métodos estadísticos de la evaluación de la exactitud de productos derivados de...
TRANSCRIPT

1
Métodos estadísticos de la evaluación de la exactitud de productos derivados de sensores remotos Instituto de Clima y Agua, INTA Castelar
Teresa Boca; Gabriel Rodríguez

2
INDICE Introducción .............................................................................................................................................................. 4 Etapas en la determinación de Precisión Diseño y Análisis de mapas temáticos ........................................ 4
1.Diseño de muestreo ......................................................................................................................................... 5 1.1.Ventajas de un buen muestreo. .............................................................................................................. 5 1.2.Principios y consideraciones prácticas .................................................................................................. 6 1.3.Tipos de muestreo .................................................................................................................................... 6
Muestreo aleatorio simple .......................................................................................................................... 7 Muestreo aleatorio sistemático .................................................................................................................. 7 Muestreo aleatorio estratificado ................................................................................................................ 7 Muestreo por Rutas o itinerarios aleatorios ............................................................................................ 8
2. Validación de los resultados ......................................................................................................................... 8 2.1. ¿Qué se utiliza como verdad de terreno? ............................................................................................ 8
Muestreo a campo ....................................................................................................................................... 8 Otras imágenes o fotografías que se considere verdad de terreno .................................................... 9 Conocimiento idóneo de la zona. ............................................................................................................ 10
2.2. Costos ..................................................................................................................................................... 10 2.3 ¿Cuanta información se debe tomar? ................................................................................................. 10
3. Medidas y técnicas utilizadas para medir la calidad de los productos generados ............................. 11 3.1.Tipos de error y referencias .................................................................................................................. 11 3.2. Matriz de confusión: .............................................................................................................................. 11 3.3. Índices Globales .................................................................................................................................... 13
Exactitud global ........................................................................................................................................ 13 Intervalo de confianza para la exactitud global ....................................................................................... 14 Índice Kappa ............................................................................................................................................. 15
3.4. Índices por clases .................................................................................................................................. 15 Exactitud del productor ........................................................................................................................... 15 Exactitud de usuario ................................................................................................................................. 16
4. Consideraciones finales ............................................................................................................................... 17
ANEXO 1: Introducción al uso de R ............................................................................................................... 18
ANEXO 2: Algoritmo en R para el cálculo de las medidas de calidad de los productos derivados de sensores remotos. ............................................................................................................................................. 21
Bibliografía .............................................................................................................................................................. 24
INDICE de Figuras Figura 1: Etapas de trabajo en la validación de mapas .................................................................................... 5
Figura 2 Disposición espacial de las observaciones bajo un muestreo aleatorio ......................................... 7
Figura 3 Trabajo de muestreo a campo, profesional de INTA con mapas y GPS ........................................ 8

3
Figura 4 Fotografías tomadas in INTA Castelar a 1, 0.5 y 0.25 metros respectivamente. ......................... 9
Figura 5 Imagen de la zona de estudio provista desde google maps ............................................................. 9
Figura 6 Formato de los datos a analizar para obtener la matriz de confusión y sus índices derivados 12
Figura 7 Representación grafica de la matriz de confusión ........................................................................... 13
INDICE de Tablas Tabla 1 Esquema general de la matriz de información ................................................................................... 12
Tabla 2 Matriz de confusión resultante del ejemplo ........................................................................................ 13
Tabla 3 Cálculo de la exactitud del productor ................................................................................................... 15
Tabla 4 Errores de omisión .................................................................................................................................. 16
Tabla 5 Valores estimados de exactitud del usuario ....................................................................................... 16
Tabla 6 Errores de comisión ................................................................................................................................ 16

4
Métodos estadísticos de la evaluación de la exactitud de productos derivados de sensores remotos
Introducción
A partir del uso de la información derivada de sensores remotos se elaboran mapas de variables ambientales, tales como mapas de cobertura, de cultivos, de uso de la tierra, etc. A pesar de su creciente utilización, no es muy habitual realizar una validación del producto y acompañarlo de sus medidas de exactitud. Una de las causas podría ser que no existe entre la bibliografía técnica muchas descripciones accesibles de cómo obtener tales medidas. Este pequeño manual pretende poner al alcance de aquellos que trabajan en laboratorios de teledetección una herramienta para realizarlo.
Etapas en la determinación de Precisión Diseño y Análisis de mapas temáticos
De forma muy sintética podemos describir el proceso en las etapas diagramadas en la Figura 1. Primeramente la información obtenida del muestreo de campo a través de un diseño de muestreo apropiado, será utilizada en la definición de clases de la imagen bruta, este paso se obvia si se utiliza un método de clasificación no supervisado. Una vez completado el proceso de clasificación se obtendrá el mapa temático. Nuevamente a través de un diseño de muestreo se generará información de campo o verdad de terreno que será contrastada con la información del mapa y se logrará la validación de resultados. De esta forma se calcularán las distintas medidas de exactitud. La interpretación de las distintas medidas de exactitud nos generará el informe de validación o de calidad temática. En este manual nos concentraremos en el diseño de muestro de validación de resultados, el cálculo de las medidas de exactitud y la elaboración del informe de validación.
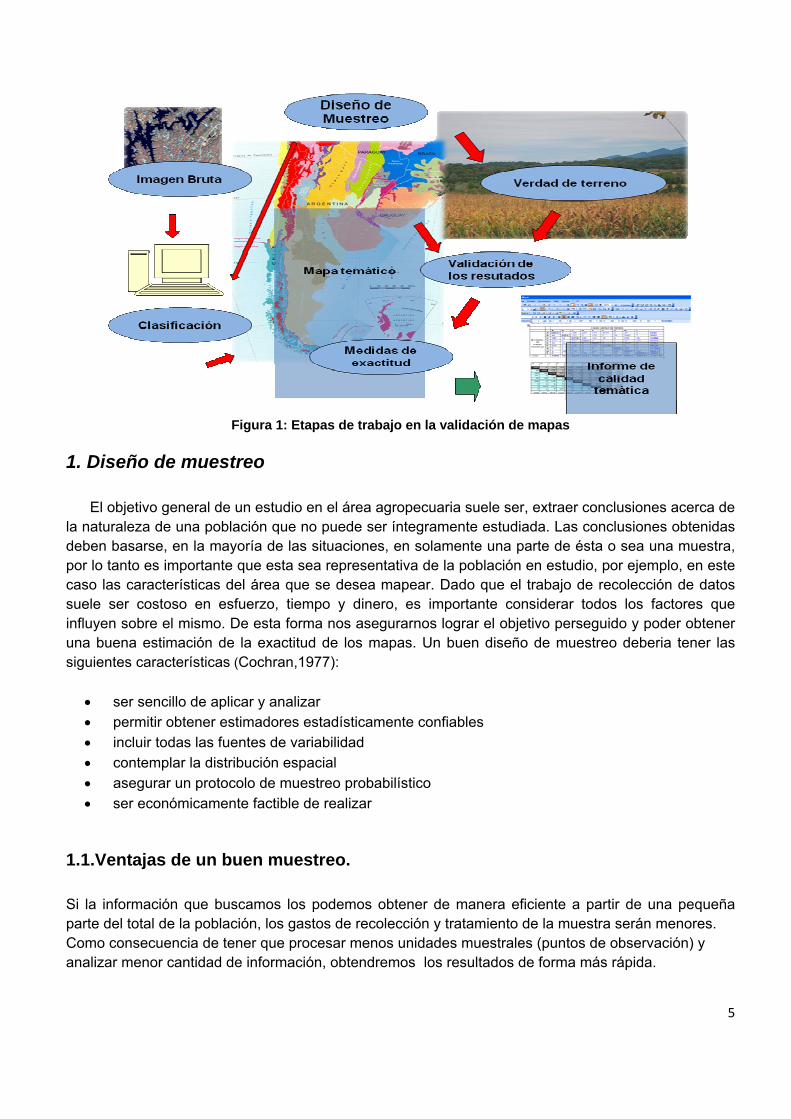
5
Figura 1: Etapas de trabajo en la validación de mapas
1. Diseño de muestreo El objetivo general de un estudio en el área agropecuaria suele ser, extraer conclusiones acerca de
la naturaleza de una población que no puede ser íntegramente estudiada. Las conclusiones obtenidas deben basarse, en la mayoría de las situaciones, en solamente una parte de ésta o sea una muestra, por lo tanto es importante que esta sea representativa de la población en estudio, por ejemplo, en este caso las características del área que se desea mapear. Dado que el trabajo de recolección de datos suele ser costoso en esfuerzo, tiempo y dinero, es importante considerar todos los factores que influyen sobre el mismo. De esta forma nos asegurarnos lograr el objetivo perseguido y poder obtener una buena estimación de la exactitud de los mapas. Un buen diseño de muestreo deberia tener las siguientes características (Cochran,1977):
• ser sencillo de aplicar y analizar • permitir obtener estimadores estadísticamente confiables • incluir todas las fuentes de variabilidad • contemplar la distribución espacial • asegurar un protocolo de muestreo probabilístico • ser económicamente factible de realizar
1.1.Ventajas de un buen muestreo. Si la información que buscamos los podemos obtener de manera eficiente a partir de una pequeña parte del total de la población, los gastos de recolección y tratamiento de la muestra serán menores. Como consecuencia de tener que procesar menos unidades muestrales (puntos de observación) y analizar menor cantidad de información, obtendremos los resultados de forma más rápida.

6
1.2.Principios y consideraciones prácticas
• Objetivo de la medición: Antes de organizar o seleccionar el método de muestreo, es muy importante tener bien definido el objetivo deseado, ya que este modificará la precisión necesaria y los datos a recolectar.
• Población a ser muestreada: Definir claramente la misma puede ser simple en muchos casos, pero no en todos. Esta debe coincidir con la población a la cual se quieren referir los resultados.
• Datos o información a colectar: Es importante relevar solo aquella información que nos es de utilidad y coincide con el objetivo en estudio de forma de hacer más eficiente el trabajo.
• Grado de precisión deseado: Los resultados estarán siempre sujetos a cierta incertidumbre, debido a los errores propios de los métodos de muestreo. Estos se pueden reducir al aumentar el tamaño de muestra (cantidad de observaciones realizadas), u obteniendo instrumental más preciso. El límite en el número de observaciones muchas veces lo determina el costo. El investigador debe tener en claro el error que puede ser tolerado en las estimaciones para determinar el número de muestras a tomar.
• Métodos de medición: Es necesario calibrar y conocer bien el método e instrumental de medición antes de aplicar el muestreo, para reducir al mínimo los errores de medición que se puedan controlar. Muchas veces los errores generados por el mal uso de los instrumentos de medición, o el trabajo sin un protocolo bien organizado puede ser causante de una variabilidad más alta que la propia de la variable observada.
• Prueba de entrenamiento Es necesario tener algún grado de conocimiento sobre las características de la población a muestrear, ya que de esto depende la precisión obtenida, y por ende el número de observaciones a realizar. En los casos donde no se cuente con dicha información habría que realizar una prueba de entrenamiento a campo antes de aplicar el diseño en la población de referencia.
• Organización del trabajo de campo Es necesario construir un organigrama de trabajo, contemplando los inconvenientes y sus posibles soluciones.
1.3.Tipos de muestreo
Existen diferentes criterios de clasificación de los tipos de muestreo, aquí solo se describirán los comúnmente utilizados en los muestreos a campo para la validación de mapas. Los métodos descriptos son aquellos que se basan en el principio de equiprobabilidad, lo que significa que trabajaremos de forma tal que todas las situaciones tengan igual probabilidad de ser observadas. Esto nos asegura la representatividad de la muestra extraída y son, por tanto, los más recomendables.
Entre los tipos de muestreo más aplicados se encuentran:

7
Muestreo aleatorio simple Primeramente se asigna un número a cada u.m.1 de la población y luego a través de algún método (tablas de números aleatorios, un ordenador, etc) se eligen tantas u.m. como sea necesario para completar el tamaño de muestra requerido (Figura 2 A).
Este procedimiento, atractivo por su simpleza, considera que las unidades experimentales son homogéneas y tiene poca o nula utilidad práctica cuando la población que estamos manejando podría llegar a ser heterogénea.
Existen varios programas que manejan datos espaciales, que nos permiten “tirar” un número “n” de puntos al azar sobre una imagen, obteniendo de esta forma las coordenadas de las u.m..
Muestreo aleatorio sistemático Primeramente se numeran los elementos de la población, aleatoriamente se extrae 1 (i).
Partiendo del numero aleatorio (i), las u.m. serán solo aquellas que ocupan los lugares i, i+k, i+2k,...,i+(n-1)k (Figura 2 B). Siendo k el resultado de dividir el tamaño de la población por el tamaño de la muestra: k=N/n. En los casos en que se dan periodicidades en la población ya podemos introducir una homogeneidad que no se da.
Muestreo aleatorio estratificado Consiste en considerar categorías típicas diferentes entre sí (estratos) que poseen gran
homogeneidad respecto a alguna característica. Lo que se pretende con este tipo de muestreo es asegurarse de que todos los estratos de interés estarán representados adecuadamente en la muestra.
Cada estrato funciona independientemente, pudiendo aplicarse dentro de ellos el muestreo aleatorio simple (Figura 2 C). Exige un conocimiento detallado de la población.
Figura 2 Disposición espacial de las observaciones bajo un muestreo aleatorio
A: simple; B: sistemático y C: estratificado
1 Para seguir con la terminología más común de la bibliografía, llamaremos unidad muestral
(u.m.) a cada punto de observación.

8
Muestreo por Rutas o itinerarios aleatorios Consiste en realizar los muestreos sobre itinerarios, que van ligados a la red vial o cualquier
terreno por el que se pueda circular y hacer observaciones a distancias prefijadas a los márgenes. Este método cuenta con numerosos adeptos por la comodidad de verificación sobre el terreno, a pesar de contar con críticas desfavorables. 2. Validación de los resultados.
El proceso de validación consiste en la comparación entre el valor asignado a un punto dado en el mapa y el valor observado en el mismo punto en el campo o u otra fuente considerada “verdad”. Los valores estimados de exactitud de clasificación son determinados para un producto y para la comparación entre diferentes productos. Antes de describir las distintas medidas de exactitud, veremos algunos criterios generales sobre las características de la información utilizada como verdad de terreno.
2.1. ¿Qué se utiliza como verdad de terreno?
Muestreo a campo Consiste en verificar de a través de observación directa el valor que corresponde a cada sitio.
Como se comentó en los párrafos anteriores, esta labor debe de estar acompañada de un protocolo de trabajo adecuado y un buen diseño de muestreo previo. Actualmente los avances tecnológicos tales como los GPS, el acceso a internet satelital, etc facilitan la labor (Figura ). Este procedimiento es el más adecuado, ya que tenemos total certeza del dato relevado. En muchas ocasiones, el área de muestreo no es totalmente accesible, por lo que se debe realizar un muestreo siguiendo las rutas o caminos existentes. Esto podría limitar las ventajas propias del método.
Figura 3 Trabajo de muestreo a campo, profesional de INTA con mapas y GPS

9
Otras imágenes o fotografías que se considere verdad de terreno. Dependiendo de la escala de validación, estas fotografías han resultado ser de mucha utilidad cuando se trata de zonas de grandes dimensiones, o cuando se trabaja en una región de difícil acceso. Por ejemplo el Instituto de Clima y Agua (http://climayagua.inta.gob.ar/), del Centro Nacional de Investigaciones Agropecuarias (CNIA) de INTA utiliza un Sistema de Sensores Aerotransportados (SSA) instalados a bordo de un avión Sky Arrow 650 TCNS E.R.A. (Environmental Research Aircraft)
Figura 4 Fotografías tomadas in INTA Castelar a 1, 0.5 y 0.25 metros respectivamente.
También podemos utilizar imágenes de mayor escala como las provistas por Google Maps
(http://maps.google.com.ar), que utiliza las imágenes del satélite QuickBird y recorre una órbita polar cada 90 minutos. Estas herramientas son de gran utilidad cuando se está trabajando en el reconocimiento de grandes áreas, donde un muestreo a campo se hace poco factible debido al costo que implicaría.
En un futuro próximo se espera que varios sistemas ópticos de alta resolución sean puestos en funcionamiento, dando por resultado mejores resoluciones, disponibilidad, variedad, y costos de las imágenes. Esto causará un permanente crecimiento en el uso de las imágenes derivadas de sensores remotos.
Figura 5 Imagen de la zona de estudio provista desde google maps

10
Conocimiento idóneo de la zona. Si bien la bibliografía especializada no se extiende mucho sobre esta posibilidad, es sabido que
es un procedimiento utilizado muy frecuentemente. En este caso no es posible evaluar el grado del conocimiento necesario, ni de aquel que está en condiciones de hacerlo, pero esto no lo invalida, en especial en aquellos centros e instituciones que están en contacto directo con productores y tienen gran experiencia acumulada. Tampoco es factible estimar ninguna medida de exactitud.
2.2. Costos
Si bien las imágenes de alta resolución como las Quickbird, ikonos, spot , o las fotografías aéreas suelen ser costosas (alrededor de u$a 25/ha), al momento de tomar las decisiones habría que comparar sus costos con los generados a campo considerando el jornal del observador de campo, los gastos de traslado, etc. Por otro lado, al momento de decidir por el uso de una imagen de alta resolución o una fotografía aérea hay que considerar además el costo de interpretación de las mismas, ya que muchas veces la integración de las imágenes, como la diferenciación de los distintas clases a campo, no es evidente y debe realizarse a través de un experto.
2.3 ¿Cuanta información se debe tomar?
Una de las etapas críticas del diseño de muestreo es la determinación del tamaño de muestra. Una muestra más grande que lo necesario implica utilizar más recursos mientras que una muestra más pequeña disminuye la utilidad de los resultados. Existen en la bibliografía algunas “recetas” prácticas, por ejemplo, Congalton (2009) sugiere como una guía general o buena "regla de oro", recoger un mínimo de 50 muestras para cada clase de mapa. Para un mapa con 8 clases debería pensarse en un mínimo de 400 muestras.
La estadística nos da otras herramientas, supongamos que estamos interesados en conocer la proporción que cubre un cultivo un área determinada (p). Previo al cálculo del tamaño de muestra debemos decidir cual queremos que sea la precisión de nuestra estimación (por ejemplo si decido trabajar con una precisión del 5% y observo un 43% podría confiar que el área cubierta por cultivo estaría entre un 38% y 48%) y el valor de confianza, dado que no se puede asegurar la precisión deseada, debido que trabajamos con una muestra. Generalmente se trabaja con valores de confianza del 95 o el 99%.
Podemos suponer que al observar una unidad de muestreo esta tengo o no la clase de interés, asignamos un valor de probabilidad de 50% y entonces utilizar la función de distribución binomial para los cálculos, y la formula correspondiente será: Donde: Z = valor de la función de distribución Normal acumulada para un área (1-α)/2
d = precisión. Como vemos la formula de n depende de la precisión, la confianza y del valor que queremos estimar (p), que en la mayoría de los casos no se conoce. Entonces podemos utilizar el valor p=0.5 propuesto
38505.0
5.0*5.0*96.1)1(2
2
2
2
==−
=d
ppZn

11
anteriormente, dado que maximiza el numerador (p(1-p)) y nos dará el tamaño máximo de muestra para obtener nuestro estimador con la precisión y confianza deseada.
3. Medidas y técnicas utilizadas para medir la calidad de los productos generados
3.1. Tipos de error y referencias Existen en la bibliografía distintas citas sobre valores de referencia de los índices de exactitud de
los productos derivados de sensores remotos. Entre ellos podemos referirnos al valor utilizado para los mapas de cobertura y ocupación del suelo por el Servicio Geológico de los Estados Unidos (Fallas, 2002) que indica que la exactitud global debe ser de al menos un 85% y que las categorías mapeadas deben tener un nivel de exactitud similar. Se pueden cometer distintos tipos de errores que pueden ser clasificados como:
• De atributo: se refiere a la asignación errónea de la clase en el mapa. • De localización: se refiere a la ubicación errónea de la clase en el mapa. • Globales: corresponde a errores de atributo y localización simultáneamente.
Según las técnicas que apliquemos podemos clasificarlas en
• Técnicas descriptivas: describen la situación a través de índices que resumen la información o Matriz de error o de confusión o Índices derivados de la matriz
• Técnicas analíticas: asignan valores de confianza a los índices calculados bajo ciertos supuestos.
o Intervalos de confianza de los índices estimados o Pruebas de hipótesis para los índices estimados
Las técnicas descriptas en este manual para medir el error en la clasificación generalmente no diferencian entre ambos.
3.2. Matriz de confusión: La misma es una matriz cuadrada en la que se compara la clasificación de la imagen con la
verdad de terreno. A través de la matriz de confusión se evalúa la exactitud de la clasificación, situando en las filas las clases o categorías de nuestro mapa y en las columnas las mismas clases para la verdad de terreno o campo. Las características más destacadas de esta matriz son:
• Presenta una visión general de las asignaciones, tanto de las clasificaciones correctas (elementos de la diagonal) como de las migraciones o fugas (elementos fuera de la diagonal).
• Recoge los denominados errores de omisión y de comisión o Errores de comisión: elementos que no perteneciendo a una clase aparecen en
ella. o Errores de omisión: elementos que perteneciendo a esa clase no aparecen en ella
por estar erróneamente incluidos en otra.
12
Tabla 1 Esquema general de la matriz de información
CLASES EN EL CAMPO
A1 A2 … AM Total mapa
EXACTITUD USUARIO
ERROR COMISION
CLASES MAPA
A1 a11* a12 … a1m a.1 a.1 / a.. 1- (a.1 / a..)
A2 a21 a22 … a2m a.2 a.2 / a.. 1- (a.2 / a..)
…. …
AM am1 … amm a.m a.m / a.. 1- (a.m / a..)
Total campo a1. a2. … a2. a..
EXACTITUD PRODUCTOR a1. / a.. a2.. / a.. … am. / a..
ERROR OMISIÓN 1-(a1. / a..) 1-(a2.. / a..) … 1-(am. / a..)
*Esta notación indica en los subíndices la posición dentro de la matriz, por ejemplo en valor con a12 hace referencia al valor correspondiente a la fila 1, columna 2. El . (punto) indica que el valor corresponde a la sumatoria del mismo a lo largo de la fila o columna, por ejemplo: a1. indica los valores de a sumados para toda la columna 1.
Para ejemplificar el cálculo de los índices derivados de la matriz de confusión se utilizarán los datos que corresponden a un muestro de validación de un mapa de cobertura con 10 clases codificadas como 13000, 13200, 21200; 22100; 22200; 22300; 23100; 23200; 41100; 52200 y 71000. Los datos fueron ordenados en 2 columnas, una de valores observados (a campo) y otra de valores clasificados (de mapa). Para los cálculos de los siguientes puntos se utilizó el programa de distribución libre y gratuito R (R, 2011). En el ANEXO 1 se encuentran la descripción del mismo, nociones básicas de uso y las sentencias necesarias para realizar los cálculos de este manual. Para utilizar el programa descripto en el anexo adjunto, el archivo con los datos de campo y sus correspondientes valores en la imagen pueden armarse en un tabla Excel y guardarse como archivos separado por comas (csv). Este programa admite múltiples formatos de archivo, utilizamos este por ser uno de los más extendidos y sencillos.
Figura 6 Formato de los datos a analizar para obtener la matriz de confusión y sus índices derivados

13
Ejemplo de matriz de confusión Tabla 2 Matriz de confusión resultante del ejemplo
CAMPO 13000 13200 21200 22100 22200 22300 23100 23200 41100 52200 71000 suma MAPA
MAPA
13000 39 0 0 0 1 0 2 0 0 0 0 42 13200 0 1 0 0 0 0 0 0 0 0 0 1 21200 10 0 33 0 11 0 32 1 1 0 0 88 22100 1 0 0 8 7 0 0 0 0 0 0 16 22200 0 0 1 7 489 1 62 8 0 1 0 569 22300 0 0 0 0 1 11 0 0 0 2 0 14
23100 16 0 11 14 106 2 77 0 0 0 0 226
23200 0 0 2 0 6 0 3 3 0 0 0 14 41100 0 0 0 0 0 0 0 0 0 0 0 0 52200 0 0 0 0 0 0 0 0 0 1 0 1 71000 0 0 0 0 0 0 0 0 0 0 4 4
suma CAMPO 74 1 47 29 621 14 176 4 1 4 4 975
Gráfico matriz confusión:
En la Figura 7 se puede visualizar en forma descriptiva el comportamiento de las distintas clases. Cada color representa en forma horizontal como los valores en la imagen se corresponden a los observados en el campo. Lo ideal seria que solo hubiese rectángulos en la línea diagonal como sucede con la clase 71000, 52200 y 13200. Las demás clases presentan errores, por ejemplo se clasificó como 23100 a clases que correspondían a 13000, 21200, 22100 y 22200.
C la s e s c a m p o
Cla
ses
imag
en
1 3 0 0 0
1 3 2 0 0
2 1 2 0 0
2 2 1 0 0
2 2 2 0 0
2 2 3 0 0
2 3 1 0 0
2 3 2 0 0
4 1 1 0 0
5 2 2 0 0
7 1 0 0 0
0 . 2 0 . 4 0 . 6 0 . 8
1 3 0 0 0
0 . 2 0 . 4 0 . 6 0 . 8
1 3 2 0 0
0 . 2 0 . 4 0 . 6 0 . 8
2 1 2 0 0
0 . 2 0 . 4 0 . 6 0 . 8
2 2 1 0 0
0 . 2 0 . 4 0 . 6 0 . 8
2 2 2 0 0
0 . 2 0 . 4 0 . 6 0 . 8
2 2 3 0 0
0 . 2 0 . 4 0 . 6 0 . 8
2 3 1 0 0
0 . 2 0 . 4 0 . 6 0 . 8
2 3 2 0 0
0 . 2 0 . 4 0 . 6 0 . 8
4 1 1 0 0
0 . 2 0 . 4 0 . 6 0 . 8
5 2 2 0 0
0 . 2 0 . 4 0 . 6 0 . 8
7 1 0 0 0
Figura 7 Representación grafica de la matriz de confusión
Los errores que se observan en la Figura 7 pueden ser cuantificados mediante distintos índices.
3.3. Índices Globales
Exactitud global

14
Se calcula como el número de unidades clasificadas correctamente, sobre el número total de unidades consideradas. Se obtiene sumando los elementos de la diagonal divididos por el Total de observaciones. Este índice tiende a sobrestimar la bondad de la clasificación. Sus valores se encuentran en el intervalo [0, 1], siendo la clasificación mejor cuanto más se acerque a la unidad.
Para el ejemplo el valor de Exactitud Global es de =
Suma de los valores de la diagonal / número de observaciones = (39 + 1 + 33 + 8 + 489 + 11 + 77 + 3 + 0 + 1 + 4)/975=666 /975= 0.68 %
Intervalo de confianza para la exactitud global
Si consideramos al valor calculado como estimador de la probabilidad de que cada muestra haya sido correctamente clasificada, además suponemos que el evento “número de errores y aciertos” sigue una distribución binomial, y que puede calcularse su función de distribución a través de una aproximación a la distribución Normal, entonces podemos hacer algunas inferencias sobre este estimador.
En este caso el intervalo de confianza de (1-α) para p esta dado por:
( )nn
ppzpICp21
11
21+
−−⋅
⋅±=−α
Si n×p ≥5 ; Donde: α= error admitido; n = tamaño de la muestra; p = proporción de la población que presenta determinada característica. Z = valor de la función normal acumulada para un área igual a 1- α/2 Para su cálculo en R (ver anexo Introducción al uso de R) debemos utilizar la función prop.test, cuyos argumentos son, el número de aciertos, el número total de datos. prop.test( aciertos,n,alternative = "two.sided") 95 percent confidence interval: 0.6474470 0.7070293 IC: { 0.65; 0.70} Existe un 95% de confianza que el intervalo calculado cruce el verdadero valor de la exactitud global de la zona estudiada. La función admite el cálculo para otros valores de α (R, 2011).
Prueba de hipótesis para la exactitud global Podemos realizar una prueba de hipótesis
01
00
ppHppH
<=≥=
Hipótesis nula: La exactitud global es mayor o igual al valor de referencia Hipótesis alternativa: La exactitud global es menor al valor de referencia La función en R a utilizar para un valor de referencia de 95% seria: prop.test( aciertos,n, p=0.95, alternative = "less") data: aciertos out of n, null probability 0.95

15
X-squared = 1513.470, df = 1, p-value < 2.2e-16 Esto nos dice que no existe evidencia para pensar que la hipótesis nula sea verdadera, se acepta que la exactitud global es menor al valor de referencia.
Índice Kappa
Este estadístico es una medida de la diferencia entre la exactitud lograda en la clasificación y la chance de lograr lo mismo con una clasificación correcta con un clasificador aleatorio. Se calcula como:
( )
( )∑∑ ∑
=
= =
−
−= l
i ii
l
i
l
iiiii
aan
aaanK
1 ..21 1
..(ˆ
Donde: i = dimensión de la matriz (número de clases); aii = número de observaciones en la línea i, columna i; ai. y a.i = total marginal de línea i y de columna i, n = número total de observaciones Cálculo en R kappa<- (n*aciertos-prod_marginal)/(n^2-prod_marginal) Para nuestro ejemplo el coeficiente Kappa es de 0.4517478 (ver anexo). Esto muestra cuánto ha mejorado la clasificación respecto a una asignación aleatoria de N elementos en M grupos. Da idea del porcentaje de acuerdo, una vez que se ha eliminado la parte debida al azar. Su utilidad es relativa, o sea es un índice útil para comparar distintos sistemas o tipos de clasificación.
3.4. Índices por clases
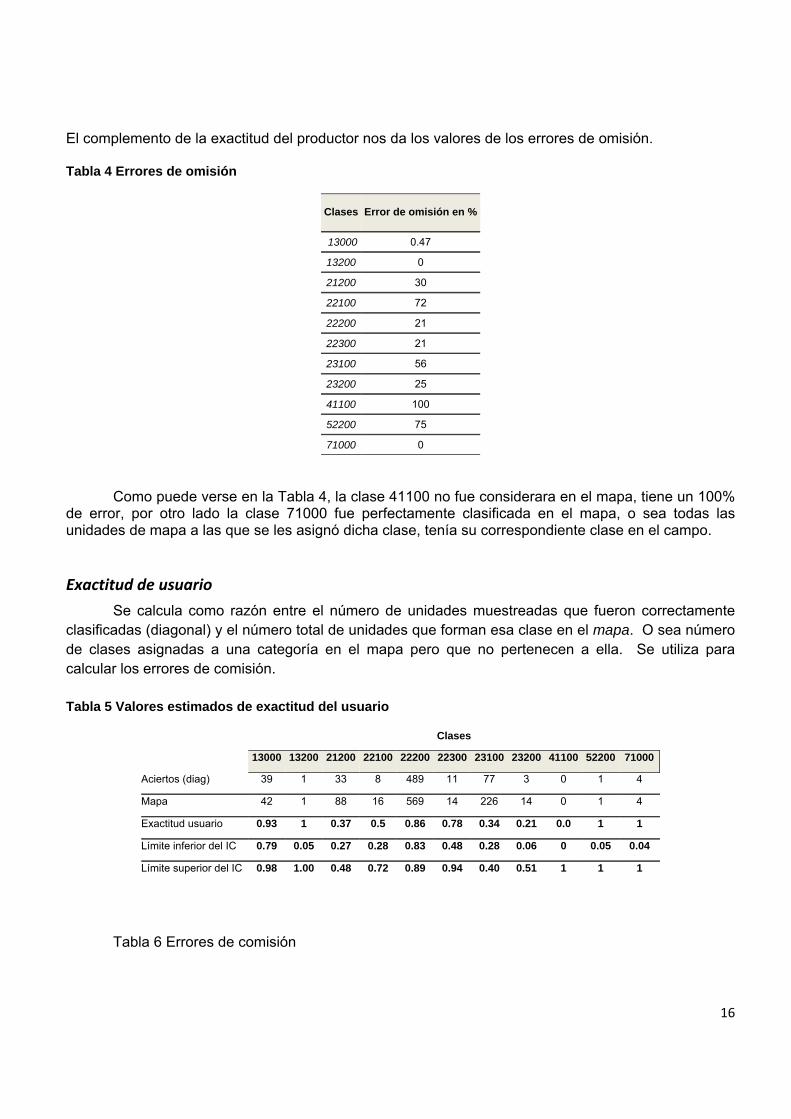
Exactitud del productor
Se calcula como la razón entre el número de unidades muestreadas que fueron correctamente clasificadas (diagonal) y el número de unidades que pertenecen a esa categoría (campo). O sea que no fueron asignadas en el mapa a la clase correspondiente. Se utiliza para calcular los errores de omisión. Tabla 3 Cálculo de la exactitud del productor
Clases
13000 13200 21200 22100 22200 22300 23100 23200 41100 52200 71000
Aciertos (diag) 39 1 33 8 489 11 77 3 0 1 4
Campo 74 1 47 29 621 14 176 4 1 4 4
Exactitud productor 0.53 1 0.70 0.27 0.79 0.78 0.43 0.75 0 0.25 1
Límite inferior del IC 0.41 0.05 0.55 0.13 0.75 0.49 0.36 0.22 0.00 0.00 0.4
Límite superior del IC 0.64 1 0.82 0.47 0.81 0.94 0.51 0.98 0.94 0.78 1
16
El complemento de la exactitud del productor nos da los valores de los errores de omisión. Tabla 4 Errores de omisión
Clases Error de omisión en %
13000 0.47
13200 0
21200 30
22100 72
22200 21
22300 21
23100 56
23200 25
41100 100
52200 75
71000 0
Como puede verse en la Tabla 4, la clase 41100 no fue considerara en el mapa, tiene un 100% de error, por otro lado la clase 71000 fue perfectamente clasificada en el mapa, o sea todas las unidades de mapa a las que se les asignó dicha clase, tenía su correspondiente clase en el campo.
Exactitud de usuario
Se calcula como razón entre el número de unidades muestreadas que fueron correctamente clasificadas (diagonal) y el número total de unidades que forman esa clase en el mapa. O sea número de clases asignadas a una categoría en el mapa pero que no pertenecen a ella. Se utiliza para calcular los errores de comisión.
Tabla 5 Valores estimados de exactitud del usuario
Clases
13000 13200 21200 22100 22200 22300 23100 23200 41100 52200 71000
Aciertos (diag) 39 1 33 8 489 11 77 3 0 1 4
Mapa 42 1 88 16 569 14 226 14 0 1 4
Exactitud usuario 0.93 1 0.37 0.5 0.86 0.78 0.34 0.21 0.0 1 1
Límite inferior del IC 0.79 0.05 0.27 0.28 0.83 0.48 0.28 0.06 0 0.05 0.04
Límite superior del IC 0.98 1.00 0.48 0.72 0.89 0.94 0.40 0.51 1 1 1
Tabla 6 Errores de comisión

17
Clases Error de comisión en %
13000 7
13200 0
21200 62
22100 50
22200 14
22300 21
23100 65
23200 78
41100 100
52200 0
71000 0
En la Tabla 6 podemos ver que error se cometió en las asignaciones, por ejemplo la clase 41100 fue asignada a otra (en el Figura 8 se ve que fue asignada a la clase 21200).
4. Consideraciones finales
Si bien pueda parecer dificultoso realizar los diseños de muestreo y los análisis estadísticos debido a los supuestos en los que se basan, existen hoy en día muchas herramientas que nos facilitan la tarea de validación. Cuando estos cálculos forman parte de la rutina de trabajo de aquellos que elaboran mapas temáticos, la exactitud de los productos tiende a aumentar con el tiempo, ya que los índices obtenidos en un momento dado nos dan un diagnostico de aquellos errores cometidos, y podemos de esta manera hacer más eficiente cada día nuestro trabajo.

18
ANEXO 1: Introducción al uso de R ¿Qué es R?
R es un soft libre y gratuito muy flexible. Los procedimientos estadísticos estándar se pueden aplicar con sólo utilizar el comando apropiado. Además, existen multitud de librerías programadas por los usuarios de todo el mundo para llevar a cabo procedimientos más específicos. En última instancia, podemos programar nuestros propios procedimientos y aplicaciones.
Obtención e instalación de R
El sitio web se encuentra en la dirección: http://www.r-project.org/.
Desde este sitio se debe seleccionar el sitio (CRAN mirror) desde donde se desea obtener los archivos del programa. CRAN es el acrónimo de Comprehensive R Archive Network. Existen sitios de descarga en Argentina, Australia, Brasil, Canadá, Dinamarca, EEUU, Francia, Hungría, Japón, Sudáfrica, Reino Unido, etc. Una vez seleccionado el sitio, se debe seleccionar la versión (Linux, Mac, Windows...). Las actualizaciones son frecuentes – cada 3 meses aproximadamente. Después de seleccionar el CRAN aparecerá una ventana dos subdirectorios, uno tiene el archivo del programa (ejecutable) base y el otro el código fuente contrib. Para la instalación del programa necesitamos el archivo base. Una vez descargado, ejecutar el archivo. Instalará el sistema base y los paquetes recomendados. Se recomienda la instalación estándar (por default). Instalado R, al abrirlo aparecerá la siguiente consola:
Paquetes
R consta de un sistema base y de paquetes (packages) o módulos adicionales que extienden la funcionalidad. La instalación básica ya contiene algunos paquetes con funciones y procedimientos para la realización de gráficos, procedimientos estadísticos y utilidades básicas para el manejo de datos, como: base, graphics, stats, utils, etc. Existen además numerosos paquetes adicionales que no son instalados automáticamente. Para adicionar estos paquetes una forma es seleccionarlos desde un CRAN e instalarlos individualmente.
El archivo se debe guardar en una carpeta especifica en nuestra PC, luego añadirlo desde la consola de R. Para ello, en el menú principal de R, abrimos Paquetes e instalamos los paquetes adicionales siguiendo las instrucciones de las pantallas. La instalación también puede hacerse directamente desde R.
Documentación acerca de R
Hay una enorme cantidad de información acerca de R en la web, aunque el punto de partida es en CRAN http://cran.r-project.org/. Aquí se encuentran disponibles gran variedad de manuales de R:

19
• An introduction to R (de lectura sugerida): introduce al lenguaje R y sobre cómo efectuar gráficos y análisis estadísticos. Existe una traducción al español (Manuals > Contributed).
• R installation and administration: manual autoexplicatorio para la instalación y uso de R.
• R data import/export: describe las facilidades de importación y exportación disponibles tanto en R como a través de paquetes.
• R: A Language and Environment for Statistical Computing: contiene todos los archivos de ayuda de R y de los paquetes recomendados en formato imprimible.
• The R language definition: describe cómo trabajan los objetos y los detalles de los procesos de evaluación de expresiones, útiles cuando se programan funciones R.
• Writing R extensions: explica cómo crear paquetes propios, escribir archivos de ayuda y usar interfaces en otros lenguajes (C, C + +, Fortran).
Varios de estos manuales están también disponibles en el mismo R: en la barra de Menú > Ayuda > Manuales (en pdf). También están disponibles las respuestas a las preguntas más frecuentes (Frequently Asked Questions, FAQs) y R News, un boletín informativo que contiene artículos, reseñas de libros y noticias de próximos lanzamientos. La parte más útil del sitio, sin embargo, es el motor de búsqueda que permite investigar el contenido de la mayoría de los documentos, funciones y archivos de correo electrónico.
Ayuda en R
Las ayudas incluidas en el programa sobre los distintos comandos y funciones pueden solicitarse de distintas formas:
Tecleando help(nombre de comando) se abre una ventana con información sobre un comando especifico. Pruebe, por ejemplo tipear el siguiente comando: help(mean).
Otro comando muy útil es help.search (’palabra clave’). En este caso obtenemos una lista de los comandos relacionados con la palabra clave. Por ejemplo, al teclear help.search(’median’) se obtendrá una lista de comandos de R relacionados con la mediana.
Una forma de obtener ayuda en formato html consiste en teclear help.start().
Para conocer como funciona cualquier función de R, tipear en la consola principal el signo ? y el nombre de la función. Por ejemplo ? plot nos mostrará como funciona la función plot.
Para ver una salida estándar de una función, sólo se debe tipear example(). Por ejemplo, para ver un ejemplo de análisis de la varianza, tipear example(anova.glm) y se verá la salida generada por la función anova.glm.
En relación a los paquetes, en la página de cada uno existe información acerca de: Versión de R, otros paquetes adicionales necesarios, datos del autor, el código fuente, el archivo del programa y el manual de referencia.

20
Uso de editores externos. RStudio
Las sentencias necesarias para la ejecución de los distintos análisis deben escribirse en la consola de R, pero existen editores externos que facilitan esta tarea. Uno de ellos es el RStudio. Se trata de un editor de código abierto y libre. Tiene características interesantes y está especialmente orientado a R. RStudio integra todas las herramientas que se utilizan cuando se trabaja con R en un único entorno personalizable.
Este programa de distribución gratuita se puede descargar de: http://www.rstudio.org/

21
ANEXO 2: Algoritmo en R para el cálculo de las medidas de calidad de los productos derivados de sensores remotos. # Lectura de datos library(lattice) sanluis<-read.table("http://www.teresaboca.com/r/pampasanluis.csv",header=TRUE, sep=",", na.strings="NA", dec=".") ################################## FUNCION MATRIZ DE CONFUSION ############################# # observado y clasificado son los unicos valores que hay que cambiar en funcion del nombre que tengan en el archivo datos<-mesopotamia # Acá hay que poner el nombre del archivo que se va a analizar names(datos) clases.campo<-factor(datos$OBSERVADO)#; campo<-datos$observado clases.imagen<-factor(datos$CLASIFICADO)#; imagen<-(datos$clasificado) levels(clases.campo) levels(clases.imagen) #########################MATRIZ DE CONFUSIÓN################################################ class <- c(1:length(imagen)) dat <- data.frame(imagen, campo) m <- max(c(length(unique(imagen)), length(unique(campo)))) for(i in 1:length(class)) {class[i] <- sub(' ','',paste(dat[i,1],dat[i,2])) } dat <- data.frame(imagen, campo, class) mat <- matrix(0, nrow=m, ncol=m) for (i in 1:m){ for (j in 1:m){ mat[i,j] <- sub(' ','',paste(i,j)) }} A <- matrix(0, nrow=(m+1), ncol=(m+1)) for (i in 1:m){ for(j in 1:m){ A[i,j]<- nrow(dat[dat$class==mat[i,j],]) }} for (i in 1:m) {A[(m+1),i]<-sum(A[1:m,i]) A[i,(m+1)]<- sum(A[i,1:m]) A[(m+1),(m+1)] <- sum(A[1:m,(m+1)]) } colnames(A)<-c(levels(factor(datos$OBSERVADO)),"suma clasificado") rownames(A)<-c(levels(factor(datos$OBSERVADO)),"suma observado" ) niveles<-levels(factor(datos$OBSERVADO)) # Este es el resultado de la matriz de confusión A ##################################################################################### # Calculo de la exactitud global n=A[nrow(A),ncol(A)] Am<-A[1:ncol(A)-1,1:ncol(A)-1] # Am es la matriz de datos sin los valores marginales PA<-sum(diag(Am)) /n EXACTITUD_GLOBAL<-PA EXACTITUD_GLOBAL ##################################################################################### #Intervalo de confianza para la exactitud global aciertos= sum(diag(Am)) prop.test( aciertos,n,alternative = "two.sided") ##################################################################################### # Prueba de hipotesis para saber si existen diferencias significativas entre la # exactitud lograda y la esperado de 95%) prop.test( aciertos,n, p=0.90, alternative = "less") ##################################################################################### # Calculo del coeficiente Kappa prod_marginal<-(A[1:nrow(Am),nrow(A)]%*%A[nrow(A),1:nrow(Am)]) kappa<- (n*aciertos-prod_marginal)/(n^2-prod_marginal); kappa

22
###############INDICES POR CATEGORIA################################################ ##################################### Exactitud del PRODUCTOR ######################### Clases_bien <-as.vector(diag(A)[1:ncol(A)-1]) Clases_campo<-as.vector(A[nrow(A),1:ncol(A)-1]) EXACTITUD_PRODUCTOR<- as.vector(Clases_bien /Clases_campo)# en funcion de los errores de omisión EXACTITUD_PRODUCTOR #######################Calculo de los intervalos de confianza de la exactitud del PRODUCTOR para cada clase EXACTITUD_PRODUCTOR<-ifelse(EXACTITUD_PRODUCTOR=="NaN" , 0.001, EXACTITUD_PRODUCTOR) Clases_campo<-ifelse(Clases_campo==0, 0.001, Clases_campo) Clases_bien<-ifelse(Clases_bien==0, 0.001, Clases_bien) clases<-seq(1, length(EXACTITUD_PRODUCTOR), 1) IC<-matrix( 0, nrow=1,ncol=length(EXACTITUD_PRODUCTOR) ) for (i in clases){ tere<-prop.test(Clases_bien[i], Clases_campo[i] ) a<-as.data.frame(tere$conf.int) IC[i]<-a } IC_productor<-as.data.frame(do.call("rbind",IC)) rownames(IC_productor)<-levels(factor(clases.campo)) colnames(IC_productor)<-c("LI", "LS") IC_productor ####################Calculo de errores de omisión ##################################################### Om<-100*(1-EXACTITUD_PRODUCTOR) EO<- data.frame(niveles, Om) EO barchart(Om ~ niveles, ylab = "Errores de Omisión", ylim=c(1, 110)) ############################# Exactitud del usuario ################################################## Clases_mapa<-as.vector(A[1:ncol(A)-1,nrow(A)]) EXACTITUD_USUARIO<- as.vector(Clases_bien/Clases_mapa)# en funcion de los errores de omisión EXACTITUD_USUARIO ########################## Calculo de los intervalos de confianza para cada clase########################### EXACTITUD_USUARIO<-ifelse(EXACTITUD_USUARIO=="NaN" , 0.001, EXACTITUD_USUARIO) Clases_mapa<-ifelse(Clases_mapa==0, 0.001, Clases_mapa) Clases_bien<-ifelse(Clases_bien==0, 0.001, Clases_bien) clases<-seq(1, length(EXACTITUD_USUARIO), 1) # ojo saque un ya que tenia un valor faltante IC<-matrix( 0, nrow=1,ncol=length(EXACTITUD_USUARIO) ) for (i in clases){ test<-prop.test(Clases_bien[i], Clases_mapa[i]) b<-as.data.frame(test$conf.int) IC[i]<-b } IC_usuario<-as.data.frame(do.call("rbind",IC)) rownames(IC_usuario)<-levels(factor(clases.campo)) colnames(IC_usuario)<-c("LI", "LS") IC_usuario ####################Calculo de errores de comision (1- exactitud del usuario #################################### niveles.mapa<-levels(clases.imagen) Com<-100*(1-EXACTITUD_USUARIO) EC<- data.frame(niveles, Com) EC barchart(Com ~ niveles, ylab = "Errores de Comisión", ylim=c(1, 110)) ############################ Secuencia para armar el grafico final######################################### #Calculo de matriz en frecuencias , divido la columna de observados a campo, #dentro de los clasificados , por el total observado para esa categoría, P/E si a campo tengo 3 muestras # que son monte y en el mapa asigné 2 a monte y una a pastura, monte tendrá 2/3 y pastura 1/3 clas<-seq(1:ncol(A)) suma<-A[nrow(A),] Afreq<-Am # Acá hago el calculo de la frecuencia por columna ( for (i in 1:ncol(Am)){ Afreq[,i]<-Am[,i]/suma[i] }

23
# Lo pasa a un vector columna con 49 datos ( 7*7) frecuencia<-as.vector(Afreq[1:nrow(Afreq),1:ncol(Afreq) ]) # Le agrego las clases mapa<-rep(niveles, length(niveles)) campo<-as.character (gl(length(niveles),length(niveles), labels = niveles)) error_freq<-data.frame(frecuencia,mapa, campo) barchart(mapa ~ frecuencia|campo , data=error_freq, stack = TRUE, layout = c(length(niveles), 1), beside=TRUE, col=c(rainbow(length(niveles))),xlim=c(0.01,1), ylab="Clases imagen", xlab= "Clases campo") ################################################################################################

24
Bibliografía Cochran, W.G. (1977). Sampling Techniques; Third Edition; Wiley. New York. Congalton, R. G., K. Green. (2009). Assessing the Accuracy of Remotely Sensed Data Principles and Practices
.Taylor & Francis Group. Boca Raton. Fallas, J. (2002). Normas y Estándares para datos geoespaciales. Laboratorios de Teledetección y Sistemas de Información Geográfica. Escuela de Ciencias Ambientales y Programas Regional en Manejo de Vida Silvestre. Universidad Nacional Heredia, Costa Rica. Disponible en http:\\www.una.ac.cr/ambi/telesig. R Development Core Team (2011). R: A language and environment for statistical computing. R Foundation for
Statistical Computing, Vienna, Austria. ISBN 3-900051-07-0, URL http://www.R-project.org. AGRADECIMIENTOS Este trabajo fue realizado dentro del marco del AERN 294432 en articulación con el PNECO 1664, agradecemos a los integrantes de ambos proyectos.