ccc-graph - senior thesis report
TRANSCRIPT

PROYECTO FIN DE CARRERA
CCC-GRAPH
Ingeniería Informática
Curso 2013 / 2014
Autor: Jesús Larrubia Quero
Director:
José Parets Llorca
Departamento: Lenguajes de sistemas informáticos
Granada, Junio de 2014


Resumen
La navegación conceptual en Drupal debe limitarse a vistas. Mediante el uso de
hipergrafos es posible conseguir una navegación gráfica que muestre la estructura
conceptual.
En el proyecto CCC-Graph se pretende adaptar el módulo Hypergraph de Drupal a una
estructura conceptual que pueda definirse mediante un lenguaje intermedio.

Agradecimientos
A mis padres y amigos, sin ellos no sería lo que soy.
A Pepe, por estar ahí a pesar de las circunstancias. Por ser una persona a seguir.
A Sheila.

Índice general
PARTE I. Prolegómeno…………………………………………………………...…….1
1. Introducción…..…………………………………………..……….…………...…….3
1.1. Contexto..……………………………………………….……...…….......….3
1.1.1. Sistemas hipermedia.…………………………..……….….……...3
1.1.2. Sistemas hipermedia adaptativos...……………….……….……....3
1.1.3. El modelo SEM HP………………………………………………..4
1.2. Objetivos y pasos.………………………………………………….……......5
1.3. Alcance.………………………………………………………...….……......5
2. El modelo. SEM HP..…………………………………………………….…..……....6
2.1. Modelo sistémico, evolutivo, semántico y adaptativo...……...……..……....6
2.2. Desarrollo de un sistema hipermedia adaptativo………………...…….........6
2.3. Proceso evolutivo.………………………………………...……….….…......9
2.4. Estructura de navegación.…………………………………....…….……......9
2.5. Modos de navegación.…………………………………...……….……......12
3. Primer intento. DSEM HP.…………………………………….………………......14
3.1. Objetivos alcanzados.…………………………………….……………......14
3.2. Limitaciones y deficiencias.………………………………..…….……......14
3.3. Puntos clave.……………………………………………………...……......15
3.3.1. Puntos útiles.…………………………………………....……......15
3.3.2. Puntos fuera del alcance de CCC-Graph.……………….……......15
3.3.3. Puntos a mejorar.……………………………….……….……......16
4. Las bases Hypergraph.………………………………………………...….……......17
4.1. Proyecto Hypergraph.…………………………………………….……......17
4.1.1. Visualización de árboles hiperbólicos.………………….……......17
4.1.2. Instalación.…………………………………………..….……......18
4.1.3. Uso. Características principales.……………….……….……......19
4.1.4. Documentación.……………………………………..….……......20
4.1.5. Mejoras introducidas por DSEM HP.……………….….……......21
4.1.6. Limitaciones.…………………………………………………......21
4.2. Módulo Hypergraph.…………………………………….……....................22
4.2.1. Visualización de la estructura conceptual.…………..….……......22
4.2.2. Instalación.…………………………………………..….……......24
4.2.3. Uso. Características principales.………………………..……......24
4.2.4. Documentación.………………………..……………….……......26
4.2.5. Limitaciones.……………………………...…………….……......26
PARTE II. Desarrollo.…………………………………….………………………......28
5. CCC-Graph.……………………………………………………………….……......30
5.1. Introducción.…………………………………….…………………..…......30
5.2. Modelado del problema.………………………………………….……......31
5.2.1. Requisitos funcionales.………………………………………......31
5.2.2. Requisitos no funcionales.………………..…………….……......32
6. Desarrollo de CCC-Graph.…………………………………….………………......34
6.1. Arquitectura de componentes..…………………………………...……......34
6.1.1. Determinación de objetivos.…………………………………......34
6.1.2. Análisis de riesgos.………………….………………….……......35
6.1.3. Ingeniería, desarrollo del producto.………………………….......35
6.1.4. Evaluación.…………………………………….……….……......36
6.2. Filtrado de relaciones……………………………………………..……......36
6.2.1. Determinación de objetivos.…………………………………......36
6.2.2. Análisis de riesgos.………………….………………….……......37
6.2.3. Ingeniería, desarrollo del producto.……………………….…......42
6.2.4. Evaluación.…………………………………….…………….......44
6.3. Arquitectura de almacenamiento…………………….………………….....44
6.3.1. Determinación de objetivos.…………………………………......45
6.3.2. Análisis de riesgos.…………………………………….…….......45
6.3.2.1. Almacenamiento de las opciones.………………….......45
6.3.2.2. Comunicación applet-módulo.……….……….……......47
6.3.3. Ingeniería, desarrollo del producto.…………………….……......48
6.3.4. Evaluación.…………………………………………..….…….....49
6.4. Extracción de la estructura conceptual.…………………….…….……......50
6.4.1. Determinación de objetivos.…………………………………......50
6.4.2. Análisis de riesgos.………………………………….….……......50
6.4.3. Ingeniería, desarrollo del producto.…………………….……......52
6.4.3.1. Estructuración de la información.…………….……......52
6.4.3.2. Extracción de la información.…………………...…......54
6.4.4. Evaluación.…………………………….……………….……......55
6.5. Diseño de la configuración…………………….………………….…….....56
6.5.1. Determinación de objetivos.…………………………....……......56

6.5.2. Análisis de riesgos.……………………………………..……......56
6.5.3. Ingeniería, desarrollo del producto.…………………….……......57
6.5.3.1. Representación a partir del contexto del nodo actual…..57
6.5.3.2. Creación del menú de configuración.………………......57
6.5.4. Evaluación.………………………..…………………….……......60
6.6. Administración de la estructura conceptual………………...…….……......61
6.6.1. Determinación de objetivos.…………………………....……......61
6.6.2. Análisis de riesgos.……………………………………..……......61
6.6.3. Ingeniería. Desarrollo del producto.…………………………......62
6.6.4. Evaluación.…………………………………….……....................65
6.7. Visualización de relaciones múltiples.……………….…….........................66
6.7.1. Determinación de objetivos.…………………………………......66
6.7.2. Análisis de riesgos.……………………………………..……......66
6.7.2.1. Definición de estados.……………………………….....66
6.7.2.2. Estudio de la implementación.………………..……......69
6.7.3. Ingeniería. Desarrollo del producto.…………………………......70
6.7.4. Evaluación.…………………………………….……...................76
PARTE III. Epílogo.…………………………………….……………………...…......78
7. Evaluación…………………………………………………………………………..80
7.1. Evaluación general.…………………………………….………......80
7.2. Evaluación personal.…………………………..………….……......80
7.3. Arquitectura.…………………………………………...….…….....81
8. CCC-Ética informática.……………………………………….………….……......82
8.1. Propósito de la página.………………………………..…….…….……......82
8.2. Estructura conceptual.………………………………………....….……......82
8.3. Nuestra misión.……………………………………………..…….……......82
8.4. Instalación.…………………………………….…………………….…......83
8.5. Pruebas.…………………………………….………………..…………......83
Anexo I – Documentación Hypergraph.…………………………………..….……......87
Anexo II – Modelado de CCC Graph.……………………………………….…….....110
Anexo III – Algoritmos de extracción de la EC.………………………….…...…......112
Anexo IV – Instalación.…………………………………….…………………….......116
Anexo V – Guía de uso.…………………………………….………………….…......118
Referencias.………………………………………………………………....……......120



PARTE I - PROLEGÓMENO
1
PARTE I
PROLEGÓMENO

PARTE I - PROLEGÓMENO
2

INTRODUCCIÓN
3
1. Introducción
Podemos comenzar la memoria de este proyecto fin de carrera situándonos en el
contexto que nos lleva a realizarlo.
1.1. Contexto
Abrimos el navegador. Accedemos al último sitio web de moda. Nos encontramos en un
mundo repleto de datos. Podemos saltar de una página a otra mediante diferentes
mecanismos, se nos presentan múltiples tipos de información, tanto en la forma como
en el contenido.
1.1.1. Sistemas hipermedia
Hemos descrito una de las formas más habituales, se podría asegurar que lo hacemos
casi a diario, en la que nos enfrentamos a un sistema hipermedia. Los sistemas
hipermedia se basan en la presentación no lineal de información, en cualquier tipo de
formato, posibilitando la interacción del usuario que puede decidir el camino a seguir
para recuperar las distintas partes de las que se compone [13].
La visión que obtiene el usuario es transparente e integrada de manera que no resulta
complicado navegar de una página a otra. Por otro lado, el usuario se encuentra
sumergido en un mar de información al que puede ser complicado dar orden y sentido
en su recorrido. Dos son los problemas más reiterados: desbordamiento cognitivo y
desorientación [3].
1.1.2. Sistemas hipermedia adaptativos
Los sistemas hipermedia adaptativos (SHA) surgen con el propósito de mejorar la
usabilidad de los sistemas hipermedia tradicionales. La mayoría de ellos consiguen
facilitar la actividad del usuario, haciendo que el sistema se ajuste a determinadas
características de éste. [2]
La utilización de SHAs disminuye en gran proporción los problemas de desorientación
y falta de comprensión al incluir técnicas adaptativas como:
Establecimiento de prerrequisitos en el acceso a páginas.
Adaptación de los contenidos mostrados dependiendo de las características
del usuario y sus acciones.
Anotación y ocultación de enlaces.
Aportación de consejos locales y globales para la navegación en el
hiperespacio.
Soporte local de orientación que permite la visión global de la estructura de
enlaces.

INTRODUCCIÓN
4
Además, se facilita el desarrollo del sistema y posterior mantenimiento al obligar autor a
estructurar y ordenar el conocimiento.
Sin embargo, la utilización de estos medios puede desembocar en algunos problemas,
ya que incrementan el trabajo del autor que tiene que estructurar la información, pueden
producir aún más desorientación y una compresión más lenta si la adaptación al usuario
no es la correcta, y normalmente incrementan la duración de los procesos de desarrollo
al no encontrarse muy consolidados, dificultando además, la escalabilidad.
1.1.3. El modelo SEM HP
SEM HP es un modelo sistémico, evolutivo y semántico para el desarrollo de sistemas
hipermedia adaptativos [2] planteado como solución a los problemas descritos.
La capacidad de evolución facilita al autor la realización de modificaciones, tanto
funcionales como estructurales, para mejorar el sistema a partir de un modelo evolutivo
definido. De esta forma, se podrá “ajustar” la adaptación al usuario según las
modificaciones y actualizaciones del contenido que vayan siendo necesarias.
La distinción de subsistemas (memorización, presentación, navegación y aprendizaje)
facilita la aplicación de ingeniería del software al dividir el proceso de desarrollo en
cuatro fases, bien definidas, focalizadas en cada uno de ellos.
En [1] se afrontó el objetivo de elaborar una aproximación del modelo SEM HP
mediante la implementación de una herramienta, DSEM HP, en el sistema de gestión de
contenidos Drupal. El trabajo abarca tres de los subsistemas que se componen el
modelo:
El subsistema de memorización. Construido haciendo uso del gestor de
contenidos ofrecido por Drupal. Su función es albergar el conocimiento del
modelo, basándose en una estructura de conceptos, ítems y relaciones que
forman una red semántica.
Los subsistemas de presentación y navegación representan, por medio de un
hipergrafo interactivo, la estructura conceptual presentada por el subsistema de
memorización. Hace uso de un visualizador de hipergrafos construido siguiendo
la tecnología de Applets de Java, integrándolo en Drupal mediante la
implementación de un módulo.
El subsistema de aprendizaje, con mayor utilidad para sistemas hipermedia orientados a
la enseñanza, quedó fuera del alcance del proyecto y expuesto como una posible mejora.
El diseño realizado presenta un gran inconveniente, existe un gran acoplamiento entre
los distintos subsistemas, de forma que el de presentación y el de navegación,
representados mediante el módulo desarrollado, DSEM HP, no soportan posibles
cambios en la estructura conceptual (subsistema de memorización).

INTRODUCCIÓN
5
1.2. Objetivos y pasos
El objetivo del presente proyecto es reimplementar los subsistemas de presentación y
navegación de forma que sean capaz de soportar cualquier estructura conceptual
presentada en el subsistema de memorización.
Los pasos seguidos serán los siguientes:
Estudio del applet Hypergraph. Se investigará el funcionamiento e
implementación del applet Hypergraph. Se concluirán y llevarán a cabo los
puntos a modificar para alcanzar la correcta visualización y navegación de
cualquier estructura conceptual mediante la utilización de un hipergrafo.
Estudio del módulo DSEM HP. Se realizará un análisis del módulo para saber
cómo y qué información almacenada extrae del sitio, cómo es transferida a su
vez al applet encargado de su visualización y de qué forma es integrado el
visualizador en la interfaz de Drupal.
Diseño de la comunicación de la estructura. Se trata del punto más
importante, en el que se deberá presentar algún tipo de interfaz que permita
trasladar la estructura almacenada por medio páginas (nodos en Drupal) al applet
para que se mostrada en forma red semántica por medio de un grafo. Tras los
estudios realizados en los anteriores puntos se deberán plantear varias
alternativas de comunicación y, según las ventajas e inconvenientes mostrados,
tomar una decisión, presentando el diseño completo.
Reimplementación del sistema. Con el diseño de la solución realizado se
procederá a su implementación, tomando como base el módulo existente DSEM
HP.
Integración y realización de pruebas sobre el portal Ética Informática. El
módulo será instalado para comprobar que realiza correctamente la visualización
de la estructura conceptual y permite su navegación a través de ésta.
1.3. Alcance
Además del desarrollo completo del proyecto, siguiendo los puntos mencionados, se
realizará un exhausto seguimiento que se plasmará en el presente documento. Serán
descritos los problemas encontrados, el estudio de las diferentes soluciones
buscadas/existentes y las soluciones llevadas a cabo.
Todo el desarrollo comentado se realizará partiendo de la versión anterior. Se
aprovechará el trabajo de un módulo en funcionamiento para facilitar el proceso de
desarrollo y testeo.
EL MODELO. SEM-HP
6
2. El modelo. SEM-HP
En la introducción hemos situado el contexto del que parte el proyecto tratando
ligeramente la solución propuesta por el modelo SEM HP. Ya que puede considerarse la
base en la que se apoya el trabajo, vamos a exponer de una forma más extensa los
puntos principales de su funcionamiento.
SEM HP surge de las deficiencias presentadas por los sistemas hipermedia
tradicionales, presentando un enfoque evolutivo para la construcción y mantenimiento
de los sistemas hipermedia adaptativos.
2.1. Modelo sistémico, evolutivo, semántico y adaptativo
El modelo considera un sistema hipermedia formado por cuatro partes diferenciadas,
donde el autor puede ofrecer diferentes vistas o subdominios, según las características
de cada usuario, del dominio conceptual definido.
Además, soporta y facilita las continuas modificaciones realizadas en los sistemas de
este tipo, presentando un proceso de desarrollo iterativo dividido en fases para su
construcción y una serie de mecanismos evolutivos para el mantenimiento y navegación
[3].
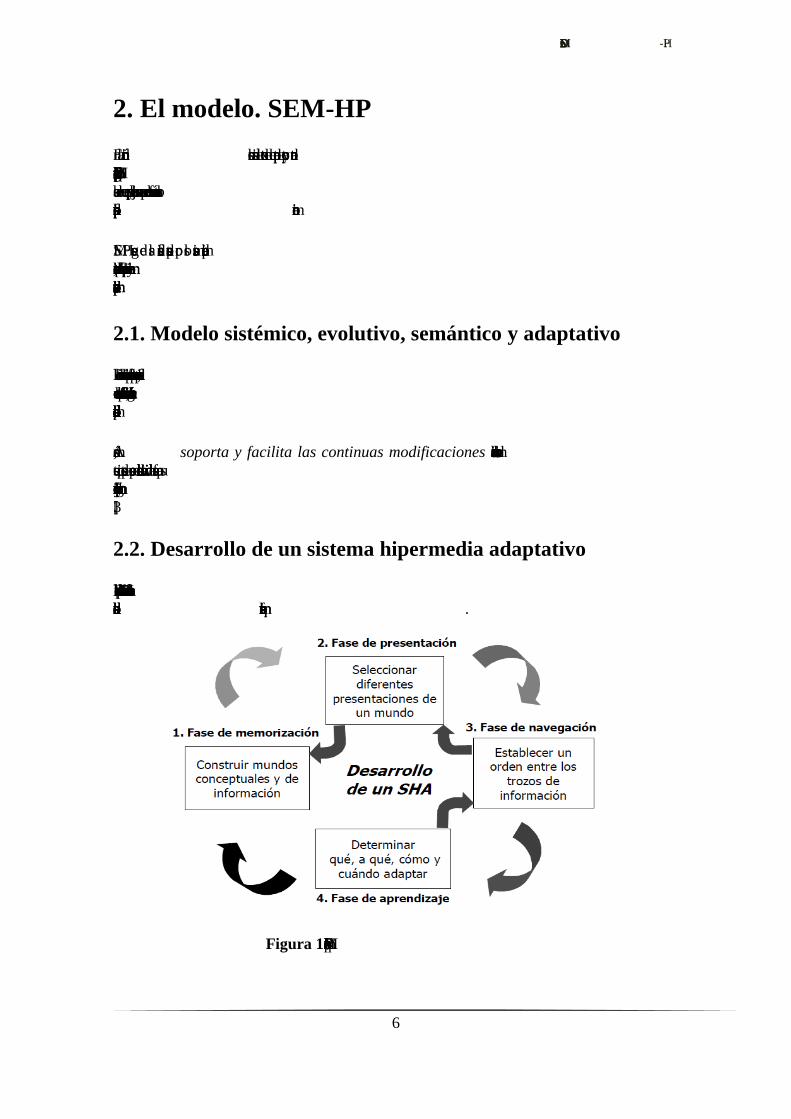
2.2. Desarrollo de un sistema hipermedia adaptativo
El desarrollo presentado por el modelo SEM HP se divide en cuatro fases inherentes a
cada uno de los subsistemas que forman la arquitectura.
Figura 1. Fases que componen SEM HP

EL MODELO. SEM-HP
7
Fase de memorización
El autor define el dominio de información del sistema, haciendo explícito el dominio
conceptual en el que se basa. El subsistema de memorización será el encargado de
memorizar, estructurar y mantener los dominios definidos.
Los dominios conceptual y de información se encuentran representados por dos tipos de
unidades de información y sus asociaciones:
Conceptos: construcciones mentales que pueden ser etiquetadas con el fin de
proporcionar algún tipo de conocimiento.
Items: unidades información relativas a un concepto.
Asociaciones: relaciones de cualquier tipo que pueden mantener los conceptos.
El subsistema de memorización utiliza, por tanto, una estructura conceptual como
modelo de representación para describir los dominios. La estructura conceptual forma
un grafo dirigido débilmente conectado donde conceptos e ítems se muestran como
nodos y las asociaciones vendrían representadas por aristas. Al etiquetarse cada uno de
los elementos, tanto relaciones como nodos, el grafo podría considerarse como una red
semántica.
Fase de presentación
A partir de la información incluida en la fase de presentación, el autor selecciona los
distintos subdominios que serán visualizables.
El subsistema de presentación almacena varios subconjuntos de la estructura
conceptual, lo que permitirá ofrecer distintas vistas de la información albergada. Así, el
usuario sólo accederá a la información que le interesa o puede asimilar, evitando
además, los posibles problemas de desorientación y dificultad en la asimilación de
conceptos, típicos en los sistemas hipermedia.

EL MODELO. SEM-HP
8
Figura 2. Diferentes vistas de la estructura conceptual
Fase de navegación
Se define la forma en la que los usuarios llegarán a la información. Es decir, qué
información es alcanzable por el usuario y cómo podrá llegar a ella.
El subsistema de navegación dispone y ordena la forma de acceder a las vistas ofrecidas
por las estructuras conceptuales de presentación creadas en la anterior fase. Se trata del
tema principal del proyecto. Recogiendo el trabajo realizado en [1] se propondrá un
sistema de navegación intuitivo, configurable y flexible, capaz de soportar cualquier
estructura conceptual.
Fase de aprendizaje
Se establecen los mecanismos necesarios para que la navegación y presentación se
adapten de forma automática al usuario según sus características e interacción con el
sistema.
El subsistema de aprendizaje debe almacenar un modelo de usuario que sea capaz de
describirlo lo más detalladamente posible: nivel de conocimiento en la materia tratada y
del funcionamiento propio sistema, información accedida, intereses… lo que permitirá
que la adaptación al usuario sea lo más certera posible.

EL MODELO. SEM-HP
9
Para realizar el proceso adaptativo se partirá del modelo de usuario, aplicando los
mecanismos definidos a partir de reglas procedentes de los subconjuntos actualización,
peso y conocimiento.
El citado subsistema queda fuera del alcance del actual proyecto.
2.3. Proceso evolutivo
Siguiendo el esquema de la arquitectura del modelo SEM HP, visualizado en la figura 2,
se han explicado las partes que componen el sistema. Procederemos a exponer la
funcionalidad del llamado meta-sistema, donde se definen las acciones que marcan la
evolución de la capa superior (de menor abstracción).
El meta-sistema proporciona los mecanismos evolutivos necesarios para realizar las
modificaciones y actualizaciones que el autor considere oportunos, tanto en la estructura
conceptual como en el funcionamiento, según las necesidades que vayan surgiendo.
Los mecanismos se basan en tres elementos: acciones evolutivas, restricciones y
propagación del cambio. Según la modificación a realizar, el autor seleccionará una
acción evolutiva. La acción podrá desembocar en un conjunto de transformaciones que
afecten a más partes del sistema siguiendo el camino marcado por la propagación del
cambio. El conjunto de restricciones decidirán si los cambios producidos por la
ejecución de la acción y su propagación son válidos de forma que siempre se mantenga
la consistencia del sistema.
El objetivo de proporcionar a priori mecanismos evolutivos facilita la tarea al autor, que
podrá realizar de una forma rápida y eficaz las transformaciones necesarias para que
tanto la adaptación, como el contenido mostrado y el funcionamiento del sistema sean el
correcto, evitando los problemas de los sistemas hipermedia tradicionales y
manteniendo la consistencia del sistema.
2.4. Estructura de navegación
Centrándonos en el tema principal del proyecto, el sistema de navegación, se expondrán
los diferentes modos seleccionables por el usuario, haciendo hincapié en su estructura.
Como se introdujo al principio del proyecto, en los sistemas hipermedia es muy común
que el usuario llegue a la situación en la que se pregunta ¿dónde estoy?, ¿cómo he
llegado aquí?, ¿adónde puedo ir? e, incluso, ¿qué estoy leyendo y por qué? La razón, el
sistema de navegación utilizado.
El usuario se encuentra en una página con cierta información, a la que ha accedido
siguiendo un camino no identificable y desde la que podrá acceder a otra serie de

EL MODELO. SEM-HP
10
páginas seleccionando uno de los enlaces, usualmente colocados, cuando no de forma
aleatorio, no óptima.
Una red semántica como estructura navegacional
Siguiendo la disposición de información que hace uso de nodos y relaciones, se presenta
la red semántica como estructura navegacional adecuada. En ella, el usuario visualizará
las unidades de información como nodos (distinguiendo entre los tipos ítem y concepto)
y las asociaciones como aristas. Ambos elementos se encontrarán etiquetados, dando
significado a su aparición.
El sistema navegacional que nosotros presentaremos, variará esta visión en cuanto a la
flexibilidad de estructuras conceptuales soportadas, siendo capaz de representar una
estructura como la presentada en el modelo SEM HP, o cualquier otra, basada en una
combinación de diferentes tipos de nodos y relaciones.
Como estructura navegacional debemos entender el conjunto de nodos y relaciones que
la forman, sin tener en cuenta las reglas que marcan su navegabilidad, nombrándose
entonces como “estructura conceptual de navegación”.
Navegación por páginas vs navegación semántica
Una de las principales ventajas de la navegación utilizando una red semántica es la
visión de conjunto que ofrece a golpe de vista. Conociendo la representación utilizada,
el usuario puede extraer valiosa información de la estructura de navegación al disponer
de toda la información semántica.
En la navegación típica por páginas el usuario sólo tiene visión de los conceptos
ubicados en la página actual. A lo máximo podrá acceder a los conceptos contenidos en
las páginas enlazadas, perdiendo la procedencia y el entorno de conceptos relacionados.
Nos encontramos de nuevo con el típico problema de desorientación y dificultad de
asimilación de la información.
El uso de una red semántica hace explícito los dominios conceptual y de información,
situando al usuario en el contexto del concepto actual y dando pistas sobre el camino a
seguir para obtener el conocimiento albergado. Es importante para ello que los nodos
cumplan la función de enlaces, llevando al usuario a la información que representan
cuando son seleccionados.
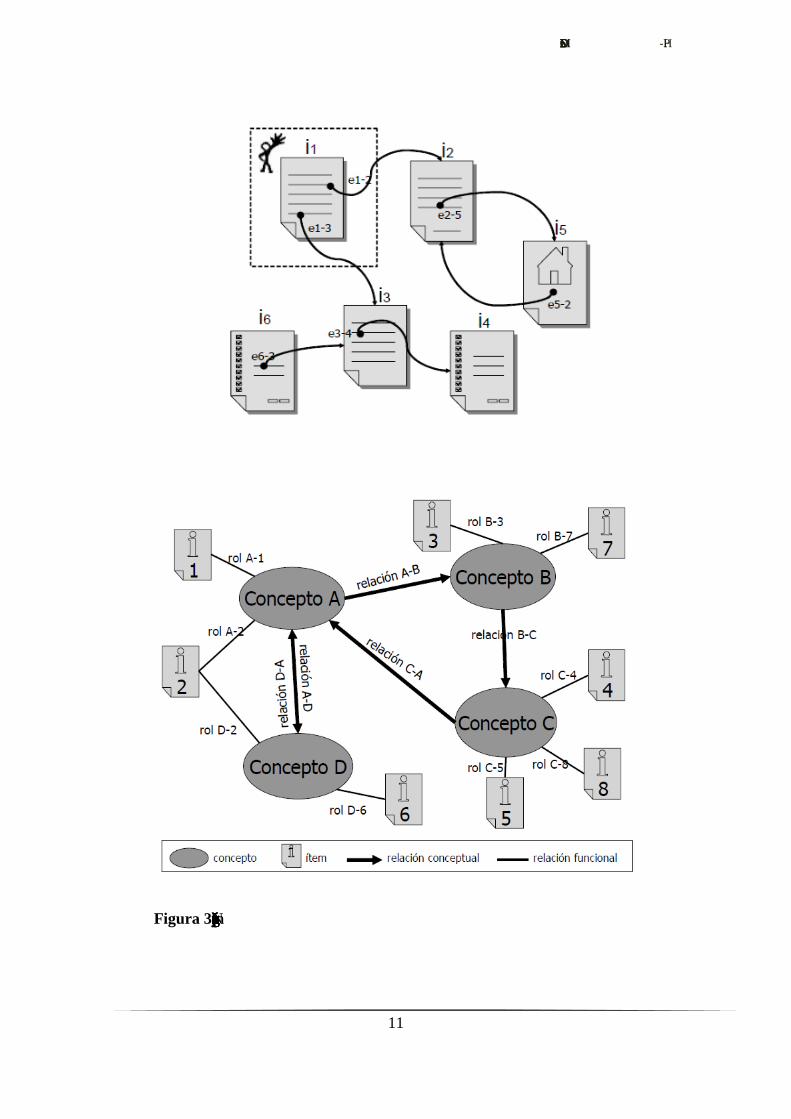
EL MODELO. SEM-HP
11
Figura 3. Navegación semántica (arriba) vs navegación por páginas (abajo)
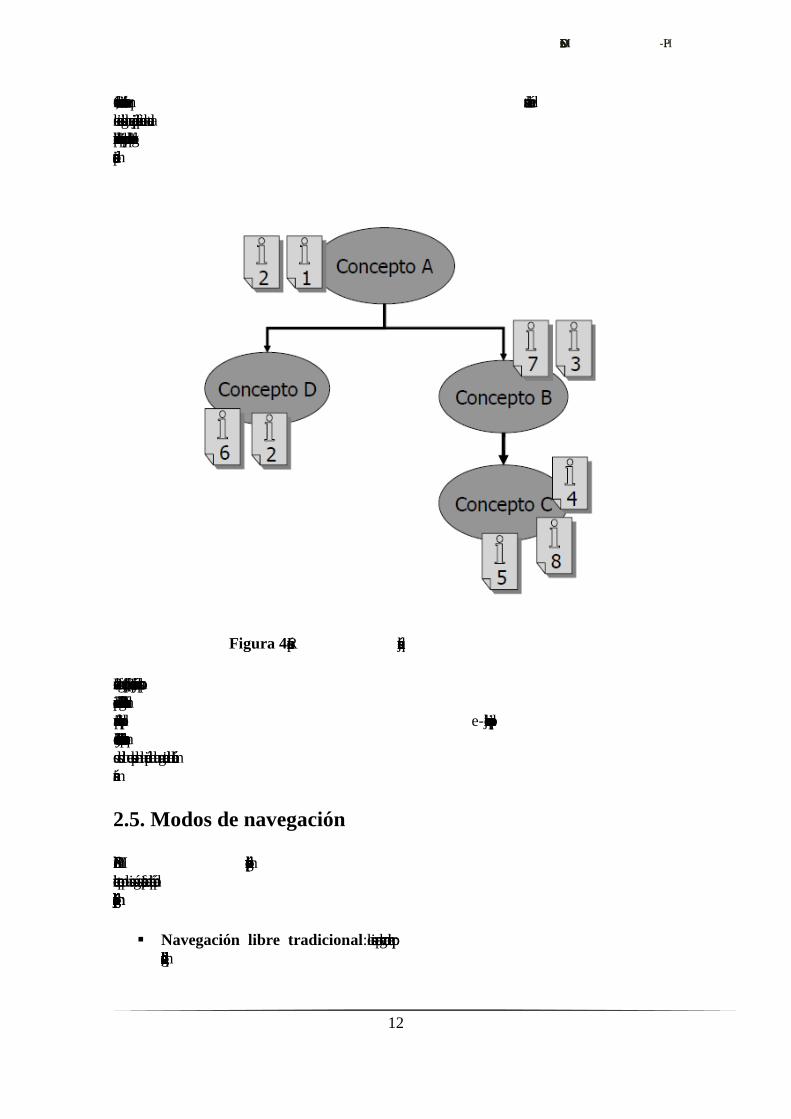
EL MODELO. SEM-HP
12
Como alternativa, muchos sistemas ofrecen herramientas que muestran la relación de
los contenidos siguiendo un esquema jerárquico, insuficiente teniendo en cuenta la
multiplicidad de relaciones que pueden existir y comparado con el potencial del grafo
representado en una red semántica.
Figura 4. Representación jerárquica de la estructura
Ponemos la figura 4 como ejemplo [3] de representación jerárquica de los conceptos
aparecidos en la red semántica de la figura 3. Podemos observar cómo la utilización de
una representación estricta con relaciones del tipo padre-hijo hace que se pierdan tipos
de relaciones y la ciclicidad existente, no siendo posible varios caminos que relacionen
dos nodos lo que desemboca en la pérdida de una gran cantidad de información
semántica.
2.5. Modos de navegación
El modelo SEM HP expone cuatro modos de navegación, en principio seleccionables en
cualquier momento por el usuario según sus preferencias, aunque también podrían
restringirse según el carácter del sistema (por ejemplo en el ámbito educacional).
Navegación libre tradicional: el usuario puede navegar cuando quiera por
donde quiera, siendo la unidad de navegación el ítem.

EL MODELO. SEM-HP
13
Navegación libre por conceptos: se accede libremente cualquier nodo concepto
(la unidad de navegación), mostrándose un resumen de los ítems que contiene.
Navegación restringida por relación conceptual: el usuario solo puede
navegar a través de los enlaces existentes entre los conceptos, en función de las
reglas de orden y navegabilidad.
Navegación restringida por conocimiento: solo se encuentran accesibles los
conceptos comprensibles para el usuario, de acuerdo a las reglas de
conocimiento.
Nuestro proyecto presentará un sistema de navegación basado en el modo tradicional
libre, quedando la implementación de los demás como posible mejora a afrontar en
futuros proyectos.

PRIMER INTENTO. DSEM-HP
14
3. Primer intento. DSEM-HP
DSEM HP nació con la idea de plasmar las ideas presentadas en el modelo SEM HP en
una herramienta real. El camino para hacerlo, la utilización de sistema de gestión de
contenidos Drupal.
En [1] se afronta el desarrollo de una herramienta con capacidad de visualización y
edición de estructuras conceptuales. La idea principal es estudiar y representar el
contenido teórico sobre el tema tratado por el autor, mecanismos de persuasión
publicitaria en Internet, haciendo uso de un sistema que siga el modelo SEM HP.
Nuestro proyecto surge con la idea de continuar el trabajo realizado en la herramienta
DSEM HP, por lo que es fundamental su estudio, haciendo énfasis en los objetivos
iniciales, dificultades encontradas, objetivos alcanzados y las limitaciones del sistema.
Esperamos con ello orientar nuestros esfuerzos conociendo, a priori, los puntos más
difíciles y retos a los que nos vamos a enfrentar.
3.1. Objetivos alcanzados
Haciendo un repaso general sobre el desarrollo se puede concluir los objetivos
alcanzados fueron:
Lograr la representación del contenido teórico del tema tratado, mecanismos de
persuasión en Internet, haciendo uso de una estructura conceptual.
Alcanzar una aproximación correcta de un sistema hipermedia adaptativo
siguiendo el modelo SEM HP para marcar los pasos a seguir en la construcción
de otros sistemas similares en Drupal.
Conseguir la creación de un sistema de navegación con alto grado de usabilidad
que permite, además, la edición de los elementos de la estructura conceptual.
Mejorar los proyectos utilizados, aumentando su funcionalidad (al soportar la
visualización de grafos por ejemplo), migrando el módulo de la versión 5 de
Drupal a la 6 e incrementando la usabilidad del applet.
3.2. Limitaciones y deficiencias
El estudio del proyecto nos lleva a exponer una serie de aspectos mejorables:
El grafo muestra una red semántica que recoge la estructura conceptual al
completo, de forma que no sitúa al usuario en el contexto directo del nodo
actual.

PRIMER INTENTO. DSEM-HP
15
La extracción de la estructura conceptual del sistema de memorización se realiza
de forma estática. Si cambia algún aspecto de la estructura conceptual actual o se
requiere la utilización de otra diferente, el módulo no es capaz de obtener la
información contenida en el sistema para su posterior visualización.
El diseño e implementación planteados presenta un fuerte acoplamiento entre los
distintos componentes que integran el sistema (principalmente módulo y applet).
Por tanto, la principal baza del proyecto, el applet, encargado de la
representación gráfica y la navegación, es dependiente del funcionamiento actual
del módulo. No soporta, al menos de forma correcta, la visualización de grafos
que representen estructuras conceptuales diferentes a la estudiada.
Deficiente estudio y exposición de las herramientas recogidas para realizar el
proyecto. No es una deficiencia del sistema, pero sí un aspecto mejorable. Como
pone de manifiesto el autor, se tratan de proyectos de software libre
documentados pobremente por los que consideramos que el estudio realizado
para lograr su entendimiento podría haber sido documentado siendo de ayuda
para posteriores desarrolladores en la misma situación.
3.3. Puntos clave
Después del estudio realizado, podemos analizar los puntos clave que debemos afrontar
en nuestro proyecto, recogiendo los logros alcanzados y mejorando las deficiencias
encontradas.
3.3.1. Puntos útiles
La usabilidad mejorada del applet, corrigiendo algunas de sus deficiencias e
incrementando su navegabilidad.
La capacidad de representación gráfica de grafos y su navegación.
La migración del módulo, de la versión 5 a la 6 de Drupal. Nos permitirá recoger
un módulo creado en la versión en la que desarrollaremos el nuestro.
El método a utilizar para la extracción estructuras conceptuales del contenido de
un sitio Drupal.
Ejemplos y mecanismos útiles para realizar la comunicación applet-módulo.
3.3.2. Puntos fuera del alcance de CCC-Graph
La creación, modificación y eliminación de elementos de la estructura
conceptual. El objetivo de poder representar cualquier tipo de estructura
necesitaría la abstracción de este mecanismo para todas las posibilidades. Se
presenta como un desarrollo demasiado extenso e innecesario, quedando fuera
del alcance de nuestro proyecto.

PRIMER INTENTO. DSEM-HP
16
Debido a la decisión planteada en el punto anterior, se torna innecesaria la
opción de rehacer y deshacer acciones realizadas.
La representación de cualquier tipo de contenido en forma de nodo hace inútil el
plegado de un tipo determinado (ítem).
3.3.3. Puntos a mejorar
Se procederá a una clara división de los componentes que forman el sistema. El
objetivo es impedir que los cambios en uno de ellos afecte a otras partes.
Se abstraerá la extracción de la estructura conceptual almacenada en el sitio de
forma que sea capaz extraer y representar otras estructuras con cualquier
combinación de nodos y relaciones. Para ello, se realizará un estudio del
conjunto de tipos de estructuras que será posible representar.
Se llevará a cabo un estudio y documentación más completos de las
herramientas de software libre utilizadas.
Otros aspectos que se mejorarán respecto a la actual implementación son los
relacionados con la usabilidad y configurabilidad de la herramienta:
o Se pretende permitir la elección por parte del usuario de los elementos
visualizados, haciendo hincapié en el filtrado de relaciones.
o Se requiere la posibilidad de selección de los elementos pertenecientes a
la estructural conceptual dentro del conjunto de tipos de contenidos
creados en el sistema.
o Serán editables algunos aspectos de la visualización del grafo y la
configuración del applet desde algún tipo de interfaz gráfica. Se pretende
de esta forma permitir ajustar el funcionamiento de la herramienta a las
características del sitio en el que use, mejorando la experiencia del
usuario final.

LAS BASES.HYPERGRAPH
17
4. Las bases. Hypergraph
El primer paso, previo al desarrollo, será el estudio de las herramientas, en las que se
basó DSEM HP y en las que se basará nuestro proyecto. Éstas son:
HyperGraph. Proyecto Java que proporciona todo tipo de funcionalidades para
trabajar con geometría hiperbólica. Entre ellas destaca la posibilidad de
representar gráficamente árboles hiperbólicos. Se tratará con mayor extensión
debido a su magnitud y complejidad.
Módulo Hypergraph. Integra el visualizador de árboles hiperbólicos en Drupal
mediante la implementación de un módulo.
Los motivos por los que se realiza el estudio son principalmente dos:
El conocimiento de las herramientas que utilizaremos es fundamental para sacar
el mayor provecho de ellas y afrontar las mejoras necesarias para cubrir los
requerimientos de nuestro proyecto.
Como ya se ha comentado, al tratarse de proyectos de software libre, no
incluyen una documentación demasiado elaborada. En [1] se pone de manifiesto
este problema, tratando por encima su funcionalidad Se explicarán los puntos
más importantes de las herramientas, se expondrá su funcionamiento y el
potencial ofrecido, completando las partes que se consideren necesarias de la
documentación existente.
4.1 Proyecto HyperGraph
HyperGraph es un proyecto de código abierto, publicado en 2003, que proporciona un
conjunto de utilidades Java para trabajar con geometría hiperbólica y, especialmente,
con árboles hiperbólicos. Su API permite la visualización de geometría hiperbólica, el
manejo de grafos y la correcta disposición de los elementos de un árbol hiperbólico [6].
Nos centraremos en la funcionalidad para visualizar geometría hiperbólica, y en
concreto árboles hiperbólicos.
4.1.1. Visualización de árboles hiperbólicos
HyperGraph ofrece un visualizador de árboles hiperbólicos utilizando un applet de Java.
La herramienta es capaz de mostrar el conjunto de nodos y aristas que forman un árbol,
disponiéndolos de una forma clara y legible, sin solapamientos.
Se ofrece la posibilidad de recorrer el árbol mediante su arrastre, manteniendo en todo
momento la forma del plano hiperbólico. Se resaltan los elementos más cercanos al
LAS BASES.HYPERGRAPH
18
centro, disminuyendo el tamaño de los más lejanos. Los elementos son etiquetables,
siendo posible mantener en todo momento la referencia de su posición.
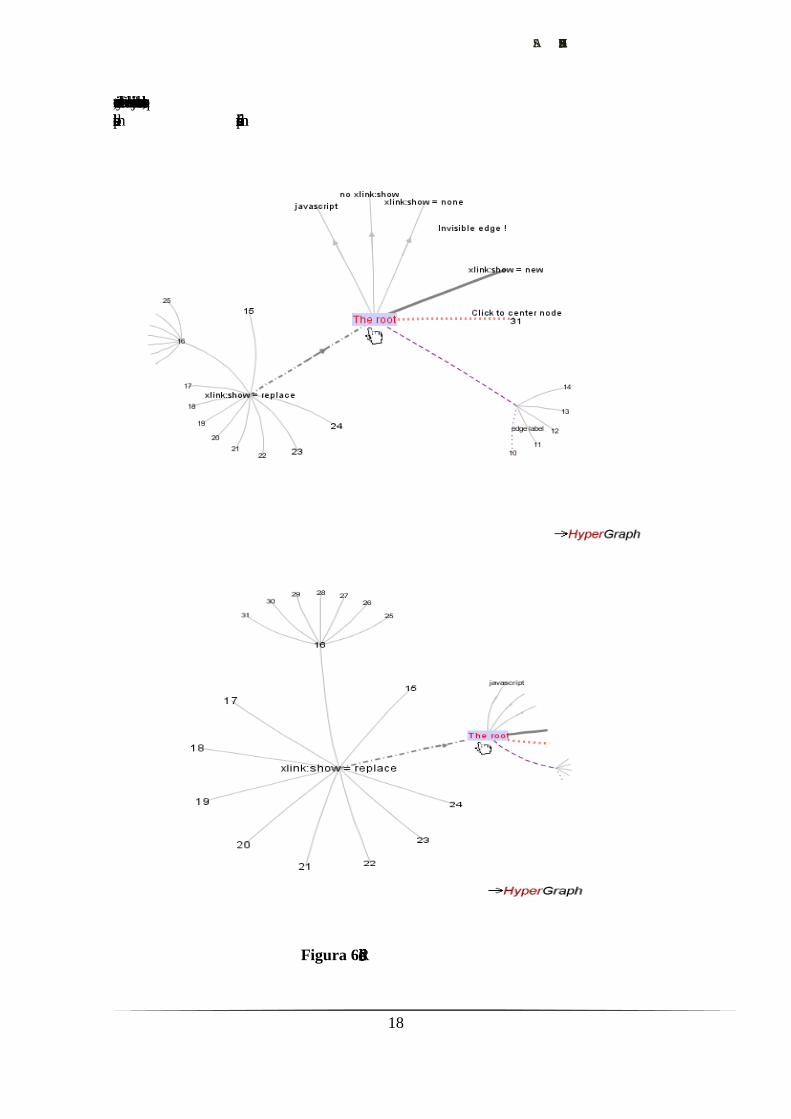
Figura 6. Recorrido del árbol

LAS BASES.HYPERGRAPH
19
La lista de nodos y relaciones que los unen son pasados a través de un documento XML
siguiendo la especificación del DTD aportado en [7].
4.1.2. Instalación
Se sigue la instalación estándar de cualquier applet. El applet se integra en un sitio web
mediante la inserción de código HTML, utilizando el tag <applet> que realiza su
llamada.
La llamada debe incluir la configuración de los parámetros estándar como ubicación del
jar del applet y el archivo XML con la especificación del grafo, la alineación y el
tamaño que ocupará en la página [16].
<applet code="hypergraph.applications.hexplorer.HExplorerApplet"
align="baseline" archive="path-to-jar/hyperapplet.jar"
width="500" height="500">
<param name="file" value="path-to-graphs/my-graph.xml">
</applet>
4.1.3. Uso. Características principales
Como se ha comentado, el árbol a representar es especificado mediante un archivo
XML siguiendo la sintaxis definida en GraphXML.dtd. El applet es el encargado de
reconocer dicha especificación, para su posterior visualización, ofreciendo un gran
número de posibilidades en la caracterización visual del grafo:
Etiquetado de elementos. El texto de la etiqueta visualizada por un elemento.
Propiedades de las aristas, entre las que se encuentran:
- Color: color de la línea. Se podrá dibujar una línea con dos colores
diferentes, uno para cada mitad.
- Dirección: se ofrece la posibilidad de darle dirección a una relación,
añadiendo una flecha a la arista.
- Color de la etiqueta: color del texto mostrado.
- Estilo de la línea: se podrá seleccionar entre continua, discontinua, línea
de puntos e invisible.
- Grosor: ancho de la línea que forma la arista.

LAS BASES.HYPERGRAPH
20
Propiedades de los nodos que se podrán editar:
- Color: color de fondo del nodo
- Color de la etiqueta: color del texto mostrado.
- Imagen: se podrá seleccionar una imagen pequeña como representación
del nodo.
Creación de grupos. Es posible la creación de grupos de elementos, con
características propias. Todos los elementos pertenecientes al grupo heredarán
las características visuales definidas en el grupo.
Referencias a páginas. Los elementos del grafo podrán dirigir a las direcciones
url que les sean asignadas. Se podrá seleccionar el lugar de aparición de la
página direccionada: la página actual o, nueva página en otra pestaña o ventana.
Por otro lado, utilizando el archivo de configuración general designado con la extensión
“.prop” reconocible por el applet, existe la posibilidad de editar otras propiedades como:
Tamaño y fuente del texto utilizado en las etiquetas.
Color de fondo del applet.
Otras características de la visualización de elementos del applet: máximo
ángulo formado entre las aristas, tamaño de los nodos y longitud de las aristas
según su cercanía al centro…
4.1.4. Documentación
El código del proyecto HyperGraph supera las 100000 líneas de código, haciendo uso
de más de 100 clases diferentes divididas en un total de 8 clases. Sin embargo, toda la
documentación que encontramos es la generada mediante la herramienta Javadoc
procedente de los comentarios incluidos en el código.
Encontramos una gran disparidad en la cantidad de información incluida en las
diferentes clases. Encontramos paquetes explicados al mínimo detalle y multitud de
clases y funciones ignoradas. Además, no se incluye ningún tipo de diagrama o dibujo
que modele la arquitectura del sistema.
Se ha aprovechado el estudio de la aplicación para completar la documentación
existente. Por un lado, se ha realizado el trabajo de traducir el Javadoc (en inglés),
comentando los apartados sin información (Anexo 1). Por otro, se ha creado un
diagrama de paquetes y un diagrama con la relación de las clases más relevantes del
sistema (Anexo 2).
LAS BASES.HYPERGRAPH
21
4.1.5. Mejoras introducidas por DSEM HP
El proyecto DSEM HP recogió el trabajo analizado, introduciendo una serie de mejoras
que permitieran su utilización en el sistema de navegación de un sistema hipermedia:
Capacidad para representar grafos, no sólo árboles. Es decir, se permitirá la
existencia de relaciones cíclicas.
Soporte y visualización de relaciones bidireccionales entre nodos
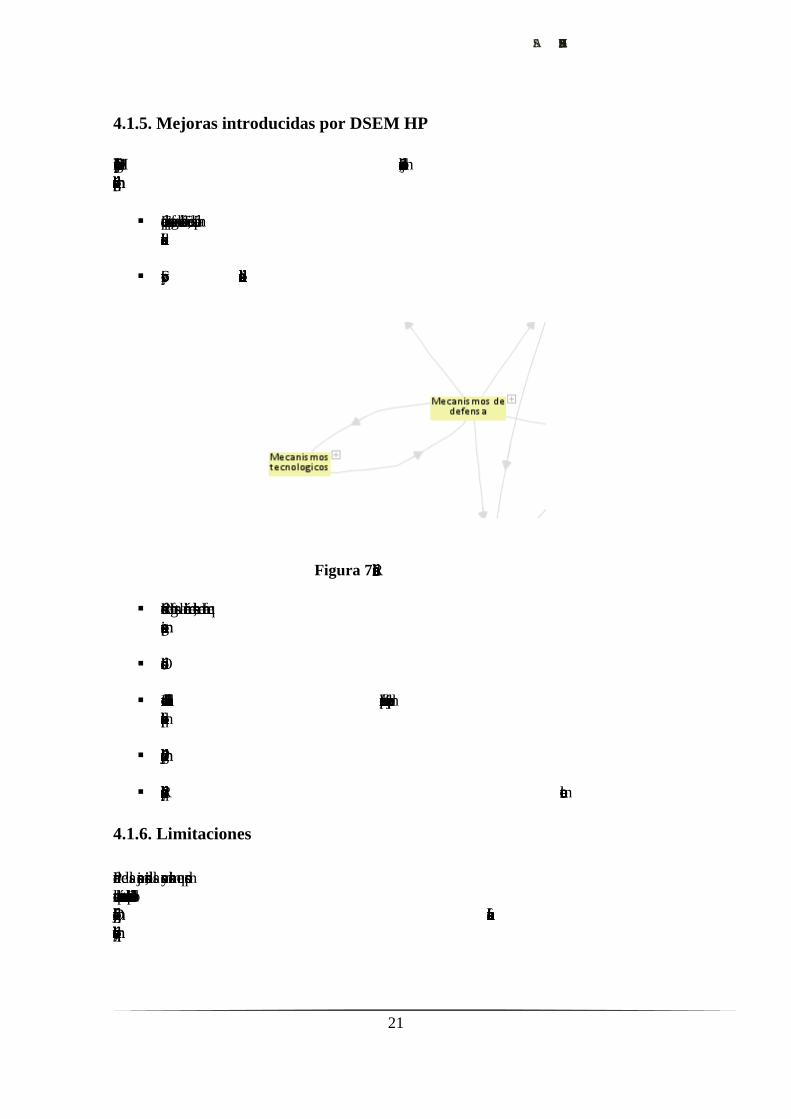
Figura 7. Relación bidireccional
Reestructuración del grafo tras la eliminación de elementos, de forma que
siempre se mantenga conexo.
Ocultación de nodos.
Incremento de la fiabilidad de la aplicación, entre las que destaca el manejo de
excepciones no controladas que provocaban un funcionamiento incorrecto.
Posibilidad de agrandar y disminuir el tamaño del applet en ejecución.
Resaltado y aparición de etiquetas al posicionar el ratón sobre un elemento.
4.1.6. Limitaciones
Partiendo de las mejoras introducidas, las mayores limitaciones que podemos
encontrarle a la aplicación se encuentran en torno a la imposibilidad de edición de los
elementos visualizados del grafo en ejecución. De forma que sería interesante facilitar al
usuario la posibilidad de seleccionar los elementos que quiere ver y cómo los quiere ver.
LAS BASES.HYPERGRAPH
22
En concreto se propone:
El filtrado de elementos por tipo.
La selección del número de niveles del grafo que se visualizan.
La elección de los colores utilizados por los distintos grupos de elementos.
4.2 Módulo Hypergraph
El módulo Hypergraph integra el applet del mismo nombre en Drupal con el fin de
mostrar una visualización en forma de árbol, no de grafo, de menús, taxonomías y
contenido en general de un sitio web.
En [1] se procedió a su total remodelación, de forma que su misión era visualizar la
estructura conceptual construida para poder navegar y editar sobre ella. Como nuestro
trabajo se basará mayoritariamente en el funcionamiento del segundo, vamos a realizar
el análisis sobre él.
4.2.1. Visualización de la estructura conceptual
Para realizar la representación visual de la estructura conceptual albergada, ésta debe
soportarse sobre tipos de contenido en Drupal con el siguiente nombre y formato:
Tipo de contenido Campos Tipo Descripción
Concepto Title Text Nombre del concepto
Body Text Contenido del nodo
Taxonomy Content taxonomy
fields
Establece el dominio
conceptual
Ítem Title Text Clasificación del ítem
Body Text Información del nodo
concepto al que define
conceptos
relaciones
Node reference Referencia al nodo
concepto
Relación Entre
Conceptos
Title Text Etiqueta de la relación
Body Text Información de la
relación
concepto destino Node reference Referencia al nodo
destino
-> Node reference Referencia al nodo
origen

LAS BASES.HYPERGRAPH
23
De aquí procede la principal desventaja del módulo, no será capaz de visualizar
estructuras conceptuales creadas sobre otros tipos de contenidos.
Una vez creados, las instancias de estos tipos serán detectadas mediante consultas a la
base de datos y visualizadas de la siguiente forma:
Figura 8. Visualización mostrada por DSEM HP de la estructura conceptual contenida*
Podemos observar como las relaciones entre conceptos presentan dirección, mientras
que las halladas entre un ítem y un concepto no lo hacen. Se permite, además, el
plegado de los nodo ítems (haciendo clic en +).

LAS BASES.HYPERGRAPH
24
4.2.2. Instalación
Se ha de seguir la instalación típica de módulos en Drupal. Debe copiarse la carpeta
hypergraph, que contiene el módulo, en el directorio modules y activarlo en la opción
Administer > Site building > Modules.
El applet es integrado en el sitio web haciendo uso de un bloque por lo que será
necesario su habilitación y posicionarlo mediante el menú Administer > Site building >
Blocks del administrador.
Las características generales de configuración como la anchura y altura del applet o el
uso de caché, son accesibles desde la entrada Hypergraph creada en el menú principal.
4.2.3. Uso. Características principales
Una vez visualizado el applet, con el contenido conceptual detallado, será posible su
navegación.
La característica de edición de la estructura conceptual proporcionada por el applet se
presenta a través de diferentes menús contextuales al hacer clic con el botón derecho del
botón.
Figura 9. Opciones de edición disponibles*

LAS BASES.HYPERGRAPH
25
Figura 10. Formulario de creación de una relación*
Al realizar alguna modificación, el applet transmite la acción realizada y los elementos
implicados a través del envío de paths. El módulo reconoce la función a realizar y los
argumentos pasados, modificando el contenido del sitio web mediante actualizaciones
de la base de datos.
Por último resaltar que la selección mediante el ratón de un nodo provoca que se
muestre la información del concepto o ítem del nodo en el espacio dedicado para la
visualización de contenidos en Drupal.
* Los ejemplos de visualización y uso del módulo se han realizado sobre la página web creada
como desarrollo práctico de los mecanismos de persuasión publicitaria en Internet. Para
asegurar el correcto funcionamiento se debería realizar una batería de pruebas haciendo uso
del módulo en distintas páginas, lo que queda fuera del alcance de nuestro propósito, que es el
estudio de las posibilidades y descripción del funcionamiento de la herramienta.

LAS BASES.HYPERGRAPH
26
4.2.4. Documentación
La documentación existente del módulo es fundamentalmente la facilitada en [1] y los
comentarios añadidos sobre el mismo código de la implementación. La mayor parte ya
se ha expuesto y no es necesaria completarla para su comprensión.
La documentación añadida será la elaborada a partir de las mejoras realizadas en el
desarrollo del presente proyecto.
4.2.5. Limitaciones
Los logros y limitaciones del módulo implementado en [1] ya fueron comentados en el
punto 3.5.
Recogeremos todas las deficiencias encontradas para transformarlas en requerimientos
funcionales a cumplir por nuestro proyecto.

PARTE II - DESARROLLO
27

PARTE II - DESARROLLO
28
PARTE II
DESARROLLO

PARTE II - DESARROLLO
29

CCC GRAPH
30
5. CCC Graph
5.1. Introducción
En este apartado procederemos a exponer el camino seguido para llevar a cabo los
objetivos de nuestro proyecto.
Al partir de un sistema en funcionamiento, de magnitud considerable, al que queremos
añadir una serie de funcionalidades, nos hemos decantado por seguir un modelo de
desarrollo de software en espiral. Las características principales de este modelo son [9]
[10]:
Tiene en cuenta los riesgos que pueden aparecer en el desarrollo software.
Contempla las posibles alternativas de cada problema, se opta por la de riesgo
más asumible y se hace un ciclo de la espiral.
Si se desea seguir haciendo mejoras en el software, se vuelven a evaluar de
nuevo las distintas alternativas y riesgos y se realiza otra vuelta de la espiral. Se
realizarán las vueltas necesarias hasta que llegue un momento en el que el
producto software desarrollado sea aceptado y no necesite seguir mejorándose
con otro nuevo ciclo.
Cada ciclo se divide en cuatro fases:
- Determinación de objetivos: especificación de los objetivos a obtener,
restricciones, identificación de los riesgos y alternativas para
solucionarlos. En el primer ciclo se realizará una planificación inicial.
- Análisis de riesgos: se evalúan las alternativas. Se identifican las fuentes
de riesgo y se proponen y comienzan a aplicar estrategias para
resolverlas.
- Ingeniería: se profundiza en la resolución de los riesgos pendientes y se
avanza en la obtención del producto una vez eliminados. Se desarrolla el
producto de siguiente nivel.
- Evaluación del producto: la evaluación del prototipo permite identificar
nuevos requisitos. Dependiendo del resultado de la evaluación se decide
si finalizar el proceso o continuar.
Entre los motivos para su elección destacan [10]:
Las especificaciones generales a afrontar ya son conocidas pero, al tratarse de un
entorno en el que no se ha trabajado con anterioridad y las diferentes dificultades

CCC GRAPH
31
y/o necesidades que puedan surgir, vamos a afrontar el proyecto dividiéndolo en
fases funcionales.
Permite manejar la complejidad del proyecto, apuntando a la resolución de los
problemas por partes, y no caer en la inanición del “súper análisis” del producto.
El aprendizaje y experiencia obtenido ciclo tras ciclo, mejora exponencialmente
el trabajo, aumenta la productividad y permite optimizar el proceso.
Reduce riesgos del proyecto e incorpora objetivos de calidad.
Por tanto, nuestros pasos a seguir serán: especificar la lista de objetivos generales que
deberá cumplir el sistema e ir asignando el trabajo adecuado a cada iteración en función
de las necesidades encontradas y el conocimiento alcanzado del sistema.
5.2. Modelado del problema
En esta sección se expondrán los objetivos generales a alcanzar por el sistema,
seleccionando el trabajo a realizar en la primera iteración. Sucesivamente, se evaluará el
producto resultante y, haciendo uso de una mejor comprensión del sistema, se asignará
un conjunto de las tareas restantes a la siguiente iteración.
5.2.1. Requisitos funcionales
Filtrado de relaciones. El sistema debe permitir la elección de relaciones
visibles y no visibles en la representación gráfica del grafo.
Abstracción de los tipos de contenido que forman la estructura conceptual
representada. El sistema debe soportar la navegación sobre diferentes estructuras
conceptuales.
Representación de la estructura conceptual a partir de la página actual:
- El sistema debe situar el contexto de la representación gráfica en el nodo
que represente la página en la que se encuentra situado el usuario, de
forma que se visualice la red semántica formada a partir de las relaciones
que presenta con otros nodos.
- Debe ser seleccionable el nivel de anidamiento de las relaciones
representadas a partir del nodo principal.
- El nodo principal debe ser diferenciable respecto al resto, siendo situado
en el centro del cuadro que contiene el grafo. Se deberá poder configurar
el aspecto del mismo.

CCC GRAPH
32
Elección de los elementos específicos representados:
- Se requiere la posibilidad de selección de los elementos pertenecientes a
la estructural conceptual dentro del conjunto de tipos de contenidos
creados en el sistema.
- El sistema permitirá elegir los colores con los que serán representados
los distintos grupos de elementos.
5.2.2. Requisitos no funcionales
Facilidad de uso
La interacción del usuario con el sistema se producirá ajustándose al modo de
navegación tradicional libre.
La interfaz debe ser potencialmente usable e intuitiva:
- La representación del grafo deberá ofrecer elementos interactivos que
faciliten su navegación: resaltado de elementos, cambios de cursor,
cambios de color y ocultación de etiquetas.
- La configuración y elección de opciones se realizará mediante menús
contextuales en el applet y formularios en Drupal.
Soporte
El sistema debe presentar una clara división de los componentes que lo forman
con el objetivo de impedir que los cambios en uno de ellos afecte a los demás.
Rendimiento
La integración del applet no debe incrementar, de forma apreciable, el tiempo de
carga normal de la página.
La creación, visualización y posibilidad de navegación del grafo debe estar
disponible en un tiempo de entre dos y tres segundos
Implementación
Los lenguajes de programación utilizados serán PHP (versión 5), haciendo uso
de la API de Drupal, y Java para la implementación del módulo y applet
respectivamente.

CCC GRAPH
33
Empaquetamiento e instalación
Debe ser posible añadir el módulo a un sitio realizado en Drupal siguiendo los
pasos típicos de instalación de módulos. Cualquier configuración extra para su
correcto funcionamiento deberá ser explícitamente documentado en un manual
de utilización.
Otras consideraciones
La utilización del CMS Drupal y la tecnología Java permiten potenciar la flexibilidad y
portabilidad del sistema. El proyecto será construido íntegramente bajo licencias de
software libre.
No existen requerimientos especiales en cuanto a temas de capacidad de memoria,
fiabilidad, tolerancia a fallos, integridad y protección de datos.

DESARROLLO DE CCC-GRAPH
34
6. Desarrollo de CCC-Graph
6.1. Arquitectura de componentes
6.1.1. Determinación de objetivos
En esta primera iteración procederemos a definir la silueta que presentará la arquitectura
del sistema. Procederemos a solucionar la dependencia entre los distintos componentes
que forman el sistema, partiendo de la herramienta DSEM HP.
Haciendo un análisis de la arquitectura existente podemos distinguir entre dos
componentes muy definidos: el formado por el módulo y el del applet.
En este momento, la navegación de la estructura conceptual ofrecida por el applet
presenta una implementación ajustada al modelo de memorización puro presentado por
SEM HP. De esta forma, muchas de las características de visualización no son
funcionales haciendo uso de otras estructuras conceptuales:
Edición de la estructura conceptual, basada en la utilización de menús
contextuales estáticos.
Diferenciación en la visualización de nodos ítems y concepto.
Diferenciación entre la visualización de relaciones ítem-concepto y concepto-
concepto.
Estructuración de los nodos, dependiendo de su tipo.
Ocultación de los nodos ítems.
Paso de parámetros al applet personalizado, recogiendo la lista de las funciones
a la que pueden pertenecer los ítems.
Por tanto, nos encargaremos de independizar ambos componentes. El applet no deberá
ser consciente de la estructura conceptual existente en el sitio y abstraída por el módulo.
En esta iteración, nos centraremos en que la función del applet se limite a la recepción
de una serie de tipos de nodos y relaciones, e instancias de éstos, y represente de forma
correcta el grafo que forman.
Es necesario, además, que el applet soporte diferentes propiedades de visualización de
los elementos del grafo, que facilitarán la comprensión por parte del usuario:
Debe ser posible la especificación de tipos de relaciones y nodos.
DESARROLLO DE CCC-GRAPH
35
Las propiedades de los grupos de elementos pertenecientes a estos tipos deben
ser configurables (color y etiquetado). Las relaciones, además podrán marcarse
como dirigidas y presentar diferentes tipos de línea.
Los nodos deben ser etiquetables individualmente ya que representan la
existencia de un concepto (entendiéndolo como la abstracción de una idea).
6.1.2. Análisis de riesgos
A través del estudio realizado sobre el funcionamiento del applet (apartado 4.1.3)
podemos concluir que la mayoría de las funcionalidades buscadas ya se encuentran
disponibles.
Haremos uso de la característica del applet que permite pasarle la especificación de un
grafo a través de un documento XML, siguiendo la especificación definida por el DTD.
Recordemos que la definición de elementos que éste ofrece permite la definición de
todas las características buscadas tanto para elementos individuales como para grupos
[15].
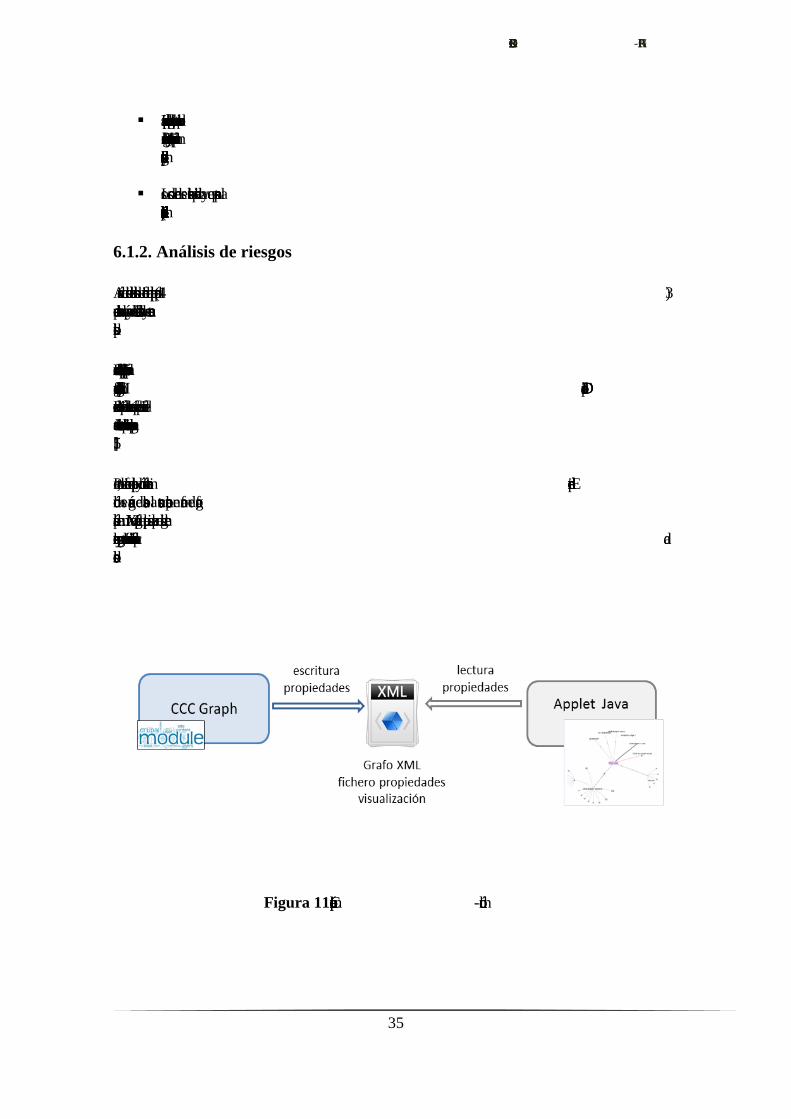
Por tanto, el funcionamiento de applet y módulo será totalmente independiente. El
módulo se encargará de abstraer la estructura conceptual en forma de grafo,
plasmándola en un XML que recogerá el applet, siendo capaz de distinguir entre
elementos y grupos, y mostrar las características de visualización definidas para cada
uno de ellos.
Figura 11. Comunicación applet-módulo

DESARROLLO DE CCC-GRAPH
36
Como ya se ha comentado, en [1] se realizaron las modificaciones necesarias para que
el applet soportara la representación gráfica de grafos y no sólo árboles. Además, se
hizo posible la representación gráfica de relaciones bidireccionales entre dos nodos, es
decir, una en cada sentido. Como requerimiento a cumplir encontramos la completa
representación de la estructura conceptual, incluyendo la posibilidad de que existan
múltiples relaciones en cada sentido por cada dos nodos. La estructura de datos utilizada
para almacenar la disposición de los nodos y relaciones no permite una modificación
sencilla de este problema, por lo que una vez descubierto, afrontaremos su solución en
posteriores iteraciones.
Por tanto, como único punto de desarrollo, procederemos “limpiar” la implementación
del applet, para desproveerla de elementos dependientes de una estructura conceptual
fija.
6.1.3. Ingeniería, desarrollo del producto
Se ha repasado el código por completo, identificando los elementos orientados a ofrecer
una navegación y edición sobre el sistema de memorización del modelo SEM HP
basado en ítems y conceptos. Las modificaciones reseñables llevadas a cabo han sido:
Eliminación del paquete visualSEMHP.
Supresión en el paso de parámetros de elementos auxiliares concretos para una
estructura fija.
Repaso de todos los paquetes y clases, eliminando cualquier estructura de datos,
variable y función ajustada a la representación del sistema de presentación SEM-
HP.
6.1.4. Evaluación
La tarea ha resultado bastante tediosa al tener que examinar el código de cada una de las
clases, distinguiendo las partes prescindibles. Sin embargo, como resultado de la
iteración hemos obtenido un completo conocimiento del funcionamiento del applet.
6.2. Filtrado de relaciones
6.2.1. Determinación de objetivos
La búsqueda de representar gráficamente diferentes estructuras conceptuales en sitios
web es lo que es probable que exista gran cantidad de contenido, desemboca en la
posibilidad de obtener grafos muy complejos con un gran número de relaciones.

DESARROLLO DE CCC-GRAPH
37
Para solucionarlo, se propone el filtrado de relaciones visibles en la representación
mostrada, de forma que la visualización del grafo resulte más limpia y su asimilación
por parte del usuario más fácil.
Ahora, deberemos responder preguntas como: ¿El filtrado se realizará a nivel de usuario
o administrador? ¿Desde el applet o desde el sitio web? o ¿Qué tipo de filtrado es el más
efectivo?
6.2.2. Análisis de riesgos
Tipos de filtrado
Comenzaremos intentando responder a la última pregunta. Primero aclararemos que el
filtrado buscado se realiza sobre los tipos de relaciones existentes, no las relaciones
individuales, de forma que eliminemos de la visualización grupos de elementos no
relevantes o no tan importantes como otros.
Encontramos, entonces, dos tipos de filtrado:
Tipo 1: filtrado por tipo de relación en todos los nodos.
Tipo 2: filtrado de un tipo de relación de relación de un nodo.
A tener en cuenta:
El filtrado de cualquier tipo de relación no puede ocultar al nodo principal (el
representante de la página en la que se sitúa actualmente el usuario). Es decir:
En el tipo 1, el filtrado se realizará recursivamente comenzando desde el nodo
principal.
En el tipo 2, siempre deberá mantenerse el camino entre el nodo en el que se
aplica el filtrado y el nodo principal. Los nodos hojas no permiten este tipo de
filtrado.
Para mostrar el funcionamiento de ambos tipos de filtrado expondremos el resultado de
distintos ejemplos de su aplicación sobre un grafo concreto:
DESARROLLO DE CCC-GRAPH
38
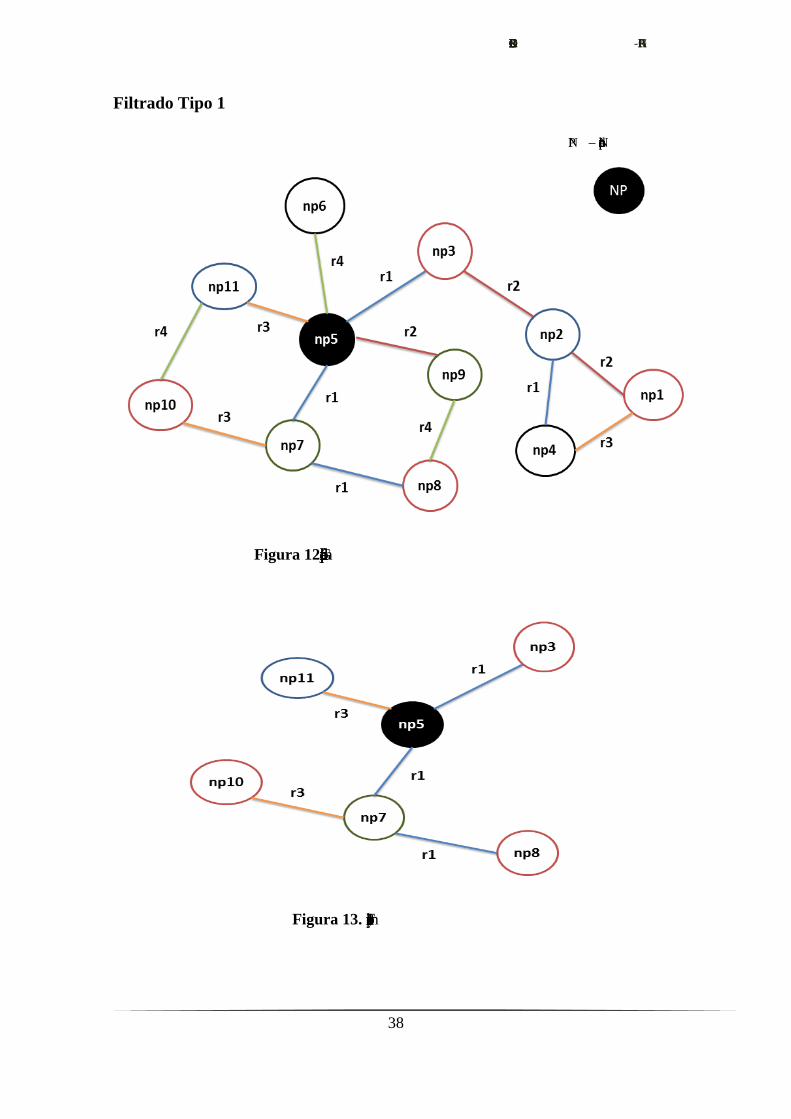
Filtrado Tipo 1
NP – Nodo principal
Figura 12. Grafo de ejemplo para el filtrado
Figura 13. Filtramos por r1 y r3
DESARROLLO DE CCC-GRAPH
39
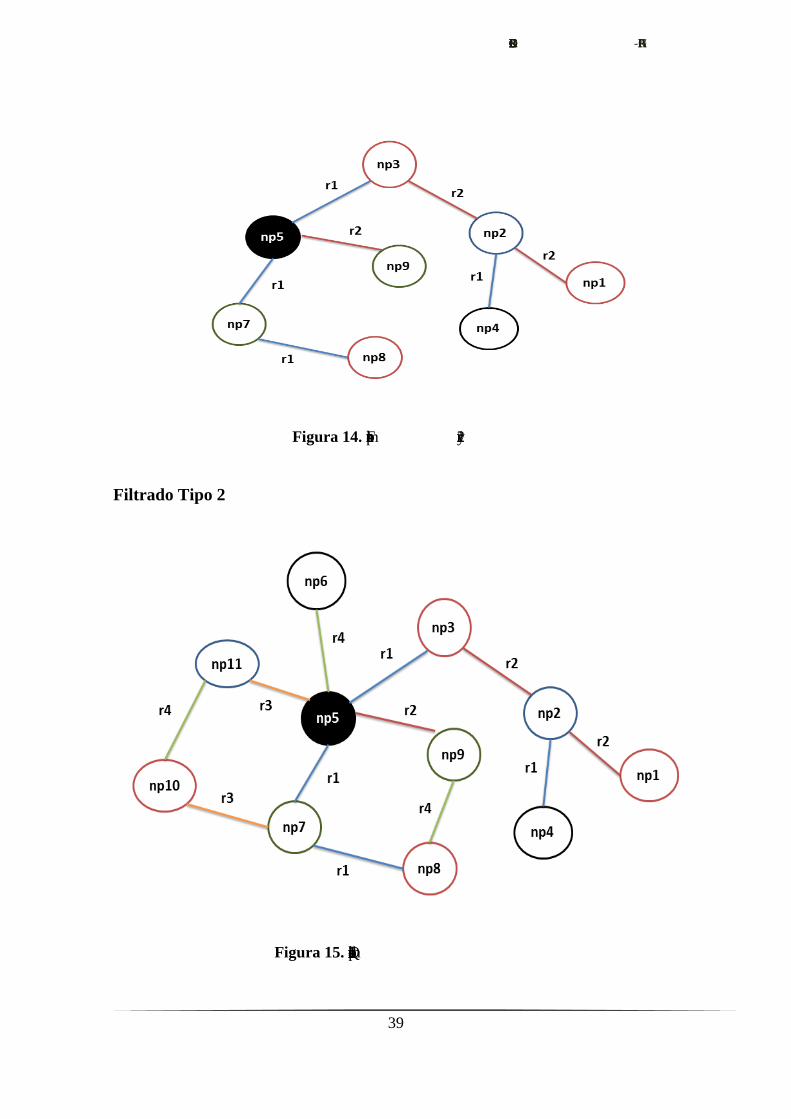
Figura 14. Filtramos por r1 y r2
Filtrado Tipo 2
Figura 15. Quitamos de np1 las relaciones r3
DESARROLLO DE CCC-GRAPH
40
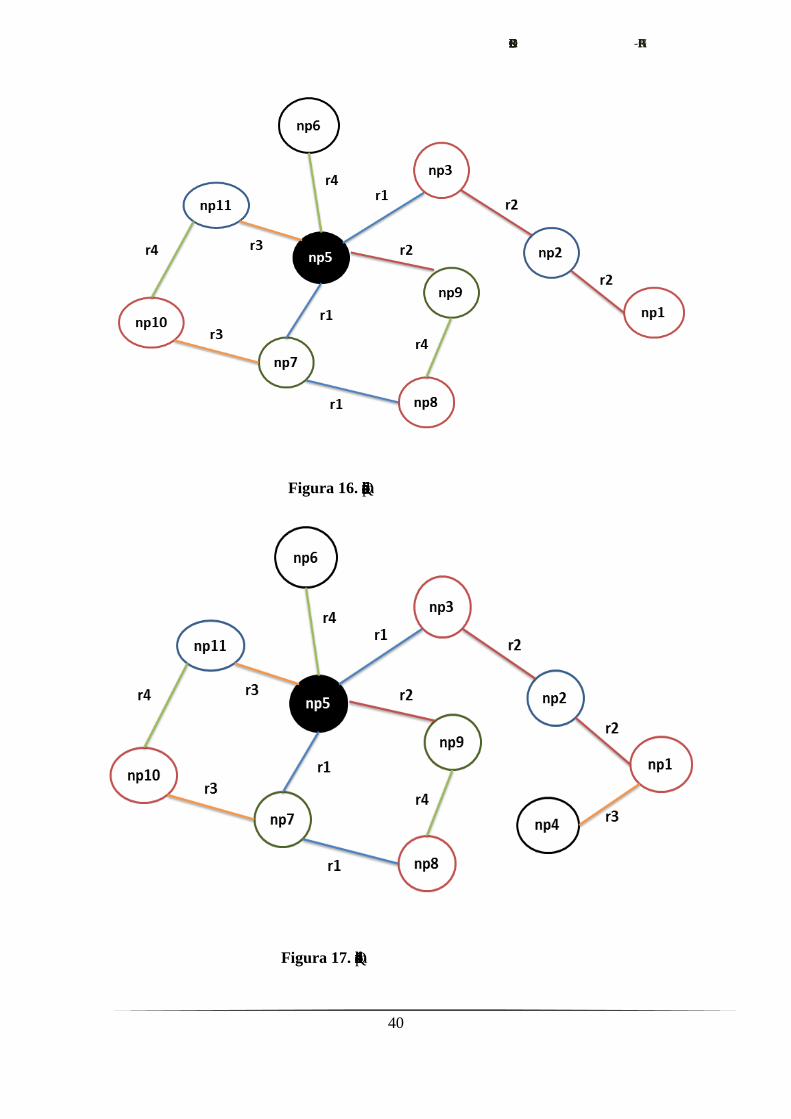
Figura 16. Quitamos de np2 la relación r
Figura 17. Quitamos de np4 las relación r1

DESARROLLO DE CCC-GRAPH
41
Quitamos ahora de np2 la relación r2
-- No permitido –
Figura 19. Quitamos de np3 la relación de tipo r2
Según el comportamiento mostrado por ambos tipos de filtrado, nos decantamos por la
implementación del primero. Los motivos de la decisión han sido propiciados debido a
que en el segundo tipo de filtrado:
La capacidad de filtrado es bastante limitada al aplicarse a un único nodo.
El filtrado de varias relaciones es bastante más costoso.
Su implementación y utilización parece demasiado compleja en comparación a
su poca utilidad.
Nivel del filtrado
Atendiendo a la primera pregunta, a qué nivel se realizará el filtrado, la respuesta es
clara. El sistema de navegación busca la facilidad de uso y la comprensión final por

DESARROLLO DE CCC-GRAPH
42
parte del usuario, por lo que será éste el que realice el filtrado de las relaciones que
considere necesarias.
Lugar
Por último, debemos decidir desde dónde realizarlo. Las opciones son realizarlo desde
el sitio web a través de algún mecanismo dinámico o formulario, o directamente sobre
el applet haciendo uso de menús contextuales.
Recogiendo de nuevo la propiedad de usabilidad que debe ofrecer la navegación nos
hemos decidido por la implementación de la segunda opción. El usuario podrá filtrar las
relaciones que desee como un elemento más de la navegación, interaccionando
directamente con el grafo.
6.2.3. Ingeniería, desarrollo del producto
Como primer punto del desarrollo, aunque pueda parecer obvio, puntualizar la
necesidad de un filtrado reversible, es decir se podrán volver a mostrar las relaciones
filtradas.
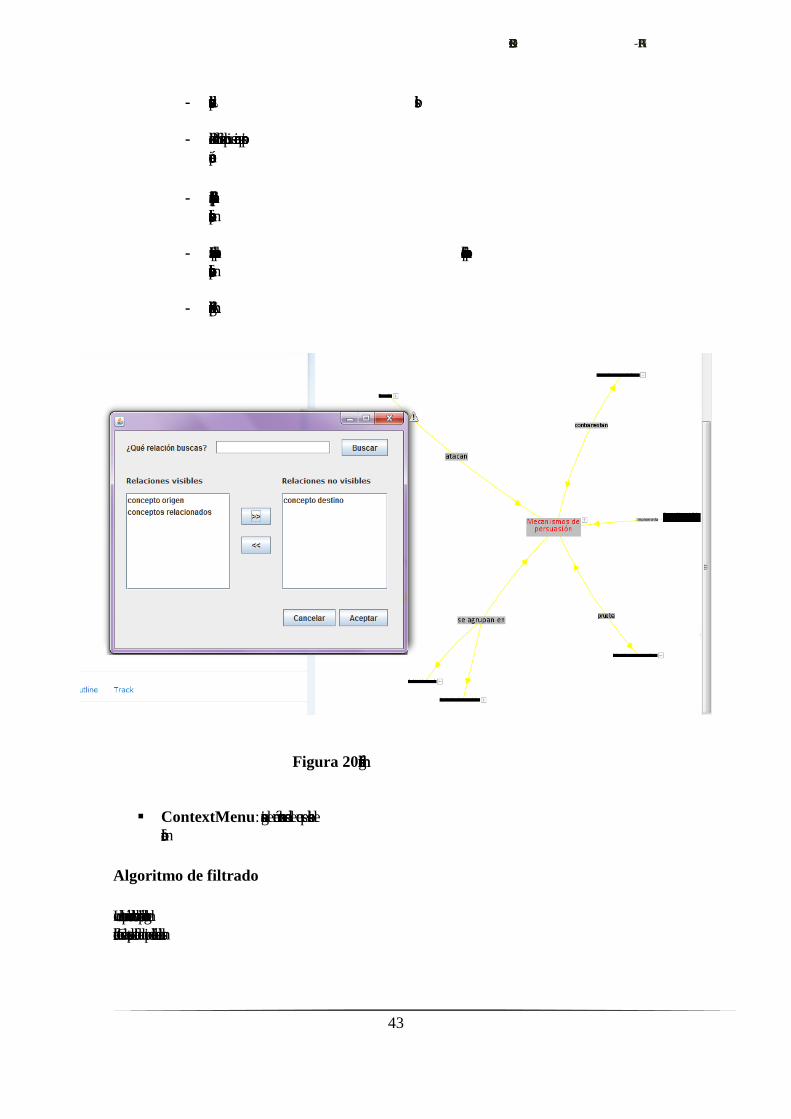
El filtrado se llevará a cabo desde un formulario que incluirá todos los tipos de
relaciones, listando, de forma separada y definida, los visibles y los no visibles. Se
podrán seleccionar y pasar, una o varias relaciones de forma simultánea, de una lista a
otra, haciéndose efectivos los cambios sobre el grafo cuando el usuario confirme.
Maximizando la facilidad de uso, se implementará un buscador en vista a la
representación de estructuras con un gran número de tipos de relaciones.
El formulario se mostrará de forma emergente a partir de su selección en el menú
contextual mostrado al pulsar con el botón derecho sobre la representación gráfica.
Para su implementación se ha creado el paquete navigationSupport compuesto por tres
clases:
NavigationHandler: clase gestora, contiene y gestiona los objetos que soportan
el filtrado de relaciones.
RelationsFilterPanel: extensión de la clase JPanel de la librería Swing de Java
que contiene el formulario anteriormente descrito. Su edición ha sido realizada
con la herramienta gráfica ofrecida por el IDE NetBeans.
Contiene además toda la información y lógica necesaria para realizar la
selección de relaciones representadas:
- Lista de tipos de relaciones visibles.
DESARROLLO DE CCC-GRAPH
43
- Lista de tipos de relaciones no visibles.
- Relaciones filtradas. Son almacenadas por si se requiere su posterior
recuperación.
- Lista de tipos de relaciones a filtrar. Seleccionadas por el usuario para no
ser visibles, pero sin confirmar.
- Lista de tipos de relaciones recuperar. Seleccionadas por el usuario para
volver a ser visibles, pero sin confirmar.
- Algoritmo de filtrado. Expuesto más adelante.
Figura 20. Imagen del menú de flitrado
ContextMenu: gestiona el menú contextual desde el que es accesible el
formulario.
Algoritmo de filtrado
Uno de los puntos más delicados se encontraba la implementación del algoritmo de
filtrado. Como se ha expuesto, el filtrado de un tipo de relación debe eliminar las

DESARROLLO DE CCC-GRAPH
44
relaciones pertenecientes al tipo de forma recursiva, comenzando desde el nodo
principal, de forma que solo aparezca la componente conexa que lo incluye.
Antes de llevar a cabo el algoritmo con la complejidad que comprendía el proceso. Se
analizó detenidamente la implementación de la eliminación de relaciones y la
estructuración del grafo.
La formación de la estructura se basa en el origen de la herramienta, que proporcionaba
la representación de árboles. Así, desde el nodo considerado raíz, se extraen todos los
nodos alcanzables (es decir, con los que mantiene una relación) para añadirlos al árbol.
La construcción de la estructura completa se alcanza utilizando recursivamente el
mismo mecanismo para todos los nodos alcanzados. Así, un nodo que no presente un
camino hasta el principal que los mantenga conectados no será incluido como elemento
del grafo y, por tanto, no mostrado en la representación.
Por otro lado, la aplicación ya provee la funcionalidad que permite la reestructuración
del grafo tras la eliminación de cada relación.
Por tanto, haciendo uso de estos recursos, la eliminación de una serie de relaciones y su
posterior reestructuración de la forma anteriormente descrita, habiendo definido el nodo
actual como nodo raíz del “árbol”, logramos el filtrado de relaciones buscado sin la
necesidad de la implementación de un algoritmo específico.
6.2.4. Evaluación
Se ha terminado con éxito la segunda iteración llevando a cabo un filtrado de relaciones
consistente, intuitivo y que aumenta en gran proporción la usabilidad del sistema de
navegación.
Por otro lado, como consecuencia de las decisiones tomadas se ha detectado un nuevo
requerimiento. La utilización del applet como herramienta de filtrado hace volátil la
edición de relaciones cuando cambiamos de página al ser cargado de nuevo, perdiendo
la selección realizada.
6.3. Arquitectura de almacenamiento
6.3.1. Determinación de objetivos
Como consecuencia de la anterior iteración nos surge un nuevo problema: el
almacenamiento de las opciones de filtrado tomadas por parte del usuario. En cada
cambio de página el applet es cargado desde cero, perdiendo la información de la
relaciones elegidas por el usuario como no visibles.

DESARROLLO DE CCC-GRAPH
45
El objetivo es claro, buscar un mecanismo que nos permita almacenar esta información
y recuperarla en cada cambio de página.
6.3.2. Análisis de riesgos
6.3.2.1. Almacenamiento de las opciones
Realizando un análisis de las opciones de almacenamiento existentes, hemos encontrado
hasta cuatro posibles formas de realizarlo:
Almacenamiento en BBDD (usuarios registrados)
La primera opción que manejamos es el almacenamiento de las opciones de filtrado en
una tabla específicamente creada en la base de datos de Drupal.
Así, cada usuario se le asignaría una tupla con la información de las relaciones
escogidas. La tabla debería ser creada en la instalación del módulo y eliminada a su
desinstalación [17].
Ventajas
Seguridad
Control absoluto de la información.
Incovenientes
La opción solo estaría disponible para usuarios registrados.
Alteración del esquema de base de datos de Drupal. Implica añadir un proceso
de instalación, desinstalación y mantenimiento que asegure la consistencia de los
datos y el esquema.
Almacenamiento permanente. Se almacenarían permanentemente datos no
relevantes.
Cookies
Otra opción posible se encontraría en la utilización de cookies. La información sería
almacenada en una variable almacenada en el navegador del usuario. Ventajas e
inconvenientes [11]:

DESARROLLO DE CCC-GRAPH
46
Ventajas
Se puede especificar la duración de la cookie. Puede permanecer de forma
ilimitada o durante un periodo determinado.
Control de la variable independiente de las demás cookies.
Disponible para usuarios no registrados
Inconvenientes
Al almacenarse en la parte del usuario, éste puede acceder a ella, modificándola
o eliminándola.
Ley de cookies: desde hace un tiempo se exige el cumplimiento de la Ley de
Cookies para proteger los derechos de los usuarios en la red. Su utilización debe
ser posible solo tras la aceptación del usuario, mostrando la definición y función
de las cookies, tipos de cookies utilizadas y finalidad, forma de desactivarlas y
quién las utiliza [14].
El navegador puede estar configurado para bloquear su utilización.
La información es enviada a través de la Internet por lo que puede verse
comprometida su seguridad (en este caso no es relevante.)
Uso de la variable SESSION
Como último recurso hemos encontrado el uso de las variables de sesión. En este caso
los datos son almacenados en el servidor web tras crear un número de identificación
único para el usuario.
Ventajas
Seguridad: la información no atraviesa Internet por lo que no puede ser
accedida.
El usuario no puede modificar su valor.
El navegador no puede bloquear su utilización.
Su utilización no se encuentra sujeta al cumplimiento de la Ley de Cookies.
Disponible para usuarios no registrados.

DESARROLLO DE CCC-GRAPH
47
Inconvenientes
La configuración de las funciones de sesión (como su durabilidad) se realiza a
través de archivo php.ini almacenado en el servidor [12]. Su modificación solo
puede realizarse por parte del administrador afectando al comportamiento de las
demás variables de sesión.
Capacidad limitada a la memoria del servidor (en un principio no relevante para
nuestro problema).
Valoración
Tras analizar los tres mecanismos de almacenamiento expuestos nos hemos decantado
por la utilización de la tercera opción al presentar el mejor equilibrio entre ventajas e
inconvenientes. Su utilización no requiere una implementación extra como en los otros
dos casos (proceso de instalación y mantenimiento en base de datos o cumplimiento de
una serie de condiciones para un uso legal) y proporciona la funcionalidad completa que
se busca.
6.3.2.2. Comunicación applet-módulo
El siguiente dilema a afrontar será el paso de las opciones de filtrado escogidas desde el
applet al módulo, donde se realizará su almacenamiento en las variables de sesión y
viceversa.
La comunicación entre el applet y el módulo se divide en dos fases: la primera en
sentido applet-módulo, demandando el almacenamiento de la información de filtrado
enviada y, la segunda, en sentido contrario, encargada de la recuperación de los datos
almacenados. Ambas presentan diferentes mecanismos de paso de información.
Sentido Applet → Módulo
Tras la elección del filtrado a través del formulario implementado y, su posterior
confirmación, se procederá a la comunicación con el módulo y el almacenamiento de las
opciones. Se podría haber elegido como momento de la comunicación el instante en el
que usuario realiza un cambio de página, lo que minimizaría el número de
comunicaciones establecidas. Sin embargo, el almacenamiento de las opciones solo se
produciría cuando se tratara de un cambio de página controlable, es decir, haciendo uso
del sistema de navegación.
La comunicación se realizará haciendo uso del hook menu de Drupal, que permite la
ejecución de funciones y paso de argumentos, a través del envío de urls que hayan sido
especificadas en el hook menu [19]. El applet se encargará de enviar una url reconocible
por el módulo con la acción y opciones de filtrado pertinentes.
DESARROLLO DE CCC-GRAPH
48
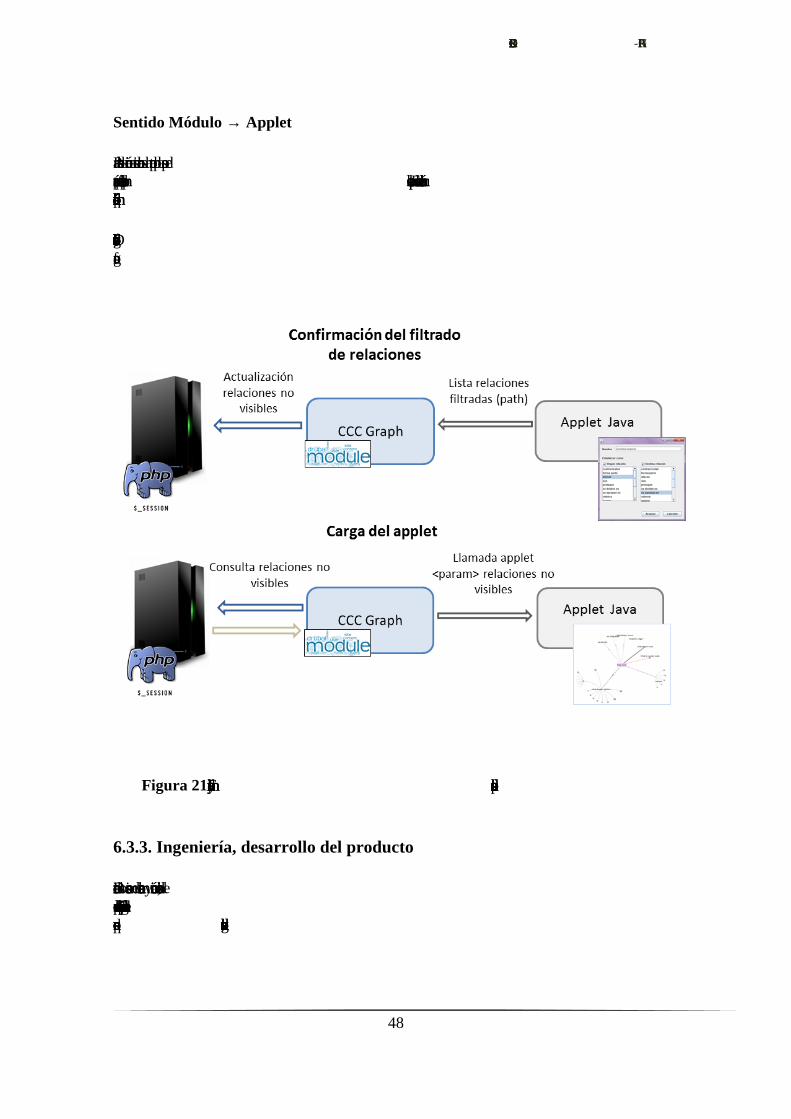
Sentido Módulo → Applet
Para establecer la comunicación en sentido contrario se ha optado por el paso de
parámetros, por defecto implementado para los applets. En su llamada se incluirá un
parámetro más que incluirá la información de filtrado.
Durante la carga, las relaciones filtradas no serán incluidas en la visualización inicial del
grafo.
Figura 21. Flujo la comunicación y almacenamiento de las opciones de filtrado
6.3.3. Ingeniería, desarrollo del producto
Determinando los mecanismos de almacenamiento y comunicación utilizados, el
proceso de desarrollo es relativamente simple. Su descripción, siguiendo el orden en el
que se producen cada uno de los eventos, es el siguiente:

DESARROLLO DE CCC-GRAPH
49
Applet, mandando la información…
Tras la selección y confirmación, por parte del usuario de las relaciones filtradas y las
visibles, se envía a la pestaña actual del navegador la url:
http://direccion_pagina_actual/hfilterrelations/lista_relaciones
Al tratarse de un envío por url, la lista se trata de un string con la forma:
accion;nombre_relacion||accion;nombre_relacion…
Donde accion puede tomar el valor “add” o “remove”.
Esta implementación permite la selección de grupos de relaciones a añadir y eliminar de
la visualización, a la vez, en un único envío.
Módulo, recibiendo la información…
En el hook menu del módulo se ha definido la componente “hfilterrelations” que detecta
el envío de la url anteriormente descrita. Será el encargado de obtener y pasar a la
función encargada de su almacenamiento, la lista de relaciones que pasarán a no ser
visibles y viceversa.
La variable de sesión “relations” contiene a su vez la lista de los tipos de relaciones no
visibles separados por “||”. En función de la acción a realizar para cada relación, se
modificará su valor, añadiendo o quitando de la lista a filtrar.
Módulo, recuperando la información…
En la llamada el applet, se incluye el parámetro “relations”, que tomará como valor la
lista de los tipos de relaciones no visibles almacenada en la variable de sesión.
Applet, procesando la información…
La lista, recogida como parámetro en forma de String, es pasada al paquete
NavigationSupport, encargado del filtrado, donde se hace uso de la clase
StringTokenizer para extraer el nombre de cada relación a eliminar.
6.3.4. Evaluación
Al término de esta iteración hemos conseguido resolver completamente el problema del
filtrado de relaciones. Además, conocemos distintas posibilidades de almacenamiento y
comunicación entre módulo y applet.

DESARROLLO DE CCC-GRAPH
50
6.4. Extracción de la estructura conceptual
6.4.1. Determinación de objetivos
Una vez que hemos conseguido que el applet soporte la funcionalidad esperada de él,
podemos afrontar el que se puede denominar como objetivo principal del proyecto: la
navegación gráfica en Drupal sobre distintas estructuras conceptuales.
Como se ha expuesto en su estudio, DSEM HP presenta una gran limitación,
únicamente soporta la navegación sobre una configuración de contenidos en Drupal que
representa la estructura conceptual pura definida por SEM HP basada en nodos
concepto, ítem y las relaciones entre ellos. La configuración se basa en la creación de
tres tipos de contenido “concepto”, “ítem” y “relación” que utilizan campos de tipo
node reference, para modelar las relaciones entre ellos, y tipo taxonomía, para la
definición del dominio conceptual.
El más mínimo cambio en la configuración, como modificar el nombre de uno de estos
campos, provoca la incorrecta visualización gráfica, y por ende, de la navegación del
contenido existente. No se ofrece, por tanto, ningún tipo de flexibilidad ni abstracción
en la representación tipo.
Como mejora fundamental proponemos, la abstracción de todas las configuraciones
posibles utilizadas para la representación de diferentes estructuras conceptuales, siendo
posible su representación gráfica y navegación.
Las configuraciones podrán estar construidas por cualquier combinación de campos de
los tipos que hayan sido determinados.
6.4.2. Análisis de riesgos
Siguiendo la filosofía de Drupal, la unidad de información con la que se transmite el
conocimiento son los nodos, por lo que consideramos lógico cumplan el rol de concepto
dentro del CMS. Sin embargo, las formas que ofrece Drupal para relacionar el
contenido de los nodos y la accesibilidad entre ellos es muy variada y en ocasiones algo
abstracta.
Siguiendo la configuración presentada en [1] consideramos adecuada la representación
de las relaciones entre conceptos utilizando campos de tipo node reference. También
haremos uso de las taxonomías para la definición del dominio conceptual pero
consideramos que debe añadirse como componente gráfico de la representación
visualizada.
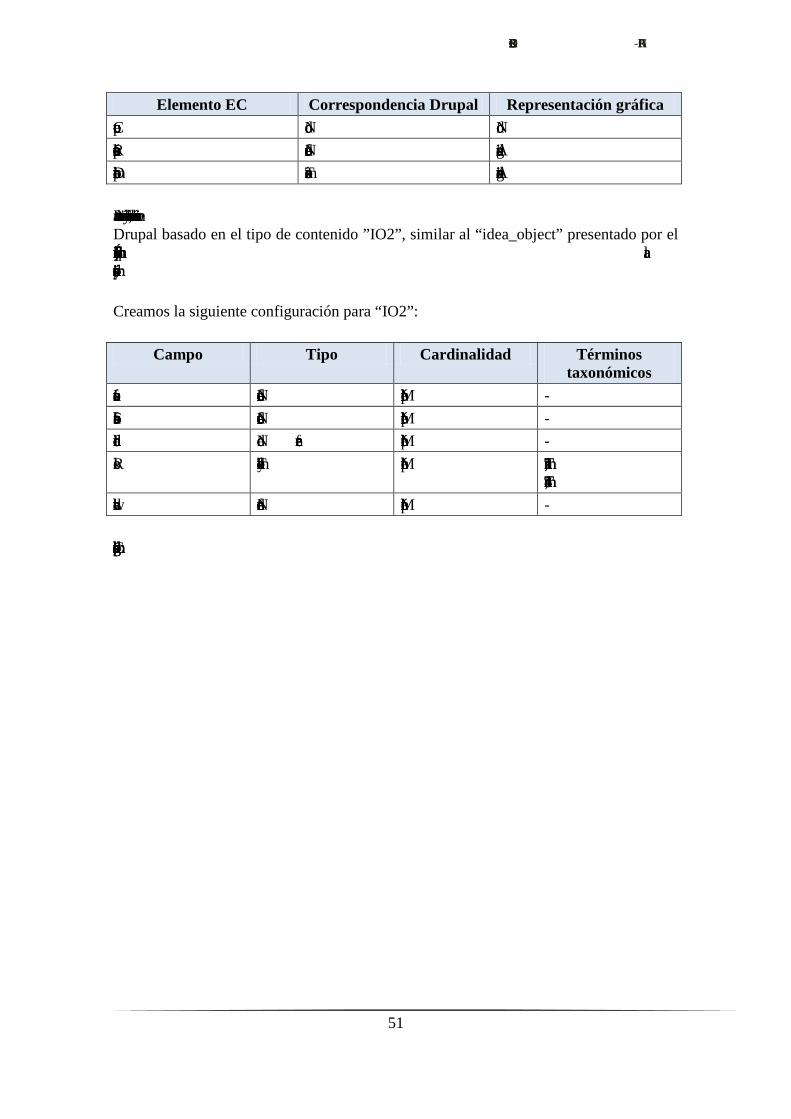
Por tanto, el subsistema de navegación abstraerá la estructura de contenidos construida
sobre estos mecanismos según el siguiente esquema:
DESARROLLO DE CCC-GRAPH
51
Elemento EC Correspondencia Drupal Representación gráfica
Concepto Nodo Nodo
Relación entre conceptos Node reference Arista dirigida
Dominio conceptual Taxonomías Arista no dirigida
Para testear la correcta extracción y visualización del contenido, se creará un sitio en
Drupal basado en el tipo de contenido ”IO2”, similar al “idea_object” presentado por el
sitio Ética Informática y que veremos más adelante, como elemento fundamental para la
representación y transmisión de conocimiento.
Creamos la siguiente configuración para “IO2”:
Campo Tipo Cardinalidad Términos
taxonómicos
Instance of Node reference Múltiple -
Subclass of Node reference Múltiple -
Included in Node reference Múltiple -
Roles Taxonomy field Múltiple Term11, Term12,
Term13, Term14
related with Node reference Múltiple -
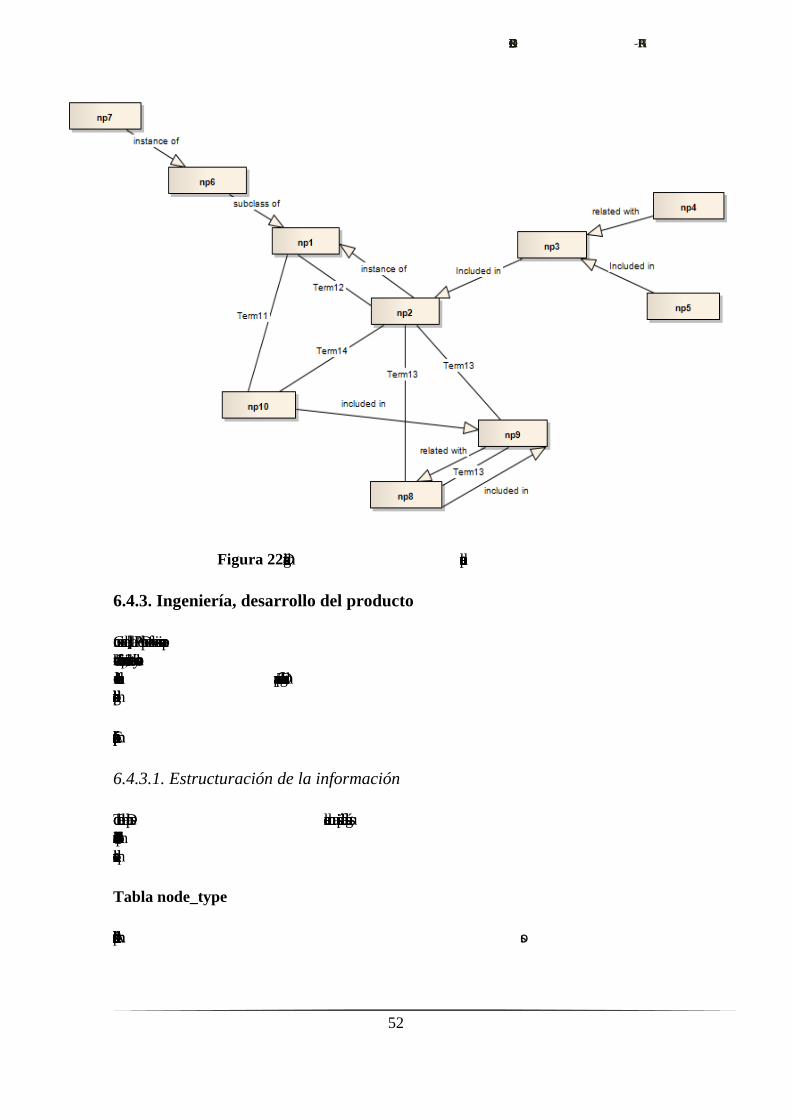
Con él, creamos la estructura conceptual modelada por el siguiente diagrama:
DESARROLLO DE CCC-GRAPH
52
Figura 22. Diagrama de la estructura conceptual creada
6.4.3. Ingeniería, desarrollo del producto
Como se dice en [1], la API de Drupal no ofrece los mecanismos necesarios para
obtener la información sobre tipos de contenidos, instancias de éstos y sus relaciones
con el detalle suficiente para su representación mediante un grafo. Deberemos acceder
directamente a la base de datos para conseguirla.
El primer paso para extraer la información es conocer su estructuración.
6.4.3.1. Estructuración de la información
Todo contenido en Drupal es almacenado con una disposición definida según sus
características. El estudio de la base de datos nos ha permitido conocer la estructuración
del contenido que vamos a extraer:
Tabla node_type
Almacena la información básica de los tipos de contenido creados.

DESARROLLO DE CCC-GRAPH
53
Campos destacables
type: identificador alfanumérico del tipo de contenido.
name: nombre del tipo de contenido
Tabla content_node_field
Lista los campos pertenecientes a los tipos de contenido creados, almacenando sus
propiedades.
Campos destacables
field_name: identificador alfanumérico del campo.
type: tipo de dato almacenado en el campo.
multiple: define si la cardinalidad del campo es 1 (0) o múltiple (1).
Tabla content_node_field_instance
Como la anterior, lista todos los campos de los tipos de contenido creados, incluyendo
información concerniente, principalmente, a la visualización.
Campos destacables
field_name: identificador alfanumérico del campo.
type_name: tipo de contenido al que pertenece.
label: nombre del campo.
Tabla term_data
Contiene todos los términos incluidos en algún vocabulario.
Campos destacables
tid: identificador único del término.
name: nombre del término
Tabla node
Almacena todos los nodos existentes (instancias de los tipos de contenido).
Campos destacables
nid: identificador único del nodo.
type: tipo de contenido instanciado.

DESARROLLO DE CCC-GRAPH
54
title: título del nodo.
Tabla content_type_nombretipodecontenido
Alberga el valor de los campos de cardinalidad uno de los nodos de tipo
nombretipodecontenido.
Campos destacables
nid: identificador del nodo definido.
Para campos de tipo node reference:
nombrecampo_nid: identificador del nodo al que referencia.
Para otro tipo de campos:
nombrecampo_value: para campos de otro tipo, valor contenido.
Tabla content_field_nombrecampo
Contiene los valores del campo nombrecampo para cada nodo. Existente únicamente
para campos de cardinalidad múltiple.
Campos destacables
nid: identificador del nodo definido.
Para campos de tipo node reference:
nombrecampo_nid: identificador del nodo al que referencia.
Para otro tipo de campos:
nombrecampo_value: valor del campo.
6.4.3.2. Extracción de la información
Siguiendo el funcionamiento actual, el fichero encargado de la extracción y
construcción del grafo será hg.php. En concreto, la función cccgraph_get_menu
devolverá el XML con la definición del grafo que se le pasará al applet.
En el primer punto del anexo 3 se incluye una descripción en pseudocódigo del
algoritmo utilizado para la extracción de la estructura conceptual existente, basada en la
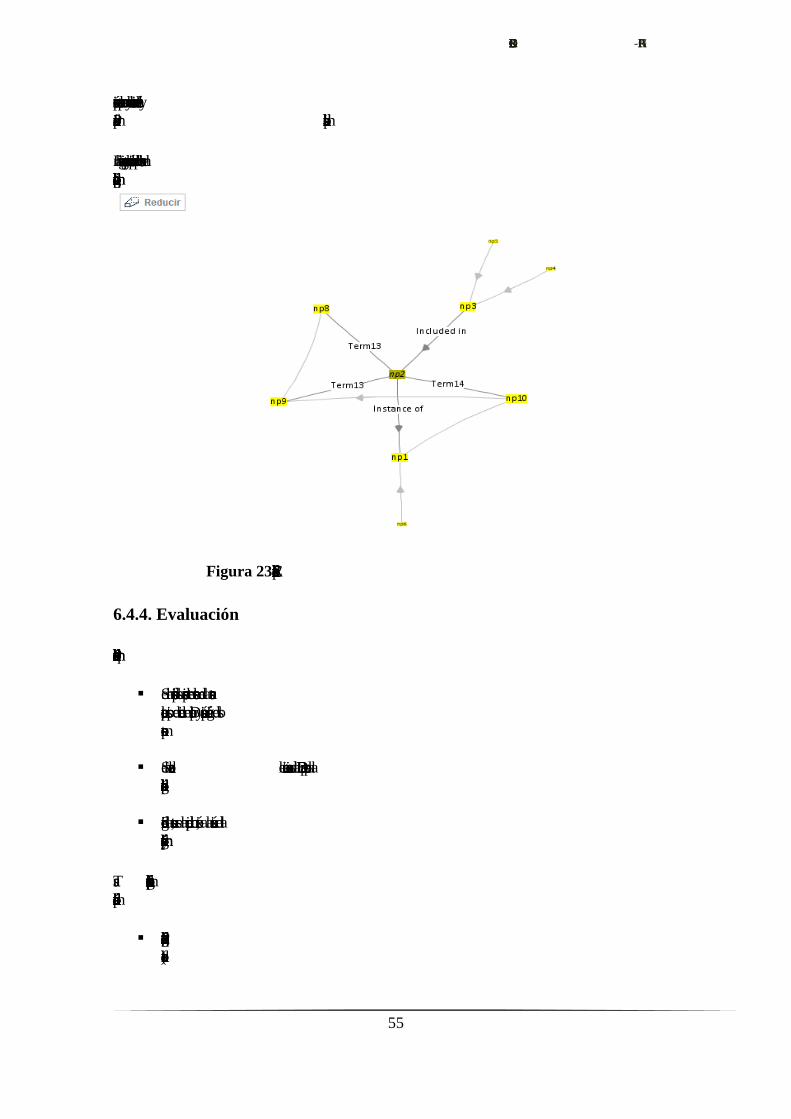
DESARROLLO DE CCC-GRAPH
55
representación de conceptos como nodos y sus relaciones mediante node reference y
taxonomías. Para cada paso se indican las tablas implicadas.
En la siguiente imagen capturamos la representación alcanzada por el subsistema de
navegación de la estructura conceptual que habíamos modelado:
Figura 23. Representación de la EC al finalizar la iteración
6.4.4. Evaluación
Podemos considerar como exitoso el resultado de la iteración debido a que:
Se han especificado las correspondencias entre elementos de la estructura
conceptual, tipos de contenido en Drupal y representación gráfica de los
componentes.
Se ha alcanzado el conocimiento necesario de la BBDD para proceder a la
abstracción de la estructura conceptual albergada.
Siguiendo la estructura, se ha procedido, con éxito, a la extracción de la
información para su representación y navegación mediante el applet.
Tras la representación de la estructura completa, los siguientes esfuerzos se centrarán en
la acotación de la información representada:
Por contexto, centrándonos en la página en la que se encuentra situado el usuario
(nodo actual).

DESARROLLO DE CCC-GRAPH
56
Por niveles de recursividad respecto al nodo actual.
Por elección del autor
6.5. Diseño de la configuración
6.5.1. Determinación de objetivos
Los objetivos de la quinta iteración se dividen en dos grandes bloques. Por un lado, nos
centraremos en realizar la representación gráfica de la estructura a partir del nodo
actual. Las características que deberá presentar son:
El nodo actual se visualizará en el centro del panel de visualización, presentando
un aspecto que lo haga distintivo del resto.
El grafo mostrado se creará a partir de las relaciones que muestre el nodo
principal con otros nodos, y éstos a su vez con otros, recursivamente, hasta un
número de niveles determinado.
El número de niveles representados debe ser elegible por el usuario.
Por otro, diseñaremos el menú de configuración del módulo desde el que se podrán
gestionar aspectos, tanto funcionales como visuales o de administración.
6.5.2. Análisis de riesgos
La API de Drupal nos proporciona el nodo de la página donde nos encontramos
mediante la función menu_get_object().
Por otro lado, el módulo Hypergraph ya proporcionaba un menú, situado en el bloque
de Administración del sitio, que permitía la configuración de aspectos generales del
módulo, como tamaño del panel de visualización o el cacheado de datos. El formulario
utilizado en el menú nos parece un lugar adecuado para añadir como elementos
configurables el aspecto del nodo actual o la selección del número niveles de
visualización.
Mejoraremos la gestión de permisos del módulo, creando un bloque propio para situar
el menú de configuración de CCC-Graph. En él, distinguiremos los elementos
modificables a nivel de usuario de los modificables a nivel de administrador.

DESARROLLO DE CCC-GRAPH
57
6.5.3. Ingeniería, desarrollo del producto
6.5.3.1. Representación a partir del contexto del nodo actual
La acotación de la información representada se realizará mediante la modificación de la
función cccgraph_get_menu(), implementada en la anterior iteración, encargada de la
construcción del grafo. La extracción de la estructura conceptual se realizará a partir del
nodo actual, recibiendo como argumentos el identificador del nodo y el número de
niveles de profundidad mostrados. El pseudocódigo de la función puede encontrarse en
el segundo punto del anexo 3.
6.5.3.2. Creación del menú de configuración
La creación del menú de configuración comprende la asignación de un bloque propio, la
división de permisos según roles, para controlar la gestión de los aspectos
configurables. Los pasos seguidos han sido:
1. Construcción de un nuevo bloque para el módulo CCC-Graph (cccgraph.install)
Para colocar el menú de configuración en un bloque propio es necesaria su creación
[22][23] por medio del archivo de instalador del módulo, cccgraph.install.
El nuevo archivo de instalación nos servirá además para mantener la base de datos en el
mismo estado en el que encontraba tras la desinstalación del módulo (eliminación de
variables de configuración y otros datos guardados para su funcionamiento).
2. La creación y asignación de permisos (cccgraph.module)
Se ha modificado el hook perm para crear un nuevo permiso 'access cccgraph' que se
asigna por defecto al rol de usuario registrado (authenticated user) en el proceso de
instalación.
Así, en el mismo formulario de configuración habrá elementos editables por cualquier
usuario registrado, almacenados en variables de sesión, y elementos que solo un usuario
administrador podrá modificar, almacenado en BBDD.
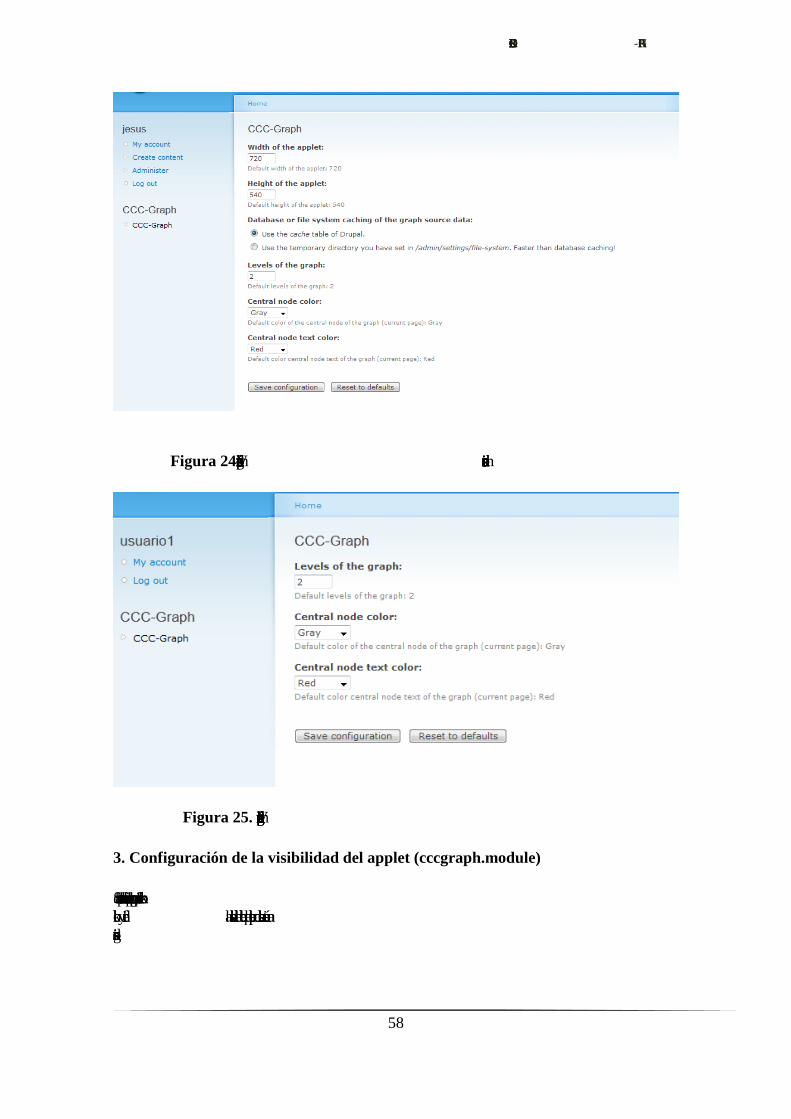
DESARROLLO DE CCC-GRAPH
58
Figura 24. Vista del menú de configuración por usuario administrador
Figura 25. Vista del menú de configuración por usuario registrado
3. Configuración de la visibilidad del applet (cccgraph.module)
Se ha aprovechado la creación del permiso 'access cccgraph' para modificar el hook
block y definir la visibilidad del bloque del applet como accesible únicamente a
usuarios registrados.
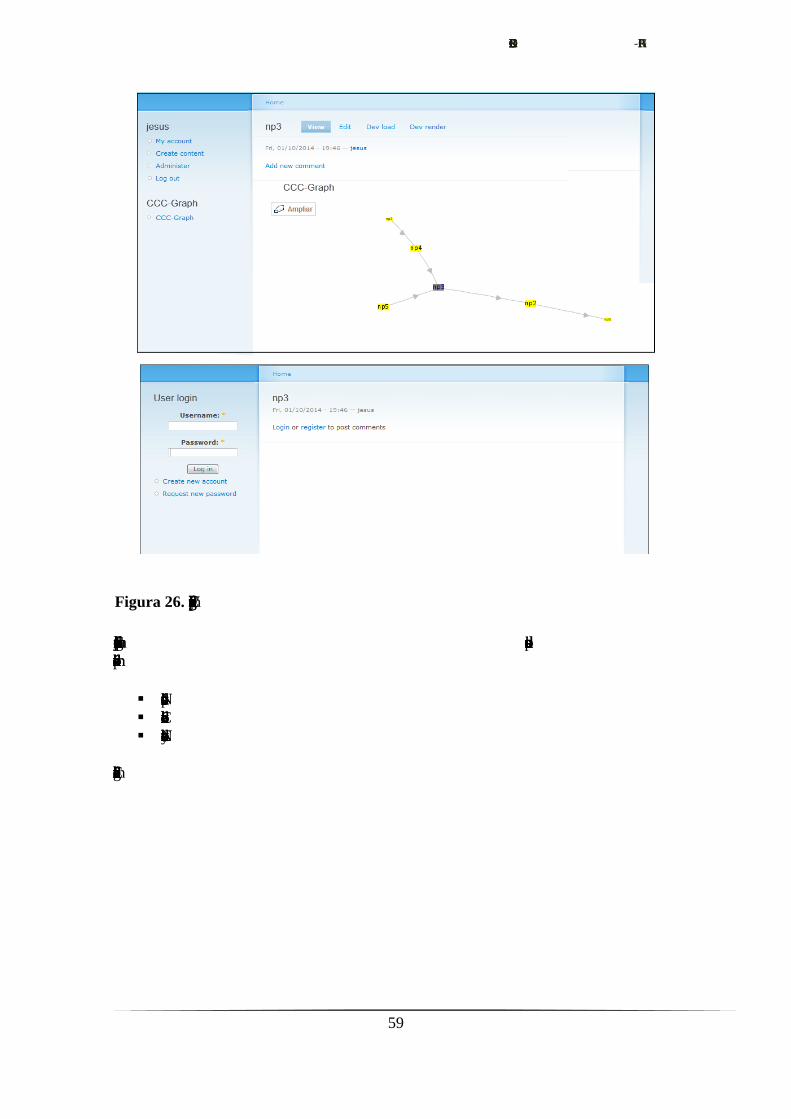
DESARROLLO DE CCC-GRAPH
59
Figura 26. Vista limpia del applet para usuarios no registrados y páginas fuera de la EC
Como ejemplo de visualización nos hemos situado en la página correspondiente al nodo
3 seleccionando como valores de los parámetros:
Niveles de representación: 2
Color del nodo actual: Silver
Color del texto del nodo actual: Navy
El resultado se muestra en la figura 27.
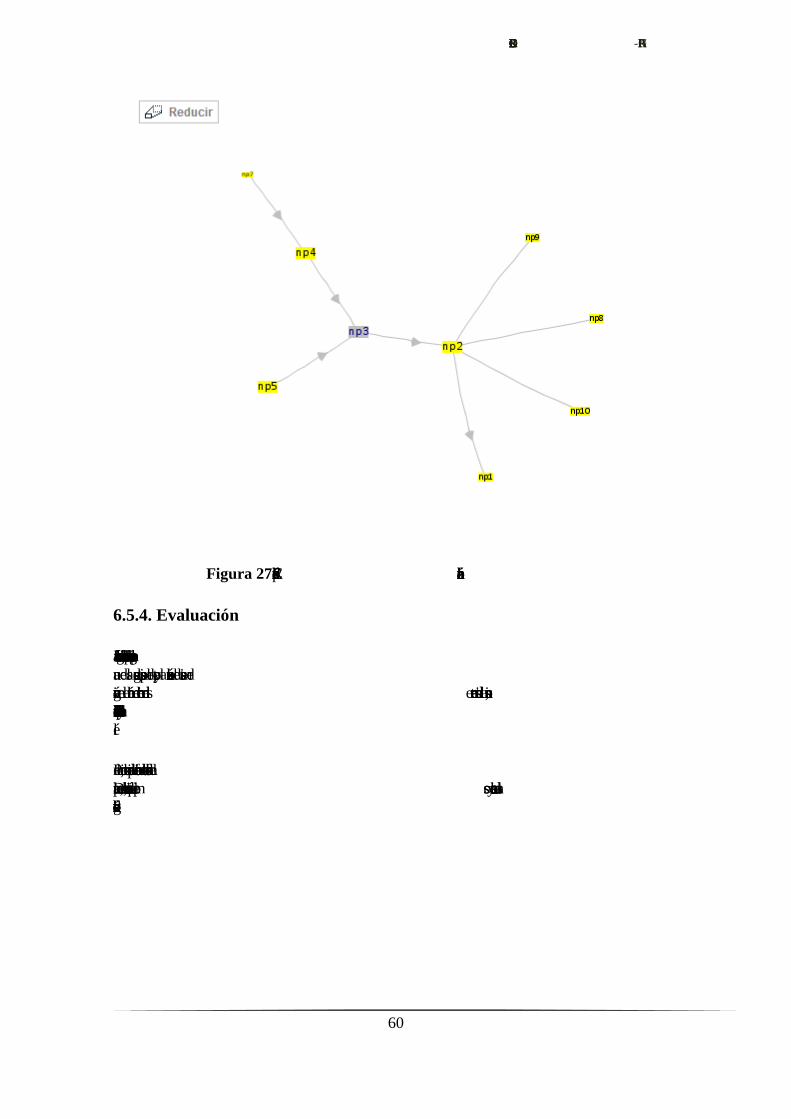
DESARROLLO DE CCC-GRAPH
60
Figura 27. Representación de la EC al finalizar la iteración
6.5.4. Evaluación
La iteración ha llegado a su fin con los deberes cumplido. Se ha dado un gran paso en
una de las grandes premisas del proyecto, la contextualización del sistema de
navegación en el ámbito de conocimiento donde se encuentra situado el usuario,
facilitando la asimilación de la semántica del concepto estudiado y los relacionados con
él.
Por el camino, hemos aprendido el funcionamiento de elementos fundamentales de
Drupal como menús, bloques, administración de permisos y almacenamiento de las
variables de configuración.

DESARROLLO DE CCC-GRAPH
61
6.6. Administración de la estructura conceptual
6.6.1. Determinación de objetivos
Hemos llevado a cabo prácticamente la totalidad de los requerimientos especificados en
un principio. La aplicación es capaz de representar cualquier estructura conceptual que
siga la abstracción definida, el sistema de navegación sitúa al usuario en el contexto del
conocimiento que está intentado adquirir, permitiendo eliminar de la visualización las
relaciones que le molestan mediante el filtrado.
El último requerimiento a desarrollar surge de la cuestión, ¿Es lógico y/o deseable que
todos los elementos definidos como un tipo determinado (nodos relacionados mediante
node reference o taxonomías) sean incluidos como parte de la estructura conceptual?
Claramente la respuesta es negativa, por dos motivos principalmente:
La evolución del sistema puede requerir que los campos incluidos en un
principio en la estructura conceptual, dejen de estarlo. Sin embargo, podría ser
deseable que la información que contienen se conserve.
Son campos con multitud de utilidades, por lo que su uso no siempre implica
relaciones semánticas entre conceptos y, por tanto, deben excluirse de la
representación de la estructura.
Por tanto, el objetivo de la iteración será la posibilidad de selección de los elementos
que pertenecen a la estructura conceptual, siendo visualizados por el subsistema de
navegación. El mecanismo desarrollará una función equivalente a la del subsistema de
presentación al permitir al autor seleccionar el subconjunto de la información albergada
en el sistema de almacenamiento que el usuario final podrá visualizar.
6.6.2. Análisis de riesgos
De nuevo, analizamos las vías existentes. Como se ha comentado, la elección de los
elementos que forman parte de la estructura conceptual debe ser realizada por el autor,
en este caso el administrador del sitio. Por tanto, nuestras posibilidades quedan
limitadas al ámbito del sitio en Drupal, donde podemos definir los permisos de los
usuarios.
Haciendo uso del aprendizaje obtenido en la anterior iteración, se baraja como buena
posibilidad la utilización de un formulario dinámico [21] que liste los elementos
existentes en el sitio que pueden formar parte de la estructura conceptual: tipos de
contenido que incluyen campos de tipo taxonomía o node reference. El administrador
podrá decidir, a golpe de clic, los elementos incluidos.
Como función extra, aprovechando el formulario creado con el listado de elementos
visualizables, añadiremos la posibilidad de elegir el color del componente en el grafo.

DESARROLLO DE CCC-GRAPH
62
6.6.3. Ingeniería. Desarrollo del producto
Como primer paso definiremos la accesibilidad del formulario. Se ha creado un nuevo
submenú “Administer available content”, en el bloque creado para el módulo, que nos
llevará al formulario. Se han especificado los permisos de accesibilidad para hacerlo
visible únicamente al usuario con rol de administrador en el sistema.
Apoyándonos en los pasos marcados por [18] y [20] hemos implementado un
formulario con componentes dependientes del contenido existente y cuya creación se
realiza dinámicamente.
El desarrollo implica un cambio en la lógica de funcionamiento. Se separan los procesos
de abstracción de la estructura conceptual y extracción de la información, hasta ahora
realizados conjuntamente según el algoritmo descrito en el anexo 3. El trabajo se ha
dividido en las siguientes tareas:
1. Implementación de la función administer_cccgraph_content (cccgraph.module)
Encargada de la abstracción de la estructura conceptual y su visualización a través del
formulario. Contiene todas las consultas necesarias para la extracción de la estructura,
hasta ahora situadas en la función cccgraph_get_menu. La elección de los elementos
que formarán parte de la visualización de la EC se realizará mediante el uso de una lista
desplegable en la que se podrá seleccionar el color de su representación o la no
inclusión.
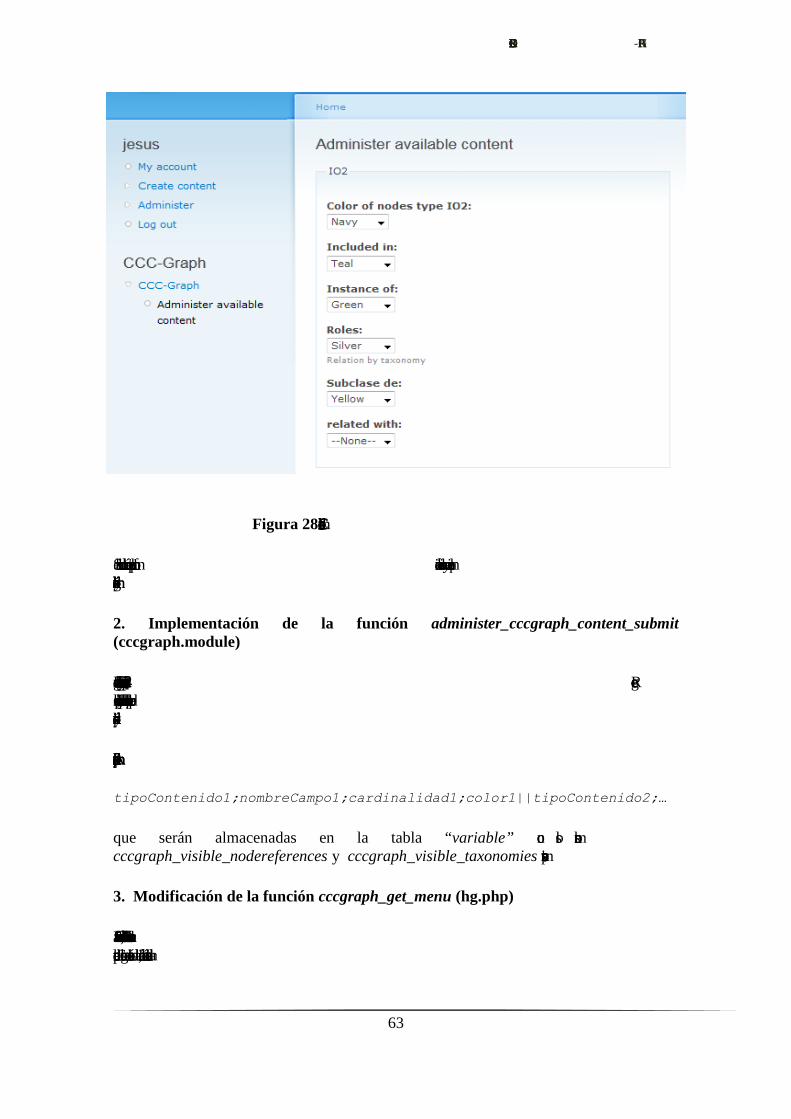
DESARROLLO DE CCC-GRAPH
63
Figura 28. Formulario de selección de la EC
Se ha incluido un botón que permite la confirmación del usuario y que comience la
gestión y almacenamiento de la selección realizada.
2. Implementación de la función administer_cccgraph_content_submit
(cccgraph.module)
Encargado de la gestión y almacenamiento de las opciones seleccionadas [24]. Recoge
los campos seleccionados, incluyendo tipo de contenido al que pertenecen, el color de
representación y su cardinalidad.
Así, tendremos dos listas, para campos node reference y taxonomía, con la forma:
tipoContenido1;nombreCampo1;cardinalidad1;color1||tipoContenido2;…
que serán almacenadas en la tabla “variable” con los nombres
cccgraph_visible_nodereferences y cccgraph_visible_taxonomies respectivamente.
3. Modificación de la función cccgraph_get_menu (hg.php)
La función ha sido modificada de nuevo, liberándola de la abstracción de la estructura
conceptual. El algoritmo de extracción de la información, obtendrá directamente la
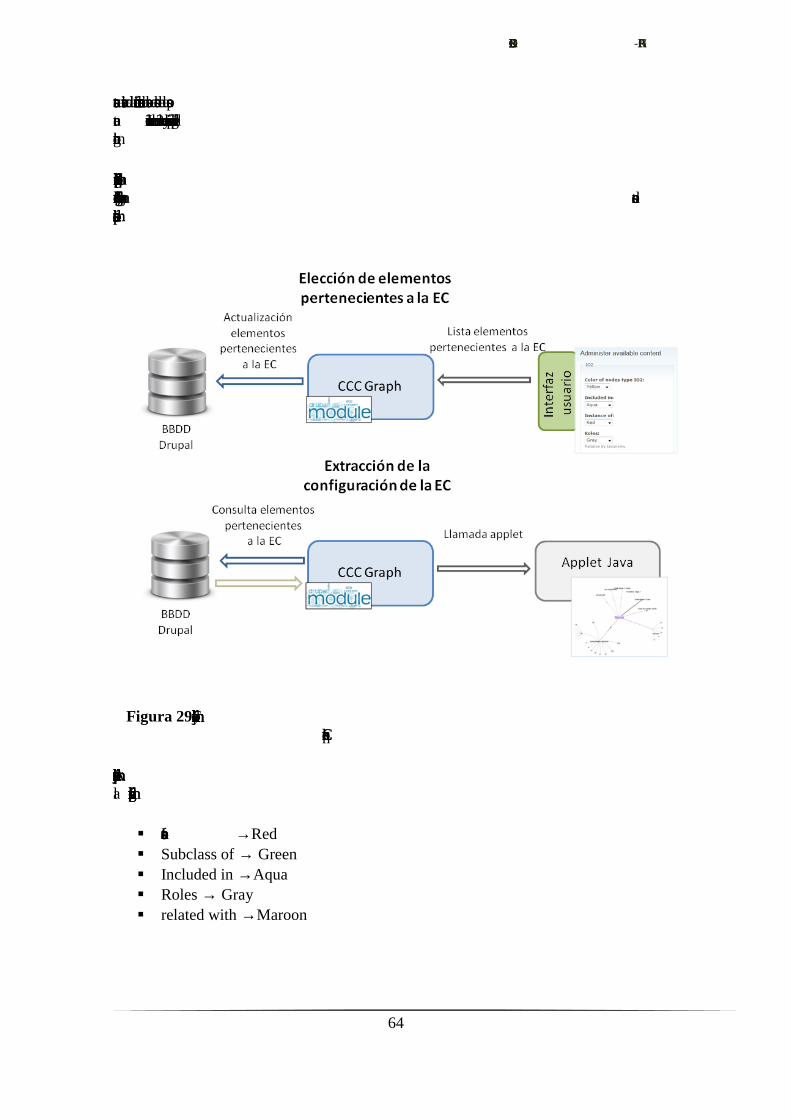
DESARROLLO DE CCC-GRAPH
64
estructura a visualizar de la información almacenada en base de datos en el paso
anterior. Incluimos en el anexo 3 la nueva y última descripción en pseudocódigo del
algoritmo.
Por último, se ha modificado el código para que el applet no sea mostrado en caso de no
contener elementos. El siguiente diagrama modela el funcionamiento global, mostrando
la interacción de los componentes implicados:
Figura 29. Flujo la comunicación y almacenamiento en la elección de los elementos
que pertenecen a la EC
Al término de la implementación, tomando el ejemplo utilizado en la iteración anterior y
la selección de colores mostrada a continuación, el grafo muestra el siguiente aspecto:
Instance of →Red
Subclass of → Green
Included in →Aqua
Roles → Gray
related with →Maroon
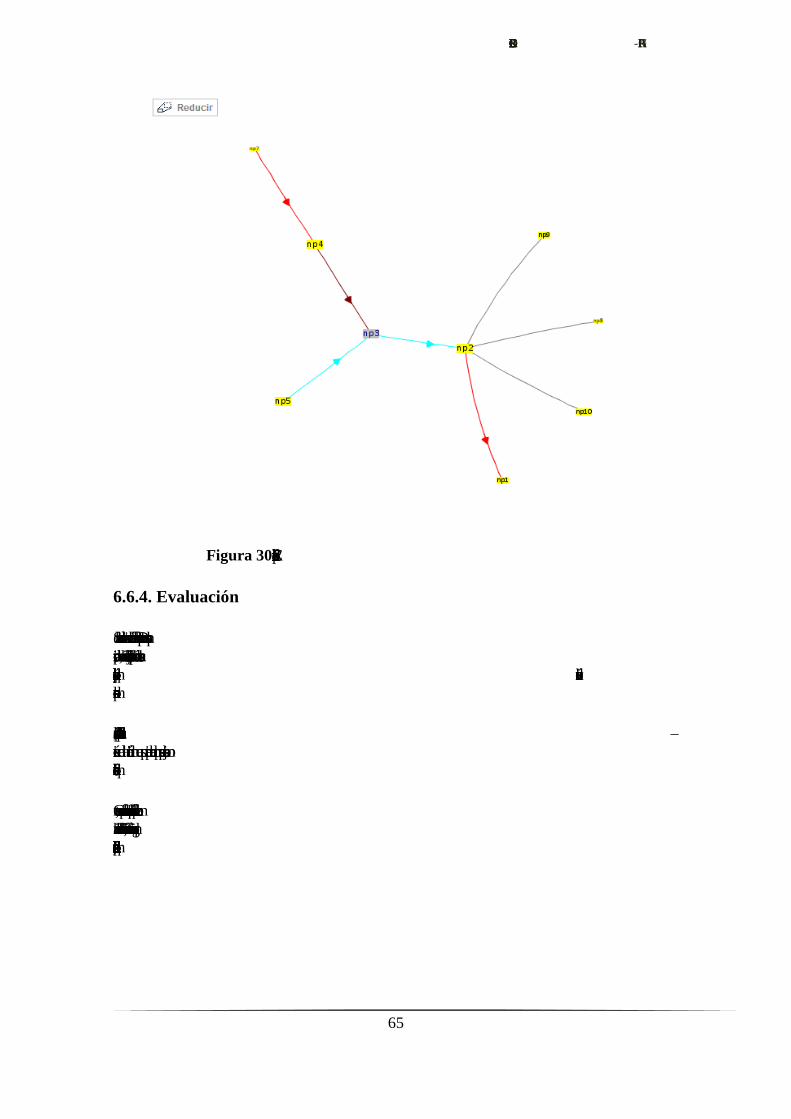
DESARROLLO DE CCC-GRAPH
65
Figura 30. Representación de la EC al finalizar la iteración
6.6.4. Evaluación
Se ha ahondado en el estudio de creación de formularios en Drupal. Lo que nos has
permitido, a la vez, la consecución del objetivo principal, la elección de la estructura
conceptual representada y un requerimiento extra, la selección del color de visualización
de los componentes.
Además, hemos independizado en dos fases el proceso de abstracción de la estructura –
extracción de la información lo que nos permite abordar por separado mejoras o
modificaciones en cualquiera de ellos en un futuro.
Con esto, se puede afirmar que los requerimientos funcionales definidos al comienzo
han sido cubiertos. En la última iteración, se afrontarán otros requerimientos surgidos
en el desarrollo, que perfeccionarán el sistema, dando el salto de calidad final.

DESARROLLO DE CCC-GRAPH
66
6.7. Visualización de relaciones múltiples
6.7.1. Determinación de objetivos
En el análisis de riesgos de la primera iteración se hizo mención del problema al que
haremos frente en la que consideramos última iteración. El applet no soporta la
visualización de múltiples relaciones entre dos nodos en un mismo sentido.
El funcionamiento actual muestra representaciones tales como la mostrada en la figura 7
para pares de nodos con una o más relaciones en cada sentido.
Consideramos insuficiente la actual representación para el proyecto CCC Graph,
pensado para sistemas con múltiples tipos de nodos y relaciones entre ellos, por dos
motivos:
Las relaciones múltiples entre nodos deben formar, íntegramente parte
íntegramente de la representación visual del grafo.
La duplicación de aristas en la forma mostrada en la figura 7 dificulta la
visualización del grafo y, por tanto, su comprensión.
Se debe desarrollar algún mecanismo capaz de mostrar todas las relaciones existentes
entre cada par de nodos siguiendo una visualización limpia.
6.7.2. Análisis de riesgos
La estructura de datos utilizada para almacenar la disposición de los nodos y aristas en
el applet no permite una simple modificación del sistema de representación de
relaciones actual, por lo que buscaremos basarnos todo lo que podamos en la
implementación actual.
Como solución planteamos la integración de todas las relaciones en la arista que conecta
cada par de nodos. La forma de la arista variará según la cantidad y tipos de relaciones
que represente.
6.7.2.1. Definición de estados
Las formas que tomarán las aristas, dependiendo de las relaciones que representen,
pueden determinarse como por medio de estados. Especificamos el significado de cada
estado y su representación gráfica:

DESARROLLO DE CCC-GRAPH
67
ESTADO 1: Estado inicial. No hay relaciones entre el par de nodos. Sin
representación gráfica.
ESTADO 2: Existencia de una única relación entre ambos nodos de tipo
node reference.
Representación gráfica:
- Tipo de línea: continua, dirigida.
- Color: el definido por el administrador para la relación.
- Etiqueta: nombre de la relación.
ESTADO 3: Existencia de una única relación de tipo taxonomía.
Representación gráfica:
- Tipo de línea: continua, no dirigida.
- Color: el definido por el administrador para la relación.
- Etiqueta: nombre de la relación.
ESTADO 4: Varias relaciones de tipo node reference, en una misma
dirección. Es posible la existencia de una o varias relaciones de tipo
taxonomía.
Representación gráfica:
- Tipo de línea: discontinua, dirigida
- Color: rojo (conflicto de relaciones).
- Etiqueta: nombres de la relaciones separados por ‘/’.
ESTADO 5: Varias relaciones de tipo taxonomía exclusivamente.
Representación gráfica:
- Tipo de línea: discontinua, no dirigida
- Color: rojo (conflicto).
- Etiqueta: nombres de la relaciones separados por ‘/’.
ESTADO 6: Varias relaciones de tipo node reference en ambas direcciones.
Es posible la existencia de una o varias relaciones de tipo taxonomía.
Representación gráfica:
- Tipo de línea: discontinua, no dirigida
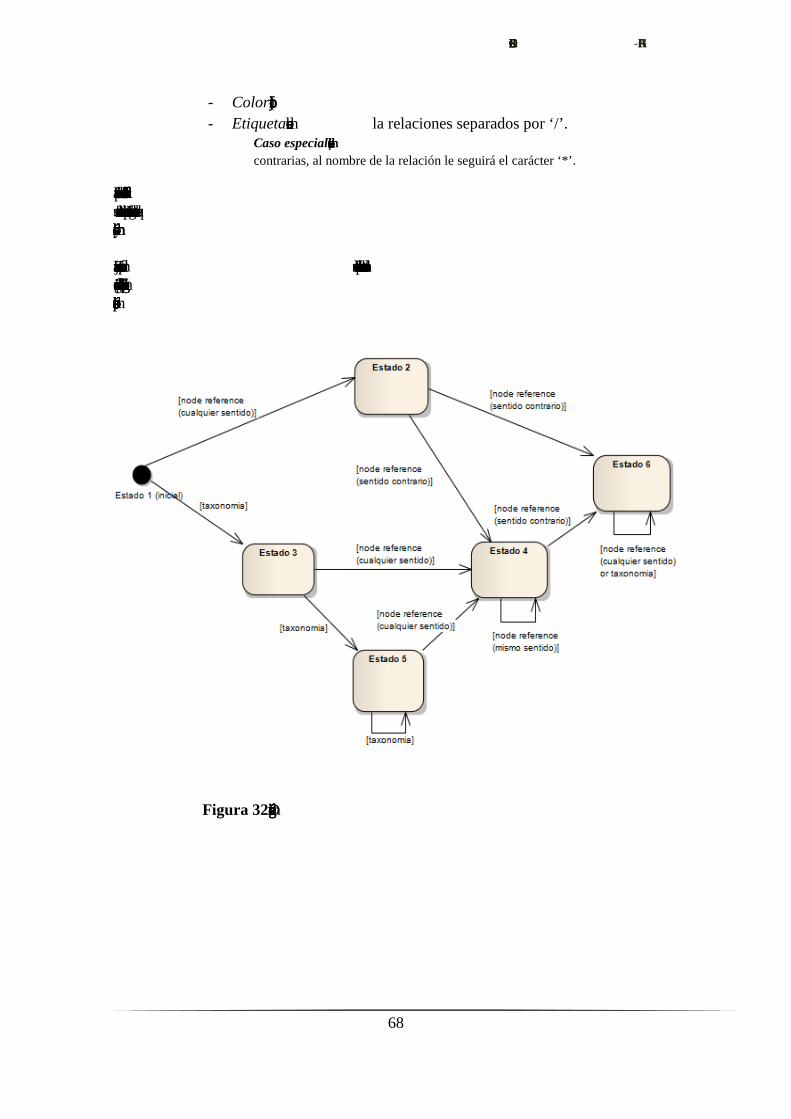
DESARROLLO DE CCC-GRAPH
68
- Color: rojo (conflicto).
- Etiqueta: nombres de la relaciones separados por ‘/’.
Caso especial: dos relaciones del mismo tipo en direcciones
contrarias, al nombre de la relación le seguirá el carácter ‘*’.
La representación de las aristas como estados con características bien definidas facilita
su tratamiento. Modelaremos su comportamiento mediante diagramas de estados que
nos ayudarán en la implementación del mecanismo.
Para mejorar su comprensión, dividimos el comportamiento del cambio de estados en
dos diagramas distintos dependiendo de si la acción realizada comprende la agregación
de una relación o, por el contrario, su eliminación.
Figura 32. Diagrama de estados: agregación de una relación
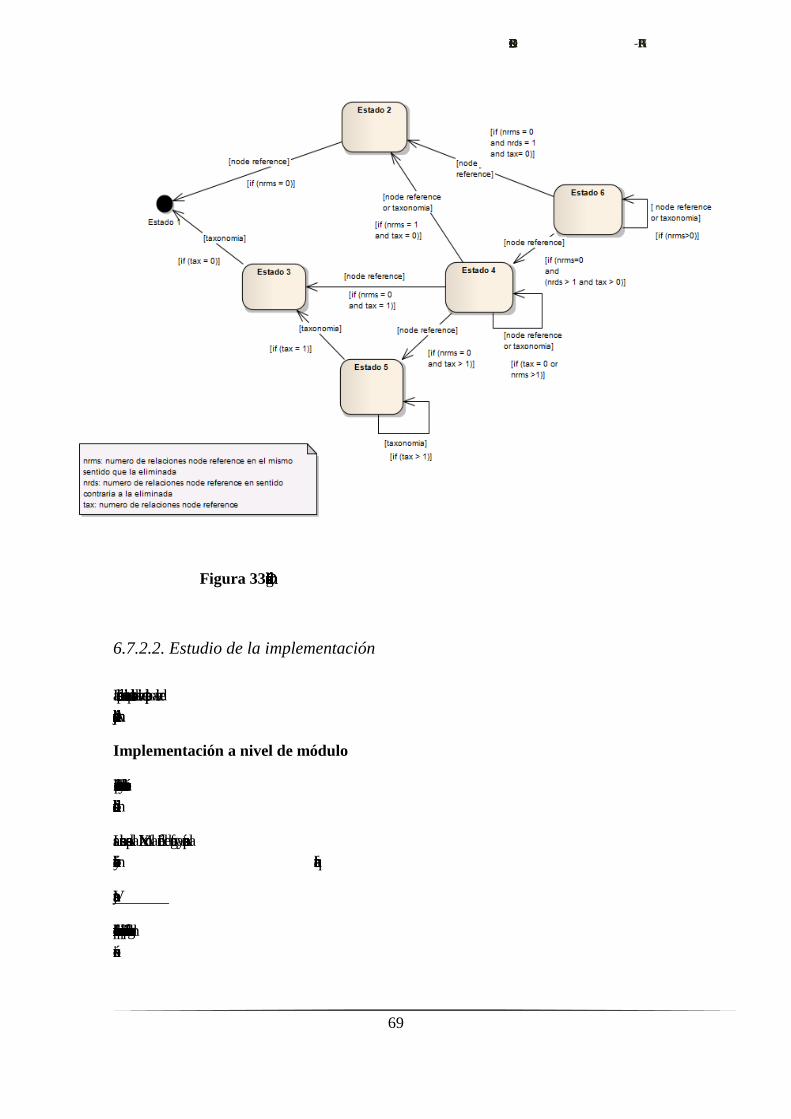
DESARROLLO DE CCC-GRAPH
69
Figura 33. Diagrama de estados: eliminación de una relación
6.7.2.2. Estudio de la implementación
La implementación del mecanismo puede abordarse a nivel de applet o a nivel de
módulo. Analizaremos las ventajas e inconvenientes de cada opción.
Implementación a nivel de módulo
El procesamiento de las relaciones obtenidas y su estado se realizaría tras la extracción
de la información en la base de datos.
Las relaciones pasadas al XML con la definición del grafo ya presentarían la
visualización con la forma y etiqueta final.
Ventajas
Implementación relativamente simple que implicaría la modificación del algoritmo de
extracción.

DESARROLLO DE CCC-GRAPH
70
Incovenientes
El sistema actual de filtrado, implementado en el applet, no permitiría la gestión de las
relaciones individuales entre dos nodos agrupadas en una arista. El filtrado, por tanto,
produciría el cambio de estados definido, debería crearse un mecanismo auxiliar o la
reimplemetación del actual.
Implementación a nivel de applet
El módulo mantendría su funcionamiento, extrayendo y pasando al applet las relaciones
individualmente. Sería este último el encargado del procesamiento de múltiples
relaciones por arista y el cambio de estados.
Ventajas
Se podría modificar el componente encargado de la disposición de nodos y gestión de
relaciones, añadiendo los elementos necesarios que modelen el cambio de estados. El
sistema de filtrado actual sería totalmente funcional sin apenas cambios.
Inconvenientes
Las modificaciones requieren la reimplementación de diferentes elementos
fundamentales para el correcto funcionamiento de la aplicación, por lo que deben ser
aplicadas con un perfecto conocimiento de la lógica aplicada y tras un exhaustivo
trabajo de análisis.
Aunque en un principio presenta un desarrollo bastante más complejo, optamos por la
segunda opción, integrando el modelo de cambio de estados en la estructura del applet
que soporta la gestión y que nos permitirá la utilización del sistema de filtrado ya
implementado.
6.7.3. Ingeniería. Desarrollo del producto
La actual implementación del componente de gestión de las relaciones entre nodos solo
permite la existencia de dos relaciones, una en cada sentido, para cada par de nodos. Si
recibe una nueva relación, es desechada, sin quedar registro de su existencia.
Cambiaremos el modelo de gestión desarrollando las siguientes modificaciones:
Se mantendrá la estructura que alberga las relaciones existentes entre
nodos. Sólo existirá una arista por cada par, siendo la visualizada en el
grafo. Representará el conjunto de relaciones existentes entre ambos
nodos por lo que deberá conservar el estado y la forma pertinente.

DESARROLLO DE CCC-GRAPH
71
Se ha construido una nueva estructura que contendrá la lista de relaciones
individuales existentes. De tal forma, se podrá cambiar el estado de la arista
correspondiente tras el filtrado de una de las relaciones que la forman,
recuperando las restantes.
Se ha modificado la función encargada de la eliminación de una relación.
Éstas sólo se desecharan de la lista creada en el anterior punto. La arista
mostrada será cambiada de estado y, únicamente en caso de que el número
de relaciones que represente sea cero, eliminada.
Se ha modificado la función encargada de gestionar la agregación de una
nueva relación. Las nuevas relaciones no serán desechadas en caso de que ya
existan otras entre los mismos nodos, se añadirán a lista que agrupa el
conjunto total, modificándose el estado de la arista representante.
La realización de los cambios ha afectado a:
GraphImpl.java
Creación de la ArrayList multipleRelations. Lista con todas las relaciones
entre nodos existentes.
Reimplementación de la función addElement. Añade una relación
soportando la lógica del cambio de estados.
Implementación de la función removeMultipleRelation. Elimina una relación
soportando la lógica del cambio de estados.
EdgeImpl.java
Se incluye el estado de la relación como variable de instancia.
Otros pequeños cambios que permiten el almacenamiento de la lista de
relaciones existentes.
La implementación realizada soporta el filtrado de relaciones desarrollado en la segunda
iteración al integrar el cambio de estados de una arista en la lógica de gestión de
relaciones, mostrándose transparente a los demás componentes.
Se incluyen los siguientes ejemplos como muestra del funcionamiento alcanzando:
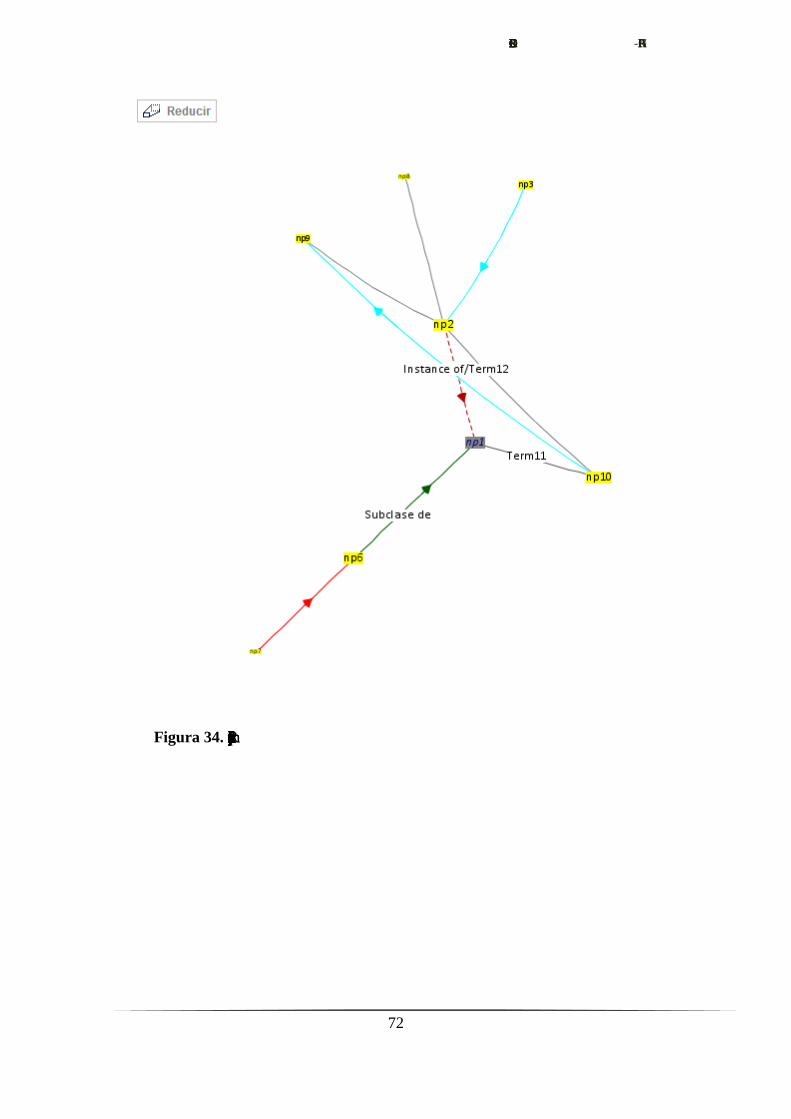
DESARROLLO DE CCC-GRAPH
72
Figura 34. Relación múltiple entre np1 y np2 (taxonomía y node reference)
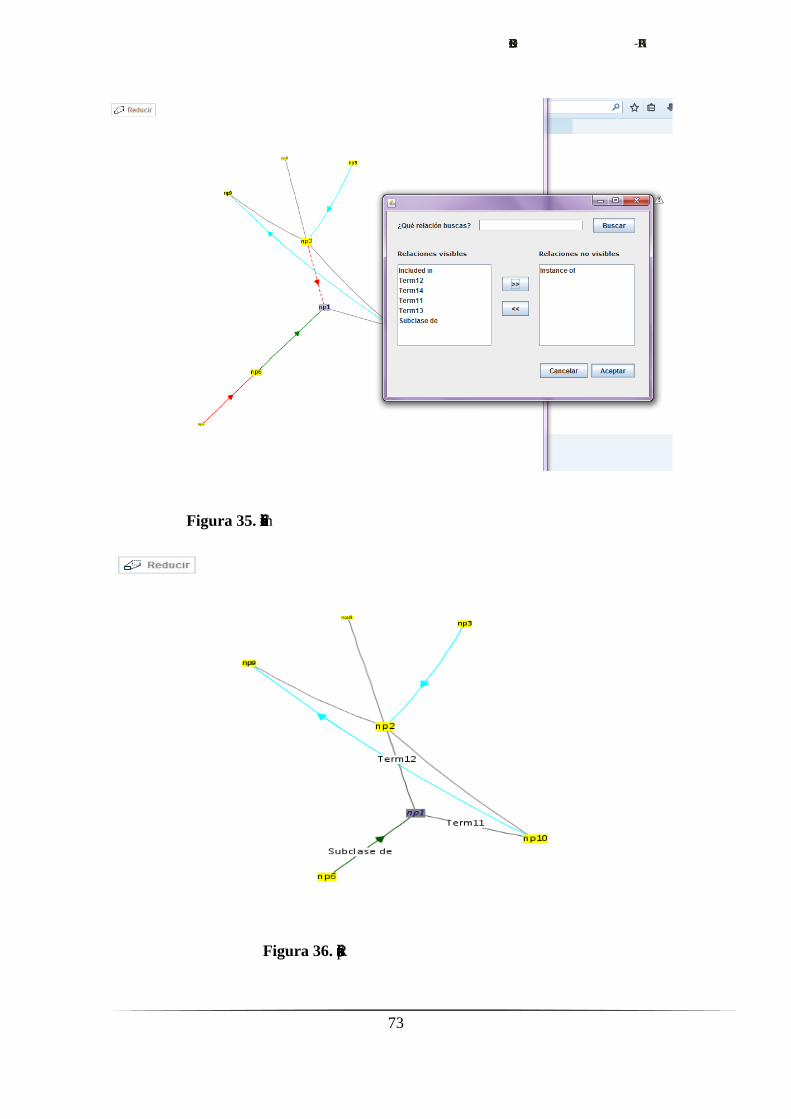
DESARROLLO DE CCC-GRAPH
73
Figura 35. Filtrado de la relación node reference como no visible
Figura 36. Representación tras el filtrado
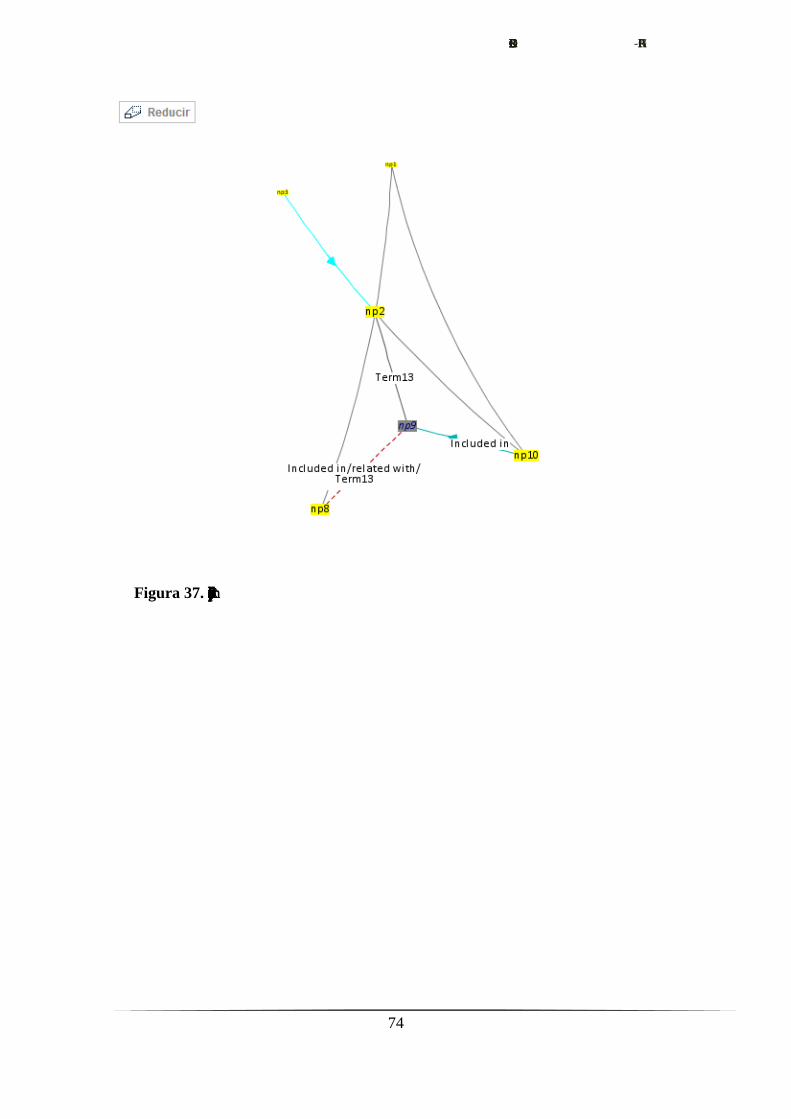
DESARROLLO DE CCC-GRAPH
74
Figura 37. Relación múltiple entre np1 y np2 (taxonomía y doble node reference)
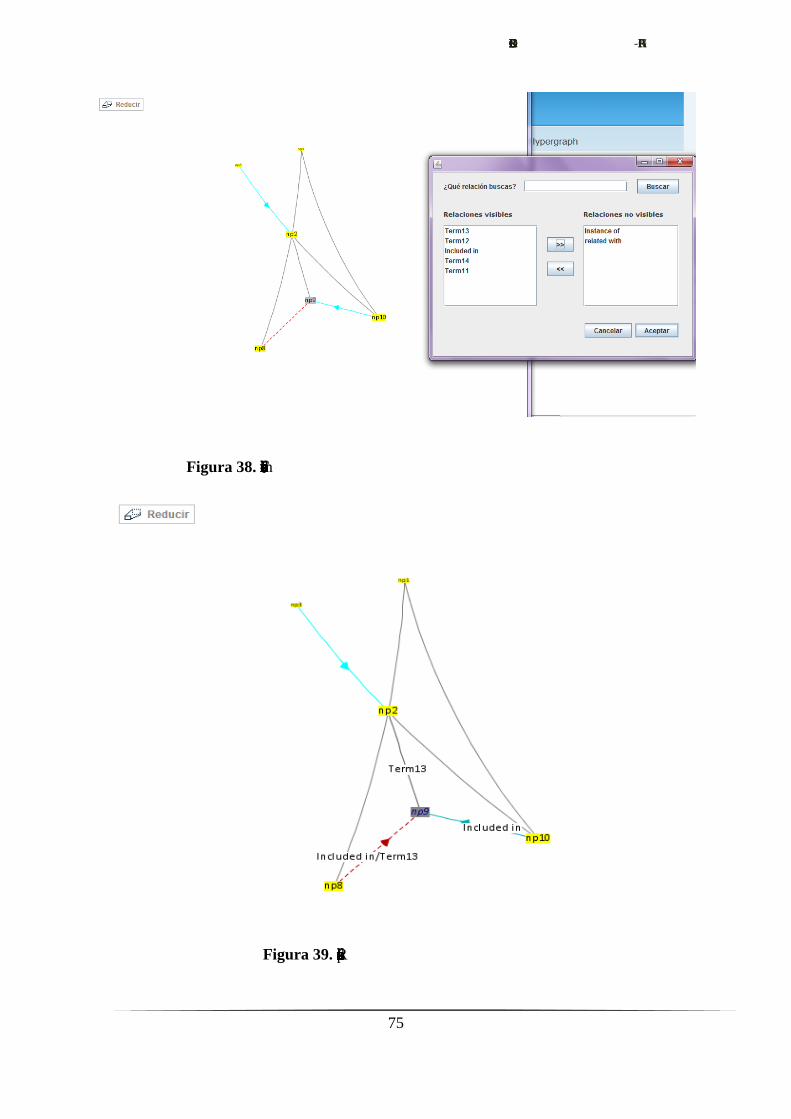
DESARROLLO DE CCC-GRAPH
75
Figura 38. Filtrado de la relación node reference como no visible
Figura 39. Representación tras el filtrado

DESARROLLO DE CCC-GRAPH
76
6.7.4. Evaluación
Aunque los cambios introducidos en el applet eran complejos y afectaban al
funcionamiento general de la aplicación, se han finalizado con éxito. Mediante la
utilización del filtrado se proporciona la posibilidad de realizar el cambio de estado de
las aristas de forma consistente, pudiendo evolucionar de un estado a otro en ambas
direcciones (eliminación o agregación de una relación) sin problemas.
El desarrollo de la iteración ha sido completado, por tanto, con un resultado claramente
favorable. Con su finalización se considera completado el desarrollo de un proyecto que
cumple con todos los requerimientos especificados.

PARTE III- EPÍLOGO
77

PARTE III- EPÍLOGO
78
PARTE III
EPÍLOGO

PARTE III- EPÍLOGO
79

RESUMEN
80
7. Resumen
Una vez completado el desarrollo del proyecto, podemos realizar un análisis general que
presente las principales características del sistema.
7.1. Evaluación general
Se ha creado un sistema de navegación que:
Maximiza la usabilidad. Permite la elección de colores de nodos y
relaciones, ofrece la posibilidad de filtrar las relaciones representadas y
provee la opción de modificar el aspecto del nodo actual. Todos estos
aspectos son configurables desde menús intuitivos y dinámicos.
Contextualiza al usuario. La representación de la red semántica se focaliza
en el nodo en el que se encuentra situado el usuario.
Proporciona total flexibilidad. Es capaz de representar y proporcionar la
posibilidad de navegar sobre cualquier estructura conceptual basada en
contenidos relacionados mediante node reference y taxonomías.
Sigue un modelo evolutivo y cognitivo:
Evolutivo porque es capaz de abstraer la introducción de nuevos contenidos
e integrarlos en la estructura conceptual existente. El autor, será capaz
además de determinar los elementos visualizados según las necesidades que
vaya mostrando el sistema y sus usuarios a lo largo del tiempo.
Cognitivo ya que las características mencionadas hasta ahora, usabilidad,
flexibilidad, evolutividad y contextualización facilitan el aprendizaje del
usuario, evitando los problemas de desorientación habituales. El usuario
conocerá perfectamente el concepto que está viendo, los conceptos
relacionados y cómo se relacionan y por tanto, de dónde viene y a dónde
puede ir.
Por tanto, consideramos el resultado final del proyecto como exitoso al cumplir con
todas las necesidades planteadas de una forma ampliamente satisfactoria.
7.2. Evaluación personal
La evaluación personal tras la realización del proyecto puede considerarse como
bastante favorable. Se ha obtenido conocimiento de lenguajes de programación como
PHP. Se ha alcanzado una gran destreza en el uso y comprensión de los distintos
componentes y funcionamiento de herramientas como Drupal y las tecnologías que
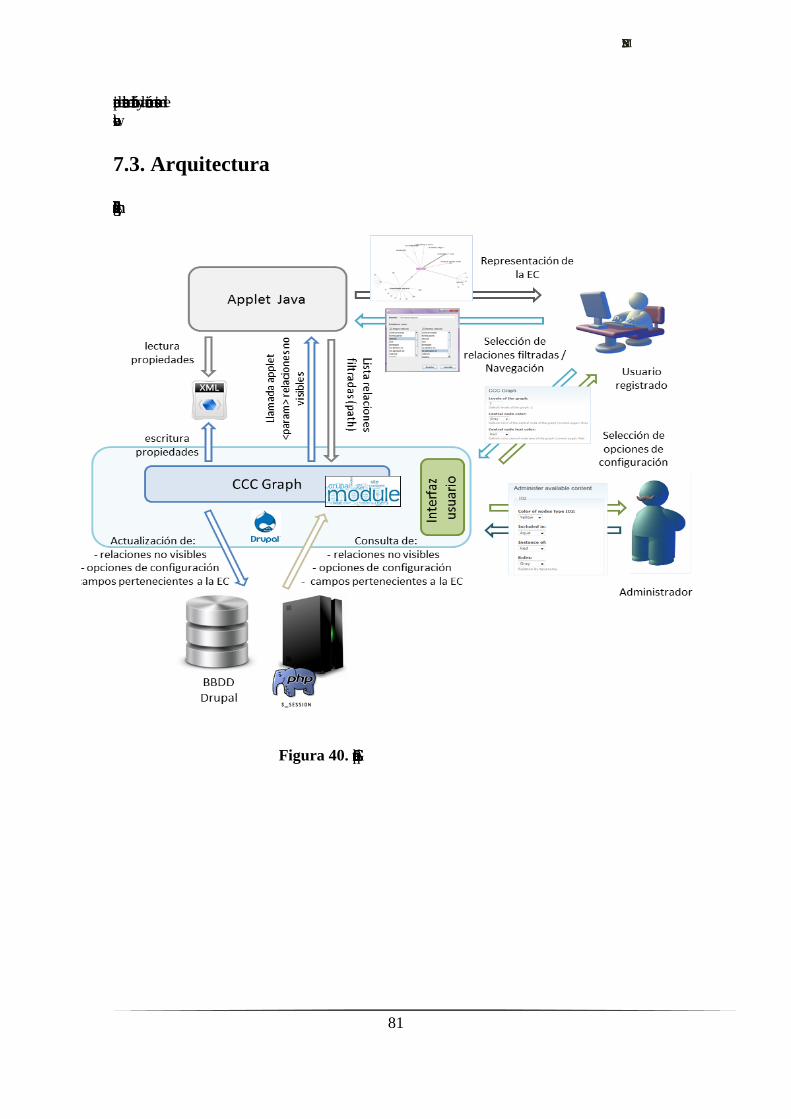
RESUMEN
81
permiten el almacenamiento de información y la comunicación en sistemas en el
entorno web.
7.3. Arquitectura
La figura 40 muestra la arquitectura global de funcionamiento del sistema.
Figura 40. Arquitectura CCC Graph

CCC-ÉTICA INFORMÁTICA
82
8. CCC-Ética informática
CCC-Ética Informática es un proyecto del Departamento de Lenguajes y Sistemas
Informáticos de la Universidad de Granada [26] de donde se inspira el nombre, y en
general, la idea de nuestro trabajo.
8.1. Propósito de la página
Pretende recoger bibliografía, comentarios, experiencias y contenidos
relacionados con la Ética Informática. De forma que estos contenidos se puedan
ofrecer de dos modos diferentes:
1. Como material conceptual que relaciona los aspectos de la Ética
Informática en toda la complejidad que permite un gestor de contenidos.
2. Como cursos, talleres y actividades que pueden ser desarrollados de
forma autónoma o guiados por un experto.
Se desarrolla de forma desinteresada para contribuir a la reflexión ética sobre
Informática y Tecnologías de la Información.
Experimenta con herramientas de software libre.
Experimenta con la Construcción-Colectiva-de-Conocimiento (CCC).
8.2. Estructura conceptual
La estructura conceptual utilizada se separa de las pautas marcadas por el modelo SEM-
HP . Todo el contenido del sitio web se basa en un único tipo de nodo “idea_object” con
la configuración descrita en el punto 6.4.2. en la que se imitaba en la creación del tipo
de contenido de desarrollo “IO2”.
Todo la información encontrada se alberga en el tipo de contenido idea_object
formando una inmensa red de conocimiento cuya semántica es proporcionada por las
relaciones de tipo node reference “Instance of”, “Subclass of”, “Included in” y “IO
destino” y la taxonomía “Roles”.
8.3. Nuestra misión
El módulo CCC-Graph será incluido con la idea de:

CCC-ÉTICA INFORMÁTICA
83
Proporcionar una visión global del conocimiento ofrecido, mostrando los
conceptos existentes y cómo se relacionan a golpe de vista.
Contextualizar al usuario en el entorno del concepto en el que se ubica,
facilitando su aprendizaje y evitando su confusión entre la multitud de términos.
Permitir la navegación conceptual de una forma visual e intuitiva dentro de la
red de conocimiento.
8.4. Instalación
El módulo ha sido instalado siguiendo los pasos del Anexo IV, con los siguientes
parámetros de configuración seleccionados:
Width of the applet: 720
Height of the applet: 380
Levels of the graph: 2
Central node color: Gray
Central node text color: Red
El bloque de configuración ha sido ubicado en la región “Lef sidebar” mientras que el
del applet en la “Top content” buscando su integración en la armonía estética del
conjunto del sitio.
Los campos pertenecientes a la estructura conceptual del sitio y el color elegido para su
reprentación han sido:
Instance of: Aqua
Subclass of: Yellow
Included in: Navy
IO destino: Maroon
Se ha decidido descartar la inclusión del campo taxónomico “Roles” dentro de la
estructura conceptual representada para favorecer una aspecto visual del grafo más
limpio.
8.5. Pruebas
El resultado de la utilización del applet en el sitio se muestra en las siguientes figuras,
con representaciones espectaculares en la mayoria de casos:
CCC-ÉTICA INFORMÁTICA
84
Figura 41. Página principal del sitio
Figura 42. Página de ayuda del sitio
CCC-ÉTICA INFORMÁTICA
85
Figura 43. Nodo “Conceptos”
Figura 44. Concepto “Alienación”

CCC-ÉTICA INFORMÁTICA
86
Figura 45. Concepto sobre la alienación, “Alienación del trabajador respecto al
producto de su trabajo”

ANEXO I
87
Anexo I – Documentación Hypergraph
Documentación completada del proyecto de software libre Hypergraph que incluye el
applet utilizado en nuestro módulo. En español.
Package hypergraph.hyperbolic
Proporciona las clases e interfaces que permiten visualizar el espacio hiperbólico
Description
Proporciona clases e interfaces necesarias para visualizar el espacio hiperbólico.
Realmente, la estructura de clases está configurada de tal manera que todo tipo de
geometría no euclidiana puede ser representada. Se utiliza la variante Swing del
paradigma MVC para separar el modelo matemático geométrico, la visualización y la
interacción del usuario.
Modelando la geometría
El espacio geométrico se encuentra codificado en las implementaciones de la interfaz
Model. La única implementación la podemos encontrar en la clase PoincareModel que
utiliza el conocido modelo Poincaré para modelar el plano hiperbólico de dos
dimensiones. Model está diseñado para ser independiente del número de dimensiones.
Podría ser interesante disponer de un modelo tridimensional, por supuesto, la
visualización cambiaría significativamente para un espacio tridimensional, pero la
estructura de clases es lo suficientemente flexible para contemplar esta posibilidad.
Para mantener el modelo lo más flexible posible, las interfaces ModelPoint y ModelVector
ofrecen la posibilidad de almacenar los puntos y vectores según el modelo. La
utilización del modelo Poincaré utiliza la clase Complex como implementación de
ModelPoint.
En un principio, puede resultar algo raro que un vector tenga una interfaz diferente a un
punto. La razón es que un vector, como (1, 0), que apunta hacia la derecha en un
sistema de coordenadas normal, tiene las mismas propiedades en cualquier punto del
sistema de coordenadas. Podrías mover el vector y siempre apuntaría hacia la derecha y
tendría longitud 1 ¡en la geometría euclidiana! En la geometría no euclidiana es
importante, además, la posición del vector. Por ejemplo, en el modelo de Poincaré,
siempre apuntará a la derecha, pero la longitud del vector dependerá de la posición -
cuanto más cerca de la frontera del modelo, más largo se hará el vector en el plano. Es
por eso que cualquier vector tiene un punto base, el punto en el que "comienza" el
vector.
ANEXO I
88
Las traslaciones y rotaciones en el modelo no-euclidiano están representadas por las
implementaciones de la interfaz Isometry (una isometría en el plano es una transformación
que conserva las distancias). No hay ninguna implementación pública de esta interfaz, la
única existente se encuentra como clase interna de PoincareModel. Cualquier modelo
tendrá que implementar un cierto conjunto de métodos para crear isometrías. Por
ejemplo, puedes realizar una rotación alrededor de un punto fijo utilizando
Model.getRotation(ModelPoint,double). Por supuesto, se podrán aplicar transformaciones
isométricas tanto a puntos como a vectores.
Interface Summary
Isometry
La interfaz Isometry proporciona la configuración para todas las
isometrías de un Model. La implementación real depende del modelo y,
por lo tanto, se sitúa junto a éstos. Cada implementación deberá
proporcionar, al menos, un constructor por defecto que cree la
transformación identidad.
Implementing Classes:
PoincareModel.Isometry
LineRenderer Interfaz para el renderizado de una línea
All Superinterfaces:
Renderer
All Known Implementing Classes:
DefaultLineRenderer
Model Esta interfaz se basa en todas las descripciones del plano hiperbólico.
All Known Implementing Classes:
AbstractModel
ModelPoint Interfaz que representa un punto en una geometría no euclidiana
modelada por una implementación de Model.
All Superinterfaces:
java.lang.Cloneable
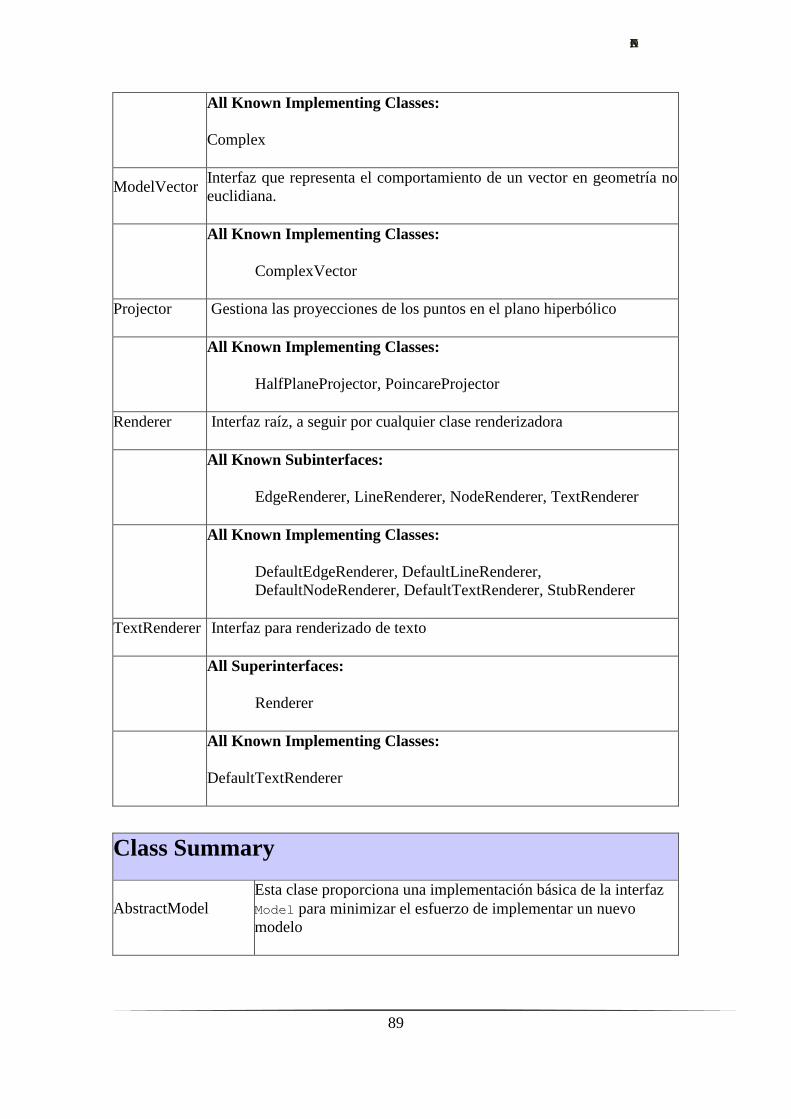
ANEXO I
89
All Known Implementing Classes:
Complex
ModelVector Interfaz que representa el comportamiento de un vector en geometría no
euclidiana.
All Known Implementing Classes:
ComplexVector
Projector Gestiona las proyecciones de los puntos en el plano hiperbólico
All Known Implementing Classes:
HalfPlaneProjector, PoincareProjector
Renderer Interfaz raíz, a seguir por cualquier clase renderizadora
All Known Subinterfaces:
EdgeRenderer, LineRenderer, NodeRenderer, TextRenderer
All Known Implementing Classes:
DefaultEdgeRenderer, DefaultLineRenderer,
DefaultNodeRenderer, DefaultTextRenderer, StubRenderer
TextRenderer Interfaz para renderizado de texto
All Superinterfaces:
Renderer
All Known Implementing Classes:
DefaultTextRenderer
Class Summary
AbstractModel
Esta clase proporciona una implementación básica de la interfaz
Model para minimizar el esfuerzo de implementar un nuevo
modelo
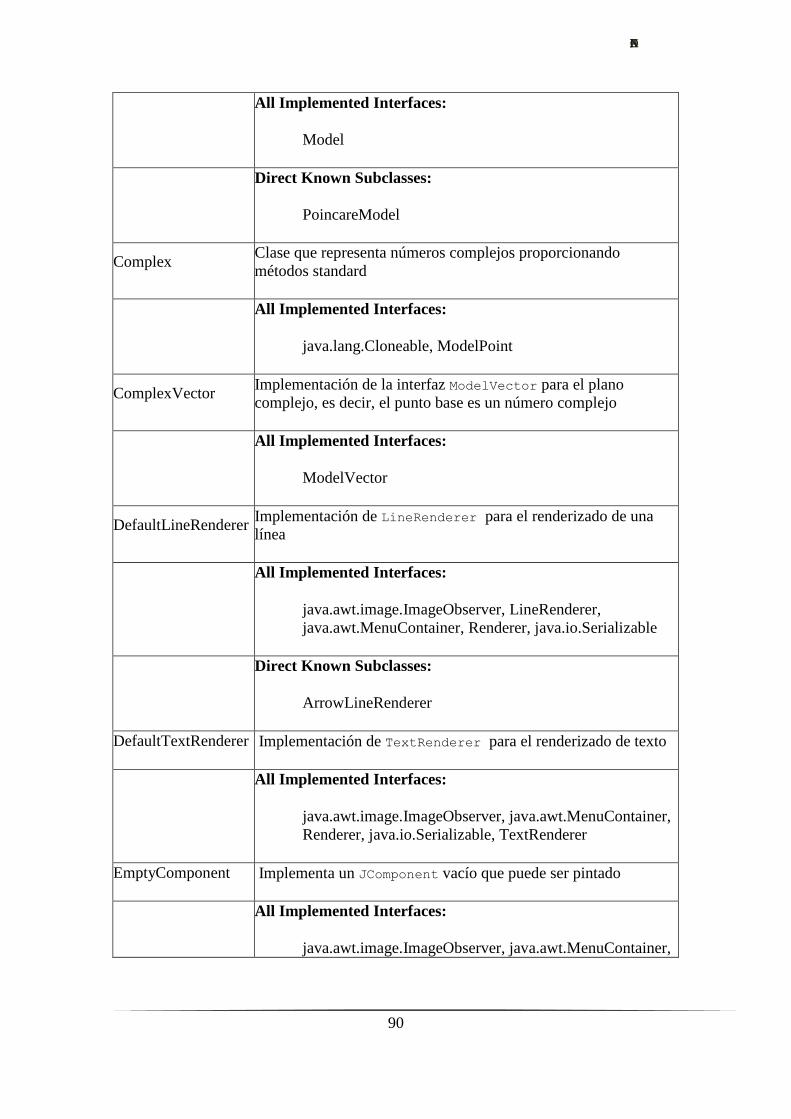
ANEXO I
90
All Implemented Interfaces:
Model
Direct Known Subclasses:
PoincareModel
Complex Clase que representa números complejos proporcionando
métodos standard
All Implemented Interfaces:
java.lang.Cloneable, ModelPoint
ComplexVector Implementación de la interfaz ModelVector para el plano
complejo, es decir, el punto base es un número complejo
All Implemented Interfaces:
ModelVector
DefaultLineRenderer Implementación de LineRenderer para el renderizado de una
línea
All Implemented Interfaces:
java.awt.image.ImageObserver, LineRenderer,
java.awt.MenuContainer, Renderer, java.io.Serializable
Direct Known Subclasses:
ArrowLineRenderer
DefaultTextRenderer Implementación de TextRenderer para el renderizado de texto
All Implemented Interfaces:
java.awt.image.ImageObserver, java.awt.MenuContainer,
Renderer, java.io.Serializable, TextRenderer
EmptyComponent Implementa un JComponent vacío que puede ser pintado
All Implemented Interfaces:
java.awt.image.ImageObserver, java.awt.MenuContainer,
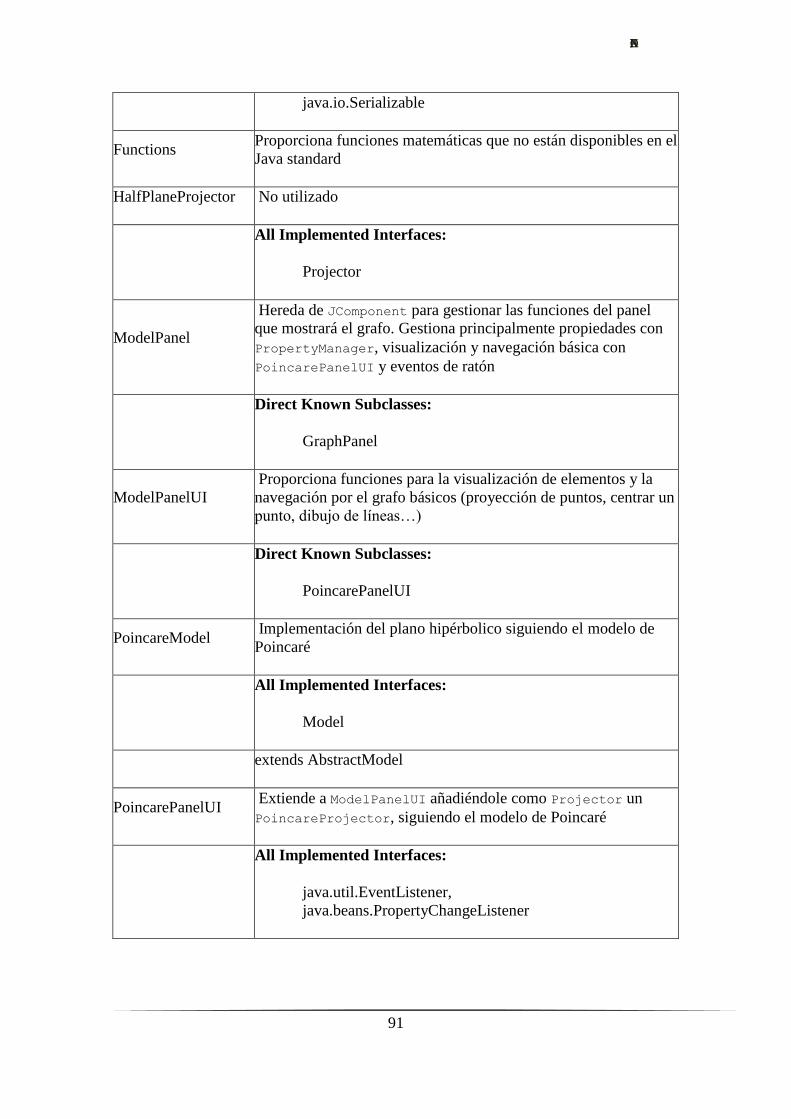
ANEXO I
91
java.io.Serializable
Functions Proporciona funciones matemáticas que no están disponibles en el
Java standard
HalfPlaneProjector No utilizado
All Implemented Interfaces:
Projector
ModelPanel
Hereda de JComponent para gestionar las funciones del panel
que mostrará el grafo. Gestiona principalmente propiedades con
PropertyManager, visualización y navegación básica con
PoincarePanelUI y eventos de ratón
Direct Known Subclasses:
GraphPanel
ModelPanelUI
Proporciona funciones para la visualización de elementos y la
navegación por el grafo básicos (proyección de puntos, centrar un
punto, dibujo de líneas…)
Direct Known Subclasses:
PoincarePanelUI
PoincareModel Implementación del plano hipérbolico siguiendo el modelo de
Poincaré
All Implemented Interfaces:
Model
extends AbstractModel
PoincarePanelUI Extiende a ModelPanelUI añadiéndole como Projector un
PoincareProjector, siguiendo el modelo de Poincaré
All Implemented Interfaces:
java.util.EventListener,
java.beans.PropertyChangeListener

ANEXO I
92
extends ModelPanelUI
PoincareProjector Implementación de Projector utilizando el modelo de Poincaré
All Implemented Interfac
Projector
PropertyManager
La clase PropertyManager almacena propiedades como nombre
de las clases de visualizado tamaño de texto por defecto, etc en
una Hashtable.
StubRenderer Renderizador de elementos residuales
All Implemented Interfaces:
java.awt.image.ImageObserver, java.awt.MenuContainer,
Renderer, java.io.Serializable
Package hypergraph.graphApi
Sencilla API para manejar grafos.
Description
Sencilla API para manejar grafos. Aunque este paquete es parte del proyecto
hypergraph, las clases pueden ser utilizadas en otros contextos para manejar grafos.
Todos los elementos de un grafo, incluso el mismo grafo, son derivadas de la interfaz
Element. Esta interfaz gestiona tres propiedades: el nombre del elemento, el grupo y un
identificador de tipo. El nombre del elemento es usado para identificar y etiquetar un
elemento, identificándolo de forma única dentro de un GraphSystem. Este nunca podrá
ser cambiado y tiene que ser fijado durante la instanciación. La propiedad “grupo” es
utilizada para agrupar conjuntos de elementos, por ejemplo, para establecer atributos
comunes por defecto. El identificador de tipo puede ser utilizado para identificar si un
elemento es una arista, un nodo u otra cosa. Ya que podría haber más de una
implementación de nodos y aristas, la funcionalidad proporcionada por java para su
distinción no es utilizable.
A menudo, es importante asignar ciertas propiedades o atributos a un elemento del
grafo, por ejemplo el color utilizado en su visualización u otro atributo dentro de la
teoría de grafos. Una posibilidad podría ser implementar las interfaces de tal manera que
estos atributos estuvieran almacenados en cada nodo o arista, con el inconveniente de
que los valores por defecto serían difíciles de gestionar. El enfoque en este paquete tiene
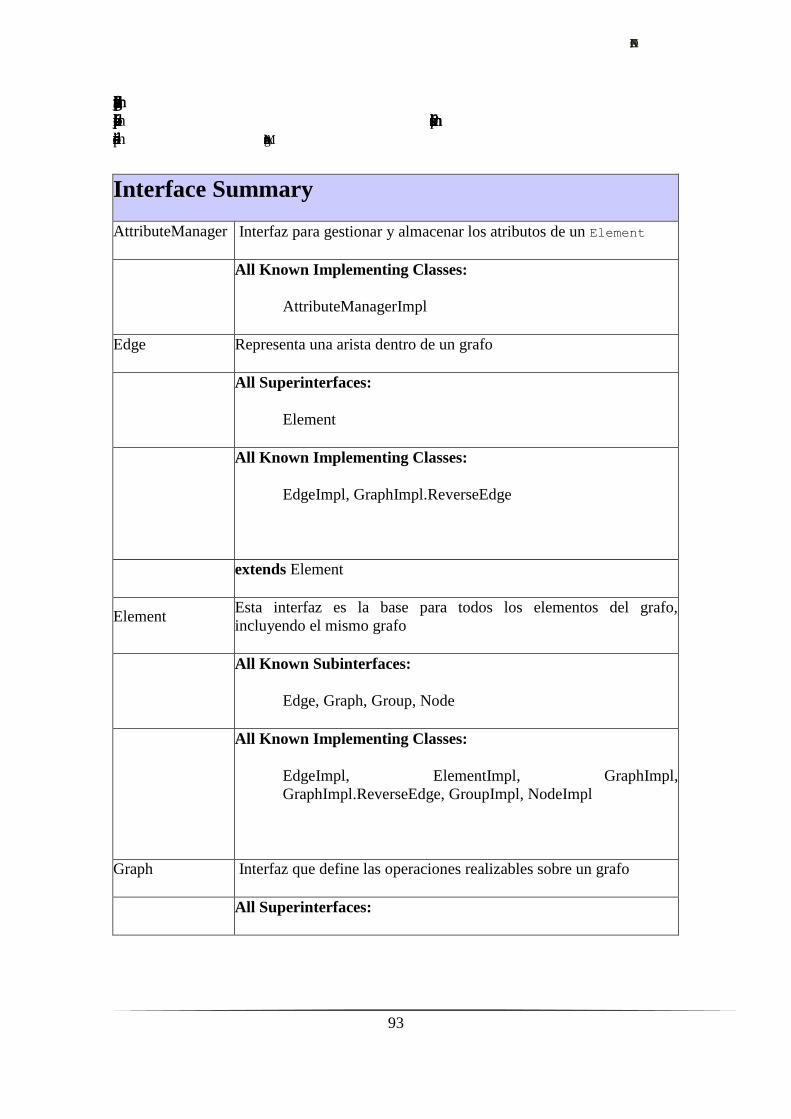
ANEXO I
93
la ventaja de poder conferir atributos a grupos de elementos o al grafo completo, siendo,
por ejemplo, bastante fácil colorear todos los nodos al mismo tiempo. Para más detalles,
mirar la descripción de AttributeManager.
Interface Summary
AttributeManager Interfaz para gestionar y almacenar los atributos de un Element
All Known Implementing Classes:
AttributeManagerImpl
Edge Representa una arista dentro de un grafo
All Superinterfaces:
Element
All Known Implementing Classes:
EdgeImpl, GraphImpl.ReverseEdge
extends Element
Element Esta interfaz es la base para todos los elementos del grafo,
incluyendo el mismo grafo
All Known Subinterfaces:
Edge, Graph, Group, Node
All Known Implementing Classes:
EdgeImpl, ElementImpl, GraphImpl,
GraphImpl.ReverseEdge, GroupImpl, NodeImpl
Graph Interfaz que define las operaciones realizables sobre un grafo
All Superinterfaces:
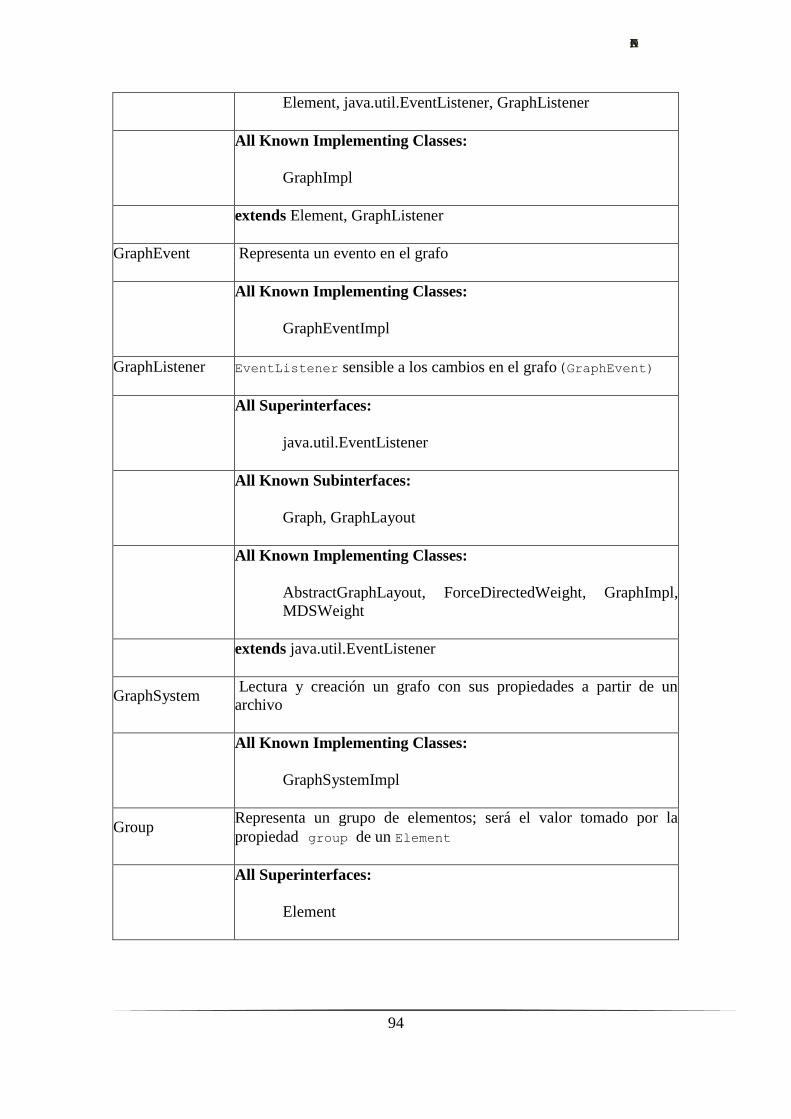
ANEXO I
94
Element, java.util.EventListener, GraphListener
All Known Implementing Classes:
GraphImpl
extends Element, GraphListener
GraphEvent Representa un evento en el grafo
All Known Implementing Classes:
GraphEventImpl
GraphListener EventListener sensible a los cambios en el grafo(GraphEvent)
All Superinterfaces:
java.util.EventListener
All Known Subinterfaces:
Graph, GraphLayout
All Known Implementing Classes:
AbstractGraphLayout, ForceDirectedWeight, GraphImpl,
MDSWeight
extends java.util.EventListener
GraphSystem Lectura y creación un grafo con sus propiedades a partir de un
archivo
All Known Implementing Classes:
GraphSystemImpl
Group Representa un grupo de elementos; será el valor tomado por la
propiedad group de un Element
All Superinterfaces:
Element
ANEXO I
95
All Known Implementing Classes:
GroupImpl
extends Element
Node Esta interfaz representa un nodo dentro de un grafo
All Superinterfaces:
Element
All Known Implementing Classes:
NodeImpl
extends Element
Class Summary
GraphSystemFactory
Proporciona el acceso a un GraphSystem. Crea un nuevo objeto
GraphSystem, especificando la clase implementadora y las
propiedades de inicialización utilizadas
Exception Summary
GraphException Esta excepción (y sus posibles subclases) es utilizada para informar de
errores en la conexión con los algoritmos del grafo
All Implemented Interfaces:
java.io.Serializable
Package hypergraph.graphApi.algorithms
Funcionalidades algorítmicas para grafos como obtener todos los elementos
conectados.

ANEXO I
96
Class Summary
BFSGraphWalker Recorrido primero en anchura del grafo
extends GraphWalker
GraphUtilities
Esta clase proporciona un conjunto de algoritmos de utilidades
teóricas para grafos, como la devolución de todos los componentes
conectados. También incluye métodos para la creación de grafos
standard como árboles, grids y grafos completos
GraphWalker Mantiene una lista de GraphWalkerListener
Direct Known Subclasses:
BFSGraphWalker
LayerAssignment No utilizado
Package hypergraph.graphApi.io
Permite extraer u obtener un grafo mediante la lectura/escritura de un archivo en
formato XML especificado en un DTD.
Interface Summary
ContentHandler Interfaz para la creación de componentes de un grafo a partir de su
lectura de un archivo
All Superinterfaces:
org.xml.sax.ContentHandler
All Known Implementing Classes:
GraphMLContentHandler, GraphXMLContentHandler,
GXLContentHandler
GraphWriter Interfaz que define la descripción textual de un grafo en formato
XML.
ANEXO I
97
All Known Implementing Classes:
AbstractGraphWriter
LexicalHandler Interfaz que extiende al lector XML SAXReader. Proporciona
información léxica de los documentos.
All Superinterfaces:
org.xml.sax.ext.LexicalHandler
All Known Implementing Classes:
DefaultLexicalHandler
extends org.xml.sax.ext.LexicalHandler
Class Summary
AbstractGraphWriter Escritura de las características de un grafo, comunes para todos
los tipos de documento XML
All Implemented Interfaces:
GraphWriter
Direct Known Subclasses:
GraphMLWriter, GraphXMLWriter, GXLWriter
ContentHandlerFactory Controla la creación de un único ContentHandler
Direct Known Subclasses:
hypergraph.applications.hexplorer.ContentHandlerFact
ory
CSSColourParser Analizador sintáctico de colores
DefaultLexicalHandler Implementación de LexicalHandler
ANEXO I
98
All Implemented Interfaces:
org.xml.sax.ext.LexicalHandler, LexicalHandler
GraphMLContentHandl
er
Crea las componentes de un grafo a partir de un archivo XML
que sigue la definición de tipo de documento graphml.dtd
All Implemented Interfaces:
org.xml.sax.ContentHandler, ContentHandler,
org.xml.sax.DTDHandler, org.xml.sax.EntityResolver,
org.xml.sax.ErrorHandler
GraphMLWriter Escribe un grafo en formato XML siguiendo la definición de
tipo de documento graphml.dtd
All Implemented Interfaces:
GraphWriter
extends AbstractGraphWriter
GraphXMLContentHan
dler
Crea las componentes de un grafo a partir de un archivo XML
que sigue la definición de tipo de documento GraphXML.dtd
All Implemented Interfaces:
org.xml.sax.ContentHandler, ContentHandler,
org.xml.sax.DTDHandler, org.xml.sax.EntityResolver,
org.xml.sax.ErrorHandler
Direct Known Subclasses:
hypergraph.applications.hexplorer.GraphXMLContent
Handler
GraphXMLWriter Escribe un grafo en formato XML siguiendo la definición de
tipo de documento GraphXML.dtd
All Implemented Interfaces:
GraphWriter
extends AbstractGraphWriter
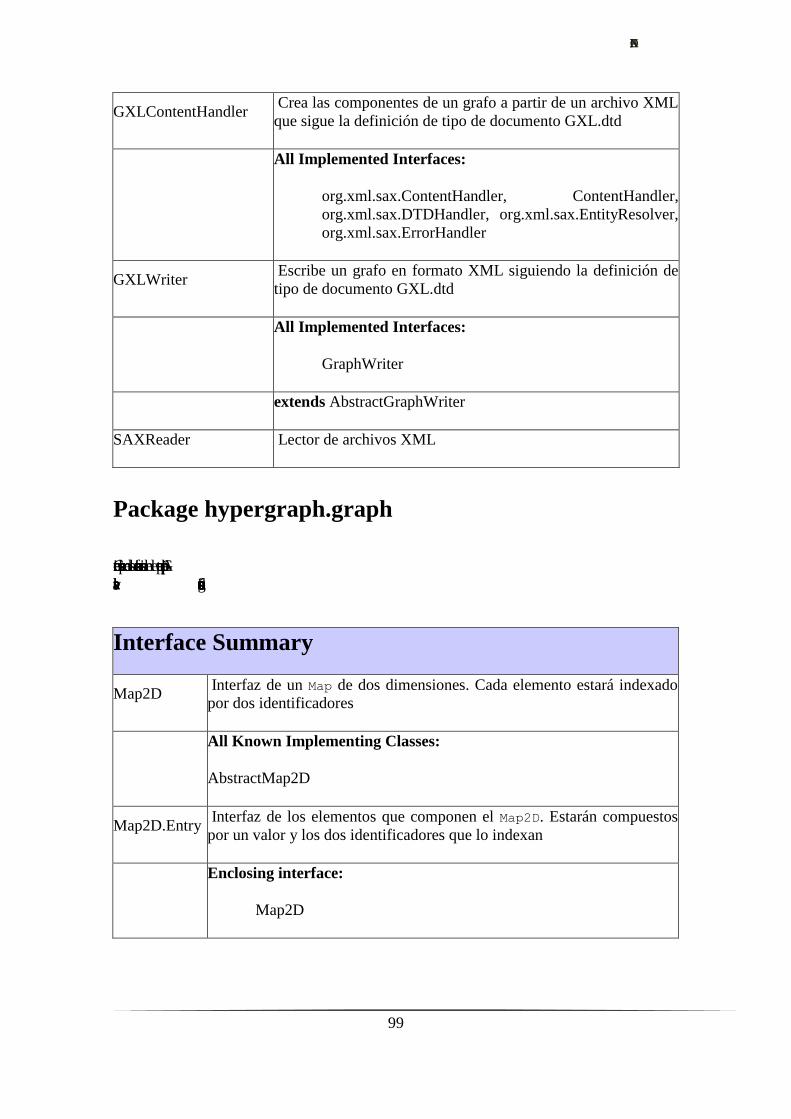
ANEXO I
99
GXLContentHandler Crea las componentes de un grafo a partir de un archivo XML
que sigue la definición de tipo de documento GXL.dtd
All Implemented Interfaces:
org.xml.sax.ContentHandler, ContentHandler,
org.xml.sax.DTDHandler, org.xml.sax.EntityResolver,
org.xml.sax.ErrorHandler
GXLWriter Escribe un grafo en formato XML siguiendo la definición de
tipo de documento GXL.dtd
All Implemented Interfaces:
GraphWriter
extends AbstractGraphWriter
SAXReader Lector de archivos XML
Package hypergraph.graph
Contiene implementaciones de las interfaces contenidas en el paquete GraphApi,
relativas a la construcción de un grafo
Interface Summary
Map2D Interfaz de un Map de dos dimensiones. Cada elemento estará indexado
por dos identificadores
All Known Implementing Classes:
AbstractMap2D
Map2D.Entry Interfaz de los elementos que componen el Map2D. Estarán compuestos
por un valor y los dos identificadores que lo indexan
Enclosing interface:
Map2D
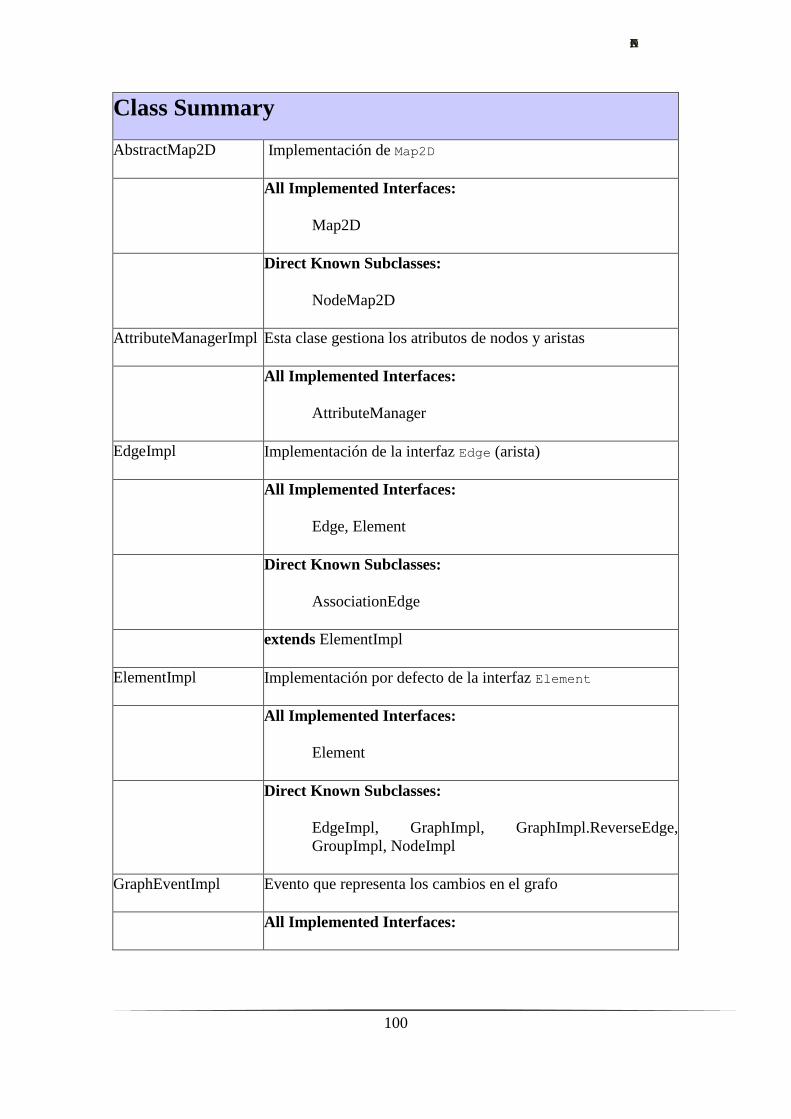
ANEXO I
100
Class Summary
AbstractMap2D Implementación de Map2D
All Implemented Interfaces:
Map2D
Direct Known Subclasses:
NodeMap2D
AttributeManagerImpl Esta clase gestiona los atributos de nodos y aristas
All Implemented Interfaces:
AttributeManager
EdgeImpl Implementación de la interfaz Edge (arista)
All Implemented Interfaces:
Edge, Element
Direct Known Subclasses:
AssociationEdge
extends ElementImpl
ElementImpl Implementación por defecto de la interfaz Element
All Implemented Interfaces:
Element
Direct Known Subclasses:
EdgeImpl, GraphImpl, GraphImpl.ReverseEdge,
GroupImpl, NodeImpl
GraphEventImpl Evento que representa los cambios en el grafo
All Implemented Interfaces:
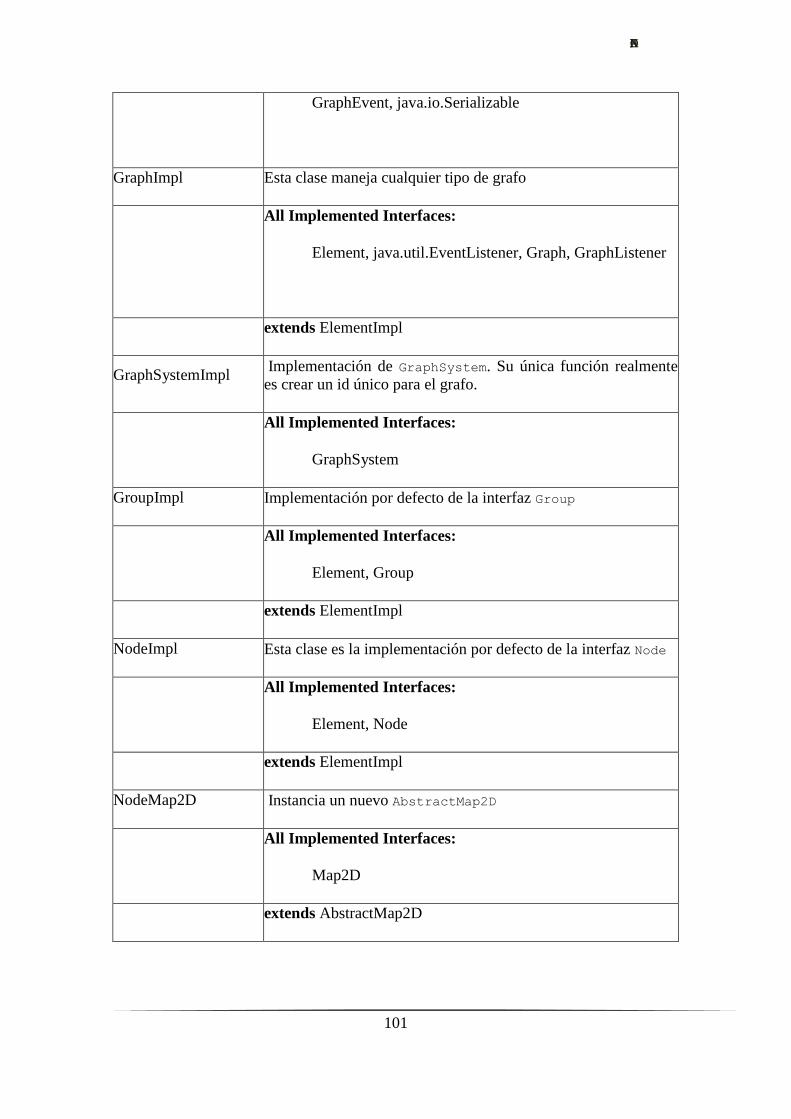
ANEXO I
101
GraphEvent, java.io.Serializable
GraphImpl Esta clase maneja cualquier tipo de grafo
All Implemented Interfaces:
Element, java.util.EventListener, Graph, GraphListener
extends ElementImpl
GraphSystemImpl Implementación de GraphSystem. Su única función realmente
es crear un id único para el grafo.
All Implemented Interfaces:
GraphSystem
GroupImpl Implementación por defecto de la interfaz Group
All Implemented Interfaces:
Element, Group
extends ElementImpl
NodeImpl Esta clase es la implementación por defecto de la interfaz Node
All Implemented Interfaces:
Element, Node
extends ElementImpl
NodeMap2D Instancia un nuevo AbstractMap2D
All Implemented Interfaces:
Map2D
extends AbstractMap2D
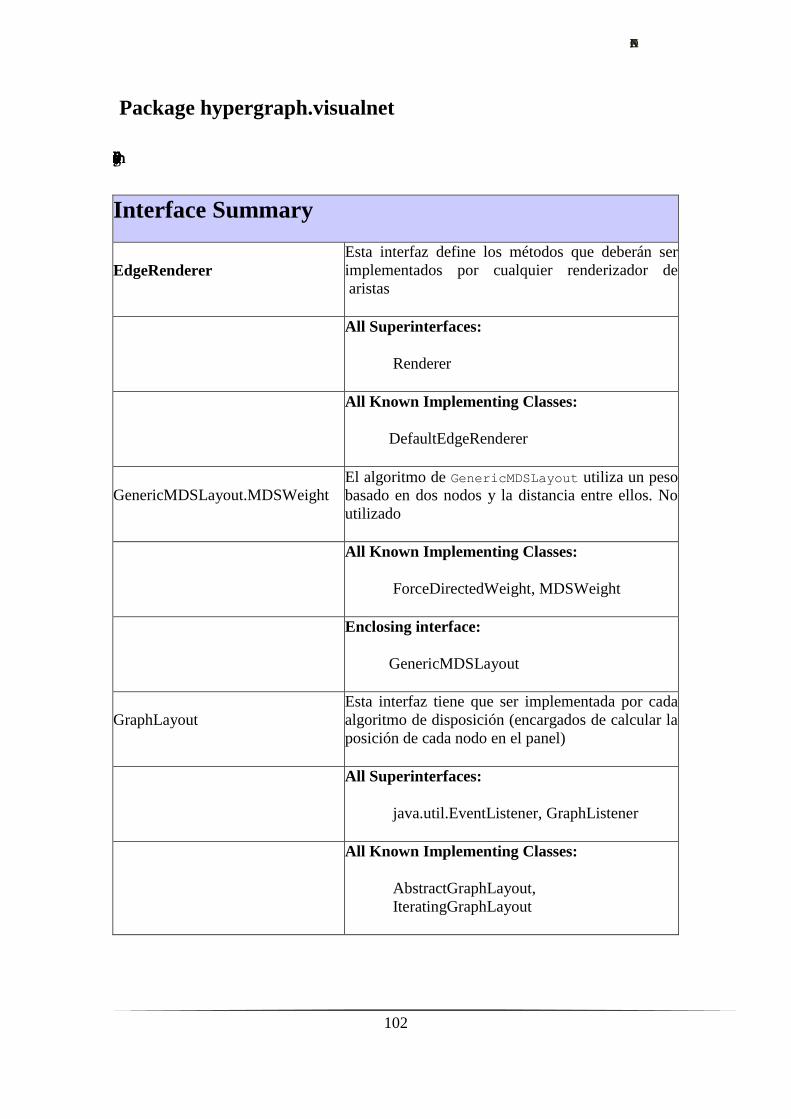
ANEXO I
102
Package hypergraph.visualnet
Permite definir la visualización de los elementos del grafo, tales como nodos y aristas
Interface Summary
EdgeRenderer
Esta interfaz define los métodos que deberán ser
implementados por cualquier renderizador de
aristas
All Superinterfaces:
Renderer
All Known Implementing Classes:
DefaultEdgeRenderer
GenericMDSLayout.MDSWeight El algoritmo de GenericMDSLayout utiliza un peso
basado en dos nodos y la distancia entre ellos. No
utilizado
All Known Implementing Classes:
ForceDirectedWeight, MDSWeight
Enclosing interface:
GenericMDSLayout
GraphLayout
Esta interfaz tiene que ser implementada por cada
algoritmo de disposición (encargados de calcular la
posición de cada nodo en el panel)
All Superinterfaces:
java.util.EventListener, GraphListener
All Known Implementing Classes:
AbstractGraphLayout,
IteratingGraphLayout
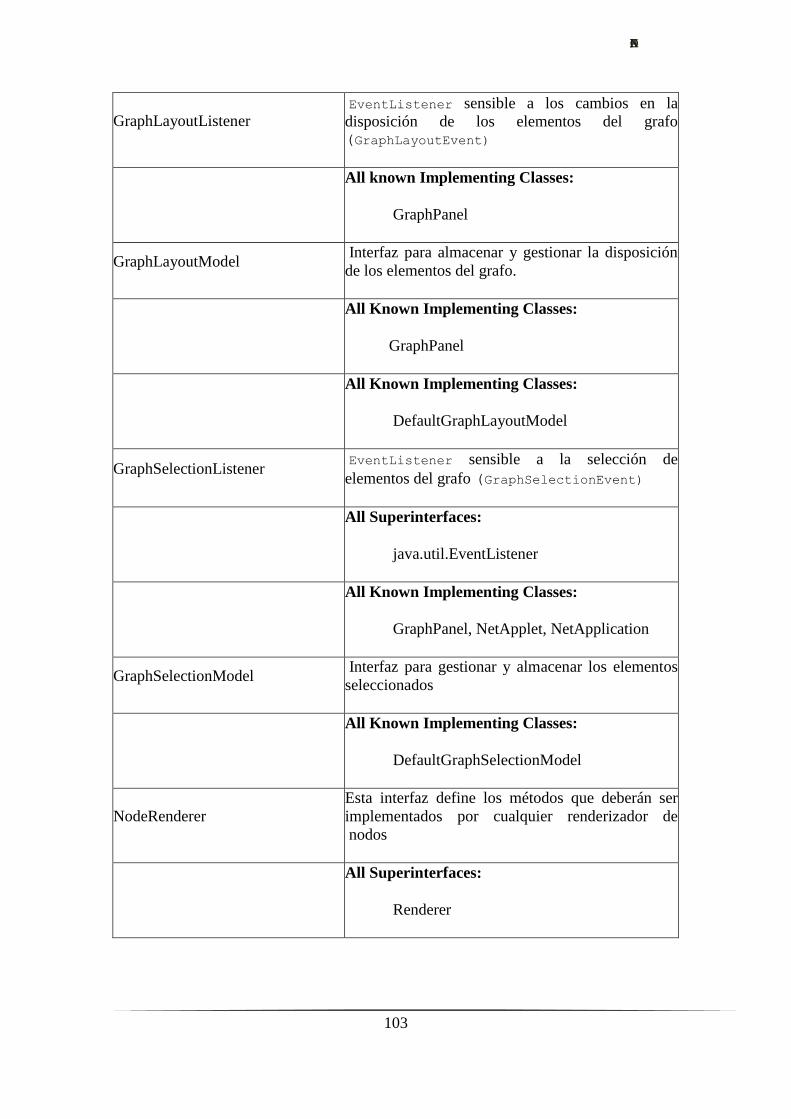
ANEXO I
103
GraphLayoutListener EventListener sensible a los cambios en la
disposición de los elementos del grafo (GraphLayoutEvent)
All known Implementing Classes:
GraphPanel
GraphLayoutModel Interfaz para almacenar y gestionar la disposición
de los elementos del grafo.
All Known Implementing Classes:
GraphPanel
All Known Implementing Classes:
DefaultGraphLayoutModel
GraphSelectionListener EventListener sensible a la selección de
elementos del grafo (GraphSelectionEvent)
All Superinterfaces:
java.util.EventListener
All Known Implementing Classes:
GraphPanel, NetApplet, NetApplication
GraphSelectionModel Interfaz para gestionar y almacenar los elementos
seleccionados
All Known Implementing Classes:
DefaultGraphSelectionModel
NodeRenderer
Esta interfaz define los métodos que deberán ser
implementados por cualquier renderizador de
nodos
All Superinterfaces:
Renderer
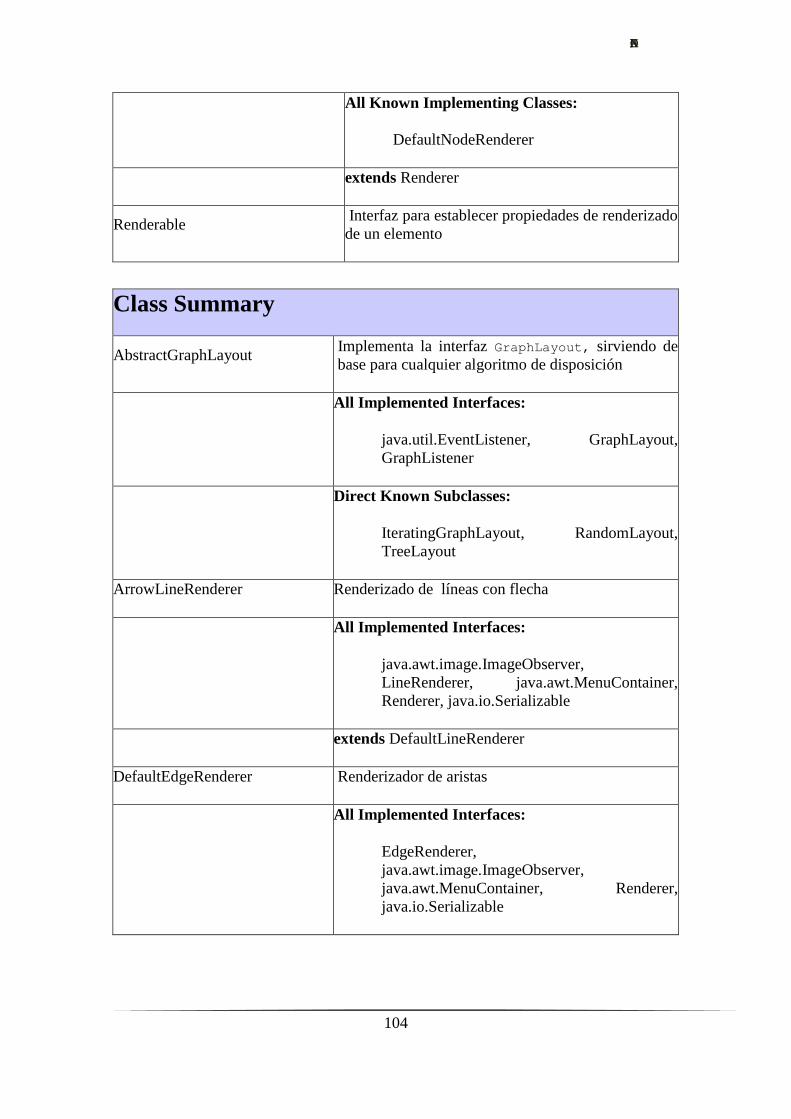
ANEXO I
104
All Known Implementing Classes:
DefaultNodeRenderer
extends Renderer
Renderable Interfaz para establecer propiedades de renderizado
de un elemento
Class Summary
AbstractGraphLayout Implementa la interfaz GraphLayout, sirviendo de
base para cualquier algoritmo de disposición
All Implemented Interfaces:
java.util.EventListener, GraphLayout,
GraphListener
Direct Known Subclasses:
IteratingGraphLayout, RandomLayout,
TreeLayout
ArrowLineRenderer Renderizado de líneas con flecha
All Implemented Interfaces:
java.awt.image.ImageObserver,
LineRenderer, java.awt.MenuContainer,
Renderer, java.io.Serializable
extends DefaultLineRenderer
DefaultEdgeRenderer Renderizador de aristas
All Implemented Interfaces:
EdgeRenderer,
java.awt.image.ImageObserver,
java.awt.MenuContainer, Renderer,
java.io.Serializable
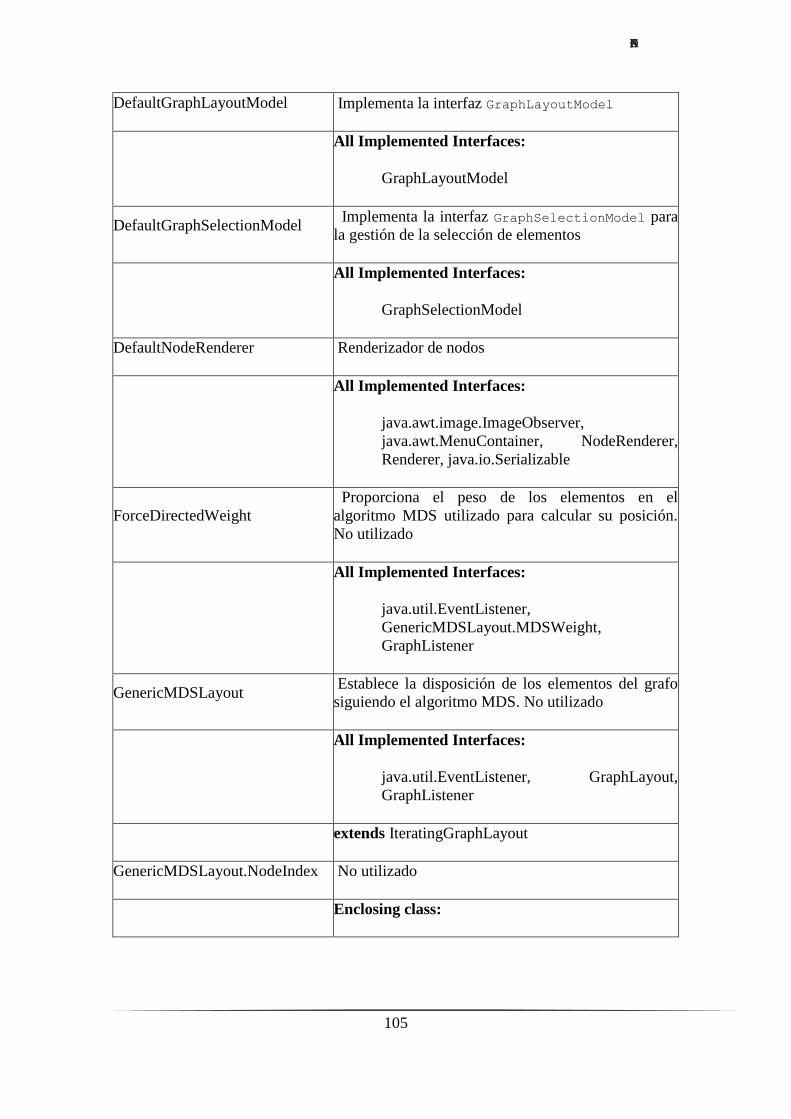
ANEXO I
105
DefaultGraphLayoutModel Implementa la interfaz GraphLayoutModel
All Implemented Interfaces:
GraphLayoutModel
DefaultGraphSelectionModel Implementa la interfaz GraphSelectionModel para
la gestión de la selección de elementos
All Implemented Interfaces:
GraphSelectionModel
DefaultNodeRenderer Renderizador de nodos
All Implemented Interfaces:
java.awt.image.ImageObserver,
java.awt.MenuContainer, NodeRenderer,
Renderer, java.io.Serializable
ForceDirectedWeight
Proporciona el peso de los elementos en el
algoritmo MDS utilizado para calcular su posición.
No utilizado
All Implemented Interfaces:
java.util.EventListener,
GenericMDSLayout.MDSWeight,
GraphListener
GenericMDSLayout Establece la disposición de los elementos del grafo
siguiendo el algoritmo MDS. No utilizado
All Implemented Interfaces:
java.util.EventListener, GraphLayout,
GraphListener
extends IteratingGraphLayout
GenericMDSLayout.NodeIndex No utilizado
Enclosing class:
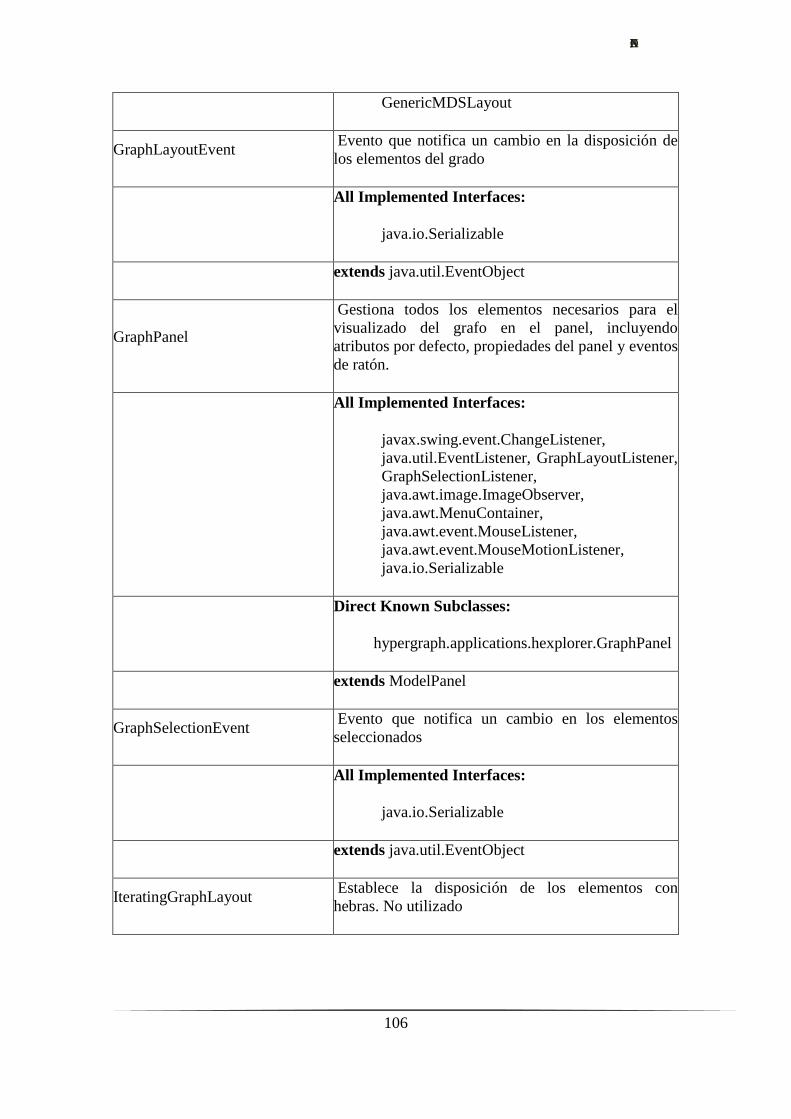
ANEXO I
106
GenericMDSLayout
GraphLayoutEvent Evento que notifica un cambio en la disposición de
los elementos del grado
All Implemented Interfaces:
java.io.Serializable
extends java.util.EventObject
GraphPanel
Gestiona todos los elementos necesarios para el
visualizado del grafo en el panel, incluyendo
atributos por defecto, propiedades del panel y eventos
de ratón.
All Implemented Interfaces:
javax.swing.event.ChangeListener,
java.util.EventListener, GraphLayoutListener,
GraphSelectionListener,
java.awt.image.ImageObserver,
java.awt.MenuContainer,
java.awt.event.MouseListener,
java.awt.event.MouseMotionListener,
java.io.Serializable
Direct Known Subclasses:
hypergraph.applications.hexplorer.GraphPanel
extends ModelPanel
GraphSelectionEvent Evento que notifica un cambio en los elementos
seleccionados
All Implemented Interfaces:
java.io.Serializable
extends java.util.EventObject
IteratingGraphLayout Establece la disposición de los elementos con
hebras. No utilizado
ANEXO I
107
All Implemented Interfaces:
java.util.EventListener, GraphLayout,
GraphListener
Direct Known Subclasses:
GenericMDSLayout
extends AbstractGraphLayout
MDSWeight Proporciona el peso de los elementos en el algoritmo
MDS utilizado para calcular su posición. No utilizado
All Implemented Interfaces:
java.util.EventListener,
GenericMDSLayout.MDSWeight,
GraphListener
RandomLayout Dispone los nodos de un grafo de forma aleatoria.
No utilizado
All Implemented Interfaces:
java.util.EventListener, GraphLayout,
GraphListener
extends AbstractGraphLayout
SearchDialog No utilizado
SearchListModel No utilizado
TreeLayout Establece la disposición de los nodos de un grafo a
partir de su árbol de expansión
All Implemented Interfaces:
java.util.EventListener, GraphLayout,
GraphListener
extends AbstractGraphLayout
ANEXO I
108
Package hypergraph.applications.hexplorer
Contiene todas las clases que se comunican con el entorno web en el que se integra el
applet
Class Summary
ContentHandlerFactory Extiende a ContentHandlerFactory para utilizar el
GraphXMLContentHandler de application.hexplorer
extends ContentHandlerFactory
GraphPanel
Define y gestiona las características específicas del
panel a mostrar del Applet que se visualiza en el
explorador.
All Implemented Interfaces:
javax.swing.event.ChangeListener,
java.util.EventListener, GraphLayoutListener,
GraphSelectionListener,
java.awt.image.ImageObserver,
java.awt.MenuContainer,
java.awt.event.MouseListener,
java.awt.event.MouseMotionListener,
java.io.Serializable
extends GraphPanel
GraphXMLContentHandler
Extiende a GraphXMLContentHandler de
GraphApi.io. Recoge un mayor número de
propiedades asignables a los elementos creados,
permitiendo su atribución a grupos.
All Implemented Interfaces:
org.xml.sax.ContentHandler, ContentHandler,
org.xml.sax.DTDHandler,
org.xml.sax.EntityResolver,
org.xml.sax.ErrorHandler

ANEXO I
109
extends GraphXMLContentHandler
HExplorerApplet Hereda de JApplet, sobrescribe el método init()
All Implemented Interfaces:
javax.accessibility.Accessible,
java.awt.image.ImageObserver,
java.awt.MenuContainer,
javax.swing.RootPaneContainer,
java.io.Serializable
extends javax.swing.JApplet
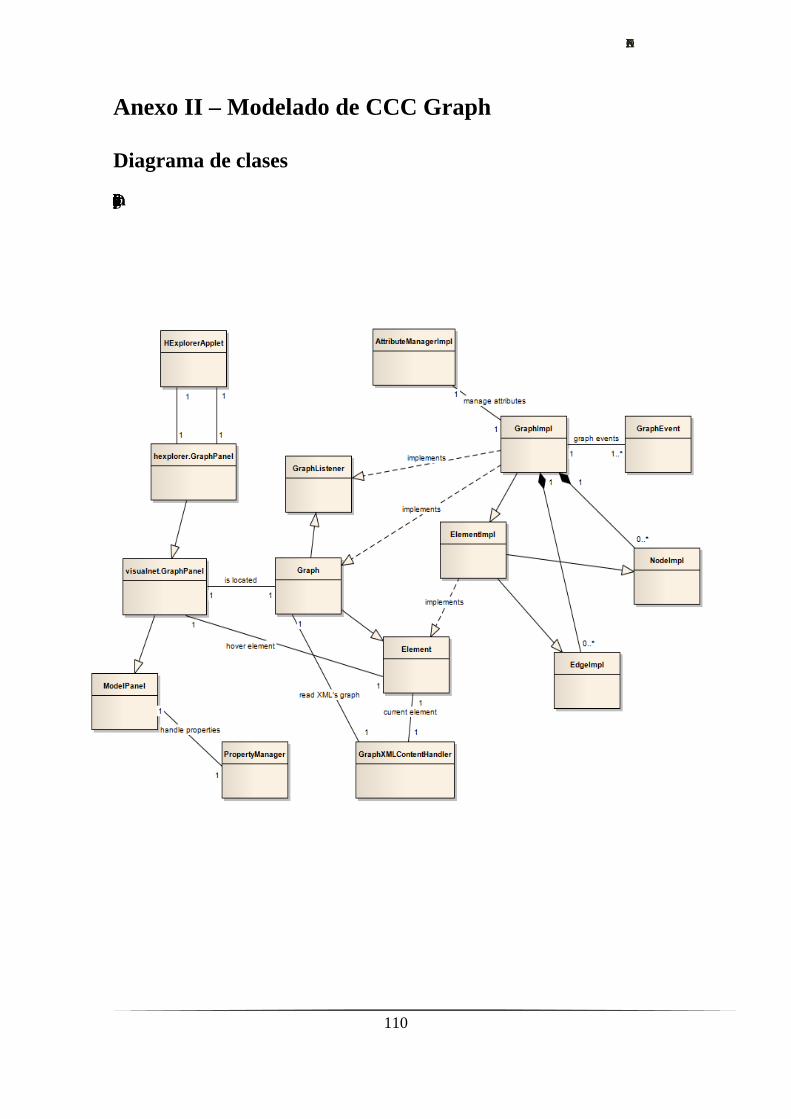
ANEXO II
110
Anexo II – Modelado de CCC Graph
Diagrama de clases
Diagrama de clases simplificado, incluye las clases más importantes y sus relaciones.
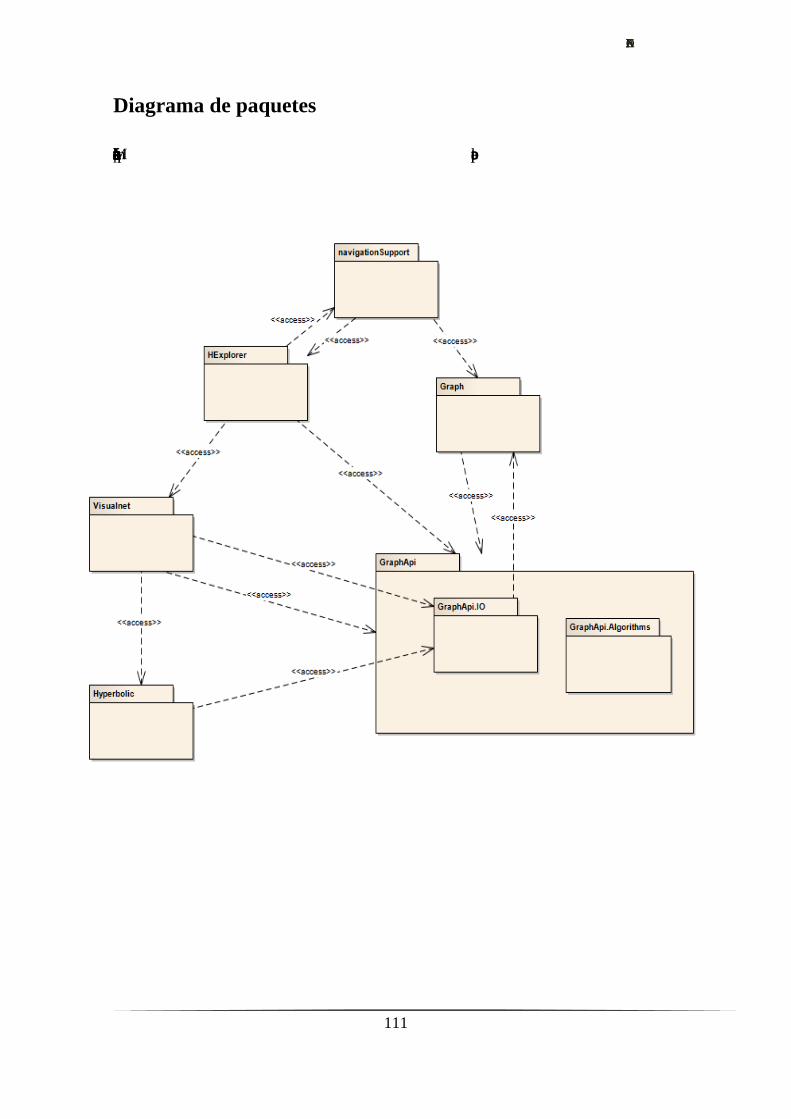
ANEXO II
111
Diagrama de paquetes
Muestra la interacción entre los paquetes que forman el applet

ANEXO III
112
Anexo III – Algoritmos de extracción de la EC
Versión 1
Extraemos la lista de relaciones node_reference y taxonomia
existentes, lnr y lnt respectivamente
(tablas content_node_field_instance y content_node_field)
Para cada tipo de relacion r de lnr
Si r.cardinalidad = 0 //uno
Para cada tupla de content_type_nombretipocontenido
listaRel.AñadirRelacion("nombrer", source=nid,
target=field_nombrer_nid)
Si r.cardinalidad = 1 //multiple
Para cada tupla de content_field_nombretipocontenido
listaRel.AñadirRelacion("nombrer", source=nid,
target=field_nombrer_nid)
Para cada tipo de relacion r de lnt
Si r.cardinalidad = 0 //uno
Para cada tupla de content_type_nombretipocontenido
listaTerm.AñadirTerm(nodo=nid, term=field_nombrer_value)
Si r.cardinalidad = 1 //multiple
Para cada tupla de content_field_nombretipocontenido
listaTerm.AñadirTerm(nodo=nid, term=field_nombrer_value)
Para cada lt de listaTerm
Para cada lt2 desde lt.posicion hasta listaTerm.size
Si lt.term=lt2.term
listaRel.AñadirRelacion(taxonomia, source=lt.nodo,
target=lt2.nodo)
Versión 2
Extraemos la lista de relaciones node_reference y taxonomia
existentes, lnr y lnt respectivamente
(tablas content_node_field_instance y content_node_field)
procesado=nodo_actual
Mientras nivel<=niveles_max and no_visitados>visitados
Para cada tipo de relacion r de lnr
Si r.cardinalidad = 0 //uno
Para cada tupla de content_type_nombretipocontenido
Si nid = procesado
listaRel.AñadirRelacion("nombrer", source=procesado,
target=field_nombrer_nid)
no_visitados.Incluir(field_nombrer_nid)

ANEXO III
113
Sino si field_nombrer_nid = procesado
listaRel.AñadirRelacion("nombrer",
source=nid, target=procesado)
no_visitados.Incluir(field_nombrer_nid)
Si r.cardinalidad = 1 //multiple
Para cada tupla de
content_field_nombretipocontenido
Si field_nombrer_nid != procesado
listaRel.AñadirRelacion("nombrer",
source=procesado, target=field_nombrer_nid)
no_visitados.Incluir(field_nombrer_nid)
Sino si field_nombrer_nid = procesado
listaRel.AñadirRelacion("nombrer",
source=nid, target=procesado)
no_visitados.Incluir(field_nombrer_nid)
Para cada tipo de relacion r de lnt
Si r.cardinalidad = 0 //uno
Para cada tupla de content_type_nombretipocontenido
Si nid = procesado
listaTerm.AñadirTermino(term=field_nombrer_value)
Si r.cardinalidad = 1 //multiple
Para cada tupla de content_field_nombretipocontenido
Si nid = procesado
listaTerm.AñadirTermino(term=field_nombrer_value)
Para cada tipo de relacion r de lnt
Si r.cardinalidad = 0 //uno
Para cada tupla de content_type_nombretipocontenido
con nid != procesado
Si listaTerm.Contiene(field_nombrer_value)
listaTerm.AñadirRelacion("nombrer",
source=procesado, target=nid)
no_visitados.Incluir(nid)
Si r.cardinalidad = 1 //multiple
Para cada tupla de content_field_nombretipocontenido
con nid != procesado
Si listaTerm.Contiene(field_nombrer_value)
listaTerm.AñadirRelacion("nombrer",
source=procesado, target=nid)
no_visitados.Incluir(nid)
visitados.Incluir(procesado)

ANEXO III
114
Versión final
Extraemos la lista de relaciones node_reference y taxonomia
seleccionadas por el administrador, lnrs y lnts respectivamente
(tabla variable, campos cccgraph_visible_nodereferences y
cccgraph_visible_taxonomies)
procesado=nodo_actual
Mientras nivel<=niveles_max and no_visitados>visitados
Para cada tipo de relacion r de lnrs
Si r.cardinalidad = 0 //uno
Para cada tupla de content_type_nombretipocontenido
Si nid = procesado
listaRel.AñadirRelacion("nombrer", source=procesado,
target=field_nombrer_nid)
no_visitados.Incluir(field_nombrer_nid)
Sino si field_nombrer_nid = procesado
listaRel.AñadirRelacion("nombrer",
source=nid, target=procesado)
no_visitados.Incluir(field_nombrer_nid)
Si r.cardinalidad = 1 //multiple
Para cada tupla de
content_field_nombretipocontenido
Si field_nombrer_nid != procesado
listaRel.AñadirRelacion("nombrer",
source=procesado, target=field_nombrer_nid)
no_visitados.Incluir(field_nombrer_nid)
Sino si field_nombrer_nid = procesado
listaRel.AñadirRelacion("nombrer",
source=nid, target=procesado)
no_visitados.Incluir(field_nombrer_nid)
Para cada tipo de relacion r de lnts
Si r.cardinalidad = 0 //uno
Para cada tupla de content_type_nombretipocontenido
Si nid = procesado
listaTerm.AñadirTermino(term=field_nombrer_value)
Si r.cardinalidad = 1 //multiple
Para cada tupla de content_field_nombretipocontenido
Si nid = procesado
listaTerm.AñadirTermino(term=field_nombrer_value)
Para cada tipo de relacion r de lnts
Si r.cardinalidad = 0 //uno

ANEXO III
115
Para cada tupla de content_type_nombretipocontenido
con nid != procesado
Si listaTerm.Contiene(field_nombrer_value)
listaTerm.AñadirRelacion("nombrer",
source=procesado, target=nid)
no_visitados.Incluir(nid)
Si r.cardinalidad = 1 //multiple
Para cada tupla de content_field_nombretipocontenido
con nid != procesado
Si listaTerm.Contiene(field_nombrer_value)
listaTerm.AñadirRelacion("nombrer",
source=procesado, target=nid)
no_visitados.Incluir(nid)
visitados.Incluir(procesado)

ANEXO IV
116
Anexo IV – Instalación
En este anexo procederemos a exponer los pasos a seguir para utilizar el software
desarrollado.
Al estar diseñada la aplicación para su funcionamiento como módulo de Drupal, es
necesario, en primer lugar, disponer de un sitio web construido sobre este CMS. En caso
de tener un sitio en funcionamiento, puede pasar directamente al punto 1.2. Instalación
de CCC-Graph.
Si lo que desea es probar el funcionamiento y utilización de CCC-Graph puede dirigirse
directamente al punto 2, “Guía de instalación rápida”, donde podrá hacer uso del
módulo, ya instalado y configurado, sobre un sitio web de prueba.
1. Instalación completa
1.1. Instalación de Drupal
En [24] podemos encontrar todos los aspectos a tener en cuenta, y pasos a seguir, para
llevar a cabo la instalación de un sitio web en Drupal desde cero.
Requisitos mínimos
1. Un servidor web que ejecute scripts PHP.
Recomendado: Apache.
2. PHP
Al igual que Drupal 4.2, se requiere la versión 4.1 o superior de PHP.
3. Un servidor de base de datos soportado por PHP
Recomendado: MySQL v3.23.17 o superior
Podemos instalar Drupal de una forma rápida y sencilla si preparamos un entorno AMP
(Apache, MySQL y PHP). Para ello nos puede ser bastante utilidad el paquete Xampp
[25].
1.2. Instalación de CCC-Graph
Debe seguir el método de instalación ordinario de módulos en Drupal.
1. Copie la carpeta del módulo (/Código fuente/cccgraph) en la carpeta modules.
2. Diríjase a la sección Administer > Modules, seleccione el módulo que acaba de
agregar y guarde los cambios para proceder a su activación.

ANEXO IV
117
Configuración
1. Diríjase al apartado Administer > Blocks para seleccionar la posición que
ocupará el bloque contenedor del applet “Applet CCC-Graph ” dentro del sitio.
2. Active y seleccione el lugar que desee que ocupe el bloque “CCC-Graph” con el
menú de configuración del módulo
3. Acceda al menú CCC-Graph, dentro del bloque que acaba de añadir, para
personalizar los aspectos de la configuración general del applet, tales como
altura y anchura, que facilitan la adaptación al conjunto estético del sitio.
4. Dentro del submenú CCC-Graph > Administer avaiable content, seleccione los
campos (tipo node reference y taxonomía) y tipos de contenido, indicando el
color con el que serán representados, que se incluirán como parte de la estructura
conceptual del sitio y serán representados en forma de nodos y relaciones en el
grafo. Este paso se considera como imprescindible ya que todos los elementos
del sitio se encuentran fuera de la estructura conceptual por defecto.
2. Guía de instalación rápida
Para facilitar la instalación de CCC-Graph se proporciona una versión portable de
XAMPP que contiene una copia del sitio web CCC-Ética Informática con el módulo
instalado y configurado, listo para usarse.
Se han de seguir estos pasos:
1. Copia la carpeta xampp (ubicada en la carpeta CCC-Graph) al disco duro.
2. Ejecuta el fichero setup_xampp.
3. Selecciona la opción 1 (Refresh Now)
4. Introduce la dirección localhost/drupal
5. Para registrarse como administrador utilizar:
usuario: etica_admin
password: etica_admin
Para registrarse como usuario normal:
usuario: usuario1
password: usuario1
6. Ya puede disfrutar de la aplicación

ANEXO V
118
Anexo V – Guía de uso
Tras la instalación del módulo y la elección de los elementos pertenecientes a la
estructura conceptual, con su color de representación, ya puede proceder a la utilización
del grafo.
Resumiremos las pautas generales de su uso y funcionamiento.
Usuarios
Al instalarse el módulo quedarán definidos dos tipos de permisos 'access cccgraph' y
'administer cccgraph' asignados, por defecto, a los usuarios registrados y al usuario
administrador respectivamente.
Para poder visualizar el applet los usuarios deberán pertenecer, al menos, al primer
grupo.
Configuración del módulo
El permiso 'access cccgraph' les permitirá, además, acceder al menú principal de
configuración del módulo, pudiendo modificar:
Levels of the graph. El número de niveles de profundidad a partir del nodo
actual (página en la que se encuentra situado el usuario) que serán mostrados.
Central node color. Color del nodo actual.
Central node text color. Color de la etiqueta del nodo actual.
Navegación con el grafo
Las principales funcionalidades que presenta el applet para la navegación del grafo son:
Exploración del grafo mediante el arrastre de ratón con el botón izquierdo.
Clic izquierdo sobre nodo, dirige a la página que representa.
Clic izquierdo sobre punto sin contenido, centra la visualización del applet sobre
el punto seleccionado.
Clic derecho, muestra el menú contextual.
Colocación del cursor sobre arista, muestra el nombre de la relación.
Colocación del cursor sobre nodo, muestra el nombre de todas sus relaciones.

ANEXO V
119
Filtrado de relaciones
La selección de la opción “Seleccionar relaciones” en el menú contextual mostrará el
formulario de filtrado de relaciones.
El cuadro “¿Qué relación buscas?” permitirá localizar un tipo de relación por su
nombre.
El filtrado de relaciones no se hará efectivo hasta que sea seleccionado el botón
Aceptar.
Se permite la selección de varias relaciones para su traspaso en ambos sentidos.

REFERENCIAS
120
Referencias
[1] José Marcos Moreno Cabrera. “Un enfoque ético-tecnológico de los mecanismos de
persuasión publicitaria en la Red y su modelado en SEM-HP”. Proyecto Fin Carrera,
2009
[2] Medina Medina, N; García Cabrera, Lina; Rodríguez Fortiz, M. J.; Parets Llorca, J.
“Adaptación al Usuario de Sistemas Hipermedia: El Modelo SEM-HP”. Dep. LSI,
Universidad de Granada; Dep. Informática, Universidad de Jaén, 2002;
[3] Medina Medina, N. “Un Modelo de Adaptación Integral y Evolutivo para Sistemas
Hipermedia”. Tesis Doctoral, 2004.
[4] García Cabrera L. “SEM-HP: Un Modelo Sistémico, Evolutivo y Semántico para el
desarrollo de Sistemas Hipermedia”. Tesis Doctoral, 2001.
[5] García-Cabrera, L, Parets-Llorca, J. “A Cognitive Model for Adaptive
Hypermedia Systems”. The 1st International Conference on WISE, Workshop on
World Wide Web Semantics. June 2000. Hong-Kong, China.
[6] Hypergraph: “hyperbolic graphs and trees”
http://hypergraph.sourceforge.net/index.html
[7] I. Herman, M.S. Marshall: “GraphXML -- An XML based graph interchange
format”. Centrum voor Wiskunde en Informatica. INS-R0009 April 30, 2000
[8] Integration of Java hyperbolic tree geometry visualization
http://vacilando.org/en/article/hypergraph
[9] “Desarrollo en espiral”. Wikipedia
http://es.wikipedia.org/wiki/Desarrollo_en_espiral
[10] Boehm, B.W. “A Spiral Model of Software Development and Enhacement”. IEE
Computer, volumen 21(5). Mayo 1988.
[11] “Does Session use Cookies?”. ASP.NET Forums http://forums.asp.net/t/1466982.aspx?Does+Session+use+Cookies+
[12] “Configuración en tiempo de ejecución”. php.net
http://www.php.net/manual/es/session.configuration.php
[13] “Sistemas hipermedia en la educación”. Nelson Ubaldo Quispe Mamani,
Monografías.com
http://www.monografias.com/trabajos96/sistemas-hipermedia-educacion/sistemas-
hipermedia-educacion.shtml#hipermedia#ixzz2x0I9rLTz

REFERENCIAS
121
[14] Ley 34/2002, de 11 de julio, de servicios de la sociedad de la información y de
comercio electrónico. Artículo 22.
[15] Hypergraph: “Groups of graph elements”
http://hypergraph.sourceforge.net/grouping.html
[16] Hypergraph: “Installation”
http://hypergraph.sourceforge.net/installation.html
[17] “Writing .install files”. Drupal.org
https://drupal.org/node/51220
[18] “Creating a basic Form with Drupal 7”. Jose Luis Bellido, joseluisbellido.net. 2013
http://joseluisbellido.net/creating-a-basic-form-with-drupal-7/
[19] “Function hook_menu”. Drupal.org
https://api.drupal.org/api/drupal/developer%21hooks%21core.php/function/hook_menu/
6
[20] “Formularios avanzados en Drupal 7 usando #states”. Jose Luis Bellido,
joseluisbellido.net. 2013
http://joseluisbellido.net/formularios-avanzados-en-drupal-7-usando-states/
[21] “Form API reference”. Drupal.org
https://api.drupal.org/api/drupal/developer!topics!forms_api_reference.html/6
[22] “Cómo crear un menu item básico en Drupal 7”. Jose Luis Bellido,
joseluisbellido.net. 2013
http://joseluisbellido.net/como-crear-un-menu-item-basico-en-drupal-7/
[23] “Blocks”. Drupal.org
https://drupal.org/documentation/blocks
[24] “Instalación y configuración de Drupal”. Drupal.org
http://drupal.org.es/manuales/manual_del_administrador
[25] “Download XAMPP”. Apachefriends.org
https://www.apachefriends.org/download.html
[26] “CCC-Ética Informática”
http://lsi.ugr.es/etica/es