identificação de oradores para estação de anotação...
TRANSCRIPT

UNIVERSIDADE DO PORTO
Faculdade de Engenharia Departamento de Engenharia Electrotécnica e de computadores
Identificação de Oradores Para Estação de Anotação Audiovisual
Trabalho realizado no âmbito da disciplina de Projecto, Seminário ou trabalho Final de Curso
do curso de Licenciatura em Engenharia Electrotécnica e de Computadores
Projecto realizado no Instituto de Engenharia de Sistemas e Computadores do Porto
Orientadores FEUP: Eng.ª Maria Teresa Andrade Prof. Artur Pimenta Alves
Orientadores INESC: Eng.º Luís Gustavo Martins
Eng.º Sílvio Macedo
Rui Miguel Martins Costa
Julho de 2005

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
2
SUMÁRIO
Este trabalho apresenta o resultado de um estudo sobre segmentação automática de
oradores e integração com um anotador de conteúdos audiovisuais.
Segmentação automática de oradores é detectar as fronteiras de mudança de oradores
num ficheiro áudio.
Assumiu-se que o número de oradores era desconhecido, tal e qual, como se tratasse, por
exemplo, de segmentação de um noticiário, em que à partida é desconhecido o número de
jornalistas.
Foram testados dois tipos de segmentadores. Um primeiro segmentador que utiliza dois
níveis de threshold e um outro segmentador que utiliza um método de refinação
denominado por Bayesian Information Criterion.
Foi utilizada a framework MARSYAS para se extrair as características do sinal áudio. O
anotador, 4VDO ANNOTATOR, serviu como interface gráfico, onde foram criadas
tracks com as devidas segmentações.
Palavras-chave: Anotador – Segmentador – Detecção de potencial mudança de orador
– Divergence Shape – Line Spectrum Pairs – Sons vozeados, ão-vozeados e silêncio

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
3
AGRADECIMENTOS
Quero agradecer aos meus dois orientadores do INESC Porto, Sílvio Macedo e Luís
Gustavo Martins, pela sua disponibilidade, ajuda e orientação dada ao longo deste
trabalho.
Quero agradecer aos meus colegas da Unidade de Telecomunicações e Multimédia do
INESC Porto pelo seu companheirismo.
Last but not the least, quero agradecer aos meus pais e aos meus irmãos pelo indiscutível
apoio desde o primeiro dia.
A todos, um muito obrigado!

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
4
ÍNDICE SUMÁRIO .....................................................................................................................2
AGRADECIMENTOS ..................................................................................................3
ÍNDICE .........................................................................................................................4
ÍNDICE DE FIGURAS ................................................................................................7
ÍNDICE DE TABELAS................................................................................................8
INTRODUÇÃO .............................................................................................................9
1 PRODUÇÃO DE FALA .........................................................................................11
2 CARACTERÍSTICAS DE SINAIS DE VOZ ...........................................................15
2.1 SONS VOZEADOS.............................................................................................. 15
2.2 SONS NÃO-VOZEADOS.................................................................................... 16
2.3 SONS PLOSIVOS ................................................................................................ 16
3 EXTRACÇÃO DE PARAMETROS ........................................................................17
3.1 ANÁLISE DE PREDIÇÃO LINEAR................................................................. 17
3.2 LINE SPECRUM PAIRS .................................................................................... 21
3.3 COEFICIENTES CEPSTRAIS .......................................................................... 22
3.4 COEFICIENTES MEL-CEPSTRAIS................................................................ 24
4 DESCRIÇÃO DO TRABALHO..............................................................................27
4.1 SEGMENTAÇÃO EM SONS VOZEADOS, NÃO VOZEADOS E SILÊNCIO 27
4.1.1 TAXA PASSAGENS POR ZERO (NZ) .................................................................. 27
4.1.2 ENERGIA .................................................................................................................... 28
4.1.3 COEFICIENTE DE AUTOCORRELAÇÃO NORMALIZADO PARA O ATRASO
DE UMA AMOSTRA (C1)...................................................................................................... 28

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
5
4.1.4 PRIMEIRO COEFICIENTE DE PREDIÇÃO (a1) ................................................ 29
4.1.5 ERRO DE PREDIÇÃO NORMALIZADO (Ep) .................................................... 29
4.2 SELECÇÃO DOS SONS – BASE DE DADOS ................................................. 31
5 MARSYAS.............................................................................................................32
5.1 ARQUITECTURA............................................................................................... 32
5.2 CLASSIFICADORES.......................................................................................... 33
6 SPEAKERID - SEGMENTAÇÃO NÃO SUPERVISIONADA DE ORADORES ......34
6.1 DESCRIÇÃO GERAL DO SISTEMA............................................................... 34
6.2 SELECÇÃO DE CARACTERÍSTICAS E MEDIDA DE DISTÂNCIA ........ 35
6.2.1 SELECÇÃO DE CARACTERÍSTICAS................................................................. 35
6.2.2 MEDIÇÃO DIVERGENCE SHAPE....................................................................... 36
6.3 DETECÇÃO MUDANÇA DE ORADORES..................................................... 38
6.3.1 PROCESSAMENTO FRONT-END........................................................................ 38
6.3.2 DETECÇÃO DE POTENCIAL MUDANÇA DE ORADOR ............................. 39
6.3.3 ACTUALIZAÇÃO DO MODELO DE ORADOR ............................................... 40
6.3.4 REFINAMENTO DA FRONTEIRA DE MUDANÇA DE ORADOR.............. 41
7 ANOTADOR .........................................................................................................44
7.1 4VDO ANNOTATOR.......................................................................................... 44
7.2 ARQUITECTURA DO 4VDO ANNOTATOR ................................................. 46
7.2.1 ORGANIZAÇÃO ....................................................................................................... 46
7.3 INTEGRAÇÃO DO SEGMENTADOR ............................................................ 49
8 SEGMENTADOR AUTOMÁTICO ........................................................................51
8.1 COMUNICAÇÃO ENTRE ANOTADOR E SEGMENTADOR..................... 53
8.2 TESTE DO SEGMENTADOR DE ORADORES............................................. 53

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
6
9 TESTES e RESULTADOS.....................................................................................56
10 CONCLUSÕES .....................................................................................................67
11 FUTUROS DESENVOLVIMENTOS .....................................................................68
12 ANEXOS ...............................................................................................................69
12.1 ANEXOS 1 – SEGMENTADOR SEM BIC....................................................... 69
12.2 ANEXOS 2 – SEGMENTADOR COM BIC ..................................................... 88
12.3 ANEXOS 3 – SEGMENTADOR COM BIC ...................................................132
13 REFERÊNCIAS E BIBLIOGRAFIA ...................................................................142

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
7
ÍNDICE DE FIGURAS
Figura 1 – Diagrama esquemático do mecanismo de produção da fala
Figura 2 – Modelo Excitação-Filtro
Figura 3 – Cálculo do número de LPCs
Figura 4 – Zeros de LSP
Figura 5 – Diagrama de blocos do processo (heurístico) para cálculo dos coeficientes mel-
cepstrais
Figura 6 – Escala de Mel
Figura 7 – Diagrama de blocos do algoritmo de classificação de segmentos em vozeado, não-
vozeado e silêncio
Figura 8 – Diagrama utilizado na detecção não supervisionada de mudança de oradores
Figura 9 – Mapa de distância de divergência LSP
Figura 10 – 4VDO ANNOTATOR
Figura 11 – Exemplo de uma segmentação
Figura 12 – Anotação no 4VDO
Figura 13 – Esquema representativo da integração do SPEAKERID no anotador
Figura 14 – Esquema representativo do segmentador
Figura 15 – API para criação manual de segmentos
Figura 16 – API usada para a segmentação automática de oradores
Figura 17 – Esquema de como são usados os intervalos de confiança
Figura 18 – Exemplo de um possível teste realizado
Figura 19 – Tabela com os valores calculados de FDR, MDR, Precision e Recall
Figura 20 – Nova API usada para a segmentação automática de oradores
Figura 21 – Histograma da duração dos segmentos do teste 13
Figura 22 – Curva Recall-False, do teste 13, com � igual 0,4
Figura 23 – Curva Recall-False, do teste 13, com � igual 0,3

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
8
ÍNDICE DE TABELAS
Tabela 1: Quadro resumo dos vários testes realizados
Tabela 2: Resumo com os melhores resultados para o segmentador sem BIC
Tabela 3: Resumo com os melhores resultados para o segmentador com BIC
Tabela 4: Tabela do teste 13, com � igual 0,4
Tabela5: Tabela do teste 13, com � igual 0,3
Tabela 6: Resumo com os melhores resultados para o segmentador com BIC

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
9
INTRODUÇÃO
As tendências e os paradigmas actuais na computação apontam para a utilização
crescente de materiais multimédia, nomeadamente do vídeo. A crescente disponibilidade
de materiais audiovisuais coloca problemas de armazenamento e acesso e sugere modelos
de reutilização para aproveitar toda a riqueza da informação existente.
Estes arquivos de multimédia necessitam de ferramentas de software capazes de
automaticamente analisar os seus conteúdos, para se proceder a operações de
identificação e pesquisa. É neste contexto que surge este projecto, detecção de mudança
de oradores para integração num sistema de anotação de conteúdos audiovisuais.
O presente relatório está essencialmente dividido em duas partes principais: uma parte
teórica (do capítulo 1 ao capítulo 7), e uma parte prática (capítulo 8 e 9). Assim será feita
uma apresentação de cada metodologia com a respectiva fundamentação teórica e com a
devida ilustração realizadas nos capítulos 8 e 9.
Inicialmente, no primeiro capítulo, é apresentado um breve estudo sobre a fala, onde é
explicado mecanismo para a produção de fala.
No segundo capítulo são apresentadas as características de sinais de voz. É explicado
qual a diferença entre sons vozeados, não vozeados e silêncio.
No terceiro capítulo apresenta-se métodos para a extracção de características, como por
exemplo Linear Spectral Pairs, LPSs.
No quarto capítulo é explicado como se realiza a segmentação de sons vozeados, não
vozeados e silêncio.
No quinto capítulo é apresentada uma breve descrição da framework MARSYAS,
ferramenta que irá servir de suporte na extracção de características.
No sexto capítulo é apresentada a solução adoptada para a segmentação não
supervisionada de oradores. É explicado todo o processo do sistema, bem como os três
módulos que o constituem: módulo de processamento front-end (I), módulo de
segmentação (II) e módulo de clustering e actualização do modelo do orador.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
10
No sétimo capítulo é constituído por uma descrição de um anotador e é feita a
apresentação do 4VDO ANNOTATOR. É também descrito o modo como foi integrado o
segmentador no anotador.
No oitavo capítulo é descrita a solução adoptada para a integração do segmentador no
anotador bem como o método adoptado para a avaliação do segmentador.
No nono capítulo são apresentados os resultados obtidos bem como algumas reflexões
sobre os mesmos.
1.1 – Apresentação da empresa
O projecto foi realizado no INESC Porto - Instituto de Engenharia de Sistemas e
Computadores do Porto, na unidade de Telecomunicações e Multimédia.
O INESC Porto é uma associação privada sem fins lucrativos reconhecida como
instituição de utilidade pública, tendo adquirido recentemente o estatuto de Laboratório
Associado. Desenvolve actividades de investigação e desenvolvimento, consultoria,
formação avançada e transferência de tecnologia nas áreas de Telecomunicações e
Multimédia, Sistemas de Energia, Sistemas de Produção, Sistemas de Informação e
Comunicação e Optoelectrónica.
A Unidade de Telecomunicações e Multimédia actua em áreas chave no âmbito das
modernas redes e serviços de comunicações, em especial Processamento de Sinal e
Imagem, Arquitecturas de Redes, Serviços de Telecomunicações e Microelectrónica.
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
11
1 - PRODUÇÃO DE FALA
Falar é algo tão natural para nós humanos que nem nos damos ao trabalho de perguntar
por vezes o que é a fala. Nesta introdução iremos dar-lhe um tratamento mais científico e
explicar o que é a fala.
Há um modelo de comunicação geralmente aceite, designado cadeia de fala, que
considera três fases fundamentais neste processo de comunicação: a produção, a
transmissão e a recepção da fala.
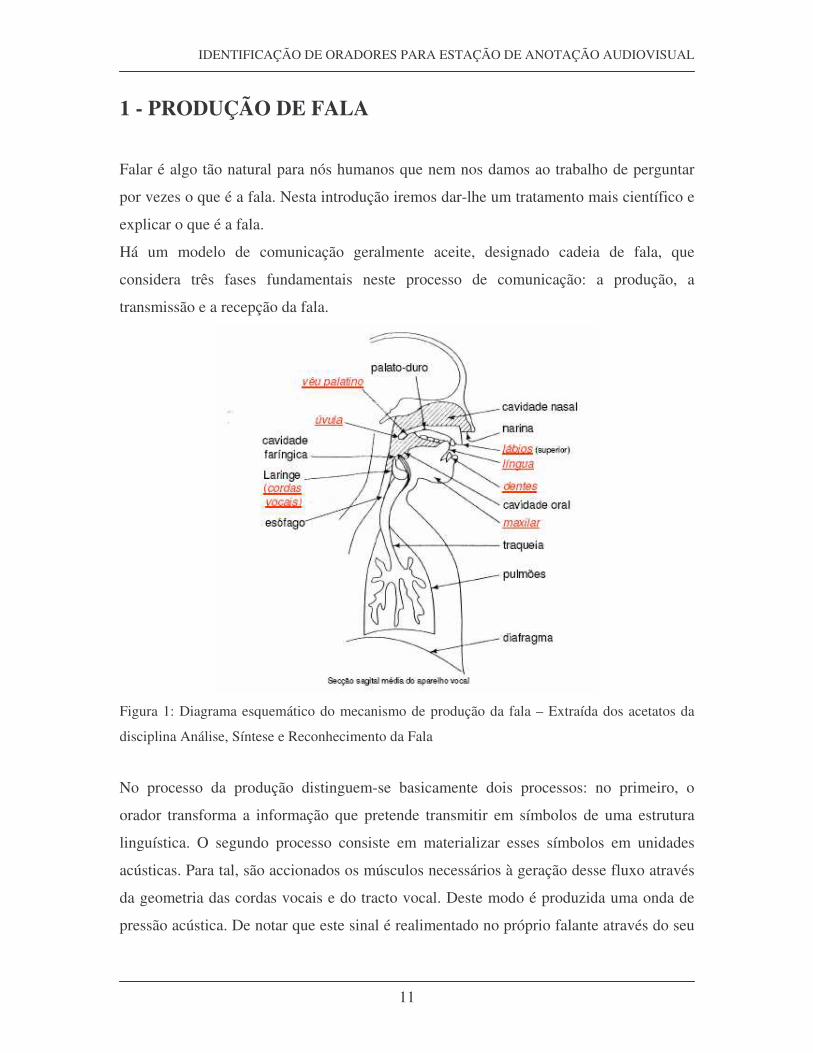
Figura 1: Diagrama esquemático do mecanismo de produção da fala – Extraída dos acetatos da
disciplina Análise, Síntese e Reconhecimento da Fala
No processo da produção distinguem-se basicamente dois processos: no primeiro, o
orador transforma a informação que pretende transmitir em símbolos de uma estrutura
linguística. O segundo processo consiste em materializar esses símbolos em unidades
acústicas. Para tal, são accionados os músculos necessários à geração desse fluxo através
da geometria das cordas vocais e do tracto vocal. Deste modo é produzida uma onda de
pressão acústica. De notar que este sinal é realimentado no próprio falante através do seu

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
12
aparelho auditivo, permitindo-lhe, assim, avaliar e controlar o processo de produção de
fala.
Na transmissão, o sinal de fala é normalmente afectado pelos mais diversos tipos de ruído
(por exemplo, a fala de outras pessoas) e por distorções de canal de transmissão (por
exemplo, o corte das frequências superiores a 4 KHz numa comunicação via telefone).
Por fim, na recepção da fala, o(s) ouvinte(s) capta(m) a onda de pressão acústica através
do ouvido e tenta(m) extrair a informação nela contida por um processo de análise
auditiva.1
A fala é produzida através da libertação de ar dos pulmões para o tracto vocal, que é
formado basicamente por cavidades e órgãos articuladores. O ar é conduzido para fora
dos pulmões pela traqueia, passando pela laringe, onde estão as cordas vocais. O espaço
compreendido entre as cordas vocais é chamado de glote, e a sua abertura pode ser
controlada movimentando-se as cartilagens aritenóide e tiróide. É lá que o fluxo contínuo
de ar dos pulmões é geralmente transformado em vibrações rápidas e audíveis quando
falamos.
Durante a respiração, a passagem laríngea está aberta. Quando se inicia a fonação, as
cordas vocais juntam-se e inicia-se a expiração. Ao juntarem-se, as cordas vocais
provocam um aumento de pressão na área, pressão que aumenta até “forçar” as cordas a
abrirem outra vez. A pressão baixa e as cordas voltam a fechar. Este processo repete-se
rapidamente criando ondas regulares. Além da pressão subglotal, exerce-se ainda no
processo de funcionamento das cordas vocais o chamado efeito de Bernoulli que assenta
no princípio de conservação de energia. Este princípio estabelece que a velocidade e a
pressão de um fluxo de ar são inversamente relacionados: isto é, se a velocidade aumenta
a pressão diminui. Quando um fluxo de ar chega às cordas vocais quase fechadas ou
fechadas, a sua área de passagem diminui, logo a velocidade do ar aumenta e atinge o seu
máximo na glote. Em consequência, a pressão baixa à medida que o fluxo de ar vai
saindo e atravessa a glote. A redução de pressão leva as cordas a juntar-se.
Estes dois processos aerodinâmicos – a pressão glotal e efeito de Bernoulli – actuam
sobre as cordas que têm uma elasticidade que lhes permite ser modificadas de várias
maneiras. Podem ser esticadas e podem aumentar ou diminuir o volume do próprio
1 Para mais informação consultar http://telecom.inescn.pt/research/audio/cienciaviva/index.html

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
13
músculo das cordas. A espessura das cordas altera igualmente o seu movimento. Estas
variações são responsáveis pela variação do “tom” da voz, isto é, definem o pitch ou a
frequência fundamental de cada voz.
Este processo produz uma sequência de pulsos cuja frequência é controlada pela pressão
do ar e pela tensão e comprimento das cordas vocais. Os sons produzidos são chamados
de vozeados ou sonoros, e normalmente incluem as vogais. A faixa de frequência da
vibração das cordas vocais, o pitch, é de aproximadamente de 90 a 500 Hz, sendo que
entre os homens varia de 100 a 150 Hz, nas mulheres de 200 a 250 Hz e nas crianças
entre 300 a 500 Hz. A entoação é produzida pelas variações do tom da voz mais alta ou
mais baixas que o tom natural. Se o tom se mantivesse igual, seria de uma voz
monocórdica, parecendo-se a ao som produzido por um robot, lembrando-nos dos velhos
filmes de Frankenstein.
O tracto vocal é um tubo acústico não uniforme que se estende desde a glote até aos
lábios, incluindo a laringe, faringe, cavidade oral, cavidade nasal, língua, palato e dentes.
Os espaços formados entre esses componentes funcionam como cavidades ressonantes,
modificando as ondas sonoras provenientes da glote.
Para além da vibração das cordas vocais, o fluxo de ar pode tornar-se audível de duas
outras maneiras. O fluxo pode ser constringido em algum ponto do tracto vocal, por
exemplo, elevando-se a língua em direcção ao palato, tornando-se turbulento e
produzindo um ruído de espectro largo. Os sons assim formados são normalmente
chamados de fricativos, normalmente presentes em fonemas como /s/2 e /�/.
Outro método é interromper totalmente o fluxo de ar em algum ponto do tracto, e então
liberar de uma só vez a pressão formada. O som transiente é produzido por uma abertura
repentina, brusca, de uma oclusão no tracto vocálico, onde se criou uma alta pressão de
um lado da oclusão. A rápida igualização de pressão de ar de um lado e outro lado da
oclusão produz “uma explosão” sonora. Os sons assim produzidos são chamados de
oclusivos ou plosivos, presentes em consoantes como /p/ e /t/.
Estes últimos dois métodos são independentes do primeiro, isto é, sons fricativos ou
plosivos também podem ser, ou não, vozeados.
2 O Símbolo / / é usado ao longo deste relatório para designar um fonema, a unidade básica de informação lingística

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
14
Na fala, as chamadas fricativas não-vozeadas, são sons produzidos pela excitação do
tracto vocal com um fluxo de ar constante que se torna turbulento em algum ponto de
constrição (não-vozeamento), como por exemplo /v/ e /z/. As chamadas fricativas
vozeadas, resultam de excitação mista (não-vozeamento + vozeamento), como por
exemplo /s/.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
15
2 - CARACTERÍSTICAS DE SINAIS DE VOZ
Sons de fala podem-se classificar em três distintas classes de acordo com o seu modo de
excitação: sons vozeados, não vozeados e plosivos. Os sons fricativos vozeados não são
classificados como uma classe distinta porque o modo como são excitados é exactamente
igual aos sons vozeados. A única diferença entre eles, é que existe uma constrição ao ar
no caso dos fricativos.
2.1 - SONS VOZEADOS
Estes são criados pela produção quasi-periódica de pulsos de ar, que passam pela glottis,
excitando o tracto vocal. No domínio dos tempos, estes sons são ondas periódicas que
podem ter várias formas diferentes de acordo com o som produzido. A representação no
domínio das frequências destes sinais evidencia que a excitação periódica origina tons
harmónicos, relacionados com a frequência fundamental. Isto significa que o espectro
será caracterizado por ter uma estrutura harmónica, tal e qual como uma nota musical
quando tocada por um instrumento. A amplitude de cada componente do harmónico é
determinada pelo timbre. O timbre é a forma que a envolvente espectral toma aos
diferentes sons. Para sons diferentes (por exemplo, para vogais diferentes) o timbre varia.
Os formantes são as frequências em que a envolvente espectral toma valores máximos. O
que se conclui é que é possível determinar a vogal produzida com base nos dois primeiros
formantes detectados. Existe uma componente harmónica quando um som vozeado é
produzido, evidenciado pela periodicidade da forma de onda. De notar, as diferentes
localizações dos formantes em duas vogais. É por isso que os formantes constituem um
conceito muito importante no processamento da fala: dois sons vozeados podem ser
diferenciados pelo pitch em que são produzidos e pelas frequências dos seus formantes.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
16
2.2 - SONS NÃO-VOZEADOS
Como já foi dito os sons não-vozeados não têm excitação glotal. Em vez disso, o ar é
forçado através de uma constrição algures no tracto vocal, com velocidade suficiente para
criar turbulência. As formas de onda não têm periodicidade, isto é, o seu período é
considerado como infinito, e o correspondente espectro é caracterizado como ruído. As
formas de onda são quase aleatórias, evidenciando uma elevada taxa passagem por zero,
fazendo com que seja difícil modelar este tipo de onda. Analisando o comportamento dos
formantes é possível concluir que são muito instáveis, sendo esta uma das razões pela
qual estes sinais ainda não foram bem caracterizados, comparando com a caracterização
possível para os sons vozeados.
2.3 - SONS PLOSIVOS
Os sons plosivos resultam da constrição completa em alguma parte do tracto vocal, com
acumulação de pressão e libertação abrupta em seguida. O ponto de completo fechamento
pode ser efectuado em várias zonas de articulação e a excitação pode ou não causar
vibração das cordas vocais, como no caso dos sons fricativos.
Como estes sons são dinâmicos por natureza, as suas propriedades são intensamente
influenciáveis pela vogal ou consoante que se lhe segue. Por esta razão, a forma de onda
de sons plosivos dá-nos pouca informação sobre o modo de realização da consoante.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
17
3 - EXTRACÇÃO DE PARÂMETROS
Num processo de classificação, o primeiro passo baseia-se na redução da quantidade de
informação. Esta etapa de redução de informação é geralmente denominada como a fase
de extracção de características e consiste em encontrar factores importantes para a
identificação de cada evento. As características extraídas são as mesmas para cada
excerto de sinal áudio, para que posteriormente possam ser comparadas.
A extracção de todas as características foi efectuada utilizando o ambiente
MARSYAS[6].
Nos métodos tradicionais destacam-se dois grupos: os baseados no espectro de predição
linear (LPC) associado ao modelo de produção acústica da fala e os baseados no espectro
de Fourier do sinal de fala (entre eles os coeficientes mel-cepstrais – MFCC). Estes
últimos são menos exigentes computacionalmente.
Características diferentes apresentam resultados diferentes em diferentes sistemas de
reconhecimento da fala. É difícil de determinar qual a melhor característica. Contudo,
características diferentes podem complementarem-se. Tendo em consideração este facto,
iremos combinar várias características para melhorar a performance do nosso sistema.
Sendo assim, no nosso sistema utilizamos linear spectral pairs (LSPs), coeficientes mel-
cepstrais, coeficientes de predição linear (LPCs) e o pitch ou frequência fundamental.
Utiliza-se o pitch pois discrimina bem o género feminino do masculino.
3.1 - ANÁLISE DE PREDIÇÃO LINEAR (LINEAR PREDICTION
COEFFICIENTS)
Na Fala, a Análise de Predição Linear baseia-se no modelo “Excitação–Filtro” do
processo de produção da fala, conduzindo a um modelo simplificado relativamente ao
original, cuja principal diferença reside na modelação do tracto vocal por um filtro só
com pólos.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
18
O tracto vocal pode ser visto como um tubo não uniforme constituído por múltiplos
pequenos tubos concatenados, com áreas de corte transversal diferentes, mas com o
mesmo comprimento. Este tubo resultante teria um conjunto de ressonâncias semelhantes
às do tracto vocal real. Os tractos vocais reais geram ressonâncias cujo número pode ser
razoavelmente predito por modelos de tubos
Figura 2: Modelo Excitação-Filtro – Extraída dos acetatos da disciplina Análise, Síntese e
Reconhecimento da Fala.
Considere-se que uma qualquer amostra do sinal pode ser obtida através da combinação
linear das p amostras anteriores e do termo de excitação:
�=
+−=p
kk nGuknSans
1
)()()(
Aplicando a transformada-z
�=
− +=p
k
kk zGUzSzazS
1
)()()(
A função de transferência do filtro do tracto vocal fica assim definida:

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
19
�=
−−==
p
k
kk za
zGUzS
zH
1
1
1)(
)()(
Este modelo, só com pólos, apresenta limitações sobretudo na modelação de
determinadas classes de sons, como as fricativas e nasais, onde se verificam anti-
ressonâncias. Contudo este modelo funciona bem para sons vozeados, pois os filtros de
oitava ou décima ordem representam bem quatro formantes em boas condições. Os sons
não-vozeados têm um espectro mais simples, ocorrendo uma sobre parametrização.
Mesmo assim, os LPCs funcionam bem neste casos.
A questão agora é: como determinar os coeficientes do filtro? A resposta pode ser obtida
(existem várias interpretações) considerando um predictor linear de ordem p e o
respectivo erro de predição.
Seja o predictor linear, definido pelo filtro
�=
−=p
k
kk zazP
1
)(
cuja saída é
�=
−=p
kk knsans
1
)()(~
Define-se o erro de predição da amostra n como
�=
−−=−=p
kk knsansnsnsne
1
)()()(~)()(
que é a saída do sistema
�=
−−=p
k
kk zazA
1
1)(

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
20
O objectivo é então, para cada frame do sinal de fala, determinar os coeficientes ak que
minimizam uma determinada medida do erro de predição – a medida escolhida é a soma
do quadrado do erro por amostra, e(n), ao longo desse frame do sinal.
Defina-se então a função Erro de predição calculada sobre um frame do sinal (n é o
índice da amostra, ao longo do frame)
� �� ��
���
�−−==
=n
p
kk
n
knsansneE2
1
2 )()()(
Os coeficientes ak, k=1,...p podem ser obtidos fazendo
0=∂∂
kaE
, k=1,..., p
resultando o sistema de equações lineares
� � �=
��
���
� −−=−n
p
k nk lnsknsalnsns
1
)()()()( , 1� l � p
Isto resulta no método da autocorrelação da análise LPC. A autocorrelação para um
atraso � é expressa como:
�−−
+=τ
ττ1
)()()(N
lSlsr
Definindo a matriz R e os vectores r e a , onde r(�) é o estimador autocorrelação:
����
�
�
����
�
�
−−
−−
=
)0(...)2()1(............
)2(...)0()1()1(...)1()0(
rprpr
prrr
prrr
R
����
�
�
����
�
�
=
)(...
)2()1(
pr
r
r
r
�����
�
�
�����
�
�
=
pa
a
a
a...
2
1
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
21
obtém-se, a solução na forma matricial
rRa 1−=
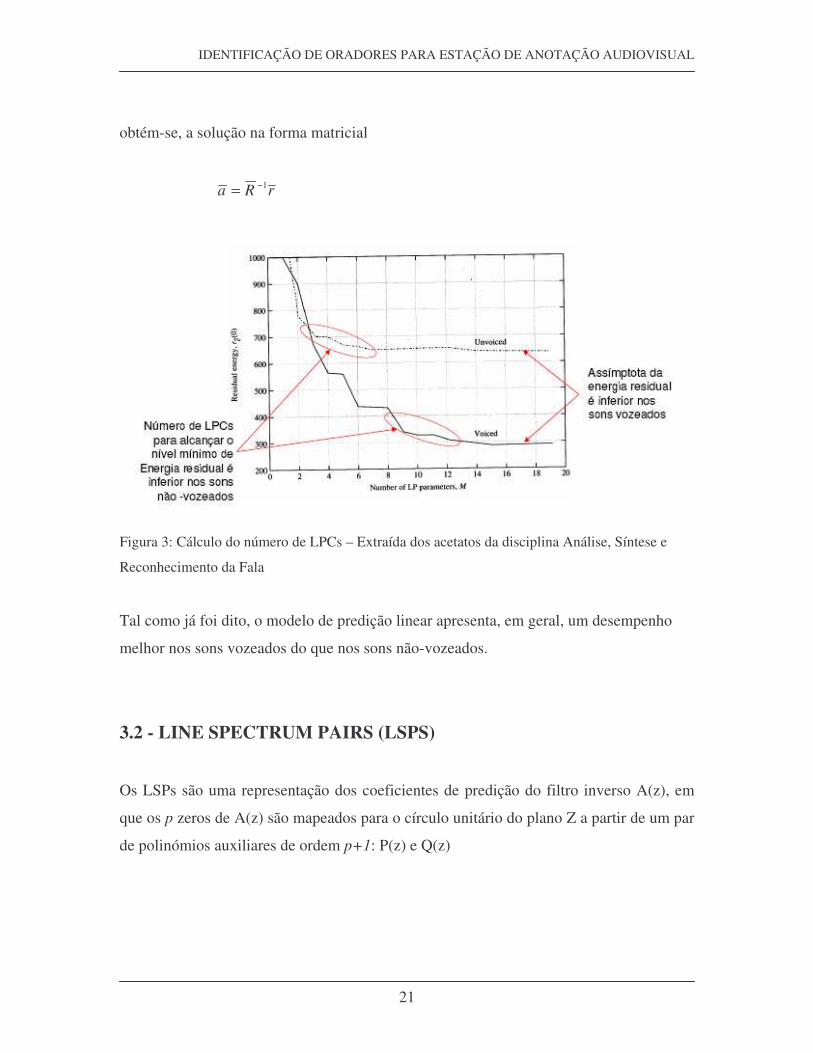
Figura 3: Cálculo do número de LPCs – Extraída dos acetatos da disciplina Análise, Síntese e
Reconhecimento da Fala
Tal como já foi dito, o modelo de predição linear apresenta, em geral, um desempenho
melhor nos sons vozeados do que nos sons não-vozeados.
3.2 - LINE SPECTRUM PAIRS (LSPS)
Os LSPs são uma representação dos coeficientes de predição do filtro inverso A(z), em
que os p zeros de A(z) são mapeados para o círculo unitário do plano Z a partir de um par
de polinómios auxiliares de ordem p+1: P(z) e Q(z)

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
22
[ ]
)()()(
)()()(
)()(21
)(
1)1(
1)1(
−−−
−+−
⋅−=
⋅+=
+=
zAzzAzQ
zAzzAzP
zQzPZA
p
p
Onde os LSPs são as frequências dos zeros de P(z) e Q(z).
Como os coeficiente de predição são reais, o teorema fundamental da álgebra garante que
as raízes de A(z), P(z) e Q(z) vão aparecer em pares complexos conjugados. Esta
propriedade garante que a metade inferior do plano Z é redundante. Os LSPs às
frequências de 0 e +� estão sempre presentes devido à construção de P(z) e Q(z). Assim,
os coeficientes de predição podem ser representados por um numero de LSPs igual à
ordem de perdição p e são representados pelas frequências dos zeros de P e Q da metade
superior do plano Z.
Os LSPs satisfazem uma propriedade de entrelaçamento dos zeros dos polinómios P e Q.
Cada Zero complexo de A(z) é mapeado para um zero em P(z) e outro em Q(z)
Fígura 4: Zeros de LSP – extraído do livro Discrete Time Processing of Speech Signals
3.3 - COEFICIENTES CEPSTRAIS
Os coeficientes cepstrais cm podem ser derivados directamente a partir dos coeficientes
LPCs

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
23
pmacmk
aC kmk
m
kmm ≤≤∨⋅�
��
+= −
−
=� 1
1
1
pmacmk
C kmk
m
pmkm >∨⋅�
��
= −
−
−=�
1
Os coeficientes cepstrais são os coeficientes da transformada de Fourier do logaritmo da
amplitude do espectro S(w):
�+∞
−∞=
−⋅=m
jwmm ecwS )(log
O número de coeficientes cepstrais dever ser superior à ordem de predição, tipicamente
igual a Q = p * 3/2.
Por causa da sensibilidade dos coeficientes cepstrais de baixa ordem à envolvente
espectral e a sensibilidade dos coeficientes de ordem alta ao ruído (ou outras formas de
variação semelhantes a ruído, adoptou-se uma técnica de pesar os coeficientes cepstrais
utilizando uma janela para minimizar estas sensibilidade [2]:
QmQm
wQ
wm ≤≤∨��
���
���
���
+= 1sin1
π
mmm wcc ⋅=ˆ
A análise homomórfica foi desenvolvida como uma forma de desconvoluir dois sinais.
Análise homomórfica é considerada útil para o processamento da fala, pois oferece uma
metodologia para a separação do sinal de excitação da resposta impulsiva do tracto vocal.
Na modelização matemática para a produção do sinal vocal [9][16], temos que um frame
f(n) do sinal vocal (pré-enfatizado) y(n) pode ser escrito como o produto da convolução
do sinal de excitação u(n) com a resposta impulsiva do trato vocal h(n), como é visto na
equação seguinte.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
24
f(n)=u(n)* h(n)
A representação no domínio das frequências desse processo através da aplicação da
transformada de Fourier, transforma a operação de convolução em multiplicação.
Aplicando-se a função logarítmica, transformamos a multiplicação na soma (ou
sobreposição) de sinais, como mostra a equação:
log(F{f(n)})=log(F{u(n)})+log(F{h(n)})
onde F{·} representa a aplicação da transformada discreta de Fourier (DFT). Aplicando-
se a transformada inversa nesse sinal tem-se o cepstrum ou coeficientes cepstrais do sinal
de voz.
Sabe-se que a parcela do sinal de excitação varia mais rapidamente que a resposta
impulsiva do tracto vocal, então os dois sinais poderiam ser separados no domínio
cepstral. Na prática, são utilizados apenas os primeiros coeficientes componentes do
cepstrum. Tais coeficientes contêm a informação relativa ao tracto vocal, que está
intimamente relacionada com o orador.
3.4 - COEFICIENTES MEL-CEPSTRAIS
Os coeficientes mel-cepstrais (Mel Frequency Cepstral Coeficientes – MFCC’s), segundo
Logan B. (2000), representam a informação essencial para o reconhecimento da fala e de
orador. Por esse facto, os MFCC’s têm vindo a tornar-se ao longo dos tempos numa das
mais populares técnicas de extracção de características em sistemas para o
reconhecimento da fala.
Para obtenção dos coeficientes mel-cepstrais a partir dos coeficientes cepstrais, deve-se
aplicar filtros digitais espaçados segundo uma escala acusticamente definida (escala mel).
Uma forma de se fazer isso seria primeiramente mapear as frequências acústicas (em Hz)
para a escala de frequências percebidas (em mels), e depois aplicar um banco de filtros

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
25
espaçados linearmente nesse domínio (domínio mel). Isso corresponderia à aplicação de
filtros digitais espaçados segundo a escala mel, no domínio das frequências reais. O
processo de obtenção dos MFCC é matematicamente descrito na equação:
��
���
��
��
−⋅=�= K
knkSncK
k
π21
cos)(log)(1
para 0 � n < P, onde c(n) é o n-ésimo coeficiente mel-cepstral, P é o número de
coeficientes mel-cepstrais extraídos, K é o número de filtros digitais utilizados e S(k) é o
sinal de saída do banco de filtros digitais.
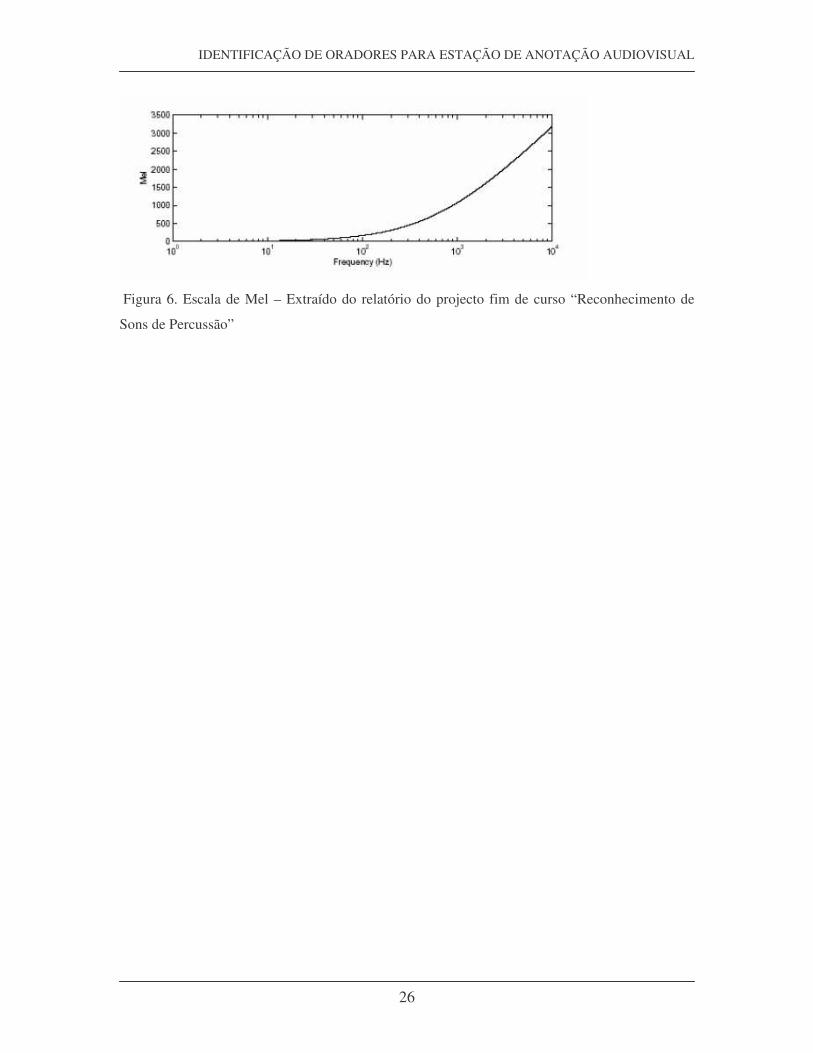
Figura 5: Diagrama de blocos do processo (heurístico) para cálculo dos coeficientes mel-cepstrais. – Extraída dos acetatos da disciplina Análise, Síntese e Reconhecimento da Fala
A sua eficácia deve-se essencialmente à sua capacidade de representar, de uma forma
compacta, a amplitude espectral através da filtragem efectuada com base na escala mel. A
escala Mel, uma compressão de gama dinâmica, é baseada no sistema auditivo humano,
que não se apercebe do pitch de uma forma linear. Assim, o mapeamento das baixas
frequências é feito de uma forma aproximadamente linear (abaixo de 1000 Hz) e nas
frequências altas (acima de 1000 Hz) de uma forma logarítmica, como pode observar-se
na figura seguinte
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
26
Figura 6. Escala de Mel – Extraído do relatório do projecto fim de curso “Reconhecimento de
Sons de Percussão”

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
27
4 - DESCRIÇÃO DO TRABALHO
Neste capítulo é descrito a segmentação dos sons vozeados, não vozeados e silêncio .E
também a apresentada o modo de selecção da base de dados.
4.1 - SEGMENTAÇÃO EM SONS VOZEADOS, NÃO-VOZEADOS,
SILÊNCIO
A necessidade de decidir se um dado segmento de fala é classificado como vozeado, não
vozeado ou silêncio aparece em muitos sistemas de análise de voz. Existe uma variedade
de métodos para fazer esta separação.
O método escolhido utiliza técnicas de reconhecimento de padrões para a classificação
dos segmentos permitindo combinar a contribuição de um número de medidas de fala
numa única medida capaz de fazer a separação entre as 3 classes. Para cada uma das
classes é calculada uma medida de distância (por exemplo euclidiana ou mahalanobis)
que é calculada a partir de um conjunto de parâmetros extraídos do segmento de fala a ser
classificado e o segmento é atribuído à classe com menor distância.
O sucesso deste teste de hipóteses depende das medidas que são usadas para o critério de
decisão. O problema está em seleccionar características que são simples de derivar a
partir dos segmentos de voz e que são eficientes em diferenciar as 3 classes. As seguintes
medidas foram utilizadas neste sistema:
4.1.1 - TAXA PASSAGENS POR ZERO (NZ)
O número de passagens por zero é um indicador da frequência em que a energia do sinal
está concentrada. A fala vozeada é produzida pela excitação do tracto vocal através de um
fluxo de ar periódico que normalmente tem um baixo número de passagens por zero. A
fala não vozeada é produzida devido à excitação do tracto vocal por uma fonte do tipo

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
28
ruído e como tal tem uma elevada taxa passagens por zero. Durante o silêncio é de
esperar que a taxa passagens por zero seja inferior à fala não-vozeada mas semelhante à
fala vozeada.
4.1.2 - ENERGIA
Medida de potência de termo longo (sinal de fala é sinal de potência)
�−=∞→ +
=N
NnN
nsN
P )(12
1lim 2 onde N= comprimento da janela e S(n) = sinal
Geralmente usa-se a energia, em vez da potência (equivalentes, na prática), e janela
rectangular.
�+−=
=m
Nmn
nSmE1
2 )()(
A energia do sinal para segmentos de fala é muito maior do que a energia de um
segmento de silêncio. A energia da fala não vozeada é normalmente menor do que a
vozeada mas superior à do silêncio.
4.1.3 - COEFICIENTE DE AUTOCORRELAÇÃO NORMALIZADO PARA O
ATRASO DE UMA AMOSTRA (C1)
É definido como:
�
��
�
��
−⋅=
��
�−
==
−
12
1
2
11
)()(
)1()(
N
on
N
n
N
n
nsns
nsnsC

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
29
Este parâmetro é a correlação entre amostras de voz consecutivas. Devido à concentração
de energia nas baixas frequências para os segmentos vozeados, as amostras adjacentes de
voz são altamente correlacionadas, sendo este parâmetro próximo de 1. Ao contrário, para
segmentos não-vozeados é próximo de zero.
4.1.4 - PRIMEIRO COEFICIENTE DE PREDIÇÃO (a1)
Este é o primeiro coeficiente de um codificador de predição linear (LPC) de ordem 10.
Pode ser demonstrado que este parâmetro é o simétrico do primeiro coeficiente do
espectro de Fourier.
4.1.5 - ERRO DE PREDIÇÃO NORMALIZADO (Ep)
É definido como:
��
���
+=
0
log10RE
E ip ε
� � ��
���
�−+−+=
=m
p
kki kmnsamnsE
2
1
()(
�−
=
=1
0
20 )(
1 N
n
nsN
R
Em que p é a ordem do codificador LPC, ak são os coeficientes LPC e N é o número de
amostras do segmento.
Para cada segmento é construído um vector X = [Nz Es C1 a1 Ep]T.
Este vector vai ser usado no cálculo da distância a cada uma das 3 classes. A distância à
classe i é dada por:
( ) )(1ii
Tii MXWMXd −−= −

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
30
�−
=
=1
0
)(1 iN
nii nX
NM
( )( )�−
=
−−−
=1
0
)()()1(
1 iN
n
Tiiii
ii MnXMnX
NW
Em que Ni é o numero de vectores de teste da classe i que foram usados para construir a
média Mi e a covariância Wi da classe.
Estes vectores de teste foram criados a partir de uma segmentação manual de várias
amostras de voz em regiões vozeadas, não-vozeadas e silêncio. Para a segmentação
manual foi usado o programa Praat. Os ficheiros de teste foram escolhidos aleatoriamente
de uma base de dados já existente. Foi segmentado um total de 6 minutos,
correspondendo a extractos de conversas de um minuto de 6 pessoas diferentes, homens e
mulheres. Foi criada uma biblioteca com os vários segmentos criados, num total de mais
de 2000 ficheiros.
Depois de calculadas as 3 distâncias di para um vector X, é escolhida a classe que
apresenta a menor distância.
�
Figura 7: Diagrama de blocos do algoritmo de classificação de segmentos em vozeado, não-
vozeado e silêncio – Extraído do relatório do projecto fim de curso “Reconhecimento de
Oradores”

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
31
4.2 - SELECÇÃO DOS SONS – BASE DE DADOS
A base de dados de oradores é constituída por gravações feitas a partir de canais de
televisão, em ambiente de estúdio de baixo ruído, sendo a maioria dos oradores
jornalistas e figuras públicas. Esta base de dados foi construída no âmbito de um projecto
de fim curso já realizado, contendo 70 ficheiros com diferentes oradores.
Para além desta colecção de ficheiros, foi utilizado uma outra colecção de ficheiros,
“MPEG Meetings”. A partir desta colecção foram criados vários ficheiros para teste,
onde ao contrário da colecção anterior, nem sempre o ruído é baixo, embora tratando-se
da transmissão de um telejornal, há várias reportagens de exterior onde existe ruído de
fundo. Foram criados ficheiros mistos, isto é, com oradores masculinos e femininos, mas
foram criados também ficheiros só com oradores masculinos ou femininos. Fez-se variar
também o número de oradores bem como o tempo que cada orador fala. Para a criação
destes ficheiros foram utilizados os programas Praat e Adobe Audition 1.5.
Foram criados 38 Ficheiros de oradores femininos, 28 ficheiros de oradores do sexo
masculino, 1 ficheiro de silêncio, e 1 ficheiro do telejornal da RTP1.
Todos estes 68 ficheiros têm tempos diferentes, mas formatos iguais: 8KHz, mono,
16bits. Alguns destes 68 ficheiros foram criados concatenando pedaços de conversas
realizadas pelo mesmo orador, para que desta forma se pudesse ter ficheiros mais longos.
Com esta base de dados foram então criados 15 ficheiros de teste.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
32
5 - MARSYAS
Esta secção descreve sucintamente a framework MARSYAS3 utilizada neste projecto
para a integração e implementação de classes e do sistema em si, bem como a sua
experimentação e validação.
A framework chama-se MARSYAS e as iniciais querem dizer Music Analysis Retrieval
and Synthesis for Audio Signals. O desenvolvimento desta framework surge num
contexto de crescimento exponencial da quantidade de informação armazenada em
formato electrónico e à também crescente necessidade de trabalhar toda essa informação.
As soluções encontradas resultam da pressão desta necessidade e assentam na utilização
de técnicas semi-automáticas que permitam uma adaptação rápida à permanente mudança
dos cenários que vão emergindo.
Os vários tipos de problemas de classificação utilizam invariavelmente o mesmo tipo de
características, classificadores e até mesmo algoritmos similares. Tirando partido deste
facto e tendo como perspectiva a obtenção de uma arquitectura flexível, capaz de suportar
vários modelos de classificação, foi desenvolvida uma arquitectura modular baseada em
blocos de processamento que representam uma pequena parte de todo o processo de
classificação.
Desta forma, torna-se facilitada a integração de diferentes técnicas sobre uma framework
e interface comum. Para além disso, permite também uma rápida construção de
protótipos, bem como o seu teste e validação.
5.1 - ARQUITECTURA
Foi implementada utilizando técnicas de programação orientada ao objecto. Foi
implementado em C++ e contém toda a parte de módulos de processamento de sinal e
reconhecimento de padrões de forma optimizada.
3 Para mais informações consultar http://opihi.cs.uvic.ca/marsyas/

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
33
5.2 - CLASSIFICADORES
A framework tem já disponíveis uma série de classificadores, tais como K-NN (K-
Nearest Neighbor), um classificador não paramétrico, ou um classificador Gaussiano, que
assume que cada classe pode ser representada como uma distribuição normal multi-
dimensional no espaço das características, vários classificadores GMM (Gaussian
Mixture) e recentemente sob desenvolvimento, redes neuronais.
Contudo e devido à flexibilidade da arquitectura do MARSYAS, podem ser facilmente
adicionados novos e mais avançados métodos de classificação.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
34
……………………………………………..................................... ...............................................................
6 - SPEAKERID – SEGMENTAÇÃO NÃO SUPERVISIONADA DE ORADORES
Neste capítulo é apresentada a solução adoptada para a segmentação não supervisionada
de oradores. É explicado todo o processo do sistema, bem como os três módulos que o
constituem: módulo de processamento front-end (I), módulo de segmentação (II) e
módulo de clustering e actualização do modelo do orador.
6.1 - DESCRIÇÃO GERAL DO SISTEMA O SPEAKERID foi uma classe desenvolvida no INESC Porto no âmbito deste projecto
utilizando a framework MARSYAS.
A figura seguinte ilustra o diagrama utilizado na implementação desta classe.
Speech Stream
Figura 8: Diagrama utilizado na detecção não supervisionada de mudança de oradores – extraído
de “Unsupervised speaker segmentation and tracking in real-time audio content analysis”
Front-end Process, feature extraction and Pre-segment
Potencial change?
Compare current segment speech with the last speaker model
Clustering and update current Speaker model
Real change?
False Speaker Change
No
Positive Speaker Change
Yes
Bayesian Decison
I
II III

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
35
Como se pode observar o diagrama é composto por 3 módulos: módulo de processamento
front-end (I), módulo de segmentação (II) e módulo de clustering e actualização do
modelo do orador.
É assumido que o stream de áudio na entrada seja só constituído apenas por fala. Tudo o
que não é fala, como por exemplo musica, é assumido que foi filtrado. No processo front-
end, o stream de áudio é dividido em subsegmentos de 3s, com 2,5s de sobreposição.
Estes subsegmentos são usados com unidade base e é realizado um pré-processamento
para remoção de sons não-vozeados e silêncio. Depois, é realizada a detecção de
mudança de oradores. Se não é detectada nenhuma mudança potencial de oradores entre
dois subsegmentos ou é confirmada como falsa uma mudança potencial de oradores4, o
modelo do orador é actualizado, com a informação do subsegmento actual.
No modelo para o orador é utilizado quasi-GMM com segmental clustering[10]. Foi
escolhido este modelo devido aos requisitos impostos, em particular o de processamento
em tempo real. Modelos como GMM não são apropriados pois consomem muito tempo
devido a número de iterações utilizadas no seu treino. Talvez se pudesse adoptar pelo
método online expectaction-maximization (EM) na actualização em tempo real de um
modelo GMM, todavia não seria possível actualizar o número de misturas, requisito
necessário também em processamento em tempo real. Assim foi utilizado, quasi-GMM,
com segmental clustering. Com este método é possível actualizar o número de misturas e
consome menos tempo. Embora não seja tão eficaz como EM tradicional, é capaz de
capturar os parâmetros principais do modelo de orador.
6.2 - SELECÇÃO DE CARACTERÍSTICAS E MEDIDA DE
DISTÂNCIA
Em trabalhos já realizados muitas características foram utilizadas no reconhecimento de
oradores. As mais utilizadas são os Linear Prediction Coefficients (LPCs), Mel
Frequency Cepstral Coefficients (MFCCs) e Line Spectrum Pairs (LSPs). Cepstral Mean
Subtraction é utilizado apenas para eliminar o efeito ambiente. Efeitos como ruído do
canal, música ambiente ou simplesmente o ruído de fundo num directo numa transmissão 4 Processo descrito com mais detalhe na secção 6.3.4 – Refinamento da fronteira de mudança de orador

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
36
televisiva, continuam a ser efeitos difíceis de prever e por isso difíceis de estimar. Esta
será uma das razões que influenciará os resultados.
6.2.1 - SELECÇÃO DE CARACTERÍSTICAS
O primeiro passo num processo de classificação é selecção de características, isto é, a
redução da quantidade de informação e consiste em descobrir factores importantes para a
identificação de cada evento.
Neste trabalho, para cada segmento foram calculadas as características LPCs e LSPs. Em
geral, estas características têm performances parecidas, mas em alguns casos especiais
bem diferentes.
Para além destas características também é calculado o pitch, por se tratar de um bom
discriminador entre homens e mulheres.
Estas características foram calculadas utilizando a framework MARSYAS.
6.2.2 - MEDIÇÃO DA DIVERGENCE SHAPE
Suponhamos que o vector de características extraído de cada subsegmento é Gaussiano, a
sua função densidade de probabilidade pode ser representada como [13]:
( ) ( )���
��� −−−= − µξµξ
πξ 1
2/12/ 21
exp)2(
1)( C
Cp T
n
onde C é a matriz da covariância estimada e µ é o vector de média estimada. A distância
entre dois subsegmentos pode ser definida como:
( ) ( )[ ] ( )( )� −=
ξ
ξξξξξ d
pp
ppDj
iji ln
Tal como foi assumido anteriormente, a função de distribuição de probabilidade das
características são n-variáveis de população normal e podem ser derivadas em:

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
37
( )( )[ ] ( )( )( )[ ]Tjijiijijji uuuuCCtrCCCCtrD −−++−−= −−−− 1111
21
21
A distância é composta por duas partes. Uma primeira parte é determinada pela
covariância de dois subsegmentos, e a segunda parte é determinada pela covariância e
média. Como a média varia facilmente com as condições do ambiente (múltiplos
oradores, ruídos de fundo, etc), não se considera a segunda parte. Sendo assim só a
primeira parte representa a distância[13]. A distância final é chamada de Divergence
Shape e é definida como:
( )( )[ ]11
21 −− −−= ijji CCCCtrD
Em geral, se dois subsegmentos de fala são ditos pelo mesmo orador, a divergence shape
entre estes dois clips será pequena, caso contrário a distância seria grande. Assim foi
criado um critério: se a divergence shape entre dois segmentos de fala é maior que um
determinado threshold, estes dois segmentos podem ser considerados ditos por pessoas
diferentes. O threshold é usado para transformar a distância num valor binário (0,1)
baseado no critério enunciado anteriormente.
A figura seguinte ilustra um exemplo de um mapa usando a divergence shape LSP. Como
se pode observar na figura, existem claramente 4 regiões bem definidas que representam
4 oradores: 0 a 75, de 75 a 150, de 150 a 225 e de 225 a 300.
Valor 0 é representado pelo pixel mais escuro enquanto que o valor 1 é representado pelo
pixel mais claro.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
38
Figura 9: Mapa de distância de divergência LSP
6.3 - DETECÇÃO MUDANÇA DE ORADORES
Tal como ilustrado no diagrama inicial deste capítulo, o algoritmo para a detecção não
supervisonada de mudança de oradores é composta por três módulos, módulo de
processamento front-end, módulo de segmentação e módulo de clustering e actualização
do modelo do orador. No primeiro módulo são extraídas as características de cada
subsegmento. Depois é calculada a divergência LSP/MFCC/Pitch entre dois
subsegmentos consecutivos. Uma potencial mudança de orador é detectada se essa
distância for superior a um threshold. Caso não seja detectado o modelo do orador é
actualizado incorporando a informação do subsegmento em análise. Se é detectado uma
potencial mudança de orador, é aplicado o Bayesian Information Criterion (BIC), para
confirmar se realmente se trata de uma mudança de orador.
6.3.1 - PROCESSAMENTO FRONT-END
O stream de áudio é previamente convertido todo, e independentemente do seu formato,
para um formato uniforme mono, 8 KHz e 16 bits. O stream é então pré-enfatizado e
dividido em janelas de 3 segundos, com 2,5 segundos sobrepostos. Assim a unidade

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
39
básica de processamento são os 3s e a resolução temporal é de 0,5s. Cada subsegmento é
depois subdividido em frames, não sobrepostas, de 25 ms de duração. As características
mais importantes extraídas de cada frame são LSP, MFCC e o pitch. Outras
características, como energia e taxa passagem por zero, são extraídas para se poder
diferenciar os sons vozeados dos sons não vozeados e silêncios, mas estas características
não são incluídas na estimação do modelo do orador.
6.3.2 - DETECÇÃO DE POTENCIAL MUDANÇA DE ORADOR
Neste módulo um modelo do orador é estimado para cada subsegmento. O modelo de
orador é composto pela divergence shape do LSP. A divergence shape é usada para
calcular a disparidade entre dois subsegmentos consecutivos. Até aqui, só a LSP
divergence shape é usada para a detecção de potencial mudança de orador.
Assim uma potencial mudança de orador [14] é detectada entre o subsegmento i e i+1, se
as condições seguintes forem satisfeitas:
iThiiD
iiDiiD
iiDiiD
>+−>+
++>+
)1,(),1()1,(
)2,1()1,(
Onde D(i,j) é a distância entre o subsegmento i e o subsegmento j, e Thi é o threshold.
As duas primeiras condições garantem que um pico local é detectado enquanto que a
última previne a detecção de picos baixos. Resultados razoáveis podem ser obtidos
utilizando este critério simples. Contudo o valor do threshold é difícil de se definir. Este
valor é afectado por vários factores, tais como, dados insuficientes ou condições do meio,
assim o valor do threshold deve aumentar com o ruído ambiente. Para obter um resultado
óptimo, um método de ajuste automático é utilizado [14]
�=
−−−=N
ni niniD
NTh
0
),1(1α

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
40
onde N é o número de distâncias utilizadas previamente para prever o threshold, e � é um
coeficiente amplificador. Vários testes foram realizados para determinar qual o melhor
valor de �. Todavia e uma vez que a quantidade de dados extraída de um subsegmento
não é suficiente, o modelo do orador não pode ser estimado rigorosamente.
Para resolver este problema é usado todo o tipo de dados possíveis para poder actualizar o
modelo de orador. Um método de refinamento é utilizado para melhorar os resultados.
6.3.3 - ACTUALIZAÇÃO DO MODELO DE ORADOR
A fim de obter a quantidade de dados necessária para ter uma estimação mais rigorosa do
modelo de orador, utiliza-se o resultado da detecção potencial de mudança de oradores.
Se nenhuma mudança de orador é detectada significa que o subsegmento actual é do
mesmo orador que o subsegmento anterior. Assim, pode-se utilizar os dados do
subsegmento actual para actualizar o modelo de orador.
GMM (Gaussian Misture Model) -32 é usado para estimar o modelo do orador, o modelo
é estabelecido progressivamente com mais e mais dados disponíveis. No início como a
quantidade de dados é insuficiente para se estimar um modelo GMM-32, o modelo
GMM-1 é utilizado. Com o aumento de dados disponíveis o modelo aumentará
gradualmente até GMM-32.
Um algoritmo EM (expectaction-maximization) poderia ser utilizado para se estimar o
modelo das misturas Gaussianas. Contudo o algoritmo EM recorre a processos iterativos
que consomem tempo, requisito importante para processamento em tempo real. Uma
outra desvantagem é que o algoritmo EM requer que todas as suas variáveis sejam
gravadas em disco ou memória, enquanto que os outros não.
Suponhamos que o modelo do orador actual Gi é obtido do subsegmento (M-1) e não foi
detectado nenhuma potencial mudança de orador entre este subsegmento e o próximo
subsegmento, significando que ambos os segmentos pertencem ao mesmo orador. Assim
o modelo de orador Gi é actualizado usando a informação extraída do subsegmento M.
Se o modelo Gi é representado por N(u,c), em que o número de vectores característica
usados é N, o modelo do orador obtido dos M subsegmentos é N(um, Cm), em que o

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
41
número de vectores característica é Nm. O modelo de orador pode ser então actualizado
segundo o seguinte método [10]:
m
Tmm
m
mm
mm
mmm
NNN
NNNN
CNN
NC
NNN
C
NNN
NNN
+=
−−+⋅
++
++
=
++
+=
'
2'
'
))(()(
µµµµ
µµµ
A terceira parte é determinada pela média, que tal como já foi dito varia facilmente com
as condições do meio, e por isso será mais uma vez ignorada. A equação fica mais
simplificada:
mmm
CNN
NC
NNN
C+
++
='
Este procedimento é continuado até a disparidade entre os modelos de oradores, antes e
depois das actualizações, ser baixa ou foi detectada uma potencial mudança de oradores.
Esta disparidade é calculada pela distância da divergência. Quando a diferença é
suficientemente pequena, assume-se que o actual modelo Gaussiano foi estimado com
rigor, inicializando-se a estimação do modelo Gaussiano seguinte, Gi+1 usando o mesmo
método.
Combinando este modelos Gaussianos teremos um modelo quasi-Gaussian Mixture
Model (quasi-GMM).
Usando este método, o modelo de orador irá aumentar desde GMM-1 até GMM-32.
Quando GMM-32 é atingido, a actualização do modelo é parada. Este método quasi-
GMM usa segmental clustering e é um pouco diferente de GMM. É menos exacto, mas é
computacionalmente mais simples e cumpre com o requisito de processamento em tempo
real.
6.3.4 - REFINAMENTO DA FRONTEIRA DE MUDANÇA DE ORADOR
Frequentemente, na detecção de potencial mudança de orador, existem falsos-positivos,
isto é detecções que na verdade não deveriam ter sido detectadas pois não houve

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
42
mudança de orador. Para remover estes falsos-positivos é aplicado um algoritmo de
refinamento da fronteira de mudança de orador. Este algoritmo é baseado na diferença
entre o subsegmento actual e o último modelo de orador, obtido dos subsegmentos antes
da actual potencial fronteira. É aplicado o Bayesian Information Criterion, para medir a
diferença.
Bayesian Information Criterion[11], BIC, é um critério de probabilidade penalizado pela
complexidade do modelo, o numéro de parâmetros no modelo. Suponhamos que dois
modelos Gaussianos de dois clips de fala são N(u1,C1) e N(u2,C2), sendo que o numero de
dados usado para estimar estes dois modelos são N1 e N2 respectivamente. Um modelo
Gaussiano para estimar estes dois clips é N(u,C). A diferença BIC entre estes dois
modelos é:
)log())1(21
(21
)logloglog)((21
),( 2122112121 NNdddCNCNCNNCCBIC +++−−−+= λ
onde � é um parâmetro de penalidade para compensar os casos pequenos, e d é a
dimensão da característica. En geral �=1. De acordo com a teoria BIC, se o BIC(C1,C2) é
positivo, os dois clips podem ser considerados de oradores diferentes. A grande vantagem
de se usar BIC é que não se utiliza nenhum threshold.
Suponhamos que na fronteira de uma potencial mudança de orador, o modelo do último
orador é GMM-s, em que cada modelo Gaussiano é N(ui,Ci)(i=1,...,s) e o modelo do
actual orador é dado por N(u,C). A distância entre eles é estimada pelo soma dos pesos da
distância de N(u,C) e cada um dos N(ui,Ci).
�=
=S
iii CCBICwD
1
),(
Assim, aplicando o critério BIC, se D>0, tratasse de uma verdadeira mudança de orador,
e a sua informação será usada para actualizar o modelo do orador.
Somente se utiliza o BIC depois de se haver detectado as mudanças de oradores. Isto
porque na altura da detecção a informação disponibilizada pode ser pouca ao ponto de
não se conseguir estimar um modelo para o orador. Aplicando o BIC, este é facilmente
afectado por pequenas mudanças de palavras e desta forma surgiriam muitos falsos-
positivos. Para além desta razão e como já foi referido o BIC não utiliza thresholds. No
módulo de refinação o modelo de orador já é mais rigoroso. Por estes motivos, o BIC é

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
43
mais eficiente no módulo de refinação e não no módulo de detecção de mudança de
oradores.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
44
7- ANOTADOR A anotação tem uma longa tradição em documentos impressos e está actualmente a ser
investigada para documentos electrónicos. A maior parte do trabalho feito até agora é
para informação estática, essencialmente texto e imagens. Para vídeo, a anotação é
habitualmente uma forma de descrever o conteúdo para posterior recuperação. A
anotação permite adicionar informação a documentos existentes e pode servir múltiplos
propósitos: salientar as partes mais relevantes ou adicionar notas quando o documento é
apresentado, por exemplo numa aula ou conferência; e reestruturar o documento de forma
a que seja relevante para um determinado domínio. Há assim duas funções principais dos
mecanismos de anotação:
1 - Descrição de conteúdo existente (metadados)
2 - Adição de conteúdo por parte dos utilizadores.
A descrição de conteúdo, utilizando, por exemplo, a norma MPEG-7 para descrição de
vídeo, é essencial para a reutilização porque permite caracterizar a informação, de forma
a saber-se como e onde pode ser usada. Assim como as anotações em publicações
impressas promovem a leitura activa, as anotações de conteúdo vídeo promovem a
visualização activa, facilitando a reflexão, a aprendizagem e a criação de versões
personalizadas dos documentos.
Do ponto de vista comercial, conteúdos audio-visuais armazenados terão pouco ou
nenhum valor se não estiverem anotados, porque a pesquisa torna-se na maioria dos casos
impossível. Assim, o armazenamento de conteúdos anotados é um investimento, ao passo
que o armazenamento de contéudos não-anotados é apenas um custo.
7.1 - 4VDO ANNOTATOR A crescente utilização de vídeos digitalizados ganhou importantes recursos com o
surgimento de padrões que auxiliam a descrevê-los e indexá-los de forma padronizada,
tais como o MPEG 7, possibilitando a busca e selecção de vídeos ou partes deles.
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
45
Na gestão de um arquivo um dos problemas que se coloca é conseguir aceder facilmente
a conteúdos a partir de diferentes processos de pesquisa possíveis. É neste contexto que
surge a anotação, informação guardada com apontadores (metadata), para que se encontre
o material pretendido.
O 4VDO ANNOTATOR surge como resposta a uma necessidade de se criar um anotador
com várias funcionalidades e com uma usabilidade mais fácil. Este anotador foi
desenvolvido pela empresa 4VDO, uma spin-off do INESC Porto.
Um anotador, tal como já foi descrito, serve para facilitar a pesquisa. Neste contexto foi
objectivo deste trabalho acrescentar mais uma funcionalidade ao 4VDO ANNOTATOR,
a identificação de oradores. Se a base de dados em questão for pequena, uma pesquisa por
oradores poderia ser feita quase manualmente, onde o processo de anotação desses
mesmos oradores poderia também ser realizado manualmente. Contudo se se tratar de
uma base de dados grande e sem qualquer tipo de anotação prévia, seria muito difícil
realizar este tipo de pesquisa. Assim a segmentação e identificação automática de
oradores surge como resposta a este problema.
Figura 10: 4VDO ANNOTATOR

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
46
7.2 - ARQUITECTURA DO 4VDO ANNOTATOR Foi implementado utilizando técnicas de programação orientada ao objecto e foi
implementado em C++. O interface gráfico (GUI) foi implementado em Qt. Qt é uma
ferramenta composta por librarias de classes C++ e um conjunto de ferramentas com o
objectivo de criar aplicações multiplataformas.
7.2.1 - ORGANIZAÇÃO
O 4VDO ANNOTATOR permite fazer anotação de vários formatos video ou audio,
como por exemplo formatos mpeg, avi, mp3, wav, entre outros. Permite também capturar
video/audio a apartir do windows movie maker. Após seleccionar qual o ficheiro a anotar,
o utilizador poderá desde logo ouvir/ver o ficheiro seleccionado. Para tal poderá utilizar o
painel de teclas como play/pause, stop, etc. Caso não saiba qual a função de cada botão
basta deixar o cursor em cima do botão durante 2 segundos até aparecer o seu significado.
Poderá também utilizar o menu “Player” da barra de ferramentas ou algumas teclas de
acesso mais rápido.
Para iniciar o processo de anotação terá que criar uma track, atravez do menu. Poderá
criar até 61 tracks. A estas tracks está associado o conceito de linha de tempo, timeline,
onde poderão ser criados segmentos.
A criação de segmentos poderá ser realizada de várias maneiras, conforme a necessidade
do utilizador. Assim, poderão ser criados segmentos enquanto se ouve o ficheiro, ou
então no modo “offline”, sem se ouvir o ficheiro. Para ajudar a segmentação enquanto se
ouve o ficheiro, existe um barra que percorre a timeline frame a frame.
Após se criar os segmentos poderemos consultar o inicio e fim de cada segmento. Para tal
basta seleccionar a track, no menu Index, e no quadro ao lado aparecerá a lista com os
tempos de cada segmento. O aspecto será igual ao da figura seguinte:

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
47
Figura 11: Exemplo de uma segmentação
O processo de anotação, como por exemplo qual o nome do orador, teria que ser
efectuado após o processo de segmentação concluído.
As anotações têm associado uma ideia de vistas, views. Para cada track poderemos ter
várias vistas. Estas vistas poderão ser criadas a partir do menu Tools, views factory.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
48
Figura 12: Anotação no 4VDO
Como se pode observar da figura de cima, foi seleccionado o primeiro segmento, onde foi
anotado que o nome do orador era Olavo. Pode-se também observar que foi retirado o
quadro index, possibilitando assim ao utilizador escolher qual o tipo de visualização
deseja. Desta forma melhora a usabilidade do programa.
Neste caso a anotação é sobre a forma de texto. Contudo o 4VDO ANNOTATOR
disponibiliza também outros formatos de anotações rápidas, como data/hora, numeração e
sobre a forma booleana (check box).

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
49
7.3 - INTEGRAÇÃO DO SEGMENTADOR
Começou-se por definir que a classe SPEAKERID seria integrada no projecto do 4VDO
ANNOTATOR como uma biblioteca dinâmica (DLL). Desta maneira continuar-se-ia a
ter dois projectos independentes, que a qualquer altura se pode alterar, sem que o código
de um estivesse contido no código do outro, como se pode observar na figura seguinte.
Figura 13: Esquema representativo da integração do SPEAKERID no anotador
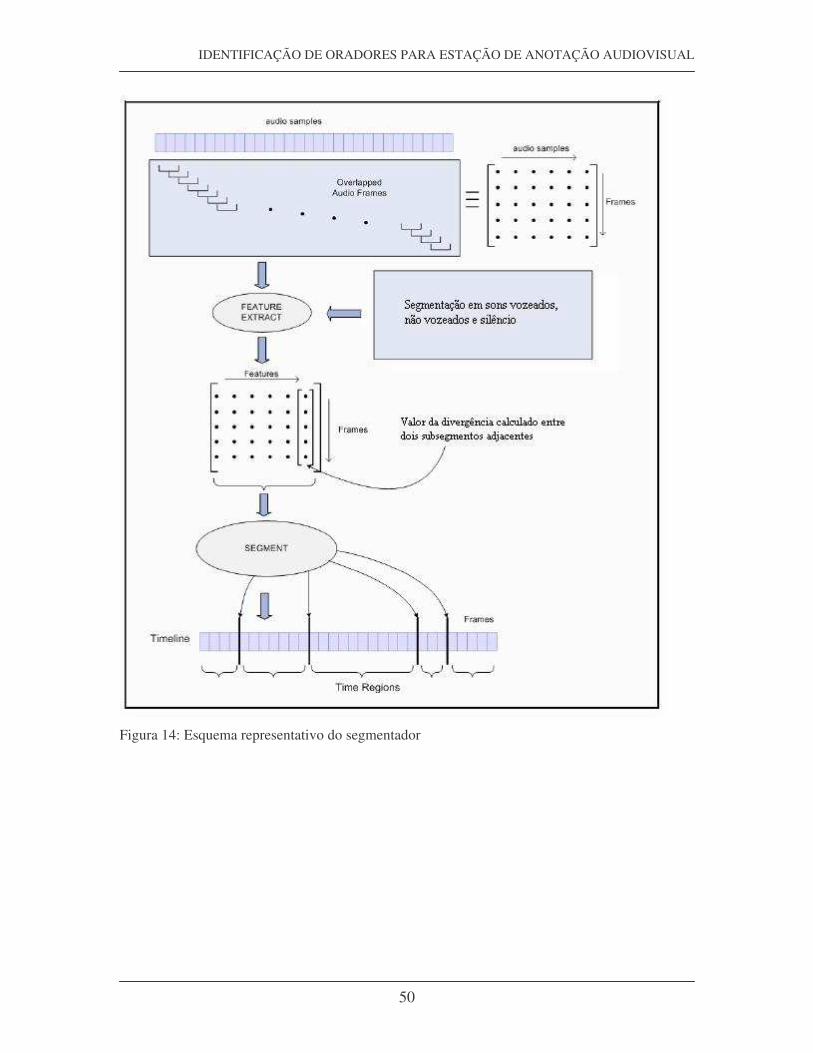
Inicialmente o sinal áudio é dividido em frames de 3s, com um overlap de 2,5s
correspondendo a um overlap de 83,3(3)%. Esta informação é guardada numa matriz de
vectores que, de seguida, vai ser submetida ao extractor. Este extractor, que recebe como
entrada uma frame áudio, vai criando à saída uma matriz de características. As
características calculadas são: taxa passagem por zero (zero crossing rate – ZCR), energia
(short term energy – STE), e 10 Line Spectrum Pairs (LSPs).
Na classe speakersegmentor é calculada a divergence shape entre dois subsegmentos
adjacentes, desencadeando a segmentação do sinal em diferentes regiões, Time Regions,
guardadas na estrutura Timeline. É nesta classe que é feita a segmentação dos sons
vozeados, não vozeados e silêncio. Só os sons vozeados são utilizados na construção da
matriz LSP.
Será o número de regiões, bem como o inicio e fim de cada região que será passado ao
anotador.
Na figura seguinte pode-se observar a esquematização do segmentador.
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
50
Figura 14: Esquema representativo do segmentador

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
51
8 - SEGMENTADOR AUTOMÁTICO
Neste capítulo é apresentado a classe desenvolvida dentro do 4VDO ANNOTADOR que
irá comunicar com o segmentador.
Ao 4VDO ANNOTATOR está associado a ideia de track, timeline, events e frame.
O utilizador cria uma track, e poderá associar a essa track um evento, que poderá ser por
exemplo um segmento. Toda esta informação é armazenada na classe AWModel, nas
estruturas AWTrack e AWEvent.
Assim a estrutura AWTrack comtém informação relativamente ao nome dado à track, o
número de eventos criados nessa track, bem como em que linha, timeline, se encontra. O
AWEvent contêm informação relativamente a que track pertence e qual o seu frame
incial e final.
Começou-se por criar um segmentador manual. Este segmentador, como se pode observar
na figura seguinte, apenas contêm funcionalidades que já existiam no anotador, mas foi
criado uma API (Appication Programming Interface – interface gráfico) diferente para
melhorar a usabilidade neste projecto.
Figura 15: API para criação manual de segmentos
Como se pode observar da figura, existem 3 botões que se poderão utilizar na
segmentação. Contudo no decorrer do trabalho veio a verificar-se que, às vezes, a
segmentação manual é tão crítica e tem que ser tão minuciosa que este segmentador não

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
52
foi utilizado, principalmente para ficheiros de longa duração, em que resolução do 4VDO
ANNOTATOR diminui, passando de frames para alguns milisegundos. Contudo para
ficheiros de duração menor, este segmentador ainda foi utilizado.
Para se começar a segmentar é necessário primeiro criar e seleccionar uma track. Depois
basta clicar em “Create Segments” que o anotador começa a tocar; para ir criando os
vários segmentos basta ir clicando no mesmo botão. Assim, com uma tecla apenas, pode-
se fazer a segmentação manual. Sempre que é criado um novo segmento é incrementado
o número que aparece em “Created Segments”.
Este segmentador foi desenvolvido para que depois da integração do segmentador
automático, se pudesse fazer um cross-validation. Isto é, para validar o segmentador
automático, é preciso comparar o seu resultado com o que deveria ser o resultado
perfeito. Este resultado perfeito, resulta da segmentação manual, motivo pela qual foi
desenvolvido este segmentador.
De seguida foi criada uma outra API, esta sim, para a segmentação automática de
oradores.
Figura 16: API usada para a segmentação automática de oradores
Ao clicar em “Detect Segments” começa a “comunicação” entre o 4VDO ANNOTATOR
e o SPEAKERID.
Antes de se começar esta comunicação é necessário que o utilizador crie um track.
Depois de clicar no botão, a API passa ao SPEAKERID a localização do ficheiro a
analisar. O SPEAKERID é inicializado automaticamente. Quando este termina os

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
53
cálculos, isto é, o processo de segmentação, retorna ao anotador o início e fim de cada
segmento, sendo criado automaticamente pelo anotador estes segmentos.
8.1 - COMUNICAÇÃO ENTRE ANOTADOR E SPEAKERID
Tal como já foi descrito o anotador está organizado segundo linhas de tempo (timeline),
tracks e eventos (events). Assim quando se pretende inserir numa timeline, um evento,
como por exemplo um segmento, é necessário criar uma track.
Quando se cria uma track, fica desde logo registado na estrutura AWTrack, o nome dado
à track bem como em que timeline se encontra. De registar que a track é inserida na
primeira timeline disponível, como se de uma lista FIFO (First In First Out) se tratasse.
Quando se inicia a segmentação automática, o SPEAKERID calcula as várias regiões. O
anotador fica à espera que estas regiões sejam calculadas. Quando o processo termina, é
passado ao anotador o início e fim de cada região, indexados pelo número da região a que
pertencem. O anotador cria então os segmentos com estes valores.
8.2 - TESTE DO SEGMENTADOR DE ORADORES
Esta classificação surge para avaliar a performance do segmentador automático. O
objectivo é averiguar e avaliar os resultados obtidos, comparando os resultados com o
que deveria ser o resultado perfeito.
Comecou-se por admitir que a primeira timeline seria reservada para a track de referência
e todas as outras, para as tracks a comparar. Sendo assim a primeira informação a saber é
quantas tracks é que serão analisadas, isto porque este algoritmo permite, através de um
ciclo, analisar várias tracks. Será útil, pois na fase de testes serão criadas várias tracks
correspondendo a diferentes tipos de testes. Depois de saber quantas tracks foram criadas
o algoritmo analisa e calcula o número de mudanças de oradores, classificando-as como
correctas, falsas ou omissas.
Este algoritmo olha para a track referência, selecciona a frame de mudança de orador, e
percorre os segmentos das tracks seguintes, pesquisando se encontra alguma mudança de
orador dentro de um intervalo de confiança. Se encontrar então actualiza a variável

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
54
correct; se não encontrar avança para o próximo frame de mudança de orador. Este
intervalo pode ser refinado conforme a precisão que se queira dar ao próprio algoritmo.
No futuro será realizado um estudo sobre qual a melhor estimativa para este intervalo.
Neste momento o valor deste intervalo é de 1segundo (0,5 segundos par cada lado). Ver
figura seguinte. Após percorrer todos os segmentos da track referência, temos o valor dos
segmentos encontrados correctamente. Após concluída esta pesquisa é possível calcular o
valor dos segmentos false e missed.
O valor de false é dado pela subtracção do número de eventos da track a analisar menos o
valor dos segmentos encontrados correctamente. Os false são todos os eventos da track a
analisar que não foram considerados correctos.
O valor de missed é dado pela subtracção do número de eventos da track referência
menos o valor dos segmentos encontrados correctamente. Os missed são todos os eventos
da track referência que não foram considerados correctos.
Figura 17: Esquema de como são usados os intervalos de confiança
Para avaliar o comportamento do segmentador automático foram calculadas quatro
medidas: False Alarm Rate, Missed Detection Rate, Precision e Recall.
O Missed Detection Rate (MDR) [3] é dado pela relação entre o número de mudança de
oradores falhados (missed) e número real de mudanças de orador (número de eventos da
track referência).
%100×=referênciaTrackeventosdeNr
MisseddeNrMDR

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
55
False Alarm Rate (FAR) [3] é definido como a divisão entre o número de falso-positivos
(false) e a soma do número de falso-positivos com o número de eventos da track
referência.
%100×+
=referênciaTrackeventosdeNrFalsedeNr
FalsedeNrFAR
A precisão (precision) é a percentagem de documentos relevantes entre todos os
documentos obtidos como resultado de uma operação de pesquisa. A cobertura (recall) é
a percentagem de documentos relevantes, entre todo o conjunto de documentos relevantes
existentes na colecção de pesquisa, obtidos como resultado de uma operação de pesquisa.
Segundo William Frakes e Ricardo Baeza-Yates [4] os valores de precision e recall são
inversamente proporcionais, ou seja, um sistema com um elevado valor de precisão
apresenta geralmente um valor baixo de cobertura e vice-versa.
Para o cálculo de recall e precision utilizou-se a definição de apresentada por William
Frakes e Ricardo Baeza-Yates [4]:
%100×=referênciaTrackeventosdeNr
CorrectdeNrRECALL
%100×=analisarTrackeventosdeNr
CorrectdeNrPRECISION

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
56
9 - TESTES e RESULTADOS
Nesta secção são apresentados os resultados obtidos ao longo do desenvolvimento do
trabalho, bem como algumas reflexões sobre os mesmos.
Para avaliar o segmentador foi criada uma base de dados, utilizando duas colecções
diferentes de sons. Uma colecção de sons, é composta por ficheiros de som gravados a
partir de canais de televisão, em ambiente de estúdio de baixo ruído, sendo a maioria dos
oradores jornalistas e figuras públicas. A outra colecção foi retirada da compilação
“MPEG Meetings”, onde ao contrário da colecção anterior, nem sempre o ruído é baixo,
embora tratando-se da transmissão de um telejornal, há várias reportagens de exterior
onde existe ruído de fundo.
A partir desta base de dados foram seleccionados 68 ficheiros com tempos diferentes,
mas com formatos iguais: 8KHz, mono, 16bits. Foram também criados alguns ficheiros,
concatenando pedaços de conversas realizadas pelo mesmo orador, para que desta forma
se pudesse ter ficheiros mais longos. Estes excertos foram criados com o programa Praat.
No final, a base de dados era composta por: 38 Ficheiros de oradores femininos, 28
ficheiros de oradores do sexo masculino, 1 ficheiro de silêncio, e 1 ficheiro do telejornal
da RTP1.
Foram criados então15 ficheiros de teste. Foram criados ficheiros mistos, isto é, com
oradores masculinos e femininos, mas foram criados também ficheiros só com oradores
masculinos ou femininos. Fez-se variar também o número de oradores bem como o
tempo que cada orador fala. Para a criação destes ficheiros foram utilizados os programas
Praat e Adobe Audition 1.5.
Em primeiro lugar foi testado uma versão inicial do SPEAKERID. Nesta primeira versão
do SPEAKERID, os subsegmentos têm comprimento dinâmico para garantir que se
obtêm, após se realizar a filtragem de sons não vozeados e silêncio, um número mínimo
de frames com sons vozeados. A divergence shape é calculada com uma janela de 3
segundos com um shift de 0,5 segundos, isto é, overlap de 2,5 segundos. Não se utiliza o
BIC no refinamento. Nesta versão fez-se variar duas variáveis de threshold, �1 e � 2.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
57
A segunda versão do segmentador, descrita já em várias secções, utiliza o BIC, bem
como uma variável de threshold. Sendo assim as duas variáveis são respectivamente � e
�1.
Tal como já descrito na secção anterior, no anotador pode-se criar várias tracks. Para
cada teste fez-se variar uma das variáveis mantendo o valor da outra. Isto é, por cada vez
que é colocado o segmentador a funcionar, este varia uma das variáveis de 0 a 2, com
incremento de 0,1. No anotador, cada track corresponde a um desses valores. Por cada
teste realizado foram criadas 22 tracks, uma de referência e 21 correspondentes à
variação de uma das variáveis.
Figura 18: Exemplo de um possível teste realizado

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
58
A figura anterior representa um possível teste onde se fez variar o � 1 entre 0,0 e 0,5
mantendo o � 2 a 1,1. Como se pode observar neste exemplo, foram criados 7 tracks, uma
de referência e 6 para os vários valores de � 1. Em seguida é medida a performance do
segmentador, calculando as quatro medidas descritas também na secção anterior, MDR,
FAR, Precision e Recall. Estas medidas são apresentadas numa tabela, criada para esse
efeito.
Figura 19: Tabela com os valores calculados de FDR, MDR, Precision e Recall
Este é um pequeno exemplo de como foi avaliado a performance do segmentador. Na
secção anterior foi dito que o intervalo de confiança seria de 1 segundo, 0,5 segundos
para cada lado. Contudo como o processo de segmentação manual é tão minucioso
decidiu-se aumentar este valor. Desta forma este intervalo passou a ser de 2 segundos, 1
segundo para cada lado.
No quadro seguinte é apresentado um resumo dos testes realizados e as suas
especificações, número de segmentos, número de oradores diferentes, que tipo de
segmentador foi testado, se o ficheiro de teste é integral, isto é, sem colagens, o número
de oradores e duração.
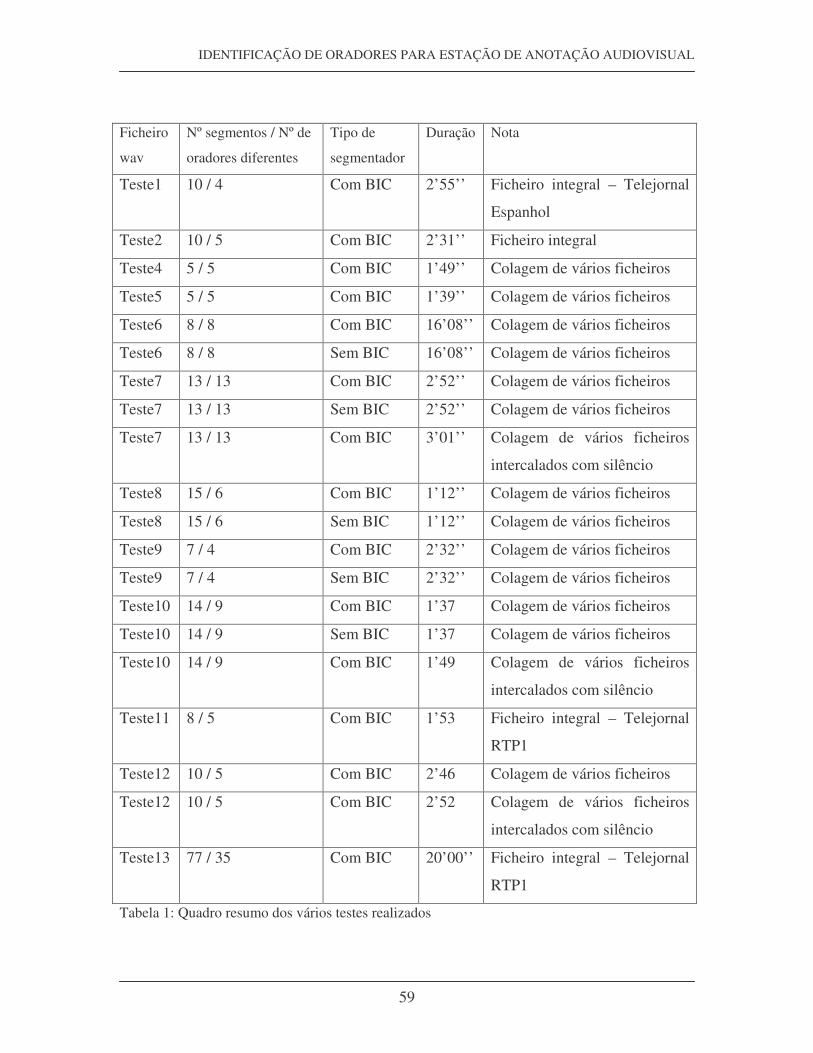
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
59
Ficheiro
wav
Nº segmentos / Nº de
oradores diferentes
Tipo de
segmentador
Duração Nota
Teste1 10 / 4 Com BIC 2’55’’ Ficheiro integral – Telejornal
Espanhol
Teste2 10 / 5 Com BIC 2’31’’ Ficheiro integral
Teste4 5 / 5 Com BIC 1’49’’ Colagem de vários ficheiros
Teste5 5 / 5 Com BIC 1’39’’ Colagem de vários ficheiros
Teste6 8 / 8 Com BIC 16’08’’ Colagem de vários ficheiros
Teste6 8 / 8 Sem BIC 16’08’’ Colagem de vários ficheiros
Teste7 13 / 13 Com BIC 2’52’’ Colagem de vários ficheiros
Teste7 13 / 13 Sem BIC 2’52’’ Colagem de vários ficheiros
Teste7 13 / 13 Com BIC 3’01’’ Colagem de vários ficheiros
intercalados com silêncio
Teste8 15 / 6 Com BIC 1’12’’ Colagem de vários ficheiros
Teste8 15 / 6 Sem BIC 1’12’’ Colagem de vários ficheiros
Teste9 7 / 4 Com BIC 2’32’’ Colagem de vários ficheiros
Teste9 7 / 4 Sem BIC 2’32’’ Colagem de vários ficheiros
Teste10 14 / 9 Com BIC 1’37 Colagem de vários ficheiros
Teste10 14 / 9 Sem BIC 1’37 Colagem de vários ficheiros
Teste10 14 / 9 Com BIC 1’49 Colagem de vários ficheiros
intercalados com silêncio
Teste11 8 / 5 Com BIC 1’53 Ficheiro integral – Telejornal
RTP1
Teste12 10 / 5 Com BIC 2’46 Colagem de vários ficheiros
Teste12 10 / 5 Com BIC 2’52 Colagem de vários ficheiros
intercalados com silêncio
Teste13 77 / 35 Com BIC 20’00’’ Ficheiro integral – Telejornal
RTP1
Tabela 1: Quadro resumo dos vários testes realizados

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
60
Para a apresentação e discussão dos vários testes iremos dividi-los pelo tipo de
segmentador. Primeiro irá ser apresentado os resultados obtidos com o primeiro
segmentados, sem BIC e de seguida utilizando o BIC no módulo de refinação.
Apresentamos de seguida um quadro com os melhores resultados para o segmentador que
não utiliza processo de refinação, apenas dois thresholds dinâmicos.
TESTE FAR (%) MDR (%) �1 �2
Teste 6 97,8593 0 1,3 1
Teste 8 61,1111 14,2857 1,2 0
Teste 9 88,8888 16,6667 1,6 1,7
Teste 10 73,4694 0 0,8 0
Tabela 2: Resumo com os melhores resultados para o segmentador sem BIC
No anexo 1 encontram-se todos os dados relativos a estes testes. Estes resultados foram
escolhidos, tendo em conta o valor mínimo para o MDR. Isto porque é preferível ter
falsos-positivos, do que o sistema não conseguir identificar uma mudança de orador. Os
falsos positivos serão tratados depois no processo de identificação. Quando dois
segmentos adjacentes são identificados pertencentes ao mesmo orador então a potencial
mudança de orador é ignorada.
A primeira conclusão sobre este segmentador é que é muito discriminativo, pois obtém-se
taxas de FAR bastante elevadas. Quando o valor de FAR começa a diminuir aumenta
consideravelmente o valor de MDR. O menor valor para FAR é de 36,3636 %
correspondendo a um MDR de 57,1429 %, isto significa que mais de metade das
mudanças verdadeiras de orador não são detectadas, e consequentemente, é um mau
resultado. Não se pode concluir muito sobre os thresholds dinâmicos �1 e �2, pois os
resultados são variados. Contudo poder-se-á dizer, que threshold �1 deverá ser definido
como um valor entre 0,8 e 1,3 pois é neste intervalo que se obtêm os melhores resultados.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
61
Para a realização dos teste com o segundo segmentador foi criado uma nova API, onde se
pode escolher o valor de �. Tal como foi dito, para este segmentador, em cada
experiência, fez variar o valor de �, mantendo o valor de �. No anexo 2 encontram-se
todos os resultados obtidos.
Figura 20: Nova API usada para a segmentação automática de oradores
Apresentamos de seguida um quadro com os melhores resultados para o segmentador que
utiliza o Bayesian Information Criterion no processo de refinação.
TESTE FAR (%) MDR (%) � �
Teste 1 57,1429 11,1111 1,1 0,4
Teste 2 52,6316 22,2222 1,1 0,5
Teste 4 55,5556 25 0,9 0,6
Teste 5 81,8182 0 1,1 0,4
Teste 6 96,6184 14,2857 0,8 0,4
Teste 7 62,5 16,6667 0,7 0,5
Teste 8 33,3333 28,5714 1 0,4
Teste 9 25 50 1,1 0,7
Teste 10 23,5294 30,7692 1,2 0,5
Teste 11 56,25 28,5714 1,4 0,4
Teste 12 30,7692 66,6667 0,9 0,8
Teste 13 73,3333 7,8947 0,9 0,4
Tabela 3: Resumo com os melhores resultados para o segmentador com BIC

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
62
Numa primeira observação sobre os resultados, poder-se-á dizer que a percentagem de
número de detecções falsas diminui no geral enquanto que a percentagem de MDR
aumenta, comparando com o primeiro segmentador.
Tal como seria de esperar, utilizando o BIC no módulo de refinação faz com o valor das
falsas detecções diminui-a.
Iremos analisar com mais cuidado os vários testes.
Os testes 1, 2, 11 e 13 são ficheiros de áudio sem colagens. Os melhores resultados, deste
conjunto, correspondem a noticiários, 1 e 13, com mais de 10 segmentos. A elevada taxa
de FAR é facilmente explicada pelos barulhos de fundo existentes nas reportagens.
O teste 5 é composto só por oradores do sexo masculino enquanto que o teste 12 é
composto por oradores só do sexo feminino. Todos os outros são mistos, homens e
mulheres. Comparando estes dois testes, 5 e 12, podemos concluir que só com oradores
femininos obtém-se piores resultados. Um justificação para este facto poderá ser a
realização de uma segmentação de sons vozeados, não vozeados e silêncio deficiente,
fazendo com que o modelo do orador estimado seja também insuficiente.
Para este segmentador já é possível estabelecer um intervalo de valores para as duas
variáveis que foram estudadas, � e �. Enquanto que � obteve os melhores resultados para
valores entre 0.9 e 1.2, � obteve melhores resultados para valores compreendidos entre
0,4 e 0,5.
Iremos agora olhar com particular atenção para o teste 13. Este teste, ficheiro integral de
uma parte de um telejornal da RTP1, será analisado com mais cuidado, pois o objectivo
deste projecto é precisamente a segmentação de oradores em ambientes idênticos.
Foi realizado um histograma com a duração de cada segmento. Como já foi dito unidade
base para formar um modelo de orador é 3s. Se os segmentos tiverem duração inferior a
3s, a detecção é mais difícil. Para segmentos de duração maior a performance do
segmentador é melhor.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
63
Figura 21: Histograma da duração dos segmentos do teste 13
Como se pode observar a probabilidade de os segmentos serem inferiores a 3 segundos é
inferior a 0,07 %.
As tabelas seguintes servem para avaliar a performance do segmentador. A curva Recall-
False, onde False é igual a 1-Precision.
Alpha1 Lambda False=1-Precision Recall 0 0,4 0,78 0.92
0,1 0,4 0,78 0,92 0,2 0,4 0,78 0,92 0,3 0,4 0,78 0,92 0,4 0,4 0,78 0,92 0,5 0,4 0,78 0,92 0,6 0,4 0,78 0,92 0,7 0,4 0,78 0,92 0,8 0,4 0,77 0,92 0,9 0,4 0,75 0,92 1 0,4 0,73 0,88
1,1 0,4 0,72 0,82 1,2 0,4 0,71 0,71 1,3 0,4 0,7 0,57 1,4 0,4 0,67 0,5 1,5 0,4 0,67 0,4 1,6 0,4 0,64 0,34 1,7 0,4 0,62 0,27 1,8 0,4 0,57 0,25 1,9 0,4 0,59 0,17 2 0,4 0,58 0,11
Tabela 4: Tabelo do teste 13, com � igual 0,4

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
64
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
0,55 0,6 0,65 0,7 0,75 0,8
False
Rec
all
Figura 22: Curva Recall-False, do teste 13, com � igual 0,4
Alpha1 Lambda False=1-Precision Recall 0 0,3 0,83 0,92
0,1 0,3 0,83 0,92 0,2 0,3 0,83 0,92 0,3 0,3 0,83 0,92 0,4 0,3 0,83 0,92 0,5 0,3 0,83 0,92 0,6 0,3 0,83 0,92 0,7 0,3 0,83 0,92 0,8 0,3 0,82 0,92 0,9 0,3 0,81 0,92 1 0,3 0,79 0,88
1,1 0,3 0,77 0,84 1,2 0,3 0,76 0,73 1,3 0,3 0,74 0,6 1,4 0,3 0,7 0,52 1,5 0,3 0,68 0,43 1,6 0,3 0,65 0,35 1,7 0,3 0,64 0,27 1,8 0,3 0,6 0,25 1,9 0,3 0,61 0,17 2 0,3 0,58 0,11
Tabela 5: Tabelo do teste 13, com � igual 0,3

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
65
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
0,5 0,55 0,6 0,65 0,7 0,75 0,8 0,85 0,9
False
Rec
all
Figura 23: Curva Recall-False, do teste 13, com � igual 0,3
Observando as tabelas podemos concluir que o valor de Recall e False diminui com o
aumento do valor de �.
Ambas as curvas não apresentam uma forma linear, mas estes testes têm como objectivo
avaliar a performance do segmentador, e escolher o melhor valor para � e �.
Com estes novos resultados, Recall e False, podemos escolher agora um valor para � e �.
Com um recall superior a 90%, o valor escolhido para � é de 0.9 e o valor de � é 0,4.
Estes são valores que se encontram dentro do intervalo anteriormente referenciado.
De lembrar que esta taxa é obtida apenas com a Divergence Shape LSP, o que se pode
concluir que esta característica é suficiente para a detecção de potencial mudança de
orador.
Contudo os valores de FAR e False são ainda elevados. Este valor pode ser explicado
pelo facto do ficheiro em causa ser um excerto de um telejornal, onde existem sons como
ruídos de fundo, sobreposição de vozes, que são mal classificados no segmentador
vozeado/não vozeado/silêncio. Estes segmentos não são classificados como não-
vozeados/silêncio e de esta forma os resultados da detecção são afectados.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
66
Por fim foi realizado uma ultima experiência, para saber qual o desempenho do
segmentador a mudanças de orador intercaladas com segmentos de silêncio. Foram então
criados mais três testes
TESTE FAR (%) MDR (%) � �
Sem silêncio intercalado
Teste 7 62,5 16,6667 0,7 0,5
Teste 10 23,5294 30,7692 1,2 0,5
Teste 12 30,7692 66,6667 0,9 0,8
Com silêncio intercalo
Teste 7 36,8421 25 0,9 0,7
Teste 10 13,3333 7,69231 1,1 0,4
Teste 12 72,723 22,2222 0,9 0,4
Tabela 6: Resumo com os melhores resultados para o segmentador com BIC
O teste 7, composto por 13 segmentos, melhorou bastante o valor de FAR mas piorou o
MDR, valor que temos vindo a tentar que seja o mínimo possível, razão pela qual a
performance piorou. Contudo foram obtidos bons resultados com os outros dois testes,
pois foi possível baixar o valor de MDR, bem como aproximar os valores de � e � para o
valor anteriormente escolhido, 0.9 e 0.4, respectivamente.
Poder-se-á dizer que a performance do segmentador melhorou. O motivo pelo qual isto
acontece deve-se com o facto de se poder estimar melhor o modelo do orador, pois a
informação disponível é maior.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
67
10 - CONCLUSÕES
A primeira reflexão a ser feita é sobre a integração do segmentador, SPEAKERID, no
anotador, 4VDO ANNOTATOR. Foi realizado o port do código fonte para torna-lo
compatível com as novas versões do Visual Studio, Qt, e xerces. Esta integração foi
realizada sem qualquer problema.
Embora a primeira versão do segmentador fosse demasiadamente discriminativa, a
segunda versão veio a revelar-se como a que melhores resultados obteve.
Dos testes efectuados com ambos os segmentadores obteve-se melhores resultados com o
segundo segmentador. Este segmentador, ao contrário do primeiro que utilizava dois
thresholds dinâmicos, utiliza apenas um threshold dinâmico, mas utiliza um processo de
refinação, Bayesian Information Criterion. Com o BIC os resultados melhoraram
significativamente.
Enquanto que com os testes realizados ao primeiro segmentador não era possível escolher
um valor fixo para as duas variáveis, os testes realizados ao segundo segmentador
revelaram que era possível escolher um valor para cada variável. Este valor não é ainda o
valor perfeito, pois embora funcione bem para uns casos ainda apresenta algumas
deficiências em alguns casos. Contudo com este valor consegue-se obter um recall de
90%, em contrapartida com piores valores para False, se bem que estes valores poderão
ser combatidos quando se acrescentar o módulo de tracking ao segmentador.
Conclui-se também, através dos vários testes, que os melhores resultados foram obtidos
para ficheiros com vários segmentos.
Outra conclusão prende-se com o facto de os oradores serem só mulheres ou só homens
ou mistos. Conclui-se que o segmentador obtém piores resultados com ficheiros
constituídos só por mulheres. Este facto está relacionado com a filtragem que é feita após
a segmentação de sons vozeados, não-vozeados e silêncio, fazendo com que o modelo do
orador não seja bem estimado.
Ficou também demonstrado que os resultados são afectados por ruídos ambiente, tais
como ruído de fundo, palmas, ou falas sobrepostas. Este é aliás um assunto que está a ser
alvo dos mais variados estudos.

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
68
11 – FUTUROS DESENVOLVIMENTOS
Neste projecto foram desenvolvidas e testadas técnicas de detecção de mudança de
oradores. Contudo para que o processo de identificação de oradores esteja completo falta
ainda implementar o último módulo, Speaker Tracking ou identificação de orador.
Quando é detectada uma fronteira de mudança de orador, o próximo passo é identificar
esse novo orador. Este novo orador pode ter o seu modelo de orador registado, ou não, na
base de dados dos modelos de oradores. Se não estiver registado acrescenta-se este novo
modelo à base de dado. A pesquisa na base de dados é realizada comparando-se o modelo
do subsegmento actual com os modelos de oradores existentes na base de dados para
descobrir qual o modelo mais semelhante. O modelo mais semelhante é o modelo mais
provável de representar o orador desse subsegmento. É com este novo módulo que se
pretende baixar o valor dos falsos positivos. Quando dois segmentos consecutivos forem
classificados como pertencentes ao mesmo orador, a fronteira que os dividia deixa de
existir. Desta forma iremos de certeza baixar o valor de FAR, tornando o processo de
segmentação ainda mais fiável.
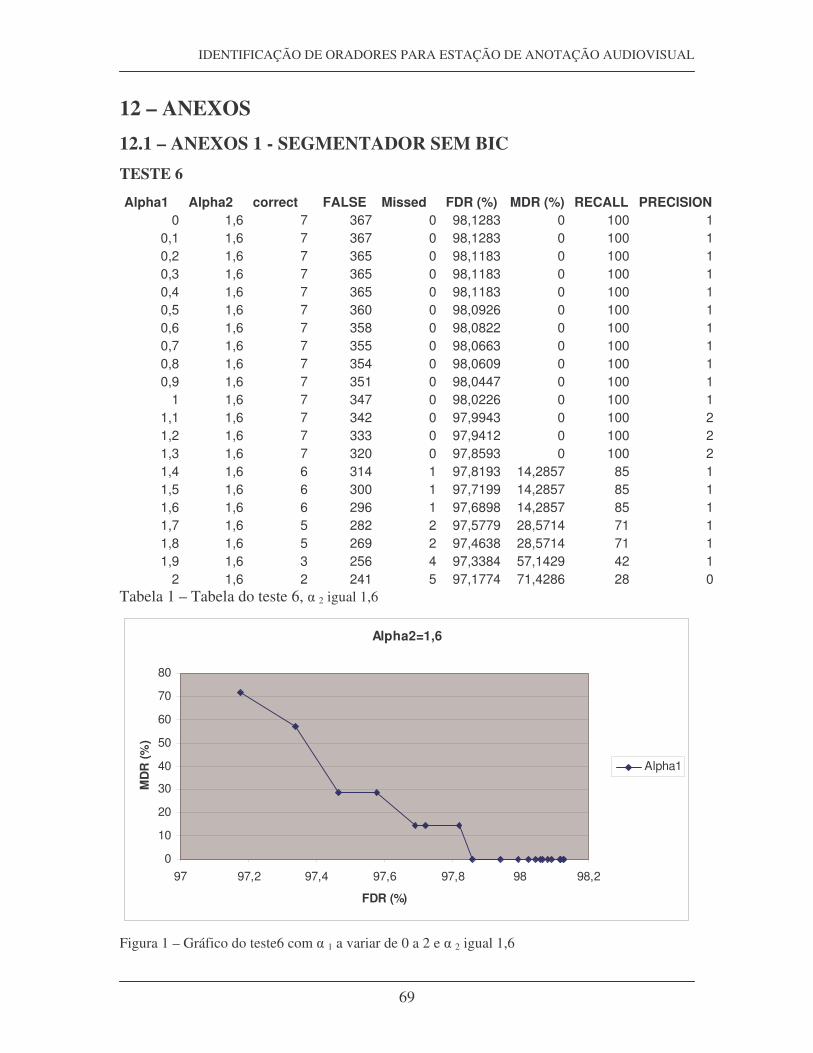
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
69
12 – ANEXOS 12.1 – ANEXOS 1 - SEGMENTADOR SEM BIC TESTE 6
Alpha1 Alpha2 correct FALSE Missed FDR (%) MDR (%) RECALL PRECISION 0 1,6 7 367 0 98,1283 0 100 1
0,1 1,6 7 367 0 98,1283 0 100 1 0,2 1,6 7 365 0 98,1183 0 100 1 0,3 1,6 7 365 0 98,1183 0 100 1 0,4 1,6 7 365 0 98,1183 0 100 1 0,5 1,6 7 360 0 98,0926 0 100 1 0,6 1,6 7 358 0 98,0822 0 100 1 0,7 1,6 7 355 0 98,0663 0 100 1 0,8 1,6 7 354 0 98,0609 0 100 1 0,9 1,6 7 351 0 98,0447 0 100 1
1 1,6 7 347 0 98,0226 0 100 1 1,1 1,6 7 342 0 97,9943 0 100 2 1,2 1,6 7 333 0 97,9412 0 100 2 1,3 1,6 7 320 0 97,8593 0 100 2 1,4 1,6 6 314 1 97,8193 14,2857 85 1 1,5 1,6 6 300 1 97,7199 14,2857 85 1 1,6 1,6 6 296 1 97,6898 14,2857 85 1 1,7 1,6 5 282 2 97,5779 28,5714 71 1 1,8 1,6 5 269 2 97,4638 28,5714 71 1 1,9 1,6 3 256 4 97,3384 57,1429 42 1
2 1,6 2 241 5 97,1774 71,4286 28 0 Tabela 1 – Tabela do teste 6, � 2 igual 1,6
Alpha2=1,6
0
10
20
30
40
50
60
70
80
97 97,2 97,4 97,6 97,8 98 98,2
FDR (%)
MD
R (%
)
Alpha1
Figura 1 – Gráfico do teste6 com � 1 a variar de 0 a 2 e � 2 igual 1,6
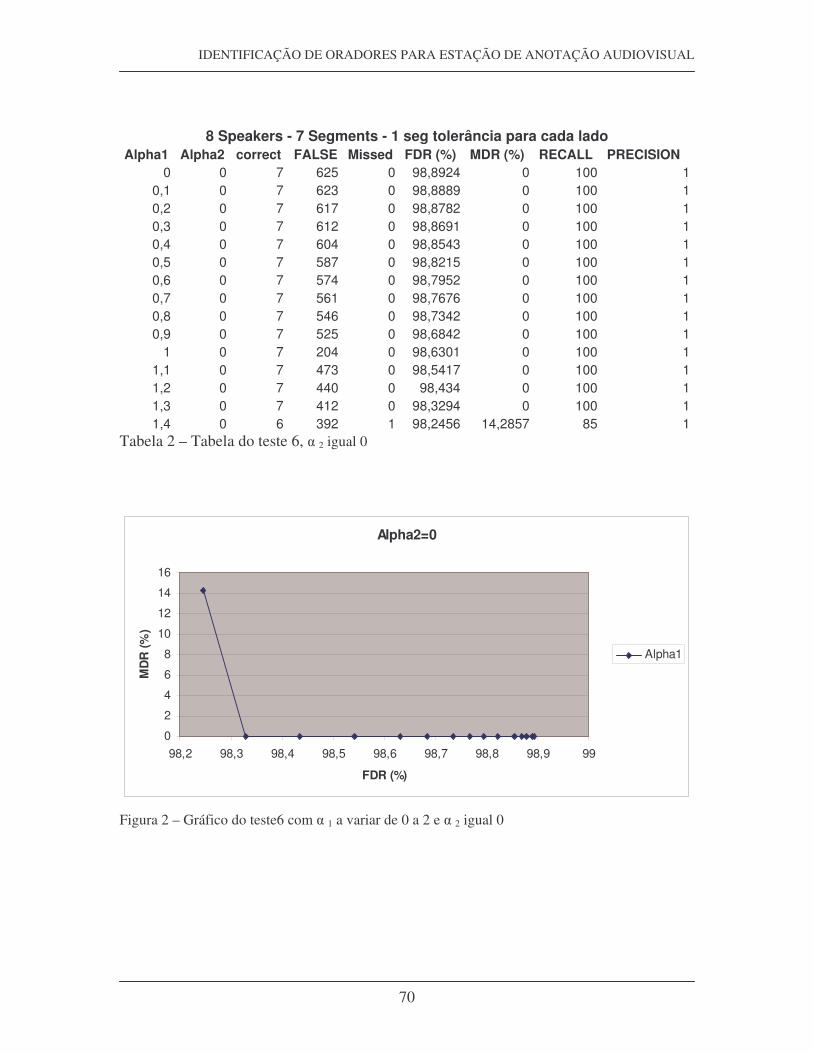
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
70
8 Speakers - 7 Segments - 1 seg tolerância para cada lado Alpha1 Alpha2 correct FALSE Missed FDR (%) MDR (%) RECALL PRECISION
0 0 7 625 0 98,8924 0 100 1 0,1 0 7 623 0 98,8889 0 100 1 0,2 0 7 617 0 98,8782 0 100 1 0,3 0 7 612 0 98,8691 0 100 1 0,4 0 7 604 0 98,8543 0 100 1 0,5 0 7 587 0 98,8215 0 100 1 0,6 0 7 574 0 98,7952 0 100 1 0,7 0 7 561 0 98,7676 0 100 1 0,8 0 7 546 0 98,7342 0 100 1 0,9 0 7 525 0 98,6842 0 100 1
1 0 7 204 0 98,6301 0 100 1 1,1 0 7 473 0 98,5417 0 100 1 1,2 0 7 440 0 98,434 0 100 1 1,3 0 7 412 0 98,3294 0 100 1 1,4 0 6 392 1 98,2456 14,2857 85 1
Tabela 2 – Tabela do teste 6, � 2 igual 0
Alpha2=0
0
2
4
6
8
10
12
14
16
98,2 98,3 98,4 98,5 98,6 98,7 98,8 98,9 99
FDR (%)
MD
R (%
)
Alpha1
Figura 2 – Gráfico do teste6 com � 1 a variar de 0 a 2 e � 2 igual 0

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
71
TESTE 8
15 Speakers - 14 Segments - 1 seg tolerância para cada lado Alpha1 Alpha2 correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0 12 33 2 70,2128 14,2857 85 26 0,1 0 12 33 2 70,2128 14,2857 85 26 0,2 0 12 33 2 70,2128 14,2857 85 26 0,3 0 12 33 2 70,2128 14,2857 85 26 0,4 0 12 33 2 70,2128 14,2857 85 26 0,5 0 12 33 2 70,2128 14,2857 85 26 0,6 0 12 32 2 69,5652 14,2857 85 27 0,7 0 12 31 2 68,8889 14,2857 85 27 0,8 0 12 31 2 68,8889 14,2857 85 27 0,9 0 12 26 2 65 14,2857 85 31
1 0 12 26 2 65 14,2857 85 31 1,1 0 12 26 2 65 14,2857 85 31 1,2 0 12 22 2 61,1111 14,2857 85 35 1,3 0 10 15 4 51,7241 28,5714 71 40 1,4 0 8 12 6 46,1538 42,8571 57 40 1,5 0 8 12 6 46,1538 42,8571 57 40 1,6 0 7 11 7 44 50 50 38 1,7 0 7 9 7 39,1304 50 50 43 1,8 0 6 9 8 39,1304 57,1429 42 40 1,9 0 6 9 8 39,1304 57,1429 42 40
2 0 4 9 10 39,1304 71,4286 28 30 Tabela 3 – Tabela do teste 8, � 2 igual 0
Alpha2=0.0
10
20
30
40
50
60
70
80
35 40 45 50 55 60 65 70 75
FDR (%)
MD
R (%
)
Alpha1
Figura 3 – Gráfico do teste 8 com � 1 a variar de 0 a 2 e � 2 igual 0
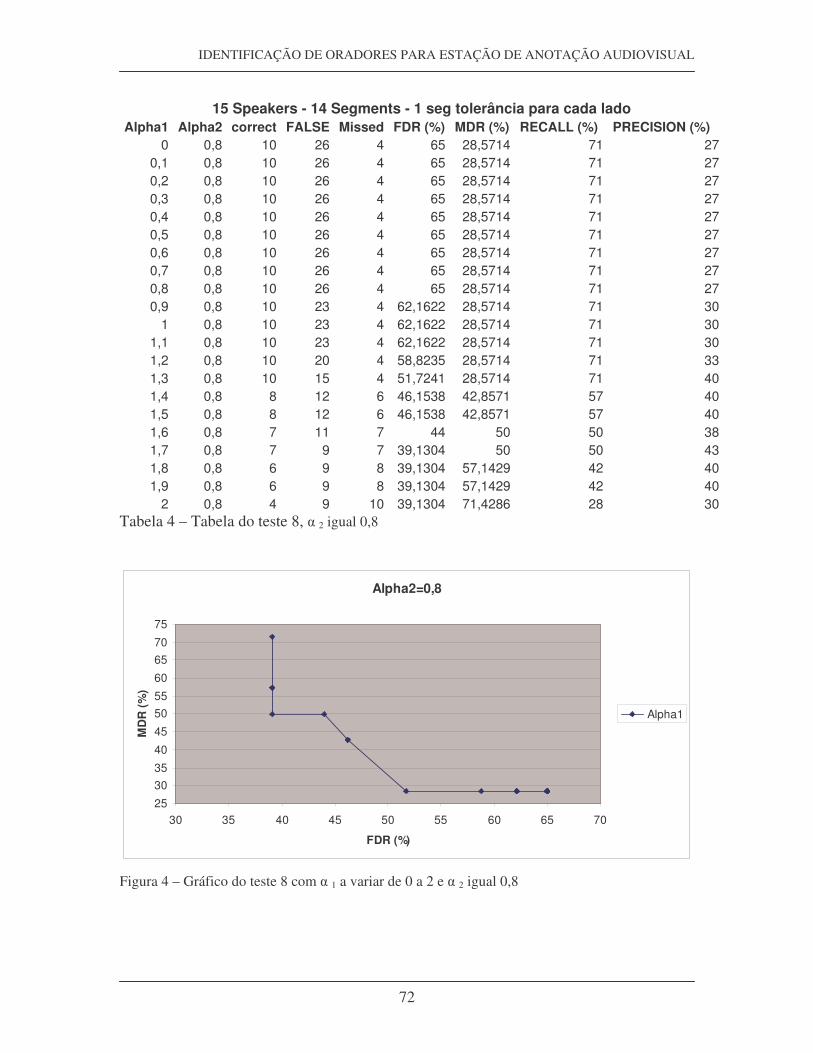
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
72
15 Speakers - 14 Segments - 1 seg tolerância para cada lado Alpha1 Alpha2 correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,8 10 26 4 65 28,5714 71 27 0,1 0,8 10 26 4 65 28,5714 71 27 0,2 0,8 10 26 4 65 28,5714 71 27 0,3 0,8 10 26 4 65 28,5714 71 27 0,4 0,8 10 26 4 65 28,5714 71 27 0,5 0,8 10 26 4 65 28,5714 71 27 0,6 0,8 10 26 4 65 28,5714 71 27 0,7 0,8 10 26 4 65 28,5714 71 27 0,8 0,8 10 26 4 65 28,5714 71 27 0,9 0,8 10 23 4 62,1622 28,5714 71 30
1 0,8 10 23 4 62,1622 28,5714 71 30 1,1 0,8 10 23 4 62,1622 28,5714 71 30 1,2 0,8 10 20 4 58,8235 28,5714 71 33 1,3 0,8 10 15 4 51,7241 28,5714 71 40 1,4 0,8 8 12 6 46,1538 42,8571 57 40 1,5 0,8 8 12 6 46,1538 42,8571 57 40 1,6 0,8 7 11 7 44 50 50 38 1,7 0,8 7 9 7 39,1304 50 50 43 1,8 0,8 6 9 8 39,1304 57,1429 42 40 1,9 0,8 6 9 8 39,1304 57,1429 42 40
2 0,8 4 9 10 39,1304 71,4286 28 30 Tabela 4 – Tabela do teste 8, � 2 igual 0,8
Alpha2=0,8
25
3035
40
45
5055
60
6570
75
30 35 40 45 50 55 60 65 70
FDR (%)
MD
R (
%)
Alpha1
Figura 4 – Gráfico do teste 8 com � 1 a variar de 0 a 2 e � 2 igual 0,8

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
73
15 Speakers - 14 Segments - 1 seg tolerância para cada lado Alpha1 Alpha2 correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 1 10 22 4 61,1111 28,5714 71 31 0,1 1 10 22 4 61,1111 28,5714 71 31 0,2 1 10 22 4 61,1111 28,5714 71 31 0,3 1 10 22 4 61,1111 28,5714 71 31 0,4 1 10 22 4 61,1111 28,5714 71 31 0,5 1 10 22 4 61,1111 28,5714 71 31 0,6 1 10 22 4 61,1111 28,5714 71 31 0,7 1 10 22 4 61,1111 28,5714 71 31 0,8 1 10 22 4 61,1111 28,5714 71 31 0,9 1 10 19 4 57,5758 28,5714 71 34
1 1 10 19 4 57,5758 28,5714 71 34 1,1 1 10 19 4 57,5758 28,5714 71 34 1,2 1 10 16 4 53,3333 28,5714 71 38 1,3 1 10 14 4 50 28,5714 71 41 1,4 1 8 11 6 44 42,8571 57 42 1,5 1 8 11 6 44 42,8571 57 42 1,6 1 7 10 7 41,6667 50 50 41 1,7 1 7 9 7 39,1304 50 50 43 1,8 1 6 9 8 39,1304 57,1429 42 40 1,9 1 6 9 8 39,1304 57,1429 42 40
2 1 4 9 10 39,1304 71,4286 28 30 Tabela 5 – Tabela do teste 8, � 2 igual 1
Alpha2=1
20
30
40
50
60
70
80
35 40 45 50 55 60 65
FDR (%)
MD
R (%
)
Alpha1
Figura 5 – Gráfico do teste 8 com � 1 a variar de 0 a 2 e � 2 igual 1

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
74
15 Speakers - 14 Segments - 1 seg tolerância para cada lado Alpha1 Alpha2 correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 1,3 7 17 7 54,8387 50 50 29 0,1 1,3 7 17 7 54,8387 50 50 29 0,2 1,3 7 17 7 54,8387 50 50 29 0,3 1,3 7 17 7 54,8387 50 50 29 0,4 1,3 7 17 7 54,8387 50 50 29 0,5 1,3 7 17 7 54,8387 50 50 29 0,6 1,3 7 17 7 54,8387 50 50 29 0,7 1,3 7 17 7 54,8387 50 50 29 0,8 1,3 7 17 7 54,8387 50 50 29 0,9 1,3 7 15 7 51,7241 50 50 31
1 1,3 7 15 7 51,7241 50 50 31 1,1 1,3 7 15 7 51,7241 50 50 31 1,2 1,3 7 13 7 48,1481 50 50 35 1,3 1,3 7 12 7 46,1538 50 50 36 1,4 1,3 6 10 8 41,6667 57,1429 42 37 1,5 1,3 6 10 8 41,6667 57,1429 42 37 1,6 1,3 6 10 8 41,6667 57,1429 42 37 1,7 1,3 6 9 8 39,1304 57,1429 42 40 1,8 1,3 6 9 8 39,1304 57,1429 42 40 1,9 1,3 6 9 8 39,1304 57,1429 42 40
2 1,3 4 9 10 39,1304 71,4286 28 30 Tabela 6 – Tabela do teste 8, � 2 igual 1,3
alpha2=1.3
40
45
50
55
60
65
70
75
35 37 39 41 43 45 47 49 51 53 55 57
FDR (%)
MD
R (%
)
Alpha1
Figura 6 – Gráfico do teste 8 com � 1 a variar de 0 a 2 e � 2 igual 1,3

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
75
15 Speakers - 14 Segments - 1 seg tolerância para cada lado Alpha1 Alpha2 correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 1,7 7 15 7 51,7241 50 50 31 0,1 1,7 7 15 7 51,7241 50 50 31 0,2 1,7 7 15 7 51,7241 50 50 31 0,3 1,7 7 15 7 51,7241 50 50 31 0,4 1,7 7 15 7 51,7241 50 50 31 0,5 1,7 7 15 7 51,7241 50 50 31 0,6 1,7 7 15 7 51,7241 50 50 31 0,7 1,7 7 15 7 51,7241 50 50 31 0,8 1,7 7 15 7 51,7241 50 50 31 0,9 1,7 7 13 7 48,1481 50 50 35
1 1,7 7 13 7 48,1481 50 50 35 1,1 1,7 7 13 7 48,1481 50 50 35 1,2 1,7 7 11 7 44 50 50 38 1,3 1,7 7 10 7 41,6667 50 50 41 1,4 1,7 6 8 8 36,3636 57,1429 42 42 1,5 1,7 6 8 8 36,3636 57,1429 42 42 1,6 1,7 6 8 8 36,3636 57,1429 42 42 1,7 1,7 6 8 8 36,3636 57,1429 42 42 1,8 1,7 6 8 8 36,3636 57,1429 42 42 1,9 1,7 6 8 8 36,3636 57,1429 42 42
2 1,7 4 8 10 36,3636 71,4286 28 33 Tabela 7 – Tabela do teste 8, � 2 igual 1,7
Alpha2=1.7
40
45
50
55
60
65
70
75
35 37 39 41 43 45 47 49 51 53
FDR (%)
MD
R (%
)
Alpha1
Figura 7 – Gráfico do teste 8 com � 1 a variar de 0 a 2 e � 2 igual 1,7

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
76
TESTE 9
7 Speakers - 6 Segments - 1seg de tolerância para cada lado
Alpha1 Alpha2 correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0 6 92 0 93,8775 0 100 6 0,1 0 6 92 0 93,8775 0 100 6 0,2 0 6 90 0 93,75 0 100 6 0,3 0 6 89 0 93,6842 0 100 6 0,4 0 6 88 0 93,617 0 100 6 0,5 0 6 86 0 93,4783 0 100 6 0,6 0 6 84 0 93,3333 0 100 6 0,7 0 5 82 1 93,1818 16,6667 83 5 0,8 0 5 78 1 92,8571 16,6667 83 6 0,9 0 5 75 1 92,5976 16,6667 83 6 1 0 5 72 1 92,3072 16,6667 83 6
1,1 0 5 64 1 91,4286 16,6667 83 7 1,2 0 5 60 1 90,9091 16,6667 83 7 1,3 0 5 59 1 90,7692 16,6667 83 7 1,4 0 5 57 1 90,4762 16,6667 83 8 1,5 0 5 57 1 90,4762 16,6667 83 8 1,6 0 5 53 1 89,8305 16,6667 83 8 1,7 0 4 45 2 88,2353 33,3333 66 8 1,8 0 3 41 3 87,234 50 50 6 1,9 0 2 39 4 86,6667 66,6667 33 4 2 0 2 35 4 85,3659 66,6667 33 5
Tabela 8 – Tabela do teste 9, � 2 igual 0
Alpha2 = 0
0
10
20
30
40
50
60
70
80
84 85 86 87 88 89 90 91 92 93 94 95
FDR (%)
MD
R (%
)
Alpha1
Figura 8 – Gráfico do teste 9 com � 1 a variar de 0 a 2 e � 2 igual 0

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
77
7 Speakers - 6 Segments - 1seg de tolerância para cada lado
Alpha1 Alpha2 correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,4 6 80 0 93,0233 0 100 6 0,1 0,4 6 80 0 93,0233 0 100 6 0,2 0,4 6 80 0 93,0233 0 100 6 0,3 0,4 6 79 0 92,9412 0 100 7 0,4 0,4 6 78 0 92,8571 0 100 7 0,5 0,4 6 76 0 92,6829 0 100 7 0,6 0,4 6 75 0 92,5926 0 100 7 0,7 0,4 6 74 0 92,5 0 100 6 0,8 0,4 5 72 1 92,3077 16,6667 83 6 0,9 0,4 5 72 1 92,3077 16,6667 83 6 1 0,4 5 69 1 92 16,6667 83 6
1,1 0,4 5 64 1 91,4286 16,6667 83 7 1,2 0,4 5 60 1 90,9091 16,6667 83 7 1,3 0,4 5 59 1 90,7662 16,6667 83 7 1,4 0,4 5 57 1 90,4762 16,6667 83 8 1,5 0,4 5 57 1 90,4762 16,6667 83 8 1,6 0,4 5 53 1 89,8305 16,6667 83 8 1,7 0,4 4 45 2 88,2353 33,3333 66 8 1,8 0,4 3 41 3 87,234 50 50 6 1,9 0,4 2 39 4 86,6667 66,6667 33 4 2 0,4 2 35 4 85,3659 66,6667 33 5
Tabela 9 – Tabela do teste 9, � 2 igual 0
Alpha2=0.4
0
10
20
30
40
50
60
70
80
84 85 86 87 88 89 90 91 92 93 94
FDR (%)
MD
R (%
)
Alpha1
Figura 9 – Gráfico do teste 9 com � 1 a variar de 0 a 2 e � 2 igual 0.4

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
78
7 Speakers - 6 Segments - 1seg de tolerância para cada lado
Alpha1 Alpha2 correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,6 5 71 1 92,2078 16,6667 83 6 0,1 0,6 5 71 1 92,2078 16,6667 83 6 0,2 0,6 5 71 1 92,2078 16,6667 83 6 0,3 0,6 5 70 1 92,1053 16,6667 83 6 0,4 0,6 5 70 1 92,1053 16,6667 83 6 0,5 0,6 5 69 1 92 16,6667 83 6 0,6 0,6 5 68 1 91,8919 16,6667 83 6 0,7 0,6 5 68 1 91,8919 16,6667 83 6 0,8 0,6 5 67 1 91,7808 16,6667 83 6 0,9 0,6 5 67 1 91,7808 16,6667 83 6 1 0,6 5 66 1 91,6667 16,6667 83 7
1,1 0,6 5 61 1 91,0448 16,6667 83 7 1,2 0,6 5 60 1 90,9091 16,6667 83 7 1,3 0,6 5 59 1 90,7692 16,6667 83 7 1,4 0,6 5 57 1 90,4762 16,6667 83 8 1,5 0,6 5 57 1 90,4762 16,6667 83 8 1,6 0,6 5 53 1 89,8305 16,6667 83 8 1,7 0,6 4 45 2 88,2353 33,3333 66 8 1,8 0,6 3 41 3 87,234 50 50 6 1,9 0,6 2 39 4 86,6667 66,6667 33 4 2 0,6 2 35 4 85,3659 66,6667 33 5
Tabela 10 – Tabela do teste 9, � 2 igual 0,6
Alpha2=0.6
0
10
20
30
40
50
60
70
80
85 86 87 88 89 90 91 92 93
FDR (%)
MD
R (%
)
Alpha1
Figura 10 – Gráfico do teste 9 com � 1 a variar de 0 a 2 e � 2 igual 0.4
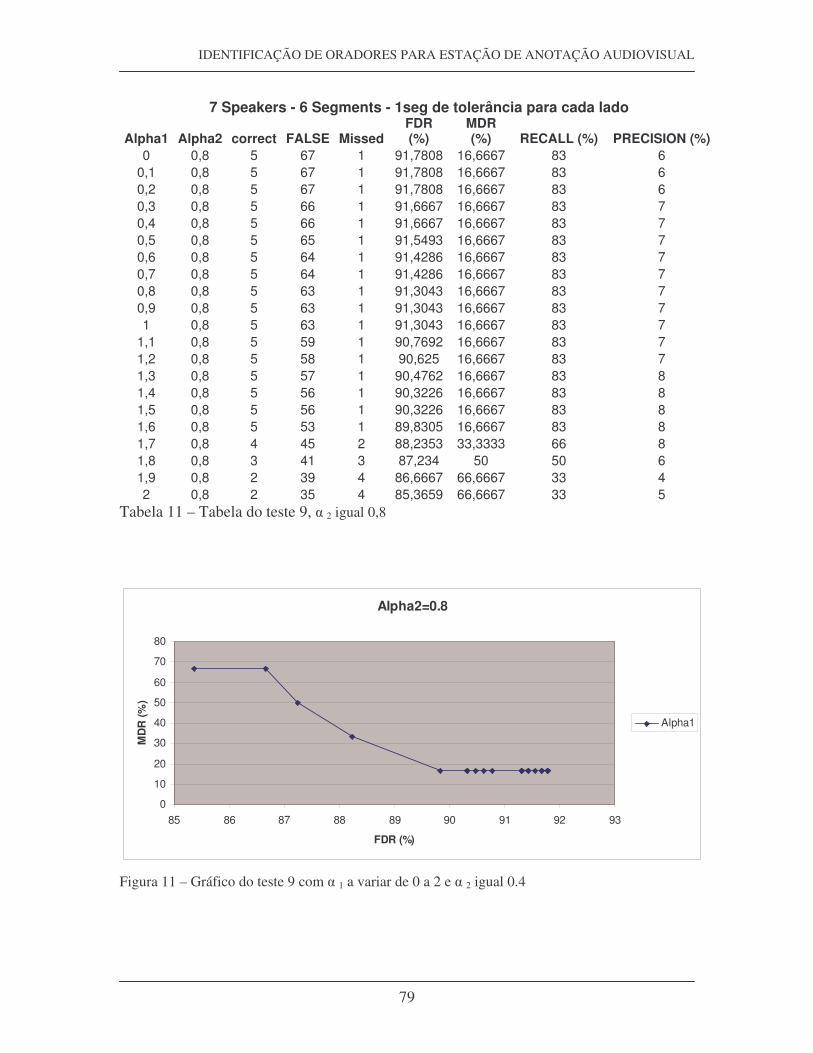
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
79
7 Speakers - 6 Segments - 1seg de tolerância para cada lado
Alpha1 Alpha2 correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,8 5 67 1 91,7808 16,6667 83 6 0,1 0,8 5 67 1 91,7808 16,6667 83 6 0,2 0,8 5 67 1 91,7808 16,6667 83 6 0,3 0,8 5 66 1 91,6667 16,6667 83 7 0,4 0,8 5 66 1 91,6667 16,6667 83 7 0,5 0,8 5 65 1 91,5493 16,6667 83 7 0,6 0,8 5 64 1 91,4286 16,6667 83 7 0,7 0,8 5 64 1 91,4286 16,6667 83 7 0,8 0,8 5 63 1 91,3043 16,6667 83 7 0,9 0,8 5 63 1 91,3043 16,6667 83 7 1 0,8 5 63 1 91,3043 16,6667 83 7
1,1 0,8 5 59 1 90,7692 16,6667 83 7 1,2 0,8 5 58 1 90,625 16,6667 83 7 1,3 0,8 5 57 1 90,4762 16,6667 83 8 1,4 0,8 5 56 1 90,3226 16,6667 83 8 1,5 0,8 5 56 1 90,3226 16,6667 83 8 1,6 0,8 5 53 1 89,8305 16,6667 83 8 1,7 0,8 4 45 2 88,2353 33,3333 66 8 1,8 0,8 3 41 3 87,234 50 50 6 1,9 0,8 2 39 4 86,6667 66,6667 33 4 2 0,8 2 35 4 85,3659 66,6667 33 5
Tabela 11 – Tabela do teste 9, � 2 igual 0,8
Alpha2=0.8
0
10
20
30
40
50
60
70
80
85 86 87 88 89 90 91 92 93
FDR (%)
MD
R (%
)
Alpha1
Figura 11 – Gráfico do teste 9 com � 1 a variar de 0 a 2 e � 2 igual 0.4

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
80
7 Speakers - 6 Segments - 1seg de tolerância para cada lado
Alpha1 Alpha2 correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 1 5 66 1 91,6667 16,6667 83 7 0,1 1 5 66 1 91,6667 16,6667 83 7 0,2 1 5 66 1 91,6667 16,6667 83 7 0,3 1 5 65 1 91,5493 16,6667 83 7 0,4 1 5 65 1 91,5493 16,6667 83 7 0,5 1 5 64 1 91,4286 16,6667 83 7 0,6 1 5 64 1 91,4286 16,6667 83 7 0,7 1 5 64 1 91,4286 16,6667 83 7 0,8 1 5 63 1 91,3043 16,6667 83 7 0,9 1 5 63 1 91,3043 16,6667 83 7 1 1 5 63 1 91,3043 16,6667 83 7
1,1 1 5 59 1 90,7692 16,6667 83 7 1,2 1 5 58 1 90,625 16,6667 83 7 1,3 1 5 57 1 90,4762 16,6667 83 8 1,4 1 5 56 1 90,3226 16,6667 83 8 1,5 1 5 56 1 90,3226 16,6667 83 8 1,6 1 5 53 1 89,8305 16,6667 83 8 1,7 1 4 45 2 88,2353 33,3333 66 8 1,8 1 3 41 3 87,234 50 50 6 1,9 1 2 39 4 86,6667 66,6667 33 4 2 1 2 35 4 85,3659 66,6667 33 5
Tabela 12 – Tabela do teste 9, � 2 igual 1
Alpha2=1
0
10
20
30
40
50
60
70
80
85 86 87 88 89 90 91 92
FDR (%)
MD
R (
%)
Alpha1
Figura 12 – Gráfico do teste 9 com � 1 a variar de 0 a 2 e � 2 igual 1

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
81
7 Speakers - 6 Segments - 1seg de tolerância para cada lado
Alpha1 Alpha2 correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 1,4 5 62 1 91,1765 16,6667 83 7 0,1 1,4 5 62 1 91,1765 16,6667 83 7 0,2 1,4 5 62 1 91,1765 16,6667 83 7 0,3 1,4 5 61 1 91,0448 16,6667 83 7 0,4 1,4 5 61 1 91,0448 16,6667 83 7 0,5 1,4 5 61 1 91,0448 16,6667 83 7 0,6 1,4 5 61 1 91,0448 16,6667 83 7 0,7 1,4 5 61 1 91,0448 16,6667 83 7 0,8 1,4 5 61 1 91,0448 16,6667 83 7 0,9 1,4 5 61 1 91,0448 16,6667 83 7 1 1,4 5 61 1 91,0448 16,6667 83 7
1,1 1,4 5 57 1 90,4762 16,6667 83 8 1,2 1,4 5 57 1 90,4762 16,6667 83 8 1,3 1,4 5 56 1 90,3226 16,6667 83 8 1,4 1,4 5 55 1 90,1639 16,6667 83 8 1,5 1,4 5 55 1 90,1639 16,6667 83 8 1,6 1,4 5 52 1 89,6552 16,6667 83 8 1,7 1,4 4 44 2 88 33,3333 66 8 1,8 1,4 3 41 3 87,234 50 50 6 1,9 1,4 2 39 4 86,6667 66,6667 33 4 2 1,4 2 35 4 85,3659 66,6667 33 5
Tabela 13 – Tabela do teste 9, � 2 igual 1,4
Alpha2=1.4
0
10
20
30
40
50
60
70
80
85 86 87 88 89 90 91 92
FDR (%)
MD
R (%
)
Alpha1
Figura 13 – Gráfico do teste 9 com � 1 a variar de 0 a 2 e � 2 igual 1,4

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
82
7 Speakers - 6 Segments - 1seg de tolerância para cada lado
Alpha1 Alpha2 correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 1,6 5 58 1 90,625 16,6667 83 7 0,1 1,6 5 58 1 90,625 16,6667 83 7 0,2 1,6 5 58 1 90,625 16,6667 83 7 0,3 1,6 5 57 1 90,4762 16,6667 83 8 0,4 1,6 5 57 1 90,4762 16,6667 83 8 0,5 1,6 5 57 1 90,4762 16,6667 83 8 0,6 1,6 5 57 1 90,4762 16,6667 83 8 0,7 1,6 5 57 1 90,4762 16,6667 83 8 0,8 1,6 5 57 1 90,4762 16,6667 83 8 0,9 1,6 5 57 1 90,4762 16,6667 83 8 1 1,6 5 57 1 90,4762 16,6667 83 8
1,1 1,6 5 54 1 90 16,6667 83 8 1,2 1,6 5 54 1 90 16,6667 83 8 1,3 1,6 5 53 1 89,8305 16,6667 83 8 1,4 1,6 5 52 1 89,6552 16,6667 83 8 1,5 1,6 5 52 1 89,6552 16,6667 83 8 1,6 1,6 5 49 1 89,0909 16,6667 83 9 1,7 1,6 4 42 2 87,5 33,3333 66 8 1,8 1,6 3 39 3 86,6667 50 50 7 1,9 1,6 2 37 4 86,0465 66,6667 33 5 2 1,6 2 33 4 84,6154 66,6667 33 5
Tabela 14 – Tabela do teste 9, � 2 igual 1,6
Alpha2=1.6
0
10
20
30
40
50
60
70
80
84 85 86 87 88 89 90 91
FDR (%)
MD
R (%
)
Alpha1
Figura 14 – Gráfico do teste 9 com � 1 a variar de 0 a 2 e � 2 igual 1,6

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
83
7 Speakers - 6 Segments - 1seg de tolerância para cada lado
Alpha1 Alpha2 correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 1,8 5 50 1 89,2857 16,6667 83 9 0,1 1,8 5 50 1 89,2857 16,6667 83 9 0,2 1,8 5 50 1 89,2857 16,6667 83 9 0,3 1,8 5 49 1 89,0909 16,6667 83 9 0,4 1,8 5 49 1 89,0909 16,6667 83 9 0,5 1,8 5 49 1 89,0909 16,6667 83 9 0,6 1,8 5 49 1 89,0909 16,6667 83 9 0,7 1,8 5 49 1 89,0909 16,6667 83 9 0,8 1,8 5 49 1 89,0909 16,6667 83 9 0,9 1,8 5 49 1 89,0909 16,6667 83 9 1 1,8 5 49 1 89,0909 16,6667 83 9
1,1 1,8 5 46 1 88,4615 16,6667 83 9 1,2 1,8 5 46 1 88,4615 16,6667 83 9 1,3 1,8 5 46 1 88,4615 16,6667 83 9 1,4 1,8 5 46 1 88,4615 16,6667 83 9 1,5 1,8 5 46 1 88,4615 16,6667 83 9 1,6 1,8 5 44 1 88 16,6667 83 10 1,7 1,8 4 39 2 86,6667 33,3333 66 9 1,8 1,8 3 37 3 86,0465 50 50 7 1,9 1,8 2 36 4 85,7143 66,6667 33 5 2 1,8 2 32 4 84,2105 66,6667 33 5
Tabela 15 – Tabela do teste 9, � 2 igual 1,8
Alpha2=1.8
0
10
20
30
40
50
60
70
80
83 84 85 86 87 88 89 90
FDR (%)
MD
R (%
)
Alpha1
Figura 15 – Gráfico do teste 9 com � 1 a variar de 0 a 2 e � 2 igual 1,8
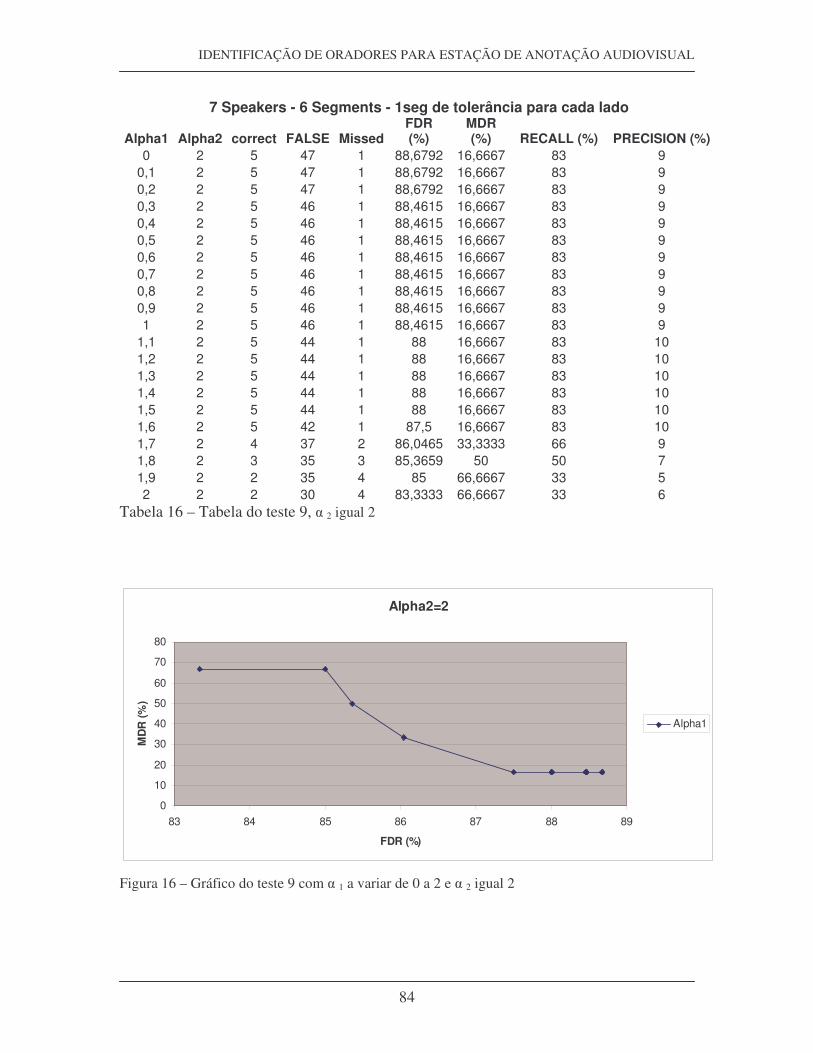
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
84
7 Speakers - 6 Segments - 1seg de tolerância para cada lado
Alpha1 Alpha2 correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 2 5 47 1 88,6792 16,6667 83 9 0,1 2 5 47 1 88,6792 16,6667 83 9 0,2 2 5 47 1 88,6792 16,6667 83 9 0,3 2 5 46 1 88,4615 16,6667 83 9 0,4 2 5 46 1 88,4615 16,6667 83 9 0,5 2 5 46 1 88,4615 16,6667 83 9 0,6 2 5 46 1 88,4615 16,6667 83 9 0,7 2 5 46 1 88,4615 16,6667 83 9 0,8 2 5 46 1 88,4615 16,6667 83 9 0,9 2 5 46 1 88,4615 16,6667 83 9 1 2 5 46 1 88,4615 16,6667 83 9
1,1 2 5 44 1 88 16,6667 83 10 1,2 2 5 44 1 88 16,6667 83 10 1,3 2 5 44 1 88 16,6667 83 10 1,4 2 5 44 1 88 16,6667 83 10 1,5 2 5 44 1 88 16,6667 83 10 1,6 2 5 42 1 87,5 16,6667 83 10 1,7 2 4 37 2 86,0465 33,3333 66 9 1,8 2 3 35 3 85,3659 50 50 7 1,9 2 2 35 4 85 66,6667 33 5 2 2 2 30 4 83,3333 66,6667 33 6
Tabela 16 – Tabela do teste 9, � 2 igual 2
Alpha2=2
0
10
20
30
40
50
60
70
80
83 84 85 86 87 88 89
FDR (%)
MD
R (%
)
Alpha1
Figura 16 – Gráfico do teste 9 com � 1 a variar de 0 a 2 e � 2 igual 2
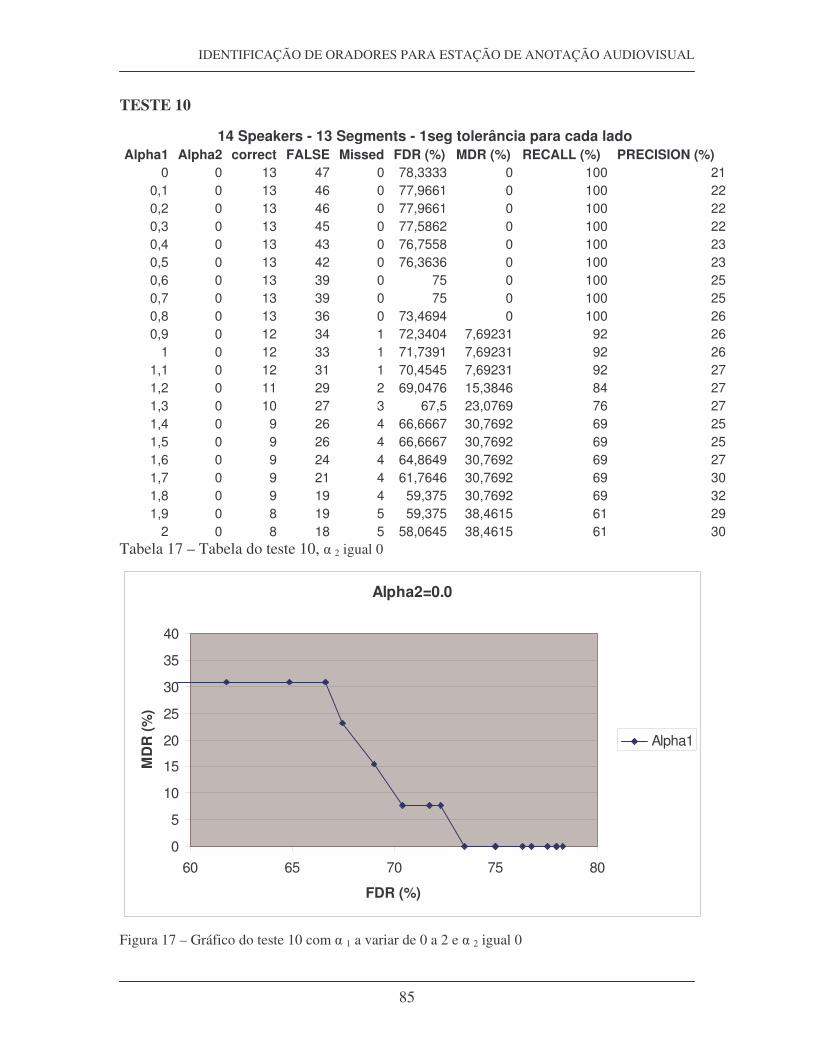
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
85
TESTE 10
14 Speakers - 13 Segments - 1seg tolerância para cada lado Alpha1 Alpha2 correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0 13 47 0 78,3333 0 100 21 0,1 0 13 46 0 77,9661 0 100 22 0,2 0 13 46 0 77,9661 0 100 22 0,3 0 13 45 0 77,5862 0 100 22 0,4 0 13 43 0 76,7558 0 100 23 0,5 0 13 42 0 76,3636 0 100 23 0,6 0 13 39 0 75 0 100 25 0,7 0 13 39 0 75 0 100 25 0,8 0 13 36 0 73,4694 0 100 26 0,9 0 12 34 1 72,3404 7,69231 92 26
1 0 12 33 1 71,7391 7,69231 92 26 1,1 0 12 31 1 70,4545 7,69231 92 27 1,2 0 11 29 2 69,0476 15,3846 84 27 1,3 0 10 27 3 67,5 23,0769 76 27 1,4 0 9 26 4 66,6667 30,7692 69 25 1,5 0 9 26 4 66,6667 30,7692 69 25 1,6 0 9 24 4 64,8649 30,7692 69 27 1,7 0 9 21 4 61,7646 30,7692 69 30 1,8 0 9 19 4 59,375 30,7692 69 32 1,9 0 8 19 5 59,375 38,4615 61 29
2 0 8 18 5 58,0645 38,4615 61 30 Tabela 17 – Tabela do teste 10, � 2 igual 0
Alpha2=0.0
0
5
10
15
20
25
30
35
40
60 65 70 75 80
FDR (%)
MD
R (%
)
Alpha1
Figura 17 – Gráfico do teste 10 com � 1 a variar de 0 a 2 e � 2 igual 0
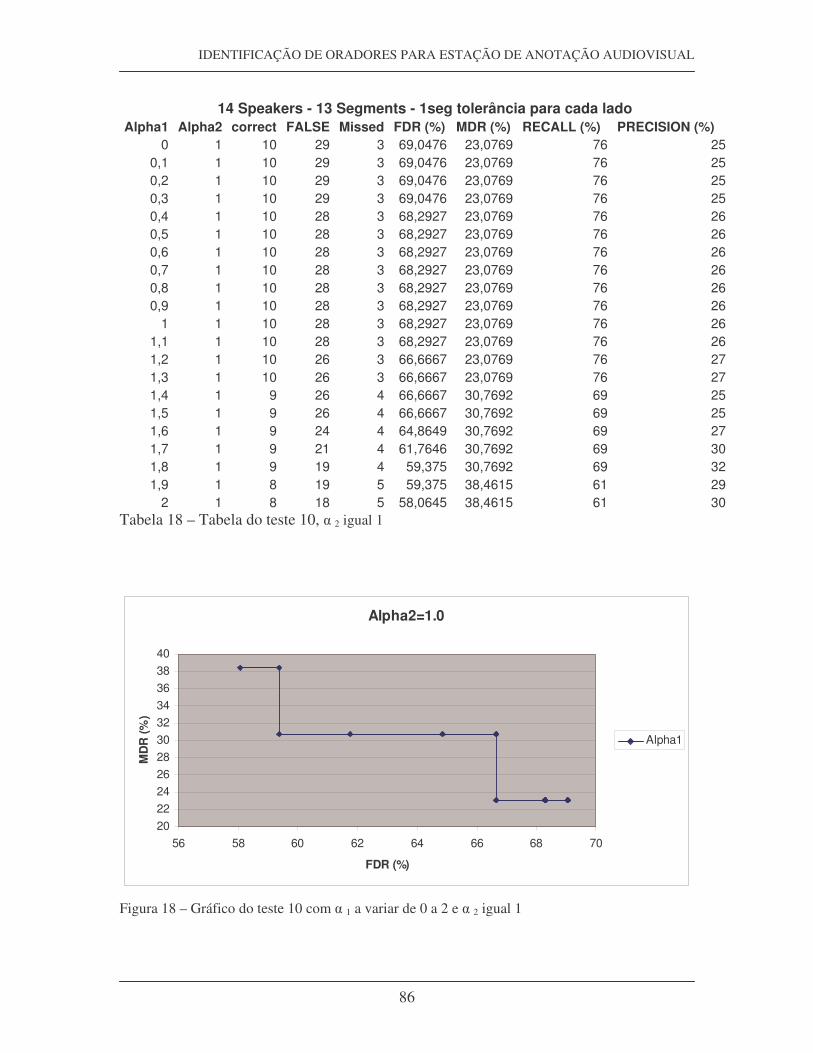
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
86
14 Speakers - 13 Segments - 1seg tolerância para cada lado Alpha1 Alpha2 correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 1 10 29 3 69,0476 23,0769 76 25 0,1 1 10 29 3 69,0476 23,0769 76 25 0,2 1 10 29 3 69,0476 23,0769 76 25 0,3 1 10 29 3 69,0476 23,0769 76 25 0,4 1 10 28 3 68,2927 23,0769 76 26 0,5 1 10 28 3 68,2927 23,0769 76 26 0,6 1 10 28 3 68,2927 23,0769 76 26 0,7 1 10 28 3 68,2927 23,0769 76 26 0,8 1 10 28 3 68,2927 23,0769 76 26 0,9 1 10 28 3 68,2927 23,0769 76 26
1 1 10 28 3 68,2927 23,0769 76 26 1,1 1 10 28 3 68,2927 23,0769 76 26 1,2 1 10 26 3 66,6667 23,0769 76 27 1,3 1 10 26 3 66,6667 23,0769 76 27 1,4 1 9 26 4 66,6667 30,7692 69 25 1,5 1 9 26 4 66,6667 30,7692 69 25 1,6 1 9 24 4 64,8649 30,7692 69 27 1,7 1 9 21 4 61,7646 30,7692 69 30 1,8 1 9 19 4 59,375 30,7692 69 32 1,9 1 8 19 5 59,375 38,4615 61 29
2 1 8 18 5 58,0645 38,4615 61 30 Tabela 18 – Tabela do teste 10, � 2 igual 1
Alpha2=1.0
2022242628303234363840
56 58 60 62 64 66 68 70
FDR (%)
MD
R (%
)
Alpha1
Figura 18 – Gráfico do teste 10 com � 1 a variar de 0 a 2 e � 2 igual 1
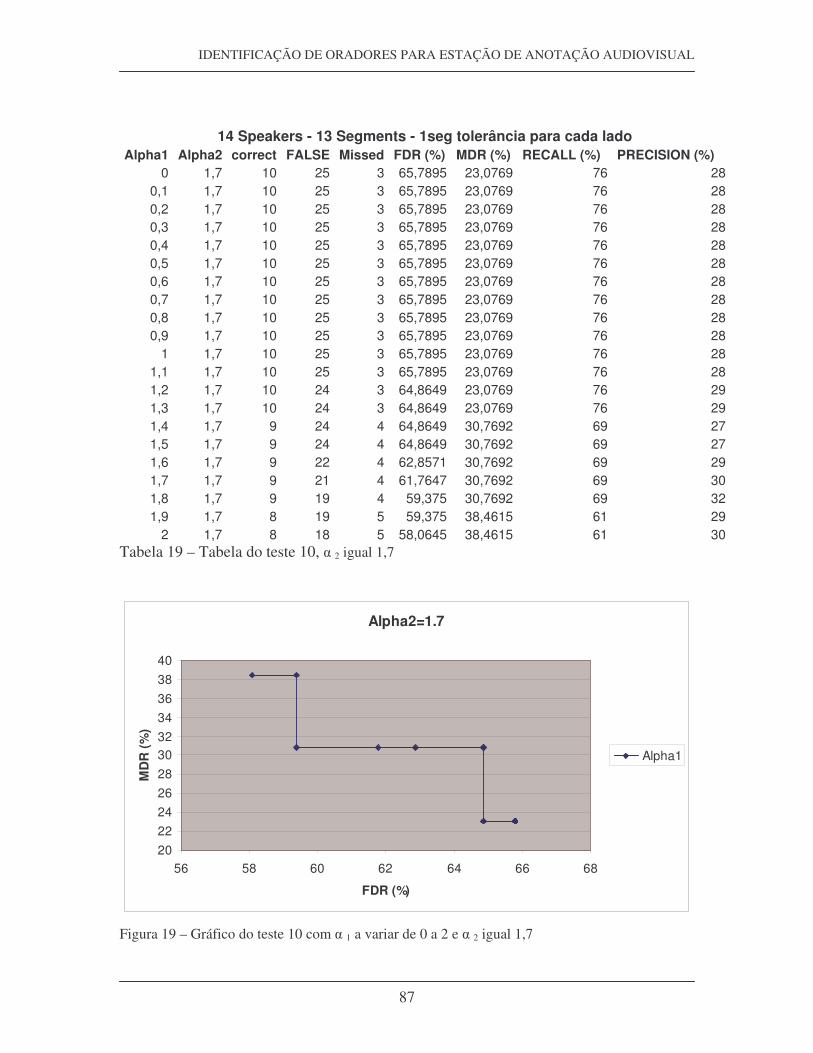
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
87
14 Speakers - 13 Segments - 1seg tolerância para cada lado Alpha1 Alpha2 correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 1,7 10 25 3 65,7895 23,0769 76 28 0,1 1,7 10 25 3 65,7895 23,0769 76 28 0,2 1,7 10 25 3 65,7895 23,0769 76 28 0,3 1,7 10 25 3 65,7895 23,0769 76 28 0,4 1,7 10 25 3 65,7895 23,0769 76 28 0,5 1,7 10 25 3 65,7895 23,0769 76 28 0,6 1,7 10 25 3 65,7895 23,0769 76 28 0,7 1,7 10 25 3 65,7895 23,0769 76 28 0,8 1,7 10 25 3 65,7895 23,0769 76 28 0,9 1,7 10 25 3 65,7895 23,0769 76 28
1 1,7 10 25 3 65,7895 23,0769 76 28 1,1 1,7 10 25 3 65,7895 23,0769 76 28 1,2 1,7 10 24 3 64,8649 23,0769 76 29 1,3 1,7 10 24 3 64,8649 23,0769 76 29 1,4 1,7 9 24 4 64,8649 30,7692 69 27 1,5 1,7 9 24 4 64,8649 30,7692 69 27 1,6 1,7 9 22 4 62,8571 30,7692 69 29 1,7 1,7 9 21 4 61,7647 30,7692 69 30 1,8 1,7 9 19 4 59,375 30,7692 69 32 1,9 1,7 8 19 5 59,375 38,4615 61 29
2 1,7 8 18 5 58,0645 38,4615 61 30 Tabela 19 – Tabela do teste 10, � 2 igual 1,7
Alpha2=1.7
2022242628303234363840
56 58 60 62 64 66 68
FDR (%)
MD
R (
%)
Alpha1
Figura 19 – Gráfico do teste 10 com � 1 a variar de 0 a 2 e � 2 igual 1,7
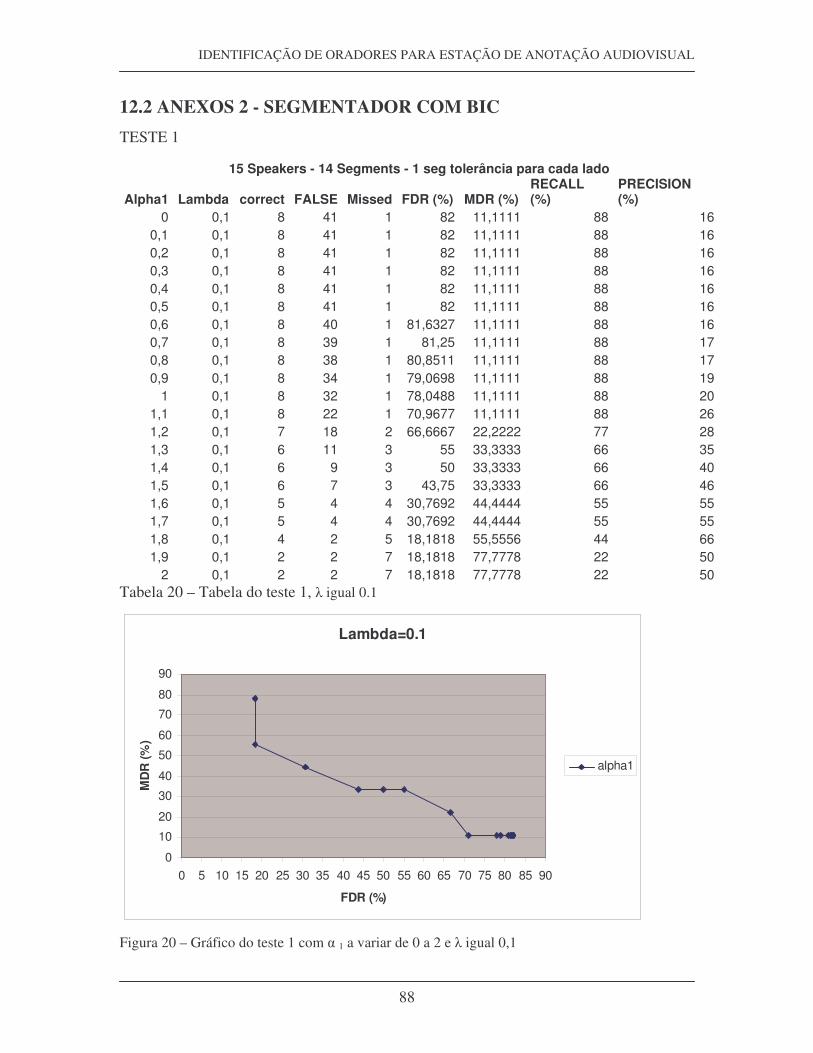
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
88
12.2 ANEXOS 2 - SEGMENTADOR COM BIC TESTE 1
15 Speakers - 14 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%)
PRECISION (%)
0 0,1 8 41 1 82 11,1111 88 16 0,1 0,1 8 41 1 82 11,1111 88 16 0,2 0,1 8 41 1 82 11,1111 88 16 0,3 0,1 8 41 1 82 11,1111 88 16 0,4 0,1 8 41 1 82 11,1111 88 16 0,5 0,1 8 41 1 82 11,1111 88 16 0,6 0,1 8 40 1 81,6327 11,1111 88 16 0,7 0,1 8 39 1 81,25 11,1111 88 17 0,8 0,1 8 38 1 80,8511 11,1111 88 17 0,9 0,1 8 34 1 79,0698 11,1111 88 19
1 0,1 8 32 1 78,0488 11,1111 88 20 1,1 0,1 8 22 1 70,9677 11,1111 88 26 1,2 0,1 7 18 2 66,6667 22,2222 77 28 1,3 0,1 6 11 3 55 33,3333 66 35 1,4 0,1 6 9 3 50 33,3333 66 40 1,5 0,1 6 7 3 43,75 33,3333 66 46 1,6 0,1 5 4 4 30,7692 44,4444 55 55 1,7 0,1 5 4 4 30,7692 44,4444 55 55 1,8 0,1 4 2 5 18,1818 55,5556 44 66 1,9 0,1 2 2 7 18,1818 77,7778 22 50
2 0,1 2 2 7 18,1818 77,7778 22 50 Tabela 20 – Tabela do teste 1, � igual 0.1
Lambda=0.1
0
10
20
30
40
50
60
70
80
90
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90
FDR (%)
MD
R (%
)
alpha1
Figura 20 – Gráfico do teste 1 com � 1 a variar de 0 a 2 e � igual 0,1

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
89
15 Speakers - 14 Segments - 1 seg tolerância para cada lado Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,4 8 23 1 71,875 11,1111 88 25 0,1 0,4 8 23 1 71,875 11,1111 88 25 0,2 0,4 8 23 1 71,875 11,1111 88 25 0,3 0,4 8 23 1 71,875 11,1111 88 25 0,4 0,4 8 23 1 71,875 11,1111 88 25 0,5 0,4 8 23 1 71,875 11,1111 88 25 0,6 0,4 8 22 1 70,9677 11,1111 88 26 0,7 0,4 8 21 1 70 11,1111 88 27 0,8 0,4 8 21 1 70 11,1111 88 27 0,9 0,4 8 19 1 67,8571 11,1111 88 29
1 0,4 8 18 1 66,6667 11,1111 88 30 1,1 0,4 8 12 1 57,1429 11,1111 88 40 1,2 0,4 7 12 2 57,1429 22,2222 77 36 1,3 0,4 6 11 3 55 33,3333 66 35 1,4 0,4 6 9 3 50 33,3333 66 40 1,5 0,4 6 7 3 43,75 33,3333 66 46 1,6 0,4 5 3 4 25 44,4444 55 62 1,7 0,4 5 3 4 25 44,4444 55 62 1,8 0,4 4 2 5 18,1818 55,5556 44 66 1,9 0,4 2 2 7 18,1818 77,7778 22 50
2 0,4 2 2 7 18,1818 77,7778 22 50 Tabela 21 – Tabela do teste 1, � igual 0,4
Lambda=0.4
0
10
20
30
40
50
60
70
80
90
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80
FDR (%)
MD
R (%
)
alpha1
Figura 21 – Gráfico do teste 1 com � 1 a variar de 0 a 2 e � igual 0,4

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
90
15 Speakers - 14 Segments - 1 seg tolerância para cada lado Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,5 7 7 2 43,75 22,2222 77 50 0,1 0,5 7 7 2 43,75 22,2222 77 50 0,2 0,5 7 7 2 43,75 22,2222 77 50 0,3 0,5 7 7 2 43,75 22,2222 77 50 0,4 0,5 7 7 2 43,75 22,2222 77 50 0,5 0,5 7 7 2 43,75 22,2222 77 50 0,6 0,5 7 7 2 43,75 22,2222 77 50 0,7 0,5 7 7 2 43,75 22,2222 77 50 0,8 0,5 7 7 2 43,75 22,2222 77 50 0,9 0,5 7 7 2 43,75 22,2222 77 50
1 0,5 7 5 2 35,7143 22,2222 77 58 1,1 0,5 7 4 2 30,7692 22,2222 77 63 1,2 0,5 7 4 2 30,7692 22,2222 77 63 1,3 0,5 6 5 3 35,7143 33,3333 66 54 1,4 0,5 6 3 3 25 33,3333 66 66 1,5 0,5 6 1 3 10 33,3333 66 85 1,6 0,5 5 1 4 10 44,4444 55 83 1,7 0,5 5 1 4 10 44,4444 55 83 1,8 0,5 4 1 5 10 55,5556 44 80 1,9 0,5 2 1 7 10 77,7778 22 66
2 0,5 2 1 7 10 77,7778 22 66 Tabela 22 – Tabela do teste 1, � igual 0,5
Lambda=0.5
20
30
40
50
60
70
80
0 10 20 30 40 50
FDR (%)
MD
R (%
)
Alpha1
Figura 22 – Gráfico do teste 1 com � 1 a variar de 0 a 2 e � igual 0,5

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
91
TESTE 2 9 Speakers - 8 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%)
PRECISION (%)
0 0,1 7 34 2 79,0698 22,2222 77 17 0,1 0,1 7 34 2 79,0698 22,2222 77 17 0,2 0,1 7 34 2 79,0698 22,2222 77 17 0,3 0,1 7 34 2 79,0698 22,2222 77 17 0,4 0,1 7 34 2 79,0698 22,2222 77 17 0,5 0,1 7 34 2 79,0698 22,2222 77 17 0,6 0,1 7 33 2 78,5714 22,2222 77 17 0,7 0,1 7 33 2 78,5714 22,2222 77 17 0,8 0,1 7 31 2 77,5 22,2222 77 18 0,9 0,1 7 29 2 76,3158 22,2222 77 19
1 0,1 7 24 2 72,7273 22,2222 77 22 1,1 0,1 7 21 2 70 22,2222 77 25 1,2 0,1 6 19 3 67,8571 33,3333 66 24 1,3 0,1 6 15 3 62,5 33,3333 66 28 1,4 0,1 6 12 3 57,1429 33,3333 66 33 1,5 0,1 5 8 4 47,0588 44,4444 55 38 1,6 0,1 5 5 4 35,7143 44,4444 55 50 1,7 0,1 4 3 5 25 55,5556 44 57 1,8 0,1 3 1 6 10 66,6667 33 75 1,9 0,1 2 1 7 10 77,7778 22 66
2 0,1 2 0 7 0 77,7778 22 100 Tabela 23 – Tabela do teste 2, � igual 0,1
Lambda=0.1
20
30
40
50
60
70
80
90
0 10 20 30 40 50 60 70 80
FDR (%)
MD
R (%
)
Alpha1
Figura 23 – Gráfico do teste 2 com � 1 a variar de 0 a 2 e � igual 0,1

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
92
9 Speakers - 8 Segments - 1 seg tolerância para cada lado Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,3 7 34 2 79,0698 22,2222 77 17 0,1 0,3 7 34 2 79,0698 22,2222 77 17 0,2 0,3 7 34 2 79,0698 22,2222 77 17 0,3 0,3 7 34 2 79,0698 22,2222 77 17 0,4 0,3 7 34 2 79,0698 22,2222 77 17 0,5 0,3 7 34 2 79,0698 22,2222 77 17 0,6 0,3 7 33 2 78,5714 22,2222 77 17 0,7 0,3 7 33 2 78,5714 22,2222 77 17 0,8 0,3 7 31 2 77,5 22,2222 77 18 0,9 0,3 7 29 2 76,3158 22,2222 77 19
1 0,3 7 24 2 72,7273 22,2222 77 22 1,1 0,3 7 21 2 70 22,2222 77 25 1,2 0,3 6 19 3 67,8571 33,3333 66 24 1,3 0,3 6 15 3 62,5 33,3333 66 28 1,4 0,3 6 12 3 57,1429 33,3333 66 33 1,5 0,3 5 8 4 47,0588 44,4444 55 38 1,6 0,3 5 5 4 35,7143 44,4444 55 50 1,7 0,3 4 3 5 25 55,5556 44 57 1,8 0,3 3 1 6 10 66,6667 33 75 1,9 0,3 2 1 7 10 77,7778 22 66
2 0,3 2 0 7 0 77,7778 22 100 Tabela 24 – Tabela do teste 2, � igual 0,3
Lambda=0.3
20
30
40
50
60
70
80
90
0 10 20 30 40 50 60 70 80
FDR (%)
MD
R (%
)
Alpha1
Figura 24 – Gráfico do teste 2 com � 1 a variar de 0 a 2 e � igual 0,3
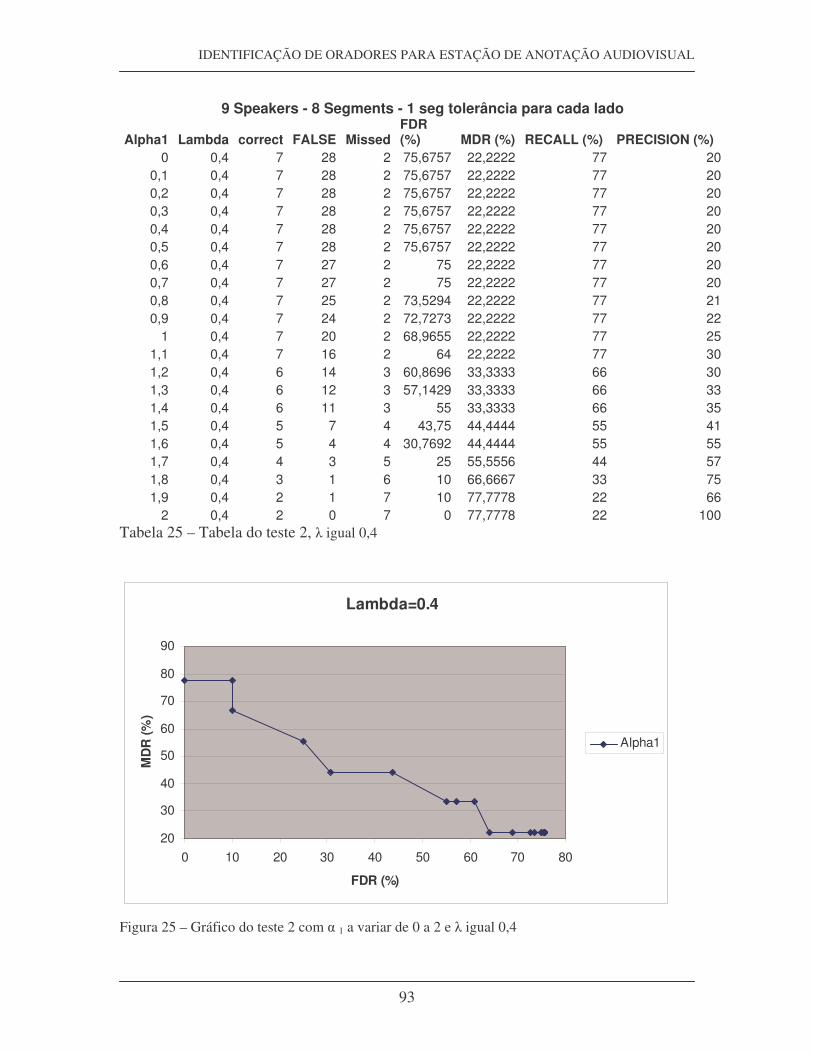
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
93
9 Speakers - 8 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,4 7 28 2 75,6757 22,2222 77 20 0,1 0,4 7 28 2 75,6757 22,2222 77 20 0,2 0,4 7 28 2 75,6757 22,2222 77 20 0,3 0,4 7 28 2 75,6757 22,2222 77 20 0,4 0,4 7 28 2 75,6757 22,2222 77 20 0,5 0,4 7 28 2 75,6757 22,2222 77 20 0,6 0,4 7 27 2 75 22,2222 77 20 0,7 0,4 7 27 2 75 22,2222 77 20 0,8 0,4 7 25 2 73,5294 22,2222 77 21 0,9 0,4 7 24 2 72,7273 22,2222 77 22
1 0,4 7 20 2 68,9655 22,2222 77 25 1,1 0,4 7 16 2 64 22,2222 77 30 1,2 0,4 6 14 3 60,8696 33,3333 66 30 1,3 0,4 6 12 3 57,1429 33,3333 66 33 1,4 0,4 6 11 3 55 33,3333 66 35 1,5 0,4 5 7 4 43,75 44,4444 55 41 1,6 0,4 5 4 4 30,7692 44,4444 55 55 1,7 0,4 4 3 5 25 55,5556 44 57 1,8 0,4 3 1 6 10 66,6667 33 75 1,9 0,4 2 1 7 10 77,7778 22 66
2 0,4 2 0 7 0 77,7778 22 100 Tabela 25 – Tabela do teste 2, � igual 0,4
Lambda=0.4
20
30
40
50
60
70
80
90
0 10 20 30 40 50 60 70 80
FDR (%)
MD
R (%
)
Alpha1
Figura 25 – Gráfico do teste 2 com � 1 a variar de 0 a 2 e � igual 0,4

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
94
9 Speakers - 8 Segments - 1 seg tolerância para cada lado Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,5 7 15 2 62,5 22,2222 77 31 0,1 0,5 7 15 2 62,5 22,2222 77 31 0,2 0,5 7 15 2 62,5 22,2222 77 31 0,3 0,5 7 15 2 62,5 22,2222 77 31 0,4 0,5 7 15 2 62,5 22,2222 77 31 0,5 0,5 7 15 2 62,5 22,2222 77 31 0,6 0,5 7 15 2 62,5 22,2222 77 31 0,7 0,5 7 15 2 62,5 22,2222 77 31 0,8 0,5 7 17 2 65,3846 22,2222 77 29 0,9 0,5 7 16 2 64 22,2222 77 30
1 0,5 7 14 2 60,8696 22,2222 77 33 1,1 0,5 7 10 2 52,6316 22,2222 77 41 1,2 0,5 6 9 3 50 33,3333 66 40 1,3 0,5 6 9 3 50 33,3333 66 40 1,4 0,5 6 9 3 50 33,3333 66 40 1,5 0,5 5 6 4 40 44,4444 55 45 1,6 0,5 5 3 4 25 44,4444 55 62 1,7 0,5 4 3 5 25 55,5556 44 57 1,8 0,5 3 1 6 10 66,6667 33 75 1,9 0,5 2 1 7 10 77,7778 22 66
2 0,5 2 0 7 0 77,7778 22 100 Tabela 26 – Tabela do teste 2, � igual 0,5
Lambda=0.5
20
30
40
50
60
70
80
90
0 10 20 30 40 50 60 70
FDR (%)
MD
R (%
)
alpha1
Figura 26 – Gráfico do teste 2 com � 1 a variar de 0 a 2 e � igual 0,5

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
95
9 Speakers - 8 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,6 5 5 4 35,7143 44,4444 55 50 0,1 0,6 5 5 4 35,7143 44,4444 55 50 0,2 0,6 5 5 4 35,7143 44,4444 55 50 0,3 0,6 5 5 4 35,7143 44,4444 55 50 0,4 0,6 5 5 4 35,7143 44,4444 55 50 0,5 0,6 5 5 4 35,7143 44,4444 55 50 0,6 0,6 5 5 4 35,7143 44,4444 55 50 0,7 0,6 5 5 4 35,7143 44,4444 55 50 0,8 0,6 5 4 4 30,7692 44,4444 55 55 0,9 0,6 5 4 4 30,7692 44,4444 55 55
1 0,6 5 4 4 30,7692 44,4444 55 57 1,1 0,6 4 3 5 25 55,5556 44 57 1,2 0,6 4 3 5 25 55,5556 44 57 1,3 0,6 4 3 5 25 55,5556 44 57 1,4 0,6 4 3 5 25 55,5556 44 57 1,5 0,6 4 3 5 25 55,5556 44 57 1,6 0,6 4 3 5 25 55,5556 44 57 1,7 0,6 4 3 5 25 55,5556 44 57 1,8 0,6 3 0 6 0 66,6667 33 100 1,9 0,6 2 0 7 0 77,7778 22 100
2 0,6 2 0 7 0 77,7778 22 100 Tabela 27 – Tabela do teste 2, � igual 0,6
Lambda=0.6
40
45
50
55
60
65
70
75
80
0 5 10 15 20 25 30 35 40
FDR (%)
MD
R (%
)
Alpha1
Figura 27 – Gráfico do teste 2 com � 1 a variar de 0 a 2 e � igual 0,6
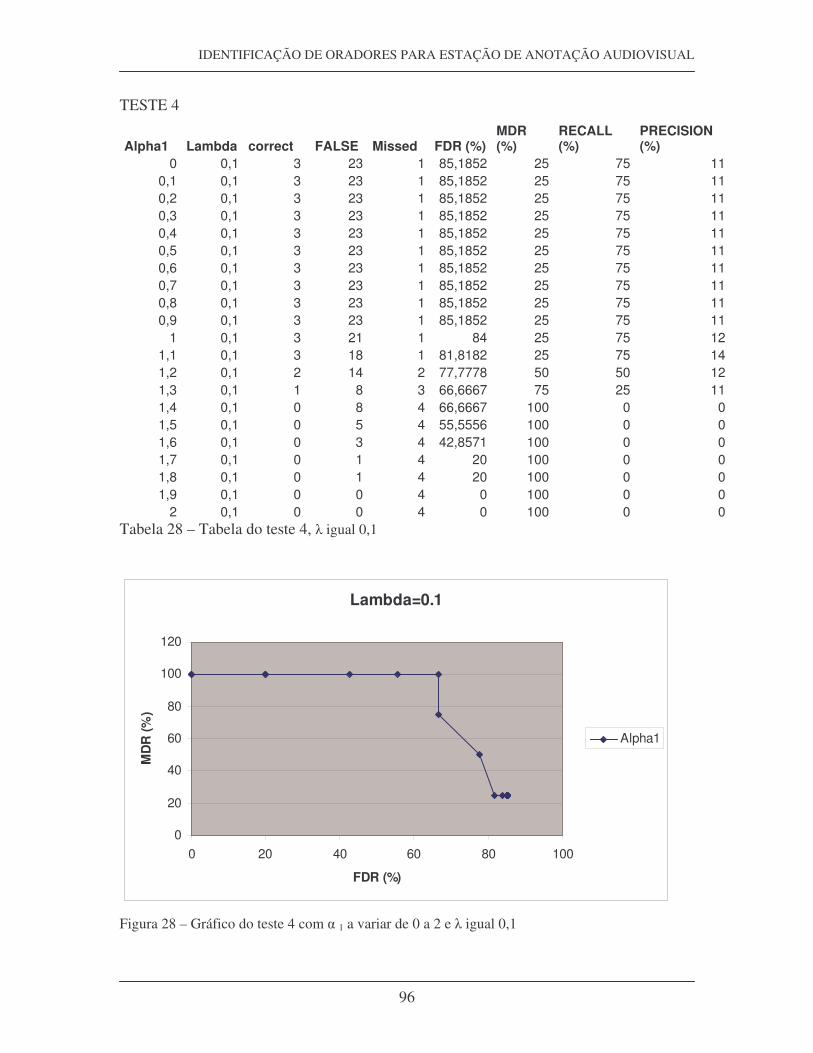
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
96
TESTE 4
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%)
RECALL (%)
PRECISION (%)
0 0,1 3 23 1 85,1852 25 75 11 0,1 0,1 3 23 1 85,1852 25 75 11 0,2 0,1 3 23 1 85,1852 25 75 11 0,3 0,1 3 23 1 85,1852 25 75 11 0,4 0,1 3 23 1 85,1852 25 75 11 0,5 0,1 3 23 1 85,1852 25 75 11 0,6 0,1 3 23 1 85,1852 25 75 11 0,7 0,1 3 23 1 85,1852 25 75 11 0,8 0,1 3 23 1 85,1852 25 75 11 0,9 0,1 3 23 1 85,1852 25 75 11
1 0,1 3 21 1 84 25 75 12 1,1 0,1 3 18 1 81,8182 25 75 14 1,2 0,1 2 14 2 77,7778 50 50 12 1,3 0,1 1 8 3 66,6667 75 25 11 1,4 0,1 0 8 4 66,6667 100 0 0 1,5 0,1 0 5 4 55,5556 100 0 0 1,6 0,1 0 3 4 42,8571 100 0 0 1,7 0,1 0 1 4 20 100 0 0 1,8 0,1 0 1 4 20 100 0 0 1,9 0,1 0 0 4 0 100 0 0
2 0,1 0 0 4 0 100 0 0 Tabela 28 – Tabela do teste 4, � igual 0,1
Lambda=0.1
0
20
40
60
80
100
120
0 20 40 60 80 100
FDR (%)
MD
R (%
)
Alpha1
Figura 28 – Gráfico do teste 4 com � 1 a variar de 0 a 2 e � igual 0,1

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
97
5 Speakers (all Female) - 4 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,3 3 23 1 85,1852 25 75 11 0,1 0,3 3 23 1 85,1852 25 75 11 0,2 0,3 3 23 1 85,1852 25 75 11 0,3 0,3 3 23 1 85,1852 25 75 11 0,4 0,3 3 23 1 85,1852 25 75 11 0,5 0,3 3 23 1 85,1852 25 75 11 0,6 0,3 3 23 1 85,1852 25 75 11 0,7 0,3 3 23 1 85,1852 25 75 11 0,8 0,3 3 23 1 85,1852 25 75 11 0,9 0,3 3 23 1 85,1852 25 75 11
1 0,3 3 21 1 84 25 75 12 1,1 0,3 3 18 1 81,8182 25 75 14 1,2 0,3 2 14 2 77,7778 50 50 12 1,3 0,3 1 8 3 66,6667 75 25 11 1,4 0,3 0 8 4 66,6667 100 0 0 1,5 0,3 0 5 4 55,5556 100 0 0 1,6 0,3 0 3 4 42,8571 100 0 0 1,7 0,3 0 1 4 20 100 0 0 1,8 0,3 0 1 4 20 100 0 0 1,9 0,3 0 0 4 0 100 0 0
2 0,3 0 0 4 0 100 0 0 Tabela 29 – Tabela do teste 4, � igual 0,3
Lambda=0.3
0
20
40
60
80
100
120
0 20 40 60 80 100
FDR (%)
MD
R (%
)
Alpha1
Figura 29 – Gráfico do teste 4 com � 1 a variar de 0 a 2 e � igual 0,3

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
98
5 Speakers (all Female) - 4 Segments - 1 seg tolerância para cada lado Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,5 3 10 1 71,4286 25 75 23 0,1 0,5 3 10 1 71,4286 25 75 23 0,2 0,5 3 10 1 71,4286 25 75 23 0,3 0,5 3 10 1 71,4286 25 75 23 0,4 0,5 3 10 1 71,4286 25 75 23 0,5 0,5 3 10 1 71,4286 25 75 23 0,6 0,5 3 10 1 71,4286 25 75 23 0,7 0,5 3 10 1 71,4286 25 75 23 0,8 0,5 3 10 1 71,4286 25 75 23 0,9 0,5 3 10 1 71,4286 25 75 23
1 0,5 3 8 1 66,6667 25 75 27 1,1 0,5 3 8 1 66,6667 25 75 27 1,2 0,5 2 8 2 66,6667 50 50 20 1,3 0,5 1 5 3 55,5556 75 25 16 1,4 0,5 0 5 4 55,5556 100 0 0 1,5 0,5 0 3 4 42,8571 100 0 0 1,6 0,5 0 2 4 33,3333 100 0 0 1,7 0,5 0 0 4 0 100 0 0 1,8 0,5 0 0 4 0 100 0 0 1,9 0,5 0 0 4 0 100 0 0
2 0,5 0 0 4 0 100 0 0 Tabela 30 – Tabela do teste 4, � igual 0,5
Lambda=0.5
0
20
40
60
80
100
120
0 10 20 30 40 50 60 70 80
FDR (%)
MD
R (%
)
Alpha1
Figura 30 – Gráfico do teste 4 com � 1 a variar de 0 a 2 e � igual 0,5
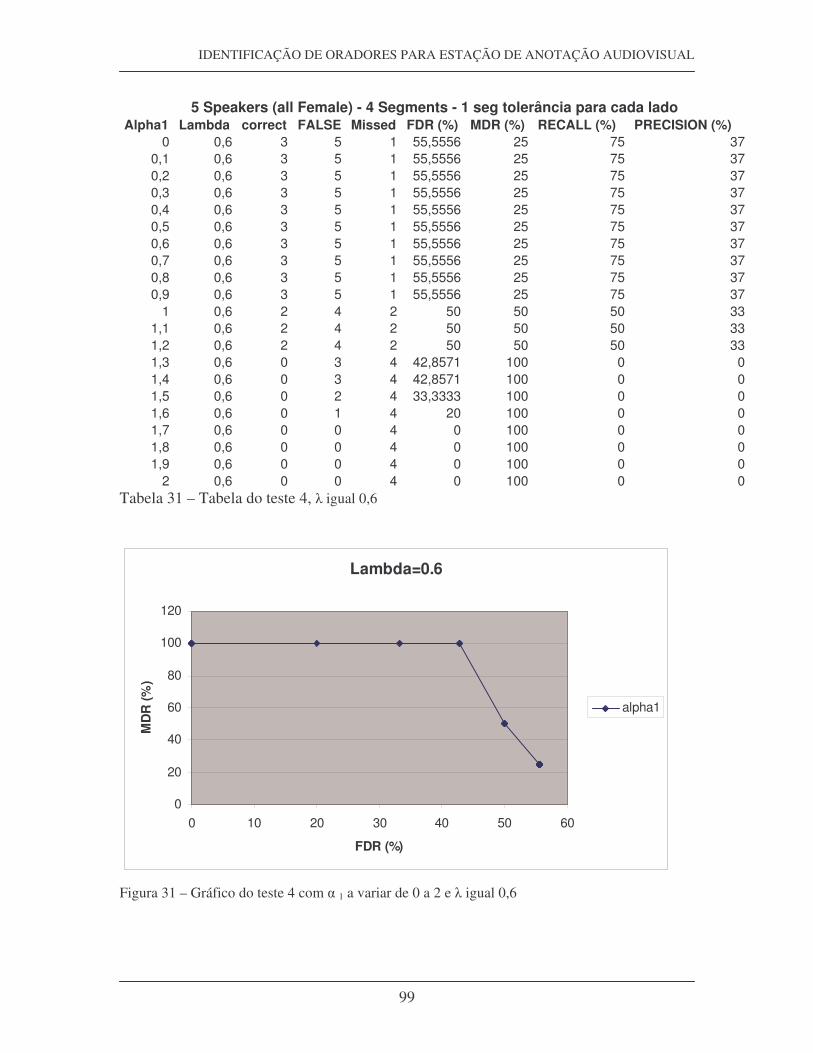
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
99
5 Speakers (all Female) - 4 Segments - 1 seg tolerância para cada lado Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,6 3 5 1 55,5556 25 75 37 0,1 0,6 3 5 1 55,5556 25 75 37 0,2 0,6 3 5 1 55,5556 25 75 37 0,3 0,6 3 5 1 55,5556 25 75 37 0,4 0,6 3 5 1 55,5556 25 75 37 0,5 0,6 3 5 1 55,5556 25 75 37 0,6 0,6 3 5 1 55,5556 25 75 37 0,7 0,6 3 5 1 55,5556 25 75 37 0,8 0,6 3 5 1 55,5556 25 75 37 0,9 0,6 3 5 1 55,5556 25 75 37
1 0,6 2 4 2 50 50 50 33 1,1 0,6 2 4 2 50 50 50 33 1,2 0,6 2 4 2 50 50 50 33 1,3 0,6 0 3 4 42,8571 100 0 0 1,4 0,6 0 3 4 42,8571 100 0 0 1,5 0,6 0 2 4 33,3333 100 0 0 1,6 0,6 0 1 4 20 100 0 0 1,7 0,6 0 0 4 0 100 0 0 1,8 0,6 0 0 4 0 100 0 0 1,9 0,6 0 0 4 0 100 0 0
2 0,6 0 0 4 0 100 0 0 Tabela 31 – Tabela do teste 4, � igual 0,6
Lambda=0.6
0
20
40
60
80
100
120
0 10 20 30 40 50 60
FDR (%)
MD
R (%
)
alpha1
Figura 31 – Gráfico do teste 4 com � 1 a variar de 0 a 2 e � igual 0,6
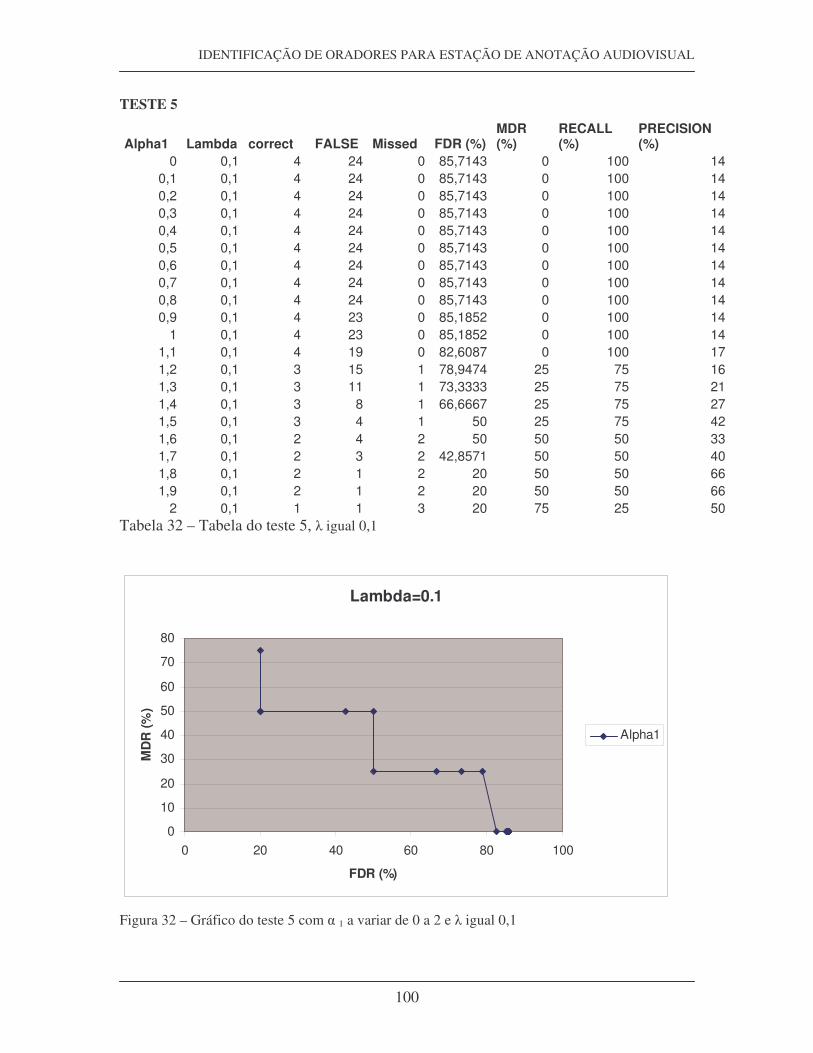
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
100
TESTE 5
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%)
RECALL (%)
PRECISION (%)
0 0,1 4 24 0 85,7143 0 100 14 0,1 0,1 4 24 0 85,7143 0 100 14 0,2 0,1 4 24 0 85,7143 0 100 14 0,3 0,1 4 24 0 85,7143 0 100 14 0,4 0,1 4 24 0 85,7143 0 100 14 0,5 0,1 4 24 0 85,7143 0 100 14 0,6 0,1 4 24 0 85,7143 0 100 14 0,7 0,1 4 24 0 85,7143 0 100 14 0,8 0,1 4 24 0 85,7143 0 100 14 0,9 0,1 4 23 0 85,1852 0 100 14
1 0,1 4 23 0 85,1852 0 100 14 1,1 0,1 4 19 0 82,6087 0 100 17 1,2 0,1 3 15 1 78,9474 25 75 16 1,3 0,1 3 11 1 73,3333 25 75 21 1,4 0,1 3 8 1 66,6667 25 75 27 1,5 0,1 3 4 1 50 25 75 42 1,6 0,1 2 4 2 50 50 50 33 1,7 0,1 2 3 2 42,8571 50 50 40 1,8 0,1 2 1 2 20 50 50 66 1,9 0,1 2 1 2 20 50 50 66
2 0,1 1 1 3 20 75 25 50 Tabela 32 – Tabela do teste 5, � igual 0,1
Lambda=0.1
0
10
20
30
40
50
60
70
80
0 20 40 60 80 100
FDR (%)
MD
R (%
)
Alpha1
Figura 32 – Gráfico do teste 5 com � 1 a variar de 0 a 2 e � igual 0,1
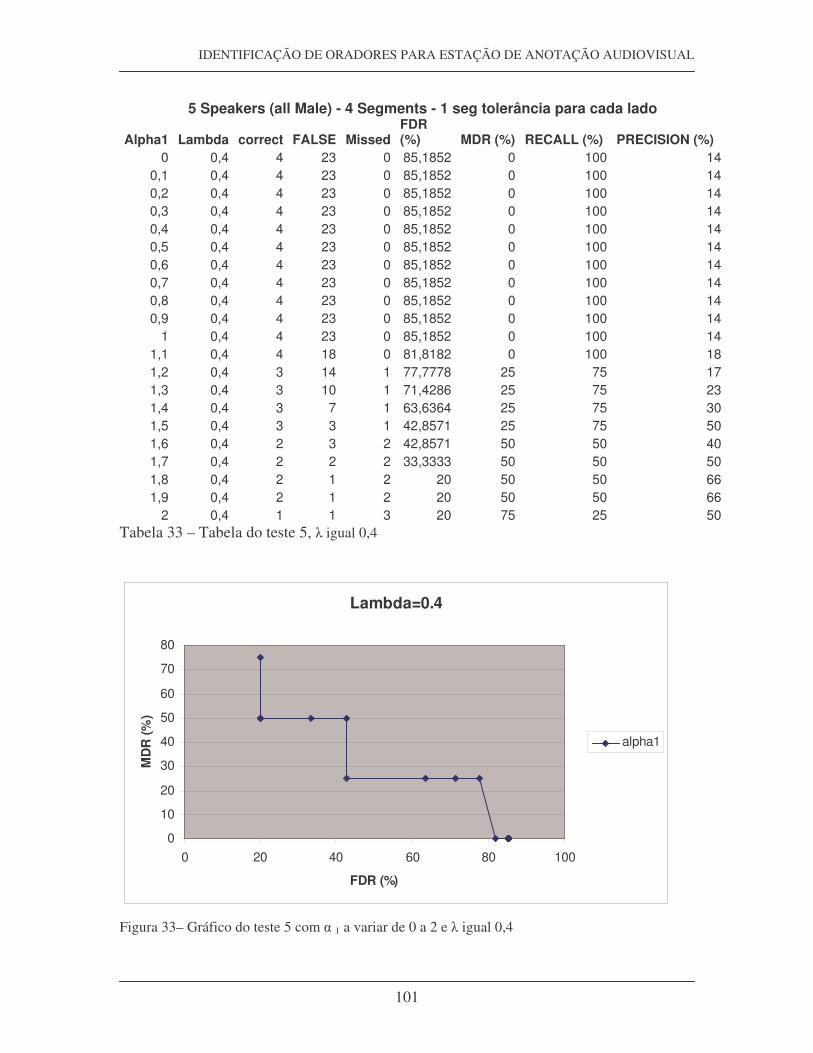
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
101
5 Speakers (all Male) - 4 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,4 4 23 0 85,1852 0 100 14 0,1 0,4 4 23 0 85,1852 0 100 14 0,2 0,4 4 23 0 85,1852 0 100 14 0,3 0,4 4 23 0 85,1852 0 100 14 0,4 0,4 4 23 0 85,1852 0 100 14 0,5 0,4 4 23 0 85,1852 0 100 14 0,6 0,4 4 23 0 85,1852 0 100 14 0,7 0,4 4 23 0 85,1852 0 100 14 0,8 0,4 4 23 0 85,1852 0 100 14 0,9 0,4 4 23 0 85,1852 0 100 14
1 0,4 4 23 0 85,1852 0 100 14 1,1 0,4 4 18 0 81,8182 0 100 18 1,2 0,4 3 14 1 77,7778 25 75 17 1,3 0,4 3 10 1 71,4286 25 75 23 1,4 0,4 3 7 1 63,6364 25 75 30 1,5 0,4 3 3 1 42,8571 25 75 50 1,6 0,4 2 3 2 42,8571 50 50 40 1,7 0,4 2 2 2 33,3333 50 50 50 1,8 0,4 2 1 2 20 50 50 66 1,9 0,4 2 1 2 20 50 50 66
2 0,4 1 1 3 20 75 25 50 Tabela 33 – Tabela do teste 5, � igual 0,4
Lambda=0.4
0
10
20
30
40
50
60
70
80
0 20 40 60 80 100
FDR (%)
MD
R (%
)
alpha1
Figura 33– Gráfico do teste 5 com � 1 a variar de 0 a 2 e � igual 0,4
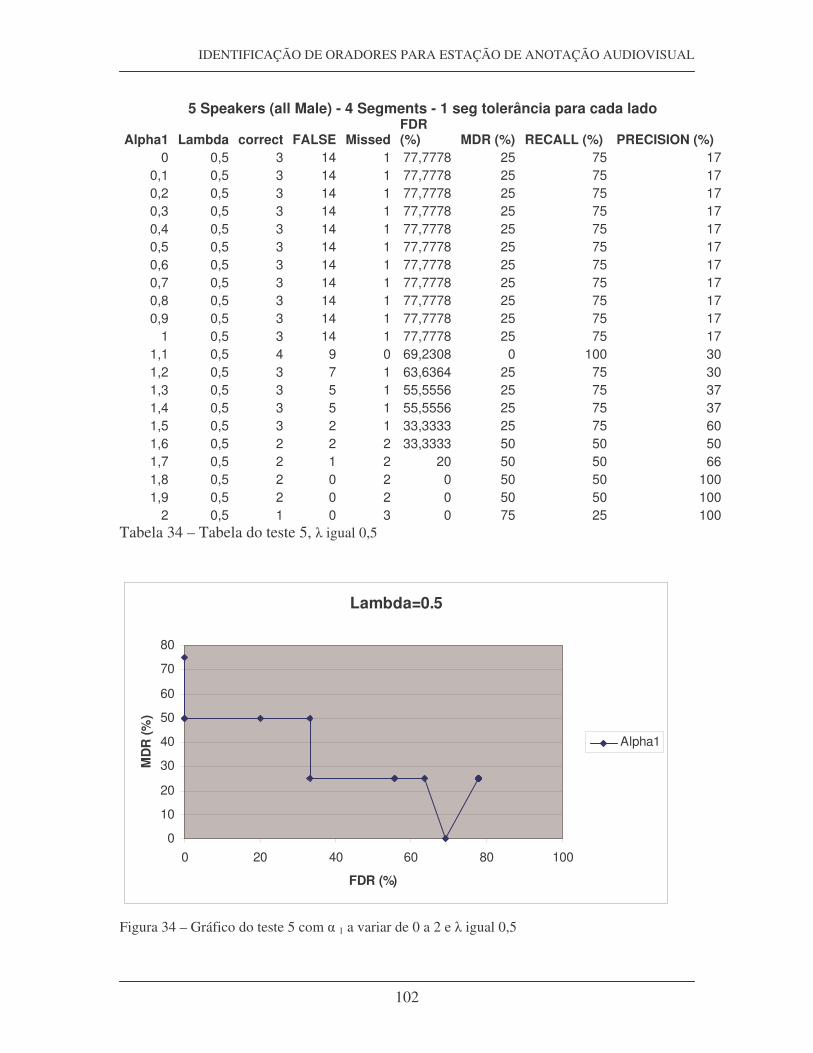
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
102
5 Speakers (all Male) - 4 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,5 3 14 1 77,7778 25 75 17 0,1 0,5 3 14 1 77,7778 25 75 17 0,2 0,5 3 14 1 77,7778 25 75 17 0,3 0,5 3 14 1 77,7778 25 75 17 0,4 0,5 3 14 1 77,7778 25 75 17 0,5 0,5 3 14 1 77,7778 25 75 17 0,6 0,5 3 14 1 77,7778 25 75 17 0,7 0,5 3 14 1 77,7778 25 75 17 0,8 0,5 3 14 1 77,7778 25 75 17 0,9 0,5 3 14 1 77,7778 25 75 17
1 0,5 3 14 1 77,7778 25 75 17 1,1 0,5 4 9 0 69,2308 0 100 30 1,2 0,5 3 7 1 63,6364 25 75 30 1,3 0,5 3 5 1 55,5556 25 75 37 1,4 0,5 3 5 1 55,5556 25 75 37 1,5 0,5 3 2 1 33,3333 25 75 60 1,6 0,5 2 2 2 33,3333 50 50 50 1,7 0,5 2 1 2 20 50 50 66 1,8 0,5 2 0 2 0 50 50 100 1,9 0,5 2 0 2 0 50 50 100
2 0,5 1 0 3 0 75 25 100 Tabela 34 – Tabela do teste 5, � igual 0,5
Lambda=0.5
0
10
20
30
40
50
60
70
80
0 20 40 60 80 100
FDR (%)
MD
R (%
)
Alpha1
Figura 34 – Gráfico do teste 5 com � 1 a variar de 0 a 2 e � igual 0,5

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
103
5 Speakers (all Male) - 4 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,6 3 5 1 55,5556 25 75 37 0,1 0,6 3 5 1 55,5556 25 75 37 0,2 0,6 3 5 1 55,5556 25 75 37 0,3 0,6 3 5 1 55,5556 25 75 37 0,4 0,6 3 5 1 55,5556 25 75 37 0,5 0,6 3 5 1 55,5556 25 75 37 0,6 0,6 3 5 1 55,5556 25 75 37 0,7 0,6 3 5 1 55,5556 25 75 37 0,8 0,6 3 5 1 55,5556 25 75 37 0,9 0,6 3 5 1 55,5556 25 75 37
1 0,6 3 5 1 55,5556 25 75 37 1,1 0,6 3 4 1 50 25 75 42 1,2 0,6 3 4 1 50 25 75 42 1,3 0,6 3 3 1 42,8571 25 75 50 1,4 0,6 3 3 1 42,8571 25 75 50 1,5 0,6 3 1 1 20 25 75 75 1,6 0,6 2 1 2 20 50 50 66 1,7 0,6 2 0 2 0 50 50 100 1,8 0,6 2 0 2 0 50 50 100 1,9 0,6 2 0 2 0 50 50 100
2 0,6 1 0 3 0 75 25 100 Tabela 35 – Tabela do teste 5, � igual 0,6
Lambda=0.6
20
30
40
50
60
70
80
0 10 20 30 40 50 60
FDR (%)
MD
R (%
)
Alpha1
Figura 35 – Gráfico do teste 5 com � 1 a variar de 0 a 2 e � igual 0,6

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
104
TESTE 6
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%)
RECALL (%)
PRECISION (%)
0 0,4 6 205 1 96,6981 14,2857 85 2 0,1 0,4 6 205 1 96,6981 14,2857 85 2 0,2 0,4 6 205 1 96,6981 14,2857 85 2 0,3 0,4 6 205 1 96,6981 14,2857 85 2 0,4 0,4 6 205 1 96,6981 14,2857 85 2 0,5 0,4 6 204 1 96,6825 14,2857 85 2 0,6 0,4 6 204 1 96,6825 14,2857 85 2 0,7 0,4 6 202 1 96,6507 14,2857 85 2 0,8 0,4 6 200 1 96,6184 14,2857 85 2 0,9 0,4 5 196 2 96,5517 28,5714 71 2
1 0,4 5 180 2 96,2587 28,5714 71 2 1,1 0,4 5 137 2 95,1389 28,5714 71 3 1,2 0,4 5 113 2 94,1667 28,5714 71 4 1,3 0,4 5 78 2 91,7647 28,5714 71 6 1,4 0,4 5 61 2 89,7059 28,5714 71 7 1,5 0,4 5 45 2 86,5385 28,5714 71 10 1,6 0,4 5 34 2 82,9268 28,5714 71 12 1,7 0,4 4 27 3 79,4118 42,8571 57 12 1,8 0,4 4 19 3 73,0769 42,8571 57 17 1,9 0,4 4 14 3 66,6667 42,8571 57 22
2 0,4 4 8 3 53,3333 42,8571 57 33 Tabela 36 – Tabela do teste 6, � igual 0,4
Lambda=0.4
10
15
20
25
30
35
40
45
45 55 65 75 85 95 105
FDR (%)
MD
R (
%)
Alpha1
Figura 36 – Gráfico do teste 6 com � 1 a variar de 0 a 2 e � igual 0,4

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
105
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%)
RECALL (%)
PRECISION (%)
0 0,6 5 32 2 82,0513 28,5714 71 13 0,1 0,6 5 32 2 82,0513 28,5714 71 13 0,2 0,6 5 32 2 82,0513 28,5714 71 13 0,3 0,6 5 32 2 82,0513 28,5714 71 13 0,4 0,6 5 32 2 82,0513 28,5714 71 13 0,5 0,6 5 32 2 82,0513 28,5714 71 13 0,6 0,6 5 32 2 82,0513 28,5714 71 13 0,7 0,6 5 31 2 81,5789 28,5714 71 13 0,8 0,6 5 31 2 81,5789 28,5714 71 13 0,9 0,6 4 29 3 80,5556 42,8571 57 12
1 0,6 4 28 3 80 42,8571 57 12 1,1 0,6 4 21 3 75 42,8571 57 16 1,2 0,6 4 20 3 74,0741 42,8571 57 16 1,3 0,6 4 18 3 72 42,8571 57 18 1,4 0,6 4 13 3 65 42,8571 57 23 1,5 0,6 4 12 3 63,1579 42,8571 57 25 1,6 0,6 4 12 3 63,1579 42,8571 57 25 1,7 0,6 3 11 4 61,1111 57,1429 42 21 1,8 0,6 3 10 4 58,8235 57,1429 42 23 1,9 0,6 3 8 4 53,3333 57,1429 42 27
2 0,6 3 7 4 50 57,1429 42 30 Tabela 37 – Tabela do teste 6, � igual 0,6
Lambda=0.6
25
30
35
40
45
50
55
60
45 50 55 60 65 70 75 80 85
FDR (%)
MD
R (
%)
Alpha1
Figura 37 – Gráfico do teste 6 com � 1 a variar de 0 a 2 e � igual 0,6
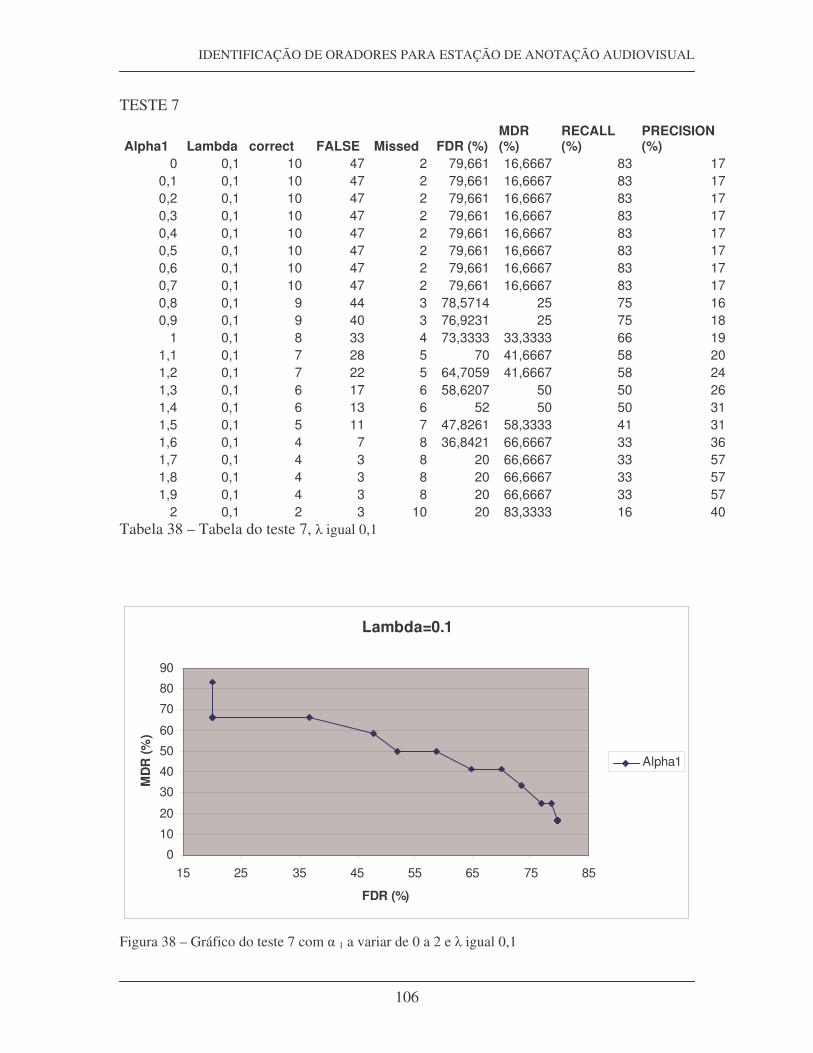
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
106
TESTE 7
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%)
RECALL (%)
PRECISION (%)
0 0,1 10 47 2 79,661 16,6667 83 17 0,1 0,1 10 47 2 79,661 16,6667 83 17 0,2 0,1 10 47 2 79,661 16,6667 83 17 0,3 0,1 10 47 2 79,661 16,6667 83 17 0,4 0,1 10 47 2 79,661 16,6667 83 17 0,5 0,1 10 47 2 79,661 16,6667 83 17 0,6 0,1 10 47 2 79,661 16,6667 83 17 0,7 0,1 10 47 2 79,661 16,6667 83 17 0,8 0,1 9 44 3 78,5714 25 75 16 0,9 0,1 9 40 3 76,9231 25 75 18
1 0,1 8 33 4 73,3333 33,3333 66 19 1,1 0,1 7 28 5 70 41,6667 58 20 1,2 0,1 7 22 5 64,7059 41,6667 58 24 1,3 0,1 6 17 6 58,6207 50 50 26 1,4 0,1 6 13 6 52 50 50 31 1,5 0,1 5 11 7 47,8261 58,3333 41 31 1,6 0,1 4 7 8 36,8421 66,6667 33 36 1,7 0,1 4 3 8 20 66,6667 33 57 1,8 0,1 4 3 8 20 66,6667 33 57 1,9 0,1 4 3 8 20 66,6667 33 57
2 0,1 2 3 10 20 83,3333 16 40 Tabela 38 – Tabela do teste 7, � igual 0,1
Lambda=0.1
0
10
20
30
40
50
60
70
80
90
15 25 35 45 55 65 75 85
FDR (%)
MD
R (%
)
Alpha1
Figura 38 – Gráfico do teste 7 com � 1 a variar de 0 a 2 e � igual 0,1
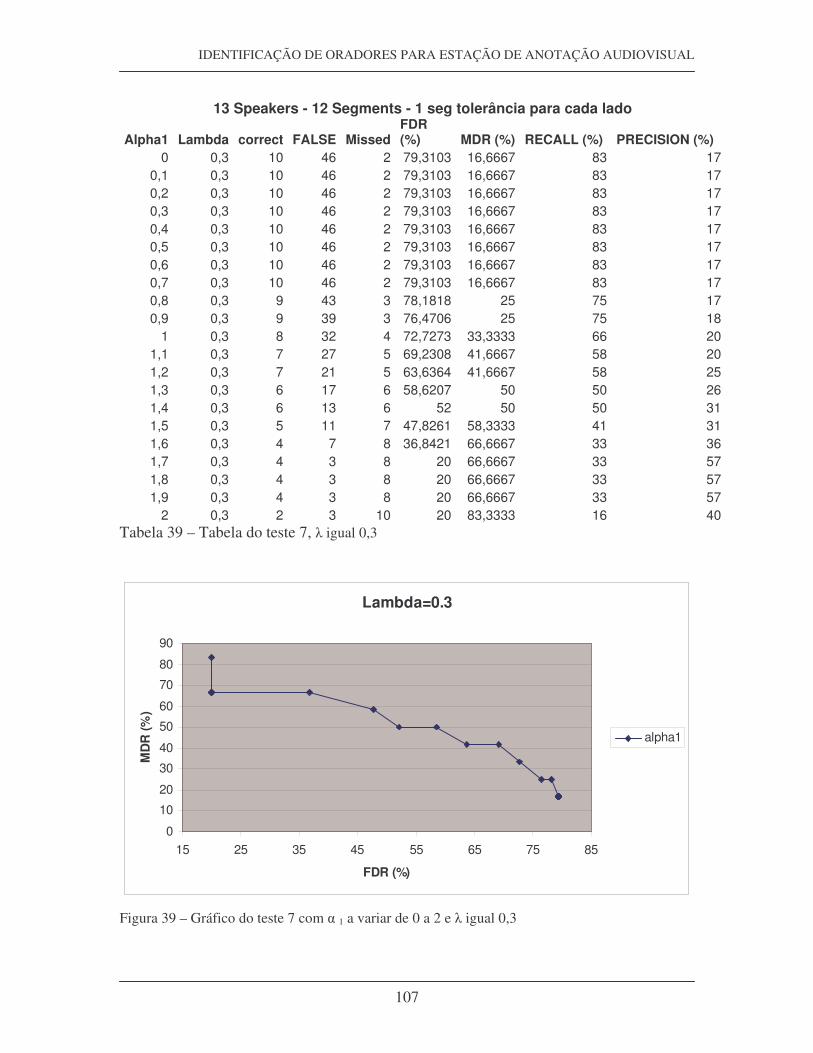
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
107
13 Speakers - 12 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,3 10 46 2 79,3103 16,6667 83 17 0,1 0,3 10 46 2 79,3103 16,6667 83 17 0,2 0,3 10 46 2 79,3103 16,6667 83 17 0,3 0,3 10 46 2 79,3103 16,6667 83 17 0,4 0,3 10 46 2 79,3103 16,6667 83 17 0,5 0,3 10 46 2 79,3103 16,6667 83 17 0,6 0,3 10 46 2 79,3103 16,6667 83 17 0,7 0,3 10 46 2 79,3103 16,6667 83 17 0,8 0,3 9 43 3 78,1818 25 75 17 0,9 0,3 9 39 3 76,4706 25 75 18
1 0,3 8 32 4 72,7273 33,3333 66 20 1,1 0,3 7 27 5 69,2308 41,6667 58 20 1,2 0,3 7 21 5 63,6364 41,6667 58 25 1,3 0,3 6 17 6 58,6207 50 50 26 1,4 0,3 6 13 6 52 50 50 31 1,5 0,3 5 11 7 47,8261 58,3333 41 31 1,6 0,3 4 7 8 36,8421 66,6667 33 36 1,7 0,3 4 3 8 20 66,6667 33 57 1,8 0,3 4 3 8 20 66,6667 33 57 1,9 0,3 4 3 8 20 66,6667 33 57
2 0,3 2 3 10 20 83,3333 16 40 Tabela 39 – Tabela do teste 7, � igual 0,3
Lambda=0.3
0
10
20
30
40
50
60
70
80
90
15 25 35 45 55 65 75 85
FDR (%)
MD
R (%
)
alpha1
Figura 39 – Gráfico do teste 7 com � 1 a variar de 0 a 2 e � igual 0,3

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
108
13 Speakers - 12 Segments - 1 seg tolerância para cada lado Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,4 10 32 2 72,7273 16,6667 83 23 0,1 0,4 10 32 2 72,7273 16,6667 83 23 0,2 0,4 10 32 2 72,7273 16,6667 83 23 0,3 0,4 10 32 2 72,7273 16,6667 83 23 0,4 0,4 10 32 2 72,7273 16,6667 83 23 0,5 0,4 10 32 2 72,7273 16,6667 83 23 0,6 0,4 10 32 2 72,7273 16,6667 83 23 0,7 0,4 10 32 2 72,7273 16,6667 83 23 0,8 0,4 9 30 3 71,4286 25 75 23 0,9 0,4 9 28 3 70 25 75 24
1 0,4 8 28 4 70 33,3333 66 22 1,1 0,4 7 23 5 65,7143 41,6667 58 23 1,2 0,4 7 18 5 60 41,6667 58 28 1,3 0,4 6 12 6 50 50 50 33 1,4 0,4 6 11 6 47,8261 50 50 35 1,5 0,4 5 10 7 45,4545 58,3333 41 33 1,6 0,4 4 7 8 36,8421 66,6667 33 36 1,7 0,4 4 3 8 20 66,6667 33 57 1,8 0,4 4 3 8 20 66,6667 33 57 1,9 0,4 4 3 8 20 66,6667 33 57
2 0,4 2 3 10 20 83,3333 16 40 Tabela 40 – Tabela do teste 7, � igual 0,4
Lambda=0.4
0
10
20
30
40
50
60
70
80
90
15 25 35 45 55 65 75 85
FDR (%)
MD
R (%
)
Alpha1
Figura 40 – Gráfico do teste 7 com � 1 a variar de 0 a 2 e � igual 0,4

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
109
13 Speakers - 12 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,6 8 12 4 50 33,3333 66 40 0,1 0,6 8 12 4 50 33,3333 66 40 0,2 0,6 8 12 4 50 33,3333 66 40 0,3 0,6 8 12 4 50 33,3333 66 40 0,4 0,6 8 12 4 50 33,3333 66 40 0,5 0,6 8 12 4 50 33,3333 66 40 0,6 0,6 8 12 4 50 33,3333 66 40 0,7 0,6 8 12 4 50 33,3333 66 40 0,8 0,6 7 13 5 52 41,6667 58 35 0,9 0,6 7 12 5 50 41,6667 58 36
1 0,6 7 11 5 47,8261 41,6667 58 38 1,1 0,6 6 10 6 45,4545 50 50 37 1,2 0,6 6 7 6 36,8421 50 50 46 1,3 0,6 5 7 7 36,8421 58,3333 41 41 1,4 0,6 5 7 7 36,8421 58,3333 41 41 1,5 0,6 5 7 7 36,8421 58,3333 41 41 1,6 0,6 4 4 8 25 66,6667 33 50 1,7 0,6 4 3 8 20 66,6667 33 57 1,8 0,6 4 3 8 20 66,6667 33 57 1,9 0,6 4 3 8 20 66,6667 33 57
2 0,6 2 3 10 20 83,3333 16 40 Tabela 41 – Tabela do teste 7, � igual 0,6
Lambda=0.6
30
40
50
60
70
80
90
15 25 35 45 55
FDR (%)
MD
R (
%)
Alpha1
Figura 41 – Gráfico do teste 7 com � 1 a variar de 0 a 2 e � igual 0,6

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
110
13 Speakers - 12 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,7 7 7 5 36,8421 41,6667 58 50 0,1 0,7 7 7 5 36,8421 41,6667 58 50 0,2 0,7 7 7 5 36,8421 41,6667 58 50 0,3 0,7 7 7 5 36,8421 41,6667 58 50 0,4 0,7 7 7 5 36,8421 41,6667 58 50 0,5 0,7 7 7 5 36,8421 41,6667 58 50 0,6 0,7 7 7 5 36,8421 41,6667 58 50 0,7 0,7 7 7 5 36,8421 41,6667 58 50 0,8 0,7 6 7 6 36,8421 50 50 46 0,9 0,7 6 7 6 36,8421 50 50 46
1 0,7 6 7 6 36,8421 50 50 46 1,1 0,7 5 6 7 33,3333 58,3333 41 45 1,2 0,7 5 5 7 29,4118 58,3333 41 50 1,3 0,7 5 4 7 25 58,3333 41 55 1,4 0,7 5 4 7 25 58,3333 41 55 1,5 0,7 5 4 7 25 58,3333 41 55 1,6 0,7 4 3 8 20 66,6667 33 57 1,7 0,7 4 3 8 20 66,6667 33 57 1,8 0,7 4 3 8 20 66,6667 33 57 1,9 0,7 4 3 8 20 66,6667 33 57
2 0,7 2 3 10 20 83,3333 16 40 Tabela 42 – Tabela do teste 7, � igual 0,7
Lambda=0.7
4045505560657075808590
15 20 25 30 35 40
FDR (%)
MD
R (%
)
Alpha1
Figura 42 – Gráfico do teste 7 com � 1 a variar de 0 a 2 e � igual 0,7

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
111
13 Speakers - 12 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,8 5 4 7 25 58,3333 41 55 0,1 0,8 5 4 7 25 58,3333 41 55 0,2 0,8 5 4 7 25 58,3333 41 55 0,3 0,8 5 4 7 25 58,3333 41 55 0,4 0,8 5 4 7 25 58,3333 41 55 0,5 0,8 5 4 7 25 58,3333 41 55 0,6 0,8 5 4 7 25 58,3333 41 55 0,7 0,8 5 4 7 25 58,3333 41 55 0,8 0,8 4 4 8 25 66,6667 33 50 0,9 0,8 4 4 8 25 66,6667 33 50
1 0,8 4 4 8 25 66,6667 33 50 1,1 0,8 2 4 10 25 83,3333 16 33 1,2 0,8 2 3 10 20 83,3333 16 40 1,3 0,8 2 3 10 20 83,3333 16 40 1,4 0,8 2 3 10 20 83,3333 16 40 1,5 0,8 2 3 10 20 83,3333 16 40 1,6 0,8 2 2 10 14,2857 83,3333 16 50 1,7 0,8 2 2 10 14,2857 83,3333 16 50 1,8 0,8 2 2 10 14,2857 83,3333 16 50 1,9 0,8 2 2 10 14,2857 83,3333 16 50
2 0,8 1 2 11 14,2857 91,6667 8 33 Tabela 43 – Tabela do teste 7, � igual 0,8
Lambda=0.8
50
55
60
65
70
75
80
85
90
95
10 15 20 25 30
FDR (%)
MD
R (
%)
Alpha1
Figura 43 – Gráfico do teste 7 com � 1 a variar de 0 a 2 e � igual 0,8

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
112
TESTE 8
15 Speakers - 14 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,1 10 11 4 44 28,5714 71 47 0,1 0,1 10 11 4 44 28,5714 71 47 0,2 0,1 10 11 4 44 28,5714 71 47 0,3 0,1 10 11 4 44 28,5714 71 47 0,4 0,1 10 11 4 44 28,5714 71 47 0,5 0,1 10 11 4 44 28,5714 71 47 0,6 0,1 10 11 4 44 28,5714 71 47 0,7 0,1 10 10 4 41,6667 28,5714 71 50 0,8 0,1 10 9 4 39,1304 28,5714 71 52 0,9 0,1 10 9 4 39,1304 28,5714 71 52
1 0,1 10 7 4 33,3333 28,5714 71 58 1,1 0,1 9 6 5 30 35,7143 64 60 1,2 0,1 9 6 5 30 35,7143 64 60 1,3 0,1 9 5 5 26,3158 35,7143 64 64 1,4 0,1 8 3 6 17,6471 42,8571 57 72 1,5 0,1 7 2 7 12,5 50 50 77 1,6 0,1 4 1 10 6,6667 71,4286 28 80 1,7 0,1 4 1 10 6,6667 71,4286 28 80 1,8 0,1 3 0 11 0 78,5714 21 100 1,9 0,1 2 0 12 0 85,7143 14 100
2 0,1 1 0 13 0 92,8571 7 100 Tabela 44 – Tabela do teste 4, � igual 0,1
Lambda=0.1
25
35
45
55
65
75
85
95
105
0 10 20 30 40 50
FDR (%)
MD
R (%
)
Alpha1
Figura 44 – Gráfico do teste 7 com � 1 a variar de 0 a 2 e � igual 0,1
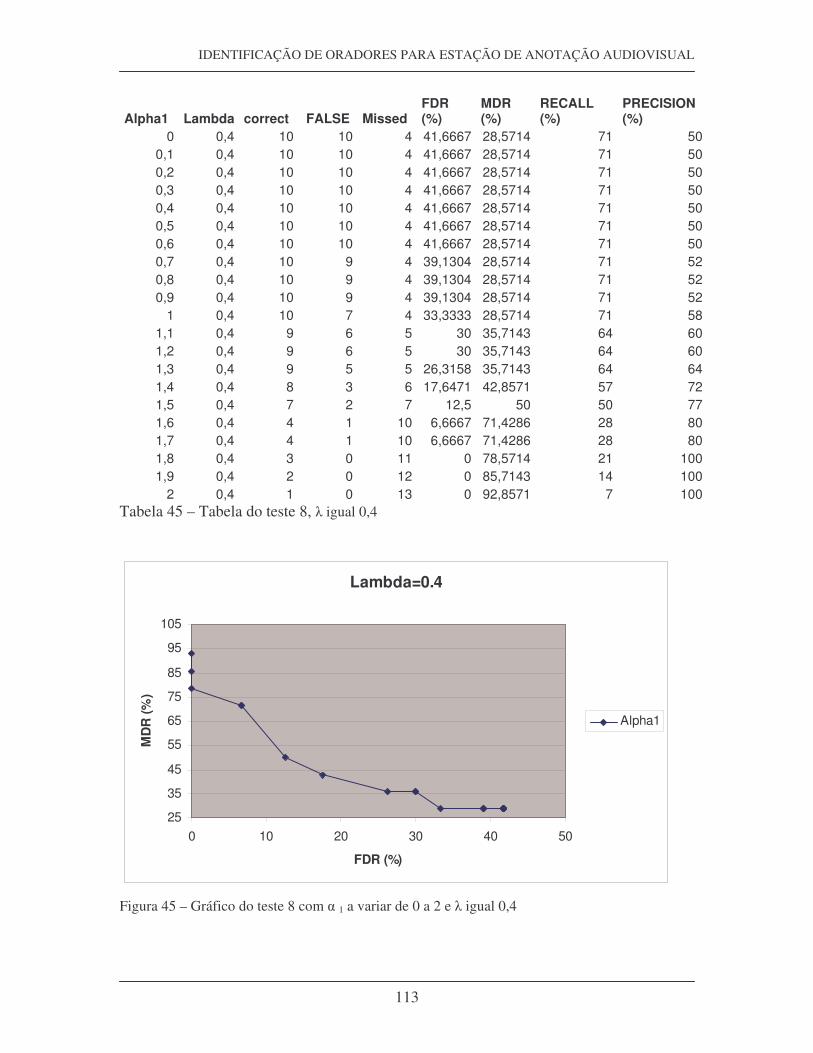
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
113
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%)
RECALL (%)
PRECISION (%)
0 0,4 10 10 4 41,6667 28,5714 71 50 0,1 0,4 10 10 4 41,6667 28,5714 71 50 0,2 0,4 10 10 4 41,6667 28,5714 71 50 0,3 0,4 10 10 4 41,6667 28,5714 71 50 0,4 0,4 10 10 4 41,6667 28,5714 71 50 0,5 0,4 10 10 4 41,6667 28,5714 71 50 0,6 0,4 10 10 4 41,6667 28,5714 71 50 0,7 0,4 10 9 4 39,1304 28,5714 71 52 0,8 0,4 10 9 4 39,1304 28,5714 71 52 0,9 0,4 10 9 4 39,1304 28,5714 71 52
1 0,4 10 7 4 33,3333 28,5714 71 58 1,1 0,4 9 6 5 30 35,7143 64 60 1,2 0,4 9 6 5 30 35,7143 64 60 1,3 0,4 9 5 5 26,3158 35,7143 64 64 1,4 0,4 8 3 6 17,6471 42,8571 57 72 1,5 0,4 7 2 7 12,5 50 50 77 1,6 0,4 4 1 10 6,6667 71,4286 28 80 1,7 0,4 4 1 10 6,6667 71,4286 28 80 1,8 0,4 3 0 11 0 78,5714 21 100 1,9 0,4 2 0 12 0 85,7143 14 100
2 0,4 1 0 13 0 92,8571 7 100 Tabela 45 – Tabela do teste 8, � igual 0,4
Lambda=0.4
25
35
45
55
65
75
85
95
105
0 10 20 30 40 50
FDR (%)
MD
R (%
)
Alpha1
Figura 45 – Gráfico do teste 8 com � 1 a variar de 0 a 2 e � igual 0,4

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
114
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,5 7 8 7 36,3636 50 50 460,1 0,5 7 8 7 36,3636 50 50 460,2 0,5 7 8 7 36,3636 50 50 460,3 0,5 7 8 7 36,3636 50 50 460,4 0,5 7 8 7 36,3636 50 50 460,5 0,5 7 8 7 36,3636 50 50 460,6 0,5 7 8 7 36,3636 50 50 460,7 0,5 7 8 7 36,3636 50 50 460,8 0,5 7 8 7 36,3636 50 50 460,9 0,5 7 8 7 36,3636 50 50 46
1 0,5 7 6 7 30 50 50 531,1 0,5 7 5 7 26,3158 50 50 581,2 0,5 7 5 7 26,3158 50 50 581,3 0,5 7 4 7 22,2222 50 50 631,4 0,5 7 2 7 12,5 50 50 771,5 0,5 7 2 7 12,5 50 50 771,6 0,5 4 1 10 6,6667 71,4286 28 801,7 0,5 4 1 10 6,6667 71,4286 28 801,8 0,5 3 0 11 0 78,5714 21 1001,9 0,5 2 0 12 0 85,7143 14 100
2 0,5 1 0 13 0 92,8571 7 100Tabela 46 – Tabela do teste 8, � igual 0,5
Lambda=0.5
45
55
65
75
85
95
105
0 10 20 30 40
FDR (%)
MD
R (%
)
Alpha1
Figura 46 – Gráfico do teste 8 com � 1 a variar de 0 a 2 e � igual 0,5

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
115
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,6 5 3 9 17,6471 64,2857 35 62 0,1 0,6 5 3 9 17,6471 64,2857 35 62 0,2 0,6 5 3 9 17,6471 64,2857 35 62 0,3 0,6 5 3 9 17,6471 64,2857 35 62 0,4 0,6 5 3 9 17,6471 64,2857 35 62 0,5 0,6 5 3 9 17,6471 64,2857 35 62 0,6 0,6 5 3 9 17,6471 64,2857 35 62 0,7 0,6 5 3 9 17,6471 64,2857 35 62 0,8 0,6 5 3 9 17,6471 64,2857 35 62 0,9 0,6 5 3 9 17,6471 64,2857 35 62
1 0,6 5 3 9 17,6471 64,2857 35 62 1,1 0,6 5 2 9 12,5 64,2857 35 71 1,2 0,6 5 2 9 12,5 64,2857 35 71 1,3 0,6 4 1 10 6,6667 71,4286 28 80 1,4 0,6 4 1 10 6,6667 71,4286 28 80 1,5 0,6 4 1 10 6,6667 71,4286 28 80 1,6 0,6 3 1 11 6,6667 78,5714 21 75 1,7 0,6 3 1 11 6,6667 78,5714 21 75 1,8 0,6 1 0 13 0 92,8571 7 100 1,9 0,6 0 0 14 0 100 0 0
2 0,6 0 0 14 0 100 0 0 Tabela 47 – Tabela do teste 8, � igual 0,6
lambda=0.6
60
65
70
75
80
85
90
95
100
105
0 5 10 15 20
FDR (%)
MD
R (%
)
alpha1
Figura 47 – Gráfico do teste 8 com � 1 a variar de 0 a 2 e � igual 0,6

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
116
TESTE 9
7 Speakers - 6 Segments - 1seg de tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%)
RECALL (%)
PRECISION (%)
0 0,1 3 37 3 86,0465 50 50 7 0,1 0,1 3 37 3 86,0465 50 50 7 0,2 0,1 3 37 3 86,0465 50 50 7 0,3 0,1 3 37 3 86,0465 50 50 7 0,4 0,1 3 37 3 86,0465 50 50 7 0,5 0,1 3 37 3 86,0465 50 50 7 0,6 0,1 3 36 3 85,7143 50 50 7 0,7 0,1 3 35 3 85,3659 50 50 7 0,8 0,1 3 34 3 85 50 50 8 0,9 0,1 3 33 3 84,6154 50 50 8
1 0,1 3 29 3 82,8571 50 50 9 1,1 0,1 3 25 3 80,6452 50 50 10 1,2 0,1 2 20 4 76,9231 66,6667 33 9 1,3 0,1 2 17 4 73,913 66,6667 33 10 1,4 0,1 2 12 4 66,6667 66,6667 33 14 1,5 0,1 1 8 5 57,1429 83,3333 16 11 1,6 0,1 1 7 5 53,8462 83,3333 16 12 1,7 0,1 1 3 5 33,3333 83,3333 16 25 1,8 0,1 1 2 5 25 83,3333 16 33 1,9 0,1 0 2 6 25 100 0 0
2 0,1 0 2 6 25 100 0 0 Tabela 48 – Tabela do teste 9, � igual 0,1
Lambda=0.1
40
50
60
70
80
90
100
110
20 30 40 50 60 70 80 90
FDR (%)
MD
R (%
)
Alpha1
Figura 48 – Gráfico do teste 9 com � 1 a variar de 0 a 2 e � igual 0,1

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
117
7 Speakers - 6 Segments - 1seg de tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%)
RECALL (%) PRECISION (%)
0 0,4 3 31 3 83,7838 50 50 8 0,1 0,4 3 31 3 83,7838 50 50 8 0,2 0,4 3 31 3 83,7838 50 50 8 0,3 0,4 3 31 3 83,7838 50 50 8 0,4 0,4 3 31 3 83,7838 50 50 8 0,5 0,4 3 31 3 83,7838 50 50 8 0,6 0,4 3 30 3 83,33333 50 50 9 0,7 0,4 3 29 3 82,8571 50 50 9 0,8 0,4 3 28 3 82,3529 50 50 9 0,9 0,4 3 27 3 81,8182 50 50 10
1 0,4 3 24 3 80 50 50 11 1,1 0,4 3 21 3 77,7778 50 50 12 1,2 0,4 2 17 4 73,913 66,6667 33 10 1,3 0,4 2 16 4 72,7273 66,6667 33 11 1,4 0,4 2 10 4 62,5 66,6667 33 16 1,5 0,4 1 8 5 57,1429 83,3333 16 11 1,6 0,4 1 7 5 53,8462 83,3333 16 12 1,7 0,4 1 3 5 33,3333 83,3333 16 25 1,8 0,4 1 2 5 25 83,3333 16 33 1,9 0,4 0 2 6 25 100 0 0
2 0,4 0 2 6 25 100 0 0 Tabela 49 – Tabela do teste 9, � igual 0,4
Lambda=0.4
40
50
60
70
80
90
100
110
20 30 40 50 60 70 80 90
FDR (%)
MD
R (%
)
Alpha1
Figura 49 – Gráfico do teste 9 com � 1 a variar de 0 a 2 e � igual 0,4
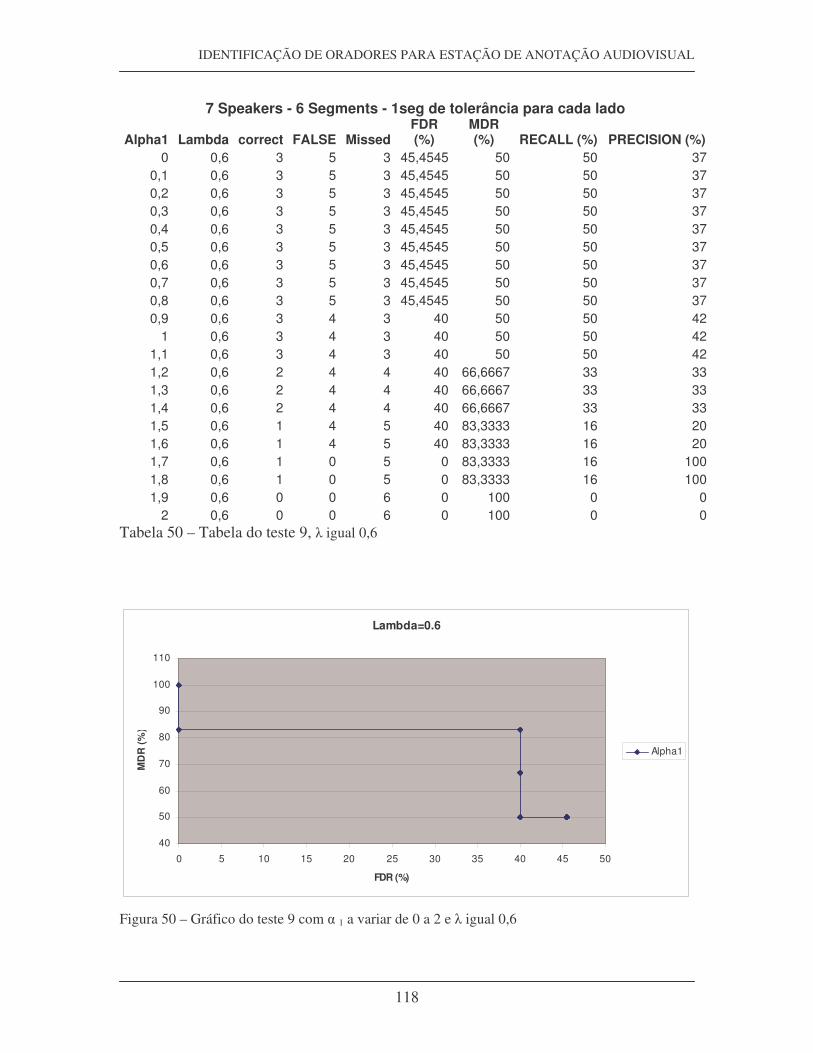
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
118
7 Speakers - 6 Segments - 1seg de tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,6 3 5 3 45,4545 50 50 37 0,1 0,6 3 5 3 45,4545 50 50 37 0,2 0,6 3 5 3 45,4545 50 50 37 0,3 0,6 3 5 3 45,4545 50 50 37 0,4 0,6 3 5 3 45,4545 50 50 37 0,5 0,6 3 5 3 45,4545 50 50 37 0,6 0,6 3 5 3 45,4545 50 50 37 0,7 0,6 3 5 3 45,4545 50 50 37 0,8 0,6 3 5 3 45,4545 50 50 37 0,9 0,6 3 4 3 40 50 50 42
1 0,6 3 4 3 40 50 50 42 1,1 0,6 3 4 3 40 50 50 42 1,2 0,6 2 4 4 40 66,6667 33 33 1,3 0,6 2 4 4 40 66,6667 33 33 1,4 0,6 2 4 4 40 66,6667 33 33 1,5 0,6 1 4 5 40 83,3333 16 20 1,6 0,6 1 4 5 40 83,3333 16 20 1,7 0,6 1 0 5 0 83,3333 16 100 1,8 0,6 1 0 5 0 83,3333 16 100 1,9 0,6 0 0 6 0 100 0 0
2 0,6 0 0 6 0 100 0 0 Tabela 50 – Tabela do teste 9, � igual 0,6
Lambda=0.6
40
50
60
70
80
90
100
110
0 5 10 15 20 25 30 35 40 45 50
FDR (%)
MD
R (%
)
Alpha1
Figura 50 – Gráfico do teste 9 com � 1 a variar de 0 a 2 e � igual 0,6
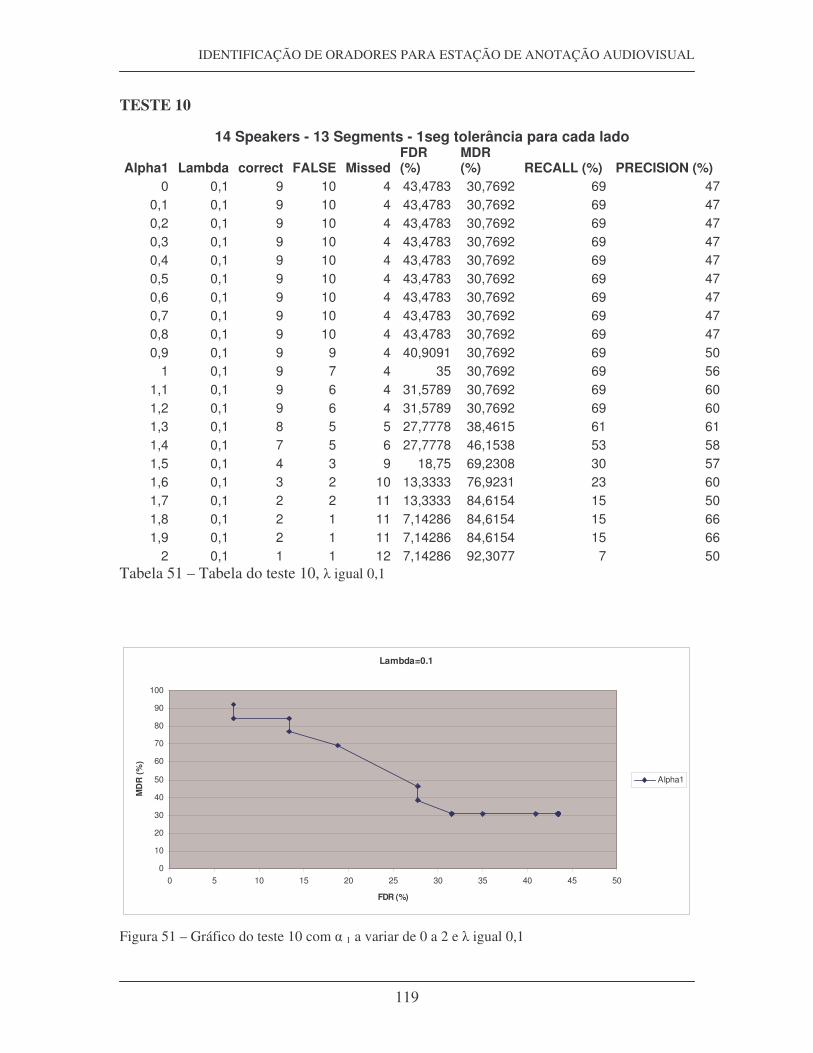
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
119
TESTE 10
14 Speakers - 13 Segments - 1seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,1 9 10 4 43,4783 30,7692 69 47 0,1 0,1 9 10 4 43,4783 30,7692 69 47 0,2 0,1 9 10 4 43,4783 30,7692 69 47 0,3 0,1 9 10 4 43,4783 30,7692 69 47 0,4 0,1 9 10 4 43,4783 30,7692 69 47 0,5 0,1 9 10 4 43,4783 30,7692 69 47 0,6 0,1 9 10 4 43,4783 30,7692 69 47 0,7 0,1 9 10 4 43,4783 30,7692 69 47 0,8 0,1 9 10 4 43,4783 30,7692 69 47 0,9 0,1 9 9 4 40,9091 30,7692 69 50
1 0,1 9 7 4 35 30,7692 69 56 1,1 0,1 9 6 4 31,5789 30,7692 69 60 1,2 0,1 9 6 4 31,5789 30,7692 69 60 1,3 0,1 8 5 5 27,7778 38,4615 61 61 1,4 0,1 7 5 6 27,7778 46,1538 53 58 1,5 0,1 4 3 9 18,75 69,2308 30 57 1,6 0,1 3 2 10 13,3333 76,9231 23 60 1,7 0,1 2 2 11 13,3333 84,6154 15 50 1,8 0,1 2 1 11 7,14286 84,6154 15 66 1,9 0,1 2 1 11 7,14286 84,6154 15 66
2 0,1 1 1 12 7,14286 92,3077 7 50 Tabela 51 – Tabela do teste 10, � igual 0,1
Lambda=0.1
0
10
20
30
40
50
60
70
80
90
100
0 5 10 15 20 25 30 35 40 45 50
FDR (%)
MD
R (
%)
Alpha1
Figura 51 – Gráfico do teste 10 com � 1 a variar de 0 a 2 e � igual 0,1

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
120
14 Speakers - 13 Segments - 1seg tolerância para cada lado Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,4 9 10 4 43,4783 30,7692 69 47 0,1 0,4 9 10 4 43,4783 30,7692 69 47 0,2 0,4 9 10 4 43,4783 30,7692 69 47 0,3 0,4 9 10 4 43,4783 30,7692 69 47 0,4 0,4 9 10 4 43,4783 30,7692 69 47 0,5 0,4 9 10 4 43,4783 30,7692 69 47 0,6 0,4 9 10 4 43,4783 30,7692 69 47 0,7 0,4 9 10 4 43,4783 30,7692 69 47 0,8 0,4 9 10 4 43,4783 30,7692 69 47 0,9 0,4 9 9 4 40,9091 30,7692 69 50
1 0,4 9 7 4 35 30,7692 69 56 1,1 0,4 9 6 4 31,5789 30,7692 69 60 1,2 0,4 9 6 4 31,5789 30,7692 69 60 1,3 0,4 8 5 5 27,7778 38,4615 61 61 1,4 0,4 7 5 6 27,7778 46,1538 53 58 1,5 0,4 4 3 9 18,75 69,2308 30 57 1,6 0,4 3 2 10 13,3333 76,9231 23 60 1,7 0,4 2 2 11 13,3333 84,6154 15 50 1,8 0,4 2 1 11 7,14286 84,6154 15 66 1,9 0,4 2 1 11 7,14286 84,6154 15 66
2 0,4 1 1 12 7,14286 92,3077 7 50 Tabela 52 – Tabela do teste 10, � igual 0,4
Lambda=0.4
0
10
20
30
40
50
60
70
80
90
100
0 5 10 15 20 25 30 35 40 45 50
FDR (%)
MD
R (
%)
Alpha1
Figura 52 – Gráfico do teste 10 com � 1 a variar de 0 a 2 e � igual 0,4

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
121
14 Speakers - 13 Segments - 1seg tolerância para cada lado Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,5 9 6 4 31,5789 30,7692 69 60 0,1 0,5 9 6 4 31,5789 30,7692 69 60 0,2 0,5 9 6 4 31,5789 30,7692 69 60 0,3 0,5 9 6 4 31,5789 30,7692 69 60 0,4 0,5 9 6 4 31,5789 30,7692 69 60 0,5 0,5 9 6 4 31,5789 30,7692 69 60 0,6 0,5 9 6 4 31,5789 30,7692 69 60 0,7 0,5 9 6 4 31,5789 30,7692 69 60 0,8 0,5 9 6 4 31,5789 30,7692 69 60 0,9 0,5 9 5 4 27,7778 30,7692 69 64
1 0,5 9 4 4 23,5294 30,7692 69 69 1,1 0,5 9 4 4 23,5294 30,7692 69 69 1,2 0,5 9 4 4 23,5294 30,7692 69 69 1,3 0,5 8 4 5 23,5294 38,4615 61 66 1,4 0,5 7 4 6 23,5294 46,1538 53 63 1,5 0,5 4 2 9 13,3333 69,2308 30 66 1,6 0,5 3 1 10 7,14286 76,9231 23 75 1,7 0,5 2 1 11 7,14286 84,6154 15 66 1,8 0,5 2 1 11 7,14286 84,6154 15 66 1,9 0,5 2 1 11 7,14286 84,6154 15 66
2 0,5 1 1 12 7,14286 92,3077 7 50 Tabela 53 – Tabela do teste 10, � igual 0,5
Lambda=0.5
0
10
20
30
40
50
60
70
80
90
100
0 5 10 15 20 25 30 35
FDR (%)
MD
R (
%)
Alpha1
Figura 53 – Gráfico do teste 10 com � 1 a variar de 0 a 2 e � igual 0,5

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
122
14 Speakers - 13 Segments - 1seg tolerância para cada lado Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,7 6 2 7 13,3333 53,8462 46 75 0,1 0,7 6 2 7 13,3333 53,8462 46 75 0,2 0,7 6 2 7 13,3333 53,8462 46 75 0,3 0,7 6 2 7 13,3333 53,8462 46 75 0,4 0,7 6 2 7 13,3333 53,8462 46 75 0,5 0,7 6 2 7 13,3333 53,8462 46 75 0,6 0,7 6 2 7 13,3333 53,8462 46 75 0,7 0,7 6 2 7 13,3333 53,8462 46 75 0,8 0,7 6 2 7 13,3333 53,8462 46 75 0,9 0,7 6 2 7 13,3333 53,8462 46 75
1 0,7 6 2 7 13,3333 53,8462 46 75 1,1 0,7 6 2 7 13,3333 53,8462 46 75 1,2 0,7 6 2 7 13,3333 53,8462 46 75 1,3 0,7 6 2 7 13,3333 53,8462 46 75 1,4 0,7 6 2 7 13,3333 53,8462 46 75 1,5 0,7 3 1 10 7,14286 76,9231 23 75 1,6 0,7 1 0 12 0 92,3077 7 100 1,7 0,7 1 0 12 0 92,3077 7 100 1,8 0,7 1 0 12 0 92,3077 7 100 1,9 0,7 1 0 12 0 92,3077 7 100
2 0,7 1 0 12 0 92,3077 7 100 Tabela 54 – Tabela do teste 10, � igual 0,7
Lambda=0.7
0
10
20
30
40
50
60
70
80
90
100
0 2 4 6 8 10 12 14
FDR (%)
MD
R (
%)
Alpha1
Figura 54 – Gráfico do teste 10 com � 1 a variar de 0 a 2 e � igual 0,7

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
123
TESTE11
15 Speakers - 14 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,4 5 21 2 75 28,5714 71 19 0,1 0,4 5 21 2 75 28,5714 71 19 0,2 0,4 5 21 2 75 28,5714 71 19 0,3 0,4 5 21 2 75 28,5714 71 19 0,4 0,4 5 21 2 75 28,5714 71 19 0,5 0,4 5 21 2 75 28,5714 71 19 0,6 0,4 5 21 2 75 28,5714 71 19 0,7 0,4 5 21 2 75 28,5714 71 19 0,8 0,4 5 18 2 72 28,5714 71 21 0,9 0,4 5 17 2 70,83333 28,5714 71 22
1 0,4 5 15 2 68,1818 28,5714 71 25 1,1 0,4 5 14 2 66,6667 28,5714 71 26 1,2 0,4 5 11 2 61,1111 28,5714 71 31 1,3 0,4 5 10 2 58,8235 28,5714 71 33 1,4 0,4 5 9 2 56,25 28,5714 71 35 1,5 0,4 4 8 3 53,3333 42,8571 57 33 1,6 0,4 3 4 4 36,3636 57,1429 42 42 1,7 0,4 3 3 4 30 57,1429 42 50 1,8 0,4 3 2 4 22,2222 57,1429 42 60 1,9 0,4 2 2 5 22,2222 71,4286 28 50
2 0,4 2 1 5 12,5 71,4286 28 66 Tabela 55 – Tabela do teste 11, � igual 0,4
Lambda=0.4
2530354045505560657075
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80
FDR (%)
MD
R (%
)
Alpha1
Figura 55 – Gráfico do teste 11 com � 1 a variar de 0 a 2 e � igual 0,4

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
124
15 Speakers - 14 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,5 4 14 3 66,6667 42,8571 57 22 0,1 0,5 4 14 3 66,6667 42,8571 57 22 0,2 0,5 4 14 3 66,6667 42,8571 57 22 0,3 0,5 4 14 3 66,6667 42,8571 57 22 0,4 0,5 4 14 3 66,6667 42,8571 57 22 0,5 0,5 4 14 3 66,6667 42,8571 57 22 0,6 0,5 4 14 3 66,6667 42,8571 57 22 0,7 0,5 4 14 3 66,6667 42,8571 57 22 0,8 0,5 4 11 3 61,1111 42,8571 57 26 0,9 0,5 4 10 3 58,8235 42,8571 57 28
1 0,5 4 9 3 56,25 42,8571 57 30 1,1 0,5 4 9 3 56,25 42,8571 57 30 1,2 0,5 4 7 3 50 42,8571 57 36 1,3 0,5 4 7 3 50 42,8571 57 36 1,4 0,5 4 6 3 46,1538 42,8571 57 40 1,5 0,5 3 6 4 46,1538 57,1429 42 33 1,6 0,5 3 3 4 30 57,1429 42 50 1,7 0,5 3 2 4 22,2222 57,1429 42 60 1,8 0,5 3 1 4 12,5 57,1429 42 75 1,9 0,5 2 1 5 12,5 71,4286 28 66
2 0,5 2 1 5 12,5 71,4286 28 66 Tabela 56 – Tabela do teste 11, � igual 0,5
Lambda=0.5
40
45
50
55
60
65
70
75
0 20 40 60 80
FDR (%)
MD
R (%
)
Alpha1
Figura 56 – Gráfico do teste 11 com � 1 a variar de 0 a 2 e � igual 0,5

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
125
15 Speakers - 14 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,6 4 6 3 46,1538 42,8571 57 40 0,1 0,6 4 6 3 46,1538 42,8571 57 40 0,2 0,6 4 6 3 46,1538 42,8571 57 40 0,3 0,6 4 6 3 46,1538 42,8571 57 40 0,4 0,6 4 6 3 46,1538 42,8571 57 40 0,5 0,6 4 6 3 46,1538 42,8571 57 40 0,6 0,6 4 6 3 46,1538 42,8571 57 40 0,7 0,6 4 5 3 41,6667 42,8571 57 40 0,8 0,6 4 5 3 41,6667 42,8571 57 44 0,9 0,6 4 4 3 36,3636 42,8571 57 44
1 0,6 4 4 3 36,3636 42,8571 57 50 1,1 0,6 4 4 3 36,3636 42,8571 57 50 1,2 0,6 4 4 3 36,3636 42,8571 57 50 1,3 0,6 4 4 3 36,3636 42,8571 57 50 1,4 0,6 4 4 3 36,3636 42,8571 57 50 1,5 0,6 3 4 4 36,3636 57,1429 42 42 1,6 0,6 2 3 5 30 71,4286 28 40 1,7 0,6 2 2 5 22,2222 71,4286 28 50 1,8 0,6 2 1 5 12,5 71,4286 28 66 1,9 0,6 2 1 5 12,5 71,4286 28 66
2 0,6 2 1 5 12,5 71,4286 28 66 Tabela 57 – Tabela do teste 11, � igual 0,6
Lamda1=0.6
40
45
50
55
60
65
70
75
0 10 20 30 40 50
FDR (%)
MD
R (%
)
Alpha1
Figura 57 – Gráfico do teste 11 com � 1 a variar de 0 a 2 e � igual 0,6

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
126
TESTE 12
9 Speakers Changes- 10 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,1 3 10 6 52,6316 66,6667 33 23 0,1 0,1 3 10 6 52,6316 66,6667 33 23 0,2 0,1 3 10 6 52,6316 66,6667 33 23 0,3 0,1 3 10 6 52,6316 66,6667 33 23 0,4 0,1 3 10 6 52,6316 66,6667 33 23 0,5 0,1 3 10 6 52,6316 66,6667 33 23 0,6 0,1 3 10 6 52,6316 66,6667 33 23 0,7 0,1 3 10 6 52,6316 66,6667 33 23 0,8 0,1 3 10 6 52,6316 66,6667 33 23 0,9 0,1 3 9 6 50 66,6667 33 25
1 0,1 2 8 7 47,0588 77,7778 22 20 1,1 0,1 2 8 7 47,0588 77,7778 22 20 1,2 0,1 2 6 7 40 77,7778 22 25 1,3 0,1 2 4 7 30,7692 77,7778 22 33 1,4 0,1 2 3 7 25 77,7778 22 40 1,5 0,1 2 2 7 18,1818 77,7778 22 50 1,6 0,1 2 2 7 18,1818 77,7778 22 50 1,7 0,1 2 1 7 10 77,7778 22 66 1,8 0,1 2 1 7 10 77,7778 22 66 1,9 0,1 0 1 9 10 100 0 0
2 0,1 0 0 9 0 100 0 0 Tabela 58 – Tabela do teste 12, � igual 0,1
Lambda=0.1
60
65
70
75
80
85
90
95
100
105
0 10 20 30 40 50 60
FDR (%)
MD
R (%
)
alpha1
Figura 58 – Gráfico do teste 12 com � 1 a variar de 0 a 2 e � igual 0,1

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
127
9 Speakers Changes- 10 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,5 3 9 6 50 66,6667 33 25 0,1 0,5 3 9 6 50 66,6667 33 25 0,2 0,5 3 9 6 50 66,6667 33 25 0,3 0,5 3 9 6 50 66,6667 33 25 0,4 0,5 3 9 6 50 66,6667 33 25 0,5 0,5 3 9 6 50 66,6667 33 25 0,6 0,5 3 9 6 50 66,6667 33 25 0,7 0,5 3 9 6 50 66,6667 33 25 0,8 0,5 3 9 6 50 66,6667 33 25 0,9 0,5 3 8 6 47,0588 66,6667 33 27
1 0,5 2 7 7 43,75 77,7778 22 22 1,1 0,5 2 7 7 43,75 77,7778 22 22 1,2 0,5 2 5 7 35,7143 77,7778 22 28 1,3 0,5 2 3 7 25 77,7778 22 40 1,4 0,5 2 3 7 25 77,7778 22 40 1,5 0,5 2 2 7 18,1818 77,7778 22 50 1,6 0,5 2 2 7 18,1818 77,7778 22 50 1,7 0,5 2 1 7 10 77,7778 22 66 1,8 0,5 2 1 7 10 77,7778 22 66 1,9 0,5 0 1 9 10 100 0 0
2 0,5 0 0 9 0 100 0 0 Tabela 59 – Tabela do teste 12, � igual 0,5
Lambda=0.5
60
65
70
75
80
85
90
95
100
105
0 10 20 30 40 50 60
FDR (%)
MD
R (%
)
Alpha1
Figura 59 – Gráfico do teste 12 com � 1 a variar de 0 a 2 e � igual 0,5

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
128
9 Speakers Changes- 10 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,6 3 7 6 43,75 66,6667 33 30 0,1 0,6 3 7 6 43,75 66,6667 33 30 0,2 0,6 3 7 6 43,75 66,6667 33 30 0,3 0,6 3 7 6 43,75 66,6667 33 30 0,4 0,6 3 7 6 43,75 66,6667 33 30 0,5 0,6 3 7 6 43,75 66,6667 33 30 0,6 0,6 3 7 6 43,75 66,6667 33 30 0,7 0,6 3 7 6 43,75 66,6667 33 30 0,8 0,6 3 7 6 43,75 66,6667 33 30 0,9 0,6 3 6 6 40 66,6667 33 33
1 0,6 2 6 7 40 77,7778 22 25 1,1 0,6 2 6 7 40 77,7778 22 25 1,2 0,6 2 5 7 35,7143 77,7778 22 28 1,3 0,6 2 3 7 25 77,7778 22 40 1,4 0,6 2 3 7 25 77,7778 22 40 1,5 0,6 2 2 7 18,1818 77,7778 22 50 1,6 0,6 2 2 7 18,1818 77,7778 22 50 1,7 0,6 2 1 7 10 77,7778 22 66 1,8 0,6 2 1 7 10 77,7778 22 66 1,9 0,6 0 1 9 10 100 0 0
2 0,6 0 0 9 0 100 0 0 Tabela 60 – Tabela do teste 12, � igual 0,6
Lambda=0.6
60
65
70
75
80
85
90
95
100
105
0 10 20 30 40 50
FDR (%)
MD
R (%
)
Alpha1
Figura 60 – Gráfico do teste 12 com � 1 a variar de 0 a 2 e � igual 0,6

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
129
TESTE 13
77 Segments - 1seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,3 70 331 6 81,3268 7,8947 92 17 0,1 0,3 70 331 6 81,3268 7,8947 92 17 0,2 0,3 70 331 6 81,3268 7,8947 92 17 0,3 0,3 70 331 6 81,3268 7,8947 92 17 0,4 0,3 70 331 6 81,3268 7,8947 92 17 0,5 0,3 70 331 6 81,3268 7,8947 92 17 0,6 0,3 70 331 6 81,3268 7,8947 92 17 0,7 0,3 70 328 6 81,1881 7,8947 92 17 0,8 0,3 70 317 6 80,6616 7,8947 92 18 0,9 0,3 70 285 6 78,9474 7,8947 92 19
1 0,3 67 248 9 76,5432 11,8421 88 21 1,1 0,3 64 211 12 73,5192 15,7895 84 23 1,2 0,3 56 174 20 69,6 26,3158 73 24 1,3 0,3 46 130 30 63,1068 39,4737 60 26 1,4 0,3 40 90 36 54,2169 47,3684 52 30 1,5 0,3 33 70 43 47,9452 56,5789 43 32 1,6 0,3 27 50 49 39,6825 64,4737 35 35 1,7 0,3 21 37 55 32,7434 72,3684 27 36 1,8 0,3 19 28 57 26,9231 75 25 40 1,9 0,3 13 20 63 20,8333 82,8947 17 39
2 0,3 9 12 67 13,6364 88,1579 11 42 Tabela 61 – Tabela do teste 13, � igual 0,3
Lambda=0.3
0102030405060708090
100
10 20 30 40 50 60 70 80
FDR (%)
MD
R (%
)
Alpha1
Figura 61 – Gráfico do teste 13 com � 1 a variar de 0 a 2 e � igual 0,3
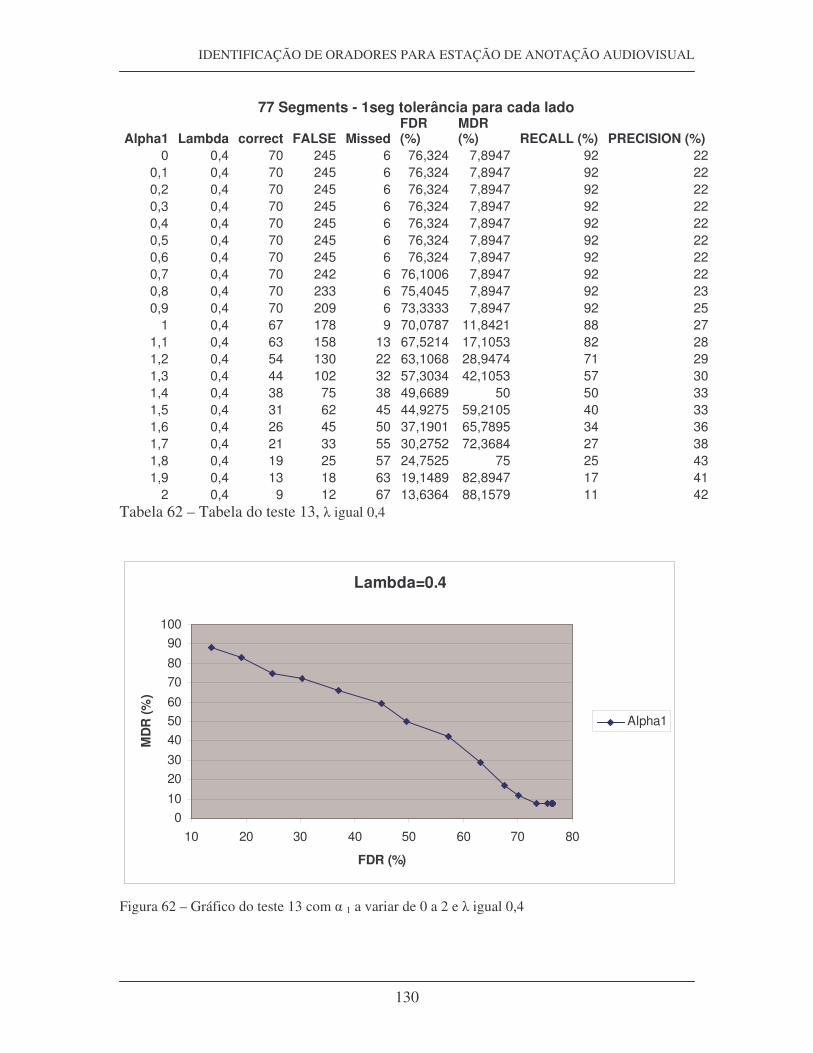
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
130
77 Segments - 1seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,4 70 245 6 76,324 7,8947 92 22 0,1 0,4 70 245 6 76,324 7,8947 92 22 0,2 0,4 70 245 6 76,324 7,8947 92 22 0,3 0,4 70 245 6 76,324 7,8947 92 22 0,4 0,4 70 245 6 76,324 7,8947 92 22 0,5 0,4 70 245 6 76,324 7,8947 92 22 0,6 0,4 70 245 6 76,324 7,8947 92 22 0,7 0,4 70 242 6 76,1006 7,8947 92 22 0,8 0,4 70 233 6 75,4045 7,8947 92 23 0,9 0,4 70 209 6 73,3333 7,8947 92 25
1 0,4 67 178 9 70,0787 11,8421 88 27 1,1 0,4 63 158 13 67,5214 17,1053 82 28 1,2 0,4 54 130 22 63,1068 28,9474 71 29 1,3 0,4 44 102 32 57,3034 42,1053 57 30 1,4 0,4 38 75 38 49,6689 50 50 33 1,5 0,4 31 62 45 44,9275 59,2105 40 33 1,6 0,4 26 45 50 37,1901 65,7895 34 36 1,7 0,4 21 33 55 30,2752 72,3684 27 38 1,8 0,4 19 25 57 24,7525 75 25 43 1,9 0,4 13 18 63 19,1489 82,8947 17 41
2 0,4 9 12 67 13,6364 88,1579 11 42 Tabela 62 – Tabela do teste 13, � igual 0,4
Lambda=0.4
0102030405060708090
100
10 20 30 40 50 60 70 80
FDR (%)
MD
R (%
)
Alpha1
Figura 62 – Gráfico do teste 13 com � 1 a variar de 0 a 2 e � igual 0,4

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
131
77 Segments - 1seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,5 67 118 9 60,8247 11,8421 88 36 0,1 0,5 67 118 9 60,8247 11,8421 88 36 0,2 0,5 67 118 9 60,8247 11,8421 88 36 0,3 0,5 67 118 9 60,8247 11,8421 88 36 0,4 0,5 67 118 9 60,8247 11,8421 88 36 0,5 0,5 67 118 9 60,8247 11,8421 88 36 0,6 0,5 67 118 9 60,8247 11,8421 88 36 0,7 0,5 67 117 9 60,6218 11,8421 88 36 0,8 0,5 67 115 9 60,2094 11,8421 88 36 0,9 0,5 67 109 9 58,9189 11,8421 88 38
1 0,5 65 85 11 52,795 14,4737 85 43 1,1 0,5 60 74 16 49,3333 21,0526 78 44 1,2 0,5 52 63 24 45,3237 31,5789 68 45 1,3 0,5 42 60 34 44,1176 44,7368 55 41 1,4 0,5 37 54 39 41,5385 51,3158 48 40 1,5 0,5 31 44 45 36,6667 59,2105 40 41 1,6 0,5 25 32 51 29,6296 67,1053 32 43 1,7 0,5 21 26 55 25,4902 72,3684 27 44 1,8 0,5 19 19 57 20 75 25 50 1,9 0,5 13 17 63 18,2796 82,8947 17 43
2 0,5 9 10 67 11,6279 88,1579 11 47 Tabela 63 – Tabela do teste 13, � igual 0,5
Lambda=0.5
0102030405060708090
100
10 20 30 40 50 60
FDR (%)
MD
R (%
)
Alpha1
Figura 63 – Gráfico do teste 13 com � 1 a variar de 0 a 2 e � igual 0,5

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
132
12.3 ANEXOS 3 - SEGMENTADOR COM BIC TESTE 7 – intercalado com silêncio
13 Speakers - 12 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,5 9 22 3 64,7059 25 75 29 0,1 0,5 9 22 3 64,7059 25 75 29 0,2 0,5 9 22 3 64,7059 25 75 29 0,3 0,5 9 22 3 64,7059 25 75 29 0,4 0,5 9 22 3 64,7059 25 75 29 0,5 0,5 9 22 3 64,7059 25 75 29 0,6 0,5 9 22 3 64,7059 25 75 29 0,7 0,5 9 21 3 63,6364 25 75 30 0,8 0,5 9 21 3 63,6364 25 75 30 0,9 0,5 9 19 3 61,2903 25 75 32
1 0,5 9 15 3 55,5556 25 75 37 1,1 0,5 9 13 3 52 25 75 40 1,2 0,5 8 12 4 50 33,3333 66 40 1,3 0,5 7 8 5 40 41,6667 58 46 1,4 0,5 6 5 6 29,4118 50 50 54 1,5 0,5 6 5 6 29,4118 50 50 54 1,6 0,5 6 4 6 25 50 50 60 1,7 0,5 6 3 6 20 50 50 66 1,8 0,5 6 1 6 7,6923 50 50 85 1,9 0,5 5 0 7 0 58,3333 41 100
2 0,5 4 0 8 0 66,6667 33 100 Tabela 64 – Tabela do teste 7, intercalado com silêncio, � igual 0,5
Lambda=0.5
2025303540455055606570
15 25 35 45 55 65 75
FDR (%)
MD
R (%
)
Alpha1
Figura 64 – Gráfico do teste 17, intercalado com silêncio, com � 1 a variar de 0 a 2 e � igual 0,5

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
133
13 Speakers - 12 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,6 9 15 3 55,5556 25 75 37 0,1 0,6 9 15 3 55,5556 25 75 37 0,2 0,6 9 15 3 55,5556 25 75 37 0,3 0,6 9 15 3 55,5556 25 75 37 0,4 0,6 9 15 3 55,5556 25 75 37 0,5 0,6 9 15 3 55,5556 25 75 37 0,6 0,6 9 15 3 55,5556 25 75 37 0,7 0,6 9 14 3 53,8462 25 75 39 0,8 0,6 9 14 3 53,8462 25 75 39 0,9 0,6 9 12 3 50 25 75 42
1 0,6 8 11 4 47,8261 33,3333 66 42 1,1 0,6 8 9 4 42,8571 33,3333 66 47 1,2 0,6 7 8 5 40 41,6667 58 46 1,3 0,6 6 6 6 33,3333 50 50 50 1,4 0,6 6 3 6 20 50 50 66 1,5 0,6 6 2 6 14,2857 50 50 75 1,6 0,6 6 1 6 7,6923 50 50 85 1,7 0,6 6 1 6 7,6923 50 50 85 1,8 0,6 6 1 6 7,6923 50 50 85 1,9 0,6 5 0 7 0 58,3333 41 100
2 0,6 4 0 8 0 66,6667 33 100 Tabela 65 – Tabela do teste 7, intercalado com silêncio, � igual 0,6
Lambda=0.6
2025303540455055606570
0 10 20 30 40 50 60
FDR (%)
MD
R (
%)
Alpha1
Figura 65 – Gráfico do teste 17, intercalado com silêncio, com � 1 a variar de 0 a 2 e � igual 0,6
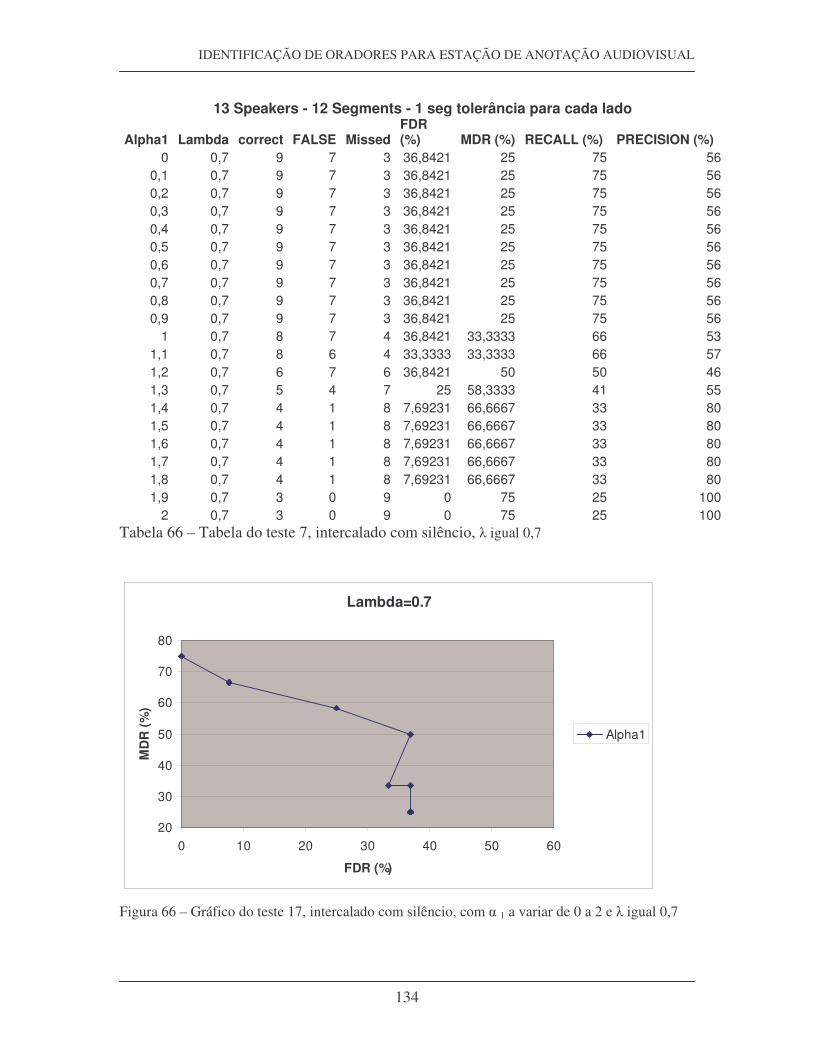
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
134
13 Speakers - 12 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%) MDR (%) RECALL (%) PRECISION (%)
0 0,7 9 7 3 36,8421 25 75 56 0,1 0,7 9 7 3 36,8421 25 75 56 0,2 0,7 9 7 3 36,8421 25 75 56 0,3 0,7 9 7 3 36,8421 25 75 56 0,4 0,7 9 7 3 36,8421 25 75 56 0,5 0,7 9 7 3 36,8421 25 75 56 0,6 0,7 9 7 3 36,8421 25 75 56 0,7 0,7 9 7 3 36,8421 25 75 56 0,8 0,7 9 7 3 36,8421 25 75 56 0,9 0,7 9 7 3 36,8421 25 75 56
1 0,7 8 7 4 36,8421 33,3333 66 53 1,1 0,7 8 6 4 33,3333 33,3333 66 57 1,2 0,7 6 7 6 36,8421 50 50 46 1,3 0,7 5 4 7 25 58,3333 41 55 1,4 0,7 4 1 8 7,69231 66,6667 33 80 1,5 0,7 4 1 8 7,69231 66,6667 33 80 1,6 0,7 4 1 8 7,69231 66,6667 33 80 1,7 0,7 4 1 8 7,69231 66,6667 33 80 1,8 0,7 4 1 8 7,69231 66,6667 33 80 1,9 0,7 3 0 9 0 75 25 100
2 0,7 3 0 9 0 75 25 100 Tabela 66 – Tabela do teste 7, intercalado com silêncio, � igual 0,7
Lambda=0.7
20
30
40
50
60
70
80
0 10 20 30 40 50 60
FDR (%)
MD
R (
%)
Alpha1
Figura 66 – Gráfico do teste 17, intercalado com silêncio, com � 1 a variar de 0 a 2 e � igual 0,7

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
135
TESTE 10 – intercalado com silêncio
14 Speakers - 13 Segments - 1seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%)
RECALL (%) PRECISION (%)
0 0,3 12 5 1 27,7778 7,69231 92 70 0,1 0,3 12 5 1 27,7778 7,69231 92 70 0,2 0,3 12 5 1 27,7778 7,69231 92 70 0,3 0,3 12 5 1 27,7778 7,69231 92 70 0,4 0,3 12 5 1 27,7778 7,69231 92 70 0,5 0,3 12 5 1 27,7778 7,69231 92 70 0,6 0,3 12 5 1 27,7778 7,69231 92 70 0,7 0,3 12 5 1 27,7778 7,69231 92 70 0,8 0,3 12 5 1 27,7778 7,69231 92 70 0,9 0,3 12 3 1 18,75 7,69231 92 80
1 0,3 12 3 1 18,75 7,69231 92 80 1,1 0,3 12 3 1 18,75 7,69231 92 80 1,2 0,3 10 2 3 13,3333 23,0769 76 83 1,3 0,3 9 2 4 13,3333 30,7692 69 81 1,4 0,3 9 2 4 13,3333 30,7692 69 81 1,5 0,3 8 2 5 13,3333 38,4615 61 80 1,6 0,3 7 2 6 13,3333 46,1538 53 77 1,7 0,3 6 0 7 0 53,8462 46 100 1,8 0,3 6 0 7 0 53,8462 46 100 1,9 0,3 5 0 8 0 61,5385 38 100
2 0,3 5 0 8 0 61,5385 38 100 Tabela 67 – Tabela do teste 10, intercalado com silêncio, � igual 0,3
Lambda=0.3
0
10
20
30
40
50
60
70
0 5 10 15 20 25 30
FDR (%)
MD
R (
%)
Alpha1
Figura 67 – Gráfico do teste 10, intercalado com silêncio, com � 1 a variar de 0 a 2 e � igual 0,3
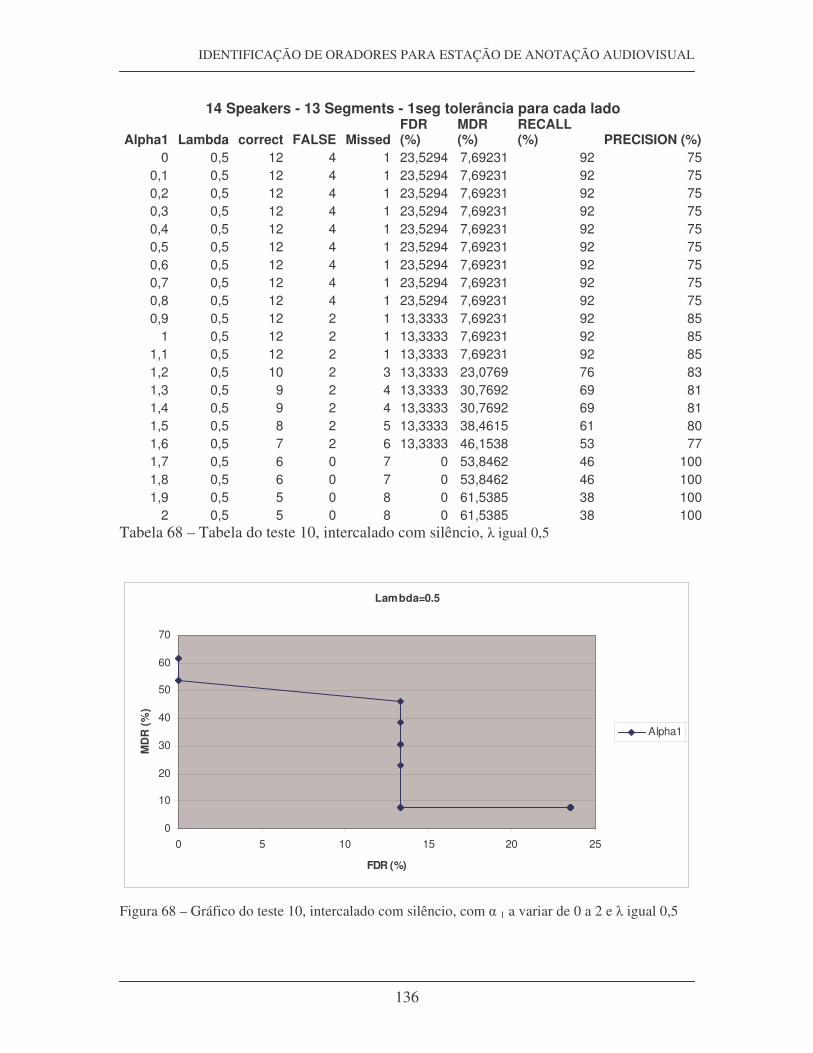
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
136
14 Speakers - 13 Segments - 1seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%)
RECALL (%) PRECISION (%)
0 0,5 12 4 1 23,5294 7,69231 92 75 0,1 0,5 12 4 1 23,5294 7,69231 92 75 0,2 0,5 12 4 1 23,5294 7,69231 92 75 0,3 0,5 12 4 1 23,5294 7,69231 92 75 0,4 0,5 12 4 1 23,5294 7,69231 92 75 0,5 0,5 12 4 1 23,5294 7,69231 92 75 0,6 0,5 12 4 1 23,5294 7,69231 92 75 0,7 0,5 12 4 1 23,5294 7,69231 92 75 0,8 0,5 12 4 1 23,5294 7,69231 92 75 0,9 0,5 12 2 1 13,3333 7,69231 92 85
1 0,5 12 2 1 13,3333 7,69231 92 85 1,1 0,5 12 2 1 13,3333 7,69231 92 85 1,2 0,5 10 2 3 13,3333 23,0769 76 83 1,3 0,5 9 2 4 13,3333 30,7692 69 81 1,4 0,5 9 2 4 13,3333 30,7692 69 81 1,5 0,5 8 2 5 13,3333 38,4615 61 80 1,6 0,5 7 2 6 13,3333 46,1538 53 77 1,7 0,5 6 0 7 0 53,8462 46 100 1,8 0,5 6 0 7 0 53,8462 46 100 1,9 0,5 5 0 8 0 61,5385 38 100
2 0,5 5 0 8 0 61,5385 38 100 Tabela 68 – Tabela do teste 10, intercalado com silêncio, � igual 0,5
Lambda=0.5
0
10
20
30
40
50
60
70
0 5 10 15 20 25
FDR (%)
MD
R (
%)
Alpha1
Figura 68 – Gráfico do teste 10, intercalado com silêncio, com � 1 a variar de 0 a 2 e � igual 0,5

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
137
14 Speakers - 13 Segments - 1seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%)
RECALL (%) PRECISION (%)
0 0,6 11 2 2 13,3333 15,3846 84 84 0,1 0,6 11 2 2 13,3333 15,3846 84 84 0,2 0,6 11 2 2 13,3333 15,3846 84 84 0,3 0,6 11 2 2 13,3333 15,3846 84 84 0,4 0,6 11 2 2 13,3333 15,3846 84 84 0,5 0,6 11 2 2 13,3333 15,3846 84 84 0,6 0,6 11 2 2 13,3333 15,3846 84 84 0,7 0,6 11 2 2 13,3333 15,3846 84 84 0,8 0,6 11 2 2 13,3333 15,3846 84 84 0,9 0,6 11 1 2 7,14286 15,3846 84 91
1 0,6 11 1 2 7,14286 15,3846 84 91 1,1 0,6 11 1 2 7,14286 15,3846 84 91 1,2 0,6 9 1 4 7,14286 30,7692 69 90 1,3 0,6 8 1 5 7,14286 38,4615 61 88 1,4 0,6 8 1 5 7,14286 38,4615 61 88 1,5 0,6 7 1 6 7,14286 46,1538 53 87 1,6 0,6 7 1 6 7,14286 46,1538 53 87 1,7 0,6 6 0 7 0 53,8462 46 100 1,8 0,6 6 0 7 0 53,8462 46 100 1,9 0,6 5 0 8 0 61,5385 38 100
2 0,6 5 0 8 0 61,5385 38 100 Tabela 69 – Tabela do teste 10, intercalado com silêncio, � igual 0,6
Lambda=0.6
0
10
20
30
40
50
60
70
0 2 4 6 8 10 12 14
FDR (%)
MD
R (
%)
Alpha1
Figura 69 – Gráfico do teste 10, intercalado com silêncio, com � 1 a variar de 0 a 2 e � igual 0,6

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
138
14 Speakers - 13 Segments - 1seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,7 10 0 3 0 23,0769 76 100 0,1 0,7 10 0 3 0 23,0769 76 100 0,2 0,7 10 0 3 0 23,0769 76 100 0,3 0,7 10 0 3 0 23,0769 76 100 0,4 0,7 10 0 3 0 23,0769 76 100 0,5 0,7 10 0 3 0 23,0769 76 100 0,6 0,7 10 0 3 0 23,0769 76 100 0,7 0,7 10 0 3 0 23,0769 76 100 0,8 0,7 10 0 3 0 23,0769 76 100 0,9 0,7 10 0 3 0 23,0769 76 100
1 0,7 10 0 3 0 23,0769 76 100 1,1 0,7 10 0 3 0 23,0769 76 100 1,2 0,7 8 0 5 0 38,4615 61 100 1,3 0,7 7 0 6 0 46,1538 53 100 1,4 0,7 7 0 6 0 46,1538 53 100 1,5 0,7 6 0 7 0 53,8462 46 100 1,6 0,7 6 0 7 0 53,8462 46 100 1,7 0,7 5 0 8 0 61,5385 38 100 1,8 0,7 5 0 8 0 61,5385 38 100 1,9 0,7 5 0 8 0 61,5385 38 100
2 0,7 5 0 8 0 61,5385 38 100 Tabela 70 – Tabela do teste 10, intercalado com silêncio, � igual 0,7
Lambda=0.7
0
10
20
30
40
50
60
70
-0,1 0 0,1 0,2 0,3 0,4 0,5
FDR (%)
MD
R (
%)
Alpha1
Figura 70 – Gráfico do teste 10, intercalado com silêncio, com � 1 a variar de 0 a 2 e � igual 0,7
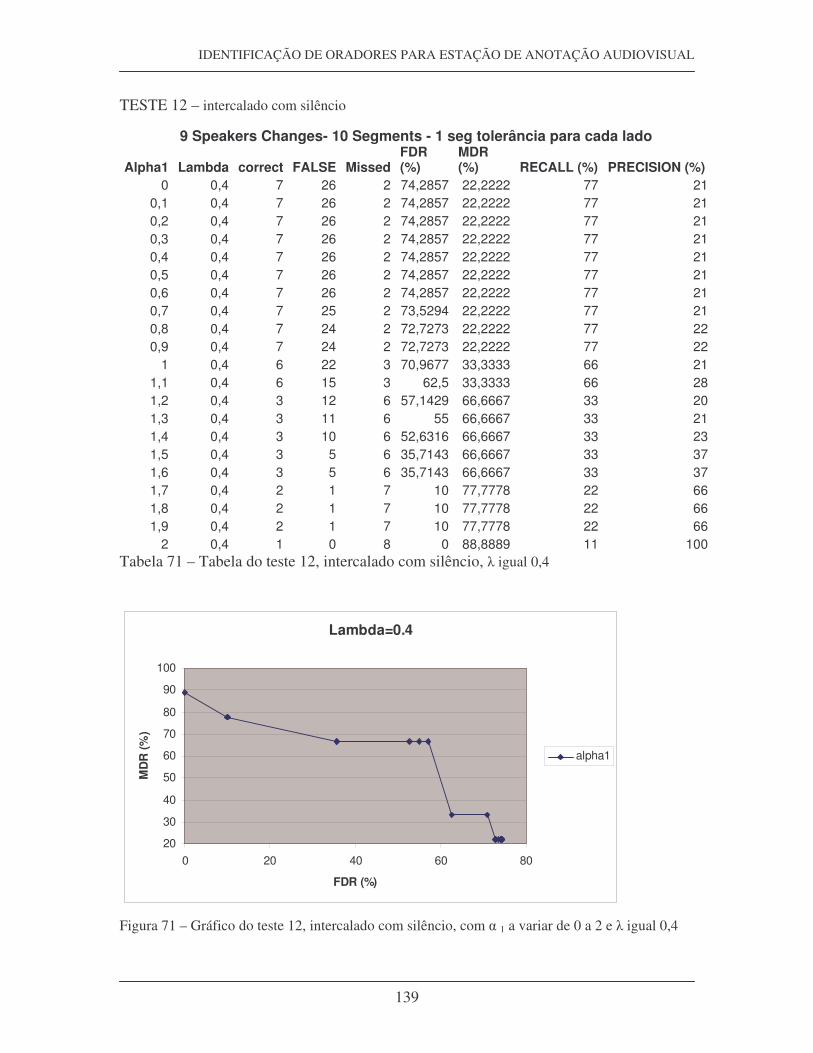
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
139
TESTE 12 – intercalado com silêncio
9 Speakers Changes- 10 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,4 7 26 2 74,2857 22,2222 77 21 0,1 0,4 7 26 2 74,2857 22,2222 77 21 0,2 0,4 7 26 2 74,2857 22,2222 77 21 0,3 0,4 7 26 2 74,2857 22,2222 77 21 0,4 0,4 7 26 2 74,2857 22,2222 77 21 0,5 0,4 7 26 2 74,2857 22,2222 77 21 0,6 0,4 7 26 2 74,2857 22,2222 77 21 0,7 0,4 7 25 2 73,5294 22,2222 77 21 0,8 0,4 7 24 2 72,7273 22,2222 77 22 0,9 0,4 7 24 2 72,7273 22,2222 77 22
1 0,4 6 22 3 70,9677 33,3333 66 21 1,1 0,4 6 15 3 62,5 33,3333 66 28 1,2 0,4 3 12 6 57,1429 66,6667 33 20 1,3 0,4 3 11 6 55 66,6667 33 21 1,4 0,4 3 10 6 52,6316 66,6667 33 23 1,5 0,4 3 5 6 35,7143 66,6667 33 37 1,6 0,4 3 5 6 35,7143 66,6667 33 37 1,7 0,4 2 1 7 10 77,7778 22 66 1,8 0,4 2 1 7 10 77,7778 22 66 1,9 0,4 2 1 7 10 77,7778 22 66
2 0,4 1 0 8 0 88,8889 11 100 Tabela 71 – Tabela do teste 12, intercalado com silêncio, � igual 0,4
Lambda=0.4
20
30
40
50
60
70
80
90
100
0 20 40 60 80
FDR (%)
MD
R (%
)
alpha1
Figura 71 – Gráfico do teste 12, intercalado com silêncio, com � 1 a variar de 0 a 2 e � igual 0,4
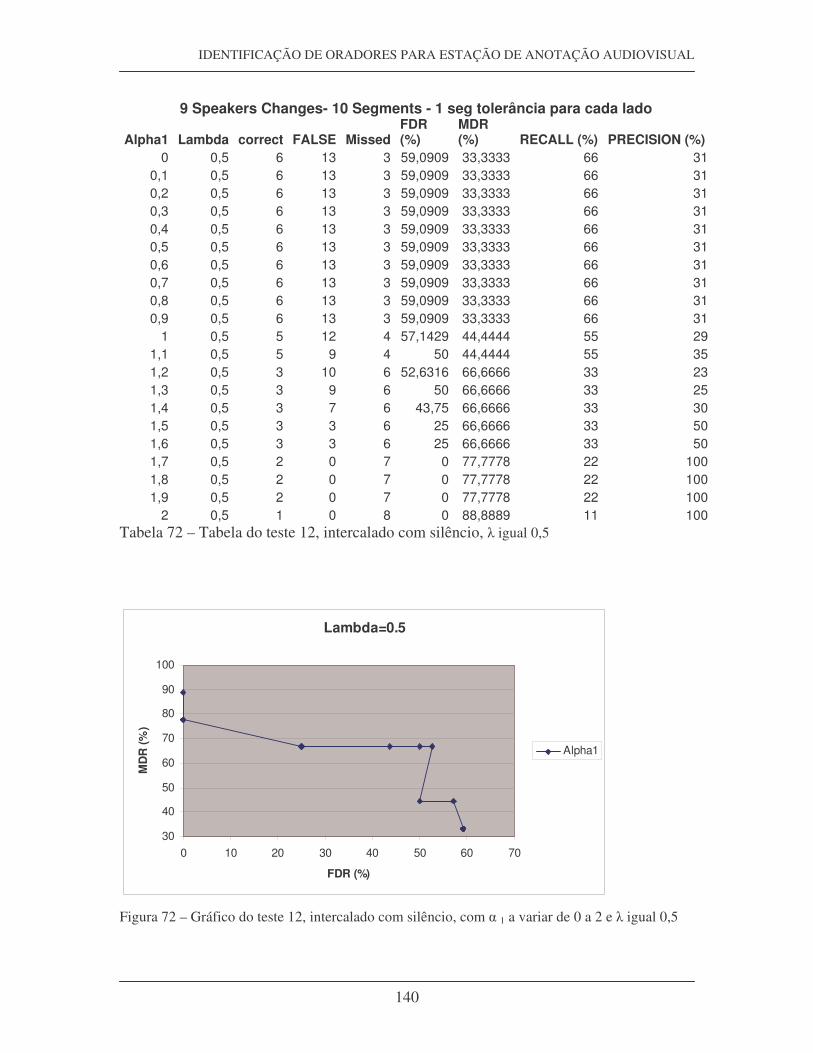
IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
140
9 Speakers Changes- 10 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,5 6 13 3 59,0909 33,3333 66 31 0,1 0,5 6 13 3 59,0909 33,3333 66 31 0,2 0,5 6 13 3 59,0909 33,3333 66 31 0,3 0,5 6 13 3 59,0909 33,3333 66 31 0,4 0,5 6 13 3 59,0909 33,3333 66 31 0,5 0,5 6 13 3 59,0909 33,3333 66 31 0,6 0,5 6 13 3 59,0909 33,3333 66 31 0,7 0,5 6 13 3 59,0909 33,3333 66 31 0,8 0,5 6 13 3 59,0909 33,3333 66 31 0,9 0,5 6 13 3 59,0909 33,3333 66 31
1 0,5 5 12 4 57,1429 44,4444 55 29 1,1 0,5 5 9 4 50 44,4444 55 35 1,2 0,5 3 10 6 52,6316 66,6666 33 23 1,3 0,5 3 9 6 50 66,6666 33 25 1,4 0,5 3 7 6 43,75 66,6666 33 30 1,5 0,5 3 3 6 25 66,6666 33 50 1,6 0,5 3 3 6 25 66,6666 33 50 1,7 0,5 2 0 7 0 77,7778 22 100 1,8 0,5 2 0 7 0 77,7778 22 100 1,9 0,5 2 0 7 0 77,7778 22 100
2 0,5 1 0 8 0 88,8889 11 100 Tabela 72 – Tabela do teste 12, intercalado com silêncio, � igual 0,5
Lambda=0.5
30
40
50
60
70
80
90
100
0 10 20 30 40 50 60 70
FDR (%)
MD
R (%
)
Alpha1
Figura 72 – Gráfico do teste 12, intercalado com silêncio, com � 1 a variar de 0 a 2 e � igual 0,5

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
141
9 Speakers Changes- 10 Segments - 1 seg tolerância para cada lado
Alpha1 Lambda correct FALSE Missed FDR (%)
MDR (%) RECALL (%) PRECISION (%)
0 0,6 4 4 5 30,7692 55,5556 44 50 0,1 0,6 4 4 5 30,7692 55,5556 44 50 0,2 0,6 4 4 5 30,7692 55,5556 44 50 0,3 0,6 4 4 5 30,7692 55,5556 44 50 0,4 0,6 4 4 5 30,7692 55,5556 44 50 0,5 0,6 4 4 5 30,7692 55,5556 44 50 0,6 0,6 4 4 5 30,7692 55,5556 44 50 0,7 0,6 4 4 5 30,7692 55,5556 44 50 0,8 0,6 4 4 5 30,7692 55,5556 44 50 0,9 0,6 4 4 5 30,7692 55,5556 44 50
1 0,6 3 5 6 35,7143 66,6667 33 37 1,1 0,6 3 4 6 30,7692 66,6667 33 42 1,2 0,6 2 4 7 30,7692 77,7778 22 33 1,3 0,6 2 3 7 25 77,7778 22 40 1,4 0,6 2 3 7 25 77,7778 22 40 1,5 0,6 2 2 7 18,1818 77,7778 22 50 1,6 0,6 2 2 7 18,1818 77,7778 22 50 1,7 0,6 2 0 7 0 77,7778 22 100 1,8 0,6 2 0 7 0 77,7778 22 100 1,9 0,6 2 0 7 0 77,7778 22 100
2 0,6 1 0 8 0 88,8889 11 100 Tabela 73 – Tabela do teste 12, intercalado com silêncio, � igual 0,6
Lambda=0.6
50556065707580859095
100105
0 10 20 30 40
FDR (%)
MD
R (%
)
Alpha1
Figura 73 – Gráfico do teste 12, intercalado com silêncio, com � 1 a variar de 0 a 2 e � igual 0,6

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
142
13 - REFERÊNCIAS E BIBLIOGRAFIA
[1] - “Voice and Unvoice Decision” http://www.owlnet.rice.edu/~elec512/PROJECTS00/vocode/uv/uvdet.html [2] - Rabiner, L., Juang, B. H., “Fundamental of Speech Recognition”, 1993 [3] - Ting-Yao, Wu; L. Lu; Ke, Chen; H. J. Zhang (2001) Universal Background Models for Real-Time Speaker Change Detection [4] - W.B. Frakes and R.S. Baeza-Yates. Information Retrieval: Data Structures and Algorithms. Prentice Hall, 1992 [5] - Acetatos da disciplina Análise, Sintese e Reconhecimento da Fala [6] - Cook P., Tzanetakis G. (200) MARSYAS: A Framework for Audio Analysis [7] – Oliveira, Ricardo; Faria, Carlos (2001) Reconhecimento do Orador [8] – Salselas, Inês (2003) Reconhecimento de Sons de Percussão [9] - Deller, J., Hansen, J., Proakis, J., (200) “Discrete-Time Processing of Speech Signals” [10] - H. J. Zhang; L. Lu (2005) “Unsupervised speaker segmentation and tracking in real-time audio content analysis” [11] – H. J. Zhang; L. Lu (2002) “Real-time Unsupervised Speaker Change Detection” [12] – Ting-Yao, Wu; L. Lu; Ke, Chen; H. J. Zhang (2003) “UBM-based incremental Speaker adaptation” [13] – Joseph P. Campbell, JR., (1997) “Speaker Recognition - A Tutorial” [14] – H. J. Zhang; L. Lu (2002) “Speaker change detection and tracking in real-time news broadcasting analysis” [15] - http://www.ines.org.br/paginas/revista/espaco17/ESPACO2.pdf [16] – Petry, A., Zanuz, A. e Barone, D. A. C. () “Reconhecimento automático de pessoas pela voz através de técnicas de processamento digitais de sinais [17] – VISNET D40 – Network Audiovisual Media Technologies, “Rewiew of the work done in Audio-Video Fusion” 2004

IDENTIFICAÇÃO DE ORADORES PARA ESTAÇÃO DE ANOTAÇÃO AUDIOVISUAL
143
[18] – Martins, Maria Raquel Delgado, 1988, “Introdução á Fonética do Português” [19] – Rabiner, L. R., Schafer, R. W.”Digital Processing of Speech Signals”