metodos matem´ aticos para telecomunicaciones´ practicas ... · duda, el comando mas importante...
TRANSCRIPT

Metodos Matematicos para TelecomunicacionesPracticas de Laboratorio
Javier Vıa
Septiembre de 2017

Introduccion al Laboratorio
Funcionamiento del LaboratorioLas clases del Laboratorio de Metodos Matematicos para Telecomunicaciones (MMT) se impartiran
en el Laboratorio de Docencia del Grupo de Tratamiento Avanzado de Senal (laboratorio +1.109 de laETSIIT). Todas las practicas se realizaran en Matlab, y en alguna de ellas se empleara la toolbox CVX(http://cvxr.com/cvx/). El objetivo de las practicas consiste en experimentar gran parte de los contenidosque se ven en la teorıa de la asignatura, y al mismo tiempo complementar esta teorıa con conceptos basicosde optimizacion.
La realizacion de las practicas requiere llevar al dıa la asignatura. Cada practica viene acompanada deun guion explicativo, que se ha de leer antes de asistir al laboratorio. Tenga en cuenta que algunas practi-cas requieren la solucion teorica de ciertos ejercicios de las Hojas de Problemas de MMT. Resuelva losproblemas antes de asistir al laboratorio.
Asistencia, Calendario y EvaluacionLas practicas se realizaran en uno de los siguientes horarios
Lunes 12:30 - 14:30
Martes 12:30 - 14:30
Martes 16:30 - 18:30
Martes 18:30 - 20:30
y aproximadamente cada dos semanas. La asignacion de horarios la realizara la ETSIIT, y las semanasconcretas en las que se puede asistir al laboratorio se iran publicando en la web de la asignatura. La coin-cidencia de los horarios de practicas con otras asignaturas o actividades no constituira, en ningun caso,derecho a elegir grupo.
La asistencia al laboratorio es opcional, y no se debera entregar ningun trabajo relacionado con el mis-mo. La evaluacion de las competencias a adquirir en el laboratorio se realizara en las pruebas de evaluacionescritas (Parciales y Examen Final), siendo su peso del 30 % de la nota.
Gestion de CuentasLos alumnos podran asistir al laboratorio con sus portatiles. No obstante, si se opta por utilizar los PCs
del laboratorio, cada alumno tendra una cuenta de usuario y una contrasena que elegira en la primera sesionde practicas. Es muy importante que recuerde su contrasena. De no ser ası, perdera una sesion de practicas.
MatlabEn este laboratorio se asume que el alumno ya esta familiarizado con el entorno Matlab, por lo que estas
lıneas han de ser entendidas como un breve recordatorio, y no como un curso de introduccion a Matlab. Sin
1

2
duda, el comando mas importante de Matlab es el comando help, el cual le proporcionara una explicaciondetallada sobre cada funcion de Matlab (ej: help ones).
En ninguna de las practicas se utilizara la Toolbox de calculo simbolico de Matlab. Todos los desarro-llos teoricos necesarios para la realizacion de las practicas deberan ser realizados por el alumno antes deasistir al laboratorio.
En ocasiones sera deseable vaciar el workspace (funcion clear), cerrar las figuras (close), y limpiarla pantalla (clc). Debe recordar tambien que puede (y debe) introducir comentarios a sus programasutilizando %. Es una buena costumbre documentar correctamente sus programas, e incluir cabeceras deltipo que se muestra a continuacion:
% METODOS MATEMATICOS PARA TELECOMUNICACIONES%% Javier Vıa Rodrıguez% 17 de Septiembre de 2017%% Practica 1% Ejercicio 1%% En la primera parte se obtienen las soluciones teoricas% En la segunda se comprueban los resultados mediante simulaciones de Monte-Carlo
close allclc
Creacion de Vectores y MatricesEn Matlab se debe pensar en terminos de vectores y matrices, lo cual dara lugar a la eliminacion de
un gran numero de ciclos for innecesarios. Algunos comandos utiles para la generacion de vectores ymatrices se muestran en la Tabla 1.
Tabla 1: Generacion de Vectores y Matrices en MatlabFuncion/Operador Explicacion
: Creacion de vectores (ej 4:-2:-7)linspace Creacion de vectoreslogspace Creacion de vectoreszeros Matriz de cerosones Matriz de unoseye Matriz identidad
toeplitz Matriz con estructura de Toeplitz
Operaciones entre Vectores y MatricesLas operaciones entre matrices y vectores se pueden realizar elemento a elemento, o de la manera
estandar en algebra lineal. Por ejemplo, es importante tener en cuenta la diferencia entre los comandosA.*B y A*B. Mientras el primero realiza el producto de las matrices A y B elemento a elemento, el segundorealiza el producto matricial. En general, cuando hay lugar a confusion, la version del operador precedidadel punto indica que la operacion se realiza elemento a elemento. Ası, queda clara la diferencia entre lasoperaciones A.ˆ2 y Aˆ2.
Un tipo importante de operaciones entre vectores consiste en las operaciones logicas y las comparacio-nes. Este tipo de operaciones dan lugar a vectores logicos que se pueden emplear para indexar vectores.Para entender esto con un ejemplo, ejecute las siguientes lıneas de codigo y observe el resultado.

3
n = linspace(0,4*pi,200);x = sin(n);select = x > 0.8;x2 = x(select);
Otros comando utiles para operar sobre vectores o matrices se muestran en la Tabla 2.
Tabla 2: Operaciones MatlabFuncion Explicacionsum Suma de los elementosprod Producto de los elementos
cumsum Suma cumulativacumprod Producto cumulativofilter Operaciones de filtradoconv Operacion de convolucionerf Funcion error (relacionada con G)mean Media (empırica)var Varianza (empırica)std Desviacion estandar (empırica)
length Longitud de un vectorsize Dimensiones de una matrizsort Ordena vectoresfind Encuentra elementos en un vectormax Maximomin Mınimoabs Valor absolutonorm Norma de un vector o matriz
Generacion de Variables AleatoriasEn este laboratorio se trabajara con variables aleatorias. Las funciones Matlab mas utiles para nosotros
se muestran en la Tabla 3.
Tabla 3: Generacion de Variables AleatoriasFuncion Explicacionrand V.a. uniforme en (0, 1)randn V.a. Normal media cero y varianza unidad
randint Nos naturales equiprobables
Ademas, algunas herramientas graficas le podran resultar de ayuda a la hora de asimilar los conceptosteoricos. Pruebe las funciones disttool y randtool.
Representacion Grafica y Presentacion de ResultadosUna de las principales caracterısticas de Matlab consiste en la facilidad para obtener graficas. En este
laboratorio haremos un uso intensivo de estas propiedades, y recurriremos a funciones como las mostradasen la Tabla 4.

4
Tabla 4: Representacion GraficaFuncion Explicacionfigure Crea una nueva figura
subfigure Crea una subfiguraplot Representacion de un vector frente a otro
semilogx Semieje x en escala logarıtmicasemilogy Semieje y en escala logarıtmicaloglog Ambos ejes en escala logarıtmicastem representacion de secuencias discretasbar Grafico de barrashist Histogramasurf Representacion de superficies
contour Curvas de nivel
A la hora de presentar los resultados, resultara imprescindible la correcta identificacion de los ejes, asıcomo la utilizacion de leyendas y tıtulos para las figuras. La Tabla 5 contiene varias funciones que le serande gran ayuda.
Tabla 5: Documentacion/EtiquetacionFuncion Explicaciontitle Tıtulo de la figuraxlabel Semieje xylabel Semieje ylegend Leyendagrid Rejillazoom Zoomhold Mantiene las graficas anteriores
waitbar Crea una barra de esperadisp Mensajes por pantalla
sprintf Texto dependiente de parametros
Creacion de FuncionesCrear nuevas funciones en Matlab es muy sencillo. Solo necesita guardar un fichero .m con el nombre
deseado, el cual debera comenzar de la siguiente manera:
function [output1,output2] = nombrefunc(input1,input2,input3)
Tras la linea de definicion (y la correspondiente documentacion), la funcion realizara las operacionesdeseadas para generar, a partir de los argumentos de entrada input1, input2, input3, los argumentosde salida output1 y output2. Ası, podra llamar a su funcion desde la linea de comandos u otra funciono script de Matlab.

Indice general
1. Probabilidad y Simulaciones de Monte Carlo 61.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.2. Calculo Combinatorio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3. Teoremas de Bayes y Probabilidad Total . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2. Optimizacion I: Gradiente y Newton 82.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.2. Descenso por Gradiente y Metodo de Newton . . . . . . . . . . . . . . . . . . . . . . . . 102.3. Aplicacion a la Igualacion Ciega de Canales . . . . . . . . . . . . . . . . . . . . . . . . . 11
3. Transformacion de V.A.’s y Teoremas Asintoticos 133.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.2. Transformacion de V.A.’s y Teoremas Asintoticos . . . . . . . . . . . . . . . . . . . . . . 143.3. Deteccion de Impulsos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
4. Optimizacion II: Problemas Convexos y CVX 164.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164.2. Desigualdad de Chebychev . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174.3. Distribuciones de Maxima Entropıa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184.4. Asignacion de Potencias y Waterfilling . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5. Estimacion de una Variable Aleatoria 215.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215.2. Estimacion de una Variable Aleatoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215.3. Estimacion con Estadısticos Desconocidos . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5

Practica 1
Probabilidad y Simulaciones de MonteCarlo
1.1. IntroduccionEn esta practica se utilizara Matlab para simular dos experimentos aleatorios diferentes. En ambos ca-
sos, comprobaremos que las soluciones proporcionadas por la Teorıa de la Probabilidad (Tema 1 de MMT)concuerdan con los resultados empıricos obtenidos mediante simulaciones de Monte Carlo. La idea de lassimulaciones de Monte Carlo se sustenta en la Ley de los Grandes Numeros (Tema 3 de MMT), y con-siste en la realizacion de un elevado numero de experimentos aleatorios independientes y en la aplicacionde la definicion frecuencial de Probabilidad (Tema 1 de MMT). Es decir, dadas N realizaciones indepen-dientes de un determinado experimento aleatorio, contaremos el numero de veces (M ) que se satisface undeterminado suceso A y obtendremos
P (A) =M
N,
donde (·) indica que estamos obteniendo una estima de la probabilidad P (A). Obviamente, la estima seramas fiable a medida que aumentemos el numero de realizaciones N .
1.2. Calculo CombinatorioComenzaremos resolviendo el Problema 1 de la Hoja de Problemas 1.
Enunciado del ProblemaEn una clase de N alumnos se pide:
a) Probabilidad de que dos o mas de ellos celebren su cumpleanos en la misma fecha.
b) Probabilidad de que exactamente dos tengan la misma fecha de cumpleanos.
Considere el ano de 365 dıas sin tener en cuenta los anos bisiestos.
Ejercicio 1El objetivo de este ejercicio consiste en obtener una grafica que represente las dos probabilidades pe-
didas en funcion del numero de alumnos. La grafica debera mostrar las curvas teoricas y las obtenidasmediante simulaciones de Monte Carlo (4 curvas en total), y es imprescindible que se encuentre correcta-mente documentada. Algunos detalles a tener en cuenta son:
Se deberan obtener los resultados para todos los valores de N entre 2 y 100.
6

PRACTICA 1. PROBABILIDAD Y SIMULACIONES DE MONTE CARLO 7
Para evitar problemas numericos en las soluciones teoricas debera simplificar las expresiones de lasprobabilidades. La funcion prod puede ser util en esta parte.
En las simulaciones de Monte Carlo necesitaremos generar fechas de cumpleanos aleatorias, para loque emplearemos la funcion randint.
El experimento aleatorio consiste en la generacion aleatoria de N fechas de cumpleanos y en laobservacion de posibles coincidencias.
Las simulaciones de Monte Carlo se basaran en 1000 realizaciones independientes del experimentopara cada valor de N .
El tiempo de simulacion ha de ser bastante inferior a un minuto.
Evite el uso innecesario de ciclos for. Por ejemplo, al generar la fechas.
Utilice una barra de espera (funcion waitbar) para mostrar la evolucion de las simulaciones.
1.3. Teoremas de Bayes y Probabilidad Total
Enunciado del ProblemaEn la segunda parte de esta practica se profundizara en el ejemplo del Test de las Vacas Locas (Tema
1 de MMT). Para ello calcularemos la probabilidad de que, al someter al test a una ganaderıa de N vacas,se produzcan exactamente k falsos positivos. Es decir, para k vacas no enfermas, el test arroja un resultadopositivo.
Ejercicio 2 (Opcional)Al igual que en el ejercicio anterior, nuestro objetivo consiste en obtener una grafica que represente
la probabilidad pedida, en funcion de k, para una ganaderıa de N = 100 vacas. La grafica mostrara laprobabilidad teorica y la calculada mediante simulaciones de Monte Carlo, debera estar correctamentedocumentada, y tendra en cuenta los siguientes detalles:
Definiremos los sucesos:
• L: {“La vaca esta loca”}• T : {“El resultado del test es positivo”}
y trabajaremos con las probabilidades P (L) = 0.005, P (T |L) = 0.95, P (T |L) = 0.95.
En las simulaciones de Monte Carlo necesitaremos generar vectores que indiquen si las vacas estanlocas y si los tests resultan positivos. Para generar estas variables con las probabilidades deseadas sepuede utilizar la funcion rand.
Ademas de la grafica, el script de Matlab debera mostrar por pantalla (utilice las funciones dispy sprintf) las probabilidades (teoricas y obtenidas mediante simulaciones) P (T ), P (L|T ) yP (L|T ).
Genere al menos 10000 experimentos independientes. La ejecucion del programa deberıa ser practi-camente instantanea.

Practica 2
Optimizacion I: Descenso porGradiente y Metodo de Newton
2.1. IntroduccionEn esta practica se presentaran dos algoritmos basicos de optimizacion, capaces de encontrar un mınimo
local de una determinada funcion de coste. A pesar de su simplicidad, estos algoritmos constituyen losingredientes basicos para las sofisticadas tecnicas de optimizacion que se analizaran en la Practica 4. Engeneral, un problema de optimizacion se puede escribir de la siguiente manera:
minimizarx
f0(x)
sujeto a fi(x) ≤ bi, i = 1, . . . ,m,
hj(x) = cj , j = 1, . . . , n,
donde x es un vector con las variables a optimizar, f0(x) es una funcion de coste, y las funciones fi(x),hj(x) establecen ciertas restricciones en el diseno de nuestro vector x.
En esta practica nos centraremos en el caso particular en el que no se tienen restricciones. Es decir, elproblema anterior se reduce a
minimizarx
f0(x).
Para resolver este tipo de problemas, recurriremos a algoritmos de descenso, que son algoritmos iterativosen los cuales la solucion x se actualiza como
xn+1 = xn + µ∆xn ,
donde xn representa el valor de x en la n-esima iteracion, µ es una constante (paso o factor de aprendizaje),y el vector ∆xn indica la direccion en la que se va a mover nuestra solucion x. La diferencia entre distintosalgoritmos de descenso radica en la eleccion del vector ∆xn , y los dos mas importantes son el descensopor gradiente y el metodo de Newton.
Descenso por GradienteEn el algoritmo de descenso por gradiente, la direccion ∆xn
se elige como el gradiente de la funcionde coste f0(x) cambiado de signo
∆x = −∇f0(x).
Ası, en cada iteracion del algoritmo, el vector x se movera (con paso µ) en la direccion de maximo descensode la funcion de coste.
8

PRACTICA 2. OPTIMIZACION I: GRADIENTE Y NEWTON 9
Metodo de NewtonEl principal problema del algoritmo de descenso por gradiente radica en su lenta convergencia en casos
en los que la curvatura de la funcion de coste es muy diferente para distintas direcciones. El metodo deNewton evita este problema seleccionando
∆x = −(∇2f0(x)
)−1∇f0(x),
donde x = [x1, . . . , xm]T , y
∇2f0(x) =
δ2f0(x)δx1δx1
· · · δ2f0(x)δx1δxm
.... . .
...δ2f0(x)δxmδx1
· · · δ2f0(x)δxmδxm
,es el Hessiano de la funcion de coste. Ası, el metodo de Newton elige ∆x para minimizar la aproximacionde segundo orden de la funcion de coste1
f0(x + ∆x) ' f0(x) +∇f0(x)T∆x +1
2∆T
x∇2f0(x)∆x,
o equivalentemente, para resolver la version linealizada de la condicion de optimalidad
∇f0(x + ∆x) ' ∇f0(x) +∇2f0(x)∆x = 0.
Convexidad y Factor de AprendizajeComo se ha comentado, los algoritmos propuestos permitiran encontrar un mınimo local de la funcion
de coste, el cual podrıa no coincidir con el mınimo global (ver Figura 2.1). Es aquı donde surge por primeravez la importancia del concepto de convexidad. Matematicamente, una funcion f0(x) es convexa si y solosi (sii)
f0(αx1 + (1− α)x2) ≤ αf0(x1) + (1− α)f0(x2), 0 ≤ α ≤ 1, ∀x1,x2,
o de manera grafica, sii el segmento que une dos puntos de la funcion no pasa por debajo de esta (ver Figura2.2). Existen diversas formas de comprobar si una determinada funcion es convexa, pero para nosotros serasuficiente con saber que la funcion f0(x) es convexa sii
∇2f0(x) � 0,
es decir, si su Hessiano ∇2f0
(x) es semidefinido positivo (no tiene autovalores negativos). Finalmente, ydesde un punto de vista practico, la convexidad de la funcion de coste f0(x) nos permite asegurar que losalgoritmos presentados en esta practica convergen al mınimo global.
Figura 2.1: Mınimos locales y mınimo global.
1En el caso de funciones de coste cuadraticas convexas, el metodo de Newton con paso µ = 1 proporcionarıa la solucion exactaen una sola iteracion.

PRACTICA 2. OPTIMIZACION I: GRADIENTE Y NEWTON 10
Figura 2.2: Ejemplos de funciones convexas (izquierda) y no convexas (derecha).
Por ultimo, debemos tener en cuenta que la seleccion del paso µ controlara la velocidad de conver-gencia del algoritmo. Sin embargo, si tomamos un valor de µ demasiado alto, los algoritmos propuestosno convergeran. Ası, en la practica se debera encontrar un compromiso entre la estabilidad y la velocidadde convergencia de los algoritmos. Para profundizar en los conceptos mencionados en esta introduccion,ası como para conocer tecnicas de optimizacion mucho mas sofisticadas, el alumno puede consultar lassiguientes referencias:
[1] J. Nocedal and S. J. Wright, Numerical Optimization, ser. Springer Series in Operations Research.New York, NY: Springer-Verlag, 1999.
[2] S. Boyd and L. Vandenberghe, Convex Optimization. Cambridge University Press, March 2004.
2.2. Descenso por Gradiente y Metodo de Newton
Enunciado del ProblemaEn la primera parte de la practica aplicaremos los algoritmos presentados para resolver el siguiente
problema de optimizacion
minimizarx
(xTAx
)2+ xTBx + xT c,
donde A y B son matrices y c es un vector columna.
Ejercicio 1El objetivo de este ejercicio consiste en representar las curvas de convergencia de los algoritmos de
descenso por gradiente y Newton. Se deberan obtener dos graficas, cada una de ellas dividida en dossubfiguras, en las cuales se represente la convergencia del algoritmo de descenso por gradiente y del metodode Newton. Cada una de las subfiguras mostrara 100 curvas (y el promedio de las mismas), las cuales seobtendran aplicando el algoritmo correspondiente con distintas inicializaciones aleatorias del vector x.Debera tener en cuenta lo siguiente:
La primera grafica mostrara la convergencia de los algoritmos para el caso con:
A =
1 0 00 1 00 0 1
, B =
2 1 01 2 10 1 2
, c =
111
.La segunda grafica mostrara la convergencia de los algoritmos para el caso con:
A =
1 0 00 1 00 0 1
, B =
0 1 −21 0 1−2 1 0
, c =
111
.

PRACTICA 2. OPTIMIZACION I: GRADIENTE Y NEWTON 11
Para estructurar su codigo, cree las funciones [f,x] = gradiente(mu,A,B,c,N) y[f,x] = newton(mu,A,B,c,N), las cuales toman como argumentos de entrada el paso, losparametros de la funcion de coste, y el numero de iteraciones del algoritmo correspondiente, y de-vuelve el vector f con la evolucion de la funcion de coste, y el valor final del vector x tras las Niteraciones. Cada una de las funciones inicializara el vector x con entradas Gaussianas de media ceroy varianza unidad (funcion randn) e implementara el algoritmo correspondiente.
Para implementar los algoritmos debera calcular el gradiente y el Hessiano de la funcion de coste.Esto lo puede realizar “a mano”, o consultando la literatura.
Ajuste los pasos de cada algoritmo por separado para maximizar la velocidad de convergencia ga-rantizando la estabilidad.
En ningun caso realice mas de 100 iteraciones de cada algoritmo. La ejecucion del script para obtenerlas dos graficas deberıa ser practicamente instantanea.
Observe las diferencias entre los dos algoritmos y entre los dos ejemplos. Reflexione sobre ellas.
2.3. Aplicacion a la Igualacion Ciega de Canales
Enunciado del ProblemaEn la segunda parte de la practica aplicaremos el algoritmo de descenso por gradiente a un problema
practico de comunicaciones. Considere una senal de comunicaciones discreta s[n] con sımbolos BPSK(s[n] = ±1). Dicha senal atraviesa un canal con respuesta al impulso h[n] y se le anade ruido blanco yGaussiano de media cero y varianza σ2. Es decir, nuestro modelo de senal es
x[n] = s[n] ∗ h[n] + r[n].
En el receptor unicamente tenemos acceso a x[n] (s[n], h[n] y r[n] son desconocidos), y nuestro objetivoconsiste en recuperar s[n]. Para hacer esto, construiremos un igualador w[n] tal que la senal a su salida
y[n] = x[n] ∗ w[n],
tenga la estructura de una senal BPSK, es decir, intentaremos obtener y[n] ' ±1. Para lograr este objetivo,minimizaremos la funcion de coste
f0(w) =1
N
N∑n=1
(y2[n]− 1
)2,
donde el vector w contiene los coeficientes del igualador, y la dependencia de la funcion de coste con westa implıcita en y[n]. Finalmente, todo el proceso queda ilustrado en la Figura 2.3.
Figura 2.3: Igualacion en un Sistema de Comunicaciones.

PRACTICA 2. OPTIMIZACION I: GRADIENTE Y NEWTON 12
Ejercicio 2 (Opcional)En este ejercicio evaluaremos las prestaciones del algoritmo de igualacion ciega basado en descenso
por gradiente. Para ello obtendremos una figura en la que se represente el MSE de la senal recuperada y[n],definido como
MSE =1
N
N∑n=1
E[(y[n]− s[n])2].
El MSE se debera representar en funcion de la SNR (SNR = 10 log10(σ2)), y se evaluara para dos numerosde muestras diferentes (N = 100 y N = 1000). Ademas, se representara la senal recibida x[n] y la senalrecuperada y[n] para una realizacion con alta SNR. Los detalles de este ejercicio son los siguientes:
Genere la funcion [w,f] = blind_eq(x,n,mu,N_iter) que toma como argumentos de en-trada la senal x[n], la longitud (n) del igualador w, el paso µ y el numero de iteraciones, y quedevuelve el valor final del igualador, y el vector f con la evolucion de la funcion de coste. La funciondebera inicializar el igualador w en un vector de ceros con un uno en su posicion central.
A la hora de aplicar el algoritmo de descenso por gradiente le resultara util expresar la senal y[n] demanera matricial
y = Xw,
donde la matriz X se obtiene a partir de la senal recibida x[n]. Para construir X le sera de ayuda lafuncion toeplitz.
Utilice un paso µ = 0.01 y limite el algoritmo a 500 iteraciones.
Utilice h = [-0.1 0.2 1 0.2 -0.1] como filtro distorsionador, y obtenga igualadores den = 7 coeficientes.
Para las operaciones de filtrado utilice la funcion filter.
En la evaluacion del MSE, tenga en cuenta que la senal recuperada y[n] puede estar retrasada ycambiada de signo con respecto a s[n]. Corrija este efecto (utilizando la senal original) antes decalcular el MSE.
Para obtener el MSE, promedie los resultados de 100 experimentos aleatorios. En cada uno de ellosse generara la senal de comunicaciones y el ruido de manera independiente.
Evalue el MSE para SNRs entre 0 y 30 dB, con pasos de 5 dB. Represente el MSE en decibelios,esto es 10 log10(MSE).
Utilice una barra de espera (funcion waitbar) y evite el uso innecesario de ciclos for. La ejecu-cion del script para obtener las tres figuras deberıa llevar menos de un minuto.

Practica 3
Transformacion de Variables Aleatoriasy Teoremas Asintoticos
3.1. IntroduccionEn esta practica se trabajara con variables aleatorias, profundizando en los conceptos presentados en
los Temas 2, 3 y 4 de MMT. En concreto, se generaran variables aleatorias con una fdp determinada (Tema3 de MMT), y se analizaran las consecuencias de Teorema del Lımite Central (Tema 3 de MMT) y delTeorema de la Convolucion (Tema 4 de MMT).
Generacion de Variables AleatoriasTal como se explica en el Tema 3 de MMT, para generar una variable aleatoriaX con Funcion Distribu-
cion FX(x), unicamente necesitamos obtener una variable aleatoria Y uniforme en [0, 1] (funcion rand)y aplicar la transformacion
X = F−1X (Y ).
Teorema del Lımite CentralEl Teorema del Lımite Central asegura que, bajo ciertas condiciones sencillas (ver Tema 3 de MMT),
la combinacion lineal de N →∞ variables aleatorias independientes (Xk)
Y = lımN→∞
N∑n=1
anXn,
se distribuye como una variable aleatoria Gaussiana de parametros
ηY =
N∑n=1
anηXn , σ2Y =
N∑n=1
a2nσ2Xn.
Teorema de la ConvolucionEn el Tema 4 de MMT se demuestra que, dadas dos variables aleatorias independientes X1, X2, con
fdp’s fX1(x1), fX2
(x2), la fdp de la suma Y = X1 +X2 se obtiene como
fY (y) = fX1(y) ∗ fX2
(y).
13

PRACTICA 3. TRANSFORMACION DE V.A.’S Y TEOREMAS ASINTOTICOS 14
3.2. Transformacion de V.A.’s y Teoremas Asintoticos
Enunciado del ProblemaEn la primera parte de la practica generaremos variables aleatorias Xk con fdp
fXk(xk) = a+ xk, 0 ≤ xk ≤ 1,
donde a es una constante que debera obtener “a mano”. Ademas, comprobaremos la validez de los Teo-remas de la Convolucion y del Lımite Central, para lo cual se sumaran hasta 15 variables aleatorias Xk
independientes.
Ejercicio 1En este ejercicio se obtendran dos graficas. La primera de ellas mostrara la fdp fXk
(xk) y la compararacon la version normalizada del histograma obtenida a partir de la definicion frecuencial de la probabili-dad. La segunda grafica ira mostrando los resultados, para la suma de n = 2, . . . , 15 variables aleatoriasindependientes, de la fdp teorica (obtenida mediante el Teorema de la Convolucion), la aproximacion pro-porcionada por el Teorema del Lımite Central, y la version normalizada del histograma. En la resolucionde este problema debera tener en cuenta:
Obtenga los histogramas a partir de 105 realizaciones de la variable aleatoria en cuestion. Utilice lasfunciones de Matlab hist y bar con 100 bins en el rango de la variable aleatoria correspondiente.
Para aplicar el Teorema de la Convolucion, utilice la funcion conv.
Dibuje las fdp’s teoricas y la aproximacion mediante el Teorema del Lımite Central evaluando 1000puntos en el rango de la variable aleatoria.
Haga pausas de 2 segundos entre las graficas utilizando la funcion pause.
Para aplicar el Teorema del Lımite Central necesitara calcular “a mano” la media y la varianza(teoricas) de las v.a.’s Xk.
Evite ciclos for innecesarios. La ejecucion del script deberıa llevar aproximadamente un minuto ymedio.
3.3. Deteccion de Impulsos
Enunciado del ProblemaLa segunda parte de la practica esta inspirada en el Problema 9 de la Hoja de Problemas 2. En concreto,
se considera un transmisor que emite impulsos de dos tipos. La amplitud de los impulsos tipo I sigue unafdp de Rayleigh
fX(x) = xe−x2/2, x ≥ 0.
La amplitud de los impulsos de tipo II sigue una fdp normal con media ηX = 5 y varianza σ2 = 1. Elreceptor decide el tipo de impulso transmitido comparando la amplitud de cada impulso recibido con unumbral µ. Si la amplitud es mayor que µ se decide que el impulso transmitido fue de tipo II; en casocontrario se decide que fue de tipo I.

PRACTICA 3. TRANSFORMACION DE V.A.’S Y TEOREMAS ASINTOTICOS 15
Ejercicio 2 (Opcional)En este ejercicio generaremos amplitudes aleatorias con las distribuciones correspondientes a los dos
tipos de impulsos, y obtendremos la fdp de la amplitud considerando que la probabilidad a priori de losimpulsos de tipo I es P (I) = 0.7. Ademas dibujaremos la ROC (Receiver Operation Characteristic) deldetector, la cual representa la probabilidad de perdida (decidir tipo I cuando en realidad era tipo II) frentea la de falsa alarma (decidir tipo II cuando en realidad era tipo I). En concreto, se han de obtener cuatrograficas teniendo en cuenta lo siguiente:
La primera grafica representara la fdp teorica y el histograma normalizado para los impulsos de tipoI.
La segunda grafica representara la fdp teorica y el histograma normalizado para los impulsos de tipoII.
La tercera grafica representara la fdp teorica y el histograma normalizado de la amplitud de losimpulsos.
La cuarta grafica representara la ROC en escala logarıtmica (funcion loglog).
Dibuje las fdp’s en el intervalo [0, 10]. Evalue las fdp’s teoricas en 100 puntos, y obtenga los histo-gramas a partir de 106 realizaciones independientes y empleando 100 bins.
Para obtener la ROC debera ir variando el umbral µ. Ası, para cada µ obtendra una probabilidad defalsa alarma y una probabilidad de perdida.
Tome 100 valores de µ equiespaciados entre 0 y 10, y represente tanto la ROC teorica (debera ob-tenerla de manera analıtica) como la estima basada en simulaciones de Monte Carlo (a partir de las106 realizaciones).
Dibuje la ROC para valores de las probabilidades de perdida y falsa alarma entre 10−5 y 1.
Evite ciclos for innecesarios. La ejecucion del script deberıa llevar unos diez segundos.

Practica 4
Optimizacion II: Problemas Convexos yCVX
4.1. Introduccion
Optimizacion Convexa y CVXEn esta practica revisitaremos los problemas de optimizacion
minimizarx
f0(x)
sujeto a fi(x) ≤ bi, i = 1, . . . ,m,
hj(x) = cj , j = 1, . . . , n.
Al igual que en la Practica 2, el concepto clave en los problemas de optimizacion es el concepto deconvexidad. En concreto, el problema de optimizacion anterior es un problema convexo sii
La funcion de coste f0(x) es convexa.
Las funciones fi(x) en las restricciones con desigualdades son convexas.
Las funciones hj(x) en las restricciones con igualdades son lineales. Es decir hj(x) = aTj x.
De manera equivalente, el problema de optimizacion es convexo sii la funcion de coste es convexa y elfeasible set, definido como el conjunto de vectores x que satisfacen las restricciones, es convexo (verFigura 4.1).
Figura 4.1: Ejemplos de conjuntos convexos (izquierda) y no convexos (derecha).
Aunque la resolucion de problemas de optimizacion requerirıa un curso completo, la idea principal quetodo ingeniero debe conocer es que “una vez que un problema de optimizacion esta formulado como unproblema convexo, podemos decir que el problema esta resuelto”. El alumno interesado podra profundizaren la teorıa y aplicaciones de la optimizacion convexa consultando el libro:
[2] S. Boyd and L. Vandenberghe, Convex Optimization. Cambridge University Press, March 2004.
16

PRACTICA 4. OPTIMIZACION II: PROBLEMAS CONVEXOS Y CVX 17
donde encontrara un gran numero de detalles sobre la aplicacion del metodo de los multiplicadores deLagrange, la funcion dual, y las condiciones de optimalidad de un vector x.
En esta practica resolveremos varios problemas de optimizacion convexos mediante la toolbox CVX deMatlab. Esta toolbox, desarrollada por M. Grant y S. Boyd en la universidad de Stanford, permite resolverproblemas de optimizacion presentados de una manera muy intuitiva. La toolbox y su documentacion, asıcomo un gran numero de ejemplos, se pueden descargar de manera gratuita desde http://cvxr.com/cvx/.
Entropıa y CapacidadAdicionalmente, esta practica nos permitira introducir algunos conceptos clave en Teorıa de la Infor-
macion. En concreto, se introduce el concepto de entropıa de una variable aleatoria discreta
H(X) = −∑k
pk log2(pk),
y su analogo (entropıa diferencial) para variables aleatorias continuas
H(X) = −∫fX(x) log2(fX(x))dx,
donde pk son las probabilidades de los diferentes valores en el rango de la variable aleatoria y fX(x)es la fdp. La entropıa es una medida de incertidumbre (diferente a la varianza) de una variable aleatorıa,y nos indica el numero medio de bits necesarios para codificar dicha variable (para recuperarla con unadeterminada precision en el caso de v.a.’s continuas).
El segundo concepto de Teorıa de la Informacion con el que trabajaremos es el de la Capacidad deShannon
C(SNR) = BW log2(1 + SNR),
la cual indica la maxima tasa binaria a la que es posible la transmision sin errores por un canal de ancho debanda BW y relacion senal a ruido
SNR = P |h|2/σ2,
donde P es la potencia transmitida, h es la ganancia del canal, y σ2 es la varianza del ruido aditivo blancoy Gaussiano. Finalmente, para el alumno interesado en la Teorıa de la Informacion se recomienda el libro:
[3] T. Cover and J. Thomas, Elements of Information Theory. New York, NY, USA: Wiley-Interscience,1991.
4.2. Desigualdad de Chebychev
Enunciado del ProblemaComenzaremos esta practica utilizando la Toolbox CVX para evaluar la desigualdad de Chebychev, la
cual asegura que, para cualquier variable aleatoria X con media ηX y varianza σ2X , se cumple
P (|X − ηX | < KσX) ≥ 1− 1
K2.
Como se ha visto en la teorıa (Tema 3 de MMT), esta desigualdad es en general muy conservadora. En estaparte de la practica trataremos de obtener la distribucion que proporciona unos resultados mas cercanos ala cota de Chebychev.
Ejercicio 1El objetivo de este ejercicio consiste en obtener y dibujar la fdp fX(x) de la variable aleatoria X , con
media ηX y varianza σ2X , que maximiza la probabilidad
P (|X − ηX | ≥ KσX).
Para resolver el problema debera tener en cuenta lo siguiente:

PRACTICA 4. OPTIMIZACION II: PROBLEMAS CONVEXOS Y CVX 18
Para encontrar la distribucion discretizaremos (tome 200 puntos equiespaciados) los posibles valoresde X en el intervalo [ηX − 2Kσ, ηX + 2Kσ].
Debera tener en cuenta las restricciones propias de una fdp:∫fX(x)dx = 1, fX(x) ≥ 0.
Ademas debera introducir las restricciones que garantizan ηX = 0 y σX = 3.
Obtenga la distribucion para un valor de K = 1.5.
Presente en pantalla (funciones disp y sprintf) la probabilidad predicha por la desigualdad deChebychev y la obtenida mediante CVX.
La ejecucion del script deberıa ser practicamente instantanea.
¿Podrıa obtener la fdp fX(x) de manera analıtica?
4.3. Distribuciones de Maxima Entropıa
Enunciado del ProblemaEn esta parte de la practica encontraremos mediante CVX las distribuciones de maxima entropıa entre
aquellas que satisfacen un conjunto de restricciones. En concreto, consideraremos las variables aleatoriascon rango acotado, las v.a.’s con varianza acotada, y las v.a.’s con rango positivo y media predeterminada.
Ejercicio 2El objetivo de este ejercicio consiste en representar las tres fdp’s buscadas. En la busqueda de las fdp’s
debera tener en cuenta lo siguiente:
Al igual que en el ejercicio anterior, necesitara discretizar la variable aleatoria. Elija un intervaloadecuado y discretice utilizando 50 puntos.
Si introduce como funcion de coste la expresion de la entropıa obtendra un error. Consulte en ladocumentacion de CVX la lista de funciones soportadas.
Genere las funciones:
• [x,f] = maxent_rango_acotado(a,b,N)
• [x,f] = maxent_var_acotada(mu,sigma,N)
• [x,f] = maxent_media_fija_rango_pos(mu,N)
que devuelven la fdp en el vector f evaluada en los puntos indicados en el vector x para cada uno delos problemas. Los parametros de entrada seran el numero de puntos (N = 50), el rango (a, b), ladesviacion tıpica (sigma), y la media (mu).
Una vez observadas las distribuciones, aproxımelas por una fdp conocida y superponga las dos curvasen la misma figura. ¿Podrıa obtener las soluciones de manera analıtica?
4.4. Asignacion de Potencias y Waterfilling
Enunciado del ProblemaEn la ultima parte de la practica se aborda un problema de asignacion de potencias. En concreto, con-
sideramos que disponemos de N canales ortogonales (por ejemplo, N bandas de frecuencia), donde cadacanal tiene una ganancia hk (k = 1, . . . , N ) y una varianza de ruido (blanco y Gaussiano) σ2. Disponemos
PRACTICA 4. OPTIMIZACION II: PROBLEMAS CONVEXOS Y CVX 19
de una potencia de transmision P , la cual deberemos repartir entre los diferentes canales con el objetivo demaximizar la capacidad resultante. Es decir, tenemos el problema de optimizacion
maximizarp
N∑k=1
log
(1 +
pk|hk|2
σ2
)sujeto a pk ≥ 0, k = 1, . . . , N,
N∑k=1
pk ≤ P,
donde p = [p1, . . . , pN ] es el vector de potencias a optimizar, el cual representa la potencia asignada acada canal.
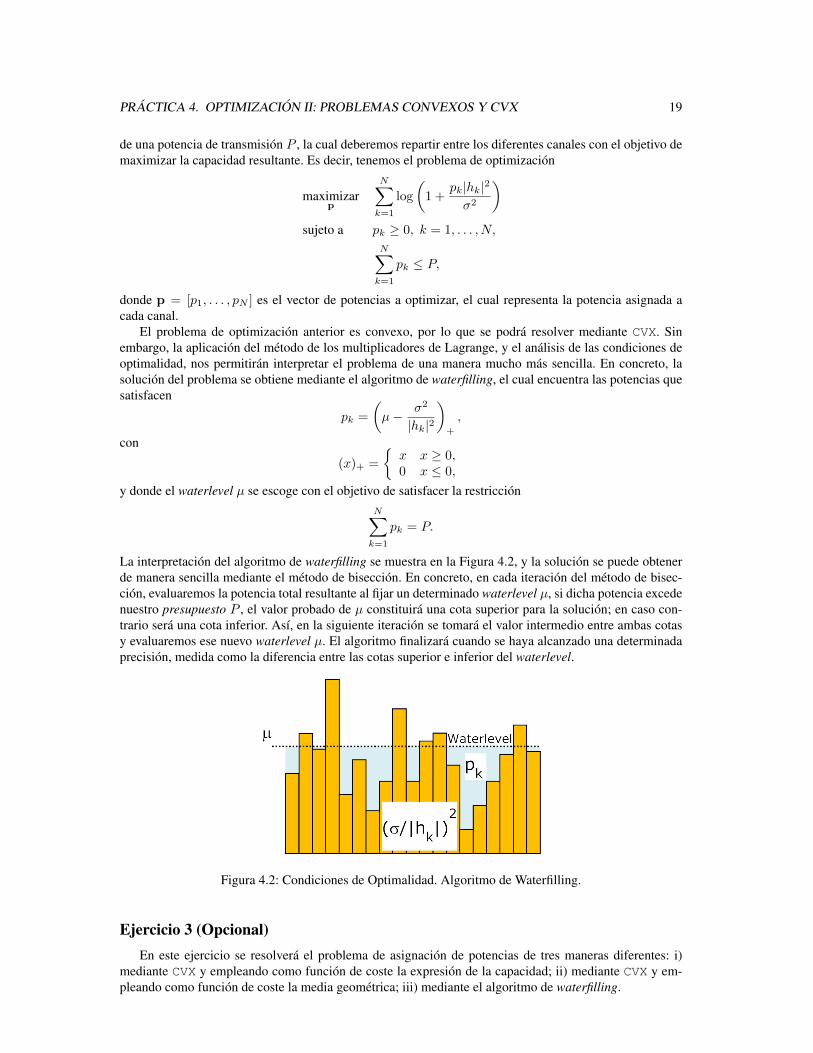
El problema de optimizacion anterior es convexo, por lo que se podra resolver mediante CVX. Sinembargo, la aplicacion del metodo de los multiplicadores de Lagrange, y el analisis de las condiciones deoptimalidad, nos permitiran interpretar el problema de una manera mucho mas sencilla. En concreto, lasolucion del problema se obtiene mediante el algoritmo de waterfilling, el cual encuentra las potencias quesatisfacen
pk =
(µ− σ2
|hk|2
)+
,
con
(x)+ =
{x x ≥ 0,0 x ≤ 0,
y donde el waterlevel µ se escoge con el objetivo de satisfacer la restriccionN∑k=1
pk = P.
La interpretacion del algoritmo de waterfilling se muestra en la Figura 4.2, y la solucion se puede obtenerde manera sencilla mediante el metodo de biseccion. En concreto, en cada iteracion del metodo de bisec-cion, evaluaremos la potencia total resultante al fijar un determinado waterlevel µ, si dicha potencia excedenuestro presupuesto P , el valor probado de µ constituira una cota superior para la solucion; en caso con-trario sera una cota inferior. Ası, en la siguiente iteracion se tomara el valor intermedio entre ambas cotasy evaluaremos ese nuevo waterlevel µ. El algoritmo finalizara cuando se haya alcanzado una determinadaprecision, medida como la diferencia entre las cotas superior e inferior del waterlevel.
Figura 4.2: Condiciones de Optimalidad. Algoritmo de Waterfilling.
Ejercicio 3 (Opcional)En este ejercicio se resolvera el problema de asignacion de potencias de tres maneras diferentes: i)
mediante CVX y empleando como funcion de coste la expresion de la capacidad; ii) mediante CVX y em-pleando como funcion de coste la media geometrica; iii) mediante el algoritmo de waterfilling.

PRACTICA 4. OPTIMIZACION II: PROBLEMAS CONVEXOS Y CVX 20
Como resultado del ejercicio se obtendran dos graficas. La primera de ellas mostrara la asignacion depotencias (el vector p) obtenida con cada metodo. En la segunda grafica se comprobara que la solucioncumple las condiciones de optimalidad. Para ello, se representara el vector con las inversas de las SNRsindividuales (σ2/|hk|2), y la suma de este con el vector de asignacion de potencias. Otros detalles son:
Utilice N = 128 canales, una potencia total P = 1, y una varianza de ruido de σ2 = 0.01.
Genere los canales hk como variables aleatorias independientes, con distribucion Gaussiana de mediacero y varianza unidad.
Genere una funcion p = wf(snr,P) con parametros la potencia total (P ) y el vector de SNRs(con elementos |hk|2/σ2). La funcion debera inicializar las cotas superior e inferior del waterlevelen valores adecuados, y obtener la solucion (vector p) de waterfilling con una precision de 10−4.
Para comprobar las condiciones de optimalidad, dibuje los niveles de potencia en decibelios (10 log10(p)).
Compare el tiempo de ejecucion de los tres metodos para la asignacion de potencias utilizando loscomandos tic y toc.
Ejercicio 4 (Opcional)En este ejercicio se evaluara la ganancia proporcionada por la asignacion optima de potencias con
respecto a una distribucion uniforme de las mismas. Utilizando N = 128 y P = 1 debera obtener losresultados promediados (para realizaciones independientes de los canales) de la capacidad obtenida por losdos metodos. Tenga en cuenta:
Realice 500 simulaciones de Monte Carlo y promedie los resultados.
Represente en una grafica la capacidad (media o “ergodica”) obtenida por el algoritmo de waterfilling(funcion wf) y por la asignacion uniforme (pk = P/N ). La figura mostrara la capacidad frente a laSNR total (definida como −10 log10(σ2)). Emplee valores de SNR entre -10 y 40 dB con pasos de2dB.
Represente en una segunda figura la ganancia proporcionada por el algoritmo de waterfilling. Paraello, dibuje el cociente de las capacidades frente a la SNR. Interprete los resultados para altas y bajasSNRs.
La ejecucion del script no deberıa tardar mas de 20 segundos.

Practica 5
Estimacion de una Variable Aleatoria
5.1. IntroduccionEn esta ultima practica se aplicara la teorıa del Tema 5 de MMT. En concreto, se obtendran los esti-
madores de mınimo error cuadratico medio (MSE) mediante una constante, una recta (estimador lineal), yuna funcion generica (estimador sin restricciones). Los ejercicios propuestos se basan en el Problema 5 dela Hoja de Problemas 5, el cual debera resolverse antes de asistir al laboratorio.
5.2. Estimacion de una Variable Aleatoria
Enunciado del ProblemaDadas dos variables aleatorias independientes Y , G y uniformes en (0, 1), se obtiene una nueva v.a.
X = GY . Intentaremos estimar Y a partir de la observacion deX , para lo que obtendremos los estimadoresde mınimo error cuadratico medio mediante un constante, una recta, o una funcion generica.
Ejercicio 1En este ejercicio se evaluaran los estimadores lineal y sin restricciones de mınimo MSE. Ademas, se
dibujara el MSE (obtenido mediante simulaciones de Monte Carlo) de los estimadores lineales
Y = aX + b,
en funcion de los valores de a y b. Para resolver el ejercicio debera tener en cuenta lo siguiente:
Obtenga las estimas del MSE a partir de 105 realizaciones independientes de las variables aleatoriasG, Y y X . El MSE se obtendra como
1
N
N∑n=1
(Yn − Yn)2,
donde Yn, Yn representan una realizacion concreta de las variables aleatorias Y , Y .
Muestre por pantalla (disp y sprintf) el MSE de los estimadores optimos lineal y sin restriccio-nes.
Evalue el MSE de los estimadores lineales en funcion de a y b. Utilice 100 valores para cadaparametro, equiespaciados entre -2 y 2. Represente los resultados utilizando las funciones surfy contour.
21

PRACTICA 5. ESTIMACION DE UNA VARIABLE ALEATORIA 22
Superponga, en la figura con las curvas de nivel, el punto que representa el estimador lineal demınimo MSE.
Utilice una barra de espera y evite ciclos innecesarios. La ejecucion del script no deberıa llevar masde 40 segundos.
5.3. Estimacion con Estadısticos Desconocidos
Enunciado del ProblemaEn la derivacion de los estimadores optimos, ya sea mediante una cte., mediante una recta, o sin restric-
ciones, se asume conocida cierta informacion estadıstica, como la media, las varianzas, el coeficiente decorrelacion, o las medias condicionadas. Sin embargo, es frecuente que estos estadısticos no se conozcana priori. En este ejercicio evaluaremos el rendimiento de los estimadores anteriores en el caso en que losestadısticos se han de extraer de los datos. Ası, a partir de N observaciones de las variables aleatorias X eY , obtendremos las estimas de los estadısticos de la siguiente manera:
ηX =1
N
N∑n=1
Xn, σ2X =
1
N
N∑n=1
(Xn − ηX)2, CXY =1
N
N∑n=1
(Xn − ηX)(Yn − ηY ),
con expresiones analogas para la media y varianza de Y . A partir de estos estadısticos se podra obtener unaaproximacion a los estimadores optimos mediante una cte. y una recta. Para aproximar el estimador optimosin restricciones nos basaremos en el metodo de Parzen para estimar funciones densidad de probabilidad,que en nuestro caso se reduce a:
fXY (x, y) =1
2NπwXwY
N∑n=1
e− (x−Xn)2
2w2X e
− (y−Yn)2
2w2Y ,
es decir, obtenemos una estima de la fdp conjunta “colocando” una Gaussiana (de parametros wX , wY ) encada punto observado.1 A partir de esta estima podemos aproximar la media condicionada como:
E[Y |X = x] =
∫ ∞∞
yfY (y|x)dy =
∫∞∞ yfXY (x, y)dy∫∞∞ fXY (x, y)dy
=
∑Nn=1 Yne
− (x−Xn)2
2w2X∑N
n=1 e− (x−Xn)2
2w2X
.
Finalmente, la anchura del kernel wX se seleccionara mediante la Silverman’s rule:
wX = 1.06σXN−1/5.
Ejercicio 2 (Opcional)En este ejercicio se evaluaran las prestaciones de los tres estimadores para diferentes numeros de ob-
servaciones N . En particular, se obtendra una figura que represente el MSE de los tres estimadores paravalores de N entre 2 y 20. Para resolver el ejercicio tenga en cuenta lo siguiente:
Para cada valor de N debera obtener la aproximacion del estimador optimo y calcular su MSE.Para promediar los resultados, se repetira este procedimiento 1000 veces, obteniendo un estimadordiferente en cada caso.
Para un estimador fijo, el MSE se obtendra a partir de 1000 realizaciones independientes.
Genere una funcion y_opt = Estima_Parzen(x_test,x,y) que implemente la aproxima-cion del estimador optimo sin restricciones. La funcion tomara como argumentos los vectores x e y,conteniendo las N observaciones, y el vector xtest, a partir del cual se obtendran las estimas yopt. Lafuncion calculara el parametro wX empleando la Silverman’s rule.
1Note la relacion entre este metodo y el del histograma.

PRACTICA 5. ESTIMACION DE UNA VARIABLE ALEATORIA 23
Dibuje el MSE en escala logarıtmica (funcion semilogy).
Con la aproximacion del estimador sin restricciones observara ciertos errores (o malos resultados)para valores de N bajos. Intente corregir este problema modificando la funcion Estima_Parzen.
Utilice una barra de espera y evite ciclos innecesarios. El tiempo de ejecucion deberıa ser inferior aun minuto.