ibm y la analitica del dato no estructurado enfoque y soluciones
TRANSCRIPT

Analítica del dato no estructurado: Enfoque y Soluciones
Francisco J. Izquierdo
Técnico especialista en gestión de analítica de la información, IBM
@fjizquie

2
¿Guardar toda la documentación es la solución?
Tenemos poca visibilidad sobre qué información
guardar, dónde y por qué
Cuesta mucho conseguir información crítica en
escenarios de requisitos legales y en fechas
límite
Los costes de almacenamiento en espacio, energía e infraestructuras se
disparan
La información válida está enterrada con mucha otra innecesaria
(obsoleta, irrelevante, duplicada)
El modelo de “Guardar todo eternamente”
ya no es válido

Web Pages
Text Messages
Emails
Documents
* AIIM website, accepted industry percentage
El Imperativo del Análisis TextualEl concepto de Análisis de Información está cambiando desde datos
transaccionales y estructurados hacia información interactiva y no
estructurada
Más del 80% de la información almacenada es no estructurada
3
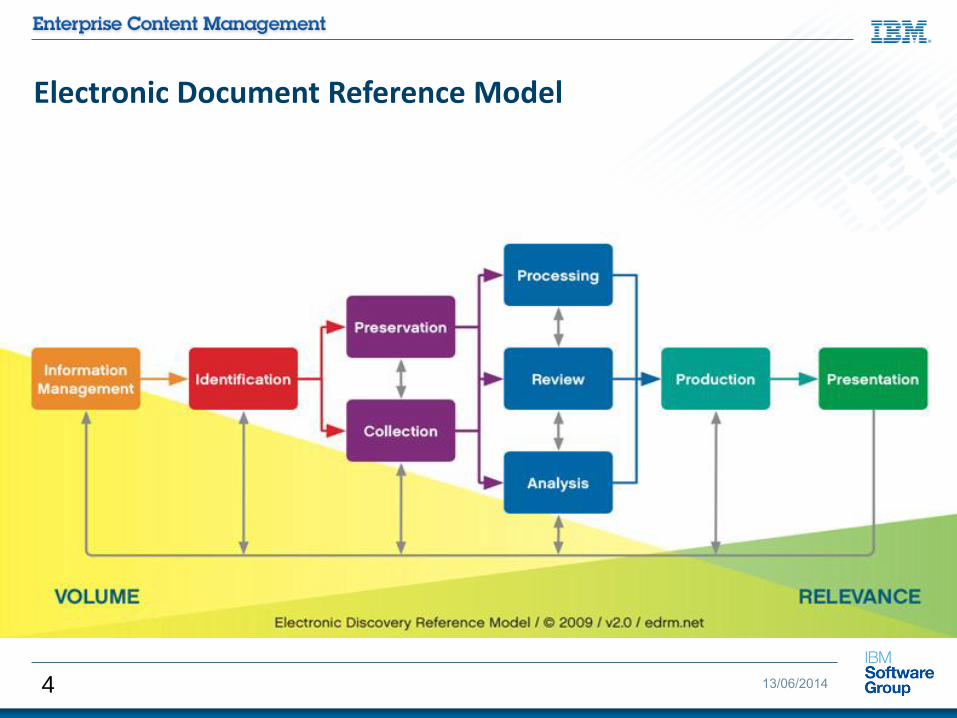
Electronic Document Reference Model
4
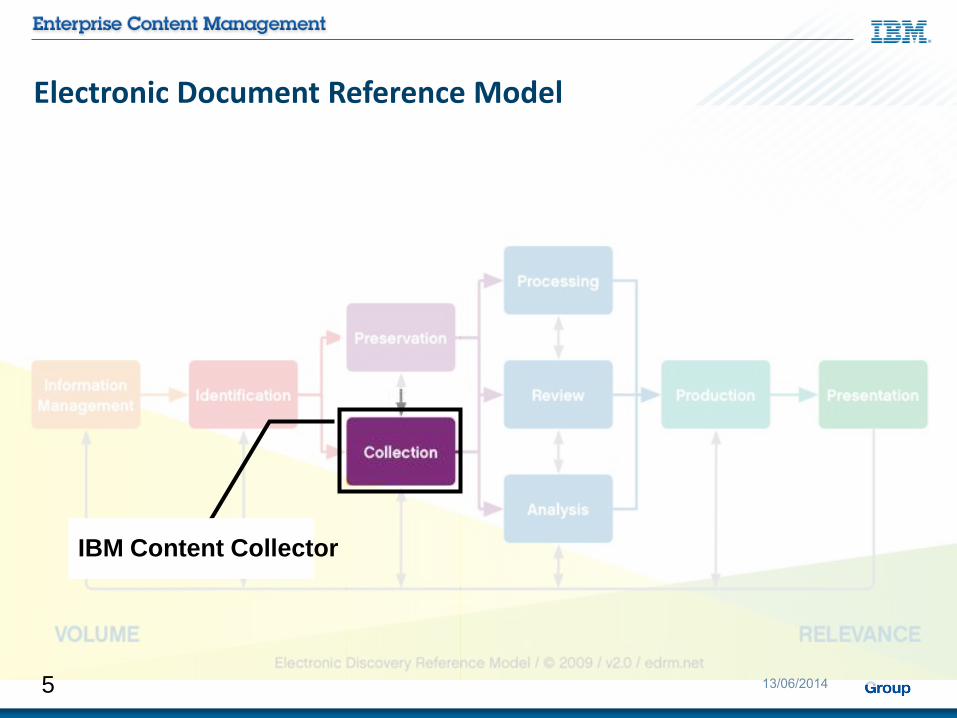
Electronic Document Reference Model
IBM Content Collector
5
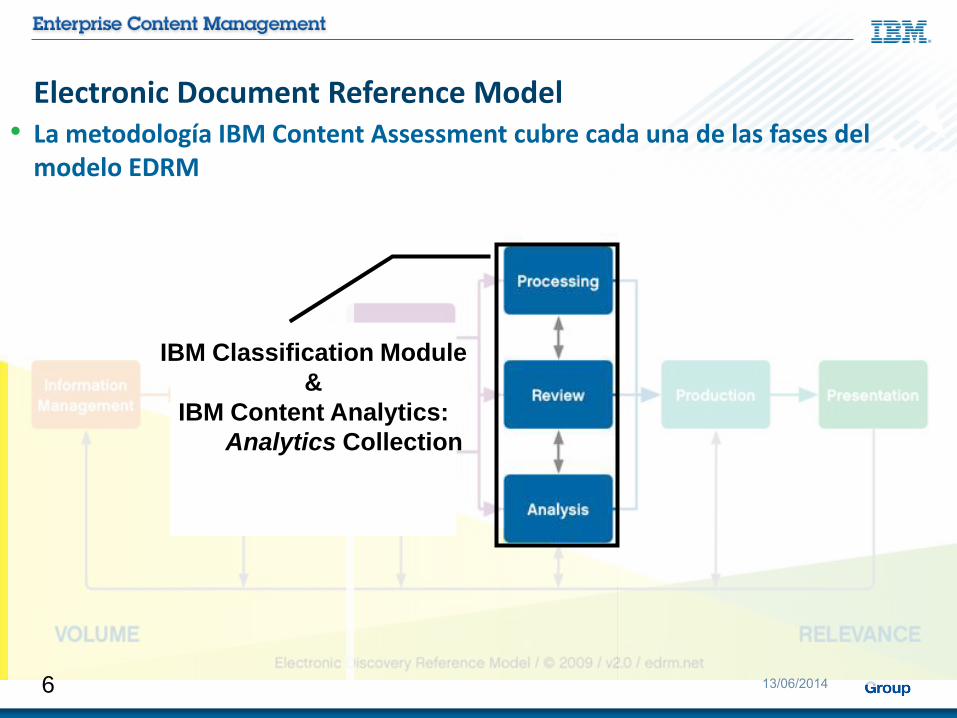
Electronic Document Reference Model• La metodología IBM Content Assessment cubre cada una de las fases del
modelo EDRM
IBM Classification Module
&
IBM Content Analytics:
Analytics Collection
6

7
El papel del Análisis de Texto

8
¿Qué es él Análisis de Texto?
Text Analytics (NLP) describe un
conjunto de técnicas
estadísticas lingüísticas, y de
aprendizaje automático que
permiten que el texto a analizar
y la extracción de información
sea clave para la integración de
negocios.Qué es Content Analytics?
Content Analytics (Text Analytics + Mining)
se refiere al proceso de análisis de texto
además de la capacidad para identificar
visualmente y explorar las tendencias,
patrones, y los hechos estadísticamente
relevantes encontrados en distintos tipos
de difusión de contenidos a través de
fuentes de contenido internas y externas
Definiciones

El Análisis de Contenidos facilita su correcta eliminación
11
Contenido en origen
Sistemas sobrecargados con un almacenamiento poco eficiente
Informaciónnecesaria
Informacióninnecesaria
La eliminación de contenidos
favorece el control sobre
los mismos, eliminando
aquella información
que ya no es necesariaUn cliente encontró en sus unidades de red 1200
copias de un mismo documento, incluyendo 5
versiones diferentes.
12
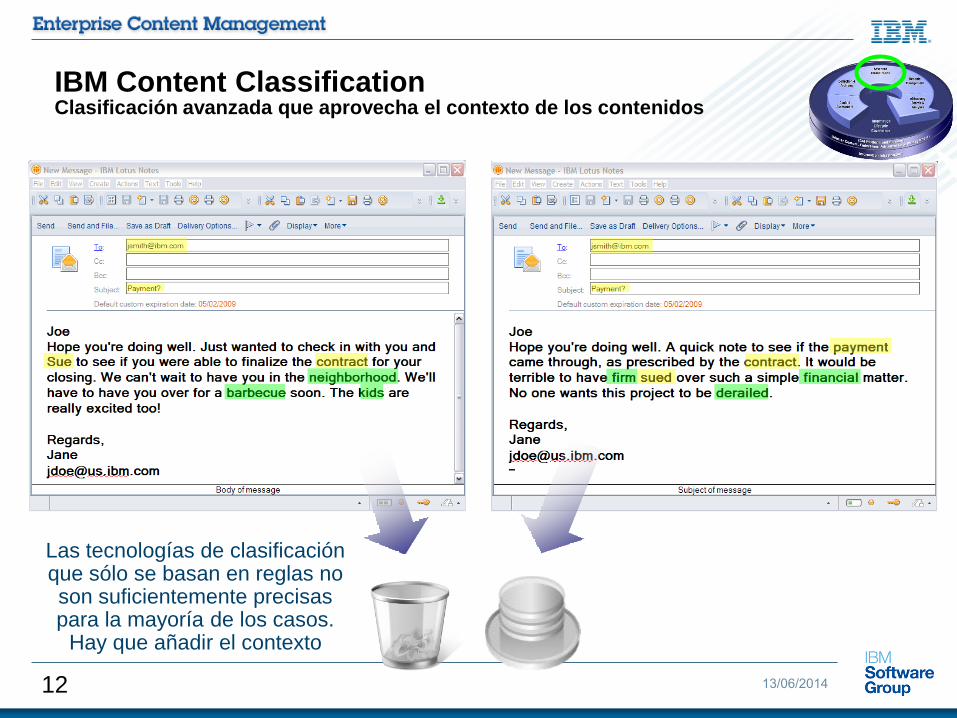
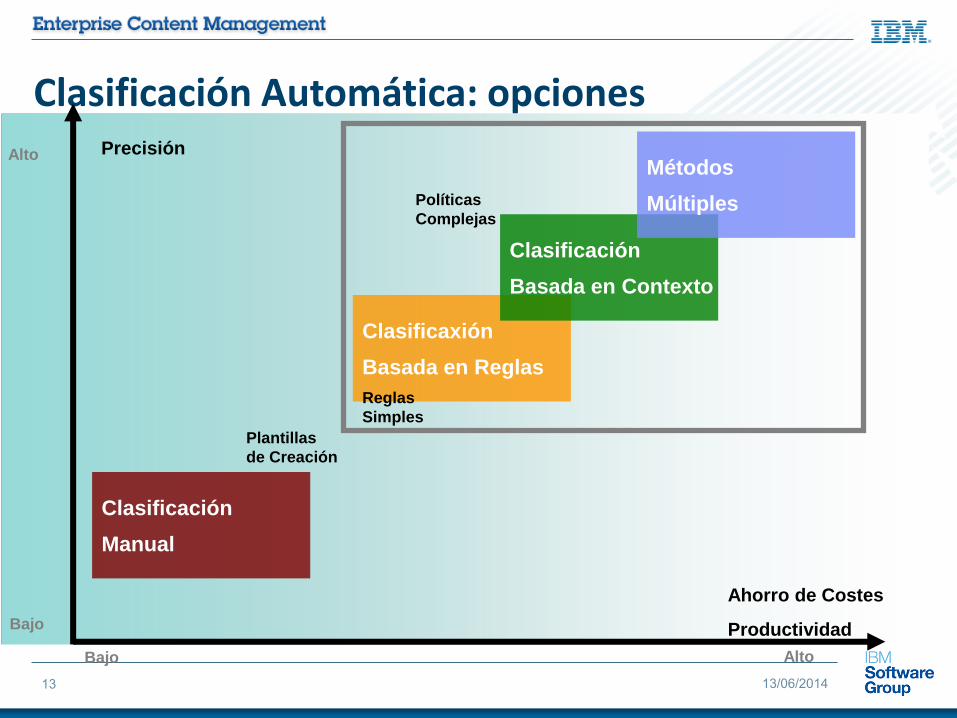
IBM Content ClassificationClasificación avanzada que aprovecha el contexto de los contenidos
Las tecnologías de clasificación que sólo se basan en reglas no son suficientemente precisas para la mayoría de los casos.
Hay que añadir el contexto
Clasificación Automática: opciones
Bajo Alto
Alto
Bajo
Ahorro de Costes
Productividad
Precisión
Clasificación
Manual
Plantillas
de Creación
Clasificaxión
Basada en Reglas
Clasificación
Basada en Contexto
Reglas
Simples
Políticas
Complejas
Métodos
Múltiples
Classification Workbench
14
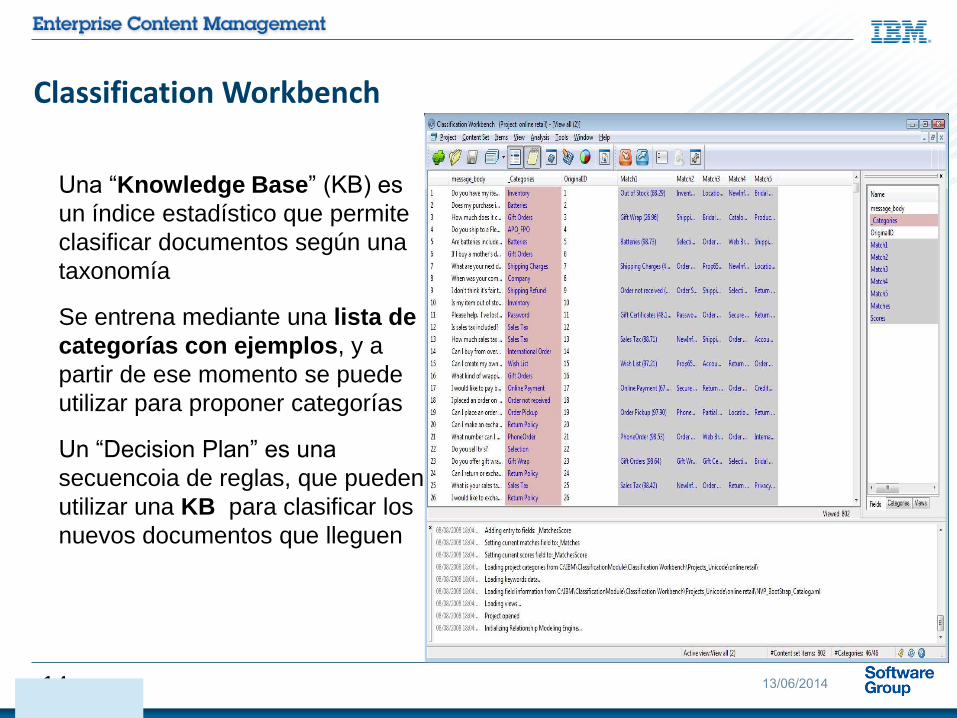
Una “Knowledge Base” (KB) es
un índice estadístico que permite
clasificar documentos según una
taxonomía
Se entrena mediante una lista de
categorías con ejemplos, y a
partir de ese momento se puede
utilizar para proponer categorías
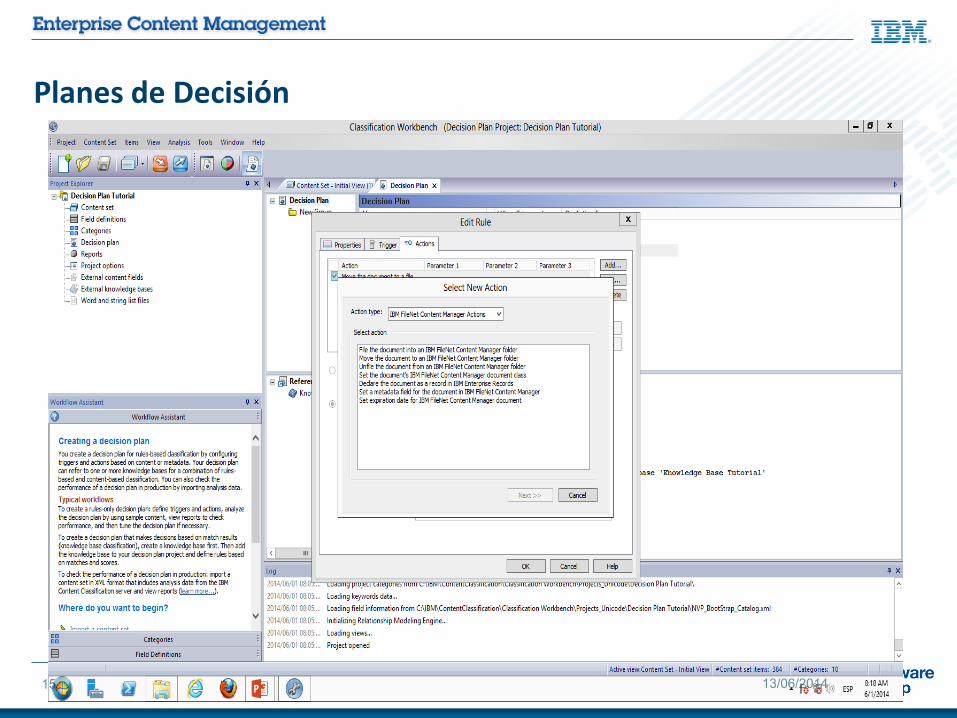
Un “Decision Plan” es una
secuencoia de reglas, que pueden
utilizar una KB para clasificar los
nuevos documentos que lleguen
Planes de Decisión
Ruta de Captura
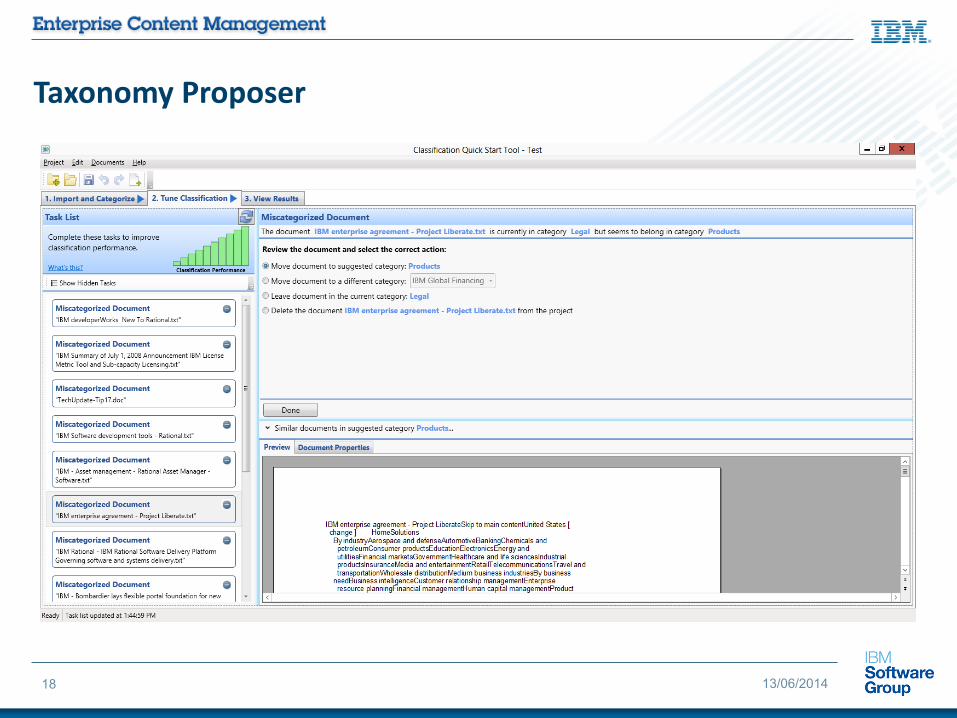
Taxonomy Proposer
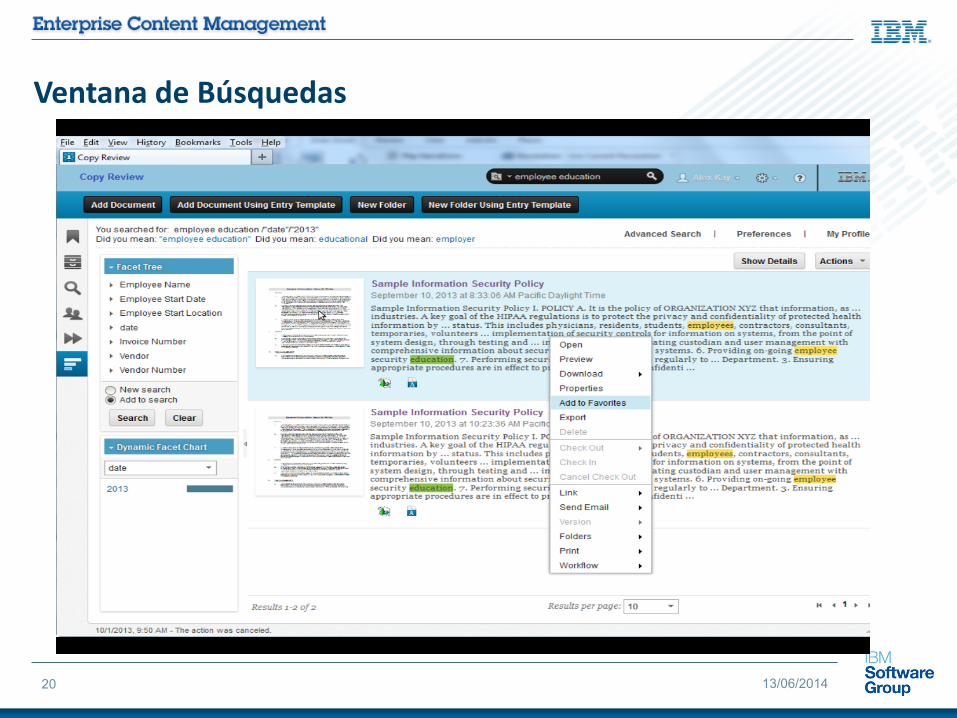
Ventana de Búsquedas

GRACIAS
www.ibm.com/software/es/ecm
@fjizquie