detección de intrusión en redes de computación en la nube
TRANSCRIPT

Detección de intrusión en redes de
computación en la nube mediante
métodos de clustering
Marcio Alexander Abreu Cano
Universidad Nacional de Colombia
Facultad de Ingeniería, Departamento de ingeniería de Sistemas e Industrial
Bogotá D.C, Colombia
2019


Detección de intrusión en redes de
computación en la nube mediante
métodos de clustering
Marcio Alexander Abreu Cano
Tesis presentada como requisito parcial para optar al título de:
Magíster en Ingeniería - Telecomunicaciones
Director (a):
MSc Jesús Guillermo Tovar Rache
Línea de Investigación:
Redes y Sistemas de Telecomunicaciones
Grupo de Investigación:
UNeTRT
Universidad Nacional de Colombia
Facultad de Ingeniería, Departamento de ingeniería de Sistemas e Industrial
Bogotá D.C, Colombia
2019




Resumen
En esta investigación, se explora el uso de métodos de clustering para el diseño de
sistemas de detección de intrusión (IDS) distribuidos capaces de funcionar en entornos de
computación en la nube. Para ello, se propone un algoritmo de detección de anomalías
basado en clustering y técnicas de aprendizaje supervisado, así como una arquitectura de
IDS modular que facilite el despliegue del sistema en entornos de procesamiento paralelo.
Finalmente, de desarrolla un entorno de pruebas basado en datasets públicos para medir
la efectividad del sistema, logando una tasa de detección de 99.9937% y una tasa de falsos
positivos de 0.0345% con el dataset de prueba seleccionado, lo que demuestra la
efectividad del sistema logrado. Además, se realiza un análisis de la capacidad de
procesamiento paralelo con el esquema propuesto, permitiendo extrapolar el desempeño
del sistema a entornos con diferentes capacidades de cómputo, lo que conlleva a una serie
de recomendaciones para la implementación de sistema en entornos de producción.
Palabras clave: IDS, cloud, clustering, supervised learning

Abstract
In this research, the use of clustering methods for the design of distributed intrusion
detection systems (IDS) capable of operating in cloud computing environments is explored.
For this purpose, an anomaly detection algorithm based on clustering and supervised
learning techniques is proposed, as well as a modular IDS architecture that facilitates the
deployment of the system in parallel processing environments. Finally, a test environment
based on public datasets to measure the effectiveness of the system is developed,
achieving a detection rate of 99.9937% and a false positive rate of 0.0345% with the
selected test dataset, which demonstrates the effectiveness of the system. In addition, an
analysis of the parallel processing capacity with the proposed scheme is shown, allowing
extrapolation of the performance of the system to environments with different computing
capacities, which leads to a series of recommendations for the implementation of the
system in production environments.
Keywords: IDS, cloud, clustering, supervised learning

Contenido
1. SEGURIDAD EN REDES DE COMPUTACIÓN EN LA NUBE ..................................................................... 2
1.1 REDES DEFINIDAS POR SOFTWARE ........................................................................................................... 2 1.2 ENRUTAMIENTO Y CONTROL DE CONGESTIÓN ............................................................................................ 4 1.3 ENRUTAMIENTO EN REDES DINÁMICAS Y DISTRIBUIDAS ................................................................................ 5
1.3.1 OSPF y BGP .......................................................................................................................... 6 1.3.2 Protocolo DCTCP .................................................................................................................. 7
1.4 GESTIÓN DE IDENTIDAD Y ACCESO ........................................................................................................... 7 1.4.1 Autenticación basada en contraseñas ................................................................................... 9 1.4.2 Single Sign-On y autenticación basada en Tokens................................................................ 10
1.5 VULNERABILIDADES .......................................................................................................................... 12 1.5.1 Denial of Service (DoS). ....................................................................................................... 13 1.5.2 Malware Injection. ............................................................................................................. 15 1.5.3 Side Channel....................................................................................................................... 16
2. SISTEMAS DE DETECCIÓN DE INTRUSIÓN ........................................................................................ 19
2.1 IDS DESPLEGADOS EN RED .................................................................................................................. 20 2.2 IDS EN HOSTS ................................................................................................................................. 21 2.3 IDS DISTRIBUIDO ............................................................................................................................. 22 2.4 SISTEMAS BASADOS EN VMM / CONTROLADOR / HYPERVISOR: .................................................................. 23 2.5 MÉTODOS DE DETECCIÓN ................................................................................................................... 26
2.5.1 Clasificadores de patrones .................................................................................................. 26 2.5.2 Sistemas basados en anomalías .......................................................................................... 27
2.6 IDS EN ENTORNOS DINÁMICOS ............................................................................................................ 28 2.6.1 Migración de máquinas virtuales ........................................................................................ 28 2.6.2 Proceso de migración de máquinas virtuales ....................................................................... 29 2.6.3 Tipos de migración ............................................................................................................. 31 2.6.4 Riesgos de seguridad asociados a la migración ................................................................... 32
3. CLUSTERING .................................................................................................................................... 33
3.1 MÉTODOS DE CLUSTERING JERÁRQUICOS ................................................................................................ 34 3.2 MÉTODOS DE PARTICIÓN.................................................................................................................... 35
3.2.1 K-means ............................................................................................................................. 35 3.2.2 Affinity propagation ........................................................................................................... 36
3.3 SPECTRAL CLUSTERING....................................................................................................................... 37 3.4 CLUSTERING PARA DETECCIÓN DE INTRUSIÓN .......................................................................................... 38
4. DESARROLLO DEL MODELO DE DETECCIÓN DE INTRUSIÓN ............................................................. 40
4.1 FORMACIÓN DE CLÚSTERES ................................................................................................................. 41 4.2 PROCESADOR DE TRÁFICO................................................................................................................... 42 4.3 ASIGNACIÓN DE CLÚSTERS .................................................................................................................. 42 4.4 CLASIFICACIÓN ................................................................................................................................ 42 4.5 AGREGACIÓN .................................................................................................................................. 44
5. METODOLOGÍA DE EVALUACIÓN ..................................................................................................... 45
5.1 MÉTRICAS DE EVALUACIÓN ................................................................................................................. 45

5.1.1 Matriz de confusión ............................................................................................................ 46 5.2 ESCENARIO DE PRUEBAS ..................................................................................................................... 48
5.2.1 Almacenamiento ................................................................................................................ 50 5.2.2 Módulos de software .......................................................................................................... 50 5.2.3 Interfaz de control .............................................................................................................. 50 5.2.4 Datos.................................................................................................................................. 51
6. DESARROLLO DE UN PROTOTIPO DE IDS .......................................................................................... 56
6.1 ARQUITECTURA ................................................................................................................................ 56 6.2 ENTRENAMIENTO ............................................................................................................................. 60
6.2.1 Preprocesamiento y reducción de características ................................................................. 60 6.3 FORMACIÓN DE CLÚSTERES ................................................................................................................. 62
7. EVALUACIÓN DEL MODELO DE DETECCIÓN...................................................................................... 66
8. CONCLUSIONES Y RECOMENDACIONES ........................................................................................... 85
8.1 CONCLUSIONES ................................................................................................................................ 85 8.2 RECOMENDACIONES .......................................................................................................................... 86

Lista de figuras
Figura 1- Red definida por software ...................................................................................4
Figura 2- Enrutamiento ......................................................................................................5
Figura 3- PAP ....................................................................................................................9
Figura 4- CHAP ...............................................................................................................10
Figura 5- SAML ...............................................................................................................11
Figura 6 - Oauth ..............................................................................................................12
Figura 7 - DoS .................................................................................................................14
Figura 8- Side channel ....................................................................................................17
Figura 9 – Tipos de IDS ...................................................................................................25
Figura 10- Migración LAN Figura 11- Migración WAN ...............................31
Figura 12 Flujo de pruebas ..............................................................................................48
Figura 13 – Arquitectura de IDS ......................................................................................57
Figura 14 - Capa de IDS ..................................................................................................58
Figura 15 - matriz de correlación KDD cup 99 - 10% .......................................................61
Figura 16 - matriz de correlación kdd cup 99 - 10%, eliminando variables altamente
correlacionadas. ..............................................................................................................62
Figura 17 - Distribución de etiquetas de entrenamiento; Capa 1......................................63
Figura 18 – Distribución de etiquetas de entrenamiento; Capa 2 .....................................63
Figura 19 – Distribución de etiquetas de entrenamiento; Capa 3 .....................................63
Figura 20 - Distribución de etiquetas de entrenamiento; Capa 4......................................64
Figura 21 - Distribución de etiquetas de entrenamiento; Capa 5......................................64
Figura 22 - Uso de CPU (todos los núcleos) ....................................................................67
Figura 23 - Uso de memoria RAM ...................................................................................68

Figura 24 - Uso de CPU (1)............................................................................................. 69
Figura 25 - Uso de CPU (2)............................................................................................. 69
Figura 26 - Uso de CPU (3)............................................................................................. 69
Figura 27 - Uso de CPU (4)............................................................................................. 70
Figura 28 - Uso de CPU (5)............................................................................................. 70
Figura 29 - Uso de CPU (6)............................................................................................. 70
Figura 30 - Uso de CPU (7)............................................................................................. 71
Figura 31 - Uso de CPU (8)............................................................................................. 71
Figura 32 - Uso de CPU (9)............................................................................................. 71
Figura 33 - Uso de CPU (10) ........................................................................................... 72
Figura 34 - Uso de CPU (11) ........................................................................................... 72
Figura 35 - Uso de CPU (12) ........................................................................................... 72
Figura 36 - Uso de CPU (13) ........................................................................................... 73
Figura 37 - Uso de CPU (14) ........................................................................................... 73
Figura 38 - Uso de CPU (15) ........................................................................................... 73
Figura 39 - Uso de CPU (16) ........................................................................................... 74
Figura 40 - Tiempo de ejecución en paralelo .................................................................. 74
Figura 41 - Matriz de confusión, capa 1 .......................................................................... 75
Figura 42 - Matriz de confusión, capa 2 .......................................................................... 76
Figura 43 - Matriz de confusión, capa 3 .......................................................................... 76
Figura 44 - Matriz de confusión, capa 4 .......................................................................... 77
Figura 45 - Matriz de confusión, capa 5 .......................................................................... 77
Figura 46 - Matriz de confusión normalizada ................................................................... 78
Figura 47 - Matriz de confusión binaria; Capa 1 .............................................................. 78
Figura 48 - Matriz de confusión binaria; Capa 2 .............................................................. 79
Figura 49 - Matriz de confusión binaria; Capa 3 .............................................................. 79
Figura 50 - Matriz de confusión binaria; Capa 4 .............................................................. 80
Figura 51 - Matriz de confusión binaria; Capa 5 .............................................................. 80
Figura 52 - Matriz de confusión binaria ........................................................................... 81
Figura 53 - Matriz de confusión binaria, sin optimización ................................................ 81

Lista de tablas
Tabla 1 Medidas de distancia ..........................................................................................34
Tabla 2 - Métricas de evaluación .....................................................................................49
Tabla 3 Características básicas[78] .................................................................................52
Tabla 4 Características basadas en contenido[78] ..........................................................53
Tabla 5 Características basadas en tiempo[78] ...............................................................54
Tabla 6 Características basadas en tráfico[78] ................................................................55
Tabla 7 - Datos KDD cup 99 ............................................................................................67
Tabla 8 - Distribución de etiquetas ..................................................................................75
Tabla 9 – resultados KDD cup 99, 2 etiquetas .................................................................82
Tabla 10- Impacto del proceso de agregación .................................................................82
Tabla 11 - Comparativa con experimentos previos ..........................................................83


Introducción
La computación en la nube es una de las tecnologías de mayor crecimiento en la industria
de las tecnologías de la información y las comunicaciones, debido a la creciente necesidad
de contar con redes escalables y adaptativas ante necesidades particulares, pues este tipo
de sistemas aportan facilidad de uso, alta disponibilidad y en general, una mejor relación
costo-beneficio [1]. Por ello, cada vez más organizaciones optan por la migración de sus
sistemas de cómputo a éste nuevo paradigma [2].
Los IDS (sistemas de detección de intrusión) son sistemas computacionales que se
encargan del monitoreo y protección de una red mediante la aplicación de 4 funciones
principales: Recolección de información, selección de atributos, análisis y acción [3]. Estos
sistemas tienen su origen en la investigación con fines militares. Específicamente, en el
año 1972 la Fuerza Aérea de los Estados unidos comenzó a tratar el problema de la
seguridad en sus redes computacionales, al pretender compartir el uso de sus
computadores entre varios usuarios con diferentes privilegios de acceso [4].
En esta investigación, se explora el uso de algoritmos de clustering para la detección de
amenazas sobre redes elásticas y auto-escalables, mediante el desarrollo de una
arquitectura de IDS, que permita explotar las particularidades de este tipo de red para
lograr un sistema eficiente y escalable. Particularmente, se centra en caracterizar las
amenazas de seguridad comunes en las redes de computación en la nube, conduciendo
al desarrollo de un modelo enfocado a la detección de intrusión en este tipo de entornos,
tomando como base los desarrollos hechos en métodos de clustering para la clasificación
de datos. Para ello, se define un entorno de prueba basado en DARPA IDS dataset [18]
que permita medir la efectividad del modelo de detección desarrollado y se implementa un
prototipo del sistema propuesto.

1. Seguridad en redes de computación en la
nube
La computación en la nube es un paradigma de computación que permite la asignación de
recursos compartidos de procesamiento y almacenamiento según sean requeridos por un
determinado servicio. Esta característica, lo convierte en un paradigma apetecido por las
organizaciones ya que a través de las virtualización de sus servidores se puede optimizar
el consumo de recursos mejorando el desempeño y reduciendo costos[5].
Para este año, el negocio de Infraestructura como servicio (IaaS) encargada de proveer
servicios de computación en la nube a personas y organizaciones, generará a los
proveedores ganancias cercanas a los 38.000 millones de dólares. Se estima que esta
cifra ascienda 127.000 millones en 2018 y 167.000 millones en 2020. Para el año 2020 se
estima que el 50% de las organizaciones estarán soportando sus servicios de cómputo por
infraestructura en la nube. [2]
Estas características se logran principalmente mediante la virtualización, que es el proceso
por el cual se puede simular el entorno de ejecución de uno o varios dispositivos dentro de
un solo equipo físico[6]. La migración de una red convencional a una red basada en
máquinas virtuales conlleva por sí misma una amenaza de seguridad, pues se añade una
capa adicional de software que constituye un posible blanco de ataques[7].
1.1 Redes definidas por software
El principal reto tecnológico al que nos enfrentamos a la hora de desplegar servicios en la
nube es la asignación de recursos de cómputo, así como la reconfiguración de una red
intrínsecamente dinámica que suele estar limitada por ciertas configuraciones, recursos de
almacenamiento y conexiones físicas de los dispositivos de red. Las redes definidas por
software (SDN, software defined networking) son un paradigma emergente que hace frente
2

a este problema al permitir al administrador de red realizar actividades de gestión de
manera programática sobre una red.[6]
Esto se consigue mediante la separación del plano de control (El conjunto de entidades
que se encargan de decidir cómo se en-ruta el tráfico a través de la red) y el plano de datos
(El conjunto de entidades encargadas del envío de paquetes). El punto crítico de una red
definida por software está ligado justamente al plano de control donde existe un controlador
principal, encargado de gestionar toda la red. Mientras la redes tradicionales requieren la
reconfiguración de varios equipos de red cuando se realiza una actualización, se añaden
o se modifican recursos, una red definida por software solo requiere una actualización de
software reduciendo notablemente la complejidad de la operación de la red y los costos
asociados a ella[8].
En el plano de datos coexiste toda la infraestructura virtual y/o física de la red, es decir que
dispositivos virtuales tales como OpenVSwitch, Nettle e Indigo pueden coexistir con
equipos de red físicos como switches y routers. Esto se debe a que los dispositivos
compatibles con software como Openflow pueden ser gestionados sin que exista una
diferencia desde el punto de vista lógico o funcional con los equipos virtualizados[6].
Por otra parte, plano de control consiste en un controlador capaz de gestionar toda la red,
si bien generalmente se tiene un controlador centralizado, desarrollos recientes abordan
el despliegue de entidades de control distribuidas que permiten mejorar aspectos de
desempeño y seguridad. El controlador se encarga exclusivamente de tomar decisiones
de enrutamiento, reenvío y políticas de descarte de paquetes.
El mecanismo de comunicación entre planos más popular es el protocolo Openflow, sin
embargo, existe gran variedad de protocolos propietarios para este fin.
3

Figura 1- Red definida por software
Recientemente se ha presentado un importante fenómeno de migración de datacenters a
redes definidas por software, esto debido a la facilidad para agregar recursos globales de
almacenamiento y cómputo sin afectar la disponibilidad y el desempeño de los servicios
soportados. Esto ha motivado el desarrollo de nuevas soluciones de virtualización basadas
en SDN por parte de fabricantes de software y hardware tales como Cisco, H3C, VMWare.
Microsoft y Google.[6][9]
1.2 Enrutamiento y control de congestión
Las redes de computación en la nube se caracterizan por la capacidad de proveer acceso
a un recurso determinado según la demanda. Por ello, encontrar el recurso disponible más
próximo a la ruta más rápida, a determinada información en la red es un aspecto de vital
importancia. También, es común que los servicios en la nube sean desplegados en
datacenters, donde los diferentes componentes de una red lógica particular no están
necesariamente contenidos en el mismo equipo físico o red de área local.
Por consiguiente, el principal reto para vencer en cuanto al enrutamiento consiste en
encontrar la ruta óptima que permita enviar un mensaje de la fuente F al destino D con el
menos impacto posible sobre la red y los recursos de cómputo. Al tratarse de redes
distribuidas, dinámicas y de gran escala, los algoritmos y protocolos tradicionales son
insuficientes para afrontar este problema. [10]
4

En la actualidad, el enrutamiento en redes de computación en la nube y en general en
redes de topología dinámica como las redes ad hoc, constituyen un campo de investigación
activo, por lo que si bien, existen en la actualidad estrategias de enrutamiento, ninguna de
ellas resulta óptima en todos los puntos de interés[11].
1.3 Enrutamiento en redes dinámicas y distribuidas
El enrutamiento basado en contenidos es un algoritmo sencillo en el que todos los
mensajes son enviados a un enrutador sin información de destino. Para decidir el destino,
el enrutador lee el cuerpo del mensaje y aplica una serie de reglas que le permiten decidir
a qué cliente va dirigido el mensaje. Generalmente se trata del nodo que provee el servicio
especificado en el mensaje, aunque pueden existir reglas más complejas. La principal
ventaja de esta clase de enrutamiento, es que se adapta fácilmente ante cambios en la
ubicación de servicios específicos[10].
Sin embargo, este tipo de enrutamiento resulta altamente ineficiente para las redes en la
nube modernas, pues la complejidad de la red puede crecer exponencialmente y
modificarse constantemente, lo que hace altamente ineficiente escanear toda la red para
definir la ruta a cada servicio o pieza información en la red y sobrescribir las tablas de
enrutamiento en todos los equipos [10][11].
Figura 2- Enrutamiento
Existen otros tipos de enrutamiento comunes en redes distribuidas, que permiten prescindir
de conocer toda la topología de la red, tales como el enrutamiento basado en ubicación o
el enrutamiento basado en tablas hash.
En primer lugar, el enrutamiento basado en ubicación es aquel que realiza información de
la ubicación geográfica de los hosts en lugar de direcciones IP. En la actualidad, existen
varios algoritmos capaces de realizar el enrutamiento basado en la información de
5

ubicación, tales como greedy forwarding (must forward within radius, neares forward
progress, compass routing, random progress forward), face forwarding, y flooding. A pesar,
de la flexibilidad que portan estas estrategias de enrutamiento, en el caso de los algoritmos
de un solo camino no existe garantía de que el mensaje llegue a su destino, y puede
generar tráfico innecesario en la red [10], [11].
Por otro lado, los métodos basados en tablas hash son comunes en las redes peer-to-peer,
donde básicamente las tablas hash se almacenan de manera distribuida a través de los
nodos de la red y permiten conocer la ubicación de un determinado recurso, mediante la
consulta de dichas tablas en otros nodos. Este tipo de estrategias, son altamente
escalables y tolerantes a fallos. Sin embargo, resulta difícil verificar la integridad del recurso
obtenido lo que constituye un problema de seguridad que lo hace inutilizable, por ejemplo
para redes empresariales. En la actualidad su uso se limita a redes de archivos
compartidos[10][11].
1.3.1 OSPF y BGP
Open Shortest Path First (OSPF) es un protocolo de enrutamiento para redes IP que se
usa de manera interna dentro de un mismo dominio de direcciones, como al interior de un
centro de datos. Este protocolo se usa para dirigir paquetes a través de la ruta de menor
costo computacional basándose en la IP de destino. Esto se logra construyendo un mapa
de topología de red basándose en la información de estado de enlaces. Este mapa puede
ser actualizado en pocos segundos, en caso de que un enlace cambie su estado. Para ello
OSPF usa métodos basados en el algoritmo de Djisktra.
En este algoritmo, el costo de visitar un nodo de la red puede definirse con diferentes
métricas tales como la distancia entre nodos (Tiempo que se tarda en recibir respuesta
tras enviar una señal), el throughput del enlace o la disponibilidad conocida de cada enlace.
Por ello, el protocolo OSPF es ampliamente usado en las redes de computación en la nube
que funcionan de manera distribuida pues permite minimizar el costo de dirigir un paquete
hacia el puerto de salida de un centro de datos. El protocolo OSPF en su versión básica
está definido como OSPF Versión 2 por IETF [12]
BGP (Border Gateway Protocol) es un protocolo usado principalmente para el intercambio
de tablas de enrutamiento entre centros de datos. Este proceso se lleva a cabo mediante
la comunicación entre los routers externos de 2 sistemas autónomos, es decir 2 grupos de
6

redes IP con tablas de enrutamiento independientes y capaces de operar
independientemente.
El protocolo BGP parte de la caracterización del tráfico entrante y saliente. Para ello, se
cuenta con una serie de atributos configurables que ayudan al direccionamiento y filtrado
de paquetes hacia los routers internos del sistema autónomo: ORIGIN, AS-PATH, NEXT-
HOP, MULTI-EXIT-DISCRIMINATOR, LOCAL-PRE, COMMUNITY, los cuales están
descritos por IETF en la especificación del protocolo BGP [13]
En conjunto, los protocolos BGP y OSPF el uso de tablas de enrutamiento eficientes en
redes de alta complejidad y sistemas autónomos interconectados para los que el protocolo
Spanning tree resulta altamente ineficiente, pues puede generar demasiadas posibles
rutas, lo que conlleva una degradación del desempeño, además de agotar el tiempo de
vida de los paquetes antes de que estos sean entregados dada la complejidad de las
posibles rutas.
1.3.2 Protocolo DCTCP
Los centros de datos soportan gran variedad de aplicaciones y entornos vitalizados en su
interior. En estos sistemas algunas aplicaciones desplegadas requieren un mayor flujo de
datos, lo que desencadena una degradación del desempeño en otras aplicaciones. Esta
degradación obedece principalmente a la formación de colas que superan la capacidad de
los enlaces causando fluctuación en los tiempos de respuesta y perdida de paquetes. El
protocolo TCP (Transmission Control Protocol) utilizado en las redes IP convencionales no
cuenta con los mecanismos de control de congestión necesarios para hacer frente a estos
problemas ante el crecimiento exponencial de la complejidad de estas redes[14].
1.4 Gestión de identidad y acceso
La gestión de identidad se compone de todos los procesos encargados de identificar y
categorizar a los usuarios que se conectan a la red, así como los permisos otorgados a
cada uno de ellos. Los procesos de autenticación de usuarios son variados, como el uso
de contraseñas, certificados, tokens o sistemas físicos de identificación biométrica.
Para los procesos de identificación, es importante contar con un repositorio central que
debe contener la información actualizada de todos los usuarios y sus roles dentro del
sistema por lo que va de la mano con los procesos organizacionales de gestión de
7

personal. Este componente debe garantizar la integridad y confidencialidad de dicha
información, mediante una política de acceso único y el cifrado de su información pues
se asume que este constituye la única fuente confiable de identidades en la red.[5]
El desempeño de estos sistemas depende en gran medida de la cantidad de operaciones
de lectura y escritura que se realicen. Es por ello, por lo que se deben tener políticas claras
sobre los procesos de aprovisionamiento, que permitan automatizar las actividades de
solicitud y revocación de permisos. Desde el punto de vista de la seguridad, el uso
adecuado de un repositorio central facilita el desarrollo de actividades de auditoria, pues
permite la observación de tendencias de uso y la identificación precisa de los usuarios o
grupos que pueden acceder cada servicio o recurso. De esta manera se pueden identificar
potenciales riesgos de seguridad ligados a las políticas de gestión de usuarios, por
ejemplo:
• Grupos de usuarios con más permisos de los necesarios.
• Usuarios realizando cantidades inusuales de solicitudes de permisos.
• Políticas faltantes o redundantes.
Otro aspecto clave para mecanismos de gestión de identidad en la red, es la gestión de
contraseñas, que se refiere al conjunto de componentes de software encargados
almacenar y asegurar contraseñas y otros mecanismos de identificación como huellas
biométricas o certificados. Para ello, estos componentes se encargan de asegurar que las
contraseñas son lo suficientemente fuertes y son almacenadas en forma cifrada.
Además, debe permitir una serie de procesos de actualización y recuperación de
contraseñas. La automatización de los procesos de gestión de contraseñas, no solo mejora
la seguridad general del sistema al eliminar la intervención humana, sino que además
reduce costos al no tener que escalar los problemas comunes de autenticación a un
miembro de la organización administradora de la red.
Los sistemas de gestión de identidad tienen como objetivo facilitar el control de acceso
mediante una serie de mecanismos encargados de determinar qué usuarios pueden
acceder a un determinado servicio y cómo pueden hacerlo.
Estos sistemas, si bien son necesarios, constituyen un blanco potencial para cualquier
atacante, pues la suplantación de identidad o la modificación de los roles de usuarios
supone obtener acceso total a la red, sus servicios y recursos. El principal riesgo está
8

asociado al factor humano, pues es difícil llevar un seguimiento adecuado de las políticas
de seguridad en la organización y el mal uso o almacenamiento de contraseñas,
certificados y tokens puede comprometer el control de acceso.
1.4.1 Autenticación basada en contraseñas
El uso de contraseñas es el método más común de autenticación para toda clase de
sistemas computarizados y permite aceptar la identidad de un usuario mediante la
verificación de una contraseña que el usuario conoce. La seguridad de esta clase de
autenticación depende en gran medida de la complejidad de la contraseña y del manejo
que el usuario le dé, pues cualquiera que pueda inferir la contraseña podría suplantar la
identidad del usuario.
PAP (Password Authentication Protocol) es uno de los protocolos de autenticación más
antiguos que se usan en la actualidad y se considera un método inseguro de autenticación,
ya que transmite contraseñas sin cifrar a través de la red, lo que lo hace altamente
vulnerable a ataques tipo Eavesdropping y man in the middle. Como no es necesario
realizar ningún tipo de operación sobre la contraseña usada este protocolo resulta el más
eficiente en términos computacionales[15].
Figura 3- PAP
CHAP (Challenge-Handshake Authentication Protocol) [16] Es un protocolo que permite
realizar procesos de autenticación entre 2 actores sin transmitir la contraseña a través de
la red, y requiere que ambas partes conozcan de antemano la contraseña sin cifrar. Para
esto, se hace uso de una función de hash calculada sobre la combinación de la contraseña
con una cadena aleatoria generada por el servidor. Este proceso se considera
computacionalmente seguro, sin embargo, la principal vulnerabilidad recae la necesidad
9

de poder obtener contraseñas en texto plano en el servidor de autenticación, por lo que un
atacante con acceso a este servidor puede comprometer todas las contraseñas del
sistema.
Figura 4- CHAP
1.4.2 Single Sign-On y autenticación basada en Tokens
Una característica importante de las redes en la nube es la capacidad de contar con un
repositorio central de identidades, esto permite que una sola instancia de identificación
brinde acceso a todos los servicios disponibles en la red según los permisos de usuario. A
esta característica se le conoce como Single Sign-On, y en la actualidad existen varios
protocolos y estándares que soportan esta funcionalidad. Algunos de los más exitosos son
OAuth, SAML y OIDC[17].
Existen características en común de los diferentes estándares y protocolos de gestión de
identidad: El uso de tokens. Un token es básicamente un objeto de software único
generado al realizar una acción, que sirve como identificador de la sesión o transacción.
SAML (Security Assertion Markup Language), es un estándar basado en XML pensado
para comunicar información de autenticación y atributos ligados a esta entre diferentes
instancias y servicios. SAML permite brindar 3 tipos de información a la instancia que lo
requiera:
10

Identidad el usuario.
Atributos del usuario.
Autorización de usuario.
La especificación SAML no trabaja en la capa de transporte, razón por la cual se
recomienda su uso en conjunto con otros mecanismos que garanticen la integridad del
canal de comunicación y la confidencialidad de los mensajes, tales como SSL para la
protección del canal y el cifrado de los documentos XML.
Cuando un usuario solicita acceso a un servicio, se envía una petición al servidor de
gestión de identidades (identity provider) el cual se encarga de autenticar al usuario y
generar un token según los niveles de permiso asignados a dicho usuario. Este token está
acompañado de un certificado firmado por el proveedor de identidades que garantiza su
fuente. Posteriormente se envía una petición al servicio solicitado que contiene el token, el
proveedor del servicio verifica la autenticidad del token y responde al usuario con el recurso
o servicio solicitado[17].
Figura 5- SAML
OAuth (Open Authorization) es un protocolo pensado para proveer un capa de autorización
que permite proveer de recursos y servicios restringidos a una aplicación externa sin la
necesidad de compartir la credenciales de acceso del usuario que solicita el acceso. Para
esto, en lugar de reusar las credenciales de usuario, el dueño del recurso otorga un token
que otorga acceso al recurso y le permite identificar al usuario autorizado[17]. La
especificación OAuth trabaja exclusivamente sobre el protocolo HTTP [18]
11

Para este proceso, el protocolo contempla 4 roles básicos que interactúan:
Dueño del recurso: Es la entidad que posee las credenciales necesarias para
acceder a un recurso restringido, este puede ser un servidor o un usuario final.
Servidor del recurso: Es el servidor que guarda el recurso protegido y que debe ser
capaz de aceptar peticiones basándose el token de acceso.
Servidor de autorización: Es el servidor encargado de autenticar, autorizar y
proveer los tokens de acceso.
Cliente: Se refiere a la aplicación (software) que se encarga de solicitar los recursos
en nombre de un usuario.
Figura 6 - Oauth
1.5 Vulnerabilidades
Las redes de computación en la nube están soportadas sobre dispositivos físicos y como
tal comparten todas las vulnerabilidades propias de la capa física en cualquier red de
comunicaciones. Además, se introduce una capa adicional de software correspondiente a
los componentes de virtualización y control, así como ciertos comportamientos propios de
las redes en la nube como el auto-escalamiento. Estas características añades nuevos retos
12

al momento de garantizar la seguridad de la red pues constituyen potenciales
vulnerabilidades y blancos de ataque.
Es difícil estimar la cantidad total de ciberataques que se llevan a cabo cada día a sistemas
de cómputo soportados en la nube. Sin embargo, ciertas firmas especializadas como
Kaspersky labs, Panda labs o algunas agencias gubernamentales de seguridad, realizan
análisis que permiten caracterizar el panorama de la seguridad digital en el mundo. En el
tercer cuatrimestre de 2016 Panda Labs, detectó 18 millones de nuevos malware y cada
40 segundos se reportó un ataque tipo ransomware en el mundo[19]. Si bien los ataques
tipo ransomware, constituyen hoy por hoy la mayor preocupación de los expertos en
seguridad, este tipo de ataques no explotan ninguna característica particular de las redes
computación en la nube[19].
Se estima que el porcentaje de ciberataques dirigidos a organizaciones pequeñas y
medianas pasó del 34% al 43% entre 2014 y 2015 [20]. Para el 2016 se contempla que
alrededor del 50% de las organizaciones de mediano y gran tamaño sufrieron algún tipo
de intento de intrusión durante el 2016 y cerca del 35% fueron víctimas de ataques
exitosos. En 2016, 52 de cada 100% organizaciones afirmaron no tener planes de mejora
en sus sistemas de seguridad computacional y solo el 31% afirmaron tener algún plan en
marcha[21].
1.5.1 Denial of Service (DoS).
Los ataques de denegación de servicio (DoS), son ataques usados con el objetivo de
inhabilitar un equipo o una red mediante la sobrecarga o inhabilitación de sus recursos de
cómputo, impidiendo la ejecución de los servicios soportados[22]–[25].
Existen 2 clases de ataque DoS. Los ataques de denegación de servicio por saturación
son aquellos que realizan peticiones en gran volumen o con gran cantidad de datos con el
fin de saturar los recursos de la red impidiendo su correcto funcionamiento. Mientras que
los ataques de denegación de servicio por explotación de vulnerabilidad son aquellos que
hacen uso de un fallo detectado en el sistema para hacer que una tarea o servicio critico
dejen de funcionar[25].
Este tipo de ataques no pretenden robar o alterar ningún tipo de recurso o información,
suelen ser usados con el fin de afectar negativamente servicios y organizaciones
deteniendo su operación. Si bien los ataque DoS no usan mecanismos sofisticados, estos
13

siguen siendo efectivos contra cualquier sistema conectado a una red pública sin importar
su arquitectura o sistema operativo[25].
Cuando el ataque se realiza desde varias fuentes simultáneamente, se conoce como
ataque DDoS (DoS distribuido). Estos se enfocan generalmente a la saturación de los
recursos mediante el envío simultáneo de grandes cantidades de peticiones o gran
volumen de datos, afectando la capacidad de procesamiento del sistema o su ancho de
banda. El principal reto que imponen los ataques distribuidos respecto a los ataques con
una sola fuente, es la dificultad para identificar y aislar la fuente del ataque, pues es
necesario contar con un mecanismo, que permita diferenciar las peticiones reales (que
obedecen al uso legítimo del sistema) de las peticiones maliciosas[22], [25].
Figura 7 - DoS
Las redes de computación en la nube son especialmente vulnerables a ataques DoS
producto de su capacidad de escalamiento y balanceo de carga, pues el comportamiento
natural de la red ante un ataque DoS, es aumentar más y más la cantidad de recursos
disponibles para el servicio blanco del ataque. Los ataques distribuidos (DDoS),
constituyen una amenaza aún mayor pues su detección resulta más difícil. En este tipo de
ataques, la capacidad de escalamiento de la red puede en principio mitigar el efecto del
ataque, sin embargo dicha capacidad de expansión está limitada siempre por el hardware
disponible o por servicios críticos como bases de datos que suelen constituir un cuello de
botella, por lo que un ataque puede no solo llevar a la denegación del servicio para los
usuarios legítimos, sino que también puede llevar a enorme desperdicio de recursos
computacionales con su respectivo costo económico[22], [25].
La firma especializada en seguridad informática Kaspersky labs realiza constantemente
análisis de reportes de ataques en todo el mundo con una detallada caracterización de los
14

ataques de este tipo. Al cierre del año 2018 llegaron a reportarse en ciertos días más de
800 ataques DoS y DDoS de gran escala producto de actividad criminal[26]. Un análisis de
la distribución geográfica de los ataques establece a China como el principal foco de esta
actividad con el 50.43% de los eventos seguido de estados unidos con el 24.90%.
Con el fin de prevenir este tipo de ataques en las redes de computación en la nube,
comúnmente se recurre al uso de firewalls e IDS que permitan la detección oportuna de
patrones de ataque, y el bloqueo del tráfico proveniente de dichas fuentes. Sin embargo,
las medidas defensivas no se limitan a esto, pues es necesario contar con la infraestructura
suficiente, que permita a los sistemas mantenerse estables durante dichos eventos de alta
carga. Algunas de estas medidas son:
- Mantener un ancho de banda muy superior al tráfico normal de la red, este debe
permitir al sistema soportar ataques en pequeña escala, dificulta la labor del
atacante y brinda un mayor margen de respuesta.
- Aplicar a servicios expuestos mecanismos de throttling (limitar los recursos
asignados para responder a un usuario, dirección o servicio específico) y de rate-
imiting (limitar la cantidad de peticiones atendidas por periodo de tiempo para cada
usuario, dirección o servicio específico). De esta manera se limita el impacto de los
ataques y se obliga al atacante a aumentar la escala.
- Mantener canales alternos seguros, como enlaces o servidores dedicados para su
uso con usuarios o servicios críticos. De esta manera, dichos enlaces pueden
mantenerse funcionales aun en eventos de ataque sobre servicios públicos.
1.5.2 Malware Injection.
El trabajo principal de un sistema de cómputo en la nube, suele ser la coordinación
instancias de máquinas virtuales o de servicios particulares. Una vez se realiza una
petición el sistema debe ser capaz de identificar la localización del servicio o la información
solicitada, desplegarlos si es necesario y encontrar la ruta óptima para entregar el
contenido al usuario. Malware Injection, es un tipo de ataque que consiste en la
implantación de servicios maliciosos dentro de la red de computación en la nube afectando
uno o varios de los procesos involucrados en la entrega de contenido[25], [27].
Este tipo de ataque requiere que el atacante cree su propio módulo de servicio (SaaS o
PaaS) o una instancia de máquina virtual (IaaS) y anexarlo a la red de cómputo en la nube
15

haciéndolo pasar como un componente auténtico de la red. El componente malicioso
puede desarrollar varias tareas como interceptar información privada, suplantar un servicio
de la red o incluso tomar el control de otros nodos de la red. Por lo que constituye una de
las mayores amenazas para un sistema de computación en la nube[25]. De acuerdo AV-
TEST durante el año 2018, cada mes se detectaron en promedio 11.46 millones de nuevos
malware[28].
Un mecanismo común de mitigación ante este tipo de ataques consiste en la
implementación de verificaciones de integridad generando códigos hash de los
componentes auténticos y verificando su integridad cada vez que hay comunicación entre
servicios, dispositivos o instancias virtuales. Como resultado de este proceso un atacante
deberá ser capaz de generar un componente malicioso con un código hash valido
(Colisión)[25].
1.5.3 Side Channel
Una de las características más importantes de los sistemas de computación en la nube, es
la capacidad desplegar y configurar recursos virtuales compartiendo hardware, software,
librerías y sistemas de archivos. Todo esto, constituye una vulnerabilidad propia de este
tipo de redes, pues resulta imposible lograr un aislamiento completo de los recursos
virtuales ejecutados en un hardware compartido[29].
Este ataque explota una vulnerabilidad propia de las redes virtualizadas y consiste en alojar
una máquina virtual alterada en el mismo host de la maquina original, lo que le permite
tener acceso a información clave para vulnerar sistemas criptográficos. Este tipo de
ataques requieren un extenso conocimiento de la implementación del sistema criptográfico
que toma como blanco y en teoría permitiría al atacante obtener información crítica como
cuentas de usuarios, contraseñas y otra información clasificada[29], [30].
16

Figura 8- Side channel
Algunos de los componentes que originan estas vulnerabilidades son:
- Caché: Explotan el hecho de que, en las arquitecturas modernas, el caché es
compartido por todos los procesos impidiendo que exista aislamiento físico,
monitoreando los accesos a memoria caché de máquinas virtuales o procesos
críticos.
- Reloj: Este tipo de ataques monitorea el tiempo de ejecución de las tareas para,
por ejemplo, intentar predecir el tamaño de una contraseña, al comparar el tiempo
que tarda un algoritmo de hashing en verificar su autenticidad.
- Memoria: A pesar del aislamiento, se han detectado vulnerabilidades que permiten
a un proceso acceder a memoria adyacente al forzar fallos de código.
Otros tipos de ataques Side Channel pueden ser ejecutados externamente mediante el uso
de dispositivos físicos, monitoreando y analizando patrones de consumo de energía,
acústicos, de radiaciones electromagnéticas, o ópticas que permiten obtener información
total o parcial sobre aspectos de las llaves criptográficas u otra información sensible[29].
Para mitigar estos riesgos, se suele recurrir a diferentes técnicas de aislamiento, como
aislamiento en tiempo de ejecución, aislamiento por usuario, aislamiento por contenedores
o el aislamiento por máquinas[29]. Experimentalmente, se ha comprobado que el
aislamiento por maquinas, es el que proporciona los mejores resultados pues en este se
asignan recursos de hardware específicos a cada instancia de máquina virtual tanto en
procesados, memoria y sistema de archivos. Sin embargo los ataques tipo side cannel,
17

siguen siendo altamente efectivos, pues a que a pesar de localizar recursos particulares
para cada instancia o contenedor y aislarlos de manera lógica a través de un hypervisor el
hardware común sigue permitiendo que los ataque tipo side channel tengan altas tasas de
éxito principalmente asociadas al uso del caché del host[29].
Investigaciones recientes sugieren nuevas tácticas para mitigar y combatir los riesgos
asociados a este tipo de ataque; Mohamed Azab y Mohamed Eltoweissy proponen un
framework de gestión de contenedores que modifica la localización de los recursos
asociados mediante técnicas probabilísticas con el fin de dificultar la tarea de localización
a una instancia maliciosa[29]. Using Bloom y Filter F[30], proponen un sistema de
verificación de integridad de caché para la detección de código malicioso haciendo uso del
caché compartido del host. Younis A Younis, Kashif Kifayat Qi Shi y Bob Askwith[31]
proponen un sistema similar basado en la generación de números primos. Además de otros
estudios recientes que abordan la misma problemática [32]–[35]
18

2. Sistemas de detección de intrusión
El concepto de IDS surge en 1980, cuando James P. Anderson produce el artículo titulado
“Computer Security Threat Monitoring and Surveillance” donde se propone el modelo
básico para un IDS en tiempo real capaz de detectar y clasificar amenazas en la red basado
en reglas simples [36]. El trabajo de James P. Anderson sirvió de inspiración para el diseño
e implementación de los primeros IDS durante las décadas de 1980 y 1990 mediante el
financiamiento del gobierno de los Estados Unidos [4]. El primer IDS funcional se logró
1986 cuando Dorothy Denning y Peter Neumann, desarrollaron un sistema capaz de
analizar el tráfico de la red y detectar posibles amenazas mediante la aplicación de reglas,
de manera similar a un antivirus [4].
Los IDS se clasifican principalmente de acuerdo con el mecanismo de despliegue en la
red, existen IDS desplegados a nivel de red y a nivel Host, así como arquitecturas
distribuidas. Para el caso particular de las redes de computación en la nube, se han
desarrollado IDS desplegados a nivel de Hypervisor o controlador que permiten la
detección de amenazas mediante el análisis de la capa de virtualización[37].
Recientemente el estudio y desarrollo de esta clase de sistemas se ha enfocado en el uso
de técnicas de inteligencia artificial para la implantación de estos sistemas de detección de
intrusión en redes de arquitectura dinámica, debido a que los sistemas de detección
tradicionales no son efectivos en esta clase de redes [38]. Las limitaciones de los IDS
tradicionales para su uso en sistemas en la nube se deben principalmente a las
propiedades de escalabilidad, auto-adaptación, y principalmente la naturaleza estocástica
de los patrones de tráfico y de su propia topología de red [37].
Generalmente, es el dueño de la infraestructura quien se encarga del desarrollo de los
mecanismos de seguridad de las redes desplegadas sobre su infraestructura. Sin
embargo, en los servicios de IaaS estas medidas de seguridad suelen limitarse a garantizar
la integridad de la red, y evitar que esta colapse por el volumen de tráfico.
19

Estas medidas usualmente se refieren a la implementación de protocolos y políticas que
garantizan un óptimo enrutamiento y utilización de los recursos de cómputo y
almacenamiento. Así, como la gestión de los mecanismos de gestión de identidad y acceso
necesarios para el correcto despliegue del servicio. En este sentido, gran parte de las
medidas de seguridad recaen sobre la capa de aplicación[37], [38].
2.1 IDS desplegados en red
Estos funcionan básicamente capturando y analizando el tráfico de la red, contrastando
esta información con la información en tiempo real del estado de la red, así como los
niveles de permiso y servicios activos en cada host [6]. La localización del IDS dentro de
la red puede incluso ser dinámica o estar replicada, con el fin de esconderlo ante un posible
atacante. Este tipo de IDS debe tener acceso completo a los equipos que interactúan con
redes externas y es incapaz de realizar análisis sobre tráfico encriptado [7].
Los IDS basados en red analizan el tráfico principalmente a nivel de capa de transporte y
protocolos de la capa de aplicación, mediante una serie de sensores que capturan
información particular[37], [39].
Los sensores, pueden ser desplegados en el enlace, haciendo que todo el tráfico del
segmento pase por el para su análisis. Esto se suele lograr integrando la lógica del sensor
en un dispositivo de red físico como un firewall o un switch por lo que no requieren
hardware especial para su funcionamiento. La gran ventaja que representa este esquema
al estar integrado como equipos de red físicos, es que se pueden crear esquemas de
detección y reacción inmediata; por ejemplo, bloqueando el tráfico de la fuente que genera
la alarma.[39], [40]
Sin embargo, el tipo más común de sensor en red es desplegado de manera pasiva. Es
decir que no interactúa con el tráfico del enlace, sino que analiza una copia de este. Desde
el punto de vista del desempeño de la red, este esquema permite un mayor desempeño al
no agregar demoras a los paquetes producto del proceso de análisis de datos del
segmento de red.
Una ubicación común para los sensores es tras el firewall externo[39], pues este permite:
- Analizar tráfico en búsqueda de posibles ataques originados en redes externas.
- Descubrir problemas con las políticas o desempeño del firewall
20

- Descubrir ataques dirigidos a los dispositivos abiertos al exterior como servidores
web o FTP
- Analiza el tráfico saliente que puede evidenciar respuestas a ataques no
detectados.
También, es común desplegar sensores tras firewalls internos o servicios críticos. La
información de los sensores desplegados puede ser procesada por un dispositivo particular
o emitir alertas a un sistema centralizado (interfaz de gestión), que se encarga de realizar
las tareas necesarias en la red para mitigar el ataque o realizar las reconfiguraciones
necesarias[40].
Diversas investigaciones abordan el tema de los IDS desplegados en red para redes de
computación en la nube, especialmente enfocados a la reducción de falsos positivos, pues
algunos estudios indican que hasta el 90% de las alertas emitidas por este tipo de IDS
corresponden a falsos positivos[41]. Hong Tanhg[42], propone un sistema basado en
sistemas inmunes artificiales, que permite la reconfiguración automática de sensores. Risto
Vaarandi y Karlins Podins[43], proponen el uso de métodos de clustering como pos-
procesamiento para descartar alertas clasificarlas según su nivel de gravedad. Claudio
Mazzariello, Roberto Bifulco y Roberto Canonico[40], describen los mecanismos de
integración de este tipo de IDS en un entorno de computación en la nube tomando en
cuenta su naturaleza dinámica.
2.2 IDS en hosts
Estos funcionan mediante el análisis del tráfico y los logs de determinado host, estos
permiten detectar ataques internos mediante la detección de actividad anormal en
determinados puertos o en el uso de determinados servicios.
Su funcionamiento se basa en los llamados agentes o sensores que se refieren al módulo
de software que se instala en el host para monitorear, recolectar y analizar la información
que tiene lugar en el host. La información recolectada generalmente viene del sistema
operativo (a través de audit trails), logs del sistema, logs de procesos u objetos generados
por programas específicos en ejecución.
Las implementaciones de IDS en host usualmente se encuentran limitadas por los audit
trails debido a que estos los provee el sistema operativo y pueden no responder a las
necesidades del sistema, por lo que muchas implementaciones implican agregar código al
21

kernel del host, con el fin de generar los eventos deseados, lo que en contraprestación
degrada el desempeño general del sistema. A pesar, de esta limitación de fondo la
información de los audit trails, se sigue considerando la más confiable y los sistemas
operativos más comunes tienen información cada vez más detallada, haciendo más
efectivos este tipo de IDS. Estas características, los hacen ideales para detectar ejecución
de código malicioso, ya que a través de la información recolectada permite responder
preguntas como “¿Qué proceso lanzo el evento?”, “¿Qué usuario lanzó el proceso?” o
“¿Quién accedió al recurso?”.
Si bien, cuanto más detallada y abundante sea la información recolectada, mayor será el
eficacia de los sensores, un problema común de este tipo de IDS yace en las grandes
cantidades de información recolectada, que es acumulada y ocupa un gran espacio de
almacenamiento. Además, cuanto más detallada es la información también aumenta la
demanda de recursos de procesamiento, al no aumentar proporcionalmente al volumen de
datos, es más fácil para un atacante esconder sus huellas, pues la eficiencia del
procesamiento disminuye. Al no tener control sobre la red estos suelen ser susceptibles a
ataques DoS [7], [6].
Otro problema común, con este tipo de implementaciones está relacionado con su costo y
su baja portabilidad, ya que implican mucho desarrollo y están diseñados para una
arquitectura y sistema operativo particular, por lo que no se puede portar fácilmente de un
servidor a otro.
2.3 IDS distribuido
Consiste en varios IDS (de red o de host) desplegados a través de la red, analizando tráfico
y comunicándose entre sí. Esta comunicación puede realizarse mediante comunicación
directa entre ellos o el uso de un servidor central [7]. En general, este tipo de IDS permiten
una gestión eficiente de los registros de incidentes al permitir que estos sean centralizados
y analizados conjuntamente. Estas características le permiten lograr asociaciones
computacionalmente más complejas y comportarse como sistemas de agentes inteligentes
distribuidos [13], [11].
La entidad centralizada de este tipo de sistemas no solo recopila datos, también permite
realizar análisis para relacionar eventos en diferentes segmentos de la red, así como la
generación de estadísticas y punto de configuración de los agentes desplegados en la red.
22

Además, el servidor central es capaz de realizar análisis de agregación, descubriendo
patrones de ataque que serían imposibles de detectar por un solo sensor. El análisis de
agregación consiste es combinar datos similares o relacionados en diferentes segmentos,
permitiendo observar, por ejemplo, como un patrón de ataque avanza a través de los
segmentos de la red o como un ataque puede originarse desde varias fuentes internas y
externas de manera conjunta.
La agregación se realiza por parámetros tales como:
- IP: Permite realizar análisis del patrón de uso desde una fuente particular.
- Puertos de destino: Permite realizar análisis sobre tipos de ataque o revelar
vulnerabilidades.
- Agente: Permite relacionar información histórica para detectar posibles patrones
repetidos que correspondan a intentos de ataque.
- Tiempo: Permite identificar patrones recurrentes de comportamiento, como, por
ejemplo, código malicioso que realiza una tarea a cierta hora especifica.
- Tipo de ataque: Permite revelar ataques coordinados en diferentes segmentos de
la red.
Para el caso particular de las redes de computación en la nube, este tipo de IDS representa
una gran ventaja pues es un esquema permite adaptaciones topológicas con redes de
sensores dinámicas. Investigaciones recientes, han abordado el uso de este tipo de
arquitecturas con diferentes estrategias de detección. Zhe Li[44], propone la
implementación de un sistema distribuido basado en redes neuronales artificiales que se
adapta a los cambios en la topología de la red. Yasir Mehmood, Ayesha Kanwal,
Muhammad Awais Shibli y Rahat Masood, proponen un sistema de agentes móviles
colaborativos capaz de detectar e informar correlaciones, patrones de ataque y
vulnerabilidades mediante la comunicación entre agentes[37].
2.4 Sistemas basados en VMM / Controlador /
Hypervisor:
Hypervisor, se refiere a la entidad responsable de la comunicación entre máquinas
virtuales [6]. Este tipo de IDS son desplegados en dicha capa y tienen la capacidad de
23

analizar el tráfico entra las máquinas virtuales para detectar actividades anómalas
relacionadas con la comunicación y la gestión de recursos [8].
El hypervisor tiene acceso a la información de desempeño de las maquinas que hospeda,
lo que provee información de lo que sucede en la máquina, sin tener que interactuar con
el sistema operativo, aplicaciones o datos de estas[45]. Usualmente, en los sistemas IDS
basados en hypervisor hacen uso de un nodo central encargado de recopilar, analizar y
emitir alertas de los datos provenientes de los hypervisor de las diferentes maquinas; De
manera, similar al nodo central de un IDS distribuido, este permite la agregación de datos
para la búsqueda de correlaciones entre varios componentes. Además, existen
componentes de software asociados a cada hypervisor encargados de clasificar y dar
formato a la información mostrada por el hypervisor.
Los IDS además pueden funcionar de manera nativa (ejecutando nativamente el código de
la máquina virtual en hardware), o de forma emulada (ejecutando el código sobre una capa
de software)[46]. Existen 2 formas de desplegar un IDS de este tipo:
- En el hardware del host, controlando directamente el hardware y el sistema
operativo de la máquina virtual. Xen, VMware ESX, y Microsoft Hyper-V son
ejemplos de este tipo de IDS[46].
- En el sistema operativo del host, donde se añade una capa de software entre el
sistema operativo del host y el sistema operativo de la máquina virtual. KVM,
VMware Workstation, VirtualBox, y QEMU son ejemplos de este tipo de IDS[46].
24

Figura 9 – Tipos de IDS
Gracias a que estos sistemas se despliegan en la capa de hypervisor, estos operan, en
teoría a un menor nivel que el sistema monitoreado, manteniéndose aislado y seguro de
cualquier ataque que ocurra al interior del entorno virtual[46][45].
Las principales ventajas que presentan este tipo de IDS son:
- Aislamiento: Como el hypervisor y la máquina virtual funcionan en un nivel de
abstracción diferente, existe un fuerte aislamiento entre ambos componentes. Este
aislamiento impide posibles ataques o fenómenos de degradación de desempeño
en el entorno virtual afecten al hypervisor o los sensores desplegados sobre él.
- Transparencia: Al estar en capas diferentes, el despliegue de un IDS basado en
hypervisor pasa totalmente desapercibido para el entorno virtual, pues no es
necesario instalar componentes en la red o agregar capas de software en el sistema
operativo virtual, permitiendo en muchos casos realizar despliegues en tiempo de
ejecución sin afectar el funcionamiento del entorno.
- Alcance: Al estar fuera de la máquina virtual, los sensores tienen acceso a los
estados de memoria, disco y registros de las máquinas virtuales permitiendo ver
los estados de las aplicaciones y el kernel del sistema. Además, puede coordinar
25

el despliegue de máquinas de reemplazo para instancias corruptas y tomar
imágenes de estas para su posterior análisis.
A pesar, de las claras ventajas, también se caracterizan por su bajo rendimiento, producto
de la cantidad de operaciones que requiere es traducir direcciones de memoria del host a
direcciones de memoria en el entorno virtual constantemente. Además, resulta un reto
identificar plenamente el problema solo con este tipo de IDS, ya que al estar desplegado
en un nivel de abstracción diferente dificulta la tarea de identificar plenamente el código,
usuarios o procesos maliciosos dentro del entorno[46][45].
2.5 Métodos de detección
La detección de amenazas parte de una abstracción de las características de tráfico de la
red, estas características son el objeto de análisis de sistemas experto que pretenden
detectar amenazas en la red. Estos sistemas expertos de clasifican de acuerdo con la
naturaleza de los algoritmos usados para el análisis de la información.
2.5.1 Clasificadores de patrones
Este tipo de IDS realiza un análisis sobre los eventos de la red y los contrasta con patrones
de ataques conocidos, con el fin de detectar ataques comunes mediante diferentes
algoritmos de clasificación, por lo que estos son incapaces de detectar ataques que
empleen técnicas desconocidas [7], [10].
Los patrones son definidos mediante la abstracción de un conjunto de características de
patrones de ataque conocidos. Generalmente, se trata características de tráfico entrante
tales como la geo-localización de grupos de direcciones, bucles de peticiones, peticiones
con comportamientos determinísticos a través del tiempo o información de sesión. Esto les
permite tener una baja tasa de falsas alarmas; es decir, tienen un nivel muy alto de
precisión en la detección de intrusiones dentro de la red[37].
Entre los algoritmos de clasificación de patrones encontramos los árboles de decisión,
redes neuronales, máquinas de soporte vectorial, redes neuronales, regresión, clustering
o modelos ocultos de Markov[37].
A fin de mantener su eficiencia a través del tiempo las bases de datos de los sistemas de
detección basados en patrones deben ser constantemente actualizadas, agregando
nuevos patrones o actualizando la información de los ya existentes[47].
26

Los IDS basados en clasificadores de patrones, resultan especialmente útiles para el
monitoreo del tráfico entrante de la red, debido a que al estar desplegados en los puertos
de entrada de la red permiten el monitoreo del tráfico en un punto centralizado
eficientemente. También, pueden ser útiles para detectar intrusiones internas si se
despliegan al interior de la red. Sin embargo, se requieren implementaciones más
complejas, y no resultan tan precisos pues la complejidad de la redes hace difícil la
caracterización de ciertos tipos de ataques [37], [38], [48].
2.5.2 Sistemas basados en anomalías
Permite detectar anomalías al contrastar la información de perfiles de uso de red conocidos
con la actividad en tiempo real de los actores de la red, es decir, este se centra en detectar
actividades fuera del comportamiento esperado de la red. Este tipo de sistemas son ideales
para la detección de amenazas que usen métodos de ataque desconocidos [7], [14]. En
esta categoría encontramos los métodos de clustering, que son algoritmos encargados
agrupar y clasificar grandes conjuntos de datos en base a sus características implícitas
[15]. Estos métodos son particularmente útiles como detectores de intrusión, pues permiten
discriminar conjuntos de datos que presentan comportamientos alejados de las tendencias
del conjunto estudiado [16].
Los algoritmos de detección de anomalías se pueden clasificar en 3 grupos
principales[49][50]:
- Detección no supervisada: Son aquellos algoritmos capaces de detectar anomalías
en conjuntos de datos no etiquetados, donde se asume que la gran mayoría de los
datos corresponden al comportamiento normal del sistema.
- Detección supervisada: Son aquellas que requieren un conjunto de datos
etiquetados para su entrenamiento, donde cada dato es catalogado como
comportamiento normal o anormal.
- Detección semi-supervisada: Son aquellos algoritmos capaces de generar un
modelo de clasificación a partir de un conjunto de entrenamiento de datos
normales, que es capaz de discriminar datos que no correspondan a dichos
patrones de comportamiento.
27

Entre los algoritmos de detección de anomalías están los algoritmos basados en modelos
de densidad (Como KNN “k-nearest neighbor”), técnicas basadas en correlación, máquinas
de soporte vectorial, redes neuronales, clustering o lógica difusa[37].
Los IDS basados en detección de anomalías son usados a diferentes niveles en las redes
de computación en la nube. Estos sistemas generalmente son desarrollados para entornos
particulares, donde la integridad de los datos constituye una prioridad debido a que los
costos computacionales suelen ser altos en relación a la capacidad total de la red debido
justamente a la complejidad de los flujos de información[37], [38], [51].
2.6 IDS en entornos dinámicos
Una de las características clave de los entornos de computación en la nube, es la
capacidad de estos para mantenerse operacionales ante eventos de aumento de carga o
corrupción del propio entorno. Esto se logra, mediante la migración o replicación
automática de servicios y máquinas virtuales a diferentes nodos físicos en esquemas de
carga balanceada. Los entornos virtualizados de computación en la nube, permiten
actualmente realizar este proceso de reasignación de recursos sin interrumpir las
conexiones o procesos activos transfiriendo el estado de ejecución y memoria de un nodo
físico a otro, que permiten mantener la disponibilidad de servicios críticos o servicios en
tiempo real que la demanden.
La propiedad de elasticidad de la red requiere la implementación a nivel de red y aplicación
de los procesos que permitan identificar, definir y ejecutar las medidas de reestructuración
de la topología y los recursos de la red.
La elasticidad de la red trae consigo retos para la detección de anomalías en la red, pues
un sistema de detección de intrusión desplegado a nivel de red podría fácilmente identificar
erróneamente una migración legitima de la red, como un evento de suplantación de VM o
enmascarar verdaderos eventos maliciosos, que podrían ocurrir simultáneamente con
estos procesos de migración y reestructuración de la topología de red.
2.6.1 Migración de máquinas virtuales
La migración de máquinas virtuales (VM), se refiere al proceso de mover una máquina
virtual de un nodo físico a otro en un entorno de computación en la nube, sin afectar el
funcionamiento continuo del servicio con el objetivo de mejorar la capacidad de respuesta
28

(Por ejemplo, llevando el nodo a un punto de menor latencia con el origen de las peticiones,
auto-escalamiento (aumentar el número de máquinas virtuales a media que la demanda
del recurso aumenta, tolerancia a fallos (Moviendo las instancias de infraestructura
comprometida a infraestructura optima) o incluso para mantener el servicio activo durante
de ventanas de mantenimiento en el hardware o red[52].
Además, de la migración de máquinas virtuales es posible realizar migración de servicios,
que consiste en transferir la implementación entre maquinas físicas sin que existan
procesos de copiado de memoria o estado de ejecución[52]. Sin embargo, como esta
migración se realiza con procesos activos con conexiones de red abiertas, la migración a
nivel de servicio sin interrupciones requiere procesos de partición acoplados en la
arquitectura del servicio que permitan transferir la carga de un entorno a otro.
En un proceso de migración en una red de área local, las máquinas virtuales se mueven
entre maquinas físicas de la misma subred, lo que permite a la nueva instancia conservar
la interfaz de red completando la migración sin interrupción de las conexiones activas. En
estos entornos de área local, el almacenamiento, no suele ser parte de la máquina virtual,
sino que es un punto de montaje lógico apuntando a un directorio en un disco de red, lo
que permite acceso inmediato e ininterrumpido al almacenamiento en la nueva
instancia[53].
Sin embargo, cuando los procesos de migración se realizan fuera de área local (Wide area)
entre diferentes subredes o centros de datos, los procesos de migración son más
complejos. El estado de la maquina a transferir es mucho mayor, pues incluye el
almacenamiento, la transferencia generalmente implica el paso por redes de menor
capacidad entre los puntos físicos, la nueva máquina virtual deberá mantener la dirección
IP, lo que implica reconfiguración de los dispositivos de red para redirigir el tráfico sin
pérdida de las conexiones activas[52]
2.6.2 Proceso de migración de máquinas virtuales
El proceso de migración consiste en tomar una máquina virtual activa y moverla a equipo
físico diferente sin que se afecte el estado y la ejecución continua del sistema operativo de
la máquina virtual, así como para los clientes remotos conectados a la máquina virtual. En
otras palabras, una migración exitosa es aquella que pasa desapercibida por todos los
miembros de la red[54].
29

Las máquinas virtuales permiten este tipo de procesos al poder encapsular los estados del
hardware y el software en ejecución. Los 3 tipos de estado a considerar son:
- Estado de dispositivos virtuales (CPU, adaptadores de red, de almacenamiento y
gráficos).
- Estado de conexiones externas (conexiones de red abiertas, dispositivos de
almacenamiento o dispositivos removibles).
- Estado de memoria.
Encapsulando estos 3 estados es posible crear un flujo de procesos que permita la
migración entre maquinas físicas[54], [55]:
- Preparación: Se inicia el proceso de migración seleccionando la máquina virtual y
definiendo un host de destino. Se establece conexión TCP entre las maquinas
físicas involucradas y se realizan procesos de reserva de espacio y memoria en la
máquina de destino.
- Transferencia de memoria: Se copia la memoria de la máquina virtual en la maquina
física de destino mientras la máquina virtual sigue corriendo en la primera máquina
física.
- Transferencia de almacenamiento: El control de almacenamiento se transfiere a la
máquina de destino, de tal manera que se tiene una copia de la máquina virtual.
- Transferencia de red: Para mantener la transparencia del proceso de migración, al
final de esta, todas las conexiones deben ser redirigidas sin interrupciones a la
nueva máquina virtual, en esta etapa la VNIC de la máquina virtual de origen debe
ser reconfigurada para dirigir los paquetes a la nueva instancia.
30

2.6.3 Tipos de migración
Figura 10- Migración LAN Figura 11- Migración WAN
Existen 2 tipos básicos de migración: Migración LAN y migración WAN. Las migraciones
WAN son aquellas que mueven una máquina virtual entre diferentes subredes. En este
proceso el enrutamiento de la red debe adaptarse para dirigir el tráfico a la nueva
ubicación del servicio, para ello existen varios mecanismos[54], [55]:
Usando servicios adicionales: Se usa un proxy en el servicio original que permita redirigir
el tráfico a la nueva ubicación una vez la nueva máquina está operativa. También se han
propuesto soluciones alternativas como el uso de máquinas virtuales tras routers NAT o
el uso de VPN que permitan mantener un enlace de acceso externo único, delegando el
enrutamiento interno a estos componentes de la red.
SIP signaling: Se hace uso del Protocol SIP (Session Initiation Protocol). Los usuarios
conectados al servicio se subscriben a eventos de conectividad, cuando un servicio
migra, hay un cambio en la dirección IP que es notificada a los usuarios redirigiendo el
tráfico del cliente a esta nueva dirección
Tunneling: Asumiendo que el router de acceso es funcional (Es decir, que la migración no
se realiza a causa de una falla en la subred) es posible usar Link Tunneling. Un enlace
virtual es creado entre el router de acceso original del servicio y su nueva ubicación, este
enlace se usa para redirigir el tráfico entrante del primero al segundo.
31

2.6.4 Riesgos de seguridad asociados a la migración
Existen consideraciones de seguridad asociadas a los procesos de migración, el lugar
estado de ejecución transferido de una maquina física a otra puede contener información
sensible, como contraseñas, llaves criptográficas o información de sesiones activas.
Además, la actividad de red asociada a la migración puede ser vulnerable a ataques a nivel
de ARP o DNS, así como ataques man-in-the-middle. El hecho de que estos procesos
suelan hacerse a nivel redes de área local o que los recursos sean compartidos entre
entidades/personas incrementa el nivel de vulnerabilidad.
El comportamiento de las máquinas virtuales implica la introducción de vulnerabilidades a
nivel de la red y dificulta la correcta caracterización del tráfico y el comportamiento de los
nodos. Adicionalmente, resulta natural que las aplicaciones o servicios soportados se
comporten diferentes durante y después de una migración debido al cambio en el tráfico
de red, tamaño de memoria u otros recursos disponibles.
32

3. Clustering
En general, el análisis de clúster es el nombre que recibe la tarea de agrupar conjuntos de
datos de acuerdo con las similitudes entre ellos. Estas similitudes, son utilizadas en
diversos campos como el análisis estadístico, la minería de datos, inteligencia artificial,
compresión de datos y computación gráfica. Los métodos de clustering o agrupamiento,
son un conjunto de algoritmos diseñados para llevar a cabo dicha tarea de acuerdo a una
serie de características abstraídas de los elementos objeto de análisis. En otras palabras,
son algoritmos capaces de identificar similitudes entre objetos y clasificarlos en categorías
de acuerdo a cierta medida de “distancia”[56][57].
Sean 𝑎 y 𝑏 puntos en ℝ𝐷:
Nombre Formulación
Distancia euclidiana
||𝑎 − 𝑏||2 = √∑(𝑎𝑖 − 𝑏𝑖)2
𝐷
𝑖=1
Distancia euclidiana
al cuadrado ||𝑎 − 𝑏||2
2 = ∑(𝑎𝑖 − 𝑏𝑖)2
𝐷
𝑖=1
Distancia Manhattan ||𝑎 − 𝑏||1 = ∑ |𝑎𝑖 − 𝑏𝑖|
𝐷
𝑖=1
Distancia máxima ||𝑎 − 𝑏||∞ = max𝑖
|𝑎𝑖 − 𝑏𝑖|
Distancia de
Mahalanobis
Sea 𝑆 la matriz de covarianza: √(𝑎 − 𝑏)𝑇𝑆−1(𝑏 − 𝑎)
33

Similitud coseno 𝑎 ∙ 𝑏
‖𝑎‖‖𝑏‖
Tabla 1 Medidas de distancia
Con el fin de definir la similitud entre 2 objetos se debe crear esta medida de distancia,
algunas medidas comunes de distancia están definidas en la Tabla1. La matriz de similitud,
es una es una matriz que representa la similitud entre 2 objetos de acuerdo a una medida
de distancia y está definida de la siguiente manera[56]:
Sea {𝑋𝑖} un conjunto de N puntos en 𝑅𝐷, se define la matriz de similitud como una matriz
𝑁𝑥𝑁 tal que:
𝑆𝑖,𝑗 = 𝐷𝑖𝑠𝑡𝑎𝑛𝑐𝑖𝑎(𝑋𝑖 , 𝑋𝑗)
3.1 Métodos de clustering jerárquicos
Son algoritmos que funcionan mediante el sub-agrupamiento de grupos previamente
establecidos mediante técnicas aglomerativas (bottom-up), n los se comienza con cada
elemento como un grupo y se unen incrementalmente en grupo más grandes con cada
iteración, o divisivas (top-down) en las que se comienza con todo el conjunto como un solo
grupo y se divide en sub-grupos con cada iteración[56][58].
Técnica aglomerativa básica:
Paso 1 Cada objeto está en su propio grupo, N grupos son creados.
Paso 2 Encuentra el par de grupos con mayor similitud y los combinan, quedando N -
1 grupos.
Paso 3 Actualiza la matriz de similitud calculando la distancia entre el nuevo grupo y
todos los demás.
Paso 4 Repetir 2 y 3 hasta que solo exista un grupo de tamaño N.
Técnica divisiva básica:
34

Paso 1 Se crea un grupo de tamaño N.
Paso 2 Se divide el grupo en 2 de acuerdo con una heurística o subrutina
Paso 3 Crea las 2 nuevas matrices de similitud
Paso 4 Repetir 2, 3 y 4 sobre cada uno de los nuevos grupos hasta que estos sean
indivisibles.
Las técnicas divisivas suelen ser más complejas que las aglomerativas debido a la
necesidad de una subrutina, que no es más que otro algoritmo de clustering,
experimentalmente se suele determinar que estos resultan ser más precisos que los
métodos aglomerativos.
3.2 Métodos de partición
Son métodos generalmente usados para determinar todos los grupos del conjunto con una
sola ejecución. Además de ser la familia de métodos más usada, su uso es común a modo
de subrutina en los métodos jerárquicos divisivos descritos anteriormente en la sección
2.2. A continuación se describirán algunos de los métodos de partición más comunes[56].
3.2.1 K-means
La lógica de K-means se basa en el uso de k centroides para un conjunto de datos del que
se supone hay k clases de objetos, en un pre procesamiento se asumen estos centroides
como uniformemente distribuidos sobre el espacio de solución y se asigna cada objeto del
conjunto al centroide más cercano. Posteriormente se ejecuta un algoritmo iterativo que
recalcula la posición de los centroides de acuerdo los objetos asociados en cada iteración,
el algoritmo se comporta como un método de minimización de la función del error cuadrado
medio[56][58]:
𝐽 = ∑ ∑ ‖𝑥𝑖(𝑗)
− 𝑐𝑗‖2
𝑁
𝑖=1
𝑘
𝑗=1
Donde ‖𝑥𝑖(𝑗)
− 𝑐𝑗‖2es la distancia entre el punto 𝑥𝑖
(𝑗)y el centroide 𝑐𝑗
Paso 1 Definir K centroides uniformemente distribuidos en el espacio
35

Paso 2 Asignar cada punto al centroide más cercano
Paso 3 Recalcular la posición de cada centroide de acuerdo con los puntos asignados
Paso 4 Repetir los pasos 3 y 4 hasta que no los centroides no se muevan
3.2.2 Affinity propagation
Este algoritmo consiste en determinar la afinidad entre objetos, es decir, definir qué tanta
afinidad hay entre el objeto i y el objeto j como para afirmar que uno pertenece a la misma
clase del otro. Esto se realiza mediante la “comunicación” entre objetos, permitiendo que
la información recopilada se propague a otros objetos del conjunto. La principal ventaja de
este algoritmo respecto a otros como k-means, es que no requiere conocer o asumir
previamente el número de clusters en el conjunto[59].
El algoritmo opera definiendo 2 tipos de mensajes cuya información es recopilada en forma
de matrices[49]: Disponibilidad (Availability, escrita como 𝑎(𝑖, 𝑘)) y Responsabilidad
(Responsability, escrita como 𝑟(𝑖, 𝑘)); La Responsabilidad representa la evidencia del
grado en el que el elemento k puede ser usado como un ejemplar del elemento i y es
comunicada por el elemento i al elemento k. Por su parte la disponibilidad representa en n
qué grado el punto i podría seleccionar al punto k como un ejemplar suyo, esta es
comunicada por el punto k al punto i.
Paso 1 Actualizar la matriz de responsabilidad
Paso 2 Actualizar la matriz de disponibilidad
Paso 3 Combinar los datos de ambas matrices para identificar los grupos
Los cálculos se realizan de la siguiente manera:
𝑟(𝑖, 𝑘) = (1 − 𝜆) 𝑟(𝑖, 𝑘) + 𝜆(𝑆𝑖,𝑘 − max𝑘′:𝑘′≠𝑘
( 𝑎(𝑖, 𝑘′) + 𝑆𝑖,𝑘′))
𝑎(𝑖, 𝑘) = (1 − 𝜆) 𝑎(𝑖, 𝑘) + 𝜆 ∗ min {0, 𝑟(𝑘, 𝑘) + ∑ 𝑚𝑎𝑥( 0, 𝑟(𝑖′, 𝑘))
𝑖′:𝑖′∉{𝑖,𝑘}
}
𝑎(𝑘, 𝑘) = (1 − 𝜆) 𝑎(𝑘, 𝑘) + 𝜆 ∑ 𝑚𝑎𝑥( 0, 𝑟(𝑖′, 𝑘))
𝑖′:𝑖′≠𝑘
36

Donde 𝜆 es el factor de damping, introducido para evitar oscilaciones y permitir
convergencia.
3.3 Spectral clustering
Los métodos de spectral clustering (Agrupamiento espectral) son aquellos que hacen uso
del espectro de la matriz de similitud para realizar procesos que reduzcan la
dimensionalidad y facilitar agrupamientos simples. Mientras la mayoría de los métodos de
clustering están fuertemente relacionados con la medida de distancia euclidiana y asumen
grupos de datos definidos por envolventes convexas, los métodos de clustering son mucho
más flexibles y permiten capturar un rango más amplio de geometrías como soluciones[56],
[57], [60].
Dado un conjunto de puntos {𝑋𝑖}𝑖=1𝑁 de dimensión 𝑑:
Paso 1
Calcular una matriz de similitud S tal que 𝑆𝑖𝑗 = 𝑒−
‖𝑋𝑖−𝑋𝑗‖2
2𝜎2 para 𝑖 ≠ 𝑗 y 0 para
𝑖 = 𝑗, done 𝜎2 es llamado factor de escalamiento y controla que tan rápido la
afinidad entre 2 puntos disminuye con la distancia
Paso 2 Definimos 𝐷 como la matriz diagonal cuyo elemento (𝑖, 𝑖) es la suma de los
elementos de la fila 𝑖 de la matriz 𝑆 y construimos la matriz 𝐿 = 𝐷−1/2𝐴𝐷−1/2
Paso 3 Calculamos 𝑉1, 𝑉2, 𝑉3, … , 𝑉𝑘, como los 𝑘 mayores vectores propios de 𝐿 y
formamos la matriz 𝑋 = [𝑉1, 𝑉2, … , 𝑉𝐾]
Paso 4 Creamos la matriz 𝑌 como una versión normalizada de la matriz 𝑋
Paso 5 Tratamos cada fila en 𝑌 como un punto y realizamos el agrupamiento de estos
mediante k-means.
Paso 6 Asignamos el punto 𝑋𝑖 original al grupo 𝑗 si y solo si la fila 𝑖 de la matriz 𝑌 es
asignada al grupo 𝑗
El algoritmo es paralelizadle parcialmente, dado que es posible calcular el laplaciano
mediante el cálculo de cada uno de sus factores por separado construyendo la matriz final
a partir de ellos.
37

3.4 Clustering para detección de intrusión
Algunos trabajos recientes en el área exploran el uso de diversos métodos para afrontar
estos problemas en cada una de las 4 funciones básicas de los IDS. (Nikolai, Jason) [45]
Propone un IDS en la nube basado en Hypervisor para monitorear la actividad global de la
red y un nodo principal (controlador) encargado de la clasificación, análisis y acción. En
trabajos recientes, (Zhi Li , Yanzhu Liu, Sujingtao) [61] aplica métodos de la teoría de
adversarios para el diseño de un IDS basado en la premisa de nodos no cooperativos, es
decir, cada equipo en la red es un potencial atacante. Por su parte, (Sudhansu Ranjan
Lenka) [62] Propone un sistema de protección de servicios en la nube basado en análisis
de tráfico y clasificadores bayesianos. Finalmente, algunos autores proponen también
sistema híbridos donde se usa más de un método o se usan algoritmos paralelos y
distribuidos para satisfacer diferentes requerimientos [3], [63]–[65].
Queda claro que los modelos enfocados a la detección de patrones son los de mayor
precisión en la detección, sin embargo, estos son generalmente incapaces de adaptarse
ante cambios de topología o nuevos patrones de ataque. Por su parte los medios de
detección de anomalías supervisados son propensos a generar falsas alertas, sin
embargo, el mayor obstáculo para estos métodos es la dificultad que existe para generar
conjuntos de datos suficientemente grandes, correctamente etiquetados y lo
suficientemente actualizados como para obedecer a tendencias actuales de tráfico y uso
de las redes[48].
Los modelos no supervisados enfocados a la detección de anomalías son aquellos que
pretenden realizar detecciones de intrusión sobre datos sin etiquetar, estos modelos parten
de 2 premisas básicas[66]:
- Que las intrusiones en una red son relativamente pocas, es decir, se asume que la
gran mayoría del tráfico corresponde a actividades legítimas y normales de la red.
- Que existen características que diferencian la actividad normal de la red y una
actividad maliciosa.
Bajo estos supuestos, es posible desarrollar heurísticas que etiqueten los datos y se
adapten a la nueva información recibida durante su funcionamiento permitiendo detectar
nuevos patrones de ataque y reconocer nuevos patrones de uso de la red.
38

Las implementaciones típicas de algoritmos como spectral clustering, basadas en
operaciones sobre matrices suelen demandar grandes recursos de tiempo y memoria a
medida que los conjuntos analizados se hacen más grandes, por esta razón es difícil su
implementación para sistemas en tiempo real puesto que dependen en gran medida de la
capacidad de paralelización del algoritmo[67].
La arquitectura dinámica de las redes en la nube también supone un reto para su
despliegue, pues supone procesos de obtención y normalización de datos que respondan
a cualquier cambio en la red sin alterar la lógica de detección y clasificación de amenazas
[37].
En investigaciones recientes se ha usado spectral clustering para la clasificación de
eventos maliciosos en una red, los resultados evidencian una efectividad del 100% en
ataques DoS usando el conjunto de datos DARPA IDS dataset, así como una simulación
de ataque DDoS en un entorno de infraestructura en la nube. No obstante, el 12% de los
eventos clasificados como ataques DoS resultaron ser falsos positivos. En el caso de los
ataques tipo Probe (Escaneo de puertos, dispositivos y enlaces en busca de
vulnerabilidades) y U2R (Usuarios forzando fallos en el sistema para obtener acceso root
a un dispositivo) la clasificación fue menos eficaz, consolidando 90% de efectividad y un
10% de detecciones incorrectas[68].
39

4. Desarrollo del modelo de detección de
intrusión
Se propone un algoritmo de detección multicapa basado en métodos de clustering y
técnicas de aprendizaje supervisado como medio de optimización en clústeres no
atómicos. Particularmente se hace uso de un algoritmo basado en k-means, esto debido a
que el tiempo de asignación de un punto tras la formación de los clústeres depende
únicamente de la cantidad de clústeres mediante un algoritmo simple que calcula la
distancia del punto a cada centroide en búsqueda del más cercano[69], característica que
nos permite ejecutar el algoritmo en tiempo real con bajo costo computacional. El proceso
de detección propuesto consta de 3 etapas: Procesador de tráfico (Los paquetes de tráfico
son procesados para obtener una serie de características estándar), asignación de clúster
(Se asigna un clúster a cada paquete) y clasificación (Se ejecuta un proceso de
clasificación que nos dice la probabilidad de que el paquete sea un ataque). Haciendo uso
de la facilidad para el despliegue se servicios distribuidos, se propone un método modular
y paralelizable que podría ser desplegado de forma distribuida en la red mediante el uso
de redes definidas por software o en un host centralizado. Dicha paralelización puede
realizarse a nivel de capas que procesan cada paquete en paralelo o a nivel de clasificación
con esquemas de balanceo de carga, optimizando así el uso de los recursos libres de la
red.
Paso 1 Extraer el vector de características del paquete
Paso 2 Calcular el centroide más cercano
Paso 3 Realizar el proceso de clasificación en las capas con clústeres no atómicos
Paso 4 Realizar el proceso de agregación sobre los vectores de probabilidad
resultantes
40

4.1 Formación de clústeres
Para el agrupamiento se hará uso de mini-batch k-means[70], un método de clustering
basado en k-means. K-means consiste en una función de optimización, que encuentra el
conjunto centroides C que minimiza el error medio min (∑ ∑ ‖𝑥𝑖(𝑗)
− 𝑐𝑗‖2
)𝑁𝑖=1
𝑘𝑗=1 , esta
función es computacionalmente costosa para conjuntos de datos grandes pues se ejecuta
en 𝑂(𝑘𝑛𝑠) donde 𝑘 es la cantidad de clústeres, 𝑛 la cantidad de datos y 𝑠 la máxima
cantidad de atributos no nulos en el conjunto de datos[71]. Una forma de optimizar la
velocidad de ejecución es el uso de lotes pequeños de ejemplos aleatorios almacenados
en memoria, cada nueva iteración recalcula los centroides hasta que el algoritmo determina
un punto de convergencia (que tras una iteración la ubicación de los centroides no cambia).
Para optimizar el tiempo de ejecución, se hace uso de una tasa de aprendizaje que se
reduce con cada iteración, esta tasa reduce el impacto de cada nuevo lote de datos en la
formación de los datos. Todo esto reduce sustancialmente el tiempo de ejecución del
algoritmo con bajo costo en el resultado final[70].
Algoritmo 2 - Mini-batch k-Means[70].
1. Given: k, mini-batch size b, iterations t, data set X
2. Initialize each c ∈ C with an x picked randomly from X
3. v ← 0
4. for i = 1 to t do
5. M ← b examples picked randomly from X
6. for x ∈ M do
7. d[x] ← f(C, x) // Cache the center nearest to x
8. end for
9. for x ∈ M do
10. c ← d[x] // Get cached center for this x
11. v[c] ← v[c] + 1 // Update per-center counts
12. η ← 1
13. v[c]
14. // Get per-center learning rate
41

15. c ← (1 − η)c + ηx // Take gradient step
16. end for
17. end for
Definiremos como atómico a un clúster tal que a partir de un conjunto de datos etiquetados
todos los elementos clasificados en dicho grupo pertenecen al mismo tipo.
4.2 Procesador de tráfico
Se hace uso de un módulo de procesamiento de paquetes capaz de realizar el análisis y
procesamiento estadístico sobre estos con el fin de generar vectores de características
similares a los obtenidos en KDD cup 99. Este módulo consta de un sniffer capaz de
monitorear una interfaz o un conjunto de interfaces de red, un reconstructor de secuencias
que nos permite reconstruir las características básicas (características 1 – 9) y un motor
estadístico (Características 23 – 41)
4.3 Asignación de clústers
El proceso de asignación de clústeres consiste en encontrar el centroide más cercano a
cada punto según la medida de distancia. En este caso, se toma el vector de características
del procesador de tráfico y se calcula el vector de distancias, si el clúster asignado es un
clúster atómico, asignamos la etiqueta del clúster al punto con probabilidad del 100%. En
el caso de clústeres no atómicos, el paquete es redirigido a un nodo de clasificación con
la referencia al clúster asignado.
4.4 Clasificación
Una vez se han calculado los centroides y se han identificado la distribución de etiquetas
en cada uno de ellos, se realiza un proceso de clasificación sobre los puntos de cada
clúster no atómico, en este proceso se pretende calcular la probabilidad de que un
elemento dado sea un ataque. Para esto, se implementa un proceso de clasificación
mediante una implementación de SAMME[72], un algoritmo propuesto originalmente por Ji
Zhu, Saharon Rosset, Hui Zou y Trevor Hastie, en el cual se presenta una generalización
del algoritmo AdaBoost, en el cual se genera un sistema de clasificadores que minimizan
42

el error de detección sobre el conjunto de entrenamiento, dichos clasificadores (conocidos
clasificadores débiles) son tomados de un conjunto predefinido de técnicas de
clasificación.
Esta técnica resulta ideal para la clasificación en clústeres no atómicos, pues dada la
naturaleza estocástica de la distribución de los elementos en los clústeres, no podemos
predecir fácilmente la forma de la solución en cada uno de ellos. Por lo tanto, no podríamos
seleccionar y optimizar un clasificador débil adecuado sin un análisis exhaustivo de la
conformación de cada clúster en una ejecución del algoritmo.
Algoritmo 2 - SAMME[72].
1. Given a vector of weights 𝑤 = (𝑤1 , 𝑤2, … , 𝑤𝑛) , a vector of
classifiers 𝑚 = (𝑚1, 𝑚2, … , 𝑚𝑖) that assign a tag to variable 𝑥,
the number of clases 𝑘, the number of classifiers 𝑛 the
class label c ∀ {1,2,…,k}
2. Initialize 𝑤𝑖 = 1/𝑛
3. for 𝑚𝑖 in 𝑚 do
4. 𝑚𝑖.fit(x)
5. 𝑒𝑟𝑟𝑜𝑟𝑖 = ∑ 𝑤𝑗𝕀(𝑐𝑖 ≠ 𝑚𝑖(𝑥𝑗))/ ∑ 𝑤𝑗𝑛𝑗=1
𝑛𝑗=1
6. 𝛼𝑖 = log (1−𝑒𝑟𝑟𝑜𝑟𝑖
𝑒𝑟𝑟𝑜𝑟𝑖) +. log (𝑘 − 1)
7. for j = 1 to n do
8. 𝑤𝑖 ← 𝑤𝑖𝑒𝑚𝑖𝕀(𝑐𝑖≠𝑚𝑖(𝑥𝑗))
9. end for
10. normalize(𝑤)
11. end for
12. probabilities = ∑ 𝛼𝑖𝕀(𝑚𝑗(𝑥) = 𝑦)𝑀𝑗−1 ) ∀ 𝑦 ∈ {1,2, … , 𝑘}
13. return probabilities
Este proceso nos permite generar un vector de probabilidades
(𝑃𝑛𝑜𝑟𝑚𝑎𝑙 , 𝑃𝑎𝑡𝑡𝑎𝑐𝑘1, 𝑃𝑎𝑡𝑡𝑎𝑐𝑘2
, . . , 𝑃𝑎𝑡𝑡𝑎𝑐𝑘𝑚) que nos indica la posibilidad de que un elemento
(paquete) 𝑥 pertenezca a cada uno de los grupos definidos.
43

4.5 Agregación
En clasificación, se conoce como ensemble a un grupo de clasificadores cuyas salidas
pasan por un proceso de agregación con el fin de emitir un juicio colectivo logrado mediante
esquemas de votación o agregación probabilística, diversas investigaciones sugieren que
el uso de esquemas de clasificación paralelos fuertemente dependientes de las variables
de inicialización puede aumentar el desempeño para sistemas con datos de entrenamiento
o datos de entrada de baja calidad[73], [74]. Se han planteado en la literatura mejoras a
este tipo de algoritmos mediante la ponderación de clasificadores según su desempeño,
con los datos de prueba dicha optimización permite desarrollar modelos de clasificación
eficientes cuando los datos de entrada del modelo suelen tener datos faltantes[73].
En este caso, se propone un esquema de ponderación sobre los vectores de resultados
de la ejecución paralela de varias capas de clasificación, entendiendo que dada la
cardinalidad de los datos de entrada disponibles los modelos de detección están
fuertemente sesgados hacia tipos de eventos comunes como los DoS.
En términos generales, el método de agregación propuesto consiste agregación
probabilística sobre todas las posibles clases. Dados 𝑛 vectores de probabilidades de
tamaño 𝑚 con la forma 𝑉𝑖 = (𝑃1, 𝑃2, 𝑃3, … , 𝑃𝑚) y un vector de pesos de tamaño 𝑚 de la
forma 𝑊 = (𝑊1, 𝑊2, 𝑊3, . . . , 𝑊𝑚), se realiza una reducción formando un único vector 𝑉𝑓 =
(𝑃𝑓1, 𝑃𝑓2
, 𝑃𝑓3, … , 𝑃𝑓𝑚
) donde
𝑃𝑓𝑗= 𝑊𝑗 ∗
∑ 𝑉𝑖𝑗𝑛𝑖=1
𝑚
44

5. Metodología de evaluación
5.1 Métricas de evaluación
En general un sistema de detección puede evaluarse desde 2 puntos de vista: Eficiencia y
efectividad. Donde eficiencia se refiere a la cantidad de recursos del sistema necesarios
para ejecutar el algoritmo, esto incluye los recursos de espacio, procesamiento, memoria
y red; Y efectividad se refiere a la habilidad del sistema para distinguir entre eventos
intrusivos y tráfico legítimo de la red. Se conocen en la literatura diversas métricas para
evaluar sistemas de detección de anomalías, sistemas de clasificación y clustering
aplicadas a sistemas de detección de intrusión[75], [76]. A la fecha no existe un framework
que nos permita fácilmente comparar la eficiencia de 2 sistemas distribuidos sin que sea
necesario reproducir las mismas condiciones a nivel de hardware y recursos disponibles.
Con el fin de medir la efectividad del modelo, se definen métricas de clasificación (aquellas
en las no importa qué tan cerca se esté de predecir el resultado correcto, sino la predicción
sobre el conjunto de prueba comparada con las etiquetas reales conocidas) y de
probabilidad (Indicadores que nos permiten evaluar la confiabilidad del modelo
estadísticamente). Para efectos de pruebas del método propuesto se hará uso de las
siguientes métricas de evaluación:
Verdaderos Negativos (true negatives) abreviado 𝑇𝑁, Es el número de eventos
correctamente clasificados como negativos (normales).
Falsos Negativos (false negatives) abreviado 𝐹𝑁, es el número de eventos
incorrectamente clasificados como negativos.
Verdaderos positivos (true positives) abreviado 𝑇𝑃, es el número de eventos
correctamente clasificados como positivos.
45

Falsos Positivos (false positives) abreviado 𝐹𝑃, es el número de eventos
incorrectamente clasificados como positivos.
Precisión (precision) abreviado 𝑃𝑅; Representa el porcentaje de eventos anómalos
correctamente identificados.
𝑃𝑅 =𝑇𝑃
(𝑇𝑃 + 𝐹𝑁)
Tasa de falsos positivos (false positive rate) abreviado 𝐹𝑃𝑅; Representa el
porcentaje de eventos no anómalos detectados incorrectamente respecto al total
de eventos no anómalos en el conjunto de pruebas.
𝐹𝑃𝑅 = 𝐹𝑃
(𝐹𝑃 + 𝑇𝑁)
Tasa de clasificación (classification rate) abreviado 𝐶𝑅; Representa a tasa de
clasificación correcta del algoritmo.
𝐶𝑅 = 𝑇𝑃+𝑇𝑁
𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁
F-Measure abreviado 𝐹𝑀; Es la media harmónica de la precisión y la tasa de
detección.
𝐹𝑀 =2𝑇𝑃
2𝑇𝑃 + 𝐹𝑃 + 𝐹𝑁
Los valores de 𝑇𝑁, 𝐹𝑁, 𝑇𝑃 y 𝐹𝑃 son calculados partir del vector de etiquetas conocidas y
el vector de etiquetas producidas por el algoritmo, esta información será ilustrada a través
de una matriz de confusión normalizada.
5.1.1 Matriz de confusión
La matriz de confusión es una matriz que representa el resultado de un proceso de
clasificación. Por cada grupo de datos en el conjunto de prueba, se determinará cuántos
datos fueron clasificados en cada una de las posibilidades. En un escenario ideal (precisión
del 100%) esta matriz debería contener solamente elementos no nulos en su diagonal.
46

Predicted
class a class b class c
Ac
tua
l
class a a predicted as a a predicted as b a predicted as c
class b b predicted as a b predicted as b b predicted as c
class c c predicted as a c predicted as b c predicted as c
En el caso de clasificaciones binarias (como ataque/normal) la matriz de confusión
muestra directamente los valores de 𝑇𝑃, 𝐹𝑃, 𝑇𝑁 y 𝐹𝑁.
Predicted
TRUE FALSE
Ac
tua
l TRUE TP FN
FALSE FP TN
Una forma común de ilustrar las matrices de confusión es mediante su forma normalizada,
que permite ilustrar fácilmente el grado de correctitud de la clasificación sin importar la
disparidad entre los tamaños de los grupos. En un escenario ideal, la matriz de confusión
con precisión del 100% corresponde a una matriz diagonal.
47

5.2 Escenario de pruebas
Figura 12 Flujo de pruebas
El escenario de pruebas consiste en un pipeline automatizado implementado en software,
con un hilo de ejecución, que toma como entradas un conjunto de prueba con datos pre-
procesados que contienen el vector de características del clasificador y ejecuta el proceso
de clasificación.
1 Se leen los datos del conjunto de entrenamiento de KDD cup 99 a partir de un
archivo de texto plano y son convertidos a objetos en el módulo de software
de entrenamiento.
2 Se genera el modelo de clasificación a partir de los datos de entrenamiento,
estos datos son usados como inicialización del IDS y a su vez son
almacenados de manera local en forma de objeto serializado para
experimentos futuros.
3 Se leen los datos del conjunto de prueba de KDD cup 99 a partir de un archivo
de texto plano y son convertidos a objetos de software para ser procesados
por el IDS.
4 La salida del IDS es enviada a un módulo de análisis que contrasta los
resultados con la información de las etiquetas del dataset, generando las
estadísticas y métricas de evaluación.
48

5 Los resultados son serializados y guardados en el almacenamiento local.
Este proceso genera un vector de predicciones el cual es evaluado mediante un módulo
estadístico que nos permite contrastar las predicciones con las etiquetas conocidas y
generar las métricas desempeño del modelo, así como las representaciones de los
resultados como matrices de confusión.
NÚMERO DE DATOS La cantidad total de datos en el conjunto
DATOS CON ETIQUETA A La cantidad total de datos con etiqueta A
DATOS CON ETIQUETA B La cantidad total de datos con etiqueta B
DATOS CON ETIQUETA NORMAL La cantidad total de datos con etiqueta
normal
DATOS CON ETIQUETA ATAQUE La cantidad total de datos con etiqueta
diferente de NORMAL
TN Verdaderos negativos
FN Falsos negativos
TP Verdaderos positivos
FP Falsos positivos
PR Precisión
FPR Tasa de falsos positivos
CR Tasa de clasificación
F-MEASURE F-measure
Tabla 2 - Métricas de evaluación
De esta manera, generamos métricas claras del desempeño del modelo que permitan
medir su efectividad y evaluar el impacto de los parámetros de entrada sobre conjuntos de
datos específicos, como, por ejemplo, la cantidad de capas del modelo, la cantidad de
clasificadores y la cantidad de clústeres. El entorno de pruebas es ejecutado sobre un
49

equipo AMD Threadripper 1950x - 16 núcleos, 32 hilos @ 4 GHZ; 32GB de RAM @ 3000
MHZ; 128GB de swap; Ubuntu 18.04
5.2.1 Almacenamiento
En el almacenamiento local del equipo se encuentran los conjuntos de datos de prueba y
entrenamiento basados en KDD cup 99, codificados como CSV (comma-separated values)
que sirven como insumo principal para los procesos de entrenamiento y clasificación del
flujo de pruebas. Adicionalmente, se almacenan registros de la salida del proceso de
entrenamiento y de los resultados del algoritmo codificados como archivos binarios de
objetos serializados (pickle), almacenar estos datos localmente nos permite reproducir los
escenarios en un menor tiempo, dado que actúan como cache permitiendo cargar los
objetos serializados directamente en los componentes de software del flujo de pruebas sin
tener que recalcular el proceso.
5.2.2 Módulos de software
El flujo de pruebas se implementa como módulos de software escritos en Python,
particularmente el flujo se divide en 3 módulos de software, entrenamiento, clasificación y
análisis de resultados. El módulo entrenamiento genera un objeto que contiene las capas
entrenadas del modelo de clasificación, este objeto es serializado y guardado en el
almacenamiento local del equipo. Además es usado como entrada para el módulo de
clasificación IDS que ejecuta el modelo y realiza una predicción sobre los datos.
Finalmente, la predicción se pasa al módulo de análisis que genera las estadísticas y
métricas establecidas, guardando un objeto serializado con los resultados y una serie
representaciones graficas de estos, como las matrices de confusión y la distribución de
etiquetas en los clústeres.
5.2.3 Interfaz de control
El flujo de pruebas se ejecuta mediante la línea de comandos del sistema operativo de la
máquina de pruebas. Mediante esta interfaz se realizan procesos de preparación del
sistema, tales como la limpieza de del cache de memoria RAM y la eliminación de procesos
no críticos del sistema que puedan afectas los tiempos de ejecución entre ejecuciones del
mismo flujo. Además, mediante esta interfaz visualizamos el progreso y las salidas de cada
50

módulo de software incluyendo las métricas desempeño que nos ayudan a medir el
desempeño del algoritmo
5.2.4 Datos
Los conjuntos de datos usados en este estudio provienen de fuentes de libre acceso,
disponibles en internet y generados por diferentes entidades. En este caso, se usan con el
fin de medir el desempeño de los algoritmos planteados en escenarios determinísticos
basados en tráfico real.
El laboratorio Lincoln del Massachusetts Institute of Technology (MIT), Defence Advanced
Research Projects Agency (DARPA) y Air Force Research Laboratory (AFRL), crearon el
primer estándar para sistemas de detección de intrusión con el DARPA dataset for
intrussion detection evaluation[77], que puede ser usado para entrenar y evaluar diferentes
IDSs. Este dataset en particular constituye una de las principales referencias globales en
evaluación de sistemas de detección de intrusión debido a su nivel de objetividad,
formalidad y significancia estadística.
DARPA dataset consiste en una colección de tráfico de red que se asemeja al tráfico entre
una base militar real e internet. Conteniendo ataques tipo DoS, R2L (Remote to local,
usuarios intentando ganar acceso a la red desde un dispositivo externo), U2R (User to
Root) y Probing. Donde todos los ataques se originan en el exterior y con capturados por
un sniffer ubicado en el punto de acceso a la red.
DARPA dataset se divide en 2 conjuntos de datos[77]:
- 7 semanas de datos de entrenamiento que contienen tráfico normal y tráfico
anómalo etiquetado.
o DoS: Back, Land, Neptune, Pod, Smurf, Teardrop.
o Probing: Satan, Ipsweep, Nmap, Portsweep.
o R2L: Guess_Passwd, Ftp_write, Imap, Phf, Multihop, Warezmaster,
Warezclient, Spy.
o U2R: Buffer_overflow, Loadmodule, Rootkit, Perl.
- 2 semanas de datos de prueba con tráfico no etiquetado que incluye nuevos
patrones de ataque.
51

o DoS: Back, Land, Neptune, Pod, Smurf, Teardrop, Mailbomb,
ProcessTable, Udpstorm, Apache2, Worm.
o Probing: Satan, Ipsweep, Nmap, Portsweep, Mscan, Saint.
o R2L: Guess_Passwd, Ftp_write, Imap, Phf, Multihop, Warezmaster, Xlock,
Xsnoop, Snmpguess, Snmpgetattack, Httptunnel, Sendmail, Named.
o U2R: Buffer_overflow, Loadmodule, Rootkit, Perl, Sqlattack, Xterm, Ps.
Para verificar la efectividad del método de detección se hará uso KDD Cup 99, un dataset
basado en DARPA dataset que consta un pre procesamiento del tráfico para generar
vectores de características etiquetados. KDD cup 99[78] es usado ampliamente en
investigación relacionada con detección de intrusión. Este dataset contiene
aproximadamente 7 millones de datos etiquetados.
Características básicas:
No. Nombre Descripción
1 Duration Duración de la conexión
2 protocol_type Protocolo usado en la conexión
3 Service Servicio en la red de destino
4 Flag Estado de la conexión: normal o error
5 src_bytes Número de bytes transferidos desde la fuente hasta el
destino durante la conexión
6 dst_bytes Número de bytes transferidos desde el destino hasta la
fuente durante la conexión
7 Land 1 si las IPs y puertos de destino son igual; 0 en caso
contrario
8 wrong_fragment Número total de fragmentos erróneos en la conexión
9 Urgent Número de paquetes en la conexión con el bit de
urgente activado
Tabla 3 Características básicas[78]
Características basadas en contenido:
52

No. Nombre Descripción
10 Hot Número de indicadores hot en el contenido, como
acceso a directorios del sistema, creación o ejecución
de programas
11 num_failed_logi
ns
Conteo de intentos fallidos de inicio de sesión
12 logged_in 1 si hay sesión activa; 0 en caso contrario
13 num_compromis
ed
Número de condiciones comprometidas
14 root_shell 1 si obtiene acceso root; 0 en caso contrario
15 su_attempted 1 si intenta ejecutar un comando como root; 0 en caso
contrario
16 num_root Número de accesos root o número de operaciones
ejecutadas como root en la conexión
17 num_file_creatio
ns
Número de operaciones de creación de archivos en la
conexión
18 num_shells Número de líneas de comando
19 num_acess_files Número de operaciones de acceso a archivos
20 num_outbound_
cmds
Número de comandos de salida en una sesión FTP
21 is_hot_login 1 si la sesión pertenece a la lista hot ejemplo: root o
admin; 0 en caso contrario
22 is_guest_login 1 si la sesión es guest; 0 en caso contrario
Tabla 4 Características basadas en contenido[78]
Características basadas en tiempo:
No. Nombre Descripción
23 Count Número de conexiones dirigidas al mismo host de
destino que la conexión actual en los últimos 2
segundos
53

24 srv_count Número de conexiones dirigidas al mismo servicio de
destino que la conexión actual en los últimos 2
segundos
25 serror_rate Porcentaje de conexiones que han activado el flag (4)
s0, s1, s2 o s3, entre las conexiones agregadas en (23)
26 srv_serror_rate Porcentaje de conexiones que han activado el flag (4)
s0, s1, s2 o s3, entre las conexiones agregadas en (24)
27 rerror_rate Porcentaje de conexiones que han activado el flag (4)
REJ, entre las conexiones agregadas en (23)
28 srv_rerror_rate Porcentaje de conexiones que han activado el flag (4)
REJ, entre las conexiones agregadas en (24)
29 same_srv_rate Porcentaje de conexiones el mismo servicio, entre las
conexiones agregadas en (23)
30 diff_srv_rate Porcentaje de conexiones a diferentes servicios, entre
las conexiones agregadas en (23)
31 srv_diff_host_rat
e
Porcentaje de conexiones a diferentes máquinas de
destino entre las conexiones agregadas en (24)
Tabla 5 Características basadas en tiempo[78]
Características basadas en tráfico:
No. Nombre Descripción
32 dst_host_count Número de conexiones con la misma IP de destino
33 dst_host_svr_count Número de conexiones con el mismo puerto de
destino
34 dst_host_same_svr_rat
e
Porcentaje de conexiones al mismo servicio, entre
las conexiones agregadas en (32)
35 dst_host_diff_svr_rate Porcentaje de conexiones a diferentes servicios,
entre las conexiones agregadas en (32)
36 dst_host_same_src_por
t_rate
Porcentaje de conexiones desde el mismo puerto
de origen, entre las conexiones agregadas en (33)
54

37 dst_host_srv_diff_host_
rate
Porcentaje de conexiones hacia diferentes puertos
de destino; entre las conexiones agregadas en (33)
38 dst_host_serrror_rate Porcentaje de conexiones que activaron el flag (4)
s0, s1, s2 o s3, entre las conexiones agregadas en
(32)
39 dst_host_srv_s_error_r
ate
Porcentaje de conexiones que activaron el flag (4)
s0, s1, s2 o s3 entre las conexiones agregadas en
(33)
40 dst_host_rerror_rate Porcentaje de conexiones que activaron el flag (4)
REJ, entre las conexiones agregadas en (32)
41 dst_host_srv_rerror_rat
e
Porcentaje de conexiones que activaron el flag (4)
REJ, entre las conexiones agregadas en (33)
Tabla 6 Características basadas en tráfico[78]
55

6. Desarrollo de un prototipo de IDS
6.1 Arquitectura
Una vez definido un algoritmo de detección, se plantea un IDS de red capaz de monitorear
comunicaciones entre máquinas virtuales, para esto se propone la implantación de
máquinas virtuales (Nodos del IDS) en una DMZ lógica dentro de la infraestructura
alimentado por dispositivos de red que redirijan una copia del tráfico de la red a la DMZ
para análisis y acción. Dado que se comparten recursos, es de esperar que esta
configuración impacte directamente el desempeño de los servicios soportados pues
implica replicar el tráfico internamente, aumentando el uso general de la red.
Las máquinas virtuales dentro del entorno están conectadas por switch virtuales (vSwitch)
en cada host mientras que los hosts están conectados entre sí por switches físicos. Cada
vSwitch se encarga de replicar el tráfico para enviarlo al nodo central en la DMZ, mediante
un mecanismo de duplicación que se asegura de que cada trama solo sea procesada una
vez.
56

Figura 13 – Arquitectura de IDS
Las tramas pasan por un preprocesamiento en el cual se transforman en vectores de
características similares a las contenidas en KDD cup 99. Los nodos de preprocesamiento
se encuentran tras un balanceador de carga que asigna cada trama a uno de los nodos.
Este proceso de paralelización permite procesar tramas en un esquema de escalabilidad
horizontal. Sin embargo, requiere un mecanismo de gestión de estado compartido entre
los nodos, ejemplo de ello es Redis1, un motor de estructuras de datos en memoria, que
permite mantener el esquema paralelo sin degradación del desempeño por el proceso de
sincronización entre los nodos.
1 Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. https://redis.io/
57

Figura 14 - Capa de IDS
Posteriormente, se clasifica cada trama usando el algoritmo previamente descrito con
etiqueta “normal” o “ataque” y se le asigna un nivel de confianza a cada detección. Esta
información es enviada a un nodo agregador a través de un balanceador de carga, cuando
el agregador ha recibido las salidas de todas las capas emite una predicción, esta
información es finalmente enviada a un nodo de gestión que debería contener un actuador,
cuya implementación exhaustiva esta fuera del alcance de esta investigación. En un
contexto ideal, este actuador debería estar conectado al controlador de la red que permite
ejecutar acciones preventivas y correctivas sobre la red tales como la limitación de la tasa
de peticiones, el bloqueo de direcciones IP, encabezados, protocolos o acciones
específicas sobre la red.
El prototipo puede ser fácilmente desplegado en entornos como OpenStack2, el cual
permite un manejo sencillo de la infraestructura virtualizada en un entorno de máquinas
físicas. Esto debido a que en un entorno de producción con alto tráfico es necesario
2 OpenStack is a cloud operating system that controls large pools of compute, storage, and networking resources
throughout a datacenter, all managed through a dashboard that gives administrators control while empowering their users
to provision resources through a web interface. https://www.openstack.org
58

mantener un esquema de alta disponibilidad, por lo que el balanceo de carga se convierte
un aspecto fundamental de la arquitectura. Dado que los ataques DoS siguen siendo una
de las mayores amenazas a los entornos de computación en la nube es crítico para el
Sistema poder soportar flujos repentinos de carga realizando la detección oportuna de la
amenaza y filtrando el tráfico sin afectaciones a los servicios soportados por la red. Un
ejemplo de este componente, son los balanceadores de carga Octavia3 sobre Openstack.
Por otra parte, los módulos principales de clasificación están configurados en un esquema
que permite el despliegue de múltiples nodos con el fin de distribuir la carga entre varias
instancias, donde los clasificadores son cargados en cada una de las instancias haciendo
uso de objetos de Python serializados en archivos binarios mediante pickle. Esto, permite
mantener clasificadores congruentes en todas las instancias sin que tengan que ser
entrenados nuevamente; Además, la carga mediante objetos serializados permite el
aprovisionamiento del clasificador en pocos segundos.
Los nodos agregadores son aquellos encargados de colectar las respuestas de los
clasificadores y emitir un juicio final sobre cada uno de los datos procesados. En el caso
de un IPS, seria este el módulo encargado de notificar al nodo de gestión sobre la detección
de anomalías en la red.
En la Figura 13, se muestra un esquema de ejemplo en el cual el clúster de IDS se
encuentra lógicamente separado del resto de la red por un switch, el cual envía una copia
de todo el tráfico de la red al sistema de detección. En este escenario se presenta una
configuración de 2 nodos de preprocesamiento, 3 capas de clasificación y 2 nodos
agregadores. Sin embargo, la cantidad de nodos requeridos en cada etapa del proceso
depende de la carga soportada por la red y la capacidad de procesamiento de paquetes
que tenga el clúster de IDS según los recursos disponibles.
3 Octavia is an open source, operator-scale load balancing solution designed to work with OpenStack.
https://docs.openstack.org/octavia/latest/reference/introduction.html
59

6.2 Entrenamiento
6.2.1 Preprocesamiento y reducción de características
Se hace uso del 10% de los datos de KDD cup 99 dataset, conteniendo un total de 494,021
datos etiquetados[78]. Las etiquetas de los datos son clasificadas y reducidas a NORMAL,
PROBE, DOS, U2R, R2. Análisis detallados sobre el proceso de selección de
características han sido desarrollados en el pasado sobre los datos de DARPA dataset,
KDD cup 99 y variantes como NSL KDD usando diversos métodos como Optimal Genetic
Algorithm, Sequencial Search, Maximal information compression index, Least square
regression error[79]–[81]. Dado que se plantea un sistema de propósito general, el módulo
de preprocesamiento de tráfico en vivo no soporta parámetros específicos de la capa de
aplicación, por esta razón las siguientes características son removidas:
num_failed_logins
logged_in, num_compromised
root_shell
su_attempted
num_root
num_file_creations
num_shells
num_access_files
num_outbound_cmds
is_host_login
is_guest_login
Los datos numéricos son normalizados linealmente en intervalos en intervalos de 0 a 1,
esto con el fin de prevenir que una variable tome relevancia sobre las otras. Con las
variables normalizadas se realiza un análisis de correlación mediante el coeficiente de
60

correlación de Pearson definido de manera genérica como 𝑐𝑜𝑟𝑟(𝑋, 𝑌) =𝑐𝑜𝑣(𝑋,𝑌)
𝜎𝑋𝜎𝑌=
𝐸[(𝑋−𝜇𝑋)(𝑌−𝜇𝑌)]
𝜎𝑋𝜎𝑌
Figura 15 - matriz de correlación KDD cup 99 - 10%
La figura 15, nos muestra la representación de la correlación entre las características sobre
el conjunto pruebas, donde se evidencia gráficamente la existencia de características con
valores unitarios que pueden ser removidas del modelo, además de varias características
con alto grado de correlación. En este caso se decide descartar características basado en
un criterio de tolerancia del 90%, es decir 𝑎𝑏𝑠(𝑐𝑜𝑟𝑟(𝑋, 𝑌)) > 0.9. Dado que la correlacion
se da en pares, en cada caso se conserva la característica que mantiene la menor
correlacion promedio con el resto de variables. De ser igual, se descarta cualquiera de
ellas pues se asume que la decisión no impacta el resultado. La Figura 16 nos muestra la
misma matriz de correlación tras la eliminación de variables.
Tras este proceso las siguientes características son descartadas:
dst_host_rerror_rate
dst_host_serror_rate
dst_host_same_srv_rate
61

dst_host_same_src_port_rate
dst_host_srv_rerror_rate
srv_rerror_rate
srv_serror_rate
srv_count
dst_host_srv_serror_rate
Figura 16 - matriz de correlación kdd cup 99 - 10%, eliminando variables altamente
correlacionadas.
6.3 Formación de clústeres
Se generan N conjuntos de 𝑘 clusters mediante mini-batch k-means donde cada uno de
estos conjuntos constituye una 𝐿 del modelo de clasificación, 𝐿𝑖 = {𝑐𝑖,1, 𝑐𝑖,2 . . . 𝑐𝑖,𝑘} cuya
única diferencia es factor aleatorio de inicialización de los centroides y SAMME en clusters
no atómicos. Este proceso genera grupos que pueden o no sobreponerse, como resultado
un dato no necesariamente pertenece al mismo grupo en diferentes capas.
Para la evaluación del modelo ha definido 𝑁 = 5 y 𝑘 = 16 valores que experimentalmente
minimizan el error medio en la clasificación de datos atípicos respecto a los datos
62

normales. Dado que el foco de la implementación es la detección de tráfico anómalo y no
la clasificación del tráfico anómalo en tipos de ataque.
Figura 17 - Distribución de etiquetas de entrenamiento; Capa 1
Figura 18 – Distribución de etiquetas de entrenamiento; Capa 2
Figura 19 – Distribución de etiquetas de entrenamiento; Capa 3
63

Figura 20 - Distribución de etiquetas de entrenamiento; Capa 4
Figura 21 - Distribución de etiquetas de entrenamiento; Capa 5
Al examinar la distribución de etiquetas dentro de las capas, resulta evidente la efectividad
del algoritmo de clustering al clasificar de forma no supervisada los datos que cuentan con
mayor cantidad de muestras. Particularmente, se encuentran ejemplos de clústeres
atómicos con etiquetas normal y DoS; las etiquetas R2L, U2R Y Probe, suelen estar
distribuidas a través de pocos clústeres. Pese a que los ataques DoS suelen representar
la mayor preocupación para los entornos de computación en la nube actuales, por la
facilidad para realizarlos. Cabe mencionar, que ataques como el U2R o el R2L son más
perjudiciales para cualquier sistema, dado que no solo comprometen la disponibilidad de
la red, sino que podrían generar vectores de ataque que dificulten la recuperación del
sistema o accedan a información crítica.
Cada capa pasa por un proceso de análisis en el cual se clasifica cada clúster según su
nivel de homogeneidad. Para esto se analizan las etiquetas originales de los elementos
asignados a cada clúster, un clúster será considerado atómico si y solo si el 100% de sus
elementos pertenecen al mismo grupo (NORMAL, DOS, PROBE, U2R, R2L). A cada
64

clúster se le asigna la etiqueta del grupo mayoritario y el porcentaje de miembros de este
grupo, que constituye el nivel de confianza del clúster.
La existencia de clústeres vacíos, además, presenta información importante. El algoritmo
inicializa y reajusta los centroides incrementalmente dejando al final del proceso centroides
aislados del conjunto de datos. Si bien no se puede determinar una etiqueta para estos
clústeres, queda claro que la existencia de un elemento asignado a estos clústeres
representaría una anomalía en la red, por lo cual, estos clústeres son etiquetados como
ataque con probabilidad 100%.
65

7. Evaluación del modelo de detección
Con el fin de determinar el desempeño del prototipo con una configuración de 5 capas,
tolerancia del 99% y grupos de 32 clasificadores débiles, se realiza el experimento de
detección sobre KDD cup 99, reduciendo las etiquetas a true (tráfico sospechoso) y false
(tráfico normal), en el cual se simula la entrada de paquetes preprocesados a los nodos de
predicción. La elección de los parámetros del modelo para este experimento se basa en la
exploración del impacto de cada una de estas variables en el desempeño del modelo.
Particularmente. no se observa mayor ganancia en precisión al aumentar la tolerancia del
modelo, mientras que si se impacta negativamente el tiempo de ejecución al encontrar
menos clusters atómicos. De igual manera, no se observa mayor ganancia promedio tras
el proceso de agregación con más de 5 capas bajo el mismo conjunto de entrenamiento.
Por su parte, la velocidad de ejecución del modelo se degrada a medida que aumenta el
número de clasificadores débiles, sin encontrarse mayor ganancia más allá de los 32
clasificadores.
Tal como se explica en detalle en el capítulo 6, el prototipo logrado fue entrenado en base
al dataset KDD cup 99 usando una partición del 10% de los datos. Para la prueba se hace
uso de los datos restantes etiquetados del dataset.
Total de
muestras
4898431
DoS 3883370
Probe 41102
R2L 1126
U2R 52
66

Normal 972781
Total ataques 3925650
Tabla 7 - Datos KDD cup 99
El experimento se realiza sobre un equipo Procesador AMD ryzen 1700 - 8 núcleos, 16
hilos @ 3.7 GHZ; 32 GB de RAM @ 2666 MHZ; Ubuntu 18.04. La salida de la ejecución
en el entorno permite determinar el tiempo de ejecución para detección de anomalías por
bloques.
Figura 22 - Uso de CPU (todos los núcleos)
67

Durante la ejecución del escenario de pruebas usando todos los núcleos de procesamiento
disponibles, se muestra un uso extenso de CPU cercano al 100% durante los procesos de
asignación de clústeres y clasificación, con un uso antes y después de la ejecución inferior
al 1%, evidenciando la capacidad de ejecución paralela del algoritmo. También se
visualizan fácilmente los procesos de ejecución de las 5 capas secuencialmente y cómo
entre capa y capa existe un periodo de baja actividad de procesamiento que corresponde
a la serialización de datos del entorno para análisis. Las ilustraciones 24 a 39 nos muestran
el comportamiento particular de cada núcleo del sistema durante la ejecución del
experimento.
Figura 23 - Uso de memoria RAM
En este caso, se evidencia que la operación del IDS no ha agotado la capacidad del
servidor de prueba, manteniendo más de un 30% de memoria RAM disponible durante
toda la ejecución. Esto pese a la enorme cantidad de datos de entrada aplicados durante
el experimento, siendo 10% el valor medio de uso de memoria cuando no se está
ejecutando el experimento. De todo esto, se puede concluir que se ha logrado un sistema
altamente eficiente en el uso de recursos y altamente paralelizable. Dicha capacidad de
paralelización sobre las entradas nos permite fácilmente extrapolar los tiempos de
ejecución a entornos en paralelo.
68
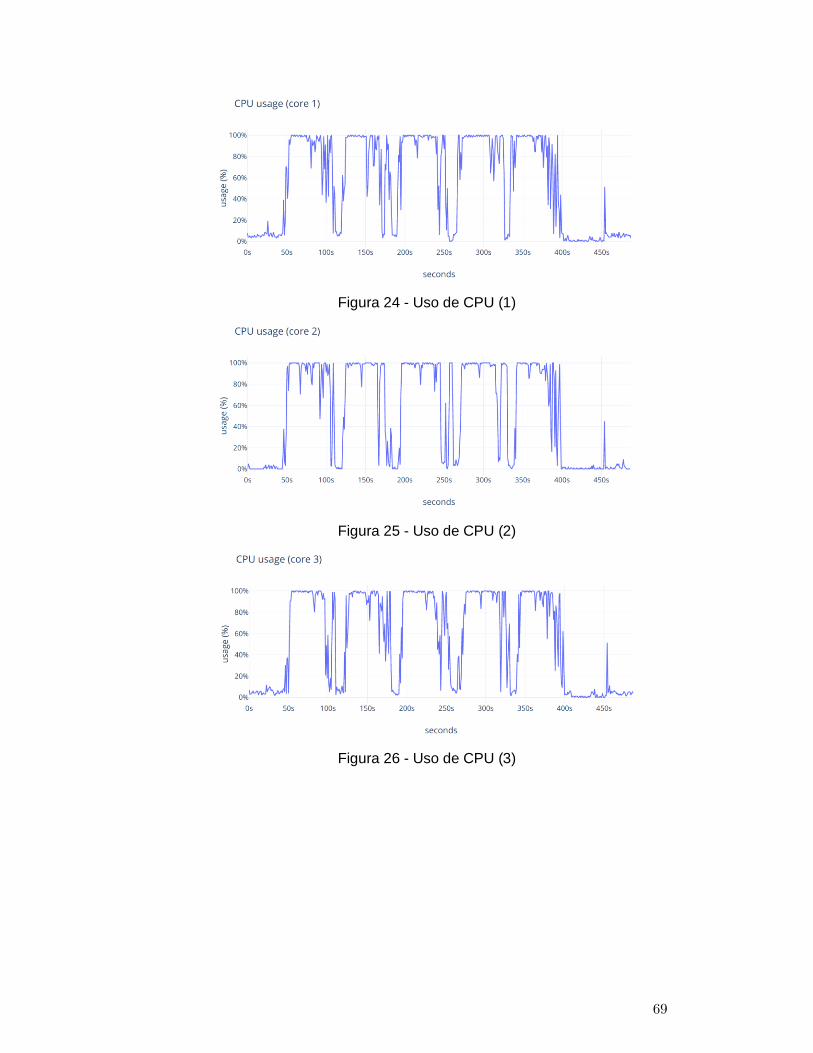
Figura 24 - Uso de CPU (1)
Figura 25 - Uso de CPU (2)
Figura 26 - Uso de CPU (3)
69

Figura 27 - Uso de CPU (4)
Figura 28 - Uso de CPU (5)
Figura 29 - Uso de CPU (6)
70

Figura 30 - Uso de CPU (7)
Figura 31 - Uso de CPU (8)
Figura 32 - Uso de CPU (9)
71

Figura 33 - Uso de CPU (10)
Figura 34 - Uso de CPU (11)
Figura 35 - Uso de CPU (12)
72

Figura 36 - Uso de CPU (13)
Figura 37 - Uso de CPU (14)
Figura 38 - Uso de CPU (15)
73

Figura 39 - Uso de CPU (16)
El tiempo promedio de clasificación en 5 capas sobre este entorno para 4898431 datos de
entrada es de 2453.990391 segundos, por lo que, en este entorno particular, el tiempo de
ejecución del proceso de clasificación por paquete es de 0.000500975 segundos. Por su
parte, el tiempo de agregación total fue en promedio de 11.8185267448 segundos o
0.00000241271 segundos por paquete. Esto se resume en una capacidad bruta de
procesamiento en un solo hilo de ejecución sobre este entorno de 1986.541225 paquetes
por segundo.
Por otra parte, al ejecutar el proceso de clasificación de forma paralela, se evidencia una
mejora sustancial en los tiempos de ejecución, pasando a 1303.783215 segundos con 2
núcleos, 774.8536615 segundos con 4 núcleos, 463.6882784 segundos con 8 núcleos,
386.3378847 segundos con 16 núcleos.
Figura 40 - Tiempo de ejecución en paralelo
El resultado de esta ejecución particular arroja la distribución de etiquetas mostrada en la
tabla 6. Las figuras 41 a 45 muestran como las matrices de confusión varían
74

considerablemente entre una capa y otra. Esto se debe al efecto de los parámetros de
inicialización en la formación final de clústeres en cada ejecución del experimento.
Figura 41 - Matriz de confusión, capa 1
LAYER 1 LAYER 2 LAYER 2 LAYER 4 LAYER 5 AGGREGATED
SAMPLES 4898431 4898431 4898431 4898431 4898431 4898431
DoS 3888601 3888555 3888436 3888427 3884126 3888558
Probe 36094 35957 36006 54471 40406 35905
R2L 1198 1234 1243 1252 1207 1206
U2R 82 76 62 193 70 69
normal 972456 972609 972684 972622 972693 972693
attack 4898431 4898431 4898431 4898431 4031947 4898431
Tabla 8 - Distribución de etiquetas
75

Figura 42 - Matriz de confusión, capa 2
Figura 43 - Matriz de confusión, capa 3
76

Figura 44 - Matriz de confusión, capa 4
Figura 45 - Matriz de confusión, capa 5
Como se puede observar, la discrepancia en el desempeño capa a capa muestra cómo el
uso de clústeres superpuestos inicializados aleatoriamente le permite al modelo generar
modelos de clústeres con mejor desempeño hacia un grupo particular. Dada la cardinalidad
del conjunto de pruebas los clústeres atómicos tienden a ser del tipo normal y DoS. El uso
de una combinación lineal sencilla en la fase de agregación parece interpretar de forma
efectiva este hecho pues la probabilidad combinada refuerza las buenas tasas de
detección en clases específicas produciendo un mejor resultado del que producen las
capas individualmente.
77

Figura 46 - Matriz de confusión normalizada
A pesar de la evidente mejora al agregar un paso de agregación en el experimento con
KDD cup 99, es de destacar que este modelo ha sido optimizado para lograr la mejor tasa
de detección en el conjunto {𝑎𝑡𝑎𝑞𝑢𝑒, 𝑛𝑜𝑟𝑚𝑎𝑙}. Por ello, el modelo con los mismos
parámetros de inicialización es probado realizando una agregación sobre las etiquetas,
reduciéndolas a estos 2 valores: false (tráfico normal) y true (tráfico sospechoso).
Figura 47 - Matriz de confusión binaria; Capa 1
78

Figura 48 - Matriz de confusión binaria; Capa 2
Figura 49 - Matriz de confusión binaria; Capa 3
79

Figura 50 - Matriz de confusión binaria; Capa 4
Figura 51 - Matriz de confusión binaria; Capa 5
En este caso, se hace evidente la influencia del proceso de agregación sobre los vectores
de probabilidad, logrando una mejora importante en la tasa de detección respecto al
promedio obtenido al analizar las capas antes de dicho proceso. Si bien sería posible
determinar un factor de sensibilidad en el modelo que permita optimizar individualmente
cada una de las capas, dicho proceso solo se puede realizar conociendo a priori las
etiquetas del conjunto, situación imposible de realizar en un escenario real, por lo que no
se realiza dicha optimización individual. Las figuras 52 y 53 nos muestran la matriz de
80

confusión binaria resultante del proceso de agregación con y sin clasificación en clústeres
no atómicos respectivamente.
Figura 52 - Matriz de confusión binaria
Figura 53 - Matriz de confusión binaria, sin optimización
LAYER 1 LAYER 2 LAYER 2 LAYER 4 LAYER 5 AGGREGATED
PE
RF
OR
MA
NC
E
TN (quantity) 972228 972323 972306 953700 972294 972445
FN (quantity) 228 286 378 388 328 248
TP (quantity) 3925422 3925364 3925272 3925262 3925322 3925402
FP (quantity) 553 458 475 19081 487 336
PR (percentage) 99.994192% 99.992715% 99.990371% 99.990116% 99.991645% 99.993683%
81

FPR
(percentage)
0.000568% 0.047082% 0.048829% 1.961490% 0.050063% 0.034540%
CR
(percentage)
99.984056% 99.984811% 99.982586% 99.602546% 99.983362% 99.988078%
F-MEASURE
(percentage)
99.990053% 99.990524% 99.989136% 99.752617% 99.989620% 99.992562%
Tabla 9 – resultados KDD cup 99, 2 etiquetas
Se logra una detección del 99.9937% de las anomalías de la red, con una tasa de falsos
positivos de 0.0345%, lo que supone una precisión del 99.9937% tras ejecutar el proceso
de agregación. Por otra parte, el efecto más evidente de la agregación es la reducción de
la tasa de falsos positivos (FPR) pasando de 0.4216% a 0.0345%, lo que reduce la
cantidad de falsos positivos a menos de una décima parte.
Before aggregation After aggregation
PR 99.991808% 99.993683%
FPR 0.421606% 0.034540%
CR 99.907472% 99.988078%
F-MEASURE 99.942390% 99.992562%
Tabla 10- Impacto del proceso de agregación
En la literatura, encontramos propuestas recientes de algoritmos de detección de intrusión
probadas sobre KDD cup 99, gracias a ello, es posible comprar el resultado obtenid con
dichos algoritmos e implementaciones. Vivek Nandan Tiwari, Satyendra Rathore y Kailash
Patidar[82] proponen una serie de algoritmos de clasificación basados en Naïve Bayes,
J48 y Random Forest, comparando sus resultados con trabajos anteriores vados en C4.5
y SVM. En la figura 54 se muestra un cuadro comparativo entre dichos métodos y el método
de detección propuesto en la configuración de 5 capas, 32 clasificadores débiles y
tolerancia del 99%.
PR
C4.5 SVM Naïve Bayes
J48 Random forest
Clustering
DoS 93.87% 93.84% 99.50% 100.00% 100.00% 99.87%
Probe 95.38% 89.09% 13.00% 85.70% 95.60% 99.34%
U2R 33.33% 66.67% 8.00% 98.50% 99.60% 93.37%
R2L 16.44% 15.90% 41.00% 81.00% 81.60% 73.91%
82

Tabla 11 - Comparativa con experimentos previos
83

84

8. Conclusiones y recomendaciones
8.1 Conclusiones
Se propuso y desarrolló satisfactoriamente un prototipo de sistema de detección de
intrusión basado en métodos de clustering y aprendizaje supervisado. Permitiendo
aprovechar las capacidades de procesamiento paralelo y distribuido, propios de este tipo
de entornos. Todo esto, motivado principalmente por la falta de desarrollos públicos e
investigación en el uso de sistemas de detección de intrusión en la nube pasados en este
tipo de algoritmos.
El prototipo logrado obtiene una tasa de detección promedio de 99.9937% tras el proceso
de agregación y una tasa de falsos positivos de 0.0345% al ser ejecutado sobre el
escenario de pruebas con dataset KDD cup 99, lo que demuestra que es factible usar
métodos de clustering para agrupar los patrones normales de tráfico y detectar datos que
se alejan de dichos clústeres.
El esquema desarrollado se compone de una serie de procesos que incrementalmente
aumentan el desempeño de la detección, la agrupación, la clasificación en clústeres no
atómicos y, finalmente, la agregación; La detección basada en k-means con etiquetado de
clústeres sin ningún tipo de optimización alcanza una precisión binaria de 98.4075% con
una tasa de falsos positivos de 0.7727%. Al realizar el proceso de clasificación sobre
clústeres no atómicos mediante algoritmos de clasificación supervisada, la precisión
lograda sobre el mismo experimento es de 99.9936% y la tasa de falsos positivos de
0.0345%.
El esquema de ejecución en paralelo permite adicionalmente optimizar el uso de recursos
y escalar horizontalmente, las pruebas realizadas con ejecución paralela sobre las
entradas a nivel de procesos evidencian un incremento lineal del desempeño respecto a
la cantidad de procesos ejecutados sobre núcleos dedicados. Logrando una mejora en la
85

velocidad de ejecución del 635% al usar los 16 hilos de procesamiento disponibles en la
máquina de pruebas respecto a la prueba de ejecución sobre un solo hilo. Esta capacidad
de escalar horizontalmente, lo hace ideal para el despliegue en entornos de computación
en la nube bajo esquemas de auto-escalado.
8.2 Recomendaciones
Este trabajo se enfoca en la conceptualización y el desarrollo de un IDS funcional basado
en algoritmos de clustering, este ha sido desarrollado usando principalmente
implementaciones sobre CPU basadas en librerías en Python y C++ de código abierto y
de propósito general. Dichas implementaciones podrían ser optimizadas para esta
aplicación particular. Por otra parte, en este trabajo, no se aborda el proceso técnico del
aislamiento del IDS como un componente seguro de la red o la implementación de auto-
escalabilidad sobre esta arquitectura; pese que dicha implementación no presenta
mayores retos a nivel técnico, si es dependiente de la tecnología y el esquema de
despliegue de infraestructura utilizado, por lo que el prototipo aquí presentado debe ser
complementado para poder ser llevado a un entorno de producción. Puntualmente:
- Varios de los procesos implementados, especialmente el cálculo de operaciones
matriciales en los algoritmos de clasificación, pueden ser mejorados
considerablemente mediante el uso de implementaciones sobre GPU. You Li,
Kaiyong Zhao, Xiaowen Chu y Jiming Liu[83] proponen una variación de k-means
sobre GPU que puede aplicarse al prototipo desarrollado.
- Con el fin de lograr un sistema lo suficientemente flexible para funcionar a gran
escala es necesaria la automatización de los procesos de aprovisionamiento y
configuración de la infraestructura del clúster de IDS como DMZ dentro de la red.
Dicha automatización, se puede lograr con el uso de herramientas como Ansible4,
un software de aprovisionamiento, configuración y despliegue de infraestructura en
la nube podrían ayudar a generar esquemas de despliegue más rápidos, flexibles
4 Ansible is an open-source software provisioning, configuration management, and application deployment tool.
https://www.ansible.com/
86

y tolerantes a errores. Además de permitir la portabilidad del sistema entre
diferentes entornos y proveedores de IaaS como AWS5, Azure6, Google Cloud7 y
Openstack
- La arquitectura y el proceso lineal propuesto para el prototipo de IDS, está pensada
para permitir etapas de procesos que sean altamente paralelizables en cada una
de las capas. Herramientas de orquestación como Kubernetes8, podrían permitir
empaquetar todo el Sistema en un clúster de máquinas virtuales fácilmente
escalable, prescindiendo de los balanceadores de carga explícitos y con óptima
utilización de recursos, delegando al nodo de gestión de kubernetes la labor de
escalar los recursos del propio IDS y facilitando un flujo de información más rápido
y eficiente.
- Es necesario el desarrollo de un módulo de notificación de amenazas y un módulo
actuador, con permisos de gestión sobre la red que permitan tomar acciones
automatizadas como la modificación de reglas del firewall o la reconfiguración de
la red y mantener registros en tiempo real de las alertas generadas por el IDS.
Dichos componentes complementarían el sistema comportándose como un IPS
aplicable a entornos de producción.
El sistema propuesto ha sido optimizado para la detección binaria {ataque, normal},
investigaciones como la de A. Little, X. Mountrouidou, y D. Moseley[68] exploran el uso
de métodos de clustering para la clasificación de tráfico anómalo que podrían ser
fácilmente añadidos al flujo gracias a la arquitectura modular propuesta. También es
posible la optimización del modelo clústeres desarrollado para generar un criterio multi-
clase más preciso mediante un análisis detallado de la composición de los clústeres
5 Amazon Web Services (AWS) is a subsidiary of Amazon that provides on-demand cloud computing platforms to
individuals, companies and governments, on a metered pay-as-you-go basis. https://aws.amazon.com/
6 Microsoft is a cloud computing service created by Microsoft for building, testing, deploying, and managing applications
and services through Microsoft-managed data centers. https://azure.microsoft.com/
7 Google Cloud Platform (GCP), offered by Google, is a suite of cloud computing services that runs on the same
infrastructure that Google uses internally for its end-user products. https://cloud.google.com/
8 Kubernetes (K8s) is an open-source system for automating deployment, scaling, and management of containerized
applications. https://kubernetes.io/
87

que facilite el entrenamiento del modelo con gran diferencia en la cardinalidad de las
clases.
Actualmente, son abundantes los estudios referentes a nuevos métodos de clustering
y variaciones de métodos ya existentes para aplicaciones generales. En esta
investigación se hace uso de métodos basados en k-means por la facilidad para las
asignaciones de clústeres con bajo uso de recursos. Sin embargo, existen en la
literatura propuestas de algoritmos de clustering con capacidad de predicción que
podrían ser adaptados a esta arquitectura. Dicha adaptación podría llevar a
implementaciones más precisas, por ejemplo, al eliminar el supuesto de clústeres con
soluciones convexas.
Otro aspecto clave para el desarrollo de más investigación en el área es la creación de
nuevos y mejores datasets de prueba de intrusión que contengan, no solo nuevos vectores
de ataque, sino actividades de gestión de la red correctamente etiquetadas. De esta
manera seria posible generar estudios comparativos más acertados entre propuestas de
sistemas de detección de intrusión.
88

A. Anexo: Código del prototipo y flujo de pruebas
Código del prototipo de IDS y el flujo de pruebas desarrollado. Incluido en la copia digital.


B. Anexo: Logs del sistema
Logs de uso de recursos de CPU y memoria durante la ejecución del flujo de pruebas con
16 hilos. Incluidos en copia digital.

Bibliografía
[1] S. Teh, S. Ho, G. Chan, and C. Tan, “A Framework for Cloud Computing Use to Enhance
Job Productivity,” pp. 73–78, 2016.
[2] L. Columbus, “Roundup Of Small & Medium Business Cloud Computing Forecasts And
Market Estimates ,” 2016. [Online]. Available:
http://www.forbes.com/sites/louiscolumbus/2016/03/13/roundup-of-cloud-computing-
forecasts-and-market-estimates-2016/#1ae22a2174b0. [Accessed: 01-Sep-2016].
[3] S. Vijayarani and M. Sylviaa, “Intrusion Detection System,” Int. J. Secur. Priv. Trust
Manag., vol. 4, no. 1, pp. 31–44, 2015.
[4] G. Bruneau, “The History and Evolution of Intrusion Detection,” 2001.
[5] I. Indu and A. I. Management, “Identity and Access Management for Cloud Web Services,”
no. December, pp. 406–410, 2015.
[6] K. Discovery, C. Yu, T. Wang, J. Fan, and Y. Li, “Application of Software-Defined
Network with Software-based Architecture in Enterprise Data,” 2016.
[7] A. Mahjani, “Security Issues of Virtualization in Cloud Computing Environments,” 2015.
[8] D. Drutskoy, E. Keller, and J. Rexford, “Scalable network virtualization in software-
defined networks,” IEEE Internet Comput., vol. 17, no. 2, pp. 20–27, 2013.
[9] S. Sezer, S. Scott-Hayward, P. Chouhan, B. Fraser, D. Lake, J. Finnegan, N. Viljoen, M.
Miller, and N. Rao, “Are we ready for SDN? Implementation challenges for software-
defined networks,” IEEE Commun. Mag., vol. 51, no. 7, pp. 36–43, 2013.

[10] K. Kuppusamy and D. Ph, “A Survey on Routing Algorithms for Cloud Computing,” pp. 5–
8, 2013.
[11] P. P. Ponnusamy, “Virtual network Routing in Cloud Computing Environment,” 2016.
[12] J. Moy, “OSPF Version 2,” IETF RFC, vol. 53, no. 9, pp. 1689–1699, 1998.
[13] Y. Rekhter, T. Li, and S. Hares, “A Border Gateway Protocol 4 (BGP-4) Status,” pp. 1–
104, 2006.
[14] M. Alizadeh, A. Greenberg, D. a. Maltz, J. Padhye, P. Patel, B. Prabhakar, S. Sengupta, and
M. Sridharan, “Data center TCP (DCTCP),” ACM SIGCOMM Comput. Commun. Rev., vol.
40, no. 4, p. 63, 2010.
[15] P. Wang, Y. Kim, V. Kher, and T. Kwon, “Strengthening Password-based Authentication
Protocols Against Online Dictionary Attacks.”
[16] W. Simpson, “PPP Challenge Handshake Authentication Protocol (CHAP),” 1996.
[Online]. Available: https://tools.ietf.org/html/rfc1994. [Accessed: 01-Jan-2017].
[17] N. Naik and P. Jenkins, “An Analysis of Open Standard Identity Protocols in Cloud
Computing Security Paradigm,” 2016.
[18] D. Hardt, “The OAuth 2.0 Authorization Framework,” 2012. [Online]. Available:
https://tools.ietf.org/html/rfc6749. [Accessed: 01-Jan-2017].
[19] PandaLabs, “bercrime Reaches New Heights in the Third Quarter.” [Online]. Available:
http://www.pandasecurity.com/mediacenter/pandalabs/pandalabs-q3/.
[20] S. Joshua, “43 Percent of Cyber Attacks Target Small Business,” 2016. [Online]. Available:
smallbiztrends.com/2016/04/cyber-attacks-target-small-business.html.
[21] J. Crowe, “Cyber Attack Statistics: Majority of Victims Aren’t Changing Their Security in
2017.” [Online]. Available: https://blog.barkly.com/cyber-attack-statistics-2016.
[22] A. Balobaid, W. Alawad, and H. Aljasim, “A study on the impacts of DoS and DDoS
attacks on cloud and mitigation techniques,” Int. Conf. Comput. Anal. Secur. Trends, CAST
2016, pp. 416–421, 2017.
[23] P. Rengaraju, R. R. V, and C. Lung, “Detection and Prevention of DoS attacks in Software-
Defined Cloud Networks,” pp. 217–223.

[24] G. Somani, M. S. Gaur, D. Sanghi, M. Conti, and R. Buyya, “DDoS Attacks in Cloud
Computing: Issues, Taxonomy, and Future Directions,” ACM Comput. Surv., vol. 1, no. 1,
pp. 1–44, 2015.
[25] A. A. Shaikh, “Attacks on cloud computing and its countermeasures,” Int. Conf. Signal
Process. Commun. Power Embed. Syst. SCOPES 2016 - Proc., pp. 748–752, 2017.
[26] A. G. Oleg Kupreev, Ekaterina Badovskaya, “DDoS Attacks in Q4 2018.” .
[27] M. Jensen, J. Schwenk, N. Gruschka, and L. Lo Iacono, “On technical security issues in
cloud computing,” CLOUD 2009 - 2009 IEEE Int. Conf. Cloud Comput., pp. 109–116,
2009.
[28] av-set, “Malware statistics,” 2017. [Online]. Available: https://www.av-
test.org/en/statistics/malware/. [Accessed: 20-Jul-2010].
[29] M. Azab and M. Eltoweissy, “MIGRATE: Towards a Lightweight Moving-Target Defense
Against Cloud Side-Channels,” Proc. - 2016 IEEE Symp. Secur. Priv. Work. SPW 2016, pp.
96–103, 2016.
[30] M. Chouhan, “Adaptive Detection Technique for Cache-Based Side Channel Attack Using
Bloom Filter for Secure Cloud Adaptive Detection Technique For Cache-Based Side
Channel Attack Using Bloom Hasbullah For Secure Cloud,” pp. 293–297, 2016.
[31] Y. A. Younis, K. Kifayat, Q. Shi, and B. Askwith, “A new prime and probe cache side-
channel attack for cloud computing,” Proc. - 15th IEEE Int. Conf. Comput. Inf. Technol.
CIT 2015, 14th IEEE Int. Conf. Ubiquitous Comput. Commun. IUCC 2015, 13th IEEE Int.
Conf. Dependable, Auton. Secur. Comput. DASC 2015 13th IEEE Int. Conf. Pervasive
Intell. Comput. PICom 2015, pp. 1718–1724, 2015.
[32] F. Liu, Q. Ge, Y. Yarom, F. Mckeen, C. Rozas, G. Heiser, and R. B. Lee, “CATalyst :
Defeating Last-Level Cache Side Channel Attacks in Cloud Computing,” Hpca, no. Vm,
pp. 406–418, 2016.
[33] M. M. Godfrey and M. Zulkernine, “Preventing cache-based side-channel attacks in a cloud
environment,” IEEE Trans. Cloud Comput., vol. 2, no. 4, pp. 395–408, 2014.
[34] M. Godfrey and M. Zulkernine, “A server-side solution to cache-based side-channel attacks
in the cloud,” IEEE Int. Conf. Cloud Comput. CLOUD, pp. 163–170, 2013.

[35] Ziqi Wang, Rui Yang, Xiao Fu, Xiaojiang Du, and Bin Luo, “A shared memory based
cross-VM side channel attacks in IaaS cloud,” 2016 IEEE Conf. Comput. Commun. Work.
(INFOCOM WKSHPS), vol. 2016–Septe, pp. 181–186, 2016.
[36] J. P. Anderson, “Computer Security Threat Monitoring and Surveillance.”
[37] Y. Mehmood, M. A. Shibli, U. Habiba, and R. Masood, “Intrusion detection system in
cloud computing: Challenges and opportunities,” Conf. Proc. - 2013 2nd Natl. Conf. Inf.
Assur. NCIA 2013, pp. 59–66, 2013.
[38] N. A. Premathilaka, A. C. Aponso, and N. Krishnarajah, “Review on state of art intrusion
detection systems designed for the cloud computing paradigm,” 2013 47th Int. Carnahan
Conf. Secur. Technol., pp. 1–6, 2013.
[39] W. S. Lawrie Brown, No Computer Security: Principles and Practice. 2008.
[40] C. Mazzariello, R. Bifulco, and R. Canonico, “Integrating a network IDS into an open
source cloud computing environment,” 2010 6th Int. Conf. Inf. Assur. Secur. IAS 2010, pp.
265–270, 2010.
[41] M. Shimamura and K. Kono, “Using attack information to reduce false positives in network
IDS,” Proc. - Int. Symp. Comput. Commun., pp. 386–393, 2006.
[42] H. Tang, “A Network IDS Model Based on Improved Artificial Immune Algorithm,” 2016
Int. Conf. Intell. Transp. Big Data Smart City, pp. 46–50, 2016.
[43] R. Vaarandi, K. Podi, R. Vaarandi, and K. Podi, “Network IDS Alert Classification with
Frequent Itemset Mining and Data Clustering Network IDS Alert Classification with
Frequent Itemset Mining and Data Clustering,” pp. 451–456, 2010.
[44] Z. Li, “A Neural Network Based Distributed Intrusion Detection System on Cloud
Platform,” 2013.
[45] J. Nikolai, “Hypervisor-based cloud intrusion detection system,” 2014 Int. Conf. Comput.
Netw. Commun., pp. 989–993, 2014.
[46] E. Bauman, G. Ayoade, and Z. Lin, “A Survey on Hypervisor-Based Monitoring,” ACM
Comput. Surv., vol. 48, no. 1, pp. 1–33, 2015.
[47] H.-J. Liao, C.-H. Richard Lin, Y.-C. Lin, and K.-Y. Tung, “Intrusion detection system: A
comprehensive review,” J. Netw. Comput. Appl., vol. 36, no. 1, pp. 16–24, 2013.

[48] H. Chou and S. Wang, “An Adaptive Network Intrusion Detection Approach for the Cloud
Environment.”
[49] M. Namratha and T. R. Prajwala, “A Comprehensive Overview of Clustering Algorithms in
Pattern Recognition,” J. Comput. Eng., vol. 4, no. 6, pp. 23–30, 2012.
[50] T. Salman, D. Bhamare, A. Erbad, R. Jain, and M. Samaka, “Machine Learning for
Anomaly Detection and Categorization in Multi-Cloud Environments,” Proc. - 4th IEEE
Int. Conf. Cyber Secur. Cloud Comput. CSCloud 2017 3rd IEEE Int. Conf. Scalable Smart
Cloud, SSC 2017, pp. 97–103, 2017.
[51] N. Pandeeswari and G. Kumar, “Anomaly Detection System in Cloud Environment Using
Fuzzy Clustering Based ANN,” Mob. Networks Appl., pp. 494–505, 2016.
[52] S. Kaur and P. V. Pandey, “A Survey of Virtual Machine Migration Techniques in Cloud
Computing,” vol. 6, no. 7, pp. 28–35, 2015.
[53] P. Jamshidi, A. Ahmad, and C. Pahl, “Cloud Migration Research : A Systematic Review,”
no. February, 2014.
[54] A. Ruprecht, D. Jones, D. Shiraev, G. Harmon, M. Spivak, M. Krebs, and T. Sanderson,
“VM Live Migration At Scale,” 2018.
[55] M. Noshy, A. Ibrahim, and H. A. Ali, “Optimization of live virtual machine migration in
cloud computing : A survey and future directions Journal of Network and Computer
Applications Optimization of live virtual machine migration in cloud computing : A survey
and future directions,” J. Netw. Comput. Appl., vol. 110, no. March, pp. 1–11, 2018.
[56] M. Hefeeda, F. Gao, and W. Abd-Almageed, “Distributed approximate spectral clustering
for large-scale datasets,” Proc. 21st Int. Symp. High-Performance Parallel Distrib. Comput.
- HPDC ’12, p. 223, 2012.
[57] Yu and Shi, “Multiclass spectral clustering,” in Proceedings Ninth IEEE International
Conference on Computer Vision, 2003, pp. 313–319 vol.1.
[58] A. W. Moore, “K-means and Hierarchical Clustering,” Stat. Data Min. Tutorials, pp. 1–24,
2001.
[59] K. Wang, J. Zhang, D. Li, X. Zhang, and T. Guo, “Adaptive Affinity Propagation
Clustering,” Automatica, vol. 33, no. 12, pp. 1242–1246, 2007.

[60] W. L. Yeqing Li Junzhou Huang, “Scalable Sequential Spectral Clustering,” Proc. Thirtieth
AAAI Conf. Artif. Intell., pp. 1809–1815, 2016.
[61] Z. Li, Y. Liu, and S. Tao, “A non-cooperative game model of intrusion detection system in
cloud computing,” IET Conf. Publ., vol. 2015, no. CP678, 2015.
[62] S. R. Lenka, “HTTP Service based Network Intrusion Detection System in Cloud
Computing,” no. 1, pp. 44–51, 2015.
[63] A. Patel, M. Taghavi, K. Bakhtiyari, and J. Celestino Júnior, “An intrusion detection and
prevention system in cloud computing: A systematic review,” J. Netw. Comput. Appl., vol.
36, no. 1, pp. 25–41, 2013.
[64] P. K. Rajendran, B. Muthukumar, and G. Nagarajan, “Hybrid Intrusion Detection System
for Private Cloud: A Systematic Approach,” Procedia Comput. Sci., vol. 48, no. 0, pp. 325–
329, 2015.
[65] B. Trivedi, J. Rajput, C. Dwivedi, and P. Jobanputra, “Distributed Intrusion Detection
System using Mobile Agents,” vol. 1, no. Isccc 2009, pp. 57–61, 2011.
[66] L. Portnoy, E. Eskin, and S. J. Stolfo, “Intrusion detection with unlabeled data using
clustering,” ACM CSS Work. Data Min. Appl. to Secur., pp. 5–8, 2001.
[67] Y. Song, W. Y. Chen, H. Bai, C. J. Lin, and E. Y. Chang, “Parallel spectral clustering,” in
Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial
Intelligence and Lecture Notes in Bioinformatics), 2008, vol. 5212 LNAI, no. PART 2, pp.
374–389.
[68] A. Little, X. Mountrouidou, and D. Moseley, “Spectral Clustering Technique for
Classifying Network Attacks,” 2016 IEEE 2nd Int. Conf. Big Data Secur. Cloud
(BigDataSecurity), IEEE Int. Conf. High Perform. Smart Comput. (HPSC), IEEE Int. Conf.
Intell. Data Secur., pp. 406–411, 2016.
[69] S. Trivedi, Z. A. Pardos, and N. T. Heffernan, “The Utility of Clustering in Prediction
Tasks,” no. September, pp. 1–11, 2011.
[70] D. Sculley, “Web-Scale K-Means Clustering,” pp. 4–5, 2010.
[71] N. N. Almanza-ortega and D. Romero, “Balancing effort and benefit of K -means clustering
algorithms in Big Data realms,” pp. 1–19, 2018.

[72] J. Zhu, A. Arbor, and T. Hastie, “Multi-class AdaBoost,” pp. 0–20, 2006.
[73] T. G. Dietterich, “Ensemble Methods in Machine Learning,” 1990.
[74] M. Re and G. Valentini, Ensemble methods : A review, no. May 2014. 2019.
[75] S. Bhagat, S. State, and T. Campus, “Evaluation Metrics for Intrusion Detection Systems -
A Study,” no. June 2015, 2018.
[76] V. R. Shewale, “Performance Evaluation of Attack Detection Algorithms using Improved
Hybrid IDS with Online Captured Data,” vol. 146, no. 8, pp. 35–40, 2016.
[77] Cyber Systems and Technology Group on MIT Lincoln Laboratory, “DARPA Intrusion
Detection Data Sets.” [Online]. Available: https://www.ll.mit.edu/ideval/data/.
[78] “The UCI KDD Archive. KDD Cup 1999 Data.” .
[79] S. Parsazad, E. Saboori, and A. Allahyar, “Fast Feature Reduction in Intrusion Detection
Datasets,” pp. 1023–1029, 2012.
[80] M. H. Aghdam and P. Kabiri, “Feature Selection for Intrusion Detection System Using Ant
Colony Optimization,” vol. 18, no. 3, pp. 420–432, 2016.
[81] R. M. Amin Dastanpour, Raja Azlina, “Feature Selection Based on Genetic Algorithm and
Support Vector Machine for Intrusion Detection System,” no. November, 2013.
[82] V. N. Tiwari, P. S. Rathore, and P. K. Patidar, “International Journal of Current Trends in
Engineering & Technology Enhanced Method for Intrusion Detection over KDD Cup 99
Dataset International Journal of Current Trends in Engineering & Technology ISSN :,” vol.
2, 2016.
[83] Y. Li, K. Zhao, X. Chu, and J. Liu, “Speeding up K-Means Algorithm by GPUs,” no. Cit,
pp. 115–122, 2010.