mediciÓn del riesgo de mercado bajo condiciones … · el caso de las distribuciones híbridas se...
TRANSCRIPT

MEDICIÓN DEL RIESGO DE MERCADOBAJO CONDICIONES PROPICIAS PARA
LA DISTORSIÓN DE LOS PRECIOS
20 de Febrero 2009

Contenido
Introducción General 1
1 Preliminares 51.1 Conceptos Básicos de Probabilidad . . . . . . . . . . . . . . . . . 51.2 Medidas de Riesgo . . . . . . . . . . . . . . . . . . . . . . . . . . 71.3 Los Conceptos de VaR y CVaR . . . . . . . . . . . . . . . . . . . 91.4 Derivada del VaR y CVaR . . . . . . . . . . . . . . . . . . . . . . 141.5 El VaR y CVaR de una distribución normal . . . . . . . . . . . . 151.6 El VaR y CVaR de una distribución t no central . . . . . . . . . 191.7 Teoría de Valores Extremos . . . . . . . . . . . . . . . . . . . . . 21
2 Factores de Ajuste de la Volatilidad 232.1 Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.2 Formulación Matemática . . . . . . . . . . . . . . . . . . . . . . . 232.3 Propiedades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.3.1 Caso Normal . . . . . . . . . . . . . . . . . . . . . . . . . 252.3.2 No Negatividad . . . . . . . . . . . . . . . . . . . . . . . . 262.3.3 F ∗ y El Nivel de Aversión al Riesgo δ . . . . . . . . . . . 282.3.4 F ∗ y el Nivel de Confianza α . . . . . . . . . . . . . . . . 31
2.4 Aplicaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322.4.1 Bono M Diciembre 2007 . . . . . . . . . . . . . . . . . . . 332.4.2 Bono M Junio 2011 . . . . . . . . . . . . . . . . . . . . . . 34
2.5 Descomposición del Efecto de Distorsión . . . . . . . . . . . . . 352.5.1 Bono M Diciembre 2024 . . . . . . . . . . . . . . . . . . . 362.5.2 Factor de Distorsión del bono M Diciembre 2007 . . . . 36
2.6 Otras variables de referencia . . . . . . . . . . . . . . . . . . . . 362.7 Aplicación de la Teoría de Valores Extremos . . . . . . . . . . . 38
2.7.1 Dificultades en la estimación del VaR y CVaR . . . . . . 382.7.2 Estimadores del VaR y CVaR usando TVE . . . . . . . . 402.7.3 Aplicación en la determinación de F ∗ . . . . . . . . . . . 41
2.8 Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
i

3 Aplicación de Distribuciones Híbridas 463.1 Introducción y Motivación . . . . . . . . . . . . . . . . . . . . . . 463.2 Distribuciones Híbridas . . . . . . . . . . . . . . . . . . . . . . . 473.3 Formulación Matemática . . . . . . . . . . . . . . . . . . . . . . . 513.4 Propiedades del VaRH(β)
α , CVaRH(β)α y β∗ . . . . . . . . . . . . . 52
3.4.1 Propiedades Básicas . . . . . . . . . . . . . . . . . . . . . 533.4.2 Monotonicidad y Continuidad del VaRH(β)
α y CVaRH(β)α 54
3.4.3 Existencia y algunas propiedades de β∗ . . . . . . . . . 593.5 Determinación de la probabilidad óptima β∗ . . . . . . . . . . . 60
3.5.1 Determinación de la Distribución Híbrida . . . . . . . . 633.6 Caso Gaussiano-Gaussiano . . . . . . . . . . . . . . . . . . . . . 64
3.6.1 Solución utilizando simulación . . . . . . . . . . . . . . . 653.6.2 Solución mediante integración numérica . . . . . . . . . 66
3.7 Caso Gaussiano-t . . . . . . . . . . . . . . . . . . . . . . . . . . . 713.7.1 Solución utilizando simulación . . . . . . . . . . . . . . . 713.7.2 Solución mediante integración numérica . . . . . . . . . 723.7.3 Comparación entre el modelo Gaussiano-Gaussiano y el
Gaussiano-t . . . . . . . . . . . . . . . . . . . . . . . . . . 773.8 Comparación de β∗ con el factor de ajuste F ∗ . . . . . . . . . . 783.9 Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
Conclusiones Generales 83
A Convexidad y Condiciones de Optimalidad 85
B Simulación 87B.1 Método Monte Carlo . . . . . . . . . . . . . . . . . . . . . . . . . 87B.2 Simulación de Distribuciones Híbridas . . . . . . . . . . . . . . 89
C El caso del sesgo en la estimación de β∗ 90
Bibliografía 93
ii

Introducción General
En las últimas tres décadas la mayor parte de las instituciones financieras haninvertido mucho tiempo y recursos en la evaluación y medición de los ries-gos a los que están expuestos sus activos. De igual manera, los reguladoresde los sistemas financieros mundiales y locales han puesto un gran empeñoen la medición de los riesgos sistémicos a los que están expuestos los partici-pantes de los distintos mercados financieros, así como en la determinación delineamientos generales que estos participantes deben seguir a fin de mitigardichos riesgos. De esta manera, se han desarrollado clasificaciones muy pre-cisas de estos riesgos y metodologías especiales para determinar y monitorearcada uno de éstos.
No obstante dicho esfuerzo, la crisis financiera actual ha demostrado, en-tre otras cosas, que este esfuerzo debe redoblarse, poniendo especial énfasisen el seguimiento y la evolución de los riesgos, así como en una constanterevisión de la adecuación de las metodologías utilizadas para tal efecto. Enparticular, respecto a esto último, deben revisarse o evaluarse los supuestosque los correspondientes modelos hacen ya que, como cualquier otro modelo,estos supuestos buscan, por un lado, que el modelo capture de manera aprox-imada la realidad del contexto de aplicación y, por el otro, que se simplifiquelo suficiente la complejidad de dicha realidad a fin de que la instrumentacióndel modelo sea factible.
Este trabajo de tesis se avoca en la adecuación de las metodologías están-dar de medición de riesgos. En particular, se enfoca en las adecuaciones enlos casos en que no se cumplan supuestos menos evidentes que aquellos rela-cionados, por ejemplo, con las medidas de riesgo usadas o las distribucionesde pérdidas utilizadas. A saber, se considera el supuesto de que los precios delos activos considerados reflejen toda la información disponible hasta el mo-mento. Es decir, el presente trabajo considera la medición de riesgos cuandoeste supuesto no se cumple. Esto es, cuando los precios de los activos consi-derados se encuentran "distorsionados". Por ejemplo, cuando la variabilidadde los precios no refleja la verdadera incertidumbre del valor del activo. Enespecífico, se estudia el caso en que esta distorsión ha sido propiciada por unaalta concentración de dichos activos en el mercado financiero en que éstos seoperan.
1

Desde el punto de vista de la medición de riesgos, la distorsión de losprecios de los activos puede conllevar varios problemas. Entre otros, se tienelos siguientes:
• Desde el punto de vista de una institución reguladora, se puede subes-timar el riesgo sistémico del mercado correspondiente.
• Desde la perspectiva de un participante, puede significar una pérdidainesperada, por ejemplo, en el caso de que dicho participante haya acep-tado dichos activos como colateral de una operación crediticia.
• Desde la óptica del mismo tenedor del activo concentrado, éste esta su-jeto al riesgo de que el precio de dicho activo sea impugnado por unainstitución reguladora.
Para tal efecto, se considera el riesgo de mercado, dado que es el tipo deriesgo más sencillo de distinguir y para el cual existe un consenso universalrespecto a su definición; y se toma en cuenta como motivación, una situaciónespecífica observada recientemente en el mercado nacional de instrumentosde renta fija. A saber, el comportamiento, un tanto peculiar, del Bono M Di-ciembre 2007, el cual cerca de su fecha de vencimiento mostró una distorsiónnotable de su precio debido a la alta concentración de la tenencia del mismopor un solo participante del mercado. En particular, como se puede apreciaren la Figura 1, la variación diaria porcentual de los precios de dicho bono,medida en términos de la desviación estándar, experimentó una reduccióndrástica una vez que la tenencia de toda la emisión del título estuvo en manosde un solo participante1. Dicha reducción de la variabilidad conlleva, comose demuestra más adelante en este trabajo de tesis, una subestimación impor-tante del riesgo de mercado.
En este trabajo de tesis se desarrollan dos metodologías para medir elriesgo de mercado, las cuales tienen dos características comunes:
• Parten del supuesto estándar de una distribución de pérdidas Gaus-siana.
• Utilizan el Valor en Riesgo (VaR) y el Valor en Riesgo Condicional (CVaR)como medidas de riesgo.
La primera de estas características busca que la metodología estándar seadecúe solo si es necesario, en cuyo caso se desviará de ésta, dependiendo decada metodología, lo suficiente para medir el riesgo de mercado de maneraadecuada. Por su parte, la segunda característica garantiza que ambas meto-dologías no solamente utilicen la misma forma de medir de riesgo, sino queademás usen dos medidas de riesgo relevantes en el ámbito financiero. El
1La concentración de un instrumento de deuda puede llegar a ser superior al 100% debido aque algunos participantes del mercado pueden vender en corto dicho instrumento.
2
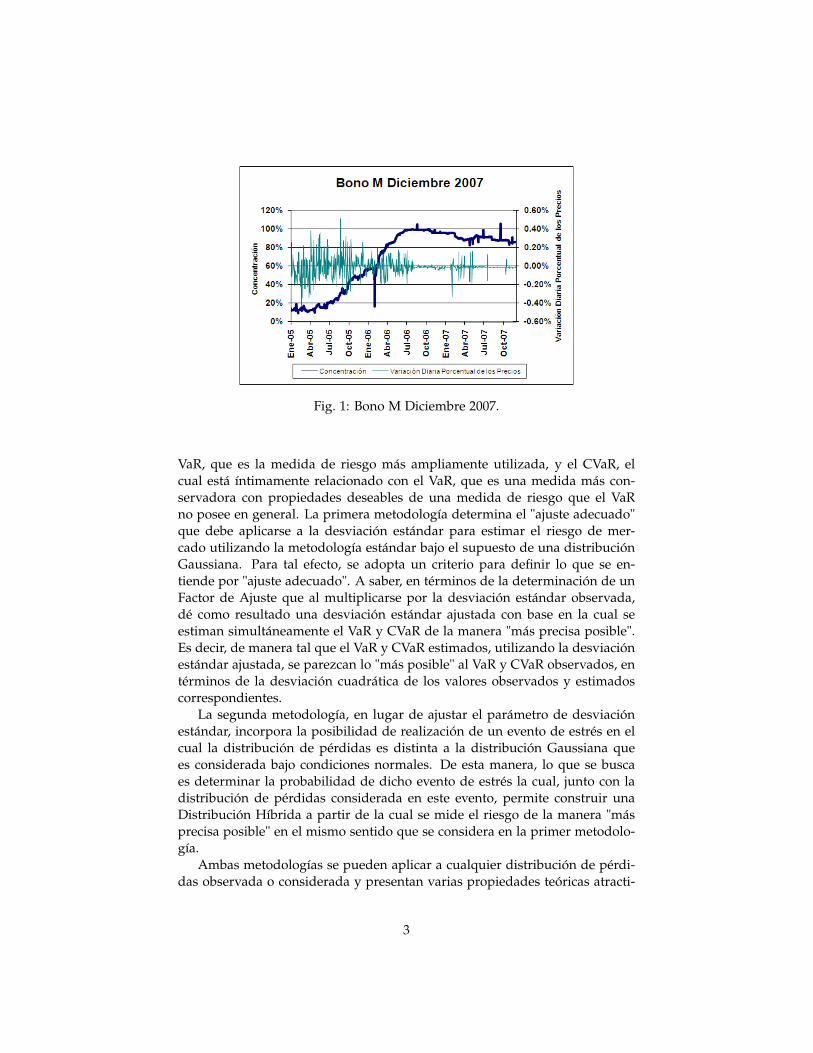
Fig. 1: Bono M Diciembre 2007.
VaR, que es la medida de riesgo más ampliamente utilizada, y el CVaR, elcual está íntimamente relacionado con el VaR, que es una medida más con-servadora con propiedades deseables de una medida de riesgo que el VaRno posee en general. La primera metodología determina el "ajuste adecuado"que debe aplicarse a la desviación estándar para estimar el riesgo de mer-cado utilizando la metodología estándar bajo el supuesto de una distribuciónGaussiana. Para tal efecto, se adopta un criterio para definir lo que se en-tiende por "ajuste adecuado". A saber, en términos de la determinación de unFactor de Ajuste que al multiplicarse por la desviación estándar observada,dé como resultado una desviación estándar ajustada con base en la cual seestiman simultáneamente el VaR y CVaR de la manera "más precisa posible".Es decir, de manera tal que el VaR y CVaR estimados, utilizando la desviaciónestándar ajustada, se parezcan lo "más posible" al VaR y CVaR observados, entérminos de la desviación cuadrática de los valores observados y estimadoscorrespondientes.
La segunda metodología, en lugar de ajustar el parámetro de desviaciónestándar, incorpora la posibilidad de realización de un evento de estrés en elcual la distribución de pérdidas es distinta a la distribución Gaussiana quees considerada bajo condiciones normales. De esta manera, lo que se buscaes determinar la probabilidad de dicho evento de estrés la cual, junto con ladistribución de pérdidas considerada en este evento, permite construir unaDistribución Híbrida a partir de la cual se mide el riesgo de la manera "másprecisa posible" en el mismo sentido que se considera en la primer metodolo-gía.
Ambas metodologías se pueden aplicar a cualquier distribución de pérdi-das observada o considerada y presentan varias propiedades teóricas atracti-
3

vas. Entre otras, se encuentran las siguientes:
• Bajo ciertos supuestos, los cuales se cumplen típicamente en la práctica,los modelos matemáticos asociados con cada metodología tienen solu-ción.
• La formulación de ambos modelos permite asignar el peso relativo quese le da al CVaR con respecto al VaR. Por lo tanto, el valor de dichaponderación, la cual denominamos δ , se puede asociar, al menos intui-tivamente, con un cierto nivel de aversión al riesgo.
• Tanto los Factores de Ajuste como las Distribuciones Híbridas se puedencaracterizar en términos de una variable de referencia que determine laforma de la distribución de pérdidas (e. g. el nivel de concentración deciertos activos).
• La adición o inclusión de otras medidas de riesgo distintas al VaR yCVaR es relativamente fácil.
• La incorporación de restricciones adicionales sobre los Factores de Ajusteo las Distribuciones Híbridas es relativamente sencilla.
Es importante mencionar que aunque el objetivo primario de las metodolo-gías aquí desarrolladas fue la medición del riesgo de mercado en condicionespropicias para la distorsión de los precios, dichas metodologías se puedenaplicar para adecuar la metodología estándar por cualquier característica dela distribución de pérdidas que se aleje de los supuestos de dicha metodolo-gía.
Las metodologías desarrolladas se aplicaron al caso del Bono M Diciem-bre 2007, suponiendo que se desea medir el riesgo de la posición en dichobono. Para el caso de la metodología de Factores de Ajuste, se obtuvieron, enentre otros resultados, que los Factores de Ajuste, para un nivel de confianzadel 99%, varían en un rango de [1.38, 1.67], lo que significa incrementar elparámetro de desviación estándar entre un 38% y un 67%. Por su parte, parael caso de las Distribuciones Híbridas se obtuvieron, entre otras cosas, que lasprobabilidades de estrés se encuentren en un rango de [0.00344%, 3.81709%]considerando un nivel de confianza en el cálculo del VaR y CVaR de 95%.En los resultados obtenidos para ambas metodologías, se observó que tantolos Factores de Ajuste como las probabilidades de estrés de las DistribucionesHíbridas se incrementan conforme el parámetro de aversión al riesgo así lohace.
4

Capítulo 1
Preliminares
En este capítulo se presentan los conceptos y resultados teóricos necesariospara los temas que son abordados en los capítulos posteriores y se encuentraorganizado de la siguiente manera: en la Sección 1.1 se presentan conceptosbásicos de probabilidad; en la Sección 1.2 se introduce el concepto de medidasde riesgo; en la Sección 1.3 se definen los conceptos de VaR y CVaR; en la Sec-ción 1.4 se dan fórmulas explícitas, bajo ciertas condiciones, de las derivadasdel VaR y CVaR con respecto al nivel de confianza; en las Secciones 1.5 y 1.6se estudian el VaR y el CVaR de las distribuciones normal y t no central, res-pectivamente; finalmente, en la Sección 1.7 se exponen algunos resultados dela Teoría de Valores Extremos.
1.1 Conceptos Básicos de Probabilidad
En esta sección se establecen algunos resultados y definiciones que serán uti-lizadas en secciones posteriores del presente trabajo.
Definición 1.1 (σ-álgebra). Una colección de subconjuntos de Ω es una σ-álgebra,denotada S , si satisface las siguientes tres propiedades:
1. ∅ ∈ S .
2. Si A ∈ S entonces Ac ∈ S .
3. Si A1, A2, . . . ∈ S entonces ∪∞i=1 Ai ∈ S .
Definición 1.2 (Medida de Probabilidad). Dado un conjunto Ω y una σ-álgebraS de subconjuntos de Ω, una medida de probabilidad P es una función condominio S que satisface:
1. P[A] ≥ 0 para toda A ∈ S .
5

2. P[Ω] = 1.
3. Si A1, A2, . . . ∈ S son conjuntos disjuntos, entonces P[∪∞i=1 Ai] = ∑∞
i=1 P[Ai].
Definición 1.3 (Espacio de Probabilidad). Un espacio de probabilidad es unatríada (Ω,S , P) donde Ω es un conjunto cualquiera, S es la σ-álgebra desubconjuntos de Ω, y P es una medida de probabilidad definida sobre S .
Definición 1.4 (Variable Aleatoria). Sea (Ω,S , P) un espacio de probabilidad.Una variable aleatoria es una función X : Ω→ R tal que para toda a ∈ R
ω ∈ Ω|X(ω) ≥ a ∈ S . (1.1)
Un caso particular de una variable aleatoria, es la función indicadora deun conjunto A ∈ S definida por:
1A(x) =
1 si x ∈ A0 si x /∈ A
(1.2)
Definición 1.5 (Función de Distribución Acumulada). Sea (Ω,S , P) un espa-cio de probabilidad y X : Ω→ R una variable aleatoria, entonces
FX(y) = P[ω ∈ Ω|X(ω) ≤ y] = PX [(−∞, y)] (1.3)
es la función de distribución acumulada (FDA) correspondiente a la variablealeatoria X.
Definición 1.6. Sea X una variable aleatoria con función de distribución acu-mulada dada por F, si existe una función integrable f tal que
FX(x) =∫ x
−∞f (z)dz (1.4)
se dirá entonces que X es una variable aleatoria continua. La función f serállamada la función de densidad correspondiente a X.
Definición 1.7. Sea (Ω,S , P) un espacio de probabilidad. Las variables aleato-rias X y Y se distribuyen de manera idéntica si para todo conjunto A ∈ S setiene que
P[X ∈ A] = P[Y ∈ A] (1.5)
La distribución de una variable aleatoria queda totalmente caracterizadapor su FDA como se establece en la siguiente proposición.
Proposición 1.1. Dos variables aleatorias X y Y se distribuyen de forma idéntica siy sólo si tienen la misma FDA.
Demostración. Ver demostración del Teorema 1.5.2 de Casella & Berger (1990).
6

Definición 1.8 (Valor Esperado). Sea X una variable aleatoria con FDA dadapor F. El valor esperado de X, denotado E[X], se define como
E[X] =∫ ∞
−∞xdF(x) (1.6)
siempre que ∫ ∞
−∞|x|dF(x)
exista.
Definición 1.9 (Varianza). Sea X una variable aleatoria, la varianza de X sedefine como
V[X] = E[(X− E[X])2] (1.7)
siempre que el valor esperado exista.
1.2 Medidas de Riesgo
En esta sección se definen las medidas de riesgo y se describen algunas de suspropiedades generales. En particular, se establece la propiedad de coherenciade una medida de riesgo, en el sentido de Artzner et al. (1999).
Para introducir el concepto de medidas de riesgo, se representará el valorde una posición financiera como una variable aleatoria definida dentro de unespacio de probabilidad (Ω,S , P).
Definición 1.10 (Medida de Riesgo). Sea D un conjunto de posiciones fi-nancieras. Se dirá que la función M : D → R es una medida de riesgo siy sólo si satisface las siguientes propiedades:
• Monotonía: Para toda X ∈ D y Y ∈ D con X ≤ Y c.s. (casi segura-mente1) se tiene que
M(X) ≥ M(Y).
• Invariante bajo Traslaciones: Para toda m ∈ R se cumple
M(X + m) = M(X)−m.
La propiedad de monotonía significa que si una posición tiene un valormayor o igual al valor de otra posición finaciera, bajo cualquier escenario,entonces está última posición se considera más riesgosa que la primera. Porsu parte, la propiedad de invarianza bajo traslaciones indica que si se agrega
1Una propiedad se satisface casi seguramente para una variable aleatoria X si se cumple paratodos puntos de su dominio, excepto posiblemente para algún subconjunto con probabilidadcero.
7

un monto m de efectivo, o de activo libre de riesgo, a una posición financiera,entonces el riesgo de está disminuye por el mismo monto m.
Es importante notar que la propiedad de invarianza implica en particularque si el monto de efectivo que se agrega a la posición es precisamente elriesgo de la posición, entonces el riesgo se neutraliza. Esta observación seformaliza en el siguiente resultado.
Lema 1.1. Sea X una posición financiera y M una medida de riesgo, de acuerdo a laDefinición 1.10. Entonces, si se agrega una cantidad de efectivo igual al riesgo de laposición M(X), el riesgo de la nueva posición, X + M(X), se neutraliza.
Demostración. Por la propiedad de invarianza bajo traslaciones, se cumple que
M(X + m) = M(X + M(X)) = M(X)−M(X) = 0.
Por lo tanto, el riesgo de la nueva posición es de cero.
Definición 1.11 (Medida de Riesgo Coherente). Sea M : D → R una medidade riesgo. Se dirá que M es coherente si satisface las siguientes propiedades:
• Homogeneidad Positiva: Para toda X ∈ D y λ ≥ 0 se cumple que
M(λX) = λM(X).
• Subaditividad: Para toda X, Y ∈ D se satisface
M(X + Y) ≤ M(X) + M(Y).
La homogeneidad positiva indica que si la posición se incrementa por unfactor positivo entonces el riesgo se incrementa por el mismo factor2. Lasubaditividad indica que si dos posiciones se combinan en una sola posición,entonces el riesgo de combinar las posiciones es menor o igual a la suma desus riesgos considerados por separado. Resulta ser que la subaditividad estáintimamente relacionada con la propiedad de convexidad como se estableceen la siguiente proposición:
Proposición 1.2. Sea M una medida de riesgo que satisface la propiedad de home-geneidad positiva, entonces M es una función convexa si y sólo si es subaditiva.
Demostración. Sean X y Y dos posiciones financieras y M una medida deriesgo homogenea positiva. Supóngase que M es subaditiva y sea 0 ≤ λ ≤ 1.Entonces, se cumple que
M(λX + (1− λ)Y) ≤ M(λX) + M((1− λ)Y)= λM(X) + (1− λ)M(Y).
2Este axioma no se cumple si existe un riesgo de liquidez, ya que en ese caso el riesgo de laposición aumentará más rápido que el tamaño de la misma.
8

Por lo tanto, M es una función convexa. Para demostrar el recíproco supón-gase que M es una medida de riesgo convexa. Entonces se sigue que
12
M(X + Y) = M(
12
X +12
Y)
≤ 12
M(X) +12
M(Y),
de donde,
M(X + Y) ≤ M(X) + M(Y).
Luego entonces, M es una medida de riesgo subaditiva.
1.3 Los Conceptos de VaR y CVaR
En esta sección se definen los conceptos de Valor en Riesgo (VaR) y Valor enRiesgo Condicional (CVaR) y se demuestra que son medidas de riesgo en elsentido de la Definición 1.10. Asimismo, se exponen algunas de sus ventajasy desventajas más importantes.
Definición 1.12 (VaR). El Valor en Riesgo o VaR de una posición financiera Xa un nivel de confianza α se define como:
VaRα(X) = infx ∈ R |P[−X ≤ x] ≥ α (1.8)
Es decir el VaR no es más que el percentil más pequeño de orden α de ladistribución de pérdidas asociadas a la posición financiera X. En ocasiones seasociará directamente una función de distribución acumulada FX a las pérdi-das de la posición financiera X y estará dada por:
FX(x) = P[−X ≤ x]. (1.9)
El subíndice X se omitirá para simplificar la notación en caso de que se so-breentienda por el contexto que se hace referencia a la variable aleatoria X.
Dada una variable aleatoria X, El VaR para un nivel de confianza α estarádado por VaRα = F←(α) = infx ∈ R | F(x) ≥ α. Para ilustrar lo anterior sepresenta una posible función de distribución acumulada F en la Figura 1.1 yel correspondiente valor de VaRα = F←(α) en la Figura 1.2. Obsérvese que elVaR esta definido para toda α ∈ (0, 1), inclusive para el valor x = 3 donde Fpresenta una discontinuidad. Asimismo el VaR presenta una discontinuidaden α = 1/3 debido a que F(x) = 1/3 para toda x ∈ [1, 2].
Proposición 1.3. El VaR es una medida de riesgo.
9

−3 −2 −1 0 1 2 3 4 5
0
0.2
0.4
0.6
0.8
1
Fig. 1.1: Gráfica de la FDA
0 0.2 0.4 0.6 0.8 1−1
−0.5
0
0.5
1
1.5
2
2.5
3
Fig. 1.2: Gráfica del VaRα
10

Demostración. Sean X y Y dos posiciones financieras, entonces si X ≤ Y setiene que −X ≥ −Y, por lo que
ω ∈ Ω| − X(ω) ≤ x ⊂ ω ∈ Ω| −Y(ω) ≤ x,de donde
P[−X ≤ x] ≤ P[−Y ≤ x] para toda x ∈ R.
Entonces para toda x ∈ R y para toda α ∈ [0, 1], tal que P[−Y ≤ x] ≥ α, setendrá que P[−X ≤ x] ≥ α. Por lo tanto dado un nivel de confianza α se tieneque
infx ∈ R |P[−X ≤ x] ≥ α ≥ infx ∈ R |P[−Y ≤ x] ≥ αo equivalentemente, que VaRα(X) ≥ VaRα(Y).
La propiedad de Invarianza bajo Traslaciones se sigue de
VaRα(X + m) = infx ∈ R |P[−(X + m) ≤ x] ≥ α= infx ∈ R |P[−X ≤ x + m] ≥ α= infy−m, y ∈ R |P[−X ≤ y] ≥ α= infy ∈ R |P[−X ≤ y] ≥ α −m
= VaRα(X)−m.
Una de las desventajas del VaR es que en general no es una medida suba-ditiva, como se ilustra en el siguiente ejemplo:3
Ejemplo 1.1. Considérense dos bonos distintos A y B de forma tal que susprobabilidades de incumplimiento sean mutuamente excluyentes (es decir siel bono A incumple en su pago entonces el bono B no incumple y viceversa).Un portafolio compuesto de ambos bonos puede tener un VaR global mayora la suma de los VaR individuales. Por ejemplo, supóngase que ambos bonostienen como valores de recuperación 70 y 90 con probabilidades de 3% y 2%respectivamente, y que en el resto de los casos se pueden redimir por un valorde 100. Las distribuciones de probabilidad de los bonos A, B y del portafoliocompuesto por ambos bonos se resumen en la Tabla 1.1.
Asumiendo que el valor inicial de cada bono es simplemente el valor es-perado del payoff como se describe en la Tabla 1.1, este puede ser fácilmentecalculado mediante dicha tabla. Por ejemplo, para el bono A se tiene un valorinicial de
70 · 3% + 90 · 2% + 100 · 95% = 98.9
y para el portafolio A+B se tiene un valor inicial de
170 · 6% + 190 · 4% + 200 · 90% = 197.8
Notando que la pérdida potencial en cada escenario esta dada por el valorincial menos el valor del rescate de cada bono, se obtiene la Tabla 1.2.
3El Ejemplo 1.1 fue tomado de Acerbi et al. (2001).
11

Tab. 1.1
Evento A B A+B Prob
E1 70 100 170 3%E2 90 100 190 2%E3 100 70 170 3%E4 100 90 190 2%E5 100 100 200 90%
Tab. 1.2
A B A+B
Valor inicial 98.9 98.9 197.8VaR 95% 8.9 8.9 27.8
A partir de dicha tabla se puede observar que VaR95%(A + B) > VaR95%(A)+VaR95%(B). Por ende el VaR no es una medida de riesgo subaditiva en estecaso.
Para remediar algunas de las desventajas del VaR, incluyendo la falta desubaditividad, se introduce el concepto de CVaR, definido a continuación.
Definición 1.13 (CVaR). El Valor en Riesgo Condicional o CVaR de una posi-ción financiera X para un nivel de confianza α se define como:
CVaRα(X) = El valor esperado de la α-cola de la distribución de pérdidas FX
donde la distribución en cuestión esta dada por
FαX(z) =
FX(z)−α
1−α para z ≥ VaRα(X)0 para z < VaRα(X)
(1.10)
A continuación se demuestra que el CVaR es una medida de riesgo.
Proposición 1.4. El CVaR es una medida de riesgo.
Demostración. Sean X y Y dos posiciones financieras. Si X ≤ Y entonces sesigue que P[−X ≤ x] ≤ P[−Y ≤ x], por lo que FX(x) ≤ FY(x), lo cual implicaque Fα
X(x) ≤ FαY(x), de donde
∫ ∞−∞ zdFα
X(x) ≥∫ ∞−∞ zdFα
Y(x), o equivalente-mente, CVaRα(X) ≥ CVaRα(Y).
12

Para demostrar que el CVaR es invariante bajo traslaciones, considérese elcaso en que Y = X + m, para ese caso se tiene que
FY(x) = P[−Y ≤ x] = P[−(X + m) ≤ x] = P[−X ≤ x + m] = FX(x + m)
por definición
FαY(z) =
FY(z)−α
1−α para z ≥ VaRα(Y)0 para z < VaRα(Y)
(1.11)
por ende
FαY(z) =
FX(z+m)−α
1−α para z + m ≥ VaRα(X)0 para z + m < VaRα(X)
por lo que FαY(z) = Fα
X(z + m), luego entonces∫ ∞
−∞zdFα
Y(z) =∫ ∞
−∞zdFα
X(z + m)
=∫ ∞
−∞(y−m)dFα
X(y)
=∫ ∞
−∞ydFα
X(y)−m∫ ∞
−∞dFα
X(y)
= CVaRα(X)−m.
Proposición 1.5. El CVaR es una medida de riesgo coherente.
Demostración. Por la proposición anterior se tiene que el CVaR es una medidade riesgo. Para demostrar que es coherente considerénse dos posiciones finan-cieas X y Y cualesquiera. Para demostrar la homgeneidad positiva del CVaRconsidérese el caso en que Y = λX con λ > 0, entonces:
FY(x) = P[−λX ≤ x] = P[−X ≤ x/λ] = FX(x/λ) (1.12)
por definición se tiene que
FYα (z) =
FY(z)−α
1−α para z ≥ VaRα(Y)0 para z < VaRα(Y)
(1.13)
sustituyendo (1.12) en (1.13) se tiene que
FαY(z) =
FX( z
λ )−α
1−α para z/λ ≥ VaRα(X)0 para z/λ < VaRα(X)
(1.14)
13

por lo que FαY(z) = Fα
X(z/λ) para toda z ∈ R, de donde se sigue que
CVaRα(Y) =∫ ∞
−∞zdFα
Y(z)
=∫ ∞
−∞zdFα
X(z/λ)
=∫ ∞
−∞λydFα
X(y)
= λ∫ ∞
−∞ydFα
X(y)
= λ CVaRα (X).
Rockafellar & Uryasev (2002) demuestran la convexidad de CVaRα, esto au-nado a la Proposición 1.2 demuestra que el CVaR es una medida de riesgocoherente.
En el caso de que la distribución de la variable aleatoria correspondientea la distribución de pérdidas F sea continua, el CVaR no es más que el valoresperado de las pérdidas que exceden al VaR, como se detalla y demuestracontinuación.
Proposición 1.6. Sea X una posición financiera continua con función de distribuciónde pérdidas FX , entonces
CVaRα(X) = E[−X| − X > VaRα] (1.15)
Demostración. Sea f la función de densidad correspondiente a la distribuciónFX , se sigue que
CVaRα(X) =∫ ∞
−∞zdFα
X(z)
=1
1− α
∫ ∞
VaRα
z f (z)dz
=
∫ ∞VaRα
z f (z)dz
1− F(VaRα)
=E[−X 1−X>VaRα]
P(−X > VaRα)= E[−X| − X > VaRα]
1.4 Derivada del VaR y CVaR
En esta sección se obtienen fórmulas generales de las derivadas del VaR yCVaR con respecto al nivel de confianza α, para el caso en que la función
14

de distribución acumulada es estrictamente creciente y diferenciable. Estasfórmulas serán de utilidad cuando se analice el comportamiento del factor deajuste con respecto al nivel de confianza en el Capítulo 2.
Lema 1.2. Sea F una función de distribución acumulada asociada a una variablealeatoria X. Supóngase que F es una función estrictamente creciente y diferenciableentonces
∂ VaR(X)∂α
y∂ CVaR(X)
∂α
existen y sus derivadas estan dadas por:
∂ VaR(X)∂α
=1
f (F−1(α))(1.16a)
∂ CVaR(X)∂α
=1
(1− α)2 E([X−VaRα(X)]+) (1.16b)
Demostración. Por definición se tiene que:
VaRα(X) = F←(α) = inft ∈ R | F(t) ≥ α (1.17)
Cómo F es estrictamente creciente, F es una función inyectiva. Además si F esdiferenciable en α, será continua, por lo que para cada α ∈ (0, 1) existirá t ∈ R
tal que F(t) = α y por ende la función F será suprayectiva también4. Luegoentonces F−1 existe y F←(α) = F−1(α) para toda α ∈ (0, 1). Así se tendrá que:
∂ VaR∂α
=1
dFdα
∣∣∣F−1(α)
=1
f (F−1(α))(1.18)
El segundo resultado es consecuencia directa de la existencia de F−1 y de laproposición 13 en Rockafellar & Uryasev (2002).
1.5 El VaR y CVaR de una distribución normal
La distribución normal es una de las distribuciones de probabilidad más útilesen el estudio del comportamiento de los activos financieros. En el presente tra-bajo se recurrirá con frecuencia a la distribución normal para estudiar el riesgode los bonos gubernamentales y como punto de referencia para estudiar otrasdistribuciones de riesgo. En particular, en esta sección se deducirán fórmulasexplícitas para el cálculo del VaR y CVaR de una distribución normal.
La función de densidad de una distribución normal5 con media µ y des-viación estándar σ está dada por
4Este último punto es un tanto sutil y posiblemente valga la pena detallarlo más. Si α ∈ (0, 1)como F es una función de distribución acumulada existirán t∗ y t∗ tales que F(t∗) ≥ α y F(t∗) < α,aplicando el teorema del valor intermedio sabemos que existe t ∈ [t∗, t∗] tal que F(t) = α.
5En ocasiones se hará referencia a la distribución normal como distribución Gaussiana.
15

f (x) =1√2π
exp(− (x− µ)2
2σ2
)(1.19)
y tiene como función de distribución acumulada N(x) =∫ x−∞ f (z)dz.
Proposición 1.7. Dado un nivel de confianza α ∈ (0, 1), para una variable aleatoriaque se distribuye según una normal con media µ y desviación estándar σ se tiene que:
VaRα = σN−1(α) + µ (1.20a)
CVaRα =
(σ√
2π(1− α)
)exp
(−N−1(α)2
2
)+ µ (1.20b)
Demostración. Sea m(z) = (z− µ)/σ entonces por definición
α =∫ VaRα
−∞
1√2π
exp(− z− µ
2σ
)2dz
=∫ m(VaRα)
−∞
1√2π
exp(−m2
2
)dm
= N(m(VaRα))
por ende m−1(N−1(α)) = VaRα y como m−1(z) = σz + µ se obtiene la fórmuladel VaR descrita.
Para demostrar la fórmula del CVaR nótese que la función de densidad dela cola de la distribución para valores de z mayores a VaRα es
fα(z) =
1√
2πσ(1−α)exp
(−(z−µ)2
2σ2
)para z ≥ VaRα
0 para z < VaRα
Por lo que:
CVaRα =∫ ∞
VaRα
z fα(z)dz
=∫ ∞
VaRα
1√2πσ(1− α)
z exp(
(z− µ)2
2σ2
)dz
=1√
2πσ(1− α)
∫ ∞
m(VaRα)(σm + µ)e−m2/2σdm
=σ2
√2πσ(1− α)
∫ ∞
m(VaRα)me−m2/2dm +
σµ√2πσ(1− α)
∫ ∞
m(VaRα)e−m2/2dm
=
(σ√
2π(1− α)
)exp
(−m(VaRα)
2
2
)+(
µ
1− α
)(1−N(m(VaRα))
)
=
(σ√
2π(1− α)
)exp
(−N−1(α)2
2
)+ µ
16

donde la última igualdad se sigue del hecho de que m(VaRα) = N−1(α) yN(m(VaRα)) = α.
Los siguientes corolarios caracterizan el VaR y CVaR de cualquier distribu-ción normal en términos del VaR y CVaR de una distribucíón normal estándar,así como su comportamiento respecto a cambios en el nivel de confianza. Es-tos resultados serán aplicados en el Capítulo 2.
Corolario 1.1. Sean χα y ηα el VaRα y CVaRα de una normal estándar respectiva-mente, entonces el VaRα y CVaRα de una normal con media µ y desviación estándarσ están dados por:
VaRα = σχα + µ (1.21a)
CVaRα = σηα + µ (1.21b)
Demostración. Se sigue inmediatamente de la Proposición 1.7.
Corolario 1.2. El VaR y CVaR de una distribución normal estándar son funcionesinfinitamente diferenciables en α ∈ (0, 1) y sus primeras dos derivadas están dadaspor:
dχ
dα=
1(1− α)ηα
(1.22a)
dη
dα=
ηα − χα
1− α(1.22b)
d2χ
dα2 =χα
(1− α)2η2α
(1.22c)
d2η
dα2 =2(ηα − χα)− 1/ηα
(1− α)2 (1.22d)
Demostración. De la Proposición 1.7 se puede ver que tanto el VaRα comoel CVaRα son composiciones de funciones infinitamente diferenciables en elintervalo (0, 1). Asimismo sus derivadas de cualquier orden pueden ser ob-tenidas mediante un cálculo directo como se detalla a continuación para lasderivadas de primer y segundo orden:
dχ
dα=
1dNdα
∣∣∣N−1(α)
=1
exp(−N−1(α)2/2)√2π
=1
(1−α) exp(−N−1(α)2/2)√2π(1−α)
=1
(1− α)ηα
17

dη
dα=
ddα
(1√
2π(1− α)
)e−N−1(α)2/2 +
(1√
2π(1− α)
)d
dα
(e−N−1(α)2/2
)
=e−N−1(α)2/2√
2π(1− α)2 −(
e−N−1(α)2/2√
2π(1− α)
)χα
(dχ
dα
)=
ηα
1− α− ηαχα
(1− α)ηα
=ηα − χα
1− α
d2χ
dα2 =d
dα
(1
1− α
)1ηα
+(
11− α
)d
dα
(1ηα
)=
1
(1− α)2ηα
− ηα − χα
(1− α)2η2α
=χα
(1− α)2η2α
d2η
dα2 =d(ηα−χα)
dα (1− α)− (ηα − χα)d(1−α)
dα
(1− α)2
=
(ηα − χα − 1
ηα
)+ (ηα − χα)
(1− α)2
=2(ηα − χα)− 1/ηα
(1− α)2
A partir de (1.22a)-(1.22d) se puede deducir el comportamiento global deχα y ηα. A saber, de (1.22a) y (1.22b) se sigue inmediatamente que tanto χα
como ηα son funciones estrictamente crecientes en α. Además, de (1.22c) sededuce que χα tiene un punto de inflexión en α = 0.5 y de (1.22d) que ηα tieneun punto de inflexión en α ≈ 0.291. Por último, de (1.22c) se sigue que χα esuna función cóncava para α < 0.5 y convexa para α > 0.5 y de (1.22d) que ηα
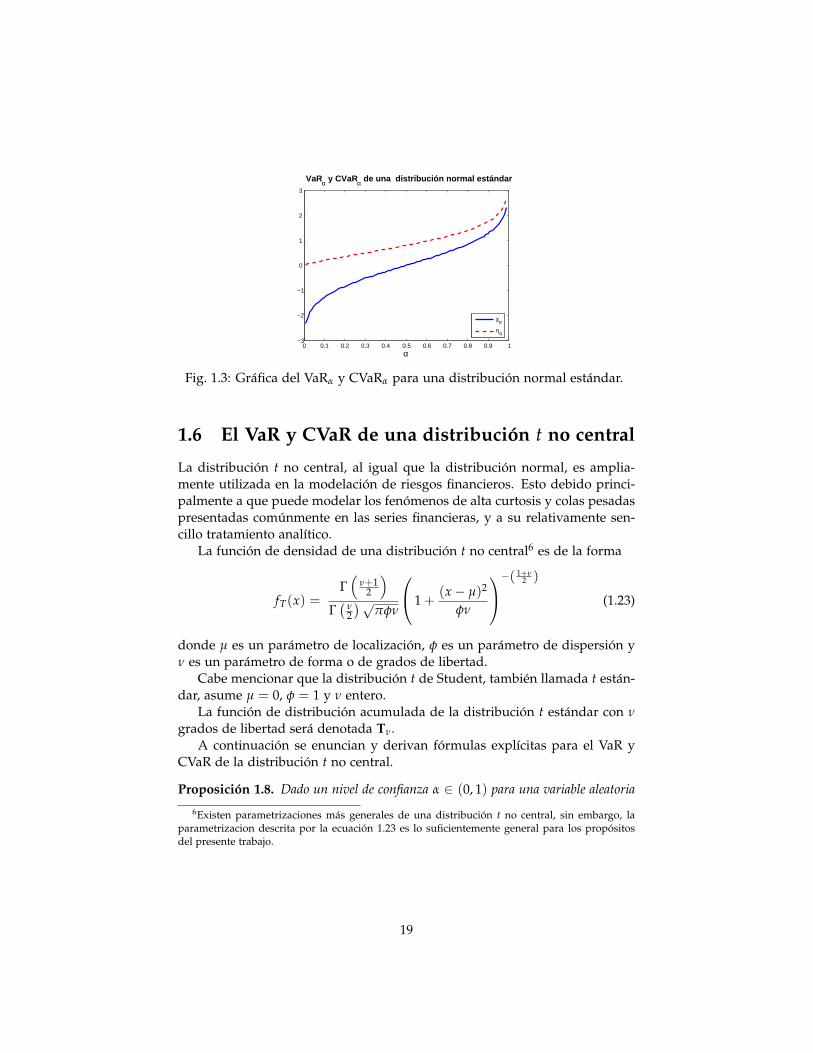
es una función cóncava para α < 0.291 y convexa para α > 0.291.Las observaciones anteriores se ilustran en la Figura 1.3 donde se grafican
χα y ηα.
18
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1−3
−2
−1
0
1
2
3
α
VaRα y CVaRα de una distribución normal estándar
χα
ηα
Fig. 1.3: Gráfica del VaRα y CVaRα para una distribución normal estándar.
1.6 El VaR y CVaR de una distribución t no central
La distribución t no central, al igual que la distribución normal, es amplia-mente utilizada en la modelación de riesgos financieros. Esto debido princi-palmente a que puede modelar los fenómenos de alta curtosis y colas pesadaspresentadas comúnmente en las series financieras, y a su relativamente sen-cillo tratamiento analítico.
La función de densidad de una distribución t no central6 es de la forma
fT(x) =Γ(
ν+12
)Γ(
ν2)√
πφν
1 +(x− µ)2
φν
−( 1+ν2 )
(1.23)
donde µ es un parámetro de localización, φ es un parámetro de dispersión yν es un parámetro de forma o de grados de libertad.
Cabe mencionar que la distribución t de Student, también llamada t están-dar, asume µ = 0, φ = 1 y ν entero.
La función de distribución acumulada de la distribución t estándar con νgrados de libertad será denotada Tν.
A continuación se enuncian y derivan fórmulas explícitas para el VaR yCVaR de la distribución t no central.
Proposición 1.8. Dado un nivel de confianza α ∈ (0, 1) para una variable aleatoria
6Existen parametrizaciones más generales de una distribución t no central, sin embargo, laparametrizacion descrita por la ecuación 1.23 es lo suficientemente general para los propósitosdel presente trabajo.
19

con distribución t no central con parámetros µ, φ y ν > 1 se tiene que:
VaRα =√
φT−1ν (α) + µ (1.24)
CVaRα =√
φν
ν− 1
(1 +
T−1ν (α)2
ν
)(ft(T−1
ν (α))1− α
)+ µ (1.25)
donde ft es la función de densidad de una distribución t estándar con ν grados delibertad.
Demostración. Sea m(x) = x−µ√φ
, entonces por definición
α =∫ VaRα
−∞
Γ(
ν+12
)Γ(
ν2)√
πφν
1 +(x− µ)2
φν
−( 1+ν2 )
dx
=∫ m(VaRα)
−∞
Γ(
ν+12
)Γ(
ν2)√
πν
1 +m2
ν
−( 1+ν2 )
dm
= Tν(m(VaRα))
por ende m−1(T−1ν (α)) = VaRα de donde se sigue que VaRα =
√φT−1
ν (α) + µ.En el caso del CVaR se tiene que
CVaRα =1
1− α
∫ ∞
VaRα
Γ(
ν+12
)x
Γ(
ν2)√
πφν
1 +(x− µ)2
φν
−( 1+ν2 )
dx (1.26)
=1
1− α
∫ ∞
T−1ν (α)
Γ(
ν+12
)(√
φm + µ)
Γ(
ν2)√
πν√
φ
1 +m2
ν
−( 1+ν2 )√
φdm (1.27)
=1
1− α
∫ ∞
T−1ν (α)
(√
φm + µ) ft(m)dm (1.28)
=√
φ
1− α
∫ ∞
T−1ν (α)
m ft(m)dm +1
1− α
∫ ∞
T−1ν (α)
µ ft(m)dm (1.29)
donde se ha hecho uso del cambio de variable de x por m en (1.27). Haciendoel cambio de variable y = m2/v en la primera integral de (1.29) y tomando
20

C = Γ( ν+12 )
Γ( ν2 )√
πνse tiene que:
∫ ∞
T−1ν (α)
m ft(m)dm =∫ ∞
T−1ν (α)
Cm(
1 +m2
ν
)−( 1+v2 )
dm
=∫ ∞
T−1ν (α)
2
ν
C(v
2
)(1 + y)−( 1+ν
2 )dy
=C( v
2)(1 + y)−( 1+ν
2 )+1
−(
1+ν2
)+ 1
∣∣∣∣∣∣∞
T−1ν (α)
2
ν
=(
ν
1− ν
)(1 + y)C(1 + y)−( 1+ν
2 )∣∣∣∣∞T−1
ν (α)2
ν
= −(
ν
1− ν
)(1 +
T−1ν (α)2
ν
)ft(T−1
ν (α)).
Para obtener la segunda integral de (1.29) nótese que
∫ ∞
T−1ν (α)
ft(m)dm = 1−∫ T−1
ν (α)
−∞ft(m)dm = 1− α
por lo que
CVaRα =( √
φ
1− α
)(ν
ν− 1
)(1 +
T−1ν (α)2
ν
)ft(T−1
ν (α)) +µ(1− α)
1− α
=√
φν
ν− 1
(1 +
T−1ν (α)2
ν
)(ft(T−1
ν (α))1− α
)+ µ.
1.7 Teoría de Valores Extremos
En esta sección se exponen brevemente algunos de los resultados claves de laTeoría de Valores Extremos. Para una exposición más detallada, incluyendolas demostraciones de los resultados, se puede consultar, por ejemplo, Em-brechts et al. (1997).
Definición 1.14 (Dominio de Atracción de Máximos). Sea Xn una sucesión devariables aleatorias independientes e idénticamente distribuidas con funciónde distribución acumulada dada por F y Mn = max1≤i≤n (Xi). Si existen dossucesiones an : N → R+ y bn : N → R y H(x) una función de distribuciónno degenerada, tales que
limn→∞
P
[Mn − bn
an≤ x
]= H(x) (1.30)
21

para toda x en los puntos de continuidad de H, entonces se dice que Fpertenece al dominio de atracción de máximos de H, y a esta propiedad se ledenota F ∈ DAM(H).
Definición 1.15 (Distribución de Extremos Generalizada). La distribución deextremos generalizada está dada por
Hξ(x) =
exp
(−(1 + ξx)−1/ξ
)para ξ 6= 0,
exp (−e−x) para ξ = 0,(1.31)
donde x es tal que 1 + ξx > 0 y ξ es un parámetro de forma. Si ξ > 0, H esuna distribución tipo Fréchet; si ξ < 0, H es una distribución tipo Weibull; siξ = 0, H es una distribución de tipo Gumbel.
Teorema 1.1 (Fisher-Tippett). Sea Xn una sucesión de variables aleatorias indepen-dientes e idénticamente distribuidas con función de distribución acumulada dada porF. Si F ∈ DAM(H), entonces H es una distribución de extremos generalizada deacuerdo a la definición (1.31).
Definición 1.16 (Distribución Pareto Generalizada).
Gξ,β(x) =
1− (1 + ξx/β)−
1ξ para ξ 6= 0,
1− exp(−x/β) para ξ = 0.(1.32)
donde β > 0 y x ≥ 0 cuando ξ ≥ 0 mientras que 0 ≤ x ≤ −β/ξ, si ξ < 0.
Definición 1.17. Dada una variable aleatoria X con función de distribuciónacumulada F, se define la función de excesos sobre el umbral u como
Fu(x) = P[X− u ≤ x|X > u] (1.33)
para 0 ≤ x < xF − u, donde xF es el extremo derecho de la distribución Fdefinido como xF = sup x ∈ R|F(x) < 1.
Teorema 1.2 (Pickands-Balkema-de Haan). Sea F una función de distribuciónacumulada con funciones de exceso Fu, para u ≥ 0. Entonces, dado ξ ∈ R, F ∈DAM(Hξ) si y sólo si existe una función medible positiva β(u) tal que
limx↑xF
sup0≤x≤xF−u
∣∣∣Fu(x)− Gξ,β(u)(x)∣∣∣ = 0 (1.34)
donde G es la función de distribución acumulada de una v.a. Pareto Generalizada conpárametros ξ y β, definida como en (1.32).
22

Capítulo 2
Factores de Ajuste de laVolatilidad
2.1 Introducción
El objetivo principal de este capítulo es exponer una metodología para ajus-tar el parámetro de desviación estándar usado para determinar el VaR y elCVaR bajo el supuesto de normalidad de la distribución de pérdidas. Para talefecto, este capítulo está organizado de la siguiente manera: en la Sección 2.2se formula matemáticamente la determinación del factor de ajuste. En la Sec-ción 2.3 se estudian algunas de las propiedades del factor de ajuste. En laSección 2.4 se aplican los resultados derivados en las secciones anteriores enel contexto de los bonos que motivaron este trabajo de tesis. En la Sección 2.5se descomponen los factores obtenidos en la sección anterior con el objeto deaislar otros fenómenos capturados por el factor de ajuste. En la Sección 2.6 seaplica la metodología desarrollada, en el mismo contexto considerado en laSección 2.4, pero usando otra variable de referencia. En la Sección 2.7 se mo-tiva el uso de la Teoría de Valores Extremos para una estimación más precisadel VaR y CVaR y con base en estas estimaciones se recalculan los factores deajuste y se comparan con los obtenidos en secciones anteriores. Finalmente,en la Sección 2.8 se concluye.
2.2 Formulación Matemática
Como se menciona en la introducción, el objetivo de este capítulo es, deter-minar el "ajuste adecuado" que debe aplicarse a la desviación estándar delas pérdidas para estimar el riesgo de mercado de manera más precisa, bajocondiciones de distorsión de los precios.
23

Para tal efecto, se adopta como criterio de "ajuste adecuado" la determi-nación de un factor de ajuste que al multiplicarse por la desviación estándarobservada, dé como resultado una desviación estándar ajustada con base en lacual se estiman simultáneamente el VaR y el CVaR, de la manera "más precisaposible". Es decir, de manera tal que el VaR y CVaR estimados, utilizando ladesviación estándar ajustada, se parezca lo "más posible" al VaR y CVaR obser-vados. Concretamente, que la desviación cuadrática de los valores estimadosy observados de estas medidas de riesgo sea mínima.
En términos matemáticos, el factor de ajuste F ∗ se determina al resolverel problema de optimización
MinF
(1− δ)(VaREα −[µE + χα(F σE)])2 + δ(CVaRE
α −[µE + ηα(F σE)])2 (2.1)
donde 0 < δ < 1 es un parámetro que indica la ponderación relativa entreajustar el VaR de la distribución empírica VaRE
α y el CVaR de la distribuciónempírica1 CVaRE
α y cuyo valor se determina a priori. Los parámetros µE yσE son, respectivamente, la media y desviación estándar de la distribuciónempírica. Las funciones χα y ηα representan, respectivamente, el VaR y CVaRde una distribución normal estándar y pueden ser calculadas mediante lasfórmulas (1.20a) y (1.20b) del Capítulo 1.
El problema de optimización (2.1) tiene una única solución explícita, lacual se enuncia y demuestra formalmente en el Teorema 2.1.
Teorema 2.1. Sea α ∈ (0, 1), un nivel de confianza dado. Entonces, el factor deajuste óptimo F ∗ que resuelve (2.1) es
F ∗ =(1− δ)χα(VaRE
α −µE) + δηα(CVaREα −µE)
σE[(1− δ)χ2α + δη2
α](2.2)
Demostración. Dado que la función objetivo del problema (2.1) es convexa ydiferenciable en F , basta demostrar que F ∗ satisface las condiciones de opti-malidad de primer orden (ver apéndice A). Dichas condiciones se reducen eneste caso a la ecuación
0 = 2(1− δ)(VaREα −[µE + χα(F ∗σE)])(−χασE)+
2δ(CVaREα −[µE + ηα(F ∗σE)])(−ηασE)
o equivalentemente a la condición
0 =F ∗[(1− δ)χα2 + δηα
2]σE
−[(1− δ)χα(VaREα −µE) + δηα(CVaRE
α −µE)]. (2.3)
1El VaR y CVaR empíricos fueron calculados a partir de la Proposición 8 de Rockafellar &Uryasev (2002).
24

Obsérvese que δ ∈ (0, 1) implica
(1− δ)χ2α + δη2
α > 0 (2.4)
dado que χα 6= ηα para toda α ∈ (0, 1). Por lo tanto, despejando F ∗ de (2.3)se deduce (2.2).
2.3 Propiedades
En esta sección se estudian algunas de las propiedades elementales del factorde ajuste F ∗, a saber las siguientes:
• El valor de F ∗ cuando las pérdidas se comportan de acuerdo a unadistribución normal.
• Condiciones bajo las cuales F ∗ es mayor o igual a cero.
• La relación entre F ∗ y el parámetro de aversión al riesgo δ.
• La relación entre F ∗ y el nivel de confianza α.
2.3.1 Caso Normal
Si las pérdidas se distribuyeran de acuerdo a una distribución normal y seconocieran los parámetros verdaderos de ésta, se esperaría intuitivamente queel factor de ajuste óptimo fuese igual a uno. El siguiente resultado corroboramatemáticamente dicha intuición.
Corolario 2.1. Supóngase que la distribución empírica de las pérdidas Π es normalcon media µE y desviación estándar σE. Entonces, F ∗ = 1 para toda δ ∈ (0, 1) ytoda α ∈ (0, 1).
Demostración. Supóngase que Π ∼ N(µE, σE). Entonces, por el Corolario 1.1,se cumple que
VaREα = µE + χασE y CVaRE
α = µE + ηασE
Luego entonces, por el Teorema 2.1, se tiene que
F ∗ =(1− δ)χα(VaRE
α −µE) + δηα(CVaREα −µE)
σE[(1− δ)χ2α + δη2
α]
=(1− δ)χα(σEχα + µE − µE) + δηα(σEηα + µE − µE)
σE[(1− δ)χ2α + δη2
α]
=(1− δ)χ2
α + δη2α
(1− δ)χ2α + δη2
α
= 1
25

0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.10
5
10
15
20
25
30
35
Magnitud del Error
Den
sida
d
Error en la estimación de F* cuando la muestra proviene de una distribución normal
(a) Densidad
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
0
0.02
0.04
0.06
0.08
0.1
Probabilidad
Cua
ntil
Error en la estimación de F* cuando la muestra proviene de una distribución normal
Error
(b) Cuantil
Fig. 2.1: Error en la estimación de F ∗.
Cuando la distribución empírica de pérdidas Π sigue una distribuciónnormal con media µE y varianza σE, ambas desconocidas, el factor de ajusteestá dado por la expresión:
F ∗ =σE
σE +(1− δ)χα(µE − µE) + δηα(µE − µE)
σE [(1− δ)χ2α + δη2
α]
Por lo que basta con que ambos estimadores µE y σE sean consistentes, comolo serían los estimadores por máxima verosimilitud, para que el factor deajuste óptimo F ∗ converja a 1 conforme el tamaño de la muestra se incre-menta.
En la Figura 2.1 se muestra la función de densidad (histograma normali-zado) y la función cuantil del error2, dado por |F ∗ − 1| en la estimación deF ∗, cuando se tiene una muestra de 1000 datos proveniente de una distribu-ción normal estándar, para un nivel de confianza del α = 95% y un valor deδ = 0.5. Ambas gráficas fueron generadas a partir de 100,000 muestras de1000 datos cada una, provenientes de una distribución normal estándar. Sepuede observar que la mayor parte de los errores son cercanos a cero y que laprobabilidad de tener un error mayor a 6% es prácticamente cero.
2.3.2 No Negatividad
El factor de ajuste óptimo F ∗, definido en (2.2), no siempre es positivo. Parailustrar esto considerése el caso en que las pérdidas se comportan de acuerdoa una distribución Pareto con función de densidad dada por
f (x) =3x4 1(1,∞)(x), (2.5)
2En este caso coinciden el error relativo y el error absoluto, por lo cual se referirá a ambossimplemte como el "error".
26

donde 1(1,∞) es igual a 1 si x ∈ (1, ∞) y cero en otro caso. Bajo esta dis-tribución, el factor de ajuste F ∗ es negativo, por ejemplo, para δ ∈ [0, 0.05] yα ∈ [0.55, 0.625] como se puede apreciar en la Figura 2.2.
0
0.5
1
0.50.6
0.70.80.91
−0.5
0
0.5
1
1.5
2
Valor de δ
Valor de F* Para Una Variable Aleatoria con Distribución Pareto
Valor de α
Val
or d
el F
acto
r de
Aju
ste
Ópt
imo
Fig. 2.2: Gráfica de F ∗ para el caso de una distribución Pareto, con función dedensidad dada por (2.5) y distintos niveles de confianza entre 50% y 100%.
La siguiente proposición establece condiciones suficientes para garantizarque F ∗ ≥ 0.
Proposición 2.1. Sea δ ∈ (0, 1) y α ∈ [0.5, 1). Supóngase VaREα ≥ µE. Entonces
F ∗ ≥ 0.
Demostración. De (2.2) se deduce que F ∗ ≥ 0 si y sólo si
(1− δ)(VaREα −µE)χα + δ(CVaRE
α −µE)ηα ≥ 0.
Nótese que la condición anterior se puede reescribir como
(VaREα −µE)χα + δ[(CVaRE
α −µE)ηα − (VaREα −µE)χα] ≥ 0. (2.6)
Por definición del CVaR se cumple que CVaREα ≥ VaRE
α y ηα ≥ χα, para todaα ∈ (0, 1). Por lo tanto,
(CVaREα −µE)ηα − (VaRE
α −µE)χα ≥ (CVaREα −µE)χα − (VaRE
α −µE)χα
= (CVaREα −VaRE
α )χα
≥ 0,
donde la última desigualdad es consecuencia del supuesto α ∈ [0.5, 1). Luegoentonces, es claro que VaRE
α ≥ µE implica (2.6) y por lo tanto se satisface queF ∗ ≥ 0.
27

Obsérvese que la condición de suficiencia de la Proposición 2.1 para ladistribución Pareto descrita en (2.5) es equivalente a la condición3 α ≥ 0.7037.Es decir, a que el nivel de confianza sea al menos de 70.37%. Por lo tanto,el factor de ajuste debe ser mayor o igual a cero para niveles de confianzamayores a 70.37%, lo cual se cumple como se puede apreciar en la Figura 2.2.
Una consecuencia importante de la Proposición 2.1 es que el factor deajuste F ∗ es mayor o igual a cero para cualquier distribución simétrica depérdidas, bajo niveles de confianza mayores o iguales a 50%. En particular, laProposición 2.1 garantiza que tanto la distribución normal, como la distribu-ción t de Student tienen factores de ajuste positivos para niveles de confianzamayores a 50%.
2.3.3 F ∗ y El Nivel de Aversión al Riesgo δ
Proposición 2.2. Sea δ ∈ (0, 1) y α ∈ (0.5, 1). Supóngase que VaREα > µE.
Entonces ∂F ∗∂δ ≥ 0 si y sólo si
CVaREα −µE
VaREα −µE
≥ ηα
χα(2.7)
Demostración. Del Teorema 2.1 se tiene que
F ∗ =(1− δ)χα(VaRE
α −µE) + δηα(CVaREα −µE)
(1− δ)χα2σE + δηα
2σE
=(ηα(CVaRE
α −µE)− χα(VaREα −µE))δ + χα(VaRE
α −µE)(ηα
2σE − χα2σE)δ + χα
2σE
=(B− A)δ + A(D− C)δ + C
(2.8)
donde
A ≡ χα(VaREα −µE) (2.9a)
B ≡ ηα(CVaREα −µE) (2.9b)
C ≡ χα2σE (2.9c)
D ≡ ηα2σE (2.9d)
Derivando (2.8) con respecto a δ se obtiene
∂F ∗∂δ
=(B− A)[(D− C)δ + C]− [(B− A)δ + A](D− C)
[(D− C)δ + C]2
=C(B− A)− A(D− C)
[(D− C)δ + C]2(2.10)
3Para la distribución Pareto con función de densidad dada por (2.5) se tiene que VaRα =(1− α)−1/3 y µ = 3/2. Por ende, VaRα ≥ µ si y sólo si α ≥ 1−
( 23
)3 ≈ 0.7037.
28

Claramente el denominador de (2.10) es positivo, luego entonces ∂F ∗∂δ ≥ 0 si y
sólo siC(B− A) ≥ A(D− C). (2.11)
Sustituyendo (2.9) en (2.11) y cancelando el término común χασE, el cual espositivo por consecuencia del supuesto α ∈ (0.5, 1), se deduce que la condi-ción (2.11) es equivalente a
χαηα(CVaREα −µE)− χα
2(VaREα −µE) ≥ (VaRE
α −µE)[ηα2 − χα
2].
Dividiendo ambos lados de la desigualdad anterior por
χαηα(VaREα −µE) > 0
se obtieneCVaRE
α −µE
VaREα −µE
− χα
ηα≥ ηα
χα− χα
ηα
o, de manera equivalente, que
CVaREα −µE
VaREα −µE
≥ ηα
χα
de donde se concluye (2.7).
La proposición anterior indica que, dado un nivel de confianza α, el factorde escala F ∗ crece conforme δ se incrementa si y sólo si la pérdida en exceso,respecto a la pérdida esperada (µE), asociada con el CVaRα es suficientementegrande con respecto a la correspondiente pérdida en exceso relacionada conel VaRα, donde suficientemente grande significa mayor en una proporción deal menos (ηα/χα − 1)%. Dicho porcentaje es la proporción en que el CVaRα
es mayor que el VaRα para el caso de una normal estándar y representa ladistancia relativa entre el CVaRα y el VaRα. Si se generaliza este concepto dedistancia relativa para cualquier distribución, la Proposición 2.2 implica queF ∗ es creciente en δ si la distancia relativa entre el CVaRα y el VaRα para ladistribución de pérdidas Π es mayor o igual que la correspondiente distanciarelativa para una distribución normal estándar.
Una vez establecidas condiciones necesarias y suficientes para la mono-tonicidad de F ∗ con respecto a δ es de interés analizar la manera en que F ∗se incrementa bajo dichas condiciones. Como se demuestra en la Proposi-ción 2.2, entre mayor sea la aversión al riesgo, menor será el incremento deF ∗. Para tal efecto, se usa el siguiente lema.
Lema 2.1. Sea δ ∈ (0, 1) y α ∈ (0, 1). Entonces,
∂2F ∗∂δ2 = −K
∂F ∗∂δ
(2.12)
donde K = 2(D−C)(D−C)δ+C > 0.
29

Demostración. Derivando (2.10) con respecto a δ se obtiene:
∂2F ∗∂δ2 = −2[(D− C)δ + C][C(B− A)− A(D− C)]
[(D− C)δ + C]4
= −(
2[(D− C)δ + C](D− C)[(D− C)δ + C]2
)(C(B− A)− A(D− C)
[(D− C)δ + C]2
)
= −(
2(D− C)(D− C)δ + C
)(∂F ∗∂δ
)tomando K = 2(D−C)
(D−C)δ+C se concluye de forma inmediata (2.12).
Proposición 2.3. Sea δ ∈ (0, 1) y α ∈ (0, 1). Entonces,
∂2F ∗∂δ2 ≤ 0 si y sólo si
∂F ∗∂δ≥ 0 (2.13)
Demostración. Se sigue de forma inmediata del lema anterior.
En términos geométricos, el resultado anterior indica que F ∗, como fun-ción de δ, es cóncava si y sólo si es creciente. Por lo tanto, cualquier condiciónnecesaria y suficiente para la monotonicidad de F ∗ con respecto a δ lo es tam-bién para la concavidad de F ∗. El siguiente corolario vincula las condicionesde monotonicidad de la Proposición 2.2 con la concavidad de F ∗.
Corolario 2.2. Sea δ ∈ (0, 1), α ∈ (0.5, 1) y VaREα > µE. Entonces, ∂2F ∗
∂δ2 ≤ 0 si ysólo si se satisface la condición (2.7).
Demostración. Se concluye de manera inmediata a partir de la proposiciónanterior y la Proposición 2.2.
Con el objeto de ilustrar los resultados anteriores, se grafica en la Figura 2.3ala diferencia
CVaRα
VaRα− ηα
χα,
para el caso de una distribución t de Student con 10 grados de libertad4, con-siderando niveles de confianza entre 50% y 100%. Como se puede observar,la condición (2.7) se satisface. Por lo tanto, F ∗ es creciente en δ (Figura 2.3b).
Andreev & Kanto (2005) muestran que la condición (2.7) se satisface paracualquier nivel de curtosis entre 0 y 50, y para distintos niveles de confianza,como son α = 90%, 95%, 97.5%, 99% y 99.5%.
4El VaR y el CVaR de la distribución t de Student fueron calculados usando la Proposición 1.8del Capítulo 1.
30

0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 10
0.5
1
1.5
2
2.5
3
3.5
4
Diferencia entre el cociente del CVaR al VaR de una t de Student con 10 grados de libertad y el cociente del VaR al CVaR de una normal estándar
(a) Verificación de la condición (2.7)
00.2
0.40.6
0.81
0.4
0.6
0.8
10.9
0.95
1
1.05
1.1
1.15
Valor de δ
Valor de F* Para Una Variable Aleatoria Con Distribuciónt de Student con 10 grados de libertad
Valor de α
Val
or d
el F
acto
r de
Aju
ste
Ópt
imo
(b) Gráfica de F ∗
Fig. 2.3: Distribución t de Student con 10 grados de libertad.
2.3.4 F ∗ y el Nivel de Confianza α
Al igual que los resultados de monotonicidad de F ∗ con respecto a δ obtenidosen la Proposición 2.2, se pueden derivar condiciones de monotonicidad de F ∗respecto al nivel de confianza α. La siguiente proposición establece la sufi-ciencia de dichas condiciones.
Proposición 2.4. Sea δ ∈ (0, 1) y α ∈ (0, 1). Si la función de distribución acumu-lada correspondiente a Π es una función estrictamente creciente y diferenciable en αentonces ∂F ∗
∂α existe y ∂F ∗∂α ≥ 0 si y sólo si
K1(VaRα−µE) + K2(CVaRα−µE) + K3(∂ VaR
∂α) + K4(
∂ CVaR∂α
) ≥ 0
donde K1, K2, K3 y K4 son funciones de δ y α dadas por:
K1(δ, α) = −(1− δ)2[
χ2α
(1− α)ηα
]+ δ(1− δ)ηα
[1− 2χα(ηα − χα)
1− α
](2.14a)
K2(δ, α) = −δ2[
η2α(ηα − χα)
1− α
]+ δ(1− δ)χα
[χα(ηα − χα)− 2
1− α
](2.14b)
K3(δ, α) = (1− δ)2χα3 + δ(1− δ)χαηα
2 (2.14c)
K4(δ, α) = δ2ηα3 + δ(1− δ)ηαχα
2 (2.14d)
Demostración. Si la función de distribución acumulada correspondiente a Π esestrictamente creciente y diferenciable en α entonces por el Lema 1.2, ∂ VaR
∂α y∂ CVaR
∂α existen. Asimismo por el corolario 1.2 las derivadas de χα y ηα existeny están dadas por (1.22a) y (1.22b).
Partiendo de la ecuación (2.2) el factor de ajuste óptimo puede expresarsecomo una función del nivel de confianza α de la siguiente manera:
31

F ∗(α) =Q(α)R(α)
(2.15)
donde
Q(α) = (1− δ)χα(VaRα−µE) + δηα(CVaRα−µE) (2.16a)
R(α) = (1− δ)χα2σE + δσEηα
2 (2.16b)
Partiendo de (2.15) se obtiene entonces la siguiente expresión para la derivadade F ∗
∂F ∗∂α
=∂Q∂α R(α)−Q(α) ∂R
∂α
R(α)2 (2.17)
DefiniendoS(α) ≡ ∂Q
∂αR(α)−Q(α)
∂R∂α
(2.18)
es inmediatio notar que
∂F ∗∂α≥ 0 si y sólo si S(α) ≥ 0
Luego entonces basta probar que (2.18) es no negativo. Desarrollando (2.18) ycancelando el término común σE se obtiene:
S(α) = K1(VaRα−µE) + K2(CVaRα−µE) + K3(∂ VaR
∂α) + K4(
∂ CVaR∂α
) (2.19)
donde K1, K2, K3 y K4 estan dados por (2.14)
Una vez fijados el nivel de confianza α y el parámetro δ las constantes K1,K2, K3 y K4 pueden calcularse por medio de (2.14). Sin embargo se necesitauna forma funcional o parámetrica de la función de distribución acumuladapara poder obtener ∂ VaR
∂α y ∂ CVaR∂α por lo que la Proposición 2.4 sólo es útil
para estudiar distribuciones "teóricas".
2.4 Aplicaciones
En esta sección se obtienen y analizan los factores de ajuste para dos casosparticulares: el caso del Bono M Diciembre 2007, el cual corresponde al fenó-meno que motivó el presente trabajo, y el caso del Bono M Junio 2011, el cualcorresponde a un bono altamente concentrado, como el Bono Diciembre M2007, pero que a diferencia de este último, no ha mostrado una distorsión tansignificativa en sus precios. La consideración del Bono M Junio 2011 se hacecon el objeto de contrastar los factores de ajuste para dicho bono, respecto aaquellas obtenidas para el Bono M Diciembre 2007.
32

2.4.1 Bono M Diciembre 2007
Para poder aplicar el Teorema 2.1 es necesario determinar la distribución depérdidas a considerar. Para tal efecto, se consideraron en primera instancialas variaciones diarias porcentuales de los precios del Bono M Diciembre 2007,comprendidas entre el 4 de enero del 2001 y el 30 de noviembre del 2007. Dadoque es de interés asociar el comportamiento del factor de ajuste con los altosniveles de concentración mostrados por este bono, se determinaron las dis-tribuciones de pérdidas empíricas de las variaciones porcentuales asociadascon distintos niveles de concentración predeterminados. A partir de cada unade estas distribuciones se determinaron los factores de ajuste para distintosvalores de δ, dado un nivel de confianza α. Por ejemplo, en la Figura 2.4 segrafica F ∗ para distintos valores de δ, en el caso de concentraciones mayoreso iguales a 50% y considerando un nivel de confianza del 99%.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 11.36
1.38
1.4
1.42
1.44
1.46
1.48
Valor de F* para una concentración mayor o igual al 50%Nivel de Confianza del 99%
Valor de δ
Val
or d
e F
*
Fig. 2.4: Bono Diciembre 2007. Gráfica de F ∗ con respecto a δ, para C0 ≥ 50%y α = 99%.
Por su parte en la Figura 2.5 se grafica el factor F ∗ como función de δ,para un nivel de confianza del 99%, pero considerando distintos niveles deconcentración C0.
Como se puede observar en las Figuras 2.4 y 2.5, el factor F ∗ es una fun-ción creciente respecto a δ. Esto se debe a que las distribuciones consideradassatisfacen la condición (2.7) de la Proposición 2.2. Para ilustrar esto último, setabularon los valores de
CVaREα −µ
VaREα −µ
yηα
χα
en el caso de una concentración mínima de 80%, considerando distintos nive-
33

00.2
0.40.6
0.81
0.5
0.6
0.7
0.8
0.91.3
1.4
1.5
1.6
1.7
1.8
Valor de δ
Valor de F* para distintos niveles de concentraciónNivel de Confianza del 99%
Rango de Concentración
Val
or d
el F
acto
r de
Aju
ste
Ópt
imo
F*
Fig. 2.5: Bono Diciembre 2007. Gráfica de F ∗ para distintos niveles de con-centración mínima y α = 99%.
les de confianza. Esto se muestra en la Tabla 2.1.
Tab. 2.1: Verificación de la Condición 2.7
αCVaRE
α −µE
VaREα −µE
ηαχα
95% 1.8291 1.25496% 1.7437 1.230697% 1.5074 1.205998% 1.4116 1.178899% 1.3246 1.1457
2.4.2 Bono M Junio 2011
De la misma manera en que se procedió en la sección anterior, se obtuvieronlos factores de ajuste para el caso del Bono M Junio 2011 para distintos valoresde δ y rangos de concentración mínimos, considerando un nivel de confianzadel 99%, como se muestra en la Figura 2.6.
34

00.2
0.40.6
0.81
0.5
0.6
0.7
0.8
0.92
2.2
2.4
2.6
2.8
Valor de δ
Valor de F* para distintos niveles de concentraciónNivel de Confianza del 99%
Rango de Concentración
Val
or d
el F
acto
r de
Aju
ste
Ópt
imo
F*
Fig. 2.6: Bono Junio 2011. Gráfica de F ∗ para distintos niveles de concen-tración mínima y α = 99%.
2.5 Descomposición del Efecto de Distorsión
Un factor de ajuste F ∗ distinto a uno no implica necesariamente una distor-sión de los precios. Esto se puede deber a otras causas. Por ejemplo, lassiguientes:
• La distribución de pérdidas no es normal.
• La distribución de pérdidas es normal, pero los parámetros estimadosno son los verdaderos.
Por esta razón, en esta sección se propone una manera de extraer el efectode distorsión a partir del factor de ajuste. Para tal efecto, se supone que elfactor F ∗ se descompone de la siguiente forma:
F ∗ = F ∗NF ∗D (2.20)
donde F ∗N es el factor de ajuste debido a las condiciones de mercado "nor-males" en las que no se presentan distorsiones de los precios, y F ∗D es el factorque se aplica adicionalmente por distorsión de los precios. Para determinarF ∗N se considera el conjunto de aquellos títulos que no presentan dicha dis-torsión. En el caso particular de los bonos M Diciembre 2007 y Junio 2011, seconsideró al bono M Diciembre 2024 como un bono representativo en condi-ciones de mercado "normales" y para el cual se determinan los factores deajuste como a continuación se especifica.
35

0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 11.15
1.2
1.25
1.3
Valor de F* para una concentración mayor o igual al 50% Nivel de Confianza del 99%
Valor de δ
Val
or d
e F
*
Fig. 2.7: Bono Diciembre 2024. Gráfica de F ∗ con respecto a δ, α = 99%.
2.5.1 Bono M Diciembre 2024
Aplicando el mismo procedimiento utilizado para los casos de los bonos MDiciembre 2007 y Junio 2011, se obtuvieron los factores de ajuste para el bonoM Diciembre 2024, considererando distintos valores de δ y un nivel de con-fianza α = 99%. Sin embargo, dada la muy baja concentración del bono, noes necesario tomar distintos rangos de concentración como en los casos ante-riores. El resultado del cálculo se muestra en la Figura 2.7.
Obsérvese que para el nivel de confianza del considerado, el factor deajuste es mayor a uno para cualquier valor de δ. Esto se debe a que la dis-tribución de pérdidas para el bono M Diciembre 2024 no es normal.
2.5.2 Factor de Distorsión del bono M Diciembre 2007
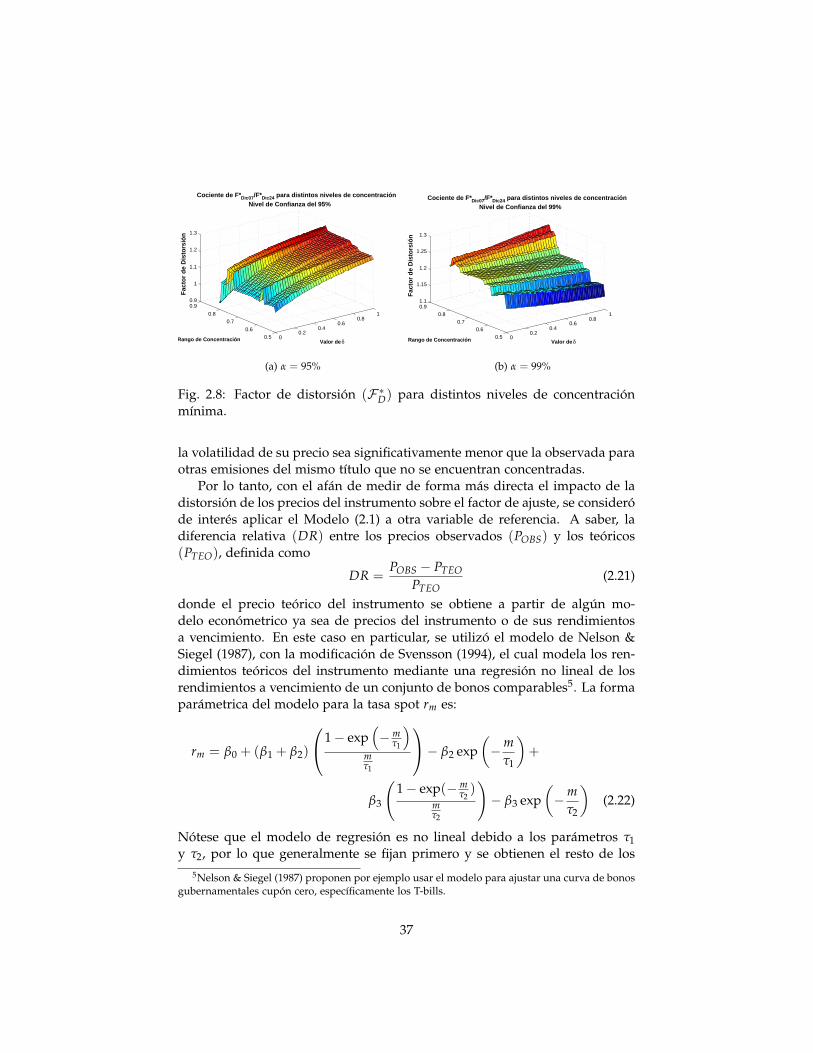
A partir de la relación (2.20) y utilizando los factores calculados en las sec-ciones 2.4.1 y 2.5.1, se determinaron los factores de distorsión del bono MDiciembre 2007 para distintos valores de δ y rangos de concentración mínima.Dichos factores se muestran en la Figura 2.8.
2.6 Otras variables de referencia
Aunque un alto nivel de concentración en la tenencia de la emisión de untítulo en particular genera condiciones propicias para la distorsión del preciodel mismo, no necesariamente se sigue que dicha distorsión se de, o bien que
36
00.2
0.40.6
0.81
0.50.6
0.70.8
0.90.9
1
1.1
1.2
1.3
Valor de δ
Cociente de F* Dic07/F*Dic24 para distintos niveles de concentraciónNivel de Confianza del 95%
Rango de Concentración
Fac
tor
de D
isto
rsió
n
(a) α = 95%
00.2
0.40.6
0.81
0.50.6
0.70.8
0.91.1
1.15
1.2
1.25
1.3
Valor de δ
Cociente de F* Dic07/F*Dic24 para distintos niveles de concentraciónNivel de Confianza del 99%
Rango de Concentración
Fac
tor
de D
isto
rsió
n
(b) α = 99%
Fig. 2.8: Factor de distorsión (F ∗D) para distintos niveles de concentraciónmínima.
la volatilidad de su precio sea significativamente menor que la observada paraotras emisiones del mismo título que no se encuentran concentradas.
Por lo tanto, con el afán de medir de forma más directa el impacto de ladistorsión de los precios del instrumento sobre el factor de ajuste, se consideróde interés aplicar el Modelo (2.1) a otra variable de referencia. A saber, ladiferencia relativa (DR) entre los precios observados (POBS) y los teóricos(PTEO), definida como
DR =POBS − PTEO
PTEO(2.21)
donde el precio teórico del instrumento se obtiene a partir de algún mo-delo económetrico ya sea de precios del instrumento o de sus rendimientosa vencimiento. En este caso en particular, se utilizó el modelo de Nelson &Siegel (1987), con la modificación de Svensson (1994), el cual modela los ren-dimientos teóricos del instrumento mediante una regresión no lineal de losrendimientos a vencimiento de un conjunto de bonos comparables5. La formaparámetrica del modelo para la tasa spot rm es:
rm = β0 + (β1 + β2)
1− exp(− m
τ1
)mτ1
− β2 exp(−m
τ1
)+
β3
(1− exp(− m
τ2)
mτ2
)− β3 exp
(−m
τ2
)(2.22)
Nótese que el modelo de regresión es no lineal debido a los parámetros τ1y τ2, por lo que generalmente se fijan primero y se obtienen el resto de los
5Nelson & Siegel (1987) proponen por ejemplo usar el modelo para ajustar una curva de bonosgubernamentales cupón cero, específicamente los T-bills.
37

00.2
0.40.6
0.81
0.05
0.06
0.07
0.080.8
1
1.2
1.4
1.6
Valor de δ
Valor de F* para distintos niveles de diferencialesNivel de Confianza del 95%
Rango de Diferenciales
Val
or d
el F
acto
r de
Aju
ste
Ópt
imo
F*
(a) α = 95%
00.2
0.40.6
0.81
0.05
0.06
0.07
0.081.3
1.4
1.5
1.6
1.7
1.8
Valor de δ
Valor de F* para distintos niveles de diferencialesNivel de Confianza del 99%
Rango de Diferenciales
Val
or d
el F
acto
r de
Aju
ste
Ópt
imo
F*
(b) α = 99%
Fig. 2.9: Bono Diciembre 2007. Factor F ∗ para distintos niveles de diferen-ciales mínimos.
parámetros por mínimos cuadrados ordinarios, repitiéndose el proceso paradistintos valores de τ1 y τ2. Una vez obtenidos los rendimientos teóricosa través de (2.22) por medio del proceso descrito anteriormente, es posiblecalcular los precios teóricos del instrumento, con lo que se obtiene a su vezlos diferenciales relativos dados por (2.21). En la Figura 2.9 se muestran losresultados para el bono Diciembre 2007.
2.7 Aplicación de la Teoría de Valores Extremos
2.7.1 Dificultades en la estimación del VaR y CVaR
Típicamente, el VaR y el CVaR se estiman utilizando la distribución empíricaconstruida a partir de los datos observados. Por lo tanto, bajo estas circuns-tancias, siempre es posible encontrar un nivel de confianza α suficientementecercano al 100% tal que el VaR y el CVaR coincidan para niveles de confianzamayores o iguales a α en la pérdida máxima registrada. Este hecho, en el casode contar con relativamente pocos datos y considerando que la distribuciónde pérdidas verdadera es no acotada (e.g. normal), implica que para nivelesde confianza relativamente altos se subestime el riesgo en términos del VaR yCVaR.
Esta última observación es particularmente relevante en el contexto deaplicación del análisis realizado ya que a medida que se incrementa el valorde la variable de referencia (e.g. concentración) se reduce la cantidad de ob-servaciones correspondientes.
De manera sinóptica, las dificultades anteriores se describen de maneraesquemática en la Figura 2.10.
38

↑ Nivel de la variable de referencia (c)
↓ Número de Observaciones Consideradas (N)
↑ Nivel de Confianza (α) VaRα→ CVaRα→ Máxima Pérdida
F* no es creciente respecto a δ(Condición (2.7)) Subestimación del Riesgo
Fig. 2.10: Dificultades en la estimación del VaR y CVaR.
Para ilustrar la problemática antes descrita, considérese el caso de las pér-didas asociadas a una concentración mayor o igual al 50% para el Bono MDiciembre 2007. Dado que la muestra contiene 501 datos, para percentilessuperiores al 99.8%, se tendrá que el VaR, el CVaR y la máxima pérdida soniguales a 0.3301%, como se puede ver a partir de la Tabla 2.2.
Tab. 2.2: Pérdidas asociadas a una concentración mayor o igual a 50%.
Percentil Pérdidas
99.20% 0.1881%99.40% 0.1907%99.60% 0.1951%99.80% 0.1962%100% 0.3301%
Debido a las dificultades de estimación anteriormente mencionadas, esde interés práctico encontrar una metodología que permita remediar parcialo totalmente dichas dificultades. Dado que la Teoría de Valores Extremosestudia precisamente el comportamiento de valores extremos, que conlleva aluso de muestras reducidas, los estimadores obtenidos mediante esta teoríason candidatos naturales para resolver estos problemas.
39

2.7.2 Estimadores del VaR y CVaR usando TVE
A partir de la Teoría de Valores Extremos, McNeil (1999) deriva los esti-madores del VaR y CVaR
VaRα = u +β
ξ
((n
Nu(1− α)
)−ξ
− 1
)(2.23)
CVaRα =VaRα
1− ξ+
β− ξu1− ξ
(2.24)
donde n es el número total de datos, Nu es el número de datos que exceden elumbral u; y ξ, β son los estimadores de los parámetros ξ y β de la distribuciónPareto Generalizada dada por
Gξ,β(x) =
1− (1 + ξx/β)−
1ξ para ξ 6= 0,
1− exp(−x/β) para ξ = 0.(2.25)
donde β > 0, y x ≥ 0 cuando ξ ≥ 0 y 0 ≤ x ≤ −β/ξ si ξ < 0.La derivación de los estimadores (2.23) y (2.24) se lleva acabo a partir de
la relación
F(x) = (1− F(u))Fu(x− u) + F(u) (2.26)
dondeFu(y) = P(X− u ≤ y|X > u) (2.27)
es la distribución de los excesos sobre el umbral u, para 0 ≤ y ≤ xF − u,y donde xF es el extremo derecho de la distribución F, definido como xF =supx ∈ R|F(x) < 1. Por el teorema de Pickands-Balkema-de Haan6 la dis-tribución de excesos Fu se puede aproximar por una distribución Pareto Ge-neralizada con parámetros ξ y β, para un umbral u "suficientemente grande".Es decir,
Fu(y) ≈ Gξ,β(y) (2.28)
para u suficientemente grande. Por lo tanto,
F(x) ≈ (1− F(u))Gξ,β(x− u) + F(u) (2.29)
para x > u. Luego entonces, estimando F(u) con
n− Nun
(2.30)
6Ver Teorema 1.2.
40

donde Nu es el número de datos que exceden el umbral u, se deduce que
F(x) = 1− Nu
n
(1 + ξ
x− uβ
)− 1ξ
(2.31)
Así, para obtener la aproximación del VaRα basta usar la definición F(VaRα) =α y despejar el VaR usando (2.31). Para obtener la aproximación (2.24) delCVaRα, se parte de la Proposición 1.6 para obtener la identidad
CVaRα = VaRα +E[X−VaRα |X > VaRα] (2.32)
demostrada en la Proposición 1.6, de la relación
E[X−VaR |X > VaR] = E[Z] (2.33)
donde Z ∼ FVaRα , y de la aproximación
FVaRα(y) ≈ Gξ(VaRα −u),β(y)
para deducir que
E[X−VaRα |X > VaRα] ≈β + ξ(VaRα−u)
1− ξ(2.34)
Por lo tanto, de (2.34) y (2.32) se obtiene (2.24).
2.7.3 Aplicación en la determinación de F ∗
Con el fin de mitigar las dificultades en la estimación del VaR y CVaR se ob-tuvo el factor de ajuste F ∗ aplicando TVE . Para ello se siguieron los siguientespasos:
1. Se filtraron los datos respecto al nivel de concentración.
2. A partir de los datos obtenidos, y dado un nivel de confianza α, seescogió el umbral u tomando u = VaRα.
3. Una vez determindo el umbral se estimaron los parámetros de la dis-tribución Pareto Generalizada.
4. A partir de la estimación anterior de los parámetros, se obtuvieron losestimadores del VaR dado por (2.23) y del CVaR dado por (2.24).
5. Con los estimadores del VaR y CVaR se obtuvo el Factor de Ajuste paradistintos valores de δ y niveles de la variable de referencia.
41
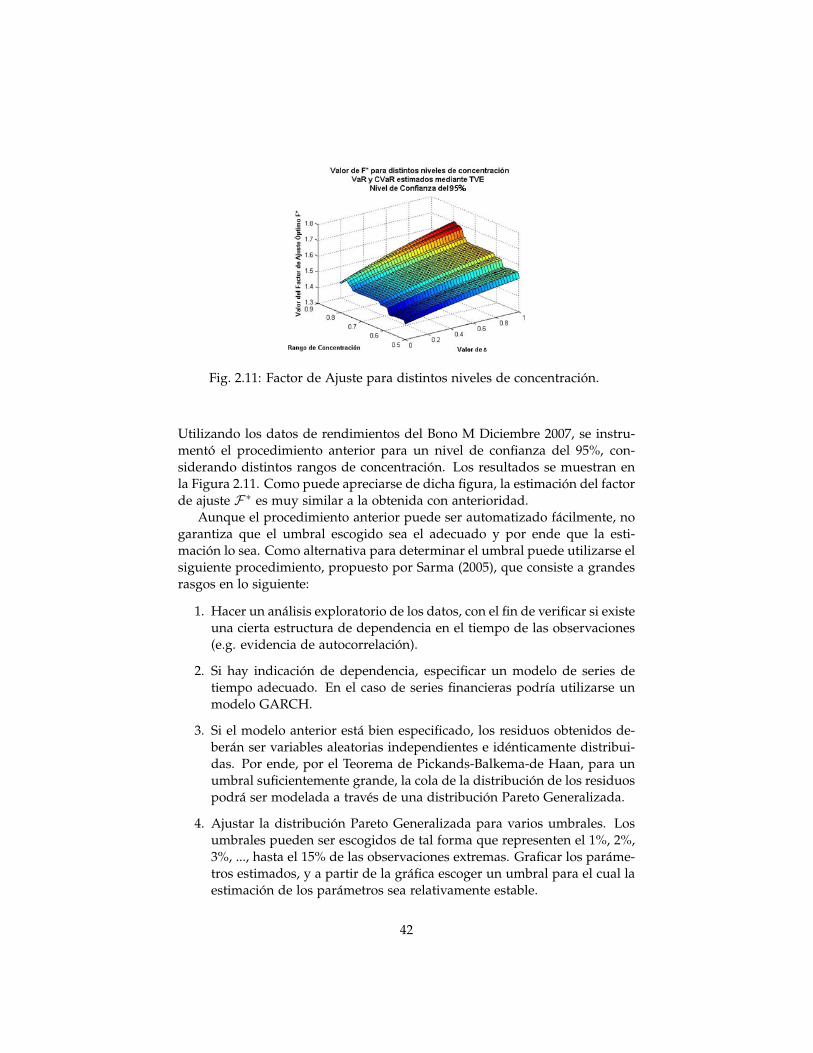
Fig. 2.11: Factor de Ajuste para distintos niveles de concentración.
Utilizando los datos de rendimientos del Bono M Diciembre 2007, se instru-mentó el procedimiento anterior para un nivel de confianza del 95%, con-siderando distintos rangos de concentración. Los resultados se muestran enla Figura 2.11. Como puede apreciarse de dicha figura, la estimación del factorde ajuste F ∗ es muy similar a la obtenida con anterioridad.
Aunque el procedimiento anterior puede ser automatizado fácilmente, nogarantiza que el umbral escogido sea el adecuado y por ende que la esti-mación lo sea. Como alternativa para determinar el umbral puede utilizarse elsiguiente procedimiento, propuesto por Sarma (2005), que consiste a grandesrasgos en lo siguiente:
1. Hacer un análisis exploratorio de los datos, con el fin de verificar si existeuna cierta estructura de dependencia en el tiempo de las observaciones(e.g. evidencia de autocorrelación).
2. Si hay indicación de dependencia, especificar un modelo de series detiempo adecuado. En el caso de series financieras podría utilizarse unmodelo GARCH.
3. Si el modelo anterior está bien especificado, los residuos obtenidos de-berán ser variables aleatorias independientes e idénticamente distribui-das. Por ende, por el Teorema de Pickands-Balkema-de Haan, para unumbral suficientemente grande, la cola de la distribución de los residuospodrá ser modelada a través de una distribución Pareto Generalizada.
4. Ajustar la distribución Pareto Generalizada para varios umbrales. Losumbrales pueden ser escogidos de tal forma que representen el 1%, 2%,3%, ..., hasta el 15% de las observaciones extremas. Graficar los paráme-tros estimados, y a partir de la gráfica escoger un umbral para el cual laestimación de los parámetros sea relativamente estable.
42

5. Aplicar una prueba de bondad de ajuste para evaluar que tan significa-tiva es la diferencia entre la cola de la distribución empírica y la colaestimada mediante la distribución Pareto Generalizada. Para ello podríautilizarse, por ejemplo, la prueba de Kolmogorov-Smirnoff (KS).
Aunque el ajuste de los datos observados a partir de un modelo GARCHse encuentra más alla del alcance del presente trabajo, el lector interesadopuede consultar el trabajo de Sarma (2005) para una exposición más detalladadel procedimiento antes delineado.
2.8 Conclusiones
La motivación principal de este capítulo fue determinar el "ajuste adecuado"que debe aplicarse a la desviación estándar de las pérdidas para estimar elriesgo de mercado de manera más precisa, bajo condiciones de distorsión delos precios.
De esta manera, se adoptó un criterio para definir lo que se entenderíapor "ajuste adecuado". A saber, en términos de la determinación de un factorde ajuste que al multiplicarse por la desviación estándar observada, dé comoresultado una desviación estándar ajustada con base en la cual se estiman si-multáneamente el VaR y el CVaR, de la manera "más precisa posible". Es decir,de manera tal que el VaR y CVaR estimados, utilizando la desviación estándarajustada, se parezca lo "más posible" al VaR y CVaR observados. Concreta-mente, que la desviación cuadrática de los valores estimados y observados deestas medidas de riesgo sea mínima.
El criterio anterior se formuló matemáticamente como la solución de unproblema de optimización que presenta las siguientes ventajas:
• La formulación permite asignar el peso relativo que tiene la desviacióncuadrática relacionada con el CVaR respecto a aquélla vinculada con elVaR. El valor de dicho peso relativo, denominado δ, se puede asociar,al menos intuitivamente, a un cierto nivel de aversión al riesgo en el sen-tido de que entre mayor sea el valor de este ponderador, mayor es laimportancia se le da al valor estimado del CVaR, la medida de riesgomás conservadora de las dos consideradas en el presente análisis.
• El problema de optimización tiene solución explícita y única, lo cualimplica lo siguiente:
– Existe una fórmula explícita para el factor de ajuste.
– El factor de ajuste está caracterizado por dicho problema de opti-mización.
• El factor de ajuste caracterizado de esta manera tiene propiedades teóri-cas atractivas. Por ejemplo:
43

– Es igual a uno para el caso en que la distribución de pérdidas seauna distribución normal. Es decir, en caso de que el supuesto es-tándar de la distribución de pérdidas se cumpla en la realidad, nohay ajuste que hacer a la desviación estándar observada. Esto im-plica que en la forma en que se caracteriza el factor de ajuste, noexiste ningún sesgo bajo el supuesto estándar de la distribución depérdidas.
– Es mayor o igual que cero para niveles de confianza mayores oiguales al 50%, en los que el VaR observado es mayor o igual quela pérdida promedio; condiciones que típicamente se cumplen enla práctica.
– Es una función creciente del ponderador δ, es decir, el factor deajuste aumenta conforme el nivel de aversión al riesgo se incre-menta, bajo las siguientes dos condiciones:
∗ El VaR observado es mayor que la pérdida promedio.∗ La pérdida en exceso, respecto a la pérdida promedio, asociada
con el CVaR es mayor que la correspondiente pérdida en excesorelacionada con el VaR en una proporción mayor o igual a laproporción en que el CVaR es mayor al VaR de una distribuciónnormal estándar.
Ambas condiciones se cumplen típicamente en la práctica. La pri-mera debido a que usualmente la medición del VaR se hace paraniveles de confianza superiores al 95%, para los cuales el VaR ob-servado es mayor que la pérdida promedio. La segunda, dado quela distribución de las pérdidas en la práctica por lo general tienecolas pesadas.
En el contexto particular en el que se aplicó la metodología desarrollada seobtuvieron los siguientes resultados:
• Para el caso del Bono M Diciembre 2007, se obtuvieron los factores deajuste considerando dos niveles de confianza, 95% y 99%, para cada unode los cuales se tomaron en cuenta distintos niveles de concentración,variando el nivel de aversión al riesgo del 0% al 100%. Para dichosfactores se observa lo siguiente:
– El rango de los factores de ajuste es [0.92, 1.4], para α = 95%, y de[1.38, 1.67], para α = 99%.
– Para cualquier nivel de concentración considerado se cumple quelos factores de ajuste aumentan conforme el nivel de aversión alriesgo se incrementa.
44

• Para el caso del Bono M Junio 2011, el rango de los factores de ajustepara α=99% es [2.08,2.51]. En este caso los factores de ajuste disminuyenconforme se incrementa el nivel de aversión al riesgo para cualquiernivel de concentración considerando.
• Para el caso del Bono M Diciembre 2024, el rango de los factores deajuste es [1.17,1.29]. En este caso los factores de ajuste se incrementanconforme el nivel de aversión al riesgo se incrementa.
• Utilizando los resultados del Bono M Diciembre 2024, se aisló el efectode distorsión de los precios del Bono M Diciembre 2007, en términos defactores de distorsión para los que se observa lo siguiente:
– En general el valor de los factores disminuyen para cualquier nivelde concentración considerado, respecto al valor de los factores sinconsiderar el Bono M Diciembre 2024.
– Considerando un nivel de confianza del 95% los factores de ajustese incrementam conforme se incrementa el nivel de aversión alriesgo para cualquier nivel de concentración considerando.
– Considerando un nivel de confianza del 99% los factores de ajustese incrementan conforme se incrementa el nivel de aversión al riesgopara niveles de concentración superiores al 77% y disminuyen con-forme se incrementa el nivel de aversión al riesgo para niveles deconcentración inferiores al 77%.
La metodología desarrollada en este capítulo se puede adaptar fácilmentepara
• Añadir o incluir otras medidas de riesgo distintas al VaR y CVaR.
• Incorporar restricciones adicionales sobre el factor de ajuste.
• Utilizar otras variables de referencia.
45

Capítulo 3
Aplicación de DistribucionesHíbridas
3.1 Introducción y Motivación
En el capítulo anterior se desarrolla y ejemplifica la aplicación de una metodo-logía para ajustar el parámetro de desviación estándar con el objeto de medirel riesgo de mercado -en términos del VaR y del CVaR- de manera más precisaen condiciones de distorsión de los precios, bajo el supuesto estándar de quelos rendimientos de los mismos se distribuyen de acuerdo a una distribuciónGaussiana.
En este capítulo, al igual que el anterior, se busca medir dicho riesgo par-tiendo del supuesto estándar de una distribución de pérdidas Gaussiana. Sinembargo, en lugar de ajustar el parámetro de desviación estándar, se incor-pora la posibilidad de realización de un evento de estrés en el cual la distribu-ción de pérdidas es distinta a la distribución Gaussiana que es consideradabajo condiciones normales. De esta manera, lo que se busca es determinarla verosimilitud de dicho evento de estrés la cual, junto con la distribuciónde pérdidas considerada en este evento, permite construir una distribución"híbrida" a partir de la cual se mide el riesgo de manera más precisa. Por lotanto, el objetivo central de este capítulo es describir una metodología paradeterminar dicha distribución "híbrida".
Este capítulo se encuentra organizado de la siguiente manera: en la Sec-ción 3.2 se define, de manera formal, e ilustra el concepto de distribucionesde probabilidad híbridas. En la Sección 3.3 se formula matemáticamente elmodelo para la determinación de la probabilidad de condiciones de estrés,la cual se utiliza para establecer la distribución de pérdidas híbrida. En laSección 3.4 se estudian algunas propiedades teóricas de la probabilidad deestrés obtenida a través de dicho modelo. En la Sección 3.5 se describe la
46

instrumentación del modelo para la obtención de la probabilidad de estrésmediante la aplicación de simulación. En las Secciones 3.6 y 3.7 se aplica lametodología desarrollada en el contexto de los bonos que motivaron este tra-bajo de tesis. A saber, se desarrollan dos casos particulares de distribucioneshíbridas considerando, en ambos casos, una distribución Gausssiana para lascondiciones normales y una Gaussiana y una t de Student, respectivamente,para las condiciones de estrés. Finalmente en la Sección 3.8 se concluye.
3.2 Distribuciones Híbridas
De manera formal, la distribución híbrida asociada a dos distribuciones esla distribución no condicional correspondiente a dichas distribuciones, supo-niendo que éstas son distribuciones condicionales de eventos complementa-rios. En términos matemáticos,
Definición 3.1 (Distribución Híbrida). Sea X una variable aleatoria tal queX ∼ FA si el evento A ocurre y X ∼ FB si el evento B ocurre, donde A y B sonconjuntos complementarios. Entonces la distribución híbrida FH de FA y FBsatisface
FH(x) = βFA(x) + (1− β)FB(x) (3.1)
para toda x ∈ Rango(X), donde P[A] = β.
Las distribuciones híbridas surgen de manera natural en el contexto deriesgos cuando es necesario medir el riesgo en dos circunstancias mutuamenteexcluyentes cuyas distribuciones son típicamente muy diferentes. Para ilus-trar el concepto y la aplicación de distribuciones híbridas considerénse lossiguientes ejemplos:
Ejemplo 3.1 (Pérdidas por Riesgo de Crédito). Una institución financiera de-sea medir sus pérdidas por riesgo de crédito. Para ello, la institución estimaque dichas pérdidas, en términos relativos, y las cuales se denotan por Π,ascienden a un porcentaje M, en caso de incumplimiento de sus deudores conprobabilidad p, y a cero en caso contrario con probabilidad 1− p. Dicho por-centaje M se comporta de acuerdo a una distribución triangular Λ(·|a, υ, b),donde a > 0 es el valor mínimo, υ es la moda y b su valor máximo; y cuyafunción de densidad (Figura 3.1) es
Λ(x|a, υ, b) =
2(x−a)
(b−a)(υ−a) para a ≤ x < υ2(b−x)
(b−a)(b−υ) para υ ≤ x < b0 en otro caso
(3.2)
Para medir sus pérdidas, la institución determina la distribución de Π dela siguiente manera:
47

Fig. 3.1: Función de densidad de la distribución triangular Λ(·|a, υ, b).
Sea I el evento en que los deudores incumplen. Entonces, se cumple
P(Π ≤ x) = P(I)P(Π ≤ x|I) + P(Ic)P(Π ≤ x|Ic)= pP(Π ≤ x|I) + (1− p)P(Π ≤ |Ic) (3.3)
donde
P(Π ≤ x|Ic) =
0 para x < 01 para x ≥ 0
(3.4)
y
P(Π ≤ x|I) =
0 para x < a
(x−a)2
(b−a)(υ−a) para a ≤ x < υ
1− (b−x)2
(b−a)(b−υ) para υ ≤ x < b1 para x ≥ b
(3.5)
Por lo tanto, de (3.3) a (3.5), se deduce que
P(Π ≤ x) =
0 para x < 01− p para 0 ≤ x < a
p (x−a)2
(b−a)(υ−a) + 1− p para a ≤ x < υ
1− p (b−x)2
(b−a)(b−υ) para υ ≤ x < b1 para x ≥ b
(3.6)
La institución financiera estima que sus pérdidas relativas pueden variardesde un valor mínimo de 30% hasta un valor máximo de 70%, con una modade 65% y una probabilidad p de 5%. Considerando estos parámetros, se deter-mina la distribución híbrida correspondiente utilizando (3.6) y la cual, juntocon su densidad correspondiente, se ilustran en la Figura 3.2.
Con base en esta distribución híbrida, la institución determina un VaR95% =0% y un CVaR95% = 55%. Para complementar su análisis, la institución con-sidera otros valores para la probabilidad p, a saber p = 1% y p = 10%. Enla Figura 3.3 se grafican las densidades híbridas correspondientes. El VaR y
48

0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Pérdida en términos relativos
Pro
babi
lidad
Función de Densidad de las Pérdidas Π.Probabilidad de Incumplimiento P=5%
0.95
(a) Función de Densidad
−0.2 0 0.2 0.4 0.6 0.80
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Pérdida en términos relativos
Pro
babi
lidad
Función de Distribución Acumulada de las Pérdidas Π.
Probabilidad de Incumplimiento P=5%
(b) Función de Distribución Acumulada
Fig. 3.2: Densidad y Distribución Híbrida del Ejemplo 3.1.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Pérdida en términos relativos
Pro
babi
lidad
Función de Densidad de las Pérdidas Π. Probabilidad de Incumplimiento P=1,5 y 10%
P=5%P=1%P=10%
Fig. 3.3: Densidad Híbrida para distintas probabilidades de incumplimiento(Ejemplo 3.1).
CVaR para estas distribuciones híbridas son, respectivamente, VaR95% = 0%,CVaR95% = 11% y VaR95% = 56.47%, CVaR95% = 62.31%.
Ejemplo 3.2. Considerése la institución financiera del Ejemplo 3.1, pero ahoradicha institución desea considerar también en su medición de riesgo los rendi-mientos que obtendría en caso de que sus deudores no incumpliesen. Esto es,se desea tomar en cuenta tanto el riesgo de crédito como el riesgo de mercado.Los rendimientos en caso de que no se presenten incumplimientos, según es-timaciones de la misma institución, se distribuyen como una distribución nor-mal con media µ = 10% y desviación estándar σ = 3%. Con base en estasconsideraciones, la institución financiera determina la distribución híbrida co-rrespondiente1 la cual, junto con sus marginales, se exhibe en la Figura 3.4.A partir de dicha distribución híbrida de pérdidas, la institución estima unVaR95% = 2.59% y un CVaR95% = 54.96%.
1Para tal efecto se utilizó simulación, en el apéndice B se describe dicho proceso de simulación.
49
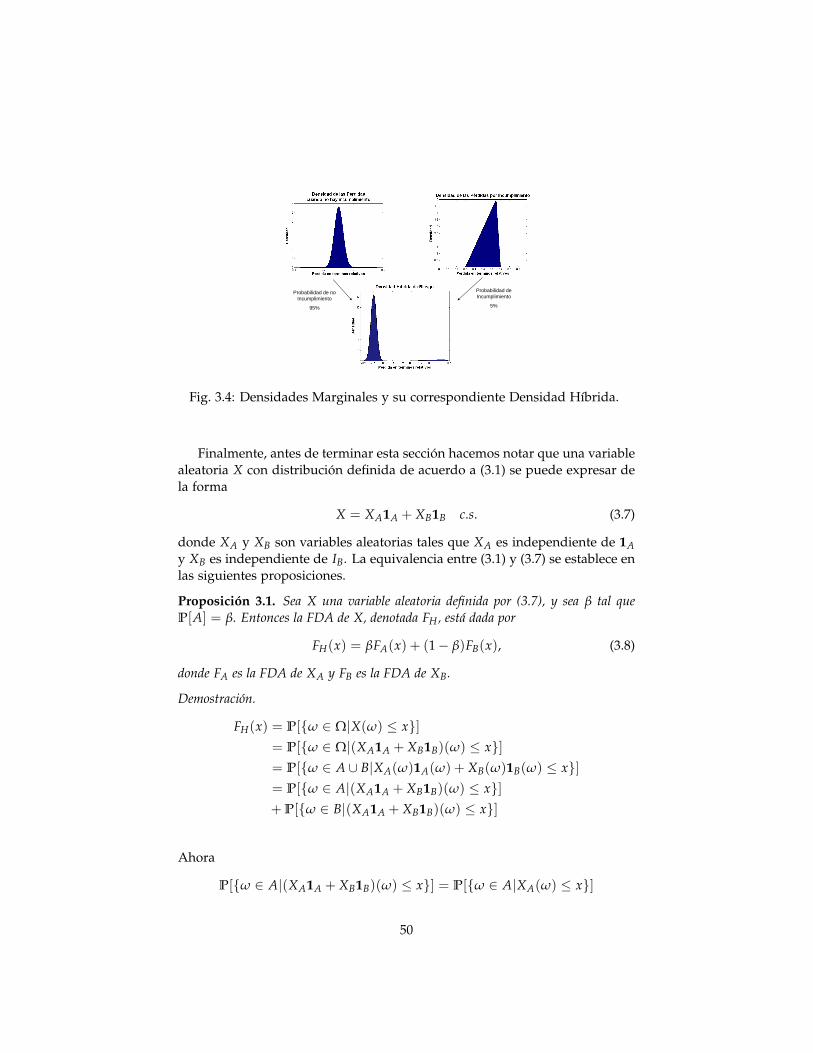
Probabilidad deProbabilidad de no Probabilidad de Incumplimiento
5%
Probabilidad de no Incumplimiento
95%
Fig. 3.4: Densidades Marginales y su correspondiente Densidad Híbrida.
Finalmente, antes de terminar esta sección hacemos notar que una variablealeatoria X con distribución definida de acuerdo a (3.1) se puede expresar dela forma
X = XA1A + XB1B c.s. (3.7)
donde XA y XB son variables aleatorias tales que XA es independiente de 1Ay XB es independiente de IB. La equivalencia entre (3.1) y (3.7) se establece enlas siguientes proposiciones.
Proposición 3.1. Sea X una variable aleatoria definida por (3.7), y sea β tal queP[A] = β. Entonces la FDA de X, denotada FH , está dada por
FH(x) = βFA(x) + (1− β)FB(x), (3.8)
donde FA es la FDA de XA y FB es la FDA de XB.
Demostración.
FH(x) = P[ω ∈ Ω|X(ω) ≤ x]= P[ω ∈ Ω|(XA1A + XB1B)(ω) ≤ x]= P[ω ∈ A ∪ B|XA(ω)1A(ω) + XB(ω)1B(ω) ≤ x]= P[ω ∈ A|(XA1A + XB1B)(ω) ≤ x]+ P[ω ∈ B|(XA1A + XB1B)(ω) ≤ x]
Ahora
P[ω ∈ A|(XA1A + XB1B)(ω) ≤ x] = P[ω ∈ A|XA(ω) ≤ x]
50

ya que 1A(ω) = 1 para toda ω ∈ A y 1B(ω) = 0 para toda ω ∈ A. Asimismose tiene que
P[ω ∈ A|XA(ω) ≤ x] = P[A ∩ ω ∈ Ω|XA(ω) ≤ x]= P[A]P[ω ∈ Ω|XA(ω) ≤ x]= βFA(x)
donde la penúltima igualdad se sigue de la hipótesis de independencia entreXA e IA. Análogamente se puede demostrar que
P[ω ∈ B|(XA1A + XB1B)(ω) ≤ x] = (1− β)FB(x).
Por lo tanto, se concluye que FH(x) = βFA(x) + (1− β)FB(x).
A continuación se establece el recíproco de la proposición anterior.
Proposición 3.2. Sea X una variable aleatoria cuya FDA, denotada por FH , estádada por
FH(x) = βFA(x) + (1− β)FB(x),
donde β = P[A]. Entonces
X = XA1A + XB1B c.s.
donde XA se distribuye de acuerdo a FA y es independiente de 1A y XB se distribuyede acuerdo a FB y es independiente de 1B.
Demostración. Se sigue directamente de la Proposición 3.1 que
X y XA1A + XB1B
tienen la misma FDA, por lo cual, por la Proposición que 1.1
X = XA1A + XB1B c.s.
3.3 Formulación Matemática
En términos matemáticos, la distribución híbrida se determina al resolver elproblema de optimización
Minβ∈[0,1]
(1− δ)(
VaREα −VaRH(β)
α
)2+ δ
(CVaRE
α −CVaRH(β)α
)2(3.9)
donde β ∈ [0, 1] es la probabilidad con la que las pérdidas se distribuyende acuerdo a la distribución en condiciones de estrés; y VaRH(β)
α y CVaRH(β)α
51

β−1 β Probabilidad de Estrés ( β)
Se minimiza la distanciaentre VaRH (CVaRH) yVaRE (CVaRE)
Fig. 3.5: Ajuste de la distribución híbrida por medio del Modelo 3.9.
denotan, respectivamente, el VaR y CVaR de la distribución híbrida asociadaa la probabilidad β. El proceso de determinación de la distribución híbridamediante la solución del problema (3.9) es esquematizado en la Figura 3.5.
Obsérvese que, en esencia, el problema (3.9) es el mismo que el pro-blema (2.1), formulado para obtener el factor de ajuste óptimo. La diferenciaestriba en que en un caso, el del problema (2.1), se supone que la distribuciónde pérdidas es normal mientras que en el otro caso, el del problema (3.9),se considera que dicha distribución de pérdidas es una distribución híbridaproveniente de dos distribuciones predeterminadas.
En contraste con (2.1), en el caso del problema (3.9) no existe una soluciónexplícita. La razón principal de ello radica en que, en general, el VaRH(β)
α y elCVaRH(β)
α no pueden expresarse como funciones explícitas de la probabilidadβ. Por lo tanto, el problema (3.9) debe ser típicamente resuelto de maneranumérica y la derivación de propiedades teóricas generales sobre la proba-bilidad óptima β∗ es más difícil que en el caso del factor de ajuste óptimoF ∗, tratado en el capítulo anterior. No obstante dicha dificultad se derivanalgunas propiedades generales en la siguiente sección.
3.4 Propiedades del VaRH(β)α , CVaRH(β)
α y β∗
En esta sección se estudian propiedades sobre el VaR y el CVaR determinadosa partir de una distribución híbrida, así como de la probabilidad de estrés
52

óptima β∗ obtenida al resolver (3.9). A saber, las siguientes:
• La relación del VaR de la distribución híbrida de pérdidas con los co-rrespondientes valores de las distribuciones de pérdidas en condicionesde normales y condiciones de estrés.
• Condiciones suficientes para la continuidad y monotonicidad del VaRH(β)α
y CVaRH(β)α como función de la probabilidad de estrés β.
• Condiciones suficientes para la existencia de una probabilidad de estrésóptima β∗.
Para establecer las propiedades anteriores, es conveniente denotar por Ny CE a los eventos en que las pérdidas Π se comporten en condiciones nor-males y condiciones de estrés, respectivamente. De esta manera, la distribu-ción híbrida considerada H(β) para las pérdidas Π implica, por las Proposi-ciones 3.1 y 3.2 , que éstas se pueden expresar como
Π = ΠN1N + ΠCE1CE c.s.
donde ΠN y ΠCE son las pérdidas en condiciones normales y en condicionesde estrés, respectivamente; 1N y 1CE son variables indicadores de los eventosN y CE, respectivamente, y donde se cumple que P[CE] = β. Las funcionesde distribución acumulada de ΠN y ΠCE serán denotadas FN y FCE respecti-vamente.
3.4.1 Propiedades Básicas
Proposición 3.3. Supóngase que ΠN y ΠCE son variables aleatorias continuas y queVaRα(ΠN) ≤ VaRα(ΠCE). Entonces,
VaRα(ΠN) ≤ VaRH(β)α ≤ VaRα(ΠCE)
para toda β ∈ [0, 1].
Demostración.
FH(VaRH(β)α ) = α
= βα + (1− β)α
= β FCE(VaRα(ΠCE)) + (1− β) FN(VaRα(ΠN))≤ β FCE(VaRα(ΠCE)) + (1− β) FN(VaRα(ΠCE))= FH(VaRα(ΠCE)).
Por lo tanto,FH(VaRH(β)
α ) ≤ FH(VaRα(ΠCE)),
53

lo cual implica, por lo monotonía de FH , que
VaRH(β)α ≤ VaRα(ΠCE).
De manera análoga se demuestra que VaRα(ΠN) ≤ VaRH(β)α .
Corolario 3.1. Supóngase que ΠN y ΠCE son variables aleatorias continuas, y que−∞ < VaRα(ΠN) ≤ VaRα(ΠCE) < ∞, entonces
∣∣∣VaRH(β)α
∣∣∣ < ∞ para toda β ∈[0, 1].
Demostración. Por la Proposición 3.3 se tiene que VaRH(β)α ≤ VaRα(ΠCE) para
toda β ∈ [0, 1] por lo que VaRH(β)α < ∞ y de manera similar se demuestra que
−∞ < VaRH(β)α .
3.4.2 Monotonicidad y Continuidad del VaRH(β)α y CVaRH(β)
α
Para demostrar la monotonicidad y continuidad del VaRH(β)α y CVaRH(β)
α sehace uso del concepto de dominancia estocástica que a continuación se define.
Definición 3.2. Sean X y Y dos variables aleatorias que representan las pérdi-das de un portafolio, se dice que X domina estocásticamente2 a Y, lo cual sedenota como X Y, si
P[X > u] ≤ P[Y > u], para toda u ∈ R. (3.10)
En palabras, la definición anterior indica que X domina a Y si y sólo si,dado un umbral u, la probabibilidad de que X sea mayor a u es menor oigual a la probabilidad que Y sea mayor a u. En particular, si X y Y denotanpérdidas financieras, la dominancia estocástica de X sobre Y significa quedado un umbral de pérdidas u, es más probable que las pérdidas de Y superendicho umbral que las pérdidas de X. Es decir, en un contexto de pérdidas, ladominancia estocástica de X sobre Y captura la idea de que X "es menosriesgoso" que Y. Esta idea es formalizada en la Proposición 3.4.
Antes de exponer los resultados de esta sección, se presenta el siguientelema, que demuestra una caracterización alternativa del concepto de domi-nancia estocástica anteriormente definido, la cual es útil para demostrar losresultados que se presentan posteriormente.
Lema 3.1. Sean X y Y dos variables aleatorias. Entonces X Y si y sólo siFX(u) ≥ FY(u), ∀ u ∈ R.
2Dentro de la teoría estándar de dominancia estocástica, ésta dominancia es una del tipo deprimer orden. De hecho, obsérvese que la desigualdad en la Definición 3.2 va en sentido inversoa la definición tradicional, ya que en este caso todo se encuentra en términos de pérdidas.
54

Demostración. Supóngase que X Y. Entonces, por definición se cumple
P[X > u] ≤ P[Y > u], ∀ u ∈ R,
lo cual se cumple si y sólo si,
1−P[X ≤ u] ≤ 1−P[Y ≤ u], ∀ u ∈ R,
o equivalentemente si,
FX(u) ≡ P[X ≤ u] ≥ P[Y ≤ u] ≡ FY(u), ∀ u ∈ R.
Proposición 3.4. Sean X y Y variables aleatorias tales que X Y. EntoncesVaRα(X) ≤ VaRα(Y) para toda α ∈ [0, 1].
Demostración. Por el Lema 3.1 si X Y, entonces
FX(u) ≥ FY(u), ∀ u ∈ R.
Sea α ∈ [0, 1], entonces
FX(u) ≥ α⇒ FY(u) ≥ α, ∀ α ∈ [0, 1],
de donde
u ∈ R|FX(u) ≥ α ⊂ u ∈ R|FY(u) ≥ α, ∀ α ∈ [0, 1],
lo cual su vez implica que,
infu ∈ R|FX(u) ≥ α ≤ infu ∈ R|FY(u) ≥ α, ∀ α ∈ [0, 1],
o equivalentemente que,
VaRα(X) ≤ VaRα(Y), ∀ α ∈ [0, 1].
Proposición 3.5 (Monotonicidad del VaRH(β)α ). Sean FCE y FN funciones estric-
tamente crecientes, y supóngase que ΠN ΠCE. Entonces, para cualquier nivelde confianza α ∈ [0, 1] predeterminado, se cumple que la función β 7→ VaRH(β)
α
VaRH(β)α es no decreciente.
Demostración. Obsérvese que basta demostrar que FH(β) es decreciente en βpara toda x ∈ R, dado que β1 ≤ β2 implica que FH(β1)(x) ≥ FH(β2)(x) paratoda x ∈ R, lo que a su vez implica, por el Lema 3.1 y la Proposción 3.4, queVaRH(β1)
α ≤ VaRH(β2)α ∀ α ∈ [0, 1]. Para demostrar que FH(β) es decreciente
55

en β, nótese que ΠN ΠCE implica, por el Lema 3.1, que FN(x) ≥ FCE(x), oequivalentemente, que FCE(x)− FN(x) ≤ 0. Por lo tanto,
FH(β)(x) = βFCE(x) + (1− β)FN(x)
= β(FCE(x)− FN(x)) + FN(x).
es una función (lineal) decreciente en β, para toda x ∈ R.
Proposición 3.6 (Monotonicidad del CVaRH(β)α ). Sean FCE y FN funciones estric-
tamente crecientes, y supóngase que ΠN ΠCE, y
−∞ < VaRα(ΠN) ≤ VaRα(ΠCE) < ∞.
Entonces, para cualquier nivel de confianza predeterminado α ∈ [0, 1] la funciónβ 7→ CVaRH(β)
α es no decreciente.
Demostración. Antes de demostrar la proposición, se hace la siguiente obser-vación: Dado que ΠN ΠCE, se sigue del Lema 3.1 que β1 ≤ β2 implica queFH(β1) ≥ FH(β2), y por lo tanto
FαH(β1)
=FH(β1) − α
1− α≥
FH(β2) − α
1− α= Fα
H(β2)(3.11)
y por ende se tiene que 1− FαH(β1)
(z) ≤ 1− FαH(β2)
(z).Para demostrar la proposición, nótese que el valor esperado de una va-
riable aleatoria continua con soporte [L, ∞) y FDA dada por F, puede serrepresentado como
E[X] = L +∫ ∞
L[1− F(z)]dz. (3.12)
Así tomando L = VaRα(X), CVaRα(X) puede ser expresado como
CVaRα(X) = VaRα(X) +∫ ∞
VaRα
[1− Fα(z)]dz (3.13)
donde Fα(z) representa la α− cola de la distribución de pérdidas como definidoen la Definición 1.13. Por ende, denotando u1 = VaRH(β1)
α y u2 = VaRH(β2)α se
56

sigue que
CVaRH(β1)α = u1 +
∫ ∞
u1
[1− Fα
H(β1)(z)]dz (3.14)
= u1 +∫ u2
u1
[1− Fα
H(β1)(z)]dz +
∫ ∞
u2
[1− Fα
H(β1)(z)]dz (3.15)
≤ u1 + (u2 − u1) · 1 +∫ ∞
u2
[1− Fα
H(β1)(z)]dz (3.16)
= u2 +∫ ∞
u2
[1− Fα
H(β1)(z)]dz (3.17)
≤ u2 +∫ ∞
u2
[1− Fα
H(β2)(z)]dz (3.18)
= CVaRH(β2)α . (3.19)
Donde (3.14) se sigue de (3.13), (3.16) se sigue del hecho que 1− FαH(β1)
(z) ≤1, (3.18) se sigue de (3.11) y (3.19) se sigue de (3.13).
Proposición 3.7 (Continuidad del VaRH(β)α ). Sean FN y FCE funciones estricta-
mente monótonas y continuas y supóngase ΠN ΠCE y que
−∞ < VaRα(ΠN) ≤ VaRα(ΠCE) < ∞.
Entonces, la función β 7→ VaRH(β)α es continua, para toda α ∈ [0, 1].
Demostración. Sea β ∈ [0, 1] y βn : N → [0, 1] una sucesión que converge alvalor β. Se probará que
limn→∞
βn = β⇒ limn→∞
VaRH(βn)α = VaRH(β)
α .
Por el Corolario 3.1 la sucesión VaRH(βn)α esta acotada y por la Proposición 3.5
es no decreciente, por lo que limn→∞ VaRH(βn)α existe. Por lo tanto basta con
probar que dicho límite es igual a VaRH(β)α . Para tal efecto, obsérvese que
α = limn→∞
α (3.20)
= limn→∞
FH(βn)
(VaRH(βn)
α
)(3.21)
= limn→∞
[βnFCE
(VaRH(βn)
α
)+ (1− βn)FN
(VaRH(βn)
α
) ](3.22)
= β limn→∞
FCE
(VaRH(βn)
α
)+ (1− β) lim
n→∞FN
(VaRH(βn)
α
)(3.23)
= βFCE
(lim
n→∞VaRH(βn)
α
)+ (1− β)FN
(lim
n→∞VaRH(βn)
α
)(3.24)
= βFCE(x∗) + (1− β)FN(x∗). (3.25)
57

donde x∗ = limn→∞ VaRH(βn)α . Sea y∗ = VaRH(β)
α , entonces por (3.20) y (3.25),se deduce que
βFCE(x∗) + (1− β)FN(x∗) = α = βFCE(y∗) + (1− β)FN(y∗), (3.26)
para toda β ∈ [0, 1]. En particular, para β = 1 y β = 0 se obtiene que
FCE(x∗) = FCE(y∗) y FN(x∗) = FN(y∗)
lo cual implica, por la monotonía estricta de FCE y FN , que x∗ = y∗, o lo quees lo mismo, que el limn→∞ VaRH(βn)
α = VaRH(β)α .
Para demostrar la continuidad del CVaRH(β)α se requiere del siguiente re-
sultado:
Lema 3.2. Si g es una función integrable en R, entonces la función
G(u) =∫ ∞
ug(z)dz (3.27)
es continua en u, para toda u ∈ R.
Demostración. Si g es una función integrable en R, se sigue del Teorema 8 delCapítulo 13 de Spivak (1996) que la sucesión de funciones definidas por
Gn(u) =∫ n
ug(z)dz
son continuas en u ∈ R, para toda n ∈N. Dado que
G(u) = limn→∞
Gn(u) =∫ ∞
ug(z)dz (3.28)
Se sigue que
limn→∞
supu∈R
|G(u)− Gn(u)| = limn→∞
supu∈R
∣∣∣∣∫ ∞
ug(z)dz−
∫ n
ug(z)dz
∣∣∣∣
(3.29)
= limn→∞
supu∈R
∣∣∣∣∫ ∞
ng(z)dz
∣∣∣∣ (3.30)
= 0 (3.31)
Por lo tanto, Gn(u) converge uniformemente a G(u). Como Gn(u) es continuapara toda u ∈ R y para toda n ∈ N, se sigue que la función G(u) es continuapara toda u ∈ R.
Proposición 3.8 (Continuidad del CVaRH(β)α ). Sean FCE y FN funciones estricta-
mente monótonas y continuas; y supóngase que ΠN ΠCE y que
−∞ < VaRα(ΠN) ≤ VaRα(ΠCE) < ∞.
Entonces, la función β 7→ CVaRH(β)α es continua para toda α ∈ [0, 1].
58

Demostración. De la definición de CVaRH(β)α se sigue que
CVaRH(β)α =
11− α
∫ ∞
VaRH(β)α
z [β fCE(z) + (1− β) fN(z)]dz (3.32)
=(
β
1− α
) ∫ ∞
VaRH(β)α
z fCE(z)dz +(
1− β
1− α
) ∫ ∞
VaRH(β)α
z fN(z)dz (3.33)
Por el Lema 3.2 se deduce que
GCE(u) ≡∫ ∞
uz fCE(z)dz y GN(u) ≡
∫ ∞
uz fN(z)dz (3.34)
son continuas en u, para toda u ∈ R. Por lo tanto, dado que VaRH(β)α
es una función continua con respecto a β, se concluye que la composiciónGN(VaRH(β)
α ) y GCE(VaRH(β)α ) son continuas con respecto a β, de donde se
concluye de (3.33) que el CVaRH(β)α es una función continua con respecto a
β.
3.4.3 Existencia y algunas propiedades de β∗
En la siguiente Proposición se establece la existencia de una solución para elproblema de optimización (3.9). Es decir, se establece la existencia de unaprobabilidad óptima de estrés óptima β∗.
Proposición 3.9. Sean FN y FCE funciones estrictamente monótonas y continuas, ysupóngase ΠN ΠCE y que −∞ < VaRα(ΠN) ≤ VaRα(ΠCE) < ∞. Entonces elproblema de optimización (3.9) tiene solución.
Demostración. Dado que la función objetivo del problema de optimización (3.9)se puede expresar como
G(β) ≡ (1− δ)(
VaREα −VaRH(β)
α
)2+ δ
(CVaRE
α −CVaRH(β)α
)2
y que las funciones VaRH(β)α y CVaRH(β)
α son continuas en β, por las Proposi-ciones 3.7 y 3.8, se desprende entonces que G(β) es una función continua, alser una composición de funciones continuas. Por lo tanto, dado que la fun-ción objetivo G(β) se minimiza sobre el intervalo [0, 1] el cual es un cojuntocompacto, se concluye que G(β) alcanza un mínimo en [0, 1] y por ende que(3.9) tiene solución.
A continuación se establecen dos resultados con respecto a la soluciónóptima de (3.9) para dos casos particulares. A saber, para el caso δ = 0, esdecir cuando sólo es de interés ajustar el VaR, y el caso en que el VaR y CVaRobservado coinciden con aquellos derivados en condiciones normales.
59

Proposición 3.10. Supóngase VaRα(ΠCE) ≥ VaRα(ΠN) y δ = 0. Entonces lasolución óptima de (3.9) es β = 0
Demostración. Por la Proposición 3.3 se cumple que
VaRα(ΠN) ≤ VaRH(β)α ≤ VaRα(ΠCE)
para toda β ∈ [0, 1]. Si β = 0 se tiene que
FH(x) = 0 · FCE(x) + 1 · FN(x) = FN(x)
por lo que VaRH(β)α = VaRα(ΠN), luego entonces β = 0 es un óptimo para (3.9).
Proposición 3.11. Supóngase VaREα (X) = VaRα(ΠN) y CVaRE
α (X) = CVaRα(ΠN).Entonces β∗ = 0 es una solución óptima para el problema de optimización (3.9).
Demostración. Obsérvese que
G(0) = (1− δ)(
VaREα −VaR(ΠN)
)2+ δ
(CVaRE
α −CVaR(ΠN))2
(3.35)
= 0 (3.36)
donde la última igualdad es consecuencia de la hipótesis. Por lo tanto, dadoque G(β) ≥ 0 para toda β ∈ [0, 1], se concluye que β∗ = 0 es un mínimo.
Una vez formulada formalmente la determinación de la distribución híbridaen términos de la probabilidad de crisis β y de haber establecido algunaspropiedades de esta última, se aborda en la siguiente sección la resoluciónnumérica del problema de optimización (3.9).
3.5 Determinación de la probabilidad óptima β∗
La resolución numérica del problema (3.9) requiere la determinación de
G(β) = (1− δ)(
VaREα −VaRH(β)
α
)2+ δ
(CVaRE
α −CVaRH(β)α
)2(3.37)
para cada β ∈ [0, 1]. Para ello, es necesario obtener la distribución híbridaH(β) y a partir de ésta obtener VaRH(β)
α y CVaRH(β)α . Dado que no siempre es
posible encontrar fórmulas explicitas para VaRH(β)α y CVaRH(β)
α , se deben esti-mar sus valores. Para tal efecto, se propone utilizar simulación. Esto debido aque es fácil de instrumentar y de adaptar para cualquier par de distribucionesque se consideren para conformar la distribución híbrida. A saber, se generauna muestra de la distribución híbrida, de tamaño m, a partir de la cual se
60

estiman VaRH(β)α y CVaRH(β)
α . De esta manera, la función objetivo (3.37) esaproximada por la función
G(β) = (1− δ)(
VaREα −VaR
H(β)α
)2+ δ
(CVaRE
α −CVaRH(β)α
)2(3.38)
donde VaRH(β)α y CVaR
H(β)α son estimadores de VaRH(β)
α y CVaRH(β)α obtenidos
a partir de la muestra generada. Con base en dicha aproximación, se re-suelve (3.9), obteniéndose una probabilidad óptima aproximada β∗i . Clara-mente, la precisión de dicho valor depende tanto del tamaño de la muestracomo de la muestra particular generada. Por lo tanto, es natural generarvarias muestras, obtener una probabilidad óptima aproximada para cada unade ellas y utilizar el promedio de estos valores como un valor aproximado dela probabilidad de estrés óptima. Por lo tanto, se propone utilizar el siguientealgoritmo genérico:
I. Se generan n muestras de tamaño m de la distribución híbrida3.
II. A partir de cada muestra i generada, i = 1 . . . n, se determina G(β) y seresuelve (3.9), obteniéndose el valor óptimo β∗i .
III. Se estima la probabilidad óptima β∗ como
β∗ =1n
n
∑i=1
β∗i (3.39)
Para la determinación de estos valores se hacen las siguientes consideraciones:
• El error en la estimación se mide por medio del error relativo, definidocomo
εR(β∗) ≡∣∣∣∣∣ β∗ − β∗
β∗
∣∣∣∣∣ (3.40)
donde β∗ es la probabilidad de estrés óptima que resuelve el problemade optimización (3.9).
• Si las n muestras son independientes, entonces, dado que por construc-ción son idénticamente distribuidas, el teorema del límite central implica
β∗ − E[β∗i ]σ
β∗i/√
n→ N(0, 1) (3.41)
donde σβ∗i
denota la desviación estándar común pero desconocida de
cada β∗i ; y N(0, 1) representa una distribución normal estándar.3Esta muestra se genera utilizando un vector de valores aleatorios con distribución uniforme,
un vector de valores aleatorios con distribución idéntica a la de condiciones normales y un vectorde valores aleatorios con distribución idéntica a la de condiciones de estrés. La construcción dela distribución híbrida a partir de estos vectores se especifica en el Apéndice B, Sección B.2.
61

• Reemplazando la desviación estándar poblacional σβ∗i
en (3.41) por la
desviación estándar muestral
Sn,β∗i=
1n− 1
√n
∑i=1
(β∗i − β∗
)2(3.42)
se tiene queβ∗ − E[β∗i ]Sn,β∗i
/√
n→ tn−1 (3.43)
donde tn−1 es una distribución t de Student con n− 1 grados de libertad.Por tanto, se deduce
P
∣∣∣∣∣∣ β∗ − E[β∗i ]
Sn,β∗i/√
n
∣∣∣∣∣∣ ≤ tn−1,1−θ/2
= 1− θ. (3.44)
donde θ ∈ [0, 1] es el nivel de significancia en la estimación del errorεR(β∗).
• Obsérvese que
∆(n, θ) ≡ tn−1,1−θ/2
(Sn,β∗i√n
)(3.45)
satisfacelim
n→∞∆(n, θ) = 0 (3.46)
Por lo tanto, es posible escoger una n suficientemente grande, de formatal que
∆(n, θ) ≤ γ|β∗| (3.47)
para un valor 0 < γ < 1 predeterminado. Luego entonces de (3.44)y (3.47) se sigue que
1− θ = P[∣∣∣β∗ − E[β∗i ]
∣∣∣ ≤ ∆(n, θ)]
(3.48)
≤ P[∣∣∣β∗ − E[β∗i ]
∣∣∣ ≤ γ∣∣∣β∗∣∣∣] (3.49)
= P[∣∣∣β∗ − E[β∗i ]
∣∣∣ ≤ γ∣∣∣β∗ − E[β∗i ] + E[β∗i ]
∣∣∣] (3.50)
≤ P[∣∣∣β∗ − E[β∗i ]
∣∣∣ ≤ γ(∣∣∣β∗ − E[β∗i ]
∣∣∣+ ∣∣∣E[β∗i ]∣∣∣)] (3.51)
= P[(1− γ)
∣∣∣β∗ − E[β∗i ]∣∣∣ ≤ γ|β∗|
](3.52)
= P
[|β∗ − E[β∗i ]||β∗| ≤ γ
1− γ
](3.53)
62

Si E[β∗i ] = β∗, entonces β∗ es un estimador insesgado4 de β∗ y se deducepor (3.53), que:
P
[|β∗ − β∗||β∗| ≤ γ
1− γ
]≥ 1− θ. (3.54)
A partir de las consideraciones anteriores, se utiliza el siguiente algoritmopara estimar la probabilidad óptima β∗ del modelo (3.9), dado un error rela-tivo γ′ y un nivel de confianza 1− θ.
1. Generar un número incial predeterminado n0 de muestras, de tamañom, a partir de las cuales se obtienen las estimaciones β∗i , para i = 1 . . . n0,de acuerdo a lo descrito en el inciso II; n := n0.
2. Calcular β∗, de acuerdo a (3.39), y ∆(n, θ), de acuerdo a (3.45), a partirde los valores β∗i para i = 1 . . . n.
3. Si ∆(n,θ)|β∗ |
≤ γ′
1+γ′ entonces terminar: β∗ es aproximado por el estimador
β∗ yI(γ′, θ) = [β∗(n)− ∆(n, θ), β∗(n) + ∆(n, θ)] (3.55)
es un intervalo de confianza de 100(1− θ)% para β∗.
En caso contrario, generar otra muestra de tamaño m, n := n + 1 e ir alpaso 2.
3.5.1 Determinación de la Distribución Híbrida
Para construir la distribución híbrida se deben determinar las distribucionesque se usarán para las condiciones normales y las condiciones de estrés. Paratal efecto, es natural considerar distribuciones conocidas y estimar sus pará-metros con base en datos observados, si es posible, o una opinión experta.
En el problema particular que nos atañe, se consideró una distribuciónGaussiana para el caso de condiciones normales, y una distribución Gaussianao t no central para el caso de condiciones de estrés. Los parámetros de dichasdistribuciones se determinaron de la siguiente manera:
Para cada rango de concentración c considerado5,
1. Se filtraron los datos de acuerdo al rango de concentración (c) 6.
4En el Apéndice C se discute brevemente el problema del sesgo potencial en la estimación deβ∗.
5Un rango de concentración es un intervalo de la forma [c0, ∞).6Por ejemplo los datos filtrados de acuerdo al rango de concentración [50%, ∞), representan
los datos de rendimientos diarios (en términos de pérdidas) cuya concentración diaria fue mayora 50%.
63

2. Para los datos filtrados se obtuvo una banda superior de las pérdidas,para el nivel de confianza predeterminado α, especificada por
µc + N−1(α)σc (3.56)
donde:
• µc es la media estimada (promedio aritmético) de las pérdidas quesatisfacen la restricción de concentración dada por c y
• σc es la desviación estándar estimada de las pérdidas que satisfacenla restricción de concentración dada por c.
3. La distribución en el caso de condiciones normales es N(µc, σc).
4. Los parámetros en condiciones de estrés se determinaron a partir de losdatos (pérdidas) que rebasan la banda superior.
Esta construcción tiene las siguientes ventajas:
• Si la distribución empírica de las pérdidas es Gaussiana, ésta coincidarácon la distribución en casos normales, por lo cual no habrá que hacerajuste alguno y la probabilidad de estrés β∗ sera igual a 0.
• Esta construcción hace que el ajuste dado por la probabilidad de β∗ seacomparable al ajuste dado por F ∗ en el siguiente sentido: un valor deβ∗ = 0 corresponde al caso en que no se ajusta ni el VaR ni el CVaR, quees equivalente al caso en que F ∗ = 1, y un valor de β∗ > 0 correspondeal caso en que es necesario ajustar el VaR y el CVaR, como sería el casoen que F ∗ > 1.
3.6 Caso Gaussiano-Gaussiano
El primer caso particular que se considera es aquél en que tanto la distribuciónen condiciones normales como la de estrés son distribuciones Gaussianas. Eneste caso, la densidad de la distribución híbrida esta dada por
fH(β)(x) =(
β√2πσCE
)e−
12
(x−µCE
σCE
)2
+(
1− β√2πσN
)e−
12
(x−µN
σN
)2
(3.57)
donde β es la probabilidad de ocurrencia del evento de éstres; µCE y σCE son lamedia y desviación estándar respectivas de la distribución de los rendimientosen caso de éstres; y donde µN y σN son la media y desviación estándar de losrendimientos bajo condiciones normales.
Es importante enfatizar que el supuesto de normalidad para ambas dis-tribuciones no restringe mucho la forma de la distribución híbrida. En par-ticular, ésta puede ser una distribución bimodal o leptocúrtica. Por ejemplo,
64

si β = 0.6, µCE = −1, σCE = 1, µN = 2 y σN = 1 se tiene una distribuciónbimodal (ver Figura 3.6a). Asimismo, si β = 0.5, µCE = 0, σCE = 1, µN = 0 yσN = 9, se tiene una distribución leptocúrtica (ver Figura 3.6b).
−4 −3 −2 −1 0 1 2 3 40
0.05
0.1
0.15
0.2
0.25
Densidad Híbrida combinación de dos normales
x
Den
sida
d
(a) Densidad Bimodal
−4 −3 −2 −1 0 1 2 3 40
0.05
0.1
0.15
0.2
0.25
Densidad Híbrida combinaciónde dos normales
x
Den
sida
d
(b) Densidad Leptocúrtica
Fig. 3.6: Densidades híbridas combinación de dos normales.
3.6.1 Solución utilizando simulación
Se resolvió el problema de optimización (3.9) bajo el supuesto de que las pér-didas se distribuyen de acuerdo a la densidad (3.57), utilizando los rendimien-tos diarios de los precios limpios para el bono M Diciembre 2007, tomandodistintos niveles de concentración y de aversión al riesgo. Para tal efecto, seutilizó el algoritmo de simulación descrito en la Sección 3.5, considerando lossiguientes parámetros: error relativo γ = 1%, n0 = 10, m = 10, 000. El primerparámetro fue determinado con base en un nivel de precisión deseado, mien-tras que el segundo fue definido de manera arbitraria. Por su parte, paradeterminar el valor de m se hicieron las siguientes consideraciones:
• Se determinó la distribución empírica de β∗i para distintos valores de my δ. A saber para los casos m =2’000, 5’000, 10’000 y 20’000; y δ=0, 0.5 y1. Por ejemplo, en la Figura 3.7 se ilustran las densidades para el casoparticular de δ = 0.5 y α = 0.95 7.
• En las distribuciones estimadas en el inciso anterior, se determinó elmínimo valor de m, tal que la desviación estándar de la distribuciónfuese menor o igual al 10% del valor de la media de la misma, paratodas las δ’s consideradas. Dicho valor es m = 10, 000.
7Las distribuciones empíricas fueron obtenidas resolviendo el problema de optimizacion (3.9)n=10,000 veces. Se puede notar que la dispersión de la distribución de las β∗i disminuye y quevalor de su media respectiva se reduce conforme aumenta el valor de m. Este efecto se debe,
presumiblemente, al sesgo en la estimación de VaRH(β)α y CVaRH(β)
α .
65

0.01 0.015 0.02 0.025 0.03 0.035 0.040
20
40
60
80
100
120
140
160
180
200
Beta
Den
sida
d
Distribución Empírica de βi, para distintos valores de m.
δ = 0.5, α = 95%
m=5000m=10000m=2000m=20000
Fig. 3.7: Distribución Empírica de β∗i para distintos valores de m.
En la Figura 3.8 se muestran las probabilidades óptimas β∗ obtenidas paradistintas combinaciones de aversión al riesgo (δ) y rangos de concentración,considerando un nivel de confianza α del 95%. A partir de los resultadosobtenidos se hacen las siguientes observaciones:
• Las probabilidades de estrés varían entre valores muy cercanos al 0%,asociados con δ = 0, y valores ligeramente menores al 4%, asociados conδ = 100%.
• El valor de β∗ se incrementa conforme aumenta el parámetro de aversiónal riesgo δ. Es decir, entre mayor sea la ponderación que se le da al CVaR,mayor es la probabilidad de estrés requerida para ajustar el riesgo.
• En general, no hay un efecto claramente discernible de la concentraciónsobre el valor de la probabilidad de estrés óptima β∗. Sin embargo, seobserva que a mayor nivel de concentración, mayor es en promedio laprobabilidad β∗.
Finalmente, a fin de ilustrar el requerimento computacional del algoritmo,se presenta en la Figura 3.9 el número de muestras generadas para la obten-ción de β∗. En particular, se observa claramente que el número de simula-ciones requiridas cuando δ = 0 es considerablemente mayor al resto de loscasos. Esto se debe a que la probabilidad de estrés es muy cercana a 0 y porlo tanto, el error relativo en la estimación tiende a ser relativamente grande.
3.6.2 Solución mediante integración numérica
En la Sección 3.5 se señala que, en general, es difícil obtener una expresiónexplícita del VaRH(β)
α y CVaRH(β)α , y por lo tanto, de la función objetivo del
66

00.2
0.40.6
0.81
0.5
0.6
0.7
0.8
0.90
0.01
0.02
0.03
0.04
Valor de δ
Valor de β* para distintos niveles de concentraciónNivel de Confianza del 95%
Rango de Concentración
Pro
babi
lidad
de
Ést
res
β
Fig. 3.8: Gráfica de β∗ para distintos niveles de concentración mínima.
00.2
0.40.6
0.81
0.5
0.60.7
0.80.9
0
0.5
1
1.5
2
x 105
Valor de δ
Número de muestras generadas Nivel de Confianza del 95%
Rango de Concentración
No
de m
uest
ras
gene
rada
s
Fig. 3.9: Número de muestras generadas para obtener β∗.
67

problema (3.9). Sin embargo, para el caso particular que se estudia en estasección se pueden obtener fórmulas implícitas, a partir de las cuales es posi-ble obtener una estimación mediante métodos númericos. Dichas fórmulasimplícitas se formulan y demuestran en las siguientes proposiciones.
Proposición 3.12. El VaRH(β)α es solución de la ecuación
βN(
u− µCEσCE
)+ (1− β)N
(u− µN
σN
)= α (3.58)
para u ∈ R.
Demostración. Por definición, si u = VaRH(β)α , debe satisfacer∫ u
−∞
[(β√
2πσCE
)e−
12
(x−µCE
σCE
)2
+(
1− β√2πσN
)e−
12
(x−µN
σN
)2]
dx = α (3.59)
o, de forma equivalente
β∫ u
−∞
e−12
(x−µCE
σCE
)2
√2πσCE
dx + (1− β)∫ u
−∞
e−12
(x−µN
σN
)2
√2πσN
dx = α (3.60)
simplificando la primera integral de la ecuación (3.60) se obtiene
∫ u
−∞
e−12
(x−µCE
σCE
)2
√2πσCE
dx =∫ u−µCE
σCE
−∞
e−12 x2
√2π
dx = N(
u− µCEσCE
)(3.61)
Análogamente para la segunda integral de la ecuación (3.60) se obtiene
∫ ∞
u
e−12
(x−µN
σN
)2
√2πσN
dx = N(
u− µNσN
)(3.62)
y, sustituyendo (3.61) y (3.62) en (3.60), se obtiene la ecuación (3.58).
La Proposición 3.12 permite encontrar el VaRH(β)α para una distribución
híbrida, combinación de dos normales, con función de densidad dada por (3.57),resolviendo la ecuación (3.58) para u. Aunque la ecuación (3.58) no tiene unasolución explícita para el VaRH(β)
α , puede ser resuelta por métodos numéricos.Una vez obtenido VaRH(β)
α , es posible calcular de forma explícita el CVaRH(β)α
como se establece en la siguiente Proposición.
Proposición 3.13. El CVaRH(β)α está dado por
CVaRH(β)α =
11− α
[βN
(µCE − u
σCE
)µCE + (1− β)N
(µN − u
σN
)µN
+βσCEe−
12
(u−µCE
σCE
)2
+ (1− β)σNe−12
(u−µN
σN
)2
√2π
](3.63)
68

donde u = VaRH(β)α .
Demostración. Tomando u = VaRH(β)α , el CVaRH(β)
α estará dado por la expre-sión
11− α
∫ ∞
u
[(β√
2πσCE
)xe−
12
(x−µCE
σCE
)2
+(
1− β√2πσN
)xe−
12
(x−µN
σN
)2]
dx (3.64)
Nótese que la integral de la expresión anterior puede ser escrita como
β∫ ∞
u
xe−12
(x−µCE
σCE
)2
√2πσCE
dx + (1− β)∫ ∞
u
xe−12
(x−µN
σN
)2
√2πσN
dx (3.65)
Usando el cambio de variable m(u) = (u− µCE)/σCE en la primera integralde la expresión anterior, se obtiene que
∫ ∞
u
xe−12
(x−µCE
σCE
)2
√2πσCE
dx =∫ ∞
m(u)
(σCEm + µCE)e−12 x2
√2πσCE
σCEdm (3.66)
= σCE
∫ ∞
m(u)
me−12 m2
√2π
dm + µCE
∫ ∞
m(u)
e−12 m2
√2π
dm (3.67)
=σCEe−
12 m(u)2
√2π
+ µCEN(−m(u)) (3.68)
Por lo tanto,
∫ ∞
u
xe−12
(x−µCE
σCE
)2
√2πσCE
dx =σCEe−
12
(u−µCE
σCE
)2
√2π
+ µCEN(
µCE − uσCE
)(3.69)
Analogamente para la segunda integral de la expresión (3.65) se obtiene
∫ ∞
u
xe−12
(x−µN
σN
)2
√2πσN
dx =σNe−
12
(u−µN
σN
)2
√2π
+ µNN(
µN − uσN
)(3.70)
Finalmente, sustituyendo (3.69) y (3.70) en (3.65) y multiplicando por 11−α
se obtiene (3.63).
Con base en las dos proposiciones anteriores se obtuvo la probabilidadde estrés óptima β∗, para mismos niveles de aversión al riesgo y rangos deconcentración considerados en la Subsección 3.6.1. Los resultados se muestranen la Figura 3.10.
Como se puede observar, los resultados son muy parecidos a aquéllosobtenidos aplicando el algoritmo de simulación. De hecho, para verificar estode manera más precisa, se calcularon las diferencias entre las superficie deβ∗ determinada por simulación β∗sim y aquélla calculada mediante integraciónnumérica β∗num. Dicha superficie "diferencia" se muestra en la Figura 3.11 y apartir de ésta se observa lo siguiente:
69

00.2
0.40.6
0.81
0.5
0.6
0.7
0.8
0.90
0.01
0.02
0.03
0.04
Valor de δ
Valor de β* para distintos niveles de concentraciónNivel de Confianza del 95%
Rango de Concentración
Pro
babi
lidad
de
Ést
res
β
Fig. 3.10: Gráfica de β∗ con respecto a δ, para distintos niveles de concentaciónmínima y α = 95%.
• Las diferencias son mínimas, ya que su valor máximo es igual a 0.002.
• Las diferencias, en general, son positivas, lo cual indica que la probabi-lidad de estrés se encuentra consistentemente sobreestimada aplicandoel método de simulación.
• Las mayores diferencias se encuentran para el caso en que δ = 0. Esto sedebe a que la probabilidad de estrés es más cercana a 0, y por ende másdifícil de estimar mediante la simulación, debido a que el error relativoen la estimación de β∗ es relativamente grande.
00.2
0.40.6
0.81
0.50.6
0.70.8
0.9−1
0
1
2
3
x 10−3
Valor de δ
Diferencias de β* simulada vs β* por integración numérica,para distintos niveles de concentración.
Nivel de Confianza del 95%
Rango de Concentración
Dife
renc
ias
en e
l cál
culo
de
β*
Fig. 3.11: Gráfica de las diferencias de β∗sim − β∗num, para distintos valores de δy rangos de concentación, con α = 95%.
70

3.7 Caso Gaussiano-t
El segundo caso particular que se considera es aquél en que la distribuciónen condiciones normales es una Gaussiana y la distribución en condicionesde estrés es una t no central8. De esta manera, la densidad de la distribuciónhíbrida en este caso está dada por
fH(x) = βCν
(1 +
(x− µCE)2
φCEν
)−( 1+ν2 )
+ (1− β)
e−12
(x−µN
σN
)2
σN√
2π
, (3.71)
donde Cν es una constante de normalización de la distribución t no centraldefinida como
Cν =Γ(
ν+12
)Γ(
ν2)√
πφCEν. (3.72)
µCE es la media de la distibución t no central y φCE es un parámetro dedispersión que se relaciona con la desviación estándar σCE de la siguientemanera:
σCE =√
φCE
√ν
ν− 2, (3.73)
donde ν es un parámetro relacionado con los grados de libertad de la dis-tribución y el cual se supondrá en lo sucesivo mayor a 2 a fin de que de quela ecuación (3.73) tenga sentido.
De igual forma que en el caso Gaussiano-Gaussiano, µCE y σCE represen-tan la media y la desviación estándar respectivamente de los rendimientosen condiciones de estrés, mientras que µN y σN representan la media y des-viación estándar de los rendimientos en condiciones normales. Asimismo, βrepresenta la probabilidad de estrés.
El caso Gaussiano-t tiene la ventaja de presentar mayor flexibilidad enla modelación de los rendimientos en condiciones de estrés, dado que, poruna parte, la distribución t permite modelar las colas pesadas y alta curtosisque regularmente se presentan en las series financieras, y por otra parte ladistribución Gaussiana puede ser considerada un caso particular de la t, yaque, por el teorema del límite central, la distribución t converge a una normalcuando el parámetro ν tiende a infinito.
3.7.1 Solución utilizando simulación
Para poder resolver el problema (3.9) en este caso es necesario determinar losparámetros de la distribución t-no central para las condiciones de estrés. Paratal efecto, se procedió de la siguiente manera:
8Ver Capítulo de Preliminares, sección 1.6
71

1. Se obtuvieron los grados de libertad ν de la distribución, a partir dela curtosis en exceso estimada de los datos Kν, mediante la relación9
ν = 6Kν
+ 4.
2. Se estimó la desviación estándar de la distribución en condiciones deestrés a partir de los datos. Usando dicha estimación, se obtuvo elparámetro de dispersión mediante la relación10 φCE =
(ν−2
ν
)σ2
CE.
Con base en las consideraciones anteriores, se resolvió el problema de op-timización (3.9) bajo el supuesto (3.71) utilizando los rendimientos diarios delprecio limpio para el bono M Diciembre 2007; y tomando en cuenta distintosniveles de concentración y de aversión al riesgo. Para tal efecto, y al igualque en el caso Gaussiano, se utilizó el algoritmo de simulación descrito en laSección 3.5, considerando los parámetros de error relativo γ = 1%, n0 = 10y m = 10, 000. Estos parámetros fueron obtenidos de manera análoga a lodescrito en la Subsección 3.6.1. Los resultados obtenidos se ilustran en laFigura 3.12, a partir de la cual se hacen las siguientes observaciones:
• Las probabilidades de estrés obtenidas son muy similares a las del casoGaussiano-Gaussiano11.
• Al igual que en el caso Gaussiano-Gaussiano el valor de β∗ se incrementaconforme aumenta el parámetro de aversión al riesgo.
• Conforme aumenta la concentración la probabilidad de estrés β∗ au-menta (en promedio).
Asimismo, al igual que se hizo en el caso Gaussiano-Gaussiano, se pre-senta en la Figura 3.13 el número de muestras generadas para obtener la pro-babilidad de estrés óptima β∗ en el caso Gaussiano-t. Esto con el fin de vi-sualizar el esfuerzo computacional del algoritmo de simulación. De la mismamanera que en el caso Gaussiano-Gaussiano, el esfuerzo computacional paraδ = 0 es mayor que en el resto de los casos, debido a que la probabilidad deestrés en dicho caso es muy cercana a cero.
3.7.2 Solución mediante integración numérica
Al igual que en el caso Gaussiano-Gaussiano, en el caso Gaussiano-t tambiénse pueden obtener condiciones que el VaRH(β)
α y CVaRH(β)α deben satisfacer
y a partir de las cuales ser obtenidos. Dichas condiciones se describen ydemuestran en las siguientes Proposiciones.
9La curtosis en exceso de la distribución t no central está dada por Kν = 6ν−4 . Despejando el
parámetro ν en términos de Kν se obtiene la relación descrita.10Se obtiene despejando el parámetro φCE de la ecuación (3.73).11Esto se analizará con un poco más de profundidad en la Subsección 3.7.3.
72
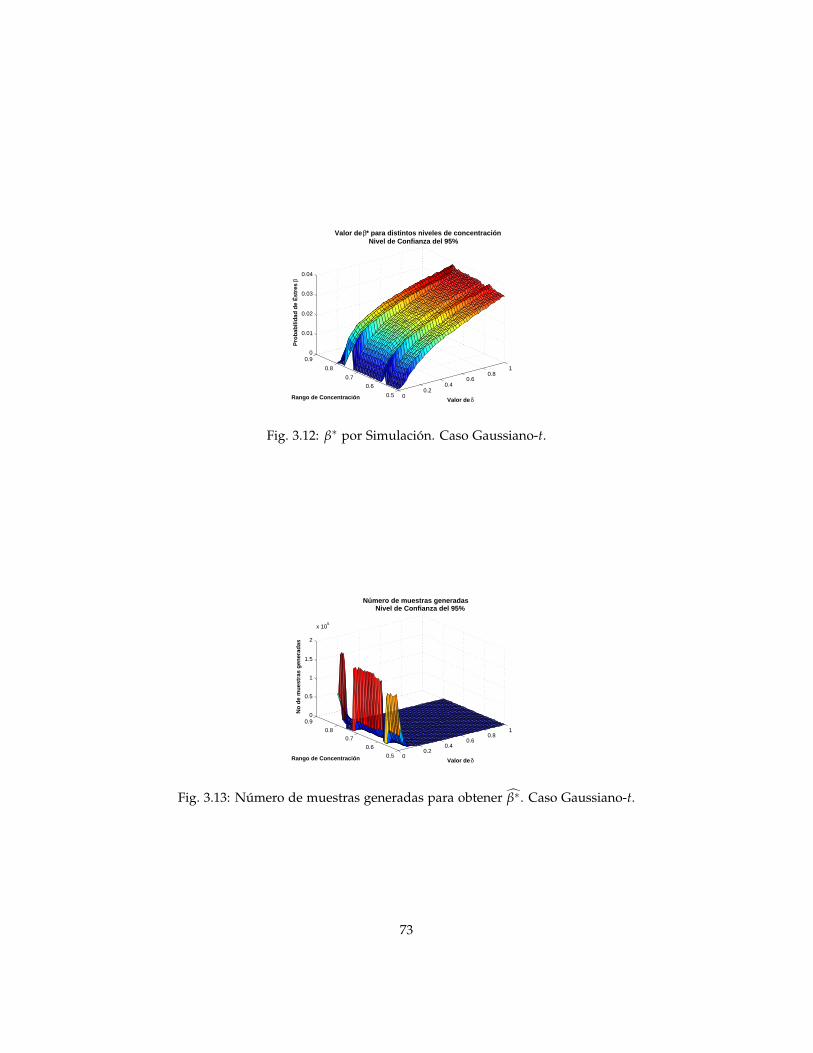
00.2
0.40.6
0.81
0.5
0.6
0.7
0.8
0.90
0.01
0.02
0.03
0.04
Valor de δ
Valor de β* para distintos niveles de concentraciónNivel de Confianza del 95%
Rango de Concentración
Pro
babi
lidad
de
Ést
res
β
Fig. 3.12: β∗ por Simulación. Caso Gaussiano-t.
00.2
0.40.6
0.81
0.5
0.6
0.70.8
0.90
0.5
1
1.5
2
x 105
Valor de δ
Número de muestras generadas Nivel de Confianza del 95%
Rango de Concentración
No
de m
uest
ras
gene
rada
s
Fig. 3.13: Número de muestras generadas para obtener β∗. Caso Gaussiano-t.
73

Proposición 3.14. El VaRH(β)α es solución de la ecuación
βTν
(u− µCE√
φCE
)+ (1− β)N
(u− µN
σN
)= α (3.74)
para u ∈ R.
Demostración. Por definición, si u = VaRH(β)α , debe satisfacer
∫ u
−∞
βCν
(1 +
(x− µCE)2
φCEν
)−( 1+ν2 )
+(
1− β√2πσN
)e−
12
(x−µN
σN
)2dx = α (3.75)
o, de forma equivalente
β∫ u
−∞Cν
(1 +
(x− µCE)2
φCEν
)−( 1+ν2 )
dx + (1− β)∫ u
−∞
e−12
(x−µN
σN
)2
√2πσN
dx = α (3.76)
Para simplificar la primera integral de la ecuación anterior, se puede hacer elcambio de variable m(u) = u−µCE√
φCE, y notando que
√φCECν es la constante de
normalización para una distribución t de Student, se tiene que
∫ u
−∞Cν
(1 +
(x− µCE)2
φCEν
)−( 1+ν2 )
dx =∫ m(u)
−∞
√φCECν
(1 +
m2
ν
)−( 1+v2 )
dm
= Tν(m(u))
= Tν
(u− µCE√
φCE
)(3.77)
La segunda integral de la ecuación (3.76) es idéntica la ecuación (3.62) de lademostración de la Proposición 3.12.
Proposición 3.15. El CVaRH(β)α está dado por
CVaRH(β)α =
(β
1− α
) [(√φCEν
ν− 1
)(1 +
m(u)2
ν
)ft(m(u)) + µCETν(−m(u))
]
+(
1− β
1− α
)σBe−12
(u−µN
σN
)2
√2π
+ µNN(
µN − uσN
) (3.78)
donde u = VaRH(β)α y m(u) = (u−µCE)√
φCE.
Demostración. Dado u = VaRH(β)α , el CVaRH(β)
α está dado por la expresión
74

11− α
∫ ∞
u
βCνx(
1 +(x− µCE)2
φCEν
)−( 1+ν2 )
+(
1− β√2πσN
)xe−
12
(x−µN
σN
)2dx
La integral de la expresión anterior puede ser escrita como
β∫ ∞
uCνx
(1 +
(x− µCE)2
φCEν
)−( 1+ν2 )
dx + (1− β)∫ ∞
u
xe−12
(x−µN
σN
)2
√2πσN
dx (3.79)
Haciendo el cambio de variable m(u) = u−µCE√φCE
en la primera integral de laexpresión anterior, se obtiene:
∫ ∞
uCνx
(1 +
(x− µCE)2
φCEν
)−( 1+ν2 )
dx =
∫ ∞
m(u)C(√
φCEm + µCE)(
1 +m2
ν
)−( 1+ν2 )
dm (3.80)
donde C = Cν√
φCE es la constante de normalización de una distribución t deStudent. La ecuación (3.80) a su vez es igual a
√φCE
∫ ∞
m(u)Cm
(1 +
m2
ν
)−( 1+ν2 )
dm + µCE
∫ ∞
m(u)C(
1 +m2
ν
)−( 1+v2 )
dm
(3.81)
La primera integral de la expresión (3.81) puede ser simplificada usando elcambio de variable y(m) = m2/ν, obteniéndose:
∫ ∞
m(u)Cm
(1 +
m2
ν
)−( 1+ν2 )
dm =∫ ∞
m(u)2/νC(1 + y)−( 1+ν
2 )(ν
2
)dy
=C(1 + y)−( 1+ν
2 )+1
−(
1+ν2
)+ 1
∣∣∣∣∣∣∞
m(u)2ν
=(
ν
1− ν
)(1 + y)C(1 + y)−( 1+ν
2 )∣∣∣∣∞m(u)2
ν
= −(
ν
1− ν
)(1 +
m(u)2
ν
)ft(m(u)), (3.82)
por otra parte,
∫ ∞
m(u)C(
1 +m2
ν
)−( 1+v2 )
dm = 1− Tν(m(u)) = Tν(−m(u)). (3.83)
75

Sustituyendo (3.82) y (3.83) en (3.81), se tiene que(√φCEν
ν− 1
)(1 +
m(u)2
ν
)ft(m(u)) + µCETν(−m(u)) (3.84)
es igual a la primera integral en la ecuación (3.79), mientras que la segunda in-tegral de la ecuación (3.79) puede ser obtenida de directamente de la ecuación(3.70).
Con base en las dos proposiciones anteriores se obtuvo la probabilidad deestrés óptima β∗, para los mismos niveles de aversión al riesgo y rangos deconcentración considerados en la Subsección 3.7.1. Los resultados se muestranen la Figura 3.14.
00.2
0.40.6
0.81
0.5
0.6
0.7
0.8
0.90
0.01
0.02
0.03
0.04
Valor de δ
Valor de β* para distintos niveles de concentraciónNivel de Confianza del 95%
Rango de Concentración
Pro
babi
lidad
de
Ést
res
β
Fig. 3.14: Gráfica de β∗ con respecto a δ, para distintos niveles de concentaciónmínima y α = 95%.
Como era de esperarse, los resultados son muy parecidos a los obtenidosaplicando el algoritmo de simulación. Para verificar esto, se calcularon ladiferencias entre las superficies de β∗ calculada mediante simulación β∗sim yaquélla obtenida por integración numérica β∗num. Dicha superficie "diferencia"se muestra en la Figura 3.15.
Como se puede observar a partir de la Figura 3.15, las diferencias en gene-ral son positivas, indicando que el método de simulación tiende a subestimarla probabilidad de estrés óptima. También puede observarse que al igual queen el caso Gaussiano-Gaussiano las mayores diferencias se dan cuando β∗ esaproximadamente cero.
76
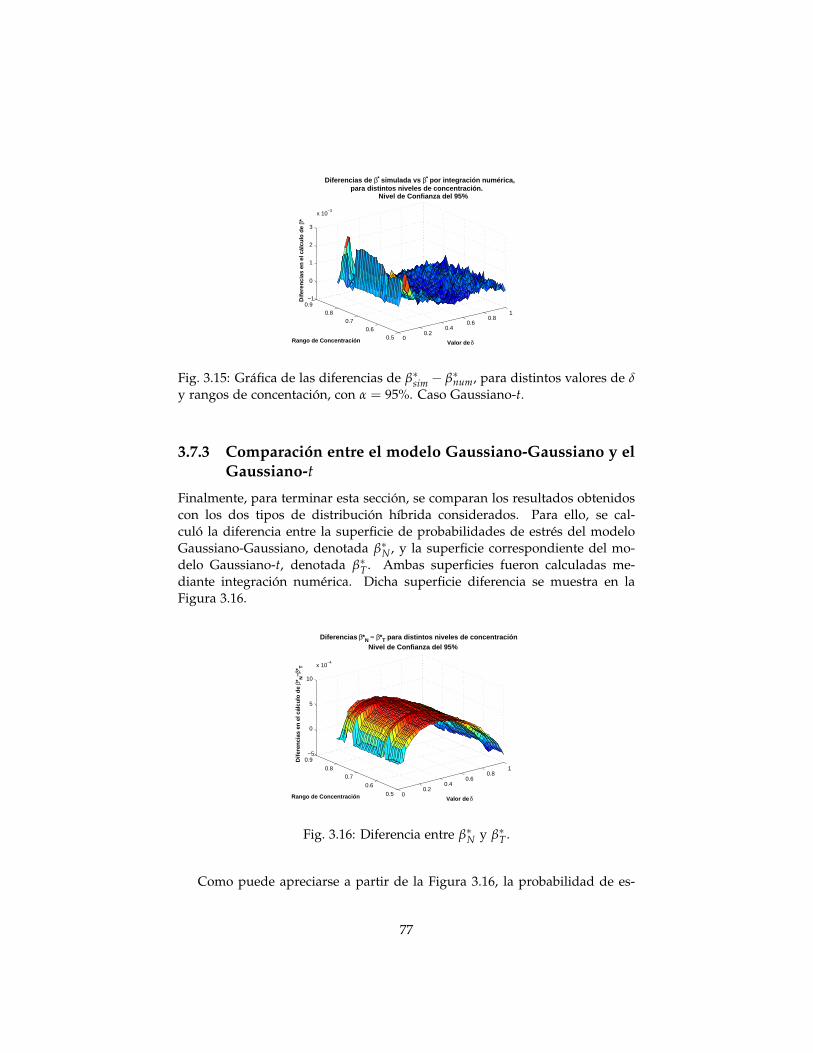
00.2
0.40.6
0.81
0.50.6
0.70.8
0.9−1
0
1
2
3
x 10−3
Valor de δ
Diferencias de β* simulada vs β* por integración numérica,para distintos niveles de concentración.
Nivel de Confianza del 95%
Rango de Concentración
Dife
renc
ias
en e
l cál
culo
de
β*
Fig. 3.15: Gráfica de las diferencias de β∗sim − β∗num, para distintos valores de δy rangos de concentación, con α = 95%. Caso Gaussiano-t.
3.7.3 Comparación entre el modelo Gaussiano-Gaussiano y elGaussiano-t
Finalmente, para terminar esta sección, se comparan los resultados obtenidoscon los dos tipos de distribución híbrida considerados. Para ello, se cal-culó la diferencia entre la superficie de probabilidades de estrés del modeloGaussiano-Gaussiano, denotada β∗N , y la superficie correspondiente del mo-delo Gaussiano-t, denotada β∗T . Ambas superficies fueron calculadas me-diante integración numérica. Dicha superficie diferencia se muestra en laFigura 3.16.
00.2
0.40.6
0.81
0.5
0.6
0.70.8
0.9−5
0
5
10
x 10−4
Valor de δ
Diferencias β*N − β*T para distintos niveles de concentraciónNivel de Confianza del 95%
Rango de Concentración
Dife
renc
ias
en e
l cál
culo
de
β*N−β
* T
Fig. 3.16: Diferencia entre β∗N y β∗T .
Como puede apreciarse a partir de la Figura 3.16, la probabilidad de es-
77

trés obtenida mediante una distribución híbrida del tipo Gaussiano-Gaussianoprácticamente no difiere respecto a la obtenida mediante una distribuciónhíbrida del tipo Gaussiano-t, ya que las diferencias más grandes son del ordende 10−4.
También puede observarse a partir de la Figura 3.16, que las diferenciasson en general positivas, o equivalentemente, que la probabilidad de estrés enel caso Gaussiano-Gaussiano es mayor a la probabilidad de estrés en el casoGaussiano-t. Esto se debe a que la distribución t no central modela mejorlas colas pesadas de la distribución empírica y por ende se requiere de unaponderación menor de la distribución en condiciones de estrés para obtenerun buen ajuste.
3.8 Comparación de β∗ con el factor de ajuste F ∗
Tanto en este capítulo como en el anterior, el objetivo central ha sido el mismo:desarrollar una metodología para medir el riesgo de mercado -en términosdel VaR y CVaR- de manera más precisa bajo condiciones de distorsión delos precios. Para ello, en ambos casos se ha partido del mismo supuestoestándar consistente en que los rendimientos se comportan de acuerdo a unadistribución Gaussiana. La diferencia entre ambas metodologías estriba en laforma en que se parte, o se adecua dicho supuesto. En un caso se optó porajustar el parámetro de desviación estándar mediante un cierto factor de ajusteF ∗. En el otro caso se decidió construir una distribución, que fuera por unlado consistente con la distribución Gaussiana bajo condiciones normales y,por el otro, que considerará la probabilidad de condiciones de estrés, medidaen términos de una probabilidad β∗, en que las pérdidas se distribuyen deacuerdo a otra distribución no necesariamente Gaussiana y no necesariamentecon los mismos parámetros. Dado que tanto el factor de ajuste F ∗ como laprobabilidad de estrés β∗ son determinadas esencialmente por el mismo tipode criterio, se puede afirmar que son equivalentes y por lo tanto, es de interésestudiar esta equivalencia. Para tal efecto, se decidió usar el nivel de aversiónal riesgo δ como variable de "triangulación" o de "vinculación", suponiendoun nivel de concentración c y un nivel de confianza α fijos. Es decir, dados cy α se conocen F ∗(δ) y β∗(δ) para cada δ ∈ [0, 1], de donde F ∗ se asocia aβ∗ si y sólo si F ∗ y β∗ corresponden a la misma δ. De esta manera, para elcaso concreto del Bono M Diciembre 2007, se construyeron las gráficas de lasFiguras 3.17 y 3.18, que corresponden, respectivamente, a los casos Gaussiano-Gaussiano y Gaussiano-t.
Como se observa claramente en dichas gráficas, la probabilidad de estrésβ∗ se incrementa conforme el factor de ajuste F ∗ así lo hace también. Estecomportamiento es consecuencia del comportamiento monotónico de F ∗ y β∗
con respecto a δ anteriormente observado.Desde un punto de vista práctico, la relación derivada entre F ∗ y β∗ es útil
78

0.8 0.9 1 1.1 1.2 1.3 1.4 1.50
0.005
0.01
0.015
0.02
0.025
0.03
0.035
0.04
Valor de F*
Val
or d
e β*
Relación entre F* y β*
50%60%70%80%
Fig. 3.17: Relación entre F ∗ y β∗ para distintos rangos de concentración yα = 95%. Caso Gaussiano-Gaussiano.
0.8 0.9 1 1.1 1.2 1.3 1.4 1.50
0.005
0.01
0.015
0.02
0.025
0.03
0.035
0.04
Valor de F*
Val
or d
e β*
Relación entre F* y β*
50%60%70%80%
Fig. 3.18: Relación entre F ∗ y β∗ para distintos rangos de concentración yα = 95%. Caso Gaussiano-t.
79

ya que, por ejemplo, permite al administrador de riesgos determinar el factorde ajuste a aplicar a la desviación estándar estimada dada una evaluación,posiblemente subjetiva, de la probabilidad de estrés o crisis implícita asociadaa dicho factor.
80

3.9 Conclusiones
La motivación central de este capítulo fue desarrollar una metodología paramedir el riesgo de mercado en condiciones de distorsión de los precios la cual,a diferencia de lo que se hizo en el Capítulo 2, incorpora la posibilidad de unevento de estrés en el que la distribución de probabilidad de las pérdidas esdistinta a la distribución Gaussiana típicamente considerada en condicionesnormales.
De esta forma, se desarrolló una metodología para la construcción deuna distribución de probabilidad "híbrida", que considera simultáneamenteel comportamiento de los rendimientos tanto en condiciones normales comoen condiciones de estrés, a partir de la cual se mide el riesgo de mercado entérminos del VaR y CVaR. Para determinar dicha distribución híbrida, se re-quiere predeterminar un par de distribuciones, una que caracteriza los rendi-mientos en condiciones normales y otra que lo hace en condiciones de estrés,las cuales se combinan probabilísticamente, en términos de una probabilidadde estrés, de tal forma que las mediciones de riesgo obtenidas con base endicha distribución híbrida se ajusten "lo mejor posible" a las correspondien-tes medidas de riesgo observadas. Específicamente, bajo el criterio de quela desviación cuadrática de los valores estimados y observados sea mínima.Por lo tanto, la determinación de la distribución híbrida se formula matemáti-camente como la solución de un problema de optimización, muy similar alplanteado en el capítulo anterior para determinar el factor de ajuste. Dichaformulación presenta las siguientes ventajas:
• La formulación permite asignar el peso relativo que tiene la desviacióncuadrática relacionada con el CVaR respecto a aquélla vinculada con elVaR. El valor de dicho peso relativo, denominado δ, se puede asociar,al menos intuitivamente, a un cierto nivel de aversión al riesgo en el sen-tido de que entre mayor sea el valor de este ponderador, mayor es laimportancia se le da al valor estimado del CVaR, la medida de riesgomás conservadora de las dos consideradas en el presente análisis.
• El problema de optimización tiene solución para cualquier par de dis-tribuciones que conforman la distribución híbrida, bajo el supuesto deque dichas distribuciones satisfagan una cierta condición de dominanciaestocástica. Dicho supuesto es típicamente satisfecho en la práctica.
Por otro lado, dado que desafortunadamente el problema de optimiza-ción no tiene una solución explícita, se propuso y desarrolló una me-todología, basada en simulación, para resolver el problema de maneranumérica. Esta metodología presenta las siguientes ventajas:
– No se necesitan conocer fórmulas explícitas (o implícitas) para elcálculo del VaR y CVaR de la distribución híbrida considerada.
81

– El método se puede aplicar fácilmente para cualquier tipo de dis-tribuciones en condiciones normales y en condiciones de estrés con-sideradas.
– Es posible, en principio, acotar arbitrariamente el error en la esti-mación de la probabilidad de estrés con un cierto nivel de confianzapredeterminado.
La metodología desarrollada se aplicó en el contexto particular del Bono MDiciembre 2007 para dos casos concretos: uno en el que se supone que tantola distribución en condiciones normales como la de estrés son Gaussianas, yotra en el que la distribución en condiciones normales es Gaussiana, pero t nocentral en condiciones de estrés. Los resultados obtenidos en cada caso sonlos siguientes:
• Gaussiano-Gaussiano:
– El rango de probabilidades es [0.00344%, 3.78408%], para α=95%.
– Para cualquier nivel de concentración la probabilidad de estrés seincrementa conforme el parámetro de aversión al riesgo δ se incre-menta.
– No hay un efecto claramente discernible de la concentración sobrela probabilidad de estrés, sin embargo, hay una ligera tendencia deestá a incrementarse conforme aumenta la concentración.
• Gaussiano-t:
– El rango de probabilidades es [0.00346%, 3.81709%], para α=95%.
– Para cualquier nivel de concentración la probabilidad de estrés seincrementa conforme el parámetro de aversión al riesgo δ se incre-menta.
– No hay un efecto claramente discernible de la concentración sobrela probabilidad de estrés, sin embargo, hay una ligera tendencia deestá a incrementarse conforme aumenta la concentración.
La metodología desarrollada en este capítulo se puede adaptar fácilmentepara
• Incoporar distintos tipos de distribuciones híbridas de riesgo.
• Considerar otro tipo de medidas de riesgo, diferentes al VaR y CVaR.
• Utilizar otras variables de referencia.
82

Conclusiones Generales
El objetivo primario de este trabajo de tesis fue proponer una metodologíapara medir el riesgo de mercado en condiciones propicias para la distorsiónde los precios. Así, se determinaron dos metodologías para tal efecto. Ambasdesarrolladas bajo la premisa de adecuar la metodología estándar, que suponeque la distribución de pérdidas se distribuye de acuerdo a una variable aleato-ria normal, y considerando como medidas de riesgo el VaR y el CVaR. Una deestas metodologías determina un Factor de Ajuste que escala el parámetro dedesviación estándar, mientras que la otra construye una Distribución Híbridaque considera simultáneamente una distribución Gausssiana, para modelarlas pérdidas en condiciones normales, y otra distribución, no necesariamenteGaussiana, para modelar las pérdidas en condiciones de estrés. En amboscasos, se busca estimar el riesgo de la manera "más precisa posible". Es decir,se determinan el Factor de Ajuste y la Distribución Híbrida tales que el riesgoestimado a partir de ellos sea lo más parecido posible al riesgo observado.
Aunque las metodologías aquí desarrolladas fueron en principio desarro-lladas para medir el riesgo de mercado en condiciones propicias para la dis-torsión de los precios, éstas pueden aplicarse para adecuar la metodologíaestándar por cualquier característica o conjunto de características de la dis-tribución de pérdidas que se aleje de los supuestos de dicha metodología. Porlo tanto, su aplicabilidad es potencialmente bastante amplia.
Tanto la metodología de Factores de Ajuste como la de DistribucionesHíbridas son formuladas en términos de modelos matemáticos, similares enespíritu, a partir de los cuales se demuestran varias propiedades teóricas in-teresantes y los cuales pueden incorporar fácilmente restricciones adicionales,a fin de adaptarlas a contextos más específicos, así como considerar medidasde riesgo adicionales o distintas al VaR o CVaR.
Entre las propiedades teóricas demostradas en este trabajo que, en nues-tro juicio, sobresale del resto es aquélla relacionada con el comportamientomonótono creciente del Factor de Ajuste respecto al parámetro de aversión alriesgo δ . Dicha propiedad, además de ser intuitivamente correcta, se cumpleesencialmente bajo la condición de que la distancia relativa entre el VaR y elCVaR de la distribución de pérdidas sea "suficientemente grande". A saber,mayor o igual que la correspondiente distancia en el caso que la distribu-
83

ción de pérdidas sea una Gaussiana. Esta condición es interesante ya queinduce una partición de las distribuciones de pérdidas: aquéllas que cumplenla condición, las cuáles denominamos riesgosas, y aquéllas otras que no lacumplen, llamadas no riesgosas. Creemos que sería de interés ahondar en lasconsecuencias de dicha condición.
84

Apéndice A
Convexidad y Condiciones deOptimalidad
Definición A.1 (Conjunto Convexo). Un subconjunto C de Rn es convexo si ysólo si
(1− λ)x + λy ∈ C
∀ x, y ∈ C y λ ∈ (0, 1).
Definición A.2 (Función Convexa). Sea C un conjunto convexo en Rn, en-tonces f : C → R es una función convexa si y sólo si
f ((1− λ)x + λy) ≤ (1− λ) f (x) + λ f (y)
∀ x, y ∈ C y λ ∈ (0, 1).
Definición A.3 (Función Cóncava). Sea C un conjunto convexo en Rn. Unafunción f : C → R con C convexo, es cóncava si y sólo − f es convexa.
Proposición A.1. Sea f : (a, b) → R una función dos veces diferenciable y cuyasegunda derivada es continua. Entonces f es convexa (cóncava) en (a, b) si y sólo sisu segunda derivada f ′′ es no negativa (no positiva) en (a, b).
Demostración. Ver, por ejemplo, Teorema 4.4 de Rockafellar (1970).
Definición A.4 (Condiciones de Optimalidad de Primer Orden). Seaf : D ⊂ Rn → R. Entonces, se dice que x∗ ∈ D satisface las condicionesde optimalidad de primer orden si y sólo si
∇ f (x∗) = 0.
Teorema A.1. Sea C un conjunto convexo abierto en Rn y f : C → R una funciónconvexa y diferenciable en C. Entonces x∗ ∈ C es un mínimo global si y sólo si x∗
satisface las condiciones de optimalidad de primer orden.
85

Demostración. Es consecuencia directa de la Proposición 2.6 de Zangwill (1969).
86

Apéndice B
Simulación
B.1 Método Monte Carlo
El método Monte Carlo consiste, en su forma más sencilla, en formular algúnjuego de azar o proceso estocástico cuyo valor esperado sea la solución alproblema planteado (Bauer, 1958). Sin embargo, puede ser utilizado paraobtener prácticamente cualquier estadística de una distribución por medio deun muestreo repetido aún si no se conoce su forma parámetrica. Para ilustrarel método considerése el siguiente ejemplo.
Ejemplo B.1 (Simulación de π). Supóngase que se desea estimar el valor πcon un cierto nivel de precisión. Para ello se formula el siguiente problemaprobabilístico: se escogen puntos al azar uniformemente distribuidos sobreun cuadrado cuyo lado tiene longitud uno, y se cuentan el número de puntosque se encuentran dentro del cuarto de circunferencia inscrita en el cuadrado,como se muestra en la Figura B.1.
Así la probabilidad de que un punto se encuentre dentro del área delimi-tada será exactamente π/4. Más formalmente, sean X y Y variables aleatoriascon distribución uniforme en el intervalo [0, 1], y Sn una variable aleatoriaque cuente el número de ocasiones, en n intentos, en los que X2 + Y2 ≤ 1.Entonces Sn ∼ Binomial( nπ
4 , nπ4 (1− π
4 )) y E[Sn/n] = π/4. Para ver que tanbuena es la aproximación obtenida por medio de la simulación, se calculará laprobabilidad de que el error relativo sea menor o igual a una cierta constante
87
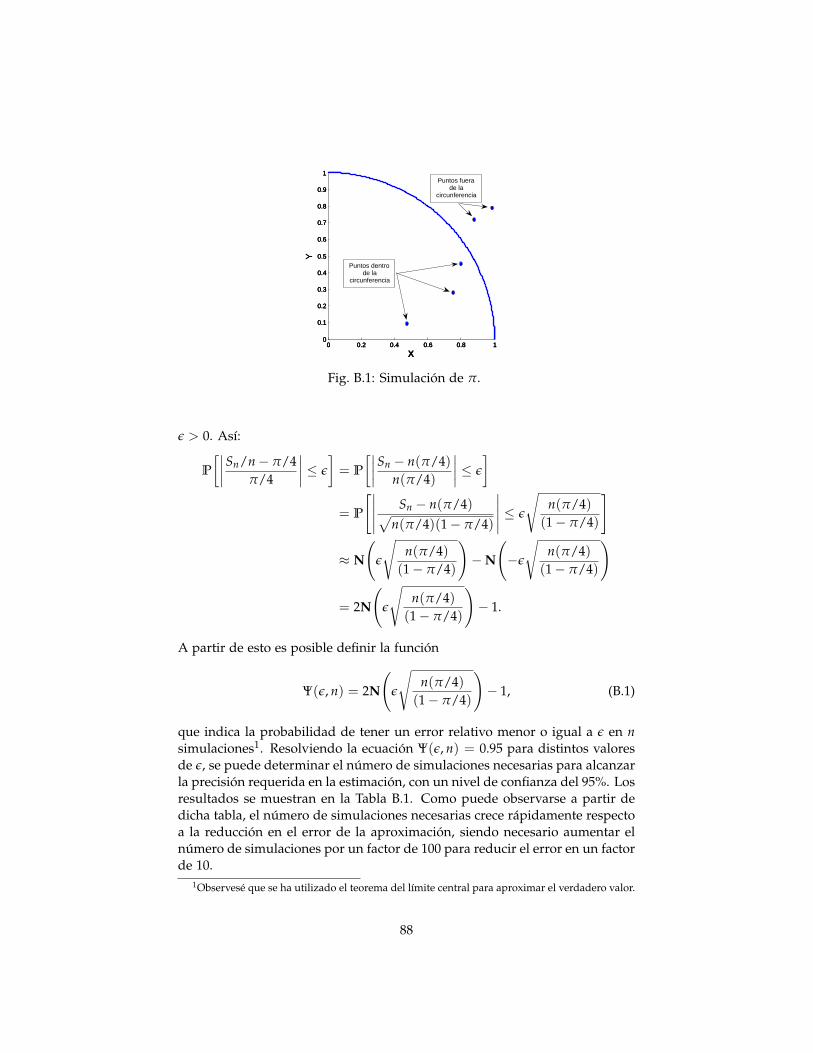
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
X
Y
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
X
Y
Puntos dentrode la
circunferencia
Puntos fuerade la
circunferencia
Fig. B.1: Simulación de π.
ε > 0. Así:
P
[∣∣∣∣Sn/n− π/4π/4
∣∣∣∣ ≤ ε
]= P
[∣∣∣∣Sn − n(π/4)n(π/4)
∣∣∣∣ ≤ ε
]= P
[∣∣∣∣∣ Sn − n(π/4)√n(π/4)(1− π/4)
∣∣∣∣∣ ≤ ε
√n(π/4)
(1− π/4)
]
≈ N
(ε
√n(π/4)
(1− π/4)
)−N
(−ε
√n(π/4)
(1− π/4)
)
= 2N
(ε
√n(π/4)
(1− π/4)
)− 1.
A partir de esto es posible definir la función
Ψ(ε, n) = 2N
(ε
√n(π/4)
(1− π/4)
)− 1, (B.1)
que indica la probabilidad de tener un error relativo menor o igual a ε en nsimulaciones1. Resolviendo la ecuación Ψ(ε, n) = 0.95 para distintos valoresde ε, se puede determinar el número de simulaciones necesarias para alcanzarla precisión requerida en la estimación, con un nivel de confianza del 95%. Losresultados se muestran en la Tabla B.1. Como puede observarse a partir dedicha tabla, el número de simulaciones necesarias crece rápidamente respectoa la reducción en el error de la aproximación, siendo necesario aumentar elnúmero de simulaciones por un factor de 100 para reducir el error en un factorde 10.
1Observesé que se ha utilizado el teorema del límite central para aproximar el verdadero valor.
88

Tab. B.1: Simulación de π
Error Relativo Número de Simulaciones
10−1 1.04964 × 102
10−2 1.04964 × 104
10−3 1.04964 × 106
10−4 1.04964 × 108
10−5 1.04964 × 1010
10−6 1.04964 × 1012
B.2 Simulación de Distribuciones Híbridas
Sea X una v.a. cuya función de distribución es
FH(x) = βFA(x) + (1− β)FB(x), (B.2)
donde FA y FB son funciones de distribución y β ∈ [0, 1]. Este tipo de dis-tribuciones se denominan distribuciones híbridas y se definen formalmenteen la Sección 3.2. Para generar una v.a. con dicha distribución se puede usarel siguiente algoritmo:
1. Se genera un valor aleatorio de una distribución uniforme [0,1], digamosU .
2. Si U < β entonces se genera un valor aleatorio a partir de la distribu-ción FA. En caso contrario, se genera un valor aleatorio a partir de ladistribución FB.
El procedimiento anterior se repite un número predeterminado de veces, di-gamos n, a fin de obtener una muestra de tamaño n de la v.a. X.
89

Apéndice C
El caso del sesgo en laestimación de β∗
Koji & Maasaki (2005) analizan el problema del sesgo porcentual en los esti-madores tradicionales del VaR y CVaR. El sesgo porcentual del VaR es definidopor:
λvm =
Media del VaR −VaR∗
VaR∗(C.1)
donde VaR∗ denota el valor teórico del VaR. Asimismo el sesgo porcentual delCVaR es definido por:
λcvm =
Media del CVaR −CVaR∗
CVaR∗(C.2)
donde CVaR∗ denota el CVaR teórico. El procedimiento utilizado por Koji& Maasaki (2005) consiste en obtener por simulación N muestras aleatoriasindepedientes, de tamaño m cada una, y a partir de cada muestra, estimar elVaR y CVaR promedios, los cuales se comparan contra su valor teórico paraobtener el sesgo porcentual como definido por (C.1) y (C.2). Koji & Maasaki(2005) analizan el caso particular de la distribución t con 3, 4 y 5 gradosde libertad, tomando N = 1000 y m = 100, 200 y 300 y concluyen que param = 300, λv
m varía entre -2.97% y -4.18% mientras que λcvm varía entre -0.79%
y 1.1%.
Ya que la estimación de β∗i depende de los estimadores VaRH(β)α y CVaR
H(β)α
del VaRH(β)α y CVaRH(β)
α , respectivamente, es de esperarse que exista un sesgoen su estimación. Luego entonces se tendrá que
E[β∗] = (1 + λβ∗m )β∗ (C.3)
90

donde λβ∗m denota el sesgo porcentual en la estimación de β∗ y esta definido
como:
λβ∗m =
E[β∗]− β∗
β∗(C.4)
Asimismo Koji & Maasaki (2005) muestran evidencia de que el sesgo enla estimación del VaR y CVaR se reducen conforme se incrementa el tamañode la muestra, o en otras palabras, que los estimadores son asintóticamenteinsesgados, por lo que es plausible suponer que λ
β∗m sea asintóticamente inses-
gado. Por lo tanto, es de esperarse que para un valor de m "suficientementegrande", el sesgo en la estimación de β∗ sea "pequeño".
91

Bibliografía
Acerbi, C., Nordio, C., & Sirtori, C. (2001). Expected Shortfall as a Tool forFinancial Risk Management. ArXiv Condensed Matter e-prints.
Andreev, A. & Kanto, A. (2005). Conditional Value-at-Risk estimation usingnon-integer values of degrees of freedom in Students t-distribution. TheJournal of Risk, 7(2).
Artzner, P., Delbaen, F., Eber, J. M., & Heath, D. (1999). Coherent measures ofrisk. Mathematical Finance, 9(3), 203–228.
Bauer, W. F. (1958). The Monte Carlo Method. Journal of the Society for Industrialand Applied Mathematics, 6(4).
Casella, G. & Berger, R. L. (1990). Statistical Inference. Duxbury Press.
Embrechts, P., Klüppelberg, C., & Mikosch, T. (1997). Modelling Extremal Eventsfor Insurance and Finance. Berlin: Springer.
Koji, I. & Maasaki, K. (2005). On the significance of expected shortfall as acoherent risk measure. Journal of Banking and Finance.
McNeil, A. J. (1999). Internal Modelling and CAD II, chapter Extreme ValueTheory for risk managers, (pp. 93–113). RISK Books.
Nelson, C. R. & Siegel, A. F. (1987). Parismonious modeling of yield curves.The Journal of Business, 60(4).
Rockafellar, T. R. (1970). Convex Analysis. Princeton University Press.
Rockafellar, T. R. & Uryasev, S. P. (2002). Conditional Value-at-Risk for GeneralLoss Distributions. Journal of Banking and Finance.
Sarma, M. (2005). Characterization of the tail behavior of financial returns:studies from India. Working Paper, EURANDOM.
Spivak, M. (1996). CALCULUS, Second Edition. W.A. Benjamin, Inc., New York.
92

Svensson, L. (1994). Estimating and Interpreting Forward Interest Rates: Swe-den. Working Paper No. 4871, NBER. National Bureau of Economic Re-search.
Zangwill, W. (1969). Nonlinear Programming: A Unified Approach. Prentice-Hall.
93