herramientas computacionales en el...
TRANSCRIPT

Herramientas Computacionales en el Laboratorio11 Primer curso del Grado en Física dela Universidad de Cantabria.
R. Alcaraz de la Osa
Apuntes Curso 2017-2018
Índice
Introducción 2
Origen de la Estadística 2
Lenguaje: algunas definiciones 2
Pensamiento crítico y estadístico 3
Ramas de la Estadística 4
Estadística Descriptiva 5
Representación gráfica 5
Medidas de centralización 10
Medidas de dispersión 11
Probabilidad 14
Algunas definiciones 14
Conjuntos 14
Definición frecuentista de probabilidad 14
Definición axiomática de probabilidad 15
Propiedades de la probabilidad 15
Determinación sistemática de probabilidades 16
Técnicas para contar 16
Probabilidad condicionada 18
Variable Aleatoria 19
Distribuciones de probabilidad 19
Parámetros estadísticos de una variable aleatoria 21
Variables Aleatorias más Comunes en Física 22
Distribución binomial 22
Distribución uniforme discreta 23
Distribución de Poisson 23
Distribución uniforme continua 24
Distribución normal 24
Regresión y Correlación 28
Correlación lineal 28
Regresión lineal simple 29
Análisis de los residuos: evaluación del modelo 31
Mínimos Cuadrados pesados 32

herramientas computacionales en el laboratorio 2
Introducción
La estadística es la ciencia que se encarga de la planificaciónde estudios y experimentos: obtener datos; y después organizar,resumir, presentar, analizar e interpretar esos datos para sacarconclusiones basadas en ellos.
Los conceptos y métodos estadísticos no solo son útiles sino amenudo indispensables para comprender el mundo que nos rodea.Proporcionan formas de obtener nuevas visiones sobre el compor-tamiento de muchos fenómenos que nos podemos encontrar enfísica
2. La estadística nos permite hacer juicios inteligentes y 2 Una de las ramas más importantesde la física es la llamada física
estadística, que se encarga del estu-dio de las propiedades de la materiacondensada en términos de las leyesfísicas que gobiernan el movimientode los átomos que la forman, utilizan-do teoría de probabilidad y métodosestadísticos.
tomar decisiones informadas ante preguntas desconcertantes queinvolucran incertidumbre y variación3.
3 La presencia de incertidumbre ovariación es un requisito para poderaplicar los métodos estadísticos. Sitodas las medidas experimentalesfueran iguales, una sola observaciónsería suficiente para obtener toda lainformación deseada.
Origen de la Estadística
La palabra estadística se deriva del latín status (estado). Los mé-todos estadísticos se han desarrollado a lo largo de muchos siglos.Los primeros usos de la estadística consistieron en recopilacionesde datos y gráficos que describían diversos aspectos de un estado oun país. En 1662, John Graunt publicó información estadística sobrenacimientos y defunciones. Al trabajo de Graunt le siguieron estu-dios de tasas de mortalidad y enfermedad, tamaños de poblacionesy de tasas de ingresos y de desempleo4. Tanto hogares, gobiernos 4 Para ampliar información, recomen-
damos recurrir al excelente libro deHald [2003].
como negocios dependen de datos estadísticos para orientarse. Porejemplo, las tasas de desempleo, de inflación, índices de consumoy tasas de natalidad y mortalidad se recopilan cuidadosamente deforma regular, sirviendo a los líderes de los negocios para tomardecisiones que afectan a contrataciones futuras, niveles de produc-ción y expansiones hacia otros mercados.
Lenguaje: algunas definiciones
En este apartado damos definiciones formales de algunos con-ceptos básicos:
Datos Colecciones de observaciones, como medidas, géneros, orespuestas a encuestas.
Población Colección completa de todas las medidas o datos que seestán considerando5. 5 Las medidas numéricas que describen
características de una población sedenominan parámetros.Censo Colección de datos de todos y cada uno de los miembros de
una población.6 6 Limitaciones de tiempo, dinero uotros recursos escasos suelen hacer loscensos poco prácticos o imposibles.Muestra Subcolección de miembros seleccionados de una población7.7 Las medidas numéricas que describencaracterísticas de una muestra sedenominan estadísticos.
Variable Cualquier característica cuyo valor puede variar de unmiembro a otro de una población.8
8 Los datos resultan de realizar ob-servaciones sobre una sola variable(conjunto de datos univariado) o simul-táneamente sobre dos (bivariado) o másvariables (multivariado).

herramientas computacionales en el laboratorio 3
Variable discreta: el conjunto de posibles valores es, o bienfinito (“numerable”), o bien se puede enumerar en una se-cuencia infinita.
Variable continua: el conjunto de posibles valores consiste enun intervalo entero sobre la recta numérica (la colección deposibles valores no es numerable).
Pensamiento crítico y estadístico
Cuando llevamos a cabo un estudio estadístico9, debemos reali- 9 En nuestro contexto, pensemos siem-pre en un experimento, involucrandomedidas experimentales de algunamagnitud física/química.
zar un proceso de “preparación, análisis y conclusión” (ver esque-ma más abajo, adaptado de Triola [2012]). Comenzamos con unapreparación que implica consideraciones sobre el contexto, la fuentede los datos y el método de muestreo. Continuamos construyendográficos adecuados, explorando los datos y ejecutando los cálculosnecesarios para el método estadístico que estemos utilizando. Final-mente sacamos conclusiones determinando si los resultados tienensignificancia estadística y práctica10. 10 La significancia estadística se logra
cuando obtenemos un resultado quees muy poco probable que ocurra porazar. En ocasiones, sin embargo, losresultados encontrados pueden tenersignificancia estadística pero no serprácticos —por ejemplo, el sentidocomún sugiere que las diferenciasencontradas no justifican el uso de unnuevo tratamiento.
Preparación
1. Contexto
¿Qué significan los datos?
¿Cuál es el propósito del estudio?
2. Fuente de los Datos
¿Los datos provienen de una fuente con especial interésde forma que existan presiones para obtener resultadosfavorables a la fuente?
3. Método de Muestreo
¿Hubo o no hubo sesgo al recopilar los datos? 11 11 Por ejemplo, existe sesgo si losparticipantes de una encuesta sonvoluntarios.Análisis
1. Representar los Datos
2. Explorar los Datos
¿Existen valores atípicos12? 12 Outliers en inglés, son números muydistantes de cualquier otro.¿Qué estadísticos13 importantes resumen los datos?13 Como la media o la desviaciónestándar que veremos más adelante.¿Cómo están distribuidos los datos?
¿Faltan datos?
3. Aplicar Métodos Estadísticos
Utilizar tecnología (software) para obtener resultados.
Conclusión
1. Significancia Estadística
¿Tienen los resultados significancia estadística?
¿Tienen los resultados significancia práctica?

herramientas computacionales en el laboratorio 4
Ramas de la Estadística
Los estudios estadísticos suelen producir tal número de datosque suele ser necesario resumirlos, para así poder describir suscaracterísticas más importantes. La estadística descriptiva —elarte de resumir datos— se ocupa de la representación gráfica14 y 14 Pensemos en histogramas, diagramas
de barras, diagramas de dispersión,etc.
del estudio de las medidas de resumen (como las de centralización15,15 Media, mediana (percentiles) ymoda.
dispersión16, etc). La Estadística Descriptiva también se encarga
16 Rango, varianza y desviación están-dar.
del análisis de las relaciones —las dependencias— entre variables,donde la correlación y la regresión son los principales temas.
Habiendo obtenido una muestra de una población, podemos(debemos) estar interesados en sacar conclusiones de la poblacióna partir de información obtenida de la muestra. La estadística
inferencial es la rama de la Estadística que se ocupa de hacergeneralizaciones válidas a partir de muestras. Los procedimientosde inferencia más importantes son la estimación puntual17, los tests 17 En este curso estudiaremos única-
mente el muestreo y la estimaciónpuntual.
de hipótesis y la estimación por intervalos de confianza.El puente que une ambas ramas es la probabilidad. Tanto la
Estadística como la Probabilidad se ocupan de preguntas que invo-lucran poblaciones y muestras, pero lo hacen de “forma inversa”una a la otra. En un problema de probabilidad, las propiedades dela población se dan por conocidas, y se hacen y responden pregun-tas sobre una muestra tomada de esa población. En un problemaestadístico, el experimentador tiene acceso a las características deuna muestra, y mediante técnicas inferenciales es capaz de sacarconclusiones sobre la población. La relación entre ambas discipli-nas se puede resumir diciendo que la Probabilidad razona desdela población a la muestra (razonamiento deductivo), mientras quela Estadística Inferencial razona desde la muestra a la población(razonamiento inductivo). Esto se ilustra en la Figura 1.
MuestraPoblación
Probabilidad
EstadísticaInferencial
Figura 1: La relación entre la Proba-bilidad y la Estadística Inferencial.Adaptada de Devore [2014].

herramientas computacionales en el laboratorio 5
Estadística Descriptiva
La estadística descriptiva puede dividirse en dos grandesáreas. Por un lado la representación gráfica de los datos y por otroel resumen numérico de los datos mediante medidas de centraliza-ción y dispersión.
Las principales cinco características de los datos son:
1. Centro: Valor representativo que indica dónde se encuentra elcentro del conjunto de datos.
2. Variación: Medida de la cantidad que varían los valores de losdatos.
3. Distribución: Naturaleza o forma de la dispersión de los datosen el rango de valores.
4. Valores atípicos: Valores de la muestra que se encuentran muylejos de la gran mayoría de los otros valores de la muestra.
5. Tiempo: Cualquier cambio con el tiempo en las características delos datos.
Representación gráfica
Muchas muestras de datos son tan grandes que para compren-derlas necesitamos organizar y resumir los datos, o bien numérica-mente en tablas, o bien visualmente en gráficas, como describire-mos a continuación.
A la hora de organizar y resumir conjuntos muy grandes de da-tos, una distribución de frecuencias (o tabla de frecuencias) puedeser muy útil para entender la naturaleza de la distribución de losdatos (ver Tablas 1 y 2).
Tabla 1: Números que salen al tirar undado 100 veces.
Número Frecuencia Frecuencia%
(clase) absoluta relativa
1 16 0.16 16
2 19 0.19 19
3 12 0.12 12
4 12 0.12 12
5 23 0.23 23
6 18 0.18 18
total 100 1 100
Tabla 2: Números que salen al tirar undado 1000 veces.
Número Frecuencia Frecuencia%
(clase) absoluta relativa
1 154 0.15 15
2 177 0.18 18
3 162 0.16 16
4 164 0.16 16
5 176 0.18 18
6 167 0.17 17
total 1000 1 100
Distribución de frecuencias Una distribución de frecuencias
(o tabla de frecuencias) muestra cómo están agrupados losdatos en categorías (clases) mutuamente excluyentes, enumerandolas categorías junto con el número (frecuencia) de valores en cadacategoría.
Distribución de frecuencias relativa Una variación de la distribuciónde frecuencias básica (absoluta) es la distribución de frecuen-cias relativa, en la que cada frecuencia se reemplaza por unafrecuencia relativa (proporción) o un porcentaje.
Frecuencia relativa de una clase =frecuencia de la clase
suma de todas las frecuencias
Porcentaje de una clase =frecuencia de la clase
suma de todas las frecuencias× 100 %

herramientas computacionales en el laboratorio 6
De cara a construir tablas de frecuencias y sus representacionesgráficas correspondientes, necesitamos definir una serie de términosasociados a las clases:
Límites inferiores de clase Son los números más pequeños que pue-den pertenecer a las distintas clases.
Límite superiores de clase Son los números más grandes que puedenpertenecer a las distintas clases.
Fronteras de clase Son los números que se utilizan para separar lasclases, pero sin los huecos creados por los límites. También seconocen como límites reales de clase.
Marcas de clase Son los puntos intermedios de cada clase. Se obtie-nen promediando los límites inferior y superior de clase.
Anchura de clase Es la diferencia entre dos límites de clase consecu-tivos en una distribución de frecuencias.
Construimos distribuciones de frecuencias para (1) resumir con-juntos grandes de datos, (2) analizar los datos para ver su distribu-ción e identificar valores atípicos, y (3) tener una base para cons-truir gráficos (como histogramas, que introduciremos más adelante).
Para construir una distribución o tabla de frecuencias se puedeutilizar el siguiente procedimiento:
1. Seleccionar el número de clases, habitualmente entre 5 y 2018. 18 Existen varios algoritmos para
determinar el número adecuado declases en las que tenemos que dividirnuestros datos. Por ejemplo, segúnla llamada regla de Sturges, el númeroideal de clases puede aproximarse por1 + log2 n, siendo n el número de datosen nuestra muestra.
2. Calcular la anchura de clase.
Anchura de clase ≈ (valor máximo− valor mínimo)número de clases
Generalmente conviene redondear hacia arriba este valor.
3. Elegir el valor del primer límite inferior de clase bien utilizandoel valor mínimo de los datos bien otro valor por debajo de él.
4. Utilizando el primer límite inferior y la anchura de clase, enu-merar el resto de límites inferiores de clase, añadiendo la anchu-ra de clase en cada caso.
5. Enumerar los límites inferiores de clase en una columna verticaly determinar entonces los límites superiores de clase.
6. Tomar cada valor individual de los datos y asignarlo a una claseconcreta. La frecuencia (absoluta) de esa clase es el número devalores existente en ella.
Tabla 3: Números que salen al tirar undado 100 veces.
Número Frecuencia(clase) cumulativa
1 o menos 16
2 o menos 35
3 o menos 47
4 o menos 59
5 o menos 82
6 o menos 100
Distribución de frecuencias cumulativa Otra variación de la distribu-ción de frecuencias es la llamada distribución de frecuencias
cumulativa, en la que la frecuencia de cada clase es la suma delas frecuencias de esa clase y todas las anteriores (ver Tabla 3).

herramientas computacionales en el laboratorio 7
Histogramas Si bien una distribución de frecuencias es una he-rramienta útil para resumir datos e investigar su distribución, unaherramienta aún mejor es el histograma, que consiste en un gráficoque es más fácil de interpretar que una tabla de números.
Un histograma es un gráfico consistente en barras de la mis-ma anchura adyacentes unas a otras (a menos que existan huecosen los datos). El eje horizontal representa clases de valores cuan-titativos y el eje vertical representa frecuencias. Las alturas de lasbarras corresponden a los valores de las frecuencias, de forma queun histograma es básicamente un gráfico de una distribución defrecuencias.
1 2 3 4 5 60
5
10
15
20
25
Número
Frec
uenc
iaab
solu
ta
Figura 2: Histograma asociado a laTabla 1.
herramientas computacionales en el laboratorio 8
−4 −2 0 2 40
200
400
600
800
Frec
uenc
iaab
solu
taDistribución normal
−4 −2 0 2 40
100
200
300Distribución uniforme
−4 −2 0 2 40
200
400
600
800
Frec
uenc
iaab
solu
ta
Distribución asimétrica positiva
−4 −2 0 2 40
200
400
600
800
Distribución asimétrica negativa
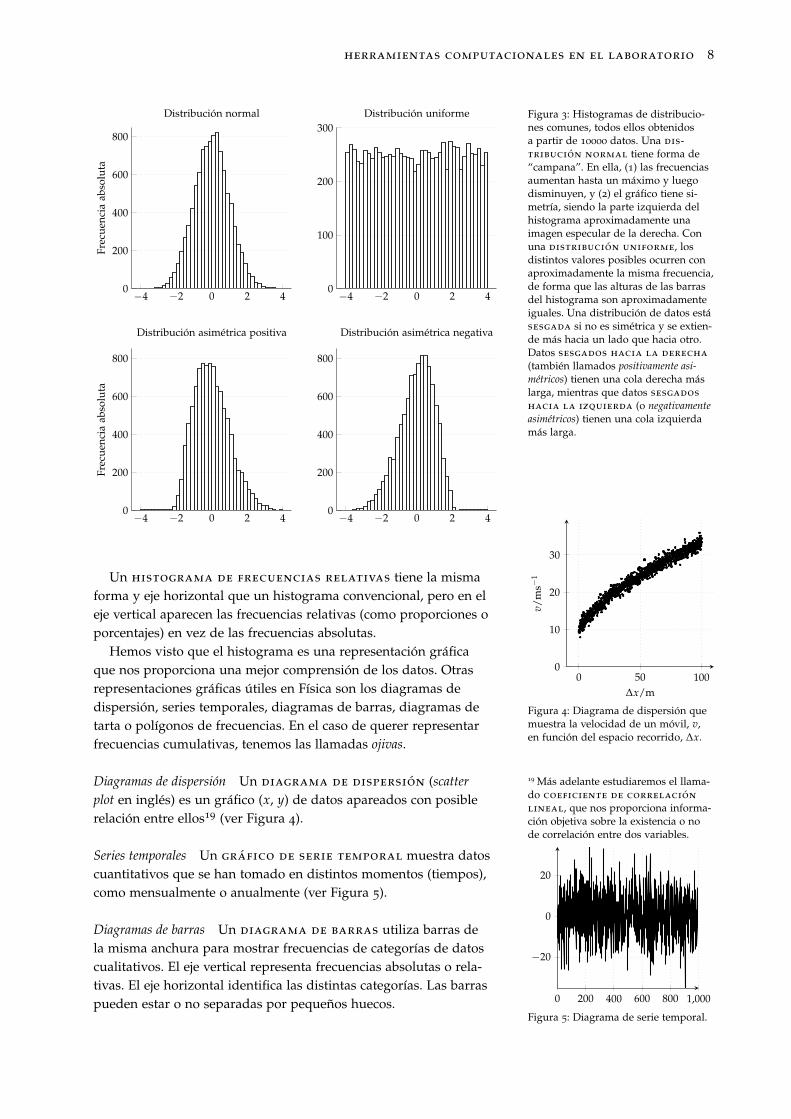
Figura 3: Histogramas de distribucio-nes comunes, todos ellos obtenidosa partir de 10000 datos. Una dis-tribución normal tiene forma de“campana”. En ella, (1) las frecuenciasaumentan hasta un máximo y luegodisminuyen, y (2) el gráfico tiene si-metría, siendo la parte izquierda delhistograma aproximadamente unaimagen especular de la derecha. Conuna distribución uniforme, losdistintos valores posibles ocurren conaproximadamente la misma frecuencia,de forma que las alturas de las barrasdel histograma son aproximadamenteiguales. Una distribución de datos estásesgada si no es simétrica y se extien-de más hacia un lado que hacia otro.Datos sesgados hacia la derecha
(también llamados positivamente asi-métricos) tienen una cola derecha máslarga, mientras que datos sesgados
hacia la izquierda (o negativamenteasimétricos) tienen una cola izquierdamás larga.
Un histograma de frecuencias relativas tiene la mismaforma y eje horizontal que un histograma convencional, pero en eleje vertical aparecen las frecuencias relativas (como proporciones oporcentajes) en vez de las frecuencias absolutas.
0 50 1000
10
20
30
∆x/m
v/m
s−1
Figura 4: Diagrama de dispersión quemuestra la velocidad de un móvil, v,en función del espacio recorrido, ∆x.
Hemos visto que el histograma es una representación gráficaque nos proporciona una mejor comprensión de los datos. Otrasrepresentaciones gráficas útiles en Física son los diagramas dedispersión, series temporales, diagramas de barras, diagramas detarta o polígonos de frecuencias. En el caso de querer representarfrecuencias cumulativas, tenemos las llamadas ojivas.
Diagramas de dispersión Un diagrama de dispersión (scatterplot en inglés) es un gráfico (x, y) de datos apareados con posiblerelación entre ellos19 (ver Figura 4).
19 Más adelante estudiaremos el llama-do coeficiente de correlación
lineal, que nos proporciona informa-ción objetiva sobre la existencia o node correlación entre dos variables.
0 200 400 600 800 1,000
−20
0
20
Figura 5: Diagrama de serie temporal.
Series temporales Un gráfico de serie temporal muestra datoscuantitativos que se han tomado en distintos momentos (tiempos),como mensualmente o anualmente (ver Figura 5).
Diagramas de barras Un diagrama de barras utiliza barras dela misma anchura para mostrar frecuencias de categorías de datoscualitativos. El eje vertical representa frecuencias absolutas o rela-tivas. El eje horizontal identifica las distintas categorías. Las barraspueden estar o no separadas por pequeños huecos.
herramientas computacionales en el laboratorio 9
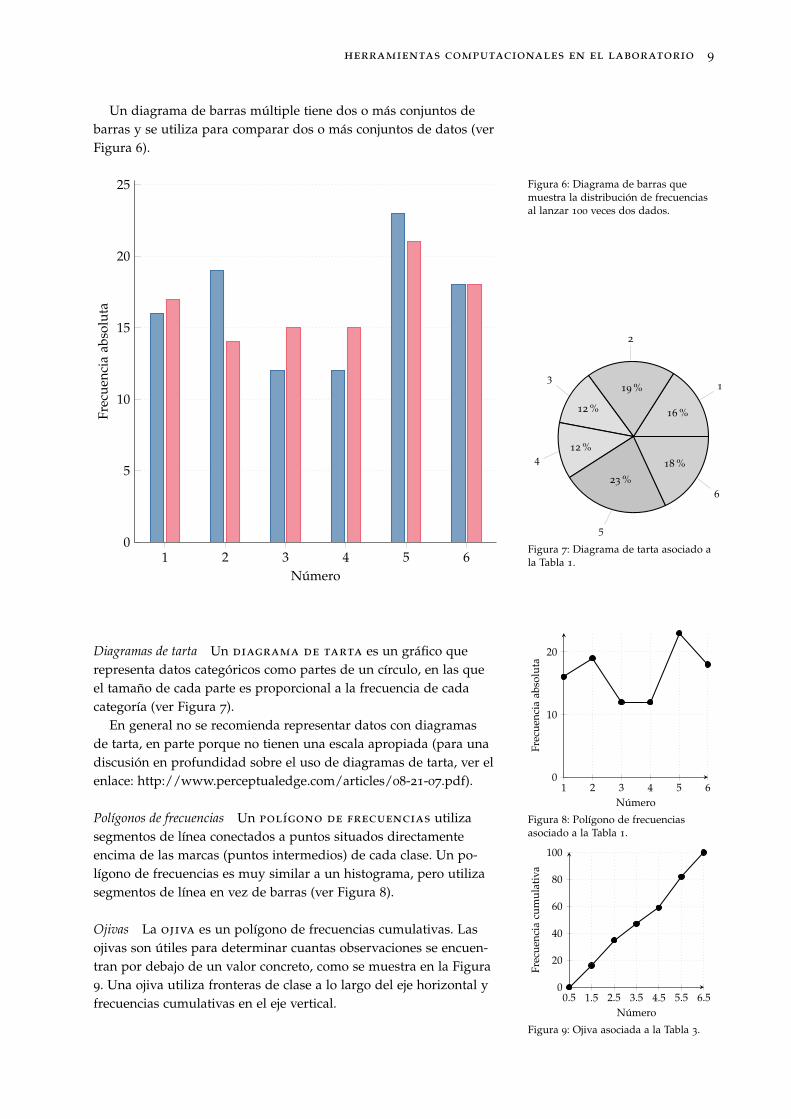
Un diagrama de barras múltiple tiene dos o más conjuntos debarras y se utiliza para comparar dos o más conjuntos de datos (verFigura 6).
1 2 3 4 5 60
5
10
15
20
25
Número
Frec
uenc
iaab
solu
ta
Figura 6: Diagrama de barras quemuestra la distribución de frecuenciasal lanzar 100 veces dos dados.
1
16 %
2
19 %3
12 %
4
12 %
5
23 %6
18 %
Figura 7: Diagrama de tarta asociado ala Tabla 1.
1 2 3 4 5 60
10
20
Número
Frec
uenc
iaab
solu
ta
Figura 8: Polígono de frecuenciasasociado a la Tabla 1.
0.5 1.5 2.5 3.5 4.5 5.5 6.50
20
40
60
80
100
Número
Frec
uenc
iacu
mul
ativ
a
Figura 9: Ojiva asociada a la Tabla 3.
Diagramas de tarta Un diagrama de tarta es un gráfico querepresenta datos categóricos como partes de un círculo, en las queel tamaño de cada parte es proporcional a la frecuencia de cadacategoría (ver Figura 7).
En general no se recomienda representar datos con diagramasde tarta, en parte porque no tienen una escala apropiada (para unadiscusión en profundidad sobre el uso de diagramas de tarta, ver elenlace: http://www.perceptualedge.com/articles/08-21-07.pdf).
Polígonos de frecuencias Un polígono de frecuencias utilizasegmentos de línea conectados a puntos situados directamenteencima de las marcas (puntos intermedios) de cada clase. Un po-lígono de frecuencias es muy similar a un histograma, pero utilizasegmentos de línea en vez de barras (ver Figura 8).
Ojivas La ojiva es un polígono de frecuencias cumulativas. Lasojivas son útiles para determinar cuantas observaciones se encuen-tran por debajo de un valor concreto, como se muestra en la Figura9. Una ojiva utiliza fronteras de clase a lo largo del eje horizontal yfrecuencias cumulativas en el eje vertical.

herramientas computacionales en el laboratorio 10
Medidas de centralización
Representar los datos visualmente nos permite obtener impresio-nes preliminares y comprender muchas características de los datos,en especial cómo están distribuidos. Para llevar a cabo un análisismás formal, necesitamos extraer distintas medidas de resumen. Enesta sección nos interesamos por las medidas de centraliza-ción, en particular la media, mediana y moda.
Media La media (aritmética) es generalmente la medida másimportante, familiar y útil de un conjunto de datos. Se calcula su-mando todos los datos y dividiendo por el número de datos20, y se 20 En caso de tener los datos resumidos
en una tabla de frecuencias, la mediapuede calcularse según la expresión:
x =∑(
f · x)
∑ f
, donde f y x representan la frecuenciay marca (punto intermedio) de cadaclase.
Si asignamos distintos pesos, w, acada dato podemos computar unamedia ponderada:
x =∑ (w · x)
∑ w
suele denotar por x en caso de tener una muestra de datos, o por µ
en caso de ser la media de una población completa.
x =∑ xn
µ =∑ xN
La media puede considerarse como elpunto de equilibro de la distribución delas observaciones.
Las medias de muestras obtenidas de la misma población suelenvariar menos que otras medidas centrales.
La media de un conjunto de datos utiliza todos los valores.
Una desventaja de la media es que un solo valor atípico (outlier)puede hacer variar la media sustancialmente.
Mediana La mediana de un conjunto de datos es la medida cen-tral que es el valor medio, siempre que los datos estén ordenados. Sesuele denotar por x en el caso de una muestra de datos o por µ encaso de ser la mediana de una población entera. Para calcularla, loprimero que hay que hacer es ordenar los datos (de menor a mayor)para después:
1. Si el número de datos es impar, la mediana es el número ubica-do en el medio exacto de la lista ordenada.
2. Si el número de datos es par, la mediana se calcula computandola media entre los dos valores medios de la lista ordenada.
La mediana no cambia demasiado al incluir unos pocos valoresextremos (atípicos).
La mediana no utiliza todos los valores disponibles.
La mediana divide el conjunto de datos en dos partes del mismotamaño. Con el fin de obtener medidas de localización más finas,podemos dividir los datos en más partes. Los cuartiles dividenlos datos en cuatro partes iguales (conteniendo cada parte el 25 %de los datos aproximadamente), mientras que los percentiles lohacen en cien partes iguales (conteniendo cada parte aproximada-mente el 1 % de los datos)21. 21 A menos que el número de datos
sea un múltiplo de cien, hay quetener cuidado a la hora de obtenerpercentiles.

herramientas computacionales en el laboratorio 11
Moda La moda de un conjunto de datos es el valor que ocurrecon mayor frecuencia. Un conjunto de datos puede tener tener unamoda, más de una moda, o ninguna:
0 50
200
400
600
800
Frec
uenc
iaab
solu
ta
Figura 10: Histograma de una distribu-ción bimodal.
Cuando dos valores ocurren con la misma frecuencia máxima,cada uno de ellos es una moda y el conjunto de datos es bimo-dal.
Cuando más de dos valores ocurren con la misma frecuenciamáxima, cada uno de ellos es una moda y el conjunto de datos sedice que es multimodal.
Si ningún valor se repite, entonces decimos que no hay moda.
Medidas de dispersión
Ya hemos dicho previamente que la variación de los datos esprobablemente el tema más importante de la Estadística. En es-ta sección vamos a hablar de conceptos tan importantes como elrango, la desviación estándar y la varianza. Una medida de centrali-zación como la media nos proporciona información parcial sobreun conjunto de datos o distribución. Distintas muestras o pobla-ciones pueden tener medias idénticas pero diferir entre sí de otrasmaneras importantes.
Rango El rango de un conjunto de datos no es más que la di-ferencia entre los valores máximo y mínimo. Cuanto mayor es elrango mayor es la variabilidad de un conjunto de datos. Como elrango utiliza los valores máximo y mínimo, es muy sensible a va-lores extremos, por lo que no es tan útil como las otras medidas dedispersión.
Desviación estándar La desviación estándar es la medida dedispersión más utilizada en Estadística. La desviación estándar deuna muestra, s, es una medida de cuánto se desvían los datos de lamedia. Se calcula según la expresión22: 22 Notar que el denominador es n− 1
en vez de n, debido a varias razones.Se puede mostrar que si dividimos porn tendemos a subestimar el valor de ladesviación estándar. En realidad sólotenemos n− 1 valores independientes(grados de libertad).
En caso de tener los datos resumidosen una tabla de frecuencias, la desvia-ción estándar puede calcularse segúnla expresión:
s =
√√√√∑[
f · (x− x)2]
n− 1
, donde f y x representan de nuevo lafrecuencia y marca de cada clase.
Para calcular la desviación estándarde una población, denotada por σ,utilizamos la expresión:
σ =
√∑(x− µ
)2
N
s =
√∑ (x− x)2
n− 1
La desviación estándar es una medida de cuánto se desvían losdatos de la media.
El valor de la desviación estándar suele ser positivo (nunca ne-gativo). Sólo es cero cuando todos los datos son iguales. Cuantomayor es s mayor es la variación.
El valor de la desviación estándar puede aumentar drásticamenteal incluir uno o más valores atípicos (outliers).
La desviación estándar se mide en las mismas unidades que losdatos originales.

herramientas computacionales en el laboratorio 12
Regla de oro del rango Para poder entender e interpretar valoresde desviación estándar podemos recurrir a la llamada regla de
oro del rango. Ésta se basa en el hecho de que, para muchosconjuntos de datos, la gran mayoría de los datos (sobre el 95 %) seencuentran dentro de dos desviaciones estándar de la media, deforma que la desviación estándar de la muestra, s, se puede estimara partir del rango según la expresión:
s ≈ rango4
, donde rango = (valor máximo) − (valor mínimo). En casode conocer la desviación estándar, la regla de oro del rango nospermite obtener estimaciones de los valores mínimo y máximotípicos:
valor mínimo típico = x− 2s
valor máximo típico = x + 2s
s denota la desviación estándar de la muestra.
Varianza A partir de la desviación estándar podemos calcular lavarianza, definida como el cuadrado de la desviación estándar:
varianza muestral: s2 = cuadrado de la desviación estándar muestral s
varianza poblacional: σ2 = cuadrado de la desviación estándar poblacional σ
La varianza se mide en las unidades de los datos originales alcuadrado.
Como la desviación típica, el valor de la varianza puede aumen-tar drásticamente al incluir uno o más valores atípicos (outliers).
La varianza siempre es mayor o igual que cero, siendo nulaúnicamente cuando todos los datos son iguales.
El hecho de que la varianza no tenga las mismas unidades quelos datos originales hace que su interpretación sea menos intuitivaque la de la desviación típica.
Desviaciones de la media Cuando hablamos de variabilidad, lo pri-mero que se nos ocurre son desviaciones de la media, x1 − x,x2 − x, . . . , xn − x. Podríamos sumar todas las desviaciones para ob-tener una medida única de la variabilidad. Por desgracia esa sumasiempre es cero:
n
∑i=1
(xi − x) =n
∑i=1
xi −n
∑i=1
x =n
∑i=1
xi − nx =n
∑i=1
xi − n
(1n
n
∑i=1
xi
)= 0
Podemos tomar el valor absoluto de las desviaciones, para evitarque los términos positivos y negativos se cancelen. De esa formaobtenemos la llamada desviación absoluta media
23: 23 En la práctica no se utiliza la des-viación absoluta media debido acomplicaciones algebraicas a la horade aplicar los métodos de la estadísticainferencial (la función valor absolutono es derivable).
desviación absoluta media =∑ |x− x|
n
herramientas computacionales en el laboratorio 13
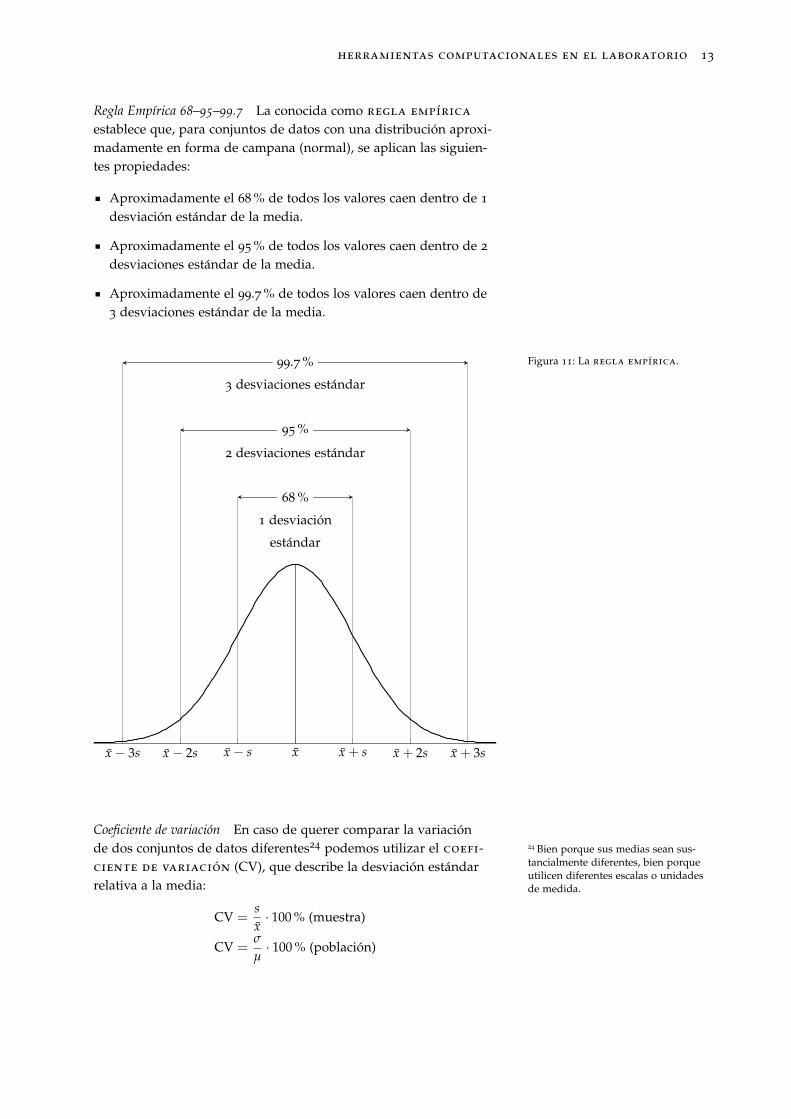
Regla Empírica 68–95–99.7 La conocida como regla empírica
establece que, para conjuntos de datos con una distribución aproxi-madamente en forma de campana (normal), se aplican las siguien-tes propiedades:
Aproximadamente el 68 % de todos los valores caen dentro de 1
desviación estándar de la media.
Aproximadamente el 95 % de todos los valores caen dentro de 2
desviaciones estándar de la media.
Aproximadamente el 99.7 % de todos los valores caen dentro de3 desviaciones estándar de la media.
x− 3s x− 2s x− s x x + s x + 2s x + 3s
68 %
1 desviación
estándar
95 %
2 desviaciones estándar
99.7 %
3 desviaciones estándar
Figura 11: La regla empírica.
Coeficiente de variación En caso de querer comparar la variaciónde dos conjuntos de datos diferentes24 podemos utilizar el coefi- 24 Bien porque sus medias sean sus-
tancialmente diferentes, bien porqueutilicen diferentes escalas o unidadesde medida.
ciente de variación (CV), que describe la desviación estándarrelativa a la media:
CV =sx· 100 % (muestra)
CV =σ
µ· 100 % (población)

herramientas computacionales en el laboratorio 14
Probabilidad
Muchos razonamientos estadísticos dependen de la teoríade probabilidades, a través de modelos de azar. El término proba-bilidad se refiere al estudio de la aleatoriedad y la incertidumbre.En cualquier situación en la que puede ocurrir uno de una serie deresultados posibles, la disciplina de la probabilidad proporcionamétodos para cuantificar las posibilidades, o probabilidad, asocia-das con los diversos resultados.
Algunas definiciones
En el estudio de un cierto fenómeno aleatorio, llamaremos:
S
A B
Figura 12: Diagrama de Venn de lossucesos A y B.
Suceso elemental Cada uno de los posibles resultados de un experi-mento aleatorio.
Espacio muestral Conjunto de todos los posibles resultados (contie-ne todos los sucesos elementales). Lo denotaremos por S .
Suceso Subconjunto del espacio muestral.
Conjuntos
Un suceso es un conjunto, por lo que podemos utilizar relacionesy resultados de teoría de conjuntos básica para estudiar sucesos.
S
A
Figura 13: La región sombreada es A.
Suceso contrario (complementario) de A Se denota por A y es el con-junto de todos los resultados no contenidos en A.
S
A B
Figura 14: La región sombreada esA ∪ B.
Suceso unión La unión de dos sucesos A y B se denota por A ∪ B yse lee como “A o B”. Consiste en el suceso que contiene todos losresultados que están bien en A, bien en B o en ambos (es decir,todos los casos que están en al menos uno de los dos sucesos).
S
A B
Figura 15: La región sombreada esA ∩ B.
Suceso intersección Se denota por A ∩ B y se lee “A y B”. Es elsuceso que se verifica si lo hacen a la vez A y B.
S
A B
Figura 16: Sucesos incompatibles.
El suceso imposible (o nulo) es aquel que no contiene ningún re-sultado en absoluto, y se denota por ∅. Cuando A ∩ B = ∅, se diceque A y B son mutuamente excluyentes o sucesos incompatibles.
Definición frecuentista de probabilidad
Imagina un experimento que pueda ser repetido de forma idén-tica e independiente tantas veces como queramos25. Si contamos el
25 Ejemplos de tales experimentospueden ser lanzar una moneda o undado.
número de veces que el suceso A ocurre, entonces la probabilidadP(A) se puede aproximar por:
P(A) =número de veces que ocurre A
número de veces que se repite el experimento
herramientas computacionales en el laboratorio 15
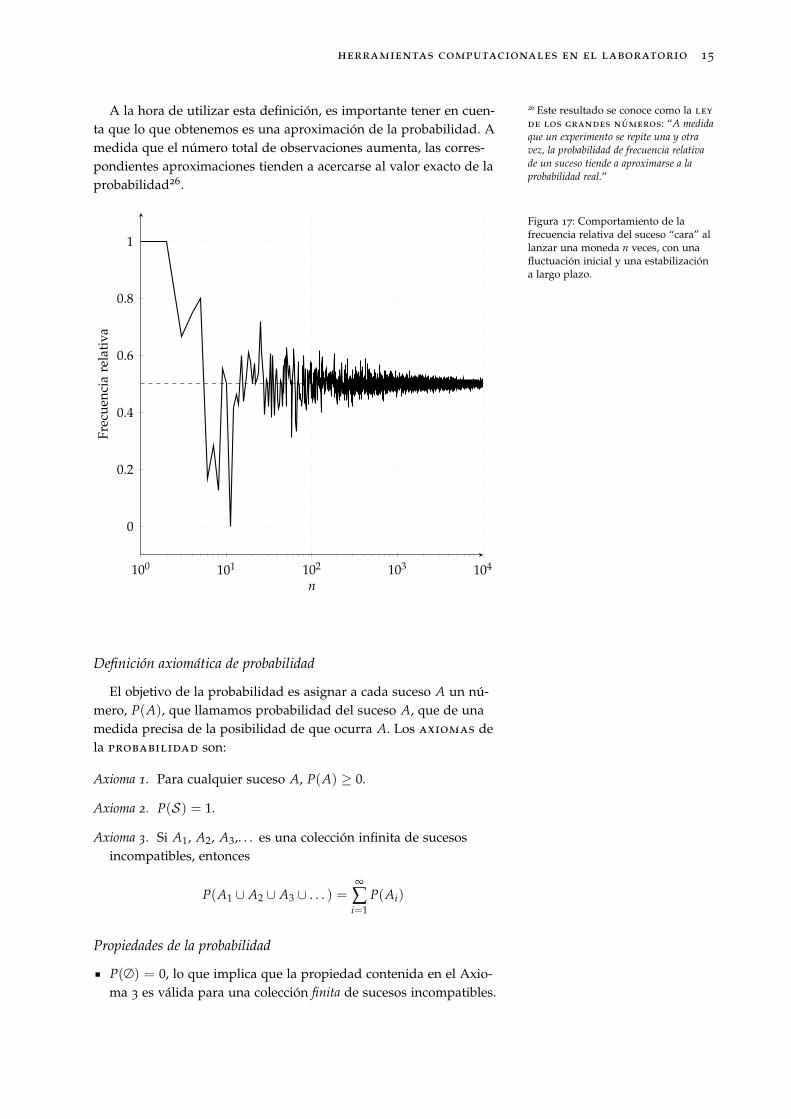
A la hora de utilizar esta definición, es importante tener en cuen-ta que lo que obtenemos es una aproximación de la probabilidad. Amedida que el número total de observaciones aumenta, las corres-pondientes aproximaciones tienden a acercarse al valor exacto de laprobabilidad26.
26 Este resultado se conoce como la ley
de los grandes números: “A medidaque un experimento se repite una y otravez, la probabilidad de frecuencia relativade un suceso tiende a aproximarse a laprobabilidad real.”
100 101 102 103 104
0
0.2
0.4
0.6
0.8
1
n
Frec
uenc
iare
lati
va
Figura 17: Comportamiento de lafrecuencia relativa del suceso “cara” allanzar una moneda n veces, con unafluctuación inicial y una estabilizacióna largo plazo.
Definición axiomática de probabilidad
El objetivo de la probabilidad es asignar a cada suceso A un nú-mero, P(A), que llamamos probabilidad del suceso A, que de unamedida precisa de la posibilidad de que ocurra A. Los axiomas dela probabilidad son:
Axioma 1. Para cualquier suceso A, P(A) ≥ 0.
Axioma 2. P(S) = 1.
Axioma 3. Si A1, A2, A3,. . . es una colección infinita de sucesosincompatibles, entonces
P(A1 ∪ A2 ∪ A3 ∪ . . . ) =∞
∑i=1
P(Ai)
Propiedades de la probabilidad
P(∅) = 0, lo que implica que la propiedad contenida en el Axio-ma 3 es válida para una colección finita de sucesos incompatibles.

herramientas computacionales en el laboratorio 16
Para cualquier suceso A, P(A) + P(A) = 1, por lo que P(A) =
1− P(A).
Para cualquier suceso A, P(A) ≤ 1.
Para cualquiera dos eventos A y B,
P(A ∪ B) = P(A) + P(B)− P(A ∩ B)
Determinación sistemática de probabilidades
La probabilidad de un suceso A, compuesto por una serie finitade sucesos elementales E1, E2, E3,. . . , se puede calcular a partir dela probabilidad de cada uno de los sucesos elementales Ei, con elrequisito ∑ P(Ei) = 1:
P(A) = ∑todos los Ei en A
P(Ei)
Sucesos igualmente probables En muchos experimentos en los quetenemos un número N de posibles resultados, es razonable asig-nar una misma probabilidad a todos los N sucesos elementales.En este caso la probabilidad de cada resultado viene dada por27 27 Sea p = P(Ei) para todo i:
1 =N
∑i=1
P(Ei) =N
∑i=1
p = p · N
, de manera que p = 1/N.
1/N. Consideremos ahora un suceso A, siendo N(A) el número deresultados contenidos en A (número de casos favorables). Entonces
P(A) =N(A)
NEs decir, cuando los posibles resultados son igualmente proba-
bles, el cálculo de probabilidades se reduce a contar: determinartanto el número de resultados N(A) en A como el número total decasos posibles N en S , y calcular su cociente.
Técnicas para contar
Existen muchos experimentos en los que construir una lista detodos los posibles resultados (para poder contarlos) es prohibitivo,por lo que se hace necesario el uso de algunas técnicas para contar.
Regla del producto para pares ordenados La primera técnica para con-tar se aplica a cualquier situación en la que un conjunto (suceso)consiste en pares ordenados de objetos y queremos contar el nú-mero de dichos pares. Un par ordenado implica que si O1 y O2 sondos objetos, entonces el par (O1, O2) es distinto al par (O2, O1).
Si el primer elemento u objeto de un par ordenado se puede seleccio-nar de n1 maneras, y para cada una de esas n1 maneras el segundoelemento se puede seleccionar de n2 maneras, entonces el número depares es n1n2.

herramientas computacionales en el laboratorio 17
Regla del producto para k-tuplas
Suponer un conjunto que consiste en una colección ordenada de kobjetos (k-tuplas), y que hay n1 posibles elecciones para el primerelemento; para cada elección del primer elemento, hay n2 posibleselecciones del segundo elemento;. . . ; para cada posible elección delos primeros k− 1 elementos, hay nk posibles elecciones del elementok-ésimo. Entonces hay n1n2 . . . nk k-tuplas posibles.
Diagrama de árbol Una forma de representar todas las posibilida-des en problemas de conteo y probabilidad es mediante diagra-mas de árbol. Comenzando en un punto en el extremo izquierdodel diagrama, dibujamos una línea recta hacia la derecha para ca-da posible primer elemento de un par. Ahora para cada rama deprimera generación construimos otro segmento para cada elecciónposible de un segundo elemento del par.
V
G0.25 · 0.58
0.58
no G0.25 · 0.42
0.42
0.25
no V
G0.75 · 0.62
0.62
no G0.75 · 0.38
0.38
0.75
Figura 18: Diagrama de árbol corres-pondiente al siguiente enunciado:“En una universidad en que la poblaciónestudiantil es muy numerosa, y basándoseen la experiencia de años anteriores, se sabeque el 25 % de los estudiantes son vegeta-rianos (V); entre los vegetarianos, el 58 %llevan gafas; entre los no vegetarianos, el62 % llevan gafas.”.
Regla del factorial Se utiliza para encontrar el número total demaneras en las que n elementos distintos28 se pueden reordenar 28 Entendiendo por distintos que existe
alguna característica que diferencia unobjeto concreto de cualquier otro.
(teniendo en cuenta el orden), denotándose por n! = n · (n − 1) ·(n− 2) · · · · · 1. Por definición, 0! = 1.
Permutaciones y Combinaciones Considerar un grupo (conjunto) den objetos distintos. ¿Cuántas formas hay de elegir un subconjunto dek elementos a partir del grupo? En función de que el orden de loselementos juegue o no papel, se distinguen:
Permutaciones Una permutación es un subconjunto ordenado. Elnúmero de permutaciones de tamaño k que se pueden formara partir de n objetos se denota por Pk,n y se calcula según la

herramientas computacionales en el laboratorio 18
expresión:
Pk,n =n!
(n− k)!
Combinaciones Una combinación es un subconjunto no ordenado.El número de combinaciones posibles se puede denotar por Ck,n
pero es muy común la notación (nk), que se lee “n en k”, y se
calcular según la expresión:
Ck,n =
(nk
)=
Pk,n
k!=
n!k!(n− k)!
Probabilidad condicionada
El número que asignamos como probabilidad a un suceso varíasegún la información que tenemos sobre él. En el momento enque tenemos más información, el número de casos posibles es másreducido y la probabilidad puede cambiar.
Dados dos sucesos A y B, llamamos suceso A condicionado alsuceso B (denotado por A|B) a aquel suceso que se verifica cuandose verifica A sabiendo que ya se ha verificado B. La probabili-dad condicionada de A sabiendo que B ya ha ocurrido se definecomo:
P(A|B) = P(A ∩ B)P(B) S
A B
Figura 19: Motivación de la definiciónde probabilidad condicionada. La de-finición de probabilidad condicionadada lugar al resultado conocido como laregla de multiplicación:
P(A∩B) = P(A|B) · P(B) = P(B|A) · P(A)
A menudo la probabilidad de que ocurra A no depende de otrosuceso B, de forma que P(A|B) = P(A). En ese caso se dice que Ay B son sucesos independientes
29.
29 En otras palabras, A y B son inde-pendientes si y solo si
P(A ∩ B) = P(A) · P(B)
, lo que se conoce como la regla de
multiplicación para P(A ∩ B).

herramientas computacionales en el laboratorio 19
Variable Aleatoria
En cualquier experimento, existen numerosas característicasque pueden ser observadas o medidas, pero en la mayoría de loscasos un experimentador se centrará en aspectos específicos de unamuestra. Llamamos variable aleatoria
30 a cualquier regla de 30 Variable porque puede tomar distin-tos valores y aleatoria porque el valorobservado depende de los posiblesresultados experimentales. Las varia-bles aleatorias se denotan con letrasmayúsculas, típicamente empezandopor el final de alfabeto, como X o Y.
asociación (aplicación —función) que hace corresponder un númeroreal a cada suceso elemental de un cierto espacio muestral S .
Variable aleatoria discreta Su conjunto de posibles valores es o bienfinito o bien se puede listar en una secuencia infinita ordenada.
Variable aleatoria continua Cumple:
1. Su conjunto de posibles valores es infinito (consiste en todoslos números existentes bien en un intervalo o en la unión deintervalos en la línea numérica.
2. Ningún valor posible de la variable tiene probabilidad positi-va, es decir, P(X = c) = 0 para cualquier valor c.
Distribuciones de probabilidad
Las probabilidades asignadas a los distintos sucesos en S de-terminan a su vez las probabilidades asociadas con los valores deuna variable aleatoria cualquiera X. La distribución de proba-bilidad de una variable aleatoria X nos dice cómo se distribuye laprobabilidad total de 1 entre los distintos posibles valores.
Función de probabilidad La función de probabilidad (tambiénllamada función de masa de probabilidad o fmp) de una variable alea-toria discreta X se define para cada x por p(x) = P(X = x).
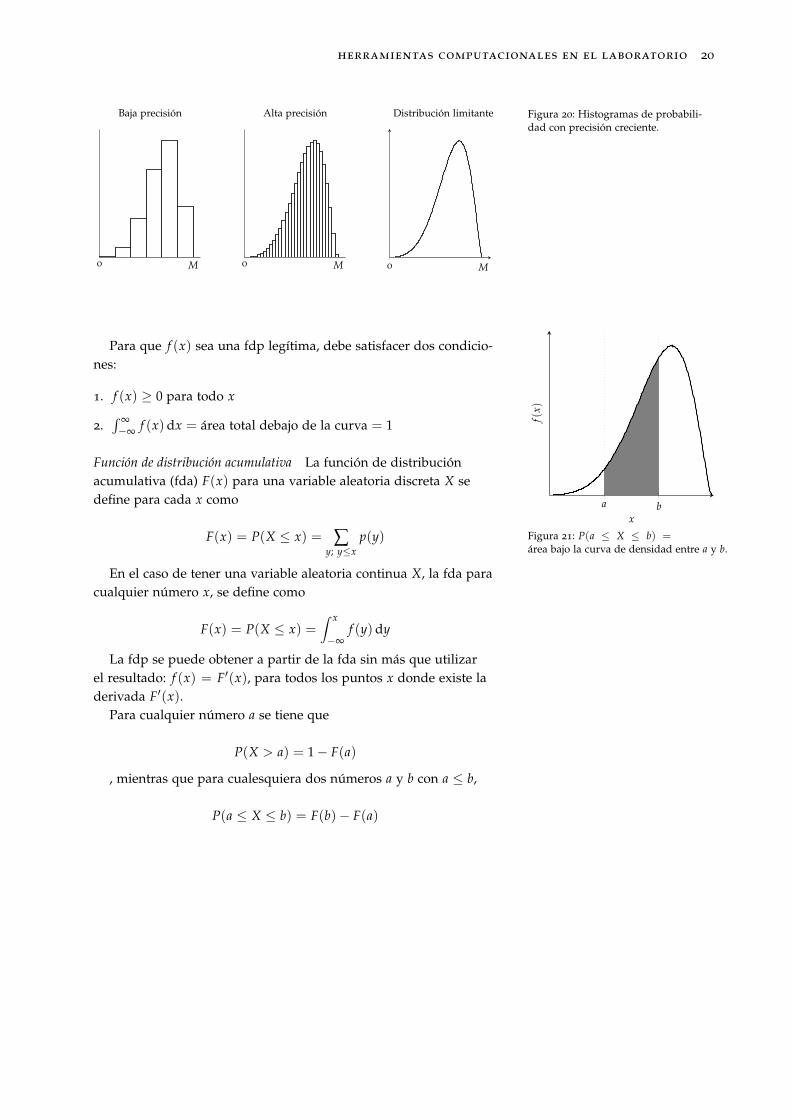
Función de densidad de probabilidad Imaginemos que somos capacesde medir una magnitud X (continua) cuyos posibles valores se en-cuentran en el intervalo [0, M]. Midiendo X con una precisión baja,podemos representar su distribución mediante un histograma deprobabilidad31 (ver Figura 20). Si ahora medimos la misma magni- 31 Un histograma cuyo área total es
igual a 1.tud con mayor precisión, cada rectángulo será más estrecho pero elárea total seguirá siendo 1. Repitiendo este proceso con precisióncreciente, la secuencia resultante de histogramas se aproxima a unacurva suave (llamada distribución limitante, ver paragraph 20), cuyoárea total bajo la curva también es 1.
La función de densidad de probabilidad (fdp) de una va-riable aleatoria continua X es una función tal que para cualesquierados números a y b con a ≤ b,
P(a ≤ X ≤ b) =∫ b
af (x)dx
Es decir, la probabilidad de que X tome un valor en el intervalo[a, b] es el área sobre ese intervalo y la gráfica de la función dedensidad (típicamente llamada curva de densidad).
herramientas computacionales en el laboratorio 20
0 M
Baja precisión
0 M
Alta precisión
0 M
Distribución limitante Figura 20: Histogramas de probabili-dad con precisión creciente.
a bx
f(x)
Figura 21: P(a ≤ X ≤ b) =área bajo la curva de densidad entre a y b.
Para que f (x) sea una fdp legítima, debe satisfacer dos condicio-nes:
1. f (x) ≥ 0 para todo x
2.∫ ∞−∞ f (x)dx = área total debajo de la curva = 1
Función de distribución acumulativa La función de distribuciónacumulativa (fda) F(x) para una variable aleatoria discreta X sedefine para cada x como
F(x) = P(X ≤ x) = ∑y; y≤x
p(y)
En el caso de tener una variable aleatoria continua X, la fda paracualquier número x, se define como
F(x) = P(X ≤ x) =∫ x
−∞f (y)dy
La fdp se puede obtener a partir de la fda sin más que utilizarel resultado: f (x) = F′(x), para todos los puntos x donde existe laderivada F′(x).
Para cualquier número a se tiene que
P(X > a) = 1− F(a)
, mientras que para cualesquiera dos números a y b con a ≤ b,
P(a ≤ X ≤ b) = F(b)− F(a)

herramientas computacionales en el laboratorio 21
Parámetros estadísticos de una variable aleatoriaA veces nos puede interesar calcularel valor esperado de una función h(x)en vez de solo E(X). Simplementetenemos que sustituir x por h(x) en lasexpresiones del valor esperado.
Valor esperado Supongamos que tenemos una variable aleatoriadiscreta X con un conjunto de valores posibles D y una fmp p(x).El valor esperado o media de X, denotado por E(X), µX o simple-mente µ viene dado por
µX = E(X) = ∑x∈D
x · p(x)
En el caso de una variable aleatoria continua X con fdp f (x), elvalor esperado es
µX = E(X) =∫ ∞
−∞x · f (x)dx
Varianza El valor esperado de X describe dónde está centrada ladistribución de probabilidad. La varianza de X nos da una ideade la cantidad de variación en la distribución de X. Si X tiene unafmp p(x) y valor medio µ, entonces la varianza de X, denotada porV(X) o σ2
X , o simplemente σ, viene dada por
σ2X = V(X) = ∑
x∈D
(x− µ
)2 · p(x) = E[(
X− µ)2]
En el caso de una variable aleatoria continua X con fdp f (x) yvalor medio µ, la varianza es
σ2X = V(X) =
∫ ∞
−∞
(x− µ
)2 · f (x)dx = E[(
X− µ)2]
Es posible probar que V(X) = E(X2)−[E(X)
]2.La desviación estándar (DE) de X es σX =
√V(X).
herramientas computacionales en el laboratorio 22
Variables Aleatorias más Comunes en Física
Distribución binomial
0 20 400
0.1
0.2
0.3
x
b(x;
n,p)
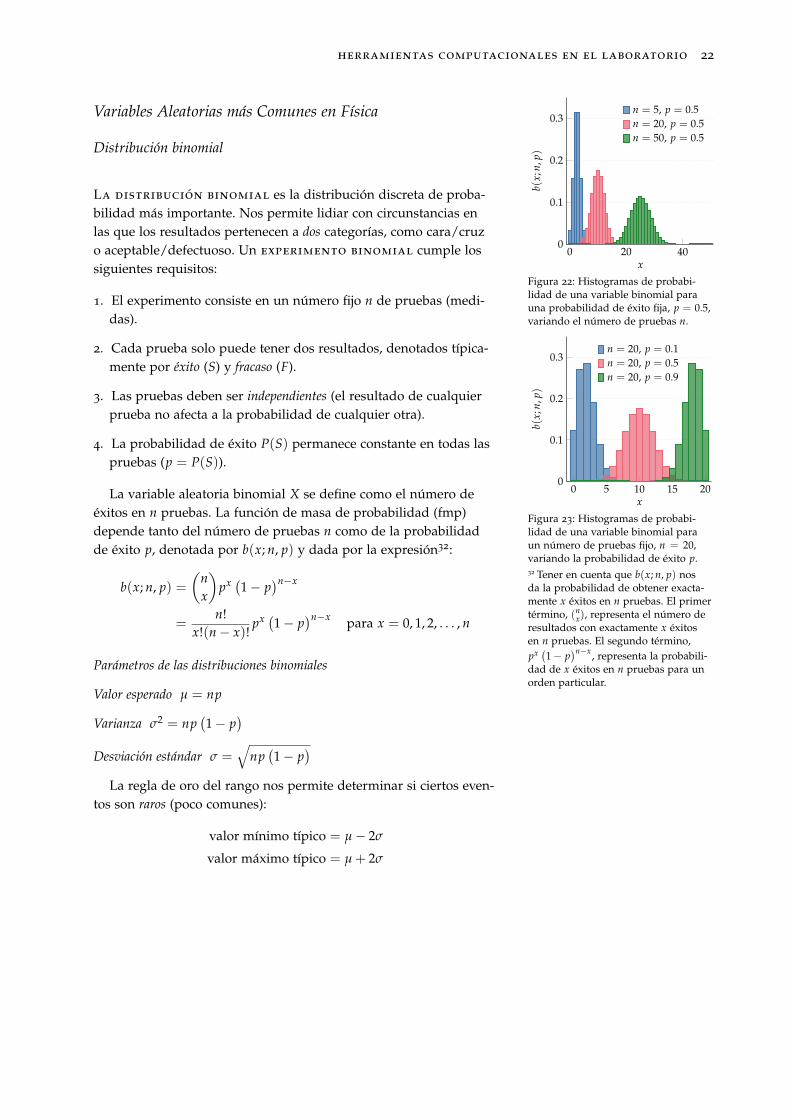
n = 5, p = 0.5n = 20, p = 0.5n = 50, p = 0.5
Figura 22: Histogramas de probabi-lidad de una variable binomial parauna probabilidad de éxito fija, p = 0.5,variando el número de pruebas n.
0 5 10 15 200
0.1
0.2
0.3
x
b(x;
n,p)
n = 20, p = 0.1n = 20, p = 0.5n = 20, p = 0.9
Figura 23: Histogramas de probabi-lidad de una variable binomial paraun número de pruebas fijo, n = 20,variando la probabilidad de éxito p.
La distribución binomial es la distribución discreta de proba-bilidad más importante. Nos permite lidiar con circunstancias enlas que los resultados pertenecen a dos categorías, como cara/cruzo aceptable/defectuoso. Un experimento binomial cumple lossiguientes requisitos:
1. El experimento consiste en un número fijo n de pruebas (medi-das).
2. Cada prueba solo puede tener dos resultados, denotados típica-mente por éxito (S) y fracaso (F).
3. Las pruebas deben ser independientes (el resultado de cualquierprueba no afecta a la probabilidad de cualquier otra).
4. La probabilidad de éxito P(S) permanece constante en todas laspruebas (p = P(S)).
La variable aleatoria binomial X se define como el número deéxitos en n pruebas. La función de masa de probabilidad (fmp)depende tanto del número de pruebas n como de la probabilidadde éxito p, denotada por b(x; n, p) y dada por la expresión32:
32 Tener en cuenta que b(x; n, p) nosda la probabilidad de obtener exacta-mente x éxitos en n pruebas. El primertérmino, (n
x), representa el número deresultados con exactamente x éxitosen n pruebas. El segundo término,px (1− p
)n−x , representa la probabili-dad de x éxitos en n pruebas para unorden particular.
b(x; n, p) =(
nx
)px (1− p
)n−x
=n!
x!(n− x)!px (1− p
)n−x para x = 0, 1, 2, . . . , n
Parámetros de las distribuciones binomiales
Valor esperado µ = np
Varianza σ2 = np(1− p
)Desviación estándar σ =
√np(1− p
)La regla de oro del rango nos permite determinar si ciertos even-
tos son raros (poco comunes):
valor mínimo típico = µ− 2σ
valor máximo típico = µ + 2σ

herramientas computacionales en el laboratorio 23
Distribución uniforme discreta
1 2 3 4 5 60
0.05
0.1
0.15
x
p(x)
Figura 24: Distribución uniforme dis-creta correspondiente al lanzamientode un dado, donde la probabilidad decada uno de los posibles números es1/6.
Una variable aleatoria discreta tiene una distribución uni-forme si sus valores se distribuyen uniformemente en el rango deposibilidades. La función de masa de probabilidad viene dada por
p(x) =
1/n x = 1, 2, 3, . . . , n
0 en otro caso
Parámetros de la distribución uniforme discreta
Valor esperado µ = 12 (n + 1)
Varianza σ2 = 112
(n2 − 1
)Desviación estándar σ = 1
2√
3
√n2 − 1
Distribución de Poisson
Una distribución de Poisson es una distribución discretade probabilidad que se aplica a ocurrencias de algún suceso duran-te un intervalo especificado. La variable aleatoria x es el número deocurrencias del suceso en el intervalo. El intervalo puede ser tiem-po, distancia, área, volumen, etc. La probabilidad de que el sucesoocurra x veces en el intervalo viene dado por la expresión
0 5 10 15 200
0.1
0.2
0.3
0.4
x
p(x;
λ)
λ = 1λ = 5λ = 10
Figura 25: Histogramas de probabi-lidad de una variable poissonianavariando el número medio de ocurren-cias λ.
p(x; λ) =λxe−λ
x!, donde λ representa el número medio de ocurrencias del suceso enel intervalo.
Se puede ver que la distribución de Poisson es el límite de ladistribución binomial en el caso n→ ∞ y p→ 0.
Requisitos de la Distribución de Poisson
1. La variable aleatoria x es el número de ocurrencias de un sucesoen un intervalo.
2. Las ocurrencias han de ser aleatorias.
3. Las ocurrencias han de ser independientes unas de otras.
4. Las ocurrencias han de estar uniformemente distribuidas sobre elintervalo utilizado.
Parámetros de la distribución de Poisson
Valor esperado µ = λ
Varianza σ2 = λ2
Desviación estándar σ = λ
Una distribución de Poisson está únicamente determinada porsu media λ, y los posibles valores de x son 0, 1, 2,. . . sin límitesuperior.
herramientas computacionales en el laboratorio 24
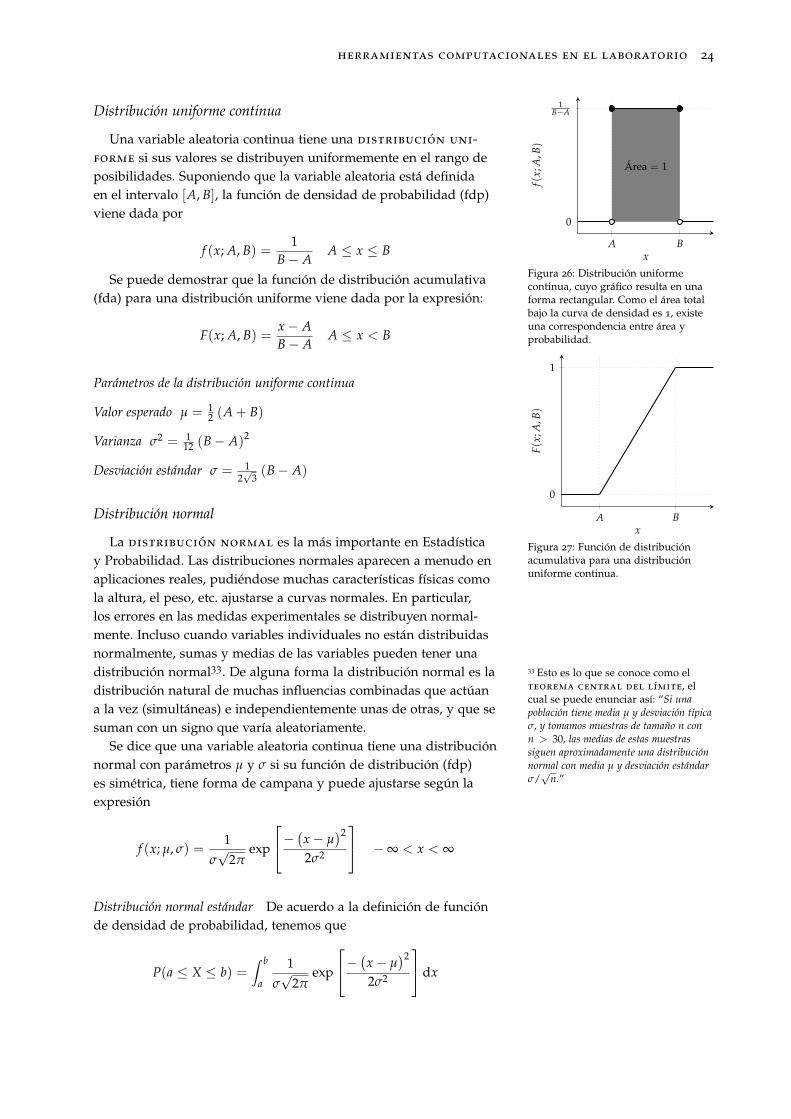
Distribución uniforme continua
A B
0
1B−A
Área = 1
x
f(x;
A,B
)
Figura 26: Distribución uniformecontinua, cuyo gráfico resulta en unaforma rectangular. Como el área totalbajo la curva de densidad es 1, existeuna correspondencia entre área yprobabilidad.
Una variable aleatoria continua tiene una distribución uni-forme si sus valores se distribuyen uniformemente en el rango deposibilidades. Suponiendo que la variable aleatoria está definidaen el intervalo [A, B], la función de densidad de probabilidad (fdp)viene dada por
f (x; A, B) =1
B− AA ≤ x ≤ B
Se puede demostrar que la función de distribución acumulativa(fda) para una distribución uniforme viene dada por la expresión:
F(x; A, B) =x− AB− A
A ≤ x < B
A B
0
1
xF(
x;A
,B)
Figura 27: Función de distribuciónacumulativa para una distribuciónuniforme continua.
Parámetros de la distribución uniforme continua
Valor esperado µ = 12 (A + B)
Varianza σ2 = 112 (B− A)2
Desviación estándar σ = 12√
3(B− A)
Distribución normal
La distribución normal es la más importante en Estadísticay Probabilidad. Las distribuciones normales aparecen a menudo enaplicaciones reales, pudiéndose muchas características físicas comola altura, el peso, etc. ajustarse a curvas normales. En particular,los errores en las medidas experimentales se distribuyen normal-mente. Incluso cuando variables individuales no están distribuidasnormalmente, sumas y medias de las variables pueden tener unadistribución normal33. De alguna forma la distribución normal es la 33 Esto es lo que se conoce como el
teorema central del límite, elcual se puede enunciar así: “Si unapoblación tiene media µ y desviación típicaσ, y tomamos muestras de tamaño n conn > 30, las medias de estas muestrassiguen aproximadamente una distribuciónnormal con media µ y desviación estándarσ/√
n.”
distribución natural de muchas influencias combinadas que actúana la vez (simultáneas) e independientemente unas de otras, y que sesuman con un signo que varía aleatoriamente.
Se dice que una variable aleatoria continua tiene una distribuciónnormal con parámetros µ y σ si su función de distribución (fdp)es simétrica, tiene forma de campana y puede ajustarse según laexpresión
f (x; µ, σ) =1
σ√
2πexp
− (x− µ)2
2σ2
−∞ < x < ∞
Distribución normal estándar De acuerdo a la definición de funciónde densidad de probabilidad, tenemos que
P(a ≤ X ≤ b) =∫ b
a
1σ√
2πexp
− (x− µ)2
2σ2
dx
herramientas computacionales en el laboratorio 25
−8 −6 −4 −2 0 2 40
0.1
0.2
0.3
0.4
0.5
0.6
0.7
x
f(x;
µ,σ)
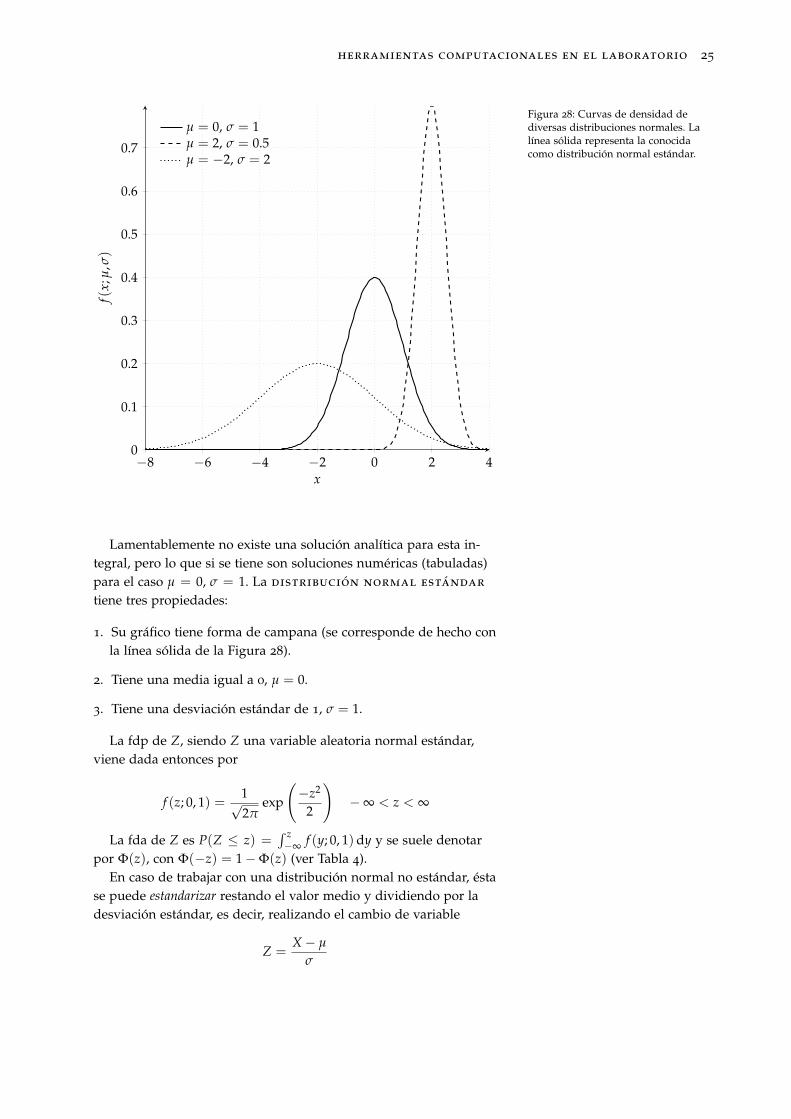
µ = 0, σ = 1µ = 2, σ = 0.5µ = −2, σ = 2
Figura 28: Curvas de densidad dediversas distribuciones normales. Lalínea sólida representa la conocidacomo distribución normal estándar.
Lamentablemente no existe una solución analítica para esta in-tegral, pero lo que si se tiene son soluciones numéricas (tabuladas)para el caso µ = 0, σ = 1. La distribución normal estándar
tiene tres propiedades:
1. Su gráfico tiene forma de campana (se corresponde de hecho conla línea sólida de la Figura 28).
2. Tiene una media igual a 0, µ = 0.
3. Tiene una desviación estándar de 1, σ = 1.
La fdp de Z, siendo Z una variable aleatoria normal estándar,viene dada entonces por
f (z; 0, 1) =1√2π
exp
(−z2
2
)−∞ < z < ∞
La fda de Z es P(Z ≤ z) =∫ z−∞ f (y; 0, 1)dy y se suele denotar
por Φ(z), con Φ(−z) = 1−Φ(z) (ver Tabla 4).En caso de trabajar con una distribución normal no estándar, ésta
se puede estandarizar restando el valor medio y dividiendo por ladesviación estándar, es decir, realizando el cambio de variable
Z =X− µ
σ

herramientas computacionales en el laboratorio 26
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09
0 0.5000 0.5040 0.5080 0.5120 0.5160 0.5199 0.5239 0.5279 0.5319 0.5359
0.1 0.5398 0.5438 0.5478 0.5517 0.5557 0.5596 0.5636 0.5675 0.5714 0.5753
0.2 0.5793 0.5832 0.5871 0.5910 0.5948 0.5987 0.6026 0.6064 0.6103 0.6141
0.3 0.6179 0.6217 0.6255 0.6293 0.6331 0.6368 0.6406 0.6443 0.6480 0.6517
0.4 0.6554 0.6591 0.6628 0.6664 0.6700 0.6736 0.6772 0.6808 0.6844 0.6879
0.5 0.6915 0.6950 0.6985 0.7019 0.7054 0.7088 0.7123 0.7157 0.7190 0.7224
0.6 0.7257 0.7291 0.7324 0.7357 0.7389 0.7422 0.7454 0.7486 0.7517 0.7549
0.7 0.7580 0.7611 0.7642 0.7673 0.7704 0.7734 0.7764 0.7794 0.7823 0.7852
0.8 0.7881 0.7910 0.7939 0.7967 0.7995 0.8023 0.8051 0.8078 0.8106 0.8133
0.9 0.8159 0.8186 0.8212 0.8238 0.8264 0.8289 0.8315 0.8340 0.8365 0.8389
1 0.8413 0.8438 0.8461 0.8485 0.8508 0.8531 0.8554 0.8577 0.8599 0.8621
1.1 0.8643 0.8665 0.8686 0.8708 0.8729 0.8749 0.8770 0.8790 0.8810 0.8830
1.2 0.8849 0.8869 0.8888 0.8907 0.8925 0.8944 0.8962 0.8980 0.8997 0.9015
1.3 0.9032 0.9049 0.9066 0.9082 0.9099 0.9115 0.9131 0.9147 0.9162 0.9177
1.4 0.9192 0.9207 0.9222 0.9236 0.9251 0.9265 0.9279 0.9292 0.9306 0.9319
1.5 0.9332 0.9345 0.9357 0.9370 0.9382 0.9394 0.9406 0.9418 0.9429 0.9441
1.6 0.9452 0.9463 0.9474 0.9484 0.9495 0.9505 0.9515 0.9525 0.9535 0.9545
1.7 0.9554 0.9564 0.9573 0.9582 0.9591 0.9599 0.9608 0.9616 0.9625 0.9633
1.8 0.9641 0.9649 0.9656 0.9664 0.9671 0.9678 0.9686 0.9693 0.9699 0.9706
1.9 0.9713 0.9719 0.9726 0.9732 0.9738 0.9744 0.9750 0.9756 0.9761 0.9767
2 0.9772 0.9778 0.9783 0.9788 0.9793 0.9798 0.9803 0.9808 0.9812 0.9817
2.1 0.9821 0.9826 0.9830 0.9834 0.9838 0.9842 0.9846 0.9850 0.9854 0.9857
2.2 0.9861 0.9864 0.9868 0.9871 0.9875 0.9878 0.9881 0.9884 0.9887 0.9890
2.3 0.9893 0.9896 0.9898 0.9901 0.9904 0.9906 0.9909 0.9911 0.9913 0.9916
2.4 0.9918 0.9920 0.9922 0.9925 0.9927 0.9929 0.9931 0.9932 0.9934 0.9936
2.5 0.9938 0.9940 0.9941 0.9943 0.9945 0.9946 0.9948 0.9949 0.9951 0.9952
2.6 0.9953 0.9955 0.9956 0.9957 0.9959 0.9960 0.9961 0.9962 0.9963 0.9964
2.7 0.9965 0.9966 0.9967 0.9968 0.9969 0.9970 0.9971 0.9972 0.9973 0.9974
2.8 0.9974 0.9975 0.9976 0.9977 0.9977 0.9978 0.9979 0.9979 0.9980 0.9981
2.9 0.9981 0.9982 0.9982 0.9983 0.9984 0.9984 0.9985 0.9985 0.9986 0.9986
3 0.9987 0.9987 0.9987 0.9988 0.9988 0.9989 0.9989 0.9989 0.9990 0.9990
Tabla 4: Áreas de la curva normalestándar. Φ(−z) = 1−Φ(z).
herramientas computacionales en el laboratorio 27
Así:
P(a ≤ X ≤ b) = P(
a− µ
σ≤ Z ≤ b− µ
σ
)= Φ
(b− µ
σ
)−Φ
(a− µ
σ
)
P(X ≤ a) = Φ(
a− µ
σ
)P(X ≥ b) = 1−Φ
(b− µ
σ
)Con este resultado estamos en condiciones de probar la Regla
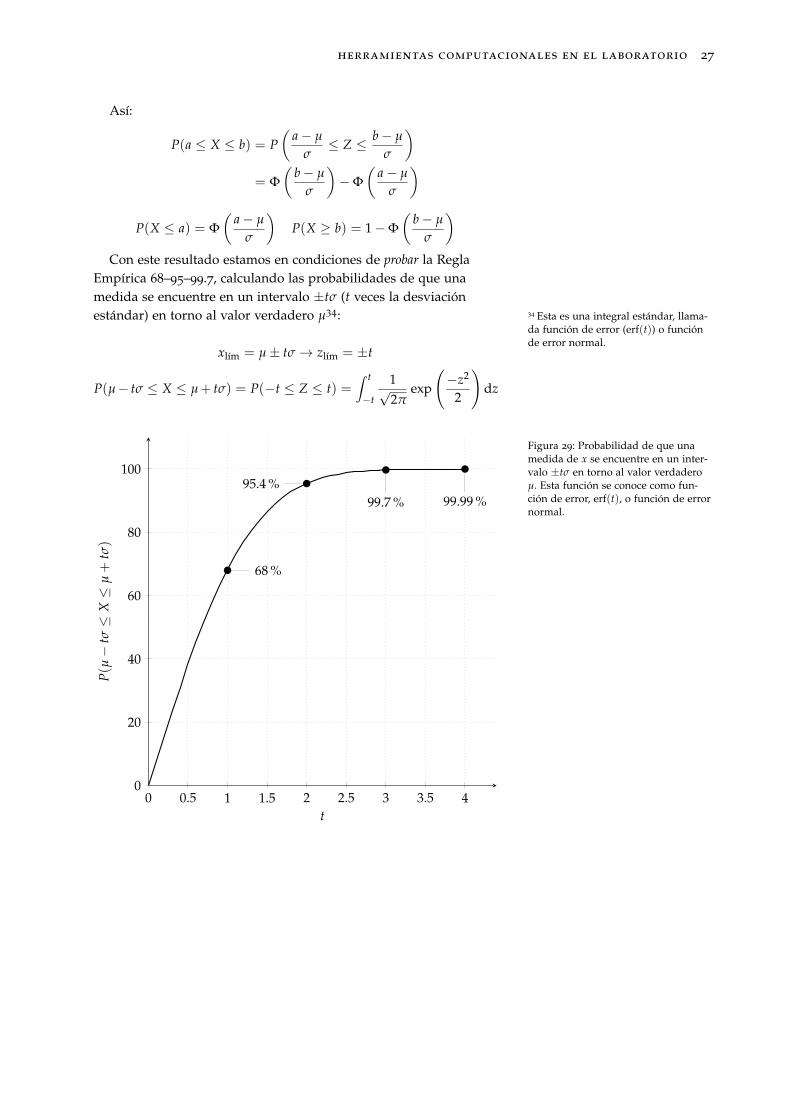
Empírica 68–95–99.7, calculando las probabilidades de que unamedida se encuentre en un intervalo ±tσ (t veces la desviaciónestándar) en torno al valor verdadero µ34: 34 Esta es una integral estándar, llama-
da función de error (erf(t)) o funciónde error normal.
xlım = µ± tσ→ zlım = ±t
P(µ− tσ ≤ X ≤ µ+ tσ) = P(−t ≤ Z ≤ t) =∫ t
−t
1√2π
exp
(−z2
2
)dz
0 0.5 1 1.5 2 2.5 3 3.5 40
20
40
60
80
100
68 %
95.4 %99.7 % 99.99 %
t
P(µ−
tσ≤
X≤
µ+
tσ)
Figura 29: Probabilidad de que unamedida de x se encuentre en un inter-valo ±tσ en torno al valor verdaderoµ. Esta función se conoce como fun-ción de error, erf(t), o función de errornormal.

herramientas computacionales en el laboratorio 28
Regresión y Correlación
En este tema vamos a analizar datos apareados. El objetivo delanálisis de la regresión35 es explotar la relación entre dos (o más) 35 El análisis de la regresión es la
parte de la Estadística que investigala relación entre dos o más variables.El término regresión proviene delestudio hereditario sobre la alturallevado a cabo por Sir Francis Galton(1822–1911), quien mostró que cuandoparejas altas o bajas tienen hijos, laaltura de éstos tiende a regresar, avolver a la altura media típica.
variables para que podamos obtener información sobre una deellas a través del conocimiento de los valores de la(s) otra(s). Va-mos a introducir métodos para determinar si dos variables estáncorrelacionadas36, y si esa correlación es lineal37. Para correlacio-
36 Una correlación entre dos variablesexiste cuando los valores de unavariable están de alguna maneraasociados con los valores de la otravariable.37 Existe una correlación lineal en-tre dos variables cuando existe unacorrelación y el diagrama de disper-sión de los datos apareados se puedeaproximar por una línea recta.
nes lineales, podemos identificar una ecuación de una línea rectaque mejor se ajusta a los datos, pudiendo utilizar esa ecuación parapredecir el valor de una variable dado el valor de la otra variable.
Correlación lineal
Requerimientos para que exista una correlación lineal Si queremossacar alguna conclusión sobre la correlación en la población utili-zando los datos de la muestra, se deben cumplir estos requisitos:
1. Los datos apareados (x,y) han de ser una muestra aleatoria.
2. Una inspección visual del diagrama de dispersión nos tiene queconfirmar que los puntos se pueden aproximar por una línearecta.
3. Cualquier valor atípico (outlier) que se sepa que proviene de unerror ha de ser eliminado38. 38 Los efectos de los valores atípicos
han de considerarse calculando r con ysin ellos.
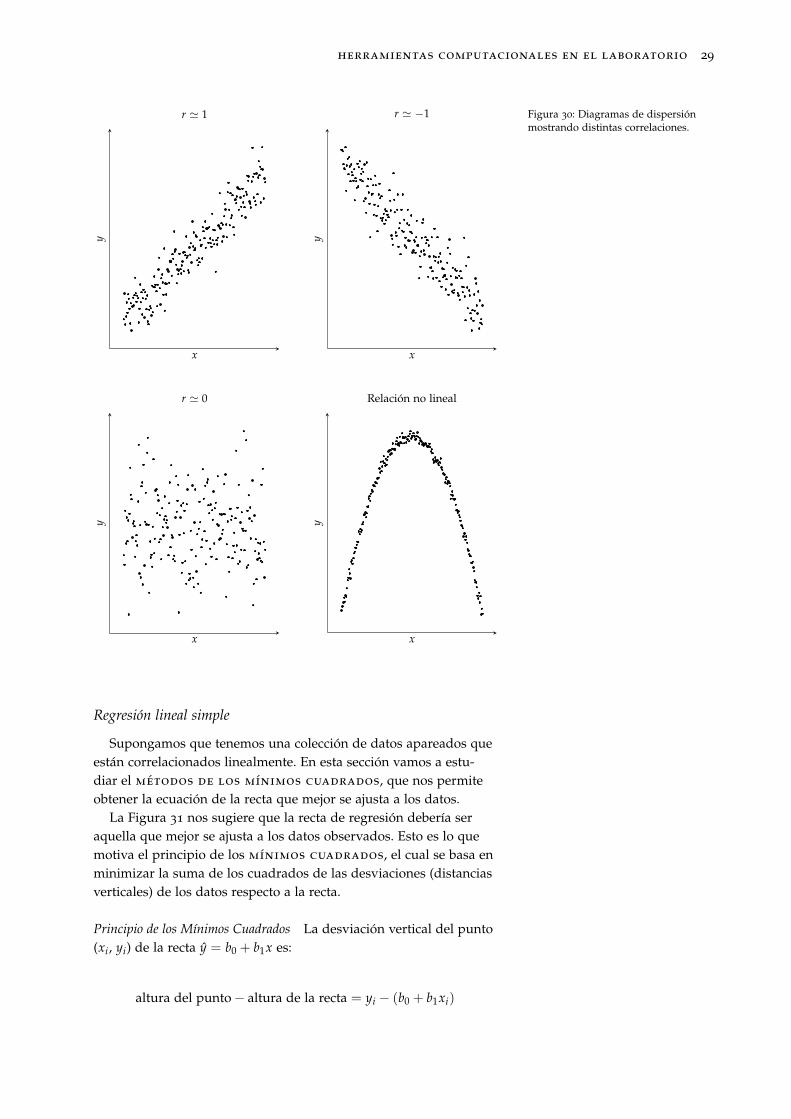
Coeficiente de correlación lineal r No podemos basar nuestras con-clusiones en inspecciones visuales de diagramas de dispersión, porlo que introducimos el llamado coeficiente de correlación
lineal39 r, el cual mide la fuerza de la relación (lineal) entre dos 39 También llamado coeficiente de
correlación de Pearson, en honor aKarl Pearson (1857–1936), quien lodesarrolló originalmente.
variables:
r =n ∑ xy− (∑ x)
(∑ y)√
n(∑ x2
)− (∑ x)2
√n(∑ y2
)−(∑ y)2
Propiedades del coeficiente de correlación lineal r
1. El valor de r no depende de cuál de las dos variables se etiquetecomo x y cual como y (son intercambiables).
2. El valor de r es independiente de las unidades en las que semidan x e y.
3. −1 ≤ r ≤ 1.
4. r mide cómo de fuerte es una relación lineal40. No está diseñado 40 Consideraremos que existe una fuer-te relación lineal entre dos variablescuando el valor absoluto de r sea igualo mayor que 0.8.
para medir la fuerza de una relación no lineal.
5. r es muy sensible a la presencia de valores atípicos, los cualespueden modificar drásticamente su valor.
herramientas computacionales en el laboratorio 29
x
yr ' 1
x
y
r ' −1
x
y
r ' 0
x
y
Relación no lineal
Figura 30: Diagramas de dispersiónmostrando distintas correlaciones.
Regresión lineal simple
Supongamos que tenemos una colección de datos apareados queestán correlacionados linealmente. En esta sección vamos a estu-diar el métodos de los mínimos cuadrados, que nos permiteobtener la ecuación de la recta que mejor se ajusta a los datos.
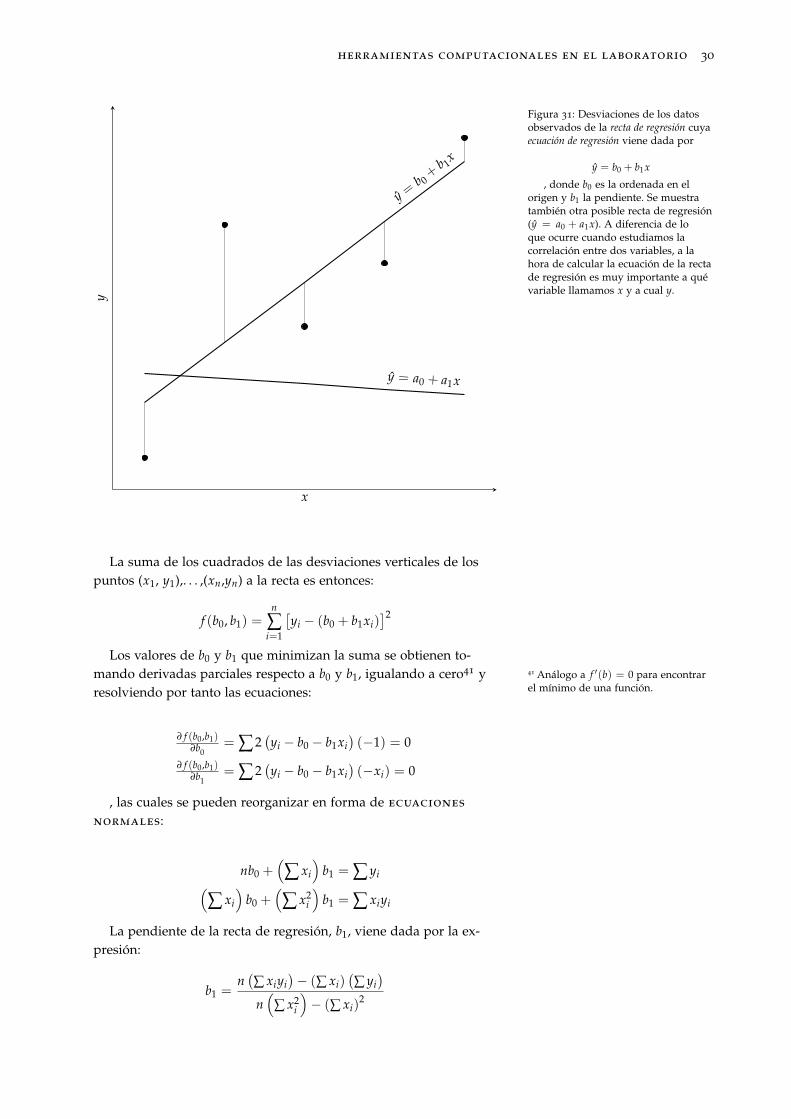
La Figura 31 nos sugiere que la recta de regresión debería seraquella que mejor se ajusta a los datos observados. Esto es lo quemotiva el principio de los mínimos cuadrados, el cual se basa enminimizar la suma de los cuadrados de las desviaciones (distanciasverticales) de los datos respecto a la recta.
Principio de los Mínimos Cuadrados La desviación vertical del punto(xi, yi) de la recta y = b0 + b1x es:
altura del punto− altura de la recta = yi − (b0 + b1xi)
herramientas computacionales en el laboratorio 30
y =b 0+
b 1x
y = a0 + a1x
x
yFigura 31: Desviaciones de los datosobservados de la recta de regresión cuyaecuación de regresión viene dada por
y = b0 + b1x
, donde b0 es la ordenada en elorigen y b1 la pendiente. Se muestratambién otra posible recta de regresión(y = a0 + a1x). A diferencia de loque ocurre cuando estudiamos lacorrelación entre dos variables, a lahora de calcular la ecuación de la rectade regresión es muy importante a quévariable llamamos x y a cual y.
La suma de los cuadrados de las desviaciones verticales de lospuntos (x1, y1),. . . ,(xn,yn) a la recta es entonces:
f (b0, b1) =n
∑i=1
[yi − (b0 + b1xi)
]2Los valores de b0 y b1 que minimizan la suma se obtienen to-
mando derivadas parciales respecto a b0 y b1, igualando a cero41 y 41 Análogo a f ′(b) = 0 para encontrarel mínimo de una función.resolviendo por tanto las ecuaciones:
∂ f (b0,b1)∂b0
= ∑ 2(yi − b0 − b1xi
)(−1) = 0
∂ f (b0,b1)∂b1
= ∑ 2(yi − b0 − b1xi
)(−xi) = 0
, las cuales se pueden reorganizar en forma de ecuaciones
normales:
nb0 +(∑ xi
)b1 = ∑ yi(
∑ xi
)b0 +
(∑ x2
i
)b1 = ∑ xiyi
La pendiente de la recta de regresión, b1, viene dada por la ex-presión:
b1 =n(∑ xiyi
)− (∑ xi)
(∑ yi
)n(
∑ x2i
)− (∑ xi)
2

herramientas computacionales en el laboratorio 31
La ordenada en el origen b0 de la recta de regresión es:
b0 = y− b1 x =
(∑ yi
) (∑ x2
i
)− (∑ xi)
(∑ xiyi
)n(
∑ x2i
)− (∑ xi)
2
Análisis de los residuos: evaluación del modelo
Podemos utilizar la ecuación de regresión para predecir el valorde una variable42, dado un valor concreto de la otra variable en 42 Los valores ajustados o predichos
y1, y2,. . . ,yn se obtienen al sustituirx1,. . . ,xn en la ecuación de regresión:y1 = b0 + b1x1, y2 = b0 + b1x2,. . . ,yn =b0 + b1xn.
juego. A la hora de hacer predicciones, conviene tener en cuenta:
1. Utilizaremos la ecuación de regresión solo si vemos que la rectade regresión ajusta los puntos razonablemente bien.
2. Utilizaremos la ecuación de regresión para predicciones solosi el coeficiente de correlación lineal nos indica que existe unacorrelación lineal entre ambas variables.
3. Utilizaremos la recta de regresión para predecir valores que noestén muy lejos de los datos disponibles43. 43 Predecir fuera del rango de los
datos disponibles se llama extrapolar,y puede dar lugar a prediccioneserróneas.
4. En caso de que la ecuación de regresión no parezca ser útil parahacer predicciones, la mejor estimación es la media de la mues-tra.
Llamamos residuo a la diferencia entre el valor observado (real)y el ajustado (predicho):
residuo = y observado− y predicho = y− y
Al igual que con la incertidumbre asociada a una muestra, pode-mos calcular la desviación estándar asociada al conjunto de medi-das yi mediante la expresión44: 44 Notar que los valores y1,. . . ,yn
no son n repeticiones de la mismamedida. Aquí estamos suponiendoque todos los residuos tienen lamisma incertidumbre. El divisorn − 2 es el número de grados delibertad asociados con σy, ya que, apartir de las n medidas, estimamos 2
parámetros (b0 y b1).
σy =
√∑(yi − yi
)2
n− 2
σy nos permite obtener las incertidumbres para las constantes b0
y b145:
45 Tanto b0 como b1 están expresadasen términos de yi , por lo que podemosobtener el error en estas magnitudespropagando el error asociado a yi ,despreciando cualquier error en lavariable independiente. En caso detener un error también en la variablex, σx , podemos seguir utilizando estasexpresiones sin más que sustituir σy
por√
σ2y + (b1σx)
2.
σb1 = σy
√√√√ n
n(
∑ x2i
)− (∑ xi)
2
σb0 = σy
√√√√ ∑ x2i
n(
∑ x2i
)− (∑ xi)
2

herramientas computacionales en el laboratorio 32
Mínimos Cuadrados pesados
Supongamos que ahora medimos n pares de valores (xi,yi) dedos variables x e y que se supone que satisfacen una relación linealy = b0 + b1x. Supongamos además que los errores en xi son des-preciables, mientras que los yi tienen errores distintos σi (σ1 es elerror de y1, σ2 es el error de y2, etc.). Podemos definir el peso de lamedida i-ésima como wi = 1/σ2
i . En este caso tenemos:
b1 =∑ wi
(∑ wixiyi
)− (∑ wixi)
(∑ wiyi
)∑ wi
(∑ wix2
i
)− (∑ wixi)
2
b0 =
(∑ wiyi
) (∑ wix2
i
)− (∑ wixi)
(∑ wixiyi
)∑ wi
(∑ wix2
i
)− (∑ wixi)
2
siendo las incertidumbres asociadas:
σb1 =
√√√√ ∑ wi
∑ wi
(∑ wix2
i
)− (∑ wixi)
2
σb0 =
√√√√ ∑ wix2i
∑ wi
(∑ wix2
i
)− (∑ wixi)
2
Referencias
D. C. Baird. Experimentation: An Introduction to Measurement Theoryand Experiment Design. Prentice-Hall, Inc., 3rd edition, 1995.
George Casella and Roger L. Berger. Statistical Inference. Duxbury,2nd edition, 2002.
Jay L. Devore. Probability and Statistics for Engineering and the Scien-ces. CENGAGE Learning, 9th edition, 2014.
David Freedman, Robert Pisani, and Roger Purves. Statistics. W. W.Norton & Company, 4th edition, 2007.
Anders Hald. A History of Probability and Statistics and Their Applica-tions before 1750. John Wiley & Sons, 2003.
Darrel Huff. How To Lie With Statistics. W. W. Norton & Company,3rd edition, 1993.
John R. Taylor. An Introduction to Error Analysis. University ScienceBooks, 2nd edition, 1997.
Mario F. Triola. Elementary Statistics. Pearson, 12th edition, 2012.