chat dr. raul santiago montero
TRANSCRIPT

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 1/106
INSTITUTO POLITÉCNICO NACIONAL
CENTRO DE INVESTIGACIÓN EN COMPUTACIÓN
Clasificador Híbrido de Patrones basado en la Lernmatrix de Steinbuch y
el Linear Associator de Anderson-Kohonen
T E S I S
que para obtener el grado de
MAESTRO EN CIENCIAS DE LA COMPUTACIÓN
presenta
RAÚL SANTIAGO MONTERO
Director de tesis: Dr. Cornelio Yáñez MárquezCodirector de tesis: Dr. Juan Luis Díaz de León Santiago
México, D. F. Junio de 2003

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 2/106
Agradecimientos
Al pueblo de México
Al Instituto Politécnico Nacional
Al Centro de Investigación en Computación

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 3/106
Dedicatoria
A Lucia, Fernanda y Rodrigo.
A mi madre.
En memoria de mi padre.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 4/106
v
ÍndiceResumen .................................................................................................................................
Abstract...................................................................................................................................Glosario ..................................................................................................................................
Índice de tablas y figuras.........................................................................................................
1 Introducción................................................................................................................1
1.1. Objetivo.................................................................................................................1
1.2. Motivación ............................................................................................................2
1.3. Planteamiento del problema ...................................................................................3
1.4. Contribuciones.......................................................................................................4
1.5. Organización de la tesis .........................................................................................4
2 Antecedentes ...............................................................................................................6
2.1 Memorias asociativas..............................................................................................6
2.1.1. Conceptos básicos de memorias asociativas................................................6
2.1.2. Lernmatrix de Steinbuch ............................................................................9
2.1.3. Linear Associator de Anderson-Kohonen .................................................10
2.1.4. Memoria asociativa Hopfield....................................................................12
2.2 Reconocimiento de patrones .................................................................................16
2.2.1. Conceptos básicos del reconocimiento de patrones...................................16
2.2.2. Clasificación de patrones.......................................................................... 17
2.2.3. Clasificadores de mínima distancia...........................................................19
2.2.4. Enfoque neuronal .....................................................................................23
2.2.5. Enfoque probabilístico-estadístico............................................................27
2.2.6. Enfoque sintáctico-estructural ..................................................................29
2.2.7. Génesis del enfoque asociativo para clasificación de patrones ..................35
3 Estado del arte ..........................................................................................................374 Herramientas matemáticas ......................................................................................39
4.1. Sumatorias...........................................................................................................39
4.2. Operador máximo................................................................................................40
4.3. Operaciones matriciales .......................................................................................40
4.4. Vectores n-dimensionales ....................................................................................41

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 5/106
vi
4.5. Producto interno y producto externo de vectores ..................................................42
4.5.1. Producto interno.......................................................................................42
4.5.2. Producto externo ......................................................................................43
4.5.3. Producto de una matriz y un vector...........................................................43
4.6. Traslación de ejes ................................................................................................43
5 Desarrollo..................................................................................................................47
5.1. El CHA................................................................................................................48
5.1.1. Algoritmo del CHA..................................................................................48
5.2. El CHAT .............................................................................................................54
5.2.1. Interpretación teórica del CHAT...............................................................55
5.2.1. Algoritmo del CHAT................................................................................55
6 Disquisiciones experimentales ..................................................................................61
6.1. Bases de datos......................................................................................................61
6.1.1. Iris plants database ...................................................................................62
6.1.2. Wine recognition data ..............................................................................62
6.1.3. Contaceptive method choice.....................................................................63
6.1.4. Credit Approval........................................................................................64
6.2. Metodología.........................................................................................................64
6.3. Estudio comparativo entre el CHAT y otros algoritmos de clasificación...............65
6.3.1. Iris plants database ...................................................................................656.3.2. Contraceptive method choice....................................................................69
6.3.3. Credit Approval........................................................................................74
6.3.4. Wine recognition data ..............................................................................77
7 Conclusiones y trabajo futuro ..................................................................................81
7.1. Conclusiones .......................................................................................................81
7.2. Trabajo futuro......................................................................................................82
Apéndice A: Simbología ....................................................................................................84
Apéndice B: CHAT 1.0., manual de uso ...........................................................................86Apéndice C: KNN 1.0., manual de uso .............................................................................91
Bibliografía ........................................................................................................................95

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 6/106
Resumen
En este trabajo de tesis se muestra la creación de un nuevo algoritmo para laclasificación de patrones en el dominio real, eficiente y de baja complejidadcomputacional, denominado Clasificador Híbrido Asociativo con Traslación (CHAT).Con el CHAT se establece un nuevo enfoque en la clasificación de patrones, el enfoqueasociativo.
El CHAT está basado en la combinación ingeniosa de dos modelos de memoriasasociativas, la Lernmatrix y el Linear Associator. El CHAT combina los principios deálgebra de matrices que utiliza el Linear Associator y el criterio de clasificación de laLernmatrix; superando ampliamente las limitaciones que presentan dichas memorias
asociativas en el que este nuevo clasificador se basa.En el presente trabajo de tesis se prueba el CHAT con diferentes bases de datos
publicas. Los resultados experimentales muestran un alto rendimiento en la clasificaciónde los patrones contenidos en estas bases de datos.
El CHAT puede rivalizar con los clasificadores más utilizados en las tareas dediscriminación de patrones; además, cuenta con características deseables en unclasificador, como son: eficacia, bajo costo computacional y baja dependencia defactores heurísticos. Lo anterior hace del CHAT una herramienta útil para el área deReconocimiento de Patrones, con posibilidades reales de convertirse en un factorimportante para el desarrollo de esta área en el ámbito de la investigación nacional.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 7/106
viii
Abstract
The creation of a new algorithm for the classification of patterns in the real domain is presented in this thesis, efficient an with low computational complexity and it is calledAssociative Hybrid Classifier with translation (CHAT). With the CHAT algorithm, a newapproach for the classification of patterns it’s creates, the associative approach.
The CHAT algorithm is the combination of operations from two models of associativememories; the Lernmatrix and the Linear Associator. The CHAT algorithm combine matrixalgebra of the Linear Associator in the learning phase and the criterion of the Lernmatrix inthe recovering phase, overcoming some of the restriction in both models.
In this thesis, the CHAT is tested with different public databases. Experimental results thatthe algorithm has high performance in the process of classification of patterns within this public databases.
The CHAT algorithm can be compared with the most classifiers used on patternsdiscrimination. Also, the CHAT algorithm has some ideal characteristics as a classifier:efficient, with low computational complexity and with low dependence of the heuristics
factors. Thus, the CHAT algorithm is a new classifier as well as useful tool in the area ofPattern Recognition, with real possibilities to become an important factor to develop in thisarea in the national and international research.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 8/106
Glosario.
Clase: son los grupos o conjuntos de patrones que representan un mismo tipo de concepto(Marqués de Sá, 2001; Schürmann, 1996).
Patrones abstractos: son representaciones de conceptos. Patrones concretos: son representaciones de objetos con una manifestación física. Patrones: son representaciones abstractas de un objeto en el mundo físico . Los cuales
exhiben cierta regularidad en una colección de observaciones conectadas en eltiempo, en el espacio o en ambas, y que pueden servir como modelo (Schürmann,1996).
Rasgos o características: primitivas o atributos obtenidas de los objetos a través de unaserie de observaciones, las cuales son susceptibles de ser trasladadas a una medida ocualidad (Schürmann, 1996).
Reconocimiento de patrones: Es la rama científica se encarga de emular la habilidadhumana de reconocer objetos, mediante técnicas y métodos que sean implementadosen máquinas desarrolladas y construidas para este fin (Duda, Hart & Stork 2001;Marqués de Sá, 2001).
Similaridad : concepto que está presente y forma parte esencial del RP. Se reconoce quedos objetos se parecen o son similares, por que tienen atributos que les son comunesy cuyas medidas o cualidades relativas se ajustan a un grado de variación. Por loregular este concepto se aplica, no entre un conjunto de objetos, sino entre un objetoy su prototipo.
Vector de rasgos o vector de características: Es la organización de rasgos en un vectorcolumna; que podrán contener valores cualitativos, cuantitativos o ambos (Duda,Hart & Stork 2001; Kuncheva, 2002; Schürmann, 1996).

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 9/106
Índice de tablas y figuras
Fig. 2.1 Tipos de características ......................................................................................16
Fig. 2.2 Mapeo en una representación abstracta de generación / clasificación de patrones.17Fig. 2.3 Modelo canónico de un clasificador. ..................................................................18
Fig. 2.4 Representación del perceptron ...........................................................................24
Fig. 2.5 Asignación de símbolos .....................................................................................35
Fig. 2.6 Autómata resultante ...........................................................................................35
Fig. 4.1 Gráfica de la ecuación y=3x-2...........................................................................44
Fig. 4.2 Gráfica de (x-2)²+(y+2)²=25 ..............................................................................44
Fig. 4.3 Gráfica de x²+y²=25........................................................................................... 45Fig. 4.4 Gráfica de los puntos X y Z................................................................................45
Fig. 4.5 Representación de X' y Z'...................................................................................46
Tabla 6.1 Descripción de rasgos (Iris plants) .....................................................................62
Tabla 6.2 Descripción de rasgos (Wine recognition data)...................................................63
Tabla 6.3 Descripción de rasgos (Cmc)..............................................................................64
Fig. 6.1 Rendimiento del 1-NN, base de datos Iris plants ................................................66
Fig. 6.2 Rendimiento del 3-NN base de datos Iris plants. ................................................67Fig. 6.3 Rendimiento del clasificador C-means, base de datos Iris plants......................... 67
Fig. 6.4 Rendimiento del clasificador C-means difuso, base de datos Iris plants ..............68
Fig. 6.5 Rendimiento obtenido por el C-means difuso usando funciones de disimilaridad68
Fig. 6.6 Rendimiento del CHAT con la base de datos Iris plants .....................................69
Tabla 6.4 Comparación del rendimiento de los clasificadores (Iris plants) .........................69
Fig. 6.7 Rendimiento del 1-NN con la base de datos Cmc...............................................70
Fig. 6.8 Rendimiento del 3-NN con la base de datos Cmc. ..............................................71Fig. 6.9 Rendimiento del C-means con la base de datos Cmc ..........................................71
Fig. 6.10 Rendimiento del C-means difuso con la base de datos Cmc................................72
Fig. 6.11 Rendimiento del C-means difuso usando funciones de disimilaridad.................. 72
Fig. 6.12 Rendimiento del CHAT con la base de datos Cmc .............................................73

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 10/106
Tabla 6.5 Comparación del rendimiento de los clasificadores (Cmc) .................................73
Fig. 6.13 Rendimiento del 1-NN con la base de datos Credit.............................................74
Fig. 6.14 Rendimiento del 3-NN con la base de datos Credit.............................................75
Fig. 6.15 Rendimiento del C-means con la base de datos Credit........................................75
Fig. 6.16 Rendimiento del C-means difuso con la base de datos Credit .............................76
Fig. 6.17 Rendimiento del C-means difuso usando funciones de disimilaridad.................. 76
Fig. 6.18 Rendimiento del CHAT con la base de datos Credit........................................... 77
Tabla 6.6 Comparación del rendimiento de los clasificadores (Credit)...............................77
Fig. 6.19 Rendimiento del 1-NN con la base de datos Wine..............................................78
Fig. 6.20 Rendimiento del 3-NN con la base de datos Wine..............................................79
Fig. 6.21 Rendimiento del C-means difuso usando funciones de disimilaridad.................. 79
Fig. 6.22 Rendimiento del CHAT con la base de datos Wine ............................................80
Tabla 6.7 Comparación del rendimiento de los clasificadores (Wine) ................................80

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 11/106
Capítulo 1
Introducción
En este trabajo de tesis se muestra que las memorias asociativas son útiles en lastareas de clasificación de patrones; además, a partir del resultado principal de la tesis,que consiste en la creación de un nuevo algoritmo para clasificar patrones, el CHAT(Clasificador Híbrido Asociativo con Traslación), se establece el nacimiento delnuevo enfoque asociativo para clasificacón de patrones, el cual promete convertirse enun campo fructífero en esta área. La base inicial de este trabajo de tesis se sustenta endos modelos pioneros de memorias asociativas: la Lernmatrix y el Linear Associator.
El CHAT puede rivalizar con los clasificadores más utilizados en las tareas dediscriminación de patrones; además, cuenta con características deseables en un clasi-
ficador, como son: eficacia, bajo costo computacional y no dependencia determinantede factores heurísticos. Lo anterior hace del CHAT una herramienta útil para el áreade Reconocimiento de Patrones, con posibilidades reales de convertirse en un factorimportante para el desarrollo de esta área en el ámbito de la investigación nacional einternacional.
En la sección 1.1 de este capítulo introductorio se plasma el objetivo de la tesis,y en las secciones 1.2 y 1.3, se incluyen la motivación que dio lugar a este trabajo detesis y el planteamiento del problema, respectivamente. Después, en la sección 1.4 seenuncian las contribuciones originales; para finalizar, en la sección 1.5, se describe laorganización del trabajo escrito.
1.1. Objetivo
Crear un nuevo algoritmo para la clasificación de patrones en el dominio real,eficiente y de baja complejidad computacional, basado en la combinación de modelosconocidos de memorias asociativas. Agregar, con este algoritmo, un nuevo enfoqueen la clasificación de patrones: el asociativo. Mostrar la utilidad práctica del enfoqueasociativo, a través de la aplicación del nuevo algoritmo en procesos de clasificación endiferentes bases de datos públicas y hacer un estudio experimental comparativo entreel nuevo algoritmo y otros algoritmos ya establecidos en la clasificación de patrones,basados en otros enfoques.
1

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 12/106
1. Introducción 2
1.2. Motivación
El reconocer objetos es una tarea cotidiana y automática que realiza la especiehumana. Esta habilidad que ha desarrollado el ser humano le ha servido, en su evolu-ción, para identificar su entorno en tareas que van desde identificar alimentos hastareconocer virus; esta habilidad es fundamental en la vida y desarrollo del hombre.
Existe una infinidad de problemas que involucran el reconocimiento de objetos.Desafortunadamente, las capacidades del humano están limitadas cuando su habilidadde reconocer objetos se emplea en tareas repetitivas o que requieren de un alto gradode especialización para tratar dicho problema.
Desde los inicios de la computación se ha buscado simular, por medio de máquinas,
la habilidad de reconocer objetos (Marqués de Sá, 2001; Duda, Hart & Strork, 2001).A lo largo del tiempo, dentro de la novel ciencia de la computación, se ha desarrolladoun área que aborda esta tarea, el Reconocimiento de Patrones (RP).
Durante varias décadas, han aparecido diversos enfoques o metodologías, que sonsusceptibles de implementarse en máquinas, para simular la habilidad humana de re-conocer objetos. Se han creado diferentes algoritmos, denominados clasificadores, queresuelven el problema de forma parcial; algunos con mayor éxito que otros. Estos clasi-ficadores están basados en una variedad de enfoques, desde los sustentados por sólidasteorías matemáticas hasta los basados fuertemente en técnicas heurísticas (Marquésde Sá, 2001; Duda, Hart & Strork, 2001; Shalkoff , 1992).
Una metodología en el RP, conocida desde hace varias décadas, es la denomina-da como memorias asociativas; tiene como propósito fundamental recuperar correc-tamente patrones completos a partir de patrones de entrada, los cuales pueden estaralterados con ruido (Amari, 1972; Anderson & Rosenfeld, 1990; Díaz-de-León & Yánez,1999; Hopfield, 1982; Kohonen, 1972; Ritter, Díaz-de-León & Susser, 1999).
Este enfoque tiene sus bases en el concepto de memoria para almacenar y recuperarinformación, y está sustentado por teorías matemáticas establecidas, como el álgebralineal, la morfologia matemática o las álgebras min-max.
Hasta ahora, las memorias asociativas se han utilizado en reconocimiento de pa-
trones, y algunos autores reconocidos (Duda, Hart & Stork, 2001) afirman lo siguienterespecto de la clasificación de patrones: “In acts of associative memory, the system takes in a pattern and emits another pattern which is representative of a general groupof patterns. It thus reduces the information somewhat, but rarely to the extent that pattern classi fi cation does.”
Lo anterior ha motivado que este trabajo de tesis tenga como propósito funda-mental crear, diseñar y aplicar algoritmos, basados en modelos conocidos de memoriasasociativas, que realicen tareas de clasificación de patrones, y muestren que es posibleobtener clasificadores eficientes, con la combinación ingeniosa de métodos matemáticos,especí ficamente geométricos, con los modelos matemáticos subyacentes en las memo-
rias asociativas.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 13/106
1. Introducción 3
1.3. Planteamiento del problema
Uno de los problemas más apremiantes a resolver en la tarea de clasificación depatrones, dentro del área de reconocimiento de patrones, es lograr la creación y diseñode una metodología que tenga un bajo costo computacional, un grado mínimo deheurística, y que sea factible de implementarse en computadoras. Cada uno de losenfoques hasta ahora existentes, tienen en un grado mayor o menor la ausencia dealguna o algunas de las características mencionadas, hecho que limita su eficacia oeficiencia.
Actualmente los investigadores a nivel mundial tratan, mediante diferentes méto-dos, de optimizar los clasificadores ya conocidos, combinar los difentes enfoques o
los diferentes clasifi
cadores, intentando reducir las limitaciones de cada algoritmo ocombinación particular.
En este trabajo de tesis se atacará el problema de clasificar patrones en el dominioreal, a través de la creación y diseño de un algoritmo que combine, de manera eficaz yeficiente, algunos métodos matemáticos, especí ficamente geométricos, con los modelosmatemáticos que sustentan el diseño y operación de algunos modelos de memoriasasociativas.
Todas las memorias asociativas constan de dos fases: la fase de aprendizaje y lafase de recuperación. Existen diversos modelos de memorias asociativas y cada unaimplementa estas fases de manera diferente (Hassoun, 1993; Yáñez-Márquez, 2002).
En el año de 1961, un alemán llamado Karl Steinbuch ideó y desarrolló una memo-ria asociativa denominada Lernmatrix (Steinbuch, 1961; Steinbuch & Frank, 1961);esta memoria ha estado olvidada por la comunidad cientí fica y no se han realizado in-vestigaciones suficientes sobre ella hasta la fecha. La Lernmatrix volvió a formar partedel interés cientí fico cuando se incluyó dentro del estado del arte de la tesis donde sedesarrollaron las memorias alfa-beta (Yánez-Márquez, 2002), y se publicó un informetécnico (Yánez-Márquez & Díaz de León, 2001a), con lo que se revive el interés sobreesta antigua memoria. Por otro lado, el Linear Associator (Anderson & Rosenfeld,1990; Kohonen, 1989) de manera simultánea e independiente fue desarrollado por elneurofisiólogo James A. Anderson y por el ingeniero finlandés Teuvo Kohonen.
El trabajo relevante de esta tesis es combinar de cierta manera estos dos modelosde memorias asociativas, para crear un algoritmo de memoria asociativa que superaampliamente a la Lernmatrix y al Linear Associator , en la tarea de clasificación depatrones en el dominio real.
Dentro de este trabajo, se someterá el nuevo clasificador a distintas bases dedatos públicas que sirven como parámetro para probar clasificadores (UCI MachineLearning Data Bases Repository, del ICS, de la universidad de California, Irvine:http://ftp.ics.uci.edu/pub/machine-learning-databases).

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 14/106

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 15/106

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 16/106
Capítulo 2
Antecedentes
Este capítulo consta de dos secciones. En la sección 2.1 se describen los conceptosbásicos sobre memorias asociativas y los dos modelos en que se basa el clasificadorpresentado en este trabajo de tesis; en la sección 2.2, por otro lado, se describe elárea denominada reconocimiento de patrones, y se explica brevemente cada uno delos diferentes enfoques, para finalmente mencionar el nuevo enfoque asociativo de re-conocimiento de patrones, que se inicia precisamente con esta tesis.
2.1. Memorias asociativas
En la primera parte de esta sección se presentan los conceptos básicos relacionadoscon el diseño y funcionamiento de las memorias asociativas. Las dos partes restantesse enfocan a los dos modelos en que se basa esta tesis, la Lernmatrix y el Linear Associator .
2.1.1. Conceptos básicos de memorias asociativas
Por su naturaleza, el problema que representa el funcionamiento de las memoriasasociativas se divide en dos fases claramente distinguibles:
1. Fase de aprendizaje (generación de la memoria asociativa)
2. Fase de recuperacion (operación de la memoria asociativa)
Para estar en condiciones de realizar el planteamiento del problema, es preciso pre-viamente proporcionar los conceptos básicos, las notaciones y la nomenclatura rela-cionados con el diseño y funcionamiento de las memorias asociativas.
Los conceptos básicos son conocidos desde hace más de tres décadas, y se presentancomo originalmente fueron establecidos en las referencias (Kohonen, 1972, 1977, 1987,1989; Anderson, 1972; Anderson & Bower, 1977; Anderson & Rosenfeld, 1990; Hassoun,1993, 1995, 1997).
6

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 17/106
2. Antecedentes 7
El propósito fundamental de una memoria asociativa es recuperar patrones com-
pletos a partir de patrones de entrada que pueden estar alterados con ruido aditivo,sustractivo o combinado. De acuerdo con esta afirmación, una memoria asociativa Mpuede formularse como un sistema de entrada y salida, idea que se esquematiza acontinuación:
x −→ M −→ y
El patron de entrada está representado por un vector columna denotado por x yel patron de salida, por el vector columna denotado por y.
Cada uno de los patrones de entrada forma una asociacion con el correspondi-ente patrón de salida. La notación para una asociación es similar a la de una parejaordenada; por ejemplo, los patrones x y y del esquema forman la asociación (x,y).
Para facilitar la manipulación algebraica de los patrones de entrada y de salida, losdenotaremos con las mismas letras negrillas, x y y, agregándoles números naturalescomo superíndices para efectos de discriminación simbólica. Por ejemplo, a un patrónde entrada x1 le corresponderá un patrón de salida y1, y ambos formarán la asociación(x1,y1); del mismo modo, para un número entero positivo k especí fico, la asociacióncorrespondiente será (xk,yk).
La memoria asociativa M se representa mediante una matriz cuya componenteij-ésima es mij (Palm, Schwenker, Sommer & Strey, 1997); la matriz M se genera apartir de un conjunto finito de asociaciones conocidas de antemano: este es el conjunto
fundamental de asociaciones, o simplemente conjunto f undamental. Se denota por p la cardinalidad del conjunto fundamental ( p es un número entero positivo).
Si µ es un índice, el conjunto fundamental se representa de la siguiente manera:
(xµ,yµ) | µ = 1, 2,...,p
A los patrones que conforman las asociaciones del conjunto fundamental, se lesllama patrones fundamentales.
La naturaleza del conjunto fundamental proporciona un importante criterio paraclasificar las memorias asociativas. Si se cumple que xµ = yµ ∀µ ∈ 1, 2,...,p, se
dice que la memoria es autoasociativa; de otro modo, la memoria es heteroasociativa(Kohonen,1972). Para una memoria heteroasociativa se puede afirmar lo siguiente:∃µ ∈ 1, 2,...,p para el que se cumple que xµ 6= yµ.
Es posible que los patrones fundamentales sean alterados con diferentes tipos deruido. Para diferenciar un patrón alterado del correspondiente patrón fundamental,usaremos la tilde en la parte superior; así, el patrón exk es una versión alterada delpatrón fundamental xk, y el tipo de alteración que representa exk se evidenciará en elcontexto especí fico donde se use.
Si al presentarle a la memoria M un patrón alterado
exω como entrada (ω ∈
1, 2,...,p), M responde con el correspondiente patrón fundamental de salida yω,

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 18/106
2. Antecedentes 8
se dice que la recuperación es perfecta . Una memoria perfecta es aquella que realiza
recuperaciones perfectas para todos los patrones fundamentales.
Naturalmente, también los patrones de salida pueden ser alterados; por ejemplo,si y3 es un patrón fundamental, entonces ey3 representa una versión alterada de y3.
Abundemos en la caracterización de los patrones de entrada, de salida y de lamatriz M.
Primeramente se requiere la especificación de dos conjuntos a los que llamaremosarbitrariamente A y B . La importancia de estos dos conjuntos radica en que las com-ponenetes de los vectores columna que representan a los patrones, tanto de entradacomo de salida, serán elementos del conjunto A, y las entradas de la matriz M serán
elementos del conjunto B .No hay requisitos previos ni limitaciones respecto de la elección de estos dos con-
juntos, por lo que no necesariamente deben ser diferentes o poseer características es-peciales. Esto significa que el número de posibilidades para escoger A y B es infinito;a continuación se ejemplifican algunas de ellas:
• A = B = R, donde R es el símbolo que representa al conjunto de los númerosreales.
• A = R y B = 0, 1.• A = B = 0, 1.
• A = B = −
1, 1.• A = R y B = −1, 1.• A = Z y B = −1, 1, donde Z es el conjunto de los números enteros.• A ⊂ Z y B ⊂ Z
Ya que se tienen especificados los conjuntos A y B, es necesario establecer lasdimensiones de los patrones, tanto de entrada como de salida.
Sean m, n números enteros positivos. Se denota por n la dimensión de los patronesde entrada, y por m la dimensión de los patrones de salida; claramente, nada impideque los valores de m y de n sean iguales. Aún más, uno de los requisitos que debecumplir una memoria autoasociativa es que la dimensión de los patrones de entradasea igual a la dimensión de los patrones de salida; por otro lado, si en una memoria
sucede que m 6= n, es evidente que la memoria debe ser heteroasociativa.Cada vector columna que representa un patrón de entrada tiene n componentes
cuyos valores pertenecen al conjunto A, y cada vector columna que representa unpatrón de salida posee m componentes cuyos valores pertenecen al conjunto A. Esdecir:
xµ ∈ An y yµ ∈ Am ∀µ ∈ 1, 2,...,p
La j-ésima componente de un vector columna se indica con la misma letra del vec-tor, pero sin negrilla, colocando a j como subíndice ( j ∈ 1, 2,...,n o j ∈ 1, 2,...,msegún corresponda). La j-ésima componente de un vector columna xµ se representa
por

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 19/106
2. Antecedentes 9
xµ j
Ejemplos:
• La i-ésima componente del vector columna xµ se representa por xµi
• La tercera componente del vector columna x5 se representa por x53
• La j -ésima componente del vector columna yµ se representa por yµ j
• La l-ésima componente del vector columna yω se representa por yωl
Al usar el superíndice t para indicar el transpuesto de un vector, se obtienen lassiguientes expresiones para los vectores columna que representan a los patrones fun-damentales de entrada y de salida, respectivamente:
xµ = (xµ1 , xµ
2 ,...,xµn)
t=
xµ1
xµ2...
xµn
∈ An
yµ = (yµ1 , yµ2 ,...,yµm)t
=
yµ1yµ2...
yµm
∈ Am
Con lo anterior, es ya posible presentar el planteamiento del problema general delas memorias asociativas:
1. Fase de aprendizaje. Encontrar los operadores adecuados y una manera de gener-ar una matriz M que almacene las p asociaciones del conjunto fundamental©¡x1,y1
¢,¡x2,y2
¢,..., (x p,y p)
ª, donde xµ ∈ An y yµ ∈ Am ∀µ ∈ 1, 2,...,p.
Si ∃µ ∈ 1, 2,...,p tal que xµ 6= yµ, la memoria será heteroasociativa; si m = ny xµ = yµ ∀µ ∈ 1, 2,...,p, la memoria será autoasociativa.
2. Fase de recuperación. Hallar los operadores adecuados y las condiciones suficientespara obtener el patrón fundamental de salida yµ, cuando se opera la memoria Mcon el patrón fundamental de entrada xµ; lo anterior para todos los elementos delconjunto fundamental y para ambos modos: autoasociativo y heteroasociativo.Exhibir y caracterizar, además, el ruido que puede soportar la memoria en elpatrón de entrada exω, para entregar una salida perfecta yω.
2.1.2. Lernmatrix de Steinbuch
Karl Steinbuch fue uno de los primeros investigadores en desarrollar un métodopara codificar información en arreglos cuadriculados conocidos como crossbar (Simp-son, 1990). La importancia de la Lernmatrix (Steinbuch, 1961; Steinbuch & Frank,1961) se evidencia en una afirmación que hace Kohonen en su artículo de 1972 (Ko-honen, 1972), donde apunta que las matrices de correlación, base fundamental de su
innovador trabajo, vinieron a sustituir a la Lernmatrix de Steinbuch.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 20/106
2. Antecedentes 10
La Lernmatrix es una memoria heteroasociativa que puede funcionar como un
clasificador de patrones binarios si se escogen adecuadamente los patrones de salida;es un sistema de entrada y salida que al operar acepta como entrada un patrón binarioxµ ∈ An, A = 0, 1 y produce como salida la clase yµ ∈ A p que le corresponde(de entre p clases diferentes), codificada ésta con un método simple, a saber: pararepresentar la clase k ∈ 1, 2,...,p, se asignan a las componentes del vector de salidayµ los siguientes valores: yµ
k = 1, y yµ j = 0 para j = 1, 2...,k − 1, k + 1, ...p.
El siguiente esquema (crossbar ) ilustra la fase de aprendizaje para la Lernmatrix deSteinbuch, al incorporar la pareja de patrones de entrenamiento (xµ,yµ) ∈ An × A p.
xµ1 xµ
2 · · · xµ j · · · xµ
n
yµ1 m11 m12 · · · m1 j · · · m1n
yµ2 m21 m22 · · · m2 j · · · m2n...
... ...
... ...
yµi mi1 mi2 · · · mij · · · min...
... ...
... ...
yµ p m p1 m p2 · · · m pj · · · m pn
(2.1)
Cada uno de los componentes mij de M, la Lernmatrix de Steinbuch, tiene valorcero al inicio, y se actualiza de acuerdo con la regla mij + ∆mij, donde:
∆mij =
+ε si xµi = 1 = yµ
j
−ε si xµi = 0 y yµ
j = 1
0 en otro caso(2.2)
siendo ε una constante positiva escogida previamente.
La fase de recuperación consiste en encontrar la clase a la que pertenece un vectorde entrada xω ∈ An dado. Encontrar la clase significa obtener las coordenadas delvector yω ∈ A p que le corresponde al patrón xω; en virtud del método de construcción
de los vectores yµ la clase debería obtenerse sin ambigüedad.La i-ésima coordenada yω
i del vector de clase yω ∈ A p se obtiene como lo indica lasiguiente expresión, donde
W es el operador máximo:
yωi =
( 1 si
Pn j=1 mij.xω
j = W p
h=1
hPn j=1 mhj.xω
j
i0 en otro caso
(2.3)
2.1.3. Linear Associator de Anderson-Kohonen
Respecto a la creación de este modelo de memoria asociativa, es pertinente men-cionar un hecho curioso, que se ha presentado en personajes dedicados a otras ramas

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 21/106
2. Antecedentes 11
de la ciencia: James A. Anderson y Teuvo Kohonen obtuvieron resultados asombrosa-
mente similares a pesar de que trabajaron independientemente y sin tener noticia unodel otro, hasta tiempo después de que aparecieron los artículos; además, estos autorestienen formaciones profesionales totalmente diferentes: Anderson es neurofisiólogo yKohonen es físico e ingeniero eléctrico (Anderson & Rosenfeld, 1990; Kohonen, 1989).
Para presentar el Linear Associator , consideremos de nuevo el conjunto fundamen-tal (xµ,yµ) | µ = 1, 2,...,p con:
A = 0, 1, xµ =
xµ1
xµ2...
xµn
∈ An y yµ =
yµ1yµ2...
yµm
∈ Am
La fase de aprendizaje consiste de dos etapas:
1. Para cada una de las p asociaciones (xµ,yµ) se encuentra la matriz yµ · (xµ)t dedimensiones m × n
yµ · (xµ)t =
yµ1yµ2...
yµm
· (xµ
1 , xµ2 ,...,xµ
n) (2.4)
yµ · (xµ)t =
yµ1 xµ1 yµ1 xµ
2 · · · yµ1 xµ j · · · yµ1 xµn
yµ2 xµ1 yµ2 xµ
2 · · · yµ2 xµ j · · · yµ2 xµ
n
... ...
... ...
yµi xµ1 yµi x
µ2 · · · yµi x
µ j · · · yµi x
µn
... ...
... ...
yµmxµ1 yµmxµ
2 · · · yµmxµ j · · · yµmxµ
n
(2.5)
2. Se suman la p matrices para obtener la memoria
M =
p
Xµ=1
yµ · (xµ)t = [mij]m×n (2.6)
de manera que la ij -ésima componente de la memoria M se expresa así:
mij =
pXµ=1
yµi xµ j (2.7)
La fase de recuperación consiste en presentarle a la memoria un patrón de entradaxω, donde ω ∈ 1, 2,...,p y realizar la operación
M · xω =
p
Xµ=1
yµ · (xµ)t
·xω (2.8)

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 22/106
2. Antecedentes 12
El Linear Associator tiene una fuerte restricción: los vectores de entrada xµ deben
ser ortonormales. Esta condición de ortonormalidad se puede resumir en la siguienteexpresión:
(xµ)t ·xω = δ µω =
1 si µ = ω
0 si µ 6= ω(2.9)
donde δ µω es la conocida delta de Kronecker (Moore, 1968).
Si se cumple la condición que se manifiesta en la expresión 2.9, entonces la recu-peración es perfecta para todo el conjunto fundamental; es decir:
M · xω = yω (2.10)
Sin embargo, si los vectores de entrada no son ortonormales, suceden dos cosas:
1. el factor £
(xω)t ·xω¤
no es 1
2. el término P
µ6=ω yµ ·£
(xµ)t ·xω¤
no es 0
Este último término, llamado cross-talk , representa el ruido producido por la in-teracción entre los patrones de entrada, y tiene como consecuencia inmediata que larecuperación no es perfecta, excepto si el número de patrones almacenados es pequeñocomparado con la dimensión n de los vectores de entrada. Algunos investigadores afir-man que ese número pequeño de patrones debe estar entre 0,1n y 0,2n (Anderson &
Rosenfeld, 1990; Hassoun, 1995; Ritter, Sussner & Díaz-de-León, 1998).
2.2. Reconocimiento de patrones
2.2.1. Conceptos básicos del reconocimiento de patrones
En RP cada rasgo o característica de un objeto se le asigna una variable, x1, x2,...,xn.Estas variables son organizadas como un vector columna, que podrán contener valorescualitativos, cuantitativos o ambos (Duda, Hart & Stork 2001; Kuncheva, 2002; Schür-mann, 1996), llamado vector de rasgos o vector de características; para los fines de estatesis, las variables sólo contendrán valores reales.
Fig. 2.1. : Tipos de característisticas

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 23/106
2. Antecedentes 13
El vector de rasgos será la representación formal de un patrón, tal que:
x =
x1
x2...
xn
es un patrón y podrá ser representado como un punto en espacio Rn. El espacioreal Rn es llamado espacio de características.
Nota 2.1 Generalmente, las estructuras de datos que son utilizadas en los sistemas de reconocimiento de patrones son de dos tipos: vectores y datos relacionados (cadenas o palabras) (Pal, 1999). En este trabajo de tesis solo trataremos con vectores.
Definición 2.2 Sea Ω un conjunto de clases ω, tal que a Ω se le denomina espaciode interpretación:
Ω = ω1, ω2,...,ωi
Como se muestra en el diagrama de la figura 2.2, el RP se puede caracterizarcomo un proceso de mapeo de información, reducción de información o etiquetadode información (Shalkoff , 1992). Este mapeo entre el espacio de interpretación y elespacio de características se hace mediante una relación G para cada clase; lo ideal esque esta función sea biyectiva, pero existen casos, como lo muestran las clases ω1 yω2, que algunos patrones puedan pertenecer a distintas clases a la vez. Esto dificultael proceso de asignar un patrón a una clase especí fica.
Figura 2.2. : Representación abstracta de generación / clasificación de patrones.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 24/106
2. Antecedentes 14
2.2.2. Clasificación de patrones
Esta tarea del RP es una de las más antiguas y más estudiadas. Los trabajosen la clasificación de patrones tienen más de cinco décadas y dentro de ellos, se handesarrollado varias metodologías y decenas de algoritmos para clasificar. Algunos deellos desde la década de los 50’s y que aún hoy son tema de estudio. Tal es el caso delclasificador KNN (Dasarathy, 1991).
La tarea de clasificación básicamente consiste en hacer particiones del espacio decaracterísticas para formar regiones, donde a cada región se le asignará una categoría oclase. Los diferentes patrones deberán ser asignados en alguna de las posibles regionescreadas en el espacio de características.
En problemas reales, la descripción completa de las clases no es conocida. En lugarde ésta, se tiene un conjunto finito y generalmente reducido de patrones que proveeninformación parcial sobre un problema especí fico.
El objetivo principal en la tarea de clasificación es: diseñar y construir extractoresde características o clasificadores que puedan llevar a cabo la segmentación del espaciode características de forma eficiente (Pal, 1999).
Un clasificador es cualquier función:
D : Rn−→ Ω
En el modelo canónico de un clasificador (Duda, Hart & Stork 2001), mostrado en
la fi
gura 2.3, se considera un conjundo de c funciones discriminantes.G = g1(x), g2(x),...,gc(x)
donde:
gi : Rn −→ R i = 1, 2, ...c
Típicamente el patrón x es asignado en la clase ω i,si el valor de gi(x) es máximo;a esto se le conoce como “maximum membership rule”.
D(x) = ωi ∈ Ω ⇐⇒ gi(x) = maxi=1,...c
gi(x)
Figura 2.3.: Modelo canónico de un clasificador.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 25/106
2. Antecedentes 15
Las funciones discriminantes segmentan el espacio de caracteristicas Rn en regiones
de decisión o regiones de clasi fi cación (Kuncheva, 2002).
Las regiones para cada clase ωi son el conjunto de puntos para los cuales la i-esimafunción discriminante tiene el más alto valor. Todos los puntos en la región i-esimaserán asignados en la clase ωi. Estas regiones serán determinadas por el clasificador Dmediante el conjunto de funciones discriminantes G. Las fronteras de las regiones sonllamadas fronteras de clasificación, y contienen los puntos que no pueden pertenecer auna clase en particular (Kuncheva, 2002).
Enfoques de entrenamiento
Existen básicamente dos enfoques:
Supervisado. En este enfoque se debe contar con un conjunto de patrones, enlos cuales se tiene determinada previamente la clase a la cual están asociadoscada uno de ellos y se denomina generalmente conjunto de entrenamiento. Enel caso de las memorias asociativas este conjunto recibe el nombre de conjunto
fundamental .
No supervisado. Se trata de encontrar agrupamientos de patrones que formen lasdiferentes clases existentes en un determinado problema mediante la similaridadentre éstos.
2.2.3. Clasificadores de mínima distancia
Los clasificadores diseñados dentro de este enfoque emplean aprendizaje supervisa-do; generalmente son empleados si el conjunto de patrones de entrenamiento formanagrupamientos por cada clase existente en un problema dado. Esto da lugar a poderemplear una función de distancia para su clasificación. Cada clase involucrada en elproblema es representada por un patrón llamado centro del agrupamiento, determina-do por la media aritmética del conjunto de patrones de entrenamiento de cada clase.Este centro del agrupamiento permite al clasificador determinar una clase determinadaa la cual pertenece un nuevo vector si la distancia es mínima con respecto de los otros
centros de agrupamiento involucrados, representativos de las otras clases.Existen diversos clasificadores que emplean este método, entre los cuales los más
conocidos son el clasificador euclidiano, el KNN y el c-Means (Friedman, M, 1999). Sedarán algunos conceptos y definiones que son necesarios para el mejor entendimiento deeste tipo de metodología; también se presenta uno de los clasificadores básicos dentrode este enfoque, el clasificador euclideano.
Métricas
Si tenemos un conjunto de patrones clasificados, es decir, que de antemano sabe-
mos a qué clase pertenecen cada uno de ellos, y también supongamos que tenemos

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 26/106
2. Antecedentes 16
otro conjunto de patrones, los cuales no han sido clasificados. Una forma "simple"de
clasificar estos últimos patrones, es decir no clasificados, es encontrar una función quenos diga con qué clase tienen una mayor similaridad cada uno de ellos. Aunque casitodos los enfoques de reconocimiento de patrones se basan en esta idea, la función estárepresentada por una métrica .
Intuitivamente, y dado que los patrones con los que se trabaja tienen todos losrasgos numéricos, un patrón puede verse como un vector en un espacio en R
n, para unn en particular. Ahora, una métrica es una forma de medir la distancia entre dos deestos vectores, así, diremos que un patrón tiene una mayor similaridad a otro cuandola distancia entre ellos sea menor. Usualmente, la forma más sencilla de encontraresta distancia es con base en el famoso teorema de Pitágoras extendido a un espacio
n-dimensional, que se conoce como distancia euclideana. Sin embargo, no es la únicaforma de medir la distancia entre dos puntos, por lo que en esta sección nos ocuparemosde las formas de medir.
Definición de métrica
Aunque intuitivamente ya se tiene idea de que una métrica es una forma de mediruna distancia, la definición formal es la siguiente:
Definición 2.3 Sean x,y y z tres puntos en Rn. Una métrica o norma denominada d(x,y), es una función d : Rn×R
n → R+, que cumple con las siguientes propiedades:
1. d(x,y) ≥ 0 y d(x,y) = 0 si y sólo si x = y.
2. d(x,y) = d(y,x)
3. d(x,y) ≤ d(x, z) + d(z,y) (Desigualdad del triángulo).
En general, existe un número infinito de funciones que cumplen con la definiciónanterior, y por tanto, la distancia entre dos puntos calculada por una métrica puedeser completamente distinta a la calculada por otra. Pensando en función de que unamétrica nos servirá para definir la forma en cómo un patrón tienen una mayor similar-idad a otro, podemos esperar un funcionamiento radicalmente distinto de un sistemade clasificación con base en la métrica seleccionada.
Las métricas de Minkowski
Unas de las métricas más utilizadas, son las llamadas métricas de Minkowski.Minkowski fue un brillante físico y matemático Ruso de fines del siglo XIX y principiosdel XX que fue maestro de Albert Einstein. Sus trabajos en el campo de la físicase enfocaron principalmente a la relatividad, en el continuo espacio-tiempo y a laelectrodinámica y muchos de sus resultados le son atribuidos al propio Einstein. Sustrabajos en matemáticas incluyen las formas cuadráticas, las fracciones continuas y enla forma en como una figura de una forma puede caber en otra figura de otra forma,
que a la postre sería la base de la Morfología Matemática.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 27/106
2. Antecedentes 17
La forma general de las métricas de Minkowski es la siguiente:
dr(x,y) =
" nXi=1
|xi − yi|r
#1
r
(2.11)
Donde r es un número entero positivo. Dependiendo de r, es la forma en como secomporta la métrica. Existen 3 valores que son los más comunes y que definen tresdistancias conocidas:
1. Distancia city-block . r = 1.
d1(x,y) = " nXi=1
|xi − yi|1#1
1
=nXi=1
|xi − yi| (2.12)
2. Distancia euclideana . r = 2.
d2(x,y) =
" nXi=1
|xi − yi|2
# 1
2
(2.13)
3. Distancia infinito . r −→∞.
d∞(x,y) = lımr→∞" nXi=1
|xi − yi|r#1
r
= maxi
|xi − yi| (2.14)
Ejemplo 2.4 Sean x =
2−294
y y =
110−3−1
, calcular la distancia entre ellos
de acuerdo a las métricas city-block, euclideana e in fi nito.
d1(x,y) =
4Pi=1 |xi − yi| = |2− 1| + |−2− 10| + |9− (−3)| + |4− (−1)|= 1 + 12 + 12 + 5 = 30
d2(x,y) =
· 4Pi=1
|xi − yi|2
¸ 1
2
=h|2− 1|2 + |−2− 10|2 + |9− (−3)|2 + |4− (−1)|2
i 12
= [1 + 144 + 144 + 25]1
2 = 17. 72
d∞(x,y) = maxi
|xi − yi| = max [|2− 1| , |−2− 10| , |9− (−3)| , |4− (−1)|]
= max[1, 12, 12, 5] = 12

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 28/106
2. Antecedentes 18
El Clasificador Euclideano
El clasificador euclideano es un clasificador que toma precisamente la distanciaeuclideana para determinar cuándo un patrón es más similar a otro. La distanciaeuclideana es un caso especial de las métricas de Minkowski para el caso en que r = 2.Esta norma es, intuitivamente, la que se utiliza para medir una distancia, ya queequivale a medir el tamaño del segmento de recta que une a dos puntos, y es la quenormalmente se utiliza en geometría analítica y en análisis vectorial. Un patrón puedeser visto como un vector en R
n, por lo que el análisis que haremos sobre él serápuramente vectorial, y es conveniente expresar esta distancia en forma alterna.
Definición 2.5 Sean x,y dos puntos en Rn, es decir, x =
x1
x2
...xn
y y =
y1y2
...yn
.
La distancia euclideana entre x y y, denotada d2(x,y) se calcula de la siguiente forma:
d2(x,y) =
" nXi=1
(xi − yi)2
# 1
2
(2.15)
o en forma vectorial:
d2(x,y) =
£(x− y)T (x− y)
¤1
2 (2.16)
donde (x− y)T
es el vector transpuesto del vector (x− y).
Ejemplo 2.6 Sean x =
2−294
y y =
110−3−1
. Entonces la distancia euclideana
entre x y y de acuerdo a la ecuación 2.15 es:
d2(x,y) =
" 4
Xi=1
(yi − xi)2
#1
2
=
£(1− 2)2 + (10− (−2))2 + (−3− 9)2 + (−1− 4)2
¤1
2
= [314]12 = 17. 72
y de acuerdo a la ecuación 2.16 es:
d2(x,y) =£
(y− x)T (y− x)¤ 12 =
¡ −1 12 12 −5
¢−11212−5
1
2
= [1 + 144 + 144 + 25]1
2 = [314]1
2 = 17. 72

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 29/106
2. Antecedentes 19
Algoritmo 2.7 Algoritmo del clasi fi cador euclideano.
1. Se escoge una muestra de patrones clasificada de antemano en n clases C 1, C 2,..,C ny la métrica d2 será la distancia euclideana.
2. Con base en la muestra y para cada clase C i , calculamos el patrón representanteµi =
1k
Pxj∈C i
x j, donde k es el número de elementos en la muestra que pertenecen a C i .
3. Se generan funciones discriminantes dij(x) para cada par de clases C i, C j, de
forma que dij(x) = (µi − µ j)T x−(µi−µj)
T (µi+µj)
2 .4. En el momento de clasificar, el patrón x será clasificado en la clase i, si se cumple
lo siguiente:
∀ j, j 6= i, dij(x) ≥ 0
Ejemplo 2.8 Sean los vectores x1 =
µ1. 23. 0
¶, x2 =
µ4. 30. 7
¶, x3 =
µ2. 33. 1
¶, con x1, x3
miembros de la clase C 1 y x2 miembro de la clase C 2. Determinar la clase a la que
pertenece el patrón x4 =
µ2. 71. 5
¶.
Como ya se tiene la muestra clasificada en 2 clases, comenzaremos por calcular losvectores medios de cada una de las clases.
µ1 = 12(x1 + x3) =
µ 1. 753. 05 ¶
. y µ2 = x2 =
µ 4. 30. 7 ¶
. Ahora, como solamente
tenemos dos clases, una función discriminante es suficiente, que sería: d12(x) = (µ1 −
µ2)T x− (µ1−µ
2)T (µ
1+µ
2)
2 =¡ −2. 55 2. 98
¢x + 2. 1263
Finalmente, probaremos el clasificador con todos los vectores:−2. 55 ∗ 6. 05 + 2.98 ∗ 3. 75 = −4. 2525/2 = −2. 1263
d12(x1) =¡ −2. 55 2. 98
¢µ 1. 23. 0
¶ + 2. 1263 = −2. 55 ∗ 1. 2 + 2. 98 ∗ 3. 0 + 2.
1263 = 8. 0063 > 0 → x1 ∈ C 1
d12(x2) =¡ −2. 55 2. 98
¢µ 4. 30. 7
¶ + 2. 1263 = −2. 55 ∗ 4. 3 + 2. 98 ∗ 0. 7 + 2.
1263 = −6. 7527 < 0 → x2 ∈ C 2
d12(x3) = ¡ −2. 55 2. 98 ¢µ 2. 33. 1¶ + 2. 1263 = −2. 55 ∗ 2. 3 + 2. 98 ∗ 3. 1 + 2.
1263 = 5. 4993 > 0 → x3 ∈ C 1
d12(x4) =¡ −2. 55 2. 98
¢µ 2. 71. 5
¶ + 2. 1263 = −2. 55 ∗ 2. 7 + 2. 98 ∗ 1. 5 + 2.
1263 = −0. 2887 < 0 → x4 ∈ C 2
2.2.4. Enfoque neuronal
En 1943 McCulloch & Pitts (McCulloch & Pitts, 1943) propusieron una teoríageneral del procesamiento de la información basado en redes de interrupción binaria,
las cuales son llamadas eufemísticamente neuronas, aunque ellas estén lejos de sus

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 30/106
2. Antecedentes 20
contrapartes biológicas. Cada una de estas neuronas sólo puede tomar como valores de
salida 1 o 0, donde 0 representa un estado inactivo de la neurona y 1 un estado activo.McCulloch & Pitts mostraron que tales redes podían, en principio, implementarse ensistemas de procesos de cómputo. Frank Rosemblatt presentó posteriormente en el añode 1958 un modelo neural llamado perceptron junto con su regla de aprendizaje, el cualestá basado en el gradiente descendiente. El gradiente modifica una matriz, nombradamatriz de acoplamiento o pesos, dependiendo del comportamiento de las neuronas.
Sin embargo, la simplicidad de este diseño fue también su punto débil; existentareas en RP que un perceptron no es capaz de resolver, como lo mostraron Minsky& Paper (Minsky & Papert, 1969). Esto provocó que el interés en las redes neuronalesdecayera. No fue hasta la aparición del trabajo de Hopfield (Hopfield,.1982; Hopfield,
1984) que el interés renaciera en este tipo de algoritmos.Las redes neuronales pueden aplicarse a tareas de clasificación o regresión; utilizan
tanto el enfoque de entrenamiento supervisado como el no supervisado. La arquitecturade la red incluye tres tipos de capas, la de entrada, la oculta y la de salida. Este tipode redes pueden llegar a ser muy complejas, se caracterizan por tener un conjuntode pesos los cuales se van modificando, y funciones de activación con las cuales sedetermina cómo la información será transmitida a las capas siguientes (Marqués deSá, 2001).
En el enfoque generalmente existen dos etapas claras: la de entrenamiento, dondemediante un conjunto de patrones la red va ajustando el conjunto de pesos que tiene
asociados, hasta obtener en la capa de salida una clasificación correcta de los patronesde entrenamiento; y la segunda etapa, donde se somete un conjunto de patrones mayoral conjunto de entrenamiento para probar su rendimiento. Una clara desventaja, am-pliamente referida, es el grado de heurística implicada en el diseño de los clasificadoresbajo este enfoque.
Existen muchos tipos de redes neuronales que funcionan como clasificadores, desdeel simple perceptron hasta las más avanzadas.
Perceptron
Minsky and Papper (Minsky, M. & Papert, S. (1969) describen al perceptron comoun algoritmo estocástico de gradiente descendente, que intenta la separación lineal deun conjunto de datos de entrenamiento n-dimensional.
El perceptron tiene una sola salida y n entradas. El valor que toma la salidaesta determinada por un conjunto de valores, llamados pesos, y los valores de lasentradas. Este valor que toma la salida determina la clase a la cual pertenece unpatrón representado por un vector, cuyos componentes son los valores de las entradasdel perceptron. Es un algoritmo que emplea aprendizaje supervisado.
Un perceptron puede ser representado por un solo nodo que aplica una funciónescalón a la suma de los productos de pesos y entradas (Kishan, Chilukuri & Sanjay,
1997).

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 31/106
2. Antecedentes 21
f(x0,...,x
n )
x0
w0
xn
x2
x1
w1
w2
wn
.
.
.
Figura 2.4. : Representación del perceptron
De la figura 2.4., w0, w1,...,wn son los valores que representan a los pesos delperceptron y x0, x1,...,xn son los valores del patrón de entrada.
Para espacios n-dimensiónales debe existir al menos un hiperplano que pueda sepa-rar un conjunto n-dimensionales en regiones. Un hiperplano n dimensional está definidopor la ecuación:
w0 + w1x1 + ... + wnxx = 0
El cual podrá dividir un espacio n-dimensional en dos regiones. Donde para unade las regiones que forma el hiperplano:
w0 + w1x1 + ... + wnxx > 0
Para la otra región:
w0 + w1x1 + ... + wnxx < 0
El vector de pesos w será ajustado a través de un algoritmo desarrollado porRosenblatt (Rosenblatt, 1958) y se demuestra que si los patrones usados para entrenarel perceptron se pueden agrupar en clases linealmente separables, entonces, el algoritmoconverge. La posición de la superficie de decisión es un hiperplano entre las dos clases(Haykin,. 1999).
Algoritmo de entrenamiento para el perceptron.Un proceso iterativo, llamado algoritmo de entrenamiento para el perceptron, es
usado para obtener de manera automática los pesos que separan las clases.Sea w un vector de pesos de la forma:
w = (w1, w2,...,wn)
y x un patrón de entrada de la forma:
x = (x1, x2,...,xn)
Entonces el producto punto w · x está definido. Si el producto w · x > 0, entonces
la salida será 1 y —1 si w · x < 0.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 32/106
2. Antecedentes 22
En el algoritmo no se especí fica inicialmente un valor para los pesos w. Los valores
de w se escogen aleatoriamente al comienzo del proceso. Los patrones de entrenamien-to son evaluados repetidamente y la respuesta obtenida es sensada, si la salida es ladeseada, w no sufre cambios, por el contrario, si no se obtiene una respuesta satisfac-toria entonces w deberá ser modificado, esto a manera de que se reduzca el margende error en la respuesta del algoritmo.
En cada iteración, si x provoca una salida con valor —1, pero w · x > 0, entonceslos pesos deberán ser cambiados, lo mismo para salida 1 y w · x < 0.
Los pesos se modificarán en cada iteración con salida no deseada, de acuerdo conla siguiente regla:
w0
= w+∆w
Siendo w0 el nuevo valor para los pesos.Para el caso en que w · x >0. Entonces (w+ ∆w) · x deberá ser menor que w · x,
esto puede lograrse si ∆w es -ηx, siendo η una constante positiva, entonces:
(w+ ∆w) · x = (w− ηx) · x = w · x− ηx·x < w · x
Para el caso en que w · x <0. Entonces (w+ ∆w) · x deberá ser menor que w · x,esto puede lograrse si ∆w es -ηx, siendo η una constante positiva, entonces:
(w+ ∆w) · x = (w+ ηx) · x = w · x+ ηx·x > w · x
Este proceso de modificación de los pesos se repetirá cada vez que se obtenga unasalida no deseada. El proceso se detendrá cuando se encuentre un w , tal que w separelinealmente a los patrones de entrenamiento.
Ejemplo 2.9 Este ejemplo muestra el funcionamiento del algoritmo de entrenamientodel perceptron. Se aplica el algoritmo con 7 patrones de entrenamiento uno-dimensional.Cuatro de ellos en una de las clases y los otros 3 en la clase restante. Los patrones de entrenamiento están agrupados en clases linealmente separables, por lo que la con-vergencia está garantizada. Los pesos inicialmente se escogerán de forma aleatoria y el algoritmo intentará encontrar los valores de los pesos para determinar el hiperplanoque separa las clases.
Sea el conjunto de patrones uno-dimensional: 0. 0, 0. 17, 0. 33, 0. 5, donde loselementos pertenecen a la clase cuya salida es: -1, y sea el conjunto 0. 67, 0. 83, 1. 0,donde los elementos pertenecen a la clase cuya salida es: 1.
Al aplicar el algoritmo se evalúan cada uno de los componente de ambas clases;generalmente éstos se aplican sin seguir un orden determinado.
Evaluamos los patrones en el algoritmo para determinar los pesos. Los valores delos pesos serán asignados de forma aleatoria, para este ejemplo w0 = −1 y w1 = −0.36. Así, para la primera iteración tenemos:
w0 + w1x1 = (−1) + (−0. 36)(0. 17) = −1. 061 < 0 =⇒ La salida será -1.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 33/106
2. Antecedentes 23
Por lo tanto, los pesos no sufrirán cambio alguno. Este mismo resultado se obtiene
para todo el conjunto de esta clase.
w0 + w1x1 = (−1) + (−0. 36)(0. 83) = −1. 2 < 0 =⇒ La salida será -1.
En este caso los pesos deberán ajustarse, y de acuerdo con el algoritmo se debesugerir un η, en este caso η = 0,1. Así, los nuevos pesos serán:
w00 = w0 + ηx0 = (−1) + (0. 1)(1) = −0. 9
w01 = w1 + ηx1 = (−0. 36) + (0. 1)(0. 83) = −0. 28
Nuevamente es evaluado un patrón, ahora con los nuevos pesos. En el caso de lospatrones de la clase con salida -1 todos darán un resultado satisfactorio, por lo que sóloevaluaremos los patrones de la clase con salida 1. Entonces para el siguiente patróntenemos:
w00 + w0
1x1 = (−. 9) + (−0. 28)(0. 67) = −1. 0876
Una vez más los pesos deber ser modificados, dado que esperábamos un resultadopositivo. Los nuevos pesos serán:
w00 = w0 + ηx0 = (−0. 9) + (0. 1)(1) = −0. 8
w01 = w1 + ηx1 = (−0. 28) + (0. 1)(0. 67) = −0. 213
Volvemos a evaluar alguno de los patrones de la clase. Así:
w00 + w0
1x1 = (−. 8) + (−0. 212)(1. 0) = −1. 012
Como podemos observar, al ajustar los pesos, la salida tiende a obtener el valoresperado. Este proceso se repetirá hasta que en la salida se tenga un resultado satis-factorio. Para este ejemplo, los valores de los pesos que den una salida esperada paratodos los patrones, quedan: w0 = −0. 2 y w1 = 0. 3.
Como se muestra en el ejemplo, los valores de los pesos se van ajustando hasta queel valor de la salida converge en un valor esperado.
2.2.5. Enfoque probabilístico-estadístico
El enfoque probabilístico-estadístico es clásico en el área del reconocimiento depatrones. Este enfoque se basa en métodos y fórmulas de la teoría de probabilidad yestadística. Los modelos probabilísticos se usan para distribuir los vectores de rasgosen clases mediante un conjunto de patrones, de los cuales se conoce su distribución enlas clases previamente. Los algoritmos creados en este enfoque usan, por lo tanto, unentrenamiento supervisado, que le indicará al algoritmo cómo aplicar la clasificación
(Marqués de Sá, 2001).

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 34/106
2. Antecedentes 24
Existen diferentes tipos de clasificadores dentro de este enfoque; desde los paramétri-
cos, como el clasificador Bayesiano, hasta los clasificadores no paramétricos o tambiénllamados modelos de técnica libre, como el KNN o las ventanas Parzen (Kuncheva,2000). Todos estos clasificadores y sus variantes están basados en modelos probabilís-ticos. Dentro de los clasificadores estadísticos se cuenta con los árboles de decisión ytablas (Marqués de Sá, 2000).
El clasificador Bayesiano no forma parte del presente trabajo de tesis, pero suimportancia en el enfoque hace indispensable su mención. Este clasificador se desarrollabajo el marco teórico de la probabilidad. Se usan probabilidades a priori, para estimarla probabilidad a posteriori de que un determinado patrón pertenezca a cierta clase.
Algortimo del clasificador Bayesiano.1. Obtener una muestra representativa S de los objetos a clasificar.
2. Determinar cada una de las clases C k que formarán parte del sistema.
3. Determinar, con base en la muestra y en la cardinalidad de cada clase, las prob-abilidades P (C k).
4. Determinar los rasgos útiles que se van a utilizar para clasificar, y elaborar cadadistribución de probabilidad p(X | C k) la cual va a ser dependiente del númeroy naturaleza de cada rasgo de la variable aleatoria vectorial X .
5. Para clasificar un patrón desconocido de entrada X , aplicar la siguiente regla:
X ∈ C i, si di > d j ∀i 6= j , con dk = ln(P (C k)) + ln( p(X | C k)) (2.17)
Clasificador KNN (K-Nearest Neighbours Method)
El algoritmo NN ha recibido una atención considerable desde su creación hastanuestro días. La sencillez conceptual, con la cual se concibió el algoritmo, ha hecho delNN un método muy popular entre los investigadores. Una revisión integral está hechapor Dasarathy (Dasarathy, 1991), donde se incluyen muchos de las más importantescontribuciones hechas en el estudio de NN (Webb, 1999). Este es, tal vez, concep-tualmente hablando, el más sencillo algoritmo de clasificación presentado junto con suregla de decisión (Schürmann, 1996; Webb, 1999).
El método requiere un conjunto de patrones etiquetados, también conocidos comoconjunto de prototipos. Este conjunto de patrones es usado para clasificar un conjuntode patrones de prueba, con lo cual se podrá medir el rendimiento del clasificador.
El método del NN calcula la distancia de un patrón de prueba respecto a cada
miembro del conjunto de prototipos, ordena las distancias de menor a mayor y retiene

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 35/106
2. Antecedentes 25
la clase del k patrón más cercano, siendo k una constante entera arbitraria. Este proceso
es en términos computacionales caro, para conjuntos de datos relativamente grandes(Webb, 1999).
Un hecho importante de mencionar es la métrica que se emplee en el algoritmo.Obviamente el resultado de las distancias dependerá de la métrica empleada. Normal-mente se emplea la métrica euclidiana, pero se puede emplear cualquier otra (Webb,1999).
Ejemplo 2.10 Este ejemplo mostrará en funcionamento del KNN, con k = 1 y usandola métrica euclidiana.
Sean los vectores x1 = µ 1. 23. 0 ¶ , x2 = µ 4. 3
0. 7 ¶ , x3 = µ 2. 33. 1 ¶ , con x1 y x3
que pertenecen a la clase C 1 y x2 que pertenece a la clase C 2, el conjuto de patrones
prototipo y sea x4 =
µ 3. 70. 5
¶ el patrón que se desea clasificar
De a cuerdo con el algoritmo del KNN:
Primero se calculará la distancia ente el patrón x4 y cada uno de los patronesprototipo. De acuerdo con 2.16.
d(x1
,x4
) = £(x4− x
1)T (x
4− x
1)¤
1
2 = ·¡2. 5 −2. 5¢ ·µ 2. 5
−2. 5¶¸1
2
= (12. 5)1/2 = 3. 53
d(x2,x4) =£
(x4 − x2)T (x4 − x2)¤ 12 =
·¡−0. 6 −0. 2
¢·
µ−0. 6−0. 2
¶¸ 1
2
= (0. 76)1/2 = 0. 8717
d(x3,x4) =£
(x4 − x3)T (x4 − x3)¤12 =
·¡1. 4 −2. 6
¢·
µ 1. 4−2. 6
¶¸ 1
2
= (8. 72)1/2 = 2. 95
Se ordenan las distancias de menor a mayor:
d(x2,x4) 0. 8717d(x3,x4) 2. 95d(x1,x4) 3. 53
Por lo tanto el patrón x4 pertenece a la clase 2.
La alta eficacia que presenta en problemas reales el KNN, hacen de este algoritmouno de los más usados.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 36/106
2. Antecedentes 26
2.2.6. Enfoque sintáctico-estructural
Este enfoque está basado en la teoría de los lenguajes y en la teoría de autómatas,que establecen si una determinada estructura pertenece a cierto lenguaje al cumplircon un conjunto de reglas establecidas llamado gramática. Así, en lugar de analizarlos rasgos cuantitativos de los patrones, se hace énfasis en la interrelación de estascaracterísticas con las cuales se podrá discernir si pertenece al lenguaje. La estructuraque se puede determinar por medio de estas interrelaciones de los rasgos hace posibleque los patrones puedan ser tratados como palabras, donde sea factible establecerreglas gramaticales que nos permitan establecer un determinado lenguaje.
La clasificación en este enfoque opera con información simbólica, con una analogíaentre la estructura de algún patrón y la sintaxis de un lenguaje, que estará determinado
por una gramática que hace atractivo este enfoque.
Al introducir la teoría de los lenguajes formales se diseñan clasificadores sintác-ticos llamados “parsers” que pueden clasificar un patrón determinado, el cual serápresentado como una cadena de símbolos y se decidirá si pertenece al lenguaje o no.
Teoría de Autómatas y Lenguajes Formales
La teoría de autómatas y lenguajes formales es una de las teorías más importantesque existen dentro de las ciencias de la computación, puesto que explica el porquéfuncionan las computadoras como las conocemos. El principal objetivo de esta teoría
es modelar lenguajes y estudiar los sistemas que generan y reconocen a los mismos;es precisamente esta última característica la que más adelante nos va a servir en elreconocimiento de patrones. Los principales avances en esta disciplina fueron hechospor Noam Chomsky en las décadas de los 40 y 50 del siglo XX. Comenzaremos esteestudio breve sobre esta teoría con algunas definiciones básicas.
Definición 2.11 Un alfabeto Σ es un conjunto fi nito de símbolos, por ejemplo el conjunto de las letras minúsculas a,b,c,..,z.
Definición 2.12 Una cadena o palabra w es una secuencia fi nita de símbolos del alfabeto Σ. La longitud de w se denota |w| .
Definición 2.13 La concatenación de dos cadenas w1 y w2, es la cadena w1w2 de longitud |w1| + |w2|
Definición 2.14 Denotamos ε al símbolo nulo y λ a la cadena de longitud 0.
Definición 2.15 Sea un V ⊆ Σ. Denotamos como V ∗ a la cerradura de V y es el conjunto de todas las posibles cadenas que se pueden hacer con los símbolos de V ,incluyendo a λ.
Ejemplo 2.16 Sea Σ = a,d,e,p,r un alfabeto. w = padre es una cadena sobre Σ,
puesto que p,a,d,r,e ∈ Σ; |w| = 5.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 37/106
2. Antecedentes 27
Ejemplo 2.17 Sean w1 = pad, y w2 = re, dos cadenas sobre el mismo alfabeto del
ejemplo anterior. La cadena w = w1w2 = padre, es la concatenación de w1 y w2.
Ejemplo 2.18 Sea V = a ⊆ Σ, donde Σ es el alfabeto de los ejemplos anteriores.La cerradura de V es V ∗ = λ,a,aa,aaa,....
La materia prima para trabajar en esta teoría son los símbolos y secuencias desímbolos. Sin embargo, hay que notar que la teoría no incluye una semántica o sig-nificado de los símbolos y las cadenas. Esto es importante puesto que se nos permitemodelar y procesar ideas sin preocuparnos por el significado que puedan tener lasmismas. El ejemplo más palpable sobre esta ventaja son las computadoras: una com-
putadora procesa símbolos que pertenecen al alfabeto 0, 1, y aunque aparentementepuede hacer muchas funciones, el significado de las mismas se lo da el usuario, no lamáquina.
La siguiente definición es una de las más importantes en esta teoría, puesto que todoel desarrollo subsecuente se enfocará a generar y reconocer estos objetos matemáticos:los lenguajes formales.
Definición 2.19 Un lenguaje formal £ es un conjunto fi nito, o in fi nito contable, de palabras sobre un alfabeto. Evidentemente £ ⊆ Σ∗.
Ejemplo 2.20 Sea Σ = a, b, £ es el lenguaje de fi nido de la siguiente forma: £ =w|w comienza con una a = a,aa,ab,aaa,aab,aba,abb,....
Al igual que podemos concatenar cadenas, también se pueden concatenar lenguajes.Esta propiedad es muy importante, puesto que nos da una idea de cómo se puedenconstruir lenguajes complejos a partir de otros más sencillos. La definición formal esla siguiente:
Definición 2.21 Sean £1 y £2 dos lenguajes. la concatenación de £1 y £2, denotada £1£2 = w|w = w1w2, w1 ∈ £1 y w2 ∈ £2
Ejemplo 2.22 Sea £1 = a y £2 = a, b∗, entonces el lenguaje del ejemplo 2.20 se puede representar como la concatenación de £1 y £2 de la siguiente forma: £ =£1£2 = a a, b∗ = a, aa, ab, aaa, aab, aba, abb, ....
Gramáticas
Definición 2.23 Una gramática G es una tupla (Σ, N , S , P ), donde:
1. Σ es un alfabeto. Los elementos de Σ se llaman comúnmente símbolos terminales.
2. N es un conjunto de símbolos llamados no-terminales y N ∩Σ = ∅.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 38/106
2. Antecedentes 28
3. S ∈ N , es llamado el símbolo inicial.
4. P es un conjunto de reglas de producción o reglas de reescritura"del tipo α → β ,donde α y β son cadenas compuestas de símbolos terminales y no terminales,con la restricción de que α debe de contener al menos un no-terminal.
Ejemplo 2.24 Sea G = (Σ, N , S , P ), con Σ = a, b, N = S, B, y P = S → aB,B → aB|bB|ε.La parte más interesante en la gramática es el conjunto de producciones y nos dice losiguiente: que el símbolo S sólo puede ser sustituido por la cadena aB, donde a es un símbolo terminal y B uno no-terminal. Ahora, B puede ser sustituido por 3 distintas cadenas aB,bB o ε, de aquí que | represente a una .o"en las producciones. Supongamos que queremos ver si la cadena abba puede ser producida a partir de G, entonces se hace la siguiente derivación:
S ⇒G aB =⇒G abB =⇒G abbB =⇒G abbaB =⇒G abbaε = abba.Primero, el símbolo =⇒Grepresenta la relación derivación usando la gramática G
y significa que se ha ocupado una regla de producción para transformar una cadena enotra. Ahora, cuando queremos producir una cadena a partir de G, siempre se comienzacon el símbolo inicial, en este caso S , y se ocupa alguna regla se sustitución para elmismo. Aquí, sólo tenemos una opción que es S → aB, entonces S sólo puede derivarla cadena aB y se escribe: S ⇒G aB. Luego, tenemos una cadena formada por unterminal a y un no terminal B, entonces tenemos que sustituir de alguna forma elno-terminal con otra regla, en este caso elegimos B → bB, así, la cadena aB puedederivar la cadena abB y se escribe aB =⇒G abB. El proceso continúa hasta que se llega
a una cadena formada exclusivamente de símbolos terminales y es cuando terminamosla derivación (nótese también que se hizo uso del símbolo nulo, que por su naturalezapuede o no puede ser escrito).
Finalmente, como abba pudo ser producida por la gramática G, entonces esta ca-dena pertenece al lenguaje aceptado por G y se expresa abba ∈ £(G).
Dado que las producciones pueden tener una gran cantidad de variantes, Chomskyclasificó las gramáticas según la forma de sus producciones. la llamada jerarquía de
Chomsky es la siguiente:
1. Tipo 0. Gramáticas sin restricciones . Tienen producciones de la forma α → β
donde α y β son cadenas arbitrarias sobre el conjunto Σ ∪N .
2. Tipo 1. Gramáticas sensibles al contexto . Tienen producciones de la forma αAβ →αBβ , con α, β ∈ Σ y A, B ∈ N , o de la forma S → ε. Algunos lenguajes naturalescomo el alemán suelen tener estructuras de este tipo.
3. Tipo 2. Gramáticas libres de contexto . Tienen producciones de la forma A → α,donde A ∈ N y α ∈ Σ∗.
4. Tipo 3. Gramáticas regulares . Tienen producciones de la forma A → αB oA → α, con α ∈ Σ y B ∈ N y se les llama regular por la derecha. Tambiénpueden ser regulares por la izquierda y las producciones son de la forma:A → Bα
o A → α, con α ∈ Σ y B ∈ N .

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 39/106
2. Antecedentes 29
La jerarquía de Chomsky es importante puesto que para cada tipo de gramática,
existe un autómata que las reconoce y más aún, existe un método para hacerlo. Losdetalles sobre autómatas y su relación con las gramáticas se presentarán en la siguientessecciones.
Autómatas
Un autómata es un modelo matemático que nos permite reconocer palabras quepertenecen a un lenguaje formal. En general, la idea detrás de cualquier tipo de autó-mata está en tener un conjunto de estados que nos indican cuándo comienza el re-conocimiento, cuándo se está en un estado intermedio y cuándo se termina el re-conocimiento. Existen varios tipos de autómatas, los cuales se enlistan a continuación.
1. Máquinas de Turing . Son máquinas que reconocen los lenguajes generados porlas gramáticas sin restricción. Las computadoras son un caso especial de estetipo de autómata. Utilizan un concepto llamado cinta infinita que es el análogoa la memoria de una computadora.
2. Autómatas linealmente restringidos . Son los autómatas que reconoces lenguajesgenerados por las gramáticas sensibles al contexto.
3. Autómatas de Pila . Utilizan una estructura de datos tipo FIFO (First In-FirstOut : Primero en Entrar, Primero en Salir) para simular una memoria restringida.
Reconocen los lenguajes generados por gramáticas libres de contexto.4. Autómatas Finitos . Son los más sencillos y reconocen los lenguajes generados
por las gramáticas regulares.
Definición 2.25 Un Autómata Finito AF es una tupla (Σ, Q , q o, F , T ) donde:
1. Σ es un alfabeto de entrada.
2. Q, es un conjunto finito de estados.
3. q 0 ∈ Q es el estado inicial.
4. F ⊆ Q es un conjunto de estados finales y
5. T es una función T : Q ×Σ→ Q..
La forma de reconocer es la siguiente:
1. Se tiene una cadena w, se lee el primer símbolo y se toma q 0 como estado actual.
2. Con el estado actual y el símbolo leído, se utiliza la función T para saber cuál
es el estado siguiente.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 40/106
2. Antecedentes 30
3. Se lee el siguiente símbolo y se repite el paso 2 hasta que no haya más símboloes
por leer.4. Si al terminar de leer la cadena, nos encontramos en un estado final, entonces
la cadena pertenece al lenguaje que acepta el autómata, denominado £(AF ). Sino, no pertenece.
Equivalencia entre un AF y una Gramática
En esta última parte de esta sección mostraremos cómo se puede crear un autómataa partir de una gramática.
Algoritmo 2.26 Algoritmo para convertir una gramática regular en un AF .
1. Sea G = (Σ, N , S , P ) y AF = (Σ, Q , q o, F , T ) , donde los alfabetos de G y AF son los mismos e inicialmente, Q = N , q 0 = S , T = ∅ y F = ∅
2. Para cada transición t en P hacer los pasos siguientes:
3. Si t es de la forma A → aB, con A, B ∈ N y a ∈ Σ, añadir a T una relación dela forma ((A, a), B).
4. Si t es de la forma A → a, con A ∈ N y a ∈ Σ, añadir a F y a Q un estado X y añadir a T una relación de la forma ((A, a), X ).
5. Si t es de la forma A → ε, con A ∈ N , añadir A a F 6. Si t es de la forma A → aw, con A ∈ N , a ∈ Σ y w ∈ Σ∗ ∪N ∗, añadir a Q un
estado X , añadir a T una relación de la forma ((A, a), X ) y repetir los datos 3a 6 para una producción del tipo X → w.
Ejemplo 2.27 Diseñar un clasi fi cador basado en el enfoque sintáctico-estructural para identi fi car cuadrados de una longitud l en una imagen. Una fase de preprocesamientode la imagen permite obtener líneas del tamaño deseado en alguna dirección, puntos donde se cortan dos líneas y la apertura entre las líneas que forman.
Queremos identificar cuadrados de un tamaño dado, pero no sabemos si los cuadra-
dos están o no rotados y además, lo único que podemos identificar son líneas de tamañofi jo, vértices y ángulos en cada vértice.
De acuerdo al paso 1 de la fase de entrenamiento, tenemos que identificar los rasgosque nos son útiles para describir nuestros patrones. Como lo único que puedo medirson algunas características geométricas de la imagen, es lo que se va a aprovechar.Supongamos que podemos recorrer una figura por su perímetro, entonces para identi-ficar un cuadrado, necesitamos comenzar en un vértice, luego encontrar una línea deltamaño deseado en alguna dirección, enseguida en ese punto identificar un vértice queforme 90 con la otra línea ( se supone que los ángulos se miden siempre en el mismosentido), luego identificar que esa línea es de longitud l y repetir lo mismo para los
cuatro vértices.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 41/106
2. Antecedentes 31
Así, las mediciones que vamos a tomar como rasgos son a) líneas de tamaño fi jo
en una dirección; b) vértices que forman 90
con la otra línea.
Luego, según el paso 2 hay que asignar a cada rasgo un símbolo, así, a las líneasde tamaño fi jo en una dirección les llamaremos L y a los vértices que forman 90 conla otra línea le llamaremos V . Así, podemos darnos cuenta, que para identificar uncuadrado tenemos que comenzar en un vértice de tipo V , luego tenemos que encontrar4 veces la siguiente secuencia: una línea L y un vértice V , figura 2.5.
Figura 2.5. Asignación de símbolos
De esta forma, proponemos que la gramática para este tipo de cadenas sea la quetiene las siguientes reglas:
S → V L V L V L V L V
con N = S, P y Σ = L, V .Y un el autómata generado que reconoce este lenguaje sería:
Figura 2.6. : Autómata resultante
Como se puede notar, aunque la gramática es muy simple, funciona para reconocerun tipo de objetos sin importar la rotación.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 42/106
2. Antecedentes 32
2.2.7. Génesis del enfoque asociativo para clasificación de patrones
En las postrimerías del año 1997, inmerso en el ambiente juvenil del incipienteCentro de Investigación en Computación del Instituto Politécnico Nacional, se inicióel aglutinamiento de una masa crítica de elementos humanos proclives a incursion-ar de manera seria y profesional en esas fascinantes disciplinas llamadas Robótica yReconocimiento de Patrones, y en los apasionantes recovecos del Procesamiento, elAnálisis y el Álgebra de Imágenes.
Como resultado de ese aglutinamiento nació el GRAI, acrónimo de la expresión:Grupo de Robótica y Análisis de Imágenes. Este grupo tiene por lema la siguientemáxima: Es mejor equivocarse por actuar y experimentar, que salvarse delerror al precio de no hacer nada.
En la actualidad, el GRAI cuenta entre sus filas con investigadores, profesores,alumnos de maestría y de doctorado del CIC-IPN, y algunas personas de otras insti-tuciones con intereses congruentes con los propósitos y acciones del grupo.
Las bases teóricas de las actividades que se realizan en el GRAI provienen de áreastan interesantes y útiles como la Morfología Matemática, el Álgebra de Imágenes, laTeoría del Control, las Matemáticas Discretas, las Redes Neuronales, las MemoriasAsociativas, el Reconocimiento de Patrones, la Teoría de la Información y la Teoría delas Transformadas Matemáticas, entre otras.
La actividad ha sido productiva y creciente. El GRAI tiene en su haber un premio
nacional "Luis Enrique Erro", una presea "Lázaro Cárdenas", un proyecto REDII-Conacyt, media decena de proyectos CGPI-IPN, la autoría de un libro y la edición deotro, varios capítulos de libro, algunos artículos en revista internacional o nacional,media decena de graduados en maestría y tres de doctorado, y más de media docenade tesis en proceso.
Como tema del presente trabajo de tesis, la cual forma parte de esa media docena,durante el año 2002 se planteó la creación del enfoque asociativo para reconocimientoy clasificación de patrones. Así, los miembros del GRAI fueron testigos del nacimientode un nuevo enfoque en reconocimiento automático de patrones: el enfoque asociativo,el cual se ha revelado como una alternativa real en clasificación automática de patrones
n-dimensionales reales.
El primer clasificador de patrones basado en el enfoque asociativo es el CHAT, crea-do, diseñado y aplicado en el marco de los trabajos cientí ficos realizados por miembrosdel GRAI, y presentado en este trabajo de tesis. El novedoso algoritmo fusiona, de al-guna manera, dos prominentes ramas de las ciencias de la computación: la calsificaciónautomática de patrones en el dominio real por un lado, y la aplicación de las memoriasasociativas, por el otro. En el diseño del clasificador se han tomado libremente las ven-tajas de dos modelos de memorias asociativas, la Lernmatrix de Steinbuch y el Linear Associator de Anderson-Kohonen, evitando, al mismo tiempo, sus desventajas.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 43/106
Capítulo 3
Estado del arte
En el campo de las memorias asociativas, que es el marco en el que se desarro-lla este trabajo, no existen referencias sobre la tarea especí fica de la clasificación depatrones; los trabajos más recientes son los realizados en el desarrollo de las memo-rias morfológicas (Ritter, Sussner, Diaz-de-León, 1999) y de las memorias αβ (Yáñez-Márquez, 2002). Estos trabajos no están enfocados directamente a la clasificación, sinoal reconocimiento de patrones.
Por otro lado, las dos memorias en que está basado el producto de este trabajode tesis (CHAT), la Lernmatrix (Steinbuch, 1961; Steinbuch & Frank, 1961; Yáñez-Márquez, 2001a) y el Linear Associator (Anderson & Tosenfeld, 1990; Kohonen, 1989,
Yáñez-Márquez, 2002b), no fueron diseñadas para la clasificación de patrones. Stein-buch, creador de la Lermatrix, no dejó ningún trabajo que sustente el funcionamientode la Lernmatrix de forma matemática, y en el caso del Linear Associator el cualsi quedó fundamentado matemáticamente, aún sigue siendo referencia en el área dememorias asociativas.
El campo donde compite directamente el CHAT es la tarea de clasificación depatrones. Existe un vasto campo donde residen varios enfoques que atacan este pro-blema, desde los sustentados fuertemente por una base teórica como la probabilidad,hasta enfoques donde el grado de heurística es muy alto; tal es el caso de las redesneuronales.
Actualmente, existen tres áreas donde el trabajo dedicado a la investigación de laclasificación de patrones se está enfocando. La primera es la de buscar aumentar elrendimiento de los clasificadores ya conocidos, mediante la optimización del proceso ode alguno de los componentes del mismo (Bandyopadhyay & Maulik, 2002; Demeni-coni, Peng & Gunopulos, 2002; Ho, Liu, & Liu, 2002; Huang, & et. al., 2002; Rueda& Oommen, 2002; Wu, Ianekiev & Govindaraju, 2002); la segunda área es la de bus-car combinaciones entre los clasificadores ya conocidos, ya sea combinando etapas oresultados de unos sirviendo de entradas para otros (Acharya & et. al., 2003; Kittler& Alkoot, 2003; Kuncheva, 2002; Lu & Tan, 2002; Murua, 2002; Nicola, Masulli &Sperduti, 2002); y la tercera se refiere a la búsqueda de unificar enfoques (Abe, 2001;
Šarunas, 2001).
33

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 44/106
3. Estado del arte 34
Este trabajo de tesis se centra en mostrar un nuevo algoritmo: el CHAT. Uno de
los puntos principales será mostrar el comportamiento de este clasificador frente aclasificadores sólidos en el área, tanto en su base teórica como práctica.
Uno de los clasificadores más utilizados es el KNN (Cover & Hart, 1967), conmás de 40 años dentro del área del reconocimiento de patrones, siendo uno de losclasificadores más longevos y estudiados de la actualidad; las sencillez del algoritmoy su alta efectividad (Ho, Liu & Liu, 2002) hacen de este clasificador, uno de losmás usados en el ámbito de los clasificadores de patrones por los investigadores. Estascaracterísticas hacen del KNN un clasificador ideal para la comparación del CHAT alreunir ambos la sencillez de los algoritmos.
Exiten otros clasificadores en el área de reconocimiento de patrones, pero éstosrequieren de condiciones diferentes al CHAT o KNN, tal es el caso del clasificadorBayesiano que requiere de la función de densidad de probabilidad o de las ventanasParzen (Duda, Hart & Stork, 2001); otros como las redes neuronales tienen una grancantidad de heurística implícita en su funcionamiento y aunque está presente en elKNN, ésta es menor (limitada al valor de k).
El KNN tiene tres principales limitaciones (Huang & et. al. 2002), el excesivotiempo de cómputo, el requerimiento de una gran capacidad de almacenamiento dememoria, y la sensibilidad a los patrones ruidosos. El trabajo de investigación sobreel KNN se centra en disminuir estas limitaciones del clasificador al tratar de reducir
el tamaño del conjunto de patrones con los cuales se ha de determinar a qué clasepertenece un patrón desconocido (Bandyopadhyay & Maulik, 2002; Ho, Liu, & Liu,2002; Huang & et. al. 2002; Wu, Ianekiev & Govindaraju, 2002; Rueda & Oommen,2002).
La característica más importante en el CHAT es que requiere de un conjunto fun-damental reducido, por lo que su complejidad computacional es mucho menor que ladel KNN para lograr la tarea de clasificación, como se muestra en los hechos experi-mentales y que repercute directamente en el tiempo de cómputo.
Un algoritmo que se toma en cuenta con fines comparativos es el C-means, usandofunciones de disimilaridad (Ayaquica, 2002), el cual muestra un mejor rendimientofrente al C-means y C-means difuso. Los resultados comparativos mostrarán que elCHAT es superior en rendimiento a estos algoritmos ya establecidos.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 45/106
Capítulo 4
Herramientas matemáticas
En virtud de que las memorias asociativas se representan por medio de matrices,es preciso exponer algunos conceptos ya conocidos sobre las notaciones, el uso de lasmatrices y los vectores, que serán usados de manera intensiva en los capítulos 5 y 6.
4.1. Sumatorias
En matemáticas se introduce la notación P
para facilitar la escritura de la sumade los elementos de una sucesión y se pueden escribir de la siguiente manera:
am + am+1 + am+2 + ... + an =
nXi=m
ai
Donde m y n son enteros y m ≤ n.El número m se denomina límite inferior de lasuma y n se llama límite superior. El símbolo i es un símbolo convencional y puedeser sustituido por cualquier otro.
Ejemplo 4.1 Sea la suma de los elementos de la sucesión:
43 + 53 + 63
esta sucesión se puede representar a través de la notación sigma, de la siguienteforma:
6Xi=4
i3
Ejemplo 4.2 Si la notación de sumatoria es:
3Xi=−2
i2
entonces, i toma valores que van de -2 a 3 y mediante la notación P se representa
a la suma de los elementos de la sucesión:
35

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 46/106
4. Herramientas matemáticas 36
(−2)2 + (−1)2 + (0)2 + (1)2 + (2)2 + (3)2
Ejemplo 4.3 Sea la suma de los elementos de la sucesión:
−3a3 + 4a4 − 5a5 + 6a6 − 7a7 + 8a8
esta sucesión se puede representar a través de la notación sigma, de la siguienteforma:
−3a3 + 4a4 − 5a5 + 6a6 − 7a7 + 8a8 =8
Xi=3
(−1)iiai
4.2. Operador máximo
El operador máximo se denota con el símbolo W
y se aplica a un conjunto decomponentes para dar como resultado el valor máximo de todos ellos.
Ejemplo 4.4 Sea un conjunto de componentes contenidos en un vector de dimensión 5:
x =
6
1238
12
al aplicar el operador máximo al conjunto de componentes del vector x, tenemos:
4_i=0
xi = 12
4.3. Operaciones matriciales
Notación 4.5 Las matrices se representan con esta notación: si m, n y r son números enteros positivos, A = [aij]m×r representa una matriz de dimensiones m × r, cuya ij -ésima entrada es aij, y B = [bij ]r×n representa una matriz de dimensiones r ×n, cuya ij-ésima entrada es bij.
Definición 4.6 Una matriz A es un arreglo rectangular de m×r números dispuestos en m renglones y r columnas.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 47/106
4. Herramientas matemáticas 37
a11 a12 · · · a1 j · · · aira21 a22 · · · a2 j · · · a2r...
... ...
...ai1 ai2 · · · aij · · · air
... ...
... ...
am1 am2 · · · amj · · · amr
Definición 4.7 Suma de matrices: Sean A y B dos matrices de m × n.Entonces la suma de A y B es la matriz m × n, A + B dada por:
A + B = (aij + bij) =
a11 + b11 a12 + b12 · · · a1n + b1na21 + b21 a22 + b22 · · · a2n + b2n
... ...
...am1 + bm1 am2 + bm2 · · · amn + bmn
es decir, A + B es la matriz m × n que se obtiene al sumar las componentescorrespondientes de A y B .
Definición 4.8 Producto de matrices: Sea A una matriz m× r, y sea B una matriz de r × n. Entonces el producto de AB está de fi nido y es una matriz C de m × n, en donde cada componente de la matriz cij está dado:
cij = ai1b1 j + ai1b1 j + · · · + airbrj
Es decir, que si el número de columnas de A es igual al número de renglones de B,entonces se dice que A y B son compatibles bajo la multiplicación.
4.4. Vectores n-dimensionales
Dentro de la literatura del álgebra lineal se considera a un vector como un tipoespecial de matriz (Lang, S. 1976, Grossman, S.I. 1996, Leithold, L. 1998). Así, ciertascombinaciones en los valores de m, n y r, dan lugar a casos especí ficos, los cuales valela pena mencionar porque simplifican las operaciones:
Si m = 1 y r = 1, a consta de una única entrada, a11. En este caso se trata deun número que indicaremos con la letra a sin subíndices.
Si m = 1 y r > 1, a es un vector fila con r entradas: a = a11, a12,...,a1r. Seeliminará el subíndice 1 que corresponde a m para simplificar la notación, y elvector fila se denotará así: a = a1, a2,...,ar.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 48/106
4. Herramientas matemáticas 38
Si r > 1 y n = 1, b es un vector columna con r entradas:
b =
b11b21
...br1
Se eliminará el subíndice 1 que corresponde a r para simplificar la notación, y elvector columna se denotará así:
b =
b1b2...
br
por lo anterior, los vectores se sujetan a las definiciones citadas en las secciónanterior.
Desde el punto de vista del análisis vectorial se hace el estudio de los vectores de dosformas, analítica y geométrica. En la forma analítica tenemos que un vector se sujetaa la siguiente definición cuando el vector es de dimensión dos y se desea representarloen el plano bidimensional.
Definición 4.9 Vector en un plano bidimensional es un par ordenado de número
reales (x, y).Donde a los números x, y, se denominan componentes del vector.
Sea el vector bidimensional x el par ordenado de números reales (x, y). Si A esel punto (x,y) y O es el origen en el plano, entonces el vector x puede representarsegeométricamente por el segmento rectilíneo dirigido
−→OA, denominado representación
del vector x.
4.5. Producto interno y producto externo de vectores.
Estos productos entre vectores que en la literatura se denominan producto puntoo interno y producto externo, aquí serán tratados como el producto entre matrices,
donde los vectores deberán cumplir con los requisitos de la definición de productomatricial.
4.5.1. Producto interno
Sea a una matriz de 1 × r, donde a = a1, a2,...,ar y sea b una matriz de r × 1donde
b =
b1b2...
br

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 49/106
4. Herramientas matemáticas 39
por lo tanto el producto esta definido, tal que:
a · b =¡
a1 a2 · · · ar¢·
b1b2...
br
= (a1b1 + a2b2 + · · · + arbr)
como resultado tenemos un escalar.
4.5.2. Producto externo
Sea A una matriz de m × 1, donde:
a =
a1a2...
am
y sea B una matriz de 1 × n, tal que:
b = (b1, b2, . . . , bn)
por lo tanto el producto esta definido y esta dado por:
a · b =
a1
a2...
am
·¡
b1 b2 · · · bn¢
=
a1b1 a1b2 · · · a1bn
a2b1 a2b2 · · · a2bn...
... ...
amb1 amb2 · · · ambn
dando por resultado una matriz de dimensión m × n.
4.6. Producto de una matriz y un vector.
El producto de una matriz A de dimensión m × n y un vector de columna x dedimension n esta definido (Gill, Murray & Wright, 1989). Denotado como Ax, da comoresultado un vector de dimensión m, donde cada componente del vector resultante estádado por:
(Ax)i =nX
j=1
aijx j
4.7. Traslación de ejes
Un sistema coordenado nos permite asociar una gráfica (concepto geométrico) conuna ecuación (concepto algebraico), donde una ecuación algebraica es un enunciadoen el que se establece la igualdad de dos expresiones, las cuales contienen variables.
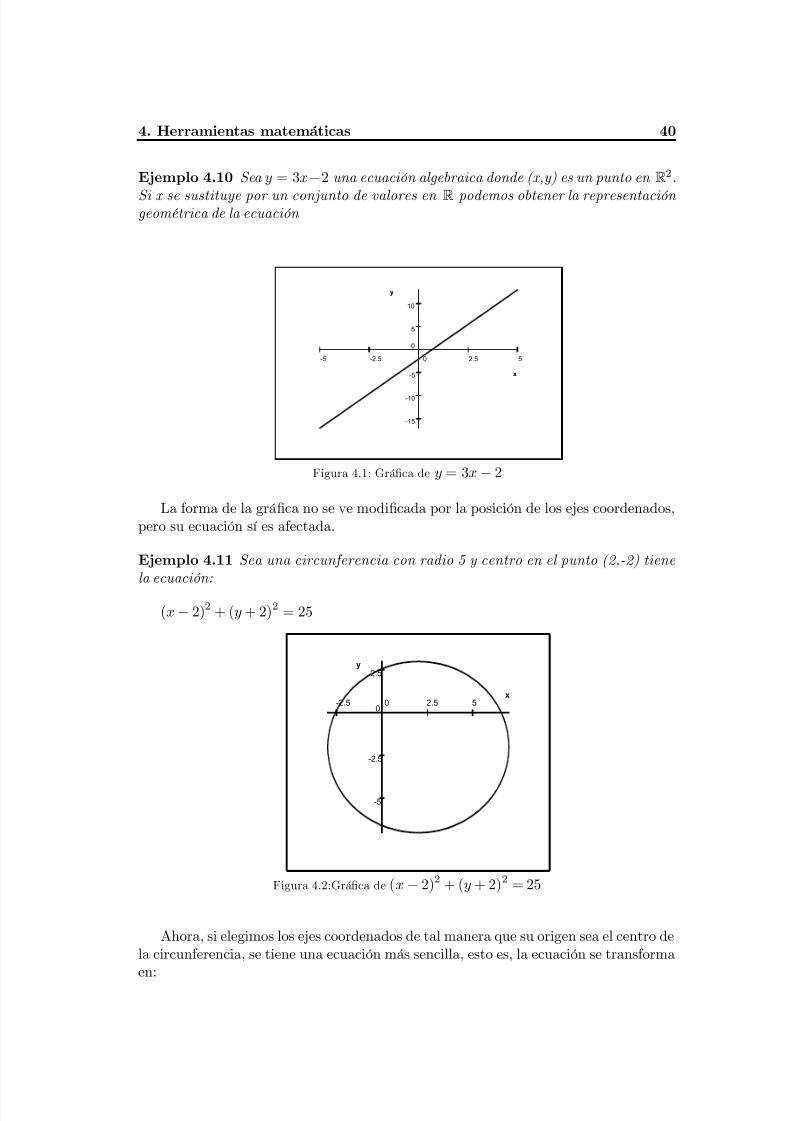
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 50/106
4. Herramientas matemáticas 40
Ejemplo 4.10 Sea y = 3x−2 una ecuación algebraica donde (x,y) es un punto en R2.
Si x se sustituye por un conjunto de valores en R podemos obtener la representación geométrica de la ecuación
52.50-2.5-5
10
5
0
-5
-10
-15
x
y
x
y
Figura 4.1: Gráfica de y = 3x− 2
La forma de la gráfica no se ve modificada por la posición de los ejes coordenados,pero su ecuación sí es afectada.
Ejemplo 4.11 Sea una circunferencia con radio 5 y centro en el punto (2,-2) tiene la ecuación:
(x− 2)2 + (y + 2)2 = 25
52.50-2.5
2.5
0
-2.5
-5
x
y
x
y
Figura 4.2:Gráfica de (x− 2)2 + (y + 2)2 = 25
Ahora, si elegimos los ejes coordenados de tal manera que su origen sea el centro dela circunferencia, se tiene una ecuación más sencilla, esto es, la ecuación se transformaen:
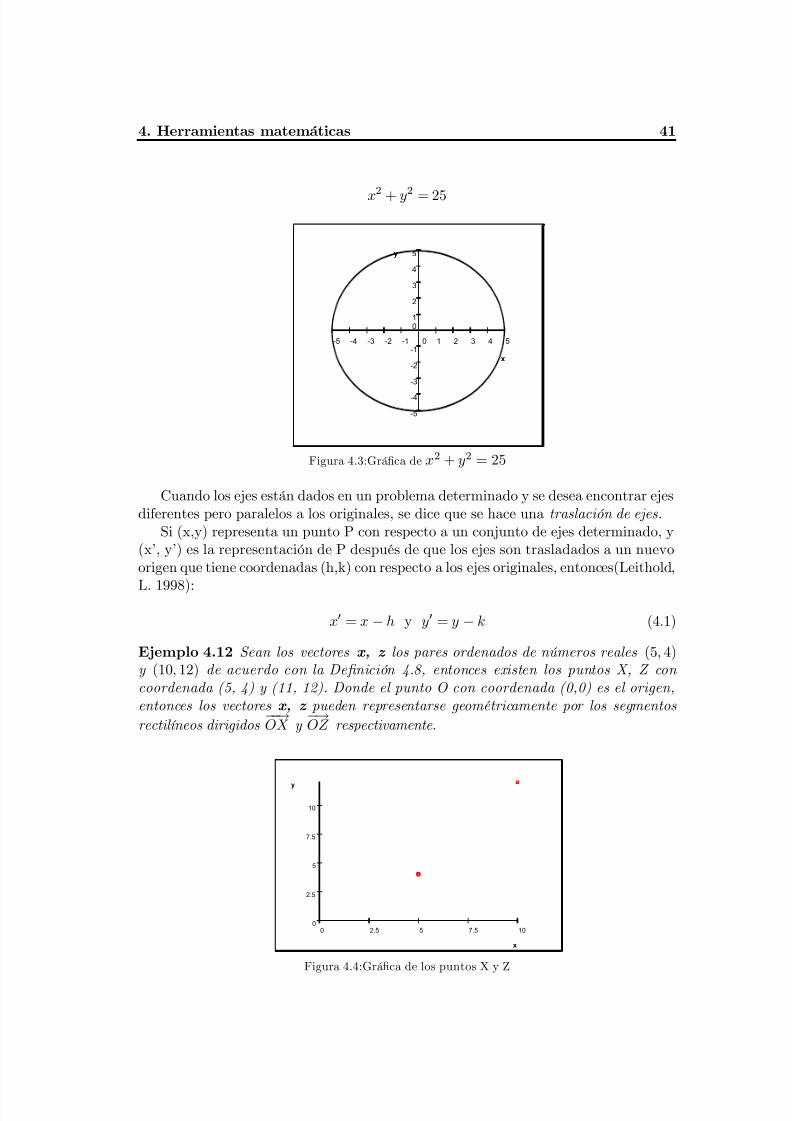
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 51/106
4. Herramientas matemáticas 41
x2 + y2 = 25
543210-1-2-3-4-5
5
4
3
2
10
-1
-2
-3
-4
-5
x
y
x
y
Figura 4.3:Gráfica de x2 + y2 = 25
Cuando los ejes están dados en un problema determinado y se desea encontrar ejesdiferentes pero paralelos a los originales, se dice que se hace una traslación de ejes .
Si (x,y) representa un punto P con respecto a un conjunto de ejes determinado, y(x’, y’) es la representación de P después de que los ejes son trasladados a un nuevoorigen que tiene coordenadas (h,k) con respecto a los ejes originales, entonces(Leithold,
L. 1998):
x0 = x − h y y0 = y − k (4.1)
Ejemplo 4.12 Sean los vectores x, z los pares ordenados de números reales (5, 4)y (10, 12) de acuerdo con la De fi nición 4.8, entonces existen los puntos X, Z con coordenada (5, 4) y (11, 12). Donde el punto O con coordenada (0,0) es el origen,entonces los vectores x, z pueden representarse geométricamente por los segmentos
rectilíneos dirigidos −−→OX y
−→OZ respectivamente.
107.552.50
10
7.5
5
2.5
0
x
y
x
y
Figura 4.4:Gráfica de los puntos X y Z

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 52/106
4. Herramientas matemáticas 42
ahora, tomaremos de manera arbitraria un punto H con coordenadas (8,8) como
un nuevo origen y de acuerdo con la expresión 4.1, los vectores x y z tendrán larepresentación en los nuevos ejes marcados por el origen H como:
x0 = (−3,−4)
y
z0 = (3, 4)
Donde los nuevos puntos X’ y Z’ están representados en la siguiente gráfica.
32.521.510.50-0.5-1-1.5-2-2.5-3
4
3.53
2.5
2
1.5
1
0.50
-0.5
-1
-1.5
-2
-2.5
-3
-3.5
-4
x
y
x
y
Figura 4.5: representación de X’ y Z’.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 53/106
Capítulo 5
Desarrollo
Es aquí, en este capítulo, donde se presenta la parte sustantiva del presente trabajode tesis.
El capítulo está dividido en dos secciones; en la primera, se muestra el desarrollode un clasificador de patrones en el dominio real, que da lugar a la creación de unnuevo enfoque, el asociativo, para la tarea de clasificación de patrones, que es unarama del reconocimiento de patrones.
En la segunda sección se presenta otra versión del primer clasificador que se hacreado bajo el enfoque asociativo de clasificacón de patrones; esta nueva versión, a
través de un proceso de traslación de ejes, convierte a la primera versión en un clasi-ficador robusto capaz de competir con los clasificadores más longevos y estudiados,basados en otros enfoques.
El clasificador de la primera sección se denomina CHA, Clasificador HíbridoAsociativo, y está basado en dos memorias asociativas pioneras: la Lernmatrix deSteinbuch y el Linear Associator de Anderson-Kohonen.
El CHA supera ampliamente las limitaciones que presentan cada una de estasmemorias asociativas, lo cual se logra al combinar las fases de aprendizaje o recu-peración de ambas de forma ingeniosa. El CHA, puede aceptar valores reales en lascomponentes de sus vectores de entrada ( a diferencia de la Lernmatrix , que sólo
acepta valores binarios, 1 y 0) y a sus vectores de entrada no se les exige que seanortonormales (los vectores de entrada del Linear Associator deber ser ortonormales,para tener recuperación perfecta en todo su conjunto fundamental). Además el CHAes un clasificador que se comporta como una memoria asociativa perfecta, según losconceptos y definiciones expuestas en el capítulo 2, bajo condiciones más débiles quelas que se requieren para las dos memorias asociativas clásicas mencionadas.
Hay algunos casos en que el CHA falla en su tarea de clasificación. Para superarestas limitaciones, se ideó y diseñó una nueva versión del CHA, mediante la adición deun nuevo paso al algoritmo: la traslación ingeniosa de los ejes coordenados. La nuevaversión, denominada CHAT, Clasificador Híbrido Asociativo con Traslación,
se desarrolla y ejemplifica en la segunda sección.
43

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 54/106
5. Desarrollo 44
5.1. El CHA
En el trascurso de este trabajo se diseñó una nueva memoria asociativa. Estamemoria asociativa, denominada CHAT, está basada en la combinación de las fasesde aprendizaje del Linear Associator y la fase de recuperación de la Lernmatrix . Alcombinar de esta forma las fases se eliminan las limitantes de ambas. Esta partedel trabajo de tesis fue presentada en el CIARP 2002, VII Congreso Iberoamericanode Reconocimiento de Patrones (Santiago-Montero, Yáñez-Márquez & Diaz de León,2002), bajo el título de Clasificador Híbrido de Patrones. Esta memoria ya muestra lasposibilidades de poder clasificar patrones que no están en la fase de aprendizaje de lamemoria asociativa y puede asignarlos acertadamente a una determinada clase.
Como se ilustra en los ejemplos, con la sola combinación de fases no es posible re-cuperar y clasificar patrones con alguna determinada configuración. Esto nos presentadificultades al aplicar el CHA en problemas serios de clasificación. Para remediar loanterior, se creó el CHAT.
5.1.1. Algoritmo del CHA
1. Sea un conjunto fundamental de patrones de entrada de dimensión n con valoresreales en sus componentes (a la manera del Linear Associator ), que se aglutinanen m clases diferentes.
2. A cada uno de los patrones de entrada que pertenece a la clase k se le asigna elvector formado por ceros, excepto en la coordenada k-ésima, donde el valor esuno (a la manera de la Lernmatrix ).
3. La fase de aprendizaje es similar a la del Linear Associator .
4. La fase de recuperación es similar a la que usa la Lernmatrix .
Este algoritmo simple nos permite diseñar un clasificador de patrones, como seilustra en el siguientes ejemplos:
Ejemplo 5.1 Cinco patrones de dimensión 2 con valores reales, aglutinados en dos
clases diferentes:
A la primera clase pertenecen dos patrones:
x1 =
µ −4. 13. 8
¶ y x2 =
µ −4. 84. 2
¶Tres patrones pertenecen a la segunda clase:
x3 =
µ −6. 3−3. 8
¶,x3 =
µ −6. 2−3. 1
¶ y x4 =
µ −7. 0−3. 0
¶Lo anterior significa, de acuerdo con el inciso 2 del algoritmo, que los patrones de
salida son los siguientes:

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 55/106
5. Desarrollo 45
y1 = y2 = µ 10 ¶ y y3 = y4 = y5 = µ 01 ¶Para la fase de aprendizaje, de acuerdo con el inciso 3 del algoritmo, se calculan
los términos yµ · (xµ)t usando la expresión 2.4 y el clasificador C se obtiene a partirde las expresiones 2.5 y 2.6:
C =5X
µ=1
yµ · (xµ)t =
µ −8. 9 8. 0−19. 5 −9. 9
¶ (5.1)
El inciso 4 del algoritmo indica que la fase de recuperación se lleva acabo de acuerdocon la expresión 2.3.
µ −8. 9 8. 0−19. 5 −9. 9
¶·
µ −4. 13. 8
¶ =
µ 66. 8942. 33
¶→
µ 10
¶→ clase 1µ
−8. 9 8. 0−19. 5 −9. 9
¶·
µ −4. 84. 2
¶ =
µ 76. 3252. 02
¶→
µ 10
¶→ clase 1µ
−8. 9 8. 0−19. 5 −9. 9
¶·
µ −6. 3−3. 8
¶ =
µ 25. 67160. 47
¶→
µ 01
¶→ clase 2µ
−8. 9 8. 0−19. 5 −9. 9
¶·
µ −6. 2−3. 1
¶ =
µ 30. 38151. 59
¶→
µ 01
¶→ clase 2
µ −8. 9 8. 0−19. 5 −9. 9
¶ · µ −7. 0−3. 0
¶ = µ 38. 3166. 2¶→ µ 01
¶→ clase 2
Ejemplo 5.2 Ahora probemos el clasi fi cador con dos patrones que no pertencen al conjunto fundamental:
µ −8. 9 8. 0−19. 5 −9. 9
¶·
µ −4. 06. 0
¶ =
µ 83. 618. 6
¶→
µ 10
¶→ clase 1
µ −8. 9 8. 0−19. 5 −9. 9 ¶ ·µ
−6. 0−4. 0 ¶ = µ
21. 2117. 6 ¶→ µ
01 ¶→ clase 2
Nota 5.3 Resulta evidente que este problema de clasi fi cación no puede ser resueltopor la Lernmatrix de Steinbuch, ya que los patrones de entrada no son binarios, comolo requiere ese modelo. Por otro lado, tampoco es posible resolverlo por el Linear As-
sociator , debido a que los patrones de entrada no son ortonormales, como lo exige la expresión 2.9.
Ejemplo 5.4 Cuatro patrones de dimensión 3 con valores reales, aglutinados en dos clases diferentes:

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 56/106
5. Desarrollo 46
A la primera clase pertenecen dos patrones:
x1 =
12. 03. 0
11. 0
y x2 =
10. 01. 0
12. 0
Dos patrones pertenecen a la segunda clase:
x3 =
2. 08. 0
12. 0
, y x4 =
1. 09. 0
11. 0
Lo anterior significa, de acuerdo con el inciso 2 del algoritmo, que los patrones desalida son los siguientes:
y1 = y2 =
µ 10
¶ y y3 = y4 =
µ 01
¶Para la fase de aprendizaje, de acuerdo con el inciso 3 del algoritmo, se calculan
los términos yµ · (xµ)t usando la expresión 2.4 y el clasificador C se obtiene a partirde las expresiones 2.5 y 2.6:
C =5X
µ=1
yµ · (xµ)t =
µ22. 0 4. 0 23. 03. 0 17. 0 23. 0
¶ (5.2)
El inciso 4 del algoritmo indica que la fase de recuperación se lleva acabo de acuerdocon la expresión 2.3.
µ22. 0 4. 0 23. 03. 0 17. 0 23. 0
¶·
12. 03. 0
11. 0
=
µ529. 0340. 0
¶−→
µ 10
¶−→ clase 1
µ22. 0 4. 0 23. 03. 0 17. 0 23. 0
¶·
10. 01. 0
12. 0
=
µ500. 0323. 0
¶−→
µ 10
¶−→ clase 1
µ22. 0 4. 0 23. 03. 0 17. 0 23. 0¶ ·
2. 08. 0
12. 0
= µ
352. 0418. 0¶ −→ µ
01 ¶ −→ clase 2
µ22. 0 4. 0 23. 03. 0 17. 0 23. 0
¶·
1. 09. 0
11. 0
=
µ311. 0409. 0
¶−→
µ 01
¶−→ clase 2
Ejemplo 5.5 Ahora probemos el clasi fi cador con dos patrones que no pertencen al conjunto fundamental:

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 57/106
5. Desarrollo 47
µ22. 0 4. 0 23. 03. 0 17. 0 23. 0
¶·
9. 81. 4
11. 6
=
µ488. 0320. 0
¶−→
µ 10
¶−→ clase 1
µ22. 0 4. 0 23. 03. 0 17. 0 23. 0
¶·
2. 27. 7
12. 6
=
µ369. 0427. 3
¶−→
µ 01
¶−→ clase 2
Nota 5.6 En el ejemplo anterior se ha cambiado la dimensión de los patrones de entrada a 3. El clasi fi cador tiene nuevamente recuperación perfecta y también ha re-cuperado patrones que no pertenecen al conjunto fundamental de manera correcta, al agrupar cada patrón en su respectiva clase.
Ejemplo 5.7 Seis patrones de dimensión 5 con valores reales, aglutinados en tres clases diferentes:
A la primera clase pertenecen dos patrones:
x1 =
1210242
y x2 =
12. 610. 92. 33. 51. 8
Dos patrones pertenecen a la segunda clase:
x3 =
121
1112
y x4 =
1. 12. 21. 5
10. 611. 8
Y dos patrones para la tercera clase:
x
5
=
12
13111
y x6
=
1. 21. 9
13. 211. 40. 9
Lo anterior significa, de acuerdo con el inciso 2 del algoritmo, que los patrones desalida son los siguientes:
y1 = y2 =
100
, y3 = y4 =
010
y y5 = y6 =
001
Para la fase de aprendizaje, de acuerdo con el inciso 3 del algoritmo, se calculanlos términos yµ · (xµ)t usando la expresión 2.4 y el clasificador C se obtiene a partir
de las expresiones 2.5 y 2.6:
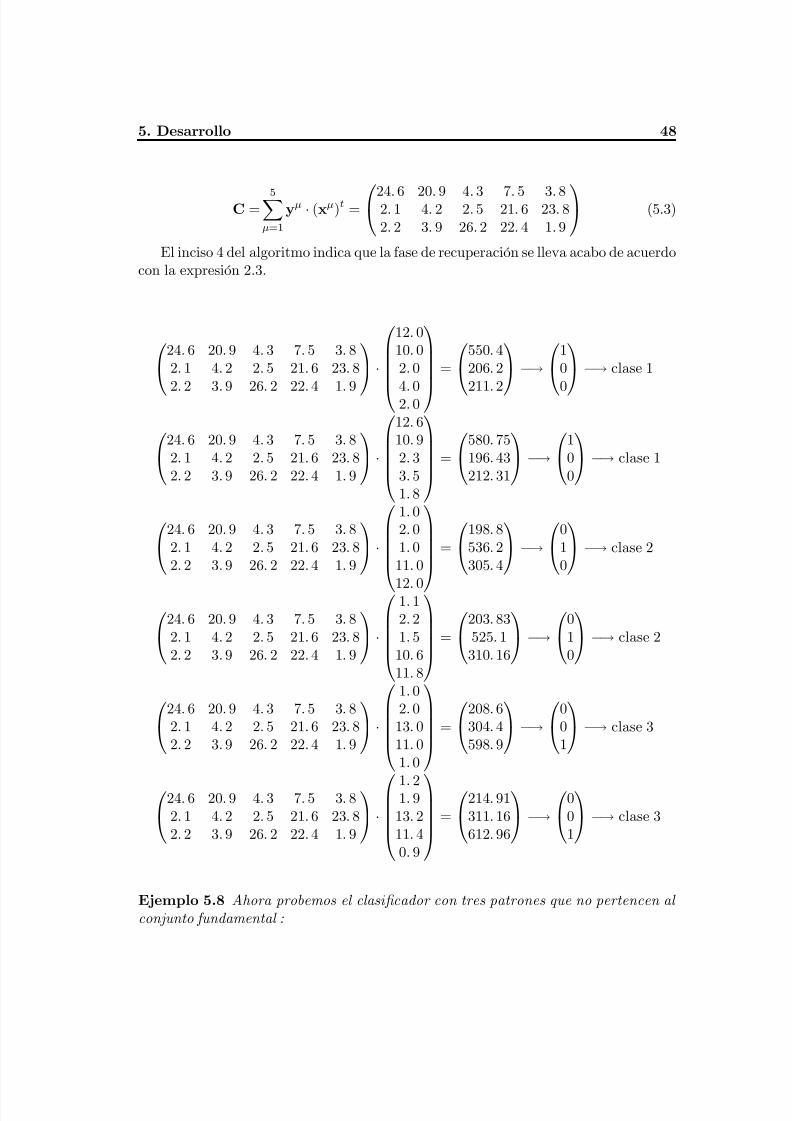
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 58/106
5. Desarrollo 48
C =5X
µ=1
yµ · (xµ)t =24. 6 20. 9 4. 3 7. 5 3. 82. 1 4. 2 2. 5 21. 6 23. 8
2. 2 3. 9 26. 2 22. 4 1. 9
(5.3)
El inciso 4 del algoritmo indica que la fase de recuperación se lleva acabo de acuerdocon la expresión 2.3.
24. 6 20. 9 4. 3 7. 5 3. 82. 1 4. 2 2. 5 21. 6 23. 8
2. 2 3. 9 26. 2 22. 4 1. 9
·
12. 010. 02. 0
4. 02. 0
=
550. 4206. 2
211. 2
−→
10
0
−→ clase 1
24. 6 20. 9 4. 3 7. 5 3. 82. 1 4. 2 2. 5 21. 6 23. 82. 2 3. 9 26. 2 22. 4 1. 9
·
12. 610. 92. 33. 51. 8
=
580. 75196. 43212. 31
−→
100
−→ clase 1
24. 6 20. 9 4. 3 7. 5 3. 82. 1 4. 2 2. 5 21. 6 23. 82. 2 3. 9 26. 2 22. 4 1. 9
·
1. 02. 01. 0
11. 0
12. 0
=
198. 8536. 2305. 4
−→
010
−→ clase 2
24. 6 20. 9 4. 3 7. 5 3. 82. 1 4. 2 2. 5 21. 6 23. 82. 2 3. 9 26. 2 22. 4 1. 9
·
1. 12. 21. 5
10. 611. 8
=
203. 83525. 1
310. 16
−→
010
−→ clase 2
24. 6 20. 9 4. 3 7. 5 3. 82. 1 4. 2 2. 5 21. 6 23. 82. 2 3. 9 26. 2 22. 4 1. 9
·
1. 02. 0
13. 011. 01. 0
=
208. 6304. 4598. 9
−→
001
−→ clase 3
24. 6 20. 9 4. 3 7. 5 3. 82. 1 4. 2 2. 5 21. 6 23. 82. 2 3. 9 26. 2 22. 4 1. 9
·
1. 21. 913. 211. 40. 9
=
214. 91311. 16612. 96
−→
001
−→ clase 3
Ejemplo 5.8 Ahora probemos el clasi fi cador con tres patrones que no pertencen al conjunto fundamental :

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 59/106
5. Desarrollo 49
24. 6 20. 9 4. 3 7. 5 3. 82. 1 4. 2 2. 5 21. 6 23. 82. 2 3. 9 26. 2 22. 4 1. 9
·
11. 410. 61. 94. 12. 3
=
549. 64216. 51212. 41
−→
100
−→ clase 1
24. 6 20. 9 4. 3 7. 5 3. 82. 1 4. 2 2. 5 21. 6 23. 82. 2 3. 9 26. 2 22. 4 1. 9
·
1. 12. 11. 3
10. 512. 9
=
204. 31548. 2
304. 38
−→
010
−→ clase 2
24. 6 20. 9 4. 3 7. 5 3. 82. 1 4. 2 2. 5 21. 6 23. 82. 2 3. 9 26. 2 22. 4 1. 9
·
1. 12. 513. 8
11. 561. 2
=
229. 91325. 57634. 95
−→
001
−→ clase 3
Nota 5.9 Nuevamente el clasi fi cador ha recuperado todo su conjunto fundamental de forma correcta, para tener una vez más recuperacion perfecta. Lo mismo ha ocurridoal someter al clasi fi cador, patrones que no pertenecen al conjunto fundamental clasi- fi cándolos de manera correcta, aquí las dimensiones tanto de los patrones de entrada
como los de salida que codi fi can las clases, son diferentes y no han in fl uido en el comportamiento del clasi fi cador.
Ejemplo 5.10 2 patrones de dimensión 2 con valores reales, aglutinados en dos clases diferentes:
A la primera clase pertenece el patrón:
x1
= µ 2. 13. 8 ¶
A la segunda clase:
x2 =
µ 6. 33. 8
¶Lo anterior significa, de acuerdo con el inciso 2 del algoritmo, que los patrones de
salida son los siguientes:
y1 =
µ 10
¶ y y2 =
µ 01
¶

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 60/106
5. Desarrollo 50
Para la fase de aprendizaje, de acuerdo con el inciso 3 del algoritmo, se calculan
los términos yµ · (xµ)t
usando la expresión 2.4 y el clasificador C se obtiene a partirde las expresiones 2.5 y 2.6:
C =5X
µ=1
yµ · (xµ)t =
µ2. 1 3. 86. 3 3. 8
¶ (5.4)
El inciso 4 del algoritmo indica que la fase de recuperación se lleva a cabo deacuerdo con la expresión 2.3.µ
2. 1 3. 86. 3 3. 8
¶·
µ2. 13. 8
¶ =
µ18. 8527. 67
¶−→
µ01
¶−→¿clase 2?
µ2. 1 3. 86. 3 3. 8¶ · µ6. 33. 8¶ = µ27. 6754. 13¶ −→ µ01¶ −→clase 2
Nota 5.11 El ejemplo anterior nos muestra los efectos causados cuando tenemos al menos un patrón de entrada de magnitud mucho mayor a las magnitudes de los otros patrones de entrada, el clasi fi cador tiende a asignar los patrones de menor magnitud a la clase cuyos patrones tienen la mayor magnitud.
5.2. El CHAT
En esta sección mostraremos ejemplos, en los que se puede observar cómo el CHA
se transforma en CHAT y así supera las limitaciones mencionadas de las dos memo-rias asociativas, el Linear Associator y la Lernmatrix y además, de qué manera setransforma en un clasificador de alto rendimiento, al agregar la traslación de ejes.
El ejemplo 5.10 muestra una desventaja para la clasificación de patrones agrupadosen un mismo cuadrante del plano, con una clase con patrones cuya magnitud es muchomayor a la magnitud de los patrones de las otras clases presentes en el problema declasificación. Esto para efectos prácticos representa una gran desventaja, dado que enel área de clasificación de patrones es una constante que los patrones de las clases aclasificar se encuentren en el mismo plano y con magnitudes diferentes en sus vectores.
La solución, que en el presente trabajo se realiza para resolver este problema, esla traslación de ejes, con el nuevo origen situado en el centroide de los vectores querepresentan a los patrones de entrada.
Sean x1,x2,...xµ un conjunto de patrones de entrada, y sea x el vector medio detodos ellos (González & Woods, 2001), donde:
x = 1
p
p
X j=1
xµ (5.5)

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 61/106
5. Desarrollo 51
Trasladando los ejes a un nuevo origen cuyas coordenadas son las del vector medio
de los patrones de entrada del conjunto fundamental, se crea un nuevo conjunto depatrones trasladados x10
, x20
,...,x p0
, donde:
xµ0
= xµ − x (5.6)
∀xµ con µ ∈ 1, 2,...,p
Una vez trasladado todo el conjunto de patrones de entrada, se procede con el
algoritmo descrito en la sección anterior. Este proceso de traslación se hace tambiéncon todo nuevo patrón de entrada que se desee clasificar.
5.2.1. Interpretación teórica del CHAT
En esencia el CHAT utiliza las representaciones vectoriales de los patrones paraclasificar. Esto lo hace mediante la medición del menor ángulo entre un vector pro-totipo, de alguna de las clases contenidas en la memoria del clasificador y un vectordesconocido del cual se desea obtener su clase asociada. Para una medición del ánguloantes mencionado, y obtener una asociación más precisa con su clase, es necesaria latraslación de ejes a un punto, en el espacio de características, donde los ángulos entrevectores, representantes de las diferentes clases involucradas, sean significativos paraclases distintas y muy reducidos para la misma clase.
5.2.2. Algoritmo del CHAT
1. Sea un conjunto fundamental de patrones de entrada de dimensión n con valoresreales en sus componentes (a la manera del Linear Associator ), que se aglutinanen m clases diferentes.
2. A cada uno de los patrones de entrada que pertenece a la clase k se le asigna elvector formado por ceros, excepto en la coordenada k-ésima, donde el valor esuno (a la manera de la Lernmatrix ).
3. Se calcula el vector medio del conjunto de patrones muestra o prototipos conque se cuente.
4. Se toman las coordenadas del vector medio a manera de centro de un nuevoconjunto de ejes coordenados.
5. Se realiza la traslación de todos los patrones del conjunto fundamental.
6. Aplicamos la fase de aprendizaje, que es similar a la del Linear Associator .

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 62/106
5. Desarrollo 52
7. Aplicacos la fase de recuperación, que es similar a la que usa la Lernmatrix .
8. Trasladamos todo patrón a clasificar en los nuevos ejes.
9. Procedemos a clasificar los patrones desconocidos.
Ejemplo 5.12 Sea el mismo conjunto de patrones del ejemplo 5.10:
A la primera clase pertenece el patrón:
x1 = µ 2. 13. 8 ¶
A la segunda clase:
x2 =
µ 6. 33. 8
¶Se realiza la traslación de los vectores de entrada, de acuerdo con 5.5, entonces
tenemos que:
x = 1
p
p
X j=1
xµ = 1
2 ·µ 2. 13. 8 ¶
+
µ 6. 33. 8 ¶¸
=
µ4. 23. 8¶
donde de acuerdo con 5.6 los patrones de entrada ahora son:
x10
=
µ2. 13. 8
¶−
µ4. 23. 8
¶ =
µ−2. 10. 0
¶
x20
=
µ6. 33. 8
¶−
µ4. 23. 8
¶ =
µ2. 10. 0
¶Lo anterior significa, de acuerdo con el inciso 2 del algoritmo, que los patrones de
salida son los siguientes:
y10
= µ 10 ¶ y y20
= µ 01 ¶Para la fase de aprendizaje, de acuerdo con el inciso 3 del algoritmo, se calculan
los términos yµ · (xµ)t usando la expresión 2.4 y el clasificador C se obtiene a partirde las expresiones 2.5 y 2.6:
C =5X
µ=1
yµ · (xµ)t =
µ−2. 1 02. 1 0
¶ (5.7)
El inciso 4 del algoritmo indica que la fase de recuperación se lleva acabo de acuerdocon la expresión 2.3.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 63/106
5. Desarrollo 53
µ−2. 1 02. 1 0¶ ·µ−2. 10. 0 ¶ = µ 4. 41−4. 41¶ −→ µ10¶ −→clase 1µ
−2. 1 02. 1 0
¶·
µ2. 10. 0
¶ =
µ−4. 414. 41
¶−→
µ01
¶−→clase 2
Ejemplo 5.13 2 patrones de dimensión 3 con valores reales, aglutinados en dos clases diferentes:
A la primera clase pertenece el patrón:
x1 =
2. 0
3. 06. 0
A la segunda clase:
x2 =
6. 08. 0
10. 0
Lo anterior significa, de acuerdo con el inciso 2 del algoritmo, que los patrones desalida son los siguientes:
y1 = µ 10 ¶ y y2 = µ 0
1 ¶Para la fase de aprendizaje, de acuerdo con el inciso 3 del algoritmo, se calculan
los términos yµ · (xµ)t usando la expresión 2.4 y el clasificador C se obtiene a partirde las expresiones 2.5 y 2.6:
C =5X
µ=1
yµ · (xµ)t =
µ2. 0 3. 0 6. 06. 0 8. 0 10. 0
¶ (5.8)
El inciso 4 del algoritmo indica que la fase de recuperación se lleva a cabo deacuerdo con la expresión 2.3.
µ2. 0 3. 0 6. 06. 0 8. 0 10. 0
¶·
2. 03. 06. 0
=
µ49. 096. 0
¶−→
µ01
¶−→¿clase 2?
µ2. 0 3. 0 6. 06. 0 8. 0 10. 0
¶·
6. 08. 0
10. 0
=
µ 96. 0200. 0
¶−→
µ01
¶−→clase 2
Probemos el clasificador con otros patrones desconocidos pero que pertenecen a lasclases involucradas en el ejemplo.
A la primera clase pertenece el patrón:

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 64/106
5. Desarrollo 54
x3 =1. 93. 8
5. 5
A la segunda clase:
x4 =
6. 47. 29. 7
El inciso 4 del algoritmo indica que la fase de recuperación se lleva a cabo deacuerdo con la expresión 2.3.
µ2. 0 3. 0 6. 06. 0 8. 0 10. 0
¶·
1. 93. 85. 5
=
µ48. 296. 8
¶−→
µ01
¶−→¿clase 2?
µ2. 0 3. 0 6. 06. 0 8. 0 10. 0
¶·
6. 47. 29. 7
=
µ 92. 6193. 0
¶−→
µ01
¶−→clase 2
De acuerdo con el algoritmo del CHA, la recuperación del conjunto no es perfectay patrones que pertenecen a la clase 1 son clasificados como clase 2.
Con la de traslación de ejes se prueba el mismo conjunto de fundamental y lospatrones desconocidos en la fase de aprendizaje.
A la primera clase pertenece el patrón:
x1 =
2. 03. 06. 0
A la segunda clase:
x2 =
6. 08. 0
10. 0
Se realiza la traslación de los vectores de entrada, de acuerdo con 5.5, entoncestenemos que:
x = 1
p
pX j=1
xµ = 1
2
2. 03. 06. 0
+
6. 08. 0
10. 0
=
4. 05. 58. 0
donde de acuerdo con 5.6 los patrones de entrada ahora son:
x10
=
2. 03. 0
6. 0
−
4. 05. 5
8. 0
=
−2. 0−2. 5
−2. 0

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 65/106
5. Desarrollo 55
x20
= 6. 08. 0
10. 0
−
4. 05. 5
8. 0
=
2. 02. 5
2. 0
Lo anterior significa, de acuerdo con el inciso 2 del algoritmo, que los patrones desalida son los siguientes:
y10
=
µ 10
¶ y y2
0
=
µ 01
¶Para la fase de aprendizaje, de acuerdo con el inciso 3 del algoritmo, se calculan
los términos yµ · (xµ)t usando la expresión 2.4 y el clasificador C se obtiene a partirde las expresiones 2.5 y 2.6:
C =5X
µ=1
yµ · (xµ)t =
µ−2. 0 −2. 5 −2. 02. 0 2. 5 2. 0
¶ (5.9)
El inciso 4 del algoritmo indica que la fase de recuperación se lleva acabo de acuerdocon la expresión 2.3.
µ−2. 0 −2. 5 −2. 02. 0 2. 5 2. 0
¶·
−2,0−2. 5−2. 0
=
µ 14. 25−14. 25
¶−→
µ10
¶−→clase 1
µ−2. 0 −2. 5 −2. 02. 0 2. 5 2. 0
¶·2. 02. 5
2. 0
=
µ−14. 2514. 25
¶−→
µ01¶−→clase 2
Se procede ahora a probar el Clasi fi cador Híbrido Asociativo con Traslación (CHAT)con los vectores que no pertenecen al conjunto fundamental.
A la primera clase pertenece el patrón:
x3 =
1. 93. 85. 5
A la segunda clase:
x4 =
6. 47. 29. 7
donde de acuerdo con 5.6 los patrones de entrada ahora son:
x30
=
1. 93. 85. 5
−
4. 05. 58. 0
=
−2. 1−1. 7−2. 5

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 66/106
5. Desarrollo 56
x40
=6. 47. 2
9. 7
−
4. 05. 5
8. 0
=
2. 41. 7
1. 7
El inciso 4 del algoritmo indica que la fase de recuperación se lleva acabo de acuerdocon la expresión 2.3.
µ−2. 0 −2. 5 −2. 02. 0 2. 5 2. 0
¶·
−2. 1−1. 7−2. 5
=
µ 13. 45−13. 45
¶−→
µ10
¶−→clase 1
µ−2. 0 −2. 5 −2. 0
2. 0 2. 5 2. 0 ¶ ·
2. 4
1. 71. 7
= µ−12. 45
12. 45 ¶ −→ µ0
1¶ −→clase 2

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 67/106
Capítulo 6
Disquisiciones experimentales
En este capítulo se muestra experimentalmente el rendimiento del CHAT: Clasi-ficador Híbrido Asociativo con Traslación, ante conjuntos de patrones contenidosen 4 bases de datos públicas; estos patrones están agrupados en clases. Los aspectosde interés que se tomaron en cuenta para realizar los experimentos son los mismos quese han registrado en la literatura sobre clasificadores, donde el punto de interés radicaesencialmente en el porcentaje de clasificación correcta del conjunto de patrones con-tenidos en las bases respectivas. Las bases de datos públicas se encuentran en la UCI Machine Learning Data Bases Repository, del ICS, de la universidad de California,Irvine: http://ftp.ics.uci.edu/pub/machine-learning-databases.
Las bases de datos que fueron usadas en los experimentos son:-Iris plants database.-Wine recognition data.-Contraceptive method choice (cmc).-Credit approval database.
En cada una de las bases de datos, un renglón representa un patrón, con la primeracolumna señalando la clase a la cual pertenece el patrón de la fila respectiva. Las sub-secuentes columnas en la misma fila contienen datos que representan las característicasdel objeto.
Los experimentos se llevaron a cabo en una PC genérica con procesador PentiumII a 350MHz, 128 MBytes de RAM y un disco duro de 6 Gbytes, con sistema operativoWindows 2000 de Microsoft. El programa se realizó en el lenguaje C++ y se utilizóel compilador de Borland, C++ Builder 5 . Las bases de datos se almacenaron enarchivos secuenciales, así como los resultados obtenidos de la clasificación.
6.1. Base de datos
A continuación se exhiben breves comentarios respecto de cada una de las basesde datos que se usaron para llevar a cabo los experimentos.
57

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 68/106
6. Disquisiciones experimentales 58
6.1.1. Iris plants database
Esta es tal vez la base de datos más conocida que se encuentra en la literatura delreconocimiento de patrones. Usada por Fisher (Fisher, 1936), es un clásico en el campoy una referencia frecuente hasta nuestros días (Duda, Hart, & Strork, 2001; Gonzalez& Woods, 2001). El conjunto de datos contiene 3 clases de 50 instancias cada una,donde cada clase hace referencia a un tipo de planta de iris (Iris Setosa, Iris Versicolore Iris Virginia). Cada patrón que representa una planta de iris tiene 4 atributos, másuno que representa la clase. En esta base de datos los rasgos que representan el largoy ancho de los pétalos están altamente correlacionados.
Información de los atributos
Rasgos Descripción
1 Clase: 1:Iris Setosa,2:Iris Versicolour, 3:Iris Virginia
2 Largo del sépalo en centímetros
3 Ancho del sépalo en centímetros
4 Largo del pétalo en centímetros
5 Ancho del pétalo en centímetros
Tabla 6.1: Descripción de rasgos (Iris plants).
6.1.2. Wine recognition dataEsta base de datos presenta los resultados de un análisis químico de vinos produci-
dos en una misma región de Italia pero que provienen de diferentes cultivos (Forina,et al, 1991). Los patrones están agrupados en 3 clases con una distribución de 59 pa-trones para la clase 1, 71 patrones para la clase 2 y 48 patrones para la clase 3. Elanálisis determina las cantidades de 13 constituyentes encontrados en cada uno de lostres tipos de vinos. En el contexto de clasificadores, es un buen problema para probarun nuevo clasificador.
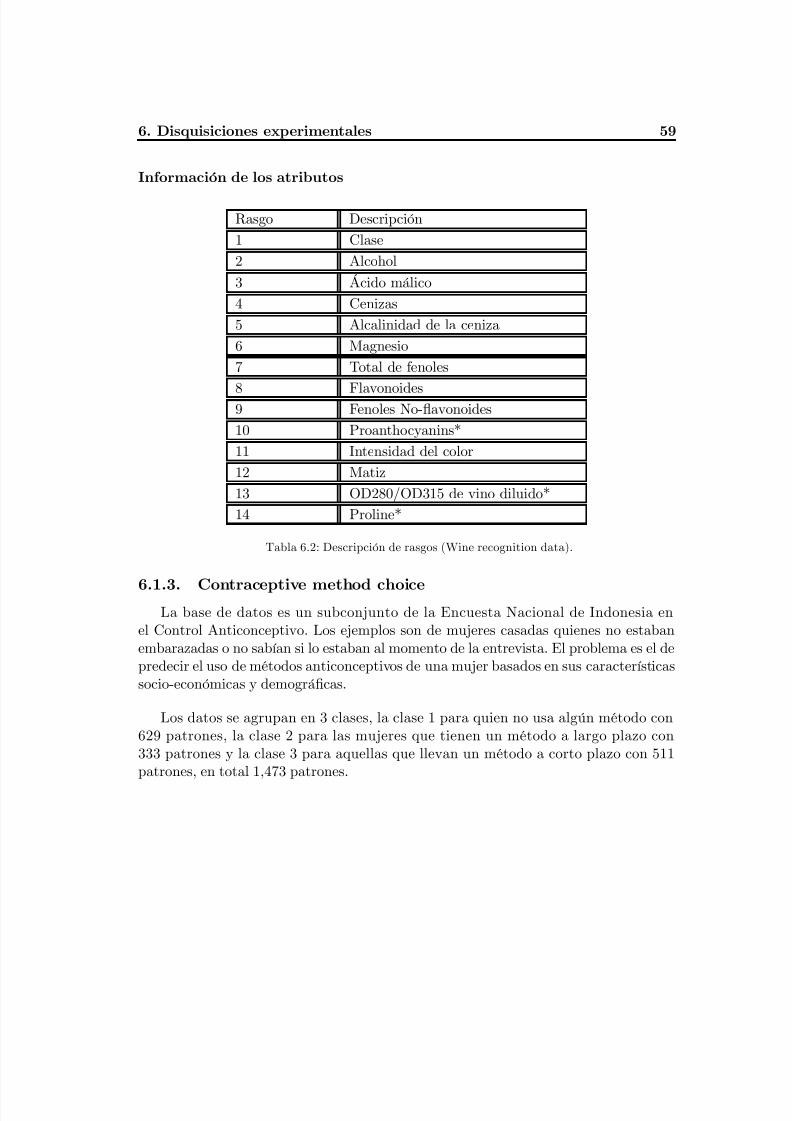
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 69/106
6. Disquisiciones experimentales 59
Información de los atributos
Rasgo Descripción
1 Clase
2 Alcohol
3 Ácido málico
4 Cenizas
5 Alcalinidad de la ceniza
6 Magnesio
7 Total de fenoles
8 Flavonoides9 Fenoles No-flavonoides
10 Proanthocyanins*
11 Intensidad del color
12 Matiz
13 OD280/OD315 de vino diluido*
14 Proline*
Tabla 6.2: Descripción de rasgos (Wine recognition data).
6.1.3. Contraceptive method choiceLa base de datos es un subconjunto de la Encuesta Nacional de Indonesia en
el Control Anticonceptivo. Los ejemplos son de mujeres casadas quienes no estabanembarazadas o no sabían si lo estaban al momento de la entrevista. El problema es el depredecir el uso de métodos anticonceptivos de una mujer basados en sus característicassocio-económicas y demográficas.
Los datos se agrupan en 3 clases, la clase 1 para quien no usa algún método con629 patrones, la clase 2 para las mujeres que tienen un método a largo plazo con333 patrones y la clase 3 para aquellas que llevan un método a corto plazo con 511patrones, en total 1,473 patrones.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 70/106
6. Disquisiciones experimentales 60
Información de los atributos
Rasgo Descripción
1 Clase
2 Edad
3 Grado educativo
4 Grado educativo de la pareja
5 Número de niños ya concebidos
6 Religión
7 Trabajo
8 Ocupación de la pareja9 Índice del estandar de vida
10 Riesgo de vida
Tabla 6.3: Descripción de rasgos (Cmc).
6.1.4. Credit approval database
En esta base de datos se encuentra recabada la información de personas sujetasa crédito por parte de alguna institución financiera la cual, con base en los datosobtenidos, formula una aprobación o no, de crédito para el cliente. No existe informa-
ción complementaria a esta base de datos y la descripción de datos se omite por serde tipo confidencial; se sabe que existen 2 clase distribuidas de la siguiente forma: 307patrones para la clase 1 y 383 para la clase 2 para un total de 690 patrones.
6.2. Metodología
Se forma un vector de rasgos (también conocido como vector patrón o vector característico) con dimensión igual al número de características representadasen el patrón; dado que la primera columna de la base de datos señala la clase,no se incluirá en el vector de rasgos .
Cada componente del vector de rasgos toma sus valores de cada uno de los valorescontenidos en el patrón, respetando el orden ya establecido. Este procedimientose hace con cada uno de los patrones de la base de datos.
Posteriormente se obtiene del conjunto de vectores un vector prototipo o vector medio (Gonzalez & Woods, 2001).
Una vez obtenido el vector medio, en el punto terminal de este vector establecidopor sus n-componentes se determina el centroide del conjunto de vectores derasgos.
Mediante este centroide se hace una traslación de todos los vectores de rasgos,
respetando el orden de la base de datos original.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 71/106
6. Disquisiciones experimentales 61
Trasladados los vectores de rasgos, se toma un subconjunto de vectores de ca-
racterísticas de forma aleatoria de cada una de las clases involucradas; cada claseaportará al conjunto fundamental un número igual de vectores de rasgos para serutilizados en la fase de aprendizaje y en la fase de recuperación del ClasificadorHíbrido Asociativo con Traslación.
Ya que se ha obtenido el CHAT en la fase de aprendizaje, se someten al clasifi-cador los vectores de rasgos uno a uno y se procede a la clasificación, obteniendoen cada caso un número que representa la clase.
Una vez obtenidos todos los resultados se procede a realizar un análisis de éstos,donde se establece como clasificación correcta, si la clase resultante es igual ala clase ya establecida para cada uno de los vectores de rasgos sometidos a la
clasificación; calculando así un porcentaje de clasificaciones.
6.3. Estudio comparativo entre el CHAT y otros algorit-mos de clasificación
En esta sección mostramos el rendimiento que se obtuvo del Clasificador HíbridoAsociativo con Traslación (CHAT) en cada una de las base de datos descritas anteri-ormente en este capítulo; además se confrontan estos resultados con los obtenidos enestas mismas bases de datos por diversos clasificadores, los resultados mostrados estánen porcentajes de correcta clasificación de los patrones contenidos en las diversas bases
de datos.
Los clasificadores que se han tomado en cuenta para esta comparación son el yamuy conocido KNN (K- Nearest Neighbours) con dos variantes, 1-NN y KNN con K=3.Estos clasificadores fueron implementados en su totalidad en lenguaje C++ bajo elambiente visual del compilador C++ Builder 5 de Borland, bajo las mismas condicionesque el CHAT. Además, de estos 2 clasificadores se tomaron los estudios comparativosque se realizaron en la tesis de maestría Algoritmo C-means difuso usando funciones de disimilaridad (Ayaquica, 2002) y se sometieron estas mismas bases de datos alos clasificadores c-means y c-means difuso contra el rendimiento presentado por elc-means difuso usando funciones de disimilaridad.
En el caso de los clasificadores 1-NN y 3-NN se ha utilizado un conjunto prototipode 5 y 8 elementos por cada clase respectivamente, todos escogidos de forma aleato-ria, para el CHAT se ha utilizado un conjunto fundamental de 4 patrones por clasetambién escogidos de manera aleatoria.
6.3.1. Iris plants database
Con esta base de datos se realizaron 20 pruebas de clasificación para el clasificadorCHAT y los KNN. Los resultados tomados del trabajo de tesis de maestría sólopresentan 10 pruebas de clasificación y se han tomado directamente del trabajo.
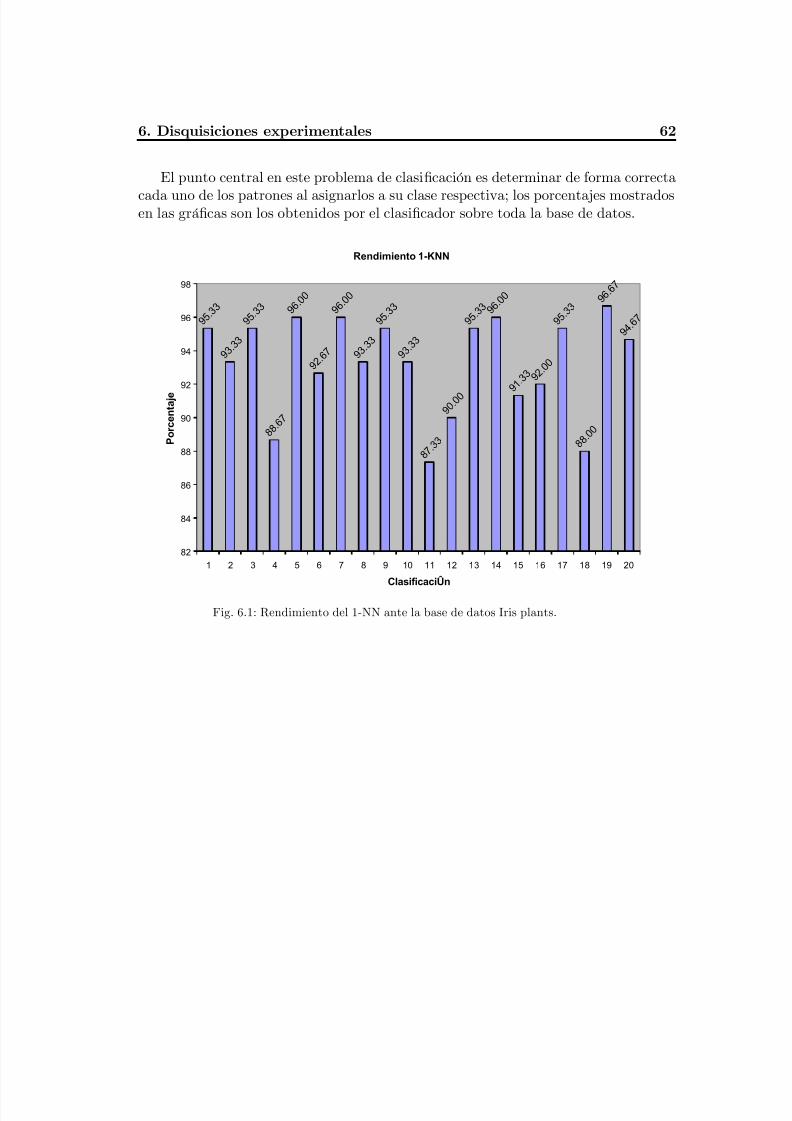
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 72/106
6. Disquisiciones experimentales 62
El punto central en este problema de clasificación es determinar de forma correcta
cada uno de los patrones al asignarlos a su clase respectiva; los porcentajes mostradosen las gráficas son los obtenidos por el clasificador sobre toda la base de datos.
Rendimiento
1-KNN
9 5 . 3 3
9 3 . 3 3
9 5 . 3 3
8 8 . 6 7
9 6 . 0 0
9 2 . 6 7
9 6 . 0 0
9 3 . 3 3
9 5 . 3 3
9 3 . 3 3
8 7 . 3 3
9 0 . 0 0
9 5 . 3 3 9 6
. 0 0
9 1 . 3 3 9 2
. 0 0
9 5 . 3 3
8 8 . 0 0
9 6 . 6 7
9 4 . 6 7
82
84
86
88
90
92
94
96
98
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
ClasificaciÛn
P o r c e n t a j e
Fig. 6.1: Rendimiento del 1-NN ante la base de datos Iris plants.
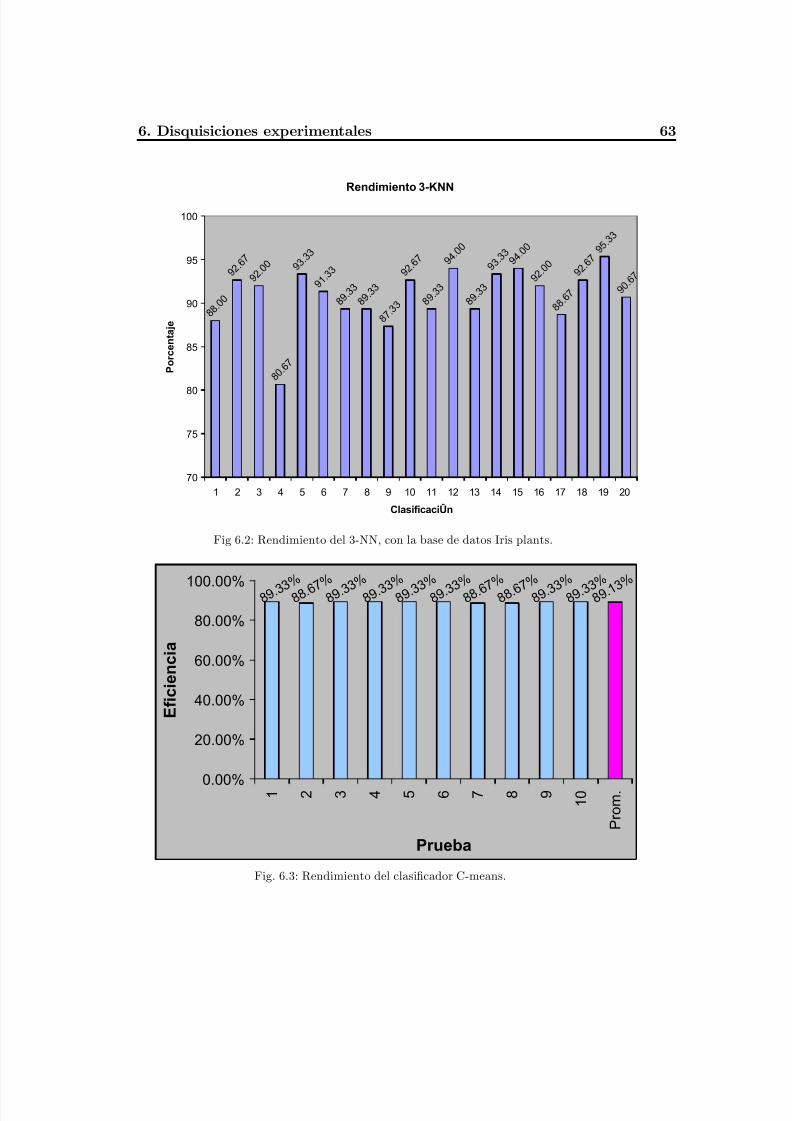
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 73/106
6. Disquisiciones experimentales 63
Rendimiento 3-KNN
8 8 . 0 0
9 2 . 6 7
9 2 . 0 0
8 0 . 6 7
9 3 . 3 3
9 1 . 3 3
8 9 . 3 3
8 9 . 3 3
8 7 . 3 3
9 2 . 6 7
8 9 . 3 3
9 4 . 0 0
8 9 . 3 3
9 3 . 3 3
9 4 . 0 0
9 2 . 0 0
8 8 . 6 7
9 2 . 6 7
9 5 . 3 3
9 0 . 6 7
70
75
80
85
90
95
100
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
ClasificaciÛn
P o r c e n t a j e
Fig 6.2: Rendimiento del 3-NN, con la base de datos Iris plants.
8 9. 3 3 %
8 8. 6 7 %
8 9. 3 3 %
8 9. 3 3 %
8 9. 3 3 %
8 9. 3 3 %
8 8. 6 7 %
8 8. 6 7 %
8 9. 3 3 %
8 9. 3 3 %
8 9. 1 3 %
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
1 2 3 4 5 6 7 8 9 1 0
P r o m
.
Prueba
E f i c i e n c i a
Fig. 6.3: Rendimiento del clasificador C-means.
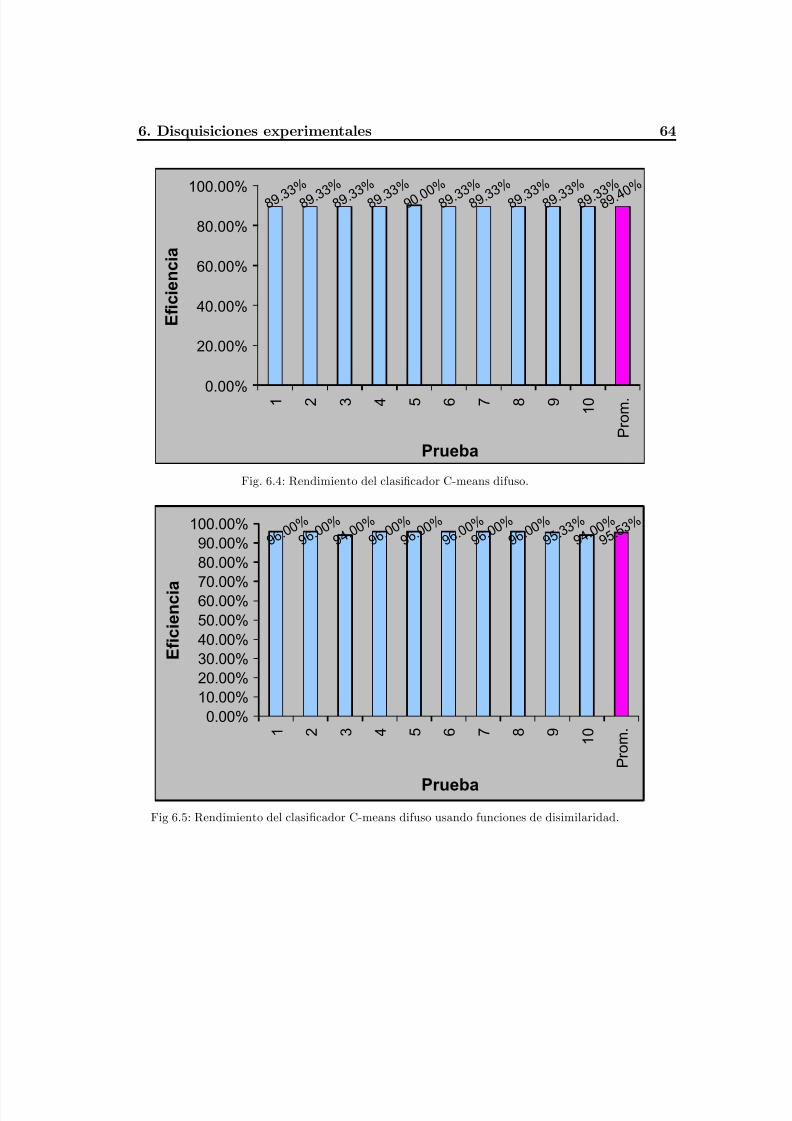
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 74/106
6. Disquisiciones experimentales 64
8 9. 3 3 %
8 9. 3 3 %
8 9. 3 3 %
8 9. 3 3 %
9 0. 0 0 %
8 9. 3 3 %
8 9. 3 3 %
8 9. 3 3 %
8 9. 3 3 %
8 9. 3 3 %
8 9. 4 0 %
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
1 2 3 4 5 6 7 8 9 1 0
P r o m
.
Prueba
E f i c i e n c i a
Fig. 6.4: Rendimiento del clasificador C-means difuso.
9 6. 0 0 %
9 6. 0 0 %
9 4. 0 0 %
9 6. 0 0 %
9 6. 0 0 %
9 6. 0 0 %
9 6. 0 0 %
9 6. 0 0 %
9 5. 3 3 %
9 4. 0 0 %
9 5. 5 3 %
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%70.00%
80.00%
90.00%
100.00%
1 2 3 4 5 6 7 8 9 1 0
P r o m
.
Prueba
E f i c i e n c i a
Fig 6.5: Rendimiento del clasificador C-means difuso usando funciones de disimilaridad.
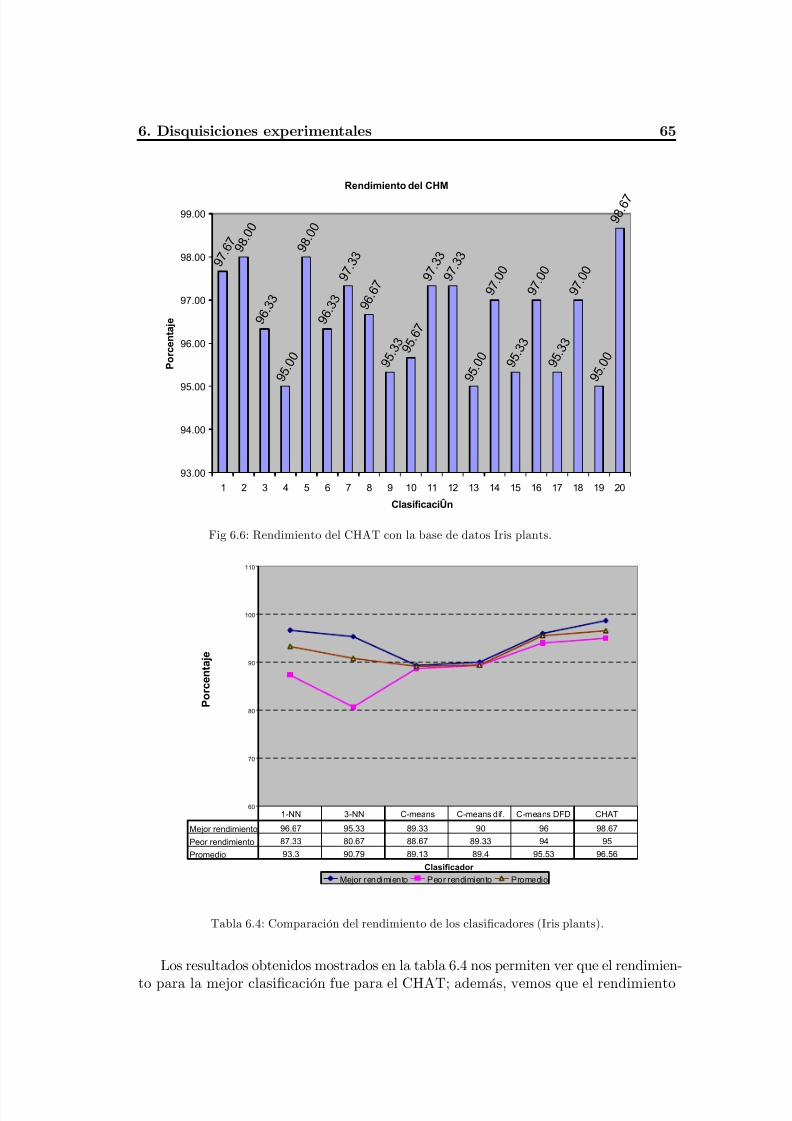
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 75/106
6. Disquisiciones experimentales 65
Rendimiento del CHM
9 7
. 6 7
9 8
. 0 0
9 6
. 3 3
9 5
. 0 0
9 8
. 0 0
9 6
. 3 3
9 7
. 3 3
9 6
. 6 7
9 5
. 3 3
9 5
. 6 7
9 7
. 3 3
9 7
. 3 3
9 5
. 0 0
9 7
. 0 0
9 5
. 3 3
9 7
. 0 0
9 5
. 3 3
9 7
. 0 0
9 5
. 0 0
9 8
. 6 7
93.00
94.00
95.00
96.00
97.00
98.00
99.00
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
ClasificaciÛn
P o r c e n t a j e
Fig 6.6: Rendimiento del CHAT con la base de datos Iris plants.
60
70
80
90
100
110
Clasificador
P o r c e n t a j e
Mejor rendimiento Peor rendimiento Promedio
Mejor rendimiento 96.67 95.33 89.33 90 96 98.67
Peor rendimiento 87.33 80.67 88.67 89.33 94 95
Promedio 93.3 90.79 89.13 89.4 95.53 96.56
1-NN 3-NN C-means C-means dif. C-means DFD CHAT
Tabla 6.4: Comparación del rendimiento de los clasificadores (Iris plants).
Los resultados obtenidos mostrados en la tabla 6.4 nos permiten ver que el rendimien-
to para la mejor clasificación fue para el CHAT; además, vemos que el rendimiento
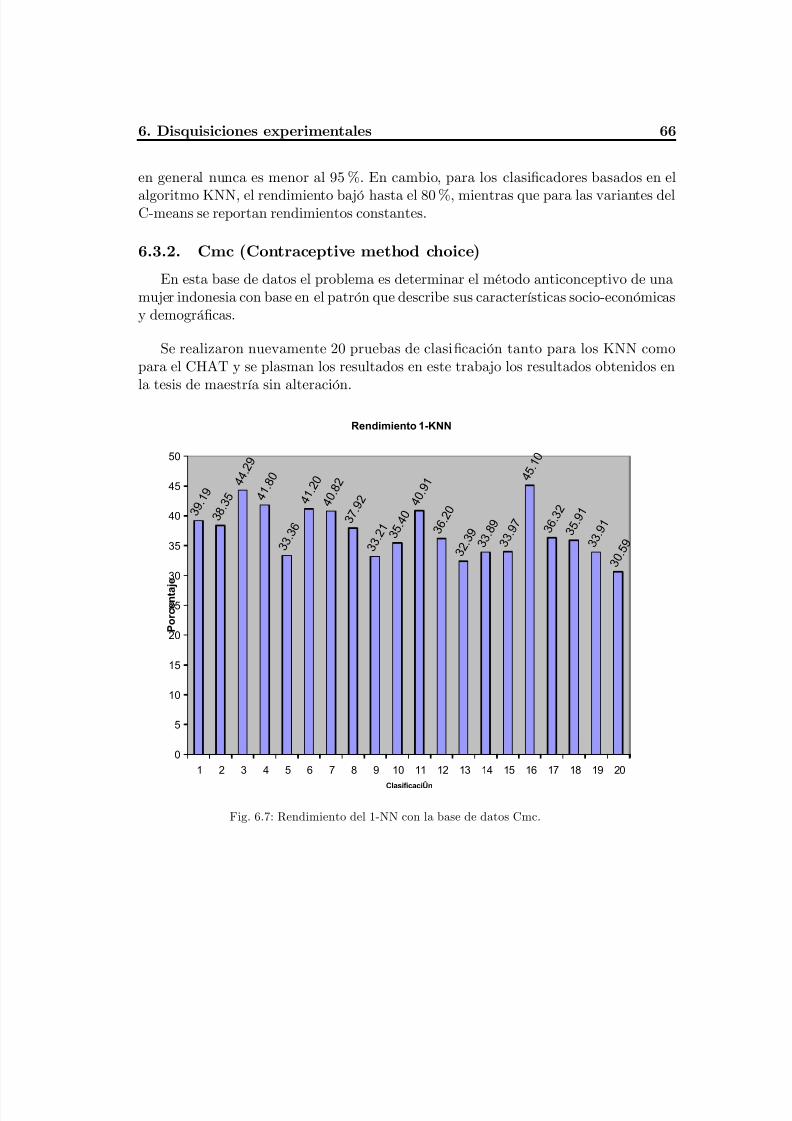
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 76/106
6. Disquisiciones experimentales 66
en general nunca es menor al 95 %. En cambio, para los clasificadores basados en el
algoritmo KNN, el rendimiento bajó hasta el 80 %, mientras que para las variantes delC-means se reportan rendimientos constantes.
6.3.2. Cmc (Contraceptive method choice)
En esta base de datos el problema es determinar el método anticonceptivo de unamujer indonesia con base en el patrón que describe sus características socio-económicasy demográficas.
Se realizaron nuevamente 20 pruebas de clasificación tanto para los KNN comopara el CHAT y se plasman los resultados en este trabajo los resultados obtenidos enla tesis de maestría sin alteración.
Rendimiento 1-KNN
3 9
. 1 9
3 8
. 3 5
4 4
. 2 9
4 1
. 8 0
3 3
. 3 6
4 1
. 2 0
4 0
. 8 2
3 7
. 9 2
3 3
. 2 1
3 5
. 4 0
4 0
. 9 1
3 6
. 2 0
3 2
. 3 9
3 3
. 8 9
3 3
. 9 7
4 5
. 1 0
3 6
. 3 2
3 5
. 9 1
3 3
. 9 1
3 0
. 5 9
0
5
10
15
20
25
30
35
40
45
50
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
ClasificaciÛn
P o r c e n t a
j e
Fig. 6.7: Rendimiento del 1-NN con la base de datos Cmc.
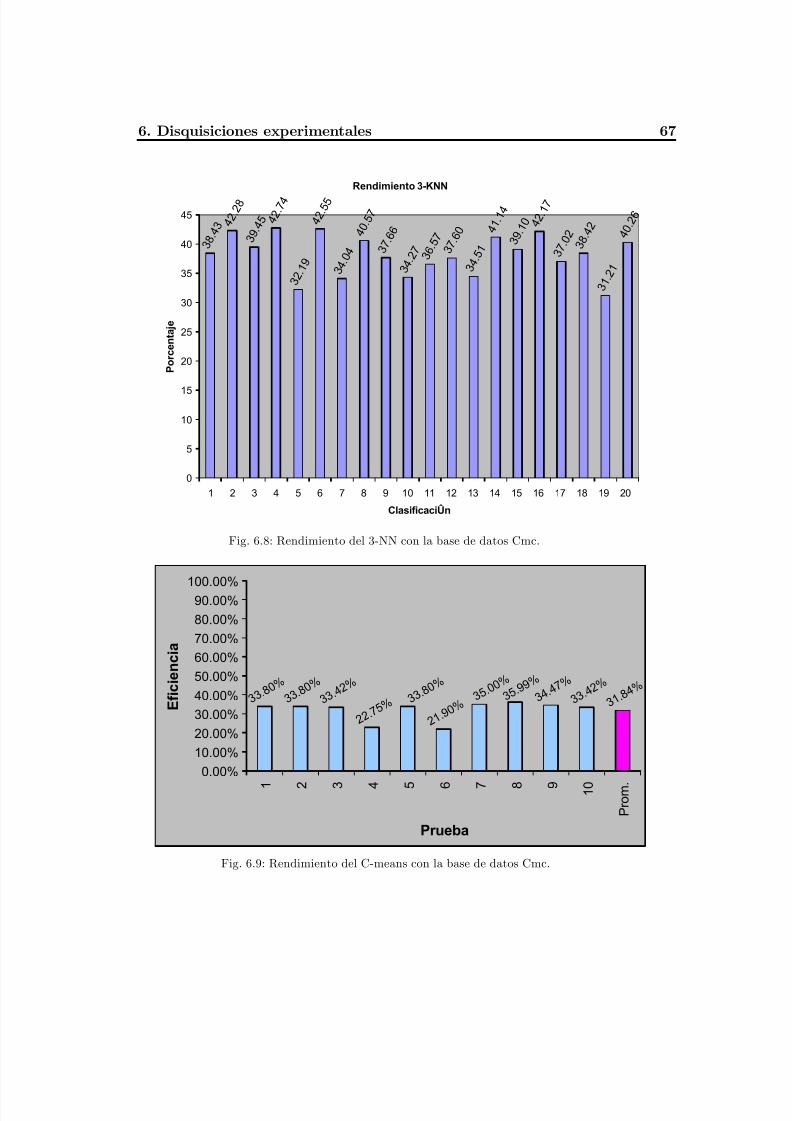
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 77/106
6. Disquisiciones experimentales 67
Rendimiento 3-KNN
3 8
. 4 3 4
2 . 2 8
3 9
. 4 5 4
2 . 7 4
3 2
. 1 9
4 2
. 5 5
3 4
. 0 4
4 0
. 5 7
3 7
. 6 6
3 4
. 2 7
3 6
. 5 7
3 7
. 6 0
3 4
. 5 1
4 1
. 1 4
3 9
. 1 0 4
2 . 1 7
3 7
. 0 2
3 8
. 4 2
3 1
. 2 1
4 0
. 2 6
0
5
10
15
20
25
30
35
40
45
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
ClasificaciÛn
P o r c e n t a j e
Fig. 6.8: Rendimiento del 3-NN con la base de datos Cmc.
3 3. 8 0 %
3 3. 8 0 %
3 3. 4 2 %
2 2. 7 5 %
2 1. 9 0 %
3 4. 4 7 %
3 3. 4 2 %
3 1. 8 4 %
3 5. 9 9 %
3 5. 0 0 %
3 3. 8 0 %
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
80.00%
90.00%
100.00%
1 2 3 4 5 6 7 8 9 1 0
P r o m
.
Prueba
E f i c i e n c i a
Fig. 6.9: Rendimiento del C-means con la base de datos Cmc.
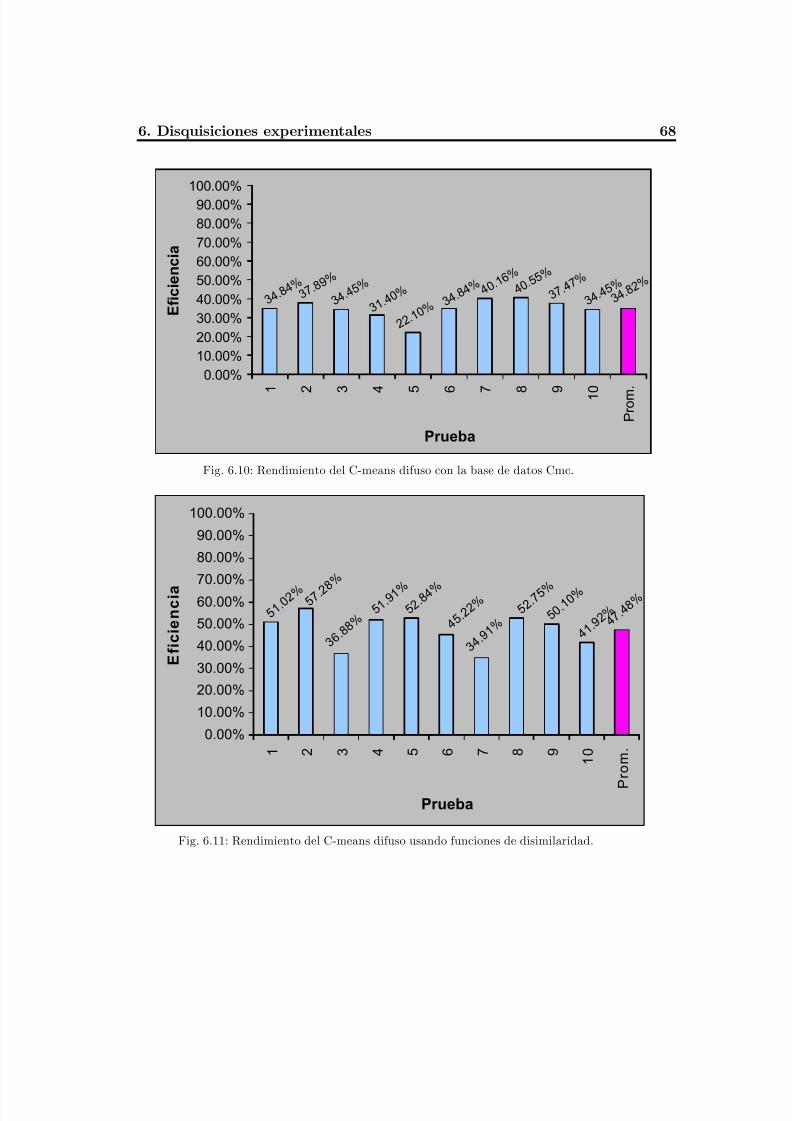
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 78/106
6. Disquisiciones experimentales 68
2 2. 1 0 %
3 4. 8 4 % 3 7
. 8 9 %
3 4. 4 5 %
3 1. 4 0 %
3 4. 8 4 % 4 0
. 1 6 % 4 0
. 5 5 %
3 7. 4 7 %
3 4. 4 5 % 3 4
. 8 2 %
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
80.00%
90.00%
100.00%
1 2 3 4 5 6 7 8 9 1 0
P r o m
.
Prueba
E f i c i e n c i a
Fig. 6.10: Rendimiento del C-means difuso con la base de datos Cmc.
3 6. 8 8 %
3 4. 9 1 %
5 1. 0 2 % 5 7. 2 8
%
5 1. 9 1 %
5 2. 8 4 %
4 5. 2 2 % 5 2
. 7 5 %
5 0. 1 0 %
4 1. 9 2 % 4 7
. 4 8 %
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
80.00%
90.00%
100.00%
1 2 3 4 5 6 7 8 9 1 0
P
r o m
.
Prueba
E f i c i e n c i a
Fig. 6.11: Rendimiento del C-means difuso usando funciones de disimilaridad.
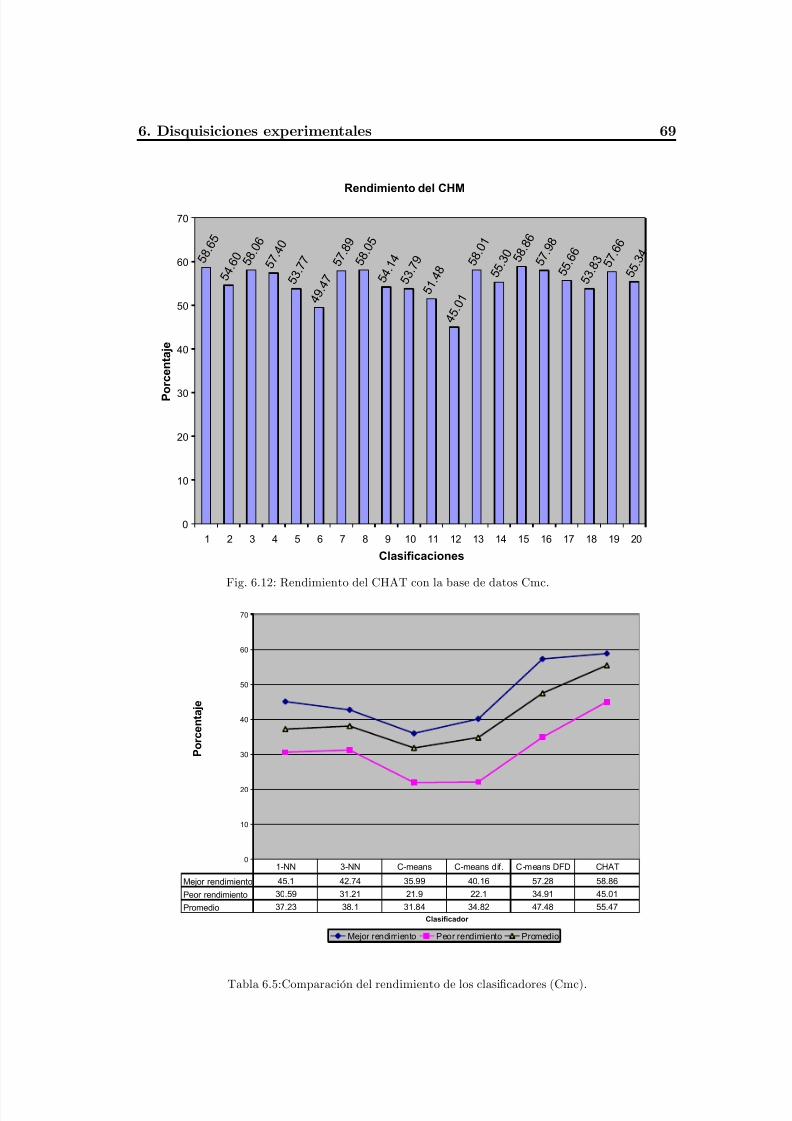
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 79/106
6. Disquisiciones experimentales 69
Rendimiento del CHM
5 8
. 6 5
5 4
. 6 0
5 8
. 0 6
5 7
. 4 0
5 3
. 7 7
4 9
. 4 7
5 7
. 8 9
5 8
. 0 5
5 4
. 1 4
5 3
. 7 9
5 1
. 4 8
4 5
. 0 1
5 8
. 0 1
5 5
. 3 0
5 8
. 8 6
5 7
. 9 8
5 5
. 6 6
5 3
. 8 3 5
7 . 6 6
5 5
. 3 4
0
10
20
30
40
50
60
70
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Clasificaciones
P o
r c e n t a j e
Fig. 6.12: Rendimiento del CHAT con la base de datos Cmc.
0
10
20
30
40
50
60
70
Clasificador
P o r c e n t a j e
Mejor
rendimiento Peor
rendimiento Promedio
Mejor
rendimiento 45.1 42.74 35.99 40.16 57.28 58.86
Peor
rendimiento 30.59 31.21 21.9 22.1 34.91 45.01
Promedio 37.23 38.1 31.84 34.82 47.48 55.47
1-NN 3-NN C-means C-means
dif. C-means
DFD CHAT
Tabla 6.5:Comparación del rendimiento de los clasificadores (Cmc).
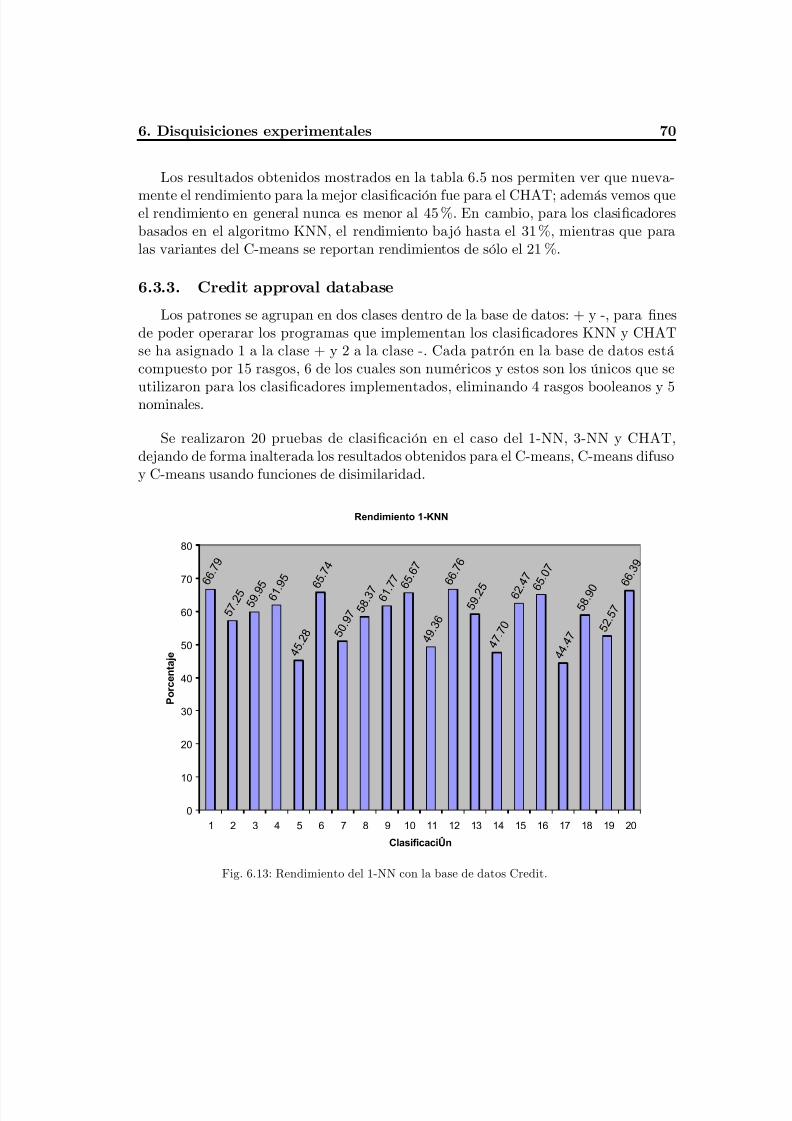
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 80/106
6. Disquisiciones experimentales 70
Los resultados obtenidos mostrados en la tabla 6.5 nos permiten ver que nueva-
mente el rendimiento para la mejor clasificación fue para el CHAT; además vemos queel rendimiento en general nunca es menor al 45 %. En cambio, para los clasificadoresbasados en el algoritmo KNN, el rendimiento bajó hasta el 31 %, mientras que paralas variantes del C-means se reportan rendimientos de sólo el 21 %.
6.3.3. Credit approval database
Los patrones se agrupan en dos clases dentro de la base de datos: + y -, para finesde poder operarar los programas que implementan los clasificadores KNN y CHATse ha asignado 1 a la clase + y 2 a la clase -. Cada patrón en la base de datos estácompuesto por 15 rasgos, 6 de los cuales son numéricos y estos son los únicos que se
utilizaron para los clasifi
cadores implementados, eliminando 4 rasgos booleanos y 5nominales.
Se realizaron 20 pruebas de clasificación en el caso del 1-NN, 3-NN y CHAT,dejando de forma inalterada los resultados obtenidos para el C-means, C-means difusoy C-means usando funciones de disimilaridad.
Rendimiento
1-KNN
6 6
. 7 9
5 7
. 2 5
5 9 . 9
5
6 1 . 9 5
4 5
. 2 8
6 5
. 7 4
5 0
. 9 7
5 8
. 3 7 6 1 . 7 7
6 5
. 6 7
4 9
. 3 6
6 6
. 7 6
5 9
. 2 5
4 7
. 7 0
6 2 . 4 7
6
5 . 0 7
4 4
. 4 7
5 8
. 9 0
5 2
. 5 7
6 6
. 3 9
0
10
20
30
40
50
60
70
80
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
ClasificaciÛn
P o r c e n t a j e
Fig. 6.13: Rendimiento del 1-NN con la base de datos Credit.
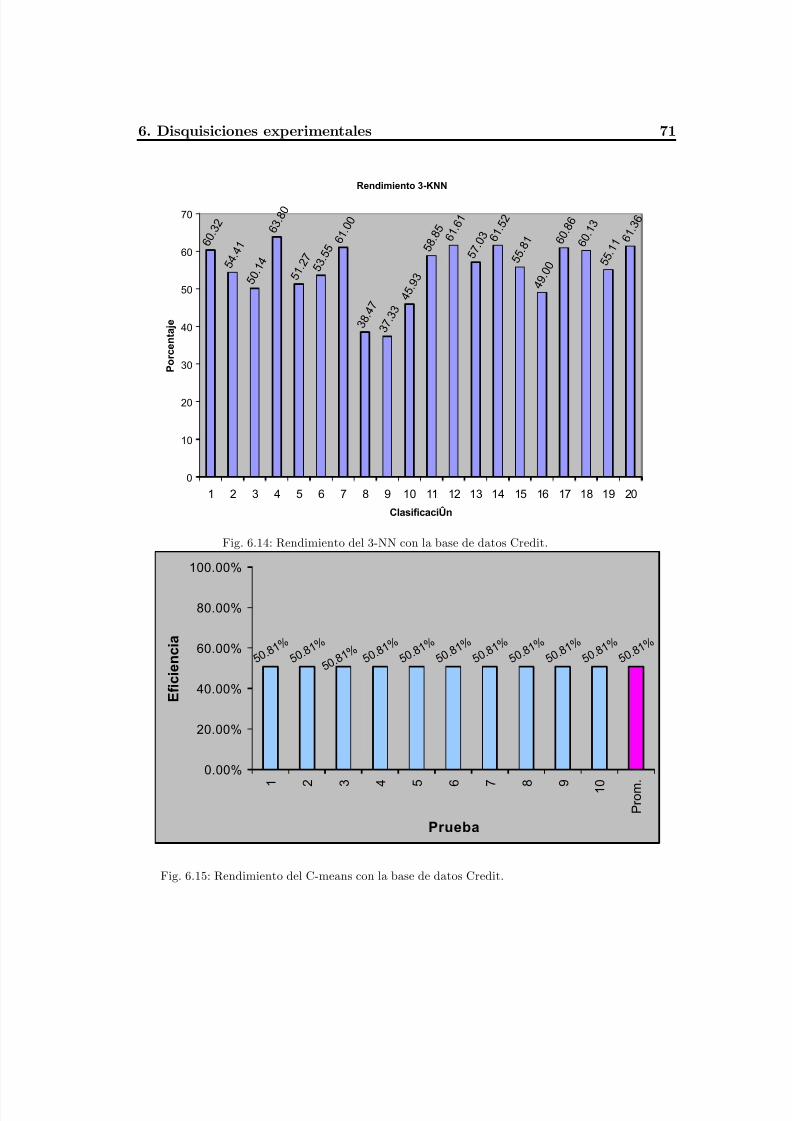
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 81/106
6. Disquisiciones experimentales 71
Rendimiento
3-KNN
6 0
. 3 2
5 4
. 4 1
5 0
. 1 4
6 3
. 8 0
5 1
. 2 7
5 3
. 5 5
6 1
. 0 0
3 8
. 4 7
3 7
. 3 3
4 5
. 9 3
5 8
. 8 5
6 1
. 6 1
5 7
. 0 3 6
1 . 5 2
5 5
. 8 1
4 9
. 0 0
6 0
. 8 6
6 0
. 1 3
5 5
. 1 1 6
1 . 3 6
0
10
20
30
40
50
60
70
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
ClasificaciÛn
P o r c e n t a j e
Fig. 6.14: Rendimiento del 3-NN con la base de datos Credit.
5 0. 8 1 %
5 0. 8 1 %
5 0. 8 1 %
5 0. 8 1 %
5 0. 8 1 %
5 0. 8 1 %
5 0. 8 1 %
5 0. 8 1 %
5 0. 8 1 %
5 0. 8 1 %
5 0. 8 1 %
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
1 2 3 4 5 6 7 8 9 1 0
P r o m
.
Prueba
E f i c i e n c i a
Fig. 6.15: Rendimiento del C-means con la base de datos Credit.
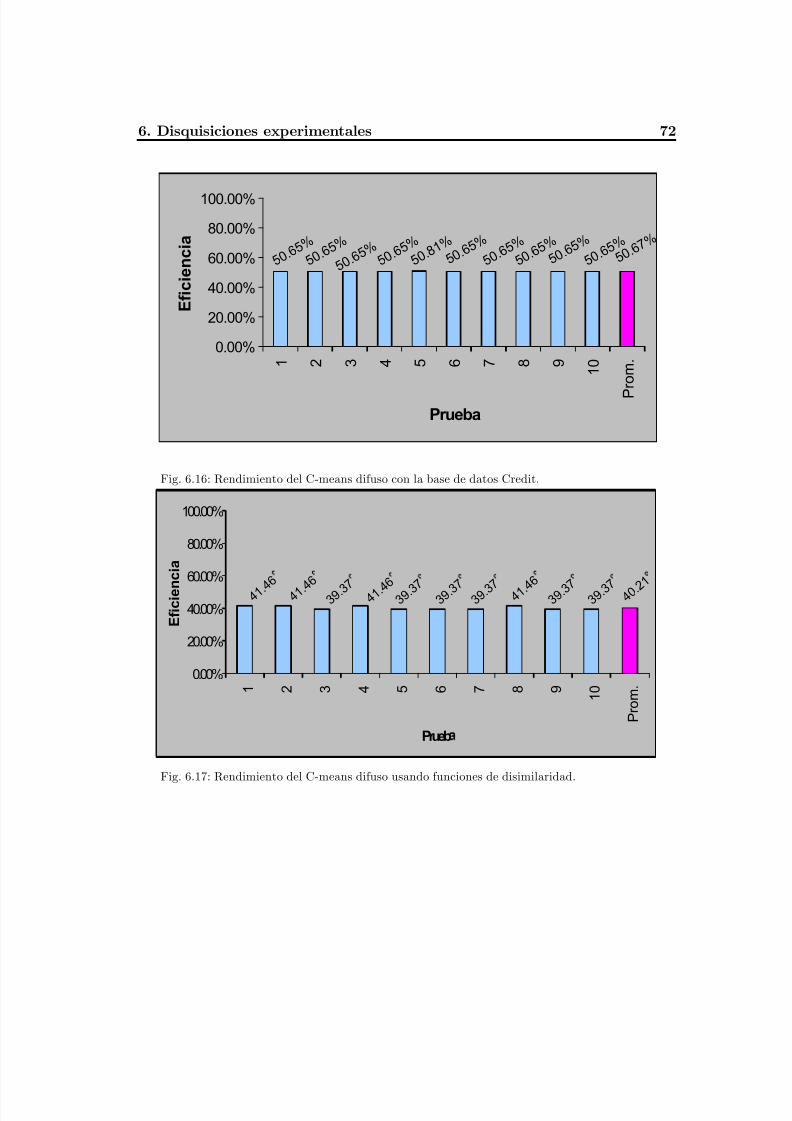
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 82/106
6. Disquisiciones experimentales 72
5 0. 6 5 %
5 0. 6 5 %
5 0. 6 5 %
5 0. 8 1 % 5 0
. 6 5 %
5 0. 6 5 %
5 0. 6 5 % 5 0
. 6 5 %
5 0. 6 5 % 5 0
. 6 7 %
5 0. 6 5 %
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
1 2 3 4 5 6 7 8 9 1 0
P
r o m
.
Prueba
E f i c i e n c i a
Fig. 6.16: Rendimiento del C-means difuso con la base de datos Credit.
3 9. 3 7
4 1. 4 6
4 1. 4
6
4 1. 4
6
4 0. 2 1
3 9. 3 7
3 9. 3 7
4 1. 4
6
3 9. 3 7
3 9. 3 7
3 9. 3 7
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
1 2 3 4 5 6 7 8 9 1 0
P r o m
.
Prueb
E f i c i e n
c i a
Fig. 6.17: Rendimiento del C-means difuso usando funciones de disimilaridad.
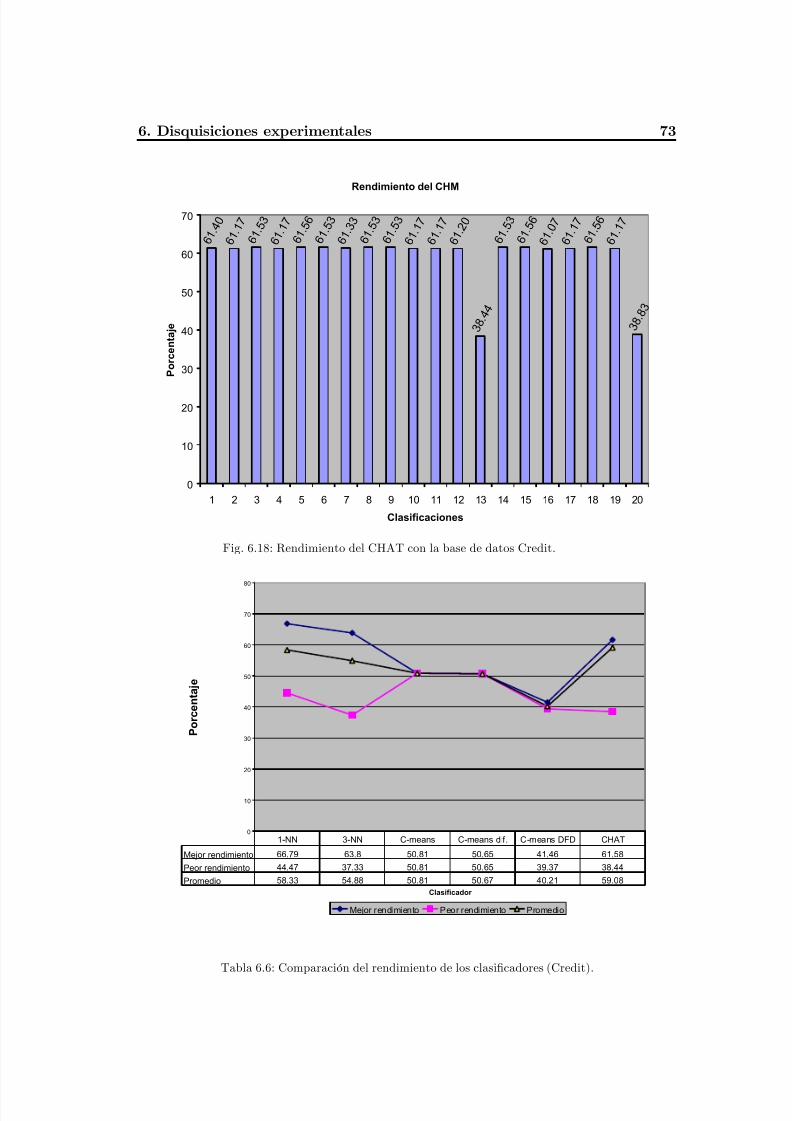
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 83/106
6. Disquisiciones experimentales 73
Rendimiento del CHM
6 1
. 4 0
6 1
. 1 7
6 1
. 5 3
6 1
. 1 7
6 1
. 5 6
6 1
. 5 3
6 1
. 3 3
6 1
. 5 3
6 1
. 5 3
6 1
. 1 7
6 1
. 1 7
6 1
. 2 0
3 8
. 4 4
6 1
. 5 3
6 1
. 5 6
6 1
. 0 7
6 1
. 1 7
6 1
. 5 6
6 1
. 1 7
3 8
. 8 3
0
10
20
30
40
50
60
70
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Clasificaciones
P o r c e n t a j e
Fig. 6.18: Rendimiento del CHAT con la base de datos Credit.
0
10
20
30
40
50
60
70
80
Clasificador
P o r c e n t a j e
Mejor rendimiento Peor rendimiento Promedio
Mejor
rendimiento 66.79 63.8 50.81 50.65 41.46 61.58
Peor rendimiento 44.47 37.33 50.81 50.65 39.37 38.44
Promedio 58.33 54.88 50.81 50.67 40.21 59.08
1-NN 3-NN C-means C-means dif. C-means DFD CHAT
Tabla 6.6: Comparación del rendimiento de los clasificadores (Credit).
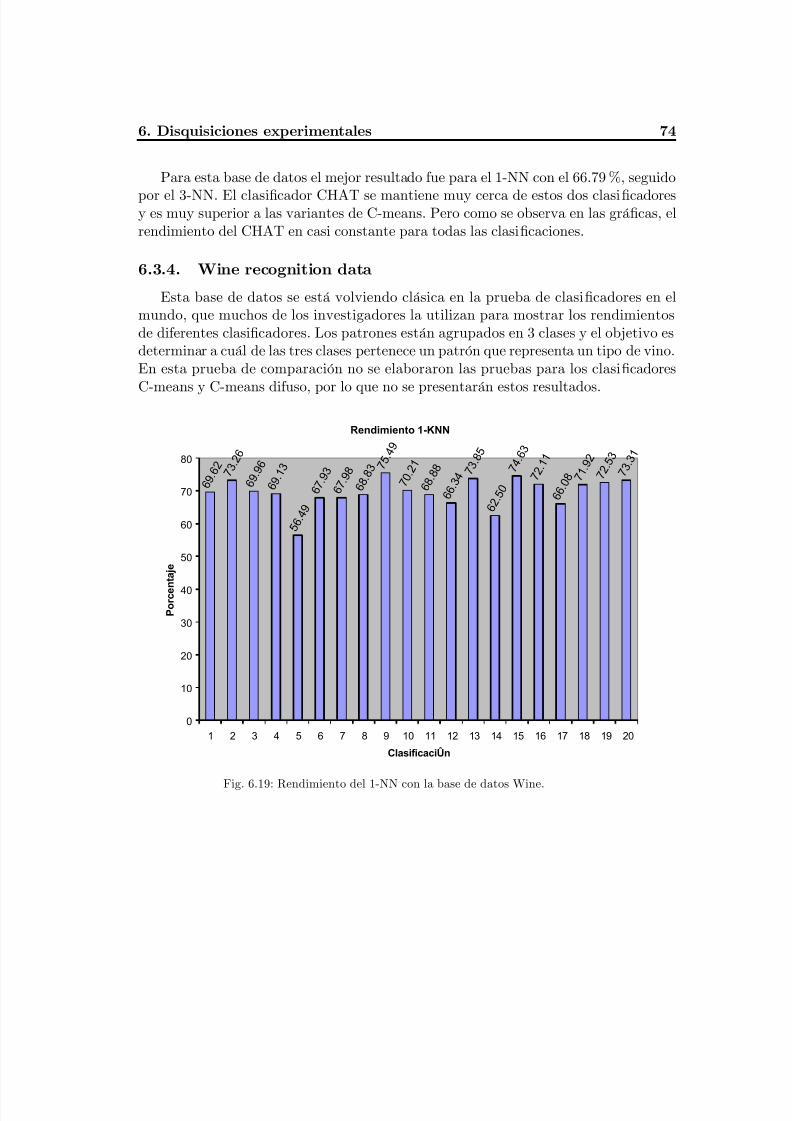
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 84/106
6. Disquisiciones experimentales 74
Para esta base de datos el mejor resultado fue para el 1-NN con el 66.79 %, seguido
por el 3-NN. El clasificador CHAT se mantiene muy cerca de estos dos clasificadoresy es muy superior a las variantes de C-means. Pero como se observa en las gráficas, elrendimiento del CHAT en casi constante para todas las clasificaciones.
6.3.4. Wine recognition data
Esta base de datos se está volviendo clásica en la prueba de clasificadores en elmundo, que muchos de los investigadores la utilizan para mostrar los rendimientosde diferentes clasificadores. Los patrones están agrupados en 3 clases y el objetivo esdeterminar a cuál de las tres clases pertenece un patrón que representa un tipo de vino.En esta prueba de comparación no se elaboraron las pruebas para los clasificadores
C-means y C-means difuso, por lo que no se presentarán estos resultados.
Rendimiento 1-KNN
6 9
. 6 2
7 3
. 2 6
6 9
. 9 6
6 9
. 1 3
5 6
. 4 9
6 7
. 9 3
6 7
. 9 8
6 8
. 8 3 7
5 . 4 9
7 0
. 2 1
6 8
. 8 8
6 6
. 3 4
7 3
. 8 5
6 2
. 5 0
7 4
. 6 3
7 2
. 1 1
6 6
. 0 8 7
1 . 9 2
7 2
. 5 3
7 3
. 3 1
0
10
20
30
40
50
60
70
80
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
ClasificaciÛn
P o r c e n t a j e
Fig. 6.19: Rendimiento del 1-NN con la base de datos Wine.
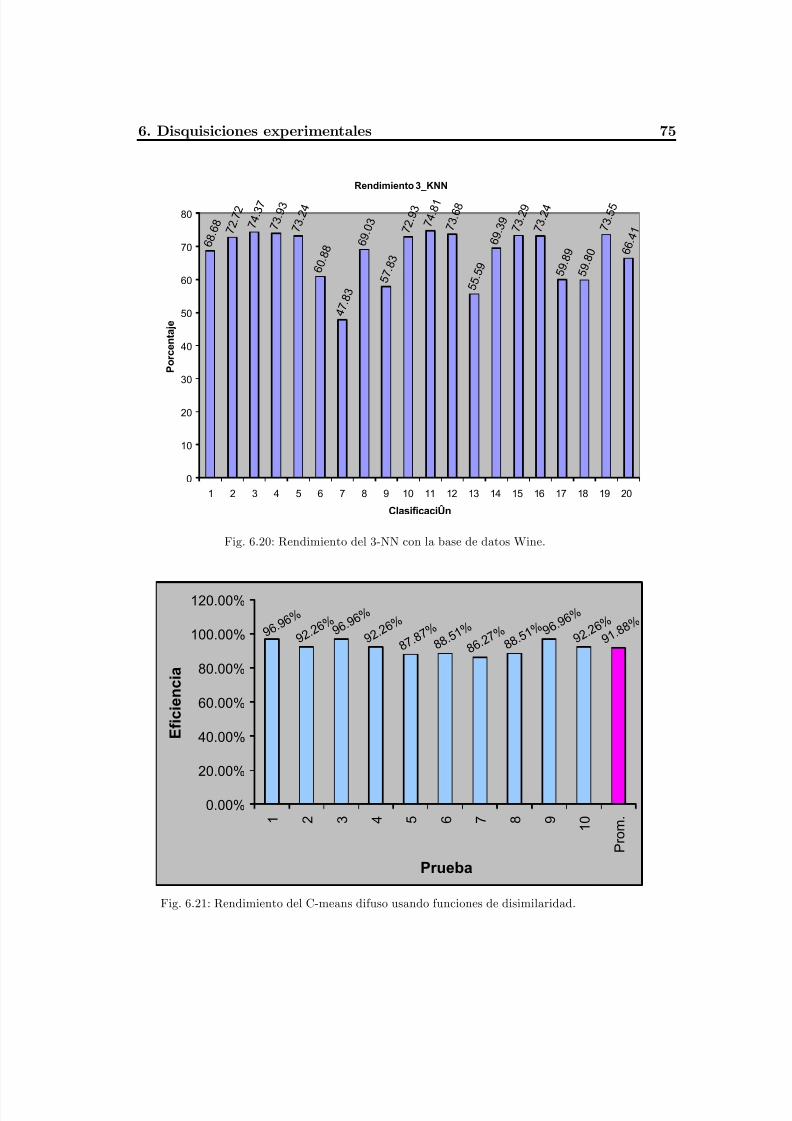
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 85/106
6. Disquisiciones experimentales 75
Rendimiento 3_KNN
6 8
. 6 8
7 2
. 7 2
7 4
. 3 7
7 3
. 9 3
7 3
. 2 4
6 0
. 8 8
4 7
. 8 3
6 9
. 0 3
5 7
. 8 3
7 2
. 9 3
7 4
. 8 1
7 3
. 6 8
5 5
. 5 9
6 9
. 3 9
7 3
. 2 9
7 3
. 2 4
5 9
. 8 9
5 9
. 8 0
7 3
. 5 5
6 6
. 4 1
0
10
20
30
40
50
60
70
80
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
ClasificaciÛn
P o r c e n t a j e
Fig. 6.20: Rendimiento del 3-NN con la base de datos Wine.
9 6. 9 6 %
9 2. 2 6 % 9 6
. 9 6 %
9 2. 2 6 %
8 7. 8 7 % 8 8
. 5 1 %
8 6. 2 7 % 8 8
. 5 1 % 9 6
. 9 6 %
9 2. 2 6 %
9 1. 8 8 %
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
120.00%
1 2 3 4 5 6 7 8 9 1 0
P r o m
.
Prueba
E f i c i e n c i a
Fig. 6.21: Rendimiento del C-means difuso usando funciones de disimilaridad.
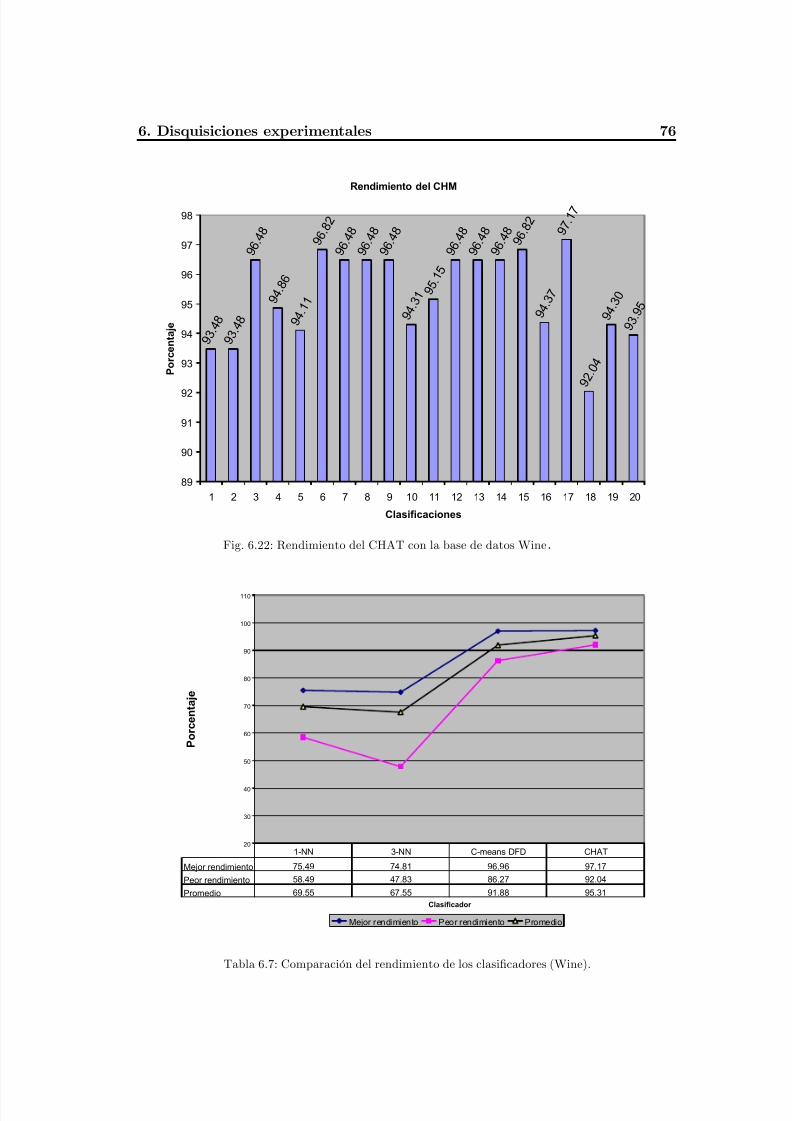
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 86/106
6. Disquisiciones experimentales 76
Rendimiento del CHM
9 3
. 4 8
9 3
. 4 8
9 6
. 4 8
9 4
. 8 6
9 4
. 1 1
9 6
. 8 2
9 6
. 4 8
9 6
. 4 8
9 6
. 4 8
9 4
. 3 1 9
5 . 1 5
9 6
. 4 8
9 6
. 4 8
9 6
. 4 8
9 6
. 8 2
9 4
. 3 7
9 7
. 1 7
9 2
. 0 4
9 4
. 3 0
9 3
. 9 5
89
90
91
92
93
94
95
96
97
98
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Clasificaciones
P o r c e n t a j e
Fig. 6.22: Rendimiento del CHAT con la base de datos Wine.
20
30
40
50
60
70
80
90
100
110
Clasificador
P o r c e n t a j e
Mejor
rendimiento Peor
rendimiento Promedio
Mejor
rendimiento 75.49 74.81 96.96 97.17
Peor rendimiento 58.49 47.83 86.27 92.04
Promedio 69.55 67.55 91.88 95.31
1-NN 3-NN C-means
DFD CHAT
Tabla 6.7: Comparación del rendimiento de los clasificadores (Wine).

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 87/106
6. Disquisiciones experimentales 77
En esta última base de datos el clasificador CHAT muestra un rendimiento muy
superior a los KNN y vuelve a superar a la variante del clasificador C-means.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 88/106
Capítulo 7
Conclusiones y trabajo futuro
En este capítulo se presentan las conclusiones obtenidas de los resultados del pre-sente trabajo de tesis, una vez desarrolladas las ideas que inicialmente se propusieron alo largo de los capítulos anteriores, plasmando de manera puntual el cumplimiento delos objetivos propuestos. Conjuntamente con las conclusiones, daremos algunas de lasposibles tareas que se podrán desarrollar para el cabal entendimiento de lo que aquí seestablece, dando la pauta a futuros investigadores sobre los puntos no cubiertos, peroque pudiesen ser abordados de forma inmediata.
7.1. Conclusiones1. Los experimentos sugieren que las memorias asociativas, combinadas adecuada-
mente, pueden funcionar como clasificadores de patrones, no solamente en casosraros o aislados, sino en la clasificación de patrones contenidos en bases de datospúblicas, probadas reiteradamente con métodos de clasificación reconocidos. Laeficiencia que presentan los clasificadores asociativos se encuentra a la altura delos clasificadores más longevos, estudiados y probados que existen actualmentebasados en otros tipos de enfoque.
2. En este trabajo se da a conocer un producto original basado en el paradigma dememorias asociativas.
3. Con este nuevo producto original, denominado CHAT, Clasificador HíbridoAsociativo con Traslación, se agrega un nuevo clasificador, dentro del áreadel reconocimiento de patrones.
4. Se inicia con este trabajo un nuevo enfoque en la clasificación de patrones: elenfoque asociativo.
5. Los resultados experimentales dan evidencia de la utilidad práctica del CHATen procesos de clasificación.
6. El CHAT, a través de los resultados experimentales, presenta un rendimien-
to semejante al de otros clasificadores y en la mayoría de los casos superior a
78

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 89/106
7. Conclusiones y trabajo futuro 79
los reportados o probados en el presente trabajo. De esta forma, ponemos a la
disposición de la investigación nacional e internacional un producto útil paraproblemas de clasificación.
7. Se superan las mayores desventajas de los dos modelos de memorias asociativasen los que se basa el CHAT; por una parte, la imposibilidad de la Lernmatrix de aceptar valores reales, y por otra, la fuerte restricción de ortonormalidad delos patrones de entrada que se debe cumplir en el Linear Associator .
8. La sencillez del algoritmo con el cual se llevan a cabo las dos etapas que confor-man al CHAT, tiene repercusiones directas en su complejidad computacional ytiempo de respuesta.
9. Los resultados experimentales sugieren que con un conjunto fundamental relati-vamente reducido, el CHAT puede generalizar de forma adecuada para llevar acabo su tarea de clasificación, y esto nuevamente contribuye a un menor costocomputacional.
7.2. Trabajo futuro
Es esta sección presentaremos ideas tentativas que pueden ser atacadas de maneradirecta a fin de contribuir al desarrollo del CHAT y del nuevo enfoque asociativo para
clasificación de patrones. Se explica brevemente cada idea, y se incluyen una o variasreferencias bibliográficas que le permitirán al investigador interesado, introducirse enel tema.
1. Encontrar la base teórica en la cual se sustenta el buen funcionamiento delCHAT (Duda, Hart, & Stork, 2001; Gill, Murray & Wright, 1989; Grimaldi,1998; Grossman, 1996).
2. Hacer un estudio comparativo más amplio del CHAT con otros clasificadoresbasados en diferentes enfoques ( Abe, 2001; Šarunas, 2001; Shalkoff , 1992;).
3. Experimentar el CHAT en combinación con otros clasificadores, ya sea reci-
biendo los resultados de otros o iniciando el proceso de clasificación (Acharya &et. al., 2003; Kittler & Alkoot, 2003; Kuncheva, 2002; Lu & Tan, 2002; Murua,2002; Nicola, Masulli & Sperduti, 2002).
4. Realizar trabajos que busquen optimizar el algoritmo propuesto (Bandyopadhyay& Maulik, 2002; Demeniconi, Peng & Gunopulos, 2002; Ho, Liu, & Liu, 2002;Huang, & et. al., 2002; Rueda & Oommen, 2002; Wu, Ianekiev & Govindaraju,2002).
5. Investigar sobre la combinación del CHAT con alguna o algunas memorias aso-ciativas recientes o pasadas (Díaz-de-León & Yáñez 1999; Ritter, Diaz-de-Leon& Sussner, 1999; Ritter, Sussner, & Diaz-de-Leon, 1998; Yáñez-Márquez, 2002;
Yáñez-Márquez & Diaz de León, 2001a; Yáñez-Márquez & Diaz de León, 2001b).

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 90/106
7. Conclusiones y trabajo futuro 80
6. Probar exhaustivamente el CHAT con más bases de datos y comparar los resul-
tados con otros clasificadores (Ayaquica-Martínez, 2002; Kuncheva, 2000; Mar-qués de Sá, 2001).
7. Llevar a cabo experimentos en los que el CHAT acepte patrones con rasgos nonuméricos.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 91/106
Apéndice A
Simbología
memorias αβ memorias asociativas αβ α, β operadores originales en que se basan las memorias αβ M memoria asociativa, memoria asociativa morfológica max W memoria asociativa morfológica min
mij ij-ésima componente de la memoria asociativa MB conjunto al que pertenecen las componentes mij
∈ pertenencia de un elemento a un conjuntox vector columna que corresponde a un patrón de entrada
y vector columna que corresponde a un patrón de salidaA conjunto al que pertenecen las componentes de x y y(x,y) asociación de un patrón de entrada con uno de salida
(xk,yk) asociación de la k-ésima pareja de patrones(xµ,yµ) | µ = 1, 2,...,p conjunto fundamentalexk versión alterada del patrón fundamental xk
xµ j j-ésima componente de un vector columna xµ
(xµ)t transpuesto del vector xµ
n dimensión de los patrones de entradam dimensión de los patrones de salida p número de parejas del conjunto fundamental
∆mij incremento en mijW operador máximoV operador mínimo
· producto usual entre vectores o matrices× producto cruz (entre conjuntos)
δ ij delta de Kronecker (afecta a los índices i y j)5 producto máximo (entre matrices)4 producto mínimo (entre matrices)
81

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 92/106
A. Simbología 82
α(x, y) operación binaria α con argumentos x y y
β (x, y) operación binaria β con argumentos x y yP = [ pij ]m×r matriz P de dimensiones m × r y componente ij -ésima pij
∀ cuantificador universal∃ cuantificador existencial
dα operador αmaxdβ operador β maxeα operador αmineβ operador β min£ símbolo que representa a las dos operaciones dα y eα
V memorias αβ tipo VΛ memorias αβ tipo Λ
⊗ operación para calcular la distancia de Hamming⊕ operación lógica or exclusiva

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 93/106
Apéndice B
CHAT 1.0, manual de uso
En este apéndice se presenta el procedimiento de operación del programa queimplementa el CHAT. El algoritmo fue desarrollado en el compilador visual C++Builder 5 de Borland, bajo la plataforma Windows 2000 de Microsoft.
El programa se inicia con la ejecución del archivo ClasificadorH.exe. Al iniciar suejecución el programa presenta la ventana de inicio, representada en la figura 1.
Figura 1: Presentación
Dentro de esta ventana sólo se aprecia una opción; este comando despliega dosopciones, donde la primera configura y opera el CHAT de forma manual, lo cualquiere decir que se opera con un conjunto fundamental definido previamente y quedeberá ser obtenido de un archivo secuencial. La segunda opción configura y opera
el CHAT para utilizar un conjunto fundamental escogido de forma aleatoria en cadaclasificación. Esto se muestra en la figura 2.
Figura 2.
83

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 94/106
B. CHAT 1.0, manual de uso 84
B.0.1. Forma manual.
Al iniciar el programa en forma manual, la ventana de la figura 3 se muestra enla pantalla. Existen tres botones: configuración, aprendizaje, y recuperación y clasi-ficación; con el primer botón se muestra una ventana con la que podemos configurarel CHAT, mientras que el botón .Aprendizaje y recuperación"nos permite utilizar elconjunto fundamental cargado en la configuración, generar la memoria del CHAT yprobar el rendimiento del CHAT al tratar de recuperar el conjunto fundamental. Conel botón Çlasificación", podemos someter toda la base de datos al proceso de clasifi-cación y obtener así mismo el rendimiento obtenido por el CHAT. Los rendimientosserán mostrados en las barras "Edit1 2"Edit2".
.
Figura 3
Al ingresar a la ventana de configuración debemos indicarle al programa, la ubi-cación de los archivos secuenciales que contendrán al conjunto fundamental y a la basede datos a clasificar; además de ingresar la ruta de los archivos, tenemos qué determi-nar tres parámetros, los cuales tienen una etiqueta que indica el tipo de variable. Laventana de configuración se muestra en la figura 4.
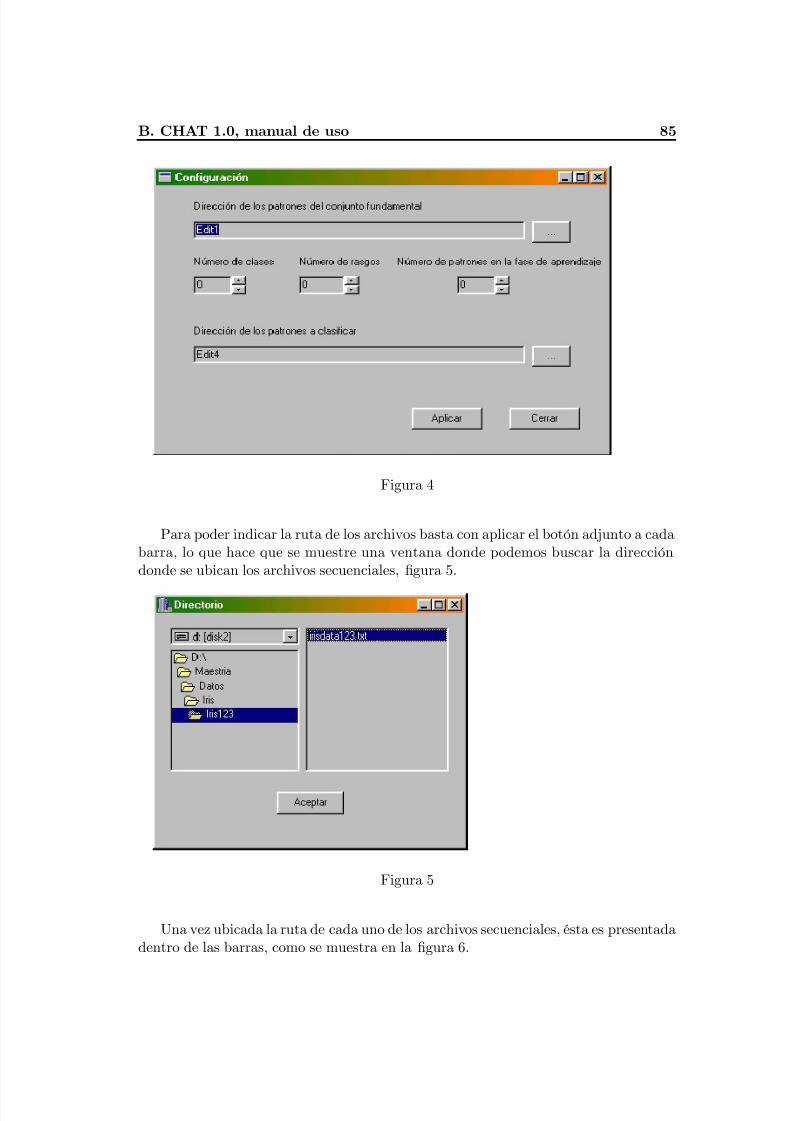
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 95/106
B. CHAT 1.0, manual de uso 85
Figura 4
Para poder indicar la ruta de los archivos basta con aplicar el botón adjunto a cadabarra, lo que hace que se muestre una ventana donde podemos buscar la direccióndonde se ubican los archivos secuenciales, figura 5.
Figura 5
Una vez ubicada la ruta de cada uno de los archivos secuenciales, ésta es presentadadentro de las barras, como se muestra en la figura 6.
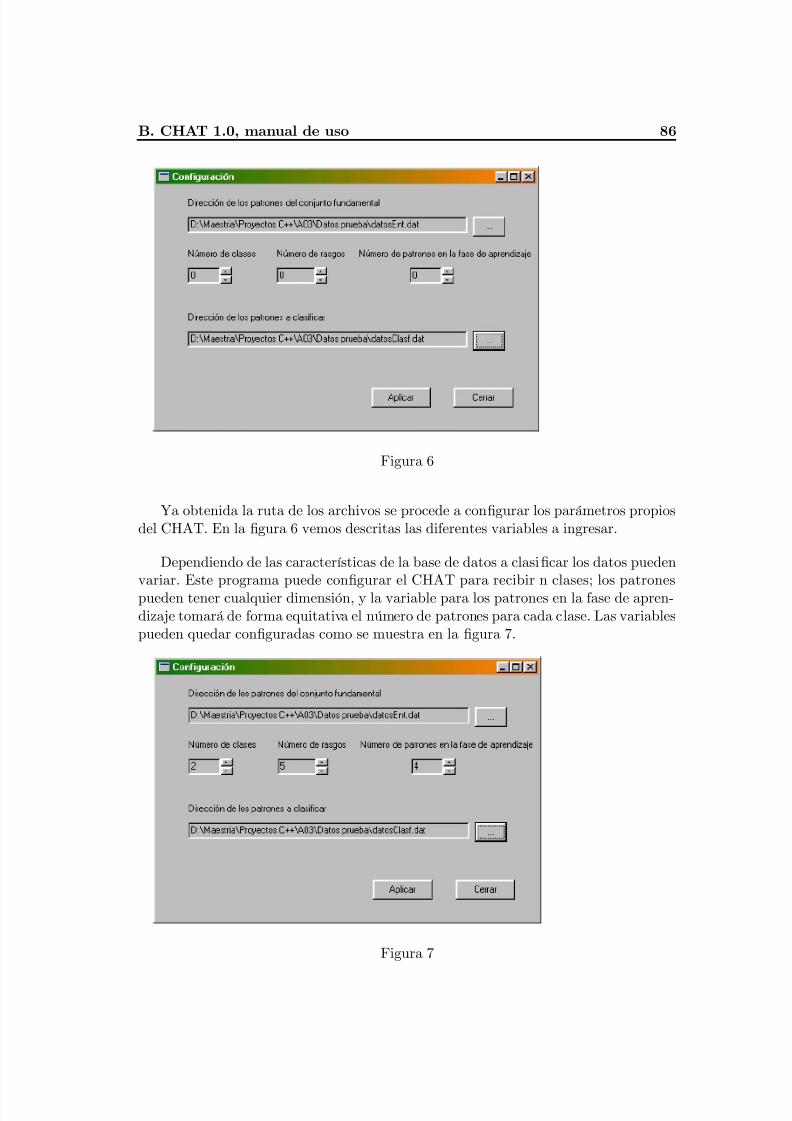
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 96/106
B. CHAT 1.0, manual de uso 86
Figura 6
Ya obtenida la ruta de los archivos se procede a configurar los parámetros propiosdel CHAT. En la figura 6 vemos descritas las diferentes variables a ingresar.
Dependiendo de las características de la base de datos a clasificar los datos puedenvariar. Este programa puede configurar el CHAT para recibir n clases; los patronespueden tener cualquier dimensión, y la variable para los patrones en la fase de apren-dizaje tomará de forma equitativa el número de patrones para cada clase. Las variablespueden quedar configuradas como se muestra en la figura 7.
Figura 7

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 97/106
B. CHAT 1.0, manual de uso 87
El botón Aplicar carga todos los parámetros en el programa, se procede a cerrar la
ventana mediante el botón así designado y se regresa a la ventana de la figura 3, en lacual podremos ya aplicar los botones Aprendizaje y recuperación y Clasi fi cación . Paracambiar el conjunto fundamental o la base de datos, es necesario cerrar la ventana dela figura 3, lo que nos regresará a la ventana principal, volviendo a iniciar el procesode forma manual.
B.0.2. Forma automática.
Esta opción se distingue de la manual porque no necesita que se le proporcione unconjunto fundamental especí fico, el programa elige un conjunto de manera aleatoria.Al ingresar a esta opción se muestra la ventana de configuración y operación, figura 8.
Figura 8
Aquí podemos observar los diferentes parámetros necesarios para la operación delprograma; para poder ingresar la ruta como la mostrada en la figura 8 basta con aplicarel botón adjunto a la barra, este botón hace mostrar la ventana de búsqueda de ruta,figura 5. Las demás variables se ingresan de forma manual o a través de los botones
adjuntos a cada barra.
Terminado el proceso de ingreso de variables, al hacer clic en el botón Aplicar ,el programa realiza el número de clasificaciones asignadas con diferentes conjuntosfundamentales aleatorios.
Si se desea realizar una nueva serie de clasificaciones, se procede a cerrar la ventana,regresando a la ventana principal e iniciar el proceso nuevamente.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 98/106
Apéndice C
KNN 1.0, manual de uso
En este apéndice se muestra el uso del programa diseñado para implementar elclasificador KNN, el cual forma parte de las disquisiciones experimenteles y es útilpara realizar el estudio comparativo. Este clasificador fue implementado en C++ através del compilador C++ Builder 5 de Borland, bajo la plataforma Windows 2000de Microsoft.
El programa se inicia mediante la ejecución del archivo knn.exe; el programa pre-senta la ventana de inicio, representada en la figura 1.
Figura 1.
Dentro de la ventana de la figura 1 se observan dos botones; el botón Aplicar abreuna ventana con la cual podremos configurar las distintas variables y rutas que usaráel clasificador implementado para clasificar, como lo muestra la figura 2.
88
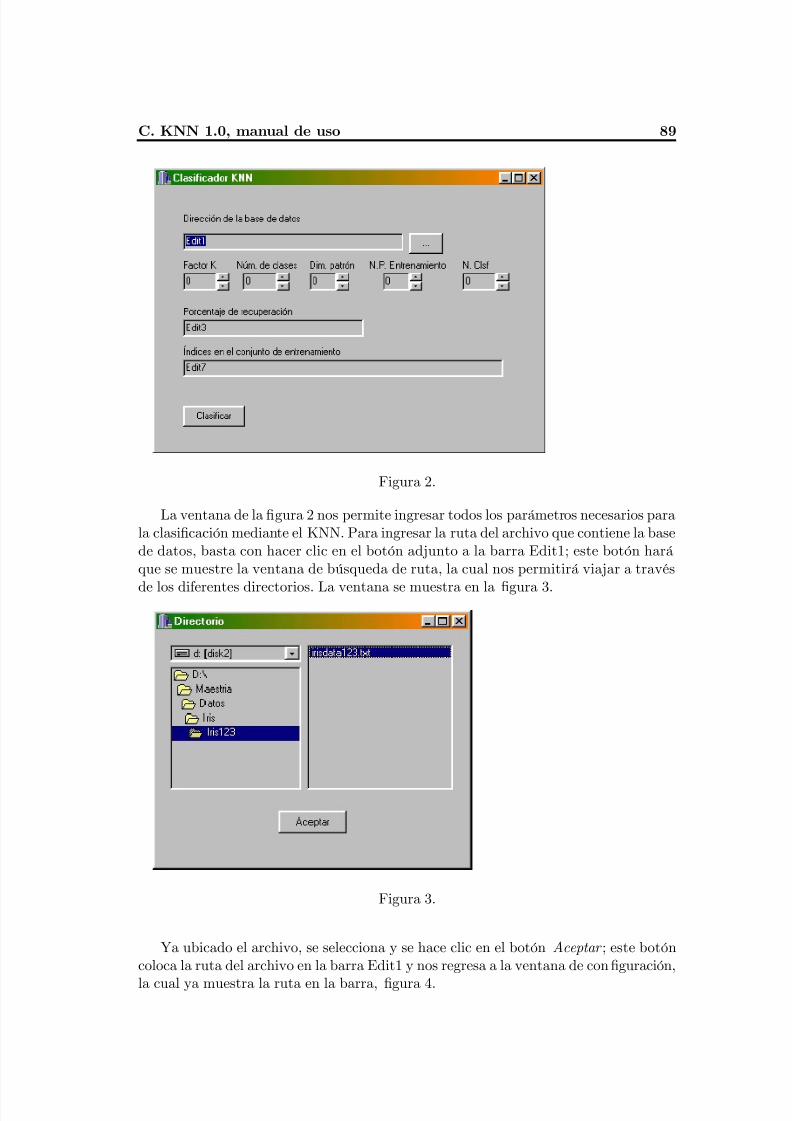
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 99/106
C. KNN 1.0, manual de uso 89
Figura 2.
La ventana de la figura 2 nos permite ingresar todos los parámetros necesarios parala clasificación mediante el KNN. Para ingresar la ruta del archivo que contiene la basede datos, basta con hacer clic en el botón adjunto a la barra Edit1; este botón haráque se muestre la ventana de búsqueda de ruta, la cual nos permitirá viajar a través
de los diferentes directorios. La ventana se muestra en la figura 3.
Figura 3.
Ya ubicado el archivo, se selecciona y se hace clic en el botón Aceptar ; este botóncoloca la ruta del archivo en la barra Edit1 y nos regresa a la ventana de configuración,
la cual ya muestra la ruta en la barra, figura 4.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 100/106
C. KNN 1.0, manual de uso 90
Figura 4.
El siguiente paso es colocar todos los parámetros en sus diferentes casillas. El pro-grama recibe un factor K que puede estar entre 1 y 100, igual rango para el número declases, dimensión del patrón, patrones de entrenamiento y clasificaciones. Un ejemplose muestra en la figura 5.
Figura 5.
La clasificación se realiza mediante el botón así designado, y el programa procede amostrar para este ejemplo la ventana con los resultados de la clasificación; en la figura6 se muestra la ventana de porcentaje para la configuración anterior al clasificar la
clase 1 de la base de datos Iris plant.
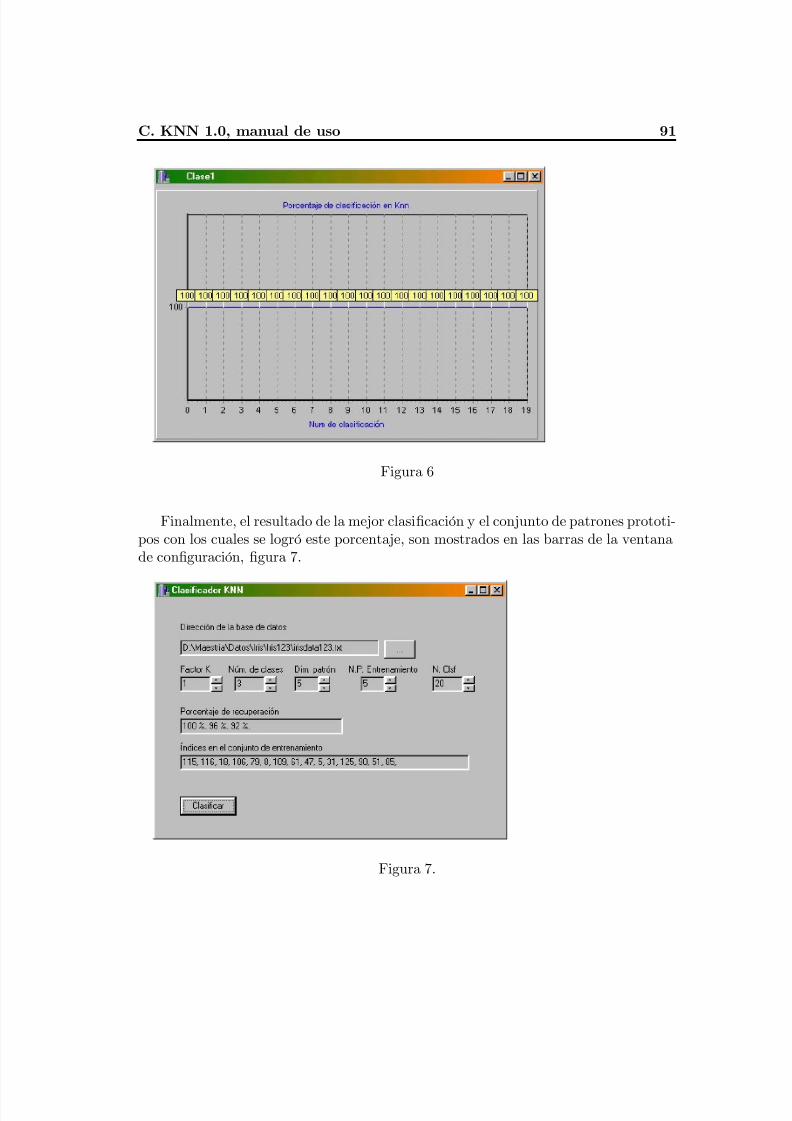
7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 101/106
C. KNN 1.0, manual de uso 91
Figura 6
Finalmente, el resultado de la mejor clasificación y el conjunto de patrones prototi-pos con los cuales se logró este porcentaje, son mostrados en las barras de la ventanade configuración, figura 7.
Figura 7.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 102/106
Bibliografía
[1] Abe, S. (2001). Pattern classi fi cation, Neuro-Fussy Methods and their Compari-son , Grat Britain: Springer-Verlag.
[2] Acharya, U. R. & et. al. (2003). Classification of Herat rate data using artificialneural network and fuzzy equivalence relation, Pattern Recognition, 36 (2003),61-81.
[3] Ammeraal, L. (1997). STL for C++ programmers, USA: John Wiley & Sons.
[4] Amari, S. (1977). Neural theory of association and concept-formation, Biological Cybernetics, 26 , 175-185.
[5] Anderson, J. A. (1972). A simple neural network generating an interactive mem-ory, Mathematical Biosciences, 14, 197-220.
[6] Anderson, J. A. & Rosenfeld, E. (Eds.) (1990). Neurocomputing: Fundations of Research , Cambridge: MIT Press.
[7] Anderson, J. A., Silverstein, J., Ritz, S. & Jones, R. (1977). Distinctive features,categorical perception, and probability learning: some applications of a neuralmodel, Psichological Review, 84, 413-451.
[8] Anderson, J. R. & Bower, G. (1977). Memoria Asociativa , México: Limusa.
[9] Ayaquica-Martínez, I. O. (2002). Algoritmo C-means usando funciones de disim-ilarida , Tesis de maestría, CIC-IPN, México.
[10] Bandyopadhyay, S. & Maulik, U. (2002). Efficient prototy reordering in nearestneighbor classifation, Pattern Recognition, 35 (2002), 2791-2799.
[11] Daconta, C. M. (1995). C++ pointers andDynamic memory manayement, USA:John Wiley & Sons.
[12] Dasarathy, B. V. (1991). Nearest Neighbor (NN) Norms: NN pattern Classi fi cation Techniques , USA:IEEE Computer Society Pres
[13] Demeniconi, C., Peng J. & Gunopulos, D. (2002). Locally Adaptive MetricNearest-Neighbor Classification, IEEE Transations on Pattern Análisis and Ma-chine Intellegence, vol. 24, no. 9,1281-1285.
92

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 103/106
BIBLIOGRAFÍA 93
[14] Díaz-de-León, J. L. & Yáñez, C. (1999). Memorias asociativas con respuesta per-
fecta y capacidad infinita, Memoria del TAINA’99, México, D.F., 23-38.[15] Díaz-de-León, J. L., Yáñez-Márquez, C. & Sánchez-Garfias, F. A. (2003a), Re-
conocimiento de patrones. Enfoque probabilístico-estadístico, IT 83, Serie Verde,CIC-IPN, México.
[16] Díaz-de-León, J. L., Yáñez-Márquez, C. & Sánchez-Garfias, F. A. (2003b), Clasi-ficador euclideano de patrones, IT 80, Serie Verde, CIC-IPN, México.
[17] Dietel, H. M. & Dietel, P. J. (1999). Como programar en C++, México: Pearson.
[18] Duda, R. O., Hart, P. E. & Stork, D. G. (2001). Pattern Classi fi cation , USA: John
Wiley & Sons.[19] Eckel, B: (1995). Thinking in C++, USA: Prentice Hall.
[20] Fisher, R. A., (1936). The use of multiple measurements in taxonomic problems,Anual Eugenics, 7, Part II, 179-188.
[21] Friedman, M. & Kandel, A. (2000). Introduction to Pattern Recognition (Statisti-cal, Structural, Neural and Fuzzy logic Approaches), Singapore, World Scientific.
[22] Forina, M. et al, (1991), An extendible Package for Data Exploration, Classifi-cation and Correlation. Institute of Pharmaceutical and Food Analisys and Tech-nologies, Via Brigata Salerno, 16147 Genoa, Italy.
[23] Gill, P. E., Murray, W. & Wright, M. H. (1989). Numerical Linear Algebra and Optimization, vol. 1, USA: Adisson Wesley.
[24] González, R. C. & Woods, R. E. (2001). Digital Image Processing ,USA: PrenticeHall.
[25] Grimaldi, R. P. (1998). Matemáticas discreta y combinatoria, México: AddisonWesley.
[26] Grossman, S. I. (1996). Algebra lineal, México: McGraw-Hill.
[27] Haykin, S. (1999). Neural Networks, A Comprehensive Foundation, USA: PrenticeHall.
[28] Haralick, R. M., Sternberg, S. R. & Zhuang, X. (1987). Image analysis usingmathematical morphology, IEEE Transactions on Pattern Analysis and Machine Intelligence, PAMI-9, 4, 532-550.
[29] Hassoun, M. H. (Ed.) (1993). Associative Neural Memories , New York: OxfordUniversity Press.
[30] Hassoun, M. H. (1995). Fundamentals of Arti fi cial Neural Networks , Cambridge:MIT Press.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 104/106
BIBLIOGRAFÍA 94
[31] Ho, S. Y., Liu, C. C. & Liu, S. (2002). Disign of an optimal nearest neighbor
classifier using an intelligent genetic algorithm, Pattern Recognition Letters, 23 (2002), 1495-1503.
[32] Hopfield, J.J. (1982). Neural networks and physical systems with emergent col-lective computational abilities, Proceedings of the National Academy of Sciences,79 , 2554-2558.
[33] Hopfield, J.J. (1984). Neurons with graded respose have collective computationalproperties like those of two-state neurons, Proceedings of the National Academy of Sciences, 81, 3088-3092.
[34] Huang, Y. S., & et. al. (2002). Prototype optimization for nearest-neighbor clas-
sification, Pattern Recognition, 35 (2002), 1237-1245.
[35] Kittler, J. & Alkoot, F.M. (2003). Sum vesus Vote Fusion in Multiple ClassifierSystems, IEEE Transations on Pattern Análisis and Machine Intellegence, vol.25, no. 1, 110-115.
[36] Kishan, M., Chilukuri, K. M. & Sanjay, R. (1997). Elements of Arti fi cial Neural Networks , USA: MIT Press.
[37] Kohonen, T. (1972). Correlation matrix memories, IEEE Transactions on Com-puters, C-21, 4, 353-359.
[38] Kohonen, T. (1974). An adaptive associative memory principle, IEEE Transac-tions on Computers, C-24, 4, 444-445.
[39] Kohonen, T. (1987). Content-Addressable Memories , Berlin: Springer-Verlag.
[40] Kohonen, T. (1989). Self-Organization and Associative Memory , Berlin: Springer-Verlag.
[41] Kohonen, T. (1997). Self-Organizing Maps , Berlin: Springer.
[42] Kohonen, T. & Ruohonen, M. (1973). Representation of associated data by matrixoperators, IEEE Transactions on Computers, C-22 , 701-702.
[43] Kuncheva, L. I. (2000). Fuzzy Classi fi er Design , Germany: Physica-Verlag.
[44] Kuncheva, L. I. (2002). A theoritical Study on Six Classifier Fusion Strategies,IEEE Transations on Pattern Análisis and Machine Intellegence, vol. 24, no. 2,281-286.
[45] Lang, S. (1976). Algebra lineal, México: Fondo Educativo Interamericano.
[46] Leithold, L. (1994). Matemáticas previas al cálculo, México: Harla.
[47] Lewis, R. H. & Papadimitriou, C. H. (1998). Element of the theory of compatation,USA: Prentice-Hall.

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 105/106
BIBLIOGRAFÍA 95
[48] Lu, Y. & Tan, C. L. (2002). Combination of múltiple classifiers using probabilistic
dictionary and its application to pastcode recognition, Pattern Recognition , 35(2002), 2823-2832.
[49] Marqués de Sá, J. P. (2001). Pattern Recognition, Concepts, Methods and Appli-cation, Germany: Springer.
[50] McCulloch, W. & Pitts, W. (1943). A logical calculus of the ideas immanent innervous activity, Bulletin of Mathematical Biophysics, 5 , 115-133.
[51] McEliece, R., Posner, E., Rodemich, E. & Venkatesh, S. (1987). The capacityof the Hopfield associative memory, IEEE Transactions on Information Theory,IT-33, 4, 461-482.
[52] Minsky, M. & Papert, S. (1969). Perceptrons , Cambridge: MIT Press.
[53] Murua, A. (2002). Upper Bounds for Error Rates of Linear Combinations of Clas-sifiers, IEEE Transations on Pattern Análisis and Machine Intellegence, vol. 24,no. 5, 591-602.
[54] Nakano, K. (1972). Associatron-A model of associative memory, IEEE Transac-tions on Systems, Man, and Cybernetics, SMC-2, 3 , 380-388.
[55] Nicola, G., Masulli, F. & Sperduti, A. (2002). Theorical and experimental análisisof a two-stage system for classification, IEEE Transations on Pattern Análisis and Machine Intellegence, vol 24, no. 7, 893-904.
[56] Pal, S. (1999). Neuro - Fuzzy, Pattern Recognition: Methods in Soft Computing ,USA: John Wiley & Sons.
[57] Palm, G., Schwenker, F., Sommer F. T. & Strey, A. (1997). Neural associativememories, In A. Krikelis & C. C. Weems (Eds.), Associative Processing and Pro-cessors , (pp. 307-326). Los Alamitos: IEEE Computer Society.
[58] Pandya, A. S. (1996). Pattern recognition with neural networks in C++, GreatBritain: Springer-Verlag.
[59] Rosenblatt, F. (1958). The Perceptron: A probabilistic model for information
storage and organization in the brain, Psychological Review, vol. 65, 386-408.[60] Pitas, I. (2000). Digital Image Processing Algorithms and Applications , J. Wiley
Sons, Inc.
[61] Ritter, G. X., Sussner, P. & Diaz-de-Leon, J. L. (1998). Morphological associativememories, IEEE Transactions on Neural Networks, 9 , 281-293.
[62] Ritter, G. X., Diaz-de-Leon, J. L. & Sussner, P. (1999). Morphological bidirec-tional associative memories, Neural Networks, 12 , 851-867.
[63] Rueda, L. & Oommen, B. J. (2002). On optimal pairwise linear classifiers for nor-mal distributions the two-dimensional case, IEEE Transations on Pattern Análisis
and Machine Intellegence, vol. 24, no. 2, 274-273 .

7/25/2019 CHAT Dr. Raul Santiago Montero
http://slidepdf.com/reader/full/chat-dr-raul-santiago-montero 106/106
BIBLIOGRAFÍA 96
[64] Sánchez-Garfias, F. A., Díaz-de-León, J. L. & Yáñez, C. (2003), Reconocimiento
automático de patrones. Conceptos básicos , IT 79, Serie Verde, CIC-IPN, México[65] Santiago-Montero, R., Yáñez-Márquez, C. & Diaz de León, J. L (2002). Clasifi-
cador híbrido de patrones basado en la Lenmarix de Steinbuch y el Linear Asso-ciator de Anderson-Kohonen, Research on computing science, Reconocimiento de patrones, avances y perspectivas, 449-460. México: CIC-IPN.
[66] Šarunas, R. (2001). Statistical and Neural Classi fi ers, An integrated Approach todisign, England: MIT Press.
[67] Schürmann, J. (1996). Pattern classi fi cation, A uni fi ed view of statistical and neural approaches, USA: John Wiley.
[68] Seed, G. (1996). An Introduction to object-oriented programming in C++, GreatBritain: Springer-Verlag.
[69] Serra, J. (1992). Image Analysis and Mathematical Morphology, Volume 2: The-oretical Advances , London: Academic Press.
[70] Shalkoff , R. (1992). Pattern recognition, Statical, Structural and Neural Approach-es, USA: John Wiley.
[71] Sonka, M., Vaclav, H. & Boyle, R. (1999). Imagen Processing, Analysis and Ma-chine Vision, USA: ITP.
[72] Steinbuch, K. (1961). Die Lernmatrix, Kybernetik, 1, 1, 36-45.
[73] Steinbuch, K. & Frank, H. (1961). Nichtdigitale Lernmatrizen als Perzeptoren,Kybernetik, 1, 3 , 117-124.
[74] Webb, A. (1999). Statical Pattern Recognition, USA: Oxford University Press.
[75] Wu, Y., Ianekiev, K. & Govindaraju, V. (2002). Improved k-nearest neighborclassification, Pattern Recognition, 35 (2002), 2311-2318.
[76] Yáñez-Márquez, C. & Diaz de León, J. L. (2001a). Lernmatrix de Steinbuch , IT