apuntes de la asignatura metodos num´ ericos de...
TRANSCRIPT

UNIVERSIDAD DE SEVILLA
Dpto. de Matematica Aplicada I
Apuntes de la asignatura
METODOS NUMERICOS DE CALCULOTercer curso de Arquitectura.
Profesores: Marıa Angeles Rodrıguez Bellido
y Enrique Domingo Fernandez Nieto


Indice General
1 Introduccion al Calculo Numerico 3
1.1 Introduccion al Calculo Numerico . . . . . . . . . . . . . . . . . . . . . . . 4
1.1.1 Introduccion al estudio del error . . . . . . . . . . . . . . . . . . . . 4
1.1.2 Notacion decimal en coma flotante . . . . . . . . . . . . . . . . . . 5
1.1.3 Condicionamiento de un problema: . . . . . . . . . . . . . . . . . . 6
1.1.4 Estabilidad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2 Normas vectoriales y matriciales . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2.1 Normas vectoriales . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2.2 Norma de una matriz . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2 Resolucion numerica de sistemas de ecuaciones lineales 11
2.1 Condicionamiento de sistemas . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.1.1 Propiedades de cond(A) . . . . . . . . . . . . . . . . . . . . . . . . 13
2.1.2 Observaciones finales . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2 Metodos directos e iterativos . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Metodos directos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3.1 Observaciones concernientes a la resolucion de sistemas lineales . . 15
2.3.2 El metodo de Gauss . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.3.3 El metodo de Cholesky . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.4 Metodos iterativos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.4.1 Estudio general del Metodo Iterativo . . . . . . . . . . . . . . . . . 24
2.4.2 Metodos de Jacobi, Gauss-Seidel y relajacion . . . . . . . . . . . . . 26
2.4.3 Metodo de Jacobi . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.4.4 Metodo de Gauss-Seidel . . . . . . . . . . . . . . . . . . . . . . . . 29
2.4.5 Test de parada de las iteraciones . . . . . . . . . . . . . . . . . . . 32
1

2
3 Resolucion numerica de ecuaciones diferenciales ordinarias 35
3.1 El metodo de Euler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.1.1 Tamano del paso frente al error . . . . . . . . . . . . . . . . . . . . 40
3.1.2 Orden de un metodo . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.2 El metodo de Heun . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.3 Metodos de Runge-Kutta . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.3.1 Algoritmos de Runge-Kutta de cuarto orden . . . . . . . . . . . . . 50
3 Parte II (e. d. o. s): Resolucion numerica de ecuaciones diferenciales
ordinarias 53
3.4 Sistemas de Ecuaciones Diferenciales . . . . . . . . . . . . . . . . . . . . . 53
3.4.1 Resolucion numerica . . . . . . . . . . . . . . . . . . . . . . . . . . 54
3.4.2 Ecuaciones diferenciales de orden superior . . . . . . . . . . . . . . 56
3.5 Problemas de contorno . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.5.1 Caso lineal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4 El metodo de Diferencias Finitas 67
4.1 Esquema de mejora de Richardson . . . . . . . . . . . . . . . . . . . . . . . 71
4.2 Otras condiciones de frontera. . . . . . . . . . . . . . . . . . . . . . . . . . 73
Apendice: Aproximacion de la derivada de una funcion a partir del desarrollo
de Taylor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
5 Ecuaciones en derivadas parciales 77
5.1 Ecuaciones elıpticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5.2 Diferencias Finitas para EDP’s . . . . . . . . . . . . . . . . . . . . . . . . 80
5.2.1 Tratamiento de la condicion de contorno de tipo Neumann . . . . . 82

Tema 1
Introduccion al Calculo Numerico
1. Introduccion al Caculo Numerico
(a) Introduccion al estudio del error
• Error absoluto
• Error relativo
• Notacion decimal en coma flotante (numeros maquina)
• Propagacion del error
Condicionamiento
Estabilidad
(b) Condicionamiento de un problema
(c) Estabilidad - algoritmo inestable.
2. Normas vectoriales y matriciales
3

4
1.1 Introduccion al Calculo Numerico
El Analisis Numerico es una herramienta fundamental en el campo de las Ciencias
Aplicadas.
Objetivo: Disenar metodos numericos de calculo que aproximen, de modo eficiente, la
solucion de problemas practicos previamente formulados matematicamente.
Algoritmo: Secuencia finita de operaciones algebraicas y logicas que producen una
solucion aproximada del problema matematico.
AN =⇒ diseno de algoritmos y estudio de su eficiencia
eficiencia
- requerimientos de memoria
- tiempo de calculo (rapidez)
- estimacion del error (precision)
1.1.1 Introduccion al estudio del error
El error nos proporciona la precision del metodo.
errores de
entrada
(en medidas)
+errores de
almacenamiento+
errores de
algoritmo︸ ︷︷ ︸a analizar
=
errores
de
salida
Sobre los errores de entrada nada podemos decir.
Antes de comenzar recordemos algunso conceptos que en la terminologıa estandar de
los errores se suelen usar.
Definicion 1 Error absoluto: Sea z la solucion exacta del problema y z la solucion
aproximada, se define el error absoluto como
‖z − z‖
donde ‖ · ‖ es una norma (se definira mas adelante).
(Pensar en ‖ · ‖ como el modulo).

5
Desde el punto de vista de las aplicaciones, resulta mucho mas relevante el
error relativo ∥∥∥∥z − z
z
∥∥∥∥
Nota 1 Si z = 0 solo se trabaja con errores absolutos.
1.1.2 Notacion decimal en coma flotante
Es una forma de representacion de numero que contiene la informacion relevante com-
puesta por:
signo + fraccion + signo para el exponente + exponente.
Por ejemplo, -618.45 se puede expresar como:
−618.45 + 0 − 61.845 + 1 − 6184.5− 1 − 6.1823 + 2
que significa:
−618.45× 100 − 61.845× 10 − 6184′5× 10−1 − 6.1845× 102
De todas ellas, se llama notacion decimal en coma flotante normalizada a aquella en
la que la fraccion esta comprendida entre 0 y 10.
±m ± E 1 ≤ m < 10, E ∈ N ∪ 0
• Los numeros representables de forma exacta en el ordenador se llaman numeros maquina
Nota 2 Los ordenadores almacenan la informacion en posiciones de memoria (o bit ≡Binary Digit), que solo toman valores 0/1, encendido/apagado, positivo/negativo . . . . . .
luego utilizan la representacion binaria.
Progagacion del error: Los errores anteriores se propagan a traves de los calculos, debido
a la estructura propia del algoritmo. Para estudiar esta propagacion, y por tanto el error
final, atendemos dos conceptos:
- Condicionamiento
- Estabilidad

6
Condicionamiento: mide la influencia que tendrıan los errores en los datos en el caso en que
se puede trabajar con aritmetica exacta (⇒ no depende del algoritmo, sino del problema
en si).
Estabilidad: Esta relacionada con la influencia que tienen en los resultados finales la
acumulacion de errores que se producen al realizar las diferentes operaciones elementales
que constituyen el algoritmo.
1.1.3 Condicionamiento de un problema:
Diremos que un problema esta mal condicionado cuando pequenos cambios en los
datos dan lugar a grandes cambios en las respuestas.
Para estudiar el condicionamiento de un problema se introduce el llamado numero
de condicion de dicho problema, especıfico del problema, que es mejor cuanto mas cerca de
1 (el problema esta bien condicionado) y peor cuanto mas grande sea (peor condicionado).
objetivo: Definir el numero de condicion de un problema.
La gravedad de un problema mal condicionado reside en que su resolucion puede
producir soluciones muy dispares en cuanto los datos cambien un poco (algo muy frecuente
en las aplicaciones).
Ejemplo: Tenemos el siguiente sistema lineal:
Sistema 1:
10x1 + 7x2 + 8x3 + 7x4 = 32,
7x1 + 5x2 + 6x3 + 5x4 = 23,
8x1 + 6x2 + 10x3 + 9x4 = 33,
7x1 + 5x2 + 9x3 + 10x4 = 31
=⇒
x1 = 1
x2 = 1
x3 = 1
x4 = 1
.
Sistema 2:
10x1 + 7x2 + 8x3 + 7.2x4 = 32,
7.08x1 + 5.04x2 + 6x3 + 5x4 = 23,
8x1 + 5.98x2 + 9.89x3 + 9x4 = 33,
6.99x1 + 4.99x2 + 9x3 + 9.98x4 = 31
=⇒
x1 = −81
x2 = 137
x3 = −34
x4 = 22
.
Sistema 3:
10x1 + 7x2 + 8x3 + 7.2x4 = 32,
7x1 + 5x2 + 6x3 + 5x4 = 22.9,
8x1 + 6x2 + 10x3 + 9x4 = 32.98,
7x1 + 5x2 + 9x3 + 10x4 = 31.02
=⇒
x1 = 7.28
x2 = −9.36
x3 = 3.54
x4 = −0.5
.

7
Como se ve, pequenos cambios en los datos (del orden de 2 centesimas) en algunos
elementos, producen grandes cambios en las soluciones: 136 unidades del sistema 1 al
sistema 2.
Lo mismo ocurre al perturbar el segundo miembro del sistema: cambios de aproxima-
damente 1 decima producen cambios en la solucion de aproximadamente 13 unidades.
Lo anterior se debe a que el sistema esta mal condicionado.
La gravedad de un problema mal condicionado reside en que su resolucion puede
producir soluciones muy dispares en cuanto los datos cambien un poco, cosa muy frecuente
en las aplicaciones.
1.1.4 Estabilidad
Todo algoritmo que resuelve un problema numericamente produce en cada paso un
error numerico.
Un algoritmo se dice inestable cuando los errores que se cometen en cada etapa del
mismo van aumentado de forma progresiva, de manera que el resultado final pierde gran
parte de su exactitud.
Un algoritmos es estable cuando no es inestable (controlado).
Condicionamiento y estabilidad =⇒Permiten estudiar la precision
de un algoritmo para
un problema concreto
1.2 Normas vectoriales y matriciales
Objetivo: Introducir herramientas de medicion de la variacion de los resultados:
1.2.1 Normas vectoriales
Definicion 2 Una aplicacion ‖ · ‖ : Rn −→ R+ ∪ 0 es una norma si:
a) ‖~v‖ = 0 ⇔ ~v = ~0 ∈ Rn
b) ‖λ~v‖ = |λ|‖~v‖, ∀λ ∈ R, ~v ∈ Rn
c) ‖~u + ~v‖ ≤ ‖~u‖+ ‖~v‖ ∀ ~u, ~v ∈ Rn (desigualdad triangular)
Ejemplo:

8
Dado ~v ∈ R3,
‖~v‖1 =n∑
i=1
|vi|,
‖~v‖2 =
√√√√n∑
i=1
|vi|2,
y
‖~v‖∞ = max1≤i≤n
|vi|son normas vectoriales.
~v = (1,−1, 3)
‖~v‖1 = |1|+ | − 1|+ |3| = 5, ‖~v‖2 =√
1 + 1 + 9 =√
11, ‖~v‖∞ = max1, 1, 3 = 3.
Ejercicio: Comprobar que ‖ · ‖1, ‖ · ‖2 y ‖ · ‖∞ son normas vectoriales.
Definicion 3 Dos normas vectoriales son equivalente ‖ · ‖ y ‖ · ‖′ si existen constantes
c1, c2 > 0 tales que:
c1‖~v‖′ ≤ ‖~v‖ ≤ c2‖~v‖′ ∀~v ∈ Rn.
En la practica esto significa que cuando ‖ · ‖′ esta acotada, tambien ‖ · ‖ y viceversa.
1.2.2 Norma de una matriz
Definicion 4 Una norma matricial es una aplicacion ‖| · ‖| : Mn −→ R+ ∪ 0 que
verifica las siguientes propiedades:
a) ‖|A‖| = 0 ⇔ A ≡= 0
b) ‖|λA‖| = |λ|‖|A‖|, λ ∈ R, A ∈Mn
c) ‖|A + B‖| ≤ ‖|A‖|+ ‖|B‖|, A,B ∈Mn.
d) ‖|A ·B‖| ≤ ‖|A‖| ‖|B‖|.
Las tres primeras propiedades garantizanq ue es una normal vectorial y la ultima que
es compatible con el producto de matrices.
Un resultado que nos da una forma simple de construir una norma matricial es el
siguiente:
Definicion 5 Sea ‖ · ‖ una norma en Rn, se define la norma ‖| · ‖| : Mn → R+ ∪ 0como
‖|A‖| = sup~v 6=~0
‖A~v‖‖~v‖ = sup
‖~v‖=1
‖A~v‖

9
Cuando una norma matricial se define de la forma anterior (a traves de una norma
vectorial), se dice que es una norma matricial subordinada a la norma vectorial.
Tenemos las siguiente normas matriciales subordinadas a las vectoriales:
a)
‖|A‖|1 = sup~v 6=0
‖A~v‖1
‖~v‖1
b)
‖|A‖|2 = sup~v 6=0
‖A~v‖2
‖~v‖2
c)
‖|A‖|∞ = sup~v 6=0
‖A~v‖∞‖~v‖∞
Nota 3 No todas las normas matriciales son normas matriciales subordinadas a normas
vectoriales.
Algunas propiedades de las normas matriciales subordinadas
1) ‖A~v‖ ≤ ‖|A‖|‖~v‖, A ∈Mn, ~v ∈ Rn
2) Existe un vector ~v ∈ Rn para el que se da la igualdad, es decir,
‖A~v‖ = ‖|A‖| ‖~v‖
3) ‖|I‖| = 1 (Por I denotamos la matriz identidad).
Veamos como calcular las normas matriciales subordinadas a las normas vectoriales
anteriores:
Teorema 1 Sea A = (ai,j)ni,j=1 ∈Mn, se tiene:
a)
‖|A‖|1 = max1≤j≤n
n∑i=1
|ai,j|
b)
‖|A‖|2 =√
ρ(A∗ A) =√
ρ(AA∗) = ‖|A∗‖|2donde ρ(A∗ A) es el radio espectral de A∗ A, que es el maximo de los valores absolutos
de A∗ A. (Por A∗ denotamos a la matriz adjunta de A, la cual coincide con la matriz
transpuesta cuando todos sus elementos son reales).

10
c)
‖|A‖|∞ = max1≤i≤n
n∑j=1
|ai,j|
Nota 4 ‖| · ‖|1 y ‖| · ‖|∞ se calculan a partir de los elementos de la matriz, ‖| · ‖|2 no.
Es inmediato observar que ‖|AT‖|∞ = ‖|A‖|1.
Ejemplo:
Sea
A =
1 0 −7
0 2 2
−1 −1 0
.
Calculamos la norma uno, dos e infinito:
‖|A‖|1 = max2, 3, 9 = 9
‖|A‖|∞ = max8, 4, 2 = 8
AT A =
2 0 −7
1 5 4
−7 4 53
‖|A‖|2 = 7.3648
Norma Frobenius:
Es una norma matricial no subordinada a ninguna norma vectorial. Viene dada por:
‖|A‖|F =
√√√√n∑
i,j=1
|ai,j|2
Como vemos, se calcula a traves de los elementos de la matriz.
Ejemplo:
‖|A‖|F =√
1 + 49 + 4 + 4 + 1 + 1 =√
60

Tema 2
Resolucion numerica de sistemas de
ecuaciones lineales
1. Resolucion numerica de sistemas de ecuaciones lineales
(a) Condicionamiento de sistemas
(b) Metodos directos:
• Gauss
• Gauss pivote parcial
• Gauss pivote total
• Cholesky
(c) Metodos iterativos
• Jacobi
• Gauss-Seidel
• Relajacion
11

12
2.1 Condicionamiento de sistemas
Objetivo: Resolver sistemas lineales de ecuaciones mediante metodos numericos de calculo.
La existencia de un sistema mal condicionado es una fuente de posibles errores y
dificultades a la hora de resolver un sistema lineal mediante metodos numericos.
El primer problema que se plantea es como definir y cuantificar el condicionamiento
de un sistema.
Supongamos que tenemos que resolver el sistema lineal Ax = b, donde A es una matriz
de coeficientes, b es el termino independiente y x es la solucion exacta del sistema,
que llamaremos u (el vector x recibira diferentes nombres a lo largo del tema):
Ax = b ⇒ x = u
Si modificamos el termino independiente mediante una perturbacion δb, entonces te-
nemos que resolver el sistema Ax = b + δb, que tendra una nueva solucion (distinta de la
solucion exacta) que llamaremos u + δu:
A x = b + δb ⇒ x = u + δu
El sistema esta bien condicionado si cuando δb es pequena, δu tambien lo es. Ob-
servemos que:
Au + A(δu) = b + δb
Au = b
⇒
A(δu) = δb
δu = A−1(δu)
Usando ahora la propiedad para normas matriciales, obtenemos que:
‖δu‖ ≤ ‖|A−1|‖‖δb‖ (2.1)
De la solucion exacta, ‖b‖ ≤ ‖|A‖|‖u‖, lo que implica que:
1
‖u‖ ≤‖|A|‖‖b‖ (2.2)
De (2.1) y (2.2), obtenemos:
‖δu‖‖u‖ ≤ ‖|A|‖‖|A−1‖|‖δb‖‖b‖ , (2.3)
donde‖δu‖‖u‖ representa el error relativo en los resultados, y
‖δb‖‖b‖ el error relativo en los
datos. De la relacion (2.3), parece deducirse que el numero ‖|A|‖‖|A−1‖| es el factor
determinante de la relacion, ya que si es pequeno tenemos el efecto deseado, y si no,
ocurre lo contrario. Si ‖|A|‖‖|A−1‖| = 1 y‖δb‖‖b‖ = 0.01, entonces
‖δu‖‖u‖ ≤ 0.01.
Parece entonces natural la siguiente definicion:

13
Definicion 6 Sea || · |‖ una norma matricial subordinada y A una matriz invertible.
Llamamos numero de condicion de la matriz A respecto de la norma ‖| · |‖ a la
expresion:
cond(A) = ‖|A|‖‖|A−1‖|.
De (2.3) deducimos entonces que:
‖δu‖‖u‖ ≤ cond(A)
‖δb‖‖b‖ .
En el caso en el que las perturbaciones se produzcan en la matriz del sistema A, la
matriz se transforma en A+∆A, llamaremos u+∆u a la solucion aproximada del sistema:
(A + ∆A)(u + ∆u) = b.
Usando que Au = b, obtenemos:
(∆A)(u + ∆u) + A∆u = 0 ⇒ ∆A(u + ∆u) = −A∆u,
luego
∆u = −A−1(∆A)(u + ∆u) ⇒ ‖∆u‖ ≤ ‖|A−1|‖‖|A|‖‖u + ∆u‖,y
‖∆u‖‖u + ∆u‖ ≤ ‖|A−1|‖‖|A|‖‖|∆A|‖
‖|A|‖ = cond(A)‖|∆A|‖‖|A|‖ (2.4)
2.1.1 Propiedades de cond(A)
Proposicion 1 Para cualquier norma subordinada |‖ · ‖|, se verifica:
1. cond(A) ≥ 1.
2. cond(A) = cond(A−1),
3. cond(k · A) = cond(A), ∀k ∈ R\0.
Demostracion:
1. 1 = ‖|I|‖ = ‖|AA−1|‖ ≤ ‖|A‖|‖|A−1|‖ = cond(A),
2. cond(A−1) = ‖|A−1|‖‖|(A−1)−1|‖ = ‖|A−1|‖‖|A|‖ = cond(A),
3. cond(kA) = ‖|kA|‖‖|(kA)−1|‖ = |k|‖|A|‖|k|−1‖|A−1|‖ = cond(A).

14
2
Ejemplo: Estudiar el condicionamiento del sistema Ax = b con A =
(1 1 + ε
1− ε 1
)
siendo ε > 0 en la norma ‖| · |‖∞.
Solucion: A−1 =1
ε2
(1 −ε− 1
ε− 1 1
), ‖|A|‖∞ = 2 + ε y |‖A−1‖|∞ =
2 + ε
ε2, luego
cond(A,∞) =(2 + ε)2
ε2>
4
ε2. Si ε ≤ 0.01, entonces cond(A,∞) > 40000. Esto indica que
una perturbacion de los datos de 0.01 puede originar una perturbacion de la solucion del
sistema de 40000.
Ejercicio: Repetir el ejemplo anterior con la norma |‖ · ‖|1.
2.1.2 Observaciones finales
• Un sistema lineal esta bien condicionado si la matriz A esta bien condicionada.
• Como cond(A) ≥ 1 cuanto mas cerca este su valor de 1, mejor condicionado esta el
sistema.
• En los casos en los que tenemos que resolver el sistema Au = b y cond(A) sea muy
grande, podemos intentar alterar el sistema mediante un precondicionador que
rebaje cond(A). Como cond(kA) = cond(A), no vale multiplicar el sistema por un
escalar k. Normalmente, lo que se hace es multiplicar a izquierda por una matriz
M invertible, de modo que:
A = M A,
tenga cond(A) pequeno, para despues resolver el sistema:
Au = b, donde b = M b.
2.2 Metodos directos e iterativos
Hay dos tipos de metodos para la resolucion de sistemas lineales:
• Directos: proporcionan la solucion exacta (salvo errores de redondeo) en un numero
finito de pasos: Gauss, Cholesky, etc.

15
• Iterativos: proporcionan una sucesion xk que aproxima, o converge, a la solucion
exacta:
xk −→ x.
El calculo se detiene cuando se alcanza un cierto nivel de precision.
2.3 Metodos directos
Consideramos la resolucion numerica de un sistema lineal Au = b, donde A es una
matriz inversible.
El principio de los metodos directos que vamos a estudiar reside en determinra una
matriz M inversible, tal que la matriz MA sea triangular superior. Tenemos que resolver
entonces el sistema lineal:
MAu = Mb,
por lo que llamaremos el metodo de remontada.
Este principio es la base del metodo de Gauss para la resolucion de sistemas lineales
con matrices cualesquiera, y del metodo de Cholesky para sistemas lineales para matrices
simetricas definidas positivas.
Notemos la inutilidad del calculo de la inversa de una matriz para la resolucion de un
sistema lineal (ver parrafo 2.3.1)
Por ultimo, la interpretacion matricial del metodo de Gauss es la factorizacion LU de
una matriz, que en el caso de aplicarse a matrices simetricas y definida positivas no es
sino la factorizacion de Cholesky.
2.3.1 Observaciones concernientes a la resolucion de sistemas
lineales
Contrariamente a lo que se piensa, la resolucion de un sistema lineal no es equivalente
al calculo de la matriz inversa del sistema A−1 y despues calcular A−1b. El calculo de la
matriz inversa es equivalente a la resolucion de n sistemas lineales (donde n es el orden
de la matriz A):
Auj = ej 1 ≤ j ≤ n,
donde ej es el n-esimo vector de la base Rn. Pasamos ası de resolver un sistema lineal a
resolver n sistemas lineales y multiplicar A−1 por el termino independiente b.

16
Los metodos que vamos a estudiar estan basados en el siguiente hecho: si tuviesemos
una matriz triangular superior, la resolucion numerica de un sistema lineal Au = b es
inmediata. Tendrıamos, en forma matricial:
a1,1 . a1,n−1 an
0 . . .
0 . . .
0 . . .
0 . an−1,n−1 an−1,n
0 . . an,n
u1
.
.
.
un−1
un
=
b1
.
.
.
bn−1
bn
y en forma de ecuaciones:
a1,1u1 + ... + a1,n−1un−1 + a1,nun = b1
... .
... .
... .
an−1,n−1un−1 + an−1,nun = bn−1
an,nun = bn
El determinante es det(A) = a11a22...ann 6= 0, luego el sistema se resuelve:
un = a−1nnbn
un−1 = a−1n−1,n−1(bn−1 − an−1,nun)
...
...
...
u1 = a−111 (b1 − a12u2 − ...a1,n−1un−1 − a1nun)
De ese modo, cada componente ui se escribe como combinacion lineal de las bi, bi+1, ..., bn,
luego estamos resolviendo un sitema lineal u = Cb donde C es una matriz triangular
superior. Este metodo se conoce como metodo de remontada. Dicho metodo necesita
un total de
1 + 2 + ... + n− 1 =n(n− 1)
2sumas
1 + 2 + ... + n− 1 =n(n− 1)
2multiplicaciones
n divisiones

17
2.3.2 El metodo de Gauss
El metodo de Gauss es un metodo general de resolucion de un sistema lineal de la
forma Au = b donde A es una matriz inversible. Se compone de tres etapas:
1. procedimiento de eliminacion, que equivale a determinar una matriz inversible M
tal que la matriz MA sea una matriz triangular superior,
2. calculo del vector Mb,
3. resolucion del sistema lineal MAu = Mb, por el metodo de remontada.
a) Etapa de eliminacion:
1) Al menos uno de los elementos de la primera columna de A, ai,j, 1 ≤ i ≤ n es diferente
de cero (o det(A) =0), ai,j, que llamaremos el primer pivote de la eliminacion.
2) Intercambiamos la lınea donde esta el pivote con la primera lınea, lo que equivale a
multiplicar a izquierda por la matriz de trasposicion
T (i0, i1) =
1 | |. . . | |
−− −− 0 −− 1 −− −− i0
| |−− −− 1 −− 0 −− −− i1
| | . . .
|︸︷︷︸i0
|︸︷︷︸i1
1
con det(T (i0, i1)) = −1.
P =
I si a1 1 6= 0
T (1, i) si ai 1, i 6= 1 es el pivote, det(P ) = −1
y P A = (αi j) tal que α1 1 6= 0.
Multiplicamos por combinaciones lineales adecuadas de la primera lınea de P A con
las otras lıneas de P A, de forma que se anulan todos los elementos de la primera columna

18
situados debajo de la diagonal. Es decir, multiplicamos E P A, donde
E =
1 0 . . . 0
−α2 1
α1 1
1
.... . .
−α1 1
α1 1
0 . . . 1
det(E) = 1
Nota 5 Cuando se aplican tecnicas de eliminacion, el coste (numero de operaciones ar-
titmeticas requeridas) suele ser proporcional al numero de coeficientes no cero de la matriz,
puesto que se usan tecnicas especiales para evitar los calculos asociados a los coeficientes
nulos de la matriz. Ademas, el coste de calcular A−1 suele ser del orden de n3.
Ejemplo del metodo de Gauss
A =
0 1 2 1
1 2 1 3
1 1 −1 1
0 1 8 12
b =
1
0
5
2
→
1 2 1 3 | 0
0 1 2 1 | 1
1 1 −1 1 | 5
0 1 8 12 | 2
→
1 2 1 3 | 0
0 1 2 1 | 1
0 −1 −2 −2 | 5
0 1 8 12 | 2
P1 =
0 1 0 0
1 0 0 0
0 0 1 0
0 0 0 1
, E1 =
1 0 0 0
0 1 0 0
−1 0 1 0
0 0 0 1
→
1 2 1 3 | 0
0 1 2 1 | 1
0 0 0 −1 | 6
0 0 6 11 | 1
→
1 2 1 3 | 0
0 1 2 1 | 1
0 0 6 11 | 1
0 0 0 −1 | 6
E2 =
1 0 0 0
0 1 0 0
0 1 1 0
0 −1 0 1
, P3 =
1 0 0 0
0 1 0 0
0 0 0 1
0 0 1 0

19
luego M = P3 E2 E1 P1
En la practica, la matriz “de paso” M no se calcula explıcitamente, sino que se obtienen
directamente M A y M b.
Nota 6 La matriz M verifica
det(M) =
1 si Λ es par
−1 si Λ es impar
Λ es el numero de matrices de permutacion P distintas de la identidad.
A u = b ⇔ M Au = M b.
Nota 7 En el caso de que la matriz A no es inversible, el metodo sigue siendo valido, ya
que en ese caso se considerarıa P = E = I.
Comparacion de metodos:
Cramer
(n + 1) (n!− 1) sumas
(n + 1) (n− 1) n! productos
n divisiones
Cuadro operacion operaciones totales
n Gauss Cramer Cholesky
10 805 399167999 393333
100 681500 ' 10162 338433,3
1000 668165500 ' 102573 33383433,3
El metodo de Gauss es el utilizado mas comunmente para resolver sistemas lineales
cuyas matrices no poseen propiedades particulares (sobre todo llenas).
Todo lo anterior nos permite enunciar el siguiente resultado (que no demostraremos):
Teorema 2 Sea A una matriz cuadrada, inversible o no. Existe al menos una matriz
inversible M tal que MA es triangular superior.

20
Nota 8 Para evitar divisiones por cero en la resolucion de sistemas de ecuaciones, es
conveniente intercambiar ecuaciones. El siguiente ejemplo es una muestra de la ventaja
que este intercambio supone.
Ejemplo: Consideramos el sistema de matriz A =
(2−26 1
1 1
), termino indepen-
diente b =
(1
2
), y solucion u =
(u1
u2
), donde la solucion exacta es
u1 = 2− u2 = 1.00000001490116
u2 =1− 2−25
1− 2−26≈ 0.99999998509884
luego la solucion aproxima a u1 = u2 = 1.
Resolvemos ahora con pivote de dos formas distintas:
a) Tomando 2−26 como pivote:
A =
(2−26 1
1 1
)→
(2−26 1
0 1− 226
)≈
(2−26 1
0 −226
)
b =
(1
2
)→
(1
2− 226
)≈
(1
−226
)
Luego estamos resolviendo el sistema:
−226u2 = −226 → u2 = 1
2−26u1 + u2 = 1 → u1 = 0
b) Tomando 1 como pivote:
A =
(2−26 1
1 1
)→
(1 1
2−26 1
)→
(1 1
0 1− 2−26
)≈
(1 1
0 1
)
b =
(1
2
)→
(2
1
)→
(2
1− 227
)≈
(2
1
)
luego el sistema que resolvemos es:
u1 + u2 = 2
u2 = 1
⇒ u1 = 1
Este ejemplo pone de manifiesto que los errores de redondeo con efecto desastroso
provienen de la division por pivotes “muy pequenos”. En la practica, se utiliza una de
las dos estrategias siguientes en cada etapa k:

21
a) estrategia del pivote parcial: se toma como pivote el elemento de mayor modulo
de entre los n− k ultimos elementos de la columna k-esima.
b) estrategia del pivote total: se toma como pivote el elemento de mayor modulo
de la submatriz correspondiente. Si el pivote elegido esta en la k-esima columna hay
que efectuar un cambio de columnas. Esto cambia el orden de las incognitas, lo que
introduce una dificultad adicional que hace que se use normalmente la estrategia a).
Ejemplo: Aplicamos las dos estrategias anteriores a la matriz ampliada (matriz que
posee como ultima columna el termino independiente):
−1 13 2 | 1
2 0 −1 | 2
1 9 −2 | 0
Si aplicamos la estrategia de pivote parcial, obtenemos:
2 0 −1 | 2
−1 13 2 | 1
1 9 −2 | 0
→
2 0 −1 | 2
0 13 3/2 | 2
0 9 −3/2 | −1
→
2 0 −1 | 2
0 13 3/2 | 2
0 0 −33/13 | −31/13
luego el sistema asociado tiene como solucion:
x =97
66, y =
1
22, z =
31
33.
Si aplicamos la estrategia de pivote total, obtenemos:
13 −1 2 | 1
0 2 −1 | 2
9 1 −2 | 0
→
13 −1 2 | 1
0 2 −1 | 2
0 22/13 −44/13 | −9/13
→
13 2 −1 | 1
0 −1 2 | 2
0 −44/13 22/13 | −9/13
→
13 2 −1 | 1
0 −44/13 22/13 | −9/13
0 −1 2 | 2
→
13 2 −1 | 1
0 −44/13 22/13 | −9/13
0 0 3/2 | 97/44
x =97
66, y =
1
22, z =
31
33.

22
2.3.3 El metodo de Cholesky
Definicion 7 Una matriz A se dice definida positiva si v? Av > 0 para todo vector
v distinto de 0. Si ademas A es simetrica, entonces es definida positiva si todos los
autovalores son reales y estrictamente positivos.
Si A es una matriz simetrica y definida positiva, entonces se puede obtener una factori-
zacion de la forma:
A = B C,
donde B es una matriz triangular inferior y C = BT . Los elementos de la matriz B son
de la forma:
bii =
√√√√aii −i−1∑
k=1
|bik|2
bji =1
bii
(aij −
i−1∑
k=1
bikbjk
), j = i + 1, i + 2, ..., n.
Como A = BBt, se resuelve realmente el sistema lineal Au = b en dos pasos:
Bw = b
Btu = w
Ejemplo: Usando las formulas anteriores para el sistema de matriz
A =
1 −1 0 0
−1 2 −1 2
1 −1 5 2
0 2 2 6,
obtenemos que B es de la forma
B =
1 0 0 0
−1 1 0 0
1 0 2 0
0 2 1 1
En este caso, se realizan:

23
n3
6sumas
n3
6multiplicaciones
n2
2divisiones
n raıces cuadradas
n3
3+
n2
2+ n operaciones totales
2.4 Metodos iterativos
Comenzamos enunciando algunos problemas que pueden presentar los metodos direc-
tos, como motivacion a la introduccion de los metodos iterativos que veremos a continua-
cion.
Problemas de los metodos directos para la resolucion de (SL).
1. Cuando el tamano de la matriz A es grande (n >> 100), la propagacion del error
de redondeo es tambien grande, y los resultados obtenidos pueden diferir bastante
de los exactos.
2. Muchas de las matrices que aparecen en (SL) son de gran tamano ( ' 100 000) pero
la mayorıa de sus elementos son nulos (Esto ocurre, por ejemplo, en la resolucion
de problemas mediante Elementos Finitos). Estas matrices reciben el nombre de
matrices vacıas o huecas, y se dan cuando numero de elemtnos no nulos es de orden
n.
(a) Si los elementos no nulos estan distribuidos alrededor de la diagonal principal,
son de aplicacion todavıa los metodos directos que conservan la estructura
diagonal, como LU o Cholebsky.
(b) Si no ocurre lo anterior, la matriz se dice que es dispersa, y al aplicarle los
metodos directos se produce un fenomeno conocido como rellenado (elementos
que eran nulos en la matriz A, ahora ya no lo son). Entonces, si no se realiza una

24
adaptacion de los metodos directos al caso de matrices dispersas los resultados
no van a ser, en general, buenos (No vamos a estudiar esa adaptacion).
Los metodos iterativos no tienen esos problemas porque se basan en la resolucion
(reiteradas veces) de sistemas diagonales o triangulares (por puntos o por bloques). Lo
que se intenta es que en cada iteracion el numero de operaciones sea mınimo.
2.4.1 Estudio general del Metodo Iterativo
Supongamos un (SL) Au = b, buscamos una matriz B ∈ Mn y un vector c ∈ RN de
forma que la matriz I −B sea inversible y que la unica solucion del sistema lineal
u = B u + c︸ ︷︷ ︸(I−B) u=c
es la solucion Au = b.
Sea A una matriz, dad una matriz Q inversible, podemos descomponer
A = A−Q + Q → Q = (Q−A) + A → Q×Q−1 : I = Q−1(Q−A) + Q−1A ⇒
I = (I −Q−1 A) + Q−1A.
Por lo tanto, multiplicando la ultima expresion por u y teniendo en cuenta que Au = b,
tenemos
u = (I −Q−1A)u + Q−1b.
Si definimos
B = (I −Q−1A) y c = Q−1b
tenemos que: u es solucion del sistema lineal Au = b, sı y solo sı u es solucion de
u = Bu + c. (2.5)
Tenemos entonces que encontrar la solucion de un sistema lineal se puede ver como un
problema de punto fijo (Problema (2.5)). En este caso, la forma de construir un metodo
iterativo es la siguiente:
Considermos u0 ∈ RN un vector arbitrario, se construye una sucesion de vectores
uk∞k=0 dada por
uk+1 = Buk + c, k ∈ N ∪ 0 (2.6)
y se pretende que la sucesion ukk converja a la solucion del sistema lineal.

25
Definicion 8 El metodo iterativo (2.6) es convergente si existe un vector u ∈ RN tal
que:
limk→+∞
uk = u
para cualquier vector inicial u0 ∈ RN . En ese caso,
u = B u + c
El error en cada iteracion se puede medir, por tanto como:
ek = uk − u
Se tiene que,
ek = uk − u = (Buk−1 + c)− (Bu + c) = B(uk−1 − u) = Bek−1 = . . . = Bke0
⇒ eK = BKe0.
De ese modo, el error en las iteraciones depende de las potencias sucesivas de la matriz B,
lo que nos dara el criterior para la convergencia del Metodo Iterativo.
Supondremos que A es no singular en el sistema.
Teorema 3 Sea B la matriz del Metodo Iterativo. Son equivalente:
1. El metodo iterativo es convergente.
2. ρ(B) < 1.
3. Existe una norma matricial ‖| · ‖| (que se puede tomar subordinada) tal que
‖|B‖| < 1
Recordemos que
ρ(B) = max1≤i≤n
|λi(A) : λi(A) ∈ sp(A)es el radio espectral de B.
Teorema 4 Sea B ∈Mn. Si exsite una norma matricial (subordinada o no) tal que
‖|B‖| < 1
entonces I + B es inversible y
‖|(I + B)−1‖| ≤ ‖|I‖|1− ‖|B‖| .

26
Nota 9 1) Si I + B es una matriz singular, ‖|B‖| ≥ 1, para toda norma matricial.
2) Si ‖| · ‖| es una normal matricial subordinada,
‖|(I + B)−1‖| ≤ 1
1− ‖|B‖| .
Ejemplo: La sucesion de vectores
vk =
(2
k3, 1− 1
k2, e1/k
)T
∈ R3
es convergente al vector v = (0, 1, 1)T , v = limk→+∞ vk.
Vskip 0.7 cm
El estudio de Metodos Iterativos reposa sobre la solucion de los dos problemas siguien-
tes:
1) Dada la mariz del metodo iterativo B, determinar si el Metodo Iterativo es conver-
gente.
2) Dados dos metodos iterativos convergentes, compararlos: el metodo iterativo mas
rapido es aquel cuya matriz tiene menor radio espectral.
Nota 10 1. Sea B una matriz real cualquiera y ‖| · ‖| una norma matricial (subordi-
nada o no). Entonces,
ρ(B) ≤ ‖|B‖|
2. Dada una matriz B y ε > 0, existe al menos una norma matricial subordinada tal
que
‖|B‖| ≤ ρ(B) + ε
2.4.2 Metodos de Jacobi, Gauss-Seidel y relajacion
Introducimos tres metods iteraivos clasicos para resolver el Sistema Lineal Au = b.
Todos se basan en descomponer la matriz del sistema A como suma de submatrices:
A = M −N,
donde M es una matriz inversible facil de invertir (en el sentido de que el sistema asociado
sea facil de resolver). Se verifica entonces
Au = b ⇔ (M −N) u = b ⇔ M u = N u + b ⇔

27
u = B u + c con
B = M−1N
c = M−1b
Consideramos entonces el Metodo Iterativo:
u0 ∈ RN
uk+1 = B uk + c, k ∈ N ∪ 0
Como N = M − A, entonces B = M−1N = M−1(M − A) = I −M−1A. Luego,
I −B = M−1A
que es inversible, y por lo tanto el sistema (I −B) u = c tiene solucion unica.
En la practica, en vez de resolver uk+1 como uk+1 = Buk + c, se resuleve el
sistema
Muk+1 = Nuk + M c︸︷︷︸b
. (2.7)
Nota 11 La construccion de la matrices M y N parece que “toma” elementos de A.
Parece que cuanto mas parecida sea la matriz M a A, mas se acercara la solucion a la
exacta (si N = 0 entonces M = A). Pero esto va en contra de que el sistema asociado a
la matriz M (2.7) sea facil de resolver.
Introducimos la siguiente notacion:
Dada A = (ai,j)ni,j=1 ∈ Mn con ai i 6= 0, consideramos la siguiente descomposicion de
la matriz
A =
−F
D
−E
A = D − E − F , donde
D = diag(a1 1, a2 2, . . . , an n) E = (ei j)ni,j=1 F = (fi j)
ni,j=1
con
ei j =
−ai j si i > j
0 si i ≤ j
, fi j =
−ai j si i < j
0 si i ≥ j
.
La llamamos descomposicion D − E − F por puntos de la matriz A.

28
2.4.3 Metodo de Jacobi
Consiste en tomar M = D, N = E + F .
Ası pues,
Au = b ⇔ D u = (E + F ) u + b ⇔ u = D−1(E + F ) u + D−1 b
lo que conduce al metodo de Jacobi iterativo por puntos::
u0 ∈ RN
uk+1 = D−1(E + F ) uk + D−1b k ∈ N ∪ 0o equivalentemente
u0 ∈ RN
Duk+1 = (E + F )uK + b k ∈ N ∪ 0La matriz de Jacobi (por puntos) es B = D−1(E + F ) = I −D−1A
Observemos que si
D =
a1 1
a2 2
. . .
an n
, entoncesD−1 =
1/a1 1
1/a2 2
. . .
1/an n
,
luego,
D−1A =
1 a1 2/a1 1 . . . a1 n/a1 1
a2 1/a2 2 1 . . . a2 n/a2 2
......
an 1/an n an 2/an n . . . 1
.
Por tanto, queda
xk+11
xk+12...
xk+1n
=
0 −a1 2/a1 1 . . . −a1 n/a1 1
−a2 1/a2 2 0 . . . −a2 n/a2 2
......
−an 1/an n −an 2/an n . . . 0
xk1
xk2...
xkn
+
b1/a1 1
b2/a2 2
...
bn/an n
.
de donde:
xk+1j =
bj − aj 1xk1 − aj 2x
k2 − . . .− aj j−1x
kj−1 − aj j+1x
kj−1 − . . . aj nx
kn
aj j
j = 1, . . . , n

29
Observemos que las n componentes del vector xk+1 se calculan simultaneamente a par-
tir de las componente de xk. Por eso el metodo de Jacobi tambien se conoce como el
metodo de iteraciones simultaneas.
La primera cuestion que nos planteamos es la convergencia del metodo. Observamos
que
‖I −D−1A‖∞ = max1≤i≤n
n∑
j=1,j 6=i
∣∣∣∣ai j
ai i
.
Ejemplo 1:
A =
2 −2 0
2 3 −1
α 0 2
, α ∈ R.
D =
2 0 0
0 3 0
0 0 2
, E =
0 0 0
−2 0 0
−α 0 2
, F =
0 2 0
0 0 1
0 0 0
,
J = D−1(E + F ) =
1/2 0 0
0 1/3 0
0 0 1/2
0 2 0
−2 0 1
−α 0 0
=
0 1 0
−2/3 0 1/3
−α/2 0 0
.
Definicion 9 Una matrix A = (ai j)ni,j=1 ∈ Mn se dice que es diagonal estrictamente
dominante si
|ai i| >n∑
j=1 j 6=i
|ai,j|, i = 1, . . . , n.
Teorema 5 Si A ∈ Mn es una matriz diagonal estrictamente dominante, el metodo
iterativo de Jacobi por puntos es convergente.
2.4.4 Metodo de Gauss-Seidel
Una estrategia adecuada para mejorar la convergencia del metodo de Jacobi serıa
utilizar en el paso de calculo de la componente
uk+1i
las componentes calculadas hasta el momento:
uk+11 , uk+1
2 , . . . , uk+1i−1 en vez de uk
1, uk2, . . . , u
ki−1

30
Es decir, consiste en reemplazar el sistema correspondiente al metodo de Jacobi:
ai iuk+1i = bi −
i−1∑j=1
ai jukj −
n∑j=i+1
ai jukj , (2.8)
por
ai iuk+1i = bi −
i−1∑j=1
ai juk+1j −
n∑j=i+1
ai jukj , (2.9)
Matricialmente, las ecuaciones anteriores se escriben como:
D uk+1 = b + E uk+1 + F uk,
es decir,
(D − E) uk+1 = F uk + b
Luego,
M = D − E, N = F
el metodo iterativo de Gauss-Seidel por puntos se escribe:
u0 ∈ Rn
uk+1 = (D − E)−1F uk + (D − E)−1 b, k ∈ N ∪ 0
o equivalentemente
u0 ∈ Rn
(D − E) uk+1 = F uk + b k ∈ N ∪ 0
La matrix de Gauss-Seidel (por puntos) es entonces:
B = (D − E)−1 F = I − (D − E)−1 A.
En este metodo, para calcular las componentes del vector uk+1, necesitamos tanto
las componentes de uk+1 ya calculadas, como las restantes del vector uk, por lo que se
denomina metodo de las aproximaciones sucesivas. Dicho metodo sera mas rapido ya que
la matriz M contiene mas elementos de A.

31
Ejemplo: Sea
A =
2 −2 0
2 3 −1
α 0 2
, α ∈ R.
GS = (D − E)−1 F =
2 0 0
2 3 0
α 0 2
−1
0 2 0
0 0 1
0 0 0
=
0 1 0
0 −2/3 1/3
0 −α/2 0
.
La siguiente tabla nos da los radios espectrales de las matrices de los metodos de
Jacobi y Gauss-Seidel para valores concretos del parametro α.
α ρ(GS) ρ(J)
−1 0.848656 0.860379
−3 0.97263 1.11506
−5 1.08264 1.305158
Teorema 6 Si A es diagonal estrictamente dominante, entonces el metodo de Gauss-
Seidel es convergente.
Hay muchas otras condiciones de convergencia particulares para los distintos metodos.
Entre ellas, la mas significativa es:
Teorema 7 Si A es simetrica y definida positiva, el metodo de Gauss-Seidel es conver-
gente.
Definicion 10 Una matriz A se dice definida positiva si:
vtav > 0, ∀v ∈ Rn ∪ 0
o equivalentemente si sp(A) ⊂ R+, todos sus autovalores son positivos (no nulos).
Problema:
Estudiar la convergencia de los metodos de Jacobi y Gauss-Seidel por puntos para las
matrices:
A =
1 2 −2
1 1 1
2 2 1
A =
2 −1 1
2 2 2
−1 −1 2
Problema: Metodo iterativo para el calculo de la inversa de una matriz.

32
Se consideran las sucesiones de matrices
An = An−1(I + En + E2n), En = I − AAn−1
siendo A ∈Mn inversible y A0 ∈Mn una matriz arbitraria.
1. Demostrar que En = (E1)3n−1
.
2. Probar que si ρ(E1) < 1, entonces
limn→+∞
An = A−1
3. Mostrar que si se toma A0 = A∗/tr(AA∗), entonces
limn→+∞
An = A−1.
2.4.5 Test de parada de las iteraciones
Cuando un metodo iterativo es convergente, la solucion del sistema lineal Au = b
se obtiene como lımite de la sucesion uk∞k=0 de iteraciones. Ante la impoisibilidad de
calcular todas las iteraciones, se plantea el problema de determinar un valor k ∈ N∪ 0para el cual podemos considerar que uk sea una buena aproximacion de u. Es decir, si se
desea que el error relativo sea inferior a una cierta cantidad prefijada ε, se debe cumplir,
‖uk − u‖ < ε‖u‖
para alguna norma vectorial.
Sin embargo, como u es desconocido, no se puede trabajar con esa cantidad.
Si calculamos:
‖uk+1 − uk‖ < ε‖uk+1‖puede que uk+1 no este proximo a u.
Una condicion de parada de las iteraciones adecuada viene dada a partir del vector
residuo
rk = b− Auk = A(u− uk), k ∈ N ∪ 0.Entonces, si uk ' u y Auk ' b,
‖rk‖‖b‖ =
‖A(uk − u)‖‖Au‖ < ε

33
Es decir, buscamos k ∈ N ∪ 0 tal que
‖rk‖ < ε‖b‖.
Debe procurarse que la comprobacion de los tests de parada no incremente en exceso
el numero de operaciones necesarias para realizar una iteracion. Reescribiendo los calculos
de forma adecuada obtenemos:
1. Metodo de Jacobi:
D uk+1 = b + (E + F ) uk = b + (−A + D) uk =
= b− Auk + D uk = rk + D uk
Por tanto,
D (uk+1 − uk) = rk.
De ese modo, el metodo de jacobi se implementa de la siguiente forma:
1) Se calcula rk como rk = b− Auk.
2) Se resuelve el sistema D dk = rk.
3) uk+1 = uk + dk
De esta forma, se calcula el valor uk+1 a partir de uk y se aprovechan los calculos
intermedios, en concreto rk, para el test de parada. Tenemos el esquema:
rki = bi −
∑nj=1 ai j uk
j
dki =
rki
ai i
uk+1i = uk
i + dki
2. Metodo de Gauss-Seidel Analogamente, la implementacion del metodo de Gauss-
Seidel, se realiza en las siguiente etapas:
rki = bi −
∑i−1j=1 ai j uk+1
j −∑nj=i+1 ai j uk
j
dki =
erki
ai i
uk+1i = uk
i + dki
Nota 12 Las normas vectoriales que suelen usarse con mas frecuencia en los test de
parada son ‖ · ‖2 y ‖ · ‖∞.

34

Tema 3
Resolucion numerica de ecuaciones
diferenciales ordinarias
El objetivo de este tema sera la resolucion numerica de ecuaciones diferenciales or-
dinarias (e.d.o.). Nuestro problema de partida sera determinar de forma aproximada,
mediante el uso de Metodos Numericos de Calculo, una solucion de una e.d.o. de primer
orden, conociendo el valor de la curva solucion en un punto.
Otros problemas que se estudiaran seran la resolucion numerica de ecuaciones diferen-
ciales de orden superior y problemas de valores frontera.
Interes: Las ecuaciones diferenciales se usan de forma habitual para construir modelos
matematicos en una amplia variedad de problemas de la ciencia y la ingenierıa. En dichos
problemas se buscan los valores de ciertas funciones desconocidas a traves de lo unico que
somos capaces de medir: como los cambios de una variable afectan a otra. Cuando esta
relacion de cambios se traducen a un modelo matematico, el resultado es una ecuacion
diferencial.
Ejemplo: Consideremos la temperatura de un objeto y(t) que se enfrıa. Podrıamos con-
jeturar que la velocidad del cambio de la temperatura del cuerpo esta relacionada con
la diferencia entre su temperatura y la del medio que lo rodea: los experimentos lo con-
firman y la ley del enfriamento de Newton establece que dicha velocidad de cambio es
directamente proporcional a la diferencia de estas temperaturas. Si denotamos por y(t)
la temperatura del cuerpo en el instante t, y A la temperatura del medio que lo rodea,
∂y
∂t= −k(y − A).
donde k es una constante positiva, y el signo negativo indica que la temperatura decrece
35
36
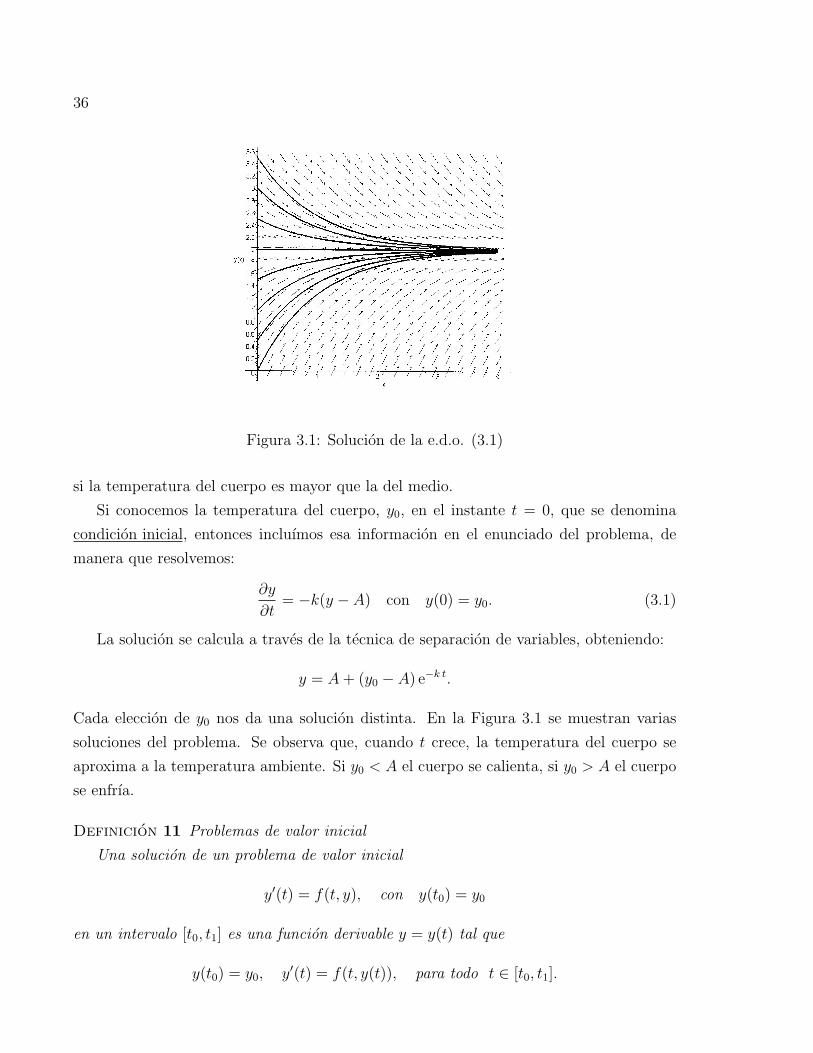
Figura 3.1: Solucion de la e.d.o. (3.1)
si la temperatura del cuerpo es mayor que la del medio.
Si conocemos la temperatura del cuerpo, y0, en el instante t = 0, que se denomina
condicion inicial, entonces incluımos esa informacion en el enunciado del problema, de
manera que resolvemos:
∂y
∂t= −k(y − A) con y(0) = y0. (3.1)
La solucion se calcula a traves de la tecnica de separacion de variables, obteniendo:
y = A + (y0 − A) e−k t.
Cada eleccion de y0 nos da una solucion distinta. En la Figura 3.1 se muestran varias
soluciones del problema. Se observa que, cuando t crece, la temperatura del cuerpo se
aproxima a la temperatura ambiente. Si y0 < A el cuerpo se calienta, si y0 > A el cuerpo
se enfrıa.
Definicion 11 Problemas de valor inicial
Una solucion de un problema de valor inicial
y′(t) = f(t, y), con y(t0) = y0
en un intervalo [t0, t1] es una funcion derivable y = y(t) tal que
y(t0) = y0, y′(t) = f(t, y(t)), para todo t ∈ [t0, t1].

37
Campo de direcciones o pendientes
En cada punto (t, y) del rectangulo R = (t, y); a ≤ t ≤ b, c ≤ y ≤ d
a b
c
d
t
y
la pendiente m de la solucion y = y(t) (derivada) se puede calcular mediante la formula
implıcita
m = f(t, y(t)).
Por tanto, cada valor mi,j = f(ti, yj), calculado para cada punto del rectangulo representa
la pendiente de la recta tangente a la solucion que pasa por el punto (ti, yj).
Un campo de direcciones o campo de pendientes es una grafica en la que se representan
las pendientes mi,j en una coleccion de puntos del rectangulo, y puede usarse para ver
como se va ajustando una solucion a la pendiente dada: Calculamos la pendiente en el
punto inicial (t0, y0) → f(t0, y0) para determinar en que direccion debemos movernos.
Damos un paso horizontal desde t0, t0 + h y nos desplazamos verticalmente una distancia
apropiada h f(t0, y0), llegando al punto (t1, y1) de manera que el desplazamiento total que
resulta tenga la inclinacion requerida. Una vez en el punto (t1, y1) se repite el proceso
a lo largo de la solucion. Como solo podemos dar un numero finito de pasos, el metodo
reproduce una aproximacion de la solucion.

38
3.1 El metodo de Euler
Sea [a, b] el intervalo en el que queremos hallar la solucion de un problema de valor
inicial
y′(t) = f(t, y(t))
y(t0) = y0
con f lipschitziana.
Construimos un conjunto finito de puntos (tk, yk) que son aproximaciones de la solucion
(y(tk) ≈ yk).
Problema: Construir dichos puntos verificando una ecuacion diferencial. Para f(t, y), t
seran las abcisas, y las ordenadas de los puntos (t, y). Dividimos el intervalo [a, b] en M
subintervalos (de igual tamano) en la siguiente particion:
tk = a + k h, k = 0, 1, . . . , M, h =b− a
M.
El valor de incremento de h se llama tamano del paso.
Resolucion aproximada: De y′(t) = f(t, y(t)) en [t0, tM ] con y(t0) = y0.
Suponiendo que y(t), y′(t), y′′(t) son continuas y usando el Teorema de Taylor para
desarrollar y(t) alrededor del punto t = t0, para cada punto t existe un punto c1 entre t0
y t tal que
y(t) = y(t0) + y′(t0)(t− t0) + y′′(c1)(t− t0)
2
2.
Al sustituir y′(t0) = f(t0, y(t0)), h = t1 − t0, obtenemos una expresion para y(t1):
y(t1) = y(t0) + h f(t0, y(t0)) + y′′(c1)h2
2.
Si el tamano de paso es suficientemente pequeno, h2 se puede considerar despreciable
y
y(t1) ≈ y1 = y0 + h f(t0, y0)
que es la aproximacion de Euler.
Repitiendo el proceso, generamos una sucesion de puntos que se aproximan a la grafica
de la solucion y = y(t). El paso general del metodo de Euler es:
tk+1 = tk + h, yk+1 = yk + h f(tk, yk), k = 0, 1, . . . ,M − 1.
Ejemplo:

39
Usamos el metodo de Euler para hallar una solucion aproximada del problema de valor
inicial
y′(t) = R y(t), t ∈ [0, 1], y(0) = y0, R = constante.
Debemos:
1. Elegir el tamano de paso h.
2. Usar la formula para calcular las ordenadas y(t), que se llama ecuacion en diferencia.
yk+1 = yk + hR yk = yk (1 + hR) = yk−1(1 + h R)2 =
= . . . = y0(1 + hR)k+1, k = 0, 1, . . . , M − 1.
En la mayorıa de los casos no se puede hallar una formula explıcita para determinar las
aproximaciones, pero este es un caso especial. Concretamente, es la
formula para calcular el interes compuesto a partir de un deposito inicial.
Ejemplo: Supongamos que se depositan 1000 euros durante 5 anos a un interes compuesto
del 10 %. Cual es el capital acumulado al cabo de esos 5 anos?.
y′(t) = 0.1 y en [0, 5]
y(0) = 1000
y(t) = 1000 e0.1 t
yk = y0(1 + hR)k = 1000(1 + 0.1 h)k
Tamano paso Numero iteraciones M yM ≈ y(5)
1 5 1000(1 + 0.1)5 = 1610.51
1/12 60 1000(1 + 0.1
12
)60= 1645.31
1/360 1800 100(1 + 0.1
360
)1800= 1648.61
La solucion exacta es y(5) = 1648.72 = 1000e0.5.

40
Descripcion geometrica
3.1.1 Tamano del paso frente al error
Los metodos que presentamos se llaman metodos de difererencias o metodos de varia-
ble discreta. En ellos la solucion se aproxima en un numero finito de puntos llamados
nodos. Son de la forma:
yk+1 = yk + hφ(tk, yk) (3.2)
donde φ se llama funcion incremental, y es de paso simple (o de un solo paso) porque en
el calculo del nuevo punto solo interviene el punto inmediatamente anterior.
Cuando usamos metodos de variable discreta para resolver de manera aproximada un
metodo de valor inicial, existen 2 fuentes de error:
- discretizacion
- redondeo
Definicion 12 Error de discretizacion
Supongamos que (tk, yk)Mk=0 es un conjunto finito de aproximaciones a la unica so-
lucion y = y(t) de un problema de valor inicial.
Se define el error de truncamiento global o error de discretizacion global ek como:
ek = y(tk)− yk, k = 0, 1, . . . , M.
que es la diferencia entre la solucion exacta y la calculada con el metodo en el nodo
correspondiente.

41
Se llama error de consistencia (o error de truncamiento local) εk+1 a:
εk+1 = y(tk+1)− y(tk)− hφ(tk, y(tk)), k = 0, 1, . . . , M − 1.
y es el error que se comete en un solo paso (el que lleva desde el nodo tk al tk+1).
En el metodo de Euler, en cada paso se desprecia un termino
y′′(ck)h2
2.
Si ese fuera el unico error que se comete en cada paso, al llegar al extremo superior del
intervalo (dar M pasos) el error acumulado serıa:
M∑
k=1
y′′(ck)h2
2≈ My′′(c)
h2
2=
hM
2y′′(c)h =
=(b− a)
2y′′(c) h = O(h).
Podrıa haber otros errores, pero esta estimacion es la que predomina.
Teorema 8 (Precision del metodo de Euler)
Sea y(t) la solucion de y′(t) = f(t, y)
y(t0) = y0
Si y ∈ C2([t0, b]) y (tk, yk)Mk=0 es la sucesion de aproximaciones generada por el metodo
de Euler, entonces
|ek| = |y(tk)− yk| = O(h)
|εk+1| = |y(tk+1)− y(tk)− h f(tk, y(tk))| = O(h2)
El error al final del intervalo, llamado error global final, viene dado por
E(y(b), h) = |y(b)− yM | = O(h).
Nota 13 El error global final se usa para estudiar el comportamiento del error para ta-
manos de paso diferentes, luego nos da una idea del esfuerzo computacional a realizar
para obtener las aproximaciones deseadas
E(y(b), h) ≈ c h
E(y(b),h
2) ≈ c
2h ≈ 1
2E(y(b), h)
luego si reducimos a la mitad el tamano de paso en el metodo de Euler, el error global
final tambien se reduce a la mitad.

42
Figura 3.2: Aproximacion de Euler con paso h = 1 para resolver la e.d.o. (3.1)
Figura 3.3: Aproximacion de Euler con tamanos de paso diferentes para resolver la e.d.o.
(3.1)
La siguiente tabla compara las soluciones obtenidas con el metodo de Euler, con dife-
rentes tamanos, para y′(t) = (t− y)/2 en [0, 2] con condicion inicial y(0) = 1:

43
yk
tk h = 1 h = 12
h = 14
h = 18
y(tk) exacto
0 1.0 1.0 1.0 1.0 1.0
0.125 0.9375 0.943239
0.25 0.875 0.886719 0.897491
0.325 0.846924 0.862087
0.50 0.75 0.796875 0.817429 0.836402
0.75 0.759766 0.786802 0.811868
1.00 0.5 0.6875 0.758545 0.790158 0.819592
1.50 0.765625 0.846386 0.882855 0.917100
2.00 0.75 0.949219 1.030827 1.068222 1.103638
2.5 1.211914 1.289227 1.325176 1.359514
3.00 1.375 1.533936 1.604252 1.637429 1.669390
Por ultimo, comparamos los errores globales finales para la e. d. o. con valor incial
anterior, aproximada por el metodo de Euler, usando los tamanos de paso h = 1, 12, ..., 1
64.
Tamano de
paso h
No de
pasos N
Aproximacion
yN a y(3)
Error global final,
y(3)− yN
O(h2) ≈ C h2
con C = −0.0432
1 3 1.375 0.294390 0.25612
6 1.533936 0.135454 0.12814
12 1.604252 0.065138 0.06418
24 1.637429 0.031961 0.032116
48 1.653557 0.015833 0.016132
96 1.661510 0.007880 0.008164
192 1.665459 0.003931 0.004
3.1.2 Orden de un metodo
Supongamos que al resolver un problema tenemos
e1 −→ error h1 error correspondiente al uso del paso h1
e2 −→ error h2 error correspondiente al uso del paso h2

44
Tenemos que el error que comete es e ' c hp, y queremos determinar el valor de la
pontencia p. Entonces:
e1 = c hp1
e2 = c hp2
→ e1
e2
=hp
1
hp2
⇒ ln
(e1
e2
)= p ln
(h1
h2
)
⇒ p =ln(e1/e2)
ln(h1/h2).
Estimacion de la precision:
Si yh e yh/2 coinciden en n dıgitos, se puede suponer que esos n dıgitos son exactos.
Definicion 13 Se dice que un metodo es de orden mayor o igual a p (p > 0) si para toda
solucion y(t) del problema en [a, b], si y ∈ Cp+1([a, b]) y existe k > 0 (que solo depende
de y, φ, pero es independiente de h) tal que:
M−1∑n=0
|εn+1| ≤ k hp
Consistencia y estabilidad del metodo
Definicion 14 El metodo es consistente al problema
y′(t) = f(t, y) en [a, b]
y(a) = y0
si
limh→0
M−1∑n=0
|y(tn+1)− y(tn)− hφ(tn, y(tn); h)| = 0,
es decir, segun la definicion de εn+1, el error de consistencia,
limh→0
M−1∑n=0
|εn+1| = 0
Definicion 15 Un metodo se dice estable si existe c > 0 (constante de estabilidad)
independiente de h, tal que
yk+1 = yk + hφ(tk, yk; h)
zk+1 = zk + hφ(tk, zk; h) + ρk
0 ≤ k ≤ N, ∀yk, zk, ρk
max0≤k≤M
|yk − zk| ≤ c |y0 − z0|︸ ︷︷ ︸error inicial
+∑
0≤k≤N−1
|ρk|︸ ︷︷ ︸
suma de errores en cada etapa

45
Definicion 16 Un metodo es convergente a la solucion del problema si
limh→0
max0≤k≤M
|yk − y(tk)| = 0
Teorema 9 El metodo es consistente si y solo si φ(t, y; 0) = f(t, y) ∀t ∈ [a, b], ∀y ∈ R.
Teorema 10 Si el metodo es estable y consistente, entonces es convergente.
3.2 El metodo de Heun
La siguiente tecnica introduce una nueva idea en la construccion del algoritmo para
resolver el problema de valor inicial:
y′(t) = f(t, y(t)) en [a, b],
y(t0) = y0
Para obtener el punto (t1, y1), usamos el Teorema fundamental del Calculo, integrando
y′(t) en [t0, t1] de manera que:
∫ t1
t0
f(t, y(t)) dt =
∫ t1
t0
y′(t) dt = y(t1)− y(t0),
⇒ y(t1) = y(t0) +
∫ t1
t0
f(t, y(t)) dt.
Usamos ahora un metodo de integracion para aproximar la integral que aparece a la
derecha de la expresion anterior. Usando la regla del trapecio con incremento h = t1− t0,
el resultado es:
y(t1) ≈ y(t0) +h
2(f(t0, y(t0)) + f(t1, y(t1))) .
Ahora bien, como y(t1) (que es lo queremos aproximar) aparece tambien en la expresion
de la aproximacion, entonces aplicamos el metodo de Euler para aproximar la y(t1) que
aperece en f(t1, y(t1)):
y(t1) ≈ y(t0) + h f(t, y(t0)),
y obtenemos:
y(t1) ≈ y0 +h
2(f(t0, y0) + f(t1, y0 + h f(t0, y0)))
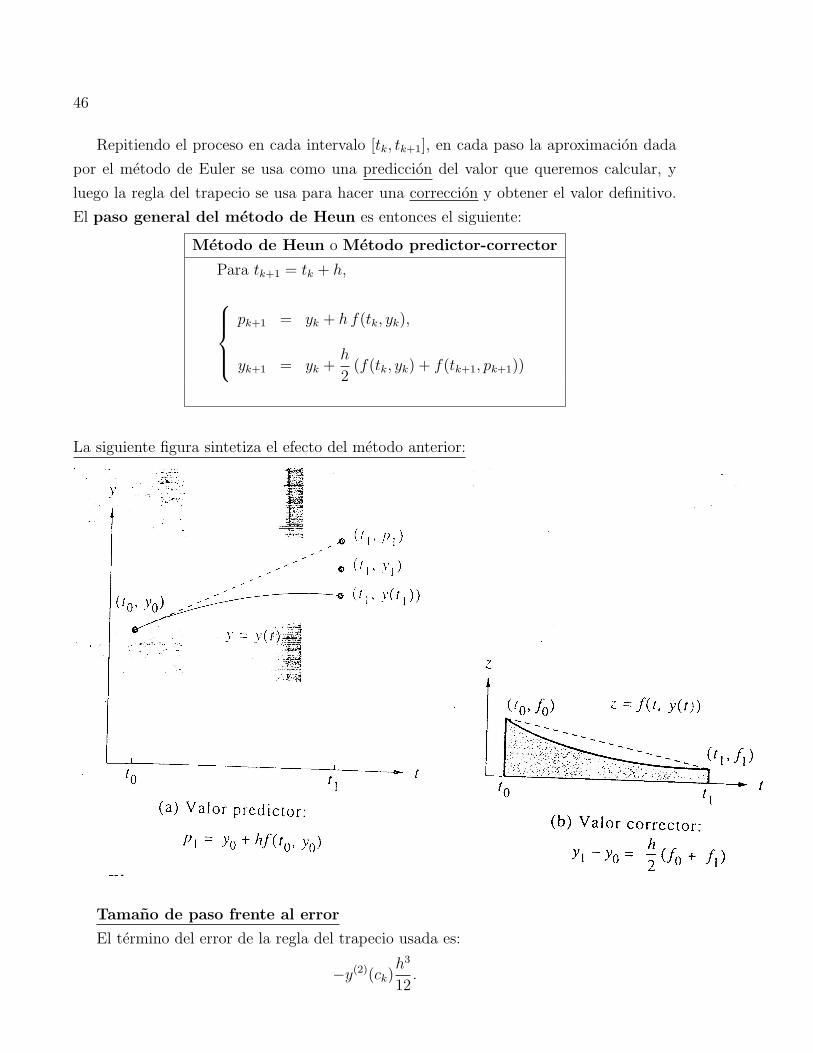
46
Repitiendo el proceso en cada intervalo [tk, tk+1], en cada paso la aproximacion dada
por el metodo de Euler se usa como una prediccion del valor que queremos calcular, y
luego la regla del trapecio se usa para hacer una correccion y obtener el valor definitivo.
El paso general del metodo de Heun es entonces el siguiente:
Metodo de Heun o Metodo predictor-corrector
Para tk+1 = tk + h,
pk+1 = yk + h f(tk, yk),
yk+1 = yk +h
2(f(tk, yk) + f(tk+1, pk+1))
La siguiente figura sintetiza el efecto del metodo anterior:
Tamano de paso frente al error
El termino del error de la regla del trapecio usada es:
−y(2)(ck)h3
12.

47
Si el unico error que se cometiese en cada paso fuese el anterior, entonces despues de M
pasos del metodo de Heun el error acumulado serıa:
−M∑
k=1
y(2)(ck)h3
12≈M y(2)(c)
b− a
M
h2
12= y(2)(c) (b− a)
h2
12= O(h2)
El siguiente teorema establece la relacion entre el error final y el tamano de paso, y se
puede usar para dar una idea del esfuerzo computacional requerido para el metodo si
queremos obtener una precision fijada de antemano.
Teorema 11 (Precision del metodo de Heun)
Supongamos que y(t) es la solucion de un problema de valor inicial
y′(t) = f(t, y(t)),
y(t0) = y0.
Si y(t) ∈ C3([t0, b]), y (tk, yk)Nk=0 es la sucesion de aproximaciones dadas por el metodo
de Heun, entonces:
|ek| = |y(tk)− yk| = O(h2),
|εk| = |y(tk+1)− y(tk)− h φ(tk, y(tk))| = O(h3),
donde φ(tk, y(tk)) =1
2(f(tk, y(tk)) + f(tk+1, y(tk) + h f(tk, y(tk)))). En particular, el
error global final en el extremo derecho del intervalo verifica:
E(y(b), h) = |y(b)− yM | = O(h2).
Los siguientes ejemplos ilustran el Teorema de la precision del metodo:
Si usasemos tamanos de paso h y h/2, obtendrıamos:
E(y(b), h) ≈ C h2,
E(y(b), h2) ≈ C
h2
4=
1
4C h2 ≈
1
4E(y(b), h).
Entonces, si en el metodo de Heun el tamano de paso se reduce a la mitad, el
error global final se reduce a su cuarta parte.
Ejemplo: Usamos el metodo de Heun para resolver el problema:
y′(t) =t− y
2, en [0, 3], con y(0) = 1,
y comparamos las soluciones obtenidas para tamano de paso h = 1, h = 12, h = 1
4, y
h = 18. La solucion exacta es y(t) = 3 e−t/2 + t− 2.

48
Para h = 14, t0 = 0, t1 = 1
4, y0 = 1, luego:
f(t0, y0) =0− 1
2= −0.5,
p1 = y0 + h f(t0, y0) = 1− 1
4
1
2= 0.875,
f(t1, p1) =0.25− 0.875
2= −0.3125,
y1 = y0 +h
2(f(t0, y0) + f(t1, y1)) = 1 +
1
8(−0.5− 0.3125) = 0.8984375.
Iterando en cada nodo, obtenemos:
y(3) ≈ y12 = 1.672269.
La siguiente figura nos da idea de la aproximacion obtenida con el metodo de Heun
con tamano h = 1 y h = 1/2 para y′(t) = (t−y)/2 en [0, 2] con condicion inicial y(0) = 1:
La siguiente tabla compara las soluciones obtenidas con el metodo de Heun, con dife-
rentes tamanos, para y′(t) = (t− y)/2 en [0, 2] con condicion inicial y(0) = 1:

49
yk
tk h = 1 h = 12
h = 14
h = 18
y(tk) exacto
0 1.0 1.0 1.0 1.0 1.0
0.125 0.943359 0.943239
0.25 0.898438 0.897717 0.897491
0.325 0.862406 0.862087
0.50 0.84375 0.838074 0.836801 0.836402
0.75 0.814081 0.812395 0.811868
1.00 0.875 0.831055 0.822196 0.820213 0.819592
1.50 0.930511 0.920143 0.917825 0.917100
2.00 1.171875 1.117587 1.106800 1.104392 1.103638
2.5 1.373115 1.362593 1.360248 1.359514
3.00 1.732422 1.682121 1.672269 1.670076 1.669390
Por ultimo, comparamos los errores globales finales para la e. d. o. con valor incial
anterior, aproximada por el metodo de Heun, usando los tamanos de paso h = 1, 12, ..., 1
64.
Tamano de
paso h
No de
pasos N
Aproximacion
yN a y(3)
Error global final,
y(3)− yN
O(h2) ≈ C h2
con C = −0.0432
1 3 1.732422 -0.063032 -0.04320012
6 1.682121 -0.012731 -0.01080014
12 1.672269 -0.002879 -0.00270018
24 1.670076 -0.000686 -0.000675116
48 1.669558 -0.000168 -0.000169132
96 1.669432 -0.000042 -0.000042164
192 1.669401 -0.000011 -0.000011
Nota 14 El metodo de Heun tambien es conocido con el nombre de metodo de Euler
mejorado.

50
3.3 Metodos de Runge-Kutta
Para disenar estos metodos, la pendiente usada es un promedio entre los valores de la
pendiente en el lımite izquierdo del intervalo [tk, tk+1] y en otros puntos intermedios:
yk+1 = yk + h funcionpromedio
donde funcionpromedio = a fk + b fk′ con a y b pesos a elegir de la forma:
fk = f(tk, yk),
fk′ = f(tk + α h, yk + β h fk)
donde los parametros α, β especifican la posicion del punto intermedio.
Runge y Kutta disenaron el algoritmo eligiendo 4 parametros a, b, α y β de manera
que el resultado fuese lo mas preciso posible. Los parametros son independientes entre sı.
Las restricciones se obtienen desarrollando en serie de Taylor la funcion f en (t, y):
a + b = 1
α b = β b = 12,
que es un sistema de 3 ecuaciones con 4 incognitas. Si elegimos a = 0, b = 1, α = β = 12,
obtenemos:
Euler modificado
yk+1 = yk + h f(tk +h
2, yk +
h
2f(tk, yk))
Si a = b = 12, α = β = 1, se obtiene el metodo de Heun o Euler mejorado. Dicho
metodo y el anterior son metodos de segundo orden.
3.3.1 Algoritmos de Runge-Kutta de cuarto orden
Si incluimos mas puntos en el muestreo dentro del intervalo, el metodo basico de
Runge-Kutta puede mejorarse para que el error de truncamiento global (final) sea pro-
porcional a h4 (es decir, se trata de un metodo de cuarto orden). Despues de hacer
desarrollos en serie de Taylor, se obtiene:
yk+1 = yk +h
6(f1 + 2 f2 + 2 f3 + f4) ,

51
donde
f1 = f(tk, yk)
f2 = f(tk + h2, yk + h
2f1)
f3 = f(tk + h2, yk + h
2f2)
f4 = f(tk + h, yk + h f3)
Nota 15 En general, los metodos de Runge-Kutta son de la forma:
y0 dado
yk+1 = yk + h
(r∑
i=1
ωi ki
),
donde ki = f(tk + ci h, yk + h
(i−1∑j=1
aij kj
)), con c1 = 0, ci ∈ [0, 1], ωi ∈ R, aij ∈ R.
Tamano de paso frente al error
El termino del error de la regla de Simpson con incremento h/2 es:
−y(4)(c1)h5
2880.
Si el unico error que apareciese en cada paso fuera el anterior, entonces en N pasos el
error acumulado al llevar a cabo el metodo serıa:
−N∑
k=1
y(4)(ck)h5
2880≈
b− a
5760y(4)(c) h4 ≈ O(h4).
Teorema 12 (Precision del metodo de Runge-Kutta)
Supongamos que y(t) es la solucion del problema de valor inicial
y′(t) = f(t, y(t)),
y(0) = y0
.
Si y(t) ∈ C5([t0, b]) y (tk, yk)Nk=0 es la sucesion de aproximaciones generada por el
metodo de Runge-Kutta de cuarto orden, entonces:
|ek| = |y(tk)− yk| = O(h4),
|εk| = |y(tk+1)− yk − hTr(tk, yk)| = O(h5),
donde Tr(tk, yk) es la funcion promedio del metodo. En particular, el error global final
verifica:
E(y(b), h) = |y(b)− yM | = O(h4).
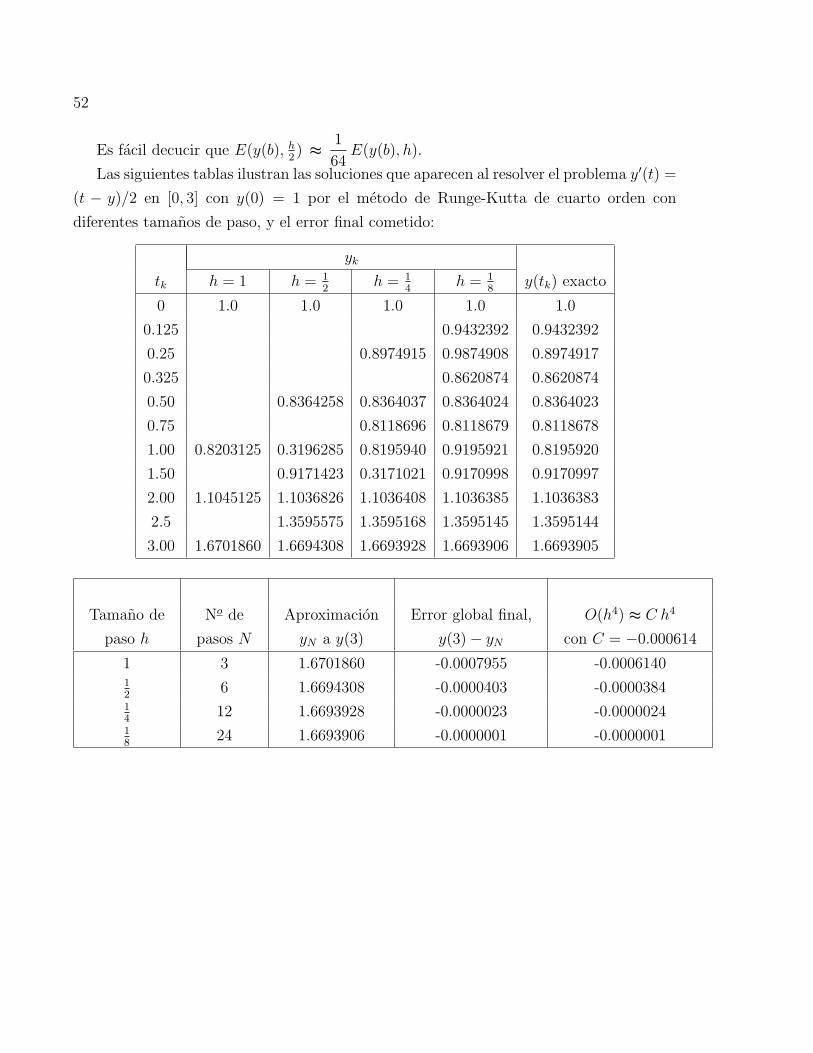
52
Es facil decucir que E(y(b), h2) ≈
1
64E(y(b), h).
Las siguientes tablas ilustran las soluciones que aparecen al resolver el problema y′(t) =
(t − y)/2 en [0, 3] con y(0) = 1 por el metodo de Runge-Kutta de cuarto orden con
diferentes tamanos de paso, y el error final cometido:
yk
tk h = 1 h = 12
h = 14
h = 18
y(tk) exacto
0 1.0 1.0 1.0 1.0 1.0
0.125 0.9432392 0.9432392
0.25 0.8974915 0.9874908 0.8974917
0.325 0.8620874 0.8620874
0.50 0.8364258 0.8364037 0.8364024 0.8364023
0.75 0.8118696 0.8118679 0.8118678
1.00 0.8203125 0.3196285 0.8195940 0.9195921 0.8195920
1.50 0.9171423 0.3171021 0.9170998 0.9170997
2.00 1.1045125 1.1036826 1.1036408 1.1036385 1.1036383
2.5 1.3595575 1.3595168 1.3595145 1.3595144
3.00 1.6701860 1.6694308 1.6693928 1.6693906 1.6693905
Tamano de
paso h
No de
pasos N
Aproximacion
yN a y(3)
Error global final,
y(3)− yN
O(h4) ≈ C h4
con C = −0.000614
1 3 1.6701860 -0.0007955 -0.000614012
6 1.6694308 -0.0000403 -0.000038414
12 1.6693928 -0.0000023 -0.000002418
24 1.6693906 -0.0000001 -0.0000001

Tema 3
Parte II (e. d. o. s): Resolucion
numerica de ecuaciones diferenciales
ordinarias
3.4 Sistemas de Ecuaciones Diferenciales
Consideramos el problema de valor inicial:
(S)
dx
dt(t) = f(t, x(t), y(t))
dy
dt(t) = g(t, x(t), y(t))
con
x(t0) = x0
y(t0) = y0
Definicion 17 Una solucion de (S) es un par de funciones derivables x(t), y(t), tales
que cuando t, x(t), y(t) se sustituyen en f(t, x(t), y(t)), g(t, x(t), y(t)) el resultado es igual
a las derivadas x′(t), y′(t) respectivamente, es decir:
x′(t) = f(t, x(t), y(t))
y′(t) = g(t, x(t), y(t))
con
x(t0) = x0
y(t0) = y0
Ejemplo: Consideramos el sistema
dx
dt(t) = x + 2y
dy
dt(t) = 3x + 2y
con
x(0) = 6
y(0) = 4
53

54
La solucion exacta es:
x(t) = 6e4t + 2e−t
y(t) = 6e4t − 2e−t
3.4.1 Resolucion numerica
Podemos encontrar una solucion numerica del sistema (S) en un intervalo [a, b] consi-
derando los diferenciales:
d x = f(t, x, y) dt, dy = g(t, x, y) dt
Reescribiendo los incrementos dt = tk+1 − tk, dx = xk+1 − xk, dy = yk+1 − yk, es facil
implementar el metodo de Euler:
xk+1 − xk ≈ f(tk, xk, yk) (tk+1 − tk)
yk+1 − yk ≈ g(tk, xk, yk) (tk+1 − tk)
Dividiendo el intervalo [a, b] en N subintervalos de anchura h =b− a
N, y tomando los
nodos tk+1 = tk + h, obtenemos las formulas correspondientes al metodo de Euler:
Metodo de Euler
tk+1 = tk + h
xk+1 = xk + h f(tk, xk, yk)
yk+1 = yk + h g(tk, xk, yk)), para k = 0, 1, ..., N − 1.
Sin embargo, para obtener un grado de precision razonable, es necesario utilizar un
metodo de orden mayor. Por ejemplo, las formulas para el metodode Runge-Kutta de
orden 4 son:

55
Metodo de Runge-Kutta de orden 4
xk+1 = xk +h
6(f1 + 2 f2 + 2 f3 + f4),
yk+1 = yk +h
6(g1 + 2 g2 + 2 g3 + g4) ,
donde
f1 = f(tk, xk, yk), g1 = g(tk, xk, yk),
f2 = f(tk + h2, xk + h
2f1, yk + h
2g1), g2 = g(tk + h
2, xk + h
2f1, yk + h
2g1),
f3 = f(tk + h2, xk + h
2f2, yk + h
2g2), g3 = g(tk + h
2, xk + h
2f2, yk + h
2g2),
f4 = f(tk + h, xk + h f3, yk + h g3), g4 = g(tk + h, xk + h f3, yk + h g3).
Ejemplo: Aplicamos al sistema
x′ = x + 2y,
y′ = 3x + 2ycon
x(0) = 6,
y(0) = 4
el metodo de Runge-Kutta de orden 4 en el intervalo [0, 0.2] tomando 10 subintervalos de
paso h =0.2
10= 0.02.
Para obtener el primer punto t1 = 0.02, las operaciones intermedias necesarias para
obtener x1 e y1 son:
f1 = f(t0, x0, y0) = f(0, 6, 4) = 14, g1 = g(t0, x0, y0) = g(0, 6, 4) = 26
x0 + h2f1 = 6.14 y0 + h
2= 4.26
f2 = f(0.01, 6.14, 4.26) = 14.66, g2 = g(0.01, 6.14, 4.26) = 26.94
x0 + h2f2 = 6.1466 y0 + h
2g2 = 4.2694
f3 = f(0.01, 6.1466, 4.2694) = 14.68.54, g3 = g(0.01, 6.1466, 4.2694) = 26.9786
x0 + h f3 = 6.293708 y0 + h g3 = 4.539572
f4 = f(0.02, 6.293708, 4.539572) = 15.372852 g4 = g(0.02, 6.293708, 4.539572) = 27.960268

56
Luego
x1 = x0 +h
6(f1 + 2 f2 + 2 f3 + f4)
= 6 + 0.026
(14 + 2(14.66) + 2(14.6854) + 15.372852) = 6.29354551
y1 = y0 +h
6(g1 + 2 g2 + 2 g3 + g4)
= 4 + 0.026
(26 + 2(26.94) + 2(26.9786) + 27.960868) = 4.53932490
En la siguiente tabla se recogen los valores en cada nodo para xk e yk.
k tk xk yk
0 0.00 6.00000000 4.00000000
1 0.02 6.29654551 4.53932490
2 0.04 6.61562213 5.11948599
3 0.06 6.96852528 5.74396525
4 0.08 7.35474319 6.41653305
5 0.10 7.77697287 7.14127221
6 0.12 8.23813750 7.92260406
7 0.14 8.74140523 8.76531667
8 0.16 9.29020955 9.67459538
9 0.18 9.88827138 10.6560560
10 0.2 10.5396230 11.7157807
Las soluciones ası calculadas presentan errores que se acumulan en cada paso. En el
extremo derecho del intervalo:
x(0.2)− x10 = 0.0000022
y(0.2)− y10 = 0.0000034
3.4.2 Ecuaciones diferenciales de orden superior
Las edo de orden superior son las que involucran derivadas de x(t) de orden superior,
x′′(t), x′′′(t),... Este tipo de ecuaciones aparecen en modelos matematicos de problemas
de la fısica y la ingenierıa. Por ejemplo,
mx′′(t) + c x′(t) + k x(t) = g(t)

57
representa un sistema mecanico en el que un muelle, cuya constante de recuperacion es
k, atado a una masa m, que ha sido separado de su posicion de equilibrio a la que tiende
a volver. Se supone que la amortiguacion debida al rozamiento es proporcional a la
velocidad, que g(t) es una fuerza externa, y que se conocen la posicion inicial x(t0) y la
velocidad inicial x′(t0). Despejando la derivada segunda, el problema de valor inicial se
puede escribir como:
(E)
x′′(t) = f(t, x(t), x′(t))
x(t0) = x0,
x′(t0) = y0
Si llamamos y(t) = x′(t), la e. d. o. de segundo orden se puede reescribir como un
problema de valor inicial para sistemas de primer orden con 2 ecuaciones:
(S)
dx
dt(t) = y(t),
dy
dt(t) = f(t, x(t), y(t)),
x(t0) = x0,
y(t0) = y0
Al resolver el sistema (S) con un metodo numerico de Runge-Kutta de orden 4, se generan
dos sucesiones xk, yk, siendo xk la sucesion de (E).
Ejemplo 1: Movimiento armonico amortiguado.
x′′(t) + 4 x′(t) + 5 x(t) = 0, x(0) = 3, x′(0) = −5.
a) Reescritura como sistema equivalente:
x′′(t) = −4 x′(t)− 5 x(t),
x′(t) = y(t)
y′(t) = −5 x(t)− 4 y(t)con
x(0) = 3
y(0) = −5
b)En la tabla siguiente mostramos los resultados de RK4 en el intervalo [0, 5], con N = 50
y h = 0.1, y la comparacion con la solucion exacta x(t) = 3 e−2t cos(t) + e−2t sen(t):

58
k tk xk x(tk)
0 0.0 3.00000000 3.00000000
1 0.1 2.52564583 2.52565822
2 0.2 2.10402783 2.10404686
3 0.3 1.73506269 1.73508427
4 0.4 1.41653369 1.41655509
5 0.5 1.14488509 1.14490455
10 1.0 0.33324302 0.33324661
20 2.0 -0.00620684 -0.00621162
30 3.0 -0.00701079 -0.00701204
40 4.0 -0.00091163 -0.00091170
48 4.8 -0.00004972 -0.00004969
49 4.9 -0.00002348 -0.00002345
50 5.0 -0.00000493 -0.00000490
Ejemplo 2: Deflexion de un mastil de un velero.
Consideramos un velero azotado por una fuerza f uniformemente distribuida a lo
largo del mastil. Los cables que soportan el mastil se han quitado, pero el mastil se
monta firmemente en el casco del velero. La fuerza del viento causa que el mastil se
desvıe. Las siguientes figuras representan dicha deflexion:

59
La desviacion es similar a la de una viga en voladizo. Se puede usar la siguiente
ecuacion diferencial, basada en las leyes de la mecanica, para calcular la deflexion:
d2
dz2y(z) =
f
2 E I(L− z)2 (3.1)
donde E es el modulo de elasticidad, L es la altura del mastil e I es el momento de inercia.
En z = 0,dy
dz= 0. Calcular la deflexion en el tope del mastil en donde z = L usando
metodos analıticos y numericos. Supongase que el casco no gira.
Solucion: La solucion exacta es y(z) =f
24 E I(L− z)4 + C1 z + C2. Su derivada es:
y′(z) =−f
6 E I(L− z)3 + C1 ⇒ y′(0) =
−f
6 E IL3 + C1 = 0 C1 =
f L3
6 E I

60
Para calcular la constante C2, usamos la hipotesis logica de que y(0) = 0, es decir, el
mastil no se mueve en el sitio de union con el casco del barco, lo que hace que:
C2 =f L4
24 E I,
de manera que la solucion es:
y(z) =f
6 E I
[1
4(L− z)4 + z L3 − L4
4
],
y entonces,
y(L) =f L4
8 E I.
El modelo anterior es valido siempre que el intervalo de integracion [0, L] sea pequeno,
y la desviacion del mastil (que acabamos de calcular) tambien. Los valores de f y E se
basan en datos experimentales variables y difıciles de medir exactamente.
Reescribimos la ecuacion (3.1) como un sistema de e. d. o. de primer orden que
resolvemos usando el metodo de Euler:
dy
dz= u,
du
dz=
f
2 E I(L− z)2
Usamos f = 50 libras/pie, L = 30 pies, E = 1.5 × 108 libras/pie, I = 0.06 pies4, y
obtenemos que la desviacion el el extremo superior del mastil es y(30) = 0.5625 pies.
Concretamente, para distintos valores de h:
Tamano de paso de Euler y(30)
1.0 0.5744
0.1 0.5637
0.05 0.5631
Los resultados se pueden usar para propositos de diseno. Esto es valioso en el caso en
que la fuerza no es constante sino que varıa de forma complicada en funcion de la altura
sobre la cubierta del velero.

61
3.5 Problemas de contorno
Otro tipo de ecuaciones diferenciales son de la forma:
x′′(t) = f(t, x(t), x′(t)) para a ≤ t ≤ b,
con condiciones de contorno (o frontera)
x(a) = α,
x(b) = β
Observemos que hemos sustituido las condiciones iniciales para x(t0) = x0, x′(t0) = y0
por dos condiciones para x(t). Esto se conoce como problema de contorno o problema de valores frontera.
En este caso, antes de implementar el metodo numerico es necesario garantizar que el pro-
blema de contorno posee solucion. Para ello, usamos el siguiente resultado:
Teorema 13 (Problema de contorno) Supongamos que f(t, x, y) es una funcion con-
tinua en la region:
R = (t, x, y) : a ≤ t ≤ b, −∞ < x < ∞, −∞ < y < ∞,
con derivadas parciales∂f
∂x,
∂f
∂ycontinuas en R.
Si fx(t, x, y) > 0 para todo (t, x, y) ∈ R y existe una constante M > 0 tal que
|fy(t, x, y)| ≤ M para todo (t, x, y) ∈ R, entonces el problema de contorno
x′′(t) = f(t, x(t), x′(t))
x(a) = α, x(b) = β
tiene solucion unica x = x(t) en a ≤ t ≤ b.
Nota 16 Observemos que se ha usado que y = x′(t) para la notacion del teorema anterior.
3.5.1 Caso lineal
Corolario 1 (Problemas de contorno lineales) Supongamos que la funcion f del
Teorema anterior es lineal y se puede escribir de la forma:
f(t, x, y) = p(t) y + q(t) x + r(t)
y que sus derivadas parciales∂f
∂x= q(t),
∂f
∂y= p(t) son continuas en R (lo que garantiza
que |p(t)| = |fy| ≤ M = max [a, b]|p(t)|). Si q(t) > 0 para todo t ∈ [a, b], entonces el
problema de contorno lineal:
x′′(t) = p(t) x′(t) + q(t) x(t) + r(t),
x(a) = α, x(b) = β
tiene solucion unica en a ≤ t ≤ b.

62
Metodo del disparo lineal
Pemite resolver un problema de contorno lineal descomponiendolo como dos problemas
de valor inicial especiales:
(Pb1)
u′′(t) = p(t) u′(t) + q(t) u(t) + r(t)
u(a) = α, u′(a) = 0
(Pb2)
v′′(t) = p(t) v′(t) + q(t) v(t)
v(a) = 0, v′(a) = 1.
Entonces, la combinacion lineal x(t) = u(t) + C v(t) es solucion de x′′(t) = p(t) x′(t) +
q(t) x(t) + r(t). En efecto,
x′′(t) = u′′(t) + c v′′(t) = p(t) (u′(t) + c v′(t)) + q(t)(u)t) + c v(t)) + r(t)
= p(t) x′(t) + q(t) x(t) + r(t)
La solucion x(t) toma los siguientes valores en la frontera del intervalo [a, b]:
x(a) = u(a) + c v(a) = α, x(b) = u(b) + c v(b).
Si imponemos la condicion x(b) = β, entonces debemos calcular la constante anterior de
manera que C =β − u(b)
v(b). En consecuencia, si v′(b) 6= 0, entonces la solucion unica del
problema de contorno inicial es:
x(t) = u(t) +β − u(b)
v(b)v(t).
Nota 17 La hipotesis q(t) > 0 evita el caso v(t) = 0.
Ejemplo: Resolvemos el problema de contorno:
x′′(t) =2t
1 + t2x′(t)− 2
1 + t2x(t) + 1
x(0) = 1.25, x(4) = −0.95
(3.2)
en el intervalo [0, 4]. Siguiendo los pasos del metodo del disparo lineal, descomponemos
el problema en:
(Pb1)
u′′(t) =2t
1 + t2u′(t)− 2
1 + t2u(t) + 1
x(0) = 1.25, x′(0) = 0

63
Figura 3.1: Funciones u(t), v(t) y x(t) asociadas a (3.2)
Figura 3.2: Grafica de la solucion numerica de (3.2) con h = 0.2

64
(Pb2)
v′′(t) =2t
1 + t2v′(t)− 2
1 + t2v(t)
x(0) = 0, x′(0) = 1
Usando el metodo de Runge-Kutta de orden 4 con h = 0.2, calculamos las soluciones
numericas uj, vj asociadas a los problemas 1 y 2.
Por otro lado, tomando u(4) ≈ u20 = −2.893535, v(4) ≈ v20 = 4, entonces conside-
ramos la sucesion wj definida por:
wj =b− u(4)
v(4)= 0.485884 vj.
Entonces, la sucesion numerica del problema de contorno viene dada por uj + wj. La
soluci’on exacta del problema es:
x(t) = 1.25 + 0.4860896526 t− 2.25 t2 + 2t arctg(t) +1
2(t2 − 1) ln(1 + t2).
Las siguientes tablas reflejan las aproximaciones numericas obtenidas de las funciones uj,
wj y uj + wj:

65
tj uj wj xj = uj + wj
0.0 1.250000 0.000000 1.250000
0.2 1.220131 0.097177 1.317308
0.4 1.132073 0.194353 1.326426
0.6 0.990122 0.291530 1.281652
0.8 0.800569 0.388707 1.189276
1.0 0.570844 0.485884 1.056728
1.2 0.308850 0.583061 0.891911
1.4 0.022522 0.680237 0.702759
1.6 -0.280424 0.777413 0.496989
1.8 -0.592609 0.874591 0.281982
2.0 -0.907039 0.971767 0.064728
2.2 -1.217121 1.068944 -0.148177
2.4 -0.516639 1.166121 -0.350518
2.6 -1.799740 1.263297 -0.536443
2.8 -2.060904 1.360474 -0.700430
3.0 -2.294916 1.457651 -0.837265
3.2 -2.496842 1.554828 -0.942014
3.4 -2.662004 1.652004 -1.010000
3.6 -2.785960 1.749181 -1.036779
3.8 -2.864481 1.846358 -1.018123
4.0 -2.893535 1.943535 -0.950000
Tabla 3.1: Soluciones numericas
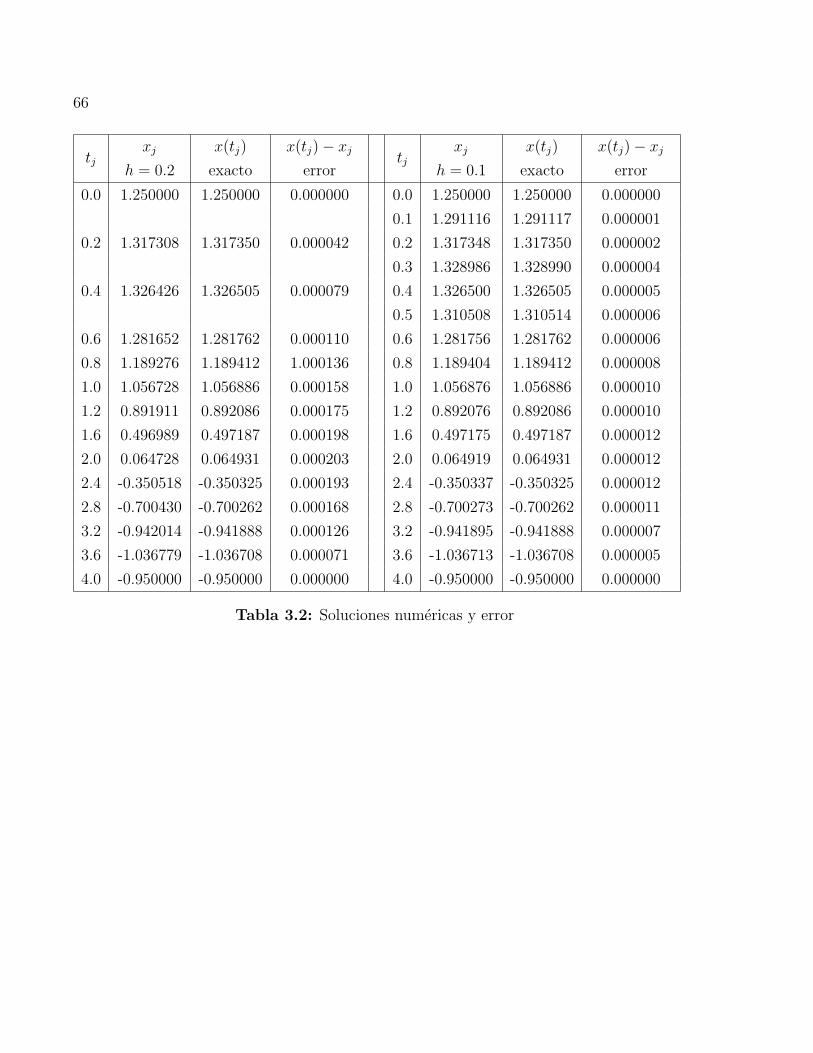
66
tjxj
h = 0.2
x(tj)
exacto
x(tj)− xj
errortj
xj
h = 0.1
x(tj)
exacto
x(tj)− xj
error
0.0 1.250000 1.250000 0.000000 0.0 1.250000 1.250000 0.000000
0.1 1.291116 1.291117 0.000001
0.2 1.317308 1.317350 0.000042 0.2 1.317348 1.317350 0.000002
0.3 1.328986 1.328990 0.000004
0.4 1.326426 1.326505 0.000079 0.4 1.326500 1.326505 0.000005
0.5 1.310508 1.310514 0.000006
0.6 1.281652 1.281762 0.000110 0.6 1.281756 1.281762 0.000006
0.8 1.189276 1.189412 1.000136 0.8 1.189404 1.189412 0.000008
1.0 1.056728 1.056886 0.000158 1.0 1.056876 1.056886 0.000010
1.2 0.891911 0.892086 0.000175 1.2 0.892076 0.892086 0.000010
1.6 0.496989 0.497187 0.000198 1.6 0.497175 0.497187 0.000012
2.0 0.064728 0.064931 0.000203 2.0 0.064919 0.064931 0.000012
2.4 -0.350518 -0.350325 0.000193 2.4 -0.350337 -0.350325 0.000012
2.8 -0.700430 -0.700262 0.000168 2.8 -0.700273 -0.700262 0.000011
3.2 -0.942014 -0.941888 0.000126 3.2 -0.941895 -0.941888 0.000007
3.6 -1.036779 -1.036708 0.000071 3.6 -1.036713 -1.036708 0.000005
4.0 -0.950000 -0.950000 0.000000 4.0 -0.950000 -0.950000 0.000000
Tabla 3.2: Soluciones numericas y error

Tema 4
El metodo de Diferencias Finitas
La idea del metodo de Diferencias Finitas consiste en aproximar las derivadas que
aparecen en el problema de ecuaciones diferenciales ordinarias (e.d.o.) de forma que
se reduzca a resolver un sistema lineal. Una vez definido el sistema lineal se estudiara
teniendo en cuenta los resultados de los Temas 1 y 2.
Comenzamos viendo el metodo de Diferencias Finitas para un problema de contorno
de segundo orden lineal. En concreto, consideramos la ecuacion lineal:
x′′(t) = p(t) x′(t) + q(t)x(t) + r(t) t ∈ [a, b] (4.1)
con
x(a) = α, x(b) = β.
Recordamos que, segun vimos en el tema anterior, suponemos que
q(t) > 0 y que p(t) esta acotada,
bajo estas condiciones el problema de contorno tiene solucion.
Hagamos una particion de [a, b], donde:
a = t0 < t1 < . . . < tN = b,
h =b− a
Ntj = a + j h j = 0, 1, . . . , N
Usando las formulas de diferencias centradas para aproximar las derivadas tenemos (En
el Apendice de este tema se explica como se deduce la siguiente igualdad):
x′(tj) =x(tj+1)− x(tj−1)
2 h+O(h2) (4.2)
67

68
x′′(tj) =x(tj+1)− 2x(tj) + x(tj−1)
h2+O(h2) (4.3)
Reemplazando (4.2) y (4.3) en (4.1), aproximando xj ≈ x(tj) ∀ j, obtenemos:
xj+1 − 2 xj + xj−1
h2+O(h2) = p(tj)
(xj+1 − xj−1
2 h+O(h2)
)+ q(tj)xj + r(tj) (4.4)
Eliminando los terminos de ordenO(h2) en (4.4) e introduciendo la notacion pj = p(tj),
qj = q(tj), rj = r(tj), obtenemos la ecuacion en diferencias:
xj−1 − 2 xj + xj−1
h2= pj
xj+1 − xj−1
2 h+ qj xj + rj (4.5)
que se usa para calcular aproximaciones numericas a la solucion de la ecuacion diferencial
(4.1).
Reagrupando, teniendo en cuenta que las incognitas son xj j = 1, . . . , N , tenemos el
sistemas lineal de ecuaciones:
(−h
2pj − 1
)xj−1 +
(2 + h2qj
)xj +
(h
2pj − 1
)xj+1 = −h2 rj j = 1, 2, . . . , N − 1
x0 = α
xN = β
(4.6)
El sistema (4.6) es un sistema tridiagonal de N − 1 ecuaciones y N − 1 incognitas,
x1, . . . , xN−1 (pues x0 y xN son datos, las condiciones de contorno del problema). En
notacion matricial podemos escribirlo como
Ax = b,
donde x =
x1
...
xN−1
,
A =
2 + h2q1 p1h/2− 1 0 . . . . . . 0
−p2h/2− 1 2 + h2q2 p2h/2− 1 . . . . . . 0. . .
−pjh/2− 1 2 + h2qj pjh/2− 1. . .
−pN−1h/2− 1 2 + h2qN−1

69
Ademas, si denotamos e0 = (p1h/2 + 1)α, eN = (−pN−1h/2 + 1)β, tenemos
b =
−h2r1 + e0
−h2r2
...
−h2rj
...
−h2rN−1 + eN
Aplicamos ahora algunos de los resultados que hemos estudiado para resolucion numerica
de sistemas lineales. Por ejemplo, veamos si podemos utilizar los metodos iterativos de
Jacobi y Gaus-Seidel. Uno de los criterios para ver si ambos metodos son convergentes
es probar que la matriz es estrictamente diagonal dominante. Para ello, tenemos que ver
que
|2 + h2qj| > |1 + pjh/2|+ |1− pjh/2|, j = 1, . . . , N − 1.
Por un lado tenemos que h es el tamano de paso en la discretizacion, por lo que lo podemos
tomar suficientemente pequeno, de forma que
1− pjh/2 ≥ 0, 1 + pjh/2 ≥ 0 ∀j
Como ademas, tenemos que q > 0, por hipotesis (lo suponıamos al principio del tema,
para poder asegurar que el problema de contorno tiene solucion), llegamos a que
|1 + pjh/2|+ |1− pjh/2| = 1 + pjh/2 + 1− pjh/2 = 2
y
|2 + h2qj| > 2 (pues qj > 0).
Por lo tanto, la matriz del sistema es estrictamente diagonal dominante. Entonces, pode-
mos aplicar los metodos iterativos de Jacobi y Gaus-Seidel para resolver el sistema lineal
(no os parece apasionante, como justo la hipotesis que se necesita para asegurar la exis-
tencia de solucion en el problema de contorno (q > 0) es la que asegure que el sistema es
estrictamente diagonal dominante?, acabamos de relacionar dos problemas en apariencia
distintos).
En definitiva, de esta forma, resolviendo el problema lineal, con tamano de paso h,
conseguimos una aproximacion numerica: un conjunto finito de puntos (tj, xj)N−1j=1 .
Si se conoce la solucion exacta x(tj), entonces podemos comparar xj con x(tj).
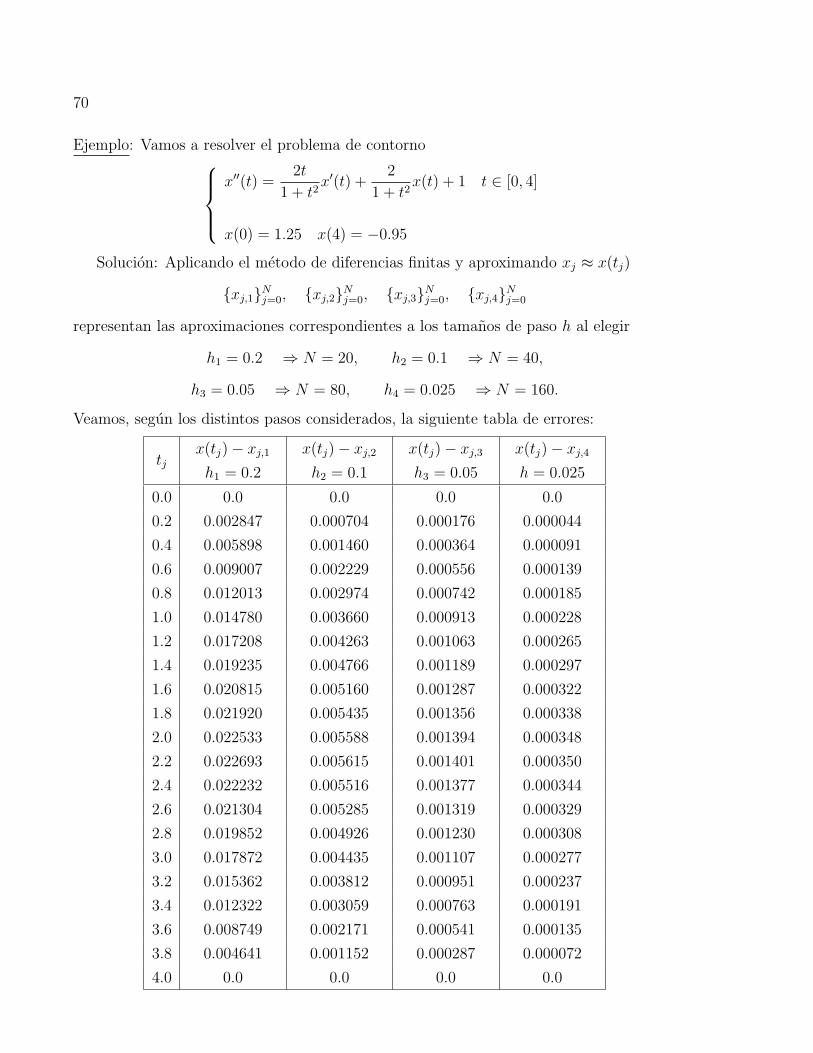
70
Ejemplo: Vamos a resolver el problema de contorno
x′′(t) =2t
1 + t2x′(t) +
2
1 + t2x(t) + 1 t ∈ [0, 4]
x(0) = 1.25 x(4) = −0.95
Solucion: Aplicando el metodo de diferencias finitas y aproximando xj ≈ x(tj)
xj,1Nj=0, xj,2N
j=0, xj,3Nj=0, xj,4N
j=0
representan las aproximaciones correspondientes a los tamanos de paso h al elegir
h1 = 0.2 ⇒ N = 20, h2 = 0.1 ⇒ N = 40,
h3 = 0.05 ⇒ N = 80, h4 = 0.025 ⇒ N = 160.
Veamos, segun los distintos pasos considerados, la siguiente tabla de errores:
tjx(tj)− xj,1
h1 = 0.2
x(tj)− xj,2
h2 = 0.1
x(tj)− xj,3
h3 = 0.05
x(tj)− xj,4
h = 0.025
0.0 0.0 0.0 0.0 0.0
0.2 0.002847 0.000704 0.000176 0.000044
0.4 0.005898 0.001460 0.000364 0.000091
0.6 0.009007 0.002229 0.000556 0.000139
0.8 0.012013 0.002974 0.000742 0.000185
1.0 0.014780 0.003660 0.000913 0.000228
1.2 0.017208 0.004263 0.001063 0.000265
1.4 0.019235 0.004766 0.001189 0.000297
1.6 0.020815 0.005160 0.001287 0.000322
1.8 0.021920 0.005435 0.001356 0.000338
2.0 0.022533 0.005588 0.001394 0.000348
2.2 0.022693 0.005615 0.001401 0.000350
2.4 0.022232 0.005516 0.001377 0.000344
2.6 0.021304 0.005285 0.001319 0.000329
2.8 0.019852 0.004926 0.001230 0.000308
3.0 0.017872 0.004435 0.001107 0.000277
3.2 0.015362 0.003812 0.000951 0.000237
3.4 0.012322 0.003059 0.000763 0.000191
3.6 0.008749 0.002171 0.000541 0.000135
3.8 0.004641 0.001152 0.000287 0.000072
4.0 0.0 0.0 0.0 0.0

71
Se puede probar que las soluciones numericas tienen un error de O(h2): Veamos que si
reducimos el tamano del paso a la mitad, el error disminuye una cuarta parte (Recordamos
que si un metodo es de orden p, entonces e(h/2) = e(h)/2p):
Vamos a fijarnos en la tabla anterior, por ejemplo en t = 2, vemos que el error que
cometemos en este punto, para h1 = 0.2 es 0.022533. Dividiendo esta cantidad por cuatro
y ası sucesivamente tenemos
0.022533 0.00563325 0.0014083125 0.0035207
mientras que los valores de la tabla son
0.022533 0.005588 0.001394 0.000348
Es un pequeno ejemplo, comprobando que el esquema es de orden dos.
Teorema 14 Si la solucion del problema de contorno es suficientemente regular, x ∈C4([a, b]), entonces el error e para el metodo de diferencias finitas satisface:
‖e‖∞ ≤ C h2,
es decir, es un metodo de segundo orden.
Realmente habra ocasiones en las que nos interesa conseguir metodos de mayor orden.
Con esta finalidad estudiamos el esquema de mejora de Richardson.
4.1 Esquema de mejora de Richardson
Vamos a mejorar la precision de las aproximaciones numericas anteriormente obte-
nidas usando el esquema de mejora de Richardson para extrapolar los valores xj,1Nj=0,
xj,2Nj=0, xj,3N
j=0 xj,4Nj=0, correspondiente a los pasos h1, h2, h3 y h4, donde
h2 =h1
2, h3 =
h2
2, h4 =
h3
2,
con la finalidad de obtener 6 cifras de precision.
Para ello, primero eliminamos los terminos de orden O(h2) de xj,1Nj=0 y O((h
2)2) de
xj,2Nj=0, generando los valores
zj,1 =
4xj,2 − xj,1
3

72
Despues, se eliminan los terminos de orden O((h2)2) y O((h
4)2) de xj,2N
j=0 y xj,3Nj=0,
generando
zj,2 =
4xj,3 − xj,2
3
Se puede aplicar un segundo nivel de mejora a las sucesiones zj,1 y zj,2, generando
una tercera mejora:
zj,3 =
16zj,2 − zj,1
15
Los valores correspondientes a zj,3 ya tienen 6 cifras de precision. Como ejemplo, vease
la siguiente tabla
tj(4xj,2 − xj,1)/3
= zj,1
(4xj,3 − xj,2)/3
= zj,2
(16zj,2 − zj,1)/3x(tj)
Sol. exacta
0.0 1.250000 1.250000 1.250000 1.250000
0.2 1.317360 1.317351 1.317350 1.317350
0.4 1.326524 1.326506 1.326504 1.326505
0.6 1.281792 1.281764 1.281762 1.281762
0.8 1.189451 1.189414 1.189412 1.189412
1.0 1.056932 1.056889 1.056886 1.056886
1.2 0.892138 0.892090 0.892086 0.892086
1.4 0.703003 0.702951 0.702947 0.702948
1.6 0.497246 0.497191 0.497187 0.497187
1.8 0.282244 0.282188 0.282184 0.282184
2.0 0.064991 0.064935 0.064931 0.064931
2.2 -0.147918 -0.147973 -0.147977 -0.147977
2.4 -0.350268 -0.350322 -0.350325 -0.350325
2.6 -0.536207 -0.536258 -0.536261 -0.536261
2.8 -0.700213 -0.700259 -0.700263 -0.700262
3.0 -0.837072 -0.837119 -0.837116 -0.837116
3.2 -0.941850 -0.941885 -0.941888 -0.941888
3.4 -1.009870 -1.009898 -1.009899 -1.009899
3.6 -1.036688 -1.096707 -1.036708 -1.036708
3.8 -1.018075 -1.018085 -1.018086 -1.018086
4.0 -0.950000 -0.950000 -0.950000 -0.950000

73
4.2 Otras condiciones de frontera.
Las condiciones de frontera pueden ser distintas. Concretamente, en lugar de tomar
x(a) = α, podemos tener x′(a) y x′(b) en lugar de x(b).
Supongamos por ejemplo que:
x′(a) = α
x′(b) = βo
x′(a) = α
x(b) = βo
x(a) = α
x′(b) = β
Ahora x0 y xN son tambien incognitas, luego debemos tener 2 ecuaciones mas en el sistema
resultante.
Supongamos que tenemos la condicion x′(a) = α, podemos aproximar esta condicion
mediante:x1 − x−1
2h= α (4.7)
donde x−1 es un punto ficticio de la busqueda de x0. Entonces, escribiendo la ecuacion
aproximada por diferencias finitas para el nodo x0:
x1 − 2x0 + x−1
h2= r0 + q0x0 + p0
x1 − x−1
2h
que reordenamos como:
(−1− 1
2hq0)x−1 + (2 + h2p0)x0 + (−1 +
1
2hq0)x1 = −h2r0,
de donde, teniendo en cuenta que por (4.7)
x−1 = x1 − 2hα
La ecuacion queda
(2 + h2p0)x0 − 2x1 = −(2 + h q0)h α− h2r0. (4.8)
Razonando asimismo en el extremo b, tenemos que si imponemos x′(b) = β la ecuacion
resultante es
−2xN−1 + (2 + h2qN)xN = −h2rN + (2− h pN)hβ. (4.9)
De esta forma, las ecuaciones (4.8) y (4.9) se anadirian al sistema (4.6), obteniendo un
problema de (N + 1) incognitas con (N + 1) ecuaciones.

74
Apendice: Aproximacion de la derivada de una fun-
cion a partir del desarrollo de Taylor
En esta seccion vamos a introducir aproximaciones de y′(x) e y′′(x), a partir del desa-
rrollo de Taylor. Estas aproximaciones es la base de los metodos de diferencias finitas.
Consideramos en primer lugar el desarrollo de Taylor de tercer orden, para una funcion
y(x). Entonces,
y(t) = y(t0) + y′(t0)(t− t0) + y′′(t0)(t− t0)
2
2+ y′′′(c)
(t− t0)3
6
de donde tomando t0 = x y t = x + h, tenemos
y(x + h) = y(x) + y′(x)h + y′′(x)h2
2+ y′′′(c1)
h3
6
Tomando ahora, t0 = x, t = x− h, obtenemos:
y(x− h) = y(x)− hy′(x) + y′′(x)h2
2− y′′′(c2)
h3
6.
Restando ambas expresiones tenemos:
y(x + h)− y(x− h) = 2 h y′(x) +h3
6(y′′′(c1) + y′′′(c2))
De esta ultima aproximacion deducimos
y′(x) =y(x + h)− y(x− h)
2 h+
h2
12(y′′′(c1) + y′′′(c2))
Por lo tanto, tenemos una aproximacion de segundo orden a la derivada a la funcion en
un punto:
y′(x) ≈ y(x + h)− y(x− h)
2 h
Aproximacion de y′′(x)
Usando el desarrollo de Taylor de cuarto orden, llegamos a que
y(t) = y(t0) + y′(t0)(t− t0) + y′′(t0)(t− t0)
2
2+ y′′′(t0)
(t− t0)3
6+ yiv(c)
(t− t0)4
4!
Si t = x + h, t0 = x
y(x + h) = y(x) + y′(x)h + y′′(x)h2
2+ y′′′(x)
h3
6+ yiv(c1)
h4
4!

75
Si t = x− h, t0 = x
y(x + h) = y(x)− y′(x)h + y′′(x)h2
2− y′′′(x)
h3
6+ yiv(c2)
h4
4!
Sumando ambas expresiones y despejando el valor de y′′(x) tenemos:
y′′(x) =y(x + h)− 2y(x) + y(x− h)
h2+
h2
4!(yiv(c1) + yiv(c2))
Luego usamos la aproximacion de segundo orden de y′′(x):
y′′(x) ≈ y(x + h)− 2y(x) + y(x− h)
h2.

76

Tema 5
Ecuaciones en derivadas parciales
Muchos problemas en ciencia aplicada, fısica e ingenierıa se modelan mediante EDP’s.
Una EDP es una ecuacion diferencial en la que aparecen dos o mas variables indepen-
dientes. El orden de la EDP es (igual que en las edo) el de la mayor derivada parcial
que aparezca en dicha ecuacion. Nosotros nos restringiremos al caso de EDPs de segun-
do orden. Empezaremos clasificando los tres tipos de ecuaciones que vamos a estudiar,
introduciendo un problema fısico tıpico de cada clase.
Estudiamos EDPs de la forma
Aφxx + Bφxy + Cφyy = f(x, y, φ, φx, φy)
donde A, B, C son constantes. Dichas ecuaciones reciben el nombres de quasi-lineales y
son de 3 tipos:
1. Si B2 − 4AC < 0, la ecuacion se llama elıptica.
2. Si B2 − 4AC = 0, la ecuacion se llama parabolica.
3. Si B2 − 4AC > 0, la ecuacion se llama hiperbolica.
Como ejemplo de una ecuacion hiperbolica podemos considerar el modelo unidimensional
de la cuerda vibrante. El desplazamiento de la cuerda u(x, t) viene gobernado por la
llamada ecuacion de ondas
ρutt(x, t) = T uxx(x, t) 0 < x < L 0 < t < ∞
(por ρ denotamos la masa de la cuerda por unidad de longitud y por T la tension de la
77

78
cuerda) con posicion y velocidad iniciales dadas por
u(x, 0) = f(x) para t = 0, 0 ≤ x ≤ L
ut(x, 0) = g(x) para t = 0, 0 ≤ x ≤ L
y siendo los valores en los extremos de la cuerda
u(0, t) = 0 y(L, t) = 0 0 ≤ t < ∞
Como ejemplo de una ecuacion parabolica consideramos el modelo unidimensional del
flujo de calor en un alambra aislado de longitud L.
La ecuacion del calor que nos da la temperatura u(x, t) en la posicion x del alambre y en
el instante t, es
K ux x(x, t) = σ ρ ut(x, t) 0 < x < L 0 < t < ∞
donde u(x, 0) = f(x) para t = 0, 0 ≤ x ≤ L y la condicion de contorno en los extremos es
u(0, t) = c1 u(L, t) = c2
Por K denotamos el coeficiente de conductividad termica. σ es el calor especıfico del
material. ρ es la densidad del material.

79
Figura 5.1: Curvas de nivel de la funcion potencial
Como ejemplo de ecuacion elıptica consideramos la funcion potencial u(x, t), que po-
drıa representar el regimen permante de un potencial electrostatico o el regimen per-
manente de la distribucion de temperatura en una region rectangular del plano. Estas
situaciones se modelan mediante la llamada ecuacion de Laplace en un rectangulo
ux x(x, y) + uy y(x, y) = 0 0 < x < 1 0 < y < 1
con condiciones de contorno especıficadas sobre cada uno de los lados del rectangulo
anteriorment mencionado:
u(x, 0) = f1(x), u(x, 1) = f2(x) 0 ≤ x ≤ 1
u(0, y) = f3(y), u(1, y) = f4(y) 0 ≤ y ≤ 1
En la figura 5.1 se muestran las curvas de nivel u(x, y) = c cuando f1(x) = 0,
f2(x) = sen(π x), f3(y) = f4(y) = 0.
Nota 18 Las condiciones de contorno tambien se podrıan haber elegido para derivadas
normales de u, aunque no estudiaremos este caso.
5.1 Ecuaciones elıpticas
Llamamos laplaciano de la funcion u(x, y) a
∆u = ∇2u = uxx + uyy.
A partir de este operador, se pueden escribir las siguientes ecuaciones que surgen en
muchos problemas fısicos:

80
1. ∆u = 0 → Ecuacion de Laplace.
2. ∆u = g(x, y) → Ecuacion de Poisson.
3. ∆u + f(x, y) u = g(x, y) → Ecuacion de Helmholtz.
Si se conocen los valores que toma u en la frontera de la region donde esta definida (que
nosotros consideraremos un rectangulo) (problema de Dirichlet) o su derivada normal
∂u/∂η(x, y) = 0 (problema de Newmann), entonces cada uno de esos problema se
pueden resolver. Vamos a verlos mediante la tecnica de diferencias finitas.
5.2 Diferencias Finitas para EDP’s
Queremos resolver el siguiente problema de EDP con condicion de contorno de tipo
Dirichlet,
uxx + uyy = 0 en Ω
u(x, y) = g(x, y) en ∂Ω
u continua en Ω
(5.1)
Si suponemos g continua y algunas condiciones de regularidad (poco exigentes) sobre Ω,
el problema tiene solucion unica.
Para introducir el metodo, supondremos que Ω es un cuadrado:
Ω = (x, y) ∈ R2; 0 < x < 1, 0 < y < 1
Discretizacion: Introducimos una malla o red de puntos sobre Ω:
x x xy
y
y
0 1 N
0
1
N
x
y
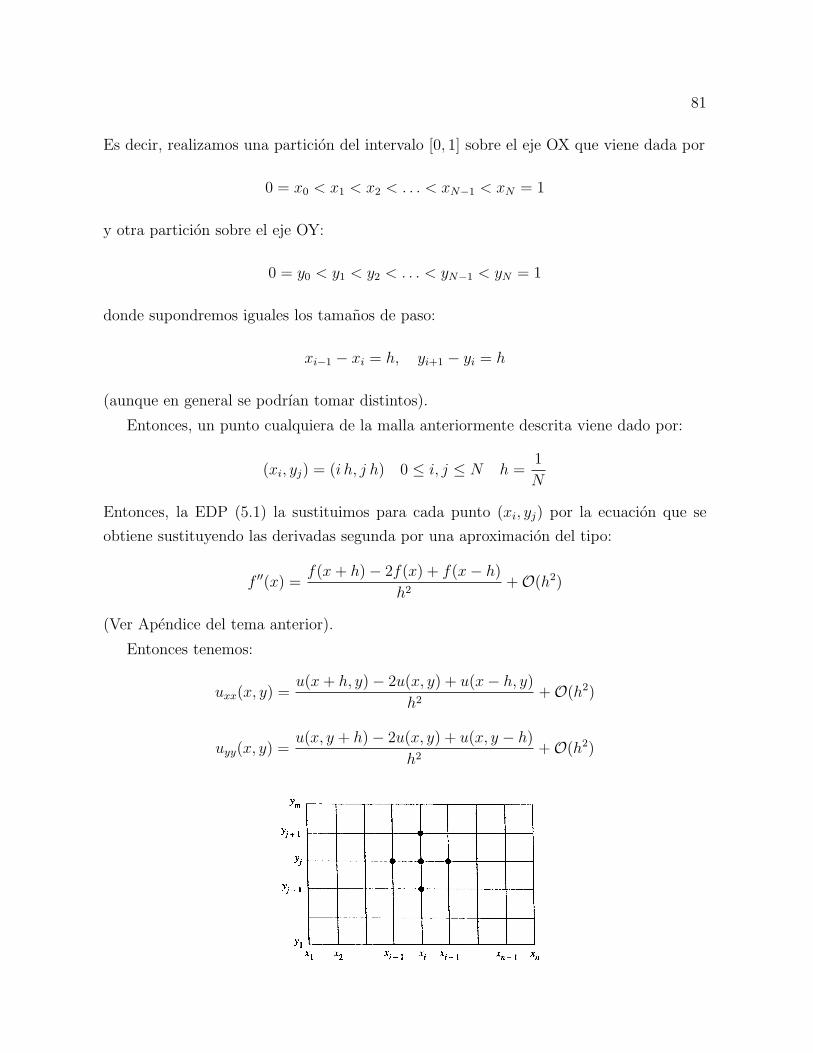
81
Es decir, realizamos una particion del intervalo [0, 1] sobre el eje OX que viene dada por
0 = x0 < x1 < x2 < . . . < xN−1 < xN = 1
y otra particion sobre el eje OY:
0 = y0 < y1 < y2 < . . . < yN−1 < yN = 1
donde supondremos iguales los tamanos de paso:
xi−1 − xi = h, yi+1 − yi = h
(aunque en general se podrıan tomar distintos).
Entonces, un punto cualquiera de la malla anteriormente descrita viene dado por:
(xi, yj) = (i h, j h) 0 ≤ i, j ≤ N h =1
N
Entonces, la EDP (5.1) la sustituimos para cada punto (xi, yj) por la ecuacion que se
obtiene sustituyendo las derivadas segunda por una aproximacion del tipo:
f ′′(x) =f(x + h)− 2f(x) + f(x− h)
h2+O(h2)
(Ver Apendice del tema anterior).
Entonces tenemos:
uxx(x, y) =u(x + h, y)− 2u(x, y) + u(x− h, y)
h2+O(h2)
uyy(x, y) =u(x, y + h)− 2u(x, y) + u(x, y − h)
h2+O(h2)

82
Llamamos ui,j a la aproximacion del valor exacto u(xi, yj). Al sustituir la derivada exac-
ta en (5.1) por las aproximaciones anteriormente mencionadas, la ecuacion (5.1) queda
descrita para cada punto de la malla (xi, yj) como:
ui+1,j − 2ui,j + ui−1,j
h2+
ui,j+1 − 2ui,j + ui,j−1
h2= 0,
que reordenando se convierte en:
−(4ui,j − ui−1,j − ui+1,j − ui,j−1 − ui,j+1) = 0 0 ≤ i, j ≤ N (5.2)
Con lo que tenemos un sistema de ecuaciones lineales, con incognitas ui,j, que son 2(N +1)
incognitas, y un numero equivalente de ecuaciones.
Sin embargo, conocemos los valores frontera u = g sobre ∂Ω. Luego tenemos que
u0,j = g0,j = g(0, yj), uN,j = gN+1,j = g(1, yj) j = 0, . . . , N
ui,0 = gi,0 = g(xi, 0), ui,N = gi,N = g(xi, 1) i = 0, . . . , N
De esta forma, las incognitas solo son
ui,j 1 ≤ i, j ≤ N − 1
y el sistema (5.2) solo se considera para 1 ≤ 1, j ≤ N − 1, con lo que tenemos el mismo
numero de ecuaciones que incognicas.
Nota 19 El sistema lineal que se obtiene es hueco, pues a lo sumo hay 5 terminos no
nulos en cada ecuacion. Ademas, es diagonal dominante, luego los metodos iterativos de
Jacobi y Gaus-Seidel se pueden aplicar.
5.2.1 Tratamiento de la condicion de contorno de tipo Neumann
Vamos a suponer el caso mas simple:
∂u
∂η(x, y) = 0.

83
η
En el contexto de los problemas de distribucion de temperaturas, esto significa que el
contorno esta aislado y que no hay flujo de calor a traves de el.
Supongamos que solo consideramos la condicion de contorno Neumann sobre uno de
los lados de la region, en concreto sobre el lado x = 1. La condicion de contorno sobre
ese lado es:
∂u
∂η(x, y) = (
∂u
∂x,∂u
∂y) · η = 0.
En este caso, x = 1, el vector normal es η = (1, 0), por lo que la condicion queda reducida
a
∂u
∂x(1, y) = 0.
La ecuacion de diferencias finitas correspondiente a los puntos de x = 1, es decir, (1, yj)
es:
uN+1,j + uN−1,j + uN,j+1 + uN,j−1 − 4uN,j = 0, (5.3)
donde el valor de uN+1,j es desconocido, al estar fuera de la region. Usamos entonces la
formula de derivacion numerica
uN+1,j − uN−1,j
2 h≈ ∂u
∂x(xN , yj) = 0
Por lo tanto, tenemos que
uN+1,j = uN−1,j
Luego sustituyendo en la expresion (5.3) queda:
2uN−1,j + uN,j+1 + uN,j−1 − 4uN,j = 0

84
Esta nueva formula sigue el esquema