h ector tejeda v abril, 2010 -...
TRANSCRIPT

Estructuras de Datos con Java
Hector Tejeda V
Abril, 2010

Indice general
1. Introduccion 71.1. Clases, tipos, y objetos . . . . . . . . . . . . . . . . . . . . . . 7
1.1.1. Tipos base . . . . . . . . . . . . . . . . . . . . . . . . . 101.1.2. Objetos . . . . . . . . . . . . . . . . . . . . . . . . . . 101.1.3. Tipo enum . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.2. Metodos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171.3. Expresiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
1.3.1. Literales . . . . . . . . . . . . . . . . . . . . . . . . . . 231.3.2. Operadores . . . . . . . . . . . . . . . . . . . . . . . . 241.3.3. Conversiones tipo base . . . . . . . . . . . . . . . . . . 28
1.4. Control de flujo . . . . . . . . . . . . . . . . . . . . . . . . . . 301.4.1. Sentencias if y switch . . . . . . . . . . . . . . . . . . 301.4.2. Ciclos . . . . . . . . . . . . . . . . . . . . . . . . . . . 321.4.3. Sentencias explıcitas de control de flujo . . . . . . . . . 35
1.5. Arreglos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 371.5.1. Declaracion de arreglos . . . . . . . . . . . . . . . . . . 391.5.2. Arreglos como objetos . . . . . . . . . . . . . . . . . . 40
1.6. Entrada y salida . . . . . . . . . . . . . . . . . . . . . . . . . 411.7. Clases anidadas y paquetes . . . . . . . . . . . . . . . . . . . . 45
2. Diseno orientado al objeto 472.1. Metas, principios, y patrones . . . . . . . . . . . . . . . . . . . 47
2.1.1. Metas del diseno orientado a objetos . . . . . . . . . . 472.1.2. Principios del diseno orientado al objeto . . . . . . . . 492.1.3. Patrones de diseno . . . . . . . . . . . . . . . . . . . . 51
2.2. Herencia y polimorfismo . . . . . . . . . . . . . . . . . . . . . 522.2.1. Herencia . . . . . . . . . . . . . . . . . . . . . . . . . . 522.2.2. Polimorfismo . . . . . . . . . . . . . . . . . . . . . . . 54

INDICE GENERAL 3
2.2.3. Uso de herencia en Java . . . . . . . . . . . . . . . . . 552.3. Excepciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
2.3.1. Lanzamiento de excepciones . . . . . . . . . . . . . . . 632.3.2. Atrapar excepciones . . . . . . . . . . . . . . . . . . . 66
2.4. Interfaces y clases abstractas . . . . . . . . . . . . . . . . . . . 682.4.1. Implementacion de interfaces . . . . . . . . . . . . . . 682.4.2. Herencia multiple en interfaces . . . . . . . . . . . . . 702.4.3. Clases abstractas y tipado fuerte . . . . . . . . . . . . 72
2.5. Conversiones y genericos . . . . . . . . . . . . . . . . . . . . . 732.5.1. Conversiones para objetos . . . . . . . . . . . . . . . . 732.5.2. Genericos . . . . . . . . . . . . . . . . . . . . . . . . . 78
3. Arreglos, listas enlazadas y recurrencia 833.1. Que son las estructuras de datos . . . . . . . . . . . . . . . . . 83
3.1.1. Generalidades de las Estructuras de Datos . . . . . . . 833.2. Arreglos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
3.2.1. Guardar entradas de juego en un arreglo . . . . . . . . 853.2.2. Ordenar un arreglo . . . . . . . . . . . . . . . . . . . . 923.2.3. Metodos para arreglos y numeros aleatorios . . . . . . 953.2.4. Arreglos bidimensionales y juegos de posicion . . . . . 101
3.3. Listas simples enlazadas . . . . . . . . . . . . . . . . . . . . . 1063.3.1. Insercion en una lista simple enlazada . . . . . . . . . . 1083.3.2. Quitar un elemento de una lista simple enlazada . . . . 110
3.4. Listas doblemente enlazadas . . . . . . . . . . . . . . . . . . . 1113.4.1. Insercion en el centro de la LDE . . . . . . . . . . . . . 1143.4.2. Remocion en el centro de la LDE . . . . . . . . . . . . 1153.4.3. Una implementacion . . . . . . . . . . . . . . . . . . . 116
3.5. Listas circulares y ordenamiento . . . . . . . . . . . . . . . . . 1193.5.1. Lista circular enlazada . . . . . . . . . . . . . . . . . . 1193.5.2. Ordenar una LDE . . . . . . . . . . . . . . . . . . . . . 124
3.6. Recurrencia . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1243.6.1. Recurrencia binaria . . . . . . . . . . . . . . . . . . . . 1323.6.2. Recurrencia multiple . . . . . . . . . . . . . . . . . . . 135
4. Herramientas de analisis 1394.1. Funciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
4.1.1. La funcion constante . . . . . . . . . . . . . . . . . . . 1394.1.2. La funcion logarıtmica . . . . . . . . . . . . . . . . . . 140

4 INDICE GENERAL
4.1.3. La funcion lineal . . . . . . . . . . . . . . . . . . . . . 1414.1.4. La funcion N-Log-N . . . . . . . . . . . . . . . . . . . 1414.1.5. La funcion cuadratica . . . . . . . . . . . . . . . . . . . 1414.1.6. La funcion cubica y otras polinomiales . . . . . . . . . 1424.1.7. La funcion exponencial . . . . . . . . . . . . . . . . . . 1444.1.8. Relaciones de crecimiento . . . . . . . . . . . . . . . . 146
4.2. Analisis de algoritmos . . . . . . . . . . . . . . . . . . . . . . 1474.2.1. Estudios experimentales . . . . . . . . . . . . . . . . . 1484.2.2. Operaciones primitivas . . . . . . . . . . . . . . . . . . 1504.2.3. Notacion asintotica . . . . . . . . . . . . . . . . . . . . 1524.2.4. Analisis asintotico . . . . . . . . . . . . . . . . . . . . . 1564.2.5. Uso de la notacion O-grande . . . . . . . . . . . . . . . 1584.2.6. Algoritmo recursivo para calcular potencias . . . . . . 162
5. Pilas y colas 1655.1. Pilas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
5.1.1. El tipo de dato abstracto pila . . . . . . . . . . . . . . 1655.1.2. Implementacion de una pila usando un arreglo . . . . . 1685.1.3. Implementacion de una pila usando lista simple . . . . 1735.1.4. Invertir un arreglo con una pila . . . . . . . . . . . . . 1765.1.5. Aparear parentesis y etiquetas HTML . . . . . . . . . . 177
5.2. Colas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1815.2.1. Tipo de dato abstracto cola . . . . . . . . . . . . . . . 1825.2.2. Implementacion simple de la cola con un arreglo . . . . 1855.2.3. Implementacion con una lista enlazada . . . . . . . . . 1885.2.4. Planificador Round Robin . . . . . . . . . . . . . . . . 189
5.3. Colas con doble terminacion . . . . . . . . . . . . . . . . . . . 1915.3.1. Tipo de dato abstracto deque . . . . . . . . . . . . . . 1915.3.2. Implementacion de una deque . . . . . . . . . . . . . . 192
6. Listas e Iteradores 1976.1. Lista arreglo . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
6.1.1. El tipo de dato abstracto lista arreglo . . . . . . . . . . 1986.1.2. Patron de diseno adaptador . . . . . . . . . . . . . . . 1996.1.3. Implementacion simple con un arreglo . . . . . . . . . 1996.1.4. Interfaz ListaIndice y la clase java.util.ArrayList 2026.1.5. Lista arreglo usando un arreglo extendible . . . . . . . 203
6.2. Listas nodo . . . . . . . . . . . . . . . . . . . . . . . . . . . . 207

INDICE GENERAL 5
6.2.1. Operaciones basadas en nodos . . . . . . . . . . . . . . 2086.2.2. Posiciones . . . . . . . . . . . . . . . . . . . . . . . . . 2086.2.3. El tipo de dato abstracto lista nodo . . . . . . . . . . . 2096.2.4. Implementacion con lista doblemente enlazada . . . . . 213
6.3. Iteradores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2216.3.1. Tipos de dato abstracto Iterador e Iterable . . . . . . . 2216.3.2. El ciclo for-each . . . . . . . . . . . . . . . . . . . . . . 2226.3.3. Implementacion de los iteradores . . . . . . . . . . . . 2246.3.4. Iteradores lista en Java . . . . . . . . . . . . . . . . . . 226
6.4. ADT listas y el marco de colecciones . . . . . . . . . . . . . . 2276.4.1. Listas en el marco de colecciones Java . . . . . . . . . 2286.4.2. Secuencias . . . . . . . . . . . . . . . . . . . . . . . . . 232
6.5. Ejemplo: Heurıstica mover al frente . . . . . . . . . . . . . . . 2356.5.1. Implementacion con una lista ordenada y una clase
anidada . . . . . . . . . . . . . . . . . . . . . . . . . . 2356.5.2. Lista con heurıstica mover al frente . . . . . . . . . . . 237
7. Arboles 2437.1. Arboles generales . . . . . . . . . . . . . . . . . . . . . . . . . 243
7.1.1. Definiciones de arboles y propiedades . . . . . . . . . . 2437.1.2. El tipo de dato abstracto arbol . . . . . . . . . . . . . 2477.1.3. Interfaz del ADT arbol . . . . . . . . . . . . . . . . . . 248
7.2. Algoritmos de recorrido para arboles . . . . . . . . . . . . . . 2517.2.1. Profundidad y altura . . . . . . . . . . . . . . . . . . . 2517.2.2. Recorrido en preorden . . . . . . . . . . . . . . . . . . 2547.2.3. Recorrido en postorden . . . . . . . . . . . . . . . . . . 257
7.3. Arboles Binarios . . . . . . . . . . . . . . . . . . . . . . . . . 2607.3.1. El ADT arbol binario . . . . . . . . . . . . . . . . . . . 2627.3.2. Una interfaz arbol binario en Java . . . . . . . . . . . . 2637.3.3. Propiedades del arbol binario . . . . . . . . . . . . . . 2647.3.4. Una estructura enlazada para arboles binarios . . . . . 2667.3.5. Arbol binario con lista arreglo . . . . . . . . . . . . . . 2757.3.6. Recorrido de arboles binarios . . . . . . . . . . . . . . 2787.3.7. Plantilla metodo patron . . . . . . . . . . . . . . . . . 286

6 INDICE GENERAL

Capıtulo 1
Introduccion
1.1. Clases, tipos, y objetos
Para la construccion de estructuras de datos y algoritmos se necesitandar instrucciones precisar a la computadora, lo cual se puede lograr usandoun lenguaje de computadora de alto nivel, como Java. Se presenta en estecapıtulo un repaso breve de los elementos usados en Java y en el siguientecapıtulo se repasan los principios del diseno orientado al objeto. No se dauna descripcion completa del lenguaje Java porque hay algunos aspectosimportantes que no son relevantes en el diseno de estructuras de datos.
Los programas en Java manipulan objetos. Los objetos guardan datos ydan metodos para acceder y modificar sus datos. Cada objeto es una instanciade una clase, la cual define el tipo del objeto, y las operaciones que realiza.Los miembros importantes de una clase en Java son los siguientes:
Datos de objetos Java son guardados en variables de instancia, ocampos. Por lo tanto, si un objeto de alguna clase es para guardardatos, entonces la clase debe especificar variables de instancia paraguardar. Las variables de instancia pueden ser tipos base, como enteros,numeros punto flotante, o booleanos, o ser referencias a objeto de otrasclases.
Las operaciones que se pueden realizar con los datos son llamadosmetodos. Estos consisten de constructores, procedimientos, y funciones.Los cuales definen el comportamiento de los objetos de esa clase.

8 Introduccion
Declaracion de una clase
Un objeto es una combinacion especıfica de datos y metodos que puedenprocesar y comunicar esos datos. Las clases definen los tipos para los objetos:por lo tanto, los objetos son en ocasiones referidos como instancias de su clasedefinidora, porque toman el nombre de esa clase como su tipo.
Un ejemplo de la definicion de una clase Java se muestra en el listado 1.1con la clase Contador.
1 public class Contador
2 private int cuenta; // una variable entera de instancia
3 /** El constructor por defecto para un objeto Contador */
4 Contador () cuenta = 0;
5 /** Un metodo accesor para obtener el valor actual */
6 public int getCuenta () return cuenta;
7 /** Un metodo modificador para incrementar la cuenta */
8 public void incrementaCuenta () ++ cuenta;
9 /** Un metodo modificador para decrementar la cuenta */
10 public void decrementaCuenta () --cuenta;
11
Listado 1.1: Clase Contador usada para llevar una cuenta simple, la cual puede seraccesada, incrementada y decrementada
La definicion de la clase esta delimitada por llaves, se usa “” para marcarel inicio y “” para marcar el final. Cualquier conjunto de sentencias entrellaves definen un bloque de programa.
La clase Contador es una clase publica, por lo tanto cualquier otra clasepuede crear y usar un objeto Contador. La clase Contador tiene una variableentera de instancia llamada cuenta. La variable es inicializada a cero enel metodo constructor, Contador, el cual es llamado cuando se crea unnuevo objeto Contador. La clase tiene un metodo accesor, getCuenta(),el cual devuelve el valor actual del contador. Tambien tiene dos metodosactualizadores, incrementaCuenta() y decrementaCuenta(). Esta clase notiene metodo main() y por lo tanto no hace nada por sı misma.
El nombre de una clase, metodo, o variable en Java es llamado un identifi-cador, el cual puede ser cualquier cadena de caracteres de tamano arbitrario,debiendo iniciar con una letra seguida de letras, numeros, y guiones bajos,siendo letra y numero de cualquier lenguaje escrito definido en el conjunto decaracteres Unicode. La excepciones a la regla anterior son los identificadoresJava del cuadro 1.1.
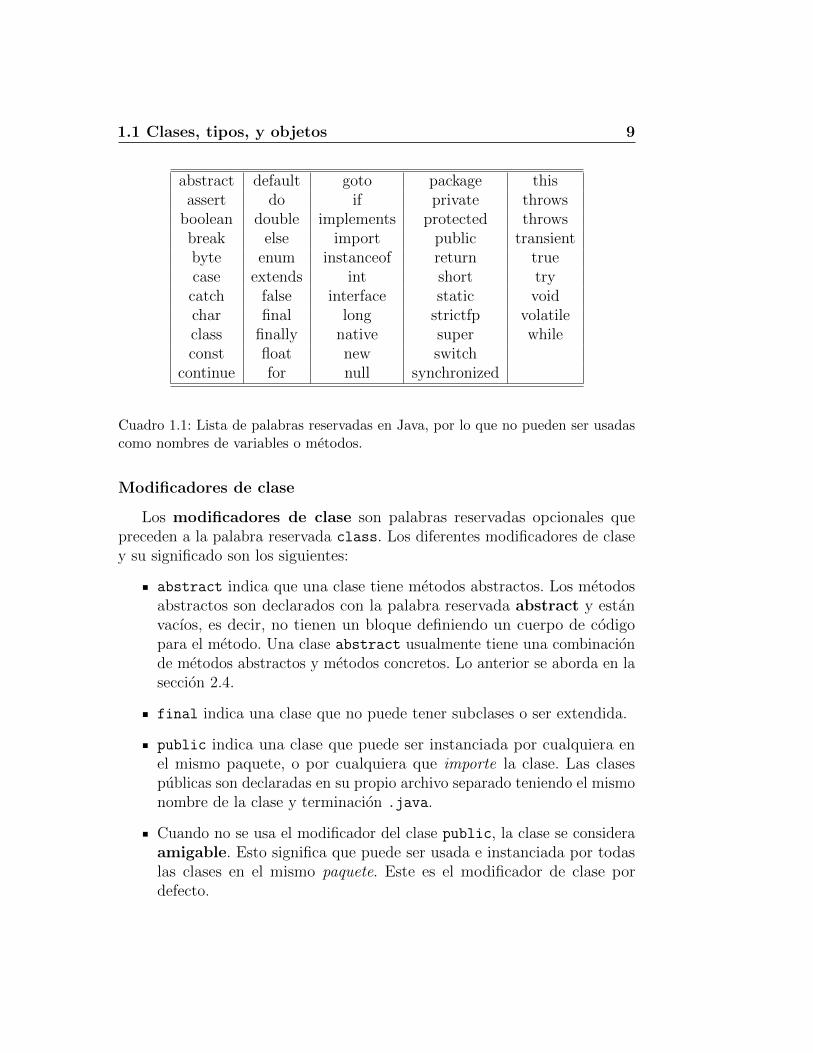
1.1 Clases, tipos, y objetos 9
abstract default goto package thisassert do if private throws
boolean double implements protected throwsbreak else import public transientbyte enum instanceof return truecase extends int short trycatch false interface static voidchar final long strictfp volatileclass finally native super whileconst float new switch
continue for null synchronized
Cuadro 1.1: Lista de palabras reservadas en Java, por lo que no pueden ser usadascomo nombres de variables o metodos.
Modificadores de clase
Los modificadores de clase son palabras reservadas opcionales quepreceden a la palabra reservada class. Los diferentes modificadores de clasey su significado son los siguientes:
abstract indica que una clase tiene metodos abstractos. Los metodosabstractos son declarados con la palabra reservada abstract y estanvacıos, es decir, no tienen un bloque definiendo un cuerpo de codigopara el metodo. Una clase abstract usualmente tiene una combinacionde metodos abstractos y metodos concretos. Lo anterior se aborda en laseccion 2.4.
final indica una clase que no puede tener subclases o ser extendida.
public indica una clase que puede ser instanciada por cualquiera enel mismo paquete, o por cualquiera que importe la clase. Las clasespublicas son declaradas en su propio archivo separado teniendo el mismonombre de la clase y terminacion .java.
Cuando no se usa el modificador del clase public, la clase se consideraamigable. Esto significa que puede ser usada e instanciada por todaslas clases en el mismo paquete. Este es el modificador de clase pordefecto.

10 Introduccion
1.1.1. Tipos base
Los tipos de los objetos estan determinados por la clase de la cual vienen.Para propositos de eficiencia y simplicidad, Java tambien tiene los siguientestipos base, o tipos primitivos, los cuales no son objetos:
Tipo base Descripcionboolean Valor booleano: true o false
char Caracter Unicode de 2 bytesbyte Entero con signo en complemento a dos de 1 byteshort Entero con signo en complemento a dos de 2 bytesint Entero con signo en complemento a dos de 4 byteslong Entero con signo en complemento a dos de 8 bytesfloat Numero de punto flotante 4 bytes (IEEE 754-1985)double Numero de punto flotante 8 bytes (IEEE 754-1985)
Alguna variable teniendo uno de estos tipos guarda un valor de ese tipo, envez de una referencia a algun objeto. Las constantes enteras, como 18 o -255,son de tipo int, a menos que vayan seguidos inmediatamente por una ‘L’ o ‘l’,siendo en tal caso del tipo long. Constantes de punto flotante, como 3.1416 o2.78e5, son de tipo double, a menos que vayan seguidos inmediatamente poruna ‘F’ o ‘f’, siendo en tal caso del tipo float. Se muestra en el listado 1.2una clase sencilla, Base, que define tipos base como variables locales para elmetodo main().
Comentarios
Los comentarios son anotaciones para los lectores humanos y no sonprocesados por el compilador Java. Java permite dos tipos de comentarios,comentarios de bloque y comentarios en lınea, los cuales definen el textoignorado por el compilador. Un comentario de bloque inicia con “/*” y secierra con “*/”. Un comentario que inicia con “/**” es usado por el programajavadoc, para generar la documentacion del software.
Se usa tambien “//” para iniciar comentarios en lınea y se ignora todohasta el final de la lınea.
1.1.2. Objetos
Un nuevo objeto es creado usando el operador new. Este operador creaun objeto nuevo de una clase especificada y devuelve una referencia a ese

1.1 Clases, tipos, y objetos 11
1 public class Base
2 public static void main(String [] args)
3 boolean bandera = true;
4 char c = ’z’;
5 byte b = -127;
6 short s = 32000;
7 int i = 12345;
8 long l = 6789L;
9 float f = 3.1416f;
10 double d = 2.1232 e8;
11 System.out.println("bandera = " + bandera ); // + operador concatenaci on
12 System.out.println("c = " + c);
13 System.out.println("b = " + b);
14 System.out.println("s = " + s);
15 System.out.println("i = " + i);
16 System.out.println("l = " + l);
17 System.out.println("f = " + f);
18 System.out.println("d = " + d);
19
20
Listado 1.2: La clase Base muestra ejemplos de uso de tipos base.
objeto. Enseguida inmediatamente del operador new se pone una llamada alconstructor para ese tipo de objeto. Cualquier constructor que este incluidoen la definicion de la clase se puede usar. En las lıneas 4 y 5 de la de la claseEjemplo, listado 1.3, se muestra el uso del operador new para crear objetos yasignar la referencia a esos objetos a una variable.
1 public class Ejemplo
2 public static void main(String [] args)
3 Contador c; // declaraci on de la variable c del tipo Contador
4 Contador d = new Contador (); // declaracion y creaci on
5 c = new Contador (); // se crea un objeto Contador , devolviendo una ref.
6 d = c; // la referencia de c se asigna a d
7
8
Listado 1.3: Ejemplos de uso del operador new.
Al usar el operador new con algun tipo de clase, se suceden los siguientestres eventos:
Un nuevo objeto es asignado dinamicamente en memoria, y todas susvariables de instancia son inicializadas a valores por defecto. El valorpor defecto para las variables objeto es null y para todos los tipos basees cero, excepto las variables booleanas, puestas a false.

12 Introduccion
El constructor para el nuevo objeto es llamado con los parametrosindicados.
Despues que el constructor termina, el operador new devuelve unareferencia, o direccion de memoria, para el objeto nuevo creado. Si laexpresion esta en la forma de una sentencia de asignacion, entonces sudireccion se guarda en la variable objeto, ası la variable objeto se refiereal objeto nuevo creado.
Objetos numero
Cuando se requiere guardar numeros como objetos, se pueden usar lasclases envoltura de Java. A estas se les conoce como clases numero y hayuna clase numero por cada tipo base.
El cuadro 1.2 muestra los tipos base numericos y su correspondiente clasenumerica. Desde Java 5, una operacion de creacion es realizada automatica-mente en cualquier momento que se pasa un numero base a un metodo queespera un objeto. De igual forma, el metodo accesor correspondiente es usadoautomaticamente cada vez que se quiere asignar el valor de objeto Number aun tipo base numerico.
Tipo Nombre Ejemplo Ejemplobase de la clase de creacion de accesobyte Byte n=new ((byte)1); n.byteValue()
short Short n=new ((short)1); n.shortValue()
int Integer n=new (1); n.intValue()
long Long n=new (1L); n.longValue()
float Float n=new Floate(3.9F); n.floatValue()
double Double n=new Double(3.9); n.doubleValue()
Cuadro 1.2: Clases numero de Java. Cada clase esta dada con su correspondientetipo base y ejemplos para crear y acceder tales objetos.
Objetos String
Una cadena es una secuencia de caracteres que provienen de algun alfa-beto, el conjunto de todos los posibles caracteres. Cada caracter c que forma

1.1 Clases, tipos, y objetos 13
una cadena s puede ser referenciado por su ındice en la cadena, que es lacantidad de caracteres que estan antes de c en s, ası el primer caracter tieneındice cero. El alfabeto usado para definir cadenas es el conjunto de caracteresinternacional Unicode, una codificacion de caracteres de 2 bytes que cubre lamayorıa de los lenguajes escritos. Java define una clase especial incorporadade objetos llamados objetos String. Las cadenas literales en Java debe serencerradas entre comillas dobles.
Concatenacion
El procesamiento de cadenas requiere manejar cadenas. La operacionprimaria para combinar cadenas es llamada concatenacion, la cual tomauna cadena p y una cadena q y las combina en una nueva cadena, indicada porp + q, la cual consiste de todos los caracteres de p seguidos de los caracteresde q. En Java, la operacion de concatenacion funciona como se indica en ladescripcion. Ası es legal en Java escribir una sentencia de asignacion como
String s = "fut" + "bol";
La sentencia define una variable s que refiere un objeto de clase String,y le asigna la cadena "futbol". En Java se asume que cada objeto tiene unmetodo incorporado toString() que devuelve una cadena asociada con elobjeto.
Referencias a objetos
Crear un nuevo objeto involucra el uso del operador new para asignar elespacio de memoria del objeto y usar el constructor del objeto para inicializareste espacio. La localidad, o direccion, de este espacio, generalmente, es luegoasignado a una variable referencia. Por lo tanto, una variable de referenciapuede ser vista como un “apuntador” a algun objeto. Es como si la variablefuera un contenedor para un control remoto que puede ser usado para manejarel objeto nuevo creado. La variable tiene una forma de apuntar al objeto ypedir que haga cosas o de acceso a sus datos.
El operador punto
Cada variable referencia objeto debera referirse a algun objeto, a menosque esta sea null, en tal caso no apunta a nada.

14 Introduccion
Puede haber varias referencias al mismo objeto, y cada referencia a unobjeto especıfico puede ser usada para llamar metodos en ese objeto. Si seusa una variable referencia objeto para cambiar el estado del objeto, entoncessu estado cambia para todas las referencias a este. Este comportamiento seda por el hecho de que todas las referencias apuntan al mismo objeto.
Uno de los usos primarios de una variable referencia objeto es para accederlos miembros de la clase para este objeto, una instancia de su clase. Esto es,una variable referencia objeto es util para acceder los metodos y las variablesinstancias asociadas con un objeto. Este acceso es realizado con el operadorpunto (“.”). Se llama a un metodo asociado con un objeto usando el nombrede la variable referencia, seguida por el operador punto y luego el nombre delmetodo y sus parametros.
Si hay varios metodos definidos con el mismo nombre para el objeto,entonces el sistema de ejecucion Java usa el que empate en la cantidad deparametros y este mas cercano a sus tipos respectivos. Un nombre de metodocombinado con la cantidad y los tipos de sus parametros es llamado la firmadel metodo. Cuando se hace la llamada a cierto metodo se usa la firma paradeterminar el metodo actual a usar. Considerar los siguientes ejemplos:
estufa.cocinaCena();
estufa.cocinaCena(comida);
estufa.cocinaCena(comida,temporada);
Cada una de las llamadas a metodos se refiere a un metodo diferentecon el mismo nombre definido en la clase a la cual pertenece estufa. Sinembargo, la firma de un metodo en Java no incluye el tipo que regresa elmetodo, ası Java no permite dos metodos con la misma firma para regresartipos diferentes.
Variables de instancia
Las clases de Java pueden definir variables de instancia, las cuales sonllamadas tambien campos. Estas variables representan los datos asociadoscon los objetos de una clase. Las variables de instancia deberan tener untipo, el cual puede ser un tipo base, tal como int, long, double, o un tiporeferencia, esto es, una clase, tal como un String, una interfaz, o un arreglo.
Dada una variable referencia v, la cual apunta a un objeto o, se puedeacceder cualquier variable de instancia para o que las reglas de acceso lopermitan. Por ejemplo, las variables de instancia public son accesibles para
1.1 Clases, tipos, y objetos 15
todos. Usando el operador punto se puede acceder y poner el valor de talesvariables de instancia. Por ejemplo, si estudiante se refiere a un objetoEstudiante que tiene variables de instancia publicas llamadas nombre yedad, entonces las siguientes sentencias son permitidas:
estudiante.nombre = "Enrique";
estudiante.edad = 18;
Una referencia objeto no tiene que ser solamente una variable de referencia.Tambien puede ser cualquier expresion que devuelva una referencia objeto.
Modificadores de variables
Cuando se declara una variable de instancia se puede opcionalmente definirun modificador de variable seguido por el tipo de la variable y el identificadorque sera usado para la variable. Adicionalmente, se puede opcionalmenteasignar un valor inicial a la variable con el operador de asignacion “=”. Lasreglas para un nombre de variable son las misma que para cualquier otroidentificador. El parametro del tipo de la variable puede ser un tipo base,indicando que guarda valores de ese tipo, o un nombre de clase, indicandoque guarda una referencia a un objeto de esa clase. El valor inicial opcionalque se podrıa asignar a una variable de instancia debera empatar el tipo de lavariable. La clase Duende tiene varias definiciones de variables de instancias,mostrado en el listado 1.4. Las variables edad, magico, y estatura son tiposbase, la variable nombre es una referencia a una instancia de la clase String,y la variable amigoDuende es una referencia a un objeto de la clase que sedefine. Los valores constantes asociados con una clase deberan ser siempredeclarados como static y final, como lo es la “variable” ESTATURA MAX.
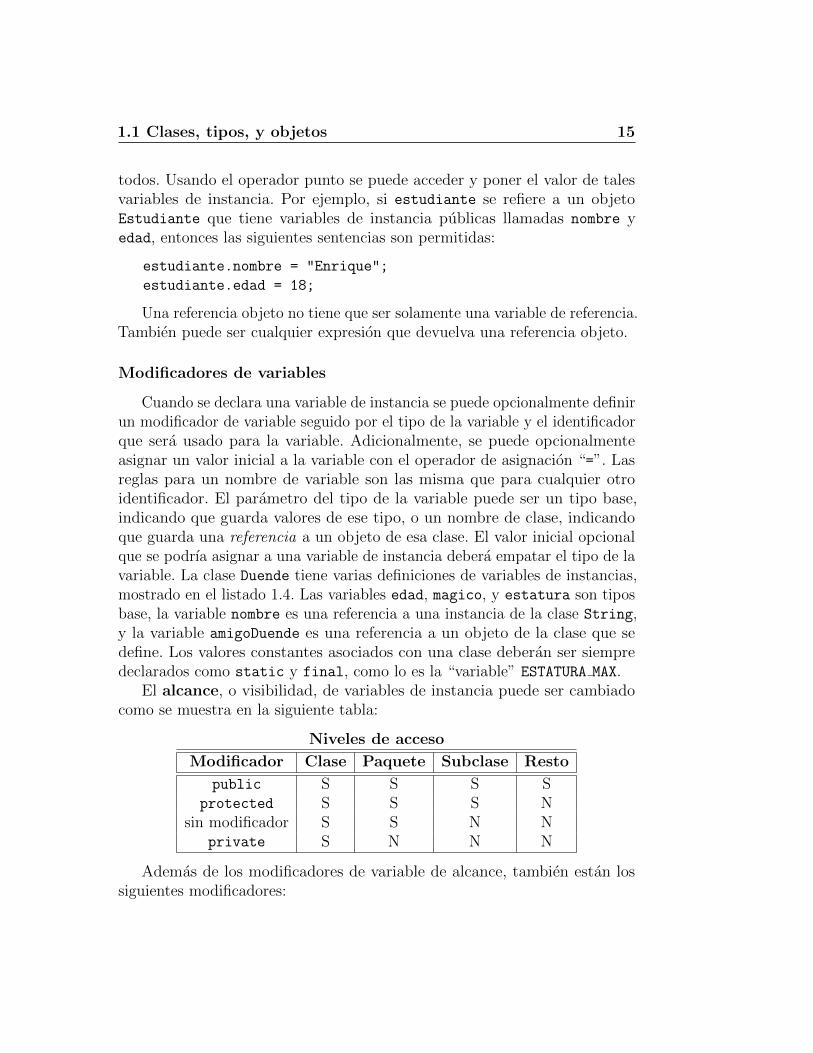
El alcance, o visibilidad, de variables de instancia puede ser cambiadocomo se muestra en la siguiente tabla:
Niveles de acceso
Modificador Clase Paquete Subclase Resto
public S S S Sprotected S S S N
sin modificador S S N Nprivate S N N N
Ademas de los modificadores de variable de alcance, tambien estan lossiguientes modificadores:

16 Introduccion
1 public class Duende
2 // variables de instancia
3 public String nombre;
4 public int edad;
5 public Duende amigoDuende;
6 private boolean magico = false;
7 protected double estatura = 85;
8 public static final int ESTATURA_MAX = 100;
9 // constructores
10 Duende(String n, int e, Duende a, double est) // parametrizado compl
11 nombre = n;
12 edad = e;
13 amigoDuende = a;
14 estatura = est;
15
16 Duende () // constructor por defecto
17 nombre = "Puck";
18 edad = 128;
19 amigoDuende = null;
20 estatura = 95;
21
22 // me todos
23 public static void hacerRey(Duende d)
24 d.nombre = "Rey " + d.getNombreReal ();
25 d.magico = true;
26
27 public void hacerRey ()
28 nombre = "Rey " + getNombreReal ();
29 magico = true;
30
31 public boolean esMagico () return magico;
32 public void setEstatura(int nvaEst) estatura = nvaEst;
33 public String getNombre () return "¡No te lo dir e!";
34 public String getNombreReal () return nombre;
35 public void renombrar(String s) nombre = s;
36
Listado 1.4: La clase Duende

1.2 Metodos 17
1. static. Se usa para declarar que una variable que esta asociada con laclase, no con instancias individuales de esa clase. Las varibles static
son usadas para guardar informacion global de la clase y existen aun sino se han creado instancias de la clase.
2. final. Una variable de instancia final es una a la que se le debe asignarun valor inicial, y entonces nunca puede se puede asignar un nuevovalor. Si esta es un tipo base, entonces es una constante. Si una variableobjeto es final, entonces siempre se referira al mismo objeto (aun si elobjeto cambia su estado interno).
1.1.3. Tipo enum
Desde Java 5 se soportan tipos enumerados, llamados enum. Estos sontipos a los cuales se les permite tomar solo valores dados de un conjuntoespecificado de nombres. Estos pueden ser declarados dentro de una clasecomo sigue:
[modificador] enum nombre nombre valor0, nombre valor1, ...;
donde el modificador es opcional, o puede ser public, protected, o private.El nombre es cualquier identificador legal de Java. Cada uno de los valoresidentificadores es el nombre de un valor posible que variables de este tipo enum
puede tomar. Cada uno de estos nombre valor puede ser cualquier identificadorJava, pero por convencion estos deberan ser palabras en mayusculas.
El tipo enum definido se puede usar para definir otras variables, como sifuera el nombre de una clase. Los tipos enum tiene unos cuantos metodosincorporados, como el metodo valueOf() que devuelve el valor enum quecorresponde con la cadena dada. Se muestra en la clase DiaCurso, listado 1.5,el uso de un tipo enum.
1.2. Metodos
Los metodos en Java son conceptualmente similares a funciones y procedi-mientos en otro lenguajes de programacion de alto nivel. Son lıneas de codigoque son llamadas para un objeto particular de alguna clase. Los metodospueden aceptar parametros como argumentos y entonces el comportamientodependera de estos y del objeto. Cada metodo es indicado en el cuerpo de

18 Introduccion
1 public class DiaCurso
2 public enum Dia LUN , MAR , MIE , JUE , VIE , SAB , DOM;
3 public static void main(String [] args)
4 Dia d = Dia.LUN;
5 System.out.println("Inicialmente d es " + d);
6 d = Dia.VIE;
7 System.out.println("Ahora es " + d);
8 Dia o = Dia.valueOf("VIE");
9 System.out.println("¿Son d y t lo mismo? "+(d==o));
10
11
Listado 1.5: Un ejemplo del uso del tipo enum
alguna clase. La definicion de un metodo tiene dos partes: la firma, la cualdefine el nombre y los parametros del metodo, y el cuerpo, el cual define loque el metodo hace.
Un metodo permite al programador mandar un mensaje a un objeto. Lafirma del metodo indica como un mensaje debera parecer y el cuerpo delmetodo indica que hara el objeto cuando reciba tal mensaje.
Declaracion de metodos
La sintaxis para definir un metodo es:
[modificadores] tipo nombre(tipo0 parametro0, tipo1 parametro1, . . . )// cuerpo del metodo ...
Los modificadores incluyen los mismos tipos de los modificadores de alcanceusados para variables, como public, protected, y static, con significadosimilar. El tipo de la declaracion define el tipo devuelto por el metodo. Elnombre es cualquier identificador Java valido. La lista de parametros y sustipos declaran variables locales que corresponden a valores que son pasadoscomo argumentos al metodo. Cada declaracion tipo puede ser cualquier tipoJava y cada parametro es un identificador Java. La lista de parametros ysus tipos puede estar vacıa, por lo cual no se pasan valores al metodo al serllamado. Las variables parametro, al igual que las variables de instancia de laclase, pueden ser usadas dentro del cuerpo del metodo. De igual forma, otrosmetodos de esta clase pueden ser llamados desde el cuerpo de un metodo.
Cuando un metodo de una clase es llamado, se invoca con una instanciaparticular de esa clase y puede cambiar el estado de ese objeto, excepto para

1.2 Metodos 19
un metodo static, el cual esta asociado con la propia clase. Al invocar elmetodo renombrar() de la clase Duende, listado 1.4, cambia su nombre.
Modificadores de metodo
Al igual que las variables de instancia, los modificadores de metodo puedenrestringir el alcance de un metodo:
1. public. Cualquiera puede llamar al metodo.
2. protected. Solo metodos del mismo paquete o de sus subclases puedenllamar al metodo.
3. private. Solo metodos de la misma clase pueden llamar.
4. Si ninguno de los anteriores modificadores es usado, el metodo es ami-gable, por lo que puede ser llamado por objetos de clases en el mismopaquete.
Los modificadores anteriores podrıan ser seguidos por los modificadoresadicionales:
1. abstract. Un metodo declarado como abstracto no tiene codigo. Lafirma de tal metodo esta seguida por un punto y coma sin cuerpo delmetodo. Por ejemplo:
public abstract void setEstatura( double nvaEst );
Los metodos abstractos pueden aparecer solo en clases abstractas. Serevisa su utilidad en la seccion 2.4.
2. final. El metodo no puede ser anulado por una subclase.
3. static. El metodo esta asociado con la propia clase, y no con algunainstancia particular de la clase. Estos metodos pueden ser usados paracambiar el estado de variables estaticas asociadas a la clase, siempre ycuando estas no sean final.

20 Introduccion
Tipos devueltos
Una definicion de metodo debera indicar el tipo de valor que el metodoregresara. Si el metodo no regresa un valor, entonces se debe usar la palabrareservada void. Si el tipo devuelto es void, el metodo es llamado un procedi-miento; de otra forma, es llamado una funcion. Para regresar un valor en Java,un metodo debera usar la palabra reservada return y una expresion, la cualdebe empatar con el tipo regresado por el metodo. En el metodo esMagico()
de la clase Duende, listado 1.4 se devuelve un valor usando return. Tanpronto como return es ejecutado, el metodo termina.
Las funciones Java pueden devolver solo un valor. Para regresar valoresmultiples se deberan combinar todos los valores que se quieran devolver en unobjeto compuesto, cuyas variables de instancia incluiran todos los valoresque se quieran devolver, y luego regresar una referencia al objeto compuesto.Ademas, se puede cambiar el estado interno de un objeto que es pasado a unmetodo como otra forma de “devolver” resultados multiples.
Parametros
Los parametros de un metodo estan definidos en una lista separada porcomas y encerrada entre parentesis despues del nombre del metodo. Unparametro consiste de dos partes, el tipo y el nombre. Si un metodo no tieneparametros, entonces solo un par de parentesis vacıos es usado.
Todos los parametros en Java son pasados por valor, es decir, cuando sepasa un parametro a un metodo, una copia de ese parametro es hecha paraser usada dentro del cuerpo del metodo. El metodo puede cambiar la copiapero no el original. Si se pasa una referencia objeto como un parametro a unmetodo, entonces la referencia tambien es copiada. Cambiando la referenciainterna dentro de un metodo no cambiara la referencia que fue pasada. Porejemplo si se pasa una referencia Duende x a un metodo que llame a esteparametro d, entonces el metodo puede cambiar la referencia d para queapunte a un objeto diferente, pero x seguira refiriendose al mismo objeto. Porsupuesto, el metodo puede usar la referencia d para cambiar el estado internodel objeto, y esto tambien cambiara al objeto de x, ya que ambos apuntan almismo objeto. Esto ultimo se hace en el metodo de clase hacerRey(Duende)
de la clase Duende, listado 1.4.

1.2 Metodos 21
Constructores
Un constructor es un tipo especial de metodo usado para inicializarobjetos nuevos creados. Java tiene una forma particular para declarar elconstructor y una forma especial para llamar al constructor. La sintaxis paradeclarar un constructor es:
[modificadores] nombre(tipo0 parametro0, tipo1 parametro1, . . . )// cuerpo del constructor ...
La sintaxis es casi la misma que para el metodo, excepto que el nombre delconstructor debera ser el mismo nombre de la clase que construye, y ademas nose indica que tipo devuelve, ya que su tipo devuelto es implıcitamente el mismoque su nombre. Los modificadores del constructor siguen las mismas reglasque los metodos, excepto que abstract, static y final no se permiten.
El constructor para una clase Camaron podrıa ser el siguiente:
public Camaron(int p, String n) peso = p;
nombre = n;
Definicion del constructor e invocacion
El cuerpo de un constructor es como el cuerpo de un metodo, con elsiguiente par de excepciones menores. Una es el encadenado del constructor yla otra es la prohibicion del uso de la sentencia return.
Los constructores son invocados en una forma unica: deberan ser llamadoscon el operador new. Cuando se invoca una nueva instancia de la clase esautomaticamente creada y entonces su constructor es llamado para inicializarsus variables de instancia y realizar otras tareas de configuracion. Por ejemploconsiderar la siguiente llamada al constructor y declaracion de la variablemiCamaron:
Camaron miCamaron = new Camaron(50,"Popeye");
Una clase puede tener varios constructores, pero cada uno debera teneruna firma diferente, es decir, cada uno debera distinguirse por el tipo y lacantidad de parametros que toma.

22 Introduccion
Metodo main()
Algunas clases en Java son disenadas para ser usadas por otras clases,otras son programas independientes. Las clases que definen programas inde-pendientes deberan contener un tipo especial de metodo, el metodo main().Cuando se quiere ejecutar una programa Java independiente, se refiere elnombre de la clase que define el programa precedido del siguiente comando:
java Acuario
En este caso, el sistema de ejecucion Java busca una version compilada dela clase Acuario, y luego llama al metodo especial main en esa clase. Estemetodo se debe declarar como sigue:
public static void main(String[] args) // cuerpo del metodo main
Los argumentos pasados como los parametros args al metodo main() sonlos argumentos lınea de comandos dados cuando el programa es ejecutado.La variable args es un arreglo de objetos String, es decir, una coleccionde cadenas indizadas, con la primera cadena siendo args[0], la segundaargs[1], etc.
Bloques de sentencias y variables locales
El cuerpo de un metodo es un bloque de sentencias, el cual es unasecuencia de sentencias y declaraciones entre las llaves “” y “”. Los cuerposde los metodos y otros bloques de sentencias pueden tener bloques anidadosdentro de ellos. Los bloques de sentencias pueden contener declaracionesde variables locales. Estas variables son declaradas dentro del cuerpo desentencias, generalmente al inicio, pero dentro de las llaves. Las variableslocales son similares a variables de instancia, pero solo existen mientras elbloque de sentencias esta siendo ejecutado. Tan pronto como el flujo delprograma sale del bloque, todas las variables locales dentro de este no puedenser referenciadas mas. Una variable local puede ser un tipo base, como int,float, o double, o una referencia a una instancia de alguna clase. Lassentencias y declaraciones son siempre terminadas con punto y coma.
Hay dos formas de declarar variables locales:

1.3 Expresiones 23
tipo nombre;tipo nombre = valor inicial;
La primera declaracion solo define el identificador, nombre, para ser detipo especificado. La segunda define el identificador, su tipo, e inicializa lavariable al valor inidicado. Enseguida estan algunos ejemplos de declaracionesde variables locales:
double r;
Punto p1 = new Punto(1, 2);
Punto p2 = new Punto(5, 6);
int i = 1024;
double e = 2.71828;
1.3. Expresiones
Las variables y constantes son usadas en expresiones para definir nuevosvalores y para modificar variables. Las expresiones involucran el uso de literales,variables, y operadores.
1.3.1. Literales
Una literal es cualquier valor “constante” que puede ser usado en unaasignacion u otra expresion. Java permite los siguientes tipos de literales:
La referencia objeto null. Es la unica literal objeto y se permite usarcon cualquier tipo de referencia.
Las constantes booleanas true y false.
Entero. El tipo por defecto para un entero como 176, o -12 es int, elcual es un entero de 4 bytes. Una literal entera long debe terminar con“L” o “l”, como 176L, o -12l, y define un entero de 8 bytes.
Punto flotante. El tipo por defecto para un punto flotante, como 3.1416
y -432.1 es double. Para indicar una literal como float, esta debeterminar con “F” o “f”. Literales punto flotante en notacion cientıfica

24 Introduccion
tambien son permitidas, tal como 3.14E5 o -0.19e8. La “E” o “e” indicapor diez elevado a la potencia, del mismo modo que una calculadora.
Caracter. Las constantes caracter son tomadas del alfabeto Unicode.Un caracter esta definido como un sımbolo individual encerrado entrecomillas simples. Por ejemplo, ’a’ y ’?’ son caracteres constantes.Ademas Java define las constantes caracter especial siguientes:
’\n’ nueva lınea ’\t’ tabulador’\b’ retroceso ’\r’ retorno’\f’ avance forma ’\\’ diagonal invertida’\’’ comilla simple ’\”’ comilla doble
Cadena. Una cadena literal es una secuencia de caracteres encerradoscon comillas dobles. Por ejemplo, la siguiente es una literal de cadena:
"Monarcas permanecera en primera division"
1.3.2. Operadores
Las expresiones Java involucran componer literales y variables con opera-dores.
Operador de asignacion
El operador de asignacion es “=”. Es usado para asignar un valor, prin-cipalmente, a una variable de instancia o variable local. Su sintaxis es lasiguiente:
variable = expresion;
donde variable refiere a una variable que es permitida ser referenciada por elbloque conteniendo la expresion. El valor de una operacion es el valor de laexpresion que fue asignada. Por ejemplo, si i y j son ambas declaradas deltipo int, es correcto tener una sentencia de asignacion como:
i = j = 25;
La asignacion anterior funciona ya que los operadores de asignacion sonevaluados de derecha a izquierda.

1.3 Expresiones 25
Operadores aritmeticos
Los siguientes son los operadores aritmeticos binarios en Java:
+ adicion− sustraccion∗ multiplicacion/ division% modulo
El operador modulo tambien es conocido como el operador “residuo”,porque es el residuo sobrante despues de realizar la division entera.
Java tambien proporciona un menos unario (−), el cual puede ser colocadoantes de la expresion aritmetica para invertir su signo. Los parentesis puedenser usados en cualquier expresion para definir el orden de evaluacion. Java usareglas de precedencia de operadores para determinar el orden de evaluacioncuando los parentesis no son usados.
Java proporciona los operadores incremento en uno (++) y decrementoen uno (−−). Si los operadores son usados antes de la variable, entonces unoes agregado, o sustraido de, la variable y su valor es leido en la expresion. Sies usado despues de una variable, entonces el valor es primero leido y luego lavariable es incrementada o decrementada en uno. Por ejemplo, el fragmentode codigo
int i = 20;
int j = i++;
int k = ++i;
int m = i--;
int n = 9 + i++;
asigna 20 a j, 22 a k, 22 a m, 30 a n, y deja i con 22.
Operadores logicos
Java permite los operadores de comparacion estandar entre numeros:
< menor que<= menor que o igual a> mayor que>= mayor que o igual a== igual a!= no igual a

26 Introduccion
Los operadores == y != tambien pueden ser usados con referencias objetos.El tipo del resultado de una comparacion es un boolean.
Los operadores que pueden operar con valores booleanos son los siguientes:
! negacion (prefijo)&& condicional y|| condicional o
Los operadores logicos && y || no evaluaran el segundo operador ensu expresion si no es necesario determinar el valor de la expresion. Estacaracterıstica es util para construir expresiones booleanas donde primero seprueba que una cierta condicion se cumpla, como que una referencia no seanula, y luega se prueba una condicion que podrıa haber generado de otraforma una condicion de error si la primera prueba no hubiera sucedido.
Operadores a nivel bit
Java proporciona los siguientes operadores a nivel bit (bitwise) paraenteros:
~ complemento (operador unario prefijo)& y bitwise| o bitwise^ o-exclusivo bitwise<< desplazamiento a la izquierda>> desplazamiento a la derecha sin signo>>> desplazamiento a la izquierda con signo
Operadores de asignacion
Para expresiones del tipo
variable = variable operador expresion;
Java proporciona operadores de asignacion que tienen efectos laterales deoperacion. Estos operadores son de la forma
variable operador= expresion;
excepto si la variable contiene una expresion, como un ındice arreglo, laexpresion es evaluada una sola vez. Ası, el fragmento de codigo

1.3 Expresiones 27
a[5] = 20;
i = 5;
a[i++] += 3;
deja a[5] con el valor 23 e i con valor 6.
Concatenacion de cadenas
Las cadenas pueden ser compuestas usando el operador de concatenacion(+).
Precedencia de operadores
Los operadores en Java tienen precedencia, la cual sirve para determinarel orden en el cual las operaciones son hechas. Los operadores son evaluadosde acuerdo a la siguiente tabla si lo parentesis no son usados para determinarel orden de evaluacion. Los operadores en la misma lınea son evaluadosde izquierda a derecha, excepto para la asignacion y operaciones prefijas,las cuales son evaluadas de derecha a izquierda, de acuerdo a la regla deevaluacion condicional para las operaciones logicas Y y O. Sin parentesis, losoperadores de mayor precedencia son evaluados antes que los operadores demenor precedencia.
Tipo SımbolosPostfijo exp++ exp−−Prefijo ++exp −−exp +exp −exp ˜exp !expConversion (tipo)expMult./div. ∗ / %add./subs. + −desplazamiento << >> >>>comparacion < <= > >= instanceof
igualdad == !=y bitwise &xor bitwise ˆo bitwise |y &&o ||condicional ? :
asignacion = += -= /= %= >>= <<= >>>= &= ˆ= |=

28 Introduccion
1.3.3. Conversiones tipo base
La conversion es una operacion que permite cambiar el tipo de un valor.Se puede tomar un valor de algun tipo y convertirlo en un valor equivalente deotro tipo. Las conversiones son utiles para hacer ciertas operaciones numericasy de entrada/salida.
La sintaxis para conversion de una expresion a un tipo deseado es:
(tipo) exp
donde tipo indica a que tipo se quiere convertir la expresion que se tiene. Haydos tipos fundamentales de conversiones que pueden ser hechas. Se puedeconvertir respecto a tipos base numerica o con respecto a objetos. Se abordaen este capıtulo la conversion numerica y de cadenas, y la de objetos en laseccion 2.5.1.
Conversion ordinaria
Cuando se convierte de un tipo double a un int, se podrıa perder precision,siendo el valor double truncado. Pero se puede convertir un int a un double
sin problema. Por ejemplo, considerar lo siguiente:
double d1 = 1.2;
double d2 = 3.9999;
int i1 = (int )d1; // i1 tiene valor 1
int i2 = (int )d2; // i2 tiene valor 3
double d3 = (double )i2; // d3 tiene valor 3.0
Conversion con operadores
Ciertas operaciones binarias, como la division, daran resultados diferentesdependiendo de los tipos de variables usadas. Se debe asegurarse que lasoperaciones realizadas con los valores de los tipos pretendidos son las deseadas.Por ejemplo, cuando se usan enteros, la division no considera la parte fraccional,pero si cuando se usan numeros punto flotante, como se muestra en el siguienteejemplo:
int i1 = 4;
int i2 = 8;
dResultado = (double )i1 / (double )i2; // dResultado <-- 0.5
dResultado = i1 / i2; // dResultado <-- 0.0

1.3 Expresiones 29
Cuando i1 e i2 fueron convertidos a dobles, se realizo una division paranumeros reales. Cuando no fueron convertidos, se realizo una division enteray ası el resultado fue cero. Java no hace una conversion implıcita para asignarun valor int al resultado double.
Conversion implıcita y autoempacado/desempacado
Hay casos donde Java realiza una conversion implıcita, de acuerdo altipo de la variable de asignacion, dado que no exista perdida de precision.Por ejemplo:
int iResultado = 3;
double dResultado = 3.2;
dResultado = i/d; // dResultado <-- 0.9375. i convertido a double
iResultado = i/d; // perdida de precision -> error de compilacion
iResultado = (int )i/d; // iResultado <-- 0, se pierde la fraccion
Como Java no realiza conversiones implıcitas donde se pierda precision, laconversion explıcita en la ultima lınea es requerida.
A partir de Java 5 hay un nuevo tipo de conversion explıcita, para ir entreobjetos Number, como Integer y Float, a su tipo base relacionado, comoint y float. En cualquier momento que un objeto Number es esperado comoparametro para un metodo, el correspondiente tipo base puede ser pasado. Eneste caso, Java realizara una conversion implıcita, llamada autoempacado,la cual convertira el tipo base a su correspondiente objeto Number. De igualforma, cada vez que un tipo base es esperado en una expresion que involucrauna referencia Number, el objeto Number es cambiado al correspondiente tipobase, en uno operacion llamada desempacado. Se muestra enseguida codigoque usa las nuevas conversiones explıcitas.
Integer a = 5; // autoempacado de un tipo base
int b = a + 3; // desempacado de un objeto Number
Una advertencia, del autoempacado y desempacado, es que si un referenciaNumber es null, entonces intentando desempacar generara un error, llamadoNullPointerException. Otra advertencia, es con el operador ==, ya que esusado para probar la igualdad de valores tipo base, ası como si dos referenciasNumber estan apuntando al mismo objeto. Ası que cuando se intenta probarla igualdad, evitar las conversiones implıcitas hechas por el autoempacada

30 Introduccion
y desempacado. Por ultimo, las conversiones implıcitas, de cualquier tipo,toman tiempo, por lo tanto se deben tratar de minimizar para no retardar laejecucion del programa.
En cualquier momento que una cadena es concatenada con cualquierobjeto o tipo base, este es automaticamente convertido a cadena. Conversionexplıcita de un objeto o tipo base a una cadena no esta permitida. Por lotanto, las siguientes sentencias son incorrectas:
String s = (String) 4.5; // incorrecto
String t = "Valor = " + (String) 67; // incorrecto
String u = 22; // incorrecto
Para realizar una conversion a cadena, se debera usar el metodo toString()apropiado o realizar una conversion implıcita usando la operacion de concate-nacion, como se muestra en las siguientes sentencias:
String s = "" + 4.5; // correcto, pero estilo pobre
String t = "Valor = " + 67; // correcto
String u = Integer.toString(22); // correcto
1.4. Control de flujo
El control de flujo en Java es parecido al de otros lenguajes de alto nivel.Se revisa la estructura basica y la sintaxis del control de flujo en esta seccion,incluyendo regreso del metodo, sentencia if, sentencia switch, ciclos, y formasrestringidas de saltos, sentencia break y continue.
1.4.1. Sentencias if y switch
Los condicionales dan una forma de evaluar una decision y luego ejecutaruna sentencia o mas bloques de sentencias diferentes de acuerdo a la salidade la decision.
Sentencia if
La sintaxis de una sentencia if simple es:
if (expresion booleana)sentencia true;

1.4 Control de flujo 31
elsesentencia false;
donde sentencia true y sentencia false tienen una sola sentencia, o bien, unbloque de sentencias encerradas entre llaves. La parte else y su sentenciaasociada en una sentencia if es opcional. Se puede agrupar una cantidad depruebas booleanas, como sigue:
if (primera expresion booleana)sentencia true;
else if (segunda expresion booleana)segunda sentencia true;
elsesentencia false;
Si la primera expresion booleana es falsa, la segunda expresion boolenasera probada, y ası sucesivamente. Una sentencia if puede tener una cantidadarbitraria de partes else if. Para estar seguro cuando se definan sentenciasif complicadas, usar llaves para encerrar todas las sentencias de los cuerpos.
Por ejemplo, la siguiente es una sentencia correcta if.
if (nivelAgua < 20) irAClase();
regresarACasa();
else if (nivelAgua < 50)
salirEnLancha();
recogerTrampas();
else
quedarseEnCasa();
Sentencia switch
Java proporciona para control de flujo de valores multiples la sentenciaswitch, la cual es util con tipos enum. El siguiente es un ejemplo la cual usauna variable d del tipo enum Dia del listado 1.5 de la seccion 1.1.3.
switch (d) case LUN:

32 Introduccion
System.out.println("Exito");
break ;
case MAR:
System.out.println("Triunfo");
break ;
case MIE:
System.out.println("Fe");
break ;
case JUE:
System.out.println("Paz");
break ;
case VIE:
System.out.println("Amor");
break ;
default :
System.out.println("Salud");
La sentencia switch evalua un entero o enum y hace que el control deflujo salte a la localidad del codigo etiquetado con el valor de esta expresion.Si no hay una etiqueta que empate, entonces del flujo del programa salta a lalocalidad etiquetada como default. Este es el unico salto explıcito hecho porla sentencia switch, sin embargo, el control de flujo “pasa” a otros casos si elcodigo para cada caso no es terminado con una sentencia break, la cual haceque el control de flujo pase a la siguiente sentencia despues de switch.
1.4.2. Ciclos
Otro mecanismo importante del control de flujo en un lenguaje de progra-macion es la repeticion. Java tiene tres tipos de ciclos.
Ciclos while
El tipo de ciclo mas simple es el ciclo while. Este ciclo prueba que unacierta condicion se cumpla y realizara el cuerpo del ciclo cada vez que lacondicion sea evaluada a true. La sintaxis para probar una condicion antesque el cuerpo del ciclo sea ejecutado es:
while (condicion)

1.4 Control de flujo 33
sentencia ciclo;
Al inicio de cada iteracion, el ciclo prueba la expresion y luego ejecutael cuerpo del ciclo, solo si la expresion booleana evalua a true. La sentenciadel cuerpo del ciclo tambien puede ser un bloque de sentencias y la condiciondebera ser una expresion booleana.
Considerar por ejemplo, un duende que intenta regar todas sus zanahoriasen su huerta, lo cual el hara mientras su regadera no este vacıa. Como suregadera podrıa estar vacıa, se podrıa escribir el codigo que haga esta tareacomo:
public void regarZanahorias() Zanahoria actual = huerta.encontrarSigZanahoria();
while (!regadera.estaVacıa()) regar(actual,regadera);
actual = huerta.encontrarSigZanahoria():
Ciclos for
Otro tipo de ciclo es el ciclo for. Los ciclos for, en su forma mas simple,proporciona repeticion de codigo para una determinada cantidad de veces,pero se pueden hacer otras tareas tambien. La funcionalidad de un ciclo for
es flexible, gracias a que esta dividido en cuatro secciones: la inicializacion, lacondicion, el incremento, y el cuerpo.
La sintaxis para un ciclo for es:
for (inicializacion; condicion; incremento)sentencia ciclo;
donde las secciones inicializacion, condicion, e incremento pueden estar vacıas.En la seccion de inicializacion, se puede declarar una variable ındice que
solo existe en el alcance del ciclo for. Por ejemplo, si se quiere un ciclo queindice en un contador, y no se tiene necesidad de la variable contador fueradel ciclo for, entonces declarando algo como lo siguiente
for (int contador=0; condicion; incremento)
sentencia ciclo;

34 Introduccion
declarara una variable contador cuyo alcance es solo el cuerpo del ciclo.En la seccion condicion, se indica la condicion para repetir el ciclo. Esta
debera ser una expresion booleana. El cuerpo del ciclo for sera ejecutadocada vez que la condicion sea true cuando sea evaluado al inicio de unaiteracion posible. Tan pronto como la condicion evalue a false, entonces elcuerpo del ciclo ya no es ejecutado, y la ejecucion del programa continua conla siguiente sentencia despues del ciclo for.
En la seccion incremento, se declara la sentencia de incremento para elciclo. Esta debera ser cualquier sentencia legal permitida para flexibilidad enla codificacion. La sintaxis de un ciclo for es equivalente a:
inicializacion;
while (condicion) sentencia ciclo;
incremento;
excepto que en Java, un ciclo while no puede tener una condicion booleanavacıa, mientras en un ciclo for esta permitido. El siguiente ejemplo muestraun ciclo for
public void comerManzanas(Manzanas manzanas) int cantManzanas = manzanas.getCantidad();
for (int x=0; x<cantManzanas; ++x) comerManzana(manzanas.getManzana(x));
tirarCorazon();
En el ejemplo anterior, la variable de ciclo x fue declarada en int x =
0. Antes de cada iteracion, el ciclo prueba la condicion x<cantManzanas yejecuta el cuerpo del ciclo solo si esto es verdadero. Al final de cada iteracionel ciclo usa la sentencia ++x para incrementar la variable de ciclo antes deprobar nuevamente la condicion.
Ciclos do...while
El ciclo do...while prueba una condicion despues del cuerpo del ciclo,a diferencia de los ciclos anteriores, los cuales prueban una condicion antes

1.4 Control de flujo 35
de realizar una iteracion en el cuerpo del ciclo. La sintaxis para el ciclodo...while es:
dosentencia ciclo;
while(expr booleana);
La sentencia del cuerpo del ciclo puede ser una sola sentencia o un bloquede sentencias, y la condicion debe ser una expresion booleana. En este ciclose repite el cuerpo del ciclo tanto como la condicion sea verdadera cada vezque es evaluada.
Por ejemplo, considerar que se quiere pedir al usuario una entrada y luegohacer algo util con esa entrada. Una condicion posible, en este caso, para salirdel ciclo es cuando el usuario ingresa una cadena vacıa. Sin embargo, aun eneste caso, se podrıa querer manejar la entrada e informar al usuario que sequiere salir. El siguiente ejemplo ilustra ese caso:
public void getEntradaUsuario() String entrada;
do entrada = getEntradaString();
manejarEntrada(entrada);
while (entrada.length()>0);
Observar en el ejemplo anterior que la condicion de salida es cuando lacondicion es no verdadera.
1.4.3. Sentencias explıcitas de control de flujo
Java tambien proporciona sentencias que permiten explıcitamente el cam-bio en el flujo de un programa.
Regresar de un metodo
Si un metodo esta declarado con un tipo de retorno void, entonces el flujoregresa cuando alcanza la ultima lınea de codigo en el metodo, o cuando seencuentra una sentencia return sin argumento. Sin embargo, si un metodoesta declarado con un tipo de retorno, el metodo es una funcion y estedebera salir regresando el valor de la funcion como un argumento a una

36 Introduccion
sentencia return. El siguiente ejemplo correcto ilustra el regreso de unafuncion:
// Revisar por un cumplea~nos particular
public boolean revisaCumple(int fecha) if (fecha == Cumples.CUMPLE JUAN)
return true ;
return false ;
Se sigue que la sentencia return debera ser la ultima sentencia ejecutadaen una funcion, ya que el resto del codigo nunca sera ejecutado.
Observar que hay una diferencia significativa entre una sentencia que esla ultima lınea de codigo ejecutada en un metodo y la ultima lınea de codigoen el metodo. En el ejemplo anterior, la lınea return true; no es la ultimalınea de codigo escrita en la funcion, pero podrıa ser la ultima lınea que esejecutada cuando la condicion involucrando a fecha sea true. Tal sentenciaexplıcitamente interrumpe el flujo en el metodo.
Sentencia break
El uso tıpico de la sentencia break tiene la siguiente sintaxis simple:
break ;
Se usa break para salir del cuerpo de la sentencia switch, for, while,o do...while mas interna. Cuando es ejecutado break, el flujo pasa a lasiguiente sentencia despues del cuerpo del ciclo o switch que contiene elbreak.
La sentencia break tambien puede ser usada en una forma etiquetadapara salir del ciclo mas externo o sentencia switch. La sintaxis es:
break etiqueta;
donde etiqueta es un identificador Java que es usado para etiquetar un cicloo sentencia switch. Tal etiqueta puede aparecer una sola vez al inicio de ladeclaracion de un ciclo.
Se muestra el uso de una etiqueta con una sentencia break en el siguienteejemplo:

1.5 Arreglos 37
public static boolean tieneEntradaCero( int [][] a) boolean banderaEnc = false ;
busquedaCero:
for (int i=0; i<a.length; ++i)
for (int j=0; j<a[i].length; ++j)
if (a[i][j] == 0) banderaEnc = true ;
break busquedaCero;
return banderaEnc;
Sentencia continue
La sentencia continue tambien cambia explıcitamente el flujo en unprograma, la cual tiene la siguiente sintaxis:
continue [etiqueta];
donde etiqueta es un identificador opcional Java que es usado para etiquetarun ciclo. Esta sentencia solo puede ser usada adentro de ciclos. La sentenciacontinue causa que la ejecucion salte sobre los pasos restantes del cuerpo delciclo en la iteracion actual, pero el ciclo continua si su condicion es satisfecha.
1.5. Arreglos
Una tarea de programacion comun es manejar un grupo numerado deobjetos relacionados. Por ejemplo, se podrıa querer que un videojuego manejelas diez puntuaciones mejores del juego. En vez de usar diez variables diferentespara esa tarea, se podrıa preferir usar un solo nombre para el grupo y usarun ındice numerico para referirse a cada unna de las puntucaciones. De igualforma, se podrıa querer que un sistema de informacion medico maneje lospacientes asignados a camas en un cierto hospital. De nueva cuenta no setienen que introducir 200 variables solo por que el hospital tenga 200 camas.
En situaciones como las anteriores, se puede ahorrar esfuerzo de programa-cion usando un arreglo, el cual es una coleccion numerada de variables todasellas con el mismo nombre. Cada variable, o celda, en un arreglo tiene un

38 Introduccion
ındice, el cual se refiere de forma unica al valor guardado en esa celda. Lasceldas del arreglo a estan numeradas por 0, 1, 2, etc. Se muestra enseguidaun arreglo de las diez puntuaciones mas altas para un vıdeo juego.
Puntuaciones mejores987 876 765 654 543 432 321 210 109 980 1 2 3 4 5 6 7 8 9
ındices
Esta organizacion es util, ya que permite hacer calculos interesantes. Enel siguiente ejemplo, listado 1.6, el metodo, de la clase DemoArreglos sumatodos los numeros en un arreglo de enteros:
1 /** Agrega todos los nu meros en un arreglo de enteros */
2 public static int suma(int[] a)
3 int total = 0;
4 for (int i=0; i<a.length; ++i)
5 total += a[i];
6 return total
7
Listado 1.6: Metodo para sumar todos los elementos de un arreglo de enteros
En este ejemplo se usa una caracterıstica importante de Java para losarreglos, el tamano de celdas que un arreglo guarda, es decir, su tamano(length). En Java, un arreglo es un tipo especial de objeto donde el tamanodel arreglo es guardado en una variable de instancia, length, la cual se accedede la siguiente forma:
nombre arreglo.length
Las celdas de un arreglo a estan numeradas como 0, 1, 2, y ası hastaa.length-1.
Elementos y capacidades del arreglo
Cada objeto guardado en un arreglo es llamado un elemento del arreglo.Elemento numero 0 es a[0], elemento numero 1 es a[1], y ası sucesivamente.Como el tamano de un arreglo determina la cantidad maxima de cosas quepueden ser guardadas en el arreglo, en ocasiones se refiere el tamano de unarreglo como su capacidad. Enseguida se muestra otro uso simple de unarreglo en el listado 1.7, clase DemoArreglos, el cual cuenta la cantidad deveces que cierto numero aparece en un arreglo:

1.5 Arreglos 39
1 /** Cuenta la cantidad de veces que un entero est a en el arreglo. */
2 public static int encuentraCuenta(int[] a, int k)
3 int cuenta = 0;
4 for (int i=0; i<a.length; ++i)
5 if (a[i]==k) // revisar si el elemento actual es igual a k
6 ++ cuenta;
7 return cuenta;
8
Listado 1.7: Metodo para contar las veces que se encuentra k en el arreglo.
Error fuera de los lımites
Es un descuido serio intentar indizar un arreglo a con un numero fuera delrango de 0 a a.length-1. Se dice que tal referencia esta fuera de los lımites.Las referencias fuera de los lımites han sido usadas numerosas ocasiones porlos hackers usando un metodo llamado el ataque de desbordamiento del buferpara comprometer la seguridad del sistema de computo, escrito en lenguajesque no son Java. Como medida de seguridad, los ındices de los arreglos sonsiempre revisados en Java para que no esten fuera de los lımites. En el casode que un ındice se encuentre fuera de los lımites, el ambiente de ejecucionJava indica una condicion de error, indicada por la clase ArrayIndexOutOf-
BoundsException. Mediante esta revision Java evita problemas de seguridaddonde otros lenguajes deben hacer frente.
Se pueden evitar errores fuera de los lımites asegurandose que siemprese indiza en un arreglo, a, usando un valor entero entre cero y a.length.Una forma breve de lograrlo es usando cuidadosamente la caracterıstica determinacion temprana de los operadores logicos de Java. Por ejemplo, unasentencia como la siguiente nunca generara un error fuera de los lımites:
if ((i>=0) && (i<a.length) && (a[i]>2) )
x = a[i];
para la comparacion a[i]>2 solo sera hecha si las primeras dos comparacionesson exitosas.
1.5.1. Declaracion de arreglos
Una forma para declarar e inicializar un arreglo es la siguiente:
tipo elemento[] nombre arreglo = val 0, val 1, ...;

40 Introduccion
El tipo elemento puede ser cualquier tipo base Java o nombre de clase, ynombre arreglo es un identificador Java valido. Los valores iniciales deberanser del mismo tipo que el del arreglo. Por ejemplo, la siguiente declaracion deun arreglo que es inicializado con los primeros diez numeros primos:
int [] primos = 2,3,5,7,11,13,17,19,23,29;
Para declarar una variable arreglo sin inicializarlo, se hace como sigue:
tipo elemento[] nombre arreglo;
Una vez que se ha declarado un arreglo de la forma anterior, se puedecrear la coleccion de celdas para el arreglo usando la siguiente sintaxis:
new tipo elemento[tamano]
donde tamano es un entero positivo indicando el tamano del arreglo creado.Usualmente esta expresion aparece en una sentencia de asignacion con elnombre del arreglo en lado izquierdo del operador de asignacion. Los arregloscreados son inicializados con ceros si el tipo del arreglo es un tipo basenumerico. Los arreglos de objetos son inicializados a referencias null. En elsiguiente codigo se define una variable de arreglo llamada a, y despues se leasigna un arreglo de diez celdas, cada una de tipo double, siendo despues loselementos inicializados a 1.0:
double [] a;
a = new double [10];
for (int k=0; k<a.length; ++k)
a[k] = 1.0;
1.5.2. Arreglos como objetos
Los arreglos en Java son un tipo especial de objeto. Por esta razon sepuede usar el operador new para crear una nueva instancia de un arreglo. Elarreglo puede ser usado como cualquier otro objeto general, pero se tieneuna sintaxis especial, usando los corchetes, para referirse a sus miembros.Como un arreglo sea un objeto, el nombre de un arreglo es una referenciaa la direccion en memoria donde esta el arreglo guardado, de igual manera,no hay nada especial en usar el operador punto y la variable de instancia,length, para referirse al tamano del arreglo.
Como los arreglos son objetos, entonces cuando se tiene una sentenciacomo la siguiente, donde a y b son referencias a arreglos del mismo tipo

1.6 Entrada y salida 41
b = a;
significa que a y b se refieren al mismo objeto. Ası que cuando se tenga unasentencia como
b[3] = 5;
entonces tambien se tiene que a[3] guarda un 5.
Clonacion de un arreglo
Cuando se quiere crear una copia exacta del arreglo, a, y asignar esearreglo al arreglo variable, b, se podrıa escribir
b = a.clone();
el cual copia el contenido de todas las celdas de a en un arreglo nuevo y loasigna b para que apunte a este. El metodo clone() es un metodo incorporadode cada objeto Java. Si antes de la asignacion b[3] = 5; se hubiera clonadoel arreglo a en b, entonces los elementos en a y b para el ındice 3 podrıan serdiferentes, ya que cada referencia apunta a su propio arreglo.
Se debe observar que las celdas de un arreglo son copiadas cuando este esclonado. Si las celdas son un tipo base, como int, sus valores son copiados.Pero si las celdas son referencias objetos, entonces estas referencias soncopiadas. Esto significa que hay dos formas para referirse a un objeto.
1.6. Entrada y salida
Java tiene un conjunto de clases y metodos para la entrada y salida enun programa. Hay clases para el diseno de interfaces graficas de usuario, conventanas pop-up (emergentes) y menus, al igual que metodos para mostrare introducir texto y numeros. Tambien hay metodos para manejar objetosgraficos, imagenes, sonidos, paginas web, y eventos de raton. Varios de estosmetodo de entrada y salida pueden ser usados en programas autonomos o enapplets.
La entrada y salida simple se da con la ventana consola Java. Dependiendodel ambiente Java donde se este usando, la ventana es una ventana emergenteespecial que puede ser usada para mostrar e introducir texto, o una ventanausada para introducir comandos al sistema operativo, estas ventanas sonreferidas como ventanas shell, DOS o terminal.

42 Introduccion
Metodos de salida simple
Java proporciona un objeto estatico incorporado, llamado System.out,que realiza salida al dispositivo de la “salida estandar”, siendo este la ventanaconsola Java. El objeto System.out es una instancia de la clase java.io.-
PrintStream. Esta clase define metodos para un flujo de salida de memoria,donde los caracteres son puestos en una localidad temporal, llamada buffer,el cual despues es vaciado cuando la ventana consola esta lista para imprimirlos caracteres.
En particular, la clase java.io.PrintStream tiene los siguientes metodospara realizar salida simple (se usa tipo base para referirse a cualquiera de lostipos base posibles):
print(Object o) Imprime el objeto o usando su metodotoString().
print(String s) Imprime la cadena s.print(tipo base t) Imprime el valor del tipo base t.println(String s) Imprime la cadena s, seguida del caracter
nueva lınea.Cuando el siguiente fragmento de codigo:
System.out.print("Valores Java: ");
System.out.print(3.1416);
System.out.print(’,’);
System.out.print(15);
System.out.print(" (double,char,int).");
es ejecutado, mostrara lo siguiente en la ventana consola Java:
Valores Java: 3.1416,15 (double,char,int).
Entrada simple con la clase java.util.Scanner
Para realizar entrada desde la ventana consola Java se emplea el objetoespecial System.in. La entrda viene del dispositivo de “entrada estandar”,el cual por defecto es el teclado de la computadora replicando sus teclaspresionadas en la consola. El objeto System.in esta asociado con el dispositivode entrada estandar. Una forma simple de leer la entrada de este objeto esusandolo para crear un objeto Scanner de la siguiente forma:
new Scanner(System.in)

1.6 Entrada y salida 43
La clase Scanner tiene un conjunto de metodos adecuados que leen desdeel flujo de entrada dado. En la clase EjemploEntrada, listado 1.8, se usa unobjeto Scanner para procesar la entrada:
1 import java.io.IOException;
2 import java.util.Scanner;
3 public class EjemploEntrada
4 public static void main(String [] args) throws IOException
5 Scanner s = new Scanner(System.in);
6 System.out.print("Ingresa tu edad en a~nos: ");
7 int edad = s.nextInt ();
8 System.out.print("Ingresa la frecuencia card ıaca maxima: ");
9 double frecuencia = s.nextDouble ();
10 double qg = (frecuencia - edad )*0.65;
11 System.out.println("Su meta de ı ndice de quema de grasa es: " +
12 qg + ".");
13
14
Listado 1.8: La clase EjemploEntrada.
Cuando se ejecuta, la aplicacion podrıa generar lo siguiente en la consolaJava:
Ingresa tu edad en a~nos: 48
Ingresa la frecuencia cardıaca maxima: 170
Su meta de ındice de quema de grasa es: 79.3.
Metodos de la clase java.util.Scanner
La clase Scanner lee el flujo de entrada y lo divide en tokens, los cualesson cadenas de caracteres separados por delimitadores. Un delimitador es unacadena de separacion especial, y el delimitador por defecto es el espacio blanco.De esta forma, los tokens son separados por cadenas de espacios, tabuladores,y nuevas lıneas, por defecto. Los tokens pueden ser leıdos inmediatamentecomo cadenas o un objeto Scanner puede convertir un token a un tipo base,siempre que token este con la sintaxis correcta. La clase Scanner incluye lossiguientes metodos para trabajar con tokens :

44 Introduccion
hasNext() Devuelve true si y solo si hay otro tokenen el flujo de entrada.
next() Devuelve la siguiente cadena token en unflujo de entrada; se genera un error si yano quedan mas tokens.
hasNextTipo () Devuelve true si y solo si hay otro tokenen el flujo de entrada y este puede ser inter-pretado como el Tipo base correspondiente,siendo tipo Boolean, Byte, Double, Float,Int, Long, Short.
nextTipo () Devuelve el siguiente token en el flujo deentrada, devuelto como el correspondienteTipo base; se genera un error si ya no que-dan mas tokens o si el siguiente token nopuede ser interpretado como un tipo basecorrespondiente a Tipo.
Adicionalmente, los objetos Scanner pueden procesar la entrada lınea porlınea, ignorando los delimitadores, y tambien buscar patrones dentro de lıneas.Los metodos para procesar la entrada de esta forma incluyen los siguientes:
hasNextLine() Devuelve true si y solo si el flujo de entradatiene otra lınea de texto.
nextLine() Avanza la entrada pasando al final de lalınea actual y regresando la entrada que fuesaltada.
findInLine(String s) Intenta encontrar una cadena que empateel patron s en la lınea actual. Si el patron esencontrado, este se devuelve y se avanza alprimer caracter despues del apareamiento.Si el patron no es encontrado, se devuelvenull y no se avanza.
Algunos de los metodos mencionados se podrıan usar como se muestraenseguida para lograr que el usuario ingrese un entero:
Scanner entrada = new Scanner(System.in);
System.out.print("Favor de ingresar un entero: ");
while (!entrada.hasNextInt()) input.nextLine();
System.out.print("No se ingreso un entero. ");

1.7 Clases anidadas y paquetes 45
System.out.print("Por favor ingrese un entero: ");
int i = entrada.nextInt();
1.7. Clases anidadas y paquetes
Java tiene una forma util y general para la organizacion de clases enprogramas. Cada clase publica autonoma definida en Java debera estar enarchivo separado. El nombre del archivo es el nombre de la clase con laextension .java. Se describe enseguida dos maneras que Java tiene paraorganizar multiples clases en forma util.
Clases anidadas
Java permite que definiciones de clases sean anidadas, o puestas, dentrode las definiciones de otras clases. El principal uso para tales clases anidadases para definir una clase que esta fuertemente afiliada con otra clase. Porejemplo, definir la clase cursor como clase anidada en la definicion de la claseeditor de texto mantiene a estas dos clases altamente relacionadas en el mismoarchivo. Mas aun, permite que cada una de ellas acceda a los metodos nopublicos de la otra. Un punto tecnico respecto a las clases anidadas es quela clase anidada debe ser declarada como static. Esta declaracion implicaque la clase anidada esta asociada con la clase externa, no una instancia dela clase externa, que es, un objeto especıfico.
Paquetes
Un conjunto de clases, todas definidas en un subdirectorio comun, puedenser un paquete Java. Cada archivo en un paquete inician con la lınea:
package nombre paquete;
El subdirectorio conteniendo el paquete debera ser nombrado igual que elpaquete. Se puede tambien definir un paquete en solo archivo que contengavarias definiciones de clases, pero cuando este es compilado, todas las clasesseran compiladas en archivos separados en el mismo subdirectorio.
En Java, se pueden usar clases que estan definidos en otros paquetesprefijando los nombres de las clases con puntos que correspondan a lasestructuras de directorios de otros paquetes.

46 Introduccion
public boolean temperatura(
TA.Medidas.Termometro termometro, int temp) //...
En la firma del metodo temperatura se usa una clase Termometro comoparametro. Termometro esta definido en el paquete TA en un subpaquetellamado Medidas. Los puntos en TA.Medidas.Termometro corresponden di-rectamente a la estructura de directorios en el paquete TA.
Para evitar todo el tecleado extra para referirse a una clase foranea delpaquete actual, en Java se puede usar la palabra reservada import paraincluir clases externas o paquetes enteros en el archivo actual. Para importarclases individuales de un paquete particular, se pone lo siguiente al inicio delarchivo:
import nombrePaquete.nombreClase;
Por ejemplo, se podrıa teclear
package Proyecto;
import TA.Medidas.Termometro;
import TA.Medidas.Escala;
al inicio de una clase del paquete Proyecto, para indicar que se estan impor-tando las clases llamadas TA.Medidas.Termometro y TA.Medidas.Escala.
Tambien se puede importar un paquete entero, con la siguiente sintaxis:
import nombrePaquete.*;
Cualquiera de las dos formas de importacion usadas permiten codigos masbreves, ası el metodo Temperatura() se podrıa reescribir como:
import TA.Medidas.*;
public boolean temperatura(Termometro termometro, int temp) //...
En resumen, la estructura de un programa Java, permite tener variablesde instancia y metodos dentro de una clase, y clases dentro de un paquete.

Capıtulo 2
Diseno orientado al objeto
2.1. Metas, principios, y patrones
Los “actores” principales en el paradigma del diseno orientado al objetosson llamados objetos. Un objeto viene de una clase, la cual es una especifica-cion de los campos de datos, tambien llamados variables de instancia, que elobjeto contiene, al igual los metodos u operaciones que el objeto puede ejecu-tar. Cada clase presenta al mundo exterior una vista concisa y consistente delos objetos que son instancias de esta clase, sin requerir ir en muchos detallesinnecesarios o dando otros accesos a las tareas internas de los objetos. Estavista computacional intenta llenar varias metas e incorporar varios principiosde diseno.
2.1.1. Metas del diseno orientado a objetos
Las implementaciones de software deben lograr robustez, adaptabilidad, yreutilizacion.
Robustez
Como buen programador se quiere desarrollar software que sea correcto,es decir, que un programa de la salida correcta para todas las entradasanticipadas. Ademas, se quiere que el software sea robusto, esto es, capaz demanejar entradas no esperadas las cuales no estan explıcitamente definidaspara la aplicacion. Por ejemplo, si un programa esta esperando un numeropunto flotante positivo, ya que representa el precio de un artıculo, y en vez de

48 Diseno orientado al objeto
esto se da un valor negativo, entonces el programa se debe poder recuperarde este error. En aplicaciones de seguridad crıtica, donde un error de softwarepuede llevar a una lesion, o la perdida de la vida, el software que no es robustopodrıa ser mortal. Un caso de este tipo se presento entre 1985 y 1987 enaccidentes que involucraron a la maquina de radioterapia therac-25, dondeal menos seis pacientes recibieron sobredosis de radiacion, y tres de estosmurieron como consecuencia directa. Una comision investigadora concluyo quela razon primaria deberıa ser atribuida al mal diseno de software y malaspracticas de desarrollo, y no explıcitamente a varios errores de codificacionque fueron encontradas.
Adaptabilidad
Las aplicaciones actuales de software, como los navegadores Web y losmotores de busqueda de Internet, generalmente involucran programas grandesque son usados por muchos anos. Por lo tanto el software necesita ser capaz deevolucionar en el tiempo en respuesta a condiciones cambiantes en su ambiente.Ası, otra meta importante de calidad del software es la adaptabilidad oevolucionabilidad. Relacionado a este concepto es la portabilidad, la cuales la habilidad del software para ejecutarse con cambios mınimos en hardwarey plataformas de sistemas operativos diferentes. El software escrito en Javaes portable.
Reutilizacion
Otra capacidad deseable del software es la reutilizacion, es decir, el mismocodigo deberıa ser utilizable como un componente de diferentes sistemaspara varias aplicaciones. El desarrollo de software de calidad puede ser unaactividad costosa, y su costo se puede recuperar si el software es disenado demanera que sea facilmente reutilizado en aplicaciones futuras. La reutilizaciondebera hacerse con cuidado, sin embargo, una de las mayores fuentes de erroresde software en la therac-25 se debio por el reuso inadecuado del software dela therac-20, la cual no estaba orientada al objeto y no estaba disenada parala plataforma de hardware de la therac-25.

2.1 Metas, principios, y patrones 49
2.1.2. Principios del diseno orientado al objeto
Para lograr las metas indicadas previamente se puede hacer con los princi-pios de la aproximacion orientada al objeto, los cuales son:
Abstraccion
Encapsulacion
Modularidad
Abstraccion
La nocion de abstraccion es extraer de un sistema complejo sus partesmas fundamentales y describirlas de una forma precisa y simple. Describirlas partes de un sistema involucra nombrarlas y explicar su funcionalidad.Aplicando el paradigma de abstraccion al diseno de estructuras de datos dalugar a tipos de datos abstractos o ADT (abstract data type). Un ADTes un modelo matematico de una estructura de datos que especifica el tipo dedato guardado, las operaciones soportadas, y los tipos de parametros de lasoperaciones. Un ADT indica que puede realizar cada operacion, pero no comose hace. En Java, un ADT puede ser expresado por una interfaz, la cual esuna lista de declaraciones de metodos, donde cada metodo tiene un cuerpovacıo. En la seccion 2.4 se abordan las interfaces.
Un ADT es realizado por una estructura de datos concreta, la cual esta mo-delada en Java por una clase. Una clase define los datos que son guardados ylas operaciones soportadas por los objetos que son instancias de la clase. Di-ferente a las interfaces, las clases indican como las operaciones son realizadasen el cuerpo de cada metodo. Implementar una interfaz, por una clase,es cuando la clase incluye todos los metodos declarados en la interfaz, dandoun cuerpo para estos. Sin embargo, una clase puede tener mas metodos quelos de la interfaz.
Encapsulacion
El concepto de encapsulacion es otro principio importante en el disenoorientado al objeto, el cual establece que los diferentes componentes de unsistema de software no deberan mostrar los detalles internos de sus respectivasimplementaciones. Una de las ventajas principales de la encapsulacion esque esta da libertad al programador para implementar los detalles de un

50 Diseno orientado al objeto
sistema. La unica restriccion para el programador es que mantenga la interfazabstracta que los externos ven.
Modularidad
Otro principio fundamental del diseno orientado al objeto es la modu-laridad. Los sistemas actuales de software generalmente consisten de varioscomponentes diferentes que deben interactuar correctamente en orden paraque el sistema completo trabaje correctamente. Mantener estas interaccionesen orden requiere que estos componentes diferentes esten bien organizados.En el diseno orientado al objeto, este enfoque de estructuracion del codigose logra con el concepto de modularidad. La modularidad se refiere a unprincipio de organizacion para el codigo, en el cual diferentes componentes deun sistema de software son divididos en unidades funcionales separadas.
Organizacion jerarquica
La estructura impuesta por la modularidad ayuda a permitir la reutili-zacion del software. Si los modulos de software son escritos en una formaabstracta para resolver problemas generales, entonces los modulos pueden serreusados con instancias de estos mismos problemas generales que surgen enotros contextos.
Por ejemplo, la definicion estructural de un muro es la misma para cualquiercasa, siendo definido generalmente por cantidad de soportes, espaciamiento delos soportes, etc. De esta forma, un constructor puede reusar su definiciones demuro de una casa a otra. En la reutilizacion, algunas partes podrıan requerirajustes, por ejemplo un muro en un edificio comercial podrıa ser similar al deuna casa, pero el sistema electrico y el soporte podrıan ser diferentes.
Una forma natural de organizar varios componentes estructurales de unpaquete de software es de modo jerarquico, la cual agrupa definicionesabstractas similares por nivel, yendo de lo mas especıfico a lo mas generalconforme se recorre hacia arriba la jerarquıa. Un uso comun de tales jerarquıases con una grafica organizacional, donde cada enlace hacia arriba puedeleerse como “es un”, como en “un rancho es una casa, y una casa es unaconstruccion”. Este tipo de jerarquıa es util en el diseno de software, porqueagrupa la funcionalidad comun en el nivel mas general, y vistas especializadasdel comportamiento como una extension de la vista general.

2.1 Metas, principios, y patrones 51
2.1.3. Patrones de diseno
Investigadores y profesionales de la computacion han desarrollado unavariedad de conceptos organizacionales y metodologıas para disenar softwarede calidad orientado al objeto para que sea conciso, correcto, y reutilizable.El concepto de patron de diseno es importante en el material tratadoen estas notas, ya que describe una solucion para un problema de disenode software tıpico. Un patron es un modelo general para una solucion quepuede ser aplicada en varias situaciones diferentes. Este describe los elementosprincipales de una solucion en una forma abstracta que puede ser especializadapara un problema particular. El patron tiene un nombre para identificacion,un contexto para describir los escenarios donde puede ser aplicado, un modelopara indicar como el modelo es aplicado, y un resultado que describe y analizalo que el patron produce.
Se revisan varios patrones de diseno en este material, y se muestra comopueden ser aplicados consistentemente a implementaciones de estructuras dedatos y algoritmos. Los patrones de diseno caen en dos grupos, patrones pararesolver problemas de diseno de algoritmos y para problemas de ingenierıa desoftware. Algunos de los patrones de diseno de algoritmos son:
Recursion
Amortizacion
Divide y venceras
Recortar y buscar o, divide y venceras
Fuerza bruta
Metodo voraz
Programacion dinamica
Algunos de los patrones de diseno de ingenierıa de software que seranrevisados son:
Posicion
Adaptador

52 Diseno orientado al objeto
Iterador
Metodo modelo
Composicion
Comparador
Decorador
2.2. Herencia y polimorfismo
Para poder emplear las relaciones jerarquicas, las cuales son comunes enproyectos de software, la aproximacion de diseno orientada al objeto da variasformas de reusar codigo.
2.2.1. Herencia
El paradigma orientado al objeto da una estructura organizacional modulary jerarquica para reusar codigo, mediante la tecnica de herencia. Esta tecnicapermite el diseno de clases generales que pueden ser especializadas a clasesmas particulares, con las clases especializadas reutilizando el codigo de la clasegeneral. La clase general, la cual tambien es conocida como una clase base osuperclase, puede definir variables de instancia y metodos generales que sonaplicables la mayorıa de las veces. Una clase que especializa, o extiende ohereda de, una superclase no necesita dar nuevas implementaciones para losmetodos generales, para eso los hereda. Solo deberıa definir aquellos metodosque son especializados para la subclase particular.
Ejemplo. Considerar una clase S que define objetos con un campo, x
entero, y tres metodos, a(), b(), y c() devolviendo diferentes tipos. Suponerque se define una clase T que extiende a S e incluye un campo adicional, yentero, y dos metodos, d() y e() devolviendo diferentes tipos. La clase T
hereda los miembros de la clase S. Se ilustra la relacion entre la clase S y T enun diagrama de Lenguaje Unificado de Modelado o UML (Unified ModelingLanguage) en la figura 2.1. Cada rectangulo en el diagrama indica una clase,poniendo en subrectangulos el nombre, los campos, y los metodos.

2.2 Herencia y polimorfismo 53
S
-x : int
+a : int
+b : int
+c (int n) : void~wwwwT
-y : int
+d : int
+e (int n) : void
Figura 2.1: Diagrama UML de la relacion entre las clases S y T.
Creacion y referencia de objetos
Cuando un objeto o es creado, memoria es asignada para sus campos dedatos, y estos campos son inicializados a valores especıficos. Generalmente,se asocia un objeto nuevo o con una variable, la cual sirve como un “enlace”al objeto o, y se dice que referencia o. Para acceder al objeto o se puedesolicitar la ejecucion de algunos de los metodos de o, o mirar uno de loscampos de o. La forma primaria como un objeto p interactua con otro objetoo es mandando un “mensaje” a o usando alguno de los metodos de o. Lasegunda forma como p puede interactuar con o es accediendo alguno de loscampos de o directamente, siempre y cuando o de los permisos para ello.
Enlazado dinamico
Cuando un programa desea llamar un cierto metodo a() de algun objetoo, este manda un mensaje a o, el cual se denota, usando la sintaxis operadorpunto, como o.a(). Cuando se ejecuta la version compilada del programa se leindica al ambiente de ejecucion que revise la clase T de o para indicar si la claseT soporta un metodo a(), y si es ası, lo ejecute. En la revision, primero, se vesi la clase T define un metodo a() para ejecutarlo, si no lo define, entonces serevisa la superclase S de T. Si S lo define, entonces se ejecuta. Si S tampocodefine a(), entonces se repite la busqueda en la superclase de S. La busqueda

54 Diseno orientado al objeto
continua hacia arriba en la jerarquıa de clases hasta que se encuentra el metodoa() y lo ejecuta, o hasta que se alcanza la clase raız, la clase Object, sin unmetodo a(), lo cual genera un error en tiempo de ejecucion. El algoritmo queprocesa el mensaje o.a() para encontrar el metodo especıfico invocado esllamado el algoritmo de enlazado dinamico, o envıo dinamico, el cual daun mecanismo efectivo para encontar software reutilizable. Tambien permiteotra tecnica poderosa de la programacion orientada al objeto, polimorfismo.
2.2.2. Polimorfismo
Polimorfismo significa varias formas. En el contexto del diseno orientadoal objeto, se refiere a la habilidad de una variable objeto de tomar diferentesformas. Java direcciona objetos usando variables referencia. La variable refe-rencia o debera definir cual clase de objetos se le permite referir, en terminosde alguna clase S. Pero esto implica que o pueda tambien referirse a cualquierobjeto perteneciente a una clase T que extienda S. Ahora suponer lo quesucede cuando S define un metodo a() al igual que T. El algoritmo de enlazadodinamico para la invocacion del metodo siempre inicia su busqueda desdela clase mas restrictiva que aplique. Cuando o refiere a un objeto de clase T,entonces usara el metodo a de T cuando se pida por o.a(), y no el de S. Sedice, en este caso, que T anula el metodo a() de S. Por otra parte, cuandoo se refiere a un objeto de clase S , se ejecutara el metodo a() de S parao.a(). El polimorfismo es util porque la llamada o.a() no necesita saber siel objeto o se refiere a una instancia de T o S para lograr que el metodo a()
se ejecute correctamente. Ası, la variable objeto o puede ser polimorfica,dependiendo de la clase especıfica de los objetos que sean referenciados. Conesta funcionalidad se permite que una clase especializada T que extiende unaclase S, herede los metodos estandar de S, y redefina otros metodos de S paraconsiderar las propiedad particulares de objetos de T.
Java tambien permite una tecnica util relacionada al polimorfismo, llamadasobrecarga de metodos. La sobrecarga se da cuando una clase T tiene metodosmultiples con el mismo nombre, y cada uno con firma diferente. La firma deun metodo es la combinacion del nombre y el tipo y la cantidad de argumentosque le son pasados. No importa que varios metodos en una clase tengan elmismo nombre, ya que pueden diferenciarse por el compilador, dado queestos tienen firmas diferentes. En los lenguajes que permiten sobrecarga demetodos, el ambiente de ejecucion determina cual metodo actual llamar paraun metodo especıfico buscando hacia arriba en la jerarquıa de clases para

2.2 Herencia y polimorfismo 55
encontrar el primer metodo con una firma que empate con el metodo llamado.Por ejemplo, para una clase T, la cual define un metodo a() y extiende ala clase U, qua a su vez define un metodo a(x,y). Si un objeto o de clase T
recibe el mensaje o.a(x,y), entonces esta es la version de U del metodo a()
que es llamada. El polimorfismo verdadero aplica solo a metodos que tenganla misma firma, pero que estan definidos en clases diferentes.
Herencia, polimorfismo, y sobrecarga de metodos soportan el desarrollo desofware reutilizable. Se pueden definir clases que hereden variables y metodosde instancia y luego se pueden definir variables y metodos de instancia nuevosque traten los aspectos especiales de objetos de la nueva clase.
2.2.3. Uso de herencia en Java
Hay dos formas basicas de usar herencia de clases en Java, la especiali-zacion y la extension.
Especializacion
Se realiza cuando se especializa una clase general a subclases particulares.Tales subclases tienen una relacion “es un(a)” a su superclase. Una subclasehereda todos los metodos de la superclase. Para cada metodo heredado, siese metodo funciona correctamente no importando si esta funcionando parauna especializacion, no se requiere trabajo adicional. Por otra parte, si unmetodo general de la superclase no trabaja correctamente en la subclase,entonces se podrıa anular el metodo para lograr la funcionalidad correcta enla subclase. Por ejemplo, se podrıa tener una clase general, Perro, la cualtiene metodos beber() y olfatear(). Especializando esta clase a Sabueso
quizas no requiera anular el metodo beber(), pero podrıa requerirse anularel metodo olfatear(), ya que un sabueso tiene mas desarrollado su olfato.Ası, la clase Sabueso especializa los metodos de su superclase, Perro.
Extension
En la extension se usa herencia para reutilizar el codigo escrito parametodos de la superclase, pero luego se agregan nuevos metodos en la subclasepara extender su funcionalidad. Por ejemplo, para la clase Perro, se podrıacrear una subclase, Xolo, la cual hereda los metodos de la superclase, paroluego agregar un metodo nuevo, curiosidad(), ya que estos tienen un instinto

56 Diseno orientado al objeto
curioso que no esta presente en los perros en general. Cuando se agrega elmetodo nuevo, se esta extendiendo la funcionalidad del perro en general.
En Java, cada clase puede extender a una sola classe. Aun si una definicionde clase no hace uso explıcito de la clausula extends, esta todavıa heredade la clase java.lang.Object. Por lo anterior, se dice que Java solo permiteherencia unica entre clases.
Formas de anulacion de metodos
En la declaracion de una nueva clase, Java usa dos formas de anulacionde metodos, refinamiento y reemplazo. En el reemplazo, un metodo com-pletamente sustituye el metodo de la superclase que esta anulando. En Java,todos los metodos regulares utilizan esta forma.
Sin embargo, en el refinamiento un metodo no reemplaza el metodo de susuperclase, pero en su lugar agrega codigo adicional al de la superclase. EnJava, todos los constructores utilizan la forma de refinamiento, un esquemallamado, encadenamiento constructor. Es decir, un constructor inicia suejecucion llamando un constructor de la superclase. Esta llamada puede serhecha explıcitamente o implıcitamente. Para llamar un constructor de lasuperclase explıcitamente, se usa la palabra reservada super para referirse ala superclase. Por ejemplo, super() llama el constructor de la superclase sinargumentos. Sin embargo, si no se hace una llamada explıcita en el cuerpo delconstructor, el compilador inserta automaticamente, como la primera lıneadel constructor, una llamada a super(). En resumen, los constructores usanla forma refinamiento mientras los metodos usan reemplazo.
Palabra reservada this
En ocasiones, en una clase Java es conveniente referirse a la instanciaactual de esa clase. Java proporciona la palabra reservada, this, para talreferencia. La referencia this es util, por ejemplo, si se quisiera pasar elobjeto actual como parametro a un metodo. Otra aplicacion de this es parareferenciar un campo dentro del objeto actual que tenga un nombre quecolisione con el nombre del parametro de una clase, o la variable definida enel bloque actual, como se muestra en la clase ProbadorThis, listado 2.1.
Cuando ProbadorThis es ejecutado, se muestra lo siguiente:
La variable local perro = 8
El campo perro = 1

2.2 Herencia y polimorfismo 57
1 public class ProbadorThis
2 public int perro = 1; // variable de instancia
3 public static void main(String args [])
4 ProbadorThis t = new ProbadorThis ();
5 t.golpear ();
6
7 public void golpear ()
8 int perro = 8; // ¡un perro diferente!
9 System.out.println("La variable local perro = " + perro );
10 System.out.println("El campo perro = " + this.perro);
11
12
Listado 2.1: Programa de ejemplo que muestra el uso de la referencia this pararesolver la ambiguedad entre un campo del objeto actual y la variable local con elmismo nombre
Ejemplo de herencia
Se consideran los siguientes ejemplos simples para mostrar los conceptosprevios de herencia y polimorfismo revisados previamente.
Se considera un conjunto de varias clases para generar y mostrar progresio-nes numericas. Una progresion numerica es una secuencia de numeros, dondecada uno depende de uno, o de mas numeros previos. En una progresionaritmetica se determina el siguiente numero por adicion y en una progre-sion geometrica se determina el siguiente numero por multiplicacion. Encualquier caso, una progresion requiere una forma para definir su primer valory tambien para identificar el valor actual.
Se inicia definiendo una clase, Progresion, mostrada en el listado 2.2, lacual define los campos estandares y los metodos de una progresion numerica.En particular, se definen los siguientes dos campos entero largo:
primero. Primer valor de la progresion;
actual. Valor actual de la progresion;
y los siguientes tres metodos:
primerValor(). Reinicia la progresion al primer valor y devuelve este.
siguienteValor(). Avanza la progresion al siguiente valor y lo devuel-ve.

58 Diseno orientado al objeto
mostrarProgresion(). Reinicia la progresion e imprime los primerosn valores de la progresion.
El metodo mostrarProgresion() no tiene “salida” en el sentido de que noregresa ningun valor, mientras ambos metodos primerValor() y siguiente-
Valor() devuelven enteros largos. Entonces, primerValor() y siguiente-
Valor() son funciones, y mostrarProgresion() es un procedimiento.La clase Progresion tambien incluye un metodo Progresion(), el cual es
un constructor. Los constructores configuran todas las variables de instanciaal momento que un objeto de esta clase es creado. El objetivo de la claseProgresion es ser una superclase desde la cual las clases especializadashereden, ası el constructor esta codificado por lo que sera incluido en losconstructores de cada clase que extienda la clase Progresion.
1 public class Progresion
2 /** Primer valor de la progresi on. */
3 protected long primero;
4 /** Valor actual de la progresi on. */
5 protected long actual;
6 /** Constructor por defecto. */
7 Progresion ()
8 actual = primero = 0;
9
10 /** Reinciar la progresi on al primer valor.
11 *
12 * @return primer valor
13 */
14 protected long primerValor ()
15 actual = primero;
16 return actual;
17
18 /** Avanzar la progresi on al siguiente valor.
19 *
20 * @return siguiente valor de la progresi on
21 */
22 protected long siguienteValor ()
23 return ++ actual; // siguiente valor por defecto
24
25 /** Imprimir los primeros n valores de la progresi on
26 *
27 * @param n numero de valores a imprimir
28 */
29 public void mostrarProgresion(int n)
30 System.out.print(primerValor ());
31 for (int i = 2; i <= n; i++)
32 System.out.print(" " + siguienteValor ());
33 System.out.println (); // salto del lınea
34
35
Listado 2.2: Clase progresion numerica general.

2.2 Herencia y polimorfismo 59
Una clase de progresion aritmetica
Se considera ahora el diseno de la clase ProgresionAritmetica, la cual semuestra en el listado 2.3. Esta clase define una progresion aritmetica, dondeel siguiente valor es determinado agregando un incremento constante, inc, alvalor previo. ProgresionAritmetica hereda los campos primero y actual ylos metodos primerValor() y mostrarProgresion() de la clase Progresion.Ademas esta agrega un campo nuevo, inc, para guardar el incremento, y dosconstructores para configurar el incremento. ProgresionAritmetica anulael metodo siguienteValor() para calcular el siguiente valor de acuerdo auna progresion aritmetica.
El polimorfismo es usado en las clases senaladas previamente. Cuando unareferencia Progresion esta apuntando a un objeto ProgresionAritmetica,entonces los constructores y siguienteValor() de ProgresionAritmetica
seran usados. El polimorfismo esta tambien disponible dentro de la ver-sion heredada de mostrarProgresion(), ya que las llamadas a los metodosprimerValor() y siguienteValor() estan implıcitas para el objeto actual,siendo de la clase Progresion y de la clase ProgresionAritmetica respecti-vamente.
1 class ProgresionAritmetica extends Progresion
2 /** Incremento. */
3 protected long inc;
4 // Se heredan las variables primero y actual de Progresion.
5 /** Constructor por defecto que fija un incremento unitario. */
6 ProgresionAritmetica ()
7 this (1);
8
9 /** Constructor parametrizado que proporciona el incremento. */
10 ProgresionAritmetica(long incremento)
11 inc = incremento;
12
13 /** Avanza la progresi on agregando el incremento al valor actual.
14 *
15 * @return valor siguiente de la progresi on.
16 */
17 protected long siguienteValor ()
18 actual += inc;
19 return actual;
20
21 // Se heredan los me todos primerValor () y mostrarProgresion(int).
22
Listado 2.3: Clase para progresiones aritmeticas que extiende a la clase Progresion(listado 2.2).

60 Diseno orientado al objeto
Ejemplo de constructores y this
En la definicion de la clase ProgresionAritmetica, se agregaron dosconstructores, uno por defecto, el cual no toma parametros, y el otro conun parametro, el cual toma un parametro entero como el incremento de laprogresion. El constructor por defecto llama al de un parametro, usandothis y pasando un uno como el parametro incremento. Los dos constructoresmuestran sobrecarga de metodo, ya que un metodo es especificado por sunombre, la clase del objeto que llama, y los tipos de argumentos que sonpasados a este. En este caso, la sobrecarga es para los constructores, unconstructor por defecto y un constructor parametrizado.
La llamada this(1), lınea 13, listado 2.3, al constructor parametrizadocomo la primera sentencia del constructor por defecto lanza una excepciona la regla encadenamiento constructor general revisada en la seccion 2.2.3.Es decir, siempre que la primera sentencia de un constructor C ′ llama otroconstructor C ′′ de la misma clase usando la referencia this, el constructor de lasuperclase no es implıcitamente llamado por C ′. Observar que el constructor dela superclase sera eventualmente llamado en la cadena, ya sea explıcitamenteo implıcitamente.
Una clase de progresion geometrica
La clase ProgresionGeometrica, listado 2.4, incrementa y muestra unaprogresion geometrica, donde el siguiente valor se calcula multiplicando elvalor previo por una base fija, base. Una progresion geometrica es parecida auna progresion general, excepto en la forma como se determina el siguientevalor. Por lo anterior, ProgresionGeometrica es declarada como una sub-clase de la clase Progresion. ProgresionGeometrica hereda los camposprimero y actual, y los metodos primerValor() y mostrarProgresion()
de Progresion.

2.2 Herencia y polimorfismo 61
1 /**
2 * Progresi on geom e trica
3 */
4 class ProgresionGeometrica extends Progresion
5 /** Base. */
6 protected long base;
7 // Se heredan las variables primero y actual
8 /** Constructor por defecto poniendo base 2. */
9 ProgresionGeometrica ()
10 this (2);
11
12 /** Constructror parametrizado que proporciona la base.
13 *
14 * @param b base de la progresi on.
15 */
16 ProgresionGeometrica(long b)
17 base = b;
18 primero = 1;
19 actual = primero;
20
21 /** Avanza la progresi on multiplicando la base con el valor actual.
22 *
23 * @return siguiente valor de la progresi on
24 */
25 protected long siguienteValor ()
26 actual *= base;
27 return actual;
28
29 // Se heredan los me todos primerValor () e imprimirProgresion(int).
30
Listado 2.4: Clase para progresiones geometricas.
Una clase de progresion Fibonacci
Se define la clase ProgresionFibonacci, listado 2.5, que representa laprogresion Fibonacci, donde el siguiente valor es la suma del valor actualy del previo. Se usa un constructor parametrizado en la clase Progresion-
Fibonacci para dar una forma diferente de iniciar la progresion.
1 /**
2 * Progresi on de Fibonacci
3 */
4 class ProgresionFibonacci extends Progresion
5 /** Valor previo. */
6 long prev;
7 // Se heredan las variables primero y actual
8 /** Constructor por defecto poniendo 0 y 1 como los primeros dos valores. */
9 ProgresionFibonacci ()
10 this(0, 1);
11
12 /** Constructor param e trizado dando el primer valor y el segundo.

62 Diseno orientado al objeto
13 *
14 * @param valor1 primer valor.
15 * @param valor2 segundo valor.
16 */
17 ProgresionFibonacci(long valor1 , long valor2)
18 primero = valor1;
19 prev = valor2 - valor1; // valor ficticio precediendo al primero
20
21 /** Avanza la progresi on agregando el valor previo al valor actual.
22 *
23 * @return valor siguiente de la progresi on
24 */
25 protected long siguienteValor ()
26 long temp = prev;
27 prev = actual;
28 actual += temp;
29 return actual;
30
31 // Se heredan los me todos primerValor () e imprimirProgresion(int).
32
Listado 2.5: Clase para la progresione Fibonacci.
La clase ProbarProgresion, listado 2.6, realiza una prueba simple decada una de las tres subclases anteriores. La variable prog es polimorficaporque se asignan referencias objeto de la subclases Progresion.
1 /** Aplicaci on para las clases progresion */
2 class ProbarProgresion
3 public static void main(String [] args)
4 Progresion prog;
5 // probar ProgresionAritmetica
6 System.out.println("La progresi on aritm etica con el incremento por defecto:");
7 prog = new ProgresionAritmetica ();
8 prog.mostrarProgresion (10);
9 System.out.println("Progresi on aritm etica con incremento 5:");
10 prog = new ProgresionAritmetica (5);
11 prog.mostrarProgresion (10);
12 // probar ProgresionGeometrica
13 System.out.println("Progresi on geom e trica con base por defecto:");
14 prog = new ProgresionGeometrica ();
15 prog.mostrarProgresion (10);
16 System.out.println("Progresi on geom e trica con base 3:");
17 prog = new ProgresionGeometrica (3);
18 prog.mostrarProgresion (10);
19 // probar ProgresionFibonacci
20 System.out.println("Progresi on de Fibonacci con valores de inicio por defecto:");
21 prog = new ProgresionFibonacci ();
22 prog.mostrarProgresion (10);
23 System.out.println("Progresion de Fibonacci iniciando con valores 4 y 6:");
24 prog = new ProgresionFibonacci (4,6);
25 prog.mostrarProgresion (10);
26
27
Listado 2.6: Aplicacion para probar las clases progresion.

2.3 Excepciones 63
Al ejecutar la aplicacion ProbarProgresion genera la siguiente salida:
La progresion aritmetica con el incremento por defecto:
0 1 2 3 4 5 6 7 8 9
Progresion aritmetica con incremento 5:
0 5 10 15 20 25 30 35 40 45
Progresion geometrica con base por defecto:
1 2 4 8 16 32 64 128 256 512
Progresion geometrica con base 3:
1 3 9 27 81 243 729 2187 6561 19683
Progresion de Fibonacci con valores de inicio por defecto:
0 1 1 2 3 5 8 13 21 34
Progresion de Fibonacci iniciando con valores 4 y 6:
4 6 10 16 26 42 68 110 178 288
La clase Progresion, sus subclases, y el programa de prueba tienen unacantidad de fallas. Un problema se presenta con la progresion geometrica y lade Fibonacci porque crecen rapidamente, y no se realiza algo para manejar elsobreflujo inevitable de los enteros largos involucrados. Por ejemplo, como340 > 263, una progresion geometrica con base tres desbordara un entero largodespues de 40 iteraciones. De igual modo, el 94o (nonagesimo cuarto) numerode Fibonacci es mayor que 264; ası, la progresion de Fibonacci desbordara unentero largo despues de 94 iteraciones. Otro problema es que no se deberıapermitir iniciar una progresion Fibonacci con valores arbitrarios. Manejarerrores de entrada o de condicion que suceden en la ejecucion de un programaJava requiere de un mecanismo que lo maneje. Este se comenta en la siguienteseccion.
2.3. Excepciones
Las excepciones son eventos no esperados que ocurren en la ejecucionde un programa. Una excepcion se puede deber a una condicion de error ouna entrada no anticipada. Las excepciones, en Java, pueden ser vistas comoobjetos.
2.3.1. Lanzamiento de excepciones
Las excepciones son objetos que son lanzados por el codigo que encuentraalgun tipo de condicion no esperada. Tambien pueden ser lanzadas por el

64 Diseno orientado al objeto
ambiente de ejecucion cuando se encuentra una condicion no esperada, comoejecucion fuera de memoria. Una excepcion lanzada es atrapada por otrocodigo que “maneja” la excepcion de algun modo, o el programa es terminadoinesperadamente.
Las excepciones se originan cuando una pieza de codigo Java encuentraalgun tipo de problema durante la ejecucion y lanza un objeto excepcion. Esconveniente dar un nombre descriptivo a la clase del objeto excepcion. Porejemplo, si se intenta borrar el decimo elemento de una secuencia que tiene solocinco elementos, el codigo podrıa lanzar una ExcepcionViolacionLimites.Esta accion podrıa hacerse usando el siguiente fragmento de codigo:
if (indice >= A.length)
throw new
ExcepcionViolacionLimites("Indice "+indice+" invalido.");
Es conveniente instanciar un objeto excepcion al momento que la excepciontiene que ser lanzada. Ası, una sentencia throw se usa como sigue:
throw new tipo excepcion(param 0, param 1,. . . );
donde tipo excepcion es el tipo de la excepcion y los param i forman lalista de parametros para un constructor de este tipo de excepcion.
Las excepciones son tambien lanzadas por el propio ambiente de ejecucionJava. Por ejemplo, si se tiene un arreglo de seis elementos y se pide elnoveno elemento, entonces la excepcion ArrayIndexOutOfBoundsException
es lanzada por el sistema de ejecucion Java.
La clausula throws
Al declarar un metodo es apropiado indicar las excepciones que podrıalanzar, debido a que tiene un proposito funcional y de cortesıa. Le permite alusuario saber que esperar y le indica al compilador las excepciones a las quese debe preparar. Enseguida se muestra un ejemplo de tal definicion en unmetodo:
public void irCompras() throws
ExcepcionListaComprasCorta, ExcepcionSinDinero // cuerpo del metodo ...

2.3 Excepciones 65
Indicando todas las excepciones que podrıan ser lanzadas por un metodo,se prepara a otros para que puedan manejar todos los casos excepcionales quepodrıan surgir por usar este metodo. Otro beneficio de declarar excepciones esque no se necesitan atrapar estas excepciones en el metodo. En ocasiones estoes apropiado cuando otro codigo es el responsable del origen de la excepcion.
Se muestra enseguida una excepcion que es “pasada”:
public void estarListoParaClases() throws
ExcepcionListaComprasCorta, ExcepcionSinDinero irCompras();
/* no se tiene que intentar o atrapar las excepciones
que irCompras() podrıa lanzar, ya que estarListo-
ParaClase() las pasara de largo.
*/
hacerGalletas();
Un metodo puede declarar lanzar tantas excepciones como se quiera. Tallista puede simplificarse si todas las excepciones lanzadas son subclases de lamisma excepcion. En tal caso, solo se tiene que declarar que un metodo lanzala superclase apropiada.
Tipos de lanzables
Java define las clases Exception y Error como subclases de Throwable.Throwable indica que cualquier objeto podrıa ser lanzado y atrapado. Laclase RuntimeException esta definida como subclase de Exception. La claseError es usada para condiciones anormales en el ambiente de ejecucion, comoagotamiento de memoria. Los errores pueden ser atrapados, pero quizas no sedeberıa, porque estos avisan de problemas que no pueden ser manejados apro-piadamente. Un mensaje de error o una repentina terminacion de programaesta mas alla de lo manejable. La clase Exception es la raız de la jerarquıaexcepcion. Excepciones especializadas, como ExcepcionViolacionLimites,deberıan ser definidas como subclases de Exception o de RuntimeException.Las excepciones que no son subclases de RuntimeException deberan serdeclaradas en la clausula throws de cualquier metodo que pueda lanzarla.

66 Diseno orientado al objeto
2.3.2. Atrapar excepciones
Cuando una excepcion es lanzada, esta deber ser atrapada o el programaterminara. En cualquier metodo particular, una excepcion puede ser pasada almetodo llamador o puede ser atrapada en el metodo. Cuando una excepciones atrapada, esta puede ser analizada y manejada. La forma para manejar lasexcepciones es try (intentar) ejecutar alguna porcion de codigo que podrıalanzar una excepcion. Si se lanza una excepcion, entonces la excepcion esatrapada y el flujo de control pasa a un bloque catch predefinido con elcodigo para manejar la excepcion.
La sintaxis para un bloque try...catch es:
try bloque principal de sentencias
catch(tipo excepcion1 variable 1) bloque de sentencias 1
catch(tipo excepcion2 variable 2) bloque de sentencias 2...
finally bloque de sentencias n
donde debe haber al menos un catch, siendo finally opcional. Cada tipo -
de sentencias i es el tipo de alguna excepcion.El ambiente de ejecucion Java inicia ejecutando un bloque try...catch
con la ejecucion del bloque de sentencias, bloque principal de sentencias.Si esta ejecucion no genera excepciones, entonces el flujo de control siguecon la primera sentencia despues de la ultima lınea del bloque completotry...catch, a menos que se incluya la parte finally opcional.
Por otra parte, si el bloque, bloque principal de sentencias, generauna excepcion, entonces la ejecucion en el bloque try...catch termina enese punto y la ejecucion pasa al bloque catch cuyo tipo excepcion sea mascercana a la excepcion lanzada. La variable para esta sentencia catch refiereal propio objeto excepcion, el cual puede ser usado en el bloque de la sentenciacatch apareado. Una vez que la ejecucion de ese bloque catch se completa,el flujo de control es pasado al bloque finally opcional, si este existe, o a laprimera sentencia despues de la ultima lınea del bloque try...catch. De otraforma, si no hay bloque catch que empate la excepcion lanzada, entonces el

2.3 Excepciones 67
control es pasado al bloque finally opcional, si existe, y luego la excepciones lanzada de regreso al metodo llamador.
Considerar el siguiente ejemplo del fragmento de codigo:
int indice = Integer.MAX VALUE; // -1+2E31
try // El codigo podrıa tener un problema ...
String aComprar = listaCompras[indice];
catch (ArrayIndexOutOfBoundsException e)
System.out.println("Indice "+indice+" invalido.");
Si el codigo anterior no atrapa una excepcion lanzada, entonces el flujode control saldra inmediatamente del metodo y regresara al codigo quellamo al metodo. En el metodo que hizo la llamada, el ambiente de ejecucionbuscara nuevamente por un bloque catch. Si no lo hay, el flujo de controlpasara al que hizo la llamada para ir a ese metodo, y ası sucesivamente.Eventualmente, si ningun codigo atrapa la excepcion, el ambiente de ejecucion,el originador del flujo de control del programa, atrapara la excepcion. Eneste punto, un mensaje de error y la traza de la pila es mostrada en la salidaestandar y el programa es terminado.
El siguiente es un mensaje de error en tiempo de ejecucion:
java.lang.NuIlPointerException: Returned a null locator
at java.awt.Component.handleEvent(Component.java:900)
at java.awt.Component.postEvent(Component.java:838)
at java.awt.Component.postEvent(Component.java:845)
at sun.awt.motif.MButtonPeer.action(MButtonPeer.java:39)
at java.lang.Thread.run(Thread.java)
Una vez que una excepcion es atrapada, hay varias cosas que un progra-mador podrıa querer hacer. Una posibilidad es mostrar un mensaje de error yterminar el programa. Tambien hay algunos casos interesantes en los cualesla mejor forma para manejar una excepcion es ignorarla (usando un bloquecatch vacıo).
Ignorar una excepcion es hecho usualmente, por ejemplo, cuando el pro-gramador no le importa si hay o no hay excepcion. Otra manera legıtimade manejar excepciones es creando y lanzando otra excepcion, quizas unaque indique la condicion excepcional mas precisa. El siguiente codigo es unejemplo de esta forma:

68 Diseno orientado al objeto
catch (ArrayIndexOutOfBoundsException e) throw new ExcepcionListaComprasCorta(
"Indice del producto no esta en lista de compras");
La mejor forma de manejar una excepcion, aunque no siempre es posible,es encontrar el problema, arreglarlo, y continuar la ejecucion.
2.4. Interfaces y clases abstractas
Para que dos objetos puedan interactuar, estos deben “conocer” acerca delos mensajes que cada uno podra aceptar, es decir, los metodos que cada objetosoporta. Para reforzar este “conocimiento”, el paradigma del diseno orientadoal objeto requiere que las clases indiquen la interfaz de programacion deaplicaciones o API (Application Programming Interface), o interfaz, quesus objetos presentan a otros objetos. En la aproximacion ADT usada, seccion2.1.2, para estructuras de datos en este texto, una interfaz definiendo un ADTes indicado como un tipo definicion y una coleccion de metodos para este tipo,con los argumentos para cada metodo siendo de tipos especificados. En sumomento, esta especificacion es reforzada por el compilador o el sistema deejecucion, los cuales requieren que los tipos de los parametros que son pasadosa los metodos sean del tipo indicado en la interfaz. Este requerimiento esconocido como tipado fuerte . El programador es obligado a tener que definirinterfaces y usar en estas tipado fuerte, pero esta carga es recompensada, porobligar a emplear el principio de encapsulacion y porque atrapa errores deprogramacion que de otra forma no se sabrıan.
2.4.1. Implementacion de interfaces
El elemento estructural principal en Java que forza una API es la interfaz.Una interfaz es una coleccion de declaraciones de metodos sin datos y sincuerpos. Es decir, los metodos de una interfaz siempre estan vacıos, son solofirmas de metodos. Cuando una clase implementa una interfaz, debera im-plementar todos los metodos declarados en la interfaz. De esta forma, lasinterfaces hacen cumplir los requisitos que una clase implementadora tengametodos con ciertas firmas especificadas.
Por ejemplo, suponer que se quiere crear un inventario de antiguedades,categorizadas como objetos de tipos varios y con propiedades diversas. Se

2.4 Interfaces y clases abstractas 69
podrıa querer identificar algunos de los objetos como vendibles, en tal casoestos deberıan implementar la interfaz Vendible, listado 2.7.
1 /** Interfaz para objetos que pueden ser vendidos. */
2 public interface Vendible
34 /** descripci on del objeto */
5 public String descripcion ();
67 /** precio de lista */
8 public float precioLista ();
910 /** precio mınimo de venta */
11 public float precioMinimo ();
12
Listado 2.7: Interfaz Vendible.
Despues se puede definir una clase concreta, Fotografia, listado 2.8,que implementa la interfaz Vendible, para indicar que se estarıa dispuestoa vender cualquiera de los objetos fotografıa. Esta clase define un objetoque implementa cada uno de los metodos de la interfaz Vendible, como serequiere. Ademas, agrega el metodo esColor() especializado para objetosFotografia.
1 /** Clase para fotograf ıas que pueden ser vendidas. */
2 public class Fotografia implements Vendible
3 private String descripcion;
4 private float precio; // precio puesto
5 private boolean color; // true si foto es a color
67 // constructor
8 public Fotografia(String d, float p, boolean c)
9 descripcion = d;
10 precio = p;
11 color = c;
12
1314 public String descripcion () return descripcion;
15 public float precioLista () return precio;
16 public float precioMinimo () return precio /4;
17 public boolean esColor () return color;
18
Listado 2.8: Clase Fotografia implenentando la interfaz Vendible.
Otro tipo de antiguedades en el inventario podrıa ser algo que se deba

70 Diseno orientado al objeto
transportar. Para tales objetos, se define la interfaz Transportable, listado2.9.
1 /** Interfaz para objetos que pueden ser transportados. */
2 public interface Transportable
34 /** peso en gramos */
5 public int peso ();
67 /** si el objeto es peligroso */
8 public boolean esPeligroso ();
9
Listado 2.9: Interfaz Transportable.
Se podrıa luego definir la clase ArticuloEmpacado, listado 2.10, paraantiguedades diversas que puedan ser vendidas, empacadas, y enviadas. Porlo tanto, la clase ArticuloEmpacado implementa los metodos de la interfazVendible y Transportable, ademas tambien se agregan los metodos espe-cializados para poner un seguro y las dimensiones de un artıculo empacado.
La clase ArticuloEmpacado muestra otra caracterıstica de las clases y lasinterfaces, una clase puede implementar varias interfaces, lo cual da flexibilidadcuando se definen clases que deberıan cumplir varias API. Mientras queuna clase en Java puede extender solamente una clase, puede sin embargoimplementar varias interfaces.
2.4.2. Herencia multiple en interfaces
La habilidad de extender de mas de una clase se conoce como herenciamultiple. En Java, herencia multiple esta permitida para interfaces perono para clases. En Java no se permite la herencia multiple en clases, por laposible confusion cuando una clase intente extender de dos clases que tenganmetodos con cuerpo diferente y firma igual. Esta confusion no existe en lasinterfaces porque sus metodos estan vacıos. Al no haber confusion, la herenciamultiple de interfaces es util.
En Java, el uso de herencia multiple de interfaces es para aproximar unatecnica de herencia multiple llamada mezcla. Se mezclan los metodos de dos omas interfaces no relacionadas para definir una interface que combine su funcio-nalidad, posiblemente agregando mas metodos por su cuenta. Para el ejemplode los objetos antiguedad, se podrıa definir la interfaz ArticuloAsegurable
para los artıculos asegurados, como se muestra enseguida:

2.4 Interfaces y clases abstractas 71
1 /** Clase para objetos que pueden ser vendidos , empacados ,
2 * y enviados. */
3 public class ArticuloEmpacado implements Vendible ,Transportable
4 private String descripcion;
5 private float precio;
6 private int peso;
7 private boolean pelig;
8 private int largo = 0; // largo empaque en cm
9 private int ancho = 0; // ancho empaque en cm
10 private int alto = 0; // alto empaque en cm
11 /** Constructor */
12 public ArticuloEmpacado(String d, float p, int pes , boolean pel)
13 descripcion = d;
14 precio = p;
15 peso = pes;
16 pelig = pel;
17
18 public String descripcion () return descripcion;
19 public float precioLista () return precio;
20 public float precioMinimo () return precio /4;
21 public int peso() return peso;
22 public boolean esPeligroso () return pelig;
23 public float valorAsegurado () return precio *1.5f;
24 public void setCaja(int l, int an , int al)
25 largo = l;
26 ancho = an;
27 alto = al;
28
29
Listado 2.10: Clase ArticuloEmpacado

72 Diseno orientado al objeto
public interface ArticuloAsegurable
extends Transportable, Vendible /** Devolver el valor asegurado */
public int valorAsegurado();
La interfaz ArticuloAsegurable mezcla los metodos de la interfaz Trans-portable con los metodos de la interfaz Vendibles, y agrega el metodo extravalorAsegurado(). La interfaz ArticuloAsegurable podrıa permitir definirla clase ArticuloEmpacado como:
public class ArticuloEmpacado
implements ArticuloAsegurable // mismo codigo de la clase ArticuloEmpacado
Las interfaces de Java que aproximan la mezcla son: java.lang.Cloneable,la cual agrega una caracterıstica de copia para una clase; java.lang.-
Comparable, la cual agrega una caracterıstica de comparacion para unaclase; y java.util.Observer, la cual agrega una caracterıstica de actualiza-cion a una clase que quiere ser notificada cuando ciertos objetos “observables”cambien de estado.
2.4.3. Clases abstractas y tipado fuerte
Una clase abstracta es una clase que contiene declaraciones de metodosvacıos, o sea, declaraciones de metodos sin cuerpo, y posiblemente definicionesde metodos concretos y variables de instancia. Ası, una clase abstractaesta entre una interfaz y una clase concreta. Al igual que una interfaz, unaclase abstracta no puede ser instanciada, o sea, crear un objeto desde la claseabstracta. Una subclase de una clase abstracta debera dar una implementacionpara los metodos abstractos de su superclase, a menos que esta misma seaabstracta. Al igual que una clase concreta, una clase abstracta A puedeextender otra clase abstracta, y clases abstractas o concretas pueden tambienextender a A. Una clase nueva que no sea abstracta y extienda superclasesabstractas debera implementar todos los metodos abstractos. Una claseabstracta usa el estilo de especificacion de herencia, pero tambien permite laespecializacion y estilos de extension.

2.5 Conversiones y genericos 73
La clase java.lang.Number
Las clases numero Java, cuadro 1.2, especializan la clase abstracta java.-
lang.Number. Cada clase numero concreta, tales como java.lang.Integer
y java.lang.Double, extienden la clase java.lang.Number y completan losdetalles para los metodos abstractos de la superclase. Por ejemplo, los metodosintValue(), floatValue(), longValue(), y doubleValue() son todos abs-tractos en java.lang.Number. Cada clase numero concreta debera especificarlos detalles de estos metodos.
Tipado fuerte
Un objeto puede ser visto como siendo de varios tipos. El tipo primario deun objeto o es la clase C indicada al momento que o fue instanciado. Ademas,o es del tipo S para cada superclase S de C y es del tipo I para cada interfazI implementada por C.
Sin embargo, una variable puede ser declarada para ser de un solo tipo,ya sea clase o interfaz, la cual determina como la variable es usada y comociertos metodos actuaran en esta. De igual forma, un metodo tiene un unicotipo de regreso. En general, una expresion tiene un tipo unico.
La tecnica de tipado fuerte de Java, forzar a que todas las variables seantipadas y que los metodos declaren el tipo que se espera y que se regresa,ayuda a prevenir errores. Pero por los requerimientos rıgidos con tipos, es enocasiones necesario cambiar, o convertir, un tipo en otro. Tales conversionespodrıan tener que ser especificadas por un operador de conversion explıcito.En la seccion 1.3.3 se indica como convertir a tipos base. En la siguienteseccion se indica como se realizan las conversiones para variables referencia.
2.5. Conversiones y genericos
2.5.1. Conversiones para objetos
Se comenta enseguida varios metodos para conversiones de tipo paraobjetos.

74 Diseno orientado al objeto
Conversiones anchas
Una conversion ancha ocurre cuando un tipo T es convertido a un tipoU “amplio”. Los siguientes son casos comunes de conversiones anchas:
T y U son tipos clase y U es una superclase de T.
T y U son tipos interfaz y U es una superinterfaz de T.
T es una clase que implementa la interfaz U.
Las conversiones anchas son hechas automaticamente para guardar elresultado de una expresion en una variable, sin la necesidad de una conversionexplıcita. Por lo tanto, se puede asignar directamente el resultado de unaexpresion de tipo T en una variable v de tipo U cuando la conversion de T
a U es una conversion ancha. El siguiente fragmento de codigo muestra unaexpresion de tipo Integer, un objeto nuevo construido, asignandose a unavariable de tipo Number.
Integer i = new Integer(3);
Number n = i; // conversion ancha
La correctez de una conversion ancha es revisada por el compilador y suvalidez no requiere prueba por el ambiente de ejecucion Java al ejecutar elprograma.
Conversiones estrechas
Una conversion estrecha ocurre cuando un tipo T es convertido a untipo S “estrecho”. Los siguientes son casos comunes de conversiones estrechas:
T y S son tipos clase y S es una subclase de T.
T y S son tipos interfaz y S es una subinterfaz de T.
T es una interfaz implementada por la clase S.
En general, una conversion estrecha de tipos referencia necesita unaconversion explıcita. Tambien, la correctez de una conversion estrecha podrıano ser verificada por el compilador. Por lo tanto, su validacion deberıa serprobada por el ambiente de ejecucion en la ejecucion del programa.
El siguiente fragmento de codigo ejemplo muestra como usar una conversionpara realizar una conversion estrecha desde el tipo Number al tipo Integer.

2.5 Conversiones y genericos 75
Number n = new Integer(2); // conv. ancha Integer->Number
Integer i = (Integer) n; // conv. estrecha Number->Integer
En la primera sentencia, un objeto nuevo de la clase Integer es creado yasignado a una variable n del tipo Number. Ası, una conversion ancha ocurrey no se ocupa conversion. En la segunda sentencia, se asigna n a una variablei del tipo Integer usando una conversion. La asignacion es posible porque n
se refiere a un objeto del tipo Integer. Sin embargo, como la variable n esdel tipo Number, una conversion estrecha ocurre y la conversion es necesaria.
Excepciones en conversiones
Se puede convertir una referencia objeto o de tipo T en un tipo S, si elobjeto o referido es en realidad del tipo S. Por otra parte, si el objeto o noes del tipo S, entonces intentar convertir o al tipo S lanzara la excepcionClassCastException. Lo anterior se presenta en el siguiente fragmento decodigo:
Number n;
Integer i;
n = new Integer(3);
i = (Integer) n; // valido
n = new Double(3.1416);
i = (Integer) n; // no valido
Para evitar problemas como el anterior y evitar poner en el codigo bloquestry...catch cada vez que se haga una conversion, Java proporciona unaforma de asegurarse que una conversion objeto sera correcta mediante eloperador, instanceof, el cual prueba si una variable objeto se refiere a unobjeto de una cierta clase o implementa una cierta interfaz. La sintaxis es:
referencia objeto instanceof tipo referencia
siendo referencia objeto una expresion que evalua a una referencia objetoy tipo referencia es el nombre de alguna clase, interfaz, o enumeracion exis-tente. Si referencia objeto es una instancia de tipo referencia entoncesel operador da true, de otra forma da false. Para evitar una excepcionClassCastException que lanzarıa el codigo previo, se debera modificar dela siguiente forma:

76 Diseno orientado al objeto
Number n;
Integer i;
n = new Integer(3);
if (n instanceof Integer)
i = (Integer) n; // valido
n = new Double(3.1416);
if (n instanceof Integer)
i = (Integer) n; // no sera intentado
Conversiones con interfaces
Las interfaces permiten obligar que los objetos implementen ciertos meto-dos, pero usando variables interfaz con objetos concretos en ocasiones serequiere conversion. Suponer que se declara una interfaz Persona, listado 2.11.Observar que el metodo igualA() de la interfaz Persona toma un parametrode tipo Persona. De esta forma, se puede pasar un objeto de cualquier claseque implemente la interfaz Persona a este metodo.
1 public interface Persona
2 public boolean igualA (Persona otra); // ¿misma persona?
3 public String getNombre (); // obtener nombre de la persona
4 public int getEdad (); // obtener edad de la persona
5
Listado 2.11: Interfaz Persona
En la clase Estudiante, listado 2.12, se implementa la interfaz Persona.Se asume en el metodo igualA() que el argumento, declarado de tipo Persona,es tambien del tipo Estudiante y se realiza una conversion estrecha del tipoPersona, una interfaz, al tipo Estudiante, una clase, con una conversionexplıcita. La conversion es permitida en este caso, porque es una conversionestrecha desde una clase T a una interfaz U, en donde se tiene un objetotomado desde T tal que T extiende S y S implementa U.
Se requiere asegurar que en la implementacion del metodo igualA() de laclase Estudiante, no se intente la comparacion de objetos Estudiante conotros tipos de objetos, o de otra forma, la conversion en el metodo igualA()
fallara.La posibilidad de realizar conversiones estrechas desde tipos interfaz a
tipos clase permite escribir tipos generales de estructuras de datos que solo

2.5 Conversiones y genericos 77
1 public class Estudiante implements Persona
2 String id;
3 String nombre;
4 int edad;
5 public Estudiante(String i, String n, int e)
6 id = i;
7 nombre = n;
8 edad = e;
9
10 protected int horasEstudio () return edad /3;
11 public String getId() return id; // id del estudiante
12 public String getNombre () return nombre; // de interfaz
13 public int getEdad () return edad; // de interfaz
14 public boolean igualA(Persona otra) // de interfaz
15 Estudiante otroEstudiante = (Estudiante) otra;
16 return (id.equals(otroEstudiante.getId ()));
17
18 public String toString () // para mostrar
19 return "Estudiante(Id: " + id +
20 ", Nombre: " + nombre +
21 ", Edad: " + edad + ")";
22
23
Listado 2.12: Clase Estudiante implementando la interfaz Persona
hagan suposiciones mınimas acerca de los elementos que guardan. Se bosquejaenseguida como construir un directorio para guardar parejas de objetos queimplementan la interfaz Persona. El metodo quitar() realiza una busquedaen el contenido del directorio y quita el par de personas indicadas, si existe, yal igual que el metodo encontrarOtra(), usa el metodo igualA() para labusqueda.
public class DirectorioPareja // ... variables de instancia ...
public DirectorioPareja() public void insertar(Persona persona, Persona otra) public Persona encontrarOtra(Persona persona)
return null ;
public void quitar (Persona persona, Persona otra)
Suponer que se ha llenado un directorio, miDirectorio, con parejas deobjetos Estudiante que representan parejas de companeros de cuarto. Para

78 Diseno orientado al objeto
lograr encontrar el companero de cuarto de un objeto Estudiante dado,estudiante1, se podrıa intentar hacer lo siguiente, lo cual esta mal:
Estudiante estudiante2 =
miDirectorio.encontrarOtra(estudiante1);
Esta sentencia provoca un error de compilacion “explicit-cast-required”(conversion explıcita requerida), debido a que se intenta hacer una conver-sion estrecha sin una conversion explıcita. Es decir, el valor devuelto porel metodo encontrarOtra() es del tipo Persona mientras que la variableestudiante2, a la cual es asignada, es del tipo estrecho Estudiante, unaclase que implementa la interfaz Persona, Ası, se debe hacer una conversiondel tipo Persona al tipo Estudiante, como se muestra enseguida:
Estudiante estudiante2 =
(Estudiante)miDirectorio.encontrarOtra(estudiante1);
Convertir el valor del tipo Persona regresado por el metodo encontrar-
Otra() al tipo Estudiante trabaja bien siempre que se asegure que lallamada a miDirectorio.encontrarOtra() realmente devuelva un objetoEstudiante. En general, las interfaces pueden ser una herramienta valiosapara el diseno de estructuras de datos generales, las cuales pueden entoncesser especializados por otros programadores usando la conversion.
2.5.2. Genericos
A partir de Java 5.0 se incluye una estructura generica para usartipos abstractos con la finalidad de evitar conversiones de tipos. Un tipogenerico es un tipo que no esta definido en tiempo de compilacion, pero quedaespecificado completamente en tiempo de ejecucion. La estructura genericapermite definir una clase en terminos de un conjunto de parametros detipo formal, los cuales podrıan ser usados, por ejemplo, para abstraer lostipos de algunas variables internas de la clase. Se usan parentesis angulares(<>) para encerrar la lista de los parametros de tipo formal. Aunque cualquieridentificador valido puede ser usado para un parametro de tipo formal, porconvencion son usados los nombres de una sola letra mayuscula. Dada unaclase que ha sido definida con tales tipos parametrizados, se instancia unobjeto de esta clase usando los parametros de tipo actual para indicar lostipos concretos que seran usados.

2.5 Conversiones y genericos 79
En el listado 2.13, se muestra la clase Par que guarda el par llave-valor,donde los tipos de la llave y el valor son especificados por los parametros L y V,respectivamente. El metodo main() crea dos instancias de esta clase, una paraun par String-Integer (por ejemplo, para guardar un tipo de dimension ysu valor), y otro para un par Estudiante-Double (por ejemplo, para guardarla calificacion dada a un estudiante).
1 public class Par <L, V> // entre < y > los par a metros de tipo formal
2 L llave;
3 V valor;
4 public void set(L l, V v)
5 llave = l;
6 valor = v;
7
8 public L getLlave () return llave;
9 public V getValor () return valor;
10 public String toString ()
11 return "[" + getLlave () + ", " + getValor () + "]";
12
13 public static void main (String [] args)
14 Par <String ,Integer > par1 = new Par <String ,Integer >();
15 par1.set(new String("altura"), new Integer (2));
16 System.out.println(par1);
17 Par <Estudiante ,Double > par2 = new Par <Estudiante ,Double >();
18 par2.set(new Estudiante("8403725A","Hector" ,14), new Double (9.5));
19 System.out.println(par2);
20
21
Listado 2.13: Clase Par
La salida de la ejecucion de la clase Par se muestra enseguida:
[altura, 2]
[Estudiante(Matricula: 8403725A, Nombre: Hector, Edad: 14), 9.5]
En el ejemplo, el parametro del tipo actual puede ser un tipo arbitrario. Pa-ra restringir el tipo de parametro actual se puede usar la clausula extends, co-mo se muestra enseguida, donde la clase DirectorioParejaGenerico esta de-finida en terminos de un parametro de tipo generico P, parcialmente especifi-cado declarando que extiende la clase Persona.

80 Diseno orientado al objeto
public class DirectorioParejaGenerico<P extends Persona> // ... variables de instancia ...
public DirectorioParejaGenerico() public void insertar(P persona, P otra) public P encontrarOtra(P persona) return null ; public void quitar (P persona, P otra)
Esta clase deberıa ser comparada con la clase DirectorioPareja de laseccion 2.5.1. Dada la clase anterior, se puede declarar una variable refiriendoa una instancia de DirectorioParejaGenerico, que guarde pares de objetosde tipo Estudiante:
DirectorioParejaGenerico<Estudiante> miDirectorioEstudiante;
La estructura generica permite definir versiones genericas de metodos. Eneste caso, se puede incluir la definicion generica entre los metodos modifi-cadores. Por ejemplo, se muestra enseguida la definicion de un metodo quepuede comparar las llaves de cualesquiera dos objetos Par, dado que sus llavesimplementen la interfaz Comparable:
public static <K extends Comparable,V,L,W> int
comparaPares(Par<K,V> p, Par<L,W> q) return p.getLlave().compareTo(q.getLlave());
// la llave de p implementa compareTo()
Una advertencia importante relacionada a los tipos genericos es quelos elementos guardados en un arreglo no pueden ser de un tipo variableo parametrizado. Java permite que un arreglo sea definido con un tipoparametrizado, pero no permite que un tipo parametrizado sea usado paracrear un nuevo arreglo. Java permite que para un arreglo definido con un tipoparametrizado sea inicializado con un arreglo nuevo no parametrizado, comose muestra en la clase UsaPar, listado 2.14. Aun ası, este mecanismo tardıocausa que el compilador de Java emita una advertencia, porque esto no estipado 100 % seguro.

2.5 Conversiones y genericos 81
1 public class UsaPar
2 public static void main(String [] args)
3 Par <String ,Integer >[] a = new Par [10]; // correcto , pero da una advertencia
4 Par <String ,Integer >[] b = new Par <String ,Integer >[10]; // incorrecto
5 a[0] = new Par <String ,Integer >(); // est a completamente bien
6 a[0]. set("Gato" ,10); // esta y la siguiente tambien est an bien
7 System.out.println("Primer par es "+a[0]. getLlave ()+","+a[0]. getValor ());
8
9
Listado 2.14: Ejemplo que muestra que un tipo parametrizado sea usado para crearun nuevo arreglo.

82 Diseno orientado al objeto

Capıtulo 3
Arreglos, listas enlazadas yrecurrencia
3.1. Que son las estructuras de datos
Una estructura de datos es un arreglo de datos en la memoria deuna computadora, y en algunas ocasiones en un disco. Las estructuras dedatos incluyen arreglos, listas enlazadas, pilas, arboles binarios, y tablasde dispersion entre otros. Los algoritmos manipulan los datos en estasestructuras de varias formas, para buscar un dato particular u ordenar losdatos.
3.1.1. Generalidades de las Estructuras de Datos
Una forma de ver las estructuras de datos es enfocandose en sus fortalezasy debilidades. En el cuadro 3.1 se muestran las ventajas y desventajas delas estructuras de datos que se revisaran, los terminos que se usan seranabordados en otros capıtulos.
Las estructuras mostradas en el cuadro 3.1, excepto los arreglos, puedenser pensados como tipos de datos abstractos o ADT (Abstract DataType). Un ADT, de forma general, es una forma de ver una estructura dedatos: enfocandose en lo que esta hace e ignorando como hace su trabajo, esdecir, el ADT debera cumplir con ciertas propiedades, pero la manera como
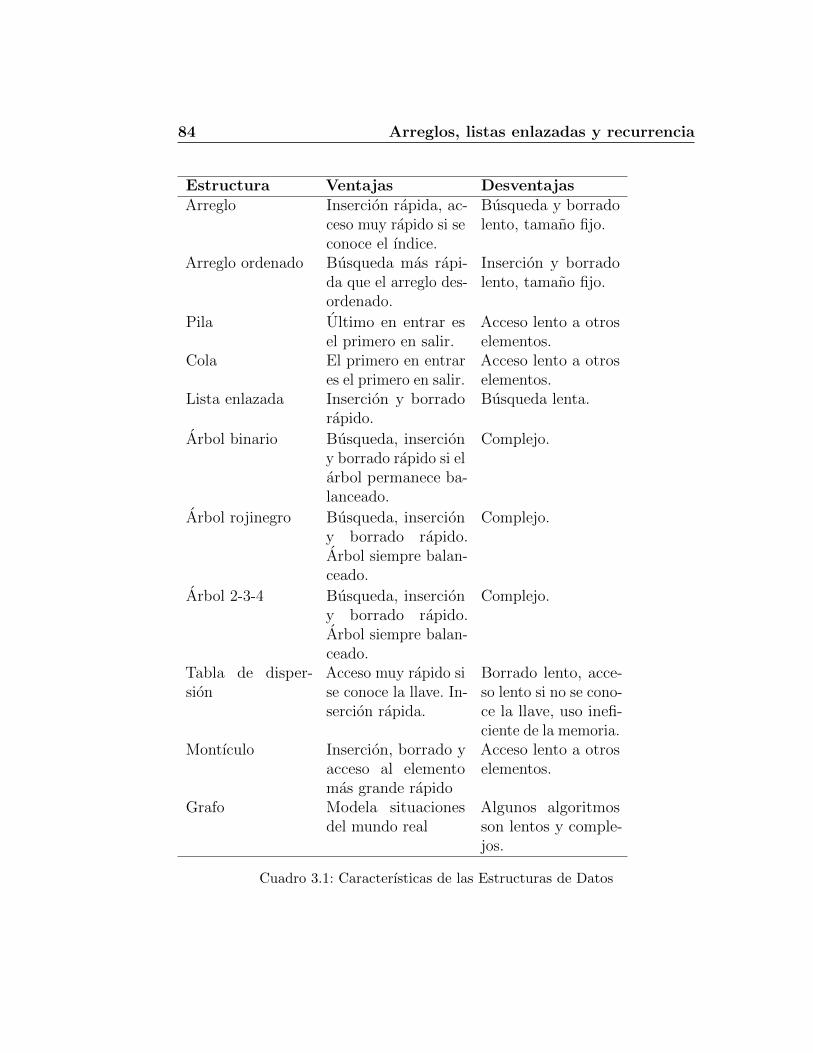
84 Arreglos, listas enlazadas y recurrencia
Estructura Ventajas DesventajasArreglo Insercion rapida, ac-
ceso muy rapido si seconoce el ındice.
Busqueda y borradolento, tamano fijo.
Arreglo ordenado Busqueda mas rapi-da que el arreglo des-ordenado.
Insercion y borradolento, tamano fijo.
Pila Ultimo en entrar esel primero en salir.
Acceso lento a otroselementos.
Cola El primero en entrares el primero en salir.
Acceso lento a otroselementos.
Lista enlazada Insercion y borradorapido.
Busqueda lenta.
Arbol binario Busqueda, inserciony borrado rapido si elarbol permanece ba-lanceado.
Complejo.
Arbol rojinegro Busqueda, inserciony borrado rapido.Arbol siempre balan-ceado.
Complejo.
Arbol 2-3-4 Busqueda, inserciony borrado rapido.Arbol siempre balan-ceado.
Complejo.
Tabla de disper-sion
Acceso muy rapido sise conoce la llave. In-sercion rapida.
Borrado lento, acce-so lento si no se cono-ce la llave, uso inefi-ciente de la memoria.
Montıculo Insercion, borrado yacceso al elementomas grande rapido
Acceso lento a otroselementos.
Grafo Modela situacionesdel mundo real
Algunos algoritmosson lentos y comple-jos.
Cuadro 3.1: Caracterısticas de las Estructuras de Datos

3.2 Arreglos 85
estara implementado puede variar, aun empleando el mismo lenguaje. Porejemplo, el ATD pila puede ser implementado con un arreglo o bien con unalista enlazada.
Varios de los algoritmos que seran discutidos en este material se apli-caran directamente a estructuras de datos especıficas. Para la mayorıa de lasestructuras de datos, se requiere que hagan las siguientes tareas:
1. Insertar un nuevo dato.
2. Buscar un elemento indicado.
3. Borrar un elemento indicado.
Tambien se necesitara saber como iterar a traves de todos los elementos enla estructura de datos, visitando cada uno en su turno ya sea para mostrarlo,o para realizar alguna accion en este.
Otro algoritmo importante es el ordenamiento. Hay varias formas paraordenar los datos, desde ideas simples hasta otras que permiten realizarlo demanera rapida.
El concepto de recurrencia es importante en el diseno de ciertos algoritmos.La recurrencia involucra que un metodo se llame a si mismo.
3.2. Arreglos
En esta seccion, se exploran unas cuantas aplicaciones con arreglos.
3.2.1. Guardar entradas de juego en un arreglo
La primera aplicacion que sera revisada se usa para guardar las entradasen un arreglo—en particular, las mejores marcas para un videojuego. Losarreglos tambien se podrıan usar para guardar registros de pacientes en unhospital, o los nombres de estudiantes.
En primer lugar se debe determinar lo que se quiere incluir en el registrode una puntuacion alta. Por supuesto, un componente que se debera incluir esun entero representando los puntos obtenidos, al cual llamaremos puntuacion.Otra caracterıstica que debera incluirse es el nombre de la persona que obtuvola puntuacion, la cual denominaremos nombre. La clase EntradaJuego, listado3.1, tiene el diseno para manejar una puntuacion.

86 Arreglos, listas enlazadas y recurrencia
1 public class EntradaJuego
2 protected String nombre; // nombre del due~no de la puntuaci on
3 protected int puntuacion; // el valor de la puntuaci on
4 /** Constructor para crear una entrada del juego */
5 public EntradaJuego(String n, int p)
6 nombre = n;
7 puntuacion = p;
8
9 /** Recupera el campo nombre */
10 public String getNombre () return nombre;
11 /** Recupera el campo puntuaci on */
12 public int getPuntuacion () return puntuacion;
13 /** Regresa una cadena de esta entrada */
14 public String toString ()
15 return "(" + nombre + ", " + puntuacion + ")";
16
17
Listado 3.1: Clase EntradaJuego.java
Clase para las mayores puntuaciones
La cantidad de puntuaciones que seran guardadas se indica mediante unaconstante con nombre, MAX ENTRADAS, la cual es inicializada con el valor 10.Se usa esta constante para el caso en el que se quiera cambiar facilmente lacantidad de puntuaciones guardadas. Se define un arreglo, entradas, paraque sea un arreglo de tamano MAX ENTRADAS. Cuando se crea el arreglo susentradas son null, pero conforme se juega, se van llenando las entradas delarreglo con referencias a objetos EntradaJuego.
Se quiere almacenar los mayores registros en un arreglo llamado entradas.La cantidad de registros puede variar, por lo que se usara el nombre simbolico,maxEntradas, para representar el numero maximo de registros que se puedenguardar. Se debe poner esta variable con un valor especıfico, y usando estavariable en el codigo, se puede hacer facilmente un cambio mas tarde si serequiere. Se define despues el arreglo, entradas, para que sea un arreglode tamano maxEntradas. Inicialmente, el arreglo guarda solamente entradasnulas, pero conforme el usuario juega, se llenara en el arreglo con nuevosobjetos EntradaJuego. Por lo que se necesitara definir metodos para actualizarlas referencias EntradaJuego en las entradas del arreglo.
La forma como se mantiene organizado el arreglo entradas es simple—seguarda el conjunto de objetos EntradaJuego ordenado por sus valores enterospuntuacion, de mayor a menor. Si el numero de objetos EntradaJuego esmenor que maxEntradas, entonces se permite que al final del arreglo se

3.2 Arreglos 87
1 /** Clase para guardar las puntuaciones altas en un arreglo
2 en orden descendente. */
3 public class Puntuaciones
4 public static final int MAX_ENTRADAS = 10; // cantidad de puntuaciones
5 protected int numEntradas; // cantidad. actual de entradas
6 protected EntradaJuego [] entradas; // arreglo de entradas
7 /** Constructor por defecto */
8 public Puntuaciones ()
9 entradas = new EntradaJuego[MAX_ENTRADAS ];
10 numEntradas = 0;
11
12 /** Regresa una cadena de las mayores puntuaciones */
13 public String toString ()
14 String s = "[";
15 for (int i = 0; i < numEntradas; i++)
16 if (i > 0) s += ", "; // separar entradas con comas
17 s += entradas[i];
18
19 return s + "]";
20
21 // ... me todos para actualizar el conjunto de puntuaciones ...
Listado 3.2: Clase Puntuciones para manejar un conjunto de objetos Entrada.
guarden referencias null. Con este diseno se previene tener celdas vacıas, u“hoyos”, y los registros estan desde el ındice cero hasta antes de la cantidad dejuegos jugados. Se ilustra una instancia de la estructura de datos en la figura3.1 y en la clase Puntuaciones, listado 3.2 parcial, se muestra el diseno.
El metodo toString() devuelve una cadena representando las mayorespuntuaciones del arreglo entradas. Puede tambien ser empleado para proposi-tos de depuracion. La cadena sera una lista separada con comas de objetosEntradaJuego del arreglo entradas. La lista se genera con un ciclo for, elcual agrega una coma justo antes de cada entrada que venga despues de laprimera.
Insercion
Una de las actualizaciones mas comunes que se quiere hacer al arregloentradas es agregar una nueva entrada. Suponiendo que se quiera insertar unnuevo objeto e del tipo EntradaJuego se considera como se harıa la siguienteoperacion en una instancia de la clase Puntuaciones:

88 Arreglos, listas enlazadas y recurrencia
Figura 3.1: Una ilustracion de un arreglo de tamano 10 guardando referencias a6 objetos entradaJuego desde la celda 0 hasta la 5, y el resto siendo referenciasnull.
add(e):inserta la entrada de juego e en la coleccion de lasmayores puntuaciones. Si la coleccion esta llena,entonces e es agregado solamente si su puntuaciones mayor que la menor puntuacion en el conjunto,y en este caso, e reemplaza la entrada con la menorpuntuacion.
El reto principal en la implementacion de esta operacion es saber donde e
debera ir en el arreglo entradas y hacerle espacio a e.Se supondra que las puntuaciones estan en el arreglo de izquierda a
derecha desde la mayor hasta la menor. Entonces se quiere que dada unanueva entrada, e, se requiere saber donde estara. Se inicia buscando al finaldel arreglo entradas. Si la ultima referencia en el arreglo no es null y supuntuacion es mayor que la puntuacion de e, entonces se detiene la busqueda,ya que en este caso, e no es una puntuacion alta. De otra forma, se sabeque e debe estar en el arreglo, y tambien se sabe que el ultimo registro enel arreglo ya no debe estar. Enseguida, se va al penultima referencia, si estareferencia es null o apunta a un objeto EntradaJuego con una puntuacionque es menor que e, esta referencia debera ser movida una celda a la derechaen el arreglo entrada. Se continua comparando y desplazando referencias deentradas del juego hasta que se alcanza el inicio del arreglo o se compara la

3.2 Arreglos 89
puntuacion de e con una entrada con una puntuacion mayor. En cualquiercaso, se habra identificado el lugar al que e pertenece. Ver figura 3.2
Figura 3.2: Preparacion para agregar un nuevo objeto entradaJuego al arregloEntradas. Para hacer espacio a una nueva referencia, se tienen que desplazar lasreferencias con los registros mas pequenos que la nueva una celda a la derecha.
En el listado 3.3 se muestra la implementacion para agregar la entradajuego nuevo e al arreglo entradas. Se usa un ciclo para desplazar las referen-cias. La cantidad de veces que se repite el ciclo depende de la cantidad dereferencias que se tengan que mover para hacer espacio para la nueva entrada.La rapidez del metodo dependera de la cantidad de entradas en el arregloy del valor de la puntuacion. Cuando el arreglo esta lleno puede ser que lareferencia a la ultima entrada se pierda o se falle al agregar la nueva entradade juego, e.
Remocion de un objeto
Suponiendo que algun jugador hace trampa y obtiene una puntuacionalta, se desearıa tener un metodo que permita quitar la entrada del juego dela lista de las mayores puntuaciones. Por lo tanto se considera como deberıaimplementarse la siguiente operacion:

90 Arreglos, listas enlazadas y recurrencia
1 /** Intenta agregar una nueva puntuaci on a la coleccion si es lo
2 suficientemente alta. */
3 public void add(EntradaJuego e)
4 int nuevaPuntuacion = e.getPuntuacion ();
5 // ¿es la nueva entrada realmente un record?
6 if (numEntradas == MAX_ENTRADAS) // el arreglo est a lleno
7 if ( nuevaPuntuacion <= entradas[numEntradas -1]. getPuntuacion () )
8 return; // la nueva entrada , e, no es un record
9
10 else // el arreglo no est a lleno
11 numEntradas ++;
12 // Encontrar el lugar en donde la nueva entrada ((e )) estar a
13 int i = numEntradas -1;
14 for ( ; (i >= 1) && (nuevaPuntuacion > entradas[i-1]. getPuntuacion ()); i--)
15 entradas[i] = entradas[i - 1]; // mover entrada i un lugar a la derecha
16 entradas[i] = e; // agregar el nuevo record a entradas
17
Listado 3.3: Codificacion en la clase Puntuciones del metodo add() para insertarun objeto Entrada.
remove(i):quita y regresa la entrada de juego e con el ındicei en el arreglo entradas. Si el ındice i esta fue-ra de los lımites del arreglo entradas, entoncesel metodo debera lanzar una excepcion; de otraforma, el arreglo entradas sera actualizado paraquitar el objeto en la posicion i y todos los ob-jetos guardados con ındices mayores que i seranmovidos encima para llenar el espacio del dejadopor el objeto quitado.
La implementacion para remove() sera parecida al algoritmo para agregarun objeto, pero en forma inversa. Para remover la referencia al objeto conındice i, se inicia en el ındice i y se mueven todas las referencias con ındicesmayores que i una celda a la izquierda. Ver figura 3.3.
Los detalles para hacer la operacion de remocion consideran que prime-ramente se debe guardar la entrada del juego, llamada e, en el ındice i delarreglo, en una variable temporal. Se usara esta variable para regresar e
cuando se haya terminado de borrar. Para el movimiento de las referenciasque son mayores que i una celda a la izquierda, no se hace hasta el final delarreglo—se detiene en la penultima referencia, ya que la ultima referenciano tiene una referencia a su derecha. Para la ultima referencia en el arregloentradas, es suficiente con anularla. Se termina regresando una referencia de

3.2 Arreglos 91
Figura 3.3: Remocion en el ındice 3 en el arreglo que guarda las referencias a objetosentradaJuego.
la entrada removida, la cual no tiene una referencia que le apunte desde elarreglo entradas. En el listado 3.4 se muestra la codificacion del metodo.
Los metodos para agregar y quitar objetos en el arreglo de puntuacionesaltas son simples. Pero forman las bases de las tecnicas usadas para construirestructuras de datos mas complejas.
1 /** Quitar el record del ı ndice i y devolverlo. */
2 public EntradaJuego remove(int i) throws IndexOutOfBoundsException
3 if ((i < 0) || (i >= numEntradas ))
4 throw new IndexOutOfBoundsException("I ndice no valido: " + i);
5 // guardar temporalmente el objecto a ser quitado
6 EntradaJuego temp = entradas[i];
7 for (int j = i; j < numEntradas - 1; j++) // contar hacia adelante desde i
8 entradas[j] = entradas[j+1]; // mover una celda a la izquierda
9 entradas[ numEntradas - 1 ] = null; // anular el registro menor
10 numEntradas --;
11 return temp; // devolver objeto eliminado
12
Listado 3.4: Codificacion en la clase Puntuciones del metodo remove() de acuerdoa un ındice pasado.

92 Arreglos, listas enlazadas y recurrencia
3.2.2. Ordenar un arreglo
En la seccion previa, se mostro como se pueden agregar objetos o quitarestos en un cierto ındice i en un arreglo mientras se conserva el ordenamientoprevio de los objetos intacto. En esta seccion, se revisa una forma de iniciarcon un arreglo de objetos que no estan ordenadados y dejarlos en orden. Estose conoce como el problema de ordenamiento.
Un algoritmo simple de insercion ordenada
Se revisaran varios algoritmos de ordenamiento en este material. Comointroduccion, se describe en esta seccion, un algoritmo simple de ordenamiento,llamado insercion ordenada. En este caso, se describe una version especıficadel algoritmo donde la entrada es un arreglo de elementos comparables. Seconsideran tipos mas generales de algoritmos de ordenamiento mas adelante.
El algoritmo de insercion ordenada trabaja de la siguiente forma. Seinicia con el primer elemento en el arreglo y este elemento por sı mismo yaesta ordenado. Entonces se considera el siguiente elemento en el arreglo. Sieste es menor que el primero, se intercambian. Enseguida se considera eltercer elemento en el arreglo. Se intercambia hacia la izquierda hasta queeste en su posicion correcta respecto a los primeros dos elementos. De estamanera se considera el resto de los caracteres, hasta que el arreglo completoeste ordenado. Mezclando la descripcion informal anterior con construccionesde programacion, se puede expresar el algoritmo de insercion ordenada comose muestra enseguida.Algoritmo InsercionOrdenada(A):Entrada: Un arreglo A de n elementos comparablesSalida: El arreglo A con elementos reacomodados en orden crecientepara i← 1 hasta n− 1 hacer
Insertar A[i] en su posicion correcta en A[0], A[1], . . . , A[i− 1].
Esta es una descripcion de alto nivel de insercion ordenada y muestraporque este algoritmo recibe tal nombre—porque cada iteracion inserta elsiguiente elemento en la parte ordenada del arreglo que esta antes de este.Antes de codificar la descripcion se requiere trabajar mas en los detalles decomo hacer la tarea de insercion.
Se reescribira la descripcion de tal forma que se tenga un ciclo anidadodentro de otro. El ciclo externo considerara cada elemento del arreglo en turnoy el ciclo interno movera ese elemento a su posicion correcta en el subarreglo

3.2 Arreglos 93
ordenado de caracteres que estan a su izquierda.
Insercion ordenada refinada
Se describe a continuacion una descripcion en nivel intermedio del algo-ritmo de insercion ordenada. Esta descripcion esta mas cercana al codigoactual, ya que hace una mejor descripcion para insertar el elemento A[i] en elsubarreglo que esta antes de este. Todavıa emplea una descripcion informalpara el movimiento de los elementos si no estan todavıa ordenados.
Algoritmo InsercionOrdenada(A):Entrada: Un arreglo A de n elementos comparablesSalida: El arreglo A con elementos recodados en orden crecientepara i← 1 hasta n− 1 hacerInsertar A[i] en su sitio correcto en A[0], A[1], . . . , A[i− 1].actual← A[i]j ← i− 1mientras j ≥ 0 Y A[j] > actual hacerA[j + 1]← A[j]j ← j − 1
A[j + 1]← actual actual esta ahora en el lugar correcto
Se ilustra un ejemplo de la ejecucion del algoritmo de ordenamiento en lafigura 3.4. La parte ordenada del arreglo esta en blanco, y el siguiente elementoa ser insertado esta en azul. Este se encuentra guardado en la variable cur.Cada renglon corresponde a una iteracion del ciclo externo, y cada copia delarreglo en un renglon corresponde a una iteracion del ciclo interno. Cadacomparacion se muestra con un arco. Tambien se indica si la comparaciondio un movimiento o no.
Descripcion de insercion ordenada con Java
La clase OrdenaArreglo tiene el metodo estatico insercionOrdenada()
el cual codifica el algoritmo de insercion ordenada. El codigo proporcionadoes para el caso especial cuando A es un arreglo de caracteres, referenciadopor a.

94 Arreglos, listas enlazadas y recurrencia
Figura 3.4: Ejecucion del algoritmo de ordenamiento de un arreglo de 8 caracteres.
1 /** Inserci on ordenada de un arreglo de caracteres en orden creciente */
2 public static void insercionOrdenada( char[] a )
3 int n = a.length;
4 for (int i=1; i<n; i++) // ı ndice desde el 2 car acter en a
5 char actual = a[i]; // car acter actual a ser insertado
6 int j = i-1; // se inicia con la celda izquierda de i
7 while (j>=0 && a[j]>actual) // mientras a[j] no est e ordenado con actual
8 a[ j+1 ] = a[ j-- ]; // mover a[j] a la derecha y decrementar j
9 a[ j+1 ] = actual; // este es el lugar correcto para actual
10
11
Listado 3.5: Metodo Java para ordenar un arreglo de caracteres usando el algoritmoinsercion ordenada

3.2 Arreglos 95
3.2.3. Metodos para arreglos y numeros aleatorios
Como los arreglos son muy importantes, Java proporciona un determinadonumero de metodos incorporados para realizar tareas comunes en arreglos.Estos metodos son estaticos en la clase java.util.Arrays. Esto es, ellosestan asociados con la propia clase, y no con alguna instancia particular de laclase.
Metodos utiles de Arrays
Se listan a continuacion algunos metodos simples de la clase java.util.-
Arrays que no requieren explicacion adicional:
equals(A,B):regresa verdadero si y solo si el arreglo A y elarreglo B son iguales. Se considera que dos arreglosson iguales si estos tienen el mismo numero deelementos y cada par correspondiente de elementosen los dos arreglos son iguales. Esto es, A y Btienen los mismos elementos en el mismo orden.
fill(A, x):guarda el elemento x en cada celda del arreglo A.sort(A):ordena el arreglo A usando el ordenamiento natural
de sus elementos. Para ordenar usa el algoritmo deordenamiento rapido, el cual es mucho mas rapidoque el de insercion ordenada.
toString(A):devuelve un String representante del arreglo A.
Generacion de numeros pseudoaleatorios
Otra capacidad incorporada en Java es la habilidad para generar numerospseudoaleatorios, los cuales son utiles cuando se prueban programas que usanarreglos. Estos numeros son estadısticamente aleatorios, pero no necesaria-mente aleatorios verdaderos. En particular, Java tiene la clase incorporada,java.util.Random, cuyas instancias son generadores de numeros pseu-doaleatorios. Las secuencias no son actualmente aleatorias porque es posiblepredecir el siguiente numero en la secuencia dada la lista de numeros an-teriores. Un generador de numeros pseudoaletorios popular para generar elsiguiente numero, sig, a parte del numero actual, actual, es:
sig = (a*actual + b) % n;

96 Arreglos, listas enlazadas y recurrencia
donde a, b, y n son enteros escogidos apropiadamente. La secuencia generadase puede mostrar que es uniforme estadısticamente, lo cual esta bien para lamayorıa de las aplicaciones que requieran numeros aleatorios, como los juegos.Para aplicaciones donde se requieran secuencias aleatorias no predecibles,como en configuraciones de seguridad de computadoras, una formula como laanterior no debe ser usada. Se debe muestrear de una fuente que sea aleatoria,como la estatica de radio proveniente del espacio exterior.
Como el siguiente numero en un generador pseudoaleatorio es determinadopor el numero previo, entonces se requiere que el generador tenga un valorpara iniciar, el cual es llamado su semilla. La secuencia de numeros generadospor una semilla dada siempre sera la misma. La semilla para una instanciade la clase java.util.Random puede ser puesta en su constructor o con elmetodo setSeed().
Un truco para obtener una secuencia diferente cada vez que una aplicaciones ejecutada es usar una semilla que sera diferente para cada ejecucion. Porejemplo, se podrıa usar algun tiempo ingresado por el usuario, o se podrıaponer la semilla al tiempo actual en milisegundos desde el 1 de enero de1970, dado por el metodo System.currentTimeMillis().
Algunos de los metodos incluidos en la clase java.util.Random son lossiguientes:
nextBoolean():regresa el siguiente valor boolean pseudoaletario.nextFloat():regresa el siguiente valor float pseudoaletario,
entre 0.0 y 1.0.nextInt():regresa el siguiente valor int pseudoaletario.
nextInt(n):regresa el siguiente valor int pseudoaletario en elrango [0, n).
setSeed(s):pone la semilla de este generador de numeros pseu-doaleatorios con el entero largo s.
Ejemplo con numeros pseudoaleatorios
Se proporciona la aplicacion PruebaArreglo, listado 3.6, para mostrar eluso de las clase Arrays y Random del paquete java.util
Una posible salida de esta aplicacion es:
arreglos iguales antes de ordenar: true
arreglos iguales despues de ordenar: false
ant = [49, 41, 8, 10, 48, 87, 52, 2, 97, 81]

3.2 Arreglos 97
1 import java.util.Arrays;
2 import java.util.Random;
3 /** Programa que muestra algunos usos de los arreglos */
4 public class PruebaArreglo
5 public static void main(String [] args)
6 int num[] = new int [10];
7 Random rand = new Random (); // un generador de nu meros pseudoaleatorios
8 rand.setSeed(System.currentTimeMillis ()); // tiempo actual como semilla
9 // llenar el arreglo num con nu meros pseudoaleatorios entre 0 y 99, incl.
10 for (int i = 0; i < num.length; i++)
11 num[i] = rand.nextInt (100); // siguiente numero pseudoaleatorio
12 int[] ant = (int[]) num.clone (); // clonar arreglo num
13 System.out.println("arreglos iguales antes de ordenar: " +
14 Arrays.equals(ant ,num));
15 Arrays.sort(num); // ordenar arreglo num (ant esta sin cambios)
16 System.out.println("arreglos iguales despu es de ordenar: " +
17 Arrays.equals(ant ,num));
18 System.out.println("ant = " + Arrays.toString(ant));
19 System.out.println("num = " + Arrays.toString(num));
20
21
Listado 3.6: Aplicacion PruebaArreglo usando varios metodos incorporados enJava
num = [2, 8, 10, 41, 48, 49, 52, 81, 87, 97]
Por cierto, hay una leve posibilidad de que los arreglos ant y num per-manezcan igual, aun despues de que num sea ordenado, es decir, si num yaesta ordenado antes de que sea clonado. Pero la probabilidad de que estoocurra es menor que uno en cuatro millones, ası que es improbable que sucedaen unos cuantos miles de pruebas, per.
Criptografıa simple con cadenas y arreglos de caracteres
Una de las aplicaciones primarias de los arreglos es la representacion deString. Los objetos cadena son usualmente representados internamente comoun arreglo de caracteres. Aun si las cadenas pudieran estar representadas deotra forma, hay una relacion natural entre cadenas y arreglos de caracteres—ambos usan ındices para referirse a sus caracteres. Gracias a esta relacion,Java hace facil la creacion de objetos String desde arreglos de caracteres yviceversa. Para crear un objeto String de un arreglo de caracteres A, se usala expresion,
new String(A)

98 Arreglos, listas enlazadas y recurrencia
Esto es, uno de los constructores de la clase String toma un arreglo decaracteres como su argumento y regresa una cadena teniendo los mismoscaracteres en el mismo orden como en el arreglo. De igual forma, dado unString S, se puede crear un arreglo de caracteres de la representacion de Susando la expresion,
S.toCharArray()
es decir, la clase String tiene un metodo, toCharArray(), el cual regresaun arreglo, del tipo char[] con los mismos caracteres de S.
El cifrador Cesar
Una area donde se requiere poder cambiar de una cadena a un arreglode caracteres y de regreso es util en criptografıa, la ciencia de los mensajessecretos y sus aplicaciones. Esta area estudia varias formas de realizar elencriptamiento, el cual toma un mensaje, denominado el texto plano, ylo convierte en un mensaje cifrado, llamado el texto cifrado. Asimismo,la criptografıa tambien estudia las formas correspondientes de realizar eldescifrado, el cual toma un texto cifrado y lo convierte de regreso en el textoplano original.
Es discutible que el primer esquema de encriptamiento es el cifrador deCesar, el cual es nombrado despues de que Julio Cesar uso este esquemapara proteger mensajes militares importantes. El cifrador de Cesar es unaforma simple para oscurecer un mensaje escrito en un lenguaje que formapalabras con un alfabeto.
El cifrador involucra reemplazar cada letra en un mensaje con una letraque esta tres letras despues de esta en el alfabeto para ese lenguaje. Por lotanto, en un mensaje del espanol, se podrıa reemplazar cada A con D, cada Bcon E, cada C con F, y ası sucesivamente. Se continua de esta forma hasta laletra W, la cual es reemplazada con Z. Entonces, se permite que la sustituciondel patron de la vuelta, por lo que se reemplaza la X con A, Y con B, y Zcon C.
Usar caracteres como ındices de arreglos
Si se fueran a numerar las letras como ındices de arreglos, de tal formaque A sea 0, B sea 1, C sea 2, y ası sucesivamente, entonces se puede escribirla formula del cifrador de Cesar para el alfabeto ingles de la siguiente forma:

3.2 Arreglos 99
Reemplazar cada letra i con la letra (i+ 3) mod 26,
donde mod es el operador modulo, el cual regresa el residuo despues derealizar una division entera. El operador se denota con % en Java, y es eloperador que se requiere para dar la vuelta en el final del alfabeto. Para el 26el modulo es 0, para el 27 es 1, y el 28 es 2. El algoritmo de desciframientopara el cifrador de Cesar es exactamente lo opuesto—se reemplaza cada letracon una que esta tres lugares antes que esta, con regreso para la A, B y C.
Se puede capturar esta regla de reemplazo usando arreglos para encriptary descifrar. Porque cada caracter en Java esta actualmente guardado como unnumero—su valor Unicode—se pueden usar letras como ındices de arreglos.Para una letra mayuscula C, por ejemplo, se puede usar C como un ındicede arreglo tomando el valor Unicode de C y restando A. Lo anterior solofunciona para letras mayusculas, por lo que se requerira que los mensajessecretos esten en mayusculas. Se puede entonces usar un arreglo, encriptar,que represente la regla de encriptamiento, por lo que encriptar[i] es laletra que reemplaza la letra con codigo i, la cual es C − A para una letramayuscula C en Unicode. De igual modo, un arreglo, descrifrar, puederepresentar la regla de desciframiento, por lo que descifrar[i] es la letraque reemplaza la letra numero i.
Arreglo encriptar
D E F G H I J K L M N ... X Y Z A B C0 1 2 3 4 5 6 7 8 9 10 ... 20 21 22 23 24 25
El arreglo de encriptamiento para el cifrador Cesar quedarıa como semuestra previamente. Por ejemplo, para codificar el caracter ’J’, este esusado como ındice, haciendo ’J’ - ’A’, que es calculado por Java como 74
- 65 = 9, (los valores son sus codigos Unicode). Luego al acceder el arreglocon ese ındice se obtiene el caracter ’M’.
La aplicacion Cesar, listado 3.7, tiene un cifrador de Cesar simple ycompleto usando la aproximacion anterior. Ademas realiza las conversionesentre cadenas y arreglos de caracteres.
Cuando se ejecuta este programa, se obtiene la siguiente salida:
Orden de Encriptamiento = DEFGHIJKLMNOPQRSTUVWXYZABC
Orden de Descifrado = XYZABCDEFGHIJKLMNOPQRSTUVW
HVWUXFWXUDV GH GDWRV; DUUHJORV B OLVWDV OLJDGDV.
ESTRUCTURAS DE DATOS; ARREGLOS Y LISTAS LIGADAS.

100 Arreglos, listas enlazadas y recurrencia
1 /** Clase para encriptar y descifrar con el cifrador de Cesar. */
2 public class Cesar
3 public static final char[] abc = ’A’,’B’,’C’,’D’,’E’,’F’,’G’,’H’, ’I’,
4 ’J’,’K’,’L’,’M’, ’N’,’O’,’P’,’Q’,’R’,’S’,’T’,’U’,’V’,’W’,’X’,’Y’,’Z’;
5 protected char[] encriptar = new char[abc.length ]; // Arreglo encriptamiento
6 protected char[] descifrar = new char[abc.length ]; // Arreglo desciframiento
7 /** Constructor para inicializar los arreglos de encriptamiento y
8 * desciframiento */
9 public Cesar ()
10 for (int i=0; i<abc.length; i++)
11 encriptar[i] = abc[(i + 3) % abc.length ]; // rotar alfabeto 3 lugares
12 for (int i=0; i<abc.length; i++)
13 descifrar[encriptar[i]-’A’] = abc[i]; // descifrar inverso a encriptar
14
15 /** Metodo de encriptamiento */
16 public String encriptar(String secreto)
17 char[] mensj = secreto.toCharArray (); // arreglo mensaje
18 for (int i=0; i<mensj.length; i++) // ciclo de encriptamiento
19 if (Character.isUpperCase(mensj[i])) // se tiene que cambiar letra
20 mensj[i] = encriptar[mensj[i] - ’A’]; // usar letra como ı ndice
21 return new String(mensj);
22
23 /** Metodo de desciframiento */
24 public String descifrar(String secreto)
25 char[] mensj = secreto.toCharArray (); // arreglo mensaje
26 for (int i=0; i<mensj.length; i++) // ciclo desciframiento
27 if (Character.isUpperCase(mensj[i])) // se tiene letra a cambiar
28 mensj[i] = descifrar[mensj[i] - ’A’]; // usar letra como ı ndice
29 return new String(mensj);
30
31 /** Metodo main para probar el cifrador de Cesar */
32 public static void main(String [] args)
33 Cesar cifrador = new Cesar (); // Crear un objeto cifrado de Cesar
34 System.out.println("Orden de Encriptamiento = " +
35 new String(cifrador.encriptar ));
36 System.out.println("Orden de Descifrado = " +
37 new String(cifrador.descifrar ));
38 String secreto = "ESTRUCTURAS DE DATOS; ARREGLOS Y LISTAS LIGADAS.";
39 secreto = cifrador.encriptar(secreto );
40 System.out.println(secreto ); // el texto cifrado
41 secreto = cifrador.descifrar(secreto );
42 System.out.println(secreto ); // deber ıa ser texto plano
43
44
Listado 3.7: Una clase simple y completa de Java para el cifrador de Cesar

3.2 Arreglos 101
0 1 2 3 4 5 6
0 1 2 3 4 5 6 71 2 3 4 5 6 7 82 3 4 5 6 7 8 93 4 5 6 7 8 9 04 5 6 7 8 9 0 1
Cuadro 3.2: Representacion del arreglo de enteros bidimensional, Y, con 5 renglonesy 7 columnas. El valor de Y[2][4] es 7.
3.2.4. Arreglos bidimensionales y juegos de posicion
Varios juegos de computadora, sean juegos de estrategia, de simulacion,o de conflicto de primera persona, usan un “tablero” bidimensional. Losprogramas que manejan juegos de posicion requieren una forma de representarobjetos en un espacio bidimensional. Una forma natural de hacerlo es con unarreglo bidimensional, donde se usan dos ındices, por ejemplo i y j, parareferirse a las celdas en el arreglo. El primer ındice se refiere al numero delrenglon y el segundo al numero de la columna. Dado tal arreglo se puedenmantener tableros de juego bidimensionales, ası como realizar otros tipos decalculos involucrando datos que estan guardados en renglones y columnas.
Los arreglos en Java son unidimensionales; se puede usar un solo ındicepara acceder cada celda de un arreglo. Sin embargo, hay una forma como sepueden definir arreglos bidimensionales en Java—se puede crear un arreglobidimensional como un arreglo de arreglos. Esto es, se puede definir un arreglode dos dimensiones para que sea un arreglo con cada una de sus celdas siendootro arreglo. Tal arreglo de dos dimensiones es a veces llamado una matriz.En Java, se declara un arreglo de dos dimensiones como se muestra en elsiguiente ejemplo:
int[][] Y = new int[5][7];
La sentencia crea una “arreglo de arreglos” bidimensional, Y, el cual es5 × 7, teniendo cinco renglones y siete columnas. Es decir, Y es un arreglode longitud cinco tal que cada elemento de Y es un arreglo de longitud desiete enteros. Ver cuadro 3.2. Lo siguiente podrıa entonces ser usos validosdel arreglo Y y siendo i y j variables tipo int:

102 Arreglos, listas enlazadas y recurrencia
Y[i][i+1] = Y[i][i] + 3;
i = a.length; // i es 5
j = Y[4].length; // j es 7
Se revisa enseguida una aplicacion de un arreglo bidimensional implemen-tando un juego simple posicional, para revisar algunos detalles del uso dearreglos bidimensionales.
El gato
Es un juego que se practica en un tablero de tres por tres. Dos jugadores—X y O—alternan en colocar sus respectivas marcas en las celdas del tablero,iniciando con el jugador X. Si algun jugador logra obtener tres marcas suyasen un renglon, columna o diagonal, entonces ese jugador gana.
La idea basica es usar un arreglo bidimensional, tablero, para mantenerel tablero de juego. Las celdas en este arreglo guardan valores para indicarsi la celda esta vacıa, o guarda una X, o una O. Entonces, el tablero esuna matriz de tres por tres, donde por ejemplo, el renglon central son lasceldas tablero[1][0], tablero[1][1], tablero[1][2]. Para este caso, sedecidio que las celdas en el arreglo tablero sean enteros, un cero indica celdavacıa, un uno indica una X, y un menos uno indica O. Esta codificacionpermite tener una forma simple de probar si en una configuracion del tableroes una victoria para X o para O, sabiendo si los valores de un renglon, columnao diagonal suman -3 o 3. Se ilustra lo anterior en la figura 3.5.
Figura 3.5: Una ilustracion del juego del gato a la izquierda, y su representacionempleando el arreglo tablero.

3.2 Arreglos 103
La clase Gato, listado 3.8, modela el tablero del gato para dos jugadores.El codigo solo mantiene el tablero del gato y registra los movimientos; norealiza ninguna estrategia, ni permite jugar al gato contra la computadora.
1 /** Simulaci on del juego del gato (no tiene ninguna estrategia ). */
2 public class Gato
3 protected static final int X = 1, O = -1; // jugadores
4 protected static final int VACIA = 0; // celda vac ıa
5 protected int tablero [][] = new int [3][3]; // tablero
6 protected int jugador; // jugador actual
7 /** Constructor */
8 public Gato() limpiarTablero ();
9 /** Limpiar el tablero */
10 public void limpiarTablero ()
11 for (int i = 0; i < 3; i++)
12 for (int j = 0; j < 3; j++)
13 tablero[i][j] = VACIA; // cada celda deber a estar vac ıa
14 jugador = X; // el primer jugador es ’X’
15
16 /** Poner una marca X u O en la posici on i,j */
17 public void ponerMarca(int i, int j) throws IllegalArgumentException
18 if ( (i < 0) || (i > 2) || (j < 0) || (j > 2) )
19 throw new IllegalArgumentException("Posici on invalida en el tablero");
20 if ( tablero[i][j] != VACIA )
21 throw new IllegalArgumentException("Posici on del tablero ocupada");
22 tablero[i][j] = jugador; // colocar la marca para el jugador actual
23 jugador =- jugador; // intercambiar jugadores , se usa O es -X
24
25 /** Revisar si la configuraci on del tablero es ganadora para un jugador dado*/
26 public boolean esGanador(int marca)
27 return (( tablero [0][0] + tablero [0][1] + tablero [0][2] == marca *3) // ren. 0
28 || (tablero [1][0] + tablero [1][1] + tablero [1][2] == marca *3) // ren. 1
29 || (tablero [2][0] + tablero [2][1] + tablero [2][2] == marca *3) // ren. 2
30 || (tablero [0][0] + tablero [1][0] + tablero [2][0] == marca *3) // col. 0
31 || (tablero [0][1] + tablero [1][1] + tablero [2][1] == marca *3) // col. 1
32 || (tablero [0][2] + tablero [1][2] + tablero [2][2] == marca *3) // col. 2
33 || (tablero [0][0] + tablero [1][1] + tablero [2][2] == marca *3) // diag.
34 || (tablero [2][0] + tablero [1][1] + tablero [0][2] == marca *3)); // diag.
35
36 /** Regresar el jugador ganador o 0 para indicar empate */
37 public int ganador ()
38 if (esGanador(X))
39 return(X);
40 else if (esGanador(O))
41 return(O);
42 else
43 return (0);
44
45 /** Regresar una cadena simple mostrando el tablero actual */
46 public String toString ()
47 String s = "";
48 for (int i=0; i<3; i++)
49 for (int j=0; j<3; j++)
50 switch (tablero[i][j])
51 case X: s += "X"; break;
52 case O: s += "O"; break;

104 Arreglos, listas enlazadas y recurrencia
53 case VACIA: s += " "; break;
54
55 if (j < 2) s += "|"; // lımite de columna
56
57 if (i < 2) s += "\n-----\n"; // lımite de renglon
58
59 return s;
60
61 /** Ejecuci on de prueba de un juego simple */
62 public static void main(String [] args)
63 Gato juego = new Gato ();
64 /* mueve X: */ /* mueve O: */
65 juego.ponerMarca (1 ,1); juego.ponerMarca (0,2);
66 juego.ponerMarca (2 ,2); juego.ponerMarca (0,0);
67 juego.ponerMarca (0 ,1); juego.ponerMarca (2,1);
68 juego.ponerMarca (1 ,2); juego.ponerMarca (1,0);
69 juego.ponerMarca (2 ,0);
70 System.out.println( juego.toString () );
71 int jugadorGanador = juego.ganador ();
72 if (jugadorGanador != 0)
73 System.out.println(jugadorGanador + " gana");
74 else
75 System.out.println("Empate");
76
77
Listado 3.8: Clase Gato para simular el tablero del juego del gato.
Se muestra en la figura 3.6 el ejemplo de salida de la clase Gato.
O|X|O
-----
O|X|X
-----
X|O|X
Empate
Figura 3.6: Salida del ejemplo del juego del gato
Metodos para arreglos de arreglos
Se habıa senalado en la seccion 1.5, que una referencia arreglo apunta aun objeto arreglo. Si se tienen dos arreglos bidimensionales, A y B, con ambos

3.2 Arreglos 105
teniendo las mismas entradas, se podrıa decir que el arreglo A es igual a B.Pero los arreglos unidimensionales que forman los renglones de A y B estanguardados en localidades de memoria diferentes, a pesar de que tengan elmismo contenido interno. Por lo tanto, una llamada al metodo java.util.-
Arrays.equals(A,B) devolvera false en este caso. La razon de lo anteriores porque el metodo equals() realiza una igualdad superficial, es decir,prueba solo si los elementos correspondientes en A y B son iguales entre ellosusando solo una nocion simple de igualdad. La regla igualdad simple diceque dos variables tipo base son iguales si estas tienen el mismo valor y dosreferencias objetos son iguales si ambas se refieren al mismo objeto. Cuandose quiere realizar una igualdad profunda para arreglos de objetos, como losarreglos bidimensionales, la clase java.util.Arrays proporciona el siguientemetodo:
deepEquals(A,B) Devuelve si A y B son iguales profundamen-te. Seran profundamente iguales A y B siestos tienen la misma cantidad de elemen-tos y los dos elementos A[i] y B[i] en cadapareja de elementos correspondientes sonpor sı mismos iguales en el sentido simple,son arreglos del mismo tipo primitivo talque Arrays.equals(A[i],B[i]) podrıandevolver true, o son arreglos de referen-cia objeto tal que A[i] y B[i] son igualesprofundamente.
Ademas de la igualdad profunda, se quiere un metodo profundo paraconvertir un arreglo bidimensional o un arreglo de referencias objeto en unacadena. Tal metodo es proporcionado tambien por la clase java.util.Arrays
deepToString(A) Devuelve una cadena representando loscontenidos de A. Para convertir un ele-mento A[i] a una cadena, si A[i] esuna referencia arreglo entonces se llama aArrays.deepToString(A[i]), de otro mo-do el metodo String.valueOf(A[i]) esusado.
No esta disponible un metodo para hacer una copia identica de un arreglobidimensional, por lo tanto, si se quiere hacer lo anterior, se necesita hacer unallamada a A[i].clone() o java.util.Arrays.copyOf(A[i],A[i].length)
para cada renglon, A[i], de A.

106 Arreglos, listas enlazadas y recurrencia
3.3. Listas simples enlazadas
Los arreglos son elegantes y simples para guardar cosas en un determinadoorden, pero tienen el inconveniente de no ser muy adaptables, ya que se tieneque fijar el tamano del arreglo por adelantado.
Hay otras formas de guardar una secuencia de elementos, que no tiene elinconveniente de los arreglos. En esta seccion se explora una implementacionalterna, la cual es conocida como lista simple enlazada.
Una lista enlazada, en su forma mas simple, es una coleccion de nodosque juntos forman un orden lineal. El ordenamiento esta determinado de talforma que cada nodo es un objeto que guarda una referencia a un elemento yuna referencia, llamado siguiente, a otro nodo. Ver la figura 3.7.
Figura 3.7: Ejemplo de una lista simple enlazada cuyos elementos son cadenasindicando codigos de aeropuertos. El apuntador sig de cada nodo se muestra comouna flecha. El objeto null es denotado por Ø.
Podrıa parecer extrano tener un nodo que referencia a otro nodo, pero talesquema trabaja facilmente. La referencia sig dentro de un nodo puede servista como un enlace o apuntador a otro nodo. De igual nodo, moverse de unnodo a otro siguiendo una referencia a sig es conocida como salto de enlaceo salto de apuntador. El primer nodo y el ultimo son usualmente llamados lacabeza y la cola de la lista, respectivamente. Ası, se puede saltar a traves dela lista iniciando en la cabeza y terminando en la cola. Se puede identificar lacola como el nodo que tenga la referencia sig como null, la cual indica elfinal de la lista. Una lista enlazada definida de esta forma es conocida comouna lista simple enlazada.
Como en un arreglo, una lista simple enlazada guarda sus elementos enun cierto orden. Este orden esta determinado por la cadenas de enlaces sig
yendo desde cada nodo a su sucesor en la lista. A diferencia de un arreglo, unalista simple enlazada no tiene un tamano fijo predeterminado, y usa espacioproporcional al numero de sus elementos. Asimismo, no se emplean numerosındices para los nodos en una lista enlazada. Por lo tanto, no se puede decirsolo por examinar un nodo si este es el segundo, quinto u otro nodo en lalista.

3.3 Listas simples enlazadas 107
Implementacion de una lista simple enlazada
Para implementar una lista simple enlazada, se define la clase Nodo, listado3.9, la cual indica el tipo de los objetos guardados en los nodos de la lista.Para este caso se asume que los elementos son String. Tambien es posibledefinir nodos que puedan guardar tipos arbitrarios de elementos. Dada laclase Nodo, se puede definir una clase, ListaSimple, listado 3.10, para definirla lista enlazada actual. Esta clase guarda una referencia al nodo cabeza yuna variable guarda el total de nodos de la lista.
1 /** Nodo de una lista simple enlazada de cadenas. */
2 public class Nodo
3 private String elemento; // Los elementos son cadenas de caracteres
4 private Nodo sig;
5 /** Se crea un nodo con el elemento dado y el nodo sig. */
6 public Nodo(String e, Nodo n)
7 elemento = e;
8 sig = n;
9
10 /** Regresa el elemento de este nodo. */
11 public String getElemento () return elemento;
12 /** Regresa el nodo siguiente de este nodo. */
13 public Nodo getSig () return sig;
14 // me todos modificadores
15 /** Pone el elemento de este nodo. */
16 public void setElemento(String nvoElem) elemento = nvoElem;
17 /** Pone el nodo sig de este nodo. */
18 public void setSig(Nodo nvoSig) sig = nvoSig;
19
Listado 3.9: Implementacion de un nodo de una lista simple enlazada
1 /** Lista simple enlazada. */
2 public class ListaSimple
3 protected Nodo cabeza; // nodo cabeza de la lista
4 protected long tam; // cantidad de nodos en la lista
5 /** constructor por defecto para crear una lista vac ıa */
6 public ListaSimple ()
7 cabeza = null;
8 tam = 0;
9
10 // ... me todos de actualizacion y bu squeda deber ıan ir aqu ı
11
Listado 3.10: Implementacion parcial de una lista simple enlazada

108 Arreglos, listas enlazadas y recurrencia
3.3.1. Insercion en una lista simple enlazada
Cuando se usa una lista simple enlazada, se puede facilmente insertar unelemento en la cabeza de la lista, como se muestra en la figura 3.8.
Figura 3.8: Insercion de un elemento en la cabeza de una lista simple enlazada: (a)antes de la insercion; (b) creacion de un nuevo nodo; (c) despues de la insercion.
La idea principal es crear un nodo nuevo, poner su enlace sig para que serefiera al mismo objeto que la cabeza, y luego poner la cabeza apuntando alnuevo nodo.
Se muestra enseguida el algoritmo para insertar un nodo nuevo v al iniciode una lista simple enlazada. Observar que este metodo trabaja aun si la listaesta vacıa. Observar que se ha puesto el apuntador sig para el nuevo nodo v
antes de hacer que la variable cabeza apunte a v.
Algoritmo agregarInicio(v):v.setSiguiente(cabeza) hacer que v apunte al viejo nodo cabezacabeza← v hacer que la variable cabeza apunte al nuevo nodotam← tam+ 1 incrementar la cuenta de nodos

3.3 Listas simples enlazadas 109
Insercion de un elemento en la cola
Se puede tambien facilmente insertar un elemento en la cola de la lista,cuando se ha proporcionado una referencia al nodo cola, como se muestra enla figura 3.9.
Figura 3.9: Insercion en la cola de una lista simple enlazada: (a) antes de la insercion;(b) creacion de un nuevo nodo; (c) despues de la insercion. Observar que se puso elenlace sig para cola en (b) antes de asignar a la variable cola para que apunte alnuevo nodo en (c).
En este caso, se crea un nuevo nodo, se asigna su referencia sig para queapunte al objeto null, se pone la referencia sig de la cola para que apunte aeste nuevo objeto, y entonces se asigna a la referencia cola este nuevo nodo.El algoritmo agregarFinal inserta un nuevo nodo al final de la lista simpleenlazada. El metodo tambien trabaja si la lista esta vacıa. Se pone primeroel apuntador sig para el viejo nodo cola antes de hacer que la variable colaapunte al nuevo nodo.Algoritmo agregarFinal(v):v.setSiguiente(null) hacer que el nuevo nodo v apunte al objeto nullcola.setSiguiente(v) el viejo nodo cola apuntara al nuevo nodocola← v hacer que la variable cola apunte al nuevo nodo tam← tam+ 1 incrementar la cuenta de nodos

110 Arreglos, listas enlazadas y recurrencia
3.3.2. Quitar un elemento de una lista simple enlazada
La operacion contraria de insertar un nuevo elemento en la cabeza de unalista enlazada es quitar un elemento en la cabeza. Esta operacion es ilustradaen la figura 3.10.
Figura 3.10: Remocion de un elemento en la cabeza de una lista simple enlazada:(a) antes de la remocion; (b) desligando el viejo nodo; (c) despues de la remocion.
En el algoritmo removerPrimero se muestra la forma de realizar laremocion del elemento en la cabeza de la lista.Algoritmo removerPrimero():
si cabeza = null EntoncesIndicar un error: la lista esta vacıa.
t← cabezacabeza← cabeza.getSiguiente() cabeza apuntara al siguiente nodo t.setSiguiente(null) anular el apuntador siguiente del nodo borrado.tam← tam− 1 decrementar la cuenta de nodos Desafortunadamente, no se puede borrar facilmente el nodo cola de una
lista simple enlazada. Aun si se tiene una referencia cola directamente al

3.4 Listas doblemente enlazadas 111
ultimo nodo de la lista, se necesita poder acceder el nodo anterior al ultimonodo en orden para quitar el ultimo nodo. Pero no se puede alcanzar el nodoanterior a la cola usando los enlaces siguientes desde la cola. La unica formapara acceder este nodo es empezar en la cabeza de la lista y moverse a travesde la lista. Pero tal secuencia de operaciones de saltos de enlaces podrıa tomarun tiempo grande.
3.4. Listas doblemente enlazadas
Como se comentaba en la seccion previa, quitar un elemento de la cola deuna lista simple enlazada no es facil. Ademas, el quitar cualquier otro nodode la lista diferente de la cabeza de una lista simple enlazada es consumidorde tiempo, ya que no se tiene una forma rapida de acceder al nodo que sedesea quitar. Por otra parte, hay varias aplicaciones donde no se tiene unacceso rapido tal como el acceso al nodo predecesor. Para tales casos, serıabueno tener manera de ir en ambas direcciones en una lista enlazada.
Hay un tipo de lista enlazada que permite ir en ambas direcciones, haciaadelante y hacia atras. Esta es la lista doblemente enlazada o LDE. Tallista permite una gran variedad de operaciones rapidas de actualizacion,incluyendo la insercion y el borrado en ambos extremos, y en el centro. Unnodo en una LDE guarda dos referencias—un enlace sig, el cual apunta alsiguiente nodo en la lista, y un enlace prev, el cual apunta al nodo previo enla lista.
Una implementacion de un nodo de una LDE se muestra en la clase NodoD,listado 3.11, donde se asume que los elementos son cadenas de caracteres.
Centinelas cabeza y cola
Para simplificar la programacion, es conveniente agregar nodos especialesen los extremos de la LDE: un nodo cabeza (header) justo antes de la cabezade la lista, y un nodo cola (trailer) justo despues de la cola de la lista. Estosnodos “falsos”, o centinelas, no guardan a ningun elemento. La cabeza tieneuna referencia sig valida pero una referencia prev nula, mientras cola tieneuna referencia prev valida pero una referencia sig nula. Una LDE con estoscentinelas se muestra en la figura 3.11.
Un objeto lista enlazada podrıa necesitar guardar referencias a estosdos centinelas y un contador tam que guarde el numero de elementos, sin

112 Arreglos, listas enlazadas y recurrencia
1 /** Nodo de una lista doblemente enlazada de una lista de cadenas */
2 public class NodoD
3 protected String elemento; // Nodo guarda un elemento String
4 protected NodoD sig , prev; // Apuntadores a nodos siguiente y previo
5 /** Constructor que crea un nodo con los campos dados */
6 public NodoD(String e, NodoD p, NodoD s)
7 elemento = e;
8 prev = p;
9 sig = s;
10
11 /** Regresa el elemento de este nodo */
12 public String getElemento () return elemento;
13 /** Regresa el nodo previo de este nodo */
14 public NodoD getPrev () return prev;
15 /** Regresa el nodo siguiente de este nodo */
16 public NodoD getSig () return sig;
17 /** Pone el elemento de este nodo */
18 public void setElemento(String nvoElem) elemento = nvoElem;
19 /** Pone el nodo previo de este nodo */
20 public void setPrev(NodoD nvoPrev) prev = nvoPrev;
21 /** Pone el nodo siguiente de este nodo */
22 public void setSig(NodoD nvoSig) sig = nvoSig;
23
Listado 3.11: Clase NodoD representando un nodo de una lista doblemente enlazadaque guarda una cadena de caracteres.
Figura 3.11: Una lista doblemente enlazada con centinelas, cabeza y cola, marcandoel final de la lista.

3.4 Listas doblemente enlazadas 113
considerar a los centinelas, en la lista.Insertar o remover elementos en cualquier extremo de la LDE se hace
directo. Ademas, el enlace prev elimina la necesidad de recorrer la lista paraobtener el nodo que esta antes de la cola. Se muestran los detalles de laoperacion remover en la cola de la lista doblemente enlazada en la figura 3.12.
Figura 3.12: Remocion del nodo al final de una lista doblemente enlazada concentinelas: (a) antes de borrar en la cola; (b) borrando en la cola; (c) despues delborrado.
Los detalles de la remocion en la cola de la LDE se muestran en el algoritmoremoverUltimo.Algoritmo removerUltimo():
si tam = 0 entoncesIndicar un error: la lista esta vacıa.
v ← cola.getPrev() ultimo nodo u← v.getPrev() nodo anterior al ultimo nodo cola.setPrev(u)u.setSig(cola)v.setPrev(null)v.setSig(null)tam← tam− 1 decrementar la cuenta de nodos De igual modo, se puede facilmente hacer una insercion de un nuevo
elemento al inicio de una LDE, como se muestra en la figura 3.13.La implementacion de la insercion de un nuevo nodo v al inicio, de acuerdo
al algoritmo agregarInicio, donde la variable tam guarda la cantidad de

114 Arreglos, listas enlazadas y recurrencia
Figura 3.13: Insercion de un elemento en el frente: (a) previo; (b) final.
elementos en la lista. Este algoritmo tambien trabaja con una lista vacıa.Algoritmo agregarInicio(v):w ← cabeza.getSig() primer nodo v.setSig(w)v.setPrev(cabeza)w.setPrev(v)cabeza.setSig(v)tam← tam+ 1
3.4.1. Insercion en el centro de la LDE
Las listas dobles enlazadas no nada mas son utiles para insertar y removerelementos en la cabeza o en la cola de la lista. Estas tambien son convenientespara mantener una lista de elementos mientras se permite insercion y remocionen el centro de la lista. Dado un nodo v de una lista doble enlazada, el cualposiblemente podrıa ser la cabeza pero no la cola, se puede facilmente insertarun nuevo nodo z inmediatamente despues de v. Especıficamente, sea w elsiguiente nodo de v. Se ejecutan los siguientes pasos.
1. Hacer que el enlace prev de z se refiera a v.
2. Hacer que el enlace sig de z se refiera a w.
3. Hacer que el enlace prev de w se refiera a z.
4. Hacer que el enlace sig de v se refiera a z.

3.4 Listas doblemente enlazadas 115
Este metodo esta dado en detalle en el algoritmo agregarDespues y esilustrado en la figura 3.14. Recordando el uso de los centinelas cabeza y cola,este algoritmo trabaja aun si v es el nodo cola, el nodo que esta justo antesdel centinela cola.
Figura 3.14: Insercion de un nuevo nodo despues del nodo que guarda JFK: (a)creacion de un nuevo nodo con el elemento BWI y enlace de este; (b) despues de lainsercion.
Algoritmo agregarDespues(v, z):w ← v.getSig() nodo despues de v z.setPrev(v) enlazar z a su predecesor, v z.setSig(w) enlazar z a su sucesor, w w.setPrev(z) enlazar w a su nuevo predecesor, z v.setSig(z) enlazar v a su nuevo sucesor, z tam← tam+ 1
3.4.2. Remocion en el centro de la LDE
De igual modo, es facil remover un nodo v intermedio de una lista do-blemente enlazada. Se acceden los nodos u y w a ambos lados de v usandosus metodos getPrev y getSig, estos nodos deberan existir, ya que se estanusando centinelas. Para quitar el nodo v, se tiene que hacer que u y w seapunten entre ellos en vez de hacerlo hacia v. Esta operacion es referida comodesenlazar a v. Tambien se anulan los apuntadores prev y sig de v para queya no retengan referencias viejas en la lista. El algoritmo remover muestracomo quitar el nodo v aun si v es el primer nodo, el ultimo o un nodo nocentinela y se ilustra en la figura 3.15.

116 Arreglos, listas enlazadas y recurrencia
Figura 3.15: Borrado del nodo que guarda PVD: (a) antes del borrado; (b) desenlacedel viejo nodo; (c) despues de la remocion.
Algoritmo remover(v):u← v.getPrev() nodo predecesor a v w ← v.getSig() nodo sucesor a v w.setPrev(u) desenlazar v u.setSig(w)v.setPrev(null) anular los campos de v v.setSig(null)tam← tam− 1 decrementar el contador de nodos
3.4.3. Una implementacion
La clase ListaDoble, listado 3.12, muestra una implementacion de unaLDE con nodos que guardan un String como elementos. Enseguida se danun conjunto de observaciones de la clase ListaDoble.
Los objetos de la clase NodoD, los cuales guardan elementos String, sonusados para todos los nodos de la lista, incluyendo los nodos centinelacabeza y cola.
Se puede usar la clase ListaDoble para una LDE de objetos String

3.4 Listas doblemente enlazadas 117
solamente. Para construir una lista de otros tipos, se puede usar unadeclaracion generica.
Los metodos getPrimero() y getUltimo() dan acceso directo al primernodo y el ultimo en la lista.
Los metodos getPrev() y getSig() permiten recorrer la lista.
Los metodos tienePrev() y tieneSig() detectan los lımites de la lista.
Los metodos agregarInicio() y agregarFinal() agregan un nuevonodo al inicio y al final de la lista, respectivamente.
Los metodos agregarAntes() y agregarDespues() agregan un nodoantes y despues de un nodo existente, respectivamente.
Tener solo un metodo para borrar, remover(), no es actualmente unarestriccion, ya que se puede remover al inicio o al final de una LDE L eje-cutando L.remover(L.getPrimero()) o L.remover(L.getUltimo()),respectivamente.
El metodo toString() que convierte la lista entera en una cadena esutil para propositos de prueba y depuracion.
1 /** Lista doblemente enlazada de nodos tipo NodoD para cadenas. */
2 public class ListaDoble
3 protected int tam; // cantidad de elementos
4 protected NodoD cabeza , cola; // centinelas
5 /** Constructor que crea una lista vac ıa */
6 public ListaDoble ()
7 tam = 0;
8 cabeza = new NodoD(null , null , null); // crer cabeza
9 cola = new NodoD(null , cabeza , null); // crear terminaci on
10 cabeza.setSig(cola); // cabeza apunta a terminaci on
11
12 /** Regresa la cantidad de elementos en la lista */
13 public int tam() return tam;
14 /** Indica si la lista esta vac ıa */
15 public boolean estaVacia () return (tam == 0);
16 /** Regresa el primer nodo de la lista */
17 public NodoD getPrimero () throws IllegalStateException
18 if (estaVacia ()) throw new IllegalStateException("La lista esta vac ıa");
19 return cabeza.getSig ();
20
21 /** Regresa el u ltimo nodo de la lista */
22 public NodoD getUltimo () throws IllegalStateException
23 if (estaVacia ()) throw new IllegalStateException("La lista esta vac ıa");
24 return cola.getPrev ();

118 Arreglos, listas enlazadas y recurrencia
25
26 /** Regresa el nodo anterior al nodo v dado. Un error ocurre si v
27 * es la cabeza */
28 public NodoD getPrev(NodoD v) throws IllegalArgumentException
29 if (v == cabeza) throw new IllegalArgumentException
30 ("No se puede mover hacia atr as de la cabeza de la lista");
31 return v.getPrev ();
32
33 /** Regresa el nodo siguiente al nodo v dado. Un error ocurre si v
34 * es la cola */
35 public NodoD getSig(NodoD v) throws IllegalArgumentException
36 if (v == cola) throw new IllegalArgumentException
37 ("No se puede mover hacia adelante de la terminaci on de la lista");
38 return v.getSig ();
39
40 /** Inserta el nodo z dado antes del nodo v dado. Un error
41 * ocurre si v es la cabeza */
42 public void agregarAntes(NodoD v, NodoD z) throws IllegalArgumentException
43 NodoD u = getPrev(v); // podr ıa lanzar un IllegalArgumentException
44 z.setPrev(u);
45 z.setSig(v);
46 v.setPrev(z);
47 u.setSig(z);
48 tam ++;
49
50 /** Inserta el nodo z dado despues del nodo v dado. Un error
51 * ocurre si v es la cabeza */
52 public void agregarDespues(NodoD v, NodoD z)
53 NodoD w = getSig(v); // podr ıa lanzar un IllegalArgumentException
54 z.setPrev(v);
55 z.setSig(w);
56 w.setPrev(z);
57 v.setSig(z);
58 tam ++;
59
60 /** Inserta el nodo v dado en la cabeza de la lista */
61 public void agregarInicio(NodoD v)
62 agregarDespues(cabeza , v);
63
64 /** Inserta el nodo v dado en la cola de la lista */
65 public void agregarFinal(NodoD v)
66 agregarAntes(cola , v);
67
68 /** Quitar el nodo v dado de la lista. Un error ocurre si v es
69 * la cabeza o la cola */
70 public void remover(NodoD v)
71 NodoD u = getPrev(v); // podr ıa lanzar IllegalArgumentException
72 NodoD w = getSig(v); // podr ıa lanzar IllegalArgumentException
73 // desenlazar el nodo v de la lista
74 w.setPrev(u);
75 u.setSig(w);
76 v.setPrev(null);
77 v.setSig(null);
78 tam --;
79
80 /** Regresa si un nodo v dado tiene un nodo previo */
81 public boolean tienePrev(NodoD v) return v != cabeza;

3.5 Listas circulares y ordenamiento 119
82 /** Regresa si un nodo v dado tiene un nodo siguiente */
83 public boolean tieneSig(NodoD v) return v != cola;
84 /** Regresa una cadena representando la lista */
85 public String toString ()
86 String s = "[";
87 NodoD v = cabeza.getSig ();
88 while (v != cola)
89 s += v.getElemento ();
90 v = v.getSig ();
91 if (v != cola)
92 s += ",";
93
94 s += "]";
95 return s;
96
97
Listado 3.12: Una clase de lista doblemente enlazada.
3.5. Listas circulares y ordenamiento
En esta seccion se revisan algunas aplicaciones y extensiones de listasenlazadas.
3.5.1. Lista circular enlazada
El juego de ninos, “Pato, Pato, Ganso”, es jugado en varias culturas. Unavariacion de la lista simple enlazada, llamada la lista circular enlazada, esusada para una variedad de aplicaciones involucrando juegos circulares, comoel juego que se comenta. Enseguida se muestra la lista circular y su aplicacionen un juego circular.
Una lista circular enlazada tiene el mismo tipo de nodos que una listasimple enlazada. Esto es, cada nodo en una lista circular enlazada tiene unapuntador siguiente y una referencia a un elemento. Pero no hay una cabezao cola en la lista circular enlazada. En vez de hacer que el apuntador delultimo nodo sea null, se hace que apunte de regreso al primer nodo. Por lotanto, no hay un primer nodo o ultimo. Si se recorren los nodos de una listacircular enlazada desde cualquier nodo usando los apuntadores sig, entoncesse hara un ciclo a traves de los nodos.
Aun cuando una lista circular enlazada no tiene inicio o terminacion, noobstante se necesita que algun nodo este marcado como especial, el cualsera llamado cursor. El nodo cursor permite tener un lugar para iniciar si se

120 Arreglos, listas enlazadas y recurrencia
requiere recorrer una lista circular enlazada. Y si se recuerda esta posicioninicial, entonces tambien se puede saber cuando se haya terminado con unrecorrido en la lista circular enlazada, porque es cuando se regresa al nodoque fue el nodo cursor cuando se inicio.
Se pueden entonces definir algunos metodos simples de actualizacion parauna lista circular enlazada:
agregar(v):inserta un nuevo nodo v inmediatamente despuesdel cursor; si la lista esta vacıa, entonces v seconvierte en el cursor y su apuntador sig apuntaa el mismo.
remover():borra y regresa el nodo v inmediatamente despuesdel cursor (no el propio cursor, a menos que estesea el unico nodo); si la lista queda vacıa, el cursores puesto a null.
avanzar():pasa el cursor al siguiente nodo en la lista.
La clase ListaCircular, listado 3.13, muestra una implementacion Javade una lista circular enlazada, la cual usa la clase Nodo, listado 3.9. Tambienincluye un metodo toString() para generar una representacion de cadenade la lista.
Algunas observaciones acerca de la clase ListaCircular
Es un programa simple que puede dar suficiente funcionalidad para simularjuegos circulares, como Pato, Pato, Ganso, como se ve enseguida. No es unprograma robusto, sin embargo. En particular, si una lista circular esta vacıa,entonces llamar avanzar o remover en esa lista causara una excepcion.
Pato, Pato, Ganso
En el juego de ninos Pato, Pato, Ganso, un grupo de ninos se sienta encırculo. Uno de ellos es ellos es elegido para quedarse parado y este caminaalrededor del cırculo por fuera. El nino elegido toca a cada nino en la cabeza,diciendo “Pato” o “Ganso”. Cuando el elegido decide llamar a alguien el“Ganso”, el “Ganso” se levanta y persigue al otro nino alrededor del cırculo.Si el “Ganso” no logra tocar al elegido, entonces a el le toca quedarse para laproxima ronda, sino el elegido lo seguira siendo en la siguiente ronda.

3.5 Listas circulares y ordenamiento 121
1 /** Lista circularmente enlazada con nodos de tipo Nodo guardando cadenas. */
2 public class ListaCircular
3 protected Nodo cursor; // cursor actual
4 protected int tam; // cantidad de nodos en la lista
5 /** Constructor que crea una lista vacia */
6 public ListaCircular () cursor = null; tam = 0;
7 /** Regresa cantidad de nodos */
8 public int tam() return tam;
9 /** Regresa cursor */
10 public Nodo getCursor () return cursor;
11 /** Mueve cursor hacia adelante */
12 public void avanzar () cursor = cursor.getSig ();
13 /** Agrega nodo despu es del cursor */
14 public void agregar(Nodo nodoNuevo)
15 if (cursor == null) // ¿lista vacia?
16 nodoNuevo.setSig(nodoNuevo );
17 cursor = nodoNuevo;
18
19 else
20 nodoNuevo.setSig(cursor.getSig ());
21 cursor.setSig(nodoNuevo );
22
23 tam ++;
24
25 /** Quita nodo despu es del cursor */
26 public Nodo remover ()
27 Nodo nodo = cursor.getSig (); // nodo que ser a removido
28 if ( nodo == cursor )
29 cursor = null; // la lista quedar a vac ıa
30 else
31 cursor.setSig( nodo.getSig () ); // desenlazar el nodo
32 nodo.setSig( null );
33
34 tam --;
35 return nodo;
36
37 /** Devuelve una representaci on String de la lista ,
38 * iniciando desde el cursor */
39 public String toString ()
40 if (cursor == null) return "[]";
41 String s = "[..." + cursor.getElemento ();
42 Nodo cursorOrig = cursor;
43 for ( avanzar (); cursorOrig != cursor; avanzar () )
44 s += ", " + cursor.getElemento ();
45 return s + "...]";
46
47
Listado 3.13: Una clase de lista circular enlazada con nodos simples.

122 Arreglos, listas enlazadas y recurrencia
Simular este juego es una aplicacion ideal de una lista circular enlazada.Los nodos pueden representar a los ninos que estan sentados en cırculo. Elnino “elegido” puede ser identificado como el nino que esta sentado despuesdel cursor, y puede ser removido del cırculo para simular el recorrido alrededor.Se puede avanzar el cursor con cada “Pato” que el elegido identifique, locual se puede simular con una decision aleatoria. Una vez que un “Ganso”es identificado, se puede remover este nodo de la lista, hacer una seleccionaleatoria para simular si el “Ganso” alcanzo al elegido, e insertar el ganadoren la lista. Se puede entonces avanzar el cursor e insertar al ganador y repetirel proceso, o terminar si esta es la ultima partida del juego.
Lista circular enlazada para Pato, Pato, Ganso
La clase PatoPatoGanso, listado 3.14, muestra el codigo para simular eljuego Pato, Pato, Ganso.
Se muestra un ejemplo de la salida de la ejecucion del programa Pato,Pato, Ganso a continuacion:
Los jugadores son: [...Pedro, Alex, Eli, Paco, Gabi, Pepe, Luis, To~no...]
Alex es el elegido.
Jugando Pato, Pato, Ganso con: [...Pedro, Eli, Paco, Gabi, Pepe, Luis, To~no...]
Eli es un pAto.
¡Paco es el ganso!
¡El ganso gano!
Alex es el elegido.
Jugando Pato, Pato, Ganso con: [...Paco, Gabi, Pepe, Luis, To~no, Pedro, Eli...]
Gabi es un pato.
¡Pepe es el ganso!
¡El ganso perdio!
Pepe es el elegido.
Jugando Pato, Pato, Ganso con: [...Alex, Luis, To~no, Pedro, Eli, Paco, Gabi...]
Luis es un pato.
To~no es un pato.
¡Pedro es el ganso!
¡El ganso gano!
El circulo final es [...Pedro, Pepe, Eli, Paco, Gabi, Alex, Luis, To~no...]
Observar que cada iteracion en esta ejecucion del programa genera unasalida diferente, debido a las configuraciones iniciales diferentes y el uso deopciones aleatorias para identificar patos y gansos. Ademas, la decision deque el ganso alcance al jugador parado es una decision aleatoria.

3.5 Listas circulares y ordenamiento 123
1 import java.util.Random;
2 public class PatoPatoGanso
3 /** Simulaci on de Pato , Pato , Ganso con una lista circular enlazada. */
4 public static void main(String [] args)
5 ListaCircular lc = new ListaCircular ();
6 int n = 3; // veces que se jugar a el juego
7 Nodo eleg; // jugador elegido
8 Nodo ganso; // el ganso
9 Random rand = new Random ();
10 rand.setSeed( System.currentTimeMillis () ); // tiempo actual como semilla
11 // Los jugadores ...
12 String [] noms = "Alex","Eli","Paco","Gabi","Pepe","Luis","To~no","Pedro";
13 for ( String nombre: noms )
14 lc.agregar( new Nodo( nombre , null) );
15 lc.avanzar ();
16
17 System.out.println("Los jugadores son: "+lc.toString ());
18 for (int i = 0; i < n; i++) // jugar Pato , Pato , Ganso n veces
19 eleg = lc.remover ();
20 System.out.println(eleg.getElemento () + " es el elegido.");
21 System.out.println("Jugando Pato , Pato , Ganso con: "+lc.toString ());
22 // marchar alrededor del circulo
23 while (rand.nextBoolean () || rand.nextBoolean ())
24 lc.avanzar (); // avanzar con probabilidad 3/4
25 System.out.println( lc.getCursor (). getElemento () + " es un pato.");
26
27 ganso = lc.remover ();
28 System.out.println( "¡"+ganso.getElemento () + " es el ganso!" );
29 if ( rand.nextBoolean () )
30 System.out.println("¡El ganso gan o!");
31 lc.agregar(ganso); // meter ganso al cı rculo
32 lc.avanzar (); // cursor est a sobre el ganso
33 lc.agregar(eleg); // elegido seguir a si e ndolo en la pr oxima ronda
34
35 else
36 System.out.println("¡El ganso perdi o!");
37 lc.agregar(eleg); // poner elegido en lugar del ganso
38 lc.avanzar (); // cursor est a sobre persona elegida
39 lc.agregar(ganso); // ganso es el elegido en la siguiente ronda
40
41
42 System.out.println("El circulo final es " + lc.toString ());
43
44
Listado 3.14: El metodo main() de una aplicacion que usa una lista circular enlazadapara simular el juego de ninos Pato, Pato, Ganso.

124 Arreglos, listas enlazadas y recurrencia
3.5.2. Ordenar una LDE
Para ordenar una LDE se puede emplear el algoritmo InsercionOrde-nada.Algoritmo InsercionOrdenada(L):
Entrada: Una lista L doblemente enlazada de elementos comparablesSalida: La lista L con elementos rearreglados en orden crecientesi L.tam() ≤ 1 entoncesregresar
fin← L.getPrimero()mientras fin no sea el ultimo nodo en L hacerpivote← fin.getSig()Quitar pivote de Lins← finmientras ins no sea la cabeza y el elemento de ins sea mayor
que el del pivote hacerins← ins.getPrev()
Agregar pivote justo despues de ins en Lsi ins = fin entonces pivote no se movio por ser el mayorfin← fin.getSig()
Una implementacion en Java del algoritmo de insercion ordenada para unalista doblemente enlazada representada por la clase ListaDoble se muestraen el listado 3.15.
3.6. Recurrencia
La repeticion se puede lograr escribiendo ciclos, como por ejemplo confor, o con while. Otra forma de lograr la repeticion es usando recurrencia,la cual ocurre cuando una funcion se llama a sı misma. Se han visto ejemplosde metodos que llaman a otros metodos, por lo que no deberıa ser extrano quemuchos de los lenguajes de programacion actual, incluyendo Java, permitanque un metodo se llame a sı mismo. En esta seccion, se vera porque estacapacidad da una alternativa poderosa para realizar tareas repetitivas.
La funcion factorial
Para ilustrar la recurrencia, se inicia con un ejemplo sencillo para calcularel valor de la funcion factorial. El factorial de un entero positivo n, denotada

3.6 Recurrencia 125
1 /** Inserci on ordenada para una lista doblemente enlazada
2 de la clase ListaDoble. */
3 public static void ordenar(ListaDoble L)
4 if (L.tam() <= 1) return; // L ya est a ordenada en este caso
5 NodoD pivote; // nodo pivote
6 NodoD ins; // punto de inserci on
7 NodoD fin = L.getPrimero (); // fin de la corrida
8 while (fin != L.getUltimo ())
9 pivote = fin.getSig (); // obtener el siguiente nodo de pivote
10 L.remover(pivote ); // quitar pivote de L
11 ins = fin; // iniciar busqueda desde fin de la corrida ordenada
12 while (L.tienePrev(ins) &&
13 ins.getElemento (). compareTo(pivote.getElemento ()) > 0)
14 ins = ins.getPrev (); // mover a la izquierda
15 // agregar el pivote de regreso , despues del punto de inserci on
16 L.agregarDespues(ins ,pivote );
17 if (ins == fin) // se ha agregado pivote despu es de fin (se quedo
18 fin = fin.getSig (); // en el mismo lugar) -> incrementar marcador fin
19
20
Listado 3.15: Ordenamiento por insercion para una lista doblemente enlazadarepresentada por la clase ListaDoble.
por n!, esta definida como el producto de los enteros desde 1 hasta n. Si n = 0,entonces n! esta definida como uno por convencion. Mas formalmente, paracualquier entero n ≥ 0,
n! =
1 si n = 01 · 2 · · · (n− 2) · (n− 1) · n si n ≥ 1
Para denotar n! se empleara el siguiente formato usado en los metodos deJava, factorial(n).
La funcion factorial puede ser definida de una forma que sugiera unaformulacion recursiva. Para ver esto, observar que
factorial(5) = 5 · (4 · 3 · 2 · 1) = 5 · factorial(4)
Por lo tanto, se puede definir factorial(5) en terminos del factorial(4).En general, para un entero positivo n, se puede definir factorial(n) comon · factorial(n− 1). Esto lleva a la siguiente definicion recursiva.
factorial(n) =
1 si n = 0n · factorial(n− 1) si n ≥ 1
(3.1)
Esta definicion es tıpica de varias definiciones recursivas. Primero, esta

126 Arreglos, listas enlazadas y recurrencia
contiene uno, o mas caso base, los cuales no estan definidos recursivamente,si no en terminos de cantidades fijas. En este caso, n = 0 es el caso base.Esta definicion tambien contiene uno o mas casos recursivos, los cualesestan definidos empleando la definicion de la funcion que esta siendo definida.Observar que no hay circularidad en esta definicion, porque cada vez que lafuncion es invocada, su argumento es mas pequeno en uno.
Implementacion recursiva de la funcion factorial
Se considera una implementacion en Java, listado 3.16, de la funcion facto-rial que esta dada por la formula 3.1 con el nombre factorialRecursivo().Observar que no se requiere ciclo. Las invocaciones repetidas recursivas de lafuncion reemplazan el ciclo.
1 public static int factorialRecursivo(int n) // funci on recursiva factorial
2 if (n == 0) return 1; // caso base
3 else return n * factorialRecursivo(n-1); // caso recursivo
4
Listado 3.16: Una implementacion recursiva de la funcion factorial.
¿Cual es la ventaja de usar recurrencia? La implementacion recursiva dela funcion factorial es un poco mas simple que la version iterativa, en estecaso no hay razon urgente para preferir la recurrencia sobre la iteracion. Paraalgunos problemas, sin embargo, una implementacion recursiva puede sersignificativamente mas simple y facil de entender que una implementacioniterativa como en los ejemplos siguientes.
Dibujar una regla inglesa
Como un caso mas complejo del uso de recurrencia, considerar como dibujarlas marcas de una regla tıpica inglesa. Una regla esta dividida en intervalosde una pulgada, y cada intervalo consiste de un conjunto de marcas colocadasen intervalos de media pulgada, un cuarto de pulgada, y ası sucesivamente.Como el tamano del intervalo decrece por la mitad, la longitud de la marcadecrece en uno, ver figura 3.16.
Cada multiplo de una pulgada tambien tiene una etiqueta numerica. Lalongitud de la marca mas grande es llamada la longitud de la marca principal.No se consideran las distancias actuales entre marcas, sin embargo, se imprimeuna marca por lınea.

3.6 Recurrencia 127
---- 0 ----- 0 --- 0
- - -
-- -- --
- - -
--- --- --- 1
- - -
-- -- --
- - -
---- 1 ---- --- 2
- - -
-- -- --
- - -
--- --- --- 3
- -
-- --
- -
---- 2 ----- 1
(a) (b) (c)
Figura 3.16: Ejemplos de la funcion dibuja regla: (a) regla de 2” con longitud 4 dela marca principal; (b) regla de 1” con longitud 5; (c) regla de 3” con longitud 3.
Una aproximacion recursiva para dibujar la regla
La aproximacion para dibujar tal regla consiste de tres funciones. Lafuncion principal dibujaRegla() dibuja la regla entera. Sus argumentos sonel numero total de pulgadas en la regla, nPulgadas, y la longitud de la marcaprincipal, longPrincipal. La funcion utilidad dibujaUnaMarca() dibuja unasola marca de la longitud dada. Tambien se le puede dar una etiqueta enteraopcional, la cual es impresa si esta no es negativa.
El trabajo interesante es hecho por la funcion recursiva dibujaMarcas(),la cual dibuja la secuencia de marcas dentro de algun intervalo. Su unicoargumento es la longitud de la marca asociada con la marca del intervalocentral. Considerar la regla de 1” con longitud 5 de la marca principal mostradaen la figura 3.16(b). Ignorando las lıneas conteniendo 0 y 1, considerar comodibujar la secuencia de marcas que estan entre estas lıneas. La marca central(en 1/2”) tiene longitud 4. Los dos patrones de marcas encima y abajo deesta marca central son identicas, y cada una tiene una marca central delongitud 3. En general, un intervalo con una marca central de longitud L ≥ 1esta compuesto de lo siguiente:

128 Arreglos, listas enlazadas y recurrencia
Un intervalo con una longitud de marca central L− 1
Un solo interalo de longitud L
Un intervalo con una longitud de marca central L− 1
Con cada llamada recursiva, la longitud decrece por uno. Cuando lalongitud llega a cero, se debe regresar. Como resultado, este proceso recursivosiempre terminara. Esto sugiere un proceso recursivo, en el cual el primerpaso y ultimo son hechos llamando a dibujaMarcas(L-1) recursivamente. Elpaso central es realizado llamando a la funcion dibujaUnaMarca(L). Estaformulacion recursiva es mostrada en el listado 3.17. Como en el ejemplo delfactorial, el codigo tiene un caso base, cuando L = 0. En este ejemplo sehacen dos llamadas recursivas a la funcion.
1 // dibuja regla conteniendo nPulgadas con marca de tama~no longPrincipal
2 public static void dibujaRegla(int nPulgadas , int longPrincipal)
3 dibujaUnaMarca(longPrincipal , 0); // dibujar marca 0 y su etiqueta
4 for (int i = 1; i <= nPulgadas; i++)
5 dibujaMarcas(longPrincipal -1); // dibujar marcas para esta pulgada
6 dibujaUnaMarca(longPrincipal , i); // dibujar marca i y su etiqueta
7
8
9 // dibuja marcas de longitud dada
10 public static void dibujaMarcas(int longMarca)
11 if (longMarca > 0) // parar cuando la longitud llegue a 0
12 dibujaMarcas(longMarca -1); // recursivamente dibujar marca superior
13 dibujaUnaMarca(longMarca ); // dibujar marca principal
14 dibujaMarcas(longMarca -1); // recursivamente dibujar marca inferior
15
16
17 // dibuja una marca sin etiqueta
18 public static void dibujaUnaMarca(int longMarca)
19 dibujaUnaMarca(longMarca , -1);
20
21 // dibuja una marca
22 public static void dibujaUnaMarca(int longMarca , int etiqMarca)
23 for (int i = 0; i < longMarca; i++)
24 System.out.print("-");
25 if (etiqMarca >= 0) System.out.print(" " + etiqMarca );
26 System.out.print("\n");
27
Listado 3.17: Implementacion recursiva del metodo dibujaMarcas() para mostrarmarcas de una regla.
Sumar elementos de un arreglo recursivamente
Suponer que se da un arreglo, A, de n enteros que se desean sumar juntos.Se puede resolver el problema de la suma usando recurrencia lineal observando

3.6 Recurrencia 129
que la suma de todos los n enteros de A es igual a A[0], si n es 1, o la sumade los primeros n − 1 enteros mas la suma del ultimo elemento en A. Enparticular, se puede resolver esta suma usando el algoritmo recursivo siguiente.Algoritmo SumaLineal(A, n):
Entrada: Un arreglo A de enteros y un entero n ≥ 1 tal que A tieneal menos n elementos.
Salida: La suma de los primeros n enteros en A.si n = 1 entoncesregresar A[0]
si noregresar SumaLineal(A, n− 1) + A[n− 1]
Este ejemplo, tambien ilustra una propiedad importante que un metodorecursivo deberıa siempre tener—que el metodo termina. Se asegura estoescribiendo una sentencia no recursiva para el caso n igual a 1. Ademas,siempre se hace una llamada recursiva sobre un valor mas pequeno delparametro n menos 1 que el que fue dado, n, por lo tanto, en algun punto,en el punto mas bajo de la recurrencia, se hara la parte no recursiva delcalculo, regresando A[0]. En general, un algoritmo que usa recurrencia linealtıpicamente tiene la siguiente forma:
Prueba para los casos base. Se inicia probando un conjunto de casosbase, deberıa haber al menos uno. Estos casos basos deberıan estardefinidos, por lo que cada posible encadenamiento de llamadas recursivaseventualmente alcanzara un caso base, y el manejo de cada caso baseno deberıa usar recurrencia.
Recurrencia. Despues de probar los casos base, entonces se realizanllamadas recursivas simples. Este paso recursivo podrıa involucrar unaprueba que decida cual de varias posibles llamadas recursivas hacer, perofinalmente deberıa escoger hacer solo una de estas posibles llamadascada vez que se haga este paso. Mas aun, se deberıa definir cada posiblellamada recursiva para que esta progrese hacia el caso base.
Invertir un arreglo por recurrencia
Se considera ahora el problema de invertir los n elementos de un arreglo, A,para que el primer elemento sea el ultimo, el segundo elemento sea el penultimo,y ası sucesivamente. Se puede resolver este problema usando recurrencia lineal,

130 Arreglos, listas enlazadas y recurrencia
observando que la inversion de un arreglo se puede lograr intercambiandoel primer elemento y el ultimo, y entonces invertir recursivamente el restode los elementos en el arreglo. Se describen a continuacion los detalles deeste algoritmo, usando la convencion de que la primera vez que se llama elalgoritmo se hace como InvertirArreglo(A, 0, n− 1).
Algoritmo InvertirArreglo(A, i, j):Entrada: Un arreglo A e ındices enteros no negativos i y j.Salida: La inversion de los elementos en A iniciando en el ındice i
y terminando en j.si i < j entonces
Intercambiar A[i] y A[j]InvertirArreglo(A, i+ 1, j − 1)
regresar
En este algoritmo se tienen dos casos base implıcitos, a saber, cuandoi = j y cuando i > j. Sin embargo, en cualquier caso, se termina el algoritmo,ya que una secuencia con cero elementos, o un elemento es trivialmente igual asu inversion. Ademas, en el paso recursivo se esta garantizando ir progresandohacia uno de los dos casos base. Si n es par, eventualmente se alcanzara elcaso i = j, y si n es impar, eventualmente se alcanzara el caso i > j. Elargumento anterior implica que el algoritmo recursivo esta garantizado paraterminar.
Definir problemas para facilitar la recurrencia
Para disenar un algoritmo recursivo para un problema dado, es util pensaren las diferentes formas en que se puede subdividir el problema para definirproblemas que tengan la misma estructura general que el problema original.Este proceso en ocasiones significa que se necesita redefinir el problemaoriginal para facilitar la busqueda de problemas similares. Por ejemplo, conel algoritmo InvertirArreglo, se agregaron los parametros i y j porlo que una llamada recursiva para invertir la parte interna del arreglo Apodrıa tener la misma estructura y la misma sintaxis, como la llamada parainvertir cualquier otro par de valores del arreglo A. Entonces, en vez deinicialmente llamar al algoritmo como InvertirArreglo(A), se llama a esteinicialmente como InvertirArreglo(A, 0, n − 1). En general, si se tienedificultad para encontrar la estructura repetitiva requerida para disenar unalgoritmo recursivo, en algunos casos es util trabajar el problema con algunos

3.6 Recurrencia 131
ejemplos concretos pequenos para ver como los subproblemas deberıan estardefinidos.
Recurrencia de cola
Usar la recurrencia puede ser con frecuencia una herramienta util paradisenar algoritmos que tienen definiciones cortas y elegantes. Pero esta utilidadviene acompanado de un costo modesto. Cuando se usa un algoritmo recursivopara resolver un problema, se tienen que usar algunas de las localidades de lamemoria para guardar el estado de las llamadas recursivas activas. Cuando lamemoria de la computadora es un lujo, entonces, es mas util en algunos casospoder derivar algoritmos no recurrentes de los recurrentes.
Se puede emplear la estructura de datos pila para convertir un algo-ritmo recurrente en uno no recurrente, pero hay algunos casos cuando sepuede hacer esta conversion mas facil y eficiente. Especıficamente, se puedefacilmente convertir algoritmos que usan recurrencia de cola. Un algorit-mo usa recurrencia de cola si este usa recursion lineal y el algoritmo haceuna llamada recursiva como su ultima operacion. Por ejemplo, el algoritmoInvertirArreglo usa recurrencia de cola.
Sin embargo, no es suficiente que la ultima sentencia en el metodo definicionincluya una llamada recurrente. Para que un metodo use recurrencia de cola, lallamada recursiva debera ser absolutamente la ultima parte que el metodo haga,a menos que se este en el caso base. Por ejemplo, el algoritmo SumaLineal nousa recurrencia de cola, aun cuando su ultima sentencia incluye una llamadarecursiva. Esta llamada recursiva no es actualmente la ultima tarea que elmetodo realiza. Despues de recibir el valor regresado de la llamada recursiva,le agrega el valor de A[n− 1] y regresa su suma. Esto es, la ultima tarea quehace el algoritmo es una suma, y no una llamada recursiva.
Cuando un algoritmo emplea recurrencia de cola, se puede convertir elalgoritmo recurrente en uno no recurrente, iterando a traves de las llamadasrecurrentes en vez de llamarlas a ellas explıcitamente. Se ilustra este tipo deconversion revisitando el problema de invertir los elementos de un arreglo.El siguiente algoritmo no recursivo realiza la tarea de invertir los elementositerando a traves de llamadas recurrentes del algoritmo InvertirArreglo.Inicialmente se llama a este algoritmo como InvertirArregloIterati-vo(A, 0, n− 1).

132 Arreglos, listas enlazadas y recurrencia
Algoritmo InvertirArregloIterativo(A, i, j):Entrada: Un arreglo A e ındices enteros no negativos i y j.Salida: La inversion de los elementos en A iniciando en el ındice i
y terminando en j.mientras i < j hacer
Intercambiar A[i] y A[j]i← i+ 1j ← j − 1
regresar
3.6.1. Recurrencia binaria
Cuando un algoritmo hace dos llamadas recurrentes, se dice que usarecurrencia binaria. Estas llamadas pueden, por ejemplo, ser usadas pararesolver dos hojas similares de algun problema, como se hizo para dibujaruna regla inglesa, seccion 3.6. Como otra aplicacion de recurrencia binaria,se revisitara el problema de sumar los n elementos de un arreglo de enterosA. En este caso, se pueden sumar los elementos de A: (i) recurrentementelos elementos en la primera mitad de A; (ii) recurrentemente los elementosen la segunda mitad de A; y (iii) agregando estos dos valores juntos. Se danlos detalles en el siguiente algoritmo, el cual es inicialmente llamado comoSumaBinaria(A, 0, n).
Algoritmo SumaBinaria(A, i, n):Entrada: un arreglo A de enteros y enteros i y n.Salida: la suma de los primeros n enteros en A iniciando en el ındice i.si n = 1 entoncesregresar A[i]
regresar SumaBinaria(A, i, dn/2e)+SumaBinaria(A, i+ dn/2e, bn/2c)
Para analizar el algoritmo SumaBinaria, se considera, por simplicidad,el caso cuando n es potencia de 2. La figura 3.17 muestra el trazado de larecursion de una ejecucion del metodo SumaBinaria(0,8). Se etiqueta cadarecuadro con los valores de los parametros i y n, los cuales representan elındice inicial y el tamano de la secuencia de los elementos que seran sumados,respectivamente. Observar que las flechas en el trazado van de un recuadroetiquetado (i, n) a otro recuadro etiquetado (i, n/2) o (i+n/2, n/2). Esto es, elvalor del parametro n es dividido en dos en cada llamada recursiva. Por lo tanto,la profundidad de la recursion, esto es, el numero maximo de instancias del

3.6 Recurrencia 133
metodo que estan activas al mismo tiempo, es 1+log2 n. Entonces el algoritmousa una cantidad de espacio adicional aproximadamente proporcional a suvalor. El tiempo de ejecucion del algoritmo es todavıa proporcional a n, yaque cada recuadro es visitado en tiempo constante y hay 2n− 1 recuadros.
Figura 3.17: Trazado de la recursion de SumaBinaria(0, 8).
Fibonacci con recurrencia binaria
Se considera ahora el problema de calcular el k-esimo numero de Fibonacci.Los numeros de Fibonacci estan recursivamente definidos como:
F0 = 0F1 = 1Fi = Fi−1 + Fi−2 para i > 1.
Aplicando directamente la definicion anterior, el algoritmo FibBinario,mostrado a continuacion, encuentra la secuencia de los numeros de Fibonacciempleando recurrencia binaria.Algoritmo FibBinario(k):
Entrada: Un entero k no negativo.Salida: El k-esimo numero de Fibonacci Fk.si k ≤ 1 entoncesregresar k
si noregresar FibBinario(k − 1)+FibBinario(k − 2)
Desafortunadamente, a pesar de que la definicion de Fibonacci parece unarecursion binaria, esta tecnica es ineficiente en este caso. De hecho, toma unnumero de llamadas exponencial para calcular el k-esimo numero de Fibonaccide esta forma. Especıficamente, sea nk el numero de llamadas hechas en la

134 Arreglos, listas enlazadas y recurrencia
ejecucion de FibBinario(k). Entonces, se tienen los siguientes valores paralas diferentes nk:
n0 = 1n1 = 1n2 = n1 + n0 + 1 = 3n3 = n2 + n1 + 1 = 5n4 = n3 + n2 + 1 = 9n5 = n4 + n3 + 1 = 15n6 = n5 + n4 + 1 = 25n7 = n6 + n5 + 1 = 41n8 = n7 + n6 + 1 = 67
Si se sigue hacia adelante el patron, se ve que el numero de llamadas esmas del doble para un ındice que este dos ındices anteriores. Esto es, n4 esmas del doble que n2, n5 es mas del doble que n3, y ası sucesivamente. Porlo tanto, nk > 2k/2, lo que significa que FibBinario(k) hace un numero dellamadas que son exponenciales en k. En otras palabras, emplear recurrenciabinaria para calcular numeros de Fibonacci es muy ineficiente.
Fibonacci con recurrencia lineal
El principal problema con la aproximacion anterior, basada en recurrenciabinaria, es que el calculo de los numeros de Fibonacci es realmente un problemade recurrencia lineal. No es este un buen candidato para emplear recurrenciabinaria. Se empleo recurrencia binaria por la forma como el k-esimo numerode Fibonacci, Fk, dependıa de los dos valores previos, Fk−1 y Fk−2. Pero sepuede encontrar Fk de una forma mas eficiente usando recurrencia lineal.
Para poder emplear recurrencia lineal, se necesita redefinir ligeramenteel problema. Una forma de lograr esta conversion es definir una funcionrecursiva que encuentre un par consecutivo de numeros Fibonacci (Fk−1, Fk).Entonces se puede usar el siguiente algoritmo de recurrencia lineal mostradoa continuacion.

3.6 Recurrencia 135
Algoritmo FibLineal(k):Entrada: Un entero k no negativo.Salida: El par de numeros Fibonacci (Fk, Fk−1).si k ≤ 1 entoncesregresar (k, 0)
si no(i, j)← FibLineal(k − 1)regresar (i+ j, i)
El algoritmo dado muestra que usando recurrencia lineal para encontrarlos numeros de Fibonacci es mucho mas eficiente que usando recurrenciabinaria. Ya que cada llama recurrente a FibLineal decrementa el argumentok en 1, la llamada original FibLineal(k) resulta en una serie de k − 1llamadas adicionales. Esto es, calcular el k-esimo numero de Fibonacci usandorecurrencia lineal requiere k llamadas al metodo. Este funcionamiento essignificativamente mas rapido que el tiempo exponencial necesitado parael algoritmo basado en recurrencia binaria. Por lo tanto, cuando se usarecurrencia binaria, se debe primero tratar de particionar completamente elproblema en dos, o se deberıa estar seguro que las llamadas recursivas que setraslapan son realmente necesarias.
Usualmente, se puede eliminar el traslape de llamadas recursivas usandomas memoria para conservar los valores previos. De hecho, esta aproximaciones una parte central de una tecnica llamada programacion dinamica, la cualesta relacionada con la recursion.
3.6.2. Recurrencia multiple
La generalizacion de la recurrencia binaria lleva a la recurrencia multi-ple, que es cuando un metodo podrıa hacer varias llamadas recursivas, siendoese numero potencialmente mayor que dos. Una de las aplicaciones mas co-munes de este tipo de recursion es usada cuando se quiere enumerar variasconfiguraciones en orden para resolver un acertijo combinatorio. Por ejemplo,el siguiente es un acertijo de suma:
par + ras = assa
Para resolver el acertijo, se necesita asignar un dıgito unico, esto es,0,1,. . . ,9, a cada letra en la ecuacion, para poder hacer la ecuacion verdadera.Tıpicamente, se resuelve el acertijo usando observaciones humanas del acertijo

136 Arreglos, listas enlazadas y recurrencia
particular que se esta intentando resolver para eliminar configuraciones hastaque se pueda trabajar con las configuraciones restantes, probando la correctezde cada una.
Sin embargo, si el numero de configuraciones posibles no es muy grande, sepuede usar una computadora para enumerar todas las posibilidades y probarcada una, sin emplear observaciones humanas. Ademas, tal algoritmo puedeusar recurrencia multiple para trabajar a traves de todas las configuracionesen una forma sistematica. Se proporciona enseguida pseudocodigo para talalgoritmo. Para conservar la descripcion general suficiente para ser usado conotros acertijos, el algoritmo enumera y prueba todas las secuencias de longitudk sin repeticiones de los elementos de un conjunto dado U . Se construyen lassecuencias de k elementos mediante los siguientes pasos:
1. Generar recursivamente las secuencias de k − 1 elementos.
2. Agregar a cada una de tales secuencias un elemento que no este contenidodentro de esta.
En toda la ejecucion del algoritmo, se usa el conjunto U para saber loselementos no contenidos en la secuencia actual, por lo que un elemento e noha sido usado aun sı y solo sı e esta en U .
Otra forma de ver el algoritmo siguiente es que este enumera cada sub-conjunto ordenado posible de tamano, y prueba cada subconjunto para seruna posible solucion al acertijo.
Para acertijos de sumas, U = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 y cada posicion enla secuencia corresponde a una letra dada. Por ejemplo, la primera posicionpodrıa ser b, la segunda o, la tercera y, y ası sucesivamente.

3.6 Recurrencia 137
Algoritmo ResolverAcertijo(k, S, U):Entrada: Un entero k, secuencia S, y conjunto U .Salida: Una enumeracion de todas las extensiones k-longitud para S
usando elementos en U sin repeticiones.para cada e en U hacer
Remover e de U e esta ahora siendo usado Agregar e al final de Ssi k = 1 entonces
Probar si S es una configuracion que resuelva el acertijosi S resuelve el acertijo entoncesregresar “Solucion encontrada: ” S
si noResolverAcertijo(k − 1, S, U)
Agregar e de regreso a U e esta ahora sin uso Remover e del final de S

138 Arreglos, listas enlazadas y recurrencia

Capıtulo 4
Herramientas de analisis
4.1. Funciones
Se revisan brevemente, en esta seccion, las siete funciones mas importantesusadas en el analisis de algoritmos.
4.1.1. La funcion constante
La funcion mas simple que se emplea es la funcion constante. Esta esla funcion
f(n) = c,
para alguna constante fija c, tal como c = 7, c = 25, o c = 28. Con estafuncion, para cualquier argumento n, la funcion constante f(n) asigna el valorc, es decir, no importa cual sea el valor de n, f(n) siempre sera igual al valorconstante c.
Como se emplean generalmente funciones enteras en el analisis, la funcionconstante mas usada es g(n) = 1, y cualquier otra funcion constante, f(n) = c,puede ser escrita como una constante c veces g(n), es decir, f(n) = cg(n).
Esta funcion caracteriza el numero de pasos requeridos para hacer unaoperacion basica en la computadora, como la suma de dos numeros, asignarun valor a una variable, o comparar dos numeros.

140 Herramientas de analisis
4.1.2. La funcion logarıtmica
La funcion logarıtmica f(n) = logb n, para alguna constante b > 1 esubicua, ya que aparece con bastante frecuencia en el analisis de estructurasde datos y algoritmos. Esta funcion esta definida como sigue:
x = logbn sı y solo sı bx = n.
Por definicion, logb 1 = 0. El valor de b es conocido como la base dellogaritmo.
Para encontrar el valor exacto de esta funcion para cualquier entero n serequiere el uso de calculo, pero se puede usar una aproximacion util en elanalisis sin emplear calculo. En particular, se puede calcular el entero maspequeno que sea mayor o igual a logb n, ya que este numero es igual al numerode veces que se puede dividir n por b hasta que se obtenga un numero menorque, o igual a 1. Por ejemplo, log327 es 3, ya que 27/3/3/3 = 1. De igualmodo, log4 64 es 3, porque 64/4/4/4 = 1, y la aproximacion a log2 12 es 4, yaque 12/2/2/2/2 = 0.75 ≤ 1. La aproximacion base dos surge en el analisisde algoritmos, ya que es una operacion comun en los algoritmos “divide yvenceras” por que repetidamente dividen la entrada por la mitad.
Ademas, como las computadoras almacenan los enteros en binario, la basemas comun para la funcion logarıtmica en ciencias de la computacion es dos,por lo que tıpicamente no se indica cuando es dos, ası se tiene,
log n = log2 n.
Hay algunas reglas importantes para logaritmos, parecidas a las reglas deexponentes.Proposicion 4.1: Reglas de logaritmos dados numeros reales a > 0,b > 1, c > 0, y d > 1, se tiene:
1. logb ac = logb a+ logb c
2. logb a/c = logb a− logb c
3. logb ac = c logb a
4. logb a = (logd a)/ logd b
5. blogd a = alogd b
Como notacion abreviada, se usa logc n para denotar la funcion (log n)c.

4.1 Funciones 141
4.1.3. La funcion lineal
Otra funcion simple e importante es la funcion lineal,
f(n) = n.
Esto es, dado un valor de entrada n, la funcion lineal f asigna el propiovalor n.
Esta funcion surge en el analisis de algoritmos cuando se tiene que ha-cer una operacion basica para cada uno de los n elementos. Por ejemplo,comparar un numero x con cada uno de los elementos de una arreglo detamano n requerira n comparaciones. La funcion lineal tambien representa elmejor tiempo de ejecucion que se espera lograr para cualquier algoritmo queprocese una coleccion de n objetos que no esten todavıa en la memoria de lacomputadora, ya que leer los n objetos requiere n operaciones.
4.1.4. La funcion N-Log-N
La funcion
f(n) = n log n,
es la que asigna a una entrada n el valor de n veces el logaritmo de base dosde n. Esta funcion crece un poco mas rapido que la funcion lineal, pero esmas rapida que la funcion cuadratica. Por lo tanto, si se logra mejorar eltiempo de ejecucion de algun problema desde un tiempo cuadratico a n-log-n,se tendra un algoritmo que corra mas rapido en general.
4.1.5. La funcion cuadratica
La funcion cuadratica tambien aparece muy seguido en el analisis dealgoritmos,
f(n) = n2.
Para un valor de entrada n, la funcion f asigna el producto de n con ellamisma, es decir, “n cuadrada”.
La razon principal por la que la funcion cuadratica aparece en el analisisde algoritmos es porque hay muchos algoritmos que tienen ciclos anidados,donde el ciclo interno realiza un numero lineal de operaciones y el ciclo

142 Herramientas de analisis
externo tambien es realizado un numero lineal de veces. Ası, en tales casos, elalgoritmo realiza n · n = n2 operaciones.
Ciclos anidados y la funcion cuadratica
La funcion cuadratica puede tambien surgir en los ciclos anidados donde laprimera iteracion de un ciclo usa una operacion, la segunda usa dos operaciones,la tercera usa tres operaciones, y ası sucesivamente, es decir, el numero deoperaciones es
1 + 2 + 3 + · · ·+ (n− 2) + (n− 1) + n.
En otras palabras, este es el numero total de operaciones que seran hechaspor el ciclo anidado, si el numero de operaciones realizadas dentro del ciclose incrementa por uno con cada iteracion del ciclo exterior.
Se cree que Carl Gauss uso la siguiente identidad para resolver el problemaque le habıan dejado de encontrar la suma desde 1 hasta 100, cuando tenıaaproximadamente 10 anos.Proposicion 4.2: Para cualquier entero n ≥ 1, se tiene
1 + 2 + 3 + · · ·+ (n− 2) + (n− 1) + n =n(n+ 1)
2.
En la figura 4.1 se da la justificacion visual de la proposicion 4.2.Lo que se desprende de este resultado es que si se ejecuta un algoritmo
con ciclos anidados tal que las operaciones del ciclo anidado se incrementanen uno cada vez, entonces el numero total de operaciones es cuadratico en elnumero de veces, n, que se hace el ciclo exterior. En particular, el numero deoperaciones es n2/2 + n/2, en este caso, lo cual es un poco mas que un factorconstante (1/2) veces la funcion cuadratica n2.
4.1.6. La funcion cubica y otras polinomiales
De las funciones que son potencias de la entrada, se considera la funcioncubica,
f(n) = n3,
la cual asigna a un valor de entrada n el producto de n con el mismo tresveces. Esta funcion aparece con menor frecuencia en el contexto del analisis
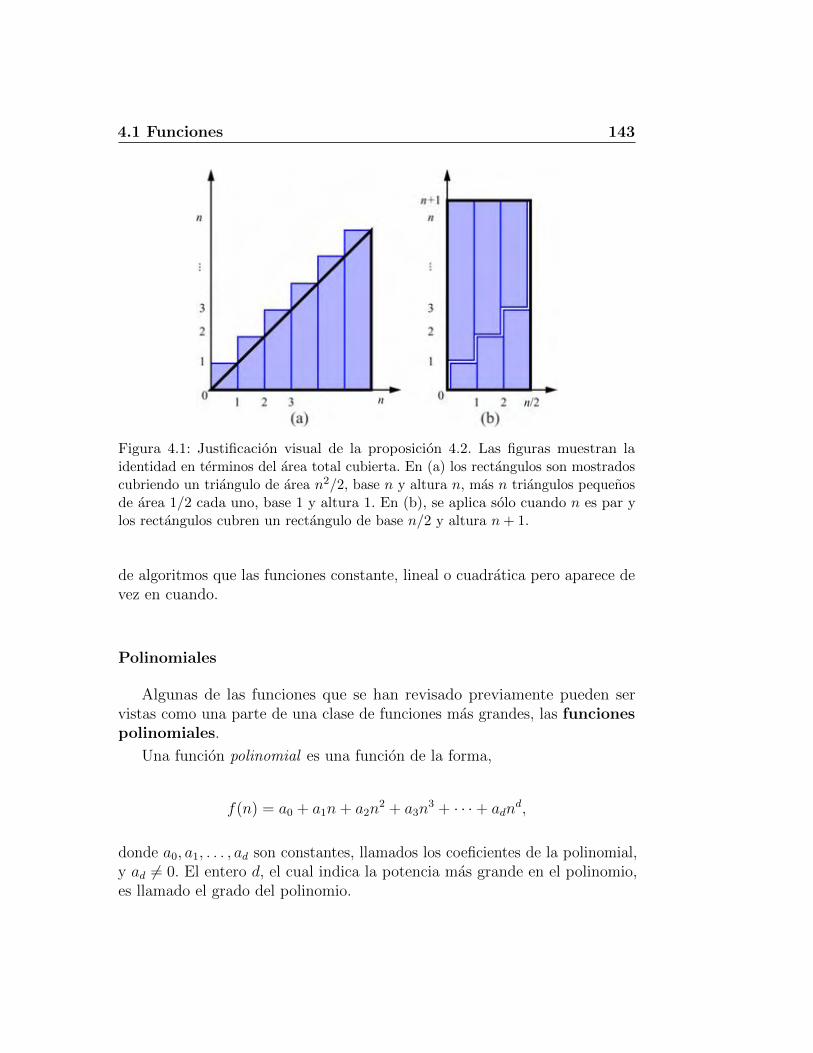
4.1 Funciones 143
Figura 4.1: Justificacion visual de la proposicion 4.2. Las figuras muestran laidentidad en terminos del area total cubierta. En (a) los rectangulos son mostradoscubriendo un triangulo de area n2/2, base n y altura n, mas n triangulos pequenosde area 1/2 cada uno, base 1 y altura 1. En (b), se aplica solo cuando n es par ylos rectangulos cubren un rectangulo de base n/2 y altura n + 1.
de algoritmos que las funciones constante, lineal o cuadratica pero aparece devez en cuando.
Polinomiales
Algunas de las funciones que se han revisado previamente pueden servistas como una parte de una clase de funciones mas grandes, las funcionespolinomiales.
Una funcion polinomial es una funcion de la forma,
f(n) = a0 + a1n+ a2n2 + a3n
3 + · · ·+ adnd,
donde a0, a1, . . . , ad son constantes, llamados los coeficientes de la polinomial,y ad 6= 0. El entero d, el cual indica la potencia mas grande en el polinomio,es llamado el grado del polinomio.

144 Herramientas de analisis
Sumatorias
Una notacion que aparece varias veces en el analisis de las estructuras dedatos y algoritmos es la sumatoria, la cual esta definida como sigue:
b∑i=a
f(i) = f(a) + f(a+ 1) + f(a+ 2) + · · ·+ f(b),
donde a y b son enteros y a ≤ b. Las sumatorias surgen en el analisis dealgoritmos y estructuras de datos porque los tiempos de ejecucion de ciclosnaturalmente dan estos.
La formula de la proposicion 4.2 se puede reescribir usando la sumatoriacomo:
n∑i=1
i =n(n+ 1)
2.
De igual forma, puede escribir un polinomio f(n) de grado d con coefi-cientes a0, . . . , ad como:
f(n) =d∑
i=0
aini.
La notacion de sumatoria da una forma breve de expresar sumas determinos incrementales que tienen una estructura regular.
4.1.7. La funcion exponencial
Otra funcion usada en el analisis de algoritmos es la funcion exponencial
f(n) = bn,
donde b es una constante positiva, llamada la base, y el argumento n es elexponente, es decir, la funcion f(n) asigna al argumento de entrada n elvalor obtenido de multiplicar la base b por sı misma n veces. En analisis dealgoritmos, la base mas comun para la funcion exponencial es b = 2. Porejemplo, si se tiene un ciclo que inicia realizando una operacion y entoncesdobla el numero de operaciones hechas con cada iteracion, entonces el numerode operaciones realizadas en la n-esima iteracion es 2n. Ademas, una palabraentera conteniendo n bits puede representar todos los enteros no negativos

4.1 Funciones 145
menores que 2n. La funcion exponencial tambien sera referida como funcionexponente.
En ocasiones se tienen otros exponentes ademas de n, por lo que es utilconocer unas cuantas reglas para trabajar con exponentes.Proposicion 4.3: REglas de exponentes dados enteros positivos a, b, yc, se tiene
1. (ba)c = bac
2. babc = ba+c
3. ba/bc = ba−c
Se puede extender la funcion exponencial a exponentes que son fraccioneso numeros reales y exponentes negativos, como sigue. Dado un entero positivok, se define b1/k como la k-esima raız de b, esto es, el numero r tal querk = b. Esta aproximacion permite definir cualquier potencia cuyo exponentepueda ser expresado como una fraccion, para ba/c = (ba)1/c, por la regla 1 deexponentes.
Se puede extender la funcion exponencial para definir bx para cualquiernumero real x, calculando series de numeros de la forma ba/c para fraccionesa/c que esten progresivamente mas y mas cerca a x. Dado un exponentenegativo d, se define bd = 1/b−d, lo cual corresponde a usar la regla 3 deexponentes con a = 0 y c = −d.
Sumas geometricas
Cuando se tiene un ciclo donde cada iteracion toma un factor multipli-cativo mayor que la previa, se puede analizar este ciclo usando la siguienteproposicion.Proposicion 4.4: Para cualquier entero n ≥ 0 y cualquier numero real a talque a > 0 y a 6= 1, considerar la sumatoria
n∑i=0
ai = 1 + a+ a2 + · · ·+ an
recordando que a0 = 1 si a > 0. Esta suma es igual a
an+1 − 1
a− 1.

146 Herramientas de analisis
Las sumatorias, como la mostrada en la proposicion anterior, son llamadassumatorias geometricas, porque cada termino es geometricamente mayorque el previo si a > 1. Por ejemplo, en la siguiente sumatoria
1 + 2 + 4 + 8 + · · ·+ 2n−1 = 2n − 1,
se calcula el entero mas grande que puede ser representado en notacion binariausando n bits.
4.1.8. Relaciones de crecimiento
El cuadro 4.1 muestra en orden de crecimiento cada una de las sietefunciones usadas principalmente en el analisis de algoritmos.
constante logarıtmica lineal n-log-n cuadratica cubica exponencial1 log n n n log n n2 n3 an
Cuadro 4.1: Clases de funciones. Se asume que a > 1 es una constante.
Se quisiera que las operaciones en estructuras de datos se ejecuten entiempos proporcionales a la constante o la logarıtmica, y que los algoritmoslo hagan en tiempo lineal o n-log-n. Los algoritmos con tiempos de ejecucioncuadratico o cubico son menos practicos, pero algoritmos con tiempos expo-nenciales son imposibles excepto para entradas pequenas. Las siete funcionesestan graficadas en la figura 4.2. Se uso base a = 2 para la funcion exponen-cial. Las funciones estan graficadas en una escala logarıtmica, para compararprincipalmente las relaciones de crecimiento como pendientes.
Funcion piso y techo
El valor de un logaritmo generalmente no es un entero, aunque el tiempode ejecucion de un algoritmo usualmente es dado por una cantidad entera, talcomo la cantidad de operaciones realizadas. Ası, el analisis de un algoritmopodrıa en ocasiones involucrar el uso de la funcion piso y la funcion techo,las cuales son definidas respectivamente como sigue:
bxc el entero mas grande menor que o igual a x.dxe el entero mas pequeno mayor que o igual a x.
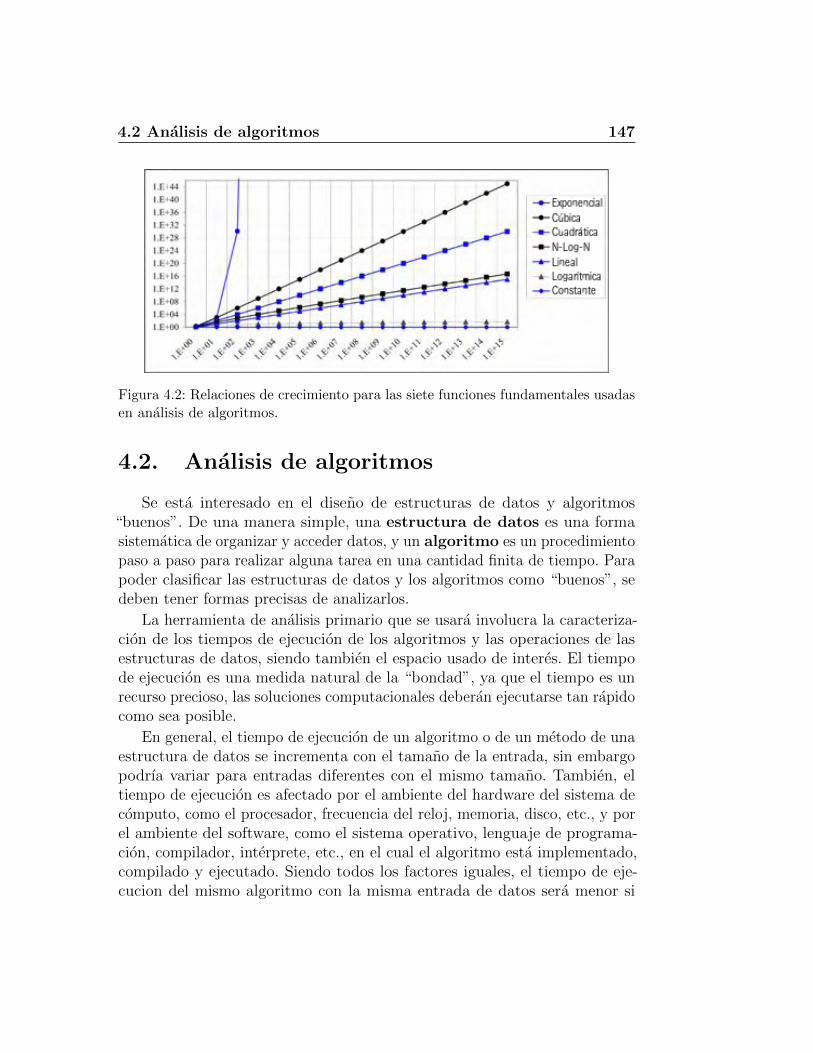
4.2 Analisis de algoritmos 147
Figura 4.2: Relaciones de crecimiento para las siete funciones fundamentales usadasen analisis de algoritmos.
4.2. Analisis de algoritmos
Se esta interesado en el diseno de estructuras de datos y algoritmos“buenos”. De una manera simple, una estructura de datos es una formasistematica de organizar y acceder datos, y un algoritmo es un procedimientopaso a paso para realizar alguna tarea en una cantidad finita de tiempo. Parapoder clasificar las estructuras de datos y los algoritmos como “buenos”, sedeben tener formas precisas de analizarlos.
La herramienta de analisis primario que se usara involucra la caracteriza-cion de los tiempos de ejecucion de los algoritmos y las operaciones de lasestructuras de datos, siendo tambien el espacio usado de interes. El tiempode ejecucion es una medida natural de la “bondad”, ya que el tiempo es unrecurso precioso, las soluciones computacionales deberan ejecutarse tan rapidocomo sea posible.
En general, el tiempo de ejecucion de un algoritmo o de un metodo de unaestructura de datos se incrementa con el tamano de la entrada, sin embargopodrıa variar para entradas diferentes con el mismo tamano. Tambien, eltiempo de ejecucion es afectado por el ambiente del hardware del sistema decomputo, como el procesador, frecuencia del reloj, memoria, disco, etc., y porel ambiente del software, como el sistema operativo, lenguaje de programa-cion, compilador, interprete, etc., en el cual el algoritmo esta implementado,compilado y ejecutado. Siendo todos los factores iguales, el tiempo de eje-cucion del mismo algoritmo con la misma entrada de datos sera menor si

148 Herramientas de analisis
la computadora tiene un procesador mas rapido, o si la implementacion eshecha en un programa compilado en codigo de maquina nativo en vez de unaimplementacion interpretada en una maquina virtual. Sin embargo, a pesarde las posibles variaciones que se dan por factores ambientales diferentes, seintenta enfocarse en la relacion entre el tiempo de ejecucion de un algoritmoy el tamano de su entrada.
Se esta interesado en caracterizar el tiempo de ejecucion del algoritmocomo una funcion del tamano de la entrada, para lo cual se requiere saber deuna forma apropiada de medirla.
4.2.1. Estudios experimentales
Si un algoritmo ha sido implementado, se puede estudiar su tiempo deejecucion usando varias pruebas de entrada y guardando el tiempo usadoen cada ejecucion. Para hacer estas mediciones de forma precisa se puedenhacer llamadas al sistema que estan construidas en el lenguaje, o en el sistemaoperativo, por ejemplo, usando el metodo System.currentTimeMillis().Tales pruebas asignan un tiempo de ejecucion especıfico a una entrada detamano especıfico, pero se esta interesado en determinar la dependenciageneral del tiempo de ejecucion de acuerdo al tamano de la entrada, paralo cual se deben hacer varios experimentos con muchas entradas de pruebadiferentes de varios tamanos. Entonces se pueden visualizar los resultados detales experimentos graficando el rendimiento de cada ejecucion del algoritmocomo un punto con coordenada x igual al tamano de la entrada, n, y lacoordenada y igual al tiempo de ejecucion, t, como se hace en la figura 4.3. Dela grafica y de los datos que lo soportan, se puede hacer un analisis estadısticoque encuentre la mejor funcion que represente el tamano de entrada a losdatos experimentales. Para que sea util, este analisis requiere que se escojanentradas de muestra buenas y se prueben lo suficiente para hacer que tengasentido lo indicado por la estadıstica acerca del tiempo de ejecucion delalgoritmo.
Las limitaciones que tienen los estudios experimentales son:
Los experimentos solo pueden hacerse en un conjunto limitado depruebas de entrada, por lo que quedaran entradas no incluidas quepodrıan ser importantes.
Es difıcil comparar los tiempos experimentales de ejecucion de dos
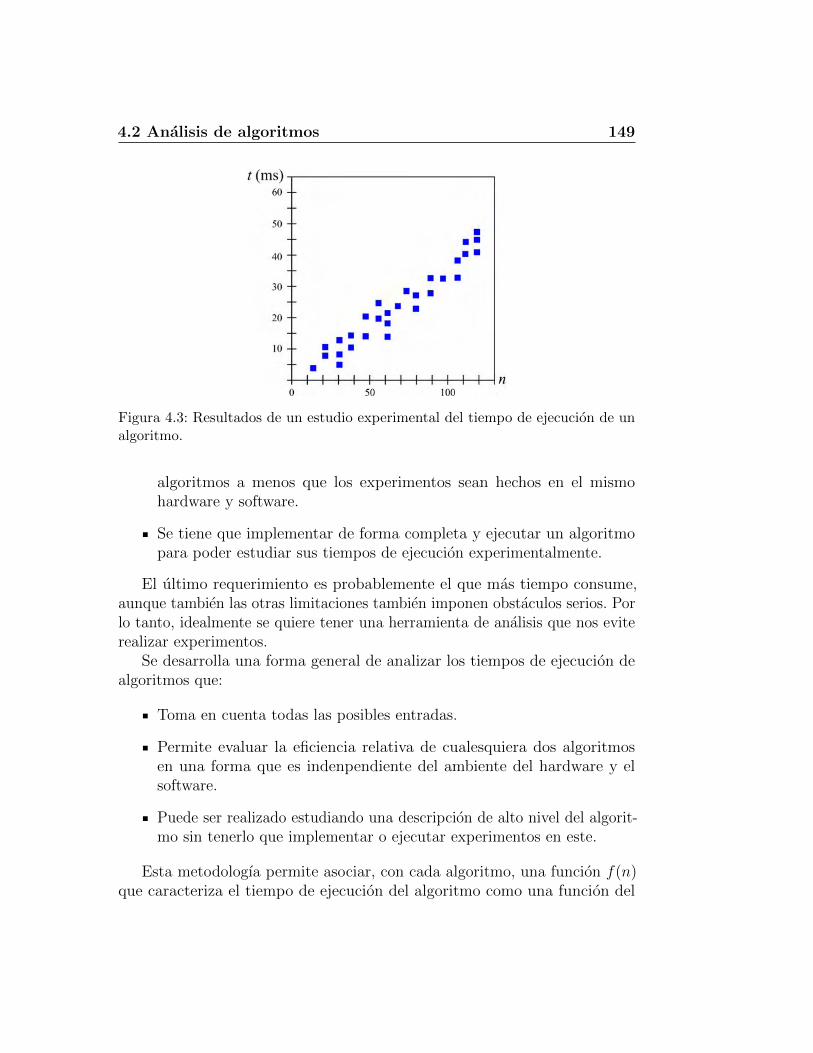
4.2 Analisis de algoritmos 149
Figura 4.3: Resultados de un estudio experimental del tiempo de ejecucion de unalgoritmo.
algoritmos a menos que los experimentos sean hechos en el mismohardware y software.
Se tiene que implementar de forma completa y ejecutar un algoritmopara poder estudiar sus tiempos de ejecucion experimentalmente.
El ultimo requerimiento es probablemente el que mas tiempo consume,aunque tambien las otras limitaciones tambien imponen obstaculos serios. Porlo tanto, idealmente se quiere tener una herramienta de analisis que nos eviterealizar experimentos.
Se desarrolla una forma general de analizar los tiempos de ejecucion dealgoritmos que:
Toma en cuenta todas las posibles entradas.
Permite evaluar la eficiencia relativa de cualesquiera dos algoritmosen una forma que es indenpendiente del ambiente del hardware y elsoftware.
Puede ser realizado estudiando una descripcion de alto nivel del algorit-mo sin tenerlo que implementar o ejecutar experimentos en este.
Esta metodologıa permite asociar, con cada algoritmo, una funcion f(n)que caracteriza el tiempo de ejecucion del algoritmo como una funcion del

150 Herramientas de analisis
tamano de entrada n. Las funciones tıpicas que seran encontradas incluyenlas siete funciones mencionadas al inicio del capıtulo.
4.2.2. Operaciones primitivas
Como se menciono previamente, los analisis experimentales son valiosos,pero tienen sus limitaciones. Si se desea analizar un algoritmo particularsin realizar experimentos en su tiempo de ejecucion, se puede realizar unanalisis directo de alto nivel en el pseudo-codigo. Se define un conjunto deoperaciones primitivas tales como las siguientes:
Asignar un valor a una variable.
Llamar un metodo.
Realizar una operacion aritmetica.
Comparar dos numeros.
Indexar en un arreglo.
Seguir la referencia a un objeto.
Regresar desde un metodo.
Conteo de operaciones primitivas
Una operacion primitiva corresponde a una instruccion de bajo nivel conun tiempo de ejecucion que es constante. Se cuentan cuantas operacionesprimitivas son ejecutadas, y se usa este numero t como una medida del tiempode ejecucion del algoritmo.
El conteo de las operaciones esta correlacionado a un tiempo de ejecu-cion actual en una computadora particular, para cada operacion primitivacorresponde a una instruccion constante en el tiempo, y solo hay numerofijo de operaciones primitivas. El numero, t, de operaciones primitivas queun algoritmo realiza sera proporcional al tiempo de ejecucion actual de esealgoritmo.
Un algoritmo podrıa ejecutarse mas rapido con algunas entradas que conotras del mismo tamano. Por lo tanto, se podrıa desear expresar el tiempode ejecucion de un algoritmo como la funcion del tamano de la entrada
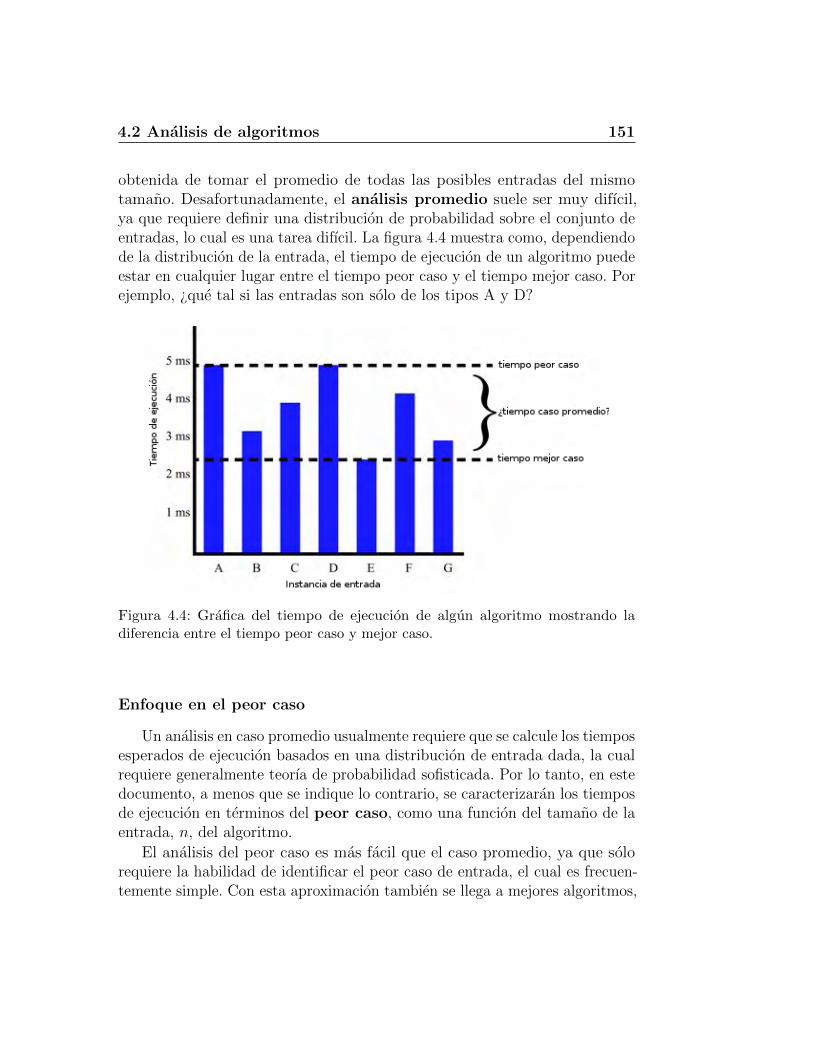
4.2 Analisis de algoritmos 151
obtenida de tomar el promedio de todas las posibles entradas del mismotamano. Desafortunadamente, el analisis promedio suele ser muy difıcil,ya que requiere definir una distribucion de probabilidad sobre el conjunto deentradas, lo cual es una tarea difıcil. La figura 4.4 muestra como, dependiendode la distribucion de la entrada, el tiempo de ejecucion de un algoritmo puedeestar en cualquier lugar entre el tiempo peor caso y el tiempo mejor caso. Porejemplo, ¿que tal si las entradas son solo de los tipos A y D?
Figura 4.4: Grafica del tiempo de ejecucion de algun algoritmo mostrando ladiferencia entre el tiempo peor caso y mejor caso.
Enfoque en el peor caso
Un analisis en caso promedio usualmente requiere que se calcule los tiemposesperados de ejecucion basados en una distribucion de entrada dada, la cualrequiere generalmente teorıa de probabilidad sofisticada. Por lo tanto, en estedocumento, a menos que se indique lo contrario, se caracterizaran los tiemposde ejecucion en terminos del peor caso, como una funcion del tamano de laentrada, n, del algoritmo.
El analisis del peor caso es mas facil que el caso promedio, ya que solorequiere la habilidad de identificar el peor caso de entrada, el cual es frecuen-temente simple. Con esta aproximacion tambien se llega a mejores algoritmos,

152 Herramientas de analisis
ya que logrando que el algoritmo se comporte bien para el peor caso, entoncestambien lo hara para cualquier entrada.
4.2.3. Notacion asintotica
En general, cada paso basico en una descripcion en pseudo-codigo o en unaimplementacion de lenguaje de alto nivel corresponde a un numero pequenode operaciones primitivas, excepto por las llamadas a metodos. Por lo tantose puede hacer un analisis simple de un algoritmo que estime el numero deoperaciones primitivas ejecutadas hasta un factor constante, por lo pasos en elpseudo-codigo. Se debe ser cuidadoso, ya que una sola lınea de pseudo-codigopodrıa comprender una cantidad de pasos en ciertos casos.
En el analisis de algoritmos se enfoca en la relacion de crecimiento deltiempo de ejecucion como una funcion del tamano de la entrada n, tomandouna aproximacion o una “foto panoramica”. Es en ocasiones suficiente consaber que el tiempo de ejecucion de un algoritmo, tal como maxArreglomostrado enseguida, crece proporcionalmente a n, siendo n veces un factorconstante que depende de la computadora, que su verdadero tiempo deejecucion
Algoritmo maxArreglo(A, n):Entrada: Un arreglo A con n ≥ 1 enteros.Salida: El elemento maximo en A.maxAct← A[0]para i← 1 hasta n− 1 hacersi maxAct < A[i] entoncesmaxAct← A[i]
regresar maxAct
Se analizan los algoritmos usando una notacion matematica para funcionesque no tiene en cuenta los factores constantes. Se caracterizan los tiemposde ejecucion de los algoritmos usando funciones que mapean el tamano dela entrada, n, a valores que corresponden al factor principal que determinala relacion de crecimiento en terminos de n. Esta aproximacion permiteenfocarse en los aspectos de la “foto panoramica” del tiempo de ejecucion deun algoritmo.
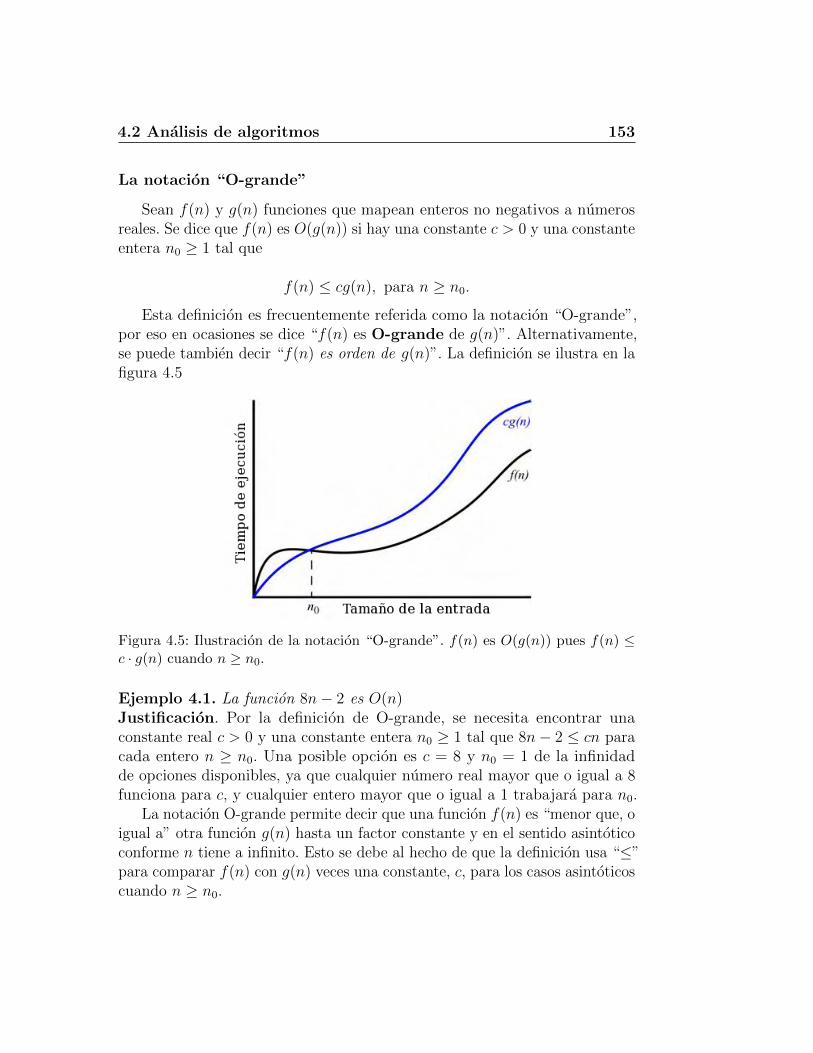
4.2 Analisis de algoritmos 153
La notacion “O-grande”
Sean f(n) y g(n) funciones que mapean enteros no negativos a numerosreales. Se dice que f(n) es O(g(n)) si hay una constante c > 0 y una constanteentera n0 ≥ 1 tal que
f(n) ≤ cg(n), para n ≥ n0.
Esta definicion es frecuentemente referida como la notacion “O-grande”,por eso en ocasiones se dice “f(n) es O-grande de g(n)”. Alternativamente,se puede tambien decir “f(n) es orden de g(n)”. La definicion se ilustra en lafigura 4.5
Figura 4.5: Ilustracion de la notacion “O-grande”. f(n) es O(g(n)) pues f(n) ≤c · g(n) cuando n ≥ n0.
Ejemplo 4.1. La funcion 8n− 2 es O(n)Justificacion. Por la definicion de O-grande, se necesita encontrar unaconstante real c > 0 y una constante entera n0 ≥ 1 tal que 8n− 2 ≤ cn paracada entero n ≥ n0. Una posible opcion es c = 8 y n0 = 1 de la infinidadde opciones disponibles, ya que cualquier numero real mayor que o igual a 8funciona para c, y cualquier entero mayor que o igual a 1 trabajara para n0.
La notacion O-grande permite decir que una funcion f(n) es “menor que, oigual a” otra funcion g(n) hasta un factor constante y en el sentido asintoticoconforme n tiene a infinito. Esto se debe al hecho de que la definicion usa “≤”para comparar f(n) con g(n) veces una constante, c, para los casos asintoticoscuando n ≥ n0.

154 Herramientas de analisis
Caracterizacion de tiempos de ejecucion con O-grande
La notacion O-grande es usada ampliamente para caracterizar los tiemposde ejecucion y el espacio requerido en terminos de algun parametro n, elcual cambia de problema a problema, pero es siempre definido como unamedida escogida del “tamano” del problema. Por ejemplo, si se esta interesadoen encontrar el elemento mas grande en un arreglo de enteros, como en elalgoritmo maxArreglo, n debera denotar la cantidad de elementos en elarreglo. Con la notacion O-grande, se puede decir la siguiente proposicionmatematicamente precisa del tiempo de ejecucion del algoritmo maxArreglopara cualquier computadora.
Proposicion 4.5: El algoritmo maxArreglo, para calcular el elementomaximo en un arreglo de n enteros, corre en tiempo O(n).
Justificacion. La cantidad de operaciones primitivas ejecutadas por el algo-ritmo maxArreglo en cada iteracion es una constante. Por lo tanto, comocada operacion primitiva se ejecuta en tiempo constante, se puede decir queel tiempo de ejecucion del algoritmo maxArreglo para una entrada detamano n es a lo mas una constante por n, esto es, se podrıa concluir que eltiempo de ejecucion del algoritmo maxArreglo es O(n).
Algunas propiedades de la notacion O-grande
La notacion O-grande permite ignorar los factores constantes y los terminosde orden menor y enfocarse en los componentes principales de una funcionque afectan su crecimiento.
Ejemplo 4.2. 5n4 + 3n3 + 2n2 + 4n+ 1 es O(n4)
Justificacion: Observar que 5n4+3n3+2n2+4n+1 ≤ (5+3+2+4+1)n4 = cn4,para c = 15, cuando n ≥ n0 = 1
Se puede caracterizar la relacion de crecimiento de cualquier funcionpolinomial.
Proposicion 4.6: Si f(n) es un polinomio de grado n, esto es
f(n) = a0 + a1n+ · · · adnd,
y ad > 0, entonces f(n) es O(nd).
Justificacion: observar que, para n ≥ 1, se tiene 1 ≤ n ≤ n2 ≤ · · · ≤ nd porlo tanto
a0 + a1n+ · · ·+ adnd ≤ (a0 + a1 + · · ·+ ad)n
d.

4.2 Analisis de algoritmos 155
Ası, se puede mostrar que f(n) es O(nd) definiendo c = a0 + a1 + · · ·+ ad yn0 = 1.
Ası, el termino de mayor grado en una funcion polinomial es el terminoque determina la razon de crecimiento asintotico del polinomio. Se muestran acontinuacion ejemplos adicionales, en donde se combinan las funciones vistasal inicio del capıtulo.
Ejemplo 4.3. 5n2 + 3n log n+ 2n+ 5 es O(n2).
Justificacion: 5n2 + 3n log n+ 2n+ 5 ≤ (5 + 3 + 2 + 5)n2 = cn2, para c =15 cuando n ≥ n0 = 2. Observar que n log n es cero para n = 1.
Ejemplo 4.4. 20n3 + 10n log n+ 5 es O(n3).
Justificacion: 20n3 + 10n log n+ 5 ≤ 35n3, para n ≥ 1.
Ejemplo 4.5. 3 log n+ 2 es O(log n).
Justificacion: 3 log n+ 2 ≤ 5 log n, para n ≥ 2. La razon por la que se usan ≥ 2 = n0 es porque log n es cero para n = 1.
Ejemplo 4.6. 2n+2 es O(2n).
Justificacion: 2n+2 = 2n22 = 4 · 2n; por lo tanto, se puede tomar c = 4 yn0 = 1 en este caso.
Ejemplo 4.7. 2n+ 100 log n es O(n).
Justificacion: 2n+ 100 log n ≤ 102n para n ≥ 2 = n0; por lo tanto, se puedetomar a c = 102 en este caso.
Caracterizacion de funciones en terminos mas simples
Se podrıa usar la notacion O-grande para caracterizar una funcion tancercana como sea posible. Para la funcion f(n) = 4n3 + 3n2 es cierto que esO(n5) o aun O(n4), pero es mas preciso decir que f(n) es O(n3). Tambiense considera de mal gusto incluir factores constantes y terminos de ordeninferior en la notacion O-grande. No esta de moda decir que la funcion 2n2
es O(4n2 + 6n log n), sin embargo esto es completamente correcto. Se debeintentar describir la funcion en O-grande en los terminos mas simples.
Las funciones descritas en la seccion 4 son las funciones mas comunesusadas en conjuncion con la notacion O-grande para caracterizar los tiemposde ejecucion y el espacio usado de los algoritmos. Ademas, se usan los nombresde estas funciones para referirse a los tiempos de ejecucion de los algoritmosque estan caracterizando. Por ejemplo, se podrıa decir que un algoritmo quese ejecuta con tiempo 4n2 + n log n en el peor caso como un algoritmo tiempocuadratico, ya que corre en tiempo O(n2). De igual forma, un algoritmo

156 Herramientas de analisis
ejecutandose en tiempo a lo mas 5n + 20 log n + 4 podrıa ser llamado unalgoritmo lineal.
Ω-grande
La notacion O-grande proporciona una forma asintotica de decir que unafuncion es “menor que o igual a” otra funcion, la siguiente notacion da unaforma asintotica para indicar que una funcion crece a un ritmo que es “mayorque o igual a” otra funcion.
Sean f(n) y g(n) funciones que mapean enteros no negativos a numerosreales. Se dice que f(n) es Ω(g(n)) (pronunciada “f(n) es notacion Omega-grande de g(n)”) si g(n) es O(f(n)), esto es, existe una constante real c > 0y una constante entera n0 ≥ 1 tal que
f(n) ≥ cg(n), para n ≥ n0.
Esta definicion permite decir asintoticamente que una funcion es mayorque o igual a otra, hasta un factor constante.Ejemplo 4.8. La funcion 3n log n+ 2n es Ω(n log n)Justificacion. 3n log n+ 2n ≥ 3n log n, para n ≥ 2.
Θ (Teta-grande)
Ademas, hay una notacion que permite decir que dos funciones crecen a lamisma velocidad, hasta unos factores constantes. Se dice que f(n) es Θ(g(n))(pronunciado “f(n) es Tetha-grande de g(n)”) si f(n) es O(g(n)) y f(n) esΩ(g(n)), esto es, existen constantes reales c′ > 0 y c′′ > 0, y una constanteentera n0 ≥ 1 tal que
c′g(n) ≤ f(n) ≤ c′′g(n), para n ≥ n0.
Ejemplo 4.9. 3n log n+ 4n+ 5 log n es Θ(n log n)Justificacion. 3n log n ≤ 3n log n + 4n + 5 log n ≤ (3 + 4 + 5)n log n paran ≥ 2.
4.2.4. Analisis asintotico
Suponiendo dos algoritmos que resuelven el mismo problema: un algoritmoA, el cual tiene tiempo de ejecuion O(n), y un algoritmo B, con tiempo de

4.2 Analisis de algoritmos 157
ejecucion O(n2). Se desea sabe cual algoritmo es mejor. Se sabe que B esO(n2), lo cual implica que el algoritmo A es asintoticamente mejor que elalgoritmo B, sin embargo para un valor pequeno de n, B podrıa tener untiempo de ejecucion menor que A.
Se puede emplear la notacion O-grande para ordenar clases de funcionespor su velocidad de crecimiento asintotico. Las siete funciones son ordenadaspor su velocidad de crecimiento incremental en la siguiente secuencia, esto es,si una funcion f(n) precede a una funcion g(n) en la secuencia, entonces f(n)es O(g(n)):
1 log n n n log n n2 n3 2n
Se muestra enseguida la tasa de crecimiento de algunas funciones impor-tantes a continuacion:
n log n n n log n n2 n3 2n
2 1 2 2 4 8 44 2 4 8 16 64 168 3 8 24 64 512 25616 4 16 64 256 4,096 65,53632 5 32 160 1,024 32,768 4,294,967,29664 6 64 384 4,096 262,144 1.84× 1019
128 7 128 896 16,384 2,097,152 3.40× 1038
256 8 256 2,048 65,536 16,777,216 1.15× 1077
512 9 512 4,608 262,144 134,217,728 1.34× 10154
La siguiente tabla explora el tamano maximo permitido para una instanciade entrada que es procesada por un algoritmo en 1 segundo, 1 minuto, y 1hora. Se muestra la importancia del diseno de un buen algoritmo, porque unalgoritmo lento asintoticamente es derrotado en una ejecucion grande porun algoritmo mas rapido asintoticamente, aun si el factor constante para elalgoritmo mas rapido es malo.
Tiempo Tamano maximo del problema (n)Ejecucion (µs) 1 segundo 1 minuto 1 hora
400n 2,500 150,000 9,000,0002n2 707 5,477 42,4262n 19 25 31

158 Herramientas de analisis
La importancia del diseno de un buen algoritmo va mas alla de que puedeser resuelto eficientemente en una computadora dada. Como se muestra enla siguiente tabla aun si se logra una aceleracion dramatica en el hardware,todavıa no se puede superar la desventaja de un algoritmo asintoticamentelento. La tabla muestra el tamano maximo del nuevo problema que se calculapara una cantidad fija de tiempo, suponiendo que los algoritmos con lostiempos de ejecucion dados son ejecutados ahora en una computadora 256veces mas rapida que la previa.
Tiempo de ejecucion Tamano maximo del nuevo problema400n 256m2n2 16m2n m+ 8
4.2.5. Uso de la notacion O-grande
Se considera un abuso de la notacion decir “f(n) ≤ O(g(n))”, ya quela notacion O-grande ya denota el concepto “menor que o igual a”. Deigual forma no es correcto completamente decir “f(n) = O(g(n)), porque nohay forma de que haga sentido la sentencia “O(g(n)) = f(n)”. Ademas, escompletamente incorrecto decir “f(n) ≥ O(g(n))” o “f(n) > O(g(n))”, yaque g(n) en la notacion O-grande indica una cota superior de f(n). Es mejordecir,
f(n)esO(g(n)).
Una expresion mas matematica para lo anterior es,
f(n) ∈ O(g(n)),
ya que la notacion O-grande esta indicando una coleccion completa defunciones.
Advertencia
El uso de la O-grande y las notaciones relacionadas puede ser enganosodebido a que los factores constantes que “ocultan” pueden ser muy grandes.Por ejemplo, es cierto que la funcion 10100n es O(n), si este es el tiempo deejecucion de un algoritmo siendo comparado con otro cuyo tiempo de ejecucion

4.2 Analisis de algoritmos 159
es 10n log n, se podrıa preferir el algoritmo de tiempo O(n log n), a pesar deque el algoritmo lineal es asintoticamente mas rapido. La decision es por elfactor constante, 10100, “un googol”, considerado por muchos astronomoscomo una cota superior de la cantidad de atomos en el universo observable.Serıa improbable tener un problema del mundo real que tenga esa cantidadcomo tamano de entrada. Por lo tanto, incluso cuando se usa la notacionO-grande, se debe ser consciente de los factores constantes y los terminos deorden inferior que se estan “ocultando”.
En general, cualquier algoritmo ejecutandose en tiempo O(n log n), conun factor constante razonable, debera ser considerado eficiente. Un metodocon tiempo O(n2) podrıa ser lo suficente rapido en algunos casos, por ejemplo,cuando n es pequeno. Pero un algoritmo ejecutandose en tiempo O(2n) casinunca deberıa ser considerado eficiente.
Tiempos de ejecucion exponencial
Si se deben separar los algoritmos eficientes de los ineficientes, se deberıandistinguir entre los algoritmos que se ejecutan en tiempo polinomial y los detiempo exponencial. Esto es, hacer la distincion entre los algoritmos con untiempo de ejecucion O(nc), para alguna constante c > 1, y aquellos con untiempo de ejecucion O(bn), para alguna constante b > 1. Podrıa existir “unprietito en el arroz” como un algoritmo ejecutandose en O(n100) no deberıa serconsiderado como eficiente. Aun ası, la distincion entre algoritmos de tiempopolinomial y exponencial es considerado una medida robusta de tratabilidad.
Las notaciones asintoticas de O-grande, Omega-grande, y Teta-grandedan un lenguaje conveniente para analizar estructuras de datos y algoritmos,ya que permiten concentrarse en la foto grande en vez de los detalles de bajonivel.
Analisis asintotico para promedios de prefijos
Se analizan dos algoritmos que resuelven el mismo problema pero teniendodiferentes tiempos de ejecucion. El problema es el calculo de promedios deprefijos de una secuencia de numeros. Es decir, dado un arreglo X con nnumeros, se quiere calcular un arreglo A tal que A[i] es el promedio de loselementos X[0], . . . , X[i], para i = 0, . . . , n− 1, esto es,
A[i] =
∑ij=0X[j]
i+ 1.

160 Herramientas de analisis
El calculo de promedios de prefijos tiene varias aplicaciones en economıay estadıstica.
Un algoritmo de tiempo cuadratico
Para el problema de promedios de prefijos, se muestra enseguida el algorit-mo promediosPrefijo1, el cual calcual cada elemento de A separadamente,de acuerdo a la definicion.Algoritmo promediosPrefijo1(X):Entrada: un arreglo X con n-elementos de numeros.Salida: un arreglo A con n-elementos de numeros
tal que A[i] es el promedio de X[0], . . . , X[i].Sea A un arreglo de n numeros.para i← 0 hasta n− 1 hacera← 0para j ← 0 hasta i hacera← a+X[j]
A[i]← a/(i+ 1)regresar arreglo A
El analisis del algoritmo promediosPrefijo1 es el siguiente:
Inicializar el arreglo A al inicio y devolver el arreglo al final puedeser hecho con una cantidad constante de operaciones primitivas porelemento, y toma tiempo O(n).
Para los dos ciclos anidados para, el cuerpo del ciclo externo, controladopor el contador i, es ejecutado n veces para i = 0, . . . , n − 1. Por loque sentencias como a← 0 y A[i]← a/(i+ 1) son ejecutadas n vecescada una. Estas dos sentencias, ademas del incremento y la pruebadel contador i, contribuyen una cantidad de operaciones primitivasproporcional a n, o sea, tiempo O(n).
El cuerpo del ciclo interno, controlado por el contador j, se ejecutai+ 1 veces, es decir, depende del valor actual del contador i del cicloexterno. De este modo, la sentencia a← a+X[j] en el ciclo interno esejecutada 1+2+3+ · · ·+n = n(n+1)/2 veces, ası que la sentencia en elciclo interno contribuye con tiempo O(n2). De igual manera sucede conel incremento y la prueba del contador j, que tambien tienen tiempoO(n2).

4.2 Analisis de algoritmos 161
El tiempo de ejecucion de promediosPrefijo1 esta dado por la suma delos tres terminos. Los primeros dos terminos son O(n), y el tercero es O(n2).Usando la proposicion 4.6, el tiempo de ejecucion es O(n2).
Un algoritmo de tiempo lineal
Para calcular los promedios de prefijos de forma mas eficiente, se puedeobservar que dos promedios consecutivos A[i− 1] y A[i] son similares:
A[i− 1] = (X[0] +X[1] + · · ·+X[i− 1])/i
A[i] = (X[0] +X[1] + · · ·+X[i])/(i+ 1)
Si se denota con Si la suma prefijo X[0] + X[1] + · · · + X[i], el calculode los promedios prefijo es A[i] = Si/(i + 1). Es facil llevar la suma prefijoactual cuando se recorre el arreglo X con un ciclo. El siguiente algoritmopromediosPrefijo2 usa la suma prefijo.Algoritmo promediosPrefijo2(X):Entrada: un arreglo X con n-elementos de numeros.Salida: un arreglo A con n-elementos de numeros
tal que A[i] es el promedio de X[0], . . . , X[i].Sea A un arreglo de n numeros.s← 0para i← 0 hasta n− 1 hacers← s+X[i]A[i]← s/(i+ 1)
regresar arreglo A
El analisis del tiempo de ejecucion del algoritmo promediosPrefijo2 esel siguiente:
Inicializar el arreglo A al inicio y devolver el arreglo al final puedeser hecho con una cantidad constante de operaciones primitivas porelemento, y toma tiempo O(n).
Inicializar la variable s al inicio toma tiempo O(1).
Hay un solo ciclo para, controlado por el contador i. El cuerpo delciclo es ejecutado n veces, para i = 0, . . . , n − 1. Ası las sentencias

162 Herramientas de analisis
s ← s + X[i] y A[i] ← s/(i + 1) son ejecutadas n veces cada uno.Ademas de las operaciones anteriores, las de incremento y prueba delcontador i tambien contribuyen una cantidad de operaciones primitivasproporcional a n, es decir, tiempo O(n).
El tiempo de ejecucion del algoritmo promediosPrefijo2 esta dado porla suma de los tres terminos. El primer termino y el ultimo son O(n), y elsegundo es O(1). Usando la proposicion 4.6, el tiempo de ejecucion es O(n),el cual es mucho mejor que el tiempo cuadratico de promediosPrefijo1.
4.2.6. Algoritmo recursivo para calcular potencias
Se revisa un ejemplo mas interesante de analisis de algoritmos, que esel elevar un numero x a un entero no negativo arbitrario, n. Es decir, sequiere calcular la funcion potencia p(x, n), definida como p(x, n) = xn.Esta funcion tiene una definicion recursiva basada en recursion lineal:
p(x, n) =
1 si n = 0x · p(x, n− 1) de otra forma.
Esta definicion da un algoritmo recursivo que usa O(n) llamadas al metodopara calcular p(x, n). Se puede calcular la funcion potencia mas rapido usandola siguiente definicion alterna, tambien basada en recursion lineal, la cualemplea una tecnica de cuadrado:
p(x, n) =
1 si n = 0x · p(x, (n− 1)/2)2 si n > 0 es imparp(x, n/2)2 si n > 0 es par.
Para mostrar como esta definicion trabaja, se dan los siguientes ejemplos:
24 = 2(4/2)2 = (24/2)2 = (22)2 = 42 = 16
25 = 21+(4/2)2 = 2(24/2)2 = 2(22)2 = 2(42) = 32
26 = 2(6/2)2 = (26/2)2 = (23)2 = 82 = 64
27 = 21+(6/2)2 = 2(26/2)2 = 2(23)2 = 2(82) = 128
De la ultima defincion se puede obtener el siguiente algoritmo Potencia:

4.2 Analisis de algoritmos 163
Algoritmo Potencia(x, n):Entrada: un numero x y un entero n ≥ 0.Salida: el valor xn.si n = 0 entoncesregresar 1
si n es impar entoncesy ← Potencia(x, (n− 1)/2)regresar x · y · y
sinoy ← Potencia(x, n/2)regresar y · y
Para analizar el tiempo de ejecucion del algoritmo, se observa que en cadallamada recursiva al metodo Potencia(x, n) se divide el exponente, n, por dos.Ası, hay O(log n) llamadas recursivas. Entonces, usando la recursion lineal yla tecnica del cuadrado, se reduce el tiempo de ejecucion para el calculo de lafuncion potencia de O(n) a O(log n).

164 Herramientas de analisis

Capıtulo 5
Pilas y colas
5.1. Pilas
Una pila (stack) es una coleccion de objetos que son insertados y removidosde acuerdo al principio ultimo en entrar, primero en salir, LIFO (last-infirst-out). Los objetos pueden ser insertados en una pila en cualquier momento,pero solamente el mas reciente insertado, es decir, el “ultimo” objeto puede serremovido en cualquier momento. Una analogıa de la pila es el dispensador deplatos que se encuentra en el mobiliario de alguna cafeterıa o cocina. Para estecaso, las operaciones fundamentales involucran push (empujar) platos y pop(sacar) platos de la pila. Cuando se necesita un nuevo plato del dispensador,se saca el plato que esta encima de la pila, y cuando se agrega un plato, seempuja este hacia abajo en la pila para que se convierta en el nuevo plato dela cima. Otro ejemplo son los navegadores Web de internet que guardan lasdirecciones de los sitios recientemente visitados en una pila. Cada vez que unusuario visita un nuevo sitio, esa direccion del sitio es empujada en la pila dedirecciones. El navegador, mediante el boton Volver atras, permite al usuariosacar los sitios previamente visitados.
5.1.1. El tipo de dato abstracto pila
Las pilas son las estructuras de datos mas simples, pero tambien estanentre las mas importantes, porque se usan en una gran cantidad de aplica-ciones diferentes que incluyen varias estructuras de datos mas sofisticadas.Formalmente, una pila es un tipo de dato abstracto que soporta los siguientesdos metodos:

166 Pilas y colas
push(e):inserta el elemento e, para que sea la cima de lapila.
pop():quita el elemento de la cima de la pila y lo regresa;un error ocurre si la pila esta vacıa.
Adicionalmente, tambien se podrıan definir los siguientes metodos:
size():regresa el numero de elementos en la pila.isEmpty():regresa un booleano indicando si la pila esta vacıa.
top():regresa el elemento de la cima de la pila, sin remo-verlo; un error ocurre si la pila esta vacıa.
La siguiente tabla muestra una serie de operaciones en la pila y su efectoen una pila de enteros inicialmente vacıa, observar que los elementos sonmetidos y sacados por el mismo lado, el lado derecho.
Operacion Salida Contenidopush(5) – (5)push(3) – (5,3)pop() 3 (5)push(7) – (5,7)pop() 7 (5)top() 5 (5)pop() 5 ()pop() “error” ()
isEmpty() true ()push(9) – (9)push(7) – (9,7)push(3) – (9,7,3)push(5) – (9,7,3,5)size() 4 (9,7,3,5)pop() 5 (9,7,3)push(8) – (9,7,3,8)pop() 8 (9,7,3)pop() 3 (9,7)
Una interfaz pila en Java
Debido a su importancia, la estructura de datos pila esta incluida co-mo una clase en el paquete java.util. La clase java.util.Stack es una

5.1 Pilas 167
estructura que guarda objetos genericos Java e incluye, entre otros, losmetodos push(), pop(), peek() (equivalente a top()), size(), y empty()
(equivalente a isEmpty()). Los metodos pop() y peek() lanzan la excep-cion EmptyStackException del paquete java.util si son llamados con pilasvacıas. Mientras sea conveniente solo usar la clase incorporada java.util.-
Stack, es instructivo aprender como disenar e implementar una pila “desdecero”.
Implementar un tipo de dato abstracto en Java involucra dos pasos. Elprimer paso es la definicion de una interfaz de programacion de aplica-ciones o API, o interfaz, la cual describe los nombres de los metodos quela estructura abstracta de datos soporta y como tienen que ser declarados yusados.
Ademas, se deben definir excepciones para cualquier condicion de errorque pueda originarse. Por ejemplo, la condicion de error que ocurre cuando sellama al metodo pop() o top() en una cola vacıa es senalado lanzando unaexcepcion de tipo EmptyStackException, la cual esta definida en el listado5.1
1 /**
2 * Excepci on Runtime lanzada cuando se intenta hacer una operaci on
3 * top o pop con una cola vac ıa.
4 */
5 public class EmptyStackException extends RuntimeException
6 public EmptyStackException(String err)
7 super(err);
8
9
Listado 5.1: Excepcion lanzada por los metodos pop() y top() de la interfaz pilacuando son llamados con una pila vacıa.
Una interfaz completa para el ADT pila esta dado en el listado 5.2. Estainterfaz es muy general ya que especifica que elementos de cualquier clase dada,y sus subclases, pueden ser insertados en la pila. Se obtiene esta generalidadmediante el concepto de genericos (seccion 2.5.2).
Para que un ADT dado sea para cualquier uso, se necesita dar una claseconcreta que implemente los metodos de la interfaz asociada con ese ADT. Seda una implementacion simple de la interfaz Stack en la siguiente subseccion.

168 Pilas y colas
1 /**
2 * Interfaz para una pila: una colecci on de objetos que son insertados
3 * y removidos de acuerdo al principio u ltimo en entrar , primero en salir.
4 * Esta interfaz incluye los me todos principales de java.util.Stack.
5 *
6 * @see EmptyStackException
7 */
8 public interface Stack <E>
9 /**
10 * Regresa el numero de elementos en la pila.
11 * @return numero de elementos en la pila.
12 */
13 public int size ();
14 /**
15 * Indica si la pila est a vacia.
16 * @return true si la pila est a vac ıa, de otra manera false.
17 */
18 public boolean isEmpty ();
19 /**
20 * Explorar el elemento en la cima de la pila.
21 * @return el elemento cima en la pila.
22 * @exception EmptyStackException si la pila est a vac ıa.
23 */
24 public E top()
25 throws EmptyStackException;
26 /**
27 * Insertar un elemento en la cima de la pila.
28 * @param elemento a ser insertado.
29 */
30 public void push (E elemento );
31 /**
32 * Quitar el elemento de la cima de la pila.
33 * @return elemento removido.
34 * @exception EmptyStackException si la pila est a vac ıa.
35 */
36 public E pop()
37 throws EmptyStackException;
38
Listado 5.2: Interfaz Stack con documentacion en estilo Javadoc. Se usa el tipoparametrizado generico, E, para que la pila pueda contener elementos de cualquierclase.
5.1.2. Implementacion de una pila usando un arreglo
Se puede implementar una pila guardando sus elementos en un arreglo. Lapila en esta implementacion consiste de una arreglo S de n elementos ademasde una variable entera t que da el ındice del elemento de la cima en el arregloS.
En Java el ındice para los arreglos inicia con cero, por lo que t se inicializa

5.1 Pilas 169
Figura 5.1: Implementacion de una pila con un arreglo S. El elemento de la cimaesta guardado en la celda S[t].
con -1, y se usa este valor de t para identificar una pila vacıa. Asimismo,se pueda usar t para determinar el numero de elementos (t+1). Se agregatambien una nueva excepcion, llamada FullStackException, para senalarel error que surge si se intenta insertar un nuevo elemento en una pila llena.La excepcion FullStackException es particular a esta implementacion y noesta definida en la ADT pila. Se dan los detalles de la implementacion de lapila usando un arreglo en los siguientes algoritmos.
Algoritmo size():regresar t+ 1
Algoritmo isEmpty():regresar (t < 0)
Algoritmo top():si isEmpty() entonces
lanzar una EmptyStackExceptionregresar S[t]
Algoritmo push(e):si size()= N entonces
lanzar una FullStackExceptiont← t+ 1S[t]← e
Algoritmo pop():si isEmpty() entonces
lanzar una EmptyStackExceptione← S[t]S[t]← nullt← t− 1regresar e

170 Pilas y colas
Analisis de la implementacion de pila con arreglos
La correctez de los metodos en la implementacion usando arreglos se tieneinmediatamente de la definicion de los propios metodos. Hay, sin embargo, unpunto medio interesante que involucra la implementacion del metodo pop().
Se podrıa haber evitado reiniciar el viejo S[t] a null y se podrıa tenertodavıa un metodo correcto. Sin embargo, hay una ventaja y desventaja enevitar esta asignacion que podrıa pensarse al implementar los algoritmos enJava. El equilibrio involucra el mecanismo colector de basura de Java quebusca en la memoria objetos que ya no son referenciados por objetos activos,y recupera este espacio para su uso futuro. Sea e = S[t] el elemento de lacima antes de que el metodo pop() sea llamado. Haciendo que S[t] tenga unareferencia nula, se indica que la pila no necesita mantener mas una referenciaal objeto e. Ademas, si no hay otras referencias activas a e, entonces el espaciode memoria usado por e sera reclamado por el colector de basura.
En la siguiente tabla se muestran los tiempos de ejecucion para los metodosen la ejecucion de una pila con un arreglo. Cada uno de los metodos de la pila enel arreglo ejecuta un numero constante de sentencias involucrando operacionesaritmeticas, comparaciones, y asignaciones. Ademas, pop() tambien llamaa isEmpty(), el cual tambien se ejecuta en tiempo constante. Por lo tanto,en esta implementacion del ADT pila, cada metodo se ejecuta en tiempoconstante, esto es, cada uno corre en tiempo O(1).
Metodo Tiemposize O(1)
isEmpty O(1)top O(1)push O(1)pop O(1)
La clase ArregloStack, listado 5.3, implementa la interfaz Stack. Se usael nombre simbolico, CAPACIDAD, para indicar el tamano del arreglo. Estevalor permite indicar la capacidad del arreglo en un solo lugar y que se vistoen todo el codigo.

5.1 Pilas 171
1 /**
2 * Implementaci on de la ADT pila usando un arreglo de longitud fija.
3 * Una excepci on es lanzada si la operaci on push es intentada cuando
4 * el tama~no de la pila es igual a la longitud del arreglo. Esta
5 * clase incluye los me todos principales de la clase agregada
6 * java.util.Stack.
7 *
8 */
9 public class ArregloStack <E> implements Stack <E>
10 protected int capacidad; // capacidad actual del arreglo del stack
11 public static final int CAPACIDAD = 1000; // capacidad por defecto
12 protected E[] S; // arreglo egenrico usado para implementar el stack
13 protected int t = -1; // ı ndice para la cima del stack
14 public ArregloStack ()
15 this(CAPACIDAD ); // capacidad por defecto
16
17 public ArregloStack(int cap)
18 capacidad = cap;
19 S = (E[]) new Object[capacidad ]; // el compilador podr ıa dar advertencia
20 // pero est a bien
21
22 public int size()
23 return (t + 1);
24
25 public boolean isEmpty ()
26 return (t < 0);
27
28 public void push(E elemento) throws FullStackException
29 if (size() == capacidad)
30 throw new FullStackException("La pila est a llena.");
31 S[++t] = elemento;
32
33 public E top() throws EmptyStackException
34 if (isEmpty ())
35 throw new EmptyStackException("La pila est a vac ıa.");
36 return S[t];
37
38 public E pop() throws EmptyStackException
39 if (isEmpty ())
40 throw new EmptyStackException("La pila est a vac ıa.");
41 E elemento = S[t];
42 S[t--] = null; // desreferenciar S[t] para el colector de basura.
43 return elemento;
44
45 public String toString ()
46 String s = "[";
47 if (size() > 0) s+= S[0];
48 for (int i = 1; i <= size ()-1; i++)
49 s += ", " + S[i];
50 return s + "]";
51
52 // Imprime informaci on del estado de la pila y de la u ltima operaci on
53 public void estado(String op, Object elemento)
54 System.out.print("------> " + op); // imprime esta operaci on
55 System.out.println(", regresa " + elemento ); // que fue regresado
56 System.out.print("resultado: num. elems. = " + size ());

172 Pilas y colas
57 System.out.print(", ¿est a vac ıo? " + isEmpty ());
58 System.out.println(", pila: " + this); // contenido de la pila
59
60 /**
61 * Prueba el programa haciendo una serie de operaciones en pilas ,
62 * imprimiendo las operaciones realizadas , los elementos regresados y
63 * el contenido de la pila involucrada , despues de cada operaci on.
64 */
65 public static void main(String [] args)
66 Object o;
67 ArregloStack <Integer > A = new ArregloStack <Integer >();
68 A.estado("new ArregloStack <Integer > A", null);
69 A.push (7);
70 A.estado("A.push (7)", null);
71 o = A.pop();
72 A.estado("A.pop()", o);
73 A.push (9);
74 A.estado("A.push (9)", null);
75 o = A.pop();
76 A.estado("A.pop()", o);
77 ArregloStack <String > B = new ArregloStack <String >();
78 B.estado("new ArregloStack <String > B", null);
79 B.push("Paco");
80 B.estado("B.push (\" Paco \")", null);
81 B.push("Pepe");
82 B.estado("B.push (\" Pepe \")", null);
83 o = B.pop();
84 B.estado("B.pop()", o);
85 B.push("Juan");
86 B.estado("B.push (\" Juan \")", null);
87
88
Listado 5.3: Implementacion de la interfaz Stack con un arreglo.
Salida ejemplo
Se muestra enseguida la salida del programa ArregloStack. Con el usode tipos genericos, se puede crear un ArregloStack A para guardar enterosy otro ArregloStack B para guardar String.
------> new ArregloStack<Integer> A, regresa null
resultado: num. elems. = 0, esta vacio = true, pila: []
------> A.push(7), regresa null
resultado: num. elems. = 1, esta vacio = false, pila: [7]
------> A.pop(), regresa 7
resultado: num. elems. = 0, esta vacio = true, pila: []
------> A.push(9), regresa null
resultado: num. elems. = 1, esta vacio = false, pila: [9]

5.1 Pilas 173
------> A.pop(), regresa 9
resultado: num. elems. = 0, esta vacio = true, pila: []
------> new ArregloStack<String> B, regresa null
resultado: num. elems. = 0, esta vacio = true, pila: []
------> B.push("Paco"), regresa null
resultado: num. elems. = 1, esta vacio = false, pila: [Paco]
------> B.push("Pepe"), regresa null
resultado: num. elems. = 2, esta vacio = false, pila: [Paco, Pepe]
------> B.pop(), regresa Pepe
resultado: num. elems. = 1, esta vacio = false, pila: [Paco]
------> B.push("Juan"), regresa null
resultado: num. elems. = 2, esta vacio = false, pila: [Paco, Juan]
Limitacion de la pila con un arreglo
La implementacion con un arreglo de una pila es simple y eficiente. Sinembargo, esta implementacion tiene un aspecto negativo—esta debe asumirun lımite superior fijo, CAPACIDAD, en el tamano de la pila. Para el ejemplomostrado en el listado 5.3 se escogio una capacidad de 1,000 arbitrariamente.Una aplicacion podrıa actualmente necesitar mucho menos espacio que esto,por lo que se tendrıa un desperdicio de memoria. Alternativamente, unaaplicacion podrıa necesitar mas espacio que esto, lo cual causarıa que laimplementacion de la pila genere una excepcion tan pronto como un programacliente intente rebasar la capacidad de la pila, por defecto 1,000 objetos. Apesar de la simplicidad y eficiencia, la pila implementada con arreglo no esprecisamente ideal.
Afortunadamente, hay otra implementacion, la cual se revisa a continua-cion, que no tiene una limitacion del tamano y usa espacio proporcional alnumero actual de elementos guardados en la pila. Sin embargo, en casos dondese tiene una buena estimacion del numero de elementos que se guardaran enla pila, la implementacion usando un arreglo es difıcil de vencer. Las pilastienen un papel importante en un numero de aplicaciones computacionales,por lo tanto es util tener una implementacion rapida del ADT pila, como unaimplementacion simple basada en el arreglo.
5.1.3. Implementacion de una pila usando lista simple
Se revisa la implementacion del ADT pila usando una lista simple enlazada.En el diseno se requiere decidir si la cima de la pila esta en la cabeza de la

174 Pilas y colas
lista o en la cola. La mejor opcion es en la cabeza ya que se pueden insertarelementos y borrar en tiempo constante. Por lo tanto, es mas eficiente tenerla cima de la pila en la cabeza de la lista. Tambien, para hacer la operacionsize() en tiempo constante, se lleva la cuenta del numero actual de elementosen una variable de instancia.
En vez de usar una lista ligada que solamente pueda guardar objetosde un cierto tipo, como se mostro en la seccion 3.3, se quiere, en este caso,implementar una pila generica usando una lista generica enlazada. Por lotanto, se necesita usar un nodo de tipo generico para implementar esta listaenlazada. Se muestra tal clase Nodo en el listado 5.4.
1 /**
2 * Nodo de una lista simple enlazada , la cual guarda referencias
3 * a su elemento y al siguiente nodo en la lista.
4 *
5 */
6 public class Nodo <E>
7 // Variables de instancia:
8 private E elemento;
9 private Nodo <E> sig;
10 /** Crea un nodo con referencias nulas a su elemento y al nodo sig. */
11 public Nodo()
12 this(null , null);
13
14 /** Crear un nodo con el elemento dado y el nodo sig. */
15 public Nodo(E e, Nodo <E> s)
16 elemento = e;
17 sig = s;
18
19 // Me todos accesores:
20 public E getElemento ()
21 return elemento;
22
23 public Nodo <E> getSig ()
24 return sig;
25
26 // Me todos modificadores:
27 public void setElemento(E nvoElem)
28 elemento = nvoElem;
29
30 public void setSig(Nodo <E> nvoSig)
31 sig = nvoSig;
32
33
Listado 5.4: La clase Nodo implementa un nodo generico para una lista simpleenlazada.

5.1 Pilas 175
Clase generica NodoStack
Una implementacion de una pila, usando una lista simple enlazada, se daen el listado 5.5. Todos los metodos de la interfaz Stack son ejecutados entiempo constante. Ademas de ser eficiente en el tiempo, esta implementacionde lista enlazada tiene un requerimiento de espacio que es O(n), donde n esel numero actual de elementos en la pila. Por lo tanto, esta implementacionno requiere que una nueva excepcion sea creada para manejar los problemasde desbordamiento de tamano. Se usa una variable de instancia cima parareferirse a la cabeza de la lista, la cual apunta al objeto null si la listaesta vacıa. Cuando se mete un nuevo elemento e en la pila, se crea un nuevonodo v para e, e es referenciado desde v, y se inserta v en la cabeza de lalista. De igual modo, cuando se quita un elemento de la pila, se remueve elnodo en la cabeza de la lista y se regresa el elemento. Por lo tanto, se realizantodas las inserciones y borrados de elementos en la cabeza de la lista.
1 public class NodoStack <E> implements Stack <E>
2 protected Nodo <E> cima; // referencia el nodo cabeza
3 protected int tam; // numero de elementos en la pila
4 /** Crear una pila vac ıa. */
5 public NodoStack ()
6 cima = null;
7 tam = 0;
8
9 public int size() return tam;
10 public boolean isEmpty ()
11 return cima == null;
12
13 public void push(E elem)
14 Nodo <E> v = new Nodo <E>(elem , cima); // crear un nuevo nodo y enlazarlo
15 cima = v;
16 tam ++;
17
18 public E top() throws EmptyStackException
19 if (isEmpty ()) throw new EmptyStackException("La pila est a vac ıa.");
20 return cima.getElemento ();
21
22 public E pop() throws EmptyStackException
23 if (isEmpty ()) throw new EmptyStackException("La pila est a vac ıa.");
24 E temp = cima.getElemento ();
25 cima = cima.getSig (); // desenlazar el antiguo nodo cima
26 tam --;
27 return temp;
28
29 public String toString ()
30 Nodo <E> cur = cima;
31 String s = "[";
32 while (cur != null)
33 if (cur == cima) // primer elemento
34 s += cur.getElemento ();
35 else

176 Pilas y colas
36 s += ", " + cur.getElemento ();
37 cur = cur.getSig ();
38
39 return s + "]";
40
41 // Imprime informaci on del estado de la pila y de la u ltima operaci on
42 public static void estado(Stack S, String op, Object elemento)
43 System.out.println("---------------------------------");
44 System.out.println(op);
45 System.out.println("Regresado: " + elemento );
46 String estadoVacio;
47 if (S.isEmpty ())
48 estadoVacio = "vac ıo";
49 else
50 estadoVacio = "no vac ıo";
51 System.out.println("tam = " + S.size() + ", " + estadoVacio );
52 System.out.println("Pila: " + S);
53
54 /**
55 * Programa de prueba que realiza una serie de operaciones en una pila
56 * e imprime la operaci on realizada , el elemento regresado
57 * y el contenido de la pila despu es de cada operaci on.
58 */
59 public static void main(String [] args)
60 Object o;
61 Stack <Integer > A = new NodoStack <Integer >();
62 estado (A, "Nueva Pila Vac ıa", null);
63 A.push (5);
64 estado (A, "push (5)", null);
65 A.push (3);
66 estado (A, "push (3)", null);
67 A.push (7);
68 estado (A, "push (7)", null);
69 o = A.pop();
70 estado (A, "pop()", o);
71 A.push (9);
72 estado (A, "push (9)", null);
73 o = A.pop();
74 estado (A, "pop()", o);
75 o = A.top();
76 estado (A, "top()", o);
77
78
Listado 5.5: Clase NodoStack implementando la interfaz Stack usando una listasimple enlazada con los nodos genericos del listado 5.4.
5.1.4. Invertir un arreglo con una pila
Se puede usar una pila para invertir los elementos en un arreglo, ası elproblema de la seccion 3.6 se resuelve sin recursion. La idea basica es metertodos los elementos del arreglo en orden en una pila y luego rellenar el arreglo

5.1 Pilas 177
sacando los elementos de la pila, el listado 5.6 muestra la implementacion deesta idea. En el metodo invertir() se muestra como se pueden usar tiposgenericos en una aplicacion simple que usa una pila generica. En particular,cuando los elementos son sacados de la pila en el ejemplo, estos son automati-camente regresados como elementos del tipo E; por lo tanto, estos pueden serinmediatamente regresados al arreglo de entrada. Se muestran dos ejemplosque usan este metodo.
1 public static <E> void invertir(E[] a)
2 Stack <E> S = new ArregloStack <E>(a.length );
3 for(int i=0; i<a.length; i++)
4 S.push(a[i]);
5 for(int i=0; i<a.length; i++)
6 a[i] = S.pop ();
7
8 /** Rutina para probar la inversi on de arreglos */
9 public static void main(String args [])
10 // autoboxing: a partir de Java 1.5, hace la conversi on de tipos
11 // primitivos a objetos autom a ticamente y viceversa.
12 // Se usa a continuaci on.
13 Integer [] a = 4, 8, 15, 16, 23, 42;
14 String [] s = "Jorge","Paco","Pedro","Juan","Marta";
15 System.out.println("a = "+Arrays.toString(a));
16 System.out.println("s = "+Arrays.toString(s));
17 System.out.println("Invirtiendo ...");
18 invertir(a);
19 invertir(s);
20 System.out.println("a = "+Arrays.toString(a));
21 System.out.println("s = "+Arrays.toString(s));
22
23
Listado 5.6: Metodo generico para invertir los elementos en un arreglo genericomediante una pila de la interfaz Stack<E>
La salida del listado 5.6 se muestra a continuacion:
a = [4, 8, 15, 16, 23, 42]
s = [Jorge, Paco, Pedro, Juan, Marta]
Invirtiendo ...
a = [42, 23, 16, 15, 8, 4]
s = [Marta, Juan, Pedro, Paco, Jorge]
5.1.5. Aparear parentesis y etiquetas HTML
En esta subseccion, se exploran dos aplicaciones relacionadas de pilas, laprimera es para el apareamiento de parentesis y sımbolos de agrupamiento enexpresiones aritmeticas.

178 Pilas y colas
Las expresiones aritmeticas pueden contener varios pares de sımbolos deagrupamiento, tales como:
Parentesis: “(” y “)”
Llaves: “” y “”
Corchetes: “[” y “]”
Sımbolos de la funcion piso: “b” y “c”
Sımbolos de la funcion techo: “d” y “e”
y cada sımbolo de apertura debera aparearse con su correspondiente sımbolode cierre. Por ejemplo, un corchete izquierdo, “[”, debera aparearse con sucorrespondiente corchete derecho, “]”, como en la siguiente expresion:
[(5 + x)− (y + z)].
Los siguientes ejemplos ilustran este concepto:
Correcto: ()(())([()])
Correcto: ((()(())([()])))
Incorrecto: )(())([()])
Incorrecto: ([ ])
Incorrecto: (
Un algoritmo para el apareamiento de parentesis
Un problema importante en el procesamiento de expresiones aritmeticas esasegurar que los sımbolos de agrupamiento se apareen correctamente. Se puedeusar una pila S para hacer el apareamiento de los sımbolos de agrupamientoen una expresion aritmetica con una sola revision de izquierda a derecha. Elalgoritmo prueba que los sımbolos izquierdo y derecho se apareen y tambienque ambos sımbolos sean del mismo tipo.
Suponiendo que se da una secuencia X = x0x1x2 . . . xn−1, donde cada xi esun sımbolo que puede ser un sımbolo de agrupamiento, un nombre de variable,un operador aritmetico, o un numero. La idea basica detras de la revision de

5.1 Pilas 179
que los sımbolos de agrupamiento en S empaten correctamente, es procesar lossımbolos en X en orden. Cada vez que se encuentre un sımbolo de apertura,se mete ese sımbolo en S, y cada vez que se encuentre un sımbolo de cierre, sesaca el sımbolo de la cima de la pila S, suponiendo que S no esta vacıa, y serevisa que esos sımbolos sean del mismo tipo. Suponiendo que las operacionespush y pop son implementadas para ejecutarse en tiempo constante, estealgoritmo corre en tiempo O(n), o sea lineal. Se da un pseudocodigo de estealgoritmo a continuacion.Algoritmo ApareamientoParentesis(X,n):Entrada: Un arreglo X de n sımbolos, cada uno de los cuales
es un sımbolo de agrupamiento, una variable, un operadoraritmetico, o un numero.
Salida: true si y solo si todos los sımbolos de agrupamientoen X se aparean.
Sea S una pila vacıapara i← 0 hasta n− 1 hacersi X[i] es un sımbolo de apertura entoncesS.push(X[i])
si no Si X[i] es sımbolo de cierre entoncessi S.isEmpty() entoncesregresar false nada para aparear
si S.pop() no empata el tipo de X[i] entoncesregresar false tipo incorrecto
si S.isEmpty() entoncesregresar true cada sımbolo apareado
si noregresar false algunos sımbolos no empataron
Apareamiento de etiquetas en un documento HTML
Otra aplicacion en la cual el apareamiento es importante es en la validacionde documentos HTML. HTML es el formato estandar para documentoshiperenlazados en el Internet. En un documento HTML, porciones de textoestan delimitados por etiquetas HTML. Una etiqueta simple de aperturaHTML tiene la forma “<nombre>” y la correspondiente etiqueta de cierre tienela forma “</nombre>”. Las etiquetas HTML comunmente usadas incluyen
body: cuerpo del documento

180 Pilas y colas
h1: seccion cabecera
blockquote: seccion sangrada
p: parrafo
ol: lista ordenada
li: elemento de la lista
Idealmente, un documento HTML deberıa tener todas sus etiquetas apa-readas, sin embargo varios navegadores toleran un cierto numero de etiquetasno apareadas.
El algoritmo de la seccion para el apareamiento de parentesis puede serusado para aparear las etiquetas en un documento HTML. En el listado 5.7se da un programa en Java para aparear etiquetas en un documento HTMLleıdo de la entrada estandar. Por simplicidad, se asume que todas las etiquetasson etiquetas simples de apertura y cierre, es decir sin atributos, y que nohay etiquetas formadas incorrectamente. El metodo esHTMLApareada usa unapila para guardar los nombres de las etiquetas
1 import java.io.IOException;
2 import java.util.Scanner;
34 /** Prueba simplificada de apareamiento de etiquetas en un documento HTML. */
5 public class HTML
6 /** Quitar el primer car acter y el u litmo de una <etiqueta > cadena. */
7 public static String quitarExtremos(String t)
8 if (t.length () <= 2 ) return null; // esta es una etiqueta degenerada
9 return t.substring (1,t.length ()-1);
10
11 /** Probar si una etiqueta desnuda (sin los sı mbolos inicial y final)
12 * esta vac ıa o es una etiqueta verdadera de apertura. */
13 public static boolean esEtiquetaApertura(String etiqueta)
14 return etiqueta.length ()==0 || etiqueta.charAt (0)!= ’/’;
15
16 /** Probar si etiqueta1 desnuda aparea con etiqueta2 de cierre. */
17 public static boolean seAparean(String etiqueta1 , String etiqueta2)
18 // probar contra el nombre despu es de ’/’
19 return etiqueta1.equals(etiqueta2.substring (1));
20
21 /** Probar si cada etiqueta de apertura tiene una etiqueta de cierre. */
22 public static boolean esHTMLApareada(String [] etiqueta)
23 Stack <String > S = new NodoStack <String >(); // Pila para aparear etiquetas
24 for (int i=0; (i<etiqueta.length )&&( etiqueta[i]!= null); i++)
25 if (esEtiquetaApertura(etiqueta[i]))
26 S.push(etiqueta[i]); // etiqueta apertura; meterla en la pila
27 else
28 if (S.isEmpty ())
29 return false; // nada para aparear

5.2 Colas 181
30 if (! seAparean(S.pop(), etiqueta[i]))
31 return false; // apareamiento incorrecto
32
33 if (S.isEmpty ()) return true; // se apareo todo
34 return false; // hay algunas etiquetas que nunca fueron apareadas
35
36 public final static int CAPACIDAD = 1000; // Capacidad del arreglo etiqueta
37 /* Dividir un documento HTML en un arreglo de etiquetas html */
38 public static String [] parseHTML(Scanner s)
39 String [] etiqueta = new String[CAPACIDAD ]; // el arreglo etiqueta
40 int contador = 0; // contador de etiquetas
41 String elemento; // elemento regresado por el scanner s
42 while (s.hasNextLine ())
43 while (( elemento=s.findInLine(" <[^>]*>"))!= null) // encontrar sig etiq
44 etiqueta[contador ++]= quitarExtremos(elemento );
45 s.nextLine (); // ir a la siguiente lınea
46
47 return etiqueta; // arreglo de etiquetas desnudas
48
49 public static void main(String [] args) throws IOException // probador
50 System.out.print("El archivo de entrada es un documento ");
51 if (esHTMLApareada(parseHTML(new Scanner(System.in))))
52 System.out.println("HTML apareado");
53 else
54 System.out.println("HTML NO apareado");
55
56
Listado 5.7: Clase HTML para revisar el apareamiento de las etiquetas en un docu-mento HTML.
5.2. Colas
Otra estructura de datos fundamental es la cola (queue). Una cola es unacoleccion de objetos que son insertados y removidos de acuerdo al principioprimero en entrar, primero en salir, o FIFO (first-in first-out). Esto es, loselementos pueden ser insertados en cualquier momento, pero solo el elementoque ha estado en la cola por mas tiempo es el siguiente en ser removido.
Se dice que los elementos entran a una cola por la parte de atras y sonremovidos del frente. La metafora para esta terminologıa es una fila de genteesperando para subir a un juego mecanico. La gente que espera para tal juegoentra por la parte trasera de la fila y se sube al juego desde el frente de lalınea.

182 Pilas y colas
5.2.1. Tipo de dato abstracto cola
El tipo de dato abstracto cola define una coleccion que guarda los objetosen una secuencia, donde el acceso al elemento y borrado estan restringidosal primer elemento en la secuencia, el cual es llamado el frente de la cola, yla insercion del elemento esta restringida al final de la secuencia, la cual esllamada la parte posterior de la cola. Esta restriccion forza la regla de quelos elementos son insertados y borrados en una cola de acuerdo al principioprimero en entrar, primero en salir, FIFO.
El ADT cola soporta los siguientes dos metodos fundamentales:
enqueue(e):insertar el elemento e en la parte posterior de lacola.
dequeue():quitar el elemento del frente de la cola y regresarlo;un error ocurre si la cola esta vacıa.
Adicionalmente, de igual modo como que con el ADT pila, el ADT colaincluye los siguientes metodos de apoyo:
size():regresar el numero de elementos en la cola.isEmpty():regresar un booleano indicando si la cola esta vacıa.front():regresar el elemento del frente de la cola, sin remo-
verlo; un error ocurre si la cola esta vacıa.
La siguiente tabla muestra una serie de operaciones de cola y su efecto enuna cola Q inicialmente vacıa de objetos enteros. Por simplicidad, se usanenteros en vez de objetos enteros como argumentos de las operaciones.

5.2 Colas 183
Operacion Salida frente← Q← colaenqueue(5) – (5)enqueue(3) – (5,3)dequeue() 5 (3)enqueue(7) – (3,7)dequeue() 3 (7)front() 7 (7)dequeue() 7 ()dequeue() “error” ()isEmpty() true ()enqueue(9) – (9)enqueue(7) – (9,7)
size() 2 (9,7)enqueue(3) – (9,7,3)enqueue(5) – (9,7,3,5)dequeue() 9 (7,3,5)
Hay varias aplicaciones posibles para las colas. Tiendas, teatros, centrosde reservacion, y otros servicios similares que tıpicamente procesen peticionesde clientes de acuerdo al principio FIFO. Una cola serıa por lo tanto unaopcion logica para una estructura de datos que maneje el procesamiento detransacciones para tales aplicaciones.
Interfaz java.util.Queue
El API de Java proporciona una interfaz cola, java.util.Queue, la cualtiene funcionalidad similar al ADT cola, dado previamente, pero la documen-tacion para esta interfaz no indica que solo soporte el principio FIFO. Cuandose soporta FIFO, los metodos de las dos interfaces son equivalentes.
ADT Queue Interfaz java.util.Queue
size() size()
isEmpty() isEmpty()
enqueue(e) add(e) o offer(e)dequeue() remove() o poll()
front() peek() o element()
Hay clases concretas del paquete java.util.concurrent de Java queimplementan la interfaz java.util.Queue con el principio FIFO como:ArrayBlockingQueue, ConcurrentLinkedQueue y LinkedBlockingQueue

184 Pilas y colas
Interfaz cola
Una interfaz Java para el ADT cola se proporciona en el listado 5.8. Estainterfaz generica indica que objetos de tipo arbitrario pueden ser insertadosen la cola. Por lo tanto, no se tiene que usar conversion explıcita cuando seremuevan elementos.
Los metodos size() e isEmpty() tienen el mismo significado como suscontrapartes en el ADT pila. Estos dos metodos, al igual que el metodofront(), son conocidos como metodos accesores, por su valor regresado y nocambian el contenido de la estructura de datos.
1 /**
2 * Interfaz para una cola: una colecci on de elementos que son insertados
3 * y removidos de acuerdo con el principio primero en entrar , primero en
4 * salir.
5 *
6 * @see EmptyQueueException
7 */
8 public interface Queue <E>
9 /**
10 * Regresa el numero de elementos en la cola.
11 * @return numero de elementos en la cola.
12 */
13 public int size ();
14 /**
15 * Indica si la cola est a vac ıa
16 * @return true si la cola est a vac ıa, false de otro modo.
17 */
18 public boolean isEmpty ();
19 /**
20 * Regresa el elemento en el frente de la cola.
21 * @return elemento en el frente de la cola.
22 * @exception EmptyQueueException si la cola est a vac ıa.
23 */
24 public E front() throws EmptyQueueException;
25 /**
26 * Insertar un elemento en la zaga de la cola.
27 * @param elemento nuevo elemento a ser insertado.
28 */
29 public void enqueue (E element );
30 /**
31 * Quitar el elemento del frente de la cola.
32 * @return elemento quitado.
33 * @exception EmptyQueueException si la cola est a vac ıa.
34 */
35 public E dequeue () throws EmptyQueueException;
36
Listado 5.8: Interfaz Queue con documentacion estilo Javadoc.

5.2 Colas 185
5.2.2. Implementacion simple de la cola con un arreglo
Se presenta una realizacion simple de una cola mediante un arreglo, Q,de capacidad fija, guardando sus elementos. Como la regla principal con eltipo ADT cola es que se inserten y borren los objetos de acuerdo al principioFIFO, se debe decidir como se va a llevar el frente y la parte posterior de lacola.
Una posibilidad es adaptar la aproximacion empleada para la implemen-tacion de la pila, dejando que Q[0] sea el frente de la cola y permitiendo quela cola crezca desde allı. Sin embargo, esta no es una solucion eficiente, paraesta se requiere que se muevan todos los elementos hacia adelante una celdacada vez que se haga la operacion dequeue. Tal implementacion podrıa tomarpor lo tanto tiempo O(n) para realizar el metodo dequeue(), donde n es elnumero actual de objetos en la cola. Si se quiere lograr tiempo constante paracada metodo de la cola, se necesita una aproximacion diferente.
Usar arreglo en forma circular
Para evitar mover objetos una vez que son colocados en Q, se definen dosvariables f y r, que tienen los siguientes usos:
f es un ındice a la celda de Q guardando el primer elemento de lacola, el cual es el siguiente candidato a ser eliminado por una operaciondequeue, a menos que la cola este vacıa, en tal caso f = r.
r es un ındice a la siguiente celda del arreglo disponible en Q.
Inicialmente, se asigna f = r = 0, lo cual indica que la cola esta vacıa.Cuando se quita un elemento del frente de la cola, se incrementa f para indicarla siguiente celda. Igualmente, cuando se agrega un elemento, se guarda esteen la celda Q[r] y se incrementa r para indizar la siguiente celda disponible enQ. Este esquema permite implementar los metodos front(), enqueue(), ydequeue() en tiempo constante, esto es, tiempo O(1). Sin embargo, todavıahay un problema con esta aproximacion.
Considerar, por ejemplo, que sucede si repetidamente se agrega y se quitaun solo elemento N veces. Se tendrıa f = r = N . Si se intentara entoncesinsertar el elemento una vez mas, se podrıa obtener un error de arreglo fuerade lımites, ya que las N localidades validas en Q son de Q[0] a Q[N − 1],aunque hay espacio en la cola para este caso. Para evitar este problema y

186 Pilas y colas
poder utilizar todo el arreglo Q, se permite que los ındices reinicien al finalde Q. Esto es, se ve ahora a Q como un “arreglo circular” que va de Q[0] aQ[N − 1] y entonces inmediatamente regresan a Q[0] otra vez, ver figura 5.2.
Figura 5.2: Usando arreglo Q en un modo circular: (a) la configuracion “normal”con f ≤ r; (b) la configuracion “envuelto alrededor de” con r < f
Implementar esta vista circular de Q es facil. Cada vez que se incrementef o r, se calcula este incremento como “(f + 1) mod N” o “(r + 1) mod N”,respectivamente.
El operador “mod” es el operador modulo, el cual es calculado tomandoel residuo despues de la division entera. Por ejemplo, 14 dividido por 4 es 3con residuo 2, ası 14 mod 4 = 2. Especıficamente, dados enteros x y y talque x ≥ 0 y y ≥ 0, se tiene x mod y = x− bx/ycy. Esto es, si r = x mod y,entonces hay un entero no negativo q, tal que x = qy + r. Java usa “ %” paradenotar el operador modulo. Mediante el uso del operador modulo, se puedever a Q como un arreglo circular e implementar cada metodo de la cola enuna cantidad constante de tiempo, es decir, tiempo O(1). Se describe comousar esta aproximacion para implementar una cola enseguida.Algoritmo size():
return (N − f + r) mod N
Algoritmo isEmpty():return (f = r)
Algoritmo front():si isEmpty() entonces
lanzar una EmptyQueueExceptionreturn Q[f ]

5.2 Colas 187
Algoritmo enqueue(e):si size()= N − 1 entonces
lanzar una FullQueueExceptionQ[r]← er ← (r + 1) mod N
Algoritmo dequeue():si isEmpty() entonces
lanzar una EmptyQueueExceptione← Q[f ]Q[f ]← nullf ← (f + 1) mod Nreturn e
La implementacion anterior contiene un detalle importante, la cual podrıaser ignorada al principio. Considerar la situacion que ocurre si se agregan Nobjetos en Q sin quitar ninguno de ellos. Se tendrıa f = r, la cual es la mismacondicion que ocurre cuando la cola esta vacıa. Por lo tanto, no se podrıadecir la diferencia entre una cola llena y una vacıa en este caso. Existen variasformas de manejarlo.
La solucion que se describe es considerando que Q no puede tener mas deN − 1 objetos. Esta regla simple para manejar una cola llena se consideraen el algoritmo enqueue dado previamente. Para senalar que no se puedeninsertar mas elementos en la cola, se emplea una excepcion especıfica, llamadaFullQueueException. Para determinar el tamano de la cola se hace conla expresion (N − f + r) mod N , la cual da el resultado correcto en unaconfiguracion “normal”, cuando f ≤ r, y en la configuracion “envuelta”cuando r < f . La implementacion Java de una cola por medio de un arregloes similar a la de la pila, y se deja como ejercicio.
Al igual que con la implementacion de la pila con arreglo, la unica desven-taja de la implementacion de la cola con arreglo es que artificialmente se ponela capacidad de la cola a algun valor fijo. En una aplicacion real, se podrıaactualmente necesitar mas o menos capacidad que esta, pero si se tiene unabuena estimacion de la capacidad, entonces la implementacion con arreglo esbastante eficiente.
La siguiente tabla muestra los tiempos de ejecucion de los metodos deuna cola empleando un arreglo. Cada uno de los metodos en la realizacionarreglo ejecuta un numero constante de sentencias involucrando operacionesaritmeticas, comparaciones, y asignaciones. Por lo tanto, cada metodo en esta

188 Pilas y colas
implementacion se ejecuta en tiempo O(1).
Metodo Tiemposize O(1)
isEmpty O(1)front O(1)enqueue O(1)dequeue O(1)
5.2.3. Implementacion con una lista enlazada
Se puede implementar eficientemente el ADT cola usando una lista genericasimple ligada. Por razones de eficiencia, se escoge el frente de la cola para queeste en la cabeza de la lista, y la parte posterior de la cola para que este enla cola de la lista. De esta forma se quita de la cabeza y se inserta en la cola.Para esto se necesitan mantener referencias a los nodos cabeza y cola de lalista. Se presenta en el listado 5.9, una implementacion del metodo queue()
de la cola, y en el listado 5.10 del metodo dequeue().
1 public void enqueue(E elem)
2 Nodo <E> nodo = new Nodo <E>();
3 nodo.setElemento(elem);
4 nodo.setSig(null); // nodo ser a el nuevo nodo cola
5 if (tam == 0)
6 cabeza = nodo; // caso especial de una cola previamente vac ıa
7 else
8 cola.setSig(nodo); // agregar nodo en la cola de la lista
9 cola = nodo; // actualizar la referencia al nodo cola
10 tam ++;
11
Listado 5.9: Implementacion del metodo enqueue() del ADT cola usando de unalista simple ligada con nodos de la clase Nodo.
1 public E dequeue () throws EmptyQueueException
2 if (tam == 0)
3 throw new EmptyQueueException("La cola est a vac ıa.");
4 E e = cabeza.getElemento ();
5 cabeza = cabeza.getSig ();
6 tam --;
7 if (tam == 0)
8 cola = null; // la cola est a ahora vac ıa
9 return e;
10
Listado 5.10: Implementacion del metodo dequeue() del ADT cola usando unalista simple ligada con nodos de la clase Nodo.

5.2 Colas 189
Cada uno de los metodos de la implementacion del ADT cola, con unaimplementacion de lista ligada simple, corren en tiempo O(1). Se evita lanecesidad de indicar un tamano maximo para la cola, como se hizo en laimplementacion de la cola basada en un arreglo, pero este beneficio viene aexpensas de incrementar la cantidad de espacio usado por elemento. A pesarde todo, los metodos en la implementacion de la cola con la lista ligada sonmas complicados que lo que se desearıa, se debe tener cuidado especial de elmanejo de los casos especiales, como cuando la cola esta vacıa y se hace laoperacion enqueue, o cuando la cola se vacıa por la operacion dequeue.
5.2.4. Planificador Round Robin
Un uso popular de la estructura de datos cola es para implementar un pla-nificador round robin, donde se itera a traves de una coleccion de elementosen forma circular y se “atiende” cada elemento mediante la realizacion deuna accion dada sobre este. Dicha pauta es usada, por ejemplo, para asignarequitativamente un recurso que debera ser compartido por una coleccionde clientes. Por ejemplo, se puede usar un planificador round robin paraasignar una parte del tiempo del CPU a varias aplicaciones ejecutandoseconcurrentemente en una computadora.
Se puede implementar un planificador round robin usando una cola, Q,mediante la repeticion de los siguientes pasos:
1. e← Q.dequeue()
2. Servir elemento e
3. Q.enqueue(e)
El problema de Josefo
En el juego de ninos de la “Papa Caliente”, un grupo de n ninos sentadosen cırculo se pasan un objeto, llamado la “papa” alrededor del cırculo. Eljuego se inicia con el nino que tenga la papa pasandola al siguiente en elcırculo, y estos continuan pasando la papa hasta que un coordinador suenauna campana, en donde el nino que tenga la papa debera dejar el juego y pasarla papa al siguiente nino en el cırculo. Despues de que el nino seleccionadodeja el juego, los otros ninos estrechan el cırculo. Este proceso es entoncescontinuado hasta que quede solamente un nino, que es declarado el ganador.

190 Pilas y colas
Si el coordinador siempre usa la estrategia de sonar la campana despues deque la papa ha pasado k veces, para algun valor fijo k, entonces determinar elganador para una lista de ninos es conocido como el problema de Josefo.
Solucion del problema de Josefo con una cola
Se puede resolver el problema de Josefo para una coleccion de n elementosusando una cola, mediante la asociacion de la papa con el elemento en elfrente de la cola y guardando elementos en la cola de acuerdo a su ordenalrededor del cırculo. Por lo tanto, pasar la papa es equivalente a retirar unelemento de la cola e inmediatamente agregarlo otra vez. Despues de queeste proceso se ha realizado k veces, se quita el elemento del frente usandodequeue y descartandolo. Se muestra en el listado 5.11, un programa Javacompleto para resolver el problema de Josefo, el cual describe una solucionque se ejecuta en tiempo O(nk).
1 public class Josefo
2 /** Soluci on del problema de Josefo usando una cola. */
3 public static <E> E Josefo(Queue <E> Q, int k)
4 if (Q.isEmpty ()) return null;
5 while (Q.size() > 1 )
6 System.out.println(" Cola: " + Q + " k = " + k);
7 for (int i=0; i<k; i++)
8 Q.enqueue(Q.dequeue ()); // mover el elemento del frente al final
9 E e = Q.dequeue (); // quitar el elemento del frente de la coleccci on
10 System.out.println("\t"+e+" est a eliminad@");
11
12 return Q.dequeue (); // el ganador
13
14 /** Construir una cola desde un arreglo de objetos */
15 public static <E> Queue <E> construirCola(E a[])
16 Queue <E> Q = new NodoQueue <E>();
17 for(E e: a)
18 Q.enqueue(e);
19 return Q;
20
21 /** Metodo probador */
22 public static void main(String [] args)
23 String [] a1 = "Jorge","Pedro","Carlos";
24 String [] a2 = "Gabi","To~no","Paco","Mari","Iv an","Alex","Nestor";
25 String [] a3 = "Rigo","Edgar","Karina","Edgar","Temo","Hector";
26 System.out.println("Primer ganador es "+Josefo(construirCola(a1),7));
27 System.out.println("Segundo ganador es "+Josefo(construirCola(a2) ,10));
28 System.out.println("Tercer ganador es "+Josefo(construirCola(a3),2));
29
30
Listado 5.11: Un programa Java completo para resolver el problema de Josefousando una cola. La clase NodoQueue es mostrada en los listados 5.9 y 5.10.

5.3 Colas con doble terminacion 191
5.3. Colas con doble terminacion
Considerar una estructura de datos parecida a una cola que soporteinsercion y borrado tanto en el frente y la parte posterior de la cola. Talextension de una cola es llamada una cola con doble terminacion o eningles double-ended queue, o deque, esta ultima se pronuncia ‘dek’, paraevitar confusion con el metodo dequeue() de un ADT cola regular, que sepronuncia como ‘dikiu’
5.3.1. Tipo de dato abstracto deque
El tipo de dato abstracto es mas completo que los ADT pila y cola. Losmetodos fundamentales del ADT deque son los siguientes:
addFirst(e):inserta un nuevo elemento e al inicio de la deque.addLast(e):inserta un nuevo elemento e al final de la deque.
removeFirst():retira y regresa el primer elemento de la deque; unerror ocurre si la deque esta vacıa.
removeLast():retira y regresa el ultimo elemento de la deque; unerror ocurre si la deque esta vacıa.
Adicionalmente, el ADT deque podrıa tambien incluir los siguientes meto-dos de apoyo:
getFirst():regresa el primer elemento de la deque; un errorocurre si la deque esta vacıa.
getLast():regresa el ultimo elemento de la deque; un errorocurre si la deque esta vacıa.
size():regresa el numero de elementos de la deque.isEmpty():determina si la deque esta vacıa.
La siguiente tabla muestra una serie de operaciones y sus efectos sobreuna deque D inicialmente vacıa de objetos enteros. Por simplicidad, se usanenteros en vez de objetos enteros como argumentos de las operaciones.

192 Pilas y colas
Operacion Salida DaddFirst(3) – (3)addFirst(5) – (5,3)removeFirst() 5 (3)addLast(7) – (3,7)
removeFirst() 3 (7)removeLast() 7 ()removeFirst() “error” ()
isEmpty() true ()
5.3.2. Implementacion de una deque
Como la deque requiere insercion y borrado en ambos extremos de unalista, usando una lista simple ligada para implementar una deque serıa inefi-ciente. Sin embargo, se puede usar una LDE, para implementar una dequeeficientemente. La insercion y remocion de elementos en cualquier extremo deuna LDE es directa para hacerse en tiempo O(1), si se usan nodos centinelaspara la cabeza y la cola.
Para una insercion de un nuevo elemento e, se puede tener acceso al nodop que estara antes de e y al nodo q que estara despues del nodo e. Parainsertar un nuevo elemento entre los nodos p y q, cualquiera o ambos de estospodrıan ser centinelas, se crea un nuevo nodo t, haciendo que los enlaces prevy sig de t hagan referencia a p y q respectivamente.
De igual forma, para quitar un elemento guardado en un nodo t, se puedeacceder a los nodos p y q que estan a los lados de t, y estos nodos deberanexistir, ya que se usan centinelas. Para quitar el nodo t entre los nodos p y q,se tiene que hacer que p y q se apunten entre ellos en vez de t. No se requierecambiar ninguno de los campos en t, por ahora t puede ser reclamado por elcolector de basura, ya que no hay nadie que este apuntando a t.
Todos los metodos del ADT deque, como se describen previamente, estanincluidos en la clase java.util.LinkedList<E>. Por lo tanto, si se necesitausar una deque y no se desea implementarla desde cero, se puede usar la claseanterior.
De cualquier forma, se muestra la interfaz Deque en el listado 5.12 y unaimplementacion de esta interfaz en el listado 5.13.

5.3 Colas con doble terminacion 193
1 /**
2 * Interfaz para una deque: una colecci on de objetos que pueden ser
3 * insertados y quitados en ambos extremos; un subconjunto de los
4 * me todos de java.util.LinkedList.
5 *
6 */
7 public interface Deque <E>
8 /**
9 * Regresa el numero de elementos en la deque.
10 */
11 public int size ();
12 /**
13 * Determina si la deque est a vac ıa.
14 */
15 public boolean isEmpty ();
16 /**
17 * Regresa el primer elemento; una excepci on es lanzada si la deque
18 * est a vac ıa.
19 */
20 public E getFirst () throws EmptyDequeException;
21 /**
22 * Regresa el u ltimo elemento; una excepci on es lanzada si la deque
23 * est a vac ıa.
24 */
25 public E getLast () throws EmptyDequeException;
26 /**
27 * Insertar un elemento para que sea el primero en la deque.
28 */
29 public void addFirst (E elemento );
30 /**
31 * Insertar un elemento para que sea el u ltimo en la deque.
32 */
33 public void addLast (E elemento );
34 /**
35 * Quita el primer elemento; una excepci on es lanzada si la deque
36 * est a vac ıa.
37 */
38 public E removeFirst () throws EmptyDequeException;
39 /**
40 * Quita el u ltimo elemento; una excepci on es lanzada si la deque
41 * est a vac ıa.
42 */
43 public E removeLast () throws EmptyDequeException;
44
Listado 5.12: Interfaz Deque con documentacion estilo Javadoc. Se usa el tipoparametrizado generico E con lo cual una deque puede contener elementos decualquier clase especificada.
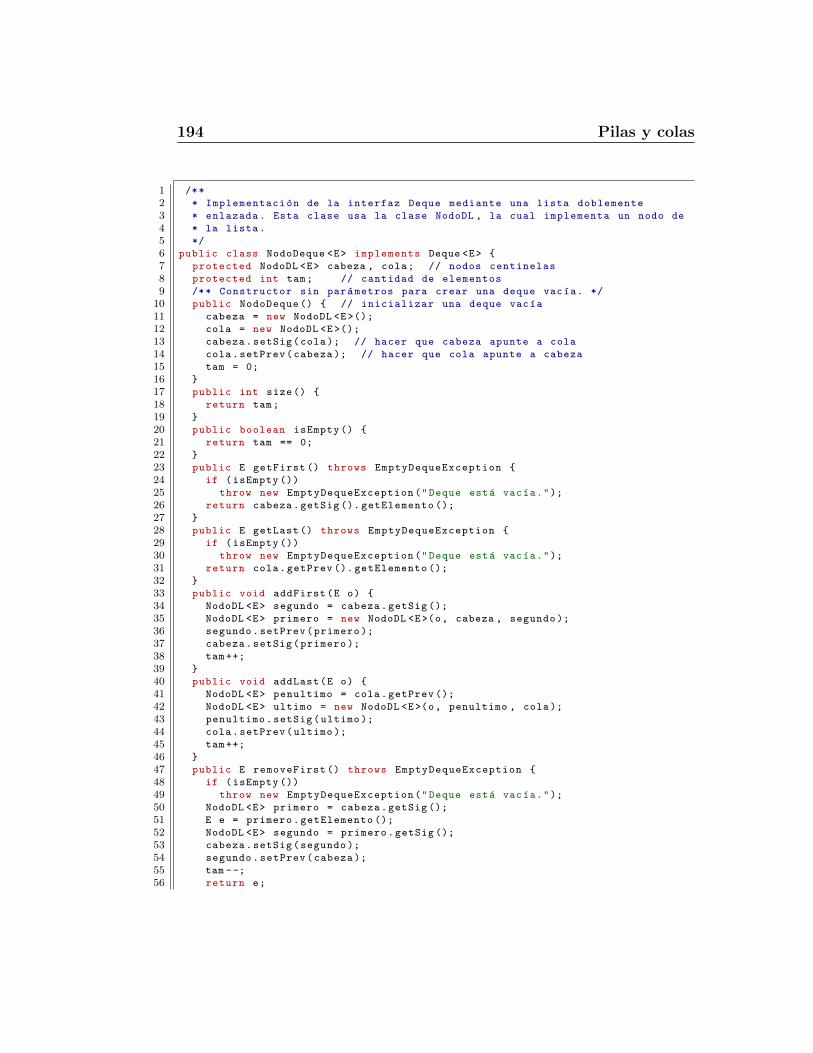
194 Pilas y colas
1 /**
2 * Implementaci on de la interfaz Deque mediante una lista doblemente
3 * enlazada. Esta clase usa la clase NodoDL , la cual implementa un nodo de
4 * la lista.
5 */
6 public class NodoDeque <E> implements Deque <E>
7 protected NodoDL <E> cabeza , cola; // nodos centinelas
8 protected int tam; // cantidad de elementos
9 /** Constructor sin par a metros para crear una deque vac ıa. */
10 public NodoDeque () // inicializar una deque vac ıa
11 cabeza = new NodoDL <E>();
12 cola = new NodoDL <E>();
13 cabeza.setSig(cola); // hacer que cabeza apunte a cola
14 cola.setPrev(cabeza ); // hacer que cola apunte a cabeza
15 tam = 0;
16
17 public int size()
18 return tam;
19
20 public boolean isEmpty ()
21 return tam == 0;
22
23 public E getFirst () throws EmptyDequeException
24 if (isEmpty ())
25 throw new EmptyDequeException("Deque est a vac ıa.");
26 return cabeza.getSig (). getElemento ();
27
28 public E getLast () throws EmptyDequeException
29 if (isEmpty ())
30 throw new EmptyDequeException("Deque est a vac ıa.");
31 return cola.getPrev (). getElemento ();
32
33 public void addFirst(E o)
34 NodoDL <E> segundo = cabeza.getSig ();
35 NodoDL <E> primero = new NodoDL <E>(o, cabeza , segundo );
36 segundo.setPrev(primero );
37 cabeza.setSig(primero );
38 tam ++;
39
40 public void addLast(E o)
41 NodoDL <E> penultimo = cola.getPrev ();
42 NodoDL <E> ultimo = new NodoDL <E>(o, penultimo , cola);
43 penultimo.setSig(ultimo );
44 cola.setPrev(ultimo );
45 tam ++;
46
47 public E removeFirst () throws EmptyDequeException
48 if (isEmpty ())
49 throw new EmptyDequeException("Deque est a vac ıa.");
50 NodoDL <E> primero = cabeza.getSig ();
51 E e = primero.getElemento ();
52 NodoDL <E> segundo = primero.getSig ();
53 cabeza.setSig(segundo );
54 segundo.setPrev(cabeza );
55 tam --;
56 return e;

5.3 Colas con doble terminacion 195
57
58 public E removeLast () throws EmptyDequeException
59 if (isEmpty ())
60 throw new EmptyDequeException("Deque est a vac ıa.");
61 NodoDL <E> ultimo = cola.getPrev ();
62 E e = ultimo.getElemento ();
63 NodoDL <E> penultimo = ultimo.getPrev ();
64 cola.setPrev(penultimo );
65 penultimo.setSig(cola);
66 tam --;
67 return e;
68
69
Listado 5.13: Clase NodoDeque que implementa la interfaz Deque con la clase NodoDL(que no se muestra). NodoDL es un nodo de una lista doblemente enlazada generica.

196 Pilas y colas

Capıtulo 6
Listas e Iteradores
6.1. Lista arreglo
Supongase que se tiene una coleccion S de n elementos guardados en uncierto orden lineal, de este modo se puede referir a los elementos en S comoprimero, segundo, tercero, etc. Tal coleccion es generalmente referida comouna lista o secuencia. Se puede referir unicamente a cada elemento e en Susando un entero en el rango [0, n− 1], esto es igual al numero de elementosde S que preceden a e en S. El ındice de un elemento e en S es el numerode elementos que estan antes que e en S. Por lo tanto, el primer elemento enS tiene ındice cero y el ultimo elemento tiene ındice n− 1. Tambien, si unelemento de S tiene ındice i, su elemento previo, si este existe, tiene ındicei− 1, y su siguiente elemento, si este existe, tiene ındice i+ 1. Este conceptode ındice esta relacionado al de rango de un elemento en una lista, el cual esdefinido para que sea uno mas que su ındice; por lo que el primer elementotiene rango uno, el segundo tiene rango dos, etc.
Una secuencia que soporte acceso a sus elementos mediante sus ındiceses llamado una lista arreglo, o tambien con el termino mas viejo vector.Como la definicion de ındice es mas consistente con la forma como los arreglosson ındizados en Java y otros lenguajes de programacion, como C y C++, sehara referencia al lugar donde un elemento es guardado en una lista arreglocomo su “ındice”, no su “rango”.
Este concepto de ındice es simple pero potente, ya que puede ser usadopara indicar donde insertar un nuevo elemento en una lista o de donde quitarun elemento viejo.

198 Listas e Iteradores
6.1.1. El tipo de dato abstracto lista arreglo
Como un ADT, una lista arreglo S tiene los siguientes metodos, ademasde los metodos estandares size() e isEmpty():
get(i):regresa el elemento de S con ındice i; una condicionde error ocurre si i < 0 o i >size()−1.
set(i, e):reemplaza con e y regresa el elemento en el ındicei; una condicion de error ocurre si i < 0 o i >size()− 1.
add(i, e):inserta un nuevo elemento e en S para tener ındicei; una condicion de error ocurre si i < 0 o i >size().
remove(i):quita de S el elemento en el ındice i; una condicionde error ocurre si i < 0 o i > size()− 1.
No se insiste en que un arreglo deberıa ser usado para implementar unalista arreglo, ası el elemento en el ındice 0 esta guardado en el ındice 0 en elarreglo, aunque esta es una posibilidad muy natural. La definicion de ındiceofrece una forma para referirse al “lugar” donde un elemento esta guardado enuna secuencia sin tener que preocuparse acerca de la implementacion exactade esa secuencia. El ındice de un elemento podrıa cambiar cuando la secuenciasea actualizada, como se muestra en el siguiente ejemplo.
Operacion Salida Sadd(0,7) – (7)add(0,4) – (4,7)get(1) 7 (4,7)add(2,2) – (4,7,2)get(3) “error” (4,7,2)
remove(1) 7 (4,2)add(1,5) – (4,5,2)add(1,3) – (4,3,5,2)add(4,9) – (4,3,5,2,9)get(2) 5 (4,3,5,2,9)set(3,8) 2 (4,3,5,8,9)

6.1 Lista arreglo 199
6.1.2. Patron de diseno adaptador
Las clases son frecuentemente escritas para dar funcionalidad similar aotras clases. El patron de diseno adaptador se aplica a cualquier contextodonde se quiere modificar una clase existente para que sus metodos empatencon los de una clase o una interfaz relacionada diferente. Una forma generalpara aplicar el patron adaptador es definir la nueva clase de tal forma que estacontenga una instancia de la clase vieja como un campo oculto, e implementarcada metodo de la nueva clase usando metodos de esta variable de instanciaoculta. El resultado de aplicar el patron adaptador sirve para que una nuevaclase realice casi las mismas funciones que alguna clase previa, pero de unaforma mas conveniente.
Con respecto al ADT lista arreglo, se observa que esta es suficiente paradefinir una clase adaptadora para el ADT deque, como se ve en la tabla 6.1:
Metodo Deque Realizacion con Metodosde Lista Arreglo
size(), isEmpty() size(), isEmpty()getFirst() get(0)getLast() get(size()-1)addFirst(e) add(0,e)addLast(e) add(size(),e)removeFirst() remove(0)removeLast() remove(size()-1)
Cuadro 6.1: Realizacion de una deque por medio de una lista arreglo.
6.1.3. Implementacion simple con un arreglo
Una opcion obvia para implementar el ADT lista arreglo es usar un arregloA, donde A[i] guarda una referencia al elemento con ındice i. Se escoge eltamano N del arreglo A lo suficientemente grande, y se mantiene el numerode elementos en una variable de instancia, n < N .
Los detalles de esta implementacion del ADT lista arreglo son simples.Para implementar la operacion get(i), por ejemplo, solo se regresa A[i]. Laimplementacion de los metodos add(i, e) y remove(i) son dados a continua-cion. Una parte importante y consumidora de tiempo de esta implementacion

200 Listas e Iteradores
involucra el desplazamiento de elementos hacia adelante y hacia atras paramantener las celdas ocupadas en el arreglo de forma continua. Estas opera-ciones de desplazamiento son requeridas para mantener la regla de guardarsiempre un elemento cuyo ındice en la lista es i en el ındice i del arreglo A,ver figura 6.1.
Algoritmo add(i, e):para j ← n− 1, n− 2, . . . , i hacerA[j + 1]← A[j] hacer espacio para el nuevo elemento
A[i]← en← n+ 1
Algoritmo remove(i):e← A[i] e es una variable temporal para j ← i, i+ 1, . . . , n− 2 hacerA[j]← A[j + 1] llenar el espacio del elemento quitado
n← n− 1regresar e
Figura 6.1: Implementacion basada en un arreglo de una lista arreglo S queesta guardando n elementos: (a) desplazando hacia adelante para una insercion enel ındice i; (b) desplazamiento hacia atras para un borrado en el ındice i.

6.1 Lista arreglo 201
Rendimiento de una implementacion simple con un arreglo
El cuadro 6.2 muestra los tiempos de ejecucion en el peor caso de unarreglo lista con n elementos realizados por medio de un arreglo. Los metodosisEmpty(), size(), get() y set() se ejecutan en tiempo O(1), pero losmetodos de insercion y borrado pueden tomar mas tiempo. En particular,add(i, e) se ejecuta en tiempo O(n). En efecto, el peor caso para esta operacionocurre cuando i es cero, ya que todos los n elementos existentes tienen queser desplazados hacia adelante. Un argumento similar se aplica al metodoremove(i), el cual corre en tiempo O(n), porque se tiene que desplazar haciaatras n − 1 elementos en el peor caso cuando i es igual a cero. De hecho,suponiendo que cada ındice posible es igualmente probable de que sea pasadocomo un argumento a estas operaciones, su tiempo promedio es O(n), ya quese tienen que desplazar n/2 elementos en promedio.
Metodo Tiemposize() O(1)
isEmpty() O(1)get(i) O(1)
set(i, e) O(1)add(i, e) O(n)
remove(i) O(n)
Cuadro 6.2: Rendimiento de un lista arreglo con n elementos usando un arreglo. Elespacio usado es O(N), donde N es el tamano del arreglo.
Para add(i, e) y remove(i) se observa que el tiempo en cada ejecucion esO(n− i+1), ya que solo aquellos elementos con ındice igual o mayor a i tienenque ser desplazadas hacia atras o adelante. Ası, insertar y quitar un elementoal final de una lista arreglo, usando los metodos add(n, e) y remove(n− 1),respectivamente toman tiempo O(1) cada uno. Por otra parte, esta observaciontiene una consecuencia interesante para la adaptacion del ADT lista arregloal ADT deque, dado en la seccion 5.12, si el ADT lista arreglo en este caso esimplementado por medio de un arreglo como se describe previamente, entonceslos metodos addLast y removeLast del deque se ejecutan en tiempo O(1).Sin embargo, los metodos addFirst y removeFirst del deque se ejecutan entiempo O(n).

202 Listas e Iteradores
Actualmente, con un poco de esfuerzo, se puede generar una implementa-cion basada en un arreglo para que el ADT lista arreglo logre tiempo O(1)para inserciones y borrados en el ındice 0, al igual que inserciones y borradosal final de la lista arreglo. Para lograrlo se requiere que no se de la regla deque un elemento con ındice i es guardado en el arreglo en el ındice i, se ocupaen este caso usar una aproximacion de arreglo circular como la que fue usadaen la seccion 5.2 para implementar una cola.
6.1.4. Interfaz ListaIndice y la clase java.util.ArrayList
Para construir una implementacion Java del ADT lista arreglo, se mues-tra, en el listado 6.1 la interfaz ListaIndice, la cual captura los meto-dos principales del ADT lista arreglo. En este caso, se usa la excepcionIndexOutOfBoundsException para indicar un argumento con ındice invalido.
1 /**
2 * Una interfaz para listas arreglo.
3 */
4 public interface ListaIndice <E>
5 /** Regresa el numero de elementos en esta lista. */
6 public int size ();
7 /** Prueba si la lista vac ıa. */
8 public boolean isEmpty ();
9 /** Insertar un elemento e para estar en el ı ndice i,
10 * desplazando todos los elementos despu es de este. */
11 public void add(int i, E e)
12 throws IndexOutOfBoundsException;
13 /** Regresar el elemento en el ı ndice i, sin quitarlo. */
14 public E get(int i)
15 throws IndexOutOfBoundsException;
16 /** Quita y regresa el elemento en el ı ndice i,
17 * desplazando los elementos despu es de este. */
18 public E remove(int i)
19 throws IndexOutOfBoundsException;
20 /** Reemplaza el elemento en el ı ndice i con e,
21 * regresando el elemento previo en i. */
22 public E set(int i, E e)
23 throws IndexOutOfBoundsException;
24
Listado 6.1: La interfaz ListaIndice para el ADT lista arreglo.

6.1 Lista arreglo 203
La clase java.util.ArrayList
Java proporciona la clase, java.util.ArrayList, la cual implementatodos los metodos que se dieron previamente para el ADT lista arreglo. Estaincluye todos los metodos dados en el listado 6.1 para la interfaz ListaIndice.Por otra parte, la clase java.util.ArrayList tiene caracterısticas adicionalesa las que fueron dadas en el ADT lista arreglo simplificado. Por ejemplo, laclase incluye el metodo, clear(), para remover todos los elementos de la listaarreglo, y el metodo, toArray(), el cual regresa un arreglo conteniendo todoslos elementos de la lista arreglo con el mismo orden. Ademas, tambien tienemetodos para buscar en la lista, como el metodo indexOf(e), el cual regresael ındice de la primera ocurrencia de un elemento igual a e en la lista arreglo,y el metodo lastIndexOf(e), el cual regresa el ındice de la ultima ocurrenciade un elemento igual a e en la lista arreglo. Ambos metodos regresan el valorındice invalido −1 si no se encuentra un elemento igual a e.
6.1.5. Lista arreglo usando un arreglo extendible
Ademas de implementar los metodos de la interfaz ListaIndice y algunosotros metodos utiles, la clase java.util.ArrayList proporciona una carac-terıstica interesante que supera una debilidad en la implementacion simple dela lista arreglo.
La mayor debilidad de la implementacion simple para el ADT lista arreglodado en la seccion 6.1.3, es que esta requiere una especificacion avanzada de lacapacidad fija, N , para el numero total de elementos que podrıan ser guardadosen la lista arreglo. Si el numero actual de elementos, n, de la lista arreglo esmucho menor que N , entonces la implementacion desperdiciara espacio. Peoraun, si n se incrementa y rebasa a N , entonces esta implementacion fallara.
Para evitar lo anterior, java.util.ArrayList usa una tecnica interesantede arreglo extendible con lo que no habra preocupacion de que el arreglo seadesbordado cuando se usa esta clase.
Al igual que la clase java.util.ArrayList, se proporciona un mediopara crecer el arreglo A que guarda los elementos de una lista arreglo S. Porsupuesto, en Java y en otros lenguajes de programacion, no se puede crecerel arreglo A; su capacidad esta fija a algun numero N , como ya se ha visto.Cuando un desbordamiento ocurre, es decir, n = N y se hace una llamada almetodo add, se realizan los siguientes pasos adicionales.

204 Listas e Iteradores
1. Reservar un nuevo arreglo B de capacidad 2N .
2. Hacer B[i]← A[i], para i = 0, . . . , N − 1.
3. Hacer A← B, esto es, se usa B como el arreglo que soporta a S.
4. Insertar el nuevo elemento en A.
Esta estrategia de reemplazo de arreglo es conocida como arreglo exten-dible, y puede ser vista como extender la terminacion del arreglo subyacentepara hacerle espacio para mas elementos, ver figura 6.2. Intuitivamente, esteestrategia es parecida a la del cangrejo ermitano, el cual se cambia a uncaracol mas grande cuando sobrepasa al anterior.
Figura 6.2: Los tres pasos para “crecer” un arreglo extendible: (a) crea un nuevoarreglo B; (b) copiar los elementos de A a B; (c) reasignar referencia A al nuevoarreglo
Implementacion de ListaIndice con un arreglo extendible
Se dan porciones de una implementacion Java del ADT lista arreglo usandoun arreglo extendible en el codigo 6.2. Esta clase solo proporciona los mediospara crecer. Un ejercicio es la implementacion para poder reducir.
1 /** Realizaci on de una lista indizada por medio de un arreglo , el cual es
2 * doblado cuando el tama~no de la lista excede la capacidad del arreglo.
3 */
4 public class ArregloListaIndice <E> implements ListaIndice <E>
5 private E[] A; // arreglo almacenando los elementos de la lista indizada
6 private int capacidad = 16; // tama~no inicial del arreglo A
7 private int tam = 0; // numero de elementos guardados en la lista
8 /** Crear la lista indizada con capacidad inicial de 16. */
9 public ArregloListaIndice ()
10 A = (E[]) new Object[capacidad ]; // compilador podr ıa advertir
11
12 /** Insertar un elemento en el ı ndice dado. */
13 public void add(int r, E e)
14 throws IndexOutOfBoundsException
15 revisarIndice(r, size() + 1);

6.1 Lista arreglo 205
16 if (tam == capacidad) // un sobreflujo
17 capacidad *= 2;
18 E[] B =(E[]) new Object[capacidad ]; // el compilador podr ıa advertir
19 for (int i=0; i<tam; i++)
20 B[i] = A[i];
21 A = B;
22
23 for (int i=tam -1; i>=r; i--) // desplazar elementos hacia adelante
24 A[i+1] = A[i];
25 A[r] = e;
26 tam ++;
27
28 /** Quitar el elemento guardado en el ı ndice dado. */
29 public E remove(int r)
30 throws IndexOutOfBoundsException
31 revisarIndice(r, size ());
32 E temp = A[r];
33 for (int i=r; i<tam -1; i++) // desplazar elementos hacia atr as
34 A[i] = A[i+1];
35 tam --;
36 return temp;
37
Listado 6.2: Parte de la clase ArregloListaIndice realizando el ADT lista arreglopor medio de un arreglo extendible. El metodo revisarIndice vigila que el ındicer este entre 0 y n− 1.
Analisis amortizado del arreglo extendible
La estrategia de reemplazo del arreglo podrıa parecer lento a simple vista,ya que para realizarlo se ocupa tiempo O(n). Pero se debe observar quedespues de que se haga el reemplazo, en el nuevo arreglo se pueden agregarhasta n nuevos elementos en la lista arreglo antes de que el arreglo deba serreemplazado nuevamente. Este hecho permite mostrar que realizando unaserie de operaciones en un lista arreglo vacıo es actualmente muy eficiente. Seconsiderara la insercion de un elemento con el ındice mas grande posible, esdecir, n. En la tabla 6.3 se muestra el tiempo que toma realizar la insercional final de la lista y el tamano actual del arreglo. El tamano inicial del arregloes uno.
Usando un patron de diseno algorıtmico llamado amortizacion, se puedemostrar que realizando una secuencia de operaciones, como las descritaspreviamente, sobre una lista arreglo implementada con un arreglo extendiblees eficiente. Para realizar un analisis amortizado, se usa una tecnica deconteo donde se ve a la computadora como una aplicacion operada conmonedas que requiere el pago de un ciber-peso para una cantidad constante de

206 Listas e Iteradores
Elementos Tiempo Tamano de A1 1 12 2 23 3 44 1 45 5 86 1 87 1 88 1 89 9 1610 1 1611 1 1612 1 1613 1 1614 1 1615 1 1616 1 16
Cuadro 6.3: Tiempo de ejecucion para la insercion de elementos en un arreglo conreemplazo.
tiempo computacional. Cuando una operacion es ejecutada, se deberan tenersuficientes ciber-pesos disponibles en la “cuenta bancaria” para pagar lastiempos de ejecucion de las operaciones. Ası, la cantidad total de ciber-pesosgastados para cualquier computo sera proporcional al tiempo gastado enese computo. La ventaja de usar este metodo de analisis es que se puedensobrecargar algunas operaciones para ahorrar ciber-pesos para pagar otras.
Proposicion 6.1: Sea S una lista arreglo implementada por medio de unarreglo extendible con un tamano inicial uno. El tiempo total para realizaruna serie de n inserciones al final de la lista en S, iniciando con S vacıa esO(n)
Justificacion. Suponiendo que un ciber-peso es suficiente para pagar por laoperacion de insercion al final de la lista en S, sin considerar el tiempo gastadoen crecer el arreglo. Suponer que el crecimiento del arreglo de tamano k a2k requiere k ciber-pesos por el tiempo gastado en copiar los elementos. Secargara en cada operacion de insercion tres ciber-pesos. Ası, se sobrecargacada operacion de insercion que no causa un sobreflujo por dos ciber-pesos.Estos dos ciber-pesos se pueden pensar como un ahorro. Un sobreflujo ocurrecuando la lista arreglo S tiene 2i elementos, para algun i ≥ 0, y el tamano

6.2 Listas nodo 207
del arreglo usado es 2i. Entonces, doblar el tamano del arreglo requerira 2i
ciber-pesos. Estos ciber-pesos se pueden tomar de los elementos guardadosdesde la celda 2i−1 hasta 2i − 1 (ver figura 6.3). Observar que sobreflujoprevio ocurrio cuando la cantidad de elementos se hizo mas grande que 2i−1 laprimera vez, y de esta forma los ciber-pesos ahorrados en las celdas 2i−1 hasta2i−1 no fueron previamente gastados. Por lo tanto, se tiene un esquema validode amortizacion en el cual cada operacion es cargada con tres ciber-pesosy todos los tiempos de computo son pagados. Es decir, se puede pagar laejecucion de n inserciones al final usando 3n ciber-pesos. Es decir, el tiempode ejecucion amortizado para cada operacion de insercion al final es O(1);por lo tanto, el tiempo total de ejecucion de n operaciones de inserciones alfinal es O(n).
Figura 6.3: Ilustracion de una serie de operaciones de insercion al final de la listaarreglo: (a) un arreglo de 8 celdas lleno, con dos ciber-pesos ahorrados en las celdasdel 4 al 7; (b) una operacion de insercion causa un sobreflujo y un doblado dela capacidad. Copiar los 8 viejos elementos al nuevo arreglo se ha pagado conlos ciber-pesos ahorrados. Insertar el nuevo elemento es pagado por uno de losciber-pesos dados, y dos ciber-pesos son ahorrados en la celda 8.
6.2. Listas nodo
Usar un ındice no es la unica forma de referirse al lugar donde un elementoaparece en una secuencia. Si se tiene una secuencia S implementada con unalista enlazada, simple o doble, entonces podrıa ser mas natural y eficiente

208 Listas e Iteradores
usar un nodo en vez de un ındice como medio de identificacion para accedera S o para actualizar. Se define en esta seccion el ADT lista nodo el cualabstrae la estructura de datos concreta lista enlazada, secciones 3.3 y 3.4,usando el ADT posicion relacionada, el cual abstrae la nocion de “lugar” enuna lista nodo.
6.2.1. Operaciones basadas en nodos
Sea S una lista enlazada simple o doble. Se desearıa definir metodos paraS que tomen nodos como parametros y proporcionen nodos como tipos deregreso. Tales metodos podrıan dar aumentos de velocidad significativos sobrelos metodos basados en ındices, porque encontrar el ındice de un elementoen una lista enlazada requiere buscar a traves de la lista incrementalmentedesde el inicio o final, contando los elementos conforme se recorra.
Por ejemplo, se podrıa definir un metodo hipotetico remove(v) que quiteel elemento de S guardado en el nodo v de la lista. Usando un nodo como unparametro permite remover un elemento en tiempo O(1) yendo directamenteal lugar donde esta guardado el nodo y entonces “desenlazando” este nodomediante una actualizacion a los enlaces sig y prev de sus vecinos. De igualmodo, se puede insertar, en tiempo O(1), un nuevo elemento e en S con unaoperacion tal como addAfter(v, e), la cual indica el nodo v despues del cualel nodo del nuevo elemento deberıa ser insertado. En este caso se “enlaza” elnuevo nodo.
Para abstraer y unificar las diferentes formas de guardar elementos en lasdiversas implementaciones de una lista, se introduce el concepto de posicion,la cual formaliza la nocion intuitiva de “lugar” de un elemento relativo a losotros en la lista.
6.2.2. Posiciones
A fin de ampliar de forma segura el conjunto de operaciones para listas,se abstrae la nocion de “posicion” la cual permite usar la eficiencia dela implementacion de las listas simples enlazadas, o dobles, sin violar losprincipios del diseno orientado a objetos. En este marco, se ve a la lista comouna coleccion que guarda a cada elemento en una posicion y que mantieneestas posiciones organizadas en un orden lineal. Una posicion es por sı mismaun tipo de dato abstracto que soporta el siguiente metodo simple:

6.2 Listas nodo 209
elemento():regresa el elemento guardado en esta posicion.
Una posicion esta siempre definida relativamente, esto es, en terminosde sus vecinos. En una lista, una posicion p siempre estara “despues” dealguna posicion q y “antes” de alguna posicion s, a menos que p sea la primeraposicion o la ultima. Una posicion p, la cual esta asociada con algun elementoe en una lista S, no cambia, aun si el ındice de e cambia en S, a menos que sequite explıcitamente e, y por lo tanto, se destruya la posicion p. Por otra parte,la posicion p no cambia incluso si se reemplaza o intercambia el elementoe guardado en p con otro elemento. Estos hechos acerca de las posicionespermiten definir un conjunto de metodos de lista basados en posiciones queusan objetos posicion como parametros y tambien proporcionan objetosposicion como valores de regreso.
6.2.3. El tipo de dato abstracto lista nodo
Usando el concepto de posicion para encapsular la idea de “nodo” enuna lista, se puede definir otro tipo de ADT secuencia llamado el ADT listanodo. Este ADT soporta los siguientes metodos para una lista S:
first():regresa la posicion del primer elemento de S; unerror ocurre si S esta vacıa.
last():regresa la posicion del ultimo elemento de S; unerror ocurre si S esta vacıa.
prev(p):regresa la posicion del elemento de S precediendoal de la posicion p; un error ocurre si p esta en laprimera posicion.
next(p):regresa la posicion del elemento de S siguiendo alde la posicion p; un error ocurre si p esta en laultima posicion.
Los metodos anteriores permiten referirse a posiciones relativas en unalista, comenzando en el inicio o final, y moviendose incrementalmente a laizquierda o a la derecha de la lista. Estas posiciones pueden ser pensadas comonodos en la lista pero, se debe observar que no hay referencias especıficas aobjetos nodos. Ademas, si se proporciona una posicion como un argumento aun metodo lista, entonces la posicion debera representar una posicion validaen esa lista.

210 Listas e Iteradores
Metodos de actualizacion de la lista nodo
Ademas de los metodos anteriores y los metodos genericos size e isEmpty,se incluyen tambien los siguientes metodos de actualizacion para el ADT listanodo, los cuales usan objetos posicion como parametros y regresan objetosposicion como valores de regreso algunos de ellos.
set(p, e):reemplaza el elemento en la posicion p con e, re-gresando el elemento anterior en la posicion p.
addFirst(e):inserta un nuevo elemento e en S como el primerelemento.
addLast(e):inserta un nuevo elemento e en S como el ultimoelemento.
addBefore(p, e):inserta un nuevo elemento e en S antes de la posi-cion p.
addAfter(p, e):inserta un nuevo elemento e en S despues de laposicion p.
remove(p):quita y regresa el elemento e en la posicion p enS, invalidando esta posicion en S.
El ADT lista nodo permite ver una coleccion ordenada de objetos enterminos de sus lugares, sin tenerse que preocupar acerca de la forma exactacomo estos lugares estan representados, ver figura 6.4.
Figura 6.4: Una lista nodo. Las posiciones en el orden actual son p, q, r, y s.
Podrıa parecer a primera vista que hay redundancia en el repertorioanterior de operaciones para el ADT lista nodo, ya que se puede hacer la ope-racion addFirst(e) con addBefore(first(),e), y la operacion addLast(e)con addAfter(last(),e). Pero estas sustituciones solo pueden ser hechaspara una lista no vacıa.
Observar que una condicion de error ocurre si una posicion pasada comoargumento a una de las operaciones de la lista es invalida. Las razones paraque una posicion p sea invalida incluyen:

6.2 Listas nodo 211
p = null
p fue previamente borrada de la lista
p es una posicion de una lista diferente
p es la primera posicion de la lista y se llama prev(p)
p es la ultima posicion de la lista y se llama next(p)
Se muestra enseguida una serie de operaciones para una lista nodo Sinicialmente vacıa. Se usan las variables p1, p2, etc., para denotar diferentesposiciones, y se muestra el objeto guardado actualmente en tal posicion entreparentesis.
Operacion Salida SaddFirst(8) – (8)p1 ← first() [8] (8)addAfter(p1, 5) – (8,5)p2 ← next(p1) [5] (8,5)
addBefore(p2, 3) – (8,3,5)p3 ← prev(p2) [3] (8,3,5)addFirst(9) – (9,8,3,5)p2 ← last() [5] (9,8,3,5)
remove(first()) 9 (8,3,5)set(p3, 7) 3 (8,7,5)
addAfter(first(), 2) – (8,2,7,5)
El ADT lista nodo, con su nocion incorporada de posicion, es util pararealizar ajustes. Por ejemplo, un programa que simula un juego de cartaspodrıa simular la mano de cada persona como una lista nodo. Ya que lamayorıa de las personas guarda las cartas de la misma figura juntas, insertary sacar cartas de la mano de una persona podrıa ser implementado usando losmetodos del ADT lista nodo, con las posiciones siendo determinadas por unorden natural de las figuras. Igualmente, un editor de texto simple encaja lanocion de insercion posicional y remocion, ya que tales editores tıpicamenterealizan todas las actualizaciones relativas a un cursor, el cual representa laposicion actual en la lista de caracteres de texto que esta siendo editada.
Una interfaz Java representando el ADT posicion esta dado en el listado6.3.

212 Listas e Iteradores
1 public interface Posicion <E>
2 /** Regresa el elemento guardado en esta posici on. */
3 E elemento ();
4
Listado 6.3: Una interfaz Java para el ADT posicion.
Una interfaz, con los metodos requeridos, para el ADT lista nodo, llamadaListaPosicion, esta dada en el listado 6.4. Esta interfaz usa las siguientesexcepciones para indicar condiciones de error.
BoundaryViolationException: lanzada si un intento es hecho al accederuna elemento cuya posicion esta fuera del rango de posiciones de lalista, por ejemplo llamando al metodo next en la ultima posicion de lasecuencia.
InvalidPositionException: lanzada si una posicion dada como argumentono es valida, por ejemplo, esta es una referencia null o esta no tienelista asociada.
1 import java.util.Iterator;
2 /**
3 * Una interfaz para listas posicionales.
4 *
5 */
6 public interface ListaPosicion <E> extends Iterable <E>
7 /** Regresa un iterador de todos los elementos en la lista. */
8 public Iterator <E> iterator ();
9 /** Regresa una colecci on iterable de todos los nodos en la lista. */
10 public Iterable <Posicion <E>> positions ();
11 /** Regresa el numero de elementos en esta lista. */
12 public int size ();
13 /** Indica si la lista est a vac ıa. */
14 public boolean isEmpty ();
15 /** Regresa el primer nodo en la lista. */
16 public Posicion <E> first ();
17 /** Regresa el u ltimo nodo en la lista. */
18 public Posicion <E> last ();
19 /** Regresa el nodo siguiente a un nodo dado en la lista. */
20 public Posicion <E> next(Posicion <E> p)
21 throws InvalidPositionException , BoundaryViolationException;
22 /** Regresa el nodo anterior a un nodo dado en la lista. */
23 public Posicion <E> prev(Posicion <E> p)
24 throws InvalidPositionException , BoundaryViolationException;
25 /** Inserta un elemento en el frente de la lista ,
26 * regresando la nueva posici on. */
27 public void addFirst(E e);
28 /** Inserta un elemento en la parte de atr as de la lista ,

6.2 Listas nodo 213
29 * regresando la nueva posici on. */
30 public void addLast(E e);
31 /** Inserta un elemento despu es del nodo dado en la lista. */
32 public void addAfter(Posicion <E> p, E e)
33 throws InvalidPositionException;
34 /** Inserta un elemento antes del nodo dado en la lista. */
35 public void addBefore(Posicion <E> p, E e)
36 throws InvalidPositionException;
37 /** Quita un nodo de la lista , regresando el elemento guardado. */
38 public E remove(Posicion <E> p) throws InvalidPositionException;
39 /** Reemplaza el elemento guardado en el nodo dado ,
40 regresando el elemento viejo. */
41 public E set(Posicion <E> p, E e) throws InvalidPositionException;
42
Listado 6.4: Interfaz para el ADT lista nodo.
Otro adaptador Deque
El ADT lista nodo es suficiente para definir una clase adaptadora para elADT deque, como se muestra en la tabla 6.4.
Metodo Deque Realizacion con Metodosde la lista nodo
size(), isEmpty() size(), isEmpty()getFirst() first().elemento()getLast() last().elemento()addFirst(e) addFirst(e)addLast(e) addLast(e)removeFirst() remove(first())removeLast() remove(last())
Cuadro 6.4: Realizacion de una deque por medio de una lista nodo.
6.2.4. Implementacion con lista doblemente enlazada
Si se quiere implementar el ADT lista nodo usando una lista doblementeenlazada, seccion 3.4, se debe hacer que los nodos de la lista enlazada im-plementen el ADT posicion. Esto es, se tiene cada nodo implementando lainterfaz Posicion y por lo tanto definen un metodo, elemento(), el cualregresa el elemento guardado en el nodo. Ası, los propios nodos actuan como

214 Listas e Iteradores
posiciones. Son vistos internamente por la lista enlazada como nodos, perodesde el exterior, son vistos solamente como posiciones. En la vista interna,se puede dar a cada nodo v variables de instancia prev y next que respecti-vamente refieran a los nodos predecesor y sucesor de v, los cuales podrıan serde hecho nodos centinelas, cabeza y cola, marcando el inicio o el final de lalista. En lugar de usar las variables prev y next directamente, se definen losmetodos getPrev, setPrev, getNext, y setNext de un nodo para acceder ymodificar estas variables.
En el listado 6.5, se muestra la clase Java, NodoD, para los nodos de unalista doblemente enlazada implementando el ADT posicion. Esta clase essimilar a la clase NodoD mostrada en el listado 3.11, excepto que ahora losnodos guardan un elemento generico en lugar de una cadena de caracteres.Observar que las variables de instancia prev y next en la clase NodoD sonreferencias privadas a otros objetos NodoD.
1 public class NodoD <E> implements Posicion <E>
2 private NodoD <E> prev , next; // Referencia a los nodos anterior y posterior
3 private E elemento; // Elemento guardado en esta posici on
4 /** Constructor */
5 public NodoD(NodoD <E> nuevoPrev , NodoD <E> nuevoNext , E elem)
6 prev = nuevoPrev;
7 next = nuevoNext;
8 elemento = elem;
9
10 // Metodo de la interfaz Posicion
11 public E elemento () throws InvalidPositionException
12 if ((prev == null) && (next == null))
13 throw new InvalidPositionException("¡La posici on no est a en una lista!");
14 return elemento;
15
16 // Me todos accesores
17 public NodoD <E> getNext () return next;
18 public NodoD <E> getPrev () return prev;
19 // Me todos actualizadores
20 public void setNext(NodoD <E> nuevoNext) next = nuevoNext;
21 public void setPrev(NodoD <E> nuevoPrev) prev = nuevoPrev;
22 public void setElemento(E nuevoElemento) elemento = nuevoElemento;
23
Listado 6.5: Clase NodoD realizando un nodo de una lista doblemente enlazadaimplementando la interfaz Posicion.
Dada una posicion p en S, se puede “desenvolver” p para revelar el nodov subyacente mediante una conversion de la posicion a un nodo. Una vez quese tiene un nodo v, se puede, por ejemplo, implementar el metodo prev(p)con v.getPrev, a menos que el nodo regresado por v.getPrev sea la cabeza,

6.2 Listas nodo 215
en tal caso se senala un error. Por lo tanto, posiciones en una implementacionlista doblemente enlazada se pueden soportar en una forma orientada al objetosin ningun gasto adicional de tiempo o espacio.
Considerar ahora como se podrıa implementar el metodo addAfter(p, e),para insertar un elemento e despues de la posicion p. Se crea un nuevo nodo vpara mantener el elemento e, se enlaza v en su lugar en la lista, y entonces seactualizan las referencias next y prev de los dos vecinos de v. Este metodoesta dado en el siguiente pseudocodigo, y se ilustra en la figura 6.5, recordandoel uso de centinelas, observar que este algoritmo trabaja aun si p es la ultimaposicion real.Algoritmo addAfter(p, e):
Crear un nuevo nodo vv.setElemento(e)v.setPrev(p) enlazar v a su predecesor v.setNext(p.getNext()) enlazar v a su sucesor (p.getNext()).setPrev(v) enlazar el viejo sucesor de p a v p.setNext(v) enlazar p a su nuevo sucesor, v
Figura 6.5: Agregar un nuevo nodo despues de la posicion “JFK”:(a) antes de lainsercion; (b) creacion de un nodo v con el elemento “BWI” y el enlazado a la lista;(c) despues de la insercion.
Los algoritmos para los metodos addBefore, addFirst, y addLast sonsimilares al metodo addAfter. Se dejan sus detalles como un ejercicio.

216 Listas e Iteradores
Considerar, ahora, el metodo remove(e), el cual quita el elemento e guar-dado en la posicion p. Para realizar esta operacion, se enlazan los dos vecinosde p para referirse entre ellos como nuevos vecinos—desenlazando p. Observarque despues de que p esta desenlazado, no hay nodos apuntando a p; por lotanto, el recolector de basura puede reclamar el espacio de p. Este algoritmoesta dado en el siguiente pseudocodigo y se ilustra en la figura 6.6. Recordandoel uso de los centinelas cabeza y cola, este algoritmo trabaja aun si p es laprimera posicion, la ultima, o solamente una posicion real en la lista.
Algoritmo remove(p):t← p.elemento() una variable temporal para guardar el valor de regreso (p.getPrev()).setNext(p.getNext()) desenlazar p (p.getNext()).setPrev(p.getPrev())p.setPrev(null) invalidar la posicion p p.setNext(null)regresar t
Figura 6.6: Quitando el objeto guardado en la posicion para “PVD”: (a) antes dela remocion; (b) desenlazando el nodo viejo; (c) despues de la remocion.
En conclusion, usando una lista doblemente enlazada, se pueden ejecu-tar todos los metodos del ADT lista nodo en tiempo O(1). Ası, una listadoblemente enlazada es una implementacion eficiente del ADT lista nodo.

6.2 Listas nodo 217
Implementacion de la lista nodo en Java
La clase Java ListaNodoPosicion, la cual implementa el ADT lista nodousando una lista doblemente enlazada, se muestra en el listado 6.6. En estaclase se tienen declaradas variables de instancia para guardar el numerode elementos en la lista, ası como los centinelas especiales para manejarmas facilmente la lista. Tambien se tiene un constructor sin parametros quepermite crear una lista nodo vacıa. En esta clase ademas de implementar losmetodos declarados en la interfaz ListaPosicion se tienen otros metodosde conveniencia, por ejemplo para revisar si una posicion es valida, probarsi una posicion es la primera o la ultima, intercambiar los contenidos de dosposiciones, u obtener una representacion textual de la lista.
1 import java.util.Iterator;
2 /**
3 * Realizaci on de una ListaPosici on usando una lista doblemente enlazada
4 * de nodos.
5 *
6 */
7 public class ListaNodoPosicion <E> implements ListaPosicion <E>
8 protected int tam; // numero de elementos en la lista
9 protected NodoD <E> cabeza , cola; // centinelas especiales
10 /** Constructor que crea una lista vac ıa; tiempo O(1) */
11 public ListaNodoPosicion ()
12 tam = 0;
13 cabeza = new NodoD <E>(null , null , null); // crea cabeza
14 cola = new NodoD <E>(cabeza , null , null); // crea cola
15 cabeza.setNext(cola); // hacer que cabeza apunte a cola
16
17 /** Regresa el numero de elementos en la lista; tiempo O(1) */
18 public int size() return tam;
19 /** Valida si la lista est a vac ıa; tiempo O(1) */
20 public boolean isEmpty () return (tam == 0);
21 /** Regresa la primera posici on en la lista; tiempo O(1) */
22 public Posicion <E> first ()
23 throws EmptyListException
24 if (isEmpty ())
25 throw new EmptyListException("La lista est a vac ıa");
26 return cabeza.getNext ();
27
28 /** Regresa la u ltima posici on en la lista; tiempo O(1) */
29 public Posicion <E> last()
30 throws EmptyListException
31 if (isEmpty ())
32 throw new EmptyListException("La lista est a vac ıa");
33 return cola.getPrev ();
34
35 /** Regresa la posici on anterior de la dada; tiempo O(1) */
36 public Posicion <E> prev(Posicion <E> p)
37 throws InvalidPositionException , BoundaryViolationException
38 NodoD <E> v = revisaPosicion(p);
39 NodoD <E> prev = v.getPrev ();

218 Listas e Iteradores
40 if (prev == cabeza)
41 throw new BoundaryViolationException
42 ("No se puede avanzar mas all a del inicio de la lista");
43 return prev;
44
45 /** Regresa la posici on despu es de la dada; tiempo O(1) */
46 public Posicion <E> next(Posicion <E> p)
47 throws InvalidPositionException , BoundaryViolationException
48 NodoD <E> v = revisaPosicion(p);
49 NodoD <E> next = v.getNext ();
50 if (next == cola)
51 throw new BoundaryViolationException
52 ("No se puede avanzar mas all a del final de la lista");
53 return next;
54
55 /** Insertar el elemento dado antes de la posici on dada: tiempo O(1) */
56 public void addBefore(Posicion <E> p, E elemento)
57 throws InvalidPositionException
58 NodoD <E> v = revisaPosicion(p);
59 tam ++;
60 NodoD <E> nodoNuevo = new NodoD <E>(v.getPrev(), v, elemento );
61 v.getPrev (). setNext(nodoNuevo );
62 v.setPrev(nodoNuevo );
63
64 /** Insertar el elemento dado despu es de la posici on dada: tiempo O(1) */
65 public void addAfter(Posicion <E> p, E elemento)
66 throws InvalidPositionException
67 NodoD <E> v = revisaPosicion(p);
68 tam ++;
69 NodoD <E> nodoNuevo = new NodoD <E>(v, v.getNext(), elemento );
70 v.getNext (). setPrev(nodoNuevo );
71 v.setNext(nodoNuevo );
72
73 /** Insertar el elemento dado al inicio de la lista , regresando
74 * la nueva posici on; tiempo O(1) */
75 public void addFirst(E elemento)
76 tam ++;
77 NodoD <E> nodoNuevo = new NodoD <E>(cabeza , cabeza.getNext(), elemento );
78 cabeza.getNext (). setPrev(nodoNuevo );
79 cabeza.setNext(nodoNuevo );
80
81 /** Insertar el elemento dado al final de la lista , regresando
82 * la nueva posici on; tiempo O(1) */
83 public void addLast(E elemento)
84 tam ++;
85 NodoD <E> ultAnterior = cola.getPrev ();
86 NodoD <E> nodoNuevo = new NodoD <E>( ultAnterior , cola , elemento );
87 ultAnterior.setNext(nodoNuevo );
88 cola.setPrev(nodoNuevo );
89
90 /** Quitar la posici on dada de la lista; tiempo O(1) */
91 public E remove(Posicion <E> p)
92 throws InvalidPositionException
93 NodoD <E> v = revisaPosicion(p);
94 tam --;
95 NodoD <E> vPrev = v.getPrev ();
96 NodoD <E> vNext = v.getNext ();

6.2 Listas nodo 219
97 vPrev.setNext(vNext);
98 vNext.setPrev(vPrev);
99 E vElem = v.elemento ();
100 // desenlazar la posici on de la lista y hacerlo inv alido
101 v.setNext(null);
102 v.setPrev(null);
103 return vElem;
104
105 /** Reemplaza el elemento en la posici on dada con el nuevo elemento
106 * y regresar el viejo elemento; tiempo O(1) */
107 public E set(Posicion <E> p, E elemento)
108 throws InvalidPositionException
109 NodoD <E> v = revisaPosicion(p);
110 E elemVjo = v.elemento ();
111 v.setElemento(elemento );
112 return elemVjo;
113
114 /** Regresa un iterador con todos los elementos en la lista. */
115 public Iterator <E> iterator () return new ElementoIterador <E>(this);
116 /** Regresa una colecci on iterable de todos los nodos en la lista. */
117 public Iterable <Posicion <E>> positions () // crea una lista de posiciones
118 ListaPosicion <Posicion <E>> P = new ListaNodoPosicion <Posicion <E>>();
119 if (! isEmpty ())
120 Posicion <E> p = first ();
121 while (true)
122 P.addLast(p); // agregar posici on p como el ult. elemento de la lista P
123 if (p == last ())
124 break;
125 p = next(p);
126
127
128 return P; // regresar P como el objeto iterable
129
130 // Me todos de conveniencia
131 /** Revisa si la posici on es valida para esta lista y la convierte a
132 * NodoD si esta es valida: tiempo O(1) */
133 protected NodoD <E> revisaPosicion(Posicion <E> p)
134 throws InvalidPositionException
135 if (p == null)
136 throw new InvalidPositionException
137 ("Posici on Null pasada a ListaNodo");
138 if (p == cabeza)
139 throw new InvalidPositionException
140 ("El nodo cabeza no es una posici on va lida");
141 if (p == cola)
142 throw new InvalidPositionException
143 ("El nodo cola no es una posici on va lida");
144 try
145 NodoD <E> temp = (NodoD <E>) p;
146 if ((temp.getPrev () == null) || (temp.getNext () == null))
147 throw new InvalidPositionException
148 ("Posici on no pertenece a una ListaNodo valida");
149 return temp;
150 catch (ClassCastException e)
151 throw new InvalidPositionException
152 ("Posici on es de un tipo incorrecto para esta lista");
153

220 Listas e Iteradores
154
155 /** Valida si una posici on es la primera; tiempo O(1). */
156 public boolean isFirst(Posicion <E> p)
157 throws InvalidPositionException
158 NodoD <E> v = revisaPosicion(p);
159 return v.getPrev () == cabeza;
160
161 /** Valida si una posici on es la u ltima; tiempo O(1). */
162 public boolean isLast(Posicion <E> p)
163 throws InvalidPositionException
164 NodoD <E> v = revisaPosicion(p);
165 return v.getNext () == cola;
166
167 /** Intercambia los elementos de dos posiciones dadas; tiempo O(1) */
168 public void swapElements(Posicion <E> a, Posicion <E> b)
169 throws InvalidPositionException
170 NodoD <E> pA = revisaPosicion(a);
171 NodoD <E> pB = revisaPosicion(b);
172 E temp = pA.elemento ();
173 pA.setElemento(pB.elemento ());
174 pB.setElemento(temp);
175
176 /** Regresa una representaci on textual de una lista nodo usando for -each */
177 public static <E> String forEachToString(ListaPosicion <E> L)
178 String s = "[";
179 int i = L.size ();
180 for (E elem: L)
181 s += elem; // moldeo impl ıcito del elemento a String
182 i--;
183 if (i > 0)
184 s += ", "; // separar elementos con una coma
185
186 s += "]";
187 return s;
188
189 /** Regresar una representaci on textual de una lista nodo dada */
190 public static <E> String toString(ListaPosicion <E> l)
191 Iterator <E> it = l.iterator ();
192 String s = "[";
193 while (it.hasNext ())
194 s += it.next (); // moldeo impl ıcito del elemento a String
195 if (it.hasNext ())
196 s += ", ";
197
198 s += "]";
199 return s;
200
201 /** Regresa una representaci on textual de la lista */
202 public String toString ()
203 return toString(this);
204
205
Listado 6.6: La clase ListaNodoPosicion implementando el ADT lista nodo conuna lista doblemente enlazada.

6.3 Iteradores 221
6.3. Iteradores
Un calculo tıpico en una lista arreglo, lista, o secuencia es recorrer suselementos en orden, uno a la vez, por ejemplo, para buscar un elementoespecıfico.
6.3.1. Tipos de dato abstracto Iterador e Iterable
Un iterador (iterator) es un patron de diseno de software que abstraeel proceso de explorar un elemento a la vez desde una coleccion de elementos.Un iterador consiste de una secuencia S, un elemento actual de S, y unaforma de pasar al siguiente elemento en S y hacerlo el elemento actual. Ası,un iterador extiende el concepto del ADT posicion que se introdujo en laseccion 6.2. De hecho, una posicion puede ser pensada como un iterador queno va a ninguna parte. Un iterador encapsula los conceptos de “lugar” y“siguiente” en una coleccion de objetos.
Se define el ADT iterador soportando los siguientes dos metodos:
hasNext():prueba si hay elementos pendientes en el iterador.next():regresa el siguiente elemento en el iterador.
El ADT iterador usa el concepto de cursor como el elemento “actual” enel recorrido de una secuencia. El primer elemento en un iterador es devueltoen la primera llamada al metodo next, siempre y cuando el iterador contengaal menos un elemento.
Un iterador da un esquema unificado para acceder a todos los elementos deuna coleccion de objetos en una forma que es independiente de la organizacionespecıfica de la coleccion. Un iterador para una lista arreglo, lista nodo, osecuencia debera regresar los elementos de acuerdo a su orden lineal.
Iteradores simples en Java
Java proporciona un iterador a traves de su interfaz java.util.Iterator.La clase java.util.Scanner implementa esta interfaz. Esta interfaz soportaun metodo adicional opcional para quitar el elemento previamente regresadode la coleccion. Esta funcionalidad, de quitar elementos a traves de un iterador,es algo controversial desde un punto de vista orientado al objeto, sin embargo,no es sorprendente que su implementacion por las clases es opcional. Javatambien da la interfaz java.util.Enumeration, la cual es historicamente

222 Listas e Iteradores
mas vieja que la interfaz iterador y en vez de los nombres anteriores, usahasMoreElements() y nextElement().
El tipo de dato abstracto Iterable
Para dar un mecanismo unificado generico para explorar a traves de unaestructura de datos, los ADT que guardan colecciones de objetos deberıansoportar el siguiente metodo:
iterator():regresa un iterador de los elementos en la coleccion.
Este metodo esta soportado por la clase java.util.ArrayList y esmuy importante, por lo que hay una interfaz completa java.lang.Iterable
conteniendo solo este metodo. Este metodo puede simplificar al usuario latarea de recorrer los elementos de una lista. Para garantizar que una listanodo soporta el metodo anterior, por ejemplo, se podrıa agregar este metodoa la interfaz ListaPosicion, como se muestra en el listado 6.4. En este caso,tambien se quisiera indicar que ListaPosicion extiende Iterable. Por lotanto, se asume que las listas arreglo y las listas nodo soportan el metodoiterator().
1 public interface ListaPosicion <E> extends Iterable <E>
2 /** Regresa un iterador de todos los elementos en la lista. */
3 public Iterator <E> iterator ();
Listado 6.7: Agregando el metodo iterator a la interfaz ListaPosicion
Dada tal definicion de una ListaPosicion, se podrıa usar el iteradordevuelto por el metodo iterator() para crear una representacion de cadenade una lista nodo, como se muestra en el listado 6.8.
6.3.2. El ciclo for-each
Para recorrer los elementos regresados por un iterador es una construccioncomun, Java proporciona una notacion breve para tales ciclos, llamada elciclo ciclo for-each. La sintaxis para tal ciclo es la siguiente:
for (tipo nombre : expresion)sentencia del ciclo

6.3 Iteradores 223
1 /** Regresar una representaci on textual de una lista nodo dada */
2 public static <E> String toString(ListaPosicion <E> l)
3 Iterator <E> it = l.iterator ();
4 String s = "[";
5 while (it.hasNext ())
6 s += it.next (); // moldeo impl ıcito del elemento a String
7 if (it.hasNext ())
8 s += ", ";
9
10 s += "]";
11 return s;
12
Listado 6.8: Ejemplo de un iterador Java usado para convertir una lista nodo auna cadena.
donde expresion evalua a una coleccion que implementa la interfaz java.lang.-Iterable, tipo es el tipo de objeto regresado por el iterador para esta clase, ynombre es el nombre de una variable que tomara los valores de los elementosde este iterador en la sentencia del ciclo. Esta notacion es la version corta dela siguiente:
for (Iterator<tipo> it=expresion.iterator(); it.hasNext(); ) Tipo nombre= it.next();sentencia del ciclo
Por ejemplo, si se tiene una lista, valores, de objetos Integer, y valores
implementa java.lang.Iterable, entonces se pueden sumar todos los enterosen valores como sigue:
List<Integer> valores;...sentencias que crean una nueva lista y la llenan con Integer.int suma = 0;for (Integer i : valores)
suma += i; // el moldeo implıcito permite esto
Se podrıa leer el ciclo anterior como, “para cada Integer i en valores,hacer el cuerpo del ciclo, en este caso, sumar i a suma”
Ademas de la forma anterior del ciclo for-each, Java tambien permite que

224 Listas e Iteradores
un ciclo for-each sea definido cuando expresion es un arreglo de tipo Tipo, elcual puede ser un tipo base o un tipo objeto. Por ejemplo se puede totalizarlos enteros en un arreglo, v, el cual guarda los primeros diez enteros positivos,como sigue:
int[] v=1, 2, 3, 4, 5, 6, 7, 8, 9, 10;int total = 0;for (int i: v)
total += i;
6.3.3. Implementacion de los iteradores
Una forma de implementar un iterador para una coleccion de elementos eshacer una “foto” de esta e iterar sobre esta. Esta aproximacion involucrarıaguardar la coleccion en una estructura de datos separada que soporte accesosecuencial a sus elementos. Por ejemplo, se podrıan insertar todos los ele-mentos de la coleccion en una cola, en tal caso el metodo hasNext() podrıacorresponder a !isEmpty() y next() podrıa corresponder a dequeue(). Conesta aproximacion, el metodo iterator() toma tiempo O(n) para una colec-cion de tamano n. Como esta sobrecarga de copiado es relativamente costosa,se prefiere, en muchos casos, tener iteradores que operen sobre la mismacoleccion, y no en una copia.
Para implementar esta aproximacion directa, se necesita solo realizar unseguimiento a donde el cursor del iterador apunta en la coleccion. Ası, crear unnuevo iterador en este caso involucra crear un objeto iterador que representeun cursor colocado solo antes del primer elemento de la coleccion. Igualmente,hacer el metodo next() involucra devolver el siguiente elemento, si este existe,y mover el cursor pasando esta posicion del elemento. En esta aproximacion,crear un iterador cuesta tiempo O(1), al igual que hacer cada uno de losmetodos del iterador. Se muestra una clase implementando tal iterador en ellistado 6.9, y se muestra en el listado 6.10 como este iterador podrıa ser usadopara implementar el metodo iterator() en la clase ListaNodoPosicion.
Iteradores posicion
Para los ADT que soporten la nocion de posicion, tal como las ADT listay secuencia, se puede tambien dar el siguiente metodo:

6.3 Iteradores 225
1 public class ElementoIterador <E> implements Iterator <E>
2 protected ListaPosicion <E> lista; // la lista subyacente
3 protected Posicion <E> cursor; // la siguiente posici on
4 /** Crea un elemento iterador sobre la lista dada. */
5 public ElementoIterador(ListaPosicion <E> L)
6 lista = L;
7 cursor = (lista.isEmpty ())? null : lista.first ();
8
9 /** Valida si el iterador tiene un objeto siguiente. */
10 public boolean hasNext () return (cursor != null);
11 /** Regresa el siguiente objeto en el iterador. */
12 public E next() throws NoSuchElementException
13 if (cursor == null)
14 throw new NoSuchElementException("No hay elemento siguiente");
15 E aRegresar = cursor.elemento ();
16 cursor = (cursor == lista.last ())? null : lista.next(cursor );
17 return aRegresar;
18
Listado 6.9: Una clase elemento iterador para una ListaPosicion.
1 /** Regresa un iterador con todos los elementos en la lista. */
2 public Iterator <E> iterator () return new ElementoIterador <E>(this);
Listado 6.10: El metodo iterator() de la clase ListaNodoPosicion.
positions():regresa un objeto Iterable, por ejemplo una listaarreglo, o una lista nodo, conteniendo las posicio-nes en la coleccion como elementos.
Un iterador regresado por este metodo permite recorrer las posiciones deuna lista. Para garantizar que una lista nodo soporta este metodo, se podrıaagregar a la interfaz ListaPosicion, por lo que se debe agregar una imple-mentacion del metodo positions() en la clase ListaNodoPosicion, como semuestra en el listado 6.12. Este metodo usa la propia clase ListaNodoPosicionpara crear una lista que contiene las posiciones de la lista original como sus ele-mentos. Regresando esta lista posicion como su objeto Iterable permitiendollamar iterator() sobre este objeto para obtener un iterador de posicionesde la lista original.
1 public interface ListaPosicion <E> extends Iterable <E>
2 // ... todos los otros me todos de la ADT lista ...
3 /** Regresa una colecci on iterable de todos los nodos en la lista. */
4 public Iterable <Posicion <E>> positions ();
5

226 Listas e Iteradores
Listado 6.11: Adicion de la interfaz Iterable a la interfaz ListaPosicion.
1 public Iterable <Posicion <E>> positions () // crea una lista de posiciones
2 ListaPosicion <Posicion <E>> P = new ListaNodoPosicion <Posicion <E>>();
3 if (! isEmpty ())
4 Posicion <E> p = first ();
5 while (true)
6 P.addLast(p); // agregar posici on p como el ult. elemento de la lista P
7 if (p == last ())
8 break;
9 p = next(p);
10
11
12 return P; // regresar P como el objeto iterable
13
Listado 6.12: El metodo positions() de la clase ListaNodoPosicion.
El iterador regresado por iterator() y otros objetos Iterable definen untipo restringido de iterador que permite solo una pasada a los elementos. Sinembargo, iteradores mas poderosos pueden tambien ser definidos, los cualespermiten moverse hacia atras y hacia adelante sobre un cierto ordenamientode los elementos.
6.3.4. Iteradores lista en Java
La clase java.util.LinkedList no expone un concepto posicion a losusuarios en su API. La forma para acceder y actualizar un objeto LinkedList
en Java, sin usar ındices, es usando un ListIterator que es generado porLinkedList, usando el metodo listIterator(). Tal iterador da metodosde recorrido hacia atras y hacia adelante al igual que metodos locales paraactualizar. Este ve su posicion actual como estando antes del primer elemento,entre dos elementos, o despues del ultimo elemento. Esto es, usa un cursorlista, parecido a como un cursor de pantalla es visto localizado entre doscaracteres en una pantalla. La interfaz java.util.ListIterator incluye lossiguientes metodos:

6.4 ADT listas y el marco de colecciones 227
add(e):agrega el elemento e al final de la lista.add(i, e):inserta el elemento e en la posicion i especificada
en la lista.hasNext():verdadero si y solo si hay un elemento despues de
la posicion actual del iterador.hasPrevious():verdadero si y solo si hay un elemento antes de la
posicion actual del iterador.previous():regresa el elemento e antes de la posicion actual y
mueve el cursor a e, por lo que puede usarse paraiterar hacia atras.
next():regresa el elemento e despues de la posicion actualy mueve el cursor a e, por lo que puede usarse paraiterar hacia adelante.
nextIndex():regresa el ındice del siguiente elemento.previousIndex():regresa el ındice del elemento previo.
set(e):reemplaza el ultimo elemento regresado por next()o previous() con el elemento indicado.
remove():quita de la lista el ultimo elemento que fue regre-sado por next() o previous().
Es riesgoso usar multiples iteradores sobre la misma lista mientras semodifica su contenido. Si inserciones, borrados, o reemplazos son ocupadosen multiples “lugares” en una lista, es mas seguro usar posiciones paraindicar estas localidades. Pero la clase java.util.LinkedList no exponesus objetos posicion al usuario. Por lo tanto, para evitar los riesgos demodificar una lista que ha creado multiples iteradores, por llamadas a sumetodo iterator, los objetos java.util.Iterator tienen una capacidadfail-fast que inmediatamente invalida tal iterador si su coleccion subyacentees modificada inesperadamente. Java permite muchos iteradores lista paraestar recorriendo una lista ligada al mismo tiempo, pero si uno de ellos lamodifica, usando add, remove o set, entonces el resto de los iteradores sehacen invalidos.
6.4. ADT listas y el marco de colecciones
Se revisa en esta seccion los ADT lista general, los cuales combinanmetodos de la deque, lista arreglo, y lista nodo y como son usados en el marcode colecciones de Java.

228 Listas e Iteradores
6.4.1. Listas en el marco de colecciones Java
Java proporciona un paquete de interfaces y clases para estructuras dedatos, las cuales conjuntamente definen el marco de colecciones Java (JavaCollections Framework). Este paquete, java.util, incluye versiones de variasde las estructuras de datos comentadas en este texto, algunas de las cualesya han sido discutidas y otras seran revisadas posteriormente. La interfazraız en el marco de colecciones Java es la interfaz Collection. Esta es unainterfaz general para cualquier estructura de datos que contenga una coleccionde elementos, como una lista. Collection extiende a java.lang.Iterable;por lo tanto, incluye el metodo iterator(), el cual regresa un iterador delos elementos en esta coleccion. Tambien es una superinterface para otrasinterfaces en el marco de colecciones que guardan elementos, incluyendo lasinterfaces Deque, List y Queue de java.util. Ademas Collection tieneuna subinterface que define el tipo de coleccion Set y tiene varias interfacesimportantes relacionadas, incluyendo las interfaces Iterator y ListIterator,al igual que la interfaz Map.
El marco de colecciones de Java tambien incluye varias clases concretasbasadas en lista que implementan varias combinaciones de interfaces basadasen lista. Las siguientes clases son incluidas en java.util:
ArrayBlockingQueue:Una implementacion con arreglo de la interfazQueue con capacidad limitada.
ArrayDeque:Una implementacion de la interfaz Deque que usaun arreglo, el cual puede crecer o decrecer, comose requiera.
ArrayList:Una implementacion de la interfaz List que usaun arreglo, el cual puede crecer o decrecer, comose requiera.
ConcurrentLinkedQueue:Una implementacion con lista enlazada de la inter-faz Queue que es proceso seguro.
LinkedBlockingDeque:Una implementacion con lista enlazada de la inter-faz Deque con capacidad limitada.
LinkedBlockingQueue:Una implementacion con lista enlazada de la inter-faz Queue con capacidad limitada.
LinkedList:Una implementacion con lista enlazada de la inter-faz List.
Stack:Una implementacion del ADT pila.

6.4 ADT listas y el marco de colecciones 229
Cada una de las clases anteriores implementan la interfaz java.lang.Iter-able, por lo tanto, incluyen el metodo iterator() y pueden ser usados en elciclo for-each. Ademas cualquier clase implementando la interfaz java.util.-
List, con las clases ArrayList y LinkedList, tambien incluyen el metodolistIterator(). Como se indico previamente, estas interfaces son utiles pararecorrer los elementos de una coleccion o lista.
Algoritmos basados en lista en el marco de colecciones Java
Ademas de las clases basadas en lista que son dadas en el marco decolecciones Java, tambien hay una cantidad de algoritmos simples que sondados. Estos metodos estan implementados como metodos de clase en la clasejava.util.Collections y se incluyen los siguientes metodos.
disjoint(C,D):regresa un valor booleano indicando si las coleccio-nes C y D son disjuntas.
fill(L, e):Reemplaza cada uno de los elementos en la listaL con el mismo elemento, e.
frecuency(C, e):Regresa la cantidad de elementos en la coleccionC que son iguales a e.
max(C):Regresa el elemento maximo en la coleccion C, ba-sados en el ordenamiento natural de sus elementos.
min(C):Regresa el elemento mınimo en la coleccion C, ba-sados en el ordenamiento natural de sus elementos.
replaceAll(L, e, f):Reemplaza cada uno de los elementos en L queson iguales a e con el mismo elemento, f .
reverse(L):Invierte el ordenamiento de los elementos en lalista L.
rotate(L, d):Rota los elementos en la lista L por la distancia d,la cual puede ser negativa, en una forma circular.
shuffle(L):Permuta pseudoaleatoriamente el ordenamiento delos elementos en la lista L.
sort(L):Ordena la lista L, usando el ordenamiento naturalde los elementos en L.
Conversion de listas a arreglos
Las listas son un concepto interesante y pueden ser aplicadas en unacantidad de contextos diferentes, pero hay algunos casos donde podrıa ser

230 Listas e Iteradores
mas util usar la lista como un arreglo. La interfaz java.util.Collection
incluye los siguientes metodos utiles para generar un arreglo que tenga losmismos elementos que la coleccion dada:
toArray():Regresa un arreglo de elementos del tipo Object
conteniendo todos los elementos en esta coleccion.toArray(A):Regresa un arreglo de elementos del mismo tipo
de A conteniendo todos los elementos en esta co-leccion.
Si la coleccion es una lista, entonces el arreglo devuelto debe tener suselementos guardados en el mismo orden que la lista original. Por lo tanto,si se tiene un metodo util basado en arreglo que se quiere usar en una listau otro tipo de coleccion, entonces se puede usar el metodo toArray() de lacoleccion para producir una representacion arreglo de esa coleccion.
Conversion de arreglos a listas
De manera similar, es util en ocasiones poder convertir un arreglo en sulista equivalente. La clase java.util.Arrays incluye el siguiente metodo:
asList(A):Regresa una representacion de lista del arreglo A,con el mismo tipo de elemento que los elementosde A.
La lista devuelta por este metodo usa el arreglo A como su representacioninterna para la lista. Por lo que esta lista esta garantizada para ser unlista basada en arreglo y cualquier cambio hecho a esta automaticamentesera reflejada en A. Por estos tipos de efectos laterales, el uso del metodoasList() debera hacerse siempre con cuidado, para evitar consecuencias nodeseadas. Usando este metodo con cuidado puede ahorrar trabajo.
La interfaz java.util.List y sus implementaciones
Java proporciona funcionalidad similar a los ADT lista arreglo y listanodo en la interfaz java.util.List, la cual es implementada con un arregloen java.util.ArrayList y con una lista ligada en java.util.LinkedList.Hay algunas compensaciones entre estas dos implementaciones. Java usaiteradores para lograr una funcionalidad similar a la del ADT lista nodo

6.4 ADT listas y el marco de colecciones 231
derivada de posiciones. El cuadro 6.5 indica la correspondencia entre losmetodos de los ADT lista (arreglo y nodo) con las interfaces java.util.Listy java.util.ListIterator.
Metodo del Metodo de Metodo deADT lista List ListIterator Notas
size() size() O(1)isEmpty() isEmpty() O(1)get(i) get(i) A es O(1),
L es O(mıni, n− i)first() listIterator() Primer elemento
es next
last() listIterator(size()) Ultimo elementoes previous
prev(p) previous() O(1)next(p) next() O(1)set(p, e) set(e) O(1)set(i, e) set(i, e) A es O(1),
L es O(mıni, n− i)add(i, e) add(i, e) O(n)remove(i) remove(i) A es O(n),
L es O(mıni, n− i)addFirst(e) add(0, e) A es O(n), L es O(1)addFirst(e) addFirst(e) Solo en L, O(1)addLast(e) add(e) O(1)addLast(e) addLast(e) Solo en L, O(1)
addAfter(p, e) add(e) A es O(n), L es O(1)insercion en el cursor
addBefore(p, e) add(e) A es O(n), L es O(1)insercion en el cursor
remove(p) remove() A es O(n), L es O(1)borrado en el cursor
Cuadro 6.5: Correspondencia entre los metodos de los ADT lista arreglo y lista nodo(1a columna) contra las interfaces List y ListIterator de java.util. Se usa A y Lcomo abreviaturas para las clases java.util.ArrayList y java.util.LinkedList

232 Listas e Iteradores
6.4.2. Secuencias
Una secuencia es un ADT que soporta todos los metodos del ADT deque(seccion 5.12), el ADT lista arreglo (seccion 6.1), y el ADT lista nodo (seccion6.2). Entonces, este proporciona acceso explıcito a los elementos en la lista yasea por sus ındices, o por sus posiciones. Por otra parte, como se proporcionacapacidad de acceso dual, se incluye en el ADT secuencia, los siguientes dosmetodos “puente” que proporcionan conexion entre ındices y posiciones:
atIndex(i):regresar la posicion del elemento con ındice i; unacondicion de error ocurre si i < 0 o i > size()− 1.
indexOf(p):regresar el ındice del elemento en la posicion p.
Herencia multiple en el ADT secuencia
La definicion del ADT secuencia incluye todos los metodos de tres ADTdiferentes siendo un ejemplo de herencia multiple. Esto es, el ADT secuenciahereda metodos de tres “super” tipos de datos abstractos. En otras palabras,sus metodos incluyen la union de los metodos de estos super ADT. Ver ellistado 6.13 para una especificacion Java del ADT como una interfaz Java.
1 /**
2 * Una interfaz para una secuecia , una estructura de datos que
3 * soporta todas las operaciones de un deque , lista indizada y
4 * lista posici on.
5 */
6 public interface Secuencia <E>
7 extends Deque <E>, ListaIndice <E>, ListaPosicion <E>
8 /** Regresar la posici on conteniendo el elemento en el ı ndice dado. */
9 public Posicion <E> atIndex(int r) throws BoundaryViolationException;
10 /** Regresar el ı ndice del elemento guardado en la posici on dada. */
11 public int indexOf(Posicion <E> p) throws InvalidPositionException;
12
Listado 6.13: La interfaz Secuencia definida por herencia multiple por las interfacesDeque, ListaIndice, y ListaPosicion y agregando los dos metodos puente.
Secuencia implementada con una lista ligada
Suponiendo que se implementa una secuencia con una lista doblemen-te enlazada, la cual, como se indica en la documentacion para la clase

6.4 ADT listas y el marco de colecciones 233
java.util.LinkedList, es la implementacion para esta clase. Con esta im-plementacion, todos los metodos de actualizacion basados en posicion seejecutan en tiempo O(1) cada uno. De igual forma, todos los metodos delADT deque corren en tiempo O(1), ya que solo se requiere actualizar o accederla lista en sus extremos. Pero los metodos del ADT lista arreglo, los cualesestan incluidos en la clase java.util.LinkedList, no son muy adecuadospara una implementacion de una secuencia con una lista doblemente enlazada.
Balance de eficiencia en una secuencia con lista enlazada
Como una lista enlazada no permite acceso indizado a sus elementos, reali-zar la operacion get(i), para regresar el elemento en un ındice i dado, requiereque se hagan “saltos” desde uno de los extremos de la lista, incrementandoo decrementando, hasta que se ubique el nodo que guarda el elemento conındice i. Como una leve optimizacion, se puede iniciar saltando del extremomas cercano de la lista, logrando ası el siguiente tiempo de ejecucion
O(mın(i+ 1, n− i))
donde n es el numero de elementos en la lista. El peor caso de este tipo debusquedas ocurre cuando
r = bn/2c
Por lo tanto, el tiempo de ejecucion todavıa es O(n).
Las operaciones add(i, e) y remove(i) tambien deben hacer saltos paraubicar el nodo que guarda el elemento con ındice i, y entonces insertar oborrar un nodo. Los tiempos de ejecucion de estas implementaciones sontambien
O(mın(i+ 1, n− i+ 1))
lo cual es O(n). Una ventaja de esta aproximacion es que, si i = 0 o i = n− 1,como en el caso de la adaptacion del ADT lista arreglo para el ADT deque dadoen la seccion 6.1.2, entonces estos metodos se ejecutan en tiempo O(1). Pero,en general, usar metodos lista arreglo con un objeto java.util.LinkedList
es ineficiente.

234 Listas e Iteradores
Secuencia implementada con un arreglo
Supongase que se quiere implementar la secuencia S guardando cadaelemento e de S en una celda A[i] de un arreglo A. Se puede definir unobjeto posicion p para guardar un ındice i y una referencia al arreglo A, comovariables de instancia en este caso. Entonces se puede implementar el metodoelemento(p) para regresar A[i]. Una desventaja importante es que las celdasen A no tendran forma de referirse a su correspondiente posicion. Ası, despuesde realizar la operacion addFirst, no se tiene forma de avisar a las posicionesexistentes en S que cada uno de sus ındices se debe incrementar en uno (lasposiciones en una secuencia estan definidas relativamente a las posicionesvecinas, no a los ındices). Por lo tanto, si se implementa una secuencia conun arreglo, se necesita una aproximacion diferente.
Considerar una solucion alterna en la cual, en vez de guardar los elementosde S en el arreglo A, se guarda un nuevo tipo de objeto posicion en cadacelda de A, y se guardan los elementos en las posiciones. El nuevo objetoposicion p guarda el ındice i y el elemento asociado con p.
Con esta estructura de datos, ilustrada en la figura 6.7, se puede buscar atraves del arreglo para actualizar la variable ındice i para cada posicion cuyoındice cambie debido a una insercion o borrado.
Figura 6.7: Una implementacion basada en un arreglo del ADT secuencia.
Balance de eficiencia en una secuencia con arreglo
En esta implementacion usando un arreglo para una secuencia, los metodosaddFirst, addBefore, addAfter, y remove toman tiempo O(n), por que setienen que desplazar objetos posicion para hacer espacio para la nueva posicion,

6.5 Ejemplo: Heurıstica mover al frente 235
o para llenar el espacio creado por la remocion de una vieja posicion, comoen los metodos insertar y remover basados en ındice. Todos los otros metodosbasados en la posicion toman tiempo O(1).
6.5. Ejemplo: Heurıstica mover al frente
Supongase que se desea mantener una coleccion de elementos ademas desaber el numero de veces que cada elemento es accedido. Conocer el numero deaccesos permite, por ejemplo, conocer cuales son los primeros diez elementosmas populares. Ejemplos de tales escenarios incluyen los navegadores Webque mantienen un registro de las direcciones Web mas populares visitadaspor un usuario o un programa album de fotos que mantiene una lista delas imagenes mas populares que un usuario ve. Adicionalmente, una lista defavoritos podrıa ser usada en una interfaz grafica para conocer las accionesmas populares de un menu desplegable, para despues presentar al usuario unmenu condensando conteniendo solo las opciones mas populares.
Se considera en esta seccion como se puede implementar el ADT lista defavoritos, el cual soporta los metodos size() e isEmpty() ademas de lossiguientes:
access(e):acceder el elemento e e incrementar su cuenta deacceso, o agregarlo a la lista de favoritos, si todavıano estaba presente.
remove(e):quitar el elemento e de la lista de favoritos, dadoque este se encuentre.
top():regresar un coleccion iterable de los k elementosmas accedidos.
6.5.1. Implementacion con una lista ordenada y unaclase anidada
La primera implementacion de una lista de favoritos que se considera (lista-do 6.14) es construyendo una clase, ListaFavoritos, guardando referencias alos objectos accesados en una lista ligada ordenada de forma decreciente, porla cantidad de accesos. La clase usa una caracterıstica de Java que permitedefinir una clase anidada y relacionada dentro de la definicion de una clase. Talclase anidada debera ser declarada static, para indicar que esta definicion

236 Listas e Iteradores
esta relacionada a la clase que la contiene, y no a una instancia especificade esa clase. Mediante clases anidadas se pueden definir clases de “ayuda” o“soporte” que pueden ser protegidas de uso externo.
La clase anidada, Entrada, guarda para cada elemento e en la lista, unpar (c, v), donde c es la cuenta de accesos para e y v es una referencia valoral propio elemento e. Cada vez que un elemento es accedido, se busca esteen la liga ligada (agregandolo si todavıa no esta) e incrementando su cuentade acceso. Remover un elemento requiere encontralo y quitarlo de la listaligada. Devolver los k elementos mas accedidos involucra copiar los valores deentrada en un lista de salida de acuerdo a su orden en lista ligada interna.
1 /** Lista de elementos favoritos , con sus cuentas de acceso. */
2 public class ListaFavoritos <E>
3 protected ListaPosicion <Entrada <E>> listaF; // lista de entradas
4 /** Constructor; tiempo O(1) */
5 public ListaFavoritos ()
6 listaF = new ListaNodoPosicion <Entrada <E>>();
7
8 /** Regresa el unmero de elementos en la lista; tiempo O(1). */
9 public int size() return listaF.size ();
10 /** Prueba si la lista est a vac ıa; tiempo O(1) */
11 public boolean isEmpty () return listaF.isEmpty ();
12 /** Quitar un elemento dado , dado que esta en la lista; tiempo O(n) */
13 public void remove(E obj)
14 Posicion <Entrada <E>> p = encontrar(obj); // bu squeda de obj
15 if( p!=null )
16 listaF.remove(p); // quitar la entrada
17
18 /** Incrementar la cuenta de accesos para el elemento dado y lo inserta
19 * si todav ıa no est a presente; tiempo O(n) */
20 public void access(E obj)
21 Posicion <Entrada <E>> p = encontrar(obj); // bu squeda de obj
22 if( p!=null )
23 p.elemento (). incrementarCuenta (); // incrementar cuenta de acceso
24 else
25 listaF.addLast(new Entrada <E>(obj)); // agregar la entrada al final
26 p = listaF.last ();
27
28 moverArriba(p);
29
30 /** Encontar la posici on de un elemento dado , o regresar null; tiempo O(n) */
31 protected Posicion <Entrada <E>> encontrar(E obj)
32 for( Posicion <Entrada <E>> p: listaF.positions ())
33 if( valor(p). equals(obj))
34 return p; // encontrado en posici on p
35 return null; // no encontrado
36
37 protected void moverArriba(Posicion <Entrada <E>> cur)
38 Entrada <E> e = cur.elemento ();
39 int c = cuenta(cur);
40 while( cur!= listaF.first () )
41 Posicion <Entrada <E>> prev = listaF.prev(cur); // posici on previa
42 if( c<= cuenta(prev) ) break; // entrada en su posic on correcta

6.5 Ejemplo: Heurıstica mover al frente 237
43 listaF.set(cur , prev.elemento ()); // descender la entrada previa
44 cur = prev;
45
46 listaF.set(cur , e); // guardar la entrada en su posici on final
47
48 /** Regresa los k elementos mas accedidos , para un k; tiempo O(k) */
49 public Iterable <E> top(int k)
50 if( k<0 || k>size() )
51 throw new IllegalArgumentException("Argumento inv alido");
52 ListaPosicion <E> T = new ListaNodoPosicion <E>(); // lista top -k
53 int i=0; // contador de las entradas agregadas a la lista
54 for( Entrada <E> e: listaF )
55 if (i++ >= k)
56 break; // todas las k entradas han sido agregadas
57 T.addLast( e.valor() ); // agregar una entrada a la lista
58
59 return T;
60
61 /** Representaci on String de lista de favoritos */
62 public String toString () return listaF.toString ();
63 /** Metodo auxiliar que extrae el valor de la entrada en una posici on */
64 protected E valor(Posicion <Entrada <E>> p) return p.elemento (). valor ();
65 /** Metodo auxiliar que extrae el contador de la entrada en una pos. */
66 protected int cuenta(Posicion <Entrada <E>> p) return p.elemento (). cuenta ();
6768 /** Clase interna para guardar elementos y sus cuentas de acceso. */
69 protected static class Entrada <E>
70 private E valor; // elemento
71 private int cuenta; // cuenta de accesos
72 /** Constructor */
73 Entrada(E v)
74 cuenta = 1;
75 valor = v;
76
77 /** Regresar el elemento */
78 public E valor() return valor;
79 public int cuenta () return cuenta;
80 public int incrementarCuenta () return ++ cuenta;
81 public String toString () return "["+cuenta+","+valor+"]";
82
83 // Fin de la clase ListaFavoritos
Listado 6.14: La clase ListaFavoritos que incluye una clase anidada, Entrada, lacual representa los elementos y su contador de accesos
6.5.2. Lista con heurıstica mover al frente
La implementacion previa de la lista de favoritos hace el metodo access(e)en tiempo proporcional al ındice de e en la lista de favoritos, es decir, si e esel k-esimo elemento mas popular en la lista, entonces accederlo toma tiempoO(k). En varias secuencias de acceso de la vida real, es comun, que una vez

238 Listas e Iteradores
que el elemento es accedido, es muy probable que sea accedido otra vez en elfuturo cercano. Se dice que tales escenarios poseen localidad de referencia.
Una heurıstica, o regla de oro, que intenta tomar ventaja de la localidadde referencia que esta presente en una secuencia de acceso es la heurısticamover al frente. Para aplicar esta huerıstica, cada vez que se accede unelemento se mueve al frente de la lista. La esperanza es que este elemento seaaccedido otra vez en el futuro cercano. Por ejemplo, considerar un escenarioen el cual se tienen n elementos donde cada elemento es accedido n veces, enel siguiente orden: se accede el primer elemento n veces, luego el segundo nveces, y ası hasta que el n-esimo elemento se accede n veces.
Si se guardan los elementos ordenados por la cantidad de accesos, einsertando cada elemento la primera vez que es accedido, entonces:
cada acceso al elemento 1 se ejecuta en tiempo O(1);
cada acceso al elemento 2 se ejecuta en tiempo O(2);
. . .
cada acceso al elemento n se ejecuta en tiempo O(n);
Ası, el tiempo total para realizar las series de accesos es proporcional a
n+ 2n+ 3n+ . . .+ nn = n(1 + 2 + 3 + . . .+ n) = n · n(n+ 1)/2
lo cual es O(n3).Por otra parte, si se emplea la heurıstica mover al frente, insertando cada
elemento la primera vez, entonces
cada acceso al elemento 1 se ejecuta en tiempo O(1);
cada acceso al elemento 2 se ejecuta en tiempo O(1);
. . .
cada acceso al elemento n se ejecuta en tiempo O(1);
Por lo que el tiempo de ejecucion para realizar todos los accesos en estecaso es O(n2). Ası, la implementacion mover al frente tiene tiempos de accesomas rapidos para este escenario. Sin embargo este beneficio vien a un costo.

6.5 Ejemplo: Heurıstica mover al frente 239
Implementacion de la heurıstica mover al frente
En el listado 6.15 se da una implementacion de una lista de favoritos usandola heurıstica mover al frente, definiendo una nueva clase ListaFavoritosMF, lacual extiende a la clase ListaFavoritos y entonces se anulan las definicionesde los metodos moverArriba y top. El metodo moverArriba en este casoquita el elemento accedido de su posicion frente en la lista ligada y la insertade regreso en la lista en el frente. El metodo top, por otra parte, es mascomplicado.
1 /** Lista de elementos favoritos con la heur ı stica mover al frente */
2 public class ListaFavoritosMF <E> extends ListaFavoritos <E>
3 /** Constructor por defecto */
4 public ListaFavoritosMF ()
5 /** Mueve una entrada a la primera posici on: tiempo O(1) */
6 protected void moverArriba(Posicion <Entrada <E>> pos)
7 listaF.addFirst(listaF.remove(pos ));
8
9 /** Regresa los k elementos mas accedidos , para un k; tiempo O(k) */
10 public Iterable <E> top(int k)
11 if( k<0 || k>size() )
12 throw new IllegalArgumentException("Argumento inv alido");
13 ListaPosicion <E> T = new ListaNodoPosicion <E>(); // lista top -k
14 if( !isEmpty () )
15 // copiar las entradas en una lista temporal C
16 ListaPosicion <Entrada <E>> C = new ListaNodoPosicion <Entrada <E>>();
17 for( Entrada <E> e: listaF )
18 C.addLast(e);
19 // encontrar los top k elementos , uno a la vez
20 for( int i=0; i<k; i++)
21 Posicion <Entrada <E>> posMax=null; // posici on de la entrada sup.
22 int cuentaMax =-1; // cuenta de accesos de la entrada top
23 for(Posicion <Entrada <E>> p: C.positions ())
24 // examinar todas las entradas de C
25 int c=cuenta( p );
26 if( c>cuentaMax) // encontr o una entrada con una cuenta mayor
27 cuentaMax = c;
28 posMax = p;
29
30
31 T.addLast( valor(posMax) ); // agregar entrada top a T
32 C.remove(posMax ); // quitar la posici on que ya fue agregada
33
34
35 return T;
36
37 // Fin de la clase ListaFavoritosMF
Listado 6.15: La clase ListaFavoritosMF implementa la heurıstica mover al frente.Esta clase extiende a la clase ListaFavoritos y anula los metodos moverArriba
y top.

240 Listas e Iteradores
El listado 6.16 muestra una aplicacion que crea dos listas de favoritos,una usa la clase ListaFavoritos y la otra ListaFavoritosMF. Las listas defavoritos son construidas usando un arreglo de direcciones Web, y despues segeneran 20 numeros pseudoaleatorios que estan en el rango de 0 al tamanodel arreglo menos uno. Cada vez que se marca un acceso se muestra el estadode las listas. Posteriormente se obtiene, de cada lista, el top del tamano de lalista. Con el sitio mas popular de la 1a lista se abre en una ventana.
1 import java.io.*;
2 import javax.swing .*;
3 import java.awt.*;
4 import java.net.*;
5 import java.util.Random;
6 /** Programa ejemplo para las clases ListaFavoritos y ListaFavoritosMF */
7 public class ProbadorFavoritos
8 public static void main(String [] args)
9 String [] arregloURL = "http :// google.com","http ://mit.edu",
10 "http :// bing.com","http :// yahoo.com","http :// unam.mx";
11 ListaFavoritos <String > L1 = new ListaFavoritos <String >();
12 ListaFavoritosMF <String > L2 = new ListaFavoritosMF <String >();
13 int n = 20; // cantidad de operaciones de acceso
14 // Escenario de simulaci on: acceder n veces un URL aleatorio
15 Random rand = new Random ();
16 for(int k=0; k<n; k++)
17 System.out.println("___________________________________________");
18 int i = rand.nextInt(arregloURL.length ); // ı ndice aleatorio
19 String url = arregloURL[i];
20 System.out.println("Accediendo: "+url);
21 L1.access(url);
22 System.out.println("L1 = " + L1);
23 L2.access(url);
24 System.out.println("L2 = " + L2);
25
26 int t = L1.size ()/2;
27 System.out.println("--------------------------------------------");
28 System.out.println("Top " + t + " en L1 = " + L1.top(t));
29 System.out.println("Top " + t + " en L2 = " + L2.top(t));
30 // Mostrar una ventana navegador del URL mas popular de L1
31 try
32 String popular = L1.top (1). iterator (). next (); // el mas popular
33 JEditorPane jep = new JEditorPane(popular );
34 jep.setEditable(false );
35 JFrame frame = new JFrame("URL mas popular en L1: "+popular );
36 frame.getContentPane ().add(new JScrollPane(jep),BorderLayout.CENTER );
37 frame.setSize (640 ,480);
38 frame.setVisible(true);
39 frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE );
40 catch( IOException e) /* ignorar excepciones I/O */
41
42
Listado 6.16: ProbadorFavoritos usa ListaFavoritos y ListaFavoritosMF paracontar la simulacion de accesos a paginas Web y mostrar la mas popular.

6.5 Ejemplo: Heurıstica mover al frente 241
El compromiso con la heurıstica mover al frente
La lista de favoritos no sera mantenida en orden por la cantidad de accesos,cuando se pide encontrar los k elementos mas accedidos, se necesita buscarlos.Se puede implementar el metodo top(k) como sigue:
1. Se copian las entradas de la lista de favoritos en otra lista, C, y se creauna lista vacıa, A.
2. La lista C se explora k veces. En cada ocasion, se encuentra una entradade C con la cuenta de acceso mas grande, quitando esta entrada de C,e insertando su valor al final de A.
3. Se regresa la lista A.
La implementacion del metodo top() toma tiempo O(kn). Ası, cuandok es una constante, el metodo se ejecuta en tiempo O(n). Esto ocurre si sequiere obtener la lista del top-ten. Sin embargo, si k es proporcional a n,entonces la ejecucion toma tiempo O(n2) y sucede cuando se quiere la listadel top 25 %.

242 Listas e Iteradores

Capıtulo 7
Arboles
7.1. Arboles generales
En este capıtulo, se discute una de las estructuras de datos no linealmas importante en computacion—arboles. Las estructuras arbol son ademasun progreso en la organizacion de datos, ya que permiten implementar unconjunto de algoritmos mas rapidos que cuando se usan estructuras linealesde datos, como una lista. Los arboles tambien dan una organizacion naturalpara datos, y por lo tanto, se han convertido en estructuras indispensablesen sistemas de archivos, interfaces graficas de usuario, bases de datos, sitiosWeb, y otros sistemas de computo.
Cuando se dice que los arboles “no son lineales”, se hace referencia auna relacion organizacional que es mas rica que las relaciones simples “antes”y “despues” entre objetos en secuencias. Las relaciones en un arbol sonjerarquicas, con algunos objetos estando “encima” y algunos otros “abajo”.Actualmente, la terminologıa principal para estructuras de dato arbol vienede los arboles genealogicos, con los terminos “padre”, “hijo”, “ancestro”,y “descendiente” siendo las palabras mas comunes usadas para describirrelaciones.
7.1.1. Definiciones de arboles y propiedades
Un arbol es un tipo de dato abstracto que guarda elementos jerarquica-mente. Con la excepcion del elemento cima, cada elemento en un arbol tieneun elemento padre y cero o mas elementos hijos. Un arbol es visualizadocolocando elementos dentro de ovalos o rectangulos, y dibujando las conexio-

244 Arboles
nes entre padres e hijos con lıneas rectas, ver figura 7.1. Se llama al elementocima la raız del arbol, pero este es dibujado como el elemento mas alto, conlos otros elementos estando conectados abajo, justo lo opuesto a un arbolvivo.
Figura 7.1: Arbol con 17 nodos para representar la organizacion de una corporacion.
Definicion formal de arbol
Se define un arbol A como un conjunto de nodos guardando elementostal que los nodos tienen una relacion padre-hijo, satisfaciendo las siguientespropiedades:
Si A no esta vacıo, este tiene un nodo especial, llamado la raız, o root,de A, que no tiene padre.
Cada nodo v de A diferente de la raız tiene un nodo padre unico w;cada nodo con padre w es un hijo de w.

7.1 Arboles generales 245
De acuerdo a la definicion, un arbol puede estar vacıo, es decir, no tenernodos. Esta convencion tambien permite definir un arbol recursivamente, talque un arbol A esta vacıo o consiste de un nodo r, llamado la raız de A, y unconjunto de arboles, posiblemente vacıo, cuyas raıces son los hijos de r.
Dos nodos que son hijos del mismo padre son hermanos. Un nodo v esexterno si v no tiene hijos. Un nodo v es interno si este tiene uno o mashijos. Los nodos externos son tambien conocidos como hojas.Ejemplo 7.1. En la mayorıa de los sistemas operativos, los archivos sonorganizados jerarquicamente en directorios anidados, tambien conocidos comocarpetas, los cuales son presentados al usuario en la forma de un arbol, verfigura 7.2. Mas especıficamente, los nodos internos del arbol estan asociadoscon directorios y los nodos externos estan asociados con archivos regulares.En el sistema operativo UNIX. la raız del arbol es llamada el “directorio raız”,y es representada por el sımbolo “/”.
Figura 7.2: Representacion de arbol de una porcion de un sistema de archivos.
Un nodo u es un ancestro de un nodo v si u = v o u es un ancestro delpadre de v. A la inversa, se dice que un nodo v es un descendiente de unnodo u si u es un ancestro de v. En la figura 7.2 cs252/ es un ancestro de

246 Arboles
papers/, y pr3 es un descendiente de cs016/. El subarbol enraızado deA en un nodo v es el arbol consistente de todos los descendientes de v enA, incluyendo al propio v. En la figura 7.2, el subarbol enraizado en cs016/
consiste de los nodos cs016/, grades, homeworks/, programs/, hw1, hw2,hw3, pr1, pr2 y pr3.
Aristas y caminos en arboles
Una arista del arbol A es un par de nodos (u, v) tal que u es el padre dev, o viceversa. Un camino de A es una secuencia de nodos tal que dos nodosconsecutivos cualesquiera en la secuencia forman una arista. Por ejemplo, elarbol de la figura 7.2 contiene el camino cs016/programs/pr2.
Ejemplo 7.2. La relacion de herencia entre clases en un programa Javaforman un arbol. La raız, java.lang.Object, es un ancestro de todas las otrasclases. Cada clase, C, es una descendiente de esta raız y es la raız de unsubarbol de las clases que extienden a C. Ası, hay un camino de C a la raız,java.lang.Object, en este arbol de herencia.
Arboles ordenados
Si hay un ordenamiento lineal definido para los hijos de cada nodo enun arbol, es un arbol ordenado; esto es, se puede identificar los hijos deun nodo como el primero, el segundo, el tercero, etc. Tal ordenamiento esvisualizado arreglando los hermanos de izquierda a derecha, de acuerdo a suordenamiento. Los arboles ordenados indican el orden lineal entre hermanoslistandolos en el orden correcto.
Ejemplo 7.3. Los componentes de un documento estructurado, tal como unlibro, estan jerarquicamente organizados como un arbol cuyos nodos internosson partes, capıtulos, y secciones, y cuyos nodos externos son parrafos, tablas,figuras, etcetera, ver figura 7.3. La raız del arbol corresponde al propio libro.Se podrıa considerar expandir mas el arbol para mostrar parrafos consistentesde sentencias, sentencias consistentes de palabras, y palabras consistentesde caracteres. Tal arbol es un ejemplo de un arbol ordenado, porque hay unordenamiento bien definido entre los hijos de cada nodo.

7.1 Arboles generales 247
Figura 7.3: Un arbol ordenado asociado con un libro.
7.1.2. El tipo de dato abstracto arbol
El ADT arbol guarda elementos en posiciones, las cuales, al igual que lasposiciones en una lista, estan definidas relativamente a posiciones vecinales.Las posiciones en un arbol son sus nodos y las posiciones vecinales satisfa-cen las relaciones padre-hijo que definen un arbol valido. Por lo tanto, se usanlos terminos “posicion” y “nodo” indistintamente para arboles. Al igual quecon una lista posicion, un objeto posicion para un arbol soporta el metodo:
elemento():regresa el objeto guardado en esta posicion.
Sin embargo, las posiciones nodo en un arbol tienen una funcionalidadmayor, ya que hay metodos accesores del ADT arbol que aceptan y regresanposiciones, como las siguientes:
root():regresa la raız del arbol; un error ocurre si el arbolesta vacıo.
parent(v):regresa el padre de v; un error ocurre si v es laraız.
children(v):regresa una coleccion iterable que lleva los hijosdel nodo v.
Si un arbol A esta ordenado, entonces la coleccion iterable, children(v),guarda los hijos de v en orden. Si v es un nodo externo, entonces children(v)esta vacıo.

248 Arboles
Ademas de los metodos accesores fundamentales previos, tambien seincluyen los siguientes metodos de consulta:
isInternal(v):indica si el nodo v es interno.isExternal(v):indica si el nodo v es externo.
isRoot(v):indica si el nodo v es la raız.
Estos metodos hacen la programacion con arboles mas facil y mas legible,ya que pueden ser usados en las condiciones de las sentencias if y de los cicloswhile, en vez de usar un condicional no intuitivo.
Hay tambien un numero de metodos genericos que un arbol probablementepodrıa soportar y que no estan necesariamente relacionados con la estructuradel arbol, incluyendo los siguientes:
size():regresa la cantidad de nodos en el arbol.isEmpty():valida si el arbol no tiene nodos.iterator():regresa un iterador de todos los elementos guarda-
dos en nodos del arbol.positions():regresa una coleccion iterable de todos los nodos
del arbol.replace(v, e):regresa el elemento del nodo v antes de cambiarlo
por e.
Cualquier metodo que tome una posicion como un argumento podrıagenerar una condicion de error si esa posicion es no valida. No se definenmetodos de actualizacion especializados para arboles. En su lugar, se describenmetodos de actualizacion diferentes de acuerdo con las aplicaciones especıficasde arboles.
7.1.3. Interfaz del ADT arbol
La interfaz Java mostrada en el listado 7.1 representa el ADT arbol.Las condiciones de error son manejadas como sigue: cada metodo puedetomar una posicion como un argumento, estos metodos podrıan lanzarInvalidPositionException para indicar que la posicion es invalida. Elmetodo parent() lanza BoundaryViolationException si este es llamadosobre un arbol vacıo. El metodo root() lanza EmptyTreeException si esllamado con un arbol vacıo.

7.1 Arboles generales 249
1 import java.util.Iterator;
2 /**
3 * Una interfaz para un arbol donde los nodos pueden tener
4 * una cantidad arbitraria de hijos.
5 */
6 public interface Tree <E>
7 /** Regresa el numero de nodos en el arbol. */
8 public int size ();
9 /** Valida si el arbol est a vac ıo. */
10 public boolean isEmpty ();
11 /** Regresa un iterador de los elementos guardados en el arbol. */
12 public Iterator <E> iterator ();
13 /** Regresa una colecci on iterable de los nodos. */
14 public Iterable <Posicion <E>> positions ();
15 /** Reemplaza el elemento guardado en un nodo dado. */
16 public E replace(Posicion <E> v, E e)
17 throws InvalidPositionException;
18 /** Regresa la ra ız del arbol. */
19 public Posicion <E> root() throws EmptyTreeException;
20 /** Regresa el padre de un nodo dado. */
21 public Posicion <E> parent(Posicion <E> v)
22 throws InvalidPositionException , BoundaryViolationException;
23 /** Regresa una colecci on iterable de los hijos de un nodo dado. */
24 public Iterable <Posicion <E>> children(Posicion <E> v)
25 throws InvalidPositionException;
26 /** Valida si un nodo dado es interno. */
27 public boolean isInternal(Posicion <E> v)
28 throws InvalidPositionException;
29 /** Valida si un nodo dado es externo. */
30 public boolean isExternal(Posicion <E> v)
31 throws InvalidPositionException;
32 /** Valida si un nodo dado es la ra ız del arbol. */
33 public boolean isRoot(Posicion <E> v)
34 throws InvalidPositionException;
35
Listado 7.1: Interfaz Java Tree para representar el ADT arbol. Metodos adicionalesde actualizacion podrıan ser agregados dependiendo de la aplicacion.
Una estructura enlazada para arboles generales
Una forma natural para crear un arbol A es usar una estructura enlaza-da, donde se representa cada nodo v de A por un objeto posicion, ver figura7.4 (a), con los siguientes campos: una referencia al elemento guardado en v,un enlace al padre de v, y algun tipo de coleccion, por ejemplo, una lista oarreglo, para guardar enlaces a los hijos de v. Si v es la raız de A entonces elcampo parent de v es null. Tambien, se guarda una referencia a la raız deA y el numero de nodos de A en variables internas. Se muestra en la figura7.4 (b) la estructura esquematicamente.
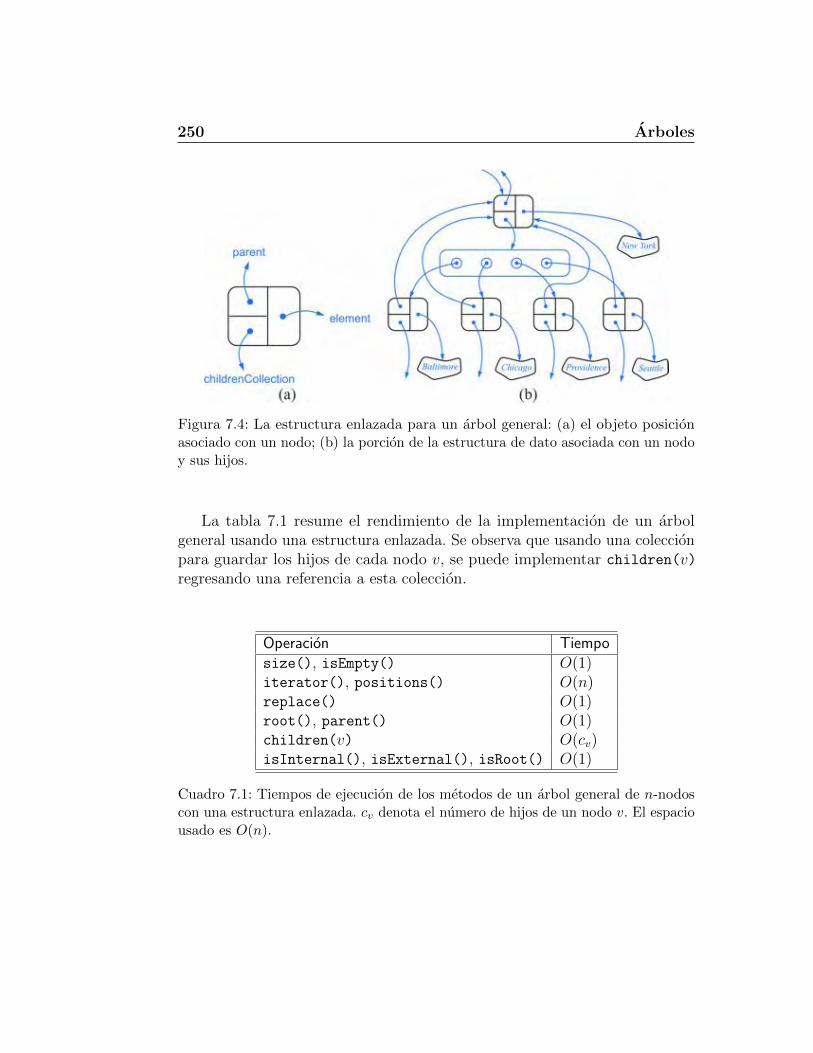
250 Arboles
Figura 7.4: La estructura enlazada para un arbol general: (a) el objeto posicionasociado con un nodo; (b) la porcion de la estructura de dato asociada con un nodoy sus hijos.
La tabla 7.1 resume el rendimiento de la implementacion de un arbolgeneral usando una estructura enlazada. Se observa que usando una coleccionpara guardar los hijos de cada nodo v, se puede implementar children(v)regresando una referencia a esta coleccion.
Operacion Tiemposize(), isEmpty() O(1)iterator(), positions() O(n)replace() O(1)root(), parent() O(1)children(v) O(cv)isInternal(), isExternal(), isRoot() O(1)
Cuadro 7.1: Tiempos de ejecucion de los metodos de un arbol general de n-nodoscon una estructura enlazada. cv denota el numero de hijos de un nodo v. El espaciousado es O(n).

7.2 Algoritmos de recorrido para arboles 251
7.2. Algoritmos de recorrido para arboles
En esta seccion, se presentan algoritmos para hacer recorridos en un arbolaccediendo este a traves de los metodos del ADT arbol.
7.2.1. Profundidad y altura
Sea v un nodo de un arbol A. La profundidad de v es el numero de ances-tros de v, excluyendo al propio v. Esta definicion implica que la profundidadde la raız de A es cero.
La profundidad de un nodo v tambien puede ser definida recursivamentecomo sigue:
Si v es la raız, entonces la profundidad de v es cero.
De otra forma, la profundidad de v es uno mas la profundidad del padrede v.
Usando la definicion previa se presenta un algoritmo recursivo simple,depth para calcular la profundidad de un nodo v de A. Este metodo se llamaa sı mismo recursivamente en el padre de v, y agrega uno al valor regresado.Algoritmo depth(A, v):
si v es la raız de A entoncesregresar 0
si noregresar 1+depth(A,w), donde w es el padre de v en A
Una implementacion Java simple de este algoritmo se da en el listado 7.2.
1 public static <E> int depth (Tree <E> T, Posicion <E> v)
2 if ( T.isRoot(v) )
3 return 0;
4 else
5 return 1 + depth(T, T.parent(v) );
6
Listado 7.2: El metodo depth() escrito en Java.
El tiempo de ejecucion del algoritmo depth(A, v) es O(dv), donde dvdenota la profundidad del nodo v en el arbol A, porque el algoritmo realizaun paso recursivo tiempo constante para cada ancestro de v. Ası, el algoritmodepth(A, v) se ejecuta en tiempo O(n) en el peor caso, donde n es el numerototal de nodos de A, ya que un nodo de A podrıa tener profundidad n− 1 en

252 Arboles
el peor caso. Aunque tal tiempo de ejecucion es una funcion del tamano deentrada, es mas preciso caracterizar el tiempo de ejecucion en terminos delparametro dv, debido a que este parametro puede ser mucho menor que n.
Altura
La altura de un nodo v en un arbol A se puede definir tambien recursiva-mente:
Si v es un nodo externo, entonces la altura de v es cero.
De otra forma, la altura de v es uno mas la altura maxima de los hijosde v.
La altura de un arbol no vacıo A es la altura de la raız de A. Porejemplo, el arbol de la figura 7.1 tiene altura 4. Ademas la altura puedetambien ser definida como sigue.
Proposicion 7.1: La altura de un arbol no vacıo A es igual a la maximaprofundidad de un nodo externo de A.
El algoritmo height1() calcula la altura de un arbol no vacıo A usandola proposicion anterior y el algoritmo depth. El listado 7.3 muestra suimplementacion en Java.Algoritmo height1(A):h← 0para cada vertice v en A hacersi v es un nodo externo de A entoncesh← max(h, depth(A, v))
regresar h
1 public static <E> int height1 (Tree <E> T)
2 int h = 0;
3 for ( Posicion <E> v : T.positions () )
4 if ( T.isExternal(v) )
5 h = Math.max( h, depth(T,v) );
6 return h;
7
Listado 7.3: Metodo height1(), que usa el metodo max() de la clase java.lang.-
Math

7.2 Algoritmos de recorrido para arboles 253
Desafortunadamente, el algoritmo height1 no es muy eficiente. Comoheight1 llama al algoritmo depth(v) en cada nodo externo v de A, el tiempode ejecucion de height1 esta dado por O(n +
∑v(1 + dv)), donde n es el
numero de nodos de A, dv es la profundidad del nodo v, y la suma se hace solocon el conjunto de nodos externos de A. En el peor caso, la suma
∑v(1 + dv)
es proporcional a n2. Ası, el algoritmo height1 corre en tiempo O(n2).El algoritmo height2, mostrado a continuacion e implementado en Java
en el listado 7.4, calcula la altura del arbol A de una forma mas eficienteusando la definicion recursiva de altura.Algoritmo height2(A, v):
si v es un nodo externo de A entoncesregresar 0
si noh← 0para cada hijo w de v en A hacerh← max(h,height2(A,w))
regresar h+1
1 public static <E> int height2 (Tree <E> T, Posicion <E> v)
2 if ( T.isExternal(v) ) return 0;
3 int h = 0;
4 for ( Posicion <E> w : T.children(v) )
5 h = Math.max(h, height2( T, w ));
6 return 1 + h;
7
Listado 7.4: Metodo height2() escrito en Java.
El algoritmo height2 es mas eficiente que height1. El algoritmo esrecursivo, y, si este es inicialmente llamado con la raız de A, este eventualmentesera llamado con cada nodo de A. Ası, se puede determinar el tiempo deejecucion de este metodo sumando, sobre todos los nodos, la cantidad detiempo gastado en cada nodo. Procesar cada nodo en children(v) tomatiempo O(cv), donde cv es el numero de hijos de un nodo v. Tambien, elciclo while tiene cv iteraciones y cada iteracion en el ciclo toma tiempo O(1)mas el tiempo para la llamada recursiva con un hijo de v. Ası, el algoritmoheight2 gasta tiempo O(1 + cv) en cada nodo v, y su tiempo de ejecucion esO(∑
v(1 + cv)).Sea un arbol A con n nodos, y cv el numero de hijos de un nodo v de A,
entonces sumando sobre los vertices en A,∑
v cv = n− 1, ya que cada nodo

254 Arboles
de A, con la excepcion de la raız, es un hijo de otro nodo, y ası contribuyeuna unidad a la suma anterior.
Con el resultado anterior, el tiempo de ejecucion del algoritmo height2,cuando es llamado con la raız de A, es O(n), donde n es el numero de nodosde A.
7.2.2. Recorrido en preorden
Un recorrido de un arbol A es una forma sistematica de acceder, “visitar”,todos los nodos de A. Se presenta un esquema basico de recorrido para arboles,llamado recorrido en preorden. En la siguiente seccion, se revisa otro esquemabasico de recorrido, llamado recorrido en postorden.
En un recorrido en preorden de un arbol A, la raız de A es visitadaprimero y entonces los subarboles enraizados con sus hijos son recorridos re-cursivamente. Si el arbol esta ordenado, entonces los subarboles son recorridosde acuerdo al orden de los hijos. La accion especıfica asociada con la “visita”de un nodo v depende de la aplicacion de este recorrido, y podrıa involucrardesde incrementar un contador hasta realizar algun calculo complejo para v.El pseudocodigo para el recorrido en preorden del subarbol enraizado en unnodo v se muestra enseguida.Algoritmo preorden(A, v):
Realizar la accion “visita” para el nodo vpara cada hijo w de v en A hacer
preorden(A,w) recursivamente recorrer el subarbol en w
El algoritmo de recorrido en preorden es util para producir un ordenamientolineal de los nodos de un arbol donde los padres deberan estar antes quesus hijos en el ordenamiento. Tales ordenamientos tienen varias aplicacionesdiferentes. Se comenta a continuacion un ejemplo simple de tal aplicacion enel siguiente ejemplo.
Ejemplo 7.4. El recorrido en preorden del arbol asociado con un documentoexamina un documento entero secuencialmente, desde el inicio hasta el fin.Si los nodos externos son quitados antes del recorrido, entonces el recorridoexamina la tabla de contenido del documento. Ver figura 7.5.
El recorrido en preorden es tambien una forma eficiente para acceder atodos los nodos de un arbol. El analisis es similar al del algoritmo height2.En cada nodo v, la parte no recursiva del algoritmo de recorrido en preordenrequiere tiempo O(1 + cv), donde cv es el numero de hijos de v, Ası, el tiempo

7.2 Algoritmos de recorrido para arboles 255
Figura 7.5: Recorrido en preorden de un arbol ordenado, donde los hijos de cadanodo estan ordenados de izquierda a derecha.
total de ejecucion en el recorrido en preorden de A es O(n). Tambien se puedeobservar que cada nodo es visitado solo una vez.
El algoritmo toStringPreorden implementado con Java, listado 7.5,hace una impresion en preorden del subarbol de un nodo v de A, es decir,realiza el recorrido en preorden del subarbol enraizado en v, e imprime loselementos guardados en un nodo cuando el nodo es visitado. El metodoA.children(v) regresa una coleccion iterable que accede a los hijos de v enorden.
1 public static <E> String toStringPreorden(Tree <E> T, Posicion <E> v)
2 String s = v.elemento (). toString (); // acci on principal de visita
3 for (Posicion <E> h: T.children(v))
4 s += ", " + toStringPreorden(T, h);
5 return s;
6
Listado 7.5: Metodo toStringPreordenque hace una impresion en preorden de loselementos en el subarbol del nodo v de A.
Hay una aplicacion interesante del algoritmo de recorrido en preordenque produce una representacion de cadena de un arbol entero. Suponiendoque para cada elemento e guardado en el arbol A, la llamada e.toString()regresa una cadena asociada con e. La representacion parentetica decadena P (A) del arbol A definida recursivamente como sigue. Si A tiene unsolo nodo v, entonces
P (A) = v.elemento().toString().

256 Arboles
De otra forma,
P (A) = v.elemento().toString()+“(”+P (A1)+“,”+ · · ·+“,”+P (Ak)+“)”,
donde v es la raız de A y A1, A2, . . . , Ak son los subarboles enraizados de loshijos de v, los cuales estan dados en orden si A es un arbol ordenado.
La definicion de P (A) es recursiva y el operador “+” indica la concatena-cion de cadenas. La representacion parentetica del arbol de la figura 7.1 semuestra enseguida, donde el sangrado y los espacios han sido agregados paraclaridad, y ademas se han retirado las comas.
Electronics R’Us (
R&D
Sales (
Domestic
International (
Canada
S. America
Overseas (
Africa
Europe
Asia
Australia
)
)
)
Purchasing
Manufacturing (
TV
CD
Tuner
)
)
El metodo Java representacionParentetica, listado 7.6, es una varia-cion del metodo toStringPreorden, listado 7.5. Esta implementado por ladefinicion anterior para obtener una representaion parentetica de cadena deun arbol A. El metodo representacionParentetica hace uso del metodotoString que esta definido para cada objeto Java. Se puede ver a este metodocomo un tipo de metodo toString() para objetos arbol.

7.2 Algoritmos de recorrido para arboles 257
1 public static <E> String representacionParentetica(
2 Tree <E> T, Posicion <E> v)
3 String s = v.elemento (). toString (); // acci on principal de visita
4 if (T.isInternal(v))
5 Boolean primeraVez = true;
6 for (Posicion <E> w : T.children(v))
7 if (primeraVez)
8 s += " ( "+representacionParentetica(T, w); // 1er hijo
9 primeraVez = false;
10
11 else
12 s += ", "+representacionParentetica(T, w); // hijos siguientes
13 s += " )"; // cerrar par e ntesis
14
15 return s;
16
Listado 7.6: Metodo representacionParentetica() donde se emplea el operador+ para concatenar dos cadenas.
7.2.3. Recorrido en postorden
El algoritmo de recorrido en postorden puede ser visto como el opuestoal recorrido en preorden, porque este recursivamente recorre los subarbolesenraizados en los hijos de la raız primero, y despues visita la raız. Al igual queen el recorrido en preorden se emplea el algoritmo para resolver un problemaparticular especializando una accion asociada con la “visita” de un nodo v. Siel arbol esta ordenado, se hacen llamadas recursivas para los hijos de un nodov de acuerdo a su orden indicado. El pseudocodigo es dado a continuacion.
Algoritmo postorden(A, v):para cada hijo w de v en A hacer
postorden(A,w) recursivamente recorrer el subarbol en wRealizar la accion “visita” para el nodo v
El nombre de recorrido en postorden se debe a que este metodo de recorridovisitara un nodo v despues de que este ha visitado todos los nodos en lossubarboles enraizados en v. Ver figura 7.6.
El analisis del tiempo de ejecucion del recorrido en postorden es analogoal del recorrido en preorden. El tiempo total gastado en las porciones norecursivas del algoritmo es proporcional al tiempo gastado en visitar los hijosde cada nodo en el arbol. Entonces el recorrido de un arbol A con n nodostoma tiempo O(n), suponiendo que cada visita tome tiempo O(1), ası elrecorrido se ejecuta en tiempo lineal.

258 Arboles
Figura 7.6: Recorrido en postorden del arbol ordenado de la figura 7.5
En el listado 7.7 se muestra el metodo Java toStringPostOrden() el cualrealiza un recorrido en postorden de un arbol A. Este metodo muestra elelemento guardado en un nodo cuando este es visitado. Este metodo tambienllama implıcitamente al metodo toString() con los elementos, cuando estaninvolucrados en una operacion de concatenacion de cadenas.
1 public static <E> String toStringPostorden(Tree <E> T, Posicion <E> v)
2 String s = "";
3 for (Posicion <E> h: T.children(v))
4 s += ", " + toStringPreorden(T, h)+" ";
5 s += v.elemento ();
6 return s;
7
Listado 7.7: Metodo toStringPostorden que realiza una impresion en postordende los elementos en el subarbol del nodo v de A.
El metodo de recorrido en postorden es util para resolver problemas dondese desea calcular alguna propiedad para cada nodo v en un arbol, pero parapoder calcular esa propiedad sobre v se requiere que ya se haya calculadoesa propiedad para los hijos de v. Se muestra una aplicacion en el siguienteejemplo.Ejemplo 7.5. Considerar un arbol sistema de archivos A, donde los nodosexternos representan archivos y los nodos internos representan directorios.Supongase que se quiere calcular el espacio en disco usado en un directorio,ver figura 7.7, lo cual es recursivamente dado por la suma de:
El tamano del directorio propio.
Los tamanos de los archivos en el directorio.
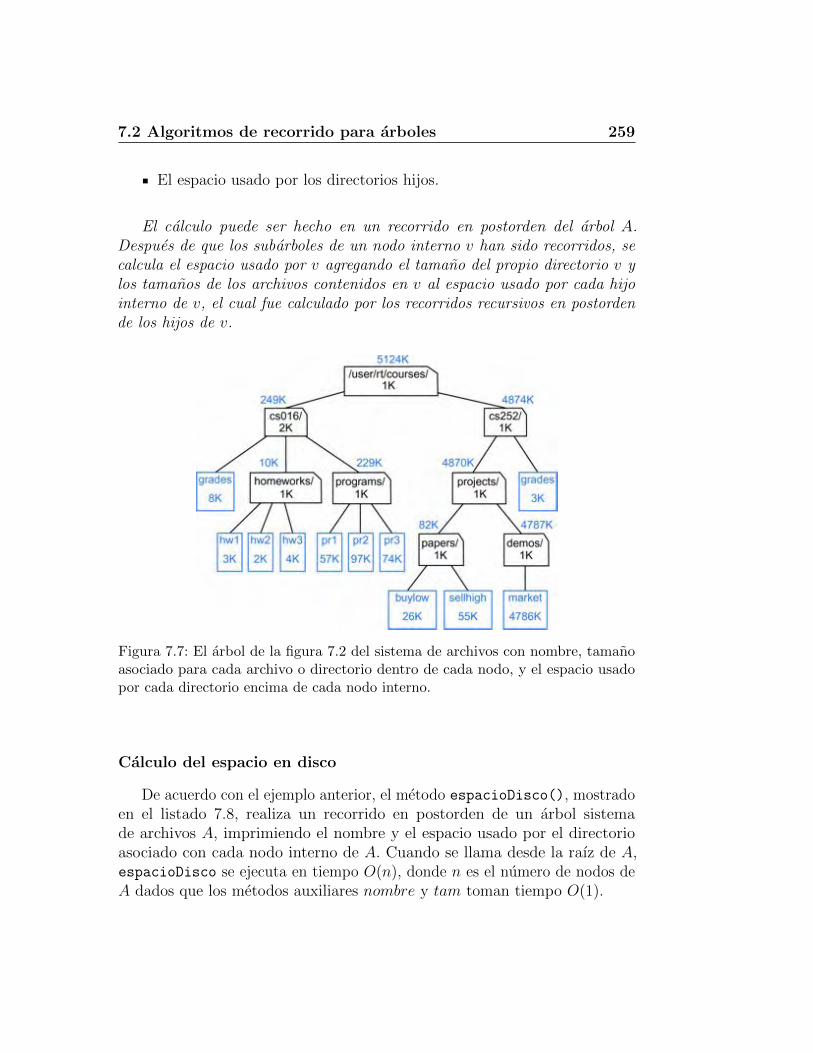
7.2 Algoritmos de recorrido para arboles 259
El espacio usado por los directorios hijos.
El calculo puede ser hecho en un recorrido en postorden del arbol A.Despues de que los subarboles de un nodo interno v han sido recorridos, secalcula el espacio usado por v agregando el tamano del propio directorio v ylos tamanos de los archivos contenidos en v al espacio usado por cada hijointerno de v, el cual fue calculado por los recorridos recursivos en postordende los hijos de v.
Figura 7.7: El arbol de la figura 7.2 del sistema de archivos con nombre, tamanoasociado para cada archivo o directorio dentro de cada nodo, y el espacio usadopor cada directorio encima de cada nodo interno.
Calculo del espacio en disco
De acuerdo con el ejemplo anterior, el metodo espacioDisco(), mostradoen el listado 7.8, realiza un recorrido en postorden de un arbol sistemade archivos A, imprimiendo el nombre y el espacio usado por el directorioasociado con cada nodo interno de A. Cuando se llama desde la raız de A,espacioDisco se ejecuta en tiempo O(n), donde n es el numero de nodos deA dados que los metodos auxiliares nombre y tam toman tiempo O(1).

260 Arboles
1 public static <E> int espacioDisco(Tree <E> T, Posicion <E> v)
2 int t = tam(v); // iniciar con el tama~no del propio nodo
3 for (Posicion <E> h: T.children(v))
4 // agregar espacio calculado recursivamente usado por los hijos
5 t += espacioDisco(T, h);
6 if (T.isInternal(v))
7 // imprimir nombre y espacio en disco usado
8 System.out.print(nombre(v) + ": " + t);
9 return t;
10
Listado 7.8: El metodo espacioDisco imprime el nombre y el espacio en discousado por los directorios asociados con cada nodo interno de un arbol sistema dearchivos. Los metodos auxiliares nombre y tam deben ser definidos para regresarel nombre y el tamano asociado con un nodo.
Otros tipos de recorridos
A pesar de que los recorridos en preorden y postorden son formas comu-nes de visitar los nodos de un arbol, se pueden tener otros recorridos. Porejemplo, se podrıa recorrer un arbol del que se visiten todos los nodos de unaprofundidad p antes que se visiten los nodos en una profundidad p+ 1. Esterecorrido es conocido “por niveles”. Cuando se recorren los nodos del arbolconsecutivamente numerandoles conforme se visitan se llama la numeracionpor nivel de los nodos de A.
7.3. Arboles Binarios
Un arbol binario es un arbol ordenado con las siguientes propiedades:
1. Cada nodo tiene a lo mas dos hijos.
2. Cada nodo hijo esta etiquetado ya se como un hijo izquierdo o como unhijo derecho.
3. Un hijo izquierdo precede a un hijo derecho en el ordenamiento de loshijos de un nodo.
El subarbol enraizado en un hijo izquierdo o un hijo derecho de unnodo interno v es llamado un subarbol izquierdo o subarbol derecho,respectivamente, de v. Un arbol binario es arbol binario propio si cada

7.3 Arboles Binarios 261
nodo tiene cero o dos hijos. Algunos autores tambien se refieren a tales arbolescomo arboles binarios arbol binario completo. Ası, en un arbol binariopropio, cada nodo interno tiene exactamente dos hijos. Un arbol binario queno es propio es arbol impropio.Ejemplo 7.6. Una clase de arboles binarios se emplean en los contextos dondese desea representar un numero de diferentes salidas que pueden resultar decontestar una serie de preguntas si o no. Cada nodo interno esta asociado conuna pregunta. Iniciando en la raız, se va con el hijo izquierdo o derecho delnodo actual, dependiendo de si la respuesta a la pregunta fue “Si” o “No”. Concada decision, se sigue una arista desde un padre a un hijo, eventualmentetrazando un camino en el arbol desde la raız a un nodo externo. Tales arbolesbinarios son conocidos como arboles de decision, porque cada nodo externoV en tal arbol representa una decision de que hacer si la pregunta asociada conlos ancestros de v fueron contestadas en una forma que llevan a v. Un arbol dedecision es un arbol binario propio. La figura 7.8 muestra un arbol de decisionpara mostrar en orden ascendente tres valores guardados en las variables A,B y C, donde los nodos internos del arbol representan comparaciones y losnodos externos representan la secuencia ordenada en forma creciente.
Figura 7.8: Un arbol de decision para ordenar tres variables en orden creciente
Ejemplo 7.7. Una expresion aritmetica puede ser representada con un arbolbinario cuyos nodos externos estan asociados con variables o constantes, ycuyos nodos internos estan asociados con los operadores +, −, × y /. Verfigura 7.9. Cada nodo en tal arbol tiene un valor asociado con este.
Si un nodo es externo, entonces su valor es aquel de su variable o

262 Arboles
constante.
Si un nodo es interno, entonces su valor esta definido aplicando laoperacion a los valores de sus hijos.
Un arbol de expresion aritmetica es un arbol binario propio, ya que losoperadores +, −, × y / requieren exactamente dos operandos.
Figura 7.9: Un arbol binario representando la expresion aritmetica ((((3 + 1) ×3)/((9− 5) + 2))− ((3× (7− 4)) + 6)).
Definicion recursiva de un arbol binario
Se puede definir un arbol binario en una forma recursiva tal que un arbolbinario esta vacıo o consiste de:
Un nodo r, llamado la raız de A y que guarda un elemento.
Un arbol binario, llamado el subarbol izquierdo de A.
Un arbol binario, llamado el subarbol derecho de A.
7.3.1. El ADT arbol binario
Como un tipo de dato abstracto, un arbol binario es una especializacionde un arbol que soporta cuatro metodos accesores adicionales:

7.3 Arboles Binarios 263
left(v):Regresa el hijo izquierdo de v; una condicion deerror ocurre si v no tiene hijo izquierdo.
right(v):Regresa el hijo derecho de v; una condicion deerror ocurre si v no tiene hijo derecho.
hasLeft(v):Prueba si v tiene hijo izquierdo.hasRight(v):Prueba si v tiene hijo derecho.
No se definen metodos de actualizacion especializados sino que se con-sideran algunas posibles actualizaciones de metodos cuando se describanimplementaciones especıficas y aplicaciones de arboles binarios.
7.3.2. Una interfaz arbol binario en Java
Se modela un arbol binario como un tipo de dato abstracto que extiende elADT arbol y agrega los cuatro metodos especializados para un arbol binario.En el listado 7.9, se muestra la interfaz que se define con esta aproximacion.Como los arboles binarios son arboles ordenados, la coleccion iterable regresadapor el metodo children(v), que se hereda de la interfaz Tree guarda el hijoizquierdo de v antes que el hijo derecho.
1 /**
2 * Una interfaz para un arbol binario donde cada nodo tiene
3 * cero , uno o dos hijos.
4 *
5 */
6 public interface ArbolBinario <E> extends Tree <E>
7 /** Regresa el hijo izquierdo de un nodo. */
8 public Posicion <E> left(Posicion <E> v)
9 throws InvalidPositionException , BoundaryViolationException;
10 /** Regresa el hijo derecho de un nodo. */
11 public Posicion <E> right(Posicion <E> v)
12 throws InvalidPositionException , BoundaryViolationException;
13 /** Indica si un un nodo tiene hijo izquierdo. */
14 public boolean hasLeft(Posicion <E> v) throws InvalidPositionException;
15 /** Indica si un un nodo tiene hijo derecho. */
16 public boolean hasRight(Posicion <E> v) throws InvalidPositionException;
17
Listado 7.9: Interfaz Java ArbolBinario para el ADT arbol binario que extiende aTree (listado 7.1).

264 Arboles
7.3.3. Propiedades del arbol binario
Las propiedades de los arboles binarios se relacionan con sus alturas y elnumero de nodos Se denota al conjunto de todos los nodos de un arbol Aque estan a la misma profundidad d como el nivel de un arbol binario deA. Para el arbol binario, el nivel 0 tiene a lo mas un nodo, la raız, el nivel 1tiene a los mas dos nodos, los hijos de la raız, el nivel 2 tiene a lo mas 4 hijos,y ası sucesivamente. Ver figura 7.10. En general, el nivel d tiene a lo mas 2d
nodos.
Figura 7.10: Numero maximo de nodos en los niveles de un arbol binario.
Se observa que el numero maximo de nodos en los niveles del arbol binariocrece exponencialmente conforme se baja en el arbol. De esta observacion, sepueden derivar las siguientes propiedades de relacion entre la altura de unarbol binario A con el numero de nodos.
Proposicion 7.2: Sea A un arbol binario no vacıo, y sean n, nE, nI y h elnumero de nodos, numero de nodos externos, numero de nodos internos, y laaltura de A, respectivamente. Entonces A tiene las siguientes propiedades:
1. h+ 1 ≤ n ≤ 2h+1 − 1

7.3 Arboles Binarios 265
2. 1 ≤ nE ≤ 2h
3. h ≤ nI ≤ 2h − 1
4. log(n+ 1)− 1 ≤ h ≤ n− 1
Tambien, si A es propio, entonces A tiene las siguientes propiedades:
1. 2h+ 1 ≤ n ≤ 2h+1 − 1
2. h+ 1 ≤ nE ≤ 2h
3. h ≤ nI ≤ 2h − 1
4. log(n+ 1)− 1 ≤ h ≤ (n− 1)/2
Tambien se cumple la siguiente relacion entre el numero de nodos internosy los nodos externos en un arbol binario propio
nE = nI + 1.
Para mostrar lo anterior se pueden quitar los nodos de A y dividirlos endos “pilas”, una pila con los nodos internos y otra con los nodos externos,hasta que A quede vacıo. Las pilas estan inicialmente vacıas. Al final, lapila de nodos externos tendra un nodo mas que la pila de nodos internos,considerar dos casos:
Caso 1: Si A tiene un solo nodo v, se quita v y se coloca enla pila externa. Ası, la pila de nodos externos tiene un solo nodoy la pila de nodos internos esta vacıa.
Caso 2: De otra forma, A tiene mas de un nodo, se quita deA un nodo externo arbitrario w y su padre v, el cual es un nodointerno. Se coloca a w en la pila de nodos externos y v en la pilade nodos internos. Si v tiene un padre u, entonces se reconecta ucon el ex-hermano z de w, como se muestra en la figura 7.11. Estaoperacion quita un nodo interno y uno externo, y deja al arbolcomo un arbol binario propio.
Se repite esta operacion, hasta que eventualmente se tiene unarbol final consistente de un solo nodo. Entonces se quita el nododel arbol final se coloca en la pila externa, teniendo ası esta pilaun nodo mas que la pila interna.

266 Arboles
Figura 7.11: Operacion para quitar un nodo externo y su nodo padre, usado en lademostracion
7.3.4. Una estructura enlazada para arboles binarios
Una forma natural de realizar un arbol binario A es usar una estructuraligada, donde se representa cada nodo v de A por un objeto Posicion, verfigura 7.12, con los campos dando referencias al elemento guardado en v y aobjetos Posicion asociados con los hijos y el padre de v.
Si v es la raız de A, entonces el campo padre de v es null. Tambien, seguarda el numero de nodos de A en la variable tam.
Implementacion Java de un nodo del arbol binario
Se emplea la interfaz Java PosicionAB para representar un nodo del arbolbinario. Esta interfaz extiende Posicion, por lo que se hereda el metodoelemento, y tiene metodos adicionales para poner el elemento en el nodo,setElemento y para poner y devolver el padre, el hijo izquierdo y el hijoderecho, como se muestra en el listado 7.10.
1 /**
2 * Interfaz para un nodo de un arbol binario. Esta mantiene un elemento ,
3 * un nodo padre , un nodo izquierdo , y nodo derecho.
4 *
5 */
6 public interface PosicionAB <E> extends Posicion <E> // hereda elemento ()
7 public void setElemento(E o);
8 public PosicionAB <E> getIzq ();
9 public void setIzq(PosicionAB <E> v);
10 public PosicionAB <E> getDer ();
11 public void setDer(PosicionAB <E> v);
12 public PosicionAB <E> getPadre ();
13 public void setPadre(PosicionAB <E> v);
14
Listado 7.10: Interfaz Java PosicionAB para definir los metodos que permitenacceder a los elementos de un nodo del arbol binario.
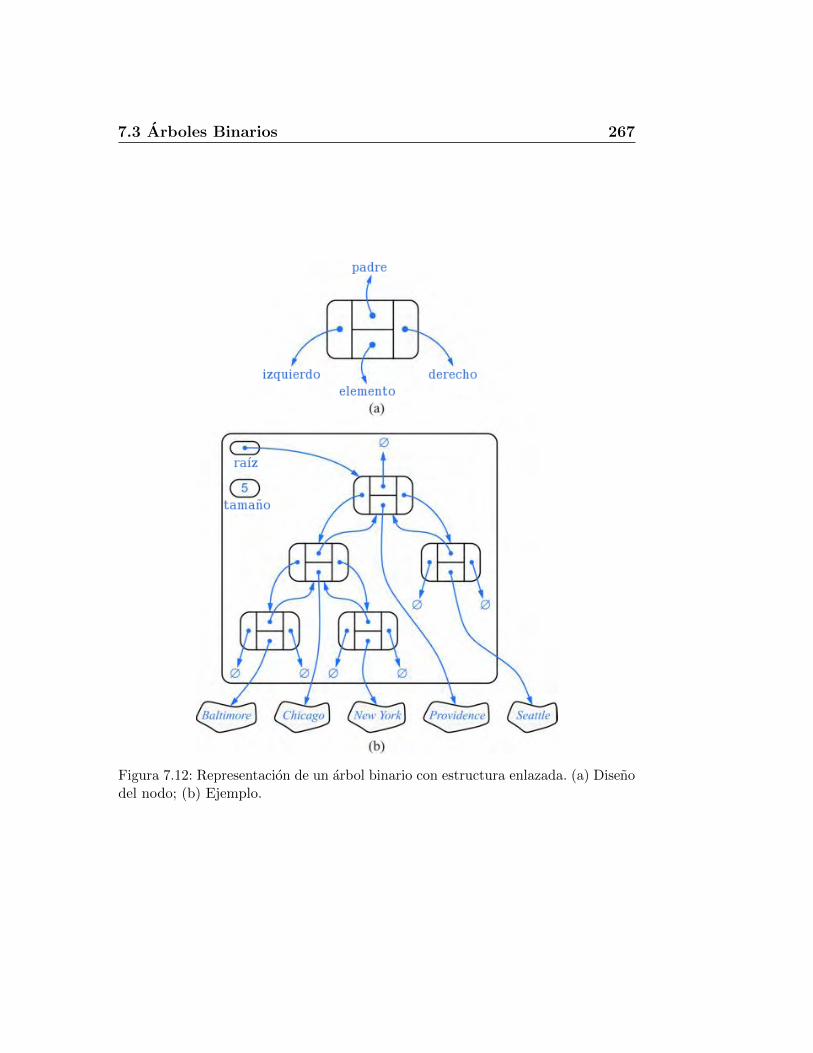
7.3 Arboles Binarios 267
Figura 7.12: Representacion de un arbol binario con estructura enlazada. (a) Disenodel nodo; (b) Ejemplo.

268 Arboles
La clase NodoAB, listado 7.11, implementa la interfaz PosicionAB para unobjeto con los campos elemento, izq, der, y padre, lo cual, para un nodo v,se refiere al elemento en v, el hijo izquierdo de v, el hijo derecho de v, y elpadre de v respectivamente.
1 /**
2 * La clase implementa un nodo de un arbol binario guardando las referencias
3 * a un elemento , un nodo padre , un nodo izquierdo , y un nodo derecho.
4 *
5 */
6 public class NodoAB <E> implements PosicionAB <E>
7 private E elemento; // elemento guardado en este nodo
8 private PosicionAB <E> izq , der , padre; // nodos adyacentes
9 /** Constructor por defecto */
10 public NodoAB ()
11 /** Constructor principal */
12 public NodoAB(E elemento , PosicionAB <E> padre ,
13 PosicionAB <E> izq , PosicionAB <E> der)
14 setElemento(elemento );
15 setPadre(padre);
16 setIzq(izq);
17 setDer(der);
18
19 /** Regresa el elemento guardado en esta posici on */
20 public E elemento () return elemento;
21 /** Pone el elemento guardado en esta posici on */
22 public void setElemento(E o) elemento=o;
23 /** Regresa el hijo izquierdo de esta posici on */
24 public PosicionAB <E> getIzq () return izq;
25 /** Pone el hijo izquierdo de esta posici on */
26 public void setIzq(PosicionAB <E> v) izq=v;
27 /** Regresa el hijo derecho de esta posici on */
28 public PosicionAB <E> getDer () return der;
29 /** Pone el hijo derecho de esta posici on */
30 public void setDer(PosicionAB <E> v) der=v;
31 /** Regresa el padre de esta posici on */
32 public PosicionAB <E> getPadre () return padre;
33 /** Pone el padre de esta posici on */
34 public void setPadre(PosicionAB <E> v) padre=v;
35
Listado 7.11: Clase auxiliar NodoAB para implementar los nodos del arbol binario.
Implementacion Java del arbol binario enlazado
En el listado 7.12 se muestra la clase ArbolBinarioEnlazado que imple-menta la interfaz ArbolBinario, listado 7.9, usando una estructura de datosenlazada. Esta clase guarda el tamano del arbol y una referencia al objetoNodoAB asociado con la raız del arbol en variables internas. Adicional a losmetodos de la interfaz ArbolBinario, la clase tiene otros metodos, incluyendo

7.3 Arboles Binarios 269
el metodo accesor sibling(v), el cual regresa el hermano de un nodo v, ylos siguientes metodos de actualizacion:
addRoot(e):Crea y regresa un nuevo nodo r que guarda elelemento e y hace a r la raız del arbol, un errorocurre si el arbol no esta vacıo.
insertLeft(v, e):Crea y regresa un nuevo nodo w que guarda a e,agrega a w como el hijo izquierdo de v y regresaw, un error ocurre si v ya tiene un hijo izquierdo.
insertRight(v, e):Crea y regresa un nuevo nodo w que guarda a e,agrega a w como el hijo derecho de v y regresa w,un error ocurre si v ya tiene un hijo derecho.
remove(v):Quita el nodo v y lo reemplaza con su hijo, sitiene, y regresa el elemento guardado en v; unerror ocurre si v tiene dos hijos.
attach(v, T1, T2):Une T1 y T2 como los subarboles izquierdo y de-recho del nodo externo v, una condicion de errorocurre si v no es externo.
La clase ArbolBinarioEnlazado tiene un constructor sin argumentos queregresa un arbol binario vacıo. Iniciando con este arbol vacıo, se puede construircualquier arbol binario creando el primer nodo con el metodo addRoot() yaplicando repetidamente los metodos insertLeft(), insertRight() o elmetodo attach(). De igual forma, se puede desmantelar cualquier arbolbinario A usando la operacion remove, llegando hasta un arbol binario vacıo.
Cuando una posicion v es pasado como un argumento a alguno de losmetodos de la clase ArbolBinarioEnlazado, su validez se revisa llamando unmetodo auxiliar de ayudo, checkPosition(v). Una lista de los nodos visitadosen un recorrido en preorden del arbol es construido por un metodo recursivopreorderPositions. Las condiciones de error son indicadas lanzando excep-ciones InvalidPositionException, BoundaryViolationException, Empty-TreeException, y NonEmptyTreeException.

270 Arboles
1 import java.util.Iterator;
2 /**
3 * Una implementaci on de la interfaz ArbolBinario usando una estructura
4 * enlazada.
5 * @see ArbolBinario */
6 public class ArbolBinarioEnlazado <E> implements ArbolBinario <E>
7 protected PosicionAB <E> raiz; // referencia a la ra ız
8 protected int tam; // numero de nodos
9 /** Crea un arbol binario vac ıo */
10 public ArbolBinarioEnlazado ()
11 raiz = null; // empezar con un arbol binario
12 tam = 0;
13
14 /** Regresa el numero de nodos en el arbol. */
15 public int size()
16 return tam;
17
18 /** Indica si el arbol est a vac ıo. */
19 public boolean isEmpty ()
20 return (tam == 0);
21
22 /** Indica si un nodo es interno. */
23 public boolean isInternal(Posicion <E> v) throws InvalidPositionException
24 revisaPosicion(v); // metodo auxiliar
25 return (hasLeft(v) || hasRight(v));
26
27 /** Indica si un nodo es externo */
28 public boolean isExternal(Posicion <E> v) throws InvalidPositionException
29 return !isInternal(v);
30
31 /** Indica si un nodo es la ra ız */
32 public boolean isRoot(Posicion <E> v) throws InvalidPositionException
33 revisaPosicion(v);
34 return (v == root ());
35
36 /** Indica si un nodo tiene hijo izquierdo */
37 public boolean hasLeft(Posicion <E> v) throws InvalidPositionException
38 PosicionAB <E> vv = revisaPosicion(v);
39 return (vv.getIzq () != null);
40
41 /** Indica si un nodo tiene hijo derecho */
42 public boolean hasRight(Posicion <E> v) throws InvalidPositionException
43 PosicionAB <E> vv = revisaPosicion(v);
44 return (vv.getDer () != null);
45
46 /** Regresa la ra ız del arbol */
47 public Posicion <E> root() throws EmptyTreeException
48 if (raiz == null)
49 throw new EmptyTreeException("El arbol est a vac ıo");
50 return raiz;
51
52 /** Regresa el hijo izquierdo de un nodo. */
53 public Posicion <E> left(Posicion <E> v)
54 throws InvalidPositionException , BoundaryViolationException
55 PosicionAB <E> vv = revisaPosicion(v);
56 Posicion <E> posIzq = vv.getIzq ();

7.3 Arboles Binarios 271
57 if (posIzq == null)
58 throw new BoundaryViolationException("Sin hijo izquierdo");
59 return posIzq;
60
61 /** Regresa el hijo izquierdo de un nodo. */
62 public Posicion <E> right(Posicion <E> v)
63 throws InvalidPositionException , BoundaryViolationException
64 PosicionAB <E> vv = revisaPosicion(v);
65 Posicion <E> posDer = vv.getDer ();
66 if (posDer == null)
67 throw new BoundaryViolationException("Sin hijo derecho");
68 return posDer;
69
70 /** Regresa el padre de un nodo. */
71 public Posicion <E> parent(Posicion <E> v)
72 throws InvalidPositionException , BoundaryViolationException
73 PosicionAB <E> vv = revisaPosicion(v);
74 Posicion <E> posPadre = vv.getPadre ();
75 if (posPadre == null)
76 throw new BoundaryViolationException("Sin padre");
77 return posPadre;
78
79 /** Regresa una colecci on iterable de los hijos de un nodo. */
80 public Iterable <Posicion <E>> children(Posicion <E> v)
81 throws InvalidPositionException
82 ListaPosicion <Posicion <E>> children = new ListaNodoPosicion <Posicion <E>>();
83 if (hasLeft(v))
84 children.addLast(left(v));
85 if (hasRight(v))
86 children.addLast(right(v));
87 return children;
88
89 /** Regresa una colecci on iterable de los nodos de un arbol. */
90 public Iterable <Posicion <E>> positions ()
91 ListaPosicion <Posicion <E>> posiciones = new ListaNodoPosicion <Posicion <E>>();
92 if(tam != 0)
93 preordenPosiciones(root(), posiciones ); // asignar posiciones en preorden
94 return posiciones;
95
96 /** Regresar un iterado de los elementos guardados en los nodos. */
97 public Iterator <E> iterator ()
98 Iterable <Posicion <E>> posiciones = positions ();
99 ListaPosicion <E> elementos = new ListaNodoPosicion <E>();
100 for (Posicion <E> pos: posiciones)
101 elementos.addLast(pos.elemento ());
102 return elementos.iterator (); // Un iterador de elementos
103
104 /** Reemplaza el elemento en un nodo. */
105 public E replace(Posicion <E> v, E o)
106 throws InvalidPositionException
107 PosicionAB <E> vv = revisaPosicion(v);
108 E temp = v.elemento ();
109 vv.setElemento(o);
110 return temp;
111
112 // Me todos adicionales accesores
113 /** Regresa el hermano de un nodo. */

272 Arboles
114 public Posicion <E> sibling(Posicion <E> v)
115 throws InvalidPositionException , BoundaryViolationException
116 PosicionAB <E> vv = revisaPosicion(v);
117 PosicionAB <E> posPadre = vv.getPadre ();
118 if (posPadre != null)
119 PosicionAB <E> posHermano;
120 PosicionAB <E> posIzq = posPadre.getIzq ();
121 if (posIzq == vv)
122 posHermano = posPadre.getDer ();
123 else
124 posHermano = posPadre.getIzq ();
125 if (posHermano != null)
126 return posHermano;
127
128 throw new BoundaryViolationException("Sin hermano");
129
130 // Me todos adicionales de actualizaci on
131 /** Agrega un nodo ra ız a un arbol vac ıo */
132 public Posicion <E> addRoot(E e) throws NonEmptyTreeException
133 if(! isEmpty ())
134 throw new NonEmptyTreeException("El arbol ya tiene ra ız");
135 tam = 1;
136 raiz = creaNodo(e,null ,null ,null);
137 return raiz;
138
139 /** Insertar un hijo izquierdo en un nodo dado. */
140 public Posicion <E> insertLeft(Posicion <E> v, E e)
141 throws InvalidPositionException
142 PosicionAB <E> vv = revisaPosicion(v);
143 Posicion <E> posIzq = vv.getIzq ();
144 if (posIzq != null)
145 throw new InvalidPositionException("El nodo ya tiene hijo izquierdo");
146 PosicionAB <E> ww = creaNodo(e, vv, null , null);
147 vv.setIzq(ww);
148 tam ++;
149 return ww;
150
151 /** Insertar un hijo derecho en un nodo dado. */
152 public Posicion <E> insertRight(Posicion <E> v, E e)
153 throws InvalidPositionException
154 PosicionAB <E> vv = revisaPosicion(v);
155 Posicion <E> posDer = vv.getDer ();
156 if (posDer != null)
157 throw new InvalidPositionException("El nodo ya tiene hijo derecho");
158 PosicionAB <E> w = creaNodo(e, vv , null , null);
159 vv.setDer(w);
160 tam ++;
161 return w;
162
163 /** Quitar un nodo con un hijo o sin hijos. */
164 public E remove(Posicion <E> v)
165 throws InvalidPositionException
166 PosicionAB <E> vv = revisaPosicion(v);
167 PosicionAB <E> posIzq = vv.getIzq ();
168 PosicionAB <E> posDer = vv.getDer ();
169 if (posIzq != null && posDer != null)
170 throw new InvalidPositionException("No se puede remover nodo con dos hijos");

7.3 Arboles Binarios 273
171 PosicionAB <E> ww = null; // el unico hijo de v, si tiene
172 if (posIzq != null)
173 ww = posIzq;
174 else if (posDer != null)
175 ww = posDer;
176 if (vv == raiz) // v es la ra ız entonces
177 if (ww != null) // hacer al hijo la nueva ra ız
178 ww.setPadre(null);
179 raiz = ww;
180
181 else // v no es la ra ız
182 PosicionAB <E> uu = vv.getPadre ();
183 if (vv == uu.getIzq ())
184 uu.setIzq(ww);
185 else
186 uu.setDer(ww);
187 if(ww != null)
188 ww.setPadre(uu);
189
190 tam --;
191 return v.elemento ();
192
193194 /** Conecta dos a rboles para ser los sub a rboles de un nodo externo. */
195 public void attach(Posicion <E> v, ArbolBinario <E> T1 , ArbolBinario <E> T2)
196 throws InvalidPositionException
197 PosicionAB <E> vv = revisaPosicion(v);
198 if (isInternal(v))
199 throw new InvalidPositionException("No se pueda conectar del nodo interno");
200 if (!T1.isEmpty ())
201 PosicionAB <E> r1 = revisaPosicion(T1.root ());
202 vv.setIzq(r1);
203 r1.setPadre(vv); // T1 deber a ser inv a lidado
204
205 if (!T2.isEmpty ())
206 PosicionAB <E> r2 = revisaPosicion(T2.root ());
207 vv.setDer(r2);
208 r2.setPadre(vv); // T2 deber a ser inv a lidado
209
210
211 /** Intercambiar los elementos en dos nodos */
212 public void swapElements(Posicion <E> v, Posicion <E> w)
213 throws InvalidPositionException
214 PosicionAB <E> vv = revisaPosicion(v);
215 PosicionAB <E> ww = revisaPosicion(w);
216 E temp = w.elemento ();
217 ww.setElemento(v.elemento ());
218 vv.setElemento(temp);
219
220 /** Expandir un nodo externo en un nodo interno con dos nodos
221 * externos hijos */
222 public void expandExternal(Posicion <E> v, E l, E r)
223 throws InvalidPositionException
224 if (! isExternal(v))
225 throw new InvalidPositionException("El nodo no es externo");
226 insertLeft(v, l);
227 insertRight(v, r);

274 Arboles
228
229 /** Quitar un nodo externo v y reemplazar su padre con el hermano de v*/
230 public void removeAboveExternal(Posicion <E> v)
231 throws InvalidPositionException
232 if (! isExternal(v))
233 throw new InvalidPositionException("El nodo no es externo");
234 if (isRoot(v))
235 remove(v);
236 else
237 Posicion <E> u = parent(v);
238 remove(v);
239 remove(u);
240
241
242 // Me todos auxiliares
243 /** Si v es un nodo de un arbol binario , convertir a PosicionAB ,
244 * si no lanzar una excepci on */
245 protected PosicionAB <E> revisaPosicion(Posicion <E> v)
246 throws InvalidPositionException
247 if (v == null || !(v instanceof PosicionAB ))
248 throw new InvalidPositionException("La posici on no es valida");
249 return (PosicionAB <E>) v;
250
251 /** Crear un nuevo nodo de un arbol binario */
252 protected PosicionAB <E> creaNodo(E elemento , PosicionAB <E> parent ,
253 PosicionAB <E> left , PosicionAB <E> right)
254 return new NodoAB <E>(elemento ,parent ,left ,right);
255 /** Crear una lista que guarda los nodos en el sub arbol de un nodo ,
256 * ordenada de acuerdo al recorrido en preordel del sub arbol. */
257 protected void preordenPosiciones(Posicion <E> v, ListaPosicion <Posicion <E>> pos)
258 throws InvalidPositionException
259 pos.addLast(v);
260 if (hasLeft(v))
261 preordenPosiciones(left(v), pos); // recursividad en el hijo izquierdo
262 if (hasRight(v))
263 preordenPosiciones(right(v), pos); // recursividad en el hijo derecho
264
265 /** Crear una lista que guarda los nodos del sub arbol de un nodo ,
266 ordenados de acuerdo al recorrido en orden del sub arbol. */
267 protected void posicionesEnorden(Posicion <E> v, ListaPosicion <Posicion <E>> pos)
268 throws InvalidPositionException
269 if (hasLeft(v))
270 posicionesEnorden(left(v), pos); // recursividad en el hijo izquierdo
271 pos.addLast(v);
272 if (hasRight(v))
273 posicionesEnorden(right(v), pos); // recursividad en el hijo derecho
274
275
Listado 7.12: ArbolBinarioEnlazado el cual implementa la interfaz ArbolBinario.

7.3 Arboles Binarios 275
Rendimiento de ArbolBinarioEnlazado
Los tiempos de ejecucion de los metodos de la clase ArbolBinarioEnlazado,el cual usa una representacion de estructura enlazada, se muestran enseguida:
Los metodos size() e isEmpty() usan una variable de instancia queguarda el numero de nodos de A, y cada uno toma tiempo O(1).
Los metodos accesores root(), left(), right(), sibling(), y parent()
toman tiempo O(1).
El metodo replace(v, e) toma tiempo O(1).
Los metodos iterator() y positions() estan implementados ha-ciendo un recorrido en preorden del arbol, usando el metodo auxiliarpreordenPosiciones(). El iterador de salida es generado con el metodoiterator() de la clase ListaNodoPosicion. Los metodos iterator()y positions() toma tiempo O(n).
El metodo children() emplea una aproximacion similar para construirla coleccion iterable que se regresa, pero este corre en tiempo O(1), yaque hay a lo mas dos hijos para cualquier nodo en un arbol binario.
Los metodos de actualizacion insertLeft(), insertRight(), attach(),y remove() corren en tiempo O(1), ya que involucran manipulacion entiempo constante de un numero constante de nodos.
7.3.5. Arbol binario con lista arreglo
Esta representacion alterna de un arbol binario A esta basado en unaforma de numerar los nodos de A. Para cada nodo v de A, sea p(v) el enterodefinido como sigue:
Si v es la raız de A, entonces p(v) = 1.
Si v es el hijo izquierdo de un nodo u, entonces p(v) = 2p(u).
Si v es el hijo derecho de un nodo u, entonces p(v) = 2p(u) + 1.
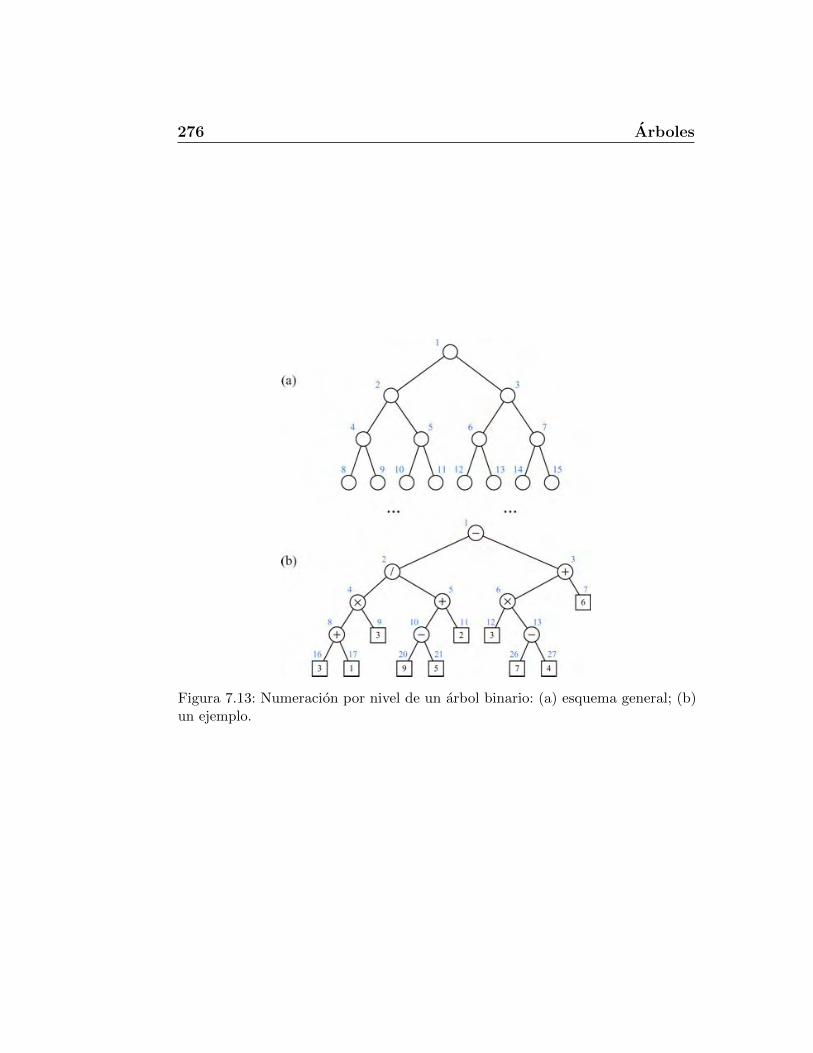
276 Arboles
Figura 7.13: Numeracion por nivel de un arbol binario: (a) esquema general; (b)un ejemplo.

7.3 Arboles Binarios 277
La funcion de numeracion p se conoce como numeracion de nivel delos nodos en un arbol binario A, esta numera los nodos en cada nivel de A enorden creciente de izquierda a derecha, pudiendo brincarse algunos numeros,ver figura 7.13.
La funcion de numeracion de nivel p sugiere una representacion de unarbol binario A por medio de una lista arreglo S tal que cada nodo v deA es el elemento de S en el ındice p(v). Como se menciono en el capıtuloprevio, se lleva a cabo la lista arreglo S mediante un arreglo extendible, verseccion 6.1. Tal implementacion es simple y eficiente, para poder usarlo paralos metodos root(), parent(), left(), right(), hasLeft(), hasRight(),isInternal(), isExternal(), e isRoot() usando operaciones aritmeticassobre los numeros p(v) asociados con cada nodo v involucrado en la operacion.
Se muestra un ejemplo de representacion lista arreglo de un arbol binarioen la figura 7.14.
Figura 7.14: Representacion de un arbol binario A por medio de una lista arregloS.
Sea n el numero de nodos de A, y sea pM el valor maximo de p(v) sobretodos los nodos de A. La lista arreglo S tiene tamano N = pM + 1 ya que elelemento de S en el ındice 0 no esta asociado con ningun nodo de A. Tambien,S tendra, en general, un numero de elementos vacıos que no se refieren anodos existentes de A. En el peor caso, N = 2n.
Los tiempos de ejecucion para un arbol binario A implementado con unalista arreglo S, son iguales a los del arbol binario enlazado, seccion 7.3.4.

278 Arboles
7.3.6. Recorrido de arboles binarios
Como en los arboles generales, los calculos de arboles binarios involucranrecorridos. Se muestra enseguida ejemplos de recorridos que pueden ocuparsepara resolver algunos problemas.
Construccion de un arbol de expresion
Para el problema de construir un arbol de expresion de una expresionaritmetica completamente parentetizada de tamano n se da el algoritmoconstruirExpresion, suponiendo que todas las operaciones aritmeticasson binarias y las variables no estan parentetizadas. Ası, cada subexpresionparentetizada contiene un operador en el centro. El algoritmo usa una pila Pmientras se explora la expresion de entrada E buscando variables, operadores,y parentesis derechos.
Cuando se ve una variable u operador x, se crea un arbol binario de unsolo nodo A, cuya raız guarda a x, y se mete A a la pila.
Cuando se ve un parentesis derecho, “)”, se sacan de la cima tres arbolesde la pila S, los cuales representan una subexpresion (E1 E2). Entoncesse conectan los arboles para E1 y E2 en uno para , y se mete el resultadode regreso a la pila P .
Se repite esto hasta que la expresion E ha sido procesada, en ese momentoel elemento de la cima en la pila es el arbol de expresion para E. El tiempototal de ejecucion es O(n).Algoritmo construirExpresion(E):Entrada: Una expresion aritmetica completamente parentetizada E =e0, e1, . . . , en−1, siendo cada ei una variable, operador, o sımbolo parentesisSalida: Un arbol binario A representando la expresion aritmetica EP ← una nueva pila inicialmente vacıapara i← 0 hasta n− 1 hacersi ei es una variable o un operador entoncesA← un nuevo arbol binario vacıoA.addRoot(ei)P.push(A)
si no si ei =′ (′ entoncesContinuar el ciclo

7.3 Arboles Binarios 279
si no ei =′)′ A2 ← P.pop() el arbol que representa a E2 A← P.pop() el arbol que representa a A1 ← P.pop() el arbol que representa a E1 A.attach(A.root(), A1, A2)P.push(A)
regresar P.pop()
Recorrido en preorden de un arbol binario
Como cualquier arbol binario puede ser visto como un arbol general, elrecorrido en preorden para arboles generales, seccion 7.2.2, puede ser aplicadoa cualquier arbol binario y simplificado como se da a continuacion.
Algoritmo preordenBinario(A, v):Realizar la accion “visita” para el nodo vsi v tiene un hijo izquierdo u en A entonces
preordenBinario(A, u) recursivamente recorrer el subarbol izquierdo si v tiene un hijo derecho w en A entonces
preordenBinario(A,w) recursivamente recorrer el subarbol derecho
Como en el caso de los arboles generales, hay varias aplicaciones derecorrido en preorden para arboles binarios.
Recorrido en postorden de un arbol binario
De manera analoga, el recorrido en postorden para arboles generales,seccion 7.2.3, puede ser especializado para arboles binarios, como se muestraenseguida.
Algoritmo postordenBinario(A, v):si v tiene un hijo izquierdo u en A entonces
postordenBinario(A, u) recursivamente recorrer el subarbol izquierdo si v tiene un hijo derecho w en A entonces
postordenBinario(A,w) recursivamente recorrer el subarbolderecho
Realizar la accion “visita” para el nodo v

280 Arboles
Evaluacion de un arbol de expresion
El recorrido en postorden de un arbol binario puede ser usado para resolverel problema de evaluacion del arbol de expresion. En este problema, se daun arbol de expresion aritmetica, es decir, un arbol binario donde cada nodoexterno tiene asociado un valor con este y cada nodo interno tiene un operadoraritmetico asociado con este, y se quiere calcular el valor de la expresionaritmetica representada por el arbol.
El algoritmo evaluarExpresion, dado enseguida, evalua la expresionasociada con el subarbol enraizado en el nodo v de un arbol A de expresionaritmetica realizando un recorrido en postorden de A iniciando en v. En estecaso, la accion “visita” consiste realizar una sola operacion aritmetica. Sesupone que el arbol de expresion aritmetica es un arbol binario propio.
Algoritmo evaluarExpresion(A, v):si v es un nodo interno en A entonces
Sea el operador guardado en vx← evaluarExpresion(A,A.left(v))y ← evaluarExpresion(A,A.right(v))regresar x y
si noregresar el valor guardado en v
El algoritmo evaluarExpresion, al hacer un recorrido en postorden,da un tiempo O(n) para evaluar un expresion aritmetica representada por unarbol binario con n nodos. Al igual que en el recorrido en postorden general,el recorrido en postorden para arboles binarios puede ser aplicado a otrosproblemas de evaluacion bottom-up (ascendente) tambien, tal como calcularel tamano dado en el ejemplo 7.5.
Recorrido en orden de un arbol binario
Un metodo de recorrido adicional para un arbol binario es el recorridorecorrido en orden. En este recorrido, se visita un nodo entre los recorridosrecursivos de sus subarboles izquierdo y derecho. El recorrido en orden delsubarbol enraizado en un nodo v de un arbol binario A se da en el siguientealgoritmo.

7.3 Arboles Binarios 281
Algoritmo enordenBinario(A, v):si v tiene un hijo izquierdo u en A entonces
enordenBinario(A, u) recursivamente recorrer el subarbol izquierdo Realizar la accion “visita” para el nodo vsi v tiene un hijo derecho w en A entonces
enordenBinario(A,w) recursivamente recorrer el subarbol derecho El recorrido en orden de un arbol binario A puede ser visto informalmente
como visitar los nodos de A “de izquierda a derecha”. Ademas, para cadanodo v, el recorrido en orden visita v despues de que todos los nodos en elsubarbol izquierdo de v y antes que todos los nodos en subarbol derecho de v,ver figura 7.15.
Figura 7.15: Recorrido en orden de un arbol binario.
Arboles binarios de busqueda
Sea S un conjunto cuyos elementos tienen una relacion de orden. Porejemplo, S podrıa ser un conjunto de enteros. Un arbol arbol binario debusqueda para S es un arbol binario propio A tal que
Cada nodo interno v de A guarda un elemento de S, denotado con x(v).
Para cada nodo interno v de A, los elementos guardados en el subarbolizquierdo de v son menores que o iguales a x(v) y los elementos guardadosen el subarbol derecho de v son mayores que x(v).
Los nodos externos de A no guardan ningun elemento.

282 Arboles
Un recorrido en orden de los nodos internos de un arbol binario de busquedaA visita los elementos en orden creciente, ver figura 7.16.
Figura 7.16: Un arbol binario de busqueda ordenando enteros. El camino azul solidoes recorrido cuando se busca exitosamente el 36. El camino azul discontinuo esrecorrido cuando se busca sin exito el 70.
Se puede usar un arbol binario de busqueda A para un conjunto S paraencontrar si un valor de busqueda y esta en S, recorriendo el camino descen-dente del arbol A, iniciando con la raız, En cada nodo interno v encontrado,se compara el valor de busqueda y con el elemento x(v) guardado en v. Siy < x(v), entonces la busqueda continua en el subarbol izquierdo de v. Siy = x(v), entonces la busqueda termina exitosamente. Si y > x(v), entoncesla busqueda continua en el subarbol derecho de v. Finalmente, si se alcanzaun nodo externo, la busqueda termina sin exito. El arbol binario de busquedapuede ser visto como un arbol de decision, donde la pregunta hecha en cadanodo interno es si el elemento en ese nodo es menor que, igual a, o mayor queel elemento que se esta buscando.
El tiempo de ejecucion de la busqueda en un arbol binario de busqueda Aes proporcional a la altura de A. La altura de un arbol binario propio con nnodos puede ser tan pequeno como log(n+1)−1 o tan grande como (n−1)/2,ver la propiedades del arbol binario, seccion 7.3.3. Por lo anterior los arbolesbinarios de busqueda son mas eficientes cuando tienen alturas pequenas.
Recorrido en orden para dibujar un arbol
El recorrido en orden puede ser aplicado al problema de dibujar un arbolbinario. Se puede dibujar un arbol binario A con un algoritmo que asigne
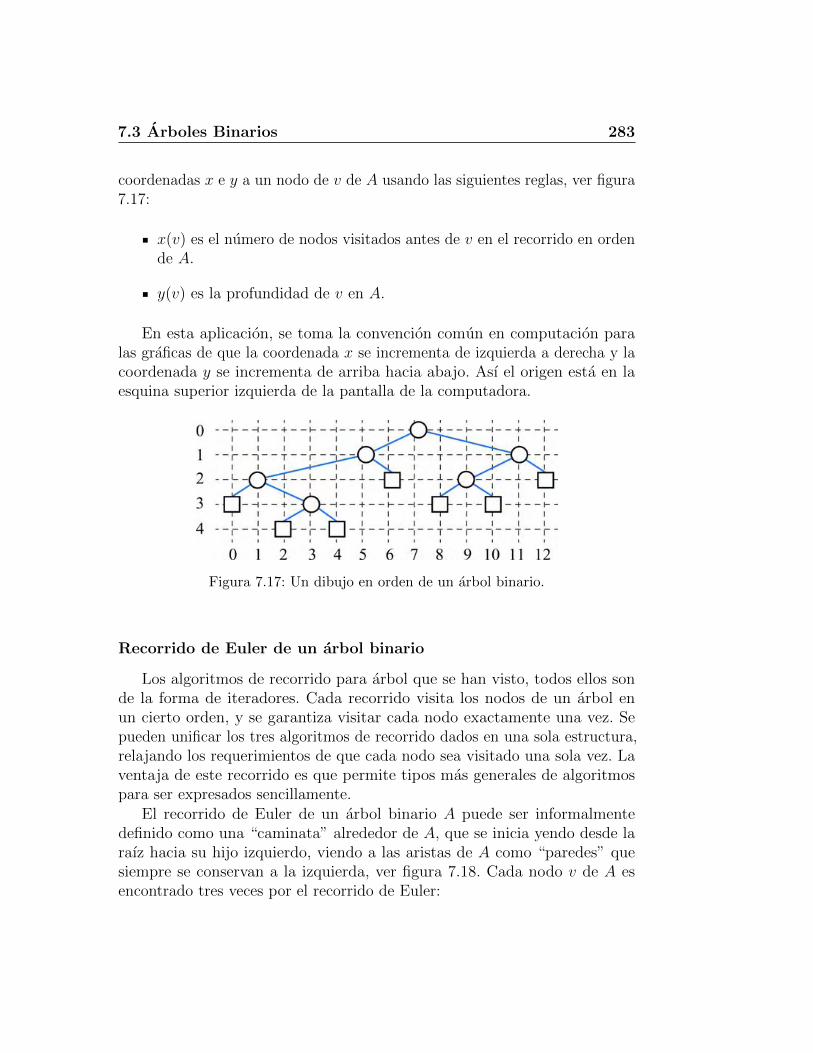
7.3 Arboles Binarios 283
coordenadas x e y a un nodo de v de A usando las siguientes reglas, ver figura7.17:
x(v) es el numero de nodos visitados antes de v en el recorrido en ordende A.
y(v) es la profundidad de v en A.
En esta aplicacion, se toma la convencion comun en computacion paralas graficas de que la coordenada x se incrementa de izquierda a derecha y lacoordenada y se incrementa de arriba hacia abajo. Ası el origen esta en laesquina superior izquierda de la pantalla de la computadora.
Figura 7.17: Un dibujo en orden de un arbol binario.
Recorrido de Euler de un arbol binario
Los algoritmos de recorrido para arbol que se han visto, todos ellos sonde la forma de iteradores. Cada recorrido visita los nodos de un arbol enun cierto orden, y se garantiza visitar cada nodo exactamente una vez. Sepueden unificar los tres algoritmos de recorrido dados en una sola estructura,relajando los requerimientos de que cada nodo sea visitado una sola vez. Laventaja de este recorrido es que permite tipos mas generales de algoritmospara ser expresados sencillamente.
El recorrido de Euler de un arbol binario A puede ser informalmentedefinido como una “caminata” alrededor de A, que se inicia yendo desde laraız hacia su hijo izquierdo, viendo a las aristas de A como “paredes” quesiempre se conservan a la izquierda, ver figura 7.18. Cada nodo v de A esencontrado tres veces por el recorrido de Euler:

284 Arboles
Figura 7.18: Un recorrido de Euler de un arbol binario.
“A la izquierda”, antes del recorrido de Euler de subarbol izquierdo dev.
“Desde abajo”, entre los recorridos de Euler de los dos subarboles de v.
“A la derecha”, despues del recorrido de Euler de subarbol derecho dev.
Si v es un nodo externo, entonces estas tres “visitas” suceden todas almismo tiempo. Se describe el recorrido de Euler del subarbol enraizado en ven el siguiente algoritmo:Algoritmo RecorridoEuler(A, v):
realizar la accion para visitar nodo v a la izquierdasi v tiene un hijo izquierdo u en A entonces
RecorridoEuler(A, u) recursivamente recorrer subarbol izquierdo de v realizar la accion para visitar nodo v desde abajosi v tiene un hijo derecho w en A entonces
RecorridoEuler(A,w) recursivamente recorrer subarbol derecho de v realizar la accion para visitar nodo v a la derecha
El tiempo de ejecucion del recorrido de Euler de un arbol de n-nodosse obtiene ası, suponiendo que cada accion visita toma tiempo O(1). Comose usa una cantidad constante de tiempo en cada nodo del arbol durante elrecorrido, el tiempo de ejecucion total es O(n).
El recorrido en preorden de un arbol binario es equivalente a un recorridode Euler tal que cada nodo tiene asociado una accion “visita” ocurriendo

7.3 Arboles Binarios 285
solamente cuando este es encontrada a la izquierda. De la misma forma, losrecorridos en orden y postorden son equivalentes a un recorrido de Eulercuando el nodo encontrado desde abajo o a la derecha, respectivamente. Sepuede usar el recorrido de Euler para hacer otros tipos de recorridos. Porejemplo, suponer que se desea calcular el numero de descendientes de cadanodo v en un arbol binario de n nodos. Se inicia un recorrido de Eulerinicializando un contador a cero, y entonces incrementando el contador cadavez que se visita un nodo a la izquierda. Para determinar el numero dedescendientes de un nodo v, se calcula la diferencia entre los valores delcontador cuando v es visitado a la izquierda y cuando es visitado a la derecha,y agregado uno. Esta regla da el numero de descendientes de v, porque cadanodo en el subarbol enraizado es contado la visita de v y la visita de v ala derecha. Por lo tanto, se tiene un metodo tiempo O(n) para calcular elnumero de descendientes de cada nodo.
Otra aplicacion del recorrido de Euler es imprimir una expresion aritmeticacompletamente parentizada a partir de su arbol de expresion. El algoritmoimprimirExpresion, mostrado a continuacion, realiza esta tarea realizandolas siguientes acciones en un recorrido de Euler:
Accion “a la izquierda”: si el nodo es interno, imprimir “(”
Accion “desde abajo”: imprimir el valor u operador guardado en el nodo
Accion “a la derecha”: si el nodo es interno, imprimir “)”
Algoritmo imprimirExpresion(A, v):si A.isInternal(v) entonces
imprimir “(”si A.hasLeft(v) entonces
imprimirExpresion(A,A.left(v))si A.isInternal(v) entonces
imprimir el operador guardado en vsi no
imprimir el valor guardado en vsi A.hasRight(v) entonces
imprimirExpresion(A,A.right(v))si A.isInternal(v) entonces
imprimir “)”

286 Arboles
7.3.7. Plantilla metodo patron
Los metodos de recorrido para arboles descritos previamente son ejemplosde patrones de diseno de software orientado al objeto, la plantilla metodopatron. La plantilla metodo patron describe un mecanismo generico de calculoque puede ser especializado para una aplicacion particular redefiniendo ciertopasos. Siguiendo la plantilla metodo patron, se disena un algoritmo queimplementa un recorrido de Euler generico de un arbol binario. Se muestraenseguida el algoritmo plantillaRecorridoEuler.Algoritmo plantillaRecorridoEuler(A, v):r ← nuevo objeto del tipo ResultadoRecorridovisitarIzquierda(A, v, r)si A.hasLeft(v) entoncesr.izq ← plantillaRecorridoEuler(A,A.left(v))
visitarAbajo(A, v, r)si A.hasRight(v) entoncesr.der ← plantillaRecorridoEuler(A,A.right(v))
visitarDerecha(A, v, r)regresar r.salida
Cuando se llama con un nodo v, el metodo plantillaRecorridoEuler()
llama varios metodos auxiliares en diferentes fases del recorrido. Como sedescribe enseguida:
Crear una variable local r del tipo ResultadoRecorrido, la cual es usadapara guardar resultados intermedios del calculo, que tiene campos izq,der y salida.
Se llama al metodo auxiliar visitarIzquierda(A, v, r), el cual realizalos calculos asociados encontrandose a la izquierda del nodo.
Si v tiene hijo izquierdo, se llama recursivamente sobre el mismo con elhijo izquierdo de v y se guarda el valor regresado en r.izq.
Se llama al metodo auxiliar visitarAbajo(A, v, r), el cual realiza loscalculos asociados encontrandose abajo del nodo.
Si v tiene hijo derecho, se llama recursivamente sobre el mismo con elhijo derecho de v y se guarda el valor regresado en r.der.

7.3 Arboles Binarios 287
Se llama al metodo auxiliar visitarDerecha(A, v, r), el cual realiza loscalculos asociados encontrandose a la derecha del nodo.
Regresar r.salida.
El metodo plantillaRecorridoEuler puede ser visto como una plantillao “esqueleto” de un recorrido Euleriano.
Implementacion Java
La clase RecorridoEuler, mostrada en el listado 7.13, implementa unrecorrido transversal de Euler usando la plantilla metodo patron. El recorridotransversal es hecha por el metodo RecorridoEuler(). Los metodos auxiliaresllamados por RecorridoEuler son lugares vacıos, tienen cuerpos vacıos osolo regresan null. La clase RecorridoEuler es abstracta y por lo tanto nopuede ser instanciada. Contiene un metodo abstracto, llamado ejecutar, elcual necesita ser especificado en las subclases concretas de RecorridoEuler.
1 /**
2 * Plantilla para algoritmos que recorren un arbol binario usando un
3 * recorrido euleriano. Las subclases de esta clase redefinir an
4 * algunos de los me todos de esta clase para crear un recorrido
5 * espec ıfico.
6 */
7 public abstract class RecorridoEuler <E, R>
8 protected ArbolBinario <E> arbol;
9 /** Ejecuci on del recorrido. Este metodo abstracto deber a ser
10 * especificado en las subclases concretas. */
11 public abstract R ejecutar(ArbolBinario <E> T);
12 /** Inicializaci on del recorrido */
13 protected void inicializar(ArbolBinario <E> T) arbol = T;
14 /** Metodo plantilla */
15 protected R recorridoEuler(Posicion <E> v)
16 ResultadoRecorrido <R> r = new ResultadoRecorrido <R>();
17 visitarIzquierda(v, r);
18 if (arbol.hasLeft(v))
19 r.izq = recorridoEuler(arbol.left(v)); // recorrido recursivo
20 visitarAbajo(v, r);
21 if (arbol.hasRight(v))
22 r.der = recorridoEuler(arbol.right(v)); // recorrido recursivo
23 visitarDerecha(v, r);
24 return r.salida;
25
26 // Me todos auxiliares que pueden ser redefinidos por las subclases
27 /** Metodo llamado para visitar a la izquierda */
28 protected void visitarIzquierda(Posicion <E> v, ResultadoRecorrido <R> r)
29 /** Metodo llamado para visitar abajo */
30 protected void visitarAbajo(Posicion <E> v, ResultadoRecorrido <R> r)
31 /** Metodo llamado para visitar a la derecha */
32 protected void visitarDerecha(Posicion <E> v, ResultadoRecorrido <R> r)

288 Arboles
3334 /* Clase interna para modelar el resultado del recorrido */
35 public class ResultadoRecorrido <R>
36 public R izq;
37 public R der;
38 public R salida;
39
40
Listado 7.13: Clase RecorridoEuler.java que define un recorrido Euleriano generi-co de un arbol binario
La clase, RecorridoEuler, por si misma no hace ningun calculo util. Sinembargo, se puede extender y reemplazar los metodos auxiliares vacıos para ha-cer cosas utiles. Se ilustra este concepto usando arboles de expresion aritmetica,ver ejemplo 7.7. Se asume que un arbol de expresion aritmetica tiene objetos detipo TerminoExpresion en cada nodo. La clase TerminoExpresion tiene sub-clases VariableExpresion (para variables) y OperadorExpresion (para ope-radores). A su vez, la clase OperadorExpresion tiene subclases para los opera-dores aritmeticos, tales como OperadorSuma y OperadorMultiplicacion. Elmetodo valor de TerminoExpresion es reemplazado por sus subclases. Parauna variable, este regresa el valor de la variable. Para un operador, este regresael resultado de aplicar el operador a sus operandos. Los operandos de unoperador son puesto por el metodo setOperandos() de OperadorExpresion.En los codigos de los listados 7.14, 7.15, 7.16 y 7.17 se muestran las clasesanteriores.

7.3 Arboles Binarios 289
1 /** Clase para un te rmino (operador o variable de una expresi on
2 * aritm etica.
3 */
4 public class TerminoExpresion
5 public Integer getValor () return 0;
6 public String toString () return new String("");
7
Listado 7.14: Clase TerminoExpresion.java para una expresion
1 /** Clase para una variable de una expresi on artim etica. */
2 public class VariableExpresion extends TerminoExpresion
3 protected Integer var;
4 public VariableExpresion(Integer x) var = x;
5 public void setVariable(Integer x) var = x;
6 public Integer getValor () return var;
7 public String toString () return var.toString ();
8
Listado 7.15: Clase VariableExpresion.java para una variable
1 /** Clase para un operador de una expresi on aritm etica. */
2 public class OperadorExpresion extends TerminoExpresion
3 protected Integer primerOperando , segundoOperando;
4 public void setOperandos(Integer x, Integer y)
5 primerOperando = x;
6 segundoOperando = y;
7
8
Listado 7.16: Clase OperadorExpresion.java para un operador generico
1 /** Clase para el operador adici on en una expresi on aritm etica. */
2 public class OperadorSuma extends OperadorExpresion
3 public Integer getValor ()
4 // desencajonar y despu es encajonar
5 return (primerOperando + segundoOperando );
6
7 public String toString () return new String("+");
8
Listado 7.17: Clase OperadorSuma.java el operador suma
En los listados 7.18 y 7.19, se muestran las clases RecorridoEvaluarExpre-sion y RecorridoImprimirExpresion, especializando RecorridoEuler, queevalua e imprime una expresion aritmetica guardada en un arbol binario,respectivamente. La clase RecorridoEvaluarExpresion reemplaza el metodoauxiliar visitarDerecha(A, v, r) con el siguiente calculo:
Si v es un nodo externo, poner r.salida igual al valor de la variableguardada en v;

290 Arboles
si no (v es un nodo interno), combinar r.izq y r.der con el operadorguardado en v, y pone r.salida igual al resultado de la operacion.
1 /** Calcular el valor de un arbol de expresi on aritm etica. */
2 public class RecorridoEvaluarExpresion
3 extends RecorridoEuler <TerminoExpresion , Integer >
45 public Integer ejecutar(ArbolBinario <TerminoExpresion > T)
6 inicializar(T); // llamar al metodo de la superclase
7 return recorridoEuler(arbol.root ()); // regresar el valor de la expresi on
8
910 protected void visitarDerecha(Posicion <TerminoExpresion > v,
11 ResultadoRecorrido <Integer > r)
12 TerminoExpresion termino = v.elemento ();
13 if (arbol.isInternal(v))
14 OperadorExpresion op = (OperadorExpresion) termino;
15 op.setOperandos(r.izq , r.der);
16
17 r.salida = termino.getValor ();
18
19
Listado 7.18: Clase RecorridoEvaluarExpresion.java especializaRecorridoEuler para evaluar la expresion asociada con un arbol de expresionaritmetica.
La clase RecorridoImprimirExpresion reemplaza los metodos visitar-Izquierda, visitarAbajo, visitarDerecha siguiendo la aproximacion dela version pseudocodigo dada previamente.
1 /** Imprimir la expresi on guardada en un arbol de expresi on aritm etica. */
2 public class RecorridoImprimirExpresion
3 extends RecorridoEuler <TerminoExpresion , String >
45 public Integer ejecutar(ArbolBinario <TerminoExpresion > T)
6 inicializar(T);
7 System.out.print("Expresi on: ");
8 recorridoEuler(T.root ());
9 System.out.println ();
10 return null; // nada que regresar
11
1213 protected void visitarIzquierda(Posicion <TerminoExpresion > v,
14 ResultadoRecorrido <String > r)
15 if (arbol.isInternal(v)) System.out.print("(");
1617 protected void visitarAbajo(Posicion <TerminoExpresion > v,
18 ResultadoRecorrido <String > r)
19 System.out.print(v.elemento ());
2021 protected void visitarDerecha(Posicion <TerminoExpresion > v,
22 ResultadoRecorrido <String > r)

7.3 Arboles Binarios 291
23 if (arbol.isInternal(v)) System.out.print(")");
24
Listado 7.19: Clase RecorridoImprimirExpresion.java especializaRecorridoEuler para imprimir la expresion asociada con un arbol de ex-presion aritmetica.

292 Arboles

Bibliografıa
[1] R. Lafore, Data Structures & Algorithms, Second Edition, Sams, 2003.
[2] M. Goodrich, R. Tamassia, Data Structures and Algorithms in Java,Fourth Edition, John Wiley & Sons, 2005.

Indice alfabetico
ındice, 38, 199arbol, 245, 246arbol binario, 263arbol binario completo, 263arbol binario de busqueda, 281arbol binario propio, 263arbol impropio, 263arbol ordenado, 248arboles, 245arboles de decision, 263Scanner, 43break, 32, 36catch, 68clone(), 41continue, 37do...while, 35double, 23enum, 17extends, 58false, 23finally, 68for, 33if, 30import, 46instanceof, 78int, 23length, 38new, 13null, 13, 23return, 20, 36
super, 58switch, 31this, 58true, 23try, 68void, 20while, 32
abstraccion, 51adaptabilidad, 50adaptador, 201ADT, 85alcance, 15alfabeto, 12algoritmo, 149algoritmos, 85altura, 254amortizacion, 207analisis amortizado, 207analisis promedio, 153ancestro, 247API, 70, 169arista, 248arreglo, 38arreglo bidimensional, 103arreglo extendible, 206atrapada, 66, 68autoempacado, 29
bloque, 8bloque de sentencias, 22

INDICE ALFABETICO 295
camino, 248campos, 7, 14capacidad, 39caso base, 128casos recursivos, 128celda, 38ciclo for-each, 224cifrador de Cesar, 100clase, 7, 49, 51
abstract, 9final, 9public, 9amigable, 9
clase base, 54clases numero, 12cola con doble terminacion, 194concatenacion, 13, 27constructor, 21conversion ancha, 76conversion implıcita, 29criptografıa, 100cuerpo, 18cursor, 213
definicion recursiva, 127deque, 194descendiente, 247descifrado, 100desempacado, 29direccion, 13double-ended queue, 194
elemento, 39encadenamiento constructor, 58encapsulacion, 51encriptamiento, 100enlazado dinamico, 56envıo dinamico, 56
especializa, 54especializacion, 57estructura de datos, 85, 149estructura generica, 81etiqueta, 37etiquetas HTML, 183evolucionabilidad, 50extension, 57externo, 247extiende, 54
FIFO, 185firma, 18for
condicion, 34incremento, 34inicializacion, 33
funcion cubica, 144funcion constante, 141funcion cuadratica, 143funcion exponencial, 146funcion exponente, 147funcion factorial, 126funcion lineal, 143funcion logarıtmica, 142funcion piso, 148funcion potencia, 164funcion techo, 148funciones polinomiales, 145
generadores de numeros pseudoaleato-rios, 97
herencia, 54herencia unica, 58herencia multiple, 74hermanos, 247heurıstica, 239heurıstica mover al frente, 239

296 INDICE ALFABETICO
hijos, 245hojas, 247
identificador, 8igualdad profunda, 107igualdad simple, 107igualdad superficial, 107Implementar una interfaz, 51insercion ordenada, 94interfaz, 70interfaz de programacion de aplicacio-
nes, 70, 169interno, 247iterador, 223iterator, 223
jerarquicas, 245jerarquico, 52
lanza, 66lanzados, 66LDE, 113LIFO, 167lista, 199lista arreglo, 199lista circular enlazada, 121lista de favoritos, 237lista doblemente enlazada, 113lista enlazada, 108lista nodo, 211lista simple enlazada, 108literal, 23localidad de referencia, 239
metodofirma, 14, 56
metodos, 7modulo, 101, 189marco de colecciones Java, 230
matriz, 103mezcla, 74miembros, 7modificador
final, 17static, 17
modificadores de clase, 9modularidad, 52
nivel de un arbol binario, 266nodo cabeza, 113nodo cola, 113nodos, 108notacion Omega-grande, 158notacion Tetha-grande, 158numeracion de nivel, 274numeracion por nivel, 261
O-grande, 155objeto, 8objeto compuesto, 20objetos, 7operaciones primitivas, 152operador
new, 10
padre, 245padre-hijo, 246paquete, 46parametros de tipo actual, 81parametros de tipo formal, 81patron de diseno, 53peor caso, 153pila, 167plantilla metodo patron, 285polimorfica, 56por valor, 20portabilidad, 50posicion, 210

INDICE ALFABETICO 297
posiciones en un arbol, 249problema de Josefo, 193profundidad, 253progresion aritmetica, 59progresion Fibonacci, 63progresion geometrica, 59
raız, 246rango, 199recorrido, 256recorrido en orden, 280recorrido en postorden, 259recorrido en preorden, 256recurrencia, 126recurrencia binaria, 134recurrencia de cola, 133recurrencia multiple, 137reemplazo, 58referencia, 10, 13, 55refinamiento, 58reglas de exponentes, 147reglas de logaritmos, 142relativamente, 211representacion parentetica de cadena,
257robusto, 49round robin, 192
secuencia, 199, 234semilla, 98sobrecarga, 56subarbol derecho, 263subarbol enraızado, 248subarbol izquierdo, 263sumatoria, 146sumatorias geometricas, 148superclase, 54
texto cifrado, 100
texto plano, 100tipado fuerte, 76tipo, 7, 14tipo generico, 81tipos, 8tipos base, 10tipos de datos abstractos, 51, 85tipos primitivos, 10
variables de instancia, 7, 14variables locales, 22vector, 199