curso de procesamiento del lenguaje...
TRANSCRIPT

César Antonio Aguilar
Facultad de Lenguas y Letras
30/05/2012
Curso de procesamiento del
lenguaje natural

ASCII y Unicode en NLTK (1)
ASCII y Unicode en NLTK (2)

ASCII y Unicode en NLTK (3)
path = nltk.data.find('corpora/unicode_samples/polish-lat2.txt')

ASCII y Unicode en NLTK (4)
file01 = codecs.open(path, encoding='latin2')

ASCII y Unicode en NLTK (5)
Para ver cómo opera Codecs, vamos a escribir el siguiente ciclo:
for line in file01: line = line.strip() print line.encode('unicode_escape')

ASCII y Unicode en NLTK (6)
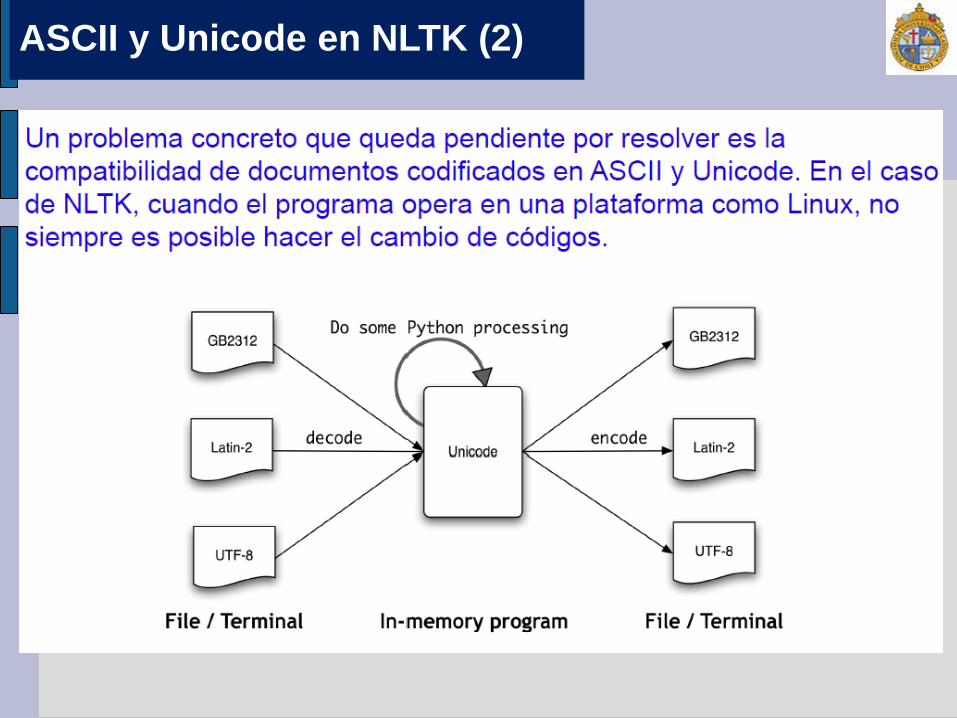
Esta solución, con todo, no es del todo completa, pues nos obliga a buscar qué carácter es representado por cada uno de las secuencias de Unicode. Una manera de resolverlo es trabajar con el código local de nuestra computadora, para lo cual necesitamos que nuestro intérprete pueda reconocerlo, recodificando nuestro texto en pantalla. Para ello, podemos ocupar las siguientes instrucciones:
sent =‘Ayer te miré y me acordé que mañana me tocaría descanso’ sent01 = sent.decode('Latin-1') sent01.lower()
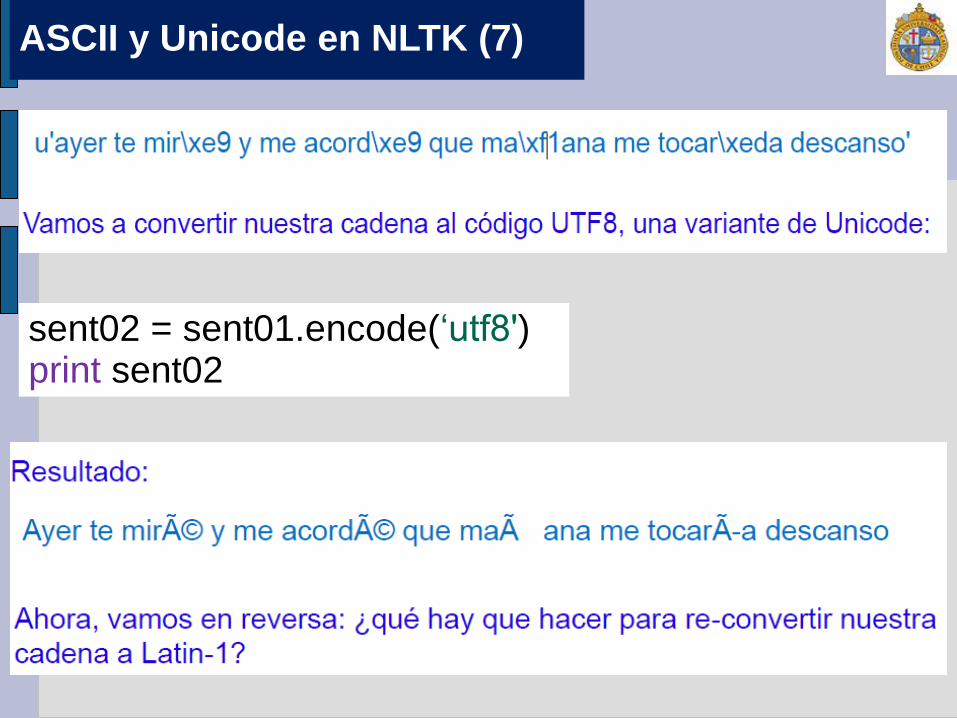
Lo que estamos haciendo aquí es transformar el código Latin-1 de nuestra cadena, a una versión de Unicode, la cual nos genera una nueva cadena con los siguientes caracteres. Veamos:
ASCII y Unicode en NLTK (7)
sent02 = sent01.encode(‘utf8') print sent02

ASCII y Unicode en NLTK (8)
>>> sent03 = sent02.decode('utf8') >>> sent03.lower() >>> sent04 = sent03.encode('Latin-1')

Análisis gramatical con NLTK (1)

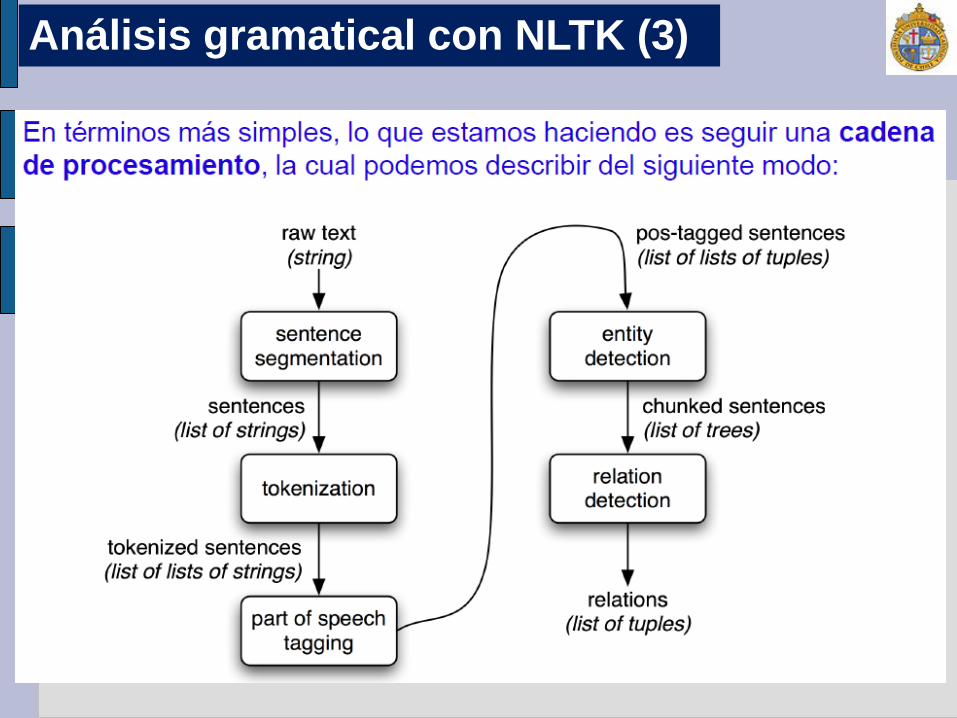
Análisis gramatical con NLTK (2)
Análisis gramatical con NLTK (3)

Chunking (1)
sentence01 =[("the", "DT"), ("little", "JJ"), ("yellow", "JJ"), ("dog", "NN"), ("barked", "VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]
Luego, escribimos la siguiente oración:

Chunking (2)
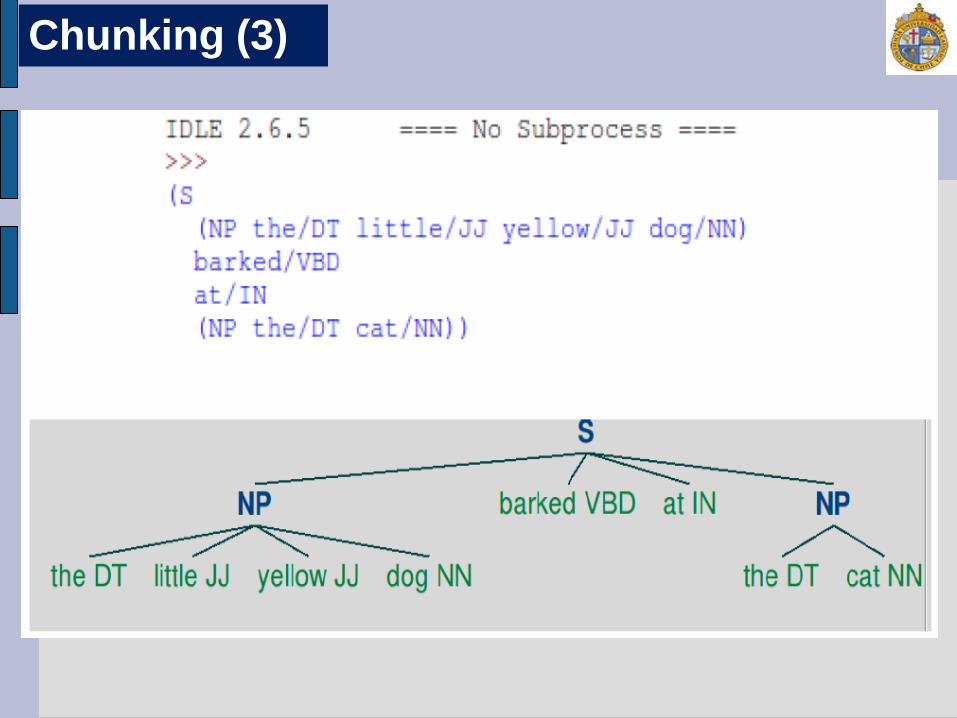
grammar01 ="NP: {<DT>?<JJ>*<NN>} cp = nltk.RegexpParser(grammar01) result01 = cp.parse(sentence) print result01 result01.draw
Chunking (3)

Chunking (4)

sentence02 =[("Rapunzel", "NNP"), ("let", "VBD"), ("down", "RP"), ("her", "PP$"), ("long", "JJ"), ("golden", "JJ"), ("hair", "NN")]
grammar02 = r””” NP: {<DT|PP\$>?<JJ>*<NN>} # Frases que tengan determinante/posesivo, adjetivo y nombre {<NNP>+} # Frases con nombres propios ””” cp = nltk.RegexpParser(grammar02) result02 = cp.parse(sentence02) print result02 result02.draw
Chunking (5)
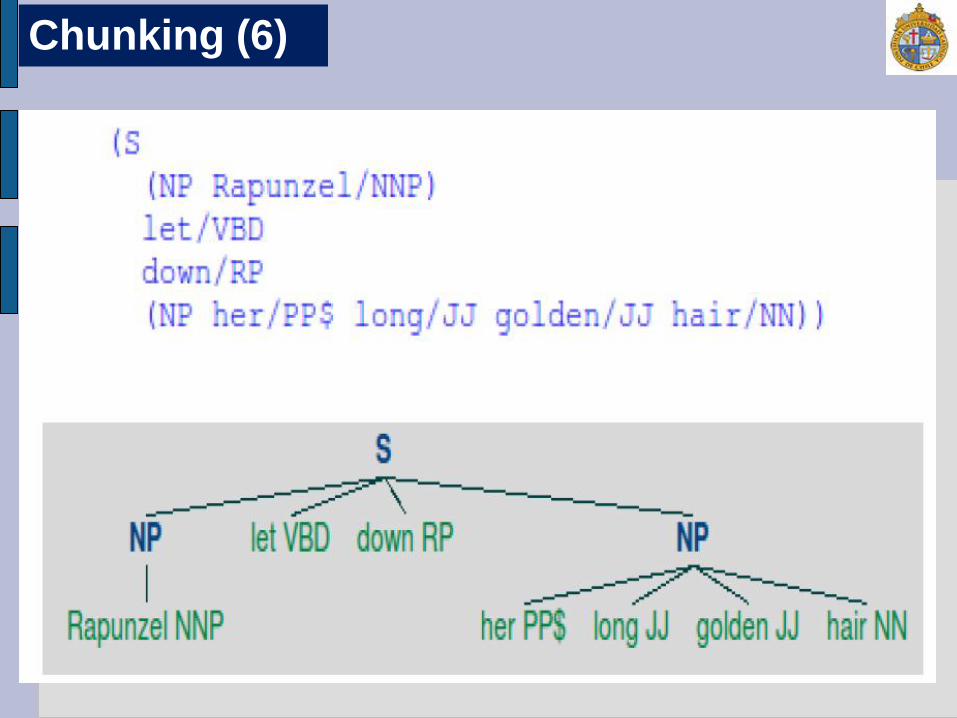
Chunking (6)

cp = nltk.RegexpParser("CHUNK: {<V.*> <TO> <V.*>}) brown = nltk.corpus.brown
Chunking (7)

>>> for sent in brown.tagged_sents(): tree = cp.parse(sent) for subtree in tree.subtrees(): if subtree.node == 'CHUNK': print subtree
Chunking (8)
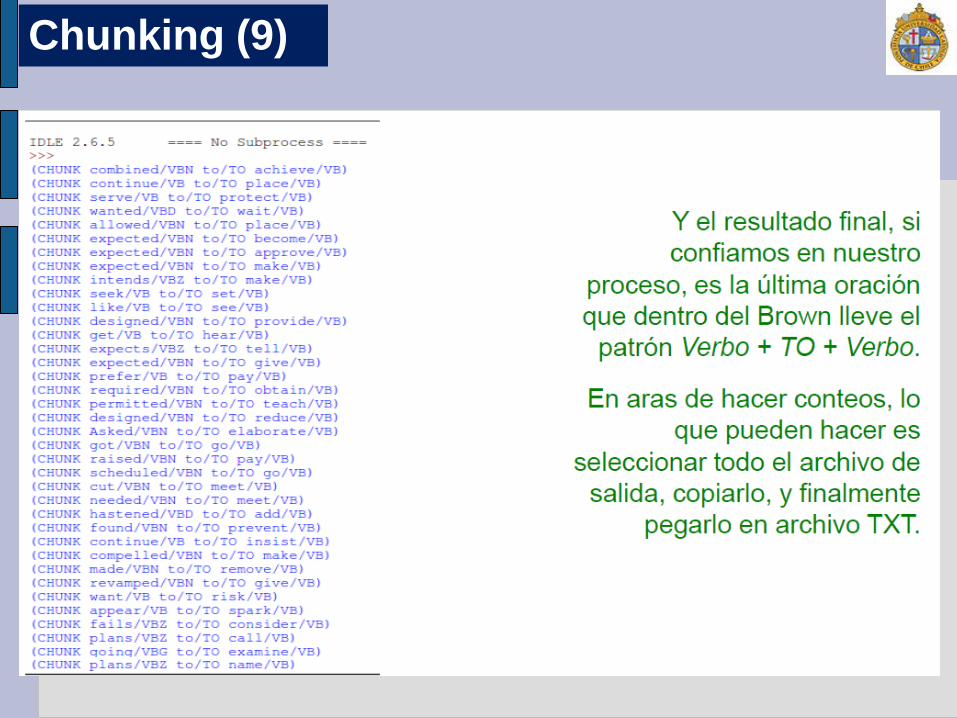
Chunking (9)

Métodos de evaluación (1)
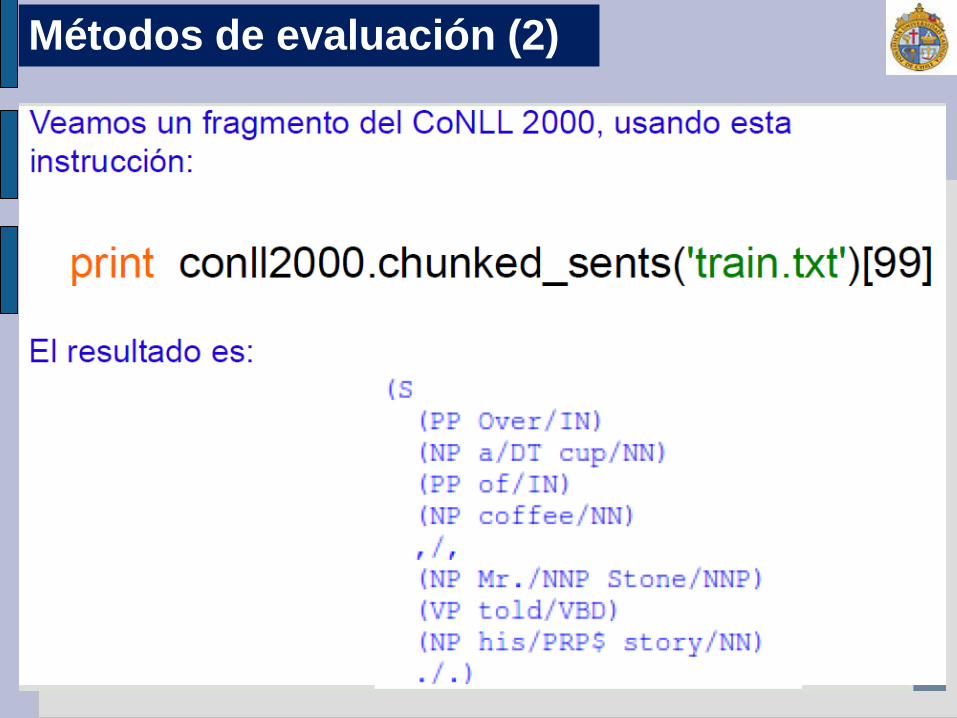
Métodos de evaluación (2)

>>> cp = nltk.RegexpParser("") >>> test_sents = conll2000.chunked_sents('test.txt', chunk_types=['NP']) >>> print cp.evaluate(test_sents)
Métodos de evaluación (3)
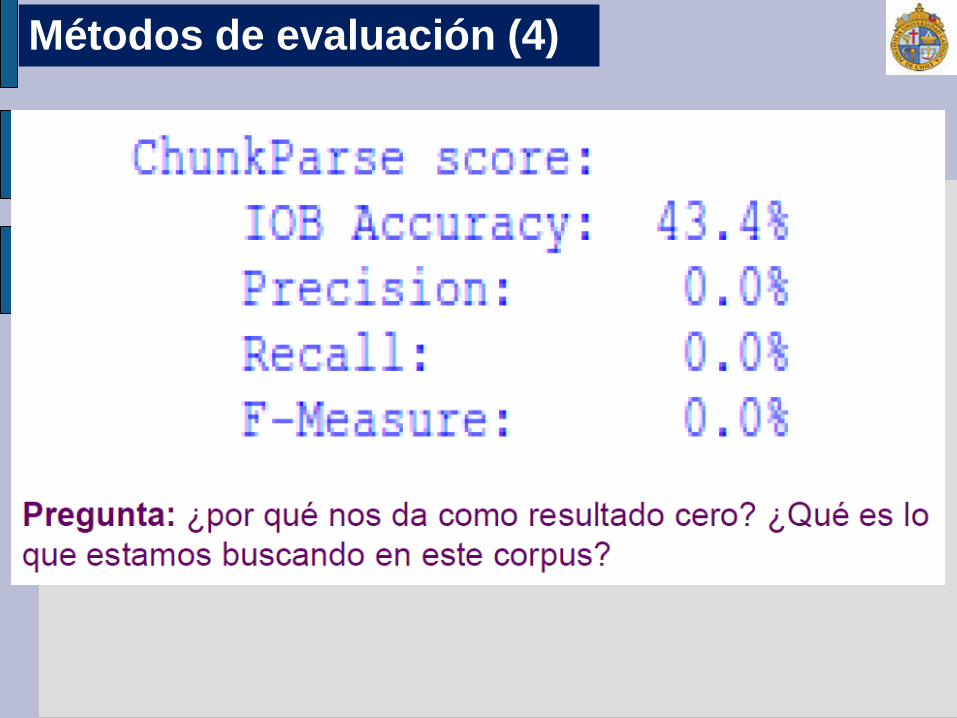
Métodos de evaluación (4)

grammar = r"NP: {<[CDJNP].*>+}"
Métodos de evaluación (5)
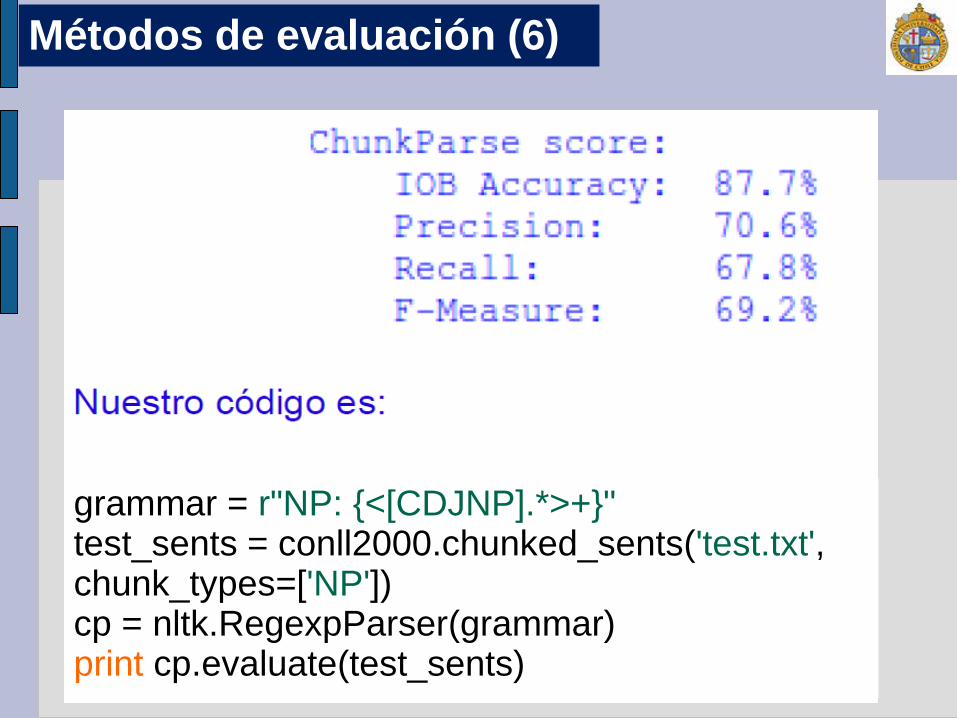
grammar = r"NP: {<[CDJNP].*>+}" test_sents = conll2000.chunked_sents('test.txt', chunk_types=['NP']) cp = nltk.RegexpParser(grammar) print cp.evaluate(test_sents)
Métodos de evaluación (6)

Métodos de evaluación (7)

Precision & Recall (1)
Cuando trabajamos con probabilidades, hay que contrastar siempre
dos hipótesis: una que llamamos hipótesis de investigación, y otra
que llamamos hipótesis nula.
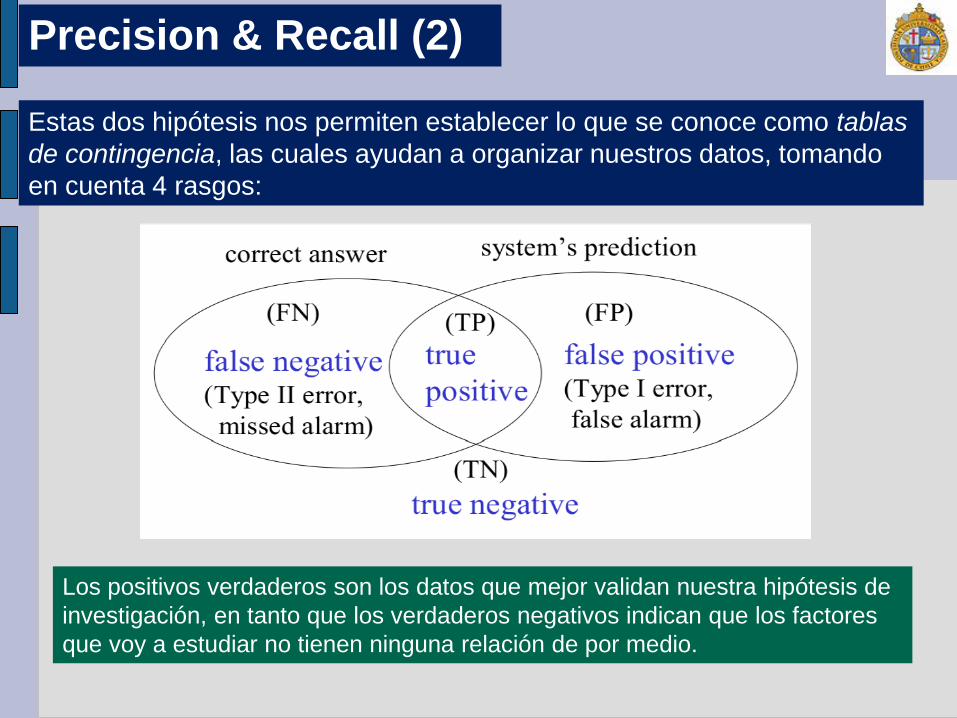
Precision & Recall (2)
Estas dos hipótesis nos permiten establecer lo que se conoce como tablas
de contingencia, las cuales ayudan a organizar nuestros datos, tomando
en cuenta 4 rasgos:
Los positivos verdaderos son los datos que mejor validan nuestra hipótesis de
investigación, en tanto que los verdaderos negativos indican que los factores
que voy a estudiar no tienen ninguna relación de por medio.

Precision & Recall (3)
La distinción anterior se emplea para desarrollar un método de evaluación
que se llama precisión y cobertura (Precision & Recall). Nos movemos
entonces entre dos polos: (i) lograr unos resultados positivos ideales de un
100% (lo cual, en la vida real, no sería posible), y unos resultados pésimos
de un 0% (lo que sería el peor de todos los mundos posibles). Cuando
decimos que somos “precisos”, queremos dar a entender que:

Precision & Recall (4)
En cambio, cuando decimos que somos “recuperamos” o “abarcamos una cobertura”, queremos dar a entender que:
En la sección dedicada a NLTK vamos a revisar con mayor detalle esta
clase de evaluaciones. De momento, tengan en mente que ésta les sirve,
prácticamente, para cualquier análisis que quieran hacer en corpus.

Supongamos que nuestro sistema reconoce muchos documentos, pero estos no necesariamente se parecen a nuestro documento “maestro”. Podríamos decir que nuestro sistema no funciona del todo mal, pero falla a la hora de reconocer qué textos son similares al documento de base.
Veamos un ejemplo típico respecto al uso de Precision & Recall: la clasificación de documentos. Nuestra precisión aquí equivale a:
Imaginemos que tenemos un documento “maestro” que nos sirve para identificar y clasificar a todos los que se parezcan a éste. Entre más cercano sea el parecido, mayor grado de precisión. En el caso contrario:
Precision & Recall (5)

Chunking y N-gramas (1)

Chunking y N-gramas (2)
http://nltk.googlecode.com/svn/trunk/doc/book/ch07.html

class UnigramChunker(nltk.ChunkParserI): def__init__(self, train_sents): train_data = [[(t,c) for w,t,c in nltk.chunk.tree2conlltags(sent)] for sent in train_sents] self.tagger = nltk.UnigramTagger(train_data)
Chunking y N-gramas (3)

Chunking y N-gramas (4)
def parse(self, sentence): [3] pos_tags = [pos for(word,pos) in sentence] tagged_pos_tags = self.tagger.tag(pos_tags) chunktags = [chunktag for(pos, chunktag) in tagged_pos_tags] conlltags = [(word, pos, chunktag) for((word,pos),chunktag) in zip(sentence, chunktags)] return nltk.chunk.conlltags2tree(conlltags)

Chunking y N-gramas (5)
>>> test_sents = conll2000.chunked_sents('test.txt', chunk_types=['NP']) >>> train_sents = conll2000.chunked_sents('train.txt', chunk_types=['NP']) >>> unigram_chunker = UnigramChunker(train_sents) >>> printunigram_chunker.evaluate(test_sents)

Chunking y N-gramas (6)

Chunking y N-gramas (7)

Chunking y N-gramas (8)

Blog del curso:
http://cesaraguilar.weebly.com/curso-de-
procesamiento-del-lenguaje-natural.html
Gracias por su atención