dpto. ciencias de la computaci´on e inteligencia artificial ... · contenido el teorema de bayes...
TRANSCRIPT

Tema 10: Aprendizaje de modelos probabilısticos
J. L. Ruiz Reina
Dpto. Ciencias de la Computacion e Inteligencia ArtificialUniversidad de Sevilla
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Contenido
El teorema de Bayes
Aprendizaje de modelos probabilısticos (¿que modeloprobabilıstico explica mejor los datos observados?)
Aprendizaje estadıstico, MAP y MLAprendizaje de redes bayesianasAprendizaje de modelos continuos
Clasificacion de nuevos ejemplos usando modelosprobabilısticos
Naive BayesVecinos mas cercanos
Aprendizaje no supervisado: clustering
k-medias
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos
Parte I
Parte I
El teorema de Bayes
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Formulacion de la regla de Bayes
De P(a ∧ b) = P(a|b)P(b) = P(b|a)P(a) podemos deducir lasiguiente formula, conocida como regla de Bayes
P(b|a) = P(a|b)P(b)P(a)
Regla de Bayes para variables aleatorias:
P(Y |X ) =P(X |Y )P(Y )
P(X )
recuerdese que esta notacion representa un conjunto deecuaciones, una para cada valor especıfico de las variables
Version con normalizacion:
P(Y |X ) = α · P(X |Y )P(Y )
Generalizacion, en presencia de un conjunto e deobservaciones:
P(Y |X , e) = α · P(X |Y , e)P(Y |e)
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Ejemplo de uso de la regla de Bayes
Sabemos que la probabilidad de que un paciente de meningitistenga el cuello hinchado es 0.5 (relacion causal)
Tambien sabemos la probabilidad (incondicional) de tenermeningitis ( 1
50000) y de tener el cuello hinchado (0.05)
Estas probabilidades provienen del conocimiento y laexperiencia
La regla de Bayes nos permite diagnosticar la probabilidad detener meningitis una vez que se ha observado que el pacientetiene el cuello hinchado
P(m|h) = P(h|m)P(m)
P(h)=
0,5× 150000
0,05= 0,0002
Alternativamente, podrıamos haberlo hecho normalizandoP(M|h) = α〈P(h|m)P(m);P(h|¬m)P(¬m)〉Respecto de lo anterior, esto evita P(h) pero obliga a saberP(h|¬m)
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Relaciones causa-efecto y la regla de Bayes
Modelando probabilısticamente una relacion entre una Causay un Efecto:
La regla de Bayes nos da una manera de obtener laprobabilidad de Causa, dado que se ha observado Efecto:
P(Causa|Efecto) = α · P(Efecto|Causa)P(Efecto)
Nos permite diagnosticar en funcion de nuestro conocimientode relaciones causales y de probabilidades a priori
¿Por que calcular el diagnostico en funcion del conocimientocausal y no al reves?
Porque es mas facil y robusto disponer de probabilidadescausales que de probabilidades de diagnostico (lo que se sueleconocer es P(Efecto|Causa) y el valor que ha tomado Efecto).
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Ejemplo
Consideremos la siguiente informacion sobre el cancer demama
Un 1% de las mujeres de mas de 40 anos que se hacen unchequeo tienen cancer de mamaUn 80% de las que tienen cancer de mama se detectan conuna mamografıaEl 9.6% de las que no tienen cancer de mama, al realizarseuna mamografıa se le diagnostica cancer erroneamente
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Ejemplo
Pregunta 1: ¿cual es la probabilidad de tener cancer si lamamografıa ası lo diagnostica?
Variables aleatorias: C (tener cancer de mama) y M(mamografıa positiva)P(C |m) = αP(C ,m) = αP(m|C )P(C ) =α〈P(m|c)P(c);P(m|¬c)P(¬c)〉 = α〈0,8 · 0,01; 0,096 · 0,99〉 =α〈0,008; 0,09504〉 = 〈0,0776; 0,9223〉Luego el 7.8% de las mujeres diagnosticadas positivamentecon mamografıa tendran realmente cancer de mama
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Ejemplo
Pregunta 2: ¿cual es la probabilidad de tener cancer si tras dosmamografıas consecutivas en ambas se diagnostica cancer?
Variables aleatorias: M1 (primera mamografıa positiva) y M2
(segunda mamografıa positiva)Obviamente, no podemos asumir independencia incondicionalentre M1 y M2
Pero es plausible asumir independencia condicional de M1 yM2 dada CPor tanto, P(C |m1,m2) = αP(C ,m1,m2) =αP(m1,m2|C )P(C ) = αP(m1|C )P(m2|C )P(C ) =α〈P(m1|c)P(m2|c)P(c);P(m2|¬c)P(m2|¬c)P(¬c)〉 =α〈0,8 · 0,8 · 0,01; 0,096 · 0,096 · 0,99〉 = 〈0,412; 0,588〉Luego aproximadamente el 41% de las mujeres doblementediagnosticadas positivamente con mamografıa tendranrealmente cancer de mama
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Parte II
Parte II
Aprendizaje de modelos probabilısticos a partir de ejemplos
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Vision estadıstica del aprendizaje
Volvemos en este tema a tratar cuestiones relacionadas con elaprendizaje a partir de observaciones
Como en los temas anteriores, el problema se plantea con unconjunto de entrenamiento d y con un conjunto de hipotesisH, candidatas a ser aprendidas
En este caso, nos moveremos en un dominio descrito porvariables aleatorias
El conjunto de datos d representa una serie de evidenciasobservadas (instancias concretas de algunas de las v.a. D)Las hipotesis de H son modelos probabilısticos de comofunciona el dominio (por ejemplo, distintas distribuciones deprobabilidad)
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Ejemplos de hipotesis y observaciones
Una urna con N bolas de colores, desconocemos la proporcionde cada color:
Observaciones: una serie de extracciones, de cada unaanotamos el colorHipotesis candidatas: cada una de las posibles distribuciones deproporcion de colores de las bolas.
Red bayesiana que describe un dominio medico, conocemos suestructura pero desconocemos las tablas de probabilidad
Observaciones: valores de las variables aleatorias para una seriede pacientes concretosHipotesis candidatas: cada una de los posibles conjuntos detablas de probabilidad de la red
Una poblacion cuyas alturas sabemos que siguen unadistribucion de Gauss
Observaciones: datos sobre alturas de algunas personas de lapoblacionHipotesis candidatas: todos los posibles pares (µ, σ) queindicarıan la media y desviacion tıpica de una distribucionnormal.
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Vision estadıstica del aprendizaje
A diferencia de los temas anteriores, las decisiones sobreque aprender se tomaran, esencialmente, calculandoprobabilidades condicionadas
No necesariamente se descarta una hipotesis que seainconsistente con d, sino que busca la hipotesis mas probable,dadas las observaciones de d
Por ejemplo, se buscan hipotesis que maximizan P(h|d), parah ∈ HPor tanto, sera esencial el uso del teorema de Bayes (de hecho,este tipo de aprendiaje se denomina llamado “aprendizajebayesiano”)
Ademas, incorpora el conocimiento a priori del que se dispone:
Probabilidades de la forma P(d|h) y P(h), esencialmente
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

El marco general del aprendizaje bayesiano
Sea H un conjunto de hipotesis, D una v.a. que representa losdatos observables.
La informacion de entrada es:
Los datos observados, dLa probabilidades a priori de las hipotesis, P(h)La verosimilitud de los datos bajo las hipotesis, P(d|h)
El aprendizaje bayesiano consiste en calcular la probabilidadde cada hipotesis de H (dados los datos) y predecir valoresdesconocidos a partir de esas probabilidades
Por el teorema de Bayes, P(h|d) se calcula de la siguientemanera:
P(h|d) = αP(d|h)P(h)Donde α es la constante que normaliza P(d|h)P(h) para todoslos h ∈ H (es decir, para que sumen 1)
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Un ejemplo (Russel & Norvig)
Un fabricante de caramelos fabrica grandes bolsas de cincotipos, cada una con una proporcion diferente entre limon ynaranja:
h1: 100% de naranjah2: 75% de naranja y 25% de limonh3: 50% de naranja y 50% de limonh4: 25% de naranja y 75% de limonh5: 100% de limon
Cada tipo de bolsa h1, h2, h3, h4 y h5 las hace el fabricantecon probabilidad 0,1, 0,2, 0,4, 0,2 y 0,1, resp.
Tomamos una bolsa y vamos abriendo algunos caramelos yanotando su sabor ¿Podemos predecir el sabor del siguientecaramelo que saquemos de la bolsa?
Lo planteamos como un problema de aprendizaje bayesiano
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Un ejemplo (Russel & Norvig)
En este caso, las hipotesis son las cinco composicionesposibles de la bolsa
Los datos son los distintos sabores de los caramelos abiertos
Las probabilidades a priori P(hi ) de cada hipotesis vienendadas por el fabricante: 0.1, 0.2, 0.4, 0.2 y 0.1, resp.
La verosimilitud de los datos, P(d|h), se puede calcularteniendo en cuenta que cada vez que se abre un caramelo esun evento independiente e identicamente distribuido (i.i.d.) delos anteriores. Por tanto P(d|hi ) =
∏
j P(dj |hi )Por ejemplo, si los datos son de 10 caramelos extraidos, todosellos de limon, P(d|h3) = 0,510
Veamos algunos ejemplos de como se calcula P(hi |d) paradistintos casos de d.
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Ejemplo para d = 〈l , l〉
Supongamos que las observaciones que tenemos son dosextracciones, ambas de caramelos de limon.
Hipotesis P(hi ) P(d |hi ) P(d |hi)P(hi ) P(hi |d) = αP(d |hi)P(hi )
h1 0,1 0 0 0
h2 0,2 (0,25)2 0,0125 ∼ 0,04
h3 0,4 (0,5)2 0,1 ∼ 0,31
h4 0,2 (0,75)2 0,1125 ∼ 0,35
h5 0,1 (1)2 0,1 ∼ 0,3
La hipotesis mas probable dados los datos es h4
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Ejemplo para d = 〈l , l , l〉
Supongamos ahora tres extracciones, todas salen de limon.
Hipotesis P(hi ) P(d |hi ) P(d |hi)P(hi ) P(hi |d) = αP(d |hi)P(hi )
h1 0,1 0 0 0
h2 0,2 (0,25)3 0,003125 ∼ 0,01
h3 0,4 (0,5)3 0,05 ∼ 0,21
h4 0,2 (0,75)3 0,084375 ∼ 0,36
h5 0,1 (1)3 0,1 ∼ 0,42
La hipotesis mas probable dados los datos es h5
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Ejemplo para d = 〈l , l , l , l〉
Un ultimo ejemplo: cuatro extracciones, y todas salen delimon.
Hipotesis P(hi ) P(d |hi ) P(d |hi)P(hi ) P(hi |d) = αP(d |hi)P(hi )
h1 0,1 0 0 0
h2 0,2 (0,25)4 0,00078125 ∼ 0,004
h3 0,4 (0,5)4 0,025 ∼ 0,13
h4 0,2 (0,75)4 0,06328125 ∼ 0,336
h5 0,1 (1)4 0,1 ∼ 0,53
La hipotesis mas probable dados los datos es h5
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Inferencia a partir de lo aprendido
Dada una v.a. X sobre la que se consulta, la informacionaprendida sera la distribucion de probabilidad P(X |d), queservira de base para predecir el valor de X
Se puede calcular de la siguiente forma (suponiendo que cadahipotesis determina completamente la distribucion deprobabilidad de X )
P(X |d) =∑
h∈H
P(X |d, hi )P(hi |d) =∑
h∈H
P(X |hi )P(hi |d)
Observacion: notese que el principio de la navaja de Occamtiene cabida en este marco general del aprendizaje bayesiano:
Simplemente, la probabilidades a priori de las hipotesis mascomplejas serıan menores
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Inferencia en el ejemplo de los caramelos
Supongamos que d = 〈l , l〉 en el ejemplo anterior y que X esla variable aleatoria correspondiente a la siguiente extraccion¿Cual es la probabillidad de que salga otra vez de limon?
P(X = l |d) = ∑5i=1 P(X = l |hi )P(hi |d) =
0× 0+0,04× 0,25+0,31× 0,5+0,35× 0,75+0,3× 1 = 0,725
De manera analoga, si d = 〈l , l , l〉, entoncesP(X = l |d) = 0,7975
Igualmente, si d = 〈l , l , l , l〉, entonces P(X = l |d) = 0,848
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos
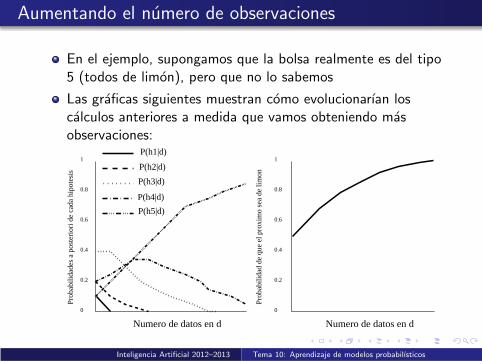
Aumentando el numero de observaciones
En el ejemplo, supongamos que la bolsa realmente es del tipo5 (todos de limon), pero que no lo sabemos
Las graficas siguientes muestran como evolucionarıan loscalculos anteriores a medida que vamos obteniendo masobservaciones:
0.2
0.4
0.6
0.8
1
0
0.2
0.4
0.6
0.8
1
0
Numero de datos en d
Prob
abili
dade
s a
post
erio
ri d
e ca
da h
ipot
esis
P(h1|d)
P(h2|d)
P(h3|d)
P(h4|d)
P(h5|d)
Numero de datos en d
Prob
abili
dad
de q
ue e
l pro
xim
o se
a de
lim
on
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Observaciones
A medida que los datos aumentan,la hipotesis verdadera eventualmente domina a las otras
Aunque la mejor manera de predecir el comportamiento deuna v.a. X es calculando P(X |d) como se ha visto, esto tieneun precio:
El espacio de hipotesis puede ser muy grande, por lo que elcalculo de P(X |d) segun la formula anterior puede serimposible en la practica
Pero algunas simplificaciones nos permitiran trabajar en lapractica
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Primera simplificacion: hipotesis MAP
En lugar de hacer predicciones teniendo en cuenta todas lashipotesis ponderadas cada una con P(h|d), las hacemos enbase solamente a la hipotesis mas probable a posteriori(notada como hMAP):
hMAP = argmaxh∈H
P(h|d) = argmaxh∈H
P(d|h)P(h)
Esta ultima igualdad, por el teorema de Bayes
En nuestro ejemplo, a partir del tercer caramelo extraıdohMAP es h5
Y por tanto nuestra prediccion serıa, con probabilidad 1, que elsiguiente caramelo es de limon
MAP no es la prediccion optima, pero a medida que se tienenmas datos, la prediccion bayesiana y la prediccion MAPtienden a coincidir, ya que esta domina a las demas:P(X |d) ≈ P(X |hMAP)
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Simplificando aun mas: hipotesis ML
Se busca la hipotesis MAP, pero suponiendo que todas lashipotesis son igualmente probables a priori:
Esta hipotesis se denomina de maxima verosimilitud, notadahML (maximum likelihood en ingles):
hML = argmaxh∈H
P(d|h)
Puede ser una buena aproximacion al aprendizaje bayesiano ya MAP, pero solo cuando se maneja un conjunto de datosgrande
Tanto MAP como ML suelen ser mas facilescomputacionalmente que el aprendizaje bayesiano puro, yaque se tratan de problemas de optimizacion, en lugar de larealizacion de sumas (o integrales) enormes
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Aprendizaje de redes bayesianas (con datos completos)
Vamos a aplicar el aprendizaje tipo ML para aprender lastablas de probabilidad condicional de una red bayesiana:
Hemos modelado nuestro dominio de conocimiento con unconjunto de variables aleatorias, en una red bayesiana de lacual desconocemos las tablas de probabilidad pero de la quesı conocemos su estructuraSupondremos que tenemos un conjunto de datos observados, yque cada dato es una observacion completa de valoresconcretos para cada v.a.
Es un ejemplo de aprendizaje de parametros: conocemos elmodelo probabilıstico, salvo los parametros (probabilidades delas tablas) de los que depende
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Un ejemplo (el mas simple)
Tenemos una bolsa de caramelos de naranja y limon enproporciones desconocidas. Supongamos que abrimos Ncaramelos y que hemos observado que n son de naranja y l delimon. Queremos aprender la proporcion de caramelos denaranja y limon de la bolsa
La respuesta va a ser obvia, pero vamos a deducirla comohipotesis ML
La situacion se describe por esta simple red bayesiana, de lacual desconocemos el valor del parametro θ:
Sabor
P(S=naranja)
θ
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Un ejemplo (el mas simple)
Aplicaremos aprendizaje ML, en el que:
El conjunto de hipotesis es {θ : θ ∈ [0, 1]} (infinito)Todas las hipotesis son igualmente probables a priori(suposicion bastante razonable)El conjunto de datos es el dado por el sabor de los caramelosque se han abierto
Puesto que las observaciones son i.i.d., la verosimilitud de losdatos es P(d|hθ) =
∏
j P(dj |hθ) = θn · (1− θ)l
Se trata de encontrar el valor de θ que maximiza dichaprobabilidad
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Un ejemplo (el mas simple)
Para maximizar, es habitual tomar el logaritmo de laverosimilitud, ya que suele facilitar la tarea y no afecta alresultado; se denomina log-verosimilitud y se representamediante la letra L. En este caso:
L(d|hθ) =∑
j
log(P(dj |hθ)) = n · logθ + l · log(1− θ)
Para encontrar el maximo, derivamos respecto de θ eigualamos a 0, obteniendo
dL
dθ=
n
θ− l
1− θ= 0 ⇒ θ =
n
n + l=
n
NLuego la hipotesis ML se obtiene cuando θ = n
N
Lo cual era obvio, pero este ejemplo ha ilustrado el que sueleser el procedimiento general en estos casos: calcularverosimilitud, tomar logaritmo y encontrar el parametro quehace la derivada igual a 0
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Otro ejemplo
Supongamos que un fabricante de caramelos de limon y denaranja fabrica bolsas de proporcion desconocida. Ademas,cada caramelo tiene un envoltorio rojo o verde, envoltorio quedepende probabilısticamente del sabor (pero tampococonocemos dichas probabilidades)
Supongamos que hemos desenvuelto N caramelos de loscuales n son de naranja y l de limon. De los de naranja, rneran rojos y vn verdes. De los de limon rl eran rojos y vl verdes
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos
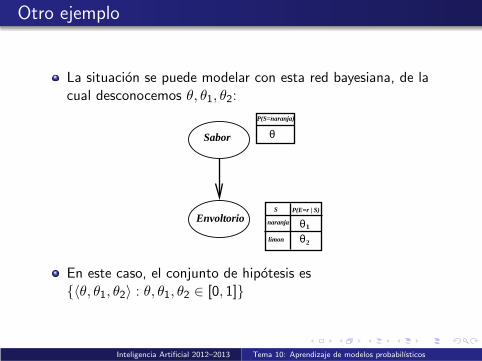
Otro ejemplo
La situacion se puede modelar con esta red bayesiana, de lacual desconocemos θ, θ1, θ2:
Sabor
Envoltorio
P(S=naranja)
θ
θ1
θ2
S
limon
P(E=r | S)
naranja
En este caso, el conjunto de hipotesis es{〈θ, θ1, θ2〉 : θ, θ1, θ2 ∈ [0, 1]}
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Otro ejemplo
La verosimilitud de los datos es:
P(d|hθ,θ1,θ2) = θn · (1− θ)l · θrn1 · (1− θ1)vn · θrl2 · (1− θ2)
vl
Como antes, tomando logaritmos, derivando parcialmenterespecto de θ, θ1 y θ2 e igualando a 0, se obtienen lossiguientes valores para los parametros:
θ =n
n + lθ1 =
rnn
θ2 =rll
Nuevamente, resultados bastante obvios
Por ejemplo, para estimar la probabilidad de que un caramelode limon tenga el envoltorio rojo, calculamos la fraccion decaramelos con envoltorio rojo de entre todos los de limon
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Aprendizaje parametrico en redes bayesianas
Los resultados del ejemplo anterior se extienden de maneranatural a cualquier red bayesiana de la cual conocemos susestructura pero desconocemos sus tablas de probabilidad
Y ademas disponemos de un conjunto D de observacionescompletas
Por ejemplo, si en una red los padres de X son Y1, . . . ,Yk ,para obtener la hipotesis ML para la entrada de la tabla deprobabilidad correspondiente aP(X = v |Y1 = a1, . . . ,Yk = ak), simplemente calculamos lafraccion de datos observados con valor de X = v de entre losque cumplen Y1 = a1, . . . ,Yk = ak
Notese que cada parametro se aprende por separado y demanera local
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Aprendizaje de redes bayesianas: cuestiones adicionales
Variables no observables:
El aprendizaje anterior no funciona cuando algunas de lasvariables de la red son no observables (p.ej. el hecho de que unpaciente tenga o no una determinada enfermedad)Existen algoritmos de aprendizaje especıficos para tratar estacuestion (por ejemplo, EM)
Solo hemos visto aprendizaje de tablas de probabilidad. Aveces es necesario aprender tambien la estructura de la red:aprender las dependencias causales
Se pueden usar tecnicas de busqueda local, donde los cambiosa los grafos pueden ser inclusion o borrado de arcosEl aprendizaje de la estructura es aun un tema de investigacionque se encuentra en sus primera etapas
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Aprendizaje parametrico en modelos continuos
La misma aproximacion ML se puede seguir para elaprendizaje de modelos probabilısticos continuos.
Un ejemplo sencillo:
Supongamos que tenemos una serie de datosd = 〈x1, x2, . . . , xn〉, con pesos de una serie de personas de unmismo pais, tomados de manera i.i.d.Esos datos pueden ser considerados valores que toma unavariable aleatoria continua PesoAsumiremos como conocido que Peso sigue una distribucionnormal o de Gauss (cuya funcion de densidad notaremosNµ,σ). Esto es:
Nµ,σ(x) =1√2πσ
e−(x−µ)2
2σ2
Pero no conocemos ni la media µ ni la desviacion tıpica σ
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Aprendizaje parametrico en modelos continuos
El problema anterior se puede plantear como un problema deaprendizaje ML en el que el espacio de hipotesis viene dadopor {(µ, σ) : µ, σ ∈ R}Los valores de µ y σ que aprenderemos seran aquellos para loscuales se maximice la verosimilitud de los datos observados
En este caso, la verosimilitud es:
P(d|hµ,σ) =N∏
i=1
Nµ,σ(xi ) =N∏
i=1
1√2πσ
e−(xi−µ)2
2σ2
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Aprendizaje parametrico en modelos continuos
Como en los casos anteriores, tomando logaritmos, derivandoparcialmente respecto de µ, y σ e igualando a 0, se obtienelos siguientes valores para los parametros:
µ =
∑Ni=1 xiN
σ =
√
∑Ni=1(xi − µ)2
N
Nuevamente, los resultados esperados
Lo que se ha obtenido es que la hipotesis ML es aquella queconsidera que los datos se han generado por una distribucionnormal cuya media y desviacion tıpica son las de la muestra
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos
Parte III
Parte III
Clasificacion de nuevos ejemplos
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Clasificadores
Supongamos que estamos ante el problema de clasificar unejemplo dentro de una serie de categorıas posibles
El conjunto de entrenamiento vendra dado por una serie deejemplos y su clasificacion (similar a lo visto en temasanteriores)
La idea es aprender un modelo probabilıstico a partir de losejemplos y luego usarlo para clasificar nuevos ejemplos
Dos tipos de clasificadores:
Parametricos: usan el conjunto de entrenamiento paraaprender el modelo explıcitamenteNo parametricos: usan directamente los datos deentrenamiento para inferir cada vez la clasificacion de un nuevoejemplo, sin construir explıcitamente un modelo probabilıstico.
Veremos un metodo parametrico (Naive Bayes) y otro noparametrico (kNN)
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Clasificadores Naive Bayes
Supongamos un conjunto de atributos A1, . . . ,An cuyosvalores determinan un valor en un conjunto finito V deposibles “clasificaciones”
Tenemos un conjunto de entrenamiento D con una serie detuplas de valores concretos para los atributos, junto con suclasificacion
Queremos aprender un clasificador tal que clasifique nuevasinstancias 〈a1, . . . , an〉
Es decir, el mismo problema en el tema de aprendizaje dearboles de decision y de reglas (pero ahora lo abordaremosdesde una perspectiva probabilıstica).
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Clasificadores Naive Bayes
Podemos disenar un modelo probabilıstico para un problemade clasificacion de este tipo, tomando los atributos y laclasificacion como variables aleatorias
El valor de clasificacion asignado a una nueva instancia〈a1, . . . , an〉, notado vMAP vendra dado por
argmaxvj∈V
P(vj |a1, . . . , an)
Aplicando el teorema de Bayes podemos escribir
vMAP = argmaxvj∈V
P(a1, . . . , an|vj)P(vj)
Y ahora, simplemente estimar las probabilidades de la formulaanterior a partir del conjunto de entrenamiento
Problema: necesitarıamos una gran cantidad de datos paraestimar adecuadamente las probabilidades P(a1, . . . , an|vj)
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos
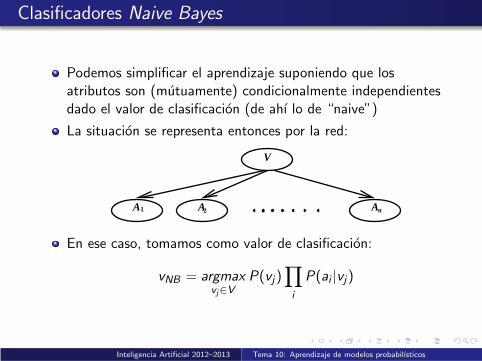
Clasificadores Naive Bayes
Podemos simplificar el aprendizaje suponiendo que losatributos son (mutuamente) condicionalmente independientesdado el valor de clasificacion (de ahı lo de “naive”)
La situacion se representa entonces por la red:
V
A A A1 n2
En ese caso, tomamos como valor de clasificacion:
vNB = argmaxvj∈V
P(vj)∏
i
P(ai |vj)
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Clasificadores Naive Bayes
Para el proceso de aprendizaje, solo tenemos que estimar lasprobabilidades P(vj) (probabilidades a priori) y P(ai |vj)(probabilidades condicionadas). Son muchas menos que en elcaso general.
Y ademas ya hemos visto como se obtienen estimaciones MLde estas probabilidades, simplemente mediante calculo de susfrecuencias en el conjunto de entrenamiento
Notese que a diferencia de otros metodos (como ID3) no hayuna busqueda en el espacio de hipotesis: simplementecontamos frecuencias
A pesar de su aparente sencillez, los clasificadores Naive Bayestienen un rendimiento comparable al de los arboles dedecision, las reglas o las redes neuronales
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos
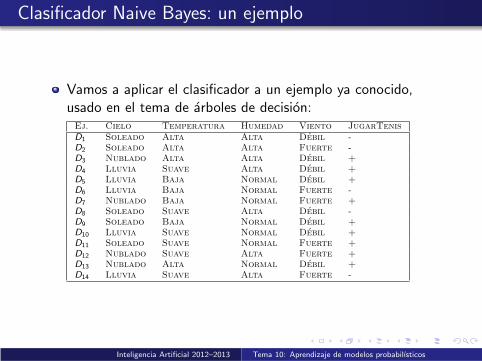
Clasificador Naive Bayes: un ejemplo
Vamos a aplicar el clasificador a un ejemplo ya conocido,usado en el tema de arboles de decision:Ej. Cielo Temperatura Humedad Viento JugarTenis
D1 Soleado Alta Alta Debil -
D2 Soleado Alta Alta Fuerte -
D3 Nublado Alta Alta Debil +
D4 Lluvia Suave Alta Debil +
D5 Lluvia Baja Normal Debil +
D6 Lluvia Baja Normal Fuerte -
D7 Nublado Baja Normal Fuerte +
D8 Soleado Suave Alta Debil -
D9 Soleado Baja Normal Debil +
D10 Lluvia Suave Normal Debil +
D11 Soleado Suave Normal Fuerte +
D12 Nublado Suave Alta Fuerte +
D13 Nublado Alta Normal Debil +
D14 Lluvia Suave Alta Fuerte -
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Clasificador Naive Bayes: un ejemplo
Supongamos que queremos predecir si un dıa soleado, detemperatura suave, humedad alta y viento fuerte es buenopara jugar al tenisSegun el clasificador Naive Bayes:
vNB = argmaxvj∈{+,−}
P(vj)P(soleado|vj )P(suave|vj )P(alta|vj )P(fuerte|vj )
Ası que necesitamos estimar todas estas probabilidades, lo quehacemos simplemente calculando frecuencias en la tablaanterior:
p(+) = 9/14, p(−) = 5/14, p(soleado|+) = 2/9,p(soleado|−) = 3/5, p(suave|+) = 4/9, p(suave|−) = 2/5,p(alta|+) = 2/9, p(alta|−) = 4/5, p(fuerte|+) = 3/9 yp(fuerte|−) = 3/5
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Clasificador Naive Bayes: un ejemplo
Por tanto, las dos probabilidades a posteriori son:
P(+)P(soleado|+)P(suave|+)P(alta|+)P(fuerte|+) = 0,0053P(−)P(soleado|−)P(suave|−)P(alta|−)P(fuerte|−) = 0,0206
Ası que el clasificador devuelve la clasificacion con mayorprobabilidad a posteriori, en este caso la respuesta es − (no esun dıa bueno para jugar al tenis)
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Detalles tecnicos sobre las estimaciones
Tal y como estamos calculando las estimaciones, existe elriesgo de que algunas de ellas sean excesivamente bajas
Si realmente alguna de las probabilidades es baja y tenemospocos ejemplos en el conjunto de entrenamiento, lo masseguro es que la estimacion de esa probabilidad sea 0
Esto plantea dos problemas:
La inexactitud de la propia estimacionAfecta enormemente a la clasificacion que se calcule, ya que semultiplican las probabilidades estimadas y por tanto si una deellas es 0, anula a las demas
Una primera mejora tecnica, intentado evitar productos muybajos: usar logaritmos de las probabilidades.
Los productos se transforman en sumas
vNB = argmaxvj∈V
[log(P(vj )) +∑
i
log(P(ai |vj))]
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Detalles tecnicos sobre las estimaciones
Otra mejora, intentando evitar probabilidades nulas o muybajas: en lugar de la estimacion directa, usar lo que sedenomina m-estimacion:
n′ +m · pn +m
n es el numero total de observaciones correspondiente a unaclasificacionn′ es el numero de observaciones, de esas, que tienen comovalor de atributo el correspondiente al que se esta estimandop es una estimacion a priori de la probabilidad que se quierecalcular. En ausencia de otra informacion, podrıa ser p = 1/k ,donde k es el numero de valores del atributom es una constante (llamada tamano de muestreo equivalente)que determina el peso de p en la formula anterior
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Clasificacion mediante vecino mas cercano
Una tecnica alternativa a construir el modelo probabilıstico escalcular la clasificacion directamente a partir de los ejemplos(aprendizaje basado en instancias)
Idea: obtener la clasificacion de un nuevo ejemplo a apartir delas categorıas de los ejemplos mas “cercanos”.
Debemos manejar, por tanto, una nocion de “distancia” entreejemplos.En la mayorıa de los casos, los ejemplos seran elementos de Rn
y la distancia, la euclıdea.Pero se podrıa usar otra nocion de distancia
Ejemplo de aplicacion: clasificacion de documentos
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

El algoritmo k-NN
El algoritmo k-NN (de “k nearest neighbors”):
Dado un conjunto de entrenamiento (vectores numericos conuna categorıa asignada) y un ejemplo nuevoDevolver la categorıa mayoritaria en los k ejemplos delconjunto de entrenamiento mas cercanos al ejemplo que sequiere clasificar
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Distancias para k-NN
Posibles distancias usadas para definir la “cercanıa”:
Euclıdea: de(x, y) =√
∑n
i=1(xi − yi )2
Manhattan: dm(x, y) =∑n
i=1 |xi − yi |Hamming: numero de componentes en las que se difiere.
La euclıdea se usa cuando cada dimension mide propiedadessimilares y la Mahattan en caso contrario; la distanciaHamming se puede usar aun cuando los vectores no seannumericos.
Normalizacion: cuando no todas las dimensiones son delmismo orden de magnitud, se normalizan las componentes(restando la media y dividiendo por la desviacion tıpica)
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Algunas observaciones sobre k-NN
Eleccion de k :
Usualmente, basandonos en algun conocimiento especıficosobre el problema de clasificacionTambien como resultado de pruebas en conjuntos maspequenosSi la clasificacion es binaria, preferiblemente impar, paraintentar evitar empates (k=5, por ejemplo)
Variante en kNN: para cada clase c , sumar la similitud (con elque se quiere clasificar) de cada ejemplo de esa clase queeste entre los k mas cercanos. Devolver la clase que obtengamayor puntuacion.
Ası un ejemplo cuenta mas cuanto mas cercano este
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos
Parte III
Parte III
Clustering
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Clustering
Como ultima aplicacion del aprendizaje estadıstico, trataremostecnicas de agrupamiento o clustering
Se trata de dividir un conjunto de datos de entrada ensubconjuntos (clusters), de tal manera que los elementos decada subconjunto compartan cierto patron o caracterısticas apriori desconocidas
En nuestro caso, los datos seran numeros o vectores denumeros y el numero de clusters nos vendra dado
Aprendizaje no supervisado: no tenemos informacion sobreque cluster corresponde a cada dato.
Aplicaciones de clustering:
Minerıa de datosProcesamiento de imagenes digitalesBioinformatica
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Dos ejemplos
Color quantization:
Una imagen digital almacenada con 24 bits/pixel (aprox. 16millones de colores) se tiene que mostrar sobre una pantallaque solo tiene 8 bits/pixel (256 colores)¿Cual es la mejor correspondencia entre los colores de laimagen original y los colores que pueden ser mostrados en lapantalla?
Mezcla de distribuciones:
Tenemos una serie de datos con el peso de personas de unpais; no tenemos informacion sobre si el peso viene de unvaron o de una mujer, pero sabemos que la distribucion depesos es de tipo normal, y que en los hombres es distinta queen las mujeresAtendiendo a los datos, ¿podemos aprender de que dosdistribuciones de probabilidad vienen?
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Clustering basado en distancia
Idea: dado el numero k de grupos o clusters, buscar k puntoso centros representantes de cada cluster, de manera que cadadato se considera en el cluster correspondiente al centro quetiene a menor “distancia”
Como antes, la distancia serıa especıfica de cada problema:
Expresara la medida de similitudLa distancia mas usada es la euclıdea
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Un algoritmo clasico: k-medias
Entrada: un numero k de clusters, un conjunto de datos{xi}Ni=1 y una funcion de distancia
Salida: un conjunto de k centros m1, . . . ,mk
k-medias(k,datos,distancia)1. Inicializar m i (i=1,...,k) (aleatoriamente o con alg un
criterio heur ıstico)2. REPETIR (hasta que los m i no cambien):
2.1 PARA j=1,...,N, HACER:Calcular el cluster correspondiente a x j, escogiendo,de entre todos los m i, el m h tal quedistancia(x j,m h) sea m ınima
2.2 PARA i=1,...,k HACER:Asignar a m i la media aritm etica de los datosasignados al cluster i- esimo
3. Devolver m 1,...,m n
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos
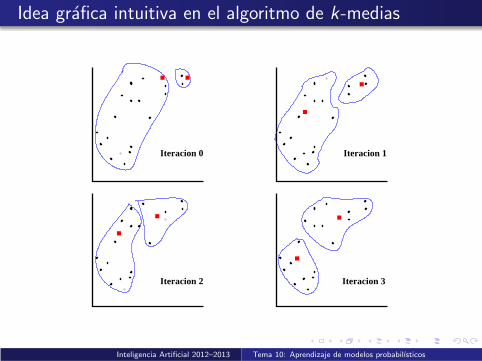
Idea grafica intuitiva en el algoritmo de k-medias
■■■
■
■ ■
Iteracion 1
Iteracion 3
Iteracion 0
Iteracion 2
■
■
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Ejemplo en el algoritmo k-medias
Datos sobre pesos de la poblacion: 51, 43, 62, 64, 45, 42, 46,45, 45, 62, 47, 52, 64, 51, 65, 48, 49, 46, 64, 51, 52, 62, 49,48, 62, 43, 40, 48, 64, 51, 63, 43, 65, 66, 65, 46, 39, 62, 64,52, 63, 64, 48, 64, 48, 51, 48, 64, 42, 48, 41
El algoritmo, aplicado con k = 2 y distancia euclıdea,encuentra dos centros m1 = 63,63 y m2 = 46,81 en tresiteraciones
19 datos pertenecen al primer cluster y 32 al segundo cluster
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Diversas cuestiones sobre el algoritmo k-medias
Busqueda local:
Puede verse como un algoritmo de busqueda local, en el que setrata de encontrar los centros mi que optimizanΣjΣibijd(xj ,mi )
2, donde bij vale 1 si xj tiene a mi como elcentro mas cercano, 0 en otro casoComo todo algoritmo de busqueda local, no tiene garantizadoencontrar el optimo global
Inicializacion: aleatoria o con alguna tecnica heurıstica (porejemplo, partir los datos aleatoriamente en k clusters yempezar con los centros de esos clusters)
En la practica, los centros con los que se inicie el algoritmotienen un gran impacto en la calidad de los resultados que seobtengan
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Otro ejemplo en el algoritmo k-medias
El archivo iris.arff del sistema WEKA contiene 150 datossobre longitudes y anchura de sepalo y petalo de plantas delgenero iris, clasificadas en tres tipos (setosa, versicolor yvirgınica)
Ejemplo de instancia de iris.arff :5.1,3.5,1.4,0.2,Iris-setosa
Podemos aplicar k-medias, con k = 3 y distancia euclıdea,ignorando el ultimo atributo (como si no se conociera):
En 6 iteraciones se estabilizaDe los tres clusters obtenidos, el primero incluye justamente alas 50 instancias que originalmente estaban clasificadas comoiris setosaEl segundo cluster incluye a 47 versicolor y a 3 virgınicasEl tercero incluye 14 versicolor y 36 virgınicasNo ha sido capaz de discriminar correctamente entre versicolory virgınica
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos

Bibliografıa
Russell, S. y Norvig, P. Artificial Intelligence (A modernapproach) (Third edition) (Prentice Hall, 2010)
Secs. 20.1 y 20.2: “Statistical Learning” y ”Learning wihComplete Data” (disponible on-line en la web de la segundaedicion)
Mitchell, T.M. Machine Learning (McGraw-Hill, 1997)
Cap. 6: “Bayesian Learning”Cap. 8: “Instance Based Learning”
Inteligencia Artificial 2012–2013 Tema 10: Aprendizaje de modelos probabilısticos