hadoop en accion
Upload: glud-grupo-de-trabajo-academico-gnulinux-universidad-distrital
Post on 22-Jul-2015
589 views
TRANSCRIPT

Hadoop en acción
Cluster de bajo perfil para el análisis de grandes volúmenes de
datos

¿Quién soy yo?
● Sergio Navarrete Suárez● Estudiante de Ingeniería de Sistemas de la Universidad
Distrital Francisco José de Caldas● Usuario de Linux desde hace tres años aproximadamente● Coordinador General Grupo GNU/Linux Universidad
Distrital Francisco José de Caldas● Equipo Webmaster - Red de Datos Universidad Distrital

Contenido
● ¿Qué es MapReduce?● ¿Qué es HDFS?● ¿Cuándo usar HDFS?● ¿Cuándo NO usar HDFS?● Partes de un HDFS● Optimización por distancia física● ¿Qué es Hadoop?● ¿Por qué Hadoop?

Contenido
● ¿Cuándo utilizar Hadoop?● Arquitectura de Hadoop● La implementación de Hadoop de MapReduce● Anatomía de un trabajo de Hadoop● Ejemplo en Hadoop● ¿Qué sigue?● Fuentes● Conclusiones● Preguntas● Agradecimientos especiales

¿Qué es MapReduce?
● Algoritmo desarrollado por Google para procesar pequeñas cantidades de archivos de gran tamaño.
● Muy rápido comparado con scripts de shell● Implementación rápida, comparado con multiprocesamiento
(preparación de los datos)● Hace uso de hardware de bajo perfil

¿Qué es HDFS?
● Sistema de archivos distribuido● Diseñado para trabajar de manera eficiente con
MapReduce● Trabaja con bloques (64 MB por defecto)

¿Cuándo usar HDFS?
● Archivos muy, muy grandes (GB o más)● Necesidad de particionar archivos● Fallo de nodos sin perder información● Una escritura, muchas lecturas

¿Cuándo NO usar HDFS?
● Baja latencia● Muchos archivos pequeños● Multiples "escritores"● Modificaciones arbitrarias a los archivos

Partes de un HDFS
● Namenode: Mantiene el árbol del sistema de archivos y los metadatos.
○ Namespace image○ Edit log
● Datanodes: Contienen los datos. Reportan al Namenode con la información acerca de los bloques actuales.
● Secondary namenode: En el cual se descarga información del edit log para que no se vuelva muy grande en el namenode.
○ Puede funcionar como namenode en caso de que este falle, pero puede haber pérdida de información (no fue diseñado para cumplir esta tarea).
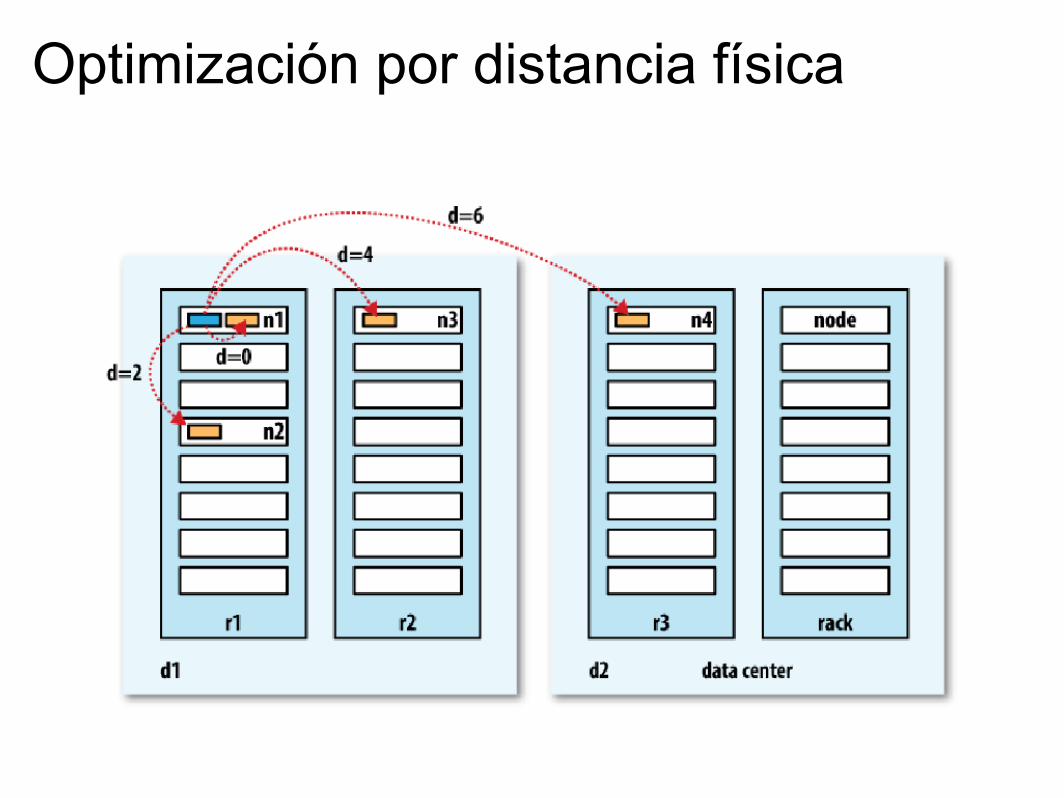
Optimización por distancia física

¿Qué es Hadoop?
● Framework para almacenar y procesar grandes volúmenes de datos.
● Don't make better hardware. Use more hardware instead.● Orientado a los datos: se enfoca en el uso de disco y el
ancho de banda de la red más que en el procesamiento (aunque esto también puede optimizarse)

Breve historia de Hadoop
● Empieza en 2002 con Doug Cutting y Mike Cafarella● Inspirado por los papers de Google en MapReduce y
Google File System● Proyecto nombrado a partir de el elefante de peluche
amarillo del hijo de Doug (de ahí el logo)● Empieza como parte de la manera de manejar los datos de
un motor de búsqueda web (Notch)● Proyecto Apache Hadoop inicia - 2006● Desarrollado y bastante usado en Yahoo!● Usado también en LastFM, Facebook y The New York
Times● 1 TB sort benchmark - 209 seg. - 2008● Minute sort - 500 GB en 59 seg. (1400 nodos)● 100 TB sort benchmark - 173 min. (3400 nodos) - 2009

¿Por qué Hadoop?
● Más rápido que un RDBMS para grandes volúmenes de datos (especialmente datos no organizados)
● Más rápido que un HPC tradicional, ya que implementa optimizaciones teniendo en cuenta la topología de la red (optimiza el uso de la red)
● Evita la pérdida de información a través de replicación● API fácil de aprender● Posibilidad de trabajar con lenguajes diferentes a Java

¿Cuándo usar Hadoop?
● Se tienen grandes archivos (GB para arriba)● No se tiene un RDBMS● Se tiene el hardware● Se van a hacer muchas más lecturas que escrituras● Programas de tipo clave -> valor
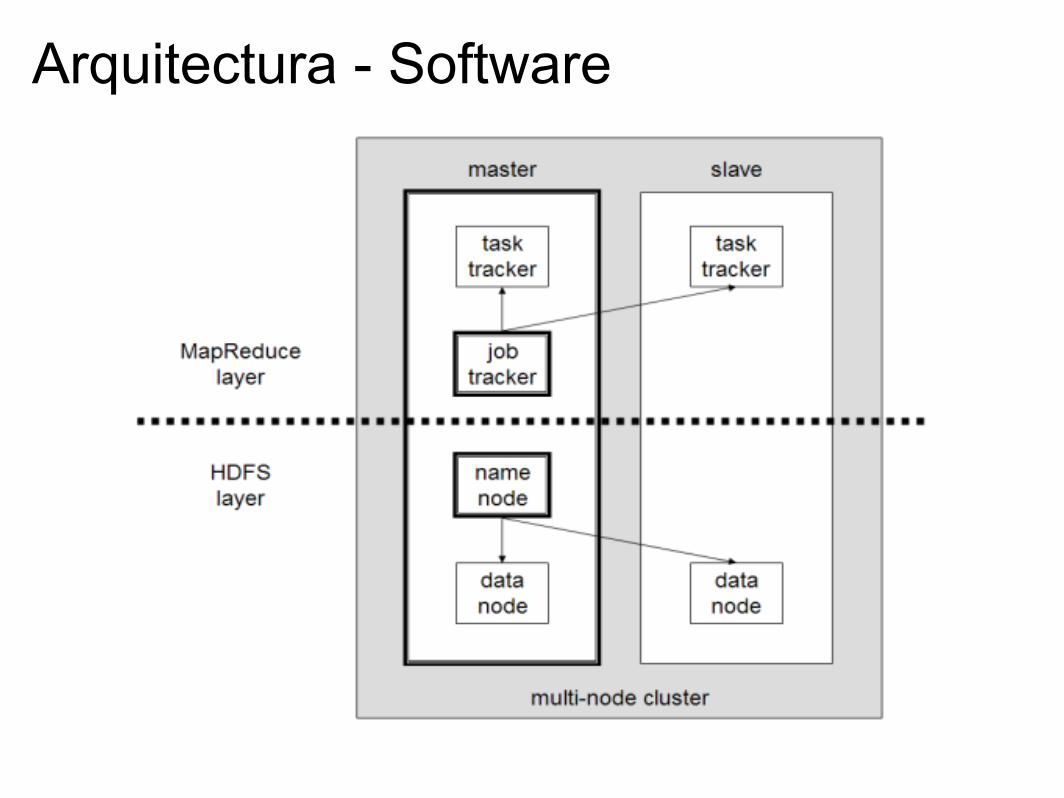
Arquitectura - Software
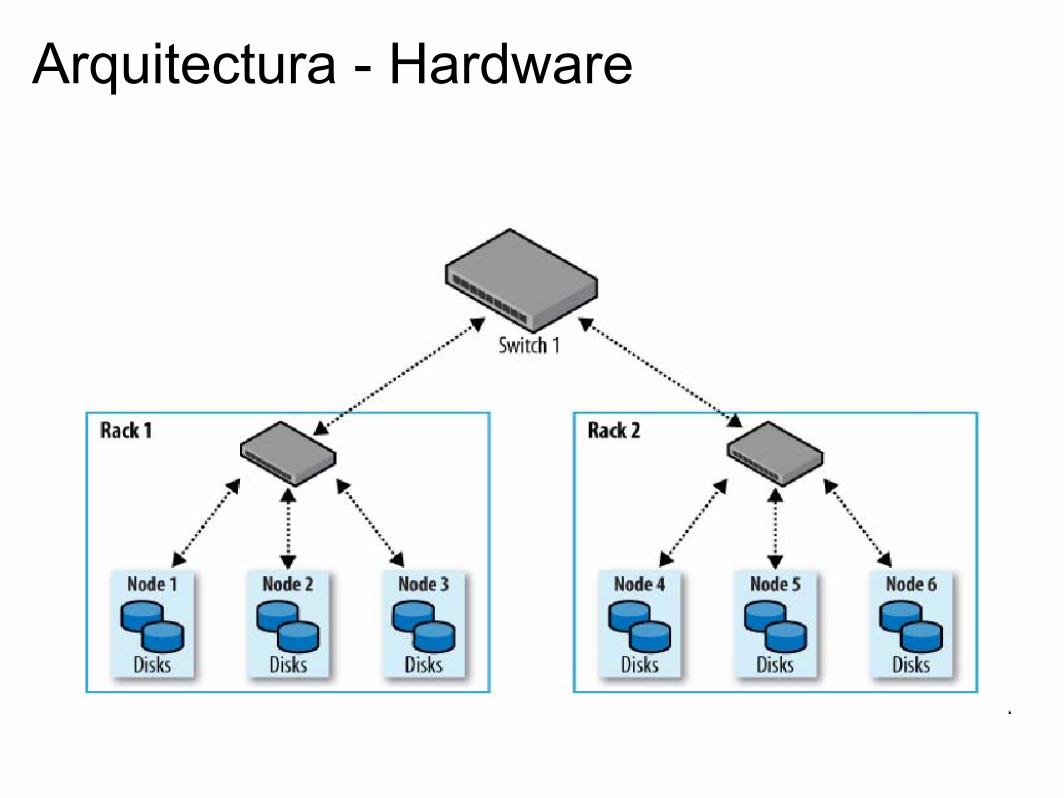
Arquitectura - Hardware

Implementación de Hadoop de MapReduce
● Fase "map"○ Se toma la entrada, se divide en subproblemas y se
distribuyen a los "worker nodes". Estos a su vez pueden hacer lo mismo.
○ Los "worker nodes" procesan los datos y retornan un resultado a su nodo maestro.
○ En algunos casos, esta fase sólo prepara la información para ser procesada por el reductor.

Implementación de Hadoop de MapReduce
● Fase "reduce"○ El nodo maestro toma los resultados de la fase "map" de
los "worker nodes" y los combina de alguna manera programada.
○ Si todos los mapeos son independientes entre sí, se puede decir que todos pueden correr en paralelo.
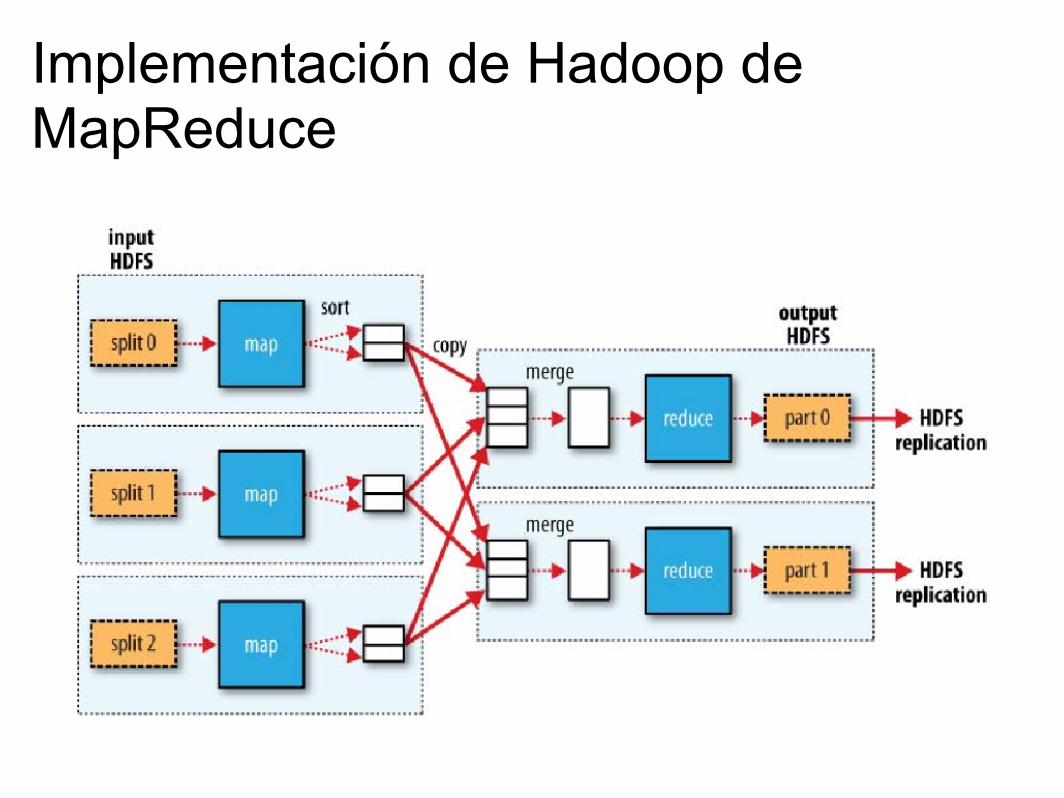
Implementación de Hadoop de MapReduce

Anatomia de un trabajo de Hadoop
● Datos de entrada, programa MapReduce e información de configuración
● Tareas de mapeo y reducción (map and reduce tasks)● Jobtracker: Coordina las tareas y las programa para que
sean resueltas por los tasktrackers.● Tasktracker: Resuelve tareas y envía el resultado al
jobtracker.● Cualquier lenguaje que pueda leer desde stdin y escribir a
stdout puede ser utilizado con Hadoop

Ejemplo en hadoop
● Construir el cluster○ Instalar software de virtualización○ Copiar la máquina virtual, configurar e iniciar○ Descargar Hadoop ○ Crear usuario hadoop○ Extraer contenidos de Hadoop○ Instalar java y ssh (servidor y cliente)○ Añadir el servidor DNS○ Montar el sistema de archivos en red○ Implementar ssh sin contraseña○ Exportar variables de Hadoop
● Echar un vistazo a la configuración● Correr el ejemplo

¿Qué sigue?
● Análisis de datos astronómicos (Gamma-ray bursts) en el Centro de Computación de Alto Desempeño (CECAD)
● Clasificación de correos electrónicos en la Red de Datos (Universidad Distrital FJC).
● Análisis de logs con el grupo de seguridad del Grupo GNU/Linux de la Universidad Distrital FJC
● Almacenamiento distribuido en espejos y repositorios de distribuciones Linux con el GLUD en el CECAD

Recursos fuente
1. White, Tom. Hadoop, the definitive guide. O'Reilly - Yahoo! Press. 2nd Edition
2. Project Gutenberg www.gutenberg.org

Conclusiones

Preguntas

Agradecimientos especiales