procesadores de lenguajes ii
TRANSCRIPT

ProcesadoresdeLenguajesIngenieríaTécnicasuperiordeIngenieríaInformá8ca
DepartamentodeLenguajesySistemasinformá6cos
JavierVé[email protected]
DepartamentodeLenguajesYSistemasInformá6cosUNED
UniversidadNacionaldeEducaciónaDistancia
Grado en Ingeniería Informática

Procesad
oresdeLengua
jes
IngenieríaTécnicasu
perio
rdeIngenieríaIn
form
á8ca
Departam
entodeLenguajesy
Sistem
asinform
á6cos
JavierVé[email protected]á?cosUNED
ParteIPresentación

ProcesadoresdeLenguajesIngenieríaTécnicasuperiordeIngenieríaInformá8ca
DepartamentodeLenguajesySistemasinformá6cos
JavierVé[email protected]
DepartamentodeLenguajesYSistemasInformáAcosUNED
1IntroducciónElprocesodecompilación

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 2
Obje6vosGenerales
Obje8vosGenerales
› Poner en contexto y justificar la relevancia de la compilación
› Aprender la diferencia entre compiladores y traductores
› Entender la diferencia entre compiladores e interpretes
› Apreciar el contexto en el que trabaja un compilador
› Apreciar cómo interactúan sus partes
› Entender la responsabilidad de cada una de ellas
› Analizar diferentes configuraciones alternativas
› Conocer el proceso completo de compilación
› Entender la responsabilidad de cada una de sus fases
› Obtener una visión general de las técnicas empleadas en cada una
› Aprender los principales artefactos que dan soporte a la compilación
› Discutir sobre la portabilidad de compiladores

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 3
Índice
Índice
› Introducción
› Traductores y compiladores
› Compiladores e interpretes
› Contexto de compilación
› Proceso de compilación
› Fases de compilación
› Etapas de compilación
› Artefactos de compilación
› Análisis de compiladores
› Representación de compiladores
› Tipos de compiladores
› Portabilidad de compiladores
› Práctica

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 4
Introducción
EsfuerzodeabstracciónLa historia de la programación puede describirse como un constante esfuerzo por acercar el lenguaje ejecutable de las arquitecturas hardware a un lenguaje más próximo al humano a través de sucesivos pasos de abstracción
I.ArquitecturasVonNeumann› Representación del programa como instrucciones en memoria
› La unidad de control va leyéndolo secuencialmente
› Cada instrucción tiene un código de operación y unos operandos
› Operaciones aritmético lógicas, comparativas, de salto, de E/S,…
111001100001011010101001110000111100001111011100
1945
MOVEAX#2MOVEBX#3MULCXAXBX
1950
Fact=1;Fori:=0to10fact:=fact*i;
1968
Wait(q);i:=fact(x);Signal(q);
1970
funmul(x,y)=x*yfunfact(n,m)=0->1|m(n,fact(n-1,m))
1990
bajo nivel
alto nivel
+ n
ivel
de
abst
racc
ión
–
ClassPunto{intx,y;intmodulo(){...}}
1995
111001100001011010101001110000111100001111011100
Código de operación
Operando 1
Operando 2
* En esta descripción se han omitido muchos paradigmas

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 5
Introducción
EsfuerzodeabstracciónLa historia de la programación puede describirse como un constante esfuerzo por acercar el lenguaje ejecutable de las arquitecturas hardware a un lenguaje más próximo al humano a través de sucesivos pasos de abstracción
II.Paradigmaensamblador› Los códigos de operación se sustituyen por acrónimos
› Los operandos se sustituyen por registros y referencias a memoria
› El juego de instrucciones sigue siendo el mismo
111001100001011010101001110000111100001111011100
1945
MOVEAX#2MOVEBX[1305]MULCXAXBX
1950
Fact=1;Fori:=0to10fact:=fact*i;
1968
Wait(q);i:=fact(x);Signal(q);
1970
funmul(x,y)=x*yfunfact(n,m)=0->1|m(n,fact(n-1,m))
1990
bajo nivel
alto nivel
+ n
ivel
de
abst
racc
ión
–
ClassPunto{intx,y;intmodulo(){...}}
1995
MOVEAX#2MOVEBX[1305]MULCXAXBX
Acrónimo de operación
Operando 1 de tipo registro
Operando 2 de tipo literal numérico
Operando 2 referencia a memoria
* En esta descripción se han omitido muchos paradigmas

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 6
Introducción
EsfuerzodeabstracciónLa historia de la programación puede describirse como un constante esfuerzo por acercar el lenguaje ejecutable de las arquitecturas hardware a un lenguaje más próximo al humano a través de sucesivos pasos de abstracción
III.Paradigmaestructuradoimpera8vo› Flujo de ejecución secuencial
› Metáfora de variables y operación de asignación
› Tipificación de los datos
› Estructuras de control iterativas y condicionales (no de salto)
› Subrutinas para modularizar los programas
111001100001011010101001110000111100001111011100
1945
MOVEAX#2MOVEBX#3MULCXAXBX
1950
Fact=1;Fori:=0to10fact:=fact*i;
1968
Wait(q);i:=fact(x);Signal(q);
1970
funmul(x,y)=x*yfunfact(n,m)=0->1|m(n,fact(n-1,m))
1990
bajo nivel
alto nivel
+ n
ivel
de
abst
racc
ión
–
ClassPunto{intx,y;intmodulo(){...}}
1995
a
b c
b(x,y);C(x,y);
d e f g
if(x>y)f(x);elseg(y);
while(x=y){d(x,y);e(x,y);}
* En esta descripción se han omitido muchos paradigmas

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 7
Introducción
EsfuerzodeabstracciónLa historia de la programación puede describirse como un constante esfuerzo por acercar el lenguaje ejecutable de las arquitecturas hardware a un lenguaje más próximo al humano a través de sucesivos pasos de abstracción
IV.Paradigmaconcurrente› Varios flujos de ejecución secuencial asociados a procesos
› Es necesario cuidar el acceso concurrente a recursos
› Mecanismos de exclusión mutua y de sincronización por condición
› Para cada proceso el algoritmo sigue siendo imperativo
› Existen lenguajes concurrentes funcionales
111001100001011010101001110000111100001111011100
1945
MOVEAX#2MOVEBX#3MULCXAXBX
1950
Fact=1;Fori:=0to10fact:=fact*i;
1968
Wait(q);i:=fact(x);Signal(q);
1970
funmul(x,y)=x*yfunfact(n,m)=0->1|m(n,fact(n-1,m))
1990
bajo nivel
alto nivel
+ n
ivel
de
abst
racc
ión
–
ClassPunto{intx,y;intmodulo(){...}}
1995
xlectorlectorlector
Leer x
lectorlectorescritor
Escribir x
* En esta descripción se han omitido muchos paradigmas

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 8
Introducción
EsfuerzodeabstracciónLa historia de la programación puede describirse como un constante esfuerzo por acercar el lenguaje ejecutable de las arquitecturas hardware a un lenguaje más próximo al humano a través de sucesivos pasos de abstracción
V.Paradigmafuncionaldeclara8vo› Únicamente declaración de funciones
› El resultado de una expresión depende sólo de sus sub-expresiones
› No hay efectos colaterales en la evaluación funcional
› No existe asignación ni estructuras de control
› Se da soporte a la definición recursiva de funciones
› Las funciones se usan como datos (orden superior, currificación,…)
› Operaciones map / reduce
111001100001011010101001110000111100001111011100
1945
MOVEAX#2MOVEBX#3MULCXAXBX
1950
Fact=1;Fori:=0to10fact:=fact*i;
1968
Wait(q);i:=fact(x);Signal(q);
1970
funmul(x,y)=x*yfunfact(n,m)=0->1|m(n,fact(n-1,m))
1990
bajo nivel
alto nivel
+ n
ivel
de
abst
racc
ión
–
ClassPunto{intx,y;intmodulo(){...}}
1995
funinvertir(l)=[]->[]|(p:resto)->invertir(resto):p
* En esta descripción se han omitido muchos paradigmas

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 9
Introducción
EsfuerzodeabstracciónLa historia de la programación puede describirse como un constante esfuerzo por acercar el lenguaje ejecutable de las arquitecturas hardware a un lenguaje más próximo al humano a través de sucesivos pasos de abstracción
VI.Paradigmadeorientaciónaobjetos› Las operaciones acompañan a las estructuras de datos
› Clases con bajo acoplamiento y fuerte cohesión
› El algoritmo se encuentra distribuido en la colaboración entre objetos
› Herencia, polimorfismo, ligadura dinámica y genericidad
› Los objetos se gestionan en el heap
111001100001011010101001110000111100001111011100
1945
MOVEAX#2MOVEBX#3MULCXAXBX
1950
Fact=1;Fori:=0to10fact:=fact*i;
1968
Wait(q);i:=fact(x);Signal(q);
1970
funmul(x,y)=x*yfunfact(n,m)=0->1|m(n,fact(n-1,m))
1990
bajo nivel
alto nivel
+ n
ivel
de
abst
racc
ión
–
ClassPunto{intx,y;intmodulo(){...}}
1995
for(iin[2..n])for(jin[0..n-1])if(c.mayor(a[j],a[j+1]))intercambiar(a[j],a[j+1]) * En esta descripción se han omitido muchos paradigmas
Lista
-ordenar()
Comparador
-mayor(x,y)
ComparadorA
ComparadorB
usa

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 10
Traductoresycompiladores
111001100001011010101001110000111100001111011100
1945
MOVEAX#2MOVEBX#3MULCXAXBX
1950
Fact=1;Fori:=0to10fact:=fact*i;
1968
Wait(q);i:=fact(x);Signal(q);
1970
funmul(x,y)=x*yfunfact(n,m)=0->1|m(n,fact(n-1,m))
1990
bajo nivel
alto nivel
+ n
ivel
de
abst
racc
ión
–
ClassPunto{intx,y;intmodulo(){...}}
1995
¿Quéesuncompilador?Para dar soporte a este proceso de abstracción es necesario idear programas capaces de traducir las expresiones abstractas en secuencias de instrucciones máquina interpretables por un ordenados
DefiniciónUn compilador es un programa que lee un programa escrito en lenguaje fuente, y lo traduce a un lenguaje objeto de bajo nivel. Además generará una lista de los posibles errores que tenga el programa fuente
CompiladorLenguaje fuente
Lenguaje objeto
Compilado
r

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 11
Traductoresycompiladores
111001100001011010101001110000111100001111011100
1945
MOVEAX#2MOVEBX#3MULCXAXBX
1950
Fact=1;Fori:=0to10fact:=fact*i;
1968
Wait(q);i:=fact(x);Signal(q);
1970
funmul(x,y)=x*yfunfact(n,m)=0->1|m(n,fact(n-1,m))
1990
bajo nivel
alto nivel
+ n
ivel
de
abst
racc
ión
–
ClassPunto{intx,y;intmodulo(){...}}
1995
¿Quéesuntraductor?Cuando lo que se pretende es cambiar la expresión sintáctica de un programa de un lenguaje de alto nivel a otro no hablamos de compilador sino de traductor
DefiniciónUn traductores un programa que lee un programa escrito en lenguaje fuente de alto nivel, y lo traduce a un lenguaje objeto también de alto nivel.
TraductorLenguaje fuente
Lenguaje objeto
fact=1;for(inti=0;i<=10;i++)fact*=i;
Pascal C traductor

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 12
Traductoresycompiladores
Traductoresycompiladores
I.Traductor
II.Compilador
Un compilador es un programa que lee un programa escrito en lenguaje fuente, y lo traduce a un lenguaje objeto de bajo nivel. Además generará una lista de los posibles errores que tenga el programa fuente
Un traductores un programa que lee un programa escrito en lenguaje fuente de alto nivel, y lo traduce a un lenguaje objeto también de alto nivel.
CompiladorLenguaje fuente
Lenguaje objeto
TraductorLenguaje fuente
Lenguaje objeto
}
Foco de atención principal de la asignatura

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 13
Compiladoreseinterpretes
Compiladoreseinterpretes
I.Compilador
Un compilador es un artefacto software capaz de generar un programa ejecutable a partir de un programa escrito en un lenguaje de alto nivel
II.Interprete
Un interprete es un artefacto software capaz de ir interpretando secuencialmente la colección de instrucciones de un programa escrito en un lenguaje de alto nivel para ejecutarlas
› Se obtiene un fichero ejecutable
› El proceso de compilación se realiza sólo una vez
› El proceso de compilación es más lento
› Mayor consumo de memoria
› Mayor cantidad de detalles de errores de compilación
› Mayor velocidad de ejecución del programa ejecutable
› Los errores en ejecución se minimizan
› No se obtiene un fichero ejecutable
› El proceso de interpretación se realiza cada vez
› El proceso de interpretación es más rápido
› Menor consumo de memoria
› Menor cantidad de detalles de errores de compilación
› Menor velocidad de ejecución del programa ejecutable
› Los errores en ejecución son mayores

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 14
Contextodecompilación
I.Precompilador
Algunos compiladores incluyen precompiladores capaces de hacer un tratamiento preliminar del fichero fuente para prepararlo para el proceso de la compilación. Esta herramienta suele eliminar comentarios, sustituir constantes simbólicas por sus valores literales, o extender en el código fuente las macros definidas
II.Compilador
El compilador es el programa encargado de realizar el proceso de traducción del programa fuente para expresarlo en términos de una secuencia de instrucciones de código máquina interpretables por un ordenador
}
Foco de atención principal de la asignatura
III.Enlazadoromontador
El producto resultante del compilador no es un fichero directamente ejecutable en la arquitectura. Muchas funciones, invocadas desde el programa fuente, y cuyo código se encuentra programado y compilado en otro fichero deben ser incorporadas al fichero resultante de la compilación para que sea autónomo. De esto se encarga el montador
Elementosdelcontextodelacompilación

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 15
Contextodecompilación
Elementosdelcontextodelacompilación
IV.Enlazadordinámico
Con el ánimo de que los programas finales no sean muy pesados, muchas funciones externas no se incluyen en el ejecutable final sino que son enlazadas dinámica y automáticamente por el sistema operativo, que se encarga de gestionarlas. Como consecuencia los ejecutables son más pequeños pero establecen dependencias con recursos que han de estar presentes en el sistema operativo
V.Depurador
Los errores producidos en tiempo de compilación son reportados por el compilador para su corrección. Sin embargo los ocurridos en tiempo de ejecución pueden ser más difíciles de detectar. Es necesario hacer ejecuciones paso a paso para comprobar el estado que va tomando cada variable del programa. El depurador ayuda a realizar este tipo de trazas
VI.Ensamblador
A veces los compiladores no generan programas directamente ejecutables en código máquina sino ficheros que corresponden a la expresión en ensamblador del código fuente. Esto puede ser tremendamente útil - aunque en la actualidad no frecuente – para permitir al programador optimizar los resultados generados por el compilador

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 16
Contextodecompilación
EjecutableDOS
EjecutableWindows
.C .H
Precompilador
.I .ASM
Compilador Ensamblador
.OBJ .OBJ .OBJ
Enlazador
.LIB
.ASM.EXE .EXE Ensamblador
Enlazadordinámico
.DLL
Proceso
Recurso
CompiladordeC
Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 17
Procesodecompilación
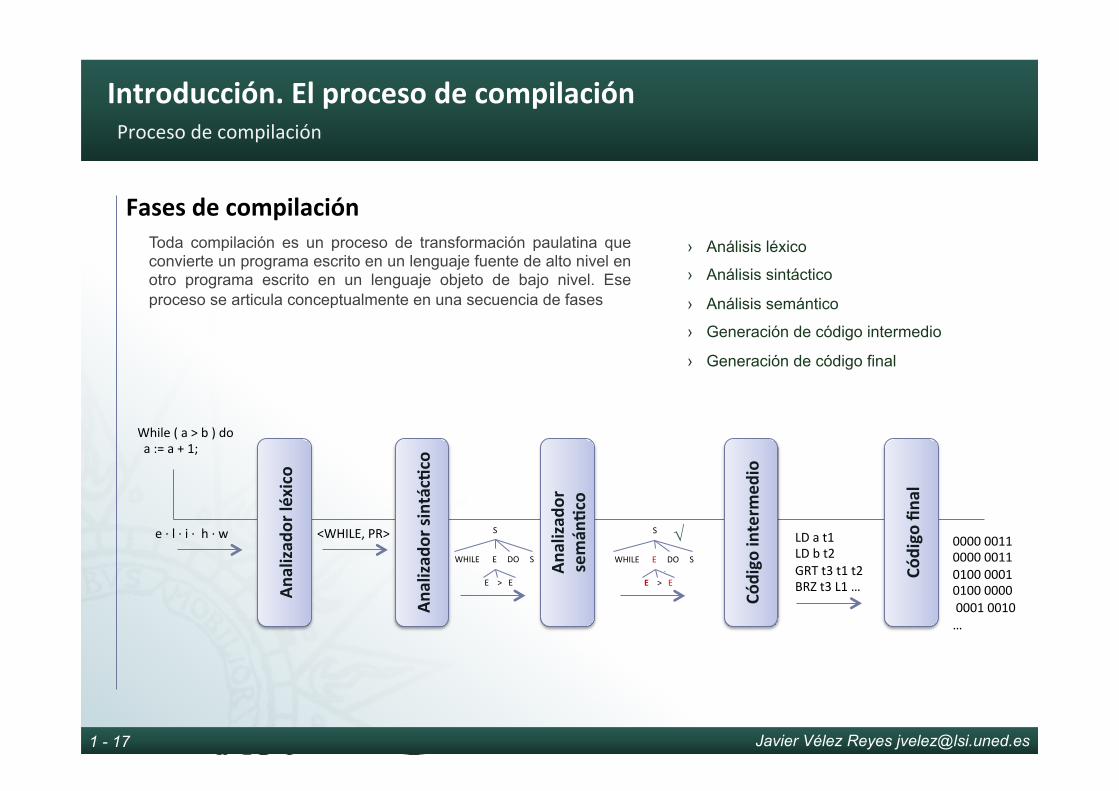
FasesdecompilaciónToda compilación es un proceso de transformación paulatina que convierte un programa escrito en un lenguaje fuente de alto nivel en otro programa escrito en un lenguaje objeto de bajo nivel. Ese proceso se articula conceptualmente en una secuencia de fases
› Análisis léxico
› Análisis sintáctico
› Análisis semántico
› Generación de código intermedio
› Generación de código final
Analizad
orléxico
Analizad
orsintác8co
Analizad
or
semán
8co
Códigointerm
edio
Códigofina
l
e·l·i·h·w <WHILE,PR> S
WHILEEDOS
E>E
S
WHILEEDOS
E>E
√ LDat1LDbt2GRTt3t1t2BRZt3L1…
0000001100000011010000010100000000010010…
While(a>b)doa:=a+1;

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 18
Procesodecompilación
FasesdecompilaciónToda compilación es un proceso de transformación paulatina que convierte un programa escrito en un lenguaje fuente de alto nivel en otro programa escrito en un lenguaje objeto de bajo nivel. Ese proceso se articula conceptualmente en una secuencia de fases
Analizadorléxico
e·l·i·h·w
<WHILE,PR>
While(a>b)doa:=a+1;
I.AnálisisléxicoEl analizador léxico (scanner) va leyendo caracteres del fichero hasta encontrar una entidad con significado léxico. Estas entidades se llaman tokens y son una estructura de datos que contiene información acerca del mismo (tipo, lexema, número de fila y columna, valor, etc.) La construcción de analizadores léxicos suele hacerse mediante herramientas que hay que configurar indicando el tipo de token que es necesario emitir para cada posible patrón léxico
while:<WHILE,PR>do:<DO,PR>l(l|d)*:<a,ID>...

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 19
Procesodecompilación
FasesdecompilaciónToda compilación es un proceso de transformación paulatina que convierte un programa escrito en un lenguaje fuente de alto nivel en otro programa escrito en un lenguaje objeto de bajo nivel. Ese proceso se articula conceptualmente en una secuencia de fases
Analizadorsintác8co
<WHILE,PR>
II.Análisissintác8coEl analizador sintáctico (parser) va pidiendo tokens al analizador léxico y los va organizando en frases de acuerdo a las reglas de construcción gramatical del lenguaje. Como resultado genera un árbol de análisis sintáctico que representa todo el programa en memoria La construcción de analizadores sintácticos suele hacerse mediante herramientas que hay que configurar indicando la colección de reglas sintácticas que definen las construcciones del lenguaje gramaticalmente correctas
S ::= SIf | Swhlile | ... SWhile ::= while PI E PD do S; E ::= E + E E ::= E * E E ::= E > E E ::= E < E E ::= id ...
SWhile
WHILEEDOS
E>E
<a,ID><>,GT><b,ID>
<DO,PR><a,ID><:=,ASIG>...
<(,PI>
<),PD>

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 20
Procesodecompilación
FasesdecompilaciónToda compilación es un proceso de transformación paulatina que convierte un programa escrito en un lenguaje fuente de alto nivel en otro programa escrito en un lenguaje objeto de bajo nivel. Ese proceso se articula conceptualmente en una secuencia de fases
Analizadorsemán8co
III.Análisissemán8coEl analizador semántico se encarga de gestionar la declaración de constantes, funciones, procedimientos y variables y de comprobar la corrección de tipos a lo largo de todo el programa. Como resultado se obtiene un árbol de análisis sintáctico anotado, con atributos en cada uno de sus nodos La implementación del analizado semántico se realiza insertando acciones semánticas en las partes derechas de las reglas de producción gramatical
S ::= SIf | Swhlile | ... SWhile ::= while PI E PD do S; {: if (E.tipo != booleano) error (); :} ...
SWhile
WHILEEDOS
E>E
SWhile
WHILEEDOS
E>E
√

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 21
Procesodecompilación
FasesdecompilaciónToda compilación es un proceso de transformación paulatina que convierte un programa escrito en un lenguaje fuente de alto nivel en otro programa escrito en un lenguaje objeto de bajo nivel. Ese proceso se articula conceptualmente en una secuencia de fases
Códigointermedio
IV.GeneracióndecódigointermedioEl generador de código intermedio traduce la representación arborescente del programa en una secuencia ordenada de instrucciones llamadas cuádruplas próximas al lenguaje máquina. Se trata de un lenguaje abstracto y genérico que aún mantiene las referencias simbólicas a los elementos declarados en el programa (variables, parámetros, funciones, etc.) La implementación del generador de código intermedio se realiza insertando acciones en las partes derechas de las reglas de producción que acumulan la traducción parcial del subárbol en cada nodo
exp ::= exp:e1 > exp:e2 {:... e.código = e1.código + e2.código + CMP e1.temp r2.temp e.temp :};
SWhile
WHILEEDOS
E>E
√
LDat1LDbt2GRTt3t1t2BRZt3L1...

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 22
Procesodecompilación
FasesdecompilaciónToda compilación es un proceso de transformación paulatina que convierte un programa escrito en un lenguaje fuente de alto nivel en otro programa escrito en un lenguaje objeto de bajo nivel. Ese proceso se articula conceptualmente en una secuencia de fases
Op8mizaciónCódigointermedio
V.Op8mizacióndecódigointermedioEn los compiladores comerciales es frecuente optimizar el resultado de la fase anterior para hacer el programa más compacto y más rápido. Suelen aplicarse estrategias de transformaciones heurísticas y elementales que ofrecen buenos resultados
LDat1LDbt2GRTt3t1t2BRZt3L1...
LDat1LDbt2GRTt3t1t2BRZt3L1...
√
WHILE(A>B)AND(A<2*B-5)DOA:=A+B
L1:IFA>BGOTOL2GOTOL3L2:T1:=2*BT2:=T1–5IFA<T2GOTOL4GOTOL3L4:A:=A+BGOTOL1L3:...
Optimización
Código intermedio
L1:IFA<=BGOTOL2T1:=2*BT2:=T1–5IFA>=T2GOTOL2A:=A+BGOTOL1
L2: …

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 23
Procesodecompilación
FasesdecompilaciónToda compilación es un proceso de transformación paulatina que convierte un programa escrito en un lenguaje fuente de alto nivel en otro programa escrito en un lenguaje objeto de bajo nivel. Ese proceso se articula conceptualmente en una secuencia de fases
VI.CódigofinalUna vez que el código intermedio ha sido generado y optimizado pueden resolverse las referencias simbólicas a posiciones de memoria física y a recursos de la máquina (registros, pila, etc.). Además debe traducirse cada cuarteto a sus equivalentes instrucciones en código máquina La traducción a código final se encarga de hacerla una rutina de traducción ubicada en la acción semántica final ubicada al final de la regla de producción del axioma
Códigofinal
LDat1LDbt2GRTt3t1t2BRZt3L1...
0000001100000011010000010100000000010010…

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 24
Procesodecompilación
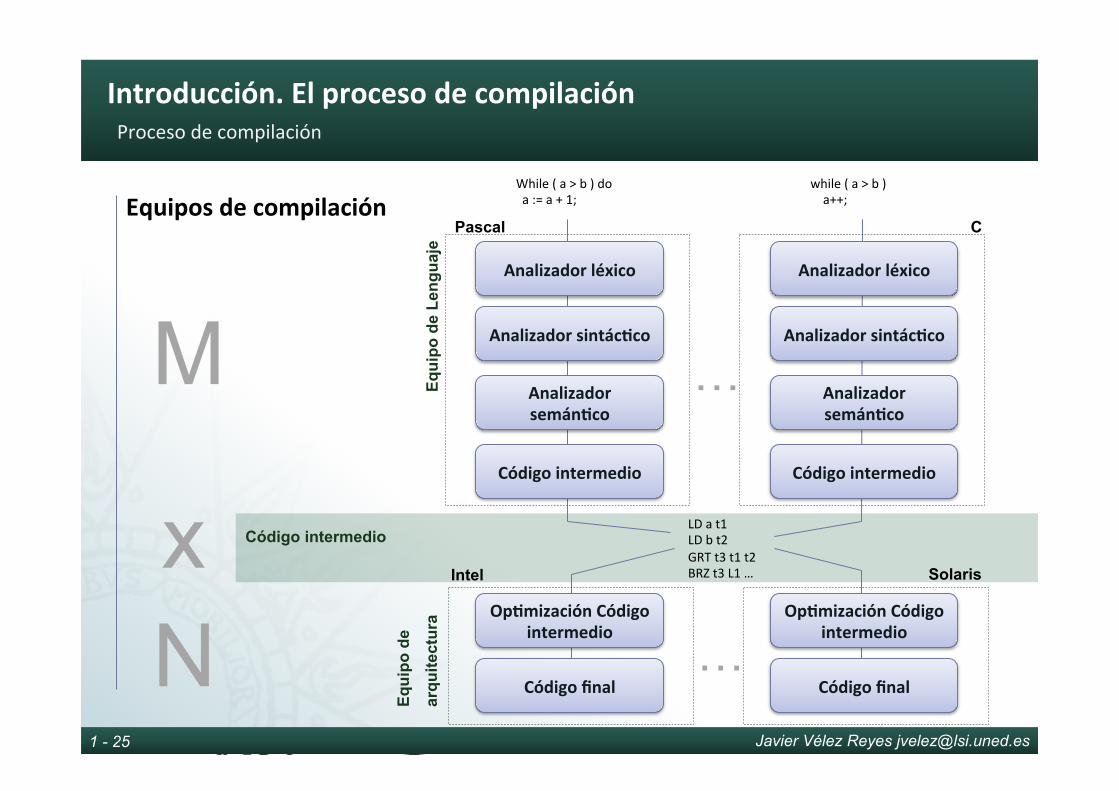
Etapasdecompilación
› Expertos en lenguajes
› Independencia de arquitectura
› Dependencia de lenguaje
› Optimización de lenguajes
Analizad
orléxico
Analizad
orsintác8co
Analizad
or
semán
8co
Códigointerm
edio
Códigofina
l
e·l·i·h·w <WHILE,PR> S
WHILEEDOS
E>E
S
WHILEEDOS
E>E
√ 0000001100000011010000010100000000010010…
While(a>b)doa:=a+1;
Etapa de análisis Etapa de síntesis
› Expertos en arquitecturas
› Dependencia de arquitectura
› Independencia de lenguaje
› Optimización de ejecución
LDat1LDbt2GRTt3t1t2BRZt3L1…
Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 25
Procesodecompilación
Equiposdecompilación
Analizadorléxico
Analizadorsintác8co
Analizadorsemán8co
Códigointermedio
While(a>b)doa:=a+1;
Equi
po d
e Le
ngua
je
Op8mizaciónCódigointermedio
Códigofinal
Analizadorléxico
Analizadorsintác8co
Analizadorsemán8co
Códigointermedio
Op8mizaciónCódigointermedio
Códigofinal
LDat1LDbt2GRTt3t1t2BRZt3L1…
Equi
po d
e
arqu
itect
ura
Pascal C
Intel Solaris
Código intermedio
M
N x
…
…
while(a>b)a++;

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 26
Procesodecompilación
ArtefactosdecompilaciónA lo largo de todo el proceso de compilación se una colección de artefactos para dar soporte al mismo. A lo largo del curso los estudiaremos en detalle. Dos son de vital importancia
I.Tabladesímbolos
La tabla de símbolos se utiliza para gestionar todos los elementos declarados por programador (constantes, tipos, variables, funciones y procedimientos)
Analizadorléxico
Analizadorsintác8co
Analizadorsemán8co
Códigointermedio
Op8mizaciónCódigointermedio
Códigofinal
Tablade
símbo
los
Analizador léxico En compiladores antiguos utilizado para reconocer palabras clave
Analizador semántico Registra los elementos declarados por el programador y los consulta para efectuar la comprobación de tipos
Código intermedio Se consulta para conocer el espacio de memoria que debe reservarse para gestionar la activación de subrutinas y p a r a d e t e r m i n a r e l á m b i t o d e declaración de los elementos
Código final Se utiliza para traducir las referencias simbólicas a posiciones de memorial
Fase Descripción

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 27
Procesodecompilación
ArtefactosdecompilaciónA lo largo de todo el proceso de compilación se una colección de artefactos para dar soporte al mismo. A lo largo del curso los estudiaremos en detalle. Dos son de vital importancia
II.Gestordeerrores
Las tres primeras fases pueden generar errores durante el proceso de compilación. El gestor de errores se encarga de emitir mensajes de los mismos para informar al programador
Gestordeerrores
Analizadorléxico
Carácterñnoválido
Whiñe(a>b)doa:=a+1;
Analizadorsintác8coAnalizadorsemán8co
SWhile::=WHILEeDOs
Analizadorléxico
While(a>b)a:=a+1;
Analizadorsintác8co
Analizadorléxico
While(a>b)doa:=a+‘c’;
Seesperabaunenteroenexpresióndesuma

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 28
Análisisdecompiladores
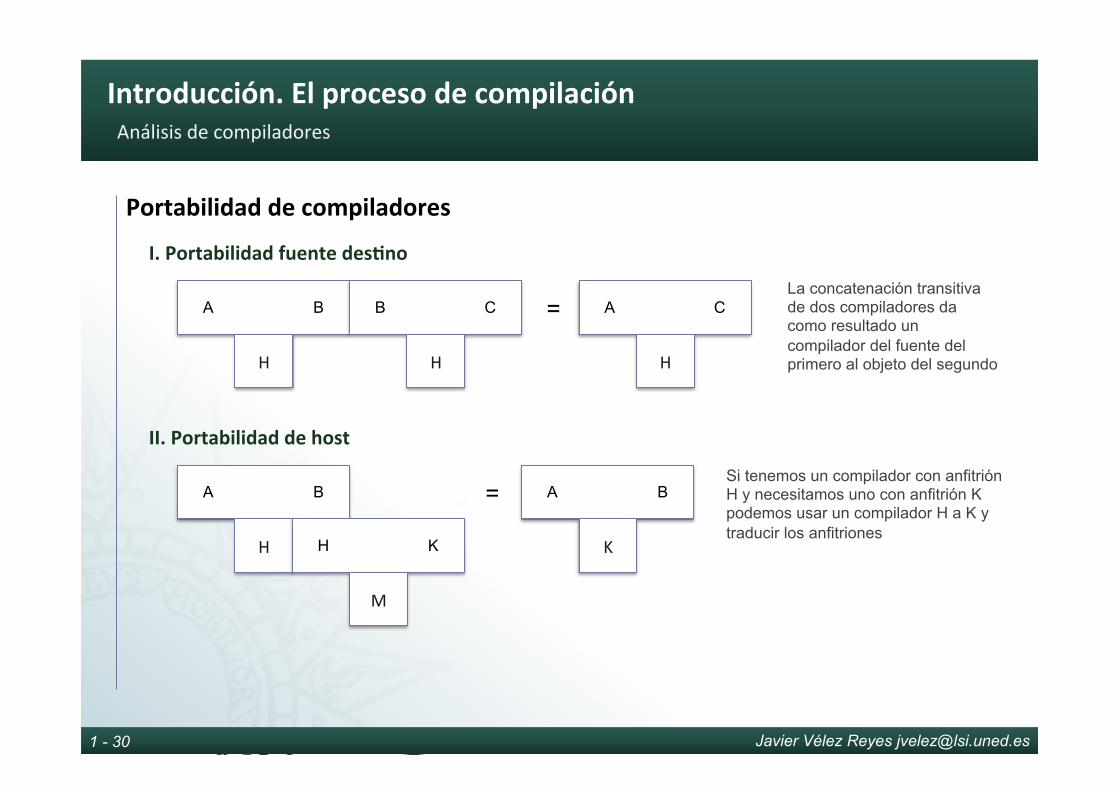
RepresentacióndeuncompiladorComo se ha discutido a lo largo del tema un compilador es una máquina de transformación capaz de traducir un programa escrito en un lenguaje fuente a otro programa escrito en otro lenguaje objeto. A su vez, éste está implementado en un tercer lenguaje llamado lenguaje anfitrión. Por tanto, para representar en abstracto un compilador suele emplearse una representación en forma de T que incluye los 3 lenguajes que lo caracterizan
› Lenguaje objeto (T)
› Lenguaje fuente (S)
› Lenguaje anfitrión (H)
S T
H }
H es un lenguaje máquina frecuentemente igual a T

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 29
Análisisdecompiladores
Tiposdecompiladores
H
I.Ensamblador
ASM Máquina
H
II.Compiladorcruzado
S T
H = T
H
III.Autocompilador
S T
H != T H = S
H
IV.Metacompilador
S T
H
V.Descompilador
T S
S especificaciones
T es un compilador
Se traduce de T a S
Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 30
Análisisdecompiladores
Portabilidaddecompiladores
I.Portabilidadfuentedes8no
A B
H
B C
H
= A C
H
II.Portabilidaddehost
A B
H H K
M
= A B
K
La concatenación transitiva de dos compiladores da como resultado un compilador del fuente del primero al objeto del segundo
Si tenemos un compilador con anfitrión H y necesitamos uno con anfitrión K podemos usar un compilador H a K y traducir los anfitriones

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 31
Análisisdecompiladores
Portabilidaddecompiladores
III.Arranqueautomá8coportransferencia
Java ENS
Java Java ENS
ENS
= Java ENS
ENS
Construimos un compilador de java provisional en ensamblador. Construirnos un compilador de java a ensamblador en java. Para compilarlo utilizamos el compilador provisional y obtenemos un compilador de java a ensamblador en ensamblador mejorado. Recurrimos iterativamente sustituyendo en cada pasada el compilador provisional por el nuevo en la iteración anterior

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 32
Construccióndecompiladoresenlaprác6ca
Descripcióndelaprác8ca
S ENS2001
Java
› Lenguaje fuente : S
› Lenguaje objeto : ENS2001
› Lenguaje anfitrión : Java
Entrega de Febrero Entrega de Junio
› Analizador léxico
› Analizador sintáctico
50% especificación
Sesión de control (Enero)
› Analizador léxico
› Analizador sintáctico
› Analizador semántico
› Generación de código intermedio
› Generación de código final
50% especificación
Sesión de control (Mayo)
Test
Entrega de Septiembre
› Analizador léxico
› Analizador sintáctico
› Analizador semántico
› Generación de código intermedio
› Generación de código final
100% especificación
Sesión de control (Junio)
Test
› JFlex
› Cup
› Ant
› Marco de desarrollo
› ENS2001
Caracterís8cas Herramientas

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 33
Construccióndecompiladoresenlaprác6ca
Primerospasosconlaprác8ca
› Instalar JDK
› Descargar JDK de la página Web
› Ejecutar el instalable
› Comprobar la actualización de las variables de entorno path y classpath
› Descargar un IDE de desarrollo
› NetBeans
› Eclipse
› Descargar el marco de desarrollo proporcionado
› Descargar del entorno virtual
› Crear un proyecto a partir del marco de desarrollo
› Actualizar el IDE para que reconozca todas las libarías
› Crear tareas ant desde el IDE para ejecutar los scripts de ejecución y prueba de la práctica
I.Instalaciónydescarga
Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 34
Construccióndecompiladoresenlaprác6ca
Primerospasosconlaprác8caII.Desarrollosobreelframeworkdesoporte
Las clases compiladas se generan aquí
Las documentación de la arquitectura (sobre todo en 2ºcuatrimestre) Tareas ant para ejecutar y depurar la práctica
§ clear § jflex § cup § build
§ flexTest § cupTest § finalTest
Memoria de la práctica según formato establecido
Consúltese el documento “Directrices de implementación”
Especificaciones gramaticales de Cup
Especificaciones léxicas de JFlex Test de prueba para las especificaciones A y B
Librerías necesarias Con8núa…
Esta primera parte del framework contiene la documentación, ficheros de configuración, librerías de ejecución, y directorios de soporte a la compilación

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 35
Construccióndecompiladoresenlaprác6ca
Primerospasosconlaprác8caII.Desarrollosobreelframeworkdesoporte
Consúltese el documento “Directrices de implementación”
Esta segunda parte del framework contiene la infraestructura de clases abiertas que el usuario debe extender o completar
Acceso a los artefactos del compilador
Entorno de ejecución donde se efectúa la generación del código final
Artefactos para la generación de código intermedio
Clase Token para comunicar el analizador léxico con el sintáctico
Clases Symbol y Type para representar los tipos y símbolos
Clases para representar los no terminales del árbol de análisis sintáctico
Programar para la prueba y depuración § LexicalTestCase § SyntaxTestCase § FinalTestCase
Con8núa…

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 36
Construccióndecompiladoresenlaprác6ca
Primerospasosconlaprác8caII.Desarrollosobreelframeworkdesoporte
Consúltese el documento “Directrices de implementación”
Esta tercera parte del framework contiene la infraestructura de clases cerradas que ofrecen al usuario funcionalidades completas para utilizar
Entorno de ejecución donde se efectúa la generación del código final
Artefactos para la generación de código intermedio
Artefactos para el análisis léxicos y el control de errores
Artefactos para el análisis semántico y el control de errores
Artefactos para el análisis sintáctico y el control de errores

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 37
Construccióndecompiladoresenlaprác6ca
Primerospasosconlaprác8ca
› La ejecución y prueba del marco de trabajo esta dirigida por tareas ant
› Clear: Borrar el contenido de /clases
› JFlex: Generar el analizador léxico (como un fichero fuente en src/lexical/scanner.java)
› Cup: Generar el analizador sintáctico (como un fichero fuente en src/syntax/parser.java)
› Build: Cup + Jflex + Compile
› flexTest: Ejecuta la prueba LexicalTestCase (generar tokens hasta final de fichero)
› cupTest: Ejecuta la prueba SyntaxTestCase (ejecuta el parser)
› finalTest: Ejecuta la prueba FinalTestCase (ejecuta el parser y traza el estado del compilador)
› Familia de tablas de símbolos creadas
› Familia de tablas de tipos creadas
III.Ejecuciónyprueba

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 38
Construccióndecompiladoresenlaprác6ca
Primerospasosconlaprác8ca
› Especificación del analizador léxico
› Generación (Jflex + compilar)
› Prueba (FlexTest)
› Especificación del analizador sintáctico
› Generación (Build)
› Prueba (CupTest)
› Integración del analizador lexico con el sintáctico
› Generación (Build)
› Prueba (CupTest)
III.Fasesdedesarrollodelcompilador
› Implementación en cup del sistema de tipos
› Generación (Build)
› Prueba (FinalTest)
› Generación de código intermedio
› Generación (Build)
› Prueba (FinalTest)
› Generación de código Final
› Generación (Build)
› Prueba (FinalTest)
› Pruebas finales con fichero de test
1er cuatrimestre 2º cuatrimestre

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 39
Bibliograca
MaterialdeestudioBibliografía básica
Construcción de compiladores: principios y práctica
Kenneth C. Louden International Thomson Editores,
2004 ISBN 970-686-299-4

Javier Vélez Reyes [email protected]
Introducción.Elprocesodecompilación
1 - 40
Bibliograca
MaterialdeestudioBibliografía complementaria
Compiladores: Principios, técnicas y herramientas.
Segunda Edición Aho, Lam, Sethi, Ullman
Addison – Wesley, Pearson Educación, México 2008
Diseño de compiladores. A. Garrido, J. Iñesta, F. Moreno
y J. Pérez. 2002. Edita Universidad de Alicante

Procesad
oresdeLengua
jes
IngenieríaTécnicasu
perio
rdeIngenieríaIn
form
á8ca
Departam
entodeLenguajesy
Sistem
asinform
á6cos
JavierVé[email protected]á?cosUNED
ParteIIEtapadeanálisis

ProcesadoresdeLenguajesIngenieríaTécnicasuperiordeIngenieríaInformá8ca
DepartamentodeLenguajesySistemasinformá6cos
JavierVé[email protected]
DepartamentodeLenguajesYSistemasInformáAcosUNED
2AnálisisléxicoLenguajesregulares

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 2
Obje6vos
Obje8vos
› Conocer las responsabilidades de un analizador léxico
› Aprender cómo funciona
› Entender los diferentes tipos de patrones que reconoce
› Aprender a especificar formalmente analizadores léxicos
› A través de gramáticas formales
› A través de expresiones regulares
› A través de autómatas finitos
› Estudiar la implementación de analizadores léxicos
› Conocer las distintas estrategias de implementación
› Entender las posibles relaciones con la tabla de símbolos
› Estudiar la generación de errores léxicos

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 3
Índice
Índice
› Introducción
› Token
› Patrón léxico
› Lexema
› Lenguaje regular
› Especificación de analizadores léxicos
› Lenguajes regulares
› Gramáticas lineales
› Expresiones regulares
› Autómatas finitos
› Conversión de formalismos
› Implementación de analizadores léxicos
› basada en casos
› dirigida por tabla
› guiada por herramientas
› Estrategias de implementación
› Gestión de errores
› Construcción de A. léxicos en en la práctica
› ¿Qué es JFlex?
› ¿Cómo funciona JFlex?
› ¿Cómo se usa JFlex?
› Gestión de errores en JFlex
› Desarrollo paso a paso
› Bibliografía

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 4
Introducción
Analizadorléxico·i·h·w
<WHILE,PR>
While(a>b)doa:=a+1;
Analizadorsintác8co
nextToken()
IntroducciónEl primer paso para procesar un programa es convertir la colección de caracteres del mismo en una colección de componentes léxicos con significado único dentro del lenguaje llamados tokens. De eso se encarga el analizador léxico o escáner
El analizador sintáctico va pidiendo nuevos tokens al analizador léxico y éste los sirve bajo demanda
Foco de atención
¿Cómo se formaliza un analizador léxico?
¿Cómo se implementa un analizador léxico?
› Formalismos
› Conversión entre formalismos
› Estrategias de implementación
› Buenas prácticas

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 5
Introducción
IntroducciónEl primer paso para procesar un programa es convertir la colección de caracteres del mismo en una colección de componentes léxicos con significado único dentro del lenguaje llamados tokens. De eso se encarga el analizador léxico o escáner
Definicióndetoken
Un token es una unidad léxica indivisible con significado único dentro del lenguaje. Desde el punto de vista tecnológico se trata de una estructura de datos que contiene información sobre
› ID: Tipo del token
› Número de línea
› Número de columna
› Lexema
› Valor…
CategoríasdetokenLos tipos de tokens existentes en un lenguaje son una característica intrínseca al mismo. No obstante, pueden encontrarse categorías generales
Categoría Ejemplos
Delimitadores
Palabrasreservadas
Iden8ficadores
Númerosenteros
Númerosflotantes
Simbolosespeciales
Cadenas
(),;:[]
whiletruedoiffor
IndexfisEven
3-45507658
4.5.30.58.4e-5
+-*/.=<><=>=!=++
“Holamundo!”

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 6
Introducción
IntroducciónCada tipo de token representa a un conjunto de tokens (construcciones léxicas diferentes) con unos mismos propósitos dentro del lenguaje. Estos tipos se definen a través de un patrón léxico al que se adscriben los lexemas del tipo
Definicióndepatrónléxico
Un patrón léxico es una expresión abstracta llamada expres ión regu la r que permi te iden t i f i ca r unívocamente un tipo de token y referenciar al conjunto de todos los tokens que se ajustan a él.
DefinicióndelexemaLa cadena de caracteres específica de un token que se ajusta al patrón léxico de su tipo se llama lexema. Existen dos tipos de lexemas
› Cadena propia: lexema idéntica al patrón
› Cadena no propia: lexema encaja con patrón
Tipodetoken Patrónléxico
While
Enteros
División
Iden8ficador
while
digito+
/
letra(letra|digito)*
Ejemplosdelexema
while
12123045
/
IndexfisEven
Cadenapropia
SI
NO
SI
NO

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 7
Introducción
IntroducciónDesde la perspectiva léxica un programa es una familia ordenada de tokens de varios tipos. Cada tipo, a través de su patrón léxico, define un micro lenguaje formado por todos aquellos lexemas que encajan con el patrón léxico. Este tipo de lenguajes sencillos se llaman lenguajes regulares
Definicióndelenguajeregular
Un lenguaje regular describe una familia de tokens que se ajustan a un determinado patrón léxico.
programburbuja;usescrt;constn=5;vari,j,temp:integer;a:array[1..n]ofinteger;beginfori:=1tondoreadln(a[i]);forj:=(n-1)downto1dofori:=1tojdoif(a[i])>(a[i+1])thenbegintemp:=a[i];a[i]:=a[i+1];a[i+1]:=temp;end;writeln('Elresultadoes:');fori:=1tondowriteln(a[i]);readln;end.
Lenguajedeiden8ficadoresPascal
burbujactrnijtempareadlnwriteln...
LenguajedepalabrasreservadasdePascal
programusesconstvarintgerofarraybeginforto
dodowntiifthenEnd...
LenguajededelimitadoresdePascal
;=,:[..]()...

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 8
Especificaciónformaldeanalizadoresléxicos
EspecificacióndelenguajesregularesAdemás de la declaración extensiva – sólo viable en los lenguajes finitos – existen 3 diferentes maneras de definir formalmente un lenguaje regular. A lo largo de esta sección estudiaremos cada una de ellas en detalle y veremos cómo se puede pasar de cada una a las otras 2
Lenguajesregulares
Gramá8caslineales
Expresionesregulares
Autómatasfinitos
› Elementos
› Gramáticas lineales
› Expresiones regulares
› Autómatas finitos
› Transformaciones
› De gramáticas a expresiones
› De gramáticas a autómatas
› De expresiones a gramáticas
› De expresiones a autómatas
› De autómatas a gramáticas
› De autómatas a expresiones

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 9
Especificaciónformaldeanalizadoresléxicos
Especificaciónmediantegramá8caslinealesUna forma de definir formalmente un lenguaje regular es utilizar una gramática lineal, que describe todas las reglas que se pueden aplicar para la construcción de lexemas que pertenecen al lenguaje regular
Definicióndegramá8calinealUna gramática lineal es un conjunto de 4 elementos G = (T, N, S, P) donde:
› T es un conjunto de símbolos terminales
› N es un conjunto de símbolos no terminales
› S Є N axioma gramatical
› P un conjunto de reglas de producción de la forma
1. A ::= B x donde A, B Є N y x Є T
2. A ::= x B donde A, B Є N y x Є T
3. A ::= x donde x Є T U { ع}
A veces T se elide, N se deduce de los antecedentes de las reglas de P y se asume que el antecedente de la primera regla es S con lo G sólo a través de P
Tiposdegramá8caslinealesExisten en realidad 2 tipos de gramáticas lineales. En función de la forma del conjunto de reglas de producción podemos distinguir entre:
› Gramáticas lineales por la izquierda
› Usan reglas A ::= B x
› Usan reglas A ::= x
› Gramáticas lineales por la derecha
› Usan reglas A ::= x B
› Usan reglas A ::= x
Dada una gramática G lineal por la izquierda siempre se puede encontrar una gramática G’ lineal por la derecha y recíprocamente
)representa la cadena vacía (ausencia de terminal ع

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 10
Especificaciónformaldeanalizadoresléxicos
Especificaciónmediantegramá8caslinealesUna forma de definir formalmente un lenguaje regular es utilizar una gramática lineal, que describe todas las reglas que se pueden aplicar para la construcción de lexemas que pertenecen al lenguaje regular
Derivacióngrama8calUna gramática debe interpretarse como un conjunto de reglas de reescritura o transformación de elementos no terminales en elementos terminales o no terminales.
› La primera transformación parte del axioma
› En cada paso se aplica una única regla
› Las reglas pueden extender la transformación ( A::= B x / A ::= x B)
› Las reglas pueden ser recursivas (A ::= A x / A ::= x A)
› Las reglas pueden ser terminales (A ::= x)
› El proceso debe ser convergente
LG = {a b*}
Sea G = (T, N A, P) con
T = {a, b}
N = {A, B}
P = {
A ::= a B
A ::= a
B ::= b B
B ::= b
}
Ejemplo

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 11
Especificaciónformaldeanalizadoresléxicos
Especificaciónmediantegramá8caslinealesUna forma de definir formalmente un lenguaje regular es utilizar una gramática lineal, que describe todas las reglas que se pueden aplicar para la construcción de lexemas que pertenecen al lenguaje regular
Derivacióngrama8calEl problema ahora se traduce en, dada una cadena formada por una secuencia de elementos terminales de T, demostrar que dicha cadena pertenece al lenguaje definido por la gramática
LG = {a b*}
Sea G = (T, N A, P) con
T = {a, b}
N = {A, B}
P = {
A ::= a B
A ::= a
B ::= b B
B ::= b
}
A → aB → abB → abbB → abbb
Ejemplo
axioma
Paso de derivación
asidero
Frase F o r m a de frase
Cadena de derivación

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 12
› L1 = conjunto de todas las palabras sobre {a, b} que empiezan por a
› L2 = conjunto de todas las palabras sobre {a, b} que empiezan por a y continúan con secuencias ab
› L3 = Números fraccionarios
› L4 = Identificadores
Especificaciónformaldeanalizadoresléxicos
Especificaciónmediantegramá8caslinealesUna forma de definir formalmente un lenguaje regular es utilizar una gramática lineal, que describe todas las reglas que se pueden aplicar para la construcción de lexemas que pertenecen al lenguaje regular
EjerciciosDefinir formalmente a través de una gramática lineal los siguientes lenguajes descritos informalmente
GD = (T, N A, P) con
T = {a, b}
N = {A, B}
P = {
A ::= a B
B ::= a B
B ::= b B
B ::= ع
}
GI = (T, N A, P) con
T = {a, b}
N = {A, B}
P = {
A ::= A a
A ::= A b
A ::= a
}
L1

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 13
Especificaciónformaldeanalizadoresléxicos
EspecificaciónmedianteexpresionesregularesOtra forma de definir lenguajes regulares es a través del uso de expresiones regulares. Una expresión regular utiliza los términos del alfabeto de terminales operados a través de operaciones con una semántica especifica
Una expresión regular sobre un conjunto T es un conjunto ER = (T, | , · , *) que cumple las siguientes propiedades:
Definicióndeexpresiónregular
› Ø es una expresión regular que define el lenguaje L = Ø
ع )es una expresión regular que define el lenguaje L (cadena vacía ) ع( = } ع { ›
› Cualquier símbolo a Є T es una expresión regular que define el lenguaje L ( a ) = { a }
› Si x, y son dos expresiones regulares, x·y es una expresión regular que define L ( x·y ) = L ( x ) L ( y )
› Si x, y son dos expresiones regulares, x | y es una expresión regular que define L (x | y) = L ( x ) U L ( y )
› Si x es una expresión regular x* es una expresión regular que define L ( x* ) = U L( x )
› Si x es una expresión regular x+ es una expresión regular que define el lenguaje L ( x* ) = U L( x )
› No existen más expresiones regulares
i =0
∞ i
∞ i =1
i

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 14
Especificaciónformaldeanalizadoresléxicos
EspecificaciónmedianteexpresionesregularesOtra forma de definir lenguajes regulares es a través del uso de expresiones regulares. Una expresión regular utiliza los términos del alfabeto de terminales operados a través de operaciones con una semántica especifica
Definir los siguientes lenguajes regulares utilizando para ello expresiones regulares
Ejercicios
› L1 = Lenguaje de identificadores
› L2 = Lenguaje de números naturales
› L3 = Lenguaje de números fraccionarios
› L4 = Lenguaje de números enteros con exponente
› L5 = Lenguaje de números fraccionarios con exponente
› L6 = Lenguaje de números pares
› L7 = Lenguaje de las cuentas de correo
› L8 = Lenguajes de las URL
L1 = l ( l | d )* l Є {a..z} d Є {0..9}
L3 = d+ . d+ d Є {0..9}
L6 = d+ p d Є {0..9} p Є {0, 2, 4, 6, 8}
L7 = nombre @ host
nombre = L1 (. L1)*
host = L1 (. L1)*

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 15
Especificaciónformaldeanalizadoresléxicos
EspecificaciónmedianteautómatasfinitosLa tercera forma de definir lenguajes regulares es a través del uso de autómatas finitos. Un autómata finito reconoce una cadena de entrada si consumidos todos los caracteres de la misma acaba en un estado final de aceptación
Un autómata finito determinista es un conjunto AFD = (T, Q, f, q, F) donde:
Autómatafinitodeterminista
› T es un alfabeto de símbolos terminales de entrada
› Q es un conjunto de estados finito no vacío
› f: Q x T → Q es una función de transición
› q Є Q es un estado inicial o estado de arranque
› F C Q es un subconjunto de estados finales de aceptación
Gráficamente, un autómata finito determinista es una colección de estados unidos por arcos, donde para cada estado existe un arco etiquetado con cada elemento de T. El estado inicial tiene una flecha entrante y los estados finales tienen un doble borde
Interpretacióngráfica
letra
letra, dígito
letra, dígito
dígito
letra Є [a..z] dígito Є [0..9]
1
2
0

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 16
Especificaciónformaldeanalizadoresléxicos
EspecificaciónmedianteautómatasfinitosLa tercera forma de definir lenguajes regulares es a través del uso de autómatas finitos. Un autómata finito reconoce una cadena de entrada si consumidos todos los caracteres de la misma acaba en un estado final de aceptación
Con el ánimo de simplificar el trabajo con los autómatas finitos deterministas, dentro de la teoría de compiladores se utilizan las siguientes extensiones notacionales
Extensióndelosautómatasfinitosdeterministas Interpretacióngráfica
› Las transiciones ausentes se asumen como errores
› Se omiten los estados de absorción de errores
› Se usa la etiqueta otro para representar el resto de alternativas
› Los estados finales paran el proceso y emiten token
› Los estados finales con * recuperan el carácter de tránsito
› Se espera a reconocer el posible toquen de lexema más largo
› El estado final ya no es final
› Al llegar un carácter terminador se pasa a uno final
› Entonces se emite el token
› Si es necesario se marca con * el estado final
0letra
letra, dígito
A continuación representamos el autómata finito determinista anterior aplicando las extensiones descritas
otro
letra Є [a..z] dígito Є [0..9]
* 2
1

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 17
Especificaciónformaldeanalizadoresléxicos
EspecificaciónmedianteautómatasfinitosLa tercera forma de definir lenguajes regulares es a través del uso de autómatas finitos. Un autómata finito reconoce una cadena de entrada si consumidos todos los caracteres de la misma acaba en un estado final de aceptación
Los autómatas arrancan en el estado de inició y comienzan a consumir caracteres de la entrada lo que provoca una transición a un nuevo estado o un error. En cuanto se alcanza un estado de aceptación final, el autómata para y se emite el token reconocido
Comoseusanlosautómatasfinitosdeterministas
→ c → o → u → n → t → e → r → 0 → 1 → +
letra
letra, dígito
otro
letra Є [a..z] dígito Є [0..9]
*
caracteres
Estado 0 Estado 1 Estado 2
transiciones
token
Carácter delimitador (otro)
0
2
1

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 18
Especificaciónformaldeanalizadoresléxicos
EspecificaciónmedianteautómatasfinitosLa tercera forma de definir lenguajes regulares es a través del uso de autómatas finitos. Un autómata finito reconoce una cadena de entrada si consumidos todos los caracteres de la misma acaba en un estado final de aceptación
Definir los siguientes lenguajes regulares utilizando para ello autómatas finitos deterministas
Ejercicios
› L1 = Lenguaje de identificadores
› L2 = Lenguaje de números naturales
› L3 = Lenguaje de números fraccionarios
› L4 = Lenguaje de números naturales con exponente
› L5 = Lenguaje de números fraccionarios con exponente
› L6 = When
letra
letra, dígito
otro *
L1
0
2
1

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 19
Especificaciónformaldeanalizadoresléxicos
EspecificaciónmedianteautómatasfinitosLa tercera forma de definir lenguajes regulares es a través del uso de autómatas finitos. Un autómata finito reconoce una cadena de entrada si consumidos todos los caracteres de la misma acaba en un estado final de aceptación
Para construir un analizador léxico completo es necesario combinar en un único autómata todos los autómatas correspondientes a los micro-lenguajes que aparecen en el lenguaje. Este proceso se puede hacer mediante una aproximación holística
Construcciónmanualcomposi8vadeautómatas
› L7 = Números naturales y fraccionarios con exponente
› L8 = {<, <<,<=, =, ==, +, ++, -, --, *, *=}
› L9 = {While, When, Do, Downto}
› L10 = L1 U L7 U L9
› L11 = U Li con i Є [1..11]
0
< *
=
+
<
*
–
= otro
= otro
+ otro
– otro
= otro
<<
<=
<
==
=
++
+
– –
–
*=
*
*
*
*
* 16
15
13
12
10
9
7
6
4
3
2
11
14
L8
Definir los siguientes lenguajes regulares utilizando para ello autómatas finitos deterministas
Ejercicios
0
5
8

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 20
Especificaciónformaldeanalizadoresléxicos
EspecificaciónmedianteautómatasfinitosLa tercera forma de definir lenguajes regulares es a través del uso de autómatas finitos. Un autómata finito reconoce una cadena de entrada si consumidos todos los caracteres de la misma acaba en un estado final de aceptación
Cuando el número de micro-lenguajes es grande y éstos son complejos la aproximación manual se convierte en un proceso prolijo por eso conviene establecer un proceso sistemático. Este proceso se basa en definir formalmente la composición de autómatas sobre las operaciones legítimas de composición de autómatas
Construcciónsistemá8cacomposi8vadeautómatas
L (x) x
L (x) L (y) x y ع
L (x) U L (y)
x ع
yع
L (x)+ x
ع
L (x)* x
ع
00 ع1
ع
Las ع– transiciones deben interpretarse como transiciones que no consumen caracteres }
x
0 n1 n-1 … ≡

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 21
Especificaciónformaldeanalizadoresléxicos
EspecificaciónmedianteautómatasfinitosLa tercera forma de definir lenguajes regulares es a través del uso de autómatas finitos. Un autómata finito reconoce una cadena de entrada si consumidos todos los caracteres de la misma acaba en un estado final de aceptación
Cuando el número de micro-lenguajes es grande y éstos son complejos la aproximación manual se convierte en un proceso prolijo por eso conviene establecer un proceso sistemático. Este proceso se basa en definir formalmente la composición de autómatas sobre las operaciones legítimas de composición de autómatas
Construcciónsistemá8cacomposi8vadeautómatas
L = {<, <<, <=} Ejemplo
0 <
1
4
7 =
otro
5
8<
<
2< ع
ع
ع
0
1
3
5 =
otro
<
Uso de ع–transiciones para construir el autómata
}
La eliminación de las ع–transiciones provoca varias transiciones iguales desde el mismo nodo
}
<
<
<
<
<<
<=
<
<<
<=
3
6
9
2
4
6

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 22
Especificaciónformaldeanalizadoresléxicos
EspecificaciónmedianteautómatasfinitosLa tercera forma de definir lenguajes regulares es a través del uso de autómatas finitos. Un autómata finito reconoce una cadena de entrada si consumidos todos los caracteres de la misma acaba en un estado final de aceptación
La construcción sistemática de autómatas genera autómatas finitos no deterministas. Un autómata finito no determinista es un autómata finito donde cada estado:
Autómatasfinitosnodeterministas
› Puede tener ع – transiciones
› Puede tener varias transiciones con la misma etiqueta
Genera indeterminación porque desde ese estado no se sabe si avanzar por otra transición normal consumiendo un carácter o hacerlo por la ع – transición sin consumir ningún carácter
Genera indeterminación porque desde ese estado, si el carácter a la entrada tiene varias posibles transiciones no se sabe cual escoger
Los autómatas finitos deterministas no son formalismos adecuados para representar lenguajes regulares

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 23
Especificaciónformaldeanalizadoresléxicos
EspecificaciónmedianteautómatasfinitosLa tercera forma de definir lenguajes regulares es a través del uso de autómatas finitos. Un autómata finito reconoce una cadena de entrada si consumidos todos los caracteres de la misma acaba en un estado final de aceptación
La construcción de un autómata finito determinista a partir de uno no determinista requiere de la identificación de todos los estados alcanzables desde cada estado a través de ع–transiciones y transiciones múltiples
Conversióndeautómatasfinitosnodeterministasaautómatasfinitosdeterministas
L = {<, <<, <=} Ejemplo
0 <
1
4
7 =
otro
5
8<
<
2< ع
ع
ع
<
<<
<=
› {0} = {1 4 7}
› {1 4 7} < = {2 5 8}
› {2 5 8} < = {6}
› {2 5 8} = = {9}
› {2 5 8} otro = {3}
{147} {258}< <
=
3
6
9
{3}
{6}
{9}

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 24
Especificaciónformaldeanalizadoresléxicos
ConversióndeformalismosDado cualquiera de los 3 formalismos de representación estudiados es posible encontrar un isomorfismo para expresarlo en cualquiera de los otros 2
Cada regla se expresa en términos de los operadores de concatenación, cierre + y cierre *
ConversióndeGramá8casaexpresiones
A ::= l B A = l B
B ::= l B B = l B = l +
B ::= d B B = d B = d +
B ::= ع B = ع
B = ( l+ | d+ | ع) = ( l | d | ع )+ = ( l | d )*
A = l ( l | d ) *
Se genera un estado por cada no terminal. El estado del axioma es el de inicio. Las reglas se traducen a transiciones. Si la regla es terminal (A ::= x) entonces se genera una transición otro a un estado de aceptación final. Si sale no determinista, convertirlo a determinista.
ConversióndeGramá8casaautómatas
A ::= l B
B ::= l B
B ::= d B
B ::= ع A
l
l, d
otro *
Lenguajesregulares
Gramá8caslineales
Expresionesregulares
Autómatasfinitos
B
2

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 25
Especificaciónformaldeanalizadoresléxicos
ConversióndeformalismosDado cualquiera de los 3 formalismos de representación estudiados es posible encontrar un isomorfismo para expresarlo en cualquiera de los otros 2
Transformar primero la expresión regular desfactorizando los cierres + y *. Después aplicar las transformaciones + a recursividad y * a recursividad con ع producción
ConversióndeExpresionesagramá8cas
L = l ( l | d ) * = l ( l * | d * )
A ::= l B B representa ( l* | d* )
B ::= l B Se captura l+
B := d B Se captura d+
B ::= ع Se captura l* | d*
La conversión de expresiones regulares a autómatas finitos se realiza utilizando las transformaciones atómicas definidas anteriormente al discutir la composición de lenguajes
ConversióndeExpresionesaautómatas
Lenguajesregulares
Gramá8caslineales
Expresionesregulares
Autómatasfinitos
x . y x yع
x | y
x ع
yع
x+ x
ع
x* x
ع
ع
ع
00 1

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 26
Especificaciónformaldeanalizadoresléxicos
ConversióndeformalismosDado cualquiera de los 3 formalismos de representación estudiados es posible encontrar un isomorfismo para expresarlo en cualquiera de los otros 2
Cada estado se convierte a un no terminal. El estado de arranque corresponde con el axioma. Cada transición A → B etiquetada con x se traduce en A ::= x B. Si B es un estado final se genera A ::= x. Si x = otro se genera A ::= ع
Conversióndeautómatasagramá8cas
[0] ::= l [1]
[1] ::= l [1]
[1] := d [1]
]1[ ::= ع
Para la transformación de autómatas a expresiones basta con hacer una lectura inversa de las transformaciones atómicas definidas anteriormente
Conversióndeautómatasaexpresión
Lenguajesregulares
Gramá8caslineales
Expresionesregulares
Autómatasfinitos
ع
x . y x yع
x | y
x ع
yع
x+ x
ع
x* x
ع
ع
ع
00 10
l
l, d
otro *
1
2

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 27
Implementacióndeanalizadoresléxicos
¿Quéesunanalizadorléxico?
El analizador léxico responde bajo demanda a las solicitudes de siguiente token que le va haciendo el analizado sintáctico. Cada vez que éste último hace una solicitud al primero, el analizador léxico consume un número de caracteres de la entrada y retorna un artefacto computacional que representa el siguiente token en la entrada. En lo venidero utilizaremos el término token para referirnos a dicho artefacto
Analizadorléxico
e·l·i·h·w
<WHILE,PR>
While(a>b)doa:=a+1;
Analizadorsintác8co
}
nextToken()Id
nFila
nColumna
lexema
valor
En la práctica el artefacto software que representa un token suele ser una estructura de datos o un objeto en los lenguajes orientados a objetos
}
Un analizador léxico o scanner es un programa capaz de descomponer una entrada de caracteres – generalmente contenidas en un fichero – en una secuencia ordenada de tokens.

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 28
Implementacióndeanalizadoresléxicos
Implementacióndeanalizadoresléxicosbasadaencasos
letra=[a..z]
digito=[0..9]
estado=0
fin=false
c=leerCaracter()
while(!fin){
switch(estado){
0:switch(c){
letra:estado=1
lexema+=c
c=leerCaracter()
break
digito:throwerror()
}
De acuerdo a esta estrategia de implementación es necesario disponer de una variable de estado para codificar el estado actual y una batería de casos que describen la lógica de transición del autómata finito determinista.
break;
1:switch(c){
letra:
digito:estado=1
lexema+=c
c=leerCaracter()
break
default:estado=2;
}
break
2:token=crearToken(lexema...)
fin=true
}
returntoken
letra
letra, dígito
otro *
0
2
1

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 29
Implementacióndeanalizadoresléxicos
Implementacióndeanalizadoresléxicosdirigidaportabla
tTransicion=[][]
sFinales={estadosfinales}
estado=0
fin=false
c=leerCaracter()
while(!fin){
s=tTransicion[s][c]
if(s!=null)
if(!(sinsFinales)){
lexema+=c
c=leerCaracter()
}elsefin=true
elsethrowerror()}
returncrearToken(lexema...)
Podemos codificar computacionalmente un autómata como una matriz bidimensional de Q x T → Q que indique, para cada entrada y estado el nuevo estado. El algoritmo se limita a leer dicha matriz
letra
letra, dígito
otro *
0
2
1

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 30
Implementacióndeanalizadoresléxicos
Implementacióndeanalizadoresléxicosguiadaporherramientas
letra=[a..z]
digito=[0..9]
letra(letra|digito)*{returnnewToken(ID);}
digito+{returnnewToken(ENT);}
digito*.digito+{returnnewToken(FRAC);}
“(”{returnnewToken(PI);}
“)”{returnnewToken(PD);}
“[”{returnnewToken(PI);}
“]”{returnnewToken(PD);}
...
Existen herramientas para la construcción automática de analizadores léxicos [Lex] [Flex] [JFlex]. Estas herramientas se basan en la definición de una colección de reglas patrón - acción
› Dan prioridad al token más largo
› DO / DOT
› > / >=
› Ante igualdad de longitud
› Anteponer la regla mas específica
› When
› While
› Id
}

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 31
Implementacióndeanalizadoresléxicos
Estrategiasdeimplementación
I.Reconocimientodepalabrasreservadas
Reconocimientodepalabrasreservadas
Resoluciónexplícita
Resoluciónimplícita
› Se indican todas con su patrón léxico
› Se integran en el diagrama global
› Se utilizan herramientas generadoras (FLex)
› Las palabras reservadas (PR) se reconocen como identificadores
› Las k palabras reservadas se meten en la tabla de símbolos (TS)
› Se busca cada id en TS. Si su índice es < k es PR
II.Reconocimientoestructurascomplejasdeformahíbrida
› Implementación manual de las estructuras más sencillas
› Operadores
› Identificadores
› Números
› Implementación tabular o guiada por herramientas con estructuras complejas
› Cadenas no específicas
› Prefijos comunes

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 32
Ges6óndeerrores
ErroresléxicosLos errores léxicos son aquellos que se producen en el ámbito del reconocimiento de patrones para construir tokens del lenguaje. Podemos establecer una clasificación de errores de naturaleza léxica
› Errores básicos
› Aparición de caracteres ajenos al conjunto T (ñ, Ç, etc.)
› Ausencia de concordancia con ningún patrón (1abc, +*, etc.)
› Errores complejos
› Cadena de caracteres sin cierre (falta “ final)
› Cadena de caracteres sin apertura (falta “ inicial)
› Comentario sin cierre (falta */ final)
› Comentario sin apertura (falta /* inicial)
› Error en el anidamiento de comentarios (/* .. /* .. */)
Son en realidad de esta categoría
No son en realidad errores capturables por un reconocedor de lenguajes regulares aunque las herramientas generadoras son capaces de reconocerlos
Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 33
Construccióndeanalizadoresléxicosenlaprác6ca
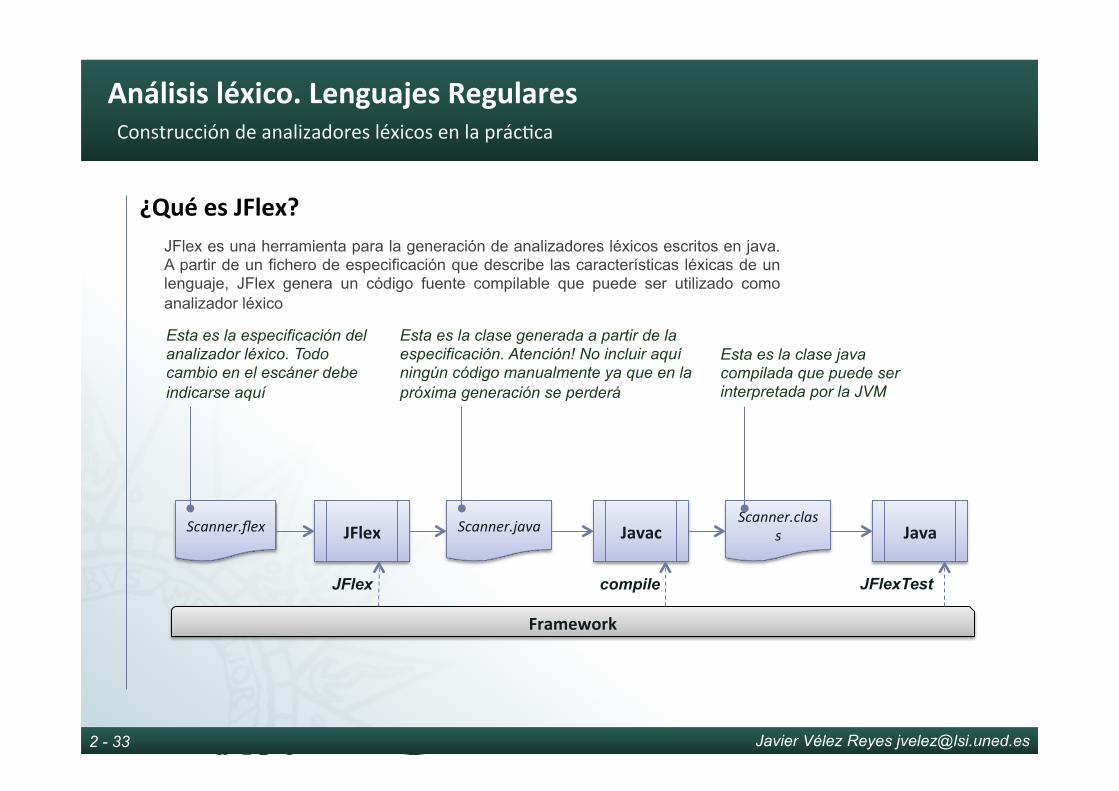
¿QuéesJFlex?JFlex es una herramienta para la generación de analizadores léxicos escritos en java. A partir de un fichero de especificación que describe las características léxicas de un lenguaje, JFlex genera un código fuente compilable que puede ser utilizado como analizador léxico
JFlex JavacScanner.flex
Framework
Scanner.java JavaScanner.clas
s
JFlex compile JFlexTest
Esta es la especificación del analizador léxico. Todo cambio en el escáner debe indicarse aquí
Esta es la clase generada a partir de la especificación. Atención! No incluir aquí ningún código manualmente ya que en la próxima generación se perderá
Esta es la clase java compilada que puede ser interpretada por la JVM

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 34
Construccióndeanalizadoresléxicosenlaprác6ca
¿CómofuncionaJFlex?El fichero de especificación de JFlex esta dividido en tres secciones separadas por el delimitador %%. Cada una de ellas tiene una semántica diferente
I.SeccióndecódigodeusuarioLa sección de código de usuario se utiliza para incluir cualquier declaración java (paquete, importación o clase) que sea necesario para compilar el scanner

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 35
Construccióndeanalizadoresléxicosenlaprác6ca
¿CómofuncionaJFlex?El fichero de especificación de JFlex esta dividido en tres secciones separadas por el delimitador %%. Cada una de ellas tiene una semántica diferente
II.Seccióndedirec8vasSe incluyen directivas de compatibilidad con cup, gestión de fila, columna y lexema, declaración de estados y macros e inclusión de código de inicialización

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 36
Construccióndeanalizadoresléxicosenlaprác6ca
¿CómofuncionaJFlex?El fichero de especificación de JFlex esta dividido en tres secciones separadas por el delimitador %%. Cada una de ellas tiene una semántica diferente
III.Seccióndereglaspatrón-acciónEn esta última sección se define una familia de escáneres léxicos, cada uno asociado a un estado distinto (YYINITIAL, COMMENT, etc.). Es posible saltar de uno a otro. La definición se basa en reglas patrón acción que indican el código java que debe ejecutarse cuando la entrada encaja con determinado patrón léxico. Si el código java no acaba con un return el scanner continua buscando un nuevo token

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 37
Construccióndeanalizadoresléxicosenlaprác6ca
¿CómofuncionaJFlex? Consúltese el documento “Manual de JFlex”
I.SeccióndecódigodeusuarioLa sección de código intermedio se copia tal cual al inicio de la clase fuente que representa el escáner (Scanner.java), por tanto todo lo que va en esta sección es código puro java de carácter declarativo
Copia en vervatim
Scanner.java

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 38
Construccióndeanalizadoresléxicosenlaprác6ca
¿CómofuncionaJFlex?
Directiva
› %full
› %unicode
› %{ … %}
› %init{ … %}
› %intthow{ … %}
› %yylexthrow{ … %}
› %eof{ … %}
› %eofval{ … %}
› %eofthrow{… %}
› %ignorecase
› %char
› %line
› %notunix
Descripción
Utiliza el código ASCII extendido 8 bits
Utiliza codificación UNICODE de 16 bits
Se incluye el código como declaración dentro de la clase Scanner
Incluye código dentro de los constructores
Declara excepciones que el constructor puede lanzar
Declara excepciones que el método de escaneo puede lanzar
Incluye código que se ejecuta tras encontrar EOF
Define el valor de retorno al encontrar EOF
Excepción de se lanza al encontrar EOF
No distinguir entre mayúsculas y minúsculas
Contabiliza el número de caracteres en la variable yychar
Contabiliza el número de líneas en la variable yyline
Reconoce \r\n como carácter (doble) de nueva línea
Consúltese el documento “Manual de JFlex”
II.Seccióndedirec8vas

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 39
Construccióndeanalizadoresléxicosenlaprác6ca
¿CómofuncionaJFlex?
Directiva
› %class name
› %public
› %function name
› %interface name
› %type name
› %integer
› %intwrap
› %yyeof
› %cup
› %state nombre
› nombre = valor
Descripción
Da nombre a la clase del escáner
Define como pública la clase del escáner
Da nombre a la función de escaneo
Declara los interfaces que debe implementar el escáner
Define el tipo de retorno de la función de escaneo
Define el tipo de retorno de la función de escaneo como un int
Define el tipo de retorno de la función de escaneo como Integer
Define la constante Yylex.YYEOF (obligatorio uso de %integer)
Habilita la compatibilidad con Cup
Define el estado nombre
Define una macro (LETRA = [A-Za-z])
Consúltese el documento “Manual de JFlex”
II.Seccióndedirec8vas

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 40
Construccióndeanalizadoresléxicosenlaprác6ca
¿CómofuncionaJFlex? Consúltese el documento “Manual de JFlex”
III.Reglaspatrón-acción
› Despliegue de macros
› Utilización de estados
{LETRA}({LETRA}|{DIGITO})*{returncrearToken(ID);}{DIGITO}*{returncrearToken(NUM);}
Se utilizan los caracteres { y } para encerrar el nombre de la macro, definida en la sección de directivas, que se quiere desplegar
Cada estado, declarado en la sección de directivas, corresponde con un autómata distinto. Cada regla debe asociarse a un estado precediendo al patrón léxico el nombre del mismo encerrando entre < y > Desde una regla r de un estado A se puede saltar a un estado B mediante la instrucción yybegin (B) invocada en la acción de r. El estado inicial por defecto es YYINITIAL. Este es un estado que no es preciso declarar
<YYINITIAL>“+”{returncrearToken(MAS);}<YYINITIAL>“-”{returncrearToken(MENOS);}<YYINITIAL>“*”{returncrearToken(MUL);}<YYINITIAL>“/”{returncrearToken(DIV);}...<YYINITIAL>“/*”{yybegin(COMMENT);}...
<COMMENT>“/*”{nComments++;}<COMMENT>“*/”{nComments--;if(nComments==0)yybegin(YYINITIAL);}<COMMENT>{COMMENT}{}

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 41
Construccióndeanalizadoresléxicosenlaprác6ca
¿CómofuncionaJFlex? Consúltese el documento “Manual de JFlex”
III.Reglaspatrón-acciónSecuencias de escape
› \b
› \n
› \t
› \f
› \r
› \ddd
› \xdd
› \udddd
› \^C
› \c
Descripción
Retroceso
Nueva línea
Tabulador
Avance de página
Retorno de carro
Número octal
Número hexadecimal
Hexadecimal de 4 dígitos
Carácter de control
Backslash seguido del c
Metacaracteres
› \b
› $
› .
› “…”
› {name}
› *
› +
› ?
› (…)
› […]
› [^…]
› a-b
Descripción
Retroceso
Fin de fichero
Cualquier carácter menos \n
…
Expansión de una macro
Clausura de Kleene
Una o más repeticiones
Opcionalidad
Agrupación de expresiones regulares
Conjunto de caracteres
Conjunto complementario
Rango a - b Secuencias de escape Descripción
› yychar
› yyline
› yytext ()
Número de columna
Numero de línea
lexema

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 42
Construccióndeanalizadoresléxicosenlaprác6ca
¿CómoseusaJFlex?Los analizadores sintácticos de JFlex están pensados para usarse bajo demanda. Se trata de artefactos con una API bien definida. El método más relevante es el de escaneo que devuelve el siguiente token a la entrada. El framework prescribe que el método de escaneo debe devolver un objeto de la clase Token
Analizad
orléxico
Analizad
orsintác8co
e·l·i·h·w <WHILE,PR>
While(a>b)doa:=a+1;
La clase Token
Token es una clase hija que hereda de la clase que u s a c u p p a r a i n t e g r a r s e c o n J F l e x (javacup.runtime.Symbol). Esta clase facilita y encapsula la comunicación entre el analizador léxico y el analizador sintáctico desarrollado en Cup proporcionando una colección de métodos de interés
Javacup.run6me.Symbol
Token
+ getID () + getLexema () + getline () + getColumn ()
JFlex Cup
next_Token()
Tokennext_Token()
}
}
Consúltese el documento “Directrices de implementación”

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 43
Construccióndeanalizadoresléxicosenlaprác6ca
¿CómoseusaJFlex?Para adaptar JFlex al framework de desarrollo es necesario realizar una serie de tareas sobre el fichero de especificación. Éstas ya vienen realizadas en la plantilla Jflex que proporciona el framework por lo tanto lo aquí contado es meramente explicativo y no requiere trabajo alguno del estudiante
› El escáner pertenece al paquete compiler.lexical
› Debe importarse
› La clase Token
› El interfaz ScannerIF
› Las clases de gestión de errores
› Debe activarse la compatibilidad con el framework
› %cup
› %implements ScannerIF
› %scanerror LexicalError
› Opcionalmente declararse la función crearToken
› Cada acción debe acabar con un return crearToken (…);
�
�
�
�
�
�
�
�
�
�

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 44
Construccióndeanalizadoresléxicosenlaprác6ca
Ges8óndeerroresenJFlexLa gestión de errores léxicos está soportada dentro del framework por la clase LexicalErrorManager. Los métodos para emitir error son
LexicalError
usa
<YYINITIAL>“+”{returncrearToken(MAS);}<YYINITIAL>“-”{returncrearToken(MENOS);}<YYINITIAL>“*”{returncrearToken(MUL);}<YYINITIAL>“/”{returncrearToken(DIV);}...<YYINITIAL>.{LexicalErrorManager.lexicalFatal(“ufff!”);}
› error (). Emite un mensaje de error
› fatal (). Emite un mensaje de error y para el scanner
Ejemplo
Estos métodos están doblemente sobrecargados. Pueden recibir un mensaje de error (String) o un objeto LexicalError que representa un error léxico
Consúltese el documento “Directrices de implementación”
LexicalErrorManager
+ lexicalDebug (String message) + lexicalInfo (String message) + lexicalWarn (String message) + lexicalError (String message) + lexicalError (LexicalError error) + lexicalFatal (String message) + lexicalFatal (LexicalError error)

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 45
Construccióndeanalizadoresléxicosenlaprác6ca
Desarrollopasoapaso
1. Especificación del escáner
› Abrir el documento de especificaciones JFlex doc/specs/scanner.flex
› No cambiar nada de lo que está escrito!
› Declarar macros necesarias (ALFA, DIGIT, SPACE, NEWLINE…)
› Declarar el estado de comentarios %%state COMMENT
› Definir las reglas de YYINITIAL
› Definir las reglas de COMMENT (contemplar el anidamiento si procede)
2. Generar el escáner
› Limpiar (tarea clear)
› Generar el escáner (tarea jflex)
› Compilar el escáner (tarea compile)
3. Probar el escáner
› Abrir fichero LexicalTestCase src/compiler/test/LexicalTestCase.java
› Descomentar y comentar lo indicado en el fichero (léelo atentamente)
› Si funciona, fin. Sino volver a 1

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 46
Bibliograla
MaterialdeestudioBibliografía básica
Construcción de compiladores: principios y práctica
Kenneth C. Louden International Thomson Editores,
2004 ISBN 970-686-299-4

Javier Vélez Reyes [email protected]
Análisisléxico.LenguajesRegulares
2 - 47
Bibliograla
MaterialdeestudioBibliografía complementaria
Compiladores: Principios, técnicas y herramientas.
Segunda Edición Aho, Lam, Sethi, Ullman
Addison – Wesley, Pearson Educación, México 2008
Diseño de compiladores. A. Garrido, J. Iñesta, F. Moreno
y J. Pérez. 2002. Edita Universidad de Alicante

ProcesadoresdeLenguajesIngenieríaTécnicasuperiordeIngenieríaInformá8ca
DepartamentodeLenguajesySistemasinformá6cos
JavierVé[email protected]
DepartamentodeLenguajesYSistemasInformáAcosUNED
3Análisissintác*coILenguajeslibresdecontexto

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 2
Obje6vos
Obje8vos
› Conocer los lenguajes libres de contexto
› Conocer las responsabilidades del analizador sintáctico
› Aprender a utilizar gramáticas libres de contexto
› Aprender a diseñar gramáticas libres de contexto
› Aprender a reconocer y resolver fuentes de ambigüedad
› Aprender a eliminar la recursividad por la izquierda
› Aprender a factorizar por la izquierda
› Conocer el uso y tipos de derivaciones y árboles sintácticos
› Conocer la representación de lenguajes mediante diagramas de sintaxis
› Presentar los diferentes tipos de autómatas utilizados para construir analizadores sintácticos
› Discutir los diferentes tipos de analizadores sintácticos

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 3
Índice
Índice› Introducción
› Gramáticas libres de contexto
› Notación BNF y EBNF
› Derivación gramatical
› Árboles sintácticos
› Limpieza gramatical
› Ambigüedad gramatical
› Recursividad por la izquierda
› Factorización por la izquierda
› Diagramas de sintaxis
› Autómatas a pila deterministas
› Bibliografía

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 4
Introducción
Análisissintác8coLa fase de análisis sintáctico tiene por objetivo solicitar tokens al analizador léxico y construir una representación arborescente de todo el código fuente. Este proceso se encuentra dirigido por el conocimiento gramatical que del lenguaje tiene el analizador sintáctico
El analizador sintáctico va pidiendo nuevos tokens al analizador léxico para construir un árbol del programa fuente
Foco de atención
¿Cómo se especifica formalmente un analizador sintáctico?
¿Cómo se implementa un analizador sintáctico?
› Formalismos
› Tratamiento de formalismos
› Conversión entre formalismos
› Estrategias análisis sintáctico
› Tipos de gramáticas
› Tipos de analizadores
Analizadorsintác8co
SWhile
WHILEEDOS
E>E
<WHILE,PR>
<a,ID><>,GT><b,ID>
<DO,PR>...
<(,PI>
<),PD>
Tema 3
Temas 4 y 5
} }

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 5
Introducción
LenguajeslibresdecontextoDesde una perspectiva sintáctica un lenguaje es una colección de construcciones sintácticas bien formadas desde un alfabeto de entrada y correctamente combinadas entre sí de acuerdo a una colección de reglas sintácticas
EjemploEl lenguaje Pascal tiene unas normas de carácter gramatical que definen su naturaleza y expresividad. Visto de manera extensiva, el lenguaje Pascal sería el conjunto infinito de todos los posibles códigos fuente correctos escritos en sintaxis Pascal
Pascal
Usescrt;varcantidad,cont,numero,s:integer;beginclrScr;s:=0;write('Cantidad:');read(canditad);forcont:=1tocantidaddobeginwrite('Numero',cont,':');Read(numero);s:=s+numero;end;write('Promedio:',s/cantidad:0:2);readKey;end;.
usescrt;varcontador:integer;beginClrScr;forcontador:=2to999dobegincontador:=contador+1;Write(contador,',');ifcontador>999thenbegincontador:=999;end;end;ReadKey;end.
Usescrt;varsuma,numero,contador:integer;beginclrScr;write('Numero:');readln(numero);suma:=0;forcontador:=1tonumerodobeginsuma:=suma+contador;end;write('Suma:',suma);readKey;end.
…

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 6
Introducción
EspecificacióndelenguajeslibresdecontextoExisten 3 diferentes maneras de definir formalmente un lenguaje de contexto libre. A lo largo de esta sección estudiaremos cada una de ellas en detalle y veremos cómo se puede pasar de cada una a las otras 2
Lenguajeslibresdecontexto
Gramá8caslibresdecontexto
Diagramasdesintaxis
Autómatasapila
› Elementos
› Gramáticas libres de contexto
› Diagramas de sintaxis
› Autómatas a pila

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 7
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Definicióndegramá8calibredecontextoUna gramática libre de contexto es un conjunto de 4 elementos G = (T, N, S, P) donde:
› T es un conjunto de símbolos terminales
› N es un conjunto de símbolos no terminales
› S Є N axioma gramatical
› P un conjunto de reglas de producción de la forma
1. A ::= X donde X es una secuencia de elementos en N U T
2. A ::= x donde x es una secuencia de elementos en T
3. A :: = ع siendo ع la cadena vacía
A veces T se elide, N se deduce de los antecedentes de las reglas de P y se asume que el antecedente de la primera regla es S con lo G sólo a través de P
Ejemplo
L = Lenguaje de operadores
Sea G = (T, N A, P) con
T = {+, -, *, /, n}
N = {E}
P = {
E ::= E + E
E ::= E - E
E ::= E * E
E ::= E / E
E ::= n
}

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 8
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Notación
E → E + E
E → E – E
E → id
¿Cómo se escriben las reglas?
Notación BNF Las reglas se escriben como A ::= X. Las reglas de un mismo antecedente se escriben como A ::= X | Y | Z… Cada regla con antecendente distinto se escribe en una nueva línea
Notación EBNF Se usa la notación BNF. Las reglas recursivas se pueden esquematizar con los meta-caracteres { y }
Notación estándar Las reglas se escriben como A → X. Cada regla se escribe en una linea distinta
D ::= T L
T ::= int | bool | char
L ::= id , L | id
D ::= T L
T ::= int | bool | char
L ::= { id , } id
Foco
de
aten
ción

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 9
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontexto
Derivacióngrama8cal
L = Lenguaje de operadores
Sea G = (T, N A, P) con
T = {+, -, *, /, n}
N = {E}
P = {
E ::= E + E
E ::= E - E
E ::= E * E
E ::= E / E
E ::= n
}
Se plantea el siguiente problema de decisión: Dado un lenguaje descrito a través de una gramática G, L(G) determinar si la colección de terminales x pertenece o no al lenguaje al mismo. Esto es ¿x Є L (G)?
E → E + E → n + E → n + E * E → n + n * E → n + n * n
axioma
Paso de derivación
asidero
Frase F o r m a de frase
Cadena de derivación
2+3*5
De manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
(2) (3) (5)

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 10
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Derivacióngrama8calSe plantea el siguiente problema de decisión: Dado un lenguaje descrito a través de una gramática G, L(G) determinar si la colección de terminales x pertenece o no al lenguaje al mismo. Esto es ¿x Є L (G)?
Cadena de derivación
Secuencia de pasos de derivación que parten del axioma gramatical para intentar alcanzar la frase analizada x. Demostración de x Є L (G)
Frase Secuenc ia de t e rm ina les que pertenece al lenguaje definido por la gramática. Si x Є L (G), x es frase de L
Forma de frase
Secuencia de terminales y no terminales que representa una colección de frases del lenguaje. Existe una cadena de derivación que llega hasta ella
Axioma Forma de frase más abstracta que representa a L (cualquier derivación de Si x Є L (G) comienza por el axioma)
Asidero Parte izquierda de cualquier forma de frase de x Є L (G) formada únicamente por símbolos terminales
Paso de derivación
Aplicación de una regla de producción que transforma una forma de frase más general en otra más especifica para x

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 11
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Derivacióngrama8calSe plantea el siguiente problema de decisión: Dado un lenguaje descrito a través de una gramática G, L(G) determinar si la colección de terminales x pertenece o no al lenguaje al mismo. Esto es ¿x Є L (G)?
E → E + E →
n + E →
n + E * E →
n + n * E →
n + n * n ¿ En qué orden se aplican las reglas?
Left Most Derivation En cada paso de derivación se escoge el no terminal más a la izquierda de la forma de frase a derivar
Right Most Derivation En cada paso de derivación se escoge el no terminal más a la derecha de la forma de frase a derivar
E → E + E →
E + E * E →
E + E * n →
E + n * n →
n + n + n

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 12
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Árbolesdeanálisissintác8coyarbolessintác8cosabstractosFrecuentemente no es preciso reflejar el orden de aplicación de las derivaciones sino solamente el proceso de derivación desde el axioma a la frase final. Para ello se interpreta cada regla como un árbol con raíz en el antecedente e hijos los símbolos terminales y no terminales del consecuente de la regla
2+3*5
L = Lenguaje de operadores
Sea G = (T, N A, P) con
T = {+, -, *, /, n}
N = {E}
P = {
R1: E ::= E + E
R2: E ::= E - E
R3: E ::= E * E
R4: E ::= E / E
R5: E ::= ( E )
R6: E ::= n
}
E
E + E
n E * E
n n (2)
(3) (5)
R1
R3
R6
antecedente
consecuente
frase

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 13
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Árbolesdeanálisissintác8coyarbolessintác8cosabstractosExisten dos tipos de representaciones arborescentes que se utilizan frecuentemente para representar las derivaciones de una frase de un lenguaje.
Tipos de árboles sintácticos
Arboles de análisis sintáctico Los hijos de cada regla son una representación exacta de la colección de terminales y no terminales que aparecen en el consecuente de la misma
Arboles sintácticos abstractos Se hace una representación abstracta de la gramática de tal manera que en los hijos del árbol solo aparecen los símbolos semánticamente relevantes
Foco de atención de la asignatura

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 14
If(a>b)thena:=belseb:=aIf(a>b)thena:=belseb:=a(2+3)*5
(2+3)*5
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Árbolesdeanálisissintác8coyarbolessintác8cosabstractos
Arbolesdeanálisissintác8co Arbolessintác8cosabstractos
E
E * E
( E ) n
E + E
n n
*
+ n
n n
IF
> := :=
ID ID ID ID
SIf
IF ( E ) THEN S ELSE S
E > E
while(a>b)doa++
SWhile
WHILE ( E ) DO S
E > E
while(a>b)doa++
WHILE
> ++
ID ID ID
ID ID

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 15
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Ejercicios
› L1. Declaración de variables en Pascal
› L2. Declaración de estructuras en C
› L3. Declaración de procedimientos en Pascal
› L4. Declaración de procedimientos en C
› L5. Declaración de sentencias en C
› L6. Declaración de sentencias en Pascal
› L7. Sentencia for en C
› L8. Sentencia Repeat – Until en Pascal
Sentencia ::= BloqueSentencias |
SentenciaIf |
Sentencia While
BloqueSentencias ::= { listaSentencias }
listaSentencias ::= sentencia ; ListaSentencias |
ع
SentenciaIf ::= …
SentenciaWhile ::= …
L5
Construya arboles de análisis sintáctico para frases en cada uno de los lenguajes anteriores

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 16
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Limpiezagrama8calPara no tener problemas en la construcción de analizadores sintácticos es conveniente aplicar ciertas operaciones de trasformación gramatical. Estos problemas son:
Limpieza gramatical
Eliminación de la ambigüedad Es necesario eliminar las expresiones gramaticales que generen una interpretación potencialmente gramatical ambigua
Factorización por la izquierda Las reglas con partes comunes a la izquierda de los consecuentes pueden también generar problemas, en función del analizador que se construya
Eliminación de la recursividad a izquierdas En algunos casos las reglas con recursividad a izquierdas de la forma A ::= A α pueden acarrear problemas en la construcción de analizadores

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 17
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Ambigüedadgrama8cal
R1: E ::= E + E
R2: E ::= E - E
R3: E ::= E * E
R4: E ::= E / E
R5: E ::= ( E )
R6: E ::= n
E
E + E
n E * E
n n
(2)
(3) (5)
E
E * E
E + E
n n (2) (3)
(5)
n
2+3*5Interpretación 1 Interpretación 2
Una gramática es inherentemente ambigua cuando es posible construir dos arboles de derivación para al menos una frase del lenguaje
¿Cuál es el problema?
Ambos árboles son sintácticamente c o r r e c t o s p e r o r e s p o n d e n a interpretaciones semánticamente diferentes, una válida y la otra no, con respecto a la semánt ica operacional matemática
} ü û

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 18
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Fuentesdeambigüedadgrama8calPara demostrar que una gramática es ambigua es suficiente con encontrar dos árboles de derivación diferentes para una misma frase. Sin embargo no existe ninguna manera de demostrar que una gramática no es ambigua. Existen criterios heurísticos que identifican fuentes de potencial ambigüedad
S::=AS::=aA::=S
E::=E…E
S:=AS:=BA:=B
S::=HRSS::=sH::=h|εR::=r|ε
S::=HRH::=h|εH::=h|ε
Gramáticas con ciclos
Reglas con igual principio y fin
Caminos alternativos
Reglas recursivas con ε en casos base
No terminales que derivan ε

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 19
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Correccióndelaambigüedadgrama8calLa forma gramatical puede inducir una interpretación semánticamente invalidada por ello es necesario introducir correcciones para evitar la ambigüedad
Corrección de la ambigüedad gramatical
Corrección explicita Se mantiene la gramática ambigua pero se añaden criterios para indicar al compilador el árbol sintáctico que debe construir en cada caso
Alteración gramatical Se modifica la gramática para conseguir otra equivalente que no presente ambigüedad.
La resolución explicita hace escoger este árbol gramatical
}
Dos gramáticas son equivalentes si reconocen el mismo lenguaje
}
Ambigüedad no esencial Hay situaciones en las que la ambigüedad no presenta problemas para construir analizadores sintácticos

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 20
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
CasosZpicosdeambigüedadgrama8calDado que resulta imposible de resulta imposible ofrecer un algoritmo para descubrir y remediar la ambigüedad gramatical analizaremos casos arquetípicos de ambigüedad que suelen aparecen en los lenguajes de programación
Estudio de casos típicos
de ambigüedad
Gramática de operadores La gramática canónica de operadores es inherentemente ambigua ya que no se sabe el orden en que deben aplicarse los operadores
El problema del else ambiguo Cuando se anidan una sentencia if con otra if–else es imposible saber a qué if emparejar el else.
2 + 3 * 5
If (a>b) if (c>d) c++; else d++;
2 + (3 * 5) (2 + 3) * 5
If (a>b) {
if (c>d) c++;
else d++;
}
If (a>b) {
if (c>d) c++;
}
else d++;

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 21
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Correccióndelaambigüedadengramá8casdeoperadoresLas gramáticas canónicas de operadores son inherentemente ambiguas. Para corregir este hecho es necesario inyectar información sobre la precedencia y la asociatividad de los operadores
Alteraciones gramaticales
Precedencia de operadores La precedencia de operadores indica la prioridad de aplicación de los operadores para combinar subexpresiones en una mayor
Asociatividad de operadores Cuando tres o mas subexpresiones se combinan a través de un mismo operador tiene sentido definir la asociatividad del mismo
E ::= E @ E
E ::= E # E
E ::= E & E
E ::= E % E
E ::= ( E )
E ::= n
Gramática canónica de operadores sobre operadores {@, #, $, %}
A # B & C
(A # B) & C A # (B & C)
# > & & > #
A # B # C
A # (B # C) (A # B) #C
a derechas a izquierdas

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 22
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Correccióndelaambigüedadengramá8casdeoperadoresLas gramáticas canónicas de operadores son inherentemente ambiguas. Para corregir este hecho es necesario inyectar información sobre la precedencia y la asociatividad de los operadores
Precedencia de operadores Se ordena en una tabla los niveles de prioridad. Para cada nivel se define un nuevo no terminal. Cada nivel incrementa en 1 la distancia al axioma
+ –
* /
( ) n
+ pr
eced
enci
a -
E ::= E + E
E ::= E – E
E ::= E * E
E ::= E / E
E ::= ( E )
E ::= n
E ::= E + T | E – T | T
T ::= T * F | T / F | F
F ::= ( E ) | n
Gramática de operadores no ambigua
E
E + T
T * F
(2) (3)
(5)
n
2+3*5
T
F F
n
n

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 23
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
Correccióndelaambigüedadengramá8casdeoperadoresLas gramáticas canónicas de operadores son inherentemente ambiguas. Para corregir este hecho es necesario inyectar información sobre la precedencia y la asociatividad de los operadores
Asociatividad de operadores La recursividad a izquierdas marca asociatividad a izquierdas. La recursividad a derecha marca asociatividad a derechas
E ::= E + T | E – T | T
T ::= F * T | T / F | F
F ::= ( E ) | n
E
E + T
E + T
(5)
(2)
(3)
2+3+5
F
n
Gramática de operadores no ambigua
T
F
n
F
n
�
�
E
F * T
F * T (2)
(3)
(5)
2*3*5
n
n F
n
�
�
T

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 24
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
ElproblemadelelseambiguoDe las dos interpretaciones que presentábamos antes la correcta es la que asocia el else al if mas cercano (esta regla se llama regla de anidamiento más cercano. Veamos cómo es la gramática original y cómo debe transformarse
sentencia ::= sentenciaIf | otra
sentenciaIf ::= IF ( exp ) sentencia |
IF ( exp ) sentencia ELSE sentencia
Sentencia
… sentencia ::= sentEmparejada | sentNoEmparejada
sentEmparejada ::= IF ( exp ) sentEmparejada ELSE sentEmparejada |
otra
sentNoEmparejada ::= IF ( exp ) sentencia |
IF ( exp ) sentEmparejada ELSE sentNoEmparejada
SentNoEmparejada
IF ( exp ) sentencia
IF ( exp ) SentEmparejada ELSE SentEmparejada
SentEmparejada
… otra otra

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 25
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
EliminacióndelarecursividadporlaizquierdaLas reglas con recursividad por la izquierda de la forma A ::= Aα | β pueden presentar problemas a la hora de construir analizadores sintácticos por tanto es conveniente reformularlas equivalentemente
A ::= Aα | β
A ::= αA’
A’ ::= β A’ | ع
Recursividaddirecta
E ::= TE’
E’ ::= + TE’ | – TE’ | ع
T ::= FT’
T’ ::= * FT’ | / FT’ | ع
F ::= ( E ) | n
Ejemplo
E ::= E + T | E – T | T
T ::= T * F | T / F | F
F ::= ( E ) | n
Gramática de operadores no ambigua Gramática de operadores LL (1)

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 26
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
EliminacióndelarecursividadporlaizquierdaLas reglas con recursividad por la izquierda de la forma A ::= Aα | β pueden presentar problemas a la hora de construir analizadores sintácticos por tanto es conveniente reformularlas equivalentemente
A →+ A NumerarlosnoterminalesA1,A2,…An
fori:=1tondo
forj:=1toi–1do
SustituircadaAi::=Ajγpor
Ai::=δ1γ|δ2γ|...|δkγdonde
Aj::=δ1|δ2|...|δksontodaslas
reglasactualesdeAjeliminarrecursividadporlaizquierdadeAi
Recursividadindirecta

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 27
Gramá6caslibresdecontexto
Especificaciónmediantegramá8caslibresdecontextoDe manera similar a como ocurre en los lenguajes regulares, los lenguajes libres de contexto se pueden expresar mediante el uso de gramáticas libres de contexto. Su definición es una extensión de las gramáticas regulares con reglas de producción potencialmente más complejas
FactorizaciónporlaizquierdaLas reglas con factores comunes por la izquierda en sus consecuentes de la forma A ::= α β1 | α β2 pueden generar problemas para construir analizadores sintácticos y conviene transformarlas
A ::= α β1 | α β2 | … | α βn | γ
A ::= αA’ | γ
A’ ::= β1 | β2 | … | βn
Ejemplo
SentenciaIf::=IF(exp)THENsentencia|
IF(exp)THENsentenciaELSEsentencia

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 28
Diagramasdesintaxis
EspecificaciónmediantediagramasdesintaxisLos diagramas de transición son una forma gráfica de representar las restricciones sintácticas de los lenguajes libres de contexto. Cada diagrama de sintaxis está etiquetada con el nombre de un no terminal al que representa y se compone de cajas y esferas que representan terminales y no terminales unidas por flechas que indican secuencias y selecciones .
E ::= E + T |
E - T |
T
T ::= T * F |
T / F |
F
F ::= ( E ) |
n
La equivalencia entre gramáticas y diagramas de sintaxis resulta evidente
T E
+
-T
F T
*
/F
Fn
( )E
}

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 29
Autómatasapiladeterministas
EspecificaciónmedianteautómatasapiladeterministasLos autómatas a pila son una extensión con memoria de los autómatas finitos deterministas que se utilizan para realizar analizadores sintácticos. Constan de una cinta de entra donde se leen los tokens del programa fuente, una pila de estados (la memoria) y una máquina de estados. Las transiciones de estados dependen ahora de la entrada y de la historia del proceso de análisis almacenada en la pila
DefinicióndeautómataapiladeterministaUn autómata a pila es una tupla AP = (T, P, Q, A0, q0, f, F) donde
› T es un alfabeto de símbolos terminales de entrada
› P es un alfabeto de estados de la pila
› Q es un conjunto de estados finito no vacío
› A0 Є P es el simbolo inicial en la pila
› q0 Є Q es un estado inicial o estado de arranque
› f: Q x T U { ع } x P → Q x P una función de transición
› F C Q es un subconjunto de estados finales de aceptación
A
x, y
x
B
2
0
Máquina de estados
BA
CPila
de
esta
dos
Cinta de entrada
}
x
1

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 30
Autómatasapiladeterministas
EspecificaciónmedianteautómatasapiladeterministasLos autómatas a pila son una extensión con memoria de los autómatas finitos deterministas que se utilizan para realizar analizadores sintácticos. Constan de una cinta de entra donde se leen los tokens del programa fuente, una pila de estados (la memoria) y una máquina de estados. Las transiciones de estados dependen ahora de la entrada y de la historia del proceso de análisis almacenada en la pila
MovimientosenunautómataapiladeterministaUn movimiento de un autómata a pila consiste en consumir un elemento de la entrada (x), la cima de la pila (A) y transitar desde el estado en curso (0) a un nuevo estado (1) apilando un nuevo estado en la cima de la pila
A
x, y
x
B
2
0
Máquina de estados
BA
CPila
de
esta
dos
Cinta de entrada
}
x
1Reconocimientodelenguajes
Reconocimiento de lenguajes
Reconocimiento por estados finales Se reconoce una frase si tras una secuencia de movimientos se llega a un estado final de aceptación. El estado final de la pila no importa
Reconocimiento por vaciado de pila Se reconoce una frase si tras una secuencia de movimientos se llega a vaciar completamente la pila. El estado del autómata no importa

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 31
Autómatasapiladeterministas
EspecificaciónmedianteautómatasapiladeterministasLos autómatas a pila son una extensión con memoria de los autómatas finitos deterministas que se utilizan para realizar analizadores sintácticos. Constan de una cinta de entra donde se leen los tokens del programa fuente, una pila de estados (la memoria) y una máquina de estados. Las transiciones de estados dependen ahora de la entrada y de la historia del proceso de análisis almacenada en la pila
Clasificacióndeanalizadoressintác8cos
Ana
lizad
ores
si
ntác
ticos
Analizadores no deterministas
Son analizadores generales que imponen pocas restricciones sobre la naturaleza sintáctica del lenguaje. Suelen tener complejidad asintótica O (n3)
Analizadores deterministas
Son analizadores que imponen ciertas restricciones sobre la naturaleza de los lenguajes que soportan
Cualquier tipo de gramática
Analizadores en backtracking
Analizadores sintácticos descendentes
Se parte del axioma y se aplica una cadena de derivaciones para construir un árbol sintáctico
Gramáticas LL
Reconocimiento por vaciado de pila
Analizadores sintácticos ascendentes
Se parte de los terminales y se construye la inversa de una derivación para intentar alcanzar el axioma
Gramáticas LR
Reconocimiento por estados finales

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 32
BibliograUa
MaterialdeestudioBibliografía básica
Construcción de compiladores: principios y práctica
Kenneth C. Louden International Thomson Editores,
2004 ISBN 970-686-299-4

Javier Vélez Reyes [email protected]
Análisissintác8co.Lenguajeslibresdecontexto
3 - 33
BibliograUa
MaterialdeestudioBibliografía complementaria
Compiladores: Principios, técnicas y herramientas.
Segunda Edición Aho, Lam, Sethi, Ullman
Addison – Wesley, Pearson Educación, México 2008
Diseño de compiladores. A. Garrido, J. Iñesta, F. Moreno
y J. Pérez. 2002. Edita Universidad de Alicante

ProcesadoresdeLenguajesIngenieríaTécnicasuperiordeIngenieríaInformá8ca
DepartamentodeLenguajesySistemasinformá6cos
JavierVé[email protected]
DepartamentodeLenguajesYSistemasInformáAcosUNED
4Análisissintác*coIIAnalizadoresdescendentes

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 2
Obje6vos
Obje8vos
› Conocer en qué consiste el análisis descendente
› Conocer los tipos de analizadores descendentes que existen
› Entender en qué consiste el análisis descendente predictivo
› Aprender las condiciones necesarias sobre gramáticas para aplicar análisis predictivos
› Aprender a transformar gramáticas para aplicar análisis predictivos
› Entender el uso de los conjuntos de predicción
› Aprender a construir conjuntos de predicción
› Aprender a calcular los conjuntos Primeros
› Aprender a calcular los conjuntos Siguientes
› Aprender a construir y utilizar analizadores sintácticos predictivos
› Aprender a construir analizadores predictivos recursivos
› Aprender a construir analizadores predictivos dirigidos por tabla

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 3
Índice
Índice› Introducción
› Análisis sintáctico descendente con retroceso
› Análisis sintáctico descendente predictivo
› Conjuntos de predicción
› Condiciones LL (1)
› Construcción de los conjuntos de predicción
› Conjuntos Primeros
› Conjuntos Siguientes
› Analizadores sintácticos descendentes predictivos
› Analizador descendente predictivo recursivo
› Analizados descendente predictivo dirigido por tabla
› Gestión de errores en analizadores descendentes
› Bibliografía

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 4
Introducción
¿Quéeselanálisisdescendente?
El análisis sintáctico descendente es una técnica de análisis sintáctico que intenta comprobar si una cadena x pertenece al lenguaje definido por una gramática L (G) aplicando los siguientes criterios
› Partir del axioma de la gramática
› Escoger reglas gramaticales estratégicamente
› Hacer derivaciones por la izquierda (Left Most Derivation)
› Procesar la entrada de izquierda a derecha
› Obtener el árbol de análisis sintáctico o error
Cadenadederivación Árboldeanálisissintác8coEn cada paso de derivación se transforma siempre el no terminal más a la izquierda de la forma de frase
R1: E ::= E + E
R2: E ::= E - E
R3: E ::= E * E
R4: E ::= E / E
R5: E ::= ( E )
R6: E ::= n
E → E + E →
n + E →
n + E * E →
n + n * E →
n + n * n
Se parte del axioma gramatical y se van aplicando reglas estratégicamente hasta alcanzar la frase X como nodos hojas del árbol
E
E + E
n E * E
n n (2)
(3) (5)
R1
R3
R6
R6
R6 �
�
� �
�

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 5
Introducción
Analizadoressintác8cosdescendentes
Ana
lizad
ores
de
term
inis
tas
Analizadores descendentes Se parte del axioma y se apl ica una cadena de derivaciones para construir un árbol sintáctico
Analizadores ascendentes
Se parte de los terminales y se construye la inversa de una derivación para intentar alcanzar el axioma
Analizadores predictivos
Se determina qué regla aplicar a partir de un análisis de los primeros tokens a la entrada
Analizadores con retroceso
Se hace una búsqueda en profundidad con retroceso para garantizar que se encuentra la frase. Coste O (kn)
¿Como se selecciona el siguiente no terminal a derivar? }
¿Como se selecciona la regla de producción en cada paso de derivación?
Analizadores predictivos LL (1)
Determinan que regla de producción aplicar en cada paso en función de token que s e e n c u e n t r a e n c a d a momento en la cabeza de lectura
Analizadores predictivos LL (k)
Determinan que regla de producción aplicar en cada paso en función de los k p r imeros tokens que se encuentra en cada momento en la cabeza de lectura
}

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 6
Análisissintác6codescendenteconretroceso
Análisissintác8codescendenteconretrocesoEn el análisis sintáctico con retroceso se van probando una por una todas las reglas candidatas a ser aplicadas para construir el árbol de análisis sintáctico. Cuando una regla seleccionada falla, entonces se retrocede y se prueba con la siguiente regla
1. Se selecciona un nuevo no terminal a derivar por la estrategia Left Most Derivation
2. Se selecciona el conjunto de todas las reglas con antecedente igual al no terminal
3. Se ordena el conjunto de reglas arbitrariamente
4. Se selecciona una regla
1. Se extrae la regla del conjunto
2. Se aplica la derivación por dicha regla
3. Si la regla encaja volver a 1 sino retroceder la derivación y volver a 4
r1. S ::= c A d
r2. A ::= a b
r3. A ::= a
S
c A d
S
c A d
c a d
S
c a d
a b
S
c A d
a
c a d
r1 r2 r3
retroceso }

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 7
Análisissintác6codescendentepredic6vo
Análisissintác8codescendentepredic8voLos analizadores sintácticos predictivos son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LL (K)
Analizadores predictivos
Se determina qué regla aplicar a partir de un análisis de los primeros tokens a la entrada
Analizadores predictivos LL (1)
Determinan que regla de producción aplicar en cada paso en función de token que se encuentra en cada momento en la cabeza de lectura
LL (k)
Derivación más a la izquierda (Left Most Derivatión)
Lectura de izquierda a derecha
Número de terminales consultados para determinar la regla de producción a aplicar
Analizadores predictivos LL (k)
Determinan que regla de producción aplicar en cada paso en función de los k primeros tokens que se encuentra en cada momento en la cabeza de lectura
Lenguajes LL (K)
Lenguajes LL (1)

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 8
Análisissintác6codescendentepredic6vo
Análisissintác8codescendentepredic8voLos analizadores sintácticos predictivos son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LL (K)
ConjuntosdepredicciónPara aplicar el análisis descendente predictivo LL (1) es necesario asociar a cada regla de producción un conjunto de predicción. El conjunto de predicción de una regla está formado por la colección de todos los posibles terminales que es necesario encontrar en la cabeza de lectura para poder aplicar dicha regla
A → a b B
a b c Entrada
Derivación
r1. A ::= a b B { a }
r2. A ::= B { b, c }
r3. B ::= b { b }
r4. B ::= c { c }
}
De todas las reglas candidatas para el no terminal en curso se escoge aquella que contiene en su conjunto de predicción el terminal a la entrada
A → a b B
a b c }
A → a b B → a b c
a b c
}
r1. A ::= a b B { a }
r2. A ::= B { b, c }
r3. B ::= b { b }
r4. B ::= c { c }
r1. A ::= a b B { a }
r2. A ::= B { b, c }
r3. B ::= b { b }
r4. B ::= c { c }
}

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 9
Análisissintác6codescendentepredic6vo
Análisissintác8codescendentepredic8voLos analizadores sintácticos predictivos son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LL (K)
CondicionesLL(1)Para poder aplicar el análisis descendente predictivo LL (1) es necesario que se cumplan las condiciones LL (1) que garanticen la predictibilidad absoluta a la hora de seleccionar una regla de producción:
r1. A ::= a b B { a }
r2. A ::= B { b, c }
r3. B ::= b { b }
r4. B ::= c { c }
Para poder aplicar el análisis predictivo LL (1) es necesario que los conjuntos de predicción de todas las reglas con un mismo antecedente
sean disjuntas entre sí
r1. A ::= a b B { a }
r2. A ::= B { b, c }
r3. B ::= b { b }
r4. B ::= c { c }
{ a } ∩ { b, c } = Ø LL (1) ü
{ b } ∩ { c } = Ø LL (1) ü
LL (1) ü

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 10
Análisissintác6codescendentepredic6vo
Análisissintác8codescendentepredic8voLos analizadores sintácticos predictivos son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LL (K)
CondicionesLL(1)Para cumplir las condiciones LL (1) la gramática debe satisfacer necesariamente 3 requisitos:
› No ambigua
› Factorizada por la izquierda
› No recursiva a izquierdas
Consúltese el tema 3 para obtener una descripción acerca de cómo se puede transformar una gramática para que cumpla estas restricciones
} E ::= TE’
E’ ::= + TE’ | – TE’ | ع
T ::= FT’
T’ ::= * FT’ | / FT’ | ع
F ::= ( E ) | n
E ::= E + T | E – T | T
T ::= T * F | T / F | F
F ::= ( E ) | n
Gramática de operadores no ambigua
Gramática de operadores LL (1)
E ::= E + E
E ::= E – E
E ::= E * E
E ::= E / E
E ::= ( E )
E ::= n
Gramática de operadores canónica
� Eliminación de la ambigüedad � Factorización por la izquierda
�
�

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 11
Análisissintác6codescendentepredic6vo
Análisissintác8codescendentepredic8voLos analizadores sintácticos predictivos son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LL (K)
ConstruccióndelosconjuntosdepredicciónLa construcción de los conjuntos de predicción de una regla A ::= α se apoya en el uso de dos conjuntos asociados respectivamente a la parte derecha e izquierda de la regla:
› Primeros (α) devuelve el conjunto de todos los terminales que se
pueden encontrar a la cabeza de cualquier derivación
de la frase α
› Siguientes (A) devuelve el conjunto de todos los terminales que se
pueden encontrar siguiendo a A en cualquier derivación
posible
α
... aβ
bγ
cδ
βAa
γAb
δAc
...
...
...
...
...

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 12
Análisissintác6codescendentepredic6vo
Análisissintác8codescendentepredic8voLos analizadores sintácticos predictivos son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LL (K)
ConstruccióndelosconjuntosdepredicciónLa construcción de los conjuntos de predicción de una regla A ::= α se apoya en el uso de dos conjuntos asociados respectivamente a la parte derecha e izquierda de la regla:
Predicción ( A ::= α ) =
Si ع Є Primeros ( α ) entonces = Primeros ( α ) – { ع } ∪ Siguientes ( A)
Sino = Primeros( α )
βAγ βAγ
ab
βAγ βAγ
entonces ع Si α no deriva en عPredicción (A ::= α) = Primeros (α) } Si α puede derivar en ع
entonces Predicción (A ::= α) incluye Siguientes (α)
}
�
�
� �

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 13
Análisissintác6codescendentepredic6vo
Análisissintác8codescendentepredic8voLos analizadores sintácticos predictivos son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LL (K)
ConjuntosprimerosSi α es una forma de frase compuesta por una concatenación de símbolos Primeros (α) es el conjunto de terminales incluyendo potencialmente ع que pueden aparecer iniciando las cadenas que derivan de α
α
... aβ
bγ
cδ
...
...
Primeros (ع { = )ع }
Primeros (a) = {a}
Primeros (A) = ∪ Primeros (αi) Para todo A := αi
Primeros (Aα) =
si ع Є Primeros (A), = Primeros (A) – { ع } U Primeros (α)
sino, = Primeros (A)
E ::= TE’
E’ ::= + TE’ | – TE’ | ع
T ::= FT’
T’ ::= * FT’ | / FT’ | ع
F ::= ( E ) | n
EjercicioCalcular el conjunto Primeros para todas las reglas de la siguiente gramática

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 14
Análisissintác6codescendentepredic6vo
Análisissintác8codescendentepredic8voLos analizadores sintácticos predictivos son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LL (K)
ConjuntosSiguientesSi A es un símbolo no terminal de la gramática SIG (A) es el conjunto de terminales potencialmente incluyendo $1 que pueden aparecer a continuación de A en alguna forma de frase derivada del axioma
1 $ representa el carácter fin de fichero
1. Inicialmente
Siguiente (A) = { }
2. Si A es el axioma
Siguiente (A) = Siguiente (A) ∪ { $ }
3. Para cada regla B := α A β
Siguiente (A) = Siguiente (A) ∪ { Primeros (β) – { ε } }
4. Para cada regla B := α A o B:= α A β con ε є Primeros (β)
Siguiente (A) = Siguiente (A) ∪ Siguiente (B)
5. Repetir 3 y 4 hasta que no se aumentar Siguiente (A)
E ::= TE’
E’ ::= + TE’ | – TE’ | ع
T ::= FT’
T’ ::= * FT’ | / FT’ | ع
F ::= ( E ) | n
EjercicioCalcular el conjunto Siguientes para todas las reglas de la siguiente gramática
βAa
γAb
δAc
...
...
...

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 15
Análisissintác6codescendentepredic6vo
Análisissintác8codescendentepredic8voLos analizadores sintácticos predictivos son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LL (K)
EjerciciosComprobar el cumplimiento de las condiciones LL (1) para las siguientes gramáticas
E ::= TE’
E’ ::= + TE’ | – TE’ | ع
T ::= FT’
T’ ::= * FT’ | / FT’ | ع
F ::= ( E ) | n
S ::= A a | b
A ::= A c | S d
S ::= A a | b
A ::= A c | S d | ع
S ::= A B | s
A ::= a S c | e B f | ع
B ::= b A d | ع
A ::= A a | B C D
B ::= b | ع
C :: = c | ع
D ::= d | Ce
A ::= A a | B C D
B ::= b | ع
C :: = c | ع
D ::= d | Ce | ع

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 16
Analizadoressintác6cosdescendentespredic6vos
Analizadoressintác8cosdescendentespredic8vosLos analizadores sintácticos descendentes predictivos son autómatas a pila deterministas que reconocen las frases de un lenguaje por la estrategia de vaciado de pila. En esta sección estudiaremos dos tipos distintos de analizadores descendentes predictivos que se diferencian en la forma de implementar el autómata y dar soporte a la pila
Analizadores descendentes predictivos
Tratarán de encontrar la cadena de entrada partiendo del axioma y aplicando pasos de derivación. La selección de reglas está dirigida por los conjuntos de predicción
Analizadores descendentes recursivos
Para dar soporte a la pila se utilizan las capacidades de recursión del lenguaje. La gramática queda expresada a través de llamadas explicitas a distintas funciones asociadas a los no terminales
Analizadores descendentes dirigidos por tabla
La pila se da soporte a través de una representación explicita. La selección de reglas se realiza con ayuda de una tabla que representa la gramática del lenguaje

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 17
Analizadoressintác6cosdescendentespredic6vos
Analizadoressintác8cosdescendentespredic8vosLos analizadores sintácticos descendentes predictivos son autómatas a pila deterministas que reconocen las frases de un lenguaje por la estrategia de vaciado de pila. En esta sección estudiaremos dos tipos distintos de analizadores descendentes predictivos que se diferencian en la forma de implementar el autómata y dar soporte a la pila
AnalizadoresdescendentesrecursivosPara dar soporte a la pila se utilizan las capacidades de recursión del lenguaje. La gramática queda expresada a través de llamadas explicitas a distintas funciones asociadas a los no terminales
E ::= TE’
E’ ::= + TE’ | – TE’ | ع
T ::= FT’
T’ ::= * FT’ | / FT’ | ع
F ::= ( E ) | n
voidmatch(Terminaltoken){
if(cabeza==token)cabeza=scanner.nextToken();
elsethrownewSyntaxError();
}
voide(){
t();
ePrima();
}
voidePrima(){
if(!(cabezain{‘+’,‘-’})thrownewSyntaxError();
switch(cabeza){
case‘+’:match(‘+’);
t();
ePrima();
break;
Ejemplo

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 18
Analizadoressintác6cosdescendentespredic6vos
Analizadoressintác8cosdescendentespredic8vosLos analizadores sintácticos descendentes predictivos son autómatas a pila deterministas que reconocen las frases de un lenguaje por la estrategia de vaciado de pila. En esta sección estudiaremos dos tipos distintos de analizadores descendentes predictivos que se diferencian en la forma de implementar el autómata y dar soporte a la pila
AnalizadoresdescendentesrecursivosPara dar soporte a la pila se utilizan las capacidades de recursión del lenguaje. La gramática queda expresada a través de llamadas explicitas a distintas funciones asociadas a los no terminales
case‘-’:match(‘-’);
t();
ePrima();
break;
default:break;
}
}
voidt(){
f();
tPrima();
}
voidtPrima(){
if(!(cabezain{‘*’,‘/’,‘+’,‘-’})thrownew
SyntaxError();
switch(cabeza){
E ::= TE’
E’ ::= + TE’ | – TE’ | ع
T ::= FT’
T’ ::= * FT’ | / FT’ | ع
F ::= ( E ) | n
Ejemplo

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 19
Analizadoressintác6cosdescendentespredic6vos
Analizadoressintác8cosdescendentespredic8vosLos analizadores sintácticos descendentes predictivos son autómatas a pila deterministas que reconocen las frases de un lenguaje por la estrategia de vaciado de pila. En esta sección estudiaremos dos tipos distintos de analizadores descendentes predictivos que se diferencian en la forma de implementar el autómata y dar soporte a la pila
AnalizadoresdescendentesrecursivosPara dar soporte a la pila se utilizan las capacidades de recursión del lenguaje. La gramática queda expresada a través de llamadas explicitas a distintas funciones asociadas a los no terminales
case‘*’:match(‘*’);
f();
tPrima();
break();
case‘/’:match(‘/’);
f();
tPrima();
break();
default:break;
}
}
voidf(){
switch(cabeza)
case‘(’:e();
match(‘)’);break;
E ::= TE’
E’ ::= + TE’ | – TE’ | ع
T ::= FT’
T’ ::= * FT’ | / FT’ | ع
F ::= ( E ) | n
Ejemplo

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 20
Analizadoressintác6cosdescendentespredic6vos
Analizadoressintác8cosdescendentespredic8vosLos analizadores sintácticos descendentes predictivos son autómatas a pila deterministas que reconocen las frases de un lenguaje por la estrategia de vaciado de pila. En esta sección estudiaremos dos tipos distintos de analizadores descendentes predictivos que se diferencian en la forma de implementar el autómata y dar soporte a la pila
AnalizadoresdescendentesrecursivosPara dar soporte a la pila se utilizan las capacidades de recursión del lenguaje. La gramática queda expresada a través de llamadas explicitas a distintas funciones asociadas a los no terminales
casen:match(n);
break;
default:thrownewSyntaxError();
}
}
Tokencabeza;
Scannerscanner=newScanner(file);
main(){
cabeza=scanner.nextToken();
e();
}
E ::= TE’
E’ ::= + TE’ | – TE’ | ع
T ::= FT’
T’ ::= * FT’ | / FT’ | ع
F ::= ( E ) | n
Ejemplo

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 21
Analizadoressintác6cosdescendentespredic6vos
Analizadoressintác8cosdescendentespredic8vosLos analizadores sintácticos descendentes predictivos son autómatas a pila deterministas que reconocen las frases de un lenguaje por la estrategia de vaciado de pila. En esta sección estudiaremos dos tipos distintos de analizadores descendentes predictivos que se diferencian en la forma de implementar el autómata y dar soporte a la pila
AnalizadoresdescendentesrecursivosPara dar soporte a la pila se utilizan las capacidades de recursión del lenguaje. La gramática queda expresada a través de llamadas explicitas a distintas funciones asociadas a los no terminales
2 + 3 * 5
e
}
2 + 3 * 5
ePrima
}
t tPrima
f
2 + 3 * 5
}
tPrima
+ 3 * 5
}
3 * 5
}
3 * 5
ePrima
}
tPrima
t
tPrima
* 5
}
t
tPrima
5
}
t
ePrima ePrima
f f
t
tPrima
$
}
t
}
$
}
$
Ok!
E ::= TE’
E’ ::= + TE’ | – TE’ | ع
T ::= FT’
T’ ::= * FT’ | / FT’ | ع
F ::= ( E ) | n
Ejemplo

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 22
Analizadoressintác6cosdescendentespredic6vos
Analizadoressintác8cosdescendentespredic8vosLos analizadores sintácticos descendentes predictivos son autómatas a pila deterministas que reconocen las frases de un lenguaje por la estrategia de vaciado de pila. En esta sección estudiaremos dos tipos distintos de analizadores descendentes predictivos que se diferencian en la forma de implementar el autómata y dar soporte a la pila
AnalizadoresdescendentesrecursivosPara dar soporte a la pila se utilizan las capacidades de recursión del lenguaje. La gramática queda expresada a través de llamadas explicitas a distintas funciones asociadas a los no terminales
Ventajas
› Fácil de entender e interpretar
› Gramática explícitamente representada
› Cada función representa un no terminal
› Adecuado para gramáticas sencillas
Inconvenientes
› Pesado de desarrollar y mantener
› Específico para cada lenguaje
› Coste computacional (recursividad)
› No da soporte a gran número de lenguajes

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 23
Analizadoressintác6cosdescendentespredic6vos
Analizadoressintác8cosdescendentespredic8vosLos analizadores sintácticos descendentes predictivos son autómatas a pila deterministas que reconocen las frases de un lenguaje por la estrategia de vaciado de pila. En esta sección estudiaremos dos tipos distintos de analizadores descendentes predictivos que se diferencian en la forma de implementar el autómata y dar soporte a la pila
AnalizadoresdescendentesdirigidosportablaLos analizadores descendentes dirigidos por tabla están constituidos por dos elementos que se utilizan para llevar a cabo el proceso de análisis sintáctico
› Una pila, donde se almacenan símbolos gramaticales
› Una tabla de doble entrada que representa la gramática
› En columnas el conjunto de terminales T U { $ }
› En filas el conjunto de no terminales N
› M ( t, n ) = la regla que debe aplicarse
Tabla gramatical (M)
Pila
Cinta de entrada
}
x
$
T
N r n,t

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 24
Analizadoressintác6cosdescendentespredic6vos
Analizadoressintác8cosdescendentespredic8vosLos analizadores sintácticos descendentes predictivos son autómatas a pila deterministas que reconocen las frases de un lenguaje por la estrategia de vaciado de pila. En esta sección estudiaremos dos tipos distintos de analizadores descendentes predictivos que se diferencian en la forma de implementar el autómata y dar soporte a la pila
AnalizadoresdescendentesdirigidosportablaEl algoritmo de análisis descendente predictivo para este tipo de analizadores consiste en ir consultando la tabla para saber que regla aplicar y apoyarse en la pila asociada:
cabeza=<<primerterminaldew$>>
pila=[$,Axioma]
do{
p=pila.cima()
a=scanner.nextToken()
if(pinTU{$})
id(cabeza==a){
cabeza=scanner.nextToken()
pila.pop()
}elsenewthrowSyntaxError();
else{
if(M(p,a)==X::=Y1...Yk){
pop()
for(i=k;i>=1;i++)push(Yi)
}elsethrownewSyntaxError();
}
while(p!=‘$’)

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 25
Analizadoressintác6cosdescendentespredic6vos
Analizadoressintác8cosdescendentespredic8vosLos analizadores sintácticos descendentes predictivos son autómatas a pila deterministas que reconocen las frases de un lenguaje por la estrategia de vaciado de pila. En esta sección estudiaremos dos tipos distintos de analizadores descendentes predictivos que se diferencian en la forma de implementar el autómata y dar soporte a la pila
AnalizadoresdescendentesdirigidosportablaEl algoritmo de análisis descendente predictivo para este tipo de analizadores consiste en ir consultando la tabla para saber que regla aplicar y apoyarse en la pila asociada: T
E’
E
T’
F
TE’
+ - * / ( ) n $
TE’
-TE’+TE’ ع ع
FT’FT’
ع ع *FT’ /FT’ ع ع
n(E)
- -- -
- -- -
- -- -
- --
-
-
- -
-
-
E ::= TE’
E’ ::= + TE’ | – TE’ | ع
T ::= FT’
T’ ::= * FT’ | / FT’ | ع
F ::= ( E ) | n
Ejemplo
$E
$E’T
$E’T’F
$E’T’n
$E’T’
$E’
Pila
n+n*n$
n+n*n$
n+n*n$
n+n*n$
+n*n$
+n*n$
Entrada
E::=TE’
T::=FT’
F::=n
match(n)
T’::=ع
E’::=+TE’
Acción
-
-
--

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 26
Analizadoressintác6cosdescendentespredic6vos
Analizadoressintác8cosdescendentespredic8vosLos analizadores sintácticos descendentes predictivos son autómatas a pila deterministas que reconocen las frases de un lenguaje por la estrategia de vaciado de pila. En esta sección estudiaremos dos tipos distintos de analizadores descendentes predictivos que se diferencian en la forma de implementar el autómata y dar soporte a la pila
AnalizadoresdescendentesdirigidosportablaEl algoritmo de análisis descendente predictivo para este tipo de analizadores consiste en ir consultando la tabla para saber que regla aplicar y apoyarse en la pila asociada: T
E’
E
T’
F
TE’
+ - * / ( ) n $
TE’
-TE’+TE’ ع ع
FT’FT’
ع ع *FT’ /FT’ ع ع
n(E)
- -- -
- -- -
- -- -
- --
-
-
- -
-
-
E ::= TE’
E’ ::= + TE’ | – TE’ | ع
T ::= FT’
T’ ::= * FT’ | / FT’ | ع
F ::= ( E ) | n
Ejemplo
$E’T+
$E’T
$E’T’F
$E’T’n
$E’T’
$E’T’F*
Pila
+n*n$
n*n$
n*n$
n*n$
*n$
*n$
Entrada
match(+)
T::=FT’
F::=n
match(n)
T’::=*FT’
match(*)
Acción
-
-
--

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 27
Analizadoressintác6cosdescendentespredic6vos
Analizadoressintác8cosdescendentespredic8vosLos analizadores sintácticos descendentes predictivos son autómatas a pila deterministas que reconocen las frases de un lenguaje por la estrategia de vaciado de pila. En esta sección estudiaremos dos tipos distintos de analizadores descendentes predictivos que se diferencian en la forma de implementar el autómata y dar soporte a la pila
AnalizadoresdescendentesdirigidosportablaEl algoritmo de análisis descendente predictivo para este tipo de analizadores consiste en ir consultando la tabla para saber que regla aplicar y apoyarse en la pila asociada: T
E’
E
T’
F
TE’
+ - * / ( ) n $
TE’
-TE’+TE’ ع ع
FT’FT’
ع ع *FT’ /FT’ ع ع
n(E)
- -- -
- -- -
- -- -
- --
-
-
- -
-
-
E ::= TE’
E’ ::= + TE’ | – TE’ | ع
T ::= FT’
T’ ::= * FT’ | / FT’ | ع
F ::= ( E ) | n
Ejemplo
$E’T’F
$E’T’n
$E’T’
$E’
$
Pila
n$
n$
$
$
$
Entrada
F::=n
match(n)
T’::=ع
E’::=ع
Ok!
Acción
-
-
--

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 28
Analizadoressintác6cosdescendentespredic6vos
Analizadoressintác8cosdescendentespredic8vosLos analizadores sintácticos descendentes predictivos son autómatas a pila deterministas que reconocen las frases de un lenguaje por la estrategia de vaciado de pila. En esta sección estudiaremos dos tipos distintos de analizadores descendentes predictivos que se diferencian en la forma de implementar el autómata y dar soporte a la pila
AnalizadoresdescendentesdirigidosportablaEl algoritmo de análisis descendente predictivo para este tipo de analizadores consiste en ir consultando la tabla para saber que regla aplicar y apoyarse en la pila asociada
Ventajas
› Ágil de desarrollar y mantener
› Representación tabular de las reglas
› Bajo coste computacional (no recursividad)
› Adecuado para gramáticas sencillas
Inconvenientes
› Más complejo de interpretar
› Gramática no explícitamente representada
› Reglas distribuidas en la tabla
› No da soporte a gran número de lenguajes

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 29
Ges6óndeerroresenanalizadoresdescendentes
Ges8óndeerroresLa labor de un analizador sintáctico no se limita exclusivamente a reconocer que una frase pertenece al lenguaje generado por una gramática. Adicionalmente, en el caso de que existan errores sintácticos (o léxicos no reconocidos en la fase de análisis léxico), el analizador debe ser capaz de reconocer errores y emitir mensajes de información asociados
I.Iden8ficacióndeerrores
II.Localizacióndeerrores
El reconocimiento de la existencia de un error debe realizarse lo más temprano posible dentro del proceso de análisis sintáctico. No hacerlo así puede provocar que el analizador abandone el contexto sintáctico donde éste se ha producido lo c u a l p r o v o c a m e n s a j e s d e e r r o r inadecuados
La gest ión de errores conl leva la localización de los mismos dentro del código fuente de la manera más precisa posible. El mensaje de error generado deberá contener información detallada y correcta acerca del número de fila y columna donde se encuentra el error
III.Emisióndemensajes
II.Recuperacióndeerrores
La existencia de errores se comunica al programación a través de la emisión de mensajes de error. Estos mensajes deben ser lo más específicos posibles de manera que el propio mensaje de información acerca de que acción correctiva debe ser aplicada
El analizador sintáctico no debe abortar el proceso de compilación al encontrar un error sino que debe escapar del contexto sintáctico de error para avanzar a una nueva situación estable. Esta técnica se reconoce por el nombre recuperación de errores

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 30
Ges6óndeerroresenanalizadoresdescendentes
Ges8óndeerroresLa labor de un analizador sintáctico no se limita exclusivamente a reconocer que una frase pertenece al lenguaje generado por una gramática. Adicionalmente, en el caso de que existan errores sintácticos (o léxicos no reconocidos en la fase de análisis léxico), el analizador debe ser capaz de reconocer errores y emitir mensajes de información asociados
Recuperacióndeerroresenanálisissintác8codescendentepredic8vo
Recuperacióndeerroresenanálisissintác8codescendentedirigidoportabla
Al identificar un error sintáctico se entra en estado de pánico y el analizador empieza a consumir tokens hasta encontrar un contexto de compilación estable, escapando del error. La identificación del contexto estable se dirige por conjuntos de sincronización asociados a cada tipo de error. El compilador consumirá tokens hasta encontrar un token perteneciente al conjunto de sincronización. El conjunto de sincronización suele construirse a partir de Primeros y Siguientes
Wile(a>b)a++;
}
El proceso de recuperación de errores es esencialmente el mismo que en los analizadores descendentes recursivos. La tabla contiene ahora información para gestionar los errores. En las celdas de error pueden aparecer 3 acciones de recuperación
› Extraer el no terminal de la cima de la pila
› Consumir tokens en estado de pánico dirigido por conjunto de sincronización
› Insertar un nuevo terminal en la pila

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 31
BibliograCa
MaterialdeestudioBibliografía básica
Construcción de compiladores: principios y práctica
Kenneth C. Louden International Thomson Editores,
2004 ISBN 970-686-299-4

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresdescendentes
4 - 32
BibliograCa
MaterialdeestudioBibliografía complementaria
Compiladores: Principios, técnicas y herramientas.
Segunda Edición Aho, Lam, Sethi, Ullman
Addison – Wesley, Pearson Educación, México 2008
Diseño de compiladores. A. Garrido, J. Iñesta, F. Moreno
y J. Pérez. 2002. Edita Universidad de Alicante

ProcesadoresdeLenguajesIngenieríaTécnicasuperiordeIngenieríaInformá8ca
DepartamentodeLenguajesySistemasinformá6cos
JavierVé[email protected]
DepartamentodeLenguajesYSistemasInformáAcosUNED
5Análisissintác*coIIIAnalizadoresascendentes

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 2
Obje6vos
Obje8vos
› Comprender el análisis ascendente por reducción desplazamiento
› Aprender el algoritmo general de análisis ascendente
› Conocer la arquitectura general de un analizador sintáctico ascendente
› Aprender a construir analizadores ascendentes en complejidad creciente
› Analizadores LR (0)
› Analizadores SLR
› Analizadores LALR
› Analizadores LR (1)
› Entender cómo los analizadores sintácticos realizan la gestión de errores
› Entender los conflictos reducción – reducción
› Entender los conflictos reducción – desplazamiento
› Entender la clasificación de gramáticas inducida en virtud de los métodos de análisis empleados

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 3
Índice
Índice› Introducción
› Análisis sintáctico ascendente
› Análisis ascendente por reducción – desplazamiento
› Arquitectura general de análisis sintáctico ascendente
› Algoritmo general de análisis sintáctico ascendente
› Analizadores sintácticos ascendentes
› Analizadores LR (0)
› Analizadores LR (1)
› Analizadores LALR
› Analizadores LR (1)
› Gestión de errores en analizadores ascendentes
› Tipos de gramáticas y análisis ascendente
› Interpretación de conflictos en los tipos de analizadores
› Clasificación de gramáticas por tipos de analizadores

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 4
Índice
Índice› Constricción de analizadores sintácticos en la práctica
› ¿Qué es Cup?
› ¿Cómo funciona Cup?
› ¿Cómo se usa Cup?
› Gestión de errores en Cup
› Desarrollo paso a paso
› Bibliografía

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 5
Introducción
¿Quéeselanálisisascendente?
El análisis sintáctico ascendente es una técnica de análisis sintáctico que intenta comprobar si una cadena x pertenece al lenguaje definido por una gramática L (G) aplicando los siguientes criterios
› Partir de los elementos terminales de la frase x
› Escoger reglas gramaticales estratégicamente
› Aplicar a la inversa derivaciones por la derecha (Right Most Derivation)
› Procesar la cadena de izquierda a derecha
› Intentar alcanzar el axioma para obtener el árbol de análisis sintáctico o error
Cadenadederivación Árboldeanálisissintác8coEl análisis ascendente genera una cadena de derivación por la derecha leída en sentido inverso
R1: E ::= E + E
R2: E ::= E - E
R3: E ::= E * E
R4: E ::= E / E
R5: E ::= ( E )
R6: E ::= n
n + n * n ←
E + n * n ←
E + E * n ←
E + E * E ←
E + E ←
E
Se parte la cadena de entrada leída de izquierda a derecha y se aplican reglas a la inversa para intentar alcanzar el axioma
E
E + E
n E * E
n n (2)
(3) (5)
R1
R3
R6
R6
R6
�
�
� �
�
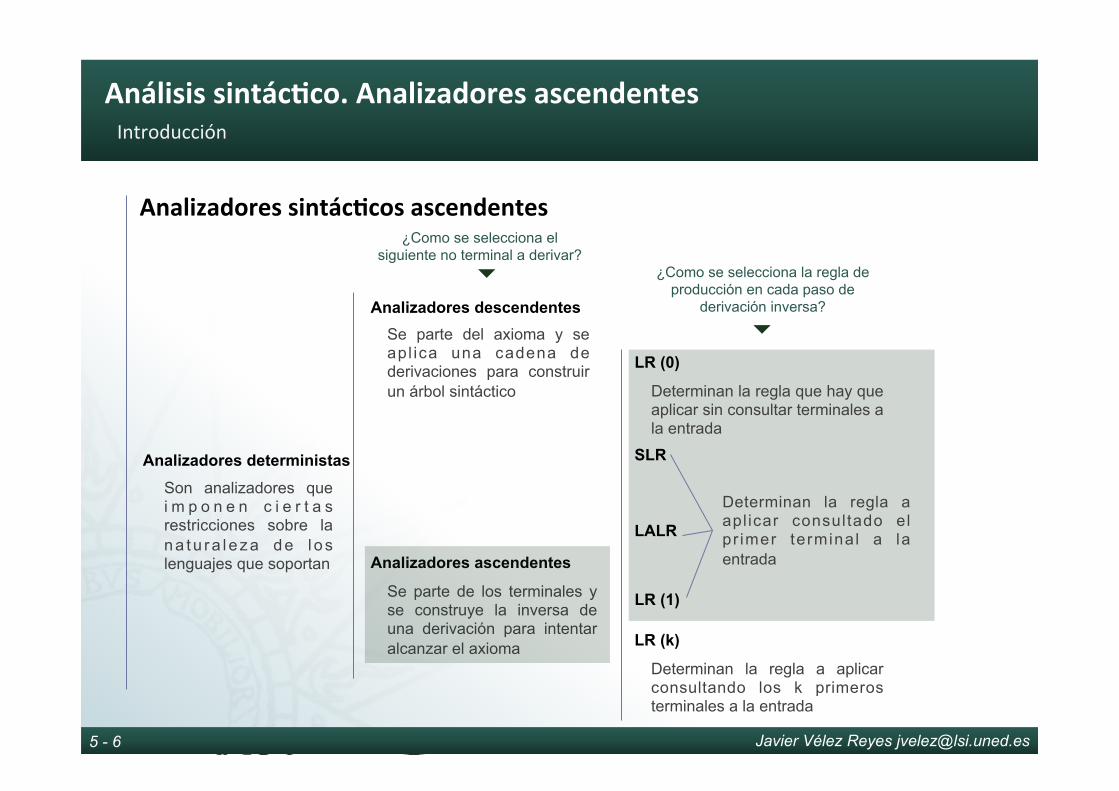
Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 6
Introducción
Analizadoressintác8cosascendentes
Analizadores deterministas
Analizadores descendentes Se parte del axioma y se apl ica una cadena de derivaciones para construir un árbol sintáctico
Analizadores ascendentes
Se parte de los terminales y se construye la inversa de una derivación para intentar alcanzar el axioma
LR (0)
Determinan la regla que hay que aplicar sin consultar terminales a la entrada
¿Como se selecciona el siguiente no terminal a derivar? } ¿Como se selecciona la regla de
producción en cada paso de derivación inversa? }
SLR
Determinan la regla a apl icar consultado el pr imer terminal a la entrada
LALR
LR (1)
LR (k)
Determinan la regla a aplicar consultando los k primeros terminales a la entrada
Son analizadores que i m p o n e n c i e r t a s restricciones sobre la n a t u r a l e z a d e l o s lenguajes que soportan

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 7
Análisissintác6coascendente
Análisissintác8coascendente
LR (k)
Derivación más a la derecha (Right Most Derivatión)
Lectura de izquierda a derecha
Número de terminales consultados para determinar la regla de producción a aplicar
Lenguajes LR (k) Lenguajes
LR (1) Lenguajes LALR Lenguajes
SLR Lenguajes LR (0)
Los analizadores sintácticos ascendentes son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LR (K) o analizadores por reducción desplazamiento

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 8
Análisissintác6coascendenteporreducción–desplazamiento
Análisissintác8coascendenteLos analizadores sintácticos ascendentes son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LR (K) o analizadores por reducción desplazamiento
2 operaciones
A cada paso el analizador decide realizar una de dos operaciones posibles
Desplazar
Reducir
Análisisporreducción–desplazamiento
El analizador debe procesar un número suficiente de terminales desplazando la cabeza lectora antes de a p l i c a r u n a r e g l a d e producción a la inversa. Esta operación se llama desplazar
Cuando se reconoce en la forma de frase en curso un fragmento igual a la parte derecha de una regla se s u s t i t u y e é s t e p o r e l antecedente. Esta operación se llama reducir
r1. E ::= E + E
r2. E ::= E - E
r3. E ::= E * E
r4. E ::= E / E
r5. E ::= ( E )
r6. E ::= n mango
ddesplazar
rreducir
}
d
}
r
n + n * n n + n * n
}
d
E + n * n
}
d
E + n * n
}
r
E + n * n
}
d
E + E * n
}
d
E + E * n
}
r
E + E * n
} r
E + E * E
}
r
E + E E

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 9
Análisissintác6coascendenteporreducción–desplazamiento
Análisissintác8coascendente
2 tipos de conflictos
Pueden surgir en este proceso 2 tipos de conflictos que el analizador debe ser capaz de resolver
Reducción - reducción
El analizador puede tanto aplicar un paso de reducción como uno de desplazamiento
El analizador puede aplicar dos reglas distintas para realizar diferentes pasos de reducción
Reducción - desplazamiento
Los analizadores sintácticos ascendentes son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LR (K) o analizadores por reducción desplazamiento
}
d
}
r
n + n * n n + n * n
}
d
E + n * n
}
d
E + n * n
}
r
E + n * n
}
d
E + E * n
}
d
E + E * n
}
r
E + E * n
} r
E + E * E
}
r
E + E E
mango
ddesplazar
rreducir
Análisisporreducción–desplazamiento
r1. E ::= E + E
r2. E ::= E - E
r3. E ::= E * E
r4. E ::= E / E
r5. E ::= ( E )
r6. E ::= n

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 10
Análisissintác6coascendenteporreducción–desplazamiento
Análisissintác8coascendente
Arquitecturageneraldeanálisissintác8coascendente
Los analizadores sintácticos ascendentes son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LR (K) o analizadores por reducción desplazamiento
El analizador sintáctico puede atravesar, a lo largo del proceso de análisis, distintos estadios de compilación que dependen del lenguaje analizado. Estos estadios se identifican con estados codificados numéricamente que se gestionan en una pila. En cada momento el estado en curso aparece en la cima de la pila
Todos los tipos de analizadores sintácticos ascendentes tienen un mismo modelo de arquitectura que consta de 3 elementos: una pila de estados, una tabla de acciones y una tabla Ir-A
Pila
de
esta
dos
Cinta de entrada
}
x
Tabla de acciones Tabla Ir-A
I. Pila de estados
Pila
de
esta
dos
1
5
7
3
}
La diferencia entre los tipos de analizadores sintácticos estriba en cómo se construyen estas tablas y en el tipo de gramáticas (lenguajes) que admiten

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 11
Análisissintác6coascendenteporreducción–desplazamiento
Análisissintác8coascendente
Arquitecturageneraldeanálisissintác8coascendente
Los analizadores sintácticos ascendentes son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LR (K) o analizadores por reducción desplazamiento
Todos los tipos de analizadores sintácticos ascendentes tienen un mismo modelo de arquitectura que consta de 3 elementos: una pila de estados, una tabla de acciones y una tabla Ir-A
Pila
de
esta
dos
Cinta de entrada
}
x
Tabla de acciones Tabla Ir-A
4
3
2
1
La diferencia entre los tipos de analizadores sintácticos estriba en cómo se construyen estas tablas y en el tipo de gramáticas (lenguajes) que admiten
}
Para cada estado y cada terminal (o $) a la entrada el analizador tiene información de que acciones debe realizar. Las operaciones posibles son:
II. Tabla de acciones 0
T
$
A i,j
› dj Desplazar y apilar el estado j
› rk Reducir por la regla r
› e Emitir un error
› Ok Aceptar la cadena de entrada

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 12
Análisissintác6coascendenteporreducción–desplazamiento
Análisissintác8coascendente
Arquitecturageneraldeanálisissintác8coascendente
Los analizadores sintácticos ascendentes son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LR (K) o analizadores por reducción desplazamiento
Todos los tipos de analizadores sintácticos ascendentes tienen un mismo modelo de arquitectura que consta de 3 elementos: una pila de estados, una tabla de acciones y una tabla Ir-A
Pila
de
esta
dos
Cinta de entrada
}
x
Tabla de acciones Tabla Ir-A
4
3
2
1
La diferencia entre los tipos de analizadores sintácticos estriba en cómo se construyen estas tablas y en el tipo de gramáticas (lenguajes) que admiten
}
En el caso de aplicar reducción, y del estado de compilación en curso, esta tabla indica el estado que hay que apilar en función del antecedente de la regla de producción aplicada
III. Tabla Ir-A 0
N
J

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 13
Análisissintác6coascendenteporreducción–desplazamiento
Análisissintác8coascendente
Algoritmogeneraldeanálisissintác8coascendenteEl algoritmo de análisis sintáctico ascendente también es independiente del tipo de analizador que se utilice. Una vez que disponemos de la información de las tablas acción e ir-A se procede de la siguiente forma
Los analizadores sintácticos ascendentes son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LR (K) o analizadores por reducción desplazamiento
pila=[0]
a=scanner.nextToken()
do{
s=pila.cima()
if(Acción[s,a]==dj){
pila.push(j)
a=scanner.nextToken()
}
}elseif(acción[s,a]==rk){
for(inti=0;i<longitud(partederechark);i++)
pila.pop()
p=pila.cima()
A=ParteIzquierda(rk)
pila.push(irA(p,A))
}elseif(Acción(s,a)=aceptar)return
elsethrownewSyntaxError()
}while(true)

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 14
Análisissintác6coascendenteporreducción–desplazamiento
Análisissintác8coascendente
Algoritmogeneraldeanálisissintác8coascendenteEl algoritmo de análisis sintáctico ascendente también es independiente del tipo de analizador que se utilice. Una vez que disponemos de la información de las tablas acción e ir-A se procede de la siguiente forma
Los analizadores sintácticos ascendentes son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LR (K) o analizadores por reducción desplazamiento
Ejemplo
0 1 2 3 4 5 6 7 8 9 10
end begin codigo tipo id $
-
-
-
-
d8
-
-
-
r2
r3
-
-
d6
-
-
-
r5
-
-
-
-
-
-
-
-
d10
-
-
-
-
d3
-
-
d3
-
-
-
-
-
-
d4
-
-
d4
-
-
-
-
-
-
-
ok
-
-
-
-
-
r1
-
-
- r4 - - - -
1
5
2
7
9
S A B C
PILA ENTRADA ACCIÓN
0
04
043
047
02
026
02610
0269
025
0258
01
idtipobegincodigoend$
tipobegincodigoend$
begincodigoend$
begincodigoend$
begincodigoend$
codigoend$
end$
end$
end$
$
$
d4
d3
r4
r5
d6
d10
r3
r2
d8
r1
Ok
r0. S ::= S’ ::= S
r1. S ::= B A end
r2. A ::= begin C
r3. C ::= codigo
r4. B ::= tipo
r5. B ::= id B
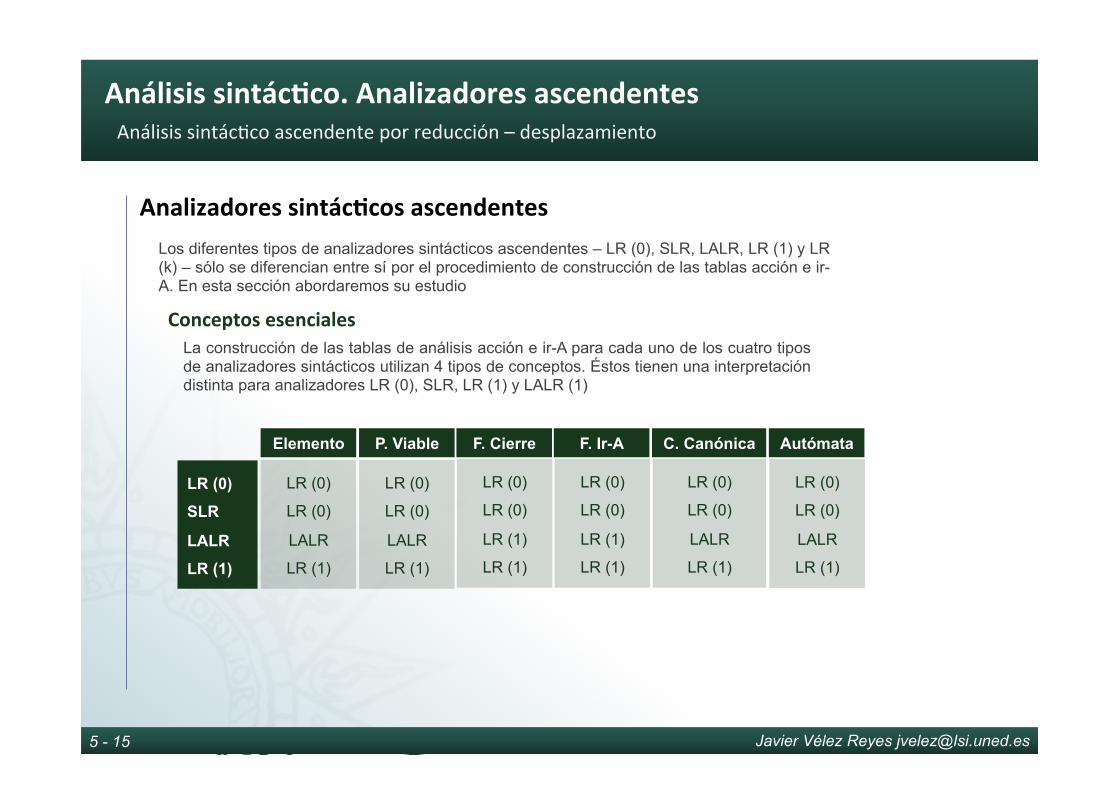
Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 15
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLa construcción de las tablas de análisis acción e ir-A para cada uno de los cuatro tipos de analizadores sintácticos utilizan 4 tipos de conceptos. Éstos tienen una interpretación distinta para analizadores LR (0), SLR, LR (1) y LALR (1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
LR (0)
SLR
LALR
LR (1)
Elemento P. Viable F. Cierre F. Ir-A C. Canónica Autómata
LR (0)
LR (0)
LALR
LR (1)
LR (0)
LR (0)
LALR
LR (1)
LR (0)
LR (0)
LR (1)
LR (1)
LR (0)
LR (0)
LR (1)
LR (1)
LR (0)
LR (0)
LALR
LR (1)
LR (0)
LR (0)
LALR
LR (1)

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 16
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLR(0)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Elementos LR (0)
Prefijo viable LR (0)
Un elemento es una regla de producción que tiene un punto (.) en algún lugar de la parte derecha de la regla. El punto se utiliza para identificar el estado de avance de procesamiento de la regla
B ::= • a A
B ::= a • A
B ::= a A •
A := ع
B ::= a A
A := •
Un prefijo viable de un elemento corresponde con la forma de frase que queda a la izquierda del punto de dicho elemento. El prefijo viable identifica, de forma abstracta, la frase que se ha reconocido a la entrada y que valida, parcialmente, la selección de esa regla para proceder con la reducción
B ::= • a A B ::= a • A B ::= a A •
Prefijo viable
Elemento reductible
Elemento de comienzo

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 17
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLR(0)ySLR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Conjunto de elementos LR (0)
Colección canoníca de los conjuntos de elementos LR (0)
Un conjunto de elementos es una colección no ordenada de elementos. Los conjuntos de e lementos se ut i l i zan para caracter izar formalmente los estados potenciales por lo que atraviesa un compilador a lo largo del proceso de análisis
I = { S’ ::= • S,
S ::= • ( S ) S,
S ::= • }
La colección de todos los conjuntos de elementos potenciales en los que se puede encontrar el analizador sintáctico se recoge en un conjunto llamado colección canónica de los conjuntos de elementos. Para su definición formal se utilizan dos funciones
S’ ::= S
S ::= ( S ) S | ع
Cierre ( I )
Ir- A (I, a)
Se cierra un conjunto para incluir todos los elementos que pueden alcanzarse a partir de uno dado
Se genera un nuevo conjunto a partir de I y del simbolo terminal o no terminal a

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 18
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLR(0)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Función Cierre ( I ) LR (0) El cierre de un conjunto I consiste en ampliar dicho conjunto con todos aquellos elementos con un punto al inicio de su parte derecha que son accesibles de forma directa o indirecta desde I
I0 = Cierre ( { S’ ::= • S } ) = {
S’ ::= • S,
S ::= • ( S ) S,
S ::= • }
S’ ::= S
S ::= ( S ) S | ع
Estar a punto de comenzar el procesamiento de S incluye estar a punto de procesar (S) S o ع
}
Cierre (I) = I
repetir
Para cada elemento A := α • B β є Cierre (I) hacer
Para cada B ::= δ1 | δ2 | … | δn hacer
Cierre (I) = Cierre (I) ∪ {B := • δi} para todo i = 1..n
hasta no se pueden añadir más elementos a Cierre (I)

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 19
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLR(0)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Función Ir-A ( I, a ) LR (0)
Ir-A ( I0, ‘(’ ) = Cierre ( { S ::= ( • S ) S } )
= { S ::= ( • S ) S,
S ::= • ( S ) S,
S ::= • }
S’ ::= S
S ::= ( S ) S | ع
La aplicación de la función Ir-A (I0, ‘(‘ ) indica cuál es la transición de estado que debe hacer el analizador sintáctico cuando se está en I0 y llega un token ‘(’ a la entrada
Ir-A es una función que toma un estado y un elemento a Є N U T y devuelve un nuevo estado. La operación consiste en avanzar el punto una posición sobre todos aquellos elementos en los que a preceda al punto. En los que no ocurra así se eliminan del conjunto. Finalmente se cierra el conjunto resultante
Para todo elemento B ::= α • Aβ є I con A Є N U T hacer
Ir-A (I, A) = Cierre ( { B ::= α A • β } )
}

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 20
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLR(0)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Colección canónica de los conjuntos de elementos C LR (0)
Se comienza por ampliar la gramática con la producción S’ ::= S donde S es el axioma y S’ es el nuevo axioma. Esto se hace para cubrir todas las alternativas de S. Después se aplica sistemáticamente el siguiente algoritmo hasta que C no pueda crecer más
Ampliar la gramática con S’ ::= S
C = Cierre ( { S’ ::= • S } ) = { I0 }
Para cada conjunto Ii є C Hacer
Para cada a є T ∪ N Hacer
Si existe un elemento B := α • a β є Ii
C = C ∪ Ir-A (Ii , a)
I0 = Cierre ({S' ::= •S}) = {S' ::= •S, S ::= •BA end, B::= •tipo, B ::= •id B}
I1 = IrA (I0, S) = Cierre ({S' ::= S•}) = {S' ::= S•}
I2 = IrA (I0, B) = Cierre ({S ::= B•A end}) = {S ::= B•A end, A ::= •begin C}
I3 = IrA (I0, tipo) = Cierre ({B ::= tipo•}) = {B ::= tipo•}
I4 = IrA (I0, id) = Cierre ({B ::= id•B}) = {B ::= id•B, B::= •tipo, B ::= •id B}
I5 = IrA (I2, A) = Cierre ({S ::= BA•end}) = {S ::= BA•end}
I6 = IrA (I2, begin) = Cierre ({A ::= begin•C}) = {A ::= begin•C, C ::= •codigo}
I7 = IrA (I4, B) = Cierre ({B ::= id B•}) = {B ::= id B•}
I8 = IrA (I4, tipo) = Cierre ({B ::= tipo•}) = {B ::= tipo•} = I3
I8 = IrA (I4, id) = Cierre ({B ::= id•B}) = {B ::= id•B, B::=•tipo, B::=•id B} = I4
I8 = IrA (I5, end) = Cierre ({S ::= BA end•}) = {S::= BA end•}
I9 = IrA (I6, C) = Cierre ({A ::= begin C•}) = {A ::= begin C•}
I10 = IrA (I6, codigo) = Cierre ({C ::= codigo•}) = {C ::= codigo•}
r0. S' ::= S
r1. S ::= B A end
r2. A ::= begin C
r3. C ::= codigo
r4. B ::= tipo
r5. B ::= id B

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 21
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLR(0)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Autómata reconocedor de prefijos viables LR (0)
De manera similar se puede construir un autómata reconocedor de prefijos viables donde cada Ii se corresponde con un Si y cada transición etiquetada con a de Si a Sj se corresponde con Ij = Ir-A (Ii, a)
S0 = Cierre( { S’ ::= • S } )
Para cada Si Hacer
Para cada a є N ∪ T Hacer
Si Existe B ::= α • aβ є Si Entonces
Crear estado nuevo Sn = Ir-A (Si, A
Crear transición de Si a Sn etiquetada con a
S'::=S•
S::=B•Aend,
A::=•beginC
B::=6po•
B::=id•B,
B::=•6po,
B::=•idB
S::=BA•end
A::=begin•C,
C::=•codigo
A::=beginC• C::=codigo•
S::=BAend•
4
1
2
3
5
8
6
9 10
B::=IdB•7
S
B
tipo
tipo
id B
A
begin
end
C codigo
r0. S' ::= S
r1. S ::= B A end
r2. A ::= begin C
r3. C ::= codigo
r4. B ::= tipo
r5. B ::= id B
S'::=•S,
S::=•BAend,
B::=•6po,
B::=•idB
id
0

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 22
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLR(0)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Obtener C = {I0, I1, …, In}
Cada Ij є C se corresponde con el estado j del analizador
Construir la tabla Ir-A [s, A]
Si Ir-A (Ii, A) = Ij, A Є N Entonces Ir-A [i, A] = j
Construir la tabla Acción [s, a]
Para todo A ::= α • aβ Є Ii, a Є T Hacer
Si Ir-A (Ii, a) = Ij Entonces Acción [i, a] = dj
Para todo A ::= β • o A ::= • Є Ii Hacer
Acción [i, a] = rk
Si S’ ::= S • Є Ii entonces Acción [i, $] = Aceptar
Todas las demás entradas de Acción [k, s] = error
A partir de la colección canónica de elementos es posible construir las tablas de los analizadores LR (0)
› Cada conjunto de elementos es un estado
› La tabla Ir-A (I, A) A Є N refleja la función Ir-A
› La tabla Ir-A (I, a) a Є T refleja los desplazamientos
› Para los elementos de reducción
› Se rellena todas las celda con reducción
TablasLR(0)apar8rdelacoleccióncanónica

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 23
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLR(0)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Obtener El autómata reconocedor de prefijos viables
Cada estado Sj corresponde con el estado j
Construir la tabla Ir-A [s, A]
Si existe transición de Si a Sj con A, A Є N Entonces
Ir-A [i, A] = j
Construir la tabla Acción [s, a]
Para todo A ::= α • aβ Є Si, a Є T Hacer
Si existe transición de Si a Sj con a entonces
Acción [i, a] = dj
Para todo A ::= β • o A ::= • Є Si Hacer
Acción [i, a] = rk
Si S’ ::= S • Є Si entonces Acción [i, $] = Aceptar
Todas las demás entradas de Acción [k, s] = error
A partir del autómata reconocedor de prefijos viables es posible construir las tablas de los analizadores SLR
› Cada estado del autómata es un estado
› Transiciones Si a Sj con A Є N reflejan Ir-A
› Transiciones Si a Sj con a Є T reflejan los desplazamientos
› Para los elementos de reducción
› Se calcula Siguientes del antecedente
› Se rellena la cela con reducción por esa regla
TablasLR(0)apar8rdelautómatadeprefijosviables

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 24
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLR(0)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Ejemploend begin código 6po id $
0
1
2
3
4
5
6
7
8
9
10
S A B C
1 2
5
7
9
Se rellena la tabla Ir-A a partir de las transiciones del autómata etiquetadas con no terminales
r0. S' ::= S
r1. S ::= B A end
r2. A ::= begin C
r3. C ::= codigo
r4. B ::= tipo
r5. B ::= id B

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 25
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLR(0)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Ejemploend begin código 6po id $
d3 d4
d6
d3 d4
d8
d10
0
1
2
3
4
5
6
7
8
9
10
S A B C
1 2
5
7
9
Se rellenan los desplazamientos de la tabla de acción a partir de las transiciones del autómata etiquetadas con terminales
r0. S' ::= S
r1. S ::= B A end
r2. A ::= begin C
r3. C ::= codigo
r4. B ::= tipo
r5. B ::= id B

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 26
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLR(0)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Ejemploend begin código 6po id $
d3 d4
Ok
d6
r4 r4 r4 r4 r4 r4
d3 d4
d8
d10
r5 r5 r5 r5 r5 r5
r1 r1 r1 r1 r1 r1
r2 r2 r2 r2 r2 r2
r3 r3 r3 r3 r3 r3
0
1
2
3
4
5
6
7
8
9
10
S A B C
1 2
5
7
9
Se rellenan las reducciones y la aceptación de la tabla Acción a partir de los estados de reducción
r0. S' ::= S
r1. S ::= B A end
r2. A ::= begin C
r3. C ::= codigo
r4. B ::= tipo
r5. B ::= id B

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 27
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLR(0)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Ejemploend begin código 6po id $
error error error d3 d4 error
error error error error error Ok
error d6 error error error error
r4 r4 r4 r4 r4 r4
error error error d3 d4 error
d8 error error error error error
error error d10 error error error
r5 r5 r5 r5 r5 r5
r1 r1 r1 r1 r1 r1
r2 r2 r2 r2 r2 r2
r3 r3 r3 r3 r3 r3
0
1
2
3
4
5
6
7
8
9
10
S A B C
1 2
5
7
9
El resto de casillas se rellenan con error
r0. S' ::= S
r1. S ::= B A end
r2. A ::= begin C
r3. C ::= codigo
r4. B ::= tipo
r5. B ::= id B

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 28
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
VentajaseinconvenientesdelosanalizadoresLR(0)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Los analizadores sintácticos ascendentes del tipo LR (0) son los más sencillos de construir que existen pero el conjunto de gramáticas que reconocen es relativamente pequeño. En efecto, estos autómatas no utilizan ninguna estrategia predictiva en función de los terminales a la cabeza para dirigir los procesos de reducción
Ventajas
› Fácil de entender y construir
› La estrategia de reducción es sencilla
› Cada estado de reducción es por 1 regla
› Los errores se delegan a desplazamiento
Inconvenientes
› Conjunto reducido de gramáticas
› No aplica estrategias predictivas
› No pueden existen 2 reducciones por estado
› Mensajes de error menos localizados

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 29
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
DesdeelLR(0)haciaelSLR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Existe un tipo de analizadores sintácticos ascendentes más potentes que utiliza los mismos artefactos que el análisis LR (0) y que sin embargo es capaz de hacer reducciones predictivamente en función del terminal a la cabeza
Sólo si x Є Siguientes (A) aparece a la en la cabeza de
lectura en el momento en curso es legítimo aplicar la
reducción por el elemento reducible A ::= α •
Precisión de errores Mayor precisión de análisis Conjunto de gramáticas
Muchas celdas marcadas como reducción en LR (0) deberían ser consideradas como errores lo que redunda en una mayor precisión de los mensajes
Al predecir la reducción que debe producirse en función en la entrada se consigue afinar el proceso de análisis
Ahora en un mismo estado de puede haber ce ldas con distintas reducciones, con desplazamientos y con error con que las restr icciones gramaticales no son tan fuertes
S ::= a A b | A c
A ::= d e
A
d e
b A
d e
c a A
d e
f …
}
r
}
r
}
r

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 30
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesSLR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Función cierre SLR
S’ ::= S
S ::= ( S ) S | ع
Para refinar el proceso de análisis sintáctico, los analizadores ascendentes del tipo SLR hacen un uso extendido del autómata de prefijos viables y la colección canónica de elementos LR (0) Sin embargo, los conceptos que manejan ambos tipos de analizadores son esencialmente los mismos
Elemento SLR
Prefijo viable SLR
Función Ir-A SLR
Colección canónica SLR
Autómata SLR
Función cierre LR (0)
Elemento LR (0)
Prefijo viable LR (0)
Función Ir-A LR (0)
Colección canónica LR (0)
Autómata LR (0)
=

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 31
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasSLR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Obtener C = {I0, I1, …, In}
Cada Ij є C se corresponde con el estado j del analizador
Construir la tabla Ir-A [s, A]
Si Ir-A (Ii, A) = Ij, A Є N Entonces Ir-A [i, A] = j
Construir la tabla Acción [s, a]
Para todo A ::= α • aβ Є Ii, a Є T Hacer
Si Ir-A (Ii, a) = Ij Entonces Acción [i, a] = dj
Para todo A ::= β • o A ::= • Є Ii Hacer
Para todo a Є Siguiente (A) hacer
Acción [i, a] = rk
Si S’ ::= S • Є Ii entonces Acción [i, $] = Aceptar
Todas las demás entradas de Acción [k, s] = error
A partir de la colección canónica de elementos es posible construir las tablas de los analizadores SLR
› Cada conjunto de elementos es un estado
› La tabla Ir-A (I, A) A Є N refleja la función Ir-A
› La tabla Ir-A (I, a) a Є T refleja los desplazamientos
› Para los elementos de reducción
› Se calcula Siguientes del antecedente
› Se rellena la celda con reducción por esa regla
TablasSLRapar8rdelacoleccióncanónica

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 32
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasSLR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Obtener El autómata reconocedor de prefijos viables
Cada estado Sj corresponde con el estado j
Construir la tabla Ir-A [s, A]
Si existe transición de Si a Sj con A, A Є N Entonces
Ir-A [i, A] = j
Construir la tabla Acción [s, a]
Para todo A ::= α • aβ Є Si, a Є T Hacer
Si existe transición de Si a Sj con a entonces
Acción [i, a] = dj
Para todo A ::= β • o A ::= • Є Si Hacer
Para todo a Є Siguiente (A) hacer
Acción [i, a] = rk
Si S’ ::= S • Є Si entonces Acción [i, $] = Aceptar
Todas las demás entradas de Acción [k, s] = error
A partir del autómata reconocedor de prefijos viables es posible construir las tablas de los analizadores SLR
› Cada estado del autómata es un estado
› Transiciones Si a Sj con A Є N reflejan Ir-A
› Transiciones Si a Sj con a Є T reflejan los desplazamientos
› Para los elementos de reducción
› Se calcula Siguientes del antecedente
› Se rellena la cela con reducción por esa regla
TablasSLRapar8rdelautómatadeprefijosviables
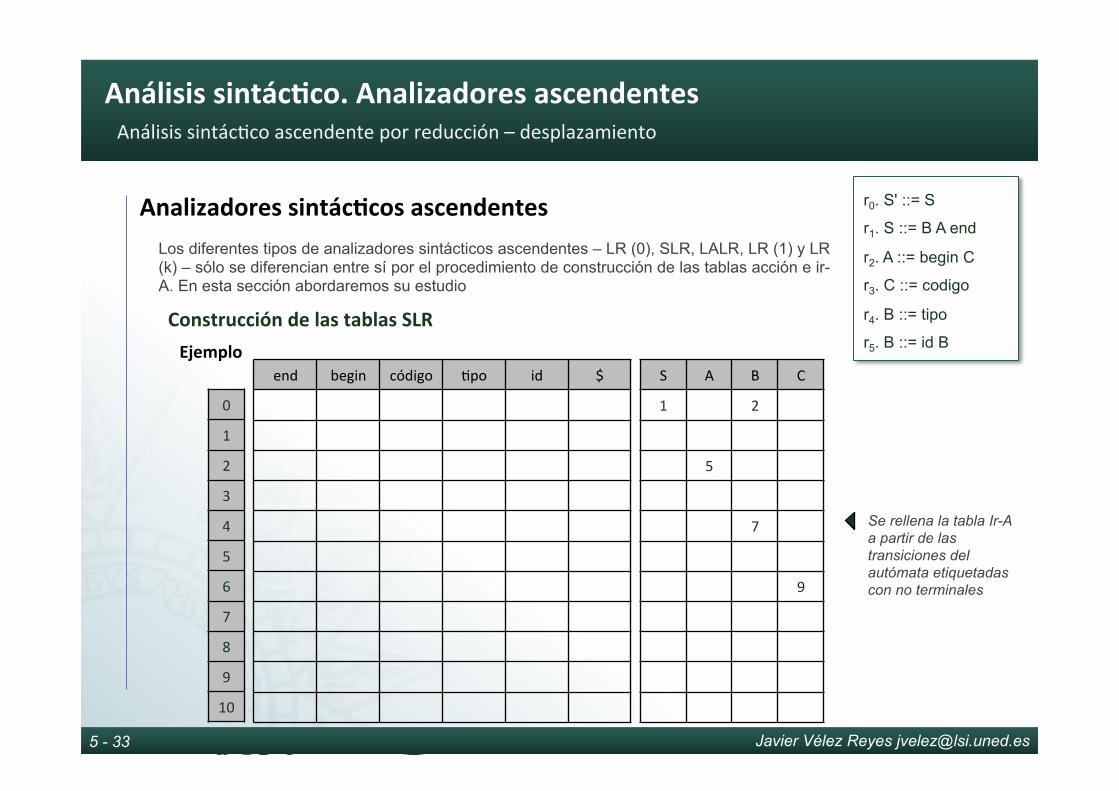
Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 33
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasSLR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Ejemploend begin código 6po id $
0
1
2
3
4
5
6
7
8
9
10
S A B C
1 2
5
7
9
Se rellena la tabla Ir-A a partir de las transiciones del autómata etiquetadas con no terminales
r0. S' ::= S
r1. S ::= B A end
r2. A ::= begin C
r3. C ::= codigo
r4. B ::= tipo
r5. B ::= id B

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 34
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasSLR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Ejemploend begin código 6po id $
d3 d4
d6
d3 d4
d8
d10
0
1
2
3
4
5
6
7
8
9
10
S A B C
1 2
5
7
9
Se rellenan los desplazamientos de la tabla de acción a partir de las transiciones del autómata etiquetadas con terminales
r0. S' ::= S
r1. S ::= B A end
r2. A ::= begin C
r3. C ::= codigo
r4. B ::= tipo
r5. B ::= id B

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 35
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasSLR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Ejemploend begin código 6po id $
d3 d4
Ok
d6
r4
d3 d4
d8
d10
r5
r1
r2
r3
0
1
2
3
4
5
6
7
8
9
10
S A B C
1 2
5
7
9
Se rellenan las reducciones y la aceptación de la tabla Acción a partir de los estados de reducción y la información de los conjuntos Siguientes
Siguiente (B) = Primero (A end)
= Primero (A) = { begin }
Siguiente (S) = Siguiente (S’) = { $ } Siguiente (C) = Siguiente (A) = { end }
r0. S' ::= S
r1. S ::= B A end
r2. A ::= begin C
r3. C ::= codigo
r4. B ::= tipo
r5. B ::= id B

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 36
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasSLR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Ejemploend begin código 6po id $
error error error d3 d4 error
error error error error error Ok
error d6 error error error error
error r4 error error error error
error error error d3 d4 error
d8 error error error error error
error error d10 error error error
error r5 error error error error
error error error error error r1
r2 error error error error error
r3 error error error error error
0
1
2
3
4
5
6
7
8
9
10
S A B C
1 2
5
7
9
El resto de casillas se rellenan con error
r0. S' ::= S
r1. S ::= B A end
r2. A ::= begin C
r3. C ::= codigo
r4. B ::= tipo
r5. B ::= id B

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 37
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
VentajaseinconvenientesdelosanalizadoresSLR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Los analizadores sintácticos ascendentes del tipo SLR suponen una mejora con respecto a los del tipo LR (0) que refinan las condiciones de entrada que deben darse para poder hacer una reducción por una determinada regla
Ventajas
› Fácil de entender y construir
› Predice reducción mediante Siguientes
› Varias reducciones por el mismo estado
› Utiliza el mismo autómata LR (0)
Inconvenientes
› Conjunto mayor pero reducido de gramáticas
› Estrategia de reducción más compleja
› No existen estados de (única) reducción
› El autómata LR (0) no contempla predicción

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 38
d
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
DesdeelSLRhaciaelLR(1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
El análisis predictivo que realizan los analizadores ascendentes del tipo SLR resulta demasiado tosco ya que aún se pueden afinar más los criterios de aplicación predictiva de desplazamientos
No todos los x Є T, ni siquiera los x Є Siguientes (B) a la
cabeza de la entrada en un momento dado son candidatos
viables para hacer un avance por el elemento A ::= α • B γ
S ::= A b | c B d
A ::= a B c | a B
B ::= d e
A
a c
b
B •
A
a
b
B•
A
a B •
Conjunto de gramáticas
Además de las características destacadas anteriormente, ahora la caracterización del conjunto de terminales que deben aparecer a la entrada para hacer un paso de derivación se ve más afinado. Esto impone menos restricciones gramaticales lo que permite articular un gran número de gramáticas
Precisión de errores
Como consecuencia también ocurre que la identificación de los tipos de errores, y sus mensajes asociados mejora ya que cada uno describe más precisamente el contexto sintáctico en el que se produce y los terminales que se deberían haber esperado
B

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 39
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLR(1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Elementos LR (1)
Prefijo viable LR (1)
Un elemento LR (1) es un par formado por un elemento LR (0) y un terminal de búsqueda hacia delante. La idea es acarrear en cada elemento el terminal que debe encontrarse a la entrada a la hora de realizar la reducción. Debe pertenecer al conjunto Siguiente del antecedente
[ B ::= • a A, x]
[ B ::= a • A , x]
[ B ::= a A •, x]
A := ع
B ::= a A
[ A := •, x]
Un prefijo viable de un elemento corresponde con la forma de frase que queda a la izquierda del punto de dicho elemento. El prefijo viable identifica, de forma abstracta, la frase que se ha reconocido a la entrada y que valida, parcialmente, la selección de esa regla para proceder con la reducción
[B ::= • a A, x] [B ::= a • A, x] [B ::= a A •, x]
Prefijo viable
Elemento reductible
Elemento de comienzo
Para todo x Є Siguientes (B)
Terminal de búsqueda hacia delante

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 40
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLR(1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Conjunto de elementos LR (1)
Colección canoníca de los conjuntos de elementos LR (1)
Un conjunto de elementos es una colección no ordenada de elementos. Los conjuntos de e lementos se ut i l i zan para caracter izar formalmente los estados potenciales por lo que atraviesa un compilador a lo largo del proceso de análisis
I = { [ S’ ::= • S , $ ],
[ S ::= • ( S ) , $ ],
[ S ::= • a , $ ] }
La colección de todos los conjuntos de elementos potenciales en los que se puede encontrar el analizador sintáctico se recoge en un conjunto llamado colección canónica de los conjuntos de elementos. Para su definición formal se utilizan dos funciones
S’ ::= S
S ::= ( S ) | a
Cierre ( I )
Ir- A (I, a)
Se cierra un conjunto para incluir todos los elementos que pueden alcanzarse a partir de uno dado
Se genera un nuevo conjunto a partir de I y del simbolo terminal o no terminal a

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 41
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLR(1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Función Cierre ( I ) LR (1) El cierre de un conjunto I consiste en ampliar dicho conjunto con todos aquellos elementos con un punto al inicio de su parte derecha que son accesibles de forma directa o indirecta desde I. Además debe actualizarse el terminal de búsqueda hacia delante
Cierre (I) = I
repetir
Para cada elemento [A := α • B β, a] є Cierre (I) hacer
Para cada B ::= δ1 | δ2 | … | δn hacer
Para cada b є Primeros (β a)
Cierre (I) = Cierre (I) ∪ { [B := • δi, b] } para todo i = 1..n
hasta no se pueden añadir más elementos a Cierre (I)
I0 = Cierre ( { [S’ ::= • S, $] } ) =
{ [S’ ::= • S, $],
[S ::= • ( S ) , $ ],
[S ::= • a , $ ] }
I2 = Cierre ( { [S’ ::= ( • S ), $] } ) =
{ [S’ ::= ( • S ), $],
[S ::= • ( S ), ‘)’ ],
[S ::= • a, ‘)’ ] }
S’ ::= S
S ::= ( S ) | a

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 42
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLR(1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Función Ir-A ( I, a ) LR (1)
Ir-A ( I0, ‘(’ ) = Cierre ( { [ S ::= ( • S ), $ ] } )
= { [ S ::= ( • S ), $ ],
[ S ::= • ( S ), ) ],
[ S ::= • a, ) ] }
Ir-A es una función que toma un estado y un elemento a Є N U T y devuelve un nuevo estado. La operación consiste en avanzar el punto una posición sobre todos aquellos elementos en los que a preceda al punto. En los que no ocurra así se eliminan del conjunto. Finalmente se cierra el conjunto resultante
Para todos los elementos B := [α • Aβ, b] є I hacer
Ir-A (I, A) = Cierre ( { [B := α A • β, b] } )
S’ ::= S
S ::= ( S ) | a

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 43
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLR(1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Colección canónica de los conjuntos de elementos C LR (1)
Se comienza por ampliar la gramática con la producción S’ ::= S donde S es el axioma y S’ es el nuevo axioma. Esto se hace para cubrir todas las alternativas de S. Después se aplica sistemáticamente el siguiente algoritmo hasta que C no pueda crecer más
Ampliar la gramática con S’ ::= S
C = Cierre ( { S’ ::= • S } ) = { I0 }
Para cada conjunto Ii є C Hacer
Para cada a є T ∪ N Hacer
Si existe un elemento B := α • a β є Ii
C = C ∪ Ir-A (Ii , a)
r1. S’ ::= S
r2. S ::= C C
r3. C ::= c C
r4. C::= d
I0 = Cierre ( { [S’ ::= •S, $] } )
= {[S’ ::= •S, $], [S ::= • CC, $],
[C ::= • cC, c],
[C ::= • cC, d],
[C ::= •d, c],
[C ::= •d, d] }
I1 = Ir-A (I0, S)
= Cierre ( { [S’ ::= S •, $] } )
= { [S’ ::= S •, $] }
I2 = Ir-A (I0, C)
= Cierre ( { [S ::= C •C,$] } )
= { [S ::= C•C,$],
[C::= •cC, $],
[C::= •d, $] }
I3 = Ir-A (I0, c)
= Cierre ( { [C ::= c•C, c] [C ::= c•C, d] } )
= { [C ::= c•C, c ],
[C::= •cC, c],
[C ::= •d, c],
[C ::= c•C, d ],
[C::= •cC, d],
[C ::= •d, d] }
I4 = Ir-A (I0, d)
= Cierre ( { [C ::= d •, c] [C::= d •, d] } )
= { [C ::= d •, c] [C::= d •, d] }
I5 = Ir-A (I2,C)
= Cierre ( { [S ::= CC•, $] } )
= { [S ::= CC•, $] }
Continúa…

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 44
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLR(1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Colección canónica de los conjuntos de elementos C LR (1)
Se comienza por ampliar la gramática con la producción S’ ::= S donde S es el axioma y S’ es el nuevo axioma. Esto se hace para cubrir todas las alternativas de S. Después se aplica sistemáticamente el siguiente algoritmo hasta que C no pueda crecer más
Ampliar la gramática con S’ ::= S
C = Cierre ( { S’ ::= • S } ) = { I0 }
Para cada conjunto Ii є C Hacer
Para cada a є T ∪ N Hacer
Si existe un elemento B := α • a β є Ii
C = C ∪ Ir-A (Ii , a)
I6 = Ir-A (I2, c)
= Cierre ( { [C::=c •C,$] } )
= { [C ::= c •C,$],
[C: := •cC, $],
[C ::= •d, $] }
I7 = Ir-A (I2, d)
= Cierre ( { [C::= d •, $] } )
= { [C ::= d •,$] }
I8 = Ir-A (I3, C)
= Cierre ( { [C ::= cC •, c],
[C ::= cC •, d] } )
= { [C ::= cC •,c],
[C ::= cC •,d] }
I9 = Ir-A (I3, c)
= Cierre( { [C::= c•C, c], [C ::= c•C, d] } ) = I3
I9 = Ir-A (I3, d)
= Cierre ( { [C ::= d •, c] [C::= d •, d] } ) = I4
I9 = Ir-A (I6, C)
= Cierre( { [C ::= cC•, $] } ) = { [C ::= cC•, $] }
I10 = Ir-A (I6, c)
= Cierre ( { [C::=c•C, $] }) = I6
I10 = Ir-A (I6, d)
= Cierre ( { [C::= d•, $] } ) = I7
r1. S’ ::= S
r2. S ::= C C
r3. C ::= c C
r4. C::= d

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 45
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLR(1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Autómata reconocedor de prefijos viables LR (1)
De manera similar se puede construir un autómata reconocedor de prefijos viables donde cada Ii se corresponde con un Si y cada transición etiquetada con a de Si a Sj se corresponde con Ij = Ir-A (Ii, a)
S0 = Cierre( { S’ ::= • S } )
Para cada Si Hacer
Para cada a є N ∪ T Hacer
Si Existe B ::= α • aβ є Si Entonces
Crear estado nuevo Sn = Ir-A (Si, A
Crear transición de Si a Sn etiquetada con a
[S’::=•S,$]
[S::=•CC,$],
[C::=•cC,c],
[C::=•cC,d],
[C::=•d,c],
[C::=•d,d]
[S’::=S•,$]
[S::=C•C,$],
[C::=•cC,$],
[C::=•d,$]
[S::=CC•,$]
[C::=c•C,$],
[C::=•cC,$],
[C::=•d,$]
[C::=cC•,$]
[C::=d•,$][C::=c•C,c],
[C::=•cC,c],
[C::=•d,c],
[C::=c•C,d],
[C::=•cC,d],
[C::=•d,d],[C::=cC•,c],
[C::=cC•,d]
[C::=d•,c],
[C::=d•,d]
c
C
c
d
S
d
C
C
c
d d
C
c
0 1
2
3
4
5
6
7
8
9
r1. S’ ::= S
r2. S ::= C C
r3. C ::= c C
r4. C::= d

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 46
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLR(1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Obtener C = {I0, I1, …, In}
Cada Ij є C se corresponde con el estado j del analizador
Construir la tabla Ir-A [s, A]
Si Ir-A (Ii, A) = Ij, A Є N Entonces Ir-A [i, A] = j
Construir la tabla Acción [s, a]
Para todo [A ::= α • aβ, b] Є Ii, a Є T Hacer
Si Ir-A (Ii, a) = Ij Entonces Acción [i, a] = dj
Para todo [A ::= α •, a] Є Ii a Є T Hacer
Acción [i, a] = rk
Si [S’ ::= S •, $] Є Ii entonces Acción [i, $] = Aceptar
Todas las demás entradas de Acción [k, s] = error
A partir de la colección canónica de elementos es posible construir las tablas de los analizadores LR (1)
› Cada conjunto de elementos es un estado
› La tabla Ir-A (I, A) A Є N refleja la función Ir-A
› La tabla Ir-A (I, a) a Є T refleja los desplazamientos
› Para los elementos de reducción
› Se mira el terminal de búsqueda adelantada
› Se rellena la celda con reducción por esa regla
TablasLR(1)apar8rdelacoleccióncanónica

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 47
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLR(1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Obtener El autómata reconocedor de prefijos viables
Cada estado Sj corresponde con el estado j
Construir la tabla Ir-A [s, A]
Si existe transición de Si a Sj con A, A Є N Entonces
Ir-A [i, A] = j
Construir la tabla Acción [s, a]
Para todo [A ::= α • aβ, b] Є Si, a Є T Hacer
Si existe transición de Si a Sj con a entonces
Acción [i, a] = dj
Para todo [A ::= α •, a] Є Si a Є T Hacer
Acción [i, a] = rk
Si [S’ ::= S •, $] Є Si Acción [i, $] = Aceptar
Todas las demás entradas de Acción [k, s] = error
A partir del autómata reconocedor de prefijos viables es posible construir las tablas de los analizadores SLR
› Cada estado del autómata es un estado
› Transiciones Si a Sj con A Є N reflejan Ir-A
› Transiciones Si a Sj con a Є T reflejan los desplazamientos
› Para los elementos de reducción
› Se mira el terminal de búsqueda adelantada
› Se rellena la cela con reducción por esa regla
TablasLR(1)apar8rdelautómatadeprefijosviables

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 48
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLR(1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Ejemploc d $
0
1
2
3
4
5
6
7
8
9
S C
1 2
5
8
9
c d $
d3 d4
d6 d7
d3 d4
d6 d7
0
1
2
3
4
5
6
7
8
9
S C
1 2
5
8
9
r1. S’ ::= S
r2. S ::= C C
r3. C ::= c C
r4. C::= d

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 49
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLR(1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
c d $
d3 d4
d6 d7
d3 d4
r4 r4
r2
d6 d7
r4
r3 r3
r3
0
1
2
3
4
5
6
7
8
9
S C
1 2
5
8
9
Ejemplo
r1. S’ ::= S
r2. S ::= C C
r3. C ::= c C
r4. C::= d
c d $
d3 d4 error
error error ok
d6 d7 error
d3 d4 error
r4 r4 error
error error r2
d6 d7 error
error error r4
r3 r3 error
error error r3
0
1
2
3
4
5
6
7
8
9
S C
1 2
5
8
9

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 50
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
VentajaseinconvenientesdelosanalizadoresLR(1)
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Los analizadores sintácticos ascendentes del tipo LR (1) son los más generales que existen y admiten un gran número de gramáticas. No obstante la complejidad de los autómatas reconocedores de prefijos viables os hacen inaplicables en la práctica
Ventajas
› Gran conjunto de gramáticas posibles
› Predicción con terminales de búsqueda
› Varias reducciones por el mismo estado
› La predicción está muy ajustada
Inconvenientes
› Mas difícil de entender y construir
› Estrategia de reducción más compleja
› No existen estados de (únicos) de reducción
› Utiliza un autómata muy complejo

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 51
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
DesdeelLR(1)haciaelLALR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
El único inconveniente del análisis LR (1) es la explosión combinatoria de estados que surge en el autómata reconocedor de prefijos viables cuando se tienen en cuenta los terminales de búsqueda adelantada. LALR simplifica estos autómatas a partir de 2 principios
El núcleo de un estado de un autómata reconocedor de
prefijos viables LR (1) es igual al estado equivalente de LR (0)
Llamamos núcleo de un estado al conjunto formado por los primeros componentes de cada elemento de dicho estado
PrimerprincipiodelanálisisLALR
Dados 2 estados s1 y s2 de un autómata LR (1) con el mismo
núcleo. Si s1 tiene una transición con X a t1, entonces s2
también lo tiene con X a algún t2 y t1 y t2 comparten el mismo
núcleo
SegundoprincipiodelanálisisLALR
I = { [ S’ ::= • S , $ ],
[ S ::= • ( S ) , $ ],
[ S ::= • a , $ ] }

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 52
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLALR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Elementos LALR
Prefijo viable LALR
Un elemento LR (1) es un par formado por un elemento LR (0) y un o varios terminales de búsqueda hacia delante. La idea es acarrear en cada elemento el/los terminales que deben encontrarse a la entrada a la hora de realizar la reducción. Debe pertenecer al conjunto Siguiente del antecedente
[ B ::= • a A, a / b…]
[ B ::= a • A , a / b…]
[ B ::= a A •, a /b,…]
A := ع
B ::= a A
[ A := •, a, b,…]
Un prefijo viable de un elemento corresponde con la forma de frase que queda a la izquierda del punto de dicho elemento. El prefijo viable identifica, de forma abstracta, la frase que se ha reconocido a la entrada y que valida, parcialmente, la selección de esa regla para proceder con la reducción
[B ::= • a A, a/b…] [B ::= a • A, a/b…] [B ::= a A •, a/b…]
Prefijo viable
Elemento reductible
Elemento de comienzo
Terminales de búsqueda hacia delante

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 53
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLALR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Conjunto de elementos LALR Un conjunto de elementos es una colección no ordenada de elementos. Los conjuntos de elementos se utilizan para caracterizar formalmente los estados potenciales por lo que atraviesa un compilador a lo largo del proceso de análisis
I = { [ S’ ::= • S , $ ],
[ S ::= • ( S ) , $ ],
[ S ::= • a , $ ] }
S’ ::= S
S ::= ( S ) | a
Cierre (I) LALR
Ir-A (I, a) LALR
Cierre (I) LR (1)
Ir-A (I, a) LR (1) =
Función Cierre ( I ) LALR El cierre de un conjunto I consiste en ampliar dicho conjunto con todos aquellos elementos con un punto al inicio de su parte derecha que son accesibles de forma directa o indirecta desde I. Además debe actualizarse el terminal de búsqueda hacia delante
Función Ir-A ( I, a ) LALR
Ir-A es una función que toma un estado y un elemento a Є N U T y devuelve un nuevo estado. La operación consiste en avanzar el punto una posición sobre todos aquellos elementos en los que a preceda al punto. En los que no ocurra así se eliminan del conjunto. Finalmente se cierra el conjunto resultante

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 54
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLALR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Colección canónica de los conjuntos de elementos C LALR
Todos los conjuntos de elementos con el mismo núcleo se fusionan en un mismo conjunto de elementos. Se devuelve la colección canónica resultante
Ampliar la gramática con S’ ::= S
C = Cierre ( { S’ ::= • S } ) = { I0 }
C’ = { }
Mientras (C != { } )
I = c.extraer ()
Js = c.buscarMismoNucleo (I)
Para todo J en Js
I = I U J
C = C U { I }
I0 = { [S ::= • CC, $],
[C ::= • cC, c/d],
[C ::= •d, c/d] }
I1 = { [S’ ::= S •, $] }
I2 = { [S ::= C •C,$],
[C::= •cC, $],
[C::= •d, $] }
I3 = { [C ::= c•C, c/d/$ ],
[C::= •cC, c/d/$],
[C ::= •d, c/d/$] } = I6
r1. S’ ::= S
r2. S ::= C C
r3. C ::= c C
r4. C::= d
I4 = { [C ::= d •, c/d/$] } = I7
I5 = { [C ::= CC•, $] }
I8 = { [C ::= cC•, $] } = I9

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 55
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConceptosesencialesLALR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Autómata reconocedor de prefijos viables LALR
Hacer el autómata para LR (1)
Para cada subconjunto S1 … Sk con el mismo núcleo
S’1 = U Si
Fusionar también todas las transiciones
[S’::=•S,$]
[S::=•CC,c/d/$],
[C::=•d,c/d],
[S’::=S•,$]
[S::=C•C,$],
[C::=•cC,$],
[C::=•d,$]
[S::=CC•,$]
[C::=c•C,c/d/$],
[C::=•cC,c/d/$],
[C::=•d,c/d/$],
[C::=cC•,c/d/$]
[C::=d•,c/d/$]
c
C
c
d
S
d
C
C
c
0 1
2
36
47
5
89
r1. S’ ::= S
r2. S ::= C C
r3. C ::= c C
r4. C::= d
Todos los conjuntos de elementos con el mismo núcleo se fusionan en un mismo conjunto de elementos. Se devuelve la colección canónica resultante
d

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 56
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLALR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Obtener C = {I0, I1, …, In} de LR (1)
Obtener C’ = {J0, J1, …, Jk} de LALR
Construir la tabla Ir-A [s, A]
Si Ji = { I0,, …, Im } Entonces
Ir-A (Ji, a) = U Ir-A (Ii, a)
Construir la tabla Acción [s, a]
Construir la tabla Acción [s, a] de LR (1)
Fusionar todas las celdas de las filas con estados fusionados
Si aparecen conflictos G no es LALR
A partir de la colección canónica de elementos es posible construir las tablas de los analizadores LALR
› Cada conjunto de elementos es un estado
› La tabla Ir-A (I, A) A Є N refleja la función Ir-A
› La tabla Ir-A (I, a) a Є T refleja los desplazamientos
› Para los elementos de reducción
› Se mira el terminal de búsqueda adelantada
› Se rellena la celda con reducción por esa regla
› Se fusionan los resultados de la tabla acción
TablasLALRapar8rdelacoleccióncanónica

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 57
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLALR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Obtener el autómata LR (1) con estados Tj
Obtener el autómata LALR con estados Si
Construir la tabla Ir-A [s, A]
Si Si = { Ta,, …, Tb }, Sj = { Tc,, …, Td } Entonces
Si existe alguna transición de Tv Є Si a Tr Є Sj con X
Trazar transición de Si a Sij con X
Construir la tabla Acción [s, a]
Construir la tabla Acción [s, a] de LR (1)
Fusionar toda celda de filas con estados fusionados
Si aparecen conflictos G no es LALR
A partir del autómata reconocedor de prefijos viables es posible construir las tablas de los analizadores LALR
› Cada estado del autómata es un estado
› Transiciones Si a Sj con A Є N reflejan Ir-A
› Transiciones Si a Sj con a Є T reflejan los desplazamientos
› Para los elementos de reducción
› Se mira el terminal de búsqueda adelantada
› Se rellena la cela con reducción por esa regla
› Se fusionan los resultados de la tabla acción
TablasLALRapar8rdelautómatadeprefijosviables

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 58
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLALR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Ejemplo
c d $
0
1
2
36
47
5
89
S C
1 2
5
89
r1. S’ ::= S
r2. S ::= C C
r3. C ::= c C
r4. C::= d
c d $
d36 d47
d36 d47
d36 d47
0
1
2
36
47
5
89
S C
1 2
5
89

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 59
Análisissintác6coascendenteporreducción–desplazamiento
Analizadoressintác8cosascendentes
ConstruccióndelastablasLALR
Los diferentes tipos de analizadores sintácticos ascendentes – LR (0), SLR, LALR, LR (1) y LR (k) – sólo se diferencian entre sí por el procedimiento de construcción de las tablas acción e ir-A. En esta sección abordaremos su estudio
Ejemplo
c d $
d36 d47
d36 d47
d36 d47
r4 r4 r4
r2
r3 r3 r3
0
1
2
36
47
5
89
S C
1 2
5
89
r1. S’ ::= S
r2. S ::= C C
r3. C ::= c C
r4. C::= d
c d $
d36 d47 error
error error ok
d36 d47 error
d36 d47 error
r4 r4 r4
error error r2
r3 r3 r3
0
1
2
36
47
5
89
S C
1 2
5
89

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 60
Análisissintác6coascendenteporreducción–desplazamiento
Análisissintác8coascendente
EjerciciosUna vez estudiados la construcción de las tablas para los 4 tipos de analizadores sintácticos ascendentes es posible comprobar su viabilidad con diferentes gramáticas
Los analizadores sintácticos ascendentes son capaces de decidir qué regla de producción aplicar a cada paso en función de los elementos terminales que se encuentran en la cabeza de lectura de la cadena de entrada. Como consecuencia se consigue un proceso de análisis con complejidad lineal O (n) con respecto al tamaño del problema. Estos analizadores son llamados genéricamente analizadores LR (K) o analizadores por reducción desplazamiento
E ::= E + T | E – T | T
T ::= T * F | T / F | F
F ::= id | n | ( E )
S ::= P
P ::= ( P ) P | ع
P ::= C L F
C ::= id ;
L ::= id ; L | ع
F ::= id ( L ) ;
P ::= L
L := S ; L | ع
S ::= E | B
B ::= { L }
E ::= id = E | n

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 61
Ges6óndeerroresenanalizadoresascendentes
Ges8óndeerroresLa labor de un analizador sintáctico no se limita exclusivamente a reconocer que una frase pertenece al lenguaje generado por una gramática. Adicionalmente, en el caso de que existan errores sintácticos (o léxicos no reconocidos en la fase de análisis léxico), el analizador debe ser capaz de reconocer errores y emitir mensajes de información asociados
I.Iden8ficacióndeerrores
r1. S’ ::= S
r2. S ::= C C
r3. C ::= c C
r4. C::= d
c d $
d3 d4 error
error error error
d6 d7 error
d3 d4 error
r4 r4 error
r2 r2 error
d6 d7 error
error error r4
r3 r3 error
error error r3
Cada entrada vacía de la tabla de acción de los analizadores ascendentes identifica una casuística diferente de error. En p r inc ip io cada e r ro r debería incorporar un mensaje característico diferente
Terminación inesperada de la frase. Se esperaba c o d
Se encontró un c inesperado
II.GeneracióndemensajesCada celda de la tabla de acción permite identificar un tipo de error distinto y asociarle un mensaje de error diferente

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 62
Ges6óndeerroresenanalizadoresascendentes
Ges8óndeerroresLa labor de un analizador sintáctico no se limita exclusivamente a reconocer que una frase pertenece al lenguaje generado por una gramática. Adicionalmente, en el caso de que existan errores sintácticos (o léxicos no reconocidos en la fase de análisis léxico), el analizador debe ser capaz de reconocer errores y emitir mensajes de información asociados
III.Localizacióndeerrores
r1. S’ ::= S
r2. S ::= C C
r3. C ::= c C
r4. C::= d
c d $
d3 d4 error
error error error
d6 d7 error
d3 d4 error
r4 r4 r4
r2 r2 r2
d6 d7 error
r4 r4 r4
r3 r3 r3
r3 r3 r3
Para reducir el número de m e n s a j e s d e e r r o r p o d e m o s f o r z a r reducciones en todos los estados donde solo se reduzca por una regla. Esto atrasa la emisión del error hasta el siguiente desplazamiento lo que p u e d e c o m p l i c a r l a localización
Como heurística general nunca se deben consumir más de 3 tokens en modo de pánico
Las reducciones en rojo corresponden en realidad a
situaciones de error
VI.RecuperacióndeerroresSe pasa a consumición de t okens en modo de pánico. Debe procurarse que el número de tokens consumido no sea muy elevado. Este proceso esta dirigido por conjuntos de predicción

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 63
Tiposdegramá6casyanálisisascendente
Interpretacióndeconflictosenlos8posdeanalizadoresComo describimos al inicio del tema, existen dos tipos de conflictos que pueden darse dentro del análisis sintáctico ascendente por reducción desplazamiento. En este apartado discutiremos, para cada tipo gramática, qué condiciones debe verificar la tabla de acción de los analizadores para que no se den tales conflictos
Nopuedehaber2reglasdis6ntasenlamismafiladeunestadodereducción
Nopuedehaberaccionesreducirydesplazarenunamismafila
› Conflictos reducción – reducción
› Conflictos reducción desplazamiento
LenguajesLR(0)
Nopuedehaber2reglasdis6ntasenlamismaceldadereducción
Nopuedehaberunaacciónreduciryotradesplazarenunamismacelda
LenguajesSLR
LenguajesLALR
LenguajesLALR
Reducción-Reducción Reducción-Desplazamiento

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 64
Tiposdegramá6casyanálisisascendente
Clasificacióndegramá8caspor8posdeanalizadoresCuando la tabla de un analizador sintáctico de un determinado tipo no presenta conflictos de análisis se puede asegurar que la gramática del lenguaje bajo análisis es del tipo del analizador utilizado. Esto, en conjunción con la información extraída del tema anterior permite trazar la siguiente clasificación conjuntista de gramáticas independientes del contexto en función del tipo de análisis que soportan
Gramáticas Independientes de contexto
LR (k) Lenguajes No Deterministas
LR (1)
LALR
SLR LR(0)
LL (k)
LL (1)

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 65
Construccióndeanalizadoressintác6cosenlaprác6ca
¿QuéesCup?Cup es una herramienta para la generación de analizadores sintácticos escritos en java. A partir de un fichero de especificación que describe las características sintácticas de un lenguaje, Cup genera un código fuente compilable que puede ser utilizado como analizador sintáctico
Cup
Javac
Parser.cup
Framework
Sym.java
Parser.class
Cup compile CupTest
Esta es la especificación del analizador sintáctico. Todo cambio en el parser debe indicarse aquí
Clase que contiene declaración de constantes para cada terminal gramatical
El scanner modifica para incorporar en los ID de los tokens los valores de Sym
Paser.java
JFlex JavacScanner.java Scanner.class
JFlex
Java
compile
Esta es la clase generada a partir de la especificación. Atención! No incluir aquí ningún código manualmente ya que en la próxima generación se perderá
Esta es la clase Parser que corresponde con un analizador ascendente de tipo LALR
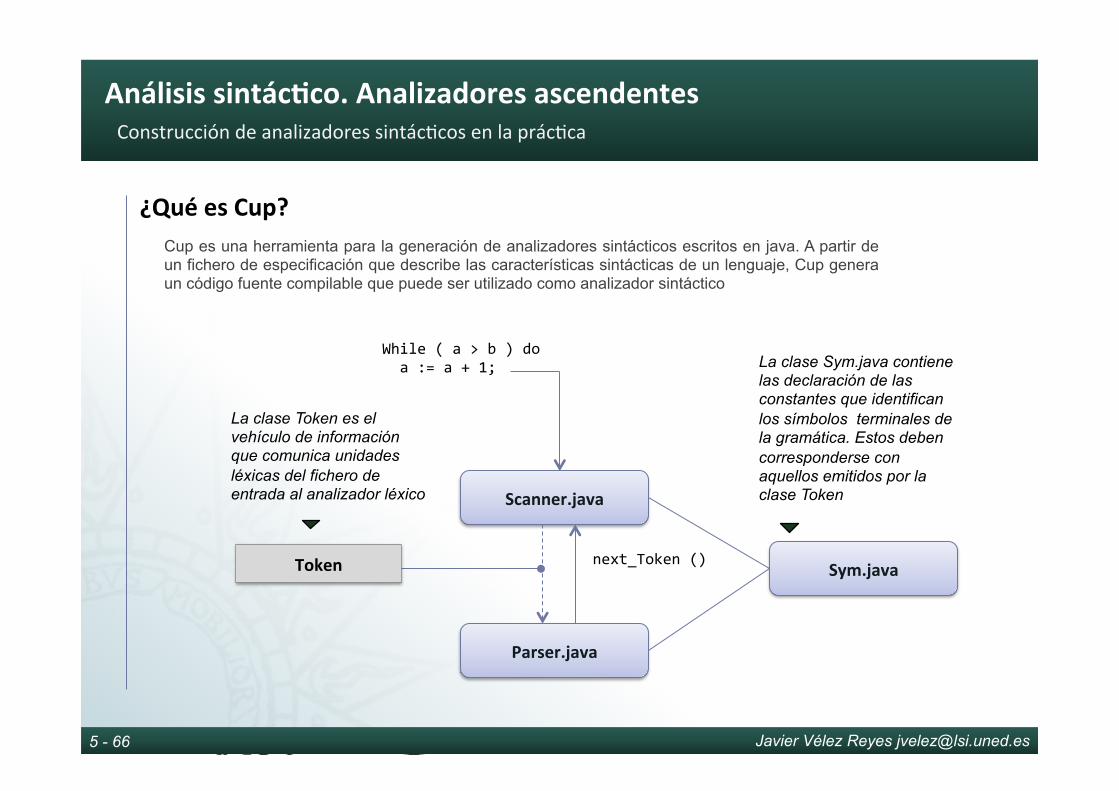
Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 66
Construccióndeanalizadoressintác6cosenlaprác6ca
¿QuéesCup?Cup es una herramienta para la generación de analizadores sintácticos escritos en java. A partir de un fichero de especificación que describe las características sintácticas de un lenguaje, Cup genera un código fuente compilable que puede ser utilizado como analizador sintáctico
Scanner.java
While(a>b)doa:=a+1;
Parser.java
next_Token() Sym.java
La clase Sym.java contiene las declaración de las constantes que identifican los símbolos terminales de la gramática. Estos deben corresponderse con aquellos emitidos por la clase Token
La clase Token es el vehículo de información que comunica unidades léxicas del fichero de entrada al analizador léxico
Token

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 67
Construccióndeanalizadoressintác6cosenlaprác6ca
¿CómofuncionaCup?La especificación de un analizador sintáctico en cup está compuesta por varias secciones diferentes. El marco de trabajo tecnológico utilizado para el desarrollo del compilador proporciona una plantilla de tal especificación que debe ser extendida pero NO modificada (seguir comentarios)
I.PaqueteseimportacionesSe incluye la declaración de todas clases y paquetes necesarias para compilar adecuadamente el analizador sintáctico. Ninguna de las importaciones de la plantilla debe ser eliminada!
Consúltese el manual de usuario de Cup

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 68
Construccióndeanalizadoressintác6cosenlaprác6ca
¿CómofuncionaCup?La especificación de un analizador sintáctico en cup está compuesta por varias secciones diferentes. El marco de trabajo tecnológico utilizado para el desarrollo del compilador proporciona una plantilla de tal especificación que debe ser extendida pero NO modificada (seguir comentarios)
II.Ac8oncodeSe incluyen declaraciones de variables y métodos auxiliares que serán utilizados dentro de la gramática. Algunas de las declaraciones presentes en la plantilla son necesarias solamente de cara al segundo cuatrimestre. Si las elimina o comenta deberá recuperarlas en la segunda entrega. En el primer cuatrimestres sólo SyntaxErrorManager es utilizado
Consúltese el manual de usuario de Cup

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 69
Construccióndeanalizadoressintác6cosenlaprác6ca
¿CómofuncionaCup?La especificación de un analizador sintáctico en cup está compuesta por varias secciones diferentes. El marco de trabajo tecnológico utilizado para el desarrollo del compilador proporciona una plantilla de tal especificación que debe ser extendida pero NO modificada (seguir comentarios)
III.ParsercodePermite incluir declaraciones de variables y métodos que ayudan a adaptar el comportamiento del analizador. La plantilla incluye la declaración del SyntaxErrorManager y funciones manejadoras de los errores recuperables y no recuperables. Ninguna de estas declaraciones deben ser eliminadas
Consúltese el manual de usuario de Cup

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 70
Construccióndeanalizadoressintác6cosenlaprác6ca
¿CómofuncionaCup?La especificación de un analizador sintáctico en cup está compuesta por varias secciones diferentes. El marco de trabajo tecnológico utilizado para el desarrollo del compilador proporciona una plantilla de tal especificación que debe ser extendida pero NO modificada (seguir comentarios)
IV.DeclaracióndeterminalesSe deben declarar extensivamente todos los símbolos terminales utilizados en la gramática. Se comienza por la palabra reservada terminal seguida de la clase java que representa el terminal y finalmente el nombre del terminal seguido de punto y coma (;)
Palabra reservada terminal
Clase que tipifica el Token
Nombre del Token
Todos y cada uno de los terminales definidos aquí aparecerán en la clase Sym para que puedan referirse desde el escáner
Consúltese el manual de usuario de Cup

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 71
Construccióndeanalizadoressintác6cosenlaprác6ca
¿CómofuncionaCup?La especificación de un analizador sintáctico en cup está compuesta por varias secciones diferentes. El marco de trabajo tecnológico utilizado para el desarrollo del compilador proporciona una plantilla de tal especificación que debe ser extendida pero NO modificada (seguir comentarios)
V.DeclaracióndenoterminalesSe deben declarar extensivamente todos los símbolos no terminales utilizados en las partes izquierda de las reglas de la gramática. Se comienza por la palabra reservada terminal seguida de la clase java que representa el no terminal y finalmente el nombre del no terminal seguido de punto y coma (;)
Palabra reservada non terminal
Clase que tipifica el no terminal
Nombre del no terminal
La tipificación de los no terminales puede omitirse y postergarse hasta el segundo cuatrimestre
Consúltese el manual de usuario de Cup

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 72
Construccióndeanalizadoressintác6cosenlaprác6ca
¿CómofuncionaCup?La especificación de un analizador sintáctico en cup está compuesta por varias secciones diferentes. El marco de trabajo tecnológico utilizado para el desarrollo del compilador proporciona una plantilla de tal especificación que debe ser extendida pero NO modificada (seguir comentarios)
VI.Declaraciónexplícitadeprecedenciayasocia8bidadEn Cup las gramáticas de operadores pueden ser ambiguas. La resolución de la ambigüedad se realiza de forma explícita a partir de la información de precedencia y asociatividad
Palabra reservada precedence
Información de asociatividad (left | right | nonassoc)
Nombre del terminal
La tipificación de los no terminales puede omitirse y postergarse hasta el segundo cuatrimestre
Igual precedencia Precedencia creciente
Consúltese el manual de usuario de Cup

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 73
Construccióndeanalizadoressintác6cosenlaprác6ca
¿CómofuncionaCup?La especificación de un analizador sintáctico en cup está compuesta por varias secciones diferentes. El marco de trabajo tecnológico utilizado para el desarrollo del compilador proporciona una plantilla de tal especificación que debe ser extendida pero NO modificada (seguir comentarios)
VII.DeclaracióndelaxiomaEn Cup es posible declarar el axioma de la gramática. Esta declaración es opcional. Si no aparece se asume por defecto que el axioma corresponde con el antecedente de la primera regla de producción. No borre esta declaración
Palabra reservada start with
Nombre del no terminal axioma
Consúltese el manual de usuario de Cup

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 74
Construccióndeanalizadoressintác6cosenlaprác6ca
¿CómofuncionaCup?La especificación de un analizador sintáctico en cup está compuesta por varias secciones diferentes. El marco de trabajo tecnológico utilizado para el desarrollo del compilador proporciona una plantilla de tal especificación que debe ser extendida pero NO modificada (seguir comentarios)
VIII.DeclaracióndelreglasdeproducciónLa última sección permite declarar las reglas de producción gramatical. Los no terminales van en minúscula, los terminales en mayúscula y el símbolo de producción es ::=
Antecedente
Consecuente
La parte derecha incluye acciones semánticas . Se usarán en el segundo cuatrimestre. No borre las acciones de la plantilla
Consúltese el manual de usuario de Cup

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 75
Construccióndeanalizadoressintác6cosenlaprác6ca
¿CómoseusaCup?El analizador sintáctico generado por Cup debe integrarse con el analizador léxico generado por JFlex. Ambas herramientas están preparadas para integrarse fácilmente. Además el marco de trabajo donde se desarrolla el compilador garantiza dicha integración
Scanner.java
While(a>b)doa:=a+1;
Parser.java
next_Token() Sym.java
Lo único que el usuario debe asegurar es que los identificadores de los tokens generados por el escaner correspondan con constantes declaradas en la clase Sym. Síganse los siguientes pasos:
Consúltese el manual de usuario de Cup y JFlex
<WHILE,PR>
1. Crear escaner con ID de token falsos
2. Crear el analizador sintáctico
1. Declarar terminales
2. Declara no terminales
3. Declarar reglas…
4. General el parser invocando a Cup
3. Reconstruir escáner
1. Sustituir los ID falsos por los de Sym
2. Generar el escaner invocando a JFlex
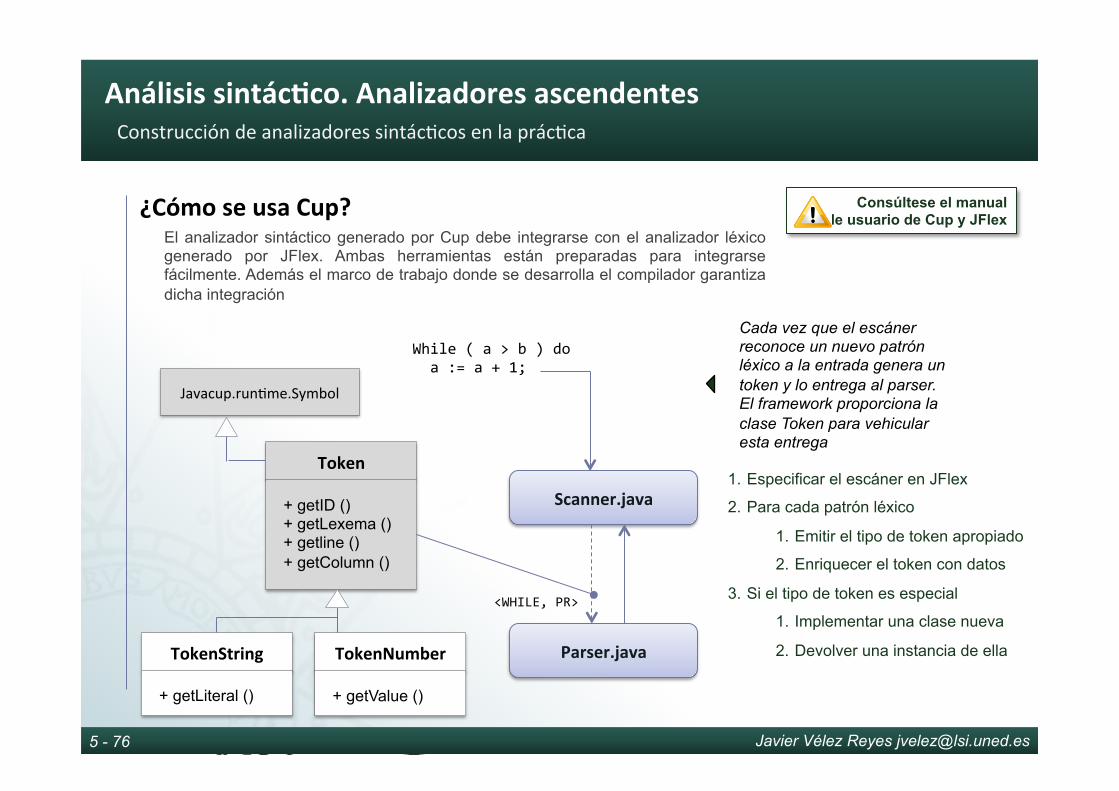
Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 76
Construccióndeanalizadoressintác6cosenlaprác6ca
¿CómoseusaCup?El analizador sintáctico generado por Cup debe integrarse con el analizador léxico generado por JFlex. Ambas herramientas están preparadas para integrarse fácilmente. Además el marco de trabajo donde se desarrolla el compilador garantiza dicha integración
Scanner.java
While(a>b)doa:=a+1;
Parser.java
Cada vez que el escáner reconoce un nuevo patrón léxico a la entrada genera un token y lo entrega al parser. El framework proporciona la clase Token para vehicular esta entrega
Consúltese el manual de usuario de Cup y JFlex
<WHILE,PR>
Javacup.run6me.Symbol
Token
+ getID () + getLexema () + getline () + getColumn ()
TokenString TokenNumber
+ getLiteral () + getValue ()
1. Especificar el escáner en JFlex
2. Para cada patrón léxico
1. Emitir el tipo de token apropiado
2. Enriquecer el token con datos
3. Si el tipo de token es especial
1. Implementar una clase nueva
2. Devolver una instancia de ella

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 77
Construccióndeanalizadoressintác6cosenlaprác6ca
Ges8óndeerroresenCupCuando se realiza un análisis ascendente en Cup de una cadena de entrada es posible que el parser generado encuentre dos posibles situaciones de error
exp::=expADDexp|expSUBexp|expMULexp|expDIVexp|NUMBER|error;
I. Errores recuperables
Los errores recuperables son aquellos de los que el compilador es capaz de escaparse en estado de pánico y continuar después en un contexto gramatical estable. Se describen con la producción error al final de la gramática
Consúltese el manual de usuario de Cup
exp::=expADDexp|expSUBexp|expMULexp|expDIVexp|NUMBER|errorPYC|errorPI;
Cada vez que se reduce por una producción de error, Cup invoca automáticamente al manejador de errores recuperables syntax_error. En la plantilla del framework el tratamiento consiste en emitir un mensaje de error con el SyntaxErrorManager . No altere este código Cuando la cadena a la entrada no encaja con
ninguna de las partes derechas de las reglas de exp se reduce por las reglas de error. Estas deben ir normativamente las últimas

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 78
Construccióndeanalizadoressintác6cosenlaprác6ca
Ges8óndeerroresenCupCuando se realiza un análisis ascendente en Cup de una cadena de entrada es posible que el parser generado encuentre dos posibles situaciones de error
II. Errores irrecuperables
Los errores irrecuperables son aquellos de los que el compilador no es capaz de recuperarse una vez que han sido encontrados y provocan que el parser aborte el proceso de análisis sintáctico
Consúltese el manual de usuario de Cup
Cada vez que se produce un error irrecuperable, Cup invoca automáticamente al manejador de errores recuperables unrecovered_syntax_error. En la plantilla del framework el tratamiento consiste en emitir un mensaje de error fatal con el SyntaxErrorManager . No altere este código

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 79
Construccióndeanalizadoressintác6cosenlaprác6ca
Ges8óndeerroresenCupCuando se realiza un análisis ascendente en Cup de una cadena de entrada es posible que el parser generado encuentre dos posibles situaciones de error
Traza de errores
Además es posible trazar los error del compilador, o la ejecución del mismo a lo largo del proceso ascendente mediante la inserción de acciones en las partes derechas de la regla que invoquen el gestor de errores sintácticos proporcionado por el framework de desarrollo
Consúltese el manual de usuario de Cup
SyntaxErrorManager
+ syntaxDebug (String message) + syntaxInfo (String message) + syntaxWarn (String message) + SyntaxError (String message) + SyntaxFatal (String message) ...
exp::=expMASexp{:syntaxErrorManager.syntaxDebug(“sumando”);:}|expPORexp{:syntaxErrorManager.syntaxDebug(“multiplicando”);:}|error{:syntaxErrorManager.syntaxDebug(“error”);:}

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 80
Construccióndeanalizadoressintác6cosenlaprác6ca
Desarrollopasoapaso
1. Seleccionar un código fuente representativo (completo)
2. Organizarlo estructuralmente en bloques sintácticos
3. Nombrar simbólicamente a cada bloque (con un no terminal)
El proceso de desarrollo del analizador sintáctico puede resumirse en una serie de pasos que pasamos a describir detalladamente a continuación
I. Análisis del lenguaje Lo primero es analizar la estructura sintáctica del lenguaje para el cual tratamos de generar un analizador sintáctico. Para este proceso recomendamos los siguientes pasos
ProgramPrueba;ConstPI=3.14TypeTPunto=RECORDx,y:INTEGER;ENDTCirculo=RECORDcentro:TPunto;radio:REAL;END;Varx,y:REAL;c:TCirculo;PROCEDUREcrear(p:TPunto,r:REAL,VARc:TCirculo)BEGINc.centro:=p;c.radio:=rEND;FUNCTIONarea(c:TCirculo):REALVARradio:REAL;FUNCTIONpotencia(r:REAL,n:INTEGER):REALBEGIN...END;BEGINradio:=c.radio;area:=PI*Potencia(radio,2);ENDBEGIN...END;
Programa Declaraciones DeclaracionConstantes DeclaracionConstante DeclaraciónTipos DeclaracionTipo DeclaraciónRegistro DeclaracionVariable…
DeclaraciónSubprogramas DeclaraciónSubprogrograma DeclaraciónProcedimiento DeclaraciónFunción DeclararaciónCabecera DeclaraciónCuerpo…
Sentencia ListaSentencias BloqueSentencias SentenciaWhile…

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 81
Construccióndeanalizadoressintác6cosenlaprác6ca
Desarrollopasoapaso
1. Declare conjunto de no terminales
2. Declare conjunto de terminales
3. Escribir reglas de producción
El proceso de desarrollo del analizador sintáctico puede resumirse en una serie de pasos que pasamos a describir detalladamente a continuación
II. Especificación gramatical El siguiente paso es realizar la especificación gramatical del lenguaje dentro de Cup.
Declaraciones ::= DeclaraciónContantes | DeclaraciónTipos | DeclaraciónVariables; DeclaraciónVariables ::= VAR ListaDeclaraciónVariables;
Las reglas de refinamiento se encargar de redefinir una abstracción sintáctica – representada por un no terminal – en un conjunto de terminales y no terminales
Reglas de refinamiento Reglas de resolución de recursividad
ListaDeclaraciónVariables ::= DeclaraciónVariable | ListaDeclaraciónVariables DeclaraciónVariable; ListaParamActuales ::= exp COMA ListaParamActuales | ;
Las reglas de resolución de recursividad se encargan de establecer las definiciones recursivas de los terminales de refinamiento
Solo deben existir en la especificación estos dos tipos de reglas. Nunca escriba una regla mezcla de ambos tipos

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 82
Construccióndeanalizadoressintác6cosenlaprác6ca
Desarrollopasoapaso
1. Genere el analizador sintáctico con Cup
1. Ejecute Clean
2. Ejecute Cup
3. Ejecute compile
2. Adapte la especificación de JFlex
1. Importe la clase Sym en JFlex
2. Cambie las acciones de JFlex para generar tokens con ID en Sym
3. Ejecute jflex para generar de nuevo el escáner
3. Pruebe el parser
1. Ejecute cupTest
2. Cambie en el build.xml el fichero fuente de entrada para probar distintos casos
El proceso de desarrollo del analizador sintáctico puede resumirse en una serie de pasos que pasamos a describir detalladamente a continuación
III. Generación y prueba del parser
El tercer y ultimo paso consiste en generar el analizador sintáctico y probarlo
Alternativamente el framework también proporciona la tarea build que ejecuta clean + cup + flex + compile

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 83
Bibliogra`a
MaterialdeestudioBibliografía básica
Construcción de compiladores: principios y práctica
Kenneth C. Louden International Thomson Editores,
2004 ISBN 970-686-299-4

Javier Vélez Reyes [email protected]
Análisissintác8co.Analizadoresascendentes
5 - 84
Bibliogra`a
MaterialdeestudioBibliografía complementaria
Compiladores: Principios, técnicas y herramientas.
Segunda Edición Aho, Lam, Sethi, Ullman
Addison – Wesley, Pearson Educación, México 2008
Diseño de compiladores. A. Garrido, J. Iñesta, F. Moreno
y J. Pérez. 2002. Edita Universidad de Alicante