
• Introducción
• Método de los mínimos cuadrados Estimación de los parámetrosValidación del modeloHeterocedasticidad y su solución
• Intervalos de confianzaDe los parámetros por separadoDe los parámetros conjuntamente
• Predicciones hechas sobre la línea ajustadaPredicción de nuevas respuestasInterpolación de x a partir de y
• Límite de detección y cantidades relacionadas
• Detección de outliers
• Otras posibilidades Regresión inversaMétodo de adiciones/sustracciones patrónComparación de pendientesIntersección de dos rectas de regresiónValidación de métodosRegresión a través de un punto fijoLinearización de funciones curvas
• Regresión vs. correlación
CALIBRADO Y REGRESIÓN
CALIBRADO Y REGRESIÓN
Introducción
Relación entre variables asociadas entre sí.- Análisis Instrumental en que la Respuesta(s) está relacionada con la Concentración de analito(s)- Construcción de modelos para predecir una variable (output) en función de una o varias entradas (inputs)
La relación se estudia mediante un Análisis de regresión y consiste en construir una función matemática que puede ser utilizada para predecir una variable a partir de las otras, o bien para interpolar.
Técnicas de regresión Modelo I: Dependencia de una variable aleatoria (variable dependiente o respuesta) en función de una variable controlada por el experimentador (variable independiente o de predicción).
Técnicas de regresión Modelo II: Dependencia entre variables cuando todas están sujetas a error
Desarrollo:- Regresión lineal simple: Ajuste lineal de una respuesta a una sola variable independiente - Regresión múltiple: Ajuste lineal de una (o varias) respuesta(s) a varias variables
independientesSimultáneamente iremos presentando las principales aplicaciones analíticas

MÉTODO DE LOS MÍNIMOS CUADRADOS
ESTIMACIÓN DE LOS PARÁMETROS
• Suponemos que existe una relación verdadera entre η (respuesta) y una variable independiente x
β0 y β1 : parámetros del modelo (ordenada en el origen y pendiente) relacionados linealmente con η
x10 β+β=η
• En la realidad, únicamente se tiene acceso a un valor experimental yi, sujeto a error:
β0 y β1 desconocidos. Se estiman mediante b0 y b1 a partir de la información de las medidas
ii10iiii xyóy ε+β+β=ε+η=
• La línea estimada se denomina línea de mínimos cuadrados si se minimiza la suma de los cuadrados de los residuales
• Se deriva R frente a b0 y b1 y se iguala a cero, obteniendo las ecuaciones normales
xbby 10 +=
iii yye −=
∑ ∑∑ −−=−==i i
2i1oi
2
iii
2i )xbby()yy(eR
∑ ∑ ∑ =−−
∑ ∑ =−−
i i i
2i1i0ii
i ii10i
0xbxbyx
0xbbny
MÉTODO DE LOS MÍNIMOS CUADRADOS
∑ ∑==−=
∑ −
∑ −−=
i iii10
i
2i
iii
1
n/)x(x;n/)y(y;xbyb
)xx(
)yy)(xx(b
2n
)yy(
2n
es i
2ii
i
2i
2e −
∑ −=
−
∑=
• La varianza residual
es la varianza no explicada por la línea de regresión. A veces se la representa como sy/x2.
• Si el modelo es correcto se2 es una estimación de la varianza de las medidas σ2 o
puro error experimental.
Condición fundamental de validez del modelo
ESTIMACIÓN DE LOS PARÁMETROS
• Las estimaciones de los parámetros son:

η=β0+ β1x
ηi
yi
x
y
MÉTODO DE LOS MÍNIMOS CUADRADOS
• Se hacen las siguientes suposiciones implícitas
- Todos los residuales vienen de una población normalmente distribuida con media cero
- Los ei son independientes- Todos los ei tienen la misma varianza σ2. Condición de la homocedasticidad. Se
comprueba mediante medidas replicadas y en caso negativo obliga a la utilización de pesos estadísticos. En calibrado eso significa que la precisión de las respuestas es independiente de la concentración.
Distribución delas respuestas
Respuestaobservada
Valor verdaderodel modelo
ETAPAS DEL PROCEDIMIENTO
• Selección de un modelo
• Establecimiento del diseño experimental
• Estimación de los parámetros del modelo
• Validación del modelo
• Determinación de los intervalos de confianza
• Utilización del modelo para predecir o interpolar
Línea recta
Cómo se eligen los puntos
Cálculo de b0 y b1
N(0,σ2), f.d.a, ¿r2?
sb0, sb1
xy tsx;tsy ±±
MÉTODO DE LOS MÍNIMOS CUADRADOS

• Gráfico de residuales: Representación de ei en función de xi. Su examen precisa experiencia previa, pero hay varios comportamientos típicos:
Los residuales aparecen esparcidos a lo largo del eje x de forma aleatoria y sin tendencias visibles sistemáticas
No se cumple la condición de homocedasticidad, ya que aumenta la dispersión a lo largo del eje x
Existe un comportamiento anómalo que indica que el modelo subyacente no es una línea recta y que probablemente la adición de un término cuadrático mejoraría el ajuste
VALIDACIÓN DEL MODELO
x
e
x
e
x
e
iii yye −=Análisis de los residuales
• Se trata de verificar la hipótesis de que los residuales son N(0,σ2) mediante una prueba χ2, rankit o un gráfico de normalidad
No suele haber bastantes datos
EXCEL
Análisis de Varianza (ANOVA)
• Se trata de demostrar que la relación que liga las variables es la correcta: no hay falta de ajuste
• Se compara la varianza debida a la presunta falta de ajuste con la varianza experimental σ2, estimada a través de medidas replicadas de la variable observada
• P.e. En una línea de calibrado alguno de los puntos se mide (observa) más de una vez.
• En este caso se tienen 14 puntos experimentales, correspondientes a k=7 situaciones diferentes .
VALIDACIÓN DEL MODELO
k=7
0,3770,3180,2590,2000,1410,0820,023
0,36240,31560,27200,20970,15090,08330,0067
2222222ni
0,36410,31790,26980,20640,14880,08420,0080
0,36070,31330,27420,21290,15290,08230,0054yij (Absorb.)
3,02,52,01,51,00,50Ci (mg/l)
x1181,00230,0y += 2001,0y =14nni
i =∑=
iy
iy
Si el modelo es correcto sy/x2 estimará σ2

VALIDACIÓN DEL MODELO
Análisis de Varianza (ANOVA)
k=7
0,3770,3180,2590,2000,1410,0820,023
0,36240,31560,27200,20970,15090,08330,0067
2222222ni
0,36410,31790,26980,20640,14880,08420,0080
0,36070,31330,27420,21290,15290,08230,0054yij (Absorb.)
3,02,52,01,51,00,50Ci (mg/l)
x1181,00230,0y += 2001,0y =14nni
i =∑=
iy
iy
Desarrollo del ANOVA
Variación total de los datos SST: ∑ ∑ −== =
k
1i
nk
1j
2ijT )yy(SS
)yy()yy()yy()yy( iiiiijij −+−+−=−
)1p()pk()kn()1n(
SSSSSS
SSSSSSSS
)yy(n)yy(n)yy()yy(
REGREST
REGFDAPET
2i
k
1i
k
1ii
2iii
k
1i
nk
1j
2iij
k
1i
nk
1j
2ij
−+−+−=−
+=
++=
−∑ ∑+−+∑ ∑ −=∑ ∑ −= == == =
SSg.d.l.
• MSFDA y MSPE solo pueden ser comparadas cuando hay replicación de al menos una experiencia, pues si n = k (es decir solo hay una experiencia de cada situación experimental) no tenemos g.d.l. para calcular MSPE
Fcrit con 5 y 7 g.d.l. y α = 0,05 vale 3,97 (p a posteriori = 0,00006)
SSTn-1Total
SSPE/(n-k)SSPEn-kPuro error
MSFDA/MSPESSFDA/(k-2)SSFDAk-p=k-2Falta de ajuste
SSRES/(n-2)SSRESn-p = n-2Residual
MSREG/MSRESSSREG/1SSREGp-1 = 1Regresión
FMSSSg.d.lFuente
• Dividiendo SS por sus g.d.l. se obtienen MS: estimaciones de las varianzas del modelo:MSPE es una estimación de σ2
MSFDA es también una estimación de σ2 si el modelo está bien elegido
• El test de falta de ajuste es una prueba F que compara MSFDA/MSPE con el Fcrít con (k-2) y (n-k) g.d.l. Si H0 se rechaza el modelo no es adecuado, mientras si se retiene sí que lo es y MSRES = se
2 es un estimador de σ2. La tabla del ANOVA que resulta es:
VALIDACIÓN DEL MODELO
Análisis de Varianza (ANOVA)
0,1969113Total
8,68.10-60,000067Puro error
38,960,0003380,001695Falta de ajuste
0,0001460,0017512Residual
1337,370,195160,195161Regresión
FMSSSg.d.lFuente
HAY FALTA DE AJUSTE

• El cociente SSREG/SST es el coeficiente de determinación múltiple R2 y es la proporción de varianza o información total explicada por el modelo. Varía entre cero, que implica que x no tiene efecto sobre y, y uno que indica que x explica perfectamente y. Su raíz cuadrada es el coeficiente de correlación múltiple.
• Existe otra comparación: MSREG con MSRES que es lo mismo que comprobar la hipótesis nula que β1 = 0.
y en este caso resulta
Fcrit con 1 y 12 g.d.l. y α = 0,05 vale 4,74 (p a posteriori 7.10-8)
La prueba dice que el modelo sí que explica una cantidad apreciable de la varianza.
VALIDACIÓN DEL MODELO
Análisis de Varianza (ANOVA)
SSTn-1Total
SSRES/(n-2)SSRESn-p = n-2Residual
MSREG/MSRESSSREG/1SSREGp-1 = 1Regresión
FMSSSg.d.lFuente
0,1969113Total
0,00014590,00017512Residual
1337,60,195160,195161Regresión
FMSSSg.d.lFuente
• Cuando el modelo es una recta (p=2), R2 se convierte en r2 y se denomina coeficiente de determinación. Su raíz cuadrada, corregida por el signo de la pendiente, se llama coeficiente de correlación y su importancia ha sido sobrestimada.
EXCEL
VALIDACIÓN DEL MODELO
Heterocedasticidad
Si no se cumple la condición de homocedasticidad, no se puede aplicar el método de mínimos cuadrados anterior.
1) TransformaciónDepende de la forma en que la varianza de y varía con y. Suele haber dos casos:
Varianza proporcional a y (desviación típica constante):
Varianza proporcional a y2, (desviación típica relativa constante):
xbby 10 +=
xlogbbylog 10 +=
2iy
i s1w =
∑ ∑ ∑∑
∑
∑
==−=
−
−−=
i i iiiiw
iiiiww1w0
i
2wii
iwiwii
1
w/)xw(x;w/)yw(y;xbyb
)xx(w
)yy)(xx(wb
2) Mínimos cuadrados con pesosSe introduce el factor de peso, inversamente proporcional a la varianza
de manera que se da más importancia a las observaciones más precisas: la línea de regresión pasa más cerca de los puntos más precisos que de los más imprecisos. Los valores de los parámetros son:

DETERMINACIÓN DE LOS INTERVALOS DE CONFIANZA
De los parámetros individuales
• Los intervalos de confianza de un parámetro con un 100(1-α)% de confianza son .
• Las estimación de las s respectivas son:
β0= b0 ± t0,025;n-2.β1= b1 ± t0,025;n-2.
• Si cualquiera de los dos intervalos incluye a cero, se puede decir que dicho parámetro es igual a cero (Cf. Test de hipótesis).
∑ −=
∑ −∑=
2i
eb
2i
2i
eb
)xx(
ss
)xx(n
xss
1
o
parámetro2n;2/ st •± −α
0bs
1bs
De los parámetros conjuntamente
• Debido a la forma de obtenerlos, los valores de b0 y b1 no son independientes entre sí. Si se desea comprobar simultáneamente la hipótesis de que β0 = 0 y β1 = 1, se usa un test de hipótesis conjunto (joint hypothesis test), o construir la región conjunta de confianza que tenga en cuenta la correlación existente entre las estimaciones b0 y b1.
• Esa región tiene forma de elipse y su fórmula es:
• La hipótesis conjunta implica calcular un valor de F
que se compara con F crítico con 2 y n-2 g.d.l. y el nivel de significación requerido.
n/sF2)b)(n/x()b)(b(x2)b( 2e2n,2;
211
2i1100
200 −α=−β+−β−β+−β ∑
n/s2
))b)((n/x()b)(b(x2)b(F
2e
i
211
2i110000 ∑ −β+−β−β+−β
=
EXCEL
DETERMINACIÓN DE LOS INTERVALOS DE CONFIANZA
0100 xbby +=
∑ −
−+± − 2
i
20
e2n,2;05,00)xx(
)xx(n1
sF2y
Intervalo de confianza de la línea de regresión
• Si x=x0, se puede calcular
• Ese valor predicho tiene un intervalo de confianza que es:
• La representación gráfica es hiperbólica y la región dentro de las dos ramas se denomina banda de confianza de Working-Hotelling
xw, yw
x
y
xbby 10 +=
• El centroide es importante, ya que la línea de regresión pasa por él.
• Se observa que el intervalo de confianza disminuye cuando x0 coincide con el centroide: la mayor precisión se obtiene en el centro de la línea de regresión.
• El intervalo también disminuye cuando
es muy grande, lo que obligaría en calibrado a utilizar patrones de muy baja y muy alta concentración lo cual no es aconsejable.
• El número de puntos también influye
( )2i xx −Σ
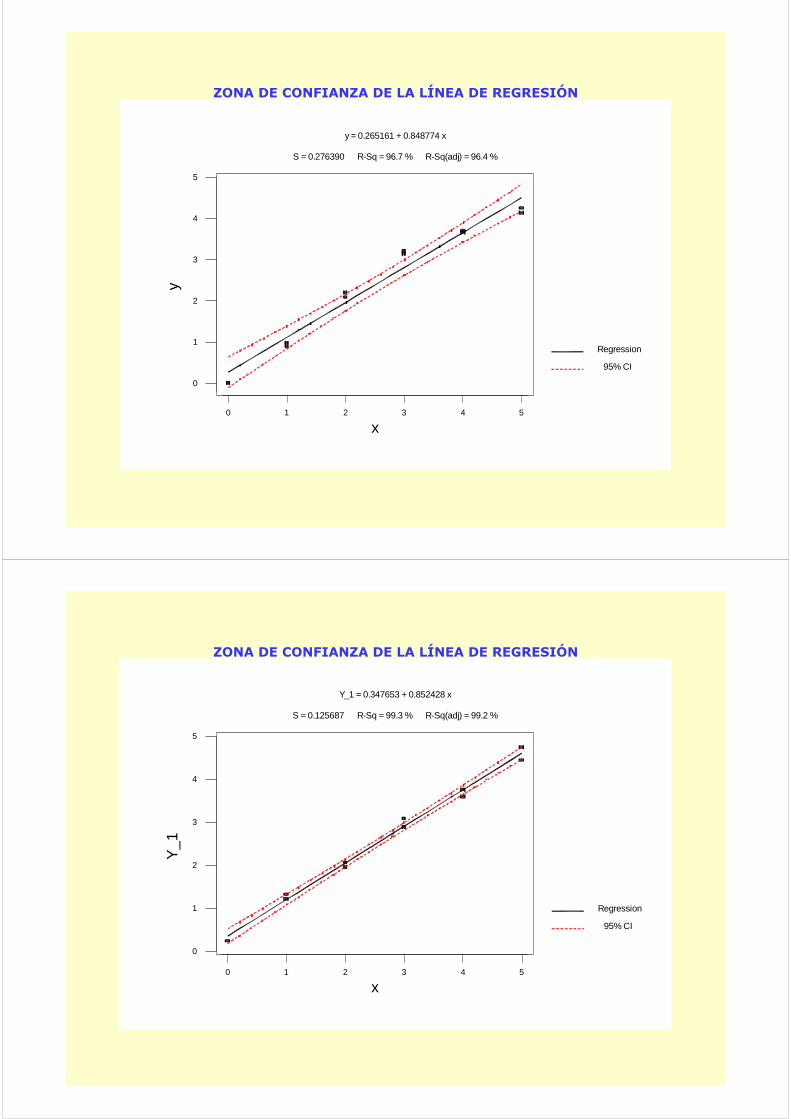
0 1 2 3 4 5
0
1
2
3
4
5
x
y
y = 0.265161 + 0.848774 x
S = 0.276390 R-Sq = 96.7 % R-Sq(adj) = 96.4 %
Regression
95% CI
ZONA DE CONFIANZA DE LA LÍNEA DE REGRESIÓN
0 1 2 3 4 5
0
1
2
3
4
5
x
Y_1
Y_1 = 0.347653 + 0.852428 x
S = 0.125687 R-Sq = 99.3 % R-Sq(adj) = 99.2 %
Regression
95% CI
ZONA DE CONFIANZA DE LA LÍNEA DE REGRESIÓN
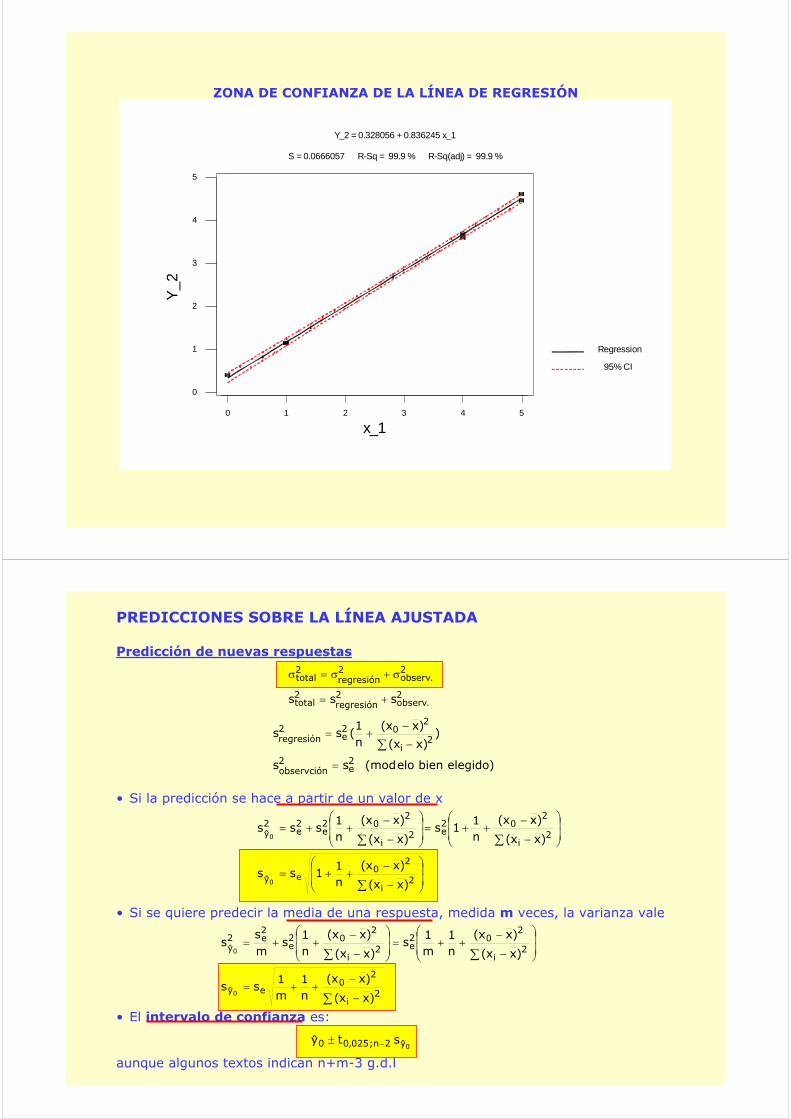
ZONA DE CONFIANZA DE LA LÍNEA DE REGRESIÓN
0 1 2 3 4 5
0
1
2
3
4
5
x_1
Y_2
Y_2 = 0.328056 + 0.836245 x_1
S = 0.0666057 R-Sq = 99.9 % R-Sq(adj) = 99.9 %
Regression
95% CI
PREDICCIONES SOBRE LA LÍNEA AJUSTADA
Predicción de nuevas respuestas
2.observ
2regresión
2total
2.observ
2regresión
2total
sss +=
σ+σ=σ
)elegidobienelo(modss
))xx(
)xx(n1
(ss
2e
2observción
2i
202
e2regresión
=
−
−+=∑
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
−++=
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
−++=
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
−++=
∑
∑∑
2i
20
ey
2i
202
e2i
202
e2e
2y
)xx(
)xx(n1
1ss
)xx(
)xx(n1
1s)xx(
)xx(n1
sss
0
0
• Si la predicción se hace a partir de un valor de x
∑
∑∑
−
−++=
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
−++=
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
−++=
2i
20
ey
2i
202
e2i
202
e
2e2
y
)xx(
)xx(n1
m1
ss
)xx(
)xx(n1
m1
s)xx(
)xx(n1
sms
s
0
0
• Si se quiere predecir la media de una respuesta, medida m veces, la varianza vale
0y2n;025,00 sty −±
• El intervalo de confianza es:
aunque algunos textos indican n+m-3 g.d.l
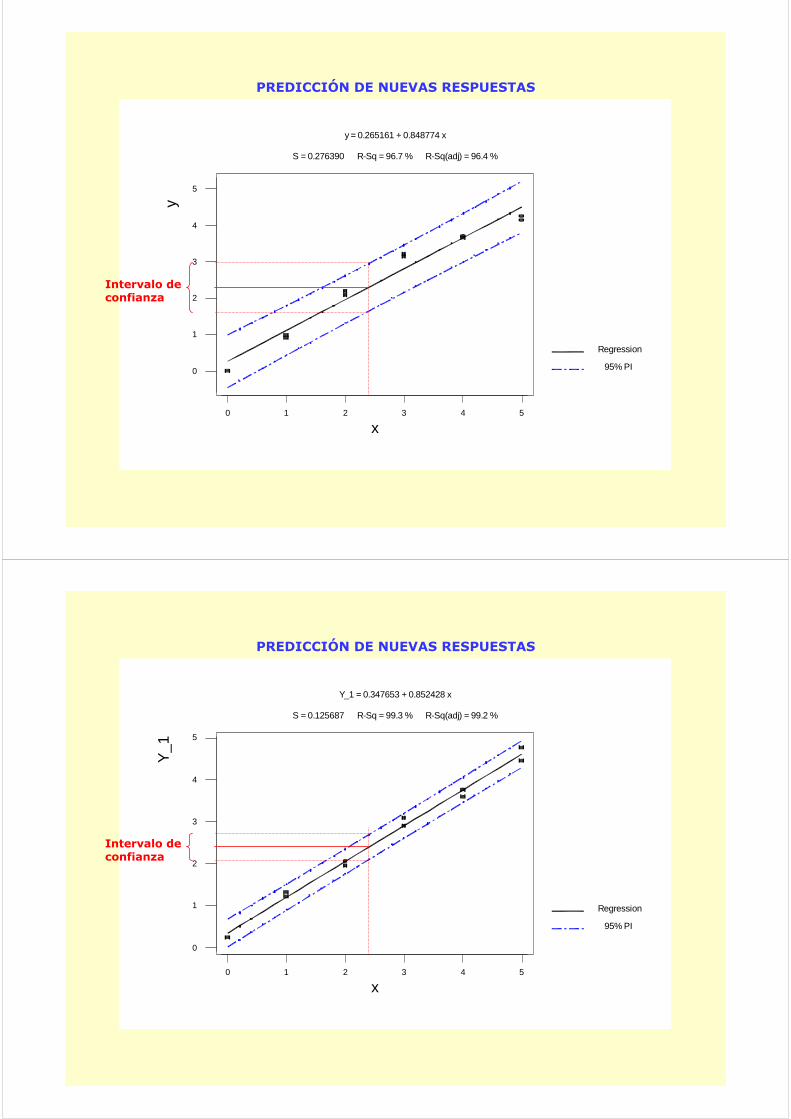
543210
5
4
3
2
1
0
x
yS = 0.276390 R-Sq = 96.7 % R-Sq(adj) = 96.4 %
y = 0.265161 + 0.848774 x
95% PI
Regression
PREDICCIÓN DE NUEVAS RESPUESTAS
Intervalo deconfianza
543210
5
4
3
2
1
0
x
Y_1
S = 0.125687 R-Sq = 99.3 % R-Sq(adj) = 99.2 %
Y_1 = 0.347653 + 0.852428 x
95% PI
Regression
PREDICCIÓN DE NUEVAS RESPUESTAS
Intervalo deconfianza
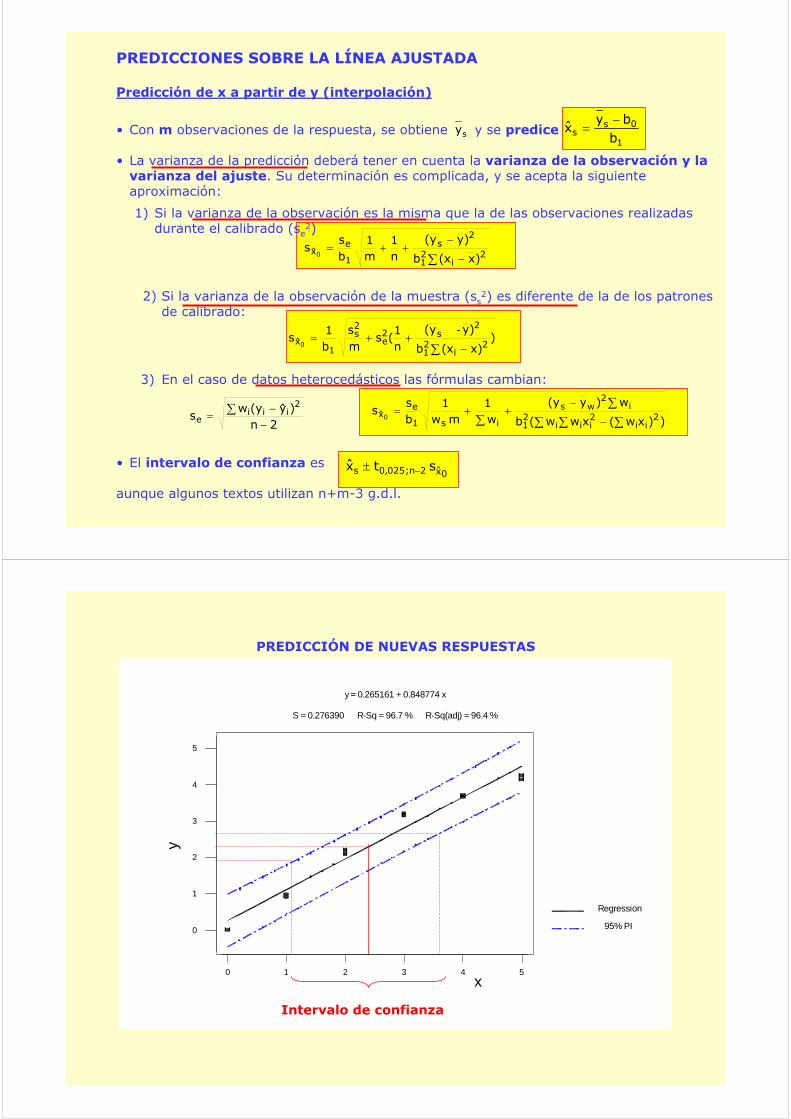
PREDICCIONES SOBRE LA LÍNEA AJUSTADA
Predicción de x a partir de y (interpolación)
sy• Con m observaciones de la respuesta, se obtiene y se predice
• La varianza de la predicción deberá tener en cuenta la varianza de la observación y la varianza del ajuste. Su determinación es complicada, y se acepta la siguiente aproximación:
1
0ss b
byx
−=
∑ −
−++=
2i
21
2s
1
ex
)xx(b
)yy(n1
m1
bs
s0
1) Si la varianza de la observación es la misma que la de las observaciones realizadas durante el calibrado (se
2)
))xx(b
)yy(n1
(sms
b1
s2
i21
2s2
e
2s
1x0 ∑ −
++= -
2) Si la varianza de la observación de la muestra (ss2) es diferente de la de los patrones
de calibrado:
0x2n;025,0s stx −±• El intervalo de confianza es
aunque algunos textos utilizan n+m-3 g.d.l.
3) En el caso de datos heterocedásticos las fórmulas cambian:
2n)yy(w
s2
iiie −
−= ∑
∑∑ ∑∑
∑ −
−++=
))xw(xww(b
w)yy(w1
mw1
bs
s2
ii2iii
21
i2
ws
is1
ex0
543210
5
4
3
2
1
0
x
y
S = 0.276390 R-Sq = 96.7 % R-Sq(adj) = 96.4 %
y = 0.265161 + 0.848774 x
95% PI
Regression
PREDICCIÓN DE NUEVAS RESPUESTAS
Intervalo de confianza
543210
5
4
3
2
1
0
x
Y_1
S = 0.125687 R-Sq = 99.3 % R-Sq(adj) = 99.2 %
Y_1 = 0.347653 + 0.852428 x
95% PI
Regression
PREDICCIÓN DE NUEVAS RESPUESTAS
Intervalo de confianza
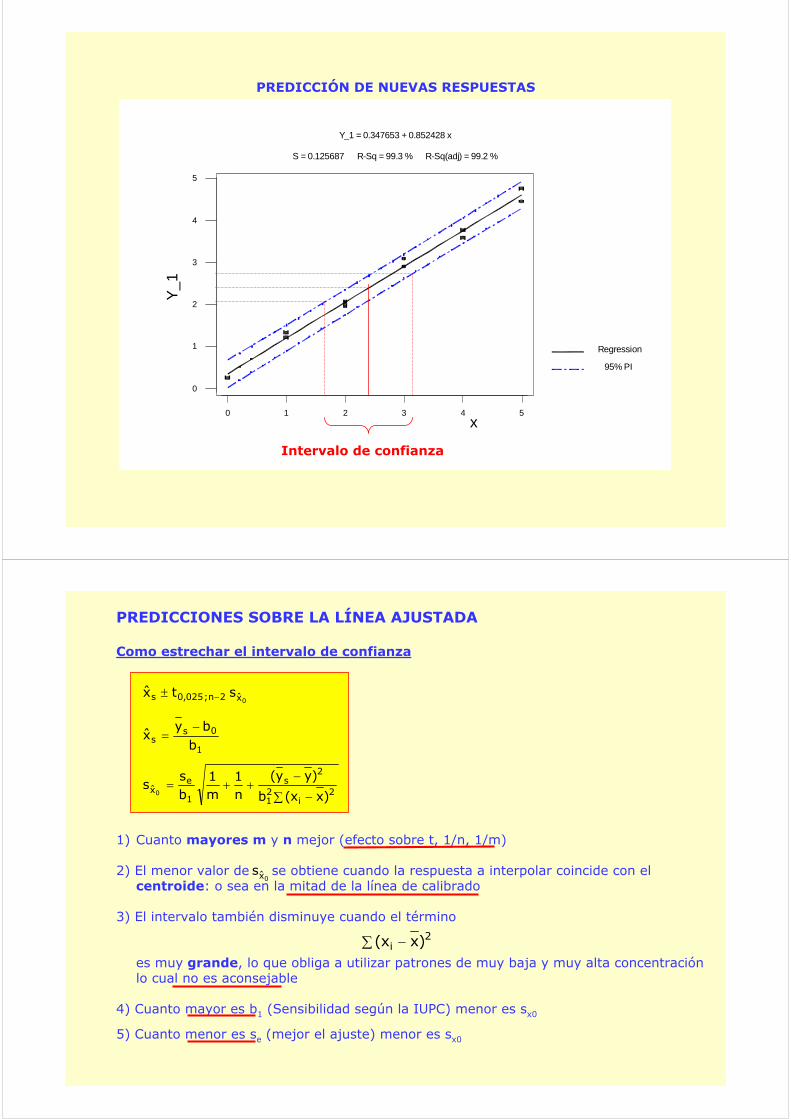
1) Cuanto mayores m y n mejor (efecto sobre t, 1/n, 1/m)
2) El menor valor de se obtiene cuando la respuesta a interpolar coincide con el centroide: o sea en la mitad de la línea de calibrado
3) El intervalo también disminuye cuando el término
es muy grande, lo que obliga a utilizar patrones de muy baja y muy alta concentración lo cual no es aconsejable
4) Cuanto mayor es b1 (Sensibilidad según la IUPC) menor es sx0
5) Cuanto menor es se (mejor el ajuste) menor es sx0
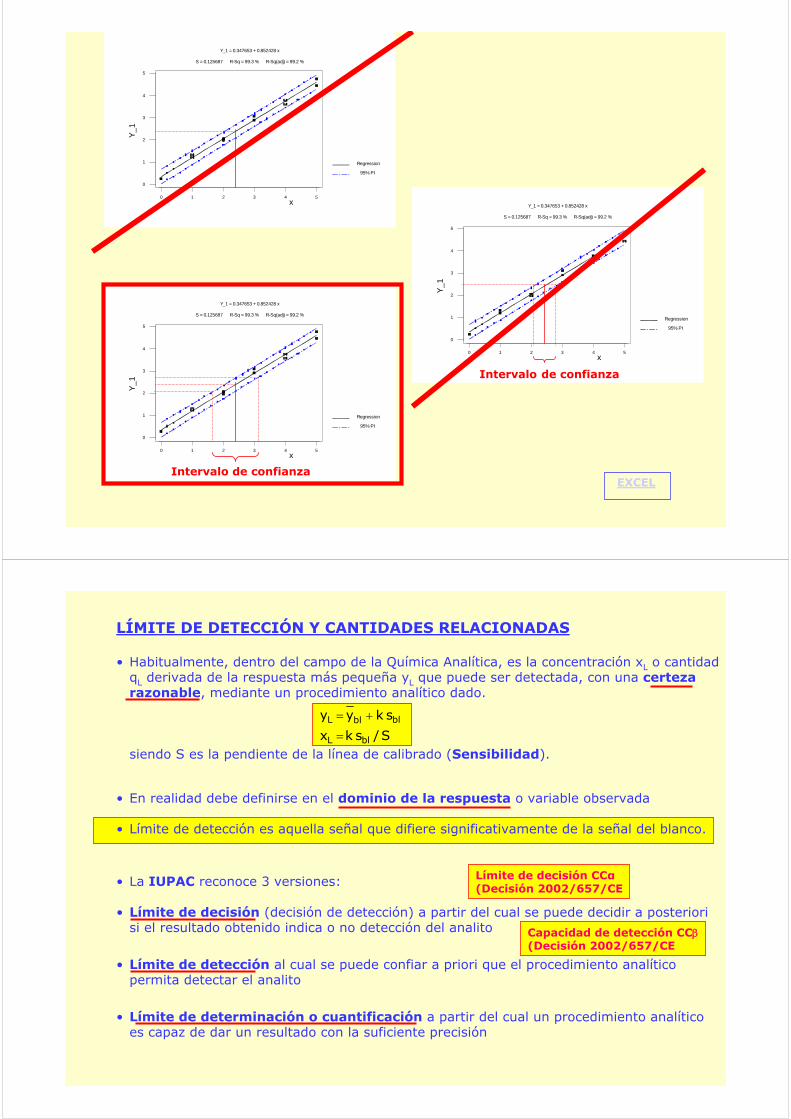
PREDICCIONES SOBRE LA LÍNEA AJUSTADA
Como estrechar el intervalo de confianza
0x2n;025,0s stx −±
1
0ss b
byx
−=
∑ −
−++=
2i
21
2s
1
ex
)xx(b
)yy(n1
m1
bs
s0
0xs
∑ − 2i )xx(
543210
5
4
3
2
1
0
x
Y_
1
S = 0.125687 R-Sq = 99.3 % R-Sq(adj) = 99.2 %
Y_1 = 0.347653 + 0.852428 x
95% PI
Regression
543210
5
4
3
2
1
0
x
Y_
1
S = 0.125687 R-Sq = 99.3 % R-Sq(adj) = 99.2 %
Y_1 = 0.347653 + 0.852428 x
95% PI
Regression
Intervalo de confianza
543210
5
4
3
2
1
0
x
Y_
1
S = 0.125687 R-Sq = 99.3 % R-Sq(adj) = 99.2 %
Y_1 = 0.347653 + 0.852428 x
95% PI
Regression
Intervalo de confianzaEXCEL
LÍMITE DE DETECCIÓN Y CANTIDADES RELACIONADAS
• Habitualmente, dentro del campo de la Química Analítica, es la concentración xL o cantidad qL derivada de la respuesta más pequeña yL que puede ser detectada, con una certeza razonable, mediante un procedimiento analítico dado.
siendo S es la pendiente de la línea de calibrado (Sensibilidad). S/skx
skyy
blL
blblL
=
+=
• En realidad debe definirse en el dominio de la respuesta o variable observada
• Límite de detección es aquella señal que difiere significativamente de la señal del blanco.
• La IUPAC reconoce 3 versiones:
• Límite de decisión (decisión de detección) a partir del cual se puede decidir a posteriori si el resultado obtenido indica o no detección del analito
• Límite de detección al cual se puede confiar a priori que el procedimiento analítico permita detectar el analito
• Límite de determinación o cuantificación a partir del cual un procedimiento analítico es capaz de dar un resultado con la suficiente precisión
Límite de decisión CCα(Decisión 2002/657/CE
Capacidad de detección CCβ(Decisión 2002/657/CE
LÍMITE DE DETECCIÓN Y CANTIDADES RELACIONADAS
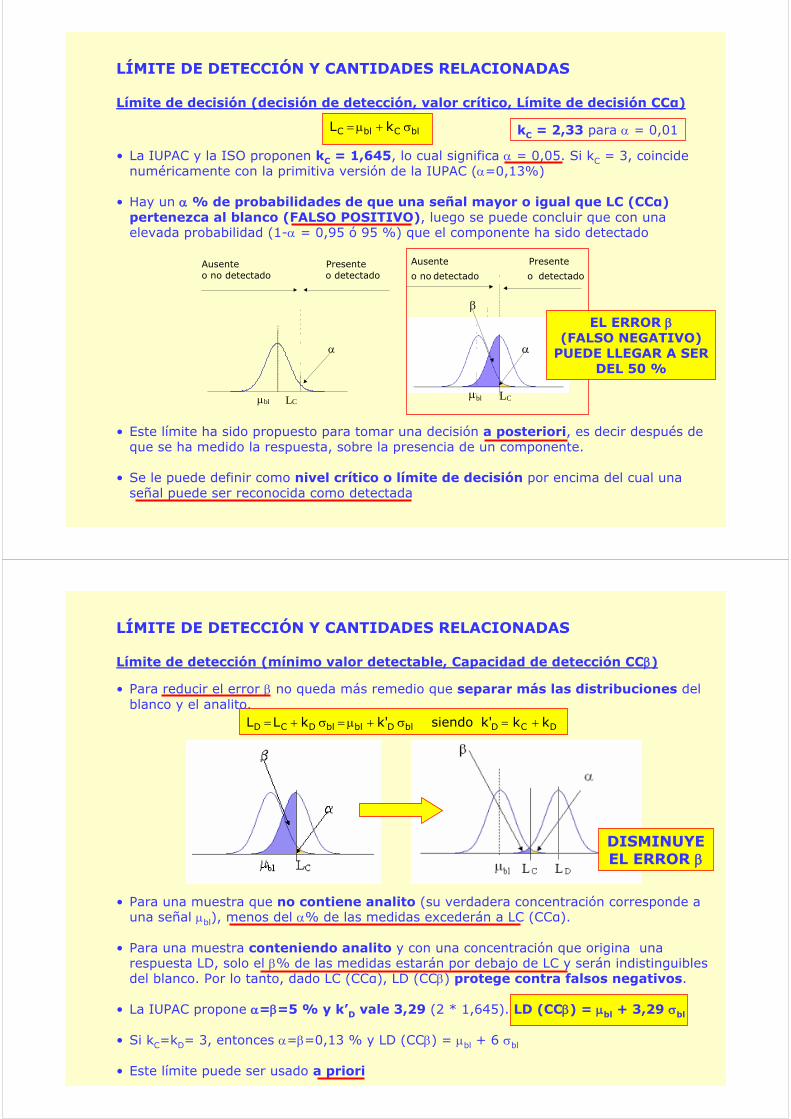
Límite de decisión (decisión de detección, valor crítico, Límite de decisión CCα)
blCblC kL σ+μ=
• La IUPAC y la ISO proponen kC = 1,645, lo cual significa α = 0,05. Si kC = 3, coincide numéricamente con la primitiva versión de la IUPAC (α=0,13%)
• Hay un α % de probabilidades de que una señal mayor o igual que LC (CCα) pertenezca al blanco (FALSO POSITIVO), luego se puede concluir que con una elevada probabilidad (1-α = 0,95 ó 95 %) que el componente ha sido detectado
• Este límite ha sido propuesto para tomar una decisión a posteriori, es decir después de que se ha medido la respuesta, sobre la presencia de un componente.
• Se le puede definir como nivel crítico o límite de decisión por encima del cual una señal puede ser reconocida como detectada
μbl LC
α
Ausente Presenteo no detectado o detectado
μbl LC
α
β
Ausente Presente
o no detectado o detectado
EL ERROR β(FALSO NEGATIVO)
PUEDE LLEGAR A SER DEL 50 %
kC = 2,33 para α = 0,01
LÍMITE DE DETECCIÓN Y CANTIDADES RELACIONADAS
Límite de detección (mínimo valor detectable, Capacidad de detección CCβ)
DCDblDblblDCD kk'k siendo 'kkLL +=σ+μ=σ+=
• Para reducir el error β no queda más remedio que separar más las distribuciones del blanco y el analito.
• Para una muestra que no contiene analito (su verdadera concentración corresponde a una señal μbl), menos del α% de las medidas excederán a LC (CCα).
• Para una muestra conteniendo analito y con una concentración que origina una respuesta LD, solo el β% de las medidas estarán por debajo de LC y serán indistinguibles del blanco. Por lo tanto, dado LC (CCα), LD (CCβ) protege contra falsos negativos.
• La IUPAC propone α=β=5 % y k’D vale 3,29 (2 * 1,645). LD (CCβ) = μbl + 3,29 σbl
• Si kC=kD= 3, entonces α=β=0,13 % y LD (CCβ) = μbl + 6 σbl
• Este límite puede ser usado a priori
DISMINUYE EL ERROR β

LÍMITE DE DETECCIÓN Y CANTIDADES RELACIONADAS
Límite de cuantificación
• Es el nivel al cual la precisión de la medida será satisfactoria para una determinación cuantitativa. Es decir es la concentración que se puede determinar con una desviación típica relativa (DTR) fijada previamente.
LQ = μbl + kQ σbl
• Si DTR es del 5%, kQ = 20.
• La IUPAC propone una DTR del 10% por lo que el valor kQ = 1/0,1 = 10
• En la definición se supone que la σ en el límite de cuantificación es igual que σbl, pero eso debe comprobarse y suele utilizarse el valor de σ al nivel que se espera para LQ
.R.T.D1
k
k1
)L(.R.T.D
kL
Q
QblQ
bl
blQblQ
=
=μ−
σ=
σ⋅+μ=
LÍMITE DE DETECCIÓN Y CANTIDADES RELACIONADAS
blCblC kCCL σ+μ=α≡
blDblD 'kCCL σ+μ=β≡
blQblQ kL σ+μ=
Si α y β valen 0,05 y la D.T.R. de LQ es el 10%
blblC 65,1CCL σ+μ=α≡
blblD 29,3CCL σ+μ=β≡
blblQ 10L σ+μ=
Señalμbl CCα LQCCβ
Analito cuantificableAnalito detectadoAnalito nodetectado
Zona “peligrosa”

DETERMINACIÓN DEL BLANCO
• Es fundamental el conocer la estimación adecuada de μbl y σbl.
• Un blanco de reactivos o de disolvente puede dar lugar a resultados demasiado optimistas. Debe emplearse un blanco analítico que contiene todos los reactivos y se analiza de la misma manera que las muestras. El blanco ideal es un blanco de matriz
blC0CC 2kkL σ=σ=
DCDblD0DD kkk' siendo 2'k'kL +=σ=σ=
1) Con cada muestra (o grupo de muestras) se analiza un blanco, y la respuesta de cada muestra (o de todas las del grupo) es corregida del blanco de forma individual
yN = ybruta - ybl por lo queσ2
N = σ2bruta + σ2
bl = 2σ2bl
Si la muestra no contiene analito, ybruta = ybl, y su diferencia será N(0, 2σ2bl). Por lo
tanto los límites de decisión y detección para señales corregidas del blanco serán:
blbrutaN yyy −=
bl0 ))n/1(1( σ+=σ
blC0CC )n/1(1kkL σ+=σ=
DCDblD0DD kkk'siendo )n/1(1'k'kL +=σ+=σ=
2) Si se determina n veces un único blanco de forma separada, la corrección se hace restando a todas las muestras la media de ese blanco
σ2N = σ2
bruta + σ2bl /n
y si σ es independiente de la concentración
• Si se usan pocas réplicas, kC, kD y kQ deben sustituirse por valores de t con n-1 g.d.l.
LÍMITES DE CONCENTRACIÓN
• Los límites en función de la respuesta pueden transformarse en límites de concentracióna partir de la pendiente de la línea de calibrado:
• En esas fórmulas se supone que el blanco es bien conocido ya que su variabilidad no se tiene en cuenta. Si este no es el caso, las fórmulas varían ligeramente
• Si se ha llevado a cabo una línea de calibrado y el modelo está bien elegido, se puede asimilar σbl con σe, y μbl con b0 de manera que:
1
e
1
eDLD
LD10D
eD0blDblD
b29,3
bk
X
XbbL
kbkL
σ=
σ′=
+=
σ′+=σ′+μ=
1
e
1
eCLC
LC10C
eC0blCblC
b65,1
bk
X
XbbL
kbkL
σ=
σ=
+=
σ+=σ+μ=
1blcc b/k)n/1(1x σ+=
1bl'DD b/k)n/1(1x σ+=
1
eDLD
1
eCLC b
kXy
bk
Xσ′
=σ
=

LÍMITES DE CONCENTRACIÓN A PARTIR DE LA LÍNEA DE CALIBRADO
La línea de calibrado es solo una estimación de la verdadera línea de regresión, debe tenerse en cuenta su incertidumbre.
1) Se calcula yC que es el límite superior de confianza con una cola para la media de m respuestas cuando la concentración de analito x0 es cero
2) Se calcula xD, lo cual puede hacerse de tres posibles formas:
2.1) Como la intersección de la línea y = yC con la curva describiendo el límite inferior de confianza y = yL siendo
que es un método engorroso
2.2) Por iteración. El valor de xD se define como el valor más pequeño de x que origina un valor para yL mayor o igual que yC.
2.3) De forma aproximada (AOAC)
siendo xC = (yC – b0)/b1
( )( )2i
2C
1x/y2-n,CDx -x
x -x2n1
m1
b/stxxΣ
+++= β
( )( )2i
2D
x/y2-n,D10Lx -x
x - x n1
m1
st- xbbyΣ
+++= β
3) A partir de xD puede calcularse también yD = b0 + b1 xD
( )( )
( )( )2i
2
x/y2-n02i
20
x/y2-n010x -x
xn1
m1
stbx -x
x -xn1
m1
stxbbΣ
+++=Σ
++±+
SENSIBILIDAD
• La IUPAC define la sensibilidad como la pendiente de la línea de calibrado. A veces se emplea erróneamente como sinónimo de límite de detección
• La pendiente por sí misma no indica nada, ya que no basta con conocerla para saber si dos concentraciones pueden ser discriminadas entre sí. Se necesita también conocer la desviación típica de esa pendiente.
• Se ha propuesto
siendo los valores t para α=0,05 (2 colas) y β=0,05 (1 cola) para el número de g.d.l. con el que se determinó s (desviación típica de la señal)
)b/1(2s)tt(d 11/2-1 β−α +=

DETECCIÓN DE OUTLIERS (ESPURIOS)
• Son observaciones atípicas (espurias) que no son representativas del ajuste. Se detectan
1) Si el valor absoluto del residual estandarizado: ≥ 2 ó 3, el punto se rechaza.
2) Calculando la distancia de Cook al cuadrado (Cook's square distance)
El valor de corte suele ser 1
• Existen además los "outliers" de nivelación ("leverage") que son puntos extremos que tienen una gran influencia sobre los parámetros
x
y
x
y
x
y
x
y
ei s/e
2e
n
1j
2)i(jj
2)i(
s2
)yy(CD
∑ −= =
nº de parámetros
APLICACIONES DE INTERÉS ANALÍTICO
Método de adiciones patrón
• Cuando hay efecto de matriz y no se puede preparar una línea de calibrado en la que aquélla se duplique exactamente, no se puede aplicar el método de calibrado lineal.
• Una solución es el método de adiciones patrón (MAP o SAM): Se añaden cantidades conocidas del analito que se quiere determinar a alícuotas de la muestra desconocida (o a la misma alícuota si el método de análisis no es destructivo) y se observa la variación producida en la Respuesta.
• Sobre V0 mL de problema de concentración C0 desconocida, se hacen adiciones iguales Vpde un patrón de concentración Cp. La concentración resultante es en cada momento:
Ci = (V0C0 + VpCp)/(V0 + Vp)
• Si se mide la Respuesta, relacionada linealmente con la concentración del componente buscado a través de una relación del tipo: R = k C, ésta valdrá en cada momento:
Ri = k Ci = k (V0C0 + VpCp)/(V0 + Vp)Qi = Ri (V0+Vp) = k (V0C0+VpCp)
siendo Q la señal corregida por la dilución (por tanto proporcional a la cantidad de componente).
• Si se representa Qi frente a Vp se debe obtener una recta, cuya extrapolación a cero origina un Volumen negativo Veq, a partir del cual se puede conocer la concentración C0:
Qi = k (V0C0 + VeqCp) = 0; (V0C0 + VeqCp) = 0C0 = - (Veq Cp)/V0
• El valor absoluto de Veq (Volumen equivalente) es el volumen de la disolución patrón añadida que contiene la misma cantidad de analito que la muestra.
APLICACIONES DE INTERÉS ANALÍTICO
Método de adiciones patrón
10eq b/bV =
• Si se ajusta Qi al Vp mediante una regresión según Qi = b0 + b1 Vp, Veq se estima
xw, yw
x
y
xbby 10 +=
-b0/b1
∑ −+=
2i
21
2
1
ex
)xx(b
)y(n1
bs
s0
• Siempre debe hacerse una determinación en blanco, cuyo volumen equivalente debe sustraerse del correspondiente a la muestra (y cuya varianza se suma a la de Veq)
• Si la dilución producida es pequeña o inexistente, no es precisa corregir la respuesta por el volumen, y se representa directamente Ri vs. Vp
• La incertidumbre del Veq el error se calcula:
• Un problema del MAP es que al extrapolar se trabaja en una zona en la cual la imprecisión es muy grande.
APLICACIONES DE INTERÉS ANALÍTICO
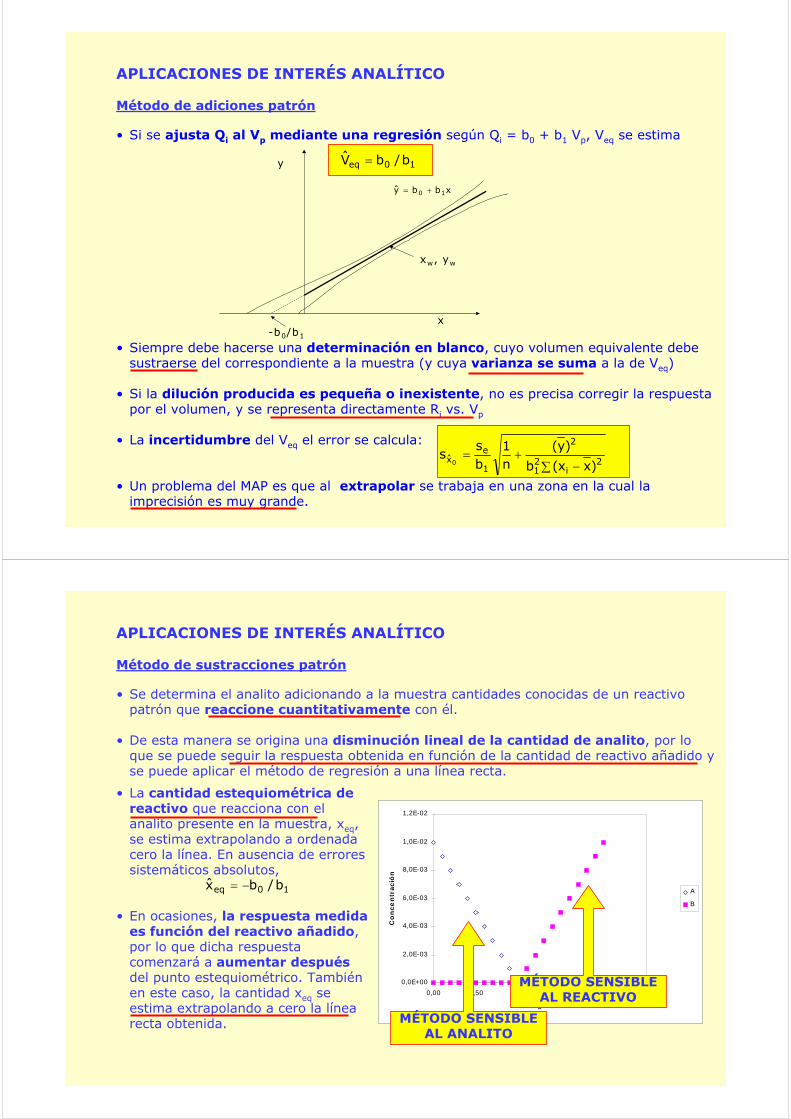
Método de sustracciones patrón
• La cantidad estequiométrica de reactivo que reacciona con el analito presente en la muestra, xeq, se estima extrapolando a ordenada cero la línea. En ausencia de errores sistemáticos absolutos,
• En ocasiones, la respuesta medida es función del reactivo añadido, por lo que dicha respuesta comenzará a aumentar después del punto estequiométrico. También en este caso, la cantidad xeq se estima extrapolando a cero la línea recta obtenida.
• Se determina el analito adicionando a la muestra cantidades conocidas de un reactivo patrón que reaccione cuantitativamente con él.
• De esta manera se origina una disminución lineal de la cantidad de analito, por lo que se puede seguir la respuesta obtenida en función de la cantidad de reactivo añadido y se puede aplicar el método de regresión a una línea recta.
0,0E+00
2,0E-03
4,0E-03
6,0E-03
8,0E-03
1,0E-02
1,2E-02
0,00 0,50 1,00 1,50 2,00 2,50
x
Co
nc
en
tra
ció
n
A
B
10eq b/bx −=
MÉTODO SENSIBLE AL ANALITO
MÉTODO SENSIBLE AL REACTIVO
APLICACIONES DE INTERÉS ANALÍTICO
Comparación de las pendientes de dos líneas de regresión
2b
2b
2b2
2b1
1211
1211
ss
stst't
+
+=
• Si las varianzas residuales de ambas líneas no son comparables, el t crítico se calcula previamente como:
• La prueba puede hacerse de forma rápida: si los intervalos de confianza de b11 y b12 no se solapan las pendientes difieren significativamente, y viceversa.
• Dadas las pendientes de dos líneas de regresión b11 y b12, se las puede compararmediante una prueba de significación (test t):
donde el t crítico se busca con n1+n2-4 g.d.l. y el nivel de significación deseado.
4nn
s)2n(s)2n(s
)xx(
1
)xx(
1s
bbt
21
2ep2
21e12
ep
22i
21i
2ep
1211
−+
−+−=
⎟⎟⎠
⎞⎜⎜⎝
⎛
∑ −+
∑ −
−=
COMPARACIÓN DE LAS SENSIBILIDADES DE DOS PROCEDIMIENTOS
APLICACIONES DE INTERÉS ANALÍTICO
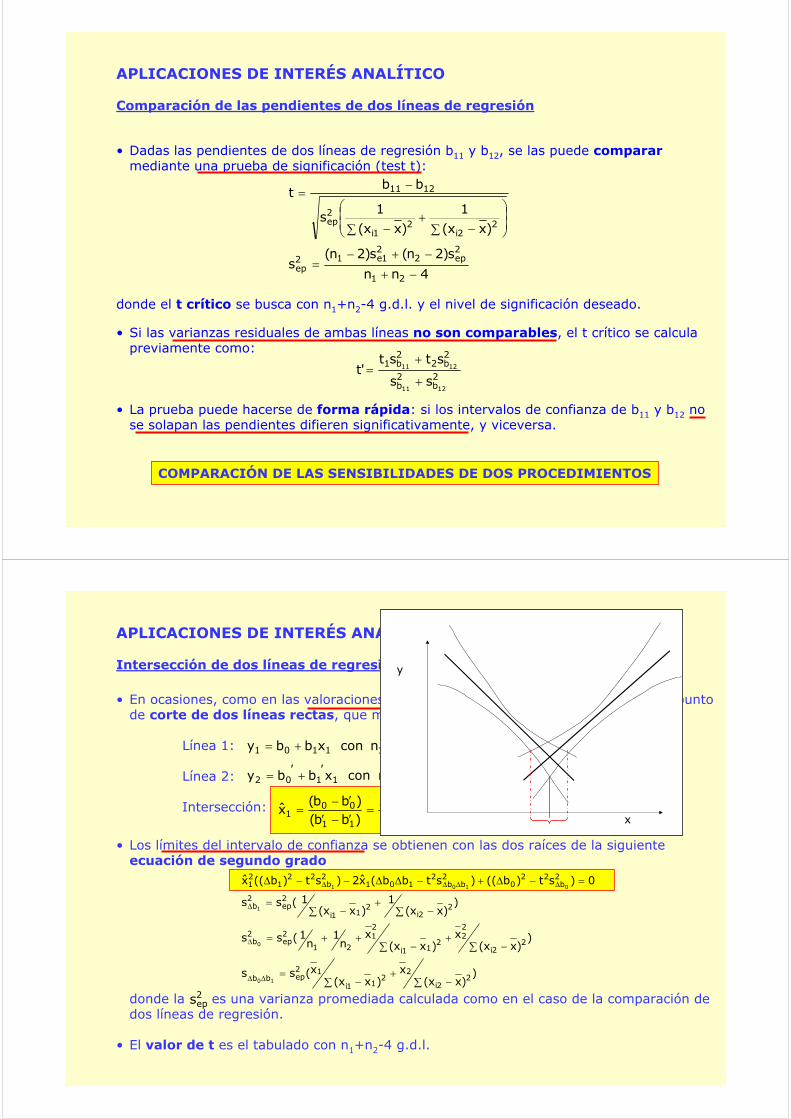
Intersección de dos líneas de regresión
puntosnconxbby 11101 +=
puntosnconxbby 21102′+′=
1
0
11
001 b
b)bb()bb(
xΔΔ
=′−′′−
=
• En ocasiones, como en las valoraciones fotométricas o conductimétricas, interesa el punto de corte de dos líneas rectas, que marca el punto final de la valoración.
Línea 1:
Línea 2:
Intersección:
))xx(
x)xx(
x(ss
))xx(
x)xx(
xn
1n
1(ss
))xx(
1)xx(
1(ss
0)st)b(()stbb(x2)st)b((x
22i
22
11i
12epbb
22i
22
211i
21
21
2ep
2b
22i
211i
2ep
2b
2b
220
2bb
2101
2b
221
21
10
0
1
0101
∑ −+
∑ −=
∑ −+
∑ −++=
∑ −+
∑ −=
=−Δ+−ΔΔ−−Δ
ΔΔ
Δ
Δ
ΔΔΔΔ
• Los límites del intervalo de confianza se obtienen con las dos raíces de la siguiente ecuación de segundo grado
donde la es una varianza promediada calculada como en el caso de la comparación de dos líneas de regresión.
• El valor de t es el tabulado con n1+n2-4 g.d.l.
2eps
x
y

APLICACIONES DE INTERÉS ANALÍTICO
Ensayos de recuperación
• Sirven para validar un procedimiento analítico
• Se analizan blancos dopados o fortalecidos (spiked) con concentraciones diferentes de analito exactamente conocidas.
• Se representa la concentración encontrada frente a la añadida
• Al hacer la regresión, se debería obtener una línea recta de ordenada en el origen cero y pendiente uno, o bien los intervalos de confianza de b0 y b1 deben incluir a cero y a uno, respectivamente.
• Si la ordenada en el origen es mayor de cero existe un error sistemático (bias, sesgo) constante (o una corrección incorrecta del blanco)
• Si la pendiente difiere de uno, existe un error sistemático (bias, sesgo) proporcional que suele ser debido a la matriz.
Analito hallado
Analito puesto
ALTERNATIVA A LA PRUEBA DE SIGNIFCACIÓN
• Sirve para comparar dos métodos o para validar uno si el otro está validado
• Se analiza la misma muestra mediante los dos procedimientos.
• Se representa la concentración (cantidad) hallada por un método frente a la del otro. En abcisas se representan los resultados del método validado si alguno lo fuere
APLICACIONES DE INTERÉS ANALÍTICO
Comparación de métodos
• Al hacer la regresión, se debería obtener una línea recta de ordenada en el origen cero y pendiente uno, o bien los intervalos de confianza de b0 y b1 deben incluir a cero y a uno, respectivamente.
• Si la ordenada en el origen es mayor de cero hay una diferencia sistemática (bias, sesgo) constante (o un bias o sesgo sistemático del Método 2)
• Si la pendiente difiere de uno, existe una diferencia sistemática (bias, sesgo) proporcional
Método 2
Método 1 (Referencia)
ALTERNATIVA A LA PRUEBA DE SIGNIFCACIÓN

APLICACIONES DE INTERÉS ANALÍTICO
Detección de efectos de matriz
• Los efectos de matriz se buscan comparando las pendientes de una línea de calibradohecha con patrones puros, y la de un M.A.P. realizado sobre una muestra real
• Las concentraciones de analito en ambos casos deben ser comparables.
• Si las pendientes son idénticas, o sus intervalos se solapan, o la prueba t dice que son comparables: no hay efecto de matriz: Las determinaciones pueden hacerse por calibrado lineal.
• Si las pendientes son diferentes, hay efecto de matriz: Es necesario utilizar el M.A.P.
Respuesta
Concentración analito
Respuesta
Analito añadido
¿Hay que aplicar el M.A.P.?
Patrones puros o blanco simplificado
Muestra real
• Se tiene pues un modelo con un único parámetro b1, y debe minimizarse la expresión
respecto de b1, para el que se obtiene la siguiente expresión:
• La varianza residual se2 o sy/x
2, que es una estimación de σ2 cuando el modelo es correcto vale:
APLICACIONES DE INTERÉS ANALÍTICO
Regresión a través de un punto fijo
0100 xbby +=
( ) )xx(byxbxbyxbby 010101010 −+=+−=+=
• En ocasiones se fuerza a que la línea pase a través de un punto (x0, y0). Por tanto la ecuación de la recta debe cumplir:
y el modelo también debe cumplir
∑ ∑ ∑ −−−=−= 20i10i
2ii
2i ))xx(byy()yy(e
1n)yy(
1n)e(
s2
ii2
i2e −
∑ −=
−∑=
∑ −∑ −−
=2
0i
0i0i1
)xx(
)yy)(xx(b
∑
∑=2i
ii1
x
yxb
• Si el punto fijo es el origen, x0 = 0 e y0 = 0, las ecuaciones se simplifican y tenemos
0100 xbyb −=⇒

• La desviaciones típicas del modelo son:
Para la pendiente
Para la estimación de la respuesta a partir de un valor xk
Para la estimación de la respuesta media a partir de un xk
Para la estimación de una xs a partir de una respuesta ys, media de m valores
• Este modelo sólo debe ser utilizado cuando haya buenas razones a priori para ello.
APLICACIONES DE INTERÉS ANALÍTICO
Regresión a través de un punto fijo
∑=
2i
ebx
1ss
1
2ikey x/xss
0=
∑+= 2i
2key x/xm/1/ss
0
∑+= )xb/(ym/1)b/s(s 2i
21
2s1ex0
APLICACIONES DE INTERÉS ANALÍTICO
Linearización de funciones curvas
• Cuando la relación entre las dos variables no puede ser representada por una línea recta, cabe la posibilidad de hacer una ajuste polinómico (Regresión Lineal Múltiple) o un ajuste no lineal. Una alternativa es transformar una o ambas variables, de manera que se obtenga una relación más sencilla.
1/[S]1/νEc. Michaelis-Menten
tln At
Ec. Decaimientoradioactivo
1/Tln kEc. Arrhenius
xyEcuación
linearizadaEcuación
)RT/E(eAk −=RTE
Alnkln −=
2/1t/t693,00t eAA −=
2/10t t
t693,0AlnAln −=
[ ][ ]SKSv
m
max
+=ν [ ]S
1vK
v11
max
m
max⋅+=
ν
• El problema es que la condición de homocedasticidad, que suele cumplirse con los datos originales, no se mantiene con los datos transformados. Eso implica el que la regresión deba hacerse utilizando pesos estadísticos.

APLICACIONES DE INTERÉS ANALÍTICO
Linearización de funciones curvas
• De forma general, si una variable y se transforma por medio de yi =f(yi), la expresión para calcular los pesos es:
2y
22
)y(f
2)y(f
i
syd
))y(f(ds
s1w
i
i
⎟⎟⎠
⎞⎜⎜⎝
⎛=
=
2x
2i
2xln
i
2x2
2x
22
xln
iis
xs
1w
sx1
sxd
)x(lnds
==
⎟⎠⎞
⎜⎝⎛=⎟⎟
⎠
⎞⎜⎜⎝
⎛=
• Por ejemplo, si se transforma x en ln x, se tiene
• Este es el caso de la Absorbancia y la Transmitancia. A = -log T
2T
2i
2A
i
2T2
22T
22A
iis
Ts
1w
sT30,2
sTd
)Tlog(ds
==
⎟⎟⎠
⎞⎜⎜⎝
⎛=⎟⎟
⎠
⎞⎜⎜⎝
⎛ −=
El factor 2,302 es cte. y no se necesita
• Coeficiente de correlación producto-momento o coeficiente de correlación de Pearson:
Varía entre –1 y +1 dependiendo del tipo de asociación. Valores de –1 y +1 indican una perfecta relación linear entre ambas variables.
• Un coeficiente de correlación que no es significativamente diferente de cero indica que las variables no están correlacionadas. Esto no significa que no hay relación entre ellas, sino que esta relación no es lineal.
∑ ∑ −−
∑ −−==
22i2
21i1
2i21i1
yy
2121
)yy()yy(
)yy)(yy(ss
)y,ycov()y,y(r
21
• Sean 2 parámetros determinados sobre n muestras: y11,...,y1n e y21,...,y2n con sus respectivas medias e . Se define la covarianza como:
• Varía entre -∞ cuando las variables están asociadas negativamente (una disminuye cuando la otra aumenta) y +∞ cuando la asociación es positiva.
∑ −−−
= )yy)(yy(1n
1)y,ycov( 2i21i121
CORRELACIÓN Y REGRESIÓN
• La correlación sirve para estudiar la asociación entre dos variables aleatorias: no hay variable dependiente ni independiente.
• Esa asociación se cuantifica mediante la covarianza y el coeficiente de correlación.
1y 2y

T
REG2
i
2i2
SSSS
)yy(
)yy(r =
∑ −∑ −
=
• Si se eleva r al cuadrado, se obtiene r2
coeficiente de determinación: proporción de variación total que es explicada por la regresión.
CORRELACIÓN vs. REGRESIÓN
• Si no hay correlación entre x e y, no existe una regresión lineal significativa entre x e y. Por tanto el test de hipótesis de que ρ=0 da idénticos resultados al de β1=0 y ambos son equivalentes.
• Si r=-1 o r=+1 todas las observaciones se ajustan perfectamente a una línea recta y por tanto toda la variación en y puede explicarse en términos de la línea de regresión (r2=1).
• Si por el contrario r=0, no hay regresión entre x e y por lo que la regresión no explica nada de la variación de y. Además en ese caso b1=0 es decir la línea de regresión es paralela al eje x.
• La utilidad real de r ha sido sobrestimada. Lo verdaderamente útil no es r sino r2
que expresa la proporción de variación explicada por la regresión
• El modelo que describe la relación lineal seráy por tanto
• Si se supone que σε2 = σδ
2, para obtener estimaciones insesgadas de los coeficientes de laregresión, lo que debe minimizarse es di
2 es decir la suma de los cuadrados de las distancias perpendiculares de los puntos experimentales a la línea de regresión.
)(xy
)x(y
i1ii10i
iii10i
δβ−ε+β+β=
ε+δ−β+β=
REGRESIÓN CON AMBAS VARIABLES SUJETAS A ERROR
iii
iii
x
y
δ+ξ=
ε+η=
• Hasta ahora se ha supuesto que sólo la respuesta estaba sujeta a error y que la variable independiente, x, se conocía exactamente (Regresión Modelo I).
• Hay situaciones en las que no es asumible que x esté libre de errores (p.e. comparación de resultados de dos métodos, o patrones preparados con gran incertidumbre). Si ηi es el verdadero valor de yi y ξi el verdadero valor de xi, entonces
i10i ξβ+β=η
yy yy

Comparación de la regresión por mínimos cuadrados y ortogonal
• El método recibe el nombre de regresión de la distancia ortogonal (orthogonal distanceregresión ORD), y los valores de los coeficientes se obtienen mediante las siguientes fórmulas:
• siendo sy2 y sx
2 las varianzas respectivas de las variables y x, y cov(y,x) la covarianza de y y x calculadas con
• Existe una relación aproximada entre los valores de b1 obtenidos por mínimos cuadrados (MC) y por regresión ortogonal (ORD):
• siendo sex2 la varianza de un valor de x individual (es decir se observa un mismo valor de
x varias veces) y sx2 la varianza de la variable x, que solo depende del intervalo estudiado
de x y de su distribución. Si el cociente sex2/sx
2 es mayor de 0,2 se pueden esperar errores significativos en la estimación de b1 por mínimos cuadrados.
REGRESIÓN CON AMBAS VARIABLES SUJETAS A ERROR
xbyb
)x,ycov(2
))x,y(cov(4)ss(ssb
10
222y
2x
2x
2y
1
−=
+−+−=
1n)xx)(yy(
)x,ycov(
1n)yy(
s
1n)xx(
s
ii
2i2
y
2i2
x
−∑ −−
=
−∑ −
=
−∑ −
=
)s
s1(
)MC(b)ORD(b
2x
2ex
11
−
=







