fundamentos estadísticos
DESCRIPTION
Contenidos de Estadística BásicaTRANSCRIPT

Apuntes Clase 1
A. Concepto de Estadística.
Es frecuente que la Estadística se identifique con una tabla o colección de datos. De hecho, eso es una estadística. Pero qué duda cabe que la Estadística no debe entenderse como una mera colección de datos, aunque los mismos se presenten de forma ordenada y sistemática.
Esta forma de entender la Estadística tiene su origen en el significado etimológico del término. La palabra Estadística deriva de la latina "status" y se remonta a los tiempos en los que los estados-naciones recababan datos, especialmente sobre renta y población, a efectos de recaudación impuestos y mantenimiento del ejército. Esos datos se identificaban con el estado, razón por la cual terminaron conociéndose como estadísticas. En este sentido, la Estadística es tan antigua casi como el propio ser humano. Pero esta es una forma muy estrecha de entender y definir la Estadística.
En cambio, la Estadística entendida como ciencia tiene un origen más reciente y el gran desarrollo de la misma ha tenido lugar, fundamentalmente, a lo largo del siglo XX. Como ciencia, la Estadística está formada por el conjunto de métodos y técnicas que permiten la obtención, organización, síntesis, descripción e interpretación de los datos para la toma de decisiones en ambiente de incertidumbre. Ese objetivo que persigue la Estadística con la organización y síntesis de los datos tiene su razón de ser en el hecho de que la misma se preocupa del estudio de los que podemos denominar como fenómenos de masas. Es decir, la Estadística no está interesada en el estudio de datos aislados, pues si la información es escasa no tiene sentido plantearse problemas de organización ni de síntesis. Así, si se estudian los gastos en publicidad de las empresas de una determinada rama de actividad y se tiene información para solo dos empresas, entonces, con esos dos datos no ha lugar plantearse si los mismos han de presentarse mediante una tabla o un gráfico o si deben resumirse mediante un promedio. Esa escasez de información no debiera ser nunca objeto de análisis estadístico, pues la descripción de la misma es irrelevante y a partir de ella poco se puede decir en relación con los gastos en publicidad de todas las empresas. La metodología estadística adquiere entidad cuando de lo que se trata es de analizar un elevado volumen de datos, pues por lo general, tras esa "masa de datos" se esconden ciertas regularidades o leyes de comportamiento que nos permitirán, una vez descritas, tomar decisiones en ambiente de incertidumbre, siempre que esta pueda cuantificarse en términos de probabilidad, pues esas decisiones se basan en una leyes que, a diferencia de las leyes de la física, no son exactas sino que están sujetas a errores.
En el párrafo anterior han aparecido, no por casualidad, tres términos que nos van a permitir desdoblar a la Estadística en dos ramas principales. Esos términos son: describir,
1

probabilidad y toma de decisiones con incertidumbre. El primero de ellos da lugar a lo que se conoce como Estadística Descriptiva. Esta rama es la más antigua de la Estadística y su objeto es el análisis de los datos para descubrir o describir las posibles regularidades que presenten. Paralelamente, aunque con posterioridad, se desarrolló la Teoría de la Probabilidad. La unión ambas ha dado lugar a lo que se conoce como Estadística Matemática o Inferencia Estadística. El instrumental propio de esta rama es el que nos permite tomar decisiones en ambiente de incertidumbre. Se trata de decisiones basadas en la información que suministran los datos y que permiten generalizar los resultados obtenidos.
La observación estadística.
Ahora bien, una vez que se tiene claro que el objeto de la Estadística es la observación y estudio de las poblaciones, la siguiente cuestión que puede plantearse es como ha de realizarse esa observación. La misma puede ser exhaustiva o parcial. Las dos formas tienen ventajas e inconvenientes. En el caso de la observación exhaustiva o total, y si se asume que no hay errores de medida entonces, lo que se consigue es eliminar la incertidumbre.
Frente a esa ventaja fundamental, la observación exhaustiva tiene un grave inconveniente: el coste. Se trata tanto de un coste monetario como en tiempo. Imaginemos la siguiente situación. Un partido político, antes de unas elecciones, quiere saber cuál es la intención de voto del electorado. Para ello tiene dos opciones. Preguntarle a todos los electores o solo a un subconjunto de los mismos. En el primer caso estamos frente a una observación exhaustiva y está claro que, ante esta situación, para el partido que lleva a delante la observación no habrá incertidumbre alguna en relación con el resultado final de las elecciones, siempre y cuando no haya errores de medida. En este caso esos errores vendrán dados por la falta de sinceridad en la respuesta de los electores y por las no respuestas, además de otras posibles causas. Pero, ¿por qué ese partido, o cualquier otro, normalmente no realizan ese tipo de observación? En este caso la respuesta parece trivial. El tamaño de la población es demasiado grande, lo que conlleva un coste tanto en tiempo como en dinero que hace desaconsejable esa opción. Un ejemplo de una operación estadística de carácter exhaustivo, dentro de la estadística oficial, son los censos de población, especialmente los realizados desde 1991, pues los anteriores eran una mezcla de observación exhaustiva y parcial.
La alternativa al enfoque anterior es la observación parcial. Esta implica que no se observa a toda la población. Dentro de esta forma de proceder se pueden distinguir dos categorías distintas. Por un lado está la subpoblación y por otro la muestra. Con la primera lo que se hace es observar a un conjunto de entes o elementos de la población que guardan entre si una cierta característica y que los diferencia de los demás. Así, siguiendo con el ejemplo anterior, los electores que no han votado antes porque en las
2

elecciones anteriores no tenían la edad mínima exigida constituyen una subpoblación. Al proceder de esta forma se consigue realizar una operación estadística en menos tiempo y a menor coste pero, en cambio, la incertidumbre acerca de la intención de voto del electorado es enorme, pues esa subpoblación no representa en absoluto a toda la población. Su intención de voto no tiene por qué coincidir con la de los demás electores.
No obstante, esta forma de observar la población puede resultar de gran interés en determinados casos. Pensemos que nuestro interés se centra es cuantificar la ocupación hotelera en una zona turística. En esta situación, en lugar de preguntar a todos los establecimientos que se dedican a esta actividad económica, podría resultar suficiente con preguntarle solo a los hoteles a partir de una cierta categoría, por ejemplo a los de tres y más estrellas pues, en este caso, esos elementos de la población son determinantes de la población total y los demás tienen poca incidencia en el volumen de ocupación.
La segunda opción de la observación parcial consiste en tomar una muestra. En este caso se observará también un subconjunto de elementos de la población. Pero ahora, a diferencia de lo que ocurría con la subpoblación, los elementos de la muestra no guardan ninguna característica especial que los diferencie de los demás. Al contrario, con una muestra lo que se pretende es representar a toda la población. Podríamos decir que la muestra es una población de tamaño reducido.
Las ventajas de observar la población de forma parcial y, en especial, para el caso de seleccionar muestras son, en algunos casos, evidentes. En primer lugar reduce el tiempo de observación. Si el tiempo que se dedica a observar los elementos de la población es excesivo podría ocurrir que los resultados llegaran más tarde de lo que es admisible. Siguiendo con el ejemplo de las elecciones, si el periodo de observación es superior al tiempo que dista hasta que tengan lugar las elecciones, entonces cuando se disponga de resultados sobre intención de voto ya no son necesarios. En general, si lo que se pretende al observar la población es analizar una característica que no cambia mucho con el transcurso del tiempo, entonces no importará demasiado que el periodo de observación sea razonablemente largo. Por el contrario, si esa característica está sometida a fuertes variaciones en periodos de tiempo cortos o si el plazo de presentación de resultados es breve, qué duda cabe que en tales circunstancias la observación parcial, mediante una muestra, es el procedimiento más indicado.
En segundo lugar está el tema de los costes monetarios, que en la observación parcial son más reducidos que en el caso de la exhaustiva.
Finalmente, la observación parcial presenta también la ventaja de que reduce las pruebas destructivas. Imaginemos que nos encontramos frente a un estudio de control de la calidad de la producción de una empresa que se dedica a la fabricación de vigas de hormigón para obras civiles. Esas vigas habrán de someterse a presiones altas para
3

conocer su resistencia a la ruptura. Pero si somete toda la producción a este tipo de pruebas destructivas entonces no hay producción. Bastaría en este caso con seleccionar una muestra y, aplicarle ese tipo de pruebas a los elementos de la misma, para tener una idea razonable de cuál es la resistencia a la ruptura de las vigas producidas por la empresa.
Pero no todo son ventajas en la observación parcial. El principal inconveniente se deriva precisamente de que la observación no es exhaustiva. En estos casos las características de la población serán desconocidas, pues aunque la muestra pretenda representar lo más fielmente posible a la población, nunca dejará de ser eso, una muestra. Con los datos de la muestra solo podremos conocer las características de esos valores muestrales. Concluir que son iguales a las de la población sería poco menos que una osadía. Entre las características observadas en la muestra y las de la población habrá siempre una diferencia que se conoce como error muestral. Es precisamente este error muestral el que lleva a que las decisiones, en relación con las características poblacionales, se tomen en situaciones de incertidumbre.
Veamos esto de una forma gráfica y sencilla. En la Figura 1 se han representado una población con todos sus elementos y una muestra de los mismos. Como puede apreciarse, la población toma valores que van del 0 al 9, mientras que en la muestra el valor 9 no está incluido. Así pues, según la muestra, los valores de la población van del 0 al 8, pero eso no es cierto, solo es aproximado. Se está cometiendo un error.
Referencia:
Sánchez Fernández, J. (2004) Introducción a la Estadística Empresarial. Edición electrónica en http://www.eumed.net/cursecon/libreria/index.htm (Extracto del capítulo 1)
4

B. El Papel del Análisis de Datos en la Investigación Educativa
Introducción
Analizar información procedente de diversas vías es una actividad común en el ser
humano. Habitualmente examinamos aspectos de nuestra realidad, indagamos en un
problema vital o damos diferentes interpretaciones a las cosas que nos ocurren. Desde
este punto de vista llevamos a cabo un proceso de asimilación de la información externa y
acomodación en nuestro intelecto, que muchas veces es realizado de manera automática.
Cuando nos referimos aquí al Análisis de Datos hablamos de un proceso de indagación
científica sobre un problema de investigación concreto con relevancia social y educativa.
La información que recogemos puede ser tanto numérica como textual, y ante ella nos
disponemos a la realización de diferentes actividades o tareas de análisis acordes con el
tipo de dato recogido, el problema de investigación formulado, y las características
propias del diseño de investigación al que nos enfrentamos. De esta manera, el Análisis
de Datos no constituye un fin en sí mismo sino que es un proceso subordinado a otro más
amplio como es la investigación educativa.
Concretamente, en esta materia nos detendremos en el Análisis Estadístico de Datos y en
la relevancia que poseen las técnicas y procedimientos estadísticos en y para la
investigación educativa. No obstante, también dedicaremos un apartado al Análisis de
Datos no cuantitativos, aludiendo al análisis de textos
El concepto de análisis estadístico de datos
El Análisis Estadístico de Datos se ha asociado de manera general con la investigación de
corte experimental, o podemos decir que es característico de los enfoques positivistas.
Este término se define de muchas maneras según se conciba desde una perspectiva más
amplia o más restringida, y según se entienda también el proceso de investigación.
El concepto de Análisis Estadístico de Datos no se agota en las acepciones que se
identifican con un conjunto de datos o enumeración de hechos, o con procedimientos de
tipo descriptivo destinados a recoger, organizar y presentar la información relativa a un
conjunto de casos. De esta manera, el Análisis Estadístico de Datos ha dejado de ser
únicamente la ciencia de recopilar datos y, tras fusionarse con la corriente de estudios
5

sobre el cálculo de probabilidades, se ha constituido en una rama de la matemática
aplicada, entendiendo ésta como el uso de principios y modelos matemáticos en diversos
ámbitos de la ciencia o la técnica.
Dentro del Análisis Estadístico de Datos encontramos dos vertientes:
• Análisis Estadístico de Datos (propiamente matemático), que supone el estudio de los
fenómenos estadísticos utilizando los métodos matemáticos y proporciona
conocimiento acerca de las técnicas que integran los métodos estadísticos.
• Análisis Estadístico de Datos Aplicado; este carácter aplicado ha estado presente
desde los inicios de esta ciencia, sobre todo en cuanto a su conexión con el estudio y
resolución de problemas prácticos con datos reales. Todo ello ha estimulado la
innovación de nuevos métodos y procedimientos, y el avance de análisis estadísticos.
A continuación expondremos las características propias que definen el concepto de
Análisis Estadístico de Datos:
• Carácter teórico y aplicado.
• Estudio de conjunto de datos.
• Trabajo con datos procedentes de observaciones o mediciones.
• Carácter cuantitativo de los datos.
• Reducción de la información.
• Generalización a colectivos más amplios.
Por tanto, como ya mencionamos, el Análisis Estadístico de Datos no se limita sólo a su
tratamiento sino que se extiende a tareas previas y posteriores a esta fase. También
puede ocuparse de la recogida de datos (referido a las técnicas y métodos de muestreo y
a la evaluación de la calidad de los instrumentos que se diseñan para la recogida de
datos) y la interpretación de los resultados (afirmaciones que se realizan como
consecuencia de la aplicación de métodos estadísticos: descripción, reducción,
generalización).
Terminaremos este apartado sintetizando los rasgos más relevantes que llevan a definir el
Análisis Estadístico de Datos:
• Es una ciencia cuyo objeto es el estudio de métodos y técnicas para el tratamiento de
conjuntos de datos numéricos.
• Las técnicas estadísticas permiten la descripción de conjuntos de datos y la inferencia
sobre conjuntos más amplios.
6

• Los métodos desarrollados por esta ciencia pueden ser aplicados a distintos campos
del saber, constituyendo un importante instrumento para el estudio científico.
Así, definimos el Análisis Estadístico de Datos como un conjunto de métodos, técnicas y
procedimientos para el manejo de datos, su ordenación, presentación, descripción,
análisis e interpretación, que contribuyen al estudio científico de los problemas planteados
en el ámbito de la educación y a la adquisición de conocimiento sobre las realidades
educativas, a la toma de decisiones y a la mejora de la práctica desarrollada por los
profesionales de la educación.
El análisis estadístico de datos en las distintas fases del proceso de investigación
El Análisis Estadístico de Datos desempeña un papel relevante dentro de campo de la
investigación educativa. No obstante, dichas técnicas de análisis cobran especial
importancia dentro del enfoque positivista. Desde esta perspectiva, existen razones que
justifican la utilización del Análisis Estadístico de Datos en la investigación Educativa.
Permite el tipo de descripción más exacta. Si el objetivo de la ciencia es la descripción
de fenómenos, el Análisis Estadístico de Datos forma parte del lenguaje descriptivo
que necesita el científico.
Nos fuerza a ser definidos y exactos en nuestros procedimientos y en nuestro
pensamiento, evitando las conclusiones vagas.
Nos permite reducir los datos en una forma significativa y conveniente, poniendo
orden en el caos.
Facilita la extracción de conclusiones generales, siguiendo reglas aceptadas para
llegar a ellas.
Permite hacer predicciones sobre lo que ocurrirá bajo condiciones que conocemos y
hemos medido. Tales predicciones pueden contener error, pero el Análisis Estadístico
de Datos nos informa también del margen de error que cometemos.
Nos permite analizar algunos de los factores causales que explican fenómenos
complejos.
También Análisis Estadístico de Datos como herramienta de trabajo útil en la
investigación educativa ya que nos ofrece técnicas y procedimientos que pueden
aplicarse en la fase de Análisis de Datos. No obstante, no queda limitado a dicha fase ya
que contribuye a otras o a diferentes momentos del proceso de investigación.
De esta manera, intentamos resalta la presencia del Análisis Estadístico de Datos en
diferentes momentos del proceso de investigación y la utilidad de las técnicas estadísticas
7

en y para el mismo. Dicho proceso constituye un todo interrelacionado en el que la toma
de decisiones que realicemos sobre cualquier elemento del mismo supone un
condicionante de cara a los demás elementos.
1. Planteamiento del problema y formulación de hipótesis
El Análisis Estadístico de Datos está presente en la formulación del problema de
investigación. Como señalamos, el proceso de investigación es un todo interrelacionado
en el que las decisiones que tomemos con respecto a algunos de sus elementos
condicionan a los demás elementos del proceso. La formulación del problema determinará
el tipo de datos que es necesario recoger, las técnicas de recogida adecuadas para ello y
los procedimientos estadísticos que se utilizarán en el análisis. En la definición del
problema aparecerá una limitación de la amplitud del estudio, de tal forma que si éste se
dirige a toda una población, tendremos que pensar en procedimientos de la estadística
Descriptiva, mientras que si nos limitamos al estudio de una muestra, habremos de
recurrir a la estadística inferencial.
Definimos problema como una laguna en el conocimiento (un interrogante que nos
hacemos) para la cual no tenemos solución aceptable. El problema ha de ser relevante y
verificable empíricamente y se debe formular de manera clara y breve. En este sentido, es
muy importante la resolubilidad del problema de investigación, aspecto que en ocasiones
sólo queda garantizado si contamos con técnicas estadísticas adecuadas y potentes,
capaces de abordar los interrogantes de partida. Por ejemplo, el planteamiento de
problemas que supongan comparaciones entre múltiples grupos no podría hacerse sin
contar con técnicas como el análisis de la varianza; un gran número de problemas de
investigación en los que se incluyen múltiples dimensiones o variables simultáneamente
no han llegado a ser estudiados hasta que no se ha contado con técnicas de análisis
multivariante que permiten abordar su estudio.
De igual manera, el Análisis Estadístico de Datos está presente en la formulación de
hipótesis, ya que ésta no puede hacerse sin tener en cuenta las técnicas estadísticas que
permiten su contrastación. El investigador se ve en la necesidad de salvaguardar la
coherencia entre la teoría, la hipótesis y el posterior análisis estadístico que le permitirá
aceptarla o rechazarla. Una hipótesis es una solución por adelantado que se da al
problema de investigación que formulamos; es una conjetura, una solución posible. En el
marco de los programas de investigación positivistas, la hipótesis científica habrá de ser
expresada en términos estadísticos para su contrastación.
2. Diseño de investigación
8

Como expusimos en un apartado anterior, el Análisis Estadístico de Datos forma parte de
los diseños de investigación experimentales. En el concepto de diseño contemplamos por
un lado la organización de los aspectos que constituyen el experimento (en los que el
Análisis Estadístico de Datos está presente en la medida que facilitan el análisis de datos
y posibilitan el control de la varianza debida a variables extrañas), y por otro, el
procedimiento estadístico que hace posible la interpretación de los resultados.
El Análisis Estadístico de Datos también está presente cuando el diseño contempla la
selección de sujetos. La teoría de muestras proporcionará tanto los procedimientos de
selección como la determinación del tamaño muestral necesario para mantener el error
dentro de los límites aceptables.
Por otro lado, la recogida de datos es una tarea para la que aparentemente las técnicas
estadísticas parecen no jugar un papel relevante. Sin embargo, el Análisis Estadístico de
Datos tiene un lugar especial en la construcción y validación de instrumentos que se
utilizan para la recogida de datos. Por ejemplo, la determinación de la fiabilidad y validez
de algunos instrumentos se apoya directamente en coeficientes de correlación, o la
aplicación de técnicas de análisis de componentes principales o análisis factorial permite
explorar la dimensionalidad de los instrumentos.
Además, el Análisis Estadístico de Datos puede participar indirectamente en la operación
de recogida proporcionando primeras elaboraciones de los datos en el momento mismo
de su registro.
3. Análisis de Datos
Tras la recogida de datos procedemos al análisis de los mismos. Es decir, pretendemos
transformar, organizar, resumir y sacar indicadores básicos de la información recogida, y
en función de dichos indicadores extraer conclusiones, y también generalizar los
resultados a las poblaciones de donde las muestras fueron extraídas. Todas estas tareas
corresponden al Análisis Estadístico de Datos.
El procedimiento de Análisis suele comenzar con una depuración de los datos para tratar
de eliminar o corregir los posibles errores que se hayan cometido en la fase de registro o
codificación de la información recogida. Una segunda fase es la descripción de las
variables que entrarán a formar parte del estudio, teniendo en cuenta el enfoque del que
partimos (univariante, multivariante o aplicación de técnicas inferenciales).
9

No obstante, existen vías diferentes al Análisis Estadístico de Datos dentro de la
investigación educativa. En ellas nos centraremos en el último tema del programa de la
asignatura. En este sentido, entre los procedimientos de Análisis de datos, entendidos
como técnicas para extraer información de los datos e interpretar su significado, cabría
hacer una distinción entre:
• Análisis Cualitativo, que expresa, ordena, describe, interpreta los datos mediante
conceptos, razonamientos y palabras, y
• Análisis Cuantitativo, en el que se recurre a conceptos y razonamientos que se
apoyan en números y estructuras matemáticas.
4. Obtención de conclusiones y redacción del informe de investigación
Aplicar técnicas de Análisis Estadístico nos lleva de manera directa a la obtención de
conclusiones, las cuales estarán, de alguna forma predeterminadas por el tipo de técnicas
que usemos.
Estas conclusiones, al igual que todo el proceso de investigación, deben contar con la
inclusión de resultados estadísticos. De esta manera, el Análisis Estadístico de Datos está
presente en la fase de redacción del informe de investigación. Para ilustrar tales
conclusiones se utilizarán cuadros, tablas y gráficos, que recogerán medias, porcentajes,
coordenadas, correlaciones, o cualquier otro tipo de estadísticos necesarios para ilustrar
de manera adecuada la investigación realizada.
Contenidos del análisis estadístico de datos
Lejos de realizar una exhaustiva revisión de todas las técnicas y métodos estadísticos
existentes, nuestra pretensión en este apartado es apuntar a grandes rasgos los
principales campos en que se estructura el Análisis Estadístico de Datos, y sobre todo el
que habitualmente se aplica en el campo de las Ciencias de la Educación.
No obstante, aquí adoptaremos la solución de distinguir entre:
Estadística descriptiva, procedimientos dirigidos a la organización y descripción de un
conjunto de datos.
Estadística inferencial, que se orientan a realizar inferencias sobre una población a
partir de las características conocidas para una muestra extraída de ella.
10

Es frecuente que se otorgue especial importancia a la Estadística inferencial,
considerándola el verdadero objetivo de la Estadística; la descriptiva tendría únicamente
la finalidad de proporcionar los índices a partir de los cuales se estimarán los parámetros.
Si adoptáramos únicamente la complejidad como criterio, basándonos en el número de
variables implicadas, podríamos hablar de:
Estadística univariada.
Bivariada.
Multivariada.
El esquema a seguir en la presentación de los contenidos de la Estadística podría estar
basado en el planteamiento clasificatorio que suele adoptarse a la hora de recoger las
técnicas estadísticas en los manuales dedicados a esta materia:
Los procedimientos de la Estadística descriptiva e inferencial se reducirían a las
técnicas que suponen el tratamiento de una o dos variables; cuando entramos en el
manejo simultáneo de más de dos variables suele considerarse un apartado diferente
de la Estadística al que se califica con el término de Estadística multivariante. Pero no
debe perderse de vista que este modo de clasificación no es sino una solución
práctica, que desde el punto de vista teórico presenta algunas dificultades.
Al diferenciar entre estos tres tipos de técnicas no hemos logrado una verdadera
clasificación del Análisis Estadístico de Datos; Estadística descriptiva, inferencial y
multivariante, en sentido estricto, no representan una partición del conjunto de
contenidos de la Estadística, es decir, no constituyen subconjuntos disjuntos ni
tampoco abarcan entre ellas todo el dominio de las técnicas estadísticas. No obstante,
en esta materia nos centraremos en los dos primeros bloques de contenidos citados:
Estadística descriptiva e inferencial.
La informática en el análisis estadístico de datos
Auge y desarrollo /expansión de la Informática desde hace algunos años en el campo
de la investigación educativa, y más concretamente en el ámbito del Análisis de Datos.
Aplicaciones de la informática muy importantes si tenemos en cuenta la cantidad de
datos que manejamos normalmente y también los diferentes tipos de análisis que se
realizan. En este sentido, los programas informáticos facilitan mucho la tarea pero es
importante que resaltemos la correcta utilización de los mismos y la coherencia y
lógica del investigador en tales procesos. Es fundamental que la informática siempre
11

responda al problema de investigador y objetivos planteados, y no sustituya al
analista.
De todas las funciones que el computador puede cubrir en la investigación educativa,
es quizá la del Análisis de Datos la que con mayor claridad puede haberse beneficiado
de este tipo de herramientas. El computador ha venido a revolucionar este campo,
permitiendo la aplicación de complejos procedimientos de análisis y, de alguna
manera, simplificándolos.
Si el impacto de la informática en el campo de la investigación educativa ha sido
considerable, en el caso del Análisis de Datos esta afirmación cobra pleno sentido. El
Análisis de Datos "ha recibido un impulso revolucionario con la generalización del uso
de los computadores", hasta tal punto que hoy es difícil concebir este proceso
desligado de la utilización de tales máquinas. Algunas de las ventajas y posibilidades
que lleva consigo el uso de la informática en el Análisis Estadístico de Datos son:
o El computador ha permitido un considerable ahorro de tiempo y esfuerzo. Los
cálculos manuales que costaban al investigador largas horas de trabajo, incluso
utilizando la calculadora, la máquina los realiza en pocos segundos.
o El computador posibilita una mayor exactitud en los cálculos. Es evidente que el
cálculo manual, además de ser lento conlleva aproximaciones o redondeos, sobre
todo cuando se trabaja con números decimales y se requieren cálculos
encadenados, que pueden llegar a suponer un considerable error en los resultados
finales obtenidos. Por otra parte, en el dominio de la inferencia estadística, el
computador nos ofrece posibilidades con mayor exactitud que las obtenidas
mediante tablas de distribuciones teóricas de probabilidad habitualmente usadas.
o El computador ha abierto la posibilidad de manejar grandes cantidades de datos,
de trabajar con muestras mayores y de incluir más variables, haciendo que el
análisis de grandes bancos de datos o la aplicación de complejas técnicas
multivariantes a grandes muestras no presenten tareas inabordables en la
práctica.
Considerando dichas ventajas, la Informática en el Análisis Estadístico de Datos:
o Al liberarnos de tiempo en la realización de cálculos el investigador puede
centrarse en otros momentos o tareas conceptuales más relevantes del proceso
de investigación como la toma de decisiones respecto al proceso estadístico a
seguir o a la técnica concreta que se deberá emplear, mayor atención al análisis
crítico del proceso y a la interpretación de resultados.
o También nos ofrecen la posibilidad de realizar cálculos para la comparación de
resultados utilizando métodos diferentes, aspecto que no se realizaba por
considerar un esfuerzo adicional para el investigador, además de la dificultad que
entrañaba un análisis.
12

o Otra de las posibilidades que abrió la informática fue el tratamiento conjunto de
múltiples variables y, por ende, el desarrollo de análisis multivariante, en los que
se observaba una creciente complejidad estadística.
o La triangulación multimétodos y el manejo de grandes muestras y elevado número
de variables contribuye al aumento de la fiabilidad y validez de los estudios y, por
ende, su poder de generalizar los resultados.
No obstante, el desarrollo de la Informática no sólo ha supuesto beneficios para el
Análisis Estadístico de Datos sino también a la mejora y desarrollo de técnicas
estadísticas más complejas e innovadoras.
Teniendo en cuenta las ventajas que representa el uso del computador y el papel que
juega en el Análisis Estadístico de Datos, hoy día resulta inconcebible la realización de
este tipo de análisis en la investigación educativa que no se apoyen en la informática.
Actualmente, gracias al avance y desarrollo del mundo de la informática contamos con
un gran número de programas para el Análisis de Datos. Los diferentes tipos de datos
(cuantitativos o cualitativos) exigen diferente software informático, ya que requieren
diferente tratamiento.
En este curso, al centrar nuestra atención principalmente en el Análisis Estadístico de
Datos, tendremos como soporte el paquete estadístico SPSS, utilizándolo para
generar archivos de datos, transformarlos y realizar análisis estadísticos, atendiendo,
como ya señalamos, tanto a la Estadística Descriptiva como a la Inferencial.
C. Organización Y Presentación De Los Datos
Conceptos previos sobre medición y escalas de medida
1. Concepto de medida
Asignación de números a los objetos con la intención de representar alguna de sus
características. Toda medición implica establecer una regla para hacer corresponder los
números con las distintas formas en que se presenta una característica de los objetos o
individuos. En el caso de la investigación educativa, se suelen asignar números a
conductas, opiniones, actitudes, intereses, etc. manifestadas por individuos o grupos.
2. Niveles de medida
Según el modo en que se utilizan los números en la medición, podemos hablar de
distintos niveles de medida:
13

a) Nivel nominal.
El nivel nominal de medición consiste en asignar números que hacen la función de meros
nombres o etiquetas.
Si empleamos un nivel de medida nominal lo único que podemos inferir es que los objetos
difieren entre sí respecto del atributo medido, aunque ello no implica ninguna otra
propiedad.
b) Nivel ordinal.
El nivel ordinal de medida supone que podemos establecer una ordenación, creciente o
decreciente, con los objetos o hechos que medimos.
Con un nivel de medida ordinal podríamos establecer sin dificultad que algo es diferente
de algo, y que es mayor o menor, pero no cuánto mayor o menor.
c) Nivel de intervalo
En este nivel de medida, distancias numéricamente iguales representan distancias iguales
con respecto a la propiedad que se está midiendo.
Una medición a nivel de intervalo posee las características de los dos niveles anteriores,
por lo que podemos establecer diferencias entre objetos, determinar una ordenación entre
ellos y además, conocer en qué cuantía unos objetos son mayores o menores que otros.
d) Nivel de cuociente, razón o proporciones.
Este nivel de medición añade a la medida en escala de intervalo la existencia de un cero
absoluto.
Además de las propiedades de los niveles anteriores, en las medidas en escala de razón
puede afirmarse que el valor cero indica ausencia total del rasgo medido.
3. Constante, variable, modalidades y clases
Una constante es una característica que se manifiesta de manera similar en todos los
objetos o individuos sobre los que se realiza la medición. Es decir, presenta un único valor
posible.
14

Una variable es una característica que puede manifestarse de manera diferente en un
grupo de objetos o individuos sobre los que se realiza la medición. Cada uno de los
valores asumidos es una modalidad.
Cuando el número de modalidades bajo el que se mide una variable es muy grande, las
modalidades pueden ser agrupadas en clases. De esta manera, se pasa de un número
amplio de modalidades a un número mucho más reducido de clases. Al definir clases,
deben respetarse al menos dos criterios:
Las clases deben ser mutuamente exclusivas. Es decir, una modalidad no puede formar
parte de dos clases; quedará incluida en sólo una clase. Las clases deben ser
exhaustivas. La definición de clases debe cubrir todas las modalidades, de forma que
ninguna modalidad quede sin pertenecer a alguna clase.
Ordenación y clasificación de los datos: distribuciones de frecuencias
1. Frecuencias y distribución de frecuencias
Las técnicas más habituales para ordenar, clasificar y presentar datos son las
distribuciones de frecuencias. Comenzaremos concretando el concepto de frecuencia.
Frecuencia hace alusión al número de veces que se da un fenómeno. En estadística, la
frecuencia va referida al número de veces en que aparece un determinado valor para una
variable. Comenzaremos diferenciando dos tipos de frecuencias:
Frecuencia absoluta individual (fi) de un valor. Es el número de veces que aparece
repetido dicho valor en un conjunto de n puntuaciones. La suma de las frecuencias fi para
todos los valores coincide con el valor de n.
Frecuencia relativa individual (pi) de un valor. Es el cociente entre la frecuencia
absoluta individual y el tamaño de la muestra. Es decir, pi = fi/n. Lo más frecuente es
utilizar este tipo de frecuencia en términos porcentuales, expresándola como Pi = (fi /n) x
100. En este caso, la suma de las Pi para todos los valores es 100.
A partir de las frecuencias alcanzadas por las distintas modalidades de una variable,
puede organizarse una distribución de frecuencias. Una distribución de frecuencias
consiste en presentar ordenadamente todos los valores asumidos por la variable
15

estudiada, situando a su derecha la frecuencia con que aparecen (al menos, su frecuencia
absoluta).
Frecuencia absoluta acumulada (fa) de un valor. Es la suma de las frecuencias
absolutas que corresponden a todos los valores iguales o menores que él. La frecuencia
fa para el valor más alto de la variable coincide con n.
Frecuencia relativa acumulada de un valor. Es la suma de las frecuencias relativas de
los valores iguales o menores que él; expresada en términos de porcentaje.
2. Distribución de frecuencias agrupadas
Una distribución de frecuencias agrupadas se origina cuando en lugar de modalidades
consideramos clases. Suele recurrirse a ellas cuando se pretende simplificar la
presentación de variables que poseen muchas modalidades posibles.
Un caso particular de agrupamientos se da en los valores correspondientes a variables
continuas, medidas al menos en escala de intervalos. En esta situación, la clase de
valores que adoptamos se denomina intervalo y comprende las modalidades de una
variable contenidas entre los dos valores que delimitan el intervalo.
Conceptos relativos al agrupamiento en intervalos:
Límites aparentes de un intervalo. Son los valores que delimitan el segmento de
valores que constituyen un intervalo. Para cada intervalo existe un límite inferior y un
límite superior.
Límites reales de un intervalo. El límite real inferior de un intervalo es el valor que
resulta de disminuir el valor del límite aparente inferior en media unidad de medida. El
límite real superior de un intervalo resulta de incrementar el límite superior aparente en
media unidad de medida.
Amplitud de un intervalo. Es la distancia existente entre el límite real inferior y el límite
real superior de un intervalo. También se podría definir como la diferencia entre los
límites aparentes del intervalo incrementada en la unidad de medida.
Punto medio de un intervalo. Es el valor que se obtiene como promedio de los dos
límites del intervalo (real o aparente).
Representación gráfica de datos
1. Diagrama de Barras
16

Consiste en indicar por medio de una barra o rectángulo las frecuencias correspondientes
a cada modalidad o clase de modalidades. Las alturas de las barras son proporcionales a
las frecuencias alcanzadas, con independencia de que se trate de frecuencias absolutas o
relativas.
Cuando representamos variables medidas en una escala nominal, las modalidades o
clases pueden ser colocadas en cualquier orden. Cuando las variables se miden en
escala ordinal, las barras deben ser colocadas en un orden determinado por la ordenación
que se establece entre las modalidades.
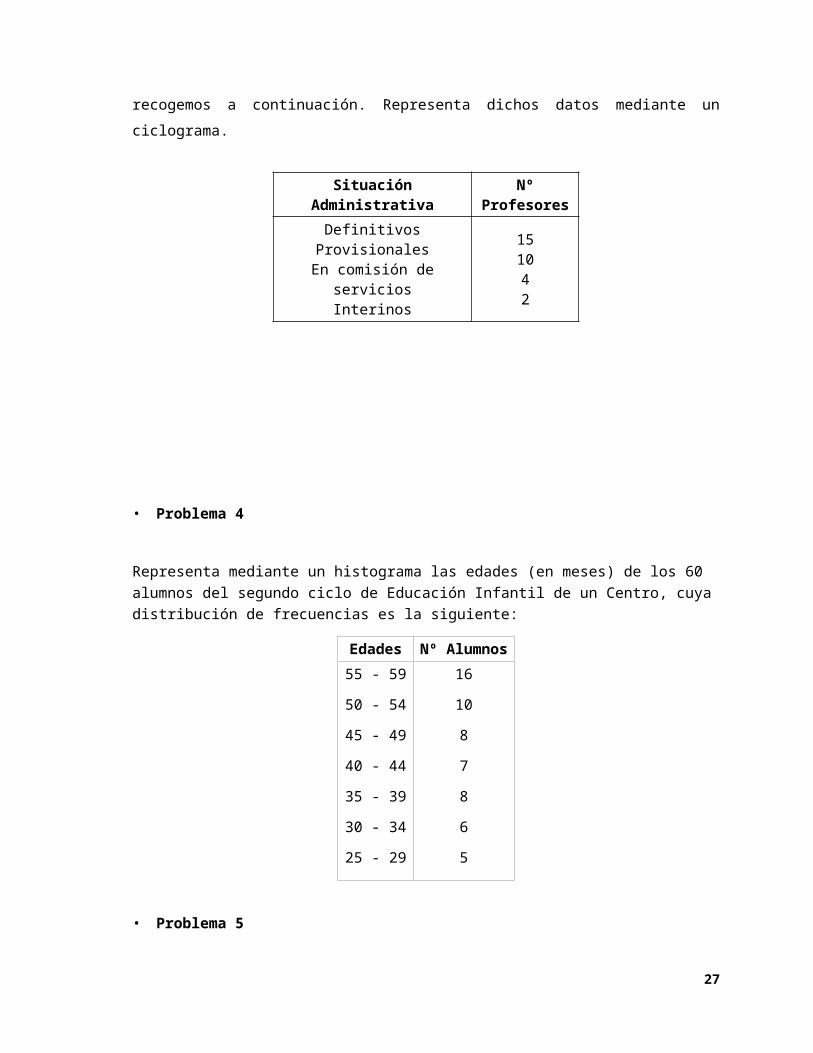
2. Histograma
Cuando la variable a representar está medida en una escala de intervalos, en lugar del
diagrama de barras recurrimos al histograma. Este es similar al diagrama de barras, pero
la base de cada rectángulo coincide con los límites reales del intervalo y el orden de
presentación de las modalidades en el eje de abscisas no es arbitrario. El histograma
puede construirse para frecuencias absolutas o relativas, tanto si son individuales como
acumuladas; también puede ser construido para representar frecuencias (también
porcentajes) o frecuencias acumuladas.
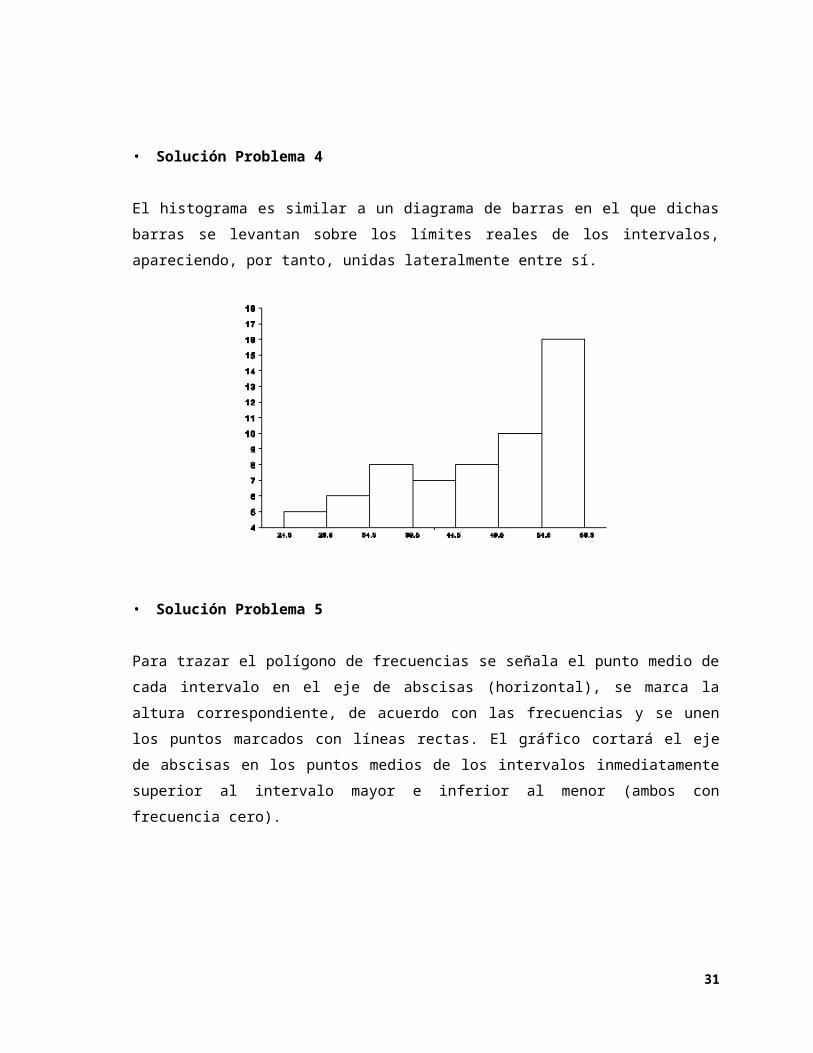
3. Polígono de Frecuencias
Consiste en una línea poligonal que une el punto medio de cada intervalo, tomado a una
altura que resulta proporcional a la frecuencia alcanzada en el intervalo. La línea obtenida
de este modo cierra el polígono al ser unida a los puntos medios del intervalo anterior y
posterior sobre el eje de abscisas Puede construirse a partir del histograma.
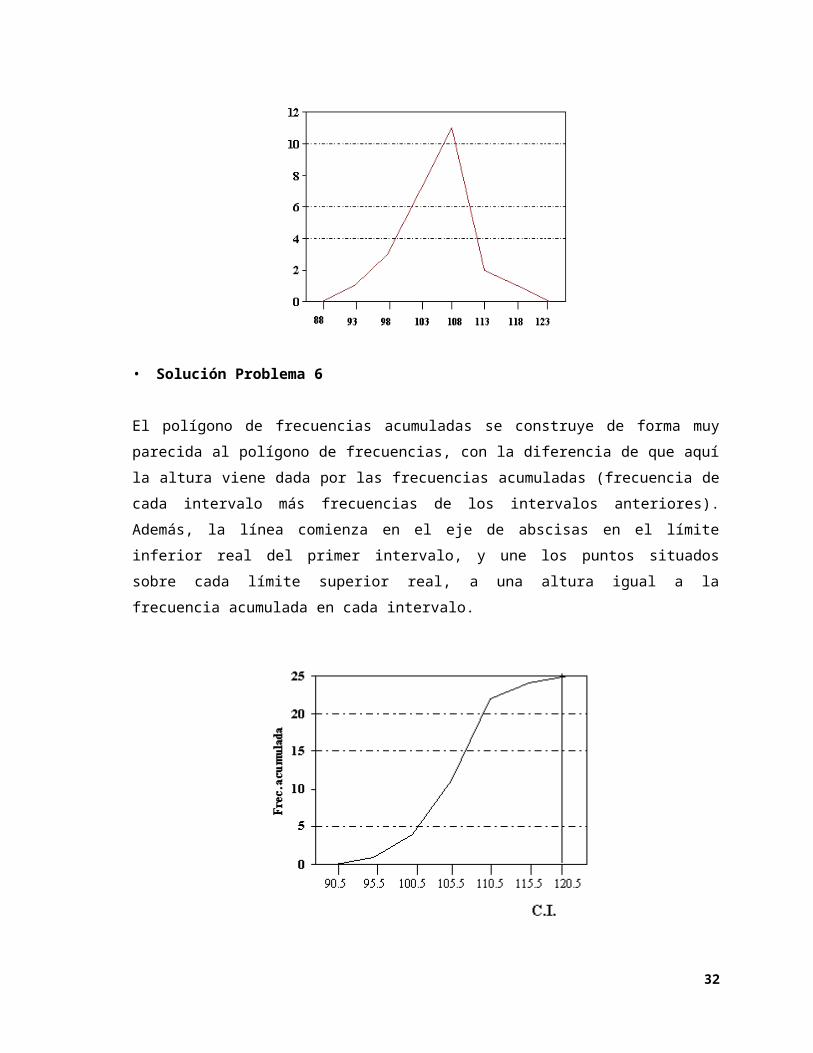
4. Polígono de Frecuencias Acumuladas
Es una línea poligonal mediante la cual se representan las frecuencias que acumulan los
intervalos. Se construye cómodamente sobre el polígono de frecuencias acumuladas,
uniendo el vértice inferior izquierdo de cada intervalo con su vértice superior derecho.
5. Ciclograma
Es un diagrama en forma de círculo, el cual se encuentra dividido en tantos sectores
circulares como modalidades presenta la variable. La amplitud de cada sector circular es
proporcional a la frecuencia de la modalidad correspondiente.
17

Problemas
• Problema 1
Hemos recogido los siguientes datos, correspondientes a las puntuaciones obtenidas por
25 alumnos en un test de inteligencia. Organízalos en una distribución de frecuencias sin
agrupar en intervalos.
105, 99, 109, 100, 94, 100, 97, 120, 99, 107, 96, 107, 100, 109, 105, 97, 100, 105, 96, 99,
100, 97, 105, 107, 99.
• Problema 2
Construye la distribución de frecuencias absolutas y relativas, tanto individuales como
acumuladas, para las siguientes puntuaciones. Agrupando los datos en intervalos de
amplitud 5.
3, 6, 7, 9, 9, 12, 12, 13, 13, 14, 14, 15, 15, 16, 16, 20, 20, 20, 20, 20, 22, 23, 24, 24, 24,
25, 25, 28, 35, 37.
• Problema 3
Los 31 profesores de un Centro de Educación Primaria se agrupan, en función de su
situación administrativa, de la forma que recogemos a continuación. Representa dichos
datos mediante un ciclograma.
Situación Administrativa Nº Profesores
DefinitivosProvisionales
En comisión de serviciosInterinos
151042
18

• Problema 4
Representa mediante un histograma las edades (en meses) de los 60 alumnos del segundo ciclo de Educación Infantil de un Centro, cuya distribución de frecuencias es la siguiente:
Edades Nº Alumnos
55 - 59
50 - 54
45 - 49
40 - 44
35 - 39
30 - 34
25 - 29
16
10
8
7
8
6
5
• Problema 5
Representa en un polígono de frecuencias los siguientes datos, correspondientes a los C.I. de un grupo de 25 alumnos de un curso de Educación Básica.
C.I. Nº Alumnos
116 - 120
111 - 115
106 - 110
101 - 105
96 - 100
91 - 95
1
3
7
11
2
1
• Problema 6
19

Representa mediante un polígono de frecuencias acumuladas los datos relativos al C.I. de un grupo de 25 alumnos utilizados en el problema anterior.
Soluciones a problemas propuestos
• Solución Problema 1
Para realizar la distribución de frecuencias debemos, en primer lugar, ordenar los datos
(de mayor a menor o de menor a mayor), representarlos en una tabla y realizar el
recuento correspondiente a cada uno de los valores (las "marcas" facilitan dicha labor), tal
y como se expresa en la tabla siguiente:
Puntuaciones Marcas Frecuencias
120
109
107
105
100
99
97
96
94
/
//
///
////
/////
////
///
//
/
1
2
3
4
5
4
3
2
1
• Solución Problema 2
En primer lugar, calculamos la amplitud total para la serie de puntuaciones con las que
vamos a trabajar.
A.T. = PMAYOR - PMENOR + 1 = 39 - 3 + 1 = 37
A continuación determinamos el número de intervalos necesarios. Teniendo en cuenta
que la amplitud del intervalo debe ser igual a 5, de acuerdo a lo indicado en el enunciado
del problema, el número de intervalos vendrá dado por la relación (cuociente) entre la
amplitud total y la de cada intervalo: 37/5 = 7.4.
20

Este valor nos indica que necesitamos un número superior a 7 intervalos para distribuir
todas nuestras puntuaciones en intervalos de amplitud 5. El número de intervalos mínimo
necesario sería 8. Una vez construidos los intervalos, determinamos la frecuencia
absoluta individual (f) en cada uno de ellos, la proporción (p), el porcentaje (P) y los
correspondientes valores acumulados para todos ellos (fa, pa y Pa).
Intervalos
Marcas f p P fa pa Pa
1 - 5 / 1,00 0.033 3.33 1 0.333 33.33
6 - 10 //// 4,00 0.133 13.33 5 0.167 16.6711 - 15 ///// /// 8,00 0.267 26.67 13 0.433 43.3316 - 20 ///// // 7,00 0.233 23.33 20 0.667 66.6721 - 25 ///// // 7,00 0.233 23.33 27 0.900 90.0026 - 30 / 1,00 0.033 3.33 28 0.933 93.3331 - 35 / 1,00 0.033 3.33 29 0.967 96.6736 - 40 / 1,00 0.033 3.33 30 1,00 100,00
No obstante, podríamos haber organizado los datos comenzando el primer intervalo con
un límite aparente inferior distinto (por ejemplo, 2 o 3). En ese caso, la distribución
resultante diferirá algo de la aquí construida.
• Solución Problema 3
En este caso la superficie del círculo (360o) se reparte proporcionalmente a las
frecuencias de cada categoría. Los profesores definitivos ocuparán un sector circular que
representa el 48.39% de los 360o, es decir, 360 x 48.39/100 = 174o que suponen algo
menos de un ángulo llano. Los profesores provisionales estarán representados por un
sector de 360 x 3226/100 = 116o, es decir, algo más que un ángulo recto. Cálculos
análogos determinan un sector circular de 47o para los profesores en comisión de
servicios y 23o para los interinos.
21

• Solución Problema 4
El histograma es similar a un diagrama de barras en el que dichas barras se levantan
sobre los límites reales de los intervalos, apareciendo, por tanto, unidas lateralmente entre
sí.
• Solución Problema 5
Para trazar el polígono de frecuencias se señala el punto medio de cada intervalo en el
eje de abscisas (horizontal), se marca la altura correspondiente, de acuerdo con las
frecuencias y se unen los puntos marcados con líneas rectas. El gráfico cortará el eje de
abscisas en los puntos medios de los intervalos inmediatamente superior al intervalo
mayor e inferior al menor (ambos con frecuencia cero).
22

• Solución Problema 6
El polígono de frecuencias acumuladas se construye de forma muy parecida al polígono
de frecuencias, con la diferencia de que aquí la altura viene dada por las frecuencias
acumuladas (frecuencia de cada intervalo más frecuencias de los intervalos anteriores).
Además, la línea comienza en el eje de abscisas en el límite inferior real del primer
intervalo, y une los puntos situados sobre cada límite superior real, a una altura igual a la
frecuencia acumulada en cada intervalo.
D. Técnicas descriptivas en una variable
1. Medidas de tendencia central
Son índices numéricos que se toman como representativos de un conjunto de
puntuaciones, utilizando para ello valores que se sitúan hacia el centro del conjunto.
a. Media (Promedio): Es el valor obtenido como suma de todas las puntuaciones de un
grupo dividida por el número de ellas.
Cálculo:
Datos sin agrupar Datos agrupados por intervalos
23

donde:
· Xi es cada puntuación
· n es el número de casos
donde:
· Xi es el punto medio de cada intervalo
· fi es la frecuencia de cada intervalo
· r es el número de intervalos
· n es el número de casos
Propiedades
La suma de las desviaciones de todas las puntuaciones respecto a la media es 0.
La media es sensible a la variación de cualquiera de las puntuaciones. Basta que
cambie un solo valor para que la media se modifique.
Si se suma una constante a las puntuaciones de un grupo, la media quedará
aumentada en dicha constante.
Si se multiplican por una constante las puntuaciones de un grupo, la media quedará
multiplicada por dicha constante.
Si una variable X es combinación lineal de r variables X1, X2, ... Xr, su media se
obtiene como combinación lineal de las medias de dichas variables.
Es decir, si entonces
Dados r grupos con n1, n2, ..., nr casos y sus respectivas medias, la media global se
obtiene ponderando dichas medias.
Cuando calculamos la media para datos agrupados en intervalos, el valor resultante
depende de los intervalos elegidos (de su amplitud, su número y de los límites fijados).
La media puede calcularse cuando las variables se han medido en una escala de
intervalo o razón.
b. Mediana: Es el valor que divide en dos partes iguales a un conjunto de puntuaciones
ordenadas, de tal forma que la mitad de las puntuaciones son mayores que la
mediana y la otra mitad son mejores que ella.
Cálculo
24

Datos sin agrupar Datos agrupados por intervalos
Se ordenan los datos de menor a
mayor.
· Si el número de casos es impar,
la mediana es el valor que ocupa
la posición central en la serie.
· Si el número de casos es par, la
mediana es el punto medio entre
los dos valores centrales.
donde:
· Li es el límite inferior del intervalo crítico
(que contiene a la mediana)
· I es la amplitud de los intervalos
· fi es la frecuencia absoluta en el intervalo
crítico
· n es el número de casos
· fa es la frecuencia acumulada en el intervalo
anterior al intervalo crítico
Propiedades.
• Es menos sensible que la media a variaciones de las puntuaciones. Podría ocurrir que
la modificación de un valor no altera la mediana
• Para datos agrupados por intervalos, el valor de la mediana dependerá de la amplitud
de los intervalos, el número de ellos y los límites fijados.
• La mediana puede calcularse cuando se han medido las variables en escala ordinal o
superior.
c. Moda: Es el valor o modalidad que más se repite en un conjunto de medidas.
Cálculo
Datos sin agrupar Datos agrupados por intervalos
· Se construye la distribución de
frecuencias.
· El valor con frecuencia máxima es la
Punto medio del intervalo con mayor
frecuencia, o bien:
25

moda.
· Si la frecuencia máxima se alcanza
para dos o más valores, éstos
constituyen modas. El grupo puede
ser bimodal o multimodal.
· · Si dos valores adyacentes
alcanzan la máxima frecuencia, la
moda es el promedio de ambos.
donde:
· Li es el límite inferior del intervalo modal
(que contiene a la moda).
· I es la amplitud de los intervalos.
· d1 es la diferencia entre las frecuencias
del intervalo modal y el intervalo inferior.
· d2 es la diferencia entre las frecuencias
del intervalo modal y el intervalo
inmediato superior.
Propiedades
• Es la medida de tendencia central más inestable, pudiendo variar mucho de una
muestra a otra extraídas de la misma población.
• Para datos agrupados por intervalos, el valor de la moda dependerá de la amplitud de
los intervalos, el número de ellos y los límites fijados.
• Puede determinarse para variables medidas en cualquier escala.
2. Medidas de posición
Son medidas que informan sobre la posición de determinadas puntuaciones individuales
en relación con el grupo del que forman parte.
a) Percentiles: Son los 99 valores que dividen en cien partes iguales a una serie de
puntuaciones ordenadas, de forma que el percentil Pm deja por debajo de sí el m por
ciento de las puntuaciones del grupo.
Cálculo
Se obtienen de forma análoga a como lo hacíamos en el caso de la mediana. La fórmula
de cálculo para el percentil m (Pm) en el caso de datos agrupados por intervalos, que
representa una generalización de la que utilizábamos para la mediana, es la siguiente:
Donde:
26
Li es el límite inferior del intervalo crítico (que contiene a Pm)
I es la amplitud de los intervalos
fi es la frecuencia absoluta en el intervalo crítico
n es el número de casos
fa es la frecuencia acumulada en el intervalo anterior al intervalo crítico
La expresión m·n/100 representa el número de puntuaciones que quedarían por
debajo del percentil m en la distribución estudiada. El intervalo crítico es precisamente
aquél donde la frecuencia acumulada alcanza o supera ese número de puntuaciones.
b) Deciles: Son los 9 valores que dividen en diez partes iguales a una serie de
puntuaciones ordenadas, de forma que el decil Dm deja por debajo de sí a m décimas
partes del total de puntuaciones del grupo.
Cálculo
Para el caso de datos agrupados por intervalos, la expresión de cálculo es:
c) Cuartiles: Son los 3 valores que dividen en cuatro partes iguales a una serie de
puntuaciones ordenadas, de manera que el cuartil Qm deja por debajo de sí m cuartas
partes del total de puntuaciones del grupo.
Cálculo
3. Medidas de dispersión
Son medidas que informan sobre la variabilidad que existe en un conjunto de
puntuaciones. Indican en qué medida las puntuaciones se sitúan próximas entre sí.
a) Rango: Es la distancia total en la escala numérica a lo largo de la cual varían las
puntuaciones.
También se denomina amplitud total o recorrido. Se utilizan dos tipos de rangos:
27

Rango excluyente: diferencia entre la mayor y la menor de las puntuaciones.
Rango incluyente: diferencia entre la mayor y la menor de las puntuaciones incrementada
en la unidad de medida. Este suele ser el más utilizado.
Rango = Punt.máxima - Punt.mínima + unidad de medida
El rango es la más imperfecta de las medidas de dispersión, pues sólo tiene en cuenta las
puntuaciones extremas.
b) Desviación media: Es la media del valor absoluto de las diferencias de todas las
puntuaciones respecto a la media aritmética.
Cálculo:
Datos sin agrupar Datos agrupados por intervalos
donde:
· Xi es cada puntuación
· es la media
· n es el número de casos
donde:
· Xi es el punto medio de cada intervalo
· es la media
· fi es la frecuencia de cada intervalo
· r es el número de intervalos
· n es el número de casos
c) Varianza y desviación típica
c1) Varianza: La varianza es el promedio del cuadrado de las diferencias de todas las
puntuaciones respecto a la media aritmética.
Cálculo
Podemos proponer dos fórmulas equivalentes, tanto para datos sin agrupar como para
datos agrupados por intervalos.
Datos sin agrupar Datos agrupados por intervalos
28

En el ámbito de la estadística inferencial, se utiliza una expresión de la varianza obtenida
recogiendo en el denominador el factor n-1. A esta varianza se le denomina varianza
insesgada.
c2) Desviación típica: Se define como la raíz cuadrada de la varianza, tomada con
signo positivo.
Propiedades de la varianza y la desviación típica
Adoptan siempre un valor positivo o igual a cero.
Se ven afectadas por la modificación de cualquiera de las puntuaciones.
Si multiplicamos un conjunto de puntuaciones por una constante, la desviación típica y
la varianza quedarán multiplicadas respectivamente por la constante y por el cuadrado
de esa constante.
Si sumamos a un conjunto de puntuaciones una constante, la desviación típica y la
varianza no se verán afectadas.
Para datos agrupados por intervalos, el valor depende de la amplitud de los intervalos,
el número de ellos y los límites fijados.
No deben calcularse en situaciones en que tampoco debe calcularse la media.
d) Coeficiente de variación: Es un índice abstracto, que permite comparar la
variabilidad de distintos grupos o distintas variables.
Se obtiene a partir del número de veces que la desviación típica contiene a la media.
29

e) Amplitud Semi-intercuartílica: Se define como la mitad de la distancia entre el
primer y el tercer cuartil. Puede ser calculada cuando se ha medido la variable en
escala ordinal o superior.
Problemas
• Problema 1
Las puntuaciones obtenidas por un grupo de 38 alumnos en una prueba valorada
de 0 a 100, las cuales se suponen medidas en escala de intervalos, son las que se
presentan en la tabla.
a) Calcula la media aritmética, mediana y moda.
b) ¿Qué puntuación deja por debajo de sí el 75% de los casos? ¿Y el 25%? ¿Cómo se
denominan dichas puntuaciones?
Intervalos f
91 - 100
81 - 90
71 - 80
61 - 70
51 - 60
41 - 50
31 - 40
21 - 30
11 - 20
1 - 10
2
0
3
6
7
9
4
5
1
1
• Problema 2
Las puntuaciones obtenidas por 59 alumnos en una prueba de diagnóstico en lectura son
las que se recogen en la tabla siguiente.
30
a) Calcula P25, P50, P75, P90, moda y mediana.
b) ¿Qué percentil corresponde a una alumna que ha obtenido una puntuación directa de
40 puntos? ¿Y a un alumno que obtuvo 34 puntos?
Intervalos F fa
47 - 49
44 - 46
41 - 43
38 - 40
35 - 37
32 - 34
29 - 31
26 - 28
23 - 25
20 - 22
17 - 19
14 - 16
11 - 13
8 - 10
5 - 7
2 - 4
4
7
4
8
4
1
5
6
6
4
3
2
2
2
0
1
59
55
48
44
36
32
31
26
20
14
10
7
5
3
1
1
• Problema 3
Los 25 niños de un aula de Educación Parvularia han sido evaluados para determinar el
nivel que presentan en ciertas variables relevantes para el aprendizaje de las
matemáticas. Teniendo en cuenta que los resultados obtenidos en una prueba de
discriminación de formas son los que aparecen a continuación, determina la tendencia
central del grupo mediante la media, la mediana y la moda, así como el grado de
dispersión que presentan las puntuaciones, expresado a partir de su rango y su
desviación típica.
27, 35, 40, 26, 32, 31, 35, 28, 29, 25, 36, 31, 27, 29, 25, 32, 34, 28, 33, 35, 29, 30, 39, 27,
25.
• Problema 4
31
Tras aplicar una prueba de cálculo mental a 70 alumnos de 4° Básico, pretendemos
describir la dispersión del conjunto de puntuaciones obtenidas. Determina el valor del
rango, la desviación media, la varianza, la desviación típica y el coeficiente de variación.
I fi
19 - 21
16 - 18
13 - 15
10 - 12
7 - 9
4 - 6
1 - 3
5
9
12
25
13
4
2
• Problema 5
La directora de Recursos Humanos de una entidad educativa utiliza determinada prueba
con la que mide la aptitud de los candidatos para desempeñar cierto puesto de trabajo. El
total de aspirantes es de 190 y los resultados alcanzados por cada uno de ellos en la
prueba son los que mostramos seguidamente.
Aptitud fi
125-129
120-124
115-119
110-114
105-109
100-104
95-99
90-94
85-89
80-84
7
8
12
20
27
41
32
30
11
2
a) Si pretendemos seleccionar a sólo 38 de los candidatos, ¿cuál es la puntuación mínima
que habría de obtenerse para ser seleccionado?
b) ¿Qué porcentaje de sujetos quedaron por debajo de un aspirante que consiguió una
puntuación de 105.5?
b) Determina la amplitud semi-intercuartil para la distribución.
32

Soluciones a problemas propuestos
• Solución Problema 1
a) La moda, valor más sencillo de calcular, es la puntuación con frecuencia máxima o
puntuación que más se repite. Al estar los datos agrupados en intervalos, la moda será el
punto medio del intervalo con frecuencia máxima, es decir Mo = 45.5.
Para calcular la media aritmética necesitamos los puntos medios de los intervalos y los
productos de dichos puntos medios por las frecuencias. Dichos cálculos se expresan en la
tabla que mostramos seguidamente.
Intervalos f Xi fiXi
91 - 100
81 - 90
71 - 80
61 - 70
51 - 60
41 - 50
31 - 40
21 - 30
11 - 20
1 - 10
2
0
3
6
7
9
4
5
1
1
95.5
85.5
75.5
65.5
55.5
45.5
35.5
25.5
15.5
5.5
191
0
226.5
393
388.5
409.5
142
127.5
15.5
5.5
n = 38 1899
La mediana es la puntuación que deja por encima y por debajo de sí el 50% de los casos.
Como tenemos 38 sujetos, la mediana será la puntuación que deje por encima y por
debajo de = 19 sujetos. Su fórmula de cálculo, para datos agrupados en intervalos, es la
siguiente:
Como n/2=38/2=19 es una frecuencia acumulada que se alcanza dentro del intervalo 41-
50 (intervalo crítico), sustituyendo en la fórmula anterior los valores del límite inferior de
33

ese intervalo (Linfer), la amplitud de los intervalos (I), la frecuencia en el intervalo crítico (f i)
y la frecuencia acumulada en el intervalo anterior al crítico (fa) tendremos
b) Las puntuaciones que dejan por debajo de sí el 25 y el 75% de los casos se conocen
con el nombre de cuartil 1 (Q1) y cuartil 3 (Q3), respectivamente. Dichas puntuaciones se
corresponden, igualmente, con los percentiles 25 y 75. Su cálculo viene dado por la
fórmula
Cada uno de ellos se sitúa en los siguientes intervalos críticos:
Q3: (338)/4=28.5 (intervalo 61 - 70)
Q1: (138)/4=9.4 (intervalo 31 - 40)
Sustituyendo los distintos valores en la fórmula, obtendremos
• Solución Problema 2
a) Cálculo de los percentiles
34

Se pide también el cálculo de la mediana y de la moda. La mediana ya está calculada,
pues coincide con el percentil 50 (Md=P50=30.6). La moda es el punto medio del intervalo
con frecuencia máxima, es decir Mo=39.
b) Se trata del problema inverso al apartado anterior, que podemos resolver aplicando la
misma fórmula. El valor que buscamos no es, como ocurría anteriormente, Pm sino el valor
m.
• Solución Problema 3
En primer lugar organizamos las puntuaciones dadas en una distribución de frecuencias,
lo cual aunque no es necesario resulta conveniente, ya que facilita los cálculos. En la
tabla que se presenta a continuación incluimos, además de la distribución de frecuencias,
los cálculos previos necesarios para resolver las cuestiones planteadas.
El cálculo de la media aritmética resulta sencillo teniendo en cuenta los cálculos previos:
Xi Marcas fi Xifi X2i X2
ifi
25 /// 3 75 625 1875
26 / 1 26 676 676
27 /// 3 81 729 2187
28 // 2 56 784 1568
29 /// 3 87 841 2523
30 / 1 30 900 900
31 // 2 62 961 1922
32 // 2 64 1024 2048
33 / 1 33 1089 1089
34 / 1 34 1156 1156
35

35 /// 3 105 1225 3675
36 / 1 36 1296 1296
39 / 1 39 1521 1521
40 / 1 40 1600 1600
n=25 768 24036
La mediana es la puntuación que ocupa el lugar central. Puesto que contamos con 25
puntuaciones, la mediana será el valor que ocupe el lugar 13 (deja 12 por debajo y 12 por
encima), es decir Md=30.
La moda es la puntuación o puntuaciones que más se repiten (las que tienen mayor
frecuencia). En este caso, la distribución es multimodal, contando con cuatro modas que
son 25, 27, 29 y 35.
El rango o amplitud total para la distribución es: A.T. = Pmayor - Pmenor + 1 = 40 - 25 + 1 = 16
La desviación típica se obtiene a partir de su expresión de cálculo:
• Solución Problema 4
En la tabla siguiente se incluyen los cálculos previos para hallar las medidas de
variabilidad solicitadas. En la primera columna se presentan los intervalos, en la segunda
las frecuencias, en la tercera los puntos medios de cada uno de los intervalos, en la
cuarta el producto de los puntos medios de cada uno de los intervalos por su frecuencia,
en la quinta las diferencias en valor absoluto de cada punto medio de los intervalos con
respecto a la media aritmética (x, por tanto, representa puntuaciones diferenciales), en la
sexta la columna anterior multiplicada por la frecuencia de cada intervalo, en la séptima
los valores de los puntos medios de cada uno de los intervalos elevados al cuadrado y, en
la octava y última el valor de la columna anterior multiplicado por la frecuencia de cada
intervalo.
I fi Xi Xifi │x│ fi│x│ X2i X2
ifi
36

19 - 21
16 - 18
13 - 15
10 - 12
7 - 9
4 - 6
1 - 3
5
9
12
25
13
4
2
20
17
14
11
8
5
2
100
153
168
275
104
20
4
8.23
5.23
2.23
0.77
3.77
6.77
9.77
41.15
47.07
26.76
19.25
49.01
27.08
19.54
400
289
196
121
64
25
4
2000
2601
2352
3025
832
100
8
70 824 229.86 10918
A.T = 21 -1 +1 = 21 (o bien, 21.5-0.5 = 21)
• Solución Problema 5
a) Si de los 190 sólo pretendemos seleccionar a 38, de 100 seleccionaríamos
38100/190=20. Por tanto, se nos pide la puntuación que deje por encima de sí el
20% de los casos, es decir el percentil 80 (puntuación que deja por debajo de sí el
80% y por encima el 20%).
Es decir, la puntuación mínima que hay que alcanzar es 111.75 puntos.
37

b) Se trata en este caso de un problema inverso al anterior. Utilizamos la misma
expresión analítica de los percentiles, pero el elemento desconocido ahora es m.
Por debajo de la puntuación 105.5 quedan el 63.89% de los sujetos.
c) Amplitud semi-intercuartil.
Para calcular cada uno de los cuartiles debemos previamente determinar el intervalo en el
que se encuentran.
Para Q3: Qn/4=3190/4=142.5 (intervalo 105-109)
Para Q1: Qn/4=1190/4=47.5 (intervalo 95-99)
E. Puntuaciones individuales y curva normal
1. Puntuación directa, puntuación transformada
38

Una puntuación directa es la que se asigna a cada individuo como resultado de una
medición; por ejemplo la nota de un examen, el número de agresiones mensuales de
cada alumno(a) a sus compañeros.
Las puntuaciones transformadas son las que se derivan de las puntuaciones directas por
combinación lineal. Por ejemplo, medimos la velocidad y la comprensión lectora a través
de dos pruebas de las cuáles obtenemos dos puntuaciones directas; a través de estas
dos puntuaciones nos interesa conocer la eficiencia lectora. En este caso, la eficiencia
lectora es una puntuación transformada, o una variable de transformación.
Hay algunas puntuaciones transformadas de uso frecuente en educación, como las
puntuaciones diferenciales, típicas y las puntuaciones típicas derivadas.
Los softwares estadísticos contienen utilidades que permiten crear variables de
transformación a partir de las puntuaciones directas. Por tanto, si en un análisis tienen
que utilizarse variables de transformación, no se tienen que introducir las puntuaciones
transformadas en el computador, sino obtenerlas a partir de las puntuaciones directas,
utilizando los recursos del paquete estadístico.
a) Puntuaciones Diferenciales
Son el resultado de restar a la puntuación directa de un individuo la media de las
puntuaciones del grupo. En estadística descriptiva suelen designarse mediante una letra
minúscula (xi). Por tanto su cálculo viene determinado por la siguiente expresión:
Por el modo en que se definen, si en un grupo de puntuaciones obtenemos las
puntuaciones diferenciales, el resultado de la suma de éstas valdrá cero.
Ejemplo
Un grupo de 8 estudiantes que rinden examen de análisis de datos han obtenido las
siguientes puntuaciones: 7, 3, 2.5, 9, 2, 8.5, 5 y 3. Calcular las puntuaciones diferenciales
para cada uno de los(as) alumnos(as).
Solución: Se debe calcular la media de las puntuaciones, a partir de ese valor, podremos
determinar las puntuaciones diferenciales restando la media a la puntuación directa.
39

Xi xi
7
3
2,5
9
2
8,5
5
3
Cálculo de la media
2
-2
-2,5
4
-3
3,5
0
-2
b) Puntuaciones típicas
Son puntuaciones transformadas de gran utilidad en estadística. Son conocidas también
por "puntuaciones z", siendo la siguiente expresión que se utiliza para su cálculo.
La media de las puntuaciones típicas vale 0 y la desviación típica es igual a 1. Por tanto,
cuando hablamos de tipificar los valores de una variable, significa que debemos
transformarlos en puntuaciones z.
Ejemplo:
Considerando las puntuaciones del ejemplo anterior, las vamos a transformar en
puntuaciones típicas.
Solución:
1º) determinar el valor de la desviación típica del grupo
2º) Luego, se divide cada una de las puntuaciones diferenciales por la desviación típica
Xi xi xi2 zi
7 2 4 0,76
40

3
2,5
2
9
8,5
5
3
-2
-2,5
-3
4
3,5
0
-2
4
6,25
9
1,6
12,25
0
4
-0,76
-0,95
-1,14
1,53
1,33
0
-0,76
c) Puntuaciones típicas derivadas
Las puntuaciones típicas permiten establecer comparaciones entre distintas variables. Sin
embargo el inconveniente de las puntuaciones típicas es que suelen ser negativas y
pueden presentar cifras decimales. Contamos solamente con siete puntuaciones enteras
posibles (-3, -2, -1, 0, 1, 2, 3), ya que la mayoría de las observaciones suelen quedar
incluidas entre tres desviaciones típicas a la derecha de la media y tres a la izquierda.
Tanto los signos negativos como las cifras decimales y los redondeos pueden ocasionar
errores de cálculo. Para evitar esto, podríamos multiplicar las puntuaciones z por una
constante S determinada y para evitar los valores negativos, sumar una constante J.
D = J + Sz
De esta forma, y teniendo en cuenta las puntuaciones de las propiedades típicas,
obtendremos una distribución de media J y de desviación típica S. A las puntuaciones
obtenidas siguiendo este proceso se les denomina puntuaciones típicas derivadas.
Entre las más usadas se encuentran el caso concreto de las puntuaciones T, que tienen
como media 50 y como desviación típica 10.
T = 50 + 10z
Asimismo los coeficientes intelectuales suelen venir expresados en puntuaciones típicas
derivadas de media 100 y desviación típica 15.
CI = 100 + 15z
41

Otra de las puntuaciones típicas que se suele utilizar en educación son los eneatipos o
estaninos, que son puntuaciones de media 5 y de desviación típica 2.
E = 5 + 2z
Ejemplo: Supongamos que un sujeto obtiene en una prueba de inteligencia una
puntuación directa de 70 puntos. Sabiendo que la media del grupo de referencia es 63,04
y su desviación típica 10,8, podremos transformar la puntuación directa en una puntuación
típica z= 0,64.
A partir de este cálculo, podemos obtener las diferentes puntuaciones derivadas:
T = 50 + 10 (0,64) = 56,4
C.I. = 10 + 15 (0,64) = 109,6
E = 5 + 2 (0,64) = 6,28
2. La curva normal
La inmensa mayoría de valores observados sobre variables cuantitativas en Ciencias
Sociales suelen aproximarse a lo que se conoce como distribución normal o curva normal.
Es considerada como una de las distribuciones continuas de más importancia. En muchos
casos, veremos que suponer el comportamiento normal de una población, permitirá
extraer conclusiones para las estimaciones efectuadas sobre muestras.
La representación gráfica de la distribución normal (figura 1) presenta forma de campana
(de ahí el nombre de campana de Gauss, como también se conoce).
42

Figura 1: Curva Normal
μ = media
σ = desviación típica
Se utilizan μ y σ, en lugar de X y s, porque hablamos de un modelo teórico.
N = número de casos, lo que significa que el área total bajo la curva es N.
La curva normal presenta las siguientes características:
Es simétrica alrededor del eje que pasa por la media.
La ordenada máxima coincide con la media en el eje de abscisas.
La media, mediana y moda coinciden.
Es asintótica respecto del eje de abscisas. Como consecuencia hay dos colas, una a
cada lado de la distribución, que se alargan hasta el infinito.
Los puntos de inflexión se encuentran en μ + σ y μ - σ
Su ecuación matemática dada por Laplace en 1874 es:
Distribución normal tipificada o estándar
Se dice que una variable aleatoria continua tiene distribución normal tipificada X ~ N (0,1),
si su función de densidad tiene la siguiente forma:
La curva normal tipificada o reducida es, por tanto, la que opera con puntuaciones z, es
un caso especial de distribución normal que tiene de media cero y de desviación típica
uno. Tiene múltiples aplicaciones y su uso es frecuente en investigación educativa.
Al observar una variable tipificada que se distribuye normalmente, puede observarse que
la mayor parte de las puntuaciones se encuentran comprendidas entre los valores que
van de -3 a +3 (figura 2)
43

Figura 2: Curva Normal para Puntuaciones z
Esta distribución es mesocúrtica
El área total comprendida entre la curva y el eje de abscisas es igual a uno
Las áreas bajo la curva normal se interpretan en términos de probabilidades, proporciones
o porcentajes
Áreas bajo la curva normal
Para muchos propósitos es necesario conocer la proporción del área bajo la curva normal
entre las ordenadas de diferentes puntos sobre la línea de base. Podemos desear
conocer:
La proporción del área bajo la curva entre la ordenada de la media y cualquier punto
específico que se encuentre por encima o por debajo de la media.
La proporción del área total por encima o por debajo de la ordenada de cualquier
punto sobre la línea base.
La proporción del área que se encuentra entre las ordenadas de dos puntos
cualesquiera sobre la línea base.
Mediante la tabla de la Ley Normal pueden calcularse las áreas entre dos puntos. Por
tanto, pueden resolverse cualquiera de las tres situaciones anteriores. A continuación se
desarrollan algunos ejemplos teniendo en cuenta las siguientes consideraciones:
El área total vale 1. La mitad es igual a 0,5.
Las puntuaciones que utiliza la tabla están tipificadas.
Para Z > 0 corresponde la mitad derecha de la curva.
Para Z < 0 corresponde la mitad izquierda de la curva.
Ejemplo
44

Se ha utilizado el test de inteligencia D-48 a un grupo de sujetos y se ha obtenido una
distribución normal de media 28 y desviación típica 5.
Caso 1: ¿Qué porcentaje de sujetos han obtenido una puntuación superior a 36?
1º) Sabemos que:
2º) Sustituyendo valores z = (36-28)/5 = 1,6
3º) Mirando en la tabla de la Ley Normal encontramos que este valor de z (buscar a la
derecha de z), corresponde a un área de 0,05480. Lo que equivale a un porcentaje de
sujetos del 5,48%.
Caso 2: ¿Qué porcentaje han obtenido puntuaciones inferiores a 30?
1º) Sabemos que
2º) Sustituyendo valores z = (30-28)/5 = 0,4
3º) Mirando en la tabla de la Ley Normal encontramos que este valor de z (buscar a la
derecha de z), corresponde a un área de 0,34458.
4º) Pero obsérvese que el área que hay que calcular es la contraria, la parte rayada. Por
tanto tendremos que quitar a 1 (valor del área total) el valor del área calculada (que es la
proporción que obtiene puntuaciones mayores).
1-0,34458 = 0,65542
45

El porcentaje de sujetos que ha obtenido puntuaciones inferiores a 30 es del 65,54%.
Caso 3: ¿Qué probabilidad existe de que al elegir un individuo al azar esté comprendido
entre 25 y 35?
1º) Sustituyendo valores z1 = (25-28)/5 = -0,6
z2 = (35-28)/5=1,4
2º) Mirando en la tabla de la Ley Normal los respectivos valores de z encontramos que el
valor de la probabilidad de z2 (buscar la izquierda) es de 0,9192 y el valor de z1 (buscar a
la derecha de z), corresponde a un área de 0,2743.
3º) se le resta al valor del área de z2, el valor del área de z1.
0,9192 - 0,2743 = 0,6449
Caso 4: ¿Qué porcentaje de alumnos/as queda comprendido entre las puntuaciones 19 y
26?
1º) Sustituyendo valores z1 = (26-28)/5 = -0,4
z2 = (19-28)/5= -1,8
2º) Mirando en la tabla de la Ley Normal los respectivos valores de z encontramos que el
valor de la probabilidad de z1 (buscar la derecha) es de 0,3446 y el valor dez2 (buscar a la
derecha de z), corresponde a un área de 0,0359.
3º) se le resta al valor del área de z1 el valor del área de z2.
0,3446-0,0359 = 0,3087
46

Lo cual supone un 30,87% de alumnos comprendidos entre ambas puntuaciones.
Bibliografía
Gil, J., Diego, J., García, E., & Rodríguez, G. (1997). Estadística básica aplicada a las ciencias de la educación. Sevilla: Kronos.
GIL, J., Diego, J., García, E., & Rodríguez, G. (1997). Problemas de estadística aplicada a las ciencias de la educación. Sevilla: Kronos.
47