detecci´on visual de humo basada en fusion de...
TRANSCRIPT

Deteccion visual de humo basadaen fusion de detectores
Proyecto Final de MasterMaster en Automatica, Robotica y Telematica
Autor: Pablo Soriano TapiaTutor: Anibal Ollero Baturone
Escuela Superior de Ingenieros - Universidad de SevillaNoviembre - 2007

Deteccion visual de Humo
2

Indice general
1. Lıneas generales 13
1.1. Estado del arte . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.2. Solucion propuesta . . . . . . . . . . . . . . . . . . . . . . . . 14
2. Fundamentacion teorica 17
2.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2. Modelo probabilıstico del mundo . . . . . . . . . . . . . . . 17
2.2.1. Estado . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.2.2. Interacciones . . . . . . . . . . . . . . . . . . . . . . . 18
2.3. Estimacion Bayesiana de estado . . . . . . . . . . . . . . . . 18
2.4. Linealidad, Estabilidad y Soluciones Analıticas . . . . . . . 20
2.5. Desarrollo de un modelo no parametrico . . . . . . . . . . . 21
2.5.1. Importance Sampling . . . . . . . . . . . . . . . . . . 21
2.5.2. Filtro de partıculas . . . . . . . . . . . . . . . . . . . 22
2.5.3. Sequential IS y reestimacion de estado . . . . . . . . 22
2.5.4. Uniformizacion . . . . . . . . . . . . . . . . . . . . . . 24
3. Detectores base. 27
3.1. Detector basado en Color . . . . . . . . . . . . . . . . . . . . 27
3.1.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . 27
3.1.2. Modelado . . . . . . . . . . . . . . . . . . . . . . . . 27
3

Deteccion visual de Humo
3.1.3. Espacio de color . . . . . . . . . . . . . . . . . . . . . 28
3.1.4. Implementacion . . . . . . . . . . . . . . . . . . . . . . 30
3.2. Detector basado en Movimiento . . . . . . . . . . . . . . . . . 31
3.3. Detector basado en textura . . . . . . . . . . . . . . . . . . 32
3.3.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . 32
3.3.2. Metodos frecuenciales puros . . . . . . . . . . . . . . 34
3.3.3. Transformadas lineales . . . . . . . . . . . . . . . . . 35
3.3.4. Transformadas No Lineales . . . . . . . . . . . . . . 36
3.3.5. Metricas . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.3.6. Implementacion . . . . . . . . . . . . . . . . . . . . . . 40
3.3.7. Resultados . . . . . . . . . . . . . . . . . . . . . . . . 40
4. Fusion de detectores 43
4.1. Derivacion de las ecuaciones . . . . . . . . . . . . . . . . . . . 43
5. Validacion 47
5.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.2. Editor de mascaras . . . . . . . . . . . . . . . . . . . . . . . 47
5.2.1. Crear un nuevo documento . . . . . . . . . . . . . . . 48
5.2.2. Edicion . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.2.3. Generacion de mascaras . . . . . . . . . . . . . . . . . 51
5.3. Banco de pruebas . . . . . . . . . . . . . . . . . . . . . . . . 52
6. Resultados 53
6.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
6.2. Parametros optimos . . . . . . . . . . . . . . . . . . . . . . 53
6.3. Experimento 1 . . . . . . . . . . . . . . . . . . . . . . . . . . 55
6.4. Experimento 2 . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4

Deteccion visual de Humo
6.5. Experimento 3 . . . . . . . . . . . . . . . . . . . . . . . . . . 60
7. Conclusiones 63
A. Notacion y Estadıstica Basica 65
5

Deteccion visual de Humo
6

Indice de figuras
1.1. Diagrama de la aproximacion propuesta. . . . . . . . . . . . . 15
2.1. Ejemplo de IS unidimensional. Las muestras son extraidas deuna distribucion de importancia uniforme y aproximan losmomentos de una normal. . . . . . . . . . . . . . . . . . . . . 21
2.2. Durante la uniformizacion, la informacion acerca de la dis-tribucion almacenada en los pesos ωi(izquierda) pasa a estaralmacenada en el estado (derecha). El conjunto resultante tie-ne pesos uniformes. . . . . . . . . . . . . . . . . . . . . . . . 25
3.1. Corpus de datos de entrenamiento en el espacio RGB. Po-demos observar que las muestras yacen sobre la diagonal delcubo, estando fuertemente correladas. Abajo a la derecha, al-gunos valores para puntos vecinos en la imagen . . . . . . . . 29
3.2. Corpus de datos de entrenamiento en el espacio HSV. Pode-mos observar que tono y brillo estan practicamente incorrela-das, ası como tono y saturacion. Abajo a la derecha, algunosvalores para puntos vecinos en la imagen . . . . . . . . . . . 30
3.3. Salida tıpica del detector de color. La imagen original se mues-tra en escala de grises para facilitar la visualizacion. . . . . . 31
3.4. Salida del detector de movimiento. . . . . . . . . . . . . . . . 33
3.5. Ejemplo de transformacion TU con δ = 2. El valor final secompone de los digitos ternarios, segun la ordenacion quemuestra la flecha. . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.6. Densidad y distribucion de probabilidad chi-cuadrado, paradistintos grados de libertad (k) . . . . . . . . . . . . . . . . . 39
7

Deteccion visual de Humo
3.7. Imagen y su transformada ILBP. Notese la regularidad de ladistribucion de valores en la region donde hay humo. . . . . 40
3.8. Distintos pasos del proceso de deteccion de textura. De iz-quierda a derecha, y de arriba a abajo, imagen original, tran-formada ILBP, diferencia de histogramas respecto al patrony resultado superpuesto . . . . . . . . . . . . . . . . . . . . . 41
3.9. Salida del detector de textura. . . . . . . . . . . . . . . . . . 42
4.1. Modelo oculto de Markov de primer orden utilizado para es-timar el estado, junto con las distribuciones que definen laprobabiliad de observacion asociada a cada estado. El modelode generacion sera lineal, utilizando constantes como proba-bilidades de transicion. . . . . . . . . . . . . . . . . . . . . . . 45
5.1. Dialogo de seleccion de fichero de imagen muestra de unasecuencia. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.2. Selector de rango de secuencia. En el ejemplo, escogemos lasimagenes de la 22 a la 62. . . . . . . . . . . . . . . . . . . . . 49
5.3. Cada capa contiene una lista enlazada de configuraciones delpolıgono, cada una con un ındice temporal asociado. . . . . . 49
5.4. En el momento de creacion de la capa definimos la primeraconfiguracion de su polıgono asociado . . . . . . . . . . . . . 50
5.5. A partir de dos configuraciones del polıgono (izquierda y de-recha) se interpola para los instantes intermedios (centro). . . 51
5.6. Ejemplos de mascaras generadas usando MaskEditor. . . . . . 51
5.7. Izquierda: fotografıa aerea de Gestosa (Portugal) donde seaprecian las parcelas quemadas en diferentes experimentos.Derecha: fotografıa de la estacion frontal tomada en unos ex-perimentos en mayo de 2006. . . . . . . . . . . . . . . . . . . 52
6.1. Experimento 1: probabilidades de falso positivo y falso ne-gativo para el detector de color del primer experimento. Elestrechamiento entre (1 − pFN ) y pFP sugiere un reentrena-miento. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
6.2. Experimento 1: probabilidades de falso positivo y falso nega-tivo para el detector de movimiento del primer experimento. 56
8

Deteccion visual de Humo
6.3. Experimento 1: probabilidades de falso positivo y falso nega-tivo para el detector de textura del primer experimento. . . . 56
6.4. Probabilidades de falso positivo y falso negativo para el de-tector de humo, una vez fusionados los detectores base, en elprimer experimento. . . . . . . . . . . . . . . . . . . . . . . . 57
6.5. Probabilidades de falso positivo y falso negativo para el de-tector de color, una vez reentrenado como se indica en ladescripcion del segundo experimento. El optimo se mantienemuy cercano al anterior, aunque mejora la probabilidad defalso negativo en tanto que empeora la de falso positivo. . . . 59
6.6. Probabilidades de falso positivo y falso negativo para el de-tector de humo, una vez fusionados los detectores base, en elsegundo experimento. . . . . . . . . . . . . . . . . . . . . . . 59
6.7. Probabilidades de falso positivo y falso negativo para el de-tector de textura, una vez reentrenado como se indica en ladescripcion del tercer experimento. La principal mejora seconsigue respecto al falso negativo, dado lo laxo de las masca-ras utilizadas. . . . . . . . . . . . . . . . . . . . . . . . . . . 61
6.8. Probabilidades de falso positivo y falso negativo para el de-tector de humo, una vez fusionados los detectores base, en eltercer experimento. . . . . . . . . . . . . . . . . . . . . . . . 61
9

Deteccion visual de Humo
10

Introduccion
La deteccion automatica de humo en espacios abiertos es un problema deimportancia en el ambito de la alarma temprana de incendios bien urbanos,bien naturales. En ambos casos la deteccion temprana de un fuego puedeevitar perdidas humanas, ecologicas y materiales, de modo que los esfuerzospara la consecucion de un sistema seguro que aporte esa funcionalidad estanmas que justificados.
El presente trabajo tiene sus raices en el marco del proyecto INFLAME,“Fire Behaviour Prediction Modelling and Testing” (ENV4-CT98.0700), fi-nanciado por la Comision Europea. en el IV Programa Marco (Environmentand Climate). El proyecto esta dedicado a la investigacion en incendios fo-restales incluyendo metodos de adquisicion de informacion, modelado, y so-porte a la extincion. En dicho proyecto se realizo una primera aproximaciona la deteccion visual de humo via computo de flujo optico, que abrıo lapuerta a subsiguientes trabajos que, aunque no relacionados tecnica ni me-todologicamente con el primero, comparten el mismo objetivo. Los frutosdel presente proyecto forman parte de los resultados de 2007 del proyectoAWARE (IST-2006-33579), y han contribuido a la publicacion [1]
El proyecto se encuentra estructurado como sigue. En primer lugar en elcapıtulo 1 se dara una vision general del estado del arte en el campo de ladeteccion de humo, y se expondra la solucion propuesta por el autor. A conti-nuacion, el capıtulo 2 sienta las bases teoricas que de la estimacion recursivade estado, desde la generalidad y aplicada a los modelos concretos utiliza-dos. En los capıtulos 3 y 4 se detalla el funcionamiento de los componentesdel sistema, i.e, los detectores base y la fusion de los mismos. Finalmen-te, los capıtulos 5 y 6 presentan los metodos de validacion utilizados y losresultados obtenidos.
11

Deteccion visual de Humo
12

Capıtulo 1
Lıneas generales
1.1. Estado del arte
La deteccion visual de humo es un problema que conlleva cierto gradode desafıo. A diferencia de otro tipo de objetivos, el humo presenta carac-terısticas que lo hacen bastante esquivo a la segmentacion automatica. Suspropiedades cambian constantemente: no tiene forma definida, su color pue-de variar desde el blanco al negro, pasando por tonos naranjas, carece derasgos estructurales fuertes (esquinas, bordes)...
A esto se suma que, en general, no ha sido un problema muy tratado perse. Existen pocos trabajos en los que no aparezca como objetivo secundarioo complementario para aplicaciones de deteccion de nubes de polvo porsatelite o el estudio de emisiones en chimeneas industriales [12] .
No todas las aproximaciones buscan una deteccion visual de humo. En[10] se utiliza el LIDAR (Light Detection and Ranging) aplicacion analogaal RADAR que estudia el patron de scattering pero en luz visible. En [8] seutilizan imagenes multibanda del satelite NOAA, mas alla del rango visible.Entre las que utilizan exclusivamente imagenes en el espectro visible figuran[12],[9] y [11], todas trabajando sobre imagenes monocromas.
Existen en la literatura dos aproximaciones principales a la deteccionvisual de humo. La primera de ellas esta basada en movimiento. La deteccionde movimiento, mediante tecnicas substraccion de fondo [9] o correlacionentre imagenes consecutivas divididas en bloques [11], es el primer paso dela deteccion. Posteriormente se ha de identificar si lo que se ha movido eshumo, lo que generalmente se persigue perfilando mejor la silueta del objetoy obteniendo caracterısticas asociadas a la forma del contorno.
13

Deteccion visual de Humo
La segunda aproximacion se basa en la deteccion de texturas [8] . Es-ta segunda tenica se utiliza sobre todo cuando se trabaja con imagenes desatelite. Las columnas de humo a esas escalas tienen una dinamica similara la de otros fenomenos atmosfericos (nubes). La utilizacion de filtros deGabor en diversas bandas del espectro parece ser lo bastante discriminantepara distinguir el humo de otro tipo de formaciones. Existen asimismo publi-caciones que tratan la caracterizacion de las llamadas “texturas dinamicas”mediante modelos ocultos de Markov. Estas texturas pueden utilizarse paradiferenciar el fluir del agua de el de las llamas en movimiento o del humo,pero los artıculos no hacen mayor hincapie en la viabilidad de su utilizacionpractica para la deteccion efectiva de humo.
Todos los metodos en la literatura tienen algo en comun: centran suatencion en una sola caracterıstica del objeto a estudio, afinandola hasta ellımite. Ası, se escogen cuidadosamente los detectores, sean de movimientoo textura, ya que el exito o fracaso de los mismos determinara, de modoabsoluto, el exito o fracaso de la deteccion del humo.
El punto de vista que se adopta en el presente proyecto es el de no depen-der de detectores perfectos, sino considerar a priori que cualquier detector,por bueno que sea, fallara de un modo u otro en ocasiones. El modus ope-randi propuesto es basar la deteccion en la fusion de multiples detectores,lo mas independientes posible entre sı. De este modo se pretende dotar derobustez al sistema.
1.2. Solucion propuesta
La aproximacion utilizada viene descrita, de un modo coloquial, por elproverbio popular
“blanco y en botella, leche”
Hay muchas cosas que pueden almacenarse dentro de una botella. Asimis-mo hay muchas cosas que pueden ser blancas. Sin embargo, cuando ambascaracterısticas, procedentes de vistas parciales y distintas, se presentan si-multaneamente, es probable que estemos ante una botella de leche. Esta esla filosofıa que seguiremos con el humo. En lugar de basarnos en un solo des-criptor y, tras ajustarlo hasta el lımite de lo posible, construir una heurısticaencima para obtener resultados aceptables, utilizaremos como base un bancode detectores trabajando sobre distintos descriptores, y combinaremos en unmarco probabilıstico las salidas de los mismos para obtener una estimacionfidedigna del estado real.
14

Deteccion visual de Humo
Figura 1.1: Diagrama de la aproximacion propuesta.
Los detectores debieran ser en principio lo mas ajenos posibles los unosrespecto de los otros. Idealmente, debieran reflejar aspectos dispares de larealidad de modo que podamos caracterizar de manera claramente distintivael objeto de nuestra busqueda. Siguiendo con el ejemplo de la leche, el colorde un objeto es bastante independiente de su forma. Construir detectoresde forma implicarıa introducir capas de reconocimiento de objetos, que sinduda serıan valiosısimas a la hora del reconocimiento, pero, como prueba deconcepto, y dado que el humo no se ajusta en cualquier caso demasiado biena la idea clasica de objeto (solido rıgido, no deformable), se opto por escogerdescriptores de muy bajo nivel.
Los descriptores escogidos son el color, el movimiento y la textura. Lostres son, a priori, bastante independientes unos de otros. De este modo, serandisenados tres detectores que trataran cada uno por su lado de detectar elhumo por el color, movimiento y textura de la imagen. Los resultados de losque denominaremos en adelante detectores base adoptaran la forma de unarejilla, del mismo tamano que la imagen original, con valores comprendidosen el intervalo (0,1).
15

Deteccion visual de Humo
Si estos detectores fuesen perfectos, en el sentido de que, una vez binari-zadas sus salidas, siempre detectasen humo donde lo hay (probabilidad defalso negativo nula) o nunca diesen falsas alarmas alli donde no lo hay (pro-babilidad de falso positivo nula ), el modo optimo para estimar el verdaderoestado subyacente ( si hay humo o no) se limitarıa a un simple AND logicoen el primer caso, y un OR logico en el segundo. Pero los detectores baseno son perfectos. Para hacer posible una estimacion probabilıstica de esta-do, veremos en secciones subsiguientes como cada detector se caracterizara,en cada estado, con una distribucion de probabilidad. Dichas distribucionestienen que ver con la fiabilidad de cada detector, de modo que el resultadode la fusion sea lo mas robusto posible.
En capıtulos posteriores mostraremos los detectores base implementados,y entraremos en detalle en el modelo de reestimacion de estado.
16

Capıtulo 2
Fundamentacion teorica
2.1. Introduccion
En este capıtulo se detallan los pormenores de la teorıa que soporta elpresente trabajo. El capıtulo esta organizado como sigue. En primer lugar, seexpondran los conceptos asociados a la estimacion probabilıstica de estado,y como se utilizaran para modelar nuestro “universo” de trabajo. Despues seexpondran las ecuaciones generales de reestimacion de estado. Finalmente,se extraeran las expresiones concretas que definen la reestimacion de estadopara un modelo no parametrico de la variables aleatorias asociadas, utilizadoen el detector de color.
Mas adelante, en el capitulo 4 se extraran, tambien en base a lo aquı ex-puesto, las expresiones concretas para la reestimacion de estado en el casode un modelo parametrico de las variables aleatorias, orientado a la fusionde los detectores.
2.2. Modelo probabilıstico del mundo
La forma de exponer los conceptos que se trataran en adelante respecto ala estimacion bayesiana se basara en la linea seguida por Thrun en [2]. Esteaporta una explicacion clara y concisa de los conceptos implicados en la re-presentacion probabilıstica de los campos de la percepcion y la actuacion.Para refrescar algunos conceptos de estadıstica basica implicados en las de-ducciones que se desarrollaran en los apartados sucesivos, vease el ApendiceA.
En este apartado vamos a describir los distintos elementos que confor-
17

Deteccion visual de Humo
maraan una descripcion probabilıstica del mundo tal que se adecue de unaforma lo mas general posible a los problemas de robotica.
2.2.1. Estado
El concepto principal es el de estado. Un entorno esta definido por suestado. Puede definirse el estado como la coleccion de aspectos que puedeninfluenciar el comportamiento futuro del sistema libre de actuaciones. Elestado puede ser de modo general estatico o dinamico, segun incorpore totalo parcialmente la dinamica del sistema a modelar. El estado se denotara porla variable x. El estado en el instante t se denominara xt.
Un estado xt se dice completo cuando es un predictor absoluto del futu-ro. No es que el futuro dependa de manera determinista de el, sino que lainformacion proveniente de estados, acciones o medidas pasadas no aportaninformacion adicional a la hora de predecir el futuro. Ninguna variable ante-rior a xt tendra una influencia en la evolucion estocastica del estado futuro,salvo a traves de xt si es completo. Los sistemas que cumplen esta asuncionson procesos de Markov de primer orden.
2.2.2. Interacciones
Las interacciones con el entorno se pueden dividir en medidas de sensoresy actuaciones. En consecuencia tendremos dos flujos de informacion: datosde medida y datos de control.
Los datos de medida proveen informacion instantanea acerca del entorno,y se denominan como zt. Un ejemplo serıa la salida de un detector en uninstante dado.
Los datos de control proveen informacion acerca de los cambios en elestado del entorno. Podrıan considerarse en esta categorıa las lecturas desensores referentes a odometrıa: son datos a los que tenemos accesos queinfluyen en el cambio del estado. El dato de control en el instante t se notacomo ut
2.3. Estimacion Bayesiana de estado
El proceso de generacion de estado viene dado por las ecuaciones del mo-delo. Sean X,Z y U las variables aleatorias que representan estado, medidasy actuaciones, respectivamente, la representacion mas general serıa
18

Deteccion visual de Humo
Xt = f(X1:t−1, U1:t, Z1:t−1)Zt = g(X1:t−1, U1:t, Z1:t−1)
Ut = h(X1:t−1, U1:t−1, Z1:t−1
donde f,g y h pueden ser funciones no lineales. Acotando, considerare-mos que el estado es completo. Como consecuencia, las probabilidades deobservacion son conocidas en base al estado en el instante actual, de maneracerrada. Formalmente:
Xt = f(Xt−1, Ut)Zt = g(Xt)
Ut = h(Xt−1)p(xt | x0:t−1, z1:t−1, u1:t) = p(xt | xt−1, ut)
p(zt | x0:t, z1:t−1, u1:t) = p(zt | xt)
La estimacion del estado en el instante actual, teniendo en cuenta todala informacion recopilada desde el inicio, es lo que se denomina creencia obelief. Lo expresaremos como
bel(xt) = p(xt | z1:t, u1:t) (2.1)
Podemos apreciar que nuestra creencia sobre el estado incorpora tambienla ultima medida realizada, la medida en el instante actual zt. Para clarificarla estimacion recursiva del estado, daremos tambien nombre a la creenciaantes de incorporar la medida actual. A esta distribucion la denotaremoscomo
bel(xt) = p(xt | z1:t−1, u1:t) (2.2)
A partir de estas dos declaraciones, es sencillo expresar la reestimacion dela creencia del estado apoyandonos en la regla de Bayes y la consideracionde que el estado es completo, en dos pasos
bel(xt) = p(xt | z1:t−1, u1:t)=
∫p(xt | xt−1, ut)p(xt−1 | z1:t−1, u1:t−1)dx
=∫
p(xt | xt−1, ut)bel(xt−1)dx(2.3)
bel(xt) = p(xt | z1:t−1, u1:t)= ηp(zt | xt)p(xt | z1:t−1, u1:t)dx= ηp(zt | xt)bel(xt)dx
(2.4)
Donde η es un factor de normalizacion, para que∫
bel(xt)dx sume uno
19

Deteccion visual de Humo
2.4. Linealidad, Estabilidad y Soluciones Analıti-cas
Las ecuaciones que rigen la generacion del estado, de las actuaciones y delas medidas ( f, g y h ) son un punto crıtico del modelo. No solo determinan elcomportamiento, sino si podremos resolver o no analiticamente el problemade la reestimacion.
En el caso en que las funciones sean lineales podemos llegar a obtenersoluciones analıticas para los parametros de la nueva distribucion resultantede la reestimacion del estado. Para ello, es necesario que las distribucio-nes implicadas en el proceso (probabilidad de observacion dado el estadop(zt|xt), etc...) pertenezcan a una familia estable.
La propiedad de estabilidad estadıstica nos dice que si definimos parauna familia estable, biparametrica en el ejemplo, las variables
X1 ∼ fam(µ1, c1)X2 ∼ fam(µ2, c2)
Y = aX1 + bX2 =⇒ Y ∼ fam(µ, c) + K
La variable Y pertenecera a la misma familia estadisticamente estable,salvo quizas por un factor K constante. Esta propiedad se hace patentesi trabajamos con funciones caracterısticas, ya que la nueva distribuciones una convolucion de las dos implicadas, lo que en Fourier se reduce aun producto. Las distribuciones que poseen esta propiedad se engloban enla familia Levy skew alpha-stable. Particularizaciones concretas serian ladistribucion Gaussiana, la de Cauchy y la de Levy.
Si alguna de estas dos suposiciones falla (linealidad y estabilidad estadısti-ca ), obtener una solucion analıtica no es, en general, posible. Esto ocurremas a menudo de lo que pudiera pensarse en la vida real; por ejemplo laceleridad de un movil con una velocidad cuyas componentes son gaussianasno posee una distribucion gaussiana, sino de Rayleigh, y si la representa-cion espacial no es cartesiana las leyes del movimiento pueden adoptar confacilidad formas no lineales.
20

Deteccion visual de Humo
Figura 2.1: Ejemplo de IS unidimensional. Las muestras son extraidas deuna distribucion de importancia uniforme y aproximan los momentos deuna normal.
2.5. Desarrollo de un modelo no parametrico
2.5.1. Importance Sampling
Una funcion densidad de probabilidad (fdp) contınua puede ser aproxi-mada arbitrariamente bien por un conjunto lo suficientemente amplio demuestras extraidas de dicha distribucion. El conjunto de muestras defineuna distribucion de probabilidad que tendra los mismos momentos que laoriginal. Si llamamos p(x) a la distribucion contınua original, y p(x) a laaproximacion discreta, diremos esta ultima es valida si cumple que
lımn→∞
Ep[g(x)] −→ Ep[g(x)] (2.5)
donde g(x) es una funcion cualquiera y N es el numero de muestras ex-traidas. La funcion g(x) define una medida sobre la distribucion, que sepuede hace coincidir con algun momento. Un ejemplo facil de visualizarserıa g(x) = x, que pone de manifiesto la convergencia de las medias. Es deresenar que en este caso todas las muestras son igualmente importantes, enel sentido de que todas tienen el mismo peso a la hora de influir sobre laaproximacion.
Lo que plantea el metodo IS es aproximar una fdp contınua a traves deuna serie de muestras extraidas, en lugar de la distribucion objetivo p(x), deuna segunda distribucion q(x), llamada distribucion de importancia. En estaocasion, cada una de estas muestras llevara asociado un peso o importancia,de manera que a pesar de haber sido extraidas de una distribucion distintapuedan aproximar los momentos de la original segun (2.5). Ası, podemosescribir
21

Deteccion visual de Humo
Ep[g(x)] =∫
g(x)p(x)dx =∫
g(x)p(x)q(x)
q(x)dx = Eq[ω(x)g(x)]
Se demuestra que la distribucion asociada a las muestras extraidas deq(x) aproximara de un modo arbitrariamente fidedigno los momentos dep(x), si cada muestra xi del conjunto va multiplicada por el peso ω(xi) talque
ω(xi) =p(x)q(x)
∣∣∣∣x=xi
(2.6)
El unico requisito para esta segunda distribucion q(x) es que sea no nulaen el soporte de p(x), para que los pesos asociados a las muestras tengansiempre un valor acotado. Se puede demostrar con facilidad que, si los pesosvan multiplicados por una constante independiente de x, todas las ecuacionesanteriores se siguen cumpliendo, salvo por un factor de escala.
2.5.2. Filtro de partıculas
El filtro de partıculas nos permite llevar a cabo una estimacion recursivade estado utilizando como aproximacion no parametrica de las densidades deprobabilidad implicadas el IS. De este modo nos liberamos de la restriccionesimpuestas por la necesidad de obtener una solucion analıtica, abriendo lapuerta a sistemas con una dinamica de estado no lineal y con distribucionesde probabilidad arbitrarias. Los filtros de particulas basan su eficacia en unMetodo de Montecarlo, el Sequential Importance Sampling (SIS).
2.5.3. Sequential IS y reestimacion de estado
Consideremos que tenemos un conjunto de muestras ponderadas xt−1 ={xi
t−1, ωit−1} que aproxima bel(xt−1), y queremos obtener un nuevo conjunto
xt = {xit, ω
it} que aproxime bel(xt). Ası, la funcion densidad de probabilidad
p(x) que es estamos aproximando mediante IS es
p(xt) = bel(xt) = probp(xt|z1:t, u1:t)
La fdp de importancia q(x), de donde sacaremos las muestras, la dejare-mos abierta en general a lo largo de este desarrollo, cinendonos simplementea que pueda factorizarse de la forma
q(xt) = probq(xt|z1:t, u1:t)= probq(zt|xt−1, ut)probq(xt−1|z1:t−1, u1:t−1)= probq(zt|xt−1, ut)q(xt−1)
22

Deteccion visual de Humo
Basandonos en las ecuaciones (2.3) y (2.4) podemos escribir la densidaden el instante actual como funcion de la misma densidad en el instanteanterior. Asi,
p(xt) = probp(xt|z1:t, u1:t)
= η · probp(zt|xt)∫
probp(xt|xt−1, ut)probp(xt−1|z1:t−1, u1:t−1)dx
= η · probp(zt|xt)∫
probp(xt|xt−1, ut)p(xt−1)dx
Ambas ecuaciones tienen una forma recursiva. Si suponemos como hi-cimos al principio que tenemos una coleccion de muestras representando ap(xt−1) , podemos calcular los pesos. La ecuacion (2.6) para los pesos quedacomo una expresion recursiva de la forma
ω(xi) =p(x)q(x)
∣∣∣∣x=xi
=η · probp(zt|xi
t)probp(xit|xi
t−1, ut)probq(zt|xi
t−1, ut
p(xit−1)
q(xit−1)
La eleccion de la funcion de importancia q(x) es un grado de libertadanadido que tenemos. Podemos en principio escoger cualquier funcion paraextraer de ella las muestras, siempre que cumpla las premisas de factoriza-cion y no nulidad sobre el soporte que hemos impuesto.
La eleccion puede hacerse buscando minimizar la varianza de los pesos.Esta eleccion ayuda a mitigar el llamado problema de degeneracion de lospesos. Este problema consiste en que, durante la reestimacion recursiva delos pesos, los pesos de la mayoria de las partıculas se van a cero, de mo-do que el numero de partıculas que tienen un peso significativo se reduce,empobreciendo la aproximacion. Lamentablemente, la eleccion de una q(x)que minimice la varianza de los pesos no siempre adopta la forma de unaexpresion analıtica.
Una eleccion para q(x) es la pobabilidad a priori o bel(xt). Es facil dehallar y simplifica las reestimaciones, aunque no es optima respecto a ladegeneracion de pesos. Fijado q(x) llegamos finalmente a las expresiones(2.7), (2.8), que se muestran de un modo procedural en el algoritmo 1.
23

Deteccion visual de Humo
xit ← bel(xt)
=∫
p(xt|xt−1, ut)bel(xt−1)dxt−1
=∑∀j
∫p(xt|xt−1, ut)δ(xt−1 − xj
t−1)dxt−1
(2.7)
ω(xit) = ηω · p(zt|xi
t)ω(xit−1) (2.8)
Algorithm 1: SequentialImportanceSampling
Input: Belief IS at time t: xt = {xjt , ω
jt } j ∈ [1..n]
Output: Belief IS at time t+1: xt+1 = {xit+1, ω
it+1} i ∈ [1..n]
beginfor i = 1 to n do
draw xit+1 from ∑
∀jp(xt+1|xt = xj
t , ut)
update ωit+1 = ηω · p(zt|xi
t)ωit ;
endend
2.5.4. Uniformizacion
La degeneracion de los pesos de la que hablamos la seccion anterior nopuede evitarse, pero se puede paliar de un modo pragmatico realizando detanto en tanto una uniformizacion de los pesos. El indicador que se esco-ge comunmente para disparar la uniformizacion (tambien conocida comoresampling) es el numero efectivo de partıculas, que se define como
Neff =1∑
∀i(wit)2
(2.9)
Si el numero efectivo disminuye por debajo de un porcentaje del total, seprocede a una uniformizacion de los pesos. Generalmente se utilizan valorespara Neff cercanos al 30 %.
La uniformizacion de pesos es un proceso sencillo. Primero se calcula lafuncion de distribucion asociada a los pesos ωi de las partıculas del conjuntoa uniformizar. Posteriormente se procede a extraer un grupo de n muestras
24

Deteccion visual de Humo
Figura 2.2: Durante la uniformizacion, la informacion acerca de la distribu-cion almacenada en los pesos ωi(izquierda) pasa a estar almacenada en elestado (derecha). El conjunto resultante tiene pesos uniformes.
de dicha distribucion. El nuevo conjunto contendra las n partıculas selec-cionadas. Varias de estas nuevas particulas pueden corresponderse con unamisma partıcula del conjunto original, que tuviese -en principio- un pesoelevado. El proceso se muestra en la figura 2.5.4. Generalmente, al nuevoconjunto de particulas se le anade algo de ruido para que cubran mejor elespacio de trabajo.
La uniformizacion de pesos hace que la informacion acerca de la distribu-cion que se trata de aproximar pase de los pesos al estado. Puede llegar a serpeligrosa, ya que si hay pocas partıculas (estados) con un peso aceptable,tras una uniformizacion casi toda la nube de partıculas acabara en sus cer-canias, y puede que dejemos de aproximar adecuadamente la distribucion,perdiendo rasgos distintivos. Existe una perdida de variedad, y se reduce elespacio de estados explorado, con lo que ello conlleva.
25

Deteccion visual de Humo
26

Capıtulo 3
Detectores base.
3.1. Detector basado en Color
3.1.1. Introduccion
El detector de color se centrara en caracterizar estadısticamente el colordel humo. Ası, quedan fuera de las atribuciones de este detector el tomaren consideracion variaciones espaciales o temporales de los planos de color.Dichas variaciones seran tenidas en cuenta, en principio, por los detectoresde textura y movimiento, respectivamente.
Limitado de este modo, el detector se basa mantener una representacionde la distribucion de probabilidad asociada al humo. De este modo, solamen-te hay dos factores a tener en cuenta a la hora del diseno: el espacio de colorutilizado (que influira en las relaciones entre las distintas componentes) y elmetodo de modelado para la distribucion de probabilidad.
3.1.2. Modelado
Dentro del enfoque probabilıstico, los distintos metodos de aprendizajedifieren, en la practica, en el tipo de modelo que se utiliza para representar lasdistribuciones de probabilidad implicadas. Existe una division fundamentalentre las distintas tecnicas de modelado: modelos parametricos, y modelosno parametricos.
En el primer caso, se realiza la suposicion de que la distribucion de proba-bilidad a representar pertenece a una familia de densidades, gobernada porun conjunto de parametros. La utilizacion de modelos parametricos permi-
27

Deteccion visual de Humo
ten en muchas ocasiones llegar a soluciones analıticas para los problemas deoptimizacion involucrados en la clasificacion. Sin embargo, su uso, aunqueampliamente extendido, debiera restringirse a los casos en que los supues-tos de aplicacion se cumplan. Ejemplos claros de esta aproximacion son elmodelado mediante gaussianas o mezcla de gaussianas.
La representacion no parametrica trata de aproximar del modo mas fielposible la distribucion subyacente, sin supuestos adicionales. Como contra-partida, utilizarlas equivale a renunciar a obtener soluciones analıticas. Contodo, son la aproximacion mas aceptable dada su flexibilidad inherente ocuando el conocimiento a priori acerca de las distribuciones a modelar esescaso, y han ganado popularidad en los ultimos tiempos de la mano detecnicas relacionadas con metodos de Monte Carlo.
El detector de color se basara en una representacion no parametrica ob-tenida a partir de la estimacion utilizando un filtro de partıculas. Para elloconsideraremos un modelo estatico, y probabilidades de observacion norma-les. De este modo
p(xt|xt−1) =1n
∑∀i
N(xit−1,Σ)
p(zt|xt) = N(xt, 2 · Id×d)
donde Σ, matriz de correlacion, es diagonal con valores muy pequenos,de modo que la distribucion de generacion de estado no sea discreta.
3.1.3. Espacio de color
El problema principal que presenta la utilizacion de IS como representa-cion no parametrica se hace patente a la hora de combinar densidades. Lamultiplicacion de densidades, o mas concretamente una forma degeneradade la misma, donde la segunda densidad es una delta de Dirac, es la que nospermite obtener la verosimilitud para un punto del espacio de color (pixel).Es necesario obtener a partir del conjunto de partıculas una representacioncon extension espacial. Esto se logra habitualmente convolucionando la nubede partıculas con un kernel, habitualmente gaussiano.
La convolucion plantea el problema de la eficiencia. El procesado puederealizarse fuera de linea, pero en tal caso se requerirıa mucha memoria paraalmacenar el espacio completo precalculado ( 2563 puntos ). Dado que elobjetivo era obtener una aplicacion capaz de ejecutarse en tiempo real, seestudio la posibilidad de realizar simplificaciones de modo que se aligeraseel calculo.
28

Deteccion visual de Humo
Figura 3.1: Corpus de datos de entrenamiento en el espacio RGB. Podemosobservar que las muestras yacen sobre la diagonal del cubo, estando fuerte-mente correladas. Abajo a la derecha, algunos valores para puntos vecinosen la imagen
RGB y HSL
Con este objetivo de mejora la eficiencia se realizo un estudio de distintosespacios de color. En RGB (Red Green Blue), los colores que toma el hu-mo yacen sobre una diagonal del espacio (figura 3.1.3). La correlacion entrecomponentes es total, y la simplificacion consistente en considerarlos es-tadısticamente independientes inaceptable. Un espacio de color prometedorpara este problema en concreto es el HSL (Hue Saturation Lightness).
Hue =
undefined max = min
60 ∗ g−b(max−min) max = r, g > b
360 + 60 ∗ g−b(max−min) max = r, b < g
120 + 60 ∗ b−r(max−min) max = g
240 + 60 ∗ r−g(max−min) max = b
Lightness =12(max + min)
29
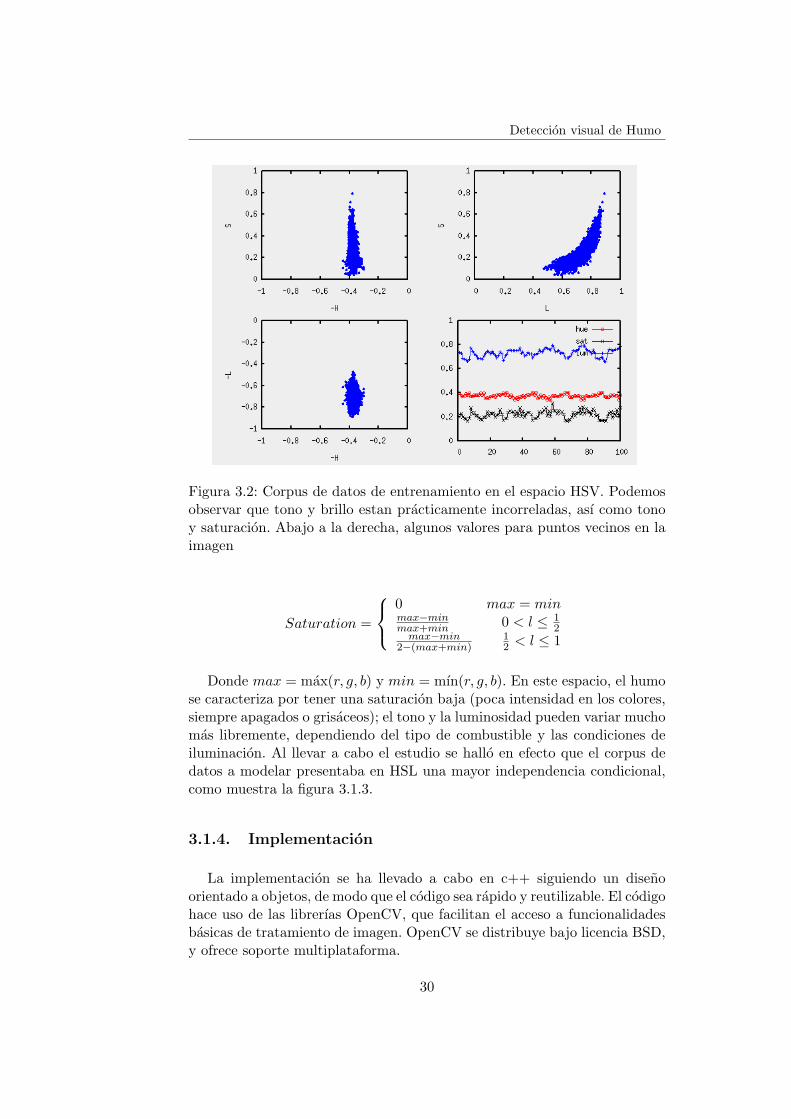
Deteccion visual de Humo
Figura 3.2: Corpus de datos de entrenamiento en el espacio HSV. Podemosobservar que tono y brillo estan practicamente incorreladas, ası como tonoy saturacion. Abajo a la derecha, algunos valores para puntos vecinos en laimagen
Saturation =
0 max = minmax−minmax+min 0 < l ≤ 1
2max−min
2−(max+min)12 < l ≤ 1
Donde max = max(r, g, b) y min = mın(r, g, b). En este espacio, el humose caracteriza por tener una saturacion baja (poca intensidad en los colores,siempre apagados o grisaceos); el tono y la luminosidad pueden variar muchomas libremente, dependiendo del tipo de combustible y las condiciones deiluminacion. Al llevar a cabo el estudio se hallo en efecto que el corpus dedatos a modelar presentaba en HSL una mayor independencia condicional,como muestra la figura 3.1.3.
3.1.4. Implementacion
La implementacion se ha llevado a cabo en c++ siguiendo un disenoorientado a objetos, de modo que el codigo sea rapido y reutilizable. El codigohace uso de las librerıas OpenCV, que facilitan el acceso a funcionalidadesbasicas de tratamiento de imagen. OpenCV se distribuye bajo licencia BSD,y ofrece soporte multiplataforma.
30

Deteccion visual de Humo
Figura 3.3: Salida tıpica del detector de color. La imagen original se muestraen escala de grises para facilitar la visualizacion.
El modelo se obtiene durante la fase de entrenamiento como ya se ha ex-plicado mediante estimacion recursiva de estado usando un filtro de partıcu-las en el espacio de color HSL. Una vez obtenido, se calculan las distribu-ciones marginales para cada eje del espacio de color, que se almacenan parasu uso posterior. La salida correspondiente a un pixel se calcula facilmentecomo la verosimilitud respecto a dichas distribuciones marginales.
Una salida tıpica del detector de color se muestra en la figura 3.3.
3.2. Detector basado en Movimiento
El detector basado en movimiento es un simple detector de movimien-to. Realmente no tiene modelo alguno de como evoluciona el humo, sinoque simplemente detecta aquellas regiones donde la imagen ha cambiado.A pesar de existir alternativas simples que mejorarıan el resultado, como lautilizacion de modelos de Markov o la substraccion de fondo, se decidio im-plementar un detector simple como prueba de concepto.
El detector de movimiento trabaja con la imagen actual y la imagen pre-via, y no requiere ningun tipo de entrenamiento. El detector de movimientoutilizado es uno de los mas sencillos: la sustraccion de imagenes. Internamen-
31

Deteccion visual de Humo
te mantiene una copia de la imagen anterior. Las imagenes son suavizadascon una mascara uniforme de 7x7 antes de la substraccion. Una vez sustrai-das se binariza utilizando un umbral equivalente al 0.20 del rango dinamicode la substraccion.
image = blur(image, 7, 7)diff = ( image - previous )bin = binarize( diff, 0.20 * (max(diff) - min(diff)) + min(diff))
Como el detector ası descrito detecta muchos movimientos espurios, yes en general ruidoso, se le aplica un filtro IIR para suavizar la dimensiontemporal, de la forma
y(z)x(z) = 1
(z−0,9)
El detector de color es rudimentario, pero cumple su funcion para laaplicacion contemplada, como puede mostrarse en la figura 3.4. Es propensoa introducir muchas senales espurias cuando la camara vibra o se muevelevemente. Una aproximacion mas apropiada ya mencionada sustituirıa elfiltrado final por una caracterizacion usando un modelo de Markov. La salidase obtendrıa ejecutando de manera contınua el algoritmo de Viterbi sobreuna ventana temporal deslizante, que contuviese las N ultimas muestras. Lapuntuacion de dicha ventana se compararıa con una referencia (en formade media y varianza), procedente de ejecuciones previas sobre secuenciasgeneradas por la cadena de Markov que usamos como modelo.
3.3. Detector basado en textura
3.3.1. Introduccion
En tratamiento de imagen, la textura es aquella cualidad que da cuentade las pequenas variaciones locales, usualmente repetitivas, de la imagen enlas inmediaciones de un punto dado. El concepto puede parecer relativo,y lo es: la textura engloba todos aquellos elementos demasiado pequenosrespecto a la escala utilizada como para ser considerados objetos.
La urdimbre de una pieza de tela, las vetas de un bloque de madera oincluso la pared de ladrillos de un bloque de pisos (vista desde la distan-cia suficiente) poseen una textura caracterıstica y estable sobre el dominioque ocupa el objeto. Los elementos componentes (hilos, estratos, ladrillos )pierden su individualidad y se prestan a una descripcion estadıstica comun.
32

Deteccion visual de Humo
Figura 3.4: Salida del detector de movimiento.
De una manera general, para realizar segmentacion o clasificacion, inde-pendientemente del campo en que tabajemos necesitaremos dos elementos:los descriptores y una metrica que opere sobre los mismos. Los descriptoresde textura nos permitiran caracterizar las variaciones de la imagen en unaregion dada, de modo que regiones con similar textura tengan descripto-res similares. Dos descriptores seran tanto mas similares cuanto menor ladistancia entre ellos, de acuerdo a una metrica.
A lo largo de los anos se han desarrollado una multitud de metodos paracaracterizar la textura de los objetos. Los distintos metodos trabajan sobredistintas caracterısticas de la imagen, como la correlacion local, el gradientede la iluminacion, etc, y muchas veces dan cuenta de los mismos fenomenos.Un estudio extensivo de los distintos metodos esta fuera de los objetivosde este trabajo, y algo parecido para un subconjunto de los mismos puedeencontrarse en [1].
A pesar de ello expondremos algunos metodos que se consideraron aestudio tras un escrutinio de la bibliografia existente. Para dar cierta es-tructuracion dividiremos los metodos en dos bloques: metodos frecuenciales( o puramente estadısticos) y metodos con transformacion. La linea entreambos es en algunos casos delgada.
33

Deteccion visual de Humo
3.3.2. Metodos frecuenciales puros
Son metodos provenientes de la estadıstica basica.
Histograma
Para caracterizar una region se calcula su histograma. Este metodo pue-de utilizarse de manera directa sobre la imagen, sin mas ambajes. Puedellevarse a cabo sobre un solo canal o sobre varios, resultando en histogra-mas multidimensionales. Normalmente previo al computo del histograma serealiza una disminucion en el numero de niveles o bins (cuantizacion), paraque la dimensionalidad del resultado sea menor. Los rasgos principales deesta aproximacion son:
1. Bajo coste computacional si construimos la imagen integral de la apa-ricion de cada nivel. Por imagen integral se entiende la acumulacionde los valores por filas y por columnas, de modo que para calcularel numero de ocurrencias en una region rectangular solo es necesariosumar los valores de dos de las esquinas y restar los de las otras dos.
g(i + 1, j + 1) .= f(i + 1, j + 1) + g(i, j + 1) + g(i + 1, j)− (gi, j)
Ası, para conocer la frecuencia de aparicion del nivel k en una regionrectangular cualquiera definida por {(i0, j0), (ir, jr)} bastarıa calcularla imagen integral de la aparicion de ese sımbolo de modo que
hist(k) = gk(ir, jr)− gk(i0, jr)− gk(ir, j0) + gk(i0, j0)
2. En general requiere un numero grande de muestras para que sea es-tadisticamente consistente, al menos ∼ 10 mueatras por nivel. Estosuele obligar a trabajar con grandes parches de la imagen y, para serconsecuentes, usar imagenes de alta resolucion. Si, por el contrario, elnumero de niveles se reduce existe siempre una perdida de informacion,y se pierde selectividad. Esta perdida de informacion sera inversamenteproporcional al numero de niveles si la magnitud de la cual se esta ex-trayendo el histograma es de naturaleza contınua. El nivel de gris deuna imagen es un ejemplo de magnitud de naturaleza contınua. Si sereduce el numero de bins al calcular un histograma que opera sobreun dominio transformado, la perdida de informacion no es en generalpredecible. Un ejemplo de dichos dominios se mostraran en la seccion3.3.4
34

Deteccion visual de Humo
Matriz de coocurrencia
La matriz de coocurrencia es un histograma bidimensional que muestrala probabilidad de aparicion de parejas de valores. Cada pareja de valoresse correspondera con dos puntos cualesquiera de la imagen relacionados poruna operacion de traslacion prefijada. Ası, si establecemos la traslacion t =[0,1], las parejas de valores se formaran con el valor de un pixel dado y el delque hay debajo suya. La matriz ası construida es simetrica. Caracterısticasidentificativas de las matriz de coocurrencia son:
1. Para un vector dado, la matriz de coocurrencia nos da informacion dela distribucion estadistica en esa direccion, y por tanto son sensiblesa la rotacion. Normalmente se utilizan matrices de coocurrencia dedistintas direcciones para caracterizar una textura, nunca una sola.
2. Las matrices de coocurrencia muestran la misma problematica respec-to al numero de niveles de cuantizacion que los histogramas, dado que,de facto, son un tipo concreto de histograma.
3.3.3. Transformadas lineales
Los metodos expuestos hasta ahora no tienen en cuenta la distribucionespacial de las frecuencias. El histograma no da ninguna informacion de ladistribucion espacial de los valores, y la matriz de coocurrencia solo caracte-riza esta distribucion para una direccion y frecuencia espacial dada (aquellacuyo numero de onda coincide con la distancia de la traslacion). Los meto-dos siguientes tienen en comun que si tienen en cuenta dicha distribucionespacial.
Fourier
La transformada de Fourier o la descomposicion en series de Fourier deuna region de la imagen nos aporta informacion sobre la variacion espacialde la misma (si esta variacion es rapida, lenta, etc ), pero usada de maneradirecta no aporta informacion explıcita acerca de la direccionalidad.
Un descriptor tıpico serıa el formado por los N primeros terminos de ladescomposicion o la frecuencia de los N mayores picos.
35

Deteccion visual de Humo
Gabor
Originalmente inspirados en la funcionalidad del cortex cerebral, los fil-tros de Gabor y mas adelante la descomposicion en wavelets de Gabor sonesencialmente bancos de filtros paso banda aplicados en una direccion con-creta de la imagen. Incluyen de este modo informacion acerca de la frecuenciaespacial en cada direccion.
Se basan en funciones optimas respecto a la incertidumbre de posicionfrente a longitud de onda ( bajo una metrica ∆x · ∆ω). Las salidas de losfiltros (o en su caso los coeficientes de la descomposicion wavelet) se tomandirectamente como descriptores.
Wavelet
Es comun utilizar otras descomposiciones wavelet dado que proporcionande manera simple informacion de la distribucion espacial de frecuencias adistintas escalas. Existen variedades para todos los gustos, dada la multipli-cidad de familias existentes, cada una con su huella espectral caracterıstica.
Es usual encontrarse con descriptores formados a partir de los histogra-mas marginales ( i.e, uno por dimension o variable, que son consideradasestadısticamente independientes) de los coeficientes asociados a la descom-posicion.
3.3.4. Transformadas No Lineales
Bajo el tıtulo de transformadas no lineales cabe casi cualquier cosa. Portransformada no lineal se denotan desde metodos procedentes del calculovariacional, sesudo y respaldado matematicamente, hasta el mas heurısticode los algoritmos, sacado del fondo de cualquier saco. Bajo este epıgrafedescribiremos dos transformadas clasicas en el mundo de la segmentacionbasada en texturas, que podrıan catalogarse como descriptores de patronesespaciales locales. Anticipo que son estas transformadas las que finalmente sehan implementado y probado utiles para la deteccion automatica de humo.
Local Binary Pattern
La idea del LBP es hacer una binarizacion de la ocho-vecindad de unpixel respecto al valor central. A cada vecino se le asignara un cero si esmenor o igual que el pixel central, y un uno si es mayor. Luego, con esos
36

Deteccion visual de Humo
ocho dıgitos se compondra, recorriendolos segun en un orden establecido, unnumero de ocho bits (0-255).
Este numero de ocho bits codifica, en cierto sentido tosco, informacionacerca del gradiente de la imagen en las ocho direcciones. Tras aplicar LBP,tenemos una nueva imagen el la que cada pixel guarda esa informacionrelativa a la distribuciın espacial de la imagen original. Caracterizaremosuna determinada textura por su histograma en este dominio transformado.Sus caracterısticas principales son:
1. Es independiente del nivel de gris. Es resistente a cambios de ilumina-cion, si suponemos que las variaciones en intensidad preservan el orden,es decir, el histograma de la luminosidad se hace cambiar usando curvamonotonicamente crecientes.
2. Es muy susceptible al ruido. Cualquier ruido en una zona poco textu-rada cambiara bastante el resultado.
Una modificacion interesante es el denominado LBP irrotacional. En esecaso, tras transformar a LBP, se asigna el mismo codigo a todos los valoresque difieran solamente por una operacion de rotacion sobre los bits en el byte.Si un pixel equivale a otro, a falta de una rotacion de sus bits componenetes,ambos seran considerados iguales
00000101 .= 10000010 .= 00101000 .= · · ·
De este modo se consigue invarianza a la rotacion y se reduce el numerode niveles de 256 a 36.
Texture Unit / Simplified Texture Unit
Texture Unit (TU) modifica la idea subyacente a LBP, de modo queanade un umbral δ que permitira hacer umbralizacion mas rica. Ası, paracada pixel de la ocho-vecindad, define la operacion
37

Deteccion visual de Humo
fTU (i, j) =
2 iff(i, j) > µ + δ
0 iff(i, j) < µ− δ
1 otherwise
donde µ es el valor del pixel central. Una vez umbralizada la imagen, losocho dıgitos ternarios se componen en un numero que variara en el rango[0..3560]. Para distintos valores de δ tendremos diferentes caracterizacionesde una misma textura. Las regiones con texturas poco marcadas seran ricaspara una valor pequeno de δ y pobres para un valor mayor. Las regiones conuna textura muy marcada o alto contraste seguiran teniendo cierta variedadincluso para valores grandes del umbral.
Figura 3.5: Ejemplo de transformacion TU con δ = 2. El valor final secompone de los digitos ternarios, segun la ordenacion que muestra la flecha.
Respecto a LBP, TU serıa mas robusta ante el ruido (para valores altosde delta) y algo mas sensible a los cambios de iluminacion. La informacionque implıcitamente porta TU acerca de los gradientes en el entorno de laimagen es mas rica, ya que usamos mas niveles de cuantizacion.
Una variante propuesta en [6] es la Simplified Texture Unit (STU). Estanueva transformada solo difiere de la anterior en que en lugar de considerarla ocho-vecindad de un pixel, considera solamente cuatro de los puntos ale-danos. Existen dos variantes STU-1 (en cruz) y STU-2 (en equis). Al reducirel numero de niveles a 81 (34), la caracterizacion mediante histogramas quesean estadısticamente consistentes requiere de regiones menores de la ima-gen. Un estudio comparativo [6] demuestra ademas que no pierde capacidadde discriminacion de manera apreciable respecto a la TU.
3.3.5. Metricas
Tan importante como el descriptor usado es la metrica escogida. Entreambos transforman el espacio de entrada en el espacio de salida, ese que hade coincidir con nuestras propias percepciones. En general la metrica suelepoder variar menos el resultado que el descriptor, pero describiremos unpar de ellas que marcan la diferencia cuando tratamos de medir similitud
38

Deteccion visual de Humo
Figura 3.6: Densidad y distribucion de probabilidad chi-cuadrado, para dis-tintos grados de libertad (k)
entre histogramas. Estas metricas son aplicables, pues, a los histogramasprocedentes de TU, STU y LBP.
χ2 Chi-square
Tambien conocido como test de Pearson, o test goodness of fit, contrastacomo hipotesis nula que una serie de muestras siguen una distribucion deprobabilidad dada.
χ2 =n∑
i=1
(Oi − Ei)2
Ei
Donde Oi es la frecuencia observada y Ei la frecuencia teorica usada comohipotesis nula. El valor obtenido se contrasta despues contra la distribucionχ2 de n-1 grados de libertad, que nos dara la probabilidad de que ambasdistribuciones sean la misma. Utilizamos n-1 grados de libertad porque todaslas frecuencias observadas estan ligadas entres sı, y obligadas a sumar unosegun la teorıa de la probabilidad.
Interseccion de histogramas
La interseccion de histogramas es un metodo estadıstico simple para com-parar histogramas. Mide el voulumen comun que comparten dos histogramas
d = 1−n∑
i=1
mın(Oi, Ei)
39

Deteccion visual de Humo
Figura 3.7: Imagen y su transformada ILBP. Notese la regularidad de ladistribucion de valores en la region donde hay humo.
Si los histogramas estan normalizados, d esta directamente acotado en elintervalo [0, 1].
3.3.6. Implementacion
El codigo del detector de textura se ha desarrollado en dos fases. En laprimera se construyeron algunas funciones en matlab para poder evaluarde manera comoda la adecuacion de cada metodo. Los metodos que se im-plementaron en matlab fueron los mas simples (frecuenciales puros y nolineales), ası como los espectrales. El estudio comparativo de las distintastecnicas, en esta primera fase consistio en baterias de pruebas cuyos resul-tados solo fueron comparados de manera subjetiva.
Los metodos que mejor se comportaron fueron los no lineales, que pasarona la segunda fase de implementacion. Los patrones asi extraidos presentabanuna buena estabilidad entre imagenes distintas, y necesitaban poco entre-namiento.
En la segunda fase, los metodos propuestos se reescribieron en c++, uti-lizando la librerıa OpenCV, y siguiendo una filosofıa multiplataforma.
3.3.7. Resultados
Como adelantamos anteriormente los metodos que mejor funcionaron enel caso de la deteccion de humo fueron STU y LBP, obteniendose los resul-tados optimos al utizar LBP irrotacional con una metrica de interseccionde histogramas. En general utilizando estos metodos era visible cierta ho-mogeneidad en la distribucion de los pıxels correspondientes a una mismatextura, como puede observarse en la figura 3.3.7.
40

Deteccion visual de Humo
Figura 3.8: Distintos pasos del proceso de deteccion de textura. De izquierdaa derecha, y de arriba a abajo, imagen original, tranformada ILBP, diferenciade histogramas respecto al patron y resultado superpuesto
Se llevaron a cabo pruebas de clasificacion. En dichas pruebas se utilizabaun unico patron, extraido de una de las imagenes, y se buscaba en el restode imagenes utilizando un criterio de distancia normalizado. Los patronesmas estables entre imagenes corresponden con LBP-I. Una salida tıpica deldetector de textura se muestra en la figura 3.9
41

Deteccion visual de Humo
Figura 3.9: Salida del detector de textura.
42

Capıtulo 4
Fusion de detectores
El estimador de estado es una parte fundamental del metodo expuesto.Hasta ahora hemos mostrado los tres detectores base. La salida de cada unode ellos es una variable que toma valores en el rango (0,1) para cada puntode la imagen. Ahora expondremos el modelo que nos permite fusionar lainformacion de dichas variables para obtener una estimacion mas robustadel estado.
En este capıtulo desarrollaremos los metodos expuestos en [3]. A partirde los conceptos relacionados con la estimacion bayesiana de estado (veaseel capıtulo 2), se extraeran las ecuaciones concretas que definen dicha esti-macion en el escenario que se expone a continuacion.
Como hemos mencionado, el paso final de fusion genera una estimaciondel estado para cada punto de la imagen, estimacion que se almacena en unarejilla o grid. El modelo que se expone a continuacion es el que correspondea cada uno de los puntos de la rejilla de salida.
4.1. Derivacion de las ecuaciones
Las observaciones en un instante dado zt estaran constituidas por lassalidas de los detectores base. La salida de dichos detectores se considerabinaria, y sera por lo tanto sometida a un proceso de binarizacion con um-brales θi antes de ser procesada por el filtro. De este modo, para el caso detres detectores tendrıamos que
zt ={z0t , z1
t , z2t
}, zi
t ⊂ {0, 1}
43

Deteccion visual de Humo
La variable de estado xt solo podra tomar dos estados, a saber: humo yno humo. Denotaremos dichos estados por H y H respectivamente para noinducir a confusion, de modo que
xt ⊂ {H, H}
La funcion de probabilidad de observacion asociada a un estado se mo-delara como una variable compuesta de Bernoulli. Para un estado dado, seconsidera que las salidas de los detectores son estadısticamente independien-tes, y que su relacion con el estado toma la forma de una distribucion deBernoulli. Ası podemos escribir que
p(zt | xt) =∏∀i
p(zit | xt) (4.1)
p(zit = 1 | xt = H) = 1− pi
FN
p(zit = 0 | xt = H) = pi
FN
p(zit = 1 | xt = H) = pi
FP
p(zit = 0 | xt = H) = 1− pi
FP
Donde piFP y pi
FN se corresponden intuitivamente con la probabilidad defalso positivo y falso negativo asociadas al detector i-esimo. Dichas probabi-lidades no son sino el parametro unico de la ya mencionada distribucion deBernoulli. Estas probabilidades tienen un claro significado fısico: la proba-bilidad de falso negativo de un detector es la probabilidad de que, habiendohumo, no lo detecte; la de falso positivo no es sino la probabilidad de falsaalarma.
Para caracterizar la generacion del estado, consideramos un modelo lineal,como se muestra en la figura 4.1. Si denotamos por p(xt = j) la probabilidadde que el sistema se encuentre en el estado j en un instante determinado,podemos escribir la ecuaciones correspondientes a un modelo de Markov deprimer orden de M estados de manera generica como
p(xt) = A× p(xt−1) A =
a11 · · · a1M... aij
...aM1 · · · aMM
p(xt = i | xt−1 = j) = aij (4.2)
donde aij es la probabilidad de transicion desde el estado j al estado i.En el problema actual no se consideran actuaciones, de modo que el estado
44

Deteccion visual de Humo
Figura 4.1: Modelo oculto de Markov de primer orden utilizado para estimarel estado, junto con las distribuciones que definen la probabiliad de observa-cion asociada a cada estado. El modelo de generacion sera lineal, utilizandoconstantes como probabilidades de transicion.
sera independiente de la actuacion: p(xt | xt−1, ut) = p(xt | xt−1). Si retoma-mos las ecuaciones (2.3), (2.4), y anadimos las caracterizaciones expuestaspara la probabilidad de observacion (4.1) y la probabilidad de cambio deestado (4.2) obtenemos
bel(xt = k) = η
[∏∀i
p(zit | xt−1 = k)
] ∑∀j
akjbel(xt−1 = j) (4.3)
donde η sigue siendo un factor de normalizacion tal que∑∀j bel(xt = j).
Pensando por un momento en nuestro modelo de dos estados, podemos hacerque la probabilidad terminal de permanencia en xt = H sea mayor que laprobabilidad de permanencia en xt = H, teniendo de ese modo un detectormas cauto o conservador, que refleje menos falsos positivos. Si miramos elestimador de estado como un filtro temporal, las probabilidades de transicionestan directamente relacionadas con las constantes de tiempo de la dinamicadel estado.
45

Deteccion visual de Humo
46

Capıtulo 5
Validacion
5.1. Introduccion
En este capıtulo se expondran las consideraciones tenidas en cuenta yherramientas utilizadas para validar la aplicacion. Esta seccion es necesariapara obtener una caracterizacion adecuada de los algoritmos utilizados, y deella se desprenden resultados que se mostraran en el capıtulo 6.
5.2. Editor de mascaras
Uno de los requisitos necesarios para poder probar la bondad de un de-tector o un segmentador es disponer de segmentaciones de referencia. Estassegmentaciones de referencia pueden ser obtenidas manualmente, o de unmodo automatico ( por consenso de segmentadores, etc). Dado que solodisponemos de un segmentador, la segmentacion de referencia habıa de serforzosamente humana. Dada la amplitud del corpus de prueba ( aproxima-damente 2500 imagenes ), la creacion estrictamente artesanal de mascarasse presentaba como una tarea ardua y esteril, de modo que se aposto por eldesarrollo de una herramienta que facilitase la tarea.
Dicha herramienta se ha denominado MaskEditor. Su funcionalidad basi-ca es la de permitir cargar secuencias de imagenes, que serviran como telonde fondo para dibujar polıgonos en distintas capas, que evolucionaran a lolargo del tiempo.
La herramienta esta desarrollada en Qt de modo que es inherentementemultiplataforma, y esta probadabajo Linux. Las mascaras necesarias paraobtener resultados experimentales se crearon finalmente con ella.
47
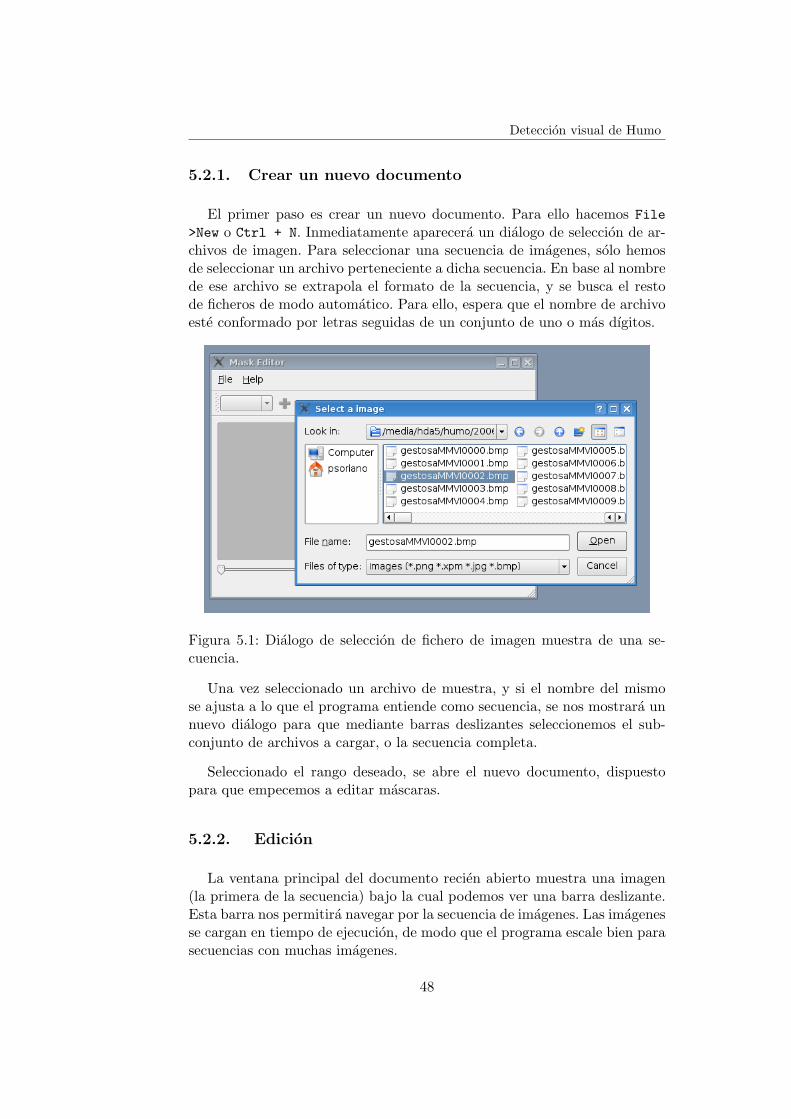
Deteccion visual de Humo
5.2.1. Crear un nuevo documento
El primer paso es crear un nuevo documento. Para ello hacemos File>New o Ctrl + N. Inmediatamente aparecera un dialogo de seleccion de ar-chivos de imagen. Para seleccionar una secuencia de imagenes, solo hemosde seleccionar un archivo perteneciente a dicha secuencia. En base al nombrede ese archivo se extrapola el formato de la secuencia, y se busca el restode ficheros de modo automatico. Para ello, espera que el nombre de archivoeste conformado por letras seguidas de un conjunto de uno o mas dıgitos.
Figura 5.1: Dialogo de seleccion de fichero de imagen muestra de una se-cuencia.
Una vez seleccionado un archivo de muestra, y si el nombre del mismose ajusta a lo que el programa entiende como secuencia, se nos mostrara unnuevo dialogo para que mediante barras deslizantes seleccionemos el sub-conjunto de archivos a cargar, o la secuencia completa.
Seleccionado el rango deseado, se abre el nuevo documento, dispuestopara que empecemos a editar mascaras.
5.2.2. Edicion
La ventana principal del documento recien abierto muestra una imagen(la primera de la secuencia) bajo la cual podemos ver una barra deslizante.Esta barra nos permitira navegar por la secuencia de imagenes. Las imagenesse cargan en tiempo de ejecucion, de modo que el programa escale bien parasecuencias con muchas imagenes.
48

Deteccion visual de Humo
Figura 5.2: Selector de rango de secuencia. En el ejemplo, escogemos lasimagenes de la 22 a la 62.
Capas
Para empezar a definir las mascaras, introducimos el concepto de capa.Una capa se extiende a lo largo de toda la duracion de la secuencia, y con-tiene un unico polıgono. Si llamamos configuracion de un polıgono al lasposiciones de sus vertices en un momento dado, podemos decir que una ca-pa esta compuesta de una lista ordenada de estas configuraciones. La listapuede contener una o mas configuraciones, y su tamano es independiente dela longitud de la secuencia. Cada configuracion esta asociada a un ındice,que la ubica temporalmente en un instante dado de la secuencia. Ası, hayinstantes en la secuencia que tienen asociada una configuracion, e instantesque no (la mayorıa). La posicion de los vertices del polıgono se obtiene paraestos ultimos por interpolacion, de modo que con solo definir la posicion delos vertices de la mascara para unas cuantas imagenes de la secuencia obten-dremos una aproximacion arbitrariamente buena de la region a delimitar.
Figura 5.3: Cada capa contiene una lista enlazada de configuraciones delpolıgono, cada una con un ındice temporal asociado.
49

Deteccion visual de Humo
Figura 5.4: En el momento de creacion de la capa definimos la primeraconfiguracion de su polıgono asociado
Nueva capa
Para anadir y empezar a editar una capa, solo necesitamos colocarnos enel instante el cual queramos que sea el inicial, y pulsar el boton de anadircapa (una cruz verde). En ese mismo instante entramos en modo de creacionde capa, de modo que con cada pulsacion del boton izquierdo del raton sobrela imagen anadimos un nuevo vertice al polıgono de esa capa. Para finalizarla creacion, pulsamos el boton derecho del raton.
La lista de seleccion de capas muestra el nombre de la capa recien crea-da. En caso de existir varias capas, la que aparezca seleccionada en estalista sera la capa de trabajo actual. Mas adelante veremos como podremosanadir nuevas configuraciones (o dicho de otro modo modificar los verticesdel polıgono) de la capa de trabajo.
Moviendo vertices
Si movemos la barra de desplazamiento temporal veremos que el polıgonorecien creado es el mismo para toda la secuencia. Para definir nuevas con-figuraciones de un polıgono, que sean validas para un intante dado, solo esnecesario desplazarse utilizando la barra hasta el momento escogido y unavez alli desplazar los vertices.
50

Deteccion visual de Humo
Figura 5.5: A partir de dos configuraciones del polıgono (izquierda y derecha)se interpola para los instantes intermedios (centro).
El cambio, en forma de adicion de una nueva configuracion a la capa detrabajo, se hace efectivo sin mas que volver a desplazarnos usando la ba-rra temporal. Ahora, cuando naveguemos por instantes comprendidos entreambas configuraciones, el polıgono se obtendra como interpolacion lineal,facilitando la tarea de demarcar objetos moviles o con cambios de forma.
5.2.3. Generacion de mascaras
Las capas se pueden exportar posteriormente como secuencia de image-nes numeradas en blanco y negro, aptas para su utilizacion desde cualquierentorno. A traves de File>Generate o usando Ctrl + G, accedemos a undialogo de seleccion de carpetas, para escoger el lugar donde deseamos guar-dar las mascaras. Las regiones internas de los polıgonos se pintaran de blan-co, y el resto de negro. Un ejemplo de las mascaras generadas para la figura5.5 se muestra en la figura 5.6
Figura 5.6: Ejemplos de mascaras generadas usando MaskEditor.
51

Deteccion visual de Humo
5.3. Banco de pruebas
Los vıdeos de los que se extrajeron las imagenes que constituyen el bancode pruebas proceden de una serie de incendios controlados llevados a cabo enGestosa (cerca de Coimbra, Portugal) en el ano 2006. Son un resultado cola-teral de los experimentos realizados dentro del proyecto INFLAME, “FireBehaviour Prediction Modelling and Testing” (ENV4-CT98.0700), financia-do por la Comision Europea. en el IV Programa Marco (Environment andClimate). El proyecto esta dedicado a la investigacion en incendios forestalesincluyendo metodos de adquisicion de informacion, modelado, y soporte ala extincion.
Los videos, que transcurren en su totalidad en entornos naturales, fueroncaptados bajo diferentes condiciones de iluminacion (a distintas horas deldia), refieren a distintos fuegos y fueron tomados desde distintas ubicaciones.La grabacion esta realizada en formato DV (720x576@25fps).
El banco de pruebas utilizado consiste en 22 secuencias de 125 imagenescada una. Las imagenes se obtuvieron a una tasa de 1Hz a partir de losvideos. La baja tasa de imagenes se escogio antes de tener estimaciones deltiempo de proceso, teniendo en mente que aun en el peor de los casos eltiempo de proceso estarıa por debajo del segundo. A posteriori, con tiem-pos de ejecucion en torno a los 100ms, se hizo patente que podrıa haberseescogido una tasa mayor.
Figura 5.7: Izquierda: fotografıa aerea de Gestosa (Portugal) donde se apre-cian las parcelas quemadas en diferentes experimentos. Derecha: fotografıade la estacion frontal tomada en unos experimentos en mayo de 2006.
52

Capıtulo 6
Resultados
6.1. Introduccion
En este capıtulo presentaremos de manera cuantitativa los resultadosobtenidos, utilizando la sergmentacion asistida y los bancos de pruebas des-critos en el capıtulo 5
6.2. Parametros optimos
Gracias a la segmentacion de referencia es inmediato obtener el valoroptimo de la gran mayorıa de los parametros que configuran el segmentadorde humo, a saber:
La probabilidad de observacion asociada al estado, respresentada porpi
FP , piFP∀i
El umbral optimo de binarizacion θi∗ para cada detector base.
Las probabilidades de transicion aij del modelo de Markov
Para obtener una estimacion de la probabilidad de observacion asociadaal estado, solo es necesario comparar la salida binarizada de cada detectorbase con la mascara de referencia. La probabilidad de falso positivo, pi
FP ,es la fraccion de puntos que, perteneciendo al fondo, son clasificados comohumo por el i-esimo detector base. La probabilidad de falso negativo, pi
FN ,es la fraccion de puntos que, perteneciendo al humo, son clasificados comofondo por el i-esimo detector base. Estas probabilidades son dependientes del
53

Deteccion visual de Humo
umbral de binarizacion, de modo que se realizaron mediciones para veintevalores del mismo. Al estar comprendida la salida de los detectores en [0, 1],se escogen concretamente los valores θi
k = (2 + k)/22, k ⊂ {0 · · · 19}. Deeste modo tendremos una caracterizacion lo bastante rica de cada detector.Es sencillo observar que los extremos del rango carecen de relevancia, ya queun umbral de cero o uno eliminarıa toda la informacion.
El siguiente paso es escoger un umbral optimo, segun algun criterio. Paraello tratamos de establecer una funcion de coste. Por el mero significado depi
FP , piFN , dicha funcion de coste a minimizar ha de cumplir las siguientes
relaciones:
piFP ↑=⇒ J(·) ↑
piFN ↑=⇒ J(·) ↑
(1− piFP )/pi
FN ↑=⇒ J(·) ↓(1− pi
FN )/piFP ↑=⇒ J(·) ↓
Las ultimas dos ecuaciones proviene del tipo de reestimacion que seesta llevando a cabo: cuanta mayor sea la diferencia entre las probabilidadesde observar zi
t en cada uno de los dos estados, mas discernibles seran estosdada una observacion. Una funcion de coste que cumple dichas relacionesviene dada por
J(piFP , pi
FN ) =(1− α)1− pi
FN
+α
1− piFP
α ⊂ (0, 1) (6.1)
Donde α es un parametro en el rango que nos permite priorizar el com-promiso entre una baja probabilidad de falso positivo ( que darıa lugar a undetector conservador, α� 0,5) y una baja probabilidad de falso negativo (que fomentarıa un comportamiento mas alarmista α� 0,5).
54

Deteccion visual de Humo
6.3. Experimento 1
El primer experimento se llevo a cabo utilizando los patrones existentespara el detector de color y de textura. Dichos patrones eran fruto de unentrenamiento que involucraba un numero reducido de imagenes segmen-tadas de modo manual. Los parametros optimos obtenidos se muestran acontinuacion.
Detector θ∗ p∗FP p∗FN
Texture 0.13636 0.021337 0.65507Color 0.63636 0.12562 0.74906
Motion 0.45455 0.13974 0.56464
Utilizando este juego de parametros, realizamos la fusion de detectores.En la tabla siguiente se muestran algunos valores que caracterizan el seg-mentador final
umbral pFP (1− pFN )0.045 4.2% 40 %0.36 1.6% 30 %
Cuadro 6.1: Parametros optimos para la fusion en el primer experimento.
Es normal que la probabilidad de falso negativo sea bastante elevada, da-do que la validacion se ha llevado a cabo utilizando la segmentacion asistida,y el entrenamiento se llevo a cabo con una segmentacion manual sensible-mente mas conservadora. Es decir, las regiones marcadas como humo en lasegmentacion manual son deliberadamente de menor area que las que poste-riormente se marcaron de manera asistida; al ser mas pesada la generacionmanual de mascaras, el cuerpo de entrenamiento es menor, y ha de ser masconservador. Ası, solo se marcaron como humo regiones lo suficientementeinternas a la columna, despreciando las estelas.
55

Deteccion visual de Humo
Figura 6.1: Experimento 1: probabilidades de falso positivo y falso negativopara el detector de color del primer experimento. El estrechamiento entre(1− pFN ) y pFP sugiere un reentrenamiento.
Figura 6.2: Experimento 1: probabilidades de falso positivo y falso negativopara el detector de movimiento del primer experimento.
Figura 6.3: Experimento 1: probabilidades de falso positivo y falso negativopara el detector de textura del primer experimento.
56

Deteccion visual de Humo
Figura 6.4: Probabilidades de falso positivo y falso negativo para el detectorde humo, una vez fusionados los detectores base, en el primer experimento.
57

Deteccion visual de Humo
6.4. Experimento 2
Para el segundo experimento se reentreno el detector de color utilizandocomo corpus de entrenamiento el 3 % del corpus de prueba. El detector detextura se deja inalterado. Los parametros optimos escogidos para el nuevodetector de color se muestran a continuacion
Detector θ∗ p∗FP p∗FN
Colorexp01 0.63636 0.12562 0.74906Colorexp02 0.63636 0.13849 0.67188
Vemos que, a pesar de que el umbral optimo es el mismo, la proababilidadde falso negativo disminuye mas de lo que aumenta la de falso positivo (-8%y +1 % respectivamente). Para estos parametros optimos, la fusion de datosnos muestra los siguientes resultados
umbral pFP (1− pFN )0.136 21.2% 60 %0.4545 8.62% 50 %0.818 4.91% 40 %
Cuadro 6.2: Resultado de la fusion para el segundo experimento.
La mejora afecta sensiblemente a la probabilidad de falso negativo, comoera de esperar. Ahora podemos alcanzar probabilidades de falso negativomenores.
58

Deteccion visual de Humo
Figura 6.5: Probabilidades de falso positivo y falso negativo para el detectorde color, una vez reentrenado como se indica en la descripcion del segundoexperimento. El optimo se mantiene muy cercano al anterior, aunque mejorala probabilidad de falso negativo en tanto que empeora la de falso positivo.
Figura 6.6: Probabilidades de falso positivo y falso negativo para el detectorde humo, una vez fusionados los detectores base, en el segundo experimento.
59

Deteccion visual de Humo
6.5. Experimento 3
En el tercer experimento se reentreno el detector de textura usando unconjunto de entrenamiento del 30%. La probabilidad de falso negativo dis-minuye de nuevo, pero manteniendo a su vez una baja probabilidad de falsopositivo. Los parametros optimos para la nueva configuracion son los mos-trados a continuacion:
Detector θ∗ p∗FP p∗FN
Textureexp03 0.31818 0.049873 0.47794Colorexp02 0.63636 0.13849 0.67188
Motion 0.45455 0.13974 0.56464
Con ellos se calcula la salida fusionada, obteniendo
umbral pFN (1− pFP )0.273 9.52% 70 %0.909 4.17% 60 %
Cuadro 6.3: Resultado de la fusion para el experimento 03.
Los resultados obtenidos son muy alentadores. El ultimo experimentomuestra cotas de un 4 % en area de falsos positivos, con un 40 % en area defalsos negativos. Es de resenar que la mayor parte de los falsos negativos seconcentran en partes alejadas del nucleo del humo, en partes poco densasde la estela. La separacion entre las curvas de pFP y (1− pFN ) de la figura6.5 muestran que el detector obtenido esta fuertemente correlado con lafuente a detectar. Si utilizasemos un proceso aleatorio como segmentadorde humo, ambas lineas coincidirıan. Si el detector fuese perfecto, estarıancompletamente separadas.
60

Deteccion visual de Humo
Figura 6.7: Probabilidades de falso positivo y falso negativo para el detectorde textura, una vez reentrenado como se indica en la descripcion del tercerexperimento. La principal mejora se consigue respecto al falso negativo, dadolo laxo de las mascaras utilizadas.
Figura 6.8: Probabilidades de falso positivo y falso negativo para el detectorde humo, una vez fusionados los detectores base, en el tercer experimento.
61

Deteccion visual de Humo
62

Capıtulo 7
Conclusiones
Se ha demostrado la potencialidad de un enfoque que implica la fusion deinformacion desde diversas fuentes en el ambito de reconocimiento del humo.Utilizando un conjunto de detectores sencillos y poco fiables se obtiene unamejora sustancial de las prestaciones, cuando se integran en un entornoprobabilistico usando parametros adecuadamente ajustados.
Es de resenar que el objetivo se puede sesgar hacia una menor probabi-lidad de falso positivo sin mas que definir unas mascaras de entrenamientomenos permisivas. En ese caso, el reentrenamiento llevarıa a una menor pro-babilidad de falsa alarma, manteniendo una buena capacidad de deteccion.Por descontado, se han mostrado los resultados sin postprocesado alguno;una simple operacion de erosion eliminarıa la mayor parte de las falsas alar-mas, mejorando la efectividad. Dado que el utilizar un postproceso para se-leccionar regiones atendiendo a caracterısticas de forma, tamano, etcetera,es algo que no tiene relacion alguna con la aproximacion que se ha expuesto,no resulta procedente exponer aquı su efecto sobre los resultados.
La opcion de construir detector de elevada fiabilidad de cara a la deteccionvisual automatica de humo esta al alcance de la mano, y no diferirıa enmucho de mostrado hasta ahora. Se realizarıan cambios en los detectoresbase, mejorando los existentes y anadiendo otros ya en estudio.
63

Deteccion visual de Humo
64

Apendice A
Notacion y EstadısticaBasica
En primer lugar daremos un repaso rapido a los conceptos basicos de pro-babilidad, exponiendo al mismo tiempo la notacion que se usara en adelante.Sea X una variable aleatoria, denotaremos por
P (X = x)
a la probabilidad de que X tome el valor x tras realizar un experimento.X es una variable discreta, como por ejemplo el lanzamiento de un dado.Segun Kolmogorov, por definicion la salida siempre pertenecera al universode salida, de modo que ∑
∀iP (X = xi) = 1
Tambien por definicion la probabilidad de un evento dado es siempreno negativa. En los sucesivo se obviara la mencion a la variable aleatoriasiempre que sea posible, usando la notacion mas compacta P (x) en vez deP (X = x).
Cuando los posibles valores de salida de la variable aleatoria son contınuos,esta viene definida por su funcion densidad de probabilidad ( pdf, probabi-lity density function ). La probabilidad individual de cada evento es nula,dado que existe un continuo de ellos y la probabilidad total suma a uno. Eneste caso tenemos que ∫
p(x) = 1
P (X < x) =∫ x
p(z)dz
65

Deteccion visual de Humo
Un ejemplo de pdf serıa una gaussiana. Como podemos inferir de las ecuacio-nes anteriores, el valor de una pdf dada no esta acotado en ningun momento.De hecho una distribucion discreta puede representarse como una pdf de laforma
p(x) =∑∀i
δ(xi)P (xi)
donde δ es una delta de Dirac centrada en xi. Aunque parezca laxo, en ade-lante se utilizara la misma notacion p(x) para los terminos probabilidad,densidad de probabilidad y funcion densidad de probabilidad. Dichos termi-nos siempre seran discernibles segun el contexto. La probabilidad conjuntade dos variables aleatorias X e Y se define como la probabilidad de que Xtome el valor x e Y tome el valor y. Se expresa como
p(x, y) = p(X = x, Y = y)
Se dice que dos variables son independientes cuando la probabilidad conjuntaes el producto de las probabilidades individuales.
p(x, y) = p(x)p(y)
En ocasiones dos variables aleatorias estan relacionadas, de manera que cadauna lleva parte de la informacion de la otra. La probabilidad de que X valgax dado que Y 4 vale y se denomina probabilidad condicional y se expresacomo
p(x|y) = p(X = x|Y = y)
p(x|y) =p(x, y)p(y)
La segunda expresion solo esta justificada si p(y) > 0 . Es inmediato com-probar que para variables independientes p(x|y) = p(x). En este caso tenerconocimiento sobre y no ayuda en absoluto a obtener informacion acerca dex, concepto que se demostrara muy util cuando hablemos de procesos deMarkov.
De la definicion de probabilidad condicional se extraen dos importantesextensiones: el teorema de la probabilidad total y el teorema de Bayes. Elteorema de la probabilidad total se expresa como
p(x) =∑∀y
p(x|y)p(y)
p(x) =∫
p(x|y)p(y)dy
66

Deteccion visual de Humo
para el caso discreto y contınuo respectivamente. Si p(y) o p(x|y) valiesencero, consideraremos que p(x) es cero, independientemente del valor de laotra variable. Mas importante aun es el teorema de Bayes, que relaciona lasprobabilidades condicionales p(x|y) y p(y|x)
p(y|x) =p(y|x)p(x)
p(y)=
p(y|x)p(x)∑∀z p(y)p(y|z)
p(y|x) =p(y|x)p(x)
p(y)=
p(y|x)p(x)∫p(y)p(y|z)dz
Es de resenar que los denominadores son independientes del valor de x, demodo que el factor 1/p(y) puede escribirse como un valor de normalizacionη, que sera identico para todos los valores de x en la probabilidad a posteriorip(x|y).
Para acabar senalaremos que es completamente valido condicionar cual-quiera de estas leyes a otras variables aleatorias, digamos, por ejemplo, aZ = z . Asi, tenemos que
p(x|y, z) =p(y|x, z)p(x|z)
p(y|z)
Condicionando la regla para variables independientes obtenemos la lla-mada independencia condicional:
p(x, y|z) = p(x|z)p(y|z)
La independencia condicional implica que una variable Y no aporta in-formacion acerca de una variable X cuando un tercera variable Z toma elvalor Z = z.. Tambien puede escribirse como
p(x|z) = p(x|z, y)p(y|z) = p(y|z, x)
La independencia condicional no implica independencia absoluta, ni vice-versa.
67

Deteccion visual de Humo
68

Bibliografıa
[1] J. Capitan y D. Mantecon, P. Soriano, A. Ollero. “Autonomous per-ception techniques for urban and industrial fire scenarios”. Proceedingsof the IEEE International Workshop on Safety, Security and RescueRobotics. Septiembre 2007. Rome, Italy
[2] S. Thrun, W. Burgard, and D. Fox. “Probabilistic Robotics”. MITPress, Cambridge, MA, 2005.http://www.probabilistic-robotics.org/
[3] L. Merino, F. Caballero, J. R. Martinez, J. Ferruz, and A. Ollero.“A cooperative perception system for multiple UAVs: Application toautomatic detection of forest fires”, Journal of Field Robotics, 2006,23(3):165-184.
[4] T. Ojala, M. Pietikainen, and D. Harwood. “A comparative study oftexture measures with classification based on feature distribution”, Pat-tern Recognition, 1996, 22(1):51-59.
[5] Timo Ojala, Matti Pietikainen, “Unsupervised texture segmentationusing feature distributions”, Pattern Recognition 32 , pag 477/486,1999.
[6] F. Madrid-Cuevas, R. Medina, M. Prieto, “Pattern Recognition andImage Analysis”, chapter 7: ”Simplified Texture Unit: A New Descriptorof the Local Texture in Gray-Level Images”, ISBN 978-3-540-40217-6,2003
[7] Yossi Rubner, Carlo Tomasi. “Texture Metrics”. Proceeding of theIEEE InternationalConference on Systems, Man, and Cybernetics, San-Diego, CA, October 1998, pages 4601-4607
[8] Khazenie, N.; Lee, T.F., “Identification Of Aerosol Features Such AsSmoke And Dust, In NOAA-AVHRR Data Using Spatial Textures,”Geoscience and Remote Sensing Symposium, 1992. IGARSS ’92. Inter-national , vol., no., pp.726-730, 26-29 May 1992
69

Deteccion visual de Humo
[9] E. Breejen, M.Breuers, F.Cremer “Autonomous forest fire detection”
[10] Armando M. Fernandes, Andrei B. Utkin, Alexander V. Lavrov, RuiM. Vilar “Design of committee machines for classification of single-wavelength lidar signals applied to early forest fire detection”
[11] Won-Ha Kim, Christopher Brislawn, “Plume detection and tracking viavideo data”, , Los Alamos National Laboratory,1999.
[12] Din-Chang Tseng, Wern-Shengshieh, “Plume extraction using entropicthresholding and region growing”
70