estadística i tema 5: modelos probabilísticostema 5. modelos probabil sticos contenidos i...
TRANSCRIPT

Estadıstica ITema 5: Modelos probabilısticos

Tema 5. Modelos probabilısticos
Contenidos
I Variables aleatorias: concepto.
I Variables aleatorias discretas:I Funcion de probabilidad y Funcion de distribucion.I Media y Varianza de una v.a. discretaI Relacion entre la media y la varianza: desigualdad de Chebyschev
I Variables aleatorias continuas:I Funcion de densidad y Funcion de distribucion.I Media y Varianza de una v.a. continua.
I Modelos probabilısticos:I Modelos de probabilidad discretos: Ensayos de Bernoulli y
distribucion Binomial.I Modelos de probabilidad continuos: Distribucion uniforme y
distribucion normal.I Teorema Central del Lımite:
I Vectores aleatorios: introduccion a la distribucion normal bivariante.

Variables aleatorias: concepto
I Sea Ω el espacio muestral asociado a cierto experimento aleatorio.
I Se denomina variable aleatoria (v.a.) a una funcion X : Ω −→ R, talque a cada elemento ei ∈ Ω le asigna un valor numericoX (ei ) = xi ∈ R.
I Intuitivamente, una variable aleatoria es una medida o cantidad quevarıa en funcion del resultado concreto ei que se observa al realizarel experimento aleatorio.
I La v.a. se denota con letras mayusculas, mientras que las letrasminusculas indican el valor concreto que toma la v.a. cuando seevalua en un punto muestral.
I OBS: Las variables estadısticas que hemos visto en los temas 1, 2 y3 son el resultado de evaluar las v.a. correspondientes en muestrasde individuos.

Variables aleatorias
V.a. discretaSi X toma valores sobre un conjunto S ⊆ R finito o infinito numerable,se dice que X es una variable aleatoria discreta.
V.a. continuaSi X toma valores sobre un conjunto S ⊆ R infinito no numerable (porejemplo, en un intervalo o en una union de intervalos de R), se dice queX es una variable aleatoria continua.
Ejemplos
I X =“Resultado al tirar un dado” es una variable discreta dondeS = 1, 2, 3, 4, 5, 6.
I Y =“Numero de coches que pasan por un cierto peaje en unasemana” es una variable discreta donde S = 0, 1, 2, . . . = N ∪ 0 esinfinito numerable.
I Z = “altura de un alumno elegido al azar” es una variable continuadonde S = [0,+∞).

Variables aleatorias discretas
Funcion de probabilidadSea X una variable aleatoria discreta con posibles valores x1, x2, . . .. Sellama funcion de probabilidad o funcion de masa, al conjunto deprobabilidades con las que X toma cada uno de sus valores, es decir,pi = P[X = xi ], para i = 1, 2, . . . .
EjemploX = resultado de lanzar un dado. La funcion de probabilidad es
x 1 2 3 4 5 6P[X = x ] 1
616
16
16
16
16
En este caso, S = 1, 2, 3, 4, 5, 6 y p1 = . . . = p6 = 16 .

Variables aleatorias discretas
Funcion de probabilidad. Propiedades
Sea X una variable aleatoria discreta que toma valores en el conjuntoS = x1, x2 . . . con probabilidades p1 = P(X = x1), p2 = P(X = x2),. . .
I 0 ≤ P[X = xi ] ≤ 1.
I∑i
P[X = xi ] = 1.
I P[X ≤ x ] =∑i,xi≤x
P[X = xi ].
I P[X > x ] = 1− P[X ≤ x ].

EjemploI Un juego consiste en ensartar 3 aros, uno a uno, en una pica.
Participar cuesta 3 euros. Los premios son 4 euros por un acierto, 6euros por dos aciertos y 30 euros por tres aciertos. Suponemos quela probabilidad de ensartar un aro es de 0.1 en cada tiro, y que lostiros son independientes.
I Definimos la v.a. X como la ganancia en el juego. El espaciomuestral esta dado por:
Ω = (f , f , f ) , (a, f , f ) , (f , a, f ) , (f , f , a) ,
(a, a, f ) , (a, f , a) , (f , a, a) , (a, a, a)
donde a denota acierto y f denota fallo. Por lo tanto, X solo admitecuatro posibles resultados con las siguientes probabilidades:
P (X = −3) = 0,93 = 0,729
P (X = 1) = 3× 0,1× 0,92 = 0,243
P (X = 3) = 3× 0,12 × 0,9 = 0,027
P (X = 27) = 0,13 = 0,001

Ejemplo
I ¿Cual es la probabilidad de ganar 3 o mas euros, descontando los 3euros por participar?
P (X ≥ 3) = P (X = 3) + P (X = 27) = 0,027 + 0,001 = 0,028
I ¿Cual es la probabilidad de no perder dinero?
P (X ≥ 0) = P (X = 1) + P (X = 3) + P (X = 27) =
= 0,243 + 0,027 + 0,001 = 0,271
o lo que es lo mismo:
P (X ≥ 0) = 1− P (X < 0) = 1− P (X = −3) = 1− 0,729 = 0,271

Variables aleatorias discretas
Funcion de distribucionLa funcion de distribucion o funcion de probabilidad acumulada de unavariable aleatoria X es una aplicacion F : R→ [0, 1], que a cada valorx ∈ R le asigna la probabilidad:
F (x) = P[X ≤ x ] =∑
xi∈S,xi≤x
P (X = xi )
OBS: Esta definida para todo x ∈ R y no solo para los valores de X .
I 0 ≤ F (x) ≤ 1 para todo x ∈ R.
I F (y) = 0 para todo y < mın S . Por tanto, F (−∞) = 0.
I F (y) = 1 para todo y > max S . Por tanto, F (∞) = 1.
I Si x1 ≤ x2, entonces F (x1) ≤ F (x2), es decir, F (x) es nodecreciente.
I Para todo a, b ∈ R,P (a < X ≤ b) = P (X ≤ b)− P (X ≤ a) = F (b)− F (a).

Ejemplo
I La funcion de probabilidad de la variable X en el ejemplo del juegoes la siguiente:
P (X = x) =
0,729 x = −30,243 x = 10,027 x = 30,001 x = 27
I La funcion de distribucion de la variable X en el ejemplo del juego esla siguiente:
F (x) = P (X ≤ x) =
0 x < −3
0,729 −3 ≤ x < 10,729 + 0,243 = 0,972 1 ≤ x < 3
0,729 + 0,243 + 0,027 = 0,999 3 ≤ x < 270,729 + 0,243 + 0,027 + 0,001 = 1 27 ≤ x
I Notar que esta funcion presenta discontinuidades de salto en lospuntos del conjunto S . El salto es de magnitud P (X = x), paratodo x ∈ S .

Esperanza de una variable aleatoria discreta
Sea X una v.a. discreta que toma valores en S = x1, x2, . . . conprobabilidades p1 = P (X = x1) , p2 = P (X = x2) , . . . Entonces, laesperanza de X esta dada por:
E [X ] =∑x∈S
xP (X = x) =∑i
xiP (X = xi ) =∑i
xipi

Esperanza de una variable aleatoria discreta. Propiedades
I Si a, b ∈ R, entonces:
E [a + bX ] = a + bE [X ]
I Sea g una funcion real. Entonces:
E [g (X )] =∑x∈S
g (x)P (X = x)
I Sean X1, . . . ,Xn, n v.a., y a1, . . . , an, n numeros reales. Entonces:
E [a1X1 + · · ·+ anXn] = a1E [X1] + · · ·+ anE [Xn]

Ejemplo
La esperanza de la variable aleatoria X del ejemplo del juego es lasiguiente:
E [X ] =∑x∈S
xP (X = x) =
= −3× P (X = −3) + 1× P (X = 1) + 3× P (X = 3) + 27× P (X = 27) =
= −3× 0,729 + 1× 0,243 + 3× 0,027 + 27× 0,001 = −1,836
Por lo tanto, la ganancia esperada es de −1,836 euros.

Varianza de una variable aleatoria discreta
I La varianza de la v.a. discreta X esta dada por:
V [X ] = E[(X − E [X ])2
]=∑x∈S
(x − E [X ])2 P (X = x) =
=∑i
(xi − E [X ])2 P (X = xi ) =∑i
(xi − E [X ])2 pi
I La raız cuadrada de la varianza se denomina desviacion tıpica y sedenota por S [X ] =
√V [X ].

Varianza de una variable aleatoria discreta. Propiedades
I La varianza se puede escribir tambien como:
V [X ] = E[X 2]− E [X ]2
I V [X ] ≥ 0 y Var [X ] = 0 si, y solo si, X es una constante.
I Si a, b ∈ R, entonces:
V [a + bX ] = b2V [X ]
I Sean X1, . . . ,Xn, n v.a. independientes, y a1, . . . , an, n numerosreales. Entonces:
V [a1X1 + · · ·+ anXn] = a21V [X1] + · · ·+ a2nV [Xn]

Ejemplo
La varianza de la variable aleatoria X del ejemplo del juego es lasiguiente:
V [X ] = E[X 2]− E [X ]2 = 7,776− (−1,836)2 = 4,405
donde:
E[X 2]
= (−3)2× 0,729 + 12× 0,243 + 32× 0,027 + 272× 0,001 = 7,776
La desviacion tıpica es por tanto S [X ] =√
4,405 = 2,0988.

Ejemplo
Consideramos la v.a. discreta X = numero de caras al tirar una monedados veces. La funcion de probabilidad de X es:
x 0 1 2P[X = x ] 1
412
14
Por un lado, su esperanza viene dada por:
E [X ] = 0× 1
4+ 1× 1
2+ 2× 1
4= 1
mientras que su varianza es:
Var [X ] = E [X 2]− E [X ]2 =3
2− 12 =
1
2
donde:
E [X 2] = 02 × 1
4+ 12 × 1
2+ 22 × 1
4=
3
2

Desigualdad de Chebyschev
Este resultado es util para estimar una probabilidad cuando se desconocela distribucion de probabilidad de una v.a. discreta X .Si X es una v.a. con esperanza y varianza finitas, entonces para todok ≥ 1:
P (|X − E [X ]| ≥ k) ≤ V (X )
k2
o, equivalentemente,
P (|X − E [X ]| < k) ≥ 1− V (X )
k2
OBS: La cota que proporciona la desigualdad de Chebyschev esdemasiado gruesa y solo debe utilizarse cuando no se disponga de ladistribucion de X .

Desigualdad de Chebyschev
Veamos como aplicar la desigualdad de Chebyschev con la variablealeatoria del ejemplo del juego. Tenemos que E [X ] = −1,836 y queV [X ] = 4,405. Entonces:
P (|X + 1,836| ≥ 3) ≤ 4,405
9= 0,4894
Por otro lado, tenemos que:
P (|X + 1,836| ≥ 3) = P (X + 1,836 ≥ 3) + P (X + 1,836 ≤ −3) =
= P (X ≥ 1,164) + P (X ≤ −4,836) =
= P (X = 3) + P (X = 27) = 0,027 + 0,001 = 0,028
que demuestra que la cota de Chebyschev puede ser muy gruesa.

Ejemplo de repaso
I Sea X , la variable aleatoria que representa el numero de caras menosel numero de cruces en 3 tiradas de una moneda trucada de maneraque es dos veces mas probable que salga cara que cruz.
I Indicamos por “c”=cara y “+”=cruz.
I El espacio muestral es:
Ω =
e1 = c , c , c , e2 = +, c , c , e3 = c ,+, c , e4 = c , c ,+ ,
e5 = +,+, c , e6 = +, c ,+ , e7 = c ,+,+ , e8 = +,+,+

Ejemplo de repaso
I El conjunto S donde toma valores es S = −3,−1, 1, 3 ya que:
X (e1) = 3− 0 = 3
X (e2) = X (e3) = X (e4) = 2− 1 = 1
X (e5) = X (e6) = X (e7) = 1− 2 = −1
X (e8) = 0− 3 = −3
I La funcion de probabilidad viene dada por:
P (X = x) =
P (X = −3) =
(13
)3= 1
27
P (X = −1) = 3×(13
)2 × 23 = 2
9
P (X = 1) = 3× 13 ×
(23
)2= 4
9
P (X = 3) =(23
)3= 8
27

Ejemplo de repaso
I Supongamos que participamos en el siguiente juego para el que hayque pagar de inicio 6 euros. Si al lanzar 3 veces la moneda anterioraparece 1 cruz, ganamos 4 euros, si aparecen 2 cruces ganamos 6euros y si aparecen 3 cruces ganamos 30 euros. ¿Cual es la gananciaesperada?
I Sea Y la variable ganancia en el juego. Entonces:
I Si no obtenemos ninguna cruz, tenemos que X = 3, por lo queY = −6 con probabilidad P (Y = −6) = P (X = 3) = 8
27.
I Si obtenemos una cruz, tenemos que X = 1, por lo que Y = −2 conprobabilidad P (Y = −2) = P (X = 1) = 4
9.
I Si obtenemos dos cruces, tenemos que X = −1, por lo que Y = 0con probabilidad P (Y = 0) = P (X = −1) = 2
9.
I Si obtenemos tres cruces, tenemos que X = −3, por lo que Y = 24con probabilidad P (Y = 24) = P (X = −3) = 1
27.
I Por lo tanto, Y toma valores en el conjunto S = −6,−2, 0, 24. Laganancia esperada es:
E [Y ] = −6× 8
27− 2× 4
9+ 0× 2
9+ 24× 1
27= −1,78 euros
Variables aleatorias continuas
Funcion de distribucionPara X v.a. continua, la funcion de distribucion es la funcionF (x) = P[X ≤ x ],∀x ∈ R
Igual que en el caso discreto, la funcion F (x) da las probabilidadesacumuladas hasta el punto x ∈ R, pero ahora se trata de una funcioncontinua y no de tipo escalon.

Variables aleatorias continuas
Propiedades
I 0 ≤ F (x) ≤ 1, para todo x ∈ RI F (−∞) = 0.
I F (∞) = 1.
I Si x1 ≤ x2, entonces F (x1) ≤ F (x2), es decir, F (x) es no decreciente.
I Para todo x1, x2 ∈ R, P(x1 ≤ X ≤ x2) = F (x2)− F (x1).
I F (x) es continua.
La funcion de probabilidad no tiene sentido en variables aleatoriascontinuas, porque P(X = x) = 0. Para sustituir la funcion deprobabilidad, en variables aleatorias continuas usaremos la funcion dedensidad.

Variables aleatorias continuas
Funcion de densidadPara una variable aleatoria continua X con funcion de distribucion F (x),la funcion de densidad de X es:
f (x) =dF (x)
dx= F ′(x)
Propiedades
I f (x) ≥ 0 ∀x ∈ R
I P(a ≤ X ≤ b) =∫ b
af (x)dx ∀a, b ∈ R
I F (x) = P(X ≤ x) =∫ x
−∞ f (u)du
I∫∞−∞ f (x)dx = 1

Variables aleatorias continuas
EjemploUna variable aleatoria X tiene funcion de densidad
f (x) =
12x2(1− x) si 0 < x < 1
0 si no
Entonces:
P(X ≤ 0,5) =
∫ 0,5
−∞f (u)du =
∫ 0,5
0
12u2(1− u)du = 0,3125
P(0,2 ≤ X ≤ 0,5) =
∫ 0,5
0,2
f (u)du =
∫ 0,5
0,2
12u2(1− u)du = 0,2853
F (x) = P(X ≤ x) =
∫ x
−∞f (u)du =
0 si x ≤ 0
12(
x3
3 −x4
4
)si 0 < x ≤ 1
1 si x > 1

Esperanza de una variable aleatoria continua
Sea X una v.a. continua que toma valores en S ⊆ R, con funcion dedensidad f (x) . Entonces, la esperanza de X esta dada por:
E [X ] =
∫S
xf (x) dx
Se verifican las mismas propiedades descritas antes para la esperanza deuna v.a. discreta. Solo cambia la forma de calcularla.

Ejemplo
La esperanza de la variable aleatoria X del ejemplo anterior es lasiguiente:
E [X ] =
∫Rx · f (x)dx =
∫ 1
0
x · 12x2(1− x)dx =
=
∫ 1
0
(12(x3 − x4)
)dx = 12
(1
4x4 − 1
5x5) ∣∣1
0 = 12
(1
4− 1
5
)=
3
5

Varianza de una variable aleatoria continua
I La varianza de la v.a. continua X esta dada por:
V [X ] = E[(X − E [X ])2
]=
∫S
(x − E [X ])2 f (x)dx =
=
∫S
x2f (x)dx − E [X ]2 = E[X 2]− E [X ]2
I La raız cuadrada de la varianza se denomina desviacion tıpica y sedenota por S [X ] =
√V [X ].
Se verifican las mismas propiedades descritas antes para la varianza deuna v.a. discreta. Solo cambia la forma de calcularla.

Ejemplo
La varianza de la variable aleatoria X del ejemplo anterior es la siguiente:
Var [X ] = E[X 2]− E [X ]2 =
2
5−(
3
5
)2
=2
5− 9
25=
1
25
donde:
E[X 2]
=
∫Rx2f (x)dx =
∫ 1
0
12x4(1− x)dx =12
5x5|x=1
x=0 −12
6x6|x=1
x=0 =
=12
5− 2 =
2
5
La desviacion tıpica es por tanto S [X ] =√
125 = 1
5 .

Modelos probabilısticos
I Modelos de probabilidad discretos: Ensayos de Bernoulli ydistribucion Binomial.
I Modelos de probabilidad continuos: Distribucion uniforme ydistribucion normal.
I Teorema Central del Lımite:

Modelo Bernoulli
DescripcionPartimos de un experimento aleatorio con solo dos posibles resultados,que calificamos de exito/fracaso.Definimos la variable aleatoria:
X =
1 si exito0 si fracaso
Sea p la probabilidad de exito. Entonces, 1− p es la probabilidad defracaso.
El experimento se llama ensayo de Bernoulli y la variable aleatoria se diceque sigue una distribucion Bernoulli de parametro p.
Se escribe X ∼ Ber(p).

Modelo Bernoulli
EjemploTirar una moneda al aire
X =
1 sale cara0 si sale cruz
Es un ensayo Bernoulli, y X sigue una distribucion Bernoulli deparametro 1/2.
EjemploUna lınea aerea estima que los pasajeros que compran un billete para unvuelo tienen una probabilidad igual a 0,05 de no presentarse al embarquede dicho vuelo.Definamos
Y =
1 si el pasajero se presenta0 si no lo hace
Y sigue una distribucion Bernoulli con parametro 0,95.

Modelo Bernoulli
Funcion de Probabilidad:
P[X = 0] = 1− p P[X = 1] = p
Funcion de distribucion:
F (x) =
0 si x < 0
1− p si 0 ≤ x < 11 si x ≥ 1
Propiedades
I E [X ] = p × 1 + (1− p)× 0 = p
I E [X 2] = p × 12 + (1− p)× 02 = p
I V [X ] = E [X 2]− E [X ]2 = p − p2 = p(1− p)
I S [X ] =√p(1− p)

Modelo Binomial
DescripcionUn ensayo Bernoulli de parametro p se repite n veces de maneraindependiente. La variable numero de exitos obtenidos, sigue unadistribucion Binomial (de parametros n y p).
DefinicionUna variable X sigue una distribucion binomial con parametros n y p si
P[X = x ] =
(nx
)px(1− p)n−x
para x = 0, 1, . . . , n donde(nx
)=
n!
x!(n − x)!
Se escribe X ∼ B(n, p).

Modelo Binomial
EjemploLa lınea aerea del ejemplo anterior ha vendido 80 billetes para un vuelo.La probabilidad de que un pasajero no se presente al embarque es de0, 05. Definimos X = numero de pasajeros que se presentan. Entonces(suponiendo independencia)
X ∼ B(80, 0,95)
I La probablidad de que los 80 pasajeros se presenten
P[X = 80] =
(8080
)0,9580 × (1− 0,95)80−80 = 0,0165
I La probabilidad de que al menos un pasajero no se presente:
P[X < 80] = 1− P[X = 80] = 1− 0,0165 = 0,9835

Modelo Binomial
Propiedades
I E [X ] = np
I Var [X ] = np(1− p)
I S [X ] =√np(1− p)

Distribucion uniforme
DescripcionLa distribucion uniforme es aquella en la que todos los intervalos de iguallongitud en su rango son igualmente probables. Es decir, que la funcionde densidad es constante para todos los valores posibles de la variable.
DefinicionSe dice que una variable X sigue una distribucion uniforme en el intervalo(a, b) (sus parametros son a y b) si
f (x) =
1
b−a si a < x ≤ b
0 si no
Se escribe X ∼ U(a, b).

Distribucion uniforme
Propiedades
I Esperanza: E [X ] = a+b2
I Varianza: V [X ] = (b−a)212
I Desviacion tıpica:S [X ] = b−a√
12
Funcion de densidad

Ejemplo: distribucion uniforme en (3,5)
Una variable aleatoria X que sigue una distribucion uniforme en elintervalo (3, 5) tiene funcion de densidad
f (x) =
12 si 3 < x < 50 si no
Calculamos algunas probabilidades:
P(X ≤ 0,5) =∫ 0,5
−∞ f (u)du = 0
P(X ≤ 4) =∫ 4
−∞ f (u)du =∫ 4
312du = 1
2u|43 = 1
2
P(3,5 ≤ X ≤ 4,5) =∫ 4,5
3,5f (u)du =
∫ 4,5
3,512du = 1
2

Ejemplo: distribucion uniforme en (3,5)
Funcion de distribucion
F (x) = P(X ≤ x) =
∫ x
−∞f (u)du = . . .
I Si x ≤ 3 entonces F (x) = P(X ≤ x) = 0.
I Si 3 < x ≤ 5 entonces F (x) = P(X ≤ x) =∫ x
312du = u
2 |x3 = x−3
2 .
I Si 5 < x entonces F (x) = P(X ≤ x) =∫ 5
312du = u
4 |53 = 5−3
2 = 1.
Es decir, que:
F (x) =
0 si x ≤ 3
x−32 si 3 < x ≤ 51 si x > 5

Ejemplo: distribucion uniforme en (3,5)
Esperanza
E [X ] =∫R x · f (x)dx =
∫ 5
3x · 12dx = x2
4
∣∣∣53
= 52−324 = 4
Varianza
Var [X ] =∫R x2 · f (x)dx − E [X ]2
=∫ 5
3x2
2 dx − 42 = x3
6
∣∣∣53− 16 = 0,33

Distribucion normal
DescripcionLa distribucion normal es un modelo teorico que aproxima bien muchassituaciones reales. La inferencia estadıstica se fundamenta basicamenteen la distribucion normal y en distribuciones que se derivan de ella.
DefinicionSe dice que una variable X sigue una distribucion normal o Gausiana conparametros µ y σ, y se denota por X ∼ N (µ, σ), si
f (x) =1
σ√
2πexp
− 1
2σ2(x − µ)2
PropiedadesE [X ] = µ V [X ] = σ2
Si X ∼ N (µ, σ), f (x) es simetrica respecto de µ.
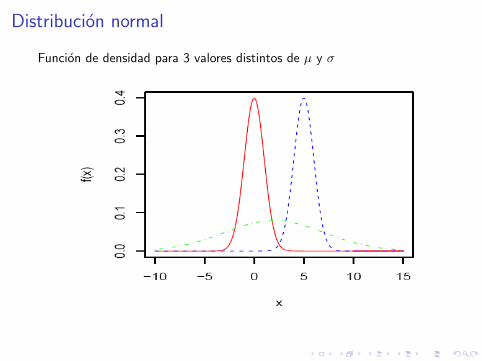
Distribucion normal
Funcion de densidad para 3 valores distintos de µ y σ

Distribucion normal
PropiedadSi X ∼ N (µ, σ),
I P(µ− σ < X < µ+ σ) ≈ 0,683
I P(µ− 2σ < X < µ+ 2σ) ≈ 0,955
I P(µ− 3σ < X < µ+ 3σ) ≈ 0,997
Desigualdad de ChebyshevLa desigualdad de Chebyschev tambien se puede aplicar en el caso devariables continuas. En particular, si X es Gaussiana de media µ ydesviacion tıpica σ, tenemos que:
P (µ− k < X < µ+ k) = P (|X − µ| < k) ≥ 1− σ2
k2
de donde, si k = cσ, tenemos que P (µ− cσ < X < µ+ cσ) ≥ 1− 1c2 .

Distribucion normal
Transformacion linealSi X ∼ N (µ, σ), entonces:
Y = aX + b ∼ N (aµ+ b, |a|σ)
EstandarizacionSi X ∼ N (µ, σ), considero
Z =X − µσ
∼ N (0, 1)
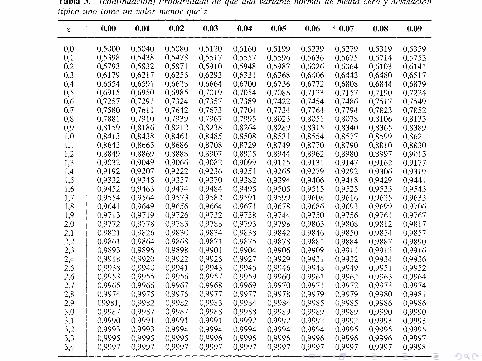
Se llama distribucion normal estandar. Es una distribucion simetrica ycentrada en 0. Ademas, esta tabulada por lo que no tenemos que haceruso de integrales para obtener probabilidades.
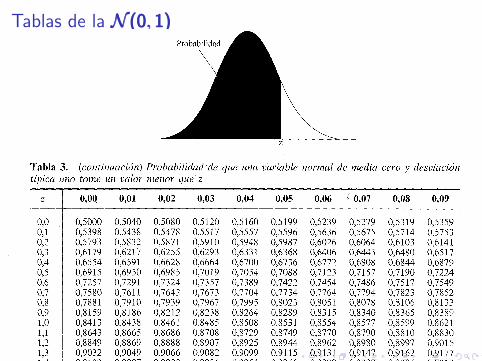
Tablas de la N (0, 1)N (0, 1)N (0, 1)

Distribucion normal: Ejemplo
Sea Z ∼ N(0, 1). Calculemos algunas probabilidades:
I Pr(Z < 1,5) = 0,9332. tabla
I Pr(Z > −1,5) = Pr(Z < 1,5) = 0,9332. ¿por que?
I Pr(Z < −1,5) = Pr(Z > 1,5) = 1− Pr(Z < 1,5) = 1− 0,9332 =0,0668. ¿por que no ≤?
I Pr(−1,5 < Z < 1,5) = Pr(Z < 1,5)− Pr(Z < −1,5) =0,9332− 0,0668 = 0,8664.

Distribucion normal: Ejemplo
Sea X ∼ N(µ = 2, σ = 3). Queremos calcular Pr(X < 4) yPr(−1 < X < 3,5):
I En primer lugar, tipificamos la variable original como sigue:
Pr(X < 4) = P
(X − 2
3<
4− 2
3
)= Pr
(Z < 0,666
)≈ 0,7454,
donde Z ∼ N(0, 1).
I A continuacion, buscamos :
Pr(−1 < X < 3,5) = Pr(−1− 2 < X − 2 < 3,5− 2)
= P
(−1− 2
3<
X − 2
3<
3,5− 2
3
)= Pr(−1 < Z < 0,5) =
= Pr(Z < 0,5)− Pr(Z < −1) = 0,6915− 0,1587 = 0,5328.
donde Z ∼ N(0, 1).

Distribucion normal: otro ejemplo
Es difıcil etiquetar la carne empaquetada con su peso correcto debido alos efectos de perdida de lıquido (definido como porcentaje del pesooriginal de la carne). Supongamos que la perdida de lıquido en unpaquete de pechuga de pollo se distribuye como normal con media 4 % ydesviacion tıpica 1 %.
Sea X la perdida de lıquido de un paquete de pechuga de pollo elegido alazar.
I ¿Cual es la probabilidad de que 3 % < X < 5 %?
I ¿Cual es el valor de x para que un 90 % de paquetes tengan perdidasde lıquido menores que x?
I En una muestra de 4 paquetes, hallar la probabilidad de que todostengan perdidas de peso de entre 3 y 5 %.
Sexauer, B. (1980) Drained-Weight Labelling for Meat and Poultry: An
Economic Analysis of a Regulatory Proposal, Journal of Consumer Affairs, 14,
307-325.

Distribucion normal: otro ejemplo
Pr(3 < X < 5) = Pr
(3− 4
1<
X − 4
1<
5− 4
1
)= Pr(−1 < Z < 1)
= Pr(Z < 1)− Pr(Z < −1) = 0,8413− 0,1587 = 0,6827
Queremos Pr(X < x) = 0,9. Entonces
Pr
(X − 4
1<
x − 4
1
)= Pr(Z < x − 4) = 0,9
Mirando las tablas, tenemos x − 4 ≈ 1,28 que implica que un 90 % de laspaquetes tienen perdidas de menores que x = 5,28 %.
Para un paquete p = Pr(3 < X < 5) = 0,6827. Sea Y el numero depaquetes en la muestra de 4 paquetes que tienen perdidas de entre 3 % y5 %. Luego Y ∼ B(4, 0,6827).
Pr(Y = 4) =
(4
4
)0,68274(1− 0,6827)0 = 0,2172.

Distribucion normal: otro ejemplo
Si la muestra fuera de 5 paquetes, ¿cual seria la probabilidad que por lomenos una tuviera perdidas de entre el 3 % y 5 %? Tenemos que n = 5 yp = 0,6827. Por lo tanto, Y ∼ B(5, 0,6827). Entonces,
Pr(Y ≥ 1) = 1− Pr(Y < 1) = 1− Pr(Y = 0) =
= 1−(
5
0
)0,68270(1− 0,6827)5−0 = 1− (1− 0,6827)5 = 0,9968.

Teorema central del lımite
El siguiente teorema nos habla de la distribucion de la media de unconjunto de muchas v.a. independientes e igualmente distribuidas:
X =1
n
n∑i=1
Xi
y nos dice que si n es grande, la distribucion de la media de v.a.independientes e identicamente distribuidas es normal, sea cual sea ladistribucion de las v.a. De aquı el papel “central” que juega ladistribucion normal.
TeoremaSean X1,X2, . . . ,Xn v.a. independientes, e identicamente distribuidas conmedia µ y desviacion tıpica σ (ambas finitas). Si n es suficientementegrande, se tiene que
X − µσ/√n∼ N (0, 1)

Aproximaciones
BinomialSi X ∼ B(n, p) con n suficientemente grande (o bien n ≥ 30 y0,1 ≤ p ≤ 0,9 o bien np ≥ 5 y n (1− p) ≥ 5), entonces:
X − np√np(1− p)
∼ N (0, 1)

TCL y aproximaciones: Ejemplo
I Sea X ∼ B(100, 1/3). Bucamos el valor de Pr(X < 40), si bien elcalculo exacto es muy largo ya que necesitamos un gran numero deoperaciones.
I Utilizando el TCL tenemos que X ∼ B(100, 1/3) ≈ N (33,3, 4,714) ,ya que:
E [X ] = 100× 1
3= 33.3
V [X ] = 100× 1
3× 2
3= 22.2
S [X ] =√
22.2 = 4,714
I Por lo tanto,
Pr(X < 40) = P
(X − 33.3
4,714<
40− 33.3
4,714
)≈ P (Z < 1,414) donde Z ∼ N(0, 1)
≈ 0,921.

Funcion de distribucion conjunta de dos variables
I La funcion de distribucion conjunta de dos variables aleatoriascontinuas X e Y es una aplicacion F : R2 → [0, 1], tal que a cadavalor (x , y) ∈ R2 le asigna la probabilidad:
F (x , y) = P(X ≤ x ,Y ≤ y) =
∫ x
−∞
∫ y
−∞f (x , y) dydx ,
donde f (x , y) es la funcion de densidad conjunta de la variablealeatoria (X ,Y ).
I La funcion de densidad conjunta, f (x , y), verifica tres propiedades:
1. f (x , y) ≥ 0, para cualquier par (x , y) ∈ R2.
2. P(a ≤ X ≤ b, c ≤ Y ≤ d) =∫ b
a
∫ d
cf (x , y) dydx .
3.∫∞−∞
∫∞−∞ f (x , y) dydx = 1.

Distribuciones marginales y condicionadasI Las funciones de densidad marginales de las variables aleatorias
continuas X e Y estan dadas por:
fX (x) =
∫ ∞−∞
f (x , y) dy y fY (y) =
∫ ∞−∞
f (x , y) dx
respectivamente.
I Las variables aleatorias continuas X e Y se dice que sonindependientes si y solo si:
f (x , y) = fX (x) fY (y)
siendo fX y fY las funciones de densidad marginales de X y de Y ,respectivamente.
I La funcion de densidad condicional de la variable continua Y , dadoel valor X = x0 de la variable aleatoria X , esta dada por:
fY |X (y |X = x0) =f (x0, y)
fX (x0)

Esperanza y covarianza
I La esperanza de la variable aleatoria (X ,Y ) es el vector formado porlas esperanzas de las distribuciones marginales de X e Y :
E
[(XY
)]=
(E [X ]E [Y ]
)I La covarianza entre dos variables aleatorias X e Y se define como:
cov [X ,Y ] = E [(X − E [X ]) (Y − E [Y ])]
y permite medir como cambian X e Y de forma conjunta.
I Si valores grandes de X se corresponden con valores grandes de Y , ylo mismo ocurre con los valores pequenos, cov [X ,Y ] sera positiva.Si valores grandes de X se corresponden con valores pequenos de Y ,y viceversa, cov [X ,Y ] sera negativa.
I Notar que la covarianza depende crucialmente de las unidades demedida de las variables X e Y lo que hace difıcil su interpretacion.

Coeficiente de correlacion
I El coeficiente de correlacion entre dos variables aleatorias X e Y sedefine como:
corr [X ,Y ] =cov [X ,Y ]√V [X ]V [Y ]
donde cov [X ,Y ] es la covarianza entre X e Y y V [X ] y V [Y ] sonlas varianzas de X e Y , respectivamente.
I Notar que −1 ≤ corr [X ,Y ] ≤ 1 independientemente de las unidadesde medida de X e Y .
I corr [X ,Y ] solamente mide relaciones lineales.
I Un valor de corr [X ,Y ] proximo a 1 indica una alta relacion linealpositiva entre X e Y . Un valor de corr [X ,Y ] proximo a −1 indicauna alta relacion lineal negativa entre X e Y . Por ultimo, un valor decorr [X ,Y ] proximo a 0 indica una relacion lineal debil entre X e Y .

Matriz de covarianzas
I La matriz de covarianza de una variable aleatoria (X ,Y ) es unamatriz de tamano 2× 2 dada por:
C [X ,Y ] =
(V [X ] cov [X ,Y ]
cov [X ,Y ] V [Y ]
)es decir, C [X ,Y ] contiene las varianzas de X e Y en la diagonalprincipal y la covarianza entre X e Y fuera de la diagonal principal.

La distribucion Gaussiana bivariante
I Se dice que una variable (X ,Y ) sigue una distribucion normal oGaussiana bivariante con parametros µ = (µX , µY )′ y matriz decovarianzas:
Σ =
(σ2X σXY
σXY σ2Y
)y se denota por (X ,Y ) ∼ N2 (µ,Σ) si tiene funcion de densidad:
f (x , y) =1
2π |Σ|1/2exp
(−1
2(X − µX ,Y − µY )
(σ2X σXY
σXY σ2Y
)−1(X − µX
Y − µY
))
I Notar que µX = E [X ], µY = E [Y ], σ2X = V [X ], σ2
Y = V [Y ] yσXY = cov [X ,Y ].

La distribucion Gaussiana bivariante
I La varianza generalizada es el valor de:
|Σ| = σ2Xσ
2Y − σ2
XY = σ2Xσ
2Y
(1− corr [X ,Y ]2
)y mide la dispersion global de la variable bivariante (X ,Y ). Notarcomo la varianza generalizada disminuye si corr [X ,Y ] tiende a ±1 yaumenta si corr [X ,Y ] tiende a 0.
I Por ultimo, la matriz Σ−1 se puede escribir como:
Σ−1 =1
σ2Xσ
2Y − σ2
XY
(σ2Y −σXY
−σXY σ2X
)
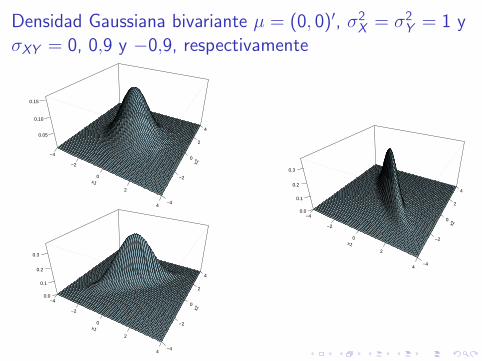
Densidad Gaussiana bivariante µ = (0, 0)′, σ2X = σ2
Y = 1 yσXY = 0, 0,9 y −0,9, respectivamente
x1
−4
−2
0
2
4
x2
−4
−2
0
2
40.05
0.10
0.15
x1
−4
−2
0
2
4
x2
−4
−2
0
2
4
0.0
0.1
0.2
0.3
x1
−4
−2
0
2
4
x2
−4
−2
0
2
4
0.0
0.1
0.2
0.3

Esperanza y varianza condicionalI Si (X ,Y ) sigue una distribucion Gaussiana bivariante con
parametros µ = (µX , µY )′ y matriz de covarianzas
Σ =
(σ2X σXY
σXY σ2Y
)entonces:
I X ∼ N(µX , σ
2X
)e Y ∼ N
(µY , σ
2Y
), respectivamente.
I X e Y son independientes si y solo si σXY = 0.I Y |X = x0 sigue una distribucion Gaussiana univariante de
parametros:
µY |X = µY +σXY
σ2X
(x0 − µX )
σ2Y |X = σ2
Y −σ2XY
σ2X
I X |Y = y0 sigue una distribucion Gaussiana univariante deparametros:
µX |Y = µX +σXY
σ2Y
(y0 − µY )
σ2X |Y = σ2
X −σ2XY
σ2Y

EjemploI Sea (X ,Y ) una variable aleatoria que sigue una distribucion
Gaussiana bivariante con parametros µ = (2, 1)′ y matriz decovarianzas:
Σ =
(5 33 10
)I Entonces, podemos afirmar que:
I Las distribuciones marginales de X e Y son X ∼ N (2, 5) eY ∼ N (1, 10), respectivamente.
I X e Y no son independientes ya que σXY 6= 0.I Y |X = 6 sigue una distribucion Gaussiana univariante de parametros:
µY |X = 1 +3
5(6− 2) = 3,4
σ2Y |X = 10− 32
5= 8,2
I X |Y = 3 sigue una distribucion Gaussiana univariante de parametros:
µX |Y = 2 +3
10(3− 1) = 2,6
σ2X |Y = 5− 32
10= 4,1