prÁcticas de la asignatura econometria ii. curso … · 2 prÁcticas de la asignatura econometria...
TRANSCRIPT

2
PRÁCTICAS DE LA ASIGNATURA ECONOMETRIA II. CURSO 2004/2005 Práctica 3 1. Planteamiento y Objetivos de la Práctica
En la presente práctica se propone la modelización univariante por medio del
enfoque de Box-Jenkins de tres series temporales con características distintas. En
cada uno de los ejemplos propuestos hay distintos pasos a detallar, pero con el fin
de ver los tres ejemplos en la sesión práctica, cada profesor puede realizar los que
considere más importantes en cada ejemplo y dejar los pasos omitidos para que los
cubran los alumnos después por su cuenta
Con la presente práctica se intenta que el alumno aprenda a construir
modelos ARIMA univariantes para una serie temporal por medio del enfoque de
Box-Jenkins. La aplicación de esta metodología conlleva recorrer diversas etapas
hasta elaborar el posible modelo generador de los datos, de forma simplificada los
pasos a realizar son los siguientes:
• Especificación inicial
• Estimación
• Chequeo o validación
• Utilización del modelo 1
En la etapa de especificación inicial se deberá determinar el orden de
integración de la serie temporal, es decir cual es el número de diferencias que se
requerirán y si una de ellas debe ser anual (estacional) para convertir en
estacionaria a la variable objeto de análisis, Zt (d,s).
Zt = (1-B)d (1-Bs ) D
1 El modelo puede utilizarse, por ejemplo, para predecir, para describir las propiedades del fenómeno económico en cuestión en cuanto a su tendencia, estacionalidad, oscilaciones (cíclicas) estacionarias, impredictibilidad, etc-, para basar sobre él la extracción de señales como el componente estacional

3
Donde : d es el número de diferencias regulares y D es el número de diferencias de
tipo estacional y habitualmente D= 0 ó 1 y 0 ≤ d+D ≤ 2.
Para verificar el orden de d y D se utiliza tanto el análisis gráfico de la serie
que nos revela determinadas características de la misma como sus correloramas
simple y parcial y los tests de raíces unitarias.
Una vez decidido el orden d y D, es decir el número de raíces unitarias que
tiene la serie temporal, habrá que decidir el orden del polinomio autorregresivo (p) y
el de medias móviles (q) para lo cual utilizamos como principales instrumentos el
correlograma simple y el parcial de la serie. Los criterios generales que deben
servir de guía para determinar el orden p del polinomio autorregresivo y el orden q
del polinomio medias móviles se recogen en las estructuras de los correlogramas
simple (FAC) y parcial (FAP) y que para los casos más sencillos se han visto en las
clases teóricas. Un resumen de las características de la estructura del correlograma
simple y del parcial se recoge en el esquema adjunto.
Características teóricas de la FAC y de la FAP de los procesos estacionarios Procesos FAC FAP
AR (p) Decrecimiento rápido hacia
cero sin llegar a anularse
P primeras autocorrelaciones
distintas de cero y el resto
ceros
MA (p) q primeras autocorrelaciones
significativas y el resto ceros
Decrecimiento rápido hacia
cero sin llegar a anularse
ARMA (p, q) Decrecimiento rápido hacia
cero sin llegar a anularse
Decrecimiento rápido hacia
cero sin llegar a anularse
Debe quedar claro que la identificación es siempre tentativa por lo que se
deben sugerir varios modelos como posibles procesos generadores de datos. Una
vez que se han sugerido uno o varios modelos se escoge el que parezca más
adecuado y se procede a su estimación, es decir se deben estimar los parámetros

4
de dicho modelo por un método de estimación apropiado, usualmente el de máxima
verosimilitud pero en Eviews este método no está implementado. Posteriormente se
debe realizar el chequeo ó validación de esas estimaciones, es decir, decidir sobre
varios criterios la validez de dichas estimaciones.
En esta práctica se realiza la modelización de tres series temporales de
datos reales y características distintas. El primer caso es el Producto Interior Bruto
a precios de mercado (PIBpm) de la economía española en términos reales y con
frecuencia anual, el segundo analiza el Índice de Producción Industrial de Estados
Unidos de frecuencia trimestral y estacionalidad y el último se refiere a una serie de
frecuencia mensual y con estacionalidad, las exportaciones de mercancías en
España.
2.Ejemplo1. El Producto Interior Bruto a Precios de Mercado (PIBpm) de la economía española
La serie que se modeliza a continuación es el PIBpm español en términos
reales. Su periodicidad es anual y el tamaño muestral abarca 51 observaciones que
comprenden el periodo 1954-2004; dada su frecuencia anual, esta serie no tendrá
componente estacional. Los datos de esta variable se encuentran en el Banco de
Datos del curso de econometría II.
El primer paso que debemos dar para elaborar el modelo univariante de la
serie es crear en Eviews el workfile con la frecuencia anual y el tamaño muestral
anterior, tal y como hemos hecho en las dos prácticas anteriores. Posteriormente
debemos importar los datos al fichero de trabajo, para ello debemos hacer lo
siguiente en Eviews:
Instrucciones: Proc/Impor /Read Text-Lotus-Excel/ Excel Tras ejecutar esta instrucción nos pide el fichero donde tenemos los datos, al darle
el nombre del fichero aparece una ventana que nos pide el nombre para la serie
que importamos, por ejemplo la denominamos PIB

5
El primer paso a la hora de modelizar la serie temporal es verificar si es
estacionaria y en caso de que no lo sea realizar las transformaciones pertinentes
hasta convertirla en estacionaria. Para ello en primer lugar graficamos la serie PIB,
gráfico que se muestra a continuación. Se observa que tiene una tendencia
creciente muy acentuada, lo que es un claro signo de que no es estacionaria en
media, además ese crecimiento es exponencial por lo que probablemente su
varianza no es constante, lo que aconseja tomar logaritmos, para ello en Eviews:
Genr LPIB = log(PIB)
Representamos gráficamente la trasformación logarítmica de la serie LPIB, la cual
se muestra en el gráfico adjunto junto con el de la serie original.
Las instrucciones en Eviews para obtener los gráficos de las dos series anteriores
son:
Quick/Graph /PIB/Line Graph
Quick/Graph /LPIB/Line Graph
0
100000
200000
300000
400000
500000
600000
55 60 65 70 75 80 85 90 95 00
PIB
11.0
11.5
12.0
12.5
13.0
13.5
55 60 65 70 75 80 85 90 95 00LPIB
Al comparar los gráficos adjuntos se observa que la serie LPIB corrige
aparentemente el crecimiento exponencial del PIB y presenta un crecimiento más
amortiguado pero manteniendo una evolución tendencial, por lo que no es
estacionaria en media. También se observa un cambio en la evolución tendencial a

6
partir de 1974, coincidiendo con la primera crisis del petróleo. El correlograma
simple de LPIB, que se muestra a continuación, confirma la sospecha anterior
sobre la no estacionariedad de la serie, al mostrar un decrecimiento muy lento.
Instrucciones en Eviews para obtener los correlogramas de LPIB:
Quick/Series Statistics/Correlogram/LPIB
También de forma alternativa en el objeto serie (LPIB)
View/Correlogram
Como un primer paso para eliminar la tendencia y convertir la serie en estacionaria
se prueba con el ajuste de una tendencia lineal determinística a la serie LPIB. Ese
ajuste muestra que ese método no es el adecuado para eliminar la tendencia de
los datos. Al ajustar una tendencia determinística a la variable LPIB del tipo:
LPIB = c +β t + µt
Cuya estimación se presenta a continuación

7
Instrucciones en Eviews para la estimación de la tendencia determinista:
Quick /estimate equation y en la ventana de la ecuación que se abre escribir: LPIB c @trend+1 El resultado de la estimación es: Ecuación para la tendencia Dependent Variable: LOG(PIB) Method: Least Squares Date: 04/17/05 Time: 11:10 Sample: 1954 2004 Included observations: 51
Variable Coefficient Std. Error t-Statistic Prob.
C 11.52228 0.034510 333.8852 0.0000@TREND+1 0.036813 0.001155 31.87190 0.0000
R-squared 0.953983 Mean dependent var 12.47942Adjusted R-squared 0.953044 S.D. dependent var 0.560312S.E. of regression 0.121416 Akaike info criterion -1.340754Sum squared resid 0.722356 Schwarz criterion -1.264996Log likelihood 36.18923 F-statistic 1015.818Durbin-Watson stat 0.052993 Prob(F-statistic) 0.000000
-.3
-.2
-.1
.0
.1
.2
.3
11.0
11.5
12.0
12.5
13.0
13.5
55 60 65 70 75 80 85 90 95 00
Residual Actual Fitted

8
Analizando esos resultados podemos observar que la estimación es totalmente
espúrea puesto que los residuos presentan un estadístico Durbin- Watson próximo
a cero, lo que es indicativo de una fuerte autocorrelación de primer orden y de que
tienen una raíz unitaria y que, por lo tanto, no cumplen las condiciones para que
sean ruido blanco. El gráfico de los residuos y de los valores reales y ajustados de
la serie LPIB que se muestra junto con la ecuación estimada también muestra esos
problemas y nos indica que los residuos se han mantenido por encima de la media
durante un periodo demasiado largo, 1965 hasta 1985. Por lo tanto, ese ajuste no
es adecuado puesto que olvida determinadas propiedades importantes de la serie
Por lo tanto, la tendencia no es determinista sino estocástica y el procedimiento
anterior no es el adecuado sino que se debe utilizar la diferenciación para eliminar
la tendencia. Para ello, como hemos visto anteriormente, la serie en niveles no es
estacionaria y pasamos, por tanto, a tomar la primera diferencia en LPIB. A tal
efecto, generamos la serie de la primera diferencia de LPIB, DLPIB, es decir,
transformamos la serie de acuerdo con la siguiente expresión:
Zt =(1-B)LPIB
La representación gráfica de la serie transformada y sus correspondientes
correlogramas se muestran a continuación.
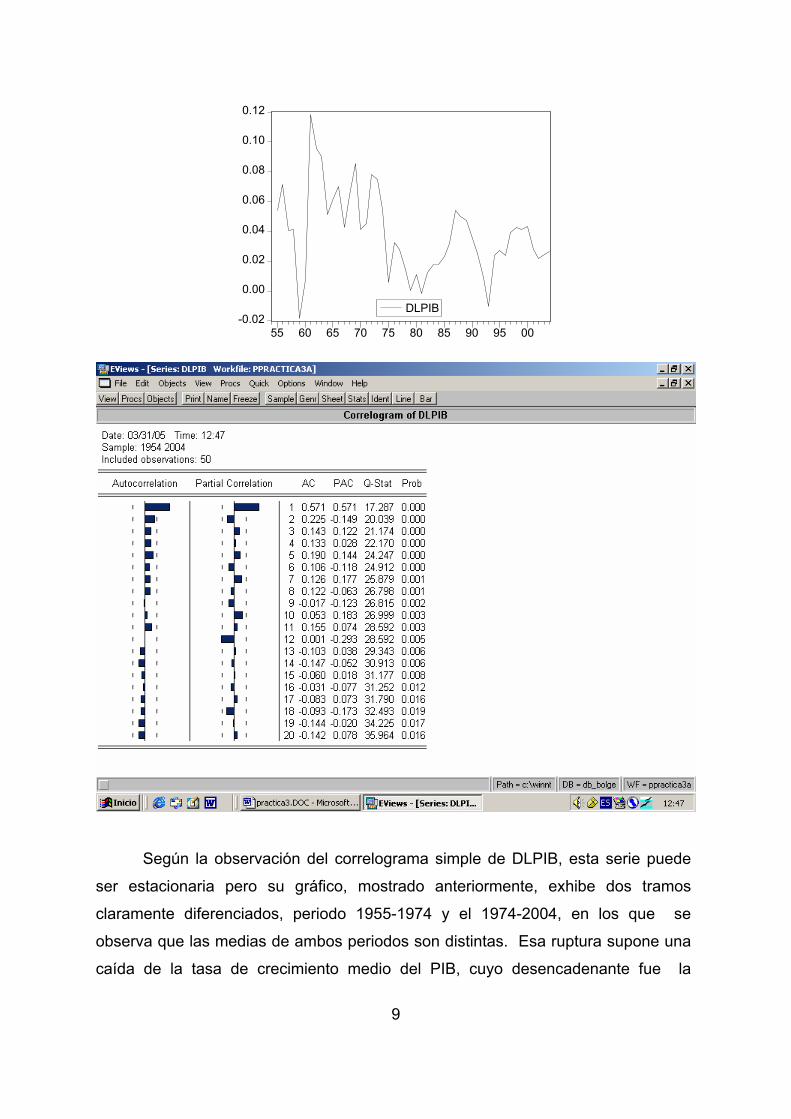
9
-0.02
0.00
0.02
0.04
0.06
0.08
0.10
0.12
55 60 65 70 75 80 85 90 95 00
DLPIB
Según la observación del correlograma simple de DLPIB, esta serie puede
ser estacionaria pero su gráfico, mostrado anteriormente, exhibe dos tramos
claramente diferenciados, periodo 1955-1974 y el 1974-2004, en los que se
observa que las medias de ambos periodos son distintas. Esa ruptura supone una
caída de la tasa de crecimiento medio del PIB, cuyo desencadenante fue la

10
primera crisis del petróleo de 1973, es decir, estamos en presencia de una
tendencia segmentada. El tema de tendencias segmentadas en el PIB ha sido
ampliamente tratado en la literatura econométrica (Perron). Por lo tanto, podemos
considerar que la primera diferencia de LPIB es estacionaria pero considerando que
tiene una media truncada, este hecho se debe incorporar en la modelización. Si se
realiza el test de Dickey Fuller Aumentado (ADF) en situación de cambio
estructural, que veremos más adelante, el resultado se inclina por una sola raíz
unitaria y la serie sería I(1,1s ), es decir, I(1) con una media truncada.
A efectos didácticos decidimos, como una alternativa, ignorar la situación de media
truncada, y en su lugar tomar una segunda diferencia en la serie LPIB. A
continuación, representamos tanto el gráfico como el correlograma de la serie
transformada, lo cual nos indica que aparentemente podemos estar en presencia
de una serie estacionaria. El test de Dickey-Fuller Aumentado sobre raíces unitarias
(DFA) sin tener en cuenta el aludido cambio estructural, que se verá más adelante
en el curso y no reportado aquí, se inclina también por una segunda raíz unitaria.
No obstante, cabe mencionar que si se realiza el test DFA a una serie que presenta
un cambio estructural, ignorando dicho hecho, el test esta sesgado hacia la
aceptación de la hipótesis nula.
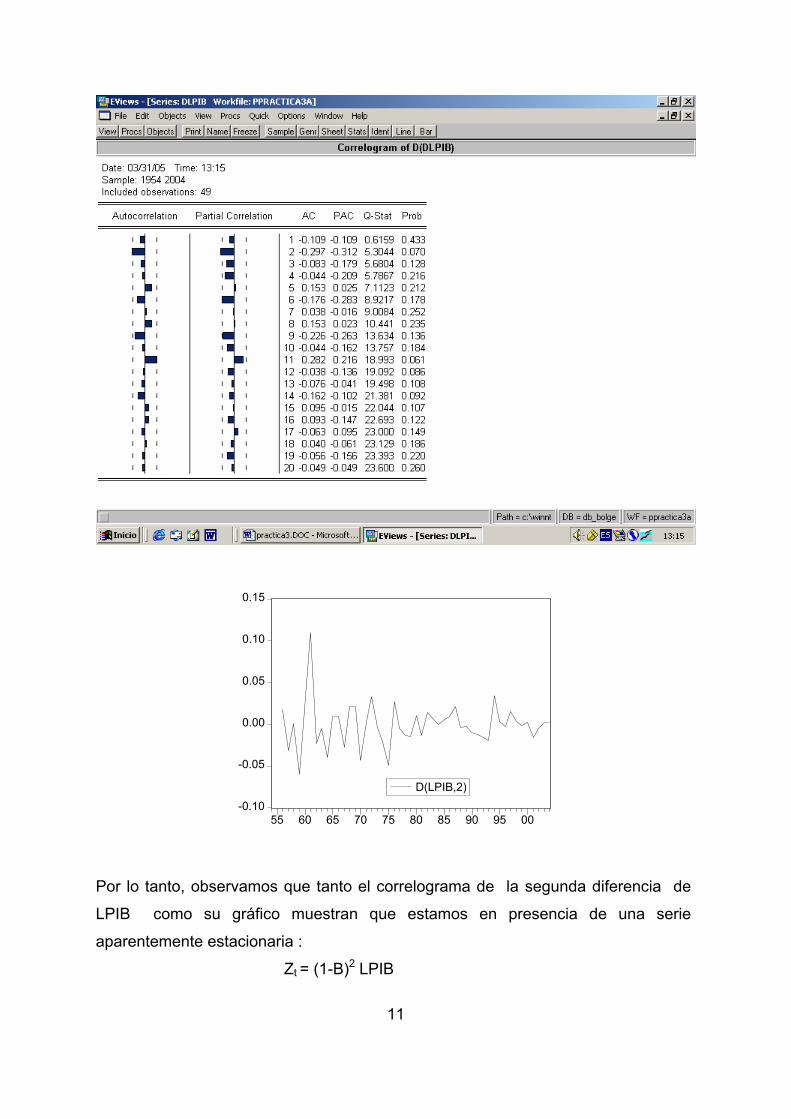
11
-0.10
-0.05
0.00
0.05
0.10
0.15
55 60 65 70 75 80 85 90 95 00
D(LPIB,2)
Por lo tanto, observamos que tanto el correlograma de la segunda diferencia de
LPIB como su gráfico muestran que estamos en presencia de una serie
aparentemente estacionaria :
Zt = (1-B)2 LPIB

12
Es decir, la serie tendría dos raíces unitarias y sería, por tanto, integrable de
segundo orden , LPIB ∼I(2)
Una vez decidido el grado de integración de la serie, es decir, el número de raíces
unitarias que tiene, se debe determinar cuales son los posibles procesos ARMA
que generan la serie. Empezamos con la primera opción de una sola raíz pero
incorporando la media truncada. Para ello analizamos tanto el correlograma simple
como el parcial de la serie DLPIB, que recogen toda la estructura de dependencia
temporal de la serie, utilizando los conocimientos explicados en el capitulo 3.
El correlograma de la serie DLPIB nos dice que el modelo que puede generar la
serie es un MA(1) puesto que el correlograma simple se anula después del primer
retardo y el parcial tiende a cero rápidamente, pero también podría ser un
ARMA(1,1). De la observación del gráfico de la serie que consideramos
estacionaria, D(LPIB,1), que vemos que tiene una media truncada, se observa que
su media es distinta de cero, por lo que procede en principio la inclusión de término
independiente. En cualquier caso, si se incluye en el modelo especificado, el
proceso de verificación de las estimaciones lo confirmará o rechazará. También si
se quiere captar el efecto del truncamiento de la media, esa ruptura se debe captar
por medio de una variable ficticia, en este caso el tipo escalón parece el más
idóneo. A esta variable la denominamos dum1 y toma valores cero antes de la
ocurrencia del suceso (1974) y unos en el resto, es decir, en el periodo 1974-2004
Los modelos sugeridos para esta primera opción serian:
1.1 ARIMA(0,1,1) ,, (1-B) LPIB = C+α Dum1 + (1- θ1B )at
1.2 ARIMA(1,1,1) ,, (1-φ1B)(1-B) LPIB = C+α Dum1 + (1- θ1B )at
Para la segunda opción, dos diferencias de LPIB haciendo caso omiso del
truncamiento de la media, el análisis de los correlogramas de la serie D(LPIB,2) nos
dice que el significativo coeficiente de orden 2 junto con el decaimiento amortiguado

13
de las autocorrelacciones parciales nos hace inclinamos por un MA(2) con el
parámetro θ1 restringido a cero, modelo 1.3
1.3 ARIMA (0, 2,2) con θ1=0 ,, (1-B)2 LPIB = (1- θ2B2 )at
No obstante, dado que el primer coeficiente de autocorrelación puede estar
sesgado, dado que la banda de confianza que marca Eviews en el correlograma es
igual que la del resto y debe ser más estrecha, nos inclinamos por incluir ese
componente y no restringirlo a cero y sugerimos el modelo 1.4 como alternativa.
1.4 ARIMA (0,2,2) ,, (1-B)2 LPIB= (1- θ1B - θ2B2 )at
El análisis de la estructura del correlograma probablemente sugiera algún modelo
adicional pero de momento nos quedamos con los propuestos.
Estimación
Una vez, especificados varios modelos alternativos como posibles generadores de
la serie se debe proceder a la estimación de los mismos. Para ello en Eviews se
deben dar las siguientes instrucciones para estimar los dos modelos sugeridos de
la primera opción
Modelo 1.1: Quick/Estimate Equation/ d(lpib,1) c dum1 ma(1)
Modelo 1.2: Quick/Estimate Equation/ d(lpib,1) c dum1 ar(1) ma(1) Para los modelos de la segunda opción, con dos raíces unitarias, d(lpib,2)
Modelo 1.3: Quick/Estimate Equation/ d(lpib,2) ma(2) Modelo 1.4: Quick/Estimate Equation/ d(lpib,2) ma(1) ma(2) Los resultados de la estimación de estos modelos se presentan a continuación :

14
Estimación Modelo1.1
Dependent Variable: DLPIB Method: Least Squares Date: 04/15/05 Time: 12:55 Sample(adjusted): 1955 2004 Included observations: 50 after adjusting endpoints Convergence achieved after 7 iterations Backcast: 1954
Variable Coefficient Std. Error t-Statistic Prob.
C 0.057039 0.007057 8.082948 0.0000DUM1 -0.030229 0.008868 -3.408711 0.0013MA(1) 0.479030 0.126800 3.777827 0.0004
R-squared 0.447599 Mean dependent var 0.038336Adjusted R-squared 0.424093 S.D. dependent var 0.027908S.E. of regression 0.021179 Akaike info criterion -4.813487Sum squared resid 0.021082 Schwarz criterion -4.698765Log likelihood 123.3372 F-statistic 19.04158Durbin-Watson stat 2.034427 Prob(F-statistic) 0.000001
Inverted MA Roots -.48
Estimación modelo 1.2
Dependent Variable: DLPIB Method: Least Squares Date: 04/15/05 Time: 12:38 Sample(adjusted): 1956 2004 Included observations: 49 after adjusting endpoints Convergence achieved after 6 iterations Backcast: 1955
Variable Coefficient Std. Error t-Statistic Prob.
C 0.057116 0.006916 8.258258 0.0000DUM1 -0.030218 0.008629 -3.501795 0.0011AR(1) -0.182796 0.265240 -0.689172 0.4943MA(1) 0.647225 0.205468 3.150002 0.0029
R-squared 0.456610 Mean dependent var 0.038018Adjusted R-squared 0.420384 S.D. dependent var 0.028106S.E. of regression 0.021398 Akaike info criterion -4.772954Sum squared resid 0.020604 Schwarz criterion -4.618520Log likelihood 120.9374 F-statistic 12.60448Durbin-Watson stat 1.960121 Prob(F-statistic) 0.000004
Inverted AR Roots -.18 Inverted MA Roots -.65
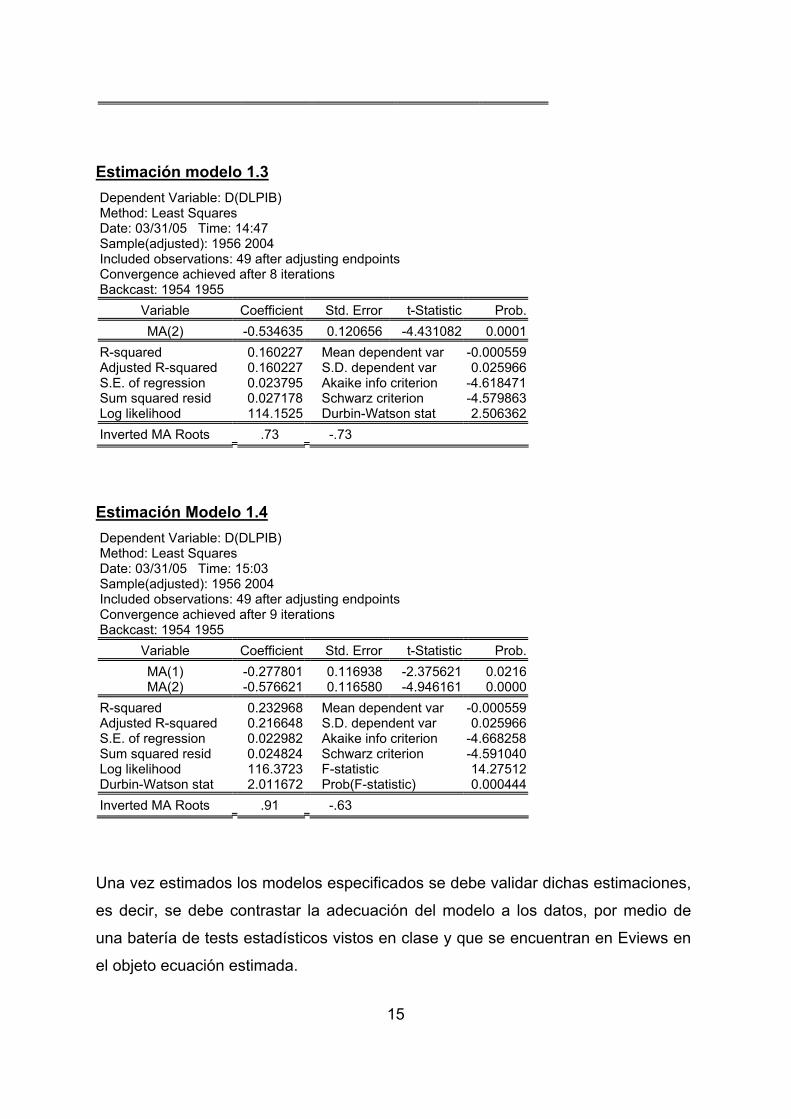
15
Estimación modelo 1.3 Dependent Variable: D(DLPIB) Method: Least Squares Date: 03/31/05 Time: 14:47 Sample(adjusted): 1956 2004 Included observations: 49 after adjusting endpoints Convergence achieved after 8 iterations Backcast: 1954 1955
Variable Coefficient Std. Error t-Statistic Prob. MA(2) -0.534635 0.120656 -4.431082 0.0001
R-squared 0.160227 Mean dependent var -0.000559Adjusted R-squared 0.160227 S.D. dependent var 0.025966S.E. of regression 0.023795 Akaike info criterion -4.618471Sum squared resid 0.027178 Schwarz criterion -4.579863Log likelihood 114.1525 Durbin-Watson stat 2.506362Inverted MA Roots .73 -.73
Estimación Modelo 1.4 Dependent Variable: D(DLPIB) Method: Least Squares Date: 03/31/05 Time: 15:03 Sample(adjusted): 1956 2004 Included observations: 49 after adjusting endpoints Convergence achieved after 9 iterations Backcast: 1954 1955
Variable Coefficient Std. Error t-Statistic Prob. MA(1) -0.277801 0.116938 -2.375621 0.0216MA(2) -0.576621 0.116580 -4.946161 0.0000
R-squared 0.232968 Mean dependent var -0.000559Adjusted R-squared 0.216648 S.D. dependent var 0.025966S.E. of regression 0.022982 Akaike info criterion -4.668258Sum squared resid 0.024824 Schwarz criterion -4.591040Log likelihood 116.3723 F-statistic 14.27512Durbin-Watson stat 2.011672 Prob(F-statistic) 0.000444Inverted MA Roots .91 -.63
Una vez estimados los modelos especificados se debe validar dichas estimaciones,
es decir, se debe contrastar la adecuación del modelo a los datos, por medio de
una batería de tests estadísticos vistos en clase y que se encuentran en Eviews en
el objeto ecuación estimada.

16
Validación o chequeo
En la etapa de validación se presentan tres bloques de análisis: Un primero
referente a los resultados de la estimación, un segundo centrado en el análisis de
los residuos y, finalmente, un tercero dedicado a la comparación de modelos
alternativos.
• Análisis de la estimación.- Referente a los modelos de la primera opción, modelos 1.1 y 1.2, el análisis de
la significatividad individual de los coeficientes por medio del estadístico t de
student pone de relieve que todos los coeficientes del modelo 1.1 son altamente
significativos y también lo son los del modelo 1.2, con excepción del parámetro
correspondiente al componente AR(1). En cuanto a los modelos de la segunda
opción, modelos 1.3 y 1.4 , también pasan con holgura las pruebas de
significatividad individual de sus coeficientes, ver cuadros anteriores de las
ecuaciones estimadas.
En cuanto a las condiciones de estacionariedad e invertibilidad de los modelos
estimados, todas las raíces de los polinomios de retardos caen fuera de circulo de
radio unidad, ver cuadros anteriores de estimaciones, debe tenerse en cuenta que
Eviews muestra la inversa de las raíces, por lo que esas inversas caen todas dentro
del circulo de radio unidad. No obstante, en los modelos de la segunda opción (1.3
y 1.4), sobre todo en el segundo, se aprecia un problema y es el de que rozan la
no invertibilidad puesto que una de las raíces invertidas es 0,91, lo cual está muy
próxima a la unidad y, tratándose de una estimación, podría significar
sobrediferenciación, recuerdese a este respecto las dudas mencionados
anteriormente a la hora de establecer el parámetro d que nos ha obligado a sugerir
las dos opciones y en la segunda nos hemos decantado por d=2. Por lo tanto, los
resultados de la estimación nos revelan que probablemente esa segunda raíz no
era del todo necesaria necesaria.
De la observación de los resultados de la estimación se deduce que el modelo
1.1 presenta un error estandar (0,021179), ligeramente más bajo que el 1.2

17
(0,021398) y el estadístico de Akaike del primer modelo también es inferior al del
segundo (-4,8134 frente a –4,7729). Los modelos de la segunda opción, 1.3 y 1.4,
tienen un error estandar mayor que los dos anteriores y también un criterio de
Akaike mayor.
En esta etapa también se suele analizar las correlaciones entre los coeficientes
estimados para verificar la posible existencia de multicolinealidad en el modelo. La
existencia de multicolinalidad indica una falta de precisión en las estimaciones
obtenidas y una cierta inestabilidad de los coeficientes estimados. Para obtener las
correlaciones entre los coeficientes se acude a su matriz de correlaciones que
proporciona Eviews, para ello nos situamos en la ecuación estimada y marcamos lo
siguiente: View/Correlation Matrix
La ejecución de esta instrucción muestra la matriz de coeficientes de la
ecuación estimada, para el modelo 1.1 se tiene:
Matriz de correlaciones del modelo 1.1 C DUM1 MA(1)
C 4.98E-05 -4.88E-05 -1.19E-05 DUM1 -4.88E-05 7.86E-05 3.22E-05 MA(1) -1.19E-05 3.22E-05 0.016078
Se observa que esa matriz presenta unas correlaciones muy bajas por lo que no
muestra indicios de multicolinealidad. Para el resto de los modelos de este ejemplo
se puede verificar de la misma forma que tampoco presentan problemas de
multicolinelidad.
Análisis de los residuos. .El siguiente paso dentro del proceso de validación es el análisis de los
residuos de ambos modelos. Para ello en el objeto ecuación de Eviews se ofrecen
varios contrastes, pero nos limitamos al contraste de que los residuos sean ruido
blanco, inspeccionando el correlograma de residuos, el estadístico Q de Box-
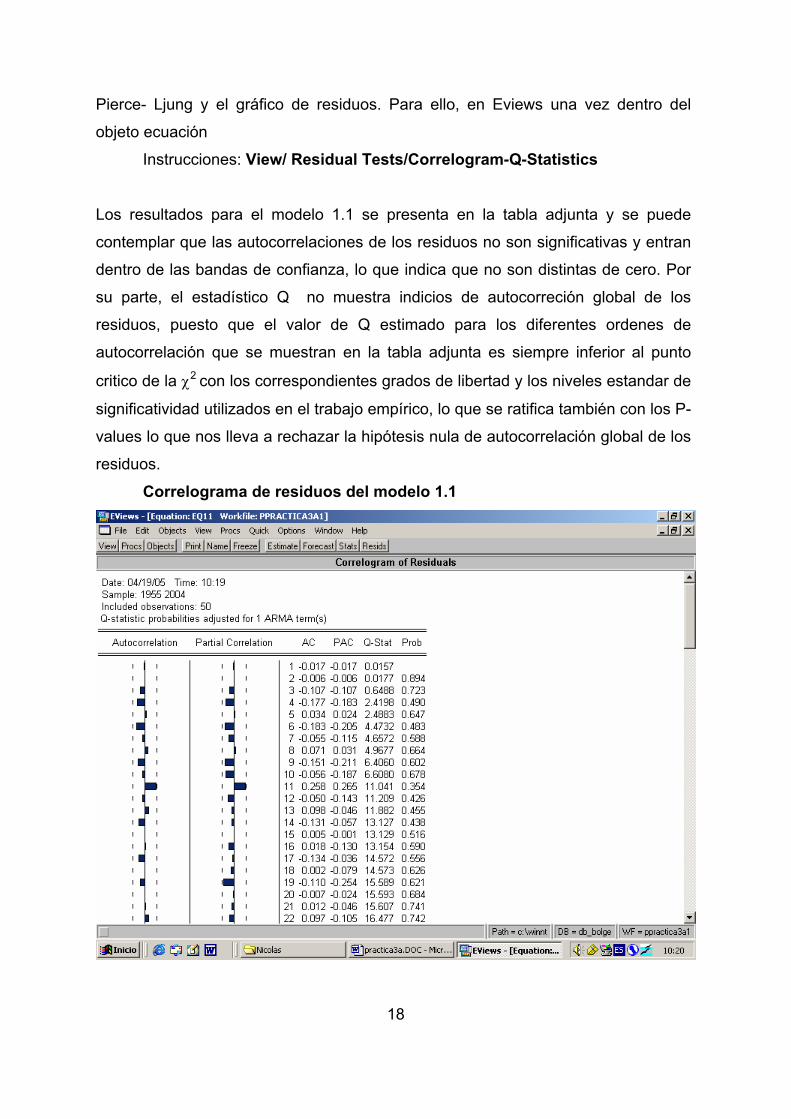
18
Pierce- Ljung y el gráfico de residuos. Para ello, en Eviews una vez dentro del
objeto ecuación
Instrucciones: View/ Residual Tests/Correlogram-Q-Statistics Los resultados para el modelo 1.1 se presenta en la tabla adjunta y se puede
contemplar que las autocorrelaciones de los residuos no son significativas y entran
dentro de las bandas de confianza, lo que indica que no son distintas de cero. Por
su parte, el estadístico Q no muestra indicios de autocorreción global de los
residuos, puesto que el valor de Q estimado para los diferentes ordenes de
autocorrelación que se muestran en la tabla adjunta es siempre inferior al punto
critico de la χ2 con los correspondientes grados de libertad y los niveles estandar de
significatividad utilizados en el trabajo empírico, lo que se ratifica también con los P-
values lo que nos lleva a rechazar la hipótesis nula de autocorrelación global de los
residuos.
Correlograma de residuos del modelo 1.1

19
Instrucciones Eviews para el gráfico de residuos: View/Actual, Fitted, residuals
,
-0.10
-0.05
0.00
0.05
0.10
-0.05
0.00
0.05
0.10
0.15
55 60 65 70 75 80 85 90 95 00
Residual Actual Fitted
El gráfico de los residuos también apoya la ausencia de autocorrelación residual,
puesto que la gran mayoría de los residuos entran dentro de las bandas de
confianza con excepción de dos en el primer tramo de la muestra. Por lo tanto,
también muestra claramente que los residuos son ruido blanco.
De la misma forma que el análisis llevado a cabo para el modelo 1.1 se puede
entrar en el objeto ecuación de los restantes modelos y se puede verificar que
todos presentan residuos ruido blanco, posiblemente el que pasa con menos
holgura las pruebas sea el 1.3.
Comparación de modelos alternativos.
Del análisis que se acaba de realizar en los dos apartados anteriores se deduce
que los modelos de primera opción con una raíz unitaria y truncamiento de la
media, considerando a la variable LPIB como (1,1s ), superan el conjunto de
pruebas estadísticas para validar sus estimaciones, aunque el modelo 1.2 presenta
un problema que es la no significatividad del parámetro del componente AR(1).

20
Además el modelo 1.1 presenta una menor varianza residual y un menor Akaike,
por lo que el modelo 1.1 es preferible al 1.2.
En cuanto a los modelos de la opción 2, modelos 1.3 y 1.4 que consideran a la
variable LPIB como I(2), si bien supera las pruebas de significatividad individual de
los parámetros y sus residuos son ruido blanco, presentan un problema de
invertibilidad, sobre todo el 1.4, lo que puede indicar sobrediferenciación, por lo que
la segunda diferencia puede que no sea necesaria. Además estos modelos (1.3 y
1.4) presentan una mayor varianza residual y un Akaike menor que los de la
primera opción, por lo que el modelo preferido es el 1.1
Por lo tanto, la tasa de crecimiento del PIB de la economía española, ∆LPIB, viene
explicada de forma satisfactoria por un modelo sencillo ARIMA(0,1,1) y con una
media truncada situándose dicha ruptura en 1974, coincidiendo con la primera crisis
del petróleo.
∆LPIB = 0,057- 0,03 Dum1 + (1- 0,479B )at
(8,1) (-3,4) (3,8)
Por lo tanto, de acuerdo con esta ecuación, la tasa de crecimiento medio anual del
PIB estimada fue del 5,7% en el periodo anterior a la crisis de 1974 pero el efecto
de la primera crisis del petróleo, recogida por la variable dum1, ha reducido ese
crecimiento medio en tres puntos porcentuales, es decir el crecimiento medio en el
periodo 1974- 2004 es del 2,7%.
3. Ejemplo 2. El Índice de Producción Industrial de USA
La serie a modelizar es el Índice de Producción Industrial de Estados Unidos y la
fuente es el Main Economic Indicator de la OCDE. El periodo muestral abarca 1955-
1998. Una vez creado el el WorKfile y establecido el periodo muestral se debe
deben importar los datos del banco de datos, tal y como se ha hecho en el ejemplo
anterior. La serie la denominamos IP.

21
El primer paso para modelizar la series es obtener la representación gráfica de la
serie (IP). Para ello en Eviews, la instrucción es:
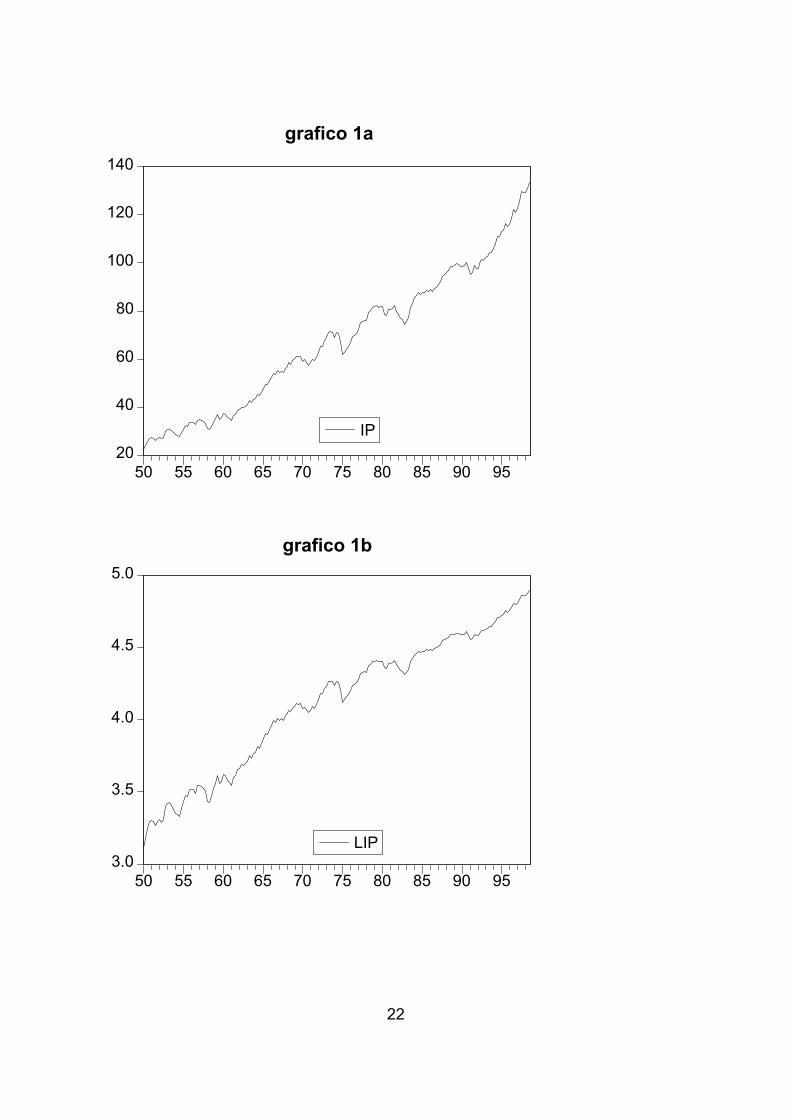
Quick/ Graph/ Graph Line/ IP El resultado es el gráfico1a en el que se puede contemplar como la serie IP muestra
un crecimiento exponencial a lo largo del tiempo, por lo que se sugiere la
transformación logarítmica. Para ello, en Eviews: GENR LIP=LOG(IP), y para su
representación gráfica : Quick/ Graph/ Graph Line/ LIP
La representación gráfica de esta serie (LIP) se muestra en el gráfico 1b en el cual
se puede contemplar que la nueva serie ha amortiguado el crecimiento exponencial
pero mostrando una clara tendencia lineal creciente y también ha estabilizado la
varianza de la serie, se observan algunas fluctuaciones de carácter netamente
estacional. Por lo tanto, el gráfico 1b nos dice que la serie no es estacionaria en
media
22
20
40
60
80
100
120
140
50 55 60 65 70 75 80 85 90 95
IP
3.0
3.5
4.0
4.5
5.0
50 55 60 65 70 75 80 85 90 95
LIP
grafico 1a
grafico 1b

23
También se muestra a continuación el correlograma de LIP:
En Eviews una vez dentro del objeto LIP: View/Correlogram
El correlograma confirma la sospecha de no estacionariedad de la serie que nos
mostraba el gráfico 1b de nivel de la serie LPIB
Dado que la serie no es estacionaria pasamos a transformarla hasta convertirla en
estacionaria. Si ajustamos una tendencia temporal lineal simple de tipo
determinístico a la serie (LIP), tal y como hicimos en el capítulo 1 y práctica 1, y
restamos LIP la serie ajustada podremos comprobar que ese no es un
procedimiento correcto para convertir a la serie en estacionaria. En efecto, si
ajustamos una función deterministica del tipo:
LIP = c +β t + µt

24
En Eviews: Quick /estimate equation Y en la ventana de la ecuación que se abre escribir: LIP c @trend+1 El resultado de la estimación es: Dependent Variable: LIP Method: Least Squares Date: 04/19/05 Time: 17:37 Sample: 1950:1 1998:3 Included observations: 195
Variable Coefficient Std. Error t-Statistic Prob. C 3.313560 0.012234 270.8386 0.0000
@TREND+1 0.008197 0.000108 75.71580 0.0000R-squared 0.967431 Mean dependent var 4.116820Adjusted R-squared 0.967262 S.D. dependent var 0.470300S.E. of regression 0.085094 Akaike info criterion -2.079917Sum squared resid 1.397511 Schwarz criterion -2.046348Log likelihood 204.7919 F-statistic 5732.882Durbin-Watson stat 0.084571 Prob(F-statistic) 0.000000
-0.3
-0.2
-0.1
0.0
0.1
0.2
3.0
3.5
4.0
4.5
5.0
50 55 60 65 70 75 80 85 90 95
Residual Actual Fitted
Estos resultados nos dicen que estamos en presencia de una regresión espúrea,
con un R2 muy elevado (0,97) y un estadístico de D-W muy bajo(0,085 ) y próximo a
cero, lo que es indicativo de que esos residuos no son estacionarios y tienen una
25
raíz unitaria. Además durante un periodo largo de tiempo, 1965-1980, la serie se
mantiene por encima de su tendencia, lo que también se refleja en el gráfico de
residuos. Por lo tanto, es obvio que el ajuste de esa tendencia determinista simple
olvida importantes aspectos dinámicos de la serie y la tendencia es estocástica y se
debe proceder con diferenciaciones para eliminar esa tendencia.
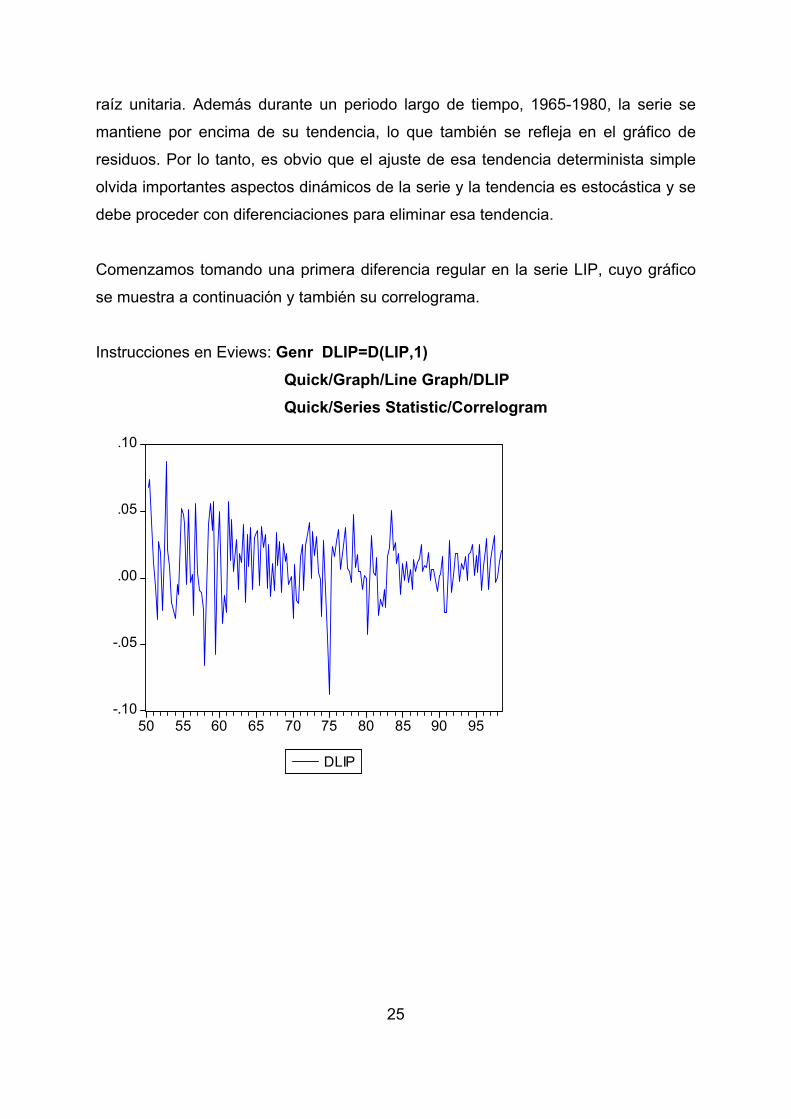
Comenzamos tomando una primera diferencia regular en la serie LIP, cuyo gráfico
se muestra a continuación y también su correlograma.
Instrucciones en Eviews: Genr DLIP=D(LIP,1) Quick/Graph/Line Graph/DLIP
Quick/Series Statistic/Correlogram
-.10
-.05
.00
.05
.10
50 55 60 65 70 75 80 85 90 95
DLIP

26
El gráfico de DLIP muestra que la serie podría ser estacionaria pero su
correlograma muestra que, si bien el componente regular parece estacionario, el
correlograma estacional puede interpretarse en el sentido de que decrece
lentamente ya que además se conoce que esta serie tiene oscilaciones
estacionales, con lo que habría que tomar una diferencia de tipo estacional. Con el
fin de no tomar más diferenciaciones de las necesarias, vamos a cambiar de
estrategia y tomamos en primer lugar la diferencia estacional sobre la serie original
(LIP), D4LIP=DLIP-DLIP(-4). Las instrucciones para la construcción de esta serie en
Eviews, su representación gráfica y correlograma son la siguientes:
Instrucciones Eviews: Genr/D4LIP=D(LIP,0,4) Quick/Graph/Line Graph/D4LIP Quick/Series Statistic/Correlogram/DLIP
27
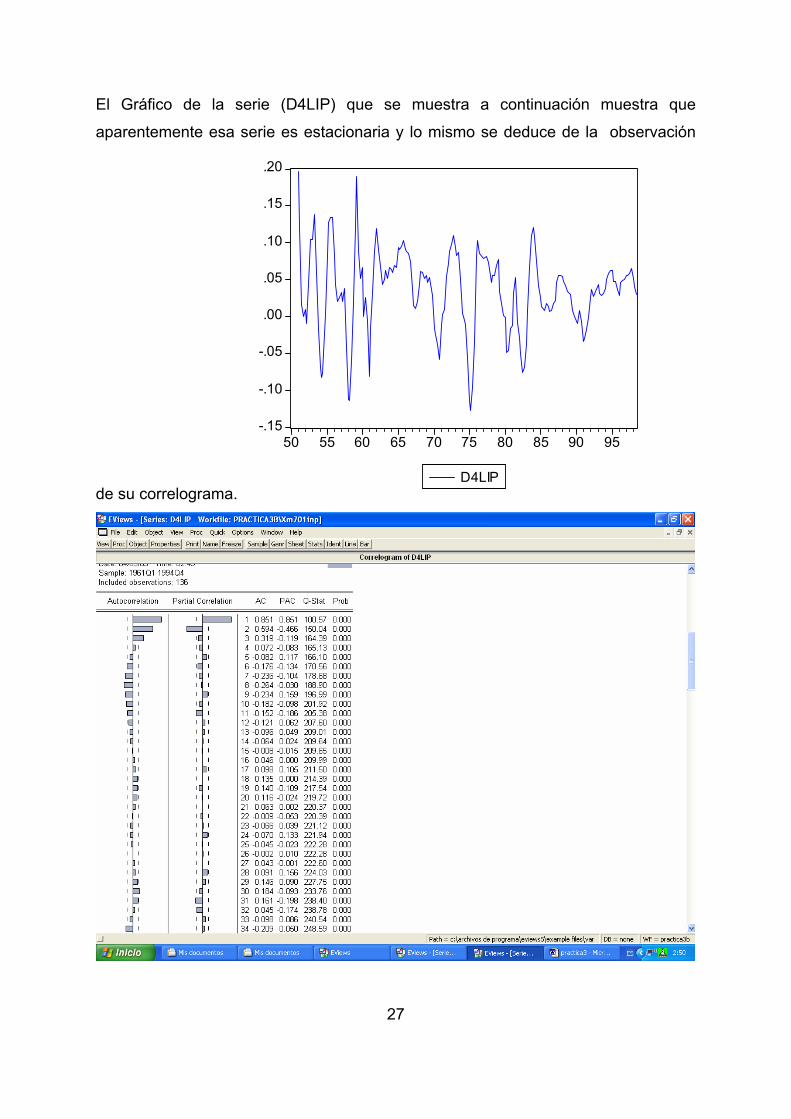
El Gráfico de la serie (D4LIP) que se muestra a continuación muestra que
aparentemente esa serie es estacionaria y lo mismo se deduce de la observación
de su correlograma.
-.15
-.10
-.05
.00
.05
.10
.15
.20
50 55 60 65 70 75 80 85 90 95
D4LIP

28
Por lo tanto, la toma de una diferencia de tipo estacional ha convertido a la serie en
estacionaria y será la transformación que utilizaremos en adelante. La
transformación ha eliminado la estacionalidad y la tendencia de la serie y es del
tipo: Zt= (1-B4)LIP . Esta transformación tiene el siguiente significado:
D4LIP= LIP- LIP(-4)= log(IP)-log(IP(-4)), que como ya sabemos esa diferencia
logarítmica es una aproximación a la tasa de variación interanual de IP. Esta tasa
tiene una media distinta de cero según muestra su gráfico.
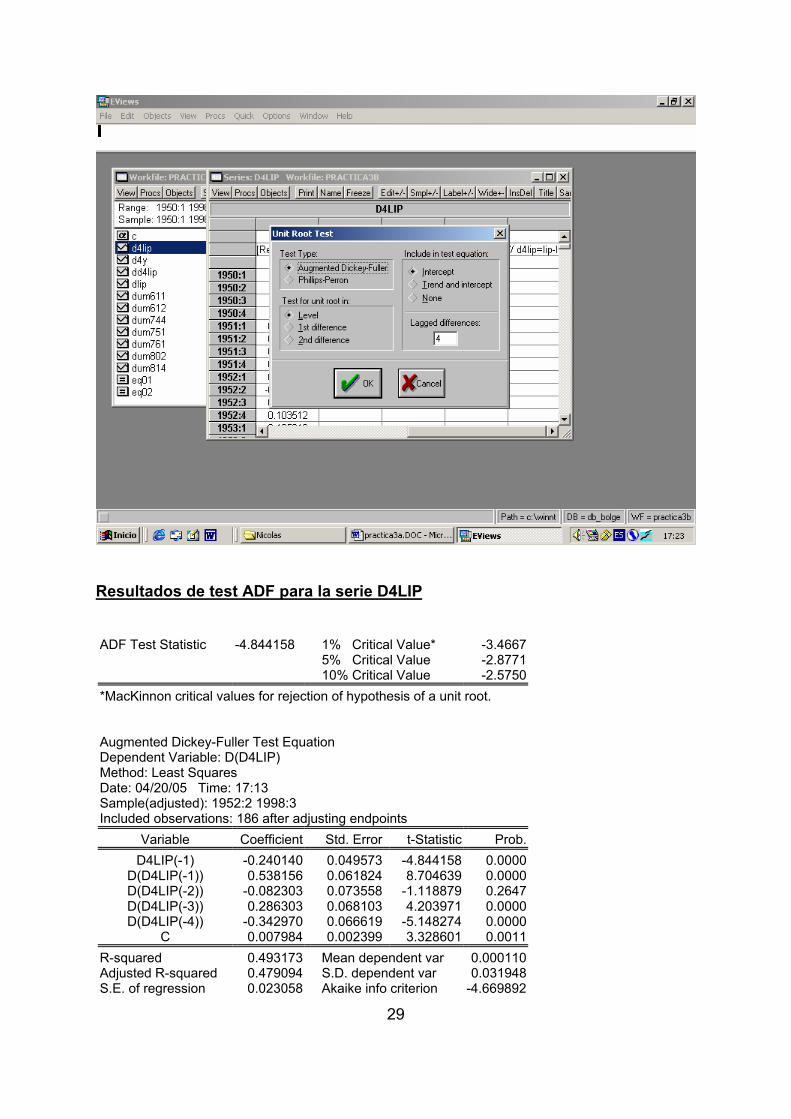
No obstante, para confirmar que esta transformación es estacionaria aplicamos el
test de Dickey-Fuller Aumentado (ADF) a la serie D4LIP para ver si es necesario
tomar alguna diferencia de tipo regular.
Instrucciones en Eviews para el ADF: Dentro del objeto serie (D4LIP) pinchamos en
View/Unit Root Test
Aparece la ventana adjunta y seleccionamos los parámetros de interés, en nuestro
caso los marcados con punto negro.
29
Resultados de test ADF para la serie D4LIP ADF Test Statistic -4.844158 1% Critical Value* -3.4667
5% Critical Value -2.8771 10% Critical Value -2.5750
*MacKinnon critical values for rejection of hypothesis of a unit root.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(D4LIP) Method: Least Squares Date: 04/20/05 Time: 17:13 Sample(adjusted): 1952:2 1998:3 Included observations: 186 after adjusting endpoints
Variable Coefficient Std. Error t-Statistic Prob. D4LIP(-1) -0.240140 0.049573 -4.844158 0.0000
D(D4LIP(-1)) 0.538156 0.061824 8.704639 0.0000D(D4LIP(-2)) -0.082303 0.073558 -1.118879 0.2647D(D4LIP(-3)) 0.286303 0.068103 4.203971 0.0000D(D4LIP(-4)) -0.342970 0.066619 -5.148274 0.0000
C 0.007984 0.002399 3.328601 0.0011R-squared 0.493173 Mean dependent var 0.000110Adjusted R-squared 0.479094 S.D. dependent var 0.031948S.E. of regression 0.023058 Akaike info criterion -4.669892

30
Sum squared resid 0.095700 Schwarz criterion -4.565836Log likelihood 440.3000 F-statistic 35.03014Durbin-Watson stat 1.826947 Prob(F-statistic) 0.000000
En la aplicación del ADF se incluye una constante y cuatro aumentos,
desfases. Los resultados del Test ADF nos llevan a rechazar la hipótesis I(2) en
favor de la I(1), es decir no es preciso tomar una raíz de tipo regular en la variable
D4LIP, puesto que el ratio t estimado para la variable D4LPIB(-1) supera
ampliamente los puntos críticos de la distribución ADF. Por lo tanto, la serie D4LIP
es estacionaria.
Pasamos, por tanto, a especificar el orden del polinomio AR y el de MA. Del
análisis de los correlogramas de D4LIP se deduce a primera vista un modelo AR(2), puesto que el correlograma simple desciende lentamente y el parcial tiene las dos
primeras autocorrelaciones significativas. También podría ser alguno de estos dos
modelos alternativos: AR(2)×MA (2)s ó AR(2)MA(1)×AR(1)s
De la observación del gráfico de la serie se deduce que la media de la serie
es distinta de cero por lo que debe incluirse el término constante en los modelos
especificados
Los modelos tentativos serian por tanto:
2.1. ARIMA(2,0,0)× (0,1,0)4 ,, (1- φ1 B-φ2 B2)(1-B4)LIP= µ + at
2.2. ARIMA(2,0,0) )× (0,1,2)4 ,, (1- φ1 B-φ2 B2)(1-B4)LIP= µ +(1- Θ4B4 - Θ8B8)at
2.3. ARIMA(2,0,1) )× (0,1,1)4 ,, (1- φ1 B-φ2 B2)(1-Φ1B4 )(1-B4)LIP= µ + (1- θ1B) at
Estimación La estimación de los modelos anteriores en Eviews se hace por medio de las
siguientes instrucciones:
31
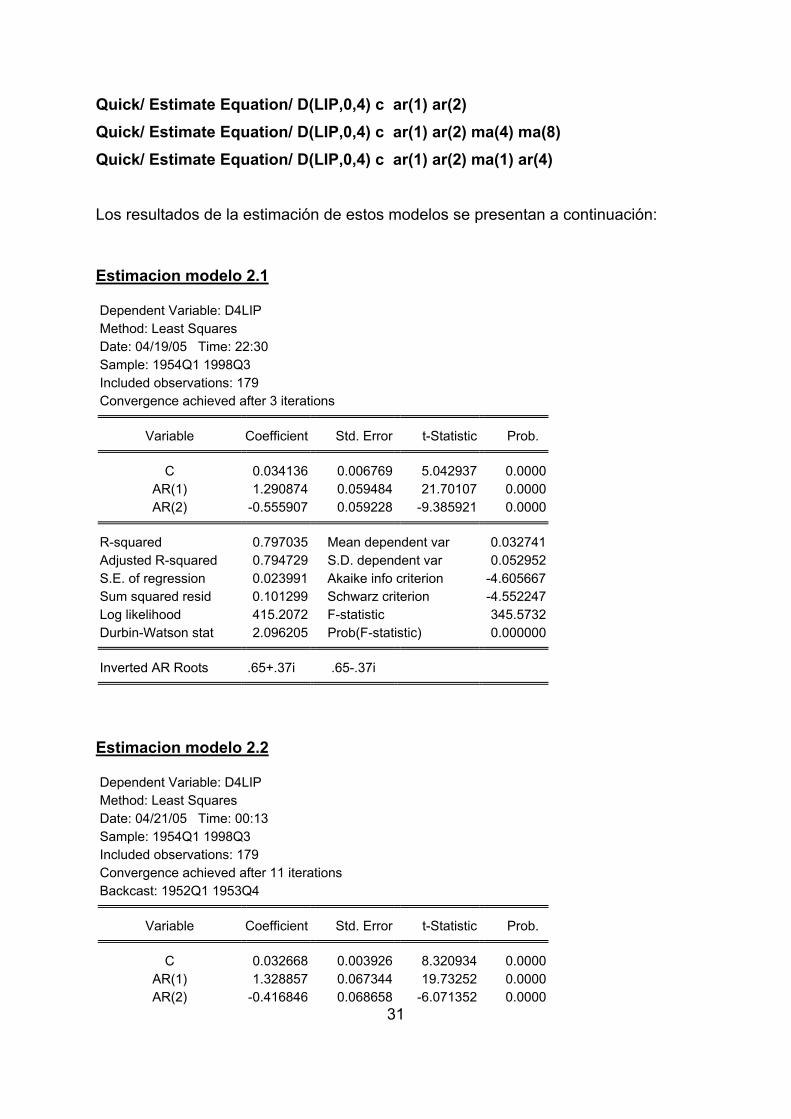
Quick/ Estimate Equation/ D(LIP,0,4) c ar(1) ar(2) Quick/ Estimate Equation/ D(LIP,0,4) c ar(1) ar(2) ma(4) ma(8) Quick/ Estimate Equation/ D(LIP,0,4) c ar(1) ar(2) ma(1) ar(4)
Los resultados de la estimación de estos modelos se presentan a continuación: Estimacion modelo 2.1 Dependent Variable: D4LIP Method: Least Squares Date: 04/19/05 Time: 22:30 Sample: 1954Q1 1998Q3 Included observations: 179 Convergence achieved after 3 iterations
Variable Coefficient Std. Error t-Statistic Prob.
C 0.034136 0.006769 5.042937 0.0000AR(1) 1.290874 0.059484 21.70107 0.0000AR(2) -0.555907 0.059228 -9.385921 0.0000
R-squared 0.797035 Mean dependent var 0.032741Adjusted R-squared 0.794729 S.D. dependent var 0.052952S.E. of regression 0.023991 Akaike info criterion -4.605667Sum squared resid 0.101299 Schwarz criterion -4.552247Log likelihood 415.2072 F-statistic 345.5732Durbin-Watson stat 2.096205 Prob(F-statistic) 0.000000
Inverted AR Roots .65+.37i .65-.37i
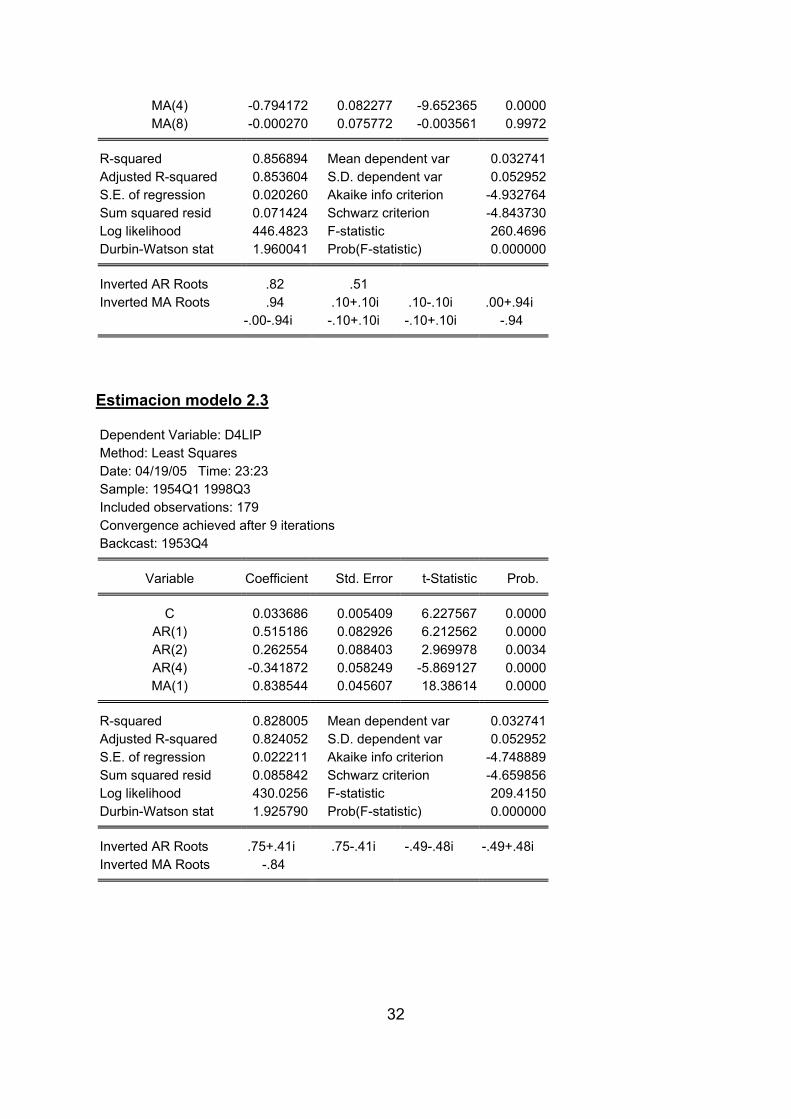
Estimacion modelo 2.2 Dependent Variable: D4LIP Method: Least Squares Date: 04/21/05 Time: 00:13 Sample: 1954Q1 1998Q3 Included observations: 179 Convergence achieved after 11 iterations Backcast: 1952Q1 1953Q4
Variable Coefficient Std. Error t-Statistic Prob.
C 0.032668 0.003926 8.320934 0.0000AR(1) 1.328857 0.067344 19.73252 0.0000AR(2) -0.416846 0.068658 -6.071352 0.0000
32
MA(4) -0.794172 0.082277 -9.652365 0.0000MA(8) -0.000270 0.075772 -0.003561 0.9972
R-squared 0.856894 Mean dependent var 0.032741Adjusted R-squared 0.853604 S.D. dependent var 0.052952S.E. of regression 0.020260 Akaike info criterion -4.932764Sum squared resid 0.071424 Schwarz criterion -4.843730Log likelihood 446.4823 F-statistic 260.4696Durbin-Watson stat 1.960041 Prob(F-statistic) 0.000000
Inverted AR Roots .82 .51 Inverted MA Roots .94 .10+.10i .10-.10i .00+.94i
-.00-.94i -.10+.10i -.10+.10i -.94
Estimacion modelo 2.3 Dependent Variable: D4LIP Method: Least Squares Date: 04/19/05 Time: 23:23 Sample: 1954Q1 1998Q3 Included observations: 179 Convergence achieved after 9 iterations Backcast: 1953Q4
Variable Coefficient Std. Error t-Statistic Prob.
C 0.033686 0.005409 6.227567 0.0000AR(1) 0.515186 0.082926 6.212562 0.0000AR(2) 0.262554 0.088403 2.969978 0.0034AR(4) -0.341872 0.058249 -5.869127 0.0000MA(1) 0.838544 0.045607 18.38614 0.0000
R-squared 0.828005 Mean dependent var 0.032741Adjusted R-squared 0.824052 S.D. dependent var 0.052952S.E. of regression 0.022211 Akaike info criterion -4.748889Sum squared resid 0.085842 Schwarz criterion -4.659856Log likelihood 430.0256 F-statistic 209.4150Durbin-Watson stat 1.925790 Prob(F-statistic) 0.000000
Inverted AR Roots .75+.41i .75-.41i -.49-.48i -.49+.48i Inverted MA Roots -.84

33
Validación
• El modelo 2.1 presenta todos sus coeficientes significativos, los coeficientes
no tienen síntomas de multicolinealidad y cumplen las condiciones de
estacionariedad. Su error estandar es 0,0252 y su AKAIKE de –4,6057. No
obstante, como veremos más adelante sus residuos presentan problemas.
Las estimaciones de los modelos 2.2 y 2.3 superan las pruebas de
significatividad individual de sus coeficientes, con excepción del parámetro
del componente MA(8) del modelo 2.2 que no resulta significativo, también
las raíces de sus polinomios caen fuera de un circulo de radio unidad por lo
que no presentan problemas de estacionariedad e invertibilidad, pero una raíz
del polinomio media móvil del modelo 2.2 roza la invertibilidad. A su vez, la
matriz de correlaciones de estos modelos no muestra signos de
multicolinealidad.
• En cuanto al análisis de residuos se analizan los correlogramas de los
residuos y el estadístico Q así como los gráficos de residuos. Para obtenerlos
en Eviews, dentro de la ecuación:
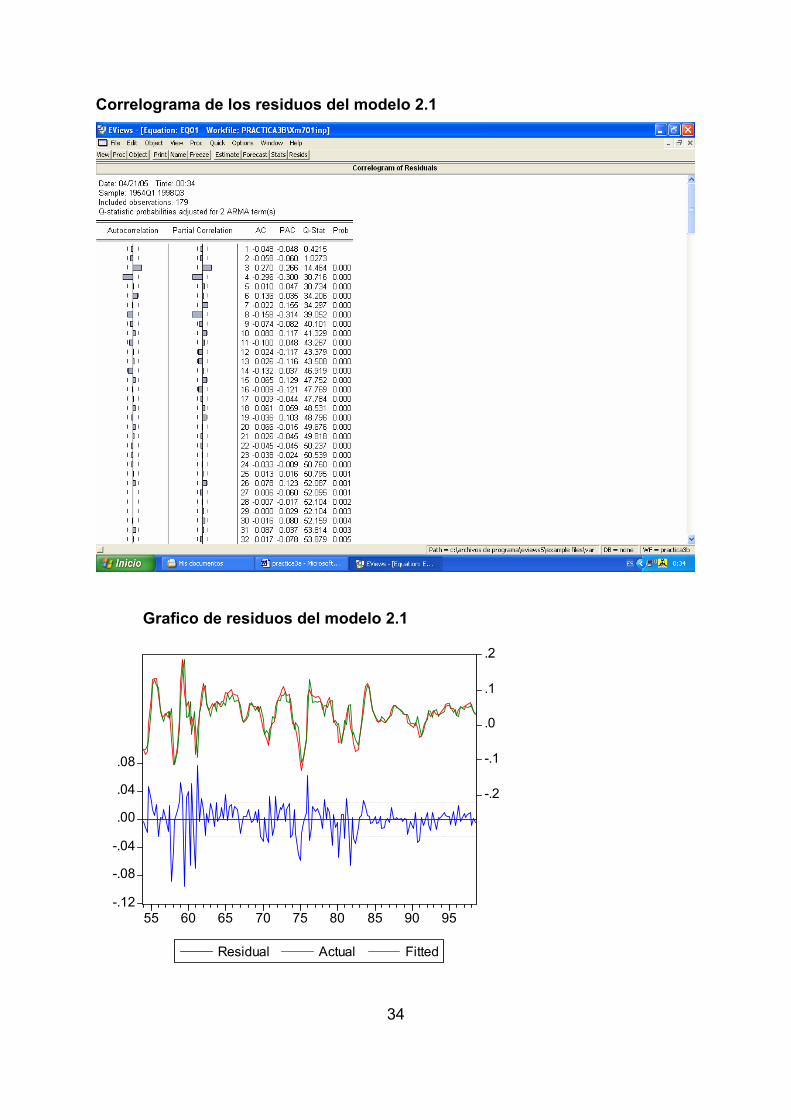
Views/ Residual tests/Correlogram-Q-Statstics Views/ Residual tests/Actual,Fitted, Residual/Actual, Fitted,Residual Graph Se puede contemplar en la tabla adjunta que los residuos del modelo 2.1 no
superan las pruebas de ausencia de autocorrelación puesto que sus correlogramas
y el estadístico Q indican que existe estructura en los residuos sin captar y no son
ruido blanco. Por ello, es un modelo incompleto y desechable. El modelo 2.2, dados
los problemas de estimación que su estimación presenta se considera no válido y no
se realiza el análisis de sus residuos. En cuanto al análisis de residuos del modelo
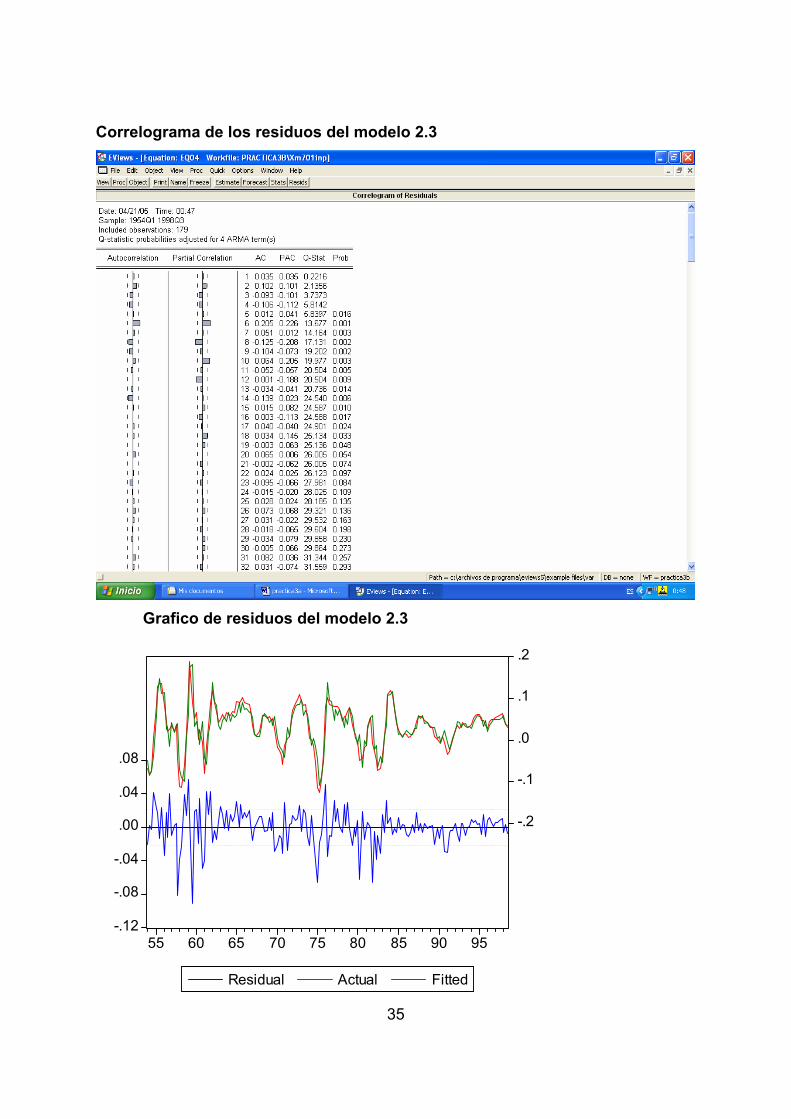
2.3, tanto el correlograma y el estadístico Q como el gráfico de sus residuos que se
presentan a continuación nos indican que estamos en presencia de residuos ruido
blanco.
34
Correlograma de los residuos del modelo 2.1
Grafico de residuos del modelo 2.1
-.12
-.08
-.04
.00
.04
.08
-.2
-.1
.0
.1
.2
55 60 65 70 75 80 85 90 95
Residual Actual Fitted
35
Correlograma de los residuos del modelo 2.3
Grafico de residuos del modelo 2.3
-.12
-.08
-.04
.00
.04
.08
-.2
-.1
.0
.1
.2
55 60 65 70 75 80 85 90 95
Residual Actual Fitted

36
• Del análisis anterior y de la valoración de las estimaciones y residuos de los
diferentes modelos, se deduce que el modelo 2.1 no tiene residuos ruido
blanco y el 2.2 presenta problemas en sus estimaciones tanto de algún
coeficiente individual como del valor de sus raíces. Sin embargo, el modelo
2.3 supera las distintas pruebas de valoración de estimaciones y presenta
residuos ruido blanco, por lo que es el modelo preferido.
4. Ejemplo 3. Las exportaciones de mercancías en España
La serie a analizar en este ejemplo es la de exportaciones de mercancías
españolas que elabora el Departamento de Aduanas de la Agencia Tributaria, tiene
frecuencia mensual y el periodo muestral comprende 1981:01 2005:01, es decir 289
observaciones. El objetivo que se persigue con este ejercicio es que el alumno
aprenda a construir un modelo univariante de una serie de frecuencia mensual con
tendencia y estacionalidad. La serie se encuentra en el banco de datos del curso de
econometria II.
Una vez creado el fichero de trabajo en Eviews para esa frecuencia y periodo
muestral, de la misma forma como se ha realizado en los dos ejercicios anteriores,
se importa la serie del Banco de Datos de econometría II, en la forma habitual ya
conocida. El primer paso a la hora de buscar un modelo para la serie es
representarla gráficamente, para lo cual en Eviews.
Instrucciones: Quick/Graph/ Expor/Line graph El resultado es el gráfico 3.1 que se muestra a continuación , en dicho gráfico se
puede contemplar que la serie muestra un claro componente tendencial por lo que
no es estacionaria en media. Probablemente tampoco lo sea en varianza puesto que
la dispersión de la serie es creciente, por lo que se debe tomar logaritmos
neperianos, para ello en Eviews: Genr LExpor =log(Expor), y graficamos la serie para ello en Eviews: Quick/graph/Lexpor/line graph.
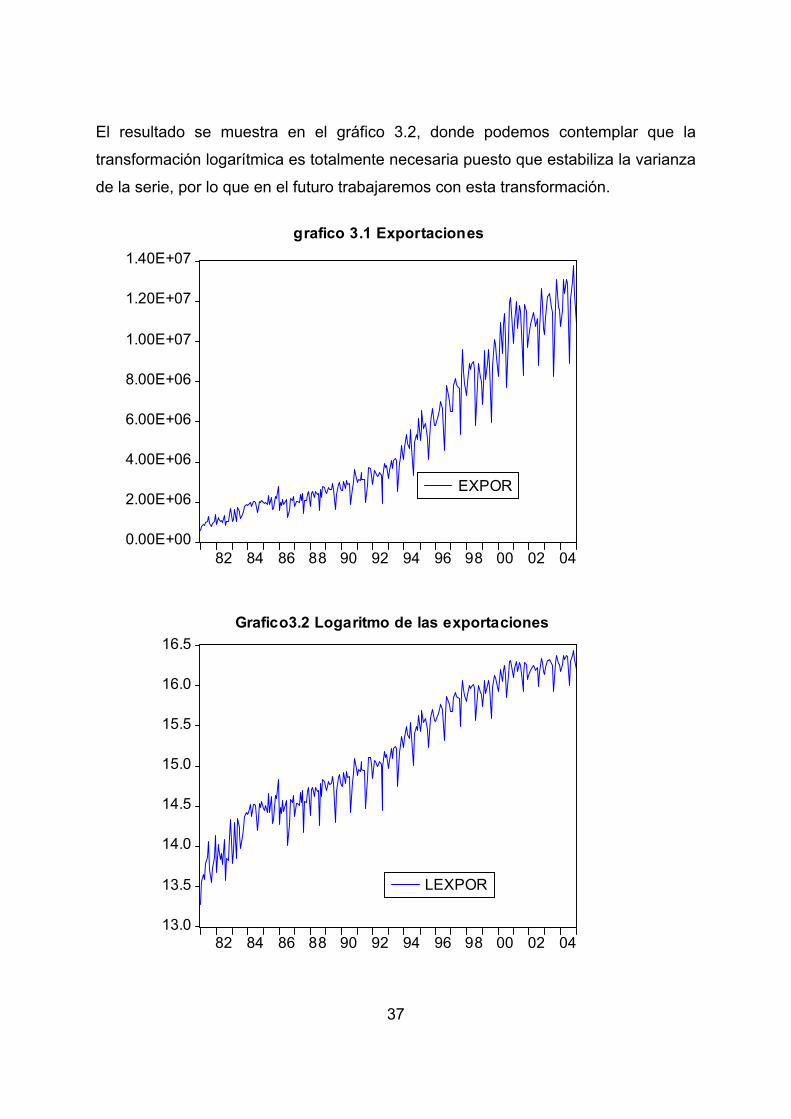
37
El resultado se muestra en el gráfico 3.2, donde podemos contemplar que la
transformación logarítmica es totalmente necesaria puesto que estabiliza la varianza
de la serie, por lo que en el futuro trabajaremos con esta transformación.
0.00E+00
2.00E+06
4.00E+06
6.00E+06
8.00E+06
1.00E+07
1.20E+07
1.40E+07
82 84 86 88 90 92 94 96 98 00 02 04
EXPOR
grafico 3.1 Exportaciones
13.0
13.5
14.0
14.5
15.0
15.5
16.0
16.5
82 84 86 88 90 92 94 96 98 00 02 04
LEXPOR
Grafico3.2 Logaritmo de las exportaciones

38
El gráfico de LEXPOR es indicativo de una serie con una fuerte tendencia
creciente y un marcado patrón estacional, por lo que no es una serie estacionaria.
Como hemos visto en los dos ejemplos anteriores el correlograma de la serie puede
ayudar a corroborar el diagnostico sobre la estacionariedad de la serie. Para ello
calculamos el correlograma de la serie:
Instrucciones: Una vez en el objeto serie LEXPOR, View/ Correlogram
El correlograma de la serie indica que las autocorrelaciones decaen muy
lentamente, como se aprecia en la figura anterior, y el correlograma parcial presenta
un valor significativo en el primer coeficiente cercano a la unidad. Ello nos confirma
la existencia de una raíz unitaria y; por tanto, la no estacionariedad en media
apuntada anteriormente. Dado que la serie no es estacionaria en media se procede
a tomar una primera diferencia regular. Par ello en Eviews en el menú principal:

39
Quick / Series Statistics/ Correlogram/D(Lexpor,1) O pulsando dos veces sobre la serie D(Lexpor,1): View/Correlogram
Correlograma de la primera diferencia regular de las exportaciones
El correlograma de la primera diferencia del logaritmo de las exportaciones (Lexpor)
muestra que la serie tiene un claro componente estacional. A este respecto, cabe
señalar que las autocorrelaciones muestrales correspondientes a los retardos
estacionales 12,14, y 36 son elevados con valores de 0,699, 0,597 y 0,523. y todos
ellos significativos, al superar las bandas de confianza. Este comportamiento de las
autocorrelaciones muestrales de los retardos estacionales refleja una tendencia en
la parte estacional de la serie, es decir la serie no es estacionaria en media en la
parte estacional. Con el fin de corregir esa no estacionariedad se toma una
diferencia de tipo estacional en la serie con una diferencia regular, para lo cual

40
generamos la serie DD12LEXPOR= DLEXPOR-DLEXPOR(-12), que en términos de
Eviews equivale a trabajar con la serie D(LEXPOR;1,12).
La transformación que se sugiere es :
Zt= (1-B12 )(1-B) LEXPOR
Construimos el Correlograma con esta serie transformada con d=D=1, para ello en
Eviews: QuicK/Series Statistics/Correlogram/ D(LEXPOR,1,12)
Correlograma de la primera diferencia regular y estacional de LEXPOR
El correlograma de D(LEXPOR1,12) nos dice que las autocorrelaciones muestrales
decaen rápidamente, lo que es indicativo de una serie estacionaria en media y en

41
varianza. La representación gráfica de la serie D(LEXPOR,1,12), ver gráfico 3.3,
también es indicativa de una serie estacionaria.
-.6
-.4
-.2
.0
.2
.4
.6
82 84 86 88 90 92 94 96 98 00 02 04
D(LEXPOR,1,12)
Gráfico 3.3Primera diferencia regular y estacional de LEXPOR
Para finalizar la etapa de especificación inicial debemos determinar cuales son los
modelos estacionales multiplicativos ARMA (p,q) × ARMA(p,Q)S que pueden generar
la serie. Para ello nos basamos en los correlograma simple y parcial de la serie
∇12∇LEXPOR que consideramos estacionaria. También se debe determinar si el
modelo debe incluir constante o no, de la observación del gráfico 3.3 de la serie
estacionaria se deduce que la serie transformada gira alrededor del valor cero, por
lo que deducimos que su media no es distinta de cero y no procede tal inclusión.
Al analizar la parte regular de los correlogramas se deduce que existe un claro
componente MA(1), puesto que el primer coeficiente de la autocorrelacción muestral
es significativo y las autocorrelaciones parciales decrecen rápidamente hacia cero:

42
También podría pensarse en un MA(2) para la parte regular puesto que la segunda
autocorrelación se encuentra en el límite y debemos tener en cuenta que en las
primeras autocorrelaciones hay ser más exigentes, por lo que planteamos un
modelo alternativo MA(2). Dado que los retardos 1 y 2 de la FACP son altamente
significativos y después el 3 y 4 no son pero repunta ligeramente en el 5 se puede
pensar como otra alternativa un modelo AR(2) ó incluso el AR(3).
Analizando ahora el componente estacional a través de la FAC y la FACP de los
retardos estacionales (los múltiplos de 12 al tratarse de datos mensuales), se
observa que el primer coeficiente de autocorrelación estacional, el 12, es
significativo (0,38) mientras que el segundo, el de orden 24, ya no lo es; podría
pensarse en un MA(1)s estacional, un MA(12),. También podría pensarse en un
AR(2)s puesto que el correlograma regular desciende lentamente y el parcial tiene
dos significativos, el 12 y 24.
Combinando estas estructuras sugeridas para la parte regular y estacional y
teniendo en cuenta la no inclusión de la constante resultan múltiples modelos,
algunos de los más sencillos y que tienen más sentido han sido los siguientes:
3.1 ARIMA(0,1,2) × (1,1,0)S
3.2 ARIMA(0,1,2) × (2,1,0)S
3.3 ARIMA(0,1,2) ×(1,1,1)s
Estimación A continuación se procede a estimar los modelos especificados y cuyos resultados
se presentan a continuación. Para ello en Eviews se deben dar las siguientes
instrucciones para estimar los modelos sugeridos:
Modelo 3.1: Quick/Estimate Equation/ D(lexpor, 1,12) MA(1) MA(2) AR(12) Modelo3.2:Quick/Estimate Equation/ D(lexpor, 1,12) MA(1) MA(2) AR(12) AR(24) Modelo3.3: Quick/Estimate Equation/D(lexpor,1,12) MA(1) MA(2) AR(12) MA(24)
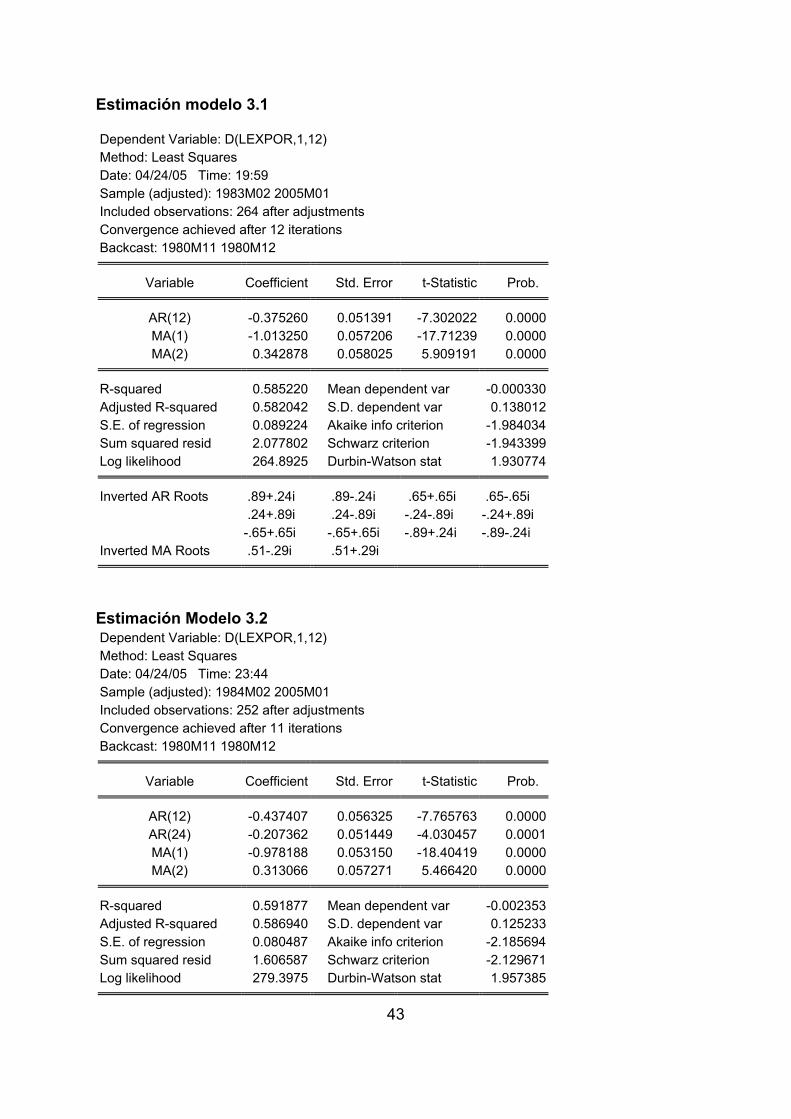
43
Estimación modelo 3.1 Dependent Variable: D(LEXPOR,1,12) Method: Least Squares Date: 04/24/05 Time: 19:59 Sample (adjusted): 1983M02 2005M01 Included observations: 264 after adjustments Convergence achieved after 12 iterations Backcast: 1980M11 1980M12
Variable Coefficient Std. Error t-Statistic Prob.
AR(12) -0.375260 0.051391 -7.302022 0.0000MA(1) -1.013250 0.057206 -17.71239 0.0000MA(2) 0.342878 0.058025 5.909191 0.0000
R-squared 0.585220 Mean dependent var -0.000330Adjusted R-squared 0.582042 S.D. dependent var 0.138012S.E. of regression 0.089224 Akaike info criterion -1.984034Sum squared resid 2.077802 Schwarz criterion -1.943399Log likelihood 264.8925 Durbin-Watson stat 1.930774
Inverted AR Roots .89+.24i .89-.24i .65+.65i .65-.65i .24+.89i .24-.89i -.24-.89i -.24+.89i -.65+.65i -.65+.65i -.89+.24i -.89-.24i
Inverted MA Roots .51-.29i .51+.29i
Estimación Modelo 3.2 Dependent Variable: D(LEXPOR,1,12) Method: Least Squares Date: 04/24/05 Time: 23:44 Sample (adjusted): 1984M02 2005M01 Included observations: 252 after adjustments Convergence achieved after 11 iterations Backcast: 1980M11 1980M12
Variable Coefficient Std. Error t-Statistic Prob.
AR(12) -0.437407 0.056325 -7.765763 0.0000AR(24) -0.207362 0.051449 -4.030457 0.0001MA(1) -0.978188 0.053150 -18.40419 0.0000MA(2) 0.313066 0.057271 5.466420 0.0000
R-squared 0.591877 Mean dependent var -0.002353Adjusted R-squared 0.586940 S.D. dependent var 0.125233S.E. of regression 0.080487 Akaike info criterion -2.185694Sum squared resid 1.606587 Schwarz criterion -2.129671Log likelihood 279.3975 Durbin-Watson stat 1.957385
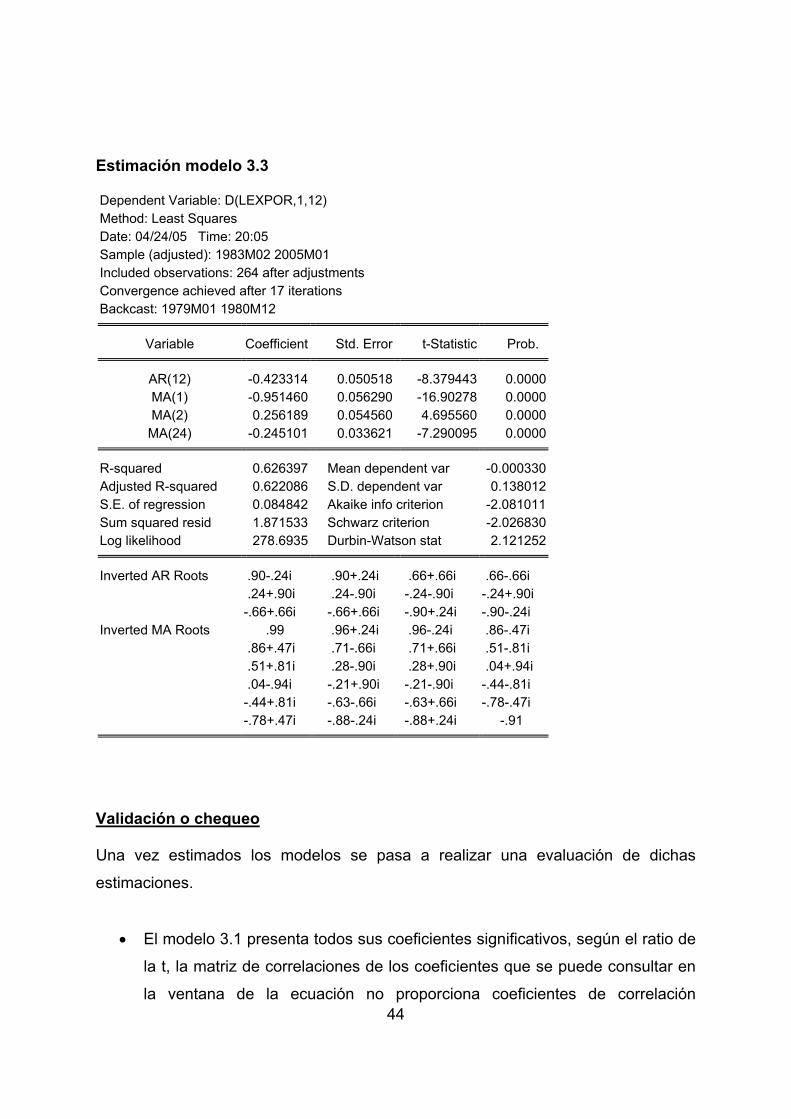
44
Estimación modelo 3.3 Dependent Variable: D(LEXPOR,1,12) Method: Least Squares Date: 04/24/05 Time: 20:05 Sample (adjusted): 1983M02 2005M01 Included observations: 264 after adjustments Convergence achieved after 17 iterations Backcast: 1979M01 1980M12
Variable Coefficient Std. Error t-Statistic Prob.
AR(12) -0.423314 0.050518 -8.379443 0.0000MA(1) -0.951460 0.056290 -16.90278 0.0000MA(2) 0.256189 0.054560 4.695560 0.0000MA(24) -0.245101 0.033621 -7.290095 0.0000
R-squared 0.626397 Mean dependent var -0.000330Adjusted R-squared 0.622086 S.D. dependent var 0.138012S.E. of regression 0.084842 Akaike info criterion -2.081011Sum squared resid 1.871533 Schwarz criterion -2.026830Log likelihood 278.6935 Durbin-Watson stat 2.121252
Inverted AR Roots .90-.24i .90+.24i .66+.66i .66-.66i .24+.90i .24-.90i -.24-.90i -.24+.90i -.66+.66i -.66+.66i -.90+.24i -.90-.24i
Inverted MA Roots .99 .96+.24i .96-.24i .86-.47i .86+.47i .71-.66i .71+.66i .51-.81i .51+.81i .28-.90i .28+.90i .04+.94i .04-.94i -.21+.90i -.21-.90i -.44-.81i -.44+.81i -.63-.66i -.63+.66i -.78-.47i -.78+.47i -.88-.24i -.88+.24i -.91
Validación o chequeo Una vez estimados los modelos se pasa a realizar una evaluación de dichas
estimaciones.
• El modelo 3.1 presenta todos sus coeficientes significativos, según el ratio de
la t, la matriz de correlaciones de los coeficientes que se puede consultar en
la ventana de la ecuación no proporciona coeficientes de correlación

45
elevados por lo que no presentan signos de multicolinealidad. La raíces de
los polinomios de esta ecuación caen fuera del circulo de radio unidad, el
proceso de estimación se alcanza en 12 iteraciones, el error estandar de la
ecuación estimada es de 0,089 y el AKAIKE es de –1,984. Los modelos 3.2 y
3.3 necesitan de 11 y 17 iteraciones, respectivamente, hasta alcanzar su
proceso de estimación, sus parámetros son individualmente significativos
según el t ratio y las correlaciones de sus parámetros de no muestran signos
de multicolinealidad, por lo que ambos modelos cumplen las condiciones de
estacionariedad e invertibilidad. El error estandar del modelo estimado 3.2 es
de 0,0805 y el del 3.3 es algo mayor (0,0848), en cuanto al AKAIKE el valor
para el modelo 3.2 es de –2,1856 y el del 3.3 es mayor (-2,081).
• En cuanto al análisis de residuos se evalúan, principalmente, a través de los
correlogramas de residuos y del estadístico Q y el gráfico de residuos. Para
obtener los correlogramas de residuos y el gráfico de residuos las
instrucciones en Eviews, una vez dentro de la ecuación estimada, son:
View / Residual Tests / Correlogram-Q- Statistics Las instrucciones para la obtención del gráfico de residuos son:
View /Actual,Fitted, Residual / Actual, Fitted, Residual Analizando los correlogramas de los residuos del modelo 3.1 se observa que
todos los coeficientes de autocorrelación del correlograma simple como el parcial
no son distintos de cero puesto que entran dentro de las bandas de confianza,
con excepción de la autocorrelación de orden 24, lo que indica que la
estacionalidad de este modelo no está del todo captada con un solo componente
estacional, un AR(12), sino que necesita otro componente estacional, los otros
dos modelos especificados incluyen un segundo componente estacional. En
cuanto a la significatividad global de los residuos por medio del estadístico Q se
observa que no hay indicios de autocorrelación puesto que las probabilidades
asociadas a todos los estadísticos Qson mayores de 0,05, por lo que se sitúa en
la región de no rechazo de la hipótesis nula, es decir, son ruido blanco. El gráfico
de residuos también indica que son ruido blanco
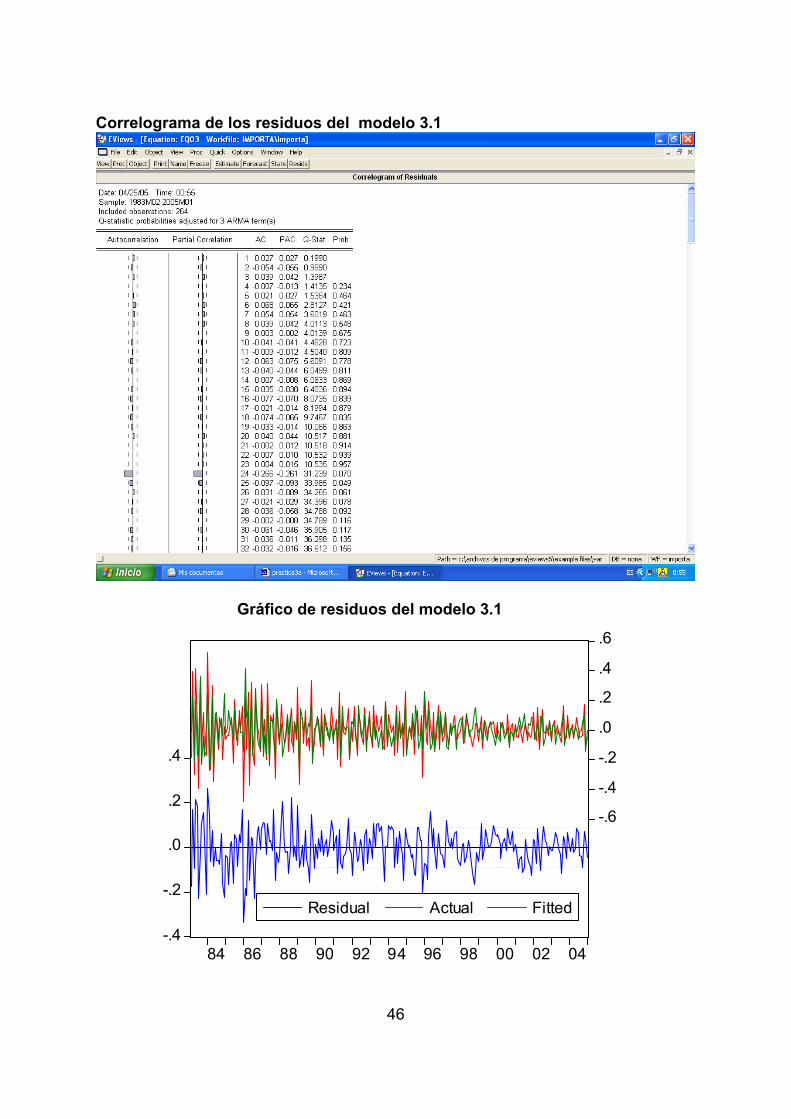
46
Correlograma de los residuos del modelo 3.1
Gráfico de residuos del modelo 3.1
-.4
-.2
.0
.2
.4
-.6
-.4
-.2
.0
.2
.4
.6
84 86 88 90 92 94 96 98 00 02 04
Residual Actual Fitted
47
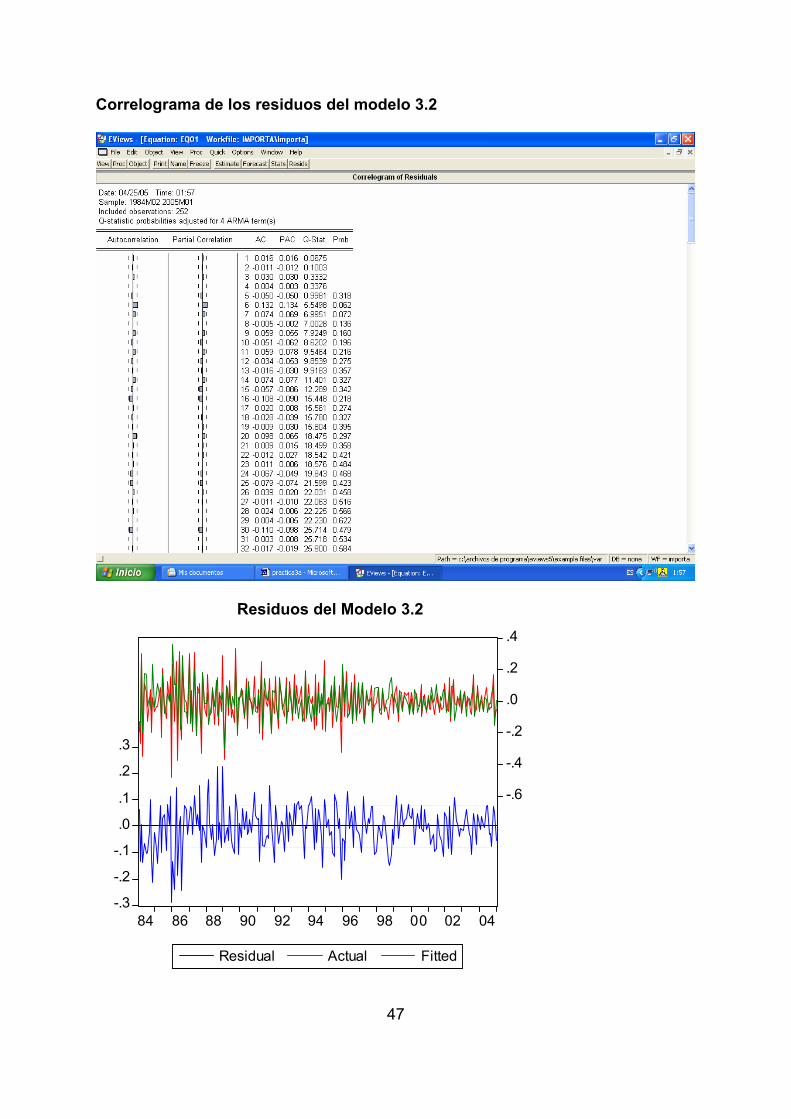
Correlograma de los residuos del modelo 3.2
Residuos del Modelo 3.2
-.3
-.2
-.1
.0
.1
.2
.3
-.6
-.4
-.2
.0
.2
.4
84 86 88 90 92 94 96 98 00 02 04
Residual Actual Fitted
48
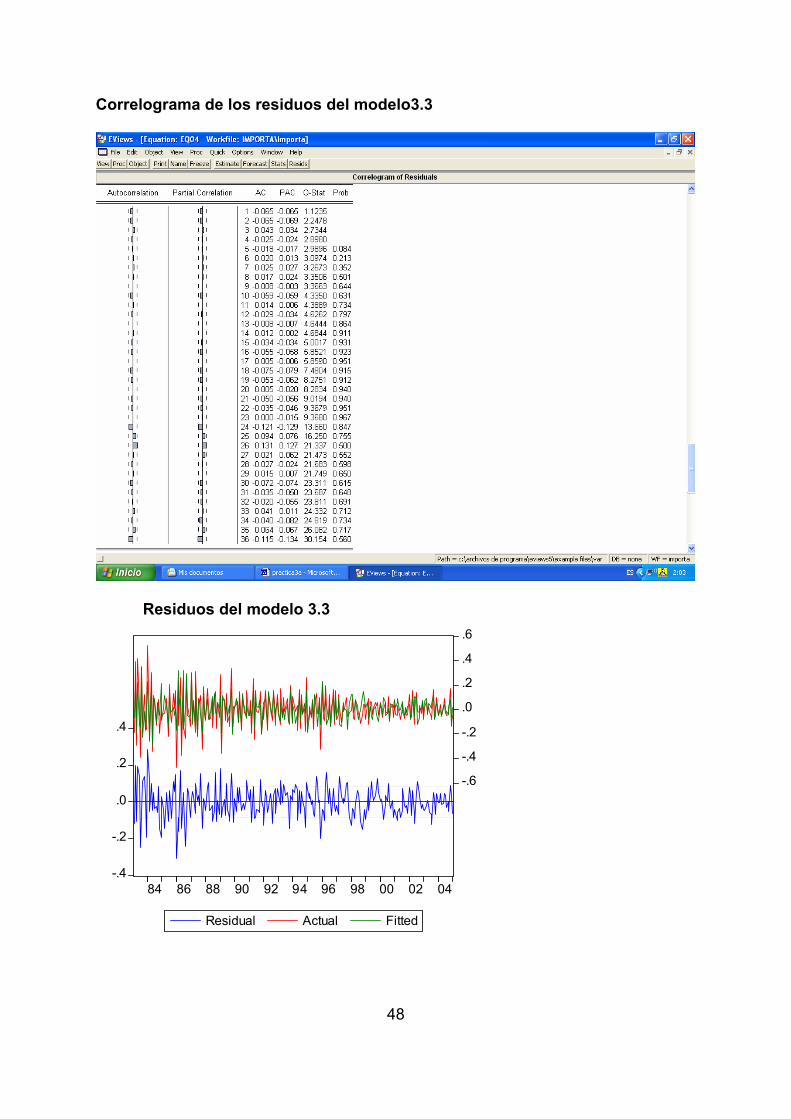
Correlograma de los residuos del modelo3.3
Residuos del modelo 3.3
-.4
-.2
.0
.2
.4
-.6
-.4
-.2
.0
.2
.4
.6
84 86 88 90 92 94 96 98 00 02 04
Residual Actual Fitted

49
El análisis de los residuos de los modelos 3.2 y 3.3, de la misma forma que se ha
hecho para el 3.1, cuyos correlogramas y gráficos nos indican que esos residuos
son ruido blanco y que la inclusión de un segundo componente estacional esta
plenamente justificado
• De la valoración de las estimaciones de los tres modelos y de sus residuos se
deduce que el modelo 3.1 es rechazable puesto que tiene cierta estructura de
tipo estacional en los residuos que no ha sido captada por el modelo. Los otros
dos modelos tienen los residuos ruido blanco y sus estimaciones pasan las
diferentes pruebas estadísticas y econométricas. No obstante, el modelo 3.2
tiene un criterio de AKAIKE inferior al del 3.3 y también un error estandar menor
por lo que es el modelo preferido .