diseño de redes neuronales multicapa y entrenamiento
DESCRIPTION
Diseño de Redes Neuronales Multicapa y EntrenamientoTRANSCRIPT

1
CogNovaTechnologies
Diseño de Redes Diseño de Redes Neuronales Neuronales Multicapa y Multicapa y
EntrenamientoEntrenamiento
(parte 1)(parte 1)

2
CogNovaTechnologies
Aplicaciones Exitosas Aplicaciones Exitosas de RNAde RNA
Donde la tecnología computacional Donde la tecnología computacional convencional no resulta capaz.convencional no resulta capaz.
En problemas que requieren de un En problemas que requieren de un razonamiento cualitativo o cuantitativo razonamiento cualitativo o cuantitativo complejo.complejo.
Donde se cuenta con una gran Donde se cuenta con una gran cantidad de datos pero estos son cantidad de datos pero estos son multivariados y contienen ruido o multivariados y contienen ruido o errores.errores.

3
CogNovaTechnologies
Algunos de los datos pueden ser Algunos de los datos pueden ser incompletos o erróneos.incompletos o erróneos.
En general:En general:– Reconocimiento de patronesReconocimiento de patrones– Validación de señalesValidación de señales– Procesos de monitoreoProcesos de monitoreo– DiagnósticosDiagnósticos– Procesamiento de señales e Procesamiento de señales e
informacióninformación– Control de sistemas complejos (no Control de sistemas complejos (no
lineales)lineales)

4
CogNovaTechnologies
Selección de un tipoSelección de un tipo de Red de Red
Supervisada: requiere de pares de datos Supervisada: requiere de pares de datos consistente de patrones de entrada y salida consistente de patrones de entrada y salida correcta.correcta.
Autosupervisada: clasifica patrones de entrada Autosupervisada: clasifica patrones de entrada internamente no requiere de resultados internamente no requiere de resultados esperados, la capacidad de la red resulta esperados, la capacidad de la red resulta significativamente inferior a la anteriorsignificativamente inferior a la anterior
En ambos casos el tiempo de entrenamiento es En ambos casos el tiempo de entrenamiento es relativamente largo.relativamente largo.

5
CogNovaTechnologies
Las redes supervisadas se utilizan Las redes supervisadas se utilizan generalmente para la predicción, generalmente para la predicción, evaluación o generalización. Estas evaluación o generalización. Estas aprenden básicamente a asociar un aprenden básicamente a asociar un conjunto de datos de entrada con su conjunto de datos de entrada con su correspondiente conjunto de salida.correspondiente conjunto de salida.
Las redes no supervisadas, se aplican Las redes no supervisadas, se aplican mejor a la clasificación, tipos de mejor a la clasificación, tipos de reconocimiento (Redes de Kohonen) reconocimiento (Redes de Kohonen)

6
CogNovaTechnologies
Selección de la Selección de la EntradaEntrada
Se debe contar con un Se debe contar con un conjunto de patrones de conjunto de patrones de entrenamiento ( Pi ) entrenamiento ( Pi ) grande. grande.
Un conjunto de patrones de Un conjunto de patrones de prueba (Ppi) razonable.prueba (Ppi) razonable.

7
CogNovaTechnologies
El número de elementos del El número de elementos del vector de entrada (Número vector de entrada (Número de características extraídas) de características extraídas) estará determinado por el estará determinado por el tipo de problema a resolver.tipo de problema a resolver.
Número de elementos del Número de elementos del
vector = numero de vector = numero de neuronas de entradaneuronas de entrada

8
CogNovaTechnologies
Selección de Selección de la salidala salida
Dependerá de la naturaleza de Dependerá de la naturaleza de la aplicaciónla aplicación
Neuronas de salida binaria (0,1 Neuronas de salida binaria (0,1 o bien -1 , 1)o bien -1 , 1)
Neuronas con valores continuos Neuronas con valores continuos (0 a 1 o bien -1 a 1)(0 a 1 o bien -1 a 1)

9
CogNovaTechnologies
La salida puede expresar clases, La salida puede expresar clases, porcentaje de aproximación, porcentaje de aproximación, etc...etc...
La selección del vector de salida La selección del vector de salida o vectores determinara el o vectores determinara el numero de neuronas en la capa numero de neuronas en la capa de salida. P/ej. 1 neurona, 2 de salida. P/ej. 1 neurona, 2 clases o bien, una medida de %, clases o bien, una medida de %, 2 neuronas 2 o 4 clases, etc.. 2 neuronas 2 o 4 clases, etc..

10
CogNovaTechnologies
Función de Función de TransferenciaTransferencia
de las neuronas de las neuronas La función más común es la La función más común es la sigmoidalsigmoidal– logarítmica (0 a +1)logarítmica (0 a +1)– Tangente hiperbólica (-1 a +1)Tangente hiperbólica (-1 a +1)
LinealLineal Base radialBase radial

11
CogNovaTechnologies
Combinaciones de Combinaciones de Funciones de Funciones de Transferencia.Transferencia.
Aproximación de funciones:Aproximación de funciones:– Función logarítmica y lineal. Función logarítmica y lineal.
Reconocimiento de patrones:Reconocimiento de patrones:– Funciones sigmoidales. Por Funciones sigmoidales. Por
ejemplo tangente hiperbólica con ejemplo tangente hiperbólica con logarítmicalogarítmica

12
CogNovaTechnologies
Guía General de Guía General de DiseñoDiseño
Usar una sola capa oculta.Usar una sola capa oculta.
Usar pocas neuronas en la Usar pocas neuronas en la capa oculta.capa oculta.
Entrenar hasta más no poder.Entrenar hasta más no poder.

13
CogNovaTechnologies
¿¿Cuantas Capas Cuantas Capas Ocultas son Ocultas son Necesarias?Necesarias? Dependerá de la complejidad del Dependerá de la complejidad del
problema.problema.
No existe razón teórica para usar No existe razón teórica para usar más de dos capas ocultas.más de dos capas ocultas.
La mayoría de los problemas La mayoría de los problemas prácticos se resuelven con una prácticos se resuelven con una sola capa oculta.sola capa oculta.

14
CogNovaTechnologies
Observaciones en el Observaciones en el Numero de Capas Numero de Capas
ocultasocultas El entrenamiento se hace mas lento El entrenamiento se hace mas lento
entre mas capas ocultas se usenentre mas capas ocultas se usen La capa adicional a través de la cual La capa adicional a través de la cual
se propaga el error hace el gradiente se propaga el error hace el gradiente más inestable.más inestable.
El número de mínimos locales El número de mínimos locales usualmente se incrementa usualmente se incrementa dramáticamente .dramáticamente .

15
CogNovaTechnologies
En resumen se recomienda una sola En resumen se recomienda una sola capa oculta como primera elección para capa oculta como primera elección para redes neuronales practicas.redes neuronales practicas.
Si se utilizan un gran número de Si se utilizan un gran número de neuronas en la capa oculta y no neuronas en la capa oculta y no solucionan el problema solucionan el problema satisfactoriamente; entonces debe usare satisfactoriamente; entonces debe usare una segunda capa reduciendo el número una segunda capa reduciendo el número de neuronas en cada capa.de neuronas en cada capa.
Resumen del número de capas ocultas

16
CogNovaTechnologies
¿¿Cuantas neuronas se Cuantas neuronas se deben usar en la capa deben usar en la capa
oculta?oculta? El uso de muchas neuronas incrementa el El uso de muchas neuronas incrementa el tiempo de entrenamiento.tiempo de entrenamiento.
Un número excesivo de neuronas en la capa Un número excesivo de neuronas en la capa oculta puede ser causante de oculta puede ser causante de Overfitting*Overfitting*. . Particulariza, no generaliza.Particulariza, no generaliza.
Un número demasiado pequeño de neuronas Un número demasiado pequeño de neuronas puede ser causante de puede ser causante de Underfitting*Underfitting*. No . No resuelve el problema.resuelve el problema.

17
CogNovaTechnologies
Regla de la Regla de la Pirámide Pirámide
GeométricaGeométrica Regla aproximada para seleccionar el Regla aproximada para seleccionar el número de neuronas en las capas ocultas.número de neuronas en las capas ocultas.
El número de neuronas sigue una forma El número de neuronas sigue una forma piramidal, con un numero decreciente de piramidal, con un numero decreciente de neuronas de la entrada hacia la salida.neuronas de la entrada hacia la salida.
La excepción es las redes autoasociativas . La excepción es las redes autoasociativas . Redes donde el numero de entradas= Redes donde el numero de entradas= numero de salidas numero de salidas

18
CogNovaTechnologies
Regla de la Regla de la Pirámide Pirámide
GeométricaGeométrica Para una red de tres capas (una sola Para una red de tres capas (una sola
capa oculta).capa oculta).
Donde: Donde: – nn es el número de neuronas de entrada es el número de neuronas de entrada– mm es el número de neuronas de salida es el número de neuronas de salida– hh es el numero inicial de neuronas en la es el numero inicial de neuronas en la
capa ocultacapa oculta
nmh *

19
CogNovaTechnologies
Ejemplo 1:Ejemplo 1: Para una red neuronal Para una red neuronal
feedforward de 3 capas con 8 feedforward de 3 capas con 8 entradas y 2 salidas. entradas y 2 salidas.
Calcule el numero de neuronas Calcule el numero de neuronas en la capa oculta usando la en la capa oculta usando la regla de la pirámide. regla de la pirámide.

20
CogNovaTechnologies
Solución al Ejemplo 1

21
CogNovaTechnologies
Red con Dos capas Red con Dos capas ocultasocultas
Para la primera Para la primera capa oculta:capa oculta:
Para la segunda Para la segunda capa oculta:capa oculta:
21 *rmH
rmH *2 3
mn
r
Donde: Donde: H1 es el numero de H1 es el numero de
neuronas en la 1a. neuronas en la 1a. Capa oculta.Capa oculta.
H2 es el numero de H2 es el numero de neuronas en la neuronas en la segunda capa segunda capa ocultaoculta

22
CogNovaTechnologies
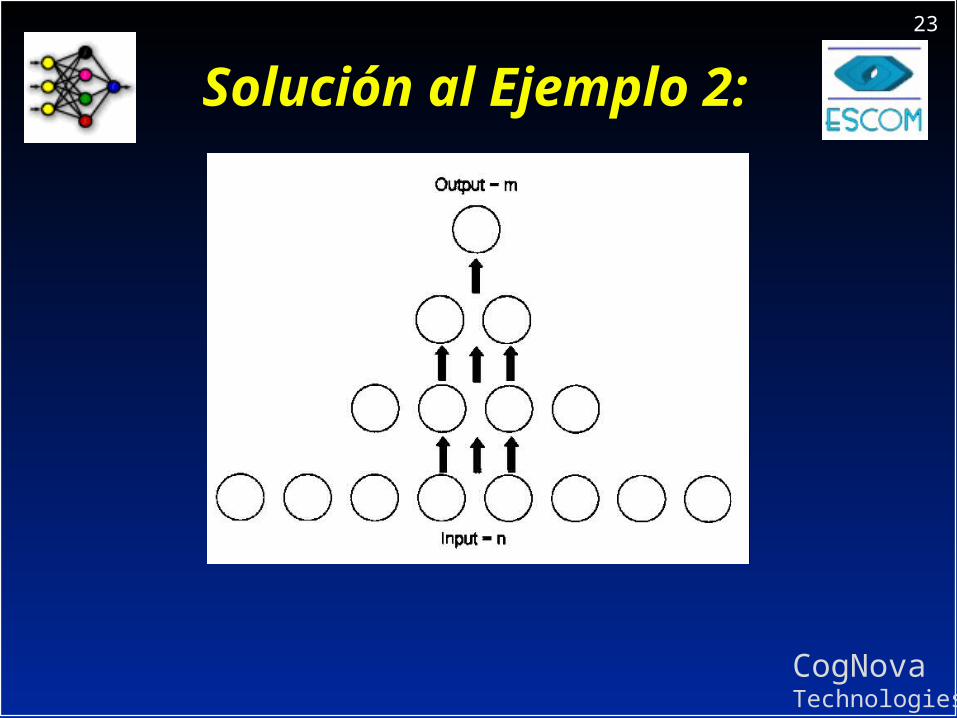
Ejemplo 2:Ejemplo 2:
Para una red neuronal Para una red neuronal feedforward de 4 capas con 8 feedforward de 4 capas con 8 entradas y 1 salida. entradas y 1 salida.
Calcule el numero de neuronas Calcule el numero de neuronas en cada una de las dos capas en cada una de las dos capas ocultas. Use la regla de la ocultas. Use la regla de la pirámide.pirámide.
23
CogNovaTechnologies
Solución al Ejemplo 2:

24
CogNovaTechnologies
Observaciones a la regla Observaciones a la regla de la Pirámide de la Pirámide GeométricaGeométrica
Las formulas anteriores solo son Las formulas anteriores solo son aproximaciones burdas del tamaño aproximaciones burdas del tamaño ideal de las capas ocultas.ideal de las capas ocultas.
En la aproximación de funciones En la aproximación de funciones complicadas que involucran una complicadas que involucran una neurona de entrada y una de salida neurona de entrada y una de salida puede requerir una docena de puede requerir una docena de neuronas ocultas o más.neuronas ocultas o más.

25
CogNovaTechnologies
Regla basada en Regla basada en Algoritmos GenéticosAlgoritmos Genéticos
nH32
El número de neuronas en la capa El número de neuronas en la capa oculta puede cambiar el tiempo de oculta puede cambiar el tiempo de entrenamiento de la misma forma entrenamiento de la misma forma su capacidad para generalizar.su capacidad para generalizar.

26
CogNovaTechnologies
Como obtener el Como obtener el número óptimo de número óptimo de
neuronasneuronas Iniciar con un número pequeño de neuronas Iniciar con un número pequeño de neuronas
en la capa oculta.en la capa oculta. Seleccione un criterio apropiado para evaluar Seleccione un criterio apropiado para evaluar
la red. Por ej. el error mínimo, clasificación de la red. Por ej. el error mínimo, clasificación de lo patrones de entrenamiento y de prueba,lo patrones de entrenamiento y de prueba,
Entrene y pruebe la red; recordando su Entrene y pruebe la red; recordando su desempeño. (Guarde los pesos y umbrales y desempeño. (Guarde los pesos y umbrales y el error obtenido)el error obtenido)

27
CogNovaTechnologies
Como obtener el Como obtener el número óptimo de número óptimo de
neuronas (2)neuronas (2) Incremente el número de neuronas Incremente el número de neuronas
ocultas (solo una neurona a la vez) ocultas (solo una neurona a la vez) entrene y pruebe de nuevo.entrene y pruebe de nuevo.
Repetir lo anterior hasta que el Repetir lo anterior hasta que el error sea pequeño, o no haya una error sea pequeño, o no haya una mejora significativa.mejora significativa.

28
CogNovaTechnologies
Network TrainingNetwork Training
Mastering ANN ParametersMastering ANN Parameters TypicalTypical RangeRange
learning rate - learning rate - 0.1 0.01 - 0.990.1 0.01 - 0.99
momentum - momentum - 0.8 0.1 - 0.90.8 0.1 - 0.9
weight-cost - weight-cost - 0.1 0.001 - 0.50.1 0.001 - 0.5
Fine tuning : Fine tuning : -- adjust individual parameters at adjust individual parameters at each node and/or connection weighteach node and/or connection weight– automatic adjustment during trainingautomatic adjustment during training

29
CogNovaTechnologies
Inicialización de Inicialización de los pesos W y los pesos W y umbrales bumbrales b
Valores iniciales aleatorios en un Valores iniciales aleatorios en un intervalo pequeño +1 a -1. O bien -intervalo pequeño +1 a -1. O bien -0.5 a 0.5.0.5 a 0.5.
Valores pequeños de pesos para Valores pequeños de pesos para neuronas con una gran numero de neuronas con una gran numero de conexiones de entrada. conexiones de entrada.

30
CogNovaTechnologies
Otra propuesta : iniciación Otra propuesta : iniciación
Regla aproximada: El Regla aproximada: El intervalo de los valores de intervalo de los valores de los pesos es de :los pesos es de :
1
# weights

31
CogNovaTechnologies
En ResumenEn Resumen
Se debe usar tan pocas neuronas Se debe usar tan pocas neuronas ocultas como sea posible.ocultas como sea posible.
Entonces, ir agregando neuronas Entonces, ir agregando neuronas conforme sea necesario para conforme sea necesario para asegurar un adecuado asegurar un adecuado desempeño con el conjunto de desempeño con el conjunto de entrenamiento.entrenamiento.

32
CogNovaTechnologies
¿Cuanto se debe ¿Cuanto se debe entrenar entrenar
una Red Neuronal?una Red Neuronal? Al iniciar el entrenamiento el Al iniciar el entrenamiento el
error decrece; Pero pasando error decrece; Pero pasando cierto tiempo, si se continua cierto tiempo, si se continua con el entrenamiento el error con el entrenamiento el error se incrementa.se incrementa.
**Ver grafica: Manifestación de **Ver grafica: Manifestación de Sobre entrenamiento.Sobre entrenamiento.

33
CogNovaTechnologies
Correcto EntrenamientoCorrecto Entrenamiento
Para un número de prueba de Para un número de prueba de neuronas ocultas, genere valores neuronas ocultas, genere valores aleatorios de pesos iniciales y aleatorios de pesos iniciales y entrene hasta que la mejora sea entrene hasta que la mejora sea despreciable.despreciable.
Genere más pesos iniciales Genere más pesos iniciales aleatorios y vuelva a entrenar. Una aleatorios y vuelva a entrenar. Una vez más, y otra vez.vez más, y otra vez.

34
CogNovaTechnologies
Cuando un número moderado Cuando un número moderado de estas repeticiones en línea de estas repeticiones en línea falle en la mejora de su falle en la mejora de su desempeño, se podrá estar desempeño, se podrá estar seguro que se ha entrenado la seguro que se ha entrenado la red lo mejor que se puedered lo mejor que se puede

35
CogNovaTechnologies
Entrenamiento de Entrenamiento de RNARNA

36
CogNovaTechnologies
Una red neuronal exitosa requiere que Una red neuronal exitosa requiere que el conjunto de datos de entrenamiento el conjunto de datos de entrenamiento y el procedimiento de entrenamiento y el procedimiento de entrenamiento sea apropiado al problemasea apropiado al problema
El conjunto de datos de entrenamiento El conjunto de datos de entrenamiento debe ser representativo de las clases debe ser representativo de las clases de patrones que la red operativa de patrones que la red operativa tendrá que reconocertendrá que reconocer

37
CogNovaTechnologies
De tal forma que se tengan De tal forma que se tengan capacidades de interpolación y capacidades de interpolación y extrapolación, las redes extrapolación, las redes neuronales se deben de entrenar neuronales se deben de entrenar con un conjunto suficientemente con un conjunto suficientemente amplio de datos de entrada para amplio de datos de entrada para generalizar partiendo de sus generalizar partiendo de sus conjuntos de entrenamientoconjuntos de entrenamiento

38
CogNovaTechnologies

39
CogNovaTechnologies
Network TrainingNetwork Training
Typical Problems During TrainingTypical Problems During TrainingE
# iter
E
# iter
E
# iter
Would like:
But sometimes:
Steady, rapid declinein total error
Seldom a local minimum - reduce learning or momentum parameter
Reduce learning parms.- may indicate data is not learnable

40
CogNovaTechnologies
Bibliografía:Bibliografía:
Practical Neural Network Recipes Practical Neural Network Recipes in C++; Timothy Masters; Editorial in C++; Timothy Masters; Editorial Morgan Kaufmann-Academic Press.Morgan Kaufmann-Academic Press.
Applying Neural Networks, A Applying Neural Networks, A Practical Guide; Kevin Swingler ; Practical Guide; Kevin Swingler ; Editorial Morgan Kaufmann. Editorial Morgan Kaufmann.

41
CogNovaTechnologies
Bibliografia Cont.Bibliografia Cont.
Fuzzy and Neural Approaches in Fuzzy and Neural Approaches in Engineering; Tsoukalas, Uhrig. Engineering; Tsoukalas, Uhrig. Ed. ?Ed. ?

42
CogNovaTechnologies

43
CogNovaTechnologies
Dudas ??Dudas ????

44
CogNovaTechnologies
Hasta la Hasta la próxima !!!próxima !!!