estima˘c~ao de m axima verossimilhan˘ca utilizando m ...mbranco/presenta_nr.pdf · i gradiente...
TRANSCRIPT

Estimacao de Maxima Verossimilhanca Utilizando MetodosIterativos
Carlos Montenegro Silva
Instituto de Matematica e EstatısticaUniversidade de Sao Paulo
Outubro, 2014
Carlos Montenegro Silva (IME-USP) Outubro, 2014 1 / 15

Motivacao
Em muitos problemas de estimacao de maxima verossimilhanca, pode ser difıcil ouate impossıvel encontrar expressoes analıticas de forma fechada para os estimadores.Exemplos:
Funcao de densidade de probabilidade Cauchy:
f(x, θ) =1
π(1 + (x− θ)2), x ∈ R, θ ∈ R
Funcao de quantıa de probabilidade Poisson truncada:
f(x, θ) =e−θθx
(1− e−θ)x!, x = 1, 2, . . . , θ > 0
Nos casos das distribuicoes Gamma e Weibull (com os dois parametrosdesconhecidos).
Problemas de regressao com Modelos Lineares Generalizados (GLM).
Problemas de regressao com Modelos nao-lineares (NLM).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 2 / 15

Motivacao
Em muitos problemas de estimacao de maxima verossimilhanca, pode ser difıcil ouate impossıvel encontrar expressoes analıticas de forma fechada para os estimadores.Exemplos:
Funcao de densidade de probabilidade Cauchy:
f(x, θ) =1
π(1 + (x− θ)2), x ∈ R, θ ∈ R
Funcao de quantıa de probabilidade Poisson truncada:
f(x, θ) =e−θθx
(1− e−θ)x!, x = 1, 2, . . . , θ > 0
Nos casos das distribuicoes Gamma e Weibull (com os dois parametrosdesconhecidos).
Problemas de regressao com Modelos Lineares Generalizados (GLM).
Problemas de regressao com Modelos nao-lineares (NLM).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 2 / 15

Motivacao
Em muitos problemas de estimacao de maxima verossimilhanca, pode ser difıcil ouate impossıvel encontrar expressoes analıticas de forma fechada para os estimadores.Exemplos:
Funcao de densidade de probabilidade Cauchy:
f(x, θ) =1
π(1 + (x− θ)2), x ∈ R, θ ∈ R
Funcao de quantıa de probabilidade Poisson truncada:
f(x, θ) =e−θθx
(1− e−θ)x!, x = 1, 2, . . . , θ > 0
Nos casos das distribuicoes Gamma e Weibull (com os dois parametrosdesconhecidos).
Problemas de regressao com Modelos Lineares Generalizados (GLM).
Problemas de regressao com Modelos nao-lineares (NLM).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 2 / 15

Motivacao
Em muitos problemas de estimacao de maxima verossimilhanca, pode ser difıcil ouate impossıvel encontrar expressoes analıticas de forma fechada para os estimadores.Exemplos:
Funcao de densidade de probabilidade Cauchy:
f(x, θ) =1
π(1 + (x− θ)2), x ∈ R, θ ∈ R
Funcao de quantıa de probabilidade Poisson truncada:
f(x, θ) =e−θθx
(1− e−θ)x!, x = 1, 2, . . . , θ > 0
Nos casos das distribuicoes Gamma e Weibull (com os dois parametrosdesconhecidos).
Problemas de regressao com Modelos Lineares Generalizados (GLM).
Problemas de regressao com Modelos nao-lineares (NLM).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 2 / 15

Motivacao
Em muitos problemas de estimacao de maxima verossimilhanca, pode ser difıcil ouate impossıvel encontrar expressoes analıticas de forma fechada para os estimadores.Exemplos:
Funcao de densidade de probabilidade Cauchy:
f(x, θ) =1
π(1 + (x− θ)2), x ∈ R, θ ∈ R
Funcao de quantıa de probabilidade Poisson truncada:
f(x, θ) =e−θθx
(1− e−θ)x!, x = 1, 2, . . . , θ > 0
Nos casos das distribuicoes Gamma e Weibull (com os dois parametrosdesconhecidos).
Problemas de regressao com Modelos Lineares Generalizados (GLM).
Problemas de regressao com Modelos nao-lineares (NLM).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 2 / 15

Motivacao
Em muitos problemas de estimacao de maxima verossimilhanca, pode ser difıcil ouate impossıvel encontrar expressoes analıticas de forma fechada para os estimadores.Exemplos:
Funcao de densidade de probabilidade Cauchy:
f(x, θ) =1
π(1 + (x− θ)2), x ∈ R, θ ∈ R
Funcao de quantıa de probabilidade Poisson truncada:
f(x, θ) =e−θθx
(1− e−θ)x!, x = 1, 2, . . . , θ > 0
Nos casos das distribuicoes Gamma e Weibull (com os dois parametrosdesconhecidos).
Problemas de regressao com Modelos Lineares Generalizados (GLM).
Problemas de regressao com Modelos nao-lineares (NLM).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 2 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest Descent
I Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-Raphson
I Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoring
I Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-Mead
I Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-Newton
I Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugado
I Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).
Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo iterativos
Nestas situacoes e necessario calcular as estimativas de maxima verossimilhancanumericamente, usando algoritmos iterativos.
Para esta tarefa existem varios tipos de algoritmos.
Alguns destes metodos requerem a avaliacao expressa das derivadas parciais dafuncao objetivo. Estes algoritmos fazem parte dos metodos do gradiente(Khuri, 2003). Exemplos:
I Steepest DescentI Newton-RaphsonI Fisher scoringI Davidon-Fletcher-Powell
Outras tecnicas de otimizacao se baseiam exclusivamente nos valores da funcaoobjetivo e sao chamados de metodos de busca direta (Direct search).Exemplos:
I Nelder-MeadI Quasi-NewtonI Gradiente conjugadoI Simulated annealing
Outra classe de algoritmos sao os da familia EM (Expectation-Maximization).Estes algoritmos sao utilizados para estimacao de maxima verossimilhanca emproblemas de dados incompletos, truncados, censurados ou com variaveislatentes (McLachlan and Krishnan, 2008).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 3 / 15

Algoritmo Newton-Raphson
O algoritmo Newton-Raphson (ou metodo de Newton) foi desenvolvido por IsaacNewton e Joseph Raphson e tem o objetivo estimar as raızes de uma funcao.
Suponha que queremos encontrar a solucao da equacao g(x0) = 0, onde g e umafuncao diferenciavel. Dado um numero x proximo de x0, segue da expansao emserie de Taylor em torno de x que:
0 = g(x0) ≈ g(x) + g′(x)(x0 − x)
Resolvendo para x0, conseguimos:
x0 ≈ x−g(x)
g′(x)
Assim, dado um valor estimado xk, entao podemos ter um novo valor estimadoxk+1 por
xk+1 ≈ xk −g(xk)
g′(xk)
Este procedimento e iterado para k = 1, 2, 3... ate |g(xk)/g′(xk)| sersuficientemente pequeno.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 4 / 15

Algoritmo Newton-Raphson
O algoritmo Newton-Raphson (ou metodo de Newton) foi desenvolvido por IsaacNewton e Joseph Raphson e tem o objetivo estimar as raızes de uma funcao.
Suponha que queremos encontrar a solucao da equacao g(x0) = 0, onde g e umafuncao diferenciavel. Dado um numero x proximo de x0, segue da expansao emserie de Taylor em torno de x que:
0 = g(x0) ≈ g(x) + g′(x)(x0 − x)
Resolvendo para x0, conseguimos:
x0 ≈ x−g(x)
g′(x)
Assim, dado um valor estimado xk, entao podemos ter um novo valor estimadoxk+1 por
xk+1 ≈ xk −g(xk)
g′(xk)
Este procedimento e iterado para k = 1, 2, 3... ate |g(xk)/g′(xk)| sersuficientemente pequeno.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 4 / 15

Algoritmo Newton-Raphson
O algoritmo Newton-Raphson (ou metodo de Newton) foi desenvolvido por IsaacNewton e Joseph Raphson e tem o objetivo estimar as raızes de uma funcao.
Suponha que queremos encontrar a solucao da equacao g(x0) = 0, onde g e umafuncao diferenciavel. Dado um numero x proximo de x0, segue da expansao emserie de Taylor em torno de x que:
0 = g(x0) ≈ g(x) + g′(x)(x0 − x)
Resolvendo para x0, conseguimos:
x0 ≈ x−g(x)
g′(x)
Assim, dado um valor estimado xk, entao podemos ter um novo valor estimadoxk+1 por
xk+1 ≈ xk −g(xk)
g′(xk)
Este procedimento e iterado para k = 1, 2, 3... ate |g(xk)/g′(xk)| sersuficientemente pequeno.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 4 / 15

Algoritmo Newton-Raphson
O algoritmo Newton-Raphson (ou metodo de Newton) foi desenvolvido por IsaacNewton e Joseph Raphson e tem o objetivo estimar as raızes de uma funcao.
Suponha que queremos encontrar a solucao da equacao g(x0) = 0, onde g e umafuncao diferenciavel. Dado um numero x proximo de x0, segue da expansao emserie de Taylor em torno de x que:
0 = g(x0) ≈ g(x) + g′(x)(x0 − x)
Resolvendo para x0, conseguimos:
x0 ≈ x−g(x)
g′(x)
Assim, dado um valor estimado xk, entao podemos ter um novo valor estimadoxk+1 por
xk+1 ≈ xk −g(xk)
g′(xk)
Este procedimento e iterado para k = 1, 2, 3... ate |g(xk)/g′(xk)| sersuficientemente pequeno.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 4 / 15

Algoritmo Newton-Raphson
O algoritmo Newton-Raphson (ou metodo de Newton) foi desenvolvido por IsaacNewton e Joseph Raphson e tem o objetivo estimar as raızes de uma funcao.
Suponha que queremos encontrar a solucao da equacao g(x0) = 0, onde g e umafuncao diferenciavel. Dado um numero x proximo de x0, segue da expansao emserie de Taylor em torno de x que:
0 = g(x0) ≈ g(x) + g′(x)(x0 − x)
Resolvendo para x0, conseguimos:
x0 ≈ x−g(x)
g′(x)
Assim, dado um valor estimado xk, entao podemos ter um novo valor estimadoxk+1 por
xk+1 ≈ xk −g(xk)
g′(xk)
Este procedimento e iterado para k = 1, 2, 3... ate |g(xk)/g′(xk)| sersuficientemente pequeno.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 4 / 15

Algoritmo Newton-Raphson
O algoritmo Newton-Raphson (ou metodo de Newton) foi desenvolvido por IsaacNewton e Joseph Raphson e tem o objetivo estimar as raızes de uma funcao.
Suponha que queremos encontrar a solucao da equacao g(x0) = 0, onde g e umafuncao diferenciavel. Dado um numero x proximo de x0, segue da expansao emserie de Taylor em torno de x que:
0 = g(x0) ≈ g(x) + g′(x)(x0 − x)
Resolvendo para x0, conseguimos:
x0 ≈ x−g(x)
g′(x)
Assim, dado um valor estimado xk, entao podemos ter um novo valor estimadoxk+1 por
xk+1 ≈ xk −g(xk)
g′(xk)
Este procedimento e iterado para k = 1, 2, 3... ate |g(xk)/g′(xk)| sersuficientemente pequeno.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 4 / 15
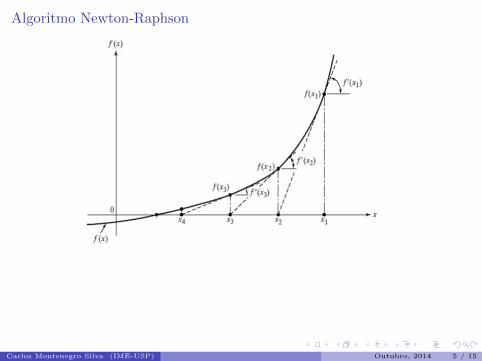
Algoritmo Newton-Raphson
Figura: Interpretacao Geometrica do algoritmo Newton-Raphson
Escolhe-se um valor inicial. Apos isso, calcula-se a equacao da reta tangente (derivada)da funcao nesse ponto e a intersecao dela com o eixo das abcissas, a fim de encontraruma melhor aproximacao para a raiz.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 5 / 15
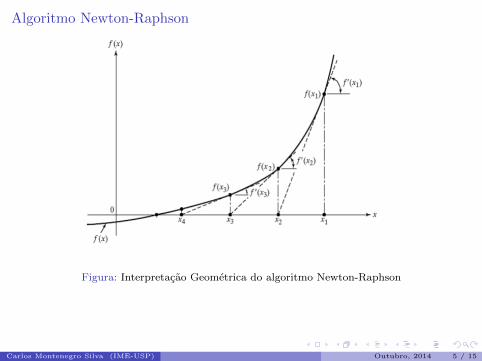
Algoritmo Newton-Raphson
Figura: Interpretacao Geometrica do algoritmo Newton-Raphson
Escolhe-se um valor inicial. Apos isso, calcula-se a equacao da reta tangente (derivada)da funcao nesse ponto e a intersecao dela com o eixo das abcissas, a fim de encontraruma melhor aproximacao para a raiz.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 5 / 15
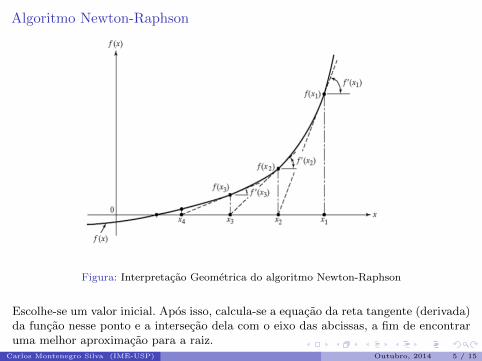
Algoritmo Newton-Raphson
Figura: Interpretacao Geometrica do algoritmo Newton-Raphson
Escolhe-se um valor inicial. Apos isso, calcula-se a equacao da reta tangente (derivada)da funcao nesse ponto e a intersecao dela com o eixo das abcissas, a fim de encontraruma melhor aproximacao para a raiz.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 5 / 15

Algoritmo Newton-Raphson
Podemos utilizar o algorıtmo Newton-Raphson para encontrar as estimativas demaxima verossimilhanca.
Seja X uma variavel aleatoria definida sob um espaco de probabilidade (Ω, σ, P ),com X ∈ Ω e funcao de densidade de probabilidade f(x, θ), onde θ ∈ R.Seja X = (x1, ..., xn) uma amostra aleatoria de X e L(θ|X) =
∏ni=1 f(xi, θ) a
funcao de verossimilhanca.
Suponha que a estimativa de maxima verossimilhanca θ satisfaz ∂
∂θlnL(θ|X) = 0.
Seja θk a estimativa de θ apos a iteracao k do algoritmo, entao:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
S(θ) =∂
∂θlnL(θ|X), H(θ) = − ∂2
∂θ2lnL(θ|X)
Se θ(0) e um estimador de θ suficientemente bom, entao o estimador:
θ(1) = θ(0) +S(θ(0))
H(θ(0))
tem virtualmente as mesmas propriedades assintoticas que o EMV (Khuri, 2003).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 6 / 15

Algoritmo Newton-Raphson
Podemos utilizar o algorıtmo Newton-Raphson para encontrar as estimativas demaxima verossimilhanca.Seja X uma variavel aleatoria definida sob um espaco de probabilidade (Ω, σ, P ),com X ∈ Ω e funcao de densidade de probabilidade f(x, θ), onde θ ∈ R.
Seja X = (x1, ..., xn) uma amostra aleatoria de X e L(θ|X) =∏ni=1 f(xi, θ) a
funcao de verossimilhanca.
Suponha que a estimativa de maxima verossimilhanca θ satisfaz ∂
∂θlnL(θ|X) = 0.
Seja θk a estimativa de θ apos a iteracao k do algoritmo, entao:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
S(θ) =∂
∂θlnL(θ|X), H(θ) = − ∂2
∂θ2lnL(θ|X)
Se θ(0) e um estimador de θ suficientemente bom, entao o estimador:
θ(1) = θ(0) +S(θ(0))
H(θ(0))
tem virtualmente as mesmas propriedades assintoticas que o EMV (Khuri, 2003).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 6 / 15

Algoritmo Newton-Raphson
Podemos utilizar o algorıtmo Newton-Raphson para encontrar as estimativas demaxima verossimilhanca.Seja X uma variavel aleatoria definida sob um espaco de probabilidade (Ω, σ, P ),com X ∈ Ω e funcao de densidade de probabilidade f(x, θ), onde θ ∈ R.Seja X = (x1, ..., xn) uma amostra aleatoria de X e L(θ|X) =
∏ni=1 f(xi, θ) a
funcao de verossimilhanca.
Suponha que a estimativa de maxima verossimilhanca θ satisfaz ∂
∂θlnL(θ|X) = 0.
Seja θk a estimativa de θ apos a iteracao k do algoritmo, entao:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
S(θ) =∂
∂θlnL(θ|X), H(θ) = − ∂2
∂θ2lnL(θ|X)
Se θ(0) e um estimador de θ suficientemente bom, entao o estimador:
θ(1) = θ(0) +S(θ(0))
H(θ(0))
tem virtualmente as mesmas propriedades assintoticas que o EMV (Khuri, 2003).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 6 / 15

Algoritmo Newton-Raphson
Podemos utilizar o algorıtmo Newton-Raphson para encontrar as estimativas demaxima verossimilhanca.Seja X uma variavel aleatoria definida sob um espaco de probabilidade (Ω, σ, P ),com X ∈ Ω e funcao de densidade de probabilidade f(x, θ), onde θ ∈ R.Seja X = (x1, ..., xn) uma amostra aleatoria de X e L(θ|X) =
∏ni=1 f(xi, θ) a
funcao de verossimilhanca.
Suponha que a estimativa de maxima verossimilhanca θ satisfaz ∂
∂θlnL(θ|X) = 0.
Seja θk a estimativa de θ apos a iteracao k do algoritmo, entao:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
S(θ) =∂
∂θlnL(θ|X), H(θ) = − ∂2
∂θ2lnL(θ|X)
Se θ(0) e um estimador de θ suficientemente bom, entao o estimador:
θ(1) = θ(0) +S(θ(0))
H(θ(0))
tem virtualmente as mesmas propriedades assintoticas que o EMV (Khuri, 2003).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 6 / 15

Algoritmo Newton-Raphson
Podemos utilizar o algorıtmo Newton-Raphson para encontrar as estimativas demaxima verossimilhanca.Seja X uma variavel aleatoria definida sob um espaco de probabilidade (Ω, σ, P ),com X ∈ Ω e funcao de densidade de probabilidade f(x, θ), onde θ ∈ R.Seja X = (x1, ..., xn) uma amostra aleatoria de X e L(θ|X) =
∏ni=1 f(xi, θ) a
funcao de verossimilhanca.
Suponha que a estimativa de maxima verossimilhanca θ satisfaz ∂
∂θlnL(θ|X) = 0.
Seja θk a estimativa de θ apos a iteracao k do algoritmo, entao:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
S(θ) =∂
∂θlnL(θ|X), H(θ) = − ∂2
∂θ2lnL(θ|X)
Se θ(0) e um estimador de θ suficientemente bom, entao o estimador:
θ(1) = θ(0) +S(θ(0))
H(θ(0))
tem virtualmente as mesmas propriedades assintoticas que o EMV (Khuri, 2003).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 6 / 15

Algoritmo Newton-Raphson
Podemos utilizar o algorıtmo Newton-Raphson para encontrar as estimativas demaxima verossimilhanca.Seja X uma variavel aleatoria definida sob um espaco de probabilidade (Ω, σ, P ),com X ∈ Ω e funcao de densidade de probabilidade f(x, θ), onde θ ∈ R.Seja X = (x1, ..., xn) uma amostra aleatoria de X e L(θ|X) =
∏ni=1 f(xi, θ) a
funcao de verossimilhanca.
Suponha que a estimativa de maxima verossimilhanca θ satisfaz ∂
∂θlnL(θ|X) = 0.
Seja θk a estimativa de θ apos a iteracao k do algoritmo, entao:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
S(θ) =∂
∂θlnL(θ|X), H(θ) = − ∂2
∂θ2lnL(θ|X)
Se θ(0) e um estimador de θ suficientemente bom, entao o estimador:
θ(1) = θ(0) +S(θ(0))
H(θ(0))
tem virtualmente as mesmas propriedades assintoticas que o EMV (Khuri, 2003).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 6 / 15

Algoritmo Newton-Raphson
Podemos utilizar o algorıtmo Newton-Raphson para encontrar as estimativas demaxima verossimilhanca.Seja X uma variavel aleatoria definida sob um espaco de probabilidade (Ω, σ, P ),com X ∈ Ω e funcao de densidade de probabilidade f(x, θ), onde θ ∈ R.Seja X = (x1, ..., xn) uma amostra aleatoria de X e L(θ|X) =
∏ni=1 f(xi, θ) a
funcao de verossimilhanca.
Suponha que a estimativa de maxima verossimilhanca θ satisfaz ∂
∂θlnL(θ|X) = 0.
Seja θk a estimativa de θ apos a iteracao k do algoritmo, entao:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
S(θ) =∂
∂θlnL(θ|X), H(θ) = − ∂2
∂θ2lnL(θ|X)
Se θ(0) e um estimador de θ suficientemente bom, entao o estimador:
θ(1) = θ(0) +S(θ(0))
H(θ(0))
tem virtualmente as mesmas propriedades assintoticas que o EMV (Khuri, 2003).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 6 / 15

Algoritmo Newton-Raphson
Podemos utilizar o algorıtmo Newton-Raphson para encontrar as estimativas demaxima verossimilhanca.Seja X uma variavel aleatoria definida sob um espaco de probabilidade (Ω, σ, P ),com X ∈ Ω e funcao de densidade de probabilidade f(x, θ), onde θ ∈ R.Seja X = (x1, ..., xn) uma amostra aleatoria de X e L(θ|X) =
∏ni=1 f(xi, θ) a
funcao de verossimilhanca.
Suponha que a estimativa de maxima verossimilhanca θ satisfaz ∂
∂θlnL(θ|X) = 0.
Seja θk a estimativa de θ apos a iteracao k do algoritmo, entao:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
S(θ) =∂
∂θlnL(θ|X), H(θ) = − ∂2
∂θ2lnL(θ|X)
Se θ(0) e um estimador de θ suficientemente bom, entao o estimador:
θ(1) = θ(0) +S(θ(0))
H(θ(0))
tem virtualmente as mesmas propriedades assintoticas que o EMV (Khuri, 2003).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 6 / 15

Algoritmo Newton-Raphson
Podemos utilizar o algorıtmo Newton-Raphson para encontrar as estimativas demaxima verossimilhanca.Seja X uma variavel aleatoria definida sob um espaco de probabilidade (Ω, σ, P ),com X ∈ Ω e funcao de densidade de probabilidade f(x, θ), onde θ ∈ R.Seja X = (x1, ..., xn) uma amostra aleatoria de X e L(θ|X) =
∏ni=1 f(xi, θ) a
funcao de verossimilhanca.
Suponha que a estimativa de maxima verossimilhanca θ satisfaz ∂
∂θlnL(θ|X) = 0.
Seja θk a estimativa de θ apos a iteracao k do algoritmo, entao:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
S(θ) =∂
∂θlnL(θ|X), H(θ) = − ∂2
∂θ2lnL(θ|X)
Se θ(0) e um estimador de θ suficientemente bom, entao o estimador:
θ(1) = θ(0) +S(θ(0))
H(θ(0))
tem virtualmente as mesmas propriedades assintoticas que o EMV (Khuri, 2003).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 6 / 15

Algoritmo Newton-Raphson
Podemos utilizar o algorıtmo Newton-Raphson para encontrar as estimativas demaxima verossimilhanca.Seja X uma variavel aleatoria definida sob um espaco de probabilidade (Ω, σ, P ),com X ∈ Ω e funcao de densidade de probabilidade f(x, θ), onde θ ∈ R.Seja X = (x1, ..., xn) uma amostra aleatoria de X e L(θ|X) =
∏ni=1 f(xi, θ) a
funcao de verossimilhanca.
Suponha que a estimativa de maxima verossimilhanca θ satisfaz ∂
∂θlnL(θ|X) = 0.
Seja θk a estimativa de θ apos a iteracao k do algoritmo, entao:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
S(θ) =∂
∂θlnL(θ|X), H(θ) = − ∂2
∂θ2lnL(θ|X)
Se θ(0) e um estimador de θ suficientemente bom, entao o estimador:
θ(1) = θ(0) +S(θ(0))
H(θ(0))
tem virtualmente as mesmas propriedades assintoticas que o EMV (Khuri, 2003).
Carlos Montenegro Silva (IME-USP) Outubro, 2014 6 / 15

Exemplo 1: Densidade Cauchy
Funcao de densidade de probabilidade Cauchy:
f(x, θ) =1
π(1 + (x− θ)2)
dado x1, ..., xn a funcao de log-verossimilhanca e:
lnL(θ|X) = −n∑i=1
ln[1 + (xi − θ)2]− n ln(π)
θ satisfaz a equacao:
S(θ) =
n∑i=1
2(xi − θ)1 + (xi − θ)2
= 0
onde S(θ) e a derivada de lnL(θ|X) (funcao escore). Como S(θ) nao e monotonaem θ, a equacao S(θ) = 0 pode ter mais de uma solucao para um dado x1, ..., xn.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 7 / 15

Exemplo 1: Densidade Cauchy
Funcao de densidade de probabilidade Cauchy:
f(x, θ) =1
π(1 + (x− θ)2)
dado x1, ..., xn a funcao de log-verossimilhanca e:
lnL(θ|X) = −n∑i=1
ln[1 + (xi − θ)2]− n ln(π)
θ satisfaz a equacao:
S(θ) =
n∑i=1
2(xi − θ)1 + (xi − θ)2
= 0
onde S(θ) e a derivada de lnL(θ|X) (funcao escore). Como S(θ) nao e monotonaem θ, a equacao S(θ) = 0 pode ter mais de uma solucao para um dado x1, ..., xn.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 7 / 15

Exemplo 1: Densidade Cauchy
Funcao de densidade de probabilidade Cauchy:
f(x, θ) =1
π(1 + (x− θ)2)
dado x1, ..., xn a funcao de log-verossimilhanca e:
lnL(θ|X) = −n∑i=1
ln[1 + (xi − θ)2]− n ln(π)
θ satisfaz a equacao:
S(θ) =
n∑i=1
2(xi − θ)1 + (xi − θ)2
= 0
onde S(θ) e a derivada de lnL(θ|X) (funcao escore). Como S(θ) nao e monotonaem θ, a equacao S(θ) = 0 pode ter mais de uma solucao para um dado x1, ..., xn.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 7 / 15

Exemplo 1: Densidade Cauchy
Funcao de densidade de probabilidade Cauchy:
f(x, θ) =1
π(1 + (x− θ)2)
dado x1, ..., xn a funcao de log-verossimilhanca e:
lnL(θ|X) = −n∑i=1
ln[1 + (xi − θ)2]− n ln(π)
θ satisfaz a equacao:
S(θ) =n∑i=1
2(xi − θ)1 + (xi − θ)2
= 0
onde S(θ) e a derivada de lnL(θ|X) (funcao escore). Como S(θ) nao e monotonaem θ, a equacao S(θ) = 0 pode ter mais de uma solucao para um dado x1, ..., xn.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 7 / 15

Exemplo 1: Densidade Cauchy
Funcao de densidade de probabilidade Cauchy:
f(x, θ) =1
π(1 + (x− θ)2)
dado x1, ..., xn a funcao de log-verossimilhanca e:
lnL(θ|X) = −n∑i=1
ln[1 + (xi − θ)2]− n ln(π)
θ satisfaz a equacao:
S(θ) =n∑i=1
2(xi − θ)1 + (xi − θ)2
= 0
onde S(θ) e a derivada de lnL(θ|X) (funcao escore). Como S(θ) nao e monotonaem θ, a equacao S(θ) = 0 pode ter mais de uma solucao para um dado x1, ..., xn.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 7 / 15

Exemplo 1: Densidade Cauchy
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) = 2
n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
(I. de Fisher observada).Para ilustrar o algoritmo Newton-Raphson, geramos uma amostra aleatoria de 100observacoes Cauchy com θ = 10 (no programa R).
k θ(k) lnL(θ(k))
0 10.04490 -239.65691 10.06934 -239.64332 10.06947 -239.64333 10.06947 -239.6433
Iteracoes do algoritmo Newton-Raphson para os dados Cauchy simulados.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 8 / 15

Exemplo 1: Densidade Cauchy
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) = 2
n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
(I. de Fisher observada).Para ilustrar o algoritmo Newton-Raphson, geramos uma amostra aleatoria de 100observacoes Cauchy com θ = 10 (no programa R).
k θ(k) lnL(θ(k))
0 10.04490 -239.65691 10.06934 -239.64332 10.06947 -239.64333 10.06947 -239.6433
Iteracoes do algoritmo Newton-Raphson para os dados Cauchy simulados.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 8 / 15

Exemplo 1: Densidade Cauchy
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) = 2
n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
(I. de Fisher observada).Para ilustrar o algoritmo Newton-Raphson, geramos uma amostra aleatoria de 100observacoes Cauchy com θ = 10 (no programa R).
k θ(k) lnL(θ(k))
0 10.04490 -239.65691 10.06934 -239.64332 10.06947 -239.64333 10.06947 -239.6433
Iteracoes do algoritmo Newton-Raphson para os dados Cauchy simulados.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 8 / 15

Exemplo 1: Densidade Cauchy
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) = 2
n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
(I. de Fisher observada).
Para ilustrar o algoritmo Newton-Raphson, geramos uma amostra aleatoria de 100observacoes Cauchy com θ = 10 (no programa R).
k θ(k) lnL(θ(k))
0 10.04490 -239.65691 10.06934 -239.64332 10.06947 -239.64333 10.06947 -239.6433
Iteracoes do algoritmo Newton-Raphson para os dados Cauchy simulados.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 8 / 15

Exemplo 1: Densidade Cauchy
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) = 2
n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
(I. de Fisher observada).Para ilustrar o algoritmo Newton-Raphson, geramos uma amostra aleatoria de 100observacoes Cauchy com θ = 10 (no programa R).
k θ(k) lnL(θ(k))
0 10.04490 -239.65691 10.06934 -239.64332 10.06947 -239.64333 10.06947 -239.6433
Iteracoes do algoritmo Newton-Raphson para os dados Cauchy simulados.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 8 / 15

Exemplo 1: Densidade Cauchy
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) = 2
n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
(I. de Fisher observada).Para ilustrar o algoritmo Newton-Raphson, geramos uma amostra aleatoria de 100observacoes Cauchy com θ = 10 (no programa R).
k θ(k) lnL(θ(k))
0 10.04490 -239.65691 10.06934 -239.64332 10.06947 -239.64333 10.06947 -239.6433
Iteracoes do algoritmo Newton-Raphson para os dados Cauchy simulados.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 8 / 15

Exemplo 1: Densidade Cauchy
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) = 2
n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
(I. de Fisher observada).Para ilustrar o algoritmo Newton-Raphson, geramos uma amostra aleatoria de 100observacoes Cauchy com θ = 10 (no programa R).
k θ(k) lnL(θ(k))
0 10.04490 -239.65691 10.06934 -239.64332 10.06947 -239.64333 10.06947 -239.6433
Iteracoes do algoritmo Newton-Raphson para os dados Cauchy simulados.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 8 / 15
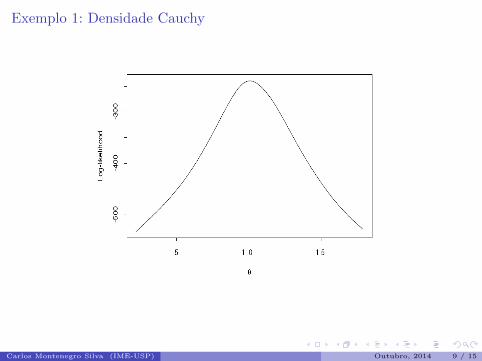
Exemplo 1: Densidade Cauchy
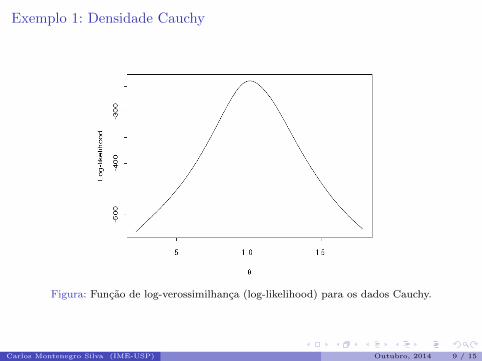
Figura: Funcao de log-verossimilhanca (log-likelihood) para os dados Cauchy.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 9 / 15
Exemplo 1: Densidade Cauchy
Figura: Funcao de log-verossimilhanca (log-likelihood) para os dados Cauchy.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 9 / 15
Exemplo 1: Densidade Cauchy
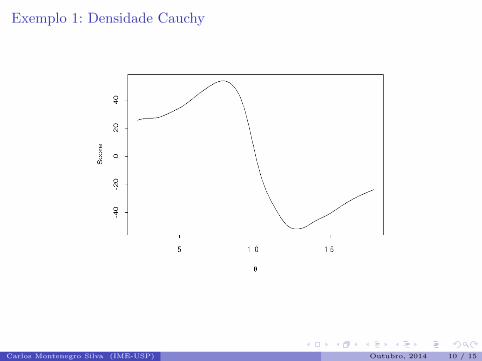
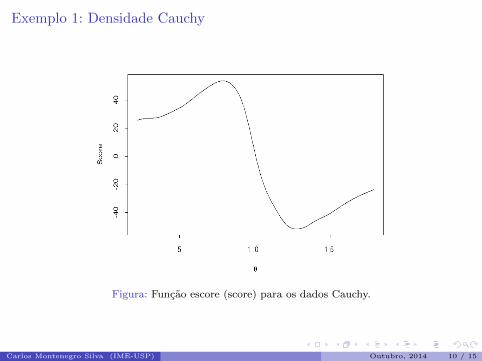
Figura: Funcao escore (score) para os dados Cauchy.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 10 / 15
Exemplo 1: Densidade Cauchy
Figura: Funcao escore (score) para os dados Cauchy.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 10 / 15

Exemplo 2: Bolfarine e Sandoval, 2010
Seja X uma v.a. com funcao de densidade de probabilidade:
f(x; θ) =1
2(1 + θx), −1 ≤ x ≤ 1 − 1 ≤ θ ≤ 1
Dada uma amostra aleatoria X = x1, ..., xn de X, a funcao de log-verossimilhanca e:
lnL(θ|X) = n ln(1/2) +
n∑i=1
ln[1 + (θxi)]
θ satisfaz a equacao:
S(θ) =
n∑i=1
xi
1 + θxi= 0
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) =
n∑i=1
x2i
(1 + θxi)2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 11 / 15

Exemplo 2: Bolfarine e Sandoval, 2010
Seja X uma v.a. com funcao de densidade de probabilidade:
f(x; θ) =1
2(1 + θx), −1 ≤ x ≤ 1 − 1 ≤ θ ≤ 1
Dada uma amostra aleatoria X = x1, ..., xn de X, a funcao de log-verossimilhanca e:
lnL(θ|X) = n ln(1/2) +
n∑i=1
ln[1 + (θxi)]
θ satisfaz a equacao:
S(θ) =
n∑i=1
xi
1 + θxi= 0
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) =
n∑i=1
x2i
(1 + θxi)2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 11 / 15

Exemplo 2: Bolfarine e Sandoval, 2010
Seja X uma v.a. com funcao de densidade de probabilidade:
f(x; θ) =1
2(1 + θx), −1 ≤ x ≤ 1 − 1 ≤ θ ≤ 1
Dada uma amostra aleatoria X = x1, ..., xn de X, a funcao de log-verossimilhanca e:
lnL(θ|X) = n ln(1/2) +
n∑i=1
ln[1 + (θxi)]
θ satisfaz a equacao:
S(θ) =
n∑i=1
xi
1 + θxi= 0
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) =
n∑i=1
x2i
(1 + θxi)2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 11 / 15

Exemplo 2: Bolfarine e Sandoval, 2010
Seja X uma v.a. com funcao de densidade de probabilidade:
f(x; θ) =1
2(1 + θx), −1 ≤ x ≤ 1 − 1 ≤ θ ≤ 1
Dada uma amostra aleatoria X = x1, ..., xn de X, a funcao de log-verossimilhanca e:
lnL(θ|X) = n ln(1/2) +n∑i=1
ln[1 + (θxi)]
θ satisfaz a equacao:
S(θ) =
n∑i=1
xi
1 + θxi= 0
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) =
n∑i=1
x2i
(1 + θxi)2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 11 / 15

Exemplo 2: Bolfarine e Sandoval, 2010
Seja X uma v.a. com funcao de densidade de probabilidade:
f(x; θ) =1
2(1 + θx), −1 ≤ x ≤ 1 − 1 ≤ θ ≤ 1
Dada uma amostra aleatoria X = x1, ..., xn de X, a funcao de log-verossimilhanca e:
lnL(θ|X) = n ln(1/2) +n∑i=1
ln[1 + (θxi)]
θ satisfaz a equacao:
S(θ) =
n∑i=1
xi
1 + θxi= 0
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) =
n∑i=1
x2i
(1 + θxi)2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 11 / 15

Exemplo 2: Bolfarine e Sandoval, 2010
Seja X uma v.a. com funcao de densidade de probabilidade:
f(x; θ) =1
2(1 + θx), −1 ≤ x ≤ 1 − 1 ≤ θ ≤ 1
Dada uma amostra aleatoria X = x1, ..., xn de X, a funcao de log-verossimilhanca e:
lnL(θ|X) = n ln(1/2) +n∑i=1
ln[1 + (θxi)]
θ satisfaz a equacao:
S(θ) =n∑i=1
xi
1 + θxi= 0
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) =
n∑i=1
x2i
(1 + θxi)2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 11 / 15

Exemplo 2: Bolfarine e Sandoval, 2010
Seja X uma v.a. com funcao de densidade de probabilidade:
f(x; θ) =1
2(1 + θx), −1 ≤ x ≤ 1 − 1 ≤ θ ≤ 1
Dada uma amostra aleatoria X = x1, ..., xn de X, a funcao de log-verossimilhanca e:
lnL(θ|X) = n ln(1/2) +n∑i=1
ln[1 + (θxi)]
θ satisfaz a equacao:
S(θ) =n∑i=1
xi
1 + θxi= 0
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) =
n∑i=1
x2i
(1 + θxi)2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 11 / 15

Exemplo 2: Bolfarine e Sandoval, 2010
Seja X uma v.a. com funcao de densidade de probabilidade:
f(x; θ) =1
2(1 + θx), −1 ≤ x ≤ 1 − 1 ≤ θ ≤ 1
Dada uma amostra aleatoria X = x1, ..., xn de X, a funcao de log-verossimilhanca e:
lnL(θ|X) = n ln(1/2) +n∑i=1
ln[1 + (θxi)]
θ satisfaz a equacao:
S(θ) =n∑i=1
xi
1 + θxi= 0
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) =
n∑i=1
x2i
(1 + θxi)2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 11 / 15

Exemplo 2: Bolfarine e Sandoval, 2010
Seja X uma v.a. com funcao de densidade de probabilidade:
f(x; θ) =1
2(1 + θx), −1 ≤ x ≤ 1 − 1 ≤ θ ≤ 1
Dada uma amostra aleatoria X = x1, ..., xn de X, a funcao de log-verossimilhanca e:
lnL(θ|X) = n ln(1/2) +n∑i=1
ln[1 + (θxi)]
θ satisfaz a equacao:
S(θ) =n∑i=1
xi
1 + θxi= 0
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) =
n∑i=1
x2i
(1 + θxi)2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 11 / 15

Exemplo 2: Bolfarine e Sandoval, 2010
Seja X uma v.a. com funcao de densidade de probabilidade:
f(x; θ) =1
2(1 + θx), −1 ≤ x ≤ 1 − 1 ≤ θ ≤ 1
Dada uma amostra aleatoria X = x1, ..., xn de X, a funcao de log-verossimilhanca e:
lnL(θ|X) = n ln(1/2) +n∑i=1
ln[1 + (θxi)]
θ satisfaz a equacao:
S(θ) =n∑i=1
xi
1 + θxi= 0
Usando a media amostral (ou a mediana) como estimativa inicial, valores sucessivosde θ(k) sao definidos por:
θ(k+1) = θ(k) +S(θ(k))
H(θ(k))
onde
H(θ) =n∑i=1
x2i
(1 + θxi)2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 11 / 15

Caso multiparametrico
Para o caso multiparametrico considere θ = (θ1, ..., θp)T e suponha que o estimador
de θ e dado por S(θ) = 0, onde:
S(θ) =( ∂
∂θ1lnL(θ|X), ...,
∂
∂θplnL(θ|X)
)T.
Entao dado θ(k)
, definimos θ(k+1)
por:
θ(k+1)
= θ(k)
+ [H(θ(k)
)]−1S(θ(k)
)
onde, H(θ) e a matriz de derivadas parciais de segunda ordem negativas de lnL(θ|X)(matriz Hessiana).Os elementos (i, j) sao dados por:
Hij(θ) = − ∂2
∂θi∂θjlnL(θ|X)
Em modelos complexos pode ser difıcil ou ate impossıvel obter a inversa da matrizHessiana ([H(θ)]−1). Naqueles casos e recomendavel utilizar algum algoritmo da clasede busca direta em lugar dos metodos do gradiente.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 12 / 15

Caso multiparametrico
Para o caso multiparametrico considere θ = (θ1, ..., θp)T e suponha que o estimador
de θ e dado por S(θ) = 0, onde:
S(θ) =( ∂
∂θ1lnL(θ|X), ...,
∂
∂θplnL(θ|X)
)T.
Entao dado θ(k)
, definimos θ(k+1)
por:
θ(k+1)
= θ(k)
+ [H(θ(k)
)]−1S(θ(k)
)
onde, H(θ) e a matriz de derivadas parciais de segunda ordem negativas de lnL(θ|X)(matriz Hessiana).Os elementos (i, j) sao dados por:
Hij(θ) = − ∂2
∂θi∂θjlnL(θ|X)
Em modelos complexos pode ser difıcil ou ate impossıvel obter a inversa da matrizHessiana ([H(θ)]−1). Naqueles casos e recomendavel utilizar algum algoritmo da clasede busca direta em lugar dos metodos do gradiente.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 12 / 15

Caso multiparametrico
Para o caso multiparametrico considere θ = (θ1, ..., θp)T e suponha que o estimador
de θ e dado por S(θ) = 0, onde:
S(θ) =( ∂
∂θ1lnL(θ|X), ...,
∂
∂θplnL(θ|X)
)T.
Entao dado θ(k)
, definimos θ(k+1)
por:
θ(k+1)
= θ(k)
+ [H(θ(k)
)]−1S(θ(k)
)
onde, H(θ) e a matriz de derivadas parciais de segunda ordem negativas de lnL(θ|X)(matriz Hessiana).Os elementos (i, j) sao dados por:
Hij(θ) = − ∂2
∂θi∂θjlnL(θ|X)
Em modelos complexos pode ser difıcil ou ate impossıvel obter a inversa da matrizHessiana ([H(θ)]−1). Naqueles casos e recomendavel utilizar algum algoritmo da clasede busca direta em lugar dos metodos do gradiente.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 12 / 15

Caso multiparametrico
Para o caso multiparametrico considere θ = (θ1, ..., θp)T e suponha que o estimador
de θ e dado por S(θ) = 0, onde:
S(θ) =( ∂
∂θ1lnL(θ|X), ...,
∂
∂θplnL(θ|X)
)T.
Entao dado θ(k)
, definimos θ(k+1)
por:
θ(k+1)
= θ(k)
+ [H(θ(k)
)]−1S(θ(k)
)
onde, H(θ) e a matriz de derivadas parciais de segunda ordem negativas de lnL(θ|X)(matriz Hessiana).Os elementos (i, j) sao dados por:
Hij(θ) = − ∂2
∂θi∂θjlnL(θ|X)
Em modelos complexos pode ser difıcil ou ate impossıvel obter a inversa da matrizHessiana ([H(θ)]−1). Naqueles casos e recomendavel utilizar algum algoritmo da clasede busca direta em lugar dos metodos do gradiente.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 12 / 15

Caso multiparametrico
Para o caso multiparametrico considere θ = (θ1, ..., θp)T e suponha que o estimador
de θ e dado por S(θ) = 0, onde:
S(θ) =( ∂
∂θ1lnL(θ|X), ...,
∂
∂θplnL(θ|X)
)T.
Entao dado θ(k)
, definimos θ(k+1)
por:
θ(k+1)
= θ(k)
+ [H(θ(k)
)]−1S(θ(k)
)
onde, H(θ) e a matriz de derivadas parciais de segunda ordem negativas de lnL(θ|X)(matriz Hessiana).
Os elementos (i, j) sao dados por:
Hij(θ) = − ∂2
∂θi∂θjlnL(θ|X)
Em modelos complexos pode ser difıcil ou ate impossıvel obter a inversa da matrizHessiana ([H(θ)]−1). Naqueles casos e recomendavel utilizar algum algoritmo da clasede busca direta em lugar dos metodos do gradiente.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 12 / 15

Caso multiparametrico
Para o caso multiparametrico considere θ = (θ1, ..., θp)T e suponha que o estimador
de θ e dado por S(θ) = 0, onde:
S(θ) =( ∂
∂θ1lnL(θ|X), ...,
∂
∂θplnL(θ|X)
)T.
Entao dado θ(k)
, definimos θ(k+1)
por:
θ(k+1)
= θ(k)
+ [H(θ(k)
)]−1S(θ(k)
)
onde, H(θ) e a matriz de derivadas parciais de segunda ordem negativas de lnL(θ|X)(matriz Hessiana).Os elementos (i, j) sao dados por:
Hij(θ) = − ∂2
∂θi∂θjlnL(θ|X)
Em modelos complexos pode ser difıcil ou ate impossıvel obter a inversa da matrizHessiana ([H(θ)]−1). Naqueles casos e recomendavel utilizar algum algoritmo da clasede busca direta em lugar dos metodos do gradiente.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 12 / 15

Caso multiparametrico
Para o caso multiparametrico considere θ = (θ1, ..., θp)T e suponha que o estimador
de θ e dado por S(θ) = 0, onde:
S(θ) =( ∂
∂θ1lnL(θ|X), ...,
∂
∂θplnL(θ|X)
)T.
Entao dado θ(k)
, definimos θ(k+1)
por:
θ(k+1)
= θ(k)
+ [H(θ(k)
)]−1S(θ(k)
)
onde, H(θ) e a matriz de derivadas parciais de segunda ordem negativas de lnL(θ|X)(matriz Hessiana).Os elementos (i, j) sao dados por:
Hij(θ) = − ∂2
∂θi∂θjlnL(θ|X)
Em modelos complexos pode ser difıcil ou ate impossıvel obter a inversa da matrizHessiana ([H(θ)]−1). Naqueles casos e recomendavel utilizar algum algoritmo da clasede busca direta em lugar dos metodos do gradiente.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 12 / 15

Algoritmo Fisher scoring
Este algoritmo e uma simples modificacao do algoritmo Newton-Raphson.
Consiste emsubstituir a informacao de Fisher observada (H(θ)) pela informacao de Fisher esperada(H∗(θ)):
H∗(θ) = Eθ[H(θ)] = −Eθ[ ∂2
∂θ2lnL(θ|X)
];
Agora se θ(k) e o estimado de θ apos k iteracoes, definimos θ(k+1) por
θ(k+1) = θ(k) + [H∗(θ(k))]−1S(θ(k))
Exemplo: Seja como antes x1, ..., xn, uma amostra aleatoria de X ∼ Cauchy. Temos:
H(θ) = 2
n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
e:
H∗(θ) =n
π
∫ ∞−∞
1− (x− θ)2
(1 + (x− θ)2)3dx =
n
2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 13 / 15

Algoritmo Fisher scoring
Este algoritmo e uma simples modificacao do algoritmo Newton-Raphson. Consiste emsubstituir a informacao de Fisher observada (H(θ)) pela informacao de Fisher esperada(H∗(θ)):
H∗(θ) = Eθ[H(θ)] = −Eθ[ ∂2
∂θ2lnL(θ|X)
];
Agora se θ(k) e o estimado de θ apos k iteracoes, definimos θ(k+1) por
θ(k+1) = θ(k) + [H∗(θ(k))]−1S(θ(k))
Exemplo: Seja como antes x1, ..., xn, uma amostra aleatoria de X ∼ Cauchy. Temos:
H(θ) = 2
n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
e:
H∗(θ) =n
π
∫ ∞−∞
1− (x− θ)2
(1 + (x− θ)2)3dx =
n
2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 13 / 15

Algoritmo Fisher scoring
Este algoritmo e uma simples modificacao do algoritmo Newton-Raphson. Consiste emsubstituir a informacao de Fisher observada (H(θ)) pela informacao de Fisher esperada(H∗(θ)):
H∗(θ) = Eθ[H(θ)] = −Eθ[ ∂2
∂θ2lnL(θ|X)
];
Agora se θ(k) e o estimado de θ apos k iteracoes, definimos θ(k+1) por
θ(k+1) = θ(k) + [H∗(θ(k))]−1S(θ(k))
Exemplo: Seja como antes x1, ..., xn, uma amostra aleatoria de X ∼ Cauchy. Temos:
H(θ) = 2
n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
e:
H∗(θ) =n
π
∫ ∞−∞
1− (x− θ)2
(1 + (x− θ)2)3dx =
n
2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 13 / 15

Algoritmo Fisher scoring
Este algoritmo e uma simples modificacao do algoritmo Newton-Raphson. Consiste emsubstituir a informacao de Fisher observada (H(θ)) pela informacao de Fisher esperada(H∗(θ)):
H∗(θ) = Eθ[H(θ)] = −Eθ[ ∂2
∂θ2lnL(θ|X)
];
Agora se θ(k) e o estimado de θ apos k iteracoes, definimos θ(k+1) por
θ(k+1) = θ(k) + [H∗(θ(k))]−1S(θ(k))
Exemplo: Seja como antes x1, ..., xn, uma amostra aleatoria de X ∼ Cauchy. Temos:
H(θ) = 2
n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
e:
H∗(θ) =n
π
∫ ∞−∞
1− (x− θ)2
(1 + (x− θ)2)3dx =
n
2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 13 / 15

Algoritmo Fisher scoring
Este algoritmo e uma simples modificacao do algoritmo Newton-Raphson. Consiste emsubstituir a informacao de Fisher observada (H(θ)) pela informacao de Fisher esperada(H∗(θ)):
H∗(θ) = Eθ[H(θ)] = −Eθ[ ∂2
∂θ2lnL(θ|X)
];
Agora se θ(k) e o estimado de θ apos k iteracoes, definimos θ(k+1) por
θ(k+1) = θ(k) + [H∗(θ(k))]−1S(θ(k))
Exemplo: Seja como antes x1, ..., xn, uma amostra aleatoria de X ∼ Cauchy. Temos:
H(θ) = 2n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
e:
H∗(θ) =n
π
∫ ∞−∞
1− (x− θ)2
(1 + (x− θ)2)3dx =
n
2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 13 / 15

Algoritmo Fisher scoring
Este algoritmo e uma simples modificacao do algoritmo Newton-Raphson. Consiste emsubstituir a informacao de Fisher observada (H(θ)) pela informacao de Fisher esperada(H∗(θ)):
H∗(θ) = Eθ[H(θ)] = −Eθ[ ∂2
∂θ2lnL(θ|X)
];
Agora se θ(k) e o estimado de θ apos k iteracoes, definimos θ(k+1) por
θ(k+1) = θ(k) + [H∗(θ(k))]−1S(θ(k))
Exemplo: Seja como antes x1, ..., xn, uma amostra aleatoria de X ∼ Cauchy. Temos:
H(θ) = 2n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
e:
H∗(θ) =n
π
∫ ∞−∞
1− (x− θ)2
(1 + (x− θ)2)3dx =
n
2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 13 / 15

Algoritmo Fisher scoring
Este algoritmo e uma simples modificacao do algoritmo Newton-Raphson. Consiste emsubstituir a informacao de Fisher observada (H(θ)) pela informacao de Fisher esperada(H∗(θ)):
H∗(θ) = Eθ[H(θ)] = −Eθ[ ∂2
∂θ2lnL(θ|X)
];
Agora se θ(k) e o estimado de θ apos k iteracoes, definimos θ(k+1) por
θ(k+1) = θ(k) + [H∗(θ(k))]−1S(θ(k))
Exemplo: Seja como antes x1, ..., xn, uma amostra aleatoria de X ∼ Cauchy. Temos:
H(θ) = 2n∑i=1
1− (xi − θ)2
(1 + (xi − θ)2)2
e:
H∗(θ) =n
π
∫ ∞−∞
1− (x− θ)2
(1 + (x− θ)2)3dx =
n
2
Carlos Montenegro Silva (IME-USP) Outubro, 2014 13 / 15

Algoritmo Fisher scoringPortanto, o algoritmo Fisher scoring fica da forma:
θ(k+1) = θ(k) +4
n
n∑i=1
xi − θ(k)
1 + (xi − θ(k))2
k θ(k) lnL(θ(k))
0 10.04490 -239.65691 10.06710 -239.64342 10.06923 -239.64333 10.06945 -239.64333 10.06947 -239.6433
Iteracoes do algoritmo de Fisher scoring para os dados Cauchy simulados.
Agora vejamos alguns exemplos na linguagem de programacao R.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 14 / 15

Algoritmo Fisher scoringPortanto, o algoritmo Fisher scoring fica da forma:
θ(k+1) = θ(k) +4
n
n∑i=1
xi − θ(k)
1 + (xi − θ(k))2
k θ(k) lnL(θ(k))
0 10.04490 -239.65691 10.06710 -239.64342 10.06923 -239.64333 10.06945 -239.64333 10.06947 -239.6433
Iteracoes do algoritmo de Fisher scoring para os dados Cauchy simulados.
Agora vejamos alguns exemplos na linguagem de programacao R.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 14 / 15

Algoritmo Fisher scoringPortanto, o algoritmo Fisher scoring fica da forma:
θ(k+1) = θ(k) +4
n
n∑i=1
xi − θ(k)
1 + (xi − θ(k))2
k θ(k) lnL(θ(k))
0 10.04490 -239.65691 10.06710 -239.64342 10.06923 -239.64333 10.06945 -239.64333 10.06947 -239.6433
Iteracoes do algoritmo de Fisher scoring para os dados Cauchy simulados.
Agora vejamos alguns exemplos na linguagem de programacao R.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 14 / 15

Algoritmo Fisher scoringPortanto, o algoritmo Fisher scoring fica da forma:
θ(k+1) = θ(k) +4
n
n∑i=1
xi − θ(k)
1 + (xi − θ(k))2
k θ(k) lnL(θ(k))
0 10.04490 -239.65691 10.06710 -239.64342 10.06923 -239.64333 10.06945 -239.64333 10.06947 -239.6433
Iteracoes do algoritmo de Fisher scoring para os dados Cauchy simulados.
Agora vejamos alguns exemplos na linguagem de programacao R.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 14 / 15

Bibliografia
McLachlan, G. and T. Krishnan. 2008. The EM Algorithm and Extensions,Second Edition. Wiley Series in Probability and Statistics.
Kuri, A.I. 2003. Advanced calculus with applications in Statistics. SecondEdition. Wiley Series in Probability and Statistics.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 15 / 15

Bibliografia
McLachlan, G. and T. Krishnan. 2008. The EM Algorithm and Extensions,Second Edition. Wiley Series in Probability and Statistics.
Kuri, A.I. 2003. Advanced calculus with applications in Statistics. SecondEdition. Wiley Series in Probability and Statistics.
Carlos Montenegro Silva (IME-USP) Outubro, 2014 15 / 15