¿que es big dimension?´edx3.cc.upv.es/c4x/poc/bigdata/asset/bigdimension1.pdf“en esta nueva era...
TRANSCRIPT


¿Que es big dimension?
Veronica Bolon Canedo 2/30

Big dimension
“En esta nueva era de Big Data, los metodos de aprendizajemaquina deben adaptarse para poder tratar con este volumen dedatos sin precedentes. Analogamente, el termino Big Dimension seha acunado para referirse al enorme numero sin predecentes decaracterısticas con las que hay que tratar.”
V. Bolon-Canedo, N. Sanchez-Marono, A. Alonso-BetanzosFeature Selection for High-Dimensional DataSpringer, 2015
Veronica Bolon Canedo 3/30

Repasemos algunos conceptos basicos...
Veronica Bolon Canedo 4/30

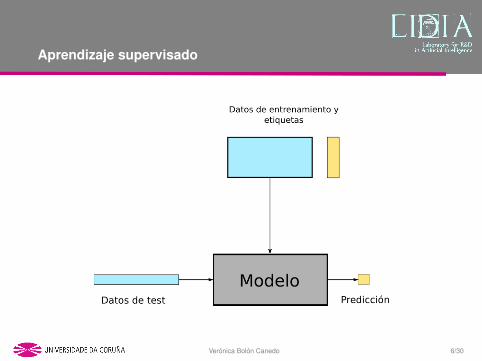
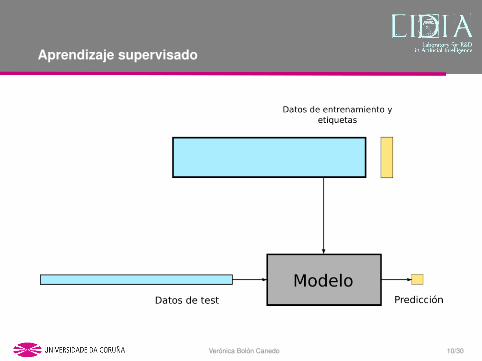
Aprendizaje supervisado
Terminologıa:
• D = {X,Y } es el conjunto de datos (o dataset).• Cada fila de X es un ejemplo (o instancia, o muestra).• Cada columna de X es una caracterıstica (o atributo).• Y es el vector de etiquetas (o clases).• N es el numero de ejemplos.
Veronica Bolon Canedo 5/30
Aprendizaje supervisado
Veronica Bolon Canedo 6/30

Hay casos, como por ejemplocuando tratamos con datosgeneticos, donde el numerode caracterısticas es muchomas grande que el deejemplos.
Veronica Bolon Canedo 7/30

Si echamos un vistazo a los datasets del repositorio UCI1...
1https://archive.ics.uci.edu/ml/index.htmlVeronica Bolon Canedo 8/30

Y si analizamos el repositorio LIBSVM Database2...
• Existen conjuntos de datos con mas de 29 millones decaracterısticas (KDD Cup 2010)
• Varios conjuntos de datos tienen mas de 1 millon de caracterısticas
2https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/Veronica Bolon Canedo 9/30
Aprendizaje supervisado
Veronica Bolon Canedo 10/30
Aprendizaje supervisado
Veronica Bolon Canedo 11/30

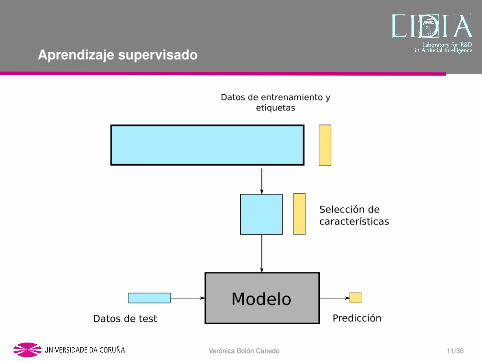
Seleccion de caracterısticas
Veronica Bolon Canedo 12/30

Reduccion de la dimension
Las tecnicas de reduccion de ladimension se aplican para reducir ladimension de los datos originales y,al mismo tiempo, mejorar elaprendizaje.
Veronica Bolon Canedo 13/30

Tecnicas de reduccion de la dimension
Extraccion de caracterısticasTransforma las caracterısticas originales en un subconjunto de nuevascaracterısticas
Seleccion de caracterısticasElimina las caracterısticas irrelevantes y/o redundantes
Veronica Bolon Canedo 14/30

¿Podemos decir como de “util” es una caracterıstica?
Imaginemos que estamos tratando de adivinar el precio de un coche...
• Relevantes: motor, edad, kilometraje, ano de compra,presencia de oxido,. . .
• Irrelevantes: color de los limpiaparabrisas, presenciade pegatinas,. . .
• Redundantes: edad/ano de compra
Veronica Bolon Canedo 15/30

¿Por que aplicar seleccion de caracterısticas?
• Tener mas caracterısticas no implica obtener mejores resultados deaprendizaje.
• Trabajar con menos caracterısticas reduce la complejidad delproblema y reduce el tiempo de ejecucion.
• Con menos caracterısticas, se mejora la capacidad degeneralizacion.
• Obtener los valores para ciertas caracterısticas pueden ser costoso odifıcil.
• Con menos caracterısticas, es mas facil comprender el modelo.
Veronica Bolon Canedo 16/30
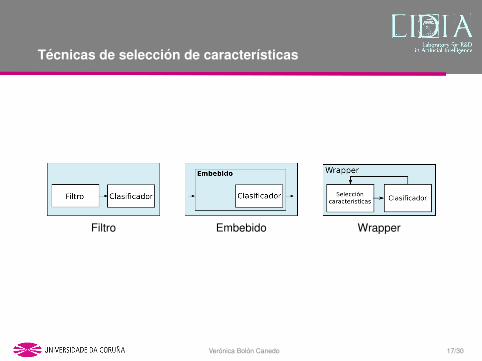
Tecnicas de seleccion de caracterısticas
Filtro Embebido Wrapper
Veronica Bolon Canedo 17/30

Filtros
Veronica Bolon Canedo 18/30

Medidas de filtrado
• Medidas de separabilidad. Estiman la separabilidad entre clases:euclıdea, Mahalanobis...
• Por ejemplo, en un problema binario, un proceso de SC basado eneste tipo de medidas determina que X es mejor que Y si X induce unadiferencia mayor que Y entre las dos probabilidades condicionales apriori entre las clases.
• Correlacion. Los buenos subconjuntos son aquellos que estancorrelacionados con la clase.
f (X1, ...,XM) =
∑Mi=1 ρic∑M
i=1
∑Mj=i+1 ρij
donde ρic es el coeficiente de correlacion entre la variable Si y la etiqueta c de la
clase C y ρij es el coeficiente de correlacion entre Xi y Xj
Veronica Bolon Canedo 19/30

Medidas de filtrado
• Teorıa de la Informacion. La correlacion solo puede detectardependencias lineales. Un metodo mas potente es la informacionmutua.
• La informacion mutua I(X1,...,M ;C) mide la cantidad de incertidumbreque se pierde en la clase C cuando los valores del vector X1,...,M sonconocidos.
• Debido a que es complejo el calculo de I, normalmente se usanreglas heurısticas
f (X1,...,M) =M∑
i=1
I(Xi ;C)− βM∑
i=1
M∑j=i+1
I(Xi ;Xj)
con β = 0.5, por ejemplo
Veronica Bolon Canedo 20/30

Filtros
Ventajas Inconvenientes Ejemplos
Independencia del clasificador No interaccion con clasificador CFSBajo coste computacional Consistency-basedRapido INTERACTBuena generalizacion ReliefF
Informacion mutua
Veronica Bolon Canedo 21/30

Embebidos
Ventajas Inconvenientes Ejemplos
Interaccion con clasificador Dependiente del clasificador SVM-RFECoste computacional mas bajo quewrappers
FS-P
Considera dependencias entre carac-terısticas
Veronica Bolon Canedo 22/30
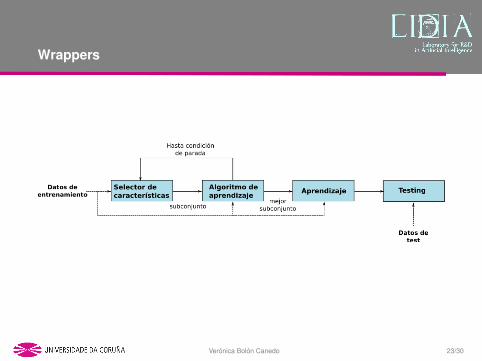
Wrappers
Veronica Bolon Canedo 23/30
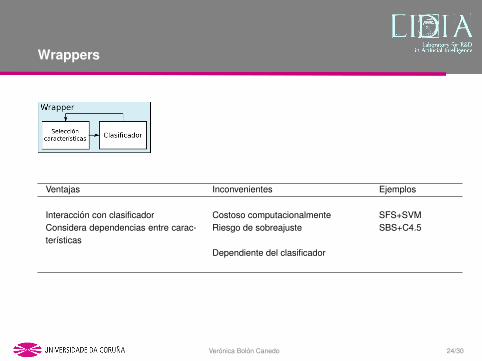
Wrappers
Ventajas Inconvenientes Ejemplos
Interaccion con clasificador Costoso computacionalmente SFS+SVMConsidera dependencias entre carac-terısticas
Riesgo de sobreajuste SBS+C4.5
Dependiente del clasificador
Veronica Bolon Canedo 24/30

Existe otra forma de categorizar los metodos de seleccion decaracterısticas de acuerdo a la salida que proporcionan:
• Metodos que devuelven un subconjunto de caracterısticas.
• Metodos que devuelven un ranking de caracterısticas.
Veronica Bolon Canedo 25/30

Metodos de subconjunto
Devuelven un subconjunto de caracterısticas optimizado de acuerdo aalgun criterio de evaluacion.
• Input: x caracterısticas, U criterio de evaluacion
• Subconjunto = {}• Repetir
• Sk = generarSubconjunto(x)• si mejora(S, Sk , U)
• Subconjunto = Sk
• Hasta CriterioParada()
• Output: Subconjunto de las caracterısticas mas relevantes
Veronica Bolon Canedo 26/30

Metodos de ranking
Devuelven una lista de caracterısticas ordenadas por un criterio deevaluacion.
• Input: x caracterısticas, U criterio de evaluacion
• Lista = {}• Para cada caracterıstica xi , i ∈ {1...N}
• vi = calcular(xi,U)• colocar xi en la Lista de acuerdo a vi
• Output: Lista con las caracterısticas mas relevantes primero
Veronica Bolon Canedo 27/30
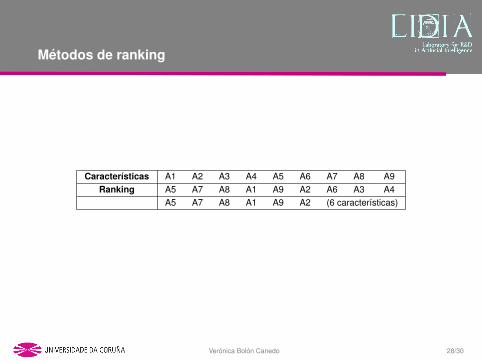
Metodos de ranking
Caracterısticas A1 A2 A3 A4 A5 A6 A7 A8 A9Ranking A5 A7 A8 A1 A9 A2 A6 A3 A4
A5 A7 A8 A1 A9 A2 (6 caracterısticas)
Veronica Bolon Canedo 28/30
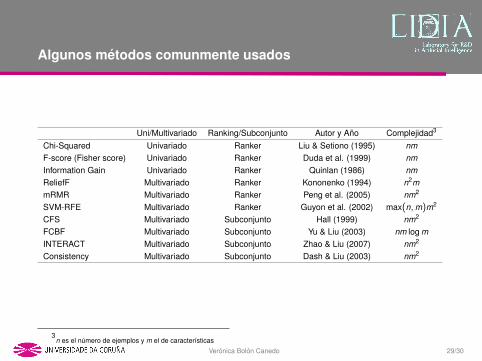
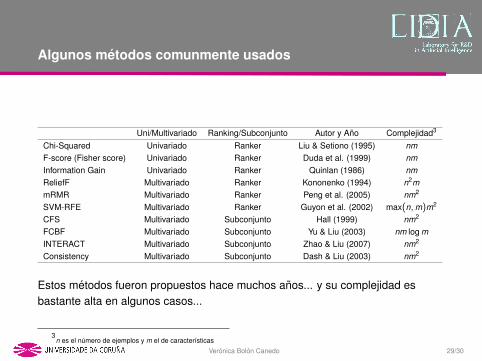
Algunos metodos comunmente usados
Uni/Multivariado Ranking/Subconjunto Autor y Ano Complejidad3
Chi-Squared Univariado Ranker Liu & Setiono (1995) nmF-score (Fisher score) Univariado Ranker Duda et al. (1999) nmInformation Gain Univariado Ranker Quinlan (1986) nmReliefF Multivariado Ranker Kononenko (1994) n2mmRMR Multivariado Ranker Peng et al. (2005) nm2
SVM-RFE Multivariado Ranker Guyon et al. (2002) max(n,m)m2
CFS Multivariado Subconjunto Hall (1999) nm2
FCBF Multivariado Subconjunto Yu & Liu (2003) nm log mINTERACT Multivariado Subconjunto Zhao & Liu (2007) nm2
Consistency Multivariado Subconjunto Dash & Liu (2003) nm2
Estos metodos fueron propuestos hace muchos anos... y su complejidad esbastante alta en algunos casos... SOLUCION: aprendizaje distribuido
3n es el numero de ejemplos y m el de caracterısticas
Veronica Bolon Canedo 29/30
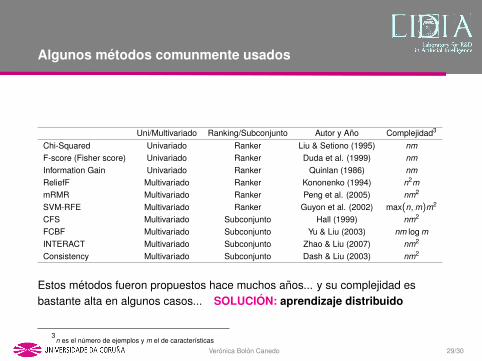
Algunos metodos comunmente usados
Uni/Multivariado Ranking/Subconjunto Autor y Ano Complejidad3
Chi-Squared Univariado Ranker Liu & Setiono (1995) nmF-score (Fisher score) Univariado Ranker Duda et al. (1999) nmInformation Gain Univariado Ranker Quinlan (1986) nmReliefF Multivariado Ranker Kononenko (1994) n2mmRMR Multivariado Ranker Peng et al. (2005) nm2
SVM-RFE Multivariado Ranker Guyon et al. (2002) max(n,m)m2
CFS Multivariado Subconjunto Hall (1999) nm2
FCBF Multivariado Subconjunto Yu & Liu (2003) nm log mINTERACT Multivariado Subconjunto Zhao & Liu (2007) nm2
Consistency Multivariado Subconjunto Dash & Liu (2003) nm2
Estos metodos fueron propuestos hace muchos anos... y su complejidad esbastante alta en algunos casos...
SOLUCION: aprendizaje distribuido
3n es el numero de ejemplos y m el de caracterısticas
Veronica Bolon Canedo 29/30
Algunos metodos comunmente usados
Uni/Multivariado Ranking/Subconjunto Autor y Ano Complejidad3
Chi-Squared Univariado Ranker Liu & Setiono (1995) nmF-score (Fisher score) Univariado Ranker Duda et al. (1999) nmInformation Gain Univariado Ranker Quinlan (1986) nmReliefF Multivariado Ranker Kononenko (1994) n2mmRMR Multivariado Ranker Peng et al. (2005) nm2
SVM-RFE Multivariado Ranker Guyon et al. (2002) max(n,m)m2
CFS Multivariado Subconjunto Hall (1999) nm2
FCBF Multivariado Subconjunto Yu & Liu (2003) nm log mINTERACT Multivariado Subconjunto Zhao & Liu (2007) nm2
Consistency Multivariado Subconjunto Dash & Liu (2003) nm2
Estos metodos fueron propuestos hace muchos anos... y su complejidad esbastante alta en algunos casos... SOLUCION: aprendizaje distribuido
3n es el numero de ejemplos y m el de caracterısticas
Veronica Bolon Canedo 29/30

Big dimensionSeleccion de caracterısticas
Veronica Bolon Canedo
Department of Computer ScienceUniversity of A Coruna (Spain)
Veronica Bolon Canedo 30/30