desarrollo e implementación de algoritmos paralelos
TRANSCRIPT

Ministerio de Educación Superior
Universidad Central “Marta Abreu” de las Villas
Facultad Matemática, Física y Computación
Licenciatura en Ciencias de la Computación
Desarrollo e implementación de algoritmos paralelos aplicados a las
extensiones de la teoría de los Conjuntos Aproximados (Rough Sets)
Autor:
Jorge Fernández Cancio
Tutor:
MSc. Leonardo Flavio Del Toro Melgarejo
“Año 50 de la Revolución”
Santa Clara
2008

Hago constar que el presente trabajo fue realizado en la Universidad Central Marta
Abreu de Las Villas como parte de la culminación de los estudios de la especialidad de
Ciencias de la Computación, autorizando a que el mismo sea utilizado por la institución,
para los fines que estime conveniente, tanto de forma parcial como total y que además
no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.
Firma del autor
Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según
acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que
debe tener un trabajo de esta envergadura referido a la temática señalada.
Firma del tutor Firma del jefe del
Seminario

Pensamiento
Emplearse en lo estéril cuando se puede hacer lo útil, Ocuparse en lo fácil cuando se tiene bríos para intentar lo difícil, Es despojar de su dignidad al talento. Todo el que deja de hacer lo que es capaz de hacer, Peca.
José Martí

Dedicatoria
Dedicatoria:
A mis padres, Eugenio Fernández Rodríguez y María Elena Cancio
Abreu quienes con amor, constancia y sacrificio me han hecho lo que soy.
A mi eterna compañera novia y amiga Anabel Fernández Niubó.

Agradecimientos
Agradecimientos
Al apoyo incansable de todos mis familiares en especial el de mi
queridísima abuela “Cachi” , los cuales a lo largo de mi carrera me han
ayudado en los momentos claves.
Un agradecimiento especial a mi tutor y amigo Leonardo del Toro por
apoyarme, aconsejarme, por estar ahí en cada momento y por darme el
impulso necesario para llegar a la línea de meta.
Pido disculpas a quien resulte olvidado o víctima de mi mala memoria.
A todos Muchas Gracias.

Resumen
Resumen
El análisis de la información incompleta ha encontrado aplicación en muchas áreas, en
particular la relacionada con la extracción de conocimiento de grandes conjuntos de
datos. Las extensiones de la Teoría de los Conjuntos Aproximados se han aplicado con
bastante éxito en el procesamiento de estos conjuntos de datos, aunque los
mecanismos son muy diversos y no existe uno en particular que supere al resto,
ofrecen actualmente una posibilidad de tratar este problema. El otro punto medular es
el tema de la semejanza entre objetos En este trabajo se describen fundamentalmente
dos algoritmos utilizados en el trabajo con información incompleta y uno empleado en
el enfoque de la semejanza entre objetos usando las extensiones de la Teoría de los
Conjuntos Aproximados, de estos se ofrecen variantes secuenciales y alternativas
paralelos. Además se muestran los resultados obtenidos experimentalmente sobre una
serie de Sistemas de Información almacenados en repositorios internacionales.

Abstract
Abstract
The analysis of incomplete information has found applications in many areas
particularly, in those related to the knowledge discovery of huge datasets. The
extensions of the Theory of the Rough Sets have been successfully applied for
processing this datasets and even though it exist many mechanisms, there is none, in
particular, that we may say that outstrip the rest; they offer today a possibility to deal
with this problem. Another important aspect is that of similarity among objects. In this
work different algorithms are developed for the processing of incomplete information,
and specifically of one based on the approach of the similarity among objects using the
extensions of Theory of Rough Sets. Here we offer several serial variants and parallel
alternatives that were experimentally tested on a set of information systems stored in
international repositories.

Indice
Introducción ............................................................................................................................. 1 Capítulo 1 “Estudio sobre las diferentes extensiones de la teoría de los Conjuntos Aproximados al tratamiento de la información incompleta” ................................................ 4
1.1 Conjuntos Aproximados (Rough Set) ................................................................................... 4
1.1.1 Sistema de información (SI) .......................................................................................... 5
1.1.1.1 Sistema de decisión (SD) ........................................................................................ 6
1.1.2 Relación de inseparabilidad ........................................................................................... 6
1.1.3 Aproximación de conjuntos ........................................................................................... 7
1.1.4 El problema de la información incompleta .................................................................... 8
1.1.4.1 Sistemas de información incompletos .................................................................... 8
1.1.4.2 Sistemas de decisión incompletos ........................................................................... 9
1.2 Acercamiento teórico a las extensiones de la teoría de los Conjuntos Aproximados para
sistemas de información incompletos. ...................................................................................... 10
1.2.1 Relación I ..................................................................................................................... 11
1.2.2 Relación II .................................................................................................................... 12
1.2.3 Relación III .................................................................................................................. 12
1.2.4 Relación IV .................................................................................................................. 13
1.2.5 Relación V ................................................................................................................... 14
1.2.6 Relación VI .................................................................................................................. 15
1.3 Análisis del comportamiento de las relaciones sobre un ejemplo de SDI ......................... 17
1.3.1 La relación I ................................................................................................................. 17
1.3.2 La relación II ............................................................................................................... 18
1.3.3 La relación III .............................................................................................................. 19
1.3.4 La relación V................................................................................................................ 20
1.3.5 La relación VI .............................................................................................................. 21
1.4 El problema de la semejanza entre objetos ......................................................................... 22
1.4.1 Funciones de semejanza. .............................................................................................. 23
1.4.2 Relación de similaridad................................................................................................ 24
1.5 Conclusiones parciales ........................................................................................................ 27 Capítulo 2 “Propuesta de paralelización” .............................................................................28
2.1 Conjuntos Aproximados (Rough Set) ................................................................................. 28
2.2 Procedimiento serial para clasificar a un SDI ..................................................................... 30
2.3 Método paralelo propuesto para el cálculo de la calidad en un SDI. .................................. 35
2.3.1 Descripción del algoritmo paralelo .............................................................................. 38
2.3.2 Pseudo código del algoritmo paralelo para clasificar un SD ....................................... 41
2.4 Algunas especificaciones generales. ................................................................................... 44
2.5 Conclusiones parciales ........................................................................................................ 44 Capítulo 3 “Evaluación de los resultados y descripción de las funciones” .......................45
3.1 Herramientas y medidas ...................................................................................................... 45
3.2 Tecnologías utilizadas ......................................................................................................... 47
3.3 Estructuras de Datos ........................................................................................................... 47
3.4 Conjuntos Aproximados (Rough Set) ................................................................................. 48
3.4.1 La versión secuencial ................................................................................................... 49
3.4.2 El método paralelo ....................................................................................................... 52
3.4.3 Análisis de algunas métricas de rendimiento ............................................................... 54
3.5 Descripción de las funciones .............................................................................................. 57

Indice
3.6 Conclusiones Parciales........................................................................................................ 57 Conclusiones generales .........................................................................................................59 Recomendaciones ..................................................................................................................60 Referencias bibliográficas ......................................................................................................61 Anexos .....................................................................................................................................63
Anexo 1 Funciones empleadas en el cálculo de la calidad ....................................................... 63
Anexo 2 Funciones auxiliares usadas en el cálculo de la calidad. ............................................ 66

Introducción
1
Introducción
En la actualidad la Inteligencia Artificial (IA) cuenta con un arsenal de importantes
técnicas que permiten extraer conocimiento de bases de datos; los Conjuntos
Aproximados es una de ellas. Pero en muchas ocasiones la información con la que
contamos no está completa y es necesario extraer conocimiento de grandes volúmenes
de datos sin perder la calidad de la información, aún cuando esta esté incompleta. Otro
problema se presenta al determinar cuándo podemos decir que dos objetos son
semejantes y hasta qué punto podemos considerarlos como “iguales”. Los métodos
utilizados para lograr esto varían en cuanto a formas e implementaciones, aunque
todas ellas tienen en común el hecho de que hacen uso intensivo de los recursos
computacionales y necesitan un tiempo considerable para su ejecución. Es por esto
que en esta investigación se realiza un estudio de las extensiones a la Teoría de los
Conjuntos Aproximados para tratar la falta de información en bases de casos ricas en
conocimiento y para modelar una solución al problema de la semejanza entre objetos,
en aras de lograr implementaciones paralelas que traten de subsanar dichos
inconvenientes.
A través de los años han tenido lugar grandes avances tecnológicos los cuales han
permitido el procesamiento paralelo efectivo. Con el desarrollo de las investigaciones
se adquirieron nuevos conocimientos sobre este tema, las cuales han posibilitado que
los algoritmos distribuidos y paralelos se enfoquen no sólo en los viejos problemas,
sino también en otros nuevos que han surgidos con el propio desarrollo tecnológico,
creando así nuevas necesidades de cálculo.
Problema de Investigación:
Teniendo en cuenta todo lo anteriormente expuesto podríamos plantearnos entonces el
siguiente problema: ¿Será posible obtener un algoritmo paralelo para implementar los
principales conceptos de las extensiones de teoría de los Conjuntos Aproximados que
mejore el rendimiento de versiones secuenciales?

Introducción
2
Hipótesis de la Investigación:
- Al aplicar las técnicas de paralelización a la extensión de la teoría de los
Conjuntos Aproximados se logran implementaciones paralelas que mejoran el
comportamiento de las implementaciones de esta teoría.
- Un diseño adecuado de los módulos computacionales y su implementación
paralela usando MPI permitirá construir una biblioteca de funciones que pueda
ser reutilizada por otras aplicaciones.
El objetivo general en este trabajo es paralelizar los algoritmos que implementan las
extensiones seleccionadas de la Teoría de los Conjuntos Aproximados usando MPI.
Los objetivos específicos que nos permitirán dar solución a esta problemática son:
Seleccionar los algoritmos más apropiados de aquellos que implementan las
extensiones de la Teoría de los Conjuntos Aproximados
Determinar las etapas donde es posible aplicar técnicas de paralelización en los
algoritmos seleccionados.
Proponer una alternativa de algoritmos paralelos para implementar los
principales conceptos de esta teoría.
Desarrollar una biblioteca con las implementaciones paralelas de los algoritmos
seleccionados.
Desarrollar una biblioteca que contenga la implementación de una función de
semejanza para el trabajo con objetos de rasgos continuos.
Comprobar el desempeño de los algoritmos implementados.
En este trabajo se propone una alternativa paralela, para la obtención de una aplicación
sobre un cluster de computadoras que implemente los conceptos básicos de las
extensiones de la teoría de los Conjuntos Aproximados. He aquí su valor científico.

Introducción
3
El valor práctico del mismo radica en que este trabajo ofrece una herramienta basada
en técnicas paralelas que permite medir el grado de consistencia de un Sistema de
Decisión Incompleto, presentando rendimientos superiores a sus equivalentes
secuenciales.
Su principal aporte es la creación de una de librería y de una aplicación que permiten
desarrollar nuevas herramientas, así como también el ya mencionado análisis de
grandes volúmenes de datos haciendo uso de las bondades de la programación en
paralelo y del juego de funciones MPI en C.
La estructura del trabajo comprende tres capítulos de los cuales:
En el Capítulo 1 se muestra el marco teórico-referencial de la investigación,
derivado de la consulta de la literatura nacional e internacional actualizada sobre
diferentes extensiones de la teoría de los Conjuntos Aproximados.
En el Capítulo 2 se exponen el conjunto de algoritmos propuestos para el cálculo
de los principales conceptos de las extensiones de esta teoría y todo lo
relacionado con el diseño y funcionalidad de los mismos.
En el Capítulo 3 se presentan los resultados experimentales que, sobre
determinados archivos de datos, brindan las aplicaciones paralelas
desarrolladas, realizando comparaciones con sus similares secuenciales.

Capítulo 1
4
Capítulo 1 “Estudio sobre las diferentes extensiones de la
teoría de los Conjuntos Aproximados al tratamiento de la
información incompleta”
En este capítulo se realiza una recopilación de información basada en conceptos y
definiciones de diferentes autores sobre las técnicas y métodos utilizados en el
tratamiento del problema de la información incompleta con el objetivo de lograr la
paralelización de algunos de esos métodos y su posterior comparación con la
implementación secuencial que se ha obtenido en esta investigación.
1.1 Conjuntos Aproximados (Rough Set)
La teoría de los Conjuntos Aproximados fue introducida inicialmente por Z. Pawlak
(Pawlak, 1982), esta teoría se ha enriquecido ampliamente durante estos años y
ha sido introducida en muchas ramas de la ciencia. Algunas de estas ramas son:
- Medicina.
- Finanzas.
- Telecomunicaciones.
- Análisis de ruido.
- Agentes inteligentes.
- Análisis de imágenes.
- Reconocimiento de patrones.
- Procesos industriales
La teoría clásica de Conjuntos Aproximados hace uso de una serie de conceptos
como por ejemplo los de sistema de información, sistema de decisión, relación de
inseparabilidad, aproximaciones (inferior y superior) y reductos; los cuales están
presentes también en sus extensiones.

Capítulo 1
5
1.1.1 Sistema de información (SI)
Un sistema de información usualmente está compuesto por un conjunto de
atributos (A) los cuales representan características o propiedades de un objeto o
fenómeno y de una serie de casos u objetos (U) a los cuales se les evaluó o se
les midió los valores de los atributos. Estos dos elementos se combinan en una
tabla tal como la que se muestra en la Fig. 1, donde las columnas representan los
atributos (A) y las filas los objetos (U). Los valores que se muestran en la tabla
varían de acuerdo a las características del problema en cuestión. Estos pueden
ser binarios, enteros, reales o simbólicos en algunos casos. Es decir, la entrada en
la columna q y en la fila x tiene el valor f(x, q) por tanto, para cada par (objeto,
atributo) se conoce un valor denominado descriptor. Cada fila de la tabla contiene
descriptores que representan la información correspondiente a un objeto del
universo. Utilizamos la noción de atributo en lugar de la de criterio porque el primer
término es más general que el segundo debido a que el dominio (escala) de un
criterio ha de ordenarse8 de menor a mayor preferencia, mientras que el dominio
de los atributos no ha de ser ordenado (Segovia et al., 2003).
Atrib1 Atrib2 Atrib
Obj1 Valor Valor …
Obj2 … … …
Obj3 … … …
Fig. 1.1 Ejemplo de un Sistema de Información
Formalmente un sistema de información se compone de un par ),( AUS donde
U, como ya se explicó anteriormente, es un conjunto no vacío y finito de objetos o
casos y A un conjunto no vacío y finito de atributos. (Komorowski et al., 1998)

Capítulo 1
6
1.1.1.1 Sistema de decisión (SD)
Un sistema de decisión (SD) es un sistema de información (Fig. 1.2) al cual se le
adiciona un atributo que representa la decisión o resultado en cada caso u objeto.
Teniendo en cuenta los valores de los atributos esto se plantea como:
),( dAUS donde d no pertenece a A.(Komorowski et al., 1998)
Atrib1 Atrib2 Atrib … d
Obj1 Valor Valor … Valor
Obj2 … … …
Obj3 … … …
Fig. 1.2 Ejemplo de Sistema de Decisión
1.1.2 Relación de inseparabilidad
Antes de tratar el concepto de relación de inseparabilidad debemos tener en
cuenta la definición de relación de equivalencia y clase de equivalencia definidas
en (Komorowski et al., 1998) como:
Definición 1.1 Una relación de equivalencia es una relación binaria XxXR que
es:
- reflexiva (cuando un objeto está relacionado con el mismo xRx )
- simétrica (si xRy entonces yRx ) y
- transitiva (si xRy y yRz entonces xRz )
Definición 1.2 Una clase de equivalencia de un elemento Xx es el conjunto de
todos los objetos Xy tal que xRy .

Capítulo 1
7
Definición 1.3 La relación de inseparabilidad se establece cuando un par de
objetos “a”, “b” de un (SI) S = <U,A>, tienen una relación de equivalencia con
cualquier conjunto de atributos AB para los cuales se cumple que:
)}()(),{()( 2 bxaxBxUbaBINSS
Esto se conoce como relación de inseparabilidad de B.
Si entonces los objetos “a” y “b” son inseparables uno del otro
teniendo en cuenta los atributos en B.
La clase de equivalencia de la relación de inseparabilidad se denota como BX .
1.1.3 Aproximación de conjuntos
La relación de inseparabilidad aplicada a un (SI) causa una fragmentación del
universo de objetos donde estos fragmentos constituyen nuevos subconjuntos del
universo.
Supongamos que tenemos el (SI) ),( AUS y definimos a AB y UP . Es
posible aproximar a P usando sólo la información de los atributos en B,
construyendo lo que se conoce como aproximaciones inferiores y superiores de P,
estas se denotan como PB y PB respectivamente, donde }{ PxxPB B y
}{ PxxPB B .
Los objetos en PB son los elementos que pueden ser clasificados ciertamente
como miembros de P sobre la base de los atributos en B, mientras que los objetos
en PB sólo pueden ser clasificados como posibles miembros de P sobre la base
de B.
Existe un grupo de objetos que no se encuentra en ninguna de las dos
aproximaciones, este conjunto está ubicado en una zona que se llama frontera BN
(ver Fig. 1.3), la cual se define como PBPBBN .
) ( ) , ( B INS b a S

Capítulo 1
8
Fig. 1.3 Aproximaciones y frontera.
1.1.4 El problema de la información incompleta
En la práctica puede que no conozcamos el valor de algunos o de ninguno de los
atributos que caracterizan a un objeto en un (SI) o en un (SD). Este
desconocimiento puede ser provocado por errores en el proceso de medición de
los datos, por la incomprensión de los datos, o por la dificultad que puede existir a
la hora de adquirir algún valor. En general, procesar información que contiene
redundancias, imprecisiones o datos omitidos puede llevar a resultados falsos o
parcialmente erróneos. En este trabajo supondremos que los valores del atributo o
de los atributos de decisión de todos los objetos son conocidos.
1.1.4.1 Sistemas de información incompletos
Como pudimos apreciar en el epígrafe 1.1.1, un sistema de información (SI) I, es
una dupla <U, A>, para todo ai є A, ai : U Vai , donde Vai es el dominio del
atributo ai.
Al sistema de información en el cual algún dominio Vai contiene valores perdidos
denotados por un “*”, se le llama sistema de información incompleto
(SII)(Kryszkiewicz, 1998), tal como el que se muestra en la tabla de la figura 1.4.
PB
PBPB
PB

Capítulo 1
9
Atrib 1 Atrib 2 Atrib 3
Obj1 3 6 *
Obj2 * * 7
Obj3 8 1 3
Fig. 1.4 Sistema de información incompleto.
1.1.4.2 Sistemas de decisión incompletos
Un sistema de decisión incompleto (SDI) según (Kryszkiewicz, 1998) no es más
que un sistema de información incompleto (SII) S=<U, A>, donde U es el universo
y A es el conjunto de atributos (A=C clase). En la tabla de la figura 1.5 se
muestra un ejemplo de un SDI en el cual las dos terceras partes de los objetos
presentan información incompleta representada por un *.
Objeto A1 A2 A3 A4 Clase
O1 a B a c 1
O2 a * a b 2
O3 a B c * 1
O4 a B * c 1
O5 b * b * 2
O6 b B a b 2
Fig. 1.5 Sistema de decisión incompleto.

Capítulo 1
10
1.2 Acercamiento teórico a las extensiones de la teoría de los
Conjuntos Aproximados para sistemas de información
incompletos.
Existen dos formas de tratar el problema de los datos incompletos en la teoría de
los Conjuntos Aproximados. La primera es una vía indirecta, mediante la cual el
sistema de información incompleto se transforma en uno completo utilizando algún
método de completamiento; la segunda es una alternativa directa en la cual se
extiende la teoría de los Conjuntos Aproximados para procesar los sistemas de
información incompletos. En esta segunda línea se ubican los trabajos de M.
Kryszkiewicz (Marzena, 1998a) y (Marzena, 1998b).También los de S. Greco
(Salvatore et al., 1999), (Greco et al., 2000), (Greco et al., 2001) y otros, en los
cuales se han realizado extensiones para el caso de datos incompletos, de modo
que la relación de inseparabilidad se define como una relación direccional donde
un sujeto se compara con un objeto referente, este último un objeto completo, es
decir, se conocen los valores para todos sus atributos.
Los principales conceptos de la teoría clásica de los Conjuntos Aproximados, la
cual no es más que un caso particular de la teoría extendida, están igualmente
definidos en sus extensiones. Los conceptos más importantes que fueron
añadidos a esta teoría son relación de tolerancia y clase de tolerancia:
Definición 1.4: Una relación de tolerancia es cualquier relación binaria entre dos
objetos que trate la pérdida de información.
Debemos señalar que las relaciones de tolerancia no tienen que cumplir ninguna
de las restricciones que cumplen las relaciones de equivalencia (reflexivilidad,
simetría y transitividad) las que, de hecho, son un subconjunto de las relaciones de
tolerancia.
Definición 1.5: Una clase de tolerancia de un elemento Ux es el conjunto de
todos los objetos Uy tal que xTy , donde T es una relación de tolerancia.

Capítulo 1
11
A continuación se muestran algunas de las extensiones de la teoría de los
Conjuntos Aproximados, basadas en relaciones de tolerancia.
1.2.1 Relación I
El hecho de tener objetos que pueden estar descritos por un número mayor o
menor de atributos, no sólo por la inconsistencia de los valores sino también por la
posibilidad de que ese objeto no pueda ser descrito por dicho atributo, nos da la
idea de que un objeto “x” es similar a un objeto “y” si y sólo si (ssi) la descripción
de “x” está incluida en la descripción de “y”, según (Slowinski, 1995).
Sean “x”, “y” U, donde “y” es el sujeto y “x” es el objeto referente. Decimos que
“y” es inseparable de “x”, con respecto al conjunto de atributos P C, denotándolo
por yIPx, si para todo q P, se cumple:
i) f(x,q)*,
ii) f(x,q)=f(y,q) or f(y,q)=*.
Donde f: aiVUxP , siendo aiV el dominio de valores que toma el atributo “ai”
Ej.: En la Fig. 1.5
f (O1,A1)= a y f(O3,A4)= *
(Nótese que el objeto referente “x” no puede tener valores desconocidos en el
conjunto de atributos P).
La clase de objetos inseparables de “x” se representa como:
IP(x)= {y U : yIPx}
La relación IP no es necesariamente reflexiva ni simétrica, pero si transitiva.
Para cada P C se define el conjunto UP de objetos sin valores desconocidos
para los atributos en P.
UP = {xU : f(x,q)* para cada qP}

Capítulo 1
12
A partir de estas definiciones y la relación I (IP), se puede construir la aproximación
inferior y superior de un conjunto X U con respecto a un conjunto de atributos de
condición P C , según la definición 1.1:
Las aproximaciones de un conjunto según la relación I son:
IP*(X)={ x UP : IP(x) X} (1.1)
IP*(X)= { x UP : IP(x) X }
1.2.2 Relación II
Una relación muy conocida dentro de esta teoría es la que define (Kryszkiewicz,
1998) según la cual dos objetos “x, y” U se dicen inseparables si están
relacionados según
a(y)))(a(x)*)(a(y)*)((a(x)y)(x,(T AaAUyx,
(La relación T es reflexiva y simétrica, pero no es transitiva)
La aproximación inferior se define como:
},)({ XxIUxxX A
T
A
Y la aproximación superior:
}))(({ XxIUxxX A
T
A .
Donde
)},(|{)( yxTUyyxI AA
1.2.3 Relación III
Según (Jerzy and Alexis, 1999) dos objetos son inseparables ssi están
relacionados según:
b(y))))(b(x)*)((b(x)y)(x,(S BbBUyx,

Capítulo 1
13
Que evidentemente no es simétrica pero es reflexiva y transitiva.
Se definen además la aproximación inferior S
BX y la aproximación superior S
BX
del conjunto UX basadas en la relación de similitud no simétrica S como:
},)(|{ XxRUxxXS
B
S
B Xx
S
B
S
B xRX
)(
Donde )},,(|{)( yxSUyyxR B
S
B )},(|{)( xySUyyxR B
S
B
1.2.4 Relación IV
La relación de tolerancia (relación II) propuesta por (Kryszkiewicz, 1998) está
basada en la asunción de que el valor faltante “*” puede ser igual a cualquier valor
conocido del atributo, lo que puede conducir a que dos elementos que sean
distintos se clasifiquen en la misma clase de tolerancia. En la relación de similitud
no simétrica (relación III) propuesta por (Jerzy and Alexis, 1999), el valor perdido
es tratado como inexistente en vez de desconocido. Es decir, el objeto no puede
ser caracterizado por ese atributo lo que puede provocar que objetos claramente
parecidos puedan ser incluidos en clases diferentes. Por esta razón se introduce
el concepto de relación de similitud no simétrica con restricciones (relación IV).
Según (Yin et al., 2006) la relación de similitud no simétrica con restricciones se
plantea como sigue:
Si se tiene un SII I = <U,A>, AB , la relación IV puede definirse como:
ybxbyxPbyxPxbyxC BBbBBbBUyx ,,*,,
Donde PB(x,y) = **| ybxbBbb
(Evidentemente la relación es reflexiva, no simétrica y no transferible)
Las aproximaciones superiores e inferiores basadas en la relación anteriormente
definida pueden expresarse como sigue:

Capítulo 1
14
Si se tiene un SII I = <U,A>, AB y UX , la aproximación inferior C
BX y la
aproximación superior C
BX del conjunto UX basado en la relación de similitud
no simétrica S con restricciones están definidas por:
},)(|{ XxRUxxXC
B
C
B Xx
C
B
C
B xRX
)(
Donde )},,(|{)( yxCUyyxR B
C
B )},(|{)( xyCUyyxR B
C
B
(Debido a la falta de simetría de la relación C, C
BR y C
BR son dos conjuntos
diferentes).
1.2.5 Relación V
Según (Wang, 2002) se puede definir una relación más exacta que la II y la III, si
se tienen en cuenta sólo aquellos atributos conocidos en el par de objetos a
comparar. Wang la nombra relación de tolerancia limitada, siendo una relación
binaria L definida sobre un SII, S=<U,A> y un subconjunto de atributos BA.
Además Wang establece que dos objetos “x,y” son inseparables ssi están
relacionados según L LB(x,y) la cual se expresa como sigue:
)))))()((*))((*))(((())()(((*))()((),( ybxbybxbyPxPybxbyxL BbBbB
Siendo *})(|{)( xbBbbxPB
Si se tiene un SII, I = <U,A>, AB y UX las aproximaciones inferior L
BX y
superior L
BX del conjunto UX , basadas en la relación de tolerancia limitada
pueden ser definidas por:
},)(|{ XxIUxxX L
B
B
L })(|{ XxIUxxX L
B
L
B
Donde )},(|{)( yxLUyyxI B
L
B

Capítulo 1
15
1.2.6 Relación VI
Según (E. A. Rady, 2007) se le puede hacer una modificación a la relación de
similitud (relación II) para mejorar los resultados de esta, pero antes de mostrar
como se define MSIM(x,y) es necesario establecer algunas notaciones y
definiciones. Por ejemplo:
a
x o ,),( ax donde a
x = v significa que el objeto “x” tiene el valor “v” para el
atributo ”a” donde vU y aA (A es el conjunto de los atributos de decisión del
sistema).
),( a
y
a
x denota al par de valores que toma el atributo ”a” en los objetos “x” , “y”
respectivamente.
Definición 1.6: Se dice que a
x es conocido ssi a
x *.
Definición 1.7: El objeto “x” está completamente definido ssi a
x * para todo
aA.
Definición 1.8: El número “EP”, EP = | ),( a
y
a
x | es el número de rasgos en que
coinciden los objetos “x”, “y” respectivamente, donde a
x y a
y son valores
definidos.
Ej. Para los objetos 1 y 2 de la Fig. 1.5 EP=2.
Para los objetos 3 y 4 de la Fig. 1.5 EP=2.
Definición 1.9: El número |mx|, |mx| denota al número de atributos perdidos del
objeto “x”.
Definición 1.10: De un elemento “x” se dice que:
Está bien definido sobre el conjunto A ssi:
|mx| 2
N si N es par o |mX|
2
1
N si N es impar
Está pobremente definido ssi:

Capítulo 1
16
|mx| 2
N si N es par o |mX|
2
1
N si N es impar
Donde N es el número de atributos del conjunto A, N= |A|.
Definición 1.11: El número |nmx|, |nmx| denota al número de valores conocidos del
objeto “x”.
Ya aclaradas todas las notaciones y definiciones podemos ilustrar como se define
la relación de similitud modificada MSIM:
i. (x,x)MSIM(A) para todo xU.
ii. (x,y)MSIM(A) para N=|A| > 1 ssi
a) a
x = a
y , Aa siendo a
x y a
y valores definidos.
b) 2
N, si N es par
2
1N, si N es impar
Definición 1.12: MSA(x) denota al conjunto {yU : (x,y)MSIM(A)} de los
elementos “y” que son inseparables de “x” según A.
Si se tiene un SII, I = <U,AT>, ATA y UX las aproximaciones inferior M
AX
y superior M
AX del conjunto UX basadas en la relación de similitud
modificada MSIM(A) se definen como:
M
AX = }.)(,{})(,{ XxMSXxXxMSUx AA
M
AX = }.),({})(,{ XxxMSXxMSUx AA
EP

Capítulo 1
17
1.3 Análisis del comportamiento de las relaciones sobre un
ejemplo de SDI
Antes de finalizar este capítulo queremos mostrar qué se obtiene al aplicar cada
una de las relaciones a un SDI de pequeña escala para obtener la esencia de
cada una de ellas. Para esto tomaremos como base de casos de estudio al
siguiente SDI:
a1 a2 A3 a4 d
o1 3 2 1 0
o2 2 3 2 0
o3 2 3 2 0
o4 * 2 * 1
o5 * 2 * 1
o6 2 3 2 1
o7 3 * * 3
o8 * 0 0 *
o9 3 2 1 3
o10 1 * * *
o11 * 2 * *
o12 3 2 1 *
Fig. 1.6 Tabla del SDI de prueba
En dicho sistema U = {o1…o12} son los objetos del sistema, A= {a1… a4} son cuatro
atributos de condición y “d” es el atributo de decisión. El dominio de los cuatro
atributos de condición es Va= {1, 2, 3,4} y el del atributo de decisión es { , }
1.3.1 La relación I
Analizando el SDI anterior con la relación I obtenemos los resultados siguientes:
Atrib
Obj

Capítulo 1
18
Las clases de inseparabilidad de cada objeto según el conjunto de atributos A por
la relación IA son:
(En este caso recordemos que sólo se calculan las de aquellos objetos que están
completamente definidos)
Las aproximaciones inferiores ( I
A , I
A ) y superiores ( I
L , I
L ) de los conjuntos
, por la relación IA y según el conjunto de atributos A son:
, I
A },{ 6oI
A
},,,,,{ 96321 oooooA
I
},,,{ 9321 ooooA
I
En los resultados anteriores algunos objetos debieron ser bien clasificados y sin
embargo no fueron bien tratados por la relación IA. Tenemos, por ejemplo, una
completa información del objeto o1 el cual no colisiona con ningún otro objeto del
SDI y desafortunadamente o1 no es la aproximación inferior de ; esto está
provocado por la falta de información en el objeto o11 , lo trae como consecuencia
que este sea tratado por IA como similar a o1.
1.3.2 La relación II
Al analizar la tabla con la relación II TA obtenemos los siguientes resultados
Las clases de inseparabilidad de cada objeto según el conjunto de atributos A por
la relación T son:
},,{)(
}{)(
},{)(
},{)(
},,{)(
12979
66
323
322
121111
ooooI
ooI
oooI
oooI
ooooI
I
A
I
A
I
A
I
A
I
A

Capítulo 1
19
},,,,,,{)(
},,,,,,,,{)(
},,,,{)(
},,,,,{)(
},,,,,{)(
},,{)(
},,,{)(
12119754112
1211109754111
1211979
12119877
121110545
323
121111
ooooooooI
oooooooooI
oooooI
ooooooI
ooooooI
oooI
ooooI
T
A
T
A
T
A
T
A
T
A
T
A
T
A
},,,,{)(
},,{)(
}{)(
},,,,{)(
},{)(
111085410
10878
66
121110544
322
ooooooI
ooooI
ooI
ooooooI
oooI
T
A
T
A
T
A
T
A
T
A
Las aproximaciones inferiores ( T
A , T
A ) y superiores ( A
T , A
T ) de los conjuntos
, por la relación T y según el conjunto de atributos A son:
,T
A },{ 6oT
A ,UA
T
},,,,,,,,,,,{ 12111098754321 oooooooooooA
T
Los resultados anteriores no son buenos, es más, algunos objetos pueden ser
clasificados intuitivamente y sin embargo no fueron bien tratados por la relación
TA., Tenemos, por ejemplo, una completa información del objeto o1 el cual no
colisiona con ningún otro objeto del SI y desafortunadamente o1 no es la
aproximación inferior de ; esto esta provocado por la falta de información en el
objeto o11 lo que trae como consecuencia que este sea tratado por TA como
similar a o1.
1.3.3 La relación III
Si hacemos un análisis de cómo trata la relación III (SA) la tabla anterior, los
resultados en este caso serían el conjunto de objetos a los que el objeto “oi” es
similar ( )(1
iA oR ) y el conjunto de objetos que son similares al objeto “oi” ( )( iA oR ),
según el conjunto de atributos A por la relación S:

Capítulo 1
20
},,,{)(
},,,,,,{)(
},{)(
},{)(
},{)(
},,{)(
},{)(
},,{)(
},,{)(
},,{)(
},,{)(
},{)(
129112
1
1211954111
1
1010
1
99
1
88
1
977
1
66
1
545
1
544
1
323
1
322
1
11
1
ooooR
oooooooR
ooR
ooR
ooR
oooR
ooR
oooR
oooR
oooR
oooR
ooR
A
A
A
A
A
A
A
A
A
A
A
A
},,{)(
},{)(
},{)(
},,,,{)(
},{)(
},{)(
},{)(
},,,{)(
},,,{)(
},,{)(
},,{)(
},,,{)(
121112
1111
1010
1211979
88
77
66
11545
11544
323
322
121111
oooR
ooR
ooR
oooooR
ooR
ooR
ooR
ooooR
ooooR
oooR
oooR
ooooR
A
A
A
A
A
A
A
A
A
A
A
A
Las aproximaciones inferiores ( S
A , S
A ) y superiores ( A
S , A
S ) de los conjuntos
, por la relación S y según el conjunto de atributos A son:
},,{ 101 ooS
A },,,{ 986 oooS
A },,,,,,,,,,{ 121198765432 ooooooooooA
S
},,,,,,,,,{ 121110754321 oooooooooA
S
Las aproximaciones resultantes de aplicar la relación no simétrica SA son más
informativas que las arrojadas por la relación TA , incluso en las aproximaciones de
los conjuntos y encontramos objetos que podemos colocar en ellas
intuitivamente. Lógicamente, este enfoque es menos preciso que el de TA, dado
que algunos objetos de los que se tiene muy poca información son precisamente
clasificados en algún conjunto. Ejemplo de ello es el objeto o10.
1.3.4 La relación V
Por la gran semejanza entre las definiciones de las relaciones IV y V, el análisis
correspondiente a la relación IV del SDI de la Fig 1.6 es omitido.
Al analizar el SDI anterior con la relación V obtenemos los resultados siguientes:

Capítulo 1
21
Las clases de inseparabilidad de cada objeto según el conjunto de atributos A por
la relación L son:
},,,,,,{)(
},,,,,,{)(
},,,,{)(
},,,{)(
},,,,{)(
},,{)(
},,,{)(
12119754112
1211954111
1211979
12977
1211545
323
121111
ooooooooI
oooooooI
oooooI
ooooI
oooooI
oooI
ooooI
L
A
L
A
L
A
L
A
L
A
L
A
L
A
}{)(
}{)(
}{)(
},,,{)(
},{)(
1010
88
66
1211544
322
ooI
ooI
ooI
oooooI
oooI
T
A
T
A
T
A
T
A
T
A
Las aproximaciones inferiores ( L
A , L
A ) y superiores ( A
L , A
L ) de los conjuntos
, por la relación L y según el conjunto de atributos A son:
},{ 10oL
A },,{ 86 ooL
A },,,,,,,,,,{ 121198765432 ooooooooooA
S
},,,,,,,,,{ 121110754321 oooooooooA
S
Teniendo en cuenta los resultados anteriores podemos concluir que la relación V
(LA) contiene las ventajas de las relaciones II (TA) y III (SA) y descarta sus
limitaciones. Un ejemplo de ello son los objetos o10 y o11 , los cuales no tienen
valores conocidos iguales, lo que evita que puedan ser discernibles en la relación
de tolerancia TA (relación II) pero sí pueden serlo en la relación de tolerancia
limitada LA (relación V). En el otro extremo está el caso de los objetos o9 y o12 que
tienen la mayoría de sus atributos iguales (c1,c2,c3) pero por la relación III (SA) son
discernibles, situación que no se presenta con la relación V (LA) que si los
clasifica como inseparables.
1.3.5 La relación VI
Analizando el SDI de la figura 1.6 con la relación VI obtenemos los resultados
siguientes.

Capítulo 1
22
Las clases de inseparabilidad de cada objeto según el conjunto de atributos A por
la relación M son:
},,{)(
},{)(
},,,{)(
},,{)(
},,{)(
},,{)(
},,{)(
129112
1111
12979
977
545
323
1211
ooooI
ooI
ooooI
oooI
oooI
oooI
oooI
M
A
M
A
M
A
M
A
M
A
M
A
M
A
}{)(
}{)(
}{)(
},{)(
},{)(
1010
88
66
544
322
ooI
ooI
ooI
oooI
oooI
M
A
M
A
M
A
M
A
M
A
Las aproximaciones inferiores ( M
A , M
A ) y superiores ( M
L , M
L ) de los conjuntos
, por la relación M y según el conjunto de atributos A son:
},,{ 101 ooM
A },,,{ 1186 oooM
A },,,,,,,,{ 1210975432 ooooooooA
M
},,,,,,,,,,{ 121198765432 ooooooooooA
M
De los resultados anteriores podemos inferir que la relación VI (MA) acaece de las
deficiencias de la relación III (SA) dado que objetos de los que se conoce muy
poco son clasificados como parte de la aproximación inferior de uno de los
conjuntos ( ), tal es el caso del objeto o11 del cual se desconoce la mayor parte
de su información (a1,a3, a4) y es clasificado inequívocamente como .
1.4 El problema de la semejanza entre objetos
Diariamente nos encontramos situaciones donde se tiene que distinguir entre
grupos similares o se tiene que clasificar algunos elementos como similares. Es
por esto que la medida de similaridad se convierte en una importante herramienta
para decidir la semejanza (grado de similaridad) entre dos grupos o entre dos
elementos. La misma puede definirse sobre un conjunto arbitrario de objetos de
interés, tales como objetos físicos, situaciones, problemas, etc. El uso del término
similaridad en la Inteligencia Artificial da la idea de una relación borrosa entre las
representaciones de dos objetos (Rudolph, 1997)

Capítulo 1
23
1.4.1 Funciones de semejanza.
La similaridad entre dos objetos se puede determinar a partir de su grado de
semejanza. En (Wilson and Martínez, 1997) se presenta un detallado estudio de
este tema; donde los atributos se clasifican en lineales o nominales. Los atributos
lineales pueden ser continuos o discretos. Se consideran continuos aquellos que
tienen como dominio los números reales y discretos aquellos cuyo dominio está
formado por un conjunto finito de valores numéricos (por lo que existe un orden
entre esos valores). Un atributo nominal o simbólico es un atributo discreto cuyos
valores no guardan un orden entre sí, por ejemplo, la variable Color.
Una manera para describir la función de semejanza que mide la similaridad entre
dos objetos P y C es:
n
i
CiPiiwiCP1
,*, (1.2)
Donde wi es la importancia del rasgo, Pi y Ci son los valores que el rasgo i tiene
en P y C respectivamente y i es la función de comparación para el rasgo i.
Una de las funciones de comparación más simple es:
a)
yxif
yxifyx
0
1, (1.3)
Otras funciones de comparación de rasgos son:
b)
0
1,i (1.4)
c) Sea i
s
t
tti MataaM
1
1, para t s 1 1,...,
i , 1 (si 1, pp aa y a ap p, 1 ) ó 0 en otro caso (1.5)

Capítulo 1
24
1.4.2 Relación de similaridad.
Numerosas aplicaciones han revelado la necesidad de extender el enfoque
clásico de los conjuntos aproximados. Una variante destacada de las extensiones
realizadas es sustituir la relación de inseparabilidad por una relación de tolerancia
(Sankar and Andrzej, 1999). De esta forma se puede obtener procedimientos de
clasificación con una eficiencia comparable a la de otros métodos basados en
casos, como k-NN, pero con más posibilidades para expresar lo que realmente
sucede en los datos (Slezak and Wroblewski, 1999). Seguidamente se presenta
una variante de este enfoque.
Una generalización del enfoque clásico de los conjuntos aproximados es
reemplazar la relación de inseparabilidad binaria, la cual es una relación de
equivalencia, por una relación de similaridad binaria más débil. En la definición
original del concepto de conjuntos aproximados, existe una relación R que define
la inseparabilidad entre los objetos que tienen el mismo valor para los atributos
considerados por R, debido a eso, cada relación es una relación de equivalencia.
Tal definición de R puede ser muy restrictiva en muchos casos. Considerar el uso
de una relación de similaridad en lugar de una relación de inseparabilidad resulta
relevante. En realidad, debido a la imprecisión en la descripción de los objetos,
pequeñas diferencias entre objetos no se consideran significativas en el proceso
de discriminación (formación de las clases de equivalencias), como sucede
frecuentemente con los atributos cuantitativos debido a imprecisiones en la
medición de los mismos, fluctuaciones aleatorias de algunos parámetros, etc.. Una
vía para el tratamiento de este problema puede ser discretizar tales atributos, peor
esto pudiera traer consecuencias indeseadas como por ejemplo el hecho de
asociar valores muy cercanos a valores discretos diferentes. Otra alternativa es
considerar la similaridad entre los valores. En nuestra investigación dos objetos x,y
con rasgos continuos, pertenecerán a una relación de similaridad S ssi la función
semejanza β evaluada en ambos es mayor que un numero real gamma. Esto es
S: ySx (x,y)> .

Capítulo 1
25
El propósito de esta relación es extender la relación de inseparabilidad R
aceptando que los objetos que no son inseparables, pero sí suficientemente
cercanos o similares se pueden agrupar en la misma clase. En otras palabras,
construir una relación de similaridad R* a partir de R, flexibilizando las condiciones
originales de inseparabilidad. En (Slowinski and Vanderpooten, 1995) se
presentan los siguientes resultados al respecto.
Definición 1.8: (Relación de similaridad extendida)
Sea R una relación de inseparabilidad que es una relación de equivalencia
definida sobre U. Se dice que R* es una relación de similaridad extendida desde
R, si y sólo si,
(i) Para todo x U, R(x)R*(x)
(ii) Para todo x U, Para todo y R*(x), R(y)R*(x)
Donde R*(x) es la clase de similaridad de “x”, es decir,
R*(x)={yU:yR*(x)} (1.6)
Realmente, las relaciones de similaridad son frecuentemente definidas
directamente y no como extensiones de relaciones de equivalencia.
Desde la perspectiva de las propiedades de las relaciones, el carácter transitivo de
la relación de separabilidad es fundamental. Si la relación es transitiva, entonces
ella define una partición de U en bloques de elementos indistinguibles; mientras
que relaciones no transitivas dan pie al uso de relaciones de similaridad. Las
similaridades entre los objetos se pueden representar por una relación binaria R
que forma clases de objetos los cuales son idénticos o al menos no notablemente
diferentes en términos de la información disponible sobre ellos.
En general las relaciones de similaridad no generan particiones sobre el universo
U, sino clases de similaridad para cada objeto x U. La clase de similaridad de
“x”, de acuerdo a la relación de similaridad R se denota por R(x) y se define como:
R(x)={ y U : yRx } (1.7)

Capítulo 1
26
Se lee como conjunto de elementos ”y” similares a ”x” de acuerdo a la relación R.
La relación R es sólo reflexiva (cada objeto es similar a si mismo). Pero no es
transitiva: “x” puede ser similar a “y” y “y” puede ser similar a “z”, pero esto no
implica que “x” sea similar a “z”.
y R(x) y y R(z) NOT z R(x), para x, y y z U.
La no transitividad de la relación de similaridad está dada por el hecho de que una
serie de pequeñas diferencias no pueden ser propagadas manteniendo el carácter
de pequeñas. Por ejemplo, sean:
x=0.5 z=0.6 y=0.7
Dada la relación xRy x-y 0.1:
x está relacionada con z,
z está relacionada con y,
PERO X NO ESTÁ RELACIONADA CON Y.
Tampoco tiene que ser simétrica: “y” pede ser similar a “x” según R, pero esto no
implica que “x” sea similar a “y” de acuerdo a R pues la relación R es direccional,
donde el sujeto es “y”, y el referente es “x”.
y R(x) NOT x R(y), para x, y U.
Aunque la mayoría de las funciones de semejanza son simétricas, varios autores
han argumentado el hecho de que la similaridad no debe ser tratada como una
relación simétrica.

Capítulo 1
27
1.5 Conclusiones parciales
Podemos decir que después de haber estudiado las diferentes alternativas de
las extensiones de la teoría de los Conjuntos Aproximados para el tratamiento
de la información incompleta:
- Algunos de los métodos encontrados tienen limitaciones en cuanto a la
calidad de la clasificación.
- Las diferentes implementaciones de estos métodos, en su mayoría, están
sobre aplicaciones secuenciales y muchas veces los programas sólo se
limitan a llevar los SDI a sistemas de decisión completos.
- La relación de tolerancia limitada L (relación V) es la más adecuada para
tratar el problema de la información incompleta de acuerdo a los
resultados teóricos anteriormente mostrados.

Capítulo 2
28
Capítulo 2 “Propuesta de paralelización”
2.1 Conjuntos Aproximados (Rough Set)
Al enfrentar una tarea que involucre el desarrollo de algoritmos paralelos para
una aplicación determinada, es necesario realizar un profundo análisis sobre los
posibles modelos de paralelización a seguir, así como del modelo serial que
daría solución a la problemática planteada. Nuestra investigación no está
desligada de este planteamiento. En el presente capítulo se muestra el conjunto
de algoritmos propuestos para el cálculo de la calidad de SD y todo lo
relacionado con el diseño y la funcionalidad de los mismos.
El análisis de los sistemas de información incompletos es abordado por las
extensiones de la teoría de los Conjuntos Aproximados. Después de haber
hecho el análisis teórico de sus principales representantes contamos con varias
alternativas encontradas en la literatura científica para abordar esta problemática
en sistemas de decisión incompletos. Dos de las relaciones propuestas serán
implementadas por el presente proyecto por la gran importancia que se les
atribuyó a las mismas en múltiples trabajos científicos.
El problema de la semejanza entre objetos en los sistemas de información
completos con rasgos continuos es tratado también en las extensiones de la
teoría de los Conjuntos Aproximados, su principal exponente son las relaciones
basadas en funciones de semejanza por lo que decidimos desarrollar esta
variante pero de una forma que la función de semejanza quedara abierta a los
usuarios que quieran hacer uso de una propia y no de la implementada en esta
investigación (suma pesada de rasgos).
Las primeras dos variantes para el trabajo con perdida de información están
basadas en relaciones de tolerancia. La primera (relación II, capítulo 1) es una
de las más usadas y referenciadas en la bibliografía y la segunda (relación V,
capítulo 1), como se comprobó teóricamente, permite obtener resultados
superiores en el cálculo de la calidad con respecto al resto de las variantes (sus
resultados son expuestos de forma experimentalmente en el capítulo 3).

Capítulo 2
29
Por otra parte se implementó una función de semejanza que mide la similaridad
entre dos objetos P y C con n rasgos de condición reales y un atributo de
decisión que puede o no ser continuo, nombrada como la suma ponderada de
los pesos. Su especificación se encuentra incluida dentro de la biblioteca
libsemej.a, la que implementa dos variantes de funciones de comparación de
rasgos (2.1 y 2.2) y que tiene como función de semejanza a (2.3) o (2.4) según
sea la función de comparación de rasgos escogida.
yxif
yxifyx
0
1, (2.1)
i ,
1
0 (2.2)
n
i
CiPiiwiCP1
,*, (2.3)
n
i
i CiPiwiCP1
,*, (2.4)
Donde”x”, ”y”, Pi , Ci , α, y β son atributos, P y C son conjuntos de atributos, ε es
un valor real que entre otras cosas decidirá, en caso de que sea 0 o diferente de
0, si se va a usar la (2.1) o (2.2) respectivamente.
En esta implementación es muy importante destacar que la función
funcionSemejanza(float * A, float * B, long columnas) desarrolla la función de
semejanza, declarándose en el archivo Semejanza.h e implementada en
libsemej.a. Por su propia concepción esta implementación puede variar según
el usuario desee con sólo cambiar el archivo libsemej.a por otro que contenga
el desarrollo de una nueva función de semejanza la cual deberá regirse por la
declaración que está definida en Semejanza.h
Estas implementaciones siguen un número de procedimientos indicados por sus
algoritmos, los cuales se muestran a continuación.

Capítulo 2
30
2.2 Procedimiento serial para clasificar a un SDI
En la versión secuencial del algoritmo un solo nodo es el encargado de ejecutar
todo el trabajo.
El procedimiento básico empleado para calcular la calidad del sistema de
información, independiente de la variante seleccionada, consta de dos pasos:
Estas variantes se resumen en el mismo algoritmo secuencial, que se muestra a
continuación:
1) Invocar a la función que determina la relación de tolerancia entre los
objetos (función tolerancia, tolerancil o similitud).
2) Imprimir la calidad de la aproximación del sistema.
program calc_calidad; 1 cargar_SDI(name); SumAinf=0;
2 Repetir Desde i:=0 hasta ctad_obj, hacer
Si la clase_d (i) esta en array_cd entonces inc(array_cd[clase_d[i]]) ;
sino add(clase_d[i],array_cd) ;
3 Repetir Desde j:=0 hasta ctad_cd hacer Repetir Desde k:=0 hasta ctad_obj hacer Si clase_d(k) = array_cd(j) entonces n:=0; válido:=true; Mientras (n<= ctad_obj) y (válido=true) hacer Si clase_d(n) = clase_d(k) entonces válido = objATobjBCD (n,k); inc(n); Si (válido=true) entonces inc(SumAinf);
4 calidad = SumAinf/ctad_obj;
5 devolver(calidad);

Capítulo 2
31
En este pseudo código es necesario aclarar el significado de algunas funciones
y variables:
add: Esta función adiciona una clase de decisión al arreglo de clases
de decisión.
array_cd: En este arreglo se almacenan las clases de decisión diferentes
que tiene el SDI.
calidad: Esta es la variable donde se guarda el objetivo final del
programa, que es calcular la calidad de aproximación del SDI
mediante los atributos entrados como parámetros.
cargar_SDI: Esta función lee de un archivo cuyo nombre fue entrado como
parámetro (name) el sistema de decisión y lo almacena en
memoria.
clase_d: Esta función devuelve el valor del atributo de decisión del objeto
que se le pasa como parámetro.
ctad_cd: Es el número de clases de decisión diferentes con que cuenta el
sistema.
ctad_obj: Es el número de objetos con que cuenta el sistema de decisión
incompleto.
SumAinf: En esta variable se van contabilizando todos los objetos que
pertenecen a la aproximación inferior de un conjunto.
válido: Esta bandera nos evita tener que recorrer todos los objetos de
una clase de tolerancia para comprobar si este objeto no
pertenece a la aproximación inferior del conjunto (siempre que el
objeto a comparar no pertenezca a la aproximación inferior del
conjunto), debido a que en el momento que se encuentre un
objeto en la misma clase de tolerancia pero que tenga una clase
de decisión diferente válido toma valor false y se detiene la
búsqueda.

Capítulo 2
32
La función objATobjBCD (n,k) marca la diferencia al utilizar tolerancia,
tolerancil, o similitud. Para cada una de estas funciones el algoritmo varía
dado al enfoque que teóricamente se le da, pero básicamente es la función que
dice si dos objetos A y B (n,k) están en la misma clase de tolerancia.
Para el anterior algoritmo tenemos que la función objATobjBCD varia en
dependencia de la variante que se implemente. Por ejemplo objATobjBCD1 es la
correspondiente a la primera extensión, la relación II del primer capítulo,
objATobjBCD2 es la correspondiente a la segunda extensión. La relación V del
primer capítulo y objATobjBCD3 es la correspondiente a la tercera extensión, o
sea, la relación de similaridad, esta última consta básicamente solamente de la
llamada a la función funcionSemejanza dado que dicha función, es la que
define si dos objetos son o no similares y no objATobjBCD3.
La función de comparación de objetos para la primera extensión se define por:
Esta es una función muy simple donde hay que aclarar que:
- La función rasgo (i,n) devuelve el valor del rasgo i en el objeto n.
- La variable ctad_rasgos tiene la cantidad de rasgos que se quieren analizar del
SDI.
- La bandera iguales que nos evita tener que recorrer todo el conjunto de rasgos
si ya uno de ellos tiene un valor diferente en ambos objetos.
función objATobjBCD1(n, k) 1. iguales=true; 2. Mientras (i<=ctad_rasgos) y (iguales=true) hacer
Si (rasgo (i, n) <> rasgo (i, k)) y (rasgo (i, n)!=*) y (rasgo (i, k)!=*) entonces
iguales = false; inc(i);
3. devolver(iguales);

Capítulo 2
33
La función de comparación de objetos para la segunda extensión se define por:
En esta función el procedimiento rasgo(i,n) es el mismo que en la variante
anterior. Lo mismo pasa con la variable iguales y la variable ctad_rasgos.
Tenemos además la bandera valido que usamos para verificar si la pareja de
objetos tiene al menos un atributo conocido en común (cuando esto sucede el
primer ciclo la incrementa). Es muy importante el papel que desempeña la
variable conocido que es la encargada de almacenar si alguno de los dos
objetos tiene al menos un atributo conocido en cuyo caso no seria posible que
ambos fuesen semejantes por falta de información total (caso que es tratado de
esa forma en la segunda relación del primer capítulo).
Conviene describir el objetivo del ciclo usado en este pseudo código.
El paso 2 (ciclo) verifica si los objetos están relacionados, es decir, si están en la
misma clase de tolerancia, comprueba que los objetos tengan al menos un
atributo común con valor conocido y que cualquiera de los dos objetos tenga al
menos un atributo con valor conocido, almacenándolo en la variable conocido la
función objATobjBCD2(n, k) 1. iguales=true; valido=true; i=0; conocido; 2. Mientras (i<=ctad_rasgos) y (iguales=true) hacer
Si ((rasgo (i, n) <> *) y (rasgo (i, k) <> *)) entonces iguales:=(rasgo (i, n)=rasgo (i, k)); inc(valido); Si ((rasgo (i, n) <> *) o (rasgo (i, k) <> *)) entonces inc(conocido);
inc(i); 3. Si (valido<>0) entonces devolver(iguales)
sino Si (conocido<>0) entonces devolver(0); sino
devolver(1);

Capítulo 2
34
cual será 0 ssi ambos objetos en cuestión tienen todos sus atributos
desconocidos.
La función de comparación de objetos para la tercera extensión (función de
semejanza) se define por:
Aquí es importante resaltar que gamma no es una variable de la función sino un
parámetro pasado a objATobjBCD3 (este parámetro ha de ser pasado a la
llamada inicial de similitud) y según sea su signo la función similitud estará
basada en una función de semejanza (cuando sea gamma > 0) o en una función
de discrepancia (cuando sea gamma < 0).
Recordemos que la función funcionSemejanza no está incluida en la biblioteca
libext.a, el usuario puede implementarla como desee. No obstante, dentro de la
biblioteca libsemej.a encontramos una implementación de esta que desarrolla
una función de comparación de rasgos conocida, mediante la suma ponderada
de los atributos.
La funcionSemejanza brindada en la biblioteca tiene básicamente los
siguientes pasos:
función objATobjBCD3(n, k, gamma) 1. iguales=true; i=0; 2. Si (gamma >=0) entonces iguales = (funcionSemejanza(n, k) >= gamma); sino gamma = gamma *(-1); iguales = (funcionSemejanza(n, k) <= gamma); 3. devolver(iguales);
3. devolver(iguales);
función funcionSemejanza (n, k) 1. epsilon=0; i=0; beta=0; 2. epsilon = loadPesos(array_pesos); 3. Repetir Desde i:=0 hasta ctad_rasgos hacer
beta = beta + array_pesos[i] *( |(rasgo[i, n] - rasgo[i, k])| <= epsilon )
4. devolver(beta);

Capítulo 2
35
En el caso de nuestra simple funcionSemejanza hay que aclarar que epsilon es
una variable en la que se guarda el valor de retorno de la función loadPesos (la
cual es responsable de cargar en la variable array_pesos el valor de los pesos
que se le dan a los atributos mediante el archivo predeterminado pesos.txt) y
que necesitamos para poder computar el valor de las expresiones 2.1 o 2.2,
según sea el valor de este (cero, o diferente de cero respectivamente).
El archivo pesos.txt es un archivo de texto que ha de tener en la primera línea
el valor de epsilon y a partir de ahí el listado de los pesos que le queremos dar a
los atributos (con que vamos a aproximar el sistema).
Por ejemplo, para un SDI con 4 atributos de condición el archivo podría ser el
siguiente:
Es muy importante señalar que si este archivo no tiene la cantidad de pesos
estrictamente necesarios la función de semejanza no trabajará apropiadamente.
Por ejemplo el archivo mostrado anteriormente deberá tener solo cinco líneas
una para el epsilon y cuatro para los pesos que vamos a asignarle a cada uno
de los atributos con que vamos a trabajar. En caso de que solo fuéramos a
calcular la calidad del sistema con un subconjunto de todos los atributos, el
archivo tendrá tantos pesos como elementos tenga este subconjunto.
2.3 Método paralelo propuesto para el cálculo de la calidad en un SDI.
La versión paralela de este módulo fue basada en un modelo de paralelización
propuesto por (Ramos, 2007) Este modelo brinda la facilidad de que cada
elemento de procesamiento (nodo) se encargue de construir y trabajar (calcular
las aproximaciones inferiores de cada clase de decisión) con sólo un
subconjunto de las clases de tolerancia.
0.2 0.5 1
0.9 1

Capítulo 2
36
Este modelo (Fig. 2.1) aprovecha, donde es posible, las ventajas de las técnicas
paralelas, razón por la que sirvió de base al modelo propuesto en esta
investigación para la implementación del cálculo de la calidad, usando
extensiones de la teoría de los Conjuntos Aproximados en nuestra variante
paralela.
Fig. 2.1 Conjuntos Aproximados
El algoritmo a modo general consta de cuatro pasos los cuales se describen a
continuación:
1) En este paso inicial se procede a la construcción de las clases de tolerancia
(CT); el nodo 0 (master) procede a difundir todos los objetos (filas del
Sistema de Decisión) al resto de los nodos. Una vez que los nodos reciben
los objetos, estos se almacenan en memoria confeccionando una copia del
SD en cada uno de los nodos del SD.
2) Una vez terminado el paso 1, el nodo 0 envía la lista de clases de decisión
del sistema a cada uno de los restantes nodos.
3) Los esclavos junto al nodo 0 proceden a verificar si los objetos que le
corresponden (indicados por 2.3 para el nodo master y por 2.4 para los
esclavos) pertenecen a la aproximación inferior del conjunto de objetos
cuya clase de decisión se esta analizando mediante la exploración de las
clases de tolerancia de cada uno de los objetos.
Desde (numtasks-1)*(filas/ (numtasks-1)) hasta filas (2.4)

Capítulo 2
37
Desde (rank-1)*(filas/(numtasks-1)) hasta rank*(filas/(numtasks-1)) (2.5)
Donde numtasks es el número de procesadores utilizados para ejecutar el
programa y rank es el identificador del procesador (ID) que está ejecutando
ese fragmento de código y filas es el número total de objetos con que
cuenta el SD.
4) Cada nodo envía al nodo 0 la cantidad de objetos que pertenecen a la
aproximación inferior de cada conjunto definido por las clases de decisión y
este posteriormente, calcula la calidad de clasificación del sistema y
devuelve el resultado.
Al analizar esta variante observamos que presenta un grupo de ventajas, de las
cuales se pueden mencionar las siguientes:
- Se cuenta con un módulo que permite usar SI con otras características
(diferentes separadores, números de filas, columnas y atributos, etc.)
- Todas las funciones que se brindan en la biblioteca pueden hacer uso de
los archivos con formato arff, muy utilizado internacionalmente.
- Se eliminaron envíos masivos de datos relacionados con el cálculo de la
calidad sin afectar la eficiencia.
Para su implementación en rset.h se encuentra todo lo relacionado con las
operaciones de los conjuntos aproximados (la construcción y operación de las
clases de tolerancia).El módulo ext.h contiene todas las funciones públicas de la
biblioteca: tolerancia, tolerancil y similitud. En aprox.h se ubican los
métodos implicados en el cálculo de las aproximaciones. En los archivos ext1.h
ext2.h y ext3.h se encuentran las funciones de las que se auxilia ext.h, las
cuales están desarrolladas dentro de la biblioteca y no son públicas.
En xtras.h se encuentran una serie funciones auxiliares que permiten realizar la
lectura de los objetos de la base de casos así como otras funciones auxiliares
para el trabajo con los parámetros de entrada y salida.
También dentro del archivo mstructs.h están declaradas las principales
estructuras de datos utilizadas en el trabajo con los conjuntos aproximados.

Capítulo 2
38
Como es lógico, muchos de los procedimientos desarrollados hacen uso de
funciones básicas ya implementadas en bibliotecas del C, las cuales están
declaradas fundamentalmente en stdio.h, stdlib.h y string.h.
Fig. 2.2 Diagrama de colaboración.
El diagrama de la Figura. 2.2, se corresponde con el gráfico de dependencias
entre la librerías de las funciones.
2.3.1 Descripción del algoritmo paralelo
Nuestra alternativa paralela debe ser capaz distribuir el trabajo entre los nodos
esclavos y el nodo master pero antes de hacer esto tiene que garantizar que
cada nodo tenga una copia del SD. Para lograrlo el nodo 0 carga el SDI en
memoria y lo difunde a cada unos de los nodos restantes. Los pasos son en
esencia los siguientes:
- El nodo 0 carga el sistema y le envía una copia a sus esclavos (Fig. 2.3).
- El master le envía el arreglo de clases de decisión al resto de los nodos
(Fig.2.4).

Capítulo 2
39
- Cada nodo realiza el trabajo con los objetos que le fueron asignados (Fig.
2.5).
- Cada nodo envía los resultados al nodo master. (Fig. 2.6).
Fig. 2.3: Paso 1, carga y envío del SDI a cada nodo
Fig. 2.4: Paso 2, envío del arreglo de clases de decisión a cada nodo.

Capítulo 2
40
Fig. 2.5: Paso 3 Cada nodo calcula las aproximaciones inferiores de los
conjuntos según los objetos que le fueron encomendados.
Fig. 2.6: Paso 4, cada nodo envía hacia el 0 el resultado del cálculo de las
aproximaciones inferiores para que este calcule la calidad.
El nodo 0 obtiene así la cantidad de objetos que pertenecen a la aproximación
inferior del conjunto en cuestión, por lo que todo lo que este tiene que hacer es

Capítulo 2
41
repetir el proceso antes expuesto para cada una de las clases de decisión con el
objetivo de calcular la calidad de la clasificación.
En este modelo se pretende minimizar el tiempo de cálculo de las
aproximaciones inferiores, puesto que el mismo era un punto importante en el
desempeño del algoritmo y reservar para el nodo master el cálculo de la calidad
y de las aproximaciones inferiores en un número menor de clases de tolerancia.
La limitación de este esquema, como se puede apreciar, es que el mismo envía
una gran cantidad de información de un nodo a otro, lo cual puede traer algunos
inconvenientes en caso que se utilicen bases de casos de tamaño considerable.
2.3.2 Pseudo código del algoritmo paralelo para clasificar un SD
En la versión paralela del algoritmo cada nodo (incluyendo el nodo master) tiene
que determinar cuáles de los objetos que le fueron asignados pertenecen a la
aproximación inferior del conjunto de objetos identificados por una clase de
decisión en particular.
Al igual que en el procedimiento serial los pasos básicos empleados para
calcular la calidad del sistema de información, independiente de la variante
seleccionada, son sólo dos:
¡Error!
1) Invocar a la función que determina la relación de tolerancia entre los
objetos (función tolerancia, tolerancil o similitud).
2) Imprimir la calidad de la aproximación del sistema.

Capítulo 2
42
Estas variantes se resumen en el mismo algoritmo, el cual se muestra a
continuación:
program Parallel_calc_calidad; 1. Si p==0 {procesador 0 o Nodo Maestro} 2. cargar_SDI(name); SumAinf=0; 3. array_cd := Ф; {Inicializa el arreglo de clases} 4. contruye array_cd; {llena el arreglo con las clases de decisión del sistema} 5. enviar array_cd a cada uno de los nodos {one to all broadcast}; 6. enviar copia del sistema de información a cada nodo; 7. determinar la cantidad de objetos (ctad_obj) a procesar en el procesador;
{ ctad_obj = filas- (numtasks-1)*(filas/ (numtasks-1)) donde filas es el total de objetos del SD}
8. Repetir Desde j:=0 hasta ctad_cd hacer
Repetir Desde k:=0 hasta ctad_obj hacer Si clase_d(k) = array_cd(j) entonces n:=0; válido:=true; Mientras (n<= filas) y (válido=true) hacer Si clase_d(n) = clase_d(k) entonces válido = objATobjBCD (n,k); inc(n); Si (válido=true) entonces inc(SumAinf);
9. Recibir de cada nodo el valor de SumAinf y determinar el total de objetos que pertenecen a la aproximación inferior. {All to One Reduce, Adition}
10. calidad = SumAinf/filas;
11. devolver(calidad) { Fin del trabajo en el procesador 0}

Capítulo 2
43
A continuación se muestra el segmento de pseudo código que ejecutan todos los
nodos esclavos:
En este pseudo código es oportuno señalar que:
- La variable ctad_obj no guarda el número de objetos del SD, sólo la
cantidad de objetos que el procesador i va a analizar.
- El número total de filas del SD estará almacenado en la variable filas.
- El resto de las funciones usadas son idénticas a las del algoritmo serial,
dígase objATobjBCD y funcionSemejanza en cada una de sus variantes
para sus respectivas variantes de cálculo de calidad empleado.
program Parallel_calc_calidad; (Continuación parte de los nodos esclavos) 12. else {procesador esclavo} 13. Recibir array_cd del procesador 0; 14. Recibir SD del procesador 0; 15. enviar copia del sistema de información a cada nodo; 16. determinar la cantidad de objetos (ctad_obj) a procesar en el procesador;
{ ctad_obj = rank*(filas/(numtasks-1)) - (rank-1)*(filas/(numtasks-1)) donde filas es el total de objetos del SD}
17. Repetir Desde j:=0 hasta ctad_cd hacer
Repetir Desde k:=0 hasta ctad_obj hacer Si clase_d(k) = array_cd(j) entonces n:=0; válido:=true; Mientras (n<= filas) y (válido=true) hacer Si clase_d(n) = clase_d(k) entonces válido = objATobjBCD (n,k); inc(n); Si (válido=true) entonces inc(SumAinf);
18. Enviar al nodo master el valor de SumAinf. {All to One Reduce, Adition}

Capítulo 2
44
2.4 Algunas especificaciones generales.
Las restricciones impuestas para el uso de nuestra librería están orientadas al
formato de los datos con lo cuales esta trabajará. Por ejemplo:
- La base de casos sólo contendrá valores numéricos ya sean reales o
discretos. Los valores que no sean conocidos en los SDI deberán estar
representados por el caracter asterisco (*) o por un signo de interrogación
(?).
- Los SD sólo contendrán un atributo de decisión y este deberá estar al
final del objeto siempre, en caso contrario el sistema lo tratara como un
atributo de condición.
- El separador de los atributos en la base de caso puede ser cualquier
caracter imprimible, a excepción del espacio en blanco.
- El nombre del archivo donde está el SD tendrá la dirección absoluta del
mismo, a menos que este se encuentre en el mismo directorio de trabajo
de la biblioteca.
2.5 Conclusiones parciales
Los métodos aplicados en este capítulo son una selección de las revisiones
bibliográficas, gracias a las cuales se pudieron obtener las conclusiones
siguientes:
- Se estructuró una propuesta de paralelización que fue aplicada a cada
una de las extensiones.
- La propuesta de paralelización se apoya en el enfoque de las limitaciones
de las implementaciones secuenciales.
- Se le aplicó la variante paralela a cada una de las tres extensiones de RS.

Capítulo 3
45
Capítulo 3. “Evaluación de los resultados y
descripción de las funciones”
En este capítulo se muestran los resultados obtenidos al aplicar los diferentes
algoritmos, herramientas y medidas a un conjunto de bases de casos obtenidas
de repositorios internacionales.
3.1 Herramientas y medidas
En las pruebas aplicadas a los algoritmos se tuvieron en cuenta dos elementos
fundamentales:
1. El tiempo que demora el algoritmo en hallar las clases de tolerancia.
2. El tiempo que demora el algoritmo en hallar las aproximaciones inferiores
de las clases de decisión de tolerancia.
El cluster de computadoras que se utilizó en las pruebas está compuesto por el
“frontside” Server, el mismo tiene las siguientes características:
- Intel Xeon/Pentium 4(R) a 3.0 GHz.
- 512 MByte.
Además tiene 10 nodos Intel Pentium 4(R) a 3.0 GHz de ellos nueve con
capacidad de memoria de 1 Gbyte y uno con capacidad de memoria de 512
Megabytes. Para ambas configuraciones se empleó una red 100/1000 Mbps.
Las pruebas realizadas a los algoritmos secuenciales se realizaron sobre uno de
estos nodos. Sobre el mismo se realizaron dos tipos de experimentos, el primero
se realizó con el objetivo de comparar los resultados de la calidad de
clasificación entre las dos primeras extensiones implementadas (las utilizadas en
bases de casos con valores perdidos). El segundo, estuvo orientado a comparar
los tiempos de ejecución de la variante secuencial y de la variante paralela,
ambas desarrolladas para la tercera extensión de la teoría (basada en la
semejanza entre objetos).

Capítulo 3
46
Los sistemas de información que se utilizaron para las pruebas en el primer
experimento fueron tomados de repositorios internacionales tales como el de la
Universidad de California, Irvine (UCI Repository) y el del Departamento de
Ciencias de la Computación de Guelph Ontario, Canadá los cuales fueron:
- Ad (Internet Advertisements). Contiene 3279 objetos y 1559 atributos
incluyendo el de decisión.
- Colic (Horse Colic database). Contiene 368 objetos con 28 atributos
incluyendo el de decisión.
- Hungarian (Hungarian Institute of Cardiology). Contiene 294 objetos con
14 atributos incluyendo el de decisión.
- Mammo (Mammographic Mass). Contiene 961 objetos con 6 atributos
incluyendo el de decisión.
- PBC (Primary Biliary Cirrhosis). Contiene 418 objetos con 19 atributos
incluyendo el de decisión.
En el segundo experimento se utilizó la tercera extensión (basada en la relación
de similaridad) con 3 sistemas de decisión completos del repositorio de la
Universidad de California, Irvine (UCI Repository) pero con atributos de tipo
continuo. Para ilustrar la ganancia en tiempo de ejecución de la versión paralela
en comparación con la secuencial se escogieron los siguientes sistemas, todos
con una gran cantidad de objetos:
- Bio (Protein Homology Dataset). Contiene 147751 objetos con 75
atributos continuos incluyendo el de decisión.
- Magic (Magic Gamma Telescope). Contiene 19020 objetos con 11
atributos continuos incluyendo el de decisión.
- Wave (Waveform Database Generator). Contiene 5000 objetos y 41
atributos continuos incluyendo el de decisión.

Capítulo 3
47
3.2 Tecnologías utilizadas
Para la creación de los diferentes algoritmos se utilizó como base el lenguaje C,
cuya selección se basó teniendo en cuenta los siguientes aspectos:
- El lenguaje C es muy portable si se tiene en cuenta el hecho de que
existe una gran variedad de compiladores y librerías para diferentes
plataformas.
- Ofrece buenos resultados de rendimiento en comparación con otros
lenguajes de programación.
- Como resultado de investigaciones anteriores existe de una serie de
módulos elaborados en este lenguaje, los cuales fueron reutilizados en la
construcción posterior de los algoritmos.
En las versiones paralelas se utilizó el conjunto de librerías MPICH2 contenidas
en un paquete de librerías y aplicaciones llamado OSCAR 5.0, las cuales
permiten desarrollar aplicaciones en paralelo sobre un cluster de computadoras
con memoria distribuida.
Para la confección de los diagramas se utilizó una herramienta muy popular de
generación automática de documentación (Doxygen) a partir del código fuente,
la misma permite:
- Generar documentación en diferentes idiomas.
- Generar diagramas compatibles con UML.
Este código soporta C, C++ y Java. Además el mismo utiliza el Látex lo que
permite que la documentación, una vez generada, sea modificable y exportable
a varios formatos como por ejemplo pdf, ps, html ó rtf.
3.3 Estructuras de Datos
En este epígrafe se abordan las estructuras de datos empleadas en la
construcción y almacenamiento de las clases de tolerancia y en el cálculo de las
aproximaciones inferiores.

Capítulo 3
48
Para el desarrollo de este trabajo se utilizaron básicamente tres estructuras de
datos:
- tname: almacena el atributo de decisión de la clase de tolerancia así
como el número del objeto.
- clase: almacena las clases de tolerancia así como el valor de los atributos
que las une.
- listaclases: Es un gran contenedor que además almacena el arreglo de
clases de decisión del SD.
Este es el diagrama de las estructuras que permiten construir la lista de Clases
de tolerancia:
Fig. 3.1 Diagrama UML de las estructuras
3.4 Conjuntos Aproximados (Rough Set)
En este epígrafe se muestran las diferentes pruebas realizadas al módulo para
el cálculo de la calidad de las dos primeras extensiones de la teoría, tanto en la
versión secuencial como en la paralela.

Capítulo 3
49
3.4.1 La versión secuencial
Después de contar con una implementación secuencial (V.S) para cada
extensión se realizaron pruebas experimentales para enmarcar las diferencias
obtenidas en cuanto a tiempo de ejecución y calidad.
Base de Datos Ext. 1
(Relación II)
Ext. 2
(Relación V)
Ad
atributos: * (1-1558)
Calidad: 0.937176
Tiempo: 2.05052
Calidad: 0.937176
Tiempo: 2.83795
Ad
atributos: 1, 2, 3
Calidad: 0.00000
Tiempo: 1.29213
Calidad: 0.603538
Tiempo: 1.35558
Colic
atributos: * (1-27)
Calidad: 1
Tiempo: 0.009134
Calidad: 1
Tiempo: 0.01021
Colic
atributos: (6-20)
Calidad: 0.423913
Tiempo: 0.007101
Calidad: 0.747283
Tiempo: 0.009462
H
atributos * (1-13)
Calidad: 1
Tiempo: 0.003439
Calidad: 1
Tiempo: 0.004081
H
atributos: 5, 11, 12, 13
Calidad: 0.00000
Tiempo: 0.002585
Calidad: 0.360544
Tiempo: 0.003098
Mammo
atributos: * (1-5)
Calidad: 0.745057
Tiempo: 0.024388
Calidad: 0.745057
Tiempo: 0.030914
Mammo
atributos: 1, 3, 4
Calidad: 0.006243
Tiempo: 0.004943
Calidad: 0.022893
Tiempo: 0.006629
PBC
atributos:* (1-18)
Calidad: 1
Tiempo: 0.014529
Calidad: 1
Tiempo: 0.016939
PBC
atributos:2,4,5,6,7,10,12,13,14,15,18
Calidad: 0.00000
Tiempo: 0.011393
Calidad: 0.746412
Tiempo: 0.02012
Nota: Los tiempos están dados en segundos y (*) significa que se probó con todos los atributos.
Tabla 3.1 Calidad y tiempo de la versión secuencial de ext1 y ext2

Capítulo 3
50
Para la realización de las pruebas experimentales se escogieron 5 bases de
casos del repositorio de la Universidad de California, Irvine (UCI Repository) que
presentaban objetos con ausencia de información en varios rasgos y un número
aceptable de objetos representativos.
Los resultados obtenidos de la ejecución de las aplicaciones secuenciales de las
extensiones 1 y 2 (Fig 3.1) fueron comparados entre sí usando dos conjuntos de
atributos, el primero formado por todos los atributos y el segundo por sólo por un
grupo de ellos para ilustrar las ventajas de la segunda extensión sobre la
primera, aún cuando esta última es más rápida que su homologa:
Después de lo analizado en el primer capítulo es lógico pensar que la segunda
extensión de la teoría sea mucho más eficiente, en lo que a clasificación se
refiere, cuando se utilizan atributos donde existen valores perdidos. Por esta
razón en la tabla anterior se muestran los resultados del cálculo de la calidad
usando, además del conjunto completo de todos los atributos, un subconjunto de
estos.
En la figura 3.2 se ofrece una comparación grafica de de los resultados
obtenidos al aproximar el SDI con los atributos seleccionados por cada una de
las implementaciones seriales (Ext. 1 y Ext. 2). Es importante destacar que en la
mayoría de los casos la calidad que resulta de aproximar el sistema por un
conjunto de atributos con valores perdidos según la Ext. 1 es cero, razón por la
cual sus representaciones no se ven reflejadas en la grafica.

Capítulo 3
51
Comparación de Calidades
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Ad
Colic H
Mam
mo
PBC
Bases de Casos
Ca
lid
ad
Ext. 1 (Relación II)
Ext. 2 (Relación V)
Fig. 3.2 Comparación de las extensiones en cuanto a calidad usando
conjuntos de atributos seleccionados.
Como se puede observar en la Fig. 3.2, el tiempo de V.S para la Ext. 1 es
ligeramente inferior que el de la Ext. 2 pero esta última es muy superior (a la
hora de aproximar) cuando es necesario usar aquellos atributos para los cuales
existen valores perdidos en el cálculo de la calidad de la aproximación. Por este
motivo es que la extensión basada en la relación II es mejor cuando lo que se
quiere es ganar en tiempo y agilizar los cálculos, o cuando estamos seguros que
el sistema tiene pocos valores perdidos, en cuyo caso es conveniente utilizar
dicha relación.
Cuando tenemos un SDI con varios atributos en los que existe una gran cantidad
de valores perdidos, es muy recomendable usar la segunda extensión; o cuando
el conjunto de atributos mediante el cual vamos a aproximar el sistema es
escaso y/o con un subconjunto grande de rasgos con valores perdidos.
En los casos en los que se probó con todo el conjunto de rasgos como criterio
de similaridad, los resultados fueron prácticamente iguales, esto se debe a que
los (SD) tienen una gran cantidad de atributos y los cuales tienen pocos valores

Capítulo 3
52
perdidos. No obstante esto no siempre ocurre y para probarlo podemos utilizar
el ejemplo del Capítulo 1 en el cual las calidades para las extensiones 1 y 2 son
bien diferentes, uno tiene y el otro .
Los resultados obtenidos de la implementación serial de la tercera extensión
utilizando las bases de casos correspondientes se muestran a continuación:
Base de Datos Ext. 3
(Relación de Similaridad)
Bio
atributos: * (1-74)
Calidad: 1
Tiempo: 2164.77
Magic
atributos: * (1-10)
Calidad: 0.923239
Tiempo: 87.393
Wave
atributos: * (1-40)
Calidad: 1
Tiempo: 32.7208
Nota: Los tiempos están dados en segundos y (*) significa que se probó con todos los atributos.
Tabla 3.2 Calidad y tiempo para la versión serial de la extensión 3
En las pruebas efectuadas se le asigno valor 1 al peso de cada atributo, con un
valor de espilon (epígrafe 2.1) igual 0 y un gamma (epígrafe 2.1) igual a la
cantidad de atributos.
3.4.2 El método paralelo
A continuación se muestran los resultados “calidad” y “tiempo” obtenidos
haciendo uso de todos los atributos de los sistemas de decisión de las pruebas
realizadas sobre el cluster utilizando la versión paralela de la implementación de
la tercera de las extensiones con un conjunto variable de procesadores:
121
41

Capítulo 3
53
SD
2
(0-1)
4
(0-3)
6
(0-5)
8
(0-7)
10
(0-9)
Bio
Atributos:*
Cal: 1
Tie: 2147.54
Cal: 1
Tie: 774.033
Cal: 1
Tie: 479.76
Cal: 1
Tie: 352.502
Cal: 1
Tie: 275.906
Magic
Atributos:*
Cal: 0.92323
Tie: 87.5507
Cal: 0.92323
Tie: 41.408
Cal: 0.92323
Tie: 24.9378
Cal: 0.92323
Tie: 17.9597
Cal: 0.92323
Tie: 14.0117
Wave
Atributos:*
Cal: 1
Tie: 32.7946
Cal: 1
Tie: 11.0683
Cal: 1
Tie: 7.02026
Cal: 1
Tie: 4.98705
Cal: 1
Tie: 3.92233
Nota: Los tiempos están dados en segundos y (*) significa que se probó con todos los atributos.
Tabla 3.3 Tiempos de la variante paralela a medida que crece la cantidad de
nodos.
La calidad se comportó igual para cada una de las bases de casos por las
mismas razones expresadas en las comparaciones de la Tabla 3.1. En cuanto a
los tiempos, estos mejoran a medida que aumenta la cantidad de nodos.
En la gráfica que aparece a continuación se muestra el comportamiento del
algoritmo para cada una de las bases de casos. A medida que aumenta el
número de nodos usados para calcular la calidad, disminuye el tiempo de
cálculo, aún cuando el cambio en los sistemas Bio y Wave no sea tan
significativo. En todos los casos se utilizaron valores de los pesos de los rasgos
igual a 1, un epsilon igual a 0 y un gamma con un valor igual a la cantidad de
atributos del sistema. Todas las pruebas fueron hechas con todos los atributos.
Nodos

Capítulo 3
54
Tiempos de la versión paralela
0
100
200
300
400
500
600
700
800
2 4 6 8 10
Número de procesadores
Tie
mp
o (
S)
Bio
Magic
Wave
Fig. 3.3 Tiempos para la versión paralela de Ext3.
Como se puede apreciar Fig. 3.3 el método paralelo se comporta de manera
estable y a medida que le asignamos una mayor cantidad de procesadores el
tiempo de ejecución disminuye.
Es valido señalar que el SD que está almacenado en Bio es el más grande de
los tres y a medida que aumentamos el número de procesadores se puede
observar un mayor decrecimiento en cuanto el tiempo de ejecución. Esto se
debe al hecho de que Bio cuenta con una gran cantidad de filas (147751) por lo
que el proceso secuencial de construcción de las Clase de Tolerancia (CT) y
cálculo de las aproximaciones se hace muy lento, sin embargo, el procesamiento
paralelo permite construir CT en cada nodo por lo que su análisis puede hacerse
en un tiempo mucho menor.
3.4.3 Análisis de algunas métricas de rendimiento
Dos de las métricas más importantes que miden el rendimiento de un programa
paralelo son S (Speedup) y E (Eficiencia) estas se definen por:

Capítulo 3
55
Definición 3.1: Ganancia del programa paralelo (Speedup) (S) expresa la
ganancia obtenida al paralelizar una aplicación dada sobre la implementación
paralela. Además define la razón del tiempo empleado para la solución de un
problema en un elemento de procesamiento p, entre el tiempo empleado para
resolver el mismo problema en una computadora paralela con p elementos de
procesamiento idénticos.
La expresión que describe esta ganancia es: S = (3.1)
Donde TS es el tiempo de ejecución de la variante serial y TP es el tiempo de
ejecución de la alternativa paralela.
Definición 3.2: Eficiencia (Efficiency) (E) expresa en qué medida los
elementos de procesamiento han sido usados al máximo de su capacidad
(100%) durante la ejecución de un algoritmo paralelo. Esta medida muestra la
fracción de tiempo en que un elemento de procesamiento es totalmente usado.
La expresión que describe está eficiencia es: E = (3.2)
Donde S es la ganancia del algoritmo paralelo sobre el serial y P es el número
de procesadores usados en la ejecución en el cluster.
A continuación se muestran los valores de estas métricas para la tercera
extensión, siempre utilizando todos los atributos en el cálculo de la calidad:
Cluster CEI,
UCLV
2
(n0-1)
4
(n0-3)
6
(n0-5)
8
(n0-7)
10
(n0-9)
Bio 1.0088 2.7967 4.5121 6.1411 7.8460
Magic 0.9981 2.1105 3.5044 4.8660 6.2371
Wave 0.9977 2.9562 4.6609 6.5611 8.3421
Tabla 3.4 Ganancia del algoritmo paralelo de la extensión 3.
Ts Tp
S P
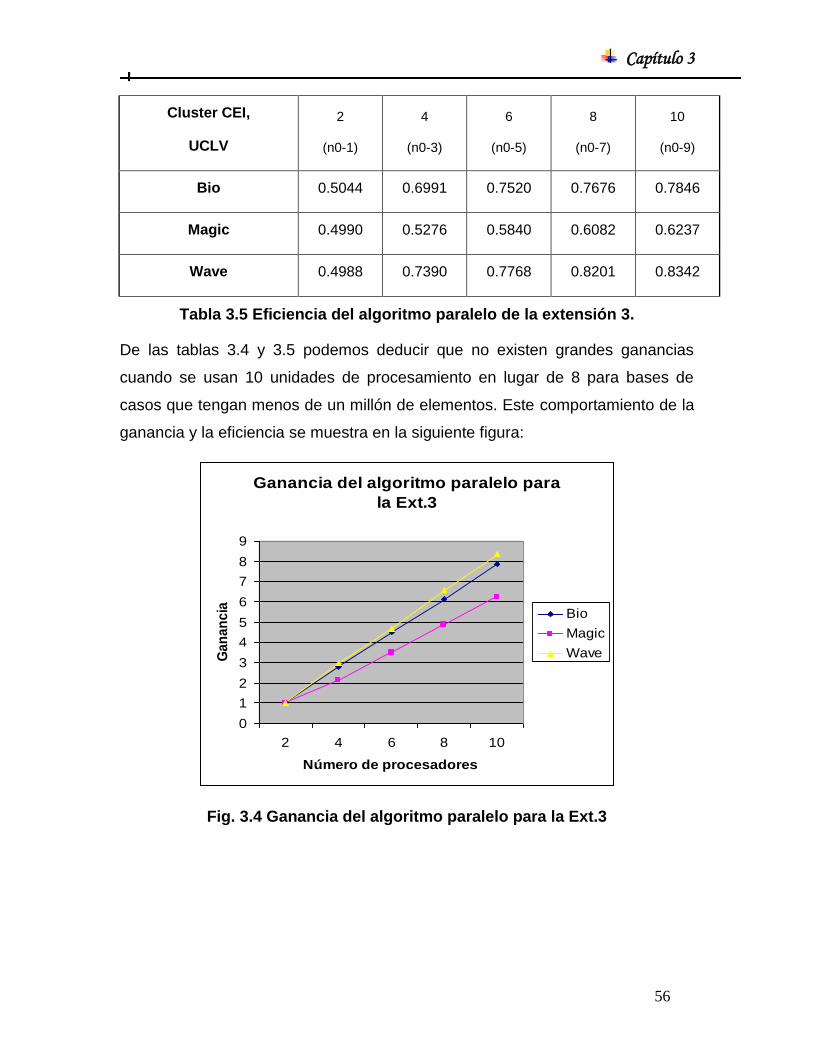
Capítulo 3
56
Cluster CEI,
UCLV
2
(n0-1)
4
(n0-3)
6
(n0-5)
8
(n0-7)
10
(n0-9)
Bio 0.5044 0.6991 0.7520 0.7676 0.7846
Magic 0.4990 0.5276 0.5840 0.6082 0.6237
Wave 0.4988 0.7390 0.7768 0.8201 0.8342
Tabla 3.5 Eficiencia del algoritmo paralelo de la extensión 3.
De las tablas 3.4 y 3.5 podemos deducir que no existen grandes ganancias
cuando se usan 10 unidades de procesamiento en lugar de 8 para bases de
casos que tengan menos de un millón de elementos. Este comportamiento de la
ganancia y la eficiencia se muestra en la siguiente figura:
Ganancia del algoritmo paralelo para
la Ext.3
0
1
2
3
4
5
6
7
8
9
2 4 6 8 10
Número de procesadores
Ga
na
nc
ia Bio
Magic
Wave
Fig. 3.4 Ganancia del algoritmo paralelo para la Ext.3

Capítulo 3
57
Eficiencia del algoritmo paralelo de la
Ext. 3
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
2 4 6 8 10
Número de procesadores
Efi
cie
nc
ia Bio
Magic
Wave
Fig. 3.5 Eficiencia del algoritmo paralelo para la Ext.3
3.5 Descripción de las funciones
La descripción de las funciones principales que se utilizaron en la
implementación de los métodos mencionados en la investigación se encuentra
en los anexos uno y dos. La revisión de estos es de suma importancia para el
trabajo con nuestra biblioteca de funciones.
3.6 Conclusiones Parciales
Como se pudo apreciar en las pruebas realizadas se comprobó que:
- El segundo modelo para el trabajo con información incompleta es el más
favorable para procesar SD con valores perdidos, sobre todo cuando
necesitamos aproximar el conjunto con atributos que tienen falta de
información.
- El método secuencial del cálculo de la calidad usando la relación de
similaridad es mucho menos eficiente que su contraparte en paralelo por
lo que no es recomendable hacer uso de este cuando se va a trabajar con
SD de gran tamaño.

Capítulo 3
58
- Los modelos paralelos son efectivos principalmente cuando los usamos
para procesar SD con gran número de atributos y de filas.

Conclusiones generales
59
Conclusiones generales
Con el presente trabajo se obtiene como resultado el desarrollo e
implementación de una técnica de paralelización utilizada en tres variantes de
las extensiones de la Teoría de los Conjuntos Aproximados.
En particular:
- Se seleccionaron las relaciones de tolerancia T y L siendo esta ultima la
más adecuada para tratar el problema de la información incompleta de
acuerdo a los resultados teóricos y experimentales obtenidos, aun cuando
la relación L es más sugerida en la bibliografía y es más sencilla de
implementar.
- La etapa más apropiada para aplicar técnicas de paralelización es la de la
construcción de las clases de tolerancia, aprovechando el paralelismo de
los datos.
- Se desarrollaron los algoritmos paralelos independientes y se conformo
una biblioteca con ellos, la cual puede ser reutilizada en otros contextos.
- Se probaron las bibliotecas construidas sobre ocho bases de casos
comprobándose que:
o La implementación basada en la relación V es la que mejor
clasifica a los SDI, sobre todo cuando necesitamos aproximar el
conjunto con atributos que tienen falta de información.
o Los resultados que brinda la implementación del algoritmo paralelo
de la relación de similaridad son muy superiores, a su equivalente
secuencial cuando se analizan sus parámetros de ganancia,
eficiencia y tiempo de ejecución.

Recomendaciones
60
Recomendaciones
- Realizar el análisis de complejidad del algoritmo paralelo desarrollado.
- Realizar pruebas a la aplicación desarrollada con sistemas de información
de mayor volumen y complejidad (mayor cantidad de rasgos con valores
perdidos).
- Evaluar el comportamiento de la aplicación sobre un cluster de
computadoras con características superiores en cuanto a elementos de
procesamiento.

Referencias bibliográficas
61
Referencias bibliográficas
E. A. RADY, M. M. E. A. E.-M., AND W. A. ABD EL-LATIF (2007) A Modified
Rough Set Approach to Incomplete Information Systems. Journal of Applied
Mathematics and Decision Sciences, vol. 2007, 13 pages.
GRECO, S., MATARAZZO, B. & SLOWINSKI, R. (2000) Dealing with missing data in
rough set analysis of multi-attribute and multi-criteria decision problems.
Decision Making: Recent Developments and Worldwide Applications. Dordrecht,
Kluwer.
GRECO, S., MATARAZZO, B. & SLOWINSKI, R. (2001) Rough sets theory for
multicriteria decision analysis. European Journal of Operational Research, 127,
1-47.
JERZY, S. & ALEXIS, T. (1999) On the Extension of Rough Sets under Incomplete
Information. Proceedings of the 7th International Workshop on New Directions in
Rough Sets, Data Mining, and Granular-Soft Computing. Springer-Verlag.
KOMOROWSKI, J., POLKOWSKI, L. & SKOWRON, A. (1998) Rough Sets: A
Tutorial. 8 - 16.
KRYSZKIEWICZ, M. (1998) Rough Set Approach to Incomplete Information Systems.
Inf. Sci., 112, 39-49.
MARZENA, K. (1998a) Properties of Incomplete Information Systems in the framework
of Rough sets., 422-450.
MARZENA, K. (1998b) Rough set approach to incomplete information systems. Inf.
Sci. %@ 0020-0255, 112, 39-49.
PAWLAK, Z. (1982) Rough sets. International Journal of Computer and Information
Sciences, 11, 341-356.
RAMOS, E. E. R. (2007) Implementaciones paralelas de métodos heurísticos para el
cálculo de reductos. Inteligencia Artificial. Santa Clara, UCLV.

Referencias bibliográficas
62
RUDOLPH, S. (1997) the foundations and applications of similarity theory to case-based
reasoning.
SALVATORE, G., BENEDETTO, M. & ROMAN, S. (1999) Handling Missing Values
in Rough Set Analysis of Multi-Attribute and Multi-Criteria Decision Problems.
Proceedings of the 7th International Workshop on New Directions in Rough Sets,
Data Mining, and Granular-Soft Computing %@ 3-540-66645-1. Springer-
Verlag.
SANKAR, K. P. & ANDRZEJ, S. (1999) Rough-Fuzzy Hybridization: A New Trend in
Decision Making, Springer-Verlag New York, Inc.
SEGOVIA, M. J. V., FANA, J. A. G., MARTINEZ, A. H. & ZANÓN, J. L. V. (2003) La
metodología Rough Set frente al análisis discriminante en la predicción de
insolvencias.
SLEZAK, D. & WROBLEWSKI, J. (1999) Classification Algorithms Based on Linear
Combinations of Features. Principles of Data Mining and Knowledge Discovery,
548-553.
SLOWINSKI, R. & VANDERPOOTEN, D. (1995) Similarity relation as a basis for
rough approximations.
WANG, G. (2002) Extension of rough set under incomplete information systems.
WILSON, D. R. & MARTINEZ, T. R. (1997) Improved Heterogeneous Distance
Functions. Journal of Artificial Intelligence Research, 6, 1-34.
YIN, X., JIA, X. & SHANG, L. (2006) A New Extension Model of Rough Sets Under
Incomplete Information. Rough Sets and Knowledge Technology.

Anexos
63
Anexos
Anexo 1 Funciones empleadas en el cálculo de la calidad
En este anexo trataremos las funciones involucradas en el cálculo de de la calidad
haciendo uso de los conjuntos aproximados para cada una de las extensiones
desarrolladas.
tolerancia: Calcula la calidad cuando se aproxima el conjunto de objetos del
SD por los atributos pasados en rasgos, basados en la relación II del primer
capítulo.
Especificación en C
float tolerancia(char * filename,char * separator, int * rasgos, int total, MPI_Comm
Cgroup)
Parámetros:
- filename: Nombre del fichero en el que está el sistema de decisión.
- separator: Es el separador que tienen los valores de los atributos del SD
(puede ser coma o espacio).
- rasgos: Es el arreglo que contienen todos los atributos que nos interesan del
SD (no incluye el atributo de decisión).
- total: Es la cantidad de características que vamos a analizar (no incluye el
atributo de decisión).
- Cgroup: Es el mundo de trabajo mpi actual.
Valor de Retorno:
Devuelve la calidad con que es aproximado el SD por los atributos pasados en la
variable rasgos.

Anexos
64
tolerancil: Calcula la calidad cuando se aproxima el conjunto de objetos del SD
por los atributos pasados en rasgos, basados en la relación V del primer
capítulo.
Especificación en C
float tolerancil(char * filename,char * separator, int * rasgos, int total, MPI_Comm
Cgroup)
Parámetros:
- filename: Nombre del fichero en el que está el sistema de decisión.
- separator: Es el separador que tienen los valores de los atributos del SD
(puede ser coma o espacio).
- rasgos: Es el arreglo que contienen todos los atributos que nos interesan del
SD (no incluye el atributo de decisión).
- total: Es la cantidad de características que vamos a analizar (no incluye el
atributo de decisión).
- Cgroup: Es el mundo de trabajo mpi actual.
Valor de Retorno:
Devuelve la calidad con que es aproximado el SD por los atributos pasados en la
variable rasgos.
similitud: Calcula la calidad de aproximar el conjunto de objetos del SD por los
atributos pasados en rasgos, basados en la relación de similaridad del primer
capítulo.
Especificación en C
float similitud(char * filename,char * separator, int * rasgos, int total, float epsilon,
MPI_Comm Cgroup)
Parámetros:
- filename: Nombre del fichero en el que está el sistema de decisión.

Anexos
65
- separator: Es el separador que tienen los valores de los atributos del SD
(puede ser coma o espacio).
- rasgos: Es el arreglo que contiene todos los atributos que nos interesan del
SD (no incluye el atributo de decisión).
- total: Es la cantidad de características que vamos a analizar (no incluye el
atributo de decisión).
- epsilon: es un valor real utilizado para definir cuando dos objetos son
semejantes, según la relación de similitud.
- Cgroup: Es el mundo de trabajo mpi actual.
Valor de Retorno:
Devuelve la calidad con que es aproximado el SD por los atributos pasados en la
variable rasgos.
Las tres funciones anteriores están públicas en la biblioteca de funciones y posibilitan
al usuario interactuar con ella.

Anexos
66
Anexo 2 Funciones auxiliares usadas en el cálculo de la calidad.
Las funciones que se muestran a continuación son propias a la biblioteca más por su
importancia conviene comentarlas.
objLowACD1: Se encarga de calcular cuantos objetos del SDI pertenecen a la
aproximación inferior de la clase de decisión clase, haciendo uso de la
relación II del capítulo 1.
Especificación en C
int objLowACD1(float ** BD,float clase,long filas, long columnas, MPI_Comm
Cgroup)
Parámetros:
- BD: Es un puntero a la matriz de datos que guarda el SDI en memoria.
- clase: Es la clase de decisión a la que se le va a calcular su aproximación
inferior.
- filas: Es el número de filas con las que cuenta el SDI.
- columnas: Es el número de atributos que se van a utilizar para aproximar el
conjunto identificado por clase, incluyendo a este último.
- Cgroup: Es el mundo de trabajo mpi actual.
Valor de Retorno:
Devuelve la aproximación inferior del conjunto definido por clase.
objLowACD2: Se encarga de calcular cuantos objetos del SDI pertenecen a la
aproximación inferior de la clase de decisión clase haciendo uso de la relación
V del capítulo 1.
Especificación en C
int objLowACD2(float ** BD,float clase,long filas, long columnas, MPI_Comm
Cgroup)

Anexos
67
Parámetros:
- BD: Es un puntero a la matriz de datos que guarda el SDI en memoria.
- clase: Es la clase de decisión a la que se le va a calcular su aproximación
inferior.
- filas: Es el número de filas con las que cuenta el SDI.
- columnas: Es el número de atributos que se van a utilizar para aproximar el
conjunto identificado por clase, incluyendo a este último.
- Cgroup: Es el mundo de trabajo mpi actual.
Valor de Retorno:
Devuelve la aproximación inferior del conjunto definido por clase.
objLowACD3: Se encarga de calcular cuantos objetos del SDI pertenecen a la
aproximación inferior de la clase de decisión clase haciendo uso de la relación
de similitud del capítulo 1.
Especificación en C
int objLowACD3(float ** BD,float clase,long filas, long columnas,double epsilon,
MPI_Comm Cgroup);
Parámetros:
- BD: Es un puntero a la matriz de datos que guarda el SDI en memoria.
- clase: Es la clase de decisión a la que se le va a calcular su aproximación
inferior.
- filas: Es el número de filas con las que cuenta el SDI.
- columnas: Es el número de atributos que se van a utilizar para aproximar el
conjunto identificado por clase, incluyendo a este último.
- epsilon: es un valor real utilizado para definir cuando dos objetos son
semejantes según la relación de similitud.
- Cgroup: Es el mundo de trabajo mpi actual.

Anexos
68
Valor de Retorno:
Devuelve la aproximación inferior del conjunto definido por clase.
lowAObjCD1: Se encarga de determinar si un objeto pertenece a la
aproximación inferior del conjunto definido por la clase de decisión a la que él
pertenece, haciendo uso de la relación II del capítulo 1.
Especificación en C
int lowAObjCD1(float ** BD, long filas,long columnas, float * obj)
Parámetros:
- BD: Es un puntero a la matriz de datos que guarda el SDI en memoria.
- filas: Es el número de filas con las que cuenta el SDI.
- columnas: Es el número de atributos que se van a utilizar para aproximar el
conjunto identificado por clase, incluyendo a este último.
- Obj: Es el objeto que se ha de incluir en la aproximación inferior o no.
Valor de Retorno:
Devuelve verdadero si el objeto pertenece a la aproximación inferior o no del
conjunto definido por la clase de decisión a la cual el pertenece, o falso en caso
contrario.
lowAObjCD2: Se encarga de determinar si un objeto pertenece a la
aproximación inferior del conjunto definido por la clase de decisión a la que el
pertenece haciendo, uso de la relación V del capítulo 1.
Especificación en C
int lowAObjCD2(float ** BD, long filas,long columnas, float * obj)
Parámetros:
- BD: Es un puntero a la matriz de datos que guarda el SDI en memoria.
- filas: Es el número de filas con las que cuenta el SDI.

Anexos
69
- columnas: Es el número de atributos que se van a utilizar para aproximar el
conjunto identificado por clase, incluyendo a este último.
- Obj: Es el objeto que se ha de incluir en la aproximación inferior o no.
Valor de Retorno:
Devuelve verdadero si el objeto pertenece a la aproximación inferior o no del
conjunto definido por la clase de decisión a la cual él pertenece, o falso en caso
contrario.
lowAObjCD3: Se encarga de determinar si un objeto pertenece a la
aproximación inferior del conjunto definido por la clase de decisión a la que él
pertenece, haciendo uso de la relación de similitud del capítulo 1.
Especificación en C
int lowAObjCD3(float ** BD, long filas,long columnas, float * obj, double epsilon)
Parámetros:
- BD: Es un puntero a la matriz de datos que guarda el SDI en memoria.
- filas: Es el número de filas con las que cuenta el SDI.
- columnas: Es el número de atributos que se van a utilizar para aproximar el
conjunto identificado por clase, incluyendo a este último.
- Obj: Es el objeto que se ha de incluir en la aproximación inferior o no.
- epsilon: es un valor real utilizado para definir cuando dos objetos son
semejantes según la relación de similitud.
Valor de Retorno:
Devuelve verdadero si el objeto pertenece a la aproximación inferior o no del
conjunto definido por la clase de decisión a la cual el pertenece, o falso en caso
contrario.

Anexos
70
objATobjBCD1: Se encarga de determinar si un objeto está en la misma clase
de tolerancia que otro, haciendo uso de la relación II del capítulo 1.
Especificación en C
int objATobjBCD1(float * A, float * B, long columnas)
Parámetros:
- A: Es el primer objeto a comparar.
- B: Es el objeto del cual se quiere determinar si está en la misma clase de
tolerancia que A.
- columnas: Es el número de atributos que se van a utilizar para aproximar el
conjunto identificado por clase, incluyendo a este último.
Valor de Retorno:
Devuelve verdadero si el objeto B pertenece a la clase de tolerancia del objeto A, o
falso en caso contrario.
objATobjBCD2: Se encarga de determinar si un objeto está en la misma clase
de tolerancia que otro haciendo uso de la relación V del capítulo 1.
Especificación en C
int objATobjBCD2(float * A, float * B, long columnas)
Parámetros:
- A: Es el primer objeto a comparar.
- B: Es el objeto del cual se quiere determinar si está en la misma clase de
tolerancia que A.
- columnas: Es el número de atributos que se van a utilizar para aproximar el
conjunto identificado por clase, incluyendo a este último.
Valor de Retorno:
Devuelve verdadero si el objeto B pertenece a la clase de tolerancia del objeto A, o
falso en caso contrario.

Anexos
71
objATobjBCD3: Se encarga de determinar si un objeto está en la misma clase
de tolerancia que otro haciendo uso de la relación de similitud del capítulo 1.
Especificación en C
int objATobjBCD3(float * A, float * B, long columnas, double epsilon)
Parámetros:
- A: Es el primer objeto a comparar.
- B: Es el objeto del cual se quiere determinar si está en la misma clase de
tolerancia que A.
- columnas: Es el número de atributos que se van a utilizar para aproximar el
conjunto identificado por clase, incluyendo a este último.
- epsilon: es un valor real utilizado para definir cuando dos objetos son
semejantes según la relación de similitud.
Valor de Retorno:
Devuelve verdadero si el objeto B pertenece a la clase de tolerancia del objeto A, o
falso en caso contrario.