introducción a la simulación bernardo calderón
TRANSCRIPT

1. SIMULACION. CONCEPTOS BÁSICOS Y APICABILIDAD La técnica de la simulación ha sido una herramienta importante en el diseño de sistemas, bien sea la simulación de un vuelo, la simulación de una distribución en planta, la simulación de un juego o la simulación de un proceso productivo. Mediante la simulación, el Investigador de Operaciones obtiene los medios de observación y experimentación que han sido la esencia de los métodos científicos. La construcción y operación de un modelo de simulación, permite la observación del comportamiento dinámico de un sistema en condiciones controladas, pudiendo efectuarse experimentos para comprobar hipótesis acerca del sistema bajo estudio. El uso moderno de la palabra simulación se debe a la popularización que hicieron Von Neumann y Ulam del término "Análisis de Montecarlo" para estudiar problemas de difusión de neutrones y a la rápida adaptación del mismo para resolver problemas no probabilísticos difíciles, tales como integrales múltiples. Al popularizarse el uso de los computadores, surgieron incontables aplicaciones y con ello un mayor número de problemas teóricos y prácticos, ya que es posible experimentar con modelos matemáticos que describen algún sistema de interés.
1.1. Definición de simulación
Existen muchas definiciones de la simulación, unas más apropiadas que otras, dependiendo de la forma como se mire a la simulación; algunas de las definiciones son las siguientes: a) Martin Shubick da la siguiente definición: "La simulación de un sistema u organismo es la operación de un modelo (o simulador) que es una
representación del sistema. Este modelo puede sujetarse a manipulaciones que serían imposibles de realizar en el sistema real, demasiado costosas o poco prácticas. La operación del modelo puede estudiarse y de ese estudio pueden inferirse las propiedades concernientes al comportamiento del sistema o subsistema real".
b) La simulación es, esencialmente, una técnica que enseña a construir el modelo de una situación real junto
con la realización de experimentos con el modelo. El principal interés de la simulación se centra en el uso del computador, el cual ha hecho que la simulación adquiera validez. Por lo tanto, estamos interesados en dar una definición que esté de acuerdo con nuestro interés. Esa definición puede ser la siguiente: c) La simulación es una técnica numérica para realizar experimentos en un computador digital, los cuales
requieren ciertos tipos de modelos lógicos y matemáticos, que describen el comportamiento de un negocio o sistema económico (o algún componente de ellos) en períodos de tiempo real.
d) La simulación por computador también puede definirse como "un método para predecir las características
dinámicas de una organización y así mejorar las bases para el proceso de la toma de decisiones". e) La simulación es esencialmente una técnica de muestreo estadístico controlado (experimentación) que se
emplea, conjuntamente con un modelo, para obtener respuestas aproximadas para preguntas sobre problemas probabilísticos complejos de múltiples factores.
La simulación es una ayuda formal para la toma de decisiones, la cual es adaptable a las complejidades y cambios de los negocios modernos y que puede desarrollarse y comunicarse eficientemente. La simulación es un desarrollo natural de la investigación de operaciones y generalmente se usa en aquellos casos en que las otras técnicas de la investigación de operaciones han fallado. Las técnicas de la investigación de operaciones usan modelos simbólicos y procesos matemáticos deductivos para predecir los efectos de las soluciones alternativas de un problema y determinar cuál es la mejor solución, o aproximadamente la mejor. La simulación de sistemas también puede definirse como "La técnica de resolver problemas siguiendo, sobre el tiempo, los cambios que ocurren en un modelo dinámico del sistema". Dado que la técnica de la simulación no intenta resolver analíticamente las ecuaciones de un modelo, el modelo matemático construido para los propósitos de la simulación es usualmente de naturaleza diferente de uno construido para solución por técnicas analíticas. Cuando se construye un modelo para encontrar la solución

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 2
analíticamente, es necesario considerar el conjunto de restricciones impuestas por la técnica analítica y evitar complicar demasiado el modelo. Un modelo de simulación puede construirse más libremente. En sistemas continuos, donde el principal interés está en cambios suaves, generalmente se usan conjuntos de ecuación diferenciales para describir el sistema. Simulaciones basadas en tales modelos reciben el nombre de simulaciones continuas. Los computadores análogos son usados con frecuencia para simulaciones continuas, aunque también es posible usar computadores digitales, empleando intervalos de tiempo pequeños para integrar las funciones. Para sistemas discretos, en los cuales el principal interés está en los eventos, las ecuaciones son esencialmente ecuaciones lógicas que establecen las condiciones necesarias para que ocurra un evento. La simulación consiste en seguir los cambios en el estado del sistema resultantes de la sucesión de eventos. Tales simulaciones reciben el nombre de "simulaciones discretas". Es posible avanzar el tiempo en pequeños incrementos y chequear en cada paso, si algunos eventos deben ser ejecutados. Sin embargo, como regla general la simulación discreta se realiza decidiendo sobre la secuencia de eventos y avanzando el tiempo al siguiente evento más inminente. En este documento solo enfocaremos la atención en el estudio de simulaciones discretas
1.2. Naturaleza experimental de la simulación La técnica de la simulación no realiza ningún intento específico por aislar las relaciones entre las variables particulares; en su lugar, observa el modo en que las variables cambian con el tiempo para tratar de reproducir su comportamiento. Las relaciones de las variables deben derivarse a partir de estas observaciones. Lo que la simulación hace es tratar de reproducir, mediante un modelo, el comportamiento del sistema, como si se estuviéramos realizando un experimento en el sistema real, y aquellos aspectos que no conozcamos, por su naturaleza aleatoria, los simulamos (generamos) mediante algunos métodos estadísticos, tratando de conservar sus propiedades. La simulación, es por lo tanto, esencialmente una técnica experimental para resolver problemas. Deben realizarse muchas corridas de una simulación para entender y poder analizar las relaciones envueltas en el sistema. Por consiguiente el empleo de la simulación en un estudio debe planearse como una serie de experimentos por computador. Para realizar una simulación debe tenerse un conocimiento completo del sistema o situación que se desee analizar. Un modelo de simulación simplemente lo que trata es de reproducir el comportamiento del sistema, como si estuviéramos realizando un experimento, y a través de dicho experimento se van produciendo todas las variables que describen su comportamiento. En el apéndice al final de este capítulo, se presenta un juego de lanzamiento de monedas, en el cual se desarrolla inicialmente un modelo analítico, luego se explica cómo se realizaría el juego en la práctica y posteriormente se desarrolla un modelo de simulación. La forma en que se realice un estudio de simulación depende de la naturaleza del estudio, es decir, del fin que se busca al estudiar el sistema. Generalmente los estudios del sistema son de tres tipos: Análisis de sistema, diseño de sistemas y postulación de sistemas; muchos estudios combinan dos o tres de los aspectos anteriores o alternan entre ellos a medida que el estudio avanza. El análisis de sistemas está orientado a entender cómo trabaja un sistema existente o un sistema propuesto. La situación ideal sería que el investigador pudiera experimentar con el sistema real. Actualmente lo que se hace es construir un modelo del sistema y, por simulación, investigar el desempeño del sistema. En los estudios de diseño de sistemas, el objeto es producir un sistema que cumpla algunas especificaciones. El diseñador puede seleccionar o planear ciertos componentes del sistema, y escoger una combinación particular de componentes para construir el sistema. El sistema propuesto es modelado y se predice su desempeño a partir del comportamiento del modelo. Si el comportamiento predicho se compara favorablemente con el comportamiento deseado, el sistema es aceptado. En caso contrario, se rediseña el sistema y se repite el proceso. La postulación de sistemas es característico del modo en que se emplea la simulación en estudios sociales, económicos, políticos, y médicos, donde se conoce el comportamiento del sistema, pero no las causas que producen ese comportamiento. Se establecen hipótesis sobre un conjunto probable de entidades y actividades que pueden explicar el comportamiento. El estudio compara la respuesta del modelo basado en las hipótesis establecidas con el comportamiento real conocido. Un parecido razonable conduce a la suposición de que la estructura del modelo representa al sistema actual, lo cual permite postular la estructura del sistema. Muy probablemente el comportamiento del modelo da una mejor comprensión del sistema y posiblemente ayuda a formular un conjunto más refinado de hipótesis.

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 3
1.3. Justificación para el uso de la simulación - Ventajas En general, la Simulación surge en dos tipos diferentes de problemas: a) Aquellos problemas que involucran alguna clase de proceso estocástico: Demanda por un artículo, tiempo
de espera antes de empezar una producción, etc. b) Ciertos problemas matemáticos completamente determinísticos que no pueden resolverse fácilmente por
métodos analíticos o determinísticos; sin embargo, es posible obtener soluciones aproximadas a estos problemas simulando un proceso estocástico cuyos momentos, función de densidad o de distribución satisfacen las relaciones funcionales o los requisitos del problema determinístico. Por ejemplo: Ecuaciones diferenciales complejas, etc.
Cuando se está estudiando un sistema por medio de la investigación de operaciones, es necesario usar la simulación en aquellas etapas que estén ocasionando dificultades. Por ejemplo: 1. Existen situaciones en las cuales es imposible o extremadamente costoso observar ciertos procesos en la
vida real. Ejemplo: Vuelos espaciales, ingreso nacional bruto en los tres próximos años, etc. 2 Ciertos sistemas observados son tan complejos que es imposible describirlos en términos de un conjunto de
ecuaciones matemáticas para las cuales sea posible obtener soluciones analíticas que puedan emplearse para predecir el comportamiento del sistema. La mayoría de sistemas económicos caen en esta categoría, por ejemplo, la economía de un país, o la operación de un negocio.
3 Aunque pueda desarrollarse un modelo matemático para describir un sistema de interés, puede no ser
posible obtener una solución al modelo por medio de técnicas analíticas. Por ejemplo: sistemas complejos de fenómenos de espera o sistemas de inventarios. Aunque este enfoque no garantiza solución óptima o exacta al modelo que describe el sistema, puede ser posible experimentar con un número de soluciones y reglas de decisión alternativas para determinar qué soluciones y reglas de decisión son más útiles para realizar predicciones acerca del comportamiento del sistema. Posteriormente se ilustrarán estos aspectos por medio de ejemplos, de problemas de inventario y de procesamiento de órdenes a través de varios procesos.
4 Puede ser imposible o sumamente costoso realizar experimentos de validación sobre el modelo matemático
que describe el sistema. Es decir, no hay forma de verificar si el modelo diseñado sí representa el sistema real o si la solución encontrada sí corresponde realmente a la solución del problema que se tiene.
Aunque la razón principal para escoger la simulación es la facilidad para vencer las dificultades explicadas antes, hay otras razones o ventajas para su empleo, tales como: 5 La simulación hace posible estudiar y experimentar con las interacciones complejas que ocurren en el
interior de un sistema. A través de la simulación se pueden estudiar ciertos cambios informativos, de organización o ambientales en la operación de un sistema, al hacer alteraciones en el modelo y observar los efectos de estas alteraciones en el comportamiento del sistema.
6 La observación detallada del sistema que se está simulando conduce a un mejor entendimiento del mismo
y proporciona sugerencias para mejorarlo. 7 La simulación puede usarse como un recurso pedagógico 8 La simulación de un sistema complejo puede producir un conocimiento valioso y profundo acerca de cuáles
variables son más importantes que otras, y cómo se relacionan entre sí. La simulación puede emplearse para experimentar con situaciones nuevas acerca de las cuales se tiene muy poca o ninguna información, con el objeto de estar preparados para cualquier eventualidad. 9 Para ciertos tipos de problemas estocásticos la secuencia de los eventos puede ser muy importante, pues la
información de los valores esperados y los momentos suele no ser suficiente para describir el proceso. En estos casos, la simulación puede ser la única forma satisfactoria de obtener la información requerida.
10 La simulación puede realizarse para verificar soluciones analíticas. 11 La simulación permite estudiar los sistemas dinámicos, ya sea en tiempo real, comprimido o expandido. 12 Cuando se presentan nuevos componentes de un sistema, la simulación puede emplearse para ayudar a
descubrir los obstáculos y otros problemas que resultan de la operación del mismo.

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 4
1.4. Desventajas de la simulación La simulación como cualquier otra técnica tiene sus desventajas, de las cuales las principales son: 1 Los modelos de la simulación para computador son muy costosos de construir y validar. En general debe
construirse un programa para cada sistema o problema. 2. La corrida del programa de simulación, una vez construido, puede necesitar una gran cantidad de tiempo de
computador. 3 La principal desventaja de la simulación está dirigida hacia la gente, en vez de la técnica. La gente tiende a
usar la simulación cuando no es el mejor método de análisis. Cuando las personas se familiarizan con la metodología de la simulación, intentan emplearla en situaciones en que otras técnicas analíticas son más apropiadas.
1.5. Etapas generales de la simulación Un estudio de simulación puede dividirse en tres grandes áreas, no completamente independientes entre sí, a saber: 1 Establecimiento del modelo de simulación, lo cual incluye aspectos tales como identificar el problema a
resolver (conocer qué preguntas se deben responder), que suposiciones se deben hacer, y definir el modelo a emplear.
2. Ejecución de la simulación en un computador digital. En este punto se consideran las técnicas y
metodologías, simples y avanzadas, requeridas para obtener los resultados. de programación. Esto incluye aspectos tales como generación de variables aleatorias, métodos para manejo de las variables, precisión de los estimativos, etc.
3 Análisis de los resultados. Dadas unas preguntas que se debían resolver y unas respuestas dadas por el
modelo, se requieren técnicas estadísticas y gráficas para interpretar los resultados y tomar las decisiones.
1.6. Ejemplo. Juego del raspa raspa. Considere una lotería instantánea. Cada tarjeta tiene tres filas, y en cada fila hay dos casillas, una de las cuales tiene un valor de $1,000 y la otra $5,000. El jugador raspa una casilla de cada renglón para descubrir el valor asociado. Si los tres números destapados son iguales, el jugador gana esa cantidad. En caso contrario no gana nada.
Para evaluar la factibilidad del negocio se desea saber, entre otras cosas, cuál es la cantidad mínima que se debe cobrar por cada boleto. Solución. El valor mínimo que se puede cobrar por cada boleto es la cantidad media que espera ganar quien lo compre.
Solución analítica La ganancia obtenida por quien compra un boleto de esta lotería instantánea es una variable aleatoria, y está dada por:

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 5
casosotrosen0
5000devaloreltienendestapadasceldastreslassi5000
1000devaloreltienendestapadasceldastreslassi1000
U
Como la utilidad es una variable aleatoria, entonces el criterio de decisión o comparación sería la utilidad esperada, dada por:
)0(p0)5000(p5000)1000(p1000)u(pu)U(Ei
ii
Para obtener la utilidad esperada necesitamos calcular la probabilidad de que las tres casillas destapadas tengan todas el valor de 1000, o el de 5000, probabilidades dadas por: Si denotamos por Xi el valor destapado en la casilla de la fila i, i = 1,2,3, entonces tenemos que: P(1000) = P(X1 = 1000, X2 = 1000, X3 = 1000) = P(X1=1000)P(X2=1000) P(X3=1000)
=(1/2)(1/2)(1/2) = 1/8 De forma similar encontramos que p(5000) = 1/8, y por lo tanto el valor esperado está dado por: E(U) = 1000 (1/8) + 5000 (1/8) + 0 (6/8) = $750 Por lo tanto, el valor mínimo del boleto será de $750. Solución por simulación La solución por simulación sería simplemente tratar de reproducir (experimentar) lo que sucede cuando una persona compra el boleto, y repetir muchas veces este procedimiento con muchas personas, para calcular la utilidad promedio. Para cada boleto, o para cada persona que compre el boleto, la utilidad está dada por:
casosotrosen0
5000devaloreltienendestapadasceldastreslassi5000
1000devaloreltienendestapadasceldastreslassi1000
U
El procedimiento para un boleto sería: Destapar celda en fila 1, y verificar el resultado Destapar celda en fila 2, y verificar el resultado Destapar celda en fila 3, y verificar el resultado Si (todas las celdas son iguales a 1000) entonces Utilidad = 1000 Si no Si (todas las celdas son iguales a 5000) entonces Utilidad = 5000
Si no Utilidad = 0 Fin si Fin si Para simular el “destape” de una celda, simplemente generamos un número aleatorio R, que representa todos los valores posibles de obtener cuando se destapa una casilla (dos en este caso), y el resultado se obtiene estableciendo una equivalencia entre el número aleatorio R y las diferentes probabilidades de los valores a destapar. Como solamente son dos valores, y cada casilla contiene o un valor de 1000 o de 5000, con igual probabilidad, entonces el generador del resultado será el siguiente:

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 6
Si R < 0.5 valor destapado = 1000
Si R 0.5 valor destapado = 5000 Una forma de conocer lo que gana cada jugador al comprar un boleto, consiste en calcular la suma de las tres filas destapadas, y si esta suma es 3,000 entonces gana $1,000, si es 15,000 entonces gana $5,000, y si no es ninguna de las dos anteriores, no gana nada. Para saber la cantidad mínima a cancelar por cada boleto, entonces se simularía el juego de muchos boletos, se calcula la ganancia de cada boleto, y luego se calcula la ganancia promedio. El algoritmo siguiente (seudo código) contiene todos los pasos a realizar
Inicio Definir Número_boletos
Para cada boleto =1 hasta Número_boletos Suma_celdas = 0 Para cada fila =1 a 3 Generar número_aleatorio Si número_aleatorio <0.5 entonces
Suma_celdas = Suma_celdas + 1,000 Sino
Suma_celdas = Suma_celdas + 5,000 Fin si Siguiente fila Si (suma_celdas=3000) entonces Utilidad(boleto) = 1000 Sino Si (suma_celdas=15000) entonces Utilidad(boleto) = 5000
sino Utilidad(boleto) = 0
Fin si Fin si
Siguiente boleto Calcular ganancia promedio Fin Para implementarlo en Excel, simplemente debemos identificar las columnas requeridas, y la información que llevaría cada una. Necesitaríamos una columna para los boletos, y dos columnas por cada fila, y una última columna para la ganancia de cada boleto. Además, se requeriría una fila por cada boleto. Esas columnas serían:
Columna A: Número del boleto, desde 1 hasta el número de boletos Columna B: Número aleatorio para la primera fila Columna C: Valor de la primera celda destapada Columna D: Número aleatorio para la segunda fila Columna E: Valor de la segunda celda destapada Columna F: Número aleatorio para la tercera fila Columna G: Valor de la tercera celda destapada Columna H: Utilidad del boleto.
La configuración de la hoja de cálculo sería la siguiente:
(A) (B) ( C ) (D) (E) (F) (G) (H)

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 7
Boleto número
Número aleatorio 1
Valor primera celda
Número aleatorio 2
Valor segunda
celda
Número aleatorio 3
Valor tercera celda
Ganancia
1
2
3
..
En la primera fila podemos colocar un título que identifique el contendido de la hoja de cálculo, en la tercera los encabezados de cada columna, y a partir de la cuarta irán los diferentes boletos. Para conocer el valor que hay en cada fila se usará la función “si” sencilla, mientras que para conocer la ganancia del juego se usará la función “si” con otro “si” anidado. Las funciones (instrucciones) que irían en las diferentes celdas son los siguientes:
Bi: = aleatorio() Ci: =si(Bi<0.5;1000;5000) Di: = aleatorio() Ei: =si(Di<0.5;1000;5000) Fi: = aleatorio() Gi: =si(Fi<0.5;1000;5000) Hi: =si(Ci+Ei+Gi=3000;1000;si(Ci+Ei+Gi=15000;5000;0))
Las anteriores celdas se escriben en la cuarta fila, y luego se copian en las filas restantes tantas veces cuantas sean necesarias, según el número de boletos. En la fila 2, columna H colocamos la ganancia promedio según el número de boletos, dada por:
H2 = promedio(h4:hn) , donde n representa la última fila de la simulación El siguiente cuadro presenta un resumen con los resultados de una simulación de 5000 boletos

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 8
Juego del raspa raspa
Utilidad media = 817,8
Boleto número
(A)
Número aleatorio 1
(B)
Valor primera
celda (C)
Número aleatorio 1
(D)
Valor segunda celda (E)
Número aleatorio 1
(F)
Valor tercera
celda (F)
Valor ganado
(G)
1 0,067 1000 0,316 1000 0,219 1000 1000
2 0,090 1000 0,759 5000 0,551 5000 0
3 0,063 1000 0,625 5000 0,774 5000 0
4 0,441 1000 0,129 1000 0,910 5000 0
5 0,002 1000 0,328 1000 0,746 5000 0
6 0,431 1000 0,323 1000 0,666 5000 0
7 0,997 5000 0,893 5000 0,777 5000 5000
8 0,191 1000 0,436 1000 0,781 5000 0
9 0,795 5000 0,659 5000 0,971 5000 5000
10 0,586 5000 0,867 5000 0,279 1000 0
11 0,461 1000 0,835 5000 0,741 5000 0
12 0,542 5000 0,148 1000 0,557 5000 0
13 0,085 1000 0,244 1000 0,712 5000 0
14 0,860 5000 0,403 1000 0,122 1000 0
15 0,746 5000 0,913 5000 0,030 1000 0
16 0,629 5000 0,463 1000 0,802 5000 0
17 0,361 1000 0,831 5000 0,645 5000 0
18 0,670 5000 0,397 1000 0,877 5000 0
19 0,761 5000 0,567 5000 0,533 5000 5000
20 0,514 5000 0,447 1000 0,091 1000 0
21 0,430 1000 0,176 1000 0,283 1000 1000
22 0,906 5000 0,038 1000 0,693 5000 0
23 0,813 5000 0,874 5000 0,539 5000 5000
24 0,689 5000 0,637 5000 0,371 1000 0
25 0,812 5000 0,278 1000 0,114 1000 0
26 0,150 1000 0,349 1000 0,859 5000 0
27 0,553 5000 0,705 5000 0,803 5000 5000
28 0,144 1000 0,397 1000 0,135 1000 1000
29 0,425 1000 0,403 1000 0,399 1000 1000
30 0,179 1000 0,051 1000 0,705 5000 0
31 0,469 1000 0,080 1000 0,902 5000 0
32 0,241 1000 0,504 5000 0,102 1000 0
33 0,301 1000 0,845 5000 0,972 5000 0
34 0,463 1000 0,217 1000 0,312 1000 1000
35 0,721 5000 0,244 1000 0,758 5000 0
36 0,896 5000 0,934 5000 0,102 1000 0
37 0,322 1000 0,487 1000 0,987 5000 0
38 0,210 1000 0,087 1000 0,055 1000 1000
39 0,521 5000 0,800 5000 0,844 5000 5000
40 0,535 5000 0,669 5000 0,773 5000 5000
Simulación del juego del raspa raspa

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 9
1.7. Un modelo de simulación. Juego del lanzamiento de la moneda El objetivo de este apéndice es mostrar, mediante un problema sencillo, la naturaleza experimental de la simulación y los casos en que debe usare la simulación como herramienta de último recurso. Es decir, se ilustrará mediante un juego de lanzamiento de monedas, en qué forma se realiza una simulación, ejecutando los mismos pasos que se realizarían en un juego real. El problema planteado es el siguiente: A usted le proponen el siguiente juego: Usted lanza una moneda y cuenta el número de caras y sellos que va obteniendo. El juego se termina sólo cuando la diferencia entre caras y sellos sea tres, no interesa cual sea mayor. En ese instante usted recibe $8.00 por el juego, pero tiene que pagar $1.00 por cada lanzamiento de la moneda que usted haya hecho. Le conviene a usted participar en este juego ? El problema consiste en determinar si es favorable o no participar en este juego. En principio diremos que es favorable participar en el juego si a la larga esperamos ganar, es decir, la utilidad esperada del juego es mayor o igual que cero. Para obtener la respuesta ensayaremos diferentes soluciones, empezando primero por una solución de tipo analítico, luego por la experimentación con el sistema real, y finalmente por una solución tipo simulación.
1.7.1. Solución analítica
Inicialmente podemos intentar solucionar analíticamente esta situación. El juego es favorable si esperamos obtener alguna utilidad del mismo. Para un juego cualquiera la utilidad U está dada por: U(x) = Ingresos - Egresos = 8 - X, x = 3, 5, 7, ..., donde X es el número de lanzamientos, y por cada lanzamiento se paga un peso. El número de lanzamientos en que puede terminarse un juego es mínimo tres, y puede ser 5, 7, 9, 11, ...; el juego no puede terminar en un número par de lanzamientos. Como el número de lanzamientos -X- es una variable aleatoria, entonces debemos hablar, como criterio de decisión, de la utilidad esperada, que está definida como:
E (U) = U(x) P(x) donde P(x) es la función de densidad del número de lanzamientos en que puede terminar el juego, y representa
la probabilidad de que el juego termine en x lanzamientos. El juego es favorable si E(U) 0. Para calcular la utilidad esperada debemos conocer P (x), para los diferentes valores de x, donde x = 3, 5, ..., hasta aquellos valores de x para los cuales P (x) sea aproximadamente cero. Cálculo de P (x) P (X=3) = Probabilidad de que el juego termine en tres lanzamientos = Probabilidad de que los tres primeros lanzamientos sean todos cara ó todos sean sellos = Prob (Tres primeros lanzamientos sean cara) + Prob (Tres primeros lanzamientos sean sello) = P(CCC) + P(SSS) = (½)
3+ (½)
3 = ¼
P (X=5) = Probabilidad de que el juego termine en 5 lanzamientos
= Probabilidad de obtener cuatro caras y un sello o cuatro sellos y una cara, dado que el juego no había terminado antes.
P (X=5) = P(CCSCC) + P(CSCCC) + P(SCCCC) + P(SSCSS) + P(SCSSS) + P(CSSSS) = 6(½)
5= 3/16
Los eventos CCCSC, CCCCS, SSSCS y SSSSC no están incluidos en el cálculo de la probabilidad de terminar en 5 lanzamientos. Por qué ?. Esta probabilidad no está dada por las combinaciones de 5 tomadas de a 4, ni de 5 tomadas de a uno. El cálculo de P (X = 7) es la probabilidad de obtener 5 caras y 2 sellos o 5 sellos y dos caras, pero para su cálculo hay que eliminar aquellas combinaciones que den como resultado que el juego termine en 3 y en 5 lanzamientos. Para el cálculo de estas probabilidades hay que tener en cuenta el orden en que van cayendo las monedas. El cálculo de las restantes probabilidades es aún más complicado (aunque no es imposible de obtener).

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 10
Como se puede apreciar en este ejemplo sencillo, es posible construir un modelo analítico para el juego, pero una solución analítica es difícil
1.7.2. Experimentar con el Sistema Real En este sistema sencillo, para tomar una decisión de participar o no en el juego, podemos experimentar con el sistema real, es decir, podemos realizar varios juegos, a manera de ensayo, y con base en esos resultados, decidir si participamos o no en el juego que nos están proponiendo. El procedimiento para experimentar con el sistema real sería el siguiente: a) Definir el tamaño de la muestra, es decir, el número de juegos a realizar (N)
b) Para cada juego j, (j = 1, N), se inicializa:
Número de caras = cero Número de sellos = cero
c) Se lanza la moneda
d) Se mira el resultado: Cara o sello
Si es cara, se aumenta el número de caras en uno Si es sello, se aumenta el número de sellos en uno
e) Si el número de caras menos sellos o sellos menos caras es igual a tres el juego termina y haríamos el paso f; si no es igual a tres, se repite el proceso de lanzar de nuevo la moneda, es decir, haríamos el paso c.
f) Cuando se termina un juego, se calcula la utilidad del juego, dada por:
Uj = Utilidad = 8 - número de lanzamiento de la moneda
donde el número de lanzamientos es igual al número de caras más el número de sellos.
g) Si quedan más juegos por realizar, se repite el paso b)
Si ya se han realizado todos los juegos, se pasa a la etapa h).
h) Se calcula la utilidad promedia de todos los juegos realizados, dada por:
N
1ijU
N
1U
Si U 0 el juego es favorable
1.7.3. Solución por Simulación Otra forma de analizar la bondad del juego es mediante la simulación. Es decir, no se lanzan "realmente" las monedas, como en la alternativa anterior, sino que "se simula" el lanzamiento de las mismas, y se examina si el resultado fue cara o sello. De nuevo, el juego se termina cuando la diferencia entre las caras y los sellos sea tres. El juego simulado se realiza varias veces y al final se obtiene la utilidad media por juego. El procedimiento para simular el juego es exactamente el mismo que para realizarlo, con la única diferencia de que no se lanza una moneda real, sino que se simula su lanzamiento.

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 11
El procedimiento para simular el juego sería prácticamente el mismo que para jugarlo, excepto que no se lanza la moneda sino que se “simula” su lanzamiento: a) Definir el número de juegos a realizar (N)
b) Para cada juego j, (j = 1, N), se inicializa:
Número de caras = cero Número de sellos = cero
c) Se simula el lanzamiento de la moneda
d) Se “investiga” el resultado: Si cara o sello
Si es cara, se aumenta el número de caras en uno Si es sello, se aumenta el número de sellos en uno
e) Si el número de caras menos sellos o sellos menos caras, es igual a tres, es decir, si termina un juego, se hace el paso f, si no, se repite el paso c, es decir, se lanza de nuevo la moneda.
f) Cuando un juego termina, se calcula la utilidad del juego dado por:
Uj = Utilidad = 8 - número de lanzamiento de la moneda
donde el número de lanzamientos es igual al número de caras más el número de sellos.
g) Si quedan más juegos por realizar, se repite el paso b)
Si ya se han realizado todos los juegos, se pasa a la etapa h).
h) Se calcula la utilidad promedia de todos los juegos realizados, dada por:
N
1ijU
N
1U
Si U 0 el juego es favorable
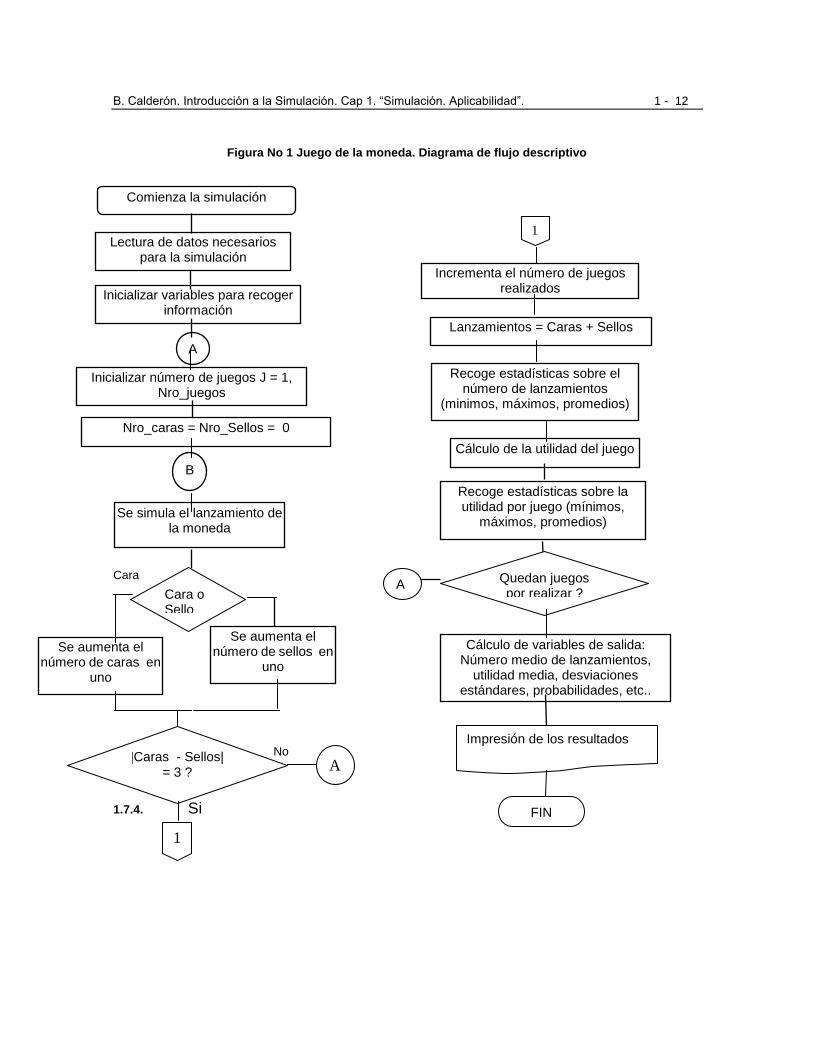
La figura 1, ilustra, mediante una diagrama de flujo descriptivo, el procedimiento necesario para realizar varios juegos. El diagrama de flujo contempla tres aspectos básicos que hay que considerar en cualquier simulación, que son: a) Inicialización del sistema a simular, la cual se realiza una sola vez y que comprende la inicialización y
definición de las variables que se van a usar (Paso 1 del procedimiento dado antes).
b) El algoritmo de la simulación, es decir, la simulación propiamente dicha, con todos los cambios que sean necesarios en el estado de sistema (Pasos 2, 3, 4 y 5).
c) El resumen e impresión de los resultados
Sin embargo, un diagrama descriptivo no es suficiente para realizar la simulación, sino que es necesario llevar ese diagrama descriptivo a un diagrama detallado y luego programarlo para su ejecución a través del computador (en lenguajes de programación o similares). Para ello es necesario realizar dos tareas:
a) La primera consiste en definir una serie de variables que describan el estado de la simulación en cualquier instante. Se necesitan, entre otras, variables que indiquen el número de juegos realizados, el número de caras y sellos, la utilidad acumulada de los juegos realizados, las utilidades mínima y máxima, etc. Estas y otras variables son definidas posteriormente.
b) La segunda tarea, y la más importante, consiste en definir:
- Cómo se simula el lanzamiento de la moneda y
- Cómo se sabe el resultado del lanzamiento
B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 12
A
B
Figura No 1 Juego de la moneda. Diagrama de flujo descriptivo
Cara No o No
1.7.4. Si
Comienza la simulación
Lectura de datos necesarios para la simulación
Inicializar número de juegos J = 1, Nro_juegos
Se simula el lanzamiento de la moneda
Se aumenta el número de caras en
uno
Inicializar variables para recoger información
Incrementa el número de juegos realizados
Lanzamientos = Caras + Sellos
Cálculo de la utilidad del juego
Recoge estadísticas sobre el número de lanzamientos
(minimos, máximos, promedios)
Cálculo de variables de salida: Número medio de lanzamientos,
utilidad media, desviaciones estándares, probabilidades, etc..
Nro_caras = Nro_Sellos = 0
Cara o Sello
=+= Se aumenta el
número de sellos en uno
|Caras - Sellos| = 3 ?
A
1
1
Recoge estadísticas sobre la utilidad por juego (mínimos,
máximos, promedios)
Quedan juegos por realizar ?
A
Impresión de los resultados
FIN

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 13
Simulación del lanzamiento de la moneda El lanzamiento de la moneda se realiza mediante lo que en simulación recibe el nombre de NUMERO ALEATORIO. Los números aleatorios, que se estudiarán en el capítulo 3, son variables aleatorias que se distribuyen uniformemente en el rango de cero a uno (0, 1). Así, si R es un número aleatorio, debe cumplirse
que 0 R < 1, y todos los números en este rango tienen igual probabilidad de ser generados. Los números aleatorios son la base de cualquier simulación, por eso se dice que "la simulación es una técnica numérica". Existen varios métodos para generar números aleatorios y con base en estos métodos pueden diseñarse diferentes subrutinas. En la mayoría de libros básicos de estadística se presentan tablas de números aleatorios, generados mediante estos métodos. La mayoría de lenguajes de programación presentan módulos o rutinas específicas para generar estos números. Igualmente las calculadoras científicas traen funciones especiales que producen números aleatorios (tecla RND o RAN#) La función RND de Visual Basic genera números aleatorios R; con esta función es posible especificar (mediante la instrucción RNADOMIZE) el valor inicial a partir del cual se generarán los números aleatorios. Este valor inicial recibe el nombre de “la semilla”, y por seguridad debe ser un número entero positivo impar. En el lenguaje Java el generador de números aleatorios
es la función RANDOM#.. La función del excel =aleatorio() es un generador de números aleatorios entre 0 y 1. En el Capitulo 3 veremos como se diseñaron estas funciones En conclusión, el lanzamiento de la moneda lo simulamos mediante la generación de un número aleatorio R, en el intervalo (0, 1), o sea mediante el uso de las funciones ya mencionadas Una vez generado el número aleatorio, el paso siguiente es establecer una relación entre las características del número aleatorio y las características del fenómeno o proceso que se desea simular. Para nuestro caso, para obtener el resultado del lanzamiento de la moneda (cara o sello) es necesario conocer las características de la moneda, es decir, si es una moneda buena o mala. Si la moneda es "buena" la probabilidad de que caiga cara es 1/2 y es igual a la probabilidad de que caiga sello. Sea p la probabilidad de que la moneda caiga cara. Si p = 0.4 quiere decir que de 100 lanzamientos que se hagan, se espera que la moneda caiga cara 40 veces, o sea, que la fracción de caras obtenidas con relación al número de lanzamientos debe tender a 0.4. Entonces para saber si la moneda cae cara o sello es necesario establecer una relación entre el número aleatorio R y la probabilidad de obtener cara en el lanzamiento de la moneda. Si consideramos números aleatorios de dos cifras cada uno, entonces entre cero y uno pueden generarse los siguientes números {00, 01, 02, 03,..., .38, .39, .40, .41,..., .97, .98, .99} El total de números de dos cifras que pueden generarse es 100. De este total de números de dos cifras debemos asignar 40 a la probabilidad de obtener cara y 60 para el resultado de sello, cuya probabilidad es 0.6. Entonces al resultado de cara le podemos asignar los primeros cuarenta números (del 0.00 al 0.39) y al resultado de sello los últimos 60 números (del 0.40 al 0.99), Así Si R < 0.40 Se obtiene cara
Si R 0.40 Se obtiene sello En general: Si R < p Se obtiene cara
Si R p Se obtiene sello, donde p es la probabilidad de obtener cara en el lanzamiento de una moneda.
1.7.5. Información para la toma de decisiones En un estudio de simulación puede recogerse diferentes tipos de estadísticas que, aunque como en el caso que nos ocupa no sean indispensables para tomar una decisión de acuerdo al criterio que hemos definido (el cual está basada en la utilidad media por juego), se emplean para facilitar la toma de decisiones y que sirven para formarnos una idea de lo que puede esperarse en el juego. Estas estadísticas pueden ser:
1. Referentes a la utilidad dejada por el juego:
- Utilidad mínima por juego - Utilidad máxima por juego - Utilidad media por juego - Desviación estándar de la utilidad
2. Referente al número de lanzamientos por juego:

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 14
- Número mínimo de lanzamientos por juego - Número máximo de lanzamientos por juego - Número medio de lanzamientos por juego - Desviación estándar del número de lanzamientos - Distribución del número de lanzamientos por juego. La figura 2 presenta los resultados de efectuar manualmente varios juegos, mediante la ayuda de la hoja de cálculo Excel, y empleando la función de excel “=aleatorio()” para generar los números aleatorios. De esta muestra de varios juegos se concluye que el juego es favorable; sin embargo el tamaño de la muestra es muy pequeño para llegar una conclusión confiable. La figura 3 nos presenta el seudocódigo para la simulación del juego y en el apéndice al final del capítulo se presenta el listado, en FORTRAN, del programa escrito para desarrollar la simulación. Ahora bien, si se quiere introducir modificaciones al juego, es relativamente fácil hacerlo. Por ejemplo, si se quiere terminar el juego cuando la diferencia entre caras y sellos sea tres o cuando se haya realizado determinado número de lanzamientos (15 por ejemplo), sólo se necesita agregar una nueva instrucción que nos compare si el número total de caras y sellos es igual a ese número. Esa instrucción iría después de la comparación entre caras y sellos, cuando el resultado da que su diferencia no es tres. A continuación se presentan los resultados obtenidos después de simular 1.000 juegos con una semilla inicial ISEM = 727 (programa en fortran). También se presenta la distribución del número de lanzamientos requeridos para terminar el juego. (La distribución de la utilidad por juego podría obtenerse de la anterior). Junto con el resultado de la anterior corrida se presenta el de otra corrida realizada con un número inicial de 5727. La probabilidad de obtener una cara es 0.5.
RESUMEN GLOBAL DE RESULTADOS
Valor de la semilla 727 5727 Número de juegos 1000 1000 Número mínimo de lanzamientos por juego 3 3 Número máximo de lanzamientos por juego 51 51 Número medio de lanzamientos por juego 9.04 9.05 Desviación del número de lanzamientos 7.00 7.07 Utilidad mínima por juego -43 -43 Utilidad máxima por juego 5 5 Utilidad media por juego -1.04 -1.05 Desviación de la utilidad por juego 7.0 7.07 Probabilidad de terminar en tres lanzamientos 23.9 23.9 El juego es, en general, desfavorable Otras estadísticas obtenidas en la simulación se muestran en las páginas siguientes. De ahí vemos que la probabilidad de que el juego termine en tres lanzamientos es 23.9% y la teórica es 25%.
Análisis estadístico de los resultados.
Uso de intervalos de confianza para el análisis de los resultados de la simulación.
Validación de los resultados. Existe alguna diferencia significativa entre el resultado muestral (0.239) y el resultado teórico (0.25) para la probabilidad de terminar el juego en tres lanzamientos?

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 15
Figura No 2
Juego de la moneda. Simulación manual
Juego Número
Lanza miento No
Número aleatorio
Resultado Total de Diferencia Utilidad
J X R (C, S) Caras Sellos ABS (C-S) 8 - X
1 0 0 0 1 0.945 S 0 1 1
2 0.973 S 0 2 2
3 0.829 S 0 3 3 5
2 0 0 0 1 0.348 C 1 0 1
2 0.119 C 2 0 2
3 0.080 C 3 0 3 5
3 0 0 0 1 0.228 C 1 0 1
2 0.695 S 1 1 0
3 0.620 S 1 2 1
4 0.964 S 1 3 2
5 0.709 S 1 4 3 3
4 0 0 0 1 0.573 S 0 1 1
2 0.262 C 1 1 0
3 0.916 S 1 2 1
4 0.635 S 1 3 2
5 0.066 C 2 3 1
6 0.178 C 3 3 0
7 0.975 S 3 4 1
8 0.750 S 3 5 2
9 0.223 C 4 5 1
10 0.086 C 5 5 0
11 0.011 C 6 5 1
12 0.794 S 6 6 0
13 0.168 C 7 6 1
14 0.361 C 8 6 2
15 0.148 C 9 6 3 -7
5 0 0 0 1 0.028 C 1 0 1
2 0.378 C 2 0 2
3 0.512 S 2 1 1
4 0.172 C 3 1 2
5 0.927 S 3 2 1
6 0.512 S 3 3 0
7 0.227 C 4 3 1
8 0.256 C 5 3 2
9 0.990 S 5 4 1
10 0.138 C 6 4 2
11 0.419 C 7 4 3 -3
6 0 0 0 1 0.342 C 1 0 1 2 0.632 S 1 1 0 3 0.213 C 2 1 1 4 0.087 C 3 1 2 5 0.108 C 4 1 3 3

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 16
ego Número
Lanza miento No
Número aleatorio
Resultado Total de Diferencia Utilidad
J X R (C, S) Cara Sello ABS(C-S) 8 - X
7 0 0 0 1 0.381 C 1 0 1
2 0.310 C 2 0 2
3 0.935 S 2 1 1
4 0.316 C 3 1 2
5 0.983 S 3 2 1
6 0.554 S 3 3 0
7 0.978 S 3 4 1
8 0.384 C 4 4 0
9 0.999 S 4 5 1
10 0.040 C 5 5 0
11 0.748 S 5 6 1
12 0.631 S 5 7 2
13 0.554 S 5 8 3 -5
8 0 0 0 1 0.370 C 1 0 1
2 0.434 C 2 0 2
3 0.773 S 2 1 1
4 0.238 C 3 1 2
5 0.968 S 3 2 1
6 0.165 C 4 2 2
7 0.782 S 4 3 1
8 0.700 S 4 4 0
9 0.668 S 4 5 1
10 0.202 C 5 5 0
11 0.704 S 5 6 1
12 0.905 S 5 7 2
13 0.594 S 5 8 3 -5
9 0 0 0 1 0.665 S 0 1 1
2 0.227 C 1 1 0
3 0.872 S 1 2 1
4 0.689 S 1 3 2
5 0.791 S 1 4 3 3
10 0 0 0 1 0.626 S 0 1 1
2 0.890 S 0 2 2
3 0.205 C 1 2 1
4 0.722 S 1 3 2
5 0.982 S 1 4 3 3
11 0 0 0 1 0.034 C 1 0 1
2 0.645 S 1 1 0
3 0.065 C 2 1 1
4 0.081 C 3 1 2
5 0.402 C 4 1 3 3
Medias7-11 8.2 3.2 3.5 -0.2
Medias 1-11 7.5 3.6 3.2 0.5

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 17
Figura No 3 - Problema del Juego de la Moneda :Seudocódigo
Lectura de datos sobre :
Semillas, Número de Juegos, Parámetros para distribuciones de frecuencia
(SEMILLA, NRO_JUEGOS, PROB_CARA, Xo, X, NRO_INT)
X = X2 = 0, Xmin = 100, Xmax = 0, U =0
FRECUENCIA(INT)=0, INT=1,NRO_INT
JUEGOS = 1
MIENTRAS (JUEGOS NRO_JUEGOS)
CARAS = SELLOS =0
MIENTRAS ( CARAS - SELLOS .NE. 3) ENTONCES
GENERAR NUMERO ALEATORIO “R”
SI (R < PROB_CARA) SI NO
CARAS = CARAS + 1 SELLOS = SELLOS + 1
FIN SI
FIN MIENTRAS
LANZA = CARAS + SELLOS
X = X + LANZA
X2 = X
2 + LANZA
2
SI (LANZA .LT. Xmin) Xmin = LANZA
SI (LANZA .GT. Xmax) Xmax = LANZA
INT=[(LANZA - Xo)/X + 2]
SI (INT. LT. 1) INT = 1
SI (INT. GT. NRO_INT) INT = NRO_INT
FRECUENCIA(INT) = FRECUENCIA(INT) + 1
JUEGOS = JUEGOS + 1
FIN MIENTRAS
MEDIA = X/NRO_JUEGOS
VARIANZA = (X2 - NRO_JUEGOS * MEDIA
2 )/(NRO_JUEGOS - 1)
DESVIACION = (VARIANZA)
UTILIDAD_MEDIA = U / NRO_JUEGOS
IMPRIMIR “NRO_JUEGOS, MEDIA, DESVIACION, Xmin, Xmax, UTILIDAD_MEDIA”
INTERV = 1
MIENTRAS (INTERV. LE. NRO_INT) ENTONCES
FRECUENCIA_RELATIVA = FRECUENCIA(INT) *100/NRO_JUEGOS
IMPRIMIR “INTERV, FRECUENCIA(INTERV), FRECUENCIA_RELATIVA”
INTERV = INTERV + 1
FIN MIENTRAS
FIN SIMULACIÓN

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 18
Distribución del número de lanzamientos de la moneda
Intervalo Numero de Lanzamientos
Frecuencia absoluta
Frecuencia relativa
Frecuencia rel. acum.
1 3 239 23.90 23.90
2 5 171 17.10 41.00
3 7 164 16.40 57.40
4 9 104 10.40 67.80
5 11 82 8.20 76.00
6 13 54 5.40 81.40
7 15 57 5.70 87.10
8 17 17 1.70 88.80
9 19 28 2.80 91.60
10 21 22 2.20 93.80
11 23 13 1.30 95.10
12 25 8 0.80 95.90
13 27 7 0.70 96.60
14 29 11 1.10 97.70
15 31 4 0.40 98.10
16 33 8 0.80 98.90
17 35 8 0.80 99.70
18 37 2 0.20 99.90
19 39 0 0.00 99.90
20 41 o mas 1 0.10 100.00
Análisis de resultados. Considere los siguientes resultados del juego de la moneda, obtenidos con otro generador diferente de números aleatorios, pero usando las mismas semillas de las simulaciones anteriores.
Concepto Corrida Replicado Semilla 727 4727 Numero de juegos 1000 1000 Utilidad media -1.00 -0.97 Desviación estándar de la utilidad 7.00 7.04 Utilidad mínima -59 -59 Utilidad máxima 5 5 Numero medio de lanzamientos 9.00 8.97 Desviación estándar de la utilidad 7.00 7.04 Numero mínimo de lanzamientos 3 3 Numero máximo de lanzamientos 67 67 ¿Cree Usted que existen diferencias significativas con los resultados anteriores?

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 19
1.8. Ejemplo : Movimiento de una partícula
Una partícula se mueve en el siguiente círculo. La partícula empieza en cero. En cada punto en el círculo la partícula dará un paso que puede ser a cualquier punto adyacente en el círculo. La probabilidad de que la partícula se mueva en el sentido de las agujas del reloj o en sentido contrarío es 1/2. Usando la simulación determine la distribución de frecuencia del número de pasos requeridos para que la partícula vuelva al punto inicial 0 7 1 6 2 5 3
4 4
1.8.1. Solución A continuación se describe la secuencia de etapas o actividades que realiza la partícula para hacer un viaje completo, entendiendo por viaje completo los pasos que da desde que sale del punto inicial (cero) hasta que regresa al mismo punto 1. La partícula se coloca en la posición inicial 2. La partícula da un paso 3. Se investiga la dirección 4. Se actualiza la nueva posición 5. Regresó al punto de partida ?
a) No regresó. Se repite el paso 2 b) Sí regresó. Se realiza el paso 6
6. Fin del viaje Para realizar la simulación es necesario definir los siguientes aspectos : Variables de Estado. Las principales variables requeridas para representar el viaje son la “posición” de la
partícula -POSICION- y el número de pasos -PASOS- que se han dado en cualquier momento de la simulación.
Realización del movimiento. El dar el paso se representa mediante la generación de un número aleatorio.
Investigar la dirección. Para conocer la dirección que toma la partícula es necesario realizar una equivalencia entre el número aleatorio R y las diferentes direcciones que puede tomar la partícula. Como solo hay dos direcciones posibles, y ambas son equiprobables (1/2), se puede hacer algo similar a lo realizado en el caso de la moneda. Es decir, la dirección que toma la partícula estará definida de la siguiente manera
Si R < 0.5 la partícula gira en el sentido de las agujas del reloj, y la nueva posición estará dada por POSICION = POSICION + 1 Si llega a la posición 8, es equivalente a llegar a la posición cero, es decir :
SI POSICION = 8 POSICION = 0
Si R 0.5 la partícula gira en sentido contrario al de las agujas del reloj, y la nueva posición estará dada por
POSICION = POSICION - 1 Si llega a la posición -1, es equivalente a llegar a la posición siete, es decir:
SI POSICION = -1 POSICION = 7 1.8.2. Estadísticas de interés
Número medio de pasos requeridos para regresar
Número mínimo de pasos requeridos para regresar
Número máximo de pasos requeridos para regresar
Desviación estándar del número de pasos requeridos para regresar

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 20
Distribución de frecuencia del número de pasos requeridos para regresar La Figura siguiente presenta el seudocódigo de la simulación, recogiendo todas las estadísticas requeridas.
Figura b1- Problema del Movimiento de la Partícula :Seudocódigo
Lectura de datos sobre :
Semillas, Número de Viajes, Parámetros para distribuciones de frecuencia
(SEMILLA, NRO_VIAJES, PROB_DERE, Xo, X, NRO_INT)
X = X2 = 0, Xmin = 100, Xmax = 0
FRECUENCIA(INT)=0, INT=1,NRO_INT
PARA VIAJES = 1, NRO_VIAJES)
PASOS = 0 POSICION = 0 FIN_VIAJE = 0
MIENTRAS (FIN_VIAJE = 0)
PASOS = PASOS + 1
GENERAR NUMERO ALEATORIO “R”
SI (R. LT. PROB_DERE) SI NO
POSICION = POSICION + 1 SI (POSICION =.8) ENTONCES POSICION = 0 FIN SI
POSICION = POSICION - 1 SI (POSICION. = -1) ENTONCES POSICION = 7 FIN SI
FIN SI
SI (POSICION. EQ. 0) FIN_VIAJE = 1 FIN SI
FIN MIENTRAS
X = X + PASOS
X2 = X
2 + PASOS
2
SI (PASOS .LT. Xmin) Xmin = PASOS
SI (PASOS .GT. Xmax) Xmax = PASOS
INT=[(PASOS - Xo)/X + 2]
SI (INT. LT. 1) INT = 1
SI (INT. GT. NRO_INT) INT = NRO_INT
FRECUENCIA(INT) = FRECUENCIA(INT) + 1
FIN PARA
MEDIA = X/NRO_VIAJES
VARIANZA = (X2 - NRO_VIAJES * MEDIA
2 )/(NRO_VIAJES - 1)
DESVIACION = (VARIANZA)
IMPRIMIR “NRO_VIAJES, MEDIA, DESVIACION, Xmin, Xmax”
INTERV = 1
MIENTRAS (INTERV. LE. NRO_INT) ENTONCES
FRECUENCIA_RELATIVA = FRECUENCIA(INT) *100/NRO_VIAJES
IMPRIMIR “INTERV, FRECUENCIA(INTERV), FRECUENCIA_RELATIVA”
INTERV = INTERV + 1
FIN MIENTRAS
FIN SIMULACION
1.8.3. Resultados

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 21
En el cuadro siguiente se resumen los resultados obtenidos al realizar varias simulaciones con dos semillas diferentes y para varios tamaños de muestra. La tabla presenta también la probabilidad de realizar el viaje en dos pasos. Se observa que, a medida que se aumenta el tamaño de la muestra, el número medio de pasos requeridos para regresar al punto cero se aproxima a ocho (8.0) y la probabilidad de hacer el viaje en dos pasos se aproxima al 0.50. Este ejemplo tiene solución analítica, modelándolo como una cadena de Markov, donde el estado del proceso es la posición de la partícula en cualquier instante. Los valores de ocho y 0.5 corresponden a las soluciones analíticas para el número medio de pasos y para la probabilidad de regresar al punto de partida en dos pasos, respectivamente.
Semilla 555 5555
Nro de viajes 50 100 500 1000 50 100 500 1000
Media 11.8 10.5 8.4 8.1 5.2 6.7 7.8 7.9
Desviación 18.6 16.5 11.3 10.5 6.5 9.3 10.1 10.2
Mínimo 2 2 2 2 2 2 2 2
Máximo 92 92 92 92 32 56 82 82
Prob(2) 42 43 48 49 66 55 50 50
1.9. Problema: La Tienda del Video Considere una tienda de alquiler de videos, que compra las cintas de estreno a $25,000 la unidad, las alquila a sus clientes a $5,000, y al final del mes, revende las cintas a otras tiendas de barrio a $ 5,000 la copia. La tienda ha estimado que la demanda diaria por cintas de estreno tiene la siguiente distribución de probabilidad:
Número de copias 0 1 2 3 4
Probabilidad 0.15 0.25 0.45 0.10 0.05 Suponga que las cintas duran en alquiler un día, y que todos los clientes devuelven las copias al siguiente día. Cuántas copias de las cintas de estreno debe ordenar la tienda cada mes? Solución Con este ejemplo se pretende hacer claridad sobre dos aspectos diferentes de la simulación: Por un lado se pretende mostrar la forma de realizar una simulación, tomando como base la forma como opera el sistema real, y por otro lado, se pretende mostrar la forma como se realizan los procesos de optimización en la simulación (mediante métodos de búsqueda). El objetivo es determinar cuántas copias deben pedirse cada mes, de tal forma que se maximice la utilidad mensual. Es decir, si Q es el número de copias que se compran cada mes, entonces se debe determinar el valor de Q que haga máxima la utilidad esperada por mes. Si para un mes se compran Q copias de una cinta, entonces la utilidad mensual estará dada por: Utilidad mensual(Q) = Ingresos por alquiler – Costo Cintas compradas + Precio reventas
=
30
1
5000000,25)(3000
j
QQjAlquiler
donde Alquiler(j) representa el número de copias alquiladas a los clientes el día j. Si X representa la demanda por cintas para el día j, entonces, el número de copias alquiladas ese día estará dada por: Alquiler (j) = X si X Q = Q si X> Q Aunque este modelo tiene solución analítica, sólo nos interesaremos en la solución por simulación. Para resolver este problema por simulación, la única variable aleatoria que tenemos es la demanda diaria por cintas, la cual se debe “generar” o “simular (inventar)” para cada día. Su generación se hará simplemente

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 22
distribuyendo el rango del número aleatorio (0,1) en forma proporcional a cada valor de la probabilidad (este procedimiento se conoce como el “método de la transformación inversa caso discreto”). Para cada valor de la demanda se calcula la probabilidad acumulada (función de distribución), según lo muestra la tabla siguiente, y los valores de la demanda se generarán de acuerdo a este valor de la siguiente manera:
Número de copias X 0 1 2 3 4
Probabilidad p(x) 0.15 0.25 0.45 0.10 0.05
Probabilidad acumulada F(x) 0.15 0.40 0.85 0.90 1.00 Se genera, mediante algún método apropiado, un número aleatorio R = r, con el cual se genera la demanda X de la siguiente manera:
Si r < 0.15 X = 0
Si 0.15 r < 0.40 X = 1
Si 0.40 r < 0.85 X = 2
Si 0.85 r < 0.95 X = 3
Si r 0.95 X = 4 Para cada valor de Q se deben simular varios meses, y calcular la utilidad promedio mensual. Para determinar la cantidad óptima Q*, es decir, la que maximice la utilidad esperada, se debe realizar la simulación para diferentes valores de Q, mediante un método de búsqueda. Si en estudios de simulación se desea optimizar una función, deben emplearse métodos numéricos de optimización, y los mas empleados son los métodos de búsqueda. Para nuestro caso, la cantidad mínima a pedir sería de una unidad, por lo tanto podemos empezar el proceso de
búsqueda en uno (Q0 = 1), usando un incremento o paso de 1 unidad (Q = 1). Se suspende el proceso de búsqueda cuando la utilidad esperada empiece a decrecer. En resumen, el procedimiento de optimización sería :
1) Se simula pidiendo una cantidad inicial Q = Q0 = 1 y se obtiene la utilidad media UM(Q0).
2) Se repite la simulación con una cantidad Q1 = Q0 + Q, y se calcula la utilidad media UM(Q1).
2.1) Si UM(Q1) UM(Q0), termina la búsqueda y la cantidad optima a pedir sería Q= Q0 = 1. 2.2 Si UM(Q1) > UM(Q0), se realizan nuevas simulaciones ordenando las siguientes cantidades :
Q2 = Q1 + Q, y se obtiene la utilidad media UM(Q2).
Q3 = Q2 + Q, y se obtiene la utilidad media UM(Q3). ...................... Qk = Qk-1 + Q, y se obtiene la utilidad media UM(Qk).
donde en Qk la función de utilidad no responde, es decir, UM(Qk) UM(Qk-1).
La cantidad óptima a pedir sería de Q* = Qk-1 El siguiente “seudo código” ilustra la forma como se realizaría la simulación: Definir Número de meses a simular, número de valores de Q Para cada valor i de Q = 1, número de valores
Para cada mes = 1, Número de meses Total(mes) = 0 Para cada día = 1 hasta 30
Generar demanda X
Si demanda Q(i), entonces Alquiler = demanda
Si no Alquiler = Q(i) Fin si
Total(mes) = Total(mes) + Alquiler Siguiente día
Siguiente mes
Promedio mensual = Total(mes)/Número meses Utilidad Media Mensual (i) = 3000 Promedio Mensual –25,000 Q(i) + 5,000 Q(i)

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 23
Siguiente valor de Q Escoger el valor de Q que maximiza utilidad media {Máximo Utilidad Media Mensual (i)} Con el fin de visualizar un poco mejor la simulación del problema, en las dos páginas siguientes se presentan el diagrama de flujo del problema, incluyendo el proceso de optimización, pero excluyendo el proceso de generación de la demanda diaria por videos, y el seudo código de la simulación, incluyendo la generación de la demanda diaria. Ambos diagramas representan lo mismo, pero en una forma diferente. Para algunas personas puede parecer más ilustrativo el diagrama de flujo, mientras que para otras lo puede ser el seudo código. La tabla que se anexa a continuación del diagrama y del seudo código resume la simulación de este problema para valores de Q = 1, 2, 3 y 4, y para doce meses, aunque sólo se presenta la simulación completa para el primer mes. La cantidad óptima a pedir es Q = 2 copias.
1.10. Ejemplo. Operación de embalse : Un modelo simple Una represa se utiliza para generar energía eléctrica y para el control del flujo de aguas. La capacidad de la represa es 4 unidades. La función de probabilidad de la cantidad de agua que fluye a la represa en el mes es la siguiente:
Cantidad 0 1 2 3
Probabilidad 1/6 1/3 1/3 1/6
Si el agua en la represa excede la capacidad máxima, el agua sobrante se bota a través del vertedero, que es
de flujo libre. Para generar energía se requieren mensualmente una o dos unidades, con igual probabilidad,
que se sueltan al final de cada mes. Si en la represa hay menos de la cantidad requerida, se genera energía con
el agua disponible, es decir, se suelta toda el agua.
Se desea desarrollar un modelo de simulación de la operación de la represa para determinar la distribución del
nivel del embalse al final del mes, la cantidad media de agua que se vierte y la demanda media que se satisface.
Desarrollo del modelo
El nivel del embalse al final de un mes está dado por :
Embalse al final del mes = Embalse inicial + Agua que entra - Agua que sale
El nivel del embalse al principio de un mes es igual al nivel del embalse al final del mes anterior. por lo tanto, si
Et representa el nivel del embalse al final del mes t, se tiene que:
Et = Et-1 + At - St
donde At corresponde al agua que llega a la represa, y St al agua que sale de la represa, bien sea el agua que
se vierte o que se suelta para generar energía.
El procedimiento general de simulación para un mes cualquiera se puede representar por los siguientes pasos :
Se determina el agua que llega a la represa At
Se calcula el volumen inicial del embalse, agregando el agua que llega : Et = Et-1 + At
Si el volumen del embalse excede la capacidad del mismo se calcula el agua que se vierte y el embalse
queda en su nivel máximo.

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 24
A
Problema de la Tienda de Video. Diagrama de flujo
Comienza la simulación
Alquiler_total = 0
Alquiler = Demanda
Util_max = 0 Q = Qo
Demanda Q
Alquiler = Q
Imprimir resultados: Q, util_media
Para mes = 1, nro_meses
Para dia = 1, 30
Generar demanda
Alquiler_total = Alquiler_total+Alquiler
Siguiente día
Siguiente mes
Promedio= Alquiler_total/nro_meses
Util_media > Util_maxima
Nro meses, valor inicial Q0, incremento Q
Util_media = 3000 Promedio – 25,000 Q + 5,000 Q
Qop = Q U_optima= util_media
Q = Q + Q
Imprimir solucion optima: Qop, U_optima
FIN

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 25
Figura No 3 – Seudocódigo Problema de la tienda de video
Lectura de datos sobre :
Semillas, Número de meses
CONTROL_OPTIMIZACIN = 0
Q = 1
UTIL_MAX=0
MIENTRAS (CONTROL_OPTIMIZACIN = 0)
UTIL_TOTAL =0
PARA MES = 1, MESES
SUMA_MES = 0
PARA DIA = 1, 30
GENERE NUMERO ALEATORIO “R”
SI (R< 0.15) ENTONCES
DEMANDA = 0
SI NO
SI (R< 0.40) ENTONCES
DEMANDA = 1
SI NO
SI (R< 0.85) ENTONCES
DEMANDA = 2
SI NO
SI (R< 0.95) ENTONCES
DEMANDA = 3
SI NO
DEMANDA = 3
FIN SI
FIN SI
FIN SI
FIN SI
SI (DEMANDA Q) ENTONCES
ALQUILER = DEMANDA
SI NO
ALQUILER = Q
FIN SI
SUMA_MES = SUMA_MES +ALQUILER
SIGUIENTE DIA
UTIL_TOTAL = UTIL_TOTAL +3000*SUMA_MES – 20000*Q
SIGUIENTE MES
UTIL_PROMEDIO(Q) = UTIL_TOTAL/MESES
IMPRIMIR Q, UTIL_PROMEDIO(Q), UTIL_PROMEDIO(Q)
SI (UTIL_PROMEDIO(Q) > UTIL_MAX)ENTONCES
UTILMAX = UTILPROMEDIO(Q) QOPTIMO = Q Q = Q + 1
SI NO
CONTROL_OPTIMIZACIN = 1
FIN SI
FIN MIENTRAS
IMPRIMIR “SOLUCION OPTIMA” QOPTIMO, UTIL_MAX
FIN SIMULACIÓN

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 26
RESULTADOS DE LA SIMULACION DE LA TIENDA DE VIDEO Precios de: Compra = 25,000, Alquiler = 3,000, Reventa = 5,000
MES NUMERO DE COPIAS Q
DIA R DEMANDA 1 2 3 4
ALQUILER ALQUILER ALQUILER ALQUILER
1 1 0.504 2 1 2 2 2
2 0.634 2 1 2 2 2
3 0.381 1 1 1 1 1
4 0.689 2 1 2 2 2
5 0.980 4 1 2 3 4
6 0.306 1 1 1 1 1
7 0.589 2 1 2 2 2
8 0.542 2 1 2 2 2
9 0.849 2 1 2 2 2
10 0.816 2 1 2 2 2
11 0.326 1 1 1 1 1
12 0.778 2 1 2 2 2
13 0.387 1 1 1 1 1
14 0.610 2 1 2 2 2
15 0.819 2 1 2 2 2
16 0.468 2 1 2 2 2
17 0.679 2 1 2 2 2
18 0.296 1 1 1 1 1
19 0.875 3 1 2 3 3
20 0.442 2 1 2 2 2
21 0.637 2 1 2 2 2
22 0.935 3 1 2 3 3
23 0.390 1 1 1 1 1
24 0.526 2 1 2 2 2
25 0.346 1 1 1 1 1
26 0.236 1 1 1 1 1
27 0.659 2 1 2 2 2
28 0.129 0 0 0 0 0
29 0.785 2 1 2 2 2
30 0.159 1 1 1 1 1
2 1 0.240 1 1 1 1 1
2 0.504 2 1 2 2 2
3 0.296 1 1 1 1 1
4 0.378 1 1 1 1 1
12 29 0.714 2 1 2 2 2
30 0.314 1 1 1 1 1
Total anual (cintas) 588 307 516 570 588
Promedio Mensual (Cintas/mes) 49.0 25.6 43.0 47.5 49.0
Promedio diario (Cintas/día) 1.63 0.85 1.43 1.58 1.63
Utilidad media mensual simulación ($/mes) 56750 89000 82500 67000
Utilidad media mensual analítica ($/mes) 56500 90500 84000 68500

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 27
Si Et > Cap Vt = Et - Cap
Et = Cap
Se calcula la demanda mensual para generar energía Dt
Si el nivel del embalse es igual o superior a la demanda, se satisface toda la demanda, y al nivel del embalse
se le resta la demanda.
Si Et Dt DSt = Dt
Et = Et - Dt
Si el nivel del embalse es inferior a la demanda, se satisface parte de la demanda, y al nivel del embalse se
hace igual a cero.
Si Et < Dt DSt = Et
Et = 0
donde Cap representa la capacidad de la represa, Vt el vertimiento en el mes t, y DSt la demanda satisfecha en
el mes t.
Para terminar de desarrollar el modelo, se requiere determinar como se genera el agua que llega al embalse y
la demanda de energía.
El cálculo del agua que llega al embalse, que es un fenómeno aleatorio, se realiza mediante la ayuda de los
números aleatorios. Para ello se genera un número aleatorio y luego se hace una equivalencia entre dicho
número y las probabilidades respectivas de que llegue cierta cantidad de agua al embalse. Es decir, el número
aleatorio, con un rango de variación de 0 a uno, debe representar las diferentes posibilidades de llegar agua al
embalse, con los valores de 0, 1, 2 y 3. El rango de variación de cero a uno debe dividirse en seis parte, y
asignarse 1/6 a la posibilidad de que no llegue agua en el mes, 1/3 a la posibilidad de que llegue una unidad, 1/3
a la posibilidad de que lleguen dos unidades y finalmente 1/6 a la posibilidad de que lleguen tres unidades de
agua. La tabla siguiente presenta una posible asignación del número aleatorio a las diferentes cantidades de
agua que pueden llegar al embalse.
Valores del número aleatorio – R
R < 1/6 1/6 R < 3/6 3/6 R <5/6 5/6
0 1 2 3
Agua que llega al embalse
La distribución sería la siguiente (la asignación se hace en forma proporcional a la respectiva probabilidad,
siguiendo la función de distribución -método de la transformación inversa):
Si r < 1/6 Agua que llega = 0
si 1/6 r < 3/6 Agua que llega = 1
si 3/6 r < 5/6 Agua que llega = 2
si r 3/6 Agua que llega = 3
El cálculo de la demanda de agua se hace en forma similar, pero sólo con dos valores (cero y uno) con igual
probabilidad. Es decir, se genera otro número aleatorio y la demanda se calcula de la siguiente manera :
Si r < 1/2 Demanda de agua = 1
Si r 1/2 Demanda de agua = 2
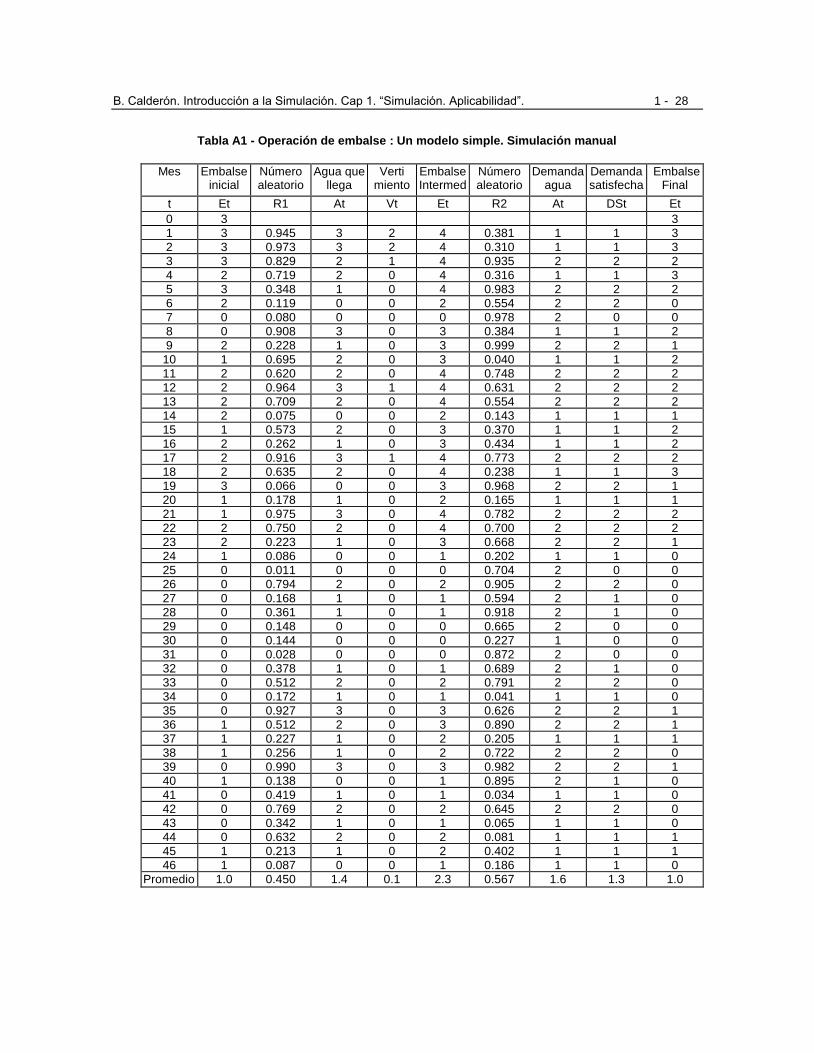
La tabla de la página siguiente presenta la simulación manual de este embalse sencillo durante 48 meses,
empezando con un inventario inicial de tres unidades.
B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 28
Tabla A1 - Operación de embalse : Un modelo simple. Simulación manual
Mes Embalse inicial
Número aleatorio
Agua que llega
Verti miento
Embalse Intermed
Número aleatorio
Demanda agua
Demanda satisfecha
Embalse Final
t Et R1 At Vt Et R2 At DSt Et
0 3 3
1 3 0.945 3 2 4 0.381 1 1 3
2 3 0.973 3 2 4 0.310 1 1 3
3 3 0.829 2 1 4 0.935 2 2 2
4 2 0.719 2 0 4 0.316 1 1 3
5 3 0.348 1 0 4 0.983 2 2 2
6 2 0.119 0 0 2 0.554 2 2 0
7 0 0.080 0 0 0 0.978 2 0 0
8 0 0.908 3 0 3 0.384 1 1 2
9 2 0.228 1 0 3 0.999 2 2 1
10 1 0.695 2 0 3 0.040 1 1 2
11 2 0.620 2 0 4 0.748 2 2 2
12 2 0.964 3 1 4 0.631 2 2 2
13 2 0.709 2 0 4 0.554 2 2 2
14 2 0.075 0 0 2 0.143 1 1 1
15 1 0.573 2 0 3 0.370 1 1 2
16 2 0.262 1 0 3 0.434 1 1 2
17 2 0.916 3 1 4 0.773 2 2 2
18 2 0.635 2 0 4 0.238 1 1 3
19 3 0.066 0 0 3 0.968 2 2 1
20 1 0.178 1 0 2 0.165 1 1 1
21 1 0.975 3 0 4 0.782 2 2 2
22 2 0.750 2 0 4 0.700 2 2 2
23 2 0.223 1 0 3 0.668 2 2 1
24 1 0.086 0 0 1 0.202 1 1 0
25 0 0.011 0 0 0 0.704 2 0 0
26 0 0.794 2 0 2 0.905 2 2 0
27 0 0.168 1 0 1 0.594 2 1 0
28 0 0.361 1 0 1 0.918 2 1 0
29 0 0.148 0 0 0 0.665 2 0 0
30 0 0.144 0 0 0 0.227 1 0 0
31 0 0.028 0 0 0 0.872 2 0 0
32 0 0.378 1 0 1 0.689 2 1 0
33 0 0.512 2 0 2 0.791 2 2 0
34 0 0.172 1 0 1 0.041 1 1 0
35 0 0.927 3 0 3 0.626 2 2 1
36 1 0.512 2 0 3 0.890 2 2 1
37 1 0.227 1 0 2 0.205 1 1 1
38 1 0.256 1 0 2 0.722 2 2 0
39 0 0.990 3 0 3 0.982 2 2 1
40 1 0.138 0 0 1 0.895 2 1 0
41 0 0.419 1 0 1 0.034 1 1 0
42 0 0.769 2 0 2 0.645 2 2 0
43 0 0.342 1 0 1 0.065 1 1 0
44 0 0.632 2 0 2 0.081 1 1 1
45 1 0.213 1 0 2 0.402 1 1 1
46 1 0.087 0 0 1 0.186 1 1 0
Promedio 1.0 0.450 1.4 0.1 2.3 0.567 1.6 1.3 1.0

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 29
1.11. Problemas 1.1 Un programa de entrenamiento ha sido desarrollado para cierta clase de trabajos en una compañía. Hay
tres fases en el programa de entrenamiento: A, B y C. Una vez se termina una fase, la persona entrenada presenta una prueba y si la aprueba pasa a la siguiente fase. Si no pasa la prueba, debe repetir la fase del programa y volver a presentar la prueba. Este procedimiento continúa hasta queaprueba las tres etapas
del programa. Sea Sea i
n
p la probabilidad de que la persona no pase la prueba de la fase i en el n-ésimo
intento. Cada etapa del proceso de instrucción requiere una semana antes de tomar la prueba, y esta duración permanece invariable no importa cuántas veces se repita la prueba. Sea p1 = 0.4, p2 = 0.5 y p3 = 0.2. Determine el tiempo medio, en semanas, requerido para terminar cada etapa y para completar todo el programa.
1.2 Un vendedor de tortas produce 50 tortas diarias a un costo de $1000/torta y las vende en un centro comercial a un precio de $3000/torta. Las tortas que no vende las tiene que tirar al final del día, sin embargo el vendedor aún no tiene permiso del municipio para tirar el producto en los basureros, por lo cual si llegan a descubrirlo tirando las tortas se le impondrá una multa de $30,000.
La demanda de tortas tiene la siguiente distribución:
Demanda 10 20 25 30 50 70 100
Probabilidad 0.1 0.2 0.3 0.2 0.1 0.06 0.04 La probabilidad de que la policía descubra al vendedor tirando las tortas es del 25%. Con base en la
anterior información desarrolle un modelo de simulación para obtener la siguiente información: a) Número medio de tortas no vendidas b) Número medio de tortas que hay que botar c) Utilidad media por día d) Si el permiso para tirar las tortas al basurero cuesta $20,000 por semana, conviene conseguir el
permiso o seguir tirando las tortas?
1.3 Considere el problema No 4.25. Desarrolle un modelo de simulación. Escriba el seudocódigo o un diagrama de flujo, detallando las diferentes actividades. No haga la simulación.
1.4 Considere el problema No 4.26. Desarrolle un modelo de simulación. Escriba el seudocódigo o un diagrama de flujo, detallando las diferentes actividades. No haga la simulación.
1.5 Considere el problema No 4.27. Desarrolle un modelo de simulación. Escriba el seudocódigo o un diagrama de flujo, detallando las diferentes actividades. No haga la simulación
1.6 Considere el problema No 4.28. Desarrolle un modelo de simulación. Escriba el seudocódigo o un diagrama de flujo, detallando las diferentes actividades. No haga la simulación
1.7 Modifique el seudocódigo y el programa de la tienda del video para tener en cuenta el hecho de que solamente un 80% de los clientes que tienen cintas alquiladas las entregan el respectivo día y el resto no lo hace. Además, suponga que cada cliente que no entrega la cinta a tiempo, tiene que pagar una multa de $2000 por cada día de retraso.
1.8 Modifique el diagrama de flujo y el programa del juego de la moneda para analizar el mismo juego de la moneda con las siguientes modificaciones: El juego termina cuando la diferencia entre caras y sellos sea 3 ó cuando el número de lanzamientos realizados sea 15.
1.9 Desarrolle un diagrama de flujo descriptivo, un diagrama de flujo detallado y el programa de computador para realizar el siguiente juego: El juego requiere que el jugador tire dos dados una o más veces hasta que se alcance la decisión de ganar o perder. Se gana si el primer lanzamiento de los dos dados resulta un una suma de 7 u 11, o alternativamente, si la primera suma es 4, 5, 6, 8, 9 ó 10 y la misma suma reaparece antes de que aparezca una suma de 7. Se pierde si el primer lanzamiento resulta en una suma de 2, 3 ó 12, o alternativamente, si la primera suma es 4, 5, 6, 8, 9 ó 10 y una suma de 7 aparece antes de que reaparezca la primera suma. Desarrolle el programa para determinar la probabilidad de ganar y para determinar la distribución del número de lanzamientos requeridos para terminar el juego. Además el programa debe indicar la probabilidad de ganar cada 50 juegos. Simule 500 juegos.

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 30
Indicaciones para el problema No 1.9
a) La probabilidad de ganar está dada por el número de juegos ganados, dividido por el número de
juegos realizados.
b) La probabilidad de que en un dado aparezca un resultado cualquiera (1, 2, 3, 4, 5 ó 6) es un sexto
(1/6). Para simular el lanzamiento de un dado se genera un número aleatorio R, 0 R < 1 y los valores entre 0 y 1 deben repartirse por igual para los seis posibles resultados. Una forma de averiguar el resultado obtenido al lanzar el dado es la siguiente:
Si R < 1/6 el resultado es 1 Si 1/6 R < 2/6 el resultado es 2
Si 2/6 R < 3/6 el resultado es 3 Si 3/6 R < 4/6 el resultado es 4
Si 4/6 R < 5/6 el resultado es 5 Si 5/6 R < 1 el resultado es 6
Otra forma de obtener el resultado es tomar la parte entera de la siguiente expresión: X = [ 6 x R + 1] c) Aunque el juego consiste en lanzar los dos dados al mismo tiempo, en la Simulación el
lanzamiento de los dos dados se hace en forma secuencial: Primero se lanza uno (se genera R y se averigua el resultado), después se lanza el otro (se genera R y se averigua el resultado) y luego se suman estos dos resultados.
1.10 Un repartidor compra periódicos en paquetes de veinte a dos pesos cada uno y los vende a tres pesos. Los periódicos no vendidos carecen de valor. Al analizar las ventas del pasado se descubre que existen tres distribuciones de la demanda, dependiendo de las noticias que figuran en el periódico. Un día de “Buenas” noticias da como resultado encabezados interesantes para muchos clientes potenciales; los días “normales” y “malos” tienen encabezados de menor interés. Históricamente, el 20% de los días han sido buenos, el 50% “normales” y el 30% “malos”. Las distribuciones de la demanda se resumen a continuación:
Demanda diaria Tipo de día, según las noticias Malo Normal Bueno
40 0.05 50 0.20 0.03 60 0.41 0.07 70 0.26 0.28 80 0.08 0.30 0.02 90 0.25 0.15
100 0.07 0.28 110 0.24 120 0.12 130 0.09 140 0.06 150 0.04
Determine la cantidad que debe pedirse.
1.11 Una empresa de alquiler de autos está tratando de determinar el número óptimo de autos a comprar. El costo promedio anual de un auto es de $ 11 000 000. Además, esta compañía ha recopilado las siguientes estadísticas sobre las operaciones de carros :
Número de autos alquilados por día 0 1 2 3 4
Probabilidad 0.10 0.10 0.25 0.30 0.25
Número de días rentados por auto 1 2 3 4
Probabilidad 0.40 0.35 0.15 0.10
Si la renta diaria por auto es de $52 000, el costo de no tener un auto disponible cuando se lo solicita es de
$30 000, y el costo de tener un carro ocioso durante un día es de $7 500, cuantos autos deberá comprar la compañía ?. Suponga que un auto que se alquila por un día está disponible al día siguiente.

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 31
1.12 Un vendedor de revistas compra mensualmente una revista el día primero de cada mes. El costo de cada ejemplar es $6 000. La demanda de esta revista en los primeros diez días del mes tiene la distribución de probabilidad dada a continuación:
Demanda 5 6 7 8 9 10 11
Probabilidad 0.05 0.05 0.10 0.15 0.25 0.25 0.15
Al final del décimo día, el vendedor puede regresar cualquier cantidad de revistas al proveedor, quien se
las pagará a 3 600 el ejemplar, o puede comprar mas revistas a un costo de $4 800 el ejemplar. La demanda en los siguientes 20 días está dada por la siguiente distribución de probabilidad:
Demanda 4 5 6 7 8
Probabilidad 0.15 0.20 0.30 0.20 0.15
Al final del mes, el vendedor puede regresar al proveedor las revistas que le sobren, las cuales se le
pagarán a $3 600 el ejemplar. Finalmente, se supone que después de un mes ya no existe demanda por parte del público, puesto que para ese entonces ya habrá aparecido el nuevo ejemplar. Si el precio al público de la revista es $ 8 000 por ejemplar, determine la política óptima de compra.
1.13 Debido a un aumento en las ventas, cierta compañía productora necesita mas espacio en su fábrica. La solución que se ha propuesto es la construcción de un nuevo depósito para almacenar los productos terminados. Este depósito estará localizado a 35 kilómetros de la planta. Además, de acuerdo con este nuevo plan, se requiere que al final del día se envíe la producción terminada al nuevo depósito.
Por otra parte, con base en información histórica, se ha estimado que la producción diaria de la empresa
tiene la siguiente distribución de probabilidad:
Producción diaria (toneladas) 50 - 55 55 - 60 60 – 65 65 - 70 70 - 75 75 - 80
Probabilidad 0.10 0.15 0.30 0.35 0.08 0.02
También se sabe que el tipo de camiones que se deben utilizar para transportar esta producción tienen
capacidad de 5 toneladas. La cantidad de viajes que se pueden realizar cada día (jornada de 8 horas), depende del tiempo de carga y descarga, como también del tiempo que se requiere para recorrer la distancia entre la planta y el depósito. Por lo tanto, la cantidad de producto terminado que un camión puede transportar de la planta al depósito, es una variable aleatoria cuya distribución de probabilidad es la siguiente:
Toneladas diarias transportadas/camión
4.0 –4.5 4.5 – 5.0 5.0 –5.5 5.5 – 6.0
Probabilidad 0.30 0.40 0.20 0.10
Si la cantidad diaria producida es mayor que la cantidad que puede transportar la flotilla de camiones, el
excedente debe ser enviado a través de camiones de otra compañía transportadora a un costo de $20 000 la tonelada. Además el costo promedio anual de un camión nuevo es de $ 20 000 000. Si se trabajan 250 días al año, cual es el número óptimo de camiones que la empresa debe comprar?

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 32
APÉNDICE
Juego de la moneda. Listado del programa en QBASIC
Principales variables:
lanza: Número de lanzamientos que se hicieron en un juego LMIN: Número mínimo de lanzamientos por juego LMAX: Número máximo de lanzamientos por juego SUMAL: Número acumulado de lanzamientos SUMAL2: Suma del cuadrado del número de lanzamientos por juego DESVL: Desviación del número de lanzamientos por juego LANZAME: Número medio de lanzamientos por juego nveces(i): Número de veces que el juego termina en I lanzamientos. REM PROGRAMA MONEDA REM OPEN "salidam.txt" FOR OUTPUT AS #4 DIM NVECES(30) PRINT "Numero de juegos" INPUT nro.juegos PRINT "Entre la probabilidad de cara" INPUT prob.cara PRINT "Entre la semilla, un numero impar" INPUT semilla PRINT "Numero de intervalos para la distribucion del numero de lanzamientos" INPUT nro.interv REM RANDOMIZE semilla delta = 2 lanza0 = 3 l = 0 REM Inicializacion de contadores para recoger estadisticas sumau = 0 sumau2 = 0 umin = 0 umax = 0 sumal = 0 sumal2 = 0 lmin = 100 lmax = 0 REM FOR inter = 1 TO nro.interv nveces(inter) = 0 NEXT inter REM REM Realizacion de los juegos REM FOR juego = 1 TO nro.juegos REM Inicialización de los juegos caras = 0 sellos = 0 WHILE (ABS(CARAS - SELLOS) <> 3) REM Lanzamiento de la moneda R = RND REM Investigación del resultado IF (R < prob.cara) THEN caras = caras + 1 ELSE sellos = sellos + 1 END IF

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 33
WEND REM Fin juego REM Si se termina el juego, se actualizan las estadisticas lanza = caras + sellos util = 8 - lanza REM Estadisticas globales sobre la utilidad sumau = sumau + UTIL sumau2 = sumau2 + util ^ 2 IF (util < umin) THEN umin = util END IF IF (util > umax) THEN umax = util END IF REM Estadisticas globales sobre el numero de lanzamientos sumal = sumal + lanza sumal2 = sumal2 + lanza ^ 2 IF (lanza < lmin) THEN lmin = lanza END IF IF (lanza > lmax) THEN lmax = lanza END IF REM REM Distribucion del Numero de lanzamientos REM inter = INT((lanza - lanza0) / delta + 1.999) IF (inter < 1) THEN inter = 1 END IF IF (inter > nro.interv) THEN inter = nro.interv END IF nveces(inter) = nveces(inter) + 1 NEXT juego REM Fin de simulacion REM PRINT #4, "Problema del juego de la moneda. Informe final de la simuacion" PRINT #4, " " PRINT #4, "Semilla = "; semilla PRINT #4, "numero de juegos = "; nro.juegos REM Resumen e impresion de resultados REM umedia = sumau / nro.juegos desvu = SQR((sumau2 - umedia * umedia * nro.juegos) / (nro.juegos - 1)) PRINT #4, "Utilidad media = "; umedia PRINT #4, "Desviacion estandar de la utilidad = "; desvu PRINT #4, "Utilidad minima = "; umin PRINT #4, "Utilidad maxima = "; umax IF (UMEDIA > 0) THEN PRINT #4, "El juego es favorable" ELSE PRINT #4, "El juego es desfavorable" END IF REM lanzame = sumal / nro.juegos desvl = SQR((sumal2 - lanzame * lanzame * nro.juegos) / (nro.juegos - 1)) PRINT #4, "Numero medio de lanzamientos = "; lanzame PRINT #4, "Desviacion estandar de la utilidad = "; desvl

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 34
PRINT #4, "Numero minimo de lanzamientos = "; lmin PRINT #4, "Numero maximo de lanzamientos = "; lmax ACUM = 0 PRINT #4, " " PRINT #4, "DISTRIBUCION DEL NUMERO DE LANZAMIENTOS DE LA MONEDA" PRINT #4, " " PRINT #4, " INTERVALO NUMERO DE FRECUENCIA FRECUENCIA FRECUENCIA" PRINT #4, " NUMERO LANZAMIENTOS ABSOLUTA RELATIVA REL.ACUM." PRINT #4, " " FOR inter = 1 TO nro.interv P = 100! * nveces(inter) / nro.juegos acum = acum + p interv = lanza0 + (inter - 1) * DELTA PRINT #4, inter, interv, nveces(inter), P, ACUM NEXT inter CLOSE #4 END

B. Calderón. Introducción a la Simulación. Cap 1. “Simulación. Aplicabilidad”. 1 - 35
Problema del juego de la moneda. Informe final de la simulación (otros resultados) Semilla = 727 727 numero de juegos = 10000 1000 Utilidad media = -.9978 -0.972 Desviacion estandar de la utilidad = 6.997978 7.0439 Utilidad minima = -59 -59 Utilidad maxima = 5 5 El juego es desfavorable Numero medio de lanzamientos = 8.9978 8.972 Desviacion estandar de la utilidad = 6.997978 7.0439 Numero minimo de lanzamientos = 3 3 Numero maximo de lanzamientos = 67 67 DISTRIBUCION DEL NUMERO DE LANZAMIENTOS DE LA MONEDA INTERVALO NUMERO DE FRECUENCIA FRECUENCIA FRECUENCIA NUMERO LANZAMIENTOS ABSOLUTA RELATIVA REL.ACUM.
1 3 2534 25.34 25.34 (25.7) 2 5 1803 18.03 43.37 (18.0)
Los valores entre paréntesis corresponden a la frecuencia relativa de la simulación de 1000 juegos

Introducción a la simulación Métodos de búsqueda
En simulación no es posible emplear los métodos clásicos de optimización, ya que todos los resultados que se producen en la simulación son numéricos, y no se emplean fórmulas o métodos analíticos. Para encontrar un valor óptimo en simulación se usan los “métodos de
búsqueda”, que aunque no usan los principios de los métodos analíticos, sí usan los criterios básicos de optimización de éstos. Por lo tanto, inicialmente se presentará un breve resumen de los métodos clásicos de optimización, y sus principios básicos, 1. Métodos clásicos de optimización
1.1. Definición del problema El objetivo es encontrar el valor x* que optimice (minimice o maximice) el valor de una función f(x). Cuando se habla de optimización, se puede tratar de un problema de minimización o de
maximización. La variable de decisión x se puede referir o a una variable simple, o a un conjunto de varias
variables (un vector). Inicialmente se presentará un resumen de los métodos clásicos de optimización para una variable, y posteriormente para el caso de dos variables. 1.2. Métodos clásicos de optimización para una variable Se desea encontrar el valor óptimo x* de una función continua, con primera y segunda derivadas
Condición necesaria. La condición necesaria para encontrar tanto un punto de mínimo como uno de máximo es que la primera derivada sea cero en dicho punto. Por lo tanto, se encuentra la primera derivada de la función, se iguala a cero y se despeja el valor correspondiente de x, el cual se denotará por x*.
*0)(
xxdx
xdf
Condición suficiente Usando la primera derivada se encuentra un valor de la variable de decisión, que como ya se indicó puede corresponder tanto a un punto de mínimo como de máximo. Si la primera derivada corresponde a un punto de mínimo, entonces a partir de dicho valor la función debe empezar a crecer de nuevo, es decir, la segunda derivada, evaluada en el punto de óptimo, debe ser mayor
de cero. Si la primera derivada corresponde a un punto de máxima, entonces a partir de dicho valor la función debe empezar a disminuir, por lo tanto la segunda derivada, evaluada en el punto de óptimo, debe ser menor de cero. Matemáticamente se tiene que:
imizarparadx
xfd
imizarparadx
xfd
xx
xx
min0|)(
max0|)(
*2
2
*2
2
Ejemplo 1: Un sistema de inventarios
Considere el modelo clásico de inventarios, cuyo costo está dado por la siguiente expresión:

Bernardo A. Calderón C. “Métodos de búsqueda” 2
2)(
Qc
Q
ADQCT m
donde A representa el costo adquisición o de efectuar un pedido, D es la tasa anual de demanda, Q es el tamaño del lote (variable de decisión) y Cm representa el costo de mantener una unidad en inventario por unidad de tiempo (año). Se sabe que: A = $2000/pedido, D = 2400 unidades/año, Cm = $150/unidad-año. Se desea encontrar la cantidad óptima que se debe pedir.
Derivando con respecto a Q, obtenemos que (condición necesaria):
mm
m
c
ADQ
Q
Q
ADC
Q
AD
sQ
QdCTc
2*
20
20
)(2
Realizando la segunda derivada y evaluándola en el punto de óptima se comprueba que la
solución hallada anteriormente corresponde efectivamente a un punto de mínimo.
0Q
AD2
Q
)Q(CTquetienese*QQPara.0
Q
)Q(CT32
2
*QQ2
2
dd
Reemplazando el valor óptimo de Q en la función de costos, se obtiene la siguiente expresión que refleja el costo mínimo.
mADcQCT 2*)(
Para A = $2000/pedido, D = 2400 unidades/año, Cm = $150/unidad-año, se tiene
33.37947)15)(2400)(2000(2)253(,25398.252150
)2400)(2000(2*
CTAD
Q
1.3. Caso discreto (minimización) Si se desea encontrar el valor óptimo x* de una variable discreta, que varía en intervalos de ,
las dos condiciones anteriores se resumen en la siguiente:
Si x* es el valor óptimo (caso minimización), es decir, el valor que minimiza la función, entonces f(x*) debe ser menor que cualquier otro valor de x. Más específicamente, en el punto óptimo se cumple que:
f(x*) f(x*- ), y
f(x*) f(x*+ )
ya que, por definición f(x*) es el óptimo (mínimo).
Para el caso de maximización las condiciones son:
f(x*) f(x*- ) y f(x*) f(x*+ )
Ejemplo 2. Determinar el punto óptimo de la siguiente función: Minimizar f(x) = x4 + x2 – 4x, donde x = 0, 0.2, 0.4, 0.6,…
Solución: La tabla presenta la evaluación de f(x) para varios valores de x, empezando en 0, y variando de a 0.2

Bernardo A. Calderón C. “Métodos de búsqueda” 3
X 0 0.2 0.4 0.6 0.8 1.0
f(x) 0 -0.7584 -1.4144 -1.9104 -2.1504 -2.0
Como se observa, el punto mínimo corresponde a x* = 0.8, con un valor de la función de -2.1504. En algunos casos es posible calcular el rango en que se encuentra el óptimo, sin necesidad de evaluar otros puntos, pero en otros casos es necesario realizar varios cálculos y verificar cuando
se cumplen las condiciones de optimalidad (como en el presente ejemplo). Ejemplo 3. Considere de nuevo el sistema de inventarios analizado previamente. Suponga que la cantidad a pedir sólo puede variar de a “u” unidades, es decir, la cantidad que se pide debe ser múltiplo de u. Determine cual debe ser el tamaño del lote óptimo a pedir. Solución. Como ya se indicó, si Q* es la cantidad óptima que se debe pedir, y CT(Q) es el costo
de ordenar Q unidades, entonces se debe cumplir que:
CT(Q*) CT(Q* - u) (1)
y CT(Q*) CT(Q* + u) (2)
Reemplazando la función de costos dada anteriormente en la ecuación (1) se tiene que:
2
)*(
*2
*
*
uQc
uQ
ADQc
Q
AD mm
:
1.4. Métodos clásicos de optimización para dos variables El objetivo es encontrar el valor x* que optimice (minimice o maximice) el valor de una función
f(x). Cuando se habla de optimización, se puede tratar de un problema de minimización o de maximización.
La variable de decisión x se refiere en este caso a un conjunto de dos variables de decisión x1 y x2. En este caso el problema es encontrar los valores de x1 y x2 que optimicen la función f(x1,x2), que supondremos que es una función continua, con primera y segunda derivadas.
Condiciones necesarias La condición necesaria para encontrar tanto un punto de mínimo como uno de máximo es que la primera derivada parcial con respecto a las variables x1 y x2 sea cero en el punto óptimo. Por lo tanto, se debe encontrar la primera derivada de la función con respecto a cada una de las variables de decisión, se igualan a cero las derivadas y se despejan los valores correspondientes
de cada variable de decisión, denotadas por *
2
*
1 xyx .
0),(
0),(
2
21
1
21
dx
xxdf
dx
xxdf
Se resuelve el sistema de dos ecuaciones y dos variables para encontrar los valores óptimos *
2
*
1 xyx

Bernardo A. Calderón C. “Métodos de búsqueda” 4
Condiciones suficientes Usando las primeras derivadas parciales se encuentran los dos valores de las variables de decisión, que pueden corresponder tanto a un punto de mínimo como de máximo. Para saber si los valores encontrados para las variables de decisión corresponden a un mínimo o a un máximo, se deben evaluar las segundas derivadas con respecto a cada variable de decisión y
con respecto a ambas variables, y la condición suficiente está dada por:
imizarparadxdx
xxfd
dx
xxfd
dx
xxfd
imizarparadxdx
xxfd
dx
xxfd
dx
xxfd
min0),(),(),(
max0),(),(),(
2
22
21
2
2
2
21
2
2
1
21
2
2
22
21
2
2
2
21
2
2
1
21
2
Ejemplo: Comprobar que el punto (x1,x2) = (-2, 3) corresponde a un mínimo global de la función
20682),( 21
2
2
2
121 xxxxxxf
2. Métodos de Búsqueda Cuando no se tiene una expresión analítica a la cual se le puedan aplicar los criterios definidos previamente, o una vez aplicados sea difícil encontrar la solución apropiada, o cuando los resultados se obtienen numéricamente, como en el caso de la simulación, es necesario usar otro
método de optimización. En este caso se emplean los “métodos de búsqueda”. El principio básico de estos métodos se basa en los conceptos empleados para la optimización en el caso discreto: Si x es la variable de decisión, se ensayan diferentes valores x0, x1, x2,…,xk, siguiendo un orden o dirección predeterminada, hasta que se cumpla el criterio de optimalidad. Si el punto óptimo no se encuentra en la dirección inicialmente asignada, se invierte la dirección de búsqueda, y se aplica de nuevo el proceso de búsqueda hasta encontrar los valores que cumplan con el criterio
de optimización. La búsqueda se suspende cuando se ha pasado por el punto óptimo. El valor x* es el “mejor” valor si f(x*) es mejor que f(x* - ) y mejor que f(x* + ).
En los métodos de búsqueda no se garantiza que llega a la solución óptima, pero sí que se logra acercar al valor óptimo dentro de cierto grado de precisión. La efectividad de un método de búsqueda depende de si se tiene una idea sobre el rango en que se encuentra el valor óptimo, o no se tiene ninguna idea a priori y la búsqueda se debe realizar dentro de un ambiente de incertidumbre, en un rango muy amplio o desconocido. Según lo
anterior, los métodos de búsqueda inicialmente se clasifican en “búsqueda en un rango no restringido” y “búsqueda en un rango restringido”. En los métodos de búsqueda, siempre se hace uso de la información que se ha ido recogiendo, bien sea para direccionar la búsqueda, o para definir los puntos iniciales de la misma.
Suposición: Unimodalidad. Se supone que la función es unimodal, es decir, que solo tiene un
punto de mínimo o un punto de máximo, según sea la función objetivo. Si se sabe o se sospecha que la función a optimizar tiene varios puntos de máxima (mínima), se deben realizar varios procesos de búsqueda, empezando cada uno con valores diferentes entre sí, ubicados lo más distantes posibles, de tal forma que se logren detectar los valores semi óptimos, y se escoja entre estos el verdadero punto óptimo.

Bernardo A. Calderón C. “Métodos de búsqueda” 5
2.1. Búsqueda en un rango no restringido (- < x* < +, x > 0)
En este caso no se tiene idea, a priori, del rango en que se encuentra el valor óptimo. Entonces, para iniciar el proceso de búsqueda, se debe definir un origen o punto de partida, una dirección de búsqueda, el tamaño del paso que se debe dar, se evalúan los valores de la variable de decisión y se suspende la búsqueda cuando se cumpla el criterio de optimización. El proceso de búsqueda se puede realizar o con un paso constante o con un paso acelerado. Si se tiene alguna
idea de que tan cerca esté el valor inicial del punto óptimo, se podría usar un método con paso constante, si no se tiene idea, se podría usar el método con el paso acelerado. 2.1.1. Búsqueda con paso constante El procedimiento a seguir, para el caso de minimización, es el siguiente:
1. Se define el punto inicial de la búsqueda x0. 2. Se define el tamaño del paso () o el incremento para los valores de x:
3. Se define la dirección inicial de búsqueda. Por lo general, se inicia hacia la derecha (+). 4. Se evalúa la función f(x) en los valores
x = x0 se evalúa f(x0)
x = x1 = x0 + se evalúa f(x1)
4.1. Si f(x1) < f(x0) (es decir, la función responde) se evalúa la función en: x2 = x1 +
x3 = x2 +
………………… xk = xk-1 +
donde en xk la función no responde, es decir, f(xk) > f(xk-1). La solución óptima x* se encuentra entre xk-2 y xk, en un intervalo de tamaño 2, y la “mejor”
solución esxk-1. Se dice que la solución óptima x* se encuentra entre xk-2 y xk, y no entre xk-2 y xk-1, o entre xk-1 y xk, ya que no se sabe si el punto xk-1 queda a la derecha o a la izquierda del punto óptimo.
En resumen: xk-2 <x* < xk, “mejor solución” = xk-1, tamaño del intervalo = 2
4.2. Si f(x1) > f(x0) (es decir, la función no responde) se evalúa la función en:
0
'
1 xxx se evalúa f(x0)
Si )()( 0
'
1 xfxf (la función responde) entonces se evalúa la función en:
'
1
'
'
2
'
3
'
1
'
2
................
kk xx
xx
xx
X’3 = x’2 +
donde en '
kx la función no responde, es decir, )()( '
1
'
kk xfxf .
La solución óptima x* se encuentra entre '
2
'
kk xyx en un intervalo de tamaño 2, y la “mejor”
solución es'
1kx .

Bernardo A. Calderón C. “Métodos de búsqueda” 6
4.3. Si )()( 0
'
1 xfxf (la función tampoco responde en x0 - ), entonces la solución óptima se
encuentra entre x0 - y x0 + , en un intervalo de tamaño 2, y la “mejor” solución es el
punto inicial x0. Ejemplo: Se desea minimizar la función f(x) = (50 – x)2, para x>0, usando un valor inicial de 0, y un paso de 3.
Solución: La tabla siguiente presenta los resultados del proceso de búsqueda
Ensayo x f(x) Mejora?
1 0 2500 -
2 3 2209 Sí
3 6 1936 Sí
4 9 1681 Sí
……….. …. …… ……
16 45 25 Sí
17 48 4 Sí
18 51 1 Sí
19 54 16 No
La solución óptima se encuentra entre 48 y 54, con un rango de 6, y el mejor punto es 51.
Mejora de la solución Como ya se mencionó, los métodos de búsqueda no garantizan que se llegue a la solución óptima, como puede apreciarse en el ejemplo anterior, pero sí que se encuentre un buen estimativo de la misma, y dentro de un rango determinado. Si queremos mejorar la solución encontrada, se debe tratar de reducir el margen de error (2), o usar otro método más eficiente,
ahora que ya se sabe en que rango se encuentra el óptimo. Por lo tanto debemos definir cual
será el proceso a seguir: si se suspende la búsqueda y se usa la mejor solución hallada, o si se reanuda o refina el proceso de búsqueda.
Las alternativas a seguir podrían ser: 1) Si se considera que el valor óptimo se encuentra dentro de un rango con una precisión
aceptable, se suspende la búsqueda, y se usa como solución el “mejor” valor encontrado
hasta el momento. 2) Se reanuda la búsqueda, usando el mismo método, pero con un paso () menor. Se usa
como valor inicial el mejor valor encontrado hasta el momento (x0 = xk-1). 3) Se reanuda la búsqueda pero usando un método de búsqueda de rango finito, ya que ahora
se sabe en que rango se encuentra la solución óptima (xk-2 <x* < xk). 4) Se puede ajustar una ecuación cuadrática que pase por los tres últimos valores ensayados
(xk-2, xk-1, xk), y luego encontrar la solución óptima de una forma analítica.
y = f(x) = a + b x + cx2 Ejemplo. Retome el ejercicio anterior -minimizar la función f(x) = (50 – x)2-, usando el mismo método, pero con un paso igual a un décimo del paso anterior, es decir, = 0.3.
Usando el nuevo paso = 0.3 y como solución inicial el mejor valor conocido hasta el momento
(51), se obtienen los resultados presentados en la siguiente tabla.
Ensayo x f(x) Mejora?
1 51 1 -
2 51.3 1.69 No
3 50.7 0.49 Sí

Bernardo A. Calderón C. “Métodos de búsqueda” 7
4 50.4 0.16 Sí
5 50.1 0.01 Sí
6 49.8 0.04 No
La solución óptima se encuentra entre 49.8 y 50.4, con un rango de 0.6, y el mejor punto es 50.1. Algoritmo computacional
El siguiente algoritmo indica un forma como podría implementarse el método de búsqueda con paso constante en un programa de simulación. Al implementar el método de búsqueda debe tenerse presente que: Si se empieza el proceso de búsqueda a la izquierda del óptimo, entonces cuando la
solución no mejore es porque se han realizado más de dos ensayos, y en este caso, se habrá pasado ya por el punto óptimo.
Si la búsqueda se inicia a la derecha del punto óptimo, entonces en el segundo ensayo la solución no mejorará, y será necesario cambiar la dirección de búsqueda, ensayando valores a la izquierda del valor inicial, hasta que la solución no mejore, lo cual indica que ya se ha pasado por el punto óptimo. En este caso se habrán realizado más de dos ensayos.
Si el proceso de búsqueda se inicia en el mejor punto, en el segundo ensayo la solución no mejorará, y por lo tanto se debe cambiar la dirección de la búsqueda, y en el tercer intento tampoco mejorará, lo cual indica que ya se ha pasado por el punto óptimo (se han hecho más de dos ensayos).
Para saber si ya se ha pasado por el punto óptimo, se usará una variable denominada “bandera” (variable dicótoma), que toma el valor de cero cuando aún no se haya pasado por el puno
óptimo, y tomará el valor de uno (“1”) cuando ya se haya pasado por el punto óptimo. En el algoritmo se supone que se trata de un proceso de minimización.
Inicio proceso de búsqueda Leer Valor inicial (X0) y el paso (x)
Número_ensayos = 0 Costo_minimo = 0 // Se inicializa el proceso de optimización X = X0
Bandera = 0 // Indica que aún no ha pasado por el óptimo Mientras bandera = 0
Número_ensayos = Número_ensayos +1 Evaluar la función (algoritmo de simulación, incluyendo el “costo”) Imprimir Número_ensayos, x, costo Si costo < costo_minimo, entonces // La función mejora Costo_minimo = costo
X_optimo = x X = x + x
Si no // La función no mejora Si Número_ensayos = 2, entonces // Se empezó la búsqueda a la derecha del óptimo x = x0 - x
x = - x // Se cambia dirección de búsqueda
Si no // Ya se pasó por el punto óptimo Bandera = 1 Fin si
Fin si Fin mientras Imprimir “Solución optima”: Número_ensayos, x_optimo, costo_minimo
Fin proceso

Bernardo A. Calderón C. “Métodos de búsqueda” 8
En la instrucción que dice “Evaluar la función (algoritmo de simulación, incluyendo el “costo”)” debe ir el algoritmo de simulación respectivo, con todas las simulaciones, y con el cálculo de la función objetivo, o criterio de evaluación, correspondiente a lo que en el algoritmo se denomina el “costo”.
2.2. Búsqueda con paso acelerado Cuando se usa el método de búsqueda con paso finito, y no se tiene idea de la localización del valor óptimo, puede suceder que el proceso se inicie en un valor inicial muy alejado del punto óptimo, o que el paso elegido para el proceso sea muy pequeño (o ambos). En estos casos el proceso de búsqueda es lento y demorado (y costoso), ya que se deben realizar muchos ensayos
antes de encontrar el rango en el cual se encuentra la solución optima. Para obviar el problema anterior, y llegar rápidamente a un rango para la solución óptima, existe una variación al método anterior, modificando el tamaño del paso: Cada vez que la función mejora con una nueva solución, se duplica el tamaño del paso usado en el proceso de búsqueda. De esta manera
se llega rápidamente a delimitar el valor de la solución óptima, lo cual permitirá refinar posteriormente el proceso de búsqueda.
El procedimiento a seguir es el siguiente (caso minimización): 1. Se evalúa la función f(x) en los valores
x = x0 se evalúa f(x0)
x = x1 = x0 + se evalúa f(x1)
Si f(x1) < f(x0) (la función responde) se evalúa la función en: x2 = x1 + 2
x3 = x2 + 4
………………… xk = xk-1 + 2k-1
donde en xk la función no responde, es decir, f(xk) > f(xk-1). La solución óptima x* se encuentra entre xk-2 y xk, en un intervalo de tamaño 2k-2 + 2k-1, y de
nuevo la “mejor” solución es xk-1. En resumen:
xk-2 <x* < xk, “mejor solución” = xk-1, tamaño del intervalo = 2k-2 + 2k-1
2. Si f(x1) > f(x0) (la función no responde) se evalúa la función en:
0
'
1 xxx se evalúa f(x’0)
Si )()( 0
'
1 xfxf (la función responde) se evalúa la función en:
1'
1
'
'
2
'
3
'
1
'
2
2
................
4
2
k
kk xx
xx
xx
donde en '
kx la función no responde, es decir, )()( '
1
'
kk xfxf .
La solución óptima x* se encuentra entre '
2
'
kk xyx en un intervalo de tamaño 2, y la “mejor”
solución es'
1kx .

Bernardo A. Calderón C. “Métodos de búsqueda” 9
3. Si )()( 0
'
1 xfxf (la función tampoco responde en x0 - ), la solución óptima se encuentra
entre x0 - y x0 + , en un intervalo de tamaño 2, y la “mejor” solución es el punto inicial
x0. Usando el proceso con paso acelerado, se llega rápidamente al rango en el cual se encuentra la solución óptima, pero este rango es por lo general bastante amplio, por lo cual generalmente se
debe refinar el proceso de optimización, para reducir dicho rango. Las alternativas a considerar incluyen las siguientes: 1) Se reanuda la búsqueda, usando el mismo método, con paso acelerado y como valor inicial
el mejor valor encontrado hasta el momento (x0 = xk-1). 2) Se reanuda la búsqueda, usando paso constante, con el mismo paso o uno menor,
dependiendo de que tan grande es el rango del óptimo. Se usa como valor inicial el mejor valor encontrado hasta el momento (x0 = xk-1).
3) Se reanuda la búsqueda usando un método de búsqueda de rango finito, ya que ahora se sabe en que rango se encuentra la solución óptima (xk-2 <x* < xk).
Ejemplo: Se desea minimizar la función f(x) = (50 – x)2, para x>0, usando paso acelerado con
un valor inicial de 0, y un paso de 3. Solución: La tabla siguiente presenta los resultados del proceso de búsqueda
Ensayo X f(x) Mejora? Nuevo paso
1 0 2500 - 3
2 3 2209 Sí 6
3 9 1681 Sí 12
4 21 841 Sí 24
5 45 25 Sí 48
6 93 1849 No
La solución óptima se encuentra entre 21 y 93, con un rango de 72, y el mejor punto es 45. Reiniciando el proceso con paso acelerado, con un paso inicial de 3 y un valor inicial de 45, se obtienen los siguientes resultados:
Ensayo X f(x) Mejora? Nuevo paso
1 45 25 - 3
2 48 4 Sí 6
3 54 16 No
La solución óptima se encuentra entre 45 y 54, con un rango de 9, y el mejor punto es 48. Dado el nuevo rango con una amplitud de 9, no tiene sentido usar ni paso acelerado con un paso inicial de 3, ni paso constante con un paso inicial de 3.
Ejemplo
Considere el siguiente modelo clásico de inventarios, cuyo costo está dado por la siguiente expresión:
2)(
Q
Q
ADQCT
Cm
donde A representa el costo adquisición o de efectuar un pedido, D es la tasa anual de demanda, Q es el tamaño del lote (variable de decisión) y Cm representa el costo de mantener una unidad
en inventario por unidad de tiempo (año). Se sabe que: A = $2000/pedido, D = 2400

Bernardo A. Calderón C. “Métodos de búsqueda” 10
unidades/año, Cm = $150/unidad-año. Se desea encontrar, con un error máximo de tres unidades, la cantidad óptima que se debe pedir. Use inicialmente un método de búsqueda en rango no restringido, y posteriormente el método elegido por Usted, usando los parámetros iniciales indicados a continuación:
Alternativa 1 2 3 4 5 6 7
Valor inicial de Q 15 20 25 30 35 40 30
Paso = Q 20 20 22 20 15 18 22
2.3. Búsqueda en un rango restringido (a < x* < b)
Una vez que se ha delimitado el rango de búsqueda a valores finitos, o si la función a optimizar tiene inicialmente un rango finito de variación a < x < b), se pueden utilizar otros métodos de búsqueda más eficientes. Usando estos métodos se puede calcular de antemano cuál sería el número de ensayos requeridos para obtener una precisión dada en la búsqueda del valor óptimo.
Existen diferentes métodos de búsqueda en rango restringido. En algunos de estos métodos se define de antemano el número máximo de experimentos a realizar, y luego se realizan los diferentes ensayos a intervalos regularmente espaciados. En otros métodos simplemente se define la precisión requerida para estimar el punto óptimo, y luego se realizan los diferentes ensayos hasta obtener la precisión requerida. Uno de estos métodos, es el de Fibonacci. 2.3.1. Búsqueda binaria. Principio general
En este método se ensayan dos valores alrededor del punto medio del intervalo de búsqueda, y dependiendo de los resultados se escoge un nuevo rango de búsqueda, que será siempre la mitad del rango anterior de búsqueda. Este procedimiento se repite hasta que el rango de búsqueda sea menor o igual a la precisión requerida. El procedimiento se puede expresar de la siguiente manera, para el caso de minimización:
a) Se evalúa la función en los valores
2
baxy
2
bax 21
b) Si f(x1) < f(x2) entonces el nuevo rango de búsqueda corresponde a la primera mitad del rango actual, es decir va desde el valor mínimo actual hasta el punto medio, y si f(x1) >
f(x2) entonces el nuevo rango de búsqueda corresponde a la segunda mitad del rango actual, es decir va desde el punto medio hasta el valor máximo. Simbólicamente tenemos que
bb,2
baa)x(f)x(fSi
2
bab,aa)x(f)x(fSi
21
21
c) El procedimiento anterior se repite tantas veces cuantas sea necesario hasta que el nuevo rango de búsqueda sea menor o igual a la precisión requerida , es decir, (b-a) ≤ .
El valor de debe ser tal que los valores a ensayar en el último intento estén dentro del rango
de búsqueda, es decir, ≤ /2. La mejor solución (solución óptima) corresponde al punto medio
del último intervalo. 2.3.2. Número de ensayos a realizar Después de realizado el primer ensayo (donde cada ensayo implica la evaluación de dos valores de la función objetivo) es (b – a)/2. El rango en el cual se encuentra la solución óptima después
de realizado cada ensayo, con relación al rango inicial está dado por:

Bernardo A. Calderón C. “Métodos de búsqueda” 11
Ensayo 1 Rango = L1 = L0/2 = (b – a)/2
Ensayo 2 Rango = L2 = L0/4 = (b – a)/4
............ Ensayo N Rango = LN = L0/2
N = (b – a)/2N
Después de realizar cada ensayo se calcula el nuevo rango en el cual se encuentra la solución óptima; si este nuevo rango es menor o igual a la precisión requerida, no es necesario realizar el nuevo ensayo ya que se sabe que la solución óptima será el punto medio del nuevo intervalo de búsqueda.
Si se conoce la precisión requerida se puede calcular el número de ensayos que se deben realizar sabiendo que
NN
0N
2
ab
2
LL
De la expresión anterior se concluye que
)2(
)()(
LN
LNabLNN
Si sólo hay fondos limitados para realizar N ensayos (donde cada ensayo implica la evaluación de dos valores de la función objetivo), entonces la precisión obtenida está dada por:
NN
0N
2
ab
2
LL
Ejemplo: Considere de nuevo el ejercicio analizado en las secciones anteriores - minimizar la función f(x) = (50 – x)2, para 21 < x < 93, que corresponde al rango hallado al usar el método
de búsqueda no restringida usando paso acelerado. Se desea encontrar el valor óptimo con una precisión de 0.5
Solución. Como se desea una solución con una precisión de 0.5, se puede usar un valor delta de 0.25. La tabla siguiente presenta los resultados del proceso de optimización.
Búsqueda usando rango finito
Ensayo a b Punto medio
x1 x2 f(x1) f(x2) Rango
1 21 93 57 56,75 57,25 45,563 52,563 72
2 21 57 39 38,75 39,25 126,563
115,563
36
3 39 57 48 47,75 48,25 5,063 3,063 18
4 48 57 52,5 52,25 52,75 5,063 7,563 9
5 48 52,5 50,25 50 50,5 0,000 0,250 4,5
6 48 50,25 49,125 48,875 49,375 1,266 0,391 2,25
7 49,125 50,25 49,6875 49,4375 49,9375 0,316 0,004 1,125
8 49,6875 50,25 49,96875 49,71875
50,21875
0,079 0,048 0,5625
9 49,96875
50,25 50,109375
0,28125

Bernardo A. Calderón C. “Métodos de búsqueda” 12
La solución óptima se encuentra entre 49.97 y 50.25, con una solución óptima de 50.109 y una precisión de 0.28125.El número de ensayos requeridos para lograr la precisión deseada de 0.5 está dado por:
Número de ensayos = 8N17.7)2(LN
)5.0(LN)2193(LNN
3. Búsqueda aleatoria pura
La búsqueda aleatoria pura consiste en generar aleatoriamente un número grande de soluciones a un problema de optimización, normalmente generadas por medio de la distribución uniforme, y seleccionar la mejor de ellas. Solamente sería aplicable cuando la variable de decisión se encuentra restringida en un rango finito (a,b). Tiene la ventaja de que no requiere que la función a optimizar sea unimodal, y por lo tanto, si se realiza un número grande de ensayos, la
búsqueda aleatoria pura casi siempre converge a la solución óptima y es aplicable a casi la
totalidad de los problemas de optimización debido a los pocos supuestos necesarios para su uso. La principal desventaja que presenta el método radica en que puede ser lento para encontrar una solución óptima o muy cercana al óptimo, aunque este problema se ve mitigado por la gran evolución que tienen los sistemas cómputo en la actualidad. Por lo tanto, se requiere realizar un número grande de ensayos.
El proceso consiste en generar aleatoriamente diferentes soluciones al problema en el intervalo (a, b), escogidas uniformemente, usando el siguiente generador: X = a + (b – a) R donde R corresponde a un número aleatorio generado en el rango (0, 1).
El algoritmo del proceso sería el siguiente:
Inicio proceso de búsqueda Leer Número_valores Costo_minimo = 0 // Se inicializa el proceso de optimización
Para ensayos = hasta Número_valores R = RND // Se genera aleatorio X = a + (b – a) R // Genera la solución Evaluar la función (algoritmo de simulación, incluyendo el “costo”) Imprimir ensayos, x, costo Si costo < costo_minimo, entonces // La función mejora
Costo_minimo = costo
X_optimo = x Fin si
Siguiente ensayos Imprimir “Solución óptima”: Número_ensayos, x_optimo, costo_minimo Fin proceso El cuadro siguiente presenta una muestra de un proceso de búsqueda pura para 20 ensayos
para minimizar la función (x – 50)2, 21 < x < 93, que se ha venido analizando.

Bernardo A. Calderón C. “Métodos de búsqueda” 13
Ensayo R Valor de x f(x) Valor
mínimo Mejor valor
1 0,1712 33,33 277,91 277,91 33,33
2 0,5091 57,66 58,63 58,63 57,66
3 0,2460 38,71 127,49 58,63 57,66
4 0,1893 34,63 236,21 58,63 57,66
5 0,9762 91,28 1704,44 58,63 57,66
6 0,7132 72,35 499,47 58,63 57,66
7 0,3588 46,83 10,02 10,02 46,83
8 0,9485 89,29 1543,78 10,02 46,83
9 0,7336 73,82 567,51 10,02 46,83
10 0,6328 66,56 274,28 10,02 46,83
11 0,2096 36,09 193,38 10,02 46,83
12 0,0800 26,76 540,16 10,02 46,83
13 0,7440 74,57 603,66 10,02 46,83
14 0,4278 51,80 3,23 3,23 51,80
15 0,6623 68,69 349,18 3,23 51,80
16 0,3453 45,86 17,12 3,23 51,80
17 0,8330 80,97 959,36 3,23 51,80
18 0,8320 80,90 955,00 3,23 51,80
19 0,6471 67,59 309,44 3,23 51,80
20 0,0789 26,68 543,82 3,23 51,80

Bernardo A. Calderón C. “Métodos de búsqueda” 14
Ensayo a B m x1 x2 f(x1) f(x2) Rango
1 45 54 49,5 49,4 49,6 0,360 0,160 9
2 49,5 54 51,75 51,65 51,85 2,723 3,423 4,5
3 49,5 51,75 50,625 50,525 50,725 0,276 0,526 2,25
4 49,5 50,625 50,063 49,963 50,163 0,001 0,026 1,125
5 49,5 50,063 49,781 49,681 49,881 0,102 0,014 0,563
6 49,781 50,063 49,922 49,822 50,022 0,032 0,000 0,281
7 49,922 50,063 49,992 49,892 50,092 0,012 0,008 0,141

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 1
CONTENIDO
2.1 Introducción 2.2 Diseño de la hoja de la simulación 2.3 Funciones útiles 2.4 Ejemplo. Juego del raspa raspa. 2.5 Construcción de histogramas y tablas de frecuencia 2.6 Generación de variables aleatorias usando Excel 2.7 Comparación de alternativas 2.8 Replicado de una corrida 2.9 Replicado de una corrida y comparación de alternativas simultáneamente 2.10 Un modelo de simulación. Juego del lanzamiento de la moneda

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 2
2 Simulación con Excel
2.1 Introducción La mayoría de modelos de simulación tipo Montecarlo se pueden programar mediante la hoja sencilla de cálculo de Excel, usando herramientas relativamente simples. Habrá otros modelos que requieran herramientas un poco más sofisticadas del Excel, y todos se pueden programar a través del Visual Basic, o de la herramienta macros que viene incorporada con el Excel. En las siguientes secciones se presentarán algunos elementos del Excel que son de gran utilidad en la formulación de los modelos de simulación. En el desarrollo de los temas, se supondrá que el lector tiene los elementos mínimos requeridos del Windows para el manejo y manipulación de archivos. 2.2 Diseño de la hoja de la simulación Las hojas deben diseñarse de tal forma que la información se pueda leer de una manera ágil y rápida, y debería tener en cuenta los siguientes aspectos:
Un título descriptivo que identifique el estudio Una sección para los datos de entrada Los datos de entrada deben usarse sólo a través de referencias a las celdas que los contienen, de
tal manera que cualquier cambio en los mismos se refleje inmediatamente en los resultados de salida
Una sección para los datos de salida Una sección para el área de trabajo. Deben usarse los formatos apropiados, de acuerdo a la naturaleza de los datos Los cálculos complejos deberían realizarse en más de una celda, para reducir las posibilidades de
error. 2.3 Funciones útiles Las siguientes son algunas de las funciones de Excel útiles para el diseño de la hoja de càlculo de la simulación.
Funciones matemáticas o estadísticas La función =aleatorio() genera un número aleatorio, cuya distribución es uniforme (0,1). Funciones para cálculo de estadísticas Una vez realizada la simulación, se pueden usar las siguientes funciones para el cálculo de algunas medidas de desempeño: • Min(rango). Encuentra el valor mínimo que hay en el rango especificado. • Max(rango). Encuentra el valor máximo que hay en el rango especificado. • Suma(rango): Calcula la suma de los valores que hay en el rango especificado. • Promedio(rango). Calcula el valor promedio de lo valores que hay en el rango especificado. • Desvest(rango). Calcula la desviación estándar de la muestra de valores que hay en el rango
especificado. • Contar(rango). Calcula el número de valores que hay en el rango especificado. • Contar.si(rango;condicíón). Calcula, dentro del rango especificado, el número de valores que cumplen la
condición especificada; función útilpara el cálculo de probabilidades Funciones lógicas Para la realización de cálculos condicionales, dependientes del valor de algún atributo o de otra variable o conjunto de variables. Entre las principales se tienen las siguientes funciones: • y(condición1;condición 2;…;condición k). Es una función lógica que devuelve el “Verdadero” si se
cumplen todas las condiciones, en caso contrario devuelve el valor “Falso”. • o(condición1;condición 2;…;condición k). Es una función lógica que devuelve el “Verdadero” si se
cumple al menos una condición, y el valor “Falso” si no se cumple ninguna. • si(condición; valor si la condición es verdadera; valor si es falsa). Es una función lógica que
retorna un valor si la condición especificada es verdadera, y retorna otro valor si la condición es falsa. En el campo de “valor si la condición es verdadera” o en “valor si es falsa” se puede colocar -anidar- otra condición tipo “si”.

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 3
La función “si” permite escoger uno de dos valores para colocar en una celda. Si la condición especificada es verdadera, el “valor si verdadero” es colocado en la celda. Si la condición es falsa, el “valor si falso” es el colocado. Esta función es el equivalente de la estructura “if ...then...else...end if” de algunos lenguajes de programación. Por ejemplo, si simulamos el lanzamiento de una moneda, cuya probabilidad de obtener cara es ½, entonces podríamos generar en la posición A1 un número aleatorio, y en la posición B1 colocaríamos el resultado del lanzamiento (cara o sello), que se genera de la siguiente manera:
Si R < 0.5 Cara
Si R 0.5 Sello
Entonces la celda B1 estaría definida como:
=si(B1<0.5;”Cara”;”Sello”) Si el resultado cara los representamos por el valor “1” y por 0 un sello, entonces la celda B1 quedaría como:
=si(B1<0.5;1;0) La función “si” incluye las siguientes condiciones:
= igual a < menor que <= menor que o igual a > mayor que >= mayor que o igual a <> diferente de
2.4 Ejemplo. Juego del raspa raspa. Considere una lotería instantánea. Cada tarjeta tiene tres filas, y en cada fila hay dos casillas, una de las cuales tiene un valor de $1,000 y la otra $5,000. El jugador raspa una casilla de cada renglón para descubrir el valor asociado. Si los tres números destapados son iguales, el jugador gana esa cantidad. En caso contrario no gana nada.
Para evaluar la factibilidad del negocio se desea saber, entre otras cosas, cuál es la cantidad mínima que se debe cobrar por cada boleto. Solución por simulación El valor mínimo que se puede cobrar por cada boleto, de tal forma que en el negocio no se pierda dinero, es la cantidad media que espera ganar quien lo compre. La solución completa, incluyendo la solución analítica, se presenta en el documento “Introducción a la simulación. Conceptos básicos”. En esta sección, tan sólo nos enfocaremos en la solución desde el punto de vista de la simulación. La utilidad bruta obtenida por quien compra un boleto de esta lotería instantánea es una variable aleatoria, dada por:
casosotrosen
devaloreltienendestapadasceldastreslassi
devaloreltienendestapadasceldastreslassi
U
0
50005000
10001000

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 4
La solución por simulación consiste en tratar de reproducir (imitar) lo que sucede cuando una persona compra el boleto, y repetir muchas veces este procedimiento con muchas boletos, y calcular la utilidad promedio. El procedimiento seguido por una persona cuando compra el boleto se detalla a continuación: Destapar celda en fila 1, y verificar el resultado Destapar celda en fila 2, y verificar el resultado Destapar celda en fila 3, y verificar el resultado Si (todas las celdas son iguales a 1000) entonces Utilidad = 1000 Si no Si (todas las celdas son iguales a 5000) entonces Utilidad = 5000
Si no Utilidad = 0 Fin si Fin si Para simular el “destape” de una celda, simplemente generamos un número aleatorio R, que representa todos los valores posibles que se pueden obtener cuando se destapa una casilla (dos en este caso), y el resultado se obtiene estableciendo una equivalencia entre el número aleatorio R y las diferentes probabilidades de los valores a destapar. Como solamente son dos valores, y cada casilla contiene o un valor de 1000 o de 5000, con igual probabilidad, entonces el generador del resultado será el siguiente:
Si R < 0.5 valor destapado = 1000
Si R 0.5 valor destapado = 5000
Una forma de conocer lo que gana cada jugador al comprar un boleto, consiste en calcular la suma de las tres filas destapadas, y si esta suma es 3,000 entonces gana $1,000, si es 15,000 entonces gana $5,000, y si no es ninguna de las dos anteriores, no gana nada. Para saber la cantidad mínima a cancelar por cada boleto, entonces se simularía la venta de muchos boletos, se calcula la ganancia de cada boleto, y luego se calcula la ganancia promedio. El algoritmo siguiente (seudo código) contiene todos los pasos a realizar
Inicio Definir Número_boletos
Para cada boleto =1 hasta Número_boletos Suma_celdas = 0 Para cada fila =1 a 3 Generar número_aleatorio Si número_aleatorio <0.5 entonces
Suma_celdas = Suma_celdas + 1,000 Sino
Suma_celdas = Suma_celdas + 5,000 Fin si Siguiente fila Si (suma_celdas=3000) entonces Utilidad(boleto) = 1000 Sino Si (suma_celdas=15000) entonces Utilidad(boleto) = 5000
sino Utilidad(boleto) = 0
Fin si Fin si
Siguiente boleto Calcular ganancia promedio Fin Para implementarlo en Excel, simplemente debemos identificar las columnas requeridas, y la información que llevaría cada una. Se necesita una columna para los boletos, y dos columnas por cada fila, y una última columna para la ganancia de cada boleto. Además, se requeriría una fila por cada boleto. Esas columnas serían:

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 5
Columna A: Número del boleto, desde 1 hasta el número de boletos Columna B: Número aleatorio para la primera fila Columna C: Valor de la primera celda destapada Columna D: Número aleatorio para la segunda fila Columna E: Valor de la segunda celda destapada Columna F: Número aleatorio para la tercera fila Columna G: Valor de la tercera celda destapada Columna H: Utilidad del boleto.
La configuración de la hoja de cálculo sería la siguiente:
(A) Boleto
número
(B) Número
aleatorio 1
( C ) Valor
primera celda
(D) Número
aleatorio 2
(E) Valor
segunda celda
(E) Número
aleatorio 3
(F) Valor
tercera celda
(G) Ganancia
1
2
3
..
En la primera fila podemos colocar un título que identifique el contenido de la hoja de cálculo, en la segunda los encabezados de cada columna, y a partir de la tercera irán los diferentes boletos. Para conocer el valor que hay en cada fila se usará la función “si” sencilla, mientras que para conocer la ganancia del juego se usará la función “si” con otro “si” anidado.
Las funciones (instrucciones) que irían en las diferentes celdas son los siguientes:
Bi: = aleatorio() Ci: =si(Bi<0.5;1000;5000) Di: = aleatorio() Ei: =si(Di<0.5;1000;5000) Fi: = aleatorio() Gi: =si(Fi<0.5;1000;5000) Hi: =si(Ci+Ei+Gi=3000;1000;si(Ci+Ei+Gi=15000;5000;0))
Las anteriores celdas se escriben en la tercera fila, y luego se copian en las filas restantes tantas veces cuantas sean necesarias, según el número de boletos. En la fila 2, columna H podríamos colocar a ganancia promedio, según el número de boletos, según:
H2 = promedio(h3:hn) , donde n representa la última fila de la simulación Otra estadística de interés podría ser la probabilidad de ganar, calculada usando la función “contar.si”. El siguiente cuadro presenta los resultados de una simulación de 5000 boletos 2.5 Construcción de histogramas y tablas de frecuencia El objetivo de una simulación es obtener información sobre el comportamiento de un sistema o para ayudar en la solución de un problema. Generalmente se recogen cantidades grandes de datos, que necesitan resumirse, bien sea a través de medidas resumen (medias, desviaciones, mínimos, máximos) o mediante gráficas. Una de las gráficas más usadas útiles es el histograma de frecuencia.
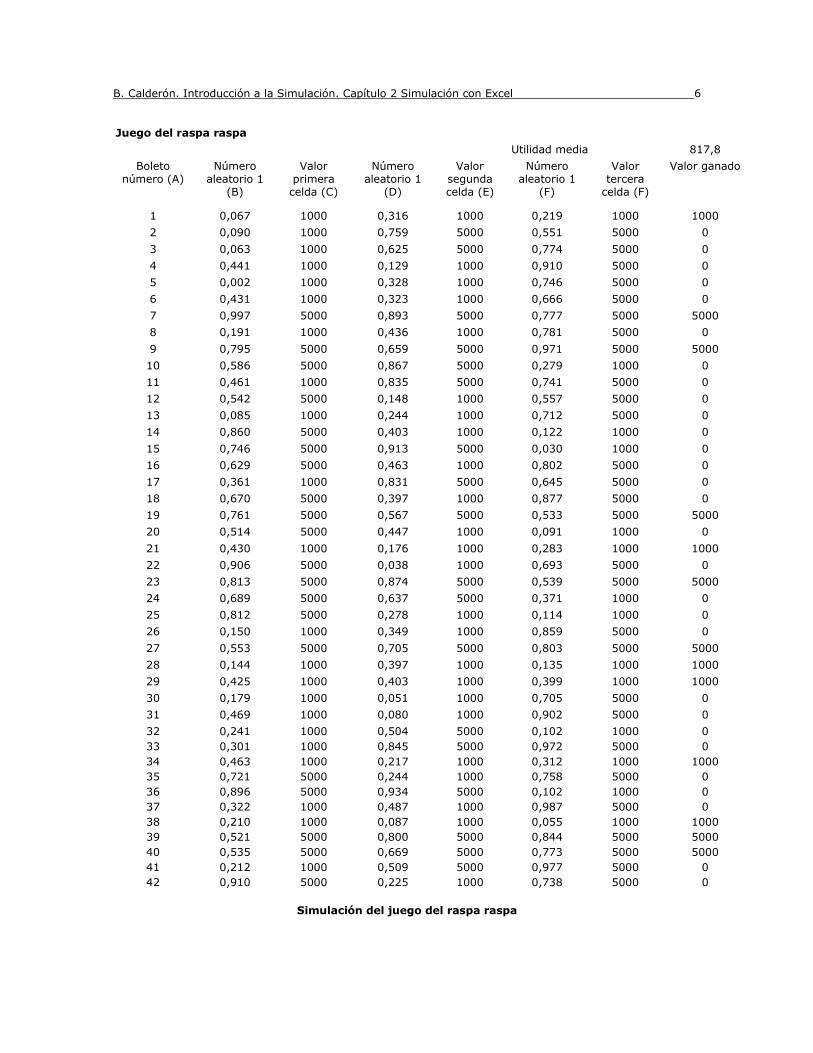
B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 6
Juego del raspa raspa
Utilidad media 817,8
Boleto número (A)
Número aleatorio 1
(B)
Valor primera celda (C)
Número aleatorio 1
(D)
Valor segunda celda (E)
Número aleatorio 1
(F)
Valor tercera
celda (F)
Valor ganado
1 0,067 1000 0,316 1000 0,219 1000 1000
2 0,090 1000 0,759 5000 0,551 5000 0
3 0,063 1000 0,625 5000 0,774 5000 0
4 0,441 1000 0,129 1000 0,910 5000 0
5 0,002 1000 0,328 1000 0,746 5000 0
6 0,431 1000 0,323 1000 0,666 5000 0
7 0,997 5000 0,893 5000 0,777 5000 5000
8 0,191 1000 0,436 1000 0,781 5000 0
9 0,795 5000 0,659 5000 0,971 5000 5000
10 0,586 5000 0,867 5000 0,279 1000 0
11 0,461 1000 0,835 5000 0,741 5000 0
12 0,542 5000 0,148 1000 0,557 5000 0
13 0,085 1000 0,244 1000 0,712 5000 0
14 0,860 5000 0,403 1000 0,122 1000 0
15 0,746 5000 0,913 5000 0,030 1000 0
16 0,629 5000 0,463 1000 0,802 5000 0
17 0,361 1000 0,831 5000 0,645 5000 0
18 0,670 5000 0,397 1000 0,877 5000 0
19 0,761 5000 0,567 5000 0,533 5000 5000
20 0,514 5000 0,447 1000 0,091 1000 0
21 0,430 1000 0,176 1000 0,283 1000 1000
22 0,906 5000 0,038 1000 0,693 5000 0
23 0,813 5000 0,874 5000 0,539 5000 5000
24 0,689 5000 0,637 5000 0,371 1000 0
25 0,812 5000 0,278 1000 0,114 1000 0
26 0,150 1000 0,349 1000 0,859 5000 0
27 0,553 5000 0,705 5000 0,803 5000 5000
28 0,144 1000 0,397 1000 0,135 1000 1000
29 0,425 1000 0,403 1000 0,399 1000 1000
30 0,179 1000 0,051 1000 0,705 5000 0
31 0,469 1000 0,080 1000 0,902 5000 0
32 0,241 1000 0,504 5000 0,102 1000 0
33 0,301 1000 0,845 5000 0,972 5000 0
34 0,463 1000 0,217 1000 0,312 1000 1000
35 0,721 5000 0,244 1000 0,758 5000 0
36 0,896 5000 0,934 5000 0,102 1000 0
37 0,322 1000 0,487 1000 0,987 5000 0
38 0,210 1000 0,087 1000 0,055 1000 1000
39 0,521 5000 0,800 5000 0,844 5000 5000
40 0,535 5000 0,669 5000 0,773 5000 5000
41 0,212 1000 0,509 5000 0,977 5000 0
42 0,910 5000 0,225 1000 0,738 5000 0
Simulación del juego del raspa raspa

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 7
Excel permite construir el histograma de frecuencia de dos maneras diferentes, a saber: a) Usando la herramienta “Análisis de datos”. Un enfoque es usar el menú ”Herramientas/Análisis de
datos/Histograma de frecuencia”, y especificar luego el rango de los datos, los límites superiores de los intervalos de clase, dejando un último intervalo vacío para los datos que excedan el límite superior especificado. Si no se especifican los límites de clase, el Excel los asigna por defecto. Si tanto el rango de datos como el de los intervalos de clase tienen un rótulo que los identifica, debe seleccionarse la celda respectiva. Además debe especificarse si se desea elaborar el gráfico. El cuadro siguiente representa el histograma de juego de raspa raspa, sólo se especifican tres límites superiores para los intervalos (0, 1,000 y 5,000) que corresponden a los únicos valores posibles de la utilidad.
b) Otra alternativa es usar la función “frecuencia” del Excel, y luego construir el histograma mediante la
opción “gráfica”. Esta opción es preferible, debido a que la opción del histograma es estática y no está ligada a los datos, por lo cual, si los datos cambian, el histograma permanece inmodificado. Para usar la función “frecuencia” se requiere:
Definir los límites superiores de los intervalos de clase. Si los datos son continuos, se deja un celda
en blanco después del último límite, para valores en exceso Seleccionar las celdas adyacentes a los límites superiores de los intervalos de clase. Si los datos son
continuos, se selecciona, una celda adicional en blanco después del último límite, para valores en exceso
Entrar la función Excel =frecuencia(rango de datos; rango de límites) Presionar ctrl-Shift-Enter simultáneamente. Construir un histograma usando las opciones de gráficas del Excel, dándole el formato y apariencia
apropiada. Construir un histograma de frecuencia para la utilidad del juego de raspa raspa.
2.6 Generación de variables aleatorias con Excel
La hoja de cálculo Excel tiene varias funciones para generar variables aleatorias de diferentes tipos. Estas funciones son las siguientes: 2.6.1 Generación de variables aleatorias discretas
Considere la siguiente tabla que representa la demanda por un artículo especificado.
Número de copias X 0 1 2 3 4
Probabilidad p(x) 0.15 0.25 0.45 0.10 0.05
Para generar aleatoriamente la demanda por dicho artículo, se genera un número aleatorio R (entre cero y uno), el cual debe representar los diferentes valores que puede tomar la demanda. Así, un 15% de los números debe representar una demanda de cero unidades, un 25% una demanda de una unidad, un 45% una demanda de 2 unidades, un 10% una demanda de 3 unidades, y un 5% una demanda de 4 unidades. Entonces, dado un número aleatorio, para saber a que demanda corresponde, se distribuye el rango de cero a uno para cada valor en forma proporcional a su probabilidad, y para realizarlo de una manera ordenada, se calcula la probabilidad acumulada F(x) –conocida como la función de distribución de la variable, y se asignan los valores siguiendo dicha función. Así: al valor X = 0 corresponde un 15% de los números aleatorios, entre el cero y 0.15, al valor X = 1 corresponde un 25% de los números aleatorios, entre 0.15 y 0.40, al valor X = 2 corresponde un 45% de los números aleatorios, entre 0.40 y 0.85, al valor X = 3 corresponde un 10% de los números aleatorios, entre el 0.85 y 0.95, y finalmente al valor X = 4 corresponde el último 5% de los números aleatorios, los que sean mayores o iguales a 0.95.
Prob. acumulada F(x) 0.15 0.40 0.85 0.90 1.00
Rango de R R<0.15 0.15R<0.40 0.40R<0.85 0.85R<0.95 R0.95
Valor de la variable X 0 1 2 3 4
La generación del valor de la demanda se hará simplemente distribuyendo el rango del número aleatorio (0,1) en forma proporcional a cada valor de la probabilidad, según lo muestra el siguiente procedimiento:
Si r < 0.15 X = 0
Si 0.15 r < 0.40 X = 1 Si 0.40 r < 0.85 X = 2
Si 0.85 r < 0.95 X = 3
Si r 0.95 X = 4

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 8
Analizando el procedimiento anterior, se observa que el valor de x es el entero que cumple la siguiente desigualdad.
Si F(x-1) r < F(x) entonces X = x
(Este procedimiento se conoce como el “método de la transformación inversa caso discreto”, y es aplicable para todas las variables discretas). Este proceso se puede representar en Excel mediante la función “si”, usando varios ciclos “si” internamente. Por ejemplo, si la celda c10 contiene un número aleatorio, la demanda se puede generar en la celda D10 usando la siguiente expresión:
D10 =SI($C10<0.15;0;SI($C10<0.4;1;SI($C10<0.85;2;SI($C10<0.95;3;4)))) Ver funciones “buscarh” y “buscarv”. 2.6.2 Distribución Beta DISTR.BETA.INV Devuelve, para una probabilidad dada, el valor de la variable aleatoria siguiendo una distribución beta. Es decir, si el argumento probabilidad = DISTR.BETA(x;...), entonces DISTR.BETA.INV (probabilidad;...) = x. La distribución beta acumulada puede emplearse en la organización de proyectos para crear modelos con fechas de finalización probables, de acuerdo con un plazo de finalización y variabilidad esperados. Sintaxis: DISTR.BETA.INV(probabilidad;alfa;beta;A;B) Probabilidad es una probabilidad asociada con la distribución beta. Para la simulación corresponde a un
número aleatorio. Alfa y Beta son los parámetros de la distribución. A y B corresponden a los límites inferior y superior, respectivamente, de la distribución de x. DISTR.BETA.INV usa una técnica iterativa para calcular la función. Dado un valor de probabilidad, DISTR.BETA.INV itera hasta que el resultado tenga una exactitud de ±3x10-7. Si DISTR.BETA.INV no converge después de 100 iteraciones, la función devuelve el valor de error #N/A. Ejemplo: DISTR.BETA.INV(0,685470581;8;10;1;3) es igual a 2 2.6.3 Distribución F DISTR.F.INV Devuelve el inverso de la distribución de probabilidad F. Si el argumento p = DISTR.F(x,...), entonces DISTR.F.INV(p,...) = x. La distribución F puede usarse en una prueba F que compare el grado de variabilidad en dos conjuntos de datos. Por ejemplo, podría analizar las distribuciones de ingresos en Venezuela y Colombia para determinar si ambos países tienen un grado de diversidad similar. Sintaxis: DISTR.F.INV(probabilitdad;grados_de_libertad1;grados_de_libertad2) Probabilidad es una probabilidad asociada con la función de distribución acumulativa F. Para la
simulación corresponde a un número aleatorio.
Grados_de_libertad1 es el número de grados de libertad del numerador. Grados_de_libertad2 es el número de grados de libertad del denominador. DISTR.F.INV puede usarse para devolver valores críticos de la distribución F. Por ejemplo, el resultado de un cálculo AN.VAR generalmente incluye datos para la estadística F, la probabilidad F y el valor crítico F con un nivel de significación de 0,05. Use el nivel de significación como argumento probabilidad de DISTR.F.INV para devolver el valor crítico de F. DISTR.F.INV usa una técnica iterativa para calcular la función. Dado un valor de probabilidad, DISTR.F.INV reitera hasta que el resultado alcance una exactitud de ± 3x10-7. Si DISTR.F.INV no converge después de 100 iteraciones, la función devuelve el valor de error #N/A. Ejemplo: DISTR.F.INV(0,01;6;4) es igual a 15,20675

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 9
2.6.4 Distribución Gamma DISTR.GAMMA.INV Devuelve, para una probabilidad dada, el valor de la variable aleatoria que sigue una distribución gamma acumulativa. Si p = DISTR.GAMMA(x,...), entonces DISTR.GAMMA.INV(p,...) = x Utilice esta función para estudiar variables cuya distribución podría ser asimétrica. Sintaxis: DISTR.GAMMA.INV(prob;alfa;beta) Prob es la probabilidad asociada con la distribución gamma. Para la simulación corresponde a un número
aleatorio. Alfa es un parámetro de la distribución. Beta es un parámetro de la distribución (parámetro de forma). Si beta = 1, DISTR.GAMMA.INV
devuelve el valor de la variable aleatoria que sigue una distribución gamma estándar. Ejemplo: DISTR.GAMMA.INV(0,068094;9;2) es igual a 10 2.6.5 Distribución logarítmica normal DISTR.LOG.INV Devuelve el inverso de la probabilidad para una variable aleatoria siguiendo una distribución logarítmica normal de x, donde ln(x) se distribuye normalmente con los parámetros media y desv_estándar. Si p = DISTR.LOG.NORM(x,...) entonces DISTR.LOG.INV(p,...) = x. La distribución logarítmica normal se emplea para analizar datos transformados logarítmicamente. Sintaxis: DISTR.LOG.INV(probabilidad;media;desv_estándar) Probabilidad es una probabilidad asociada con la distribución logarítmico-normal. Para la simulación
corresponde a un número aleatorio. Media es la media de ln(x). Desv_estándar es la desviación estándar de ln(x). Ejemplo: DISTR.LOG.INV(0,039084; 3,5; 1,2) es igual a 4,000014 2.6.6 Distribución normal estándar N(0,1) DISTR.NORM.ESTAND.INV
Devuelve, para una probabilidad dada, el valor de la variable aleatoria que tiene una distribución normal estándar acumulativa. La distribución tiene una media de cero y una desviación estándar de uno. Sintaxis: DISTR.NORM.ESTAND.INV(probabilidad) Probabilidad es una probabilidad que corresponde a la distribución normal. Para la simulación
corresponde a un número aleatorio. La función DISTR.NORM.ESTAND.INV se calcula utilizando una técnica iterativa. Dado un valor del argumento probabilidad, DISTR.NORM.ESTAND.INV itera hasta que el resultado tenga una exactitud de ± 3x10-7. Si DISTR.NORM.ESTAND.INV no converge después de 100 iteraciones, la función devuelve el valor de error #N/A. Ejemplo: DISTR.NORM.ESTAND.INV(0,908789) es igual a 1,3333 2.6.7 Distribución normal ( ) DISTR.NORM.INV Devuelve, para una probabilidad dada, el valor de la variable aleatoria siguiendo una distribución acumulativa normal para la media y desviación estándar especificadas. Sintaxis: DISTR.NORM.INV(prob;media;desv_estándar) Prob es una probabilidad asociada a la distribución normal. Para la simulación corresponde a un
número aleatorio. Media es la media aritmética de la distribución. Desv_estándar es la desviación estándar de la distribución. DISTR.NORM.INV utiliza la distribución normal estándar si el argumento media = 0 y si el argumento desv_estándar = 1 (vea DISTR.NORM.ESTAND.INV).

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 10
DISTR.NORM.INV se calcula utilizando una técnica iterativa. Dado un valor del argumento probabilidad, la función DISTR.NORM.INV reiterará hasta que el resultado obtenido tenga una exactitud de ± 3x10-7. Si DISTR.NORM.INV no converge después de 100 iteraciones, la función devuelve el valor de error #N/A. Ejemplo: DISTR.NORM.INV(0,908789;40;1,5) es igual a 42 2.6.8 Distribución T DISTR.T.INV Devuelve, para una probabilidad dada, el valor de la variable aleatoria siguiendo una distribución t de Student para los grados de libertad especificados. Sintaxis: DISTR.T.INV(probabilidad;grados_de_libertad) Probabilidad es la probabilidad asociada con la distribución t de Student dos colas. Para la simulación
corresponde a un número aleatorio. Grados_de_libertad es el número de grados de libertad para diferenciar la distribución. DISTR.T.INV se calcula como DISTR.T.INV=p( t<X ), donde X es una variable aleatoria que sigue la distribución t. DISTR.T.INV se calcula utilizando una técnica iterativa. Dado un valor del argumento probabilidad, DISTR.T.INV reitera hasta obtener un resultado con una exactitud de ± 3x10-7. Si DISTR.T.INV no converge después de 100 iteraciones, la función devuelve el valor de error #N/A. Ejemplo: DISTR.T.INV(0,054645;60) es igual a 1,96 2.6.9 Distribuciones empíricas o variables aleatorias discretas en Excel BUSCARV Las variables aleatorias discretas, o las distribuciones empíricas, cuya probabilidad se da en forma numérica, se pueden generar en Excel usando las funciones “buscarh” o “buscarv”, según la forma como se especifique la información en la hoja de cálculo. La función “buscarv” busca un valor específico en la primera columna de una matriz o arreglo y devuelve el valor correspondiente en la misma fila de una columna especificada en la tabla. Se utiliza BUSCARV cuando
los valores de comparación se encuentren en una columna situada a la izquierda de los datos que desea encontrar; cuando los valores de comparación se encuentren en una fila, se debe usar BUSCARH Sintaxis: BUSCARV(valor_buscado;matriz_de_comparación;indicador_columnas;ordenado) Valor_buscado es el valor que se busca en la primera columna de la matriz. Valor_buscado puede ser un
valor, una referencia o una cadena de texto. Para la simulación corresponde a un número aleatorio. Matriz_de_comparación es el conjunto de información donde se buscan los datos. Se define mediante
una referencia a un rango o un nombre de rango, como por ejemplo Base_de_datos o Lista, $C1:$E15. Indicador_columnas es el número de la columna de la matriz_de_comparación que contiene el valor de
la variable que debe devolverse. Si el argumento indicador_columnas es igual a 2, la función devuelve el valor de la segunda columna del argumento matriz_de_comparación; si el argumento indicador_columnas es igual a 3, devuelve el valor de la tercera columna de matriz_de_comparación y así sucesivamente.
Los valores de la primera columna del argumento matriz_de_comparación deben colocarse en orden ascendente (corresponden a la función de distribución). Los valores de la primera columna de matriz_de_comparación pueden ser texto, números o valores lógicos. El texto escrito en mayúsculas y minúsculas es equivalente. Ordenado. Es un valor lógico que indica si desea que la función BUSCARV busque un valor igual o aproximado al valor especificado. Si el argumento ordenado es VERDADERO o se omite, la función devuelve un valor aproximado, es decir, si no encuentra un valor exacto, devolverá el valor inmediatamente menor que el valor_buscado. Si ordenado es FALSO, BUSCARV devuelve el valor buscado. Si no encuentra ningún valor, devuelve el valor de error #N/A. Observaciones Si BUSCARV no puede encontrar valor_buscado y ordenado es VERDADERO, utiliza el valor más grande que sea menor o igual a valor_buscado.

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 11
SI la información viene dada por filas, se usa la función “buscarh”, con una estructura similar. Ejemplo. Considere la variable aleatoria analizada en la sección 5.1, cuya información se resume a continuación:
Demanda – xi 10 15 20 25 30
Frecuencia relativa - f(xi) 0.18 0.38 0.31 0.11 0.02
Frecuencia relativa acumulada - F(xi) 0.18 0.56 0.87 0.98 1.00
Para generar la variable aleatoria mediante la función BUSCARV, la información podría organizarse como se muestra en la siguiente tabla, y el comando podría ser el siguiente: Sintaxis: BUSCARV(aleatorio(),$D10:$F$14,3) Se genera el número aleatorio con la función =aleatorio() Si r < 0.18 x = 10
Si r < 0.56 x = 15
Si r < 0.87 x = 20
Si r < 0.98 x = 25
Si r 0.98 x = 30
Para cada valor de Xi se asocia la probabilidad acumulada anterior.
Fila\Columna A D E F G
1 . . . . . . .
…
10 0 0.18 10
11 0.18 0.56 15
12 0.56 0.87 20
13 0.87 0.98 25
14 0.98 1.0 30
15
La función BUSCARH funciona en idéntica forma, con la diferencia de que la información a buscar está dada por filas, y no por columnas. Su sintaxis es la siguiente: BUSCARH(valor_buscado;matriz_buscar_en;indicador_filas; ordenado) Donde Valor_buscado es el valor que se busca en la primera fila de matriz_buscar_en. La siguiente tabla resume las funciones generadores de variables dadas en el excel.
Distribución Nombre función Parámetros
Beta DISTR.BETA.INV
Probabilidad ó número aleatorio
Alfa Beta A y B (Valores mínimo y máximo)
Binomial BINOMCrit Probabilidad ó número aleatorio
Ensayos Probabilidad de éxito
F DISTR.F.INV Probabilidad ó número aleatorio
Grados de libertad 1 1
Grados de libertad 2 2
Gama DISTR.GAMMA.INV
Probabilidad ó número aleatorio
Alfa Beta
Logarítmica Normal
DISTR.LOG.INV
Probabilidad ó número aleatorio
Media del logaritmo de
x
Desviación estándar del
ln x
Normal estándar
N(0,1)
DISTR.NORM.ESTAND.INV Probabilidad número aleatorio
Normal DISTR.NORM.INV Probabilidad ó número aleatorio
Media Desviación estándar

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 12
Chi cuadrado Prueba.chi.inv Probabilidad número aleatorio
Grados de libertad
T DISTR.T.INV
Probabilidad ó número aleatorio
Grados de libertad
Ejemplo. Considere la variable aleatoria analizada en la sección 5.1, cuya información se resume a continuación:
Demanda – xi 10 15 20 25 30
Frecuencia relativa - f(xi) 0.18 0.38 0.31 0.11 0.02
Frecuencia relativa acumulada - F(xi) 0.18 0.56 0.87 0.98 1.00
Para generar la variable aleatoria mediante la función BUSCARV, la información podría organizarse como se muestra en la siguiente tabla, y el comando podría ser el siguiente: Sintaxis: BUSCARV(aleatorio(),$D10:$F$14,3) Se genera el número aleatorio con la función =aleatorio() Si r < 0.18 x = 10
Si r < 0.56 x = 15 Si r < 0.87 x = 20
Si r < 0.98 x = 25
Si r 0.98 x = 30
Para cada valor de Xi se asocia la probabilidad acumulada anterior.
Fila\Columna A D E F G
1 . . . . . . .
…
10 0 0.18 10
11 0.18 0.56 15
12 0.56 0.87 20
13 0.87 0.98 25
14 0.98 1.0 30
15
La función BUSCARH funciona en idéntica forma, con la diferencia de que la información a buscar está dada por filas, y no por columnas. Su sintaxis es la siguiente: BUSCARH(valor_buscado;matriz_buscar_en;indicador_filas; ordenado) Donde Valor_buscado es el valor que se busca en la primera fila de matriz_buscar_en. 2.7 Comparación de alternativas Para realizar varias simulaciones y/o comparar los resultados de simular varias alternativas, se puede hacer de dos maneras diferentes:
Simular la hoja completa, cambiando la celda que contiene la variable de decisión, ó Rediseñar la hoja para evaluar varias alternativas, y simular las diferentes alternativas de una
manera conjunta, usando una “tabla de datos de una entrada”. Para realizar esta segunda opción, los pasos a segur son los siguientes: 1) Crear una columna que contenga los valores de las diferentes alternativas 2) En las celdas contiguas a la derecha, y empezando una celda arriba del tope de la lista, se copia la
fórmula que contiene el resultado de salida del modelo. 3) Se selecciona el rango de la tabla de datos – el bloque rectangular más pequeño que incluya tanto la
fórmula como todos los valores del rango de entrada. 4) Seleccionar, de la barra principal de herramientas, la opción “Datos/Tabla y se especifica la ubicación de
la “columna” de la variable de entrada como la celda que contiene la variable de decisión (se especifica columna ya que los datos están organizados por columna).
Usar esta segunda forma es más ventajosa, ya que el Excel usa las mismas semillas (la misma secuencia de números aleatorios) para simular las diferentes alternativas, lo cual las hace perfectamente comparables. Es

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 13
necesario tener en cuenta que para comparar varias alternativas a través de la simulación, la simulación de éstas debe realizarse usando las mismas secuencias de números aleatorios. Problema de la Tienda del video. Considere una tienda de alquiler de videos, que compra las cintas de estreno a $25,000 la unidad, las alquila a sus clientes a $5,000, y al final del mes, revende las cintas a otras tiendas de barrio a $ 5,000 la copia. La tienda ha estimado que la demanda diaria por cintas de estreno tiene la siguiente distribución de probabilidad:
Número de copias 0 1 2 3 4
Probabilidad 0.15 0.25 0.45 0.10 0.05
Suponga que las cintas duran en alquiler un día, y que todos los clientes devuelven las copias al siguiente día. Cuántas copias de las cintas de estreno debe ordenar la tienda cada mes? Formulación del modelo general: Si para un mes se compran Q copias de una cinta, la utilidad mensual estará dada por: Utilidad mensual(Q) = Ingresos por alquiler – Costo Cintas compradas + Precio reventas
=
30
1
5000000,25)(3000
j
QQjAlquiler
donde Alquiler(j) representa el número de copias alquiladas a los clientes el día j. Si X representa la demanda por cintas para el día j, entonces, el número de copias alquiladas ese día estará dada por:
Alquiler (j) = X si X Q
= Q si X> Q Para resolver este problema por simulación, la única variable aleatoria que tenemos es la demanda diaria por cintas, la cual se debe “generar” o “simular (inventar)” para cada día. Su generación se hará simplemente distribuyendo el rango del número aleatorio (0,1) en forma proporcional a cada valor de la probabilidad (este procedimiento se conoce como el “método de la transformación inversa caso discreto”). Para cada valor de la demanda se calcula la probabilidad acumulada (función de distribución), según lo muestra la tabla siguiente, y los valores de la demanda se generarán de acuerdo a este valor de la siguiente manera:
Número de copias X 0 1 2 3 4
Probabilidad p(x) 0.15 0.25 0.45 0.10 0.05
Probabilidad acumulada F(x) 0.15 0.40 0.85 0.90 1.00
Se genera un número aleatorio R = r, que se usa para generar la demanda X de la siguiente manera:
Si r < 0.15 X = 0
Si 0.15 r < 0.40 X = 1
Si 0.40 r < 0.85 X = 2 Si 0.85 r < 0.95 X = 3
Si r 0.95 X = 4
Para cada valor de Q se deben simular varios meses, y calcular la utilidad promedio mensual. Para realizar la simulación en Excel, necesitamos las siguientes columnas:
Columna Contenido Fórmula
A Cada mes 1, 2, 3,…
B Cada día 1,2,3,….
C Número aleatorio para la demanda
=aleatorio()

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 14
D Demanda diaria =si(Ci<0.15;0;si(Ci<0.40,1;si(Ci<0.85;2;si(Ci<0.95;3;4))))
E Videos alquilados =si($Di<=E$4 ;$Di ;E$4)
En la fila 1 se colocará un título que identifique la simulación, en la filas 2, 3 y 4, columna E, los precios de compra, alquiler y reventa de los videos, y en la fila 4, columna E, la cantidad de videos a pedir. La columna C contiene el número aleatoria para generar la demanda diaria por cintas, y está dada por la función =aleatorio() La columna D contiene la demanda diaria por cintas de video, la cual se genera mediante la siguiente función “si”, donde “i” se refiere a la fila respectiva de la hoja de cálculo
=si(Ci<0.15;0;si(Ci<0.40,1;si(Ci<0.85;2;si(Ci<0.95;3;4))))
Como la cantidad de videos que se puede comprar varía desde un mínimo de uno hasta un máximo de 4, entonces en la columna E, fila 4, se puede colocar la cantidad Q = 1, y en las columnas siguientes (F, G, y H) los valores de Q = 2, 3 y 4. Una vez se simulen todos los días, se calcula la utilidad media mensual, teniendo en cuenta el total de cintas compradas y alquiladas, y el número de meses simulados. El cuadro de la página siguiente presenta los resultados de simular un año (12 meses, 360 días), para los diferentes valores de Q. Según dichos resultados, se deberían comprar mensualmente dos cintas. A modo de comparación, se presenta también la solución analítica, que coincide con la solución dada por la simulación. Otro enfoque En el problema anterior, en vez de agregar las columnas con las alternativas de Q = 2, 3 y 4, el proceso de simulación de estos valores se puede hacer siguiendo el procedimiento presentado anteriormente. Para ello se siguen los siguientes pasos: a) En la columna C, filas 376 a 378 se colocan los valores de Q = 2, 3 y 4. A nivel informativo, en la celda
C375 se coloca el valor inicial de Q = 1 b) En la celda D375 se copia la fórmula que contiene el resultado de salida del modelo = utilidad media
=E371. c) Se selecciona el rango C375:D378que incluye tanto la fórmula como todos los valores del rango de
entrada. d) Se selecciona la opción “Datos/Tabla y se especifica +D375 como la ubicación de la “columna” de la
variable de entrada, que es la celda que contiene la variable de decisión. AL final de la tabla se presentan los resultados respectivos. 2.8 Replicado de una corrida Una "corrida" de simulación es un registro ininterrumpido del desempeño de un sistema bajo una combinación especificada de variables controlables. Un "replicado" de una corrida es un registro del desempeño del sistema bajo la misma combinación de variables controlables, pero con diferentes variaciones aleatorias (es decir, empleando diferentes semillas para generar los números aleatorios). Una "observación" de un sistema simulado es un segmento de una corrida, suficiente para estimar el valor de cada una de las medidas del desempeño. Por lo tanto una observación puede extenderse durante un período considerable de tiempo simulado. Una corrida está compuesta de varias observaciones (replicados). Por ejemplo, para el problema de la tienda del video, una observación comprende la simulación de un mes completo, es decir, 30 días. En cambio, para el problema del raspa raspa, una observación corresponde a cada boleto destapado por el jugador.
Para simular varias observaciones, o replicar toda una corrida, se puede usar un enfoque similar al realizado para comparar varias alternativas, mediante el uso de la tabla de datos de una entrada. El procedimiento a seguir será el siguiente: 1) Crear una columna que contenga el número de ensayos u observaciones.

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 15
2) En las celdas contiguas a la derecha, y empezando una celda arriba del tope de la lista, se copia la fórmula que contiene el resultado de la observación o corrida.
3) Se selecciona el rango de la tabla de datos – el bloque rectangular más pequeño que incluya tanto la fórmula como todos los ensayos a realizar (datos de entrada).
4) Seleccionar, de la barra principal de herramientas, la opción “Datos/Tabla” y en la especificación de la ubicación de la “columna” de la variable de entrada se señala cualquier celda que esté vacía.

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 16
A B C D E F G H
1 SIMULACION DE LA TIENDA DE VIDEO
2 Precios de compra = 25000
3 Precio de alquiler = 3000
4 Precio de reventa = 5000
5 Número de copias compradas Q = 1 2 3 4
6
7 MES DIA Número aleatorio R
DEMANDA ALQUILER ALQUILER ALQUILER ALQUILER
8 1 1 0,504 2 1 2 2 2
9 2 0,634 2 1 2 2 2
10 3 0,381 1 1 1 1 1
11 4 0,689 2 1 2 2 2
12 5 0,980 4 1 2 3 4
13 6 0,306 1 1 1 1 1
14 7 0,589 2 1 2 2 2
15 8 0,542 2 1 2 2 2
16 9 0,849 2 1 2 2 2
17 10 0,816 2 1 2 2 2
18 11 0,326 1 1 1 1 1
19 12 0,778 2 1 2 2 2
20 13 0,387 1 1 1 1 1
21 14 0,610 2 1 2 2 2
22 15 0,819 2 1 2 2 2
23 16 0,468 2 1 2 2 2
… … … … … … … … …
39 2 31 0,240 1 1 1 1 1
40 32 0,504 2 1 2 2 2
… … … … … … … … …
367 12 359 0,714 2 1 2 2 2
368 360 0,314 1 1 1 1 1
369 Total anual (cintas) 588 307 516 570 588
370 Promedio Mensual (Cintas/mes) 49,0 25,6 43,0 47,5 49,0
371 Promedio diario (Cintas/día) 1,63 0,85 1,43 1,58 1,63
372 Utilidad media mensual simulación ($/mes) 56750 89000 82500 67000
373 Utilidad media mensual analítica ($/mes) 56500 90500 84000 68500
374
375 Q Utilidad
376 Número de cintas 1 56750
377 2 89000
378 3 82500
379 4 67000
Simulación de la Tienda de vides, usando varias alternativas
Considere de nuevo el problema de la tienda de video. Suponga que queremos simular, inicialmente, sólo un mes, usando las diferentes alternativas de compra de videos (Q = 1, 2, 3, 4). Suponga también que nos interesa la utilidad mensual. La tabla siguiente presenta en el rango B2:I43 los resultados de la simulación de un mes para cada una de las cuatro alternativas.

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 17
Si queremos simular varios meses (replicar la corrida anterior), lo podemos hacer de la siguiente manera: (para 100 meses) 1) Utilizando el comando “Edición/Rellenar/Series”, e iniciando con el valor de 2, en la celda E50, se
crea una columna que contenga el número de ensayos u observaciones (100 en nuestro caso). 2) En las celdas contiguas a la derecha, y empezando una celda arriba del tope de la lista (celda F49:I49 se
copian las fórmulas que contienen la utilidad mensual de las diferentes alternativas (corresponde a las celdas F42:I42.
3) Se selecciona el rango de la tabla de datos – el bloque rectangular más pequeño que incluya tanto la fórmula como todos los ensayos a realizar (datos de entrada):E49:I148.
4) Seleccionar, de la barra principal de herramientas, la opción “Datos/Tabla” y en la especificación de la ubicación de la “columna” de la variable de entrada se señala cualquier celda que esté vacía..
En las celdas E45:I46 se han calculado la utilidad media mensual y la desviación estándar de la utilidad para cada una de las cuatro alternativas simuladas, y para las 100 observaciones (replicados). Un resumen de la información se presenta en el cuadro siguiente 2.9 Replicado de una corrida y comparación de alternativas simultáneamente En la hoja de cálculo se define una celda para la variable de decisión y se define una tabla donde en una columna se definen los replicados y en una fila las alternativas. El procedimiento a seguir será el siguiente:
1) Crear columna con el número de observaciones. 2) En celdas contiguas a la derecha, y empezando una celda arriba del tope de la lista (fila superior),
se copian los valores de las alternativas (variable de decisión) 3) La fórmula que contiene el resultado de la observación o corrida se copia en el espacio vacío que
queda en la intersección de la fila y la columna.. 4) Seleccionar el rango de la tabla de datos – el bloque rectangular más pequeño que incluya tanto la
fórmula como los replicados y los valores de las diferentes alternativas 5) Seleccionar opción “Datos/Tabla”: Se especifica la ubicación de la “fila” de la variable de entrada
como la celda que contiene la variable de decisión (se especifica fila ya que estos valores están organizados en una fila), y se especifica como ubicación de la “columna” de la variable de entrada cualquier celda que esté vacía.
2.10 Un modelo de simulación. Juego del lanzamiento de la moneda A usted le proponen el siguiente juego: Usted lanza una moneda y cuenta el número de caras y sellos que va obteniendo. El juego se termina sólo cuando la diferencia entre caras y sellos sea tres, no interesa cual sea mayor. En ese instante usted recibe $8.00 por el juego, pero tiene que pagar $1.00 por cada lanzamiento de la moneda que usted haya hecho. Le conviene a usted participar en este juego ? Formulación del modelo El problema consiste en determinar si es favorable o no participar en este juego. En principio diremos que es favorable participar en el juego si a la larga esperamos ganar, es decir, si la utilidad esperada del juego es mayor o igual que cero. Para obtener la respuesta ensayaremos la solución tipo simulación. Para un juego cualquiera la utilidad U está dada por: U(x) = Ingresos - Egresos = 8 - X, x = 3, 5, 7, ..., donde X es el número de lanzamientos, y por cada lanzamiento se paga un peso. El número de lanzamientos en que puede terminar un juego es mínimo tres, y puede ser 5, 7, 9, 11, ...; el juego no puede terminar en un número par de lanzamientos. El número de lanzamientos -X- es una variable aleatoria. El lanzamiento de la moneda lo simulamos mediante la generación de un número aleatorio R, en el intervalo (0, 1), usando la función =aleatorio(). El resultado de cara lo podemos generar asignando los números aleatorios a los posibles resultados de la moneda- cara o sello- de la siguiente manera: Si R < p se obtiene cara Si R p se obtiene sello,

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 18
1 A B C D E F H H
2 SIMULACION DE LA TIENDA DE VIDEO
3 Precios de compra = 25000
4 Precio de alquiler = 3000
5 Precio de reventa = 5000
6 Número de copias compradas Q = 1 2 3 4
7
8 MES DIA Número aleatorio R DEMANDA ALQUILER ALQUILER ALQUILER ALQUILER
9 1 1 0,404 2 1 2 2 2
10 2 0,138 0 0 0 0 0
11 3 0,939 3 1 2 3 3
12 4 0,870 3 1 2 3 3
13 5 0,189 1 1 1 1 1
14 6 0,664 2 1 2 2 2
15 7 0,330 1 1 1 1 1
16 8 0,347 1 1 1 1 1
17 9 0,921 3 1 2 3 3
18 10 0,742 2 1 2 2 2
19 11 0,818 2 1 2 2 2
35 … … … … … … … …
36 28 0,456 2 1 2 2 2
37 29 0,485 2 1 2 2 2
38 30 0,929 3 1 2 3 3
39 Total mensual (cintas) 53 28 47 53 53
40 Promedio Mensual (Cintas/mes)
53,0 2,3 3,9 4,4 4,4
41 Promedio diario (Cintas/día)
1,77 0,08 0,13 0,15 0,15
42 Utilidad mensual simulación ($/mes) 64000 101000 99000 79000
43 Utilidad media ensual analítica ($/mes) 56500 90500 84000 68500
44
45 Util media 56200 89030 82020 66190
46 Desviación 6267 11890 14348 15759
47
48 Meses 1 2 3 4
49 1 64000 101000 99000 79000
50 2 67000 107000 99000 82000
51 3 61000 92000 90000 73000
52 4 43000 62000 54000 34000
53 5 58000 89000 78000 58000
145 97 55000 89000 81000 64000
146 98 64000 98000 99000 88000
147 99 61000 89000 81000 70000
48 100 64000 104000 93000 76000
Simulación de la tienda de video usando replicados donde p es la probabilidad de obtener cara en el lanzamiento de una moneda, que será 0.5 si es una moneda buena La siguiente figura presenta el algoritmo general para realizar varios juegos, y calcular la utilidad media.
Definir (leer) nro_juegos

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 19
Suma_u = 0 Para juego = 1, nro.juegos caras = 0 = sellos Mientras (ABS(caras - sellos) <> 3) R = aleatorio() si (R < .5) ENTONCES caras = caras + 1 si no sellos = sellos + 1 Fin si Fin mientras util = 8 – (caras + sellos) suma_u = suma_u + util Siguiente juego util_media = suma_u / nro.juegos Imprimir nro_juegos, util_media Fin
Para realizar la simulación de un juego en Excel se requieren las siguientes columnas: A Número del lanzamiento Ai = Ai-1 +1
B Número aleatorio que representa el lanzamiento de la moneda Bi =aleatorio()
C Resultado obtenido al lanzar la moneda Ci = si(Bi<0.5;”cara”;”sello”) D Número de caras obtenidas Di = si(Ci=”cara”;Di-1+1;Di-1)
E Número de sellos obtenidos Ei = si(Ci=”sello”;Ei-1+1;Ei-1)
F Diferencia entre caras y sellos Fi =ABS(Di - Ei)
donde el subíndice i se refiere al número de la fila de la hoja de Excel. Para el lanzamiento cero (inicialización del juego), las columnas D y E se colocan en cero (cero caras y cero sellos) Cada juego puede terminar en un número variable de lanzamientos, Para poder obtener varias observaciones -replicar varias veces la simulación- se requiere especificar en que celdas se encuentran las variables de salida, por lo tanto, se necesita asignarle a cada juego un número máximo de lanzamientos. Para nuestro caso supondremos que es 60. Si el juego termina antes de lanzamientos, dejaremos en blanco las celdas correspondientes al número aleatorio y al resultado, y en las restantes dejaremos como constantes los números de caras y sellos, una vez el juego haya terminado.
Para que la hoja de cálculo opere adecuadamente, en cada una de las columnas de la B a la F, cada instrucción se reescribir para verificar si el juego ha terminado o no. Las instrucciones quedan de la siguiente manera: B Número aleatorio= =SI(Fi-1=3;" ";ALEATORIO()) C Resultado al lanzar la moneda Ci =SI(Fi-1=3;" ";SI(Bi<$D$2;"Cara";"Sello"))
D Número de caras Di =SI(Fi-1=3;Di-1;SI($Ci="Cara";Di-1+1;Di-1))
E Número de sellos obtenidos Ei = si(Fi-1=3;Ei-1;si(Ci=”sello”;Ei-1+1;Ei-1)) F Diferencia entre caras y sellos Fi =ABS(Di - Ei)
donde el subíndice i se refiere al número de la fila de la hoja de Excel. Para realizar varias simulaciones se hace lo siguiente: A partir de la celda H11, se colocan los números de los ensayos a realizar (mediante
edit/rellenar/series...(columnas). En la celda I10 se coloca la celda que contiene el número de lanzamientos, y en la celda J10 la utilidad Se marcan las celdas I10 hasta K109 (para 100 simulaciones) Entrando por Datos/Tabla, se marca cualquier celda vacía como el indicador de columna que contiene
las variables de salida. La tabla siguiente presenta un listado parcial de los resultados de la simulación de 100 juegos.

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 20
A B C D E F G H I J
1 Simulación del juego de la moneda
2 Probabilidad de cara = 0,5 Variables endógenas principales
3 Numero medio de juegos = 100 Número medio de lanzamientos 8,6
4 Desviación del nro de lanzamientos 5,4
5 Utilidad media = -0,6
6 Nro de juegos con 3 lanzamientos = 22
7 Probabilidad de terminar en 3 lanzamientos = 0,22
8
9 Lanza miento
No
Número aleatorio
R
Resul- tado
Nro de caras
Nro de sellos
Diferencia |C - S|
Número de lanza-
mientos
Nro del juego
Número de lanza-
mientos
Utilidad
10 0 0 0 0 0 1 11 -3
11 1 0,364 Cara 1 0 1 1 2 13 -5
12 2 0,705 Sello 1 1 0 2 3 3 5
13 3 0,070 Cara 2 1 1 3 4 7 1
14 4 0,872 Sello 2 2 0 4 5 9 -1
15 5 0,696 Sello 2 3 1 5 6 7 1
16 6 0,195 Cara 3 3 0 6 7 15 -7
17 7 0,239 Cara 4 3 1 7 8 3 5
18 8 0,948 Sello 4 4 0 8 9 19 -11
19 9 0,680 Sello 4 5 1 9 10 5 3
20 10 0,864 Sello 4 6 2 10 11 9 -1
21 11 0,569 Sello 4 7 3 11 12 9 -1
22 12 4 7 3 11 13 11 -3
23 13 4 7 3 11 14 3 5
24 14 4 7 3 11 15 3 5
25 15 4 7 3 11 16 9 -1
26 16 4 7 3 11 17 3 5
27 17 4 7 3 11 18 15 -7
28 18 4 7 3 11 19 5 3
29 19 4 7 3 11 20 7 1
30 20 4 7 3 11 21 3 5
31 21 4 7 3 11 22 7 1
32 22 4 7 3 11 23 15 -7
33 23 4 7 3 11 24 11 -3
34 24 4 7 3 11 25 7 1
35 25 4 7 3 11 26 11 -3
68 58 4 7 3 11 59 5 3
69 59 4 7 3 11 60 9 -1
70 60 4 7 3 11 61 11 -3
Utilidad -3 62 5 3
63 3 5
64 17 -9
Simulación del juego de la moneda, con varios replicados

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 21
Problemas de simulación 1 (HyL) Una compañía proporciona a sus tres empleados un seguro de salud con un plan de grupo. Para cada empleado, la probabilidad de incurrir en gastos médicos es 0.9 (de manera que el número de empleados que incurren en gastos médicos durante el año tiene una distribución binomial). Para un empleado que incurre en gastos médicos durante un año, el monto total para el año tiene la distribución $100 con probabilidad 0.9 o $10,000 con probabilidad 0.1. La compañía tiene una cláusula de deducible de $5,000 de tal forma que cada año la compañía de seguros paga los gastos médicos totales del grupo que excedan los $5,000. Desarrolle un programa que calcule el monto total que paga la compañía de seguros por año. 2 Los empleados de una empresa reciben un seguro de salud a través de un plan de grupo. Durante el año pasado, 40% de los empleados no hicieron ninguna reclamación médica, 40% hicieron sólo una pequeña reclamación y 20% una grande. Las reclamaciones pequeñas se distribuyeron uniformemente entre 0 y $2000 y las grandes se distribuyen también uniformemente pero entre $2000 y $20 000. Basado en esta experiencia, el agente de seguros está negociando con la compañía el pago de la prima por empleado para el próximo año. Usted es un analista de IO que trabaja para el agente de seguros y se le ha asignado la tarea de estimar el costo promedio de la cobertura del seguro para los empleados de la empresa. 2.1 Derive analíticamente la media de la distribución de probabilidad del costo médico anual por empleado
que cubre este seguro, con base en la experiencia del año pasado. 2.2 Estime esta media usando la técnica de simulación 3 Un hotel tiene 100 habitaciones que alquila a $125 la noche. Existe un costo variable de $30 por pieza (aseo, artículos de baño, etc.) por cada noche que la pieza está ocupada. Por cada reservación aceptada, existe una probabilidad del 5% de que el cliente no llegue. Si el hotel se excede en las reservaciones, hay un costo de $200 para compensar a los clientes cuyas reservaciones no pueden garantizarse. ¿Cuántas reservas debería hacer el hotel (en temporada alta) si desea maximizar la utilidad promedio diaria?. Use 500 simulaciones. 4 La doctora Sara B es una oftalmóloga que, además de prescribir anteojos y lentes de contacto, realiza cirugías láser para corregir la miopía. Esta cirugía es relativamente sencilla y poco costosa de realizar, por lo cual representa una “minita de oro” potencial para su práctica profesional. Para informar al público acerca de este procedimiento, la doctora Sara publica avisos en la prensa local y mantiene sesiones informativas en su oficina una noche cada semana, en las cuales presenta un video acerca del procedimiento y responde las preguntas que los pacientes potenciales puedan tener. La sala donde se realizan estas
reuniones tiene una capacidad para 10 personas, y se requiere realizar previamente la reservación para asistir. El número de personas que atiende cada sesión varía de semana a semana. La doctora Sara cancela la reunión si dos personas o menos hacen la respectiva reservación. Usando datos de años anteriores, la doctora Sara determinó que la distribución de las reservaciones es la siguiente:
Número de reservaciones
0 1 2 3 4 5 6 7 8 9 10
Probabilidad 0.02 0.05 0.08 0.16 0.26 0.18 0.11 0.07 0.05 0.01 0.01
Usando datos de años anteriores, la doctora Sara ha estimado que un 25% de las personas que asisten a la reunión se hacen la cirugía. De aquellos que no se hacen la cirugía, la mayoría considera que el costo ($2,000) es la principal causa. 4.1 En promedio, ¿cuánto espera obtener semanalmente la doctora Sara por la práctica de este
procedimiento? 4.2 En promedio, ¿qué ingreso obtendría por la cirugía si no cancelara las reuniones informativas? 4.3 La doctora Sara cree que un 40% de los que asisten a las sesiones informativas se harían la cirugía si
ella redujera los honorarios a $1,500. Bajo esta suposición, en cuánto se aumentarían los ingresos de la doctora Sara por semana?
5 El administrador de un depósito dispone de un camión para entregas locales y está considerando la
compara de uno adicional para manejar entregas adicionales de alto volumen. Actualmente toma en alquiler camiones adicionales a media que los necesita a un costo de $300/día. El camión que tiene la
empresa ocasiona un costo diario de $200, sea que se use o no se use. Un camión nuevo tendría un costo diario de $200. Registros históricos indican que el número de camiones requeridos diariamente tiene la siguiente distribución:
Número requerido 0 1 2 3
Probabilidad 0.20 0.30 0.4 0.10

B. Calderón. Introducción a la Simulación. Capítulo 2 Simulación con Excel 22
Se desea desarrollar un modelo de simulación para evaluar las alternativas de alquilar camiones adicionales a media que se los requiera, y la alternativa de comparar un nuevo camión y alquilar un tercero cuando sea necesario 5.1 Elabore un algoritmo 5.2 Desarrolle un modelo usando una hoja de cálculo
6 Considere el siguiente juego. El juego requiere que el jugador tire dos dados una o más veces hasta
que se alcance la decisión de ganar o perder. Se gana si el primer lanzamiento de los dos dados resulta un una suma de 7 u 11, o alternativamente, si la primera suma es 4, 5, 6, 8, 9 ó 10 y la misma suma reaparece antes de que aparezca una suma de 7. Se pierde si el primer lanzamiento resulta en una suma de 2, 3 ó 12, o alternativamente, si la primera suma es 4, 5, 6, 8, 9 ó 10 y una suma de 7 aparece antes de que reaparezca la primera suma. Desarrolle el programa para determinar la probabilidad de ganar y para determinar la distribución del número de lanzamientos requeridos para terminar el juego. Simule 500 juegos.
Indicaciones para el problema No 1.9
a) La probabilidad de ganar está dada por el número de juegos ganados, dividido por el número de
juegos realizados.
b) La probabilidad de que en un dado aparezca un resultado cualquiera (1, 2, 3, 4, 5 ó 6) es un sexto (1/6). Para simular el lanzamiento de un dado se genera un número aleatorio R, 0 R < 1
y los valores entre 0 y 1 deben repartirse por igual para los seis posibles resultados. Una forma de averiguar el resultado obtenido al lanzar el dado es la siguiente:
Si R < 1/6 el resultado es 1 Si 1/6 R < 2/6 el resultado es 2
Si 2/6 R < 3/6 el resultado es 3 Si 3/6 R < 4/6 el resultado es 4 Si 4/6 R < 5/6 el resultado es 5 Si 5/6 R < 1 el resultado es 6
Otra forma de obtener el resultado es tomar la parte entera de la siguiente expresión: X = [ 6 x R + 1]
Aunque el juego consiste en lanzar los dos dados al mismo tiempo, en la Simulación el lanzamiento de los dos dados se hace en forma secuencial: Primero se lanza uno (se genera R y se averigua el resultado), después se lanza el otro (se genera R y se averigua el resultado) y luego se suman estos dos resultados. También pueden lanzarse los dados simultáneamente, teniendo en cuenta los resultaos posibles al lanzar dos dados

3 GENERACIÓN DE NUMEROS ALEATORIOS
1 Introducción
En muchos de los experimentos de muestreo y en los de experimentos de simulación se requiere disponer de una fuente de números aleatorios o de un método para generarlos a medida que se los vaya necesitando. Los números aleatorios son indispensables para representar todas las variaciones aleatorias del sistema, es decir, el comportamiento de las variables incontrolables, y son la base para realizar cualquier simulación. Un numero aleatorio es una variable aleatoria que sigue la distribución uniforme en el intervalo (0,1). Una variable aleatoria X tiene una distribución uniforme en el intervalo (a,b) si su función de densidad esta dada por:
f(x) =
0
ab
1
a < x < b a x b
enotroscasos
La función de distribución F(x), que representa la probabilidad de que la variable aleatoria X sea menor o igual que un valor especifico x, está definida como:
F(x) = P(X x) = =
0
1
x a
b a
x a
a x b
x b
f(x) F(x) 1.0 a b a b El valor esperado y la varianza de una distribución uniforme son los siguientes:
E X xf x dxa b
a
b
( ) ( )
2
12dx)x(fb
a )X(Ex 2)X(Varab
2
Así, un número aleatorio R tiene una función de densidad dada por:
f(r) = 1 0 r < 1 La función de distribución está dada por:
F(r) = p(R ≤ r) = r 0 r < 1

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 2
El valor esperado y la varianza están dados por: E(R) = 1/2 Var(R) = 1/12 La variable aleatoria R es continua y los valores generados deben ser estadísticamente independientes. Es posible que en algún procedimiento de generación de números aleatorios la variable R esté designando un número finito de valores -N-, equiprobables y estadísticamente independientes. En este caso R es discreta y su función de probabilidad y de distribución están dadas por:
f(r) = 1/N 0 r < 1
F(r) = r/N 0 r < 1 Para los experimentos de simulación generalmente se requiere de secuencias grandes de números aleatorios, no solamente unos pocos. Los números aleatorios generados en esta secuencia deben ser independientes. Estamos interesados en determinar métodos para generar estos números. Estos métodos deben cumplir ciertas condiciones para que sean eficientes y para que las secuencias generadas sean en realidad aleatorias. Estos métodos los denominaremos “Generadores de Números Aleatorios” o simplemente “Generadores”. Las propiedades que debe tener un generador de números aleatorios son las siguientes: 1) Los números generados deben estar distribuidos uniformemente entre cero y uno. 2) Los números generados deben ser estadísticamente independientes. 3) Las secuencias generadas deben ser reproducibles de tal forma que los diferentes experimentos de
simulación se puedan repetir bajo las mismas condiciones. 4) El método debe poseer un período largo. El período de un generador de números aleatorios indica la
cantidad de números aleatorios que se pueden generar en una secuencia antes de que estos comiencen a repetirse. El período está asociado con la reproducibilidad. Si las secuencias no son reproducibles, entonces no puede hablarse de período. El período debe ser lo suficientemente largo de tal forma que en un mismo experimento de simulación no se repita la secuencia de números aleatorios.
5) Eficiencia. El método debe requerir el mínimo tiempo para generar un número aleatorio, es decir, debe generar números a grandes velocidades.
6) El método debe requerir una mínima capacidad de almacenamiento. 7) Portabilidad. El método debe ser tal que se pueda transportar de una máquina a otra, sin ninguna
complicación. Las dos primeras condiciones están asociadas con las condiciones básicas de un generador de números aleatorios: Uniformidad e independencia. Si un método cumple estas dos condiciones, se lo puede considerar como un generador de números aleatorios. Las condiciones tercera y cuarta son básicas para poder comparar diferentes alternativas en una simulación, de tal forma que las diferencias en los resultados de una simulación se puedan explicar por las diferencias entre las alternativas, y no por las variaciones aleatorias. Las condiciones 5a y 6a son esenciales si queremos reducir el tiempo ( y el costo) de los estudios de simulación. En algunos estudios de simulación se requieren miles y a veces millones de números aleatorios, y debemos garantizar que la mayor parte del tiempo de la simulación no se utilice en la generación de los números sino en los otros procesos del sistema. En general, un generador de números aleatorios debe ser un programa corto y rápido que produzca una secuencia larga de números antes de que empiece de nuevo el ciclo. Para diseñar un buen generador de números aleatorios se deben seguir dos pasos o etapas: a) el primer paso consiste en definir el método a usar para generar los números, y b) el segundo consiste en definir el conjunto o batería de pruebas estadísticas a que se debe someter el generador para garantizar las propiedades estadísticas de los números generados. 2 Métodos para generar números aleatorios

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 3
Para generar números aleatorios se pueden usar diferentes procedimientos, siempre y cuando garanticen que se cumplen las condiciones básicas de uniformidad e independencia. La exigencia de las demás condiciones depende del uso que se le vaya a dar al generador. A continuación se hará un recuento de los diferentes métodos empleados, pero se hará énfasis en los utilizados actualmente.
2.1 Métodos Manuales
Son los métodos más simples y despaciosos. Incluye el lanzamiento de monedas, dados, cartas y ruletas. Los números producidos por estos métodos cumplen las condiciones estadísticas básicas, pero es imposible reproducir una secuencia generada por estos métodos.
2.2 Tablas de Números Aleatorios
Estos números fueron generados por otros métodos y sometidos a diferentes pruebas estadísticas de uniformidad e independencia. La ventaja del método consiste en que las secuencias siempre son reproducibles y son muy apropiados para simulaciones de tipo manual. Sin embargo tiene la desventaja de no realizarse con rapidez. Además, para simulaciones por computador requeriría mucho almacenamiento, fuera de que el proceso de lectura de los datos es muy despacioso. Una de las tabla mas conocida es la de la Rand Corporation “Un Millón de Números Aleatorios”, que fue generada mediante el computador análogo. Para usar una tabla de números aleatorios, se debe definir un punto inicial de partida, y la dirección en que se van a seleccionar los números. Estos deben escogerse siguiendo el orden determinado de antemano.
2.3 Mediante el computador análogo.
Estos métodos dependen de ciertos procesos físicos aleatorios en el computador, por ejemplo, el comportamiento de una corriente eléctrica. Se considera que estos métodos producen verdaderos números aleatorios y son mucho más rápidos que los manuales o las tablas, pero las sucesiones de números no son reproducibles. Los números aleatorios de la Rand Corporation fueron generados mediante este método. Los números deben someterse a un conjunto de pruebas estadísticas para verificar uniformidad e independencia.
2.4 Mediante el computador digital
En esta sección analizaremos el proceso de generación de números aleatorios mediante programas de computador, bien sea a través de lenguajes de compilación de uso general, o de simulación, hojas de cálculo o mediante calculadoras científicas. Estos números se generan mediante una relación de recurrencia Esta alternativa comprende la generación de números “seudoaleatorios” por medio de una transformación aplicada a un grupo de números elegidos de una manera arbitraria. Se habla de números “seudoaleatorios” ya que, estrictamente hablando, estos números no son aleatorios, pero se comportan como si lo fueran. Estos números son generados por métodos completamente determinísticos y no presentan el problema de lectura ni de la capacidad de almacenamiento. La principal objeción a estos métodos radica en aspectos un tanto filosóficos respecto a que una sucesión de números producidos por métodos completamente determinísticos resulta ser la antítesis directa de una secuencia aleatoria. Sin embargo, esta objeción puede superarse si se someten los generadores a un conjunto de pruebas estadísticas para verificar la uniformidad e independencia de las series producidas por estos métodos. Generalmente mediante estos métodos se generan inicialmente números enteros y luego se normalizan en el rango cero uno mediante la transformación apropiada, dividiendo por un valor tal que a serie resultante quede entre cero y uno. En texto hablaremos en forma genérica de números “aleatorios”, bien sea que nos estemos refiriendo a números aleatorios estrictamente hablando o a números seudoaleatorios. A nivel meramente ilustrativo mencionaremos los primeros métodos usados para generar números seudoaleatorios, como son los métodos de las cuadrados y los productos centrales, y luego enfatizaremos en los métodos usados actualmente, basados en las relacioes de congruencia.
2.4.1 Método de los cuadrados centrales

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 4
Este es uno de los primeros métodos empleados para generar números aleatorios mediante el computador (Von Neumann). Cada número de la secuencia se obtiene tomando las k cifras centrales del cuadrado del número anterior. Si es necesario puede agregarse un cero (0) al principio o al final del cuadrado del número, de tal forma que el número generado siempre tenga k dígitos. Para generar el número aleatorio R entre cero y uno, se divide el número de k cifras por la máxima cantidad de números de k cifras que pueda generarse (M). Es decir,
Xn = K cifras centrales de n - 12X = D C (
n - 12X ) 0 Xn < M
Rn = Xn / M 0 r < 1 donde M = 10
k
Por lo tanto, para aplicar este método se deben definir dos parámetros: El número de dígitos k y el primer número de K cifras, X0 , denominado la “semilla”. Suponga que se desea generar números de tres cifras, es decir, que podrían generarse teóricamente hasta 1000 números diferentes (000, 001, 002, 998, 999). Además, es necesario especificar el número inicial o semilla. Sea este 721. Por lo tanto: X0 = 721, M = 10
3 = 1000
X1 = D C (7212) = DC (519841) = DC (0519841) = 198 R1 = 198/1000 = 0.198
X2 = D C (1982) = DC (39204) = 920 R2 = 920/1000 = 0.920
X3 = D C (9202) = DC (846400) = 464 R3 = 464/1000 = 0.464
X4 = D C (4642) = DC (215296) = DC (0215296) = 152 R4 = 152/1000 = 0.198
Este método tiene tendencia a degenerarse rápidamente, dependiendo del valor inicial, y no puede lograrse el período completo (h < M). Por ejemplo, si X0 = 10, entonces X1 = 10, X2 = 10, X3 = 10,..., Además, este método es relativamente lento y estadísticamente insatisfactorio.
2.4.2 Método de los productos centrales
Este método es una variante del anterior, pero el número resultante se genera como las k cifras centrales del producto de los dos números generados previamente. Es decir, Xn = D C( Xn-1 x Xn-2 ) Para empezar una secuencia, es necesario suministrar dos valores iniciales de k cifras cada uno. Por ejemplo, X0 = 13 y X1 = 15, para M = 100
X2 = DC ( 13 x 15 ) = DC (195) = DC (0195) = 19 R2 = 19/100 = 0.19
X3 = DC ( 15 x 19 ) = DC (285) = DC (0285) = 28 R3 = 28/100 = 0.28
X4 = DC ( 19 x 28 ) = DC (532) = DC (0532) = 53 R4 = 53/100 = 0.53 Los métodos anteriores tienen períodos relativamente cortos, los cuales se ven altamente afectados por los valores iniciales asignados. Además, son estadísticamente insatisfactorios.
2.4.3 Métodos congruenciales
Estos son los métodos que se usan actualmente, bien sea en su forma original, o mediante a combinación de diferentes generadores. 3 Métodos congruenciales
Los métodos congruenciales para generar números aleatorios son completamente determinísticos debido a que el proceso aritmético involucrado en el cálculo determina unívocamente cada término de la secuencia de

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 5
números. En efecto, existen fórmulas para calcular por adelantado el i -ésimo término de la secuencia { X0 , X1, X2,..., Xi,..., } sin que se hayan calculado los términos anteriores. Aunque la secuencia de números así generada no sea estrictamente aleatoria, puede considerarse como tal si satisface un conjunto de pruebas estadísticas sobre aleatoriedad, es decir, si se puede demostrar estadísticamente que los números generados se distribuyen uniformemente y son independientes. Los métodos congruenciales están basados n la relación fundamental de congruencia que puede expresarse por medio de la siguiente ecuación recursiva:
Xi (a Xi-1 +C) Módulo M donde a, Xi-1, C y M son enteros no negativos. Para poder entender claramente la relación fundamental de congruencia y su utilización en la generación de números aleatorios es necesario tener en cuenta las siguientes definiciones. Definición No 1 “Relación de Congruencia”.
Dos enteros A y B son congruentes módulo M si su diferencia es un múltiplo de M. La relación de congruencia
se expresa mediante la notación A B Mod M, que se lee ”A es congruente con B módulo M”. El hecho de que dos enteros A y B sean congruentes módulo M significa que:
1. A - B es divisible por M, es decir, A - B/M = entero = k. 2. A y B dan el mismo residuo al ser divididas por el módulo M, es decir, Res(A/M) = Res(B/M). Por ejemplo: Son congruentes 127 y 238 módulo 100?. Res (127/100) = 27
Res ( 238/100) = 38 127 y 238 no son congruentes módulo 100. Son congruentes 115 y 435 módulo 80 ?
Aplicando la definición 1 se tiene: 435 - 115/80 = 320/80 = 4 115 435 mod 80 Aplicando la definición 2 se tiene: Res(115/80) = 35
Res(435/80) = 35 115 435 mod 80 Cómo encontrar un número B que sea congruente con otro número dado A módulo M? El método mas sencillo sería dividir el número A por el módulo M y tomar el residuo como el número B buscado, o también, tomar el residuo mas un número entero k de veces el módulo o menos un número entero de veces el módulo.
B Res (A/M) Res (A/M) + M Res (A/M) +2 M ... Res (A/M) +k M ya que si se divide Res (A/M) +k M por el módulo M se obtiene el mismo residuo.
Ejemplo: 55 5 mod 10, 55 15 mod 10, 55 25 mod 10, 55 95 mod 10, 55 185 mod 10 Otra forma sería sumarle o restarle k veces el módulo al número dado A. Si a un número A se le suma o se le resta un número entero de veces el módulo la relación de congruencia no cambia ya que el residuo sigue siendo el mismo.
A (A + M) mod M (A - M) mod M (A + 2M) mod M (A - 2M) mod M (A kM) mod M, siendo k un entero. Qué número sería congruente con 425 módulo 90? Res (425/90) = 65
425 65 155 245 355 425 -25 -115 mod 90

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 6
Para encontrar un número que sea congruente con otro número negativo basta con sumarle el módulo cuantas veces sea necesario hasta que el número se vuelva positivo. Por ejemplo, qué número es congruente con - 173 módulo 100?.
-173 -173 + 100 mod 100 -73 mod 100 -73 +100 mod 100 27 mod 100 Son congruentes 434 y -166 módulo 100?. Para un número dado A existen muchos otros números que sean congruentes con A módulo M, como se observó anteriormente. Sin embargo, sólo existe un entero no negativo menor que M, (el residuo) que sea congruente con A Módulo M, y es el que se usará para la generación de números aleatorios. Este aspecto se formaliza mediante la siguiente definición. Definición No 2 “Residuo”
Para un valor dado A el menor entero positivo m que sea congruente con A módulo M (m A mod M) recibe el nombre de “residuo de A módulo M”. Para un número dado M existen entonces M residuos diferentes {0, 1, 2, ..., M-2, M-1}. Al conjunto de números enteros mutuamente congruentes con un residuo M se le denomina “Clase residual módulo M”.
Retomando la relación fundamental de congruencia Xi (a Xi-1 +C) Módulo M, tenemos que para generar números aleatorios mediante esta relación, el valor de Xi será el residuo módulo M de la operación “a Xi-1 +C”, es decir:
Xi = Residuo de (a Xi-1 +C) Módulo M 0 Xi < M
Se tiene que 0 Xi < M, entonces de la secuencia de enteros Xi se pueden obtener números racionales en el intervalo (0,1) -números aleatorios- dividiendo Xi por el módulo M, esto es,
Ri = Xi /M, 0 ri < 1 El valor M recibe el nombre de módulo, a es el multiplicador, C la constante aditiva y X0 la semilla. Por ejemplo, si M=100, a = 13, C = 7 y X0 = 3 se tiene:
X1 13 x 3 + 7 mod 100 46 mod 100 = 46 R1 = 46/100 = 0.46
X2 13 x 46 + 7 mod 100 605 mod 100 = 5 R2 = 5/100 = 0.05
X3 13 x 5 + 7 mod 100 72 mod 100 = 72 R3 = 72/100 = 0.72
X4 13 x 72 + 7 mod 100 943 mod 100 = 43 R4 = 43/100 = 0.43
X5 13 x 43 + 7 mod 100 566 mod 100 = 66 R5 = 66/100 = 0.66
X6 13 x 66 + 7 mod 100 865 mod 100 = 65 R6 = 65/100 = 0.65
X7 13 x 65 + 7 mod 100 852 mod 100 = 52 R7 = 52/100 = 0.52 Entonces, dadas la semilla X0, las constantes multiplicativa (a) y aditivas (C) junto con el módulo, la relación de congruencia permite obtener cualquier término de la secuencia {X1 , X2,..., Xi...,}. Al realizar la operación “a Xi-1 “ puede tomarse como valor de Xi-1 o el residuo de la operación anterior o el número completo sin reducir al residuo, y los resultados no cambian, ya que el número completo sin reducir contiene el residuo mas un número entero de veces el módulo.
Tomado la relación fundamental de congruencia Xi (a Xi-1 +C) Módulo M y aplicándola en forma recursiva para X1 , X2,..., Xi se obtiene:
X1 (a X0 +C) Mod M
X2 (a X1 +C) Mod M (a[a X0 +C] Mod M +C) Mod M (a2 X0 +aC +C) Mod M

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 7
X3 (a X2 +C) Mod M (a[a2 X0 +aC +C] Mod M +C) Mod M (a
3 X0 +a
2C + aC +C) Mod M
X4 (a X3 +C) Mod M (a[a3 X0 +a
2C + aC +C] Mod M +C) Mod M (a
4 X0 +a
3C + a
2C + aC +C) Mod M.
... En general, Xi puede expresarse como:
Xi (a Xi-1 +C) Mod M
(a[ai-1
X0 +ai-2
C + ai-3
C +...+aC+C] Mod M +C) Mod M
(ai X0 +a
i-1C + a
i-2C +...+ aC +C) Mod M (a
i X0 +[a
i-1 + a
i-2 +...+ a +1]C) Mod M
= (ai X0 + C
k
k
i
a
0
1
) mod M = ai X0 + C
i
aa
1
1mod M, si a 1
Entonces, dadas la semilla X0, las constantes multiplicativa (a) y aditivas (C) junto con el módulo, la relación de congruencia expresada en la forma anterior permite obtener cualquier término de la secuencia {X1 , X2,..., Xi...,} sin haber calculado previamente los números anteriores. La máxima cantidad de números de la secuencia {Xi} que se pueden producir es M, ya que en el instante en que se repita un número se repite toda la secuencia, por ser el proceso completamente determinístico y definido por una expresión matemática fija. Es decir, el período teórico máximo sería h = M. Sin embargo, el período largo es sólo uno de los criterios que se deben tener en cuenta para juzgar la bondad de un generador. Es posible obtener un período máximo en una secuencia no aleatoria. Por ejemplo, qué sucede si se escogen a = 1, c = 1, es decir, se tiene el siguiente generador ?.
Xi ( Xi-1 + 1) Módulo M Con respecto al período h se está interesado en el caso en que Xi = X0 = Xh porque entonces Xh+1 = X1, Xh+2 = X2 ,... y así sucesivamente, donde h es el período de la secuencia. El período de la secuencia depende del módulo M. El período siempre existirá y su valor máximo depende de M, y el que se logre ese valor máximo dependerá de la adecuada selección de los parámetros del generador. Sin embargo, el valor máximo no siempre será h = M en todos los casos. Mediante el empleo de diferentes versiones de la relación fundamental de congruencia se han desarrollado varios métodos para generar números aleatorios. El objetivo de cada uno de los métodos es la generación, en un tiempo mínimo, de secuencias con un período máximo. Entre los principales están el mixto, multiplicativo y métodos compuestos.
3.1 Método congruencial multiplicativo (c = 0)
Calcula una secuencia { Xi } de enteros no negativos cada uno de los cuales es menor que M mediante la
relación Xi a Xi-1 Mod M. Es un caso especial de la relación de congruencia en que la constante aditiva toma el valor de cero (C = 0). Por lo general, este método se comporta estadísticamente de una manera muy satisfactoria, es decir, las secuencias generadas se distribuyen uniformemente y no están correlacionadas. Sin embargo, tiene un período máximo menor que M, pero se pueden imponer condiciones a “X0“ y “a” de tal forma que se garantice el período máximo. Desde el punto de vista computacional es el más rápido de todos.
3.2 Método congruencial mixto o lineal
Genera secuencias de números mediante la relación fundamental de congruencia en su forma original tomando C > 0.
Xi (a Xi-1 + C) Módulo M C > 0

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 8
Las condiciones estadísticas de las secuencias generadas por este método son generalmente buenas, aunque en ciertos casos el comportamiento resulta inaceptable, razón por la cual el generador debe ser siempre validado estadísticamente. El período máximo es h = M.
3.3 Generadores compuestos
4 Selección de los Parámetros para métodos congruenciales
Se han desarrollado estudios teóricos acerca de las propiedades que deben cumplir los diferentes parámetros de los modelos de tal forma que se logre el período máximo y sean estadísticamente satisfactorios. Todos los estudios se basan en la Teoría de Números. La fórmula de Greenberger y Coveyou da las condiciones teóricas sobre los valores óptimos de a, C y M para una determinación a priori de la autocorrelación serial de primer orden entre dos números. La magnitud del
coeficiente de correlación serial ( Xi-1 , Xi ) se encuentra entre los valores:
1/a - (6c/aM) (1-C/a) a/M
En general, a = M dará los menores valores para el coeficiente de correlación serial de primer orden, independiente del valor de C. Este resultado proporciona una condición necesaria desde este punto de vista,
pero no es suficiente. Se ha demostrado experimentalmente que aunque a = M minimiza la correlación serial
de primer orden, tiende a maximizar la correlación serial de segundo orden (Xi-2 , Xi ) y que para lograr un adecuado balance entre estos dos coeficientes de correlación a debe ser mucho mayor que M (a>>M). Los siguientes dos teoremas dan las condiciones básicas que se deben tener en cuenta para la selección de los parámetros en generadores congruenciales. Teorema No 1. Un generador congruencial lineal tendrá período máximo M si y solo si
a. C es diferente de cero y es primo relativo con M (es decir, C y M no tienen ningún factor primo común).
b. (a mod q) 1 para cada factor primo q de M.
c (a mod 4) 1 si 4 es un factor de M. Recuerde que C y M son primos relativos si y solo si C y M no tienen otro divisor común diferente de 1, lo cual es equivalente a decir que no tienen factor primo común. Teorema No 2. Si C = 0 en un generador congruencial, entonces Xi = 0 no puede estar incluido en el ciclo,
dado que a partir de ahí se repetiría el cero. Sin embargo, el generador tendrá ciclo a través de todos los M-1 enteros en el conjunto {1, 2, ..., M-1} si y solo si: a. M es un entero primo y b. a es un elemento primitivo módulo M. Todos los parámetros son función del módulo, por lo tanto, este es el primero que debe seleccionarse y su selección debe hacerse teniendo en cuenta que el período de las secuencias sea lo mas grande posible.
4.1 Selección del Módulo para un generador congruencial
Para escoger el módulo se deben tener en cuenta dos aspectos:
El módulo M debe ser bastante grande, ya que el período nunca puede ser mayor que M.
M debe escogerse de tal forma que los números se generen a la mayor velocidad posible.
4.1.1 Módulo 2e
En los computadores generalmente se usa como módulo M = p
e que representa el tamaño de la palabra del
computador, donde p denota el número de guarismos del sistema numérico del computador y e el número de
dígitos (bits) en una palabra. Para un computador binario (como son la mayoría y por lo tanto sólo nos

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 9
concentraremos en ellos) p = 2 y para uno decimal p = 10. El valor de e depende del tipo de palabra empleado por el computador en sus operaciones. La mayoría de los computadores y microcomputadores pueden trabajar dos tipos de palabras: Palabras sencillas, en cuyo caso e = 15 y palabras dobles con e = 31. Aún otros computadores como el VAX 11 de Digital pueden trabajar con la palabra cuádruple, en cuyo caso e = 63. Así el módulo para palabra sencilla sería M = 2
15 = 32768 y con palabra doble sería M = 2
31 =
2147483648. Para palabras sencillas el número de bits usados para representar una palabra es 16, pero como se requiere uno para el signo sólo quedan disponibles 15. Para palabras doble (que es la palabra normal del computador) existen 32 bits, quedando disponibles 31 para representar los números. Existen dos razones para escoger M = p
e::
Trabajando con aritmética entera el proceso de reducción módulo M se efectúa mediante el truncamiento y la retención de los e bits de orden inferior.
La conversión al intervalo unitario, para obtener números entre 0 y 1 se logra moviendo el punto binario o decimal a la izquierda del número.
La reducción módulo M = 2
e es casi automática si las operaciones se realizan en aritmética entera, ya que el
mayor entero positivo que puede almacenar el computador es 2e
-1 y el mayor entero negativo es -2e. Es
decir, cualquier entero que maneje el computador estará entre -2e y -2
e. Para el caso de un computador
binario con palabra sencilla los números estarían entre -32768 y +32767. Cuando el computador efectúe cualquier operación entera el resultado estará representado por un número entre -32768 y +32767. La forma como el computador expresa los números se representa por medio de la figura siguiente: -2 -1 0 1 2 -3 -3 -4 65536 65535 65534 32771 32770 32769 -32765 32765 -32766 32766 -32767 32767 -32768 +32768 Suponga que se está usando el método congruencial mixto, es decir:
Xi (a Xi-1 +C) Módulo 215
= (a Xi-1 +C) Módulo 32768 El computador efectuará el producto a Xi-1 y le agregará c. Si el resultado da menor que 32768 el computador almacenará ese número (positivo). Si el resultado da entre 32768 y 65535 el computador registrará un número negativo. Si el resultado es 65536 el computador guardará cero. Si está entre 65536 y 98303 el computador guardará un número positivo. Por ejemplo:
Si el resultado es 32766 el computador guardará 32766, que es el residuo módulo 32768.
Si el resultado es 32767 el computador guarda 32767, que es el mismo residuo.
Si el resultado es 32768 el computador no está en capacidad de almacenar este número, sino que lo representa como -32768. Ahora bien, el residuo de 32768 módulo 32768 es cero. Es decir, se requiere convertir -32768 en 0 que es el residuo. Para convertirlo en cero basta con sumarle el módulo (32768),

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 10
pero es necesario sumarlo en dos partes, tal como 32767+1. (Por qué es necesario hacer el cálculo de esta manera? )
Así: -32768 = -32768 + 32767 + 1 = 0
Si el resultado es 32769 (cuyo residuo es 1) el computador lo representa como -32767 y para encontrar el residuo basta con sumarle el módulo en forma similar al caso anterior.
La siguiente tabla ilustra varios posibles resultados, su representación en el computador y su residuo
RESULTADO REAL
RESIDUO MODULO 32768
RESULTADO DEL COMPUTADOR
PROCESO CONVERSION RESIDUO MOD 32768
1 1 1 No hay
20 000 20000 20000 No hay
32 766 32766 32766 No hay
32 767 32 767 32 767 No hay
32 768 1 -32 768 -32 768 + 32767 +1 = 0
32 769 2 -32 767 -32 767+32767 + 1 = 1
32 770 3 -32 766 -32 766 +32767 + 1 = 2
... ... ... ...
65 534 32766 -2 -2 +32767 + 1 = 32766
65 535 32767 -1 -1 + 32767 + 1 = 32767
65 536 0 0 0
65 537 1 1 1
65 538 2 2 2
4.1.2 Módulo 2
e – 1 (2
31 - 1)
Este módulo (2
31 – 1) se usa principalmente en generadores congruenciales multiplicativos. La razón principal
para usar el módulo 2e - 1 en lugar de 2
e es que se puede obtener un período de M-1, aprovechando el hecho
de que (231
– 1) es un número primo. Sin embargo, los métodos no serían tan eficientes como en caso en que M = 2
31 ya que habría que diseñar algoritmos mas complicados para efectuar la reducción módulo M.
4.2 Método lineal o mixto
Este método tiene la ventaja de que puede lograrse el período completo h = M, pero puede presentar problemas de aceptabilidad estadística. Está basado en la relación fundamental de congruencia con C > 0. Las condiciones impuestas al multiplicador y a la constante aditiva para obtener el período máximo son las dadas por el teorema No 1 enunciado previamente, y se resumen en las siguientes:
c > 0 debe ser primo relativo con M. si M = 2e (=2
31) c debe ser un número impar.
a 1 mod q para cada factor primo q de M. si M = 2e (=2
31) a debe ser un número impar.
a 1 mod 4 si 4 es un factor de M, es decir, “a” puede expresarse como a = 4k+1, siendo k un número entero.
Como se obtiene el período completo, entonces puede seleccionarse cualquier entero como semilla.
Además, para minimizar la correlación serial de primer y segundo orden a >> M .
Sin embargo las condiciones anteriores no son suficientes para garantizar que las secuencias generadas por el método congruencial lineal serán estadísticamente satisfactorias. Sólo mediante el uso de pruebas estadísticas se puede tener confianza en las propiedades de las secuencias generadas mediante este método.
4.3 Método congruencial multiplicativo
Los números aleatorios se generan haciendo uso de la relación Xi a Xi-1 Mod M ai mod M.

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 11
Para el módulo puede escogerse M = 2
e = 2
31 para obtener una mayor eficiencia en la generación de las
secuencias de números o M = 231
- 1 si se desea obtener una mayor aleatoriedad en las últimas cifras de los números y un período mayor.
4.3.1 Método congruencial multiplicativo , módulo 231
Para el módulo M = 2
e el período máximo es h = 2
e--2 Para palabra simple e = 15 y para palabra doble e =31,
es decir, los períodos máximos serían 8192 y 536870912, respectivamente. Para lograr el período máximo la semilla X0 y el multiplicador a deben cumplir ciertas condiciones. Las condiciones que debe cumplir el multiplicador a para obtener el período máximo son las siguientes:
a debe ser primo relativo con M. Es decir, si M = 2e
y a es primo relativo con M entonces a debe ser un número impar.
Los valores de a que garantizan período máximo residen en una clase residual representada por la
relación de congruencia: a 3 mod 8. Usando esta relación entonces a puede expresarse también como
a = 8 k 3, siendo k un número entero positivo.
De acuerdo con la fórmula Greenberger Coveyou los valores de a cercanos a M = 2e/2
minimizan la
correlación serial de primer orden entre dos números aleatorios. Sin embargo, como ya se indicó, se tiende a maximizar la correlación serial de segundo orden por lo cual se recomienda que el valor de a sea mucho
mayor que la raíz del módulo (a >> M ). Por lo tanto se deben ensayar varios valores y escoger el que
tenga un mejor comportamiento estadístico. Condiciones que debe cumplir el valor inicial o semilla:
Dado que no se puede obtener el valor de cero y M = 2e
, entonces el valor inicial o semilla X0 debe ser primo relativo con el módulo, es decir, X0 debe ser un número impar.
Como ya se indicó, todos los cálculos deben realizarse en aritmética entera. Si se desea generar números aleatorios, usando palabra sencilla, cual de los siguientes valores serían apropiados como multiplicadores (a): 131, 179, 181, 191, 715, 717 719? Las siguientes subrutinas, apropiadas para el lenguaje FORTRAN, generan números aleatorios usando palabra sencilla y palabra doble, que es la normal, por defecto, mientras no se defina lo contrario. (La primera rutina corresponde a la rutina RANDU de la IBM). Subroutine randon (semi,r) Subroutine randon (semi,r) integer *2 semi, semi1 semi1 = 899*semi semi1 = 1220703125*semi If(semi1.lt.0)then If(semi1.lt.0)then semi1=semi1+32767+1 semi1 = semi1 +2147483647+1 end if end if r = float(semi1)/32768. r = float(semi1)*0.4656613E-9 semi = semi1 semi = semi1 return return end end Para la palabra sencilla se usa un multiplicador de 899, mientras que para la palabra doble el valor es de 5
13 .
Ambas subrutinas tienen dos argumentos: 1) “semi” que corresponde al valor inicial de la semilla, la primera vez que se la llame, y las otras veces al valor generado previamente, 2) “r” que corresponde al número aleatorio generado entre 0 y 1. Las rutinas efectúan el producto entre el multiplicador a y la semilla y verifican si es negativo. Si resulta negativo, entonces calculan el residuo sumándole el módulo; si es positivo, el valor calculado es directamente el residuo y no hay que hacer ninguna operación adicional. Posteriormente se divide por el módulo (en aritmética real) para obtener el número aleatorio y se cambia el valor de la semilla, de tal forma que la próxima vez que se llamen las rutinas, empleen el último valor generado.

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 12
Para aprovechar la reducción automática módulo M es necesario investigar las características propias del lenguaje que se esté empleando, para conocer la forma como se hace el respectivo truncamiento. Por ejemplo, para trabajar en FORTRAN con palabra sencilla basta con hacer la declaración INTEGER *2; en otros caso puede ser el comando NOCHECK OVERFLOW, etc. 5 Pruebas estadísticas para generadores de números aleatorios
Las propiedades estadísticas de lo números seudoaleatorios generados por los métodos explicados en los párrafos anteriores deberían coincidir con las propiedades estadísticas de números generados por un procedimiento aleatorio idealizado que seleccione números en el intervalo (0,1), que sean independientes y que todos sean igualmente probables. Claramente los números aleatorios generados por programas de computador no son aleatorios, dado que están completamente determinados por los datos iniciales y por los parámetros del método empleado. Sin embargo, estos números pueden considerarse como verdaderos números aleatorios si pasan una serie de pruebas estadísticas sobre la uniformidad y la independencia de las secuencias de números generados. Los requisitos que se impongan a un conjunto particular de números (a una secuencia) deben estar basados principalmente en la aplicación que se desee dar a esos números en los experimentos de simulación. Se han propuesto diferentes pruebas que proveen las herramientas estadísticas necesarias para validar la aleatoriedad de un conjunto de números para unas condiciones dadas. El analista debe decidir cuáles de las pruebas ha de emplear para estar seguro de que su generador sí producirá números aleatorios, según su aplicación específica. En los párrafos siguientes se resumen las principales pruebas estadísticas.
5.1 Pruebas sobre la Uniformidad de la distribución
Un análisis básico que siempre debe realizarse es la validación de la uniformidad de la distribución. Se proponen dos pruebas básicas que pueden aplicarse: La prueba Chi - Cuadrado y la prueba de Smirnov-Kolmogorov. Ambas pruebas caen en la categoría de lo que en estadística se denominan pruebas de “Bondad de Ajuste” y miden el grado de ajuste entre la distribución obtenida de una muestra de números aleatorios y la distribución teórica que se supone debe seguir esa muestra, en nuestro caso la distribución uniforme. Ambas pruebas están basadas en la hipótesis nula de que no hay diferencias apreciables (significativas) entre la distribución muestral y la teórica. En resumen ambas pruebas están basadas en las siguientes hipótesis:
Hipótesis Nula H0: Los valores provienen de una distribución uniforme (0,1) Hipótesis Alternativa H1: Los valores no provienen de una distribución uniforme (0,1)
5.1.1 Prueba Chi Cuadrado (ji dos)
Esta prueba se usa cuando se quiere probar la hipótesis de que unos datos muestrales provienen de una determinada distribución. Se quiere demostrar que no existe una diferencia significativa entre la distribución de frecuencia de la muestra y la distribución uniforme. La prueba chi cuadrado permite determinar si las frecuencias observadas en la muestra están lo suficientemente cerca de las frecuencias esperadas bajo la hipótesis nula. Para esta prueba es necesario agrupar o distribuir los números aleatorios generados en intervalos de clase, preferiblemente del mismo tamaño. El estadístico de prueba está definido como:
2
2
1X
iO iE
Eii
k
donde: Oi = Frecuencia absoluta, o total de números aleatorios que caen en el intervalo i. Ei = Número esperado de valores en el intervalo i. k = Número de intervalos de clase en que se distribuyen las observaciones.

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 13
Si los límites del intervalo de clase están dados por Xi-1, y Xi, como lo ilustra la presente gráfica, el número esperado de observaciones para ese intervalo está dado por: Ei = pi n donde: pi = probabilidad de que una observación (un número aleatorio) quede en el intervalo i. n = Total de observaciones o números aleatorios generados. Ei X0 X1 X2 Xi-1 Xi Xk La probabilidad de que un número aleatorio caiga en el intervalo i está dada por:
kxx
xdx
x
xdxxf xxp iii
i
i
i
i
/1)(1
11
siendo f(x) la función de densidad de la variable aleatoria X, bajo la hipótesis nula. En nuestro caso, tratándose de la distribución uniforme y para k intervalos de clase igualmente espaciados, la probabilidad de que una observación quede en el intervalo i está dada por: . pi = 1/k, i = 1, 2 ,,, k Entonces el número de observaciones en cada intervalo está dado por: Ei = pi n = n/k, i = 1, 2 ,,, k Estadístico X
2 sigue una distribución chi cuadrado con k - 1 grados de libertad. Para que esta suposición sea
válida se requiere que el número esperado de observaciones en cada intervalo de clase sea por lo menos 5
(Ei 5). Si esta condición no se cumple, es necesario agrupar en uno los resultados de varios intervalos de clase. Para la prueba de uniformidad se calcula el valor X
2 como se acaba de explicar, y se acepta la hipótesis nula
si X2
k 1 1
2
, , donde el valor
k 1 1
2
, representa el valor de la distribución chi cuadrado con k-1 grados de
libertad y un nivel de significancia de , es decir, que tiene un área de 1 - a la izquierda ( a la derecha). Algunas consideraciones que hay que tener en cuenta con respecto a la aplicación de esta prueba son las siguientes:
El número de intervalos de clase debe ser por lo menos cinco. Para facilidad de los cálculos y para una
buena visualización de la distribución tampoco debería ser muy grande ( k 20).
El número esperado de observaciones en cada intervalo debe ser mayor o igual a cinco; en caso contrario, deberían agruparse varios intervalos para lograr esto.

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 14
Ejemplo. En la tabla siguiente se presentan los cálculos para realizar la prueba Chi cuadrado para una
muestra de 100 números aleatorios generados mediante el generador congruencial multiplicativo con a = 899, c = 0 y M = 32768, y distribuidos en 10 intervalos de clase.
PRUEBA DE UNIFORMIDAD CHI CUADRADO
Clase/concepto 1 2 3 4 5 6 7 8 9 10
Límite Inf Xi-1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
Límite Sup Xi 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
Oi 14 15 9 8 4 11 10 10 7 12
pi 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
Ei 10 10 10 10 10 10 10 10 10 10
2
iO iE
Ei
1.6 2.5 0.10 0.40 3.6 0.1 0.0 0.0 0.9 0.4
2
1
iO iE
Eii
k
1.6 4.1 4.2 4.6 8.2 8.3 8.3 8.3 9.2 9.6
El estadístico de prueba X2 = 9.6 y el valor crítico
k 1 1
2
, = 21.7 para un nivel de significancia del 1%, lo
cual nos lleva a aceptar la hipótesis de que los valores generados provienen de una distribución uniforme.
5.1.2 Prueba de Simirnov - Kolmogorov (s-K)
En esta prueba también se está interesado en el grado de concordancia entre la distribución de frecuencia muestral y la distribución de frecuencia teórica, bajo la hipótesis nula de que la distribución de la muestra es uniforme (0,1), e interesa probar que no existe diferencia significativa. La prueba trabaja con la función de distribución (distribución de frecuencia acumulativa), y se puede realizar para valores agrupados en intervalos de clase, o para las observaciones individuales, sin agrupar. Sea FX (x) la función de distribución teórica para la variable aleatoria X (uniforme en nuestro caso), y representa la proporción esperada de observaciones que tengan un valor menor o igual a x. Es decir:
FX (x) = P ( X x) =
x
dxxf )( = x si X es U(0,1)
Sea Sn(x) la función de distribución empírica (observada) de la muestra de n observaciones (números aleatorios). Sn(x) representa la proporción de valores observados (generados) que son menores o iguales a x, y está definida como:
Sn(x) = P(X x/dados los resultados muestrales) = m/n donde m es el número de valores observados (generados) que son menores o iguales a x. En la prueba de Smirnov-Kolmogorov se está interesado en la mayor desviación entre la función de distribución teórica y la empírica, es decir entre FX (x) y Sn(x), para todo el rango de valores de x. Bajo la hipótesis nula se espera que estas desviaciones sean pequeñas y estén dentro de los límites de errores aleatorios. Por lo tanto, en la prueba S-K se calcula la mayor desviación entre FX (x) y Sn (x), denotada por D(x) y está dada por: D(x) = Max | FX (x) – Sn(x) | La distribución de D(x) es conocida y depende del número de observaciones n. Se acepta la hipótesis nula de que no existe diferencia significativa entre las distribuciones teórica y empírica si el valor de D(x) es menor o
igual que el valor crítico Dmax(1-,n). (Ver tabla adjunta para valores críticos).

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 15
Prueba Smirnov – Kolmogorov para observaciones agrupadas en intervalos de clase
El procedimiento general para realizar esta prueba se puede resumir en los siguientes pasos: siguiente:
Especificar la distribución nula, la cual se supone que sigue la muestra aleatoria, os números generados, la uniforme en nuestro caso.
Organizar la muestra observada de números aleatorios en una distribución de frecuencia.
Con base en la distribución observada de frecuencia, se calcula la distribución acumulativa Sn(x), que corresponde a la frecuencia relativa acumulada para el intervalo.
Se calcula la función de distribución teórica FX(x).
Para cada intervalo de clase (o para cada valor de x) se calcula la diferencia entre FX (x) y Sn (x), y se busca la máxima D(x) = Max | FX (x) – Sn(x) |.
Se busca en la tabla el valor crítico Dmax(1-, n) con un nivel de significancia . Si el valor observado D(x) es menor o igual que el valor crítico, entonces se acepta la hipótesis nula de que no existen diferencias significativas entre la distribución teórica y la distribución dada por los resultados muestrales, es decir, que los valores generados siguen la distribución que se había supuesto (uniforme).
Tabla No 2
Prueba de Smirnov-Kolmogorov. Valores críticos Dmax(1-,n) de la máxima diferencia absoluta entre las función de distribución muestral y teórica.
Tamaño de la muestra
Nivel de significancia
.20 .15 0.10 0.05 0.01
1 .9000 .925 .950 .875 .995
2 .684 .726 .776 .842 .929
3 .565 .597 .642 .708 .828
4 .494 .525 .564 .624 .733
5 .446 .474 .510 .565 .669
6 .410 .436 .470 .521 .618
7 .381 .405 .438 .486 .577
8 .358 .381 .411 .457 .543
9 .339 .360 .388 .432 .514
10 .322 .342 .368 .410 .490
11 .307 .326 .352 .391 .468
12 .295 .313 .338 .375 .450
13 .284 .302 .325 .361 .433
14 .274 .292 .314 .349 .418
15 .266 .283 .304 .338 .404
16 .258 .274 .295 .328 .392
17 .250 .266 .286 .318 .381
18 .244 .259 .278 .309 .371
19 .237 .252 .272 .301 .363
20 .231 .246 .264 .294 .356
25 .210 .220 .240 .270 .320
30 .190 .200 .220 .240 .290
35 .18 .190 .201 .230 .270
35 1.07/ N 1.14/ N 1.22/ N 1.36/ N 1.63/ N
Valores de Dmax(1-,n) tales que Pr {Max | FX (x) – Sn (x) | Dmax(1-,n)} = 1- Tabla tomada parcialmente del libro “Simulation and Analysis of Industrial Systems”, de Schmidt y
Taylor.

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 16
Ejemplo: Prueba de Smirnov - Kolmogorov - Valores agrupados. En la tabla siguiente se presentan los
cálculos para realizar la prueba S-K para la muestra de 100 números aleatorios generados mediante el generador congruencial multiplicativo con a = 899, c = 0 y M = 32768, usados para la prueba chi cuadrado.
Prueba de Smirnov - Kolmogorov - Valores agrupados
Clase/concepto 1 2 3 4 5 6 7 8 9 10
Límite Inf Xi-1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
Límite Sup Xi 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
Oi 14 15 9 8 4 11 10 10 7 12
Oi 14 29 38 46 50 61 71 81 88 100
Sn(x) .14 0.29 0.38 0.46 0.50 0.61 0.71 0.81 0.88 1.00
FX (x) 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00
| FX (x) – Sn (x) | 0.04 0.09 0.08 0.06 0.00 0.01 0.01 0.01 0.02 0.00
La diferencia máxima observada es Dmax(x) = 0.09 y el valor crítico para un nivel de significancia del 1% es de
1.63/ 100 = .163. Como Dmax(x) < D(100,.99) no podemos rechazar la hipótesis nula y debemos concluir que
la muestra tomada del generador de números aleatorios proviene de una distribución uniforme (0,1). Prueba Smirnov – Kolmogorov para observaciones individuales
Para realizar la prueba de S-K no se requiere que las observaciones estén distribuidas en intervalos de clase, sino que puede realizarse sin necesidad de agrupar los valores en intervalos de clase, principalmente cuando el tamaño de la muestra es pequeño. En este caso es necesario ordenar los valores generados en forma ascendente, de menor a mayor, y calcular, para cada valor observado, (sin agrupar en intervalos de clase) las distribuciones teóricas Fx(x) y empíricas Sn(x) en la forma como se explicó anteriormente. Ejemplo. La tabla siguiente presenta la prueba para los primeros 20 valores generados mediante el generador congruencial multiplicativo considerado anteriormente (a = 899, c = 0 y M = 32768). La diferencia máxima observada es 0.123 y la máxima permitida es 0.294 para 20 valores y un nivel de significancia del 5%, lo cual lleva a la conclusión de que no existe evidencia de que las observaciones no se distribuyan uniformemente en el intervalo (0,1).
Prueba de Smirnov - Kolmogorov - Valores individuales
Observación No 1 2 3 4 5 6 7 8 9 10
Valor R 0.066 0.075 0.080 0.119 0.178 0.228 0.262 0.348 0.573 0.620
Sn(x) 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50
FX (x) 0.066 0.075 0.080 0.119 0.178 0.228 0.262 0.348 0.573 0.620
| FX (x) – Sn(x) | 0.016 0.025 0.070 0.081 0.072 0.072 0.088 0.052 0.123 0.120
Observación No 11 12 13 14 15 16 17 18 19 20
Valor R 0.635 0.695 0.709 0.719 0.829 0.908 0.916 0.945 0.964 0.973
Sn (x) 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 1.00
FX (x) 0.635 0.695 0.709 0.719 0.829 0.908 0.916 0.945 0.964 0.973
| FX (x) – Sn (x) | 0.085 0.095 0.059 0.019 0.079 0.108 0.066 0.045 0.014 0.027
La prueba de Smirnov - Kolmogorov tiene las siguientes características:
La prueba puede aplicarse para tamaños de muestra pequeños, lo que no sucede con la chi cuadrado.
Además, la prueba S-K es mas poderosa que la Ji dos, es decir, cuando se rechaza la hipótesis nula, se tiene una mayor confiabilidad en dicho resultado.
La prueba S-K debe usarse cuando la variable de análisis es continua. Sin embargo, si la prueba se usa cuando la distribución de la población no es continua, el error que ocurre en la probabilidad resultante está en la dirección segura. Es decir, cuando se rechaza la hipótesis nula, tenemos verdadera confianza en la decisión.

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 17
5.2 Pruebas de Independencia
Las dos pruebas anteriores son aplicables para verificar la uniformidad de la distribución de una secuencia de números aleatorios, pero ninguna tiene en cuenta el ordenamiento de la secuencia de números aleatorios, de acuerdo al tiempo de generación. Por ejemplo, si a la secuencia 1, 1, 1, 3, 3, 3, 5, 5, 5, 7, 7,7, 9, 9, 9, 0, 0, 0, 2, 2, 2, 4, 4, 4, 6, 6, 6, 8, 8, 8 se le aplicaran las dos pruebas anteriores las pasarían con una confiabilidad del 100%. Sin embargo, la secuencia anterior dista mucho de ser aleatoria. Esto ilustra la necesidad de efectuar otras pruebas que incluyan aspectos tales como el orden en que aparecen los números, para verificar si en realidad son independientes. Estas pruebas se las conoce con el nombre de “Pruebas de Rachas o Corridas”.
5.2.1 Pruebas de Rachas
Estamos interesados en el arreglo particular de los números dentro de una secuencia para determinar su aleatoriedad. La secuencia 0, 1, 2 , 3, 4, 5, 6, 7, 8, 9 y 1, 7, 3, 4, 9, 6, 2, 5, 0 ,8 , aunque contienen los mimos números son completamente diferentes. En la primera secuencia encontramos los números en orden ascendente, de 0 a 9, mientras que en la segunda no hay ningún ordenamiento aparente entre los mismos. En la primera secuencia los números forman lo que se denomina una “racha ascendente” de longitud 9, es decir, existe una serie de nueve aumentos sucesivos. Definición. Una racha se define como una serie de eventos o fenómenos de una misma clase. Por ejemplo,
una racha de mala suerte. La longitud de una racha es el número de elementos o eventos que contiene la racha. El propósito de estudiar las rachas es analizar el carácter aleatorio de una secuencia de números. Para la aplicación del análisis de rachas se requiere que los eventos que puedan ocurrir se puedan clasificar en una de dos categorías mutuamente excluyentes. Para una secuencia de valores, las rachas se pueden clasificar en dos formas diferentes:
Rachas ascendentes o hacia arriba y rachas descendentes o hacia abajo, dependiendo de si un número está seguido por otro mayor o por otro menor. Por ejemplo, en la secuencia 1, 5, 6, 8, 4, 2, 0, 1 , 7 se presenta una racha ascendente de longitud tres, una descendente de longitud tres y finalmente una ascendente de longitud dos.
Rachas por encima o por debajo del valor medio. En este caso la racha se clasifica dependiendo de si un valor está por encima o por debajo del valor medio (0.5 para el caso de números aleatorios). En la secuencia 0.1, 0.5, 0.6, 0.8, 0.4, 0.2, 0.0, 0.1, 0.7 se presenta una racha por debajo de longitud 1, una por encima de longitud tres (suponiendo que 5 está por encima del valor medio), una por debajo de longitud cuatro y finalmente una por encima de longitud uno.
Al examinar la aleatoriedad de una secuencia de números aleatorios, debemos analizar tanto el comportamiento del número de rachas (por encima y por debajo, ascendentes y descendentes) como la distribución de la longitud de las diferentes rachas. Inicialmente analizaremos el número total de rachas que se presentan en una secuencia de números.
5.2.1.1. Análisis del número de rachas.
Rachas hacia arriba y hacia abajo.
Una racha ascendente o hacia arriba es una sucesión de aumentos, es decir, si se tiene una secuencia de números tal que cada número de la secuencia esté seguido por otro mayor. Si la secuencia es tal que cada número está seguido por otro menor, la secuencia recibe el nombre de racha descendente o hacia abajo.. Considere la secuencia de 20 números
3, 1, 2, 3, 6, 4, 5, 4, 1, 2, 6, 8, 9, 7, 5, 2, 3, 1, 5, 1,

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 18
A cada número de la secuencia le podemos asignar un código especial (+, o un 1) si este número está seguido por otro mayor, y otro signo (- o un 0) si el número está seguido por otro menor. En la secuencia anterior tendríamos la siguiente representación:
- + + + - + - - + + + + - - - + - + - Cada secuencia de + y - constituye una racha y su longitud está dada por el número de signos iguales contenidos en la racha. Para esta secuencia, se presentan cinco rachas ascendentes y seis descendentes, para un total de once. El número mínimo de rachas ascendentes y descendentes es uno y el máximo n - 1, si hay n valores en la secuencia. Por lo tanto, una secuencia puede ser no aleatoria si hay o muy pocas o demasiadas rachas. Por ejemplo, considere las dos secuencias siguientes : Secuencia A: 10, 30, 33, 45, 50, 63, 70, 77, 81, 87 Secuencia B: 43, 17, 42, 30, 55, 19, 75, 11, 25, 07 En la secuencia A se tiene únicamente una racha, de longitud nueve, es decir, cada valor está seguido siempre por otro mayor, mientras que en la secuencia B se tienen nueve rachas, 4 ascendentes y cinco descendentes. Dado que no es lógico esperar que los números aleatorios aumenten continuamente, podríamos cuestionar la aleatoriedad de la primera secuencia. De igual forma, podríamos cuestionar la aleatoriedad de la secuencia B ya que tampoco es normal que los números aumenten y disminuyan continuamente, en forma cíclica. Esperamos que el total de rachas en una secuencia de verdaderos números aleatorios esté en algún valor entre uno y n-1. Sea A el número total de rachas ascendentes y descendentes en una secuencia de n números aleatorios. La
media y la varianza de A, A y A2 están dadas por:
A
N
2 1
3
90
29N162
A
Para n > 20 la distribución de A puede aproximarse por una distribución normal con la media y varianza dadas por las expresiones anteriores. Esta aproximación es apropiada para probar la aleatoriedad de los valores generados por un generador de números aleatorios, dado que generalmente se generan cientos de valores antes de aplicar la prueba. La hipótesis de que una secuencia es aleatoria puede rechazarse, o bien porque existan pocas rachas, o bien porque existan demasiadas. Por consiguiente, se requiere efectuar una prueba de dos colas para determinar si ha ocurrido alguno de los extremos. El estadístico de prueba sería:
ZA
A
A
donde Z se distribuye normalmente con media cero y varianza unitaria.
Si es el nivel de significancia de la prueba y Z1-/2 es el valor de la distribución normal (0,1) que tiene un área
de 1-/2 hacia la izquierda, es decir, es el valor para el cual se cumple que:
1-/2 = P( Z Z1-/2 ) P( Z Z1-/2 ) = /2 entonces se puede rechazar la hipótesis de la aleatoriedad de la secuencia si

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 19
Z Z1-/2 Ejemplo: Considere el generador congruencial multiplicativo definido por los siguientes parámetros : a = 899, c = 0 y M = 32768. Determine si las secuencias generadas pueden considerarse como aleatorias, con base en la prueba de rachas ascendentes y descendentes. Use un nivel de significancia del 5%. Para probar la hipótesis anterior, se generó una secuencia de 100 números aleatorios, los cuales se presentan a continuación. Para visualizar mejor su presentación, los valores se presentan como enteros, con dos cifras.
95 97 83 72 35 12 8 91 23 69 62 96 71 8 57 26 92 64 7 18
98 75 22 9 1 79 17 36 15 14 3 38 51 17 93 51 23 26 99 14
42 77 34 63 21 9 11 37 73 58 41 72 10 64 38 7 45 62 14 78
90 91 81 23 58 87 52 80 61 89 40 87 11 34 56 80 22 60 14 97
5 3 26 76 73 2 4 55 39 94 61 70 16 17 10 59 14 7 62 60
La secuencia de rachas ascendentes y descendentes es la siguiente :
+ - - - - - + - + - + - - + - + - - + + - - - - + - + - - - + + - + - - + + - + + - + - - + + + - - + - + - - + + - + + + - - + + - + - + - + - + + + - + - + - - + + - - + + - + - + - + - + - - + -
La distribución del número de rachas es la siguiente:
Longitud de Racha 1 2 3 4 5 Total A
Número de rachas 42 18 4 1 1 66
Se tiene entonces: n = 100, A = 66. La media y la varianza estarán dadas por:
A
N x
2 1
3
2 100 1
366 3.
A
N x2 16 29
90
16 100 29
9017 46
.
A 418.
Z
66 663
4180 072
.
..
Para un nivel de significancia del 5%, se tiene que Z1-/2 = 1.96. Por lo tanto, dado que Z <Z0.975 se acepta que, en cuanto al número de rachas ascendentes y descendentes,la secuencia es aleatoria. Rachas por encima y por debajo
La prueba anterior no es suficiente para probar la aleatoriedad de una secuencia de números. Para ilustrarlo, considere la siguiente secuencia: 35, 12, 11, 17, 41, 48, 12, 16, 40, 36, 32, 12, 25, 31, 48, 11, 51, 66, 77, 65, 75, 88, 67, 90, 96, 54, 72, 89, 86, 93, 66, 59 La secuencia de rachas ascendentes y descendentes sería :
- - + + + - + + - - - + + + - + + + - + + - + + - + + - + - -

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 20
Si se realiza el análisis de rachas ascendentes y descendentes, (a = 17, A =21, A2
=5.4, Z=-1.72) se concluye que no hay evidencia para dudar de la aleatoriedad de la secuencia. Sin embargo, esta secuencia no es aleatoria ya que la primera mitad de los valores están por debajo de la media (50) mientras que la otra mitad está por encima. Por lo tanto, se concluye que se debe realizar el análisis de rachas no sólo ascendentes y descendentes sino también por encima y por debajo de la media. Una racha por encima del valor medio es una sucesión de valores o puntos que están por encima de su valor esperado. Una racha por debajo del valor medio es una sucesión de valores o puntos que están por debajo de su valor esperado. Al analizar una secuencia de números, le asignaremos un signo “+” o un “1” a aquellos valores que estén por encima de 0.5 y un signo “-“ ó un “0” a aquellos valores que estén por debajo de 0.5. Sean n1 y n2 el número de valores individuales por encima y por debajo de la media. Sea B el número total de rachas por encima y por debajo de la media en una secuencia de n valores. El valor esperado y la varianza
del número total de rachas por encima y por debajo del valor medio (B y B2
) estén dados por :
1n2n1
n2n12B
)1n2n1()n2n1( 2
)n2n1n2n12(n2n122B
Para n1 o n2 mayores de 20 B tiende a distribuirse normalmente con la media y varianza dadas por las expresiones anteriores. El estadístico para la prueba sería:
ZB
B
B
donde Z se distribuye normalmente con media cero y varianza unitaria. Si se tiene una secuencia de n números aleatorios, el mínimo número de rachas es uno y el máximo posible es n. Dado que estamos interesados en la ocurrencia de muy pocas o de demasiadas rachas, se requiere efectuar una prueba de dos
colas para determinar si ha ocurrido alguno de los extremos. Si es el nivel de significancia de la prueba y Z1-
/2 es el valor de la distribución normal (0,1) que tiene un área de 1-/2 hacia la izquierda, rechazamos la
hipótesis de aleatoriedad si Z Z1-/2 Ejemplo : Considere el generador congruencial multiplicativo definido por los siguientes parámetros : a = 899, c = 0 y M = 32768. Determine si las secuencias generadas pueden considerarse como aleatorias, con base en la prueba de rachas por encima y por debajo del valor medio. Use un nivel de significancia del 5%. Para probar la hipótesis anterior, se generó una secuencia de 100 números aleatorios, los cuales se presentaron en el ejemplo de rachas ascendentes y descendentes presentado anteriormente. Las rachas por encima y por debajo del valor medio son las siguientes:
+ + + + - - - + - + + + + - + - + + - - + + - - - + - - - - - - + - + + - - + - - + - + - - - + + - + - + - - - + - + + + + - + + + + + + - + - - + + - + - + - - - + + - - + - + + + - - - + - - + +
La distribución del número de rachas es la siguiente:
Longitud de Racha 1 2 3 4 5 6 Total B
Número de rachas 28 13 6 4 0 2 53
Se tiene entonces : n = 100, B = 53, n1 =50, n2 = 50. La media y la varianza estarán dadas por:

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 21
B
x x
2 50 50
50 501 51
B
x x x x2 2 50 50 2 50 05 50 50
250 50 50 50 1
24 75
( )
( )
. B 4 97.
Dado que tanto n1 como n2 son mayores que 20, la aproximación normal es apropiada. Por lo tanto
Z
53 51
4 970 402
..
Dados Z = 0.402, Z0.975 = 1.96, y como Z <Z0.975 no se puede rechazar la hipótesis de la aleatoriedad de la secuencia, con base en esta prueba.
5.2.1.2. Distribución de la longitud de Rachas
Hasta ahora hemos estado interesados en el número total de rachas que aparecen en una secuencia, sin interesarnos la longitud de las mismas. En una secuencia de números aleatorios deben aparecer rachas de diferente longitud, no todas de una misma longitud, para poder aceptar plenamente la aleatoriedad de esta secuencia. Considere la siguiente secuencia de números:
11, 17, 45, 66, 99, 88, 42, 12, 30, 69, 97, 85, 21, 37, 36, 69, 92, 77, 44, 31, 22, 91, 75, 70, 44, 30, 05, 87, 97, 52, 43, 12, 19, 55, 72, 86, 32, 49, 15, 91, 81, 67
Las rachas por encima y por debajo de la línea media las podemos representar de la siguiente manera:
- - - + + + - - - + + + - - - + + + - - - + + + - - - + + + - - - + + + - - - + + + Como se observa, todas las rachas tienen la misma longitud, lo cual nos hace dudar de la aleatoriedad de esta secuencia. Por lo tanto, además de las pruebas anteriores, se requiere efectuar otras sobre la distribución de la longitud de las rachas que se presentan en una secuencia de números aleatorios. Sea Li el número de rachas de longitud i que aparecen en una secuencia de n números aleatorios. Los valores esperados, basados en muestras aleatorias están dados por las siguientes expresiones.
1) Para rachas por encima y por debajo de la media
n
n
n
ni
nLiE 22
12 , i= 1, 2, ..., n
2) Para rachas ascendentes y descendentes :
)4233()132(!3
2
iiiiin
iLiE , i n - 2
!
2
nLiE , i = n - 1
Se puede usar la prueba de bondad de ajuste chi cuadrado para comparar el número observado de rachas de longitud i con el número esperado. Esto es, si Oi es el número observado de rachas de longitud i, se puede usar el siguiente estadístico de prueba :

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 22
2
2
1X
iO E iL
E iLi
k
[ ]
[ ]
donde k = n para rachas por encima y por debajo, y k = n-1 para rachas ascendentes y descendentes. Ejemplo: Considere de nuevo el generador congruencial multiplicativo definido por los siguientes parámetros: a = 899, c = 0 y M = 32768 y la secuencia de 100 números generada previamente y presentada en los ejemplos anteriores. Determine si las secuencias generadas pueden considerarse como aleatorias, con base en las distribuciones de longitudes de rachas, usando un nivel de significancia del 5%. 1) Análisis de rachas ascendentes y descendentes. En el ejemplo realizado en la sección a) se encontraron 42 rachas de longitud 1, 18 de longitud 2, 4 de longitud 3 y una de longitudes 4 y 5 para un total de 66 rachas. El número esperado de rachas ascendentes y descendentes de las diferentes longitudes está dado por:
E L x x1
2
1 3100 21 3 1 1 31 3 21 1 4
!( ) ( ) = 41.75
E L2 181 .
E L3 515 .
E L4 110 .
E L5 019 .
Dado que el número esperado de rachas debe ser mayor o igual que 5 para poder aplicar la prueba chi cuadrado, es necesario agrupar los resultados de las rachas 3, 4 y siguientes los cuales se calculan como : 66-41.75-18.1 = 6.15. La tabla siguiente resume los principales cálculos de la prueba
Longitud de Racha 1 2 3 o mas Total A
Número observado de rachas
42 18 4+1+1 66
Número esperado de rachas
41.75 18.10 6.15 66
2
iO E iL
E iL
(
( ) 0.001 0.001 0.004 0.006
El valor experimental X
2 es de 0.006. Para dos grados de libertad, y un nivel de significancia del 5% el valor
teórico es de 7.378, lo cual lleva a la conclusión de que se puede aceptar la aleatoriedad, dado que no hay diferencia significativa entre la distribución de rachas observadas y las esperadas. 2) Análisis de rachas por encima y por debajo de la media En el ejemplo realizado en la sección b) se encontraron 28 rachas de longitud 1, 13 de longitud 2, 6 de longitud 3, 4 de longitud 4 y dos de longitudes 6 para un total de 53 rachas. Además se tiene: n1 = 50 n2 = 50 n =100

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 23
El número esperado de rachas por encima y por debajo de la media de las diferentes longitudes está dado por:
n
n
n
ni
nLiE 22
12 = 2 1001
50
100
250
100250x x .
E L2 12 5 .
E L3 6 25 .
E L4 3125 .
E L5 15625 .
E L6 0 78125 .
Dado que el número esperado de rachas debe ser mayor o igual que 5 para poder aplicar la prueba chi cuadrado, es necesario agrupar los resultados de las rachas 4, 5 y siguientes, los cuales se calculan como : 53 – 25 - 12.5 - 6.25 = 9.25. La tabla siguiente resume los principales cálculos de la prueba
Longitud de Racha 1 2 3 4 o mas Total A
Número observado de rachas 28 13 6 6 53
Número esperado de rachas 25.0 12.5 6.25 9.25 53
2
iO E iL
E iL
(
( ) 0.36 0.02 0.01 1.14 1.53
El valor experimental X
2 es de 1.53. Para tres grados de libertad, y un nivel de significancia del 5% el valor
crítico es de 9.348, lo cual lleva a la conclusión de que no se puede rechazar la hipótesis de que los números sean aleatorios con base en los resultados de esta prueba.
5.2.2 Prueba de autocorrelación
Las pruebas de autocorrelación muestran la tendencia de los números a estar seguidos por otros números, bien de iguales características, o de características opuestas, o sin ninguna característica especial. Estamos interesados en examinar la autocorrelación para cada secuencia del tipo Ri, Ri+m, Ri+2m,...,. Para realizar la
prueba se define el coeficiente de autocorrelación m como :
mn
iR miRi
mnm1
1
Para n grande con relación a m, m se distribuye aproximadamente normal con media y varianza dadas por las siguientes expresiones
25.0)m(E
)mn( 2144
m19n13)m(Var
Si los números son independientes este coeficiente debe tender a 0.25 Como estamos interesados en detectar cualquier tipo de correlación (positiva o negativa) se debe realizar una prueba de dos colas. La
independencia se rechaza si Z Z1-/2, donde

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 24
Z m E m
Var m
( )
( )
Ejemplo : Considere el generador congruencial multiplicativo definido por los siguientes parámetros : a = 899, c = 0 y M = 32768. Determine si las secuencias generadas pueden considerarse como aleatorias, con base en la prueba de autocorrelación. Use un nivel de significancia del 5%. Los resultados fueron presentados en ejemplo anterior: Los resultados para rezagos de 1, 2, y 3 se presentan en la tabla siguiente
m 1 2 3
m 0.2238 0.2128 0.2048
E(m) 0.25 0.25 0.25
Var(m) 0.090 0.089 0.089
(m) 0.300 0.299 0.298
Z -0.087 -0.125 -0.151
Como Z0.975 = 1.96 no hay ninguna evidencia para dudar de la aleatoriedad de la secuencia generada.
5.2.3 Prueba de Intervalos La prueba de intervalos (gap test) se emplea para determinar la significancia de los intervalos entre la ocurrencia de un dígito dado. Si el dígito k está seguido por x dígitos diferentes antes de que aparezca de nuevo el dígito k, entonces se dice que existe un intervalo de tamaño x. Para ilustrarlo, considere los intervalos que ocurren entre los ceros (0) sucesivos en el siguiente conjunto de dígitos:
4, 8, 9, 7, 9, 8, 3, 3, 3, 9, 9, 0, 6, 3, 0, 3, 3, 4, 4, 3, 5, 3, 8, 2, 9, 5, 5, 2, 5, 1, 5, 4, 8, 7, 9, 0, 6, 4, 8, 9, 2, 3, 9, 6, 0, 1
El cero ocurrió cuatro veces. Por lo tanto existen tres intervalos. El primer intervalo es de longitud dos, el segundo de longitud 20 y el tercero de longitud 8. Para el propósito de esta prueba estamos interesados en la frecuencia con que ocurren los diferentes intervalos. En general, para cualquier dígito dado k la probabilidad de que ese dígito esté seguido por x dígitos diferentes de k antes de que k ocurra de nuevo, está dada por : P(x/k) = P(k seguido por x dígitos diferentes de k, y luego por k) = (0.9)
k (0.1), k = 0, 1,2, ...
Para una secuencia dada de dígitos, se registra el número de veces que ocurren intervalos de 0, 1,2, 3,...,. Este procedimiento se aplica para cada dígito entre 0 y 9. Después de registrar la frecuencia con que cada intervalo ocurre, se compara la frecuencia relativa acumulada observada con la frecuencia relativa acumulada esperada mediante la prueba Smirnov Kolomogorov. Bajo la suposición de que los dígitos están ordenados aleatoriamente, la función de distribución está da dada por:
X
j
xj x
j
x
F x P j( ) ( ) ( . )( . ) ( . )
0
1
0
09 0901 1
Ejemplo: Basado en la frecuencia con que ocurren los intervalos determine si puede suponerse que los
siguientes dígitos están ordenados aleatoriamente. Use = 0.05. 2, 9, 3, 1, 6, 3, 0, 4, 6, 3, 2, 8, 7, 0, 8, 1, 3, 1, 8, 3, 6, 0, 7, 9, 6, 1, 3, 4, 8, 6, 3, 4, 9, 1, 4, 2, 8, 1, 0, 5, 5, 9, 2, 3, 1, 4, 0, 5, 8, 8, 9, 8, 3, 9, 9, 3, 3, 5, 9, 1, 1, 5, 3, 6, 8, 4, 7, 7, 9, 6, 0, 4, 0, 6, 0, 5, 7, 3, 1, 5, 9, 5, 4, 0, 1, 4, 6, 0, 0, 5, 4, 6, 2, 4, 8, 4, 2, 0, 5, 4, 4, 1, 0, 2, 0, 5, 4, 1, 3, 7, 5, 3, 3, 1, 6, 7, 1, 0, 2, 9, 6, 7, 0, 1, 7, 7
B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 25
Como la prueba debe realizarse para cada dígito y registrarse la frecuencia con que se presenta cada intervalo para cada uno, entonces, el número de intervalos registrados será igual al total de valores analizados menos 10, dado que cada dígito debe aparecer al menos una vez. Para nuestro caso se tiene:
Total de intervalos = 125 - 10 = 115 La tabla siguiente resume los resultados de la prueba para la secuencia anterior
Longitud del intervalo
Frecuencia absoluta
Frecuencia relativa
acumulada Sn(x)
FX (x) | FX (x) - SN (x) |
0 - 2 27 0.234 0.271 0.027
3 - 5 30 0.495 0.469 0.026
6 - 8 33 0.675 0.613 0.082
9 - 11 11 0.792 0.718 0.074
12 - 14 8 0.860 0.794 0.066
15 - 17 3 0.888 0.850 0.038
18 - 20 2 0.905 0.891 0.014
21 - 23 3 0.931 0.920 0.011
24 - 26 1 0.940 0.942 0.002
27 - 29 1 0.948 0.958 0.010
30 - 32 2 0.965 0.969 0.004
33 - 35 1 0.974 0.978 0.004
36 - 38 1 0.983 0.984 0.001
39 - 41 0 0.983 0.988 0.005
42 - 44 1 0.990 0.991 0.001
45 - 47 0 0.990 0.994 0.004
48 - 50 1 1.000 0.995 0.005
La diferencia máxima absoluta es 0.082 y la desviación máxima permitida es 1.36/(115) = 0.127, lo cual nos lleva a aceptar la hipótesis de que los dígitos están ordenados aleatoriamente. Esta prueba no está relacionada directamente con los números aleatorios en sí sino con los dígitos que los conforman.
5.3 Nivel de significancia Si se aplican k pruebas diferentes a una serie de números aleatorios y el nivel de significancia de cada prueba
es i, entonces el nivel de significancia total de la prueba T está dado por :
k
iiT
1
11
Si 1 = 2 = 3 =... =k = entonces
11
1
11kk
iT
Esto es, si la hipótesis nula para cada prueba es en efecto verdadera, la probabilidad de que una o más de
estas pruebas sea rechazada es T. Por consiguiente, para un nivel total de significancia dado T, el error i de cada prueba estará dado por:
T
k
i 1/1
1

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 26
Ejemplo: Se aplican cinco pruebas diferentes a una serie de números. La probabilidad de rechazar incorrectamente una prueba es 0.05, entonces el error total para la prueba será de:
T = 1-(0.95)5 = 0.226
Si se quisiera un error máximo del 5% para todas las pruebas en conjunto, entonces cada prueba debería
tener un nivel de significancia i del 1%, según se deduce de la siguiente expresión :
i = 1- (0.95)1/5
= 0.01 Problema: Se dice que las tres o cuatro últimas cifras de cada número del directorio telefónico puede utilizarse como un número aleatorio. Demuestre que el directorio telefónico sirve como un generador de números aleatorios. Indicación: Tome al azar una página y extraiga, en forma sucesiva, un centenar de números telefónicos, sin considerar los dos primeros dígitos, y aplique las pruebas expuestas en los párrafos anteriores. 6 Algunos generadores de números aleatorios
Debe tenerse mucho cuidado cuando se usan generadores de números aleatorios en microcomputadores o en algunos compiladores de uso general, ya que algunos de ellos no han sido probados muy extensamente y presentan resultados no muy deseables. A continuación se presentan algunos generadores que se han usado en algunos programas de simulación o en rutinas científicas.
6.1 Generadores Congruenciales lineales
Generador de Coveyou y MacPherson (máquina UNIVAC) a = 5
15, c = 1 y m = 2
35
Generador propuesto por Kobashy para máquinas IBM y aplicable a muchos minicomputadores
a = 314,159,269, c = 453,806,245 y m = 231
6.2 Generadores Congruenciales multiplicativos (c = 0) con módulo m = 2e
RANDU: a = 899, m = 215
= 32768 (Propiedades estadísticas buenas)
RANDU: a = 516
+ 3 = 65539, m = 231
(Propiedades estadísticas indeseables)
6.3 Generadores Congruenciales multiplicativos (c = 0) con módulo m = 2e – 1
Lews, Goodman y Millery (1969) en el paquete LLRANDOM de Learmonth y Lewis (1973) y en el generador RNUM del paquete IMSL (1987):
a = 7
5 = 16807
a = 630,360,016
Generadores en programas de simulación
GPSS/H: a = 742,938,285 GPSS/PC: a = 397,204,094 SIMAN: a = 16807 SIMCRIPTII.5: a = 630,360,016 SLAM II a = 16807

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 27
Otros generadores . Valores del multiplicador a:
950,706,376 742,938,285 1,226,874,159 62,089,911 1,343,714,438
7 Problemas
3.1 Genere 200 números aleatorios, por medio de un computador, de acuerdo con el método que usted considere apropiado.
a) Pruebe si esos números se distribuyen uniformemente en el intervalo (0.1) por medio de la prueba
chi-cuadrado o de la Smirnov Kolmogorov.. b) Verifique si la secuencia generada es independiente, mediante la aplicación de diferentes pruebas
estadísticas. c) Repita el proceso anterior para diferentes tamaños de muestra y analice el comportamiento de su
generador (muestras de 20, 50, 100, 500, 1000 números).
3.2 Para los siguientes generadores congruenciales multiplicativos, calcule Xi para valores suficientes de i
1 para cubrir un ciclo completo a) Xi = (11 Xi-1 )Mod 16, X0 = 1 b) Xi = (11 Xi-1 )Mod 16, X0 = 2 c) Xi = (2 Xi-1 )Mod 13, X0 = 1 d) Xi = (3 Xi-1 )Mod 13, X0 = 1
3.3 Sin calcular ningún Xi determine cual de los siguientes generadores congruenciales lineales tiene período completo
a) Xi = (13 Xi-1 +13)Mod 16 b) Xi = (12 Xi-1 +13)Mod 16 c) Xi = (13 Xi-1 +12)Mod 16 d) Xi = (Xi-1 +12)Mod 16
3.4 Analice el comportamiento del siguiente generador de números aleatorios. Lo considera usted adecuado?
Xi = (3 Xi-1 + 7) mod 1056
3.5 Suponga que Usted ha diseñado un generador que le produce números aleatorios R (en el rango 0,1). Sea p un número entre 0 y 1. Suponga que Usted ha generado una secuencia, dada por R1, R2, ..., Rn.
Considere la secuencia formada por R’ = (1 - R )/( 1 - p).
Considera Usted que la secuencia de números obtenida a partir de R’ puede considerarse como una secuencia de números aleatorios?
3.6 Analice el comportamiento del siguiente generador de números aleatorios. Lo considera usted adecuado?
Xi = (3 Xi-1 + 7) mod 1056
3.7 Demuestre que la suma de dos números aleatorios independientes (0, 1), módulo 1, es de nuevo uniforme (0, 1)
3.8 Determine con un nivel de confianza del 95% usando varias pruebas si la siguiente lista de números corresponde a una muestra aleatoria

B. Calderón. Introducción a la Simulación. Cap 3. “Generación de números aleatorios” 3 - 28
0.88 0.53 0.42 0.39 0.80 0.54 0.53 0.28 0.34 0.50 0.90 0.80 0.82 0.01 0.91 0.15 0.79 0.16 0.10 0.35 0.02 0.21 0.05 0.10 0.36 0.81 0.80 0.04 0.24 0.90 0.50 0.26 0.49 0.53 0.26 0.03 0.53 0.63 0.66 0.45 0.73 0.62 0.36 0.23 0.17 0.38 0.67 0.03
3.9 Suponga que Usted ha diseñado un generador que le produce números aleatorios R (en el rango 0,1). Sea p un número entre 0 y 1. Suponga que Usted ha generado una secuencia, dada por R1, R2, ..., Rn.
Considere la secuencia formada por R’ = R / p
Considera Usted que la secuencia de números obtenida a partir de R’ puede considerarse como una secuencia de números aleatorios?
3.10 Considere la siguiente secuencia de números aleatorios que fueron generados mediante un método congruencial. Pruebe que tan adecuado es este generador usando las siguientes pruebas estadísticas. Use un nivel de significancia del 5%, con 10 intervalos de clase, prueba Chi-cuadrado y número de rachas ascendentes y descendentes. Los números están amplificados por un factor de 1000. 913 661 889 378 721 671 508 214 167 534 341 449 604 228 141 966 233 562 927 159 830 662 081 143 870 429 211 307 485 254 591 274 894 808 899 191 677 804 088 676 603 415 850 401 025 096 457 502 156 449 709 613 511 476 867 356 766 182 634 332 310 981 958 498 133 361 808 340 686
Pruebas estadísticas presentadas en el libro de Averil Law Generador de Averill Law

4 GENERACION DE PROCESOS
1 Introducción Hasta el presente en los capítulos anteriores sólo hemos estudiado la generación de variables aleatorias distribuidas uniformemente en el intervalo (0,1), llamadas “números aleatorios”. Sin embargo, en cualquier experimento de simulación no sólo se necesita trabajar con variables en el intervalo (0,1) sino que principalmente estamos interesados en analizar otros procesos que no están descritos mediante estas variables. Por ejemplo, si estamos interesados en estudiar la forma como se comporta el inventario de un artículo, necesitamos generar la demanda de ese artículo durante cierto tiempo, es decir, debemos asignar valores a la variable aleatoria que nos describe esa demanda. Si esa demanda está modelada por una distribución de Poisson, entonces debemos generar valores de la distribución de Poisson. Esos valores se generan mediante el uso de los números aleatorios, generados antes. Si estuviéramos interesados en estudiar políticas sobre reemplazo de equipos, tal vez necesitemos generar valores de la distribución exponencial. Resumiendo, el interés no se centra en la generación de números aleatorios en sí, sino que va más allá. El interés está en la generación de las variables aleatorias, además de la uniforme (0,1) que nos describen el proceso de interés. Al generar los valores de las variables aleatorias que describen un proceso, lo que realmente estamos haciendo es realizando un “muestreo artificial”, el cual nos suministra la información necesaria para analizar más a fondo el proceso, información que sería sumamente costosa o imposible de conseguir en la práctica
2 METODOS GENERALES Existen varios métodos generales para generar variables aleatorias. Los más comunes son:
El método de la transformación inversa
El método del rechazo y
Método de relación con otras variables, tal como el método de convolución. El método más conocido y aplicado es el de la transformación inversa. El método del rechazo tiene su mayor aplicación en la solución de problemas determinísticos.
2.1 Método de la transformación inversa.
El método de la transformación inversa para generar variables aleatorias se basa en la función de distribución de la variable de interés, y se aplica para variables continuas, discretas y distribuciones empíricas. Y requiere que se pueda evaluar de una u otra manera la función de distribución de la variable de interés.
2.1.1 Caso continuo. Si X es una variable aleatoria continua con función de densidad dada por f(x), la función de distribución de X, denotada por F(x) está dada por:
X
dx)x(f)xX(P)x(F
El rango de la función de distribución F(x) es entre cero y uno, lo mismo que el rango de los números aleatorios. Es decir:
0 F(x) 1, 0 r < 1
Si R es un número aleatorio, sus funciones de densidad y de distribución están dada por:
1r0,rdtdt)t(f)rR(P)r(F
1r0,r)r(fr
0
r
0
R
(1)
Ahora, la probabilidad de que un número aleatorio R sea menor o igual que el valor F(x) está dada por:

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 2
P r [ R F(x) ] = F(x)), 0 F(x) 1
P r [ R r] = r, 0 r 1
Según lo anterior podemos igualar el número aleatorio generada r con la función de distribución F(x) y tendríamos que:
R = F(x) x = F-1
(r)
Por lo tanto, en el método de la transformación inversa se generan números aleatorios en el intervalo (0,1), se los iguala a la función de distribución de la variable aleatoria X, y se despeja el valor de la variable aleatoria, es decir :
r = F(x) X = F-1
(r) F(x) El valor de la función inversa F
-1 (r)
de r es el valor generado de la r variable aleatoria de interés. El valor de X se puede obtener gráficamente, como lo indica la figura 4.1 x’ X Figura 4.1
Dado que 0 F(x) 1, y F(x) es continua y ascendente, es claro que existe entre R y F(x) una relación biunívoca.
r FX (x)
Ejemplo 4.1. Desarrolle un generador del proceso descrito por una variable aleatoria X con función de densidad uniforme entre a y b.
f(x) F(x)
1
r
a b x a x b
Solución: (Ver numeral 3.1) Se tiene que bxaab
axxF
abxf
,)(,
1)(
Por lo tanto se genera el número aleatorio R = r y se hace ab
axxFr
)( x = a + (b - a ) r.
Así, para generar una variable aleatoria uniforme basta con generar un número aleatorio.
Ejemplo 4.2. Desarrolle un generador del proceso descrito por la variable aleatoria X cuya función de
densidad es exponencial con parámetro (tasa) “”.
Solución: (Ver numeral 3.2).
Se tiene que exxFe
xxf 1)(,)(
)r1(Ln1
xexr1e
x1)x(Fr

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 3
Como la distribución uniforme es simétrica y dado que R y 1 - R tienen la misma distribución (tienen los mismos momentos), entonces en vez de usar 1 - r podemos emplear r. Por lo tanto, la distribución exponencial puede generarse también mediante la siguiente expresión
)r(Ln1
x
Ejemplo 4.3. Desarrolle un generador del proceso descrito por la variable aleatoria X cuya función de densidad está dada por :
(x) =
1 6
1 3
1 12
/
/
/
0 2
2 3
3 7
x
x
x
Solución: Lo primero que debemos hacer es construir la función de distribución F(x). Esta función debe construirse en forma separada para cada intervalo, de la siguiente forma:
F(x) = P ( X x ) = f x f x f x f x
XXX
( )dx ( )dx ( )dx ( )dx 00
0
1) Para 0 x 2, se tiene:
3/1)x(F0,6
xdx
6
1)x(F)x(F
X
0
1
2) Para 2 x 3, se tiene:
3
2)(
3
1),1(
3
1
3
1
3
1)(
6
1)()()(
0
2
0 2 2
2 xFxdxdxxfdxdxxfxFxF
X X X
3) Para 3 x 7, se tiene:
1)(3
2,)5(
12
1
12
1
3
2
12
1
3
1
6
1)()()(
0
2
0 3 3
3
2
3 xFxdxdxdxdxdxxfxFxF
x X x
Resumiendo se tiene:
F(x) =
1)x(F3
2,7x3),5x(
12
1
3
2)x(F
3
1,3x2),1x(
3
1
3
1)x(F0,2x0,
6
x
)x(F
El procedimiento para generar una variable aleatoria es entonces como sigue: Se genera un número aleatorio R = r y se iguala a la función de distribución F(x). Sin embargo, debe tenerse en cuenta el rango en que queda el valor de r, así:
5r12x)5x(12
1r1r
3
2Si
1r3x)1x(3
1r
3
2r
3
1Si
r6x6
xr
3
1r0Si

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 4
El procedimiento anterior se puede explicar gráficamente como lo indican las figuras 4.2 y 4.3 d. f(x) F(x) 1/3 1 1/6 2/3
r
1/12 1/3 0 0 0 1 2 3 4 5 6 7 8 0 1 2 3 4 5 6 7 8 Figura 4.2 Figura 4.3
Figuras 4.2 y 4.3 Ejemplo del método de la Transformación Inversa. Caso Continuo
Ejemplo 4.4. Una distribución triangular. Diseñe un generador para la variable aleatoria cuya función de densidad está dada por:
2x1,x2
1x0,x)x(f f(x)
Nota: Esta función de densidad corresponde a un caso particular de la distribución triangular (ver sección 3.2) 0 1 2 x Figura 4.4 Distribución Triangular
Solución. La función de distribución está dada por :
1) Para 0 x 1
2
1)x(F0,
2
xxdx)xX(P)x(F)x(F
X
0
2
1
2) Para 1 x 2
1)x(F2
1,
2
)x2(1dx)x2(xdx)xX(P)x(F)x(F
X
1
21
0
2
Resumiendo se tiene :
1)x(F2
1,2x1,
2
)x2(1
2
1)x(F0,1x0,
2
x
)x(F2
2
Para generar una variable aleatoria X, se genera un número aleatorio r, entre 0 y 1, y se iguala a la función de distribución, de acuerdo al rango en que quede, así:
1) Si r2xr2x2
xr
2
1r
2
Se toma la raíz positiva ya que el valor de la variable debe estar entre 0 y 1.
2) Si )r1(22x)r1(22x2
)x2(1r
2
1r
2
i

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 5
Se toma la raíz negativa ya que el valor de la variable debe ser menor o igual a 2.
Resumiendo se tiene que:
2
1rsi)r1(22x
2
1rsir2x
,
Existen muchas variables aleatorias para las cuales es sumamente difícil o imposible expresar la función de distribución mediante una expresión cerrada que se pueda manipular fácilmente para obtener una solución analítica; o una vez obtenida esta expresión, puede ser complicado expresar la variable X en términos del número aleatorio r. En estos casos, será necesario emplear otro método.
2.1.2 Método de transformación inversa, caso discreto.
Cuando la variable aleatoria X no es continua sino discreta, no puede usarse el método de la transformación inversa en la forma explicada anteriormente, sino que es necesario modificarlo un poco para tener en cuenta la naturaleza discreta de la variable aleatoria. En el caso continuo para cada valor de la variable aleatoria X
existe uno y solo un valor del número aleatorio r que genera ese valor de X como se ilustró en la figura 4.1.
Es decir, existe una relación biunívoca entre X y R. Esto no es cierto cuando X es discreta. Para ilustrarlo, considere la variable aleatoria cuya función de probabilidad está dada por:
P x( )/
1 4
0 x= 1, 2, 3, 4, en otros casos.
La función de distribución F(x) está dada por:
F(x)
/
/
/
1 4
1 2
3 4
1
x
x
x
x
1
2
3
4
o simplemente F(x) = x/4, x=1, 2, 3, 4 f(x) F(x) 1 3/4 1/4 1/2
r r 1/4 0 0 1 2 3 4 0 1 2 3 4 Figura 4.5 Método de la transformación inversa caso discreto
Al generar un número aleatorio r no podemos hacer directamente r = F(x) ya que R es continua y X es
discreta. Por ejemplo, si r = .31 y aplicamos el método de la transformación inversa visto antes el valor correspondiente de X sería :
24.1r4x4
xr
Pero…el valor x = 1.24 no existe. Sin embargo, si aplicamos el método de la transformación inversa gráficamente, figura 4.5, vemos que el valor de x correspondiente a un r = 0.31 es 2. Si r fuera 0.48, x seguiría siendo 2. Igualmente sería 2 si r

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 6
fuera 0.49. Si r fuera 0.50, el valor correspondiente a x sería 3. Es decir, el valor x = 2 puede ser generado por muchos valores de r, todos aquellos que sean mayores o iguales a 1/4 y menores de 1/2. El valor de x será entonces el entero aquel que cumpla la siguiente desigualdad:
F ( x - 1 ) r < F(x) ( 1 )
En general, si X no varía en intervalos de a 1 sino de µ, el valor x sería aquel que cumpliera la siguiente desigualdad:
F ( x - µ ) r < F(x) ( 1 )
Ejemplo 4.5. Para nuestro ejemplo, el generador del proceso sería:
4/3rsi4
4/1r4/2si3
4/2r4/1si2
4/1r0si1
x
Así, teóricamente existe un número infinito de valores de r que dan el mismo valor de x. Dado que en el ejemplo anterior la función de distribución tiene una expresión matemática cerrada, podemos tratar de encontrar una forma más explícita para la variable aleatoria X. Así:
F(xx
) ,4
x = 1, 2, 3, 4
Dado un valor de r, el correspondiente valor de x será el entero que cumpla F( x - 1 ) r < F(x) ( 1 )
es decir: x
rx
1
4 4
Tomando la parte izquierda de la desigualdad se tiene: 1r4xr4
1x
( 2 )
La parte derecha de la desigualdad nos indica que: 4
xr 4r < x x > 4r ( 3 )
Combinando las expresiones ( 2 ) y ( 3 ) se obtiene que el valor X estará dado por:
4r < X 4r + 1 X = [4 r + 1], donde [Y] = parte entera de Y
Si r = 0.31 1.24 < x 2.24 x = 2
Si r = 0.43 1.92 < x 2.92 x = 2
Si r = 0.49 1.90 < x 2.96 x = 2
Si r = 0.50 2.00 < x 3.00 x = 3
Ejemplo 4.6. Considere la distribución geométrica. Una variable aleatoria X tiene una distribución geométrica si su función de probabilidad está dada por :
P x p p x( ) ( ) , 1 1 x = 1, 2, .......,
donde p representa la probabilidad de que la variable aleatoria tome el valor de 1, es decir, p =P(X=1) y la variable aleatoria X puede representar:
Número de artículos que es necesario inspeccionar antes de encontrar uno defectuoso.
Tiempo (medido en forma discreta) necesario para atender una persona.
Número de veces que es necesario jugar una lotería para ganársela Para cada uno de los casos anteriores p puede representar:
P = Probabilidad de que un artículo sea defectuoso (fracción defectuososa).
p = Probabilidad de que el servicio se termine en una unidad de tiempo.

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 7
P = Probabilidad de ganar una lotería La función de distribución está dada por:
F(x P X x P X i pqi
i
x
i
x
) ( ) ( )
1
11
F(x p qp q
q
i
i
x x
)( )
,
0
11
1 dado que Z
Z
Z
i
i
NN
0
11
1, si Z 1
F(xp q
pq
xx)
( )
( ),
1
1 11 x = 1, 2, .....,
Para generar una variable aleatoria X con distribución geométrica se genera un número aleatorio r. El valor de x será el entero que cumpla la siguiente desigualdad:
F ( x - 1 ) r < F(x) 1 - qx - 1
r < 1 - qx
Trabajando con la parte izquierda de la desigualdad, se obtiene:
1 - qx-1
r 1 - r qx-1
Ln ( 1 - r ) ( x -1 ) Ln q x - 1 Ln r
Ln q
( )
.
1,
dado que Ln q < 0 x Ln r
Lnq
( )11
(A)
Con la parte derecha de la desigualdad, se obtiene:
1 - qs > r 1 - r > q
x Ln ( 1 - r ) > x Ln q
q.Ln
)r1(Lnx
, dado que Ln q < 0 (B)
De las expresiones (A) y (B) se obtiene que el valor de la variable aleatoria X es el entero que satisfaga la siguiente desigualdad:
1Lnq
)r1(Lnx
Lnq
)r1(Ln
Analizando un poco más la expresión anterior se concluye que X es igual a la parte entera que se obtiene de
realizar el cálculo Ln r
Lnq
( )11
2.2 Método del Rechazo
El método del rechazo está basado en la función de densidad f(x) y no en la función de distribución F(x), como el de la transformación inversa. Para poder usar este método se requiere que la función de densidad
sea acotada y que el rango de variación de la variable aleatoria sea finito, esto es, a x b. El método se basa en a) encerrar la función de densidad dentro de un rectángulo cuya altura es el valor máximo de dicha función y cuyo base es el rango de variación de la variable aleatoria y b) generar parejas de números aleatorios, y aceptar aquellas parejas que queden bajo la curva definida por la función de densidad de la variable de interés. El procedimiento para aplicar este método es el siguiente. 1) Se normaliza la función de densidad f(x) mediante un factor c tal que su rango de variación esté entre
cero y uno, es decir, 0 c.f(x) 1, a x b. Por lo tanto, el valor de c debe ser tal que
c. Max f(x) =1 c= 1/Max f(x)
2) Se genera la variable aleatoria X correspondiente al rectángulo de base (b - a), es decir, como el valor perteneciente a la función de densidad uniforme entre a y b, a saber,
X= a + (b - a) r

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 8
3) Se genera una pareja de números aleatorios (r1, r2).
4) Con el primer número aleatorio se genera el valor de X, un rectángulo de base (b - a), es decir, como correspondiente a la distribución uniforme. Por lo tanto
X= a + (b -a) r1
y se calcula la ordenada de X correspondiente a la función de densidad normalizada c(f(x). Es decir, se calcula c.f[a + (b -a) r1 ]
5) Se acepta la pareja de números aleatorios si r2 c.f(x), o sea si, r2 c.f[a + (b -a) r1 ]. Por lo tanto, se acepta la pareja si la intersección de X con r2 cae bajo la curva definida por c.f(x). Si no se acepta la pareja es necesario generar una nueva pareja, es decir, repetir el procedimiento desde el paso 3.
La figura siguiente ilustra el procedimiento c.f(x) 1 r22 r21 a x1 x2 b x
x1 x2 La pareja (r11, r21), o equivalentemente la pareja (x1, r21) , donde x1 = a + (b - a ) r11, se acepta ya que r21 < c.f(x1), es decir, la intersección de x1 y r21 queda bajo la curva definida por c.f(x1). Sin embargo, la pareja (r12, r22), o equivalentemente la pareja (x2, r22), donde x2 = a + (b - a ) r12, se rechaza ya que r22 > c.f(x2), es decir, la intersección de x2 y r22 queda fuera de la curva definida por c.f(x2). Se observa que la pareja (r1, r2) genera un par de coordenadas que definen un punto en el rectángulo que tiene como base (b - a) y altura unitaria, y que de estas parejas, las que se aceptan son aquellas que quedan bajo la curva c.f(x). Si se generan N parejas de números aleatorios (r1, r2) y de estas parejas se aceptan M, entonces la probabilidad de que una pareja quede bajo la curva puede estimarse como P = M/N. Si se conoce el área del rectángulo y se desea calcular el área bajo la curva, entonces esta área puede estimarse como el área del rectángulo por la proporción de puntos que caen bajo la curva, es decir,
Área bajo la curva = Área del rectángulo x P,
donde el área del rectángulos es igual a (b - a) x Máximo f(x) Además, P puede interpretase como la probabilidad de que una pareja sea aceptada. Dependiendo de la forma de f(x), esta probabilidad podría calcularse analíticamente. El método del rechazo se base en el hecho de que la probabilidad de que un número aleatorio R sea menor o igual que c.f(x) está dada por :
p[R r] = r p[R c.f(x)] = c.f(x), 0 c.f(x) 1 Por consiguiente, si X se escoge al azar en el rango (a, b) como x = a + (b - a) r, y luego se rechaza si r > c.f(x) entonces a función de densidad de los valores aceptados sería f(x). Determinemos la probabilidad de que una pareja de números aleatorios produzca exitosamente una variable aleatoria. Esta probabilidad es igual a la probabilidad de que el primer número genere el valor de X = x, que es igual a dx/(b-a), por la probabilidad de que el segundo número sea menor o igual a c.f(x), la cual es igual a c.f(x), dado que el número aleatorio está uniformemente distribuido entre cero y uno. Por lo tanto,
P(pareja exitosa) = dx
b acf x
c
b af x
c
b aa
b
a
b
. ( ) ( )
El número esperado de ensayos para obtener una pareja exitosa es (b-a)/c.

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 9
El método del rechazo es ineficiente cuando (b-a)/c es f(x un poco grande, dado que se necesita generar una gran cantidad de números aleatorios antes de encontrar un par exitoso, como sería el caso de tener una distribución como la mostrada en la figura siguiente. a b
Ejemplo 4.7. Use el método del rechazo para generar observaciones de una variable aleatoria normal con media cero y varianza unitaria. Una variable aleatoria Z tiene una distribución normal con media cero y varianza uno si su función de densidad está dada por :
f z ze( ) / 1
2
2 2
, - < z < +
En principio, el método del rechazo no puede emplearse para generar una distribución normal, dado que su rango de variación no es finito. Sin embargo, si se acota el rango de variación de la variable, sí podría emplearse el método del rechazo. Se sabe que el 99.73% de una distribución normal se encuentra
comprendido en el rango de más o menos tres desviaciones ( 3 para nuestro caso). Es decir, tendríamos la siguiente función de densidad:
f z ze( ) / 1
2
2 2
, -3 < z < +3
Por lo tanto el procedimiento a aplicar sería : 1) Normalizar f(z). El valor máximo de f(z) ocurre en z = 0, por lo tanto se tiene que:
Max f(z) = 1/f(0) = 2 c = 2 y c f z ze. ( ) / 2 2 .
2) Se genera una pareja de números aleatorios (r1, r2).
3) Se calcula Z como z = a + (b - a) r1 = -3 + 6 r1
4) Se calcula c. f(z).
5) Se acepta la pareja si r2 c.f(z), es decir, si r2 c.f(-3+6r1) y el valor de la variable sería z =-3 + 6 r1
6) Se rechaza la pareja si r2 > c.f(z), en cuyo caso debería repetirse el proceso desde el paso 2.
Ejemplo: Si se genera la pareja de números aleatorios (0,504, 0.820) el valor de z sería z = -3 + 6(0.504) = 0,024, el valor de c.f(z) sería 0.9997, y la pareja se aceptaría dado que 0.820 < 0.9997. En cambio si la pareja generada fuera (0.233, 0.724) ésta se rechazaría ya que z = -1.602 y c f(z) = 0.277 que es menor que 0.724
Ejemplo 4.8. Use el método del rechazo para calcular el área del primer cuadrante de un círculo unitario. Este ejercicio sirve para ilustrar el método de Montecarlo para resolver problemas completamente determinísticos. y Un círculo unitario está definido mediante la siguiente ecuación: 1 x
2 + y
2 = 1
De la ecuación se obtiene que 2x1y . Dado que e l rango de
variación de y está entre cero y uno, el factor de normalización sería c = 1. Por lo tanto, el procedimiento sería : 0 1 x 1) Se genera la pareja de números aleatorios r1 y r2. 2) Se expresa x como x = a + (b - a ) r1 =r1
3) Se calcula y = c.f(x) = r21
1x1 2 y se acepta la pareja si

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 10
r21
1rr21
1r)x(f.cr 2
222 , o equivalentemente si
r12 +r2
2 1, es decir si la pareja cae bajo el primer cuadrante del círculo.
Se generan varias parejas de números aleatorios (N) y se cuenta el número de parejas aceptadas M. El área bajo el cuadrante se calcula como el área del rectángulo (la unidad) por la proporción de parejas que caen bajo la curva, es decir, el área del cuadrante se estima como M/N. Matemáticamente se sabe que el área de
un círculo está dada por R2, siendo R es el radio del círculo. Por lo tanto el área exacta del cuadrante será
/4. A medida que se aumente el número de parejas generadas la proporción de las que caen bajo la curva
debe tender a /4. Ejemplo 4.9. Use el método del rechazo para calcular el área bajo la curva Y = 3X, entre 2 y 5. El problema se puede ilustrar gráficamente como se muestra f(x) en la gráfica No 5.x. El valor máximo de f(x) para el rango de 15 variación dado ocurre en x=5, con un valor de 15, por lo tanto, el valor de c es de 1/15. 12 El procedimiento sería entonces : 8 1) Se normaliza f(x) por el factor c=1/15, por lo tanto
c.f(x) = x/5 4 2) Se genera un par de número aleatorios (r1,r2). 3) Se calcula x como x = 2 + 3 r1 0 1 2 3 4 5 6 x
Si r2 (2 + 3 r1)/5 se acepta la pareja y se contabiliza el número de parejas aceptadas (M).
Si r2 > (2 + 3 r1)/5 se rechaza la pareja.
El área total del rectángulo está dada por (5 - 2) x 15 = 45, y el área bajo la línea y = 3x entre 2 y 5 se estima como el área bajo el rectángulo por la proporción de parejas aceptadas, es decir por:
Area_Bajo_Línea = (5 - 2) x 15 x M/N = 45M/N
La tabla siguiente resume resultados obtenidos para diferentes valores de las parejas de números generados.
Parejas Generadas 25 50 100 200 500 1000
Parejas Aceptadas 22 38 69 133 353 698
Proporción 88,0 76,0 69,0 66,5 70,6 69,8
Área estimada 39,6 34,2 31,05 29,9 31,87 31,41 El área real bajo la curva está dada por la integral de la función 3x entre 2 y 5, y su valor es :
Area_Real_Bajo_Línea = 3 3152
5
xdx .
y la proporción del área bajo la curva seria de 31.5 x 100/45= 70%.
2.3 Método de relación con otras variables (Convolución). Un método muy utilizado para generar variables aleatorias es mediante el análisis de la relación matemática de la variable de interés con otras variables conocidas, o analizando el proceso que da origen a una
determinada variable. Por ejemplo, la distribución Erlang (, k) resulta de la convolución de k variables
aleatorias distribuidas exponencialmente con valor esperado 1/. Por lo tanto, para generar una varaible
aleatoria Erlang, basta con generar k variables exponenciales con media 1/ y sumarlas.
k
1i
i
k
1i
i
k
1i
i Rln1
Rln1
XX
En forma similar, la distribución binomial (n, p) resulta de la convolución (suma) de n variables aleatorias con distribución Bernoulli con parámetro p. Por lo tanto, su generación se puede realizar a partir de la distribución de Bernoulli, como se analizará mas adelante.

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 11
3 Generación de procesos continuos. En esta sección se presentará la forma de generar artificialmente las observaciones de las principales variables aleatorias continuas. Para algunas variables se presentarán varios métodos, indicando cuál de ellos puede ser más eficiente. Además, en algunos casos se presentarán algunos métodos que, aunque no sean eficientes desde el punto de vista estadístico o computacional, sirven para ilustrar la aplicación de uno de los métodos generales presentados en la sección anterior.
3.1 Distribución Uniforme Una variable aleatoria X se distribuye uniformemente en el intervalo (a,b) si su función de densidad está dada por : f(x)
casosotrosen,0
bxa,ab
1
)x(f
Su función de distribución F(x) está dada por : F(x) a b x
bx,,1
bxa,ab
ax
ax,0
)xX(P)x(F
a b x El valor esperado y la varianza de una distribución uniforme están dados por:
12
ab2
)X(Var,2
ba)X(E
Aplicación : Errores de redondeo cuando las mediciones se registran con determinada precisión. Por ejemplo, cuando se registra una calificación, generalmente se aproxima a la décima mas cercana (redondeo simétrico). Entonces la diferencia entre la nota real y la nota registrada es algún número entre -0.05 y +0.05, y el error se distribuye uniformemente en este intervalo.
Generación. Para generar una variable aleatoria uniforme, se usa del método de la transformación inversa de la siguiente manera: Se genera un número aleatorio R = r y se lo iguala a la función de distribución y se despeja el valor de x:
r)ab(axab
ax)x(Fr
Así, para generar una variable aleatoria uniforme basta con generar un número aleatorio.
Estimación de los parámetros. Cuando los parámetros de la distribución no son conocidos, debemos estimarlos con base en datos históricos. La estimación puede hacerse por el método de los momentos o el método de máxima verosimilitud. A través del método de los momentos, como se tienen dos parámetros se
deben usar los dos primeros momentos, la media y la varianza. Es decir, igualamos la media y la varianza
2 de la distribución con la media y la varianza muestrales, respectivamente.
S
12
abˆX
2
baˆ 2
2
2
Despejando a y b de las dos expresiones anteriores se obtiene:

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 12
aX2b,S3Xa 2
Utilizando el método de máxima verosimilitud, los estimativos de a y b estarán dados por:
Xb,Xa maxmin
3.2 Distribución triangular Una variable aleatoria X tiene una distribución triangular con los parámetros (a, b y c) si su función de densidad está dada por: f(x)
cxb,)ac)(bc(
)xc(2
bxa,)ac)(ab(
)ax(2
)x(f
a b c donde los parámetros tienen los siguientes significados:
a = Valor mínimo b =Valor más probable, correspondiente a la moda c = Valor máximo Se debe cumplir que a < b < c
Se tiene que :18
)(,3
)(222 bcabaccba
XVcba
XE
Generador. Esta variable aleatoria se puede generar usando el método de la transformación inversa. El cálculo de la función de distribución debe hacerse en dos etapas, debido a que existe un punto de discontinuidad en b. El procedimiento es el siguiente: a) a ≤ x < b
ac
ab)x(F0,
)ac)(ab(
ax
2
)ax(
)ac)(ab(
2
dx)ax()ac)(ab(
2dx
)ac)(ab(
)ax(2)x(F)xX(P)x(F
2x
a
2
x
a
x
a
1
b) b ≤ x ≤ c
1)(,
))((1
2
)(
))((
2
))((
)(2
))((
)(2)()()(
22
2
xFac
ab
bcac
xcxc
bcacac
ab
dxbcac
xcdx
acab
axxFxXPxF
x
b
x
b
b
a
En resumen tenemos que:
1)x(Fac
ab;cxb,
)ac)(bc(
)xc(1
ac
ab)x(F0;bxa,
)ac)(ab(
)ax(
)x(F2
2

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 13
El proceso para generar una observación de la variable aleatoria es el siguiente: Se genera un número aleatorio R = r.
a) Si < ac
abr
entonces
)(1 xFr es decir ))((
)( 2
acab
axr
, despejando x tenemos que
r)ac)(ab(ax)ac)(ab(ax
Se toma la raíz positiva ya que x ≥ a
b) Si ac
abr
entonces
)(2 xFr es decir, )ac)(bc(
)xc(1r
2
, y despejando x tenemos que
)r1)(ac)(bc(cx)r1)(ac)(bc(xc ;
Se toma la raíz negativa ya que x ≤ b En resumen tenemos que:
ac
abrsi)r1)(bc)(ac(c
ac
abrsir)ac)(ab(a
x
3.3 Distribución Exponencial
Una variable aleatoria X sigue una distribución exponencial con parámetro si su función de densidad tiene la siguiente forma: f(x)
casosotrosen
xxf e
x
0
0)(
La función de distribución está dada por:
exxF 1)(
0 x La media y la varianza están dadas por:
2
2
12)X(V,1
)X(E
La variable aleatoria exponencial puede representar: La duración de un servicio El tiempo entre llegadas de clientes a un sistema El tiempo entre fallas de un componente (la duración del componente) El metraje entre los defectos sucesivos que se encuentran en un rollo de tela

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 14
El parámetro representa una tasa (eventos por unidad de tiempo). Para los ejemplos mencionados en el párrafo anterior su significado sería: . Tasa de servicio (clientes/hora) Tasa de llegada (clientes/hora) Tasa de fallas (fallas/hora) Tasa de defectos (defectos/metro)
El parámetro representa el inverso del tiempo medio.
Observación: A veces la distribución exponencial se expresa se da en términos del tiempo medio = 1/ como:
casosotrosen0
0x1
)x(f e/x
Aplicación: Considere un evento cualquiera, un accidente, por ejemplo. Si la probabilidad de que ocurra un evento en un intervalo muy corto de tiempo es pequeña, y si la ocurrencia de este evento es estadísticamente independiente de la ocurrencia de otros eventos, entonces el intervalo de tiempo entre la ocurrencia de eventos de este tipo se distribuye exponencialmente.
Estimación del parámetro: El parámetro puede estimarse como XˆX/1ˆ .
Generación. La generación de una variable exponencial puede hacerse por varios métodos, de los cuales el rnás eficiente es el de la transformación inversa.
)r1(Ln)r1(Ln1
xx)r1(Lnr11)x(Fr eexx
Dado que la distribución uniforme es simétrica, entonces R y 1 – R tienen la misma distribución, por lo cual los valores generados de r y 1 – r pueden intercambiarse en el proceso de generación de variables aleatorias. De lo anterior se concluye que X también puede generarse como:
rLnrLn1
x
Si una variable aleatoria sigue una distribución exponencial, entonces su media y su desviación son iguales. Es decir, el coeficiente de variación es 1. El coeficiente de variación (de datos no negativos) se define como la razón entre la desviación estándar y el valor medio. El coeficiente de variación da una medida del grado en que los datos están dispersos alrededor de la media. Un coeficiente de cero significa que no hay variación, esto es, que los datos son constantes. Para el caso de una distribución exponencial, como se indicó antes, el coeficiente de variación es uno. Si el coeficiente de variación de los datos medidos está cercano a la unidad, es razonable suponer que los datos se ajustan a una distribución exponencial. Cuando el coeficiente de variación es significativamente menor o mayor que la unidad, se usan la distribución especial de Erlang y la distribución hiperexponencial respectivamente.
La distribución exponencial se basa en la suposición de que el parámetro es constante, esto es, se asume que todos los eventos han sido generados por un mismo proceso aleatorio. Esta condición no se cumple a veces en ciertos procesos reales, cuando se trabaja con eventos que son producidos por procesos aleatorios diferentes pero mezclados. Es posible que una muestra sea tomada de dos o mas distribuciones
exponenciales, teniendo cada una un valor diferente del parámetro i. Muchos problemas de fenómenos de
espera caen en esta categoría. Por ejemplo, las llegadas pueden ocurrir a tasas i con probabilidades pi,
donde i = pi. es el parámetro de la población i, i = 1,2, ..s, tal pi = 1. Tal mezcla de variables exponenciales sigue a su vez una distribución hiperexponencial particular (s = 2) ó hiperexponencial generalizada (S > 2).

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 15
3.4 Distribución Weibull La distribución exponencial se aplica bastante para describir la duración de un equipo. En este caso, el
parámetro recibe el nombre de "tasa de fallas" y el inverso 1/ recibe el nombre de "tiempo medio entre fallas". La distribución exponencial se emplea cuando la "función de tasa de fallas" ó "función de riesgo" es constante. Para una distribución continua F, definimos h (t), la función de tasa de fallas como
)(1
)()(
tF
tfth
donde f(t) es la función de densidad y es igual a f(t) = dF(t)/dt. Si F es la distribución de la vida de un artículo, entonces h(t) representa la densidad de probabilidad de que un equipo con una vida t falle. Esto es, h(t)dt es la probabilidad condicional de que un artículo fallará entre los tiempos t y t + dt dado que ha funcionado hasta el tiempo t. Decimos que F es una distribución con tasa creciente de falla (TCF) si h(t) es una función creciente de t. Similarmente, decimos ese F es una distribución con tasa decreciente de falla (TDF) si h (t) es una función decreciente de t.
La distribución exponencial se usa cuando la función de riesgo es constante, esto es h(t) = Cuando la tasa de fallas no es constante, debe usarse una distribución diferente de la exponencial. Las distribuciones más frecuentemente usadas son la distribución Weibull y la gama.. La distribución de Weibull se usa con frecuencia para representar la vida de los componentes, pues posee una serie de ventajas sobre las demás. Fue usada por Weibull (1951) para describir las variaciones en la resistencia a la fatiga del acero y posteriormente se ha usado para representar la vida y el servicio de tubos y otros equipos electrónicos. La distribución de Weibull posee, en su forma general, tres parámetros lo que le da una gran flexibilidad. Ellos son:
a) Parámetro de posición representa el tiempo antes del cual se supone que no ocurre ninguna falla. En
la mayoría de los casos se supone = 0. b) Parámetro de escala o característica de vida c) Parámetro de forma Seleccionando adecuadamente los valores de los parámetros es posible obtener mejores ajustes que los obtenidos con otras distribuciones.
Se observa que si el parámetro de forma toma el valor = 1, se obtiene la distribución exponencial con dos
parámetros. Si además = 0 se obtiene la distribución exponencial de un parámetro ( = 1/). Sus principales características son las siguientes: a) Función de densidad de probabilidad f(t):
t
ff et t
t
,0
)(,
1
b) Función de distribución F(t), que representa la probabilidad de que el producto o componente falle antes del tiempo t
t
dttftTPtF ett
t
,0
1)()()(,
0

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 16
c) Tasa o intensidad de falla h(t) (tasa instantánea de falla)
tth
1
)(
Si = 1 se tiene una intensidad de fallas constante {h(t) = 1/= }, típica de la distribución exponencial. Ade-
más si 3,75 se obtiene una buena aproximación a una distribución normal
Una elección adecuada del parámetro de forma permite usar la distribución de Weibull para casos de in-
tensidad de fallas decreciente (rodaje o fallas infantiles < 1), para casos de intensidad de fallas constantes
(período de operación normal = 1) o para casos de intensidad de fallas creciente (período de desgaste con
> 1).
d) Tiempo medio entre fallas MTBF (TMEF) o Esperanza de vida, está dado por
MTBF = T0 =
1
11
e) Varianza de Vida, 2
V(T) = E[X2] - [E(X)]
2 = )]1
1()1
2([ 2
21
Si > 1 la distribución toma la forma de campana; de lo contrario toma la forma de J como la exponencial. Esta distribución, como se indicó antes, ha encontrado amplio uso al tratar problemas relacionados con pruebas de duración y datos de confiabilidad.
Generación. Para generar una variable aleatoria que siga una distribución Weibull puede hacerse uso de la transformación inversa, ya que F(x) tiene una forma cerrada.
)1(/1
)1(1)( rLnt
e trLntFr
t
Al igual que para el caso de la distribución exponencial, podemos reemplazar r por 1 – r, con lo cual la variable Weibull se genera como:
) /1Lnrt
3.5 Distribuciones Gama y Erlang Una variable aleatoria X tiene una distribución gama si su función de densidad está dada por:
0t
)k(
te)t(f
1k
t
donde )k( representa la función gama de k, que está definida como:
dxex)k( x
0
1k
También se cumple que )1k()1k()k( .

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 17
Si el valor de k es entero, se puede demostrar que )!1k()k( y en este caso la distribución toma el
nombre de distribución de Erlang.
El parámetro recibe el nombre de “parámetro de escala”, y el parámetro k el nombre de “parámetro de
forma”. A veces, en vez del parámetro se usa el parámetro , definido como = 1/. El valor esperado y la varianza de la distribución gama están dados por:
2
2
2 kk
)T(V,kk
)T(E
La función de distribución F(t), dada por t
dxxf0
)( no puede ser evaluada en forma explícita como una
función de t, por lo cual no puede ser manipulada algebraicamente. Cuando k es grande la distribución gama tiende a la distribución normal. Si K = 1 la distribución gama es igual a la distribución exponencial.
Si los parámetros y k no son conocidos, pueden estimarse mediante el método de los momentos como:
n
Xn
Vdonde,V
Xk,V
Xˆ
2n
1i
2
i2
2
2
2
x
3.5.1 Distribución de Erlang Si un proceso consta de k eventos sucesivos e independientes y si el tiempo total transcurrido en el proceso
puede mirarse como la suma de k variables exponenciales independientes, cada una con parámetro , la
distribución de esta suma seguirá una distribución Erlang con parámetros y k. Matemáticamente, la distribución de Erlang es la convolución (suma) de k distribuciones exponenciales. Es decir, si T1, T2,…Tk son
variables aleatorias distribuidas exponencialmente con parámetro , entonces
T = T1 + T2 + … + Tk
tiene una distribución Erlang con parámetros y k, cuya función de densidad tiene la siguiente forma:
0
)!1()(
1
t
ktf
te
kt
Como la función de distribución no tiene forma explícita, no puede emplearse el método de la transformación inversa. Las variables con distribución Erlang pueden generarse reproduciendo el proceso en que se basa esta distribución, es decir, mediante la suma de k variables exponenciales. Entonces para generar una variable Erlang se puede reproducir el proceso que da origen a la distribución, mediante la generación de k
variables exponenciales T1, T2,…Tk cada una con media y luego realizando la respectiva suma. Por consiguiente la variable Erlang T puede expresarse como:
T = T1 + T2 + … + Tk , donde rT ii Ln
1
Generación: Para generar una variable Erlang basta con generar k variables aleatorias exponenciales con
tasa y sumarlas. Es decir:
)B(Ln1
Ln...LnLn1
T
)A(Ln1
...Ln1
Ln1
...T
n
1iik21
k21k21
rrrr
rrrTTT

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 18
Por lo tanto para generar una variable Erlang, se generan k números aleatorios, se multiplican, al producto se
le toma el logaritmo natural y se divide por la tasa . El negativo de este resultado será la variable Erlang de interés. Esta última forma (B) de generación es mucho mas eficiente que sumar directamente las k variables aleatorias exponenciales (A) ya que el cálculo del logaritmo requiere más tiempo que el efectuar un producto.
3.5.2 Distribución gama El problema de generar variables aleatorias con distribución gama, cuando k no es entero, es un problema no resuelto aún completamente en forma analítica, ya que no hay un modelo estocástico para este caso. Se puede resolver numéricamente. Sin embargo, para resolverlo analíticamente se puede usar el siguiente enfoque aproximado. Si k es un número racional puede expresarse como la suma de un entero y una fracción, tal como k = k1 + p, donde k1 < k < k1+1 y 0 < p < 1. Además, si k2 = k1 + 1, entonces k2 – k1 = 1 - p. Entonces una mezcla de variables gama escogiendo k2 con probabilidad p y k1 con probabilidad 1 - p se aproximará a una distribución gama con parámetro k. Esta aproximación da mejores resultados con valores altos de k. Este enfoque funciona ya que se requiere que el valor medio escogido sea igual al valor que tiene la distribución, y que expresamos como k = k1 + p. Si escogemos k1 con probabilidad 1 - p y k2 = k1 + 1 con probabilidad p, el valor medio generado de k seria:
K esperado = k1 (1 – p) + k2 p) = k1 - k1 p + (k1 + 1) p = K1 + p
Es decir, si se escoge k1 con probabilidad 1 - p y k2 con probabilidad p el valor medio usado para k sería k1 + p, que es el valor real.
3.5.3 Distribución gama. Otra alternativa
El siguiente procedimiento, propuesto por Cheng (1977) sirve para generar variables gamma con
media y parámetro de forma k, esto es, con media 1/ y varianza 1/k2. El procedimiento es el
siguiente: 1) Calcule a = (2k-1)
0.5, b =2k - ln4+1/a.
2) Genere dos números aleatorios R1 y R2.
3) Calcule X = k [R1 /(1 – R1)]a.
4) Si X > b – ln (R21 R2), rechace X y regrese al paso 2).
5) Si X b – ln (R21 R2), use X como el valor de la variable deseada.
6) Reemplace X por X/ k
3.6 Distribución normal
Una variable aleatoria X tiene una distribución normal, denotada por N(, 2) si su función de densidad está
dada por:
xxf e x ,2
1)(
22
2/
La función de distribución x
dttfxF )()( no tiene una forma analítica explícita.
La media y la varianza de la distribución están dadas por:
E(X)=. V(X) = 2
Si los parámetros de la distribución normal toman los valores de = 0 y 2 = 1, la distribución es conocida
como "la distribución normal estándar o típica" N(0, 1) con función de densidad dada por:

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 19
xzf e z ,2
1)( 2/
2
De nuevo, la función de distribución F(z) no se puede calcular analíticamente, pero debido a su extenso uso, la función ha sido calculada numéricamente y se encuentra tabulada para valores que varían, por lo general entre –4 y +4.
Cualquier distribución normal N(, 2) puede convertirse a la forma estándar N(0,1) mediante la siguiente
transformación:
XZ
Si se conoce la variable aleatoria Z puede calculares X como X = + Z. Por lo tanto, puede trabajarse tanto
con la variable X que es N(, 2) como con la variable Z que es N(0,1).
La distribución normal deriva gran parte de su utilidad del teorema central del límite. Este teorema establece que "Si se toma una muestra aleatoria X1, X2,…, Xn de n variables aleatorias, independientes e idénticamente
distribuidas con media y varianza 2, entonces la distribución de la media X tiende a distribuirse
normalmente con valor esperado igual a y varianza igual a 2/n, cuando n es grande. Es decir, si X1, X2,…,
Xn es una muestra aleatoria con E (X) = y V(X) = 2, entonces
n
iiX
nX
1
1
tiende a seguir una distribución normal, cuando n es grande, con E( X ) = = y V( X ) = 2/n. O también, la
variable Z definida como:
n/
XZ
tiende a seguir una distribución normal con media cero y varianza unitaria. Observación: A veces el teorema central del límite se expresa en términos de la suma de las variables aleatorias, y no en términos del promedio, de la siguiente manera: “Si X1, X2,…, Xn es una muestra aleatoria
con E (X) = y V(X) = 2, entonces la suma S = X1 + X2 +…+ Xn tiende a distribuirse normalmente con valor
esperado igual a n y varianza igual a n2, cuando n es grande, ó
n
nS
se aproxima a una distribución
normal con media cero y varianza unitaria. La distribución normal también es importante como una aproximación a varias distribuciones, entre ellas la binomial y la Poisson. La distribución normal puede generarse por distintos métodos, unos más eficientes que otros, dependiendo del uso que se le vaya a dar. Para el proceso de generación, se generará la variable Z que es N(0,1) y luego
se calculará la variable X mediante la transformación X = + Z.
3.6.1 Método modificado de la transformación inversa, para simulación manual Como la función de distribución F(z) no existe en forma explícita, no es posible emplear la transformación Inversa como tal. Sin embargo, para simulaciones manuales o mediante hojas de cálculo, es posible emplear un procedimiento similar al de la transformación inversa, pero en forma numérica. Sea Z una variable normal con media cero y desviación estándar unitaria. La función de distribución de Z, F(z) está tabulada, para varios valores de z y podemos generar la variable Z usando el método de la transformación inversa, haciendo uso de esta tablas. Entonces, para generar una variable aleatoria normal Z se genera un número aleatorio r, se lo iguala a la función de distribución F(z), y se busca en la tabla el valor de Z que tenga una probabilidad acumulada de r. Sea Zr este valor.
r = F(z) Zr = F-1
(r)

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 20
donde Zr es el valor de la normal (0, 1) que tiene un área o probabilidad de r hacia la izquierda. La figura siguiente ilustra el procedimiento.
Como la variable de interés es X, entonces se generará como X = + Z = + Zr
Por ejemplo: Si r = 0.10 Z = -1.28
Si r = 0.50 Z = 0.00
Si r = 0.8577 Z = 1.07
Si r = 0.4191 Z = -1.04
3.6.2 Método del teorema central del límite Sean R1, R2,…, RN un conjunto de n variables aleatorias independientes e idénticamente distribuidas, cada
una con distribución uniforme en el intervalo (0,1), con E(R) = 1/2 y V(R) = 1/12. Sea
N
1iiR
N
1R ,
entonces, en virtud del teorema central del límite R tiende a distribuirse normalmente con
N12/1)R(V,2/1)R(E .
O también, la siguiente variable
NN
N
N
N
NRER N
ii
N
ii
N
ii
RR R
RR
Z12
2/
12
2/
12
1
2/11
)(
1
11
tiende a seguir una distribución normal con media cero y varianza unitaria cuando el valor de N es grande. Para saber que tan grande debe ser el valor de N, debería lograrse un compromiso o balance entre la eficiencia computacional y la exactitud o eficiencia estadística. Desde el punto de vista estadístico, N debería ser muy grande. Las pruebas estadísticas realizadas indican que el valor mínimo aceptable de N para que la aproximación tienda a una distribución normal es 10, o sea que cualquier valor igual o superior a 10 es aceptable estadísticamente. Desde el punto de vista computacional, considerando el tiempo empleado en la generación de los N números aleatorios necesarios para cada valor de Z, debería usarse un valor pequeño de N. Analizando las operaciones involucradas en el valor de Z, se ha llegado a la conclusión de que un valor recomendable para N es 12, ya que simplifica por completo el cálculo de la variable normal estándar. Por lo tanto, la siguiente variable, sigue una distribución normal típica (0,1)
6R12
1i
iRZ
Es decir, para generar una variable normal estándar, basta con generar doce números aleatorios, sumarlos y restarles seis.
Como la variable que por lo general interesa es la variable X que es N(, 2), entonces se la genera como:
612
1iiR RZX
3.6.3 Enfoque Directo
Este método produce resultados exactos y tiene una eficiencia computacional similar a la del método basado en el teorema central del lìmite.
Sean 1 y 2 dos variables normales (0, 1) e independientes. Su representación en un plano cartesiano es la siguiente:

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 21
donde el ángulo está formado por la hipotenusa B y la abcisa Z1. Matemáticamente se tienen las siguientes relaciones:
22
21
2 ZZB
Z1 = B cos
Z2 = B seno
Como 1 y 2 son dos variables normales (0,1), se tiene que sus cuadrados siguen una distribución chi cuadrado con un grado de libertad, y su suma tiene otra distribución chi cuadrado pero con dos grados de libertad. Es decir:
2)2(
2
2)1(
2i
X~B
X~Z
Por lo tanto, la función de densidad para B2 (= x) está dada por ( = 2):
0x2
1
)1(
1
)2/(
1)x(f eex
2ex
2
2/x2/x112/x12/
2/
Es decir, B2 tiene una distribución exponencial con parámetro = 1/2, y por lo tanto se puede
generar a través de un número aleatorio r1 como
1rln2B
El ángulo formado por la hipotenusa B y la abcisa Z1 varía uniformemente entre 0 y 2 y su función de densidad está dada por:
20,2
1)(f
Como )2,0(~ U puede generarse mediante otro número aleatorio 2r como
22 r
Dado que senBZ 2 y cos1 BZ , entonces pueden finalmente expresarse como:
)r2(senorln2Z
)r2cos(rln2Z
212
211
Las variables Z1 y Z2 son dos variables aleatorias normalmente distribuidas con media cero y varianza unitaria, y además, son independientes y por lo tanto pueden usarse para generar dos variables aleatorias normales independientes. La variable X puede generarse usando Z1 ó Z2, como se muestra a continuación.
1Z 1Z
2Z
B

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 22
X = + Z1 ó X = + Z2
3.6.4 Método del Rechazo Dado que una variable distribuida normalmente no tiene un rango finito de variación, en teoría no puede usarse el método del rechazo para generarla. Sin embargo se pueden establecerse unos limites razonablemente confiables entre los cuales se espera que caiga esta variable. Se sabe que el 99.73% de los valores de una distribución normal están en el intervalo definido por la media mas o menos tres desviaciones. Es decir, para la variable Z normal (0,1), se tiene que P(-3 < Z < +3) = 0.9973. Entonces se puede emplear el método del rechazo paro generar una variable Z, normal (0,1), limitando o
truncando sus valores en 3 . (Si se quiere una mayor exactitud se puede ampliar el rango a 3.5 ó 4.0, reduciendo por consiguiente la eficiencia computacional, al aumentar la región de rechazo). En el ejemplo 4.7 se presentó el procedimiento seguido para la generación de la distribución normal mediante este método. Este método es menos exacto y más lento que los anteriores.
3.6.5 Método de Marsaglia Bray El método de Marsaglia Bray para generar variables normales (o, 1) usa el siguiente procedimiento: a) Se genera una pareja de números aleatorios R1 y R2 b) Se calculan las siguientes expresiones
V1 = 2 R1 – 1
V2 = 2 R2 – 1
VVS 22
21
c) Si S > 1 se repite el paso a)
d) Si S 1 se calculan las siguientes expresiones para Z1 y Z2, que se distribuyen normalmente con media cero y varianza unitaria:
S
SLny
S
SLnVZVZ
2,
22211
Es de anotar que Z1 y Z2 además de ser normales, son independientes, es decir, que ambas variables pueden emplearse para generar dos procesos normales diferentes, o dos variables diferentes del mismo proceso. Este método es estadísticamente tan bueno como el del enfoque directo.
3.7 Distribución Logarítmica normal Si el logaritmo de una variable aleatoria tiene una distribución normal, dicha variable aleatoria tiene una distribución continua sesgada a la derecha, conocida como la distribución logarítmica normal - lognormal. La distribución lognormal se utiliza en una amplia variedad de aplicaciones. Se puede usar para describir procesos aleatorios que representan el producto de varios eventos pequeños e independientes; esta propiedad de la distribución recibe el nombre de "la ley de los efectos proporcionales" y proporciona la base en la cual nos podemos apoyar para suponer que la distribución lognormal describe una variable aleatoria particular. Esta variable solo toma valores positivos. En hidrología, se la usa frecuentemente para describir la distribución de los caudales de un río en un sitio dado, el cual puede ser la suma de otros caudales más pequeños de los afluentes a dicho río aguas arriba del punto de medición. La variable aleatoria continua X tiene una distribución logarítmica normal si la variable aleatoria Y = ln(X)
tiene una distribución normal con media y desviación estándar . La función de densidad de X que resulta está dada por:
x0,uxln
2x
1)x(f e
22
2/

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 23
con parámetros - < < +, 0 < < +.
Los parámetros y corresponden respectivamente a la media y la desviación estándar del logaritmo de X, es decir:
)XLn(V),XLn(E 2
La media y la varianza de X están dadas por:
)1()1()X(V
)X(E
e)]X(E[ee
e222
2
222L
2/L
El proceso de cálculo de probabilidades acumuladas es relativamente simple debido a su relación con la distribución normal, ya que si X es lognormal, entonces ln(X) es normal, y por lo tanto la variable Z definida como se muestra a continuación se distribuye normal con media cero y varianza unitaria.
)ln(XZ
Por lo tanto, para generar una variable con distribución logarítmica normal, basta con generar una variable normal (0,1), con cualquiera de los métodos analizados previamente, y a partir de esta variable generar la variable de interés.
eZXZ)Xln(Y
Si los parámetros que se conocen corresponden a la media y la varianza de la variable original lognormal X, entonces es necesario calcular la media y la varianza del logaritmo. Usando las expresiones dadas anteriormente para E(X) y V(X) se obtiene:
2L
2L
2L2
2L
2L
2L Ln,Ln
:
4 Generación de procesos discretos Si una variable aleatoria es discreta, el método de la transformación inversa nos dice que para un número aleatorio r, el valor de X será aquel que cumpla la siguiente desigualdad:
F(x – u) r < F(x)
cuando la variable aleatoria varia en intervalos de u unidades. Sin embargo, en muchos casos es muy difícil encontrar una expresión cerrada para la función de distribución F(x). En estos casos, se debe acudir a otros métodos, principalmente al de buscar una relación entre la variable aleatoria de interés y otra variable aleatoria que pueda generarse en forma directa (método de convolución). Por ejemplo la variable aleatoria binomial puede generarse basándonos en el hecho de que esta variable aleatoria se puede representar como la suma de variables aleatorias con distribución de Bernoulli. Otro ejemplo: Una variable que siga una distribución de Poisson puede generarse mediante la relación que esta variable tiene con la distribución exponencial.
4.1 Distribución de Bernoulli Una variable aleatoria que tome los valores cero y uno sigue distribución de Bernoulli si su función de probabilidad está dada por:
P(x) = px (1 – p)
1 – x, x = 0, 1

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 24
o simplemente:
P(X = 1) = p
P(X = 0) = q = 1 – p F(x) La media y la varianza están dadas por:
E (X) = = p 1
V(X) = 2 = p q, q = 1 - p
1 - p La función de distribución F(x) está dada por: F(x) = 1 – p para x = 0 F(x) = 1 para x = 1 0 1 x Figura 4. Función de distribución Bernoulli
Generación. Aplicado el método de transformación inversa, se genera un número aleatorio r, el generador del proceso está dado por:
x = 0 si r < 1 – p (1)
x = 1 si r 1 – p (2) 0 {X = 0} 1 – p {X = 1} 1 Como habíamos visto en el capítulo 1, el generador de una variable Bernoulli también puede expresarse como (método del rechazo):
Si r < p x = 1 (2)
Si r p x = 0 0 {X = 1} p {X = 0} 1 En ambos caso a X = 1 se le está dando el 100p% de los números aleatorios generados, los últimos 100p% en el primer método, y los primeros 100p% en el segundo caso. Así, por ejemplo, si p = 0.20, en el primer caso el valor X = 1 es generado por todo número aleatorio mayor o igual a 0.8, y en el último caso X = 1 es generado por todo número aleatorio menor que 0.20. Para un valor específico del número aleatorio r el resultado particular cambia, pero para una secuencia larga los resultados son los mismos, ya que como se analizó en capítulos anteriores, el número aleatorio se distribuye uniformemente en el intervalo (0,1). Para generar la variable aleatoria Bernoulli, usaremos el segundo procedimiento. La variable aleatoria X puede representar por ejemplo, el resultado de examinar un artículo: Si X = 1 el artículo es defectuoso, y si X = 0 el artículo es aceptable. Otro ejemplo es el relacionado con el resultado obtenido al lanzar una moneda: X = 1 si cae cara, y X = 0 si el resultado es sello.
Si p = 0.21, entonces X = 1 si r < 0.21, y X = 0 si r 0.2l
El generador, como se indicó anteriormente, también podría ser:
X = 0 si r < 0.79 y X = 1 si r 0.79.
porque en esta forma a X = 1 se le da la misma probabilidad de ocurrencia (21 de un total de 100, a saber: 0.79, 0.80,…,0.99)
4.2 Distribución binomial La variable aleatoria X que representa el número de eventos exitosos en una secuencia de n ensayos independientes de Bernoulli, sigue una distribución binomial. Matemáticamente la distribución binomial es la convolución de n distribuciones de Bernoulli. Si p es la probabilidad de que un evento sea exitoso, la función de probabilidad de la distribución binomial está dada por:

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 25
n...,,1,0x,x
n)x(P p1p
xnx
La función de distribución, dada por la expresión siguiente no tiene una forma explícita.
)p1(pjnj
x
0j
x
0j j
n)j(p)x(F
Para valores dados de n y p, la función de distribución podría calcularse numéricamente, y luego generarse usando el método de la transformación inversa para el caso discreto. El valor esperado y la varianza de la variable binomial están dados por:
E (X) = = n p
V(X) = 2 = n p q, q = 1 - p
Para generar una variable binomial hay diferentes enfoques, dependiendo de los valores de n y p.
4.2.1 Sucesión de eventos de Bernoulli. Si X1, X2,…,Xn es una secuencia de n variables aleatorias independientes que siguen una distribución de Bernoulli con parámetro p, entonces X definida como:
n
iiXX
1
sigue una distribución binomial con parámetros n y p. Es decir, la distribución binomial surge de la suma (convolución) de n variables con distribución Bernoulli. La anterior relación da la base para definir un generador del proceso binomial. Esto es, para generar una variable aleatoria binomial con parámetro n y p, sólo necesitamos generar n variables de Bernoulli con parámetro p y luego sumarlas. El procedimiento será entonces a) Se inicializa X = 0
b) Se genera un número aleatorio ri, para i = 1, 2,..., n.
c) Si ri < p, entonces Xi = 1, en caso contrario Xi = 0
d) Se aumenta X en el nuevo valor de Xi, es decir, X = X + Xi.
e) Se repite el paso b) para cada valor de i.
El valor de la variable aleatoria será el último valor resultante del proceso anterior. El proceso dado anteriormente se resume en el siguiente seudo código, que representa una “función” en lenguaje de programación de computadores::
Función generar_binomial (n, ) X = 0 Para i = 1 hasta n
R = RNDi
Si R < p entonces X = X + 1
fin si Fin para generar_binomial = X
Fin función donde se supone que RND es una función que genera un número aleatorio entre 0 y 1.
4.2.2 Aproximación mediante la distribución normal

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 26
La distribución normal es una buena aproximación a la distribución binomial para valores grandes de n y de p. Dado que es posible obtener valores negativos en la distribución normal, entonces el valor mínimo de n para usar esta aproximación está dado por la siguiente desigualdad:
03 0)1(3 ppnnp ppn /)1(9
dado que se considera que aproximadamente cualquier valor de la distribución está comprendido entre la
media mas o menos tres desviaciones, o mas exactamente en el rango 3 está comprendido el 99.73% de la población (para efectos prácticos, en muchas aplicaciones se considera que este rango corresponde al 100% de la población). Para que la aproximación de la distribución normal a la binomial sea buena se requiere que el tamaño de
muestra sea grande (n 50) y que el parámetro p esté alrededor de 0.5 (0.4 p 0.6), ó también que n sea
lo suficientemente grande, sin importar el valor de p (n 100).
La variable binomial se puede aproximar entonces a una normal con = np y 2
= np(1-p), es decir,
)1( ppn
npXZ
se distribuye normalmente con media cero y varianza unitaria. Por lo tanto, la variable X se generaría como:
)p1(pnZpnX
donde Z corresponde a la variable normal (0,1), que se generaría mediante uno de los métodos analizados previamente para generar variables normales. Debe tenerse en cuenta que la distribución binomial es discreta, mientras que la distribución normal es continua, por lo tanto, el valor resultante para X debe ser entero. Por lo tanto, para generar la variable binomial mediante la aproximación normal, se recomienda usar el ”factor de corrección de continuidad” de ½ para aproximar distribuciones discretas mediante distribuciones continuas (usando redondeo simétrico). De acuerdo con lo anterior, el valor de la variable binomial X estará dado por:
]2/1)1([ ppnZpnX
donde [Y] quiere decir que se toma la parte entera de Y.
4.2.3 Aproximación a través de la distribución de Poisson
Si p es pequeño (p 0.1) y n es grande (n 50), la distribución binomial puede aproximarse por la
distribución de Poisson con parámetro = np. Es decir, X puede generarse en igual forma que la distribución de Poisson, según los métodos que se explicarán posteriormente. Sin embargo este método no es muy eficiente.
4.3 Distribución Geométrica Una variable aleatoria X tiene una distribución geométrica si su función de probabilidad está dada por:
P(x) = p (1 – p) x-1
, x= 1,.2,…,
donde p representa la probabilidad de que un evento o ensayo de Bernoulli sea exitoso. La variable aleatoria X puede interpretarse como el número de eventos que es necesario realizar antes de obtener el primer éxito. Algunas aplicaciones de esta distribución pueden ser:
X puede representar el número de lanzamientos requeridos de una moneda antes de obtener la primera cara; en este caso p representa la probabilidad de que la moneda caiga en cara.
X puede representar el número de artículos que es necesario inspeccionar antes de obtener el primero que sea defectuoso; en este caso p representa la probabilidad de que un artículo sea defectuoso.
X puede representar el tiempo requerido para terminar una reparación, medido en unidades discretas; en este caso p representa la probabilidad de que la reparación se termine en una unidad de tiempo.
X puede representar el número de veces que un jugador debe comprar una lotería antes de ganarse la primera; en este caso p representa la probabilidad de que el jugador se gane una lotería.

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 27
La distribución geométrica tiene, en el caso discreto, la misma propiedad que tiene la distribución exponencial en el caso continuo: La propiedad de pérdida de memora. Para ilustrarla considere la última aplicación mencionada de la distribución: número de veces que un jugador debe comprar una lotería antes de ganarse la primera. Cree Usted que el hecho de haber jugado muchas loterías cambia la probabilidad de ganarse la próxima? La función de distribución está dada por:
qpx
xx
i
ix
j
j
qpppxXPxF
1
1
1)()(
1
01
1)1(
La media y la varianza de la distribución geométrica están dadas por:
E (X) = = 1 / p, V(X) = 2 = q / p
2, q = 1 - p
La variable aleatoria geométrica puede generarse por diversos métodos.
4.3.1 Método de la transformación inversa Como se demostró antes, el valor de la variable aleatoria X será el entero que satisfaga la desigualdad
x1x q1rq1)x(Fr)1x(F
y como se demostró en el ejemplo 4.6 el valor de X es el entero que cumple la siguiente desigualdad:
1)1()1(
qLn
rLnx
qLn
rLn x es la parte entera de 1
)1(
qLn
rLn
Ver ejemplo 4.6
4.3.2 Método del rechazo Como la variable aleatoria X puede interpretarse como el número de eventos que es necesario realizar antes de obtener el primer éxito, entonces una variación de la técnica del rechazo puede emplearse para generar la variable geométrica, simplemente mediante la reproducción de ensayos de Bernoulli. Para ello se generan números aleatorios hasta encontrar el primero que sea menor que p; la variable aleatoria X corresponde al total de números aleatorios generados, que es equivalente al número de ensayos de Bernoulli real izados. El procedimiento se puede resumir en los siguientes pasos: a) Se inicializa la variable aleatoria en el valor de 1: x = 1(mínimo hay que hacer un ensayo)
b) Se genera un número aleatorio r.
c) Si r p, se hace x = x + 1 y se genera un nuevo número aleatorio (se repite b).
d) Si r p, se para el proceso. El valor de la variable aleatoria será el último que tenga la variable x.
Este método es preferido cuando el valor de p es relativamente alto, y cuando se desee una mayor exactitud. Recuérdese que el valor esperado de la variable es 1/p. Así, si p = 0.01, usando el método del rechazo se espera tener que generar 100 números aleatorias para obtener el valor de una sola variable aleatoria. El siguiente seudo código ilustra el proceso
Proceso generar_geometrica(p, X) X = 1 R = RND Mientras R > p
X = X + 1 R = RND Fin mientras
Fin proceso

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 28
4.4 Distribución Geométrica modificada Si definimos Y como la variable que representa el número de fracasos necesarios para obtener el primer éxito, la función de probabilidad estará dado por:
P(y) = p (1 – p) y-1
, y= 0,1,.2,…,
Entonces se dice que Y = X - 1 sigue una distribución geométrica modificada. La función de distribución, la media y la varianza de la distribución geométrica modificada están dadas por:
qy
yYPyF1
1)()(
E (Y) = E(X – 1) = = q / p
V(Y) = V(X – 1) = 2 = q / p
2, q = 1 - p
Para generar esta variable aleatoria se usan los mismos métodos de la distribución geométrica, y se obtienen los siguientes resultados:
4.4.1 Método de lo transformación inversa El valor de Y es el entero que satisfaga la siguiente desigualdad:
qLn
rLnx
qLn
rLn )1(1
)1(
Y es la parte entera de la expresión
qLn
)r1(Ln
Por ejemplo, si p = 0.20, y se tienen los siguientes números aleatorios, entonces:
Si r = 0.402 1.30 < x 2.30 x = 2
Si r = 0.525 2.34 < x 3.34 x = 3
Si r = 0.149 -0.38 < x 0.72 x = 0
Si r = 0.408 1.35 < x 2.35 x = 2
Si r = 0.488 2.00 < x 3.00 x = 3
Si r = 0.698 4.37 < x 5.37 x = 5
4.4.2 Método del rechazo El procedimiento es idéntico al de la variable geométrica X, excepto que el contador se inicia en cero y no en uno.
4.5 Distribución binomial negativa o de Pascal Cuando estamos interesados en el número de ensayos X necesarios para obtener k éxitos (k > 1), entonces la variable aleatoria que denota ese número de ensayos tiene una distribución binomial negativa o de Pascal. Matemáticamente, la distribución binomial negativa es la convolución de k distribuciones geométricas. En este caso k es un entero, y la distribución recibe también el nombre de Distribución de Pascal. La distribución geométrica es un caso especial de lo distribución de Pascal para k = 1. La función de probabilidad de la distribución binomial negativa está dada por:
,...,2k,1k,kx,)p1(p1k
1x)k,x(p kk
El valor esperado y la varianza de X están dados por:
E (X) = = k / p
V(X) = 2 = k q / p
2, q = 1 - p

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 29
Como k es entero, la variable de Pascal puede generarse mediante el proceso matemático que da origen a la
distribución, es decir, mediante la suma de k variables geométricas, es decir,
k
iiXX
1
, donde las Xi siguen
una distribución geométrica con parámetro p, la cual se genera mediante uno de los dos métodos analizados previamente. Recordemos que la variable aleatoria representa el número de ensayos requeridos para obtener los k primeros éxitos (Por ejemplo, X puede ser el tiempo requerido para terminar k tareas)
Observación. Si Y representa el número de fracasos que se presentan antes de obtener k éxitos, entonces Y
= X – K X = Y + K. La función de probabilidad de Y estará dada por:
,...,2,1,0y,)p1(p1k
1ky)k,y(p yk
Ahora como se cumple que
y
ky
k
ky 1
1
1 dado que
xn
n
x
n
la función de densidad toma la siguiente forma:
,...,2,1,0y,)p1(py
1ky)k,y(p yk
donde k es el número total de éxitos en y + k ensayos, y “ y ” es el número de fracasos que se presentan antes de que ocurran los k primeros éxitos. El valor esperado y lo varianza de Y están dados por:
(Y) = = k q / p
V(Y) = 2 = k q / p
2, q = 1 - p
Para generar la variable Y basta con generar k variables geométricas modificadas y sumarlas.
4.6 Distribución hipergeométrica Considere una población que consta de N elementos, los cuales pueden clasificarse en dos categorías: categoría I (elementos defectuosos) y categoría II (elementos buenos). El número de elementos que pertenecen a la categoría I es M, por lo tanto el número de elementos que pertenecen a la categoría II es N - M. Sea X el número de elementos de la categoría I que hay en una muestra aleatoria de n elementos
tomada de la población total N, n N. Además, el muestreo se hace sin reemplazo. Entonces la variable aleatoria X tiene una distribución hipergeométrica cuya función de probabilidad está dada por:
Mxnx
n
N
xn
MN
x
M
xp
,...,,1,0,)(
donde x, N y M son enteros. La fracción (inicial) de artículos defectuosos de la población (o elementos que pertenecen a la categoría I) está dada por p = M/N. El valor esperado y la varianza de la distribución hipergeométrica están dados por:
1)(
)(
N
nNqpnXV
pnXE
La distribución binomial se usa cuando se hace muestreo, con o sin reemplazo de una población infinita (o de un proceso). En cambio, la distribución hipergeométrica se aplica cuando se está haciendo muestreo de una

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 30
población finita, sin reemplazo de los elementos previamente seleccionados. Es decir, la muestra obtenida resulta de realizar n ensayos de bernoulli, con la diferencia con respecto a la distribución binomial que la probabilidad de éxito p (fracción de artículos defectuosos) no es constante a través del proceso sino que depende de los resultados obtenidos previamente. La generación de variables hipergeométricas involucra la simulación de un experimento de muestreo sin reemplazo. Por lo tanto, tenemos que modificar el método de generar ensayos de Bernoulli para tener en cuento que el tamaño de la población N y el número de elementos tipo I que quedan en la población M varían a medida que se va realizando el muestreo y por consiguiente p depende del número de elementos de la categoría l que se vayan obteniendo. A medida que se selecciona cada elemento de la muestra, el valor original de N se reduce en uno de acuerdo a la fórmula:
Ni = Ni-1 – 1, para i = 1, 2, …, n, y N0 = N
En igual forma el valor de M se modifica según el resultado obtenido en el muestreo. Se reduce en 1 si el valor extraído de la muestra pertenece a la categoría I, y queda igual si pertenece a la categoría II. El valor de p debe recalcularse siempre a medida que se van sacando los elementos de la muestra.
Mi = Mi-1 – 1 si el elemento i pertenece a la categoría I
= Mi-1 si el elemento i no pertenece a la categoría I. El procedimiento completo se ilustra en el siguiente seudo código:
Función generar_Hiper(N, M, n, X) X = 0 p = M/N Para i = 1 hasta n R = RND Si R < p entonces X = X + 1 fin si p = (M - X)/(N - i) Fin para Generar_hiper = X Fin proceso
4.7 Distribución de Poisson Considere el problema de contar el número de personas N(t) ó X que llegan a recibir servicio a una estación de gasolina en un intervalo de tiempo t. Si el número medio de personas que llegan por unidad de tiempo es
, entonces la variable aleatoria N(t) (ó X) que denota el número de eventos que ocurren en el tiempo t será
un proceso de Poisson con parámetro . Por consiguiente, la función de probabilidad estará dada por:
...,2,1,0x,!x
()x(p
)te
x
t
La función de distribución está dada por la siguiente expresión, que no puede evaluarse en una forma analítica:
x
j
jt
jxXPxF
te
0 !
()()(
)
La función de distribución también puede expresar en forma recursiva como:
Inicialmente se hace: X = 0, P= F(0) = e-t Posteriormente X se incremeta en i

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 31
)x(p)1x(F)x(F
x
t)1x(p)x(p
1xx
)0(F)0(P et
El valor esperado y la varianza están dados por:
E (X) = = t, V(X) = 2 = t
La distribución de Poisson se aplica en aquellos procesos de conteo en los cuales el número de eventos depende únicamente de la longitud del intervalo de tiempo. Por ejemplo, el número de personas que llegan a recibir servicio en un intervalo de tiempo fijo, el número de llamados por minuto que entran a un conmutador, el número de defectos por metro de tela, etc. Para generar variables aleatorios que sigan una distribución de Poisson, no es posible usar el método de la transformación inversa en su forma original, ya que F(x) no tiene uno forma explícita. Se puede emplear una versión modificada de dicho método o en forma numérica, como si fuera una distribución empírica. El método más común para generar una variable Poisson es usando la relación que existe entre las distribuciones de Poisson y la exponencial. Esta relación establece que "si el número de eventos que ocurren en un intervalo
de tiempo t es un proceso de Poisson con parámetro , entonces el tiempo entre la ocurrencia de dos
eventos sucesivos sigue una distribución exponencial, con media 1/".
Observación. En su forma más conocida la distribución de Poisson se expresa de la siguiente manera
...,2,1,0x,!x
)x(px
e
donde representa la “tasa de ocurrencia de eventos” en el período de tiempo bajo análisis. En este caso el tiempo t no se da de manera explícita, sino que está incluido de manera implícita en el valor de la tasa.
Haciendo la analogía con la anterior definición se tiene que = t. Por ejemplo, si la tasa de llegada de clientes a un supermercado es 3 por minuto, y vamos a analizar el supermercado durante una hora
podríamos considerar lo siguiente: = 3 clientes/minuto, t = 60 minutos t = 3t = 180 clientes (en una
hora). O podríamos considerar de una vez la hora y la tasa sería = t.= 3 (60) = 120 clientes/hora
4.7.1 Generación mediante relación con la exponencial Esta relación entre los variables aleatorias Poisson y exponencial provee un método para generar variables aleatorios distribuidas poissonianamente. Si X eventos ocurren en el intervalo de tiempo t, entonces la suma de los tiempos de ocurrencia de los X eventos debe ser menor que t. Es decir, si T1 es el tiempo de ocurrencia del primer evento, T2 es el tiempo entre la ocurrencia del primero y el segundo eventos, T i el tiempo entre el evento i - 1 y el evento i, entonces se debe cumplir que:
1x
1ii
x
1ii TT t
Se sabe que cada Ti, i = 1, 2,..., se distribuye exponencialmente con parámetro . Entonces para generar un valor de x simplemente basta con generar valores sucesivos de T i. hasta que la suma sea mayor de t. Dado que estamos interesados en conocer el número de eventos que ocurren en el tiempo t, generamos valores de Ti hasta que se cumpla por primera vez que:
1
1
x
ii tT , donde Ti = -Ln ri /
entonces el valor de x será el número de variables Ti generadas menos uno (dado que el último evento ocurre después de t). El valor x = 0 se genera cuando T1 > t, es decir, cuando el primer valor generado es

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 32
mayor que t. Esto es, x es el número de eventos tal que
1x
1ii
x
1ii TT t , donde la sumatoria se inicializa
en cero (0). Es decir, los primeros x eventos ocurren antes de ó en el tiempo t y el evento x + 1 ocurre
después del tiempo t, lo cual implica que en el tiempo t ocurren x eventos. Como Ti = -Ln ri / , se tiene que:
1x
1ii
x
1ii
1x
1ii
x
1ii
1x
0ii
x
0ii rrrrTT LntLnLn
1tLn
1t
1x
1ii
tx
1ii rer
Por lo tanto, y de acuerdo con la expresión anterior, para generar una variable Poisson, basta con generar
números aleatorios, multiplicarlos, y suspender el proceso cuando dicho producto sea menor que e-t
. El valor de la variable aleatoria x es igual a la cantidad de números aleatorios generados menos 1. La productoria se
inicializa en uno (1). El valor x = 0 se produce cuando r1 < e -t
, es decir, cuando el primer número aleatorio
generado es menor que e-t
. La generación de variables aleatorias mediante la fórmula anterior es más eficiente ya que no se requiere calcular los logaritmos. El seudo código siguiente ilustra el proceso
Generar Poisson X = 0 Producto = 1
Mientras Producto > e-t
haga R = RND Producto = Producto * R X = X + 1 Fin mientras Generar_Poisoon = X Fin proceso
4.7.2 Mediante la transformación inversa Calculando la función de distribución en forma numérica y recursiva se puede generar variables aleatorias Poisson, mediante el método de la transformación inversa. La ecuación recursiva para una distrobicuón
Poisson con parámetro se escribe como:
e)0(Fpdondex
)1x(p)1x(F)x(F
la siguienteEl procedimiento es el siguiente, para una distribución de Poisson con tasa :
Proceso Poisson X = 0
P = e -
F = P R = RND
Mientras R F X = X + 1
P = P * / X F = F + 1
Fin mientras Fin proceso
4.7.3 Mediante relación con la aproximación normal

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 33
Cuando la media de la distribución t es relativamente grande ( = t 30) la distribución de Poisson puede aproximarse por la distribución normal con media y varianza dados por:
= 2 = t
Por lo tanto, X puede generarse a través de la distribuciónnormal usando el factor de corrección de ½ como:
]2/1tZt[]2/1Z[X
donde Z corresponde a la variable normal (0,1), que se generaría mediante uno de los métodos analizados previamente para generar variables normales.
Observación. Si la distribución de Poisson la expresamos sólo en función de la tasa la fórmula apropiada es la siguiente: (forma normal o estándar de la distribución):
...,2,1,0x,!x
)x(px
e
En este caso la variable aleatoria se genera usando exactamente los mismos procedimientos dados antes,
pero considerando = y t = 1.
5 Distribuciones empíricas Cuando se tiene un conjunto de datos sobre una variable aleatoria, debemos tratar de ajustar esos datos a una distribución estándar, de las estudiadas antes. Para determinar si los datos se ajustan a la distribución que se supone hay disponibles varias pruebas estadísticas, conocidas como pruebas de bondad de ajuste, tales como la las pruebas chi cuadrado y Smirnov-Kolmogorov, estudiadas antes. Si no es posible describir la función de probabilidad de la muestra mediante una de las distribuciones estándares, es necesario trabajar entonces con la distribución empírica que muestran los datos (usar el histograma de frecuencia). Para generar estas variables se puede emplear el método de la transformación inversa para el caso discreto o una versión modificada de este método propuesta por Marsaglia.
5.1 Método de la transformación inversa Si X es una variable aleatoria con función de probabilidad empírica p(x) y función de distribución F(x), entonces para generar observaciones artificiales de esta variable, se puede usar el método de la transformación inversa para el caso discreto. Si la variable aleatoria puede tomar únicamente los valores xi, (variable tipo discreta) con probabilidad p(xi) y función de distribución empírica F(xi), para i = 1, 2,…,N, entonces, dado un número aleatorio r, el valor de la variable aleatoria X será aquel que satisfaga la siguiente desigualdad:
F(xi-1) x < F(xi)
Ejemplo 4.10. La demanda de un producto durante 55 semanas fue la siguiente:
Demanda 10 15 20 25 30
Frecuencia 10 21 17 6 1 Con base en la frecuencia absoluta, podemos calcular la frecuencia relativa, dividiendo la frecuencia absoluta f(xi) por la frecuencia total (n). Esta frecuencia relativa -p(xi)- nos da la probabilidad (empírica) de que la demanda en una semana sea igual a xi. Con la frecuencia relativa podemos calcular la frecuencia relativa acumulada f(xi) que corresponde a la función de distribución empírica. Estos valores se calcula como:
)()()()(
)()(
11
xxxx
xx
ii
i
jii
ii
pFpF
N
fp
La tabla siguiente presenta la información referida anteriormente.
Demanda - xi 10 15 20 25 30
Frecuencia relativa - f(xi) 0.18 0.38 0.31 0.11 0.02

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 34
Frecuencia relativa acumulada F(xi) 0.18 0.56 0.87 0.98 1.00
Si la demanda sólo puede tomar los valores anteriores, el generador del proceso usando el método de la transformación inversa sería el siguiente: Se genera un número aleatorio R = r
Si r < F(x1) x = x1
Si F(x1) r < F(x2) x = x2
………………………………………………….
Si F(xi-1) r < F(xi) x = xi
……………………………………………………………………………….
Si r F(xN) x = xN
Para el ejemplo que estamos analizando el proceso sería el siguiente: Se genera un número aleatorio R = r y el valor de la variable sería:
Si r < 0.18 x = 10
Si 0.18 r 0.56 x = 15
Si 0.56 r 0.87 x = 20
Si 0.87 r 0.98 x = 25
Si r 0.98 x = 30
5.2 Interpolación lineal Cuando la variable aleatoria X es continua, no discreta, y puede tomar cualquier valor ente xi-1 y xi es posible usar la interpolación lineal para encontrar el valor de x. También se aplica cuando la muestra está organizada en intervalos de clase. El proceso de generación sería el siguiente: Se genera un número aleatorio R = r
Si r < F(x1) x = x1
………………………………………………….
Si F(xi-1) r < F(xi)
xxx(F
xxx 1i
1ii
1ii1i r
(F)x
i
……………………………………………………………………………….
Si r F(xN) x = xN
5.3 Método de Marsaglia El método de Marsaglia está diseñado para ser usado en el computador. El método define un bloque o vector V de N posiciones, a las cuales se le asignan los valores de la variable aleatoria X, y el numero de posiciones asignadas a cada valor de xi es proporcional a su probabilidad p(xi). Para el ejemplo que estamos considerando, al valor x = 5 se le asigna el 18% de las posiciones del vector, al valor x = 10 el 38%,…, y al valor x = 30 el 2%. La tabla siguiente ilustra la forma como quedaría el vector. Posición 1 2 3 .. 17 18 19 20 .. 56 57 58 .. 86 87 88 89 .. 98 99 100
Valor 10 10 10 .. 10 10 15 15 .. 15 15 20 .. 20 20 25 25 .. 25 30 30 El número de posiciones N del vector debe ser tal que a cada valor de xi se le asigne un número entero de posiciones, de tal forma que se preserve la respectiva probabilidad. El número de posiciones asignadas a cada valor de xi está dado por N p(xi). Por lo tanto, el número de posiciones del vector N debe ser tal que:
N p(xi) = entero, para todo i .
Para nuestro caso, el valor de N debería ser mínimo 100. Si las probabilidades las hubiéramos tomado con tres cifras decimales, hubiéramos requerido un total de 1000 posiciones de memoria, en vez de 100. Una vez definido y llenado el vector con las N posiciones, para generar una observación de esa variable aleatoria, se selecciona al azar una de las N posiciones del vector, y el valor de la variable será el valor que

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 35
ocupa la posición seleccionada. Es decir, si R es el número aleatorio generado, la posición escogida j y el valor de la variable están dados por: Posición = j = [N r + 1] Variable aleatoria = Vector(j) El procedimiento para generar la variable X consta de los siguientes pasos:: 1) Se define un campo de N posiciones en la memoria del computador.
2) Al valor de xi se le asignan N p(xi) posiciones del total de N, desde la posición N F(xi-1) +1 hasta la posición N F(xi), para i = 1,2.,,,N.
3) Se genera un número aleatorio r, se calcula la posición correspondiente al valor generado, y se extrae el respectivo valor. Este es el valor de la variable x.
Los pasos 1 y 2 se realizan solo una vez, al inicializar la simulación, y el paso 3 se repite tantas veces cuantas variables haya que generar. Para el ejemplo analizado, los pasos 1 y 2 son los siguientes: 1. Se define el vector de N = 100 posiciones 2. Se llenan las 100 posiciones de la siguiente manera:
2.1. Al valor de x1 = 10 se le asignan 18 posiciones, desde la No 1 hasta la No 18.
2.2. Al valor de x2 = 15 se le asignan 38 posiciones, desde la No 19 hasta la No 56.
2.3. Al valor de x3 = 20 se le asignan 31 posiciones, desde la No 57 hasta la No 87.
2.4. Al valor de x4 = 25 se le asignan 11 posiciones, desde la No 88 hasta la No 98.
2.5. Al valor de x5 = 30 se le asignan 2 posiciones, las posiciones 99 y 100.
3. Por cada variable aleatoria que se necesite, se genera un número aleatoria, y el valor de la variable corresponde al número almacenado en la posición j = [100 r +1], El siguiente seudo código ilustra el procedimiento anterior: Función Marsaglia
Posición inicial = 1 Para i = 1, n Posición final = Posición inicial + N p(xi) Para posición = posición inicial hasta posición final Vector(posición) = xi Siguiente posición Posición inicial = posición final + 1 Siguiente i
Fin proceso
El procedimiento para generar las observaciones artificiales de la variable aleatoria sería el siguiente Función generar empírica
Generar número aleatorio (r) Posición = j = [N * r +1] X = vector(j)
Fin proceso
6 Generación de variables aleatorias con Excel La hoja de cálculo Excel tiene varias funciones para generar variables aleatorias de diferentes tipos. Estas funciones son las siguientes:
6.1 Distribución Beta DISTR.BETA.INV

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 36
Devuelve, para una probabilidad dada, el valor de la variable aleatoria siguiendo una distribución beta. La distribución beta puede emplearse en la organización de proyectos para crear modelos con fechas de finalización probables, de acuerdo con un plazo de finalización y variabilidad esperados. Sintaxis: DISTR.BETA.INV(probabilidad;alfa;beta;A;B) Probabilidad: es una probabilidad asociada con la distribución beta. Para la simulación corresponde a un
número aleatorio.
Alfa y Beta son los parámetros de la distribución.
A y B corresponden a los límites inferior y superior, respectivamente, de los valores de x. DISTR.BETA.INV usa una técnica iterativa para calcular la función. Dado un valor de probabilidad, DISTR.BETA.INV itera hasta que el resultado tenga una exactitud de ±3x10
-7. Si DISTR.BETA.INV no
converge después de 100 iteraciones, la función devuelve el valor de error #N/A. Ejemplo: DISTR.BETA.INV(0,685470581;8;10;1;3) es igual a 2
6.2 Distribución F DISTR.F.INV Devuelve el inverso de la distribución de probabilidad F. Si el argumento p = DISTR.F(x,...), entonces DISTR.F.INV(p,...) = x. La distribución F puede usarse en una prueba F que compare el grado de variabilidad en dos conjuntos de datos. Por ejemplo, podría analizar las distribuciones de ingresos en Venezuela y Colombia para determinar si ambos países tienen un grado de diversidad similar. Sintaxis: DISTR.F.INV(probabilitdad;grados_de_libertad1;grados_de_libertad2) Probabilidad es una probabilidad asociada con la función de distribución acumulativa F. Para la
simulación corresponde a un número aleatorio.
Grados_de_libertad1 es el número de grados de libertad del numerador.
Grados_de_libertad2 es el número de grados de libertad del denominador. DISTR.F.INV puede usarse para devolver valores críticos de la distribución F. Por ejemplo, el resultado de un cálculo AN.VAR generalmente incluye datos para la estadística F, la probabilidad F y el valor crítico F con un nivel de significación de 0,05. Use el nivel de significación como argumento probabilidad de DISTR.F.INV para devolver el valor crítico de F. DISTR.F.INV usa una técnica iterativa para calcular la función. Dado un valor de probabilidad, DISTR.F.INV reitera hasta que el resultado alcance una exactitud de ± 3x10
-7. Si DISTR.F.INV no converge después de
100 iteraciones, la función devuelve el valor de error #N/A. Ejemplo: DISTR.F.INV(0,01;6;4) es igual a 15,20675
6.3 Distribución Gamma DISTR.GAMMA.INV Devuelve, para una probabilidad dada, el valor de la variable aleatoria siguiendo una distribución gamma. Si p = DISTR.GAMMA(x,...), entonces DISTR.GAMMA.INV(p,...) = x Utilice esta función para estudiar variables cuya distribución podría ser asimétrica. Sintaxis: DISTR.GAMMA.INV(prob; alfa; beta) Prob es la probabilidad asociada con la distribución gamma. Para la simulación corresponde a un
número aleatorio.
Alfa es un parámetro de la distribución.
Beta es un parámetro de la distribución. Si beta = 1, DISTR.GAMMA.INV devuelve el valor de la variable aleatoria siguiendo una distribución gamma estándar.
Ejemplo: DISTR.GAMMA.INV(0,068094;9;2) es igual a 10
6.4 Distribución logarítmica normal DISTR.LOG.INV

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 37
Devuelve el inverso de la probabilidad para una variable aleatoria X que sigue una distribución logarítmica normal, donde ln(x) se distribuye normalmente con los parámetros media y desv_estándar. Si p = DISTR.LOG.NORM(x,...) entonces DISTR.LOG.INV(p,...) = x. La distribución logarítmica normal se emplea para analizar datos transformados logarítmicamente. Sintaxis: DISTR.LOG.INV(probabilidad;media;desv_estándar)
Probabilidad es una probabilidad asociada con la distribución logarítmico-normal. Para la simulación corresponde a un número aleatorio.
Media es la media de ln(x).
Desv_estándar es la desviación estándar de ln(x). Ejemplo: DISTR.LOG.INV(0,039084; 3,5; 1,2) es igual a 4,000014
6.5 Distribución normal estándar N(0,1) DISTR.NORM.ESTAND.INV Devuelve, para una probabilidad dada, el valor de la variable aleatoria que sigue una distribución normal estándar. La distribución tiene una media de cero y una desviación estándar de uno. Sintaxis: DISTR.NORM.ESTAND.INV(probabilidad)
Probabilidad es una probabilidad que corresponde a la distribución normal. Para la simulación corresponde a un número aleatorio.
La función DISTR.NORM.ESTAND.INV se calcula utilizando una técnica iterativa. Dado un valor del argumento probabilidad, DISTR.NORM.ESTAND.INV itera hasta que el resultado tenga una exactitud de ± 3x10
-7. Si DISTR.NORM.ESTAND.INV no converge después de 100 iteraciones, la función devuelve el valor
de error #N/A. Ejemplo: DISTR.NORM.ESTAND.INV(0,908789) es igual a 1,3333
6.6 Distribución normal DISTR.NORM.INV Devuelve, para una probabilidad dada, el valor de la variable aleatoria que sigue una distribución normal con la media y desviación estándar especificadas. Sintaxis: DISTR.NORM.INV(prob;media;desv_estándar)
Prob es una probabilidad asociada a la distribución normal. Para la simulación corresponde a un número aleatorio.
Media es la media aritmética de la distribución.
Desv_estándar es la desviación estándar de la distribución. DISTR.NORM.INV utiliza la distribución normal estándar si el argumento media = 0 y si el argumento desv_estándar = 1 (vea DISTR.NORM.ESTAND.INV). DISTR.NORM.INV se calcula utilizando una técnica iterativa. Dado un valor del argumento probabilidad, la función DISTR.NORM.INV iterará hasta que el resultado obtenido tenga una exactitud de ± 3x10
-7. Si
DISTR.NORM.INV no converge después de 100 iteraciones, la función devuelve el valor de error #N/A. Ejemplo: DISTR.NORM.INV(0,908789;40;1,5) es igual a 42
6.7 Distribución T DISTR.T.INV Devuelve, para una probabilidad dada, el valor de la variable aleatoria siguiendo una distribución t de Student para los grados de libertad especificados. Sintaxis: DISTR.T.INV(probabilidad;grados_de_libertad)

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 38
Probabilidad es la probabilidad asociada con la distribución t de Student dos colas. Para la simulación corresponde a un número aleatorio.
Grados_de_libertad es el número de grados de libertad para diferenciar la distribución. DISTR.T.INV se calcula como DISTR.T.INV=p( t<X ), donde X es una variable aleatoria que sigue la distribución t. DISTR.T.INV se calcula utilizando una técnica iterativa. Dado un valor del argumento probabilidad, DISTR.T.INV reitera hasta obtener un resultado con una exactitud de ± 3x10
-7. Si DISTR.T.INV no converge
después de 100 iteraciones, la función devuelve el valor de error #N/A. Ejemplo: DISTR.T.INV(0,054645;60) es igual a 1,96
6.8 Distribuciones empíricas BUSCARV Busca un valor específico en la columna más a izquierda de una matriz y devuelve el valor correspondiente en la misma fila de una columna especificada en la tabla. Se utiliza BUSCARV cuando los valores de comparación se encuentren en una columna situada a la izquierda de los datos que desea encontrar; cuando los valores de comparación se encuentren en una fila, se debe usar BUSCARH. Sintaxis: BUSCARV(valor_buscado;matriz_de_comparación;indicador_columnas;ordenado)
Valor_buscado es el valor que se busca en la primera columna de la matriz. Valor_buscado puede ser un valor, una referencia o una cadena de texto. Para la simulación corresponde a un número aleatorio.
Matriz_de_comparación es el conjunto de información donde se buscan los datos. Se define mediante una referencia a un rango o un nombre de rango, como por ejemplo Base_de_datos o Lista, $C2:$E15.
Indicador_columnas es el número de la columna de la matriz_de_comparación desde la cual debe devolverse el valor de la variable. Si el argumento indicador_columnas es igual a 1, la función devuelve el valor de la primera columna del argumento matriz_de_comparación; si el argumento indicador_columnas es igual a 2, devuelve el valor de la segunda columna de matriz_de_comparación y así sucesivamente.
Los valores de la primera columna del argumento matriz_de_comparación deben colocarse en orden ascendente (corresponden a la función de distribución). Los valores de la primera columna de matriz_de_comparación pueden ser texto, números o valores lógicos. El texto escrito en mayúsculas y minúsculas es equivalente. Esta función compara el “valor buscado” con los valores de la primera columna de la “matriz_de_comparación” hasta que encuentra el valor mas grande que sea menor o igual al “valor buscado”. Entonces retorna el valor correspondiente que haya en la columna denotada por “indicador de columna”. Ordenado Es un valor lógico que indica si desea que la función BUSCARV busque un valor igual o aproximado al valor especificado. Si el argumento ordenado es VERDADERO o se omite, la función devuelve un valor aproximado, es decir, si no encuentra un valor exacto, devolverá el valor inmediatamente menor que valor_buscado. Si ordenado es FALSO, BUSCARV devuelve el valor buscado. Si no encuentra ningún valor, devuelve el valor de error #N/A.
Observación. Si BUSCARV no puede encontrar valor_buscado y ordenado es VERDADERO, utiliza el valor más grande que sea menor o igual a valor_buscado.
Ejemplo. Considere la variable aleatoria analizada en la sección 5.1, cuya información se resume a continuación:
Demanda – xi 10 15 20 25 30
Frecuencia relativa - f(xi) 0.18 0.38 0.31 0.11 0.02
Frecuencia relativa acumulada - F(xi) 0.18 0.56 0.87 0.98 1.00 Para generar la variable aleatoria mediante la función BUSCARV, la información podría organizarse como se muestra en la siguiente tabla, y el comando podría ser el siguiente: Sintaxis: BUSCARV(aleatorio(),$D10:$F$14,3)

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 39
Se genera el número aleatorio con la función =aleatorio()
Si r < 0.18 x = 10
Si r < 0.56 x = 15
Si r < 0.87 x = 20
Si r < 0.98 x = 25
Si r 0.98 x = 30
Para cada valor de Xi se asocia la probabilidad acumulada anterior.
Fila\Columna A D E F G
1 . . . . . . .
…
10 0 0.18 10
11 0.18 0.56 15
12 0.56 0.87 20
13 0.87 0.98 25
14 0.98 1.0 30 LA función BUSCARH funciona en idéntica forma, con la diferencia de que la información a buscar está dada por filas, y no por columnas. Su sintaxis es la siguiente: BUSCARH(valor_buscado;matriz_buscar_en;indicador_filas; ordenado) Donde Valor_buscado es el valor que se busca en la primera fila de matriz_buscar_en. La siguiente tabla resume las funciones generadores de variables dadas en el Excel.
Distribución Nombre función Parámetros
Beta DISTR.BETA.INV
Probabilidad ó número aleatorio
Alfa Beta A y B (Valores mínimo y máximo)
F DISTR.F.INV Probabilidad ó número aleatorio
Grados de
libertad 1 1
Grados de
libertad 2 2
Gama DISTR.GAMMA.INV
Probabilidad ó número aleatorio
Alfa. Parámetro
de forma (k)
Beta Parámetro de escala
(inverso de
la tasa=1/)
Logarítmica Normal
DISTR.LOG.INV
Probabilidad ó número aleatorio
Media del logaritmo de
x
Desviación estándar del
ln x
Normal estándar (0,1)
DISTR.NORM.ESTAND.INV Probabilidad número aleatorio
Normal DISTR.NORM.INV Probabilidad ó número aleatorio
Media Desviación estándar
T DISTR.T.INV
Probabilidad ó número aleatorio
Grados de
libertad
7 Otros ejemplos
7.1 Ejemplo. Viaje entre dos puntos. Se desea un generador que simule el viaje entre dos puntos A y B. entre los cuales hay dos rutas posibles. La probabilidad de tomar la ruta 1 es p. Las funciones de densidad del tiempo de viaje en cada ruta son:
e x22
e x11)x(f
x ruta
x ruta
0 1
0 2
,
,

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 40
Solución: Los tiempos de viaje en cada ruta están dados por :
X
R ruta
R ruta
11
12
1
2
ln ,
ln ,
Para encontrar el tiempo que dura un viaje cualquiera se debe seleccionar primero la ruta, y luego el tiempo de viaje en esa ruta. Deben generarse entonces dos números aleatorios (r1, r2). El primero se usa para determinar la ruta que se ha de tomar, y el segundo para determinar el tiempo en la ruta seleccionada. Por lo tanto, el generador del tiempo de tiempo será:
X
R si R p
R si R p
1
12 1
1
22 1
ln ,
ln ,
.
Observación: Sería válido generar solamente un número aleatorio r, el cual nos da primero la ruta que debe seleccionarse, y luego ese mismo número nos generaría el tiempo en la ruta seleccionada ?. Es decir, puede usarse el siguiente generador? Si r < p tome la ruta No 1 y el tiempo de viaje sería -Ln r/1
Si r < p tome la ruta No 2 y el tiempo de viaje sería -Ln r/2 La figura No 4. presenta el seudo código correspondiente para simular el tiempo de viaje entre dos puntos, cuando se supone que el tiempo de viaje en cada ruta se distribuye exponencialmente con tiempos esperados de 25 y 40 minutos, y la probabilidad de tomar la ruta No 1 es 0.60. Leer Nro_Viajes Tiempo_medio_1 = 25 Tiempo_medio_2 = 40 Suma_Tiempos=0 Para cada viaje v = 1 hasta Nro_Viajes R1 = RND Si R1 < p, entonces Tiempo_medio = Tiempo_medio_1 Si no Tiempo_medio = Tiempo_medio_2 Fin Si R2 = RND Tiempo de viaje = -Tiempo_medio * Ln R2 Suma_Tiempos = Suma_Tiempos + Tiempo_Viaje Siguiente viaje
Tiempo_Medio = Suma_Tiempos/Nro_Viajes Imprimir Nro_Viajes, Tiempo_Medio
Fin La tabla presenta los resultados de la simulación de 500 viajes, para dos semillas diferentes. En la primera simulación se usó una semilla de 377 para seleccionar la ruta y una de 1425 para calcular el tiempo de viaje. El programa se implementó en Fortran 77, y se imprimían los resultados parciales cada 20 viajes.

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 41
Concepto Simulación
No 1 No 2
Semillas 377 y 1425 1797 y 971
Tiempo medio de viaje 30.6 30.1
Tiempo mínimo de viaje 0.02 0.07
Tiempo Máximo de viaje 237.3 241.1
Desviación estándar 32.0 31.0
Número de viajes 500 500
El tiempo medio de viaje calculado analíticamente está dado por:
E(T) = P x E(T1) + (1 - P) x E(T2) = 0.6 x 25 +0.4 x 40 = 31.0
La figura No muestras la forma en que varía el tiempo medio de viaje a medida que aumenta el tamaño de la muestra (número de viajes simulados). Se observa como a medida que aumenta el número de viajes el tiempo medio tiende a estabilizarse. (ver capítulo No 8, sección relacionada con la determinación del tamaño de la muestra)
7.2 Ejemplo. Un problema de inventarios: El problema del vendedor de periódicos Un voceador de prensa compra periódicos a $300 cada uno y los vende a $400 la unidad. Al final de cada día el agente de publicaciones le paga $130 por cada periódico que no haya vendido. La demanda diaria de periódicos (X) tiene la siguiente función de probabilidad:
x 75 80 85 90 95 100 105 110 115 120
p(x) 0.02 0.07 0.08 0.20 0.19 0.14 0.12 0.09 0.06 0.03
Se desea determinar por simulación el número óptimo de periódicas que el vendedor debe ordenar cada día.
Solución. El objetivo es definir cuantos periódicos debe ordenar diariamente el voceador de tal forma que se maximice la utilidad esperada con la venta de los periódicos. Este problema tiene solución analítica. El objetivo será resolverlo analíticamente y por simulación y comparar las soluciones obtenidas con ambas metodologías.
Solución analítica. Para la solución analítica y por simulación usaremos la siguiente metodología y varaibles. X : Variable aleatoria que describe la demanda diaria de periódicos. p(x) ó f(x) : Función de probabilidad o de densidad de demanda diaria de periódicos. F(x) : Función de distribución C: Costo por periódico = $ 300/periódico V: Precio unitario de venta = $ 400/periódico S: Valor de salvamento o cantidad reconocida por periódico no vendido = $ 130/unidad. Q: Cantidad a pedir diariamente Q*: Cantidad óptima a pedir para maximizar la utilidad esperada. La utilidad obtenida cuando se piden Q periódicos está dada por
Utilidad de periódicos vendidos - Pérdida por periódicos no vendidos
o también por : Utilidad = Ingresos - egresos Si el voceador ordena Q periódicos, al final del día puede encontrarse con dos situaciones:
a) La demanda diaria fue menor que o igual a la cantidad pedida : x Q En este caso se obtiene una utilidad por los periódicos vendidos (x) y una pérdida por los periódicos no
vendidos (Q-x). La utilidad está dada por :
U(Q) = x (V - C) - (Q - x) (C - S) , x Q (1)
b) La demanda es superior a la cantidad pedida: x > Q

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 42
En este caso sólo se obtiene la utilidad por los periódicos vendidos, y no se presenta ninguna pérdida. La utilidad está dada por:
U(Q) = x (V - C) , x > Q (2)
Como la demanda es una variable aleatoria, entonces el criterio de decisión se basa en la utilidad esperada, la cual estará dada por la siguiente expresión, dado que se está tratando la demanda como una variable discreta :
´
uQx
Qx
0x
)x(p)cV(Q)x(p)]SC()xQ()CV(x[)]Q(U[E (3)
cuando X es discreta y varía en intervalos de u unidades. Si Q* es la cantidad óptima a pedir que maximiza la utilidad, entonces se tienen que cumplir las siguientes condiciones:
E[U(Q*)] E[U(Q* - u)] (4)
E[U(Q*)] E[U(Q* + u)] (5)
Aplicando separadamente las condiciones (4) y (5) a la ecuación (3) se encuentra que el valor óptimo Q* es aquel que satisface la siguiente desigualdad:
p xV C
V Sx Xmin
Q
( )*
(5)
Si X es continua la utilidad estará dada por :
E U Q x V c Q x C S f x dx xf x dxXmin
Q
Q[ ( )] [ ( ) ( )( )] ( ) ( )
(6)
El valor de Q que maximiza la utilidad esperada es aquel que hace igual a cero la primera derivada de la ecuación anterior . Esto es:
0dQ
)]Q(U[dE el valor óptimo de Q es aquel que satisface la siguiente ecuación :
SV
CVdx)x(f*)Q(F
*Q
minX
(7)
Para nuestro caso se tiene:
x 75 80 85 90 95 100 105 110 115 120
p(x) 0.02 0.07 0.08 0.20 0.19 0.14 0.12 0.09 0.06 0.03
F(x) 0.02 0.09 0.17 0.37 0.56 0.70 0.82 0.91 0.97 1.00
Ahora 3703.0270
100
130400
300400
SV
CV
que la solución óptima es pedir 90 periódicos, si se desea
maximizar la utilidad esperada por la venta de los periódicos.
Solución por simulación Para determinar por medio de la simulación qué cantidad debe ordenarse, es necesario simular la operación del sistema (venta de periódicos) durante varios días (N) para diferentes alternativas de la cantidad a pedir (Q1, Q2,...,QM) y escoger aquella cantidad que maximice la utilidad esperada por día. Para simular la operación del sistema, dada una cantidad fija a pedir Q, es necesario formular un modelo para realizar los pasos o etapas que se darían en un día cualquiera si estuviéramos realizando la venta de periódicos. Este modelo para un día cualquiera está representado mediante las ecuaciones (1) y (2)

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 43
formuladas anteriormente. Este procedimiento sería necesario repetirlo para varios días, y luego obtener la utilidad promedio diaria, que es el mejor estimativo de la utilidad esperada. El procedimiento a seguir para simular la operación del sistema para una cantidad fija a pedir Q es el presentado a continuación: 1) Se define cuantos días se van a simular (N).
2) Se inicializan los registros o contadores para recoger información (la utilidad promedio, en nuestro caso
U=0).
3) Para cada día i a simular se realizan los siguientes pasos:
a) Se genera la demanda de ese día, de acuerdo con la función de probabilidad de la demanda.
b) Se calcula la utilidad diaria, según que la demanda sea menor o igual a la cantidad pedida, o que sea mayor, usando las expresiones (1) y (2) ya definidas, a saber :
Ui = x (V - C) - (Q - x) (C - S) x Q
Ui = x (V - C) x > Q
c) Se actualiza la utilidad acumulada, según la utilidad obtenida: U=U+ Ui
4) Una vez se han simulado todos los días se calcula la utilidad promedio diaria, dada por U/N La tabla siguiente presenta el seudo código del procedimiento anterior.
Definir Número de días N
Definir cantidad Q
Día = 1
Mientras Día N
Generar Demanda
Si Demanda Q Si No
U = x (V - C) - (Q – x) (C - S) U = x (V - C)
Actualizar utilidad acumulada U=U+ Ui
Día - Día + 1
Utilidad Media UM = U/N
Fin Simulación
El procedimiento anterior es necesario repetirlo para las diferentes cantidades a simular, y de todas ellas se escoge la que maximice la utilidad promedio. Para generar la demanda diaria se puede utilizar el método de la transformación inversa, con base en la función de distribución, de la siguiente manera. Se genera un número aleatorio r. El valor de la demanda será igual a: Valor de Demanda Condición 75 r < 0.02
80 0.02 r < 0.09
85 0.09 r < 0.17
90 0.17 r < 0.37
95 0.37 r < 0.56
100 0.56 r < 0.70
105 0.70 r < 0.82
110 0.82 r < 0.91
115 0.91 r < 0.97
120 r 0.97 Para definir la cantidad óptima, es decir, la que maximice la utilidad esperada, se puede usar un método de búsqueda. Si en estudios de simulación se desea optimizar una función, deben emplearse métodos numéricos de optimización, y los más empleados son los métodos de búsqueda. Para nuestro caso, la cantidad mínima a pedir sería de 75 unidades, por lo tanto podemos empezar el
proceso de búsqueda en 75 (Q0 = 75), usando un incremento o paso de 5 unidades (Q = 5). Se suspende el

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 44
proceso de búsqueda cuando la utilidad esperada empiece a decrecer. En resumen, el procedimiento de optimización sería: 1) Se simula pidiendo una cantidad inicial Q = Q0 = Xmin = 75 y se obtiene la utilidad media UM(Q0).
2) Se hace la simulación ordenado una cantidad Q1 = Q0 + Q, y se calcula la utilidad media UM(Q1).
a) Si UM(Q1) < UM(Q0), entonces termina la búsqueda y la cantidad optima a pedir sería Q= Q0 = 75.
b) Si UM(Q1) > UM(Q0), entonces se realizan nuevas simulaciones ordenando las siguientes cantidades :
Q2 = Q1 + Q, y se obtiene la utilidad media UM(Q2).
Q3 = Q2 + Q, y se obtiene la utilidad media UM(Q3).
......................
Qk = Qk-1 + Q, y se obtiene la utilidad media UM(Qk).
donde en Qk la función de utilidad no responde, es decir, UM(Qk) < UM(Qk-1). La cantidad óptima a pedir sería de Q* = Qk-1 La gráfica de la página siguiente presenta el diagrama de flujo completo de la simulación para determinar la cantidad óptima a pedir. La tabla siguiente resume los resultados de realizar varias simulaciones para determinar la cantidad óptima. Además, se presenta los resultados para varios replicados de las corridas (un replicado es el resultado de una corrida, pero cambiando las semillas usadas para generar los números aleatorios).
CANTIDAD Utilidad media diaria ($) para varios re`locaddos
No 1 No 2 No 3
75 7500.0 7500.0 7500.0
80 7974.4 7977.1 7971.7
85 8344.8 8362.3 8355.6
90 8623.4 8639.6 8628.8
95 8656.3 8671.1 8623.9
100 8411.1 8407.0 8374.6
SEMILLA 9713 1597 475
Para cada corrida se realizaron 1000 simulaciones. Puede considerarse que la cantidad óptima a pedir diariamente es de 95 periódicos. Con el fin de decidir entre 90 y 95 se realizaron corridas de 2000 simulaciones, cuyos resultados se presentan en la tabla siguiente, los cuales llevan a la misma decisión.
CANTIDAD UTILIDAD MEDIA DIARIA ($) PARA VARIAS SIMULACIONES
No 1 No 2 No 3
90 8647.7 8642.3 8612.6
95 8656.3 8646.8 8599.6
SEMILLA 9713 1597 475
Para realizar un seguimiento a una simulación, en la tabla siguiente se presentas los resultados de varias simulaciones para diferentes valores de Q, realizadas en Excel, para un total de 30 días.

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 45
Simulación del problema del vendedor de periódicos
para varios valores del tamaño del pedido
Simulaciones para varios valores del lote
Día Número Aleatorio
Demanda
Pedido Q = 85 Pedido Q = 90 Pedido Q = 95
Periódicos Vendidos
Utilidad Periódicos Vendidos
Utilidad Periódicos Vendidos
Utilidad
1 0.0370 80 80 7000 80 6000 80 5000
2 0.9553 115 85 8500 90 9000 95 9500
3 0.5208 95 85 8500 90 9000 95 9500
4 0.0656 80 80 7000 80 6000 80 5000
5 0.7514 105 85 8500 90 9000 95 9500
6 0.7971 105 85 8500 90 9000 95 9500
7 0.9048 110 85 8500 90 9000 95 9500
8 0.0747 80 80 7000 80 6000 80 5000
9 0.2364 90 85 8500 90 9000 90 8000
10 0.6483 100 85 8500 90 9000 95 9500
11 0.6962 100 85 8500 90 9000 95 9500
12 0.2358 90 85 8500 90 9000 90 8000
13 0.0335 80 80 7000 80 6000 80 5000
14 0.4260 95 85 8500 90 9000 95 9500
15 0.1117 85 85 8500 85 7500 85 6500
16 0.5401 95 85 8500 90 9000 95 9500
17 0.6454 100 85 8500 90 9000 95 9500
18 0.2605 90 85 8500 90 9000 90 8000
19 0.4186 95 85 8500 90 9000 95 9500
20 0.9268 115 85 8500 90 9000 95 9500
21 0.8607 110 85 8500 90 9000 95 9500
22 0.0872 80 80 7000 80 6000 80 5000
23 0.7895 105 85 8500 90 9000 95 9500
24 0.6240 100 85 8500 90 9000 95 9500
25 0.9751 120 85 8500 90 9000 95 9500
26 0.6145 100 85 8500 90 9000 95 9500
27 0.4680 95 85 8500 90 9000 95 9500
28 0.6953 100 85 8500 90 9000 95 9500
29 0.0680 80 80 7000 80 6000 80 5000
30 0.3132 90 85 8500 90 9000 90 8000
Total 2885 2520 246,000 2635 250,500 2730 249,000
Promedio 0.4927 96.2 84.0 8200.0 87.8 8350.0 91.0 8300.0

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 46
7.3 Problema de un camión repartidor de mercancías Todos los días un camión sale de la bodega principal (A) a repartir mercancías y efectúa paradas en B, C y D; sin embargo, no siempre toma la misma ruta. En la figura siguiente se muestra las posibles rutas, un cuadro representa un punto de entrega de mercancía, un círculo representa una intersección y una flecha
() representa una posible ruta. El número encima de cada arco representa la probabilidad de tomar dicha ruta y el número debajo sirve para identificarla. El tiempo empleado para cubrir cada ruta se distribuye normalmente con la media y desviación dadas en la tabla siguiente. Se supone que no existen retrasos en las intersecciones, pero sí en los puntos de entrega. El tiempo empleado en cada entrega se distribuye exponencialmente con las siguientes medias, en minutos.
Punto de entrega B C D
Duración media 40 20 15 Desarrolle un simulador que genere el tiempo total requerido para hacer las entregas y regresar al punto de partida, junto con su respectiva distribución de frecuencia. 0.4 0.5 1.0 0.4 a d e 0.6 1 0.5 3 7 1.0 8 1.0 2 4 1.0 6 9 10 c 1.0 b f 1. 5 11 1.0 22 0.5 j 15 h 1.0 12 1.0 19 0.8 1.0 1.0 16 l k 0.3 i j 21 20 17
Ruta Media Desviación Ruta Media Desviación Ruta Media Desviación
1 5 1.0 9 7 0.4 17 8 0.2 2 3 0.5 10 9 0.3 18 3 0.3 3 10 1.0 11 4 0.6 19 6 1.0 4 2 0.25 12 9 1.0 20 9 1.0 5 8 0.5 13 6 0.4 21 5 0.5 6 3 0.25 14 4 0.1 22 3 0.3 7 12 0.5 15 2 0.1 8 5 0.2 16 4 0.3
Solución Lo primero que se debe hacer es tratar de idearse una forma sencilla de representar el problema. Para ello podemos usar una o varias matrices que nos den información acerca de las diferentes rutas y de las características de las mismas. Esta información debe incluir el número o identificación de cada ruta, las rutas a las que desemboca, puntos de entrega a los cuales llega, probabilidad de tomar la ruta, tiempo medio y desviación estándar. Como existe una información que puede representarse en forma entera y otra que puede representarse en forma real, se diseñarán dos matrices para representar toda la información. 1) Matriz RUTAS(I,J) Esta matriz guardará información sobre la conformación de las diferentes rutas. En la fila I guardará la información de la ruta I, de la siguiente manera: Columna 1 ( J = 1): Indica si la ruta I llega a un punto de entrega, y en caso afirmativo, a cual punto. RUTAS(I,1) = 0 si la ruta I no llega a ningún punto de entrega. k > 0 si la ruta I llega a un punto de entrega k., donde RUTAS(I,1) = 1 si la ruta llega al punto de entrega No 1 (B). = 2 si la ruta llega al punto de entrega No 2 (C). = 3 si la ruta llega al punto de entrega No 3 (D). = 4 si la ruta llega al punto de entrega No 4 (A), (punto de partida.).
A B
D
C

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 47
En caso de que la ruta I no desemboque a ningún punto de entrega, entonces no se requiere la información de la columna No 2.
Columna No 2 (J = 2): Indica a cuantas rutas desemboca la ruta No I. Por lo tanto RUTAS(I,2) puede tomar el valor de 1 ó 2. Columnas Nos 3 y 4 (J = 3 y J = 4): Identifican el número de las rutas a las cuales desemboca la ruta No I. Si RUTAS(I,2) = 1 entonces RUTAS(I,3) indica a cual ruta desemboca la ruta No I, y no se requiere definir RUTAS(I,4).
Como para empezar el viaje se parte del depósito central (A), entonces se supone que se está en una ruta ficticia. Si la variable NRO_RUTAS define el número total de rutas (22 en nuestro caso), se asumirá que al empezar el recorrido, el camión se encuentra en la ruta número NRO_RUTAS + 1, que no llega a ningún punto de entrega y que desemboca a dos rutas (las rutas números 1 y 2). 2) Matriz TIEMPO(I,J) En esta matriz se guardará información sobre los tiempos de cada ruta (I) y la probabilidad de tomarla., según la siguiente convención : Fila I: El subíndice I se usará para identificar la ruta I. Columna 1 (J = 1): Probabilidad de tomar la ruta I.
Columna 2 (J = 2): Tiempo medio de viaje en la ruta I. Columna 3 (J = 3): Desviación estándar de la duración del tiempo de viaje en la ruta I. 3) Vector TM_ENTREGA(I) En este vector se guardará el tiempo medio de retraso en la entrega en el punto I. A continuación se muestra, en forma parcial, las matrices RUTAS y TIEMPO.
MATRIZ RUTA MATRIZ TIEMPO
I/J J = 1 J = 2 J = 3 j = 4 I/J J = 1 J = 2 J = 3
I=1 0 2 3 4 I=1 0.4 5 1.0
I=2 0 1 5 0 I=2 0.6 3 0.5
I=3 1 1 7 0 I=3 0.5 10 1.0
I=4 0 1 6 0 I=4 0.5 2 0.25
I=5 0 1 6 0 I=5 1.0 8 0.5
I=6 1 1 7 0 I=6 1.0 3 0.25
.... ....
I=21 0 1 22 0 I=21 1.0 5 0.5
I=22 4 2 1 2 I=22 1.0 5 0.5
I=23 0 2 1 2 I=23 1.0 3 0.3
Procedimiento general de la simulación El procedimiento general de la simulación para cada viaje se puede resumir en los siguientes pasos: 1) Se inicia el viaje en el depósito central, ubicado en A, correspondiente a la ruta ficticia NRO_RUTAS+1. 2) Desemboca la ruta en un punto de entrega?
a) En caso afirmativo, se pregunta si corresponde al punto A, en cuyo caso el viaje termina. b) Si no corresponde al punto A, se calcula el tiempo que se tarda en entregar la mercancía y se
actualiza el tiempo total de viaje. c) Si no desemboca en un punto de entrega, se realza el paso 3)
3) Desemboca a dos rutas? a) Si desemboca a dos rutas, se selecciona la ruta a seguir. b) Se calcula el tiempo de viaje a través de la ruta, y se actualiza el tiempo total de viajes.
4) Se repite el paso 2) hasta que se llegue de nuevo al depósito central ubicado en A. Para la implementación del procedimiento anterior, es necesario tener en cuenta los siguientes aspectos, relacionados con la simulación propiamente dicha, y son:

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 48
1) Selección de la ruta a seguir cuando existen dos alternativas. Si el camión se encuentra en la ruta I y esa ruta desemboca en dos rutas {RUTAS(I,3)=2}, entonces para escoger la nueva ruta a seguir, se genera un número aleatorio r y la nueva ruta estará dada por:
NUEVA_RUTA= RUTAS(I,3) si r < TIEMPO(I,1)
NUEVA_RUTA= RUTAS(I,4) si r TIEMPO(I,1)
2) Estimación del tiempo de viaje en cada ruta. El tiempo de viaje en cada ruta se distribuye normalmente con media y desviación estándar diferentes para cada ruta. Si el camión se encuentra en la ruta I, el tiempo de viaje estará dado por:
TIEMPO_RUTA =I + z I = TIEMPO(I,2) + Z * TIEMPO(I,3),
donde z corresponde a una variable normal (0,1), que se puede generar mediante uno cualquiera de los métodos estudiados previamente (teorema central del límite, transformación inversa, enfoque directo). 3) Estimación del tiempo de entrega de mercancía en cada punto de entrega. Si el camión llega al punto
de entrega K, el tiempo de entrega de la mercancía se distribuye exponencialmente con media 1/k = TM_ENTREGA(K). Por lo tanto, para calcular cuanto demora la entrega de la mercancía, se genera un número aleatorio r, y el tiempo estará dado por:
TIEMPO_ENTEGA = - TM_ENTEGA(K) ln (r)
4) Estadísticas que se van a recoger sobre el desempeño del sistema. Para este caso, se desea conocer todas las estadísticas relacionadas con el tiempo de viaje, a saber: tiempo medio y desviación estándar, tiempos mínimo y máximo, y distribución de frecuencia del tiempo de viaje.
Para la distribución de frecuencia del tiempo de viaje, es necesario definir los siguientes parámetros:
Límite superior del primer intervalo: T0.
Tamaño de cada intervalo: T.
Número de intervalos: Nro_Int. Si Tiempo_Viaje representa el tiempo gastado en un viaje, el intervalo Int en el cual cae este valor estará dado por:
IntTiempo Viaje
T
T
_0 2
Si Int < 1 Int = 1
Si Int > Nro_Int Int = Nro_Int (ver capítulo 5, sección 5.5 ”Registro de distribuciones de frecuencia”..
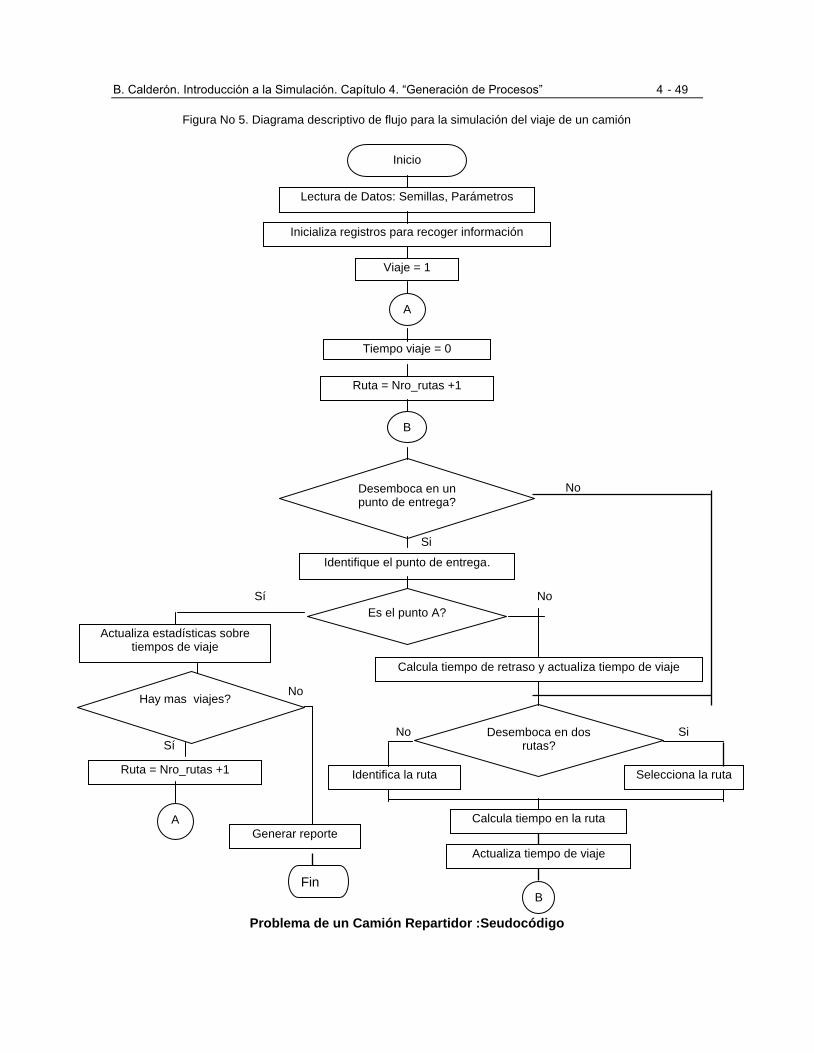
B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 49
A
B
B
Figura No 5. Diagrama descriptivo de flujo para la simulación del viaje de un camión
No
Si
Sí No
No No Si Sí
Problema de un Camión Repartidor :Seudocódigo
Lectura de Datos: Semillas, Parámetros
Inicializa registros para recoger información
Viaje = 1
Tiempo viaje = 0
Ruta = Nro_rutas +1
Identifique el punto de entrega.
Calcula tiempo de retraso y actualiza tiempo de viaje
Desemboca en un punto de entrega?
Es el punto A?
Desemboca en dos rutas?
Identifica la ruta Selecciona la ruta
Calcula tiempo en la ruta
Actualiza tiempo de viaje
Inicio
Actualiza estadísticas sobre tiempos de viaje
Hay mas viajes?
Ruta = Nro_rutas +1
A
Generar reporte
Fin

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 50
Lectura de datos sobre :
Semillas, Número de Viajes, Nro_Rutas, parámetros para distribuciones
Matriz ((RUTAS (I,J), J=1,4), I=1,NRO_RUTAS+1)
Matriz (TIEMPO(I,J),J=1,3), I=1,NRO_RUTAS)
Vector TIEMPO_ENTREGA(K), k=1,3)
SUMA_TIEMPO=0
FRECUENCIA(INT)=0, INT=1,NRO_INT
VIAJES = 1
PARA VIAJES = 1 a NRO_VIAJES)
TIEMPO_VIAJE = 0 IR =NRO_RUTAS + 1
MIENTRAS (RUTAS(IR,1) .NE. 4) ENTONCES
DESTINO = RUTAS(IR,1)
SI (DESTINO .GT. 0 ) ENTONCES
GENERAR TIEMPO_ENTREGA : EXPON(TM_ENTRGA )
TIEMPO_VIAJETIEMPO_VIAJE+TIEMPO_ENTREGA
FIN SI
SI (RUTAS(IR,2). EQ. 2) SI NO
IR1 = RUTAS(IR,3) IR2 = RUTAS(IR,4)
GENERE NUMERO ALEATORIO R IR = RUTAS(IR,3)
SI R .LT. TIEMPO(IR1,1) SI NO
IR = IR1 IR = IR2
FIN SI
FIN SI
MEDIA = TIEMPO(IR,2) SIGMA = TIEMPO(IR,3)
GENERE TIEMPO_RUTA NORMAL(MEDIA, SIGMA)
TIEMPO_VIAJETIEMPO_VIAJE + TIEMPO_RUTA
FIN MIENTRAS
SUMA_TIEMPO SUMA_TIEMPO + TIEMPO_VIAJE
INT=[(TIEMPO_VIAJE - T0)/NRO_INT + 2]
SI (INT. LT. 1)ENTONCES
INT = 1
SI (INT. GT. NRO_INT) ENTONCES
INT = NRO_INT
FRECUENCIA(INT) = FRECUENCIA(INT) + 1
FIN PARA
TIEMPO_MEDIO = SUMA_TIEMPO/NRO_VIAJES
GENERAR REPORTE DE SALIDA : IMPRIMIR TIEMPO_MEDIO, FRECUENCIA
FIN SIMULACIÓN

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 51
El seudo código del modelo se presenta en la figura No y el programa detallado en Fortran en la figura No . En la tabla siguiente se presenta un resumen de los resultados de dos simulaciones
CONCEPTOS CORRIDA No 1 CORRIDA No 2
Semillas 111, 555, 999 77, 777 y 7777 Número de viajes 1000 1000 Tiempo medio 148.4 149.6 Desviación estándar 46.8 45.4 Tiempo mínimo 78.1 75.3 Tiempo Máximo 483.5 366.4
El tiempo medio de viaje, calculado analíticamente es 149.85 minutos. La distribución del tiempo de viaje, obtenida con la corrida No 1 se presenta en la siguiente tabla
DISTRIBUCION DEL TIEMPO DE VIAJE (Minutos)
Intervalo Limite Limite Frecuencia Frecuencia Frecuencia
número inferior superior absoluta relativa Rel. acum.
1 80 ó menos 5 0.5 0.5
2 95 110 53 5.3 5.8
3 110 125 123 12.3 18.1
4 125 140 179 17.9 36.0
5 140 155 170 17.0 53.0
6 155 170 116 11.6 64.6
7 170 185 102 10.2 74.8
8 185 200 75 7.5 82.3
9 200 215 57 5.7 88.0
10 215 230 42 4.2 92.2
11 230 245 24 2.4 94.6
12 245 260 16 1.6 96.2
13 260 275 8 0.8 97.0
14 275 290 10 1.0 98.0
15 305 ó mas 20 2.0 100.0
8 Problemas
4.1 Usando los mismos números aleatorios generados en el problema 3.1, genere igual número de variables aleatorios que sigan las siguientes distribuciones: a) Exponencial con parámetro unitario (exponencial normalizada). b) Poisson con mismo parámetro de 10 c) Aplique las pruebas chi-cuadrado y de kolmogorov-Smirnov a las variables obtenidos en a) y b).
4.2 Genere 100 variables aleatorias con una distribución normal cualquiera. Aplique las pruebas de
“bondad de ajuste” chi-cuadrado y de Kolmogorov-Smirnov. Dibuje el histograma respectivo. 4.3 Genere unos 200 números aleatorios con distribución exponencial, para distintos parámetros, y luego
dibuje el histograma de frecuencia respectivos, y obtenga conclusiones con respecto a la forma de la distribución a medida que el parámetro crece. A qué distribución tiende?.
4.4 Repita el problema anterior, pero con la distribución de Poisson. 4.5 Desarrolle un generador de proceso para una variable aleatoria que siga una distribución chi-cuadrado. 4.6 Desarrolle un generador de procesos para una variable aleatoria que con una distribución F. 4.7 Desarrolle un generador de un proceso que produzca variables aleatorias que sigan una distribución t ó
de “student”.

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 52
4.8 Desarrolle generadores de procesos para las siguientes funciones de densidad
a)
2010,100
20
100,100
)(
xx
xx
xf
b) 10,)1()1()( xxbxf b 4.9 Desarrolle generadores de procesos para cada una de las variables definidas por las siguientes
funciones de probabilidad:
a)
,...,3,2,1,)1(1
)1()(
1
xp
ppxp
n
x
b) 6,...,2,,1x,6/1)x(p
4.10 La distribución del tiempo entre llegadas de órdenes a un depósito es exponencial con media de un día. La distribución del numero de unidades requeridas en cada orden es geométrica con p = 0.5. Desarrolle un generador que produzca la variable aleatoria que representa el número total de unidades pedidas en un día de ocho horas.
4.11 Una línea de producción debe ser mantenida por una cuadrilla de reparación. La línea puede fallar por
varias causas. Cuando el sistema falla, el equipo de reparación corrige el problema que ocasionó la falla y hace los ajustes necesarios en la línea para reducir la probabilidad de que la línea falle por cualquiera de las restantes causas, es decir, cuando se hace un ajuste por un problema, se corrigen las tres causas. Sea Ti el tiempo en horas hasta que el sistema falle por la i-ésima causa, medida desde el último ajuste. La función de densidad de Ti está dada por la siguiente expresión, con los parámetros dados en la tabla adjunta:
f(ti) =
3,2,1,0,
!1
1
itiint
i
i
i
nte
iii
i 1 2 3
i 0.25 0.10 0.25
ni 4 8 2
La función de densidad del tiempo requerido para completar las reparaciones está dado por:
g (x) = 5 e -5x
x > 0 donde el tiempo de reparación es independiente del tiempo de falla. Se quiere determinar por
simulación a) El porcentaje de tiempo que el sistema está inactivo durante un año y b) El porcentaje de fallas causadas por cada causa..
4.12 Un fabricante produce uno de sus productos en lotes de 300. Loas programas de producción se hacen
con 10 días de adelanto. Para cada unidad producida se requiere una unidad de materia prima. La materia prima requerida es comprada a un proveedor y la orden por la materia prima debe colocarse dentro de los 10 días precedentes al comienzo programado de la producción. La orden puede colocarse en uno cualquiera de estos 10 días. Si la orden se coloca demasiado tarde la producción se retrasa a un costo de $ 200.000 por año de retraso. Sin embargo, si la orden se coloca demasiado pronto, la materia prima debe mantenerse en inventario a un costo de $ 200 por unidad año. La distribución del tiempo de espera, en años, es Erlang con n = 200, K = 4. Se pide determinar cuándo deben colocarse las órdenes por la materia prima.

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 53
4.13 Todos los días un hombre deja su casa (A) y va a trabajar a (H). Sin embargo, no siempre toma la misma ruta. El diagrama siguiente indica las rutas que puede tomar. El valor que hay encima de cada ruta es la probabilidad de tomarla, y el valor que hay debajo identifica la ruta.
0.8 0.8 3 .7 0.3 0.5
1 0.2 0.6 7 10 9 1 4 1. 13 .5 .6 . 5 0.4 0.4 11 .6 2 8 12 .4
6 La distribución del tiempo gastado en cada ruta es normal, con los siguientes parámetros:
Ruta Media(min) Desviación Ruta Media (min) Desviac.
1 20 1.0 7 4 0.6
2 15 2.0 8 5 0.8
3 5 0.5 9 3 0.25
4 7 1.0 10 6 1.0
5 6 1.5 11 5 0.8
6 10 2.0 12 7 1.1
13 6 1.0 Determine el tiempo medio de viaje entre (A) y (H), después de 500 viajes y compárelo con la solución
analítica. 4.14 La distribución de la producción diaria de un artículo es normal, con una media de 6.000 artículos y una
desviación de 500. Cada día se debe desechar cierto porcentaje (100p) de la producción total. Esto es si el porcentaje de deshechos es 100p y si la producción diaria es x, la producción neta será y = x - px. La función de densidad de la fracción defectuosa p está dada por:
g(p) = 99 (1- p) 98,
0 < p < 1
Desarrolle un generador para la producción neta por día; genere la producción durante 500 días y demuestre, usando la prueba chi-cuadrado o la Smirnov-Kolmogorov que la producción neta diaria es
normal. Use = 0.05. 4.15 Se ha diseñado el siguiente sistema de control de calidad para controlar una dimensión particular. Se
selecciona una muestra de 9 artículos de un lote de 1.000 unidades. Se mide la dimensión de cada unidad de la muestra y luego se calcula la dimensión media x como:
n
n
iX i
X
1
siendo xi la dimensión del i -ésimo artículo de la muestra y n = 9. Si x cae entre 4.5 y 5.5 el lote es aceptado; en caso contrario el lote es rechazado. La dimensión deseada es 5. La distribución de la dimensión de cada artículo del lote es normal, con media m y desviación estándar 0.7 La distribución de la media del lote m es normal con media 5 y desviación de 0.1. Simulando la inspección de 1000 lotes determine la probabilidad de rechazar un lote.
4.16 Un sistema electrónico está compuesto de tres componentes 1,2 y 3 tal que si cualquier componente
falla, el sistema falla (sistema en serie). La distribución del tiempo hasta la falla de cada componente es normal con la media y la desviación estándar dados en la tabla dada al final de este problema. Este sistema debe funcionar en forma continua durante un año. La confiabilidad del sistema (definida como probabilidad de que sobreviva este período de tiempo) es la probabilidad de que cada uno de los componentes dure al menos un año, y está dada por:
Confiabilidad = P( T1 1) x P( T2 1) x P( T3 1) = (0.9772) (0.9961) (0.8413) = 0.8189 Una confiabilidad del 81.89% no se la considera lo suficientemente alta. Para aumentar la confiabilidad
del sistema se pueden agregar componentes en estado de alerta de respaldo, los cuales pueden desempeñar la misma función del componente principal cuando éste falle, extendiendo así la vida del sistema. La distribución de cada componente adicional (o de respaldo) es exponencial, con la media
A
B
F
G D
C
H
E

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 54
dada en la tabla mencionada. Se pueden agregar cualquier número de componentes, pero al costo dado en la misma tabla. Determine por simulación el número y el arreglo de los componentes que lleven la confiabilidad del sistema a al 98% (al mínimo costo).
Componente COMPONENTE PRINCIPAL COMPONENTES DE RESPALDO
Vida Media (años)
Desviación Estándar (años)
Vida media (años)
Costo/unidad agregada
1 1.2 0.10 0.05 200
2 1.4 0.15 0.07 300
3 1.1 0.10 0.04 250 4.17 Un centro de cómputo opera 24 horas al día y requiere tres operarios de computador por turno de 8
horas. A cada operario se le pagan $30 la hora. Si un operario no puede trabajar su turno, debe ser reemplazado en ese turno o el equipo que maneja debe apagarse, a un costo de $ 1.000 por hora. Para asegurarse contra la posibilidad de pérdidas de tiempo de máquina se ha propuesto que varios de los operarios sean mantenidos “bajo alerta” para ser llamados en aquellos turnos en que no están trabajando. Se propone que a estos operarios se les pague una bonificación de $4.00 por hora para que estén disponibles. Cuando se llame a uno de estos operarios a trabajar se les debe pagar un recargo del 50%. La probabilidad de que un operario pueda trabajar su turno es 0.95 y la probabilidad de que un operario bajo alerta puede ser localizado cuando se lo necesite es de 0.90. Determine el número óptimo de operarios que deben mantenerse “bajo alerta”, de tal manera que se minimice el costo total. Asuma que a cada operario que esté bajo alerta se le pagan los $ 4 por hora sea que se le necesite o no.
4.18 El departamento de control de calidad ha adoptado un plan de muestreo para lotes que se reciben de
un proveedor externo. Las unidades se seleccionan una a una. Si se encuentran dos unidades defectuosas., el lote debe rechazarse. Si el número de defectuosos encontrados después de inspeccionar diez artículos es cero o uno, el lote es aceptado. La fracción defectuosa p sigue la distribución siguiente, con a = 10.
f (p) = (a+1) (1-p)
a , 0 < p < 1
Cada inspección cuesta $ 10 por artículo. El costo esperado de inspección ha sido estimado en $ 85
por lote inspeccionado. Determine por simulación si este estimativo puede aceptarse. Use = 0.05 4.19 Una compañía produce mezcladores eléctricos a una tasa anual de 1 000. Cada mezclador está
garantizado por un período de 4 años. El costo de producir un mezclador que tenga una vida media de m años está dado por:
c = a + bm + cm
2
donde a = $ 250, b = $ 200, c = $ 10 El tiempo de funcionamiento de un mezclador hasta que falla se distribuye exponencialmente con la
media m. Cada falla que ocurre durante la garantía le cuesta al productor $ 333.50. Se quiere determinar por simulación el valor óptimo de m.
4.20 Resuelva el problema anterior cuando el costo de una falla (C) durante el período de garantía es una
variable aleatoria con la siguiente función de densidad: f (c) = 0.25 (20 - c) 0 < c < 20 4.21 En el problema 18 se espera que el costo de producción por unidad aumente a una tasa promedio de
7% por año para los próximos 5 años y el costo por fallas se espera que aumente en un 10% por año durante el mismo período. Encuentre el valor óptimo de m.
4.22 La tasa de nacimiento de una población se distribuye normalmente con un valor medio de 5% y una
desviación estándar de 0.5%. La tasa de muerte también se distribuye normalmente con media 6% y desviación estándar 1%. Calcule los cambios en la población para 5 años a intervalos de un año.
4.23 Un recipiente contiene 1.000.000 de galones de agua y se vacía a una tasa estable de 10.000 galones
por día. Las lluvias ocurren con una distribución de Poisson a una tasa media de una en 10 días. La cantidad de agua que cae al tanque en cada lluvia está distribuida normalmente con una media de 80.000 galones y una desviación estándar de 5.000 galones.
a) Determine el contenido del recipiente después de 60 años. Asuma que el recipiente empieza lleno
y que el agua excede la capacidad del recipiente se pierde.

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 55
b) Cuántos galones de agua fueron desaprovechados? 4.24 Los carros llegan aleatoriamente a una cabina y pagan el peaje. Si es necesario, esperan en la cola de
acuerdo al orden de llegada. El tiempo entre llegadas se distribuye uniformemente entre 0 y 9, inclusive (aproxime al segundo más cercano). El tiempo para pagar es también aleatorio y entre 0 y 9 segundos, pero con la siguiente distribución de probabilidad:
f(t) = t
- 1/2 /6, 0 < t <9
Determine los tiempos de llegada y los tiempos que necesitan para pagar los 10 primeros carros. A qué
hora termina de pagar el quinto carro?. El séptimo?. Trunque todos los números calculados al entero más cercano.
4.25 Un repartidor compra periódicos en paquetes de veinte a dos pesos cada uno y los vende a tres pesos.
Los periódicos no vendidos carecen de valor. Al analizar las ventas del pasado se descubre que existen tres distribuciones de la demanda, dependiendo de las noticias que figuran en el periódico. Un día de “Buenas” noticias da como resultado encabezados interesantes para muchos clientes potenciales; los días “normales” y “malos” tienen encabezados de menor interés. Históricamente, el 20% de los días han sido buenos, el 50% “normales” y el 30% “malos”. Las distribuciones de la demanda se resumen a continuación:
Demanda diaria Tipo de día, según las noticias
Malo Normal Bueno 40 0.05 50 0.20 0.03 60 0.41 0.07 70 0.26 0.28 80 0.08 0.30 0.02 90 0.25 0.15
100 0.07 0.28 110 0.24 120 0.12 130 0.09 140 0.06 150 0.04
Determine la cantidad que debe pedirse.
4.26 Una empresa de alquiler de autos está tratando de determinar el número óptimo de autos a comprar. El costo promedio anual de un auto es de $ 11 000 000. Además, esta compañía ha recopilado las siguientes estadísticas sobre las operaciones de carros :
Número de autos alquilados por día 0 1 2 3 4
Probabilidad 0.10 0.10 0.25 0.30 0.25
Número de días rentados por auto 1 2 3 4
Probabilidad 0.40 0.35 0.15 0.10
Si la renta diaria por auto es de $52 000, el costo de no tener un auto disponible cuando se lo solicita es
de $30 000, y el costo de tener un carro ocioso durante un día es de $7 500, cuantos autos deberá comprar la compañía ?. Suponga que un auto que se alquila por un día está disponible al día siguiente.
4.27 Un vendedor de revistas compra mensualmente una revista el día primero de cada mes. El costo de
cada ejemplar es $6 000. La demanda de esta revista en los primeros diez días del mes tiene la distribución de probabilidad dada a continuación:
Demanda 5 6 7 8 9 10 11
Probabilidad 0.05 0.05 0.10 0.15 0.25 0.25 0.15 Al final del décimo día, el vendedor puede regresar cualquier cantidad de revistas al proveedor, quien se
las pagará a 3 600 el ejemplar, o puede comprar mas revistas a un costo de $4 800 el ejemplar. La demanda en los siguientes 20 días está dada por la siguiente distribución de probabilidad:
Demanda 4 5 6 7 8
Probabilidad 0.15 0.20 0.30 0.20 0.15

B. Calderón. Introducción a la Simulación. Capítulo 4. “Generación de Procesos” 4 - 56
Al final del mes, el vendedor puede regresar al proveedor las revistas que le sobren, las cuales se le
pagarán a $3 600 el ejemplar. Finalmente, se supone que después de un mes ya no existe demanda por parte del público, puesto que para ese entonces ya habrá aparecido el nuevo ejemplar. Si el precio al público de la revista es $ 8 000 por ejemplar, determine la política óptima de compra.
4.28 Debido a un aumento en las ventas, cierta compañía productora necesita mas espacio en su fábrica. La
solución que se ha propuesto es la construcción de un nuevo depósito para almacenar los productos terminados. Este depósito estará localizado a 35 kilómetros de la planta. Además, de acuerdo con este nuevo plan, se requiere que al final del día se envíe la producción terminada al nuevo depósito.
Por otra parte, con base en información histórica, se ha estimado que la producción diaria de la
empresa tiene la siguiente distribución de probabilidad:
Producción diaria (toneladas) 50 - 55 55 - 60 60 – 65 65 - 70 70 - 75 75 - 80
Probabilidad 0.10 0.15 0.30 0.35 0.08 0.02 También se sabe que el tipo de camiones que se deben utilizar para transportar esta producción tienen
capacidad de 5 toneladas. La cantidad de viajes que se pueden realizar cada día (jornada de 8 horas), depende del tiempo de carga y descarga, como también del tiempo que se requiere para recorrer la distancia entre la planta y el depósito. Por lo tanto, la cantidad de producto terminado que un camión puede transportar de la planta al depósito, es una variable aleatoria cuya distribución de probabilidad es la siguiente:
Toneladas diarias transportadas/camión 4.0 – 4.5 4.5 – 5.0 5.0 –5.5 5.5 – 6.0
Probabilidad 0.30 0.40 0.20 0.10
Si la cantidad diaria producida es mayor que la cantidad que puede transportar la flotilla de camiones, el excedente debe ser enviado a través de camiones de otra compañía transportadora a un costo de $20 000 la tonelada. Además el costo promedio anual de un camión nuevo es de $ 20 000 000. Si se trabajan 250 días al año, cual es el número óptimo de camiones que la empresa debe comprar?

5 SIMULACIÓN DE EVENTOS DISCRETOS 1 Introducción En el Capítulo anterior se estudió el problema de la generación de muestras artificiales de diferentes procesos. Las observaciones de la muestra se generan mediante la ayuda de los números aleatorios y del conocimiento de la distribución del proceso de donde se iba a extraer la muestra. Esos procesos pueden representar el tiempo entre la llegada de los clientes a un supermercado, la longitud de un período de trabajo de una máquina, el resultado obtenido al examinar un artículo, etc. Sin embargo, se consideraba la generación del proceso o variable aleatoria en una forma aislada, como si el fin principal fuera únicamente la variable que se generaba, sin considerar que esa variable formaba parte de un sistema o un todo más complejo. Es decir, las variables aleatorias que se generan forman parte de un modelo que se construye para representar el sistema que en un momento dado se desea simular. Antes de entrar un poco más en el detalle de la forma de construir el modelo de simulación es necesario dar unas
definiciones de lo que se entiende por un sistema y de las propiedades de los mismos. 2 Definiciones Sistema. Un sistema es un conjunto de objetos o componentes unidos que interactúan dentro de ciertos límites establecidos para obtener algún objetivo común. Para la simulación el sistema representará el objeto o parte que será sometido al estudio por medio de esta técnica. Una fábrica que procese órdenes a través de diferentes secciones o procesos es un ejemplo de un sistema. En un momento dado podemos estar interesados en estudiar únicamente una de esas secciones, la cual sería un subsistema del sistema principal. Esa sección o subsistema, sería el sistema que nos interesa para la simulación. Entidad. El término entidad es usado para denotar un objeto de interés en el sistema. Las órdenes que llegan a una fábrica son un ejemplo de una entidad; las máquinas a través de las cuales pasan las órdenes son otras entidades.
Atributo. El término atributo denota una propiedad de una entidad. Así una entidad puede tener muchos atributos. Actividad. Cualquier proceso que ocasione cambios en el sistema es denominado actividad. Estado del sistema. El término "estado del sistema" es empleado para expresar una descripción de todas las entidades, actividades y atributos en la forma como existen en un momento cualquiera. El progreso del sistema es estudiado siguiendo los cambios en el estado del sistema. Un sistema se mueve de un estado a otro a medida que sus entidades se comprometen en actividades que cambien sus estados. Evento. El término evento se usa para describir la ocurrencia de un cambio en el estado del sistema en un instante cualquiera en el tiempo. Los eventos indican el comienzo, la terminación o la modificación de una actividad. El comportamiento del sistema es simulado por los cambios de estado que ocurren cuando sucede un evento. Cuando ocurre un evento el estado del sistema puede cambiar en tres formas:
a. Alterando el valor de uno o más atributos de las entidades b. Creando o destruyendo una entidad, es decir, cambiando el número de entidades del
sistema, y c. Comenzando, terminando o modificando una actividad Los eventos, al igual que las entidades, tienen atributos. En efecto, cada evento debe tener un atributo que defina el tiempo en que va a ocurrir. Otros atributos normalmente asociados con

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 2
los eventos describen el tipo de evento y a veces, las entidades y los atributos de las entidades afectadas por los eventos. Lista. Una lista es una colección de entidades asociadas (temporal o permanentemente) ordenadas de una manera lógica (. Por ejemplo, una cola que puede ordenarse por el tiempo de llegada, o por la prioridad). Lista de eventos (LEF). Corresponde a la lista de los eventos (primarios) que han de ocurrir en el futuro, junto con sus respectivos atributos. También se la conoce como “Lista o Matriz de Eventos Futuros LEF”. La figura 5.1 presenta varios ejemplos de sistemas, con sus respectivas entidades, atributos y actividades. El objeto de un estudio de simulación es reproducir las actividades en que se comprometen las entidades de un sistema y obtener información acerca del comportamiento y desempeño
potencial del mismo. Para estudiar un sistema el concepto clave es el de la "descripción del estado del sistema". Si un sistema puede caracterizarse por un conjunto de variables, con cada combinación de los valores de las variables representando un estado único del sistema, entonces la manipulación de las variables simula el movimiento del sistema de un estado a otro. Fig. 5.1 Ejemplos de sistemas
SISTEMAS ENTIDADES ATRIBUTOS ACTIVIDADES
Tráfico Carros Velocidad Distancia
Conducción
Banco Clientes Balance Estado de crédito
Depositar Retirar
Comunicaciones Mensajes Longitud Prioridad
Transmisión
Supermercado Consumidores Lista de compras Pagar
Empresa Departamentos
Ordenes Productos
Tipos
Cantidades
Proceso
de órdenes
Para realizar una simulación hay dos aspectos muy importantes que hay que analizar, a saber: a. La identificación de las entidades y los atributos, y
b. La codificación de los valores de los atributos para poder caracterizar los estados del sistema. Por ejemplo, es necesario definir cómo se va a representar una entidad que esté recibiendo un servicio o una que esté esperando que la atiendan.
De lo anterior se concluye la importancia de crear un modelo para la simulación en el cual se consideren las diferentes variables que pueden describir el estado del sistema en un instante cualquiera. A continuación se hace un resumen de los diferentes aspectos que es necesario considerar al construir el modelo. 3 Elementos del Modelo
Para la formulación del modelo matemático es necesario especificar: a. Los componentes del sistema que va a ser simulado.
b. La especificación de las variables y parámetros. Al determinar las variables es necesario especificar las variables exógenas, las de estado y las endógenas, y dentro de las variables exógenas cuales son controlables y cuales aleatorias.

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 3
c. Las relaciones funcionales. Para las variables aleatorias es necesario definir en qué forma van a ser generadas, lo cual incluye la definición del generador de números aleatorios.
Como se ha mencionado anteriormente, no es necesario llegar a expresiones muy complicadas que relacionen los componentes entre sí, sino a un conjunto de expresiones, las cuales se emplean separadamente dependiendo de las condiciones del sistema, es decir, de los valores que tomen las variables de estado.
3.1 Métodos para Analizar los Sistemas Existen dos enfoques básicos para analizar un sistema de interés. Esos enfoques son:
3.1.1 Enfoque de Flujo
Uno de los métodos más comunes para examinar una situación nueva es seguir el flujo de los principales elementos que se están procesando.
Este enfoque es apropiado para sistemas que tienen propiedades determinadas por el flujo de entidades físicas o de información a través del sistema. En el caso de un sistema de producción se empezaría con la materia prima básica y se mostraría la entrada de otros materiales y componentes a medida que el producto pasa a través de los procesos de manufactura y de ensamble. La secuencia de pasos en el sistema puede mirarse como una alternación de procesamiento (cambios en el producto) y movimiento (al próximo proceso). Enfocar el flujo revela fácilmente donde pueden ocurrir demoras en el procesamiento, y los efectos de tales retrasos en los procesos siguientes. Es natural tratar o considerar un grupo de procesos como un subsistema básico, cuando se enfoca un sistema a través del flujo. Un proceso es un punto en un sistema de producción donde el producto sufre un cambio; usualmente hay involucrada una facilidad o equipo que efectúa el cambio, un operario, materiales y algún procedimiento para ejecutar el proceso. Una vez se identifican los subsistemas, es necesario realizar estudios para indicar donde se pueden efectuar mejoras que den buenos dividendos. Una vez que un analista ha empleado este
método con éxito y ha logrado identificar los subsistemas, puede aplicarlo a uno de los subsistemas, aunque probablemente no haya nada que fluya físicamente. En estos casos, es posible "imaginar" un flujo: Por ejemplo, en un taller se pueden imaginar las máquinas que "salen" del proceso de producción cuando fallan y van en busca de un mecánico que las repare y luego regresan al proceso de producción cuando son reparadas. La conceptualización de flujos imaginarios es muy útil en a formulación del problema. En la mayoría de los sistemas hay dos flujos: productos y personas. Existen también otros flujos, de los cuales los más importantes son la información y el dinero. En la mayoría de los sistemas deben identificarse primero los elementos que fluyen y luego los subsistemas. Ejemplo: Sistema de una cola usando el enfoque de flujo Para ilustrar el enfoque de flujo, se analizará la simulación de un sistema de colas de un
servidor. Para este ejemplo se construirá inicialmente un modelo simplificado, luego el modelo ampliado, explicándolo tanto mediante un diagrama de flujo como mediante el seudo código, de tal forma que sea fácil de comprender, y posteriormente se implementará en una hoja de cálculo de Excel Para construir el modelo usando el enfoque de de flujo es necesario examinar lo que sucede con el cliente que requiere el servicio, lo cual se puede resumir en las siguientes grandes actividades, aclarando que la entidad que fluye a lo largo del sistema es el “cliente”,: 1) Inicialmente el cliente llega al sistema en busca de un servicio. 2) El cliente espera, si es

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 4
necesario. 3) El empleado o servidor atiende al cliente, durante el tiempo que sea necesario, incluyendo el tiempo para hacer el pedido y para pagar. 4) Una vez paga el cliente sale de la tienda. Estas actividades resumen el recorrido que sigue el cliente. También se presenta el diagrama esquemático de bloques, que representa, con ligeras modificaciones, el procedimiento seguido para construir el modelo.
Legada del cliente Paso a la cola Paso al servicio Salida
Figura 5.2 Flujo de un cliente en sistema de colas de una estación
El diagrama de la página siguiente presenta con un poco más de detalle el procedimiento para la simulación del sistema de colas de un servidor usando el enfoque de flujo. Tanto para el diagrama de flujo como para la hoja de cálculo se cumplen las siguientes suposiciones: El primer cliente llega en el tiempo cero (aunque podrían llegar en cualquier instante a partir
del tiempo cero).
La disciplina de la cola es FIFO, es decir, de acuerdo al orden de llegada
En el desarrollo del modelo se tienen en cuenta las siguientes relaciones: Para cada cliente se genera el tiempo que tarda en llegar, a partir de la llegada del cliente
anterior. Por lo tanto, el “tiempo de llegada” al sistema es igual al tiempo de llegada del cliente anterior, mas el tiempo que tarda en llegar (tiempo entre llegadas).
Un cliente inicia servicio tan pronto llega, si el servidor está inactivo, o tan pronto termina el servicio del cliente anterior.
El tiempo de permanencia de un cliente en la cola es igual al tiempo de inicio de servicio menos el tiempo de llegada al sistema.
Para cada cliente se debe generar el tiempo que dura su servicio. Por lo tanto, el tiempo de salida del sistema es igual al tiempo de inicio del servicio más la duración del mismo.
El tiempo de permanencia de un cliente en el sistema es igual al tiempo de salida (fin de servicio) menos el tiempo de llegada al sistema.
El tiempo de inactividad del servidor es igual al tiempo de inicio de servicio de un cliente menos el tiempo de fin de servicio del cliente inmediatamente anterior.
Llegada del cliente
Espera ser atendido
Se presta el servicio
El cliente sale

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 5
Figura 5.3 Diagrama de flujo para a simulación de un sistema de colas con un servidor. Enfoque
del flujo
Calcula tiempo de permanencia en el sistema
Cálculo de estadísticas
Inicio
Definición de parámetros
Reloj = 0
Incialización registros = 0
Para i = 1, nro_clientes tiempo entre llegadas
Genera tiempo entre llegadas
Calcula tiempo de llegada
Calcula tiempo de inicio de servicio
Calcula tiempo de espera
Genera tiempo de servicio
Calcula tiempo de inactividad del servidor espera
Calcula tiempo de fin de servicio
Siguiente cliente
Fin
Reloj = Tiempo salida último cliente

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 6
Figura 5.3a Enfoque del flujo. Sistema de colas de una estación
Inicio Definición de parámetros Reloj = 0 Inicialización de registros Para clientes = 1, nro_clientes Generación de “tiempo entre llegadas” Cálculo de tiempo de llegada Cálculo de tiempo de inicio de servicio Cálculo de tiempo de espera Cálculo del tiempo de inactividad del servidor Generación del tiempo de servicio Cálculo del tiempo de fin de servicio Cálculo del tiempo de permanencia en el sistema Siguiente cliente Cálculo de estadísticas
Fin El modelo fue implementado en Excel, para las distribuciones de tiempos entre llegadas y tiempos de servicios dados a continuación. Las columnas usadas en el modelo de Excel, su contenido y forma de cálculo se presentan en la siguiente tabla:
Figura 5.4 Sistema de colas de una estación. Diseño de la simulación en Excel
Columna Contenido Cálculo para la fila i
Observaciones
A Número del cliente (i) = (i-1) + 1 Inicia en 1
B Número aleatorio =aleatorio()
C Tiempo entre llegadas Según distribución
D Tiempo de llegada del cliente D(i-1)+C(i) D(1) = 0
E Tiempo de inicio de servicio Max(D(i), I(i-1)
F Tiempo de espera E(i) – D(i)
G Número aleatorio =aleatorio()
H Tiempo de servicio Según distribución
I Tiempo de fin de servicio E(i) + H(i)
J Tiempo de permanencia en el sistema I(i) – D(i)
K Tiempo de inactividad del servidor E(i) – I(i-1)
En el cuadro que sigue se presenta la simulación, usando la hoja de cálculo Excel, de los 20 primeros clientes del sistema de colas con las siguientes características: Distribución de tiempo entre llegadas (minutos):
Tiempo entre llegadas 1 2 3 4 5 6 7 8
Probabilidad 0.125 0.125 0.125 0.125 0.125 0.125 0.125 0.125
Distribución del tiempo de servicio (minutos):
Tiempo de servicio 1 2 3 4 5 6
Probabilidad 0.10 0.20 0.30 0.25 0.10 0.05

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 7
Figura 5.5 Simulación de un modelo de colas de un solo canal
Cliente número
R Tiempo próxima llegada
Tiemp de
llegada
Tiempo inicio
servicio
Tiempo de
espera R
Tiempo de
servicio
Tiempo fin de
servicio
Tiempo en el
sistema
Tiempo ocioso cajero
( A ) ( B ) ( C ) ( D ) ( E ) ( F ) ( G ) ( H ) ( I ) ( J ) ( K )
1 0 0 0 0 0.101 2 2 2 0
2 0.853 7 7 7 0 0.706 4 11 4 5
3 0.208 2 9 11 2 0.541 3 14 5 0
4 0.945 8 17 17 0 0.649 4 21 4 3
5 0.030 1 18 21 3 0.092 1 22 4 0
6 0.064 1 19 22 3 0.072 1 23 4 0
7 0.984 8 27 27 0 0.796 4 31 4 4
8 0.603 5 32 32 0 0.213 2 34 2 1
9 0.852 7 39 39 0 0.819 4 43 4 5
10 0.302 3 42 43 1 0.035 1 44 2 0
11 0.981 8 50 50 0 0.755 4 54 4 6
12 0.048 1 51 54 3 0.497 3 57 6 0
13 0.780 7 58 58 0 0.626 4 62 4 1
14 0.882 8 66 66 0 0.451 3 69 3 4
15 0.945 8 74 74 0 0.726 4 78 4 5
16 0.698 6 80 80 0 0.434 3 83 3 2
17 0.514 5 85 85 0 0.089 1 86 1 2
18 0.631 6 91 91 0 0.411 3 94 3 5
19 0.552 5 96 96 0 0.743 4 100 4 2
20 0.229 2 98 100 2 0.904 5 105 7 0
20 98 14 60 74 45
4.9 0.7 3 3.7 0.429
Estadísticas:
1 Tiempo promedio de espera = 0.7
2 Clientes que no esperan = 14
3 Probabilidad de esperar = 0.3
4 Tiempo medio de los que esperan = 2.3
5 Porcentaje de inactividad del cajero = 42.9
6 Tiempo medio de servicio = 3
7 Tiempo medio entre dos llegadas = 4.9
8 Tiempo medio en el sistema = 3.7
9 Tiempo medio en el sistema – control = 3.7
10 Número medio de clientes en el sistema L = 0.76
11 Número medio de clientes en la cola Lq = 0.14
12 Número medio de clientes en servicio a = 0.57
13 L aprox. Control = 0.71

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 8
En la parte final de la tabla se presentan las principales estadísticas de la simulación, las cuales son obtenidas, unas a partir de la propia simulación y otras a partir de relaciones que siempre se cumplen en los diferentes sistemas de colas, usando las fórmulas de Little (número medio de unidades en el sistema, en la cola y en servicio): 3.1.2 Enfoque hacia los cambios de estado (por eventos) En este método de análisis se requiere examinar el sistema en ciertos intervalos de tiempo y observar si en ese intervalo han ocurrido cambios en el sistema. En cada instante se observa el estado del sistema, el cual es representado especificando los valores de las variables exógenas y de estado relevantes. En este enfoque se divide el tiempo en una serie de instantes o puntos. En cada instante podemos imaginarnos que tomamos una instantánea del sistema. La foto o instantánea es el estado del sistema. El estado del sistema se representa mediante los valores que toman en ese
instante las variables exógenas y de estado más relevantes. De acuerdo con el estado del sistema, se toman las decisiones pertinentes, es decir, el curso de acción a seguir, La primera tarea en el análisis por cambios de estado consiste en identificar las variables más relevantes. La siguiente y la más difícil es definir las relaciones que describen como cambia el estado del sistema (cada una de las variables) a medida que el tiempo avanza de un instante al siguiente. Dado que cada variable no necesariamente cambia en cada avance del tiempo, las relaciones dependientes del tiempo pueden estar condicionadas a los estados pasado y presente, es decir, una variable particular puede cambiar sólo cuando el estado presente tenga ciertas características. La primera tarea en el análisis por cambios de estado consiste en identificar las variables relevantes. La siguiente y la más fácil consiste en definir las relaciones que describan en qué forma cambia el estado del sistema a medida que el tiempo avanza. Las relaciones para efectuar los cambios de estado, pueden involucrar dos procesos o etapas:
1) Un procedimiento para determinar si una variable o grupo de variables puede cambiar. 2) Un procedimiento computacional mediante el cual se actualicen las variables. El enfoque más apropiado para la simulación es el enfoque de los cambios de estado o por eventos, es decir, observar el sistema sólo cuando ocurre algo que haga cambiar su estado. En algunos casos también puede usarse el enfoque de flujo, es decir, examinando el flujo que una entidad sigue a través del sistema, desde que entra hasta que sale. Sin embargo, con el enfoque del flujo se obtiene menos información que con el enfoque hacia los cambios de estado, ya que en el enfoque del flujo se considera únicamente la entidad de interés, y en el enfoque de cambios de estado se consideran todas las entidades que hay en el sistema en un momento dado. Una vez definido el modelo con sus componentes, variables, parámetros y relaciones funcionales es necesario definir cómo vamos a representar el tiempo en la simulación y cómo vamos a hacer para desarrollar la simulación en sí. En las secciones siguientes se tratará, primero el problema de la representación del tiempo en la simulación, luego la forma básica de desarrollar la
simulación y finalmente el problema de la recolección de estadísticas.

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 9
Ejemplo: Sistema de una cola usando el enfoque por eventos Para ilustrar el enfoque por eventos, se analizará la simulación de un sistema de colas de un servidor. Los únicos eventos primarios que se presentan en esta simulación son la llegada de una unidad o cliente al sistema y la terminación de un servicio por parte de una estación. Con el fin de facilitar la implementación del modelo computaciones, también se incluye como evento primario el fin de simulación, es decir, el instante en que dejamos de observar o analizar el sistema. Además, como se explicó antes, cada uno de los eventos primarios anteriores puede generar otros eventos secundarios, dependiendo del estado del sistema, como se ilustra a continuación. Cuando una unidad llega al sistema, se puede iniciar un servicio, si hay un servidor inactivo, o cuando un servidor finaliza un servicio, puede empezar otro servicio para una nueva unidad, si hay al menos una unidad en la lista de espera.
Cuando una unidad entra al sistema, esta unidad puede quedar en uno de dos posibles estados: la unidad o se queda en la cola o pasa al servicio. El siguiente diagrama ilustra lo que debe hacer el simulador cuando una unidad llega al sistema. No Sí
No Si
Figura 5.6 Actividades realizadas cuando una unidad llega al sistema
Cuando el evento es un fin de servicio, el simulador debe realizar las actividades descritas en el diagrama de la figura 5.7 Como se indicó antes, el sistema incluye las unidades que están en la cola, las unidades que están recibiendo servicio y las estaciones de servicio. Los estados de las diferentes entidades deben incorporarse en el modelo. Los estados de una unidad, pueden ser únicamente dos : o está en la cola esperando servicio, o está siendo atendida. Igualmente, los estados de las
Llegada Cliente
Hay servidores inactivos?
Se selecciona un servidor disponible
El Cliente pasa al servicio
La unidad pasa a la Cola
Puede entrar al sistema?
Se identifica al Cliente Cliente se va

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 10
facilidades o estaciones de servicio son dos: ó están ocupadas atendiendo una unidad, o están ociosas. Por lo tanto debemos buscar la forma de representar los estados antes mencionados, y hacer que ocurran los eventos descritos. Para el sistema que se está tratando de simular se debe mantener el registro de los siguientes tiempos El tiempo de llegada de la nueva unidad al sistema. El tiempo en que finaliza el servicio de una unidad. El tiempo actual de la simulación. Este tiempo se mantendrá en la variable denominada
RELOJ (el reloj de la simulación). Por lo tanto es necesario definir la forma de determinar cuando llega una unidad o cliente al sistema y cuando se termina un servicio. En una situación real cuando llega una unidad al sistema no se sabe cuando llegará la próxima, aunque si puede saberse como se distribuye e! tiempo entre llegadas. En forma similar, cuando el servidor empieza a servir una unidad, no se
sabe cuanto tiempo durará el servicio, aunque sí puede conocerse cual es su distribución. Sin en embargo en un modelo de simulación sí podemos saber o estimar cuando ocurrirá la próxima llegada o cuando se finalizará un servicio, ya que estos tiempos pueden “generarse” con base en las respectivas distribuciones de tiempos entre llegadas o de tiempos de servicio. Así, cuando una unidad llega al sistema, inmediatamente se genera el tiempo de llegada de la próxima unidad, independientemente de lo que pase con la que acaba de llegar. Además, cuando una estación de servicio empieza a atender una unidad, se genera el tiempo que durará dicho servicio. La generación de estos tiempos debe hacerse de acuerdo con las respectivas distribuciones de tiempos entre llegadas y de tiempos de servicio.
No
Fig. 5.7 Actividades realizadas por el simulador cuando finaliza un servicio.
Fin de un servicio
Hay Clientes esperando servicio
Se selecciona una unidad para ser atendida
El servidor va a la cola
Se identifica el Servidor Se identifica el Cliente
Cliente sale del Sistema
El Cliente pasa al servicio

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 11
3.2 Etapas de un modelo de simulación Todo modelo de simulación contempla tres etapas o aspectos básicos que hay que considerar y que son: a) Inicialización. Esta etapa se realiza una sola vez y comprende, además de la definición de
los parámetros básicos del sistema, la inicialización y definición de las variables que se van a usar, los registros para recoger información y la lista inicial d eventos.
b) Algoritmo de simulación. El algoritmo de la simulación corresponde ala simulación propiamente dicha, con todos los cambios que ocurran en el estado del sistema, según los eventos que vayan ocurriendo..
c) Generación del reporte. El resumen e impresión de los resultados 3.3 Representación del Tiempo El paso del tiempo en la simulación se registra en una variable llamada "tiempo del reloj".
Usualmente se la hace igual a cero al empezar la simulación, e indica cuantas unidades de tiempo simulado han transcurrido desde que empezó la simulación. La variable que se usará para denotar el tiempo de simulación será denominada “Reloj”. Existen dos métodos básicos para actualizar el reloj: Un método consiste en avanzar el reloj al tiempo en que debe ocurrir el próximo evento. El segundo método consiste en avanzar el reloj por intervalos pequeños de tiempo (uniformes) y determinar en cada intervalo de tiempo si ocurre un evento en ese tiempo. El primer método recibe el nombre de "avance del reloj por eventos" y el segundo "avance del reloj unidad por unidad" ó "avance por unidad".
3.3.1 Avance unidad por unidad
En el método de avance del reloj unidad por unidad se avanza el reloj una unidad de tiempo (reloj = reloj + 1) y se examina el sistema para verificar si ocurrió un cambio en su estado durante el transcurso de esa unidad de tiempo. Por lo general se suponer que el cambio en el
estado del sistema ocurre al final de la unidad de tiempo. Puede suceder que durante la unidad de tiempo no hubiera ocurrido ningún cambio y el sistema siguiera en el mismo estado en que estaba antes de transcurrir este tiempo. El sistema se debe actualizar para todos los cambios que hayan ocurrido durante la unidad de tiempo. 3.3.2 Avance por eventos En el método de avance por eventos solamente se avanza el reloj cuando ocurre algún evento que modifica el estado del sistema. El intervalo que avanza el reloj no será el mismo sino que en general será variable. En este sistema de avance del reloj es necesario mantener una "lista de los eventos" que pueden ocurrir en el futuro y del tiempo en que ocurrirá cada evento. En el sistema de avance por unidad de tiempo no es necesario mantener una lista de eventos ya que al final de cada unidad de tiempo se da un vistazo a todo el sistema para examinar si ocurre algo que haga cambiar su estado. El sistema se actualiza de acuerdo con el tipo de evento que haya ocurrido y solamente se ejecutan las actividades asociadas o afectadas por el evento. 3.3.3 Ejemplo: Taller de varias máquinas y varios mecánicos
La diferencia entre el avance por eventos y el avance unidad por unidad puede ilustrarse mediante el siguiente ejemplo. Considere un taller que tiene N máquinas y M operarios para atenderlas cuando fallan. Para simular la operación de este taller se procederá de la siguiente forma, dependiendo del tipo de avance del reloj, se harán las siguientes suposiciones:

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 12
En el tiempo cero todas las máquinas empiezan a funcionar, y por lo tanto, todos los mecánicos estarán inactivos
Se conoce la distribución del tiempo de operación de las máquinas, y estas son idénticas. Se conoce la distribución del tiempo que gasta cada mecánico reparando una máquina Para la reparación de las máquinas, se usará la disciplina FIFO a) Taller de máquinas y mecánicos. Avance unidad por unidad (Ver figuras 5.8 y 5.9) En este enfoque se supone que al final de cada unidad de tiempo se analiza todo el sistema para ver que sucedió durante esa unidad y tomar las decisiones que sean necesarias. Inicialmente se examinarán las máquinas, para verificar de las que estaban funcionando cuales fallaron durante la unidad de tiempo, colocarlos en una lista provisional de espera, luego se analizarán los mecánicos para verificar si los que estaban trabajando terminaron la reparación, y finalmente se analizarán conjuntamente máquinas y los mecánicos, para asignar a los mecánicos inactivos, las máquinas que esperan reparación.
En este sistema se avanza el reloj una unidad de tiempo (una hora por ejemplo) y se examina qué sucedió durante esa unidad de tiempo. Se supone que los eventos ocurren al final de la unidad. El examen de la situación podría realizarse de la siguiente manera: 1) Inicialización. En el tiempo cero (Reloj = 0) se inicializa el estado del sistema suponiendo
que, por ejemplo, todas las máquinas están trabajando, y por lo tanto, los mecánicos empiezan inactivos
2) Algoritmo de simulación. Mientras que el Reloj sea menor o igual que el tiempo de simulación se realizarán las siguientes actividades o tareas:
a) Se avanza el reloj una unidad de tiempo (Reloj = Reloj + 1).
b) Se examina el estado de cada una de las máquinas que estaban trabajando para ver si alguna falló durante la última unidad de tiempo. Si alguna falló, se la coloca en la lista de las máquinas que esperan servicio.
c) Se examina el estado de cada operario, para verificar si terminó la reparación de la
máquina que estaba atendiendo.
d) Si hay operarios inactivos y máquinas dañadas que no estén siendo reparadas se asigna a cada operario inactivo una máquina para que la repare.
3) Generación del reporte. Si ya transcurrió el tiempo de simulación, se termina el proceso y
se genera el reporte. La figura 5.8 presenta un diagrama de flujo de las actividades requeridas para la simulación del taller usando el avance unidad por unidad, y en la figura 5.9 se presenta el seudo código con las mismas actividades, de tal forma que se pueda visualizar, de dos maneras diferentes el mismo proceso.
B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 13
INICIO
En espera En Reparación
En funcionamiento
No
Inactivo
Trabajando
Sí No
Sí
No No
Sí
Figura No 5.8 Avance del Tiempo Unidad por Unidad. Caso del taller de N máquinas y M mecánicos
Lectura de parámetros
Reloj = 0
Inicializar estado del sistema: - Todas las máquinas funcionando - Todos los operarios inactivos AAAAAAAAAAAA
Inicializar contadores
Reloj = Reloj +1
Actualizar tiempo de espera
Actualizar tiempo de inactividad
Actualizar tiempo en servicio
Estado de la maquina: en cola
Estado del mecánico: inactivo
Identificar maquina reparada: Estado maquina = en funcionamiento
Inicio
Para cada máquina I
Estado de la máquina
Falló?
Siguiente máquina
Para cada mecánico j = 1, ro_mec
Estado del mecánico?
Terminó?
Siguiente mecánico
Hay máquinas en cola y mecánicos inactivos? máquina
Asignar maquinas en espera a mecánicos inactivos, y
actualizar maquinas y mecánicos inactivos
Reloj=tiempo de simulación?
Generar el reporte de salida
Fin

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 14
Figura 5.9 Seudo código para la simulación del Taller de máquinas y mecánicos Avance unidad por unidad
Inicio
Lectura de parámetros
Reloj = 0
Máquinas trabajando = todas (Nro_máquinas) Para máquina = 1, nro_máquinas Generar tiempo de funcionamiento (opcional) Estado = Funcionando Siguiente máquina Mecánicos inactivos = todos Inicializar contadores
Mientras reloj < tiempo_simulacion
Reloj = Reloj + 1 Actualizar estadísticas sobre variables de estado
Para maquina = 1, nro_maquinas
Si estado = funcionando, entonces
Actualiza tiempo de funcionamiento Si la máquina falló, entonces
Cambiar estado = cola Disminuir máquinas funcionando y aumentar máquinas en cola
Fin si
Si no
Si estado = cola, entonces
Actualiza tiempo de espera
Si no
Actualiza tiempo de reparación
Fin si
Fin si
Siguiente máquina
Para mecánico = 1, nro_mecánicos
Si estado = reparando máquina, entonces
Actualiza tiempo de actividad Si terminó reparación, entonces
Cambiar estado de la máquina = funcionando Aumentar máquinas funcionando Estado del mecánico = inactivo (cola) Aumentar mecánicos inactivos
Fin si
Fin si
Siguiente mecánico
Mientras haya máquinas en cola y mecánicos inactivos, entonces
Seleccionar un mecánico Seleccionar una máquina Asignar máquina al mecánico
Reorganizar cola de máquinas Reorganizar cola de mecánicos
Disminuir número de mecánicos inactivos Disminuir número de máquinas en cola
Fin mientras
Fin mientras
Generar reporte
Fin programa

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 15
b) Taller de máquinas y mecánicos. Avance por eventos (Figuras 5.10 y 5.11) En el avance por eventos es necesario, antes de comenzar la simulación, definir los tipos de eventos que pueden ocurrir. Esos eventos pueden ser o la falla de una máquina que esté trabajando o el fin de una reparación. El reloj se avanza al evento que vaya a ocurrir primero, es decir, al tiempo del próximo evento. El examen de la situación podría realizarse de la siguiente manera: 1) Inicialización. En el tiempo cero (Reloj = 0) se inicializa el estado del sistema suponiendo
que, por ejemplo, todas las máquinas están trabajando. Para este tipo de enfoque es necesario generar, de acuerdo con la distribución apropiada, el tiempo de funcionamiento de cada máquina. El menor de estos tiempos de funcionamiento, será el próximo tiempo de falla. Como todas las máquinas empiezan en operación, todos los mecánicos estarán inactivos, y en consecuencia no es necesario definir cuando finalizarían una reparación.
2) Algoritmo de simulación. Mientras que el Reloj sea menor o igual que el tiempo de
simulación se realizarán las siguientes actividades o tareas:
a) Se busca el próximo evento, es decir, el menor entre los tiempos de falla de las máquinas y el tiempo de terminación de reparación de los mecánicos
b) Se avanza el reloj al tiempo del próximo evento.
c) Si el evento es la falla de una máquina, se identifica la máquina, se verifica si hay un operario inactivo que la puede reparar. Si no hay un operario inactivo, la máquina queda desatendida, a la espera de un mecánico que la repare. Si hay operarios inactivos, se escoge uno, según la disciplina de la cola, se le asigna la máquina y se genera el tiempo de servicio.
d) Si el evento es el fin de una reparación, se pone a funcionar la máquina reparada y se examina el sistema en busca de una máquina no atendida que pueda asignársele al operario que acabó la anterior reparación. Si no hay máquinas en espera de ser atendidas el operario queda inactivo. Si hay máquinas inactivas se le asigna una al operario (generalmente la que lleve más tiempo en espera- la primera de la cola) y se
genera el tiempo que dura la reparación.
3) Generación del reporte. Si ya terminó el tiempo de simulación, se genera el reporte de la misma
Las figuras 5.10 y 5.11 presentan el proceso completo de las actividades requeridas de la simulación usando el enfoque por eventos, en dos versiones diferentes, mediante un diagrama de flujo y mediante el seudo código de tal forma que se pueda visualizar de una mejor manera el proceso de simulación.. En general los cálculos se simplifican en el avance del reloj unidad por unidad, ya que no es necesario construir la lista de eventos futuros ni determinar el tiempo de ocurrencia de los mismos. Sin embargo puede existir un gran número de períodos en que no ocurra ningún evento, de tal forma que los cálculos en el avance del reloj unidad por unidad pueden ser ineficientes.
Si el avance del reloj es unidad por unidad, el tiempo se representa como una variable entera.
Sin embargo cuando el avance es por eventos el tiempo puede representarse o como una
variable entera o como una variable real. Si se representa como una variable real entonces la
variable reloj tiene exactamente las mismas unidades que el tiempo real que está
representando, sin ningún cambio de escala. Sin embargo, cuando la variable reloj se
representa como entera, entonces es necesario determinar un factor de escala para convertir el
tiempo real, que es una variable real, en el tiempo de simulación, que es una variable entera.
Para escoger ese factor de escala es necesario balancear la exactitud al determinar los

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 16
diferentes tiempos con la capacidad del computador que se esté empleando y con el tiempo de
simulación. Es decir, es necesario tener en cuenta cuál es el entero más grande que puede
manejar el computador. Así, si en un computador o un micro trabajamos con palabra sencilla
(INTEGER *2), el tiempo máximo que puede manejar el computador es: 2b-1 = 216-1 =
32767. Así, por ejemplo, si el tiempo entre la llegada de dos órdenes consecutivas un depósito
es 0.323 horas, es necesario convertir este tiempo en un entero mediante un factor de escala,
que podría ser 10, 100 ó 1.000, o trabajar en minutos (factor de escala = 60), en cuyos casos el
tiempo entre la llegada de las dos órdenes sería de 3, 32, 323 o 19 unidades de tiempo,
respectivamente. Entonces, el máximo tiempo que podría simularse en un computador o
microcomputador con palabra sencilla sería de 32767 unidades de tiempo, el cual en los casos
antes considerados sería de 3276, 327, 32 o 546 horas, respectivamente. Es necesario tener en cuenta que los cálculos en aritmética entera son más eficientes que en aritmética real, pero existen las limitaciones explicadas antes con respecto al máximo tiempo que podría simularse en una corrida. Si se trabaja en un computador con palabra sencilla es
preferible representar el tiempo como una variable real. En los simuladores de avance por unidad de tiempo se pierde información acerca del comportamiento del sistema, no importa que tan pequeño sea el incremento. La pérdida de información se puede entender como la incertidumbre acerca del tiempo en que ocurre cada evento. Por ejemplo, si la unidad de tiempo es 15 minutos, entonces un evento puede suceder o al principio de la unidad o a los dos minutos, o a los diez minutos, o a los quince y sólo se dirá que el evento sucedió al final de la unidad. Por consiguiente, el analista podrá obtener siempre el estimativo con la menor varianza (el estimativo más confiable) usando modelos de simulación con avances por eventos (Gafarian A. V. y V. Anker). Sin embargo, no puede concluirse que los métodos de avance por eventos predominen necesariamente sobre los métodos de avance por unidad ya que no se ha considerado el tiempo de computador como factor en la evaluación de los métodos. El tiempo de computador parece ser mayor en avance unidad por unidad, ya que habrá, en general, muchas unidades de tiempo en que no ocurre ningún evento.
Conway, Johnson y Maxwell concluyen que los simuladores de avance por eventos son más ventajosos a medida que el tiempo medio entre eventos aumenta, mientras que los simuladores de avance por unidad son preferidos cuando el número de variables de estados aumenta. Así los simuladores de sistemas grandes, en los que hay una probabilidad alta de que algo ocurra en una unidad de tiempo deberían usar métodos de avance por unidad.

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 17
A
Tipo de evento?
B
C
Reparación
Falla
No Sí
Figura No 5.10 Diagrama de flujo. Avance del RELOJ por eventos. Caso del Taller de N (NRO_MAQ) máquinas y M (NRO_MEC) mecánicos
Crear lista de eventos: - Tiempos de falla de las máquinas - Fin de simulación
Reloj = tiempo del próximo evento
Búsqueda del próximo evento
Escoger un mecánico Asignar máquina al mecánico
Generar evento: fin reparación Máquina en lista de
espera
Próximo evento ( A )
Aumentar en 1 las máquinas en cola
Identificar maquina Aumentar en 1 las maquinas inactivas
Reducir en 1 mecánicos inactivos
Lectura de parámetros
Reloj = 0
Inicializar estado del sistema: - Todas las máquinas funcionando - Todos los operarios inactivos AAAAAAAAAAAA
Inicializar contadores
Inicio
Hay mecánicos inactivos?
Generar Reporte
D
Fin

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 18
Hay máquinas en espera
CR
Evento = Reparación
No
Sí Sí
Figura No 5.10 (cont.) Diagrama de flujo. Avance del RELOJ por eventos. Caso del Taller de N (NRO_MAQ) máquinas y M (NRO_MEC) mecánicos
Escoger una maquina Asignar maquina al mecánico
Generar evento: fin reparación Mecánico en lista de espera
Próximo evento ( A )
Reducir en 1 maquinas en espera
Generar evento: próxima falla de la maquina
Identificar mecánico Identificar máquina reparada
Aumentar en 1 las máquinas operando
Aumentar en 1 los mecánicos inactivos

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 19
Figura 5.11 Seudo código para la simulación del Taller de máquinas y mecánicos Avance por eventos
Inicio
Lectura de parámetros
Reloj = 0
Máquinas trabajando = todas (Nro_máquinas) Para máquina = 1, nro_máquinas Generar tiempo de funcionamiento (primeros eventos) Estado = Funcionando Siguiente máquina Mecánicos inactivos = todos Inicializar contadores
Mientras reloj < tiempo_simulacion
Buscar próximo evento (menor entre tiempos de falla, tiempos de reparación y tiempo de simulación) Actualizar estadísticas sobre variables de estado Reloj = tiempo del próximo evento Identificar tipo de evento
Si tipo evento = falla, entonces
Aumentar máquinas inactivas Se identifica la máquina. Sea I la máquina que falla Si hay mecánicos inactivos, entonces
Se selecciona un mecánico J de la cola. (el primero de la cola) Se reorganiza la cola de mecánicos Se reduce el número de mecánicos inactivos
Se asigna la máquina I al mecánico J Se genera el tiempo de reparación Se actualiza el estado del mecánico J
Si no
Cambiar estado = cola Aumentar máquinas en cola
Fin si
Si no
Si tipo evento = reparación, entonces
Se identifica el mecánico (J) Se identifica la máquina (I) Se pone la máquina I en funcionamiento Se reduce el número de máquinas inactivas
Si hay máquinas en espera de reparación, entonces
Se selecciona una máquina (I) (primera de la cola) Se reorganiza la cola de máquinas Se reduce el número de máquinas en espera
Se asigna la máquina I al mecánico J Se genera el tiempo de reparación Se actualiza el estado del mecánico J
Si no
Estado del mecánico = inactivo (cola) Aumentar mecánicos inactivos
Fin si
Fin si
Fin si
Fin mientras
Generar reporte
Fin programa

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 20
3.3.4 Escogencia de la Unidad en Métodos de Avance del Reloj por Unidad1
Si el analista escoge el método de avance del tiempo unidad por unidad, el próximo paso debe ser escoger el tamaño de la unidad. La regla general para escoger la unidad de tiempo es: Escójase la unidad de tiempo mayor tal que la probabilidad de que se tenga que tomar más de una decisión durante dicha unidad de tiempo sea despreciable. Dentro de esta regla hay una regla adicional: Si las consecuencias de las decisiones van a ser determinadas simulando eventos individuales, la unidad debe ser aún más pequeña, lo suficientemente pequeña de tal forma que la probabilidad de que ocurran eventos múltiples en la unidad de tiempo sea despreciable. Por ejemplo, si estamos simulando la operación de un taller de reparación, la unidad de tiempo debe ser tan pequeña de tal forma que la probabilidad de que una máquina se dañe y sea reparada en la misma unidad de tiempo sea despreciable. Una regla que puede emplearse para escoger la unidad de tiempo es: "Escoja el intervalo de
tiempo igual a un décimo (1/10) del más corto de los tiempos esperados entre eventos" (Emshoff). A medida que la unidad de tiempo se hace mayor, el modelo puede llegar a ser una representación no realista del comportamiento del sistema. Los errores ocurren porque a medida que la unidad de tiempo crece: 1) Las probabilidades de ocurrencia de los eventos no son estimadas correctamente y 2) Aumenta la probabilidad de que dos o más eventos ocurran, cuando sólo uno es simulado. Considere un taller con varias máquinas y varios operarios para repararlas. Suponga que el tiempo de operación de cada máquina se distribuye exponencialmente con una media de 40 minutos y que el tiempo de reparación también se distribuye exponencialmente pero con una media de 10 minutos. Es decir, la tasa media de fallas es = 1/40 = 0.025 máquinas por
minuto y la tasa media de servicio es = 1/10 = 0.10 máquinas por minuto. La probabilidad
de que una máquina falle en un intervalo de tiempo pequeño dt, dado que está trabajando, es la probabilidad de que el tiempo de funcionamiento sea menor o igual a dt, y está dada por:
PF = P (TF dt) = 1 - e - dt dt + o(dt) dt
donde o(dt) es la función “cero delta t”, que es una función que tiende a cero mas rápido que dt. La probabilidad de que una máquina que está bajo reparación sea reparada en un intervalo de tiempo pequeño dt está dada por:
PR = P (TR dt) = 1 - e - dt dt + o(dt) dt
(Recuerde la propiedad de pérdida de memoria de la distribución exponencial que dice que el tiempo que aún dure la reparación o la vida de un equipo, es independiente del tiempo que ha transcurrido hasta el momento). Si dt = 1 minuto, la probabilidad de falla será 0.025 y la probabilidad de terminar la reparación será 0.1. Si dt = 1/2 minuto, las probabilidades de falla y reparación serán respectivamente 0.0125 y 0.05. Las probabilidades exactas de terminar la reparación en una unidad de tiempo de 1 minuto y de 1/2 minuto son respectivamente 0.0952 y 0.488. La tabla siguiente indica los
errores que se pueden cometer al estimar la probabilidad de terminar la reparación para varias unidades de tiempo. Si la unidad de tiempo es muy grande, entonces el error en que se incurre en la estimación de la probabilidad es grande, ya que la aproximación finita pierde validez.
1 Esta sección puede omitirse sin pérdida de continuidad.

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 21
Unidad de tiempo
Probabilidad exacta
Aproximación del Modelo
Error por minuto
de simulación
1/2 minuto 0.0848 0.05 0.00240
1 minuto 0.0952 0.10 0.00480
2 minutos 0.1813 0.20 0.00935
3 minutos 0.2592 0.30 0.01360
4 minutos 0.3297 0.40 0.01760
4 Forma para organizar modelos y programas de simulación Como se ha indicado varias veces, para desarrollar un estudio de simulación es necesario construir un modelo que represente el sistema que se desea simular. Una vez construido el modelo es necesario definir si el avance del reloj es unidad por unidad o por unidad o eventos. Definidos el modelo y el tipo de avance del reloj se debe empezar la tarea de programar la simulación por el computador. A continuación se analizarán las tareas que hay que realizar para
programar la simulación y se indicarán las estadísticas básicas que es necesario recoger y se diseñarán unas subrutinas que son de mucha utilidad para facilitar la tarea de programar la simulación. 4.1 Tareas para Programar una Simulación Hay tres tares generales que es necesario realizar para poder llevar a cabo un programa de simulación. Estas tareas son: La generación del modelo y su inicialización, el desarrollo del "algoritmo de simulación" y finalmente, la generación del reporte de salida. 1) Generación e inicialización del modelo A partir de la descripción del sistema y del modelo creado para representarlo se deben definir las variables que van a representar el estado del sistema en cualquier instante. Es decir, es necesario definir lo que se denomina la "imagen del sistema". Además, en el momento de empezar la simulación (RELOJ=0) hay que asignarles algún valor a estas variables, es decir, se
debe inicializar el estado del sistema. Por lo tanto, para la inicialización del modelo es necesario realizar las siguientes actividades: a) Lectura de Datos. Una etapa previa a la inicialización de las variables de estado es la
lectura de los datos. Se debe prestar atención a los parámetros de las diferentes rutinas que se usarán para representar las actividades. Comprende, entre otras variables, las siguientes: Tiempo total a simular, semillas, parámetros de las distribuciones de las variables aleatorias, valores iniciales a asignar a las variables de estado.
b) Creación de la Imagen del Sistema. Se deben inicializar todas las variables de estado, que como su nombre lo indica, describen el estado del sistema en cualquier instante. Estas variables definirán el estado del sistema para empezar la simulación. El sistema debe inicializarse en unos valores tales que esta actividad se simplifique al máximo posible. Por ejemplo, la forma más sencilla de inicializar un sistema de colas es el llamado “estado vacío”, es decir, que no haya clientes en el sistema, lo cual a su vez implica que las colas empiezan vacías y las estaciones o servidores están inactivos. Si se inicializa en cualquier otro estado diferente, será necesario definir el estado de los clientes que hay en el sistema,
cuanto tiempo, llevan, etc. Posteriormente se analizará la forma de eliminar el efecto que tiene sobre las estadísticas el empezar con el sistema vacío, lo cual no es un estado típico del sistema.
c) Inicialización de Contadores. Esta tarea comprende la inicialización de todos los arreglos y variables en los cuales se van a recoger las diferentes estadísticas. En el numeral 5.8 “Recolección de Estadísticas” se explican las estadísticas básicas que se pueden necesitar en un estudio de simulación.

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 22
d) Lista de Eventos. Cuando el avance del reloj es por eventos es necesario especificar una "lista o archivador de eventos". Esta lista debe contener los eventos calculados que se saben han de ocurrir en algún tiempo futuro y específico de la simulación. Esta lista debe contener los eventos denominados "primarios", que son los que han de ocasionar directamente los cambios en el estado del sistema. Esta lista de eventos debe contener el tiempo en que ocurrirán los eventos, el tipo de evento y la entidad que produce el evento. Esta lista de eventos debe ser actualizada continuamente a medida que se producen nuevos eventos y que cambia el estado del sistema. En la mayoría de las simulaciones se desarrollan rutinas que realizan las predicciones de cuándo ocurre cada tipo de evento (cuándo falla una máquina, cuándo se termina una reparación, cuándo llega una orden, etc.).
Las rutinas de predicción del tiempo de ocurrencia de los eventos son parte central de un modelo de simulación dado que representan las hipótesis del analista acerca de la forma en que el sistema y el ambiente determinan la duración de cada actividad. Esta duración puede ser determinística o estocástica.
La lista o archivador de eventos debe ser inicializada al comienzo de la simulación, o sea que es necesario determinar cuándo ocurrirán los primeros eventos. 2) El algoritmo de simulación La segunda tarea en el desarrollo de un modelo de simulación consiste en programar el procedimiento que ejecuta el ciclo de acciones necesarias para realizar la simulación propiamente dicha. Este procedimiento recibe el nombre de "Algoritmo de Simulación" (Gordon). Para la realización del algoritmo de simulación es necesario desarrollar los siguientes pasos: a) En la lista de eventos se busca "el próximo evento" que ha de ocurrir en el futuro, es
decir, el evento con menor tiempo. b) El tiempo simulado -RELOJ- es avanzado a ese tiempo, esto es, se avanza el reloj en una
base de evento a evento. c) Una vez actualizado el reloj, pero antes de cambiar el estado del sistema, se recogen
estadísticas que tengan relación con el tiempo que el sistema estuvo en determinado estado.
d) El siguiente paso consiste en determinar la clase de evento que ha ocurrido, por ejemplo, la
falla de una máquina, la llegada de una orden, el fin de una reparación, etc. La clase de evento había sido almacenada en la lista de eventos futuros. Habiendo seleccionado la actividad que ocasiona el evento hay que cambiar el estado o imagen del sistema, crear los registros que sean necesarios y realizar las otras actividades que sean consecuencia del evento que ha ocurrido. Así, por ejemplo, la llegada de una orden de trabajo requiere que se cree un registro del trabajo, con variables que representen las características de la misma (tiempo de llegada, número o identificación, prioridad, tiempo de procesamiento), y determinar que se va a hacer con la orden recibida.
e) Un evento primario puede causar directamente la creación de otro evento futuro, no
importa el estado del sistema. Así cuando llega una orden de trabajo debe determinarse
cuándo llegará la próxima orden, no importa la suerte que corra la que acaba de llegar. Para determinar cuándo llega esa orden debe usarse la subrutina apropiada para representar la actividad.
f) Como resultado del evento primario cambia el estado del sistema. Un evento primario
puede accionar la realización de eventos condicionales. Entonces las subrutinas de eventos condicionales son usadas para crear eventos futuros que son consecuencia del nuevo estado del sistema. Así, si un operario está ocioso y falla una máquina (evento primario) es

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 23
necesario asignar la máquina que ha fallado al operario que está inactivo (evento condicional).
Cuando todos los eventos condicionales originados por el evento primario han sido agregados a la lista de eventos, y se han actualizado las estadísticas necesarias, el proceso total empieza de nuevo, es decir, se busca cuál es el próximo evento. Esta repetición mueve el sistema simulado a través del tiempo y el desempeño dinámico del sistema es resumido registrando los datos apropiados. 3) Generación del reporte La tercera tarea es la generación del reporte de salida, es decir, el análisis e impresión de las diferentes estadísticas recogidas durante la simulación. El algoritmo siguiente y la figura 5.12 muestra el flujo general de control durante la ejecución del programa. Las etapas de creación e inicialización del modelo y la generación del reporte se
ejecutan sólo una vez durante la simulación, mientras que el algoritmo de simulación es necesario realizarlo muchas veces, dependiendo del número de eventos que se desea simular o del tiempo total de la simulación. Inicio de la simulación
Lectura de datos y definición de parámetros
Reloj = 0 (Inicialización del sistema)
Creación de la imagen del sistema
Inicialización de contadores
Creación lista de eventos
Mientras reloj Tiempo de simulación ¡Algoritmo de simulación
Se busca "el próximo evento"
Recolección de estadísticas sobre el estado del sistema (ntt)
RELOJ = tiempo del próximo evento
Determinar la clase de evento que ha ocurrido
Ejecución del evento. Creación de otro evento futuro
Cambio del estado del sistema
Creación de eventos condicionales
Fin algoritmo de simulación
Generación del reporte

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 24
Cuando el avance del reloj es unidad por unidad (activity scanning), el algoritmo de simulación comprende los siguientes pasos: Inicio de la simulación
Reloj = 0 (Inicialización del sistema)
Creación de la imagen del sistema
Inicialización de contadores
Mientras reloj Tiempo de simulación ¡Algoritmo de simulación
Reloj = Reloj + 1 (Avance del reloj una unidad de tiempo)
Recolección de estadísticas acerca del estado del sistema.
Examen de entidades del sistema para ver si hubo cambios en la última unidad de tiempo.
Realización de cambios o ajustes en el sistema, como consecuencia de los eventos
ocurridos durante la unidad de tiempo.
Actualización de todas las estadísticas que sean apropiadas para generar el reporte final.
Fin algoritmo de simulación
Generación del reporte 4.2 Eventos Simultáneos En los programas de simulación debe prestarse especial atención a las condiciones que existen cuando dos o más eventos son programados para ocurrir simultáneamente. Aunque los eventos ocurren en el mismo instante en el tiempo, el programa de simulación está forzado a ejecutar los eventos en secuencia. Esto implica que deben asignarse prioridades como atributos a las entidades, en cuyo caso la búsqueda de eventos considera los eventos en orden de prioridad. Si no se dan reglas de ordenamiento la secuencia de ejecución es, en efecto impredecible, y el procesamiento será de acuerdo al evento que ocurra primero en la lista de eventos.
Los eventos que ocurren simultáneamente pueden no ser independientes. Por ejemplo, dos personas pueden estar esperando el mismo servicio. El sistema puede comportarse en una forma muy diferente de acuerdo al orden de escogencia. Dos corridas de simulación que aparecen lógicamente como si fueran una misma pueden dar resultados muy diferentes de acuerdo al orden en que los programas sean ensamblados o ejecutados. Cuando se usan números aleatorios, diferencias en las secuencias de números aleatorios pueden crear diferencias significativas entre corridas de simulación que de otra manera serían idénticas. Otro aspecto relacionado con los eventos simultáneos que debe considerarse es el hecho de que una entidad puede pasar a través de una serie de actividades que no requieren tiempo. Puede, en efecto, existir una secuencia de actividades que no requieran ningún tiempo, es decir, actividades de "tiempo cero". La ejecución de un evento que requiere tiempo 0 produce inmediatamente otro evento que debe terminar en el mismo instante. Cuando existan varias entidades, las cuales participan en eventos simultáneamente, y algunas de ellas encuentran actividades de tiempo 0, entonces el problema de escoger el orden de ejecución es importante. Si no se ejerce ningún control sobre el orden en que se escogen los eventos, el orden de
ejecución es impredecible y puede conducir a violaciones de las reglas de prioridad. Existen dos reglas de selección que pueden usarse para establecer un control predecible: Cada entidad puede pasarse a través de todas las actividades potenciales que ocurran en el
mismo instante, antes de prestar atención a las otras entidades. A cada entidad puede permitírsele una sola actividad al mismo tiempo antes de que se
ejecute una actividad de la siguiente entidad.

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 25
Puede ejecutarse el
evento?
Hay más eventos que puedan ejecutarse?
Inicio
Np
Sí
Sí
No
Figura 5.12 Etapas de una Simulación
CREACIÓN DE LA IMAGEN DEL SISTEMA
- Lectura de Parámetros
- Inicialización Variables de Estado
- Creación Lista de Eventos
- Inicialización Contadores
BUSQUEDA DEL PROXIMO EVENTO
Avance del Reloj al tiempo del próximo evento
Recolección Estadísticas sobre Variables de Estado ( nt t)
Selección de la actividad que causa el evento
Cambio en la imagen del Sistema.
Actualización de Variables de Estado
Realización de los eventos condicionales
y actualización de la Lista de Eventos.
Actualización de Contadores (Recolección Estadísticas)
GENERACIÓN DEL REPORTE DE SALIDA.

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 26
En ambos casos el orden de avance es controlado por medio de reglas de prioridad. La primera regla de ejecución -(seguimiento del flujo)- es preferible porque es más fácil de interpretar la secuencia de eventos ejecutados por el programa. Otros aspectos que deben tenerse en cuenta al escribir el modelo de la simulación son los siguientes: Como regla general, el modelo debe ser construido, hasta donde sea posible, empleando
aritmética entera y variables enteras, con el fin de reducir tiempo de computador. Al final de la simulación puede usarse aritmética real para hacer el resumen de las estadísticas.
En el diseño del programa debe incorporarse hasta donde sea posible el concepto de subrutina. Cada función puede subdividirse en un subprograma si es posible. Este aspecto trae cuatro ventajas o efectos sobre el modelo final que se construya.
a) El modelo es más fácil de construir y compilar
b) El modelo que se elabora es más flexible y puede entenderse mas fácilmente.
c) La organización del modelo es, en general, más eficiente para la ejecución.
d) El programa es más fácil de actualizar y mantener Generalmente se necesitan varios arreglos o tablas (listas) para almacenar diferentes tipos de información. Debe prestarse especial cuidado al desarrollar el programa de computador para reducir o minimizar las búsquedas en los arreglos. Estas búsquedas pueden minimizarse usando "indicadores" para las entradas a los arreglos o tablas. Debe recordarse que al examinar los ahorros logrados por los resultados de la simulación, debe tenerse en cuenta el costo del tiempo de computador. 4.3 Tablas para Almacenamiento y Retiro de Información (Listas) Previamente se había definido una “lista” como una colección de entidades asociadas (temporal o permanentemente) ordenadas de una manera lógica. Por ejemplo, una cola, puede estar
ordenada de acuerdo al tiempo de llegada a la misma, o según la prioridad de las diferentes entidades que la conforma. Otro ejemplo de una lista es la Lista de eventos (LEF), que contiene los eventos (primarios) que han de ocurrir en el futuro, junto con sus atributos (también conocida como “Matriz de Eventos Futuros MEF” La forma más general para almacenar información es por medio de las “listas”, que pueden materializarse mediante las tablas o arreglos bidimensionales. Suponga que se tienen que guardar algunos datos variables acerca de objetos o entidades del sistema. Por ejemplo, se requiere guardar información acerca de las órdenes que llegan a un centro de procesamiento de datos. La información se guardará en un arreglo llamado "orden". Si para cada entidad existen M variables o datos, incluyendo el número de identificación de la entidad, y no se espera que en el sistema haya más de N entidades simultáneamente, entonces la información puede guardarse en un arreglo de orden N x M. Sea ORDEN ese arreglo. Es decir, el arreglo tendrá doble subíndice (I, J,). En las columnas puede guardarse la información acerca de las diferentes variables o atributos de cada entidad. Es decir, el subíndice J indica cuál de las M variables asociadas con una entidad ha de ser almacenada o retirada. El subíndice I indica filas o líneas
arbitrarias en el arreglo, es decir, I es, por lo general, sólo un indicador. Generalmente la primera entrada o columna del arreglo (J = 1) corresponde al número de identificación de la entidad cuya información se guarda en la fila I ó es un código, usualmente 0, que indica que la fila se encuentra vacía y que por lo tanto puede usarse para guardar información acerca de otra entidad. Así, para guardar datos acerca de una entidad, se localiza una fila vacía buscando cuando se cumple que ORDEN (I, 1) = 0, para todo I. Cuando se encuentre un I que cumpla la condición ORDEN (I, 1) = 0, se convierte en el indicador de línea,

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 27
y los atributos de la nueva entidad son guardados en ORDEN (I, 1), ORDEN (I, 2), ..., ORDEN (I, M). La figura 5.5 presenta una muestra del estado que podría tener el arreglo ORDEN en un instante cualquiera. En el arreglo o matriz se tiene que las filas 1, 4, ..., N-1 y N están vacías. Además en la fila 2 se guarda la información acerca de la entidad No. 16, en la fila tercera está la entidad No. 15, etc. Si se desea localizar una entidad particular (la entidad k, por ejemplo) se busca en la tabla hasta que se encuentre un I que cumpla ORDEN (I, 1) = k y el valor de I que cumple la condición se convierte en el indicador. Si se desea, puede buscarse una entidad que tenga un atributo especial y cambiarlo, por ejemplo, si queremos encontrar una entidad que tenga la variable o atributo (M-1) igual a 8, se busca cuando ORDEN (I, M-1) = 8, examinando I sobre el rango de 1 a N, pero teniendo cuidado de que ORDEN (I, 1) > 0, pues de lo contrario la entidad ya habría salido del sistema. En nuestro caso I = 5 cumple la condición ORDEN (1, M-1) = 8. Así, la entidad No. 14 tiene el atributo buscado.
ARREGLO ORDEN(I,J)
I/J J = 1 J = 2 J = 3 ... J=M-1 J = M
I = 1 0 3 5.0 ... 4 11
I = 2 16 32 7.2 ... 13 9
I = 3 15 30 6.2 ... 21 20
I = 4 0 12 4.2 ... 8 4
I = 5 14 22 3.5 ... 8 4
... ... ... ... ... ... ...
I = N-1 0 0 0 ... 0 0
I = N 0 0 0 ... 0 0
Figura No 5.5 Para remover los datos de una entidad (por ejemplo, cuando termina el procesamiento de una orden), se busca la fila en que se encuentra la orden y se hace ORDEN (I, 1) = 0. Aunque el
resto de la información permanezca, se escribe sobre ella cuando se obtienen nuevos datos. A manera de ilustración, considere la siguiente situación. Suponga que a un taller llegan órdenes de trabajo. Esas órdenes traen la siguiente información: Número de orden Fecha de llegada Fecha de entrega Tiempo de procesamiento
Además, es necesario saber dónde se encuentra la orden en un momento dado, si esperando el procesamiento o siendo ya procesada. Entonces para guardar la información acerca de la nueva orden pueden requerirse cinco columnas que guardarían la información de la siguiente manera: Primera columna: J = 1 = Número de orden Segunda columna: J = 2 = Fecha de llegada
Tercera columna: J = 3 = Estado de la orden Cuarta columna: J = 4 = Fecha de entrega Quinta columna: J = 5 = Tiempo de procesamiento Como se indicó, es aconsejable guardar toda la información en forma entera. Sin embargo, esto no siempre es posible ya que hay cierta información que se debe guardar en aritmética real (debido a las limitaciones del computador disponible). En el ejemplo anterior el número de la orden y el estado de la orden son variables enteras, mientras que los demás tiempos son reales

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 28
y si se fueran a convertir en enteros probablemente se restringirá el tiempo máximo que pueda simularse. En este caso, podríamos utilizar dos arreglos, uno real y otro entero, los cuales se referenciarían siempre con el mismo indicador. En el caso de las órdenes mencionadas antes, se podrían utilizar los arreglos IORDN y ORDEN, que se usarían de la siguiente manera: IORDN (I, 1) = Número de la entidad IORDN (I, 2) = Estado de la entidad ORDEN (I, 1) = Fecha de llegada de la orden IORDN (I, 1) ORDEN (I, 2) = Tiempo de procesamiento ORDEN (I, 3) = Fecha de entrega I = Indicador que es el mismo para los dos arreglos Así si se quiere buscar una orden determinada, la orden número NX, por ejemplo, se busca para que valor de I se cumple que IORDN (I, 1) = NX. Si se quiere buscar la orden que tenga la próxima fecha de entrega, se busca el mínimo valor de la columna 3 del arreglo ORDEN, siempre que IORDN(I, 1) sea mayor que cero. Es decir, se busca Min ORDEN (I, 3), dado que
IORDN (I, 1) > 0. La función BUSCAR(número) encuentra cuál es la primera fila vacía en un arreglo entero, o también busca en qué fila se encuentra determinada orden, dependiendo del valor que tome el argumento “número”. Cuando “número” = 0 la función busca cual es la primera fila vacía. Si “número” > 0 la función busca en qué fila se encuentra la orden “número”. Si no hay filas vacías o si no se encuentra la orden buscada, la subrutina escribe un mensaje que informe sobre esta situación. El seudo código siguiente ilustra el procedimiento de la subrutina.
Función Buscar (Número) I = -1 Para fila = 1, nro_filas Si orden(fila,1) = número I = fila fila = nro_filas+1 Fin si
Fin para Si (I = -1) Mensaje = “No se encontró la orden buscada” Fin si Fin procedimiento
5 Recolección de estadísticas El objetivo de un estudio de simulación es recoger información sobre el desempeño de un sistema o de alguno de sus componentes para la toma de decisiones. Esta información se refiere a los valores de una o más variables de estado, a partir de las cuales se pueden estimar las variables endógenas o de salida del modelo, también llamadas “medidas de gestión o de desempeño del sistema”. Por lo tanto, parte primordial en cualquier estudio de simulación es la recolección de estadísticas. Cuando se lleva a cabo una simulación y se obtienen sus resultados (X1, X2,…,Xn), estos valores realmente representan observaciones de alguna variable aleatoria de interés. Para realizar un
análisis preliminar de los mismos, es necesario presentar la información obtenida de una forma que facilite posteriormente su análisis e interpretación y la toma de decisiones. Inicialmente esta información puede resumirse y presentarse utilizando las herramientas que da la estadística descriptiva y del análisis exploratorio de datos, mediante medidas tales como la media, desviación estándar, percentiles, histogramas de frecuencia, etc.. El estudio de la recolección de estadísticas lo dividiremos en dos partes: En la primera parte se presentarán las diferentes estadísticas que es necesario recoger en la mayoría de los programas

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 29
de simulación, y posteriormente se explicará el proceso de cálculo en el modelo de simulación, principalmente cuando éste se representa como un seudo código para una implementación posterior en un lenguaje de programación de uso general. Las estadísticas finales requeridas de un modelo de simulación dependen del estudio que se esté realizando, pero hay ciertas estadísticas que se requieren generalmente en todos los programas de simulación. Las estadísticas más necesitadas son: 1. Contadores que den el número de entidades de un tipo particular o el número de veces que
un evento ha ocurrido.
2. Estadísticas resumen tales como valores extremos, valores medios y desviaciones típicas.
3. Utilización, definida como la fracción o porcentaje de tiempo que alguna entidad ha estado ocupada.
4. Ocupancia, definida como la fracción o porcentaje promedio de tiempo que un grupo de entidades ha estado en uso.
5. Distribuciones de frecuencia (o histogramas) de variables importantes tales como longitudes de colas, tiempos de espera, tiempos de permanencia en el sistema, etc.
Cuando hay efectos estocásticos en el sistema todas las medidas anteriores fluctuarán a medida que la simulación se realiza. Los valores particulares alcanzados al final de la simulación son tomados como estimativos de los verdaderos valores que se intentan medir. En un capítulo posterior se tratará el problema de estimación de los parámetros, su exactitud y su uso en la toma de decisiones. Para el cálculo de medidas resumen se debe distinguir si se trata de variables puntuales u observaciones que se van produciendo a medida que la simulación avanza (tales como un tiempo de permanencia en una cola, el retraso en la entrega de un producto, tiempo de ejecución de un proyecto), o si se trata de variables de estado que toman diferentes valores durante la simulación, pero que pueden cambiar de valor a medida que se van presentando los diferentes eventos de la simulación (tales como el número de clientes en el sistema o en la cola,
el nivel del inventario de un artículo, etc.) y para cuyo cálculo se requiere saber durante cuanto tiempo la variable presentó un valor específico. 5.1 Contadores y Estadísticas Resumen (Para observaciones) Los contadores son la base para manejar la mayoría de las estadísticas. En general denominamos “contadores” aquellas variables (registros) que algunas veces usamos para acumular totales, otras para registrar el número de eventos de cierto tipo que ha ocurrido, o que registran los valores actuales de algún nivel en el sistema. Cada vez que ocurre un evento, se actualiza el total de eventos ocurridos hasta la fecha. A continuación se presentan las principales estadísticas de interés en la mayoría de los estudios de simulación. Valores máximos y mínimos. Los valores máximos y mínimos están dados por:
)X...,,X,X(MinX
)X...,,X,X(MaxX
n21min
n21max
A medida que se obtiene un nuevo valor se compara con el registro actual de los mínimos y los máximos y se efectúa el cambio si es necesario:
Si Xi < Xmin Xmin = Xi

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 30
Si Xi > Xmax Xmax = Xi
Media muestral
La media muestral X de un conjunto de n observaciones {Xi, i = 1, 2,, ..., n} corresponde al
promedio aritmético de los mismos y está definida como:
n
X
X
n
1ii
y se calcula acumulando el valor de las observaciones en un contador y el total de observaciones en otro. Generalmente la media se calcula al final de la simulación a no ser que la simulación se acabe una vez se haya obtenido determinada precisión en la estimación de la media, es decir, que se tenga un mecanismo automático de parada, como se analizará posteriormente. Varianza muestral
La varianza S2 se define como la suma de los cuadrados de las desviaciones de los valores individuales con respecto al valor medio, dividido por el total de observaciones menos una. La desviación estándar (S) es la raíz cuadrada de la varianza. Es decir:
1n
X*nX
1n
XXi
S
n
1i
22i
n
1i
2
2
Entonces para calcular la varianza S2 sólo se requiere llevar un registro adicional correspondiente a la suma de los cuadrados de los valores individuales. Generalmente la media se calcula al final de la simulación a no ser que la simulación se acabe una vez se obtenga determinada precisión en la estimación de la media, es decir, que tenga un mecanismo automático de parada, como se analizará posteriormente.
Probabilidades Una de las estadísticas de mayor interés en los estudios de simulación, usado principalmente en los análisis de riesgo, es la probabilidad de que se presente un evento o situación determinada, o la proporción de veces que ocurre un evento. El cálculo de todas las probabilidades en los estudios de simulación de realizarse usando la fórmula cásica de probabilidad de “casos favorables” dividido por “casos “posibles”
posiblesCasos
favorablesCasosobabilidadPr
5.2 Factores de utilización En la mayoría de las simulaciones se requiere medir la carga de alguna entidad, por ejemplo, la carga de un equipo. La forma más simple consiste en determinar qué fracción o porcentaje de
tiempo está ocupado el equipo durante la simulación. El término utilización se usa para medir esta estadística. La historia del tiempo de uso del equipo puede aparecer como se muestra a continuación. To T1 To T1 To T1 To T1 To: Equipo ocupado T1: Equipo libre Tiempo

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 31
Figura No 5.7 Utilización de una entidad Entonces para medir la utilización del equipo es necesario guardar un registro del tiempo T0 en que el equipo empezó a utilizarse por última vez. Cuando el equipo se desocupa en el tiempo T1, se calcula el valor T1 - T0 y es agregado a un contador. Al final de la simulación se calcula el factor de utilización U dividiendo el tiempo total acumulado por el tiempo total simulado (T) como:
T
)TT(U 01
Es importante verificar si el equipo está ocupado al final de la simulación, y si lo está, agregar al contador respectivo una cantidad que represente el tiempo que el equipo ha venido laborando desde la última parada. Además, es importante examinar las condiciones iniciales para ver si la entidad estuvo ocupada al principio de la simulación.
5.3 Contadores y Estadísticas Resumen para variables de estado Cuando se trabaja con grupos de entidades en vez de valores individuales, se requiere guardar, además de la información acerca del número de entidades que están operando en un instante dado, el tiempo que han venido operando. Por ejemplo, si nos interesa calcular el número medio de máquinas en operación necesitamos saber no sólo cuantas máquinas están operando en un tempo determinado, sino que también debemos saber durante cuánto tiempo ha estados esas máquinas en operación. La figura siguiente ilustra el número de entidades nt que están operando como función del tiempo. Número de Entidades
Figura 5.8 Comportamiento del número de unidades Para encontrar el número medio de máquinas en operación es necesario llevar un registro del número de máquinas en operación y del tiempo en que ocurrió el último cambio. Si en ti el número de máquinas en operación cambia a nj, y luego el próximo cambio ocurre en ti+1, la cantidad nj (ti+1 - ti) debe calcularse y agregarse a un acumulado total. El número promedio de máquinas en uso durante la simulación es calculado al final de la simulación dividiendo el total por el tiempo de la simulación, a saber:
T
tn
T
)tt(n
n t
ti1i
i
i
El número medio de unidades en la cola o el inventario promedio de un artículo se calcularán de
la misma manera. Si hay un límite máximo en el número de entidades, por ejemplo, cuando se tiene un taller con N máquinas, el término ocupancia será usado para describir el número promedio en uso, como una proporción, con relación al número máximo. Así, si nj es el número de máquinas que están trabajando en el intervalo de ti a ti+1, la ocupancia estará dada por:

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 32
NT
tn
NT
)tt(n
O tti1i
ii
Como se explicó antes, es necesario verificar las condiciones al principio y al final de la simulación. 5.4 Tiempos de Tránsito Se denomina “tiempo de tránsito” al tiempo que una entidad gasta en pasar de un punto a otro en la simulación. Por ejemplo, el tiempo que un cliente permanece en el una cola esperando servicio, o el tiempo de permanencia en el sistema son tiempos de tránsito. Para medir los tiempos de tránsito el reloj es usado como un marcador o sello. Cuando una entidad alcanza un punto en el cual empieza un tiempo de tránsito, se debe hacer una anotación de su tiempo de llegada (marcar la llegada). Posteriormente, cuando la entidad llegue al punto de interés, se
debe hacer otra anotación del tiempo de llegada a ese punto y compararlo con el primer tiempo para derivar el tiempo transcurrido. Tiempo de tránsito = Reloj – marca de llegada 5.5 Registro de distribuciones de frecuencia El objetivo de las tablas o distribuciones de frecuencia es distribuir los datos obtenidos en el proceso de simulación en intervalos de clase, preferiblemente del mismo tamaño, y verificar cuantas observaciones se presentan en cada intervalo (frecuencia absoluta). La información resultante se puede usar para construir posteriormente un histograma de frecuencia, y tratar de inferir cuál puede ser la distribución a la cual se ajustan los datos. Para determinar la distribución de una variable se requiere contar cuántas veces el valor de la variable cae dentro de ciertos intervalos específicos. Por lo tanto es necesario establecer una tabla o arreglo en que se registren los valores que definen los intervalos y se realice el conteo.
A medida que se produce una nueva observación, se compara su valor con los límites establecidos para los intervalos (con el límite superior de cada intervalo) y se agrega un "1" para el contador del intervalo en que cae la observación. Como regla general los intervalos con de tamaño uniforme, excepto el primero y el último. Como por lo general el proceso de actualización se realiza a medida que se obtienen los resultados, es necesario definir a priori los parámetros para el cálculo de las tablas de frecuencia, y no se conocen aún cuales serían los valores mínimos y máximos de las variables. Por lo tanto, el primero y el último intervalos son abiertos. El primer intervalo contiene los valores que son muy pequeños, y va, en teoría, desde menos infinito hasta un límite definido a priori (X0), y el último intervalo contiene los valores que son muy grandes, y va desde cierto límite hasta infinito. Por lo tanto para recolectar la información para calcular la distribución de frecuenta de una variable de salida se deben definir los siguientes parámetros:
X0 : Límite superior del primer intervalo. X : Tamaño o amplitud de los intervalos de clase.
M : Número de intervalos de clase en que se van a distribuir las observaciones. El primer intervalo se destina para aquellas observaciones que son muy pequeñas e incluye aquellos valores que son menores que o iguales a X0, es decir, el primer intervalo comprende los valores entre - y X0. El último intervalo contiene aquellos valores que son muy grandes. Los
límites de los intervalos de clase se ilustran en la siguiente tabla.

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 33
La naturaleza de la variable medida determina cuándo se realizan las observaciones. Si se va a medir el tiempo de permanencia en el sistema, una observación se toma cuando la entidad sale del sistema. Para poder realizar esta observación es necesario mantener en algún registro la fecha de llegada al sistema, y cuando salga se calcula el tiempo de permanencia (tiempo de tránsito). Una vez se obtiene la observación, se determina en que intervalo cae y se agrega un uno (“1 “) a la frecuencia observada del intervalo respectivo. Para determinar en que intervalo cae una observación hay dos formas alternativas de realizarlo:
a) calculando previamente los límites de cada intervalo de clase. Se compara el valor de la observación (x) con el límite superior de cada intervalo, empezando con el primero. Para ello se toma cada valor y se lo compara sucesivamente con el límite superior del primer intervalo, luego con el del segundo, y así sucesivamente hasta que caiga en alguno. Si el valor x queda en el intervalo i, entonces se aumenta en uno la frecuencia del respectivo intervalo
FI = FI + 1
b) Sin tener que calcular previamente los límites de cada intervalo de clase. Se calcula el número del intervalo en el cual cae la observación mediante la siguiente fórmula, tomando la parte entera de dicha expresión. Si el número del intervalo calculado es menor que uno (el valor observado es muy pequeño), la observación cae en el primer intervalo y si es mayor que NI (el valor observado es muy grande) cae en el último. El último intervalo comprende aquellos valores que son mayores o iguales que X0 + (NI - 2) X, según se
observa en el cuadro siguiente.
IX X
X
0 199
.
Si I < 1 I = 1
Si I > M I = M
FI = FI + 1
Si el primer intervalo comprende aquellos valores que son estrictamente menores que X0, entonces en la fórmula anterior en vez de 1.99 se usa 2.0. Se usa el valor de 1.99 cuando el primer intervalo comprende los valores iguales a X0 (el primer intervalo es cerrado por encima).
CALCULO DE DISTRIBUCIONES
Número del Intervalo
Límite Inferior Xi – 1
Límite Superior Xi
Frecuencia Fi
Totales
1 - X0 ||
2 X0 X0 + X ||||||||
3 X0 + X X0 + 2 X ||||||||||||||||||||
4 X0 + 2 X X0 + 3 X |||||||||||||||||||||||
. .......................
J X0 + (j – 2) X X0 + (j - 1) X ||||||||||||||||||||||||
. ...................
NI – 1 X0 + (NI - 3) X X0 + (NI - 2) X ||||||
NI X0 + (NI - 2) X |||||
Se recomienda que el número de intervalos de clase esté entre 5 y 15, dependiendo del tamaño de la muestra disponible. Si se usa un número muy pequeño, los valores quedan muy concentrados, mientras que si se emplea un número muy alto y la muestra es muy pequeña, los datos quedan muy dispersos y realmente no se obtiene mucha información. Como una guía para escoger el número de intervalos puede usarse la fórmula de Sturgess, dada por

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 34
)n(log2.31M 10
donde n corresponde al número total de observaciones. Cuando se requiere calcular la distribución de frecuencia de una variable de estado (número de entidades que hay presentes en el sistema, nivel de inventario de un artículo) entonces para encontrar esta distribución de frecuencia es necesario acumular, no el número de veces que la observación cae en determinado intervalo, sino el tiempo durante el cual la variable de estado tomó determinado valor. Por ejemplo, cuando se requiere la distribución del número de unidades en la cola, es necesario guardar información acerca del tiempo que hubo determinadas unidades esperando el servicio. En vez de sumarle “1” a la frecuencia del intervalo i se le agrega el delta de tiempo “t”
FI = FI + t
Presentación de los datos. El resultado final de la simulación expresará, fuera de la
frecuencia, otros datos, muchas veces en una forma diferente a como fueron recogidos. Una vez se ha terminado la simulación y los valores están agrupados en los intervalos de clase, y se ha obtenido la frecuencia absoluta de cada intervalo, se realizan algunos cálculos para mejorar la presentación de los resultados. Por lo general, se calcula para cada intervalo la frecuencia relativa y la frecuencia relativa acumulada, las cuales están dadas por:
Frecuencia relativa del intervalo i = n
FiFRi
Frecuencia Relativa Acumulada i =
i
1kFRkFRAi
donde Fi es la frecuencia absoluta del intervalo i, es decir, corresponde al número de valores observados que quedaron en dicho intervalo. 5.6 Proceso de recolección de la información
El proceso de recolección de la información tiene las tres mismas etapas del proceso general de la simulación, a saber: Inicialización de los registros, actualización de los registros a medida que se produce la información, y el resumen (cálculo) de resultados. Cuando la simulación se realiza mediante la ayuda de una hoja de cálculo tipo Excel, el modelo guarda toda la información de las variables de salida, y el cálculo de los principales estadísticos se realiza al final de la simulación. Cuando el modelo se implementa en un lenguaje de uso general, por lo general no se almacenan todos los resultados de la simulación, sino que los registros se van actualizando a medida que los resultados se van obteniendo. Las diferentes etapas para el proceso de recolección de información son las siguientes:
a) Inicialización de contadores o registros
Esta etapa se realiza cuando se inicializa el modelo de simulación. Si se van a recolectar las principales estadísticas resumen, distribuciones de frecuencia, y probabilidades para una variable cuyo valor observados es x tendríamos los siguientes registros, con sus respectivos
valores iniciales:
Número total de observaciones: N = 0
Suma de valores X = suma_valores = 0
Suma de cuadrados = X2 = suma_cuadrados = 0
Valor mínimo = Xmin = +
Valor máximo = Xmax = -

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 35
Casos favorables = 0
Para cada intervalo de frecuencia i = 1 hasta M
Frecuencia(i) = 0
Siguiente intervalo
La mayoría de los registros se inicializan en cero, excepto los registros para los valores mínimo (que se inicializa en un valor grande) y máximo que se inicializa en un valor alto (que se inicializa en un valor pequeño), de tal forma que cuando se presente la primera observación se cambien dichos registros (l primera observación representa tanto el valor mínimo como el máximo obtenidos hasta ese insante).
b) Actualización de la información El proceso de actualización de los registros se realiza dentro del algoritmo de simulación, a medida que se va produciendo la información. Si nos interesa una variable, y ésta toma el valor
de x, se deben realizar algunas o todas de las actividades siguientes:
Número total de observaciones : N = N + 1
Suma de valores: (X = X +x)
Suma de cuadrados = X2 = X2 x2
Valor mínimo: Si x < Xmin Xmin = x
Valor máximo: Si x > Xmax Xmax = x
Casos favorables: Si se cumple la condición Casos favorables = Casos favorables +1
Se calcula el intervalo “i” en que cae la observación, según lo indicado antes y se actualiza la frecuencia como:
Frecuencia(i) = Frecuencia(i) +1 Por lo tanto cada observación Xi resultará en la adición de un "1" al contador de eventos totales, otro "1" al contador apropiado de acuerdo al intervalo en que quede la observación, la
adición de Xi al total acumulado Xi y la adición de X i
2 a la suma X2. Sin embargo, como
esa información puede recogerse por otro lado, entonces al determinar la distribución de una variable se omitirá la recolección de esta información. La distribución de las observaciones puede guardarse en un arreglo de dos dimensiones ISTO(I,J) donde el valor máximo de I depende del número de intervalos de clase, y el valor máximo de j depende de las estadísticas que se vayan a recoger.
c) Cálculo de las variables de salida Una vez terminado el algoritmo de simulación, se tiene la generación del reporte de salida y el cálculo de los principales indicadores, tales como la media, varianza, probabilidades, coeficientes, intervalos de confianza, etc. y la impresión de los principales resultados, incluyendo si es del caso la tabla de frecuencias. 6 Problemas resueltos
En esta sección se analizarán varios ejemplos relativamente simples para conocer un poco mejor la forma de realizar una simulación. En los capítulos siguientes se analizará en detalle problemas relacionados con la simulación de fenómenos de espera y el manejo de los sistemas de inventario. 6.1 Un problema de mantenimiento

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 36
Una compañía ha tenido problemas de mantenimiento con un equipo complejo. Este equipo consta, entre otros componentes, de cuatro tubos al vacío idénticos, los cuales han sido la causa de los principales problemas de fallas. El problema consiste en que los tubos fallan constantemente, lo cual obliga a parar el equipo. La práctica actual de mantenimiento consiste en reemplazar los tubos a medida que van fallando. Sin embargo, con el fin de reducir el tiempo que el equipo permanece inactivo, se ha lanzado la propuesta de reemplazar todos los tubos cuando falle uno de ellos. El objetivo del estudio es comparar ambas políticas con ayuda de la simulación y proponer la política de mantenimiento a usar en el futuro. Los datos pertinentes y que se han recolectado sobre la operación del sistema son los siguientes:
Para cada tubo el tiempo de operación normal hasta que falla tiene una distribución normal con una media de 600 horas y una desviación estándar de 100
El tiempo para reemplazar un tubo se distribuye uniformemente entre 80 y 120 horas, y el tiempo para reemplazar todos los tubos se distribuye también uniformemente pero entre 170
y 230 horas.
El costo total asociado con parar el equipo y reemplazar los tubos es $ 60 000 por hora, mas $ 80 000 por cada tubo nuevo.
Usando adecuadas condiciones iniciales, simule la operación de las dos alternativas. Solución El objetivo del problema puede plantearse como: Determinar la política de mantenimiento que minimice los costos totales asociados con las fallas del equipo. Estos costos son: Los costos ocasionados por la reparación de las fallas (reemplazo de los tubos) y los costos debidos a la inactividad del equipo mientras está siendo reparado, es decir: Costos = Costos de Reparación + Costos debidos a inactividad del equipo. El costo asociado con cada falla del equipo, para cada alternativa k se puede expresar como: Costo(k) = NTRk x Ct + Ci x D donde
NTRk = Número de tubos reemplazados en cada alternativa.
Ct = Costo de cada tubo reemplazado
Ci = Costo de inactividad del equipo, por hora
D = Duración de la falla, mientras se reemplazan los tubos.
k = Alternativa a simular, con k = 1 es la política actual y k = 2 la política propuesta. El procedimiento general de la simulación consiste en tratar de reproducir lo que sucedería en el sistema real: En la vida real se pone a funcionar el sistema y se observa lo que sucede en el sistema durante un período adecuado de tiempo, se recoge información sobre su desempeño. En la simulación se trata de reproducir lo anterior en un modelo, donde las variables aleatorias que no se conocen se generan usando la respectiva distribución de probabilidad. Las actividades que habría que realizar serían las siguientes:
a) A partir de cualquier instante (tiempo cero) se empieza a observar el funcionamiento del sistema.
b) Se registra el instante en que falla el sistema. c) Se repara el equipo, según la política de mantenimiento d) Se calcula el costo ocasionado por la falla del equipo e) Una vez reparado, se pone a funcionar de nuevo el sistema, y se repite el procedimiento
anterior hasta que termina el tiempo durante el cual se desea observar el comportamiento del sistema

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 37
En el modelo de simulación se “imita” el procedimiento anterior: Se pone a funcionar el equipo, se observa cuando se produce una falla y en ese instante se repara la falla, de acuerdo con la política que se esté analizando. Cuando se repara la falla, se recoge la información requerida para la toma de la decisión. En la vida real, se empieza a observar la operación del sistema en cualquier instante. En la simulación es necesario definir las condiciones del equipo en el momento de iniciar la simulación.
Procedimiento general de la simulación El procedimiento global de la simulación que se acaba de describir en el párrafo anterior se puede resumir en el siguiente seudo código: Para cada política
Reloj = 0
Sistema en funcionamiento (tubos nuevos).
Mientras Reloj Tiempo de simulación
Tiempo próximo evento = Tiempo mínimo de funcionamiento.
Reloj = Tiempo próximo evento
Se genera tiempo reparación (según la política)
Se actualizan estadísticas por la falla del equipo
Reloj = Reloj + Tiempo reparación
Se pone a funcionar de nuevo el sistema (según la política) y se actualiza la nueva duración de los tubos, según la política
Fin mientras Repite el procedimiento hasta que termina el tiempo de simulación
Cálculo costo de la política
Siguiente política
Escoger la mejor política
Una vez realizada la simulación y recogidas las estadísticas según las fallas presentadas, se estima el costo medio por unidad de tiempo como: Costo(k) = [NTk x Ct + Ci x D]/TSIM
donde TSIM es el tiempo total simulado. Condiciones iniciales Puede suponerse que en el momento de empezar la simulación (RELOJ = 0) se dispone de un equipo nuevo, es decir, se empieza a operar con los cuatro tubos nuevos. Si T es la duración de cada tubo, entonces T se distribuye normalmente con una media = 600
horas y una desviación = 100 horas. Además, se supone que esta duración es efectiva, es
decir, que el tiempo que el sistema permanezca inactivo bajo reparación, no se considera parte de la vida útil del tubo. Por ejemplo, si se predice que un tubo fallará en la hora 1020, pero otro
tubo falla antes en la hora 900 y su reposición dura 150 horas (el equipo empieza a trabajar de nuevo en la hora 1050), entonces el tubo no puede fallar en la hora 1020 sino en la hora 1170 (1020 + 150). El tipo de avance que se usará en la simulación será continuo, y la simulación avanzará por eventos. Solo habrá dos tipos de eventos (Fallas y reparaciones) y los eventos serán siempre secuenciales (falla, reparación, falla, reparación,...).

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 38
Procedimiento general de la simulación El procedimiento general de la simulación puede resumir en los siguientes pasos: 1) Definir los parámetros básicos de la simulación 2) Establecer las condiciones iniciales (Reloj = 0). En este caso se supone que en el tiempo
cero se dispone de un sistema nuevo, es decir, se colocan cuatro tubos nuevos. Además, debe definirse la duración de cada tubo, y cuando fallarán por primera vez.
3) Mientras (Reloj Tiempo de simulación) 4) Buscar Próxima falla. Se busca cuál es el tiempo de falla del próximo tubo se avanza el Reloj
al tiempo de la falla.
a) Se busca el tiempo mínimo de falla.
b) Reloj = Tiempo mínimo de falla
c) Próximo evento: Falla de un tubo. Se identifica el tubo que falla. Se actualizan
estadísticas sobre fallas por tubos y se calcula el tiempo de reparación, de acuerdo con la política analizada.
d) Reloj = Reloj + Tiempo de reparación
e) Próximo evento: Fin de Reparación. Es necesario: Actualizar número de tubos reemplazados, tiempo de inactividad, costo de falla y reparación, duración de los tubos reemplazados, de acuerdo con la política simulada y actualizar los tiempos de las próximas fallas.
f) Poner a funcionar de nuevo el sistema Si se está simulando la política actual (reemplazamiento individual) debe determinarse la duración y próxima falla del tubo nuevo y actualizarse el tiempo de falla de los restantes tubos, adicionando a su tiempo actual de falla el período de inactividad (tiempo de reparación). Si se está simulando la política propuesta (reemplazamiento colectivo) debe determinarse la duración de cada uno de los tubos nuevos y la próxima falla, como el tiempo actual mas la duración del tubo
5) Si no se ha terminado el tiempo de simulación, se repite los pasos 2, 3 y 4. Si ya se terminó
el tiempo de simulación, se calcula el costo medio y se imprimen las estadísticas. 6) Si se esta simulando la política actual, se reiniciliazan las semillas para comenzar de nuevo
la simulación, pero de la política propuesta. Si se está simulando la política propuesta, se comparan los costos medios de ambas políticas, y se escoge la de menor costo.
Es conveniente que para la duración de los tubos y para la reparación de las fallas se empleen semillas diferentes. Además, para la simulación de la política alternativa deben usarse las mismas semillas que se usen para la simulación de la política actual, de tal forma que la comparación de ambas políticas se realice bajo las mismas condiciones, y cualquier diferencia en los resultados se deba única y exclusivamente a la diferencia entre las alternativas, y no a las variaciones aleatorias. El procedimiento completo de la simulación se explica en el seudocódigo de la página siguiente. En el apéndice No 1 al final de este capítulo se presenta el listado en fortran del programa completo para simular esta situación. El programa está escrito de tal forma que si se lo desea, se pueda imprimir la simulación paso a paso. Basta con eliminar en la primera columna la letra D de aquellas instrucciones en las cuales aparece.

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 39
Problema de Mantenimiento: Seudo código
Lectura de datos sobre: Duración de los tubos, tiempos de reparación, Semillas, tiempo de simulación Costos unitarios por tubo y de inactividad
Política actual: REEMPLAZO INDIVIDUAL
Número de tubos reemplazados =Nro_Tubos= 1
Para política desde 1 hasta 2
Reloj=0
Inicialización del sistema Cuatro tubos nuevos Tiempo_inactividad = 0 Total_Tubos = 4 Número_Total_Fallas=0
Para cada tubo k = 1,4
Número_fallas_Tubo(k)=0
Generar Duración del tubo: Normal(600,100)
Tiempo_Falla(k) = Reloj + Duración
Siguiente tubo
Mientras (Reloj Tiempo_simulación)
Buscar Próxima Falla =Mínimo {Tiempo_Falla(k), k=1,4)}
Sea i el tubo que falla
Evento Falla Número_Total_Fallas =Número_Total_Fallas +1
Número_fallas_Tubo(i)= Número_fallas_Tubo(i)+1
Generar Tiempo_Reparación :Unif(Ak,Bk)
Evento Reparación Reloj=Reloj + Tiempo_Reparación
Tiempo_inactividad = Tiempo_inactividad + Tiempo_Reparación
Total_Tubos_Reeemplazados = Total_Tubos_Reeemplazados + Nro_Tubos
Si política actual, entonces Si No
Para cada tubo k =1,4 Tiempo_Falla(k) = Tiempo_Falla(k) + Tiempo_Reparación Siguiente tubo Generar duración de tubo nuevo :Normal(600,100) Tiempo_Falla(i) = Reloj + Duración
Para cada tubo k =1,4 Generar duración de tubo nuevo : Normal (600,100) Tiempo_Falla(i) = Reloj + Duración Siguiente tubo
Fin Si
Fin Mientras
Calcular Costo(política)
Imprimir costos y estadísticas
Si política actual, entonces Si No
Política=Política propuesta Número_tubos = 4
Comparar políticas y escoger la mejor
Fin Si
Siguiente política
Escribir la mejor política
Fin Simulación

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 40
Simulación manual del problema (usando Excel) Para la simulación manual del problema es necesario tener en cuenta los siguientes aspectos: La duración de cada tubo se genera mediante el método de la transformación inversa, para
simulación manual, y está dada por:
Duración = + Z = 600 + 100 Z
donde Z corresponde a una variable distribuida normalmente con media cero y varianza uno.
El tiempo de reparación de los tubos está dado por:
Tiempo_Reparación = a = ( b - a) r,
siendo r un número aleatorio y los valores de a y b dependen de la política simulada, con a = 80 y b = 120 para la política actual y a = 170 y b = 230 para la simulación de la política propuesta. La tabla siguiente presenta los resultados para un segmento de simulación de la política actual.
Números aleatorios usados para la duración de los tubos: .10, .09, .73, .25, .33, .76, .52, .01 Números aleatorios empleados para la reparación de los tubos: .69, .07, .49, .41
Problema de Mantenimiento: Simulación manual Política actual
Reloj Tubo No 1 Tubo No 2 Tubo No 3 Tubo No 4 Reparación Tiem. Nro de
D TF(1) D TF(2) D TF(3) D TF(4) T_rep T_fin Inact. Tubos
0 472 472 466 466 661 661 533 533 4
466 472 472 - - 661 661 533 533 108 574 0
574 580 556 1130 769 641 108 5
580 - 556 1130 769 641 83 663 108 5
663 661 1324 1213 852 724 191 6
724 1324 1213 852 - 100 824 191 6
824 1424 1313 952 605 1429 291 7
952 1424 1313 - 605 1429 96 1048 291 7
1048 1520 1409 367 1415 605 1525 387 8
El costo por unidad de tiempo, para el período simulado, está dado por:
Costo = (8*80+387*60)/1048 =
A continuación se presenta un resumen de los resultados obtenidos para dos corridas de simulación, con diferentes semillas:
Simulación No 1 Simulación No 2
Conceptos/ Política Actual Propuesta Actual Propuesta
Semilla para fallas 555 555 4729 4729
Semillas para reparación 4777 4777 8215 8215
Tiempo simulado 60241 60315 60244 60201
Tiempo de inactividad 24086 17230 24072 17443
No de tubos reemplazados 243 344 241 344
Costo por hora 243 176 243 178
Como puede observarse, la política propuesta es superior a la actual.

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 41
6.2 Problema del automóvil Los datos sobre averías de automóviles obtenidos por una compañía de taxis sugieren que el kilometraje entre las fallas de tres sistemas importantes- el carburador, el sistema eléctrico y el de enfriamiento- está uniformemente distribuido, con las siguientes medias y variaciones:
SISTEMA KILÓMETRO MEDIO VARIACIONES
Carburador 23.000 ±10.000
Sistema Eléctrico 20.000 ±7.000
Enfriamiento 40000 ±20.000
Mediante la simulación, determine el costo de las reparaciones y el mantenimiento a lo largo de la vida de los taxis de 250.000 kilómetros, cuando se utilizan las siguientes normas de mantenimiento:
1) Esperar que se produzcan fallas y reparar todos los sistemas, hasta llegar a las
condiciones originales.
2) Inspeccionar cada 15.000 kilómetros y reparar todos los sistemas, hasta alcanzar las condiciones originales; si se produce alguna falla, deben repararse todos los sistemas.
3) Lo mismo que la segunda norma, con excepción de que la inspección se hará cada 20.000 kilómetros.
4) Esperar a que se produzca alguna avería y reparar solamente esa falla.
5) Inspeccionar y reparar cada 20.000 kilómetros; si se produce alguna falla, debe repararse solamente esa avería.
El costo de inspección y reparación de todos los sistemas, hasta alcanzar las condiciones originales es de 1.000 pesos; el costo de reparación de una falla y restaurar todos los demás sistemas a la condiciones originales, al mismo tiempo, es de 1.750 pesos.
Solución: El modelo se desarrollará de tal manera que el programa permita simular las cinco políticas, en forma secuencial. La simulación se desarrollará por eventos, y el número de eventos dependerá de la política simulada: En las políticas sin revisión habrá cuatro eventos (las tres fallas de los componentes y el fin de la vida útil del carro), y en las políticas con revisión programada habrá cinco eventos (se agrega el evento revisión). Se considerará el fin de la vida útil del carro como un evento de tal forma que la vida del carro llegue exactamente a 250,000 kilómetros. El proceso general de la simulación simplemente trata de reproducir lo que sucedería si estuviéramos analizando el funcionamiento del carro en la vida real: Se pone a funcionar el carro, si es del caso se programan las revisiones preventivas, y se hacen los ajustes al carro a medida que se van presentando los eventos, que pueden ser las fallas de los componentes o la revisión del carro, según sea la política analizada. En este problema no se considera tiempo de reparación dado que la vida de los carros se está midiendo según el kilometraje recorrido, y cuando se presenta una falla se supone que no hay
un incremento sustancial en el kilometraje del vehículo. El proceso global de la simulación se resume en los siguientes pasos:
Lectura de parámetros de la simulación Para cada política
Para cada carro Reloj = 0

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 42
Carro nuevo (tres sistemas en funcionamiento). Creación de la lista de eventos
Mientras Reloj Vida útil del carro Buscar próximo evento Identificar evento Reloj = Tiempo próximo evento Si Próximo evento = falla, entonces Si política ≤ 3, entonces Se reparan todos los sistemas (componentes nuevas) Si política =2, 3, entonces Reprogramar revisión Fin si Si no Se repara únicamente componente que falla Fin si Si no
Si próximo evento es revisión, entonces Se revisan todos los sistemas (componentes nuevas)
Programar revisión Fin si
Fin si Fin mientras Se actualizan estadísticas (fin de vida útil del carro)
Siguiente carro Cálculo costo medio de la política
Siguiente política Escoger la mejor política Para el seudo código detallado se usará el vector MEF(i) – matriz o lista de eventos futuros – para llevar el tiempo de falla de los componentes, la vida útil del carro y el tiempo de la próxima revisión, según la siguiente convención:
o Mef(1) = kilometraje en que fallará el carburador o Mef(2) = kilometraje en que fallará el sistema eléctrico o Mef(3) = kilometraje en que fallará el sistema de enfriamiento o Mef(4) = Fin de la vida útil del carro. o Mef(5) = Kilometraje de la próxima revisión para aquellas políticas que la tienen.
En el desarrollo del seudo código se supone que para las políticas 2 y 3 cada vez que existe una falla, y se reparan todos los sistemas, es necesario reprogramar la próxima revisión a partir del momento de la falla. Se supone que el costo de reparar un solo componente es $750, correspondiente a la diferencia entre el costo de reparación de una falla y restaurar todos los demás sistemas a la condiciones originales (1750) menos el costo de inspección y reparación de todos los sistemas hasta alcanzar las condiciones originales que es de 1.000 pesos.
En el desarrollo del programa se usarán dos procedimientos o funciones, una para generar las duraciones de los tres componentes, que se usará al inicializar el sistema, y para aquellas políticas en que se reparan o se revisan todos los sistemas hasta alcanzar las condiciones originales, y la otra se usará para aquellas políticas en que se sólo se repara el componente que ocasiona la falla.

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 43
Problema del automóvil (Problema No 5.3)
Definir: Número_carros, Semillas, Parámetros (Ai,Bi, i =1,3)
Costo_óptimo =
Para política = 1, 5
Costo_minimo = ; Costo_máximo = 0; Costo_total = 0
Para carro = 1, Número_carros
Reloj = 0; Costo_carro = 0
Restaurar Sistema (Inicializar Sistema) Mef(4) = Vida útil del carro
Si (política = 1 ó = 4) entonces
Número eventos = 4
Si no
Si (política = 2) entonces
Tiempo_Revisión = 15,000
Si no
Tiempo_Revisión = 20,000
Fin si
Número eventos = 5 Mef(5) = Reloj + Tiempo_revisión Fin si
Mientras (reloj <= 250,000) entonces
Mínimo =1
Para i = 2, número_eventos
Si (Mef (i)<=Mef(minimo)) entonces
Mínimo = i
Fin si
Fin para
Reloj = Mef (minimo)
Si(mínimo <= 3) entonces
Si (política = 1,2 ó 3) entonces
Costo_carro = costo_carro +1700 Restaurar Sistemas Si (politica =2,3) MEF(5) = Reloj + Tiempo_Revisión
Si no (política = 4, 5)
Costo_carro = Costo_carro + 700 Restaurar Componente (mínimo)
Fin si
Si no
Si minimo = 5 entonces (revisión del carro)
Costo_carro = costo_carro +1000 Restaurar Sistemas MEF(5) = Reloj + Tiempo_Revisión Fin si
Fin si
Fin mientras
Costo_total = costo_total + costo_carro Si (costo_carro< costo_minimo) costo_minimo = costo_carro Si (costo_carro>costo_maximo) costo_maximo = costo_carro
Fin Para
Costo (politica) = costo_total/numero_carros Imprimir: Politica, costo(politica), costo_minimo, costo_maximo
Si (costo(politica)< costo_optimo) entonces
Costo_optimo = costo_politica; Politica_optima= politica
Fin si
Fin para
Imprimir politica optima: politica_optima, costo(politica) Fin simulación

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 44
Problema del automóvil
Procedimiento Restaurar Sistema
Para Sistema i = 1,3
Genere r Duración(i) = Ai + ( Bi – Ai )* R MEF(i)= Reloj + duración(i)
Siguiente sistema i
Fin Procedimiento
Procedimiento Restaurar Componente (minimo)
Genere r
Duración(minimo) = A(minimo) + ( B(minimo) – A(minimo ))* R
Mef(minimo) = Reloj + duración(minimo)
Fin procedimiento Restaurar componente
7 Problemas 5.1 Una tienda tiene un pequeño lote de estacionamiento con 6 puestos disponibles. Los
clientes llegan en forma aleatoria de acuerdo a un proceso de poisson con una tasa media de 10 clientes por hora, y se van inmediatamente si no existe espacio disponible. El tiempo que un auto permanece en el estacionamiento sigue una distribución uniforme entre 10 y 30 minutos. Desarrolle un modelo de simulación para determinar:
a) Que porcentaje de clientes se pierde por no haber espacio disponible ?
b) Cual es la probabilidad de encontrar un espacio disponible en el parqueadero ?
c) Cual es el porcentaje promedio de espacios disponibles?
5.2 La distribución de la demanda por espacios para parquear en una determinada zona de la ciudad sigue la distribución de Poisson, con una media de 200 por día de 8 horas. En esta área se ha de ubicar un parqueadero con una capacidad de 100 carros. El costo de operar y mantener el parqueadero es $ 190.000 por año. El precio que se paga por un espacio
es de $ 12, no importa cuánto tiempo esté ocupado el espacio. La distribución del tiempo que un carro pasa en el parqueadero es exponencial con una media de 2 horas. El parqueadero permanece abierto 8 horas al día, 365 días al año.
a) Determine la utilidad anual de operar el parqueadero. b) Se justifica conseguir mas espacios?
5.3 Determine la mejor política de asignación para 21 máquinas, donde se cumple que la tasa
de fallas por máquina es = 0.4 por hora y cada operario en promedio repara u = 4
máquinas por hora.
Una de las políticas es la asignación colectiva (21 máquinas y 3 operarios) y la otra es la asignación individual (7 máquinas por operario). El costo por hora de máquinas inactiva es $ 120 y el del operario inactivo es $ 20
5.4 Considere de nuevo el problema anterior. Cuál es el número óptimo de operarios que hay que asignar a las 21 máquinas, si el costo por máquina inactiva es $ 180 por hora y el costo por operario inactivo es $20/hora.
5.5 La vida de 100 válvulas electrónicas al vacío, contenidas en un computador, está distribuida normalmente con un valor esperado igual a seis meses y una desviación estándar de 2 semanas. En el caso de que todas las válvulas se reemplacen al mismo tiempo el costo de tal operación será el precio $ 2.00 por cada válvula. El costo de reemplazo de una válvula que falle estando la computadora en servicio será de $ 5.00 por unidad, más el costo del tiempo en que el computador queda fuera de servicio. En promedio, el costo que ocasiona una válvula en tiempo de máquina fuera de servicio, se estima como $ 50.00 durante el día y $ 100.00 durante la noche. La probabilidad de falla

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 45
durante el día es de 0.7 y durante la noche de 0.3. Utilice la técnica de simulación en computadora para comparar los costos de las siguientes políticas de reemplazo: 1) reemplazar cada válvula a medida que van fallando; 2) reemplazar las 100 válvulas cada 5 meses, haciéndolo con la válvulas que fallan individualmente en el período interino. Determine una política óptima de reemplazo para la compañía.
5.6 Los carros llegan aleatoriamente a una cabina y pagan el peaje. Si es necesario, esperan en la cola de acuerdo al orden de llegada. El tiempo entre llegadas se distribuye uniformemente entre 0 y 9, inclusive (aproxime al segundo más cercano). El tiempo para pagar es también aleatorio y entre 0 y 9 segundos, pero con la siguiente distribución de probabilidad:
f(t) = t - 1/2 /6, 0 < t <9 Determine los tiempos de llegada y los tiempos que necesitan para pagar los 10 primeros
carros. A qué hora termina de pagar el quinto carro?. El séptimo?. Trunque todos los números calculados al entero más cercano.
5.7 Un laboratorio de enseñanza tiene 15 computadores para prácticas de docencia. Los
alumnos que utilizan dichas máquinas descubren que requieren periódicamente que el supervisor del laboratorio responda a preguntas, efectúe ajustes menores en los computadores, etc. Los tiempos entre solicitudes de ayuda por parte de cada estudiante siguen una distribución exponencial con una media de 30 minutos. El tiempo que requiere el supervisor para responder a dichas peticiones de ayuda siguen también una distribución exponencial con una media de dos minutos.
a) Simule el funcionamiento del laboratorio para determinar el tiempo total de espera de los alumnos durante un período de estudio de una hora.
b) Determine el efecto de contratar un ayudante que pueda responder a las peticiones de ayuda en la misma forma que lo hace el supervisor.
5.8 Un mecánico atiende cuatro máquinas. Para cada máquina el tiempo medio entre
requerimientos de servicio es 10 horas y se supone que tiene una distribución exponencial. El tiempo de reparación tiende a seguir la misma distribución y tiene un tiempo medio de dos horas. Cuando una máquina se daña, el tiempo perdido tiene un valor de $ 30 por hora. El servicio del mecánico cuesta $ 100 diarios.
a) Cuál es el número esperado de máquinas en operación?. b) Cuál es el costo promedio por día?. c) Cuál es preferible: tener dos mecánicos de tal forma que cada uno atienda dos
máquinas, o tener uno solo como ocurre actualmente?.
5.9 Un camión de reparaciones a domicilio y su mecánico atienden máquinas agrícolas. El tiempo promedio de viaje más servicio es de dos horas/máquina. El tiempo promedio de requerimiento de servicio es de 4 días (exponenciales). Cuando se requiere servicio, el costo ocasionado por la reparación de las máquinas es $ 1.000/hora. El mecánico y el camión tiene un costo de $ 320/hora. Cuántas máquinas agrícolas debe atender para minimizar los costos?. Determine además:
a) Tiempo de inutilización por máquina. b) Distribución del número de máquinas dañadas. c) Distribución del tiempo de inactividad de las máquinas.
5.10 Se va contratar un mecánico para que repare unas máquinas que se descomponen a una
tasa promedio de 3 por hora. Las descomposturas se distribuyen en el tiempo de una
manera que puede considerarse como Poisson. El tiempo no productivo de una máquina cualquiera se considera que le cuesta a la empresa $ 25 por hora. La compañía ha limitado la decisión a uno de dos mecánicos, uno lento pero barato, el otro rápido pero caro. El primero de ellos pide $ 15 por hora; a cambio dará servicio a las máquinas descompuestas, de manera exponencial, a una tasa media de cuatro por hora. El segundo pide $ 25 por hora y reparará las máquinas de manera exponencial a una tasa de seis por hora. Cuál de los mecánicos debe contratarse? Suministre toda la información que considere necesaria.

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 46
Finalmente, en el apéndice No x.x se presenta el listado Fortran para ejecutar la simulación del presente ejercicio. Los resultados presentados en los párrafos anteriores fueron obtenidos mediante este programa.
Simulación de un taller de N maquinas y M mecánicos C ----------------------------------------------------------------- C Método de avance del Reloj: Por eventos C -----------------------------------------------------------------
Leer Tiempo de simulación, semillas, número de maquinas, numero de mecánicos Leer tasa de fallas, tasa de reparación
C Suposición: Tiempo de falla y de reparación exponenciales C Inicialización del Sistema C
RELOJ = 0 C
C Inicialización del Estado del Sistema nro_maq_fun = nro_maq nro_unid_cola(1) = 0 nro_unid_cola(2) = nro_mec
c c nro_unid_cola(1) = número de máquinas que esperan ser reparadas c nro_unid_cola(2) = número de mecánicos inactivos c inicialización del arreglo de las maquinas, según: c maqui(i,1) = tiempo de la próxima falla c maqui(i,2) = estado de la máquina i c = 0 en funcionamiento c = 1 en cola, esperando ser reparada c = 2 bajo reparación c maqui(i,3) = tiempo acumulado de inactividad de la maquina i c maqui(i,4) = tiempo acumulado en espera de ser reparada c maqui(i,5) = tiempo de llegada al estado actual
c para i = 1,nro_maq
maqui(i,2) = 0 maqui(i,3) = 0
maqui(i,4) = 0 c programación del evento falla.
r = rnd tfalla = -ln( r )/tasa_falla
maqui(i,1) = reloj + tfalla maqui(i,5) = reloj fin para c c Inicialización del arreglo de los mecánicos, según: c mecan(k,1) = tiempo de fin de reparación del mecánico c mecan(k,2) = estado del mecánico c = 0 en funcionamiento c = i , reparando la máquina i
c mecan(k,3) = tiempo acumulado de inactividad del mecánico c mecan(k,4) = tiempo de llegada al estado de inactividad c
para k = 1,nro_mec c programación del evento fin de reparación
mecan(k,1) = 0 mecan(k,2) = 0 mecan(k,3) =0

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 47
mecan(k,4) = reloj fin para
C C Información sobre las colas
para k = 1,nro_mec cola(k,2) = k
fin para c c Inicialización de otros contadores sum_maq_fun = 0
sum_maq_c = 0 sum_mec_i = 0
c c Algoritmo de simulación c
tipo_ev = 1
mientras (reloj < tiempo sim) c c Búsqueda del Próximo Evento. c Identifica la próxima máquina que ha de fallar
tipo_ev = 1 min = 1 tpe = maqui(1,1) para i = 1, nro_maq
si (maqui(i,2)=0)then si (maqui(i,1) < tpe)then
min = i tpe = maqui(i,1)
fin si fin si
fin para c
c Verifica si próximo evento es el fin de una reparación para k = 2,nro_mec
si (mecan(k,2)>0)then si(mecan(k,1) < tpe)then
tipo_ev = 2 min = k tpe = mecan(k,1)
fin si fin si
fin para c
dt = tpe - reloj reloj = tpe
c c actualiza contadores sobre variables de estado.
sum_maq_fun = sum_maq_fun + nro_maq_fun*dt sum_maq_c = sum_maq_c + nro_unid_cola(1)*dt
sum_mec_i = sum_mec_i + nro_unid_cola(2)*dt c c Identifica el proximo evento C
Si (tipo_ev = 1)then C Si el evento es una falla, identifica la máquina
i = min nro_maq_fun = nro_maq_fun - 1

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 48
maqui(i,5) = reloj c Si no hay mecánicos inactivos, la máquina queda en espera
Si (nro_unid_cola(2) = 0) then
nro_unid_cola(1) = nro_unid_cola(1) + 1
np = nro_unid_cola(1)
cola(np,1) = i
maqui(i,1) = 1
si no
c Si hay mecanicos, se escoge el primero
k = cola(1,2)
nro_unid_cola(2) = nro_unid_cola(2) - 1
c reorganiza las colas
si (nro_unid_cola(2) > 0) then
para j = 1,nro_unid_cola(2)
cola(j,2) = cola(j+1,2)
fin para
fin si
c
c Asignación de la maquina al mecánico
c cambia el estado de las máquinas y los mecánicos
c
maqui(i,1) = 2
r = rnd
trep = -ln( r )/tasa_repara
mecan(k,1) = reloj + trep
mecan(k,2) = i
c Actualiza el tiempo de inactividad del mecánico
mecan(k,3) = mecan(k,3) + reloj - mecan(k,4)
c fin de evento falla
fin si
si no
C Evento Fin de Reparación
C Si el evento es el fin de una reparación, identifica el
C Identifica al mecánico k y la maquina reparada i
k = min
i = mecan(k,1)+0.01
c
c Cambia el estado de la maquina, calcula el tiempo de inactividad y de
próxima falla. Actualiza eventos
c
nro_maq_fun = nro_maq_fun + 1
maqui(i,2) = 0
maqui(i,3) = maqui(i,2) + reloj - maqui(i,5)
c programacion del evento falla.
r = rnd
tfalla = -ln( r )/tasa_falla
maqui(i,1) = reloj + tfalla
c
c si no hay máquinas en espera, el mecánico queda inactivo
si (nro_unid_cola(1) = 0) then
nro_unid_cola(2) = nro_unid_cola(2) + 1
np = nro_unid_cola(2)
cola(np,2) = k
mecan(k,2) = 0
mecan(k,4) = reloj C
Si no

B. Calderón. Introducción a la Simulación. Cap 5. Desarrollo de Modelos y Programas de Simulación. 5 - 49
c Si hay máquinas en espera de ser reparada, escoge una. i = cola(1,1) nro_unid_cola(1) = nro_unid_cola(1) - 1
c Reorganiza las colas si (nro_unid_cola(1) > 0) then
para j = 1,nro_unid_cola(1) cola(j,1) = cola(j+1,1)
fin para fin si
c actualiza el tiempo de espera de la maquina maqui(i,3) = maqui(i,3) + reloj - maqui(i,5)
c cambia el estado de las maquinas y los mecanicos c
maqui(i,2) = 2 mecan(k,2) = i r = rnd
trep = -ln( r )/tasa_repara mecan(k,1) = reloj + trep
fin si c fin de evento reparacion
fin si C
Fin mientras C C Fin de la simulación, cuando el Tipo de Evento sea = 3 C C Calculo del numero medio de maquinas en funcionamiento, en cola y de mecanicos
inactivos nro_med_fu = sum_maq_fun/reloj nro_med_c = sum_maq_c/reloj nro_med_i = sum_mec_i/reloj nro_med_a = nro_mec - nro_med_i imprimir nro_maq,nro_mec,tsim,nro_med_fu,nro_med_c,nro_med_a, nro_med_i
C Para i = 1,nro_maq
porc_inac = maqui(i,2)*100./ reloj porc_col = maqui(i,3)*100./ reloj imprimir i, (maqui(i,j), j=1,5), porc_inac, porc_col
fin para C C Información sobre los mecánicos
para k = 1,nro_mec porc_inac = mecan(k,2)*100./ reloj imprimir k, (mecan(k,j),j=1,4), porc_inac
fin para C C Información sobre las colas
si (nro_unid_cola = 0)then imprimir nro_unid_cola
si no imprimir nro_unid_cola, (cola(l,1),l=1,nro_unid_cola)
fin si si (nro_unid_cola = 0)then
imprimir nro_unid_cola si no
imprimir nro_unid_cola, (cola(l,2),l=1,nro_unid_cola) fin si
c fin

6. SIMULACION DE FENOMENOS DE ESPERA 1 Introducción Las líneas de espera son fenómenos muy comunes y que se observan en diversas actividades: la gente que va a un banco a cambiar un cheque, los clientes que van a comprar y pagar una mercancía, las órdenes que llegan para ser procesadas a través de deferentes procesos, los conductores que llegan a una estación de servicio para tanguear sus autos, etc. Para que exista una cola sólo se requiere que las llegadas y/o los servicios ocurran a intervalos irregulares. El proceso básico que se asume al formular un modelo de colas es el siguiente: Las unidades que requieren servicio llegan al sistema. Estas unidades entran al sistema y se unen a la "cola". En ciertos puntos en el tiempo, un elemento de la cola es seleccionado para recibir servicio, mediante alguna regla conocida como "la disciplina de la cola". Luego el “mecanismo de servicio" del sistema realiza a la unidad escogida el servicio requerido. La figura 6.1 representa esquemáticamente un proceso de espera. Fuente Centro de espera Centro de servicio
Figura 6.1 Un sistema de colas. El gráfico representa un sistema de colas que consta de: Un centro de servicio con tres estaciones Una cola que alimenta las tres estaciones Dos fuentes suministradoras de clientes El flujo entre la fuente y la facilidad de servicio marca el proceso de llegadas. Características de los sistemas de colas Un sistema de espera tiene cuatro características: el proceso de llegadas, el mecanismo de servicio, la disciplina de la cola y el número de colas.
El proceso de llegadas El proceso de la demanda de servicios es, en general, un proceso estocástico y se describe en términos de la distribución de probabilidad del intervalo de tiempo entre llegadas. Los factores que se necesitan para especificar el proceso de llegadas son: La fuente de llegadas
El tipo de llegadas Los tiempos entre llegadas. Algunos tipos de llegadas pueden ser: a) Llegadas poisonianas, según las cuales el número de clientes que llegan a requerir servicio es un proceso de
Poisson, o equivalentemente, el tiempo entre llegadas de clientes sucesivos es exponencial. b) Llegadas regulares, a intervalos constantes. c) Llegadas en grupo. d) Llegadas regulares con impuntualidad. e) Llegadas en tiempos discretos. f) Llegadas no estacionarias. Se presenta cuando la tasa de llegada no es constante, sino que depende del
instante de tiempo considerado g) Llegadas que siguen una distribución general. h) Otros aspectos relacionados con las llegadas son:
Los clientes se desaniman según el tamaño de la cola.
Fuente 1
Fuente 2

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 2
La fuente generadora de clientes puede ser infinita, y las llegadas suelen ser independientes del tamaño de la fuente.
La fuente puede ser finita y las llegadas dependen del número actual de individuos en la fuente. Pueden llegar diferentes clases de clientes.
Es frecuente encontrar situaciones reales en que las llegadas no son estacionarias, pero se puede admitir que la tasa de llegada sea constante durante el intervalo de tiempo que sirve de base para estudiar el proceso de colas. Desde el punto de vista de la simulación no es necesario suponer que la tasa de llegadas sea estacionaria. El mecanismo de servicio Las principales características del mecanismo de servicio son: a) Número de estaciones de servicio y configuración de las mismas (serie o paralelo). b) Número de clientes que pueden ser atendidos en un instante cualquiera. c) La duración del servicio. La duración de un servicio es, en general, una variable aleatoria y se especifica de
acuerdo con una distribución de probabilidad. Los tipos de servicio más comunes son: Distribución exponencial. Distribución erlang Distribución gama Servicio constante Tiempo de servicio correlacionado con otros aspectos del sistema. Por ejemplo: servicio acelerado de
acuerdo al número de personas que haya esperando. Desde el punto de vista de la simulación, el servicio puede seguir cualquier distribución. La disciplina de la cola La disciplina de espera es el conjunto de reglas que especifican el orden de atención a las unidades. Los casos más comunes pueden ser: a) Disciplina FIFO o PEPS (Primeros el entrar, primero en salir). La primera unidad que llega, será la primera en
ser atendida. Es el caso más general de selección de la unidad que pasa al servicio. b) Disciplina LIFO o UEPS (Últimos en entrar, primeros en salir). Los últimos clientes en llegar, serán los
primeros en ser atendidos. c) Selección aleatoria de la unidad a ser atendida.
d) Selección de acuerdo con la importancia del cliente, es decir, de acuerdo con la prioridad del cliente.
El número de colas Cuando las estaciones de servicio están organizadas en serie, en general existe una cola en frente de cada estación. Cuando las estaciones de servicio están organizadas en paralelo, puede existir una cola para cada estación o puede existir una sola cola que alimente todas las estaciones. Además, el tamaño de cada una de las colas puede ser diferente. Objetivos El objetivo que se persigue al estudiar un sistema de colas puede ser muy variado. Generalmente se pretende definir cual debe ser la mejor configuración de tal forma que se minimice el costo de operación del sistema, o cual puede ser el costo de operación para una configuración dada. Entre las diferentes medidas que se pueden obtener para analizar el comportamiento de un sistema de colas están las siguientes: a) Tiempo medio que una unidad permanece en el sistema y la distribución de frecuencia del tiempo de
permanencia en el sistema. b) Utilización de las estaciones de servicio. c) Número medio de unidades en el sistema y distribución del número de unidades del sistema. d) Tiempo medio que permanece una unidad en cada una de las colas y su distribución. e) Número medio de unidades en cada una de las colas y su distribución. f) Tiempo de inactividad de las estaciones de servicio, porcentaje de utilización, etc. Los fenómenos de espera pueden estudiarse analíticamente o mediante la simulación. Sin embargo, sólo existen soluciones analíticas para unos casos particulares, generalmente cuando las llegadas y los servicios son exponenciales, y el sistema no es muy complejo. La simulación, por el contrario puede usarse para resolver cualquier problema de colas, por complejo que sea, no importa cual sea la distribución del tiempo entre llegadas y del tiempo de servicio.

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 3
Variables que deben considerarse al formular un modelo de colas En todo modelo hay tres tipos de variables que deben considerarse: Variables exógenas, variables de estado y variables endógenas. Con relación a los modelos de colas, cada una de estas categorías puede incluir las siguientes variables a) Variables exógenas o de entrada al sistema: Entre estas variables se encuentran las siguientes:
Tiempo entre llegadas al sistema. Tiempo de servicio en las diferentes estaciones. Prioridad de los clientes Número de estaciones de servicio Tasa de llegada de clientes al sistema Tasa de servicio de las diferentes estaciones o servidores Costos de prestación del servicio por unidad de tiempo Costo de espera o de inactividad por cliente
b. Variables de estado: Número de unidades en el sistema en cualquier instante. Tiempo que una orden o cliente cualquiera permanece en una cola. Tiempo que una estación esta inactiva, esperando la llegada de una orden o cliente. Número de unidades en la cada cola. Número de estaciones inactivas en cualquier instante. Número de órdenes recibiendo servicio en un instante cualquiera. Tiempo de permanencia de un cliente en el sistema
c. Variables endógenas:
Número medio unidades en el sistema. Número medio de unidades en cada una de las colas. Número medio de unidades recibiendo servicio. Número medio de estaciones inactivas. Tiempo medio que una unidad permanece en el sistema. Tiempo medio que una unidad permanece en cada una de las colas. Proporción de clientes que esperan.
2 Modelo de simulación. Características a tener en cuenta
Cuando el sistema de colas va a ser estudiado mediante la simulación es necesario identificar las entidades del sistema con sus atributos, las actividades y los eventos. Las entidades básicas que se encuentran en los modelos de colas fueron descritas brevemente al principio de este capítulo e incluyen las unidades o clientes que requieren servicio, la(s) facilidad(es) que presta(n) el servicio y la(s) cola(s) para las unidades que esperan ser atendidas. A continuación se hace un análisis somero de las anteriores entidades, en el cual se repite algo analizado previamente, pero el análisis estará orientado hacia las necesidades de la simulación. Las unidades (clientes) Las entidades que llegan al sistema de colas (llamadas unidades, órdenes, trabajos o clientes) poseen ciertas características que afectan al sistema de algún modo. Estas características pueden ser: Distribución de las llegadas o del tiempo entre llegadas. Es generalmente un proceso estocástico que gobierna
el número de llegadas al sistema. Prioridad. Es alguna medida relativa del valor o importancia que tiene una unidad para el sistema, comparada
con las otras unidades. Generalmente indica que tan rápido se va a mover una unidad a lo largo del sistema. Impaciencia. Este factor indica cuanto tiempo puede permanecer una unidad en el sistema sin ser atendida. La
impaciencia puede describirse mediante las siguientes condiciones (i) Cuando una unidad rehúsa entrar a la cola porque es muy larga, (ii) cuando una unidad deja la cola después de esperar cierto período de tiempo y (iii) cuando una unidad deja una cola para pasar a otra.
Otra característica que pueden tener las unidades es el tiempo que se van a gastar en la facilidad de servicio o tiempo de procesamiento (por ejemplo, órdenes de producción). Sin embargo, en la mayoría de los sistemas de colas este tiempo depende directamente de la facilidad de servicio.
Llegadas en lotes, cuando una llegada al sistema puede consistir de varias unidades. Facilidad de servicio La facilidad que sirve para atender las unidades o clientes puede tener varias características de interés.

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 4
El proceso de servicio, esto es, la distribución de la duración de los servicios. Generalmente es un proceso
estocástico cuya variación es inherente a la facilidad. Comúnmente se asignan los valores a los tiempos de servicio a medida que las unidades llegan a la facilidad, aunque puede suceder que estos tiempos se asignen cuando las unidades entran al sistema (órdenes de producción).
Configuración del sistema. Cuando existen varias estaciones para prestar servicio, éstas pueden estar en paralelo (cuando todas prestan el mismo servicio, y una unidad pasa solamente por una estación) o en serie (cuando una unidad debe pasar por todas las estaciones) o puede haber una combinación serie - paralelo.
Disciplina del servicio. Esta característica indica si se puede o no interrumpir un servicio una vez éste ha comenzado. Esta disciplina esta íntimamente ligada con la prioridad o importancia de las unidades, o con la necesidad del servicio de las unidades. Las unidades de mayor prioridad pueden exigir que la facilidad detenga su proceso actual para atenderlas.
El sistema puede atender también en lotes a varias unidades simultáneamente. La cola La línea de espera puede tener las siguientes características: Longitud. Es decir, el número máximo de unidades que pueden esperar en frente de una estación. Número de colas. Cuando hay varias estaciones en paralelo puede existir una cola única que alimente todas
las estaciones o puede existir una cola para cada estación. Además, en este último caso, cada unidad que llega puede escoger la cola en la cual esperará - la más corta, la más rápida, etc. Cuando las estaciones que prestan el servicio están ordenadas en serie, debe existir una cola para cada estación.
La disciplina de la cola, la cual indica el método de ordenar las unidades en la cola y escoger la próxima que va a ser atendida. Existen varias posibilidades para escoger la disciplina de la cola De acuerdo al orden de llegada, o la que tenga la menor fecha de entrega, la que vaya a permanecer el tiempo mínimo en el servicio o hacer la selección en forma aleatoria.
A continuación se analizan diferentes modelos que son útiles para simular los fenómenos de espera: Un sistema de varias estaciones en paralelo y un sistema de estaciones en serie. 3 Sistema de colas con varias estaciones de servicio en paralelo La figura 6.2 ilustra esquemáticamente un sistema de colas cuando existen varias estaciones idénticas que prestan el mismo servicio. Las unidades llegan al sistema, por lo general en forma aleatoria, entran si hay espacio disponible, esperan en una cola, si es del caso, antes de recibir el servicio, luego pasan al servicio y finalmente
abandonan el sistema. Por lo general el tiempo de llegada y el tiempo de servicio son aleatorios. Si cuando el cliente llega hay una estación vacía o inactiva, pasa inmediatamente al servicio y es atendida, en caso contrario la unidad que llega se coloca en la cola y espera mientras llega su turno para ser atendida. Cuando una estación o servidor finaliza un servicio, y hay varias unidades esperando ser atendidas, la elección de la próxima unidad que va a recibir servicio puede realizarse de varias maneras, de acuerdo al orden de llegada, es decir, los primeros que llegan pueden ser los primeros en salir, o también puede usarse alguna otra disciplina, como la prioridad o la selección aleatoria. Llegada Línea de espera Centro de servicio
Figura 6.2 Un sistema de estaciones en paralelo
El tiempo entre llegadas y el tiempo de servicio pueden seguir una distribución cualquiera, no necesariamente la distribución exponencial. El análisis de la simulación puede realizarse siguiendo el enfoque de flujo, o el enfoque de cambios de estado. Aunque en lo que resta de este capítulo usaremos siempre el enfoque de cambios de estado o por eventos, en la sección siguiente se presenta el diagrama de un sistema de colas de una estación usando la metodología del enfoque de flujo. Dentro del enfoque por eventos, se puede usar la simulación con el avance del tiempo unidad por unidad (en forma discreta) o con el avance por eventos, avanzado siempre al tiempo de próximo evento.
k
2
1

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 5
4 Simulación de un sistema de una cola usando el enfoque de flujo Para ilustrar un modelo sencillo para la simulación de colas, se usará el enfoque de flujo para el caso de un solo servidor. Para este caso se construirá inicialmente un modelo simplificado, luego el modelo ampliado, explicándolo tanto mediante un diagrama de flujo como mediante el seudo código, de tal forma que sea fácil de comprender, y posteriormente se implementará en una hoja de cálculo de Excel Para construir el modelo usando el enfoque de de flujo es necesario examinar lo que sucede con el cliente que requiere el servicio, lo cual se puede resumir en las siguientes grandes actividades, aclarando que la entidad que fluye a lo largo del sistema es el “cliente”: 1) Inicialmente el cliente llega al sistema en busca de un servicio. 2) El cliente espera, si es necesario. 3) Cuando le toque el turno, el empleado o servidor atiende al cliente, durante el tiempo que sea necesario, incluyendo el tiempo para hacer el pedido y para pagar. 4) Una vez paga el cliente sale de la tienda. Estas actividades resumen el recorrido que sigue el cliente. También se presenta el diagrama esquemático de bloques, que representa, con ligeras modificaciones, el procedimiento seguido para construir el modelo.
Legada del cliente Paso a la cola Paso al servicio Salida
Figura 6.2 Flujo de un cliente en sistema de colas de una estación
El diagrama de la página siguiente presenta con un poco más de detalle el procedimiento para la simulación del sistema de colas de un servidor usando el enfoque de flujo. Tanto para el diagrama de flujo como para la hoja de cálculo se cumplen las siguientes suposiciones: El primer cliente llega en el tiempo cero (aunque podrían llegar en cualquier instante a partir del tiempo cero).
La disciplina de la cola es FIFO, es decir, de acuerdo al orden de llegada En el desarrollo del modelo se tienen en cuenta las siguientes relaciones: Para cada cliente se genera el tiempo que tarda en llegar, a partir de la llegada del cliente anterior. Por lo
tanto, el “tiempo de llegada” al sistema es igual al tiempo de llegada del cliente anterior, mas el tiempo que tarda en llegar (tiempo entre llegadas).
Un cliente inicia servicio tan pronto llega, si el servidor está inactivo, o tan pronto termina el servicio del cliente anterior.
El tiempo de permanencia de un cliente en la cola es igual al tiempo de inicio de servicio menos el tiempo de llegada al sistema.
Para cada cliente se debe generar el tiempo que dura su servicio. Por lo tanto, el tiempo de salida del sistema es igual al tiempo de inicio del servicio más la duración del mismo.
El tiempo de permanencia de un cliente en el sistema es igual al tiempo de salida (fin de servicio) menos el tiempo de llegada al sistema.
El tiempo de inactividad del servidor es igual al tiempo de inicio de servicio de un cliente menos el tiempo de fin de servicio del cliente inmediatamente anterior.
Llegada del cliente
Espera ser atendido
Se presta el servicio
El cliente sale

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 6
Figura 6.3 Diagrama de flujo para a simulación de un sistema de colas con un servidor. Enfoque del flujo
Calcula tiempo de permanencia en el sistema
Cálculo de estadísticas
Inicio
Definición de parámetros
Reloj = 0
Incialización registros = 0
Para i = 1, nro_clientes tiempo entre llegadas
Genera tiempo entre llegadas
Calcula tiempo de llegada
Calcula tiempo de inicio de servicio
Calcula tiempo de espera
Genera el tiempo de servicio
Calcula tiempo de inactividad del servidor espera
Calcula tiempo de fin de servicio
Siguiente cliente
Fin
Reloj = Tiempo salida último cliente
B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 7
Figura 6.4 Enfoque del flujo. Sistema de colas de una estación
Inicio
Definición de parámetros
Reloj = 0
Inicialización de registros
Para clientes = 1, nro_clientes
Generación de “tiempo entre llegadas”
Cálculo de tiempo de llegada
Cálculo de tiempo de inicio de servicio
Cálculo de tiempo de espera
Cálculo del tiempo de inactividad del servidor
Generación del tiempo de servicio
Cálculo del tiempo de fin de servicio
Cálculo del tiempo de permanencia en el sistema
Siguiente cliente
Cálculo de estadísticas
Fin El modelo fue implementado en Excel, para las distribuciones de tiempos entre llegadas y tiempos de servicios dados a continuación. Las columnas usadas en el modelo de Excel, su contenido y forma de cálculo se presentan en la siguiente tabla:
Figura 6.5 Sistema de colas de una estación. Diseño de la simulación en Excel
Columna Contenido Cálculo para la fila i Observaciones
A Número del cliente (i) = (i-1) + 1 Inicia en 1
B Número aleatorio =aleatorio()
C Tiempo entre llegadas Según distribución
D Tiempo de llegada del cliente D(i-1)+C(i) D(1) = 0
E Tiempo de inicio de servicio Max(D(i), I(i-1)
F Tiempo de espera E(i) – D(i)
G Número aleatorio =aleatorio()
H Tiempo de servicio Según distribución
I Tiempo de fin de servicio E(i) + H(i)
J Tiempo de permanencia en el sistema I(i) – D(i)
K Tiempo de inactividad del servidor E(i) – I(i-1)
En el cuadro que sigue se presenta la simulación, usando la hoja de cálculo Excel, de los 20 primeros clientes del sistema de colas con las siguientes características: Distribución de tiempo entre llegadas (minutos):
Tiempo entre llegadas 1 2 3 4 5 6 7 8
Probabilidad 0.125 0.125 0.125 0.125 0.125 0.125 0.125 0.125
Distribución del tiempo de servicio (minutos):
Tiempo de servicio 1 2 3 4 5 6
Probabilidad 0.10 0.20 0.30 0.25 0.10 0.05

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 8
Figura 6.6 Simulación de un modelo de colas de un solo canal
Cliente número
R Tiempo próxima llegada
Tiemp de llegada
Tiempo inicio
servicio
Tiempo de espera
R Tiempo
de servicio
Tiempo fin de
servicio
Tiempo en el
sistema
Tiempo ocioso cajero
( A ) ( B ) ( C ) ( D ) ( E ) ( F ) ( G ) ( H ) ( I ) ( J ) ( K )
1 0 0 0 0 0.101 2 2 2 0
2 0.853 7 7 7 0 0.706 4 11 4 5
3 0.208 2 9 11 2 0.541 3 14 5 0
4 0.945 8 17 17 0 0.649 4 21 4 3
5 0.030 1 18 21 3 0.092 1 22 4 0
6 0.064 1 19 22 3 0.072 1 23 4 0
7 0.984 8 27 27 0 0.796 4 31 4 4
8 0.603 5 32 32 0 0.213 2 34 2 1
9 0.852 7 39 39 0 0.819 4 43 4 5
10 0.302 3 42 43 1 0.035 1 44 2 0
11 0.981 8 50 50 0 0.755 4 54 4 6
12 0.048 1 51 54 3 0.497 3 57 6 0
13 0.780 7 58 58 0 0.626 4 62 4 1
14 0.882 8 66 66 0 0.451 3 69 3 4
15 0.945 8 74 74 0 0.726 4 78 4 5
16 0.698 6 80 80 0 0.434 3 83 3 2
17 0.514 5 85 85 0 0.089 1 86 1 2
18 0.631 6 91 91 0 0.411 3 94 3 5
19 0.552 5 96 96 0 0.743 4 100 4 2
20 0.229 2 98 100 2 0.904 5 105 7 0
20 98 14 60 74 45
4.9 0.7 3 3.7 0.429
Estadísticas:
1 Tiempo promedio de espera = 0.7
2 Clientes que no esperan = 14
3 Probabilidad de esperar = 0.3
4 Tiempo medio de los que esperan = 2.3
5 Porcentaje de inactividad del cajero = 42.9
6 Tiempo medio de servicio = 3
7 Tiempo medio entre dos llegadas = 4.9
8 Tiempo medio en el sistema = 3.7
9 Tiempo medio en el sistema – control = 3.7
10 Número medio de clientes en el sistema L = 0.76
11 Número medio de clientes en la cola Lq = 0.14
12 Número medio de clientes en servicio a = 0.57
13 L aprox. Control = 0.71

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 9
En la parte final de la tabla se presentan las principales estadísticas de la simulación, las cuales son obtenidas, unas a partir de la propia simulación y otras a partir de relaciones que siempre se cumplen en los diferentes sistemas de colas, usando las fórmulas de Little (para el número medio de unidades en el sistema, en la cola y en servicio). 5 Sistema de colas con varias estaciones de servicio en paralelo. Enfoque por eventos 5.1 Identificación de los eventos Los únicos eventos primarios que se presentan en esta simulación son la llegada de una unidad o cliente al sistema y la terminación de un servicio por parte de una estación. Con el fin de facilitar la implementación del modelo computaciones, también se incluye como evento primario el fin de simulación, es decir, el instante en que dejamos de observar o analizar el sistema. Además, como se explicó antes, cada uno de los eventos primarios anteriores puede generar otros eventos secundarios, dependiendo del estado del sistema, como se ilustra a continuación. Cuando una unidad llega al sistema, se puede iniciar un servicio, si hay un servidor inactivo, o cuando un servidor finaliza un servicio, puede empezar otro servicio para una nueva unidad, si hay al menos una unidad en la lista de espera. Cuando una unidad entra al sistema, esta unidad puede quedar en uno de dos posibles estados: la unidad o se queda en la cola o pasa al servicio. El siguiente diagrama ilustra lo que debe hacer el simulador cuando una unidad llega al sistema. No Sí
No Sí Si
Figura 6.7 Actividades realizadas cuando una unidad llega al sistema Cuando el evento es un fin de servicio, el simulador debe realizar las actividades descritas en el diagrama de la figura 6.8 Como se indicó antes, el sistema incluye las unidades que están en la cola, las unidades que están recibiendo servicio y las estaciones de servicio. Los estados de las diferentes entidades deben incorporarse en el modelo. Los estados de una unidad, pueden ser únicamente dos : o está en la cola esperando servicio, o está siendo atendida. Igualmente, los estados de las facilidades o estaciones de servicio son dos: ó están ocupadas atendiendo una unidad, o están ociosas. Por lo tanto debemos buscar la forma de representar los estados antes mencionados, y hacer que ocurran los eventos descritos. Para el sistema que se está tratando de simular se debe mantener el registro de los siguientes tiempos El tiempo de llegada de la nueva unidad al sistema. El tiempo en que finaliza el servicio de una unidad.
Llegada Cliente
Se selecciona un servidor disponible
El Cliente pasa al servicio
La unidad pasa a la Cola
Puede entrar al sistema?
Se identifica al Cliente Cliente se va
Hay servidores inactivos?

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 10
El tiempo actual de la simulación. Este tiempo se mantendrá en la variable denominada RELOJ (el reloj de la simulación).
Por lo tanto es necesario definir la forma de determinar cuando llega una unidad o cliente al sistema y cuando se termina un servicio. En una situación real cuando llega una unidad al sistema no se sabe cuando llegará la próxima, aunque si puede saberse como se distribuye e! tiempo entre llegadas. En forma similar, cuando el servidor empieza a servir una unidad, no se sabe cuanto tiempo durará el servicio, aunque sí puede conocerse cual es su distribución. Sin en embargo en un modelo de simulación sí podemos saber o estimar cuando ocurrirá la próxima llegada o cuando se finalizará un servicio, ya que estos tiempos pueden “generarse” con base en las respectivas distribuciones de tiempos entre llegadas o de tiempos de servicio. Así, cuando una unidad llega al sistema, inmediatamente se genera el tiempo de llegada de la próxima unidad, independientemente de lo que pase con la que acaba de llegar. Además, cuando una estación de servicio empieza a atender una unidad, se genera el tiempo que durará dicho servicio. La generación de estos tiempos debe hacerse de acuerdo con las respectivas distribuciones de tiempos entre llegadas y de tiempos de servicio. No
Fig. 6.8 Actividades realizadas por el simulador cuando finaliza un servicio.
El seudo código siguiente ilustra esquemáticamente el proceso de simulación, el cual será explicado en detalle en los párrafos siguientes.
Lectura de parámetros básicos
Reloj = 0
Inicializar sistema . Invocar rutina de inicialización
Creación de la imagen del sistema
Inicialización de contadores
Creación lista de eventos
Mientras (Reloj < Tiempo de simulación)
Rutina de Próximo Evento
Si Próximo Evento es llegada, entonces
Invocar rutina de llegada al sistema
Si no
Si próximo evento = fin de servicio, entonces
Invocar rutina de Fin de Servicio
Fin de un servicio
Hay Clientes esperando servicio
Se selecciona una unidad para ser atendida
El servidor va a la cola
Se identifica el Servidor Se identifica el Cliente
Cliente sale del Sistema
El Cliente pasa al servicio

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 11
Fin si
Fin si
Fin Mientras
Invocar rutina de generación de reportes
Si hay mas experimentos de simulación, entonces
Establecer condiciones de nueva simulación
Volver a inicializar el sistema
Fin si
Fin de la simulación Figura 6.9. Procedimiento general de la simulación En el instante en que empiece la simulación en el tiempo cero (RELOJ = O), se debe definir el estado del sistema en ese instante, es decir, se debe definir si hay unidades en el sistema o en la cola, si las estaciones de servicio están ocupadas o inactivas, el tiempo en que llegara al sistema la primera unidad, y se deben inicializar todas las variables y registros que sean necesarios para la simulación. La forma más fácil de inicializar el sistema es en el estado “vacío”, es decir, no hay nadie en el sistema, y por lo tanto todas las estaciones de servicio están inactivas. Esta será la forma que consideraremos en nuestro modelo. A nivel de ilustración supongamos lo siguiente: Se tienen dos servidores, y la primera unidad demorará tres minutos en llegar. A partir de este evento se presentarán los siguientes eventos:
Avanzamos el RELOJ al tiempo de llegada de la primera unidad (RELOJ = 3). Antes de decidir el destino de la primera unidad, generamos el tiempo que transcurre para que llegue la segunda unidad. Supongamos que es dos minutos, es decir, llegará en el minuto 5. Ahora bien, como hay estaciones desocupadas, la primera unidad puede pasar al servicio a la estación número 1, para lo cual debemos generar el respectivo tiempo de servicio. Supongamos que sea 7 minutos, es decir, finalizará en el minuto 10.
Cuál es el próximo evento?. Para determinarlo, es necesario calcular que ocurrirá primero entre la llegada del cliente No 2 –en el minuto 5- y el fin de servicio en la estación número 1 –minuto 10-. Por lo tanto el próximo evento es en el minuto 5 y será la llegada del cliente No 2
Minuto No 5. Llega el cliente No 2. Lo primero que debe hacerse es generar el tiempo entre la llegada de los clientes 2 y 3. Sea 2’, es decir, que llegará en el minuto 7. Como la estación No 2 está inactiva entonces el cliente no 2 puede pasar al servicio, y generamos el tiempo respectivo. Supongamos que sea 6 minutos, por lo cual el servicio se terminará en el minuto 11.
Cuál es el próximo evento?. Para determinarlo, es necesario calcular que ocurrirá primero entre la llegada del cliente No 3 –en el minuto 7- el fin de servicio en la estación número 1 –minuto 10- y el fin de servicio en la
estación número 2 –minuto 11-. Por lo tanto el próximo evento es en el minuto 7 y será la llegada del cliente No 3.
Minuto No 7. Llega el cliente No 3. Primero generamos el tiempo de llegada del próximo (el no 4). Sean dos minutos, es decir, que llegará en el minuto 9. Como ambas estaciones están ocupadas, el cliente No 3 se queda en la cola, esperando que finalice el servicio en una de las dos estaciones.
Cuál es el próximo evento?. Para determinarlo, es necesario calcular que ocurrirá primero entre la llegada del cliente No 4 –en el minuto 9- el fin de servicio en la estación número 1 –minuto 10- y el fin de servicio en la estación número 2 –minuto 11-. Por lo tanto el próximo evento es en el minuto 9 y será la llegada del cliente No 4.
Minuto 9, llega el cliente No 4. Primero generamos el tiempo de llegada del próximo (el no 5). Sean cinco minutos, es decir, que llegará en el minuto 14. Como ambas estaciones están ocupadas, el cliente No 4 se queda en la cola, esperando que finalice el servicio en una de las dos estaciones.
Cuál es el próximo evento?. Para determinarlo, es necesario calcular que ocurrirá primero entre la llegada del cliente No 5 –en el minuto 14- el fin de servicio en la estación número 1 –minuto 10- y el fin de servicio en la estación número 2 –minuto 11-. Por lo tanto el próximo evento es en el minuto 10 y será el fin de servicio en la estación No 1
Minuto 10, fin de servicio en la estacan no 1. El cliente No 1 sale del sistema, después de haber permanecido en el durante 10 – 3 = 7 minutos. Como en la cola hay dos clientes esperando servicio, se escoge uno según la disciplina de la cola, (el que lleve mas tiempo en la cola, por ejemplo ). En este caso sería el cliente No 3, quien permaneció en la cola durante 10 – 7 = 3 minutos. Se genera el tiempo de servicio, (5 minutos), por lo cual la estación No 2 estará terminando el servicio en el minuto 15.
Y el proceso de simulación continúa en la misma forma: Buscando el próximo evento, y ejecutando las actividades requeridas de acuerdo con el evento que haya ocurrido, hasta que el próximo evento sea el fin de la simulación.

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 12
Al hacer el registro de los eventos futuros, el tiempo de ocurrencia de estos eventos puede registrarse en dos formas equivalentes. La primera forma de registrar el tiempo de ocurrencia del evento consiste en acumular al tiempo actual el tiempo de ocurrencia del evento, y el tiempo registrado será entonces el tiempo en que ocurrirá el evento. La otra forma consiste en no acumular al tiempo actual el tiempo de ocurrencia del evento y en este caso el tiempo registrado será el tiempo “dentro del cual" ocurrirá el evento. Es decir, al buscar el próximo evento, podemos hacerlo en dos formas, es decir, podemos hacer una de dos preguntas: a) cuándo ocurrirá el evento? es decir, en qué instante ocurrirá el evento, y b)) dentro de cuánto tiempo, a partir del instante actual, ocurrirá el evento? Si para registrar los tiempos de los eventos futuros se usa la segunda forma, entonces cada vez que se avance el reloj cierta cantidad de tiempo, este tiempo que se avance el reloj debe ser restado de los tiempos de cada uno de los eventos futuros (queda faltando menos tiempo para que ocurran esos eventos). Si se usa la primera forma no es necesario actualizar los tiempos de ocurrencia de los otros eventos. La primera forma será la que usaremos para la. simulación de sistemas de espera. Un objetivo que se persigue en cualquier estudio de simulación es la recolección de estadísticas acerca del comportamiento del sistema. La información que puede recogerse en el sistema que estamos estudiando puede ser la siguiente: Tiempo medio de permanencia de una unidad en una cola. Este tiempo (de tránsito) se calcula cuando una
unidad pasa de la cola a la estación de servicio, y es igual a el tiempo en que la unidad sale de la cola pasa al servicio (RELOJ) menos el tiempo de llegada al sistema. También puede calcularse su distribución en intervalos de clase.
Tiempo medio de permanencia de una unidad en el sistema. Este tiempo (de tránsito) se calcula cuando la unidad sale del sistema, y es igual al tiempo de finalización del servicio (RELOJ) menos el tiempo de llegada al sistema. También puede calcularse su distribución en intervalos de clase.
Número medio de unidades en el sistema y en la cola, y sus respectivas distribuciones de frecuencia.
Utilización de las estaciones de servicio (porcentaje de tiempo que estuvieron ocupadas) durante la simulación.
También pueden estimarse diferentes probabilidades, tales como la probabilidad de que un cliente tenga que esperar antes de ser atendido, probabilidad de que tenga que esperar mas de cierto tiempo, etc.
Para estimar el número medio de unidades en el sistema o en la cola, es necesario recoger información no sólo acerca de las unidades que hay en el sistema (o en la cola) en un tiempo dado, sino también del tiempo durante el
cual esas unidades estuvieron en el sistema (o en la cola), ya que es muy diferente que haya, por ejemplo 4 unidades en el sistema durante 5 minutos, a que haya 4 unidades en el sistema durante 20 minutos. Es decir, es necesario ponderar el número de unidades del sistema por el tiempo durante el cual existen esas unidades en el sistema (estas son estadísticas de la forma ntt). Esta información acerca de las unidades en el sistema y en la
cola debe recogerse antes de que se cambie el estado del sistema, es decir, antes de que se modifique el número de unidades en el sistema y/o en la cola. Por lo tanto, estos registros deben actualizarse después de que se busca el próximo evento, pero antes de que se procese ese evento. (Recordemos que la realización del evento cambia el estado del sistema). 5.2 Procedimiento General
El procedimiento para realizar la simulación, junto con la recolección de las estadísticas antes mencionadas puede resumirse en los siguientes pasos: 1 Inicialización del sistema. El primer paso en toda simulación consiste en la inicialización del sistema, sus
variables de estado y de los registros que se van a usar para recoger las estadísticas. Esta etapa comprende
los siguientes aspectos: 1.1 Definición de los parámetros básicos del sistema a simular: Semillas, parámetros de distribuciones de
tiempo de llegada y servicio, tiempo de simulación, etc.
1.2 Inicialización del estado del sistema (variables de estado). Por lo general el sistema se inicializa en el estado vacío. Comprende:
El número de unidades en el sistema (=0) .
El número de unidades en la cola (=0).
El estado de cada estación (=inactivas).
1.3 Inicialización de la lista de eventos futuros. Para ello debe generarse el tiempo en que llegará la primera unidad al sistema. Además, debe definirse como se representará el tiempo en que finalizará un servicio, principalmente cuando las estaciones están desocupadas.
1.4 Inicialización de todas las variables que se han de usar para recoger estadísticas.

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 13
2. Algoritmo de la simulación Una vez inicializado el sistema, viene la realización del algoritmo de simulación,
que comprende los siguientes pasos:
2.1. Se busca el próximo evento, es decir, qué ocurre primero entre la llegada de una unidad al sistema, la finalización de un servicio o el fin de la simulación. Para buscar el próximo evento se compara el tiempo en que Llegará la próxima unidad al sistema con los tiempos en que las estaciones finalizarán sus servicios, y con el tiempo de simulación y se escoge el menor. Cuando una estación está desocupada, el próximo evento no puede ser el fin de un servicio en dicha estación, por lo tanto para que al hacer la comparación de los tiempos no se escoja ese evento, es necesario suponer que el próximo servicio termina en un tiempo muy alto.
2.2 Antes de avanzar el reloj al tiempo de ocurrencia del próximo evento, se calcula en cuanto tiempo se va
a incrementar el reloj, ya que hay que recoger estadísticas acerca del tiempo durante el cual el sistema tuvo determinada configuración.
Se actualizan las estadísticas que informen acerca del estado del sistema, y en las cuales es necesario
considerar el tiempo que el sistema estuvo en determinado estado. Estas estadísticas tienen que ver con el número de unidades en el sistema, en la cola y el número de estaciones ocupadas (Son estadísticas del tipo ntt).
2.3 Finalmente se avanza el reloj al tiempo de ocurrencia del próximo evento. Si el próximo evento es una
llegada al sistema, se va al paso 3, si es la finalización de un servicio se va al paso 4 y si es el fin de la simulación al paso 5.
3. Cuando el próximo evento es una llegada, el simulador debe realizar las siguientes actividades
3.1 Incialmente4 se identifica la unidad que llega al sistema.
3.2 Como ocurrió una llegada, se debe generar el tiempo de llegada del próximo cliente y actualizar la lista de eventos futuros con este evento.
3.2 Se pregunta si la unidad que acaba de llegar puede entrar al sistema. Si no hay capacidad en el sistema, la unidad no puede entrar, por lo que se actualiza el registro de las unidades perdidas y se va a buscar el siguiente evento - paso 2. Si la unidad puede entrar al sistema, se realiza el paso siguiente (3.3), y se actualiza el número de unidades en el sistema.
3.3 Si todas las estaciones de servicio están ocupadas, el cliente se queda en la línea de espera, para lo cual se requiere actualizar el número de unidades de la cola, y colocar la unidad que acaba de llegar en el último puesto de la misma.
3.4 Si hay al menos una estación de servicio desocupada, el cliente escoge una estación para que le preste el servicio (o el sistema le asigna una –la que lleve mas tiempo inactiva, por ejemplo). Se requiere por lo tanto generar el tiempo que durará el servicio, con el cual se actualiza la lista de eventos futuros. El cliente que pasa directamente al servicio no permanece ningún tiempo en la cola. Luego se busca el próximo evento (paso 2).
Cuando el evento es llegada, se deben actualizar algunos registros para llevar información, tales como el tiempo de inactividad de la estación de servicio que empieza a trabajar, el número de clientes que no esperan, etc.
4. Cuando el próximo evento es la finalización de un servicio se requiere realizar las siguientes actividades:
4.1 Identificar la unidad o cliente que va a salir del sistema, calcular cuanto tiempo permaneció esta unidad en el sistema, actualizar este registro y disminuir el número de unidades del sistema.
4.2 Si no hay unidades en la cola esperando para ser atendidas, la estación de servicio queda inactiva (Es necesario suponer que el próximo servicio terminará en un tiempo muy alto). Luego se busca el próximo evento, paso 2.
4.3 Si hay unidades esperando el servicio, se selecciona una unidad de acuerdo con la disciplina empleada;
se calcula el tiempo de permanencia en la cola, se reorganiza la cola y se disminuye el número de unidades de la misma. Además es necesario estimar el tiempo que la unidad permanecerá en el servicio, y actualizar la lista de eventos futuros. Luego se busca el próximo evento.
5. Cuando se termina la simulación, es necesario calcular e imprimir las estadísticas de interés tales como:
Número medio de unidades en el sistema y en la cola. Tiempos medios de permanencia en el sistema y en la cola. Número de unidades atendidas. Número de unidades que no pudieron entrar al sistema.

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 14
Porcentaje de inactividad de las estaciones de servicio Numero medio de estaciones en servicio, etc.
5.3 Seudocódigo General
Los pasos o actividades que acaban de describirse para la simulación de un sistema de colas con varias estaciones idénticas en paralelo están resumidos en la figura 6.10, que es un seudocódigo descriptivo de dicho proceso. En el se describen las principales actividades que deben realizarse en las etapas de inicializacíon, el algoritmo de simulación y la generación del reporte
Figura 6.10 Seudo código descriptivo para simular sistemas de colas de estaciones en paralelo PROCEDIMIENTO GENERAL Lectura de parámetros básicos
Tiempo de simulación, semillas, variables de control
Parámetros de distribuciones de:
Tiempos entre llegadas
Tiempos de servicio
Reloj = 0
Invocar rutina de inicialización
* Algoritmo de simulación
Mientras Reloj < Tiempo de simulación
Rutina de Próximo Evento
Si Próximo Evento es llegada, entonces
Rutina de llegada al sistema
Si no
Si próximo Eventos es Fin_Servicio, entonces
Rutina de Fin_Servicio
Fin si
Fin si
Fin Mientras
Rutina de generación de reportes
Si hay mas experimentos de simulación, entonces
Establecer condiciones de nueva simulación
Volver a inicializar el sistema
Fin si
FIN DE LA SIMULACION
RUTINA DE INICIALIZACION
Reloj = 0
Inicialización del estado del sistema = vacío
Clientes en el sistema = Clientes en la cola = Estaciones Ocupadas = 0
Cola de servidores inactivos
Inicialización lista de eventos
Evento tipo 1: Fin de Simulación.
Evento tipo 2 : Llegada nuevo clientes
Eventos tipo 3: Fin de servicio de las k estaciones
Inicialización contadores para estadísticas
Tiempos medios de Permanencia en la Cola y en el Sistema (X = 0)
Número medio de : Clientes en el sistema, en la cola, en servicio y servidores inactivos (Contadores del tipo nt t = 0)
Contadores de eventos u observaciones (Clientes atendidos, en las colas, etc.)
Distribuciones de:
Tiempos de permanencia en el sistema
Tiempos de permanencia en la cola
FIN RUTINA DE INICIALIZACION

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 15
RUTINA DE PROXIMO EVENTO
Búsqueda de Próximo Evento
Tiempo del Próximo Evento: TPE = Menor { Lista de Eventos}
Tiempo de Avance del Reloj = t = TPE - RELOJ
Actualización de contadores sobre variables de estado del tipo nt t
Avance del RELOJ al tiempo del Próximo Evento: RELOJ = TPE
FIN RUTINA DE PROXIMO EVENTO RUTINA DE LLEGADA DE CLIENTE Evento: Llegada de un cliente.
Identificar cliente que llega (“I”) y crear su registro en Lista de Clientes
Actualizar Evento Primario: Llegada del Próximo Cliente.
Si hay Servidores inactivos, entonces
Seleccionar un Servidor. Sea “J” ese servidor.
Actualizar Tiempo de Inactividad del Servidor (tiempo de tránsito)
Actualizar y reorganizar Lista de Servidores Inactivos
Actualizar estado del cliente
Actualizar Clientes en Servicio.
Asignar el cliente “I” al servidor “J”.
Actualizar contador de clientes que no esperan.
Actualizar evento “Fin de Servicio”.
Si no
Si hay espacio en la Cola, entonces
Actualizar Clientes en Espera
Colocar Cliente en el último puesto de la cola
Actualizar estado del cliente
Si no
Cliente abandona el Sistema
Fin si
Fin si
FIN RUTINA LLEGADA DE CLIENTE RUTINA FIN DE SERVICIO
Evento: Fin de servicio en una estación
Identificar Servidor que termina el servicio. Sea “J” ese servidor
Identificar Cliente atendido. Sea “I” el cliente
Actualizar tiempos en el sistema y clientes atendidos
Eliminar su registro en Lista de Clientes
Reducir clientes en el sistema
Si hay Clientes en espera de servicio, entonces
Seleccionar un cliente. Sea “I” ese cliente
Calcular y actualizar tiempo de permanencia en la cola (tiempo de tránsito)
Actualizar contador de clientes que esperan.
Actualizar y reorganizar Lista de Clientes en Cola
Actualizar estado del cliente
Asignar el cliente “I” al servidor “J”.
Actualizar evento “Fin de Servicio”.
Si no
Actualizar Mecánicos Inactivos
Colocar Mecánico en el último puesto de la cola
Actualizar Lista de Evento (no fin de servicio)
Fin si
FIN RUTINA FIN DE SERVICIO Figura 6.10 Seudo código descriptivo para simular sistemas de colas de estaciones en paralelo (cont.)

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 16
RUTINA DE GENERACION DEL REPORTE DE SALIDA Cálculo de:
Tiempos medios de Permanencia en la Cola y en el Sistema
Número medio de: (Estadísticas del tipo nt t)
Clientes en el sistema
Clientes en la cola
Clientes en servicio
Porcentajes de clientes que esperan
Distribuciones de:
Tiempos de permanencia en el sistema
Tiempos de permanencia en la cola
FIN RUTINA DE GENERACION DE REPORTE Figura 6.10 Seudo código descriptivo para simular sistemas de colas de estaciones en paralelo (cont.) Para poder realizar la simulación por computador es necesario definir en que forma se van a recoger los datos, cómo se va a guardar la información acerca de las entidades que hay en el sistema y qué información debe contener la lista de los eventos futuros.
Como se indicó en el capítulo 5 la mejor manera de mantener la información es por medio de arreglos bi-dimensionales. A continuación se discuten algunos arreglos que se pueden emplear y se indica en qué forma se van a recoger las estadísticas. 5.4 Arreglos para mantener información Arreglo para guardar información acerca de las unidades CLIENTE(I,J): Para cada unidad que entra al sistema se debe guardar la siguiente información
Número que identifique la unidad.
Estado de la unidad.
Tiempo de llegada al sistema.
Tiempo de llegada al estado actual
Prioridad, en caso de existir.
Cuando se trata de órdenes de producción, éstas pueden traer también el tiempo de servicio o procesamiento de la orden y el tiempo de entrega como otros de sus atributos. Para el presente análisis, se supone que el tiempo de servicio es un atributo de la estación o servidor.
De la información que debe guardarse acerca de una unidad, hay una que es tipo entero (identificación, estado, prioridad) y otra que es tipo real (tiempos), a no ser que se represente el tiempo como entero, mediante un factor de escala. En lo que sigue supondremos que toda la información se guardará en forma real. Para guardar la información acerca de las unidades usaremos un arreglo que denominaremos CLIENTE y la información se almacenará de la siguiente manera: El subíndice I sirve sólo como un indicador, y su valor dependerá del número de unidades haya en el sistema al mismo tiempo. El subíndice I simplemente indica el número de la fila de la matriz CLIENTE en que está guarda da la información acerca de determinada unidad o cliente. Las columnas de la matriz CLIENTE se usarán de la siguiente manera: Primera columna: J = 1 Guarda el número que identifica la unidad cuya información está en la fila I. Si la fila
I está vacía, se la identifica con un cero (0). Por lo tanto, CLIENTE(I,1) representa el “número de la unidad” cuya información está almacenada en la fila I.
Segunda columna: J = 2: Guarda el estado en que se encuentro la unidad. Este estado se representará por "1" cuando la unidad está en la cola y por "2" cuando la unidad está en servicio.
Tercera columna: J = 3 : Guardará el tiempo de llegada al sistema de la unidad que se identifica con el número CLIENTE(I,1).
Cuarta columna: J = 4: En aquellos sistemas en que existen prioridades, esta información se guardará en la columna cuarta de la matriz CLIENTE.

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 17
Quinta : J = 5 : Guardará, para algunos casos de simulación, el tiempo de llegada de la unidad al estado actual. (Para nuestro caso no se usará)
Matriz de Clientes
Número del Cliente (J = 1)
Estado
(J = 2)
Tiempo de llegada (J = 3)
Prioridad
(J = 4)
I = 1
I = 2
I = 3
I = 4
……
I = Nro_C
La matriz CLIENTE mantendrá ocupadas siempre las primeras filas, es decir, si la variable Nro_clientes representa el número de clientes que hay en el sistema, entonces este arreglo mantendrá ocupadas las primeras filas (Nro_Clientes). Cuando llegue un cliente al sistema, se aumentará el número de clientes (número de filas) en uno y en la última fila se guardará la información del cliente que acaba de llegar. Cuando salga un cliente del sistema,
es necesario reorganizar el arreglo de tal forma que siempre estén ocupadas las primeras filas: Si la información del cliente que sale está en la última fila del arreglo, simplemente se disminuirá en uno el número de filas ocupadas (número de clientes del sistema), pero si la información no está guardada en la última fila, entonces en la posición que ocupa el cliente que sale se colocará la información del cliente que está en la última posición, y luego se disminuirá en uno el número de filas ocupadas (número de clientes del sistema). Información relacionada con las estaciones: ESTACION La información que es necesario guardar sobre las estaciones es la siguiente: Numero de la estación Estado de la estación: inactiva, prestando servicio, bajo reparación, etc. Tiempo acumulado de inactividad. Tiempo en que empieza un periodo de inactividad de la estación, o un período de reparación. Para guardar la anterior información se usará un arreglo -ESTACION-, con la siguiente configuración: El número de la fila I se usará para identificar la estación
ESTACION(I,1) guardará el estado de la estación I, con la siguiente convención:
= 0 si la estación está desocupada
= K > 0 si está atendiendo la unidad número K. de la estación y de
ESTACION(I,2) guardará el tiempo acumulado de inactividad de la estación I.
ESTACION(I,3) = Tiempo en que la estación I comenzó el último período de inactividad. Este registro servirá para calcular el tiempo de inactividad (tiempo de tránsito = Reloj - ESTACION(i,3)
Matriz ESTACION
Estado
(J = 1)
Tiempo de inactividad
(J = 2)
Tiempo inicio de inactividad
(J = 3)
I = 1 15
I = 2 13
I = 3 0
……
I = K 0
Arreglos para las colas
Se usarán dos arreglos independientes –COLA_CL y COLA_EST- para manejar las unidades o clientes que esperan servicio y las estaciones que están inactivas esperando clientes para atender. La primera guardará la información de las unidades que esperan servicio y la segunda la información de las estaciones que están inactivas. La información se guardará de la siguiente manera: COLA_CL(I): Identifica el número del cliente que ocupa el puesto I en la línea de espera.

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 18
COLA_EST(I): Identifica el número de la estación que ocupa el puesto I en la cola.
NRO_CL_COLA: Identifica el número de unidades o clientes que están esperando servicio.
NRO_EST_IN: Identifica el número de estaciones inactivas.
LCOLA: Número máximo de unidades que pueden estar en la cola en cualquier instante.. Estos arreglos se mantendrán ordenados, de acuerdo con el orden de llegada de los elementos, de tal forma que se mantengan ocupadas las primeras filas. Si hay elementos en una cola, no puede haber en la otra. Cuando se seleccione un elemento de una de las colas (generalmente el primero), ésta debe reorganizarse, moviendo los restantes elementos un puesto, es decir, en la posición i se colocará lo que hay en la posición siguiente i + 1. Matriz o lista de eventos futuros MEF (l,J) o EVENTOS(I,J) La lista de eventos futuros debe contener información relacionada con los eventos primarios que han de ocurrir en un futuro inmediato. Debe contener Información acerca del tiempo en que ocurrirán los eventos, los tipos de eventos y la entidad que ocasiona el evento. Para guardar la información se usará el arreglo MEF –Matriz de Eventos Futuros (EVENTOS) En la simulación de un sistema de colas existe, como ya se mencionó, los eventos llegada de una nueva unidad al sistema, finalización de un servicio por parte de una estación y el fin de la simulación. Esta información se guardará de la siguiente manera: Fila 1: Evento fin de simulación Fila 2: Evento llegada de un cliente al sistema Filas 3 en adelante: Evento Terminación de un servicio por parte de una estación. Además, en las columnas se guardará la siguiente información: Columna No 1: Tiempo de ocurrencia del evento.
Columna No 2: Número de la entidad que causa el evento. Cuando el evento es llegada de un cliente, se guardará el número que identifica al cliente, cuando sea fin de servicio el número que identifica la estación cuyo servicio finaliza. Para el evento fin de simulación no se almacenará ningún valor.
Columna 3: Tipo de evento, para lo cual se usará la siguiente convención: = 1 para fin de simulación, = 2 para una llegada , = 3 para un fin de servicio.
En esta matriz se mantendrán ocupadas las primeras posiciones, según el número de eventos que haya programados para ocurrir en el futuro. Cuando se programe un nuevo evento, se aumentará el número de las filas, y cuando un evento no se vaya a programar de nuevo, se disminuirá el número de filas, colocándose en la posición a eliminar la información que hay en la última posición ocupada. En el momento de comenzar la simulación, esta matriz sólo tendrá dos posiciones ocupadas: La primera fila con el evento fin de simulación y la segunda con la primera llegada al sistema.
Matriz de Eventos Futuros MEF
Tiempo del evento (J = 1)
Entidad (J = 2)
Tipo (J = 3)
Fin Simulación (I = 1) Tiempo Simulación - 1
Llegada cliente (I = 2) Tiempo de llegada Número del cliente 2
Fin Servicio (I = 3) Tiempo de Servicio Número Estación 3
…………….. ………… ………. ……….
Fin Servicio (I = k + 2) Tiempo de Servicio Número Estación 3
Para buscar el próximo evento se busca en matriz de eventos, cuál es el menor valor que hay en la primera columna. Así, la información del próximo evento estará guardada en la fila MIN de la matriz MEF, donde MEF(MIN,1) = Mínimo {MEF(I,1), i = 1, Número de eventos}. Esta información será la siguiente: Tiempo del próximo evento = MEF(MIN,1) Entidad que causa el evento = MEF(MIN,2) Tipo de evento: = MEF(MIN,3) La matriz MEF también puede organizarse de tal forma que siempre se mantengan ocupadas k + 2 filas, y en la fila I, para I > 2 se mantendrá la información sobre la estación J = I – 2. SI la estación J está inactiva se guardará como tiempo de fin de servicio un valor alto (= TSIM + 1) de tal forma que el próximo evento no sea el fin de servicio en dicha estación.

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 19
5.5 Recolección de Estadísticas En la simulación de un sistema de colas puede ser interesante recoger las siguientes estadísticas:: Número medio de unidades en el sistema. Número medio de unidades en la cola. Número medio de unidades recibiendo servicio, equivalente al número medio de estaciones ocupadas. Tiempo medio de permanencia de un cliente en el sistema. Tiempo medio de permanencia de un cliente en la cola. Distribución del tiempo de permanencia en el sistema y en la cola. Distribución del número de unidades en el sistema y en la cola. Probabilidad de que un cliente tenga que esperar El cálculo de estas estadísticas se realizará de acuerdo con lo indicado en el capítulo 5 “Recolección de Estadísticas”. Para la recolección de las tres primeras estadísticas se usarán contadores del tipo nt t y para las
restantes, que corresponden a tiempos de tránsito, se usarán contadores del tipo X.
5.6 Seudo código detallado para la simulación de sistemas de colas con varias estaciones en paralelo
La figura 6.6 presenta el seudo código detallado para la simulación del sistema de colas de varias estaciones en paralelo, de tal forma que su implementación pueda realizarse en cualquier lenguaje general de programación, tal como C++, Pascal, Fortran o Visual Basic. Las variables están definidas de tal manera que su nombre indica lo que cada una representa, y no se requieran explicaciones adicionales. Algunas suposiciones o consideraciones que se han tenido en cuenta en la elaboración del seudo código son las siguientes: No se ha hecho ninguna suposición con respecto a alguna distribución especial para el tiempo entre llegada de
los clientes al sistema o para la distribución de los tiempo de servicio. Para generar estos tiempos aleatorios se usan los procedimientos “generar_tpo_llegada” y “Generar_tpo_servicio”, los cuales serán diseñados por quien implemente el programa, de acuerdo con las distribuciones de probabilidad respectivas para los tiempos entre llegada de clientes sucesivos al sistema y para el tiempo de servicio.
Se supone que los clientes se atienden de acuerdo al orden de llegada. Por lo tanto, para escoger el próximo cliente que será atendido cuando una estación termina de atender uno, se tomará el que esté de primero en la cola, la cual será reorganizada de tal forma que quien ocupe el primer lugar sea el que más tiempo haya permanecido allí.
Cuando llega un cliente y hay varias estaciones para atenderlo, se escogerá la que lleve mas tiempo inactiva desde que terminó su último período de actividad. Por lo tanto, se escogerá la que esté en el primer lugar de la cola reservada para las estaciones.
En el desarrollo del seudocódigo, se supone que el sistema tiene una capacidad finita. Si el sistema a simular tiene una capacidad ilimitada, habrá que asignarle un valor grande a esta variable, valor que sea consistente con la capacidad de los arreglos usados para representar las colas y los clientes, que si se excede puede causar problemas en la ejecución del programa.
En el desarrollo del seudo código se supone que se diseña un procedimiento independiente (denominado subrutina) que realiza las actividades específicas de cada evento. Igualmente, se desarrolla un procedimiento para la inicialización del sistema. Además, se escribe un programa principal, mediante el cual se controla la ejecución de los diferentes procedimientos o subrutinas.

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 20
Figura 6.11 Programa de simulación de colas de varios servidores en paralelo Programa principal y subrutinas
C Inicio Programa Simulación_Colas Definir: Tiempo_simul, semillas, nro_servi, cap_sistema, nro_max_cl Leer: Parámetros distribuciones de: Tiempo entre llegadas Tiempo de servicio, C Establecer condiciones de alternativas Reloj = 0 Llamar Rutina de inicialización C Algoritmo de simulación Mientras {reloj tiempo_simul} entonces
Llamar proximo_evento Reloj = mef(min,1) Tipo_evento = mef(min,3) Si (tipo_evento =2) entonces
Invocar rutina llegada Si no
Si (tipo_evento =3 ) entonces Invocar rutina fin_servicio
Fin si Fin si
Fin mientras Invocar rutina generar_reporte C Calcular otras estadísticas relevantes (costos) Si hay mas experimentos de simulación, entonces
Preparar condiciones nueva simulación Reinicializar semillas
Empezar nueva simulación (reloj = 0) Fin simulación Rutina inicializar C Inicialización del estado del sistema Nro_cl_sist = 0 Nro_cl_cola = 0 Nro_estac_oc = 0 Para i = 1 hasta nro_servi
Cola_est(i) = i estación(i,1) = 0 estación(i,2) = 0 estación(i,3) = reloj
Siguiente C Inicialización de lista de eventos Mef(1,1) = tiempo_sim Mef(1,3) = 1 C Primera llegada Tiempo_lleg = generar_tpo_lleg Mef(2,1) = tiempo_lleg + reloj
Mef(2,2) = 1 Mef(2,3) = 2 Nro_eventos = 2 C Inicialización de estadísticas Suma_tpo_cola = 0 Suma_tpo_sist = 0 Suma_cl_sist = 0 Suma_cl_cola = 0 Suma_nro_estac_oc = 0 Nro_cliente_ate = 0 Nro_clie_esp = 0 Nro_clie_sevan = 0 Fin rutina inicialización

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 21
Rutina proximo_evento C Búsqueda próximo evento Min = 1 Para i = 2, Nro_eventos
Si mef(i,2) mef(min,1) entonces
Min = i Fin si
Fin para t = mef(min,1) – reloj Suma_cl_sist + = nro_cl_sist * t
Suma_cl_cola + = nro_cl_cola * t
Suma_nro_estac_oc + = nro_estac_oc * t
Fin rutina proximo_evento Rutina llegada C Identificación del cliente nro_cliente = mef(min,2) C Programar próxima llegada Tiempo_lleg = generar_tpo_lleg Mef(min,1) = tiempo_lleg + reloj Mef(min,2) + = 1 C Verifica si el cliente puede entrar Si (nro_cl_sist<cap_sistema) entonces
Nro_cl_sist + = 1 Cliente(nro_cl_sist,1) = nro_cliente Cliente(nro_cl_sist,2) = reloj
C Verifica si el cliente puede ser atendido Si (nro_estac_oc < nro_servi) entonces
C Se selecciona un servidor estac = cola_est(1) Nro_estac_oc + = 1 Nro_esta_inac= nro_servi – nro_estac_oc
C Reorganiza cola servidores inactivos Si (nro_estac_inac > 0) entonces
Para l = 1, nro_servi_inac Cola_est(l) = cola_est(l+1)
Fin para Fin si Estación(estac,2) + = reloj – estación(estac,3) Estación(estac,1) = nro_cliente Cliente(nro_cl_sist,3) = “servicio” Tiempo_serv = Generar_tser Nro_eventos + = 1 Mef(nro_eventos,1) = reloj +tiempo_serv Mef(nro_eventos,2) = estac Mef(nro_eventos,3) = 3
Si no C Cliente pasa al último puesto de la cola
Nro_cl_cola + = 1 Cola_cl(clientes_cola) = nro_cliente Cliente(nro_cl_sist,3) = “cola”
Fin si Si no C Cliente no entra al sistema
Nro_cl_sevan = nro_cl_sevan+1 Fin si Fin procedimiento llegada
Figura 6.11 Programa de simulación de colas de varios servidores en paralelo Programa principal y subrutinas

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 22
Rutina Fin_servicio C Identifica servidor y cliente estac = mef(min, 2) Nro_cliente = estación(estac,1) i = Buscar(nro_cliente) nro_cl_ate + = 1 Suma_tpo_sist + = reloj – cliente(i,2) C Reorganiza matriz de clientes Si (i < nro_cl_sist) entonces
Para k = 1,3 Clientes(i, k) = clientes(nro_cl_sist, k)
Fin para Fin si Nro_cl_sist - = 1 C Si hay clientes en cola, escoge uno Si (nro_cl_cola > 0) entonces
Nro_cliente = cola_cl(1) Nro_cl_cola - = 1
C Reorganiza cola clientes Si (nro_cli_cola > 0) entonces
Para l = 1, nro_cl_cola Cola_cl(l) = cola_cl(l +1)
Fin para Fin si i = Buscar(nro_cliente) Suma_tpo_cola + = reloj – cliente(i,2) Nro_cl_esp + = 1 Estación(estac,1) = nro_cliente Cliente(nro_cl_sist,3) = “servicio” Tiempo_serv = Generar_tser Mef(min,1) = reloj +tiempo_serv
Si no C Si no hay cola, servidor inactivo
Nro_estac_oc - = 1
Nro_estac_inac= nro_servi – nro_estac_oc Cola_est(Nro_estac_inac) = estac Estación(estac,1) = 0 Estación(estac,3) = reloj
Si (min< nro_eventos) entonces Para k = 1,3
Mef(min,k) = mef(nro_eventos,k) Fin para
Fin si Nro_eventos - = 1
Fin si Fin rutina fin_servicio Rutina Generar_reporte Nro_medio_sist = Suma_cli_sist / reloj Nro_medio_cola = suma_cl_cola / reloj Nro_medio_servicio = suma_estac_oc / reloj Tipo_medio_sist = suma_tpo_sist / Nro_cl_ate Tpo_medio_cola = Suma_tpo_cola /nro_cl_ate Tpo_medio_esp = Suma_tpo_cola /nro_cl_esp Prob_esperar = nro_cl_esp / nro_cl_ate Imprimir reloj, nro_servi, nro_cl_aten, nro_cl_esp, nro_cl_sist, nro_cl_cola, nro_estac_oc, nro_medio_sistema,
nro_medio_cola, nro_medio_servicio, tiempo_medio_sist, tiempo_medio_cola, tiempo_medio_esp, Prob_esperar
Para j = 1 hasta nro_servi Porcen_inac = estación (j,2) *100 / reloj Imprimir j, estac(j,1), estación(j,2), porcen_inac
Fin para Imprimir matrices Cliente, Estación, Mef y Cola Fin Procedimiento Generar_reporte
Figura 6.11 Programa de simulación de colas de varios servidores en paralelo

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 23
Función Buscar(numero) C Busca posición en que se encuentra un cliente buscar = -1 Para i =1, nro_cl_sist
Si (cliente(i,1) = numero) entonces Buscar = i i = nro_cl_sist+1
fin si fin para si (buscar = -1) entonces
imprima “Error. No se encontró el cliente” parar proceso
fin si Fin función buscar
Figura 6.11 Programa de simulación de colas de varios servidores en paralelo 6 Simulación de estaciones en serie El siguiente algoritmo presenta las actividades que es necesario considerar cuando se hace la simulación de varias estaciones en serie. En este caso se tienen básicamente los mismos eventos que cuando se analizan varias estaciones en paralelo, a saber: Llegada de clientes al sistema, fin de servicio en una estación, y el fin de la simulación. Evento llegada al sistema Cuando se trata de una llegada al sistema, prácticamente se realizan las mismas actividades que cuando se tienen varias estaciones paralelo, excepto que el cliente pasa al servicio si la primera estación está inactiva, y si no lo está, entonces el cliente pasa a la cola número 1. Por lo tanto, la pregunta”hay servidores inactivos?” se cambia por “está inactiva la primera estación?. Si la respuesta es afirmativa, se pasa el cliente a la estación o servidor número 1. El diagrama de flujo siguiente ilustra la situación.
NO Sí Si No Si
Figura 6.12 Sistema en serie. Actividades realizadas cuando una unidad llega al sistema
Estación No 1 está inactiva?
El Cliente pasa al servicio
Cliente pasa a la Cola No 1
Se identifica al Cliente
Puede entrar al sistema?
Llegada Cliente al sistema
Cliente se va
B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 24
Evento fin de servicio Cuando el evento es un fin de servicio, el asunto es un poco más complicado, ya que las actividades a desarrollar dependen de si se trata de la última estación, o de otra estación diferente. Si se trata de la última estación, la situación es prácticamente idéntica al caso de varias estaciones en paralelo: el cliente sale del sistema (se calculan las estadísticas respectivas) y luego se analiza que pasa con el servidor que terminó de atender a un cliente, ya que si hay clientes esperando servicio, escoge uno para atenderlo, y si no ha se queda inactivo. , ya que las actividades a desarrollar dependen de si se trata de la última estación, o de otra estación diferente. Si no se trata de la última estación, entonces primero se debe mover el cliente atendido a la siguiente estación, bien sea que pase a servicio si la siguiente estación está inactiva o que se quede en la cola en caso contrario, y luego se debe analizar que pasa con el servidor que terminó de atender a un cliente, ya que si hay clientes esperando servicio, escoge uno para atenderlo, y si no ha se queda inactivo. En ambos casos se tiene en común, el definir que pasa con el servidor que terminó de atender al cliente, bien sea que continúe activo, si hay clientes esperando servicio, o que quede inactivo, si no los hay . El diagrama de flujo siguiente ilustra la situación. Sí No No
Sí No Sí
Fig. 6.13 Sistema en serie. Actividades realizadas por el simulador cuando finaliza un servicio.
Fin de un servicio
Hay Clientes esperando servicio en estación J?
Se selecciona una unidad de la cola J para ser atendida
El servidor J queda inactivo
Se identifica el Servidor (J) Se identifica el Cliente
El Cliente pasa al servicio
Es J la última estación?
El cliente sale del sistema
Está inactiva la siguiente estación J+1?
El Cliente pasa al servicio
Cliente pasa a la cola siguiente (j+1)

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 25
El seudo código siguiente ilustra el procedimiento general que se debe seguir para simular un sistema de varias estaciones en serie. PROCEDIMIENTO GENERAL servidores en serie Lectura de: Parámetros básicos (Tiempo de simulación, semillas, variables de control, número de estaciones)
Parámetros de distribuciones de: Tiempos entre llegadas Tiempos de servicio
Establecer condiciones para la alternativa a simular Reloj = 0 Invocar rutina de inicialización Mientras (Reloj < Tiempo_simulacion) Invocar Rutina de Próximo Evento Si Próximo Evento es llegada, entonces Invocar Rutina de llegada al sistema
Si no Si próximo Eventos es Fin_Servicio, entonces Identificar estación Identificar cliente Si es última estación, entonces Sacar cliente del sistema Si no Pasar cliente a la siguiente estación Fin si Actualizar estado de la estación Fin si Fin si
Fin Mientras Rutina de generación de reportes Si hay mas experimentos de simulación, entonces
Establecer condiciones de nueva simulación Fin si
Volver a inicializar el sistema, si es del caso FIN DE LA SIMULACION
Figura 6.13 Programa de simulación de colas en serie
7 Problemas resueltos 7.1 Problema No 1 Una peluquería manejada por un solo peluquero tiene una capacidad para dos personas. Los clientes llegan a una tasa poisson de tres por hora y los tiempos de servicio son variables aleatorias exponenciales con media de 1/4 de hora. La barbería está abierta 8 horas diarias. Se requiere saber: a) El número medio de personas en la barbería. b) La proporción de clientes que entran a la barbería. c) Si el peluquero trabajara dos veces más rápido, en cuánto se incrementarían sus entradas brutas por día? d) En cuánto se incrementarían sus entradas brutas por dìa si la capacidad de la barbería fuera de tres? Solución Aunque el problema planteado tiene solución analítica, se planteará su solución por medio de la simulación, y luego se compararán los resultados obtenidos analíticamente con los resultados obtenidos a través de la simulación, para verificar la validez de esta última técnica. El problema enunciado se ajusta perfectamente al modelo de colas con llegadas Poisson (exponenciales), servicio exponencial, una estación de servicio y cola finita y se denota como un modelo M/M/1 cola finita. Para la solución analítica, ver anexo respectivo Las características principales del sistema que se desea simular son las siguientes El tiempo entre llegada de clientes al sistema es exponencial, con tasa de llegada de tres clientes por hora o
de 0.05 clientes/minuto. El tiempo de servicio es exponencial, con una tasa de cuatro clientes por hora o de 0.0667 clientes/minuto. Sólo hay un servidor.

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 26
La longitud de la cola es de 1 ó 2 dependiendo de si se simula el sistema actual o uno de los sistemas propuestos, por lo cual la capacidad del sistema será de 2 ó 3, según el sistema analizado.
El sistema debe simularse por periodos de longitud de 8 horas = 480 minutos, y al final de un día es necesario cerrar el sistema y atender a quienes están esperando.
Se quiere que la simulación termine cuando se hayan simulado 100 días. Las semillas usadas para generar los tiempos entre llegadas y los tiempos de servicio son 597 y 5139
respectivamente. La tabla siguiente presenta los resultados de simular la operación de la peluquería durante 100 días de 8 horas. Igualmente presente los resultados encontrados analíticamente usando las fórmulas adecuadas para el modelo. Analizando los datos simulados para cada una de las tres políticas se observa que se cumplen las relaciones que existen entre el número medio de unidades en el sistema, en la cola y en servicio, y entre los tiempos medio de permanencia en el sistema, en la cola y de servicio., a saber:
L = Lq + a W = Wq + 1/
Además se cumple que el número medio de unidades recibiendo servicio, que es igual al número medio de estaciones ocupadas, y es igual a la fracción de tiempo que el sistema estuvo activo. Es decir, que en cuanto a las relaciones existentes entre los diferentes componentes, el simulador produce resultados válidos. Para una política cualquiera se comparan los resultados de la simulación con resultados analíticos, se observa que las discrepancias entre los dos resultados son insignificantes, o sea que puede concluirse que este simulador produce resultados que son altamente confiables. Con base en los resultados simulados se pueden contestar los interrogantes planteados en el problema. Si el peluquero trabajara dos veces más rápido, el porcentaje clientes que entran al sistema pasaría de 75.25% al 90.59%. Si se aumenta la longitud de la cola en 1, el porcentaje de clientes que entran al sistema pasa del 75.25 al 84.45. También podrían responderse los interrogantes con base en el número medio de unidades atendidas por día. En el sistema actual se atienden por día 18.64 clientes, en promedio; si el peluquero trabajara dos veces más atendería en promedio 22.44 clientes por día, y si se aumentara en 1 la capacidad de la barbería, se atenderían en promedio 20.92 clientes por día. 8 Problemas
6.1 Un laboratorio de enseñanza tiene 15 computadores para prácticas de docencia. Los alumnos que utilizan
dichas máquinas descubren que requieren periódicamente que el supervisor del laboratorio responda a preguntas, efectúe ajustes menores en los computadores, etc. Los tiempos entre solicitudes de ayuda por parte de cada estudiante siguen una distribución exponencial con una media de 30 minutos. El tiempo que requiere el supervisor para responder a dichas peticiones de ayuda siguen también una distribución exponencial con una media de dos minutos.
a) Simule el funcionamiento del laboratorio para determinar el tiempo total de espera de los alumnos
durante un período de estudio de una hora. b) Determine el efecto de contratar un ayudante que pueda responder a las peticiones de ayuda en la misma
forma que lo hace el supervisor. 6.2 La empresa Central Car Wash tiene una ubicación excelente, en una intersección muy frecuentada de la
ciudad. Los clientes se encuentran en dos categorías: el 75% son clientes que sólo desean el lavado de sus vehículos, y el 25% restante quieren tanto el lavado como el encerado rápido de sus automóviles. Los ingresos procedentes de un cliente de lavado y encerado son el doble de los de un cliente que sólo quiera el lavado. La distribución de tiempo de servicio es normal para ambas categorías, con una media de 7 minutos y una desviación estándar de un minuto para los clientes del lavado, y una media de 11 minutos con una desviación estándar de 2 minutos para los clientes de lavado y encerado. En la actualidad, hay dos cabinas de lavado y encerado y una zona de espera que puede recibir otros dos automóviles. El propietario está considerando la posibilidad de agregar una cabina de lavado exclusivamente, a expensas de uno de los espacios de la zona de espera. El 8% de los clientes que llegan se van cuando no es posible atenderlos inmediatamente, mientras que el 92% restante están dispuestos a esperar si se dispone de espacio de estacionamiento. Debido al tráfico que hay en la zona, los clientes se dirigen a algún competidor cuando no hay espacio libre de estacionamiento. El establecimiento se abre 12 horas diarias (se procesan todos los automóviles que se encuentran en la zona de espera en el momento de cerrar). La distribución del tiempo entre llegadas es exponencial, con una media de 6 minutos durante las primeras 4 horas y una media de 4 minutos durante las horas restantes.
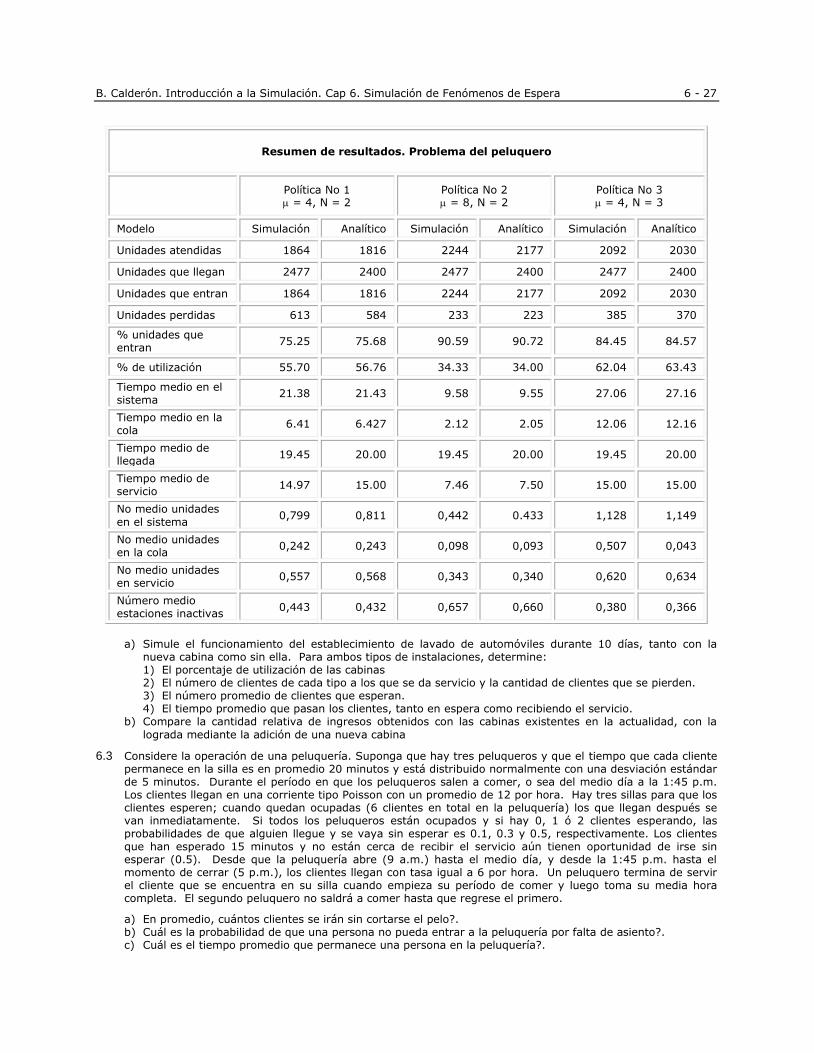
B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 27
Resumen de resultados. Problema del peluquero
Política No 1 = 4, N = 2
Política No 2 = 8, N = 2
Política No 3 = 4, N = 3
Modelo Simulación Analítico Simulación Analítico Simulación Analítico
Unidades atendidas 1864 1816 2244 2177 2092 2030
Unidades que llegan 2477 2400 2477 2400 2477 2400
Unidades que entran 1864 1816 2244 2177 2092 2030
Unidades perdidas 613 584 233 223 385 370
% unidades que entran
75.25 75.68 90.59 90.72 84.45 84.57
% de utilización 55.70 56.76 34.33 34.00 62.04 63.43
Tiempo medio en el sistema
21.38 21.43 9.58 9.55 27.06 27.16
Tiempo medio en la cola
6.41 6.427 2.12 2.05 12.06 12.16
Tiempo medio de llegada
19.45 20.00 19.45 20.00 19.45 20.00
Tiempo medio de servicio
14.97 15.00 7.46 7.50 15.00 15.00
No medio unidades
en el sistema 0,799 0,811 0,442 0.433 1,128 1,149
No medio unidades en la cola
0,242 0,243 0,098 0,093 0,507 0,043
No medio unidades en servicio
0,557 0,568 0,343 0,340 0,620 0,634
Número medio estaciones inactivas
0,443 0,432 0,657 0,660 0,380 0,366
a) Simule el funcionamiento del establecimiento de lavado de automóviles durante 10 días, tanto con la
nueva cabina como sin ella. Para ambos tipos de instalaciones, determine: 1) El porcentaje de utilización de las cabinas 2) El número de clientes de cada tipo a los que se da servicio y la cantidad de clientes que se pierden. 3) El número promedio de clientes que esperan. 4) El tiempo promedio que pasan los clientes, tanto en espera como recibiendo el servicio.
b) Compare la cantidad relativa de ingresos obtenidos con las cabinas existentes en la actualidad, con la
lograda mediante la adición de una nueva cabina 6.3 Considere la operación de una peluquería. Suponga que hay tres peluqueros y que el tiempo que cada cliente
permanece en la silla es en promedio 20 minutos y está distribuido normalmente con una desviación estándar de 5 minutos. Durante el período en que los peluqueros salen a comer, o sea del medio día a la 1:45 p.m. Los clientes llegan en una corriente tipo Poisson con un promedio de 12 por hora. Hay tres sillas para que los clientes esperen; cuando quedan ocupadas (6 clientes en total en la peluquería) los que llegan después se van inmediatamente. Si todos los peluqueros están ocupados y si hay 0, 1 ó 2 clientes esperando, las probabilidades de que alguien llegue y se vaya sin esperar es 0.1, 0.3 y 0.5, respectivamente. Los clientes que han esperado 15 minutos y no están cerca de recibir el servicio aún tienen oportunidad de irse sin esperar (0.5). Desde que la peluquería abre (9 a.m.) hasta el medio día, y desde la 1:45 p.m. hasta el momento de cerrar (5 p.m.), los clientes llegan con tasa igual a 6 por hora. Un peluquero termina de servir el cliente que se encuentra en su silla cuando empieza su período de comer y luego toma su media hora completa. El segundo peluquero no saldrá a comer hasta que regrese el primero.
a) En promedio, cuántos clientes se irán sin cortarse el pelo?. b) Cuál es la probabilidad de que una persona no pueda entrar a la peluquería por falta de asiento?. c) Cuál es el tiempo promedio que permanece una persona en la peluquería?.

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 28
6.4 Un sistema de colas posee las siguientes características:
a) La distribución de llegadas es Poisson con = 0.04/min
b) La distribución del tiempo de servicio es exponencial con u = 0.05/min. c) El número máximo permitido en la cola en cualquier tiempo es 200 unidades. d) Ninguna unidad permanecerá en la cola más de hora y media. e) La disciplina de la cola es de acuerdo al orden de llegada.
Simule el sistema por un período de tres años.
6.5 Los trabajos llegan a una estación de procesamiento por medio de una correa transportadora a una tasa de
una cada 4 minutos. La estación de servicio trabaja con una tasa exponencial, con parámetro u. Encuentre el valor u que minimice la probabilidad de tener una cola de longitud superior a tres. El sistema incurre en un costo de $ 1.000 por cada unidad que esté en la cola por encima de tres. El costo por día de prestar el servicio en la estación depende de u. La relación del costo es Cs = 20.000 u, donde Cs = costo por día. Determine el valor óptimo de u basado en la simulación de 30 días de 8 horas por turno.
6.6 Una persona maneja el taller de reparación de una planta, en el cual arregla las diferentes partes que se
dañan. La forma normal de operación consiste en permitir que las partes a reparar lleguen en la primera mitad del día y no se reciben aquellas órdenes que llegan después del medio día. El mecánico repara luego todas las partes que llegaron en la mañana, aunque para terminarlas todas tenga que trabajar tiempo extra. El turno normal de trabajo del mecánico es de 8 horas. Simule el sistema durante 30 días de trabajo, asumiendo que el proceso de llegadas es Poisson con parámetro = 0.08 y la tasa exponencial de servicio es
u = 0.10. En promedio cuántas horas de tiempo extra trabajará el mecánico por día? Qué valor de u reducirá el tiempo extra a cero?.
6.7 Simule un sistema de colas con tres estaciones en serie para el cual se cumple que el proceso de llegada es
Poisson con = 0.04. Las longitudes máximas de las colas son: LCOLA (1) = 100, LCOLA (2) = 10, LCOLA
(3) = 10. El tiempo de servicio en cada estación es exponencial, con los siguientes parámetros: u1 = 0.06, u2 = 0.06, u3 = 0.09. Simule el sistema hasta que 300 unidades hayan pasado completamente a través de todas las estaciones.
6.8 En el problema anterior efectúe los siguientes cambios: LCOLA (1) = 10, LCOLA (2) = 5 Y LCOLA (3) = 5 y
compare los resultados de los dos sistemas. 6.9 Un sistema de colas con cuatro estaciones en serie funciona con las siguientes características:
a) Llegadas exponenciales con = 0.04
b) u1 = 0.05 u2 = 0.06 u3 = 0.05 u4 = 0.07 Los tiempos de servicio son exponenciales. c) LCOLA (1) = 50, LCOLA (2) = 10 LCOLA (3) = 20, LCOLA (4) = 30 (longitudes máximas de las colas) d) Solamente un 50 por ciento de las unidades entran a la estación 2; las otras van o a la estación 3 o a la
estación 4 con igual probabilidad. 25% 50% 25% Analice el sistema. Compare la utilización de las cuatro estaciones. Qué pasaría si solamente un 20% de las
unidades entraran a la estación 2 y las demás fueran con igual probabilidad a la estación 3 o a la estación 4? 6.10 Simule un sistema de colas con varias estaciones en paralelo, en el cual el servicio es estrictamente de
acuerdo con el orden de llegada; el proceso de llegadas es poissoniano con = 0.05. Cada proceso de
servicio es exponencial con u1 = 0.08, u2 = 0.09 y u3 = 0.12. Determine todas las estadísticas que sean de interés.
6.11 La distribución del tiempo entre llegadas a una estación de servicio única estada dada por: (horas).
Tiempo entre llegadas: 0.5 1.0 1.5 2.0 2.5
Probabilidad: 0.15 0.25 0.30 0.25 0.05
El tiempo requerido para atender una unidad se distribuye exponencialmente con media 1/u. El problema
consiste en determinar el tiempo medio de servicio de tal forma que se minimice el costo total del sistema. El
1 2 3 4

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 29
costo de prestar el servicio es $ 200 por hora y el costo de espera por unidad es $ 40 por hora. Determine además el tiempo de inactividad del servicio y su utilización, el número medio de unidades en el
sistema y en la cola y los tiempos medios de permanencia en el sistema y en la cola. Además la distribución de los tiempos de permanencia en el sistema y en la cola.
6.12 Un mecánico atiende cuatro máquinas. Para cada máquina el tiempo medio entre requerimientos de servicio
es 10 horas y se supone que tiene una distribución exponencial. El tiempo de reparación tiende a seguir la misma distribución y tiene un tiempo medio de dos horas. Cuando una máquina se daña, el tiempo perdido tiene un valor de $ 30 por hora. El servicio del mecánico cuesta $ 100 diarios.
a) Cuál es el número esperado de máquinas en operación?. b) Cuál es el costo promedio por día?. c) Cuál es preferible: tener dos mecánicos de tal forma que cada uno atienda dos máquinas, o tener uno solo
como ocurre actualmente?. 6.13 Un camión de reparaciones a domicilio y su mecánico atienden máquinas agrícolas. El tiempo promedio de
viaje más servicio es de dos horas/máquina. El tiempo promedio de requerimiento de servicio es de 4 días (exponenciales). Cuando se requiere servicio, el costo ocasionado por la reparación de las máquinas es $ 1.000/hora. El mecánico y el camión tiene un costo de $ 320/hora. Cuántas máquinas agrícolas debe atender para minimizar los costos?.
Determine además:
a) Tiempo de inutilización por máquina. b) Distribución del número de máquinas dañadas. c) Distribución del tiempo de inactividad de las máquinas.
6.14 Los clientes llegan a un banco a una tasa Poisson de 20 por hora. La ventanilla del banco tiene un tiempo de
servicio exponencial con un tiempo medio de dos minutos. El 20% de los clientes son clientes especiales, que deben ser atendidos inmediatamente llegan, si la ventanilla está desocupada, o una vez finalice el servicio de la persona que está siendo atendida cuando ese cliente especial llegue:
a) Cuál es el tiempo medio de permanencia en el sistema y en la cola de un cliente especial?. b) Cuál es el tiempo medio de permanencia en el sistema y en la cola un cliente normal? c) Qué porcentaje de tiempo está ocioso el cajero? d) Cuál es la distribución del número de clientes del sistema? e) Cuál es el tiempo medio de permanencia de un cliente en el sistema?
6.15 Un aeropuerto puede atender tres aviones en dos minutos, ya sea que despeguen o aterricen. si esta tasa
tiene una distribución de Poisson, cuál es el tiempo medio entre llegadas (de aterrizaje o despegue) para asegurar que el tiempo medio de espera sea 5 minutos o menos? Suponga una distribución exponencial del tiempo entre llegadas. Dé, además, toda la información que pueda ser de alguna utilidad.
6.16 Las órdenes llegan a una empresa a una tasa Poisson de 20 por día. Estas órdenes son diferentes en cuanto
a su contenido, por lo tanto el tiempo de procesamiento no será igual para todas las órdenes, sino que se distribuye exponencialmente con una tasa de 28 por día. Sin embargo, cada una de las órdenes tiene especificado un tiempo de entrega que se distribuye uniformemente entre 15 y 25 minutos. Cuando una orden llega a la empresa, inmediatamente se hace el estimativo del tiempo que durará su procesamiento. La política actual consiste en procesar las órdenes de acuerdo con el orden de llegada. Si se pretende minimizar el tiempo medio de retraso en la entrega de las órdenes, cuál de las siguientes políticas es mejor, para el caso en que varias órdenes estén esperando ser procesadas.
a) Atenderlas de acuerdo al orden de llegada. b) Atender primero la orden que requiera un menor procesamiento. c) Atender las órdenes de acuerdo con la que tenga la próxima fecha de entrega. d) Atender las órdenes en una forma completamente aleatoria
6.17 Se va contratar un mecánico para que repare unas máquinas que se descomponen a una tasa promedio de 3
por hora. Las descomposturas se distribuyen en el tiempo de una manera que puede considerarse como Poisson. El tiempo no productivo de una máquina cualquiera se considera que le cuesta a la empresa $ 25 por hora. La compañía ha limitado la decisión a uno de dos mecánicos, uno lento pero barato, el otro rápido pero caro. El primero de ellos pide $ 15 por hora; a cambio dará servicio a las máquinas descompuestas, de manera exponencial, a una tasa media de cuatro por hora. El segundo pide $ 25 por hora y reparará las máquinas de manera exponencial a una tasa de seis por hora. Cuál de los mecánicos debe contratarse? Suministre toda la información que considere necesaria.
6.18 El administrador de un supermercado puede emplear a María o a Carmen. María quien presta servicio a una
tasa exponencial de 20 clientes por hora,. puede ser contratada a un costo de $ 12 por hora. Carmen quien presta el servicio a una tasa exponencial de 30 clientes por hora, puede ser contratada a un costo de $ C por

B. Calderón. Introducción a la Simulación. Cap 6. Simulación de Fenómenos de Espera 6 - 30
hora. La administración estima que, en promedio el tiempo del consumidor vale $ 4 por hora y que debe tenerse en cuenta en el modelo. Si los consumidores llegan a una tasa Poisson de 10 por hora, entonces:
a) Cuál es el costo promedio si se contrata a María? b) Cuál es el costo promedio si se contrata a Carmen? c) Cuál es el valor máximo por hora que puede pagarse a Carmen?
6.19 Los clientes llegan a una estación de servicio a hacer lubricar sus carros. Si no hay espacios para parquear,
los carros que llegan se van a otra estación. Una vez que el cliente ha encontrado un espacio libre, deja el carro hasta que sea lubricado
Si el cliente no ha regresado aún cuando se termina de lubricar el carro, éste es llevado a un parqueadero
cercano. Los clientes llegan de acuerdo a un proceso de Poisson a una tasa media de 32 por día. El tiempo requerido para atender un carro tiene una distribución exponencial donde la tasa media es de 40 por día. La utilidad por cada carro atendido es $ 80. El costo capitalizado de la tierra para cada espacio para un carro es aproximadamente $ 32 por día. Cuántos espacios deberían asignarse, incluyendo el designado para el gato hidráulico de tal forma que se maximice la utilidad neta esperada?
6.20 Asuma que se está estudiando la operación de un sistema que contiene dos estaciones en paralelo. Para cada
estación existe una cola. Las llegadas al sistema entran a la primera cola, mientras haya menos de 10 unidades en esta cola. Si hay 10 o más unidades en la primera cola, las unidades pasan a la segunda, para la cual no existe restricción en cuanto a su longitud. Las llegadas al sistema siguen un proceso de Poisson con parámetro = 0.10. Los tiempos de servicio para ambas facilidades son exponenciales con u1 = 0.08 y u2 =
0.09 (por hora). Simule el sistema por tres semanas para determinar.
a) El número de unidades que pasaron por el sistema.
b) Número total de unidades atendidas por la segunda estación. c) Tiempo esperado de permanencia en el sistema: (i) de una unidad, (ii) de una unidad en la estación 1 y
(iii) de una unidad en la estación 2. d) Distribución del número de unidades del sistema.
6.21 Considere un sistema de producción en el cual la estación o máquina que presta el servicio puede fallar. Esta
falla se produce únicamente durante el período en que está procesando una orden. Cuando una orden llega al sistema se estima el tiempo que durará su servicio., Además, mientras la estación está procesando la orden, existe una probabilidad p de que falle. Asuma que el tiempo de reparación del mecanismo de servicio es exponencial con un tiempo medio de 2.4 horas. Asuma que el tiempo entre llegada de las órdenes es exponencial con un tiempo medio de 4.8 horas y que el tiempo de servicio es exponencial con una media de 3.6 horas. Se pide simular este sistema para determinar, entre otras las siguientes estadísticas: número de fallas durante el período de simulación, tiempo total de inactividad por falla y el tiempo medio por falla. Asuma p = 0.05
6.22 Una estación de gasolina abre diariamente a las 7:00 AM y cierra a las 7:00 PM. A los empleados que
atienden esta gasolinera se paga generalmente $ 30.000 al día (12 horas). La llegada de los automóviles que solicitan servicio sigue una distribución de Poisson, con una llegada media igual a 10 autos por hora. El
tiempo de servicio por carro está distribuido en forma exponencial con un tiempo esperado de servicio igual a 5 minutos. Cuando excede de 3 el número de automóviles que esperan el servicio, entonces los clientes disgustados abandonan la gasolinera sin esperar el servicio. Determine por simulación el número óptimo de operarios que se deben contratar en la estación de gasolina, sabiendo que las ganancias que deja cada automóvil servido son de $ 2.00.
6.23 Los clientes de un supermercado llegan a las cajas registradoras con una frecuencia promedio de 20 clientes
pro hora, siguiendo una distribución poissoniana. El tiempo que un cliente tarda en cada caja se encuentra distribuido en forma exponencial con un valor esperado de 10 minutos. Si el criterio de la tienda es tal que permite a un cliente esperar en una cola un promedio de 5 minutos en cada caja, utilice la simulación para estimar el número de cajas registradoras que se requieren. Estime el tiempo de ocio de cada caja registradora.
6.24 Un químico ensaya diversos productos de diferentes unidades de una refinería. Este tiempo y el equipo
tienen un costo de $18 por hora. El puede realizar tres ensayos por hora, pero esta tasa varía y puede describirse mediante una distribución de Poisson. Una unidad en operación tiene un tiempo medio entre requerimientos de ensayos de 2 horas con una distribución exponencial de tiempos. Cuando la muestra requiere más de 1 hora, la utilización adicional del equipo de ensayos cuesta $100. Seis unidades funcionan
continuamente. Cuántos químicos deben emplearse?

7 SIMULACIÓN DE SISTEMAS DE INVENTARIOS 1 Conceptos generales sobre inventarios La teoría de inventarios trata sobre la determinación de los procedimientos óptimos para la adquisición de existencias de artículos que han de servir para satisfacer una demanda futura y/o una demanda ya creada. La teoría de inventarios trata de determinar estos procedimientos mediante métodos analíticos, mientras que en la simulación se trata de determinar estos procedimientos siguiendo los cambios que ocurren en el sistema de inventarios a través del tiempo. Sin embargo, como se explicó en el capítulo III, la simulación sólo debe usarse cuando los métodos analíticos hayan fallado. En el capítulo 1 “Simulación – Aplicabilidad” y en el capítulo 4 “Generación de Procesos” se estudió un modelo muy particular de inventarios, el conocido bajo el nombre del “problema del vendedor de periódicos”. En este capítulo estudiaremos cómo simular sistemas más generales de inventarios. Pero antes de entrar al detalle de cómo realizar la simulación, es necesario entender el sistema que se va a simular y sus principales características. Por esta razón, inicialmente definiremos el “sistema de inventarios”, estudiaremos sus propiedades y enunciaremos las políticas más comunes de inventarios. 2 Definiciones básicas
2.1 Sistema de Inventarios. Un sistema de inventarios puede definirse como aquel sistema en el cual sólo son relevantes los siguientes costos: 1) El costo de llevar los inventarios, el cual incluye el costo de la inversión en inventarios, de almacenamiento,
de manejo, de obsolescencia, etc. 2) El costo debido a la escasez o déficit de los artículos, el cual incluye el costo de las ventas perdidas, de la
pérdida de goodwill, el pago de trabajo extra, etc. 3) El costo de efectuar el pedido o costo de reabastecimiento del inventario, el cual incluye el costo de
preparar la maquinaria para la producción, el costo de preparar las órdenes, la tramitación de las mismas, y el costo mismo de los artículos.
Estos tres costos, que estudiaremos en detalle posteriormente, serán denominados respectivamente como “costos de mantenimiento o almacenamiento” del inventario, “costo de escasez o ruptura” y “costo de adquisición o de preparación”. Los tres costos antes mencionados están estrechamente relacionados. Cuando se trata de disminuir un costo, uno o a veces los otros dos costos aumentan. Así el costo total del sistema puede ser afectado por las decisiones que se tomen. Cualquier costo puede ser aumentado (disminuido), pero ésto tiende a disminuir (aumentar) los otros dos costos. 2.2 Problemas de inventario Se tiene un problema de inventarios cuando se tiene que encontrar una respuesta a las dos preguntas siguientes: 1) ¿Cuándo debe reabastecerse el inventario? 2) ¿Cuánto debe ordenarse? Los elementos “tiempo” y “cantidad” son las variables que están sujetas a control en un sistema de inventarios. El problema de inventarios consiste en encontrar los valores específicos de las variables de decisión que minimicen el costo total. También puede definirse el problema de inventarios como el problema de balancear los tres tipos de costos de tal forma que su suma sea mínima. En un problema de inventarios se trata entonces de responder las preguntas Cuándo y Cuánto debe ordenarse. La primera pregunta (Cuándo) puede contestarse con base en el tiempo o con base en el inventario que haya del artículo de interés, de la siguiente manera: 1) El inventario debe ser reabastecido cuando la cantidad en existencia sea igual o esté por debajo de cierto
número de unidades (R). 2) El inventario debe ser reabastecido cada T unidades de tiempo.

Simulación de Sistemas de Inventarios. Procedimiento general 7- 2
La pregunta cuándo puede responder de dos formas: 1) Ordenar siempre una cantidad fija de Q artículos. 2) Ordenar una cantidad de artículos tal que el inventario se eleve a S unidades. las cantidades R, T Q, y S reciben los nombres de “punto de reorden”, “período de programación o de revisión”, “lote económico” y “nivel máximo”, respectivamente. Generalmente cuando se coloca una orden para reabastecer el inventario transcurre cierto tiempo entre el instante en que se coloca la orden y el instante en que estos artículos son colocados en el inventario. Este intervalo de tiempo es conocido como “tiempo de espera” y lo denotaremos por L. 2.3 Políticas de inventario Una política de inventarios consiste entonces, en responder simultáneamente las preguntas “cuándo “y “cuánto”. Las políticas más comunes son las siguientes: 1. “Cuando el inventario sea igual o esté por debajo del punto de reorden R, se coloca una orden por una
cantidad fija de Q unidades”. Esta política recibe el nombre de “sistema del punto de reorden“ o “sistema de lote económico” y se la denota como sistema <R, Q>, Sistema Q o Sistema R. De ahora en adelante lo denotaremos como Sistema Q.
La Figura 7.1 describe gráficamente este sistema. Cuando el inventario alcanza el punto de reorden R se coloca una orden por una cantidad fija de Q artículos. Esta orden no llega inmediatamente, sino que demora cierto tiempo para su entrega -L-, el cual puede ser variable. En la gráfica las líneas continuas representan el inventario físico y las líneas discontinuas representan lo que hay en inventario y en órdenes. En la gráfica se asume que cuando la demanda no puede satisfacerse inmediatamente, esta demanda no se pierde sino que se acumula para ser satisfecha una vez llegue un lote de artículos, es decir, la demanda no satisfecha a tiempo se “compromete” y cuando llega un lote de artículos lo primero que se hace es satisfacer la demanda cautiva y el resto de artículos se lleva al inventario (L2). It Q Q Q R
L1 L2 L3
Figura No 7.1 Sistema de punto de reorden 2. Otra política de inventarios es la siguiente: “Cada T unidades de tiempo se revisa el inventario existente y
se coloca una orden por una cantidad tal que eleve el inventario al nivel máximo S”. ES decir, si IT es el inventario al final del tiempo T, el tamaño del lote sería de Q = S - IT.
La figura 7.2 ilustra gráficamente el comportamiento de este sistema el cual es conocido con el nombre de “Sistema de revisión periódica“ y es denotado como sistema <T, S> o Sistema T. En el sistema de revisión periódica se coloca una orden por una cantidad variable, que es igual a la demanda durante el último período de tiempo T. (QT = S - IT.)

Simulación de Sistemas de Inventarios. Procedimiento general 7- 3
En el sistema de punto de reorden en el instante en que se coloca la orden por Q unidades, debe haber en inventario existencias suficientes para satisfacer la demanda mientras llega la nueva orden que se ha colocado, es decir, el punto de reorden R define el nivel de la demanda máxima que se puede satisfacer a tiempo antes que llegue el nuevo pedido. La demanda que exceda el punto de reorden será demanda instafisfecha, que puede satisfacerse una vez llegue el pedido que se ha hecho, o que puede perderse, según las características del sistema analizado. En el sistema de revisión periódica el nivel al cual se eleva el inventario cuando se coloca una orden (S) debe ser suficiente para satisfacer la demanda durante el próximo período (T) y durante el siguiente tiempo de espera. Es decir, el nivel máximo del inventario S indica la demanda máxima que el sistema está dispuesto a satisfacer a tiempo durante el período T + L. S It Q1 Q2 Q3
L1 L2 L3 T T T
Figura 7.2 Sistema de Revisión Periódica 3. Existe otro sistema de inventarios denominado “Sistema de suministro opcional” en el cual se tratan de
combinar los aspectos principales de los dos sistemas anteriores. El procedimiento del sistema es el siguiente: “Cada T unidades de tiempo se revisa el estado del inventario. Si el inventario ha llegado al punto de reorden, o está por debajo del mismo, se coloca una orden por una cantidad tal que el inventario sea elevado a su nivel máximo. Si el inventario no ha llegado al punto de reorden, nos e coloca ninguna orden y para ordenar es necesario esperar hasta el próximo período de revisión.
La figura No 7.3 Ilustra gráficamente el procedimiento Los sistemas más empleados son el sistema de punto de reorden y el sistema de revisión periódica. El sistema de revisión periódica también se le denomina sistema T y el de punto de reorden se le denomina sistema Q. S It Q1 R
L1 L2 L3 T T T
Figura No 7.3 Sistema de suministro opcional

Simulación de Sistemas de Inventarios. Procedimiento general 7- 4
3 Propiedades de los sistemas de inventarios En todos los sistemas de inventarios e reconocen las siguientes propiedades: La demanda, el abastecimiento, los costos y las restricciones A continuación se hará un análisis somero de cada una de las propiedades. 3.1 Propiedades de la demanda El objetivo de mantener existencias de un artículo es satisfacer la demanda futura que puede haber del mismo. La demanda constituye el componente más importante de un sistema de inventarios. Sin embargo, el sistema no tiene control sobre la demanda de los artículos que se almacenan Aunque la demanda por determinado artículo no sea controlable si es posible estudiar sus propiedades. 1) El “Tamaño de la demanda” es la cantidad requerida de determinado artículos en un tiempo cualquiera. De
acuerdo a la demanda los sistemas de inventarios pueden ser:
a) Sistemas determinísticos cuando el tamaño de la demanda es conocido y constante. b) Sistemas probabilísticos cuando la demanda no es conocida, sino que es una variable aleatoria que tiene
asociada una función de densidad o de probabilidad. 2) Se denomina “Tasa de demanda” a la demanda por unidad de tiempo. Si la demanda no es constante,
entonces se hablará de “Tasa media de demanda”. 3) “Tiempo entre demandas” es el tiempo que transcurre entre dos demandas consecutivas que se hacen o
llegan al sistema. Igual que la demanda puede ser constante o variable. 3.2 Propiedades del abastecimiento o suministro El suministro se refiere a las cantidades que se programan para ser colocadas en inventario, al tiempo en que se toman las decisiones para ordenar estas cantidades y al tiempo en que estas cantidades son agregadas al inventario. Al considerar las propiedades del suministro se identifican los siguientes elementos: El período de programación -T-, el tamaño del suministro o lote -Q-, y el tiempo de espera -L 1) El “Período de Programación -o Período de Revisión T” es el tiempo que transcurre entre dos decisiones
consecutivas con respecto al reabastecimiento del inventario, es decir, con respecto a la colocación o no de una orden por un lote de artículos. Cuando los períodos de programación están prescritos, quien toma las decisiones no los puede controlar; en este caso son parámetros y generalmente tienen la misma magnitud.
2) El “tiempo de espera” -L es el intervalo de tiempo que hay entre la decisión de ordenar un lote de artículos
y la adición del mismo al inventario. El tiempo de espera generalmente no está sujeto a control. Cuando el tiempo de espera es muy pequeño, se dice que no es significativo y se lo trata como si fuera nulo (L = 0). Cuando es significativo, se dice que L 0. Si el tiempo de espera no es constante, entonces se debe
conocer su función de densidad. Cuando el tiempo de espera es constante y la demanda es conocida, entonces la demanda durante el
tiempo de espera será conocida también. Cuando la demanda es una variable aleatoria y el tiempo de espera es una constante conocida, la demanda durante el tiempo de espera no es conocida, pero es relativamente fácil encontrar su distribución. Si la demanda y el tiempo de espera son variables aleatorias, es complicado encontrar la distribución de la demanda durante el tiempo de espera. En este caso, la simulación tiene bastante aplicación.
3) El “tamaño del lote Q” es la cantidad de artículos que se ordenan para ser agregados al inventario y para
satisfacer la demanda ya causada, si ésta ha sido comprometida. El tamaño del lote puede variar de un período a otro, dependiendo del sistema que se esté usando.
4) El “período del suministro Tp“ es la longitud de tiempo en que los artículos son agregados al inventario. La
tasa suministro p es la razón del tamaño del lote al tiempo del suministro, es decir, p = Q/Tp Los modelos más comunes de suministro son el suministro instantáneo y el suministro uniforme. La figura 7.4 muestra varios modelos de suministro. El suministro a una tasa uniforme tiene lugar cuando el mismo sistema produce los artículos; en este caso la tasa de suministro recibe el nombre de “tasa de producción”. El suministro instantáneo ocurre cuando el lote de artículos es entregado todo de una vez; en este caso se dice que la tasa de suministro es p = . Cuando el suministro ocurre a una tasa uniforme, se dice que p < .

Simulación de Sistemas de Inventarios. Procedimiento general 7- 5
Uniforme Potencia Instantáneo Por lotes p =
Figura No 7.4 Modelos de suministro
3.3 Costos relevantes en sistemas de inventario Un sistema de inventarios ha sido definido como un sistema en el cual sólo son significativos tres tipos de costos y en el cual al menos dos costos cualesquiera están sujetos a control. Estos costos son los costos de adquisición, mantenimiento del inventario y de escasez.
3.3.1 Costo de adquisición de los artículos Esos costos pueden dividirse en dos partes: a) El costo de los artículos comprados. b) El costo en que incurre el sistema al efectuar un pedido. El costo de adquisición puede resultar de muchas fuentes: El procesamiento de las órdenes., el cargue y descargue de los artículos, la inspección de los mismos cuando son recibidos, el precio de comprar los artículos, el transporte, etc. Como puede observarse, los costos en que incurre el sistema de inventarios cuando se coloca una orden puede dividirse en dos clases: los costos que dependen de la cantidad ordenada, y los que son independientes de la cantidad ordenada; estos costos pueden incluir el costo de las unidades. Si se adquieren Q unidades, los costos de adquisición serán denotados por C (Q); el costo promedio por unidad será C = C (Q)/Q. Un caso que es de interés es aquel en que el costo promedio por unidad es constante, C independiente de la cantidad ordenada; el costo de adquirir Q unidades será entonces CQ. Los costos que son independientes de la cantidad ordenada se incurren cada vez que se coloca una orden; nos referimos a ellos como “costos fijos” de colocar una orden y serán denotados por A (costos de adquisición). Así, cuando se coloca una orden por Q unidades, el costo en que incurre el sistema está dando por A + C (Q). Un costo que puede estar incluido en el costo de adquisición es el “costo de revisión” del inventario, en el cual se incurre cuando se coloca una orden y es necesario revisar el inventario para determinar el número disponible de artículos y determinar la cantidad a pedir. Se incurriría en este costo si se lleva un sistema de inventario periódico. Cuando el sistema mismo produce los artículos, el costo fijo de adquisición “A” recibe el nombre de “costo de preparación” de un lote de producción y los costos asociados serían los costos de la mano de obra requerida para preparar el equipo de producción, costo de los materiales que se usen durante el período de prueba, costos del tiempo durante el cual no hay producción debido a la preparación, los costos administrativos en que se incurra con motivo de la producción del lote de artículos, etc. Los costos que dependen de la cantidad producida serán los costos de la mano de obra directa, material directo y gastos generales de la producción.
3.3.2 Costos de mantenimiento del inventario. En este costo se incluyen los costos de seguro, alquiler de depósitos (almacenamiento) y el costo de manejarlos, tales como luz, celadores, etc. Un costo que es frecuentemente el más importante, no es un costo (gasto) directo, sino un costo de oportunidad y es el costo en que se incurre por tener un capital muerto o invertido en inventarios, en vez de tenerlo invertido en otra actividad más lucrativa. Este costo es igual a la mayor tasa de retorno que el sistema podría obtener en inversiones alternativas.

Simulación de Sistemas de Inventarios. Procedimiento general 7- 6
Los costos de oportunidad son directamente proporcionales a la inversión en inventarios; en igual forma pueden variar los costos debido a daño (obsolescencia) de los artículos y al robo. La tasa en que se incurre en los costos de seguros no es estrictamente proporcional a la inversión en inventarios, sino que puede variar en forma escalonada. Por ejemplo, si la inversión en inventarios es menor o igual que K1 pesos el seguro será de N1 y si está entre K1 y K2 pesos el seguro será de N2, etc. Se denotará por CM el costo de mantener una unidad en inventario durante una unidad de tiempo. Así, si durante el tiempo t hay un inventario de It artículos, el costo de mantener este inventario estará dado por CM
It t.
Si el costo de mantener el inventario es el costo de oportunidad, entonces se supondrá que la tasa a la cual se incurre en este costo es proporcional a la inversión. Se denotará por i la constante de proporcionalidad. Si C es el costo de un artículo, el costo de mantener una unidad en inventario durante una unidad de tiempo será iC. Las unidades de i serán de “costo por unidad de tiempo por cada unidad monetaria invertida”. El costo de mantener una unidad en inventario es directamente proporcional a la longitud de tiempo que la unidad permanece en inventario. Si se supone que el nivel de un inventario se comporta como lo indica la figura 7.5, el costo de llevar el inventario durante el tiempo enmarcado en la figura está dado por: Costo = CM (I11 + I22 + I33 + ... + I88) = CM It t
I1 I2 I3 I4 I5 I6
1 2 3 4 5 6 7 8 9 10
Figura No 7.5 Variación en el nivel del Inventario
Es decir, el costo de mantenimiento del inventario durante el tiempo t es igual al costo unitario de mantenimiento por el área bajo la curva del inventario. Si se quiere encontrar el costo por unidad de tiempo, basta dividir la expresión anterior por t, y se encuentra que el costo de mantener el inventario por unidad de tiempo es directamente proporcional al “inventario promedio”. Las unidades (dimensiones) de los diferentes costos que se han considerado hasta el momento están dadas por:
[ C ] = [$]
[ ]Q, [CM ] = [iC] =
[$]
[ ][ ]Q T, [ A ] =[ $ ], [ i ] =
[$]
[$][ ]T T
1
donde [Q] denota unidades de “cantidad”, [$] denota unidades “monetarias” o de “pesos” y [T] denota unidades de “tiempo”.
3.3.3 Costos de escasez, ruptura o faltante Este costo surge cuando ocurre la demanda por un artículo y el sistema no tiene existencias. Este es el costo más difícil de determinar. Algunos de los componentes asociados con el costo unitario de escasez puede incluir: - Cotos ocasionados por trabajo extra. - Costos por procedimientos administrativos especiales. - Pérdidas de ventas específicas. - Pérdida de goodwill.

Simulación de Sistemas de Inventarios. Procedimiento general 7- 7
- Pérdida de consumidores. Para estimar el costo de escasez es necesario distinguir dos situaciones que pueden presentarse cuando no se dispone de existencias para satisfacer una demanda: - Cuando la demanda se puede satisfacer una vez se haya reabastecido el inventario. - Cuando las ventas se pierden. (a) Cuando la demanda se puede satisfacer posteriormente: Caso demanda comprometida Es muy difícil determinar el costo en que se incurre cuando una orden es devuelta al consumidor, ya que estos costos pueden incluir aspectos tales como pérdida de goodwill, o el costo o pérdida ocasionado al consumidor al no poder usar éste el artículo a tiempo. Otros aspectos de costo de escasez pueden medirse con menor grado de dificultad, tales como el costo de notificar al consumidor que el artículo no está en el depósito y que le será enviado más tarde, los costos de enviar el artículo, etc. Cuando el sistema es quien usa el artículo, este costo será el costo de mantener un equipo inactivo y un personal ocioso por falta de material; en tal caso es relativamente fácil obtener una medida del costo de escasez. Generalmente se asume que hay un costo de escasez asociado con cada unidad que se demanda; este costo dependerá del tiempo que se demore el sistema en enviar el artículo al cliente. La función más general que puede utilizarse es CE = TT1 + TT2 t, es decir, un costo fijo para cada unidad que no se despacha a tiempo, mas un costo variable que es directamente proporcional al tiempo durante el cual la orden espera se despachada. Este costo de escasez se aplica al número medio de unidades que tienen que esperar antes de ser despachadas.
Las unidades de CE son [CE ] = [$]
[ ][ ]Q T
(b) Cuando las ventas se pierden Dado que la demanda se pierde cuando el sistema está sin existencias, el costo de las pérdidas en ventas no puede depender del tiempo. Se puede asumir que cuando se incurre en costos por pérdida de ventas, existe un costo fijo asociado con cada unidad demandada y que no puede ser ordenada. El costo de las ventas perdidas incluye diferentes factores tales como la pérdida de goodwill, la pérdida de la utilidad de la venta, la pérdida de clientes que en un futuro pueden ir a otra parte, etc. Este costo también puede incluir los asociados con procedimientos especiales para informar al consumidor que su demanda no puede ser satisfecha. La forma más sencilla de estimar este costo es considerar el valor de la utilidad perdida. Este costo será denotado por CE. Así, si V es el precio unitario de venta, el costo por escasez podrá estimarse como CE = V - C
Las unidades de CE son [CE ] = [$]
[ ]Q
3.4 Propiedades de las restricciones Las restricciones en los sistemas de inventarios tienen que ver con varias propiedades que de una u otra forma representan limitaciones a las componentes discutidas antes. Algunas de las restricciones que pueden ocurrir son las siguientes: - Restricciones en las unidades. Las unidades pueden considerarse como continuas o discretas. Por ejemplo,
en algunos sistemas se deben pedir siempre por docenas. - Restricciones de espacio. El espacio para almacenar los artículos puede ser limitado. - Restricciones en los costos. En algunos sistemas de inventarios puede no permitirse la ocurrencia de
determinado tipo de costos. Por ejemplo, la política del sistema puede ser no permitir escasez. En este caso el costo de escasez es prohibitivo (CE )
- Restricciones en el capital invertido, es decir, la inversión en inventarios puede estar limitada a un capita
máximo. 4 Aspectos generales de la simulación de sistemas de inventarios Por lo general, el objetivo principal al estudiar un problema de inventario es determinar la política operativa que minimice el costo total del sistema. Si se está simulando el sistema de revisión periódica, se debe determinar el período óptimo de revisión T y el nivel máximo al cual debe llevarse el inventario S. En el sistema de punto

Simulación de Sistemas de Inventarios. Procedimiento general 7- 8
de reorden, deben determinarse los valores óptimos del punto de reorden R y del tamaño del lote Q. Sin embargo, en otras situaciones el objetivo puede ser simplemente evaluar el comportamiento de una determinada política de manejo del inventario. Antes de entrar a la simulación de los sistemas antes mencionados, es conveniente analizar algunos aspectos que son comunes a ambos sistemas, para luego estudiar cada sistema por separado y analizar posteriormente la posibilidad de diseñar un simulador para ambos sistemas. La simulación de los sistemas de inventarios se hará, al igual que la simulación de sistemas de colas, con base en eventos. Es decir, una vez definidos los eventos se buscará el de más cercana ocurrencia, se ejecutará el evento primario y se efectuarán todas las ramificaciones que resulten del evento que ha ocurrido. 4.1 Eventos En la simulación de inventarios se pueden distinguir los siguientes eventos: - La demanda por artículos - La revisión del inventario y como consecuencia la colocación de una orden para su reabastecimiento. - La llegada de un lote de artículos - El fin de la simulación Las características de los tres primeros elementos ya fueron estudiadas al analizar las propiedades de los sistemas de inventarios. Sin embargo, a continuación haremos un repaso de los mismos, pero esta vez desde el punto de vista de la simulación. 1) Características de la demanda. Generalmente se supone que el patrón de comportamiento de la demanda
es por completo independiente del sistema que se analice. Es decir, el sistema no tiene ningún control sobre la demanda.
La demanda se define mediante el tiempo entre demandas sucesivas y el número de unidades requeridas
en cada demanda. El tiempo entre demandas sucesivas puede ser una constante o una variable aleatoria. En igual forma, el número de unidades requeridas en cada demanda puede ser constante o puede ser una variable. Por ejemplo, cuando registramos las ventas diarias de determinado artículo, estamos considerando el tiempo entre demandas sucesivas como constante (un día) y el número de unidades requeridas en cada demanda como una variable aleatoria. Cuando el tiempo entre demandas sucesivas es variable, generalmente la cantidad demandada por cada cliente es constante (una unidad). Sin embargpo, tanto el tiempo como la cantidad demandada pueden ser variables aleatorias, y estarán definidos mediante la respectiva distribución de probabilidad.
2) Revisión del inventario y colocación de órdenes. En el sistema de punto de reorden se supone que se tiene
un sistema continuo de inventarios y que en cualquier instante se puede saber cuál es el inventario disponible. Sin embargo, sólo es necesario conocer el estado del inventario cuando ocurre una demanda que haga bajar el nivel del inventario (físico y en órdenes) al punto de reorden o por debajo de él. Es decir, en el sistema Q es necesario efectuar una revisión del inventario cada vez que ocurre una demanda para decidir si es necesario colocar una orden para reabastecer el inventario; esta orden sería por una cantidad fija Q.
En el sistema de revisión periódica, el nivel del inventario es revisado a intervalos fijos de tiempo (T) para
conocer el tamaño de la orden que debe colocarse. En este sistema puede suponerse que existe un sistema periódico de inventarios y que al final del período puede ser necesario hacer una revisión para conocer las existencias y con base en las mismas colocar un pedido.
Si revisado el inventario se concluye que hay que colocar una orden, es necesario estimar el tiempo que
tardaría esa orden en ser entregada y adicionada al inventario. Este tiempo de espera, como ya se indicó, puede ser constante o variable. En este momento se genera un evento futuro correspondiente a la entrega de dicho pedido.
En la simulación y en el sistema real puede suceder que en un instante haya varias órdenes colocadas, pero
no recibidas, y debido a lo aleatorio de los tiempos de espera, podría suceder que las órdenes se cruzaran, es decir, si una orden que se colocó en un tiempo t1 y otra orden se colocó en un tiempo t2, t2 > t1, la orden colocada en t2 puede llegar primero que la orden colocada en t1. Por lo tanto, el modelo de simulación que se diseñe deberá tener en cuenta este aspecto.
Cuando exista un costo de revisión del inventario, este costo deberá tenerse en cuenta en el sistema de
revisión periódica, más no en el sistema de punto de reorden (en el cual se supone que el inventario se mantiene actualizado) a no ser que se desee comparar ambos sistemas.

Simulación de Sistemas de Inventarios. Procedimiento general 7- 9
3) Recibo de órdenes. Cuando se revisa el inventario y se decide colocar una orden para reabastecer el
inventario, es necesario estimar su fecha de llegada, es decir, se debe generar un evento futuro que será la llegada de dicho pedido. Cuando el próximo evento sea la llegada de una orden, es necesario saber qué se hará con la misma, de acuerdo a las características del sistema simulado.
Si cuando llega una orden no hay demanda insatisfecha, entonces todo el lote que llegue será adicionado al
inventario existente. Si hay demanda insatisfecha y comprometida, entonces, del lote de unidades que llegue, se satisface primero la demanda insatisfecha o comprometida y el resto se agrega al inventario. Si se está simulando un sistema de ventas perdidas, todas las unidades que lleguen irán al inventario.
Cuando llegue un lote de unidades, se debe actualizar el número de órdenes que estén pendientes por llegar
y eliminar dicho evento de la lista de eventos. 4) Fin de la simulación. Se calculan las estadísticas requeridas y se genera el reporte de salida.
4.2 Formulación general del modelo Enfoques para la simulación de sistemas de inventario Enfoque por eventos Enfoque unidad por unidad Eventos primarios
1) Demanda por artículos, caracterizada por: Tiempo entre demandas sucesivas, y
Número de unidades requeridas.
2) Revisión del inventario colocación de una orden para su reabastecimiento
Sistema de Punto de Reorden: Evento condicional
Sistema de revisión periódica: Evento independiente
3) Llegada de un lote de artículos Tamaño del pedido
3) El fin de la simulación Puede haber varios lotes pendientes de entrega Reloj = 0 Inicializar sistema (estado, contadores, eventos) Mientras (Reloj < tiempo_simulacion) Buscar próximo evento (minimo tiempos eventos) Reloj = tiempo del próximo evento Identificar tipo de evento Si (evento = demanda), entonces , Manejar demanda (Actualizar inventario) Si sistema = punto de reorden, entonces Si llegó al Punto de Reorden, colocar pedido Fin si si no Si (evento = Llegada lote), entonces Actualizar inventario físico y faltantes si no (es evento Revisión) Revisar inventario y colocar pedido Fin si Fin si Fin mientras Generar reporte -Calcular variables de salida (endógenas) Modelo general de la simulación por eventos Lectura de parámetros básicos Reloj = 0 Inicialización del sistema Mientras (reloj < tiempo simulación) Búsqueda del próximo evento Reloj = tiempo del próximo evento

Simulación de Sistemas de Inventarios. Procedimiento general 7- 10
Si evento = demanda, entonces Manejo demanda Si evento = Revisión, entonces Revisión inventario Si evento = llegada lote, entonces Recibo del lote Fin mientras Generar reporte Fin simulación Un sistema de inventarios ha sido definido como aquel sistema en el cual son relevantes los costos de adquisición, de mantenimiento y de escasez. Es decir, la política que se escoja es aquella que minimice el costo total del sistema, que estará dado por la suma de los costos anteriores. Por lo tanto, se debe buscar una forma de expresar los diferentes costos del sistema de acuerdo a las variables que es necesario tener en cuenta. Con respecto a los costos unitarios se usará la misma anotación que se definió anteriormente, a saber: CM: Costo de mantener una unidad en inventario una unidad de tiempo. CE: Costos de escasez. Dependiendo de las características del sistema simulado, tendrá los siguientes
significados: - Costo por unidad de demanda no satisfecha por unidad de tiempo, cuando la demanda se
compromete. - Costo por unidad no vendida cuando la demanda se pierde.
A: Costo fijo de ordenar un lote de artículos para reabastecer el inventario. CR: Costo de revisar el inventario (sistemas de revisión periódica). Podría estar incluido en A. C: Costo unitario o precio de compra. Si It representa el inventario que hay en el tiempo t y ese inventario se mantiene durante un tiempo t,
entonces el costo de mantenimiento del inventario durante ese tiempo (CMt) estará dado por: CMt = CM. It. t
Si durante el tiempo t no hubo existencias sino un déficit de Et unidades, el costo de mantenimiento del
inventario durante ese tiempo sería cero (0) y el costo de escasez (CEt) estaría dado por: CEt = CE. Et. t
Si las ventas se pierden, el costo anterior de escasez no se aplicará, sino que en el momento en que se pierda la venta se aplicará el respectivo costo de ventas perdidas dado por CE. VP. Si en el tiempo t se examina el estado de un sistema de inventarios, entonces es necesario tener en cuenta algunos de los siguientes aspectos: 1. Si It representa las unidades que hay en inventario en el tiempo t, y esas unidades han estado en inventario
durante un tiempo t, entonces el costo en que ha incurrido el sistema para mantener esas unidades en
inventario durante t, está dado por CM. It. t, es decir, el costo de mantenimiento del inventario hasta el
tiempo t - CMt - estará dado por: CMt = CMt + CM. It t
2. Puede suceder que en el tiempo t no haya unidades en inventario sino que por el contrario exista un déficit
Et de artículos que deberá satisfacerse cuando llegue un lote de artículos. Si el déficit es Et, y se ha mantenido durante el intervalo de tiempo t, el costo acumulado de escasez hasta el tiempo t (CEt) está
dado por: CEt = CEt + CE. Et t
Si se está simulando un sistema de ventas perdidas, entonces no se aplicaría el costo anterior, ya que el
costo de escasez sería independiente del tiempo. El costo de escasez se aplicaría en el instante en que las ventas se perdieran.
3. Si en el tiempo t tiene lugar una demanda por Dt artículos, podrían presentarse las siguientes situaciones:
a. Dt It :Hay en inventario artículos suficientes para satisfacer la demanda. Entonces el inventario
resultante sería It - Dt artículos, es decir el inventario se reduce en la cantidad demandada. b. 0 < It < Dt : Aunque hay artículos en inventario éstos no son suficientes para satisfacer toda la
demanda. En este caso se satisfará parte de la demanda (It) y el resto (Dt - It) será la demanda no satisfecha a tiempo, la cual se podrá comprometer para ser satisfecha cuando se reabastezca el

Simulación de Sistemas de Inventarios. Procedimiento general 7- 11
inventario, o se perderá, de acuerdo a las características del sistema analizado. Después de satisfecha parcialmente la demanda, la escasez o ventas perdidas, según el caso, serán Et = Et + Dt - It y el nivel del inventario será Cero (0): It = 0
c. It = 0. No hay artículos en inventarios. En este caso, no se puede satisfacer ninguna parte de la
demanda, y ésta irá a formar parte de la demanda comprometida (Et = Et + Dt) o se perderá, según el sistema.
Cuando las ventas se pierden, debe actualizarse inmediatamente el costo de las ventas perdidas.
Si la variable IOt representa los artículos que hay físicamente en inventario mas las órdenes que se han
colocado pero que aún no han llegado, entonces cada vez que ocurre una demanda, esta variable debe ser actualizada de acuerdo a la demanda que se satisfaga o puede satisfacerse. Es decir, si toda demanda puede ser finalmente satisfecha (ahora o posteriormente), entonces cada vez que ocurra una demanda, a la variable IOt debe restársele la demanda total (IOt = IOt - Dt). Sin embargo, si las ventas se pierden, esta variable debe actualizarse únicamente con la parte de la demanda que se satisfaga, es decir con It (IOt = IOt - It)..
En algunos sistemas de inventarios, el costo de mantenimiento podría calcularse con base en lo que haya
en existencias y en pedidos, y no únicamente con base en las existencias. Si se está simulando el sistema de punto de reorden, entonces cada vez que ocurre una demanda se debe
examinar lo que hay en inventario y en órdenes para saber si se llegó al punto de reorden. Si se llegó al punto de reorden ( IOt R ), se coloca una orden por una cantidad fija Q, la cual puede tardar algún tiempo
en llegar. Cuando se coloca la orden el sistema incurre en un nuevo costo, el costo de adquisición -costo de colocación de la orden mas el costo de los artículos. Estos costos sería A + CQ. El costo acumulado de adquisición hasta el tiempo t (CAt) sería:
CAt = CAt + A + CQ El costo anterior se actualiza solamente cuando IOt R.
5. Si se está simulando el sistema de revisión periódica y en el tiempo t ocurre una revisión, se debe definir el
tamaño de la orden que debe colocarse, el cual está dado por Q = S - IOt, ó Q = S - It si no hay órdenes pendientes por llegar. En este momento el sistema está incurriendo en el costo de revisar el inventario (CR), en el costo de colocar la orden (A) y en el costo de los artículos. Por lo tanto, el costo acumulado de adquisición hasta el tiempo t será el dado por:
CAt = CAt + A + CR + CQ 6. Si en el tiempo t llega un lote de Q artículos, entonces lo primero que debe hacerse es satisfacer la demanda
comprometida y el resto llevarlo al inventario. Las siguientes expresiones ilustran las diferentes situaciones que pueden presentarse:
Et = Et - Q, It = 0 si Et > Q. It = It + Q - Et , Et = 0 si Et Q.
Habiendo considerado los diferentes aspectos de cualquier sistema de inventario, se puede entrar ahora a la simulación de los mismos.
5 Modelo de simulación para los sistemas Q y T 5.1 Aspectos generales Para la simulación de los sistemas de inventario se usará el enfoque por eventos, es decir, la simulación se hará siguiendo los cambios que se pueden presentar en el estado del inventario de acuerdo a los eventos que vayan ocurriendo. En el sistema Q la revisión del inventario es un evento secundario o condicional y se presenta como consecuencia de una demanda. Por lo tanto se tienen únicamente tres eventos primarios, a saber: - El fin de la simulación - La demanda por artículos (llegada de un cliente) - La llegada de un lote de artículos para reabastecer el inventario.

Simulación de Sistemas de Inventarios. Procedimiento general 7- 12
En el sistema T o de revisión periódica el inventario solamente se revisa cada T unidades de tiempo y no cada vez que ocurra una demanda. Además, cuando se coloca una orden por un lote de artículos, el tamaño del lote no es siempre el mismo, sino que será variable, dependiendo del nivel de existencias o de lo que haya en existencias y en órdenes pendientes de entrega en el momento de hacer la revisión y del nivel máximo que deben alcanzar esas existencias. Por lo tanto, en el sistema T la revisión del inventario no es consecuencia directa de una demanda, sino que es un evento independiente. Por lo tanto, además de los eventos considerados en el sistema Q se debe incluir el siguiente evento adicional: - Fin de la simulación. - Ocurrencia de una demanda. - Ocurrencia de una revisión del inventario. - Llegada de un lote de artículos. La figura 7.6 presenta en forma gráfica un diagrama de flujo descriptivo de las diferentes actividades que deben desarrollarse en la simulación, tanto para el sistema de punto de reorden como de revisión periódica. Cuando se simula el sistema Q deberán definirse los valores de Q y R y en el sistema T los valores de T y S, junto con los demás parámetros comunes a ambos sistemas, tales como costos, semillas, inventario inicial, distribuciones.,etc. Con respecto al desarrollo del programa de simulación, es necesario identificar las siguientes etapas: 1 Creación de la imagen del sistema (inicialización del sistema), que comprende
1.1 Lectura de los parámetros básicos para la simulación, tales como costos unitarios, semillas, parámetros de las distribuciones, parámetros del sistema o política a simular, inventario inicial.
1.2 Inicialización de las variables de estado, tales como nivel del inventario físico, inventario físico y en órdenes, órdenes pendientes, etc.
1.3 Inicialización de contadores para recoger estadísticas, tales como inventario medio, escasez media, costos, etc.
2 El algoritmo de simulación, que comprende: 2.1 La búsqueda del próximo evento y recolección de estadísticas de variables que dependen del
tiempo.( Contadores del tipo nt t)
2.2 La realización del evento, que como ya se indicó puede ser uno de los siguientes: 2.2.1 Ocurrencia de una demanda. 2.2.2 La llegada de un lote 2.2.3 La revisión del inventario 2.2.4 El fin de la simulación
3 La generación del reporte de salida, que tiene lugar cuando el evento es el fin de la simulación.
Para desarrollar un modelo de simulación para los sistemas Q y T es necesario definir una variable que identifique para un caso particular el sistema que se va a simular. Esa variable denominada SISTEMA podrá tomar los siguientes valores: SISTEMA = 1 Si se ha de simular el sistema Q. SISTEMA = 2 cuando se va a simular el sistema T. En los numerales siguientes se desarrollan algunos aspectos y se definen algunas variables que hay que tener en cuenta en el diseño del modelo de simulación, que puede luego implementarse en un computador.. 5.2 Lista de Eventos Futuros MEF Los eventos que pueden ocurrir en una simulación tienen tres atributos básicos, a saber: - El tiempo de ocurrencia del evento. - El tipo de evento - La entidad que causa el evento. Para la simulación de inventarios será la “cantidad” asociada con el
evento.
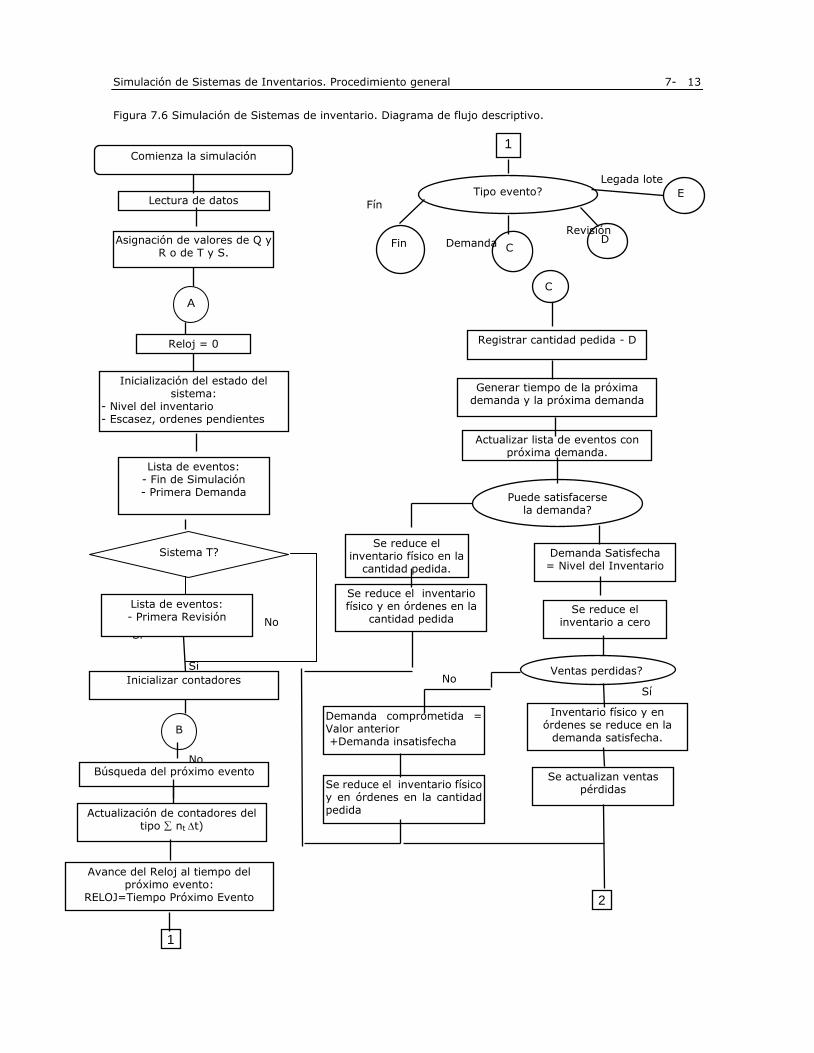
Simulación de Sistemas de Inventarios. Procedimiento general 7- 13
E Tipo evento?
C Fin D
C
Puede satisfacerse la demanda?
Ventas perdidas?
Figura 7.6 Simulación de Sistemas de inventario. Diagrama de flujo descriptivo.
Legada lote Fín
Revisión Demanda
Fin
Sí
No No No Sí
Sí No Sí
No
Comienza la simulación
Lectura de datos
Asignación de valores de Q y R o de T y S.
A
Inicialización del estado del sistema:
- Nivel del inventario - Escasez, ordenes pendientes
Lista de eventos: - Fin de Simulación - Primera Demanda
Reloj = 0
Sistema T?
Lista de eventos: - Primera Revisión
Inicializar contadores
B
Búsqueda del próximo evento
Actualización de contadores del tipo nt t)
1
1
Avance del Reloj al tiempo del próximo evento:
RELOJ=Tiempo Próximo Evento
Registrar cantidad pedida - D
Actualizar lista de eventos con próxima demanda.
Generar tiempo de la próxima demanda y la próxima demanda
Se reduce el inventario físico en la
cantidad pedida.
Inventario físico y en órdenes se reduce en la
demanda satisfecha.
Demanda Satisfecha = Nivel del Inventario
Se reduce el inventario físico y en órdenes en la
cantidad pedida Se reduce el
inventario a cero
Se actualizan ventas pérdidas
Demanda comprometida = Valor anterior +Demanda insatisfecha
Se reduce el inventario físico y en órdenes en la cantidad pedida
2

Simulación de Sistemas de Inventarios. Procedimiento general 7- 14
4 Sistema de Punto No Sí No Sí
Sí
Sí
Figura 7.6 Simulación de Sistemas de inventario. Diagrama de flujo descriptivo.
2
Actualización de estadísticas sobre demandas satisfechas y no
satisfechas
Se llegó al punto de reorden?
COLOCAR UN NUEVO PEDIDO - Generar Tiempo de Espera - Actualizar Costos de Adquisición
Actualizar Lista de Eventos con el tiempo de llegada del lote.
B
D
Calcular el tamaño del lote
COLOCAR UN NUEVO PEDIDO - Generar Tiempo de Espera - Actualizar Costos de Adquisición
Actualizar Lista de Eventos con el tiempo de llegada del lote.
B
Actualizar Lista de Eventos con la Próxima Revisión
Evento: Llegada lote
E
Evento: Revisión Inventario
Se alcanza a satisfacer demanda comprometida?
Identificar tamaño del lote Q
Se actualiza la Lista de Eventos Futuros, eliminando
esta llegada.
B
F
Evento: Fin de la Simulación
GENERAR REPORTE DE SALIDA: - Inventario y Escasez Promedio. - Inventario Físico y en órdenes promedio. - Costo promedio por unidad de tiempo. - Etc.
Desea realizar mas simulaciones?
Realizar los cambios requeridos: - Variables de Decisión (Q,R) o (T,S) - Reinicializar semillas.
A
Fin Simulación
Se satisface demanda comprometida y se lleva el
resto al inventario.
Se reduce el nivel de la demanda
comprometida

Simulación de Sistemas de Inventarios. Procedimiento general 7- 15
Para llevar la información sobre los eventos futuros, se usará un arreglo denominado “Matriz de Eventos Futuros - MEF”, que será un arreglo en dos dimensiones, con la siguiente estructura:
Fila No TIEMPO CANTIDAD TIPO
1 Tiempo de Simulación No hay Fin tipo 1
2 Tiempo Próxima Demanda Demanda Demanda tipo 2
3 Tiempo próxima revisión Nivel máximo S Revisión inv tipo 3
4 Tiempo de llegada Tamaño del lote Q Llegada lote tipo 4
5 Tiempo de llegada Tamaño del lote Q Llegada lote tipo 4
N Tiempo de llegada Tamaño del lote Q Llegada lote tipo 4
Por lo tanto el significado general de este arreglo será el siguiente: - MEF(I,1) = representa el tiempo de ocurrencia del evento. - MEF(I,2) = representa la cantidad asociada con el evento (demanda, nivel máximo, lote). - MEF(I,3) = representa el tipo de evento, según la siguiente convención:
= 1 si el evento es el fin de la simulación = 2 si el evento es una demanda. = 3 si el evento es la revisión del inventario (solamente se da si se simula el sistema T). = 4 si el evento es la llegada de un lote para reabastecer el inventario.
El número de filas ocupadas dependerá del sistema a simular y del número de lotes que estén pendientes por llegar. Cuando se inicialice el sistema en el tiempo cero (RELOJ = 0) se llenarán, las dos primeras filas en el sistema Q y las tres primeras en el sistema T, siendo la tercera la relacionada con la próxima revisión. Cuando se haga la revisión y se coloque un pedida para reabastecer el inventario, estos lotes pendientes por llegar irán a partir de la fila tres en el sistema Q y de la fila cuatro en el sistema T. El tiempo de ocurrencia de los futuros eventos puede definirse como una variable entera, para lo cual puede ser necesario definir un factor de escala de tal forma que al calcular los tiempos de los eventos no se pierda información en el momento de truncar o redondear los valores. Por ejemplo, si el tiempo medio entre ocurrencia de una demanda es 0.5 horas, entonces puede usarse como unidad de tiempo el minuto (factor de escala de 60) y no la hora, o un factor de escala de 30. Esta información se guardará de la siguiente manera: MEF (1,1) = Tiempo de simulación MEF (1,2) = 1, que indica que el evento es el fin de la simulación. MEF (2,1) = Tiempo de ocurrencia de la próxima demanda. Puede ser aleatorio. MEF (2,2) = Guarda la cantidad que demandará el próximo cliente. Puede ser una variable aleatoria. MEF (2,3) = 2 que indica que el evento es una demanda. MEF (I,1), I > 2 Para I=3 guardará el tiempo de la próxima revisión en el sistema T y para I 3 en el
sistema Q el tiempo de llegada de un lote para reabastecer el inventario. MEF (I,2), I > 2: Para I=3 guardará el nivel máximo del inventario S, y para I 3 en el sistema Q el tamaño
del lote que está pendiente por llegar. MEF(I,3), I > 2: Para I = 3 guardará el valor de tres (3) en el sistema T, lo cual indica que el evento es la
revisión del inventario, y en el sistema Q el valor de cuatro (4), que indica que el evento es la llegada de un lote.
Como en un momento dado puede que no haya lotes pendientes por llegar al sistema, o por el contrario puede que haya varias órdenes que se han colocado pero que no han llegado, entonces el arreglo “MEF” debe ser abierto y debe existir alguna variable que indique o cuántas órdenes están pendientes por llegar o cuántas filas haya ocupadas en este arreglo. Se usará la variable NFILA para indicar el número de filas ocupadas en el arreglo MEF. El valor mínimo de NFILA es dos en el sistema Q y tres en el sistema T. Además, las filas ocupadas serán las primeras; por lo tanto, cuando llegue un lote será necesario disminuir el número de filas ocupadas y reorganizadas, si es del caso, de tal forma que cuando se vaya a buscar el próximo evento, se busque únicamente en las primeras filas de la matriz. 5.3 Recolección de estadísticas En la simulación de inventarios hay variables cuyo valor debe darse en función del tiempo, es decir, al recoger información acerca de esta variable, es necesario indicar el tiempo durante el cual la variable tomó determinado valor. Esas variables son el “inventario” y la “escasez”, pero esta última sólo se da cuando el

Simulación de Sistemas de Inventarios. Procedimiento general 7- 16
sistema se compromete a satisfacer la demanda cuando haya existencias. Si las ventas se pierden la única variable que depende del tiempo es el inventario. Se recogerá información acerca de las unidades requeridas en cada demanda y sobre la parte de la demanda que es satisfecha inmediatamente y sobre la demanda que debe esperar ser satisfecha o que se pierde. Costos La información de costos es la siguiente: - Costos de mantenimiento: CMt = CMt + CM. It t
- Costos de Escasez: CEt = CEt + CE. Et t, cuando la demanda se compromete.
- CEt = CEt + CE. VPt , si la demanda no satisfecha se pierde. - Costos de adquisición: CAt = CAt + A + CQ 5.4 Seudo código. Simulación de sistemas de inventarios PROCEDIMIENTO GENERAL (1) CREACIÓN IMAGEN DEL SISTEMA
LECTURA DE PARÁMETROS BÁSICOS Tiempo de simulación, semillas, costos, Tipo_Sistema, Tipo_escasez, inventario inicial Parámetros de distribuciones de: Tiempos entre llegada de clientes (demandas) Cantidad demandada Tiempo de espera Si Tipo_Sistema = Sistema Q, entonces Leer Tamaño Lote (Q) y Punto de Reorden (R) Si no Leer Nivel Máximo (S) y Período de Revisión (T) Fin Si INVOCAR RUTINA DE INICIALIZACIÓN
(2) ALGORITMO DE SIMULACIÓN
Próximo Evento: Demanda (Llegada Cliente al Sistema) Mientras Próximo Evento Fin_Simulación
Rutina de Próximo Evento Si Próximo Evento = Demanda ,entonces Invocar Rutina de Demanda Si no Si Próximo Evento = Revisión, entonces Invocar Rutina de Revisión
Si no Si próximo Evento = Llegada Lote, entonces Invocar Rutina Llegada Lote Fin si Fin si Fin si Fin Mientras
(3) INVOCAR RUTINA DE GENERACIÓN DE REPORTES Si hay mas experimentos de simulación, entonces Establecer condiciones de nueva simulación Volver a inicializar el sistema Fin si FIN DE LA SIMULACIÓN
RUTINA DE INICIALIZACIÓN
RELOJ = 0 * Inicialización del estado del sistema
Inventario = Inventario Inicial (It = II) Inventario Físico y en Ordenes = Inventario Inicial (IOt = II)
* Inicialización lista de eventos * Evento tipo 1: Fin de Simulación. MEF(1,1) = Tiempo Simulación MEF(1,2) = 1 * Evento tipo 2 : Llegada nuevo cliente (Generar Tiempo entre Demandas y Cantidad pedida MEF(2,1) = Reloj + Tiempo entre demandas MEF(2,2) = 2
MEF(2,3) = Cantidad Pedida

Simulación de Sistemas de Inventarios. Procedimiento general 7- 17
Número de Eventos = 2
* Eventos tipo 3: Fin de servicio de las k estaciones Si Tipo Sistema = Sistema T
MEF(3,1) = Reloj + Tiempo entre demandas MEF(3,2) = 3 MEF(3,3) = S Número de Eventos = 3
Fin si * Inicialización contadores para estadísticas
Número Clientes (demandas)= 0 Numero demandas atendidas = 0 Suma _It = 0 (tipo nt t )
Suma_Et = 0 (tipo nt t)
Ventas Perdidas = 0 Número pedidos = 0 Artículos pedidos = 0
FIN RUTINA DE INICIALIZACION RUTINA DE PROXIMO EVENTO * Búsqueda de Próximo Evento
Min = 1 Para fila = 2 hasta Número de eventos Si (MEF(fila,1) MEF(min,1) entonces
Min = fila Fin si Fin para Tiempo del Próximo Evento: TPE = MEF(min,1) t = TPE - RELOJ
* Actualización de contadores sobre variables de estado del tipo nt t
Suma _It+ = It * t
Suma_Et+ = It * t
RELOJ = TPE FIN RUTINA DE PRÓXIMO EVENTO RUTINA DE LLEGADA DE DEMANDA * Evento tipo 2 : Llegada nuevo cliente
Evento: Llegada de un cliente (Demanda). Demanda_actual = MEF(min,3)
* Actualizar Evento Primario: Programar nueva demanda Generar Tiempo de Próxima demanda (TD) Generar próxima cantidad pedida (D) MEF(2,1) = Reloj + Tiempo entre demandas MEF(2,3) = D Número de Clientes (demandas)+ = 1 Si Demanda_actual It, entonces
Numero de demandas atendidas+ = 1 It = It – demanda actual. IOt = IOt - demanda actual
Si no Demanda satisfecha = It Demanda insatisfecha = Demanda actual – It It = 0 Si Tipo_escasez = Demanda comprometida, entonces Et = Et +demanda insatisfecha IOt = IOT – Demanda actual Si no Ventas perdidas+ = demanda insatisfecha IOt = IOT – Demanda satisfecha Fin si
Fin si * Revisión del inventario (Sistema Q)
Si Tipo Sistema = Punto de Reorden, entonces Si IOT Punto de Reorden, entonces
Número de pedidos+ = 1 Artículos pedidos+ = Q IOt+ = Q. Generar Tiempo de espera (L) Número de eventos+ = 1

Simulación de Sistemas de Inventarios. Procedimiento general 7- 18
MEF(número de eventos,1) = Reloj + Tiempo de espera MEF(número de eventos,2) = 4 MEF(número de eventos,3) = Q
Fin si Fin
FIN RUTINA DEMANDA RUTINA DE REVISIÓN * Actualizar Evento Primario: Programar nueva revisión
MEF(min,1) = Reloj + Tiempo de revisión (T) Q = S – IOT Número pedidos+ = 1 Artículos pedidos+ = Q IOt+ = Q. Generar Tiempo de espera (L) Número de eventos+ = 1 MEF(número de eventos,1) = Reloj + Tiempo de espera MEF(número de eventos,2) = 4 MEF(número de eventos,3) = Q
FIN RUTINA LLEGADA DE CLIENTE RUTINA DE LLEGADA DE LOTE
Q = MEF(min,3) Si Et Q, entonces
It = It + Q - Et Et = 0.
Si no Et = Et - Q
Fin si Si min < Número de eventos
MEF(min,1) = MEF(número de eventos,1) MEF(min,2) = MEF(número de eventos,2) MEF(min,3) = MEF(número de eventos,3)
Fin si Número de eventos- = 1
FIN RUTINA LLEGADA DE LOTE RUTINA DE GENERACION DEL REPORTE DE SALIDA * Cálculo de:
Inventario promedio = Suma_It/Reloj Escasez promedio = Suma_Et/Reloj Nivel Servicio = (Número de demandas – Número demandas atendidas)/ Número demandas Promedio lote = Artículos pedidos/Número pedidos Costo Inventario = Inventario Promedio * Costo_manto Costo Pedido = Número pedidos * Costo_pedido/Reloj Costo_artículos = Artículos pedidos *costo_unitario/Reloj Si Tipo_escasez =Demanda comprometida, entonces
Costo escasez = Suma_Et * Costo_escasez Si no Costo escasez = Ventas perdidas * Costo_escasez/Reloj Fin si Costo = Costo Pedido + Costo artículos + Costo Inventario + Costo escasez Imprimir: Estadísticas
FIN RUTINA DE GENERACION DE REPORTE 5.5 Ejemplo. Simulación en hoja de cálculo Ejemplo. La tabla siguiente presenta la simulación realizada en Excel durante 45 días del siguiente sistema de inventarios: Se hace un pedido por 50 unidades cuando el inventario llegue a un nivel de 20 unidades. La demanda que no se pueda satisfacer a tiempo se pierde. La demanda y el tiempo de espera tienen las distribuciones empírica mostradas a continuación:
Demanda 0 1 2 3 4 5 6 7 8 9 10
Probabilidad 0.01 0.02 0.04 0.06 0.09 0.14 0.18 0.22 0.16 0.06 0.02
Tiempo de espera 3 4 5
Probabilidad 0.2 0.6 0.2

Simulación de Sistemas de Inventarios. Procedimiento general 7- 19
Simulación de sistemas de inventario. Sistema de Punto de Reorden
Reloj (días)
Inv inicial
Lote Demanda Demanda. Satisf.
Total Ventas
Perdidas
Invent. físico final
Inv físico y en
órdenes
Ordenes?
Tiempo de
espera
Llegada lote
0 50 0 50 50
1 50 0 5 5 0 45 45 0 0 0
2 45 0 7 7 0 38 38 0 0 0
3 38 0 4 4 0 34 34 0 0 0
4 34 0 7 7 0 27 27 0 0 0
5 27 0 7 7 0 20 20 50 5 11
6 20 0 5 5 0 15 65 0 0 0
7 15 0 5 5 0 10 60 0 0 0
8 10 0 3 3 0 7 57 0 0 0
9 7 0 6 6 0 1 51 0 0 0
10 1 0 5 1 4 0 50 0 0 0
11 0 50 8 8 4 42 42 0 0 0
12 42 0 8 8 4 34 34 0 0 0
13 34 0 6 6 4 28 28 0 0 0
14 28 0 7 7 4 21 21 0 0 0
15 21 0 8 8 4 13 13 50 4 20
16 13 0 6 6 4 7 57 0 0 0
17 7 0 4 4 4 3 53 0 0 0
18 3 0 8 3 9 0 50 0 0 0
19 0 0 2 0 11 0 50 0 0 0
20 0 50 7 7 11 43 43 0 0 0
21 43 0 5 5 11 38 38 0 0 0
22 38 0 7 7 11 31 31 0 0 0
23 31 0 8 8 11 23 23 0 0 0
24 23 0 9 9 11 14 14 50 4 29
25 14 0 7 7 11 7 57 0 0 0
26 7 0 5 5 11 2 52 0 0 0
27 2 0 2 2 11 0 50 0 0 0
28 0 0 8 0 19 0 50 0 0 0
29 0 50 7 7 19 43 43 0 0 0
30 43 0 3 3 19 40 40 0 0 0
31 40 0 2 2 19 38 38 0 0 0
32 38 0 5 5 19 33 33 0 0 0
33 33 0 6 6 19 27 27 0 0 0
34 27 0 9 9 19 18 18 50 5 40
35 18 0 5 5 19 13 63 0 0 0
36 13 0 2 2 19 11 61 0 0 0
37 11 0 4 4 19 7 57 0 0 0
38 7 0 4 4 19 3 53 0 0 0
39 3 0 7 3 23 0 50 0 0 0
40 0 50 7 7 23 43 43 0 0 0
41 43 0 8 8 23 35 35 0 0 0
42 35 0 9 9 23 26 26 0 0 0
43 26 0 6 6 23 20 20 50 4 48
44 20 0 6 6 23 14 64 0 0 0
45 14 0 5 5 23 9 59 0 0 0
Promedio
20.5 50 5.87 5.36 0.51 19.6 41.8 50.0 4.4

Simulación de Sistemas de Inventarios. Procedimiento general 7- 20
6 Organización del modelo de simulación. Subprogramas Con el fin de facilitar la ejecución de las actividades anteriores, y para permitir una mayor flexibilidad para realizar los cambios que pueden surgir, debido principalmente a las fuentes de variaciones aleatorias, todas las etapas anteriores serán desarrolladas en módulos independientes (procedimientos o subprogramas), pero todas las variables aleatorias serán generadas en el programa principal. En el programa principal se deben leer las características generales de la simulación y los parámetros de las distribuciones que definen el tiempo entre demandas sucesivas, la cantidad requerida en cada demanda y el tiempo de espera. Además, se debe ejecutar el control de las diferentes rutinas o procedimientos, de acuerdo con el tipo del evento que ocurra. Finalmente se debe realizar la organización de las diferentes simulaciones, si se van a simular varias alternativas. (definir proceso de optimización, si es del caso). Todas las variables aleatorias que se necesiten serán generadas en el programa principal, de tal forma que los subprogramas sean independientes de estas distribuciones. 6.1 Programa principal Las actividades generales que se desarrollarán en el programa principal se describen a continuación, y se resumen en la figura siguiente: 1) Leer las características generales de la simulación y los parámetros de las distribuciones que definen el
tiempo entre demandas sucesivas, la cantidad requerida en cada demanda y el tiempo de espera. 2) Cuando se desee simular el sistema Q se deben leer los valores del punto de reorden (R) y del tamaño del
lote (Q) y si se trata del sistema T se deben leer los valores del nivel máximo del inventario (S) y del período entre dos revisiones sucesivas (T). Si se trata de determinar una política óptima, inicialmente se deben leer los valores iniciales de las características de operación e iniciar el algoritmo de optimización, y al final de la simulación se deben realizar las modificaciones del caso.
3) En el programa principal se debe generar, de acuerdo con las respectivas distribuciones, el tiempo en que ocurrirá la primera demanda (TD) y la cantidad que será requerida.
Simulación de Sistema de Inventarios. Programa Principal.
Inicio del programa
Leer características generales de la simulación
Reloj = 0
Inicializar el sistema
Próximo evento = demanda
Mientras próximo evento Fin de simulación, entonces
Buscar próximo evento
Actualizar contadores
Reloj = tiempo del próximo evento
Si (Próximo evento = demanda) entonces
Procedimiento demanda
Si (sistema = Punto de Reorden) entonces
Si ( Inventario <= Punto de Reorden) entonces
Realizar Pedido (Q)
Fin si
Fin si
Si no
Si (evento = Revisión) entonces
Realizar Revisión (Hacer pedido)
Si no
Si (evento = Llegada lote) entonces
Recibir lote
Fin si
Fin si
Fin si
Fin mientras
Generar Reporte
Fin Simulación
4) Inicializar todo el estado del sistema de inventarios y de las subrutinas que recogerán estadísticas.
(INICIALIZAR)

Simulación de Sistemas de Inventarios. Procedimiento general 7- 21
5) Buscar el próximo evento y actualizar las estadísticas acerca de variables que dependen del tiempo. La
información sobre el próximo evento se encuentra en la fila min del arreglo MEF, y está definido por el valor que tome MEF (min, 3). Según su valor se realizarán los subprogramas enunciados en los siguientes párrafos.
6) Evento = Demanda. Si MEF (min, 3) = 2 el próximo evento es una demanda. En este caso, en el
programa principal se genera el tiempo de la próxima demanda (TD) y la cantidad requerida (D) y la subrutina DEMANDA se encarga de manejar el sistema. Si se trata del sistema Q, se pregunta si se alcanzó el punto de reorden; si no se alcanzó el punto de reorden o si se trata del sistema T, se busca el próximo evento. Si se alcanzó el punto de reorden, se genera el tiempo que va a demorar el pedido y todas las actividades relacionadas con el nuevo pedido son desarrolladas por la subrutina REVISIÓN.
7) Evento = Revisión. Si MEF (min, 3) = 3 el próximo evento es la revisión del inventario (sistema T) y se
debe calcular el tamaño del lote que debe colocarse. En el programa principal se genera el tiempo de espera L y la subrutina REVISIÓN realiza las demás actividades relacionadas con la colocación del pedido.
8) Evento = Recibo lote. Si MEF (min, 3) = 4 el próximo evento es la llegada de un lote de artículos para
reabastecer el inventario. La subrutina RECIBO realiza las actividades relacionadas con el recibo y almacenamiento del lote.
9) Evento = Fin de simulación. Si MEF (min, 3) = 1 el próximo efecto es el fin de la simulación. En este caso
se hace la generación del reporte de salida, es decir, se realiza un resumen de la simulación, (subrutina REPORTE), se calculan costos y valores medios y se imprimen los resultados.
Si terminada la simulación se desea realizar otro experimento de simulación, se hacen las modificaciones que sean necesarias y se vuelve a inicializar el sistema. A continuación se da una breve explicación de las actividades desarrolladas en cada subrutina. 6.2 Subrutina INICIALIZAR Esta subrutina inicializa todas las variables de estado, los primeros eventos y las variables para recoger estadísticas. Las actividades realizadas se pueden resumir en las siguientes: 1) Variables de estado. Se inicializa el inventario físico (It) y el inventario físico y en órdenes (IOt) en el
inventario inicial. El inventario inicial se puede leer al definir las características generales del sistema, o se puede asignar de acuerdo con la característica del sistema a simular en los valores Q +R para el sistema Q o en S para el sistema de revisión periódica. Además, se define en cero el valor de la demanda comprometida.
2) Primeros eventos. Se deben programar los primeros eventos de la simulación, los cuales serán: El fin de la simulación, el tiempo de ocurrencia de la primera demanda con la cantidad demandada, y si se simula el sistema de revisión periódica, se debe programar el tiempo de la primera revisión.
3) Contadores para recoger información. La información básica que puede ser de interés en la simulación de un sistema de inventarios es la siguiente:
Demanda satisfecha a tiempo Demanda no satisfecha a tiempo Número de demandas Número de demandas satisfechas a tiempo, para calcular el nivel de servicio. Inventario físico promedio. Se usará también para calcular el costo medio de mantenimiento del
inventario. Demanda comprometida o escasez promedio. Se usará también para calcular el costo medio de escasez o
demanda comprometida. Número total de pedidos. Costo total de adquisición. Ventas perdidas, si es del caso. 6.3 Subrutina Próximo evento Esta subrutina busca cuándo ha de ocurrir el próximo evento, y su tiempo de ocurrencia. Además recoge información acerca de las variables que dependen del tiempo, como son el inventario promedio y la escasez media. Cuando ocurren eventos simultáneos, se le da prelación al último evento que se ha encontrado, así, cuando ocurren simultáneamente una demanda y la llegada de un lote para reabastecer el inventario, se le da prelación a este último evento. 6.4 Subrutina DEMANDA

Simulación de Sistemas de Inventarios. Procedimiento general 7- 22
Esta subrutina, mostraba en la figura 7.11 maneja el sistema cuando el próximo evento es una demanda. La subrutina lo primero que hace es guardar la cantidad pedida (KD) y actualizar la lista de eventos futuros con la nueva demanda (tiempo y cantidad). Posteriormente, la subrutina examina lo que puede suceder a la demanda que acaba de llegar, si puede ser o no satisfecha. Posteriormente recoge información acerca de la demanda que se satisfizo o no se satisfizo. Además, se actualiza el estado del sistema. 6.5 Subrutina REVISIÓN Esta subrutina revisa el inventario para determinar, dependiendo del sistema simulado, la cantidad a pedir y la próxima revisión. Esta subrutina determina cuándo llegará la orden que se acaba de colocar, actualiza el registro de inventario físico y en órdenes (IOT) y los costos de adquisición. Además recoge información acerca del tiempo de espera y del tamaño del lote. 6.6 Subrutina RECIBO Esta subrutina maneja el sistema cuando se recibe una orden para reabastecer el inventario, y realiza, básicamente, dos actividades: Actualizar los registros de “demanda comprometida (Et)” y del nivel de inventario (It), y Reorganizar la lista de eventos futuros de tal manera que en el arreglo MEF estén ocupadas las primeras
filas. 6.7 Subrutina REPORTE En esta rutina se presentan los resultados básicos de la simulación, lo cual incluye el cálculo de los diferentes indicadores, incluyendo los costos promedio del sistema y el nivel de servicio, que como ya se indicó previamente corresponde al porcentaje de veces que se satisface a tiempo la demanda total. También incluye la impresión de los anteriores resultados, junto con las características básicas del sistema simulado Ejemplo. El costo de mantener un artículo en inventario es $ 1 por unidad y por año. Cuando la demanda no se satisface inmediatamente, se pierde a un costo de $5 por unidad. Cuando se coloca una orden se incurre en un costo de $ 20, además de costo de los artículos comprados, a razón de $ 5 por unidad. La demanda diaria y el tiempo de espera, en días, siguen las distribuciones que se dan a continuación.
Distribución de probabilidad de la demanda diaria
Distribución de probabilidad del tiempo de espera (días)
Demanda Diaria Probabilidad Tiempo de espera (día)
Probabilidad
5 0.01 2 0.15
6 0.03 3 0.20
7 0.06 4 0.03
8 0.11 5 0.20
9 0.19 6 0.15
10 0.31
11 0.17
12 0.07
13 0.03
14 0.02
Se desea obtener las estadísticas básicas de la simulación y cual política es mejor, entre las siguientes: Un sistema <Q,R> con Q = 330 y R = 20, ó la política <S, T>, con un nivel máximo de 350 unidades y un período de revisión de un mes (días). La figura VII-16 presenta además del programa principal, los resultados de simular el sistema Q para Q =330 y R = 20 (proyecto de simulación No. 9) y los resultados de simular el sistema T para L = 350 y T = 30 días. Los datos y variables usados para las dos simulaciones fueron los siguientes: Costo de mantenimiento Cm: $1/unidad-año = $1/300 por unidad - día = $0.00333/unidad-día Costo de escasez : $5/unidad Costo de pedido A : $20/orden Costo unitario c : $5/unidad Tiempo de simulación: 1000 días

Simulación de Sistemas de Inventarios. Procedimiento general 7- 23
Inventario inicial II : 500 Semillas : 787 para el tiempo entre demandas, 329 para la cantidad demandada y 1477 para
el tiempo de espera. Sistema de ventas perdidas IX (I), 1 = 1, 10 : Valores de la demanda diaria P (I), I = 1, 10 : Probabilidad de que ocurra la demanda IX (I) L (I), I = 1, 5 : Valores del tiempo de espera PL (I), I = 1, 5 : Probabilidad de ocurrencia de un tiempo de espera IL (I) Vector_demanda: :Vector que contiene la demanda, de 100 posiciones Vector_tpo_espera :Vector que contiene los valores del tiempo de espera, usando el método de Marsaglia,
para variables empíricas. Para definir la distribución de probabilidad tanto de la demanda como del tiempo de espera se usó el método de Marsaglia. Los principales resultados de las dos simulaciones realizadas en el lenguaje de programación Fortran fueron los siguientes:
Concepto \ Sistema Sistema de revisión continua
Q = 330, R = 20
Sistema de Revisión periódica
T = 30, S = 350
Tiempo simulado (días) 1000 1000
Nivel de Servicio (%) 95.4 99.70
Costo total de Mantenimiento 533.63 564.93
Costo de ventas perdidas 1835 105
Costo de adquisición 540 660
Costo de los artículos 44550 47315
Número de pedidos 27 33
Costo por unidad de tiempo 47.46 48.64
Demanda media satisfecha 9.37 9.72
Demanda media insatisfecha 0.37 0.02
Inventario físico medio 160.1 169.5
Inventario medio físico y en órdenes 193.8 204.3
7 Optimización en sistemas de inventarios Generalmente el objetivo que se persigue al estudiar un sistema de inventarios es la determinación de una política óptima, por lo general aquella que minimice el costo total del sistema. Mediante la simulación y debido a las características propias de la misma, y a los costos de efectuarla, no se puede garantizar que se obtiene exactamente la política óptima de cualquier sistema, pero sí se puede obtener una política que esté muy cerca de la óptima, sin que el costo de obtenerla sea demasiado alto. En el sistema de punto de reorden, se deben determinar los valores del Punto de Reorden y del Tamaño del Lote óptimos <R*,Q*>, y en el sistema de Revisión Periódica el objetivo será la determinación del período entre revisiones y el nivel máximo al cual debe elevarse el inventario <T*,S*>. 7.1 Métodos de búsqueda Para determinar un valor óptimo mediante la simulación hay varios procedimientos dependiendo de las características de las variables cuyo valor se trate de determinar. Los dos procedimientos más comunes son los siguientes: Simulación de todas las alternativas. Cuando el número de alternativas es limitado, se pueden simular todas
las alternativas y escoger la mejor. Es decir, cuando las políticas que se pueden simular son pocas, o cuando las variables de interés sólo pueden tomar determinados valores, y la combinación de los diferentes valores de esas variables no es muy elevado (lo cual haría que el costo de determinar la política óptima no fuera muy alto) se pueden simular todas las alternativas y escoger la mejor.
Proceso de optimización. Cuando el número de alternativas es muy alto, o no se conozca a priori cuantas
son, o cuando las variables de interés varían en forma continua y pueden tomar, en teoría un número infinito de valores, entonces es necesario usar un procedimiento de optimización, que para el caso de la simulación sería “método de búsqueda”.
Cuando se tiene una sola variable (X) y se requiere determinar su valor óptimo (X*) mediante un procedimiento de búsqueda, se le asigna a esa variable un valor inicial (X0) y un incremento (X), y se

Simulación de Sistemas de Inventarios. Procedimiento general 7- 24
determina el valor de la función objetivo en el punto inicial, y luego en un nuevo punto situado a una distancia X hacia la derecha del punto inicial (X0 + X); si la función objetivo es mejor en este punto que en el punto
inicial, se ensayan nuevos valores ubicados a la derecha del punto inicial hasta que no se obtenga ninguna mejora en la función objetivo. Si la función objetivo en el punto X0 + X es peor que en el punto inicial X0,
entonces se ensaya el punto X0 - X; si la función objetivo es mejor en este punto que en el punto inicial, se
ensayan nuevos valores a la izquierda del valor inicial, hasta que no se obtenga ninguna mejora significativa en la función objetivo. Si la función objetivo en el punto (X0 - X) es peor que la función en X0, entonces el
mejor punto es el punto inicial. El procedimiento anterior puede reiniciarse tomando como punto inicial el mejor valor que se haya obtenido, y disminuyendo el incremento. Cuando se tienen varias variables, puede usarse el procedimiento para una sola variable, dejando constantes todas las variables menos una, y variando ésta hasta que no se obtenga ninguna mejora en la función objetivo. Enseguida se deja esta última variable constante y se varía otra de las restantes variables. Este procedimiento se repite hasta que no se obtenga ninguna mejora significativa en la función objetivo. Este procedimiento recibe el nombre de “Búsqueda de un solo Factor”. En la simulación de sistemas de inventarios se tiene, en general, un número ilimitado de alternativas, ya que el punto de reorden o la cantidad a pedir, pueden tomar muchos valores. Sin embargo se le podrían asignar a las variables de interés un número limitado de valores y considerar el problema como si se tuviera un número limitado de alternativas. Más específicamente, si se está simulando el sistema Q de inventarios se podría proceder de la siguiente manera: Se asignan N valores a la cantidad a pedir -Q. sean Q1, Q2, ,,,QN los valores asignados. Se asignan M valores al punto de reorden. Sean R1, R2,... RM los valores asignados. Se simulan las diferentes parejas de cantidad y punto de reorden que sean posibles, y se escoge la pareja
que dé el menor costo. Sea (Q*, R*) la mejor política.
Si se encuentra que la mejor solución para una o las dos variables queda en uno ó en los dos puntos extremos considerados, esto nos indica que probablemente la solución óptima no fue simulada y se hace necesario ensayar nuevos valores en la región no analizada. Por ejemplo, si se encuentra que Q* = QN, entonces es probable que la solución óptima para Q quede a la derecha de QN. Si R* = R1 es probable que el mejor valor del punto de reorden sea inferior a R1.
Si se quiere obtener una solución más exacta, se pueden asignar nuevos valores a las variables de decisión, que estén alrededor de los mejores valores que ya se tienen. (Esto es equivalente a la reducción en el tamaño del incremento). Para la política óptima del sistema T se puede usar el mismo procedimiento indicado para el sistema Q, asignando valores al período de revisión y al nivel máximo. 7.2 Valores iniciales para el proceso de búsqueda A continuación se dan unas indicaciones de cómo escoger el valor inicial para cada una de las diferentes variables de decisión, ya que si se escoge adecuadamente el punto inicial, se reducirá el costo de encontrar la solución óptima. Básicamente el proceso consiste en darle valores iniciales a las variables de decisión usando los valores óptimos que se calculan suponiendo que se tiene un sistema completamente determinístico.
a) Tamaño del Lote Q Para escoger un valor inicial para el tamaño del lote, que esté cerca de la solución óptima, se puede considerar la solución para un sistema determinístico, considerando que la demanda es constante e igual a la demanda media. (Fórmula de Harris o de lote económico) Si la demanda para un intervalo de tiempo t está descrita por la función continua de densidad f(x), entonces la demanda media para el tiempo t estará dada por x(t):
0
dx)x(xf)t(x
Si la demanda está descrita por una función discreta de probabilidad p(x), entonces la demanda media estará dada por
0x
)x(px)t(x
La tasa media de demanda estará dada por ttx /)( . Es decir nos describe la demanda media por
unidad de tiempo.

Simulación de Sistemas de Inventarios. Procedimiento general 7- 25
Si se asume que la demanda es constante a una tasa de unidades por unidad de tiempo (año, mes, etc.) se
puede demostrar que el costo de sistema de inventarios cuando se colocan órdenes por Q unidades, está dado por (Fórmula de Harris):
CT(Q) = A /Q + C +Cm (Q / 2 +B)
Donde: A = Costo de colocar una orden para reabastecer el inventario. C = Costo unitario. CM = Costo unitario de mantenimiento del inventario B = Inventario de seguridad La solución óptima se encuentra derivando la expresión del costo total con respecto a Q e igualando a cero, lo cual nos da el siguiente valor par Q*:
Ci
AA
CQ
m
22*
El valor que se encuentra para Q* puede usarse como punto inicial Q0 para el proceso de búsqueda del óptimo o para definir los diferentes valores que se le asignan a Q, de acuerdo con el procedimiento empleado para encontrar el óptimo. Si no se usa el método de búsqueda sino el de ensayar varios valores, entonces la mayoría de los valores que se asignen a Q deben estar por encima de Q*. Para los datos del ejemplo analizado anteriormente el valor inicial para Q estará dado por
34200333.0
72.9202*
xxQ
b) Punto de Reorden R Las existencias que deben haber disponibles cuando se decida reabastecer el inventario deben ser suficientes para satisfacer la demanda mientras llega la orden colocada. Es decir, y como se ha indicado varias veces el punto de reorden R debe ser la cantidad que se necesita para satisfacer la demanda durante el tiempo de espera, sin que se presente escasez con mucha frecuencia, pero también sin que el costo de almacenamiento sea demasiado elevado. Si el tiempo de espera L está comprendido en el rango (Lmin 1 Lmax) y la demanda por unidad de tiempo está comprendida entre Xmin y Xmax, entonces la demanda durante el tiempo de espera, denotada por X (L) estará comprendida en el rango: Lmin * Xmin X (L) Lmax * Xmax
La demanda media durante el tiempo de espera está dada por: Lxtx )(
Si el punto de reorden es R, entonces a la diferencia entre el punto de reorden y la demanda media durante el tiempo de espera se le denomina “Inventario de seguridad” –B, es decir:
LxtxRB )(
El inventario de seguridad B se usa para absorber las fluctuaciones que se puedan presentar en la demanda y/o en el tiempo de espera. Es decir, sirve para amortiguar las variaciones en la demanda cuando ésta exceda, hasta cierto punto, a la demanda media. Para los datos del ejemplo analizado anteriormente tenemos que el punto de reorden estará entre 10 y 84 unidades, con una demanda media de 39 (38.8) unidades. Para determinar el punto óptimo de reorden mediante la simulación, pueden emplearse varios enfoques, que serán descritos a continuación: Proceso de optimización. Pueden asignarse varios valores al punto de reorden, como se indicó antes,
simular para las diferentes combinaciones que pueden obtenerse con los valores asignados a Q y escoger la mejor combinación. Los valores que se asignen al punto de reorden deben estar comprendidos entre la demanda mínima y máxima durante el tiempo de espera. Como el costo de escasez es generalmente mucho mayor que el costo de mantenimiento del inventario, los valores que se asignen a R deben estar por encima de la demanda media durante el tiempo de espera. Aun, el número de valores que se asignen al punto de reorden podría no estar definido de antemano, sino que, al principio podría asignársele al punto de

Simulación de Sistemas de Inventarios. Procedimiento general 7- 26
reorden el valor máximo, simular para los diferentes valores de Q, e ir disminuyendo el valor del punto de reorden hasta llegar al punto de reorden de mínimo costo.
Nivel de servicio. Mediante la determinación de la distribución de la demanda durante el tiempo de espera. Si el tiempo de espera es constante, entonces mediante el uso de las convoluciones se podría determinar analíticamente la demanda durante el tiempo de espera. Por ejemplo, si el tiempo de espera para la entrega de un pedido es 3 días, y la demanda diaria de ese artículo puede ser 0, 1 2, ó 3 con probabilidades de 0.15, 0.25, 0.40 y 0.20 respectivamente, la demanda durante el tiempo de espera estará comprendido entre 0 y 9 unidades y tiene la siguiente distribución:
Demanda durante L
Probabilidad
Probabilidad Acumulada * 100
0 0.003375 0.3375
1 0.016875 2.0250
2 0.055125 7.5375
3 0.119125 19.4500
4 0.192000 38.6500
5 0.229500 61.6000
6 0.202000 81.8000
7 0.126000 94.40000
8 0.048000 99.20000
9 0.008000 100.0000
Analizando la función de distribución (probabilidad acumulada) se observa que la demanda durante el tiempo de espera será 8 unidades o menos en el 99.2 por ciento de las veces; será menor o igual a 7 unidades el 94.4 por ciento de las veces, será menor o igual a 6 unidades el 81.8 por ciento de las veces. La determinación del punto de reorden puede realizarse entonces con base en un nivel de servicio. Se entiende por “nivel de servicio” al porcentaje de veces que el sistema de inventarios puede satisfacer la demanda que ocurra durante el tiempo de espera1. Así un nivel de servicio del 95% quiere decir que el sistema satisface completamente la demanda en el 95% de los casos. Si en el problema que estamos analizando deseamos un nivel de servicio del 95% el punto de reorden debe ser igual a 7 unidades. Si el nivel de servicio fuera del 81.8% el punto de reorden debería ser de 6 unidades. Para determinar el punto óptimo de reorden pueden definirse varios niveles de servicio, y con base en dichos niveles se escogen los valores posibles del punto de reorden. Sin embargo cuando el tiempo de espera es aleatorio la determinación de la distribución de la demanda durante el tiempo de espera es más complicada, ya que al calcular la probabilidad de que la demanda tome un valor específico es necesario considerar además de la variación en la demanda, la variación en el tiempo de espera. Por ejemplo, si el tiempo de espera puede ser 1, 2, 3, ó 4 días y la demanda diaria puede ser 0, 1, 2 ó 3 unidades y si se quiere calcular la probabilidad de que la demanda durante el tiempo de espera sea 3 unidades es necesario considerar: a) que el tiempo de espera puede ser 1, 2, 3 ó 4 días; b) que para cada uno de esos tiempos hay muchas formas en que la demanda puede ser 3 unidades. (Hay 35 maneras diferentes en que la demanda durante el tiempo de espera puede ser 3 unidades). La distribución de la demanda durante el tiempo de espera puede determinarse más fácilmente mediante la simulación. El procedimiento para su determinación es el siguiente: Simular (generar) el tiempo de espera. Simular la demanda que tiene lugar durante el tiempo de espera. Repetir varias veces el procedimiento anterior, tabulando los resultados para determinar la distribución
empírica de la demanda durante el tiempo de espera y con base en esta distribución fijar los puntos de reorden para varios niveles de servicio.
A continuación se muestra la distribución del tiempo de espera y de la demanda diaria.
1 Otra definición del “nivel de servicio” está relacionada con el porcentaje de la demanda que el sistema es
capaz de satisfacer a tiempo. Por ejemplo, si la demanda media es 10 unidades, y el sistema entrega a tiempo, en promedio 9 unidades, entonces el nivel de servicio sería del 90%. Sin embargo, usaremos como nivel de servicio la definición dada previamente, relacionada con el porcentaje de veces que se satisface la demanda.

Simulación de Sistemas de Inventarios. Procedimiento general 7- 27
Tiempo de espera (L)
Probabilidad P (L) Demanda diaria (X) Probabilidad P (X)
1 0.10 0 0.15
2 0.20 1 0.25
3 0.40 2 0.40
4 0.30 3 0.20
La demanda durante el tiempo de espera está comprendida entre 0 y 12 unidades y la determinación analítica de su distribución es bastante complicada. Los resultados de simular 1.000 tiempos de espera se dan a continuación.
Demanda
Frecuencia
Probabilidad
Probabilidad Acumulada * 100
0 19 0.019 1.9
1 58 0.058 7.7
2 86 0.086 16.3
3 150 0.150 31.3
4 149 0.149 46.2
5 159 0.159 62.1
6 138 0.138 75.9
7 110 0.110 86.9
8 74 0.074 94.3
9 33 0.033 97.6
10 17 0.017 99.3
11 6 0.006 99.9
12 1 0.001 100.0
Con base en la distribución de la demanda durante el tiempo de espera pueden definirse los niveles de servicio; así, se desea un nivel de servicio del 97.6 por ciento, el punto de reorden debe ser de 9 unidades; para un nivel de servicio del 95 por ciento el punto de reorden debe ser de 8 unidades y para un nivel de servicio del 90 por ciento el punto de reorden debe ser 7 unidades.
c) Período de revisión T Si cada T unidades de tiempo se coloca una orden para reabastecer el inventario y si la demanda ocurre a una tasa constante de unidades por unidad de tiempo, el tamaño de la orden que se coloque estará dado por:
Q = T T = Q/
Como punto inicial para el período de revisión puede usarse el valor que se encuentra cuando se asume demanda determinística a una tasa media , y que está dado por:
Ci
AA
CT
m22*
Para el ejemplo que hemos estado analizando, este valor sería igual a
díasx
xA
CT
m
3572.900333.0
2022*
d) Nivel máximo del inventario S El nivel al cual se eleva el inventario debe ser suficiente para satisfacer de la demanda que ocurra durante el período de revisión más el tiempo de espera. Es decir: S = demanda durante (T + L) o sea que el nivel máximo es función no sólo del período de revisión (que es otra variable de decisión) sino también del tiempo de espera (que puede ser aleatorio). Para un T dado, el nivel máximo al cual se debe elevar el inventario debe ser menor o igual que la demanda máxima durante T + L. Es decir:

Simulación de Sistemas de Inventarios. Procedimiento general 7- 28
S )( LD maxmax TS
La tabla siguiente presenta los resultados de la simulación del siguiente problema para varios valores de la cantidad a pedir (Q) y del punto de reorden. La demanda diaria de un artículo en un sistema de producción se muestra a continuación. El costo de mantener una unidad en inventario es de $ 0.10 por unidad/día. Si el sistema se queda sin existencias se incurre en un costo de $ 5 por unidad/día. Cada orden de producción que se coloque tiene un costo de $ 2.000 más el costo de los artículos que se estima en $ 150 la unidad. Sin embargo, la orden de producción no se puede empezar inmediatamente, sino que hay que esperar unos días antes de que se haga efectiva. A continuación se muestra la distribución del número de días que demora en ser ejecutada la orden de producción. Se desea determinar el punto de reorden (R) y la cantidad que debe ordenarse (Q) de tal forma que se minimice el costo total del sistema.
DEMANDA DIARIA
PROBABILIDAD TIEMPO DE ESPERA (DÍAS)
PROBABILIDAD
10 0.200
15 0.100 1 0.05
20 0.070 2 0.18
25 0.098 3 0.26
30 0.170 4 0.33
35 0.156 5 0.08
40 0.090 6 0.10
45 0.074
50 0.042
La tabla siguiente presente los resultados de simular varias políticas. Como se observa, para varias políticas los costos por unidad de tiempo son bastante cercanos. Para cada política se simularon 1000 días, 3 años).
Optimización en sistemas de inventarios. Sistema Q
Punto de Reorden
Conceptos Tamaño del Lote Q
900 1000 1100
70 Nivel de servicio 97.0 96.4
Costo de Mantenimiento 41,941 46,815
Costo de escasez 5,150 6,875
Costo de Pedido 60,000 54,000
Costo de compra 4,050,000 4,050,000
Costo unitario 4,157.1 4,157.7
80 Nivel de servicio 97.8 97.0 96.6
Costo de Mantenimiento 42,898 47,780 51,648
Costo de escasez 3,475 5,150 7,500
Costo de Pedido 60,000 54,000 50,000
Costo de compra 4,050,000 4,050,000 4,125,000
Costo unitario 4,156.4 4,156.9 4,234.1
100 Nivel de servicio 98.8 98.7 97.9
Costo de Mantenimiento 44,756 50,303 53,896
Costo de escasez 1,900 1,275 4,425
Costo de Pedido 60,000 54,000 50,000
Costo de compra 4,050,000 4,050,000 4,125,000
Costo unitario 4,156.7 4,155.6 4,233.3
120 Nivel de servicio 99.4 99.3
Costo de Mantenimiento 46,895 51,989
Costo de escasez 875 575
Costo de Pedido 60,000 54,000
Costo de compra 4,050,000 4,050,000
Costo unitario 4,157.8 4,156.6

Simulación de Sistemas de Inventarios. Procedimiento general 7- 29

Simulación de Sistemas de Inventarios. Procedimiento general 7- 30
8 Problemas 8.1 La demanda de un artículo sigue una distribución de Poisson con una media de 100 unidades por año. El
costo de colocar una orden es de $ 1.000, el costo de mantener una unidad en inventario es $ 200 por año y el costo de escasez es de $6 000 por unidad y por año. El tiempo de espera es 0.08 años. Determine el costo de operación cuando se ordenan lotes de 34 unidades, de acuerdo con un punto de reorden de 8. (simule 10 años de operación del sistema).
8.2 En el problema anterior, determine la política óptima. 8.3 Simule el problema 8.1 cuando se tienen las siguientes distribuciones para el tiempo de espera:
a) Tiempo exponencial con = 12.5
b) Tiempo gama con = 25, n = 2
c) Tiempo gama con = 125, n = 10
Simule cada situación durante 50 años. Cuál situación da un costo más cercano al costo del sistema que tiene un tiempo de espera de 0.08 años?
8.4 Considere el siguiente sistema de inventarios: El costo de colocar una orden es de $ 100, el costo de
mantener una unidad en inventario es $ 20 por año y el costo de escasez es de $ 60 por unidad por año. El tiempo que transcurre entre la colocación de una orden y la llegada de la misma es de 0.08 años. Determine el costo medio de operación por año, para el caso en que se coloca una orden por 34 unidades cuando el inventario llegue a 8 unidades, y se tienen las siguientes condiciones:
a) La demanda es Poisson con una media de 50 demandas por año. En cada demanda se piden 2 unidades.
b) La demanda es Poisson con una media de 25 demandas por año y en cada demanda se piden 4 unidades.
c) La demanda es Poisson con una media de 50 demandas por año y en cada demanda el número de unidades pedidas se distribuye geométricamente con p = 0.5
d) Igual que c) con una media de 25 demandas por año y p = 0.25 Simule 50 años de operación del sistema. 8.5 En el problema anterior, determine la política óptima para cada una de las condiciones dadas. 8.6 Se desea simular un sistema de revisión periódica con ventas perdidas para varias condiciones de la
demanda. El tiempo de espera es 0.1 años, y en cada demanda se pide sólo una unidad. Cada revisión cuesta $ 600 y cada orden colocada cuesta $1 000. Cada venta perdida cuesta $ 100 y el mantener una unidad en inventario cuesta $ 200 por año. El período entre revisiones sucesivas es 0.3 años y el número de unidades en cada orden es la cantidad suficiente para llevar el inventario a 42. Se desea determinar el costo medio por año para las siguientes condiciones de demanda:
a) El tiempo entre demandas sucesivas es constante e igual a 0.005
b) El tiempo entre demandas sucesivas es exponencial con = 200
c) El tiempo entre demandas sucesivas es gama con = 1.000, n = 5
d) El tiempo entre demandas sucesivas es gama con = 3.000, n = 15
Explique el efecto de la variación en la demanda sobre el costo. 8.7 Simule el problema 8.1 con la siguiente modificación: En vez de revisar el inventario cada que ocurre una
demanda, se lo revisa cada 0.01 años. Si en cada revisión, el inventario está en 8 o por debajo de 8, se coloca una orden por 34 unidades. El costo de efectuar la revisión es cero. Simule este sistema por un período de 50 años y compare el costo anual con el costo anual del problema 53.
8.8 La demanda por aparatos de televisión se estima en 300 unidades para el próximo año. Cada vez que se
coloca una orden se incurre en un costo de $ 2.400. El costo de mantener un artículo en existencia es de $ 400 por año. Si no hay existencias cuando se solicita un artículo, la venta se pierde a un costo de $ 560 por artículo. El tiempo de espera es 0.0083 años. Determine el costo promedio por año cuando se tiene Q = 61, R = 4
8.9 En el problema anterior, determine el sistema Q de mínimo costo, si el tiempo de espera es una variable
aleatoria normal con una media de 0.0083 años y una desviación de 0.002 años.

Simulación de Sistemas de Inventarios. Procedimiento general 7- 31
8.10 En el problema 8.1 suponga que el espacio está limitado a 36 unidades. Cada vez el inventario físico
excede de 36 unidades, se incurre en un costo de $ 5 por cada unidad que haya en inventario por encima de 36. Usando un punto de reorden de 8 unidades y un tamaño de lote de 34 unidades, determine el costo anual de operación.
8.11 Simule el sistema descrito en el problema anterior cuando cada unidad que esté en inventario por encima
de 36 es almacenada a un costo de $40 por unidad-año, más un costo de manejo de $ 2 por unidad. Qué método de manejo es preferible: El del problema anterior o el del presente problema?.
8.12 Considere el problema No. 8.1, suponga que se ofrece el siguiente programa de descuentos: Programa Costo Unitario Q 35 $ 80.00
36 Q 105 $ 75.00
106 Q 245 $ 73.00
Q 246 $ 70.00
Para un punto de reorden de 8 unidades, determine cuál de las siguientes políticas es la de menor costo:
a) Q = 35?
b) Q = 36?
c) Q = 105?
d) Q = 246 8.13 En el problema anterior suponga que las primeras 35 unidades cuestan a $ 80 cada una; de la unidad 36
a la unidad 105 el costo unitario es $ 75; de la unidad 106 a la unidad 245 el costo unitario es $ 73. Todas las unidades por encima de 246 cuestan a $ 70 cada una.
8.14 La siguiente es la distribución de la demanda de neveras en un almacén: Enero 0 julio 70 Febrero 1 Agosto 85 Marzo 2 Septiembre 50 Abril 10 Octubre 3 Mayo 25 Noviembre 4 Junio 40 Diciembre 2 Se espera que la demanda mensual de Mayo a Septiembre aumente a una tasa de un 10 por ciento anual para los próximos cinco años. No se espera que la demanda durante los otros meses cambie. El tiempo de espera es de 2 semanas. La política actual consisten en colocar una orden por 25 neveras cuando el inventario esté en 6 o menos unidades. El costo de mantener una nevera almacenada es de $900 por unidad - año. Cuando se pide una nevera y no hay existencias, la venta se pierde a un costo de $ 3.000 por unidad. El costo de colocar una orden es de $ 250.
a) Simule 5 años del sistema y determine qué tan adecuada es esta política.
b) Desarrolle políticas separadas para el tiempo en que hay más demanda, y para el tiempo en que haya menor demanda, de tal forma que el costo de operación se reduzca.
8.15 Cinco artículos de un sistema de se obtienen de la misma fuente. La demanda para el artículo A es
independiente de la demanda para el B; pero ambos tienen la distribución de la demanda que se mostrará a continuación. Así mismo, la demanda para los artículos C, D y E es independiente; pero los tres tienen la distribución de la demanda que se muestra a continuación (se trata de una distribución de Poisson, con una media de 3).
La distribución del tiempo de espera es idéntica para los cinco artículos, ya que se obtienen de una sola fuente y es igual a la que se muestra a continuación. La demanda que no puede satisfacerse se pierde. Se están considerando dos métodos diferentes de abastecimiento del inventario.
Demanda A, B Demanda C, D, E
Unidades Probabilidad Unidades Probabilidad
0 0.135 0 0.050
1 0.271 1 0.149
2 0.271 2 0.224

Simulación de Sistemas de Inventarios. Procedimiento general 7- 32
3 0.180 3 0.224
4 0.090 4 0.168
5 0.036 5 0.101
6 0.012 6 0.050
7 0.004 7 0.022
8 0.001 8 0.008
9 0.003 9 0.003
10 10 0.001
Tiempo de espera (días) Probabilidad
2 0.30
3 0.40
4 0.30
Método 1: Se piden los artículos por separado, cuando el inventario de cada uno de ellos llega al punto de
pedido. Para los artículos A y B, el punto de pedido es de 10 unidades para cada uno y la cantidad de la orden es de 20 unidades. Para los artículos C, D y E, el punto de pedido para cada uno de ellos es de 15, y la cantidad a ordenar es de 30 unidades.
Método 2: Siempre que cualquiera de los 5 artículos alcance su punto de pedido, hágase inmediatamente un
pedido para los 5 artículos. En este caso, la cantidad de pedido para cada artículo es la diferencia entre el nivel de inventario y la cantidad objetivo. Para los artículos A y B la cantidad objetivo es de 30, y para los artículo C, D, y E dicha cantidad es de 45.
e) Simule el sistema para 250 días de funcionamiento para cada método. Compárense los métodos de acuerdo con estos criterios:
i. Número de pedidos ii. Inventario promedio de cada artículo iii. Unidades de demanda perdida para cada artículo
f) Qué información de costos se necesitará para evaluar ambos métodos?
Xxxxxxxxxxxx d) Costos. La información de costos es la siguiente: - Costos de mantenimiento: CMt = CMt + CM. It t
- Costos de Escasez: CEt = CEt + CE. Et t, cuando la demanda se compromete.
- CEt = CEt + CE. VPt , si la demanda no satisfecha se pierde. - Costos de adqusición: CAt = CAt + A + CQ Toda la información anterior se recogerá de la siguiente manera: a) Observaciones puntuales - Subrutina U555X (X, N) Esta subrutina recogerá la siguiente información: N = 1 Número de unidades requeridas en cada demanda. N = 2 Parte de la demanda que se satisface inmediatamente. N = 3 Número de unidades que no son satisfechas inmediatamente y que tienen que esperar o que se
pierden, según el sistema. N = 4 Tiempo medio de espera

Simulación de Sistemas de Inventarios. Procedimiento general 7- 33
b. Variables de estado. Subrutina U555T (NX, DT, N) Recogerá la siguiente información: N = 1 Inventario físico durante el tiempo DT. N = 2 Inventario físico y en órdenes. Cuando la demanda que no se satisface inmediatamente se puede satisfacer después, esta información se
guardará en la posición N = 3. Si la demanda se pierde, esta información no se recogerá. Por lo tanto se usará la variable KS para indicar qué sistema se está simulando así:
KS = 1 Si la demanda no satisfecha se compromete. KS = 2 Si la demanda no satisfecha se pierde. Si KS =- 1 entonare NESTT = 3; Si KS = 2 entonces NESTT = 2 c) Subrutina U55NU (NX0, ND, N, NX, DT) Recogerá información en la misma forma que la subrutina U555T, con un límite inferior NXO (generalmente
NXO = O) y con un intervalo de tamaño ND. La figura 7.15, en el anexo de este capítulo, presenta un listado completo de las anteriores subrutinas. Es de
observar que la mayoría de las variables que se usan en diferentes subrutinas aparecen en instrucción COMMON. Esta instrucción COMMON debe ir después de la instrucción Common que define los arreglos en que se recogen estadísticas.

Simulación de Sistemas de Inventarios. Procedimiento general 7- 34
SIMULACION DE SISTEMAS DE INVENTARIOS
Lista de Eventos Futuros MEF Los eventos que pueden ocurrir en una simulación tiene tres atributos básicos, a saber: - Tiempo de ocurrencia del evento. - Tipo de evento - Entidad que causa el evento. Para este caso corresponde a la “cantidad” asociada con el evento. Para llevar la información sobre los eventos futuros, se usará un arreglo denominado “Matriz de Eventos Futuros - MEF”, que será un arreglo en dos dimensiones, con la siguiente estructura:
Fila No TIEMPO CANTIDAD TIPO
1 Tiempo de Simulación No hay Fin tipo 1
2 Tiempo Próxima Demanda Demanda Demanda tipo 2
3 Tiempo próxima revisión Nivel máximo S Revisión inv tipo 3
4 Tiempo de llegada Tamaño del lote Q Llegada lote tipo 4
5 Tiempo de llegada Tamaño del lote Q Llegada lote tipo 4
N Tiempo de llegada Tamaño del lote Q Llegada lote tipo 4
- MEF(I,1) = representa el tiempo de ocurrencia del evento. - MEF(I,2) = representa la cantidad asociada con el evento (demanda, nivel máximo, lote). - MEF(I,3) = representa el tipo de evento, según la siguiente convención:
= 1 si el evento es el fin de la simulación = 2 si el evento es una demanda. = 3 si el evento es la revisión del inventario (solamente se da si se simula el sistema T). = 4 si el evento es la llegada de un lote para reabastecer el inventario.
Algunas variables: It = Inventario físico IOt = Inventario físico y en órdenes

Et = Demanda comprometida
9 PROCEDIMIENTO GENERAL
(1) Creación imagen del sistema * Definición de parámetros básicos:
Tiempo de simulación, semillas, costos, Tipo_Sistema, Tipo_escasez, inventario inicial
Parámetros de distribuciones de: Tiempos entre demandas (llegada clientes) Cantidad demandada Tiempo de espera Si Tipo_Sistema = Sistema Q,
Leer Tamaño Lote, Punto Reorden (Q,R)
Si no
Leer Nivel Máximo, Período Revisión (S,T)
Fin Si Invocar Rutina de Inicialización
(2) Algoritmo de simulación Próximo Evento: Demanda (Llegada Cliente)
Mientras Próximo Evento Fin Simulación Invocar Rutina de Próximo Evento Si Próximo Evento = Demanda
Invocar Rutina de Demanda Si no
Si Próximo Evento = Revisión
Invocar Rutina de Revisión Si no Si próximo Evento = Llegada Lote Invocar Rutina Llegada Lote Fin si
Fin si Fin si Fin Mientras
(3) Invocar rutina generación reportes Si hay mas experimentos de simulación,
Establecer condiciones de nueva simulación Volver a inicializar el sistema
Fin si
10 Fin de la simulación
RUTINA DE INICIALIZACION Reloj = 0 * Inicialización del estado del sistema
Inventario = Inventario Inicial (It = II) Inv Físico y en Ordenes = Inventario Inicial (IOt = II)
* Inicialización lista de eventos * Evento tipo 1: Fin de Simulación. MEF(1,1) = Tiempo Simulación MEF(1,2) = 1 * Evento tipo 2: Demanda (Llegada cliente) Generar Demanda = generar_demanda Tpo entre dem = generar Tiempo entre Demandas
MEF(2,1) = Reloj + Tiempo entre demandas MEF(2,2) = 2
MEF(2,3) = Demanda Número de Eventos = 2
* Eventos tipo 3: Revisión, en el sistema T

B. Calderón. Introducción a la Simulación. Cap 7. Simulación de Sistemas de Inventarios 7 - 36
Si Tipo Sistema = Sistema T MEF(3,1) = Reloj + Tiempo Revisión MEF(3,2) = 2 MEF(3,3) = S Número de Eventos = 3
Fin si * Inicialización contadores para estadísticas
Número Clientes (demandas)= 0 Demandas atendidas = 0
Suma _It = 0 (tipo nt t )
Suma_Et = 0 (tipo nt t) Venta Perdida = 0 Nro pedidos = 0 Artículos pedidos = 0
Fin rutina de inicialización
RUTINA DE PROXIMO EVENTO * Búsqueda de Próximo Evento
Min = 1 Para fila = 2 hasta Número de eventos
Si (MEF(fila,1) MEF(min,1) Min = fila Fin si Siguiente Tiempo Próximo Evento: TPE = MEF(min,1)
t = TPE - RELOJ * Actualización contadores variables de estado
Suma _It+ = It * t
Suma_Et+ = It * t RELOJ = TPE
Fin rutina de próximo evento
RUTINA DE LLEGADA DE DEMANDA * Evento tipo 2: Demanda (Llegada cliente)
Demanda_actual = MEF(min,2) * Actualizar Evento Primario: Nueva demanda
Generar Tiempo de Próxima demanda (TD) Generar próxima cantidad pedida (D) MEF(2,1) = Reloj + Tiempo entre demandas MEF(2,3) = D Número de Clientes (demandas)+ = 1
Si Demanda_actual I_t , Demandas atendidas+ = 1 It = It - demanda actual. IOt = IOt - demanda actual
Si no Demanda satisfecha = It Demanda insatisfecha=Demanda actual–It It = 0 Si Tipo_escasez=Demanda comprometida,
Et = Et +demanda insatisfecha IOt = IOT – Demanda actual
Si no Venta perdida+=demanda insatisfech IOt = IOT – Demanda satisfecha
Fin si Fin si
* Revisión del inventario (Sistema Q) Si Tipo Sistema = Punto de Reorden,
Si IOT Punto de Reorden, Número de pedidos+ = 1

B. Calderón. Introducción a la Simulación. Cap 7. Simulación de Sistemas de Inventarios 7 - 37
Artículos pedidos+ = Q IOt+ = Q. Generar Tiempo de espera (L) Número de eventos+ = 1 MEF(número de eventos,1) = Reloj + Tiempo de espera MEF(número de eventos,2) = 4 MEF(número de eventos,3) = Q
Fin si Fin
Fin rutina demanda
RUTINA DE REVISION * Actualizar Evento Primario: Programar nueva revisión
MEF(min,1) = Reloj + Tiempo de revisión (T) Q = S – IOT Nro pedidos+ = 1 Artículos pedidos+ = Q IOt+ = Q. Generar Tiempo de espera (L) Número de eventos+ = 1
MEF(número eventos,1) = Reloj + Tpo espera
MEF(número eventos,2) = 4 MEF(número eventos,3) = Q
Fin rutina llegada de cliente
RUTINA DE LLEGADA DE LOTE Q = MEF(min,3)
Si Et Q, It = It + Q - Et Et = 0.
Si no Et = Et - Q
Fin si Si min < Número de eventos
MEF(min,1) = MEF(número de eventos,1) MEF(min,2) = MEF(número de eventos,2) MEF(min,3) = MEF(número de eventos,3)
Fin si Número de eventos- = 1
Fin rutina llegada de lote
RUTINA GENERACION REPORTE DE SALIDA * Cálculo de:
Inv_medio = Suma_It/Reloj Escasez_media = Suma_Et/Reloj
Nivel Servicio = (Número de demandas – Demandas atendidas)/ Número demandas
Q_medio = Artículos pedidos/Número pedidos Costo_Inv = Inv_medio * Costo_manto
Costo Pedido = Nro pedidos * Costo_pedido/Reloj
Costo_artículos =Artículos pedidos*costo_unidad/Reloj Si Tipo_escasez =Demanda comprometida,
Costo_Esc = Suma_Et * Costo_deficit Si no
Costo_Esc = Venta perdida * Costo_deficit/Reloj

B. Calderón. Introducción a la Simulación. Cap 7. Simulación de Sistemas de Inventarios 7 - 38
Fin si
Costo = Costo Pedido + Costo artículos + Costo_Inv + Costo_Esc
Imprimir: Estadísticas
Fin rutina de generación de reporte

8 ANÁLISIS DE UNA SIMULACION 1 Introducción El analista debe ser capaz no sólo de diseñar, programar y correr el programa de simulación, sino también de analizar e interpretar los resultados para la toma de decisiones, y medir la significancia de estos resultados. Los valores medidos no son más que una muestra y deben usarse para estimar los parámetros de la distribución de la cual son extraídos. Un estudio de simulación se planea usualmente como una serie de corridas orientadas a comparar varias alternativas cuyos resultados deben analizarse estadísticamente. Los problemas estadísticos asociados con un estudio de simulación han sido clasificados por Conway en dos clases: a. Problemas estratégicos relacionados con el diseño de un conjunto de experimentos. b. Problemas tácticos relacionados con la especificación de cómo se va a realizar cada experimento. La planeación estratégica debe determinar las medidas por las cuales se ha de juzgar el sistema y cómo se va a medir la significancia de las diferencias de estas medidas. La planeación táctica debe decidir cómo se van a tomar las medidas de cada corrida y cuántas corridas se deben hacer para cada simulación. Los problemas estratégicos se analizarán posteriormente. Los problemas tácticos serán analizados primero. Pero antes de su análisis se estudiarán unas definiciones que son necesarias para clarificar conceptos. 2 Definiciones Una "corrida" de simulación es un registro ininterrumpido del desempeño de un sistema bajo una combinación especificada de variables controlables. Un "replicado" de una corrida es un registro del desempeño del sistema bajo la misma combinación de variables controlables, pero con diferentes variaciones aleatorias (es decir, empleando diferentes semillas para generar los números aleatorios). Una "observación" de un sistema simulado es un segmento de una corrida, suficiente para estimar el valor de cada una de las medidas del desempeño. Por lo tanto una observación puede extenderse durante un período considerable de tiempo simulado. Se dice que un sistema ha alcanzado las condiciones estables o ha llegado a un régimen permanente cuando las observaciones sucesivas del desempeño del sistema son estadísticamente independientes. Estado estable o régimen permanente significa que es posible definir una nueva observación tal que no ofrezca ninguna información adicional acerca del comportamiento futuro del sistema. La definición matemática estricta del estado estable requiere que el comportamiento del sistema sea estacionario, esto es, la distribución de probabilidad g (t) que describe el comportamiento en t debe ser idéntica a la distribución g (t + d), para todo d > O. Este criterio matemático es demasiado estricto para los fines de la simulación ya que excluye todos los sistemas que tengan un comportamiento cíclico perfectamente predecible. La definición dada inicialmente no excluye el comportamiento cíclico. Como una observación es definida como un segmento de una corrida en vez de un instante en la corrida, podemos tratar cada ciclo como una observación. Entonces si cada observación es estadísticamente idéntica, se puede definir cuándo el sistema está en el régimen permanente. Se dice que un sistema cuyo comportamiento no satisface las condiciones del régimen permanente está en un estado "transitorio". Los modelos pueden exhibir propiedades transitorias por una de dos razones: 1. Si las condiciones iniciales usadas para inicializar el sistema no son típicas de las condiciones operativas,
pero se espera que eventualmente el sistema exhiba las condiciones del estado estable, entonces hay un período transitorio hasta que los efectos de las condiciones iniciales desaparezcan o se vuelvan insignificantes. Un buen diseño experimental debe asegurar que los resultados durante tal fase de transición sean insignificantes o no sean tenidos en cuenta en el análisis.
2. Puede ocurrir un fenómeno transitorio en la situación que se está simulando.

B. Calderón. Introducción a la Simulación. Cap 8. “Análisis de una Simulación”. 8 - 2
Para algunos sistemas no existen, o no se espera que existan las condiciones del régimen permanente. Por ejemplo, el producto nacional bruto de un país, si ese es el resultado que se está simulando. En estos casos la fase transitoria es la de interés. 3 Métodos para remover estados indeseables. Condiciones iniciales En muchos estudios de simulación se está interesado en investigar sistemas que operan continuamente en condiciones del estado estable. Desafortunadamente un modelo de simulación no puede operar siempre de este modo, ya que debe empezarse y terminarse en algún instante. Existirán siempre, en general, estados transitorios porque el analista ha empezado la corrida de la simulación con valores o en estados que no son típicos del sistema. A causa de la artificialidad introducida por el comienzo repentino de la operación del sistema, el desempeño del sistema simulado no es representativo del correspondiente sistema real hasta tanto no haya alcanzado una condición o régimen estable. Por consiguiente, los datos obtenidos durante el período inicial de operación deberían excluirse del análisis. Por lo tanto, el analista debe seleccionar unas condiciones iniciales de tal forma que se empiece la simulación del sistema en un estado que sea lo más representativo posible de las condiciones que se encuentran en el estado estable (régimen permanente) con el fin de minimizar la longitud del período transitorio. Posteriormente el analista debe decidir cómo eliminar el efecto del período transitorio que ocurre de tal forma que el desempeño del simulador sea juzgado únicamente en su comportamiento normal. Hay dos enfoques que pueden usarse para reducir el efecto de las condiciones iniciales: Puede empezarse el sistema en un estado más representativo o puede ignorarse la primera parte de cada simulación. 3.1 Condiciones iniciales representativas En algunos estudios de simulación, principalmente de sistemas existentes, puede existir alguna información disponible acerca de las condiciones esperadas, lo cual hace posible seleccionar mejores condiciones iniciales, que simplemente empezar con el sistema vacío, libre de actividad. Este método reduce el período transitorio pero puede viciar (sesgar) los resultados a conclusiones preconcebidas si se recogen datos antes de eliminar los efectos transitorios. Además, debería darse un rango para las condiciones iniciales, del cual se escogerían las diferentes condiciones iniciales para cada replicado. El usar las mismas condiciones iniciales para cada replicado puede reducir el sesgo removiendo condiciones iniciales poco usuales, pero puede dejar algún grado de correlación entre las corridas. Este enfoque supone que se conoce mucho acerca del comportamiento del sistema antes de que se empiece la simulación. Sin embargo, sí hay casos en los que puede usarse este enfoque, principalmente cuando se simula un sistema existente para estudiar aspectos desconocidos de su comportamiento. Una complicación adicional resulta cuando se van a efectuar dos o más corridas bajo diferentes condiciones. Presumiblemente las dos corridas, A y B por ejemplo, conducirán a diferentes condiciones de operación. Si se han de usar estimativos a priori del estado estable para inicializar las corridas, deberían A y B empezarse en los niveles que se espera logre cada uno en el régimen permanente? Para evitar viciar los resultados, se recomienda que ambas corridas empiecen en las mismas condiciones iniciales, en una condición que represente el promedio de las dos condiciones iniciales. (Conway, 1963; Emshoff y Sisson, 1970). 3.2 Condiciones iniciales = Sistema Vacío El enfoque más común consiste en empezar la simulación con el sistema vacío, en estado de inactividad, esto es, asumir que el sistema está libre de actividad y correr la simulación hasta que los efectos transitorios sean insignificantes. Es fácil empezar el simulador bajo estas condiciones pero es muy costoso en cuanto a tiempo de computador. En este método la corrida de la simulación se empieza con el sistema vacío pero se detiene una vez haya transcurrido el período transitorio. Las entidades existentes en el sistema al final de este período se dejan como están. En seguida se empieza de nuevo la corrida y se recogen estadísticas a partir del reinicio de la simulación. Durante el período transitorio no se recogen estadísticas de ninguna clase, es decir, las estadísticas recogidas durante este período no se tienen en cuenta para el análisis. Como asunto práctico, es usual programar la simulación de tal forma que se recojan estadísticas desde el principio de la simulación,

B. Calderón. Introducción a la Simulación. Cap 8. “Análisis de una Simulación”. 8 - 3
correr la simulación hasta que se alcancen las condiciones del régimen permanente, limpiar (borrar) todas las estadísticas que se hayan recogido hasta el momento, pero dejando intacto el estado del sistema simulado y continuar la corrida de la simulación (con recolección de estadísticas). Las condiciones al final del período transitorio se convierten en los estimativos a priori de las condiciones de régimen permanente y se usan para empezar una nueva corrida. Este método es mucho más fácil de programar que el método alternativo, insertar las condiciones iniciales del régimen permanente en el modelo. Es difícil estimar qué tan largo debe ser el período de transición para alcanzar las condiciones del régimen permanente. Es decir, no existen reglas simples que se puedan dar para decidir qué tan largo debe ser el período que debe eliminarse. Usualmente se requiere realizar un número preliminar de corridas piloto, empezando con el sistema vacío, para juzgar cuánto tiempo dura el sesgo inicial. Esto puede realizarse graficando la estadística medida contra la longitud de la corrida, como lo indica la figura siguiente. Es altamente deseable que la investigación piloto se realice repitiendo varias corridas. Aunque se requiera un poco más de cálculo, la presencia del sesgo inicial puede examinarse estudiando el comportamiento de la desviación estándar. Si el efecto inicial ha desaparecido, puede esperarse que la desviación estándar sea inversamente proporcional a √n, siendo n el número de eventos simulados. Examinando gráficamente la forma en que la desviación estándar cambia con la longitud de la corrida es posible ver si la relación se cumple. Medida del Desempeño Figura No 9.1 Tiempo de Simulación Si se grafica el logaritmo de la desviación estándar contra el logaritmo de n, debe obtenerse una línea recta con pendiente negativa, si se cumple la relación. (Gordon, 1969). Otra forma de decidir cuando se ha alcanzado el régimen permanente consiste en examinar una secuencia de observaciones de la corrida de la simulación. Si el número de observaciones en que el resultado es mayor que el resultado promedio es aproximadamente igual al número de observaciones que son menores, entonces es probable que existan ya las condiciones del régimen permanente. Otro método consiste en calcular un promedio móvil de los resultados y suponer que existen las condiciones para el régimen permanente cuando el promedio no cambie significativamente con el tiempo. Hay sistemas en los cuales no se necesitan las condiciones iniciales, por ejemplo en el problema del vendedor de periódicos, o en los cuales las condiciones iniciales son completamente conocidas, por ejemplo, en un problema de inventarios en el cual sólo se necesita conocer el inventario inicial para empezar la simulación, el cual puede estar por el nivel real de inventarios del sistema estudiado. 4 Uso de modelos de simulación para estudiar fenómenos transitorios Algunos modelos de simulación se desarrollan específicamente para estudiar las características transitorias del sistema, en vez de las características del régimen permanente. Existen dos razones para analizar la fase transitoria de un modelo de simulación: 1. Las condiciones del régimen permanente pueden no existir. Tal es el caso cuando se estudia un proceso
que cambia constantemente.
2. Podemos estar interesados en estudiar los problemas asociados con el período de transición o de iniciación de un proceso. (Período de calentamiento). Este sería el caso en que estemos simulando, por ejemplo, en la operación de una planta el efecto inicial de cambios importantes en una planta existente.

B. Calderón. Introducción a la Simulación. Cap 8. “Análisis de una Simulación”. 8 - 4
En la segunda situación, el modelo de simulación alcanza el régimen permanente. El régimen permanente puede aun predecirse usando modelos analíticos. Pero es poco probable que los modelos analíticos puedan usarse para predecir las condiciones en el régimen transitorio. Tal es el caso de las teorías actuales sobre los fenómenos de espera o la teoría de inventarios. Pero existe un efecto transitorio muy conocido en la implantación de un nuevo sistema de inventarios. Los inventarios se elevan inicialmente y luego se estabilizan en los niveles deseados. Esto ocurre porque aquellos materiales que eran llevados a un nivel muy bajo son ordenados inmediatamente al nivel deseado, mientras que aquellos que están a niveles muy elevados sólo se reducen gradualmente a medida que se los va necesitando. Es muy difícil predecir analíticamente cuál es el nivel máximo que puede alcanzar el inventario en el período de transición, pero puede hacerse fácilmente mediante la simulación. El resultado de la simulación que puede ser importante para el análisis del período transitorio puede ser diferente del deseado para el análisis de las condiciones que se presentan en el régimen permanente. En el estudio del régimen permanente generalmente estamos interesados en promedios u ocurrencias típicas del sistema. En el análisis del estado transitorio podemos estar interesados en condiciones excepcionales o extremas que puedan existir durante el período de instalación o implementación de una nueva política. Por ejemplo, podemos estar interesados en el número máximo de meses requeridos para implantar el sistema, la probabilidad de exceder un nivel de seguridad en la instalación de una nueva planta o la probabilidad de fracasar en una nueva empresa. Al estudiar el régimen permanente puede obtenerse una muestra mayor más eficientemente haciendo mayor la corrida de simulación. Mientras mayor sea la muestra, más confianza hay en los estimativos. Al estudiar fenómenos transitorios en un modelo estocástico, la corrida debe replicarse, empezando de nuevo para obtener una distribución de resultados. Además, si el interés es la probabilidad de un resultado de excepción o un estimativo de un punto extremo, puede requerirse un número mayor de replicados para asegurar una alta probabilidad de incluir el evento improbable en la muestra. En algunos casos el estado transitorio puede convertirse a condiciones en que el análisis del régimen permanente es apropiado descontando los valores futuros de los eventos. Este método sería apropiado para simulaciones de sistemas económicos. En tal caso las comparaciones entre alternativas se hacen comparando el valor presente de las condiciones futuras. 4.1 Métodos de estimación Antes de discutir el problema de la determinación del número de ensayos que deben realizase en una simulación, es conveniente examinar algunos métodos estadísticos para estimar parámetros a partir de las observaciones de unas variables aleatorias. Normalmente, una variable aleatoria X es muestreada de una población que tiene una distribución estacionaria (independiente del tiempo) con media finita E (X) = µ y varianza Var (X) = σ2. Si se hacen n ensayos de esa variable, o se toman n observaciones, la media
XN
ii
N
X= =∑
1
es también una variable aleatoria. El teorema central del límite nos dice que X tiende a estar normalmente
distribuida con media E ( X ) = µ y varianza Var ( X ) = σ2/n. Es decir la variable Z definida como
Z Xn
=− µ
σ /, -∞ < z < +∞
se distribuye normalmente con media cero y varianza unitaria Como antes se indicó F (z) indica la probabilidad de que la variable aleatoria Z sea menor o igual que z. Si denotamos por zα/2 el valor de la normal (0, 1) que tiene un área de α/2 hacia la izquierda y por z1-α/2 el valor que tiene un área de 1 - α/2 hacia la izquierda, entonces por simetría zα/2 = - z1-α/2. Por lo tanto la probabilidad de que Z caiga entre zα/2 y z1-α/2 es 1 - α. Es decir:
P(zα/2 < Z < z1-α/2) = P(-z1-α/2 < Z < z1-α/2) = 1 - α

B. Calderón. Introducción a la Simulación. Cap 8. “Análisis de una Simulación”. 8 - 5
En términos de la media muestral (X) la anterior probabilidad puede expresarse como:
P( X - z1-α/2 σ/ n < µ < ( X +z1-α/2 σ/ n ) = 1 - α
Es decir, (1 - α) es la probabilidad de que la media poblacional quede en el intervalo definido por:
X ± z1-α/2 σ/ n
El intervalo de confianza antes encontrado estará dado por dos límites:
Límite inferior del intervalo de confianza = LI = X - z1-α/2 σ/ n
Límite superior del intervalo de confianza = LS = X + z1-α/2 σ/ n
El tamaño del intervalo de confianza está dado por { 2zα/2 σ/ n } y depende del nivel de confianza escogido (1 - α) y del tamaño de la muestra n. Usualmente los niveles de confianza son del orden de 90%, 95% y 99%, en cuyos casos los valores de z son 1.65, 1.96 y 2.58. El significado del intervalo de confianza es: "Si el experimento se repite muchas veces, puede esperarse que la media caiga dentro del intervalo de confianza en el 100 (1 - α)% de las veces". En la práctica o por lo menos en la simulación, la varianza poblacional no es conocida, en cuyo caso debe reemplazarse por un estimativo muestral S, calculada como
( )
2
2
1
1SX Xi
ni
n
=−
−∑=
En este caso la variable Z definida antes no tiene aplicación. Es necesario usar la variable aleatoria T definida como
T XS n
=− µ
/, -∞ < t < +∞
la cual sigue una distribución t ó de Student, con n - 1 grados de libertad, la cual también es simétrica alrededor de la media. A medida que n aumenta (n ≥ 30) la distribución de Student tiende a la distribución Normal. Por lo tanto el intervalo de confianza para la media estará dado por:
Límite Inferior = LI = X - z1-α/2 σ/ n ó X - t1-α/2 S/ n
Límite superior = LS = X + z1-α/2 σ/ n ó X + t1-α/2 S/ n σ conocido ó σ desconocido y n < 30 σ desconocido y n ≥ 30 5 Determinación del tamaño de la muestra La escogencia del tamaño de la muestra que debe usarse en un experimento de simulación es una de las decisiones más importantes que deben hacerse en la planeación de un estudio de simulación. Es esencial que se realicen estudios estadísticos para determinar los tamaños de las muestras. Para determinar el número de ensayos o eventos que deben simularse hay varios enfoques que pueden emplearse, y que se describirán a continuación: 5.1 Enfoque estadístico La formulación del problema de simulación determina qué variables van a ser generadas por el simulador y cómo se van a relacionar con el objetivo del desempeño del sistema. Suponga que se desea estimar la media de alguna medida del desempeño del sistema. Si las medidas de las observaciones del sistema son

B. Calderón. Introducción a la Simulación. Cap 8. “Análisis de una Simulación”. 8 - 6
independientes con una distribución común cuya varianza es σ², entonces puede determinarse un intervalo de confianza para la media. Este intervalo puede hacerse tan pequeño como se desee haciendo el tamaño de la muestra lo suficientemente grande. Por lo tanto si se fija un límite al tamaño del intervalo o equivalentemente,
al error máximo permisible en la estimación de la media, dado por X - µ entonces puede determinarse el número requerido de observaciones (después de que ha pasado el régimen transitorio) requiriéndose primero un estimativo de la desviación estándar a partir de las observaciones realizadas en los ensayos pilotos. Como se explicó antes, el intervalo de confianza está dado por:
P( X - z1-α/2 σ/ n < µ < ( X +z1-α/2 σ/ n ) = 1 - α
Si el error máximo permitido en la estimación de la media poblacional (u) es δ entonces se tiene que:
δ = X - µ = z1-α/2 σ/ n ⇒ n z= −
2
1 2α σδ
/
En la mayoría de los casos σ no es conocida, por lo cual se debe efectuar una corrida piloto de M observaciones (M ≥ 30), a partir de la cual se puede estimar σ como S, donde:
( )
2
2
1
1SX Xi
Mi
M
=−
−∑= con X
M
ii
M
X= =∑
1
Muchas veces no se especifica el error absoluto máximo permitido en la estimación de la media (δ) sino que en su lugar se da el error relativo máximo permitido ε, dado por:
εµ
µδµ
δ=
−= ≈
XX
⇒ δ = ε X
Como µ no es conocida se la estima por X . Por lo tanto el tamaño de la muestra estará dado por:
n z= −
2
1 2α σδ
/=
2
1 2−
α
δ/z S
=
2
1 2−
α
ε/z S
x
El método usado para determinar el tamaño de la muestra o el intervalo de confianza está basado en dos suposiciones: Que la distribución de donde se obtienen las observaciones es estacionaria y que las observaciones son independientes. Desafortunadamente a causa de la naturaleza de los problemas para los cuales se emplea la simulación, es probable que las observaciones de los experimentos de simulación estén altamente correlacionados, es decir, es muy probable que el resultado de una observación dependa del resultado de la anterior o anteriores. Por ejemplo, los tiempos de permanencia en la cola de los clientes sucesivos que son atendidos en una estación de servicio están altamente correlacionados. El término técnico para esta interdependencia es "autocorrelación". Además, muchas medidas del desempeño son tales que en el experimento de simulación se las debe calcular en forma periódica como función del tiempo, en vez de darlas como una secuencia separada de observaciones. Tal es el caso, por ejemplo, del número de clientes en un sistema. Considere un fenómeno de espera, estación única. La disciplina de espera es de acuerdo al tiempo de llegada, PEPS: primeros en llegar, primeros en ser atendidos. Suponga que uno de los objetivos del estudio es medir el tiempo medio de permanencia en el sistema, definido como el tiempo que los clientes pasan en el sistema, el cual incluye el tiempo de espera en la cola y el tiempo de servicio. En una corrida de simulación el enfoque más sencillo para estimar el tiempo medio de permanencia en el sistema consiste en acumular los
tiempos de permanencia de n entidades sucesivas y dividir por n. Esta medida será denotada por X (n),

B. Calderón. Introducción a la Simulación. Cap 8. “Análisis de una Simulación”. 8 - 7
para enfatizar el hecho de que depende de n. Si Xi, i = 1, 2,..., n son los tiempos individuales de permanencia en el sistema, entonces:
X nn i
i
n
X( ) ==∑1
1
Los tiempos de permanencia medidos en esta forma no son independientes. Cuando se forman colas, el tiempo de permanencia de cada entidad dependerá del tiempo de permanencia de la entidad anterior. Cualquier secuencia de datos que tenga la propiedad de que un valor afecte otros valores se dice que está autocorrelacionada. Existen varios modos de medir el grado de autocorrelación. En el problema particular, el grado de autocorrelación aumenta a medida que aumenta la utilización de la facilidad o estación de servicio. Bajo las condiciones que pueden esperarse en la simulación, la media muestral de datos autocorrelacionados tiende a distribuirse normalmente a medida que el tamaño de la muestra aumenta. La fórmula anterior para estimar la media proporciona aun un estimativo satisfactorio de la media de datos autocorrelacionados. Sin embargo, la varianza de datos autocorrelacionados no está relacionada con la varianza de la población mediante la formula σ2/n, como ocurre con observaciones independientes. Debe agregarse un término que tenga en cuenta o mida la autocorrelación. Este término es positivo en la mayoría de las situaciones que ocurren normalmente en los experimentos de simulación, de tal forma que si se lo ignora la varianza quedaría subestimada y el intervalo de confianza calculado sería demasiado optimista o el tamaño de la muestra quedaría también subestimado. Otro problema que puede presentarse para estimar el tamaño de la muestra estadísticamente está en que la distribución no es estacionaria, principalmente cuando se trata de estimarla con base en los primeros resultados. Sería conveniente estimar σ con base en las primeras observaciones realizadas después de que el sistema haya salido del período transitorio. Existen otros dos métodos para tratar de resolver el problema de la determinación del tamaño de la muestra cuando los datos están autocorrelacionados. Estos métodos son a) Ejecutar una serie de corridas independientes y separadas, de la misma longitud, o b) Ejecutar una sola corrida de simulación, dividida en varias partes o bloques. 5.2 Replicación de corridas En este método se ejecuta una serie de corridas de simulación, completamente separadas e independientes, de igual longitud y cada corrida (excluyendo el período inicial de estabilización) se usaría como una observación individual. Este método nos da una secuencia de observaciones estadísticamente independientes. Además como son promedios, estas observaciones tienden a estar normalmente distribuidas, en virtud del teorema central del límite. La principal desventaja de este enfoque está en el hecho de que cada replicado requiere un período de estabilización o período transitorio, para que el sistema cumpla las condiciones del régimen permanente, de tal forma que gran parte del tiempo de la simulación sería improductivo. Cada replicado debe hacerse con una semilla diferente. Suponga que cada experimento se repite p veces, con semillas diferentes. Sea Xij la i-ésima observación de la j-ésima corrida. Entonces, los estimativos del valor medio y de la varianza estarán dados por:
Xp
nnpi
i
p
iji
n
j
p
X X= == ==∑ ∑∑1 1
1 11
( )
( )22
1
11S X n Xp j
j
p
=−
−∑=
( )
Entonces X (n) y S2 (n) pueden usarse para establecer intervalos de confianza. 5.3 División de una corrida en lotes o bloques

B. Calderón. Introducción a la Simulación. Cap 8. “Análisis de una Simulación”. 8 - 8
En este método no se replican las corridas de simulación sino que se realiza una sola corrida larga y para el registro de los datos se la divide en un número de segmentos o bloques de igual longitud. La media de cada segmento es considerada como una observación individual. En este método se elimina la desventaja del método anterior, ya que sólo se necesita un período inicial transitorio y el estado del sistema al final de un bloque o segmento es tomado como el estado inicial (condiciones iniciales) para el segmento siguiente. Es decir, sólo existe una corrida continua de simulación que, para la recolección de las estadísticas, se divide en una serie de p bloques (corridas) de igual longitud. Este método de dividir una corrida es preferible a empezar cada corrida en un estado vacío. Sin embargo la conexión entre los segmentos introduce alguna correlación. A veces los segmentos son separados por intervalos de tiempos en los cuales se descartan las primeras medidas para evitar la correlación. Conway ha demostrado que la varianza que se obtiene usando todos los datos y aceptando la correlación entre los segmentos, es menor que la obtenida a partir de la cantidad reducida de datos que se obtienen separando los segmentos. Medidas del Desempeño B1 B2 B3 B4 Bp Período de recolección de estadísticas Período transitorio Corrida de simulación Figura No 9.2 División de una corrida en lotes o bloques En el método de segmentar una corrida es necesario suponer que las medias de los segmentos o bloques son independientes. Esta suposición está justificada si la longitud del segmento es suficientemente grande. El efecto de la autocorrelación está, como ya se explicó, en que el valor de un dato afecta al otro. El efecto disminuye a medida que la separación entre los datos aumenta. En los dos métodos anteriores la corrida de simulación deberá dividirse de tal forma que se obtengan al menos 15 observaciones independientes. El tamaño requerido de cada corrida puede estimarse por métodos estadísticos (primer enfoque) o mediante una corridas piloto. El tamaño de cada corrida debe ser, al menos, igual al intervalo o período usado para remover el sesgo inicial. Cuando se comparan dos sistemas alternativos, el procedimiento preferible consiste en reproducir la misma secuencia de números aleatorios para ambas simulaciones. Los resultados correspondientes a los desempeños de los dos sistemas son luego apareados y las diferencias entre resultados apareados son usados como observaciones muestrales. En este caso sería la media de las diferencias de la medida del desempeño la media que se estaría estimando. Es decir, la hipótesis de interés sería si la diferencia entre las medidas del desempeño es cero.

9 EL PROBLEMA DE LA VALIDACIÓN
1 Introducción La validación del modelo y de los resultados es uno de los aspectos más importantes que hay que tener en cuenta al desarrollar el modelo de un sistema, bien sea un modelo analítico o un modelo de simulación. La validación está íntimamente relacionada con lo que se ha denominado la "credibilidad del modelo". Es decir, quien desarrolla un modelo de simulación debe buscar la forma de mostrar que el modelo es confiable y que representa adecuadamente el comportamiento del sistema bajo estudio. Además, debe lograr que quien va a tomar la decisión final sobre el uso de los resultados de la simulación crea en la simulación y en los resultados obtenidos a través de ella. La validación de una simulación, es en su esencia, igual a la validación de cualquier otro modelo; sin embargo existen ciertas diferencias en cuanto a su realización, debido a las características especiales de la simulación. 2 Aspectos que hay que validar Al estudiar el desarrollo de un modelo se encontró que había tres clases de variables que describían el comportamiento de un sistema. Esas variables las clasificamos como: 1) Variables exógenas o independientes Estas variables afectan el comportamiento del sistema, pero que no son afectados por el sistema. Estas variables se pueden clasificar a su vez en: a. Variables controlables o incontrolables, dependiendo de si pueden ser manipulados o no por quien toma
las decisiones.
b. Variables aleatorias o parámetros, dependiendo de si su valor se da en términos de una función de densidad o como una constante. Las variables aleatorias actúan en una forma independiente del sistema.
2) Variables de Estado Son variables que describen el estado del sistema en cualquier instante. Generalmente las variables de estado son variables aleatorias secundarias, cuyos valores están completamente relacionados con otras variables aleatorias, con las variables de decisión o controlables y con los parámetros. 3) Variables endógenas o de salida Son las variables cuyo valor se trata de predecir a través del modelo. Por lo tanto, cuando se trata de validar un modelo de simulación, es necesario validar todos los aspectos que se han considerado en la construcción del mismo. Esto incluye: a. Validación de las variables exógenas, tanto las que toman la forma de variables aleatorias como las que
toman la forma de parámetros. Es necesario examinar si a las variables aleatorias se les ha asignado la función de densidad apropiada y si los estimativos de los parámetros son confiables.
b. Validación del simulador, es decir, es necesario examinar el modelo de simulación que se construyó para ver si está realizando las tareas para las cuales fue diseñado (variables de estado).
c. Validación de los resultados del simulador (variables endógenas). La validación de las variables
endógenas es la parte principal, ya que con base en estas variables se han de tomar las decisiones. La validación de estos resultados depende grandemente de si se está usando el modelo para simular un sistema existente o un sistema propuesto, no existente, ya que para el primero pueden existir datos con los cuales puedan compararse los resultados de la simulación.
3 Enfoque de Hermann

B. Calderón. Introducción a la Simulación. Cap 9. “El problema de la validación 9 - 2
Hermann presenta cinco aspectos que hay que tener en cuenta para la validación de modelos de sistema no existentes: 1) Validez Interna Se refiere a la variabilidad que haya entre los resultados de una simulación cuando se la replica, manteniendo constantes todas las variables exógenas. Se requiere una baja variabilidad interna porque un modelo estocástico que tenga una alta varianza debida a procesos internos puede oscurecer o hacer desaparecer los cambios en los resultados producidos de cambios en las variables controlables o de decisión. A nivel de ejemplo, considere el problema del juego de las monedas, o el problema de los tubos. Tienen una baja variabilidad interna? 2) Validez externa o prueba de la credibilidad del modelo Se debe analizar si el modelo es realista, es decir, si el modelo describe adecuadamente el comportamiento del sistema. Se debe preguntar a quienes conozcan el sistema real que juzguen si el modelo es una descripción razonable del sistema real. 3) Validez de las variables y los parámetros Es necesario analizar si las variables y los parámetros se ajustan a los datos observados en el mundo real. Además, pueden hacerse pruebas de sensibilidad para probar la validez de las variables y los parámetros. 4) Validez de las hipótesis Es necesario probar la validez real de las hipótesis que se hacen al construir el modelo. Además, cuando el sistema se divide en subsistemas, es necesario analizar si los modelos de los subsistemas han sido bien construidos y si han sido bien ensamblados. 5) Validez de los eventos o series de tiempo que predice Esta es la validación en el sentido estricto. Es necesario examinar si la simulación predice los eventos que se observan en el sistema real, la forma en que ocurren esos eventos y las variaciones en las variables de salida. Es decir, es necesario examinar las discrepancias que existan entre los resultados simulados y los reales, si estos se conocen. Las pruebas 1, 2, 3, y 4 son importantes para asegurar que el modelo está bien construido y que puede usarse como una ayuda en el proceso de toma de decisiones. Sin embargo, un modelo es completamente válido sólo cuando ha demostrado que predice en una forma confiable y exacta las variables endógenas. Además, un modelo es útil cuando la persona que toma las decisiones cree que es válido. Para probar completamente la validez de un modelo de simulación, es necesario probar entonces la validez de las suposiciones hechas, y estimar correctamente los parámetros y las distribuciones de las variables aleatorias, y examinar qué tan confiables son los resultados de la simulación. En los párrafos siguientes se hace un resumen de la forma de estimación de parámetros y distribuciones y de las pruebas que pueden hacerse para probar la validez de los resultados. 4 Estimación de parámetros y de distribuciones Un parámetro es un factor que afecta el comportamiento del sistema, que puede predecirse con certeza y que puede o no ser afectada por las personas que operan o toman las decisiones sobre el sistema; un parámetro no necesariamente tiene que ser constante. Ejemplo de parámetros son la tasa de llegada de clientes a un sistema, la tasa de servicio en una facilidad, la demanda media por unidad de tiempo, el número de estaciones de servicio, etc. La mayoría de los parámetros se usan para describir las funciones de densidad de las variables aleatorias del modelo de simulación. Su estimación depende de los registros que se lleven, y por supuesto, del tipo de parámetro estimado. Cuando se estudió la generación de las variables aleatorias más importantes, se indicó también la forma de estimar los parámetros de esas variables. Para estimar los parámetros de una distribución, suponiendo que ésta es conocida, existen varios métodos, de los cuales los más conocidos son el

B. Calderón. Introducción a la Simulación. Cap 9. “El problema de la validación 9 - 3
método de los momentos y el principio de máxima verosimilitud. La estimación de los parámetros se hace a partir de los resultados que se obtengan en una muestra aleatoria. 4.1 Método de los momentos En el método de los momentos se igualan los primeros momentos de la distribución con los primeros momentos obtenidos a partir de la muestra. Así, si X es una variable aleatoria con función de densidad f(x), la cual es función de dos parámetros (a,b), entonces para estimar a y b se igualan los dos primeros momentos poblacionales con los dos primeros momentos muestrales. Los dos momentos poblacionales están dados por:
E(X) = µ = xf x dx( )−∞
+∞
∫ (1)
E(X - µ)2 = σ2 = 2(x ) f x dx−∫−∞
+∞
µ ( ) (2)
Los dos primeros momentos muestrales se calculan como:
x 1n ix
i 1
jf jxj 1
k
jfj 1
k==∑ = =
∑
=∑
n (3)
( )( )
2 11
2
1
2
1
11
s n ix xi
n if ix xi
M
kfk
M=−
−=∑ =
−=∑
−=∑
(4)
donde: xi = Valor observado fi = número de veces que se observó el valor xi n = Tamaño de la muestra M = número de intervalos de clases en que se agrupan las observaciones. Entonces para estimar los parámetros a y b antes mencionados, se igualan las expresiones (1) y (3) y las expresiones (2) y (4), así: $µ = X
2 2$σ = S
donde û y $σ se usan para denotar "estimativos de los verdaderos valores de u y σ. Ejemplo: Si X sigue una distribución uniforme en el intervalo (a,b), es decir:
f xb a
( ) =−1
, a ≤ x ≤ b
= 0 en otros casos Entonces
E(X) = µ = x
b adx a b
a
b
−=
+∫ 2
σ2 = ( ) ( )2 2
12xb a
dxb a
a
−
−=
−∫ µ
Para estimar a y b se igualan u y σ2 con X y s2 respectivamente, a saber:

B. Calderón. Introducción a la Simulación. Cap 9. “El problema de la validación 9 - 4
$µ = X = a b+
2 ⇒ $b X a= −2
( )2 2
2
12σ = =−
Sb a
⇒ ( )2
2
3SX a
=−
⇒ $a X S= − 3 y $b X S= + 3 4.2 Principio de máxima verosimilitud Usando el principio de máxima verosimilitud se trata de estimar los parámetros de tal forma que se maximice la probabilidad de obtener los resultados que se obtienen en la muestra aleatoria. Así, en el principio de máxima verosimilitud se trata de maximizar la probabilidad de que X1 quede entre x1 y x1 + dx1, X2 esté entre X2 y X2 + dx2,..., y Xn esté entre Xn y Xn + dxn. Así se trata de maximizar la siguiente probabilidad. P(x1<X1<x1+dx1,x2<X2<x2+dx2,...,xn<Xn<xndxn) (5) = f(x1)dx1.f(x2).dx2...f(xn)dxn=f(x1)f(x2)...f(xn)dx1dx2...dxn La expresión: L (X,Θ) = f (x1) f (xn) = π f (Xi) (6) recibe el nombre de "función de verosimilitud" y el maximizar la expresión (5) es idéntico a maximizar la expresión (6) o a maximizar el logaritmo de la expresión (6), siendo Θ el conjunto de parámetros a estimar. Así, si Θ = (θ1 y θ2) entonces para estimar θ1 y θ2 se deriva la función de verosimilitud con respecto a θ1 y θ2, se igualan a cero las expresiones resultantes y se despejan los estimativos.. Ejemplo. Consideremos la estimación de los parámetros µ y σ2 de una distribución normal por el método de máxima verosimilitud. Si X∼ N(µ, σ2) ⇒ θ = {θ1, θ2} ⇒ θ1 = µ, θ2 = σ2. La función de verosimilitud está dada por:
( ) eπ2σ
1eσxσ
n
1i
2222σ)µxi(σµxi
π2σ1),µ,(f),µ,X(L 2/
nn
1i
2/n
1i
2i
2 ∑ −=−== =
−
=
−
=
∏∏
El logaritmo de la función de verosimilitud está dado por:
σ
)µx(σ 2
n
1i
2
2
2
i)π2σln(n),µ,X(Lln
∑−−= =
−
Derivando inicialmente con respecto al parámetro µ se tiene:
∑⇒∑⇒=−∑
=∂
∂==
= =−−− n
1i
n
1i2
n
1i2
0ii02
)1(i2
µ),µ,X(Lln µnx)µx(
σ
)µx(σ
Xn
µ
n
1iix==
∑=
Derivando con respecto al parámetro σ se tiene:
02
)2(iπ2
π2σn
σ),µ,X(Lln
σ
)µx(σ3
n
1i
22
=−∑
−−=∂
∂ =−
⇒

B. Calderón. Introducción a la Simulación. Cap 9. “El problema de la validación 9 - 5
ni
0i
σn
n
1i
2
23
n
1i
2 )xx(σ
σ
)µx( ∑=⇒=
∑+− ==
−−
En resumen tenemos que:
−=
==
∑=
XXT
T2
n
1i
2i2
1
nn1
Xµ
Las expresiones obtenidas son las mismas obtenidas haciendo uso del método de los momentos. Para estimar un parámetro es necesario conocer la distribución de la cual fue obtenida la muestra. Sin embargo, en muchas ocasiones no se sabe de qué distribución fue extraída la muestra. Por lo tanto, el proceso de estimación incluye también la estimación de la distribución de la variable aleatoria. 4.3 Definición de la Distribución Para definir la distribución de una variable aleatoria, a partir de resultados muestrales, es necesario seguir el siguiente procedimiento. a. Identificación de la distribución b. Una vez se haya recogido la información que se va a usar como guía, se resume en una distribución de
frecuencias, por medio de histogramas o de gráficas de barras. Si la variable es continua se la distribuye en intervalos de clase. En base al histograma o al gráfico de barras se hace la suposición acerca de la distribución que pueden seguir los valores de la muestra.
Al identificar la distribución hay que tener en cuenta que no siempre es necesario representar una variable
aleatoria discreta mediante una distribución discreta. La distribución normal puede emplearse para aproximar la distribución binomial o la distribución de Poisson, con buenos resultados de acuerdo a los valores de los parámetros.
c. Estimación de los parámetros: Una vez se haya identificado la distribución, es necesario estimar los
parámetros de la misma. d. Prueba de la distribución: Es necesario probar si la variable aleatoria de interés si sigue la distribución
que se supuso, es decir, hay que probar la validez de la hipótesis supuesta. Para probar esta validez se pueden usar las dos pruebas estudiadas antes al analizar la uniformidad de los números aleatorios: prueba chi- cuadrado y prueba de Smirnov-Kolmogorov. Para cualquiera de estas pruebas es necesario fijar el nivel de significancia de la prueba (α).
Si para el nivel de significancia fijado se rechaza la prueba (cualquiera que se use) es necesario suponer
una nueva distribución, y repetir de nuevo el procedimiento de estimación de la distribución. Si no es posible ajustar los datos a una distribución estándar, es necesario utilizar la distribución empírica. Debe tenerse en cuenta que al utilizar una distribución empírica se pierde a veces mucha información ya que habrá muchos valores que serán imposibles de generar. Por ejemplo, en el problema del vendedor de periódicos, al usar la distribución empírica, la demanda varía en intervalos de a 5; si se ajustaran esos datos a una distribución estándar, la demanda podría variar en intervalos de a uno; además, la demanda podría ser inferior a 75 o superior a 120. Cualquier libro de estadística puede consultarse para profundizar un poco más acerca del problema de la estimación. 5 Validación del simulador y los resultados 5.1 Validación del Programa

B. Calderón. Introducción a la Simulación. Cap 9. “El problema de la validación 9 - 6
Como se indicó antes es necesario validar la estructura del modelo de simulación para verificar si está desarrollando las tareas para las cuales fue diseñado, y para examinar si los resultados finales que se obtienen son confiables. Es decir, interesa saber si el programa de simulación está o no trabajando. Un programa de simulación puede fallar por no alcanzar su objetivo por uno de los siguientes errores. 1) Errores de codificación Estos errores son detectados fácilmente ya que ellos impiden la ejecución del programa. Además, el diagnóstico del error ayuda a su descubrimiento. 2) Errores de lógica Cuando hay un error de lógica el programa funciona pero no produce resultados correctos. Los errores de lógica pueden detectarse mediante los siguientes métodos: - Una prueba de escritorio, es decir, simular manualmente varios eventos de la simulación. En la prueba de
escritorio debe efectuarse una "corrida" corta, tratando que en la prueba se presenten todos los casos "raros", difíciles de manejar. Al realizar la prueba de escritorio hay que tener cuidado de ejecutar todos los pasos que ejecutaría el computador al hacer la simulación, y no omitir ningún detalle.
- Una verificación de las principales relaciones que hay entre las variables endógenas. Una vez se
obtengan los resultados de la simulación, es necesario verificar que se hayan cumplido todas las relaciones que existen entre las variables endógenas. Por ejemplo, cuando se hace la simulación del sistema de colas de una sola estación, se recoge la información sobre el tiempo medio de permanencia de una unidad en el sistema, el tiempo medio de permanencia en la cola, el tiempo medio entre llegados y el tiempo medio de servicio (TPS, TPC, TLLEG, TSERV respectivamente); aunque el tiempo esperado entre llegados y el tiempo esperado de servicio son conocidos (1/ y 1/u respectivamente) son calculados a través de los datos simulados para verificar que el tiempo medio en el sistema es igual al tiempo medio en la cola más el tiempo en el servicio, a saber:
TPS = TPC + TSERV Otra relación que debe cumplirse es la existente entre el número medio de unidades en el sistema con el
número medio de unidades en la cola y en el servicio, a saber: n = V + a ó NUS = NUC + IE Si se obtuviera el número medio de estaciones ocupadas (número medio de unidades en servicio) como la diferencia entre las unidades en el sistema, y las unidades en la cola, y hubiera un error en la simulación, éste no sería detectado a no ser que de negativo. Aunque no existan errores de lógica y se cumplan las diferentes relaciones que deben existir entre las variables, es necesario efectuar el análisis sobre la "credibilidad" del modelo, lo cual implica hacer un análisis detallado de la estructura interna del modelo. Además se requiere comparar los resultados obtenidos mediante la simulación con los datos históricos, si éstos existen, y analizar las discrepancias que existan. Este análisis es indispensable para asegurarnos que el modelo de simulación si sea una representación válida del sistema de interés, y no de otro sistema. 5.2 Validación de los resultados Para verificar los resultados de la simulación se pueden usar los siguientes métodos: 5.2.1 Comparación con resultados del sistema real. Cuando se simula un sistema existente, se puede simular el sistema bajo las condiciones actuales y luego comparar los resultados de la simulación con los datos históricos, o con aquellos datos que podrían obtenerse mediante la observación del sistema real. Si no existen discrepancias significativas entre los resultados simulados y los reales se concluye que el modelo de simulación es una representación válida del sistema actual, y puede suponerse que en igual forma simulará el sistema propuesto (siempre y cuando el sistema

B. Calderón. Introducción a la Simulación. Cap 9. “El problema de la validación 9 - 7
actual y el propuesto se simulen bajo las mismas condiciones). Es decir, la validación del sistema propuesto se hace con base en los resultados del sistema actual. 5.2.2 Comparación con resultados analíticos. En la mayoría de los casos que se usa la simulación, no existe un modelo matemático que pueda representar al sistema real, si este modelo existiera se usaría en vez de la simulación, ya que su costo sería menor. Sin embargo, en muchos casos, se pueden hacer modificaciones al modelo de tal forma que sin cambiar la esencia del mismo, permita resolverlo por medios analíticos. Por ejemplo, asuma que se requiere simular un sistema de colas, estación única, para el cual las llegadas al sistema siguen una distribución G y el tiempo de servicio sigue una distribución H. Para este sistema no existe un modelo analítico, con el cual puedan compararse los resultados. Sin embargo, si cambiamos las distribuciones G y H por la exponencial, entonces se pueden validar los resultados de la simulación con los resultados analíticos y si la simulación se comporta bien para la distribución exponencial, se puede suponer que se comportará bien para las distribuciones H y G. Este es el método que se usó para validar los resultados del sistema de colas en que el tiempo entre llegados era Erlang y el tiempo de servicio era normal. Este método se usó también para validar los resultados del proyecto de simulación No.8, en el cual se estudiaron diferentes disciplinas de la cola. En ese problema se estudiaron las siguientes disciplinas o políticas de atención: - Política No. 1 : Atención de acuerdo al orden de llegada - Política No. 2 : Atención de acuerdo al tiempo de procesamiento. - Política No. 3 : Atención de acuerdo a la fecha de entrega - Política No. 4 : Atención en forma aleatoria Los resultados analíticos (fórmulas) usadas para estudiar el proyecto de simulación No. 6 se aplican cuando la disciplina de la cola es de acuerdo al orden de llegada. Al estudiar este problema en el capítulo VII se calcularon los resultados analíticos para la política No. 1 y se observó que la diferencia entre los resultados teóricos y simulados eran despreciables. Entonces, si el modelo simula bien la primera política, puede esperarse que haga lo mismo para las demás políticas, ya que todas las políticas son lógicas. 5.2.3 Verificación por segmentos. Cuando el sistema de interés pueda subdividirse en subsistemas, puede validarse cada subsistema (segmento) por separado, quizás efectuándole algunas modificaciones que permitan la validación analítica, teniendo sumo cuidado al estudiar la forma de enlazar (unir) luego los modelos de los subsistemas para formar (y validar) el sistema real. Esta es una de las formas en que puede validarse el sistema de colas en serie y los sistemas complejos de producción. Al validar por segmentos es necesario obrar con cuidado, ya que los subsistemas no son independientes. 6 Conclusión Cuando se crea un nuevo modelo de simulación, y más cuando se trata de un modelo para un sistema no existente, el aspecto principal que se debe estudiar en el modelo es que sea "razonable" y muchas veces se requiere hacer un "acto de fé" y creer que el modelo será de utilidad en el proceso de toma de decisiones. Es de suma importancia que a medida que se va desarrollando el modelo de simulación exista una comunicación constante entre el analista que desarrolla el modelo y la persona que ha de tomar la decisión sobre el uso de los resultados de la simulación. Esta comunicación evita que al presentar los resultados finales, se dude de la validez de los mismos, debido a que quien toma la decisión conoce, en forma íntima, la manera como se llegó a la misma y la validez del modelo y por lo tanto de los resultados. En general, el problema de la validez de un modelo de simulación, es básicamente el mismo problema de la validez de cualquier otro modelo.

Crystal Ball
1. ASPECTOS GENERALES Crystall Ball es un programa basado en Excel (incorporado a Microsoft Excel) cuyo objetivo básico es realizar simulaciones tipo Montecarlo, de una manera sencilla automatizando los pasos más complejos y tediosos en el proceso de simulación Montecarlo en Excel, tales como el muestreo de distribuciones, realización de replicados, agregación de resultados del modelo, cálculo de estadísticas e información relacionada con el análisis de riesgo
Crystal Ball incluye íconos para las diferentes opciones del menú, y tiene otras capacidades desde el punto de vista estadístico, para facilitar el proceso de simulación, tales como • Generación de diferentes variables aleatorias
• Realización de pruebas de bondad de ajuste a una muestra de datos, o a los resultados del modelo.
• Proceso de optimización Crystal Ball fue desarrollado y publicado por Decisioneering, Inc., y actualmente es propiedad de Oracle. Apariencia: Cristal Ball agrega tres nuevos menús y una barra de herramientas al Excel. La
barra de menú incluye tres nuevas opciones: Cell, Run, CB tools (herramientas Cristal Ball)
Cell: Sirve para crear o modificar un modelo de Crystal Ball Run: Para ejecutar el modelo y analizar sus resultados CB.tools.
La barra de herramientas está ordenada de izquierda a derecha, siguiente el proceso de
modelamiento, a saber: Definir modelo, correr el modelo y analizar los resultados. Los nueve
primeros botones ayudan a organizar un modelo nuevo o uno existente, los siguientes cinco especifican los parámetros de la simulación, y los últimos siete generan gráficos y reportes, y contienen las ayudas de CB. Análisis de riesgo: El análisis del riesgo es un enfoque para desarrollar un “entendimiento comprensivo y una
conciencia del riesgo asociado con una variable particular de interés. Los pasos para desarrollar el análisis de riesgo con la técnica de Montecarlo es la siguiente: a) Construir un modelo para proveer información y un conocimiento para evaluar una
decisión. b) Reconocer e identificar la incertidumbre asociada con el modelo y sus variables
c) Generar una distribución de probabilidad para las variables de salida asociadas con la decisión
d) Analizar los efectos de la incertidumbre en las variables de salida, y sobre la decisión.
2. Simulación Montecarlo con Crystal Ball El procedimiento general de la simulación comprende los siguientes pasos:
1) Desarrollar el modelo de hoja de cálculo 2) Definir las suposiciones para las variables de incertidumbre (Assumptions), es decir,
las distribuciones de probabilidad de las variables aleatorias 3) Definir las variables de decisión, 4) Definir las variables de salida de interés (forecast cells)

Crystal Ball. Proceso general. Bernardo A. Calderón C. 2
5) Definir el número de ensayos y otras opciones de la simulación (“preferentes) 6) Ejecutar la simulación (Run) 7) Interpretar los resultados. A continuación se desarrollan en forma somera los principales aspectos a tener en cuenta para el desarrollo del modelo de simulación en Cristal Ball.
Para la aplicación del Cristal Ball usaremos el siguiente problema, relacionado con la toma de decisión sobre un plan de telefonía celular. Usted enfrenta la toma de una decisión importante: Qué plan de telefonía celular debe usar, entre dos propuestas, que llamaremos Plan 1 y Plan 2, y que tienen las siguientes
características: Plan 1 Costo del plan: $10000, con cuatrocientos (400) minutos por mes, sin cargos extras por
llamadas de larga distancia, y con un costo extra de $1000 por minuto por encima de 400 minutos.
Plan 2 Costo del plan: $87500, cantidad ilimitada de minutos, pero con un cargo de $200 por minuto de larga distancia. Sus datos básicos son los siguientes: El tiempo de conversación se distribuye aproximadamente de una manera normal, con una
media de 400 minutos, un mínimo de 340 y un máximo de 460, y el porcentaje de llamadas de larga distancia tiene una distribución triangular, con un mínimo del 10%, un máximo del 40% y un valor más probable del 30%.
2.1. Diseño de la hoja de la simulación
Como ya se ha mencionado previamente, la hoja de cálculo debe diseñarse de tal forma que
la información pueda se pueda leer de una manera ágil y rápida, y debería tener en cuenta los siguientes aspectos:
Un título descriptivo que identifique el estudio
Una sección para los datos de entrada
Los datos de entrada deben usarse sólo a través de referencias a las celdas que los contienen, de tal manera que cualquier cambio en los mismos se refleje inmediatamente en los resultados de salida
Una sección para los datos de salida
Una sección para el área de trabajo.
Deben usarse los formatos apropiados, de acuerdo a la naturaleza de los datos
Los cálculos complejos deberían realizarse en más de una celda, para reducir las posibilidades de error.
El siguiente será el modelo de hoja de cálculo empleado para la simulación.
A B C
1 Selección de plan de telefonía celular
2 Plan No 1 Plan No 2
3 Costo base $100,000 $87,500

Crystal Ball. Proceso general. Bernardo A. Calderón C. 3
4 Minutos del plan 400 Ilimitado
5 Cargo por minuto adicional $1000 $0
6 Larga distancia $0 $200
7 Costo total $100,000 $115,500
8
9 Minutos actuales 400
10 % de larga distancia 30%
11 No. de minutos de LD 120
12 Ahorro por escoger el Plan No
13 $11,500
2.2. Descripción de la incertidumbre Describir la incertidumbre en celdas sencillas usando la distribución de probabilidad apropiada, a través del botón “assumptions”, siguiendo el siguiente procedimiento: a) Se selecciona la celda y se da click en “Define Assumptions”. Cristal Ball supone que el
nombre de la variable está en la celda a la izquierda de la celda seleccionada
previamente. Se selecciona la distribución apropiada y se presiona OK. b) Se entran los parámetros de la distribución, y se presiona “Enter” y OK. La celda toma
un color verde. Si se quiere ver una “suposición” se selecciona la celda y se da clic en “definir suposiciones”. El procedimiento anterior se repite para las demás variables aleatorias.
Para este problema no existen variables de decisión
2.3. Definir las variables de decisión Para este problema no existen variables de decisión. Cuando existen las variables de decisión, se selecciona la o las variables de decisión, se usa la opción “define decision variables”, y se define el rango de valores de la variable de decisión, dependiendo de si esta es continua o discreta.
2.4. Definir los pronósticos o variables de salida Definir las variables de salida, o variables de interés que se tratan de estimar, y se denominan “pronósticos (forecasts). Se definen mediante fórmulas que dependen de las variables de entrada (suposiciones). Por ejemplo: Valor neto, utilidad, costo de operación, etc. Se pueden definir tantas variables de salida como se desee.
Cuando se ejecuta la simulación, el Cristal Ball almacena las variables de salida, y cuando la simulación termina se pueden analizar sus resultados. El procedimiento a seguir es el siguiente:
Se seleccionan las celdas y se presionan el botón “define forecasts” (las celdas toman
color azul.
2.5. Corrida de la simulación La simulación se puede realizar paso a paso (single step) o realizando todas las simulaciones de una vez (botón de Run Preference Dialog). Mediante este botón se define el número máximo de ensayos, y otros criterios si es del caso, y luego se realiza la corrida mediante el

Crystal Ball. Proceso general. Bernardo A. Calderón C. 4
botón “Run”. Si previamente se realizaron otras simulaciones, antes de ejecutar el modelo se debe presionar el botón “reset”. Cuando se inicia la simulación, se activa la ventana de “pronósticos”, y a medida que avanza la simulación, el simulador va construyendo un histograma de frecuencia con los resultados obtenidos.
2.6. Análisis de los resultados Para facilitar el análisis de la simulación, se pueden considerar los siguientes resultados: a) Probabilidad de excedencia. Si se quiere calcular la probabilidad de que la variable de
salida exceda de cierto valor, basta con entrar dicho valor en la celda inferior izquierda,
y la probabilidad aparece en la celda inferior central. Si entramos el valor de cero, entonces obtenemos la probabilidad de que la variable de salida sea positiva
b) Estadísticas resumen. En la ventana de pronósticos, mediante el menú “View” se pueden mirar las estadísticas resumen, los percentiles, o el histograma acumulado. Las estadísticas resumen incluyen, entre otros: Número de ensayos, media, mediana, moda, desviación estándar, varianza, coeficientes de simetría, de curtosis y de variabilidad, valores mínimos, máximos, el rango, y el error estándar.,
c) Análisis de sensibilidad. Usando el botón de Análisis de Sensibilidad se puede apreciar
en que forma las diferentes suposiciones afectan los resultados (pronósticos) de la simulación. Presionando el botón de “preferencias”, se escoge luego “contribución a la varianza” y se obtiene en que porcentaje contribuye cada una de las suposiciones a la variable de salida, y presenta además el tipo de correlación de cada suposición a la variable de salida (positiva o negativa)
2.7. Creación del reporte Para crear el reporte, se presiona el botón de “Creación del reporte” y se señalan los aspectos
a incluir en el mismo, tales como estadísticas resumen, distribuciones de frecuencia, percentiles, suposiciones del estudio (variables aleatorias), si se desea el informe en blanco y negro o a color, y la ubicación del reporte.
3. Otros aspectos del Cristal Ball
Ajuste de distribuciones a los datos, mediante el botón “Fit” de la galería de distribuciones.
“Suposiciones” (variables aleatorias) correlacionadas, mediante el botón “correlación”.
Uso de referencias absolutas o relativas en vez de valores al definir las suposiciones.
Control de precisión al definir las opciones de fin de simulación. Comparación de alternativas. Gráficos “overlay” (superpuestos o traslapados) que
muestran múltiples pronósticos o varias curvas de distribución en el mismo gráfico, usando “la barra de herramientas del menú “Run”.
Gráficos de tendencia.