evaluacion de resum enes automati cos mediante qarla · de resum enes automati cos la medida jack...
TRANSCRIPT

Evaluacion de resumenes automaticos mediante QARLA ∗
Enrique Amigo, Julio Gonzalo, Vıctor Peinado, Anselmo Penas, Felisa VerdejoDept. de Lenguajes y Sistemas Informaticos - UNED
c/Juan del Rosal, 16 - 28040 Madrid - Spain{enrique, julio, victor, anselmo, felisa}@lsi.uned.es
Resumen: Este artıculo muestra la aplicacion del marco de evaluacion QARLAsobre los resumenes evaluados en el foro DUC-2004, para las tareas 2 y 5. El marcoQARLA permite evaluar de forma automatica los sistemas segun diferentes aspectos(metricas de similitud) en relacion a un conjunto de resumenes modelo, identificandoası los aspectos mas deficitarios de las estrategias de resumen existentes. Por otrolado, el marco QARLA permite combinar y meta-evaluar diferentes metricas desimilitud, otorgando mas peso a los aspectos que caracterizan a los modelos enrelacion a los resumenes automaticos.Palabras clave: Resumen automatico, marco de evaluacion, QARLA, DUC
Abstract: This article shows an application of the QARLA evaluation framework onDUC-2004 (tasks 2 and 5). The QARLA framework allows to evaluate summarieswith regard to different features. Second, it allows to combine and meta-evaluatedifferent similarity metrics, giving more weigh to metrics which characterize models(manual summaries) regarding automatic summaries.Keywords: automatic summarization, evaluation framework, QARLA, DUC
1. Introduccion
A lo largo de los ultimos anos se han eval-uado en el foro DUC, sobre diferentes tar-eas, distintas aproximaciones automaticas alproblema del resumen. Existen diversos tra-bajos orientados a la evaluacion automaticadentro de la tarea de resumen o traduc-cion automatica (Culy y Riehemann, 2003;Coughlin, 2003; Joseph P. Turian y Melamed,2003; Lin y Hovy, 2003). Sin embargo, enel DUC, la evaluacion se ha realizado vıajuicios humanos. Por un lado, los jueces re-sponden a un cuestionario en relacion a lacalidad del resumen. Por otro lado, analizanla cobertura de los resumenes automaticos enrelacion a un conjunto de resumenes mode-lo, mediante un interfaz y siguiendo ciertasdirectrices. Esto permite generar un rank-ing de resumenes automaticos. Este rank-ing se puede contrastar con los resultadosobtenidos por ciertas metricas automaticas,como ROUGE (Lin y Hovy, 2003), por mediodel coeficiente de correlacion de Pearson.
Esta estrategia de evaluacion tiene la lim-itacion de que una evaluacion manual es sub-jetiva, en cuanto que depende de los juecesy del protocolo de evaluacion seguido, porejemplo, en el caso del DUC, evaluacion man-ual orientada a cobertura mediante el interfaz∗ Este trabajo ha sido financiado por el Ministerio deCiencia y Tecnologıa a traves del proyecto HERMES(TIC2000-0335-C03-1).
SEE (http://www.isi.edu/cyl/SEE/).El modelo QARLA (seccion 2), propuesto
en (Amigo et al., 2005), aborda este proble-ma:
1. QARLA dispone de un criterio au-tomatico (QUEEN) de evaluacion deresumenes sobre un conjunto de modelosy un conjunto de metricas de similitud.El resultado de la aplicacion (QUEEN)de metricas de similitud es independi-ente de la escala de las metricas. Esto im-plica que podemos comparar los valoresde calidad de un mismo resumen segundistintos criterios de similitud. (seccion2.1)
2. QARLA dispone de un criterio (KING)de meta-evaluacion automatica de metri-cas de similitud, alternativa a la cor-relacion con rankings manuales. Estasmedidas se apoyan en criterios obje-tivos, otorgando mas peso a aquellasmetricas de similitud que discriminan alos modelos respecto de los resumenesautomaticos. Es decir, otorga mas pe-so a los rasgos caracterısticos de losresumenes modelo. (seccion 2.2)
En este artıculo aplicamos el modeloQARLA sobre dos tareas del DUC 2004. Latarea 2 consiste en generar resumenes cortos(100 palabras) a partir de un conjunto de doc-
Procesamiento del Lenguaje Natural, núm. 35 (2005), pp. 59-66 recibido 30-04-2005; aceptado 01-06-2005
ISSN: 1135-5948 © 2005 Sociedad Española para el Procesamiento del Lenguaje Natural

umentos, y la tarea 5 consiste en generar unresumen corto en base a una cuestion del tipo¿Quien es...?
La seccion 2 describe el marco de evalu-acion QARLA: QUEEN como estimacion dela calidad de un resumen automatico, KINGcomo estimacion de la calidad de una metri-ca de similitud, y JACK como estimacionde la fiabilidad del proceso de evaluacionen relacion al conjunto de resumenes au-tomaticos disponibles. La seccion 3 describelas metricas de similitud empleadas en estetrabajo, ası como el metodo de seleccion delas mismas. En la seccion 4 se evaluan yanalizan los resumenes automaticos genera-dos por los sistemas participantes en DUC2004.
2. Descripcion del marco deevaluacion QARLA
El marco QARLA esta descrito en detalleen (Amigo et al., 2005). En este apartadohacemos una breve descripcion.
El marco QARLA se define a partir deun conjunto A de resumenes automaticos aevaluar, un conjunto M de resumenes mod-elo generados manualmente, y un conjuntoX de metricas de similitud entre pares deresumenes.
2.1. QUEEN : Estimacion de lacalidad de un resumenautomatico
QUEENx,M es una medida probabilısti-ca que estima la calidad de un resumen au-tomatico a ∈ A, a partir de un conjuntode resumenes modelo M y de una medidade similitud x. La medida QUEEN definela calidad de un resumen automatico a co-mo la probabilidad calculada sobre tripletesde resumenes manuales m,m′,m′′ de que aeste mas proximo a un modelo que los otrosdos modelos entre sı. Formalmente:
QUEENx,M (a) ≡ P (x(a, m) ≥ x(m′, m′′))
Podemos generalizar esta medida QUEENpara conjuntos de metricas si imponemosque el resumen evaluado cumpla la condicionQUEEN para todas las metricas de similituddel conjunto X. Es decir:
QUEENX,M (a) ≡ P (∀x ∈ X.x(a, m) ≥ x(m′, m′′))
Esta medida cumple algunas propiedadesinteresantes. El valor QUEEN aumenta a me-dida que el resumen automatico se asemeja alos modelos segun las metricas X, pero es a lavez independiente de la escala de las metri-cas de similitud, dado que cualquier metri-ca de similitud x′ monotona y estrictamentecreciente respecto de x devuelve los mismosvalores en QUEEN. Es decir, depende unica-mente de la topologıa de las metricas de simil-itud, por lo que podemos comparar los val-ores de QUEEN sobre un mismo resumen au-tomatico para distintas metricas de similitud.
QUEEN definida como probabilidad tieneun rango entre 0 y 1, en el que un valor de 0.5implica que el resumen evaluado se asemejatanto a un modelo como dos modelos entresı. Un valor de QUEEN = 0 implica queel resumen evaluado no se asemeja a ningunmodelo mas que dos modelos cualesquiera en-tre si.
Por ejemplo, un valor de QUEEN = 0,5para una metrica basada en co-seleccion defrases, y un valor de QUEEN = 0,1 sobreuna metrica basada en concurrencia de termi-nos clave, implica que el sistema es capazde comportarse como un resumen manual encuanto a las frases escogidas, pero no acier-ta con los conceptos clave que deben estarincluidos en el resumen.
Otra propiedad interesante es que, graciasal cuantificador universal sobre x, metricasredundantes en el conjunto X no sesga el val-or de QUEEN.
2.2. KING: estimacion de lacalidad de una metrica desimilitud
Un resumen automatico puede asemejarseal conjunto de resumenes modelo en relaciona una determinada metrica de similitud. Sinembargo, es posible que dicha metrica desimilitud no sea un rasgo caracterıstico de losresumenes modelo (por ejemplo, el numero deocurrencias de la letra ’a’ en el resumen). Lamedida KING estima el peso de una metri-ca de similitud en la evaluacion evitando elcoste (y la subjetividad) de un juicio hu-mano directo. Partimos de la hipotesis de quela metrica mas pesada es aquella que mejorcaracteriza resumenes manuales en oposiciona resumenes automaticos. Esa metrica de-berıa identificar los resumenes manuales co-mo mas proximos entre sı y mas distantes alos resumenes automaticos. Esta hipotesis la
E. Amigó, A. Peñas, J. Gonzalo, F. Verdejo
60

podemos expresar como:
KINGM,A(X) ≡
P (∀a ∈ A.QUEENM,x(m) > QUEENM,x(a))
que representa la probabilidad de queun modelo m ∈ M tenga mayor valorQUEENX,M , que cualquier resumen au-tomatico a ∈ A. Expresado en terminos deranking, indica la probabilidad de que unmodelo ocupe la primera posicion respecto atodos los resumenes automaticos.
Esta medida cumple ciertas propiedadesde gran interes. En primer lugar, KING es in-dependiente de la distribucion de resumenesautomaticos. Es decir, el cuantificador uni-versal sobre a evita que caracterısticas redun-dantes en los sistemas de resumen automaticoafecten a la medida.
Por otro lado, una metrica de similitud noinformativa, por ejemplo, de valor constanteo aleatorio, produce por definicion un valorKING = 0.
Por ultimo, al igual que QUEEN, KINGno depende de la distribucion de las metric-as del conjunto X. Es decir, metricas redun-dantes en X que evaluan las mismas carac-terısticas de los resumenes, no sesga el valorde KING.
2.3. JACK: fiabilidad del conjuntode resumenes automaticos
La medida JACK determina si el conjun-to A de resumenes automaticos es dispersorespecto del conjunto M de resumenes mod-elo. Esta medida es util, en primer lugar,para determinar la fiabilidad de los resulta-dos dados por KING, dado que se trata deun valor estadıstico dependiente del conjuntoA. Por tanto, si A es mas heterogeneo, en-tonces KING es mas fiable. En segundo lugar,JACK nos dice si los sistemas de resumen au-tomatico siguen estrategias redundantes.
Esta medida JACK se define como:
JACK(X, M, A) ≡
≡ P (∃a, a′ ∈ A.QUEEN(a) > 0 ∧QUEEN(a′) > 0
∧∀x ∈ X.x(a, a′) ≤ x(a, m))
es decir, la probabilidad sobre todos losresumenes modelo m de encontrar un par deresumenes automaticos a, a′ menos cercanosentre sı que a m segun todas las metricas.Las condiciones relativas a QUEEN(a) hacen
que JACK sea robusto ante resumenes au-tomaticos dispersos pero muy distantes de losresumenes modelo.
3. Seleccion de metricas desimilitud
Cada metrica de similitud permite carac-terizar los resumenes sobre la base de cri-terios diferentes. Nuestro objetivo es selec-cionar las metricas que permiten caracteri-zar mejor los resumenes manuales y, a lavez, obtener la mayor informacion posible so-bre el comportamiento de los resumenes au-tomaticos.
En primer lugar, se describen las metric-as disponibles como punto de partida (59 entotal). A continuacion se van a seleccionar12 metricas de forma que se minimice la in-formacion redundante que puede aportarnoscada una de ellas y, a la vez, se maximice lacapacidad de caracterizar resumenes.
Finalmente, se analiza brevemente las car-acterısticas de las metricas seleccionadas.Estas metricas seran las que se utilicenen el siguiente apartado de evaluacion deresumenes del DUC 2004.
3.1. Descripcion de las medidas desimilitud
Para aplicar el modelo QARLA necesi-tamos definir el conjunto X de metricasde similitud. Las metricas de similitud em-pleadas en este trabajo son:
Metricas basadas en ROUGE (R): La metri-ca de evaluacion ROUGE (Lin y Hovy,2003) estima la calidad, en terminosde cobertura de n-gramas, de un re-sumen automatico en relacion a unconjunto de resumenes modelo. Pode-mos transformar esta metrica de eval-uacion en una metrica de similitud en-tre pares de resumenes si consideramosun unico modelo en el calculo. Existendiferentes tipos de metricas ROUGE co-mo ROUGE-W, ROUGE-L, ROUGE-1,ROUGE-2, ROUGE-3, ROUGE-4 etc.(Lin, 2004). Cada una de estas metric-as puede calcularse sobre resumenes pre-procesados de tres formas: con stem-ming y sin terminos de parada (c), constemming (b) o sin ningun pre-procesado(a). En total, obtenemos 24 metricas desimilitud derivadas de ROUGE.
Evaluación de resúmenes automáticos mediante QARLA
61

Metricas basadas en ROUGE invertida(Rpre) Las metricas ROUGE estan ori-entadas a cobertura. Por tanto, si in-vertimos la direccion del calculo de lasimilitud, obtendremos metricas orien-tadas a precision. Es decir Rpre(a, b) =R(b, a). Generamos ası otras 24 metricasde similitud derivadas de ROUGE inver-tida
TruncatedVectModel (TVMn): Estas metric-as de similitud comparan la distribucionen los resumenes de n de los terminosmas frecuentes en los documentos origi-nales. El proceso de calculo consiste en:(1) obtener una lista con los n terminoslematizados, ignorando los terminos deparada, mas frecuentes en los documen-tos originales; (2) generar un vector conla frecuencia relativa de cada termino enel resumen; (3) la medida de similitud secalcula como la inversa de la distanciaeuclıdea entre los vectores asociados ados resumenes. Hemos usado nueve vari-antes de esta medida, correspondientes an = 1, 4, 8, 16, 32, 64, 128, 256, 512.
AveragedSentenceLengthSim (AVLS):Esta metrica de similitud comparala longitud promedio de las frasescontenidas en dos resumenes, y puedeser util para comparar el grado deabstraccion de los resumenes.
GRAMSIM : Esta metrica de similitud com-para la distribucion de tipos de pal-abras (verbos, adjetivos, etc.) de dosresumenes. El proceso de calculo es elsiguiente: (1) etiquetamos los resumenesmediante la herramienta tree-tagger(Schmid, 1994); (2) por cada resumengeneramos un vector con la frecuenciade cada una de las posibles etiquetasgramaticales; (3) medimos la distanciaeuclıdea entre los vectores correspondi-entes a los dos resumenes. Esta metri-ca de similitud no esta orientada a con-tenidos, y esta relacionada con el estilolinguıstico de los resumenes.
3.2. Agrupacion de metricas desimilitud
Dado el conjunto de metricas de simili-tud descrito anteriormente, tenemos un to-tal de 57 (24+24+9) metricas orientadas acontenidos, y 2 metricas dependientes de as-pectos estilısticos. El analisis de 48 aspectos
relativos a contenidos puede ser redundante.Serıa interesante por tanto poder agruparconjuntos de metricas de similitud que secomporten de manera similar.
Para ello, calculamos la similitud entre dosconjuntos de metricas como:
sim(X, X ′) ≡ Prob[HX ↔ HX′ ]
HX ≡ ∀x ∈ Xx(a, m) ≥ x(m′, m′′)
Consideramos que dos conjuntos de metri-cas son similares si se comportan de la mis-ma forma respecto a la condicion QUEEN(predicado H de la formula) ante una mues-tra {a,m,m′,m′′}. Es decir, la probabilidadde que ambos conjuntos de metricas discrimi-nen los mismos resumenes automaticos frentea los mismos pares de modelos.
La tabla de la figura 1 muestra, sobre unnumero fijado en 10, los grupos de metric-as de similitud obtenidos para la tarea 2 deDUC 2003. En cuanto a las metricas de tipoROUGE, el proceso agrupa las 48 metricasen siete grupos, dependiendo de la longitudde los n-gramas y del tipo de pre-procesadode los textos. En cuanto a las 9 metricas tipoTVM, se distinguen tres grupos: tomando so-lo el termino mas frecuente, 4 u 8 terminosmas frecuentes y otro conjunto con el restode configuraciones TVM.
3.3. Calidad de las metricas desimilitud: valores de KING
Dentro de cada grupo de la figura 1, lametrica de similitud marcada en negrita secorresponde con la metrica de mayor KING.Como puede verse, en los conjuntos basadosen n-gramas con stemming, las metricas demayor KING son de tipo R, basadas en cober-tura (grupos 2,3 y 4), mientras que en los con-juntos de metricas sobre n-gramas sin stem-ming (grupos 5,6 y 7) las metricas de may-or KING son de tipo Rpre, basadas en pre-cision. En cuanto a metricas de tipo TVM,las de mayor KING son siempre aquellas quese basan en un numero mayor de terminosfrecuentes (grupos 8,9 y 10).
Finalmente, tomamos como metricas rep-resentativas, la metrica de mayor KING encada grupo, en total 10 metricas orientadas acontenidos.
La figura 2 muestra el valor KING de lasdistintas metricas de similitud seleccionadas,es decir, la capacidad de las metricas de car-acterizar a los resumenes modelo frente a losresumenes automaticos.
E. Amigó, A. Peñas, J. Gonzalo, F. Verdejo
62
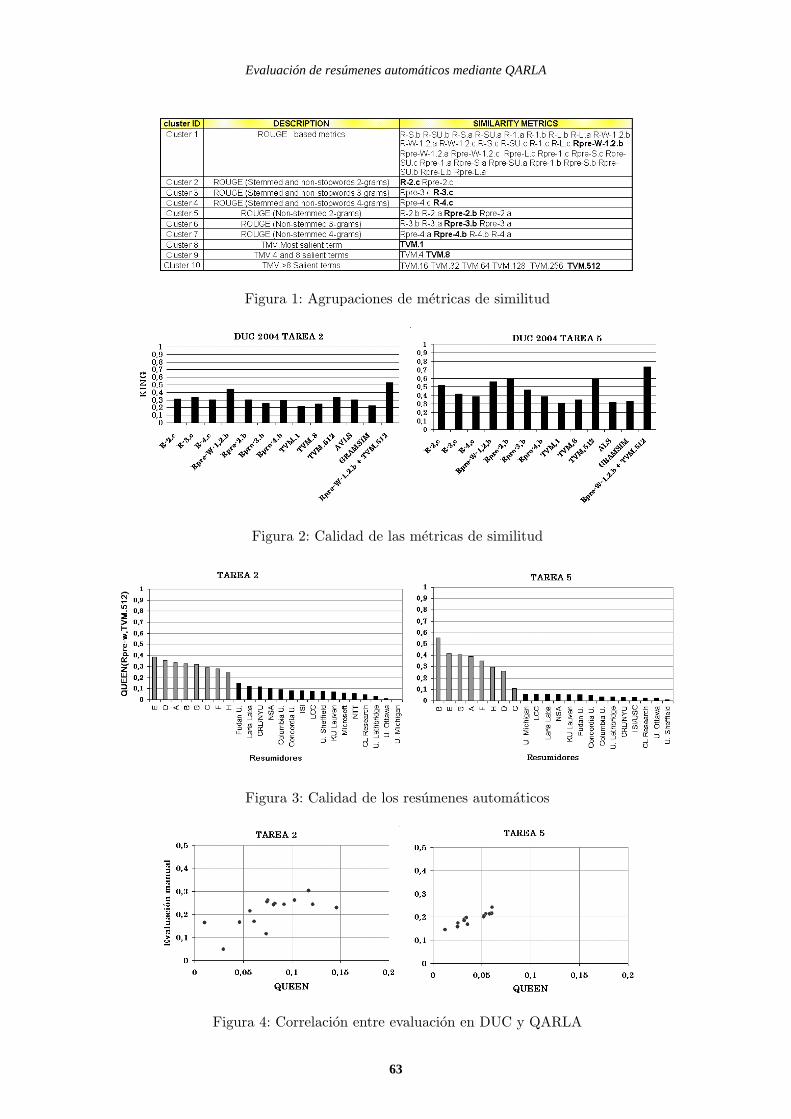
Figura 1: Agrupaciones de metricas de similitud
Figura 2: Calidad de las metricas de similitud
Figura 3: Calidad de los resumenes automaticos
Figura 4: Correlacion entre evaluacion en DUC y QARLA
Evaluación de resúmenes automáticos mediante QARLA
63

En cuanto a las metricas aisladas, Rpre-Wobtiene un alto KING en ambas tareas. Es-ta metrica de similitud se basa en precisionde secuencias no contiguas de terminos en losresumenes (ROUGE-W-1.2). Para las metri-cas de tipo TVM a medida que consideramosmas terminos frecuentes, la metrica asciendeen valores KING, es decir, caracteriza mejora los resumenes modelo.
La ultima columna representa la combi-nacion de mayor KING de entre las posi-bles combinaciones de metricas de simili-tud. En ambas tareas esta combinacion esRpre − W y TMV ,512, y supera en valorKING a cualquiera de las metricas individ-uales. Este hecho muestra que la capacidadde caracterizacion de los modelos puede au-mentar por medio de la estrategia de combi-nacion de metricas que ofrece el marco QAR-LA.
4. Evaluacion de resumenesautomaticos en DUC 2004
En esta seccion, a partir de las metri-cas seleccionadas en la seccion anterior, seabordan tres cuestiones: que resumenes au-tomaticos tienen un contenido mas similara los resumenes modelo, si siguen aproxima-ciones similares, y que caracterısticas tienen.
4.1. Ranking de resumenesautomaticos
La combinacion de mayor KING en am-bas tareas es Rpre-W y TVM.512. La figura3 representa el ranking de resumenes segundicha combinacion, de acuerdo a los val-ores de QUEEN{Rpre-W,TVM.512} obtenidos.Los resumenes modelo obtienen los may-ores valores de QUEEN en ambas tareascon una diferencia significativa respecto a losresumenes automaticos.
El ranking manual generado en DUC rep-resenta un criterio concreto de evaluacion,mientras que el modelo QARLA da mas pesoa aquellos aspectos que son mas discrimina-tivos entre modelos y resumenes automaticos.Los resultados por tanto no tienen por que co-incidir necesariamente. Sin embargo, sı de-berıa de existir cierta correlacion. La figura4 muestra la correlacion existente entre am-bas estrategias de evaluacion, es decir valoresde QUEEN{Rpre-W,TVM.512} (eje horizontal)frente a los valores de la evaluacion man-ual (eje vertical). Esta correlacion es maspatente en la tarea 5 (orientada a pregun-
ta) donde los contenidos de los resumenesson mas precisos. Por otro lado, en la tarea2 (resumenes genericos) puede verse que lossistemas con mayor puntuacion en QUEENtambien tienen una buena valoracio0n porparte de los jueces humanos en DUC.
4.2. Heterogeneidad de losresumenes automaticos
Mediante la medida JACK podemosanalizar la heterogeneidad de los resumenesautomaticos. La figura 5 muestra como creceel valor JACK, tomando como metricas lacombinacion de maximo KING, Rpre-W yTVM.512, a medida que aumentamos elnumero de resumenes automaticos. En ambastareas los resultados tienden a estabilizarsea partir de cierto numero de resumenes, loque indica cierta redundancia en las aprox-imaciones seguidas por los sistemas partici-pantes.
Por otro lado, en la tarea 2 (resumenesgenericos) el conjunto de resumenes au-tomaticos es mas heterogeneo que en la tarea5 (resumen orientado a pregunta). Es decir, sehan empleado estrategias mas diversas en lageneracion automatica de resumenes generi-cos, mientras que en la tarea 5, probable-mente, la pregunta haya centrado los sistemasen un mismo tipo de estrategia.
4.3. Caracterizacion de resumenesautomaticos
El modelo QARLA permite evaluar losresumenes automaticos en relacion a difer-entes metricas de similitud. Si la metrica o elconjunto de metricas aplicado tiene un mayorKING, entonces representa un rasgo que car-acteriza a los resumenes manuales frente aresumenes automaticos, considerandose masfiable como criterio de evaluacion.
Sin embargo ademas de evaluar un sis-tema de resumen, QARLA permite analizarlas propiedades de los resumenes evaluados.Dado que QUEEN es independiente de la es-cala de las metricas, esto se puede hacer com-parando los valores de QUEEN obtenidos porlos sistemas en relacion a distintas metricasde similitud.
Las figuras 6 y 7 muestran la calidad delos resumenes automaticos en relacion a las12 metricas de similitud seleccionadas, ex-traıdas mediante el proceso de agrupamientodescrito. Los valores de QUEEN mas eleva-dos aparecen marcados en negrita.
E. Amigó, A. Peñas, J. Gonzalo, F. Verdejo
64

Figura 5: JACK vs. numero de resumenes automaticos
Figura 6: Calidad de los resumenes automaticos en la tarea 2
Los sistemas de resumen (eje vertical)estan ordenados segun el ranking generadomanualmente en DUC. Como puede verse, enambas tareas los primeros sistemas obtienenbuena puntuacion segun la mayorıa de losrasgos orientados a contenidos (metricas R,Rpre y TVM).
A partir de estos datos, si nos fijamos enlos valores promedio (ultima fila) de QUEENsobre distintas metricas de similitud, pode-mos extraer algunas conclusiones:
Los resumenes automaticos generadosen el DUC no coindicen en longitudde frases con los resumenes modelo. Lapuntuacion promedio sobre la metricaAV LS (0.26 y 0.22) es bastante reducidaen relacion al valor obtenido por el restode las metricas.
Los resumenes automaticos son capacesde identificar los terminos mas rele-vantes (valores de QUEEN mas altos enTVM.1), mientras que no identifican el-ementos menos frecuentes de los doc-umentos originales pero que sı son co-
munes en los resumenes modelo (valoresde QUEEN mas bajos en TMV.512).
El estilo linguıstico de los resumenes au-tomaticos es especialmente diferente alde los modelos en la tarea 5 (resumenorientado a pregunta) frente a la tarea2 (resumen generico). Presumiblementelos resumenes manuales orientados a pre-gunta tienen unos rasgos de estilo masdefinidos.
Los resumenes automaticos se asemejana los modelos en secuencias de palabraslargas (valores altos en R-3,R-4) en lamisma medida que los modelos entre sı,especialmente en los resumenes de tipogenerico (tarea 2).
5. Conclusiones
El marco de evaluacion QARLA ha permi-tido nos ha permitido, por un lado, identificarmetricas de evaluacion fiables y compararresumenes automaticos entre sı. Los resulta-dos muestran que existe una alta correlacionentre la evaluacion resultante de QARLA yla evaluacion realizada por jueces humanos.
Evaluación de resúmenes automáticos mediante QARLA
65
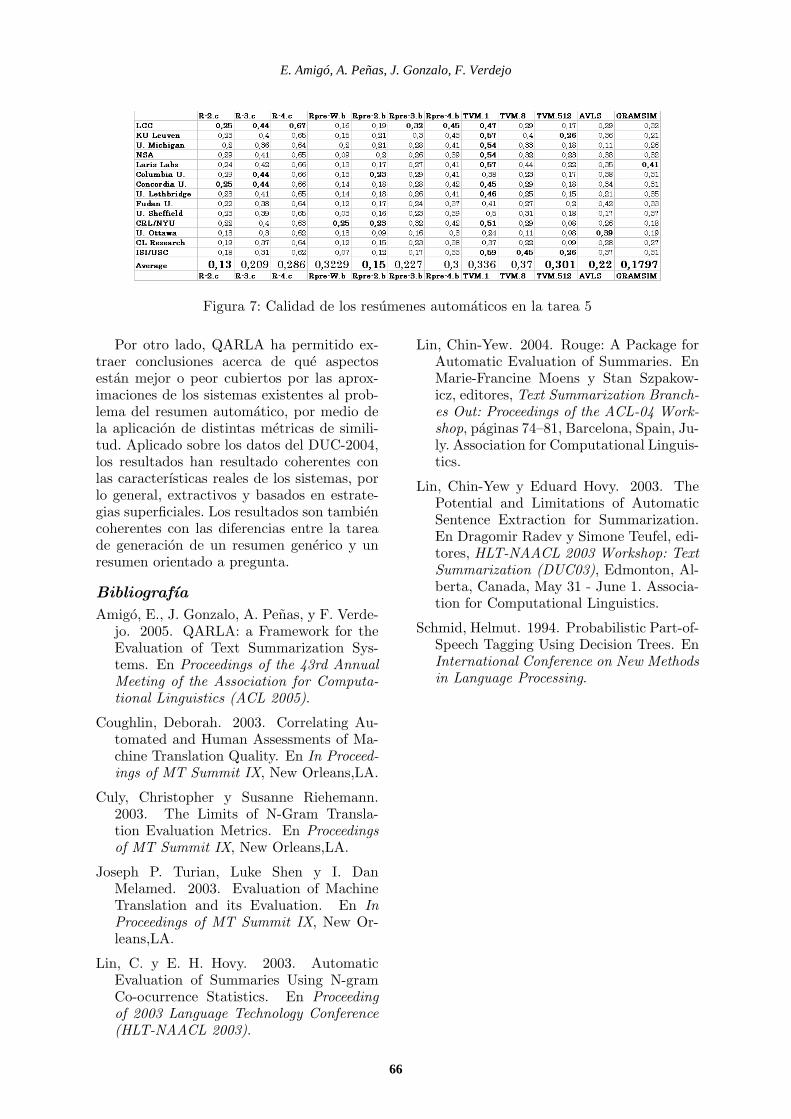
Figura 7: Calidad de los resumenes automaticos en la tarea 5
Por otro lado, QARLA ha permitido ex-traer conclusiones acerca de que aspectosestan mejor o peor cubiertos por las aprox-imaciones de los sistemas existentes al prob-lema del resumen automatico, por medio dela aplicacion de distintas metricas de simili-tud. Aplicado sobre los datos del DUC-2004,los resultados han resultado coherentes conlas caracterısticas reales de los sistemas, porlo general, extractivos y basados en estrate-gias superficiales. Los resultados son tambiencoherentes con las diferencias entre la tareade generacion de un resumen generico y unresumen orientado a pregunta.
Bibliografıa
Amigo, E., J. Gonzalo, A. Penas, y F. Verde-jo. 2005. QARLA: a Framework for theEvaluation of Text Summarization Sys-tems. En Proceedings of the 43rd AnnualMeeting of the Association for Computa-tional Linguistics (ACL 2005).
Coughlin, Deborah. 2003. Correlating Au-tomated and Human Assessments of Ma-chine Translation Quality. En In Proceed-ings of MT Summit IX, New Orleans,LA.
Culy, Christopher y Susanne Riehemann.2003. The Limits of N-Gram Transla-tion Evaluation Metrics. En Proceedingsof MT Summit IX, New Orleans,LA.
Joseph P. Turian, Luke Shen y I. DanMelamed. 2003. Evaluation of MachineTranslation and its Evaluation. En InProceedings of MT Summit IX, New Or-leans,LA.
Lin, C. y E. H. Hovy. 2003. AutomaticEvaluation of Summaries Using N-gramCo-ocurrence Statistics. En Proceedingof 2003 Language Technology Conference(HLT-NAACL 2003).
Lin, Chin-Yew. 2004. Rouge: A Package forAutomatic Evaluation of Summaries. EnMarie-Francine Moens y Stan Szpakow-icz, editores, Text Summarization Branch-es Out: Proceedings of the ACL-04 Work-shop, paginas 74–81, Barcelona, Spain, Ju-ly. Association for Computational Linguis-tics.
Lin, Chin-Yew y Eduard Hovy. 2003. ThePotential and Limitations of AutomaticSentence Extraction for Summarization.En Dragomir Radev y Simone Teufel, edi-tores, HLT-NAACL 2003 Workshop: TextSummarization (DUC03), Edmonton, Al-berta, Canada, May 31 - June 1. Associa-tion for Computational Linguistics.
Schmid, Helmut. 1994. Probabilistic Part-of-Speech Tagging Using Decision Trees. EnInternational Conference on New Methodsin Language Processing.
E. Amigó, A. Peñas, J. Gonzalo, F. Verdejo
66