apuntes de sistemas operativos distribuidos¿qué“mejoras de prestaciones”seespera conseguir?...
TRANSCRIPT

Apuntes de Sistemas Operativos DistribuidosApuntes de Sistemas Operativos Distribuidos
Autor: Fabio E. Rivalta / Carlos NeetzelMaterial: dictado de clasesTema: Procesamiento distribuidoFecha: 04/2007
Bibliografía utilizada:• Apuntes de sistemas operativos distribuidos - Carlos Neetzel• Sistemas operativos distribuidos – Andrew S. Tanenbaum• Sistemas Distribuidos – George Coulouris y otros• Apuntes de Internet (ver referencias para mayor detalle
Versión
Prel
imina
r

Procesamiento en sistemas mono-procesadorEn Sistemas Operativos convencionales se trata de la forma de compartir el (único) procesador del computador entre los procesos que han sido sometidos al sistema.
En Sistemas Distribuidos o multi-procesadores:El objetivo buscado es hacer el mejor uso posible de “todos” los recursos de procesamiento del sistema, lo que implica no solo controlar y suministrarle trabajos a un procesador que se encuentra “localmente” en la máquina que está tomando la decisión, sino que hay que brindarles trabajos a todos los otros procesadores “locales o remotos” que componen el sistema de procesamiento distribuido.
Objetivo buscado:El objetivo que debe tener cualquier planificador de procesos de SD es el de realizar la asignación de los trabajos de los usuarios utilizando los distintos procesadores con los que cuenta el sistema, con el objetivo de mejorar las prestaciones frente a la solución tradicional.
Versión
Prel
imina
r

¿Qué “mejoras de prestaciones” se espera conseguir?Las posibles mejoras que se buscan obtener mediante el procesamiento distribuido pueden estar divididas dependiendo del tipo de sistema que se construye, teniendo cada uno de ellos diferentes ventajas (y por supuesto sus desventajas atareadas).
Tipología de sistemas:• Sistemas de alta disponibilidad
• HAS: High Availability Systems• Que el servicio siempre esté operativo• Tolerancia a fallos
• Sistemas de alto rendimiento• HPC: High Performance Computing• Que se alcance una potencia de cómputo mayor• Ejecución de trabajos pesados en menor tiempo
• Sistemas de alto aprovechamiento• HTS: High Troughput Systems• Que el número de tareas servidas sea el máximo posible• Maximizar el uso de los recursos o servir a más clientes• Disminuir los costos comprarándolo con sistemas centralizados de similares
características de desempeñoVersión
Prel
imina
r

Dos preguntas significativas con respecto al los sistemas distribuidos que se pueden construir:
¿Qué arquitecturas hardware se pueden generar?¿Pueden ser compartidas?
• MPP• Son hardware específico de propósito paralelo• No, son instalaciones dedicadas
• Grids• Son hardware de propósito general (incluidas las redes), pero de altas
prestaciones. Se basa en maximizar los recursos ociosos de la red• Si, normalmente son instalaciones compartidas
• Clusters• Hardware de propósito general (pueden poseer redes de comunicaciones
comunes o redes privadas para mejorar las velocidades. • Habitualmente no, aunque no es una limitación, normalmente las
instalaciones son dedicadas y con un fin específico (Ej.: Sistema de correos corporativos, bases de datos, etc.)Vers
ión P
relim
inar

Tipos de cluster que se pueden construir:
• High Performance Clusters• Formados por miles de nodos, se usa para la ejecución de programas paralelos,
normalmente bajo el estandar MPI (Message Passing Interface)• Ejemplo: LAM/MPI Paralell Computing (http://www.lam-mpi.org )
• Load-leveling Clusters• Movimiento de procesos para aprovechar ciclos de CPI • Ejemplo: Open Mosix (http://openmosix.sourceforge.net )
• Web-Service Clusters• Se busca un equilibrio en las conexiones TCP, normalmente se trabaja con datos
replicados• Ejemplo: LVS (http://www.linuxvirtualserver.org )
• Storage Clusters• Sistemas de archivos paralelos. Se tiene una identica visión de los datos desde cada
nodo• Ejemplo: GFS (Global File System) (http://opengfs.sourceforge.net )
• Database Clusters• Servidores para bases de datos muy grandes, tanto en tamaño como en
transacciones.• Ejemplo: RAC (Real application Clusters)
(http://www.oracle.com/lang/es/database/rac_home.html )• High Availability Clusters
• Se prioriza la alta disponibilidad de los servicios brindados por el cluster de procesadores.
• Ejemplos: HP ServiceGuard, Lifekeeper
Versión
Prel
imina
r

Dentro de los métodos de procesamientos que utilizan los SD, existen dos grandes grupos que son denominados:
Load Sharing:• El objetivo buscado es que el estado de los procesadores no tiene que ser
diferente, por lo que la transferencia entre nodos se realiza en forma más continua
Load Balancing:• El objetivo buscado es que la carga de los procesadores sea igual.
Normalmente la carga varía durante la ejecución de un trabajo, por lo que no realiza la transferencia de procesos en forma tan continua
¿Qué diferencias hay?En realidad los dos son conceptos muy similares, gran parte de las estrategias usadas para LS son válidas en LB, pero no se cumple la propiedad inversa.
Versión
Prel
imina
r

Políticas de gestión de trabajos:Toda la gestión de trabajos se basa en una serie de decisiones (políticas) que hay que definir para que el SD pueda funcionar en forma eficiente:
• Política de información: cuándo propagar la información necesaria para la toma de decisiones.
• Bajo demanda: únicamente cuando desea realizar una transferencia.• Periódicas: se recoge información periódicamente, la información está
disponible en el momento de realizar la transferencia (puede estar obsoleta).• Bajo cambio de estado: cada vez que un nodo cambia de estado.• Ámbito de información:
• Completa: todos conocen toda la información del sistema• Parcial: cada nodo conoce la información propia y un nodo centraliza la de todos
(pudiendo ser siempre el mismo o variable)• ¿Qué información se transmite?:
• La carga del nodo: El problema está en determinar ¿qué es la carga?• Se puede definir a la carga de un nodo en diferentes medidas que son tomadas
sobre el estado del procesador y los procesos que en él se están ejecutando o esperando para ser ejecutados. Los valores más comunes son los siguientes:
• %CPU usado en un instante de tiempo (para atender procesos usuarios)• Número de procesos listos para ejecutar (esperando)• Números de fallos de página (swaping)• En caso de que el SD esté formado por nodos heterogéneos se debe
considerar enviar información sobre las capacidades del nodo.Versión
Prel
imina
r

Políticas de gestión de trabajos: (Cont)
• Política de transferencia: decide cuándo se deben transferir procesos de un nodo a otro y cómo se realiza esa transferencia.
• Generalmente, se basa en la política de umbral (cota máxima y cota mínima):
• Si en el nodo S la carga es mayor que T unidades, entonces S emisor de procesos
• Si en nodo S la carga es menor que T unidades, entonces S receptor de procesos
• Tipos de transferencias:• Expulsivas: se pueden transferir procesos ejecutados parcialmente.
Requiere transferir el estado del proceso (denominado migración) o reiniciar su ejecución en el nuevo nodo.
• No expulsivas: los procesos en ejecución no pueden ser transferidos, sólo se transfieren los procesos nuevos.
Versión
Prel
imina
r

Políticas de gestión de trabajos: (Cont)
• Política de selección: decide qué proceso transferir.• Elegir los procesos nuevos (transferencia no expulsiva).• Seleccionar los procesos con un tiempo de transferencia mínimo (poco
estado, mínimo uso de los recursos locales, lo que genera menos carga en la red al momento de realizar la migración).
• Seleccionar un proceso si su tiempo de respuesta estimado en un nodo remoto es menor que el tiempo de respuesta local (es muy difícil de determinar).
Versión
Prel
imina
r

Políticas de gestión de trabajos: (Cont)
• Política de ubicación: decide a qué nodo transferir. Existen diversas políticas que pueden ser resumidas en las siguientes:
• Con Muestreo: consulta a los otros nodos para encontrar el más adecuado para realizar la transferencia
• Sin muestreo: se selecciona un nodo destino en forma aleatoria (no se puede usar en sistemas heterogéneos
• Nodo más próximo: se prioriza la comunicación, por lo que se selecciona el nodo más cercano
• Basada en Broadcast: se envía un mensaje al resto de nodos para ver cual puede recibir el proceso a migrar
• Basada en información recogida anteriormente: en esta categoría se pueden englobar 3 formas de trabajo. Es importante destacar que para esta modalidad de funcionamiento se necesita contar con la información distribuida o con un coordinador central que brinde la información necesaria:
• Iniciadas por el emisor (Push): en este caso un emisor busca receptor (normalmente porque superó su cota máxima del umbral)
• Iniciadas por el receptor (Pull): en este caso un receptor busca emisor (normalmente porque superó su cota mínima del umbral)
• Combinada: es la unión de los dos métodos anteriores ya que tanto el receptor como el emisor pueden ser los que originan la transferencia.Vers
ión P
relim
inar

Asignación de procesadores a procesos distribuidos:
Un sistema distribuido consta de varios procesadores (sino no sería un SD), que se pueden organizar como una colección de estaciones de trabajo personales, una pila pública de procesadores o alguna forma híbrida (para mayor detalle ver módulo 1).
Para poder administrar los procesos y procesadores se necesita contar con un cierto algoritmo para decidir cual proceso hay que ejecutar y en que máquina (o procesador de la misma máquina).
Siempre el tema fundamental a determinar es cuando es conveniente ejecutar el proceso de manera local (aunque tenga una espera mayor que en otro nodo) y cuando buscar una estación inactiva (ya que hay que considerar que existe un tiempo de transferencia del proceso al nuevo nodo).
Las distintas modalidades de asignación de procesos a procesadores (normalmente conocido como la administración del procesador en SD) varían si los nodos integrantes del SD son heterogéneos o no.
Versión
Prel
imina
r

Administración del procesador en SD:
Podemos encontrar dos principales estrategias al momento de generar un proceso• No Migratoria: Al crearse un proceso, se toma una decisión acerca de en que
nodo ejecutarlo. Una vez asignado en una maquina, el proceso permanece ahíhasta que termina. En ésta estrategia un proceso no se puede mover, no importa lo sobrecargada que este la maquina ni que exista muchas otra maquinas inactivas.
• Migratoria: Un proceso se puede trasladar aunque haya iniciado su ejecución en un determinado nodo. Éste tipo de estrategias permiten un mejor balance de la carga, pero sobrecargan más la red y los algoritmos necesitados en la administración de procesadores son más complejos.
Versión
Prel
imina
r

Aspecto del diseño de los algoritmos de administración del procesador en SD:
Al momento de diseñar un algoritmo de administración de procesadores en SD las principales decisiones que deben tomar los diseñadores, se pueden resumir en 5 aspectos fundamentales y que determinarán el comportamiento y rendimiento del SD:
• Algoritmos Determinísticos Vs. Heurísticos• Un algoritmo Determinístico necesita conocer en cada instante la lista
completa de todos los procesos, sus necesidades de cómputos, archivos, comunicación, etc. Son adecuados cuando se sabe de antemano todo acerca del comportamiento de los procesos. En teoría esto es así, pero en pocos sistemas, se tiene un conocimiento total de antemano (sobre todo porque es muy costoso en cuanto a recursos del sistema), en general se puede obtener una aproximación razonable.
• Un algoritmo Heurístico es aquel que con una parte de la información toma las mismas decisiones efectuando un descubrimiento o suposición del resto de la información.
• El mayor problema para conocer “todo de antemano” es que las solicitudes de trabajo dependen de QUIEN ESTA HACIENDO QUE y puede variar de manera drástica en instantes de tiempo relativamente chicos, por lo que sincronizar toda esta información es prácticamente imposible. Por este motivo la asignación de procesadores en SD, no se puede hacer de manera determinista o matemáticamente, sino por necesidad y se utilizan técnicas AD HOC, llamadas HEURÍSTICAS.
Versión
Prel
imina
r

Aspecto del diseño de los algoritmos de administración del procesador en SD: (Cont)
• Algoritmos centralizados VS distribuidos• La recolección de toda la información en un lugar, permite tomar una mejor
decisión, pero es menos robusta y coloca una carga pesada en la maquinacentral (además de que el sistema cuenta con un punto de falla más importante).
• Son preferibles los algoritmos descentralizados, pero se han propuesto algunos algoritmos centralizados por la carencia de alternativasdescentralizadas adecuadas.
• Algoritmos óptimos VS subóptimos• Se pueden obtener las soluciones óptimas, tanto en los sistemas
centralizados como en los descentralizados, pero por regla son mas caros que los sub-óptimos.
• En un algoritmo óptimo hay que recolectar mas información y procesarla un poco mas.
• En la práctica, la mayoría de los SD reales buscan soluciones sub-óptimas heurísticas y distribuidas.
Versión
Prel
imina
r

Aspecto del diseño de los algoritmos de administración del procesador en SD: (Cont)
• Algoritmos locales VS Globales• Se relaciona directamente con la Política de Transferencia.• Cuando se está a punto de crear un proceso, hay que tomar una decisión
para ver si se ejecuta o no en la máquina que lo genera. • Si esa máquina esta muy ocupada, hay que transferir a otro lugar el nuevo
proceso. • Una opción viable consiste en basar o no a decisión de transferencia
solamente tomando en cuenta la información local y no la información global de todo el sistema, pero esto puede terminar en intentos fallidos de migrar procesos.
• Algoritmos iniciados por el emisor VS iniciados por el receptor• Se relaciona directamente con la política de localización. • Una vez que la política de transferencia ha decidido migrar el proceso, la
política de localización debe decidir donde enviarlo. • Este tipo de políticas no puede ser local, ya que necesita contar con la
información necesaria de la carga de todos los nodos, sino podría tomar la decisión de a donde migrar en forma errónea. Vers
ión P
relim
inar

Algoritmos de equilibrado de carga
Suponiendo que en un determinado momento se determina que los nodos de un determinado nodo tienen una carga de trabajo más alta que otros nodos.En esta situación alguno de los nodos del SD puede iniciar la solicitud de migración ya sea iniciado por el emisor o por el receptor (o mixta)
Algoritmo Iniciado por el Emisor• Política de transferencia: umbral
basado en la longitud de la cola de procesos listos.
• Política de selección: sólo se transfieren procesos nuevos.
• Política de ubicación: Distintas alternativas:
• Elegir un nodo al azar (no es recomendable)
• Probar con un Nº de nodos hasta encontrar un receptor
• Probar con un Nº de nodos y elegir aquél con menos carga
• Estabilidad: inestable con alta carga. Difícil encontrar receptores y los muestreos consumen CPUVers
ión P
relim
inar
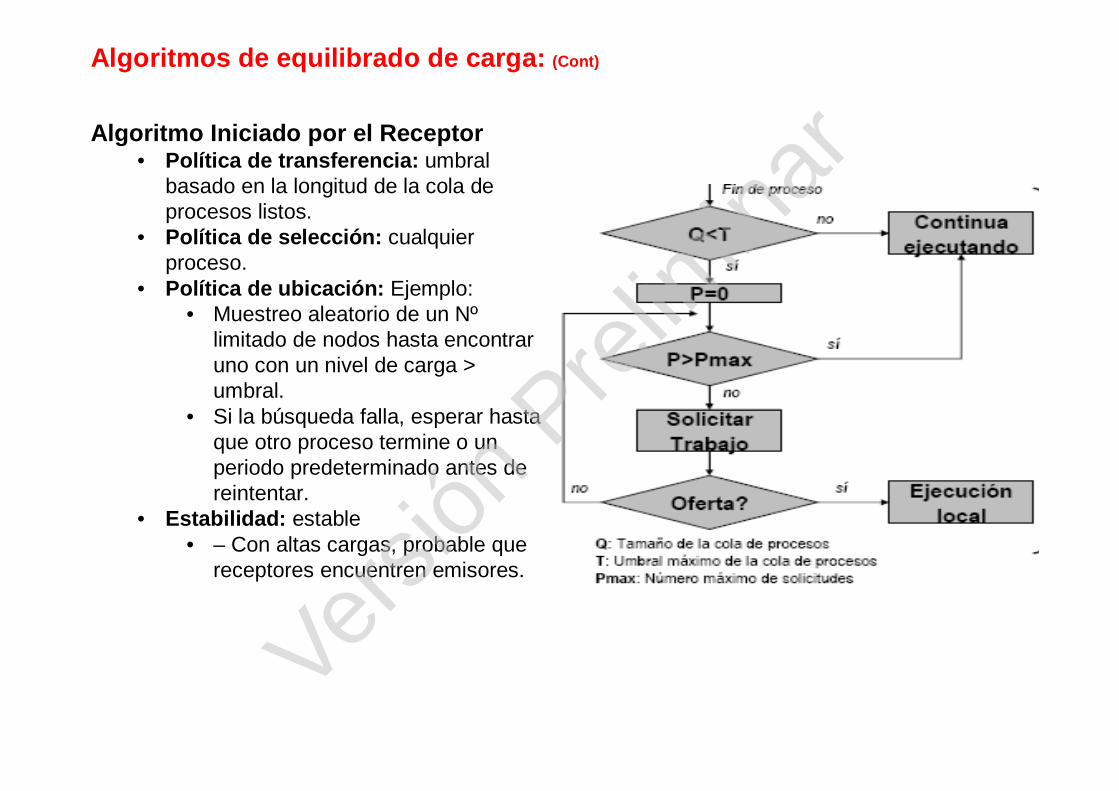
Algoritmos de equilibrado de carga: (Cont)
Algoritmo Iniciado por el Receptor• Política de transferencia: umbral
basado en la longitud de la cola de procesos listos.
• Política de selección: cualquier proceso.
• Política de ubicación: Ejemplo:• Muestreo aleatorio de un Nº
limitado de nodos hasta encontrar uno con un nivel de carga > umbral.
• Si la búsqueda falla, esperar hasta que otro proceso termine o un periodo predeterminado antes de reintentar.
• Estabilidad: estable• – Con altas cargas, probable que
receptores encuentren emisores.
Versión
Prel
imina
r

Algoritmos de equilibrado de carga: (Cont)
Algoritmo Mixto• Política de transferencia: 0 Tmin Media del sistema Tmax receptor emisor• Política de selección: cualquier proceso.• Política de ubicación:
• Dirigida por el emisor según el siguiente protocolo:• Emisor difunde mensaje SOBRECARGADO y espera ACEPTAR.• Un receptor envía ACEPTAR si puede recibir procesos o calla en caso
contrario.• Si llega ACEPTAR: y el nodo todavía es emisor, transfiere el proceso más
adecuado.• Si no llega ACEPTAR (en un lapso de tiempo), difunde un mensaje CAMBIO-
MEDIA para incrementar la carga media estimada en el resto de nodos.• Dirigida por el receptor según el siguiente protocolo:
• Un receptor difunde un mensaje DESCARGADO y espera por mensajes SOBRECARGADO.
• Si llega un mensaje SOBRECARGADO, se envía un mensaje ACEPTAR.• Si no, difundir un mensaje CAMBIO-MEDIA para decrementar la carga media
estimada en el resto de nodos.• Estabilidad: estable
• – Con altas cargas, probable que receptores encuentren emisores.
Versión
Prel
imina
r

Planificación de procesos (generalidades):
Dentro de las distintas formas de administrar los procesos en SD podemos encontrar las siguientes variantes en cuanto a la modalidad de funcionamiento de la cola de listos:
• Modalidad 1: Planificación centralizada• Existe una sola cola para todos los procesos, o varias colas con distintas
prioridades (múltiples niveles de una misma cola de listos)• Cada proceso puede correr en cualquier procesador• Las tareas de planeamiento son mucho menos importantes con varios
procesadores que si existe un único procesador• Modalidad 2: Planificación distribuida
• Para cada procesador se hace una planificación local (si tiene varios procesos en ejecución) independientemente de lo que hacen los otros procesadores.
• La planificación independiente no es eficiente cuando se ejecutan en distintos procesadores un grupo de procesos relacionados entre sí.
• Se necesita una forma de garantizar que los procesos con comunicación frecuente se ejecuten de manera simultánea.
Versión
Prel
imina
r

Planificación de procesos (algorítmos):El algoritmo de Ousterhout (1982)
• Utiliza el concepto de coplanificación, por el cual el SD al realizar la planificación de procesos toma en cuenta los patrones de comunicación entre los procesos (puede ser utilizado también en procesos livianos).
• Para cumplir con su objetivo debe garantizar que todos los miembros del grupo se ejecuten al mismo tiempo.
• Emplea una matriz conceptual donde las columnas son las tablas de procesos de los procesadores y las filas son espacios de tiempo. De esta manera en cada columna se poseen todos los procesos que se tienen que ejecutar en un determinado procesador en todos los tiempos.
• Cada procesador luego es planificado a través de un algoritmo de planificación Round Robin donde:
• Todos los procesadores ejecutan el proceso que les corresponde en el espacio “0” durante un cierto período fijo.
• Y luego todos los procesadores ejecutan el proceso en el espacio “1”durante un cierto período fijo, etc.
• Un tema importante es que se deben mantener sincronizados los intervalos de tiempo entre las distintas máquinas (y procesadores).
• Todos los miembros de un grupo de procesos deben ser colocados en el mismo número de espacio de tiempo pero en procesadores distintos.Vers
ión P
relim
inar

Planificación de procesos (algorítmos): (Cont)
Load Sharing• Los procesos no se asignan a un procesador en particular, sino que son
asignados a una cola de listos global de los cuales son asignados a los distintos procesadores.
• Hay distintas versiones, que varían en cual es el primer proceso de la cola de listos:
• FCFS: cuando llega un proceso a la cola se asigna al final de la cola. Es nonpreemptive.
• SNTF (Smallest number of thread first): la más alta prioridad la tienen los procesos con menor cantidad de threads. Es nonpreemptive o preemtive. En el caso de preemtive si llega un nuevo proceso con menos threads que el que actualmente se está ejecutando se comienza con la ejecución de éste y y se suspende la anterior.
• Ventajas:• Ningún procesador está inactivo mientras hay trabajo para hacer• No es necesario un planeamiento centralizado. Cuando un procesador está disponible,
la rutina de planeamiento del SO se carga en ese procesador para seleccionar el proceso siguiente.
• Desventajas:• Si varios procesos intentan acceder a la cola al mismo tiempo, éste se transforma en
un cuello de botella.• Cuando un proceso es reemplazado es improbable que finalice su ejecución en el
mismo procesador, lo que hace que el caché sea ineficiente y que se genere migración de procesos comenzados.
• Se requiere un alto grado de coordinación entre los procesos de un programa.Vers
ión P
relim
inar

Planificación de procesos (algorítmos): (Cont)
Gang Scheduling• Un conjunto de procesos relacionados se planean para correr en varios
procesadores al mismo tiempo. Esto facilita la comunicación entre los procesos ya que el planificador los asigna a todos al mismo tiempo a distintos procesadores, no sufriendo tiempos de espera para la comunicación ni bloqueos.
• Ventajas:• Si los procesos relacionados se ejecutan en paralelo, pueden ser necesarios
menos cambios de procesos y se incrementa la performance.• El overhead se reduce porque una sola decisión afecta una cantidad de
procesos y procesadores.• Desventajas:
• Si una aplicación no tiene todos sus procesos corriendo, su desempeño se ve seriamente afectada.
Versión
Prel
imina
r

Planificación de procesos (algorítmos): (Cont)
• Dedicated Processor Assignment• Cada proceso se coloca en un número de procesadores igual a la cantidad
de threads en la que se descompone, hasta que finalice la ejecución del mismo.
• No se utiliza la multiprogramación de procesadores, por lo que si un threadejecuta una operación de I/O, el procesador se queda esperando que finalice.
• Dynamic Scheduling• La cantidad de threads que se ejecutan en paralelo de un determinado
proceso se puede alterar durante la ejecución del mismo.• El SO ajusta la asignación de procesos para mejorar el uso de los
procesadores en desuso.• Como regla general cuando se recibe un nuevo proceso se le asignan más
de un procesador a la vez, lo que acelera el inicio del proceso. También es importante destacar que a un nuevo proceso se le otorga un procesador antes que a una aplicación que ya está corriendo desde antes.
Versión
Prel
imina
r

Ejecución remota de procesos
Uno de los principales problemas que deben solucionar los SD es el de la ejecución remota de procesos, ya que sin esto no seria posible incrementar los niveles de multiprogramación. Por lo que una de las preguntas más importantes que se debe poder responder al diseñar un SD es la siguiente:
• ¿Cómo ejecutar un proceso de forma remota?• Crear el mismo ambiente de trabajo: entorno, directorio actual, etc.• Redirigir ciertas llamadas al sistema a la máquina origen, como por ejemplo
la interacción con el Terminal
Este proceso de ejecutar un proceso en forma remota se lo conoce como migración de procesos y puede ser realizada de distintas maneras:Podemos definir a la migración de los procesos como la realocación de un proceso de su ubicación corriente (sitio fuente) en otro sitio (sitio destino).La migración de los procesos puede ser total o parcial, y puede ser realizada antes de comenzar a ejecutar únicamente (no apropiativo) o una vez que el proceso ya comenzó a ejecutarse (apropiativo).Se denomina tiempo congelado al lapso de tiempo que se demora en migrar el proceso desde el nodo origen al nodo destino. Cuanto menor sea este tiempo mejor es el algoritmo de migraciones.
Versión
Prel
imina
r

Características deseables de un buen mecanismo de migración de procesosDebido a que el proceso de migración es relativamente complejo (sobre todo si se migra en forma apropiativa), es recomendable que el protocolo de migración de los procesos cumpla con las siguientes premisas:
• Transparencia:• Representa el nivel de acceso a objetos. Tiene requisitos mínimos para la migración no
apropiativa, pero es más complejo para la apropiativa.• Debe brindar niveles de system-calls y comunicación entre procesos.
• Mínima interferencia:• Debe tratar de minimizar el tiempo congelado, ya que este timempo es puro overhead.
• Dependencias residuales mínimas:• La migración de procesos debe dejar lo mínimo o nada en el sitio origen• Impone una carga de trabajo en el sitio previo• Una falla o reboot en el sitio previo hace fallar el proceso aunque haya sido migrado exitosamente
• Eficiencia:• Cuanto mejor sean los tiempos y costos será más eficiente el proceso de migraciones. Los más
importantes son:• El tiempo requerido para migrar el proceso• El costo de localizar el objeto• El costo de soportar la ejecución remota una vez que el proceso ha migrado
• Robustez:• La falla en un sitio distinto del que corre el proceso no debe afectar la accesibilidad o ejecución de
ese proceso (ya que debería tener una copia en el sitio origen).• Comunicación entre coprocesos de un Job:
• Se deben mantener los mecanismos de comunicación entre los procesos aunque una parte haya sido migrada, por lo que el SD se debe encargar de proveer esos mecanismos substitutos en caso de ser necesarios
Versión
Prel
imina
r
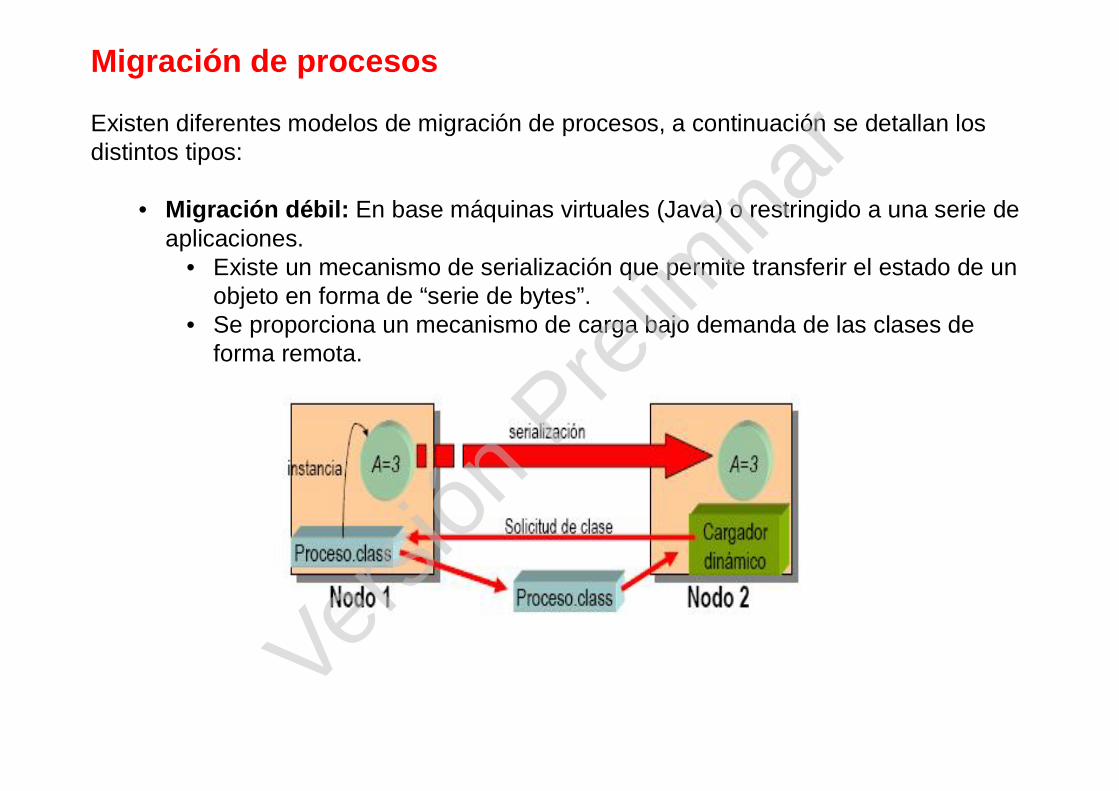
Migración de procesos
Existen diferentes modelos de migración de procesos, a continuación se detallan los distintos tipos:
• Migración débil: En base máquinas virtuales (Java) o restringido a una serie de aplicaciones.
• Existe un mecanismo de serialización que permite transferir el estado de un objeto en forma de “serie de bytes”.
• Se proporciona un mecanismo de carga bajo demanda de las clases de forma remota.
Versión
Prel
imina
r

Migración de procesos (Cont)
Migración fuerte: Realizado a nivel de código nativo, de propósito general.• Solución nativa:
• Copiar el mapa de memoria: código, datos, pila, etc.• Crear un nuevo PCB (con toda la información salvaguardada en el cambio
de contexto anterior).• Datos almacenados por el núcleo que son necesarios, y que se denominan
estado externo del proceso. Los más importantes son:• Archivos abiertos• Señales pendientes• Sockets• Semáforos• Regiones de memoria compartida
• Otros aspectos:• PID único de sistema• Credenciales y aspectos de seguridad
• Implementaciones:• A nivel de kernel:
• Versiones modificadas del núcleo como por ejemplo Mosix y OpenMosix• A nivel de usuario:
• Bibliotecas de checkpointing• Protocolos para desplazamiento de sockets• Intercepción de llamadas al sistemaVers
ión P
relim
inar

Migración de procesos (Cont)
Migración de Datos:No se migran procesos sino sólo los datos sobre los que estaba trabajando.
• Usando en aplicaciones de tipo master-slave.• Master: Distribuye el trabajo entre los trabajadores.• Slave: Trabajador (el mismo código pero con diferentes datos).
• Representa un algoritmo de distribución de trabajo (en este caso datos) que:• Evite que un trabajador esté parado porque el maestro no transmite datos.• No asigne demasiado trabajo a un nodo (tiempo final del proceso es el del
más lento)• Para solucionar los problemas se realiza la assignación de trabajos por
bloques (más o menos pequeños).
Versión
Prel
imina
r

Migración de recursos
La migración de recursos también depende de la relación de éstos con las máquinas:• Unatachment resource: un archivo de datos del programa a migrar.• Fastened resource. Son recursos movibles, pero con un alto costo, como por
ejemplo una base de datos, un sitio web.• Fixed resource. Están ligados estrechamente a una máquina y no se pueden
mover. Como por ejemplo los dispositivos locales del computador.
Versión
Prel
imina
r

Ejemplos de sistemas con migración de procesos
BProc (usado por Scyld):http://www.penguincomputing.com/index.php?option=com_content&task=view&id=309&Itemid=452
• Es una solución únicamente para procesos desarrollados bajo Scyld• Maneja un nodo maestro y nodos esclavos• Siempre se inicia el proceso en el maestro y explícitamente se invoca “move”,
“rexec” o “rfork” hacia el esclavo• Todos los archivos se cierran cuando se mueve el proceso• El nodo maestro puede “ver” todos los procesos iniciados en él• Los procesos migrados ven el espacio de procesos del maestro (mapping de
PIDs)• Las llamadas al sistema del proceso se envían al maestro (incluidos los fork)• Otras llamadas al sistema se ejecutan localmente en el nodo esclavo
Versión
Prel
imina
r

Ejemplos de sistemas con migración de procesos (Cont)
Mosix/OpenMOSIX:
• Maneja un nodo maestro y nodos esclavos• Inicia el proceso en el nodo maestro y se migra transparentemente• El nodo maestro puede ver todos los procesos (y solamente esos) iniciados en él• Los procesos migrados mantienen la visión que tenían en el nodo origen• La mayoría de las llamadas al sistema se ejecutan en el nodo original• El sistema de archivos MFS permite que la E/S se realice localmente
OpenSSI: (http://openssi.org/ )• Sistema de ficheros único de alta disponibilidad• Kernel autónomo en cada nodo• La formación del cluster se articula en tiempo de boot• Membresía fuerte• Visión única de archivos, dispositivos, procesos e IPCs• Equilibrado de conexiones y procesos
Versión
Prel
imina
r
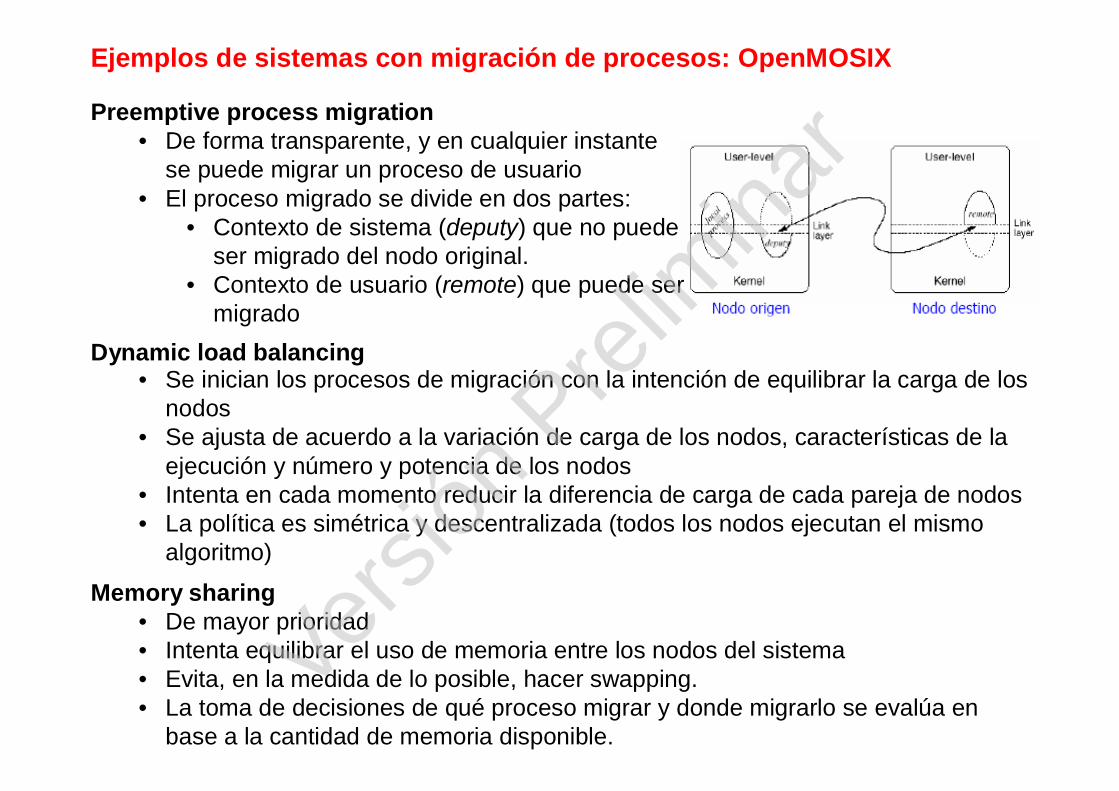
Ejemplos de sistemas con migración de procesos: OpenMOSIX
Preemptive process migration• De forma transparente, y en cualquier instante
se puede migrar un proceso de usuario• El proceso migrado se divide en dos partes:
• Contexto de sistema (deputy) que no puede ser migrado del nodo original.
• Contexto de usuario (remote) que puede ser migrado
Dynamic load balancing• Se inician los procesos de migración con la intención de equilibrar la carga de los
nodos• Se ajusta de acuerdo a la variación de carga de los nodos, características de la
ejecución y número y potencia de los nodos• Intenta en cada momento reducir la diferencia de carga de cada pareja de nodos• La política es simétrica y descentralizada (todos los nodos ejecutan el mismo
algoritmo)
Memory sharing• De mayor prioridad• Intenta equilibrar el uso de memoria entre los nodos del sistema• Evita, en la medida de lo posible, hacer swapping.• La toma de decisiones de qué proceso migrar y donde migrarlo se evalúa en
base a la cantidad de memoria disponible.
Versión
Prel
imina
r

Ejemplos de sistemas con migración de procesos: OpenMOSIX (Cont)
Probabilistic information dissemination algorithms• Proporciona a cada nodo (a su algoritmo) suficiente información sobre los
recursos disponibles en otros nodos. Sin hacer polling.• Mide la cantidad de recursos disponibles en cada nodo• La emisión de esta información se hace a intervalos regulares de tiempo a un
subconjunto aleatorio de los nodos.• En el ejecución de una migración, cada asignación de un proceso implica un
periodo durante el cual el nodo debe ejecutarlo (no puede migrarlo de nuevo).
Versión
Prel
imina
r

Pasos para la migración de un proceso
Para poder completar la migración de un proceso de un nodo a otro del SD de se deben completar al menos los siguientes pasos:
1. Congelar o eliminar el proceso en su sitio origen y reiniciarlo en su sitio destino. El proceso de congelado puede ser efectuado en forma inmediata o no según sea el estado del proceso
• Si el proceso está ejecutando puede ser bloqueado inmediatamente• Si el proceso está ejecutando un system-call pero durmiendo en una prioridad
interrumpible esperando que ocurra un evento en el kernel, puede ser bloqueado inmediatamente
• Si el proceso está ejecutando un system-call y está en una prioridad no interrumpible esperando que ocurra un evento en el kernel no puede ser bloqueado inmediatamente
2. Continuar los mensajes esperados por el proceso que se migra
Versión
Prel
imina
r

Pasos para la migración de un proceso (Cont.)
3. Transferir el espacio de direcciones correspondiente, compuesto por los siguientes componentes:
• Estado de ejecución (PCB)• Información de la planificación• Memoria usada
• Memoria principal• Memoria secundaria• Stack
• Estados de entrada/salida• Lista de objetos a los cuales el proceso tiene acceso• Identificador de usuario y grupo del proceso• Archivos abiertos, en este caso hay dos alternativas
• Se crea un link al archivo• Se recompone el nombre completo del archivo
• Información de los coprocesos con los que comparte información. Para este caso hay distintas alternativas:
• Deshabilitar la separación de coprocesos• No permitir migración de procesos que esperan que completen uno o
más subprocesos.• Asegurar que todos migren juntos.
• Concepto del sitio origen• La comunicación se lleva a cabo por sitio origen quien se encarga de
localizar al proceso en el nuevo nodoVers
ión P
relim
inar

Pasos para la migración de un proceso
4. Manejar las comunicaciones entre procesos cooperativos que han sido separados como resultado de la migración. Se deben solucionar tres problemas:
• Mensajes en ruta (emitidos por terceros y no recibidos el nodo origen del proceso migrado)
• Mensajes pendientes. Pueden ser de 3 tipos• Tipo 1: recibidos en el nodo origen luego que se ha congelado el proceso y no se ha
reiniciado en el sitio destino• Tipo 2: recibidos en el nodo origen cuando el proceso se inició en el sitio destino• Tipo 3: enviados al proceso desde otros nodos luego que éste reinició en el sitio destino
• Mensajes futuros
Los mecanismos más usados son:• Reenvío de mensajes (V-System, Amoeba)
• Tipos 1 y 2 son retornados o dejados caer para que retransmitan.• Sitio origen (AIX TCF, Sprite )
• Cada sitio tiene información sobre el traslado del proceso.• Es inseguro por caídas de los sitios intermedios, los sitios origen siguen cargados.
• Enlace transversal : (DEMOS/MP)• Los tipo 1 son encolados en el sitio fuente, luego de notificada la ubicación del
proceso le son enviados como parte del proceso de migración.• Para los tipo 2 y 3 es dejada una dirección adelantada en el sitio fuente apuntado
al sitio destino llamada link.• Actualización del link (Charlotte)
• Desde el sitio origen se manda a todos los demás kernels un mensaje de actualización de la nueva ubicación.
Versión
Prel
imina
r

Formas de efectuar la migración de un proceso:
Congelamiento total:V: Fácil de implementarD: Se pueden vencer los time-outs y los usuarios pueden notarlo.
PretransferenciaSolo se puede utilizar para transferir páginas redundantes de código (no de datos)
Transferencia por referenciaCopia las páginas que necesita cuando ello ocurra.
V: El instante de migración es mucho más rápidoV: Solo transfiere lo que se necesitaD: Deja información en el sitio fuente, esto es crítico.
Versión
Prel
imina
r

Ventajas de la migración de procesos:
ü Reducción del tiempo medio de respuesta.ü Aceleración de procesos individuales.ü Ganancia de procesamiento total.ü Efectiva utilización de recursos.ü Reducción de tráfico en la red.ü Mejora de la confiabilidad del sistema.ü Mejora de la seguridad del sistema.
Versión
Prel
imina
r
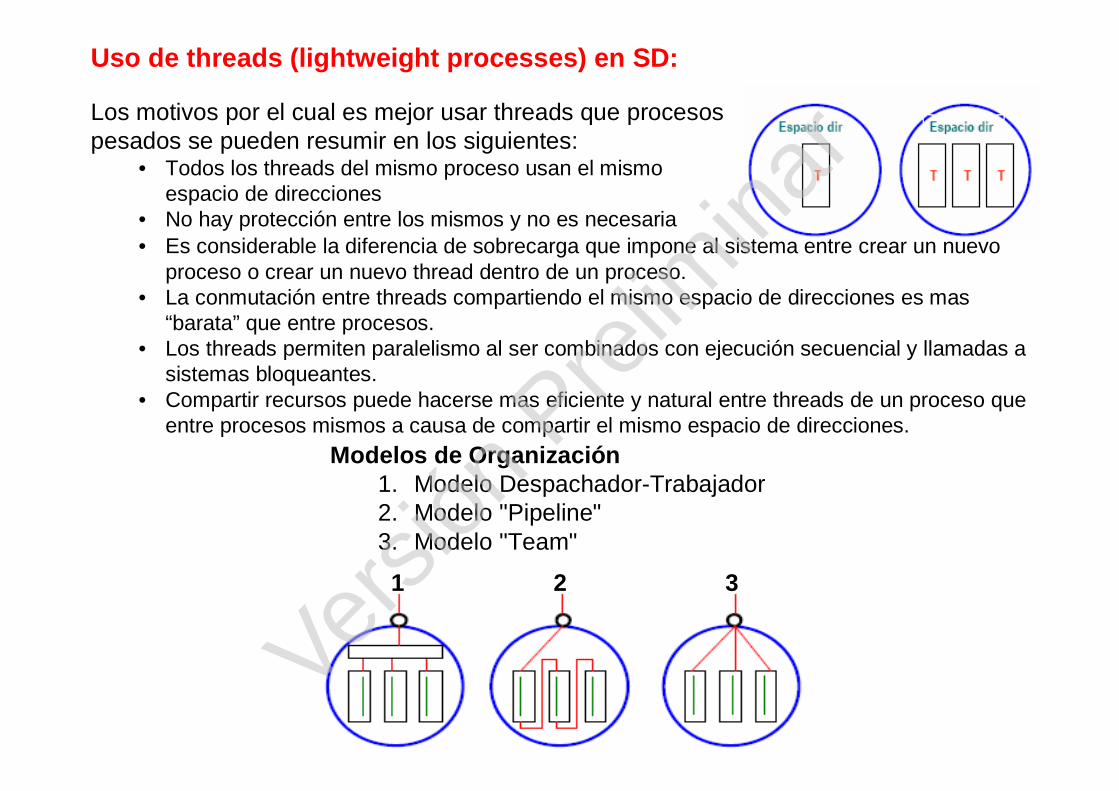
Uso de threads (lightweight processes) en SD:
Los motivos por el cual es mejor usar threads que procesos pesados se pueden resumir en los siguientes:
• Todos los threads del mismo proceso usan el mismo espacio de direcciones
• No hay protección entre los mismos y no es necesaria
Modelos de Organización1. Modelo Despachador-Trabajador2. Modelo "Pipeline"3. Modelo "Team"
1 2 3
• Es considerable la diferencia de sobrecarga que impone al sistema entre crear un nuevo proceso o crear un nuevo thread dentro de un proceso.
• La conmutación entre threads compartiendo el mismo espacio de direcciones es mas “barata” que entre procesos.
• Los threads permiten paralelismo al ser combinados con ejecución secuencial y llamadas a sistemas bloqueantes.
• Compartir recursos puede hacerse mas eficiente y natural entre threads de un proceso que entre procesos mismos a causa de compartir el mismo espacio de direcciones.
Versión
Prel
imina
r

Ejemplo de modelo despachador - trabajador:
Ejemplo: Servidor de Archivos
• Un thread simple cumple el papel de master (despachadores)
• Threads múltiples cumplen los papeles de slave (Trabajadores)
Máquina de estados finitos
Versión
Prel
imina
r

Aspectos en diseño de threads
Creación de threads Existen dos modalidades que se utilizan• Estática• Dinámica
Terminación de threads• Pueden terminar convencionalmente• Pueden autodestruirse o ser destruidos
Sincronización de threads• Usa variables mutex• Si encuentra mutex=lock
• El thread se bloquea y espera en una cola por la variable mutex.• Un cod-status indica situación. El thread puede continuar con otra tarea o
esperar.
Versión
Prel
imina
r

Espacio del kernelV: La escalabilidad es mayor. V: Las tablas en nivel-kernel son mantenidas dentro
del kernel.V: Si un thread se bloquea los otros no se
bloquean.D: Son más lentos y tienen proceso de Contex-
SwitchD: El programador no puede proveer el método de
planificación que mejor se adecue al objetivo
Implementación de threads
Existen dos formas fundamentales de implementar los threads, que dependen de cómo están programados, las funcionalidades provistas por el SO. Cada cual tiene sus ventajas y desventajas, que se asemejan a las existentes en los SO para monoprocesadores.
Espacio del usuarioV: Puede construirse encima del sistema
operativo que no soporta threads. V: Puede usar su propio esquema de
planificación. V: la conmutación de contexto de un thread en el
nivel-usuario es más rápidaD: Se bloquean todos salvo que existan métodos
para evitarloD: El programador debe ocuparse de todo
Versión
Prel
imina
r