
Tema 1Analisis exploratorio de datos
Jose R. Berrendero
Departamento de MatematicasUniversidad Autonoma de Madrid
Informacion de contacto
Jose Ramon Berrendero Dıaz
Correo electronico: [email protected]
Telefono: 91 497 66 90
Despacho: Modulo 08 - Despacho 210
Pagina web: http://www.uam.es/joser.berrendero
Ejemplo de introduccion:contaminacion por mercurio en el pescado
I El agua de los rıos contiene pequenas concentraciones demercurio que se pueden ir acumulando en los tejidos de lospeces.
I Se ha realizado un estudio en los rıos Wacamaw y Lumber enCarolina del Norte (EE.UU.), analizando la cantidad demercurio que contenıan 171 ejemplares capturados de unacierta especie de peces.
I Los datos obtenidos se encuentran en el ficheromercurio.txt (formato texto) o en el fichero mercurio.sav(formato SPSS).
Variables
Nombre variable Descripcion
RIO Codigo del rıo (0=Lumber, 1=Wacamaw)ESTACION Codigo de la estacion (de 0 a 16)
LONG Longitud (en cm) del pezPESO Peso (en g) del pezCONC Concentracion (en ppm) de mercurio

Problemas de interes relacionados con estos datos
I Resumir la informacion que contienen con unas pocas cifras ograficos.
I ¿Que valores toma cada variable? ¿Cuales son los masfrecuentes? ¿Hay grandes diferencias entre ellos?
I ¿Es significativamente mas alta la concentracion de mercurioen un rıo que en otro?
I ¿Existe relacion entre la concentracion de mercurio y lalongitud o el peso del pez?
I ¿Depende la concentracion de mercurio de la estacion en laque ha sido capturado el pez?
Temario
I Analisis exploratorio de datosI Introduccion al programa SPSS
I Nociones elementales de inferencia estadıstica.I La distribucion normal
I Contraste de hipotesis
I Regresion lineal simple
I Analisis de la varianza (en funcion del tiempo disponible)
Bibliografıa
I Freedman, D., Pisani, R., Purves, R. y Adhikari, A. (1993).Estadıstica. Antoni Bosch ed., Barcelona.
I de la Horra, J. (2003). Estadıstica Aplicada. Ediciones Dıazde Santos, Madrid.
I Milton, J.S. (2001). Estadıstica para Biologıa y Ciencias de laSalud. Mc- Graw Hill Interamericana, Madrid.
I Moore, D.S. (1998). Estadıstica aplicada basica. AntoniBosch ed., Barcelona.
I Rosner, B. (2006). Fundamentals of Biostatistics. ThomsonBrooks/Cole.

Estructura del Tema 1
I Tipos de variables
I Distribucion de una variable
I Representacion grafica de la distribucion
I Medidas numericas para resumir la distribucion
I Correlacion
I Transformaciones: estandarizacion y transformacionlogarıtmica
Introduccion
La estadıstica tiene por objetivo extraer conocimiento a partir deinformacion (principalmente) numerica.
El analisis exploratorio de datos (o estadıstica descriptiva) tiene porobjetivo identificar las principales caracterısticas de un conjunto dedatos mediante un numero reducido de graficos y/o numeros.
Los conjuntos de datos que vamos a considerar proceden de mediruna o mas variables en un conjunto de individuos.
Para describir un conjunto de datos se comienza con un analisisindividual de cada variable y posteriormente se estudian lasrelaciones entre variables.
Se suele comenzar con representaciones graficas y posteriormentese calculan resumenes numericos.
Tipos de variables
1. Variables cualitativas: Describen cualidades o atributos (ej.color del pelo).
2. Variables cuantitativas discretas: Toman un numeropequeno de valores, normalmente enteros (ej. numero dehijos).
3. Variables cuantitativas continuas: Toman valores en unintervalo (ej. tiempo hasta que llega un autobus).
En los datos sobre contenido de mercurio, ¿de que tipo es cadauna de las variables?
En general, la tecnica estadıstica adecuada para analizar unavariable depende de su tipo.
Distribucion de una variable
La distribucion de una variable viene determinada por los valoresque toma esa variable y la frecuencia con la que los toma.
La frecuencia absoluta de un valor (o de un intervalo) es el numerode individuos para los que la variable toma ese valor (o pertenece aese intervalo).
La frecuencia relativa es igual a la frecuencia absoluta dividida porel numero de datos n.
La frecuencia relativa siempre es un numero entre 0 y 1.

Aspectos interesantes de una distribucion
I Su posicion: en torno a que valor central toma valores lavariable.
I Su dispersion: el grado de concentracion de los valores quetoma la variable alrededor de su posicion central.
I Su forma: por ejemplo, la simetrıa, es decir, si los valores sereparten de la misma forma a uno y otro lado del centro.
Piensa en dos conjuntos de 5 datos que tengan:
(a) La misma posicion y distinta dispersion.
(b) La misma dispersion y distinta posicion.
Sectores o barras (solo datos cualitativos o discretos)
1,00,00
RIO
15,0014,0013,0012,0011,0010,009,008,007,006,005,004,003,002,001,00,00
25
20
15
10
5
0
Frecuencia
Histogramas
I Se divide el rango de los datos en un numero adecuado deintervalos.
I Sobre cada intervalo se dibuja un rectangulo cuya area esproporcional a la frecuencia (relativa o absoluta) de datos enel intervalo.
4,002,000,00
CONC
30
20
10
0
Frecuencia
Media =1,1918�Desviación típica =0,76166�
N =171
Aspectos a tener en cuenta para interpretar un histograma
I Normalmente la base de todos los rectangulos es la misma porlo que la altura es proporcional a la frecuencia.
I Identificar si se han usado frecuencias absolutas o relativas.
I ¿Cuantas modas hay?
I ¿Hay algun dato atıpico en relacion al resto?
I ¿Es simetrica la distribucion?
I En caso de asimetrıa, ¿es asimetrica a la izquierda o a laderecha
I ¿En torno a que valor aproximado estan centrados los datos?
I ¿Estan muy dispersos los datos en torno a este centro?
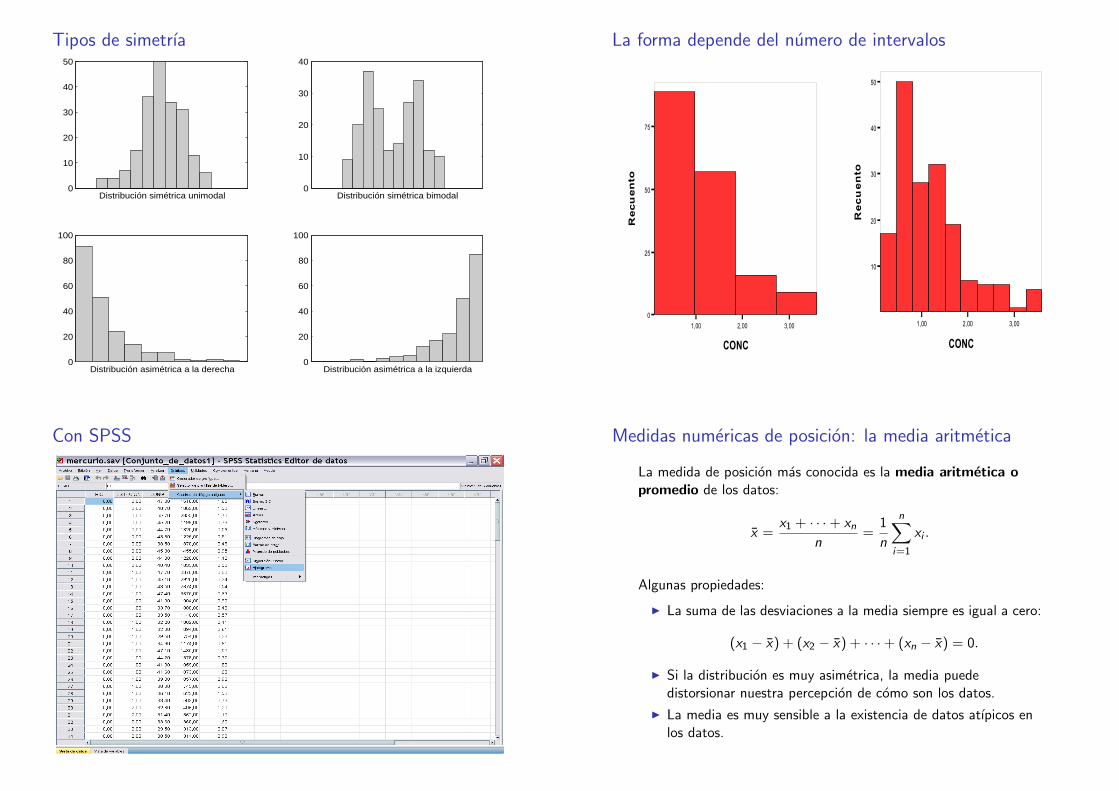
Tipos de simetrıa
0
10
20
30
40
50
Distribución simétrica unimodal0
10
20
30
40
Distribución simétrica bimodal
0
20
40
60
80
100
Distribución asimétrica a la derecha0
20
40
60
80
100
Distribución asimétrica a la izquierda
La forma depende del numero de intervalos
1,00 2,00 3,00
CONC
0
25
50
75
Recuento
1,00 2,00 3,00
CONC
10
20
30
40
50
Recuento
Con SPSS Medidas numericas de posicion: la media aritmetica
La medida de posicion mas conocida es la media aritmetica opromedio de los datos:
x =x1 + · · · + xn
n=
1
n
n∑i=1
xi .
Algunas propiedades:
I La suma de las desviaciones a la media siempre es igual a cero:
(x1 − x) + (x2 − x) + · · · + (xn − x) = 0.
I Si la distribucion es muy asimetrica, la media puededistorsionar nuestra percepcion de como son los datos.
I La media es muy sensible a la existencia de datos atıpicos enlos datos.

Posicion de la media en un histograma Medidas numericas de posicion: la mediana
Una medida alternativa de posicion es la mediana. Para calcularla mediana:
I Se ordenan los datos de menor a mayor.
I Si el numero de datos es impar, la mediana es el dato queocupa la posicion central.
I Si el numero de datos es par, la mediana es la media de losdos datos centrales.
La mediana es mas robusta que la media pero hace un uso menoseficiente de la informacion contenida en los datos.
Relacion entre la simetrıa de una distribucion y la posicion relativaentre la media y la mediana.
Medidas de dispersion: el rango y los cuartiles
Una medida de dispersion muy sencilla es el rango o recorrido delos datos: el valor maximo menos el mınimo.
El rango solo depende de los datos extremos por lo que no es muyconveniente.
Mejores propiedades tienen los cuartiles y el rango intercuartılico:
I El primer cuartil, Q1, es la mediana de los datos menores quela mediana.
I El tercer cuartil, Q3, es la mediana de los datos mayores quela mediana.
I El rango, recorrido o amplitud intercuartılica es ladiferencia entre los dos cuartiles anteriores: Q3 − Q1.
De acuerdo con las anteriores definiciones, responde a lassiguientes cuestiones:
¿Que porcentaje de datos hay...
(a) ... entre Q1 y Q3?
(b) ... a la izquierda de Q1?
(c) ... a la derecha de Q3?
(d) ... entre el mınimo y Q3?
Una descripcion util de un conjunto de datos viene dada por loscinco numeros siguientes:
Mınimo, Q1, Mediana, Q3, Maximo

Ejemplo: salarios en Espana Medidas de dispersion: la varianza y la desviacion tıpicaSon las medidas de dispersion mas utilizadas.
La varianza es el promedio de las desviaciones al cuadrado de losdatos a su media.
Datos x1, . . . , xn
Desviaciones x1 − x , . . . , xn − x
Desviaciones al cuadrado (x1 − x)2, . . . , (xn − x)2
La varianza es(x1 − x)2 + . . . + (xn − x)2
n
Se suele usar mas la (cuasi)varianza:
S2 =(x1 − x)2 + . . . + (xn − x)2
n − 1
La (cuasi)desviacion tıpica es la raız cuadrada de S2:
S =
√(x1 − x)2 + . . . + (xn − x)2
n − 1
S se usa mas que S2 porque mide la dispersion en la misma escalaque los datos originales.
Para comparar la dispersion de variables de magnitudes muydistintas a veces se usa el coeficiente de variacion:
CV =S
|x |.
El CV no depende de las unidades en las que midamos una variable.
Una formula alternativa para calcular S2:
S2 =n
n − 1
(x21 + · · · + x2
n
n− x2
)
CuestionesDa un ejemplo de un conjunto de datos tal que S2 = 0.
Dado un conjunto de observaciones medidas en kg, supongamosque cambiamos las unidades y las pasamos a gramos (es decir,multiplicamos por mil). Determina si son verdaderas o falsas lassiguientes afirmaciones:
I Tanto la media como la mediana de los nuevos datos semultiplican tambien por mil.
I La varianza se multiplica tambien por mil.
¿Como cambiarıa la desviacion tıpica?
Ahora sumamos 100 a todos los datos. Determina si sonverdaderas o falsas las siguientes afirmaciones:
I Los cuartiles no cambian.I El rango intercuartılico no cambia.I La desviacion tıpica no cambia.

Descripcion numerica
CONCPESOLONGVálidos
Perdidos
Media
Error típ. de la media
Mediana
Desv. típ.
Varianza
Rango
Mínimo
Máximo
25
50
75
N
Percentiles
1,60001455,000046,2000
,9300873,000039,0000
,5900491,000033,3000
3,604511,0065,00
,11203,0025,20
3,494308,0039,80
,580766555,86972,542
,76166875,531768,51715
,9300873,000039,0000
,0582566,95359,65132
1,19181147,912339,9708
000
171171171
Estadísticos
Página 1
Cuestiones
I Calcula el coeficiente de variacion de las tres variables. ¿Quese deduce sobre la dispersion de los valores que toman?
I Comparando los valores de la media y la mediana, ¿cual de lastres distribuciones parece ser mas simetrica?
I Verdadero o falso: Al menos para 100 peces, la concentracionde mercurio es superior a 0.93 ppm.
I Verdadero o falso: La longitud de aproximadamente 42 peceses mayor que 25.20 cm y menor que 33.3 cm.
I ¿Cual es el rango intercuartılico de la variable que mide elpeso de los peces?
Con SPSS Con SPSS

Diagrama de cajas
¿Para que sirven?
Los diagramas de cajas son especialmente utiles para compararvarios conjuntos de datos.
Ademas, proporcionan informacion sobre:
I La posicion (mediana) y la dispersion (rango intercuartılico)de los datos.
I La simetrıa de la distribucion (comparamos el tamano de lascajas).
I La existencia de datos que se desvıan del patron general(datos atıpicos).
Concentracion de mercurio y rıo
1,00,00
RIO
4,00
2,00
0,00
CONC
16270
66
Concentracion de mercurio y estacion
15,0014,0013,0012,0011,0010,009,008,007,006,005,004,003,002,001,00,00
ESTACION
4,00
2,00
0,00
CONC
76
82
24
25
66
138
75
123

Relaciona cada histograma con su diagrama de cajas−2
−10
12
●
●
●
●
●
●
34
56
7
●
●
●
01
23
45
Diagrama de dispersion: Concentracion frente a peso
4000,002000,000,00
PESO
4,00
2,00
0,00
CONC
Interpretacion de un diagrama de dispersion
I Es importante fijarse en las unidades de cada eje
I ¿Se observa alguna asociacion entre las variables?
I ¿Como es de estrecha la asociacion entre las variables?
I ¿Cual es la “direccion” de la asociacion entre las variables?
I ¿Hay algun punto o coleccion de puntos que no siga el patrongeneral del resto?
I Si hay una tercera variable cualitativa, resulta convenienteutilizar sımbolos o colores diferentes para cada valor de estatercera variable.
Concentracion frente a longitud (color segun rıo)
60,00
50,00
40,00
30,00
LONG
1,00,00
RIO

Matriz de diagramas de dispersion
CONCPESOLONG
CONC
PESO
LONG
1,00,00
RIO
CovarianzaSe dispone de un conjunto de n pares de observaciones
(x1, y1), . . . , (xn, yn).
El objetivo es definir una medida numerica para cuantificar elgrado de relacion lineal que hay entre x e y :
Para ello se usa la covarianza entre x e y :
Sxy =1
n − 1
n∑i=1
(xi − x)(yi − y)
Observaciones:
I Para entender por que esta definicion es util miramos elgrafico de la transparencia siguiente.
I Sxy = Syx .I Sxx es la varianza de x .I Sxy depende de las unidades en que se midan x e y .
Interpretacion de la covarianza
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●●
●
●
● ●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
● ●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
● ●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
● ●
●
●
●
●
●
●
●
●
●
●
●●
● ●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
● ●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
● ●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
● ●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
−2 −1 0 1 2
−4−2
02
4
Covarianza positiva
y ●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●●
●
●●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
● ●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
● ●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●● ●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
−2 −1 0 1 2
−4−2
02
4
Covarianza negativa
y
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
● ●
●
●● ●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
● ●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●
● ●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
● ●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
● ●
●
●●
●
●
● ●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●●
−2 −1 0 1 2
−2−1
01
2
Covarianza aprox. cero
y ●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●●●
●
●
●
●
●
●
●
●
●●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
● ●
●
●
●
● ●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●●
● ●
●
●
●
● ●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●●
●
●
●
● ●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●●
●●
●
●
● ●●
●●
●
● ●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
−2 −1 0 1 2
−20
24
6
Covarianza aprox. cero
y
●
Coeficiente de correlacion
Resulta conveniente disponer de una medida de relacion lineal queno dependa de las unidades. Para ello, se normaliza Sxy dividiendopor el producto de desviaciones tıpicas, lo que lleva al coeficientede correlacion:
rxy =Sxy
SxSy.
Propiedades:
I No depende de las unidades
I Siempre toma valores entre -1 y 1.
I Su signo se interpreta igual que el de la covarianza
I Solo vale 1 o -1 cuando los puntos estan perfectamentealineados.

Covarianzas y correlaciones de los datos
Correlaciones
1 ,900 ,650,000 ,000
12332,114 1141004 716,835
72,542 6711,790 4,217171 171 171,900 1 ,554,000 ,000
1141004 1E+008 62786,546
6711,790 766555,9 369,333171 171 171,650 ,554 1,000 ,000
716,835 62786,546 98,622
4,217 369,333 ,580171 171 171
Correlación de PearsonSig. (bilateral)Suma de cuadrados yproductos cruzadosCovarianzaNCorrelación de PearsonSig. (bilateral)Suma de cuadrados yproductos cruzadosCovarianzaNCorrelación de PearsonSig. (bilateral)Suma de cuadrados yproductos cruzadosCovarianzaN
LONG
PESO
CONC
LONG PESO CONC
Covarianzas y correlaciones con SPSS
Estandarizacion o tipificacion
Consiste en restarle a cada observacion la media de todos los datosy dividir por la desviacion tıpica:
zi =xi − x
S
Representa la distancia de xi a la media expresada en desviacionestıpicas (el signo indica si el dato es mayor o menor que la media).
¿Cuanto vale la media de los datos estandarizados?
¿Y su desviacion tıpica?
Efecto de estandarizar un conjunto de datos
−4 −2 0 2 4 6 8
Datos originales
−4 −2 0 2 4 6 8
Datos centrados (media cero)
−4 −2 0 2 4 6 8
Datos estandarizados (media cero y varianza uno)

Tomar logaritmos
Si las observaciones xi son positivas, a veces es convenientetrabajar con sus logaritmos log xi en lugar de con las variablesoriginales.
0 1 2 3 4 5
−3
−2
−1
01
x
log
(x)
Tomar logaritmos para hacer la distribucion mas simetrica
4,002,000,00
CONC
30
20
10
0
Frecuencia
Media =1,1918�Desviación típica =0,76166�
N =171
1,000,00-1,00-2,00
LNCONC
30
25
20
15
10
5
0
Fre
cu
en
cia
Media =-0,0268�Desviación típica =0,66104�
N =171
Tomar logaritmos para hacer que la asociacion sea lineal
4000,002000,000,00
PESO
4,00
2,00
0,00
CONC
60,0050,0040,0030,00
LONG
1,00
0,00
-1,00
-2,00
LNCONC
Transformaciones con SPSS

Transformaciones con SPSS
Calorıas y contenido en sodio en salchichas
I Se ha considerado la cantidad de calorıas y de sodio ensalchichas de varias marcas de cada uno de los tipossiguientes:
I Carne de terneraI Mezcla (hasta 15% de carne de pavo)I Carne de pavo
Nombre variable Descripcion
tipo Tipo de carne (1=ternera, 2=mezcla, 3=pavo)calorias Cantidad de calorıassodio Cantidad de sodio
Medidas descriptivas numericasEstadísticos
54 54
0 0
146,6111 424,8333
3,95691 13,04440
146,0000 405,0000
29,07727 95,85637
845,487 9188,443
86,00 144,00
195,00 645,00
132,0000 359,7500
146,0000 405,0000
173,5000 506,2500
Válidos
Perdidos
N
Media
Error típ. de la media
Mediana
Desv. típ.
Varianza
Mínimo
Máximo
25
50
75
Percentiles
calorias sodio
calorias
321
tipo
200,00
180,00
160,00
140,00
120,00
100,00
80,00
ca
loria
s
sodio
Página 1
Diagramas de cajas
Estadísticos
54 54
0 0
146,6111 424,8333
3,95691 13,04440
146,0000 405,0000
29,07727 95,85637
845,487 9188,443
86,00 144,00
195,00 645,00
132,0000 359,7500
146,0000 405,0000
173,5000 506,2500
Válidos
Perdidos
N
Media
Error típ. de la media
Mediana
Desv. típ.
Varianza
Mínimo
Máximo
25
50
75
Percentiles
calorias sodio
calorias
321
tipo
200,00
180,00
160,00
140,00
120,00
100,00
80,00
calor
ias
sodio
Página 1
321
tipo
700,00
600,00
500,00
400,00
300,00
200,00
100,00
sodio
33
200,00180,00160,00140,00120,00100,0080,00
calorias
4
3
2
1
0
Frecu
encia
4
3
2
1
0
4
3
2
1
0
12
3
tipo
Página 2

Histogramas: cantidad de calorıas
321
tipo
700,00
600,00
500,00
400,00
300,00
200,00
100,00
so
dio
33
200,00180,00160,00140,00120,00100,0080,00
calorias
4
3
2
1
0
Fre
cu
en
cia
4
3
2
1
0
4
3
2
1
0
12
3
tipo
Página 2
Histogramas: cantidad de sodio
700,00600,00500,00400,00300,00200,00100,00
sodio
6
4
2
0
Fre
cu
en
cia
6
4
2
0
6
4
2
0
12
3
tipo
Gráfico
[Conjunto_de_datos1] C:\Documents and Settings\usuario\Mis documentos\joser\docencia\estap\datos\hotdogs.sav
Página 3
Diagrama de dispersion
700,00600,00500,00400,00300,00200,00100,00
sodio
200,00
180,00
160,00
140,00
120,00
100,00
80,00
calo
rias
3
2
1
tipo
Página 4
Covarianzas y correlaciones
700,00600,00500,00400,00300,00200,00100,00
sodio
200,00
180,00
160,00
140,00
120,00
100,00
80,00
ca
lori
as
3
2
1
tipo
Correlaciones
[Conjunto_de_datos1] C:\Documents and Settings\usuario\Mis documentos\joser\docencia\estap\datos\hotdogs.sav
Correlaciones
1 ,516
,000
44810,833 76233,500
845,487 1438,368
54 54
,516 1
,000
76233,500 486987,50
1438,368 9188,443
54 54
Correlación de Pearson
Sig. (bilateral)
Suma de cuadrados yproductos cruzados
Covarianza
N
Correlación de Pearson
Sig. (bilateral)
Suma de cuadrados yproductos cruzados
Covarianza
N
calorias
sodio
calorias sodio
Página 4

Cuestiones
I (V o F) Aproximadamente 27 marcas de salchichas tienenentre 132 y 173 calorıas.
I ¿Cual es el rango intercuartılico de la cantidad de sodio?
I Calcula el coeficiente de variacion de ambas variables.
I (V o F) Aproximadamente 13 marcas de salchichas tienen uncontenido de sodio entre 506.25 y 645.
I (V o F) Con la informacion disponible en la tabla de medidasdescriptivas numericas es posible calcular la correlacion entreambas variables.
I (V o F) Al menos el 75% de las marcas de salchichas demezcla tienen mas sodio que la mediana de las marcas deternera.
I Identifica en el diagrama de dispersion el dato atıpico que seobserva en los diagramas de cajas.







