construcción de modelos probabilísticos (2010/2011) - teoria10_v03.pdf · contenidos...
TRANSCRIPT

Construcción
de Modelos
Probabilísticos
(2010/2011)
Luis Valencia Cabrera
(http://www.cs.us.es/~lvalencia)
Ciencias de la Computacion e IA
(http://www.cs.us.es/)
Universidad de Sevilla

Antecedentes Hemos estudiado sistemas expertos basados en
reglas con tratamiento de la incertidumbre a través de factores de certeza
Hemos estudiado un tema introductorio sobre los sistemas expertos basados en probabilidad
Hemos presentado algunos conceptos sobre teoría de grafos necesarios para la construcción de modelos gráficos probabilísticos
Estamos en condiciones de entrar en detalle sobre cómo construir modelos probabilísticos para representar la dependencia en SSEE probabilísticos

Contenidos
Introducción
Criterios de Separación Gráfica
Algunas Propiedades de la
Independencia Condicional
Modelos de Dependencia
Factorizaciones de una Función de
Probabilidad
Construcción de un Modelo Probabilístico

Introducción Hemos visto que la base de conocimiento de un
sistema experto probabilístico está formada por: Un conjunto de variables y Un modelo probabilístico (una función de probabilidad
conjunta) que describa las relaciones entre ellas.
El funcionamiento del sistema experto depende de la correcta definición de la función de probabilidad conjunta que define el modelo probabilístico.
Se trata por tanto de definir un modelo lo más preciso posible.
Para ello es conveniente seguir una serie de pasos estructurados que veremos a continuación.

Pasos para la definición del
modelo probabilístico
1. Planteamiento del problema
2. Selección de variables
3. Adquisición de información relevante
4. Construcción del modelo probabilístico

Planteamiento del problema
El primer paso en el desarrollo de un sistema experto es la definición del problema a resolver.
Por ejemplo, el problema del diagnóstico médico es un ejemplo clásico en el campo de los sistemas expertos:
Dado que un paciente presenta una serie de síntomas, ¿cuál es la enfermedad más probable en esa situación?.
La definición del problema es un paso crucial en el desarrollo del modelo, pues un mal planteamiento inicial tendrá consecuencias fatales para el modelo desarrollado.

Selección de variables Una vez que el problema ha sido definido, el
siguiente paso consiste en seleccionar un conjunto de variables que sean relevantes para su definición. Esta tarea debe ser realizada por expertos en el
problema a analizar. Por ejemplo, las variables relevantes para el problema
de diagnóstico médico son las enfermedades y sus correspondientes síntomas.
Las variables relevantes para la definición de un modelo han de ser cuidadosamente seleccionadas a fin de eliminar posibles redundancias. Por ejemplo, en un problema de diagnóstico médico
habrán de elegirse aquellos síntomas que mejor discriminen el conjunto de enfermedades dado.

Adquisición de información
relevante Una vez que se ha realizado el planteamiento inicial del
problema, el siguiente paso consiste en la adquisición y análisis de toda la información (datos) que sea relevante para la definición del modelo.
La información puede ser: cuantitativa o cualitativa,
obtenida de un experto, o de una base de datos.
Esta información deberá ser cuidadosamente analizada utilizando técnicas de diseño experimental apropiadas.
Es importante contar en esta etapa con la ayuda de especialistas en Estadística, pues el uso de métodos estadísticos permite mejorar la calidad de los datos y confirmar la validez de los métodos empleados para la obtención de las conclusiones.

Construcción del modelo
probabilístico Una vez que se conoce un conjunto de variables
relevantes para el problema a analizar, y que se ha adquirido suficiente información para su definición, el siguiente paso consiste en la definición de una función de probabilidad conjunta que describa las relaciones entre las variables.
Quizás el paso más crítico y difícil en el desarrollo de un sistema experto:
a) Es crítico porque la bondad de los resultados del sistema experto dependerá de la precisión con que se haya definido la función de probabilidad conjunta, es decir, la calidad de los resultados no podrá superar a la calidad del modelo. Por tanto, una incorrecta definición del modelo probabilístico redundará en un sistema experto que dará conclusiones erróneas y/o contradictorias.

Construcción del modelo
probabilístico b) La estructura de la función de probabilidad conjunta (es
decir, la estructura de dependencia e independencia entre las variables) no suele ser conocida en la práctica. Por tanto, habrá de ser inferida del conjunto de datos obtenidos previamente. Por tanto, la calidad del modelo tampoco podrá superar la calidad de los datos relevantes disponibles.
c) La estructura del modelo probabilístico puede depender de un número muy elevado de parámetros que complican su definición. Cuanto mayor sea el número de parámetros más complicada será la asignación de valores numéricos concretos en el proceso de definición del modelo. En cualquier caso, esta asignación habrá de ser realizada por un experto, o estimada a partir de la información disponible.

Construcción del modelo
probabilístico Los dos próximos temas están dedicados a la construcción
de modelos probabilísticos (funciones de probabilidad conjunta) que definen la base de conocimiento de este tipo de sistemas expertos. Para ello, existen distintas metodologías: Modelos definidos gráficamente.
Modelos definidos por un conjunto de relaciones de independencia condicional.
Estas dos metodologías se analizan en capítulos posteriores.
En este capítulo se introducen los conceptos necesarios. Describiremos algunos criterios de separación gráfica que permiten obtener las relaciones de independencia condicional asociadas a un grafo.

Construcción del modelo
probabilístico Como vimos, una relación de independencia condicional, o
simplemente una independencia, denotada por I(X, Y |Z), significa que “X e Y son condicionalmente independientes dado Z”, donde X, Y y Z son subconjuntos disjuntos de un conjunto de variables {X1, . . . , Xn}.
Cuando la relación de independencia es obtenida mediante un criterio de separación gráfico se emplea, de forma equivalente, la terminología “X e Y están separados por Z”. En una sección posterior se introducen varias propiedades de la independencia condicional. Dada una lista inicial de relaciones de independencia, estas propiedades permiten obtener independencias adicionales que estarán contenidas en el modelo probabilístico.
También analizaremos distintas formas de factorizar una función de probabilidad conjunta mediante un producto de funciones de probabilidad condicionada.
Finalmente se describen los pasos necesarios para la construcción de un modelo probabilístico.

Criterios de Separación
Gráfica Los grafos son herramientas muy potentes para describir de
forma intuitiva las relaciones de dependencia e independencia existentes en un conjunto de variables {X1, . . . , Xn}.
Por tanto, una forma de definir un modelo probabilístico es partir de un grafo que describa las relaciones existentes entre las variables (este grafo puede venir dado, por ejemplo, por un experto en el tema).
Surge el siguiente problema: ¿Pueden representarse las estructuras de dependencia e
independencia definidas por un grafo (dirigido o no dirigido) de forma equivalente por un conjunto de relaciones de independencia condicional?
En caso afirmativo, ¿cómo se puede obtener este conjunto?

Criterios de Separación
Gráfica
La respuesta al problema anterior es afirmativa.
Una forma de obtener este conjunto de independencias es utilizar un criterio de separación gráfica para comprobar cuáles, de entre todas las posibles relaciones de independencia condicional, son satisfechas por el grafo.
Los criterios de separación gráfica son las reglas para entender cómo pueden codificarse dependencias e independencias en un grafo. Estos criterios dependen del tipo de grafo (dirigido o no dirigido) que se esté considerando.

Separación en
Grafos no Dirigidos En muchas situaciones prácticas, las relaciones
existentes entre un conjunto de variables {X1, . . . , Xn} pueden ser representadas por un grafo no dirigido G.
Como ya se mencionó, cada variable puede ser representada por un nodo del grafo. Si dos variables son dependientes, esta relación puede representarse por un camino que conecte estos nodos.
Por otra parte, si dos variables son independientes, entonces no deberá existir ningún camino que una estos nodos.
De esta forma, el concepto de dependencia entre variables puede relacionarse con el concepto de conexión entre nodos.

Criterios de Separación
Gráfica De forma similar, si la dependencia entre las variables X e Y
es indirecta, a través de una tercera variable Z (es decir, si X e Y son condicionalmente dependientes dada Z), el nodo Z se representará de forma que no intersecte todos los caminos entre X y Y , es decir, Z no es un conjunto de corte (en inglés, cutset) de X e Y. Esta correspondencia entre dependencia condicional y
separación en grafos no dirigidos constituye la base de la teoría de los campos de Markov (Isham (1981), Lauritzen (1982), Wermuth y Lauritzen (1983)), y ha sido caracterizada axiomáticamente de formas diversas (Pearl y Paz (1987)).
Para representar relaciones de independencia condicional por medio de grafos no dirigidos se necesita definir de forma precisa un criterio de separación apropiado, basándose en las ideas anteriormente expuestas. Este criterio se conoce como criterio de U-separación. A continuación se da una definición de este criterio y un algoritmo que permite su aplicación.

Definición U-separación Sean X, Y y Z tres conjunto disjuntos de nodos de un grafo
no dirigido G. Se dice que Z separa X e Y si y sólo si cada camino entre nodos de X y nodos de Y contiene algún nodo de Z.
Cuando Z separe X e Y en G, y se denotará I(X, Y |Z)G para indicar que esta relación de independencia se deriva de un grafo G; en caso contrario, se denotará por D(X, Y |Z)G, para indicar que X e Y son condicionalmente dependientes dada Z, en el grafo G.
Se dice que X es gráficamente independiente de Y dada Z si Z separa X e Y .
Por tanto, el criterio de U-separación permite obtener la lista de relaciones de independencia asociadas a un grafo no dirigido.
Este criterio da la solución al problema para grafos no dirigidos. El caso de grafos dirigidos se analizará posteriormente.
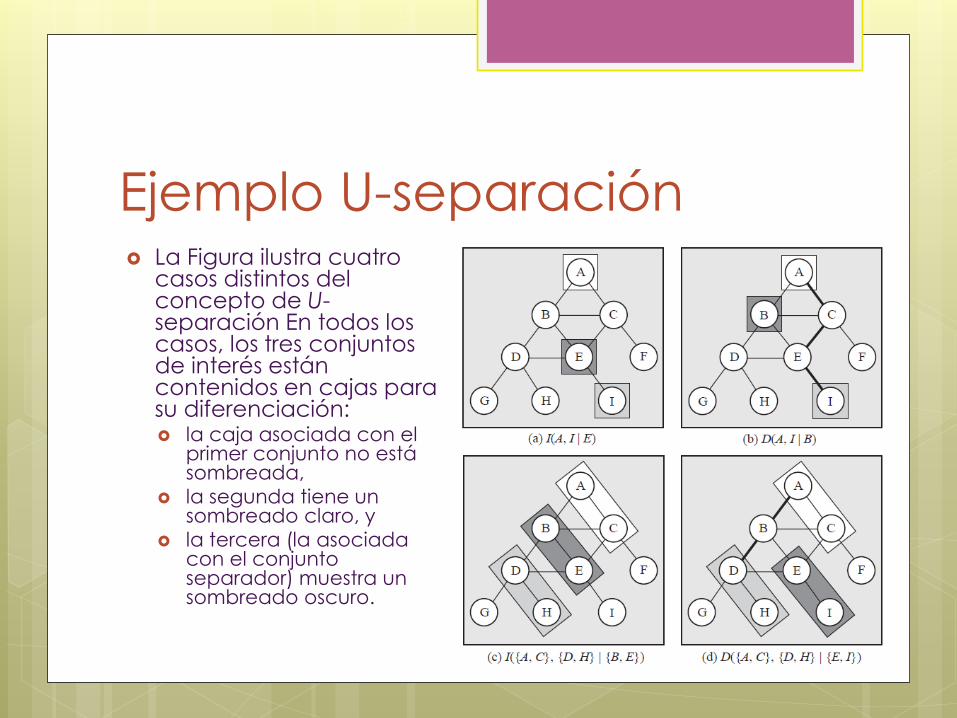
Ejemplo U-separación La Figura ilustra cuatro
casos distintos del concepto de U-separación En todos los casos, los tres conjuntos de interés están contenidos en cajas para su diferenciación: la caja asociada con el
primer conjunto no está sombreada,
la segunda tiene un sombreado claro, y
la tercera (la asociada con el conjunto separador) muestra un sombreado oscuro.

Ejemplo U-separación En la primera figura, las variables A e I son condicionalmente
independientes dada E, pues cada camino entre A e I contiene al nodo E. Por tanto, I(A, I|E)G.
En la segunda figura, los nodos A e I son condicionalmente dependientes dada B. En este caso, existe un camino, (A−C −E −I), que no contiene al nodo B.
En la tercera figura, los subconjuntos {A,C} y {D,H} son condicionalmente independientes dado el conjunto {B,E}, pues cada camino entre los dos conjuntos contiene, o bien a B, o bien a E. Por tanto, se tiene I({A,C}, {D,H}|{B,E})G.
Finalmente, en la cuarta figura, los subconjuntos {A,C} y {D,H} son condicionalmente dependientes dado {E, I}, pues el camino (A− B − D} no contiene ninguna de las variables E e I. Por tanto, D({A,C}, {D,H}|{E, I})G.
Siguiendo un proceso análogo, se puede comprobar si el grafo satisface cualquier otra relación de independencia.
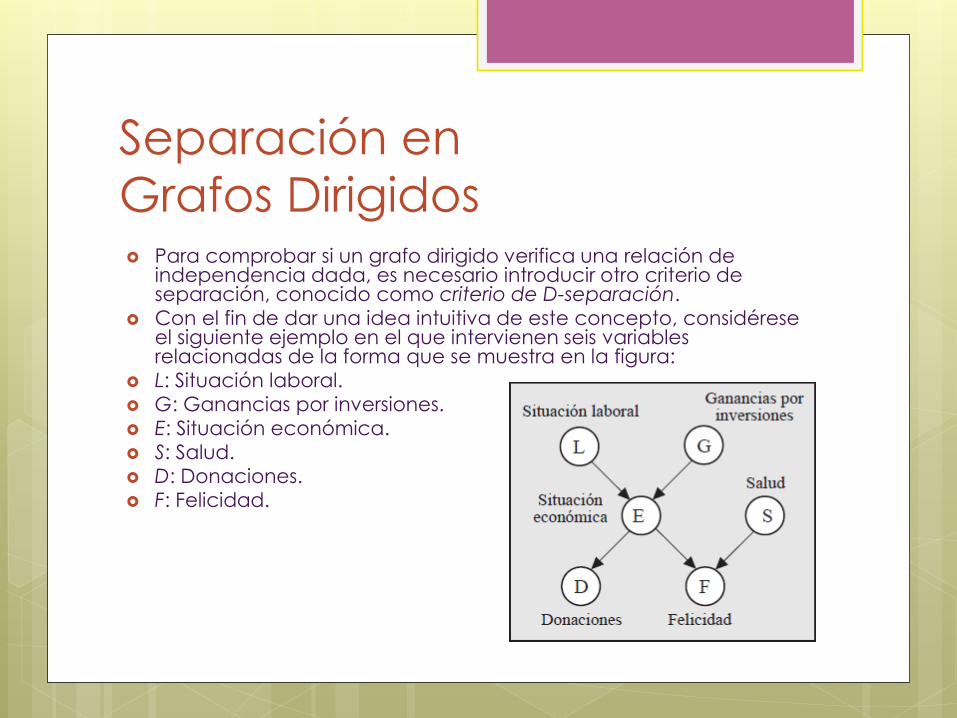
Separación en
Grafos Dirigidos Para comprobar si un grafo dirigido verifica una relación de
independencia dada, es necesario introducir otro criterio de separación, conocido como criterio de D-separación.
Con el fin de dar una idea intuitiva de este concepto, considérese el siguiente ejemplo en el que intervienen seis variables relacionadas de la forma que se muestra en la figura:
L: Situación laboral.
G: Ganancias por inversiones.
E: Situación económica.
S: Salud.
D: Donaciones.
F: Felicidad.

Separación en
Grafos Dirigidos El grafo de la figura muestra que la situación laboral y las
ganancias, fruto de inversiones, son causas directas de la situación económica de una persona. Por otra parte, la situación económica y la salud influyen en la felicidad. Finalmente, la situación económica determina las donaciones que realizada la persona. Dada esta situación, sería lógico pensar, por ejemplo, que la salud y la situación económica fuesen incondicionalmente independientes, pero condicionalmente dependientes una vez se tiene información sobre el estado de felicidad de la persona (un incremento de nuestra confianza en una variable disminuiría nuestra confianza en la otra).
Para detectar las independencias definidas por este grafo, se necesita introducir un criterio de separación apropiado para grafos dirigidos, el concepto de D-separación; ver Pearl (1988) y Geiger, Verma y Pearl (1990a).

Definición Nodo de aristas
convergentes en un camino
Dado un grafo dirigido y un camino no
dirigido (. . . − U − A − V − . . .), el nodo A
se denomina un nodo de aristas
convergentes en este camino si las dos
aristas del camino convergen a este
nodo en el grafo dirigido, es decir, si el
grafo dirigido contiene las aristas U → A y
V → A).

Ejemplo Nodo de aristas
convergentes en un camino
El nodo F es el único nodo de aristas convergentes en el camino no dirigido L − E − F − S del grafo de la figura anterior. Obsérvese que aunque el nodo E posee dos aristas convergentes, no es un nodo de aristas convergentes en el camino, pues la arista G → E no está contenida en el camino. Sin embargo, el nodo E es un nodo de aristas convergentes en el camino no dirigido L − E − G.

Definición D-separación Sean X, Y y Z tres subconjuntos disjuntos de nodos en un
grafo dirigido acíclico D; entonces se dice que Z D-separa X e Y si y sólo si a lo largo de todo camino no dirigido entre cualquier nodo de X y cualquier nodo de Y existe un nodo intermedio A tal que, o bien
1. A es un nodo de aristas convergentes en el camino y ni A ni sus descendientes están en Z, o bien
2. A no es un nodo de aristas convergentes en el camino y A está en Z.
Cuando Z D-separa X e Y en D, se escribe I(X, Y |Z)D para indicar que la relación de independencia viene dada por el grafo D; en caso contrario, se escribe D(X, Y |Z)D para indicar que X e Y son condicionalmente dependientes dado Z en el grafo D.

D-separación Si se puede encontrar un nodo en algún camino no
dirigido que no cumpla las dos condiciones anteriores, entonces D(X, Y |Z)D; en caso contrario, I(X, Y |Z)D. Estas condiciones reflejan la idea de que las causas (padres) de cualquier mecanismo causal resultan dependientes una vez que se dispone de información del efecto que producen (un hijo). Por ejemplo, en el grafo dirigido anterior, la situación laboral y las ganancias fruto de inversiones son incondicionalmente independientes, es decir, I(L,G|Φ)D.
Sin embargo, si se dispone de alguna información de la situación económica, entonces L y G se vuelven dependientes, D(L,G|E)D, porque existe una relación entre la creencia que se tiene en las dos causas.

Ejemplo D-separación Considérese el grafo dirigido mostrado en la figura.
A partir de este grafo, se pueden derivar las relaciones de independencia de la diapositiva siguiente.

Ejemplo D-separación Caso (a). Independencia incondicional,
I(L,G|Φ)D: Los nodos L y G son incondicionalmente independientes pues están D-separados por Φ. Tal y como puede observarse en la figura (a), el único camino no dirigido, L − E − G, entre los nodos L y G contiene al nodo de aristas convergentes E, y ni él ni ninguno de sus descendientes están contenidos en Φ.
Caso (b). Dependencia condicional, D(L, S|F)D: Los nodos L y S son condicionalmente dependientes dado F. En la figura (b) puede verse que el único camino no dirigido entre L y S, L − E − F −S, contiene a los nodos E y F, y ninguno de estos nodos cumple las condiciones de la D-separación. Por tanto, L y S no están Dseparados por F.

Ejemplo D-separación Caso (c). Independencia condicional,
I(D,F|{L,E})D: Los nodos D y F son condicionalmente independientes dado {L,E}, pues el único camino no dirigido D−E−F entre los nodos D y F contiene un solo nodo intermedio, E, que no es un nodo de aristas convergentes, pero está contenido en {L,E} (ver Figura (c)).
Caso (d). Dependencia condicional, D(D, {S, F}|L)D: El nodo D y el conjunto de nodos {S, F} son condicionalmente dependientes dado L (ver Figura (d)). Obsérvese que el camino no dirigido D − E − F entre D y F contiene al nodo E, que no es un nodo de aristas convergentes en este camino, pero no está contenido en {L}.

Definición alternativa El concepto de D-separación permite representar
estructuras de dependencia e independencia en grafos dirigidos y, de esta forma, proporciona una solución al problema inicial.
A continuación se introduce una definición alternativa de D-separación que es más fácil de aplicar en la práctica que la definición anterior.
Definición D-Separación. Sean X, Y y Z tres subconjuntos disjuntos en un grafo dirigido acíclico D, entonces se dice que Z D-separa a X e Y si y sólo si Z separa X e Y en el grafo moral del menor subconjunto ancestral1 que contenga a los nodos de X, Y y Z.

Definición alternativa Esta definición alternativa fue propuesta por Lauritzen y otros
(1990).
Mostraron la equivalencia de la definición anterior y ésta, a la que llamaron A-separación.
La idea de moralizar el grafo refleja la primera condición de la definición previa (A es un nodo de aristas convergentes en el camino y ni A ni sus descendientes están en Z). Si existiese un nodo de aristas convergentes A en un camino entre
los nodos X e Y , tal que A o alguno de sus descendientes estuviese en Z, entonces A también estaría contenido en el menor conjunto ancestral que contuviera a X, Y y Z.
Por tanto, puesto que A es un nodo de aristas convergentes, incluso en el caso de que A estuviera en Z, el proceso de moralización garantizaría la existencia de un camino no dirigido entre X e Y no interceptado por Z en el grafo moralizado correspondiente.
Esta definición alternativa sugiere el siguiente algoritmo para la D-separación.

Algoritmo D-Separación
Datos: Un grafo dirigido acíclico, D, y tres
subconjuntos disjuntos de nodos X, Y y Z.
Resultado: Comprobación de la relación de
independencia I(X, Y |Z) en D.
1. Obtener el menor subgrafo que contenga a
X, Y, Z y sus subconjuntos de ascendientes.
2. Moralizar el grafo obtenido.
3. Utilizar el criterio de U-separación para
comprobar si Z separa a X de Y .
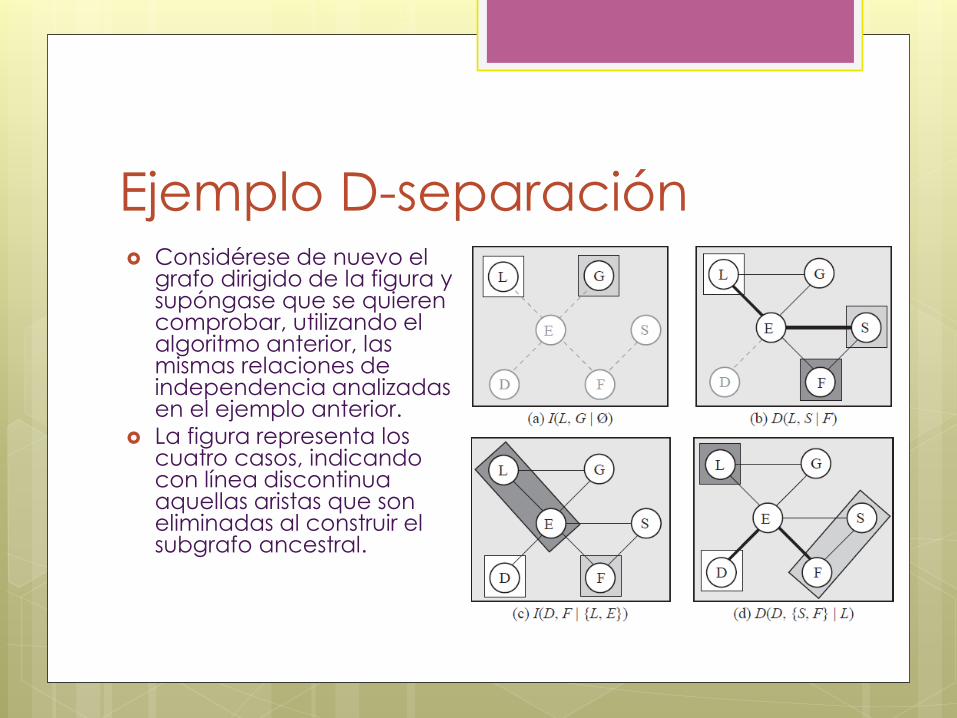
Ejemplo D-separación Considérese de nuevo el
grafo dirigido de la figura y supóngase que se quieren comprobar, utilizando el algoritmo anterior, las mismas relaciones de independencia analizadas en el ejemplo anterior.
La figura representa los cuatro casos, indicando con línea discontinua aquellas aristas que son eliminadas al construir el subgrafo ancestral.

Ejemplo D-separación Caso (a). Independencia incondicional,
I(L,G|Φ)D: No existe ningún camino que conecte los nodos L y G en el grafo moral del menor subgrafo ancestral que contenga a L, G y Φ (ver figura(a)). Por tanto, I(L,G|Φ)D.
Caso (b). Dependencia condicional, D(L, S|F)D: La figura(b) muestra que existe un camino, L − E − S, que no contiene ningún nodo en {F} y que conecta los nodos L y S en el grafo moral del menor subgrafo ancestral que contiene a L, S y F. Por tanto, D(L, S|F)D.
Caso (c). Independencia condicional, I(D,F|{L,E})D: Existen dos caminos entre D y F, D−E −F y D−E −S −F, en el grafo moral del menor subgrafo ancestral que contiene a D, L, E y F (ver figura(c)). Ambos caminos contienen al nodo E, que está contenido en el conjunto {L,E}. Por tanto, I(D,F|{L,E})D.
Caso (d). Dependencia condicional, D(D, {S, F}|L)D: La figura (d), muestra el camino D−E −F que conecta D y {S, F} en el grafo moral del menor subgrafo ancestral de {D, S, F,L}. Sin embargo, este camino no contiene al nodo L. Por tanto, D(D, {S, F}|L)D.

Algunas
Propiedades de la
Independencia Condicional Hasta ahora se han introducido tres modelos para definir
relaciones de independencia condicional: modelos probabilísticos,
modelos gráficos no dirigidos, y
modelos gráficos dirigidos.
Se analizan ahora propiedades de la independencia condicional que cumplen algunos de estos modelos. Éstas permiten obtener nuevas relaciones de independencia a partir
de un conjunto inicial de relaciones de independencia, dado por uno de estos modelos. Ej: dada la función de probabilidad conjunta p(x1, . . . , xn) de un
conjunto de variables {X1, . . . , Xn}, se puede obtener el conjunto completo de relaciones de independencia asociado a este modelo probabilístico comprobando cuáles de todas las posibles independencias en {X1, . . . , Xn} son verificadas por la función p(x1, . . . , xn).
En la práctica, esta función es a menudo desconocida sólo se dispone de un conjunto de relaciones de independencia que describen las relaciones entre las variables. Este conjunto se denomina lista inicial de independencias.

Definición Lista inicial
de independencias Una lista inicial de independencias L es un conjunto de
relaciones de independencia de la forma I(X, Y |Z), donde X, Y y Z son tres subconjuntos disjuntos de {X1, . . . , Xn}, lo cual significa que X e Y son condicionalmente independientes dado Z.
Partiendo de una lista inicial, es necesario conocer si esta lista implica otras independencias no contenidas en el modelo inicial, pero que tengan que ser satisfechas para que el modelo cumpla una serie de propiedades de independencia condicional conocidas.
Problema: Dada una lista inicial de independencias L, ¿cómo pueden obtenerse nuevas independencias a partir de L utilizando ciertas propiedades de independencia condicional?

Independencias derivadas Se introduce un algoritmo para obtener las
independencias derivadas de una lista inicial. Para que una lista de independencias sea compatible con
los axiomas de la probabilidad debe cumplir una serie de propiedades conocidas que permitirán obtener nuevas independencias del modelo. Estas independencias adicionales se denominan independencias derivadas.
En caso de que existan, habrán de ser confirmadas por los expertos para que el modelo sea consistente con la realidad.
El conjunto completo de independencias (iniciales y derivadas) describe las relaciones existentes entre las variables. Los modelos de dependencia resultantes son conocidos como modelos definidos por una lista inicial, y se verán más adelante.

Propiedades… Se introducen algunas propiedades de la independencia condicional.
Cada modelos anteriormente descrito (probabilístico, gráfico no dirigido y gráfico dirigido) verifica algunas de estas propiedades, lo que permitirá caracterizarlos parcial o totalmente.
Para ilustrar estas propiedades gráficamente, se han utilizado los modelos gráficos no dirigidos mostrados en las figuras de las diapositivas siguientes. En ellas cada uno de los tres subconjuntos que intervienen en cada relación de independencia (por ejemplo, I(X, Y |Z)) está contenido en un rectángulo.
Nota: para distinguir entre los tres subconjuntos: el rectángulo correspondiente a X no está sombreado el correspondiente a Y muestra una sombra clara el correspondiente al tercero (Z, separador), una sombra oscura.
Primero se introducen cuatro propiedades satisfechas por cualquier modelo probabilístico. Un análisis más amplio de estas propiedades puede obtenerse, por ejemplo, en Lauritzen (1974) y Dawid (1979, 1980). En un tema posterior se describen las propiedades satisfechas por los modelos gráficos no dirigidos y dirigidos, respectivamente.

Propiedades de
Simetría y descomposición 1. Simetría: Si X es condicionalmente independiente de Y dada Z, entonces Y es
condicionalmente independiente de X dada Z, es decir, I(X, Y |Z) ⇔ I(Y,X|Z).
2. Descomposición: Si X es condicionalmente independiente de Y ∪ W dada Z, entonces X
es condicionalmente independiente de Y dada Z, y X es condicionalmente independiente de W dada Z, es decir, I(X, Y ∪ W|Z) ⇒ I(X, Y |Z) y I(X,W|Z).
Y y W no tienen por qué ser necesariamente disjuntos.
La implicación recíproca de esta segunda se conoce como propiedad de composición.
Sin embargo, esta propiedad no se cumple en todos los modelos probabilísticos, como
indica el ejemplo siguiente.

Ejemplo Violación de la
propiedad de composición Sea el conjunto de variables binarias {X, Y,Z,W}.
En la tabla se muestran dos funciones de probabilidad distintas para este conjunto de variables. Estas funciones han sido obtenidas fijando valores numéricos para algunos de los parámetros (los indicados con dos cifras decimales) y calculando los valores restantes para que la función de probabilidad p1 viole la propiedad de composición, y para que la función p2 cumpla esta propiedad.
Como vemos p1(x, y, z,w) cumple las relaciones de independencia I(X, Y |Z) y I(X,W|Z) pero, en cambio, no cumple I(X, Y ∪ W|Z), lo que prueba que no satisface la propiedad de composición. Puede comprobarse que no existe ninguna combinación de valores de las variables (x, y, z,w) que cumpla la igualdad p(x|y,w, z) = p(x|z).
Por el contrario, la función de probabilidad conjunta p2(x, y, z,w) verifica I(X, Y |Z), I(X,W|Z) y I(X, Y ∪W|Z). Por tanto, esta función de probabilidad cumple la propiedad de composición mientras que p1(x, y, z,w) no la cumple.

Propiedad de Unión Débil 3. Unión Débil: I(X, Y ∪ W|Z) ⇒ I(X,W|Z ∪ Y ) y I(X, Y |Z ∪ W).
La figura ilustra gráficamente esta propiedad, que refleja el hecho de que el conocimiento de información irrelevante Y no puede hacer que otra información irrelevante W se convierta en relevante.
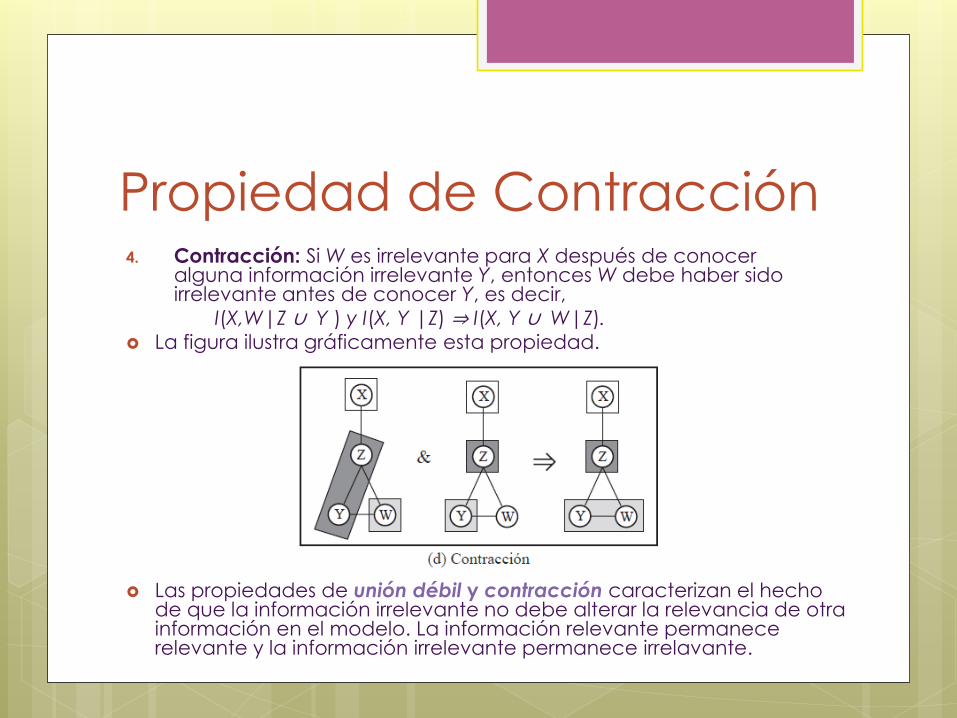
Propiedad de Contracción 4. Contracción: Si W es irrelevante para X después de conocer
alguna información irrelevante Y, entonces W debe haber sido irrelevante antes de conocer Y, es decir,
I(X,W|Z ∪ Y ) y I(X, Y |Z) ⇒ I(X, Y ∪ W|Z).
La figura ilustra gráficamente esta propiedad.
Las propiedades de unión débil y contracción caracterizan el hecho de que la información irrelevante no debe alterar la relevancia de otra información en el modelo. La información relevante permanece relevante y la información irrelevante permanece irrelavante.
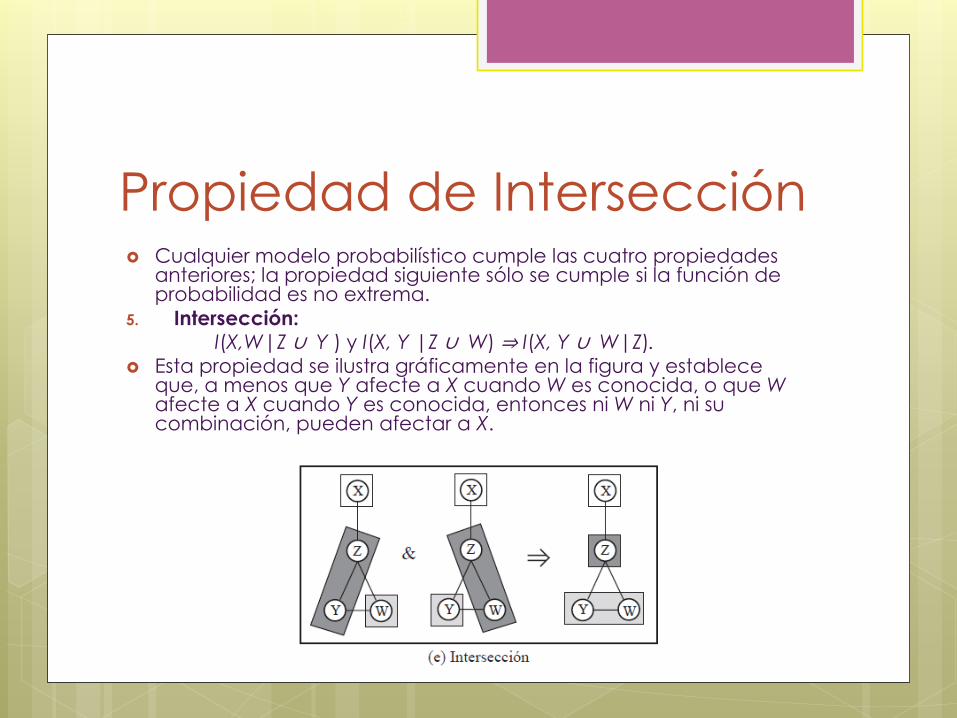
Propiedad de Intersección Cualquier modelo probabilístico cumple las cuatro propiedades
anteriores; la propiedad siguiente sólo se cumple si la función de probabilidad es no extrema.
5. Intersección: I(X,W|Z ∪ Y ) y I(X, Y |Z ∪ W) ⇒ I(X, Y ∪ W|Z).
Esta propiedad se ilustra gráficamente en la figura y establece que, a menos que Y afecte a X cuando W es conocida, o que W afecte a X cuando Y es conocida, entonces ni W ni Y, ni su combinación, pueden afectar a X.

Propiedad de Unión Fuerte Las cuatro propiedades siguientes
no son satisfechas, en general, por los modelos probabilísticos pero permiten caracterizar los modelos gráficos de dependencia.
6. Unión Fuerte: Si X es condicionalmente independiente de Y dado Z, entonces X también es condicionalmente independiente de Y dado Z ∪ W, es decir:
I(X, Y |Z) ⇒ I(X, Y |Z ∪ W).
Esta propiedad se ilustra gráficamente por medio del grafo no dirigido de la figura.
El ejemplo siguiente muestra que, por el contrario, los modelos gráficos dirigidos no cumplen esta propiedad.

Ejemplo Violación de la
propiedad de unión fuerte Sea el grafo dirigido acíclico de la figura a.
Utilizando el criterio de D-separación se concluye que el grafo cumple la relación de independencia I(X, Y |Z) (existe un único camino entre X e Y en el grafo moral del menor subgrafo ancestral que contiene a X, Y y Z, y este camino contiene al nodo Z).
Sin embargo, si se añade el nodo W al conjunto separador, entonces los nodos X e Y resultan dependientes (ver figura b). Motivo: existe un camino entre X e Y que no contiene al nodo Z en el grafo moral del menor subgrafo ancestral que contiene a {X, Y,W,Z}. Por tanto, se tiene la relación D(X, Y |{Z,W}), que muestra que los modelos gráficos dirigidos no verifican la propiedad de unión fuerte.

Propiedad de
Transitividad Fuerte 7. Transitividad Fuerte: Si X es condicionalmente dependiente de A
dado Z, y A es condicionalmente dependiente de Y dado Z, entonces X es condicionalmente dependiente de Y dado Z, es decir,
D(X,A|Z) y D(A, Y |Z) ⇒ D(X, Y |Z), o, de forma equivalente,
I(X, Y |Z) ⇒ I(X,A|Z) o I(A, Y |Z), donde A es una única variable.
La propiedad de transitividad fuerte afirma que dos variables han de ser dependientes si existe otra variable A que dependa de ambas (ver figura).

Propiedad de
Transitividad Débil 8. Transitividad Débil: Si X y A son condicionalmente dependientes
dado Z, e Y y A son condicionalmente dependientes dado Z, entonces X e Y son condicionalmente dependientes dado Z, o X e Y son condicionalmente dependientes dado Z ∪ A, es decir,
D(X,A|Z) y D(A, Y |Z) ⇒ D(X, Y |Z) o D(X, Y |Z ∪ A),
o, de forma equivalente,
I(X, Y |Z) y I(X, Y |Z ∪ A) ⇒ I(X,A|Z) o I(A, Y |Z),
donde A es una única variable. La figura ilustra esta propiedad.

Propiedad de Cordalidad 9. Cordalidad: Si A y C son condicionalmente dependientes dado B, y A y C
son condicionalmente dependientes dado D, entonces A y C son condicionalmente dependientes dado B ∪ D, o B y D son condicionalmente dependientes dado A ∪ C, es decir,
D(A,C|B) y D(A,C|D) ⇒ D(A,C|B ∪ D) o D(B,D|A ∪ C), o, de forma equivalente,
I(A,C|B ∪ D) y I(B,D|A ∪ C) ⇒ I(A,C|B) o I(A,C|D), donde A,B,C y D son conjuntos de una única variable. Esta propiedad se ilustra en la figura.

Implicaciones entre las
propiedades descritas
Las propiedades anteriores se utilizarán en la sección siguiente para concluir independencias adicionales a partir de algunas listas de independencias particulares, que verifican ciertas propiedades y permitirán caracterizar las estructuras de dependencia e independencia contenidas en los modelos probabilísticos y gráficos.

Modelos de Dependencia Introducidas algunas propiedades de la independencia
condicional es posible volver al problema: Dada una lista inicial de relaciones de independencia L, ¿cómo
pueden obtenerse nuevas independencias a partir de L utilizando ciertas propiedades de independencia condicional?
No se ha requerido que las listas de relaciones de independencia cumpliesen ninguna condición (sólo que los subconjuntos que componen cada relación sean disjuntos).
Cuando se impone alguna condición a estos modelos (ej: que cumplan un cierto conjunto de propiedades de independencia condicional) se obtienen algunos tipos especiales de listas de independencias, algunos de los cuales se describen a continuación.

Grafoides y semigrafoides Definición Grafoide. Un grafoide es un conjunto
de relaciones de independencia que es cerrado con respecto a las propiedades de simetría, descomposición, unión débil, contracción e intersección.
Definición 5.7 Semigrafoide. Un semigrafoide es un conjunto de relaciones de independencia que es cerrado con respecto a las propiedades de simetría, descomposición, unión débil y contracción.
Por tanto, un grafoide debe satisfacer las cinco primeras
propiedades, mientras que un semigrafoide debe satisfacer sólo las cuatro primeras (ver Pearl y Paz (1987) y Geiger (1990)).

Modelo de Dependencia Dada una lista inicial de independencias, un grafo, o
una función de probabilidad conjunta, siempre es posible determinar qué relaciones de independencia se cumplen en el modelo y, por tanto, determinar su estructura cualitativa. Estos tipos de modelos definen clases particulares de modelos de dependencia.
Definición Modelo de Dependencia. Cualquier modelo M de un conjunto de variables {X1, . . . , Xn} mediante el cual se pueda determinar si la relación I(X, Y |Z) es o no cierta, para todas las posibles ternas de subconjuntos X, Y y Z, se denomina modelo de dependencia.

Modelo de Dependencia
probabilístico Definición Modelo de dependencia probabilístico.
Un modelo de dependencia M se denomina probabilístico si contiene todas las relaciones de independencia dadas por una función de probabilidad conjunta p(x1, . . . , xn).
Definición Modelo de dependencia probabilístico no extremo. Un modelo de dependencia probabilístico no extremo es un modelo de dependencia probabilístico obtenido de una función de probabilidad no extrema, o positiva; es decir, p(x1, . . . , xn) toma valores en el intervalo abierto (0, 1).
Dado que todas las funciones de probabilidad satisfacen las cuatro primeras propiedades de independencia condicional, todos los modelos de dependencia probabilísticos son semigrafoides.
Por otra parte, dado que sólo las funciones de probabilidad no extremas satisfacen la propiedad de intersección, sólo los modelos de dependencia probabilísticos no extremos son grafoides.

Modelo de
dependencia compatible
con una probabilidad Definición Modelo de dependencia compatible con una
probabilidad. Un modelo de dependencia M se dice compatible con una función de probabilidad p(x1, . . . , xn) si todas las relaciones de independencia derivadas M son también satisfechas por p(x1, . . . , xn).
Un modelo de dependencia compatible con una probabilidad es aquel que puede obtenerse de una función de probabilidad conjunta p(x1, . . . , xn), pero sin necesidad de ser completo, es decir, no tienen por qué contener todas las relaciones de independencia que pueden obtenerse de p(x1, . . . , xn).
Toda función de probabilidad cumple las cuatro primeras propiedades de la independencia condicional si un modelo de dependencia M es compatible con una función de probabilidad p(x1, . . . , xn), entonces el menor semigrafoide generado por M también debe ser compatible con p(x1, . . . , xn).

Algoritmo de Generación de
un grafoide mínimo Un problema interesante desde el punto de vista práctico
es calcular el menor semigrafoide generado por un modelo de dependencia M.
El siguiente algoritmo puede ser utilizado con este fin: Algoritmo Generación de un grafoide mínimo. Datos: Un modelo de dependencia inicial M. Resultado: El mínimo grafoide que contiene a M.
1. Generar nuevas relaciones de independencia aplicando las propiedades de simetría, descomposición, unión débil, contracción e intersección a las relaciones del modelo M. El conjunto resultante es el grafoide buscado.
El algoritmo también puede ser utilizado para generar un semigrafoide, no utilizando la propiedad de intersección.
El ejemplo siguiente ilustra este algoritmo.

Ejemplo Generación grafoides Ejemplo Generación grafoides. Suponga un conjunto de
cuatro variables {X1,X2,X3,X4} y la siguiente lista de relaciones de independencia: M = {I(X1,X2|X3), I(X1,X4|X2), I(X1,X4|{X2,X3})}.
La tabla de la diapositiva siguiente muestra las relaciones de independencia iniciales, y las relaciones derivadas necesarias para completar el modelo hasta convertirlo en un semigrafoide y un grafoide, respectivamente. (Las nuevas relaciones de independencia son generadas utilizando un programa de ordenador llamado X-pert Maps,2 que implementa el algoritmo anterior).
La tabla también muestra las relaciones de independencia que se utilizan para obtener las nuevas independencias.

Ejemplo Generación grafoides

Conclusiones Las cinco primeras propiedades pueden ser utilizadas para aumentar un
modelo de dependencia M compatible con una función de probabilidad p(x1, . . . , xn). Tanto el modelo inicial como el completado son compatibles con p(x1, . . . , xn).
Pregunta: ¿Constituyen las cuatro propiedades descritas anteriormente una caracterización completa de los modelos probabilísticos?
Pearl y Paz (1987) (ver Pearl, (1988) p. 88) conjeturaron que las primeras cuatro propiedades (simetría, descomposición, unión débil, y contracción) eran completas.
Sin embargo, esta conjetura fue refutada por Studeny (1989) encontrando una propiedad que no puede derivarse de las cuatro anteriores y mostrando que no existe ningún conjunto completo de propiedades que caractericen los modelos probabilísticos (Studeny (1992)).
Como se verá en los capítulos siguientes, la estructura cualitativa de un modelo probabilístico puede ser representada mediante un modelo de dependencia que permitirá obtener una factorización de la función de probabilidad.
En la sección siguiente se introducen algunos conceptos sobre factorizaciones de una función de probabilidad.

Factorizaciones de una
Función de Probabilidad
Cualquier función de probabilidad de un
conjunto de variables aleatorias puede
ser definida por medio de funciones de
probabilidad condicionada más sencillas formando una factorización.
Se analizan distintas formas de factorizar
una función de probabilidad.

Factorización mediante
funciones potenciales
En el tema siguiente se verán ejemplos importantes de este tipo de factorización. Ojo! Los conjuntos C1, . . . , Cm no son necesariamente disjuntos y que las funciones Ψi no son necesariamente funciones de probabilidad. Cuando se exige que las funciones Ψi sean funciones de probabilidad, se obtienen factorizaciones particulares, algunas de las cuales se comentan a continuación.

Regla de la cadena Sea {Y1, . . . , Ym} una partición (subconjuntos disjuntos dos a dos
cuya unión es el conjunto total) del conjunto {X1, . . . , Xn}. Un tipo importante de factorizaciones se obtiene aplicando la fórmula siguiente, conocida como regla de la cadena.
Definición Regla de la cadena. Cualquier función de probabilidad de un conjunto de variables {X1, . . . , Xn} puede ser expresada como el producto de m funciones de probabilidad condicionada de la forma
o, de modo equivalente,
donde Bi = {Y1, . . . , Yi−1} es el conjunto de variables anteriores
a Yi y Ai = {Yi+1, . . ., Yn} es el conjunto de variables posteriores
a Yi. Obsérvese que ai y bi son realizaciones de Ai y Bi,
respectivamente.

Regla de la cadena.
Reglas canónicas Cuando los conjuntos Yi están formados por una única
variable, entonces se tiene m = n y el conjunto {Y1, . . . , Yn} es simplemente una permutación de {X1, . . . , Xn}. En este caso, las anteriores se denominan reglas canónicas de la cadena y se tiene
y
respectivamente.

Ejemplo Regla de la cadena
Sea el conjunto de variables {X1, . . . , X4} y la partición Y1 = {X1}, Y2 = {X2}, Y3 = {X3}, Y4 = {X4}.
Entonces las fórmulas anteriores proporcionan la siguientes factorizaciones equivalentes de la función de probabilidad:
p(x1,...,x4) = p(x1)p(x2|x1)p(x3|x1,x2)p(x4|x1,x2,x3) y
p(x1,...,x4) = p(x1|x2,x3,x4)p(x2|x3,x4)p(x3|x4)p(x4).
Por tanto, la función de probabilidad puede expresarse como el producto de cuatro funciones de probabilidad condicionada.

Ejemplo Regla de la cadena Nota: existen varias formas de aplicar la regla de la
cadena a una misma función de probabilidad (considerando distintas particiones), lo que origina distintas factorizaciones.
Por ejemplo, a continuación se muestran dos factorizaciones equivalentes obtenidas aplicando la regla de la cadena a distintas particiones de
{X1,..., X4}: La partición Y1 = {X1}, Y2 = {X2,X3}, y Y3 = {X4} da lugar a p(x1, . . . , x4) = p(x1)p(x2, x3|x1)p(x4|x1, x2, x3). La partición Y1 = {X1,X4} y Y2 = {X2,X3}:
factorización p(x1, . . . , x4) = p(x1, x4)p(x2, x3|x1, x4).

Nota - conclusión En un tema anterior vimos que el nº de parámetros que
definen un modelo probabilístico puede ser reducido imponiendo ciertas restricciones.
Por ejemplo, los distintos modelos presentados entonces fueron obtenidos suponiendo ciertas relaciones de independencia condicional para el modelo.
Con el fin de ilustrar la forma en la que la inclusión de una relación de independencia en un modelo probabilístico da lugar a una reducción de parámetros en el modelo, es conveniente escribir la función de probabilidad conjunta como producto de funciones de probabilidad condicionada utilizando, por ejemplo, la regla de la cadena.
Este hecho se ilustra en el siguiente ejemplo.

Ejemplo Restricciones dadas
por independencias Sea el conjunto de variables del ejemplo anterior
y supongamos que un experto propone las dos siguientes relaciones de independencia: I(X3,X1|X2) y I(X4, {X1,X3}|X2).
Para incluir estas relaciones en el modelo probabilístico, interesa calcular las restricciones que deben cumplir los parámetros del modelo para satisfacer estas condiciones de independencia. La primera de estas relaciones implica
p(x3|x1, x2) = p(x3|x2),
mientras que la segunda implica p(x4|x1, x2, x3) = p(x4|x2).

Ejemplo Restricciones dadas
por independencias La forma general del modelo probabilístico no es
conveniente para calcular las restricciones entre los parámetros («intratable»).
Pero si se sustituyen estas dos igualdades en la factorización del modelo probabilístico, se obtiene la siguiente estructura: p(x1, . . . , x4) = p(x1)p(x2|x1)p(x3|x2)p(x4|x2).
Suponiendo que las variables son binarias, la función de probabilidad depende de 24−1 = 15 parámetros libres.
Por otra parte, la función de probabilidad de arriba depende de 7 parámetros (p(x1) depende de un parámetro, y cada una de las restantes funciones de probabilidad condicionada depende de dos parámetros). Por tanto, las dos relaciones de independencia dadas por el experto dan lugar a una reducción de 8 parámetros en el modelo probabilístico.

Definición
Función de probabilidad
condicionada canónica
Sea Ui ⊂ X = {X1, . . . , Xn}. Una función de
probabilidad condicionada p(xi|ui) se dice
canónica si Xi está formada por una única
variable que no está contenida en Ui.
El siguiente teorema, probado por Gelman y
Speed (1993), garantiza que cada conjunto
de funciones de probabilidad condicionada,
dado en forma no canónica, tiene asociado
un conjunto canónico equivalente.

Teorema Existencia de formas
canónicas. Considérese el conjunto de variables X = {X1, . . . , Xn}
y supónganse las funciones de probabilidad marginales y condicionadas P = {p(u1|v1), . . . , p(um|vm)}, donde Ui y Vi son subconjuntos disjuntos de X, tal que Ui = Φ y Vi puede ser vacío (para el caso de funciones marginales). Entonces, a partir de P puede obtenerse un conjunto equivalente en el que los nuevos conjuntos Ui contienen una única variable de X.
Aplicando la regla de la cadena a p(ui|vi) pueden obtenerse tantas nuevas funciones condicionadas canónicas como variables contenga el conjunto Ui, es decir, el conjunto {p(xj |cij, vi) ∀Xj ∈ Ui},
donde Cij = {Xr |Xr ⊂ Ui, r<j}.

Algoritmo Forma canónica El algoritmo siguiente convierte un conjunto dado de funciones
condicionadas P en una representación canónica equivalente.
Algoritmo Forma canónica. Datos: Un conjunto P = {p(ui|vi), i = 1, . . . , m} de m funciones de
probabilidad condicionada, donde Ui y Vi son subconjuntos disjuntos de X.
Resultado: Un conjunto equivalente P∗ en forma canónica.
1. Iniciación: Considerar P∗ = Φ e i = 1.
2. Asignar j = 1, Si = Ui ∪ Vi y L = card(Ui).
3. Eliminar de Si una de las variables contenidas en Ui, por ejemplo Xl, y añadir p(xl|si) a P∗.
4. Si j < L, incrementar el índice j en una unidad e ir a la Etapa 3; en caso contrario, ir a la Etapa 5.
5. Si i < m, incrementar el índice i en una unidad e ir a la Etapa 2; en caso contrario, devolver P∗ como resultado.

Ejemplo Sea el conjunto de variables X = {A,B,C,D} y el conjunto de
funciones de probabilidad P = {p(a, b|c), p(a, c, d|b)}. Utilizando la notación del algoritmo, los conjuntos Ui y Vi
son U1 = {A,B}, V1 = {C},
U2 = {A,C,D}, V2 = {B}.
Para convertir las dos funciones de probabilidad condicionada de P en sus formas canónicas correspondientes, se utiliza el algoritmo obteniéndose: p(a, b|c) = p(a|b, c)p(b|c),
p(a, c, d|b) = p(a|c, d, b)p(c|d, b)p(d|b).
Por tanto, se obtiene la representación canónica P∗ = {p(a|b, c)p(b|c); p(a|c, d, b)p(c|d, b)p(d|b)}.

Ejemplo La figura muestra un programa para convertir el conjunto dado P
en forma canónica. Dada una lista de pares {U, V }, el programa devuelve la lista canónica asociada. Por ejemplo, dadas las funciones de probabilidad del ejemplo los siguientes comandos permiten obtener la forma canónica correspondiente: In:=Canonical[List[{{A,B},{C}},{{A,C,D},{B}}]] Out:=List[{{A},{B,C}},{{B},{C}},{{A},{C,D,B}},{{C},{D,B}},{{D},{B}}]

Definición
Probabilidad condicionada
canónica estándar Sea {Y1, . . . , Yn} una permutación del conjunto X =
{X1, . . . , Xn}. Una función de probabilidad condicionada p(yi|si) se dice que es una función de probabilidad condicionada en forma canónica estándar si Yi está formado por una única variable y Si contiene todas las variables anteriores a Yi, o todas las variables posteriores a Yi, es decir, o bien Si = {Y1, ..., Yi−1}, o bien, Si = {Yi+1, ..., Yn}.
Por ejemplo, dada la permutación Y = {Y1, Y2, Y3, Y4}, las funciones de probabilidad p(y1) y p(y3|y1, y2) son probabilidades condicionadas en forma canónica estándar; sin embargo, p(y2|y1, y3) y p(y1|y3, y4) son canónicas pero no están en forma estándar.

Definición
Representación canónica
estándar de una probabilidad Sea {Y1, . . . , Yn} una permutación del conjunto de variables X = {X1, . . . , Xn}.
Entonces la función de probabilidad p(x) puede expresarse como el producto de n funciones de probabilidad condicionada en forma canónica estándar de la forma siguiente
donde Bi = {Y1, . . . , Yi−1} o, de forma equivalente,
donde Ai = {Yi+1, . . . , Yn}. Las ecuaciones son representaciones canónicas estándar de la probabilidad. Los términos p(yi|bi) y p(yi|ai) se denominan componentes canónicas estándar. Por ejemplo, estas dos ecuaciones corresponden a dos representaciones canónicas estándar de p(x1, . . . , x4). Las formas canónicas estándar no son únicas, al igual que las formas canónicas, pues pueden obtenerse distintas representaciones aplicando la regla de la cadena a distintas permutaciones de X.

Consecuencias prácticas Las consecuencias prácticas de la existencia de una representación canónica
para cualquier conjunto P de funciones de probabilidad condicionada son:
1. Cualquier conjunto no canónico de funciones de probabilidad condicionada P puede ser expresado en forma canónica de forma equivalente.
2. Cualquier función de probabilidad puede ser factorizada, utilizando la regla de la cadena, como un producto de funciones de probabilidad condicionada en forma canónica estándar.
3. Sólo es necesario considerar funciones de probabilidad condicionada de una única variable para definir la función de probabilidad de un conjunto de variables.
Las principales ventajas de este tipo de representaciones son las siguientes: La definición de un modelo probabilístico se simplifica enormemente al tratar con
funciones de probabilidad condicionada de una única variable (dado un conjunto de variables). Este proceso es más sencillo que la especificación directa de una función de probabilidad pues, generalmente, las funciones de probabilidad condicionada dependen de muchas menos variables que la función de probabilidad conjunta.
La programación de algoritmos también se simplifica ya que sólo es necesario considerar un único modelo genérico para las funciones de probabilidad condicionada.
4. Las formas canónicas estándar permiten identificar fácilmente aquellos conjuntos de funciones de probabilidad condicionada que son consistentes con algún modelo probabilístico. También permiten determinar cuándo es único el modelo probabilístico definido.

Construcción de un
Modelo Probabilístico El problema de construir una función de probabilidad para un
conjunto de variables puede simplificarse notablemente considerando una factorización de la probabilidad como producto de funciones de probabilidad condicionada más sencillas.
El grado de simplificación dependerá de la estructura de independencia (incondicional o condicional) existente entre las variables del modelo.
Por tanto, para encontrar una factorización apropiada del modelo probabilístico, primero se necesita conocer su estructura de independencia.
Esta estructura de independencia (modelo de dependencia) caracteriza la estructura cualitativa de las relaciones entre las variables. Por ejemplo, se necesita definir qué variables son independientes
y/o condicionalmente independientes de otras y cuáles no.

Modelos definidos
gráficamente La estructura de independencia y, por tanto, la factorización
asociada al modelo probabilístico, puede ser obtenida de varias formas:
1. Modelos definidos gráficamente: Como se ha visto en las secciones anteriores, las relaciones existentes entre las variables de un conjunto pueden ser descritas mediante un grafo. Posteriormente, utilizando un criterio de separación apropiado, se puede obtener el conjunto de relaciones de independencia asociado. Estos modelos de dependencia se conocen como modelos definidos gráficamente, y tienen como ejemplos más importantes a las redes de Markov, y las redes Bayesianas, que se analizan en detalle en temas posteriores. Las tareas de comprobar la validez de un grafo, entender sus implicaciones, y modificarlo de forma apropiada han de ser realizadas partiendo de la comprensión de las relaciones de dependencia e independencia existentes en el conjunto de variables.

Modelos definidos por listas de
independencias 2. Modelos definidos por listas de independencias: Los grafos son muy
útiles para definir la estructura de independencia de un modelo probabilístico. El problema es que no todas las funciones de probabilidad pueden ser representadas mediante estos modelos (lo veremos en más detalle). Una descripción alternativa utiliza directamente un conjunto M de relaciones de independencia que describan las relaciones entre las variables. Este conjunto puede ser definido por un experto a partir de sus opiniones sobre las relaciones entre las variables del modelo. Cada una de las independencias del conjunto indica qué variables contienen información relevante sobre otras y cuándo el conocimiento de algunas variables hace que otras sean irrelevantes para un conjunto de variables dado. Este conjunto inicial de independencias puede ser completado incluyendo aquellas otras que cumplan una serie de propiedades de independencia condicional. El conjunto resultante puede ser finalmente utilizado para obtener una factorización de la función de probabilidad del modelo. Los modelos resultantes se conocen como modelos definidos por listas de relaciones de independencia. En un tema posterior se analiza este tipo de modelos en más detalle.

Modelos definidos
condicionalmente 3. Modelos definidos condicionalmente: Como alternativa
a los modelos gráficos y los modelos dados por listas de relaciones de independencia, la estructura cualitativa de un modelo probabilístico puede venir dada por un conjunto de funciones de probabilidad marginales y condicionadas P = {p1(u1|v1), . . . , pm(um|vm)}.
Sin embargo, las funciones de este conjunto no pueden definirse libremente, sino que han de satisfacer ciertas relaciones para ser compatibles y definir un único modelo probabilístico. En un tema posterior se analiza detalladamente la forma de comprobar la compatibilidad, la unicidad, y de obtener la función de probabilidad asociada a un conjunto de probabilidades marginales y condicionadas.

Ventajas Una ventaja de utilizar modelos gráficos, o modelos
definidos por listas de independencias, para construir un modelo probabilístico es que estos modelos definen una factorización de la función de probabilidad como producto de funciones de probabilidad condicionada que determinan la estructura cualitativa del modelo probabilístico. Normalmente, estas funciones condicionadas contienen un nº menor de variables que la función de probabilidad conjunta y, por tanto, el proceso de definición del modelo probabilístico es más sencillo. Esta técnica de romper (“de dividir y conquistar”) la función de probabilidad como producto de funciones condicionadas más sencillas se analiza en los dos temas siguientes.

Además… Una vez que se conoce la estructura cualitativa del
modelo probabilístico (la factorización de la función de probabilidad), la estructura cuantitativa de un modelo particular se define mediante la asignación de valores numéricos a los parámetros asociados a las funciones de probabilidad condicionada que intervienen en la factorización del modelo. Estos valores han de ser definidos por algún experto, o estimados a partir de un conjunto de datos. Por tanto, si la estructura cualitativa del modelo es desconocida, que es el caso habitual en la práctica, entonces tanto la estructura cualitativa, como la cuantitativa (los parámetros) han de ser estimadas a partir del conjunto de datos disponible (una base de datos, etc.). Este problema, que se conoce como aprendizaje.

Resumen Como resumen de todo lo anterior, la construcción de un
modelo probabilístico puede ser realizada en dos etapas: 1. Factorizar la función de probabilidad mediante un producto de funciones de probabilidad condicionada. Esta factorización puede obtenerse de tres formas distintas: (a) Utilizando grafos (tema siguiente).
(b) Utilizando listas de relaciones de independencia (dos temas más adelante). (c) A partir de un conjunto de funciones de probabilidad condicionada (dos temas más adelante).
2. Estimar los parámetros de cada una de las funciones de probabilidad condicionada resultantes.
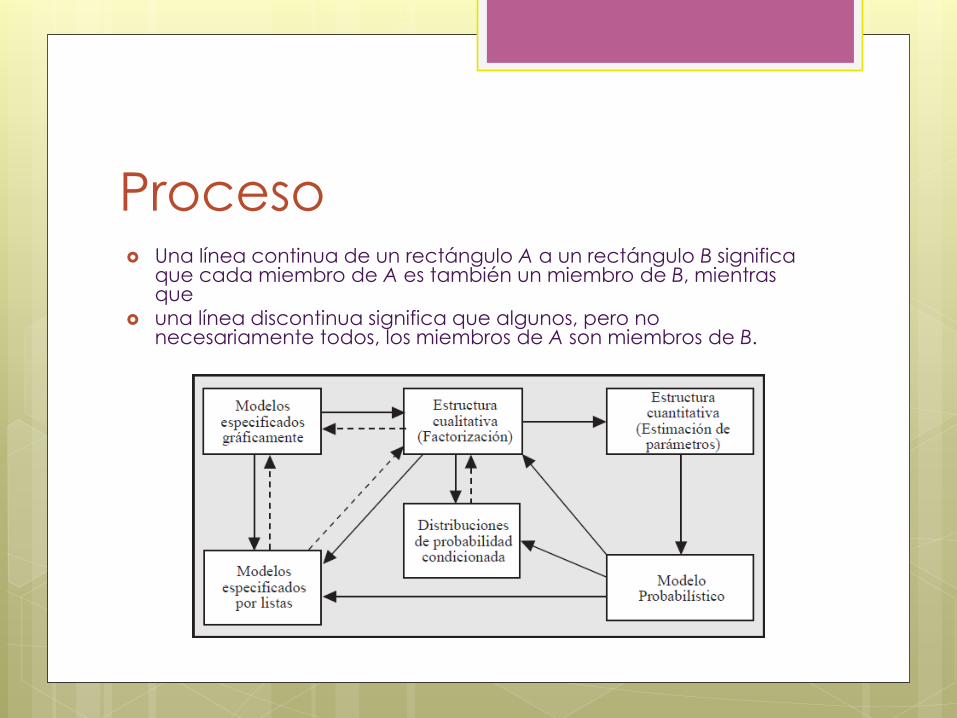
Proceso Una línea continua de un rectángulo A a un rectángulo B significa
que cada miembro de A es también un miembro de B, mientras que
una línea discontinua significa que algunos, pero no necesariamente todos, los miembros de A son miembros de B.

Definición del modelo El camino más simple para definir un modelo probabilístico
es comenzar con un grafo que se supone describe la estructura de dependencia e independencia de las variables.
A continuación: El grafo puede utilizarse para construir una factorización de la
función de probabilidad de las variables.
De forma alternativa, también puede comenzarse con una lista de relaciones de independencia y, a partir de ella, obtener una factorización de la función de probabilidad.
La factorización obtenida determina los parámetros necesarios para definir el modelo probabilístico. Una vez que estos parámetros han sido definidos, o estimados a partir de un conjunto de datos, la función de probabilidad que define el modelo probabilístico vendrá dada como el producto de las funciones de probabilidad condicionada resultantes.

Definición del modelo Por otra parte, si se conoce la función de probabilidad que
define un modelo probabilístico (que no es el caso habitual en la práctica), se puede seguir el camino inverso y obtener varias factorizaciones distintas (utilizando la regla de la cadena).
También se puede obtener la lista de independencias correspondiente al modelo comprobando cuáles de todas las posibles relaciones de independencia de las variables son verificadas por la función de probabilidad. A partir del conjunto de independencias obtenido, también puede construirse una factorización de la familia paramétrica que contiene a la función de probabilidad dada.

Problemas Problema: ¿Puede representarse cualquier lista de
relaciones de independencia mediante un grafo de forma que las independencias que se deriven del grafo coincidan con las de la lista dada?
Aunque un grafo puede ser representado de forma equivalente por una lista de relaciones de independencia, el recíproco no siempre es cierto. Por esta razón, la figura muestra una arista continua que va del rectángulo que representa a los modelos definidos gráficamente al rectángulo que representa a los modelos definidos por listas de relaciones de independencia, y una arista discontinua en la dirección opuesta.
El capítulo siguiente analiza en mayor detalle este hecho, tanto en el caso de grafos dirigidos, como en el caso de grafos no dirigidos.

Problemas Problema: ¿Cómo puede obtenerse la función de
probabilidad que contiene las independencias asociadas a un grafo dirigido o no dirigido?
Problema: ¿Cómo puede obtenerse la función de probabilidad que contiene las independencias de una lista de relaciones de independencia?
Estos dos problemas se analizan en los dos temas siguientes.
Desgraciadamente, los grafos no siempre pueden reproducir las independencias condicionales contenidas en una lista arbitraria de relaciones de independencia, o en un modelo probabilístico.

Problemas Por tanto, es importante caracterizar las clases de modelos
probabilísticos que pueden representarse mediante grafos. Esto plantea los siguientes problemas:
Problema: ¿Cuál es la clase de modelos probabilísticos que pueden representarse por medio de grafos?
Problema: ¿Qué listas de relaciones de independencia pueden ser representadas por medio de grafos?
Problema: ¿Cuál es el conjunto de funciones de probabilidad condicionadas necesario para definir un modelo probabilístico y cuáles son los parámetros necesarios para cuantificarlo?
Estos problemas se analizan en los dos temas siguientes.

A continuación… En estos temas posteriores se verá que, aunque todo grafo
define una estructura cualitativa de un modelo probabilístico (a través de una factorización), no todas las estructuras cualitativas pueden ser representadas por medio de grafos. Por tanto, la figura anterior muestra una arista sólida que va de
los modelos definidos gráficamente a los modelos factorizados, y una arista discontinua en la dirección opuesta.
De forma similar, se verá que todo modelo probabilístico define una lista de relaciones de independencia, pero no cualquier lista de independencias define un modelo probabilístico. Este hecho se ilustra en la figura anterior con las correspondientes aristas continua y discontinua.

Conclusión De la discusión anterior, y de la figura anterior,
puede concluirse que existen tres formas fundamentales de construir un modelo probabilístico: Grafo → Modelos factorizados → Estimación de
parámetros → Modelo probabilístico. Listas de relaciones de independencia → Modelos
factorizados → Estimación de parámetros → Modelo probabilístico.
Conjunto de funciones condicionadas → Modelos factorizados → Estimación de parámetros → Modelo probabilístico.
En los dos temas siguientes se verá que la forma más sencilla es comenzar con un grafo, pero que la forma más general es a partir de una lista de relaciones de independencia.