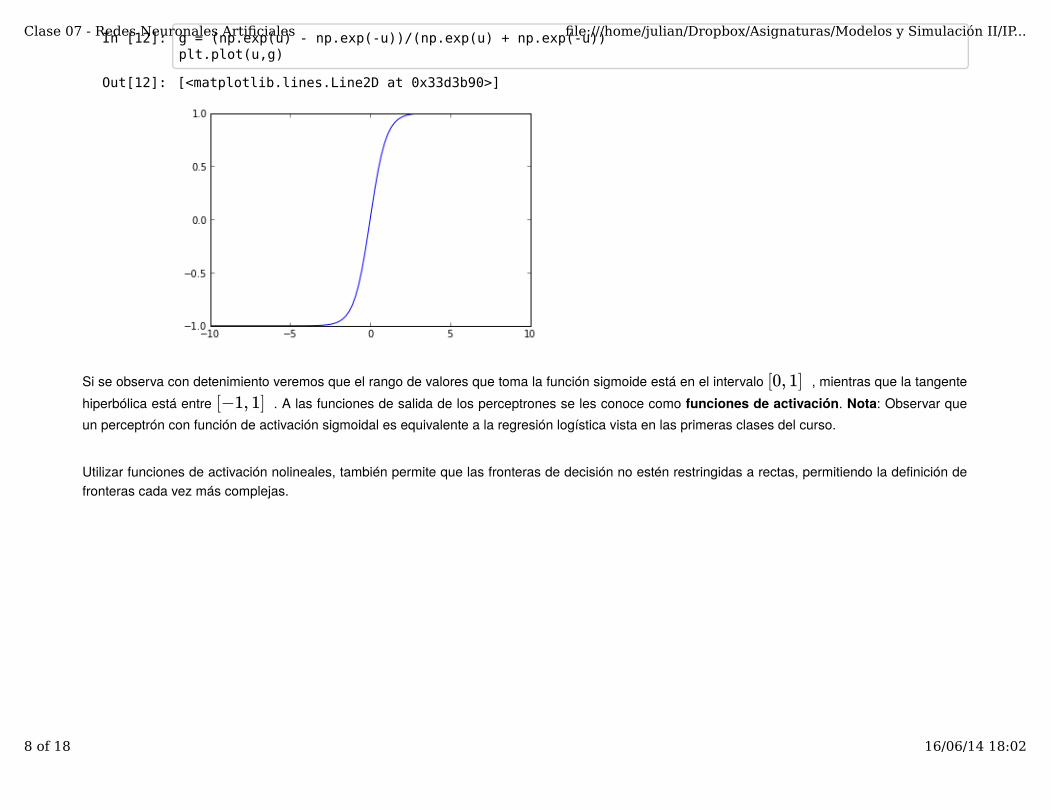
In [12]: g = (np.exp(u) - np.exp(-u))/(np.exp(u) + np.exp(-u))plt.plot(u,g)
Si se observa con detenimiento veremos que el rango de valores que toma la función sigmoide está en el intervalo , mientras que la tangentehiperbólica está entre . A las funciones de salida de los perceptrones se les conoce como funciones de activación. Nota: Observar queun perceptrón con función de activación sigmoidal es equivalente a la regresión logística vista en las primeras clases del curso.
Utilizar funciones de activación nolineales, también permite que las fronteras de decisión no estén restringidas a rectas, permitiendo la definición defronteras cada vez más complejas.
Out[12]: [<matplotlib.lines.Line2D at 0x33d3b90>]
[0, 1][−1, 1]
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
8 of 18 16/06/14 18:02
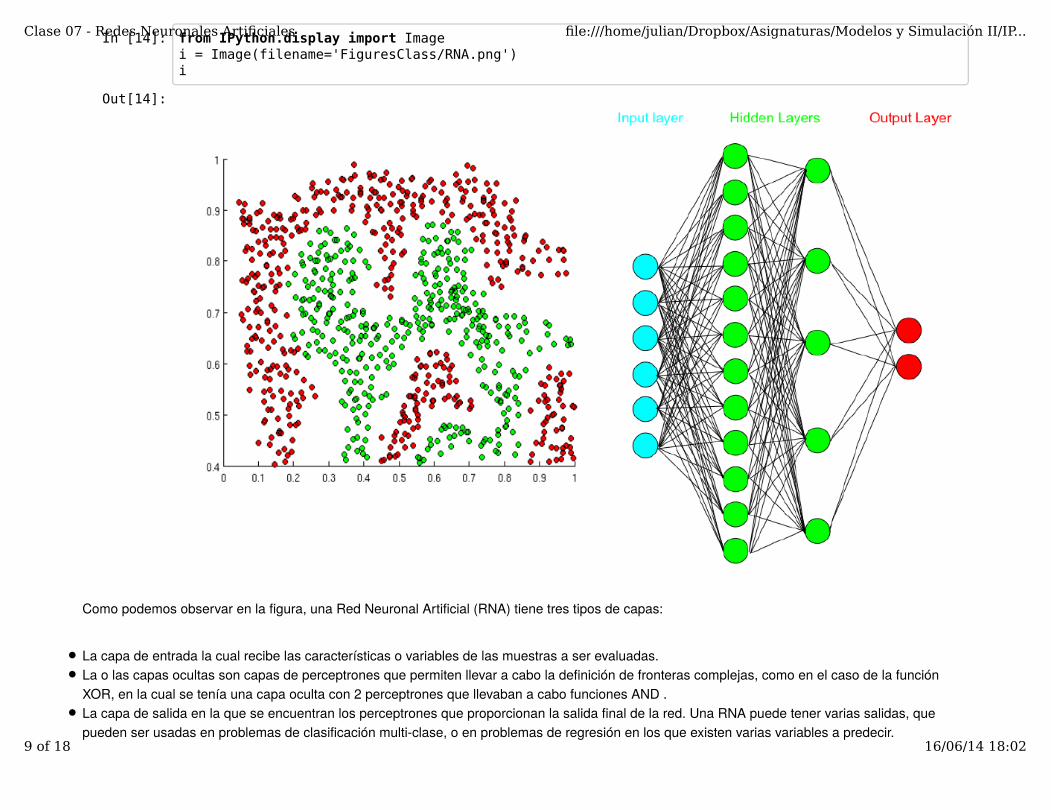
In [14]: from IPython.display import Imagei = Image(filename='FiguresClass/RNA.png')i
Como podemos observar en la figura, una Red Neuronal Artificial (RNA) tiene tres tipos de capas:
La capa de entrada la cual recibe las características o variables de las muestras a ser evaluadas.La o las capas ocultas son capas de perceptrones que permiten llevar a cabo la definición de fronteras complejas, como en el caso de la funciónXOR, en la cual se tenía una capa oculta con 2 perceptrones que llevaban a cabo funciones AND .La capa de salida en la que se encuentran los perceptrones que proporcionan la salida final de la red. Una RNA puede tener varias salidas, quepueden ser usadas en problemas de clasificación multi-clase, o en problemas de regresión en los que existen varias variables a predecir.
Out[14]:
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
9 of 18 16/06/14 18:02

Algoritmo Backpropagation
El algoritmo Backpropagation ajusta (aprende) los pesos de una red multicapa, dada una estructura de red con un conjunto fijo de unidades einterconexiones.
El criterio de entrenamiento empleado es la minimización del error cuadrático medio entre las salidas de la red y los valores deseados (objetivos)para dichas salidas. El algoritmo utiliza un técnica de gradiente descendente para llevar a cabo el entrenamiento de la red.
La principal diferencia en el caso de redes multicapa es que la función de error, utilizada como criterio para el entrenamiento, puede tener múltiplesmínimos locales a diferencia de un solo perceptrón en el cual existe un sólo mínimo. Esto significa que desafortunadamente no se puede garantizarla convergencia a un mínimo global.
Los perceptrones multicapa (MultiLayer Perceptrón - MLP) son por definición redes neuronales de propagación hacia adelante ya que la activaciónde las neuronas se hace desde la entrada (lugar donde se conectan las variables) hacia las neuronas de salida las cuales entregan la prediccióndeseada.
In [15]: from IPython.display import Imagei = Image(filename='FiguresClass/RNA2.png')i
Out[15]:
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
10 of 18 16/06/14 18:02

Para poder describir el algoritmo Backpropagation es necesario ponernos de acuerdo en la notación utilizada:La capa de entrada tendrá tantos nodos como variables (atributos o características).Un nodo es una entrada a la red o una salida de alguna unidad en la red.Cada nodo tendrá un sub-índice que indicará la posición del nodo en la capa y un super-índice que indicará la capa a la cual pertence el nodo.
denota la entrada a partir del nodo a la unidad , y denota el correspondiente peso.
El número de neuronas o unidades en cada capa es diferente y se denotará por , donde hace referencia a la capa.
De acuerdo a la notación anterior, en la primera capa oculta se construyen combinaciones lineales de las variables de entrada de la forma:
donde y el superíndice indica que los parámetros corresponden a la primera "capa" oculta de la red. Las activaciones luego se transforman usando una función de activación no lineal para dar:
Estos valores se combinan linealmente de nuevo para dar unidades de activación en otras capas ocultas o de salida
donde . Si la red sólo tiene una capa oculta, es el número total de salidas.
La diferencia fundamental entre una RNA entrenada para resolver un problema de regresión o un problema de clasificación, está en la función deactivación de la capa de salida:Regresión: Clasificación:
Combinando todas estas etapas se obtiene
xji
i j w(1)ji
Mk k
M1x = { , , . . . , }x1 x2 xd
=aj ∑i=0
d
w(1)ji xi
j = 1, . . . , M1 (1) aj
h(⋅)
= h( )zj aj
=ak ∑j=0
M1
w(2)kj zj
k = 1, . . . , M2 M2
=yk ak
= σ( )yk ak
(x, w) = σ h( + ) +yk
⎛⎝∑j=1
M1
w(2)kj ∑
i=1
d
w(1)ji xi w
(1)j0 w
(2)k0
⎞⎠
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
11 of 18 16/06/14 18:02

En la ecuación anterior, todos los parámetros se agrupan en el vector . El modelo de red neuronal es una función no lineal de un conjunto devariables de entrada a un conjunto de variables de salida controlado por el vector de parámetros ajustables .
El problema principal consiste entonces en encontrar valores adecuados para los parámetros de la red dado un conjunto de datos de entrenamiento.Es en este punto en el que necesitamos definir el algoritmo Backpropagation.
Como ya sabemos, la regla de actualización a partir del algoritmo de gradiente descendente está dada por:
En donde la función de error está dada por:
Esta aproximación hace parte de las técnicas que usan todo el conjunto de entrenamiento simultánemente es decir, calculan el error como la sumade los errores individuales por cada muestra, y se conocen como métodos Batch (lote).
Si por el contrario la medida de error se calcula para cada muestra de entrenamiento y posteriormente se actualizan los pesos de la red, el algoritmose conoce como On-Line y la regla de actualización está dada por:
a este algoritmo también se le conoce como gradiente descendente secuencial o gradiente descendente estocástico, las actualizaciones se realizancon una sola muestra al tiempo.
El principal problema con el entrenamiento de una red neuronal es que para calcular el error en cada capa es necesario conocer la salida deseada, yen el caso de las capas ocultas la salida deseada es desconocida, precisamente por esa razón reciben su nombre.
El algoritmo Backpropagation es entonces una forma eficiente de evaluar el gradiente de la función de error .
El algoritmo se realiza en dos etapas:Primera etapa: Evaluación de las derivadas de la función de error con respecto a los pesos.Segunda etapa: Las derivadas se emplean para realizar los ajustes de los pesos.
Primera etapa
w{ }xi { }yk w
= − η∇E( )w(τ+1) w(τ) w(τ)
E(w) = (w)∑n=1
N
En
= − η∇ ( )w(τ+1) w(τ) En w(τ)
E(w)
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
12 of 18 16/06/14 18:02

Teniendo en cuenta la función de error
la derivada de la función de error requiere resolver el problema de evaluar .
Consideremos el modelo lineal simple en el que las salidas son combinaciones lineales de las variables de entrada
con una función de error
donde y es la salida deseada. Note que estamos considerando un modelo que tiene salidas, razón por la cual elerror de una muestra , corresponde a la suma de los errores proporcionados por cada salida de la red para dicha muestra. El gradiente de estafunción con respecto a está dado como:
que puede interpretarse como un cálculo local que incluye el producto del error asociada a la salida del enlace y la variable asociada con la entrada de ese enlace.
En general en la red hacia adelante cada una unidad calula una suma ponderada de sus entradas
que se transforma mediante una función de activación
Lo primero que debe hacer para poder llevar a cabo el entrenamiento es presentarle a la red el vector de entrada (muestra) y calcular lasactivaciones de las correspondientes unidades ocultas y de salida. Este proceso se conoce como propagación hacia adelante.
E(w) = (w)∑n=1
N
En
∇ (w)En
yk
=yk ∑i
wki xi
= ( −En12
∑k
ynk tnk)2
= ( , w)ynk yk xn tnk k
xn
wji
= ( − )∂En
∂wij
ynj tnj xni
−ynj tnj wji xni
=aj ∑i
wjizi
= h( )zj aj
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
13 of 18 16/06/14 18:02

Si se considera la evaluación de con respecto a un peso
Se utiliza la notación
donde los 's se conocen como errores. Igualmente
Haciendo las sustituciones anteriores se obtiene
La ecuación anterior indica que la derivada requerida se obtiene multiplicando el valor de la unidad en el lado de salida del peso, por el valor de para la unidad en el lado de la entrada del peso.
Como se ha visto, para las unidades de salida se tiene
mientras que para evaluar los 's para los nodos ocultos, se emplea la regla de la cadena para derivadas parciales
la cual evalúa todos los nodos a los cuales la unidad envía una conexión.
En wji
=∂En
∂wji
∂En
∂aj
∂aj
∂wji
=δj∂En
∂aj
δ
=∂aj
∂wji
zi
=∂En
∂wji
δjzi
δ z
= −δk yk tk
δ
≡ =δj∂En
∂aj
∑k
∂En
∂ak
∂ak
∂aj
k j
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
14 of 18 16/06/14 18:02

Haciendo las sustituciones adecuadas
que expresa que el valor de para una unidad escondida en particular puede obtenerse propagando los 's hacia atrás desde unidades más altasen la red. El procedimiento de propagación hacia atrás se puede resumir como:Aplicar un vector de entrada a la red y propagarlo hacia adelante.Evaluar todos los para las unidades de salida.Propagar los 's del paso anterior para obtener los de cada nodo oculto en la red.Usar para evaluar las derivadas requeridas.
Para los métodos basados en entrenamiento por lotes, la derivada del error se calcula como:
Todo el algoritmo de entrenamiento puede ser usado para múltiple número de capas ocultas y múltiple número de salidas. Tanto en problemas deregresión como en problemas de clasificación, cuya única diferencia desde el punto de vista del entrenamiento será el cálculo de los 's para la capade salida.
Ej: Uso de la librería neurolab
= ( )δj h aj ∑k
wkjδk
δ δ
xn
δk
δ δj
∂ / =En wji δjzi
=∂E
∂wji
∑n
∂En
∂wji
δ
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
15 of 18 16/06/14 18:02

In [2]: import matplotlib.pyplot as pltfrom sklearn import cluster, datasetsn_samples = 1500X, y = datasets.make_moons(n_samples=n_samples, noise=.05)print(X.shape)plt.title('Problema de 2 clases', fontsize=14)plt.xlabel('Caracteristica 1')plt.ylabel('Caracteristica 2')plt.scatter(X[:,0], X[:,1], c=y);
(1500, 2)
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
16 of 18 16/06/14 18:02

In [12]: import numpy as npimport neurolab as nlfrom matplotlib.colors import ListedColormap# Create train samplesinput = Xtarget = np.array(y)[np.newaxis]target = target.T# Create network with 2 inputs, 5 neurons in input layer and 1 in output layernet = nl.net.newff([[X.min(), X.max()], [y.min(), y.max()]], [5, 1], [nl.trans.LogSig(),nl.trans.LogSig()])# Train processerr = net.train(input, target, show=15)# Testcmap_light = ListedColormap(['#AAAAFF','#AAFFAA','#FFAAAA',])x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100), np.linspace(y_min, y_max, 100))Z = np.zeros((100,100))for i in range(100): for j in range(100): #print([xx[1,i],yy[j,1]]) Z[i,j]=net.sim([[xx[1,i],yy[j,1]]])Z = np.round(Z)plt.title('Problema de 2 clases', fontsize=14)plt.xlabel('Caracteristica 1')plt.ylabel('Caracteristica 2')plt.pcolormesh(xx, yy, Z.T, cmap=cmap_light)plt.scatter(X[:,0], X[:,1], c=y);
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
17 of 18 16/06/14 18:02

Epoch: 15; Error: 22.3563001782;Epoch: 30; Error: 0.010221119346;The goal of learning is reached
Clase 07 - Redes Neuronales Artificiales file:///home/julian/Dropbox/Asignaturas/Modelos y Simulación II/IP...
18 of 18 16/06/14 18:02