
ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 1
SOLUCIÓN PROPUESTA
1.
a)
reg w educa exp Source | SS df MS Number of obs = 528 -------------+------------------------------ F( 2, 525) = 69.36 Model | 2914.64782 2 1457.32391 Prob > F = 0.0000 Residual | 11030.6042 525 21.0106748 R-squared = 0.2090 -------------+------------------------------ Adj R-squared = 0.2060 Total | 13945.2521 527 26.4615789 Root MSE = 4.5837 ------------------------------------------------------------------------------ w | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- educa | .9768533 .0847097 11.53 0.000 .8104416 1.143265 exp | .103667 .0173408 5.98 0.000 .0696011 .137733 _cons | -5.567325 1.257373 -4.43 0.000 -8.037426 -3.097223 ------------------------------------------------------------------------------
b)
salario = β1 + β2 educa+ β3 experiencia + u i
-5.5673 = valor que en promedio toma el salario por hora si educa= exp= 0. .9768533 = cada año adicional de educación incrementa en aproximadamente 0.98 unidades monetarias al salario promedio por hora, manteniendo constante a la variable experiencia. .103667 = cada año adicional de experiencia laboral incrementa en aproximadamente 0.10 unidades monetarias al salario promedio por hora, manteniendo constante a la variable educación. R2 = mide la proporción de la variabilidad del salario por hora que es explicada por las variables años de educación y años de experiencia laboral. R2 a= ajusta dado el número de variables incluidas en el modelo a la proporción de la variabilidad del salario por hora que es explicada por las variables años de educación y años de experiencia laboral. Es de notar que dadao que los datos provienen de un corte transversal, valores de bondad de ajuste resultan ser bajos. c) De acuerdo a los resultados del listado mostrado arriba: Considerando el valor p de cada coeficiente estimado, cada una de las variables es significativa a todos los niveles de significancia tomadas individualmente.
ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 2
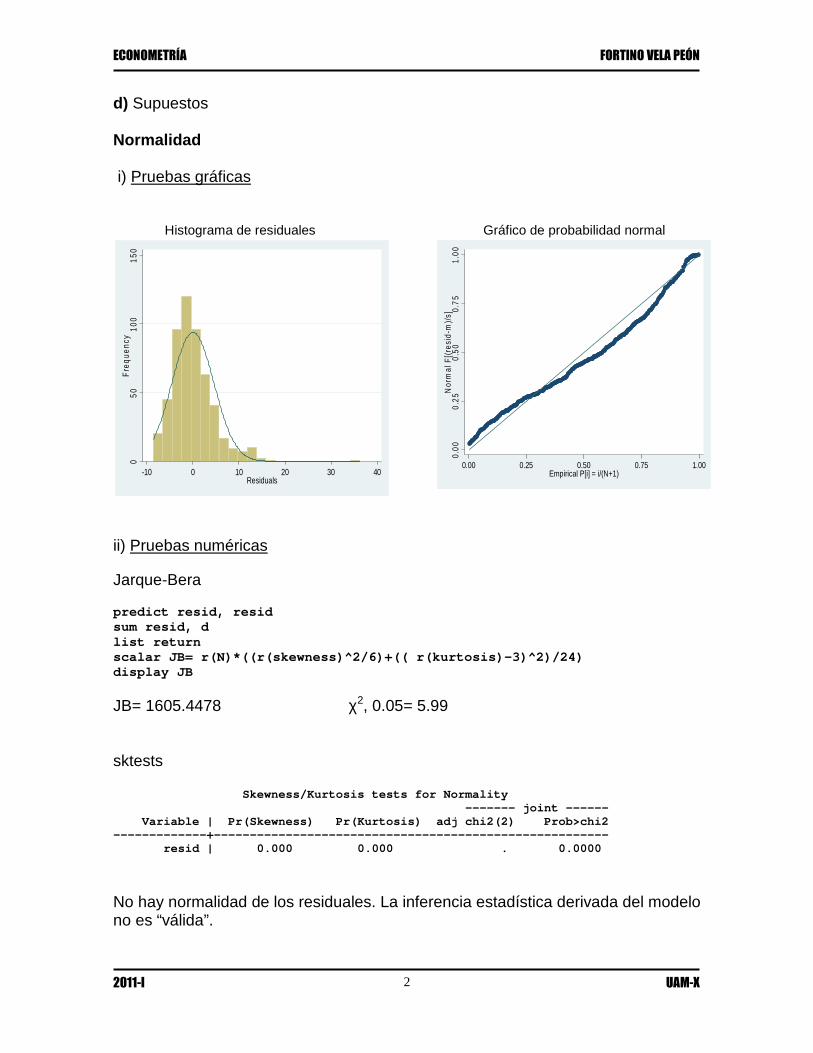
d) Supuestos Normalidad i) Pruebas gráficas Histograma de residuales Gráfico de probabilidad normal
ii) Pruebas numéricas
Jarque-Bera
predict resid, resid sum resid, d list return scalar JB= r(N)*((r(skewness)^2/6)+(( r(kurtosis)-3 )^2)/24) display JB
JB= 1605.4478 χ2, 0.05= 5.99 sktests Skewness/Kurtosis tests for Normality ------- joint ------ Variable | Pr(Skewness) Pr(Kurtosis) adj chi2(2) Prob>chi2 -------------+------------------------------------------------------- resid | 0.000 0.000 . 0.0000
No hay normalidad de los residuales. La inferencia estadística derivada del modelo no es “válida”.
050
100
150
Fre
quen
cy
-10 0 10 20 30 40Residuals
0.00
0.2
50
.50
0.7
51.
00N
orm
al F
[(re
sid-
m)/
s]
0.00 0.25 0.50 0.75 1.00Empirical P[i] = i/(N+1)

ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 3
Multicolinealidad
i) Matriz de diagramas de dispersión
ii) Matriz de correlación
| educa exp -------------+------------------ educa | 1.0000 exp | -0.3217 1.0000
iii) VIF
Variable | VIF 1/VIF -------------+---------------------- educa | 1.12 0.896517 exp | 1.12 0.896517 -------------+---------------------- Mean VIF | 1.12
iv) Regla práctica no señala nada claro.:
educacion(años)
experiencia(años)
5
10
15
20
5 10 15 20
0
50
0 50

ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 4
Heteroscedasticidad
i) Pruebas gráficas rvfplot rvpplot educa
rvfpplot experiencia
ii) Pruebas numéricas
Breusch-Pagan
Breusch-Pagan / Cook-Weisberg test for heteroskedasticity Ho: Constant variance Variables: fitted values of w chi2(1) = 42.15 Prob > chi2 = 0.0000
White
White's general test statistic : 11.64286 Chi-sq( 5) P-value = .04
-10
010
20
304
0R
esid
uals
0 5 10 15Fitted values
-10
010
20
304
0R
esid
uals
5 10 15 20educacion (años)
-10
01
020
3040
Res
idu
als
0 10 20 30 40 50experiencia (años)
ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 5
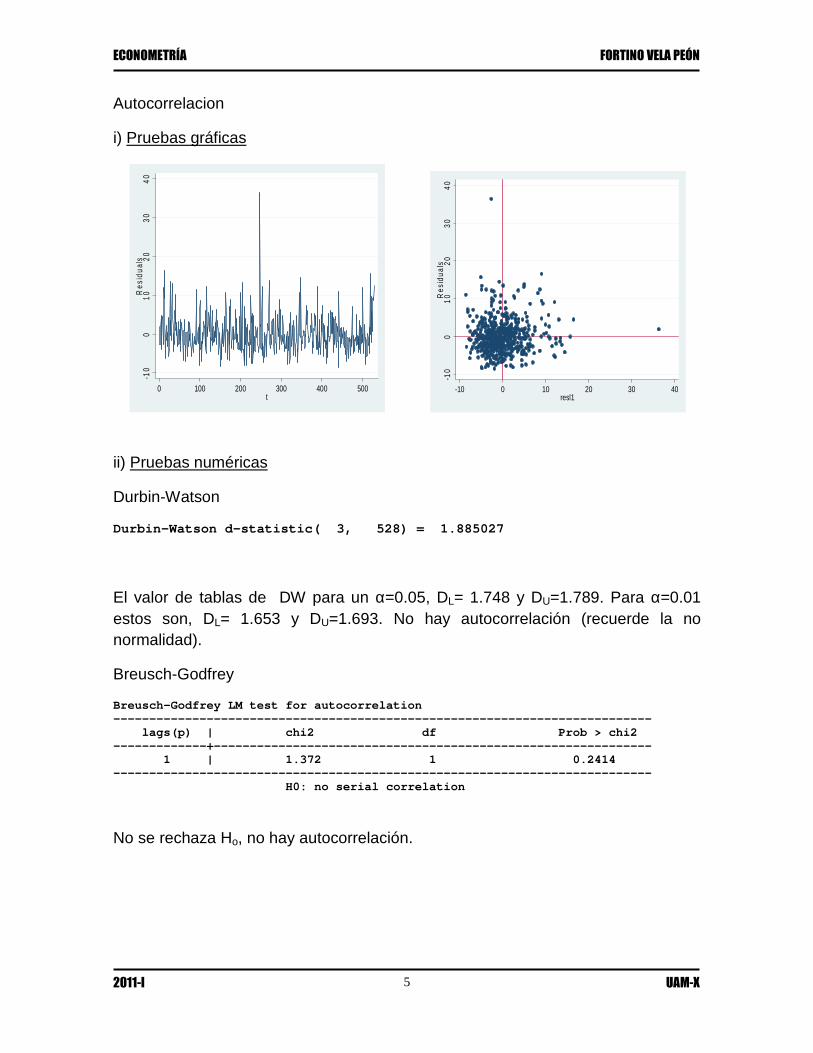
Autocorrelacion
i) Pruebas gráficas
ii) Pruebas numéricas
Durbin-Watson
Durbin-Watson d-statistic( 3, 528) = 1.885027
El valor de tablas de DW para un α=0.05, DL= 1.748 y DU=1.789. Para α=0.01 estos son, DL= 1.653 y DU=1.693. No hay autocorrelación (recuerde la no normalidad).
Breusch-Godfrey
Breusch-Godfrey LM test for autocorrelation --------------------------------------------------------------------------- lags(p) | chi2 df Prob > chi2 -------------+------------------------------------------------------------- 1 | 1.372 1 0.2414 --------------------------------------------------------------------------- H0: no serial correlation
No se rechaza Ho, no hay autocorrelación.
-10
010
2030
40R
esid
uals
0 100 200 300 400 500t
-10
01
020
3040
Res
idua
ls
-10 0 10 20 30 40resl1
ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 6
e)
A partir del análisis gráfico sobre la verificación del supuesto de homoscedasticidad, se puede considerar que el patrón de heteroscedasticidad puede ser provocado por:
1: Puntos outliers
2. Mayor heterogeneidad en el comportamiento a través de individuos por la variable educa.
3. Una combinación del comportamiento de las dos variables independientes.
Aplicaremos entonces: mínimos cuadrados ponderados, tomando a la variable educa como ponderador. Luego corrigiendo a los errores estándar con valores consistentes con la heteroscedasticidad (Hubber-White). Finalmente se comparan estas estimaciones con las originales de mínimos cuadrados.
reg w educa exp [aw=1/educa] (sum of wgt is 4.1966e+01) Source | SS df MS Number of obs = 528 -------------+------------------------------ F( 2, 525) = 68.12 Model | 2620.56916 2 1310.28458 Prob > F = 0.0000 Residual | 10097.8952 525 19.2340861 R-squared = 0.2060 -------------+------------------------------ Adj R-squared = 0.2030 Total | 12718.4643 527 24.1337084 Root MSE = 4.3857 ------------------------------------------------------------------------------ w | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- educa | .9473389 .0819504 11.56 0.000 .7863478 1.10833 exp | .0968747 .0163494 5.93 0.000 .0647565 .1289929 _cons | -5.06112 1.197135 -4.23 0.000 -7.412884 -2.709356 ------------------------------------------------------------------------------
reg w educa exp, robust Linear regression Number of obs = 528 F( 2, 525) = 60.02 Prob > F = 0.0000 R-squared = 0.2090 Root MSE = 4.5837 ------------------------------------------------------------------------------ | Robust w | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- educa | .9768533 .0902869 10.82 0.000 .7994853 1.154221 exp | .103667 .0181366 5.72 0.000 .0680378 .1392962 _cons | -5.567325 1.277397 -4.36 0.000 -8.076761 -3.057888 ------------------------------------------------------------------------------
ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 7
En términos generales, la comparación entre los distintos estimadores no muestra grandes diferencias como se puede observar a continuación:
--------------------------------------------------- -- Variable | mco ponderados robustos -------------+------------------------------------- -- educa | 0.9769*** 0.9473*** 0.9769*** exp | 0.1037*** 0.0969*** 0.1037*** _cons | -5.5673*** -5.0611*** -5.5673*** -------------+------------------------------------- -- N | 528.0000 528.0000 528.0000 r2 | 0.2090 0.2060 0.2090 r2_a | 0.2060 0.2030 0.2060 --------------------------------------------------- -- legend: * p<.1; ** p<.05; *** p<. 01
Dado los resultados en el diagnóstico del modelo (verificación de los supuestos), se puede tratar de estimar un modelo doble logarítmico para volver a verificar los supuestos. De esta manera, se tiene
Sea
lsalario = β1 + β2 leduca+ β3 lexperiencia + u i
Source | SS df MS Number of obs = 518 -------------+------------------------------ F( 2, 515) = 78.51 Model | 32.0677927 2 16.0338964 Prob > F = 0.0000 Residual | 105.178763 515 .204230608 R-squared = 0.2337 -------------+------------------------------ Adj R-squared = 0.2307 Total | 137.246556 517 .265467226 Root MSE = .45192 ------------------------------------------------------------------------------ lsal | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- leduca | 1.213169 .1031905 11.76 0.000 1.010443 1.415895 lexp | .1750682 .0238599 7.34 0.000 .1281934 .221943 _cons | -1.47408 .2870476 -5.14 0.000 -2.038008 -.9101512 ------------------------------------------------------------------------------
Ahora los estimadores son elasticidades. Así, ante un incremento de 1% en los años de educación, el salario aumenta en 1.21% (ceteris paribus); de igual manera, un incremento de 1% en los años de experiencia incrementan en 0.18% el salario por hora (ceteris paribus). Por otra parte, todos los coeficientes resulta ser significativos a los niveles convencionales. Debe notarse que al aplicar la transformación logarítmica sobre las variables, se pierde un total de 10 observaciones, las cuales toman valores cero ya sea en educa o exp.

ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 8
A continuación se verifican cada uno de los supuestos para evaluar al modelo en su conjunto.
Multicolinealidad
Variable | VIF 1/VIF -------------+---------------------- leduca | 1.08 0.927704 lexp | 1.08 0.927704 -------------+---------------------- Mean VIF | 1.08
Normalidad de los errores
Jarque-Bera scalar JB= r(N)*((r(skewness)^2/6)+(( r(kurtosis)-3)^2)/24), dado que JB=3.146492 < χ2, 0.05= 5.99. y además
sktest
Skewness/Kurtosis tests for Normality ------- joint ------ Variable | Pr(Skewness) Pr(Kurtosis) adj chi2(2) Prob>chi2 -------------+------------------------------------------------------- resid2 | 0.293 0.151 3.17 0.2050
Normalidad de los errores
02
040
60
80F
requ
ency
-1 0 1 2Residuals
0.0
00.
25
0.5
00
.75
1.0
0N
orm
al F
[(re
sid2
-m)/
s]
0.00 0.25 0.50 0.75 1.00Empirical P[i] = i/(N+1)

ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 9
Homoscedasticidad
Breusch-Pagan / Cook-Weisberg test for heteroskedasticity Ho: Constant variance Variables: fitted values of lsal chi2(1) = 1.94 Prob > chi2 = 0.1638
White's test for Ho: homoskedasticity against Ha: unrestricted heteroskedasticity chi2(5) = 11.53 Prob > chi2 = 0.0419
No heteroscedsticidad
-10
12
Res
idua
ls
1 1.5 2 2.5 3Fitted values
-10
12
Res
idua
ls
1.8 2 2.2 2.4 2.6 2.8leduca
-10
12
Res
idua
ls
0 1 2 3 4lexp

ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 10
Autocorrelación
Durbin-Watson d-statistic( 3, 518) = 1.842017
El valor de tablas de DW para un α=0.05, DL= 1.748 y DU=1.789. Para α=0.01 estos son, DL= 1.653 y DU=1.693. No hay autocorrelación (recuerde la no normalidad).
Breusch-Godfrey
Breusch-Godfrey LM test for autocorrelation --------------------------------------------------------------------------- lags(p) | chi2 df Prob > chi2 -------------+------------------------------------------------------------- 1 | 1.631 1 0.2015 --------------------------------------------------------------------------- H0: no serial correlation
En general, el modelo parece ser más adecuado.
2. a) Verdadero . El efecto sería similar al de multiplicar por una constante a cada valor de X. b) Falso . Los estimadores son insesgados pero ineficientes en ambos casos. 3. a) reg g pg i pnc puc ppt Source | SS df MS Number of obs = 27 -------------+------------------------------ F( 5, 21) = 284.74 Model | 49151.9948 5 9830.39896 Prob > F = 0.0000 Residual | 725.001999 21 34.5239047 R-squared = 0.9855 -------------+------------------------------ Adj R-squared = 0.9820 Total | 49876.9968 26 1918.34603 Root MSE = 5.8757 ------------------------------------------------------------------------------ g | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- pg | -14.39283 3.463646 -4.16 0.000 -21.59588 -7.189788 i | .040214 .0015902 25.29 0.000 .036907 .043521 pnc | 29.95765 20.19802 1.48 0.153 -12.04643 71.96174 puc | -14.12344 8.685095 -1.63 0.119 -32.18508 3.938204 ppt | -2.486702 7.926604 -0.31 0.757 -18.97098 13.99757 _cons | -120.5194 15.57343 -7.74 0.000 -152.9061 -88.13264 ------------------------------------------------------------------------------

ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 11
b) El valor del estadístico F es 284.74, el cual resulta altamente significativo (a cualquiera de los niveles convencionales). c) Valores t de tabla a diferentes valores de significancia son (en valor absoluto):
t27,0.01= t27,0.005= 2.771 t27,0.05= t27,0.025= 2.052 t27,0.10= t27,0.05= 1.703
Al comparar con los valores del estadístico de prueba calculados se observa que las variables: i y pg resultan significativas a todos los niveles; pnc, puc y ppt no lo son a ninguno
Se considera la “regla practica” existen indicios de alta multicolinealidad en el modelo.
d) Si evaluamos los valores VIF asociados a cada predictor, se afirma que existen indicios de una alta colinealidad entre los regresores.
Variable | VIF 1/VIF -------------+---------------------- ppt | 58.12 0.017205 pnc | 56.27 0.017770 puc | 53.97 0.018527 pg | 12.32 0.081145 i | 4.04 0.247820 -------------+---------------------- Mean VIF | 36.95
4. a) Source | SS df MS Number of obs = 15 -------------+------------------------------ F( 1, 13) = 42.51 Model | 7.0655963 1 7.0655963 Prob > F = 0.0000 Residual | 2.16096331 13 .166227947 R-squared = 0.7658 -------------+------------------------------ Adj R-squared = 0.7478 Total | 9.22655961 14 .659039972 Root MSE = .40771 ------------------------------------------------------------------------------ y | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- x | -.0891805 .0136788 -6.52 0.000 -.1187318 -.0596293 _cons | 24.59405 1.205603 20.40 0.000 21.98951 27.1986 ------------------------------------------------------------------------------

ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 12
No es muy clara la existencia de autocorrelación mediante el gráfico de los residuales vs el tiempo. Pero con el diagrama de dispersión entre el residual y su primer rezago si parece existir autocorrelación.
b)
Durbin-Watson d-statistic( 2, 15) = .8182965
Al calcular el estadístico DW es evidente la existencia de autocorrelación en el modelo.
c)
Para corregir con el método de Cochrane-Orcutt con una sola iteracción se procede de la siguiente manera:
gen res1=L.residual reg residual res1 , noconst Source | SS df MS Number of obs = 14 -------------+------------------------------ F( 1, 13) = 6.24 Model | .68006861 1 .68006861 Prob > F = 0.0267 Residual | 1.41637714 13 .108952088 R-squared = 0.3244 -------------+------------------------------ Adj R-squared = 0.2724 Total | 2.09644575 14 .149746125 Root MSE = .33008 ------------------------------------------------------------------------------ residual | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- res1 | .5816081 .2327941 2.50 0.027 .0786872 1.084529 ------------------------------------------------------------------------------ gen ty=.5816081*y gen tx=.5816081*x gen ys=y-ty gen xs=x-tx reg ys xs
-1-.
50
.5R
esid
ual
s
0 5 10 15t
-1-.
50
.5R
esid
ual
s
-1 -.5 0 .5res1
ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 13
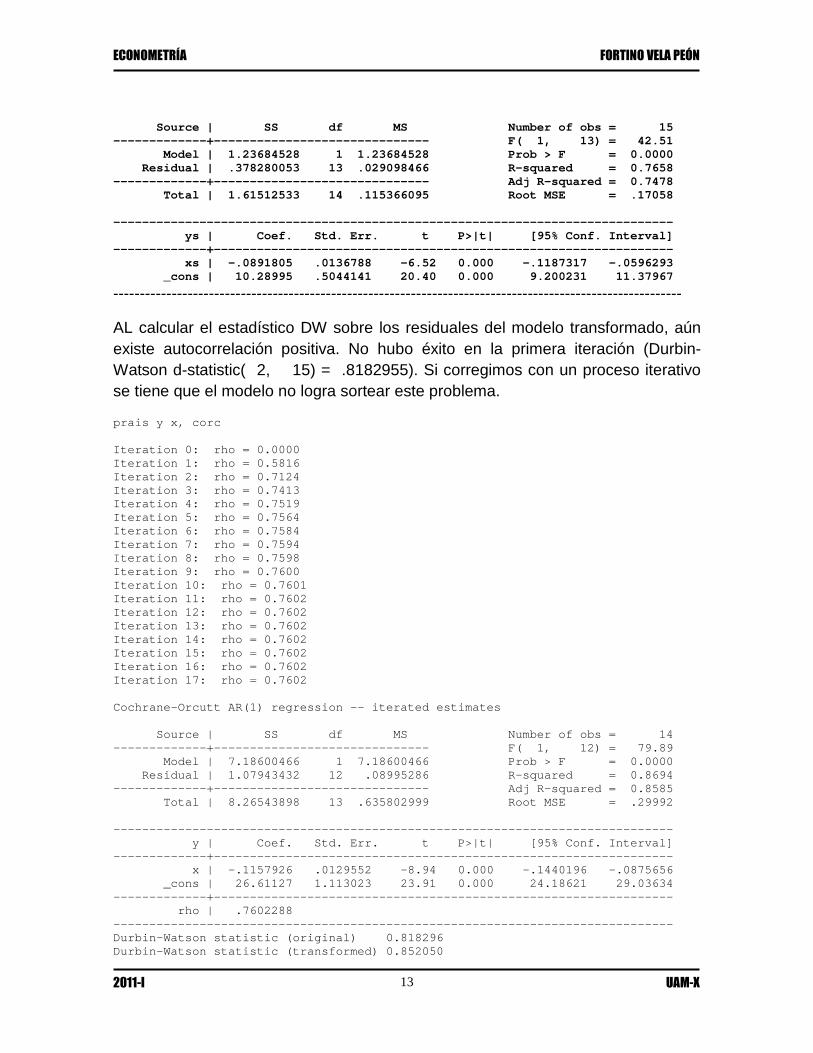
Source | SS df MS Number of obs = 15 -------------+------------------------------ F( 1, 13) = 42.51 Model | 1.23684528 1 1.23684528 Prob > F = 0.0000 Residual | .378280053 13 .029098466 R-squared = 0.7658 -------------+------------------------------ Adj R-squared = 0.7478 Total | 1.61512533 14 .115366095 Root MSE = .17058 ------------------------------------------------------------------------------ ys | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- xs | -.0891805 .0136788 -6.52 0.000 -.1187317 -.0596293 _cons | 10.28995 .5044141 20.40 0.000 9.200231 11.37967 -----------------------------------------------------------------------------------------------------------
AL calcular el estadístico DW sobre los residuales del modelo transformado, aún existe autocorrelación positiva. No hubo éxito en la primera iteración (Durbin-Watson d-statistic( 2, 15) = .8182955). Si corregimos con un proceso iterativo se tiene que el modelo no logra sortear este problema.
prais y x, corc Iteration 0: rho = 0.0000 Iteration 1: rho = 0.5816 Iteration 2: rho = 0.7124 Iteration 3: rho = 0.7413 Iteration 4: rho = 0.7519 Iteration 5: rho = 0.7564 Iteration 6: rho = 0.7584 Iteration 7: rho = 0.7594 Iteration 8: rho = 0.7598 Iteration 9: rho = 0.7600 Iteration 10: rho = 0.7601 Iteration 11: rho = 0.7602 Iteration 12: rho = 0.7602 Iteration 13: rho = 0.7602 Iteration 14: rho = 0.7602 Iteration 15: rho = 0.7602 Iteration 16: rho = 0.7602 Iteration 17: rho = 0.7602 Cochrane-Orcutt AR(1) regression -- iterated estimates Source | SS df MS Number of obs = 14 -------------+------------------------------ F( 1, 12) = 79.89 Model | 7.18600466 1 7.18600466 Prob > F = 0.0000 Residual | 1.07943432 12 .08995286 R-squared = 0.8694 -------------+------------------------------ Adj R-squared = 0.8585 Total | 8.26543898 13 .635802999 Root MSE = .29992 ------------------------------------------------------------------------------ y | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- x | -.1157926 .0129552 -8.94 0.000 -.1440196 -.0875656 _cons | 26.61127 1.113023 23.91 0.000 24.18621 29.03634 -------------+---------------------------------------------------------------- rho | .7602288 ------------------------------------------------------------------------------ Durbin-Watson statistic (original) 0.818296 Durbin-Watson statistic (transformed) 0.852050

ECONOMETRÍA FORTINO VELA PEÓN
2011-I UAM-X 14
En un caso como este se proced con la corrección Newey –wset
newey y x, lag(1) Regression with Newey-West standard errors Number of obs = 15 maximum lag: 1 F( 1, 13) = 39.49 Prob > F = 0.0000 ------------------------------------------------------------------------------ | Newey-West y | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- x | -.0891805 .0141906 -6.28 0.000 -.1198374 -.0585237 _cons | 24.59405 1.246261 19.73 0.000 21.90167 27.28644 ------------------------------------------------------------------------------
5.
El analista inicia su trabajo graficando las series de tiempo pcocoa, pcoffe y ptea. De igual manera, elabora los diagramas de dispersión correspondientes. Las dos primeras series muestran evoluciones temporales muy parecidas no así la correspondiente a ptea.
De los listados se puede ver que se estimaron 6 modelos. Los primeros tres consideran los modelos de regresión simple y uno múltiple y su estimación en términos doble logarítmicos (log-log).
Modelo 1. pcocoa = b1 + b2 pcoffe + b3 ptea + u Modelo 2. pcocoa = b1 + b2 pcoffe + u Modelo 3. pcocoa = b1 + b2 ptea + u Modelo 4. lpcocoa = b1 + b2 lpcoffe + b3 lptea + u Modelo 5. lpcocoa = b1 + b2 lpcoffe + u Modelo 6. lpcocoa = b1 + b2 lptea + u
A partir de estos modelos es posible evaluar la significancia estadística individual de los coeficientes en cada ecuación de regresión considerada. En términos generales, los predictores resultan ser altamente significativos en todos los modelos. El siguiente paso es la evaluación de los supuestos. Para ello se emplearon las pruebas siguientes: sktest para la normalidad de errores; Breusch-Pagan para la identificación de heteroscedasticidad; Durbin-Watson para autocorrelación y el índice de tolerancia (TOL) para la multicolinealidad. Finalmente, se considero un modelo que incluye como predictor a la variable dependiente con un rezago. Para esté último se utilizo el estadístico h-Durbin para identificar autocorrelación.







