midiendo el impacto de un artículo científico: modelos ... · 2.2 teoría de matrices y gráficas...
TRANSCRIPT

CENTRO DE INVESTIGACIÓN Y ESTUDIOS AVANZADOS DEL IPN
Doctorado en Ciencias en
Desarrollo Científico y Tecnológico para la Sociedad
Protocolo de tesis
Midiendo el impacto de un artículo
científico: modelos matemáticos.
Presenta:
Juan Antonio Pichardo Corpus
Directores:
Dr. José Antonio de la Peña Mena
Dr. Jesús Guillermo Contreras Nuño
Asesores:
Dr. Miguel Angel Pérez Angón
Dr. Eugenio Frixione Garduño
Dr. Ruy Fabila Monroy
Dr. Eduardo Robles Belmont

Protocolo de Tesis
Página 1 de 30
Contenido
1 La medición en la actividad científica ......................................................................................... 2
1.1 Para una revista ................................................................................................................... 2
1.2 Para un artículo ................................................................................................................... 3
1.3 Para un científico ................................................................................................................. 4
1.4 Análisis de tendencias ......................................................................................................... 4
1.5 Análisis espacial ................................................................................................................... 5
2 Herramientas matemáticas ......................................................................................................... 6
2.1 Redes ................................................................................................................................... 6
2.2 Teoría de matrices y gráficas ............................................................................................... 9
2.3 Centralidad en redes ......................................................................................................... 11
2.3.1 Centralidad por medio de la matriz exponencial. ..................................................... 12
2.3.2 Centralidad espectral ................................................................................................ 15
3 Propuesta de investigación ....................................................................................................... 20
3.1 Objetivos ........................................................................................................................... 25
3.1.1 Objetivo general ........................................................................................................ 25
3.1.2 Objetivos específicos. ................................................................................................ 25
3.2 Metodología ...................................................................................................................... 26
3.3 Bases de datos ................................................................................................................... 26
4 Cronograma ............................................................................................................................... 27
5 Bibliografía básica ..................................................................................................................... 28
6 Bibliografía complementaria ..................................................................................................... 28

Protocolo de Tesis
Página 2 de 30
1 La medición en la actividad científica
Desde la década de los años 60 del siglo pasado con los trabajos de Derek de Solla Price y
Eugene Garfield (Garfield, 2007) se creó la llamada ciencia de la ciencia o cienciometría y
paralelamente la bibliometría, dando pie a la creación del Instituto para la Información
Científica (Institute for Scientific Information (ISI), actualmente parte de la empresa
Thomson Reuters. El ISI, en ese momento, desarrolló un catálogo de las principales revistas
de ciencia (SCI) y creo el llamado Factor de Impacto (FI) de una revista, dando originen a
una de las medidas más discutidas en la actualidad (Adler et ál, 2008).
Sólo como referencia, por bibliometría se entienden los datos de citación y las estadísticas
derivadas de ellos (Adler, 2008). La cienciometría hace uso de la bibliometría con datos de
otras áreas que permean la actividad científica y pueden ser determinantes en su desarrollo,
tales como: número de investigadores, su distribución geográfica o por especialidad, fuentes
de financiamiento, productividad y repercusión, etc. (Pérez, 2006).
De acuerdo con la empresa Thomson Reuters (2008) las medidas relacionadas con la
productividad científica se pueden englobar en siete tipos:
1) Productividad
2) Reconocimiento total o influencia
3) Reconocimiento indirecto o influencia indirecta
4) Eficiencia
5) Impacto relativo o evaluación comparativa
6) Especialización
7) Análisis de tendencias
El conteo de artículos es la principal medida de productividad, el conteo de citas o el índice
h son ejemplos del tipo 2, el conteo de citas de segunda generación es un ejemplo del tipo 3,
el promedio de citas por artículo y el factor de impacto de una revistas son ejemplos del tipo
4, el número de artículos citados sobre los no citados es un ejemplo de las medidas de tipo 5,
lis indicadores de colaboración son ejemplos del tipo 6, finalmente las series de tiempo son
ejemplos del tipo 7 (Thomson Reuters, 2008).
La propuesta de investigación tocará varios tipos de los mencionados, en principio se partirá
de algo similar al conteo de citas de segunda generación, aunque se espera indagar en las
redes de coautoría y las tendencias.
A continuación se realiza una descripción más detallada de algunas medidas.
1.1 Para una revista
El FI de una revista es un número que se calcula a partir de las citas recibidas por los artículos
publicados en la revista en un periodo de dos años. Por ejemplo para calcular el FI de una
revistas en 2013 se cuentan las citas recibidas por los artículos publicados en el periodo 2011-
2012 y se divide entre el número de artículos publicados en la revista en el mismo periodo.

Protocolo de Tesis
Página 3 de 30
Adler et ál. (2008) critican fuertemente la comparación entre revistas por medio del FI, ya
que las revistas pertenecen a ciertos campos disciplinares, y en cada disciplina se tienen
formas de citación específicas, por ejemplo, en el año 2000 el promedio de citas de un artículo
de matemáticas era de 1 mientras que ciencias de la vida superaba las 6.
En algunos casos se extrapola el FI hacia un artículo o incluso hacia un científico, entonces
si un científico publica en una revista con alto impacto, su artículo es un buen artículo y por
lo tanto el mismo científico. Sin embargo, en promedio, el 90 % de las citas de una revista se
deben al 10 % de los artículos (Thomson Reuters, 2008).
Aunado a ello para algunas áreas del conocimiento como matemáticas puede pasar que en el
periodo de dos años los artículos sólo consigan el 10% de las citas totales (Adler et ál., 2008),
entonces el FI no considera el 90% de las citas.
Por supuesto el FI puede ser útil si se toman las precauciones debidas para evitar
comparaciones sin sentido o llevar ese número a una descontextualización y tomar decisiones
con un margen de error grande.
Una alternativa al FI es eigenfactor (http://www.eigenfactor.org/methods.php) que calcula
un factor de impacto basado en el algoritmo Page Rank de Google. En este enfoque una
revista se considera influyente si es citada a menudo por otras revistas consideradas
influyentes, además considera el promedio de tiempo que un lector tiene que seguir hacia
atrás la cadena de citas de los artículos de la revista. El algoritmo hace uso de la teoría de
matrices y redes, de ahí un poco el nombre de la organización ya que hace uso de los
eigenvalores o valores propios de la matriz de adyacencia que se genera.
1.2 Para un artículo
Uno de los números con mayor impacto en la evaluación de las publicaciones de un científico
es el conteo de citas y las citas promedio. Son varias las críticas al respecto, ya que las citas
a un artículo pueden darse por una gran variedad de razones, no necesariamente asociadas a
la calidad del artículo. Entre esas razones se encuentran: el reconocimiento de una deuda
intelectual, una cita retórica, la claridad de la exposición, la visibilidad del propio artículo,
entre otros (de la Peña, 2011; Adler et ál., 2008).
Existen propuestas distintas al promedio de citas para medir el impacto de un artículo
científico (de la Peña 2011). De la Peña considera las propiedades globales de la red de
citación de artículos científicos para generar una función de impacto en un conjunto de
artículos. Luego esa función proporcionará una medida del impacto de un artículo, para el
cálculo hace uso de la teoría de matrices.
En este trabajo se presenta una propuesta de investigación similar, el objetivo central es medir
el impacto de un artículo científico haciendo uso de herramientas matemáticas asociadas al
análisis de redes sobre todo la teoría de matrices y gráficas. En la segunda sección se
desarrollan las principales herramientas.

Protocolo de Tesis
Página 4 de 30
1.3 Para un científico
La principal forma de cuantificar la productividad de un científico es la cantidad de artículos
que escribe por año y luego el impacto de esa producción se mide a través del número de
citas que reciben los artículos o el promedio de las citas por artículo. Aunque el significado
de las citas no es simple y las estadísticas basadas en ellas no son tan “objetivas” como
algunos afirman (Adler, et ál., 2008).
Una medida que intenta cuantificar producción e impacto en un solo número es el índice h.
Publicado en 2005 por Hirsch (2005) con el objetivo de caracterizar la producción científica
de un investigador. Un científico tiene índice h si tiene h artículos con al menos h citas cada
uno.
De acuerdo con Hirsch (2005) una de las “bondades” del índice h es que se puede calcular
muy fácilmente, en efecto, basta con ordenar las publicaciones de un autor de mayor a menor
frecuencia de citación y dónde coincide el número de citas con el número de artículo se tiene
el índice h, actualmente en la WOS ese número se obtiene directamente en la búsqueda de
algún autor en su base de datos.
El índice h tuvo una gran influencia en las publicaciones sobre bibliometría y/o cienciometría
(Egghe, 2010), hay quienes lo consideran una buena medida (Borman y Daniel, 2005, 2007)
otros hacen críticas (Lehmann et ál., 2006, Vinkler, 2007) y algunos más lo han
complementado o extendido (Egghe, 2006; Liang, 2006).
Adler et ál (2008), mencionan que la mayoría de trabajos sobre la confiablidad del índice h
está basada en la correlación con otras medidas lo cual no es nada especial, ya que todas las
variables son función de un mismo fenómeno básico: las publicaciones. Aunque también
proponen realizar estudios más profundos al respecto.
1.4 Análisis de tendencias
Un tema recurrente en la literatura de los últimos años sobre índices o medidas
bibliométricos, es su capacidad predictiva, aunque en general se ha encontrado que es muy
limitada.
Mazloumian (2012) pone a prueba la hipótesis de que el conteo de citas es un indicador fiable
de éxito en el futuro, para el análisis compara 10 medidas. La conclusión más contundente
es que el número de citas a trabajos futuros es muy difícil de predecir.
Wang, Song y Barabasi (2013) intentan medir el impacto científico en el largo plazo, también
comparan varias medidas. Muestran que el FI es un predictor pobre de futuras citas para un
artículo. El número de citas tampoco es un buen predictor, ya que para artículos con la misma
cantidad de citas en 5 años tienen impactos muy diferentes en el largo plazo. De manera
similar el índice h e índice g.

Protocolo de Tesis
Página 5 de 30
Posiblemente la limitación en la predicción está relacionada con las características inherentes
a las medidas mismas, toda vez que intentan dar cuenta de un fenómeno complejo que es
difícil reducir a un número.
1.5 Análisis espacial
Una de las tendencias en varias investigaciones sobre cienciometría o bibliometría son los
análisis espaciales, en Frenken et ál. (2008) se hace una revisión sobre el estado del arte de
ello, se propone una agenda de investigación que se ha venido siguiendo en torno a tres
componentes centrales: la distribución espacial de la investigación y las citas, la existencia
de sesgos espaciales de colaboración, citas y movilidad, y el impacto de las citas nacionales
frente a las colaboraciones internacionales. Frenken et ál. proponen el concepto de
“proximidad” como un marco único para combinar hipótesis desde diversas posturas teóricas.
Uno de los acercamientos hacia el análisis espacial combinado con factores económicos y de
crecimiento de un país se hace en Kumar Pan et ál. (2012), ellos presentan un análisis
sistemático de las redes de citación y colaboración entre ciudades y países, mediante la
asignación de artículos para las ubicaciones geográficas de las afiliaciones de los autores.
En síntesis, hay varias medidas que intentan cuantificar la calidad del trabajo científico de un
investigador, en algunos casos esos índices se podrían utilizar en conjunto con otras formas
de medir o analizar la ciencia en su conjunto y el desempeño de un científico en particular.
Para el caso de la política científica, a nivel micro (individual) se pueden identificar tres usos
de estos indicadores: a nivel del reconocimiento de una carrera (p. ej. otorgar un premio),
otorgamiento de plazas y apoyo de proyectos; estos a nivel individual o micro. Hay otros
usos a nivel meso (institucional) o macro (país) para evaluar programas de desarrollo
científico (Ubfal y Maffioli, 2011, Benavente et ál, 2012).
Cada uno de los usos o propósitos requiere diferente capacidad de prediccion: para el
reconocimiento ninguna; para el otorgamiento de plazas a largo plazo, para apoyo de
proyectos a corto o mediano plazo, para evaluaciones institucionales y nacionales a corto,
mediano y largo plazo.
Es importante para la ciencia mexicana analizar la productividad de los científicos mexicanos
o adscritos a instituciones mexicanas y tener herramientas robustas de análisis para evitar que
“los tomadores de decisiones reemplazan calidad por números que pueden medir” Adler et
ál. (2008).

Protocolo de Tesis
Página 6 de 30
2 Herramientas matemáticas
En esta sección se presentan las principales herramientas matemáticas que se utilizarán para
elaborar el modelo propuesto.
Como antecedentes se revisan algunas ideas relacionadas con la redes en general, pasando a
la teoría de gráficas y algunos conceptos matriciales asociados para abordar la centralidad de
una red.
2.1 Redes
Para los fines de este trabajo se habla de redes a partir de las que se generan por medio de las
citas entre artículos o colaboraciones científicas, entendidas como coautorías, trabajos
conjuntos entre instituciones, ciudades o países.
Aunque las redes tuvieron su origen de estudio en las ciencias sociales (Reynoso, 2008),
después se desarrollaron matemáticas para analizar dichas redes y el caso de las redes de
investigación no es ajeno.
Bavelas, en conjunto con el matemático R. Duncan Luce, desarrolló estadísticas de
centralidad que todavía integran el repertorio analítico de los principales modelos y de los
paquetes de software más utilizados (Reynoso 2008).
La centralidad es uno de los conceptos fundamentales del análisis de redes, (ibid) Bavelas lo
utilizaba para explicar el rendimiento diferencial de las redes de comunicación y de los
miembros de una red respecto de variables tales como tiempo para resolver problemas,
percepción de liderazgo, eficiencia, satisfacción laboral y cantidad de errores cometidos
(Reynoso, 2008).
Frank Harary, uno de los padres de la teoría de gráficas, trabajó con Carltwright en trabajos
sociológicos para luego impulsar la teoría de graficas dentro del Análisis de Redes Sociales
(ARS), y promover el uso de matrices como forma de estudiar las relaciones sociales, además
según Reynoso “Hoy en día las estructuras matriciales constituyen la forma primaria de
notación de las redes sociales, la materia prima sobre la que operan el análisis y la
representación gráfica” (2008, p.22).
Una de las investigaciones pioneras en usar redes para analizar la actividad científica fue de
Solla Price (1965) haciendo un análisis de las redes de artículos científicos y las revistas
donde se publicaban para ello analizó referencias y citas de los artículos.
Matemáticamente las redes se comenzaron a estudiar en la teoría de gráficas, principalmente
con los trabajos de Paul Erdös y Alfred Renyi, hoy los modelos que ellos desarrollaron se
conocen como redes tipo ER (Barabási et ál. 1999).

Protocolo de Tesis
Página 7 de 30
El modelo ER asume que se inicia con N vértices y cada par de vértices se conectan con
probabilidad p. En el modelo, la probabilidad de que un vértice tenga k aristas sigue una
distribución de Poisson con:
𝑃(𝑘) =𝑒−𝑘𝜆𝑘
𝑘!,
Donde
𝜆 = 𝑁 (𝑁 − 1
𝑘) 𝑝𝑘(1 − 𝑝)𝑁−1−𝑘.
Pero estas redes se habían estudiado desde el punto de vista teórico, en parte porque no se
tenía la disponibilidad de datos de grandes redes, que sí se tienen actualmente.
Barabási (1999) hizo un análisis de redes con datos reales, basado en la red de actores de
películas y en la Web World Wide (WWW). En el caso de los actores cada nodo era un actor
y si habían actuado en una misma película tenían una arista que los unía. En la www las
páginas eran los nodos y si había una liga entre ellas se tenía una arista.
Barabási encontró que esas redes no crecen como el módelo ER sino que hay dos
características esenciales: las redes reales no son estáticas sino que crecen con el tiempo
añadiendo nuevos nodos; la segunda es lo que llamó “apego preferencial” (preferential
attachment), esto último implica que los nuevos nodos se enlazan con nodos que tienen
muchas conexiones o aristas. Además estableció que los nodos no siguen una distribución de
Poisson sino una ley de potencias.
Barabási estableció lo que actualmente se conoce como redes libres de escala, en éstas la
probabilidad 𝑃(𝑘) de que un nodo en la red interactue con otros k nodos decae como una ley
de potencia, es decir de la forma:
𝑃(𝑘)~𝑘−𝛾.
Para la red de autores y la WWW encontró que: 2 ≤ 𝛾 ≤ 2.4.
Las diferencias visuales entre las redes tipo ER y las libres de escala se pueden ver en las
figuras 1 y 2.
Figura 1: Red aleatoria tipo ER
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
1 2 3 4 5 6 7 8 9 10111213141516171819202122

Protocolo de Tesis
Página 8 de 30
La figura 1 muestra una red tipo ER, con 1000 nodos, donde la distribución es una normal.
La figura 2 muestra una red libre de escala, con 1000 nodos, donde la distribución sigue una
ley de potencia.
Figura 2: Red libre de escala tipo Barabási
Otra característica importante de las redes reales es que tienen la propiedad de “mundo
pequeño” también conocida como “seis grados de separación”, debido a que si dos personas
están conectadas en el mundo se puede llegar de una a la otra pasando, en promedio, por seis
personas (Watts & Strogatz, 1998). También trabajaron el coeficiente de clustering o de
agrupamiento que mide el grado en el que los nodos de una red tienden a agruparse.
Watts & Strogatz (1998) encontraron que la propiedad de mundo pequeño se encontraba en
redes reales, en su trabajo reportaron los resultados de analizar una red de autores, la red
eléctrica de los Estados Unidos y la red neuronal del gusano Caenorhabditis elegans.
Posteriormente Newman (2001) estudió las características de redes de coautoría de
científicos, encontró que las redes tenían la propiedad de “mundo pequeño” es decir que se
podía encontrar un camino corto entre dos nodos,
Además, mostró que el coeficiente de agrupamiento era grande, a diferencia de la redes tipo
ER.
Casi a la par, Barabási et ál. (2002) mostraron que las redes de coautoría de matemáticos y
neurociencientíficos correspondientes al periodo 1991-1998 eran redes libres de escala y que
la evolución de las redes está determinada por el “apego preferencial”.
Además, encontraron (ibid) que el grado promedio de los nodos se incrementa con el tiempo
y que la separación de los nodos decrece, explicando la propiedad de mundo pequeño.
También mostraron que el coeficiente de clustering o de agrupamiento decaía con el tiempo,
esto está relacionado con la probabilidad de que dos autores escribieran un artículo conjunto.
Así, a partir de los trabajos de Watts, Strogatz, Barabási etc., entre otros, en redes se han dado
importantes avances en el entendimiento de las redes reales, llamadas redes complejas,
0.001
0.01
0.1
1
1 10 100

Protocolo de Tesis
Página 9 de 30
ejemplo de ello son las redes de coautoría, redes sociales en general, redes neuronales, entre
otras.
2.2 Teoría de matrices y gráficas
Gran parte de las herramientas de análisis de este trabajo pertenecen a la teoría de matrices y
gráficas, ésta estudia modelos matemáticos que pueden representar una gran variedad de
sistemas, como las moléculas químicas donde los nodos simulan átomos y las aristas, enlaces
eléctricos; sistemas carreteros, redes de coautoría; científicos y los artículos escritos de forma
conjunta, entre otros (de la Peña, 2012), por supuesto para nuestro fines interesan los últimos
modelos mencionados.
A continuación se presentan algunos conceptos elementales desde donde se abordaran varias
ideas y la propuesta de un modelo.
Para una gráfica 𝐺 = (𝐻, 𝑈), decimos que H es un conjunto finito (cuyos elementos son
llamados vértices) junto con U un conjunto de dos elementos subconjuntos de H (los
elementos de U son llamados aristas). De manera similar una digráfica o gráfica dirigida
(𝐻, 𝑈), es definida por un conjunto finito H y un conjunto U de pares ordenados de elementos
de H (estos pares ordenados son llamados aristas dirigidas o arcos). Los conjuntos de vértices
y aristas algunas veces son denotados como 𝑉(𝐺) y 𝐸(𝐺), respectivamente (Cvetkovic et ál,
1979).
Dada una gráfica G con vértices {1,2, … , 𝑛}, supondremos que las aristas 𝑖 − 𝑗 tienen peso
𝑤𝑖𝑗 ≥ 0. El peso 𝑤𝑖𝑗 = 1 no es necesario escribirlo de manera explícita, los pesos mayores
se señalaran en cada arista de la gráfica (figura 3). La matriz de adyacencia se denotará como
𝐴(𝐺) = (𝑎𝑖𝑗) y la matriz de red o pesada, 𝐴(𝐺) = (𝑤𝑖𝑗).
Figura 3: Gráfica con pesos
La matriz de adyacencia y la matriz de red o pesada de la gráfica G de la figura 4, se muestran
a continuación:
𝐴(𝐺) =
(
0 1 1 0 0 01 0 1 1 0 01 1 0 1 1 00 1 1 0 1 00 0 1 1 0 10 0 0 0 1 0)
,𝐴(𝐺) =
(
0 5 3 0 0 05 0 1 1 0 03 1 0 1 1 00 1 1 0 2 00 0 1 2 0 10 0 0 0 1 0)
.

Protocolo de Tesis
Página 10 de 30
Claramente estas matrices son simétricas, es decir, la entrada 𝑎𝑖𝑗 = 𝑎𝑗𝑖, más adelante se
hablará de algunas propiedades de este tipo de matrices.
En la gráfica 3 cada vértice puede representar a un investigador, si hay una arista entre dos
vértices, significa que tienen al menos una colaboración. Los pesos en las aristas pueden
indicar la cantidad de trabajos en coautoría.
Si la gráfica es dirigida, como la de la figura 4, entonces la matriz de adyacencia no es
simétrica y puede ser pesada o no.
Figura 4: Gráfica dirigida con pesos.
La matriz de adyacencia y la matriz de red o pesada de la gráfica 𝐺1 de la figura 5, se muestran
a continuación:
𝐴(𝐺1) =
(
0 1 1 0 0 00 0 1 1 1 00 0 0 1 0 00 0 0 0 1 00 0 0 0 0 10 0 0 0 0 0)
,𝐴(𝐺1) =
(
0 3 5 0 0 00 0 1 1 1 00 0 0 1 1 00 0 0 0 1 00 0 0 0 0 20 0 0 0 0 0)
En la gráfica 𝐺1 se puede suponer que cada vértice es un artículo científico y que están
ordenados de acuerdo al tiempo de publicación, así el vértice A correspondería al artículo
más antiguo y el vértice F al más reciente, entonces, la arista "𝐴 → 𝐵" implica que B cita a
A.
Las matrices de adyacencia de gráficas dirigidas son matrices triangulares superiores si los
vértices se indizan de acuerdo al tiempo.
Una de los conceptos importantes en la redes de citación está relacionado con el de “camino”
de una gráfica, este no es otra cosa que la manera de ir de un vértice a otro recorriendo aristas,
es decir se puede ver como una secuencia de aristas. Dependiendo del número de aristas que
se recorre es la longitud del camino.
Llamamos 𝑎𝑥𝑦(𝑘)
al número de caminos de longitud k que van de x a y. Observemos que se
obtienen de la siguiente manera:
𝑎𝑥𝑦(𝑘+1)
=∑𝑎𝑥𝑧(𝑘)𝑎𝑧𝑦
𝑥
.

Protocolo de Tesis
Página 11 de 30
Las potencias de 𝐴(𝐺) son precisamente 𝐴(𝐺)𝑘 = (𝑎𝑖𝑗(𝑘)). Por ejemplo, para la gráfica G
(Fig. 3), el cuadrado de la matriz 𝐴(𝐺)2 = (𝑎𝑖𝑗(2)), donde 𝑎𝑖𝑗
(2) denota el número de caminos
de longitud 2 entre los nodos es:
𝐴(𝐺)2 =
(
2 1 1 2 1 01 3 2 1 2 01 2 4 2 1 12 1 2 3 1 11 2 1 1 3 00 0 1 1 0 1)
.
Entonces hay dos caminos de longitud 2 del vértice A al vértice D, en efecto, se puede hacer
A-B-D ó A-C-D.
Las gráficas 𝐺 𝑦 𝐺1 son ejemplos de gráficas conexas, una gráfica conexa es aquella que tiene
un camino entre cada par de vértices. En general, las gráficas de las redes que se trabajaran
serán conexas.
Entonces, para el caso de la red de citación se puede ver que la longitud de los caminos
permite observar cierta historia de citación. Para la gráfica 𝐺1 (Fig. 4), el cubo de la matriz
𝐴(𝐺1)3 = (𝑎𝑖𝑗
(3)), donde 𝑎𝑖𝑗
(3) denota el número de caminos de longitud 3 entre los nodos es:
𝐴(𝐺1)3 =
(
0 0 0 1 2 10 0 0 0 1 10 0 0 0 0 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 0)
A nivel de las citas implica que el artículo A tuvo una influencia de tercer orden en el artículo
E, es decir, en la historia de citación hubo dos artículos que citó E y que anteriormente citaron
a A, por ejemplo en el camino “A-B-D-E” esos dos artículos son B y D.
Esta es una forma de tener una aproximación hacia el impacto de un artículo en la red de
citación o una medida de centralidad de la red.
2.3 Centralidad en redes
Ya mencionamos que uno de los conceptos centrales en la teoría de redes es el de centralidad
(𝑓𝐺), éste asigna un valor real positivo a cada nodo de una red G de manera que si 𝑔: 𝐺 → 𝐺′ es un isomorfismo, entonces 𝑓𝐺(𝑥) = 𝑓𝐺(𝑔(𝑥) para todo nodo x de G. De esta manera, la
función de centralidad es un atributo estructural de los nodos de una red; en otras palabras,
se trata un valor asignado al nodo debido a su posición estructural en la red. Algunas medidas
de centralidad consideradas en la literatura (de la Peña, 2012) son:

Protocolo de Tesis
Página 12 de 30
Grado pesado. Se trata de la primera y más simple definición de centralidad. Se define
como el número de enlaces (con peso) que posee un nodo con otros. Suele
representarse como k. El grado se interpreta a menudo como el número de conexiones
que tiene un elemento de la red en ella.
Por cercanía. La cercanía 𝑐𝐺(𝑥) de un nodo x a la red G es el promedio de la
separación (definida como el inverso de la distancia entre ellos) de x a cada uno de
los nodos de la red. Esto es:
𝑐𝐺(𝑥) =1
𝑛
1
∑ 𝑑(𝑥, 𝑦)𝑦≠𝑥
donde n es el número de nodos en la red.
Una manera distinta de calcular o medir la centralidad de un vértice en la gráfica o de un
nodo en la red es a partir del total de caminos entre dos vértices, para ello se hará uso de la
matriz exponencial.
2.3.1 Centralidad por medio de la matriz exponencial.
Sea A una matriz de 𝑛 × 𝑛, entonces 𝑒𝐴 es una matriz de 𝑛 × 𝑛 definida por:
𝑒𝐴 = 𝐼 + 𝐴 +𝐴2
2!+𝐴3
3!+𝐴4
4!+ ⋯ =∑
𝐴𝑘
𝑘!
∞
𝑘=0
.
En donde 𝐼 es la matriz identidad.
Como se observa, por medio de la matriz exponencial se obtienen el número de caminos con
cierto peso entre dos vértices, el total de caminos es ponderado por el inverso del factorial.
Luego el peso de un vértice está dado por:
∑(𝑒𝐴)𝑖𝑗𝑗
Si 𝐴 es una matriz diagonal, 𝐴 = diag (𝜆1, 𝜆2, … , 𝜆𝑛), la matriz exponencial se obtiene de
manera muy sencilla, esto es, 𝑒𝐴 = diag (𝑒𝜆1 , 𝑒𝜆2 , … , 𝑒𝜆𝑛).
Sin embargo, las matrices con las que se trabajará no serán diagonales. Cuando 𝑒𝐴 no es
diagonal, una manera de calcular 𝑒𝐴 es haciendo uso de la forma canónica de Jordan.
Sea J la forma canónica de Jordan de una matriz A y sea 𝐽 = 𝐶−1𝐴𝐶. Entonces 𝐴 = 𝐶𝐽𝐶−1 y
𝑒𝐴 = 𝐶𝑒𝐽𝐶−1.
Ejemplo. Se tiene la matriz 𝐴 = (3 −1−2 2
). Los valores propios de A son 𝜆1 = 1 y 𝜆2 = 4
con vectores propios correspondientes:
𝑣1 = (12) y 𝑣2 = (
1−1).
Entonces:

Protocolo de Tesis
Página 13 de 30
𝐶 = (1 12 −1
) , 𝐶−1 = −1
3(−1 −1−2 1
) , 𝐽 = 𝐷 = (1 00 4
) , 𝑒𝐽 = (𝑒 00 𝑒4
),
𝑒𝐴 = 𝐶𝑒𝐽𝐶−1 = −1
3(1 12 −1
) (𝑒 00 𝑒4
) (−1 −1−2 1
)
= −1
3( −𝑒 − 2𝑒
4 𝑒4 − 𝑒−2𝑒 + 2𝑒4 −2𝑒 − 𝑒4
)~ (37.3 −17.29−34.58 20.01
)
Hay ciertas propiedades matemáticas de la exponencial de una matriz cuando se trabaja con
matrices simétricas. Una matriz 𝐴 = (𝑎𝑖𝑗) de 𝑛 × 𝑛 se denomina simétrica si 𝐴𝑇 = 𝐴, es
decir 𝑎𝑖𝑗 = 𝑎𝑗𝑖 . En otras palabras las columnas de A son también los renglones de A.
Las matrices simétricas conmutan bajo el producto, esto es si A y B son simétricas, entonces
AB = BA. Luego, si AB = BA se cumple que: 𝑒𝐴+𝐵 = 𝑒𝐴𝑒𝐵.
El teorema Golden-Thompson establece que si 𝑒𝐴+𝐵 = 𝑒𝐴𝑒𝐵 entonces:
tr (𝑒𝐴+𝐵) ≤ tr(𝑒𝐴𝑒𝐵)
Es decir, la traza de la exponencial de dos matrices es menor o igual que la traza del producto
de las exponenciales de las matrices.
Li y Zhao (2014) mencionan que la desigualdad es una herramienta básica en mecánica
cuántica y en teoría de grupos. El teorema fue demostrado por Golden y Thompson
independientemente en 1965.
A continuación se muestra un ejemplo de cómo se puede utilizar la exponencial de la matriz
para asignar un peso a los nodos de la red.
𝐹:
Figura 5: Red con 11 nodos sin pesos
La matriz de adyacencia de la gráfica F está dada por:

Protocolo de Tesis
Página 14 de 30
𝐴(𝐹) =
(
0 0 0 0 1 1 0 0 0 0 00 0 0 1 1 1 0 0 1 1 10 0 0 0 0 1 0 0 0 1 00 1 0 0 1 0 0 1 1 0 01 1 0 1 0 0 0 1 0 1 01 1 1 0 0 0 0 1 0 1 10 0 0 0 0 0 0 0 0 0 10 0 0 1 1 1 0 0 0 0 00 1 0 1 0 0 0 0 0 0 00 1 1 0 1 1 0 0 0 0 10 1 0 0 0 1 1 0 0 1 0)
Luego la exponencial de la matriz es:
𝑒𝐴(𝐹) =
3.71 5.56 2.46 3.52 5.27 5.82 0.74 3.42 1.84 5.1 3.73
5.56 15.7 5.81 9.91 12 13.3 2.35 7.84 6.34 13.2 10.4
2.46 5.81 4.16 2.94 4.38 6.54 0.97 2.99 1.71 6.33 4.53
3.52 9.91 2.94 8.14 8.56 7.53 1.04 6.11 4.87 7.36 5.4
5.27 12 4.38 8.56 11 10.3 1.45 7.3 4.7 10.2 7.31
5.82 13.3 6.54 7.53 10.3 13.7 2.28 7.3 4.38 12.6 9.92
0.74 2.35 0.97 1.04 1.45 2.28 1.83 0.92 0.67 2.25 2.68
3.42 7.84 2.99 6.11 7.3 7.3 0.92 5.95 3.14 6.56 4.77
1.84 6.34 1.71 4.87 4.7 4.38 0.67 3.14 3.86 4.38 3.39
5.1 13.2 6.33 7.36 10.2 12.6 2.25 6.56 4.38 12.8 9.73
3.73 10.4 4.53 5.4 7.31 9.92 2.68 4.77 3.39 9.73 8.71
Luego la centralidad de los vértices estaría dada por el vector 𝑣.
𝑣 = [41.18, 102.3, 42.83, 65.38, 82.55, 93.62, 17.19, 56.31, 39.28, 90.54, 70.54]
A continuación se muestra la gráfica F con el tamaño de los pesos de acuerdo al vector v.
Figura 6: Gráfica F con centralidad exponencial.

Protocolo de Tesis
Página 15 de 30
2.3.2 Centralidad espectral
Otra medida relacionada con la complejidad de una red es la que se obtiene por medio del
espectro de una gráfica.
Consideremos una matriz 𝐴 = (𝑎𝑖𝑗) de tamaño 𝑛 × 𝑛. Decimos que un vector u de tamaño
n es vector propio de A si existe un número real r tal que 𝐴𝑢 = 𝑟𝑢.
El determinante de una matriz cuadrada A se escribe como |𝐴| o det 𝐴. El polinomio
característico |𝜆𝐼 − 𝐴| de la matriz de adyacencia A de G es llamado el polinomio
característico de G y se escribe como 𝑃𝐺(𝜆). Los valores propios de A (es decir las raíces de
|𝜆𝐼 − 𝐴|) y el espectro de A (que consiste de los valores propios) son también llamados los
valores propios y el espectro de G, respectivamente. Si 𝜆1, … , 𝜆𝑛 son los valores propios de
G, el espectro es denotado por 𝑆𝑝(𝐺) = [𝜆1, … , 𝜆𝑛].
Si A es simétrica, esto es 𝑎𝑖𝑗 = 𝑎𝑗𝑖, para todas las entradas 1 ≤ 𝑖, 𝑗 ≤ 𝑛 entonces hay n
soluciones reales del polinomio característico. En caso de que la matriz sea no negativa, esto
es, 𝑎𝑖𝑗 ≥ 0 para todas las entradas 𝑖, 𝑗, entonces hay valores propios 𝑟 ≥ 0. El máximo de los
valores propios:
𝑟(𝐴) = max{𝑟: 0 ≤ 𝑟 valor propio de 𝐴} se llama radio espectral de A.
Para determinar otra medida de centralidad, se hace uso del Teorema de Perrón. En 1907, el
matemático Oskar Perron (de la Peña, 2012) demostró el siguiente teorema:
Sea A una matriz no negativa y sea r su radio espectral, entonces:
1) r es valor propio de A;
2) existe un vector propio u de A tal que 𝐴𝑢 = 𝑟𝑢 y todas las entradas de 𝑢 son no
negativas;
3) si A es la matriz de adyacencia de una gráfica conexa, entonces valen:
a. r es raíz simple del polinomio característico de A y
b. el vector 𝑢 tiene todas sus entradas > 0.
Si G es una gráfica conexa y A es su matriz de adyacencia, los valores u(x) para x nodo de G
determinan la función de centralidad espectral. Interpretamos u(x) como una medida de la
complejidad de la red G en el nodo x (de la Peña, 2012).
𝐵:
Figura 7: Gráfica B

Protocolo de Tesis
Página 16 de 30
La matriz de adyacencia de la gráfica B está dada por:
𝐴(𝐵) =
(
0 1 1 0 0 01 0 1 0 1 11 1 0 1 0 10 0 1 0 0 00 1 0 0 0 00 1 1 0 0 0)
,
luego,
𝑃𝐻(𝜆) =|
|
𝜆 −1 −1 0 0 0−1 𝜆 −1 0 −1 −1−1 −1 𝜆 −1 0 −10 0 −1 𝜆 0 00 −1 0 0 𝜆 00 −1 −1 0 0 𝜆
|
|= 𝜆6 − 7𝜆4 − 4𝜆3 + 5𝜆2,
𝑆𝑝(𝐻) = [1 − √21
2,√21 + 1
2,−√5 + 1
2,√5 − 1
2, 0].
El radio espectral es 𝑟(𝐴(𝐵)) =√21+1
2≅ 2.7912 y el vector propio u correspondiente
satisface la ecuación 𝐵𝑢 = 𝑟𝑢, esto es:
{
𝑢2 + 𝑢3 =
√21 + 1
2𝑢1
𝑢1 + 𝑢3 + 𝑢5 + 𝑢6 =√21 + 1
2𝑢2
𝑢1 + 𝑢2 + 𝑢4 + 𝑢6 =√21 + 1
2𝑢3
𝑢3 =√21 + 1
2𝑢4
𝑢2 =√21 + 1
2𝑢5
𝑢2 + 𝑢3 =√21 + 1
2𝑢6
, con solución 𝑢 =
[
2
√21 + 1
2
√21 + 1
2112 ]
Cada elemento del vector u determina la centralidad espectral de los nodos de la gráfica, en
el ejemplo anterior el nodo B y el nodo C son los más centrales, como posiblemente se habría
esperado, en la figura 11 se muestra la gráfica B con el tamaño de los nodos de acuerdo al
vector 𝑢.
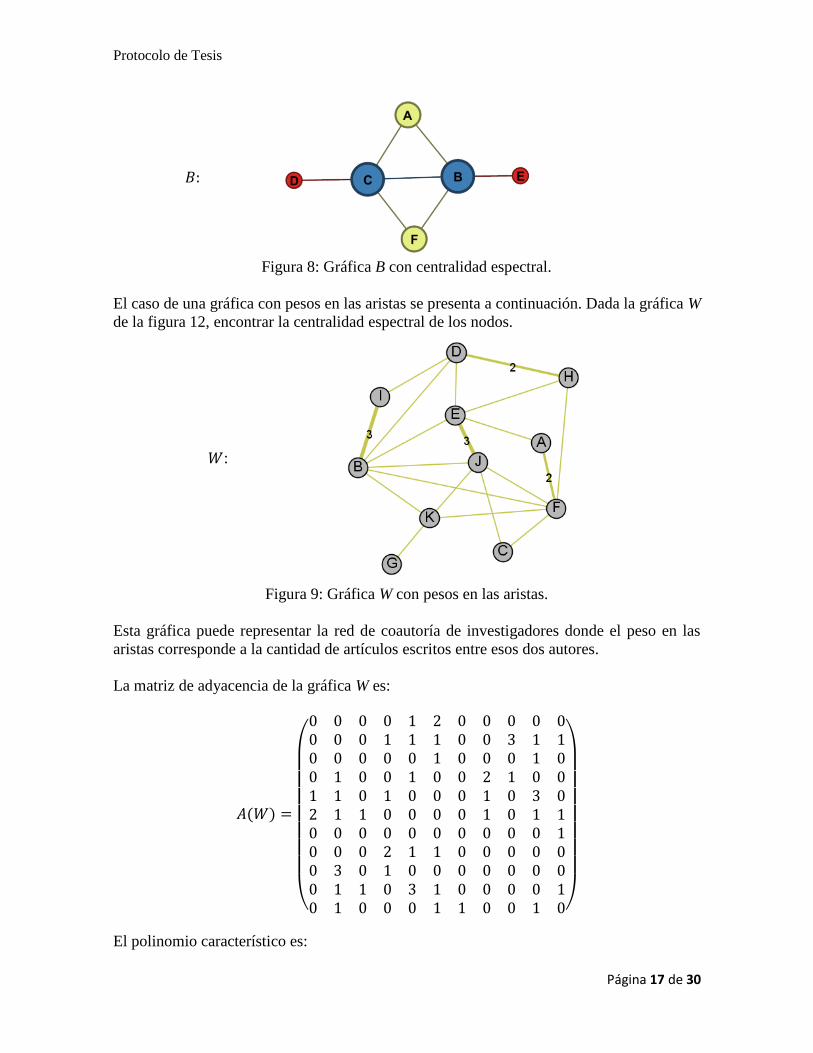
Protocolo de Tesis
Página 17 de 30
𝐵:
Figura 8: Gráfica B con centralidad espectral.
El caso de una gráfica con pesos en las aristas se presenta a continuación. Dada la gráfica W
de la figura 12, encontrar la centralidad espectral de los nodos.
𝑊:
Figura 9: Gráfica W con pesos en las aristas.
Esta gráfica puede representar la red de coautoría de investigadores donde el peso en las
aristas corresponde a la cantidad de artículos escritos entre esos dos autores.
La matriz de adyacencia de la gráfica W es:
𝐴(𝑊) =
(
0 0 0 0 1 2 0 0 0 0 00 0 0 1 1 1 0 0 3 1 10 0 0 0 0 1 0 0 0 1 00 1 0 0 1 0 0 2 1 0 01 1 0 1 0 0 0 1 0 3 02 1 1 0 0 0 0 1 0 1 10 0 0 0 0 0 0 0 0 0 10 0 0 2 1 1 0 0 0 0 00 3 0 1 0 0 0 0 0 0 00 1 1 0 3 1 0 0 0 0 10 1 0 0 0 1 1 0 0 1 0)
El polinomio característico es:
Protocolo de Tesis
Página 18 de 30
𝑃𝑤(𝜆) = 𝜆
11 − 42𝜆9 − 28𝜆8 + 494𝜆7 + 290𝜆6 − 2296𝜆5 − 584𝜆4 + 4124𝜆3 − 438𝜆2 − 1649𝜆 + 306
𝑆𝑝(𝑊) = [−4.04,−3.25,−2.70,−1.91,−0.72, 0.19, 0.80, 1.41, 1.88, 2.67, 5.67].
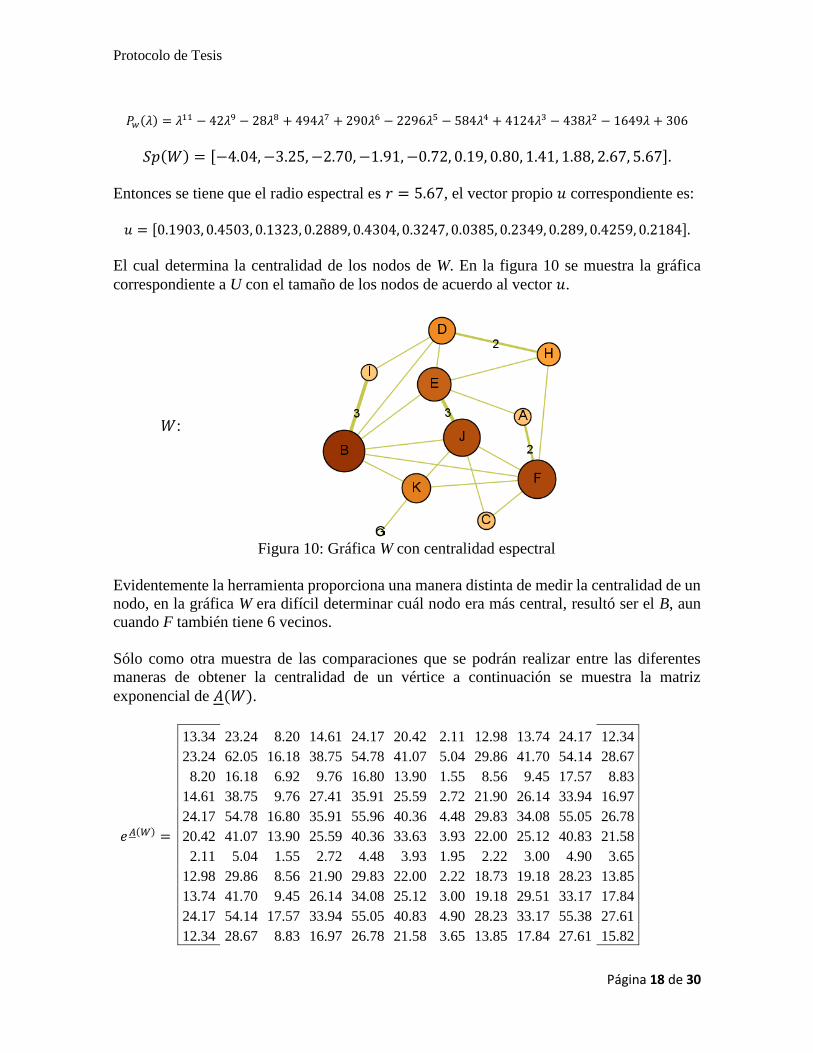
Entonces se tiene que el radio espectral es 𝑟 = 5.67, el vector propio 𝑢 correspondiente es:
𝑢 = [0.1903, 0.4503, 0.1323, 0.2889, 0.4304, 0.3247, 0.0385, 0.2349, 0.289, 0.4259, 0.2184].
El cual determina la centralidad de los nodos de W. En la figura 10 se muestra la gráfica
correspondiente a U con el tamaño de los nodos de acuerdo al vector 𝑢.
𝑊:
Figura 10: Gráfica W con centralidad espectral
Evidentemente la herramienta proporciona una manera distinta de medir la centralidad de un
nodo, en la gráfica W era difícil determinar cuál nodo era más central, resultó ser el B, aun
cuando F también tiene 6 vecinos.
Sólo como otra muestra de las comparaciones que se podrán realizar entre las diferentes
maneras de obtener la centralidad de un vértice a continuación se muestra la matriz
exponencial de 𝐴(𝑊).
𝑒𝐴(𝑊) =
13.34 23.24 8.20 14.61 24.17 20.42 2.11 12.98 13.74 24.17 12.34
23.24 62.05 16.18 38.75 54.78 41.07 5.04 29.86 41.70 54.14 28.67
8.20 16.18 6.92 9.76 16.80 13.90 1.55 8.56 9.45 17.57 8.83
14.61 38.75 9.76 27.41 35.91 25.59 2.72 21.90 26.14 33.94 16.97
24.17 54.78 16.80 35.91 55.96 40.36 4.48 29.83 34.08 55.05 26.78
20.42 41.07 13.90 25.59 40.36 33.63 3.93 22.00 25.12 40.83 21.58
2.11 5.04 1.55 2.72 4.48 3.93 1.95 2.22 3.00 4.90 3.65
12.98 29.86 8.56 21.90 29.83 22.00 2.22 18.73 19.18 28.23 13.85
13.74 41.70 9.45 26.14 34.08 25.12 3.00 19.18 29.51 33.17 17.84
24.17 54.14 17.57 33.94 55.05 40.83 4.90 28.23 33.17 55.38 27.61
12.34 28.67 8.83 16.97 26.78 21.58 3.65 13.85 17.84 27.61 15.82

Protocolo de Tesis
Página 19 de 30
Luego la centralidad de los vértices estaría dada por el vector 𝑣.
𝑣 = [169.33, 395.47, 117.71, 253.71, 378.21, 288.44, 35.55, 207.33, 252.93, 374.99, 193.95]
De acuerdo al vector 𝑣 el nodo más central sigue siendo B, pero bajo esta medida son más
centrales E y J que F. A continuación se muestra la gráfica W con centralidad exponencial.
𝑊:
Figura 11: Gráfica W con centralidad exponencial.
Luego si se compara con la centralidad espectral de la misma matriz 𝐴(𝑊), sin pesos, la cual
es la misma que la gráfica F de la figura 5. El espectro de 𝑊 sin pesos es:
𝑆𝑝(𝑊) = [−2.70,−1.99, −1.63,−1.40, −0.40, 0, 0.18, 0.55, 1.14, 1.92, 4.30].
El radio espectral es 𝑟 = 4.30, el vector propio 𝑡 correspondiente es: 𝑡 = [0.179, 0.449, 0.188, 0.284, 0.361, 0.411, 0.071, 0.245, 0.170, 0.399, 0.309].
Si la red no es pesada, proporcionalmente no hay ninguna diferencia en el tamaño de los
nodos por centralidad espectral y por la exponencial de la matriz (Fig. 12). Estos análisis
serán centrales en el desarrollo de la tesis.
Figura 12: Gráfica W sin pesos, con centralidad exponencial y espectral.

Protocolo de Tesis
Página 20 de 30
3 Propuesta de investigación
Cómo se ha puesto en evidencia, las propuestas de medidas para la calidad del trabajo
científico o su impacto y el uso de ellos en el diseño o apoyo a la política científica, es un
tema de discusión actual. Además, los desarrollos en la comprensión de las redes de
coautoría y/o citación también son recientes y han dotado de nuevas herramientas a los
investigadores en redes. Así, la propuesta de investigación se centra en temáticas de
actualidad y con impactos potenciales dentro del desarrollo de la ciencia mexicana.
A pesar de que ya se mencionaron varios trabajos donde se especifican algunas limitaciones
de los índices o medidas para determinar la calidad de un científico o de sus publicaciones,
en varios países se están adoptando políticas públicas basadas en ellos (Pérez, 2006), dejando
de lado análisis más profundos sobre los mismos datos de la ciencia como tal. Entonces la
propuesta se centra en el desarrollo de un modelo para analizar las redes de citación y
coautoría a partir de los información de artículos catalogados en la WOS y/o de la base de
datos del Atlas de la Ciencia Mexicana, en adelante Atlas (Pérez, 2012).
El modelo parte de la noción de camino en una gráfica, para desarrollar una medida del
impacto de un artículo en la literatura, esta medida se basa en la exponencial de una matriz
𝑒𝐴 u otra función de peso para los nodos, donde la matriz A es la matriz de adyacencia de la
gráfica correspondiente a la red de citación.
A continuación se presenta una muestra del tipo de trabajo y análisis que se realizará.
Seleccionamos los 500 artículos más citados de matemáticas, escritos por investigadores con
adscripción a una institución mexicana, de la WOS. Primero hacemos la red de citación de
los artículos dentro del conjunto, es decir sólo se mapean los artículos en las referencias que
están dentro del conjunto inicial. La red correspondiente se muestra en la figura 13.
Figura 13: Red de los 500 artículos mexicanos más citados de matemáticas.

Protocolo de Tesis
Página 21 de 30
Como se observa la red no es conexa, hay muchos nodos aislados, en particular nos interesa
una red que sea conexa, entonces seleccionamos la componente más grande que contiene 22
nodos. El resultado se muestra en la figura 14.
𝐷:
Figura 14: Red dirigida con 22 nodos
Como se observa la gráfica es dirigida, los vértices están ordenados de izquierda a derecha
de acuerdo al año de publicación del artículo, van de 1982 a 2012, es decir el vértice n20
corresponde a un artículo publicado en 1982 y el vértice n11 a un artículo publicado en 2012.
La matriz de adyacencia de la red D es:
𝐴(𝐷) =
0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0
0 0 0 0 0 1 0 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0
0 0 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0
0 0 0 0 0 0 0 0 1 1 1 1 0 1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0

Protocolo de Tesis
Página 22 de 30
Las filas y columnas de la matriz están ordenadas de acuerdo a los vértices como sigue:
n20, n5, n4, n10, n6, n9, n19, n13, n7, n1, n21, n17, n14, n18, n15, n0, n12, n2, n8, n3, n16, n11
La matriz exponencial 𝑒𝐷 se muestra a continuación.
1 0 1 0 0 0.5 0 0.5 0.67 0.167 0.167 0.167 0.375 0.208 0.592 0.167 0 0 0 0 0 0
0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0
0 0 1 0 0 1 0 1 1.5 0.5 0.5 0.5 1.167 0.667 1.375 0.5 0 0 0 0 0 0
0 0 0 1 0 0 0 0 0 0 0 0 1 0 1.5 0 0 0 0 0 0 0
0 0 0 0 1 1 1 0 0 0 0 0 1.5 0 0.667 0.5 0.5 0.167 0.208 0.258 0.318 0.339
0 0 0 0 0 1 0 0 0 0 0 0 1 0 0.5 1 0 0 0 0 0 0
0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0.5 0.667 0.875 1.133 1.243
0 0 0 0 0 0 0 1 1 1 1 1 0.5 1.5 0.167 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 1 0 0 0 1 0 0.5 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1.5 2.167 3.042 3.508
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1.5 2.167 2.542
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1.5 1.167
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1.5
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
Como se observa en 𝑒𝐷 el número de caminos entre 𝑛12 y 𝑛11 es 3.508. Si se ve la gráfica
D, realmente hay más caminos entre los vértices 12 y 11, sin embargo como se mencionó
con anterioridad, la matriz exponencial arroja valores ponderados con el inverso del factorial.
En este caso la centralidad de los vértices estará dado por el total de caminos que pasa por el
vértice, se calcula como:
∑(𝑒𝐷)𝑖𝑗𝑗
Entonces la centralidad de los vértices es:
n20 n5 n4 n10 n6 n9 n19 n13 n7 n1 n21 n17 n14 n18 n15 n0 n12 n2 n8 n3 n16 n11
5.51 2 9.71 3.5 7.46 3.5 6.42 7.17 2.5 2 1 1 2 1 1 1 12.22 8.21 4.67 3.5 2 1

Protocolo de Tesis
Página 23 de 30
Claramente el vértice 12 es el más central o con mayor impacto en la red. Sin embargo hay
otros vértices que es importante observar, por ejemplo el vértice 13 tiene un impacto apenas
mayor al vértice al 19 y sin embargo el vértice 13 es citado 5 veces mientras que el vértice
19 sólo una. Esta forma de calcular el impacto de un artículo en la red de citación parece
mejor que el conteo de citas globales o locales. En la figura 15 se muestra la gráfica D con el
tamaño de los vértices de acuerdo al valor obtenido con la matriz exponencial.
Figura 15: Gráfica D con vértices de acuerdo a la matriz exponencial.
Sólo como una muestra de la discusión que se desarrollará en la tesis doctoral, a continuación
se muestra la gráfica D, pero con el tamaño de los vértices de acuerdo a las citas globales, es
decir el total de citas que tiene cada artículo en la WOS.
Figura 16: Gráfica D con tamaños de vértices de acuerdo a las citas totales

Protocolo de Tesis
Página 24 de 30
El vértice 5 es el artículo más citado, sin embargo en la red local no tiene un peso
significativo, lo cual no quiere decir que no sea un artículo importante, simplemente en el
conjunto no es representativo. En este caso, el vértice 12 tiene pocas citas en comparación al
vértice 5, en parte porque éste es de 1983 y el artículo 12 de 2005 y como se sabe los artículos
en matemáticas tienen un periodo de citación distinto al de otras áreas.
Como referencia a continuación se enlistan los autores de correspondencia de los artículos
que pertenecen a la red D.
Vértice Referencia
n0 Vossieck D, 2001, J Algebra, V243, P168,
n1 Delapena Ja, 1991, Commun Algebra, V19, P1795,
n4 Bautista R, 1983, J Lond Math Soc, V27, P212
n5 Hughes D, 1983, P Lond Math Soc, V46, P347
n6 Martinezvilla R, 1983, Invent Math, V72, P359,
n7 Delapena Ja, 1990, J Pure Appl Algebra, V64, P303,
n8 Geiss C, 2007, J Lond Math Soc, V75, P718,
n9 Bautista R, 1985, Invent Math, V81, P217,
n10 Martinezvilla R, 1983, J Pure Appl Algebra, V30, P277,
n12 Geiss C, 2005, Ann Sci Ecole Norm S, V38, P193,
n13 Delapena Ja, 1988, Manuscripta Math, V61, P183
n14 Geiss C, 1993, Arch Math, V60, P25,
n15 Assem I, 1996, Commun Algebra, V24, P187,
n17 Delapena Ja, 1993, J Algebra, V161, P171,
n18 Delapena Ja, 1996, Invent Math, V126, P287,
n19 Bautista R, 1985, Comment Math Helv, V60, P392,
n20 Bautista R, 1982, J Lond Math Soc, V26, P43
n21 Delapena Ja, 1992, T Am Math Soc, V329, P733
n11 Geiss C, 2012, J Am Math Soc, V25, P21
n2 Geiss C, 2006, Invent Math, V165, P589,
n3 Geiss C, 2008, Ann I Fourier, V58, P825
n16 Geiss C, 2011, Adv Math, V228, P329,
Por supuesto será interesante observar qué pasa con este tipo de medida en una gráfica de
una red de citación más grande y cuáles podrían ser sus implicaciones en la toma de
decisiones con relación a una política científica en particular. ¿Qué se necesita? Un
investigador que tenga trabajos con un peso fuerte en una red local, o un investigador cuyos
trabajos tienen más peso fuera de lo local… se espera que una de las aportaciones de este
trabajo sea en esa dirección.
Desde otra perspectiva hay preguntas interesantes que surgen al respecto.
¿Se pueden pesar los caminos de la red con una ponderación distinta al inverso del factorial?

Protocolo de Tesis
Página 25 de 30
Por ejemplo:
∑𝐴𝑘
2𝑘
∞
𝑘=0
¿Qué diferencias existirían?
¿Cuál funciona mejor?
Paralelamente se podrán realizar varias actividades de análisis para
identificar el poder predictivo de los datos sobre citas, evidenciando las diferencias y
similitudes con otras medidas como el factor de impacto, índice h, etc.
ubicar a nivel espacial cómo se dan las relaciones, a nivel de coautorías, entre
científicos mexicanos dentro del país, por estado, ciudad o centro de investigación.
indagar sobre la interacción que los científicos mexicanos tienen con el extranjero, la
base de datos del Atlas o WOS, permite obtener también dicha información.
comparar algunos indicadores (habiendo analizado su utilidad) con los de otros
países.
Con esos análisis se espera contribuir al diagnóstico de la ciencia mexicana, en cuanto a la
información de la producción científica y su posible uso en la toma de decisiones para apoyar
proyectos de investigación o proporcionar becas, entre otros.
Potencialmente también contribuiría a situar la ciencia mexicana en un ámbito global y a
buscar medios para impulsarla desde lo local con elementos basados en la comparación con
otros países.
3.1 Objetivos
3.1.1 Objetivo general
Desarrollar y aplicar un modelo que permita entender el fenómeno de citación a partir de la
red de citación.
3.1.2 Objetivos específicos.
Aplicar el modelo en al menos dos áreas del conocimiento: ciencias biológicas, físicas,
químicas, de la tierra, matemáticas, ingenierías, agrociencias, medicina, sociales o
humanidades.
Analizar la capacidad de predicción de la medida propuesta y compararla con otras
relacionadas sobre citas, coautorías e impacto.
Determinar una función de peso para los vértices de la red de citación que permita medir
mejor el impacto de un artículo científico.

Protocolo de Tesis
Página 26 de 30
3.2 Metodología
En términos metodológicos este trabajo es de corte cuantitativo y cualitativo, en general
cualquier trabajo sobre el análisis de la ciencia tiene esos dos componentes, ya que siempre
incluyen análisis matemáticos que van desde los muy someros hasta los más especializados,
pasando por un trabajo arduo en las bases de datos y finalmente dando una interpretación de
todo ello (López-Herrera et ál, 2012; Pedlebury, 2008).
Esencialmente los trabajos relacionados con los mapas o redes científicas se componen de
ocho etapas (Ibid):
1) Recopilación de la información
2) Preprocesamiento
3) Extracción de la red
4) Normalización
5) Creación de la red
6) Análisis
7) Visualización
8) Interpretación
Estas etapas serán desarrolladas durante la realización del trabajo. La primera se realizará de
la WOS y del Atlas de la Ciencia Mexicana, como ya se mencionó. El resto será parte
fundamental de este trabajo, por supuesto no será lo único ya que en nuestro caso en la etapa
de análisis incluiremos un nuevo modelo.
De la segunda a la cuarta etapa esencialmente se trata de un manejo con la base de datos.
3.3 Bases de datos
La limpieza o normalización de la base de datos suele ser un trabajo exhaustivo, hay varios
trabajos de investigación que mencionan la metodología que siguieron para el tratamiento de
bases de datos bibliométricas (Deville, Wang, Sinatra, Song, Blondel, Barabási, 2014).
Existen herramientas de software que ayudan en esa actividad, una con varias ventajas es
“Science of Science (Sci2)” (https://sci2.cns.iu.edu/user/index.php) que desarrolló la School
of Library and Information Science y el Cyberinfrastructure for Network Science Center de
la Universidad de Indiana. Esta herramienta es de código abierto lo que implica que se pueden
modificar los algoritmos y adecuarlos a las necesidades propias. Otra herramienta
desarrollada recientemente es SciMAT (http://sci2s.ugr.es/scimat/) cuyo objetivo es analizar
la evolución del conocimiento científico.
Sin embargo, aun con las herramientas existentes posiblemente será necesario desarrollar
algunos algoritmos para aplicar el modelo propuesto. Esto se verá en el transcurso de la
investigación.

Protocolo de Tesis
Página 27 de 30
4 Cronograma

Protocolo de Tesis
Página 28 de 30
5 Bibliografía básica
1. Adler, R; Ewing, J; Taylor, P. (2008). Citation Statistics. IMU-ICIAM-IMS.
2. Barabási, A.L; Jeong, H; Néda, Z; Ravasz, E; Schubert, A; Vicsek, T. (2002). Evolution
of the social network of scientific collaborations. Physica A, 311 (3-4), 590-614.
3. De la Peña, JA. (2011). Impact functions on the citation network of scientific articles.
Journal of Informetrics 5 (2011) 565– 573.
4. Egghe, L. (2010), The Hirsch index and related impact measures. Ann. Rev. Info. Sci.
Tech., 44(1): 65–114.
5. Lemarchand, G.A. (2012). The long-term dynamics of co-authorship scientific networks:
Iberoamerican countries (1973-2010). Research Policy, 41(2), 291-305.
6. Wang, D.S; Song, C.M; Barabasi, A.L. (2013). Quantifying Long-Term Scientific
Impact. Science. 342(6154), 127-312.
6 Bibliografía complementaria
1. Barabási, AL; Albert, R. (1999). Emergence of Scaling in Random Networks. Science,
286 (5439), 509-512.
2. Batista, P; Campiteli, OK; Martínez, A. (2006). Is it possible to compare researchers
with different scientific interests? Scientometrics. 68 (1), 179-189.
3. Benavente, JM; Crespi, G; Garone, LF; Maffioli, A. (2012). The impact of national
research funds: A regression discontinuity approach to the Chilean FONDECYT.
Research Policy, 41(8), 1461-1475.
4. Bornmann, L; Daniel, HD. (2005). Does the h-index for ranking of scientists really
work? Scientometrics. 65 (3), 391-392.
5. Bornmann, L; Daniel, HD (2007). What do we know about the h index? Journal of the
American Society for Information Science and Technology. 58 (9), 1381-1385.
6. Callon, M; Courtial, J. P; Penan, H. (1993). Cienciometría: la medición de la actividad
científica: de la bibliometría a la vigilancia tecnológica. Gijón: Trea.
7. Cvetkovic, D; Doob, M; Sachs, H. (1979). Spectra of Graphs. Academic Press. New
York.

Protocolo de Tesis
Página 29 de 30
8. De la Peña, JA. (2012). Sistemas de transporte en México: un análisis de centralidad en
teoría de redes. Realidad, datos y espacio Revista Internacional de Estadística y
Geografía, 3 (3) 72– 91.
9. De Solla Price, D. (1965). Networks of Scientific Papers. Science, 149 (3683), 510-515.
10. Deville, P; Wang, D; Sinatra, R; Song, C; Blondel, V; Barabási, A.L. (2014) Career on
the Move: Geography, Stratification and Scientific Impact. Nature, Scientific Reports, 4
(470).
11. Egghe, L. (2006). Theory and practise of the g-index. Scientometrics, 69(1), 131–152.
12. Freeman, L.C. (2000). Visualizing social networks. Journal of Social Structure, 1, 1-15.
13. Frenken, K; Hardeman, S; Hoekman, J. (2009). Spatial scientometrics: Towards a
cumulative research program. Journal of Informetrics, 3(3), 222-232.
14. Garfield, E. (2005). The Agony and the Ecstasy—The History and Meaning of the
Journal Impact Factor. International Congress on Peer Review And Biomedical
Publication.
15. Garfield, E. (2007). From the science of science to Scientometrics visualizing the history
of science with HistCite software. Journal of Informetrics, 3, 173-179.
16. Hirsch, J. E. (2005). An index to quantify an individual’s scientific research output.
Proceedings of the National Academic Science of the Unites States of America. 102(46),
16569–16573.
17. Hirsch, J. E. (2007). Does the h index have predictive power? Proceedings of the
National Academic Science of the Unites States of America. 104 (49), 19193–19198.
18. Hirsch, J. E. (2010). An index to quantify an individual's scientific research output that
takes into account the effect of multiple coauthorship. Scientometrics. 85 (3), 741-754.
19. Kumar Pan, R; Kaski, K; Fortunato, S. (2012). World citation and collaboration
networks: uncovering the role of geography in science. Nature, Scientific Reports,
2(902).
20. Lehmann, S; Jackson, A; Lautrup, B. (2006). Measure for measures. Nature, 444 (7122),
1003–1004.
21. Li, H; Zhao, D. (2014). An extension of the Golden-Thompson theorem. Journal of
Inequalities and Applications, 14. Disponible en:
http://www.journalofinequalitiesandapplications.com/content/2014/1/14
22. Liang, L.M. (2006). h-index sequence and h-index matrix: Constructions and
applications. Scientometrics. 69 (1), 153-159.

Protocolo de Tesis
Página 30 de 30
23. Lopez-Herrera, A.G; Cobo, M.J; Herrera-Viedma, E; Herrera, F. (2012). SciMAT: A
New Science Mapping Analysis Software Tool. Journal of the American Society for
Information Science and Technology, 63(8), 1609–1630.
24. Mazloumian, A. (2012). Predicting Scholars' Scientific Impact. Plos One. 7 (11).
25. Newman, M.E.J. (2001). The structure of scientific collaboration networks. Proc. Natl.
Acad. Ciencia. EE.UU., 98 (2), 404-409.
26. Pendlebury, D.A. (2008). White Paper Using Bibliometrics in Evaluating Research.
Thomson Reuters, http://wokinfo.com/media/mtrp/UsingBibliometricsinEval_WP.pdf.
27. Pérez, M.A. (2006). Usos y abusos de la cienciometría. Cinvestav, 1, 29-33.
28. Pérez, M.A. coord. (2012). Atlas de la Ciencia Mexicana 2012. Academia Mexicana de
Ciencias-Consejo Nacional de Ciencia y Tecnología. México, D.F.
29. Reynoso, C. (2008). Redes libres de escala en ciencias sociales: Significado y
perspectivas. Ier. Reunión Latinoamericana de Análisis de Redes Sociales. Univ.
Nacional de La Plata.
30. Thomson Reuters. (2008). White paper using bibliometrics: a guide to evaluating
research performance with citation data. http://thomsonreuters.com/products/ip-
science/04_030/using-bibliometrics-a-guide-to-evaluating-research-performance-with-
citation-data.pdf
31. Vinkler, P. (2007). Eminence of scientists in the light of the h-index and other
scientometric indicators. Journal of Information Science. 33 (4), 481-491.
32. Watts, D.J; Strogatz, S.H. (1998) Collective dynamics of “small-world” networks.
Nature, 393 (6684), 440-442.