gráfico de dispersión - unican.es...gráfico de dispersión características de la nube de puntos....
TRANSCRIPT
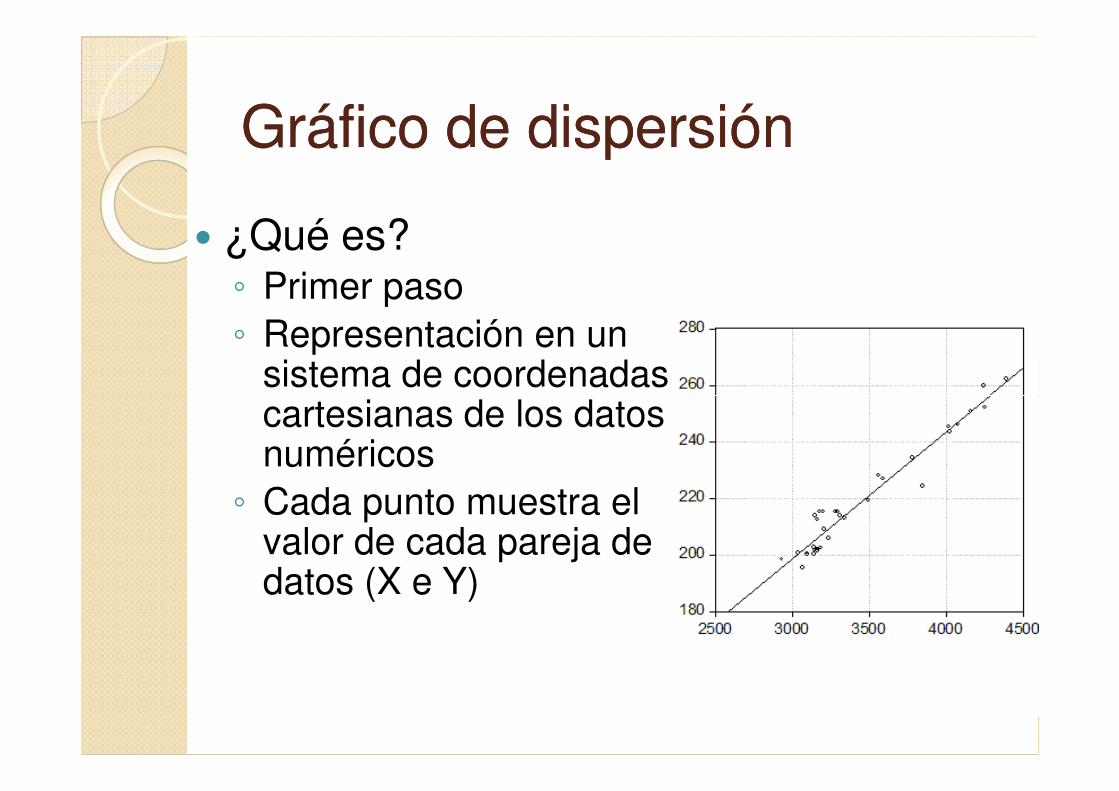
Gráfico de dispersiónGráfico de dispersión
� ¿Qué es?◦ Primer paso
◦ Representación en un sistema de coordenadas cartesianas de los datos cartesianas de los datos numéricos
◦ Cada punto muestra el valor de cada pareja de datos (X e Y)

Gráfico de dispersiónGráfico de dispersión
� Características de la nube de puntos.◦ Según la forma de la nube de puntos
podemos obtener la siguiente información:
� Si existe una relación directa o inversa entre las variables; variables;
� Si esa relación es fuerte o débil.
� Si la relación se ajusta a un modelo lineal o a otro modelo matemático (ej: exponencial…).
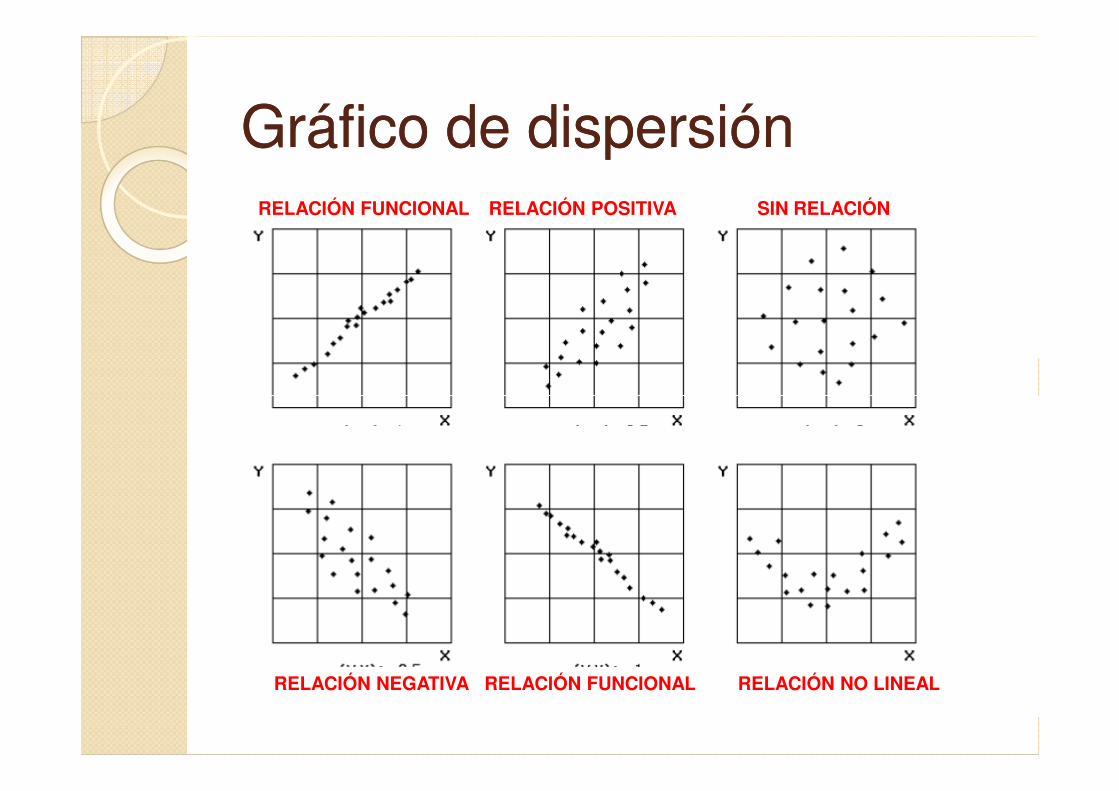
Gráfico de dispersiónGráfico de dispersiónRELACIÓN FUNCIONAL SIN RELACIÓNRELACIÓN POSITIVA
RELACIÓN FUNCIONAL RELACIÓN NO LINEALRELACIÓN NEGATIVA

Gráfico de dispersiónGráfico de dispersión
� Diferentes casos de relación entre variables◦ Relación funcional: nube de
puntos dispuesta en línea recta � cuando conocida la primera � cuando conocida la primera se puede saber con exactitud el valor de la segunda
◦ Relación positiva: nube de puntos con dispersión creciente: al aumentar la variable X aumenta la variable Y

Gráfico de dispersiónGráfico de dispersión
� Diferentes casos de relación entre variables
◦ Relación no lineal: nube de puntos en línea curva �transformación de datos originalestransformación de datos originales
◦ Sin relación: nube de puntos con máxima dispersión � ambas variables son independientes

Gráfico de dispersiónGráfico de dispersión
� Utilidad◦ Detección de puntuaciones “atípicas"
� Errores en la transcripción de la información
� Mezcla de datos correspondientes a � Mezcla de datos correspondientes a distribuciones distintas
◦ Si los estadísticos de correlación apropiados para analizar relaciones lineales deben ser sustituidos por otros

CovarianzaCovarianza
� Definición◦ Medida de la variación conjunta
◦ Formulación clásica:
� xy calculada a partir de una poblaciónσ� xy calculada a partir de una población
� Sxy a partir de una muestra
σ
YXN
yx
S
n
i
ii
xy −=
∑=1

CovarianzaCovarianza
� Características
◦ Sín límites (entre +infinito a –infinito): no determina el grado de relación solo la tendencia
� Covarianza positiva: puntuaciones bajas de la primera
variable (X) se asocian con puntuaciones bajas de la variable (X) se asocian con puntuaciones bajas de la
segunda variable (Y); puntuaciones altas de X se
asocian con los valores altos de Y.
� Covarianza de negativa: puntuaciones bajas de X se
asocian con los valores altos de Y; puntuaciones altas
de X se asocian con valores bajos de Y.
� Covarianza 0 � no existe relación entre las dos
variables estudiadas.

CovarianzaCovarianza
� Cálculoxi yi xi · yi
2 1 2
3 3 9
4 2 84 2 8
4 4 16
5 4 20
6 4 24
6 6 36
7 4 28
7 6 42
8 7 56
10 9 90
10 10 100
72 60 431
92,55612
431=•−=xyS
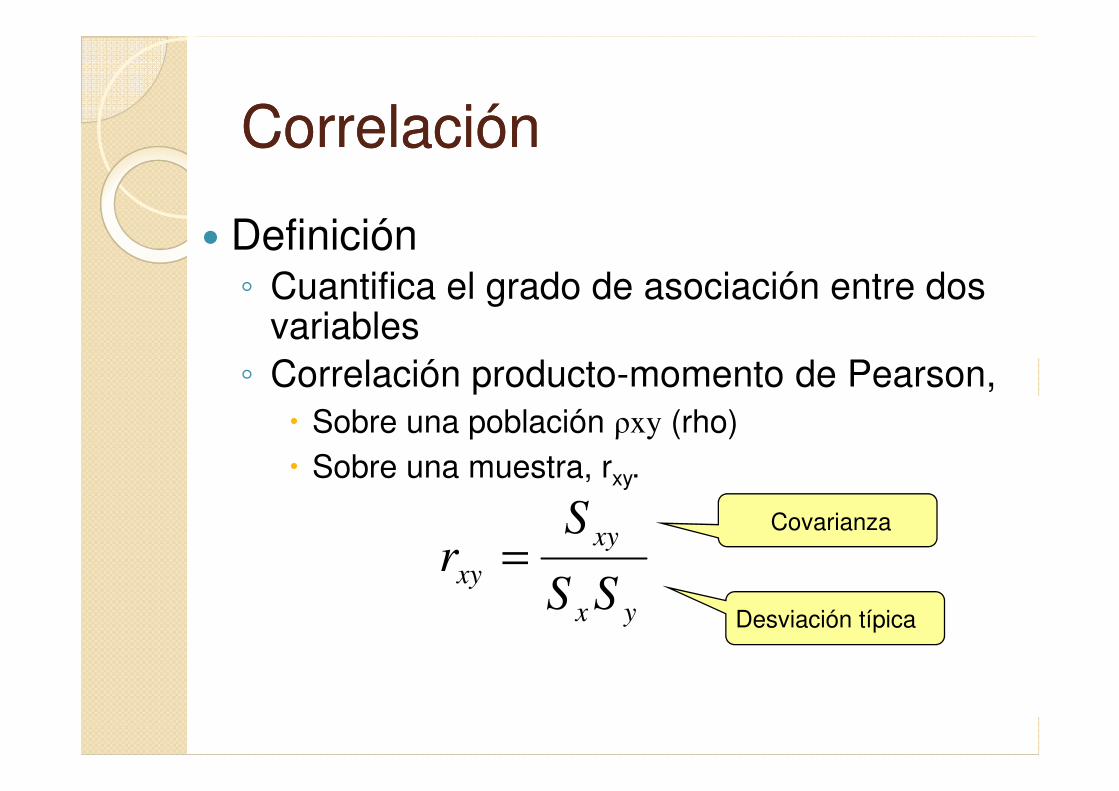
CorrelaciónCorrelación
� Definición◦ Cuantifica el grado de asociación entre dos
variables
◦ Correlación producto-momento de Pearson,
� Sobre una población ρxy (rho)
� Sobre una muestra, rxy.
Covarianza
Desviación típicayx
xy
xySS
Sr =

CorrelaciónCorrelación
� Cálculoxi yi xi ·yi xi
2 yi2
2 1 2 4 1
3 3 9 9 9
4 2 8 16 4
4 4 16 16 16
5 4 20 25 16
1º Promedio de las variables
5 4 20 25 16
6 4 24 36 16
6 6 36 36 36
7 4 28 49 16
7 6 42 49 36
8 7 56 64 49
10 9 90 100 81
10 10 100 100 100
72 60 431 504 380
2º Cálculo de la covarianza
3º Cálculo de las desviaciones típicas
4º Fórmula
92,55612
431=•−=xyS
45,2)6(12
504 2=−=xS 58,2)5(
12
380 2=−=yS

CorrelaciónCorrelación
� Significación◦ Su valor es independiente de la unidad
usada para medir las variables (adimensional)
◦ Oscila entre –1 y +1. ◦ Oscila entre –1 y +1.
� Una correlación de +1 � relación lineal perfecta (positiva) entre las dos variables.
� Una correlación de -1 � relación lineal perfecta (negativa) entre las dos variables
� Una correlación de 0 � no hay relación lineal entre las dos variables

CorrelaciónCorrelación
� Significación◦ Correlación no implica causalidad
� Causalidad: juicio de valor que requiere más información que un simple valor cuantitativo
◦ No se debe extrapolar más allá del rango de ◦ No se debe extrapolar más allá del rango de valores observado
� La relación existente entre X e Y puede cambiar fuera de dicho rango
◦ No afectado por una transformación lineal de una variable (multiplicación de una variable por una constante, suma de una constante)

CorrelaciónCorrelación
�� Significación estadísticaSignificación estadística◦ Objetivo:
� Determinar si el valor del coeficiente de correlación es estadísticamente significativo
� Fórmula sencilla al nivel de error del 0,05
96,1* >nr

CorrelaciónCorrelación
� Significación estadística
◦ Cálculo del error típico de r:
� Si el coeficiente de correlación supera al valor del
error estándar multiplicado por la t de Student con
n-2 grados de libertad� significativon-2 grados de libertad� significativo
� El nivel de significación viene dado por la decisión
(nivel de probabilidad) que adoptemos al buscar el
valor en la tabla de la t de Student
2
1 2
−
−=
n
rerror

CorrelaciónCorrelación
�� Significación estadísticaSignificación estadística◦ Cálculo test hipótesis r:
� 20 niños � grados de libertad 18
� Valor de la tabla de la t de student
� Seguridad del 97,5%: 2,10*0,109 = 0,22 < r = 0.885 � coeficiente de correlación es significativo (p<0.05).
� Seguridad del 99%: 2,88*0,109 = 0.313 �significativo con un nivel de probabilidad p<0.001

CorrelaciónCorrelación
� Significación estadística:

CorrelaciónCorrelación� Problemas◦ Sensible a valores extremos o atípicos
� Sobre todo con muestras pequeñas �perturba de forma "espurea" el grado de relación
� Solución: � Solución:
� Detección a través del diagrama de dispersión y eliminación en su caso
� Transformación de datos � cambia la escala de medición y modera el efecto de valores extremos (pe. transformación logarítmica)
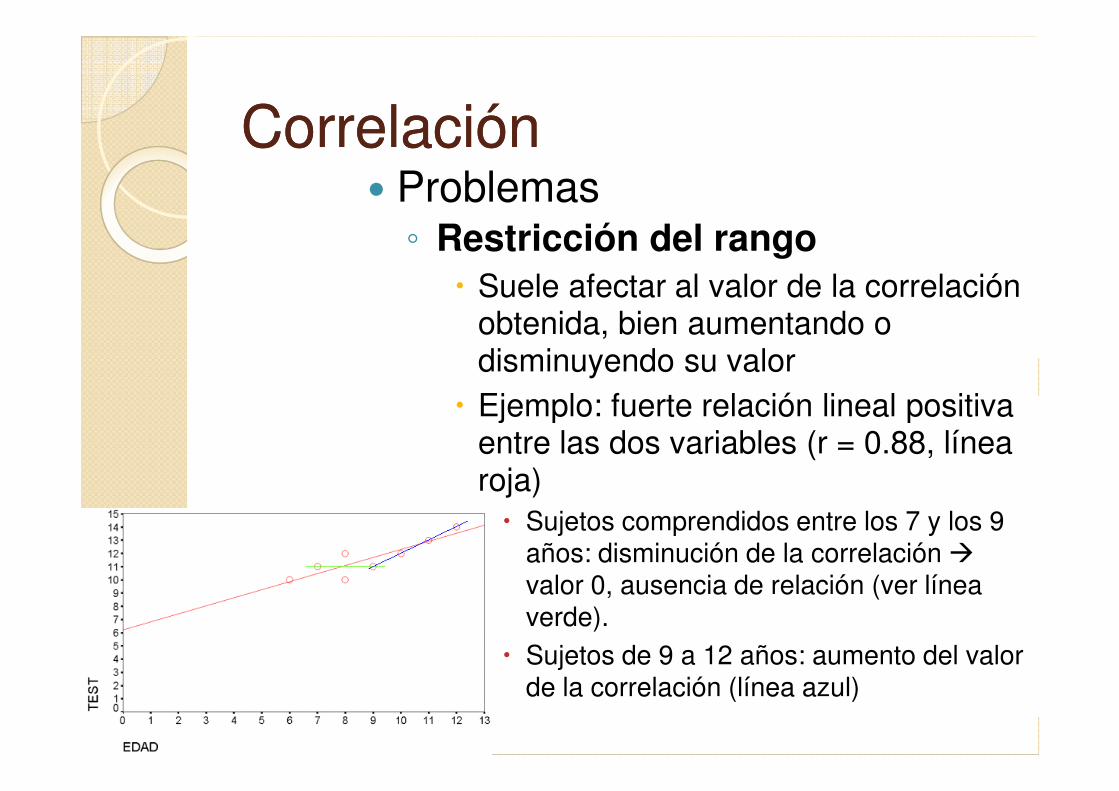
CorrelaciónCorrelación� Problemas◦ Restricción del rango
� Suele afectar al valor de la correlación obtenida, bien aumentando o disminuyendo su valor
� Ejemplo: fuerte relación lineal positiva � Ejemplo: fuerte relación lineal positiva entre las dos variables (r = 0.88, línea roja)
� Sujetos comprendidos entre los 7 y los 9 años: disminución de la correlación �valor 0, ausencia de relación (ver línea verde).
� Sujetos de 9 a 12 años: aumento del valor de la correlación (línea azul)

CorrelaciónCorrelación
� Requisitos◦ El coeficiente de Correlación de Pearson
requiere
� Que ambas variables procedan de una muestra aleatoria de individuos. aleatoria de individuos.
� Al menos una de las variables debe tener una distribución normal
◦ En caso de no cumplir esas condiciones
� Transformación de una distribución normal (transformación logarítmica)
� Alternativa: coeficiente de correlación de Spearman, tau de Kendall

CorrelaciónCorrelación
� Coeficiente de correlación de Spearman◦ Utiliza los rangos (números de orden) de dos
variables y los compara
◦ Recomendada: ◦ Recomendada:
� Datos con valores extremos
� Distribuciones no normales
◦ Métodos para calcular el coeficiente de correlación de los rangos

CorrelaciónCorrelación� Coeficiente de correlación de rangos
(Spearman)◦ Cálculo
( )1
61
2
2
−−=∑nn
dr
i
s x y d d dif 2( )11
2−
−=nn
rs xi yi dx dy dif 2
7 4 2 1 1
5 7 1 2 1
8 9 3 4 1
9 8 4 3 1
4
( )60,0
116*4
4*61 =
−−=sr
• 1er paso � ordenar los datos
• 2º paso � asignar rangos (valores coincidentes: se sustituye por el promedio de los rangos que hubiesen sido asignados si no hubiese coincidencias)

Regresión (lineal) simpleRegresión (lineal) simple
� Características generales:◦ Método que permite investigar la relación
(estadística) entre
� una variable dependiente (Y)
� una o más variables independientes (X1, X2, X3,…,Xn)
◦ La relación más utilizada es la lineal:
� Una variación en una variable supone una variación proporcional en la otra
� Se expresa mediante la siguiente ecuación
iii ebaxy ++=

Regresión (lineal) simpleRegresión (lineal) simple
� Significado de la ecuación:◦ xi valores de la variable independiente
◦ ei: errores aleatorios que representan las diferencias entre el modelo y la realidad
◦ a y b: parámetros que definen
� a (pendiente) � cuánto aumenta Y por cada aumento de una unidad en X
� b (ordenada en el origen) � el valor de Y cuando X = 0

Regresión (lineal) simpleRegresión (lineal) simple
� Significado de la ecuación:◦ a y b: se estiman mediante el método de
mínimos cuadrados: � Consiste en encontrar aquellos valores de a y de b que
hagan mínima la suma de los cuadrados de las hagan mínima la suma de los cuadrados de las desviaciones de las observaciones respecto de la recta que representa el modelo
xayb −=
2
x
xy
S
Sa =
Covarianza x y
Varianza x

Regresión (lineal simple)Regresión (lineal simple)
� Cálculo
1º Promedios
2º Cálculo covarianza
9,121∑
n
xi yi xi ·yi xi2 yi
2
0,8 1 0,8 0,64 1
1 2 2 1 4
1,2 3 3,6 1,44 9
1,3 5 6,5 1,69 25
4,3 11 12,9 4,77 39
3º Cálculo varianza
4º Parámetros a y b
28,70369,0
26875,02
===x
xy
S
Sa 075,1*28,775,2 −=b
0369,0075,14
77,4 22
1
2
2=−=−=
∑− Xn
x
S
n
i
i
x
0268,075,2*075,14
9,121
1
=−=−= ∑−
YXyxn
Sn
i
iixy

Regresión (lineal simple)Regresión (lineal simple)
� Cálculo
5º Ecuación (modelo)
6º Cálculo coeficiente de correlación
0847,528,7 −= xy
xi yi xi ·yi xi2 yi
2
0,8 1 0,8 0,64 1
1 2 2 1 4
1,2 3 3,6 1,44 9
1,3 5 6,5 1,69 25
4,3 11 12,9 4,77 39
6º Cálculo coeficiente de correlación
94,01875,2*0369,0
26875,0===
yx
xy
SS
Sr
18,275,24
39 22
1
2
2=−=−=
∑− Y
n
y
S
n
i
i
y

RegresiónRegresión
� Cálculoxi yi xi ·yi xi
2 yi2
2 1 2 4 1
3 3 9 9 9
4 2 8 16 4
4 4 16 16 16
1º Promedios
2º Cálculo covarianza 92,55*612
431=−=xyS
4 4 16 16 16
5 4 20 25 16
6 4 24 36 16
6 6 36 36 36
7 4 28 49 16
7 6 42 49 36
8 7 56 64 49
10 9 90 100 81
10 10 100 100 100
72 60 431 504 380
3º Cálculo varianza
4º Recta de regresión de Y sobre X.
98,06
92,52
===x
xy
S
Sa
92,06*98,05 =−=b
6612
504 22=−=xS

Regresión (lineal simple)Regresión (lineal simple)
� Predicción◦ El modelo de regresión lineal se utiliza
para obtener valores de Y ajustados al modelo
◦ Los puntos que representan estos valores ◦ Los puntos que representan estos valores en el gráfico de dispersión forman una recta
� El promedio de los valores ajustados es igual al promedio de los valores observados
� El promedio de las diferencias es cero.

Regresión (lineal simple)Regresión (lineal simple)
� Predicción◦ Residuo: diferencia entre el valor real y el valor
predicho por el modelo (errores de predicción).
� Cuanto más pequeños sean los residuos, mejor será el
ajuste de nuestro modelo ajuste de nuestro modelo

Regresión (lineal simple)Regresión (lineal simple)
� Predicción◦ Estimación de la varianza del error (σ):
� Calcular las diferencias entre valores calculados y observados
� Elevar al cuadrado las diferencias� Elevar al cuadrado las diferencias
� Calcular el promedio de los cuadrados de las diferencias
� Calcular la raíz cuadrada del promedio de los cuadrados de las diferencias entre los valores observados y ajustados

Regresión (lineal simple)Regresión (lineal simple)
� Coeficiente de determinación (r2)◦ Medida de bondad de ajuste del modelos
de regresión lineal a los datos.
◦ Equivale al cuadrado del coeficiente de correlacióncorrelación
◦ Refleja la cantidad de variabilidad de los datos originales que es explicado por el modelo
� Entre 0 (no se explica) hasta 1 (ajuste perfecto; todos los puntos aparecen en un línea recta)

Regresión (lineal simple)Regresión (lineal simple)
� Bandas de confianza
◦ Predicciones por intervalos de confianza verticales
� Ventaja: proporcionar una cuantificación del error de
predicción. predicción.
� Los intervalos tienen diferente ancho (según el valor
de X�
� Angostos cuando X es igual al promedio, ensanchándose
a medida que nos alejamos del promedio.
� Cuando se sale del rango de los datos, se ensanchan �
cuanto más nos alejamos del centro de los valores de la
variable X, más imprecisas serán nuestras estimaciones
del valor de la variable Y